任务
1 - 离线安装
Pigsty 默认从互联网上游 安装 所需软件包,但有些环境与互联网隔离。 为了解决这个问题,Pigsty 支持使用 离线软件包 进行离线安装。
离线软件包打包了所有需要的 RPM/DEB 软件包及其依赖;它本质上是在正常 安装 后采取的本地 APT / YUM 仓库的快照压缩包。
使用离线软件包的步骤:
- 下载 pigsty 离线软件包,将其放到
/tmp/pkg.tgz - 下载 pigsty 源码包,解压(假设解压到
~/pigsty) cd ~/pigsty; ./bootstrap,它将解压软件包并使用本地仓库vi ~/pigsty.yml,覆盖node_repo_modules设为local以使用本地仓库- 照常运行
./install.yml。它将从本地仓库安装所有内容。
离线软件包
您可以从 GitHub 发布页面 找到这些软件包,例如:
d6e9d6fa73620460ceb373a0c2f41ebe pigsty-v4.0.0.tgz
987529769d85a3a01776caefefa93ecb pigsty-pkg-v4.0.0.d12.aarch64.tgz
2d8272493784ae35abeac84568950623 pigsty-pkg-v4.0.0.d12.x86_64.tgz
090cc2531dcc25db3302f35cb3076dfa pigsty-pkg-v4.0.0.d13.x86_64.tgz
ddc54a9c4a585da323c60736b8560f55 pigsty-pkg-v4.0.0.el10.aarch64.tgz
d376e75c490e8f326ea0f0fbb4a8fd9b pigsty-pkg-v4.0.0.el10.x86_64.tgz
8c2deeba1e1d09ef3d46d77a99494e71 pigsty-pkg-v4.0.0.el8.aarch64.tgz
9795e059bd884b9d1b2208011abe43cd pigsty-pkg-v4.0.0.el8.x86_64.tgz
08b860155d6764ae817ed25f2fcf9e5b pigsty-pkg-v4.0.0.el9.aarch64.tgz
1ac430768e488a449d350ce245975baa pigsty-pkg-v4.0.0.el9.x86_64.tgz
e033aaf23690755848db255904ab3bcd pigsty-pkg-v4.0.0.u22.aarch64.tgz
cc022ea89181d89d271a9aaabca04165 pigsty-pkg-v4.0.0.u22.x86_64.tgz
0e978598796db3ce96caebd76c76e960 pigsty-pkg-v4.0.0.u24.aarch64.tgz
48223898ace8812cc4ea79cf3178476a pigsty-pkg-v4.0.0.u24.x86_64.tgz
我们通常为以下 Linux 发行版 发布离线软件包,使用最新的操作系统次要版本。
| EL 发行版 | 代号 | 架构 | 系统代码 | 软件包 |
|---|---|---|---|---|
| RockyLinux 9.6 | EL9 | x86_64 | el9.x86_64 |
pigsty-pkg-v4.0.0.el9.x86_64.tgz |
| Ubuntu 24.04.2 | U24 | x86_64 | u24.x86_64 |
pigsty-pkg-v4.0.0.u24.x86_64.tgz |
| Debian 12.11 | D12 | x86_64 | d12.x86_64 |
pigsty-pkg-v4.0.0.d12.x86_64.tgz |
| RockyLinux 9.6 | EL9 | aarch64 | el9.aarch64 |
pigsty-pkg-v4.0.0.el9.aarch64.tgz |
| Ubuntu 24.04.2 | U24 | aarch64 | u24.aarch64 |
pigsty-pkg-v4.0.0.u24.aarch64.tgz |
| Debian 12.11 | D12 | aarch64 | d12.aarch64 |
pigsty-pkg-v4.0.0.d12.aarch64.tgz |
在较低的操作系统小版本上使用更高小版本的离线软件包,大概率可以使用,但也有失败的可能。
使用离线软件包
将离线软件包放置于 /tmp/pkg.tgz 路径下,进入 ~/pigsty 目录执行 ./bootstrap,即可解包使用离线安装包。
Pigsty 会将其解压至 /www/pigsty,然后配置系统仓库列表启用此仓库,并从中安装 ansible。
自从 Pigsty v3.6 版本起,大部份配置模板都默认不再构建本地软件仓库,而是直接从互联网上游安装软件包。
少部分配置模板如 rich 与 full 依然保留了旧版本的行为 —— 先构建本地仓库再使用。
如果您想要在自己的配置中使用已经解包配置好的离线软件包,请修改以下配置:
repo_enabled:将此参数打开,设置为true,则会构建本地软件源(在大部份配置中被显式关闭)node_repo_modules:将此参数设置为local,则环境中所有节点都从本地软件仓库安装- 在大部份模板中,此参数现在被显式配置为:
node,infra,pgsql,即直接从这些上游软件仓库安装。 - 将其设置为
local,则会使用本地软件仓库安装所有软件包,速度最快,没有其他仓库的变数干扰。 - 如果你想同时使用本地软件仓库和上游软件仓库,可以将其设置为
local,node,infra,pgsql
- 在大部份模板中,此参数现在被显式配置为:
制作离线软件包
如果您选择的操作系统不在默认列表中,您可以使用内置的 cache.yml 剧本制作自己的离线软件包:
- 找到一台运行完全相同操作系统版本,且可以访问互联网的节点
- 运行标准 在线安装(建议使用
rich配置模板:configure -c rich) cd ~/pigsty; ./cache.yml:制作并获取离线软件包到~/pigsty/dist/${version}/- 将离线软件包复制到没有互联网访问的环境中(ftp、scp、usb 等),通过
bootstrap解包使用
自从 Pigsty v3.6 开始,大部份配置模板都直接从互联网上游安装软件包,而不是先下载到管理节点本地构建软件仓库,再从中安装。 你可以通过调整参数来恢复此前的默认行为,如果你需要构建自己的离线软件包,这很有用:
repo_enabled:将此参数打开,则会构建本地软件源(在大部份配置中被显式关闭)node_repo_modules:将此参数设置为local,则环境中所有节点都从本地软件仓库安装
部分配置模板,例如 rich 与 full 依然直接保留旧版本的行为 —— 先构建本地仓库再使用,故无需调整。
优缺点
如果您使用的是上述列表中给出的操作系统(精确匹配的小版本),那么建议使用离线软件包。 Pigsty 为这些系统提供了开箱即用的预制离线软件包,在 GitHub 上提供免费下载。
- 官方离线软件包经过测试。
- 在与互联网隔离的环境中交付的最简单方法。
- 通过一次性预下载所有软件包来加速安装过程。
- 快照确保可以正常工作,无需担心上游依赖项的变动导致依赖错漏。
- 如果操作系统次要版本不匹配,操作系统的 rpm/deb 软件包可能会出现问题
- 可能不包含最新的更新和操作系统安全补丁。
如果你使用的操作系统版本不在上述列表中,你可以考虑自制离线安装包,我们也提供针对更多操作系统大小版本的离线安装包 预制服务(¥200)
混合方法
有一种混合方法可以使用离线软件包作为基础,并在线补足不匹配的增量软件包,这种办法可以融合离线安装与在线安装的优点。
例如,假设您使用的是 RockyLinux 9.5,但官方离线软件包是为 RockyLinux 9.6 制作的。
您可以使用 el9 离线软件包(虽然是针对 9.6 制作的),然后在执行正式安装前,执行 make repo-build 重新下载 9.5 对应的缺失软件包,
Pigsty 将从上游仓库重新下载所需的增量。
Bootstrap
bootstrap 脚本将自动检测 /tmp/pkg.tgz 并默认将其解压到 /www/pigsty。
它还将设置操作系统软件包管理器的仓库文件,并安装 ansible 和其他工具。
./bootstrap # 确保 ansible 正确安装(如果有离线包,优先使用离线安装并解包使用)
引导程序默认会 清除 现有仓库,以确保只安装所需的仓库。
您可以在 /etc/yum.repos.d/backup (EL) 或 /etc/apt/backup (Debian / Ubuntu) 中找到它们。
您可以使用 -k|--keep 参数来保持现有仓库文件不变:
./bootstrap -k # 或 --keep
2 - 精简安装
如果您只想要高可用 PostgreSQL 本身,而不需要监控、基础设施等功能,请考虑精简安装。
没有 INFRA 模块,没有监控,没有 本地仓库,只有 ETCD 和 PGSQL 以及部分 NODE 功能
概览
使用精简安装,您需要:
- 使用
slim.yml配置模板(configure -c slim) - 运行
slim.yml剧本而不是install.yml
curl https://repo.pigsty.cc/get | bash
./configure -c slim
./slim.yml
精简安装只安装这些核心组件:
| 组件 | 必需性 | 描述 |
|---|---|---|
| patroni | ⚠️ 必需 | 引导高可用 PostgreSQL 集群 |
| etcd | ⚠️ 必需 | Patroni 的元数据库依赖(DCS) |
| pgbouncer | ✔️ 可选 | PostgreSQL 连接池 |
| vip-manager | ✔️ 可选 | L2 VIP 绑定到 PostgreSQL 集群主节点 |
| haproxy | ✔️ 可选 | 自动路由 服务 |
| chronyd | ✔️ 可选 | 与 NTP 服务器的时间同步 |
| tuned | ✔️ 可选 | 节点调优模板和内核参数管理 |
您可以关闭可选组件,只有两个必需组件是 patroni 和 etcd。
软件包直接从互联网上游仓库安装,离线安装 在此处不适用。
配置
精简安装的配置文件示例:conf/slim.yml:
all:
children:
infra: { hosts: { 10.10.10.10: { infra_seq: 1 }} ,vars: { repo_enabled: false }}
etcd: { hosts: { 10.10.10.10: { etcd_seq: 1 }} ,vars: { etcd_cluster: etcd }}
#----------------------------------------------#
