PG先写脏页还是先写WAL?

昨天在群里遇到一个有趣的关于 PostgreSQL 的问题:
”写脏数据页和写入WAL缓冲区的先后顺序是什么?“
我们都知道, WAL 就是 Write Ahead Log / 预写式日志 的缩写,那从逻辑上说,好像是先写 WAL 再写数据页才对。
但其实这个问题有趣在,写入其实是发生在两个地方的:内存与磁盘。而这对这两者的写入顺序是不一样的:在内存中,先写脏数据页,再写 WAL记录。在刷盘时,先刷 WAL 记录,再刷脏数据页。
我们可以用一个简单的例子来说明,当你执行一条 INSERT 时到底发生了什么?以及,数据库是如何确保这条插入的数据被正确持久化的。
INSERT的内存修改
当你执行 INSERT 语句时(不包括前后隐含的 BEGIN / COMMIT),修改首先在内存中发生:
1.首先排它锁定并钉住目标数据页面,准备修改。2.进入临界区,不允许打断,出错就 PANIC。3.修改内存中的数据页面。4.将修改的内存数据页面标记为脏页。5.生成一条包含修改内容的 WAL记录 ,写入内存中的 WAL 缓冲区。6.从临界区出来,以上3个操作都是内存中的高速操作7.解锁解钉数据页面。
完成这些任务之后,内存中的缓冲池数据页包含了 INSERT 后的结果,WAL缓冲区中则包含了 INSERT 的 XLogRecord 操作记录。这里我们可以看出,在内存中是先写数据页,再写 WAL 的。原因其实很简单,PostgreSQL默认使用物理复制,记录的是页面内的二进制数据变化,所以只有先把数据写入页面里,才会知道具体的页面变化到底是什么。
内存中的操作非常快,而且这里 3 和 6 中间使用了临界区(Critical Zone),确保数据页/WAL的修改整体是原子性的。不过,内存中的修改要落到磁盘上,才算真正持久化了。所以,还会涉及到 WAL 记录与 脏数据页刷盘的问题。
而这里,才是 Write-Ahead 真正约束的地方:脏数据页刷盘应当晚于WAL缓冲区刷盘。
下面是一个具体的例子,一条由单一 INSERT 语句构成的事务:
参考阅读《PostgreSQL指南:内幕探索》 9.5
testdb=# INSERT INTO tbl VALUES ('A');
执行上述语句时,内部函数exec_simple_query()会被调用,其伪代码如下所示:
exec_simple_query() @postgres.c
(1) ExtendCLOG() @clog.c /* 将当前事务的状态"IN_PROGRESS"写入CLOG */
(2) heap_insert() @heapam.c /* 插入元组,创建一条XLOG记录并调用函XLogInsert. */
(3) XLogInsert() @xlog.c /* (9.5 以及后续的版本为 xloginsert.c) */
/* 将插入元组的XLOG记录写入WAL缓冲区,更新页面的 pd_lsn */
(4) finish_xact_command() @postgres.c /* 执行提交 */
XLogInsert() @xlog.c /* (9.5 以及后续的版本为 xloginsert.c) */
/* 将该提交行为的XLOG记录写入WAL缓冲区 */
(5) XLogWrite() @xlog.c /* 将WAL缓冲区中所有的XLOG刷写入WAL段中 */
(6) TransactionIdCommitTree() @transam.c
/* 在CLOG中将当前事务的状态由"IN_PROGRESS"修改为"COMMITTED" /*
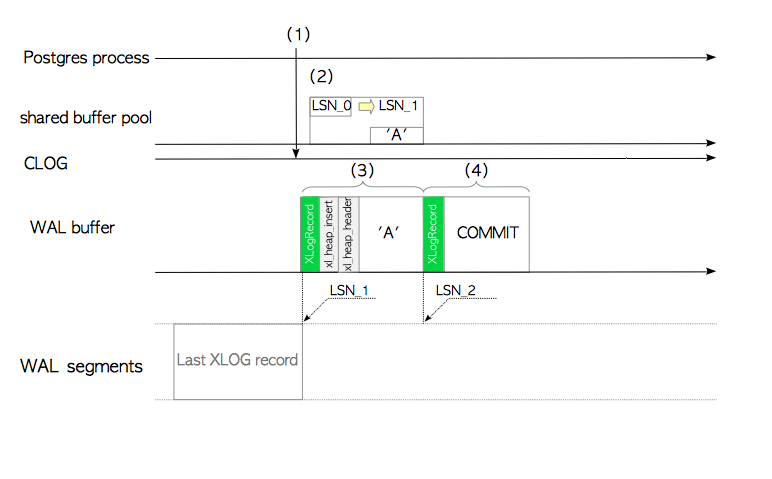
- 函数
ExtendCLOG()将当前事务的状态IN_PROGRESS写入内存中的CLOG。 - 函数
heap_insert()向共享缓冲池的目标页面中插入堆元组,创建当前页面的XLOG记录,并执行函数XLogInsert()。 - 函数
XLogInsert()会将heap_insert()创建的XLOG记录写入WAL缓冲区LSN_1处,并将被修改页面的pd_lsn从LSN_0更新为LSN_1。 - 函数
finish_xact_command()会在该事务被提交时被调用,用于创建该提交动作的XLOG记录,而这里的XLogInsert()函数会将该记录写入WAL缓冲区LSN_2处。 - 函数
XLogWrite()会冲刷WAL缓冲区,并将所有内容写入WAL段文件中。如果wal_sync_method参数被配置为open_sync或open_datasync,记录会被同步写入(译者注:而不是提交才会刷新WAL缓冲区),因为函数会使用带有O_SYNC或O_DSYNC标记的open()系统调用。如果该参数被配置为fsync,fsync_writethrough,fdatasync,相应的系统调用就是fsync(),带有F_FULLSYNC选项的fcntl(),以及fdatasync()。无论哪一种情况,所有的XLOG记录都会被确保写入存储之中。 - 函数
