PostgreSQL 正在吞噬数据库世界
PostgreSQL 并不是一个简单的关系型数据库,而是一个数据管理的抽象框架,具有吞噬整个数据库世界的力量。而这也是正在发生的事情 —— “一切皆用 Postgres” 已经不再是少数精英团队的前沿探索,而是成为了一种进入主流视野的最佳实践。
OLAP 领域迎来踢馆者
在 2016 年的一次数据库沙龙里,我提出了一个观点: 现在 PostgreSQL 生态的一个主要遗憾是,缺少一个足够好的列式存储分析插件来做 OLAP 分析。尽管PostgreSQL 本身提供了很强大的分析功能集,应付常规的分析任务绰绰有余。但在较大数据量下全量分析的性能,相比专用的实时数仓仍然有些不够看。
以分析领域的权威评测 ClickBench 为例,我们在其中标注出了 PostgreSQL 与生态扩展插件以及兼容衍生数据库在其中的性能表现。原生未经过调优的 PostgreSQL 表现较为拉垮(x1050),但经过调优后可以达到(x47);此外还有三个与分析有关系的扩展:列存 Hydra(x42),时序扩展 TimescaleDB(x103),以及分布式扩展 Citus(x262)。
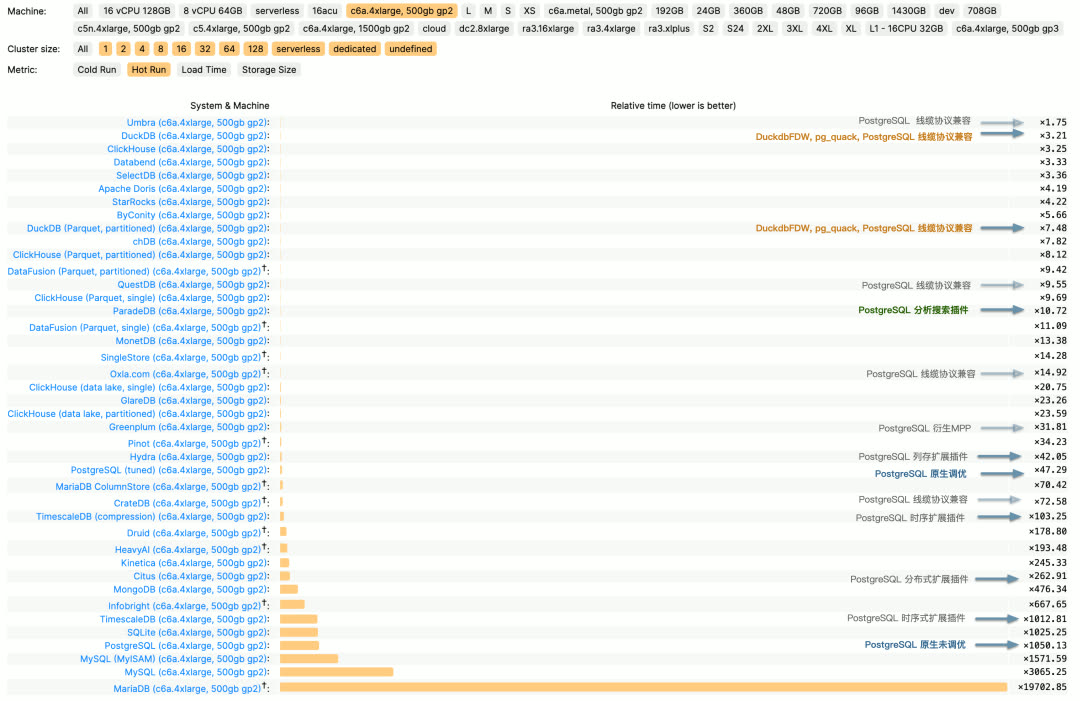
ClickBench c6a.4xlarge, 500gb gp2,Hot Run 执行相对耗时
这样的分析性能表现不能说烂,因为比起 MySQL,MariaDB 这样的纯 OLTP 数据库的辣眼表现(x3065,x19700)确实好很多;但第三梯队的性能表现也绝对说不上足够好,与专注于 OLAP 的第一梯队组件:Umbra,ClickHouse,Databend,SelectDB(x3~x4)相比,在分析性能上仍然有十几倍的性能差距。食之无味,弃之可惜。
然而, ParadeDB 和 DuckDB 的出现改变了这一点!
ParadeDB 提供的 PG 原生扩展 pg_analytics 实现了第二梯队(x10)的性能水准,与第一梯队只有 3~4 倍的性能差距。相对于其他功能上的收益,这种程度的性能差距通常是可以接受的 —— ACID,新鲜性与实时性,无需 ETL、额外学习成本、维护独立的新服务,更别提它还提供了 ElasticSearch 质量的全文检索能力。
而 DuckDB 则专注于 OLAP ,将分析性能这件事做到了极致(x3.2) —— 略过第一名 Umbra 这种学术研究型闭源数据库,DuckDB 也许是 OLAP 实战性能最快的数据库了。它并不是 PG 的扩展插件,但它是一个嵌入式文件数据库,而 DuckDB FDW 以及 pg_quack 这样的 PG 生态项目,能让 PostgreSQL 充分利用 DuckDB 带来的完整分析性能红利!
