PG中的本地化排序规则
为什么Pigsty在初始化Postgres数据库时默认指定了locale=C与encoding=UTF8
答案其实很简单,除非真的明确知道自己会用到LOCALE相关功能,否则就根本不应该配置C.UTF8之外的任何字符编码与本地化排序规则选项。特别是`
关于字符编码的部分,之前写过一篇文章专门介绍,这里表过不提。今天专门说一下LOCALE(本地化)的配置问题。
如果说服务端字符编码配置因为某些原因配置为UTF8之外的值也许还情有可原,那么LOCALE配置为C之外的任何选就是无可救药了。因为对于PostgreSQL来说,LOCALE不仅仅是控制日期和钱怎么显示这一类无伤大雅的东西,而是会影响到某些关键功能的使用。
错误的LOCALE配置可能导致几倍到十几倍的性能损失,还会导致LIKE查询无法在普通索引上使用。而设置LOCALE=C一点也不会影响真正需要本地化规则的使用场景。所以官方文档给出的指导是:“如果你真正需要LOCALE,才去使用它”。
不幸的是,在PostgreSQLlocale与encoding的默认配置取决于操作系统的配置,因此C.UTF8可能并不是默认的配置,这就导致了很多人误用LOCALE而不自知,白白折损了大量性能,也导致了某些数据库特性无法正常使用。

太长;不看
- 强制使用
UTF8字符编码,强制数据库使用C的本地化规则。 - 使用非C本地化规则,可能导致涉及字符串比较的操作开销增大几倍到几十倍,对性能产生显著负面影响
- 使用非C本地化规则,会导致
LIKE查询无法使用普通索引,容易踩坑雪崩。 - 使用非C本地化规则的实例,可以通过
text_ops COLLATE "C"或text_pattern_ops建立索引,支持LIKE查询。
LOCALE是什么
我们经常能在操作系统和各种软件中看到 LOCALE(区域) 的相关配置,但LOCALE到底是什么呢?
LOCALE支持指的是应用遵守文化偏好的问题,包括字母表、排序、数字格式等。LOCALE由很多规则与定义组成,包括:
LC_COLLATE |
字符串排序顺序 |
|---|---|
LC_CTYPE |
字符分类(什么是一个字符?它的大写形式是否等效?) |
LC_MESSAGES |
消息使用的语言Language of messages |
LC_MONETARY |
货币数量使用的格式 |
LC_NUMERIC |
数字的格式 |
LC_TIME |
日期和时间的格式 |
| …… | 其他…… |
一个LOCALE就是一组规则,LOCALE通常会用语言代码 + 国家代码的方式来命名。例如中国大陆使用的LOCALE zh_CN就分为两个部分:zh是 语言代码,CN 是国家代码。现实世界中,一种语言可能有多个国家在用,一个国家内也可能存在多种语言。还是以中文和中国为例:
中国(COUNTRY=CN)相关的语言LOCALE有:
zh:汉语:zh_CNbo:藏语:bo_CNug:维语:ug_CN
讲中文(LANG=zh)的国家或地区相关的LOCAL有:
CN中国:zh_CNHK香港:zh_HKMO澳门:zh_MOTW台湾:zh_TWSG新加坡:zh_SG
LOCALE的例子
我们可以参考一个典型的Locale定义文件:Glibc提供的 zh_CN
这里截取一小部分展示,看上去好像都是些鸡零狗碎的格式定义,月份星期怎么叫啊,钱和小数点怎么显示啊之类的东西。
但这里有一个非常关键的东西,叫做LC_COLLATE,即排序方式(Collation),会对数据库行为有显著影响。
LC_CTYPE
copy "i18n"
translit_start
include "translit_combining";""
translit_end
class "hanzi"; /
<U4E00>..<U9FA5>;/
<UF92C>;<UF979>;<UF995>;<UF9E7>;<UF9F1>;<UFA0C>;<UFA0D>;<UFA0E>;/
<UFA0F>;<UFA11>;<UFA13>;<UFA14>;<UFA18>;<UFA1F>;<UFA20>;<UFA21>;/
<UFA23>;<UFA24>;<UFA27>;<UFA28>;<UFA29>
END LC_CTYPE
LC_COLLATE
copy "iso14651_t1_pinyin"
END LC_COLLATE
LC_TIME
% 一月, 二月, 三月, 四月, 五月, 六月, 七月, 八月, 九月, 十月, 十一月, 十二月
mon "<U4E00><U6708>";/
"<U4E8C><U6708>";/
"<U4E09><U6708>";/
"<U56DB><U6708>";/
...