TransactionIdCommitTree()将提交日志clog中当前事务的状态从IN_PROGRESS更改为COMMITTED。
如何强制WAL先于脏页刷盘?
那么,先刷WAL,再刷磁盘这条规则具体是怎么确保的呢?
每一个内存中的数据页上都保存了一个状态:最后一次对本数据页进行修改的 WAL 记录 LSN:pd_lsn,因此如果要把内存中的脏页刷入磁盘中,首先需要确保最后一次对这个页面进行修改的 WAL 已经被刷入磁盘中了。
所以我们可以在在 backend/storage/buffer/bufmgr.c#FlushBuffer (L3350)中看到,刷脏页的过程中会调用 XLogFlush 函数来确保这一点,XLogFlush 函数会检查当前的 WAL 刷盘位置是不是已经大于页面的 LSN,如果不是,则会推动 WAL 刷盘。
recptr = BufferGetLSN(buf);
XLogFlush(recptr);
谁会刷脏页呢?主要是BGWriter与Checkpointer,但普通的后端进程也可以刷脏页。一个脏页具体是被哪个进程刷盘比较随机,大家都有机会出力,但通常来说刷脏页的主力是,后台刷盘进程 BGWriter。不管是哪个进程刷脏页,都会确保最后修改数据页的WAL已经落盘,从而满足 Write Ahead 的约束条件。
脏页会在什么时间被刷盘呢?首先,数据页不能被锁定,其次,数据页不能被钉住。也就是说在上面 INSERT 的例子中,只有完成步骤 7 解锁解钉数据页 后,数据页才有可能被刷盘。而这一行为是异步的,具体时间是不确定的:PostgreSQL 能提供的保证是:在下次 Checkpoint(存盘点/检查点)之前,这个脏页肯定会被刷盘。(bufmgr.c)
/*
* FlushBuffer
* Physically write out a shared buffer.
*
* NOTE: this actually just passes the buffer contents to the kernel; the
* real write to disk won't happen until the kernel feels like it. This
* is okay from our point of view since we can redo the changes from WAL.
* However, we will need to force the changes to disk via fsync before
* we can checkpoint WAL.
*
* The caller must hold a pin on the buffer and have share-locked the
* buffer contents. (Note: a share-lock does not prevent updates of
* hint bits in the buffer, so the page could change while the write
* is in progress, but we assume that that will not invalidate the data
* written.)
*
* If the caller has an smgr reference for the buffer's relation, pass it
* as the second parameter. If not, pass NULL.
*/
static void
FlushBuffer(BufferDesc *buf, SMgrRelation reln, IOObject io_object,
IOContext io_context)
{
XLogRecPtr recptr;
ErrorContextCallback errcallback;
instr_time io_start;
Block bufBlock;
char *bufToWrite;
uint32 buf_state;
/* ... */
recptr = BufferGetLSN(buf);
/* To check if block content changes while flushing. - vadim 01/17/97 */
buf_state &= ~BM_JUST_DIRTIED;
UnlockBufHdr(buf, buf_state);
/*
* Force XLOG flush up to buffer's LSN. This implements the basic WAL
* rule that log updates must hit disk before any of the data-file changes
* they describe do.
