节点
节点(node)是对硬件资源/操作系统的抽象,可以是物理机,裸金属、虚拟机、或者容器与 pods。
Pigsty 使用 模块化架构 与 声明式接口,您可以像 搭积木一样自由按需组合模块。
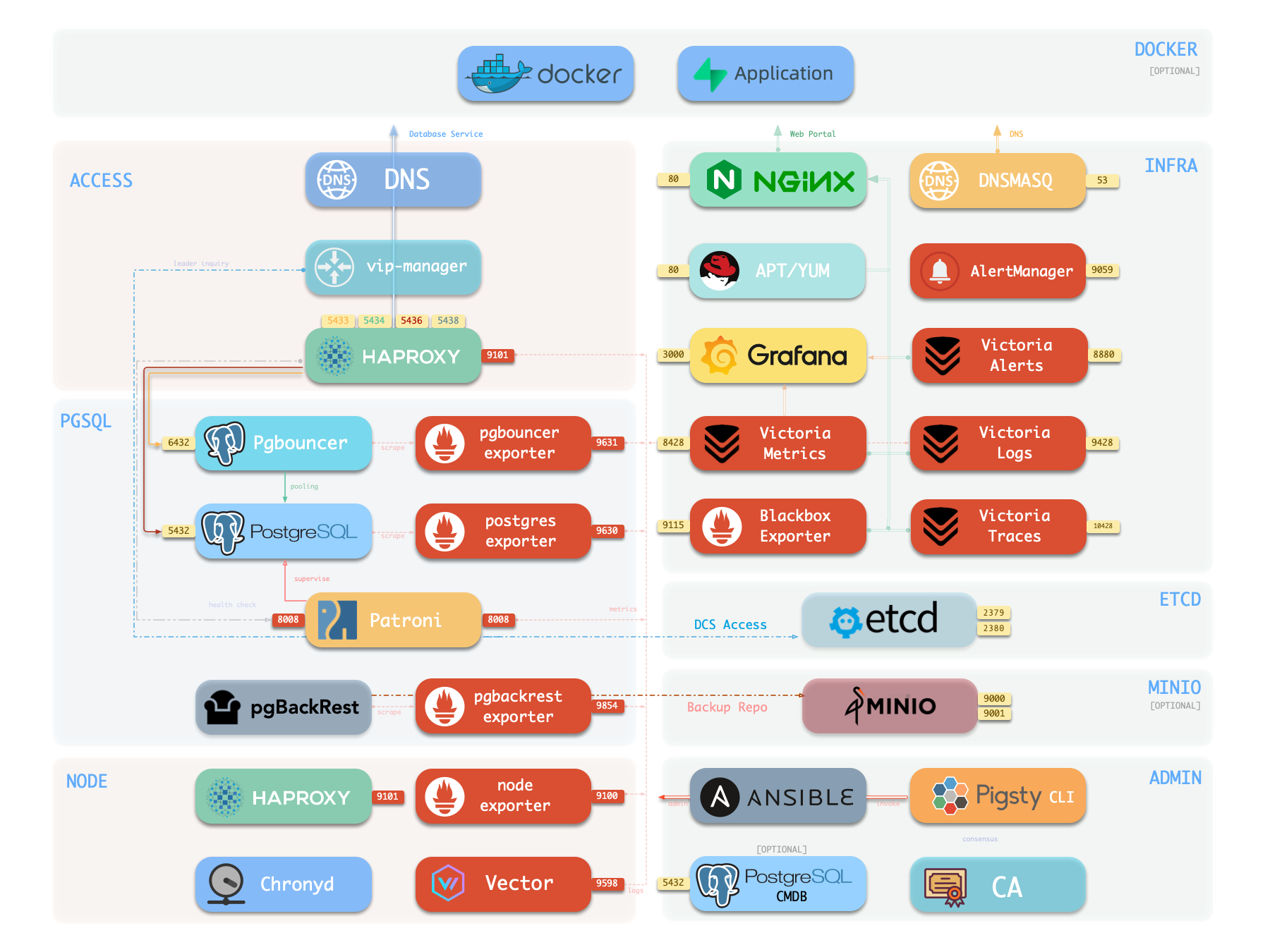
Pigsty 采用模块化设计,有六个主要的默认模块:PGSQL、INFRA、NODE、ETCD、REDIS 和 MINIO。
PGSQL:由 Patroni、Pgbouncer、HAproxy、PgBackrest 等驱动的自治高可用 Postgres 集群。INFRA:本地软件仓库、Nginx、Grafana、Victoria、AlertManager、Blackbox Exporter 可观测性全家桶。NODE:调整节点到所需状态、名称、时区、NTP、ssh、sudo、haproxy、docker、vector、keepalivedETCD:分布式键值存储,用作高可用 Postgres 集群的 DCS:共识选主/配置管理/服务发现。REDIS:Redis 服务器,支持独立主从、哨兵、集群模式,并带有完整的监控支持。MINIO:与 S3 兼容的简单对象存储服务器,可作为 PG 数据库备份的可选目的地。你可以声明式地自由组合它们。如果你想要主机监控,在基础设施节点上安装 INFRA 模块,并在纳管节点上安装 NODE 模块就足够了。