# PostgreSQL Cluster
#----------------------------------------------#
pg-meta:
hosts:
10.10.10.10: { pg_seq: 1, pg_role: primary }
vars:
pg_cluster: pg-meta
pg_users:
- { name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [dbrole_admin ] ,comment: pigsty admin user }
- { name: dbuser_view ,password: DBUser.Viewer ,pgbouncer: true ,roles: [dbrole_readonly] ,comment: read-only viewer }
pg_databases:
- { name: meta, baseline: cmdb.sql ,comment: pigsty meta database ,schemas: [pigsty] ,extensions: [ vector ]}
pg_hba_rules:
- { user: dbuser_view , db: all ,addr: infra ,auth: pwd ,title: 'allow grafana dashboard access cmdb from infra nodes' }
node_crontab: [ '00 01 * * * postgres /pg/bin/pg-backup full' ] # make a full backup every 1am
vars:
#----------------------------------------------#
# INFRA : https://pigsty.io/docs/infra/param
#----------------------------------------------#
version: v4.0.0 # pigsty version string
admin_ip: 10.10.10.10 # admin node ip address
region: default # upstream mirror region: default,china,europe
infra_portal: # domain names and upstream servers
home : { domain: h.pigsty }
grafana : { domain: g.pigsty ,endpoint: "${admin_ip}:3000" , websocket: true }
prometheus : { domain: p.pigsty ,endpoint: "${admin_ip}:9058" }
alertmanager : { domain: a.pigsty ,endpoint: "${admin_ip}:9059" }
blackbox : { endpoint: "${admin_ip}:9115" }
loki : { endpoint: "${admin_ip}:3100" }
#----------------------------------------------#
# NODE : https://pigsty.io/docs/node/param
#----------------------------------------------#
nodename_overwrite: false # do not overwrite node hostname on single node mode
node_repo_modules: node,infra,pgsql # add these repos directly to the singleton node
node_tune: oltp # node tuning specs: oltp,olap,tiny,crit
#----------------------------------------------#
# PGSQL : https://pigsty.io/docs/pgsql/param
#----------------------------------------------#
pg_version: 18 # Default PostgreSQL Major Version is 18
pg_conf: oltp.yml # pgsql tuning specs: {oltp,olap,tiny,crit}.yml
pg_packages: [ pgsql-main, pgsql-common ] # pg kernel and common utils
#----------------------------------------------#
# SLIM: https://pigsty.io/docs/setup/slim
#----------------------------------------------#
nginx_enabled: false # nginx not exists
dns_enabled: false # dnsmasq not exists
prometheus_enabled: false # prometheus not exists
grafana_enabled: false # grafana not exists
pg_exporter_enabled: false # disable pg_exporter
pgbouncer_exporter_enabled: false # disable pgbouncer_exporter
pgbackrest_exporter_enabled: false # disable pgbackrest_exporter
pg_vip_enabled: false # disable pg_vip
安装
使用 slim.yml 剧本而不是 install.yml 剧本:
./slim.yml
这个 slim.yml 剧本是专门用来在精简安装场景中取代默认 install.yml 剧本的。
3 - 声明配置
Pigsty将基础设施和数据库视为代码:Database as Code & Infra as Code
你可以通过声明式的接口/配置文件来描述基础设施和数据库集群,你只需在 配置清单 (Inventory) 中描述你的需求,然后用简单的幂等剧本使其生效即可。
配置清单
每一套 Pigsty 部署都有一个相应的 配置清单(Inventory)。它可以以 YAML 的形式存储在本地,
并使用 git 管理;或从 CMDB 或任何 ansible 兼容的方式动态生成。
Pigsty 默认使用一个名为 pigsty.yml 的单体 YAML 配置文件作为默认的配置清单,
它位于 Pigsty 源码主目录下,但你也可以通过命令行参数 -i 指定路径以使用别的配置清单。
清单由两部分组成:全局变量 (all.vars)和多个 组定义(all.children) 。 前者 all.vars 通常用于描述基础设施,并为集群设置全局默认参数。后者 all.children 则负责定义新的集群(PGSQL/Redis/MinIO/ETCD等等)。一个配置清单文件从最顶层来看大概如下所示:
all: # 顶层对象:all
vars: {...} # 全局参数
children: # 组定义
infra: # 组定义:'infra'
hosts: {...} # 组成员:'infra'
vars: {...} # 组参数:'infra'
etcd: {...} # 组定义:'etcd'
pg-meta: {...} # 组定义:'pg-meta'
pg-test: {...} # 组定义:'pg-test'
redis-test: {...} # 组定义:'redis-test'
# ...
集群
每个组定义通常代表一个集群,可以是节点集群、PostgreSQL 集群、Redis 集群、Etcd 集群或 Minio 集群等。它们都使用相同的格式:hosts 和 vars。
你可以用 all.children.<cls>.hosts 定义集群成员,并使用 all.children.<cls>.vars 中的集群参数描述集群。以下是名为 pg-test 的三节点 PostgreSQL 高可用集群的定义示例:
pg-test: # 集群名称
vars: # 集群参数
pg_cluster: pg-test
hosts: # 集群成员
10.10.10.11: { pg_seq: 1, pg_role: primary } # 实例1,在 10.10.10.11 上,主库
10.10.10.12: { pg_seq: 2, pg_role: replica } # 实例2,在 10.10.10.12 上,从库
10.10.10.13: { pg_seq: 3, pg_role: offline } # 实例3,在 10.10.10.13 上,从库
你也可以为特定的主机/实例定义参数,也称为实例参数。它将覆盖集群参数和全局参数,实例参数通常用于为节点和数据库实例分配身份(实例号,角色)。
参数
全局变量、组变量和主机变量都是由一系列 键值对 组成的字典对象。每一对都是一个命名的参数,由一个字符串名作为键,和一个值组成。值是五种类型之一:布尔值、字符串、数字、数组或对象。查看配置参数以了解详细的参数语法语义。
绝大多数参数都有着合适的默认值,身份参数 除外;它们被用作标识符,并必须显式配置,例如 pg_cluster, pg_role,以及 pg_seq。
参数可以被更高优先级的同名参数定义覆盖,优先级如下所示:
命令行参数 > 剧本变量 > 主机变量(实例参数) > 组变量(集群参数) > 全局变量(全局参数) > 默认值
例如:
- 使用命令行参数
-e pg_clean=true强制删除现有数据库 - 使用实例参数
pg_role和pg_seq来为一个数据库实例分配角色与标号。 - 使用集群变量来为集群设置默认值,如集群名称
pg_cluster和数据库版本pg_version - 使用全局变量为所有 PGSQL 集群设置默认值,如使用的默认参数和插件列表
- 如果没有显式配置
pg_version,默认值18版本号会作为最后兜底的缺省值。
模板
在 Pigsty 目录中的 conf/ 目录里,提供了针对许多不同场景的预置配置模板可供参考选用。
在 configure 过程中,您可以通过 -c 参数指定模板。否则会默认使用单节点安装的 meta 模板。
关于这些模版的功能,请参考 配置模板 中的介绍。
切换配置源
要使用不同的配置模板,您可以将模板的内容复制到 Pigsty 源码目录的 pigsty.yml 文件中,并按需进行相应调整。
您也可以在执行 Ansible 剧本时,通过 -i 命令行参数,显式指定使用的配置文件,例如:
./node.yml -i files/pigsty/rpmbuild.yml # 根据 rpmbuild 配置文件,初始化目标节点,而不是使用默认的 pigsty.yml 配置文件
如果您希望修改默认的配置文件名称与位置,您也可以修改源码根目录下的 ansible.cfg 的 inventory 参数,将其指向您的配置文件路径,这样您就可以直接执行 ansible-playbook 命令而无需显式指定 -i 参数。
Pigsty 允许您使用数据库(CMDB)作为动态配置源,而不是使用静态配置文件。 Pigsty 提供了三个便利脚本:
bin/inventory_load: 将pigsty.yml配置文件的内容加载到本机上的 PostgreSQL 数据库中(meta.pigsty)bin/inventory_cmdb: 切换配置源为本地 PostgreSQL 数据库(meta.pigsty)bin/inventory_conf: 切换配置源为本地静态配置文件pigsty.yml
参考
Pigsty 带有 280+ 配置参数,分为以下32个参数组,详情请参考 配置参数 。
| 模块 | 参数组 | 描述 | 数量 |
|---|---|---|---|
INFRA |
META |
Pigsty 元数据 | 4 |
INFRA |
CA |
自签名公私钥基础设施 CA | 3 |
INFRA |
INFRA_ID |
基础设施门户,Nginx域名 | 2 |
INFRA |
REPO |
本地软件仓库 | 9 |
INFRA |
INFRA_PACKAGE |
基础设施软件包 | 2 |
INFRA |
NGINX |
Nginx 网络服务器 | 7 |
INFRA |
DNS |
DNSMASQ 域名服务器 | 3 |
INFRA |
PROMETHEUS |
Prometheus 时序数据库全家桶 | 18 |
INFRA |
GRAFANA |
Grafana 可观测性全家桶 | 6 |
INFRA |
LOKI |
Loki 日志服务 | 4 |
NODE |
NODE_ID |
节点身份参数 | 5 |
NODE |
NODE_DNS |
节点域名 & DNS解析 | 6 |
NODE |
NODE_PACKAGE |
节点仓库源 & 安装软件包 | 5 |
NODE |
NODE_TUNE |
节点调优与内核特性开关 | 10 |
NODE |
NODE_ADMIN |
管理员用户与SSH凭证管理 | 7 |
NODE |
NODE_TIME |
时区,NTP服务与定时任务 | 5 |
NODE |
NODE_VIP |
可选的主机节点集群L2 VIP | 8 |
NODE |
HAPROXY |
使用HAProxy对外暴露服务 | 10 |
NODE |
NODE_EXPORTER |
主机节点监控与注册 | 3 |
NODE |
PROMTAIL |
Promtail日志收集组件 | 4 |
DOCKER |
DOCKER |
Docker容器服务(可选) | 4 |
ETCD |
ETCD |
Etcd DCS 集群 | 10 |
MINIO |
MINIO |
MinIO S3 对象存储 | 15 |
REDIS |
REDIS |
Redis 缓存 | 20 |
PGSQL |
PG_ID |
PG 身份参数 | 11 |
PGSQL |
PG_BUSINESS |
PG 业务对象定义 | 12 |
PGSQL |
PG_INSTALL |
安装 PG 软件包 & 扩展 | 10 |
PGSQL |
PG_BOOTSTRAP |
使用 Patroni 初始化 HA PG 集群 | 39 |
PGSQL |
PG_PROVISION |
创建 PG 数据库内对象 | 9 |
PGSQL |
PG_BACKUP |
使用 pgBackRest 设置备份仓库 | 5 |
PGSQL |
PG_SERVICE |
对外暴露服务, 绑定 vip, dns | 9 |
PGSQL |
PG_EXPORTER |
PG 监控,服务注册 | 15 |
4 - 准备工作
与 Pigsty 部署有关的 101 入门知识。
节点准备
Pigsty 支持 Linux 内核与 x86_64/amd64 架构,适用于任意节点。
所谓节点(node),指 ssh 可达并提供裸操作系统环境的资源,例如物理机,裸金属,虚拟机,或者启用了 systemd 与 sshd 的操作系统容器。
部署 Pigsty 最少需要一个节点。最低配置要求为 1C1G,推荐至少使用 2C4G 以上的机型,适用配置上不封顶,参数会自动优化适配。
作为 Demo,个人站点,或者开发环境时,可以使用单个节点。作为独立监控基础设施使用时,建议使用 1-2 个节点,作为高可用 PostgreSQL 数据库集群使用时,建议至少使用 3 个节点。用于核心场景时,建议使用至少 4-5 个节点。
手工配置大规模生产环境繁琐且容易出错,我们建议您充分利用 Infra as Code 工具,解决此类问题。
您可以使用 Pigsty 提供的 Terraform 模板与 Vagrant 模板,使用 IaC 的方式一键创建所需的节点环境,完成好网络,操作系统,管理用户,权限,安全组的置备工作。
网络准备
Pigsty 要求节点使用 静态IPv4地址,即您应当为节点显式分配指定固定的 IP 地址,而不应当使用 DHCP 动态分配的地址。
节点使用的 IP 地址应当是节点用于内网通信的首要 IP 地址,并将作为节点的唯一身份标识符。
如果您希望使用可选的 Node VIP 与 PG VIP 功能,应当确保所有节点位于一个大二层网络中。
您的防火墙策略应当保证所需的端口在节点间开放,不同模块所需的具体端口列表请参考 节点:端口。
暴露端口的方法取决于您的网络安全策略实现,例如:公有云上的安全组策略,或本地 iptables 记录,防火墙配置等。
如果您只是希望尝尝鲜,不在乎安全,并且希望一切越简单越好,那么您可以仅对外部用户按需开放 5432 端口( PostgreSQL 数据库) 与 3000 端口(Grafana 可视化界面)。
在 Infra节点 上的 Nginx 默认会对外暴露 80/443 端口提供 Web 服务,并通过域名对不同服务进行区分,这一端口应当对办公网络(或整个整个互联网)开放。
严肃的生产数据库服务端口通常不应当直接暴露在公网上,如果您确实需要这么做,建议首先查阅 安全最佳实践,并小心行事。
操作系统准备
Pigsty 支持多种基于 Linux 内核的服务器操作系统发行版,我们建议使用 RockyLinux 9.6、Ubuntu 24.04.2 或 Debian 12.11 作为安装 Pigsty 的 OS。
Pigsty 支持 RHEL (7,8,9,10),Debian (11,12,13),Ubuntu (20,22,24) 以及多种与之兼容的操作系统发行版,完整操作系统列表请参考 兼容性。
在使用多个节点镜进行部署时,我们 强烈 建议您在所有用于 Pigsty 部署的节点上,使用相同版本的操作系统发行版与 Linux 内核版本
我们强烈建议使用干净,全新安装的最小化安装的服务器操作系统环境,并使用 en_US 作为首要语言。
使用其他系统语言包时,如何确保 en_US 本地化规则集可用:
yum install -y glibc-locale-source glibc-langpack-en
localedef -i en_US -f UTF-8 en_US.UTF-8
localectl set-locale LANG=en_US.UTF-8
注:Pigsty 部署的 PostgreSQL 集群默认使用 C.UTF8 locale,但字符集定义使用 en_US 以确保 pg_trgm 扩展可以正常工作。
如果您确实不需要此功能,可以配置 pg_lc_ctype 的值为 C.UTF8 ,以避免在系统语言包缺失的情况下,数据库初始化报错的问题。
管理用户准备
在安装 Pigsty 的节点上,您需要拥有一个 “管理用户” —— 拥有免密 ssh 登陆权限与免密 sudo 权限。
免密 sudo 是必选项,用于在安装过程中执行需要 sudo 权限的命令,例如安装软件包,配置系统参数等。
假设您的管理用户名为 vagrant ,则可以创建 /etc/sudoers.d/vagrant 文件,并添加以下记录:
%vagrant ALL=(ALL) NOPASSWD: ALL
则 vagrant 用户即可免密 sudo 执行所有命令。如果你的用户名不是 vagrant,请将上面操作中的 vagrant 替换为您的用户名。
尽管使用 root 用户安装 Pigsty 是可行的,但我们不推荐这样做。
安全最佳实践 是使用一个不同于根用户(root)与数据库超级用户 (postgres) 的专用管理员用户(如:dba)
Pigsty 提供了专用剧本任务,可以使用一个现有的管理用户(例如 root),输入 ssh/sudo 密码,创建一个专用的 管理员用户。
SSH 权限准备
除了免密 sudo 权限, Pigsty 还需要管理用户免密 ssh 登陆的权限。
对于单机安装的节点而言,这意味着本机上的管理用户可以通过 ssh 免密码登陆到本机上。
如果的 Pigsty 部署涉及到多个节点,这意味着管理节点上的管理用户应当可以通过 ssh 免密码登陆到所有被 Pigsty 纳管的节点上(包括本机),并免密执行 sudo 命令。
单机安装时,在 configure 过程中,如果您的当前管理用户没有 SSH key,Pigsty 会尝试修复此问题:随机生成一对新的 id_rsa 密钥,并添加至本地 ~/.ssh/authroized_keys 文件确保本机管理用户的 SSH 登陆能力。
Pigsty 默认会为您在纳管的节点上创建一个可用的管理用户 dba (uid=88),如果您已经使用了此用户,我们建议您修改 node_admin_username 使用新的用户名与其他 uid,或通过 node_admin_enabled 参数禁用。
假设您的管理用户名为 vagrant,则以 vagrant 用户身份执行以下命令,会为其生成公私钥对 ~/.ssh/id_rsa[.pub] 用于登陆。如果已经存在公私钥对,则无需生成新密钥对。
ssh-keygen -t rsa -b 2048 -N '' -f ~/.ssh/id_rsa -q
生成的公钥默认位于:/home/vagrant/.ssh/id_rsa.pub,私钥默认位于:/home/vagrant/.ssh/id_rsa,如果您操作系统用户名不叫 vagrant,将上面的 vagrant 替换为您的用户名即可。
您应当将公钥文件(id_rsa.pub)追加写入到需要登陆机器的对应用户上:/home/vagrant/.ssh/authorized_keys 文件中。如果您已经可以直接通过密码访问远程机器,可以直接通过ssh-copy-id的方式拷贝公钥:
ssh-copy-id <ip> # 输入密码以完成公钥拷贝
sshpass -p <password> ssh-copy-id <ip> # 直接将密码嵌入命令中,避免交互式密码输入(注意安全!)