ParadeDB 与 DuckDB 的出现让 PostgreSQL 的分析性能来到了 OLAP 的第一梯队与金字塔尖,弥补了 PostgreSQL 在 OLAP 性能这最后一块关键短板。
分久必合的数据库领域
数据库诞生伊始,并没有 OLTP 与 OLAP 的分野。OLAP 数据仓库从数据库中“独立”出来,已经是上世纪九十年代时候的事了 —— 因为传统的 OLTP 数据库难以支撑起分析场景下的查询模式,数据量与性能要求。
在相当一段时间里,数据处理的最佳实践是使用 MySQL / PG 处理 OLTP 工作负载,并通过 ETL 将数据同步到专用的 OLAP 组件中去处理,比如 Greenplum, ClickHouse, Doris, Snowflake 等等。
设计数据密集型应用,Martin Kleppmann,第三章
与许多 “专用数据库” 一样,专业的 OLAP 组件的优势往往在于性能 —— 相比原生 PG 、MySQL 上有 1~3 个数量级的提升;而代价则是数据冗余、 大量不必要的数据搬运工作、分布式组件之间缺乏一致性、额外的专业技能带来的复杂度成本、学习成本、以及人力成本、 额外的软件许可费用、极其有限的查询语言能力、可编程性、可扩展性、有限的工具链、以及与OLTP 数据库相比更差的数据完整性和可用性 —— 但这是一个合理的利弊权衡。
然而天下大势,分久必合,合久必分。硬件遵循摩尔定律又发展了三十年,性能翻了几个数量级,成本下降了几个数量级。在 2024 年的当下,x86 单机可以达到几百核 (512 vCPU EPYC 9754x2),几个TB的内存,单卡 NVMe SSD 可达 64TB,全闪单机柜 2PB ;S3 这样对象存储更是能实现几乎没有上限的存储。
硬件的发展解决了数据量的问题,而数据库软件的发展(PostgreSQL,ParadeDB,DuckDB)解决了查询模式的问题,而这导致分析领域 —— 所谓的“大数据” 行业基本工作假设面临挑战。
正如 DuckDB 发表的宣言《大数据已死》所主张的:大数据时代已经结束了 —— 大多数人并没有那么多的数据,大多数数据也很少被查询。大数据的前沿随着软硬件发展不断后退,99% 的场景已经不再需要所谓“大数据”了。
如果 99% 的场景甚至都可以放在一台计算机上用单机/主从的 DuckDB 或 PostgreSQL 搞定,那么使用专用的分析组件还有多少意义?如果每台手机都可以自由自主收发短信,那么 BP 机还有什么存在价值?(北美医院还在用BP机,正好比也还有 1% 不到的场景也许真的需要“大数据”)
基本工作假设的变化,将重新推动数据库世界从百花齐放的“合久必分”阶段,走向“分久必合”的阶段,从大爆发到大灭绝,大浪淘沙中,新的大一统超融合数据库将会出现,重新统一 OLTP 与 OLAP。而承担重新整合数据库领域这一使命的会是谁?
吞食天地的 PostgreSQL
数据库领域有许多“细分领域”:时序数据库,地理空间数据库,文档数据库,搜索数据库,图数据库,向量数据库,消息队列,对象数据库。而 PostgreSQL 在任何一个领域都不会缺席。
一个 PostGIS 插件,成为了地理空间事实标准;一个 TimescaleDB 扩展,让一堆"通用"时序数据库尴尬的说不出话来;一个向量扩展 PGVector 插件,更是让整个 专用向量数据库细分领域 变成笑话。
同样的事情已经发生过很多次,而现在,我们将在拆分最早,地盘最大的一个子领域 OLAP 分析中再次见证这一点。但 PostgreSQL 要替代的可不仅仅是 OLAP 数仓,它的野望是整个数据库世界!
