快速上手
1 - 安装部署
简短版本
准备 一个安装了 兼容 操作系统的 Linux x86_64 / aarch64 节点,使用带有免密 sudo 权限的用户,执行以下命令:
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty;
该命令会 下载 并解压 Pigsty 源码至家目录,依次完成 配置 与安装 即可完成安装。
./bootstrap; ./configure; ./install.yml; # 准备依赖,生成配置,安装 Pigsty 三步走!
- bootstrap:【可选】用于确保 Ansible 正常安装,如果
/tmp/pkg.tgz离线包存在则使用它 - configure:【可选】检测环境并自动生成相应的推荐配置文件,如果知道如何 配置 Pigsty可以直接跳过
- install.yml:根据生成的配置文件开始在当前节点上执行安装,
整个安装过程根据服务器规格/网络条件需 5 到 30 分钟不等,离线安装可以显著加速。
安装完成后,您可以通过域名,或80/443端口通过 Nginx 访问 WEB 界面,
通过 5432 端口 访问 默认的 PostgreSQL 数据库 服务。
您可以继续使用 Pigsty 纳管 更多 节点,并部署各种 模块。
如果您觉得 Pigsty 的组件过于复杂,还可以考虑使用 最小化安装 ,仅安装高可用 PostgreSQL 集群所必需的组件。
视频样例:在线单机安装(EL9)

使用命令行工具
Pigsty 在 v3.2 后提供了命令行工具:pig,可用于安装 Pigsty,生成配置,执行部署等操作。
curl https://repo.pigsty.cc/pig | bash # 中国大陆
curl https://repo.pigsty.io/pig | bash # 国际区域
以上命令会自动安装 pig 命令行工具(目前支持 Linux amd64 / arm64),您可以直接使用 pig sty 子命令来完成上面的步骤:
pig sty init # 默认安装嵌入的最新 Pigsty 版本
pig sty boot # 执行 Bootstrap,安装 Ansible
pig sty conf # 执行 Configure,生成配置文件
pig sty install # 执行 install.yml 剧本完成部署
准备
关于准备工作的完整详细说明,请参考 入门:准备工作 一节。
Pigsty 支持 Linux 内核与 x86_64/aarch64 架构,运行于物理机、虚拟机环境中,要求使用静态IP地址。
最低配置要求为 1C1G,推荐至少使用 2C4G 以上的机型,上不封顶,参数会自动优化适配。
我们强烈建议您使用刚安装完操作系统的全新节点部署,从而避免无谓的安装异常问题,建议使用 RockyLinux 8.9 或 Ubuntu 22.04.3, 支持的完整操作系统列表请参考 兼容性。
在安装 Pigsty 的管理节点上,您需要拥有 ssh 登陆权限与 sudo 权限。
如果您的部署涉及多个节点,您应当确保当前管理用户在当前管理节点上,可以通过 SSH 公钥免密登陆其他被管理的节点(包括本节点)。
避免使用 root 用户安装
尽管使用root 用户安装 Pigsty 是可行的,但 安全最佳实践
是使用一个不同于根用户(root)与数据库超级用户 (postgres) 的专用管理员用户(如:dba),
Pigsty 安装过程中会默认创建由配置文件指定的可选管理员用户 dba。
Pigsty 依赖 Ansible 执行剧本,在执行安装前,您需要先安装 ansible 与 jmespath 软件包。
您可以通过 bootstrap 脚本完成这一任务,特别是当您没有互联网访问,需要进行离线安装时。
./bootstrap # 使用各种可选方式安装 Ansible 与 Jmespath 依赖,如果离线包存在则使用离线包
您也可以直接使用操作系统的包管理器安装所需的 Ansible 与 Jmespath 软件包:
sudo dnf install -y ansible python3.12-jmespath python3-cryptographysudo yum install -y ansible # EL7 无需显式安装 Jmespathsudo apt install -y ansible python3-jmespathbrew install ansible下载
您可以使用以下命令自动下载、解压 Pigsty 源码包至 ~/pigsty 目录下使用:
curl -fsSL https://repo.pigsty.cc/get | bash # 安装最新稳定版本
curl -fsSL https://repo.pigsty.cc/get | bash -s v3.3.0 # 安装特定版本 3.3.0
一键下载脚本的样例输出
$ curl -fsSL https://repo.pigsty.cc/get | bash
[v3.3.0] ===========================================
$ curl -fsSL https://repo.pigsty.cc/get | bash
[Site] https://pigsty.cc
[Demo] https://demo.pigsty.cc
[Repo] https://github.com/pgsty/pigsty
[Docs] https://pigsty.cc/docs/setup/install
[Download] ===========================================
[ OK ] version = v3.3.0 (from default)
curl -fSL https://repo.pigsty.cc/src/pigsty-v3.3.0.tgz -o /tmp/pigsty-v3.3.0.tgz
[WARN] tarball = /tmp/pigsty-v3.3.0.tgz exists, size = 1227379, use it
[ OK ] md5sums = xxxxxx /tmp/pigsty-v3.3.0.tgz
[Install] ===========================================
[WARN] os user = root , it's recommended to install as a sudo-able admin
[WARN] pigsty already installed on '/root/pigsty', if you wish to overwrite:
sudo rm -rf /tmp/pigsty_bk; cp -r /root/pigsty /tmp/pigsty_bk; # backup old
sudo rm -rf /tmp/pigsty; tar -xf /tmp/pigsty-v3.3.0.tgz -C /tmp/; # extract new
rsync -av --exclude='/pigsty.yml' --exclude='/files/pki/***' /tmp/pigsty/ /root/pigsty/; # rsync src
[TodoList] ===========================================
cd /root/pigsty
./bootstrap # [OPTIONAL] install ansible & use offline package
./configure # [OPTIONAL] preflight-check and config generation
./install.yml # install pigsty modules according to your config.
[Complete] ===========================================
你也可以使用 git 来下载 Pigsty 源代码,请 务必 检出特定版本后使用。
git clone https://github.com/pgsty/pigsty; cd pigsty; git checkout v3.3.0
配置
配置 / configure 会根据您当前的环境,自动生成推荐的(单机安装) pigsty.yml 配置文件。
提示: 如果您已经了解了如何配置 Pigsty,configure 这个步骤是可选的,可以跳过。 Pigsty 提供了许多开箱即用的预置 配置模板 供您参考。
./configure # 不带参数会自动推荐配置,并交互式问询
./configure [-i|--ip <ipaddr>] # 指定首要 IP 地址,如果不指定,将在检测到多个可用IP地址时问询。
[-c|--conf <conf>] # 指定配置模板(相对于 conf/ 目录的配置名称,不带.yml 后缀),默认使用 meta 单节点模板
[-v|--version <ver>] # 指定要安装 PostgreSQL 大版本,部分模板不适用此配置
[-r|--region <default|china|europe>] # 选择镜像源区域,如果在 GFW 区域内,将被设置为 china
[-n|--non-interactive] # 跳过交互式向导
[-x|--proxy] # 将环境变量中的代理配置写入配置文件的 proxy_env 参数中
配置 / configure 过程的样例输出
$ ./configure
configure pigsty v3.3.0 begin
[ OK ] region = china
[ OK ] kernel = Linux
[ OK ] machine = x86_64
[ OK ] package = rpm,yum
[ OK ] vendor = centos (CentOS Linux)
[ OK ] version = 7 (7)
[ OK ] sudo = vagrant ok
[ OK ] ssh = vagrant@127.0.0.1 ok
[WARN] Multiple IP address candidates found:
(1) 192.168.121.110 inet 192.168.121.110/24 brd 192.168.121.255 scope global noprefixroute dynamic eth0
(2) 10.10.10.10 inet 10.10.10.10/24 brd 10.10.10.255 scope global noprefixroute eth1
[ OK ] primary_ip = 10.10.10.10 (from demo)
[ OK ] admin = vagrant@10.10.10.10 ok
[WARN] mode = el7, CentOS 7.9 EOL @ 2024-06-30, deprecated, consider using el8 or el9 instead
[ OK ] configure pigsty done
proceed with ./install.yml
-i|--ip: 当前主机的首要内网IP地址,用于替换配置文件中的 IP 地址占位符10.10.10.10。-c|--conf: 用于指定使用的配置 配置模板,相对于conf/目录,不带.yml后缀的配置名称。-v|--version: 用于指定要安装的 PostgreSQL 大版本,如13、14、15、16、17,部分模板不支持此配置。-r|--region: 用于指定上游软件源的区域,加速下载: (default|china|europe)-n|--non-interactive: 直接使用命令行参数提供首要IP地址,跳过交互式向导。-x|--proxy: 使用当前环境变量配置proxy_env变量(影响http_proxy/HTTP_PROXY,HTTPS_PROXY,ALL_PROXY,NO_PROXY)。
如果您的机器网卡绑定了多个 IP 地址,那么需要使用 -i|--ip <ipaddr> 显式指定一个当前节点的首要 IP 地址,或在交互式问询中提供。
选用的地址应为静态 IP 地址,请勿使用公网 IP 地址。
配置过程生成的配置文件默认位于:~/pigsty/pigsty.yml,您可以在安装前进行检查与修改定制。
修改默认密码!
我们强烈建议您在安装前,事先修改配置文件中使用的默认密码与凭据,详情参考 安全考量。安装
使用 install.yml 剧本,默认在当前节点上完成标准的单节点 Pigsty 安装。
./install.yml # 一次性在所有节点上完成安装
安装过程的样例输出
[vagrant@meta pigsty]$ ./install.yml
PLAY [IDENTITY] ********************************************************************************************************************************
TASK [node_id : get node fact] *****************************************************************************************************************
changed: [10.10.10.10]
...
...
PLAY RECAP **************************************************************************************************************************************************************************
10.10.10.10 : ok=288 changed=215 unreachable=0 failed=0 skipped=64 rescued=0 ignored=0
localhost : ok=3 changed=0 unreachable=0 failed=0 skipped=4 rescued=0 ignored=0
这是一个 Ansible 剧本,您可以使用以下参数控制其执行的目标、任务、并传递额外的命令参数:
-l: 限制执行的目标对象-t: 限制要执行的任务-e: 传入额外的命令行参数-i: 指定使用不同于pigsty.yml的配置文件- …
避免重复执行安装剧本!
警告: 在已经初始化的环境中再次运行 install.yml 会重置整个环境,所以请务必小心!
此剧本仅用于初始安装,安装完毕后可以用 rm install.yml 或 chmod a-x install.yml 来避免此剧本的误执行。
用户界面
当安装完成后,当前节点会安装有四个 核心模块:PGSQL,INFRA,NODE,ETCD。
本机上的 PGSQL 模块提供了一个开箱即用的单机 PostgreSQL 数据库实例,默认可以使用以下连接串 访问:
psql postgres://dbuser_dba:DBUser.DBA@10.10.10.10/meta # DBA / 超级用户(IP直连)psql postgres://dbuser_meta:DBUser.Meta@10.10.10.10/meta # 业务管理员用户,读/写/DDL变更psql postgres://dbuser_view:DBUser.View@pg-meta/meta # 只读用户(走域名访问)本机上的 INFRA 模块为您提供了监控基础设施,默认使用的域名与端口如下所示:
| 组件 | 端口 | 域名 | 说明 | Demo地址 |
|---|---|---|---|---|
| Nginx | 80/443 | h.pigsty |
Web 服务总入口,本地YUM源 | home.pigsty.cc |
| AlertManager | 9093 | a.pigsty |
告警聚合/屏蔽页面 | a.pigsty.cc |
| Grafana | 3000 | g.pigsty |
Grafana 监控面板 | demo.pigsty.cc |
| Prometheus | 9090 | p.pigsty |
Prometheus 管理界面 | p.pigsty.cc |
Grafana 监控系统(g.pigsty / 3000端口)的默认用户名与密码为:
admin/pigsty
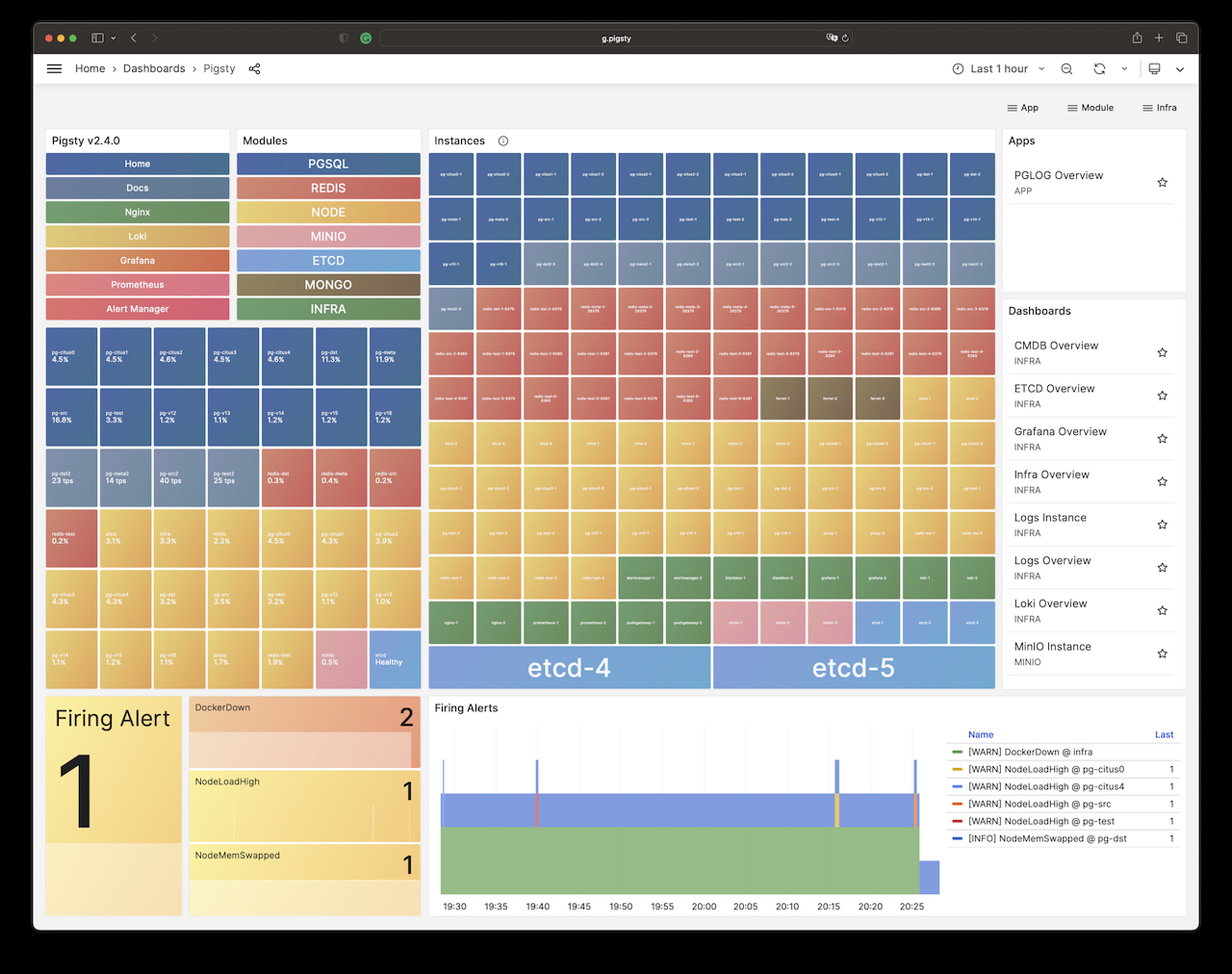
您可以通过 IP地址 + 端口的方式直接访问这些服务。但我们更推荐您使用域名通过 Nginx 80/443 端口代理访问所有组件。
使用域名访问 Pigsty WebUI 时,您需要配置 DNS 解析,或者修改本地的 /etc/hosts 静态解析文件。
如何通过域名访问 Pigsty WebUI ?