% 星期日, 星期一, 星期二, 星期三, 星期四, 星期五, 星期六
day "<U661F><U671F><U65E5>";/
"<U661F><U671F><U4E00>";/
"<U661F><U671F><U4E8C>";/
...
week 7;19971130;1
first_weekday 2
% %Y年%m月%d日 %A %H时%M分%S秒
d_t_fmt "%Y<U5E74>%m<U6708>%d<U65E5> %A %H<U65F6>%M<U5206>%S<U79D2>"
% %Y年%m月%d日
d_fmt "%Y<U5E74>%m<U6708>%d<U65E5>"
% %H时%M分%S秒
t_fmt "%H<U65F6>%M<U5206>%S<U79D2>"
% 上午, 下午
am_pm "<U4E0A><U5348>";"<U4E0B><U5348>"
% %p %I时%M分%S秒
t_fmt_ampm "%p %I<U65F6>%M<U5206>%S<U79D2>"
% %Y年 %m月 %d日 %A %H:%M:%S %Z
date_fmt "%Y<U5E74> %m<U6708> %d<U65E5> %A %H:%M:%S %Z"
END LC_TIME
LC_NUMERIC
decimal_point "."
thousands_sep ","
grouping 3
END LC_NUMERIC
LC_MONETARY
% ¥
currency_symbol "<UFFE5>"
int_curr_symbol "CNY "
比如zh_CN提供的LC_COLLATE使用了iso14651_t1_pinyin排序规则,这是一个基于拼音的排序规则。
下面通过一个例子来介绍LOCALE中的COLLATION如何影响Postgres的行为。
排序规则一例
创建一张包含7个汉字的表,然后执行排序操作。
CREATE TABLE some_chinese(
name TEXT PRIMARY KEY
);
INSERT INTO some_chinese VALUES
('阿'),('波'),('磁'),('得'),('饿'),('佛'),('割');
SELECT * FROM some_chinese ORDER BY name;
执行以下SQL,按照默认的C排序规则对表中的记录排序。可以看到,这里实际上是按照字符的ascii|unicode 码位 进行排序的。
vonng=# SELECT name, ascii(name) FROM some_chinese ORDER BY name COLLATE "C";
name | ascii
------+-------
佛 | 20315
割 | 21106
得 | 24471
波 | 27874
磁 | 30913
阿 | 38463
饿 | 39295
但这样基于码位的排序对于中国人来说可能没有任何意义。例如新华字典在收录汉字时,就不会使用这种排序方式。而是采用zh_CN 所使用的 拼音排序 规则,按照拼音比大小。如下所示:
SELECT * FROM some_chinese ORDER BY name COLLATE "zh_CN";
name
------
阿
波
磁
得
饿
佛
割
可以看到,按照zh_CN排序规则排序得到的结果,就是拼音顺序abcdefg,而不再是不知所云的Unicode码位排序。
当然这个查询结果取决于zh_CN 排序规则的具体定义,像这样的排序规则并不是数据库本身定义的,数据库本身提供的排序规则就是C(或者其别名POSIX)。COLLATION的来源,通常要么是操作系统,要么是glibc,要么是第三方的本地化库(例如icu),所以可能因为不同的实质定义出现不同的效果。
但代价是什么?