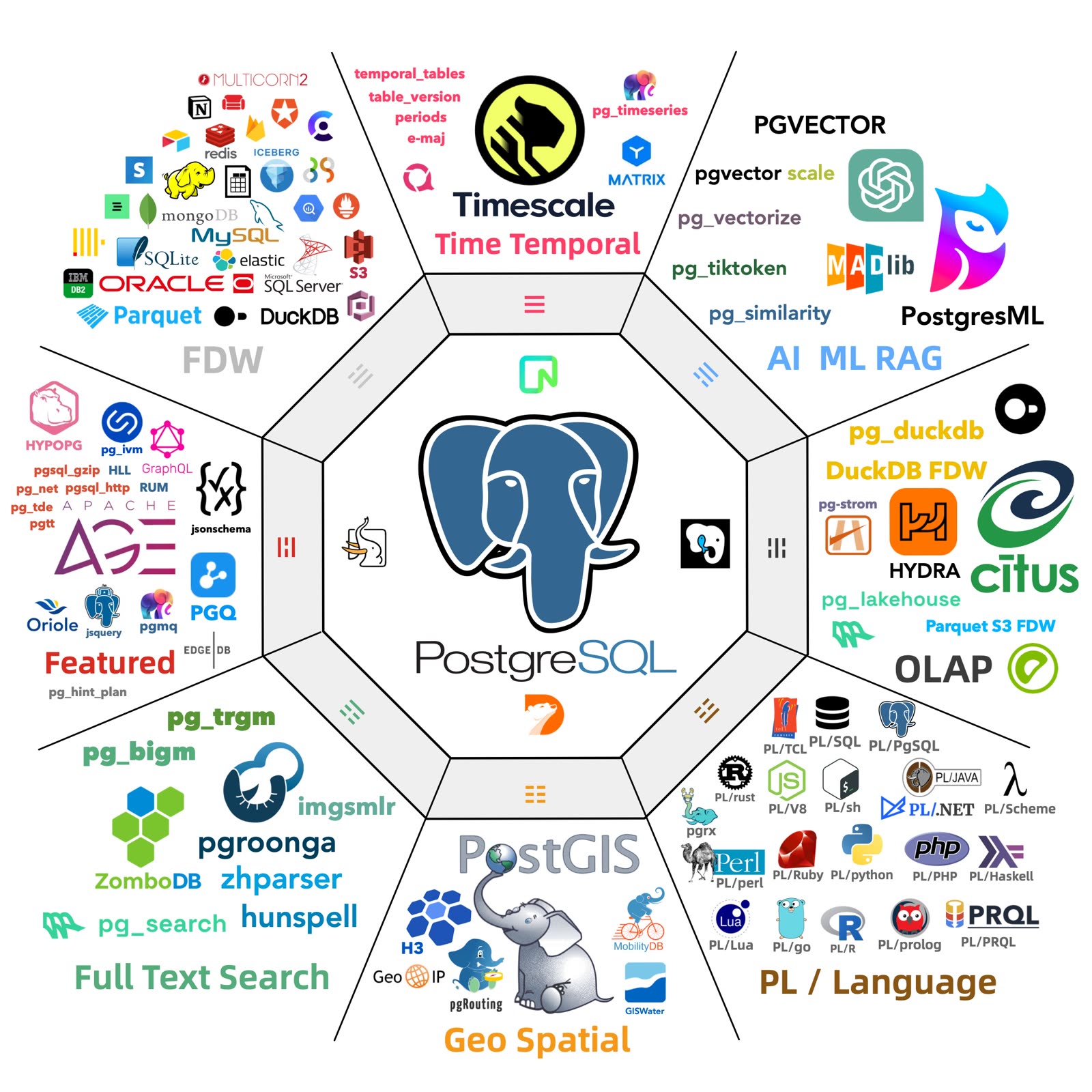
然 PostgreSQL 有何德何能,可当此大任?诚然 PostgreSQL 先进,但 Oracle 也先进;PostgreSQL 开源,但 MySQL 也开源。PostgreSQL 先进且开源,这是它与 Oracle / MySQL 竞争的底气,但要说其独一无二的特点,那还得是它的极致可扩展性,与繁荣的扩展生态!
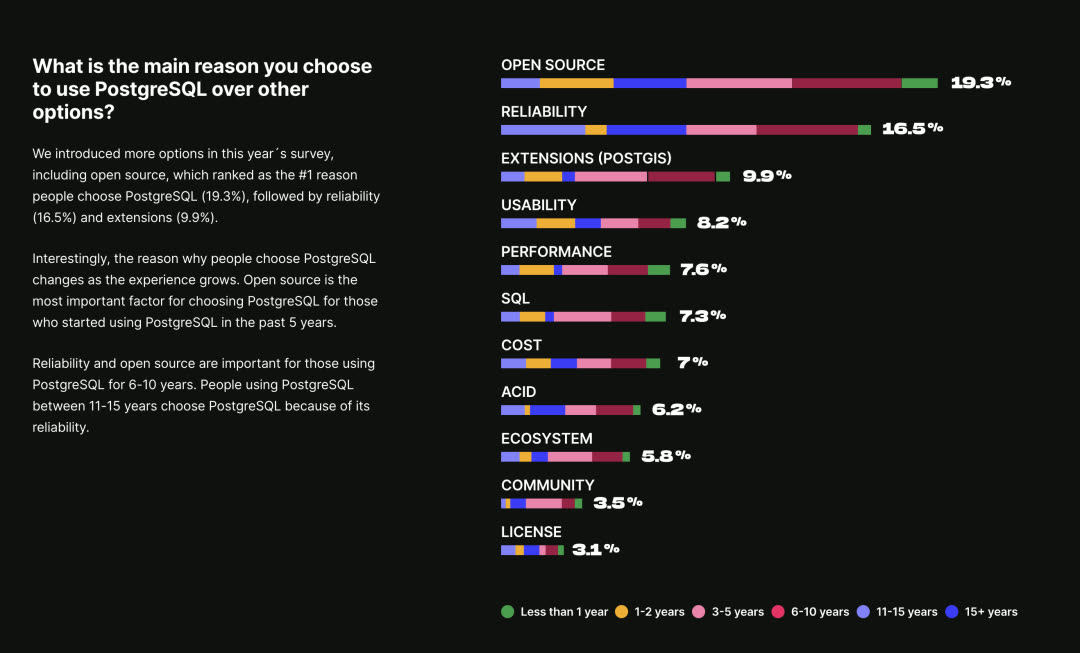
TimescaleDB 2022 社区调研:用户 选择 PostgreSQL 的原因:开源,先进,扩展。
PostgreSQL 并不是一个简单的关系型数据库,而是一个数据管理的抽象框架,具有囊括一切,吞噬整个数据库世界的力量。而它的核心竞争力(除了开源与先进)来自可扩展性,即基础设施的可复用性与扩展插件的可组合性。
