服务接入
分离读写操作,正确路由流量,稳定可靠地交付 PostgreSQL 集群提供的能力。
服务是一种抽象:它是数据库集群对外提供能力的形式,并封装了底层集群的细节。
服务对于生产环境中的稳定接入至关重要,在高可用集群自动故障时方显其价值,单机用户通常不需要操心这个概念。
单机用户
“服务” 的概念是给生产环境用的,个人用户/单机集群可以不折腾,直接拿实例名/IP地址访问数据库。
例如,Pigsty 默认的单节点 pg-meta.meta 数据库,就可以直接用下面三个不同的用户连接上去。
psql postgres://dbuser_dba:DBUser.DBA@10.10.10.10/meta # 直接用 DBA 超级用户连上去
psql postgres://dbuser_meta:DBUser.Meta@10.10.10.10/meta # 用默认的业务管理员用户连上去
psql postgres://dbuser_view:DBUser.View@pg-meta/meta # 用默认的只读用户走实例域名连上去
服务概述
在真实世界生产环境中,我们会使用基于复制的主从数据库集群。集群中有且仅有一个实例作为领导者(主库)可以接受写入。 而其他实例(从库)则会从持续从集群领导者获取变更日志,与领导者保持一致。同时,从库还可以承载只读请求,在读多写少的场景下可以显著分担主库的负担, 因此对集群的写入请求与只读请求进行区分,是一种十分常见的实践。
此外对于高频短连接的生产环境,我们还会通过连接池中间件(Pgbouncer)对请求进行池化,减少连接与后端进程的创建开销。但对于ETL与变更执行等场景,我们又需要绕过连接池,直接访问数据库。 同时,高可用集群在故障时会出现故障切换(Failover),故障切换会导致集群的领导者出现变更。因此高可用的数据库方案要求写入流量可以自动适配集群的领导者变化。 这些不同的访问需求(读写分离,池化与直连,故障切换自动适配)最终抽象出 服务 (Service)的概念。
通常来说,数据库集群都必须提供这种最基础的服务:
- 读写服务(primary) :可以读写数据库
对于生产数据库集群,至少应当提供这两种服务:
- 读写服务(primary) :写入数据:只能由主库所承载。
- 只读服务(replica) :读取数据:可以由从库承载,没有从库时也可由主库承载
此外,根据具体的业务场景,可能还会有其他的服务,例如:
- 默认直连服务(default) :允许(管理)用户,绕过连接池直接访问数据库的服务
- 离线从库服务(offline) :不承接线上只读流量的专用从库,用于ETL与分析查询
- 同步从库服务(standby) :没有复制延迟的只读服务,由同步备库/主库处理只读查询
- 延迟从库服务(delayed) :访问同一个集群在一段时间之前的旧数据,由延迟从库来处理
接入服务
Pigsty的服务交付边界止步于集群的HAProxy,用户可以用各种手段访问这些负载均衡器。
典型的做法是使用 DNS 或 VIP 接入,将其绑定在集群所有或任意数量的负载均衡器上。
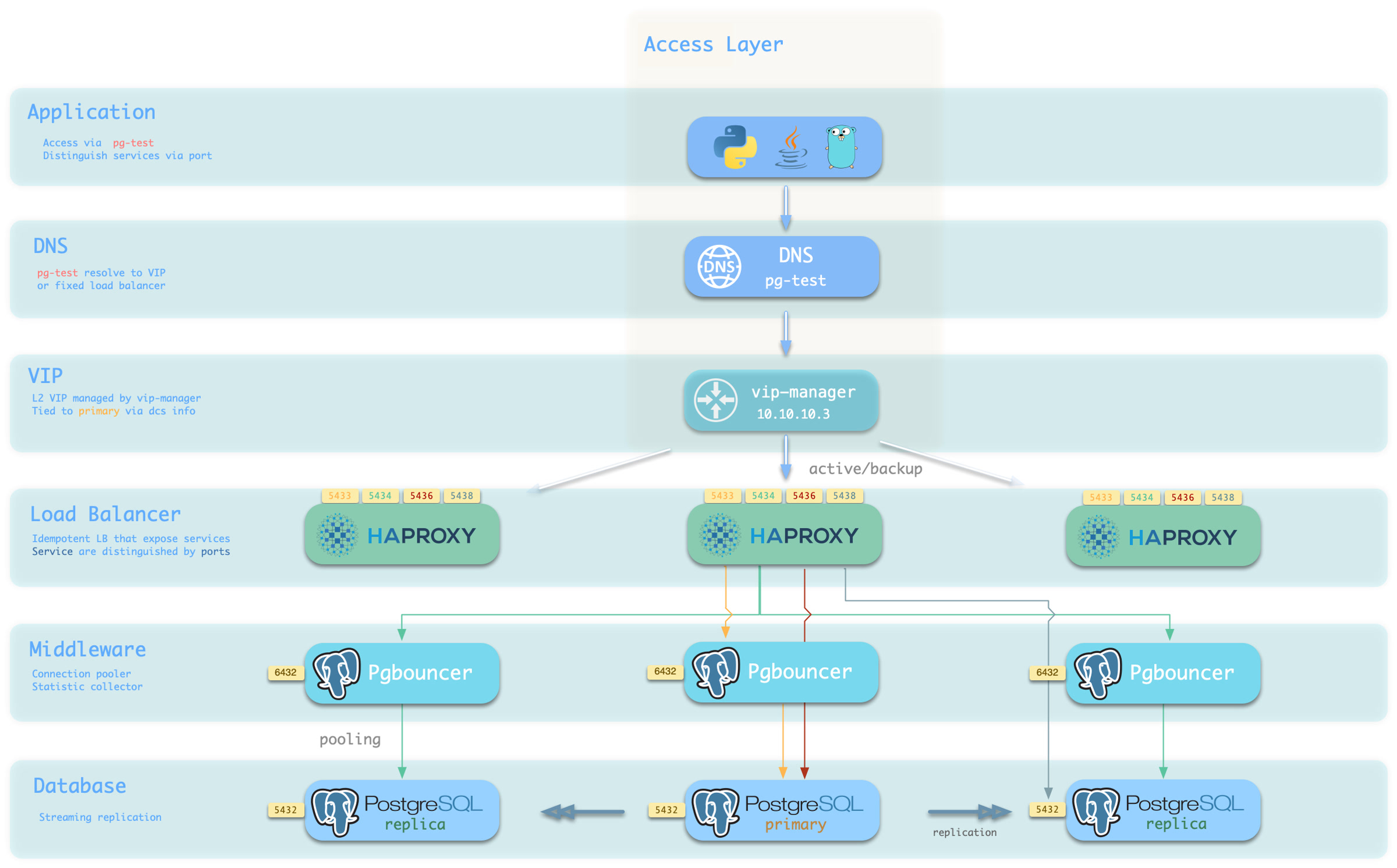
你可以使用不同的 主机 & 端口 组合,它们以不同的方式提供 PostgreSQL 服务。
主机
| 类型 | 样例 | 描述 |
|---|---|---|
| 集群域名 | pg-test |
通过集群域名访问(由 dnsmasq @ infra 节点解析) |
| 集群 VIP 地址 | 10.10.10.3 |
通过由 vip-manager 管理的 L2 VIP 地址访问,绑定到主节点 |
| 实例主机名 | pg-test-1 |
通过任何实例主机名访问(由 dnsmasq @ infra 节点解析) |
| 实例 IP 地址 | 10.10.10.11 |
访问任何实例的 IP 地址 |
端口
Pigsty 使用不同的 端口 来区分 pg services
| 端口 | 服务 | 类型 | 描述 |
|---|---|---|---|
| 5432 | postgres | 数据库 | 直接访问 postgres 服务器 |
| 6432 | pgbouncer | 中间件 | 访问 postgres 前先通过连接池中间件 |
| 5433 | primary | 服务 | 访问主 pgbouncer (或 postgres) |
| 5434 | replica | 服务 | 访问备份 pgbouncer (或 postgres) |
| 5436 | default | 服务 | 访问主 postgres |