客户端可以通过几种不同的办法来使用域名访问:
- 通过 DNS 服务商解析互联网域名,适用于公网可访问的系统。
- 通过配置内网 DNS 服务器解析记录实现内网域名解析。
- 修改本机的
/etc/hosts文件添加静态解析记录。(Windows下为:)
我们建议普通用户使用第三种方式,在使用浏览器访问 Web 系统的机器上,修改 /etc/hosts (需要 sudo 权限)或 C:\Windows\System32\drivers\etc\hosts(Windows)文件,添加以下的解析记录:
<your_public_ip_address> h.pigsty a.pigsty p.pigsty g.pigsty
这里的 IP 地址是安装 Pigsty 服务的 对外IP地址。
如何配置服务端使用的域名?
服务器端域名使用 Nginx 进行配置,如果您想要替换默认的域名,在参数 infra_portal 中填入使用的域名即可。
当您使用 http://g.pigsty 访问 Grafana 监控主页时,实际上是通过 Nginx 代理访问了 Grafana 的 WebUI:
http://g.pigsty ️-> http://10.10.10.10:80 (nginx) -> http://10.10.10.10:3000 (grafana)
如何使用 HTTPS 访问 Pigsty WebUI ?
Pigsty默认使用自动生成的自签名的 CA 证书为 Nginx 启用 SSL,如果您希望使用 HTTPS 访问这些页面,而不弹窗提示"不安全",通常有三个选择:
- 在您的浏览器或操作系统中信任 Pigsty 自签名的 CA 证书:
files/pki/ca/ca.crt - 如果您使用 Chrome,可以在提示不安全的窗口键入
thisisunsafe跳过提示 - 您可以考虑使用 Let’s Encrypt 或其他免费的 CA 证书服务,为 Pigsty Nginx 生成正式的 SSL证书。
更多
你可以使用 Pigsty 部署更多的集群,管理更多的节点,例如:
bin/node-add pg-test # 将集群 pg-test 的3个节点纳入 Pigsty 管理
bin/pgsql-add pg-test # 初始化一个3节点的 pg-test 高可用PG集群
bin/redis-add redis-ms # 初始化 Redis 集群: redis-ms
大多数模块都依赖 NODE 模块,请确保节点被 Pigsty 纳管后再加装其他模块。更多细节请参考 模块 详情:
PGSQL,INFRA,NODE,ETCD,MINIO,REDIS,MONGO,DOCKER,……
2 - 离线安装
Pigsty 默认的 标准安装 流程需要访问互联网,然而生产环境的数据库服务器通常是与互联网隔离的。
为了解决这个问题,Pigsty 提供了离线安装的功能。通过使用离线软件包,用户可以在没有互联网访问的环境中同样完成安装与部署。
离线软件包是本地软件源的快照与镜像,使用离线软件包可以避免重复的下载请求与流量消耗,显著加速安装速度,并提高安装交付过程的可靠性与一致性。
构建本地软件源
Pigsty 会在安装过程中从互联网上游的 yum/apt 软件仓库,下载所需的 rpm/deb 包并构建一个本地软件源(默认位于 /www/pigsty)。
本地软件源由 Nginx 对外提供服务,后续无论是本机还是其他节点,都默认会使用本地软件源进行安装,而不再需要访问互联网
使用本地软件源有四个主要好处:
- 本地软件源可以避免重复的下载请求与流量消耗,显著加速安装速度并提高安装过程的可靠性。
- 构建本地软件源会对当前可用软件版本取快照,确保部署环境内节点所安装软件版本的一致性。
- 使用本地快照可以避免上游依赖变化导致的依赖错漏与安装失败问题,只要首个节点成功,相同环境的节点就能成功。
- 构建好的本地软件源可以整体打包,复制到安装有相同操作系统的隔离环境中用于离线安装。
在 Pigsty 中,本地软件源的默认位置是本机上的 /www/pigsty目录(可以通过 nginx_home & repo_name 参数进行配置)。
这个本地软件源将使用 createrepo_c (EL) 或 dpkg-dev (Debian) 构建,本节点和其他节点可以通过 repo_upstream 中 module=local 的仓库定义引用并使用该软件仓库。
您可以在安装完全相同操作系统的节点上执行标准安装,一旦构建完成,你可以将这个节点上的本地软件源目录,使用各种手段(scp/rsync/ftp/usb)拷贝到另一台安装了完全相同操作系统的节点上,用于 离线安装。
更为标准通用的做法是在安装完毕的节点上,将本地软件源打包制作为 离线软件包,并将其拷贝至同环境的待安装隔离节点上使用。
制作离线软件包
Pigsty 提供了 cache.yml 剧本,用于制作离线软件包。
例如以下命令会将 infra 节点上的 /www/pigsty 本地软件源,打包成离线软件包,并取回到本地 dist/${version} 目录下。
./cache.yml -l infra
您可以使用 cache_pkg_dir 与 cache_pkg_name 参数自定义离线软件包的输出目录与名称,例如,以下命令会将离线软件包生成至 files/pkg.tgz。
./cache.yml -l infra -e '{"cache_pkg_dir":"files","cache_pkg_name":"pkg.tgz"}'
使用离线软件包
离线软件包实际上是一个使用 gzip 与 tar 制作的压缩包,使用时解压到 /www/pigsty 目录下即可。
sudo rm -rf /www/pigsty ; sudo tar -xf /tmp/pkg.tgz -C /www
更简单的做法是将离线软件包拷贝至待安装节点的 /tmp/pkg.tgz 路径下,然后 Pigsty 会在 bootstrap 过程中会自动解包,并从本地软件源安装所需软件。
Pigsty 在构建本地软件源时会生成一个标记文件 repo_complete,标记这是一个 Pigsty 本地软件源。
当 Pigsty 安装 时,如果发现本地软件源已经存在,就会进入离线安装模式。
在此模式下,Pigsty 将跳过从互联网下载并构建本地软件源的过程,使用本地软件源完成整个安装过程,期间无需互联网访问。
进入离线安装模式的判定标准
判定本地软件源存在的标准是:默认位于 /www/pigsty/repo_complete 的标记文件存在。
这个标记文件会在标准安装过程中,下载完成后自动生成,说明这是一个可用的本地软件源。
删除本地软件源的 repo_complete 标记文件后,安装时将重新从上游下载 缺失的 软件包。
离线包兼容性须知
离线软件包中的 RPM/DEB 包大体上可以分为三类:
- INFRA 软件包:例如 Prometheus,Grafana,各种监控组件,通常在任何 Linux 发行版下都可以运行。
- PGSQL 软件包:例如 PostgreSQL 内核与各种扩展插件,通常与 Linux 发行版 大版本 绑定。
- NODE 软件包:例如各种动态链接库与主机依赖,通常与 Linux 发行版 大小版本 绑定
因此,离线软件包的适用性取决于操作系统的 大版本 与 小版本,因为它包含了上面三种软件包。
通常来说,离线软件包只能用于操作系统大小版本精准匹配的场景。 如果大版本不匹配,INFRA 类软件包 通常可以成功安装,PGSQL 和 NODE 类软件包基本必定会出现依赖缺失或冲突。 如果小版本不匹配,INFRA 类软件包和 PGSQL 软件包通常可以成功安装,而 NODE 类软件包有概率成功,也有概率失败。
例如,RockLinux 8.9 下制作的离线软件包,在 RockyLinux 8.10 环境中有较大的概率可以直接使用。
而在 Ubuntu 22.04.3 下制作的离线软件,有极大概率会在 22.04.4 中出现依赖冲突问题。
(是的没错,Ubuntu 版本号里的 .3 才是小版本号,22.04 整个是 jammy 大版本号!)
如果离线软件包的操作系统小版本不匹配,您可以采用一种折中策略进行安装,即在 bootstrap 过程后,
移除 /www/pigsty/repo_complete 标记文件,让 Pigsty 重新在安装过程中从上游下载缺失的 NODE 软件包与相关依赖。
这种方式可以有效解决使用离线软件包时的依赖冲突问题,并同时获得离线安装的全部优点。
下载离线软件包
从 Pigsty v3 开始,Pigsty 不再公开提供预制的离线软件包,统一默认使用在线安装的方式。 在线安装允许您从 Pigsty 提供的官方仓库与中国大陆 CDN 下载 INFRA / PGSQL 软件包,并由您操作系统的官方源与镜像下载 NODE 类软件包,从而最大程度的避免了 NODE 软件包小版本依赖冲突问题。
不过针对以下精确的操作系统版本,我们提供有偿制作的预制离线软件包,还额外包含了全部可用扩展插件,Docker 等组件。
- RockyLinux 8.10 / 8.10 (x86_64)
- RockyLinux 9.4 / 9.4 (x86_64, aarch64)
- Ubuntu 24.04.1 (x86_64, arm64)
- Ubuntu 22.04.5 (x86_64, arm64)
- Debian 12.7 (x86_64, arm64)
Pigsty 的全套集成测试都针对于发布前预制的离线软件包快照进行,离线软件包能有效降低上游依赖变动导致的交付风险,省去您折腾的麻烦、与等待的时间。 更能体现您对开源事业的支持,物美价廉,仅需 ¥199,请联系 @Vonng 获取下载链接。
对于 Pigsty 专业版订阅,我们会针对您使用的具体操作系统大小版本,提供精确匹配,并经过集成测试后的离线软件包。
Bootstrap
Pigsty 需要使用 Ansible 来运行剧本,因此 Ansible 本身不适合通过剧本进行安装。 Bootstrap 脚本用于解决这一问题:它会尽最大努力用各种方式来确保 Ansible 在节点上安装成功。
./bootstrap # 确保 ansible 正确安装(如果有离线包,优先使用离线安装并解包使用)
如果您使用离线软件包进行安装,Bootstrap 过程会自动识别并处理位于 /tmp/pkg.tgz 的离线软件包,并优先从中安装 Ansible。
如果没有使用离线软件包,但是有互联网访问,Bootstrap 会自动添加对应操作系统/对应区域镜像的软件源,并从中安装 Ansible。
如果既没有网也没有离线包,Bootstrap 会交给用户自行处理此问题,用户需要自行保证当前节点配置的软件源包含可用的 Ansible。
Bootstrap 脚本有一些可选参数,例如您可以使用 -p|--path 参数指定一个不同于 /tmp/pkg.tgz 的离线软件包位置。
您也可以使用 -r|--region 指定一个区域,这样如果需要从互联网下载 Ansible,Pigsty 会添加对应区域的软件源(全球,中国,欧洲)。
./boostrap
[-r|--region <region] [default,china,europe]
[-p|--path <path>] specify another offline pkg path
[-k|--keep] keep existing upstream repo during bootstrap
最后, bootstrap 过程中默认会备份(/etc/yum.repos.d/backup / /etc/apt/source.list.d/backup)并移除节点当前配置的软件源,从而最大程度避免软件源冲突问题。
如果这不是你期待的行为,或者您已经配置了本地软件源,可以使用 -k|--keep 参数,保留现有软件源。
例:使用离线软件包
在一台安装了 RockyLinux 8.9 的节点上使用离线软件包安装 Pigsty:
[vagrant@el8 pigsty]$ ls -alh /tmp/pkg.tgz
-rw-r--r--. 1 vagrant vagrant 1.4G Sep 1 10:20 /tmp/pkg.tgz
[vagrant@el8 pigsty]$ ./bootstrap
bootstrap pigsty v3.0.4 begin
[ OK ] region = china
[ OK ] kernel = Linux
[ OK ] machine = x86_64
[ OK ] package = rpm,dnf
[ OK ] vendor = rocky (Rocky Linux)
[ OK ] version = 8 (8.9)
[ OK ] sudo = vagrant ok
[ OK ] ssh = vagrant@127.0.0.1 ok
[ OK ] cache = /tmp/pkg.tgz exists
[ OK ] repo = extract from /tmp/pkg.tgz
[WARN] old repos = moved to /etc/yum.repos.d/backup
[ OK ] repo file = use /etc/yum.repos.d/pigsty-local.repo
[WARN] rpm cache = updating, may take a while
pigsty local 8 - x86_64 49 MB/s | 1.3 MB 00:00
Metadata cache created.