极致可扩展性的魔法
PostgreSQL 允许用户开发功能模块,复用数据库公共基础设施,以最低的成本交付功能。例如,仅有两千行代码的向量数据库扩展 pgvector 与百万行代码的 PostgreSQL 在复杂度上相比可以说微不足道,但正是这“微不足道”的扩展,实现了完整的向量数据类型与索引能力,干翻了几乎所有专用向量数据库。
为什么?因为 PGVECTOR 作者不需要操心数据库的通用额外复杂度:事务 ACID,故障恢复,备份PITR,高可用,访问控制,监控,部署,三方生态工具,客户端驱动这些需要成百上千万行代码才能解决好的问题,只需要关注自己所需问题的本质复杂度即可。
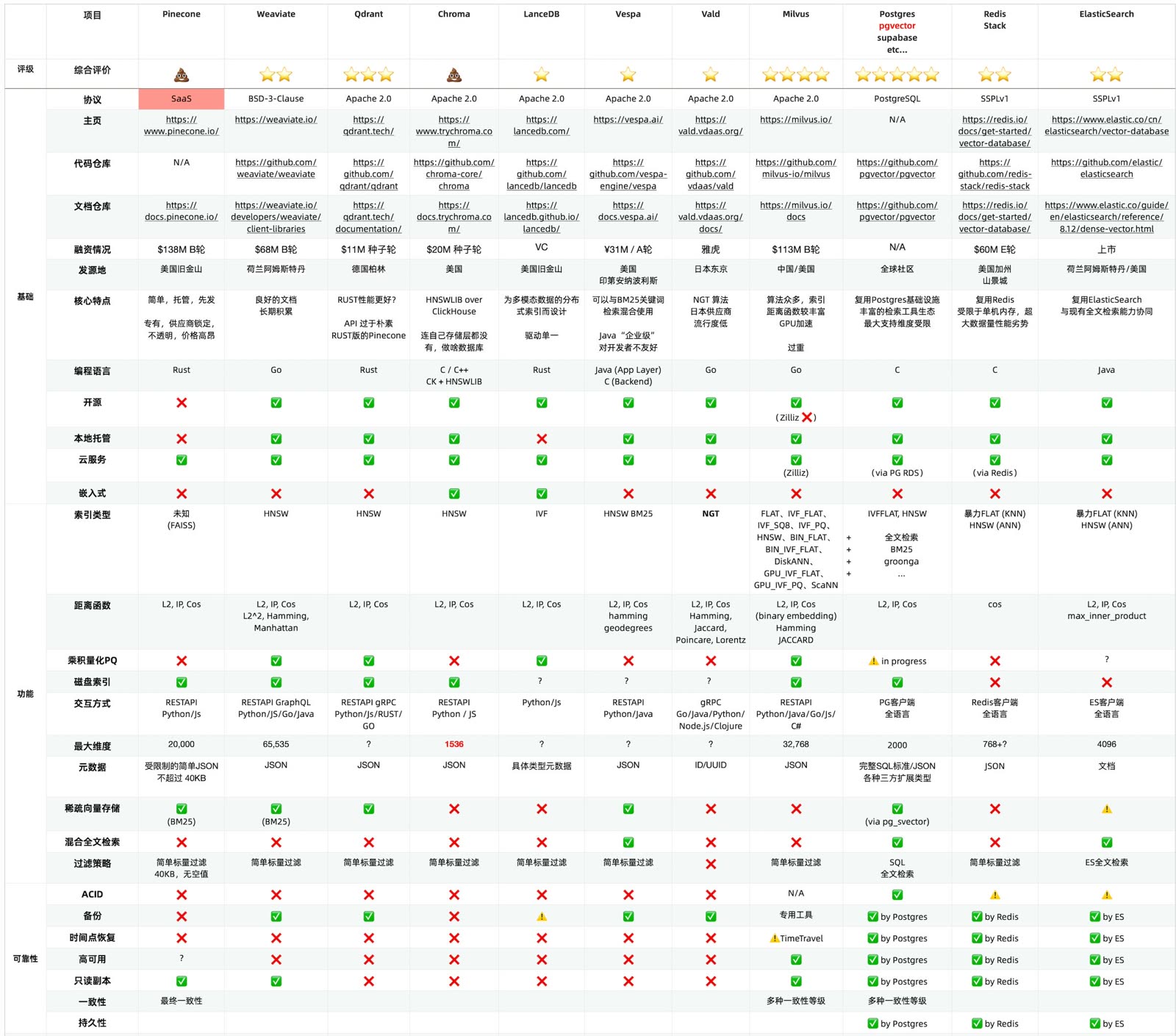
向量数据库哪家强?