Pigsty 推荐将管理用户的创建,权限配置与密钥分发放在虚拟机的置备阶段完成,作为标准化交付内容的一部分。
SSH 例外情况
如果您的 SSH 访问有一些额外限制,例如,使用了跳板机,或者进行了某些定制化修改,无法通过简单的 ssh <ip> 方式访问,那么可以考虑使用 ssh 别名。
例如,如果您的服务器可以通过 ~/.ssh/config 中定义的别名,例如 meta 通过 ssh 访问,那么可以为 配置清单 中的节点配置 ansible_host 参数,指定 SSH Alias:
nodes:
hosts: # 10.10.10.10 无法直接 ssh,但可以通过ssh别名 `meta` 访问
10.10.10.10: { ansible_host: meta }
如果 SSH 别名无法满足您的需求,Ansible 还提供了一系列自定义 ssh 连接参数,可以精细控制 SSH 连接的行为。
最后,如果以下命令可以在管理节点上使用管理用户成功执行,意味着该目标节点上的管理用户与权限配置已经妥当:
ssh <ip|alias> 'sudo ls'
软件准备
在 管理节点 上,Pigsty 需要使用 Ansible 发起控制命令。如果您使用本地单机安装,那么管理节点和被管理的节点是同一台,需要安装 Ansible。对于普通节点,则无需安装 Ansible。
在 bootstrap 过程中,Pigsty 会尽最大努力自动为您完成安装 Ansible 这一任务,但您也可以选择手工安装 Ansible。手工安装 Ansible 的过程因不同操作系统发行版/大版本而异(通常涉及到额外的弱依赖 jmespath):
sudo dnf install -y ansible python3.12-jmespath python3-cryptographysudo yum install -y ansible # EL7 无需显式安装 Jmespathsudo apt install -y ansible python3-jmespathbrew install ansible为了安装 Pigsty,您还需要准备 Pigsty 源码包。您可以直接从 GitHub Release 页面下载特定版本,或使用以下命令获取最新稳定版本:
curl -fsSL https://repo.pigsty.cc/get | bash
如果您的环境没有互联网访问,也可以考虑直接从 GitHub Release 页面或其他渠道下载针对不同操作系统发行版预先制作的 离线安装包。
5 - 执行剧本
在 Pigsty 中,剧本 / Playbooks 用于在节点上安装模块。
剧本可以视作可执行文件直接执行,例如:./install.yml.
剧本
以下是 Pigsty 中默认包含的剧本:
| 剧本 | 功能 |
|---|---|
install.yml |
在当前节点上一次性完整安装 Pigsty |
deploy.yml |
一次性在所有节点上部署所有组件 |
infra.yml |
在 infra 节点上初始化 pigsty 基础设施 |
infra-rm.yml |
从 infra 节点移除基础设施组件 |
node.yml |
纳管节点,并调整节点到期望的状态 |
node-rm.yml |
从 pigsty 中移除纳管节点 |
pgsql.yml |
初始化 HA PostgreSQL 集群或添加新的从库实例 |
pgsql-rm.yml |
移除 PostgreSQL 集群或移除从库实例 |
pgsql-user.yml |
向现有的 PostgreSQL 集群添加新的业务用户 |
pgsql-db.yml |
向现有的 PostgreSQL 集群添加新的业务数据库 |
pgsql-monitor.yml |
监控纳管远程 postgres 实例 |
pgsql-migration.yml |
为现有的 PostgreSQL 生成迁移手册和脚本 |
pgsql-pitr.yml |
PostgreSQL 时间点恢复(PITR)操作 |
redis.yml |
初始化 redis 集群/节点/实例 |
redis-rm.yml |
移除 redis 集群/节点/实例 |
etcd.yml |
初始化 etcd 集群(patroni HA DCS所需) |
etcd-rm.yml |
移除 etcd 集群 |
minio.yml |
初始化 minio 集群(pgbackrest 备份仓库备选项) |
minio-rm.yml |
移除 minio 集群 |
docker.yml |
在节点上安装 docker |
mongo.yml |
在节点上安装 Mongo/FerretDB |
app.yml |
复制并启动 Docker Compose 应用 |
cert.yml |
使用 pigsty 自签名 CA 颁发证书(例如用于客户端) |
cache.yml |
制作离线软件包 |
一次性安装
特殊的剧本 install.yml 实际上是一个复合剧本,它在当前环境上安装所有以下组件。
playbook / command / group infra nodes etcd minio pgsql
[infra.yml] ./infra.yml [-l infra] [+infra][+node]
[node.yml] ./node.yml [+node] [+node] [+node] [+node]
[etcd.yml] ./etcd.yml [-l etcd ] [+etcd]
[minio.yml] ./minio.yml [-l minio] [+minio]
[pgsql.yml] ./pgsql.yml [+pgsql]
请注意,NODE 和 INFRA 之间存在循环依赖:为了在 INFRA 上注册 NODE,INFRA 应该已经存在,而 INFRA 模块依赖于 INFRA节点上的 NODE 模块才能工作。
为了解决这个问题,INFRA 模块的安装剧本也会在 INFRA 节点上安装 NODE 模块。所以,请确保首先初始化 INFRA 节点。
如果您非要一次性初始化包括 INFRA 在内的所有节点,install.yml 剧本就是用来解决这个问题的:它会正确的处理好这里的循环依赖,一次性完成整个环境的初始化。
Ansible
执行剧本需要 ansible-playbook 可执行文件,该文件包含在 ansible rpm/deb 包中。
Pigsty 将在 准备 期间在尽最大努力尝试在当前节点安装 ansible。
您可以自己使用 yum / apt / brew install ansible 来安装 Ansible,它含在各大发行版的默认仓库中。
了解 ansible 对于使用 Pigsty 很有帮助,但也不是必要的。对于基本使用,您只需要注意四个参数就足够了:
-i|--inventory <path>:显式指定使用的配置文件-l|--limit <pattern>: 限制剧本在特定的组/主机/模式上执行目标(在哪里/Where)-t|--tags <tags>: 只运行带有特定标签的任务(做什么/What)-e|--extra-vars <vars>: 传递额外的命令行参数(怎么做/How)
指定配置文件
您可以使用 -i 命令行参数,显式指定使用的配置文件。
Pigsty 默认使用名为 pigsty.yml 配置文件,该文件位于 Pigsty 源码根目录中的 pigsty.yml。但您可以使用 -i 覆盖这一行为,例如:
./node.yml -i files/pigsty/rpmbuild.yml # 根据 rpmbuild 配置文件,初始化目标节点,而不是使用默认的 pigsty.yml 配置文件
./pgsql.yml -i files/pigsty/rpm.yml # 根据 files/pigsty/rpm.yml 配置文件中的定义,在目标节点上安装 pgsql 模块
./redis.yml -i files/pigsty/redis.yml # 根据 files/pigsty/redis.yml 配置文件中的定义,在目标节点上安装 redis 模块
如果您希望永久修改默认使用的配置文件,可以修改源码根目录下的 ansible.cfg 的 inventory 参数,将其指向您的配置文件路径。
这样您就可以在执行 ansible-playbook 命令时无需显式指定 -i 参数了。
指定执行对象
您可以使用 -l|-limit <selector> 限制剧本的执行目标。
缺少此值可能很危险,因为大多数剧本会在 all 分组,也就是所有主机上执行,使用时务必小心。
以下是一些主机限制的示例:
./pgsql.yml # 在所有主机上运行(非常危险!)