[ OK ] repo cache = created
[ OK ] install el8 utils
Last metadata expiration check: 0:00:01 ago on Sun 01 Sep 2024 10:30:52 AM UTC.
Package wget-1.19.5-11.el8.x86_64 is already installed.
Package yum-utils-4.0.21-23.el8.noarch is already installed.
Dependencies resolved.
........
Installed:
createrepo_c-0.17.7-6.el8.x86_64 createrepo_c-libs-0.17.7-6.el8.x86_64 drpm-0.4.1-3.el8.x86_64 modulemd-tools-0.7-8.el8.noarch python3-createrepo_c-0.17.7-6.el8.x86_64
python3-libmodulemd-2.13.0-1.el8.x86_64 python3-pyyaml-3.12-12.el8.x86_64 sshpass-1.09-4.el8.x86_64 unzip-6.0-46.el8.x86_64
ansible-9.2.0-1.el8.noarch ansible-core-2.16.3-2.el8.x86_64 git-core-2.43.5-1.el8_10.x86_64 mpdecimal-2.5.1-3.el8.x86_64
python3-cffi-1.11.5-6.el8.x86_64 python3-cryptography-3.2.1-7.el8_9.x86_64 python3-jmespath-0.9.0-11.el8.noarch python3-pycparser-2.14-14.el8.noarch
python3.12-3.12.3-2.el8_10.x86_64 python3.12-cffi-1.16.0-2.el8.x86_64 python3.12-cryptography-41.0.7-1.el8.x86_64 python3.12-jmespath-1.0.1-1.el8.noarch
python3.12-libs-3.12.3-2.el8_10.x86_64 python3.12-pip-wheel-23.2.1-4.el8.noarch python3.12-ply-3.11-2.el8.noarch python3.12-pycparser-2.20-2.el8.noarch
python3.12-pyyaml-6.0.1-2.el8.x86_64
Complete!
[ OK ] ansible = ansible [core 2.16.3]
[ OK ] boostrap pigsty complete
proceed with ./configure
例:不使用离线软件包,但是有互联网访问(Debian 12)
在一台有互联网访问的 Debian 12 节点上,用户不使用离线软件包,Bootstrap 会自动添加 Debian 12 的上游软件源,并安装 ansible 与依赖:
vagrant@d12:~/pigsty$ ./bootstrap
bootstrap pigsty v3.3.0 begin
[ OK ] region = china
[ OK ] kernel = Linux
[ OK ] machine = x86_64
[ OK ] package = deb,apt
[ OK ] vendor = debian (Debian GNU/Linux)
[ OK ] version = 12 (12)
[ OK ] sudo = vagrant ok
[ OK ] ssh = vagrant@127.0.0.1 ok
[WARN] old repos = moved to /etc/apt/backup
[ OK ] repo file = add debian bookworm china upstream
[WARN] apt cache = updating, may take a while
....... apt install output
[ OK ] ansible = ansible [core 2.14.16]
[ OK ] boostrap pigsty complete
proceed with ./configure
例:不使用离线软件包,也没有互联网访问(Ubuntu 22.04)
在一个没有互联网访问,也没有离线包的 Ubuntu 22.04 节点上进行 bootstrap。
我们假设用户已经通过各种方式解决这个问题,例如在当前的服务器上已经配置了 CD / FS 路径的本地软件源,或者内网中有可用的 YUM / APT 仓库。
您可以使用 -k 参数显式保留当前的软件源配置,当然如果 Pigsty 检测到了没有互联网访问,也没有离线软件包,那么默认也会保留当前的软件源配置。
vagrant@u22:~/pigsty$ ./bootstrap
bootstrap pigsty v3.3.0 begin
[ OK ] region = china
[ OK ] kernel = Linux
[ OK ] machine = x86_64
[ OK ] package = deb,apt
[ OK ] vendor = ubuntu (Ubuntu)
[ OK ] version = 22 (22.04)
[ OK ] sudo = vagrant ok
[ OK ] ssh = vagrant@127.0.0.1 ok
[WARN] old repos = moved to /etc/apt/backup
[ OK ] repo file = add ubuntu jammy china upstream
[WARN] apt cache = updating, may take a while
[ OK ] repo cache = created
...(apt update/install 输出)
[ OK ] ansible = ansible 2.10.8
[ OK ] boostrap pigsty complete
proceed with ./configure
3 - 精简安装
Pigsty 带有一整套服务于高可用 PostgreSQL 基础设施堆栈,但是这也完全是可选的,您可以通过 精简安装,只安装必要的 PostgreSQL 高可用集群组件。
概览
精简安装专注于纯粹的 HA-PostgreSQL 集群,仅安装所需的基本组件。
在精简安装模式下,不会有 Infra 模块,没有监控,没有 本地仓库
只有部分 NODE 模块的一部分,以及 ETCD 和 PGSQL 模块会被安装:您依然可以使用完整的 PGSQL 模块与 ETCD 模块的功能
在节点上会启用的 Systemd 服务有:
- patroni:必选,PostgreSQL 高可用与管控组件
- etcd:必选, Patroni 高可用依赖的配置中心
- pgbouncer:可选,数据库连接池
- vip-manager:可选,为主库绑定一个可选的二层VIP。
- haproxy:可选,提供自动路由的 服务 接入
- chronyd: 可选,同步节点时间
- tuned:可选,管理节点配置模板与系统内核参数
其中 patroni 和 etcd 是必选的组件,其他组件都是可选的,尽管如此,Pigsty 不建议关闭这些组件 —— 您可以留着它们不用。
配置
要执行精简安装,您需要额外配置几个选项开关,如 conf/slim.yml 所示:
all:
children:
infra: { hosts: { 10.10.10.10: { infra_seq: 1 } }, vars: { docker_enabled: true } }
etcd:
hosts:
10.10.10.10: { etcd_seq: 1 }
#10.10.10.11: { etcd_seq: 2 } # optional
#10.10.10.12: { etcd_seq: 3 } # optional
vars: { etcd_cluster: etcd }
pg-meta:
hosts:
10.10.10.10: { pg_seq: 1, pg_role: primary } # init one single-node pgsql cluster by default, with:
#10.10.10.11: { pg_seq: 2, pg_role: replica } # optional replica : bin/pgsql-add pg-meta 10.10.10.11
#10.10.10.12: { pg_seq: 3, pg_role: replica } # optional replica : bin/pgsql-add pg-meta 10.10.10.12
vars:
pg_cluster: pg-meta
pg_users: # define business users here: https://pigsty.cc/docs/pgsql/user/
- { name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [ dbrole_admin ] ,comment: pigsty default user }
pg_databases: # define business databases here: https://pigsty.cc/docs/pgsql/db/
- { name: meta ,comment: pigsty default database }
pg_hba_rules: # define HBA rules here: https://pigsty.cc/docs/pgsql/hba/#define-hba
- { user: dbuser_meta , db: all ,addr: world ,auth: pwd ,title: 'allow default user world access with password (not a good idea!)' }
node_crontab: # define backup policy with crontab (full|diff|incr)
- '00 01 * * * postgres /pg/bin/pg-backup full'
#pg_vip_address: 10.10.10.2/24 # optional l2 vip address and netmask
pg_extensions: # define pg extensions (345 available): https://pigsty.cc/ext/
- postgis timescaledb pgvector
vars:
version: v3.3.0 # pigsty version string
admin_ip: 10.10.10.10 # admin node ip address
region: default # upstream mirror region: default|china|europe
node_tune: tiny # use tiny template for NODE in demo environment
pg_conf: tiny.yml # use tiny template for PGSQL in demo environment
# minimal installation setup
node_repo_modules: node,infra,pgsql
nginx_enabled: false
dns_enabled: false
prometheus_enabled: false
grafana_enabled: false
pg_exporter_enabled: false
pgbouncer_exporter_enabled: false
pg_vip_enabled: false
同时在初始化安装时,您应该使用 slim.yml 剧本进行安装,而不是默认的 install.yml。
./slim.yml
然后,配置指定的节点上便会安装最小化的 PostgreSQL 高可用集群组件。
4 - 声明配置
Pigsty将基础设施和数据库视为代码:Database as Code & Infra as Code
你可以通过声明式的接口/配置文件来描述基础设施和数据库集群,你只需在 配置清单 (Inventory) 中描述你的需求,然后用简单的幂等剧本使其生效即可。
配置清单
每一套 Pigsty 部署都有一个相应的 配置清单(Inventory)。它可以以 YAML 的形式存储在本地,并使用 git 管理;或从 CMDB 或任何 ansible 兼容的方式动态生成。
Pigsty 默认使用一个名为 pigsty.yml 的单体 YAML 配置文件作为默认的配置清单,它位于 Pigsty 源码主目录下,但你也可以通过命令行参数 -i 指定路径以使用别的配置清单。
清单由两部分组成:全局变量 和多个 组定义 。 前者 all.vars 通常用于描述基础设施,并为集群设置全局默认参数。后者 all.children 则负责定义新的集群(PGSQL/Redis/MinIO/ETCD等等)。一个配置清单文件从最顶层来看大概如下所示:
all: # 顶层对象:all
vars: {...} # 全局参数
children: # 组定义
infra: # 组定义:'infra'
hosts: {...} # 组成员:'infra'
vars: {...} # 组参数:'infra'
etcd: {...} # 组定义:'etcd'
pg-meta: {...} # 组定义:'pg-meta'
pg-test: {...} # 组定义:'pg-test'
redis-test: {...} # 组定义:'redis-test'