再比如,ElasticSearch 基于 Lucene 搜索库开发,而 Rust 生态有一个改进版的下一代 Tantivy 全文搜索库作为 Lucene 的替代;而 ParadeDB 只需要将其封装对接到 PostgreSQL 的接口上,即可提供比肩 ElasticSearch 的搜索服务。更重要的是,它可以站在 PostgreSQL 巨人的肩膀上,借用 PG 生态的全部合力(例如,与 PG Vector 做混合检索),不讲武德地用数据库全能王的力量,去与一个专用数据库单品来对比。
Pigsty 中提供了 451 个可用扩展插件,在生态中还有 1000+ 扩展
可扩展性带来的另一点巨大优势是扩展的可组合性,让不同扩展相互合作,产生出 1+1 » 2 的协同效应。例如,TimescaleDB 可以与 PostGIS 组合使用,提供时空数据支持;再比如,提供全文检索能力的 BM25 扩展可以和提供语义模糊检索的 PGVector 扩展组合使用,提供混合检索能力。
再比如,分布式扩展 Citus 可以将单机主从数据库集群,原地升级改造为透明水平分片的分布式数据库集群。而这个能力是可以与其他功能正交组合的,因此,PostGIS 可以成为分布式地理数据库,PGVector 可以成为分布式向量数据库,ParadeDB 可以成为分布式全文搜索数据库,诸如此类。
更强大的地方在于,扩展插件是独立演进的,不需要繁琐的主干合并,联调协作。因此可以 Scale —— PG 的可扩展性允许无数个团队并行探索数据库前研发展方向,而扩展全部都是的可选的,不会影响主干核心能力的稳定性。那些非常强大成熟的特性,则有机会以稳定的形态进入主干中。
通过极致可扩展性的魔法,PostgreSQL 做到了**守正出奇,实现了主干极致稳定性与功能敏捷性的统一。**扎实的基本盘配上惊人的演进速度,让它成为了数据库世界中的一个异数,改变了数据库世界的游戏规则。
改变游戏规则的玩家
PostgreSQL 的出现,改变了数据库领域的游戏规则:任何试图开发“新数据库内核”的团队,都需要经过这道试炼与考验 —— 相比开源免费、功能齐备的 Postgres,价值点在哪里?
至少到硬件出现革命性突破前,实用的通用数据库新内核都不太可能诞生了,因为任何单一数据库都无法与所有扩展加持下的 PG 在整体实力上相抗衡 —— 包括 Oracle,因为 PG 还有开源免费的必杀技。
而某个细分领域的数据库产品,如果能在单点属性(通常是性能)上相比 PostgreSQL 实现超过一个数量级的优势,那也许还有一个专用数据库的生态位存在。但通常用不了多久,便会有 PostgreSQL 生态的开源替代扩展插件滚滚而来。因为选择开发 PG 扩展,而不是一个完整数据库的团队会在追赶复刻速度上有碾压性优势!