ETCD 和 PGSQL 模块用于搭建高可用 PG 集群,将模块安装在多个节点上,可以自动形成一个高可用的数据库集群。
您可以复用 Pigsty 基础架构并开发您自己的模块,REDIS 和 MINIO 可以作为一个样例。后续还会有更多的模块加入,例如对 Mongo 与 MySQL 的初步支持已经提上了日程。
请注意,所有模块都强依赖 NODE 模块:在 Pigsty 中节点必须先安装 NODE 模块,被 Pigsty 纳管后方可部署其他模块。
当节点(默认)使用本地软件源进行安装时,NODE 模块对 INFRA 模块有弱依赖。因此安装 INFRA 模块的管理节点/基础设施节点会在 deploy.yml 剧本中完成 Bootstrap 过程,解决循环依赖。
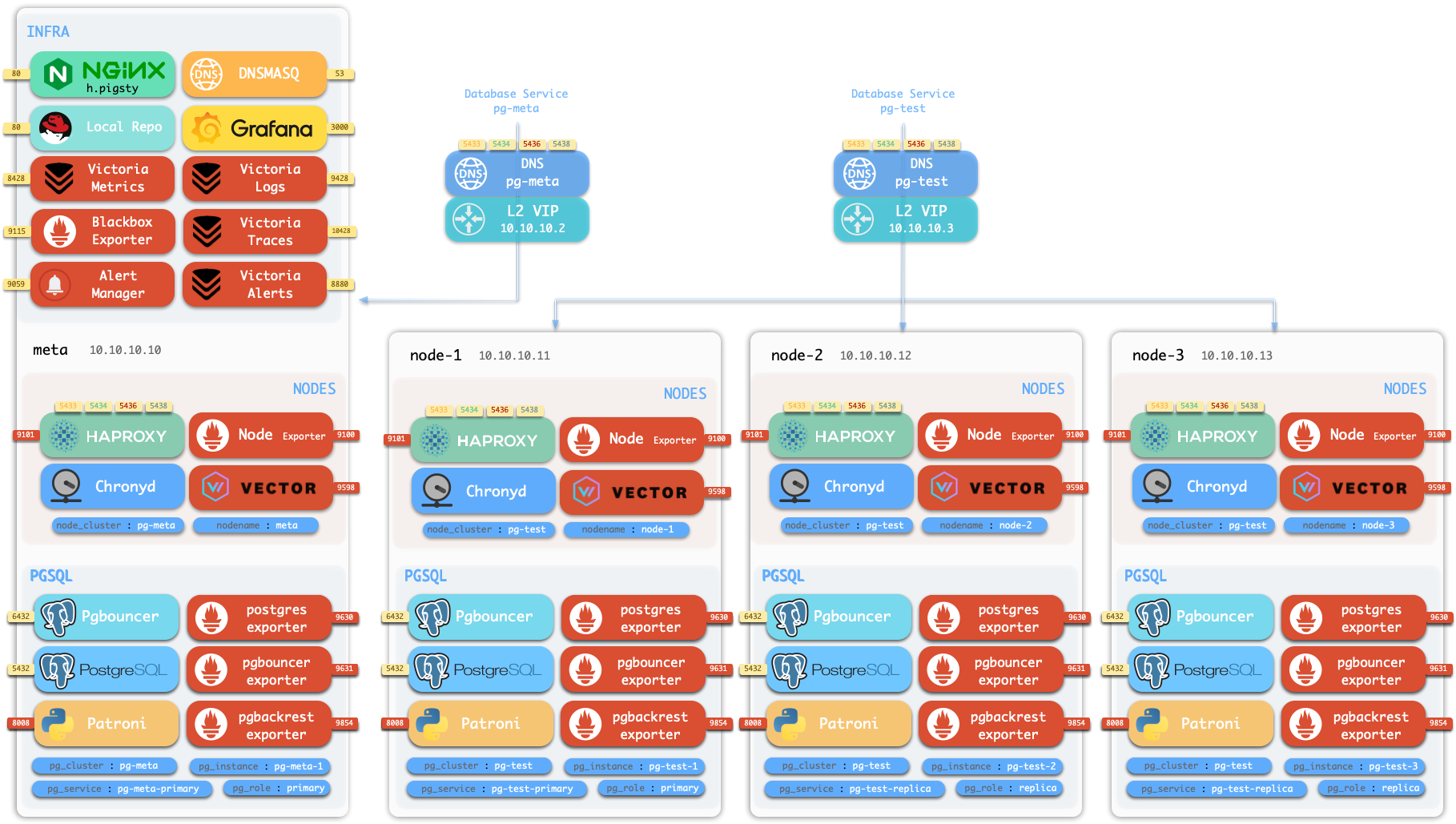
默认情况下,Pigsty 将在单个 节点 (物理机/虚拟机) 上安装。deploy.yml 剧本将在当前节点上安装 INFRA、ETCD、PGSQL 和可选的 MINIO 模块,
这将为你提供一个功能完备的可观测性技术栈全家桶(VictoriaMetrics、VictoriaLogs、VictoriaTraces、Grafana、Alertmanager、Blackbox Exporter 等),以及一个内置的 PostgreSQL 单机实例作为 CMDB,也可以开箱即用。(集群名 pg-meta,库名为 meta)