# ...
集群
每个组定义通常代表一个集群,可以是节点集群、PostgreSQL 集群、Redis 集群、Etcd 集群或 Minio 集群等。它们都使用相同的格式:hosts 和 vars。
你可以用 all.children.<cls>.hosts 定义集群成员,并使用 all.children.<cls>.vars 中的集群参数描述集群。以下是名为 pg-test 的三节点 PostgreSQL 高可用集群的定义示例:
pg-test: # 集群名称
vars: # 集群参数
pg_cluster: pg-test
hosts: # 集群成员
10.10.10.11: { pg_seq: 1, pg_role: primary } # 实例1,在 10.10.10.11 上,主库
10.10.10.12: { pg_seq: 2, pg_role: replica } # 实例2,在 10.10.10.12 上,从库
10.10.10.13: { pg_seq: 3, pg_role: offline } # 实例3,在 10.10.10.13 上,从库
你也可以为特定的主机/实例定义参数,也称为实例参数。它将覆盖集群参数和全局参数,实例参数通常用于为节点和数据库实例分配身份(实例号,角色)。
参数
全局变量、组变量和主机变量都是由一系列 键值对 组成的字典对象。每一对都是一个命名的参数,由一个字符串名作为键,和一个值组成。值是五种类型之一:布尔值、字符串、数字、数组或对象。查看各模块的配置参数以了解详细的参数语法语义。
绝大多数参数都有着合适的默认值,身份参数 除外;它们被用作标识符,并必须显式配置,例如 pg_cluster, pg_role,以及 pg_seq。
参数可以被更高优先级的同名参数定义覆盖,优先级如下所示:
命令行参数 > 剧本变量 > 主机变量(实例参数) > 组变量(集群参数) > 全局变量(全局参数) > 默认值
例如:
- 使用命令行参数
-e pg_clean=true强制删除现有数据库 - 使用实例参数
pg_role和pg_seq来为一个数据库实例分配角色与标号。 - 使用集群变量来为集群设置默认值,如集群名称
pg_cluster和数据库版本pg_version - 使用全局变量为所有 PGSQL 集群设置默认值,如使用的默认参数和插件列表
- 如果没有显式配置
pg_version,默认值16版本号会作为最后兜底的缺省值。
模板
在 Pigsty 目录中的 conf/ 目录里,提供了针对许多不同场景的预置配置模板可供参考选用。
在 configure 过程中,您可以通过 -c 参数指定模板。否则会默认使用单节点安装的 meta 模板。
关于这些模版的功能,请参考 配置模板 中的介绍。
切换配置源
要使用不同的配置模板,您可以将模板的内容复制到 Pigsty 源码目录的 pigsty.yml 文件中,并按需进行相应调整。
您也可以在执行 Ansible 剧本时,通过 -i 命令行参数,显式指定使用的配置文件,例如:
./node.yml -i conf/full.yml # 根据 full 配置文件,初始化目标节点,而不是使用默认的 pigsty.yml 配置文件
如果您希望修改默认的配置文件名称与位置,您也可以修改源码根目录下的 ansible.cfg 的 inventory 参数,将其指向您的配置文件路径,这样您就可以直接执行 ansible-playbook 命令而无需显式指定 -i 参数。
Pigsty 允许您使用数据库(CMDB)作为动态配置源,而不是使用静态配置文件。 Pigsty 提供了三个便利脚本:
bin/inventory_load: 将pigsty.yml配置文件的内容加载到本机上的 PostgreSQL 数据库中(meta.pigsty)bin/inventory_cmdb: 切换配置源为本地 PostgreSQL 数据库(meta.pigsty)bin/inventory_conf: 切换配置源为本地静态配置文件pigsty.yml
参考
Pigsty 带有 280+ 配置参数,分为以下32个参数组。
| 模块 | 参数组 | 描述 | 数量 |
|---|---|---|---|
INFRA |
META |
Pigsty 元数据 | 4 |
INFRA |
CA |
自签名公私钥基础设施 CA | 3 |
INFRA |
INFRA_ID |
基础设施门户,Nginx域名 | 2 |
INFRA |
REPO |
本地软件仓库 | 9 |
INFRA |
INFRA_PACKAGE |
基础设施软件包 | 2 |
INFRA |
NGINX |
Nginx 网络服务器 | 7 |
INFRA |
DNS |
DNSMASQ 域名服务器 | 3 |
INFRA |
PROMETHEUS |
Prometheus 时序数据库全家桶 | 18 |
INFRA |
GRAFANA |
Grafana 可观测性全家桶 | 6 |
INFRA |
LOKI |
Loki 日志服务 | 4 |
NODE |
NODE_ID |
节点身份参数 | 5 |
NODE |
NODE_DNS |
节点域名 & DNS解析 | 6 |
NODE |
NODE_PACKAGE |
节点仓库源 & 安装软件包 | 5 |
NODE |
NODE_TUNE |
节点调优与内核特性开关 | 10 |
NODE |
NODE_ADMIN |
管理员用户与SSH凭证管理 | 7 |
NODE |
NODE_TIME |
时区,NTP服务与定时任务 | 5 |
NODE |
NODE_VIP |
可选的主机节点集群L2 VIP | 8 |
NODE |
HAPROXY |
使用HAProxy对外暴露服务 | 10 |
NODE |
NODE_EXPORTER |
主机节点监控与注册 | 3 |
NODE |
PROMTAIL |
Promtail日志收集组件 | 4 |
DOCKER |
DOCKER |
Docker容器服务(可选) | 4 |
ETCD |
ETCD |
Etcd DCS 集群 | 10 |
MINIO |
MINIO |
MinIO S3 对象存储 | 15 |
REDIS |
REDIS |
Redis 缓存 | 20 |
PGSQL |
PG_ID |
PG 身份参数 | 11 |
PGSQL |
PG_BUSINESS |
PG 业务对象定义 | 12 |
PGSQL |
PG_INSTALL |
安装 PG 软件包 & 扩展 | 10 |
PGSQL |
PG_BOOTSTRAP |
使用 Patroni 初始化 HA PG 集群 | 39 |
PGSQL |
PG_PROVISION |
创建 PG 数据库内对象 | 9 |
PGSQL |
PG_BACKUP |
使用 pgBackRest 设置备份仓库 | 5 |
PGSQL |
PG_SERVICE |
对外暴露服务, 绑定 vip, dns | 9 |
PGSQL |
PG_EXPORTER |
PG 监控,服务注册 | 15 |
5 - 准备工作
与 Pigsty 部署有关的 101 入门知识。
节点准备
Pigsty 支持 Linux 内核与 x86_64/amd64 架构,适用于任意节点。
所谓节点(node),指 ssh 可达并提供裸操作系统环境的资源,例如物理机,裸金属,虚拟机,或者启用了 systemd 与 sshd 的操作系统容器。
部署 Pigsty 最少需要一个节点。最低配置要求为 1C1G,推荐至少使用 2C4G 以上的机型,适用配置上不封顶,参数会自动优化适配。
作为 Demo,个人站点,或者开发环境时,可以使用单个节点。作为独立监控基础设施使用时,建议使用 1-2 个节点,作为高可用 PostgreSQL 数据库集群使用时,建议至少使用 3 个节点。用于核心场景时,建议使用至少 4-5 个节点。
充分利用 IaC 工具完成琐事
手工配置大规模生产环境繁琐且容易出错,我们建议您充分利用 Infra as Code 工具,解决此类问题。
您可以使用 Pigsty 提供的 Terraform 模板与 Vagrant 模板,使用 IaC 的方式一键创建所需的节点环境,完成好网络,操作系统,管理用户,权限,安全组的置备工作。
网络准备
Pigsty 要求节点使用 静态IPv4地址,即您应当为节点显式分配指定固定的 IP 地址,而不应当使用 DHCP 动态分配的地址。
节点使用的 IP 地址应当是节点用于内网通信的首要 IP 地址,并将作为节点的唯一身份标识符。
如果您希望使用可选的 Node VIP 与 PG VIP 功能,应当确保所有节点位于一个大二层网络中。
您的防火墙策略应当保证所需的端口在节点间开放,不同模块所需的具体端口列表请参考 节点:端口。
应该暴露哪些端口?
暴露端口的方法取决于您的网络安全策略实现,例如:公有云上的安全组策略,或本地 iptables 记录,防火墙配置等。
如果您只是希望尝尝鲜,不在乎安全,并且希望一切越简单越好,那么您可以仅对外部用户按需开放 5432 端口( PostgreSQL 数据库) 与 3000 端口(Grafana 可视化界面)。
在 Infra节点 上的 Nginx 默认会对外暴露 80/443 端口提供 Web 服务,并通过域名对不同服务进行区分,这一端口应当对办公网络(或整个整个互联网)开放。
严肃的生产数据库服务端口通常不应当直接暴露在公网上,如果您确实需要这么做,建议首先查阅 安全最佳实践,并小心行事。
操作系统准备
Pigsty 支持多种基于 Linux 内核的服务器操作系统发行版,我们建议使用 RockyLinux 9.4 或 Ubuntu 22.04.5 作为安装 Pigsty 的 OS。
Pigsty 支持 RHEL (7,8,9),Debian (11,12),Ubuntu (20,22,24) 以及多种与之兼容的操作系统发行版,完整操作系统列表请参考 兼容性。
在使用多个节点镜进行部署时,我们 强烈 建议您在所有用于 Pigsty 部署的节点上,使用相同版本的操作系统发行版与 Linux 内核版本
我们强烈建议使用干净,全新安装的最小化安装的服务器操作系统环境,使用 en_US 作为首要语言,并使用推荐/默认生成的 Locale 配置。
Pigsty 部署的 PostgreSQL 集群默认使用
Clocale,当系统支持C.utf8或 PG 版本大于等于 17 时,则优先使用C.UTF-8Locale。
如何安装并启用 en_US locale?
使用其他系统语言包时,如何确保 en_US 本地化规则集可用:
yum install -y glibc-locale-source glibc-langpack-en
localedef -i en_US -f UTF-8 en_US.UTF-8
localectl set-locale LANG=en_US.UTF-8
管理用户准备
在安装 Pigsty 的节点上,您需要拥有一个 “管理用户” —— 拥有免密 ssh 登陆权限与免密 sudo 权限。
免密 sudo 是必选项,用于在安装过程中执行需要 sudo 权限的命令,例如安装软件包,配置系统参数等。
如何配置管理用户的免密码 sudo 权限?
假设您的管理用户名为 vagrant ,则可以创建 /etc/sudoers.d/vagrant 文件,并添加以下记录:
%vagrant ALL=(ALL) NOPASSWD: ALL
则 vagrant 用户即可免密 sudo 执行所有命令。如果你的用户名不是 vagrant,请将上面操作中的 vagrant 替换为您的用户名。
避免使用 root 用户安装
尽管使用 root 用户安装 Pigsty 是可行的,但我们不推荐这样做。
安全最佳实践 是使用一个不同于根用户(root)与数据库超级用户 (postgres) 的专用管理员用户(如:dba)
Pigsty 提供了专用剧本任务,可以使用一个现有的管理用户(例如 root),输入 ssh/sudo 密码,创建一个专用的 管理员用户。
SSH 权限准备
除了免密 sudo 权限, Pigsty 还需要管理用户免密 ssh 登陆的权限。
对于单机安装的节点而言,这意味着本机上的管理用户可以通过 ssh 免密码登陆到本机上。
如果的 Pigsty 部署涉及到多个节点,这意味着管理节点上的管理用户应当可以通过 ssh 免密码登陆到所有被 Pigsty 纳管的节点上(包括本机),并免密执行 sudo 命令。
单机安装时,在 configure 过程中,如果您的当前管理用户没有 SSH key,Pigsty 会尝试修复此问题:随机生成一对新的 id_rsa 密钥,并添加至本地 ~/.ssh/authroized_keys 文件确保本机管理用户的 SSH 登陆能力。
Pigsty 默认会为您在纳管的节点上创建一个可用的管理用户 dba (uid=88),如果您已经使用了此用户,我们建议您修改 node_admin_username 使用新的用户名与其他 uid,或通过 node_admin_enabled 参数禁用。
如何配置管理用户的 ssh 免密码登陆?
假设您的管理用户名为 vagrant,则以 vagrant 用户身份执行以下命令,会为其生成公私钥对 ~/.ssh/id_rsa[.pub] 用于登陆。如果已经存在公私钥对,则无需生成新密钥对。
ssh-keygen -t rsa -b 2048 -N '' -f ~/.ssh/id_rsa -q
生成的公钥默认位于:/home/vagrant/.ssh/id_rsa.pub,私钥默认位于:/home/vagrant/.ssh/id_rsa,如果您操作系统用户名不叫 vagrant,将上面的 vagrant 替换为您的用户名即可。
您应当将公钥文件(id_rsa.pub)追加写入到需要登陆机器的对应用户上:/home/vagrant/.ssh/authorized_keys 文件中。如果您已经可以直接通过密码访问远程机器,可以直接通过ssh-copy-id的方式拷贝公钥:
ssh-copy-id <ip> # 输入密码以完成公钥拷贝
sshpass -p <password> ssh-copy-id <ip> # 直接将密码嵌入命令中,避免交互式密码输入(注意安全!)
Pigsty 推荐将管理用户的创建,权限配置与密钥分发放在虚拟机的置备阶段完成,作为标准化交付内容的一部分。
SSH 例外情况
如果您的 SSH 访问有一些额外限制,例如,使用了跳板机,或者进行了某些定制化修改,无法通过简单的 ssh <ip> 方式访问,那么可以使用 ssh 别名。
如果您的服务器可以通过 ~/.ssh/config 中定义的别名访问,那么可以为 配置清单 中的节点配置 ansible_host 参数,指定 SSH Alias:
nodes:
hosts: # 10.10.10.10 无法直接 ssh,但可以通过ssh别名 `meta` 访问
10.10.10.10: { ansible_host: meta }
如果 SSH 别名无法满足您的需求,Ansible 还提供了一系列自定义 ssh 连接参数,可以精细控制 SSH 连接的行为。
最后,如果以下命令可以在管理节点上使用管理用户成功执行,意味着该目标节点上的管理用户与权限配置已经妥当:
ssh <ip|alias> 'sudo ls'
软件准备
在 管理节点 上,Pigsty 需要使用 Ansible 发起控制命令。如果您使用本地单机安装,那么管理节点和被管理的节点是同一台,需要安装 Ansible。对于普通节点,则无需安装 Ansible。
在 bootstrap 过程中,Pigsty 会尽最大努力自动为您完成安装 Ansible 这一任务,但您也可以选择手工安装 Ansible。手工安装 Ansible 的过程因不同操作系统发行版/大版本而异(通常涉及到额外的弱依赖 jmespath):
sudo dnf install -y ansible python3.12-jmespath python3-cryptographysudo yum install -y ansible # EL7 无需显式安装 Jmespathsudo apt install -y ansible python3-jmespathbrew install ansible为了安装 Pigsty,您还需要准备 Pigsty 源码包。您可以直接从 GitHub Release 页面下载特定版本,或使用以下命令获取最新稳定版本:
curl -fsSL https://repo.pigsty.cc/get | bash
如果您的环境没有互联网访问,也可以考虑直接从 GitHub Release 页面或其他渠道下载针对不同操作系统发行版预先制作的 离线安装包。
6 - 执行剧本
在 Pigsty 中,剧本 / Playbooks 用于在节点上安装模块。
剧本可以视作可执行文件直接执行,例如:./install.yml.