PostgreSQL中使用非C或非POSIX LOCALE的最大负面影响是:
特定排序规则对涉及字符串大小比较的操作有巨大的性能影响,同时它还会导致无法在LIKE查询子句中使用普通索引。
另外,C LOCALE是由数据库本身确保在任何操作系统与平台上使用的,而其他的LOCALE则不然,所以使用非C Locale的可移植性更差。
性能损失
接下来让我们考虑一个使用LOCALE排序规则的例子, 我们有Apple Store 150万款应用的名称,现在希望按照不同的区域规则进行排序。
-- 创建一张应用名称表,里面有中文也有英文。
CREATE TABLE app(
name TEXT PRIMARY KEY
);
COPY app FROM '/tmp/app.csv';
-- 查看表上的统计信息
SELECT
correlation , -- 相关系数 0.03542578 基本随机分布
avg_width , -- 平均长度25字节
n_distinct -- -1,意味着1508076个记录没有重复
FROM pg_stats WHERE tablename = 'app';
-- 使用不同的排序规则进行一系列的实验
SELECT * FROM app;
SELECT * FROM app order by name;
SELECT * FROM app order by name COLLATE "C";
SELECT * FROM app order by name COLLATE "en_US";
SELECT * FROM app order by name COLLATE "zh_CN";
相当令人震惊的结果,使用C和zh_CN的结果能相差十倍之多:
| 序号 | 场景 | 耗时(ms) | 说明 |
|---|---|---|---|
| 1 | 不排序 | 180 | 使用索引 |
| 2 | order by name |
969 | 使用索引 |
| 3 | order by name COLLATE "C" |
1430 | 顺序扫描,外部排序 |
| 4 | order by name COLLATE "en_US" |
10463 | 顺序扫描,外部排序 |
| 5 | order by name COLLATE "zh_CN" |
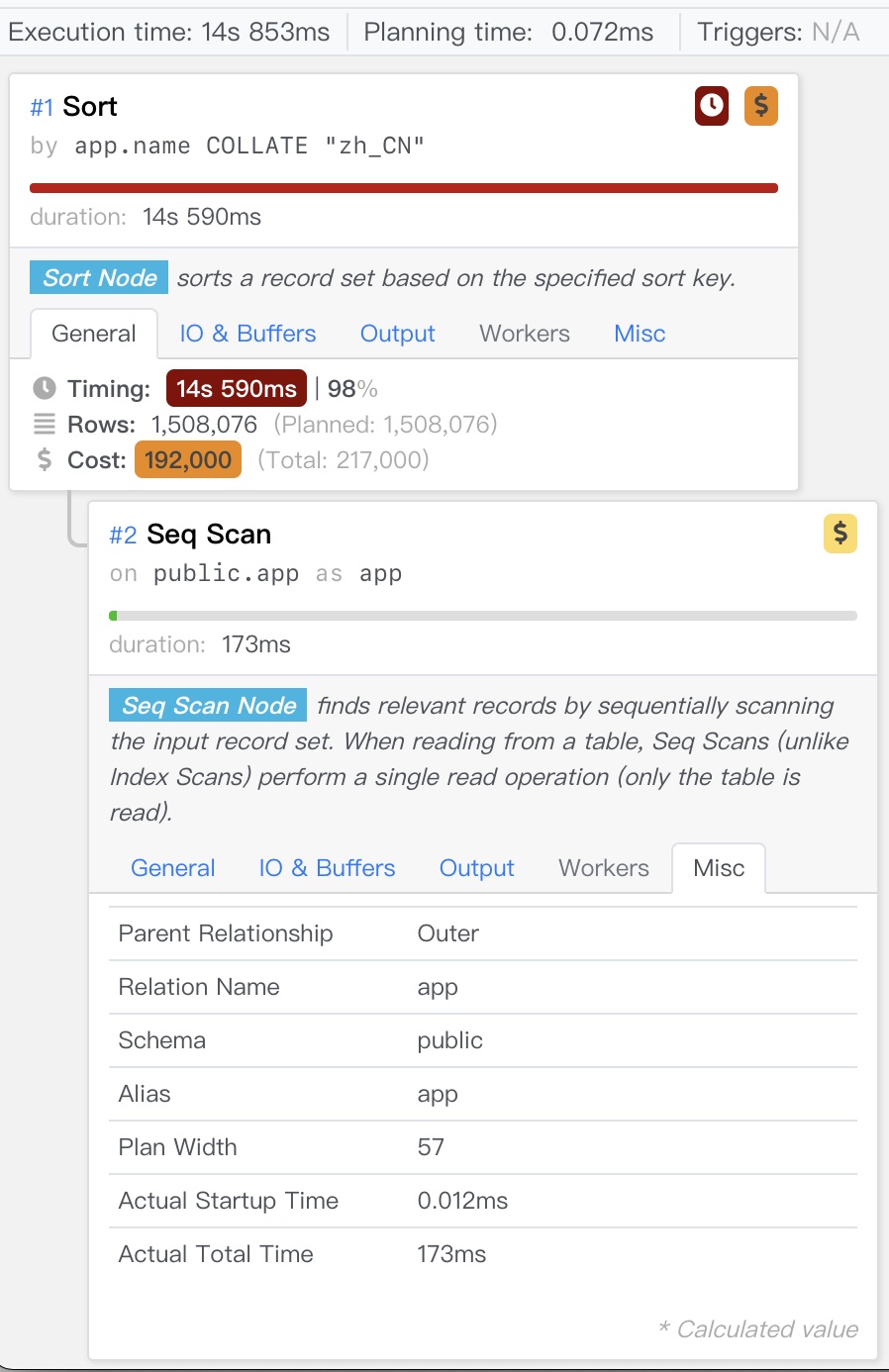
14852 | 顺序扫描,外部排序 |
下面是实验5对应的详细执行计划,即使配置了足够大的内存,依然会溢出到磁盘执行外部排序。尽管如此,显式指定LOCALE的实验都出现了此情况,因此可以横向对比出C与zh_CN的性能差距来。
另一个更有对比性的例子是比大小。
这里,表中的所有的字符串都会和World比一下大小,相当于在表上进行150万次特定规则比大小,而且也不涉及到磁盘IO。
SELECT count(*) FROM app WHERE name > 'World';
SELECT count(*) FROM app WHERE name > 'World' COLLATE "C";