./pgsql.yml -l pg-test # 在 pg-test 集群上运行
./pgsql.yml -l 10.10.10.10 # 在单个主机 10.10.10.10 上运行
./pgsql.yml -l pg-* # 在与通配符 `pg-*` 匹配的主机/组上运行
./pgsql.yml -l '10.10.10.11,&pg-test' # 在组 pg-test 的 10.10.10.10 上运行
/pgsql-rm.yml -l 'pg-test,!10.10.10.11' # 在 pg-test 上运行,除了 10.10.10.11 以外
./pgsql.yml -l pg-test # 在 pg-test 集群的主机上执行 pgsql 剧本
执行剧本子集
你可以使用 -t|--tags <tag> 执行剧本的子集。 你可以在逗号分隔的列表中指定多个标签,例如 -t tag1,tag2。
如果指定了任务子集,将执行给定标签的任务,而不是整个剧本。以下是任务限制的一些示例:
./pgsql.yml -t pg_clean # 如果必要,清理现有的 postgres
./pgsql.yml -t pg_dbsu # 为 postgres dbsu 设置操作系统用户 sudo
./pgsql.yml -t pg_install # 安装 postgres 包和扩展
./pgsql.yml -t pg_dir # 创建 postgres 目录并设置 fhs
./pgsql.yml -t pg_util # 复制工具脚本,设置别名和环境
./pgsql.yml -t patroni # 使用 patroni 引导 postgres
./pgsql.yml -t pg_user # 提供 postgres 业务用户
./pgsql.yml -t pg_db # 提供 postgres 业务数据库
./pgsql.yml -t pg_backup # 初始化 pgbackrest 仓库和 basebackup
./pgsql.yml -t pgbouncer # 与 postgres 一起部署 pgbouncer sidecar
./pgsql.yml -t pg_vip # 使用 vip-manager 将 vip 绑定到 pgsql 主库
./pgsql.yml -t pg_dns # 将 dns 名称注册到 infra dnsmasq
./pgsql.yml -t pg_service # 使用 haproxy 暴露 pgsql 服务
./pgsql.yml -t pg_exporter # 使用 haproxy 暴露 pgsql 服务
./pgsql.yml -t pg_register # 将 postgres 注册到 pigsty 基础设施
# 运行多个任务:重新加载 postgres 和 pgbouncer hba 规则
./pgsql.yml -t pg_hba,pg_reload,pgbouncer_hba,pgbouncer_reload
# 运行多个任务:刷新 haproxy 配置并重新加载
./node.yml -t haproxy_config,haproxy_reload
传递额外参数
您可以通过 -e|-extra-vars KEY=VALUE 传递额外的命令行参数。
命令行参数具有压倒性的优先级,以下是一些额外参数的示例:
./node.yml -e ansible_user=admin -k -K # 作为另一个用户运行剧本(带有 admin sudo 密码)
./pgsql.yml -e pg_clean=true # 在初始化 pgsql 实例时强制清除现有的 postgres
./pgsql-rm.yml -e pg_uninstall=true # 在 postgres 实例被删除后明确卸载 rpm
./redis.yml -l 10.10.10.11 -e redis_port=6379 -t redis # 初始化一个特定的 redis 实例:10.10.10.11:6379
./redis-rm.yml -l 10.10.10.13 -e redis_port=6379 # 删除一个特定的 redis 实例:10.10.10.11:6379
此外,您还可以通过 JSON 的方式,传递诸如数组与对象这样的复杂参数:
# 通过指定软件包与仓库模块,在节点上安装 duckdb
./node.yml -t node_repo,node_pkg -e '{"node_repo_modules":"infra","node_default_packages":["duckdb"]}'
大多数剧本都是幂等的,这意味着在未打开保护选项的情况下,一些部署剧本可能会 删除现有的数据库 并创建新的数据库。
请仔细阅读文档,多次校对命令,并小心操作。作者不对因误用造成的任何数据库损失负责。
6 - 置备机器
Pigsty 在节点上运行,这些节点可以是裸机或虚拟机。您可以手工置备它们,或使用 terraform 和 vagrant 这样的工具在云端或本地进行自动配置。
沙箱环境
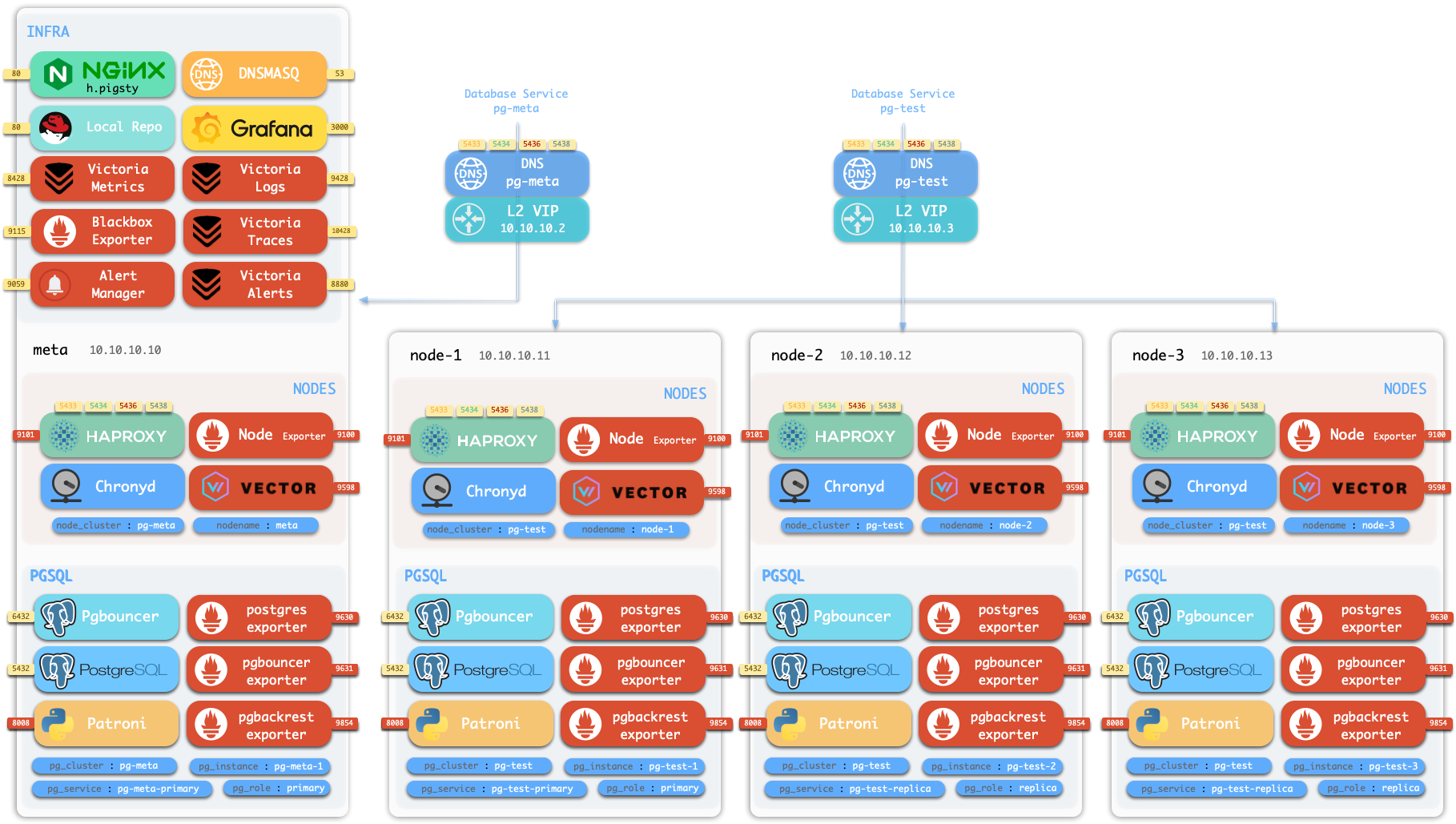
Pigsty 带有一个演示沙箱,所谓沙箱,就是专门用来演示/测试的环境:IP地址和其他标识符都预先固定配置好,便于复现各种演示用例。
默认的沙箱环境由4个节点组成,配置文件请参考 full.yml。
沙箱的 4 个节点有着固定的 IP 地址:10.10.10.10、10.10.10.11、10.10.10.12、10.10.10.13。
沙箱带有一个位于 meta 节点上的单实例 PostgreSQL 集群:pg-meta:
meta 10.10.10.10 pg-meta pg-meta-1
沙箱中还有一个由三个实例组成的 PostgreSQL 高可用集群:pg-test,部署在另外三个节点上:
node-1 10.10.10.11 pg-test.pg-test-1node-2 10.10.10.12 pg-test.pg-test-2node-3 10.10.10.13 pg-test.pg-test-3
两个可选的 L2 VIP 分别绑定在 pg-meta 和 pg-test 集群的主实例上:
10.10.10.2 pg-meta10.10.10.3 pg-test
在 meta 节点上,还有一个单实例的 etcd “集群”和一个单实例的 minio “集群”。
您可以在本地虚拟机或云虚拟机上运行沙箱。Pigsty 提供基于 Vagrant 的本地沙箱(使用 Virtualbox/libvirt 启动本地虚拟机)以及基于 Terraform 的云沙箱(使用云供应商 API 创建虚拟机)。
-
本地沙箱可以在您的 Mac/PC 上免费运行。运行完整的4节点沙箱,您的 Mac/PC 应至少拥有 4C/8G。
-
云沙箱可以轻松创建和共享,单需要一个公有云帐户才行。云上虚拟机可以按需创建/一键销毁,对于快速测试来说非常便宜省事。
此外,Pigsty 还提供了一个 42 节点以上的生产仿真环境沙箱 ha/simu.yml。
Vagrant
Vagrant 可以按照声明式的方式创建本地虚拟机。请查看 Vagrant 模板介绍 以获取详情。
安装
确保您的操作系统中已经安装并可以使用 Vagrant 和 Virtualbox。
如果您使用的是 macOS,您可以使用 homebrew 一键命令安装它们,注意安装 Virtualbox 后需要重启系统。
如果你用的是 Linux,可以使用 virtualbox,也可以考虑使用 KVM: vagrant-libvirt。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
brew install vagrant virtualbox ansible # 在 MacOS 中可以轻松一键安装,但只有 x86_64 Intel 芯片的可以
配置
vagarnt/Vagranfile 是一个 Ruby 脚本文件,用来描述 Vagrant 要创建的虚拟机节点。Pigsty 提供了一些默认的配置模板:
| 模板 | 快捷方式 | 规格 | 注释 |
|---|---|---|---|
| meta.rb | v1 |
4C8G x 1 | 单一 Meta 节点 |
| dual.rb | v2 |
2C4G x 2 | 双节点测试环境 |
| trio.rb | v3 |
2C4G x 3 | 三节点测试环境 |
| full.rb | v4 |
2C4G + 1C2G x 3 | 完整的 4 节点沙盒示例 |
| minio.rb | vm |
2C4G x 3 + Disk | 3-节点 MinIO/etcd 测试环境 |
| simu.rb | vs |
2C4G x 42+ | 生产模拟仿真环境 |
| pro.rb | vp |
2C4G x 3 | 专业版测试环境 |
| rpm.rb | vr |
2C4G x 3 | RPM 构建测试环境 |
| deb.rb | vd |
2C4G x 3 | Debian 构建测试环境 |
| oss.rb | vo |
2C4G x 3 | OSS 相关测试环境 |
| old.rb | vx |
2C4G x 3 | 旧版本兼容测试环境 |
| all.rb | va |
2C4G x 10+ | 全操作系统版本测试环境 |
| deci.rb | vi |
2C4G x 10+ | Deci 测试环境 |
每个规格文件包含一个描述虚拟机节点的 Specs 变量。例如,full.rb 包含4节点沙盒规格的描述:
Specs = [
{ "name" => "meta" , "ip" => "10.10.10.10" , "cpu" => "2" , "mem" => "4096" , "image" => "bento/rockylinux-9" },
{ "name" => "node-1" , "ip" => "10.10.10.11" , "cpu" => "1" , "mem" => "2048" , "image" => "bento/rockylinux-9" },
{ "name" => "node-2" , "ip" => "10.10.10.12" , "cpu" => "1" , "mem" => "2048" , "image" => "bento/rockylinux-9" },
{ "name" => "node-3" , "ip" => "10.10.10.13" , "cpu" => "1" , "mem" => "2048" , "image" => "bento/rockylinux-9" },
]
您可以使用 vagrant/config 脚本切换 Vagrant 配置文件,它会根据规格以及虚拟机软件类型,渲染生成最终的 Vagrantfile。
cd ~/pigsty
vagrant/config <spec>
vagrant/config meta # 单节点 Meta 环境 | 别名:`make v1`
vagrant/config dual # 双节点测试环境 | 别名:`make v2`
vagrant/config trio # 三节点测试环境 | 别名:`make v3`
vagrant/config full # 4 节点沙箱环境 | 别名:`make v4`
vagrant/config minio # 3 节点 MinIO 环境