剧本
以下是 Pigsty 中默认包含的剧本:
| 剧本 | 功能 |
|---|---|
install.yml |
在当前节点上一次性完整安装 Pigsty |
infra.yml |
在 infra 节点上初始化 pigsty 基础设施 |
infra-rm.yml |
从 infra 节点移除基础设施组件 |
node.yml |
纳管节点,并调整节点到期望的状态 |
node-rm.yml |
从 pigsty 中移除纳管节点 |
pgsql.yml |
初始化 HA PostgreSQL 集群或添加新的从库实例 |
pgsql-rm.yml |
移除 PostgreSQL 集群或移除从库实例 |
pgsql-user.yml |
向现有的 PostgreSQL 集群添加新的业务用户 |
pgsql-db.yml |
向现有的 PostgreSQL 集群添加新的业务数据库 |
pgsql-monitor.yml |
监控纳管远程 postgres 实例 |
pgsql-migration.yml |
为现有的 PostgreSQL 生成迁移手册和脚本 |
redis.yml |
初始化 redis 集群/节点/实例 |
redis-rm.yml |
移除 redis 集群/节点/实例 |
etcd.yml |
初始化 etcd 集群(patroni HA DCS所需) |
minio.yml |
初始化 minio 集群(pgbackrest 备份仓库备选项) |
docker.yml |
在节点上安装 docker |
mongo.yml |
在节点上安装 Mongo/FerretDB |
cert.yml |
使用 pigsty 自签名 CA 颁发证书(例如用于客户端) |
cache.yml |
制作离线软件包 |
一次性安装
特殊的剧本 install.yml 实际上是一个复合剧本,它在当前环境上安装所有以下组件。
playbook / command / group infra nodes etcd minio pgsql
[infra.yml] ./infra.yml [-l infra] [+infra][+node]
[node.yml] ./node.yml [+node] [+node] [+node] [+node]
[etcd.yml] ./etcd.yml [-l etcd ] [+etcd]
[minio.yml] ./minio.yml [-l minio] [+minio]
[pgsql.yml] ./pgsql.yml [+pgsql]
请注意,NODE 和 INFRA 之间存在循环依赖:为了在 INFRA 上注册 NODE,INFRA 应该已经存在,而 INFRA 模块依赖于 INFRA节点上的 NODE 模块才能工作。
为了解决这个问题,INFRA 模块的安装剧本也会在 INFRA 节点上安装 NODE 模块。所以,请确保首先初始化 INFRA 节点。
如果您非要一次性初始化包括 INFRA 在内的所有节点,install.yml 剧本就是用来解决这个问题的:它会正确的处理好这里的循环依赖,一次性完成整个环境的初始化。
Ansible
执行剧本需要 ansible-playbook 可执行文件,该文件包含在 ansible rpm/deb 包中。
Pigsty 将在 准备 期间在尽最大努力尝试在当前节点安装 ansible。
您可以自己使用 yum / apt / brew install ansible 来安装 Ansible,它含在各大发行版的默认仓库中。
了解 ansible 对于使用 Pigsty 很有帮助,但也不是必要的。对于基本使用,您只需要注意四个参数就足够了:
-i|--inventory <path>:显式指定使用的配置文件-l|--limit <pattern>: 限制剧本在特定的组/主机/模式上执行目标(在哪里/Where)-t|--tags <tags>: 只运行带有特定标签的任务(做什么/What)-e|--extra-vars <vars>: 传递额外的命令行参数(怎么做/How)
指定配置文件
您可以使用 -i 命令行参数,显式指定使用的配置文件。
Pigsty 默认使用名为 pigsty.yml 配置文件,该文件位于 Pigsty 源码根目录中的 pigsty.yml。但您可以使用 -i 覆盖这一行为,例如:
./pgsql.yml -i conf/rich.yml # 根据 rich 配置文件,初始化下载所有扩展的单节点
./pgsql.yml -i conf/full.yml # 根据 full 配置文件,初始化四节点集群
./pgsql.yml -i conf/app/supa.yml # 根据 supa.yml 配置文件,初始化单节点 Supabase 部署
如果您希望永久修改默认使用的配置文件,可以修改源码根目录下的 ansible.cfg 的 inventory 参数,将其指向您的配置文件路径。
这样您就可以在执行 ansible-playbook 命令时无需显式指定 -i 参数了。
指定执行对象
您可以使用 -l|-limit <selector> 限制剧本的执行目标。
缺少此值可能很危险,因为大多数剧本会在 all 分组,也就是所有主机上执行,使用时务必小心。
以下是一些主机限制的示例:
./pgsql.yml # 在所有主机上运行(非常危险!)
./pgsql.yml -l pg-test # 在 pg-test 集群上运行
./pgsql.yml -l 10.10.10.10 # 在单个主机 10.10.10.10 上运行
./pgsql.yml -l pg-* # 在与通配符 `pg-*` 匹配的主机/组上运行
./pgsql.yml -l '10.10.10.11,&pg-test' # 在组 pg-test 的 10.10.10.10 上运行
/pgsql-rm.yml -l 'pg-test,!10.10.10.11' # 在 pg-test 上运行,除了 10.10.10.11 以外
./pgsql.yml -l pg-test # 在 pg-test 集群的主机上执行 pgsql 剧本
执行剧本子集
你可以使用 -t|--tags <tag> 执行剧本的子集。 你可以在逗号分隔的列表中指定多个标签,例如 -t tag1,tag2。
如果指定了任务子集,将执行给定标签的任务,而不是整个剧本。以下是任务限制的一些示例:
./pgsql.yml -t pg_clean # 如果必要,清理现有的 postgres
./pgsql.yml -t pg_dbsu # 为 postgres dbsu 设置操作系统用户 sudo
./pgsql.yml -t pg_install # 安装 postgres 包和扩展
./pgsql.yml -t pg_dir # 创建 postgres 目录并设置 fhs
./pgsql.yml -t pg_util # 复制工具脚本,设置别名和环境
./pgsql.yml -t patroni # 使用 patroni 引导 postgres
./pgsql.yml -t pg_user # 提供 postgres 业务用户
./pgsql.yml -t pg_db # 提供 postgres 业务数据库
./pgsql.yml -t pg_backup # 初始化 pgbackrest 仓库和 basebackup
./pgsql.yml -t pgbouncer # 与 postgres 一起部署 pgbouncer sidecar
./pgsql.yml -t pg_vip # 使用 vip-manager 将 vip 绑定到 pgsql 主库
./pgsql.yml -t pg_dns # 将 dns 名称注册到 infra dnsmasq
./pgsql.yml -t pg_service # 使用 haproxy 暴露 pgsql 服务
./pgsql.yml -t pg_exporter # 使用 haproxy 暴露 pgsql 服务
./pgsql.yml -t pg_register # 将 postgres 注册到 pigsty 基础设施
# 运行多个任务:重新加载 postgres 和 pgbouncer hba 规则
./pgsql.yml -t pg_hba,pg_reload,pgbouncer_hba,pgbouncer_reload
# 运行多个任务:刷新 haproxy 配置并重新加载
./node.yml -t haproxy_config,haproxy_reload
传递额外参数
您可以通过 -e|-extra-vars KEY=VALUE 传递额外的命令行参数。
命令行参数具有压倒性的优先级,以下是一些额外参数的示例:
./node.yml -e ansible_user=admin -k -K # 作为另一个用户运行剧本(带有 admin sudo 密码)
./pgsql.yml -e pg_clean=true # 在初始化 pgsql 实例时强制清除现有的 postgres
./pgsql-rm.yml -e pg_uninstall=true # 在 postgres 实例被删除后明确卸载 rpm
./redis.yml -l 10.10.10.11 -e redis_port=6379 -t redis # 初始化一个特定的 redis 实例:10.10.10.11:6379
./redis-rm.yml -l 10.10.10.13 -e redis_port=6379 # 删除一个特定的 redis 实例:10.10.10.11:6379
此外,您还可以通过 JSON 的方式,传递诸如数组与对象这样的复杂参数:
# 通过指定软件包与仓库模块,在节点上安装 duckdb
./node.yml -t node_repo,node_pkg -e '{"node_repo_modules":"infra","node_default_packages":["duckdb"]}'
大多数剧本都是幂等的,这意味着在未打开保护选项的情况下,一些部署剧本可能会 删除现有的数据库 并创建新的数据库。
请仔细阅读文档,多次校对命令,并小心操作。作者不对因误用造成的任何数据库损失负责。
7 - 置备机器
Pigsty 在节点上运行,这些节点可以是裸机或虚拟机。您可以手工置备它们,或使用 terraform 和 vagrant 这样的工具在云端或本地进行自动配置。
沙箱环境
Pigsty 带有一个演示沙箱,所谓沙箱,就是专门用来演示/测试的环境:IP地址和其他标识符都预先固定配置好,便于复现各种演示用例。
默认的沙箱环境由4个节点组成,配置文件请参考 full.yml。
沙箱的 4 个节点有着固定的 IP 地址:10.10.10.10、10.10.10.11、10.10.10.12、10.10.10.13。
沙箱带有一个位于 meta 节点上的单实例 PostgreSQL 集群:pg-meta:
meta 10.10.10.10 pg-meta pg-meta-1
