在 Pigsty 中,您可以使用不同 “风味” 的 PostgreSQL 分支替换 “原生PG内核”,实现特殊的功能与效果。
PG 内核分支
如何在 Pigsty 中使用其他 PostgreSQL 内核分支?例如 Citus, Babelfish/WiltonDB,IvorySQL, PolarDB 等等……
- 1: Citus (Distributive)
- 2: Babelfish (MSSQL)
- 3: IvorySQL (Oracle)
- 4: OpenHalo (MySQL)
- 5: OrioleDB (OLTP)
- 6: PolarDB PG (RAC)
- 7: PolarDB O(racle)
- 8: PostgresML (AI/ML)
- 9: Supabase (Firebase)
- 10: Greenplum (MPP)
- 11: Cloudberry (MPP)
- 12: Neon (Serverless)
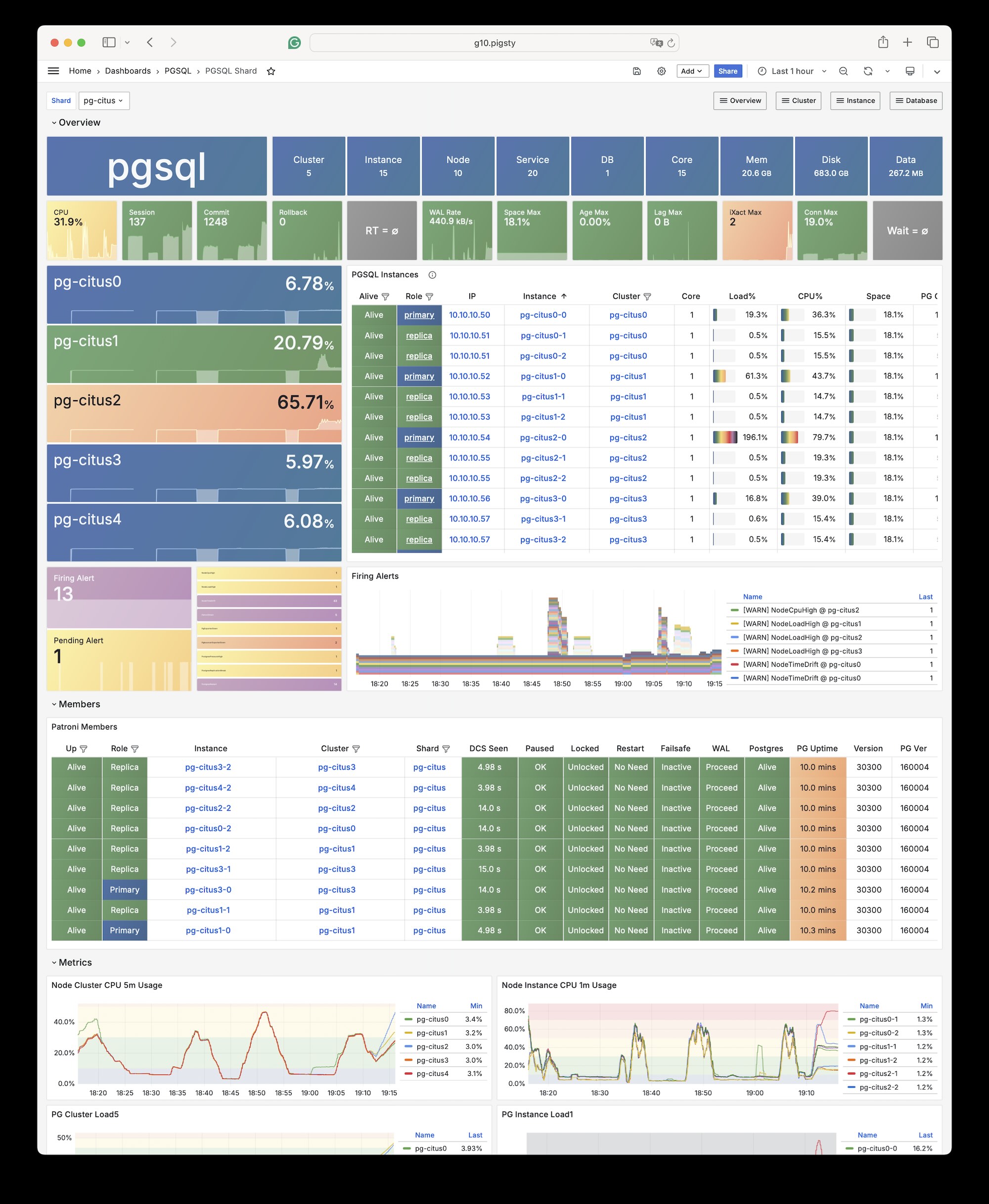
1 - Citus (Distributive)
使用 Pigsty 部署原生高可用的 Citus 水平分片集群,将 PostgreSQL 无缝伸缩到多套分片并加速 OLTP/OLAP 查询。
Pigsty 原生支持 Citus。这是一个基于原生 PostgreSQL 内核的分布式水平扩展插件。
使用 Citus 搭建水平扩展的高可用 PostgreSQL 集群,请参考:Citus教程:部署 Citus 高可用集群
安装
Citus 是一个 PostgreSQL 扩展插件,可以按照标准插件安装的流程,在原生 PostgreSQL 集群上加装启用。
./pgsql.yml -t pg_extension -e '{"pg_extensions":["citus"]}'
配置
要定义一个 citus 集群,您需要指定以下参数:
pg_mode必须设置为citus,而不是默认的pgsql- 在每个分片集群上都必须定义分片名
pg_shard和分片号pg_group - 必须定义
patroni_citus_db来指定由 Patroni 管理的数据库。 - 如果您想使用
pg_dbsu的postgres而不是默认的pg_admin_username来执行管理命令,那么pg_dbsu_password必须设置为非空的纯文本密码
此外,还需要额外的 hba 规则,允许从本地和其他数据节点进行 SSL 访问。
您可以将每个 Citus 集群分别定义为独立的分组,像标准的 PostgreSQL 集群一样,如 conf/dbms/citus.yml 所示:
all:
children:
pg-citus0: # citus 0号分片
hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary } }
vars: { pg_cluster: pg-citus0 , pg_group: 0 }
pg-citus1: # citus 1号分片
hosts: { 10.10.10.11: { pg_seq: 1, pg_role: primary } }
vars: { pg_cluster: pg-citus1 , pg_group: 1 }
pg-citus2: # citus 2号分片
hosts: { 10.10.10.12: { pg_seq: 1, pg_role: primary } }
vars: { pg_cluster: pg-citus2 , pg_group: 2 }
pg-citus3: # citus 3号分片
hosts:
10.10.10.13: { pg_seq: 1, pg_role: primary }
10.10.10.14: { pg_seq: 2, pg_role: replica }
vars: { pg_cluster: pg-citus3 , pg_group: 3 }
vars: # 所有 Citus 集群的全局参数
pg_mode: citus # pgsql 集群模式需要设置为: citus
pg_shard: pg-citus # citus 水平分片名称: pg-citus
patroni_citus_db: meta # citus 数据库名称:meta
pg_dbsu_password: DBUser.Postgres # 如果使用 dbsu ,那么需要为其配置一个密码
pg_users: [ { name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [ dbrole_admin ] } ]
pg_databases: [ { name: meta ,extensions: [ { name: citus }, { name: postgis }, { name: timescaledb } ] } ]
pg_hba_rules:
- { user: 'all' ,db: all ,addr: 127.0.0.1/32 ,auth: ssl ,title: 'all user ssl access from localhost' }
- { user: 'all' ,db: all ,addr: intra ,auth: ssl ,title: 'all user ssl access from intranet' }
您也可以在一个分组内指定所有 Citus 集群成员的身份参数,如 prod.yml 所示:
#==========================================================#
# pg-citus: 10 node citus cluster (5 x primary-replica pair)
#==========================================================#
pg-citus: # citus group
hosts:
10.10.10.50: { pg_group: 0, pg_cluster: pg-citus0 ,pg_vip_address: 10.10.10.60/24 ,pg_seq: 0, pg_role: primary }
10.10.10.51: { pg_group: 0, pg_cluster: pg-citus0 ,pg_vip_address: 10.10.10.60/24 ,pg_seq: 1, pg_role: replica }
10.10.10.52: { pg_group: 1, pg_cluster: pg-citus1 ,pg_vip_address: 10.10.10.61/24 ,pg_seq: 0, pg_role: primary }
10.10.10.53: { pg_group: 1, pg_cluster: pg-citus1 ,pg_vip_address: 10.10.10.61/24 ,pg_seq: 1, pg_role: replica }
10.10.10.54: { pg_group: 2, pg_cluster: pg-citus2 ,pg_vip_address: 10.10.10.62/24 ,pg_seq: 0, pg_role: primary }
10.10.10.55: { pg_group: 2, pg_cluster: pg-citus2 ,pg_vip_address: 10.10.10.62/24 ,pg_seq: 1, pg_role: replica }
10.10.10.56: { pg_group: 3, pg_cluster: pg-citus3 ,pg_vip_address: 10.10.10.63/24 ,pg_seq: 0, pg_role: primary }
10.10.10.57: { pg_group: 3, pg_cluster: pg-citus3 ,pg_vip_address: 10.10.10.63/24 ,pg_seq: 1, pg_role: replica }
10.10.10.58: { pg_group: 4, pg_cluster: pg-citus4 ,pg_vip_address: 10.10.10.64/24 ,pg_seq: 0, pg_role: primary }
10.10.10.59: { pg_group: 4, pg_cluster: pg-citus4 ,pg_vip_address: 10.10.10.64/24 ,pg_seq: 1, pg_role: replica }
vars:
pg_mode: citus # pgsql cluster mode: citus
pg_shard: pg-citus # citus shard name: pg-citus
pg_primary_db: test # primary database used by citus
pg_dbsu_password: DBUser.Postgres # all dbsu password access for citus cluster
pg_vip_enabled: true
pg_vip_interface: eth1
pg_extensions: [ 'citus postgis timescaledb pgvector' ]
pg_libs: 'citus, timescaledb, pg_stat_statements, auto_explain' # citus will be added by patroni automatically
pg_users: [ { name: test ,password: test ,pgbouncer: true ,roles: [ dbrole_admin ] } ]
pg_databases: [ { name: test ,owner: test ,extensions: [ { name: citus }, { name: postgis } ] } ]
pg_hba_rules:
- { user: 'all' ,db: all ,addr: 10.10.10.0/24 ,auth: trust ,title: 'trust citus cluster members' }
- { user: 'all' ,db: all ,addr: 127.0.0.1/32 ,auth: ssl ,title: 'all user ssl access from localhost' }
- { user: 'all' ,db: all ,addr: intra ,auth: ssl ,title: 'all user ssl access from intranet' }
使用
您可以像访问普通集群一样,访问任意节点:
pgbench -i postgres://test:test@pg-citus0/test
pgbench -nv -P1 -T1000 -c 2 postgres://test:test@pg-citus0/test