| 5438 | offline | 服务 | 访问离线 postgres |
组合
# 通过集群域名访问
postgres://test@pg-test:5432/test # DNS -> L2 VIP -> 主直接连接
postgres://test@pg-test:6432/test # DNS -> L2 VIP -> 主连接池 -> 主
postgres://test@pg-test:5433/test # DNS -> L2 VIP -> HAProxy -> 主连接池 -> 主
postgres://test@pg-test:5434/test # DNS -> L2 VIP -> HAProxy -> 备份连接池 -> 备份
postgres://dbuser_dba@pg-test:5436/test # DNS -> L2 VIP -> HAProxy -> 主直接连接 (用于管理员)
postgres://dbuser_stats@pg-test:5438/test # DNS -> L2 VIP -> HAProxy -> 离线直接连接 (用于 ETL/个人查询)
# 通过集群 VIP 直接访问
postgres://test@10.10.10.3:5432/test # L2 VIP -> 主直接访问
postgres://test@10.10.10.3:6432/test # L2 VIP -> 主连接池 -> 主
postgres://test@10.10.10.3:5433/test # L2 VIP -> HAProxy -> 主连接池 -> 主
postgres://test@10.10.10.3:5434/test # L2 VIP -> HAProxy -> 备份连接池 -> 备份
postgres://dbuser_dba@10.10.10.3:5436/test # L2 VIP -> HAProxy -> 主直接连接 (用于管理员)
postgres://dbuser_stats@10.10.10.3::5438/test # L2 VIP -> HAProxy -> 离线直接连接 (用于 ETL/个人查询)
# 直接指定任何集群实例名
postgres://test@pg-test-1:5432/test # DNS -> 数据库实例直接连接 (单例访问)
postgres://test@pg-test-1:6432/test # DNS -> 连接池 -> 数据库
postgres://test@pg-test-1:5433/test # DNS -> HAProxy -> 连接池 -> 数据库读/写
postgres://test@pg-test-1:5434/test # DNS -> HAProxy -> 连接池 -> 数据库只读
postgres://dbuser_dba@pg-test-1:5436/test # DNS -> HAProxy -> 数据库直接连接
postgres://dbuser_stats@pg-test-1:5438/test # DNS -> HAProxy -> 数据库离线读/写
# 直接指定任何集群实例 IP 访问
postgres://test@10.10.10.11:5432/test # 数据库实例直接连接 (直接指定实例, 没有自动流量分配)
postgres://test@10.10.10.11:6432/test # 连接池 -> 数据库
postgres://test@10.10.10.11:5433/test # HAProxy -> 连接池 -> 数据库读/写
postgres://test@10.10.10.11:5434/test # HAProxy -> 连接池 -> 数据库只读
postgres://dbuser_dba@10.10.10.11:5436/test # HAProxy -> 数据库直接连接
postgres://dbuser_stats@10.10.10.11:5438/test # HAProxy -> 数据库离线读-写
# 智能客户端:通过URL读写分离
postgres://test@10.10.10.11:6432,10.10.10.12:6432,10.10.10.13:6432/test?target_session_attrs=primary
postgres://test@10.10.10.11:6432,10.10.10.12:6432,10.10.10.13:6432/test?target_session_attrs=prefer-standby