沙箱中还有一个由三个实例组成的 PostgreSQL 高可用集群:pg-test,部署在另外三个节点上:
node-1 10.10.10.11 pg-test.pg-test-1node-2 10.10.10.12 pg-test.pg-test-2node-3 10.10.10.13 pg-test.pg-test-3
两个可选的 L2 VIP 分别绑定在 pg-meta 和 pg-test 集群的主实例上:
10.10.10.2 pg-meta10.10.10.3 pg-test
在 meta 节点上,还有一个单实例的 etcd “集群”和一个单实例的 minio “集群”。
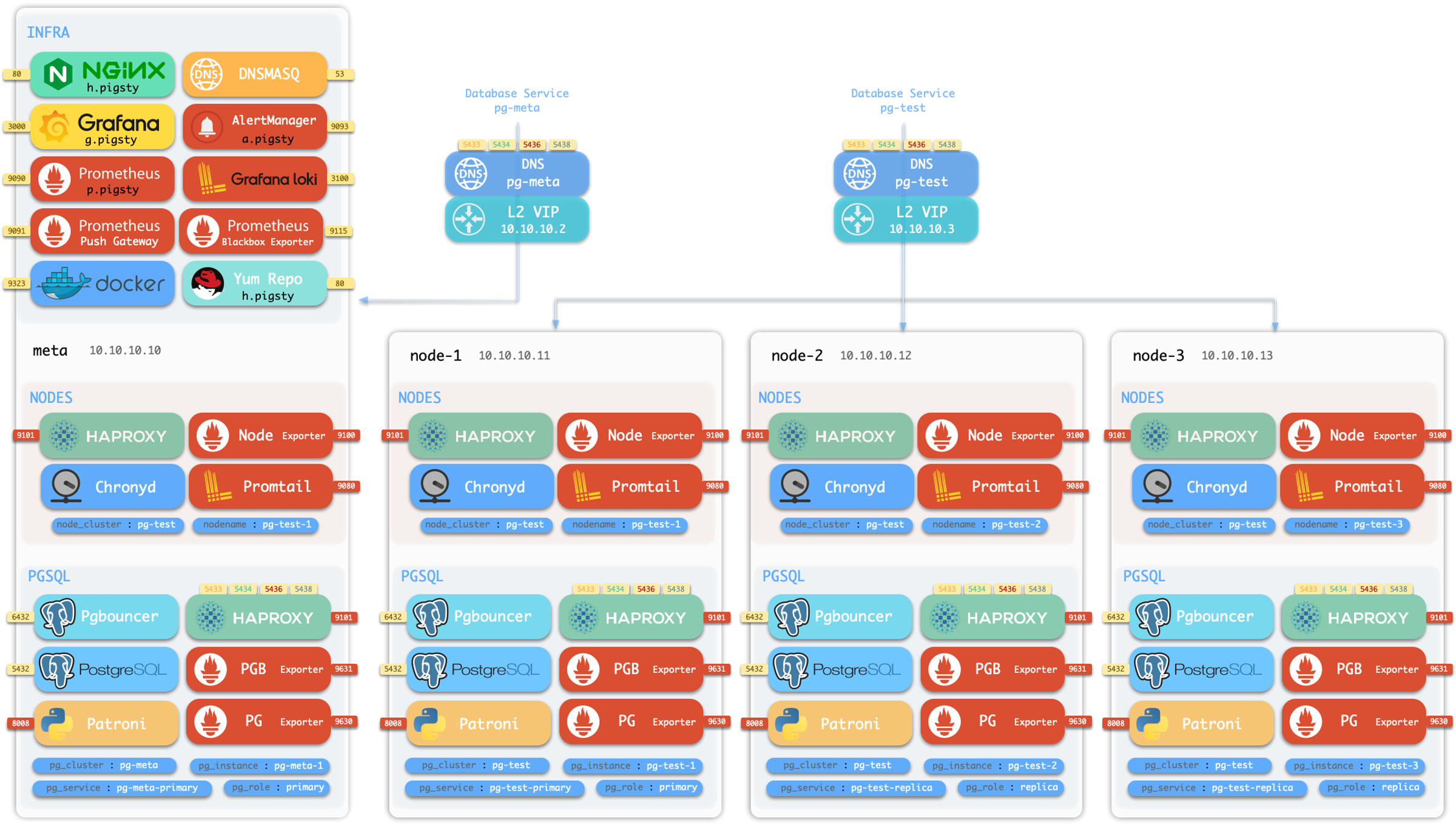
您可以在本地虚拟机或云虚拟机上运行沙箱。Pigsty 提供基于 Vagrant 的本地沙箱(使用 Virtualbox/libvirt 启动本地虚拟机)以及基于 Terraform 的云沙箱(使用云供应商 API 创建虚拟机)。
-
本地沙箱可以在您的 Mac/PC 上免费运行。运行完整的4节点沙箱,您的 Mac/PC 应至少拥有 4C/8G。
-
云沙箱可以轻松创建和共享,单需要一个公有云帐户才行。云上虚拟机可以按需创建/一键销毁,对于快速测试来说非常便宜省事。
此外,Pigsty 还提供了一个 42节点 的生产仿真环境沙箱 prod.yml。
Vagrant
Vagrant 可以按照声明式的方式创建本地虚拟机。请查看 Vagrant 模板介绍 以获取详情。
安装
确保您的操作系统中已经安装并可以使用 Vagrant 和 Virtualbox。
如果您使用的是 macOS,您可以使用 homebrew 一键命令安装它们,注意安装 Virtualbox 后需要重启系统。
如果你用的是 Linux,可以使用 virtualbox,也可以考虑使用 KVM: vagrant-libvirt。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
brew install vagrant virtualbox ansible # 在 MacOS 中可以轻松一键安装,但只有 x86_64 Intel 芯片的可以
配置
vagarnt/Vagranfile 是一个 Ruby 脚本文件,用来描述 Vagrant 要创建的虚拟机节点。Pigsty 提供了一些默认的配置模板:
| 模板 | 快捷方式 | 规格 | 注释 |
|---|---|---|---|
| meta.rb | v1 |
4C8G x 1 | 单一 Meta 节点 |
| full.rb | v4 |
2C4G + 1C2G x 3 | 完整的4节点沙盒示例 |
| el7.rb | v7 |
2C4G + 1C2G x 3 | EL7 3-节点测试环境 |
| el8.rb | v8 |
2C4G + 1C2G x 3 | EL8 3-节点测试环境 |
| el9.rb | v9 |
2C4G + 1C2G x 3 | EL9 3-节点测试环境 |
| build.rb | vb |
2C4G x 3 | 3-节点 EL7,8,9 构建环境 |
| check.rb | vc |
2C4G x 30 | 30 EL7-9, PG12-16 测试环境 |
| minio.rb | vm |
2C4G x 3 + Disk | 3-节点 MinIO/etcd 测试环境 |
| prod.rb | vp |
2C4G x 42 | 42节点的生产模拟环境 |
每个规格文件包含一个描述虚拟机节点的 Specs 变量。例如,full.rb 包含4节点沙盒规格的描述:
Specs = [
{"name" => "meta", "ip" => "10.10.10.10", "cpu" => "2", "mem" => "4096", "image" => "generic/rocky9" },
{"name" => "node-1", "ip" => "10.10.10.11", "cpu" => "1", "mem" => "2048", "image" => "generic/rocky9" },
{"name" => "node-2", "ip" => "10.10.10.12", "cpu" => "1", "mem" => "2048", "image" => "generic/rocky9" },
{"name" => "node-3", "ip" => "10.10.10.13", "cpu" => "1", "mem" => "2048", "image" => "generic/rocky9" },
]
您可以使用 vagrant/config 脚本切换 Vagrant 配置文件,它会根据规格以及虚拟机软件类型,渲染生成最终的 Vagrantfile。
cd ~/pigsty
vagrant/config <spec>
vagrant/config meta # singleton meta | 别名:`make v1`
vagrant/config full # 4-node sandbox | 别名:`make v4`
vagrant/config el7 # 3-node el7 test | 别名:`make v7`
vagrant/config el8 # 3-node el8 test | 别名:`make v8`
vagrant/config el9 # 3-node el9 test | 别名:`make v9`
vagrant/config prod # prod simulation | 别名:`make vp`
vagrant/config build # building environment | 别名:`make vd`
vagrant/config minio # 3-node minio env
vagrant/config check # 30-node check env
虚拟机管理
当您使用 vagrant/Vagrantfile 描述了所需的虚拟机后,你可以使用vagrant up命令创建这些虚拟机。
Pigsty 模板默认会使用你的 ~/.ssh/id_rsa[.pub] 作为这些虚拟机的默认ssh凭证。
在开始之前,请确保你有一个有效的ssh密钥对,你可以通过以下方式生成一对:ssh-keygen -t rsa -b 2048
此外,还有一些 makefile 快捷方式包装了 vagrant 命令,你可以使用它们来管理虚拟机。
make # 等于 make start
make new # 销毁现有虚拟机,根据规格创建新的
make ssh # 将 SSH 配置写入到 ~/.ssh/ 中 (新虚拟机拉起后必须完成这一步)
make dns # 将 虚拟机 DNS 记录写入到 /etc/hosts 中 (如果想使用名称访问虚拟机)
make start # 等于先执行 up ,再执行 ssh
make up # 根据配置拉起虚拟机,或启动现有虚拟机
make halt # 关停现有虚拟机 (down,dw)
make clean # 销毁现有虚拟机 (clean/del/destroy)
make status # 显示虚拟机状态 (st)
make pause # 暂停虚拟机运行 (suspend,pause)
make resume # 恢复虚拟机运行 (resume)
make nuke # 使用 virsh 销毁所有虚拟机 (仅libvirt可用)
快捷方式
你可以使用以下的 Makefile 快捷方式使用 vagrant 拉起虚拟机环境。
make meta # 单个元节点
make full # 4-节点沙箱
make el7 # 3-节点 el7 测试环境
make el8 # 3-节点 el8 测试环境
make el9 # 3-节点 el9 测试环境
make prod # 42 节点生产仿真环境
make build # 3-节点 EL7,8,9 构建环境
make check # 30-节点构建校验测试环境
make minio # 3-节点 MinIO 测试环境
make meta install # 进行完整的单机安装
make full install # 进行4节点沙箱安装
make prod install # 进行42节点生产仿真环境安装
make check install # 进行30节点本地测试环境安装
...
Terraform
Terraform是一个开源的实践“基础设施即代码”的工具:描述你想要的云资源,然后一键创建它们。
Pigsty 提供了 AWS,阿里云,腾讯云的 Terraform 模板,您可以使用它们在云上一键创建虚拟机。
在 MacOS 上,Terraform 可以使用 homebrew 一键安装:brew install terraform。你需要创建一个云帐户,获取 AccessKey 和 AccessSecret 凭证来继续下面的操作。
terraform/目录包含两个示例模板:一个 AWS 模板,一个阿里云模板,你可以按需调整它们,或者作为其他云厂商配置文件的参考,让我们用阿里云为例:
cd terraform # 进入 Terraform 模板目录
cp spec/alicloud.tf terraform.tf # 使用 阿里云 Terraform 模板
在执行 terraform apply 拉起虚拟机之前,你要执行一次 terraform init 安装相应云厂商的插件。
terraform init # 安装 terraform 云供应商插件:例如默认的 aliyun 插件 (第一次使用时安装即可)
terraform apply # 生成执行计划,显示会创建的云资源:虚拟机,网络,安全组,等等等等……
运行 apply 子命令并按提示回答 yes 后,Terraform 将为你创建虚拟机以及其他云资源(网络,安全组,以及其他各种玩意)。
执行结束时,管理员节点的IP地址将被打印出来,你可以登录并开始完成 Pigsty 本身的安装
8 - 安全考量
Pigsty 的默认配置已经足以覆盖绝大多数场景对于安全的需求。
Pigsty 已经提供了开箱即用的认证与访问控制模型,对于绝大多数场景已经足够安全。
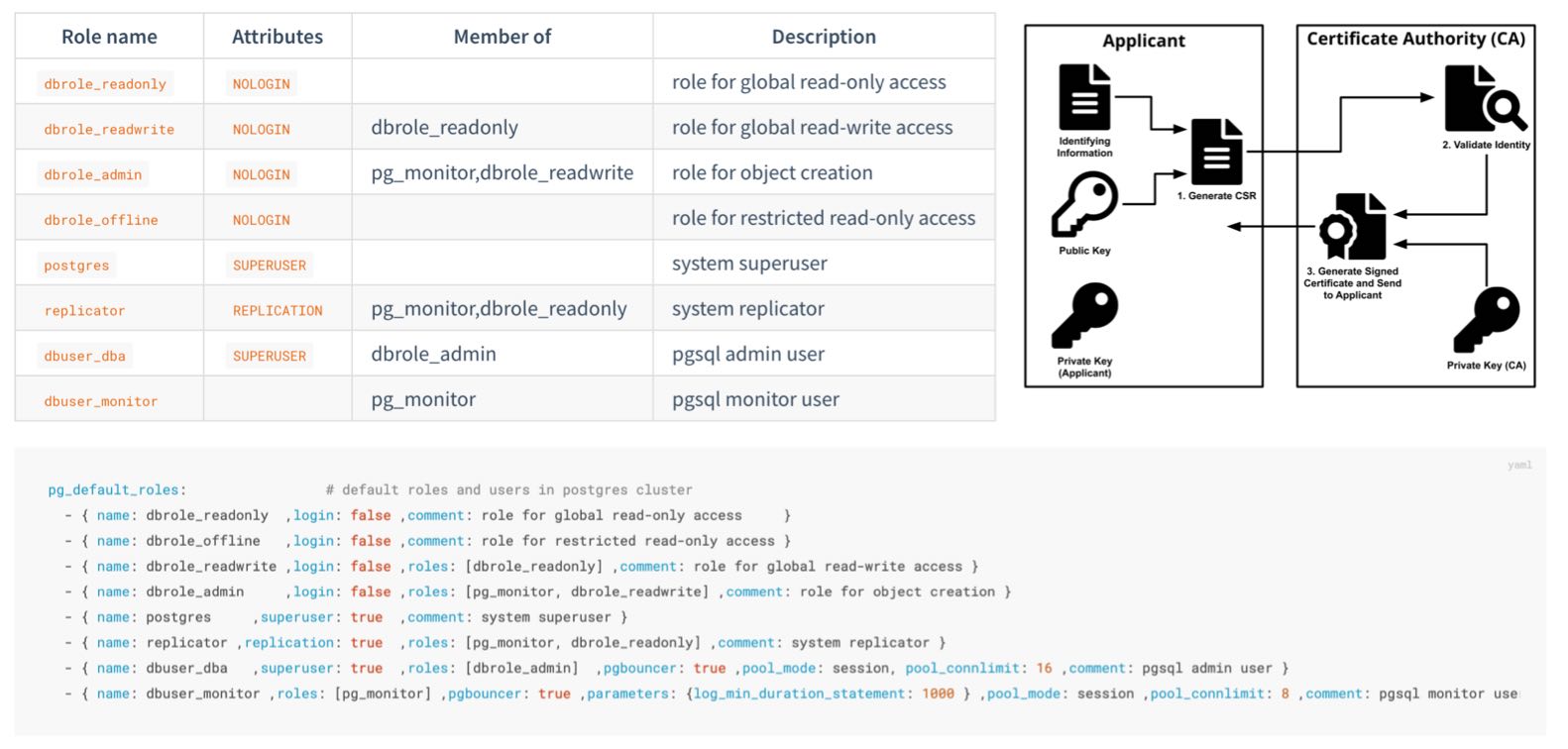
如果您希望进一步加固系统的安全性,那么以下建议供您参考:
机密性
重要文件
保护你的 pigsty.yml 配置文件或CMDB
pigsty.yml配置文件通常包含了高度敏感的机密信息,您应当确保它的安全。- 严格控制管理节点的访问权限,仅限 DBA 或者 Infra 管理员访问。
- 严格控制 pigsty.yml 配置文件仓库的访问权限(如果您使用 git 进行管理)
保护你的 CA 私钥和其他证书,这些文件非常重要。
- 相关文件默认会在管理节点Pigsty源码目录的
files/pki内生成。 - 你应该定期将它们备份到一个安全的地方存储。
密码
在生产环境部署时,必须更改这些密码,不要使用默认值!