vagrant/config simu # 生产模拟仿真环境 | 别名:`make vs`
vagrant/config pro # 专业版测试环境 | 别名:`make vp`
vagrant/config rpm # RPM 构建环境
vagrant/config deb # Debian 构建环境
虚拟机管理
当您使用 vagrant/Vagrantfile 描述了所需的虚拟机后,你可以使用vagrant up命令创建这些虚拟机。
Pigsty 模板默认会使用你的 ~/.ssh/id_rsa[.pub] 作为这些虚拟机的默认ssh凭证。
在开始之前,请确保你有一个有效的ssh密钥对,你可以通过以下方式生成一对:ssh-keygen -t rsa -b 2048
此外,还有一些 makefile 快捷方式包装了 vagrant 命令,你可以使用它们来管理虚拟机。
make # 等于 make start
make new # 销毁现有虚拟机,根据规格创建新的
make ssh # 将 SSH 配置写入到 ~/.ssh/ 中 (新虚拟机拉起后必须完成这一步)
make dns # 将 虚拟机 DNS 记录写入到 /etc/hosts 中 (如果想使用名称访问虚拟机)
make start # 等于先执行 up ,再执行 ssh
make up # 根据配置拉起虚拟机,或启动现有虚拟机
make halt # 关停现有虚拟机 (down,dw)
make clean # 销毁现有虚拟机 (clean/del/destroy)
make status # 显示虚拟机状态 (st)
make pause # 暂停虚拟机运行 (suspend,pause)
make resume # 恢复虚拟机运行 (resume)
make nuke # 使用 virsh 销毁所有虚拟机 (仅libvirt可用)
快捷方式
你可以使用以下的 Makefile 快捷方式使用 vagrant 拉起虚拟机环境。
make meta # 单个元节点
make dual # 双节点测试环境
make trio # 三节点测试环境
make full # 4 节点沙箱环境
make minio # 3 节点 MinIO 测试环境
make simu # 生产模拟仿真环境
make pro # 专业版测试环境
make rpm # RPM 构建环境
make deb # Debian 构建环境
make meta install # 进行完整的单机安装
make full install # 进行 4 节点沙箱安装
make simu install # 进行生产模拟仿真环境安装
...
Terraform
Terraform是一个开源的实践“基础设施即代码”的工具:描述你想要的云资源,然后一键创建它们。
Pigsty 提供了 AWS,阿里云,腾讯云的 Terraform 模板,您可以使用它们在云上一键创建虚拟机。
在 MacOS 上,Terraform 可以使用 homebrew 一键安装:brew install terraform。你需要创建一个云帐户,获取 AccessKey 和 AccessSecret 凭证来继续下面的操作。
terraform/目录包含两个示例模板:一个 AWS 模板,一个阿里云模板,你可以按需调整它们,或者作为其他云厂商配置文件的参考,让我们用阿里云为例:
cd terraform # 进入 Terraform 模板目录
cp spec/alicloud.tf terraform.tf # 使用 阿里云 Terraform 模板
在执行 terraform apply 拉起虚拟机之前,你要执行一次 terraform init 安装相应云厂商的插件。
terraform init # 安装 terraform 云供应商插件:例如默认的 aliyun 插件 (第一次使用时安装即可)
terraform apply # 生成执行计划,显示会创建的云资源:虚拟机,网络,安全组,等等等等……
运行 apply 子命令并按提示回答 yes 后,Terraform 将为你创建虚拟机以及其他云资源(网络,安全组,以及其他各种玩意)。
执行结束时,管理员节点的IP地址将被打印出来,你可以登录并开始完成 Pigsty 本身的安装
7 - 安全考量
Pigsty 的默认配置已经足以覆盖绝大多数场景对于安全的需求。
Pigsty 已经提供了开箱即用的认证与访问控制模型,对于绝大多数场景已经足够安全。
如果您希望进一步加固系统的安全性,那么以下建议供您参考:
机密性
重要文件
保护你的 pigsty.yml 配置文件或CMDB
pigsty.yml配置文件通常包含了高度敏感的机密信息,您应当确保它的安全。- 严格控制管理节点的访问权限,仅限 DBA 或者 Infra 管理员访问。
- 严格控制 pigsty.yml 配置文件仓库的访问权限(如果您使用 git 进行管理)
保护你的 CA 私钥和其他证书,这些文件非常重要。
- 相关文件默认会在管理节点Pigsty源码目录的
files/pki内生成。 - 你应该定期将它们备份到一个安全的地方存储。
密码
在生产环境部署时,必须更改这些密码,不要使用默认值!
grafana_admin_password:pigstypg_admin_password:DBUser.DBApg_monitor_password:DBUser.Monitorpg_replication_password:DBUser.Replicatorpatroni_password:Patroni.APIhaproxy_admin_password:pigstyminio_access_key:minioadminminio_secret_key:minioadmin
如果您使用MinIO,请修改MinIO的默认用户密码,与pgbackrest中的引用
- 请修改 MinIO 普通用户的密码:
minio_users.[pgbacrest].secret_key - 请修改 pgbackrest 中对 MinIO 使用的备份用户密码:
pgbackrest_repo.minio.s3_key_secret
如果您使用远程备份仓库,请务必启用备份加密,并设置加解密密码
- 设置
pgbackrest_repo.*.cipher_type为aes-256-cbc - 设置密码时可以使用
${pg_cluster}作为密码的一部分,避免所有集群使用同一个密码
为 PostgreSQL 使用安全可靠的密码加密算法
- 使用
pg_pwd_enc默认值scram-sha-256替代传统的md5 - 这是默认行为,如果没有特殊理由(出于对历史遗留老旧客户端的支持),请不要将其修改回
md5
使用 passwordcheck 扩展强制执行强密码。
- 在
pg_libs中添加$lib/passwordcheck来强制密码策略。
使用加密算法加密远程备份
- 在
pgbackrest_repo的备份仓库定义中使用repo_cipher_type启用加密
为业务用户配置密码自动过期实践
-
你应当为每个业务用户设置一个密码自动过期时间,以满足合规要求。
-
配置自动过期后,请不要忘记在巡检时定期更新这些密码。
- { name: dbuser_meta , password: Pleas3-ChangeThisPwd ,expire_in: 7300 ,pgbouncer: true ,roles: [ dbrole_admin ] ,comment: pigsty admin user } - { name: dbuser_view , password: Make.3ure-Compl1ance ,expire_in: 7300 ,pgbouncer: true ,roles: [ dbrole_readonly ] ,comment: read-only viewer for meta database } - { name: postgres ,superuser: true ,expire_in: 7300 ,comment: system superuser } - { name: replicator ,replication: true ,expire_in: 7300 ,roles: [pg_monitor, dbrole_readonly] ,comment: system replicator } - { name: dbuser_dba ,superuser: true ,expire_in: 7300 ,roles: [dbrole_admin] ,pgbouncer: true ,pool_mode: session, pool_connlimit: 16 , comment: pgsql admin user } - { name: dbuser_monitor ,roles: [pg_monitor] ,expire_in: 7300 ,pgbouncer: true ,parameters: {log_min_duration_statement: 1000 } ,pool_mode: session ,pool_connlimit: 8 ,comment: pgsql monitor user }
不要将更改密码的语句记录到 postgres 日志或其他日志中
SET log_statement TO 'none';
ALTER USER "{{ user.name }}" PASSWORD '{{ user.password }}';
SET log_statement TO DEFAULT;
IP地址
为 postgres/pgbouncer/patroni 绑定指定的 IP 地址,而不是所有地址。
- 默认的
pg_listen地址是0.0.0.0,即所有 IPv4 地址。 - 考虑使用
pg_listen: '${ip},${vip},${lo}'绑定到特定IP地址(列表)以增强安全性。
不要将任何端口直接暴露到公网IP上,除了基础设施出口Nginx使用的端口(默认80/443)
- 出于便利考虑,Prometheus/Grafana 等组件默认监听所有IP地址,可以直接从公网IP端口访问
- 您可以修改它们的配置文件,只监听内网IP地址,限制其只能通过 Nginx 门户通过域名访问,你也可以当使用安全组,防火墙规则来实现这些安全限制。
- 出于便利考虑,Redis服务器默认监听所有IP地址,您可以修改
redis_bind_address只监听内网IP地址。
使用 HBA 限制 postgres 客户端访问
- 有一个增强安全性的配置模板:
security.yml
限制 patroni 管理访问权限:仅 infra/admin 节点可调用控制API
- 默认情况下,这是通过
restapi.allowlist限制的。
网络流量
使用 SSL 和域名,通过Nginx访问基础设施组件
- Nginx SSL 由
nginx_sslmode控制,默认为enable。 - Nginx 域名由
infra_portal.<component>.domain指定。
使用 SSL 保护 Patroni REST API
patroni_ssl_enabled默认为禁用。- 由于它会影响健康检查和 API 调用。
- 注意这是一个全局选项,在部署前你必须做出决定。
使用 SSL 保护 Pgbouncer 客户端流量
pgbouncer_sslmode默认为disable- 它会对 Pgbouncer 有显著的性能影响,所以这里是默认关闭的。