SELECT count(*) FROM app WHERE name > 'World' COLLATE "en_US";
SELECT count(*) FROM app WHERE name > 'World' COLLATE "zh_CN";
尽管如此,比起C LOCALE来,zh_CN 还是费了接近3倍的时长。
| 序号 | 场景 | 耗时(ms) |
|---|---|---|
| 1 | 默认 | 120 |
| 2 | C | 145 |
| 3 | en_US | 351 |
| 4 | zh_CN | 441 |
如果说排序可能是O(n2)次比较操作有10倍损耗 ,那么这里的O(n)次比较3倍开销也基本能对应上。我们可以得出一个初步的粗略结论:
比起C Locale来,使用zh_CN或其他Locale可能导致几倍的额外性能开销。
除此之外,错误的Locale不仅仅会带来性能损失,还会导致功能损失。
功能缺失
除了性能表现糟糕外,另一个令人难以接受的问题是,使用非C的LOCALE,LIKE查询走不了普通索引。
还是以刚才的实验为例,我们分别在使用C和en_US作为默认LOCALE创建的数据库实例上执行以下查询:
SELECT * FROM app WHERE name LIKE '中国%';
找出所有以“中国”两字开头的应用。
在使用C的库上
该查询能正常使用app_pkey索引,利用主键B树的有序性加速查询,约2毫秒内执行完毕。
postgres@meta:5432/meta=# show lc_collate;
C
postgres@meta:5432/meta=# EXPLAIN SELECT * FROM app WHERE name LIKE '中国%';
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using app_pkey on app (cost=0.43..2.65 rows=1510 width=25)
Index Cond: ((name >= '中国'::text) AND (name < '中图'::text))
Filter: (name ~~ '中国%'::text)
(3 rows)
在使用en_US的库上
我们发现,这个查询无法利用索引,走了全表扫描。查询劣化至70毫秒,性能恶化了三四十倍。
vonng=# show lc_collate;
en_US.UTF-8
vonng=# EXPLAIN SELECT * FROM app WHERE name LIKE '中国%';
QUERY PLAN
----------------------------------------------------------
Seq Scan on app (cost=0.00..29454.95 rows=151 width=25)
Filter: (name ~~ '中国%'::text)
为什么?