因此,如果按照这样的逻辑展开,PostgreSQL 生态的雪球只会越滚越大,随着优势的积累,不可避免地进入一家独大的状态。在几年的时间内,实现 Linux 内核在服务器操作系统领域的状态。而各种开发者调研报告,数据库流行趋势都在印证着这一点。
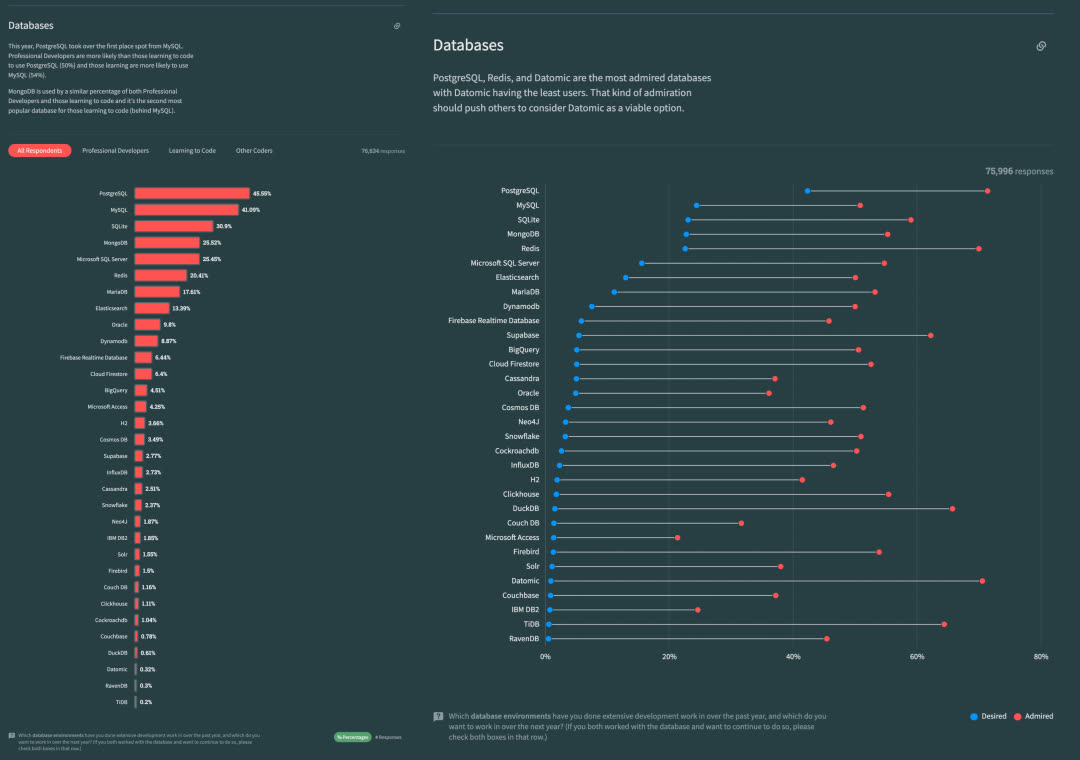
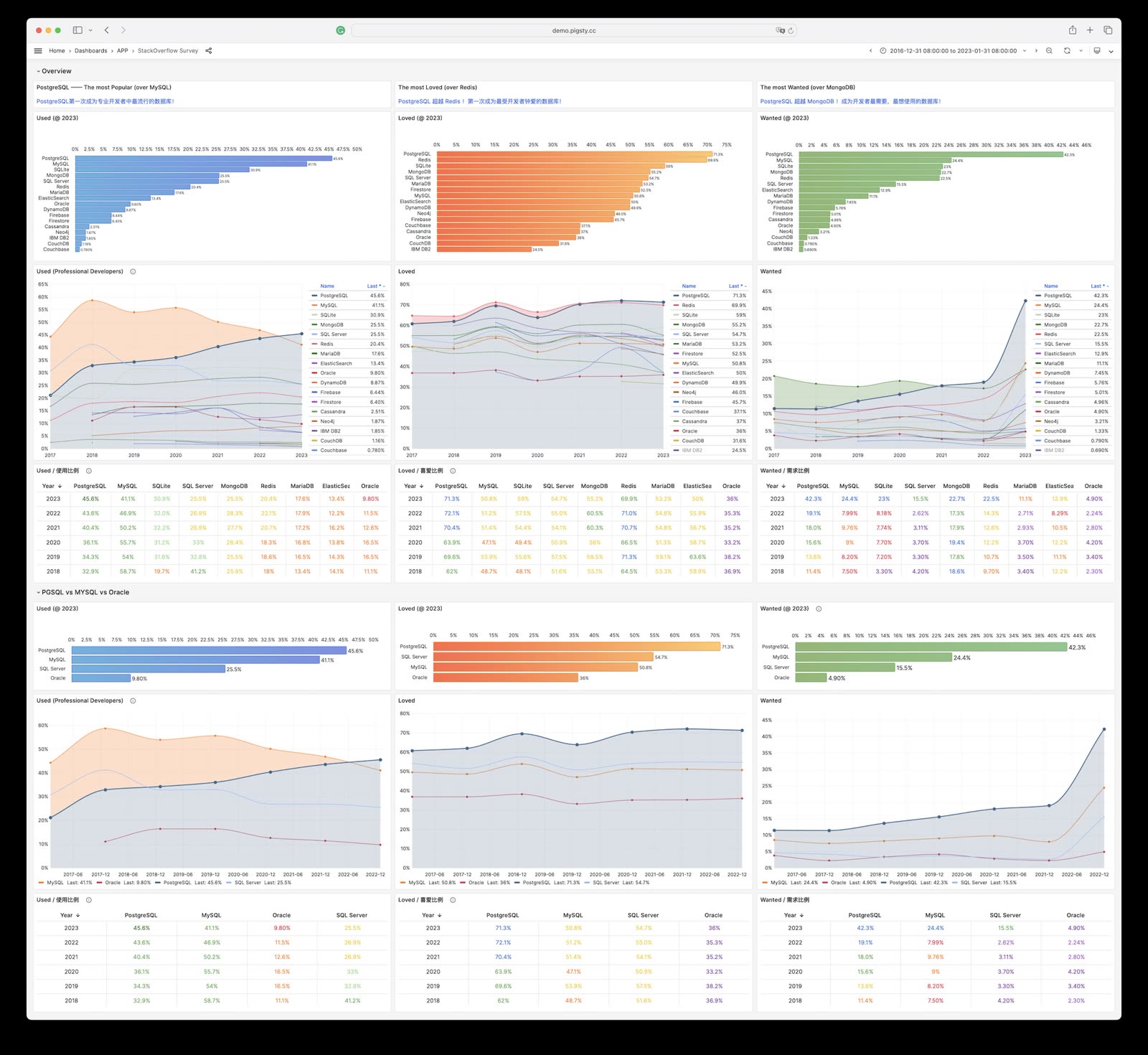
在引领潮流的 HackerNews StackOverflow 上,PostgreSQL 早已成为了最受欢迎的数据库。许多新的开源项目都默认使用 PostgreSQL 作为首要,甚至唯一的数据库 —— 例如,给各种数据库做模式管理的 Bytebase。《云时代数据库DevOps:硅谷调研》也提出,许多新一代互联网公司都开始积极拥抱并 All in PostgreSQL。
正如《技术极简主义:一切皆用 Postgres》所言:简化技术栈、减少组件、加快开发速度、降低风险并提供更多功能特性的方法之一就是 “一切皆用 Postgres”。Postgres 能够取代许多后端技术,包括 MySQL,Kafka、RabbitMQ、ElasticSearch,Mongo和 Redis,至少到数百万用户时都毫无问题。一切皆用 Postgres ,已经不再是少数精英团队的前沿探索,而是成为了一种进入主流视野的最佳实践。
还有什么可以做的?
我们已经不难预见到数据库领域的终局。但我们又能做什么,又应该做什么呢?
PostgreSQL 对于绝大多数场景都已经是一个足够完美的数据库内核了,在这个前提下,数据库内核 卡脖子纯属无稽之谈。这些Fork PostgreSQL 和 MySQL 并以内核魔改作为卖点的所谓"数据库“基本没啥出息。
这好比今天我们看 Linux 操作系统内核一样,尽管市面上有这么多的 Linux 操作系统发行版,但大家都选择使用同样的 Linux 内核,吃饱了撑着魔改内核属于没有困难创造困难也要上,会被业界当成山炮看待。
同理,数据库内核本身已经不再是主要矛盾,焦点将会集中到两个方向上 —— 数据库扩展与数据库服务!前者体现为数据库内部的可扩展性, 后者体现为数据库外部的可组合性。而竞争的形式,正如操作系统生态一样 —— 集中于数据库发行版上。对于数据库领域来说,只有那些以扩展和服务作为核心价值主张的发行版,才有最终成功的可能。
做内核的厂商不温不火,MariaDB 作为 MySQL 的亲爹 Fork 甚至都已经濒临退市,而白嫖内核自己做服务与扩展卖 RDS 的 AWS 可以赚的钵满盆翻。投资机构已经出手了许多 PG 生态的扩展插件与服务发行版:Citus,TimescaleDB,Hydra,PostgresML,ParadeDB,FerretDB,StackGres,Aiven,Neon,Supabase,Tembo,PostgresAI,以及我们正在做的 Pigsty 。

PostgreSQL 生态中的一个困境就是,许多扩展插件,生态工具都是独立演进,各自为战的,没有一个整合者能将他们凝聚起来形成合力。例如,提供分析的 Hydra 会打一个包一个 Docker 镜像, PostgresML 也会打自己的包和镜像,各家只发行加装了自己扩展的 Postgres 镜像。而这些朴素的镜像与包也距离 RDS 这样完整的数据库服务相距甚远。