完整性
为关键场景下的 PostgreSQL 数据库集群配置一致性优先模式(例如与钱相关的库)
pg_conf数据库调优模板,使用crit.yml将以一些可用性为代价,换取最佳的数据一致性。
使用crit节点调优模板,以获得更好的一致性。
node_tune主机调优模板使用crit,可以以减少脏页比率,降低数据一致性风险。
启用数据校验和,以检测静默数据损坏。
pg_checksum默认为off,但建议开启。- 当启用
pg_conf=crit.yml数据库模板时,校验和是强制开启的。
记录建立/切断连接的日志
- 该配置默认关闭,但在
crit.yml配置模板中是默认启用的。 - 可以手工配置集群,启用
log_connections和log_disconnections功能参数。
如果您希望彻底杜绝PG集群在故障转移时脑裂的可能性,请启用watchdog
- 如果你的流量走默认推荐的 HAProxy 分发,那么即使你不启用 watchdog,你也不会遇到脑裂的问题。
- 如果你的机器假死,Patroni 被
kill -9杀死,那么 watchdog 可以用来兜底:超时自动关机。 - 最好不要在基础设施节点上启用 watchdog。
可用性
对于关键场景的PostgreSQL数据库集群,请使用足够的节点/实例数量
- 你至少需要三个节点(能够容忍一个节点的故障)来实现生产级的高可用性。
- 如果你只有两个节点,你可以容忍特定备用节点的故障。
- 如果你只有一个节点,请使用外部的 S3/MinIO 进行冷备份和 WAL 归档存储。
对于 PostgreSQL,在可用性和一致性之间进行权衡
不要直接通过固定的 IP 地址访问数据库;请使用 VIP、DNS、HAProxy 或它们的排列组合
- 使用 HAProxy 进行服务接入
- 在故障切换/主备切换的情况下,Haproxy 将处理客户端的流量切换。
在重要的生产部署中使用多个基础设施节点(例如,1~3)
- 小规模部署或要求宽松的场景,可以使用单一基础设施节点 / 管理节点。
- 大型生产部署建议设置至少两个基础设施节点互为备份。
使用足够数量的 etcd 服务器实例,并使用奇数个实例(1,3,5,7)
- 查看 ETCD 管理 了解详细信息。
8 - 单机安装
部署摘要
使用 meta 单机配置模板,在单台节点上部署 Pigsty:
curl https://repo.pigsty.cc/get | bash
cd ~/pigsty; ./configure -g -c meta
./deploy.yml
| ID | NODE | PGSQL | INFRA | ETCD |
|---|---|---|---|---|
| 1 | 10.10.10.10 |
pg-meta-1 |
infra-1 |
etcd-1 |
简短版本
准备 一台具有 SSH权限 的 节点 并安装 兼容的Linux发行版,
使用带有免密 ssh 和 sudo 权限的管理用户执行以下命令:
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty;
该命令会 下载 并解压 Pigsty 源码至家目录,依次完成 配置 与安装 即可完成安装。
./configure; ./install.yml; # 生成配置文件,执行安装剧本!
- configure:【可选】检测环境并自动生成相应的推荐配置文件,如果知道如何 配置 Pigsty可以直接跳过
- install.yml:根据生成的配置文件开始在当前节点上执行安装
整个安装过程根据服务器规格/网络条件需 5~10 分钟不等,离线安装 能显著加速。
安装完成后,您可以通过域名,或80/443端口通过 Nginx 访问 WEB 界面,
通过 5432 端口 访问 默认的 PostgreSQL 数据库 服务。
您也可以继续使用 Pigsty 纳管 更多 节点,并部署各种 模块。 如果您不需要 Pigsty 的基础设施组件,可以使用 精简安装 ,仅安装高可用 PostgreSQL 集群所必需的组件。
视频样例:在线单机安装(EL9)

准备
关于准备工作的完整详细说明,请参考 入门:准备工作 一节。
安装 Pigsty 涉及一些 准备工作 ,以下是简略检查清单:
| 项目 | 要求 | 项目 | 要求 |
|---|---|---|---|
| 节点 | 至少 1C1G,推荐 2C2G |
规格 | 至少1个节点,2个为半高可用,3个以上真高可用 |
| 磁盘 | /data,主挂载点,ext4/xfs |
网络 | 静态 IPv4 地址,单节点可使用 127.0.0.1 |
| VIP | L2 VIP,可选 | 域名 | 本地/公网域名,可选 |
| 内核 | Linux |
发行版 | el8/9/10,d12/13, u22/u24 x x86_64 / aarch64 |
| Locale | C.UTF-8 或 C |
防火墙 | 端口:80 / 443 / 22 / 5432 |
| 用户 | 避免使用 root 和 postgres |
Sudo | nopass sudo 权限 |
| SSH | 通过公钥 nopass |
可达性 | ssh <ip|alias> sudo ls 无错误 |
尽管使用 root 用户安装 Pigsty 是可行的,但 安全最佳实践
是使用一个不同于根用户(root)与数据库超级用户 (postgres) 的专用管理员用户(如:dba),
Pigsty 安装过程中会默认创建由配置文件指定的可选管理员用户 dba。
下载
(推荐)您可以使用以下命令自动下载、解压 Pigsty 源码包至 ~/pigsty 目录下使用:
curl -fsSL https://repo.pigsty.cc/get | bash # 安装最新稳定版本(中国镜像)
curl -fsSL https://repo.pigsty.io/get | bash # 安装最新稳定版本(国际区域)
curl -fsSL https://repo.pigsty.io/get | bash -s v4.0.0 # 安装特定版本
您也可以通过 git、pig 或直接从 GitHub 下载源码和离线软件包 压缩包的方式安装。
git clone https://github.com/pgsty/pigsty; cd pigsty; git checkout v4.0.0
main 主干为活跃开发分支,使用 git 时请务必检出特定版本后使用,可用版本请参考 发行注记。
配置
configure 脚本将根据您的环境和输入生成具有良好默认值的 pigsty.yml 配置文件(配置清单)。
这是 可选的,您可以如 教程 所示直接编辑 pigsty.yml。
有许多 配置模板 供您参考,以下是一些快速示例:
./configure # 使用默认模板,安装默认的 PG 18,带有必要扩展
./configure -v 17 # 使用 PG 17 的版本,而非默认的 PG18
./configure -c rich # 创建本地软件仓库,下载所有扩展,安装主要扩展
./configure -c slim # 最小安装模板,与 ./slim.yml 剧本一起使用
./configure -c app/supa # 使用 app/supa 自托管 supabase 配置模板
./configure -c ivory # 使用 ivorysql 内核而非原生 PG
./configure -i 10.11.12.13 # 显式指定主 IP 地址
./configure -r china # 使用中国镜像而非默认仓库
./configure -c ha/full -s # 使用 4 节点沙箱配置模板,不进行 IP 替换和探测
配置 / configure 过程的样例输出
[vagrant@node-2 pigsty]$ ./configure
configure pigsty v4.0.0 begin
[ OK ] region = default
[ OK ] kernel = Linux
[ OK ] machine = x86_64
[ OK ] package = rpm,dnf
[ OK ] vendor = rocky (Rocky Linux)
[ OK ] version = 9 (9.6)
[ OK ] sudo = vagrant ok
[ OK ] ssh = vagrant@127.0.0.1 ok
[WARN] Multiple IP address candidates found:
(1) 192.168.121.24 inet 192.168.121.24/24 brd 192.168.121.255 scope global dynamic noprefixroute eth0
(2) 10.10.10.12 inet 10.10.10.12/24 brd 10.10.10.255 scope global noprefixroute eth1
[ IN ] INPUT primary_ip address (of current meta node, e.g 10.10.10.10):
=> 10.10.10.12 # <------- 在这里输入你的首要 IPv4 地址!
[ OK ] primary_ip = 10.10.10.12 (from input)
[ OK ] admin = vagrant@10.10.10.12 ok
[ OK ] mode = meta (el9)
[ OK ] locale = C.UTF-8
[ OK ] configure pigsty done
proceed with ./install.yml
-i|--ip: 当前主机的首要内网IP地址,用于替换配置文件中的 IP 地址占位符10.10.10.10。-c|--conf: 用于指定使用的配置 配置模板,相对于conf/目录,不带.yml后缀的配置名称。-v|--version: 用于指定要安装的 PostgreSQL 大版本,如13、14、15、16、17、18,部分模板不支持此配置。-r|--region: 用于指定上游软件源的区域,加速下载: (default|china|europe)-n|--non-interactive: 直接使用命令行参数提供首要IP地址,跳过交互式向导。-x|--proxy: 使用当前环境变量配置proxy_env变量(影响http_proxy/HTTP_PROXY,HTTPS_PROXY,ALL_PROXY,NO_PROXY)。
如果您的机器网卡绑定了多个 IP 地址,那么需要使用 -i|--ip <ipaddr> 显式指定一个当前节点的首要 IP 地址,或在交互式问询中提供。
该脚本将把 IP 占位符 10.10.10.10 替换为当前节点的主 IPv4 地址。选用的地址应为静态 IP 地址,请勿使用公网 IP 地址。
配置过程生成的配置文件默认位于:~/pigsty/pigsty.yml,您可以在安装前进行检查与修改定制。
我们强烈建议您在安装前,事先修改配置文件中使用的默认密码与凭据,详情参考 安全考量。
安装
Pigsty 中的一切都由 配置清单 所定义,也就是 上面 生成的 pigsty.yml 配置。
运行 install.yml 剧本 会实施这个部署计划:
./install.yml # 一次性在所有节点上完成安装
安装过程的样例输出
......