这个节点现在会有完整的自我监控系统、可视化工具集,以及一个自动配置有 PITR 的 Postgres 数据库(HA 不可用,因为你只有一个节点)。你可以使用此节点作为开发箱、测试、运行演示以及进行数据可视化和分析。或者,还可以把这个节点当作管理节点,部署纳管更多的节点!
安装的 单机元节点 可用作管理节点和监控中心,以将更多节点和数据库服务器置于其监视和控制之下。
Pigsty 的监控系统可以独立使用,如果你想安装 VictoriaMetrics / Grafana 可观测性全家桶,Pigsty 为你提供了最佳实践! 它为 主机节点 和 PostgreSQL数据库 提供了丰富的仪表盘。 无论这些节点或 PostgreSQL 服务器是否由 Pigsty 管理,只需简单的配置,你就可以立即拥有生产级的监控和告警系统,并将现有的主机与 PostgreSQL 纳入监管。

Pigsty 帮助您在任何地方 拥有 您自己的生产级高可用 PostgreSQL RDS 服务。
要创建这样一个高可用 PostgreSQL 集群/RDS 服务,你只需用简短的配置来描述它,并运行剧本来创建即可:
pg-test:
hosts:
10.10.10.11: { pg_seq: 1, pg_role: primary }
10.10.10.12: { pg_seq: 2, pg_role: replica }
