| alertmanager_alerts |
gauge |
ins, instance, ip, job, cls, state |
How many alerts by state. |
| alertmanager_alerts_invalid_total |
counter |
version, ins, instance, ip, job, cls |
The total number of received alerts that were invalid. |
| alertmanager_alerts_received_total |
counter |
version, ins, instance, ip, status, job, cls |
The total number of received alerts. |
| alertmanager_build_info |
gauge |
revision, version, ins, instance, ip, tags, goarch, goversion, job, cls, branch, goos |
A metric with a constant ‘1’ value labeled by version, revision, branch, goversion from which alertmanager was built, and the goos and goarch for the build. |
| alertmanager_cluster_alive_messages_total |
counter |
ins, instance, ip, peer, job, cls |
Total number of received alive messages. |
| alertmanager_cluster_enabled |
gauge |
ins, instance, ip, job, cls |
Indicates whether the clustering is enabled or not. |
| alertmanager_cluster_failed_peers |
gauge |
ins, instance, ip, job, cls |
Number indicating the current number of failed peers in the cluster. |
| alertmanager_cluster_health_score |
gauge |
ins, instance, ip, job, cls |
Health score of the cluster. Lower values are better and zero means ’totally healthy’. |
| alertmanager_cluster_members |
gauge |
ins, instance, ip, job, cls |
Number indicating current number of members in cluster. |
| alertmanager_cluster_messages_pruned_total |
counter |
ins, instance, ip, job, cls |
Total number of cluster messages pruned. |
| alertmanager_cluster_messages_queued |
gauge |
ins, instance, ip, job, cls |
Number of cluster messages which are queued. |
| alertmanager_cluster_messages_received_size_total |
counter |
ins, instance, ip, msg_type, job, cls |
Total size of cluster messages received. |
| alertmanager_cluster_messages_received_total |
counter |
ins, instance, ip, msg_type, job, cls |
Total number of cluster messages received. |
| alertmanager_cluster_messages_sent_size_total |
counter |
ins, instance, ip, msg_type, job, cls |
Total size of cluster messages sent. |
| alertmanager_cluster_messages_sent_total |
counter |
ins, instance, ip, msg_type, job, cls |
Total number of cluster messages sent. |
| alertmanager_cluster_peer_info |
gauge |
ins, instance, ip, peer, job, cls |
A metric with a constant ‘1’ value labeled by peer name. |
| alertmanager_cluster_peers_joined_total |
counter |
ins, instance, ip, job, cls |
A counter of the number of peers that have joined. |
| alertmanager_cluster_peers_left_total |
counter |
ins, instance, ip, job, cls |
A counter of the number of peers that have left. |
| alertmanager_cluster_peers_update_total |
counter |
ins, instance, ip, job, cls |
A counter of the number of peers that have updated metadata. |
| alertmanager_cluster_reconnections_failed_total |
counter |
ins, instance, ip, job, cls |
A counter of the number of failed cluster peer reconnection attempts. |
| alertmanager_cluster_reconnections_total |
counter |
ins, instance, ip, job, cls |
A counter of the number of cluster peer reconnections. |
| alertmanager_cluster_refresh_join_failed_total |
counter |
ins, instance, ip, job, cls |
A counter of the number of failed cluster peer joined attempts via refresh. |
| alertmanager_cluster_refresh_join_total |
counter |
ins, instance, ip, job, cls |
A counter of the number of cluster peer joined via refresh. |
| alertmanager_config_hash |
gauge |
ins, instance, ip, job, cls |
Hash of the currently loaded alertmanager configuration. |
| alertmanager_config_last_reload_success_timestamp_seconds |
gauge |
ins, instance, ip, job, cls |
Timestamp of the last successful configuration reload. |
| alertmanager_config_last_reload_successful |
gauge |
ins, instance, ip, job, cls |
Whether the last configuration reload attempt was successful. |
| alertmanager_dispatcher_aggregation_groups |
gauge |
ins, instance, ip, job, cls |
Number of active aggregation groups |
| alertmanager_dispatcher_alert_processing_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| alertmanager_dispatcher_alert_processing_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| alertmanager_http_concurrency_limit_exceeded_total |
counter |
ins, instance, method, ip, job, cls |
Total number of times an HTTP request failed because the concurrency limit was reached. |
| alertmanager_http_request_duration_seconds_bucket |
Unknown |
ins, instance, method, ip, le, job, cls, handler |
N/A |
| alertmanager_http_request_duration_seconds_count |
Unknown |
ins, instance, method, ip, job, cls, handler |
N/A |
| alertmanager_http_request_duration_seconds_sum |
Unknown |
ins, instance, method, ip, job, cls, handler |
N/A |
| alertmanager_http_requests_in_flight |
gauge |
ins, instance, method, ip, job, cls |
Current number of HTTP requests being processed. |
| alertmanager_http_response_size_bytes_bucket |
Unknown |
ins, instance, method, ip, le, job, cls, handler |
N/A |
| alertmanager_http_response_size_bytes_count |
Unknown |
ins, instance, method, ip, job, cls, handler |
N/A |
| alertmanager_http_response_size_bytes_sum |
Unknown |
ins, instance, method, ip, job, cls, handler |
N/A |
| alertmanager_integrations |
gauge |
ins, instance, ip, job, cls |
Number of configured integrations. |
| alertmanager_marked_alerts |
gauge |
ins, instance, ip, job, cls, state |
How many alerts by state are currently marked in the Alertmanager regardless of their expiry. |
| alertmanager_nflog_gc_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| alertmanager_nflog_gc_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| alertmanager_nflog_gossip_messages_propagated_total |
counter |
ins, instance, ip, job, cls |
Number of received gossip messages that have been further gossiped. |
| alertmanager_nflog_maintenance_errors_total |
counter |
ins, instance, ip, job, cls |
How many maintenances were executed for the notification log that failed. |
| alertmanager_nflog_maintenance_total |
counter |
ins, instance, ip, job, cls |
How many maintenances were executed for the notification log. |
| alertmanager_nflog_queries_total |
counter |
ins, instance, ip, job, cls |
Number of notification log queries were received. |
| alertmanager_nflog_query_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| alertmanager_nflog_query_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| alertmanager_nflog_query_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| alertmanager_nflog_query_errors_total |
counter |
ins, instance, ip, job, cls |
Number notification log received queries that failed. |
| alertmanager_nflog_snapshot_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| alertmanager_nflog_snapshot_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| alertmanager_nflog_snapshot_size_bytes |
gauge |
ins, instance, ip, job, cls |
Size of the last notification log snapshot in bytes. |
| alertmanager_notification_latency_seconds_bucket |
Unknown |
integration, ins, instance, ip, le, job, cls |
N/A |
| alertmanager_notification_latency_seconds_count |
Unknown |
integration, ins, instance, ip, job, cls |
N/A |
| alertmanager_notification_latency_seconds_sum |
Unknown |
integration, ins, instance, ip, job, cls |
N/A |
| alertmanager_notification_requests_failed_total |
counter |
integration, ins, instance, ip, job, cls |
The total number of failed notification requests. |
| alertmanager_notification_requests_total |
counter |
integration, ins, instance, ip, job, cls |
The total number of attempted notification requests. |
| alertmanager_notifications_failed_total |
counter |
integration, ins, instance, ip, reason, job, cls |
The total number of failed notifications. |
| alertmanager_notifications_total |
counter |
integration, ins, instance, ip, job, cls |
The total number of attempted notifications. |
| alertmanager_oversize_gossip_message_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, key, job, cls |
N/A |
| alertmanager_oversize_gossip_message_duration_seconds_count |
Unknown |
ins, instance, ip, key, job, cls |
N/A |
| alertmanager_oversize_gossip_message_duration_seconds_sum |
Unknown |
ins, instance, ip, key, job, cls |
N/A |
| alertmanager_oversized_gossip_message_dropped_total |
counter |
ins, instance, ip, key, job, cls |
Number of oversized gossip messages that were dropped due to a full message queue. |
| alertmanager_oversized_gossip_message_failure_total |
counter |
ins, instance, ip, key, job, cls |
Number of oversized gossip message sends that failed. |
| alertmanager_oversized_gossip_message_sent_total |
counter |
ins, instance, ip, key, job, cls |
Number of oversized gossip message sent. |
| alertmanager_peer_position |
gauge |
ins, instance, ip, job, cls |
Position the Alertmanager instance believes it’s in. The position determines a peer’s behavior in the cluster. |
| alertmanager_receivers |
gauge |
ins, instance, ip, job, cls |
Number of configured receivers. |
| alertmanager_silences |
gauge |
ins, instance, ip, job, cls, state |
How many silences by state. |
| alertmanager_silences_gc_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| alertmanager_silences_gc_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| alertmanager_silences_gossip_messages_propagated_total |
counter |
ins, instance, ip, job, cls |
Number of received gossip messages that have been further gossiped. |
| alertmanager_silences_maintenance_errors_total |
counter |
ins, instance, ip, job, cls |
How many maintenances were executed for silences that failed. |
| alertmanager_silences_maintenance_total |
counter |
ins, instance, ip, job, cls |
How many maintenances were executed for silences. |
| alertmanager_silences_queries_total |
counter |
ins, instance, ip, job, cls |
How many silence queries were received. |
| alertmanager_silences_query_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| alertmanager_silences_query_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| alertmanager_silences_query_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| alertmanager_silences_query_errors_total |
counter |
ins, instance, ip, job, cls |
How many silence received queries did not succeed. |
| alertmanager_silences_snapshot_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| alertmanager_silences_snapshot_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| alertmanager_silences_snapshot_size_bytes |
gauge |
ins, instance, ip, job, cls |
Size of the last silence snapshot in bytes. |
| blackbox_exporter_build_info |
gauge |
revision, version, ins, instance, ip, tags, goarch, goversion, job, cls, branch, goos |
A metric with a constant ‘1’ value labeled by version, revision, branch, goversion from which blackbox_exporter was built, and the goos and goarch for the build. |
| blackbox_exporter_config_last_reload_success_timestamp_seconds |
gauge |
ins, instance, ip, job, cls |
Timestamp of the last successful configuration reload. |
| blackbox_exporter_config_last_reload_successful |
gauge |
ins, instance, ip, job, cls |
Blackbox exporter config loaded successfully. |
| blackbox_module_unknown_total |
counter |
ins, instance, ip, job, cls |
Count of unknown modules requested by probes |
| cortex_distributor_ingester_clients |
gauge |
ins, instance, ip, job, cls |
The current number of ingester clients. |
| cortex_dns_failures_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| cortex_dns_lookups_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| cortex_frontend_query_range_duration_seconds_bucket |
Unknown |
ins, instance, method, ip, le, job, cls, status_code |
N/A |
| cortex_frontend_query_range_duration_seconds_count |
Unknown |
ins, instance, method, ip, job, cls, status_code |
N/A |
| cortex_frontend_query_range_duration_seconds_sum |
Unknown |
ins, instance, method, ip, job, cls, status_code |
N/A |
| cortex_ingester_flush_queue_length |
gauge |
ins, instance, ip, job, cls |
The total number of series pending in the flush queue. |
| cortex_kv_request_duration_seconds_bucket |
Unknown |
ins, instance, role, ip, le, kv_name, type, operation, job, cls, status_code |
N/A |
| cortex_kv_request_duration_seconds_count |
Unknown |
ins, instance, role, ip, kv_name, type, operation, job, cls, status_code |
N/A |
| cortex_kv_request_duration_seconds_sum |
Unknown |
ins, instance, role, ip, kv_name, type, operation, job, cls, status_code |
N/A |
| cortex_member_consul_heartbeats_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| cortex_prometheus_notifications_alertmanagers_discovered |
gauge |
ins, instance, ip, user, job, cls |
The number of alertmanagers discovered and active. |
| cortex_prometheus_notifications_dropped_total |
Unknown |
ins, instance, ip, user, job, cls |
N/A |
| cortex_prometheus_notifications_queue_capacity |
gauge |
ins, instance, ip, user, job, cls |
The capacity of the alert notifications queue. |
| cortex_prometheus_notifications_queue_length |
gauge |
ins, instance, ip, user, job, cls |
The number of alert notifications in the queue. |
| cortex_prometheus_rule_evaluation_duration_seconds |
summary |
ins, instance, ip, user, job, cls, quantile |
The duration for a rule to execute. |
| cortex_prometheus_rule_evaluation_duration_seconds_count |
Unknown |
ins, instance, ip, user, job, cls |
N/A |
| cortex_prometheus_rule_evaluation_duration_seconds_sum |
Unknown |
ins, instance, ip, user, job, cls |
N/A |
| cortex_prometheus_rule_group_duration_seconds |
summary |
ins, instance, ip, user, job, cls, quantile |
The duration of rule group evaluations. |
| cortex_prometheus_rule_group_duration_seconds_count |
Unknown |
ins, instance, ip, user, job, cls |
N/A |
| cortex_prometheus_rule_group_duration_seconds_sum |
Unknown |
ins, instance, ip, user, job, cls |
N/A |
| cortex_query_frontend_connected_schedulers |
gauge |
ins, instance, ip, job, cls |
Number of schedulers this frontend is connected to. |
| cortex_query_frontend_queries_in_progress |
gauge |
ins, instance, ip, job, cls |
Number of queries in progress handled by this frontend. |
| cortex_query_frontend_retries_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| cortex_query_frontend_retries_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| cortex_query_frontend_retries_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| cortex_query_scheduler_connected_frontend_clients |
gauge |
ins, instance, ip, job, cls |
Number of query-frontend worker clients currently connected to the query-scheduler. |
| cortex_query_scheduler_connected_querier_clients |
gauge |
ins, instance, ip, job, cls |
Number of querier worker clients currently connected to the query-scheduler. |
| cortex_query_scheduler_inflight_requests |
summary |
ins, instance, ip, job, cls, quantile |
Number of inflight requests (either queued or processing) sampled at a regular interval. Quantile buckets keep track of inflight requests over the last 60s. |
| cortex_query_scheduler_inflight_requests_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| cortex_query_scheduler_inflight_requests_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| cortex_query_scheduler_queue_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| cortex_query_scheduler_queue_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| cortex_query_scheduler_queue_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| cortex_query_scheduler_queue_length |
Unknown |
ins, instance, ip, user, job, cls |
N/A |
| cortex_query_scheduler_running |
gauge |
ins, instance, ip, job, cls |
Value will be 1 if the scheduler is in the ReplicationSet and actively receiving/processing requests |
| cortex_ring_member_heartbeats_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| cortex_ring_member_tokens_owned |
gauge |
ins, instance, ip, job, cls |
The number of tokens owned in the ring. |
| cortex_ring_member_tokens_to_own |
gauge |
ins, instance, ip, job, cls |
The number of tokens to own in the ring. |
| cortex_ring_members |
gauge |
ins, instance, ip, job, cls, state |
Number of members in the ring |
| cortex_ring_oldest_member_timestamp |
gauge |
ins, instance, ip, job, cls, state |
Timestamp of the oldest member in the ring. |
| cortex_ring_tokens_total |
gauge |
ins, instance, ip, job, cls |
Number of tokens in the ring |
| cortex_ruler_clients |
gauge |
ins, instance, ip, job, cls |
The current number of ruler clients in the pool. |
| cortex_ruler_config_last_reload_successful |
gauge |
ins, instance, ip, user, job, cls |
Boolean set to 1 whenever the last configuration reload attempt was successful. |
| cortex_ruler_config_last_reload_successful_seconds |
gauge |
ins, instance, ip, user, job, cls |
Timestamp of the last successful configuration reload. |
| cortex_ruler_config_updates_total |
Unknown |
ins, instance, ip, user, job, cls |
N/A |
| cortex_ruler_managers_total |
gauge |
ins, instance, ip, job, cls |
Total number of managers registered and running in the ruler |
| cortex_ruler_ring_check_errors_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| cortex_ruler_sync_rules_total |
Unknown |
ins, instance, ip, reason, job, cls |
N/A |
| deprecated_flags_inuse_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_cgo_go_to_c_calls_calls_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_cpu_classes_gc_mark_assist_cpu_seconds_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_cpu_classes_gc_mark_dedicated_cpu_seconds_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_cpu_classes_gc_mark_idle_cpu_seconds_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_cpu_classes_gc_pause_cpu_seconds_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_cpu_classes_gc_total_cpu_seconds_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_cpu_classes_idle_cpu_seconds_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_cpu_classes_scavenge_assist_cpu_seconds_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_cpu_classes_scavenge_background_cpu_seconds_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_cpu_classes_scavenge_total_cpu_seconds_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_cpu_classes_total_cpu_seconds_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_cpu_classes_user_cpu_seconds_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_gc_cycles_automatic_gc_cycles_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_gc_cycles_forced_gc_cycles_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_gc_cycles_total_gc_cycles_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_gc_duration_seconds |
summary |
ins, instance, ip, job, cls, quantile |
A summary of the pause duration of garbage collection cycles. |
| go_gc_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_gc_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_gc_gogc_percent |
gauge |
ins, instance, ip, job, cls |
Heap size target percentage configured by the user, otherwise 100. This value is set by the GOGC environment variable, and the runtime/debug.SetGCPercent function. |
| go_gc_gomemlimit_bytes |
gauge |
ins, instance, ip, job, cls |
Go runtime memory limit configured by the user, otherwise math.MaxInt64. This value is set by the GOMEMLIMIT environment variable, and the runtime/debug.SetMemoryLimit function. |
| go_gc_heap_allocs_by_size_bytes_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| go_gc_heap_allocs_by_size_bytes_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_gc_heap_allocs_by_size_bytes_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_gc_heap_allocs_bytes_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_gc_heap_allocs_objects_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_gc_heap_frees_by_size_bytes_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| go_gc_heap_frees_by_size_bytes_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_gc_heap_frees_by_size_bytes_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_gc_heap_frees_bytes_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_gc_heap_frees_objects_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_gc_heap_goal_bytes |
gauge |
ins, instance, ip, job, cls |
Heap size target for the end of the GC cycle. |
| go_gc_heap_live_bytes |
gauge |
ins, instance, ip, job, cls |
Heap memory occupied by live objects that were marked by the previous GC. |
| go_gc_heap_objects_objects |
gauge |
ins, instance, ip, job, cls |
Number of objects, live or unswept, occupying heap memory. |
| go_gc_heap_tiny_allocs_objects_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_gc_limiter_last_enabled_gc_cycle |
gauge |
ins, instance, ip, job, cls |
GC cycle the last time the GC CPU limiter was enabled. This metric is useful for diagnosing the root cause of an out-of-memory error, because the limiter trades memory for CPU time when the GC’s CPU time gets too high. This is most likely to occur with use of SetMemoryLimit. The first GC cycle is cycle 1, so a value of 0 indicates that it was never enabled. |
| go_gc_pauses_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| go_gc_pauses_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_gc_pauses_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_gc_scan_globals_bytes |
gauge |
ins, instance, ip, job, cls |
The total amount of global variable space that is scannable. |
| go_gc_scan_heap_bytes |
gauge |
ins, instance, ip, job, cls |
The total amount of heap space that is scannable. |
| go_gc_scan_stack_bytes |
gauge |
ins, instance, ip, job, cls |
The number of bytes of stack that were scanned last GC cycle. |
| go_gc_scan_total_bytes |
gauge |
ins, instance, ip, job, cls |
The total amount space that is scannable. Sum of all metrics in /gc/scan. |
| go_gc_stack_starting_size_bytes |
gauge |
ins, instance, ip, job, cls |
The stack size of new goroutines. |
| go_godebug_non_default_behavior_execerrdot_events_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_godebug_non_default_behavior_gocachehash_events_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_godebug_non_default_behavior_gocachetest_events_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_godebug_non_default_behavior_gocacheverify_events_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_godebug_non_default_behavior_http2client_events_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_godebug_non_default_behavior_http2server_events_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_godebug_non_default_behavior_installgoroot_events_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_godebug_non_default_behavior_jstmpllitinterp_events_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_godebug_non_default_behavior_multipartmaxheaders_events_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_godebug_non_default_behavior_multipartmaxparts_events_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_godebug_non_default_behavior_multipathtcp_events_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_godebug_non_default_behavior_panicnil_events_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_godebug_non_default_behavior_randautoseed_events_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_godebug_non_default_behavior_tarinsecurepath_events_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_godebug_non_default_behavior_tlsmaxrsasize_events_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_godebug_non_default_behavior_x509sha1_events_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_godebug_non_default_behavior_x509usefallbackroots_events_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_godebug_non_default_behavior_zipinsecurepath_events_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_goroutines |
gauge |
ins, instance, ip, job, cls |
Number of goroutines that currently exist. |
| go_info |
gauge |
version, ins, instance, ip, job, cls |
Information about the Go environment. |
| go_memory_classes_heap_free_bytes |
gauge |
ins, instance, ip, job, cls |
Memory that is completely free and eligible to be returned to the underlying system, but has not been. This metric is the runtime’s estimate of free address space that is backed by physical memory. |
| go_memory_classes_heap_objects_bytes |
gauge |
ins, instance, ip, job, cls |
Memory occupied by live objects and dead objects that have not yet been marked free by the garbage collector. |
| go_memory_classes_heap_released_bytes |
gauge |
ins, instance, ip, job, cls |
Memory that is completely free and has been returned to the underlying system. This metric is the runtime’s estimate of free address space that is still mapped into the process, but is not backed by physical memory. |
| go_memory_classes_heap_stacks_bytes |
gauge |
ins, instance, ip, job, cls |
Memory allocated from the heap that is reserved for stack space, whether or not it is currently in-use. Currently, this represents all stack memory for goroutines. It also includes all OS thread stacks in non-cgo programs. Note that stacks may be allocated differently in the future, and this may change. |
| go_memory_classes_heap_unused_bytes |
gauge |
ins, instance, ip, job, cls |
Memory that is reserved for heap objects but is not currently used to hold heap objects. |
| go_memory_classes_metadata_mcache_free_bytes |
gauge |
ins, instance, ip, job, cls |
Memory that is reserved for runtime mcache structures, but not in-use. |
| go_memory_classes_metadata_mcache_inuse_bytes |
gauge |
ins, instance, ip, job, cls |
Memory that is occupied by runtime mcache structures that are currently being used. |
| go_memory_classes_metadata_mspan_free_bytes |
gauge |
ins, instance, ip, job, cls |
Memory that is reserved for runtime mspan structures, but not in-use. |
| go_memory_classes_metadata_mspan_inuse_bytes |
gauge |
ins, instance, ip, job, cls |
Memory that is occupied by runtime mspan structures that are currently being used. |
| go_memory_classes_metadata_other_bytes |
gauge |
ins, instance, ip, job, cls |
Memory that is reserved for or used to hold runtime metadata. |
| go_memory_classes_os_stacks_bytes |
gauge |
ins, instance, ip, job, cls |
Stack memory allocated by the underlying operating system. In non-cgo programs this metric is currently zero. This may change in the future.In cgo programs this metric includes OS thread stacks allocated directly from the OS. Currently, this only accounts for one stack in c-shared and c-archive build modes, and other sources of stacks from the OS are not measured. This too may change in the future. |
| go_memory_classes_other_bytes |
gauge |
ins, instance, ip, job, cls |
Memory used by execution trace buffers, structures for debugging the runtime, finalizer and profiler specials, and more. |
| go_memory_classes_profiling_buckets_bytes |
gauge |
ins, instance, ip, job, cls |
Memory that is used by the stack trace hash map used for profiling. |
| go_memory_classes_total_bytes |
gauge |
ins, instance, ip, job, cls |
All memory mapped by the Go runtime into the current process as read-write. Note that this does not include memory mapped by code called via cgo or via the syscall package. Sum of all metrics in /memory/classes. |
| go_memstats_alloc_bytes |
counter |
ins, instance, ip, job, cls |
Total number of bytes allocated, even if freed. |
| go_memstats_alloc_bytes_total |
counter |
ins, instance, ip, job, cls |
Total number of bytes allocated, even if freed. |
| go_memstats_buck_hash_sys_bytes |
gauge |
ins, instance, ip, job, cls |
Number of bytes used by the profiling bucket hash table. |
| go_memstats_frees_total |
counter |
ins, instance, ip, job, cls |
Total number of frees. |
| go_memstats_gc_sys_bytes |
gauge |
ins, instance, ip, job, cls |
Number of bytes used for garbage collection system metadata. |
| go_memstats_heap_alloc_bytes |
gauge |
ins, instance, ip, job, cls |
Number of heap bytes allocated and still in use. |
| go_memstats_heap_idle_bytes |
gauge |
ins, instance, ip, job, cls |
Number of heap bytes waiting to be used. |
| go_memstats_heap_inuse_bytes |
gauge |
ins, instance, ip, job, cls |
Number of heap bytes that are in use. |
| go_memstats_heap_objects |
gauge |
ins, instance, ip, job, cls |
Number of allocated objects. |
| go_memstats_heap_released_bytes |
gauge |
ins, instance, ip, job, cls |
Number of heap bytes released to OS. |
| go_memstats_heap_sys_bytes |
gauge |
ins, instance, ip, job, cls |
Number of heap bytes obtained from system. |
| go_memstats_last_gc_time_seconds |
gauge |
ins, instance, ip, job, cls |
Number of seconds since 1970 of last garbage collection. |
| go_memstats_lookups_total |
counter |
ins, instance, ip, job, cls |
Total number of pointer lookups. |
| go_memstats_mallocs_total |
counter |
ins, instance, ip, job, cls |
Total number of mallocs. |
| go_memstats_mcache_inuse_bytes |
gauge |
ins, instance, ip, job, cls |
Number of bytes in use by mcache structures. |
| go_memstats_mcache_sys_bytes |
gauge |
ins, instance, ip, job, cls |
Number of bytes used for mcache structures obtained from system. |
| go_memstats_mspan_inuse_bytes |
gauge |
ins, instance, ip, job, cls |
Number of bytes in use by mspan structures. |
| go_memstats_mspan_sys_bytes |
gauge |
ins, instance, ip, job, cls |
Number of bytes used for mspan structures obtained from system. |
| go_memstats_next_gc_bytes |
gauge |
ins, instance, ip, job, cls |
Number of heap bytes when next garbage collection will take place. |
| go_memstats_other_sys_bytes |
gauge |
ins, instance, ip, job, cls |
Number of bytes used for other system allocations. |
| go_memstats_stack_inuse_bytes |
gauge |
ins, instance, ip, job, cls |
Number of bytes in use by the stack allocator. |
| go_memstats_stack_sys_bytes |
gauge |
ins, instance, ip, job, cls |
Number of bytes obtained from system for stack allocator. |
| go_memstats_sys_bytes |
gauge |
ins, instance, ip, job, cls |
Number of bytes obtained from system. |
| go_sched_gomaxprocs_threads |
gauge |
ins, instance, ip, job, cls |
The current runtime.GOMAXPROCS setting, or the number of operating system threads that can execute user-level Go code simultaneously. |
| go_sched_goroutines_goroutines |
gauge |
ins, instance, ip, job, cls |
Count of live goroutines. |
| go_sched_latencies_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| go_sched_latencies_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_sched_latencies_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_sql_stats_connections_blocked_seconds |
unknown |
ins, instance, db_name, ip, job, cls |
The total time blocked waiting for a new connection. |
| go_sql_stats_connections_closed_max_idle |
unknown |
ins, instance, db_name, ip, job, cls |
The total number of connections closed due to SetMaxIdleConns. |
| go_sql_stats_connections_closed_max_idle_time |
unknown |
ins, instance, db_name, ip, job, cls |
The total number of connections closed due to SetConnMaxIdleTime. |
| go_sql_stats_connections_closed_max_lifetime |
unknown |
ins, instance, db_name, ip, job, cls |
The total number of connections closed due to SetConnMaxLifetime. |
| go_sql_stats_connections_idle |
gauge |
ins, instance, db_name, ip, job, cls |
The number of idle connections. |
| go_sql_stats_connections_in_use |
gauge |
ins, instance, db_name, ip, job, cls |
The number of connections currently in use. |
| go_sql_stats_connections_max_open |
gauge |
ins, instance, db_name, ip, job, cls |
Maximum number of open connections to the database. |
| go_sql_stats_connections_open |
gauge |
ins, instance, db_name, ip, job, cls |
The number of established connections both in use and idle. |
| go_sql_stats_connections_waited_for |
unknown |
ins, instance, db_name, ip, job, cls |
The total number of connections waited for. |
| go_sync_mutex_wait_total_seconds_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| go_threads |
gauge |
ins, instance, ip, job, cls |
Number of OS threads created. |
| grafana_access_evaluation_count |
unknown |
ins, instance, ip, job, cls |
number of evaluation calls |
| grafana_access_evaluation_duration_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| grafana_access_evaluation_duration_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_access_evaluation_duration_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_access_permissions_duration_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| grafana_access_permissions_duration_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_access_permissions_duration_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_aggregator_discovery_aggregation_count_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_active_alerts |
gauge |
ins, instance, ip, job, cls |
amount of active alerts |
| grafana_alerting_active_configurations |
gauge |
ins, instance, ip, job, cls |
The number of active Alertmanager configurations. |
| grafana_alerting_alertmanager_config_match |
gauge |
ins, instance, ip, job, cls |
The total number of match |
| grafana_alerting_alertmanager_config_match_re |
gauge |
ins, instance, ip, job, cls |
The total number of matchRE |
| grafana_alerting_alertmanager_config_matchers |
gauge |
ins, instance, ip, job, cls |
The total number of matchers |
| grafana_alerting_alertmanager_config_object_matchers |
gauge |
ins, instance, ip, job, cls |
The total number of object_matchers |
| grafana_alerting_discovered_configurations |
gauge |
ins, instance, ip, job, cls |
The number of organizations we’ve discovered that require an Alertmanager configuration. |
| grafana_alerting_dispatcher_aggregation_groups |
gauge |
ins, instance, ip, job, cls |
Number of active aggregation groups |
| grafana_alerting_dispatcher_alert_processing_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_dispatcher_alert_processing_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_execution_time_milliseconds |
summary |
ins, instance, ip, job, cls, quantile |
summary of alert execution duration |
| grafana_alerting_execution_time_milliseconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_execution_time_milliseconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_nflog_gc_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_nflog_gc_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_nflog_gossip_messages_propagated_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_nflog_queries_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_nflog_query_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| grafana_alerting_nflog_query_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_nflog_query_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_nflog_query_errors_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_nflog_snapshot_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_nflog_snapshot_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_nflog_snapshot_size_bytes |
gauge |
ins, instance, ip, job, cls |
Size of the last notification log snapshot in bytes. |
| grafana_alerting_notification_latency_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| grafana_alerting_notification_latency_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_notification_latency_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_schedule_alert_rules |
gauge |
ins, instance, ip, job, cls |
The number of alert rules that could be considered for evaluation at the next tick. |
| grafana_alerting_schedule_alert_rules_hash |
gauge |
ins, instance, ip, job, cls |
A hash of the alert rules that could be considered for evaluation at the next tick. |
| grafana_alerting_schedule_periodic_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| grafana_alerting_schedule_periodic_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_schedule_periodic_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_schedule_query_alert_rules_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| grafana_alerting_schedule_query_alert_rules_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_schedule_query_alert_rules_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_scheduler_behind_seconds |
gauge |
ins, instance, ip, job, cls |
The total number of seconds the scheduler is behind. |
| grafana_alerting_silences_gc_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_silences_gc_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_silences_gossip_messages_propagated_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_silences_queries_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_silences_query_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| grafana_alerting_silences_query_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_silences_query_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_silences_query_errors_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_silences_snapshot_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_silences_snapshot_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_silences_snapshot_size_bytes |
gauge |
ins, instance, ip, job, cls |
Size of the last silence snapshot in bytes. |
| grafana_alerting_state_calculation_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| grafana_alerting_state_calculation_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_state_calculation_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_state_history_writes_bytes_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_alerting_ticker_interval_seconds |
gauge |
ins, instance, ip, job, cls |
Interval at which the ticker is meant to tick. |
| grafana_alerting_ticker_last_consumed_tick_timestamp_seconds |
gauge |
ins, instance, ip, job, cls |
Timestamp of the last consumed tick in seconds. |
| grafana_alerting_ticker_next_tick_timestamp_seconds |
gauge |
ins, instance, ip, job, cls |
Timestamp of the next tick in seconds before it is consumed. |
| grafana_api_admin_user_created_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_api_dashboard_get_milliseconds |
summary |
ins, instance, ip, job, cls, quantile |
summary for dashboard get duration |
| grafana_api_dashboard_get_milliseconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_api_dashboard_get_milliseconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_api_dashboard_save_milliseconds |
summary |
ins, instance, ip, job, cls, quantile |
summary for dashboard save duration |
| grafana_api_dashboard_save_milliseconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_api_dashboard_save_milliseconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_api_dashboard_search_milliseconds |
summary |
ins, instance, ip, job, cls, quantile |
summary for dashboard search duration |
| grafana_api_dashboard_search_milliseconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_api_dashboard_search_milliseconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_api_dashboard_snapshot_create_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_api_dashboard_snapshot_external_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_api_dashboard_snapshot_get_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_api_dataproxy_request_all_milliseconds |
summary |
ins, instance, ip, job, cls, quantile |
summary for dataproxy request duration |
| grafana_api_dataproxy_request_all_milliseconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_api_dataproxy_request_all_milliseconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_api_login_oauth_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_api_login_post_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_api_login_saml_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_api_models_dashboard_insert_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_api_org_create_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_api_response_status_total |
Unknown |
ins, instance, ip, job, cls, code |
N/A |
| grafana_api_user_signup_completed_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_api_user_signup_invite_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_api_user_signup_started_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_apiserver_audit_event_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_apiserver_audit_requests_rejected_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_apiserver_client_certificate_expiration_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| grafana_apiserver_client_certificate_expiration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_apiserver_client_certificate_expiration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_apiserver_envelope_encryption_dek_cache_fill_percent |
gauge |
ins, instance, ip, job, cls |
[ALPHA] Percent of the cache slots currently occupied by cached DEKs. |
| grafana_apiserver_flowcontrol_seat_fair_frac |
gauge |
ins, instance, ip, job, cls |
[ALPHA] Fair fraction of server’s concurrency to allocate to each priority level that can use it |
| grafana_apiserver_storage_data_key_generation_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| grafana_apiserver_storage_data_key_generation_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_apiserver_storage_data_key_generation_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_apiserver_storage_data_key_generation_failures_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_apiserver_storage_envelope_transformation_cache_misses_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_apiserver_tls_handshake_errors_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_apiserver_webhooks_x509_insecure_sha1_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_apiserver_webhooks_x509_missing_san_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_authn_authn_failed_authentication_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_authn_authn_successful_authentication_total |
Unknown |
ins, instance, ip, client, job, cls |
N/A |
| grafana_authn_authn_successful_login_total |
Unknown |
ins, instance, ip, client, job, cls |
N/A |
| grafana_aws_cloudwatch_get_metric_data_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_aws_cloudwatch_get_metric_statistics_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_aws_cloudwatch_list_metrics_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_build_info |
gauge |
revision, version, ins, instance, edition, ip, goversion, job, cls, branch |
A metric with a constant ‘1’ value labeled by version, revision, branch, and goversion from which Grafana was built |
| grafana_build_timestamp |
gauge |
revision, version, ins, instance, edition, ip, goversion, job, cls, branch |
A metric exposing when the binary was built in epoch |
| grafana_cardinality_enforcement_unexpected_categorizations_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_database_conn_idle |
gauge |
ins, instance, ip, job, cls |
The number of idle connections |
| grafana_database_conn_in_use |
gauge |
ins, instance, ip, job, cls |
The number of connections currently in use |
| grafana_database_conn_max_idle_closed_seconds |
unknown |
ins, instance, ip, job, cls |
The total number of connections closed due to SetConnMaxIdleTime |
| grafana_database_conn_max_idle_closed_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_database_conn_max_lifetime_closed_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_database_conn_max_open |
gauge |
ins, instance, ip, job, cls |
Maximum number of open connections to the database |
| grafana_database_conn_open |
gauge |
ins, instance, ip, job, cls |
The number of established connections both in use and idle |
| grafana_database_conn_wait_count_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_database_conn_wait_duration_seconds |
unknown |
ins, instance, ip, job, cls |
The total time blocked waiting for a new connection |
| grafana_datasource_request_duration_seconds_bucket |
Unknown |
datasource, ins, instance, method, ip, le, datasource_type, job, cls, code |
N/A |
| grafana_datasource_request_duration_seconds_count |
Unknown |
datasource, ins, instance, method, ip, datasource_type, job, cls, code |
N/A |
| grafana_datasource_request_duration_seconds_sum |
Unknown |
datasource, ins, instance, method, ip, datasource_type, job, cls, code |
N/A |
| grafana_datasource_request_in_flight |
gauge |
datasource, ins, instance, ip, datasource_type, job, cls |
A gauge of outgoing data source requests currently being sent by Grafana |
| grafana_datasource_request_total |
Unknown |
datasource, ins, instance, method, ip, datasource_type, job, cls, code |
N/A |
| grafana_datasource_response_size_bytes_bucket |
Unknown |
datasource, ins, instance, ip, le, datasource_type, job, cls |
N/A |
| grafana_datasource_response_size_bytes_count |
Unknown |
datasource, ins, instance, ip, datasource_type, job, cls |
N/A |
| grafana_datasource_response_size_bytes_sum |
Unknown |
datasource, ins, instance, ip, datasource_type, job, cls |
N/A |
| grafana_db_datasource_query_by_id_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_disabled_metrics_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_emails_sent_failed |
unknown |
ins, instance, ip, job, cls |
Number of emails Grafana failed to send |
| grafana_emails_sent_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_encryption_cache_reads_total |
Unknown |
ins, instance, method, ip, hit, job, cls |
N/A |
| grafana_encryption_ops_total |
Unknown |
ins, instance, ip, success, operation, job, cls |
N/A |
| grafana_environment_info |
gauge |
version, ins, instance, ip, job, cls, commit |
A metric with a constant ‘1’ value labeled by environment information about the running instance. |
| grafana_feature_toggles_info |
gauge |
ins, instance, ip, job, cls |
info metric that exposes what feature toggles are enabled or not |
| grafana_frontend_boot_css_time_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| grafana_frontend_boot_css_time_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_frontend_boot_css_time_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_frontend_boot_first_contentful_paint_time_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| grafana_frontend_boot_first_contentful_paint_time_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_frontend_boot_first_contentful_paint_time_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_frontend_boot_first_paint_time_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| grafana_frontend_boot_first_paint_time_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_frontend_boot_first_paint_time_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_frontend_boot_js_done_time_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| grafana_frontend_boot_js_done_time_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_frontend_boot_js_done_time_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_frontend_boot_load_time_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| grafana_frontend_boot_load_time_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_frontend_boot_load_time_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_frontend_plugins_preload_ms_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| grafana_frontend_plugins_preload_ms_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_frontend_plugins_preload_ms_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_hidden_metrics_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_http_request_duration_seconds_bucket |
Unknown |
ins, instance, method, ip, le, job, cls, status_code, handler |
N/A |
| grafana_http_request_duration_seconds_count |
Unknown |
ins, instance, method, ip, job, cls, status_code, handler |
N/A |
| grafana_http_request_duration_seconds_sum |
Unknown |
ins, instance, method, ip, job, cls, status_code, handler |
N/A |
| grafana_http_request_in_flight |
gauge |
ins, instance, ip, job, cls |
A gauge of requests currently being served by Grafana. |
| grafana_idforwarding_idforwarding_failed_token_signing_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_idforwarding_idforwarding_token_signing_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| grafana_idforwarding_idforwarding_token_signing_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_idforwarding_idforwarding_token_signing_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_idforwarding_idforwarding_token_signing_from_cache_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_idforwarding_idforwarding_token_signing_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_instance_start_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_ldap_users_sync_execution_time |
summary |
ins, instance, ip, job, cls, quantile |
summary for LDAP users sync execution duration |
| grafana_ldap_users_sync_execution_time_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_ldap_users_sync_execution_time_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_live_client_command_duration_seconds |
summary |
ins, instance, method, ip, job, cls, quantile |
Client command duration summary. |
| grafana_live_client_command_duration_seconds_count |
Unknown |
ins, instance, method, ip, job, cls |
N/A |
| grafana_live_client_command_duration_seconds_sum |
Unknown |
ins, instance, method, ip, job, cls |
N/A |
| grafana_live_client_num_reply_errors |
unknown |
ins, instance, method, ip, job, cls, code |
Number of errors in replies sent to clients. |
| grafana_live_client_num_server_disconnects |
unknown |
ins, instance, ip, job, cls, code |
Number of server initiated disconnects. |
| grafana_live_client_recover |
unknown |
ins, instance, ip, recovered, job, cls |
Count of recover operations. |
| grafana_live_node_action_count |
unknown |
action, ins, instance, ip, job, cls |
Number of node actions called. |
| grafana_live_node_build |
gauge |
version, ins, instance, ip, job, cls |
Node build info. |
| grafana_live_node_messages_received_count |
unknown |
ins, instance, ip, type, job, cls |
Number of messages received. |
| grafana_live_node_messages_sent_count |
unknown |
ins, instance, ip, type, job, cls |
Number of messages sent. |
| grafana_live_node_num_channels |
gauge |
ins, instance, ip, job, cls |
Number of channels with one or more subscribers. |
| grafana_live_node_num_clients |
gauge |
ins, instance, ip, job, cls |
Number of clients connected. |
| grafana_live_node_num_nodes |
gauge |
ins, instance, ip, job, cls |
Number of nodes in cluster. |
| grafana_live_node_num_subscriptions |
gauge |
ins, instance, ip, job, cls |
Number of subscriptions. |
| grafana_live_node_num_users |
gauge |
ins, instance, ip, job, cls |
Number of unique users connected. |
| grafana_live_transport_connect_count |
unknown |
ins, instance, ip, transport, job, cls |
Number of connections to specific transport. |
| grafana_live_transport_messages_sent |
unknown |
ins, instance, ip, transport, job, cls |
Number of messages sent over specific transport. |
| grafana_loki_plugin_parse_response_duration_seconds_bucket |
Unknown |
endpoint, ins, instance, ip, le, status, job, cls |
N/A |
| grafana_loki_plugin_parse_response_duration_seconds_count |
Unknown |
endpoint, ins, instance, ip, status, job, cls |
N/A |
| grafana_loki_plugin_parse_response_duration_seconds_sum |
Unknown |
endpoint, ins, instance, ip, status, job, cls |
N/A |
| grafana_page_response_status_total |
Unknown |
ins, instance, ip, job, cls, code |
N/A |
| grafana_plugin_build_info |
gauge |
version, signature_status, ins, instance, plugin_type, ip, plugin_id, job, cls |
A metric with a constant ‘1’ value labeled by pluginId, pluginType and version from which Grafana plugin was built |
| grafana_plugin_request_duration_milliseconds_bucket |
Unknown |
endpoint, ins, instance, target, ip, le, plugin_id, job, cls |
N/A |
| grafana_plugin_request_duration_milliseconds_count |
Unknown |
endpoint, ins, instance, target, ip, plugin_id, job, cls |
N/A |
| grafana_plugin_request_duration_milliseconds_sum |
Unknown |
endpoint, ins, instance, target, ip, plugin_id, job, cls |
N/A |
| grafana_plugin_request_duration_seconds_bucket |
Unknown |
endpoint, ins, instance, target, ip, le, status, plugin_id, source, job, cls |
N/A |
| grafana_plugin_request_duration_seconds_count |
Unknown |
endpoint, ins, instance, target, ip, status, plugin_id, source, job, cls |
N/A |
| grafana_plugin_request_duration_seconds_sum |
Unknown |
endpoint, ins, instance, target, ip, status, plugin_id, source, job, cls |
N/A |
| grafana_plugin_request_size_bytes_bucket |
Unknown |
endpoint, ins, instance, target, ip, le, plugin_id, source, job, cls |
N/A |
| grafana_plugin_request_size_bytes_count |
Unknown |
endpoint, ins, instance, target, ip, plugin_id, source, job, cls |
N/A |
| grafana_plugin_request_size_bytes_sum |
Unknown |
endpoint, ins, instance, target, ip, plugin_id, source, job, cls |
N/A |
| grafana_plugin_request_total |
Unknown |
endpoint, ins, instance, target, ip, status, plugin_id, job, cls |
N/A |
| grafana_process_cpu_seconds_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_process_max_fds |
gauge |
ins, instance, ip, job, cls |
Maximum number of open file descriptors. |
| grafana_process_open_fds |
gauge |
ins, instance, ip, job, cls |
Number of open file descriptors. |
| grafana_process_resident_memory_bytes |
gauge |
ins, instance, ip, job, cls |
Resident memory size in bytes. |
| grafana_process_start_time_seconds |
gauge |
ins, instance, ip, job, cls |
Start time of the process since unix epoch in seconds. |
| grafana_process_virtual_memory_bytes |
gauge |
ins, instance, ip, job, cls |
Virtual memory size in bytes. |
| grafana_process_virtual_memory_max_bytes |
gauge |
ins, instance, ip, job, cls |
Maximum amount of virtual memory available in bytes. |
| grafana_prometheus_plugin_backend_request_count |
unknown |
endpoint, ins, instance, ip, status, errorSource, job, cls |
The total amount of prometheus backend plugin requests |
| grafana_proxy_response_status_total |
Unknown |
ins, instance, ip, job, cls, code |
N/A |
| grafana_public_dashboard_request_count |
unknown |
ins, instance, ip, job, cls |
counter for public dashboards requests |
| grafana_registered_metrics_total |
Unknown |
ins, instance, ip, stability_level, deprecated_version, job, cls |
N/A |
| grafana_rendering_queue_size |
gauge |
ins, instance, ip, job, cls |
size of rendering queue |
| grafana_search_dashboard_search_failures_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| grafana_search_dashboard_search_failures_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_search_dashboard_search_failures_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_search_dashboard_search_successes_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| grafana_search_dashboard_search_successes_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_search_dashboard_search_successes_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| grafana_stat_active_users |
gauge |
ins, instance, ip, job, cls |
number of active users |
| grafana_stat_total_orgs |
gauge |
ins, instance, ip, job, cls |
total amount of orgs |
| grafana_stat_total_playlists |
gauge |
ins, instance, ip, job, cls |
total amount of playlists |
| grafana_stat_total_service_account_tokens |
gauge |
ins, instance, ip, job, cls |
total amount of service account tokens |
| grafana_stat_total_service_accounts |
gauge |
ins, instance, ip, job, cls |
total amount of service accounts |
| grafana_stat_total_service_accounts_role_none |
gauge |
ins, instance, ip, job, cls |
total amount of service accounts with no role |
| grafana_stat_total_teams |
gauge |
ins, instance, ip, job, cls |
total amount of teams |
| grafana_stat_total_users |
gauge |
ins, instance, ip, job, cls |
total amount of users |
| grafana_stat_totals_active_admins |
gauge |
ins, instance, ip, job, cls |
total amount of active admins |
| grafana_stat_totals_active_editors |
gauge |
ins, instance, ip, job, cls |
total amount of active editors |
| grafana_stat_totals_active_viewers |
gauge |
ins, instance, ip, job, cls |
total amount of active viewers |
| grafana_stat_totals_admins |
gauge |
ins, instance, ip, job, cls |
total amount of admins |
| grafana_stat_totals_alert_rules |
gauge |
ins, instance, ip, job, cls |
total amount of alert rules in the database |
| grafana_stat_totals_annotations |
gauge |
ins, instance, ip, job, cls |
total amount of annotations in the database |
| grafana_stat_totals_correlations |
gauge |
ins, instance, ip, job, cls |
total amount of correlations |
| grafana_stat_totals_dashboard |
gauge |
ins, instance, ip, job, cls |
total amount of dashboards |
| grafana_stat_totals_dashboard_versions |
gauge |
ins, instance, ip, job, cls |
total amount of dashboard versions in the database |
| grafana_stat_totals_data_keys |
gauge |
ins, instance, ip, job, cls, active |
total amount of data keys in the database |
| grafana_stat_totals_datasource |
gauge |
ins, instance, ip, plugin_id, job, cls |
total number of defined datasources, labeled by pluginId |
| grafana_stat_totals_editors |
gauge |
ins, instance, ip, job, cls |
total amount of editors |
| grafana_stat_totals_folder |
gauge |
ins, instance, ip, job, cls |
total amount of folders |
| grafana_stat_totals_library_panels |
gauge |
ins, instance, ip, job, cls |
total amount of library panels in the database |
| grafana_stat_totals_library_variables |
gauge |
ins, instance, ip, job, cls |
total amount of library variables in the database |
| grafana_stat_totals_public_dashboard |
gauge |
ins, instance, ip, job, cls |
total amount of public dashboards |
| grafana_stat_totals_rule_groups |
gauge |
ins, instance, ip, job, cls |
total amount of alert rule groups in the database |
| grafana_stat_totals_viewers |
gauge |
ins, instance, ip, job, cls |
total amount of viewers |
| infra_up |
Unknown |
ins, instance, ip, job, cls |
N/A |
| jaeger_tracer_baggage_restrictions_updates_total |
Unknown |
result, ins, instance, ip, job, cls |
N/A |
| jaeger_tracer_baggage_truncations_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| jaeger_tracer_baggage_updates_total |
Unknown |
result, ins, instance, ip, job, cls |
N/A |
| jaeger_tracer_finished_spans_total |
Unknown |
ins, instance, ip, sampled, job, cls |
N/A |
| jaeger_tracer_reporter_queue_length |
gauge |
ins, instance, ip, job, cls |
Current number of spans in the reporter queue |
| jaeger_tracer_reporter_spans_total |
Unknown |
result, ins, instance, ip, job, cls |
N/A |
| jaeger_tracer_sampler_queries_total |
Unknown |
result, ins, instance, ip, job, cls |
N/A |
| jaeger_tracer_sampler_updates_total |
Unknown |
result, ins, instance, ip, job, cls |
N/A |
| jaeger_tracer_span_context_decoding_errors_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| jaeger_tracer_started_spans_total |
Unknown |
ins, instance, ip, sampled, job, cls |
N/A |
| jaeger_tracer_throttled_debug_spans_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| jaeger_tracer_throttler_updates_total |
Unknown |
result, ins, instance, ip, job, cls |
N/A |
| jaeger_tracer_traces_total |
Unknown |
ins, instance, ip, sampled, job, cls, state |
N/A |
| kv_request_duration_seconds_bucket |
Unknown |
ins, instance, role, ip, le, kv_name, type, operation, job, cls, status_code |
N/A |
| kv_request_duration_seconds_count |
Unknown |
ins, instance, role, ip, kv_name, type, operation, job, cls, status_code |
N/A |
| kv_request_duration_seconds_sum |
Unknown |
ins, instance, role, ip, kv_name, type, operation, job, cls, status_code |
N/A |
| legacy_grafana_alerting_ticker_interval_seconds |
gauge |
ins, instance, ip, job, cls |
Interval at which the ticker is meant to tick. |
| legacy_grafana_alerting_ticker_last_consumed_tick_timestamp_seconds |
gauge |
ins, instance, ip, job, cls |
Timestamp of the last consumed tick in seconds. |
| legacy_grafana_alerting_ticker_next_tick_timestamp_seconds |
gauge |
ins, instance, ip, job, cls |
Timestamp of the next tick in seconds before it is consumed. |
| logql_query_duration_seconds_bucket |
Unknown |
ins, instance, query_type, ip, le, job, cls |
N/A |
| logql_query_duration_seconds_count |
Unknown |
ins, instance, query_type, ip, job, cls |
N/A |
| logql_query_duration_seconds_sum |
Unknown |
ins, instance, query_type, ip, job, cls |
N/A |
| loki_azure_blob_egress_bytes_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_boltdb_shipper_apply_retention_last_successful_run_timestamp_seconds |
gauge |
ins, instance, ip, job, cls |
Unix timestamp of the last successful retention run |
| loki_boltdb_shipper_compact_tables_operation_duration_seconds |
gauge |
ins, instance, ip, job, cls |
Time (in seconds) spent in compacting all the tables |
| loki_boltdb_shipper_compact_tables_operation_last_successful_run_timestamp_seconds |
gauge |
ins, instance, ip, job, cls |
Unix timestamp of the last successful compaction run |
| loki_boltdb_shipper_compact_tables_operation_total |
Unknown |
ins, instance, ip, status, job, cls |
N/A |
| loki_boltdb_shipper_compactor_running |
gauge |
ins, instance, ip, job, cls |
Value will be 1 if compactor is currently running on this instance |
| loki_boltdb_shipper_open_existing_file_failures_total |
Unknown |
ins, instance, ip, component, job, cls |
N/A |
| loki_boltdb_shipper_query_time_table_download_duration_seconds |
unknown |
ins, instance, ip, component, job, cls, table |
Time (in seconds) spent in downloading of files per table at query time |
| loki_boltdb_shipper_request_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, component, operation, job, cls, status_code |
N/A |
| loki_boltdb_shipper_request_duration_seconds_count |
Unknown |
ins, instance, ip, component, operation, job, cls, status_code |
N/A |
| loki_boltdb_shipper_request_duration_seconds_sum |
Unknown |
ins, instance, ip, component, operation, job, cls, status_code |
N/A |
| loki_boltdb_shipper_tables_download_operation_duration_seconds |
gauge |
ins, instance, ip, component, job, cls |
Time (in seconds) spent in downloading updated files for all the tables |
| loki_boltdb_shipper_tables_sync_operation_total |
Unknown |
ins, instance, ip, status, component, job, cls |
N/A |
| loki_boltdb_shipper_tables_upload_operation_total |
Unknown |
ins, instance, ip, status, component, job, cls |
N/A |
| loki_build_info |
gauge |
revision, version, ins, instance, ip, tags, goarch, goversion, job, cls, branch, goos |
A metric with a constant ‘1’ value labeled by version, revision, branch, goversion from which loki was built, and the goos and goarch for the build. |
| loki_bytes_per_line_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| loki_bytes_per_line_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_bytes_per_line_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_cache_corrupt_chunks_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_cache_fetched_keys |
unknown |
ins, instance, ip, job, cls |
Total count of keys requested from cache. |
| loki_cache_hits |
unknown |
ins, instance, ip, job, cls |
Total count of keys found in cache. |
| loki_cache_request_duration_seconds_bucket |
Unknown |
ins, instance, method, ip, le, job, cls, status_code |
N/A |
| loki_cache_request_duration_seconds_count |
Unknown |
ins, instance, method, ip, job, cls, status_code |
N/A |
| loki_cache_request_duration_seconds_sum |
Unknown |
ins, instance, method, ip, job, cls, status_code |
N/A |
| loki_cache_value_size_bytes_bucket |
Unknown |
ins, instance, method, ip, le, job, cls |
N/A |
| loki_cache_value_size_bytes_count |
Unknown |
ins, instance, method, ip, job, cls |
N/A |
| loki_cache_value_size_bytes_sum |
Unknown |
ins, instance, method, ip, job, cls |
N/A |
| loki_chunk_fetcher_cache_dequeued_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_chunk_fetcher_cache_enqueued_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_chunk_fetcher_cache_skipped_buffer_full_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_chunk_fetcher_fetched_size_bytes_bucket |
Unknown |
ins, instance, ip, le, source, job, cls |
N/A |
| loki_chunk_fetcher_fetched_size_bytes_count |
Unknown |
ins, instance, ip, source, job, cls |
N/A |
| loki_chunk_fetcher_fetched_size_bytes_sum |
Unknown |
ins, instance, ip, source, job, cls |
N/A |
| loki_chunk_store_chunks_per_query_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| loki_chunk_store_chunks_per_query_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_chunk_store_chunks_per_query_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_chunk_store_deduped_bytes_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_chunk_store_deduped_chunks_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_chunk_store_fetched_chunk_bytes_total |
Unknown |
ins, instance, ip, user, job, cls |
N/A |
| loki_chunk_store_fetched_chunks_total |
Unknown |
ins, instance, ip, user, job, cls |
N/A |
| loki_chunk_store_index_entries_per_chunk_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| loki_chunk_store_index_entries_per_chunk_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_chunk_store_index_entries_per_chunk_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_chunk_store_index_lookups_per_query_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| loki_chunk_store_index_lookups_per_query_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_chunk_store_index_lookups_per_query_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_chunk_store_series_post_intersection_per_query_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| loki_chunk_store_series_post_intersection_per_query_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_chunk_store_series_post_intersection_per_query_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_chunk_store_series_pre_intersection_per_query_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| loki_chunk_store_series_pre_intersection_per_query_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_chunk_store_series_pre_intersection_per_query_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_chunk_store_stored_chunk_bytes_total |
Unknown |
ins, instance, ip, user, job, cls |
N/A |
| loki_chunk_store_stored_chunks_total |
Unknown |
ins, instance, ip, user, job, cls |
N/A |
| loki_consul_request_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, kv_name, operation, job, cls, status_code |
N/A |
| loki_consul_request_duration_seconds_count |
Unknown |
ins, instance, ip, kv_name, operation, job, cls, status_code |
N/A |
| loki_consul_request_duration_seconds_sum |
Unknown |
ins, instance, ip, kv_name, operation, job, cls, status_code |
N/A |
| loki_delete_request_lookups_failed_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_delete_request_lookups_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_discarded_bytes_total |
Unknown |
ins, instance, ip, reason, job, cls, tenant |
N/A |
| loki_discarded_samples_total |
Unknown |
ins, instance, ip, reason, job, cls, tenant |
N/A |
| loki_distributor_bytes_received_total |
Unknown |
ins, instance, retention_hours, ip, job, cls, tenant |
N/A |
| loki_distributor_ingester_appends_total |
Unknown |
ins, instance, ip, ingester, job, cls |
N/A |
| loki_distributor_lines_received_total |
Unknown |
ins, instance, ip, job, cls, tenant |
N/A |
| loki_distributor_replication_factor |
gauge |
ins, instance, ip, job, cls |
The configured replication factor. |
| loki_distributor_structured_metadata_bytes_received_total |
Unknown |
ins, instance, retention_hours, ip, job, cls, tenant |
N/A |
| loki_experimental_features_in_use_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_index_chunk_refs_total |
Unknown |
ins, instance, ip, status, job, cls |
N/A |
| loki_index_request_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, component, operation, job, cls, status_code |
N/A |
| loki_index_request_duration_seconds_count |
Unknown |
ins, instance, ip, component, operation, job, cls, status_code |
N/A |
| loki_index_request_duration_seconds_sum |
Unknown |
ins, instance, ip, component, operation, job, cls, status_code |
N/A |
| loki_inflight_requests |
gauge |
ins, instance, method, ip, route, job, cls |
Current number of inflight requests. |
| loki_ingester_autoforget_unhealthy_ingesters_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_blocks_per_chunk_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| loki_ingester_blocks_per_chunk_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_blocks_per_chunk_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_checkpoint_creations_failed_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_checkpoint_creations_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_checkpoint_deletions_failed_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_checkpoint_deletions_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_checkpoint_duration_seconds |
summary |
ins, instance, ip, job, cls, quantile |
Time taken to create a checkpoint. |
| loki_ingester_checkpoint_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_checkpoint_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_checkpoint_logged_bytes_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_chunk_age_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| loki_ingester_chunk_age_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_chunk_age_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_chunk_bounds_hours_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| loki_ingester_chunk_bounds_hours_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_chunk_bounds_hours_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_chunk_compression_ratio_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| loki_ingester_chunk_compression_ratio_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_chunk_compression_ratio_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_chunk_encode_time_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| loki_ingester_chunk_encode_time_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_chunk_encode_time_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_chunk_entries_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| loki_ingester_chunk_entries_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_chunk_entries_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_chunk_size_bytes_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| loki_ingester_chunk_size_bytes_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_chunk_size_bytes_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_chunk_stored_bytes_total |
Unknown |
ins, instance, ip, job, cls, tenant |
N/A |
| loki_ingester_chunk_utilization_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| loki_ingester_chunk_utilization_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_chunk_utilization_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_chunks_created_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_chunks_flushed_total |
Unknown |
ins, instance, ip, reason, job, cls |
N/A |
| loki_ingester_chunks_stored_total |
Unknown |
ins, instance, ip, job, cls, tenant |
N/A |
| loki_ingester_client_request_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, operation, job, cls, status_code |
N/A |
| loki_ingester_client_request_duration_seconds_count |
Unknown |
ins, instance, ip, operation, job, cls, status_code |
N/A |
| loki_ingester_client_request_duration_seconds_sum |
Unknown |
ins, instance, ip, operation, job, cls, status_code |
N/A |
| loki_ingester_limiter_enabled |
gauge |
ins, instance, ip, job, cls |
Whether the ingester’s limiter is enabled |
| loki_ingester_memory_chunks |
gauge |
ins, instance, ip, job, cls |
The total number of chunks in memory. |
| loki_ingester_memory_streams |
gauge |
ins, instance, ip, job, cls, tenant |
The total number of streams in memory per tenant. |
| loki_ingester_memory_streams_labels_bytes |
gauge |
ins, instance, ip, job, cls |
Total bytes of labels of the streams in memory. |
| loki_ingester_received_chunks |
unknown |
ins, instance, ip, job, cls |
The total number of chunks received by this ingester whilst joining. |
| loki_ingester_samples_per_chunk_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| loki_ingester_samples_per_chunk_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_samples_per_chunk_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_sent_chunks |
unknown |
ins, instance, ip, job, cls |
The total number of chunks sent by this ingester whilst leaving. |
| loki_ingester_shutdown_marker |
gauge |
ins, instance, ip, job, cls |
1 if prepare shutdown has been called, 0 otherwise |
| loki_ingester_streams_created_total |
Unknown |
ins, instance, ip, job, cls, tenant |
N/A |
| loki_ingester_streams_removed_total |
Unknown |
ins, instance, ip, job, cls, tenant |
N/A |
| loki_ingester_wal_bytes_in_use |
gauge |
ins, instance, ip, job, cls |
Total number of bytes in use by the WAL recovery process. |
| loki_ingester_wal_disk_full_failures_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_wal_duplicate_entries_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_wal_logged_bytes_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_wal_records_logged_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_wal_recovered_bytes_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_wal_recovered_chunks_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_wal_recovered_entries_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_wal_recovered_streams_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_ingester_wal_replay_active |
gauge |
ins, instance, ip, job, cls |
Whether the WAL is replaying |
| loki_ingester_wal_replay_duration_seconds |
gauge |
ins, instance, ip, job, cls |
Time taken to replay the checkpoint and the WAL. |
| loki_ingester_wal_replay_flushing |
gauge |
ins, instance, ip, job, cls |
Whether the wal replay is in a flushing phase due to backpressure |
| loki_internal_log_messages_total |
Unknown |
ins, instance, ip, level, job, cls |
N/A |
| loki_kv_request_duration_seconds_bucket |
Unknown |
ins, instance, role, ip, le, kv_name, type, operation, job, cls, status_code |
N/A |
| loki_kv_request_duration_seconds_count |
Unknown |
ins, instance, role, ip, kv_name, type, operation, job, cls, status_code |
N/A |
| loki_kv_request_duration_seconds_sum |
Unknown |
ins, instance, role, ip, kv_name, type, operation, job, cls, status_code |
N/A |
| loki_log_flushes_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| loki_log_flushes_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_log_flushes_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_log_messages_total |
Unknown |
ins, instance, ip, level, job, cls |
N/A |
| loki_logql_querystats_bytes_processed_per_seconds_bucket |
Unknown |
ins, instance, range, ip, le, sharded, type, job, cls, status_code, latency_type |
N/A |
| loki_logql_querystats_bytes_processed_per_seconds_count |
Unknown |
ins, instance, range, ip, sharded, type, job, cls, status_code, latency_type |
N/A |
| loki_logql_querystats_bytes_processed_per_seconds_sum |
Unknown |
ins, instance, range, ip, sharded, type, job, cls, status_code, latency_type |
N/A |
| loki_logql_querystats_chunk_download_latency_seconds_bucket |
Unknown |
ins, instance, range, ip, le, type, job, cls, status_code |
N/A |
| loki_logql_querystats_chunk_download_latency_seconds_count |
Unknown |
ins, instance, range, ip, type, job, cls, status_code |
N/A |
| loki_logql_querystats_chunk_download_latency_seconds_sum |
Unknown |
ins, instance, range, ip, type, job, cls, status_code |
N/A |
| loki_logql_querystats_downloaded_chunk_total |
Unknown |
ins, instance, range, ip, type, job, cls, status_code |
N/A |
| loki_logql_querystats_duplicates_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_logql_querystats_ingester_sent_lines_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_logql_querystats_latency_seconds_bucket |
Unknown |
ins, instance, range, ip, le, type, job, cls, status_code |
N/A |
| loki_logql_querystats_latency_seconds_count |
Unknown |
ins, instance, range, ip, type, job, cls, status_code |
N/A |
| loki_logql_querystats_latency_seconds_sum |
Unknown |
ins, instance, range, ip, type, job, cls, status_code |
N/A |
| loki_panic_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_querier_index_cache_corruptions_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_querier_index_cache_encode_errors_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_querier_index_cache_gets_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_querier_index_cache_hits_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_querier_index_cache_puts_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_querier_query_frontend_clients |
gauge |
ins, instance, ip, job, cls |
The current number of clients connected to query-frontend. |
| loki_querier_query_frontend_request_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, operation, job, cls, status_code |
N/A |
| loki_querier_query_frontend_request_duration_seconds_count |
Unknown |
ins, instance, ip, operation, job, cls, status_code |
N/A |
| loki_querier_query_frontend_request_duration_seconds_sum |
Unknown |
ins, instance, ip, operation, job, cls, status_code |
N/A |
| loki_querier_tail_active |
gauge |
ins, instance, ip, job, cls |
Number of active tailers |
| loki_querier_tail_active_streams |
gauge |
ins, instance, ip, job, cls |
Number of active streams being tailed |
| loki_querier_tail_bytes_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_querier_worker_concurrency |
gauge |
ins, instance, ip, job, cls |
Number of concurrent querier workers |
| loki_querier_worker_inflight_queries |
gauge |
ins, instance, ip, job, cls |
Number of queries being processed by the querier workers |
| loki_query_frontend_log_result_cache_hit_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_query_frontend_log_result_cache_miss_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_query_frontend_partitions_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| loki_query_frontend_partitions_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_query_frontend_partitions_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_query_frontend_shard_factor_bucket |
Unknown |
ins, instance, ip, le, mapper, job, cls |
N/A |
| loki_query_frontend_shard_factor_count |
Unknown |
ins, instance, ip, mapper, job, cls |
N/A |
| loki_query_frontend_shard_factor_sum |
Unknown |
ins, instance, ip, mapper, job, cls |
N/A |
| loki_query_scheduler_enqueue_count |
Unknown |
ins, instance, ip, level, user, job, cls |
N/A |
| loki_rate_store_expired_streams_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_rate_store_max_stream_rate_bytes |
gauge |
ins, instance, ip, job, cls |
The maximum stream rate for any stream reported by ingesters during a sync operation. Sharded Streams are combined. |
| loki_rate_store_max_stream_shards |
gauge |
ins, instance, ip, job, cls |
The number of shards for a single stream reported by ingesters during a sync operation. |
| loki_rate_store_max_unique_stream_rate_bytes |
gauge |
ins, instance, ip, job, cls |
The maximum stream rate for any stream reported by ingesters during a sync operation. Sharded Streams are considered separate. |
| loki_rate_store_stream_rate_bytes_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| loki_rate_store_stream_rate_bytes_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_rate_store_stream_rate_bytes_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_rate_store_stream_shards_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| loki_rate_store_stream_shards_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_rate_store_stream_shards_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_rate_store_streams |
gauge |
ins, instance, ip, job, cls |
The number of unique streams reported by all ingesters. Sharded streams are combined |
| loki_request_duration_seconds_bucket |
Unknown |
ins, instance, method, ip, le, ws, route, job, cls, status_code |
N/A |
| loki_request_duration_seconds_count |
Unknown |
ins, instance, method, ip, ws, route, job, cls, status_code |
N/A |
| loki_request_duration_seconds_sum |
Unknown |
ins, instance, method, ip, ws, route, job, cls, status_code |
N/A |
| loki_request_message_bytes_bucket |
Unknown |
ins, instance, method, ip, le, route, job, cls |
N/A |
| loki_request_message_bytes_count |
Unknown |
ins, instance, method, ip, route, job, cls |
N/A |
| loki_request_message_bytes_sum |
Unknown |
ins, instance, method, ip, route, job, cls |
N/A |
| loki_response_message_bytes_bucket |
Unknown |
ins, instance, method, ip, le, route, job, cls |
N/A |
| loki_response_message_bytes_count |
Unknown |
ins, instance, method, ip, route, job, cls |
N/A |
| loki_response_message_bytes_sum |
Unknown |
ins, instance, method, ip, route, job, cls |
N/A |
| loki_results_cache_version_comparisons_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| loki_store_chunks_downloaded_total |
Unknown |
ins, instance, ip, status, job, cls |
N/A |
| loki_store_chunks_per_batch_bucket |
Unknown |
ins, instance, ip, le, status, job, cls |
N/A |
| loki_store_chunks_per_batch_count |
Unknown |
ins, instance, ip, status, job, cls |
N/A |
| loki_store_chunks_per_batch_sum |
Unknown |
ins, instance, ip, status, job, cls |
N/A |
| loki_store_series_total |
Unknown |
ins, instance, ip, status, job, cls |
N/A |
| loki_stream_sharding_count |
unknown |
ins, instance, ip, job, cls |
Total number of times the distributor has sharded streams |
| loki_tcp_connections |
gauge |
ins, instance, ip, protocol, job, cls |
Current number of accepted TCP connections. |
| loki_tcp_connections_limit |
gauge |
ins, instance, ip, protocol, job, cls |
The max number of TCP connections that can be accepted (0 means no limit). |
| net_conntrack_dialer_conn_attempted_total |
counter |
ins, instance, ip, dialer_name, job, cls |
Total number of connections attempted by the given dialer a given name. |
| net_conntrack_dialer_conn_closed_total |
counter |
ins, instance, ip, dialer_name, job, cls |
Total number of connections closed which originated from the dialer of a given name. |
| net_conntrack_dialer_conn_established_total |
counter |
ins, instance, ip, dialer_name, job, cls |
Total number of connections successfully established by the given dialer a given name. |
| net_conntrack_dialer_conn_failed_total |
counter |
ins, instance, ip, dialer_name, reason, job, cls |
Total number of connections failed to dial by the dialer a given name. |
| net_conntrack_listener_conn_accepted_total |
counter |
ins, instance, ip, listener_name, job, cls |
Total number of connections opened to the listener of a given name. |
| net_conntrack_listener_conn_closed_total |
counter |
ins, instance, ip, listener_name, job, cls |
Total number of connections closed that were made to the listener of a given name. |
| nginx_connections_accepted |
counter |
ins, instance, ip, job, cls |
Accepted client connections |
| nginx_connections_active |
gauge |
ins, instance, ip, job, cls |
Active client connections |
| nginx_connections_handled |
counter |
ins, instance, ip, job, cls |
Handled client connections |
| nginx_connections_reading |
gauge |
ins, instance, ip, job, cls |
Connections where NGINX is reading the request header |
| nginx_connections_waiting |
gauge |
ins, instance, ip, job, cls |
Idle client connections |
| nginx_connections_writing |
gauge |
ins, instance, ip, job, cls |
Connections where NGINX is writing the response back to the client |
| nginx_exporter_build_info |
gauge |
revision, version, ins, instance, ip, tags, goarch, goversion, job, cls, branch, goos |
A metric with a constant ‘1’ value labeled by version, revision, branch, goversion from which nginx_exporter was built, and the goos and goarch for the build. |
| nginx_http_requests_total |
counter |
ins, instance, ip, job, cls |
Total http requests |
| nginx_up |
gauge |
ins, instance, ip, job, cls |
Status of the last metric scrape |
| plugins_active_instances |
gauge |
ins, instance, ip, job, cls |
The number of active plugin instances |
| plugins_datasource_instances_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| process_cpu_seconds_total |
counter |
ins, instance, ip, job, cls |
Total user and system CPU time spent in seconds. |
| process_max_fds |
gauge |
ins, instance, ip, job, cls |
Maximum number of open file descriptors. |
| process_open_fds |
gauge |
ins, instance, ip, job, cls |
Number of open file descriptors. |
| process_resident_memory_bytes |
gauge |
ins, instance, ip, job, cls |
Resident memory size in bytes. |
| process_start_time_seconds |
gauge |
ins, instance, ip, job, cls |
Start time of the process since unix epoch in seconds. |
| process_virtual_memory_bytes |
gauge |
ins, instance, ip, job, cls |
Virtual memory size in bytes. |
| process_virtual_memory_max_bytes |
gauge |
ins, instance, ip, job, cls |
Maximum amount of virtual memory available in bytes. |
| prometheus_api_remote_read_queries |
gauge |
ins, instance, ip, job, cls |
The current number of remote read queries being executed or waiting. |
| prometheus_build_info |
gauge |
revision, version, ins, instance, ip, tags, goarch, goversion, job, cls, branch, goos |
A metric with a constant ‘1’ value labeled by version, revision, branch, goversion from which prometheus was built, and the goos and goarch for the build. |
| prometheus_config_last_reload_success_timestamp_seconds |
gauge |
ins, instance, ip, job, cls |
Timestamp of the last successful configuration reload. |
| prometheus_config_last_reload_successful |
gauge |
ins, instance, ip, job, cls |
Whether the last configuration reload attempt was successful. |
| prometheus_engine_queries |
gauge |
ins, instance, ip, job, cls |
The current number of queries being executed or waiting. |
| prometheus_engine_queries_concurrent_max |
gauge |
ins, instance, ip, job, cls |
The max number of concurrent queries. |
| prometheus_engine_query_duration_seconds |
summary |
ins, instance, ip, job, cls, quantile, slice |
Query timings |
| prometheus_engine_query_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls, slice |
N/A |
| prometheus_engine_query_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls, slice |
N/A |
| prometheus_engine_query_log_enabled |
gauge |
ins, instance, ip, job, cls |
State of the query log. |
| prometheus_engine_query_log_failures_total |
counter |
ins, instance, ip, job, cls |
The number of query log failures. |
| prometheus_engine_query_samples_total |
counter |
ins, instance, ip, job, cls |
The total number of samples loaded by all queries. |
| prometheus_http_request_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls, handler |
N/A |
| prometheus_http_request_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls, handler |
N/A |
| prometheus_http_request_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls, handler |
N/A |
| prometheus_http_requests_total |
counter |
ins, instance, ip, job, cls, code, handler |
Counter of HTTP requests. |
| prometheus_http_response_size_bytes_bucket |
Unknown |
ins, instance, ip, le, job, cls, handler |
N/A |
| prometheus_http_response_size_bytes_count |
Unknown |
ins, instance, ip, job, cls, handler |
N/A |
| prometheus_http_response_size_bytes_sum |
Unknown |
ins, instance, ip, job, cls, handler |
N/A |
| prometheus_notifications_alertmanagers_discovered |
gauge |
ins, instance, ip, job, cls |
The number of alertmanagers discovered and active. |
| prometheus_notifications_dropped_total |
counter |
ins, instance, ip, job, cls |
Total number of alerts dropped due to errors when sending to Alertmanager. |
| prometheus_notifications_errors_total |
counter |
ins, instance, ip, alertmanager, job, cls |
Total number of errors sending alert notifications. |
| prometheus_notifications_latency_seconds |
summary |
ins, instance, ip, alertmanager, job, cls, quantile |
Latency quantiles for sending alert notifications. |
| prometheus_notifications_latency_seconds_count |
Unknown |
ins, instance, ip, alertmanager, job, cls |
N/A |
| prometheus_notifications_latency_seconds_sum |
Unknown |
ins, instance, ip, alertmanager, job, cls |
N/A |
| prometheus_notifications_queue_capacity |
gauge |
ins, instance, ip, job, cls |
The capacity of the alert notifications queue. |
| prometheus_notifications_queue_length |
gauge |
ins, instance, ip, job, cls |
The number of alert notifications in the queue. |
| prometheus_notifications_sent_total |
counter |
ins, instance, ip, alertmanager, job, cls |
Total number of alerts sent. |
| prometheus_ready |
gauge |
ins, instance, ip, job, cls |
Whether Prometheus startup was fully completed and the server is ready for normal operation. |
| prometheus_remote_storage_exemplars_in_total |
counter |
ins, instance, ip, job, cls |
Exemplars in to remote storage, compare to exemplars out for queue managers. |
| prometheus_remote_storage_highest_timestamp_in_seconds |
gauge |
ins, instance, ip, job, cls |
Highest timestamp that has come into the remote storage via the Appender interface, in seconds since epoch. |
| prometheus_remote_storage_histograms_in_total |
counter |
ins, instance, ip, job, cls |
HistogramSamples in to remote storage, compare to histograms out for queue managers. |
| prometheus_remote_storage_samples_in_total |
counter |
ins, instance, ip, job, cls |
Samples in to remote storage, compare to samples out for queue managers. |
| prometheus_remote_storage_string_interner_zero_reference_releases_total |
counter |
ins, instance, ip, job, cls |
The number of times release has been called for strings that are not interned. |
| prometheus_rule_evaluation_duration_seconds |
summary |
ins, instance, ip, job, cls, quantile |
The duration for a rule to execute. |
| prometheus_rule_evaluation_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_rule_evaluation_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_rule_evaluation_failures_total |
counter |
ins, instance, ip, job, cls, rule_group |
The total number of rule evaluation failures. |
| prometheus_rule_evaluations_total |
counter |
ins, instance, ip, job, cls, rule_group |
The total number of rule evaluations. |
| prometheus_rule_group_duration_seconds |
summary |
ins, instance, ip, job, cls, quantile |
The duration of rule group evaluations. |
| prometheus_rule_group_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_rule_group_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_rule_group_interval_seconds |
gauge |
ins, instance, ip, job, cls, rule_group |
The interval of a rule group. |
| prometheus_rule_group_iterations_missed_total |
counter |
ins, instance, ip, job, cls, rule_group |
The total number of rule group evaluations missed due to slow rule group evaluation. |
| prometheus_rule_group_iterations_total |
counter |
ins, instance, ip, job, cls, rule_group |
The total number of scheduled rule group evaluations, whether executed or missed. |
| prometheus_rule_group_last_duration_seconds |
gauge |
ins, instance, ip, job, cls, rule_group |
The duration of the last rule group evaluation. |
| prometheus_rule_group_last_evaluation_samples |
gauge |
ins, instance, ip, job, cls, rule_group |
The number of samples returned during the last rule group evaluation. |
| prometheus_rule_group_last_evaluation_timestamp_seconds |
gauge |
ins, instance, ip, job, cls, rule_group |
The timestamp of the last rule group evaluation in seconds. |
| prometheus_rule_group_rules |
gauge |
ins, instance, ip, job, cls, rule_group |
The number of rules. |
| prometheus_sd_azure_cache_hit_total |
counter |
ins, instance, ip, job, cls |
Number of cache hit during refresh. |
| prometheus_sd_azure_failures_total |
counter |
ins, instance, ip, job, cls |
Number of Azure service discovery refresh failures. |
| prometheus_sd_consul_rpc_duration_seconds |
summary |
endpoint, ins, instance, ip, job, cls, call, quantile |
The duration of a Consul RPC call in seconds. |
| prometheus_sd_consul_rpc_duration_seconds_count |
Unknown |
endpoint, ins, instance, ip, job, cls, call |
N/A |
| prometheus_sd_consul_rpc_duration_seconds_sum |
Unknown |
endpoint, ins, instance, ip, job, cls, call |
N/A |
| prometheus_sd_consul_rpc_failures_total |
counter |
ins, instance, ip, job, cls |
The number of Consul RPC call failures. |
| prometheus_sd_discovered_targets |
gauge |
ins, instance, ip, config, job, cls |
Current number of discovered targets. |
| prometheus_sd_dns_lookup_failures_total |
counter |
ins, instance, ip, job, cls |
The number of DNS-SD lookup failures. |
| prometheus_sd_dns_lookups_total |
counter |
ins, instance, ip, job, cls |
The number of DNS-SD lookups. |
| prometheus_sd_failed_configs |
gauge |
ins, instance, ip, job, cls |
Current number of service discovery configurations that failed to load. |
| prometheus_sd_file_mtime_seconds |
gauge |
ins, instance, ip, filename, job, cls |
Timestamp (mtime) of files read by FileSD. Timestamp is set at read time. |
| prometheus_sd_file_read_errors_total |
counter |
ins, instance, ip, job, cls |
The number of File-SD read errors. |
| prometheus_sd_file_scan_duration_seconds |
summary |
ins, instance, ip, job, cls, quantile |
The duration of the File-SD scan in seconds. |
| prometheus_sd_file_scan_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_sd_file_scan_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_sd_file_watcher_errors_total |
counter |
ins, instance, ip, job, cls |
The number of File-SD errors caused by filesystem watch failures. |
| prometheus_sd_http_failures_total |
counter |
ins, instance, ip, job, cls |
Number of HTTP service discovery refresh failures. |
| prometheus_sd_kubernetes_events_total |
counter |
event, ins, instance, role, ip, job, cls |
The number of Kubernetes events handled. |
| prometheus_sd_kuma_fetch_duration_seconds |
summary |
ins, instance, ip, job, cls, quantile |
The duration of a Kuma MADS fetch call. |
| prometheus_sd_kuma_fetch_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_sd_kuma_fetch_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_sd_kuma_fetch_failures_total |
counter |
ins, instance, ip, job, cls |
The number of Kuma MADS fetch call failures. |
| prometheus_sd_kuma_fetch_skipped_updates_total |
counter |
ins, instance, ip, job, cls |
The number of Kuma MADS fetch calls that result in no updates to the targets. |
| prometheus_sd_linode_failures_total |
counter |
ins, instance, ip, job, cls |
Number of Linode service discovery refresh failures. |
| prometheus_sd_nomad_failures_total |
counter |
ins, instance, ip, job, cls |
Number of nomad service discovery refresh failures. |
| prometheus_sd_received_updates_total |
counter |
ins, instance, ip, job, cls |
Total number of update events received from the SD providers. |
| prometheus_sd_updates_total |
counter |
ins, instance, ip, job, cls |
Total number of update events sent to the SD consumers. |
| prometheus_target_interval_length_seconds |
summary |
ins, instance, interval, ip, job, cls, quantile |
Actual intervals between scrapes. |
| prometheus_target_interval_length_seconds_count |
Unknown |
ins, instance, interval, ip, job, cls |
N/A |
| prometheus_target_interval_length_seconds_sum |
Unknown |
ins, instance, interval, ip, job, cls |
N/A |
| prometheus_target_metadata_cache_bytes |
gauge |
ins, instance, ip, scrape_job, job, cls |
The number of bytes that are currently used for storing metric metadata in the cache |
| prometheus_target_metadata_cache_entries |
gauge |
ins, instance, ip, scrape_job, job, cls |
Total number of metric metadata entries in the cache |
| prometheus_target_scrape_pool_exceeded_label_limits_total |
counter |
ins, instance, ip, job, cls |
Total number of times scrape pools hit the label limits, during sync or config reload. |
| prometheus_target_scrape_pool_exceeded_target_limit_total |
counter |
ins, instance, ip, job, cls |
Total number of times scrape pools hit the target limit, during sync or config reload. |
| prometheus_target_scrape_pool_reloads_failed_total |
counter |
ins, instance, ip, job, cls |
Total number of failed scrape pool reloads. |
| prometheus_target_scrape_pool_reloads_total |
counter |
ins, instance, ip, job, cls |
Total number of scrape pool reloads. |
| prometheus_target_scrape_pool_sync_total |
counter |
ins, instance, ip, scrape_job, job, cls |
Total number of syncs that were executed on a scrape pool. |
| prometheus_target_scrape_pool_target_limit |
gauge |
ins, instance, ip, scrape_job, job, cls |
Maximum number of targets allowed in this scrape pool. |
| prometheus_target_scrape_pool_targets |
gauge |
ins, instance, ip, scrape_job, job, cls |
Current number of targets in this scrape pool. |
| prometheus_target_scrape_pools_failed_total |
counter |
ins, instance, ip, job, cls |
Total number of scrape pool creations that failed. |
| prometheus_target_scrape_pools_total |
counter |
ins, instance, ip, job, cls |
Total number of scrape pool creation attempts. |
| prometheus_target_scrapes_cache_flush_forced_total |
counter |
ins, instance, ip, job, cls |
How many times a scrape cache was flushed due to getting big while scrapes are failing. |
| prometheus_target_scrapes_exceeded_body_size_limit_total |
counter |
ins, instance, ip, job, cls |
Total number of scrapes that hit the body size limit |
| prometheus_target_scrapes_exceeded_native_histogram_bucket_limit_total |
counter |
ins, instance, ip, job, cls |
Total number of scrapes that hit the native histogram bucket limit and were rejected. |
| prometheus_target_scrapes_exceeded_sample_limit_total |
counter |
ins, instance, ip, job, cls |
Total number of scrapes that hit the sample limit and were rejected. |
| prometheus_target_scrapes_exemplar_out_of_order_total |
counter |
ins, instance, ip, job, cls |
Total number of exemplar rejected due to not being out of the expected order. |
| prometheus_target_scrapes_sample_duplicate_timestamp_total |
counter |
ins, instance, ip, job, cls |
Total number of samples rejected due to duplicate timestamps but different values. |
| prometheus_target_scrapes_sample_out_of_bounds_total |
counter |
ins, instance, ip, job, cls |
Total number of samples rejected due to timestamp falling outside of the time bounds. |
| prometheus_target_scrapes_sample_out_of_order_total |
counter |
ins, instance, ip, job, cls |
Total number of samples rejected due to not being out of the expected order. |
| prometheus_target_sync_failed_total |
counter |
ins, instance, ip, scrape_job, job, cls |
Total number of target sync failures. |
| prometheus_target_sync_length_seconds |
summary |
ins, instance, ip, scrape_job, job, cls, quantile |
Actual interval to sync the scrape pool. |
| prometheus_target_sync_length_seconds_count |
Unknown |
ins, instance, ip, scrape_job, job, cls |
N/A |
| prometheus_target_sync_length_seconds_sum |
Unknown |
ins, instance, ip, scrape_job, job, cls |
N/A |
| prometheus_template_text_expansion_failures_total |
counter |
ins, instance, ip, job, cls |
The total number of template text expansion failures. |
| prometheus_template_text_expansions_total |
counter |
ins, instance, ip, job, cls |
The total number of template text expansions. |
| prometheus_treecache_watcher_goroutines |
gauge |
ins, instance, ip, job, cls |
The current number of watcher goroutines. |
| prometheus_treecache_zookeeper_failures_total |
counter |
ins, instance, ip, job, cls |
The total number of ZooKeeper failures. |
| prometheus_tsdb_blocks_loaded |
gauge |
ins, instance, ip, job, cls |
Number of currently loaded data blocks |
| prometheus_tsdb_checkpoint_creations_failed_total |
counter |
ins, instance, ip, job, cls |
Total number of checkpoint creations that failed. |
| prometheus_tsdb_checkpoint_creations_total |
counter |
ins, instance, ip, job, cls |
Total number of checkpoint creations attempted. |
| prometheus_tsdb_checkpoint_deletions_failed_total |
counter |
ins, instance, ip, job, cls |
Total number of checkpoint deletions that failed. |
| prometheus_tsdb_checkpoint_deletions_total |
counter |
ins, instance, ip, job, cls |
Total number of checkpoint deletions attempted. |
| prometheus_tsdb_clean_start |
gauge |
ins, instance, ip, job, cls |
-1: lockfile is disabled. 0: a lockfile from a previous execution was replaced. 1: lockfile creation was clean |
| prometheus_tsdb_compaction_chunk_range_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| prometheus_tsdb_compaction_chunk_range_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_tsdb_compaction_chunk_range_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_tsdb_compaction_chunk_samples_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| prometheus_tsdb_compaction_chunk_samples_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_tsdb_compaction_chunk_samples_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_tsdb_compaction_chunk_size_bytes_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| prometheus_tsdb_compaction_chunk_size_bytes_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_tsdb_compaction_chunk_size_bytes_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_tsdb_compaction_duration_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| prometheus_tsdb_compaction_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_tsdb_compaction_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_tsdb_compaction_populating_block |
gauge |
ins, instance, ip, job, cls |
Set to 1 when a block is currently being written to the disk. |
| prometheus_tsdb_compactions_failed_total |
counter |
ins, instance, ip, job, cls |
Total number of compactions that failed for the partition. |
| prometheus_tsdb_compactions_skipped_total |
counter |
ins, instance, ip, job, cls |
Total number of skipped compactions due to disabled auto compaction. |
| prometheus_tsdb_compactions_total |
counter |
ins, instance, ip, job, cls |
Total number of compactions that were executed for the partition. |
| prometheus_tsdb_compactions_triggered_total |
counter |
ins, instance, ip, job, cls |
Total number of triggered compactions for the partition. |
| prometheus_tsdb_data_replay_duration_seconds |
gauge |
ins, instance, ip, job, cls |
Time taken to replay the data on disk. |
| prometheus_tsdb_exemplar_exemplars_appended_total |
counter |
ins, instance, ip, job, cls |
Total number of appended exemplars. |
| prometheus_tsdb_exemplar_exemplars_in_storage |
gauge |
ins, instance, ip, job, cls |
Number of exemplars currently in circular storage. |
| prometheus_tsdb_exemplar_last_exemplars_timestamp_seconds |
gauge |
ins, instance, ip, job, cls |
The timestamp of the oldest exemplar stored in circular storage. Useful to check for what timerange the current exemplar buffer limit allows. This usually means the last timestampfor all exemplars for a typical setup. This is not true though if one of the series timestamp is in future compared to rest series. |
| prometheus_tsdb_exemplar_max_exemplars |
gauge |
ins, instance, ip, job, cls |
Total number of exemplars the exemplar storage can store, resizeable. |
| prometheus_tsdb_exemplar_out_of_order_exemplars_total |
counter |
ins, instance, ip, job, cls |
Total number of out of order exemplar ingestion failed attempts. |
| prometheus_tsdb_exemplar_series_with_exemplars_in_storage |
gauge |
ins, instance, ip, job, cls |
Number of series with exemplars currently in circular storage. |
| prometheus_tsdb_head_active_appenders |
gauge |
ins, instance, ip, job, cls |
Number of currently active appender transactions |
| prometheus_tsdb_head_chunks |
gauge |
ins, instance, ip, job, cls |
Total number of chunks in the head block. |
| prometheus_tsdb_head_chunks_created_total |
counter |
ins, instance, ip, job, cls |
Total number of chunks created in the head |
| prometheus_tsdb_head_chunks_removed_total |
counter |
ins, instance, ip, job, cls |
Total number of chunks removed in the head |
| prometheus_tsdb_head_chunks_storage_size_bytes |
gauge |
ins, instance, ip, job, cls |
Size of the chunks_head directory. |
| prometheus_tsdb_head_gc_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_tsdb_head_gc_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_tsdb_head_max_time |
gauge |
ins, instance, ip, job, cls |
Maximum timestamp of the head block. The unit is decided by the library consumer. |
| prometheus_tsdb_head_max_time_seconds |
gauge |
ins, instance, ip, job, cls |
Maximum timestamp of the head block. |
| prometheus_tsdb_head_min_time |
gauge |
ins, instance, ip, job, cls |
Minimum time bound of the head block. The unit is decided by the library consumer. |
| prometheus_tsdb_head_min_time_seconds |
gauge |
ins, instance, ip, job, cls |
Minimum time bound of the head block. |
| prometheus_tsdb_head_out_of_order_samples_appended_total |
counter |
ins, instance, ip, job, cls |
Total number of appended out of order samples. |
| prometheus_tsdb_head_samples_appended_total |
counter |
ins, instance, ip, type, job, cls |
Total number of appended samples. |
| prometheus_tsdb_head_series |
gauge |
ins, instance, ip, job, cls |
Total number of series in the head block. |
| prometheus_tsdb_head_series_created_total |
counter |
ins, instance, ip, job, cls |
Total number of series created in the head |
| prometheus_tsdb_head_series_not_found_total |
counter |
ins, instance, ip, job, cls |
Total number of requests for series that were not found. |
| prometheus_tsdb_head_series_removed_total |
counter |
ins, instance, ip, job, cls |
Total number of series removed in the head |
| prometheus_tsdb_head_truncations_failed_total |
counter |
ins, instance, ip, job, cls |
Total number of head truncations that failed. |
| prometheus_tsdb_head_truncations_total |
counter |
ins, instance, ip, job, cls |
Total number of head truncations attempted. |
| prometheus_tsdb_isolation_high_watermark |
gauge |
ins, instance, ip, job, cls |
The highest TSDB append ID that has been given out. |
| prometheus_tsdb_isolation_low_watermark |
gauge |
ins, instance, ip, job, cls |
The lowest TSDB append ID that is still referenced. |
| prometheus_tsdb_lowest_timestamp |
gauge |
ins, instance, ip, job, cls |
Lowest timestamp value stored in the database. The unit is decided by the library consumer. |
| prometheus_tsdb_lowest_timestamp_seconds |
gauge |
ins, instance, ip, job, cls |
Lowest timestamp value stored in the database. |
| prometheus_tsdb_mmap_chunk_corruptions_total |
counter |
ins, instance, ip, job, cls |
Total number of memory-mapped chunk corruptions. |
| prometheus_tsdb_mmap_chunks_total |
counter |
ins, instance, ip, job, cls |
Total number of chunks that were memory-mapped. |
| prometheus_tsdb_out_of_bound_samples_total |
counter |
ins, instance, ip, type, job, cls |
Total number of out of bound samples ingestion failed attempts with out of order support disabled. |
| prometheus_tsdb_out_of_order_samples_total |
counter |
ins, instance, ip, type, job, cls |
Total number of out of order samples ingestion failed attempts due to out of order being disabled. |
| prometheus_tsdb_reloads_failures_total |
counter |
ins, instance, ip, job, cls |
Number of times the database failed to reloadBlocks block data from disk. |
| prometheus_tsdb_reloads_total |
counter |
ins, instance, ip, job, cls |
Number of times the database reloaded block data from disk. |
| prometheus_tsdb_retention_limit_bytes |
gauge |
ins, instance, ip, job, cls |
Max number of bytes to be retained in the tsdb blocks, configured 0 means disabled |
| prometheus_tsdb_retention_limit_seconds |
gauge |
ins, instance, ip, job, cls |
How long to retain samples in storage. |
| prometheus_tsdb_size_retentions_total |
counter |
ins, instance, ip, job, cls |
The number of times that blocks were deleted because the maximum number of bytes was exceeded. |
| prometheus_tsdb_snapshot_replay_error_total |
counter |
ins, instance, ip, job, cls |
Total number snapshot replays that failed. |
| prometheus_tsdb_storage_blocks_bytes |
gauge |
ins, instance, ip, job, cls |
The number of bytes that are currently used for local storage by all blocks. |
| prometheus_tsdb_symbol_table_size_bytes |
gauge |
ins, instance, ip, job, cls |
Size of symbol table in memory for loaded blocks |
| prometheus_tsdb_time_retentions_total |
counter |
ins, instance, ip, job, cls |
The number of times that blocks were deleted because the maximum time limit was exceeded. |
| prometheus_tsdb_tombstone_cleanup_seconds_bucket |
Unknown |
ins, instance, ip, le, job, cls |
N/A |
| prometheus_tsdb_tombstone_cleanup_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_tsdb_tombstone_cleanup_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_tsdb_too_old_samples_total |
counter |
ins, instance, ip, type, job, cls |
Total number of out of order samples ingestion failed attempts with out of support enabled, but sample outside of time window. |
| prometheus_tsdb_vertical_compactions_total |
counter |
ins, instance, ip, job, cls |
Total number of compactions done on overlapping blocks. |
| prometheus_tsdb_wal_completed_pages_total |
counter |
ins, instance, ip, job, cls |
Total number of completed pages. |
| prometheus_tsdb_wal_corruptions_total |
counter |
ins, instance, ip, job, cls |
Total number of WAL corruptions. |
| prometheus_tsdb_wal_fsync_duration_seconds |
summary |
ins, instance, ip, job, cls, quantile |
Duration of write log fsync. |
| prometheus_tsdb_wal_fsync_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_tsdb_wal_fsync_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_tsdb_wal_page_flushes_total |
counter |
ins, instance, ip, job, cls |
Total number of page flushes. |
| prometheus_tsdb_wal_segment_current |
gauge |
ins, instance, ip, job, cls |
Write log segment index that TSDB is currently writing to. |
| prometheus_tsdb_wal_storage_size_bytes |
gauge |
ins, instance, ip, job, cls |
Size of the write log directory. |
| prometheus_tsdb_wal_truncate_duration_seconds_count |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_tsdb_wal_truncate_duration_seconds_sum |
Unknown |
ins, instance, ip, job, cls |
N/A |
| prometheus_tsdb_wal_truncations_failed_total |
counter |
ins, instance, ip, job, cls |
Total number of write log truncations that failed. |
| prometheus_tsdb_wal_truncations_total |
counter |
ins, instance, ip, job, cls |
Total number of write log truncations attempted. |
| prometheus_tsdb_wal_writes_failed_total |
counter |
ins, instance, ip, job, cls |
Total number of write log writes that failed. |
| prometheus_web_federation_errors_total |
counter |
ins, instance, ip, job, cls |
Total number of errors that occurred while sending federation responses. |
| prometheus_web_federation_warnings_total |
counter |
ins, instance, ip, job, cls |
Total number of warnings that occurred while sending federation responses. |
| promhttp_metric_handler_requests_in_flight |
gauge |
ins, instance, ip, job, cls |
Current number of scrapes being served. |
| promhttp_metric_handler_requests_total |
counter |
ins, instance, ip, job, cls, code |
Total number of scrapes by HTTP status code. |
| pushgateway_build_info |
gauge |
revision, version, ins, instance, ip, tags, goarch, goversion, job, cls, branch, goos |
A metric with a constant ‘1’ value labeled by version, revision, branch, goversion from which pushgateway was built, and the goos and goarch for the build. |
| pushgateway_http_requests_total |
counter |
ins, instance, method, ip, job, cls, code, handler |
Total HTTP requests processed by the Pushgateway, excluding scrapes. |
| querier_cache_added_new_total |
Unknown |
ins, instance, ip, job, cache, cls |
N/A |
| querier_cache_added_total |
Unknown |
ins, instance, ip, job, cache, cls |
N/A |
| querier_cache_entries |
gauge |
ins, instance, ip, job, cache, cls |
The total number of entries |
| querier_cache_evicted_total |
Unknown |
ins, instance, ip, job, reason, cache, cls |
N/A |
| querier_cache_gets_total |
Unknown |
ins, instance, ip, job, cache, cls |
N/A |
| querier_cache_memory_bytes |
gauge |
ins, instance, ip, job, cache, cls |
The current cache size in bytes |
| querier_cache_misses_total |
Unknown |
ins, instance, ip, job, cache, cls |
N/A |
| querier_cache_stale_gets_total |
Unknown |
ins, instance, ip, job, cache, cls |
N/A |
| ring_member_heartbeats_total |
Unknown |
ins, instance, ip, job, cls |
N/A |
| ring_member_tokens_owned |
gauge |
ins, instance, ip, job, cls |
The number of tokens owned in the ring. |
| ring_member_tokens_to_own |
gauge |
ins, instance, ip, job, cls |
The number of tokens to own in the ring. |
| scrape_duration_seconds |
Unknown |
ins, instance, ip, job, cls |
N/A |
| scrape_samples_post_metric_relabeling |
Unknown |
ins, instance, ip, job, cls |
N/A |
| scrape_samples_scraped |
Unknown |
ins, instance, ip, job, cls |
N/A |
| scrape_series_added |
Unknown |
ins, instance, ip, job, cls |
N/A |
| up |
Unknown |
ins, instance, ip, job, cls |
N/A |