grafana_admin_password:pigstypg_admin_password:DBUser.DBApg_monitor_password:DBUser.Monitorpg_replication_password:DBUser.Replicatorpatroni_password:Patroni.APIhaproxy_admin_password:pigstyminio_access_key:minioadminminio_secret_key:minioadmin
如果您使用MinIO,请修改MinIO的默认用户密码,与pgbackrest中的引用
- 请修改 MinIO 普通用户的密码:
minio_users.[pgbacrest].secret_key - 请修改 pgbackrest 中对 MinIO 使用的备份用户密码:
pgbackrest_repo.minio.s3_key_secret
如果您使用远程备份仓库,请务必启用备份加密,并设置加解密密码
- 设置
pgbackrest_repo.*.cipher_type为aes-256-cbc - 设置密码时可以使用
${pg_cluster}作为密码的一部分,避免所有集群使用同一个密码
为 PostgreSQL 使用安全可靠的密码加密算法
- 使用
pg_pwd_enc默认值scram-sha-256替代传统的md5 - 这是默认行为,如果没有特殊理由(出于对历史遗留老旧客户端的支持),请不要将其修改回
md5
使用 passwordcheck 扩展强制执行强密码。
- 在
pg_libs中添加$lib/passwordcheck来强制密码策略。
使用加密算法加密远程备份
- 在
pgbackrest_repo的备份仓库定义中使用repo_cipher_type启用加密
为业务用户配置密码自动过期实践
-
你应当为每个业务用户设置一个密码自动过期时间,以满足合规要求。
-
配置自动过期后,请不要忘记在巡检时定期更新这些密码。
- { name: dbuser_meta , password: Pleas3-ChangeThisPwd ,expire_in: 7300 ,pgbouncer: true ,roles: [ dbrole_admin ] ,comment: pigsty admin user } - { name: dbuser_view , password: Make.3ure-Compl1ance ,expire_in: 7300 ,pgbouncer: true ,roles: [ dbrole_readonly ] ,comment: read-only viewer for meta database } - { name: postgres ,superuser: true ,expire_in: 7300 ,comment: system superuser } - { name: replicator ,replication: true ,expire_in: 7300 ,roles: [pg_monitor, dbrole_readonly] ,comment: system replicator } - { name: dbuser_dba ,superuser: true ,expire_in: 7300 ,roles: [dbrole_admin] ,pgbouncer: true ,pool_mode: session, pool_connlimit: 16 , comment: pgsql admin user } - { name: dbuser_monitor ,roles: [pg_monitor] ,expire_in: 7300 ,pgbouncer: true ,parameters: {log_min_duration_statement: 1000 } ,pool_mode: session ,pool_connlimit: 8 ,comment: pgsql monitor user }
不要将更改密码的语句记录到 postgres 日志或其他日志中
SET log_statement TO 'none';
ALTER USER "{{ user.name }}" PASSWORD '{{ user.password }}';
SET log_statement TO DEFAULT;
IP地址
为 postgres/pgbouncer/patroni 绑定指定的 IP 地址,而不是所有地址。
- 默认的
pg_listen地址是0.0.0.0,即所有 IPv4 地址。 - 考虑使用
pg_listen: '${ip},${vip},${lo}'绑定到特定IP地址(列表)以增强安全性。
不要将任何端口直接暴露到公网IP上,除了基础设施出口Nginx使用的端口(默认80/443)
- 出于便利考虑,Prometheus/Grafana 等组件默认监听所有IP地址,可以直接从公网IP端口访问
- 您可以修改它们的配置文件,只监听内网IP地址,限制其只能通过 Nginx 门户通过域名访问,你也可以当使用安全组,防火墙规则来实现这些安全限制。
- 出于便利考虑,Redis服务器默认监听所有IP地址,您可以修改
redis_bind_address只监听内网IP地址。
使用 HBA 限制 postgres 客户端访问
- 有一个增强安全性的配置模板:
security.yml
限制 patroni 管理访问权限:仅 infra/admin 节点可调用控制API
- 默认情况下,这是通过
restapi.allowlist限制的。
网络流量
使用 SSL 和域名,通过Nginx访问基础设施组件
- Nginx SSL 由
nginx_sslmode控制,默认为enable。 - Nginx 域名由
infra_portal.<component>.domain指定。
使用 SSL 保护 Patroni REST API
patroni_ssl_enabled默认为禁用。- 由于它会影响健康检查和 API 调用。
- 注意这是一个全局选项,在部署前你必须做出决定。
使用 SSL 保护 Pgbouncer 客户端流量
pgbouncer_sslmode默认为disable- 它会对 Pgbouncer 有显著的性能影响,所以这里是默认关闭的。
完整性
为关键场景下的 PostgreSQL 数据库集群配置一致性优先模式(例如与钱相关的库)
pg_conf数据库调优模板,使用crit.yml将以一些可用性为代价,换取最佳的数据一致性。
使用crit节点调优模板,以获得更好的一致性。
node_tune主机调优模板使用crit,可以以减少脏页比率,降低数据一致性风险。
启用数据校验和,以检测静默数据损坏。
pg_checksum默认为off,但建议开启。- 当启用
pg_conf=crit.yml数据库模板时,校验和是强制开启的。
记录建立/切断连接的日志
- 该配置默认关闭,但在
crit.yml配置模板中是默认启用的。 - 可以手工配置集群,启用
log_connections和log_disconnections功能参数。
如果您希望彻底杜绝PG集群在故障转移时脑裂的可能性,请启用watchdog
- 如果你的流量走默认推荐的 HAProxy 分发,那么即使你不启用 watchdog,你也不会遇到脑裂的问题。
- 如果你的机器假死,Patroni 被
kill -9杀死,那么 watchdog 可以用来兜底:超时自动关机。 - 最好不要在基础设施节点上启用 watchdog。
可用性
对于关键场景的PostgreSQL数据库集群,请使用足够的节点/实例数量
- 你至少需要三个节点(能够容忍一个节点的故障)来实现生产级的高可用性。
- 如果你只有两个节点,你可以容忍特定备用节点的故障。
- 如果你只有一个节点,请使用外部的 S3/MinIO 进行冷备份和 WAL 归档存储。
对于 PostgreSQL,在可用性和一致性之间进行权衡
不要直接通过固定的 IP 地址访问数据库;请使用 VIP、DNS、HAProxy 或它们的排列组合
- 使用 HAProxy 进行服务接入
- 在故障切换/主备切换的情况下,Haproxy 将处理客户端的流量切换。
在重要的生产部署中使用多个基础设施节点(例如,1~3)
- 小规模部署或要求宽松的场景,可以使用单一基础设施节点 / 管理节点。
- 大型生产部署建议设置至少两个基础设施节点互为备份。
使用足够数量的 etcd 服务器实例,并使用奇数个实例(1,3,5,7)
- 查看 ETCD 管理 了解详细信息。
9 - 常见问题
这里列出了Pigsty用户在下载、安装、部署时常遇到的问题,如果您遇到了难以解决的问题,可以提交 Issue 或者联系我们。
如何获取Pigsty软件源码包?
使用以下命令一键安装 Pigsty: curl -fsSL https://repo.pigsty.cc/get | bash
上述命令会自动下载最新的稳定版本 pigsty.tgz 并解压到 ~/pigsty 目录。您也可以从以下位置手动下载 Pigsty 源代码的特定版本。
如果您需要在没有互联网的环境中安装,可以提前在有网络的环境中下载好,并通过 scp/sftp 或者 CDROM/USB 传输至生产服务器。
如何加速从上游仓库下载 RPM ?
考虑使用本地仓库镜像,仓库镜像在repo_upstream 参数中配置,你可以选择 region 来使用不同镜像站。
例如,您可以设置 region = china,这样将使用 baseurl 中键为 china 的 URL 而不是 default。
如果防火墙或GFW屏蔽了某些仓库,考虑使用proxy_env 来绕过。
安装失败应该如何解决?
Pigsty 不依赖 Docker,所以期待的环境是一个全新安装操作系统后的状态,如果您使用已经跑了千奇百怪服务的系统,更容易遇到疑难杂症,我们建议不要这么做。 出现安装失败时,可以按照以下思路进行排查:
- 您应当确认当前失败的位置在哪个模块,不同模块失败有不同的原因。您应当保留 Ansible 剧本输出结果备用,并找到所有标红的 Failed 任务。
- 如果出现无法识别配置,剧本直接无法开始,请检查您的配置文件是否是合法的 YAML,缩进,括号等是否有问题。
- 如果错误与本地软件源,Nginx 有关,请检查你的系统是不是全新系统,是否已经运行了 Nginx 或其他组件?或者是否有特殊的防火墙与安全策略在运作?
- 如果是安装节点软件包时出现错误,您是否使用了OS小版本精确匹配的离线软件包?上游是否出现依赖错漏?请参考下面的内容解决
- 如果是系统配置出现错误,您的操作系统是否是全新安装的状态?或者 —— 精简安装到了 Locale 都没有配置的状态?
- 如果是 MinIO 出现问题,您是否使用了 SNMD,MNMD 部署却没有提供真实的磁盘挂载点?您的
sss.pigsty静态域名是否指向了任意 MinIO 节点或 LB 集群? - 如果是 PGSQL 安装出现了问题,您在 pg_extension 中指定安装的扩展,是否还没有添加到 repo_packages 中,或者还没有被覆盖?
- 如果是 PGSQL 启动出现了问题,例如 wait for patroni primary,请参考 PGSQL FAQ 解决。
软件包安装失败如何解决?
请注意,Pigsty 的预制 离线软件包 是针对 特定操作系统发行版小版本 打包的, 因此如果您使用的操作系统版本没有精确对齐,我们不建议使用离线软件安装包,而是直接从上游下载符合当前操作系统实际情况的软件包版本。
如果在线安装无法解决包冲突问题,您首先可以尝试修改 Pigsty 使用的上游软件源。例如在 EL 系操作系统中, Pigsty 默认的上游软件源中使用 $releasever 这样的大版本占位符,它将被解析为具体的 7,8,9 大版本号,但是许多操作系统发行版都提供了 Vault,允许您使用特定某一个版本的软件包镜像。
因此,您可以将 repo_upstream 参数中的 BaseURL 前段替换为具体的 Vault 小版本仓库,例如:
https://mirrors.aliyun.com/rockylinux/$releasever/(原始 BaseURL 前缀,不带vault)https://mirrors.tuna.tsinghua.edu.cn/centos-vault/7.6.1810/(使用 7.6 而不是默认的 7.9)https://mirrors.aliyun.com/rockylinux-vault/8.6/(使用 8.6 而不是默认的 8.9)https://mirrors.aliyun.com/rockylinux-vault/9.2/(使用 9.2 而不是默认的 9.3)
在替换前请注意目标软件源的路径是否真实存在,例如 EPEL 不提供小版本特定的软件源。支持这种方式的上游源包括:base, updates, extras, centos-sclo, centos-sclo-rh, baseos, appstream, extras, crb, powertools, pgdg-common, pgdg1*
repo_upstream:
- { name: pigsty-local ,description: 'Pigsty Local' ,module: local ,releases: [7,8,9] ,baseurl: { default: 'http://${admin_ip}/pigsty' }} # used by intranet nodes
- { name: pigsty-infra ,description: 'Pigsty INFRA' ,module: infra ,releases: [7,8,9] ,baseurl: { default: 'https://repo.pigsty.io/rpm/infra/$basearch' ,china: 'https://repo.pigsty.cc/rpm/infra/$basearch' }}
- { name: pigsty-pgsql ,description: 'Pigsty PGSQL' ,module: pgsql ,releases: [7,8,9] ,baseurl: { default: 'https://repo.pigsty.io/rpm/pgsql/el$releasever.$basearch' ,china: 'https://repo.pigsty.cc/rpm/pgsql/el$releasever.$basearch' }}
- { name: nginx ,description: 'Nginx Repo' ,module: infra ,releases: [7,8,9] ,baseurl: { default: 'https://nginx.org/packages/centos/$releasever/$basearch/' }}
- { name: docker-ce ,description: 'Docker CE' ,module: infra ,releases: [7,8,9] ,baseurl: { default: 'https://download.docker.com/linux/centos/$releasever/$basearch/stable' ,china: 'https://mirrors.aliyun.com/docker-ce/linux/centos/$releasever/$basearch/stable' ,europe: 'https://mirrors.xtom.de/docker-ce/linux/centos/$releasever/$basearch/stable' }}
- { name: base ,description: 'EL 7 Base' ,module: node ,releases: [7 ] ,baseurl: { default: 'http://mirror.centos.org/centos/$releasever/os/$basearch/' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/centos/$releasever/os/$basearch/' ,europe: 'https://mirrors.xtom.de/centos/$releasever/os/$basearch/' }}
- { name: updates ,description: 'EL 7 Updates' ,module: node ,releases: [7 ] ,baseurl: { default: 'http://mirror.centos.org/centos/$releasever/updates/$basearch/' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/centos/$releasever/updates/$basearch/' ,europe: 'https://mirrors.xtom.de/centos/$releasever/updates/$basearch/' }}
- { name: extras ,description: 'EL 7 Extras' ,module: node ,releases: [7 ] ,baseurl: { default: 'http://mirror.centos.org/centos/$releasever/extras/$basearch/' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/centos/$releasever/extras/$basearch/' ,europe: 'https://mirrors.xtom.de/centos/$releasever/extras/$basearch/' }}
- { name: epel ,description: 'EL 7 EPEL' ,module: node ,releases: [7 ] ,baseurl: { default: 'http://download.fedoraproject.org/pub/epel/$releasever/$basearch/' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/epel/$releasever/$basearch/' ,europe: 'https://mirrors.xtom.de/epel/$releasever/$basearch/' }}
- { name: centos-sclo ,description: 'EL 7 SCLo' ,module: node ,releases: [7 ] ,baseurl: { default: 'http://mirror.centos.org/centos/$releasever/sclo/$basearch/sclo/' ,china: 'https://mirrors.aliyun.com/centos/$releasever/sclo/$basearch/sclo/' ,europe: 'https://mirrors.xtom.de/centos/$releasever/sclo/$basearch/sclo/' }}
- { name: centos-sclo-rh ,description: 'EL 7 SCLo rh' ,module: node ,releases: [7 ] ,baseurl: { default: 'http://mirror.centos.org/centos/$releasever/sclo/$basearch/rh/' ,china: 'https://mirrors.aliyun.com/centos/$releasever/sclo/$basearch/rh/' ,europe: 'https://mirrors.xtom.de/centos/$releasever/sclo/$basearch/rh/' }}