TASK [pgsql : pgsql init done] *************************************************
ok: [10.10.10.11] => {
"msg": "postgres://10.10.10.11/postgres | meta | dbuser_meta dbuser_view "
}
......
TASK [pg_monitor : load grafana datasource meta] *******************************
changed: [10.10.10.11]
PLAY RECAP *********************************************************************
10.10.10.11 : ok=302 changed=232 unreachable=0 failed=0 skipped=65 rescued=0 ignored=1
localhost : ok=6 changed=3 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
输出尾部如果带有 pgsql init done,PLAY RECAP 等字样,说明安装已经完成!
上游仓库(如 Linux / PGDG 仓库)可能会因为更新而进入崩溃状态并导致安装失败(有过多次先例)! 您可以选择等待上游仓库修复后安装,或者使用预制的 离线软件包 来解决这个问题。
警告: 在已经初始化的环境中再次运行 install.yml 会重置整个环境,所以请务必小心!
此剧本仅用于初始安装,安装完毕后可以用 rm install.yml 或 chmod a-x install.yml 来避免此剧本的误执行。
用户界面
安装完成后,当前节点会安装有四个核心模块:PGSQL,INFRA,NODE,ETCD。
| ID | NODE | PGSQL | INFRA | ETCD |
|---|---|---|---|---|
| 1 | node-1 |
pg-meta-1 |
infra-1 |
etcd-1 |
您可以直接通过以下 端口 访问 WebUI 服务(不推荐用于生产环境)。或使用本地/公共域名通过 Nginx 门户访问它们。
| 组件 | 端口 | 域名 | 备注 | 公共演示 |
|---|---|---|---|---|
| Nginx | 80/443 |
h.pigsty |
门户、仓库、HAProxy 管理 | home.pigsty.io |
| Grafana | 3000 |
g.pigsty |
Grafana 仪表盘 | g.pgsty.com |
| Prometheus | 9058 |
p.pigsty |
Prometheus Web UI | p.pigsty.io |
| AlertManager | 9059 |
a.pigsty |
告警管理 | a.pigsty.io |
Grafana 监控系统(
g.pigsty/3000端口)的默认用户名与密码为:admin/pigsty
您可以通过以下数据库用户和相应的 PGURL 访问默认端口 5432 上的默认 PostgreSQL 数据库(meta):
psql postgres://dbuser_dba:DBUser.DBA@10.10.10.10:5432/meta # DBA / 超级用户psql postgres://dbuser_meta:DBUser.Meta@10.10.10.10:5432/meta # 业务管理员用户psql postgres://dbuser_view:DBUser.Viewer@10.10.10.10:5432/meta # 只读查看者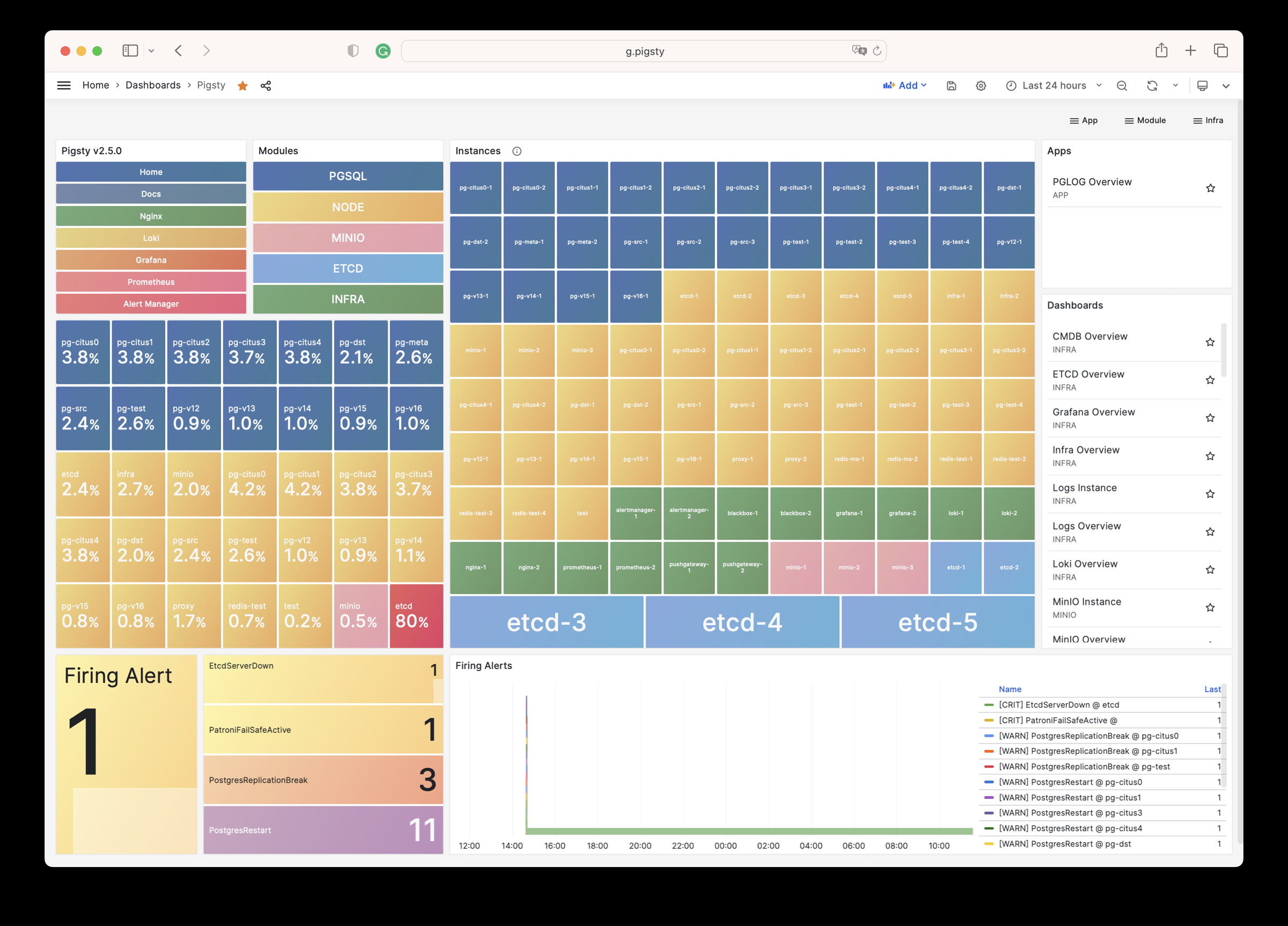
如何通过域名访问 Pigsty WebUI ?
客户端可以通过几种不同的办法来使用域名访问:
- 通过 DNS 服务商解析互联网域名,适用于公网可访问的系统。
- 通过配置内网 DNS 服务器解析记录实现内网域名解析。
- 修改本机的
/etc/hosts文件添加静态解析记录。
我们建议普通用户使用第三种方式,在使用浏览器访问 Web 系统的机器上,修改 /etc/hosts (需要 sudo 权限)或 C:\Windows\System32\drivers\etc\hosts(Windows)文件,添加以下的解析记录:
<your_ip_address> h.pigsty a.pigsty p.pigsty g.pigsty
这里的 IP 地址是安装 Pigsty 服务的 对外IP地址。
如何配置服务端使用的域名?
服务器端域名使用 Nginx 进行配置,如果您想要替换默认的域名,在参数 infra_portal 中填入使用的域名即可。
当您使用 http://g.pigsty 访问 Grafana 监控主页时,实际上是通过 Nginx 代理访问了 Grafana 的 WebUI:
http://g.pigsty ️-> http://10.10.10.10:80 (nginx) -> http://10.10.10.10:3000 (grafana)
如何使用 HTTPS 访问 Pigsty WebUI ?
Pigsty默认使用自动生成的自签名的 CA 证书为 Nginx 启用 SSL,如果您希望使用 HTTPS 访问这些页面,而不弹窗提示"不安全",通常有三个选择:
- 在您的浏览器或操作系统中信任 Pigsty 自签名的 CA 证书:
files/pki/ca/ca.crt - 如果您使用 Chrome,可以在提示不安全的窗口键入
thisisunsafe跳过提示 - 您可以考虑使用 Let’s Encrypt 或其他免费的 CA 证书服务,为 Pigsty Nginx 生成正式的 SSL证书。
更多
您可以使用 Pigsty 部署和监控 更多集群:向 配置清单 添加定义并运行:
bin/node-add pg-test # 将集群 pg-test 的3个节点纳入 Pigsty 管理
bin/pgsql-add pg-test # 初始化一个3节点的 pg-test 高可用PG集群
bin/redis-add redis-ms # 初始化 Redis 集群: redis-ms