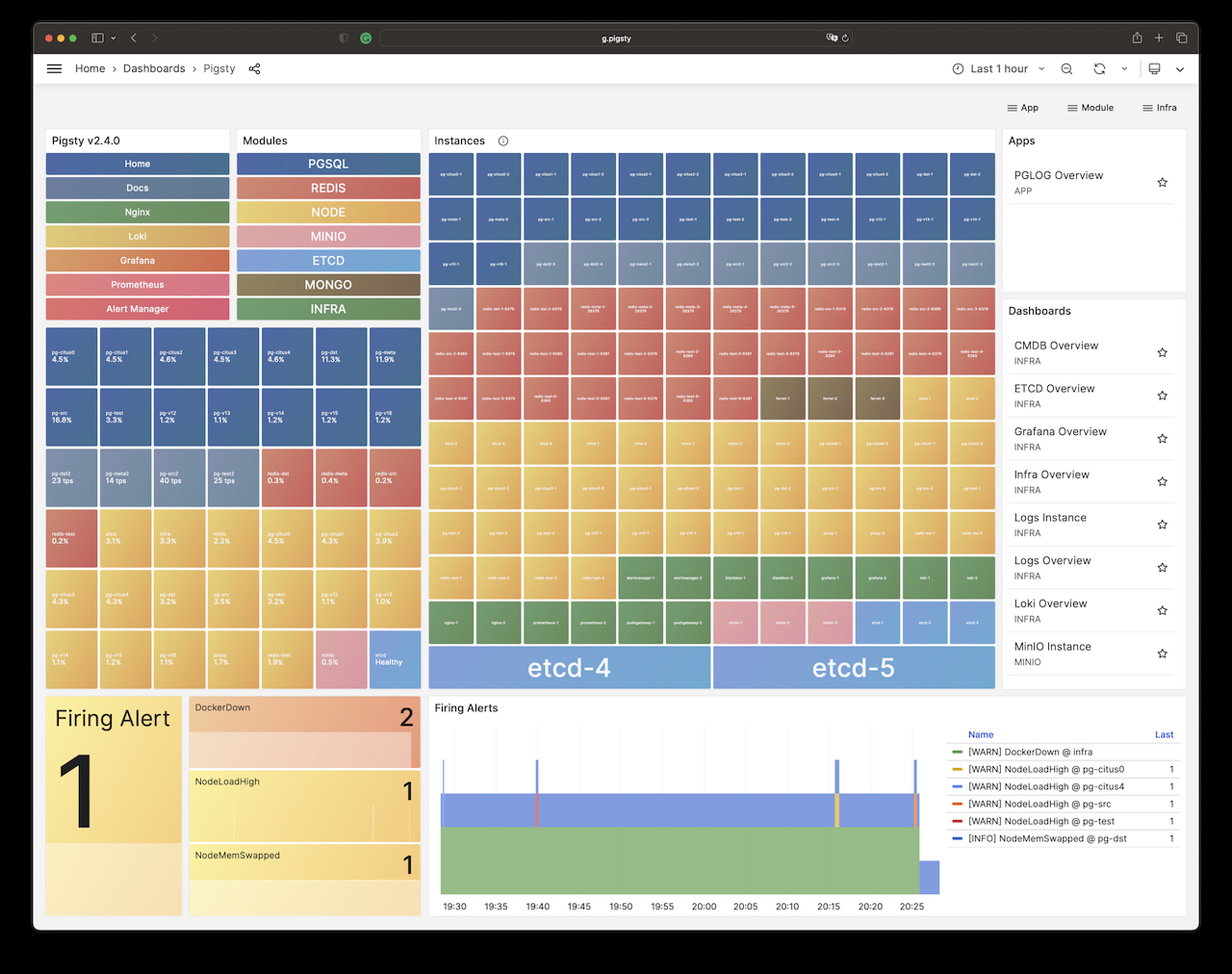
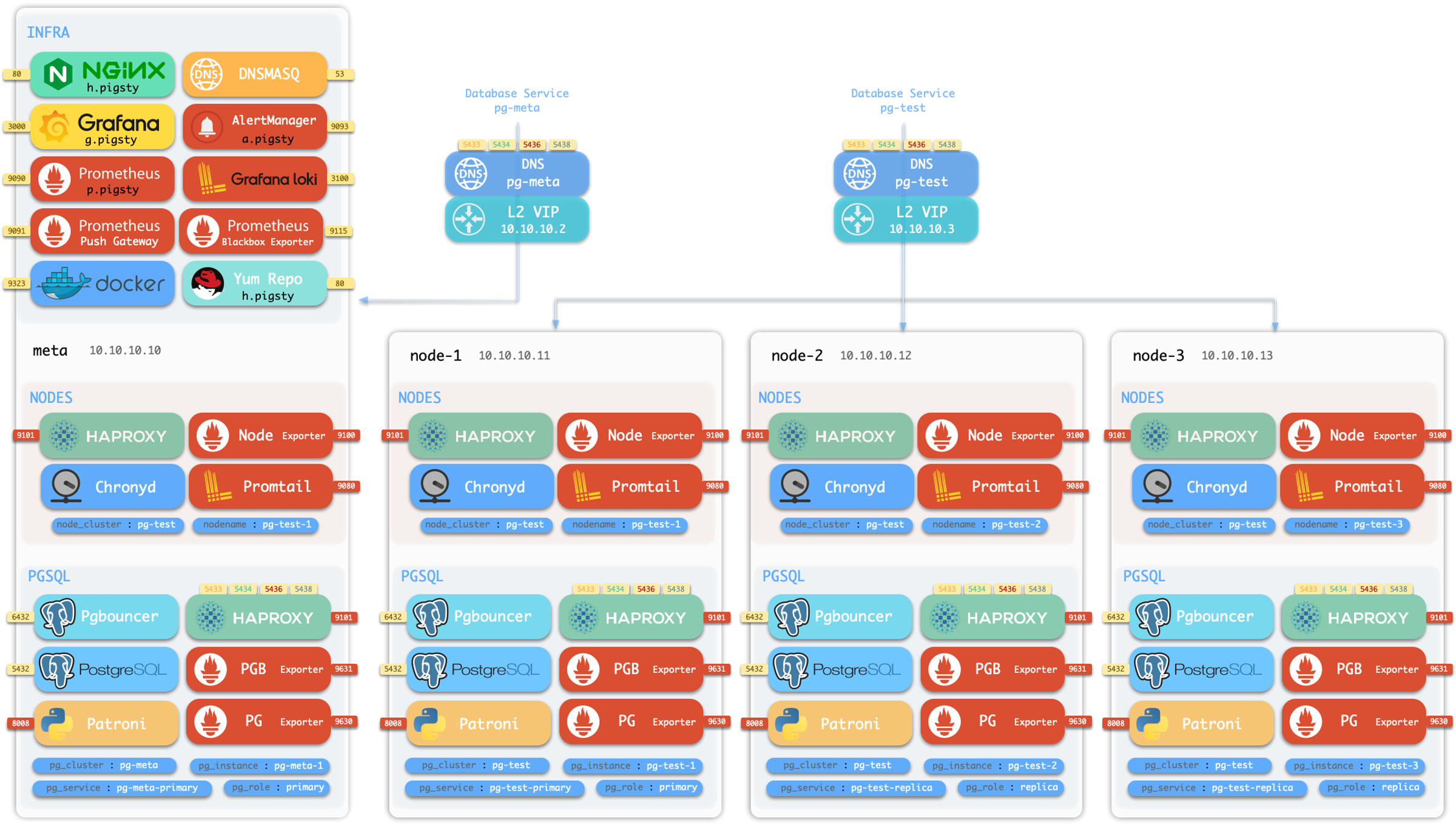
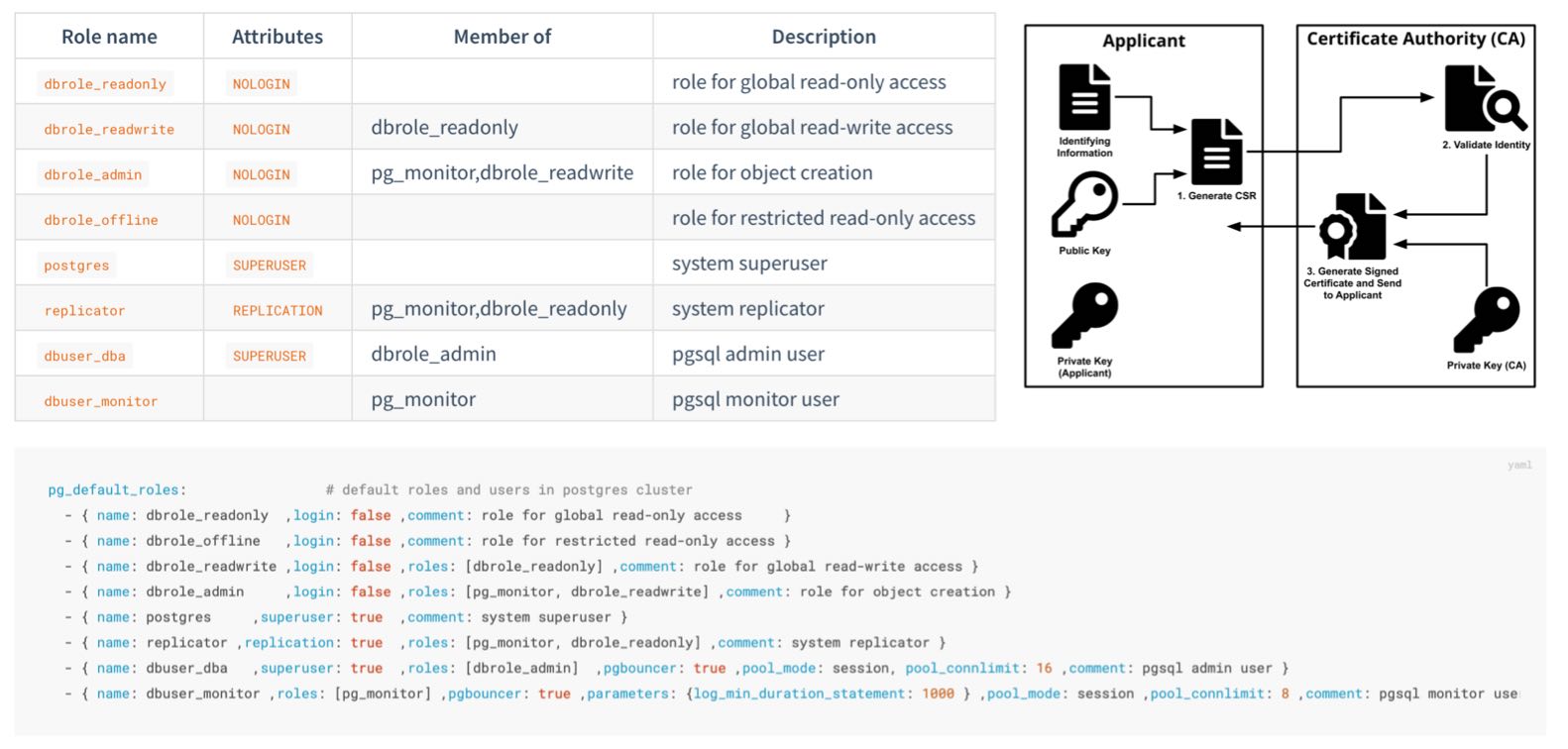
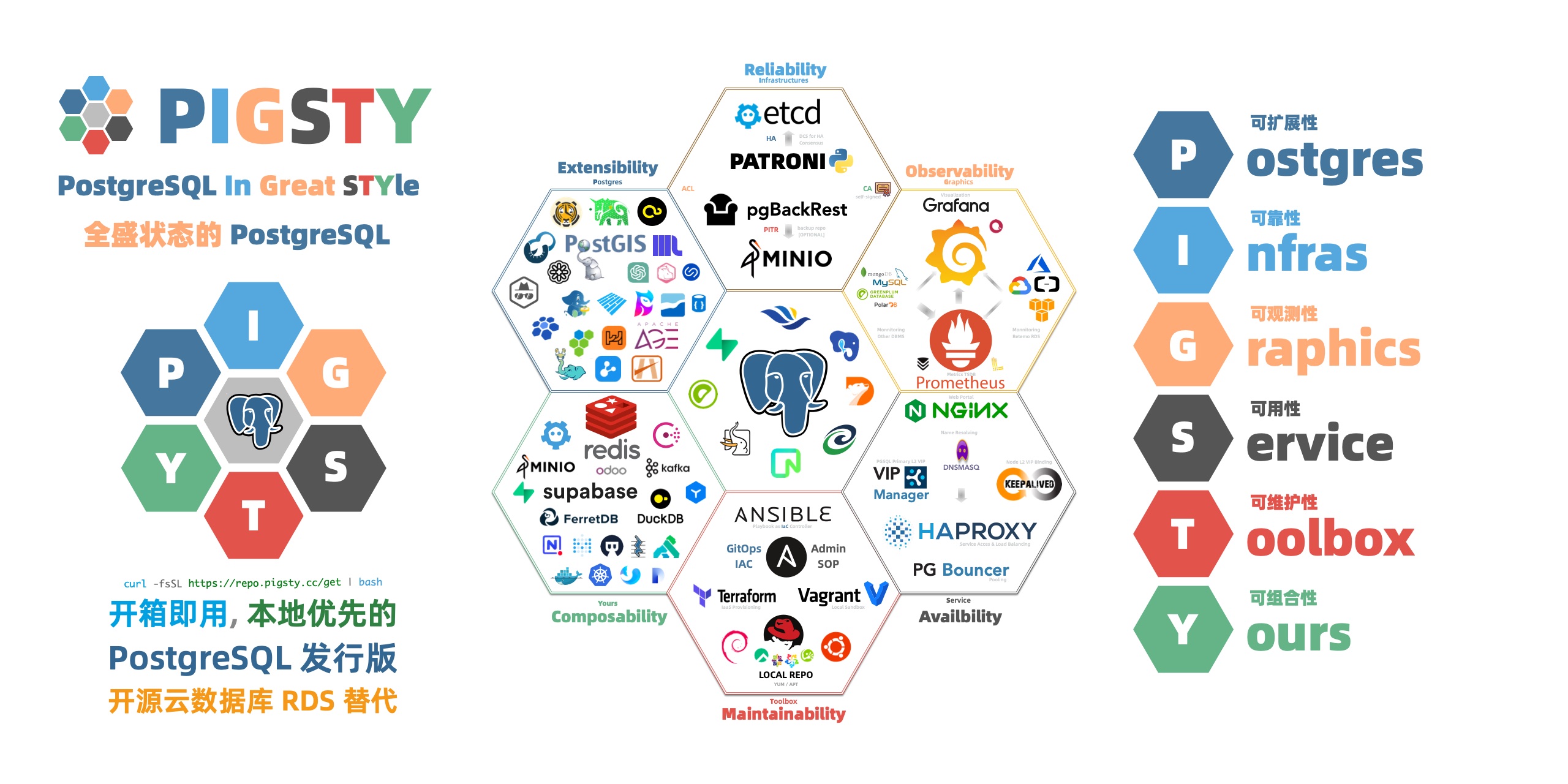
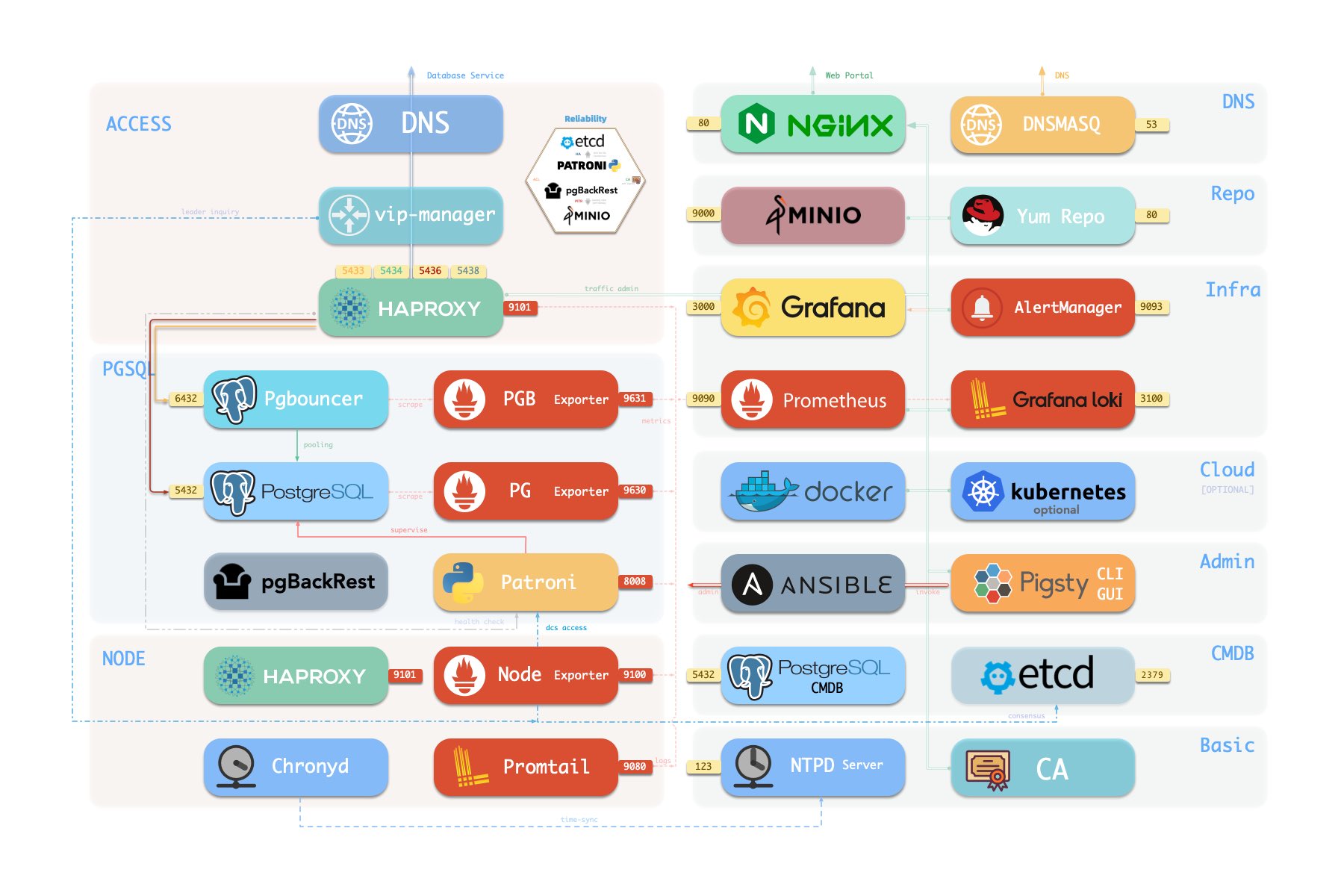
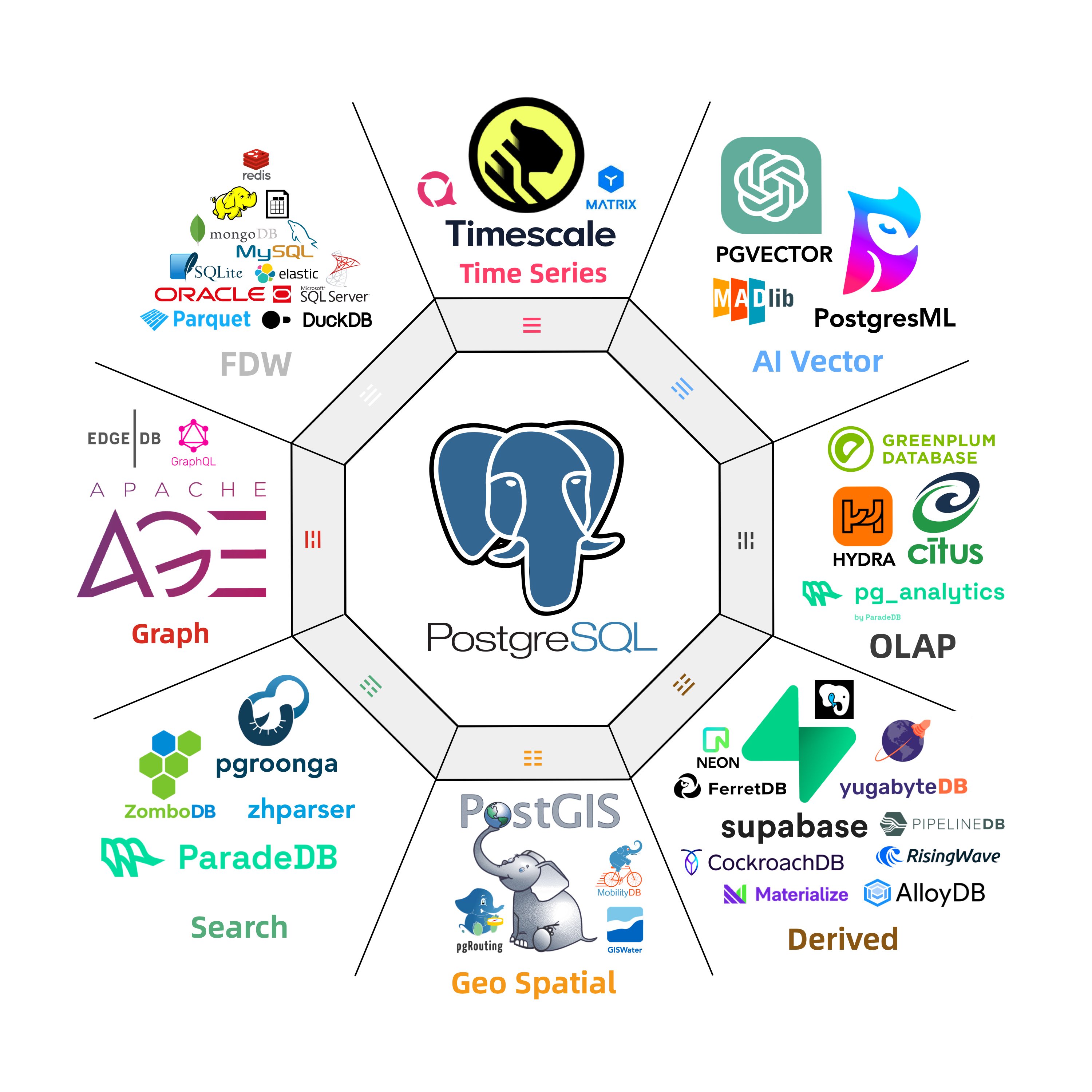