10.10.10.13: { pg_seq: 3, pg_role: replica }
vars: { pg_cluster: pg-test }
$ bin/pgsql-add pg-test # 初始化集群 'pg-test'
不到10分钟,您将拥有一个服务接入,监控,备份 PITR,高可用配置齐全的 PostgreSQL 数据库集群。
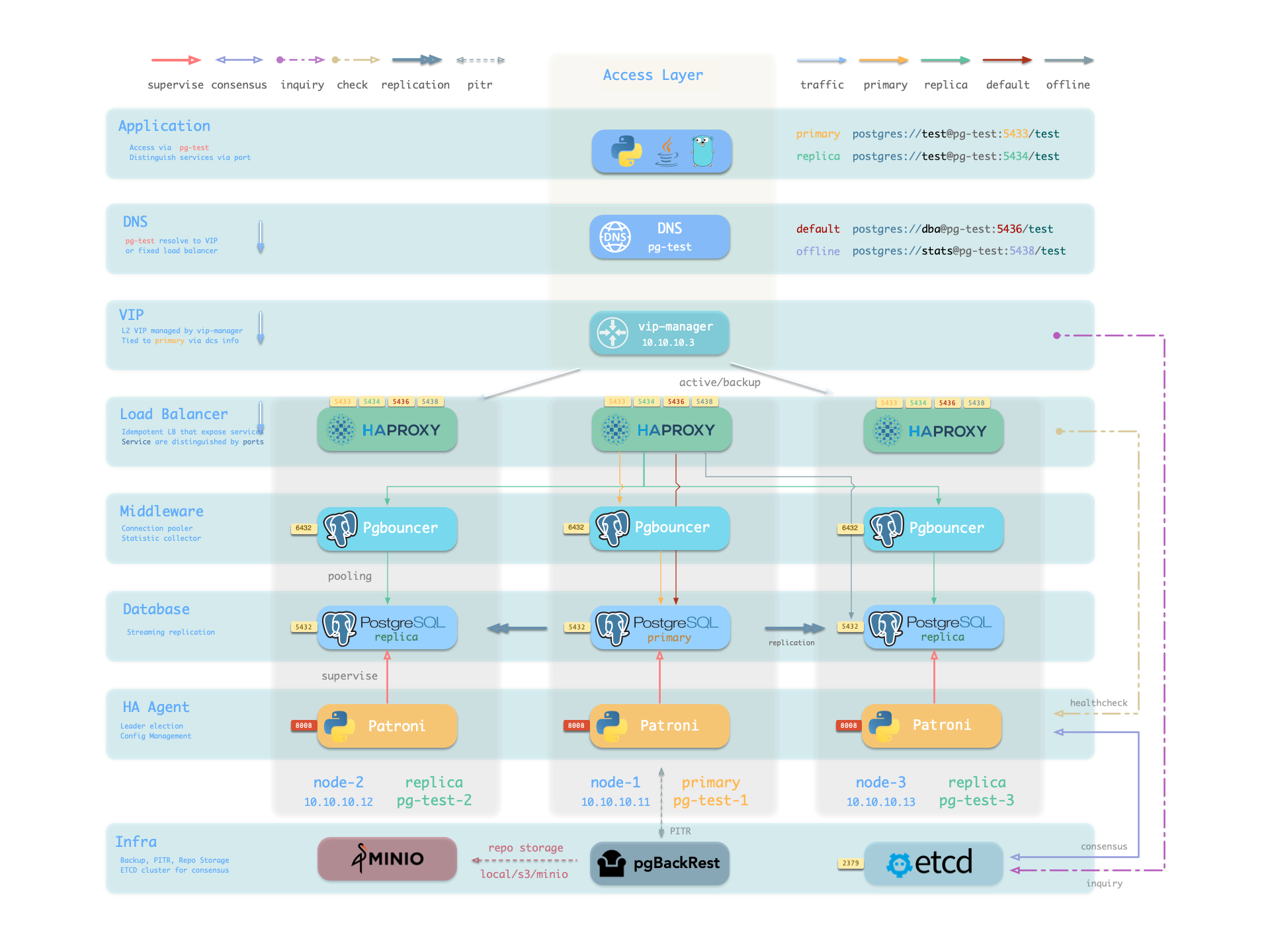
硬件故障由 patroni、etcd 和 haproxy 提供的自愈高可用架构来兜底,在主库故障的情况下,默认会在 45 秒内执行自动故障转移(Failover)。 客户端无需修改配置重启应用:Haproxy 利用 patroni 健康检查进行流量分发,读写请求会自动分发到新的集群主库中,并避免脑裂的问题。 这一过程十分丝滑,例如在从库故障,或主动切换(switchover)的情况下,客户端只有一瞬间的当前查询闪断,
软件故障、人为错误和 数据中心级灾难由 pgbackrest 和可选的 MinIO 集群来兜底。这为您提供了本地/云端的 PITR 能力,并在数据中心失效的情况下提供了跨地理区域复制,与异地容灾功能。
节点(node)是对硬件资源/操作系统的抽象,可以是物理机,裸金属、虚拟机、或者容器与 pods。
Pigsty 中基础设施模块的架构,组件与功能详解。
PostgreSQL 模块的组件交互与数据流。