因为索引(B树索引)的构建,也是建立在序的基础上,也就是等值和比大小这两个操作。
然而,LOCALE关于字符串的等价规则有一套自己的定义,例如在Unicode标准中就定义了很多匪夷所思的等价规则(毕竟是万国语言,比如多个字符复合而成的字符串等价于另一个单体字符,详情参考 现代字符编码 一文)。
因此,只有最朴素的C LOCALE,才能够正常地进行模式匹配。C LOCALE的比较规则非常简单,就是挨个比较 字符码位,不玩那一套花里胡哨虚头巴脑的东西。所以,如果您的数据库不幸使用了非C的LOCALE,那么在执行LIKE查询时就没有办法使用默认的索引了。
解决办法
对于非C LOCALE的实例,只有建立特殊类型的索引,才能支持此类查询:
CREATE INDEX ON app(name COLLATE "C");
CREATE INDEX ON app(name text_pattern_ops);
这里使用 text_pattern_ops运算符族来创建索引也可以用来支持LIKE查询,这是专门用于支持模式匹配的运算符族,从原理上讲它会无视 LOCALE,直接基于 逐个字符 比较的方式执行模式匹配,也就是使用C LOCALE的方式。
因此在这种情况下,只有基于text_pattern_ops操作符族建立的索引,或者基于默认的text_ops但使用COLLATE "C"' 的索引,才可以用于支持LIKE查询。
vonng=# EXPLAIN ANALYZE SELECT * FROM app WHERE name LIKE '中国%';
Index Only Scan using app_name_idx on app (cost=0.43..1.45 rows=151 width=25) (actual time=0.053..0.731 rows=2360 loops=1)
Index Cond: ((name ~>=~ '中国'::text) AND (name ~<~ '中图'::text))
Filter: (name ~~ '中国%'::text COLLATE "en_US.UTF-8")
建立完索引后,我们可以看到原来的LIKE查询可以走索引了。
LIKE无法使用普通索引这个问题,看上去似乎可以通过额外创建一个text_pattern_ops索引来曲线解决。但这也意味着原本可以直接利用现成的PRIMARY KEY或UNIQUE约束自带索引解决的问题,现在需要额外的维护成本与存储空间。
对于不熟悉这一问题的开发者来说,很有可能因为错误的LOCALE配置,导致本地没问题的模式结果在线上因为没有走索引而雪崩。(例如本地使用C,但生产环境用了非C LOCALE)。
兼容性
假设您在接手时数据库已经使用了非C的LOCALE(这种事相当常见),现在您在知道了使用非C LOCALE的危害后,决定找个机会改回来。
那么有哪些地方需要注意呢?具体来讲,Locale的配置影响PostgreSQL以下功能:
-
使用
LIKE子句的查询。 -
任何依赖特定LOCALE排序规则的查询,例如依赖拼音排序作为结果排序依据。
-
使用大小写转换相关功能的查询,函数
upper、lower和initcap -
to_char函数家族,涉及到格式化为本地时间时。 -
正则表达式中的大小写不敏感匹配模式(
SIMILAR TO,~)。
如果不放心,可以通过pg_stat_statements列出所有涉及到以下关键词的查询语句进行手工排查:
LIKE|ILIKE -- 是否使用了模式匹配
SIMILAR TO | ~ | regexp_xxx -- 是否使用了 i 选项
upper, lower, initcap -- 是否针对其他带有大小写模式的语言使用(西欧字符之类)
ORDER BY col -- 按文本类型列排序时,是否依赖特定排序规则?(例如按照拼音)
兼容性修改
通常来说,C LOCALE在功能上是其他LOCALE配置的超集,总是可以从其他LOCALE切换为C。如果您的业务没有使用这些功能,通常什么都不需要做。如果使用本地化规则特性,则总是可以通过**显式指定COLLATE**的方式,在C LOCALE下实现相同的效果。
SELECT upper('a' COLLATE "zh_CN"); -- 基于zh_CN规则执行大小写转换
SELECT '阿' < '波'; -- false, 在默认排序规则下 阿(38463) > 波(27874)
SELECT '阿' < '波' COLLATE "zh_CN"; -- true, 显式使用中文拼音排序规则: 阿(a) < 波(bo)
目前唯一已知的问题出现在扩展pg_trgm上。