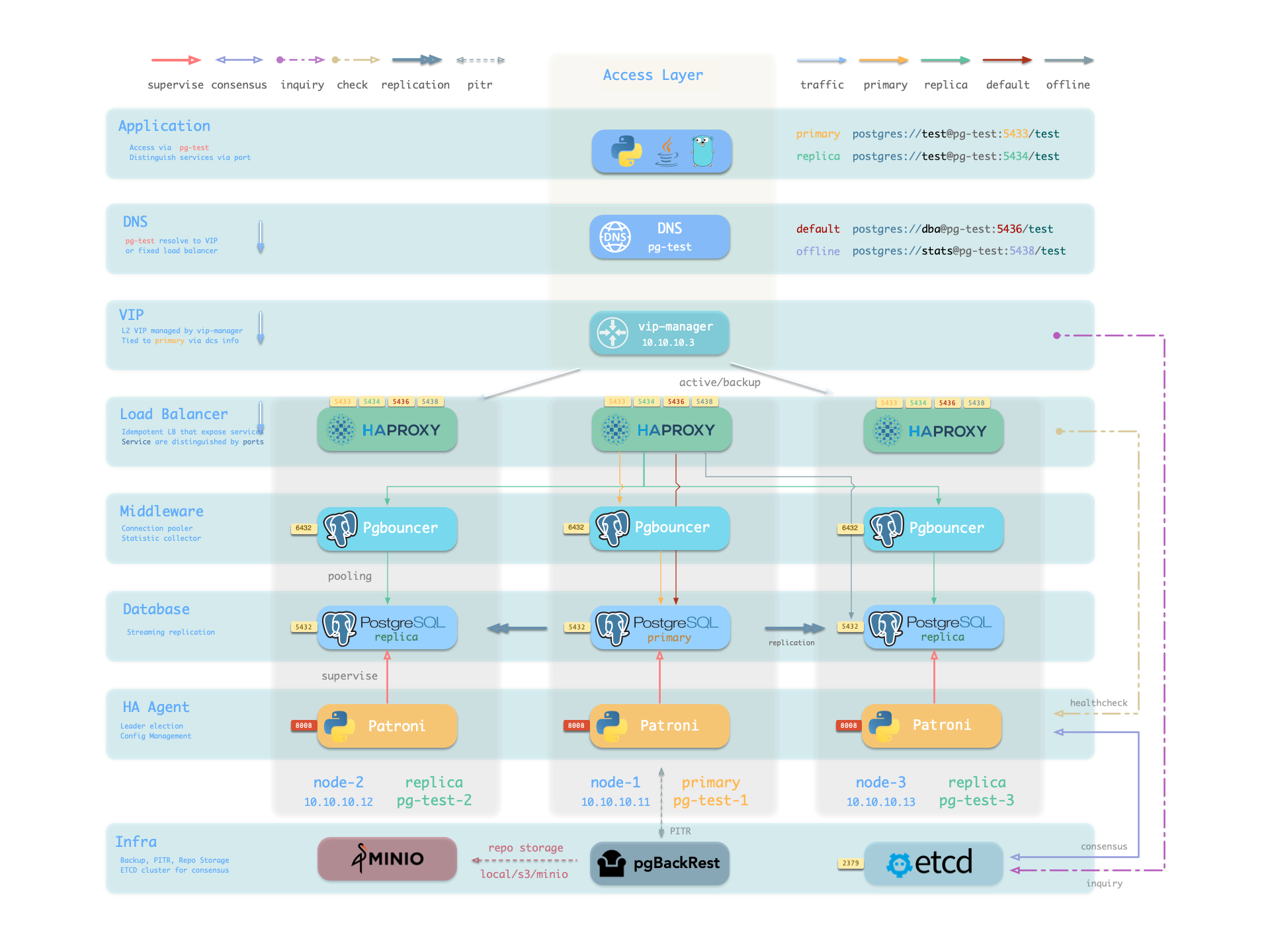

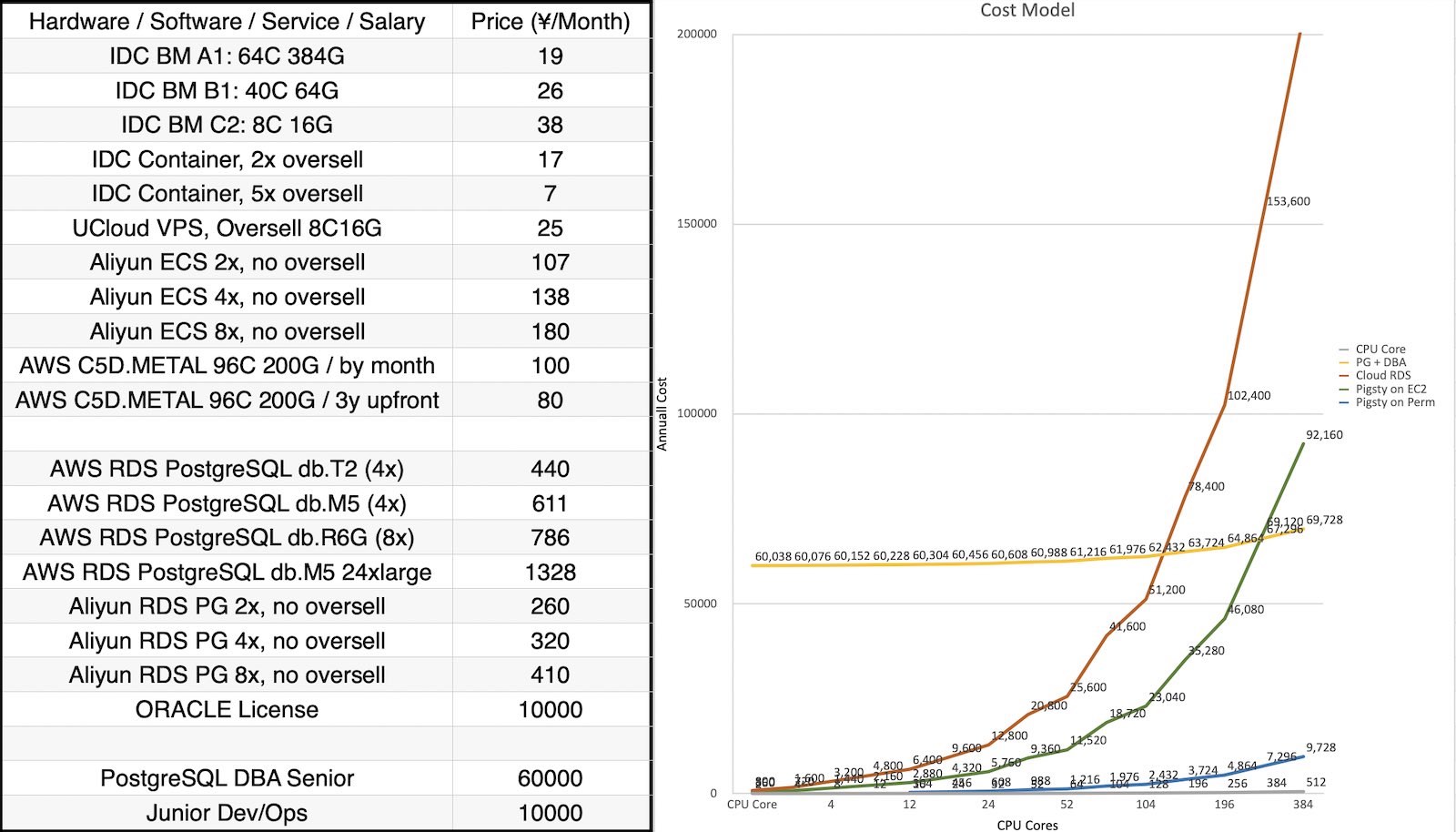

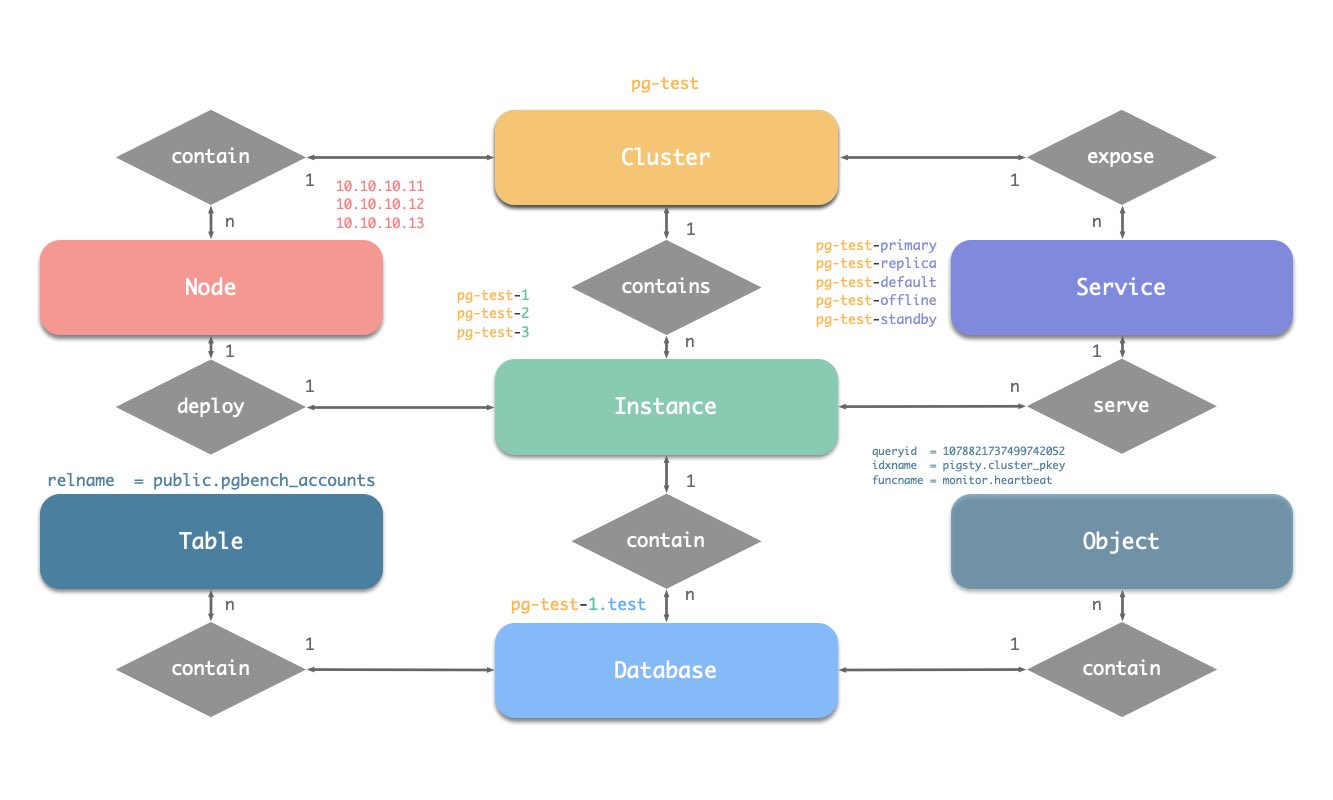
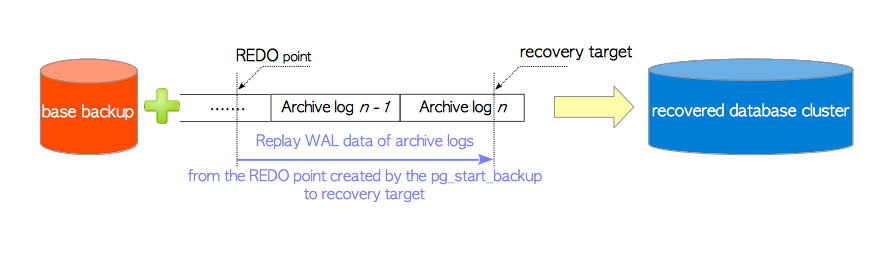
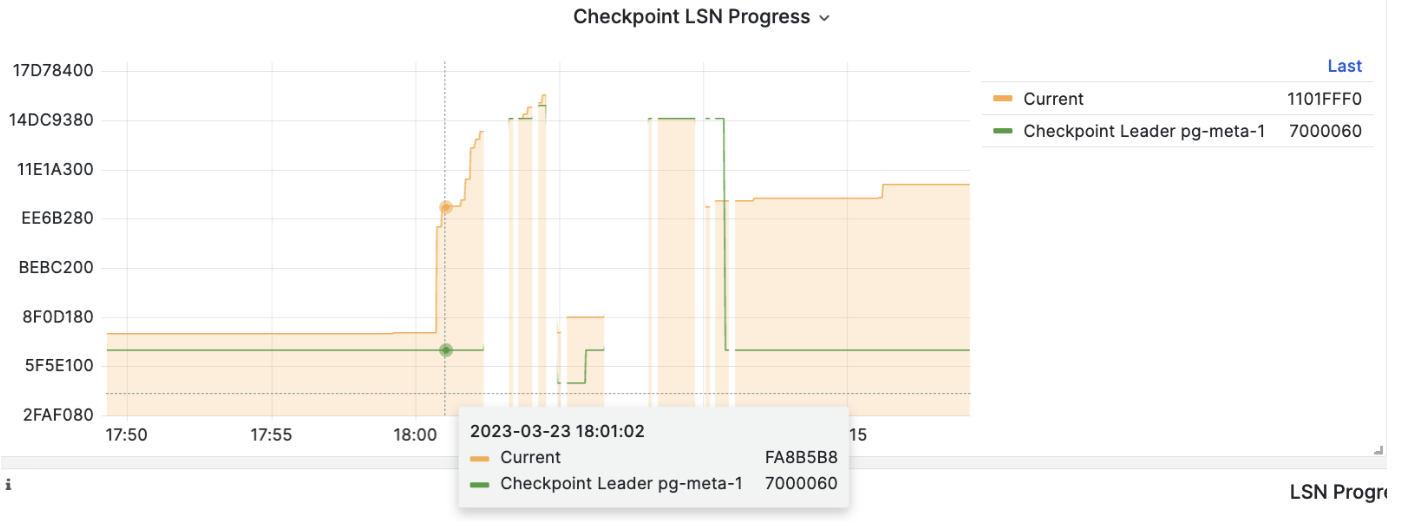
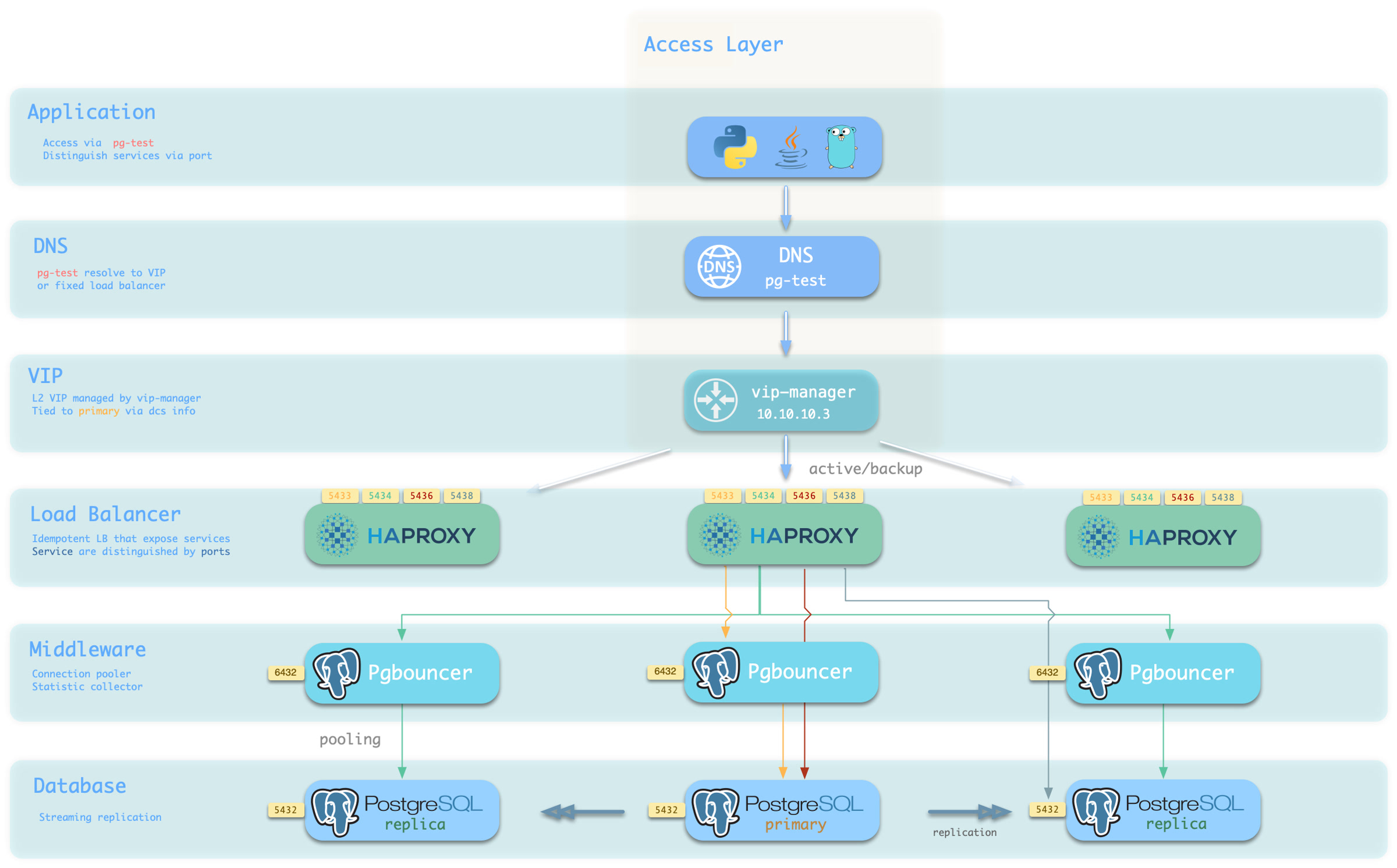