即使是类似于 AWS RDS 这样的服务提供商与生态整合者,在诸多扩展面前也依然力有所不逮,只能提供其中的少数。更多的强力扩展出于各种原因(AGPLv3 协议,多租户租赁带来的安全挑战)而无法使用。从而难以发挥 PostgreSQL 生态扩展的协同增幅作用。
这里列出了一些重要扩展,对比基于最新的 PostgreSQL 16 主干版本进行,截止至 2024-02-28
扩展类目 Pigsty RDS / PGDG 官方仓库 阿里云 RDS AWS RDS PG 加装扩展 自由加装 不允许 不允许 地理空间 PostGIS 3.4.2 PostGIS 3.3.4 / Ganos 6.1 PostGIS 3.4.1 雷达点云 PG PointCloud 1.2.5 Ganos PointCloud 6.1 向量嵌入 PGVector 0.6.1 / Svector 0.5.6 pase 0.0.1 PGVector 0.6 机器学习 PostgresML 2.8.1 时序扩展 TimescaleDB 2.14.2 水平分布式 Citus 12.1 列存扩展 Hydra 1.1.1 全文检索 pg_bm25 0.5.6 图数据库 Apache AGE 1.5.0 GraphQL PG GraphQL 1.5.0 OLAP pg_analytics 0.5.6 消息队列 pgq 3.5.0 DuckDB duckdb_fdw 1.1 模糊分词 zhparser 1.1 / pg_bigm 1.2 zhparser 1.0 / pg_jieba pg_bigm 1.2 CDC抽取 wal2json 2.5.3 wal2json 2.5 膨胀治理 pg_repack 1.5.0 pg_repack 1.4.8 pg_repack 1.5.0 许多关键扩展在RDS中并不可用
扩展是 PostgreSQL 的灵魂,无法自由使用扩展的 Postgres 就像做菜不放盐。只能和 MySQL 放在同一个 RDS 的框子里同台,龙游浅水,虎落平阳。
而这正是我们想要解决的首要问题之一。
知行合一的实践:Pigsty
虽然接触 MySQL 和 MSSQL 要早得多,但我在 2015 年第一次上手 PostgreSQL 时,就相信它会是数据库领域的未来了。快十年过去,我也从 PG 的使用者,管理者,变为了贡献者,开发者。也不断见证着 PG 走向这一目标。
在与形形色色的用户沟通交流中,我早已发现数据库领域的木桶短板不是内核 —— 现有的 PostgreSQL 已经足够好了,而是用好数据库内核本身的能力,这也是 RDS 这样的服务赚的钵满盆翻的原因。
但我希望这样的能力,应该像自由软件运动所倡导的理念那样,像 PostgreSQL 内核本身一样 —— 普及到每一个用户手中,而不是必须向赛博空间上的封建云领主花大价钱租赁。
所以我打造了 Pigsty —— 一个开箱即用的开源 PostgreSQL 数据库发行版,旨在凝聚 PostgreSQL 生态扩展的合力,并把提供优质数据库服务的能力普及到每个用户手中。