*
* However, this rule does not apply to unlogged relations, which will be
* lost after a crash anyway. Most unlogged relation pages do not bear
* LSNs since we never emit WAL records for them, and therefore flushing
* up through the buffer LSN would be useless, but harmless. However,
* GiST indexes use LSNs internally to track page-splits, and therefore
* unlogged GiST pages bear "fake" LSNs generated by
* GetFakeLSNForUnloggedRel. It is unlikely but possible that the fake
* LSN counter could advance past the WAL insertion point; and if it did
* happen, attempting to flush WAL through that location would fail, with
* disastrous system-wide consequences. To make sure that can't happen,
* skip the flush if the buffer isn't permanent.
*/
if (buf_state & BM_PERMANENT)
XLogFlush(recptr);
/* ... */
}
WAL是如何刷盘的?
我们已经知道了,刷脏数据页这件事通常是异步进行的,且肯定晚于对应的 WAL 记录刷盘。那么新的问题就是,WAL 是由谁在什么时间点来刷盘的呢:从内存中的 WAL 缓冲区刷入磁盘中?
要回答这个问题,首先要理解 WAL 的模型。WAL 在逻辑上是一个长度无限的文件,任何一个改变数据库系统状态的操作,都会生成相应的 XLogRecord,即 WAL记录。每一条 WAL 记录都会使用其起始位置的文件偏移量作为自己的唯一标识符,即 LSN(逻辑日志位点)。

各种各样修改系统状态的行为都会产生 WAL记录:例如 BEGIN 有一条 WAL记录,INSERT 有一条 WAL记录,COMMIT 也有一条WAL记录,而WAL记录会首先被写入内存中的 WAL缓冲区(最大16MB)。
PostgreSQL 支持多个客户端并发修改,所以同一时刻会有各种进程往内存中的 WAL缓冲区(最大16MB)写东西。所以不同进程、不同事务产生的 XLogRecord 会在同一个逻辑文件中相互交织。每次写入都是原子性的,一条记录一条记录的写。
内存里的WAL缓冲区中的内容,会被各种进程写入/刷入持久化磁盘上的WAL文件里。当前写入内存WAL缓冲区的逻辑日志位置点称作 INSERT LSN。写入操作系统缓冲区的日志位点叫 WRITE LSN,已经使用 FSYNC 之类的 API 确保已经成功持久化的日志位点叫 FLUSH LSN。这里面的关系是 INSERT_LSN >= WRITE_LSN >= FLUSH_LSN。原理很简单:内存中的东西最新,写入可能稍微滞后些,刷盘则可能比写入更滞后一些。
刷盘的主力是 WAL Writer 进程,但其实各种进程都可以刷写。刷盘靠 XLogFlush 函数 (backend/access/transam/xlog.c#XLogFlush),这里的逻辑很简单,就是指定一个位置点,把这个位置点及之前的 WAL 从缓冲区全刷至磁盘。具体的实现逻辑是死循环抢自旋锁,如果目标 LSN 已经被别的进程刷盘了就退出循环,否则就亲自上阵把 WAL 日志刷盘到指定位点。(xlog.c)
/*
* Ensure that all XLOG data through the given position is flushed to disk.
*
* NOTE: this differs from XLogWrite mainly in that the WALWriteLock is not
* already held, and we try to avoid acquiring it if possible.
*/
void
XLogFlush(XLogRecPtr record)
{
XLogRecPtr WriteRqstPtr;
XLogwrtRqst WriteRqst;
TimeLineID insertTLI = XLogCtl->InsertTimeLineID;
/*
* During REDO, we are reading not writing WAL. Therefore, instead of
* trying to flush the WAL, we should update minRecoveryPoint instead. We
* test XLogInsertAllowed(), not InRecovery, because we need checkpointer
* to act this way too, and because when it tries to write the
* end-of-recovery checkpoint, it should indeed flush.
*/
if (!XLogInsertAllowed())
{
UpdateMinRecoveryPoint(record, false);
return;
}
/* Quick exit if already known flushed */
if (record <= LogwrtResult.Flush)
return;
START_CRIT_SECTION();
/*
* Since fsync is usually a horribly expensive operation, we try to
* piggyback as much data as we can on each fsync: if we see any more data
* entered into the xlog buffer, we'll write and fsync that too, so that
* the final value of LogwrtResult.Flush is as large as possible. This
* gives us some chance of avoiding another fsync immediately after.