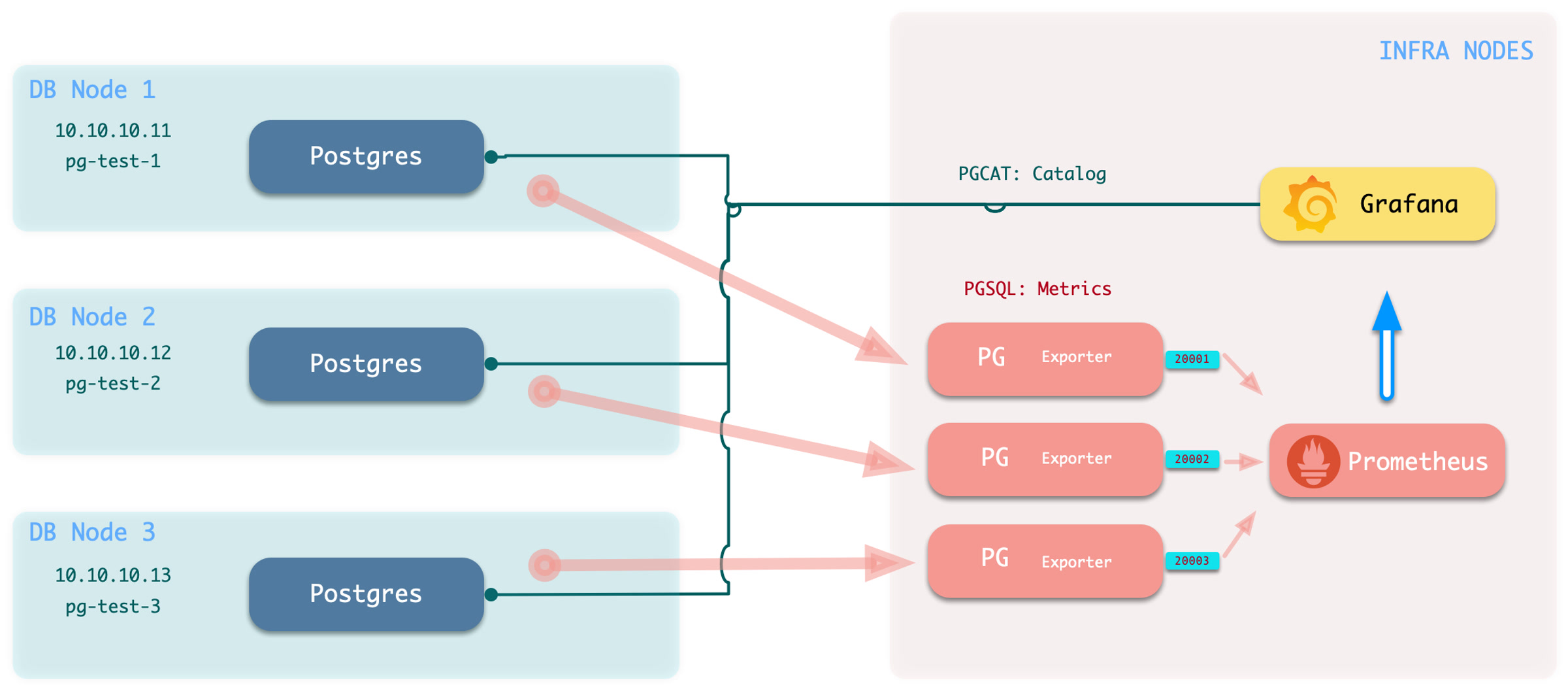
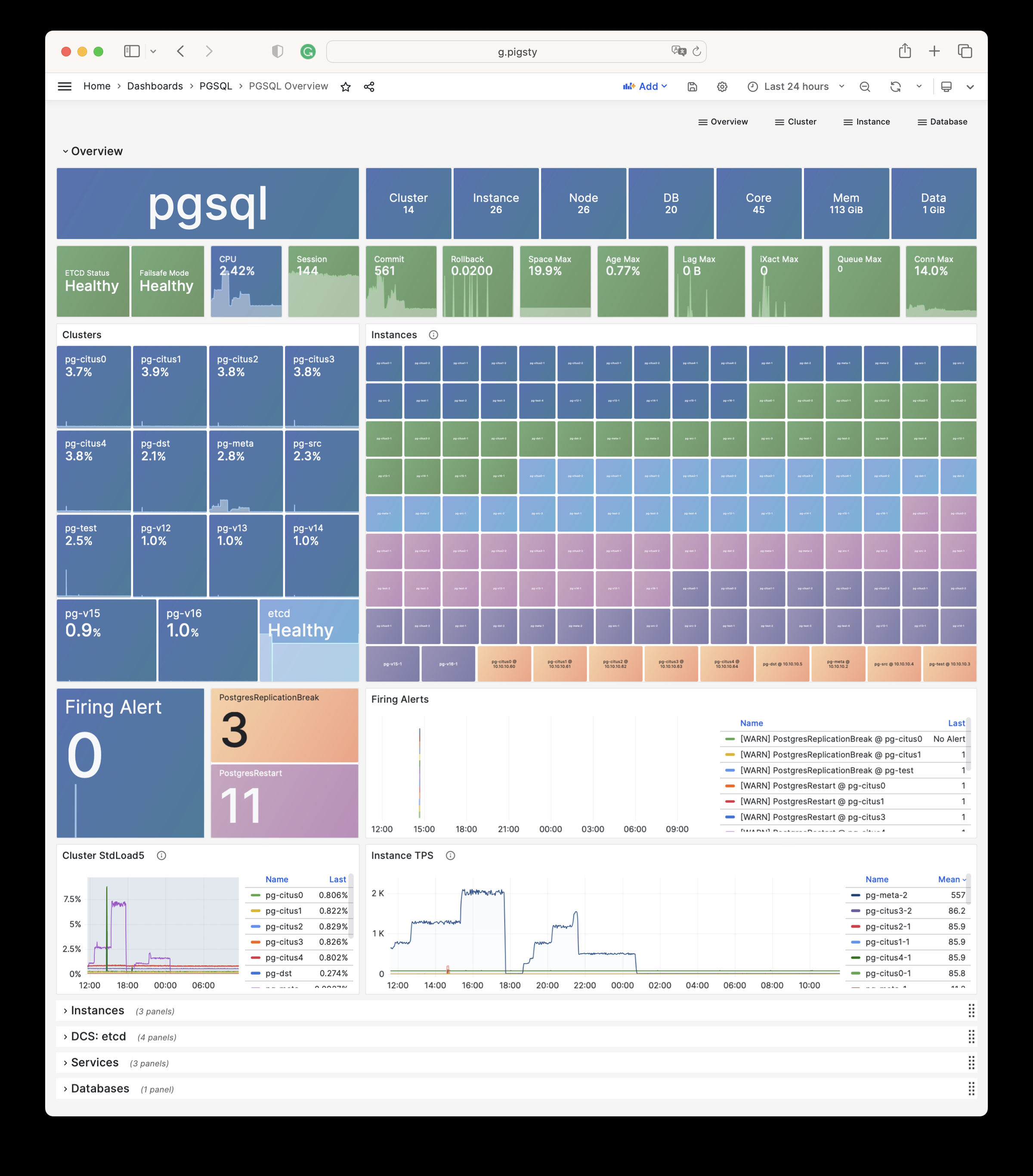
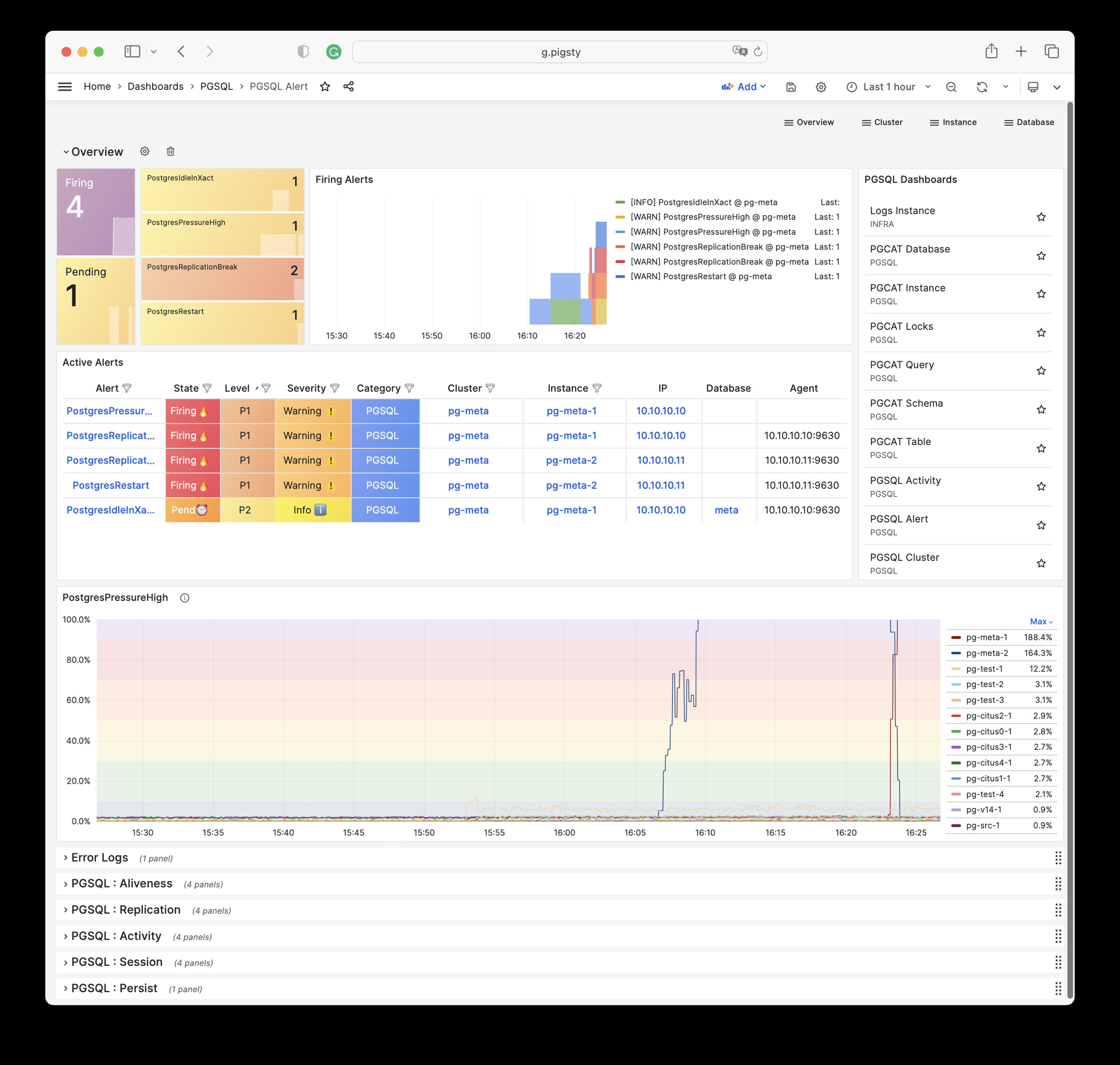
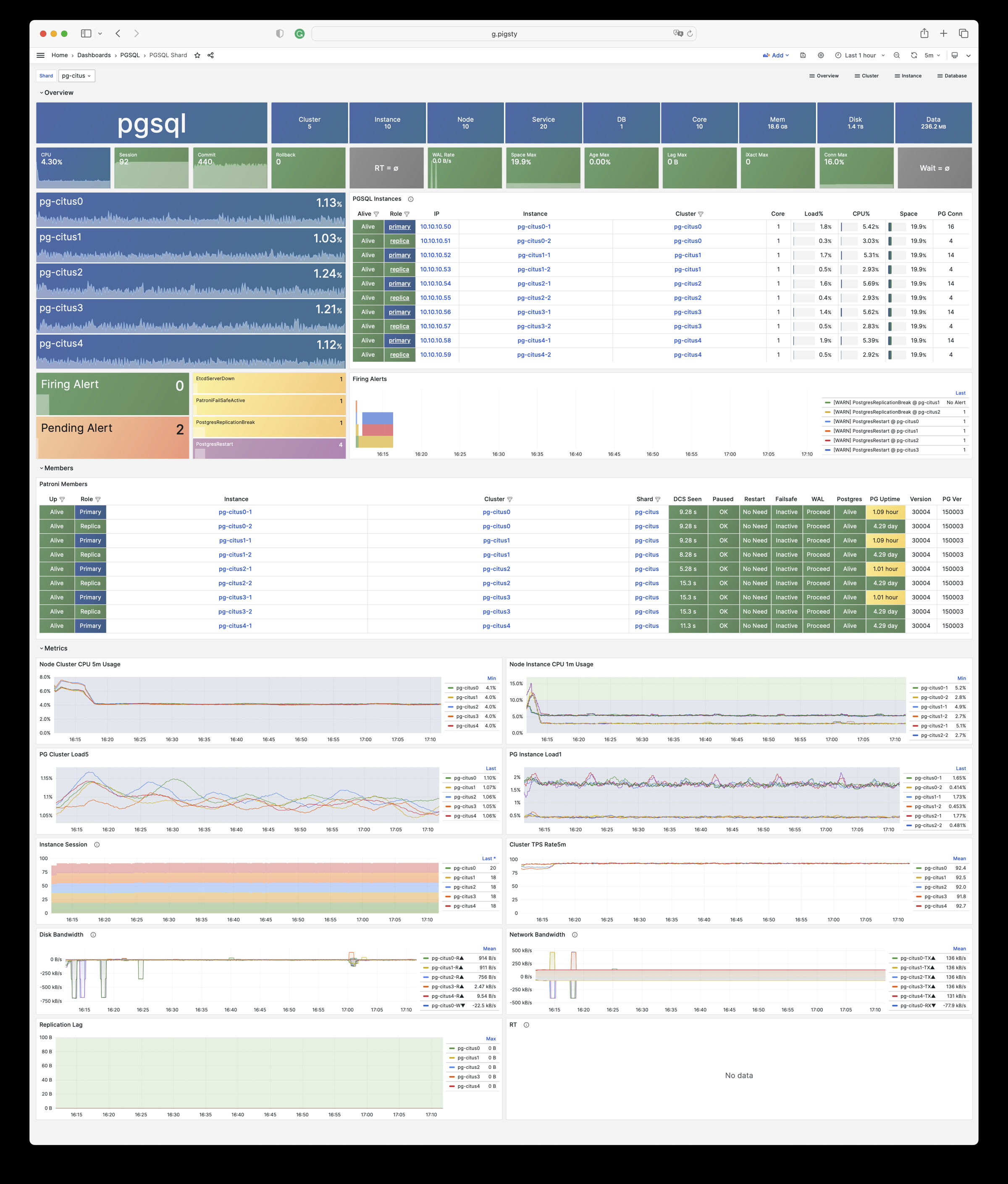
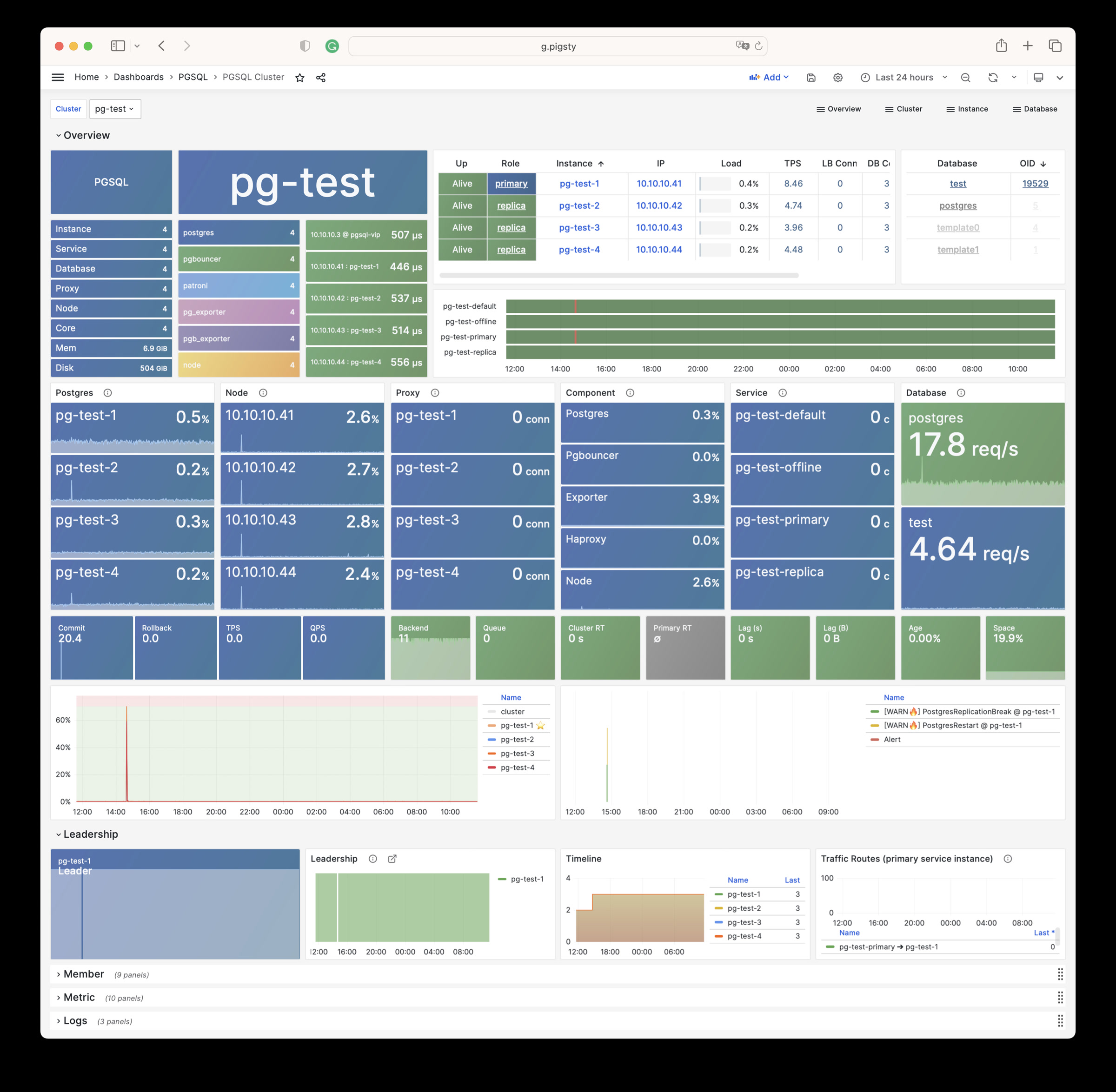
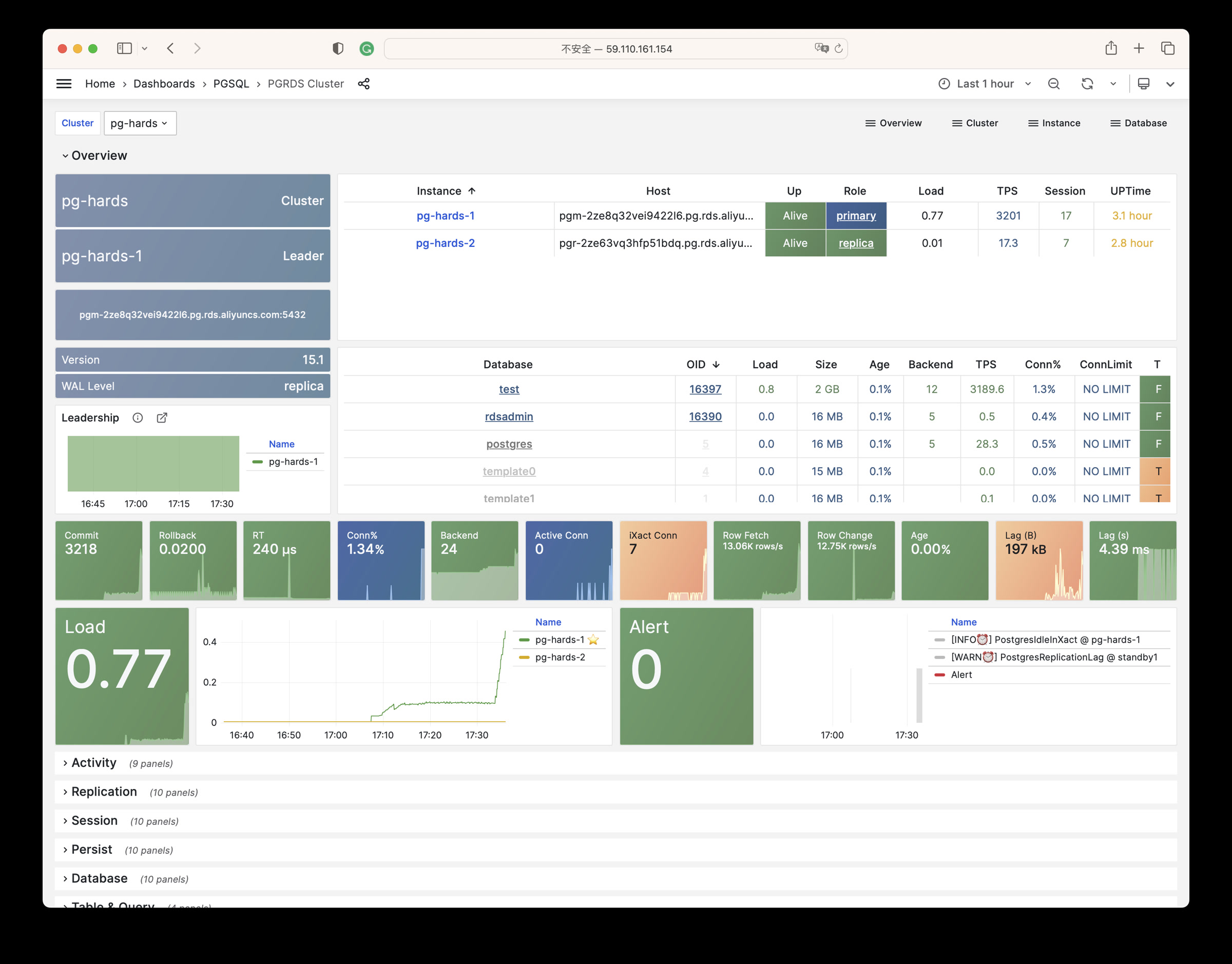
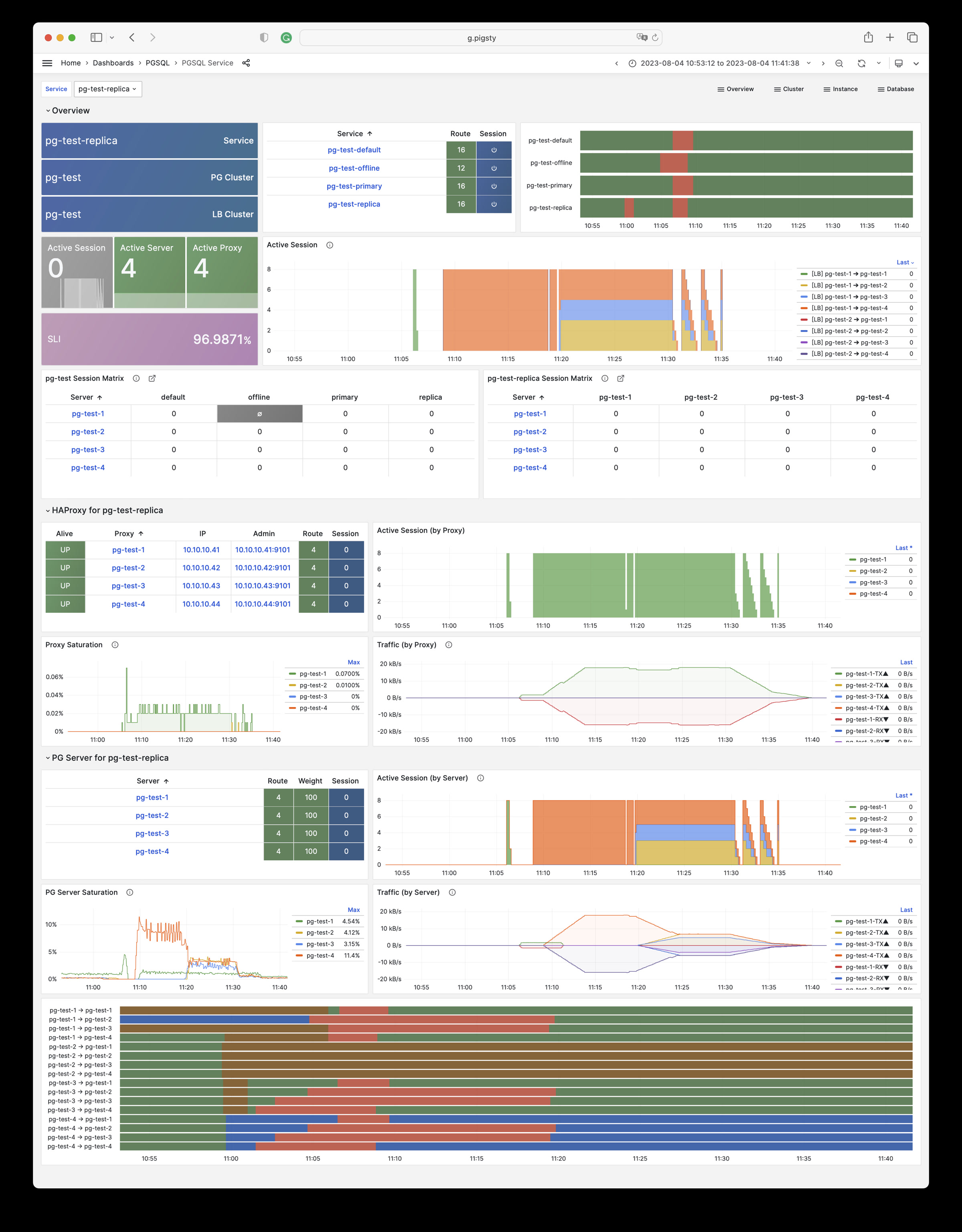
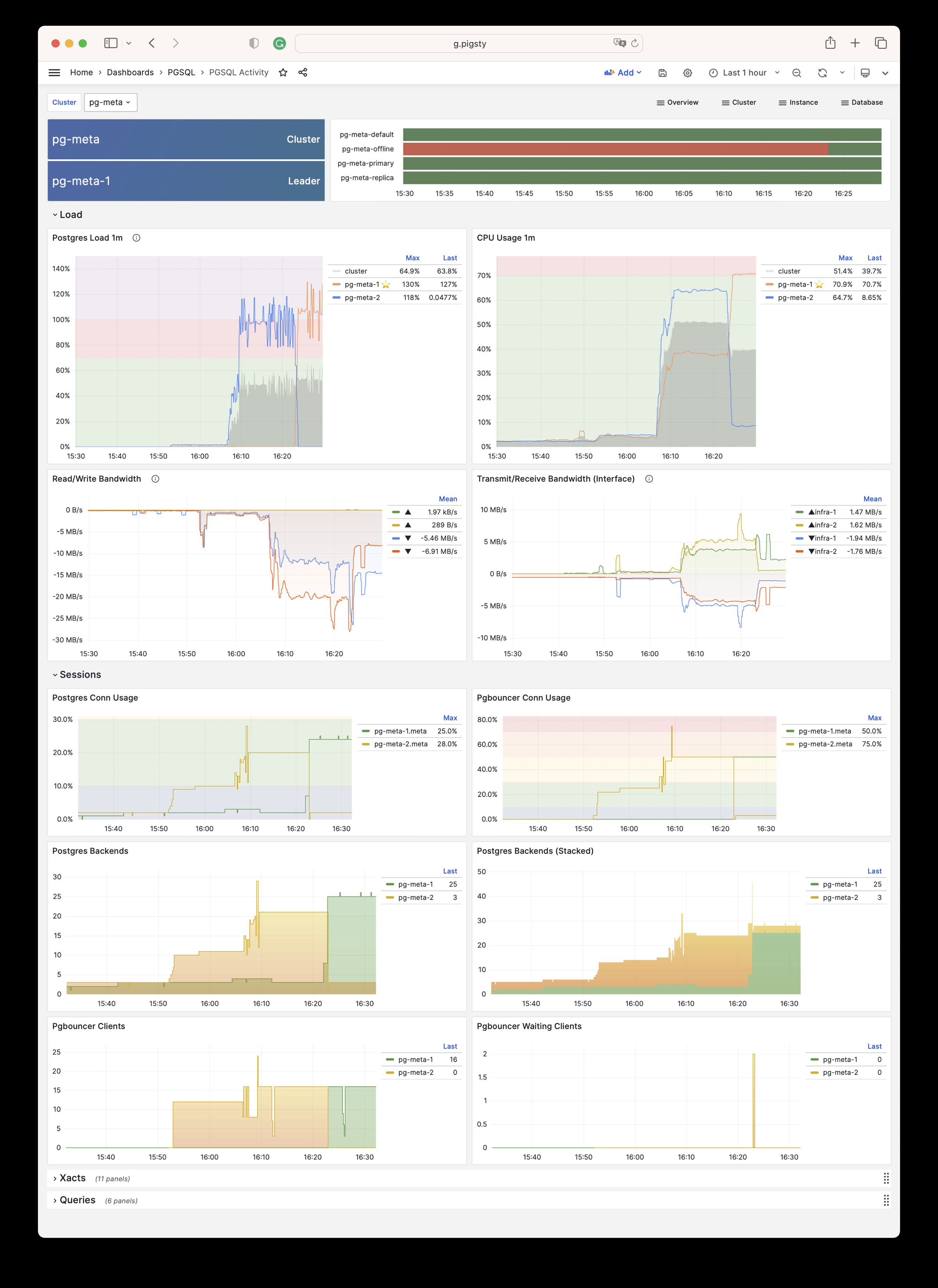
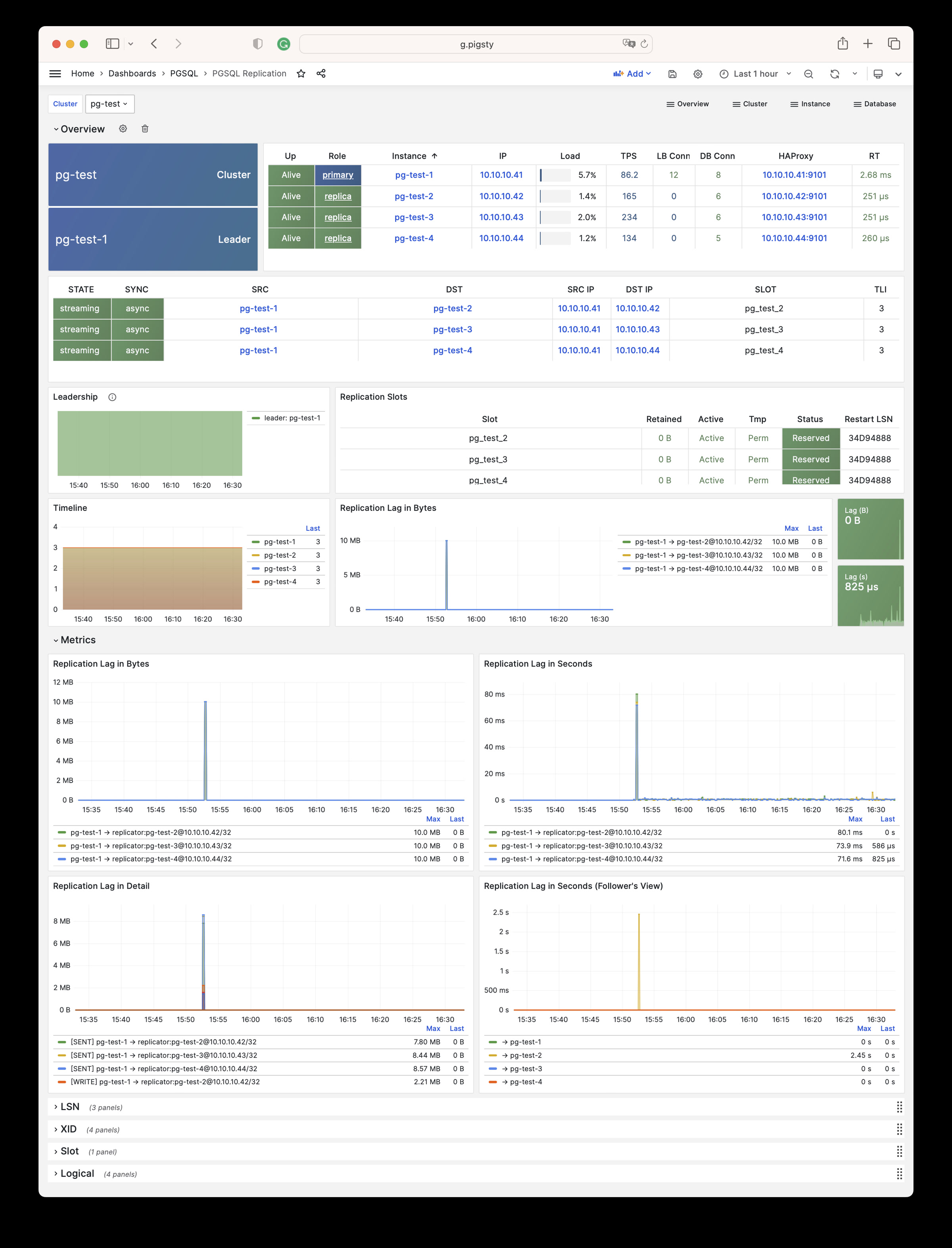