Pigsty 是 PostgreSQL in Great STYle 的缩写,意为 PostgreSQL 的全盛状态。
我们提出了六点核心价值主张,对应 PostgreSQL 数据库服务中的的六个核心问题:Postgres 的可扩展性,基础设施的可靠性,图形化的可观测性,服务的可用性,工具的可维护性,以及扩展模块和三方组件可组合性。
Pigsty 六点价值主张的首字母合起来,则为 Pigsty 提供了另外一种缩写解释:
Postgres, Infras, Graphics, Service, Toolbox, Yours.
属于你的图形化 Postgres 基础设施服务工具箱。

可扩展的 PostgreSQL 是这个发行版中最重要的价值主张。在刚刚发布的 Pigsty v2.6 中,我们整合了上面提到的 DuckdbFDW 与 ParadeDB 扩展,这两个插件让 PostgreSQL 的分析能力得到史诗级增强,而我们确保每个用户都能轻松用得上这样的能力。
来自 ParadeDB 创始人与 DuckdbFDW 作者的感谢致意
我们希望整合 PostgreSQL 生态里的各种力量,并将其凝聚在一起形成合力,打造一个数据库世界中的 Ubuntu 发行版。而我相信,内核之争早已尘埃落定,而这里才会是数据库世界的未来竞争焦点。
- PostGIS:提供地理空间数据类型与索引支持,GIS 事实标准 (& pgPointCloud 点云,pgRouting 寻路)
- TimescaleDB:添加时间序列/持续聚合/分布式/列存储/自动压缩的能力
- PGVector:添加 AI 向量/嵌入数据类型支持,以及 ivfflat 与 hnsw 向量索引。(& pg_sparse 稀疏向量支持)
- Citus:将经典的主从PG集群原地改造为水平分片的分布式数据库集群。
- Hydra:添加列式存储与分析能力,提供比肩 ClickHouse 的强力分析能力。
- ParadeDB:添加 ElasticSearch 水准的全文搜索能力与混合检索的能力。(& zhparser 中文分词)
- Apache AGE:图数据库扩展,为 PostgreSQL 添加类 Neo4J 的 OpenCypher 查询支持,
- PG GraphQL:为 PostgreSQL 添加原生内建的 GraphQL 查询语言支持。
- DuckDB FDW:允许您通过 PostgreSQL 直接读写强力的嵌入式分析数据库 DuckDB 文件 (& DuckDB CLI 本体)。
- Supabase:基于 PostgreSQL 的开源的 Firebase 替代,提供完整的应用开发存储解决方案。
- FerretDB:基于 PostgreSQL 的开源 MongoDB 替代,兼容 MongoDB API / 驱动协议。
- PostgresML:使用SQL完成经典机器学习算法,调用、部署、训练 AI 模型。
Pigsty 支持的 464 扩展列表

开发者朋友们,你们的选择会塑造数据库世界的未来。希望我的这些工作,可以帮助你们更好的用好这世界上最先进的开源数据库内核 —— PostgreSQL。