*/
/* initialize to given target; may increase below */
WriteRqstPtr = record;
/*
* Now wait until we get the write lock, or someone else does the flush
* for us.
*/
for (;;)
{
/* ... */
}
END_CRIT_SECTION();
/* wake up walsenders now that we've released heavily contended locks */
WalSndWakeupProcessRequests(true, !RecoveryInProgress());
/*
* If we still haven't flushed to the request point then we have a
* problem; most likely, the requested flush point is past end of XLOG.
* This has been seen to occur when a disk page has a corrupted LSN.
*
* Formerly we treated this as a PANIC condition, but that hurts the
* system's robustness rather than helping it: we do not want to take down
* the whole system due to corruption on one data page. In particular, if
* the bad page is encountered again during recovery then we would be
* unable to restart the database at all! (This scenario actually
* happened in the field several times with 7.1 releases.) As of 8.4, bad
* LSNs encountered during recovery are UpdateMinRecoveryPoint's problem;
* the only time we can reach here during recovery is while flushing the
* end-of-recovery checkpoint record, and we don't expect that to have a
* bad LSN.
*
* Note that for calls from xact.c, the ERROR will be promoted to PANIC
* since xact.c calls this routine inside a critical section. However,
* calls from bufmgr.c are not within critical sections and so we will not
* force a restart for a bad LSN on a data page.
*/
if (LogwrtResult.Flush < record)
elog(ERROR,
"xlog flush request %X/%X is not satisfied --- flushed only to %X/%X",
LSN_FORMAT_ARGS(record),
LSN_FORMAT_ARGS(LogwrtResult.Flush));
}
关于内核原理
关于 PostgreSQL 的内核原理,我认为有几个学习材料非常值得参考。
第一本是《PG Internal》,鈴木啓修写的,基于 PostgreSQL 9.6 与 11 的代码,讲解PG内核原理。我之前翻译了中文版《PostgreSQL指南:内部探索》。第二本是 《PostgreSQL 14 Internal》,是俄罗斯 Postgres Pro 公司 Egor Rogov 写的,基于 PostgreSQL 14 进行架构讲解。
当然我认为最有学习价值的还是 PostgreSQL 源代码,特别是源代码中的 README,比如本文中的这个问题,就在事务管理器源码 README 中详细介绍了。PostgreSQL 的源代码是自我解释的,你只需要懂英文大致就能理解这里面的逻辑。
The general schema for executing a WAL-logged action is
1. Pin and exclusive-lock the shared buffer(s) containing the data page(s)
to be modified.
2. START_CRIT_SECTION() (Any error during the next three steps must cause a
PANIC because the shared buffers will contain unlogged changes, which we
have to ensure don't get to disk. Obviously, you should check conditions
such as whether there's enough free space on the page before you start the
critical section.)
3. Apply the required changes to the shared buffer(s).
4. Mark the shared buffer(s) as dirty with MarkBufferDirty(). (This must
happen before the WAL record is inserted; see notes in SyncOneBuffer().)
Note that marking a buffer dirty with MarkBufferDirty() should only
happen iff you write a WAL record; see Writing Hints below.
5. If the relation requires WAL-logging, build a WAL record using
XLogBeginInsert and XLogRegister* functions, and insert it. (See
"Constructing a WAL record" below). Then update the page's LSN using the
returned XLOG location. For instance,
XLogBeginInsert();
XLogRegisterBuffer(...)
XLogRegisterData(...)
recptr = XLogInsert(rmgr_id, info);
PageSetLSN(dp, recptr);
6. END_CRIT_SECTION()
7. Unlock and unpin the buffer(s).
Complex changes (such as a multilevel index insertion) normally need to be
described by a series of atomic-action WAL records. The intermediate states
must be self-consistent, so that if the replay is interrupted between any
two actions, the system is fully functional. In btree indexes, for example,
a page split requires a new page to be allocated, and an insertion of a new
key in the parent btree level, but for locking reasons this has to be
reflected by two separate WAL records. Replaying the first record, to
allocate the new page and move tuples to it, sets a flag on the page to
indicate that the key has not been inserted to the parent yet. Replaying the
second record clears the flag. This intermediate state is never seen by
other backends during normal operation, because the lock on the child page
is held across the two actions, but will be seen if the operation is
interrupted before writing the second WAL record. The search algorithm works
with the intermediate state as normal, but if an insertion encounters a page
with the incomplete-split flag set, it will finish the interrupted split by
inserting the key to the parent, before proceeding.