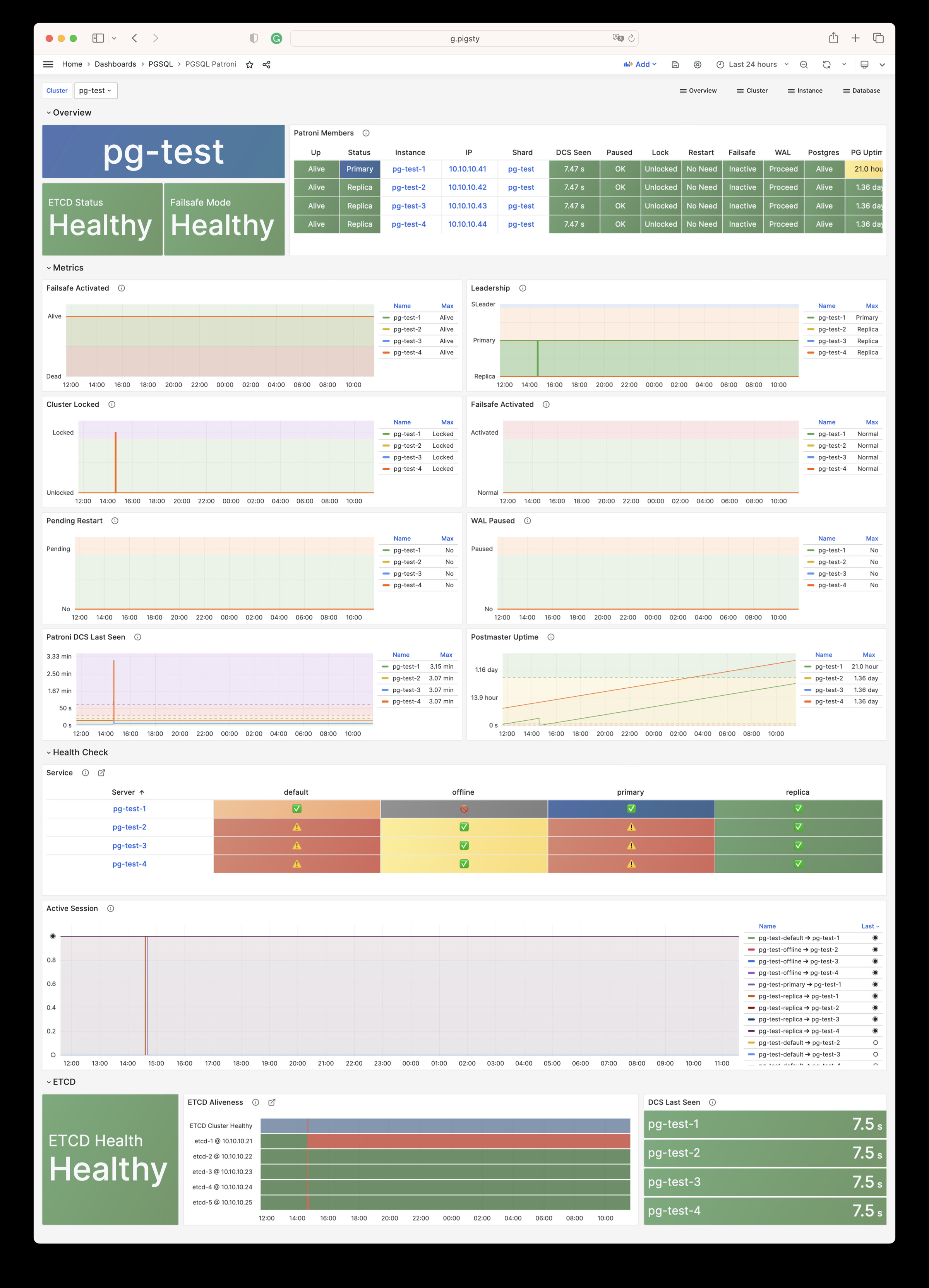
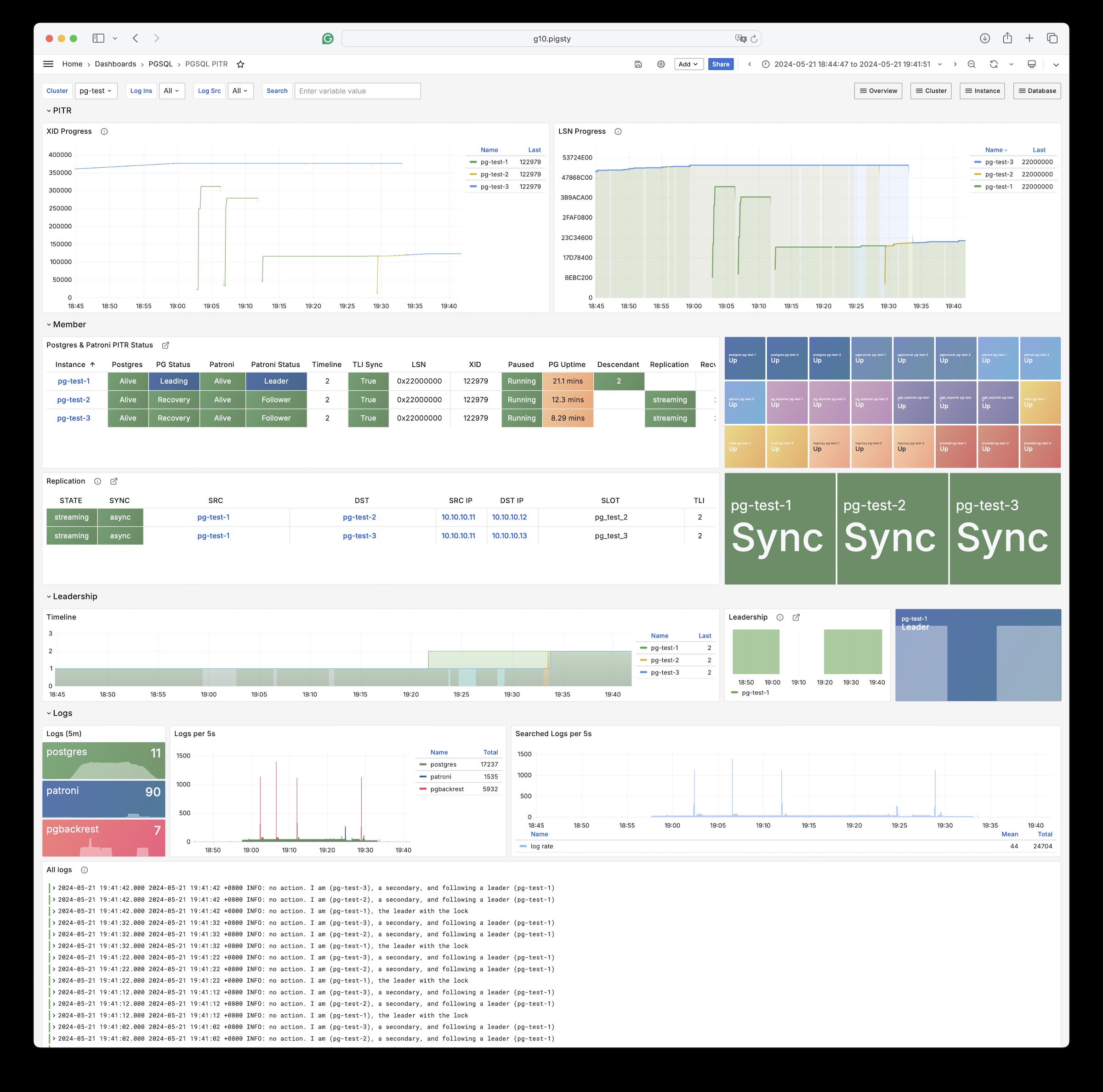
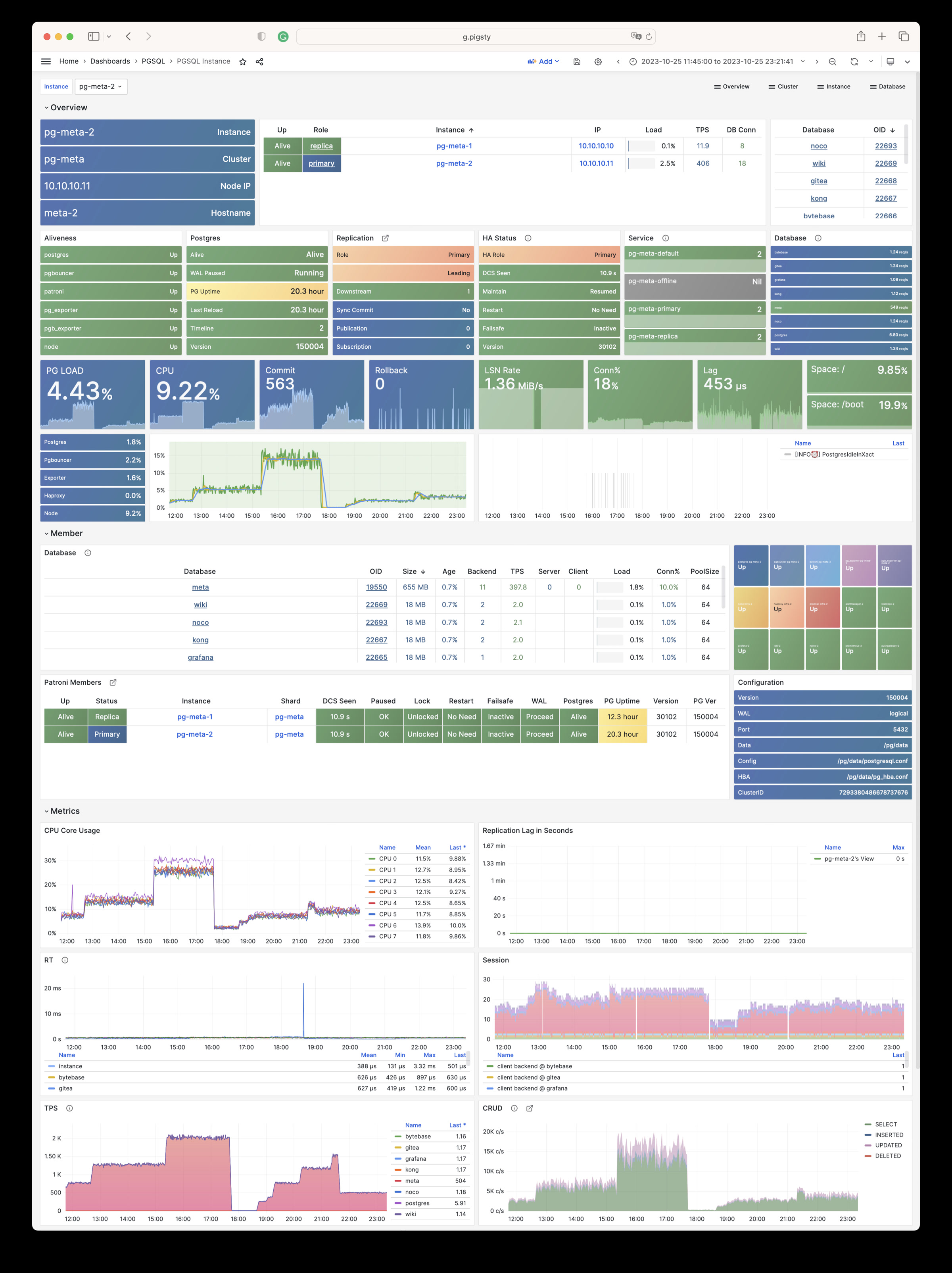
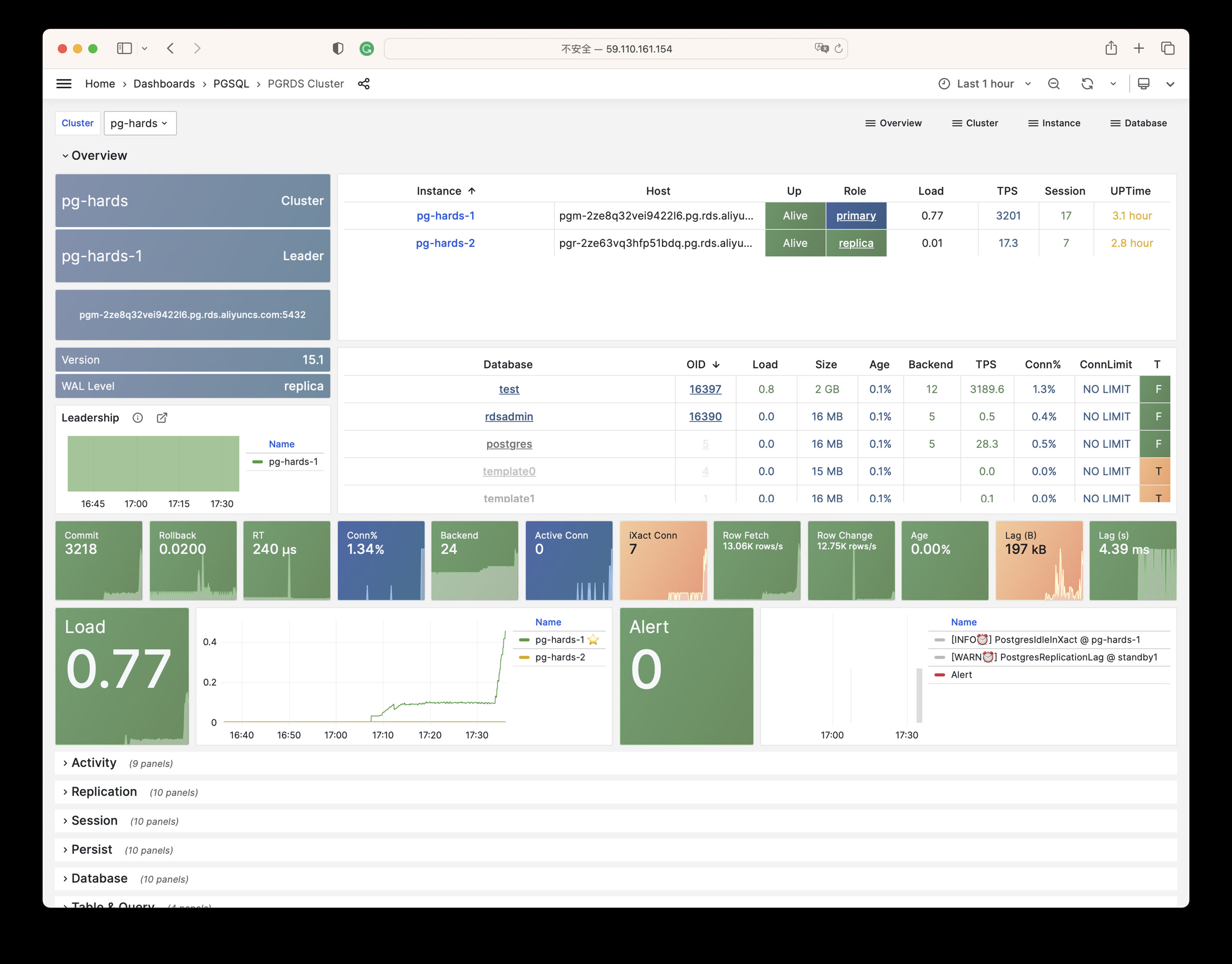
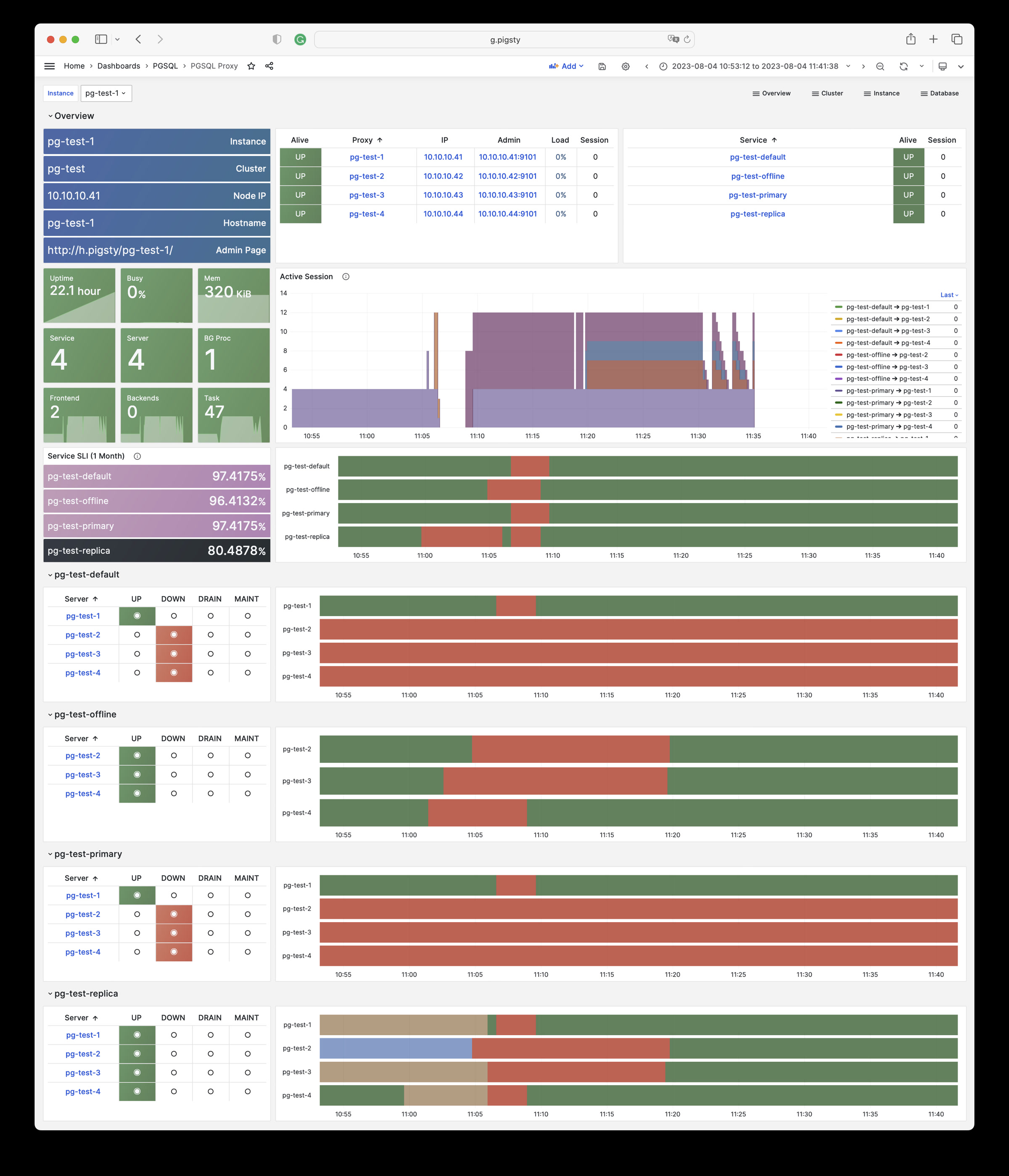
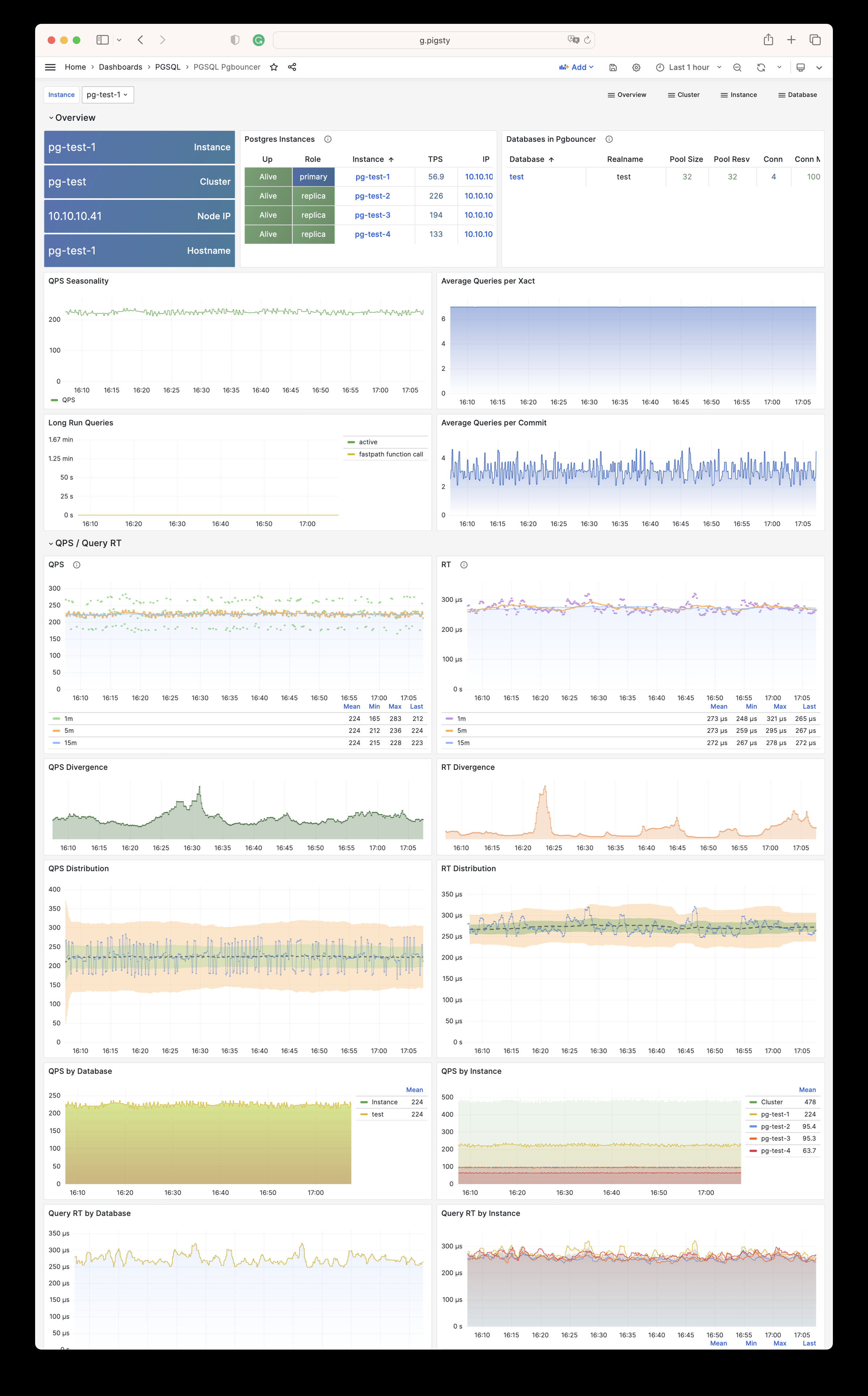
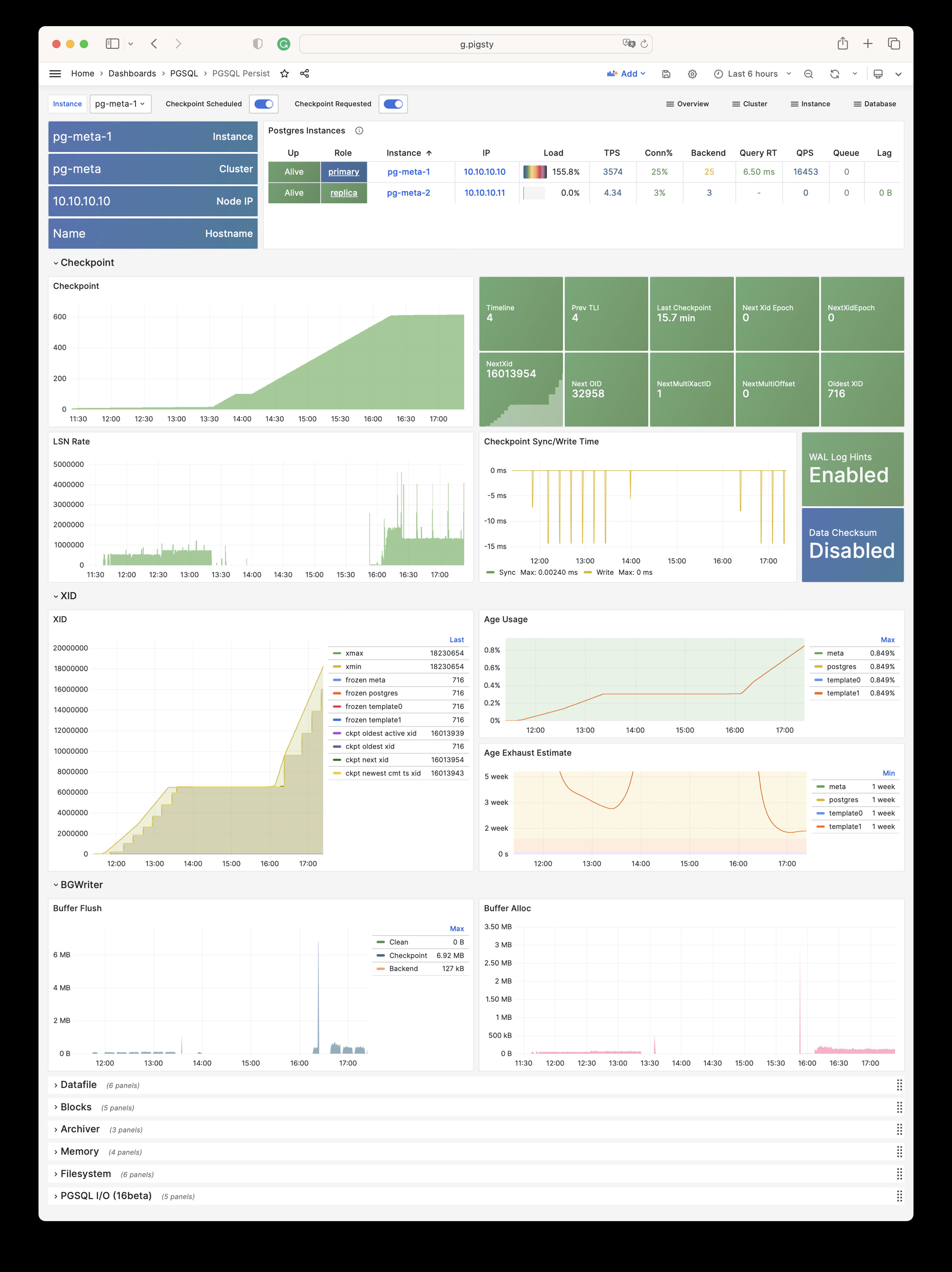
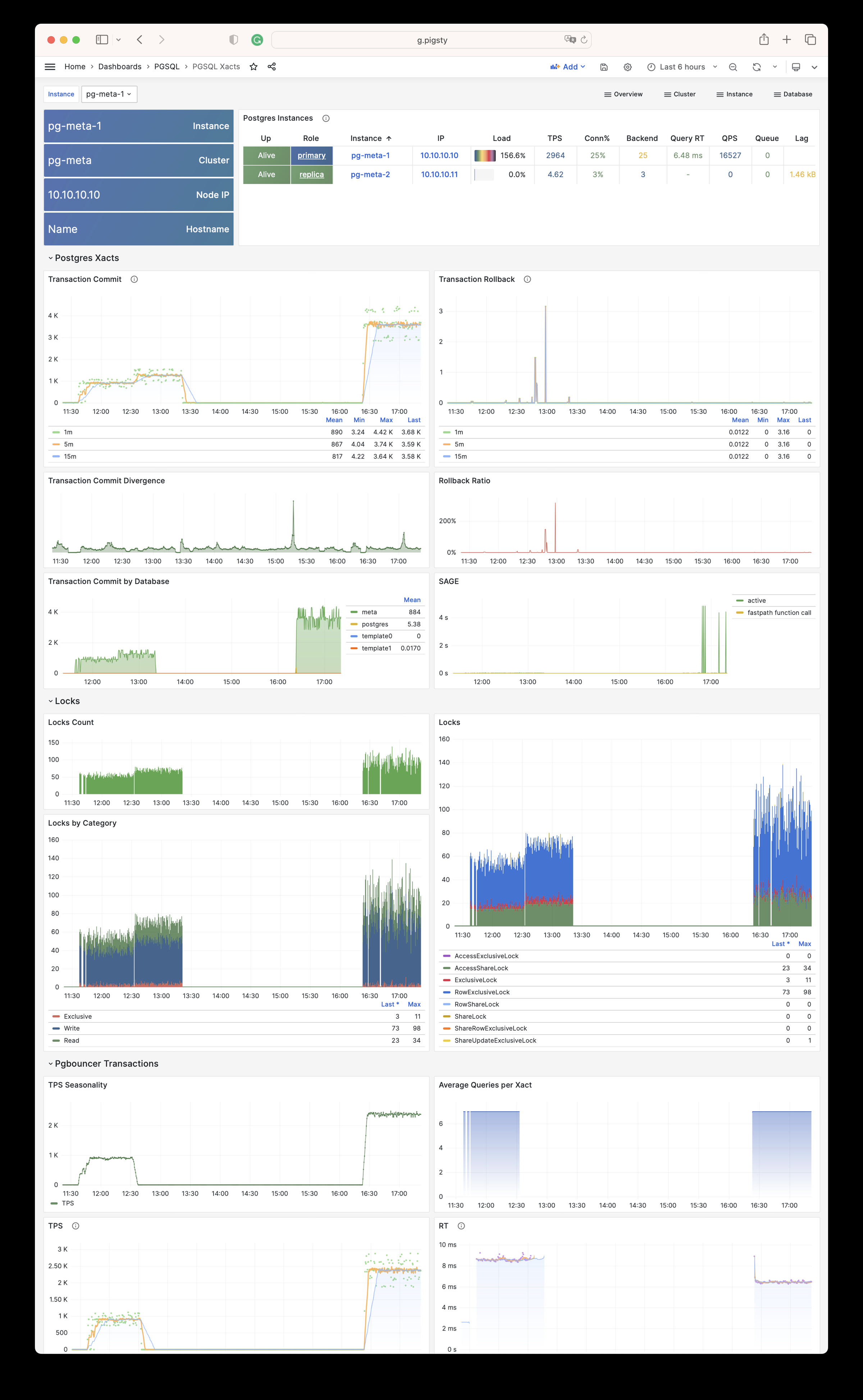
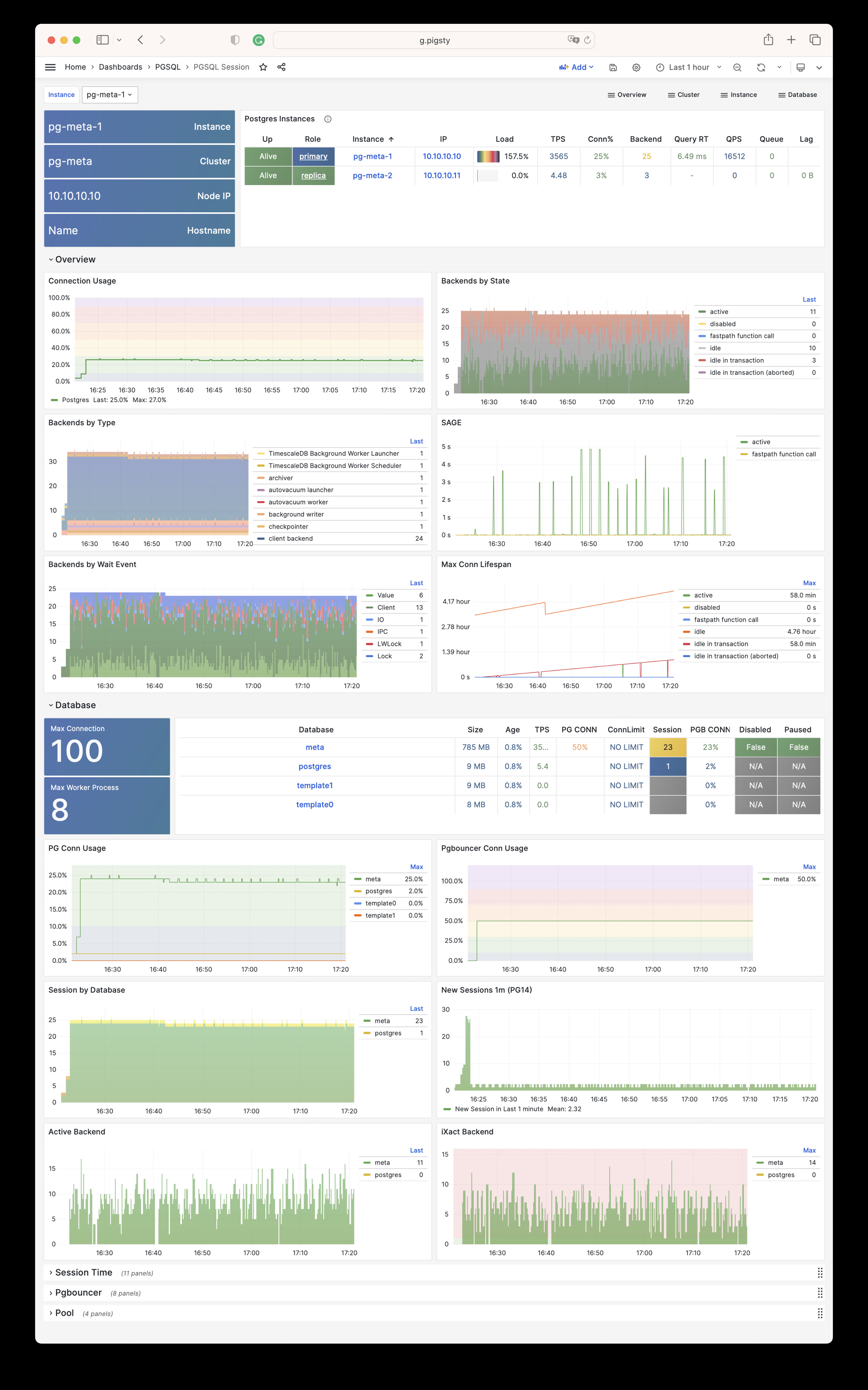
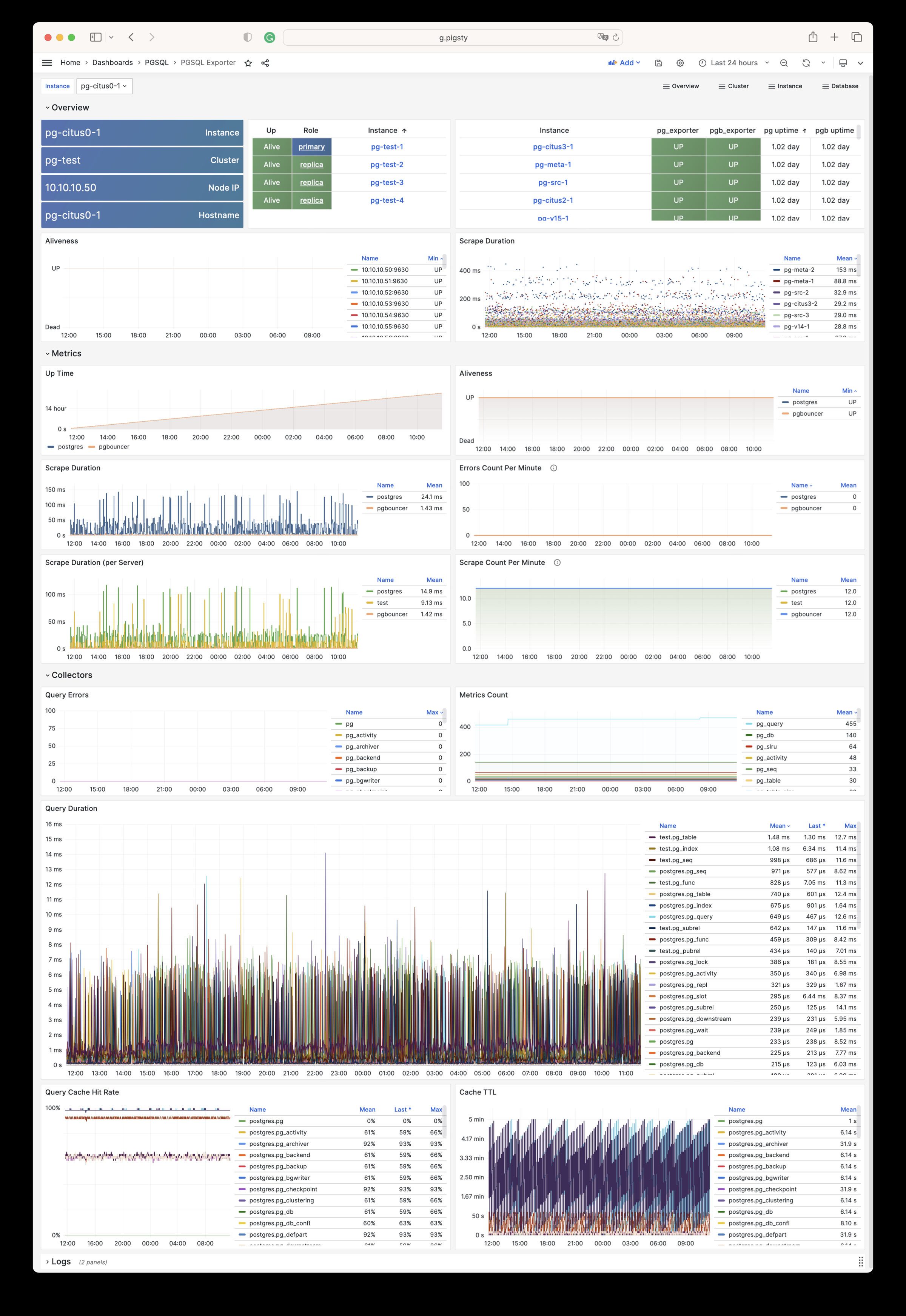
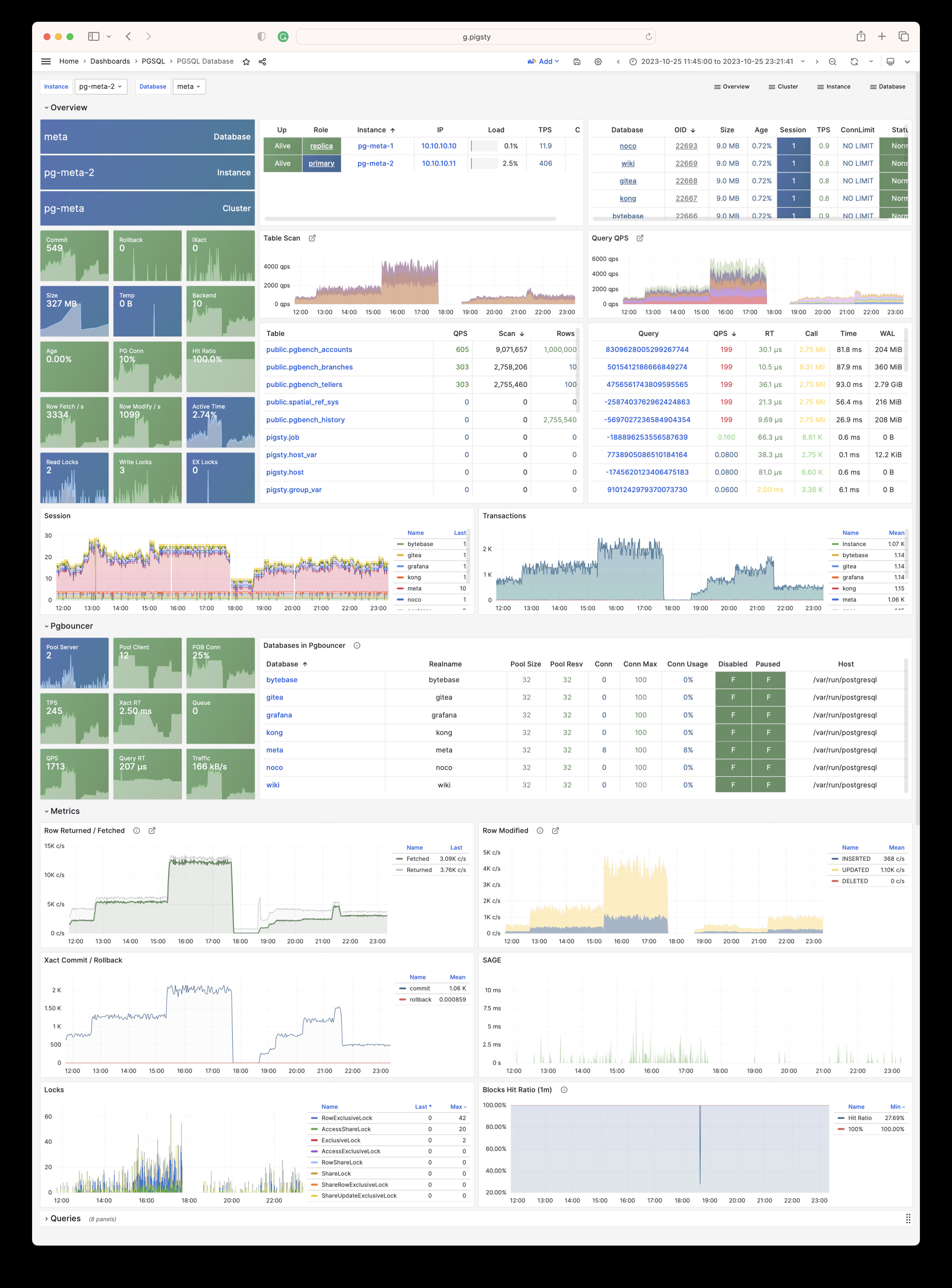
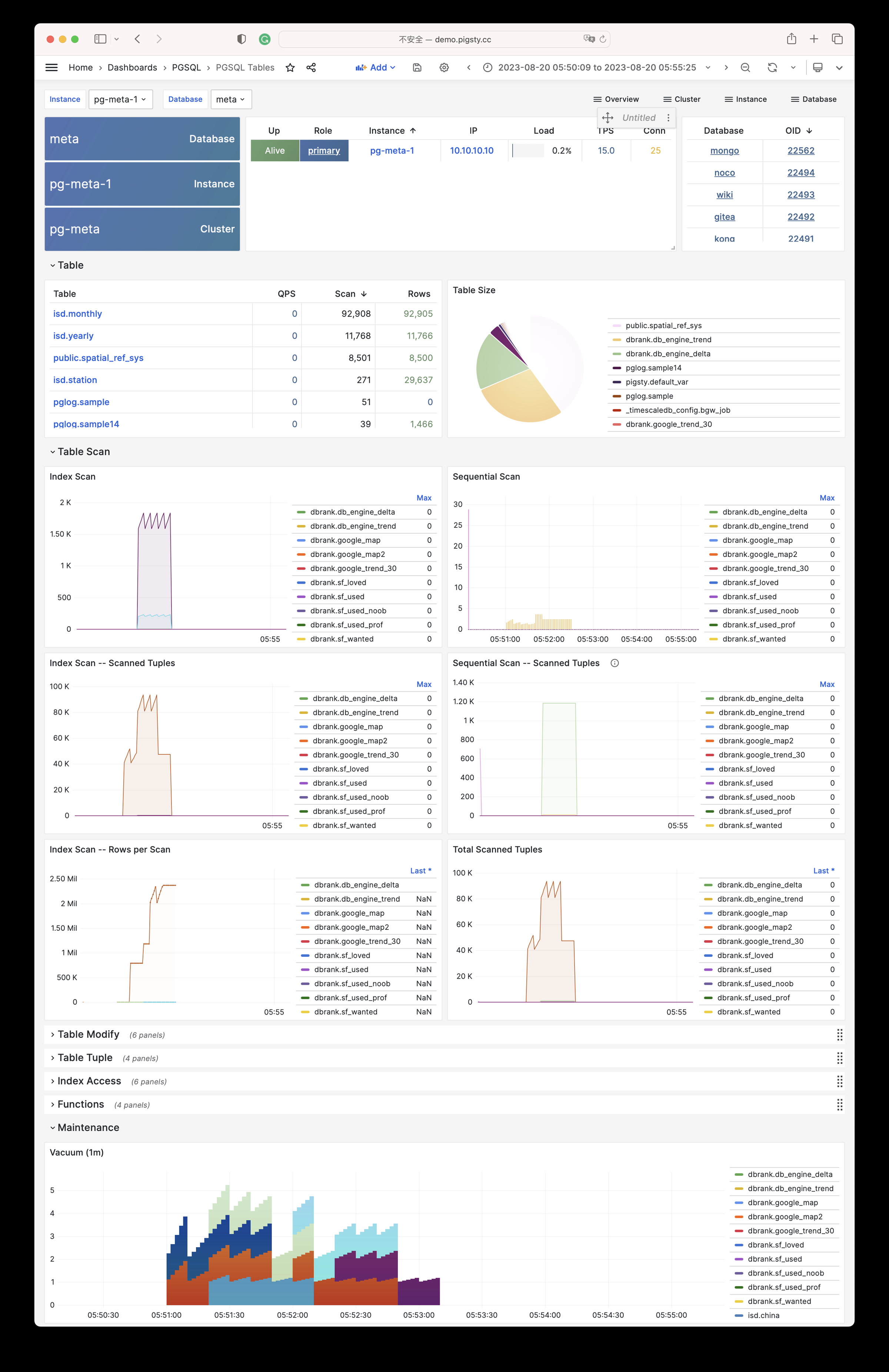
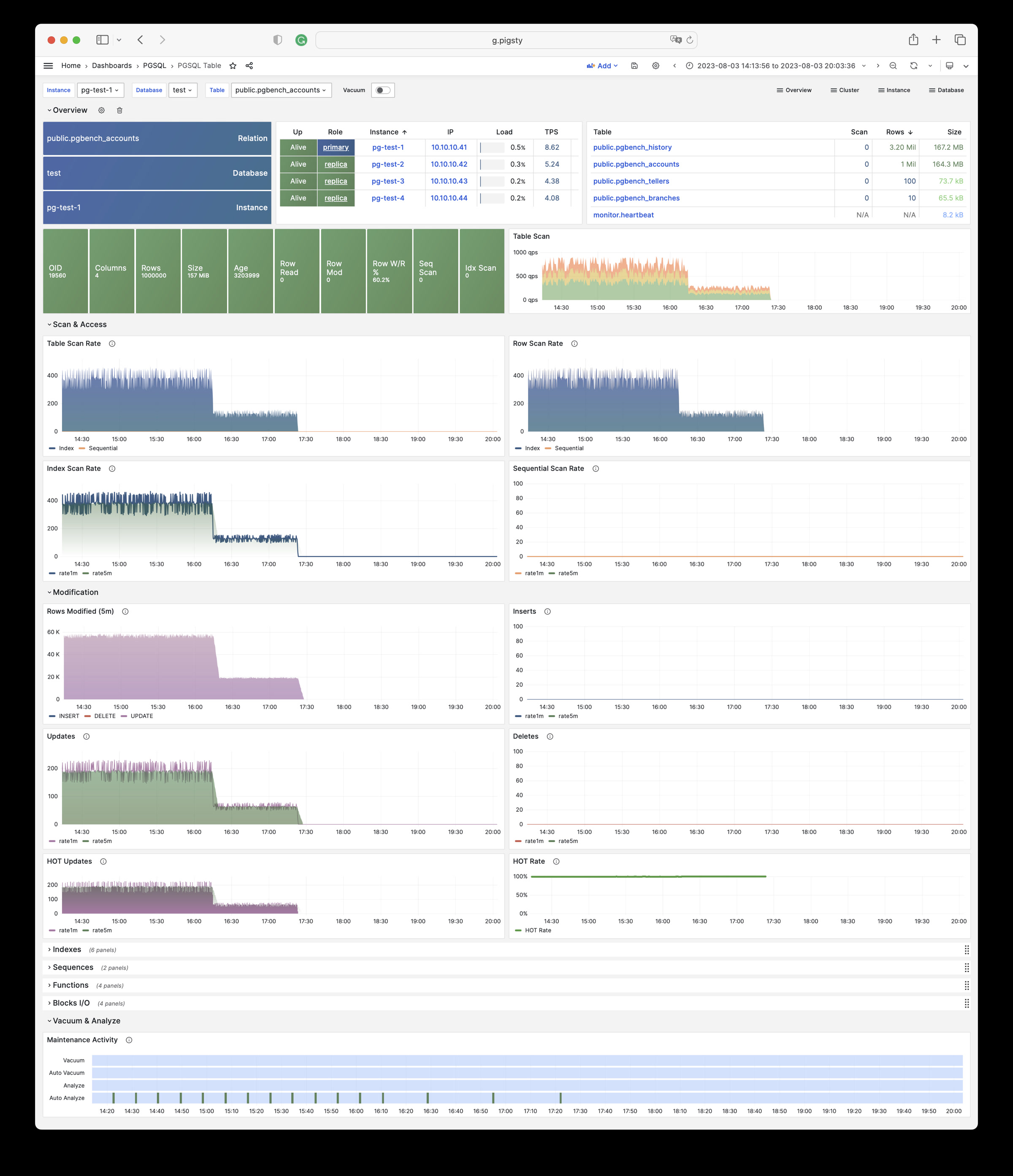
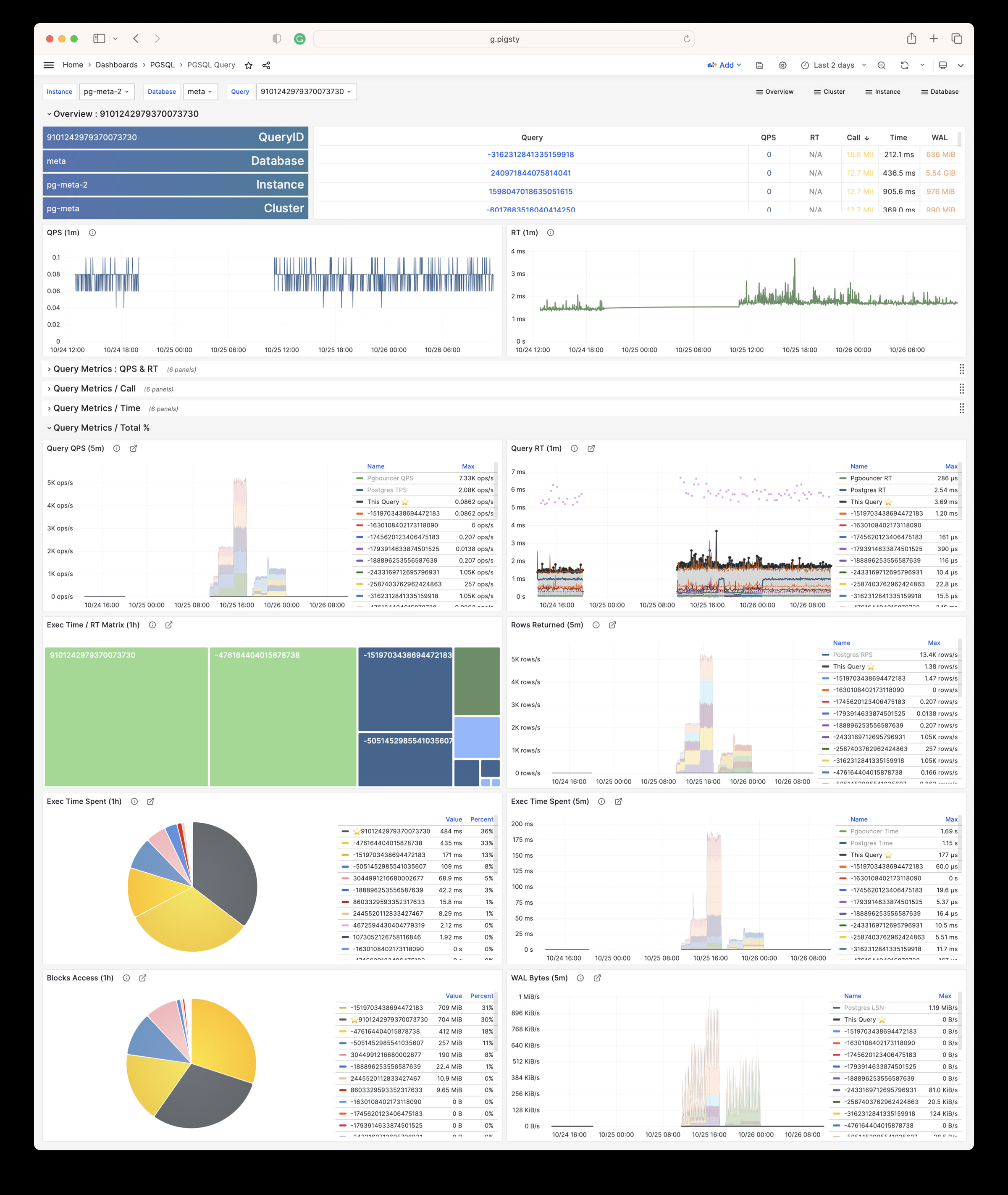
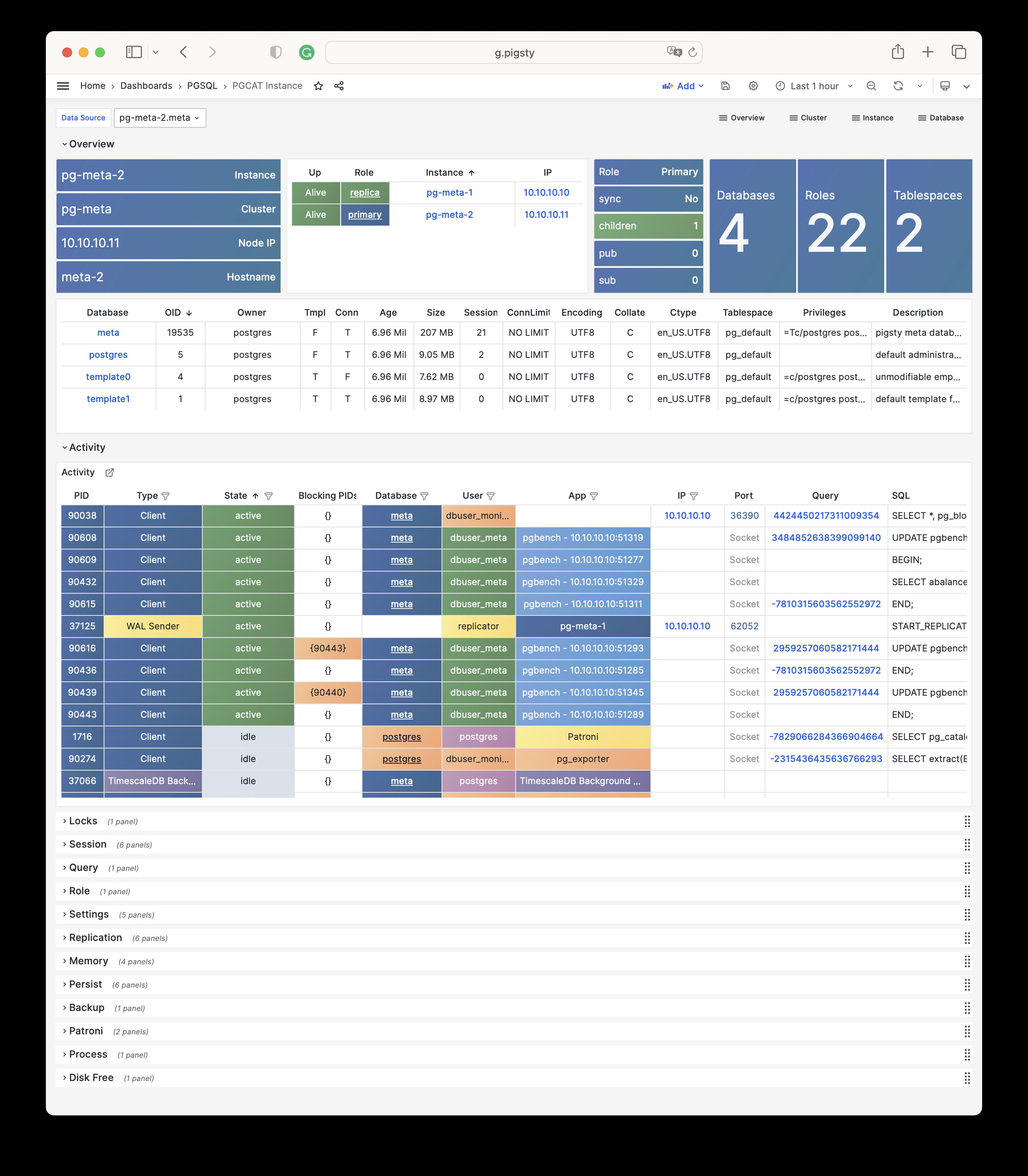
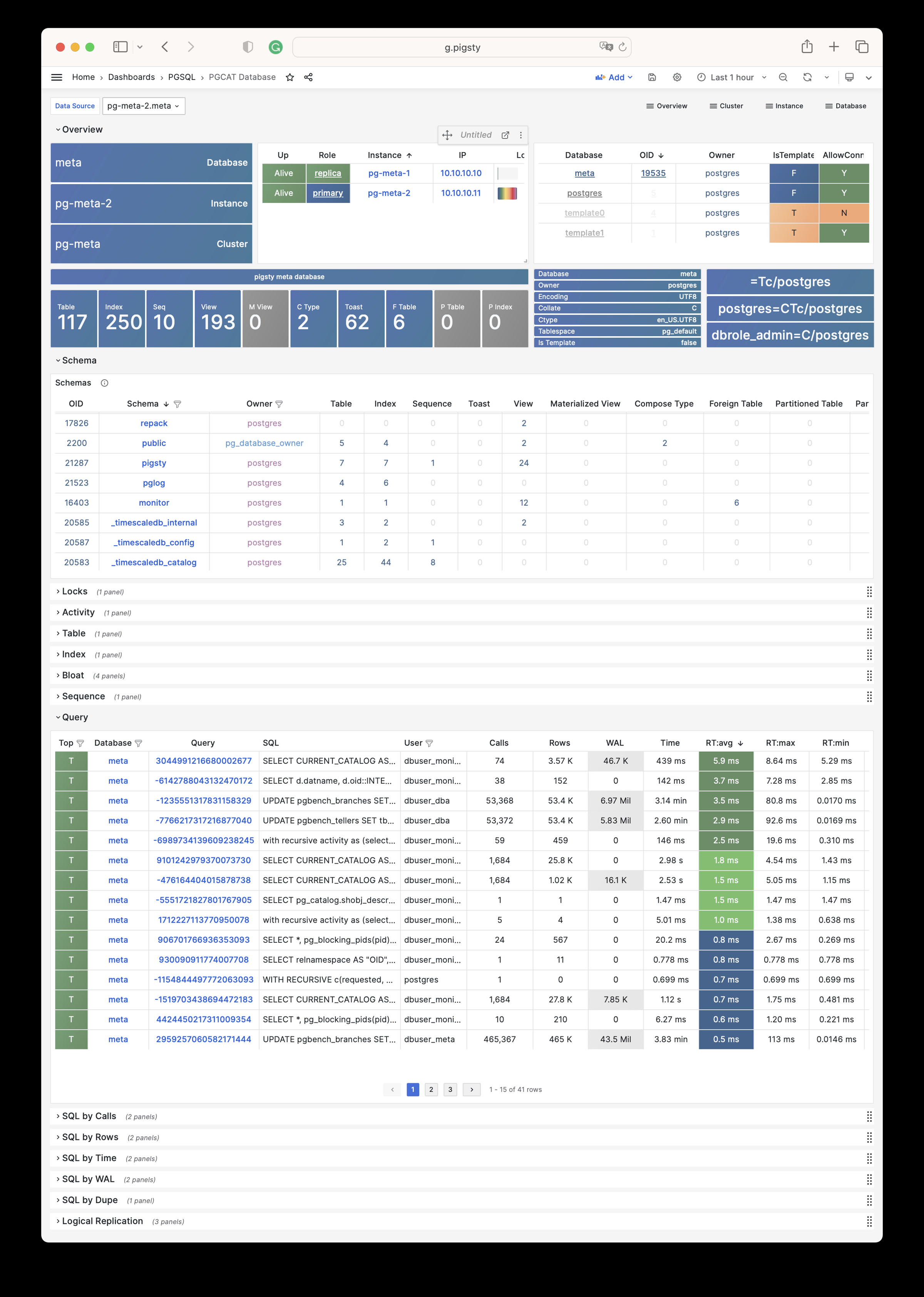
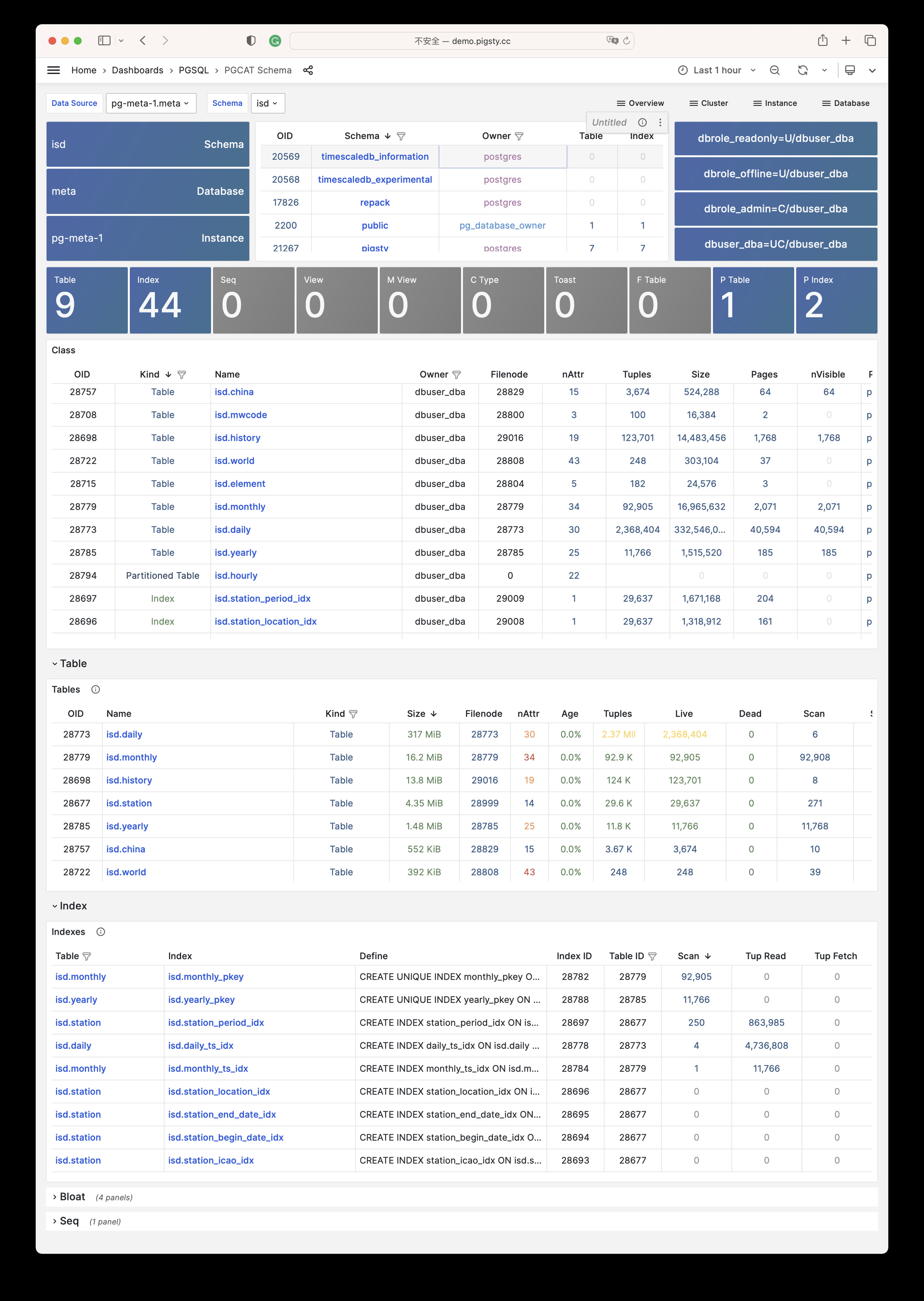