- { name: baseos ,description: 'EL 8+ BaseOS' ,module: node ,releases: [ 8,9] ,baseurl: { default: 'https://dl.rockylinux.org/pub/rocky/$releasever/BaseOS/$basearch/os/' ,china: 'https://mirrors.aliyun.com/rockylinux/$releasever/BaseOS/$basearch/os/' ,europe: 'https://mirrors.xtom.de/rocky/$releasever/BaseOS/$basearch/os/' }}
- { name: appstream ,description: 'EL 8+ AppStream' ,module: node ,releases: [ 8,9] ,baseurl: { default: 'https://dl.rockylinux.org/pub/rocky/$releasever/AppStream/$basearch/os/' ,china: 'https://mirrors.aliyun.com/rockylinux/$releasever/AppStream/$basearch/os/' ,europe: 'https://mirrors.xtom.de/rocky/$releasever/AppStream/$basearch/os/' }}
- { name: extras ,description: 'EL 8+ Extras' ,module: node ,releases: [ 8,9] ,baseurl: { default: 'https://dl.rockylinux.org/pub/rocky/$releasever/extras/$basearch/os/' ,china: 'https://mirrors.aliyun.com/rockylinux/$releasever/extras/$basearch/os/' ,europe: 'https://mirrors.xtom.de/rocky/$releasever/extras/$basearch/os/' }}
- { name: crb ,description: 'EL 9 CRB' ,module: node ,releases: [ 9] ,baseurl: { default: 'https://dl.rockylinux.org/pub/rocky/$releasever/CRB/$basearch/os/' ,china: 'https://mirrors.aliyun.com/rockylinux/$releasever/CRB/$basearch/os/' ,europe: 'https://mirrors.xtom.de/rocky/$releasever/CRB/$basearch/os/' }}
- { name: powertools ,description: 'EL 8 PowerTools' ,module: node ,releases: [ 8 ] ,baseurl: { default: 'https://dl.rockylinux.org/pub/rocky/$releasever/PowerTools/$basearch/os/' ,china: 'https://mirrors.aliyun.com/rockylinux/$releasever/PowerTools/$basearch/os/' ,europe: 'https://mirrors.xtom.de/rocky/$releasever/PowerTools/$basearch/os/' }}
- { name: epel ,description: 'EL 8+ EPEL' ,module: node ,releases: [ 8,9] ,baseurl: { default: 'http://download.fedoraproject.org/pub/epel/$releasever/Everything/$basearch/' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/epel/$releasever/Everything/$basearch/' ,europe: 'https://mirrors.xtom.de/epel/$releasever/Everything/$basearch/' }}
- { name: pgdg-common ,description: 'PostgreSQL Common' ,module: pgsql ,releases: [7,8,9] ,baseurl: { default: 'https://download.postgresql.org/pub/repos/yum/common/redhat/rhel-$releasever-$basearch' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/postgresql/repos/yum/common/redhat/rhel-$releasever-$basearch' , europe: 'https://mirrors.xtom.de/postgresql/repos/yum/common/redhat/rhel-$releasever-$basearch' }}
- { name: pgdg-extras ,description: 'PostgreSQL Extra' ,module: pgsql ,releases: [7,8,9] ,baseurl: { default: 'https://download.postgresql.org/pub/repos/yum/common/pgdg-rhel$releasever-extras/redhat/rhel-$releasever-$basearch' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/postgresql/repos/yum/common/pgdg-rhel$releasever-extras/redhat/rhel-$releasever-$basearch' , europe: 'https://mirrors.xtom.de/postgresql/repos/yum/common/pgdg-rhel$releasever-extras/redhat/rhel-$releasever-$basearch' }}
- { name: pgdg-el8fix ,description: 'PostgreSQL EL8FIX' ,module: pgsql ,releases: [ 8 ] ,baseurl: { default: 'https://download.postgresql.org/pub/repos/yum/common/pgdg-centos8-sysupdates/redhat/rhel-8-x86_64/' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/postgresql/repos/yum/common/pgdg-centos8-sysupdates/redhat/rhel-8-x86_64/' , europe: 'https://mirrors.xtom.de/postgresql/repos/yum/common/pgdg-centos8-sysupdates/redhat/rhel-8-x86_64/' } }
- { name: pgdg-el9fix ,description: 'PostgreSQL EL9FIX' ,module: pgsql ,releases: [ 9] ,baseurl: { default: 'https://download.postgresql.org/pub/repos/yum/common/pgdg-rocky9-sysupdates/redhat/rhel-9-x86_64/' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/postgresql/repos/yum/common/pgdg-rocky9-sysupdates/redhat/rhel-9-x86_64/' , europe: 'https://mirrors.xtom.de/postgresql/repos/yum/common/pgdg-rocky9-sysupdates/redhat/rhel-9-x86_64/' }}
- { name: pgdg15 ,description: 'PostgreSQL 15' ,module: pgsql ,releases: [7 ] ,baseurl: { default: 'https://download.postgresql.org/pub/repos/yum/15/redhat/rhel-$releasever-$basearch' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/postgresql/repos/yum/15/redhat/rhel-$releasever-$basearch' ,europe: 'https://mirrors.xtom.de/postgresql/repos/yum/15/redhat/rhel-$releasever-$basearch' }}
- { name: pgdg16 ,description: 'PostgreSQL 16' ,module: pgsql ,releases: [ 8,9] ,baseurl: { default: 'https://download.postgresql.org/pub/repos/yum/16/redhat/rhel-$releasever-$basearch' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/postgresql/repos/yum/16/redhat/rhel-$releasever-$basearch' ,europe: 'https://mirrors.xtom.de/postgresql/repos/yum/16/redhat/rhel-$releasever-$basearch' }}
- { name: timescaledb ,description: 'TimescaleDB' ,module: pgsql ,releases: [7,8,9] ,baseurl: { default: 'https://packagecloud.io/timescale/timescaledb/el/$releasever/$basearch' }}
在 Pigsty 配置文件中显式定义并覆盖 repo_upstream 后,(可清除 /www/pigsty/repo_complete 标记后)再次尝试安装。如果上游软件源与镜像源的软件没有解决问题,你可以考虑将上面的源替换为操作系统自带的软件源,再次尝试从上游直接安装。
最后如果以上手段都没有解决问题,你可以考虑移除 node_packages, infra_packages, pg_packages,pg_extensions 中出现冲突的软件包。或者移除、升级现有系统上的冲突软件包。
准备 / bootstrap 过程是干什么的?
检测环境是否就绪、用各种手段确保后续安装所必需的工具 ansible 被正确安装。
当你下载 Pigsty 源码后,可以进入目录并执行 bootstrap 脚本。它会检测你的节点环境,如果没有发现离线软件包,它会询问你要不要从互联网下载。
你可以选择 “是”(y),直接使用离线软件包安装又快又稳定。你也可以选“否” (n) 跳过,在安装时直接从互联网上游下载最新的软件包,这样会极大减少出现 RPM/DEB 包冲突的概率。
如果使用了离线软件包,bootstrap 会直接从离线软件包中安装 ansible,否则会从上游下载 ansible 并安装,如果你没有互联网访问,又没有 DVD,或者内网软件源,那就只能用离线软件包来安装了。
配置 / configure 过程是干什么的?
配置 / configure 过程会检测你的节点环境并为你生成一个 pigsty 配置文件:pigsty.yml,默认根据你的操作系统(EL 7/8/9)选用相应的单机安装模板。
所有默认的配置模板都在 files/pigsty中,你可以使用 -c 直接指定想要使用的配置模板。如果您已经知道如何配置 Pigsty 了,那么完全可以跳过这一步,直接编辑 Pigsty 配置文件。
Pigsty配置文件是干什么的?
Pigsty主目录下的 pigsty.yml 是默认的配置文件,可以用来描述整套部署的环境,在 conf/ 目录中有许多配置示例供你参考。在 文档站:配置模板 中相关说明。
当执行剧本时,你可以使用 -i <path> 参数,选用其他位置的配置文件。例如,你想根据另一个专门的配置文件 redis.yml 来安装 redis,可以这样做:./redis.yml -i conf/demo/redis.yml
如何使用 CMDB 作为配置清单?
Ansible 默认使用的配置清单在 ansible.cfg 中指定为:inventory = pigsty.yml
你可以使用 bin/inventory_cmdb 切换到动态的 CMDB 清单,
使用 bin/inventory_conf 返回到本地配置文件。
你还需要使用 bin/inventory_load 将当前的配置文件清单加载到 CMDB。
如果使用 CMDB,你必须从数据库而不是配置文件中编辑清单配置,这种方式适合将 Pigsty 与外部系统相集成。
配置文件中的IP地址占位符是干什么的?
Pigsty 使用 10.10.10.10 作为当前节点 IP 的占位符,配置过程中会用当前节点的主 IP 地址替换它。
当 configure 检测到当前节点有多个 NIC 带有多个 IP 时,配置向导会提示使用哪个主要 IP,即 用户用于从内部网络访问节点的 IP,此 IP 将用于在配置文件模板中替换占位符 10.10.10.10。
请注意,您应当使用静态 IP 地址,而不是 DHCP 分配的动态 IP 地址,因为 Pigsty 使用静态 IPv4 地址唯一标识节点。
请注意:不要使用公共 IP 作为主 IP,因为 Pigsty 会使用主 IP 来配置内部服务,例如 Nginx,Prometheus,Grafana,Loki,AlertManager,Chronyd,DNSMasq 等,除了 Nginx 之外的服务不应该对外界暴露端口。
我没有静态IP,可以安装Pigsty吗?
如果您的服务器没有静态IP,在 单机部署 的情况下,可以使用本地环回地址 127.0.0.1 作为这个唯一节点的 IP 地址标识。
配置文件中的哪些参数需要用户特殊关注?
Pigsty 提供了 280+ 配置参数,可以对整个环境与各个模块 infra / node / etcd / minio / pgsql 进行细致入微的定制。
通常在单节点安装中,你不需要对默认生成的配置文件进行任何调整。但如果需要,可以关注以下这些参数:
- 当访问 web 服务组件时,域名由
infra_portal指定,有些服务只能通过 Nginx 代理使用域名访问。 - Pigsty 假定存在一个
/data目录用于存放所有数据;如果数据磁盘的挂载点与此不同,你可以使用node_data调整这些路径。 - 进行生产部署时,不要忘记在配置文件中更改密码,更多细节请参考 安全考量。
在默认单机安装时,到底都安装了什么东西?
当您执行 make install 时,实际上是调用 Ansible 剧本 install.yml,根据配置文件中的参数,安装以下内容:
INFRA模块:提供本地软件源,Nginx Web接入点,DNS服务器,NTP服务器,Prometheus与Grafana可观测性技术栈。NODE模块,将当前节点纳入 Pigsty 管理,部署 HAProxy 与 监控。ETCD模块,部署一个单机 etcd 集群,作为 PG 高可用的 DCSMINIO模块如果定义,则会安装,它可以作为 PG 的可选备份仓库。PGSQL模块,一个单机 PostgreSQL 数据库实例。
安装遇到软件包冲突怎么办?
在安装 node / infra / pgsql 软件包期间,可能有微小的几率出现软件包依赖错漏冲突。这里有几种常见原因:
- 上游软件源发布了不匹配的软件包版本或缺失了依赖,您可能要等待上游修复此问题,时间以周计。事先在依赖完备时制作的离线安装包可以预防这个问题。
- 您制作离线安装包操作系统小版本与当前操作系统的小版本不匹配,您可以使用在线安装,或重新使用相同系统下制作的离线软件包的方式解决此问题
- 个别不重要,非必选的软件包,可以直接将其从安装列表,或本地软件源中剔除的方式快速绕过。
如何重建本地软件仓库?
我想要从上游仓库重新下载软件包,但是执行 ./infra.yml 和 repo 子任务都跳过下载了,怎么办?
您可以使用以下快捷命令和剧本任务,强制重建本地软件源。 Pigsty 会重新检查上游仓库并下载软件包。
make repo-build # ./infra.yml -t repo_build
如何在安装后下载最新版本的软件包?
如果您想要下载最新的软件包版本(RPM/DEB),你可以选择在 /www/pigsty 中手工使用 apt/dnf 下载特定版本的软件包。
在这种情况下,您可以使用以下命令,只更新本地软件仓库的元数据库,而不是整个重建:
./infra.yml -t repo_create
或者移除 /www/pigsty 中的旧版本软件包后重新执行仓库重建命令:
make repo-build # ./infra.yml -t repo_build
如何使用 Vagrant 创建本地虚拟机?
当你第一次使用 Vagrant 启动某个特定的操作系统仓库时,它会下载相应的 Box/Img 镜像文件,Pigsty 沙箱默认使用 generic/rocky9 镜像。
使用代理可能会增加下载速度。Box/Image 只需下载一次,在重建沙箱时会被重复使用。
阿里云上 CentOS 7.9 特有的 RPM 冲突问题
阿里云的 CentOS 7.9 额外安装的 nscd 可能会导致 RPM 冲突问题:"Error: Package: nscd-2.17-307.el7.1.x86_64 (@base)"
遇见安装失败,RPM冲突报错不要慌,这是一个DNS缓存工具,把这个包卸载了就可以了:sudo yum remove nscd,或者使用 ansible 命令批量删除所有节点上的 nscd:
ansible all -b -a 'yum remove -y nscd'
腾讯云上 Rocky 9.x 特有的 RPM 冲突问题
腾讯云的 Rocky 9.x 需要额外的 annobin 软件包才可以正常完成 Pigsty 安装。
遇见安装失败,RPM冲突报错不要慌,进入 /www/pigsty 把这几个包手动下载下来就好了。
./infra.yml -t repo_upstream # add upstream repos
cd /www/pigsty; # download missing packages
repotrack annobin gcc-plugin-annobin libuser
./infra.yml -t repo_create # create repo
Ansible命令超时(Timeout waiting for xxx)
Ansible 命令的默认 ssh 超时时间是10秒。由于网络延迟或其他原因,某些命令可能需要超过这个时间。
你可以在 ansible 配置文件 ansible.cfg 中增加超时参数:
[defaults]
timeout = 10 # 将其修改为 60,120 或更高。
如果你的SSH连接非常慢,通常会是 DNS的问题,请检查sshd配置确保 UseDNS no。