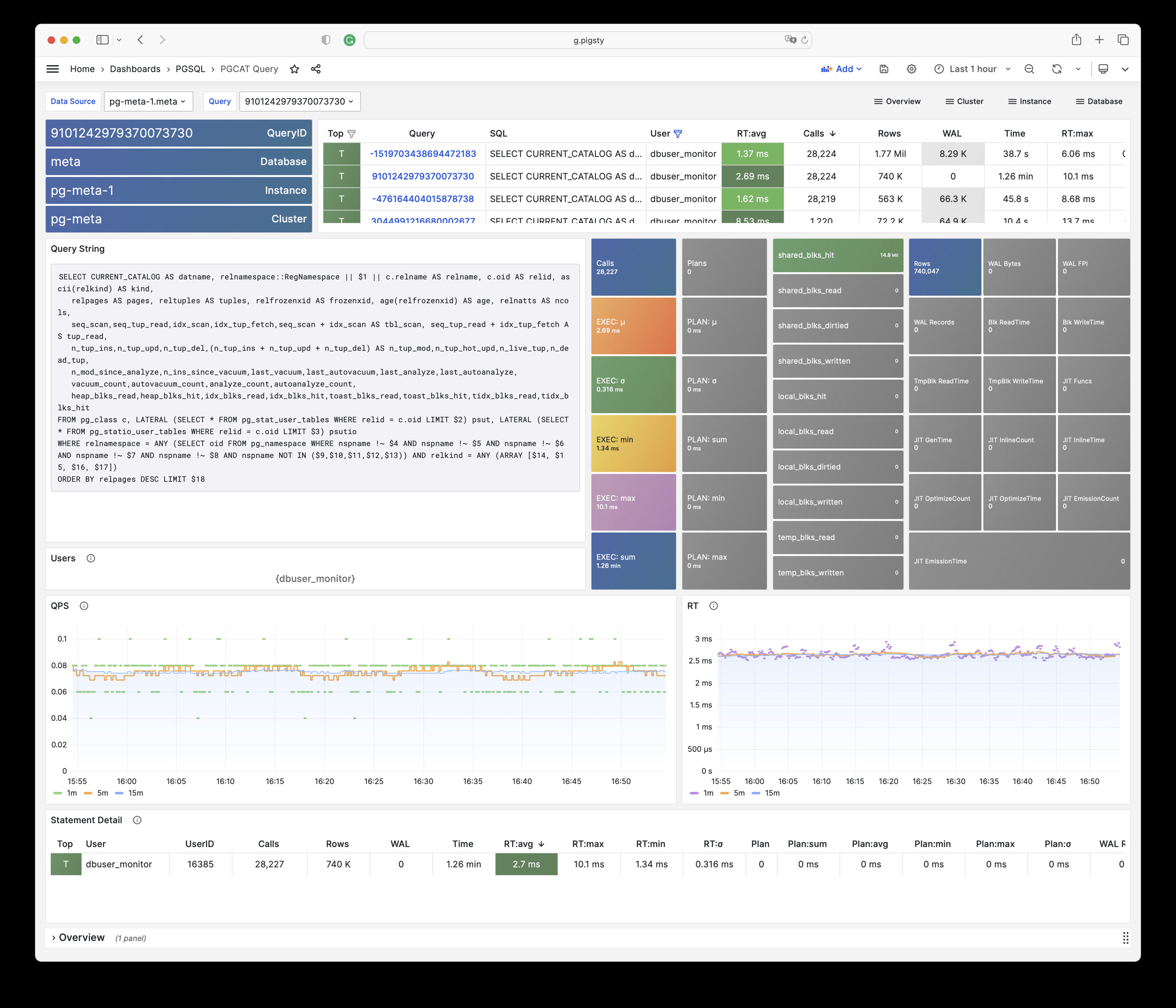
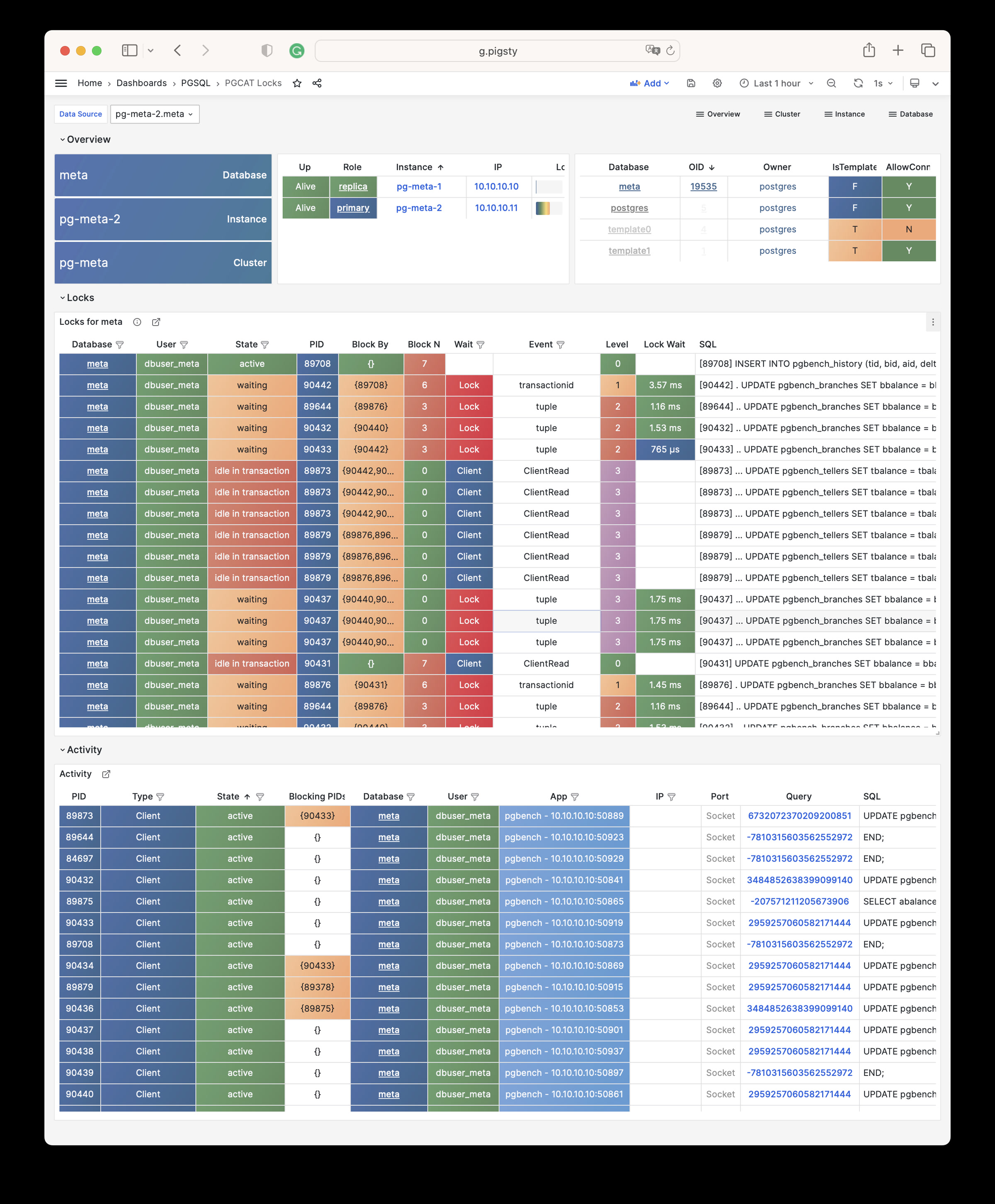
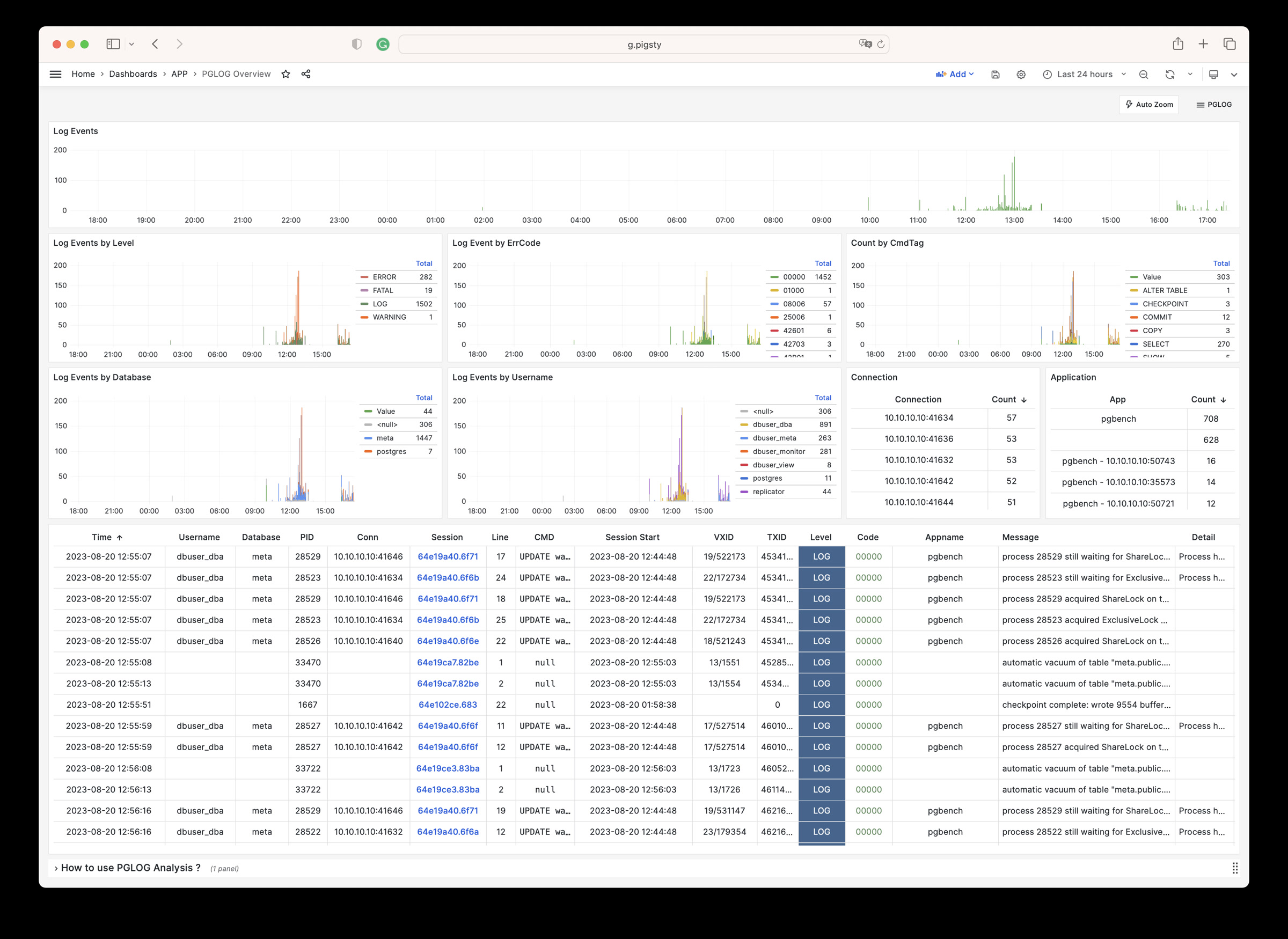
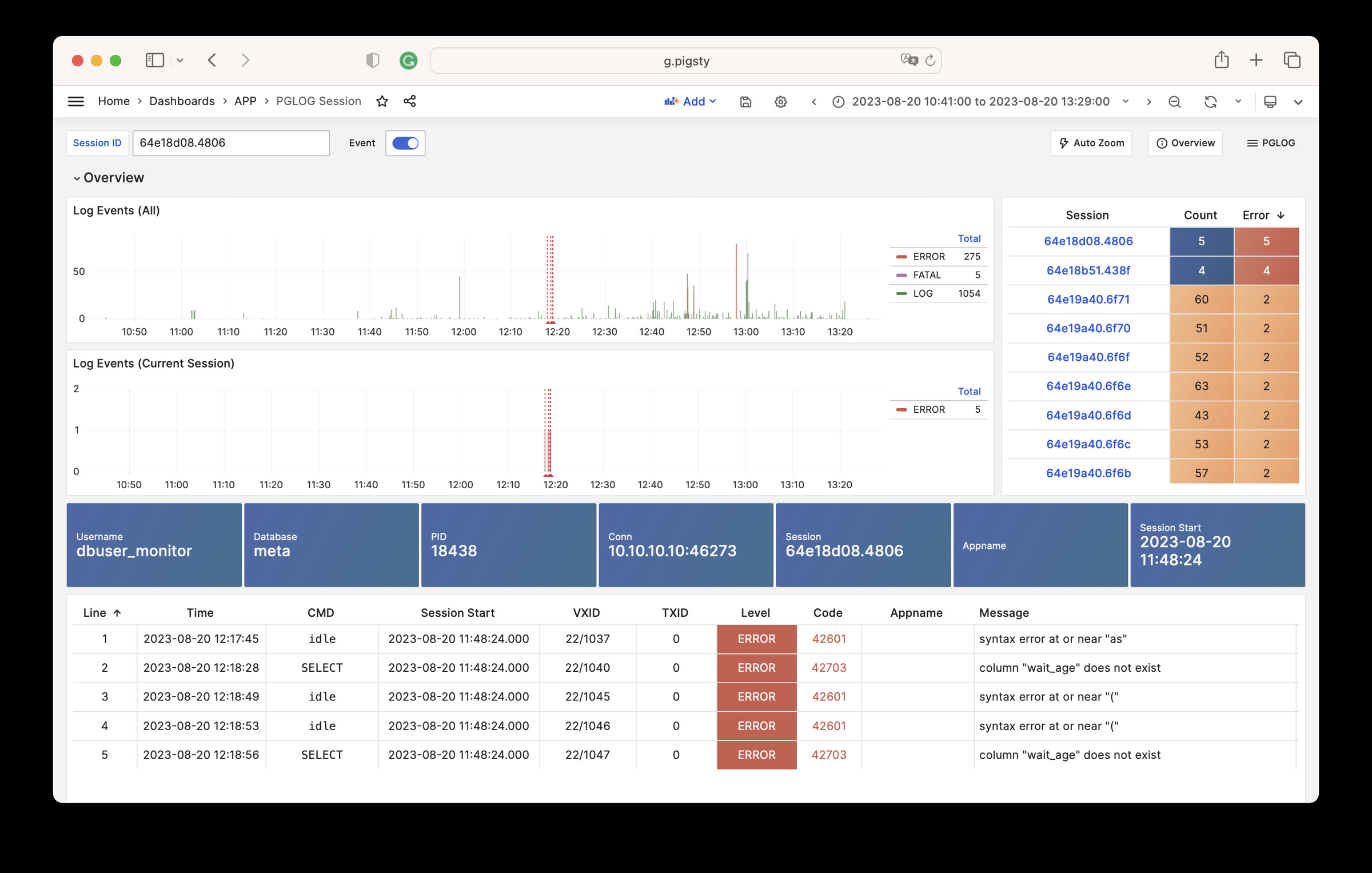
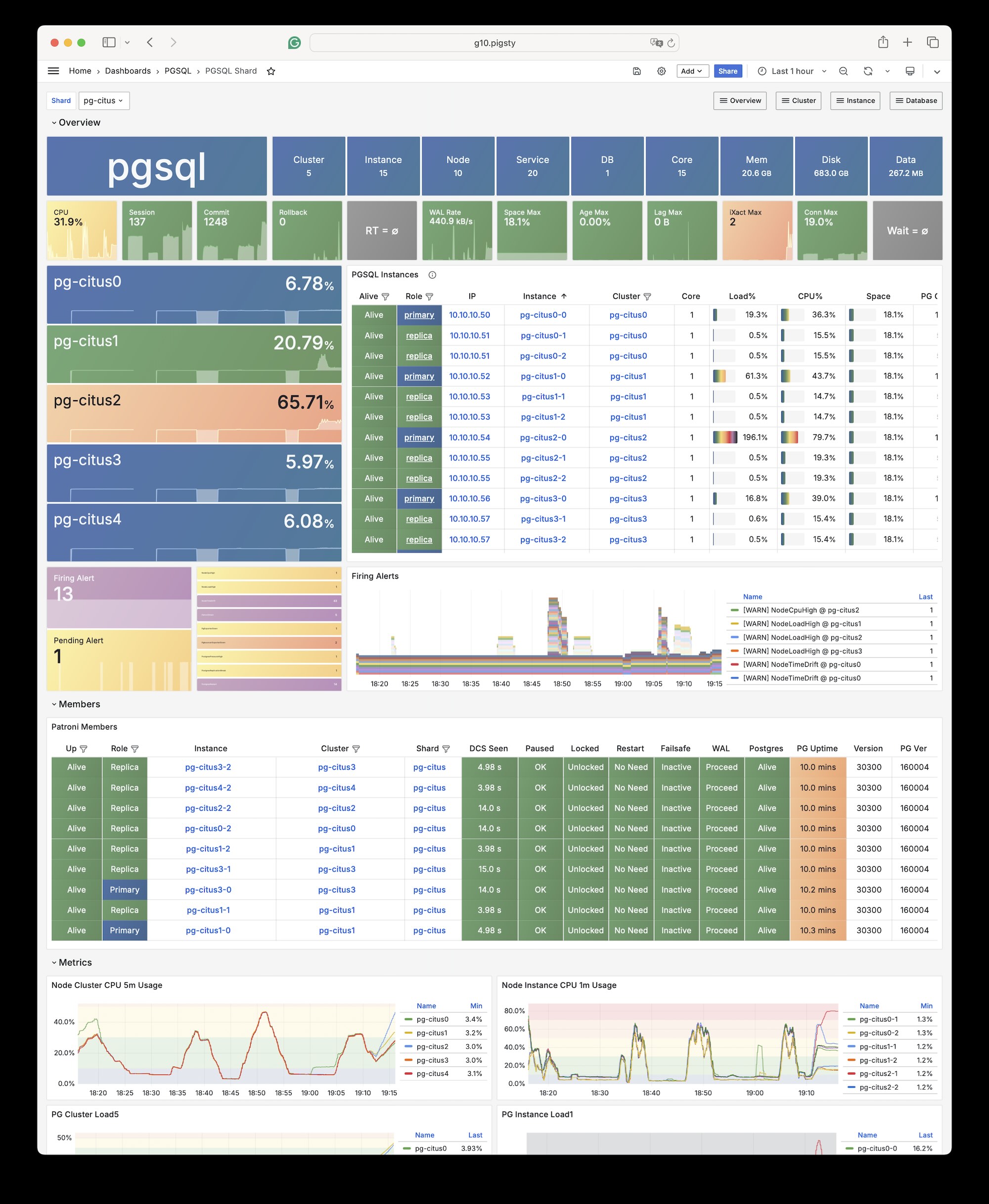
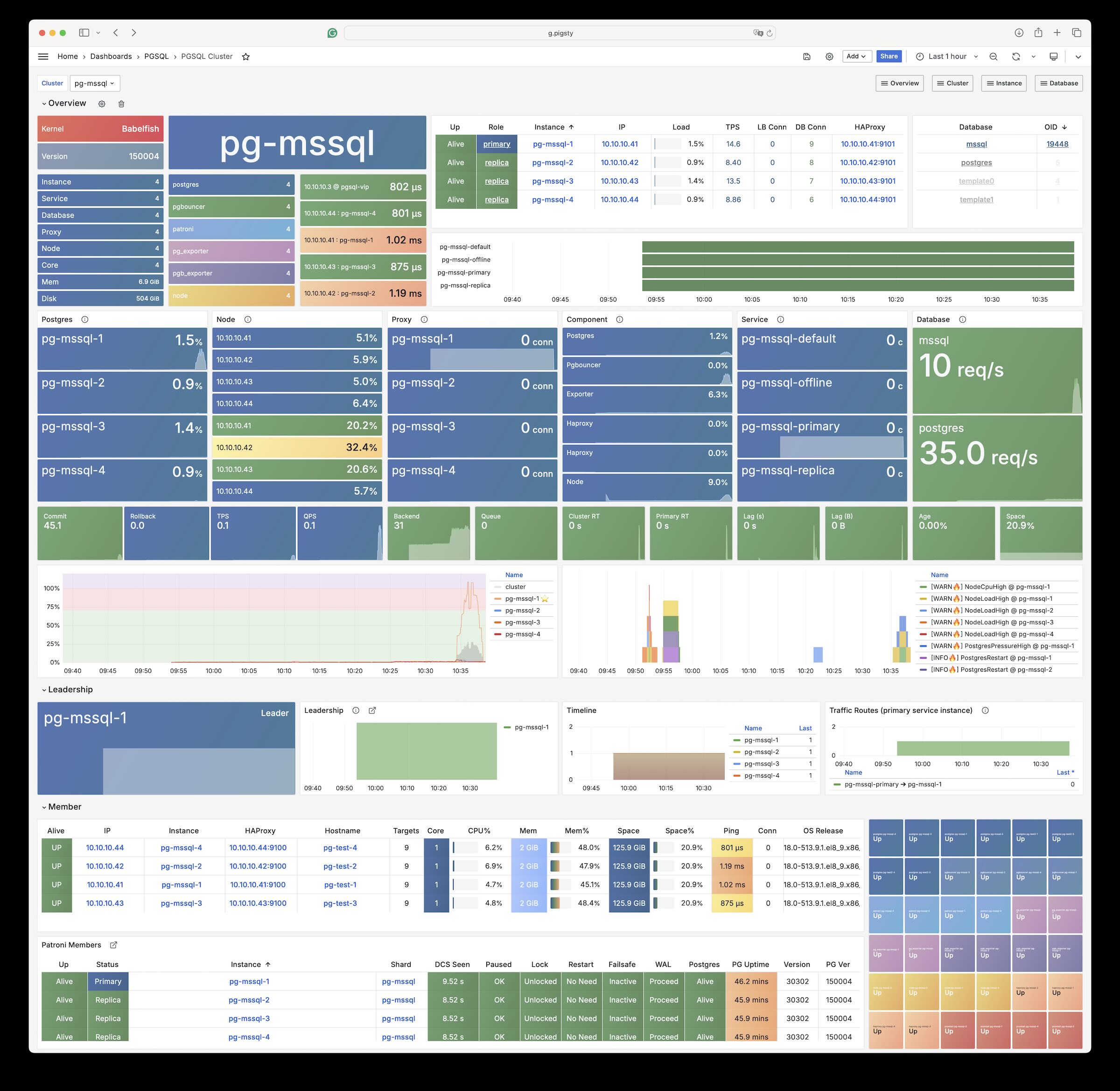
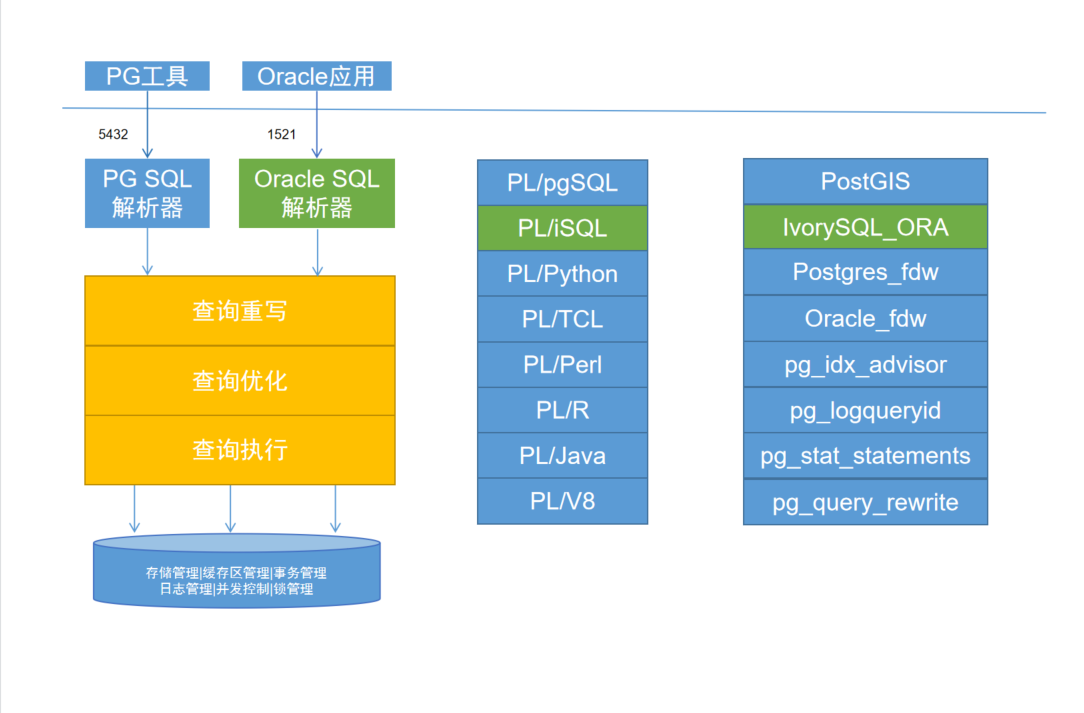
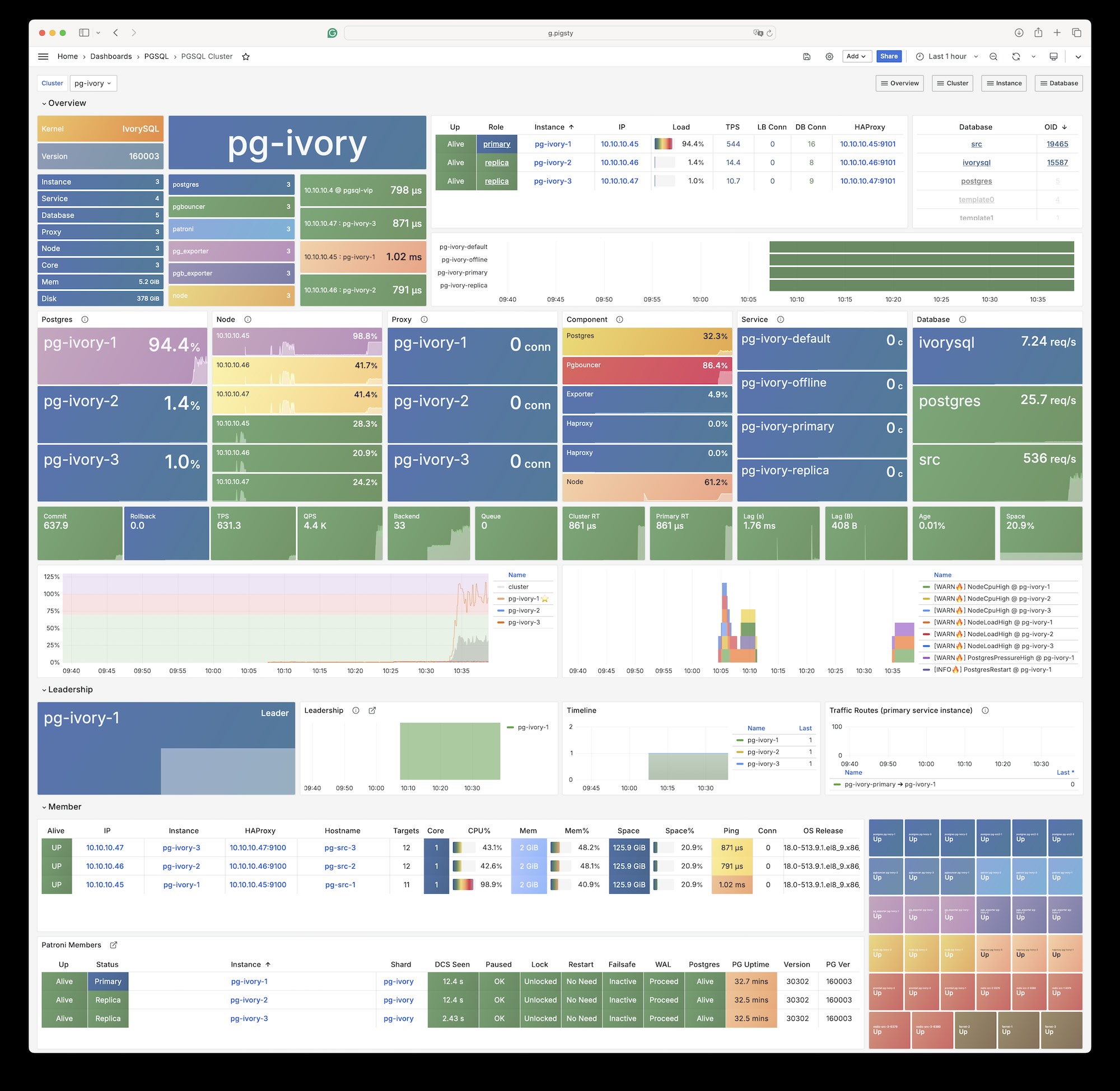
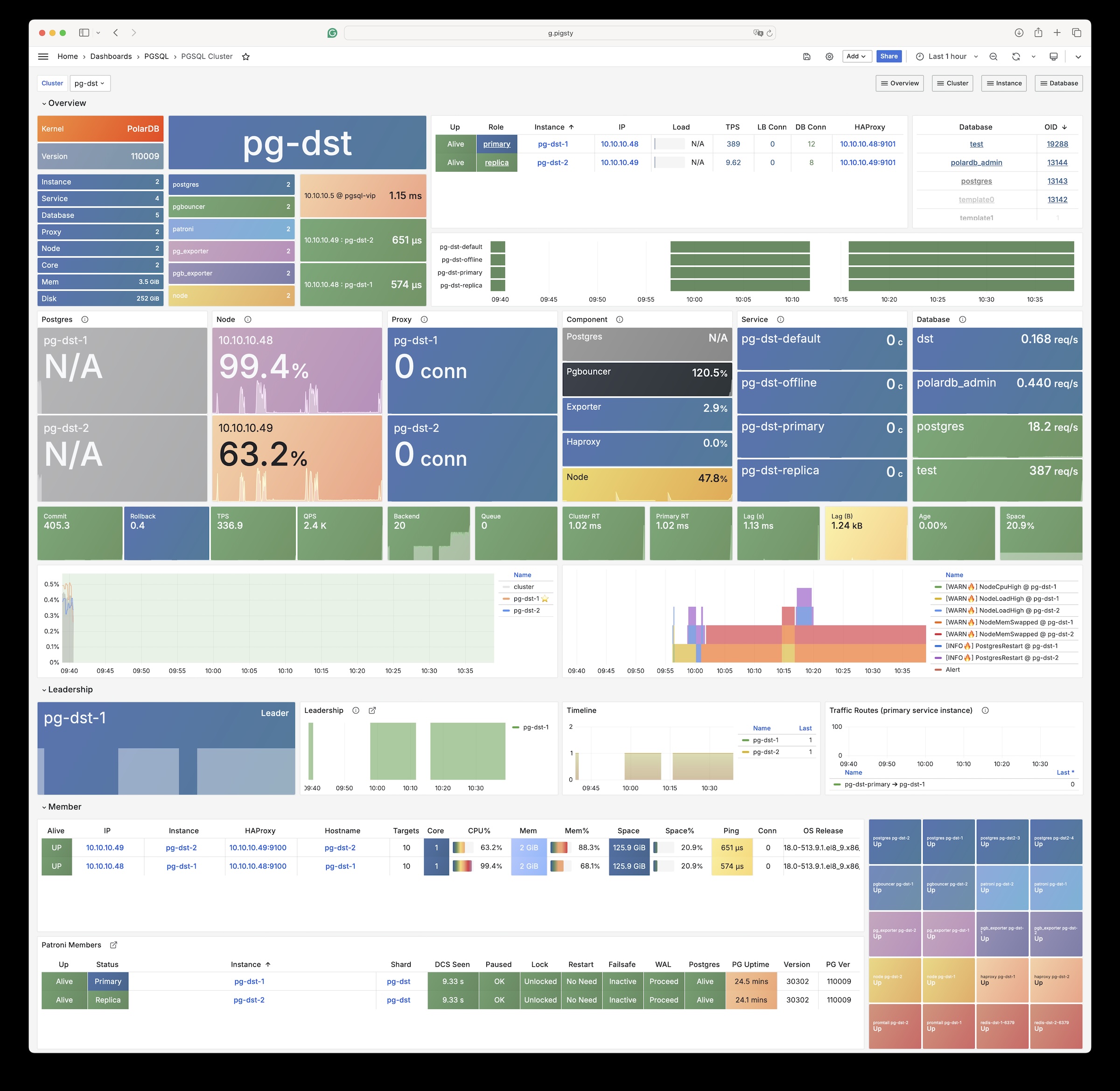



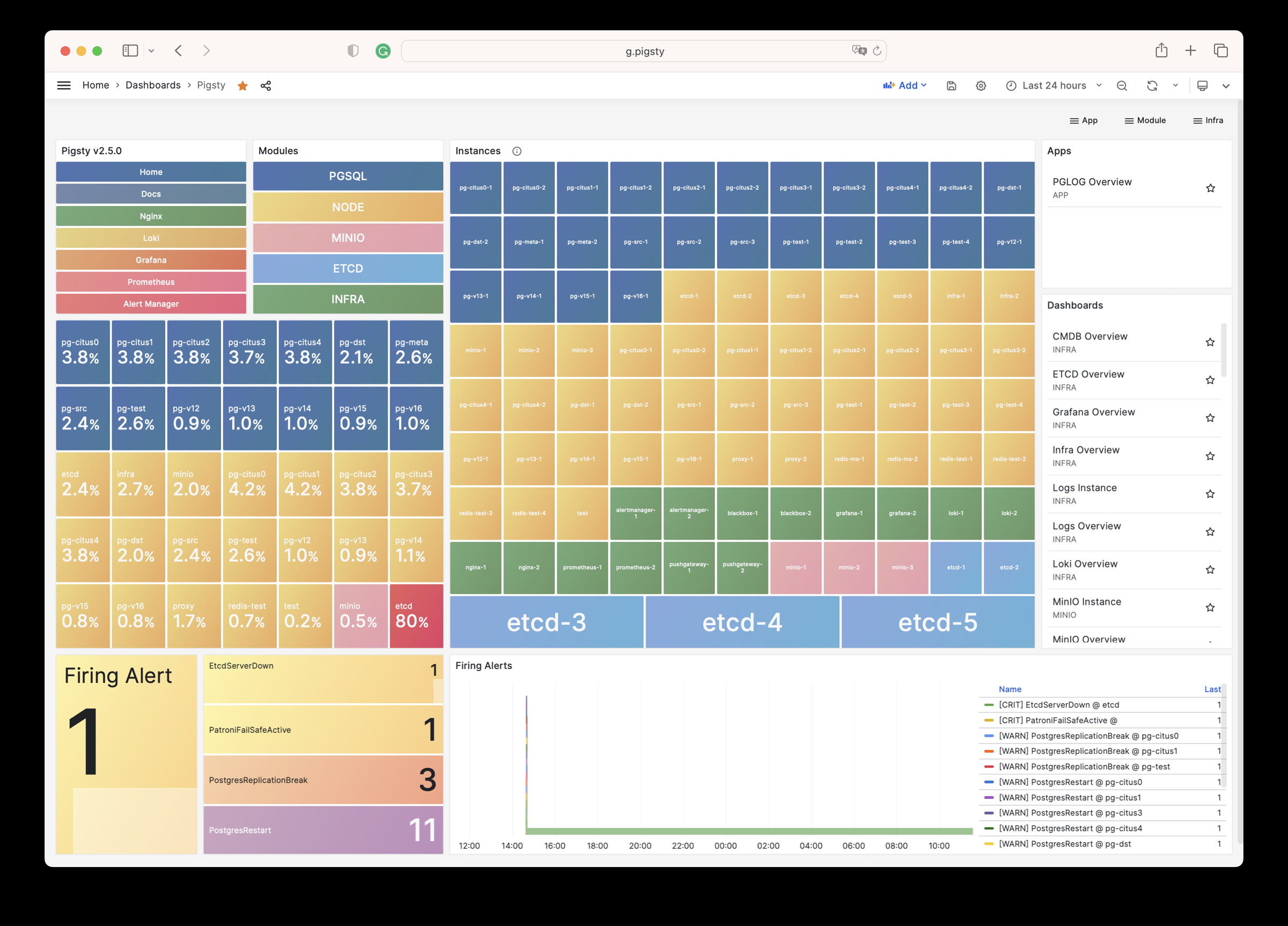

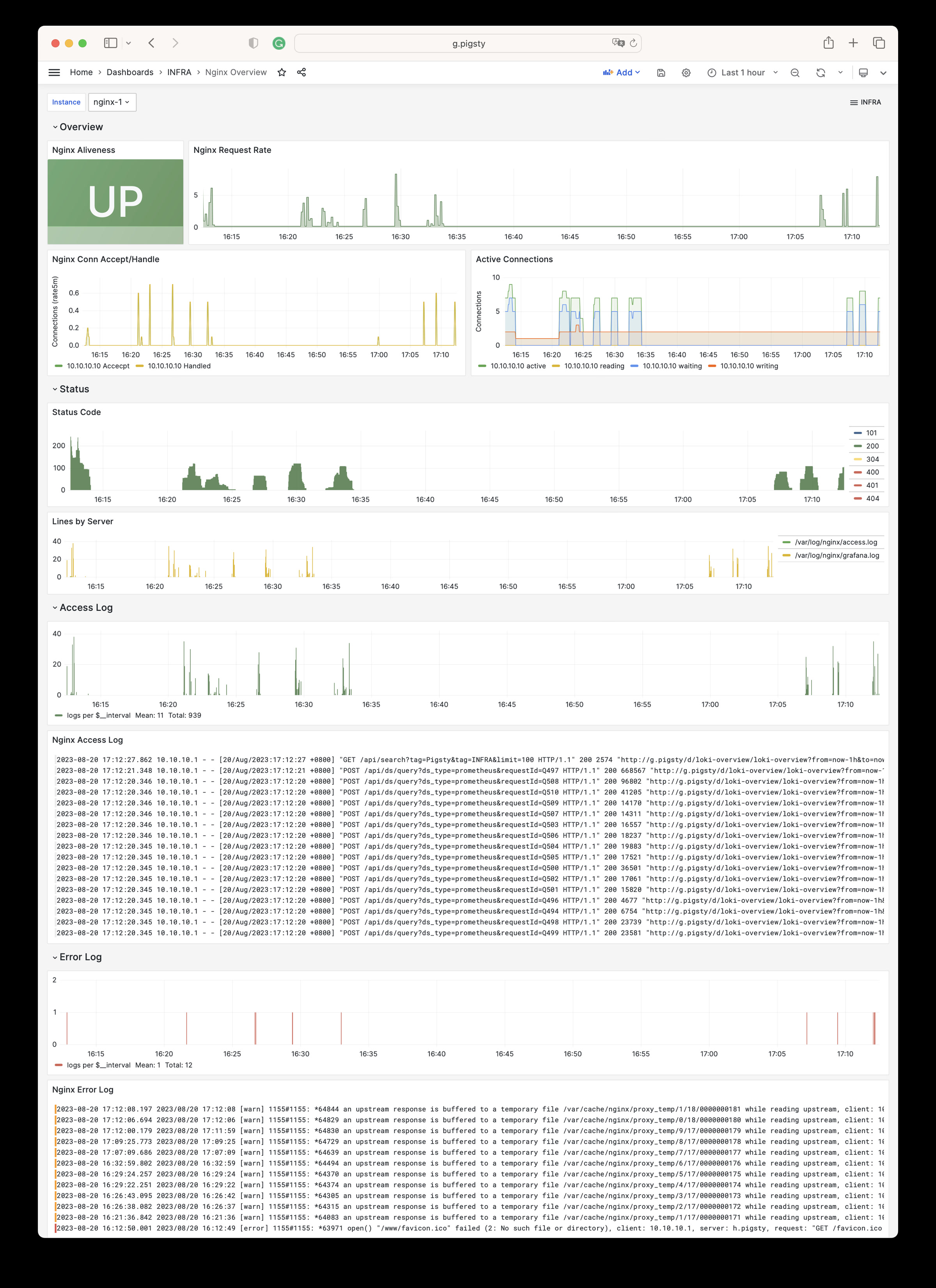
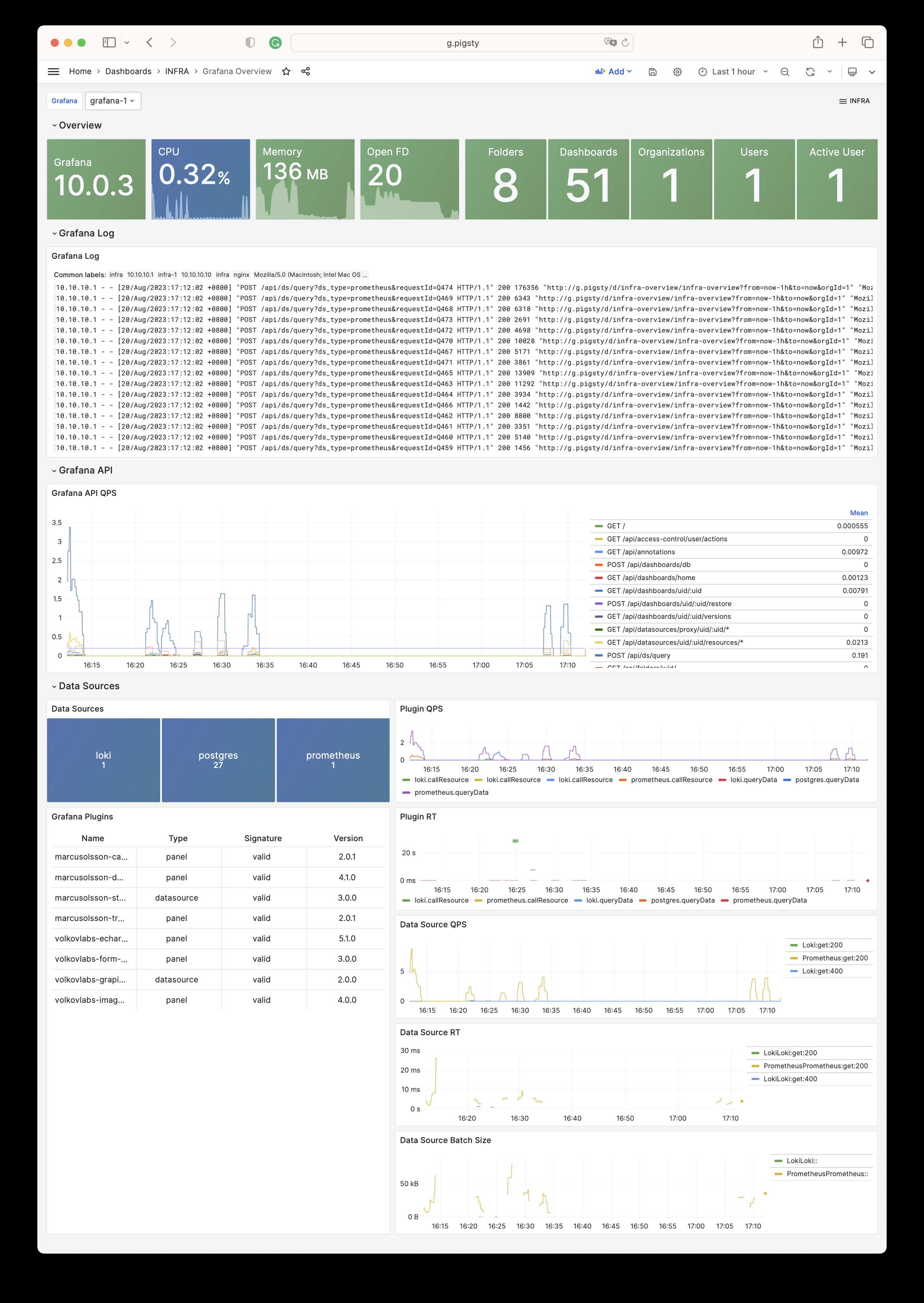
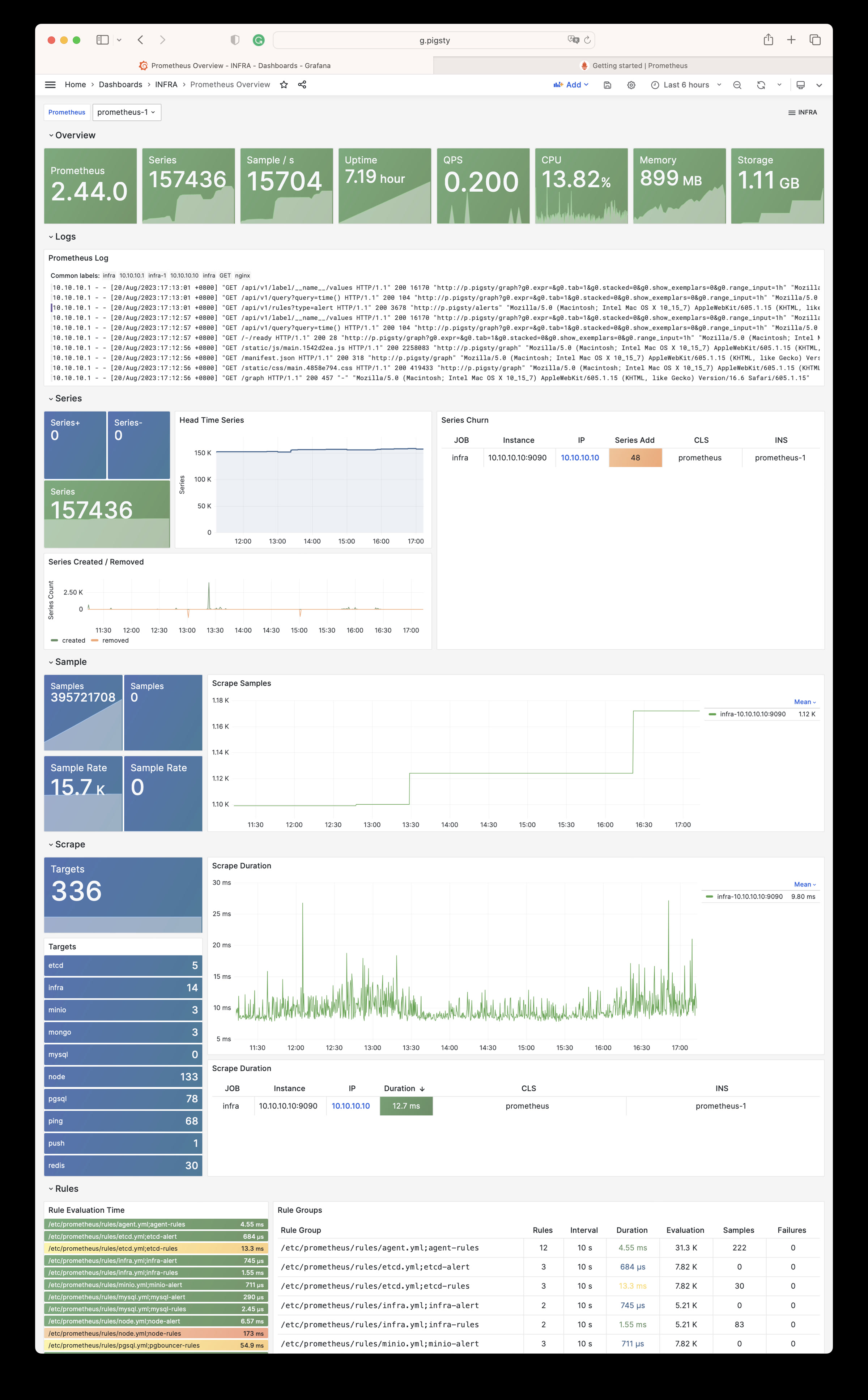
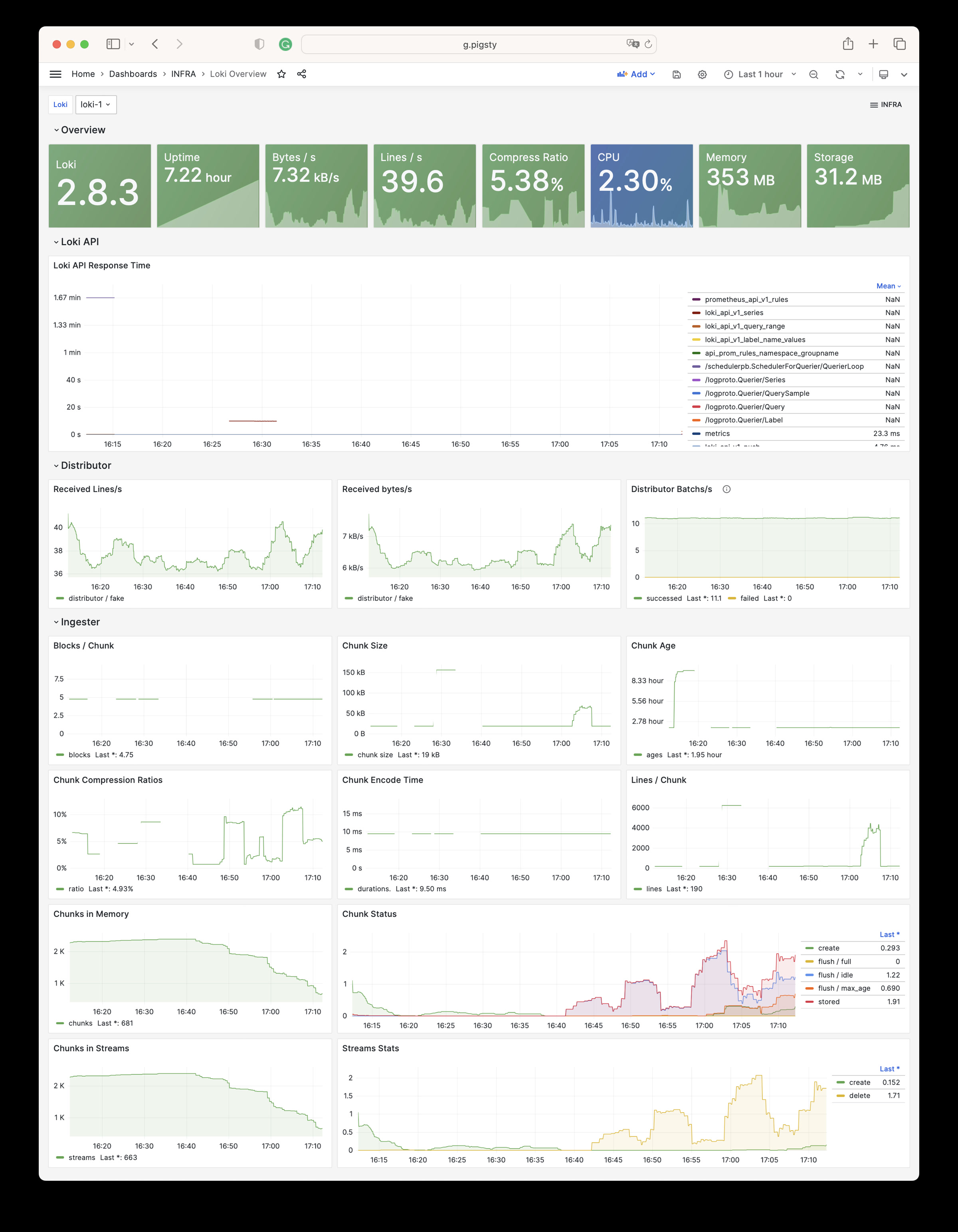
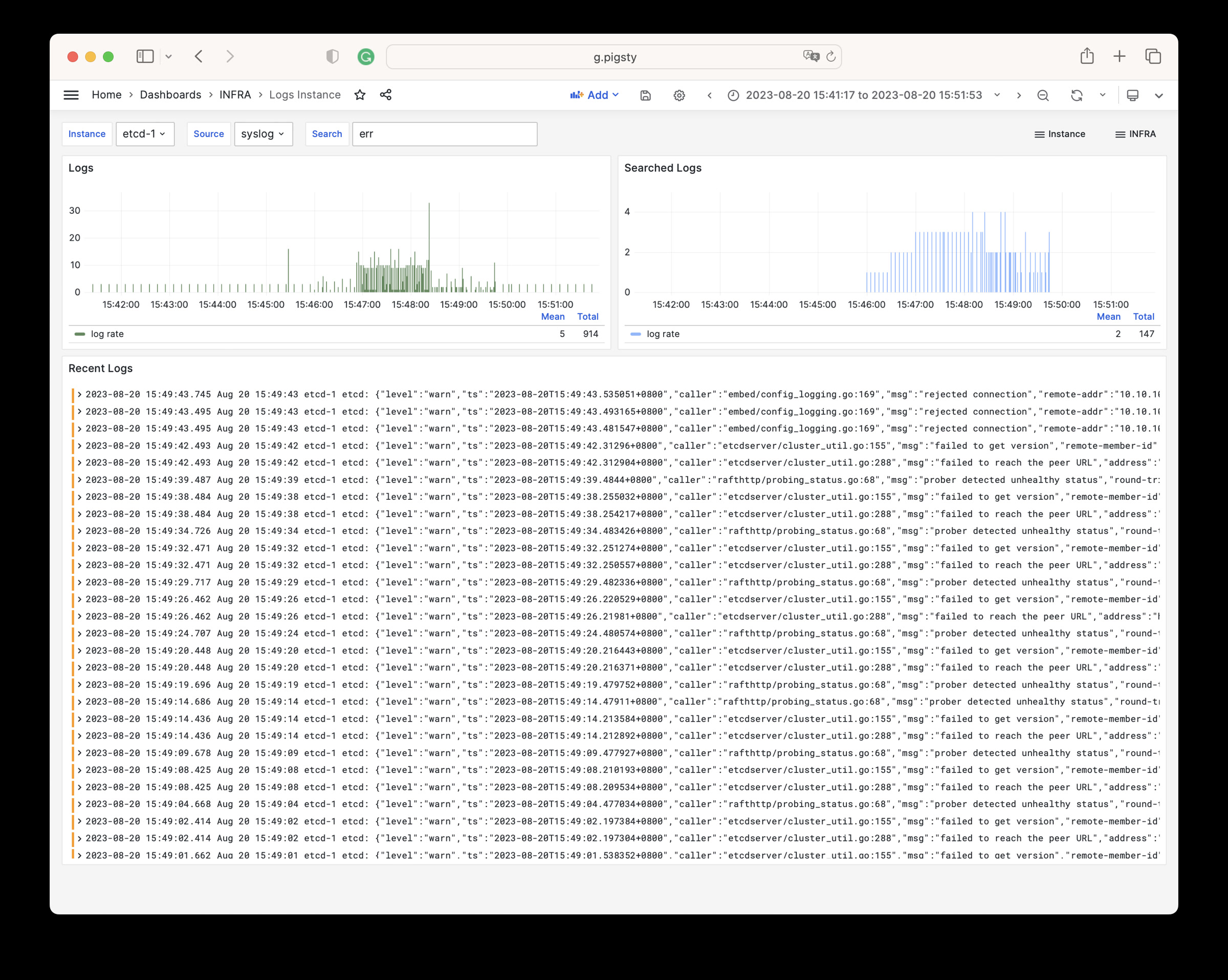
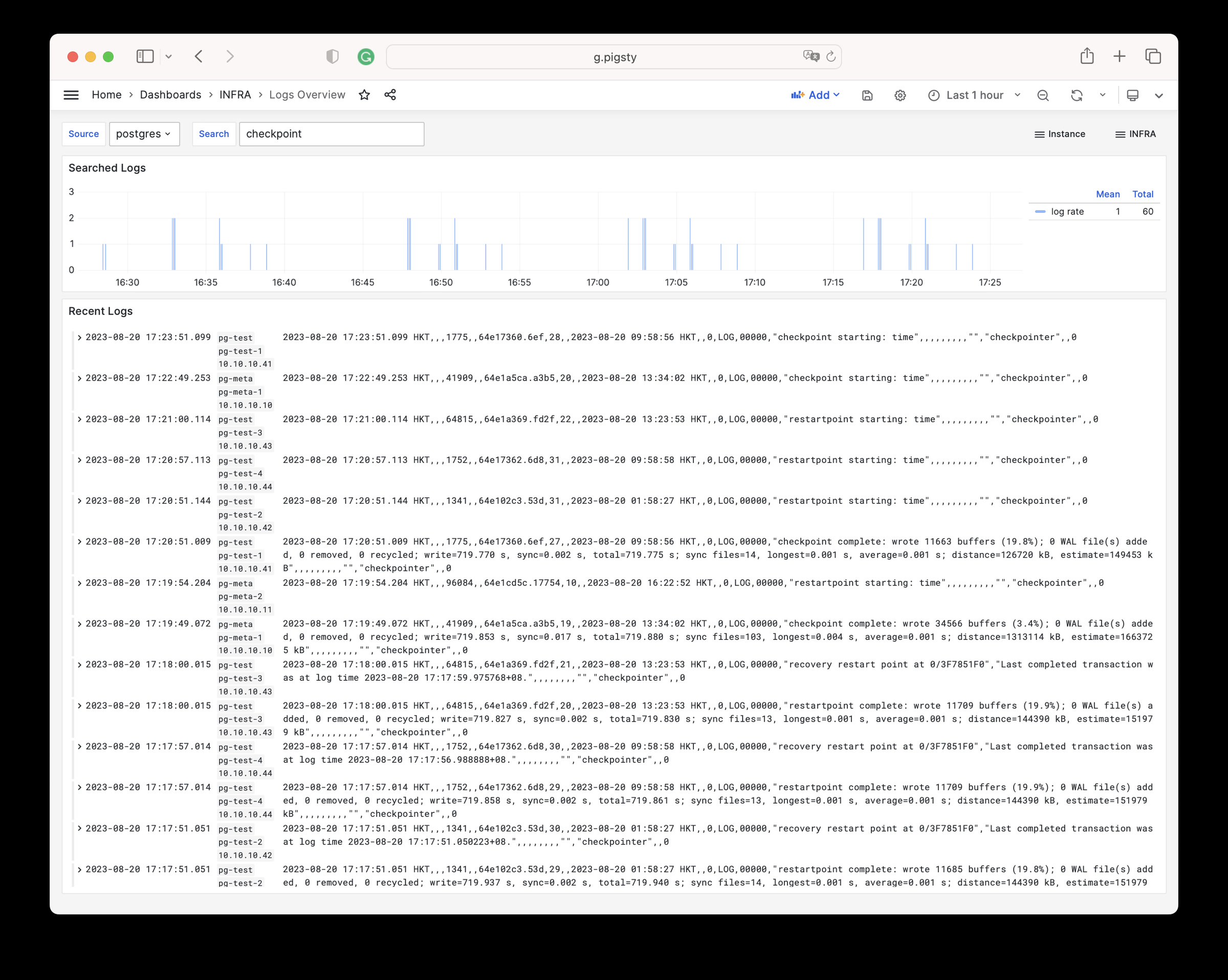
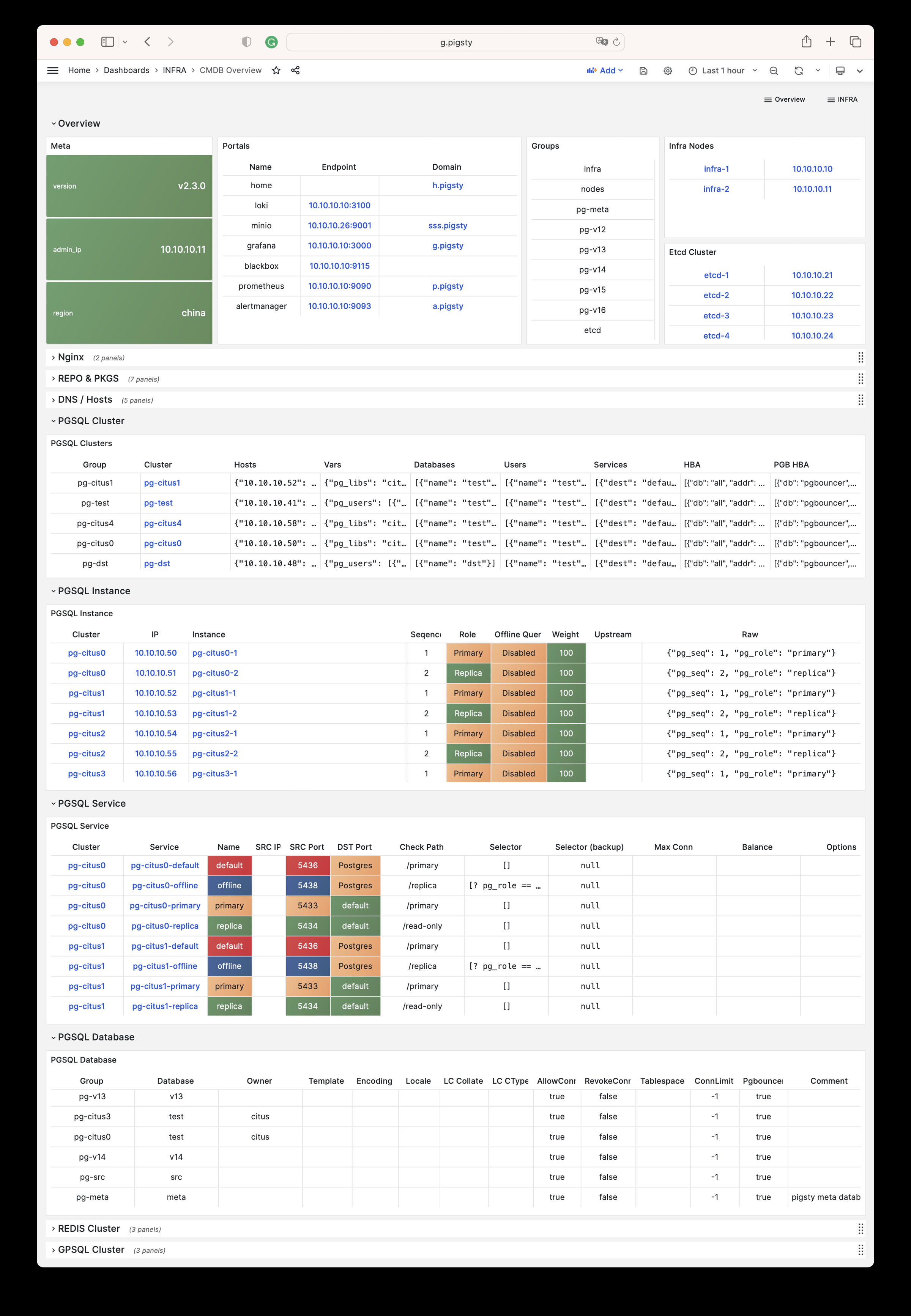



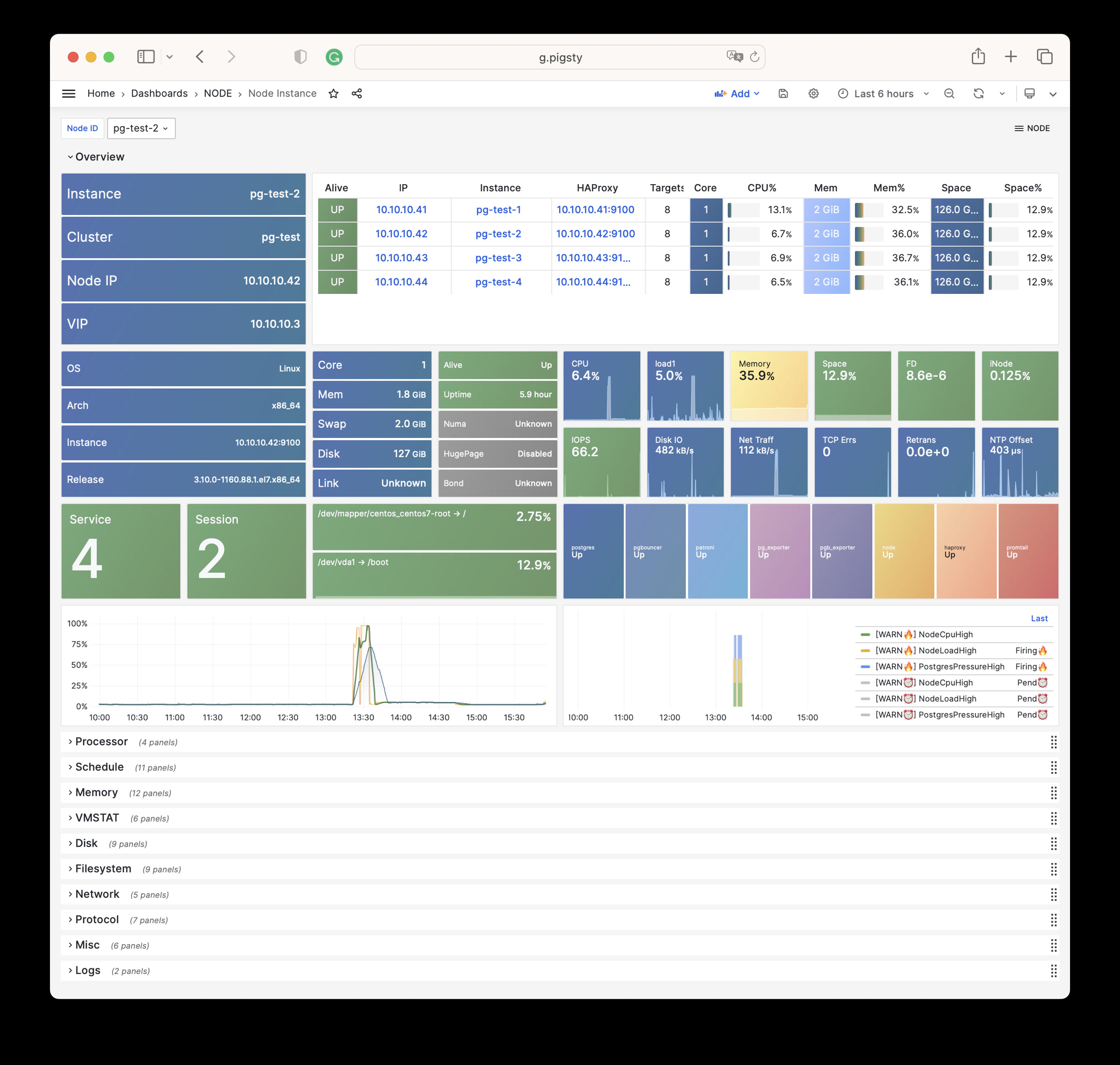

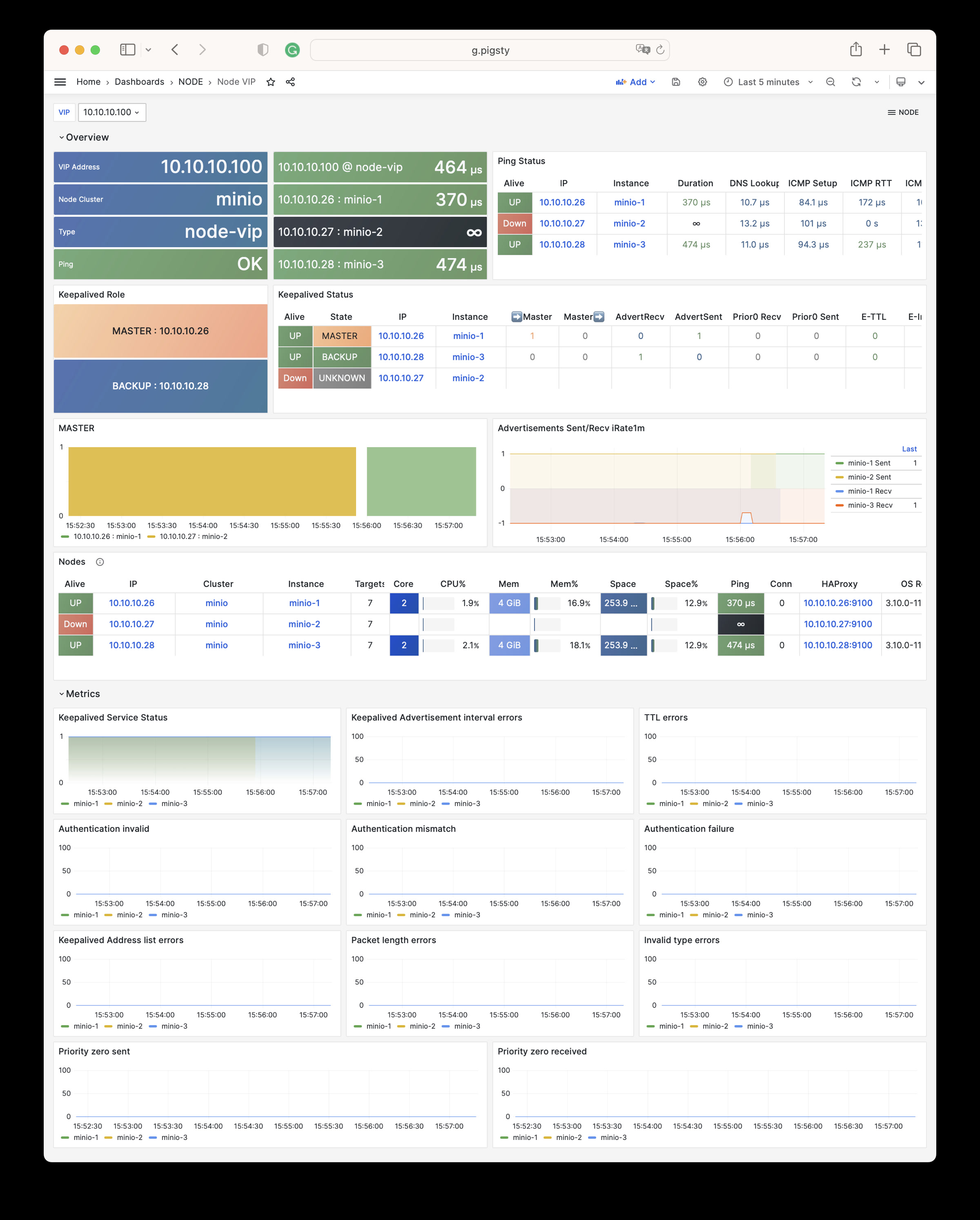
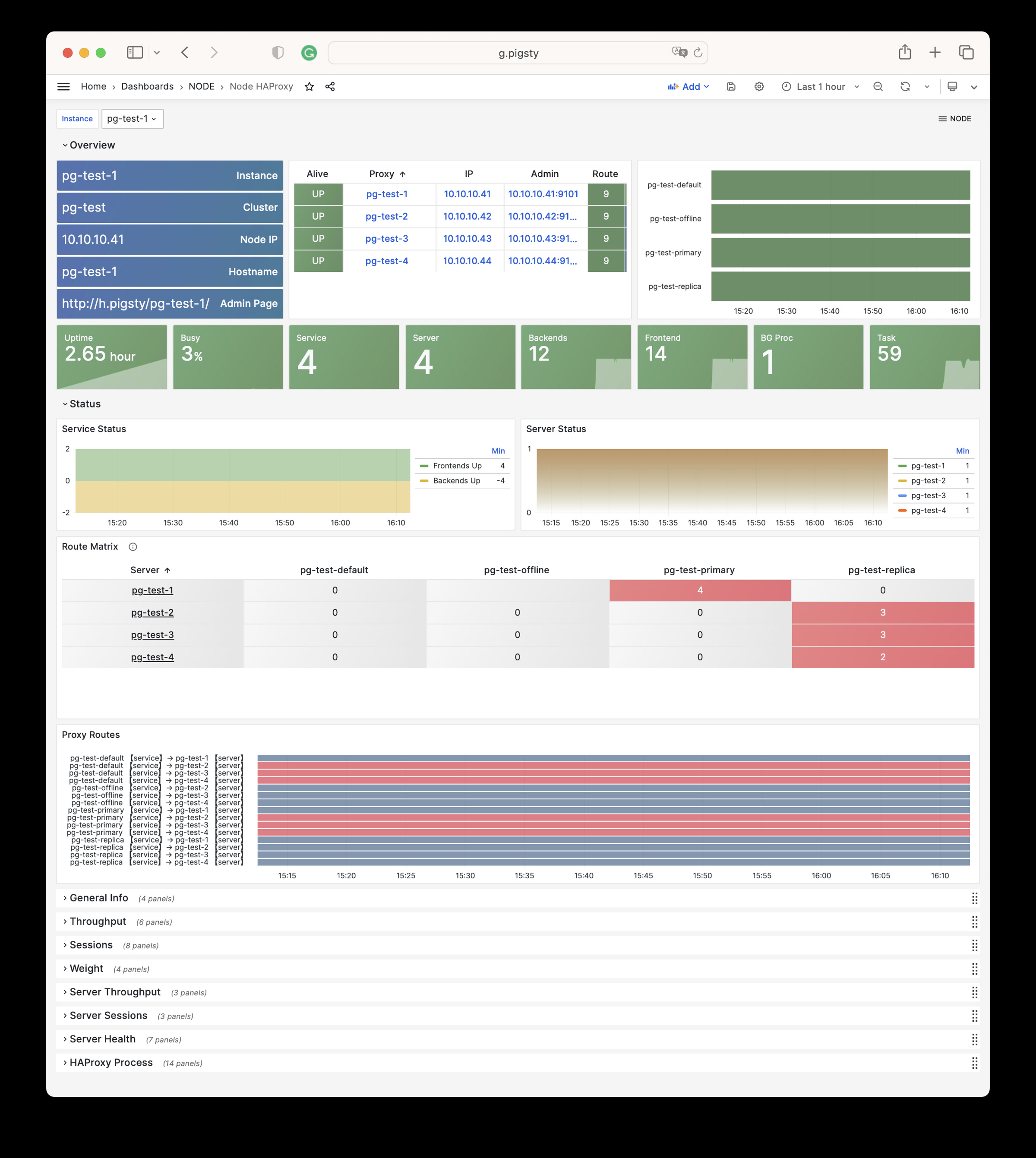

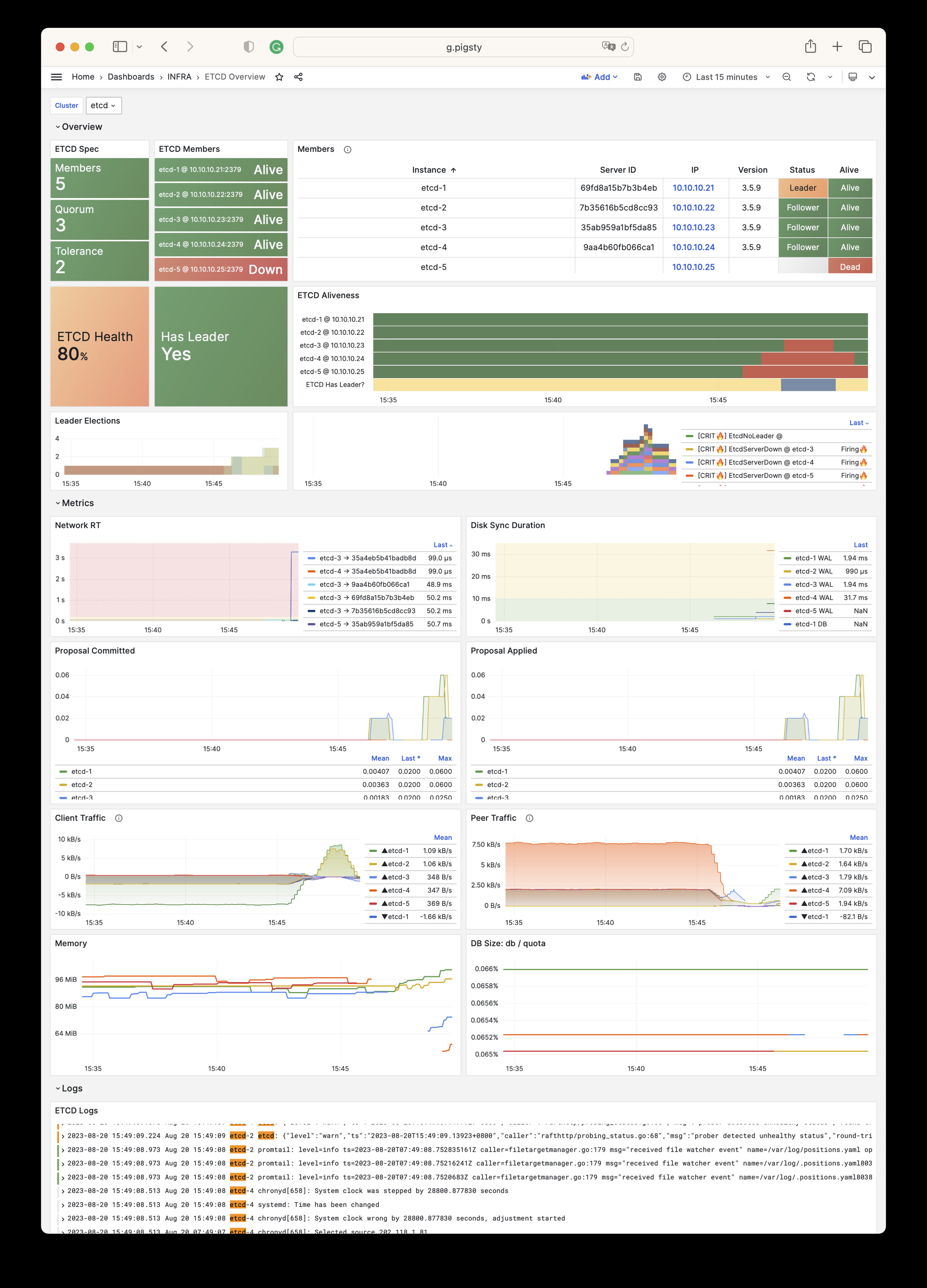

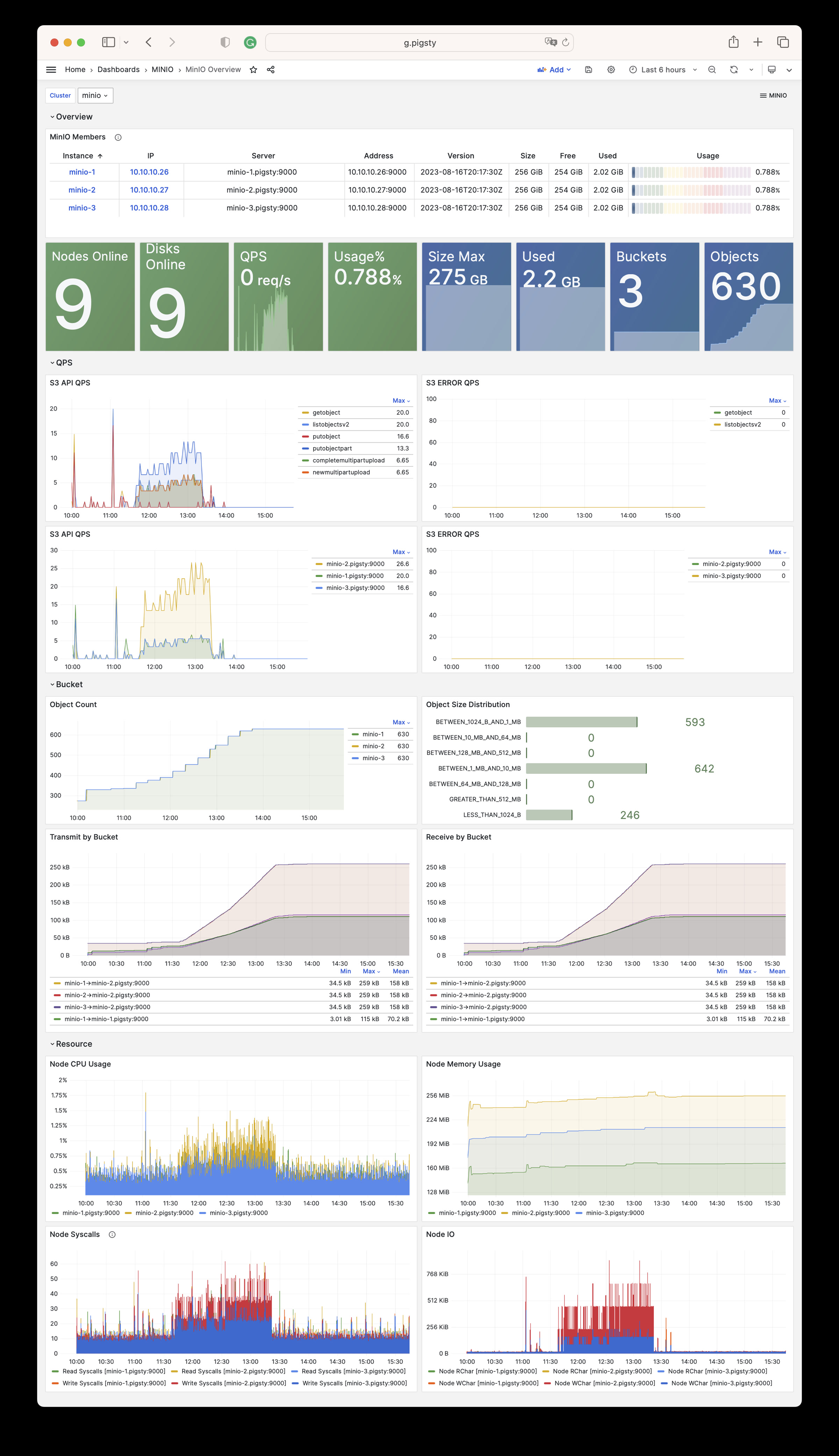

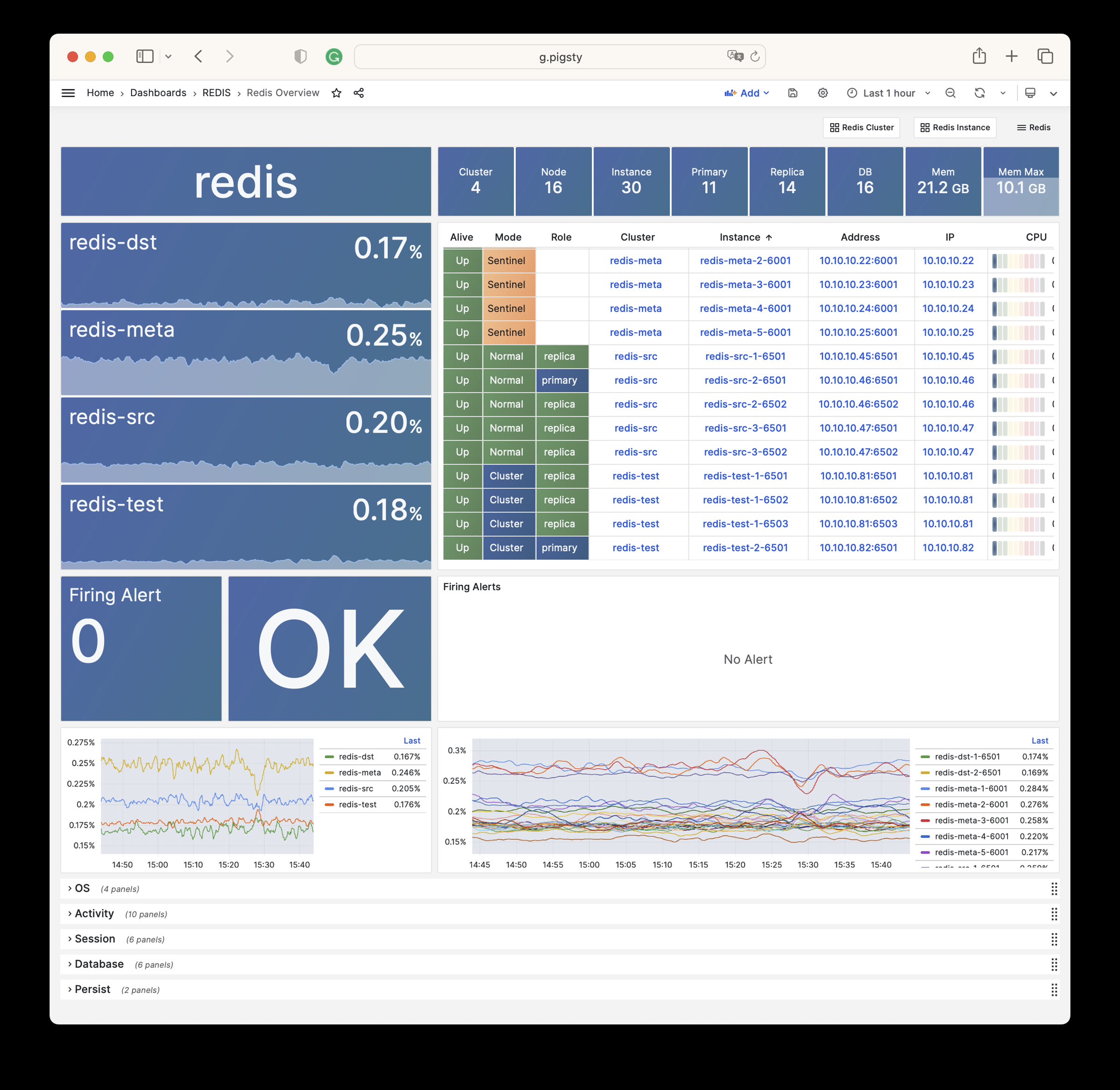
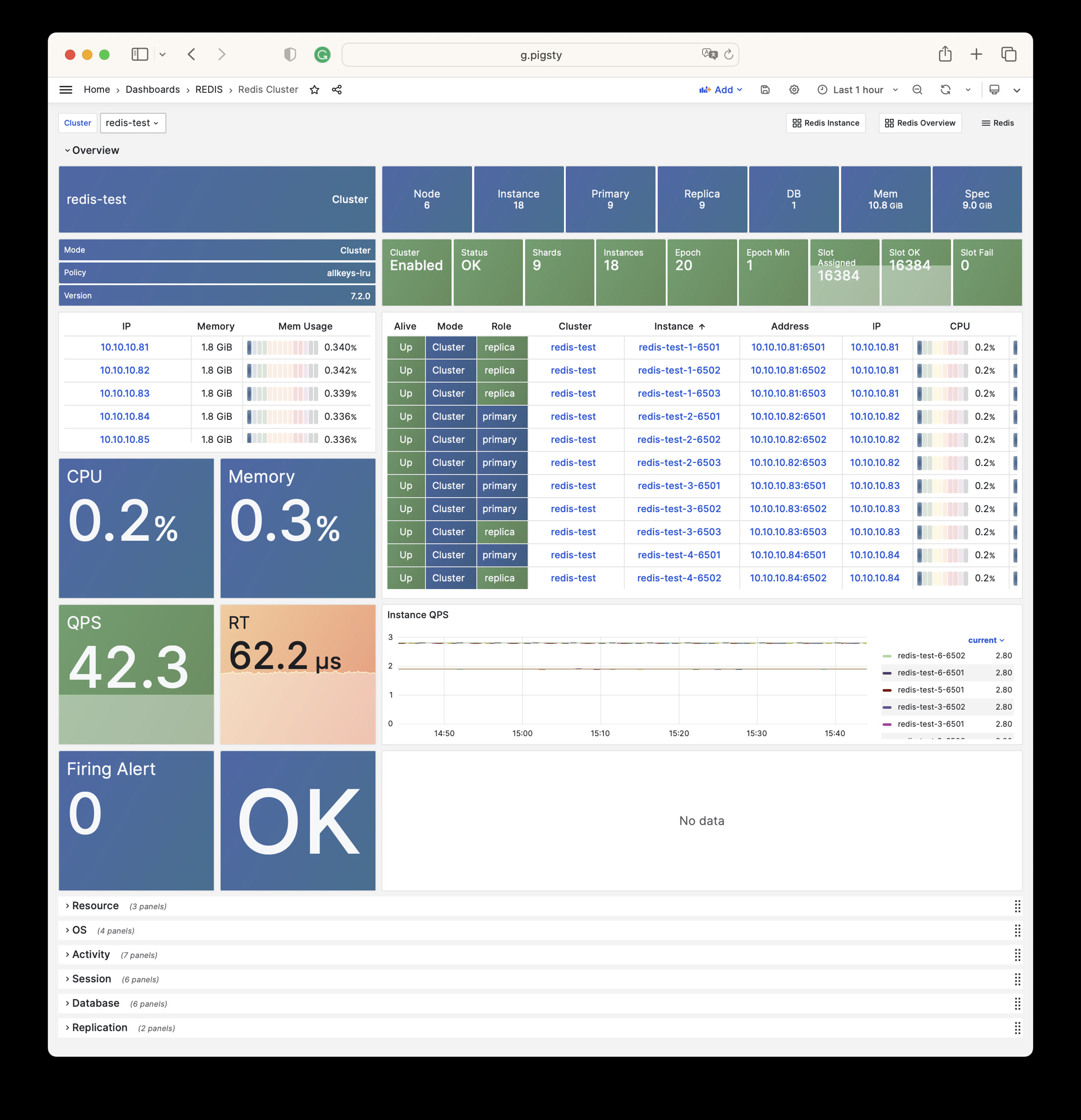
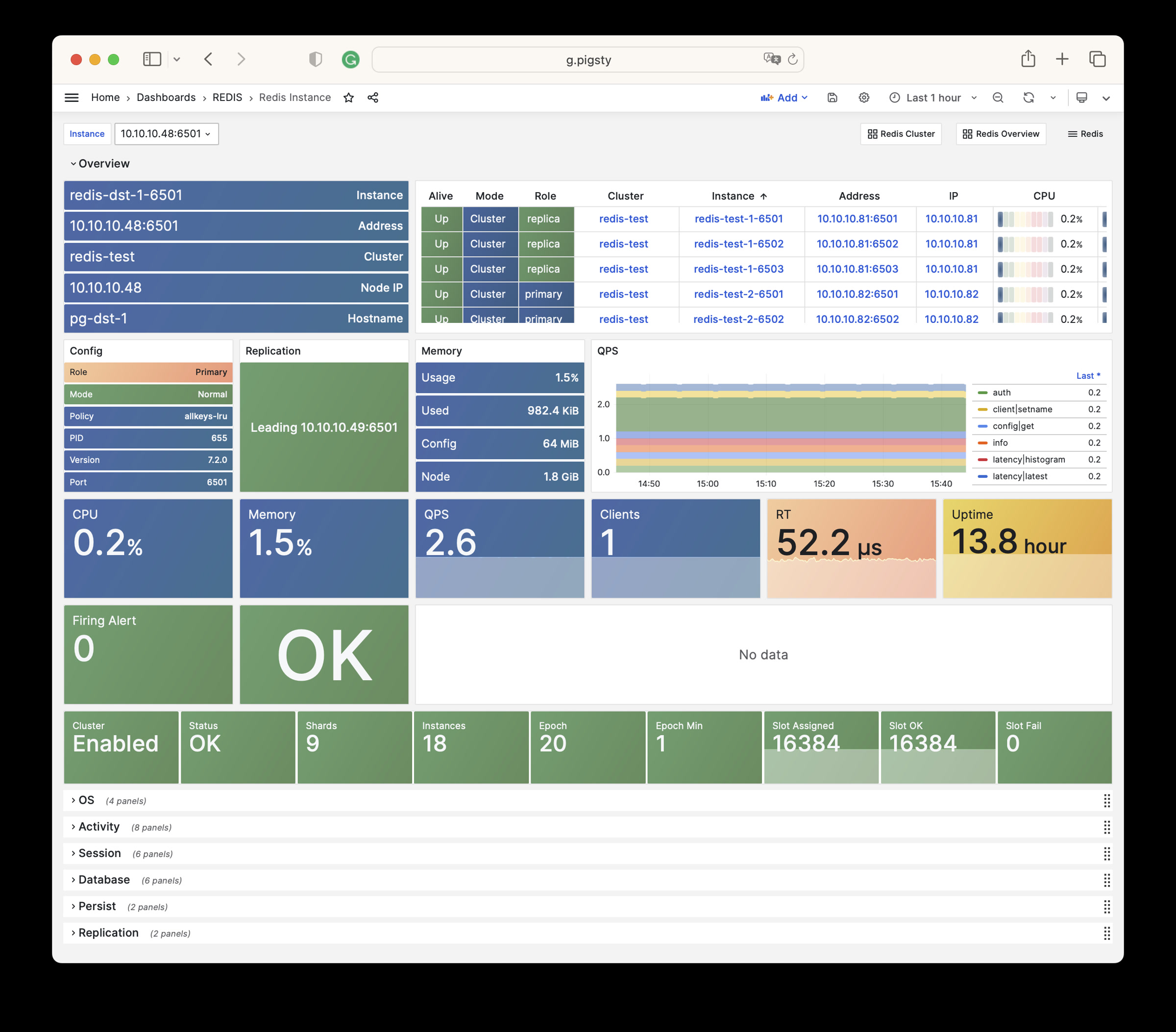
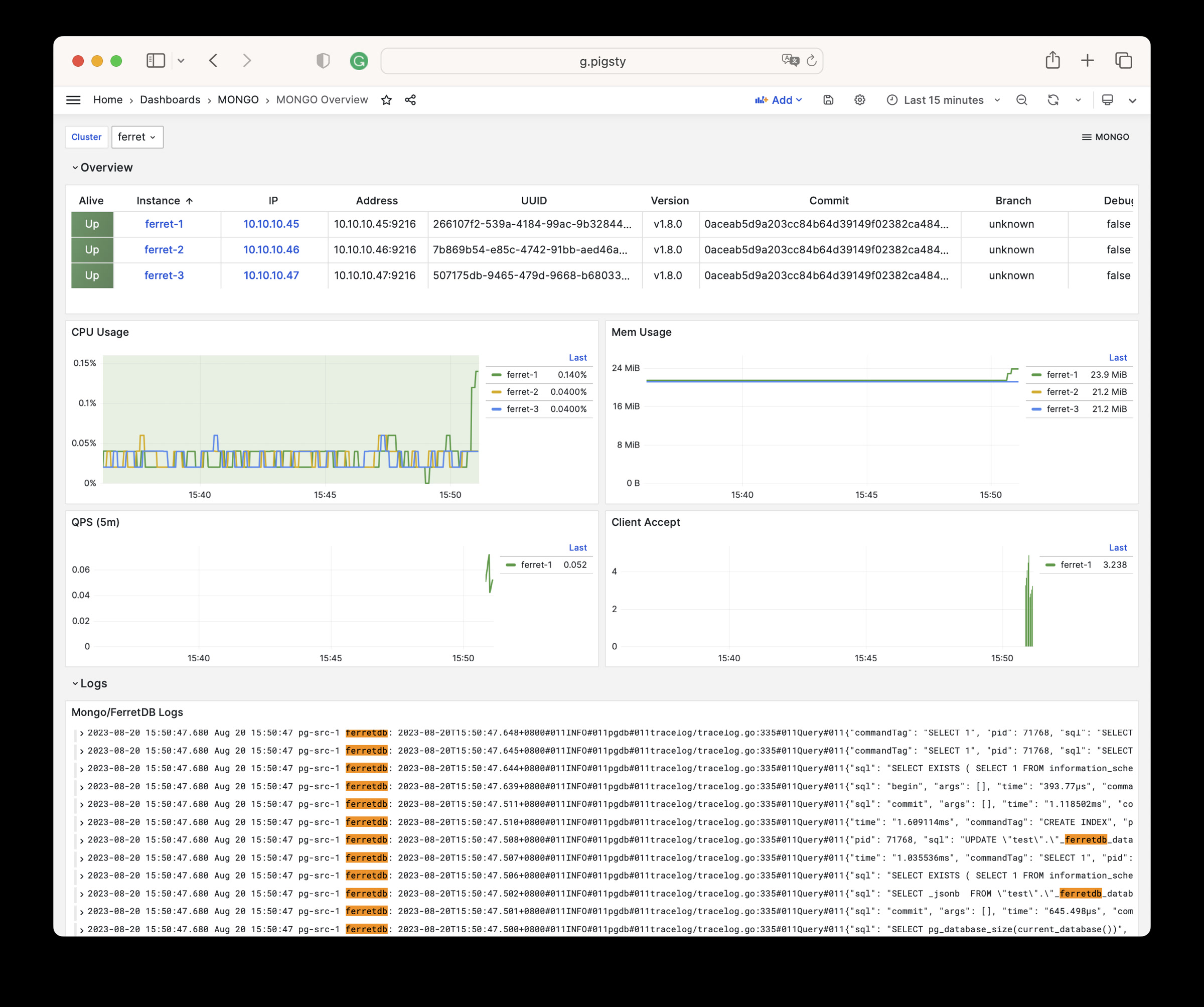


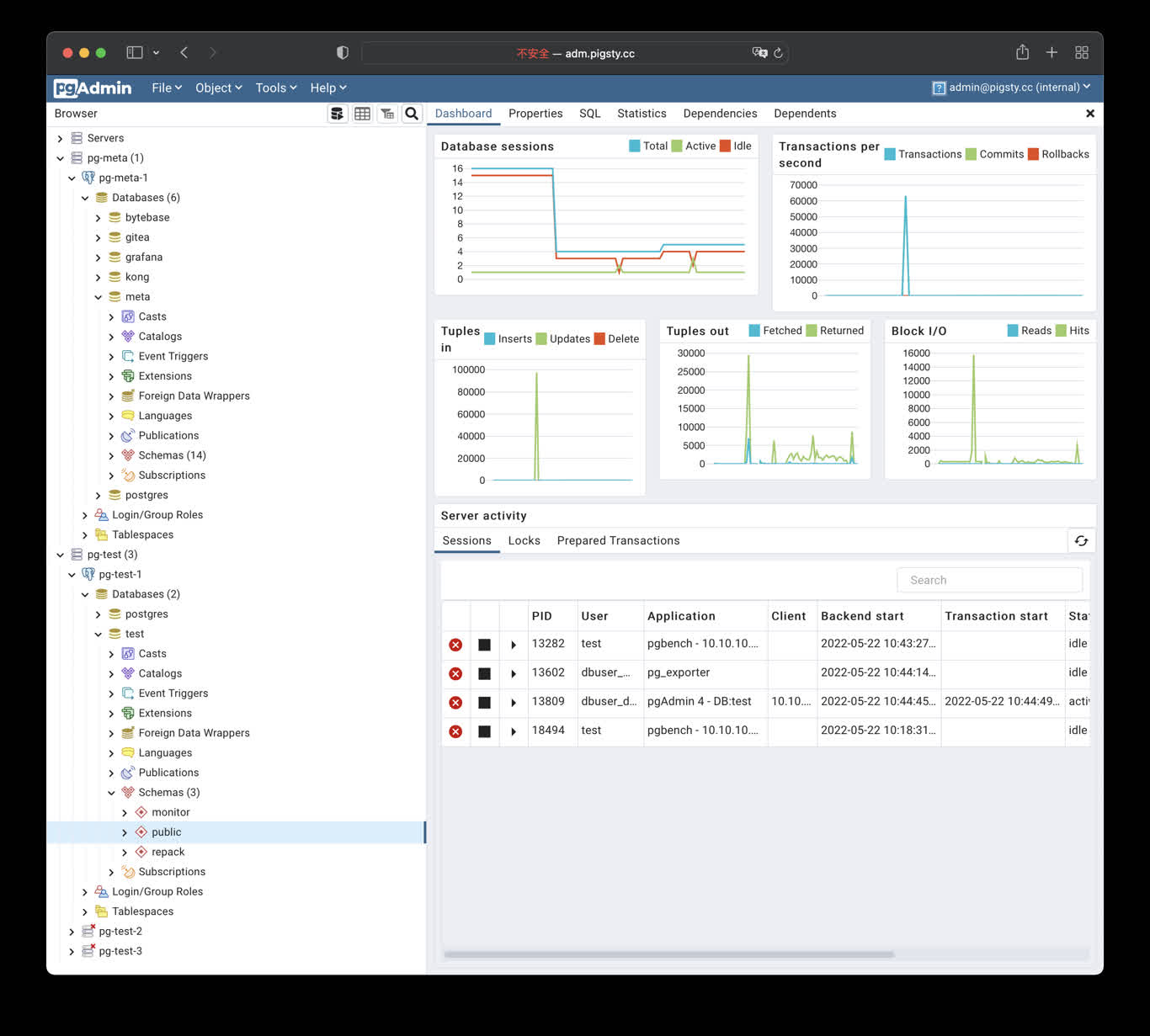
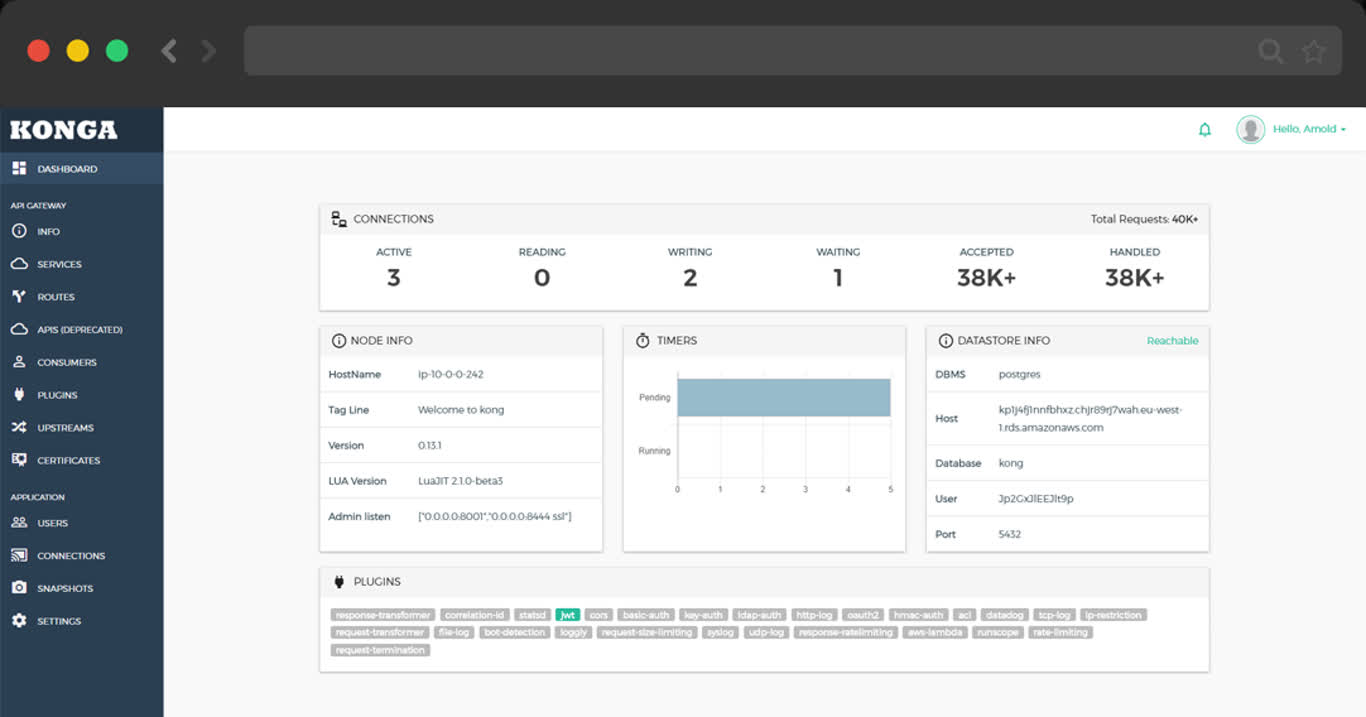
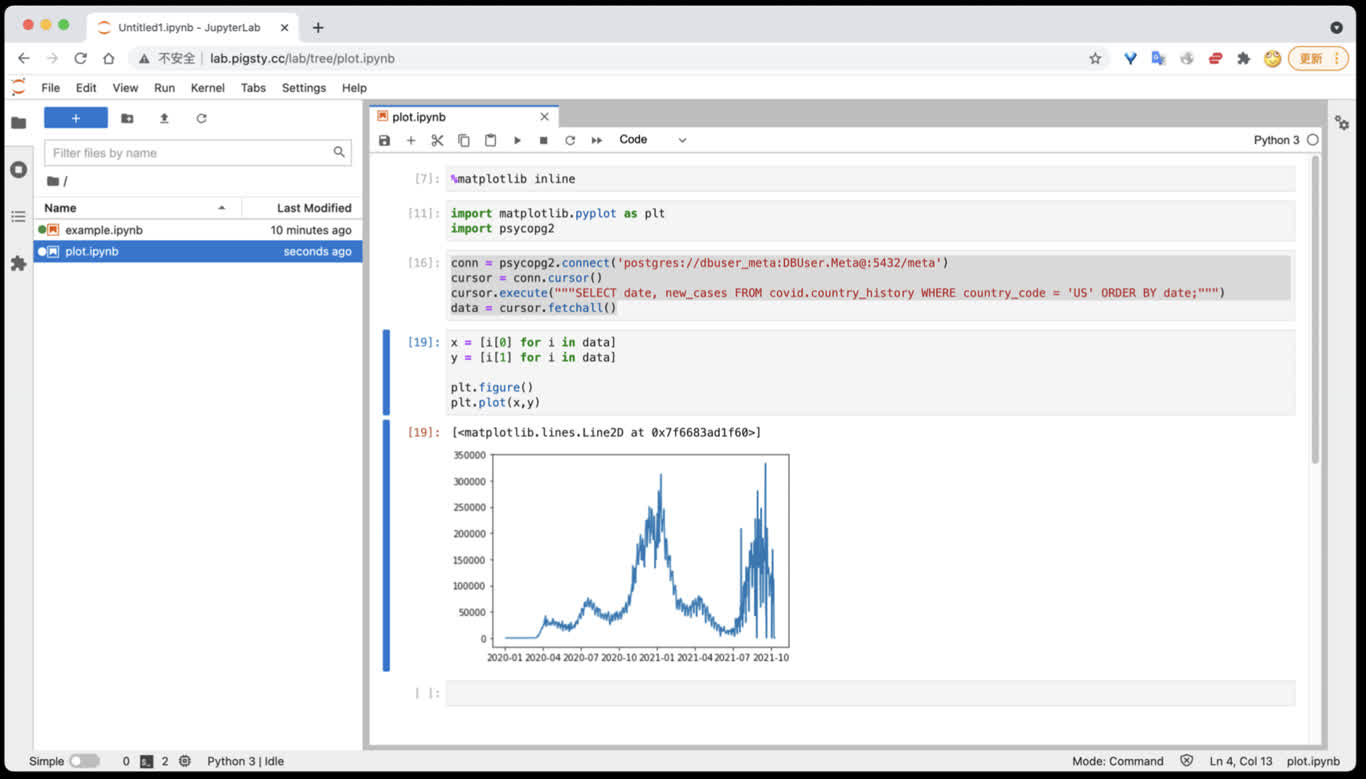
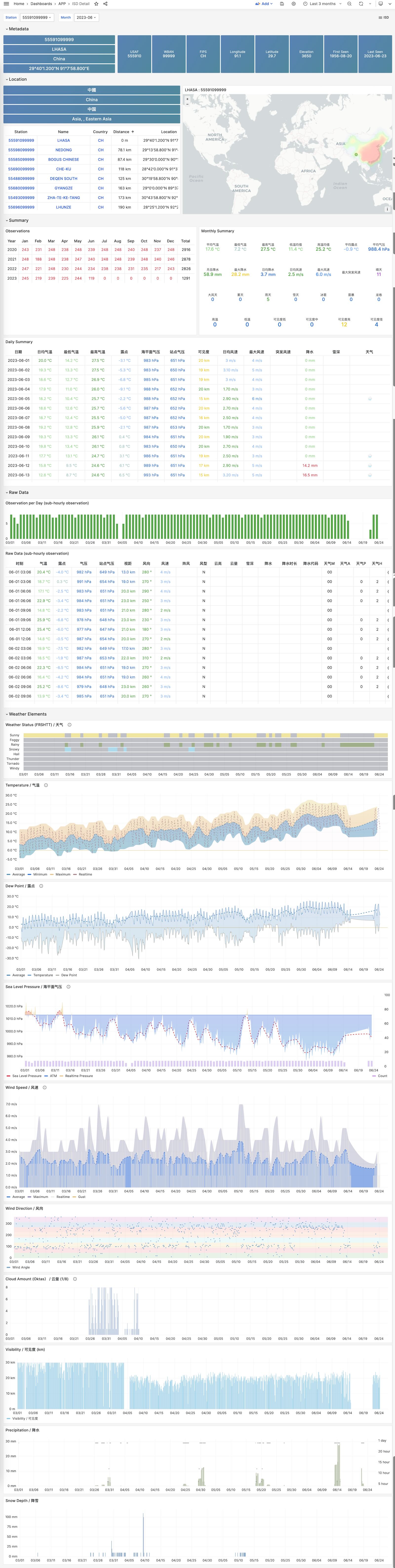
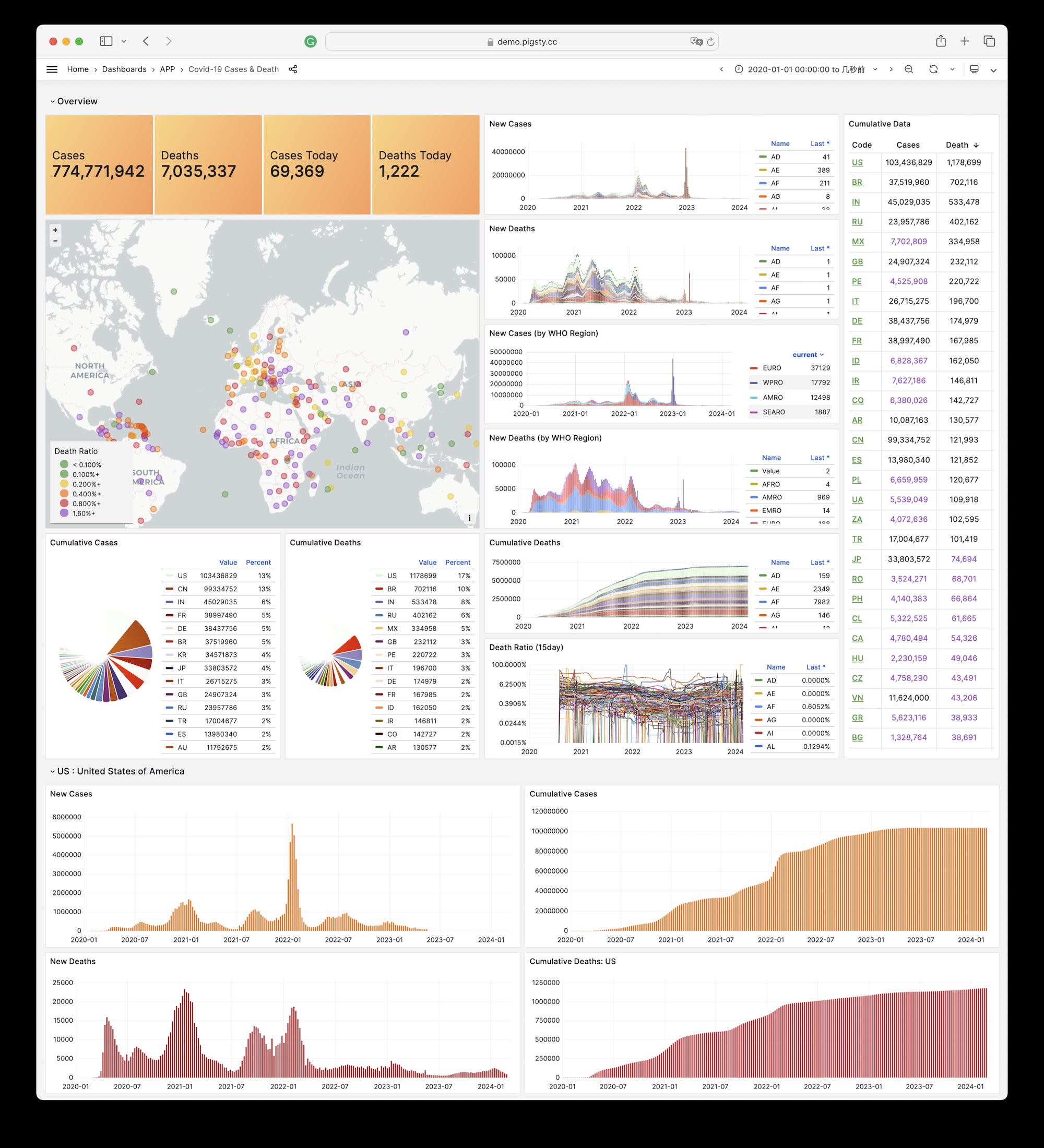
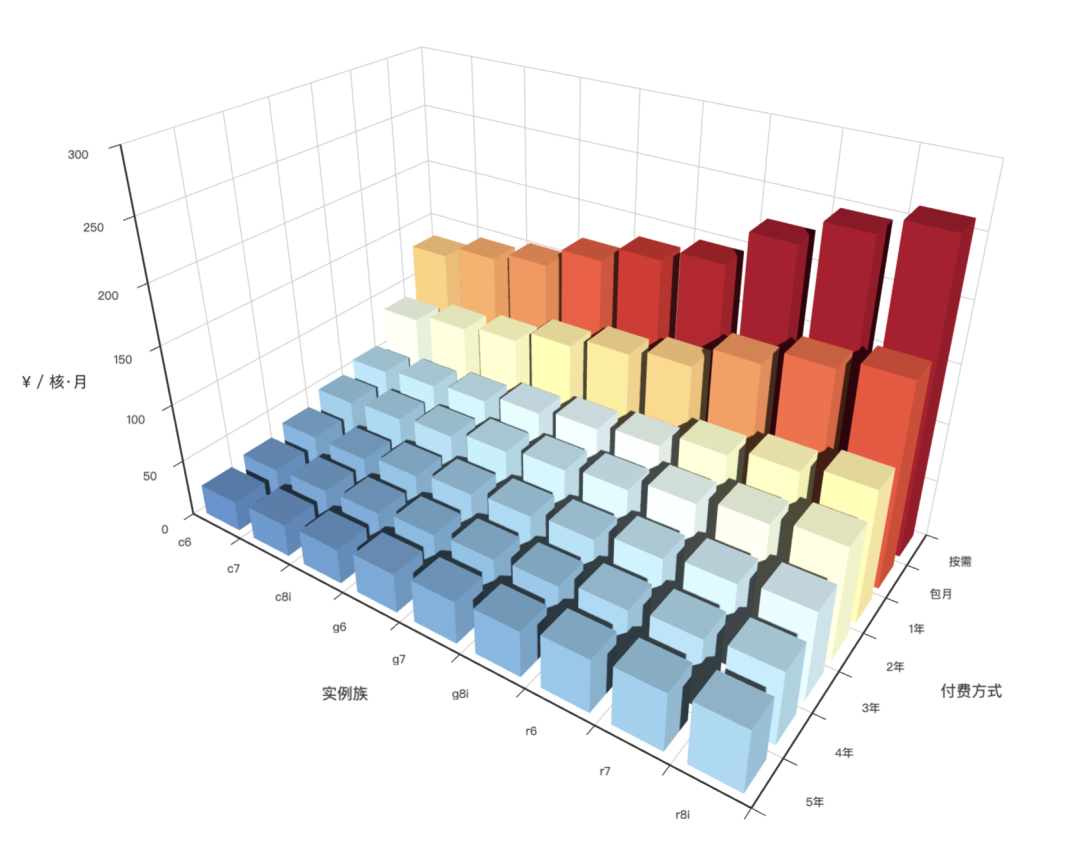
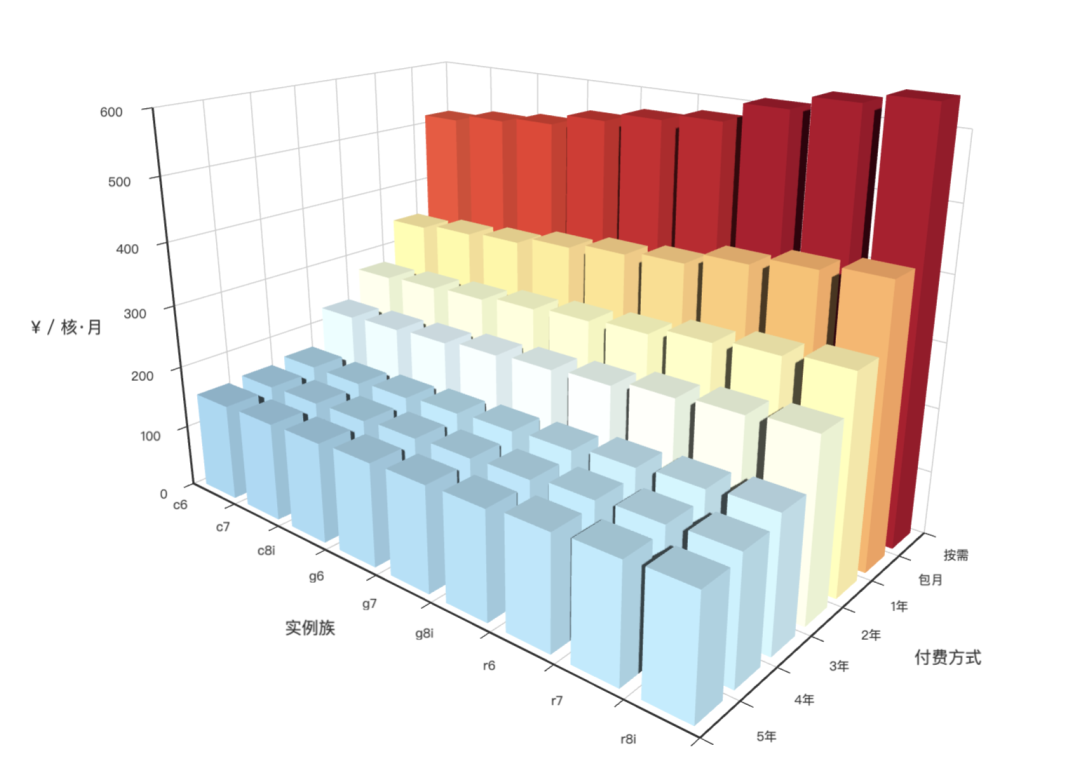
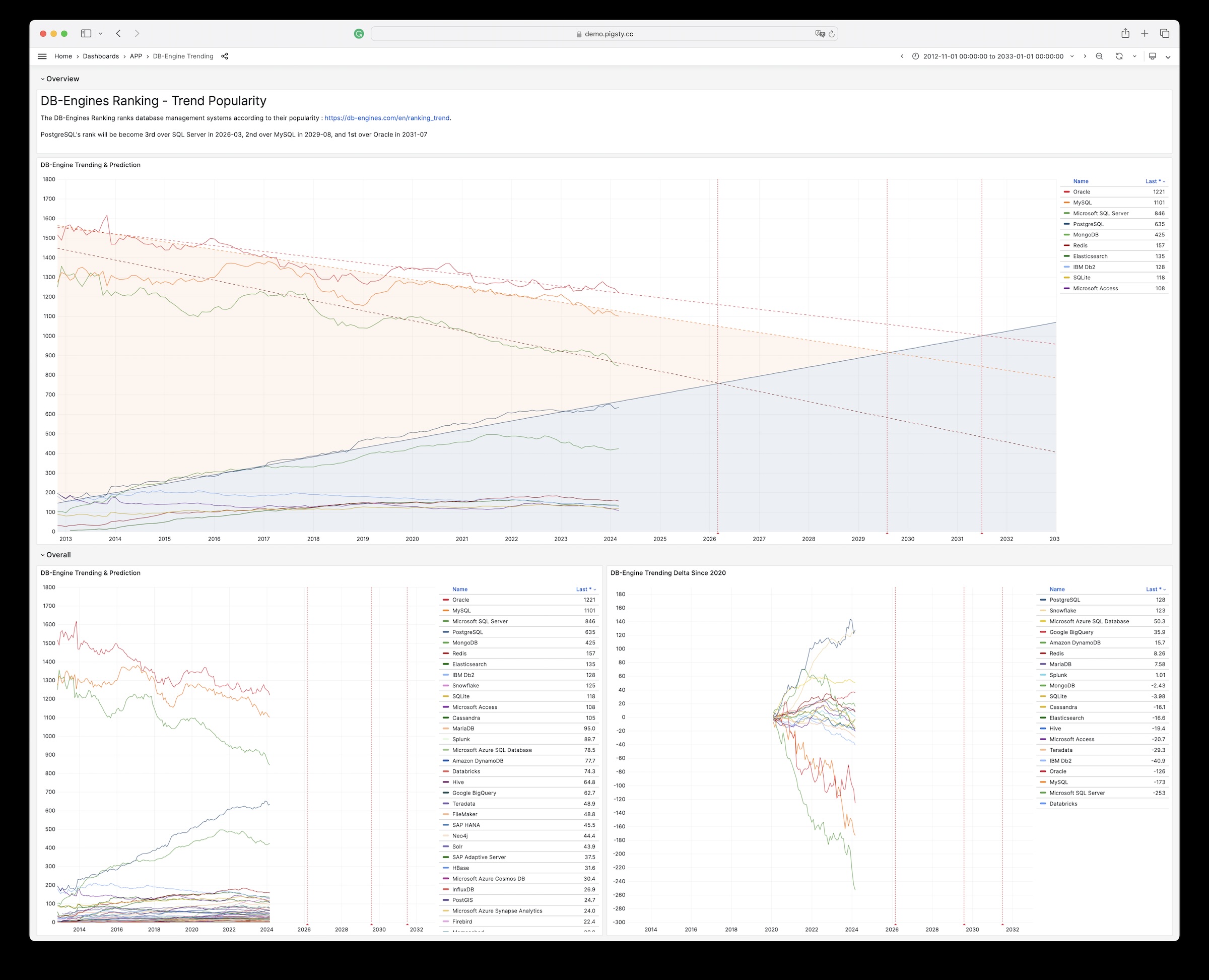
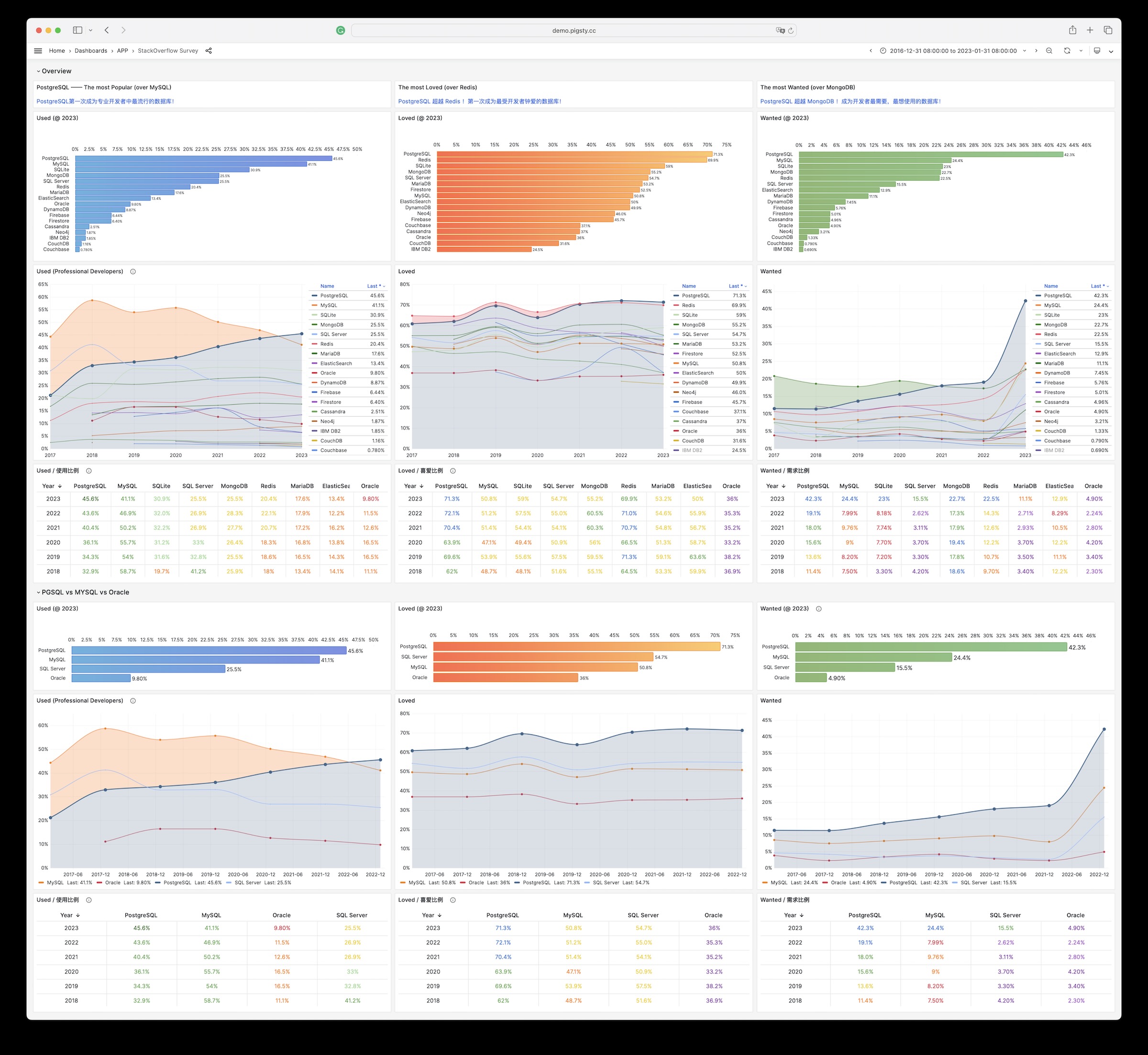
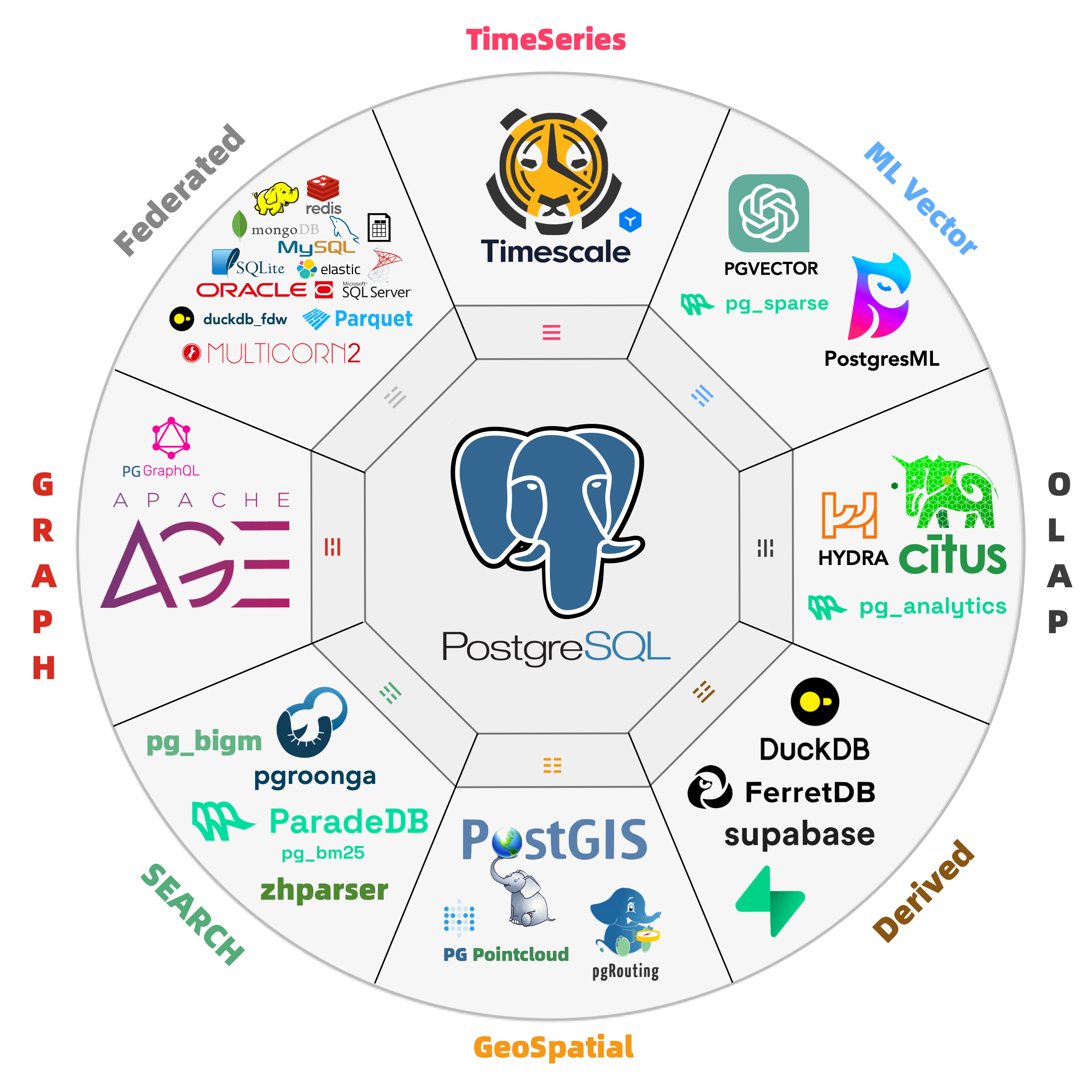{kind=link}