默认情况下,您对某一个 Shard 进行的变更,都只发生在这套集群上,而不会同步到其他 Shard。
如果你希望将写入分布到所有 Shard,可以使用 Citus 提供的 API 函数,将表标记为:
- 水平分片表(自动分区,需要指定分区键)
- 引用表(全量复制:不需要指定分区键):
从 Citus 11.2 开始,任何 Citus 数据库节点都可以扮演协调者的角色,即,任意一个主节点都可以写入:
psql -h pg-citus0 -d test -c "SELECT create_distributed_table('pgbench_accounts', 'aid'); SELECT truncate_local_data_after_distributing_table('public.pgbench_accounts');"
psql -h pg-citus0 -d test -c "SELECT create_reference_table('pgbench_branches') ; SELECT truncate_local_data_after_distributing_table('public.pgbench_branches');"
psql -h pg-citus0 -d test -c "SELECT create_reference_table('pgbench_history') ; SELECT truncate_local_data_after_distributing_table('public.pgbench_history');"
psql -h pg-citus0 -d test -c "SELECT create_reference_table('pgbench_tellers') ; SELECT truncate_local_data_after_distributing_table('public.pgbench_tellers');"
将表分布出去后,你可以在其他节点上也访问到:
psql -h pg-citus1 -d test -c '\dt+'
例如,全表扫描可以发现执行计划已经变为分布式计划
vagrant@meta-1:~$ psql -h pg-citus3 -d test -c 'explain select * from pgbench_accounts'
QUERY PLAN
---------------------------------------------------------------------------------------------------------
Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=100000 width=352)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=10.10.10.52 port=5432 dbname=test
-> Seq Scan on pgbench_accounts_102008 pgbench_accounts (cost=0.00..81.66 rows=3066 width=97)
(6 rows)
你可以从几个不同的主节点发起写入:
pgbench -nv -P1 -T1000 -c 2 postgres://test:test@pg-citus1/test
pgbench -nv -P1 -T1000 -c 2 postgres://test:test@pg-citus2/test
pgbench -nv -P1 -T1000 -c 2 postgres://test:test@pg-citus3/test
pgbench -nv -P1 -T1000 -c 2 postgres://test:test@pg-citus4/test
当某个节点出现故障时,Patroni 提供的原生高可用支持会将备用节点提升并自动顶上。
test=# select * from pg_dist_node;
nodeid | groupid | nodename | nodeport | noderack | hasmetadata | isactive | noderole | nodecluster | metadatasynced | shouldhaveshards
--------+---------+-------------+----------+----------+-------------+----------+----------+-------------+----------------+------------------
1 | 0 | 10.10.10.51 | 5432 | default | t | t | primary | default | t | f
2 | 2 | 10.10.10.54 | 5432 | default | t | t | primary | default | t | t
5 | 1 | 10.10.10.52 | 5432 | default | t | t | primary | default | t | t
3 | 4 | 10.10.10.58 | 5432 | default | t | t | primary | default | t | t
4 | 3 | 10.10.10.56 | 5432 | default | t | t | primary | default | t | t
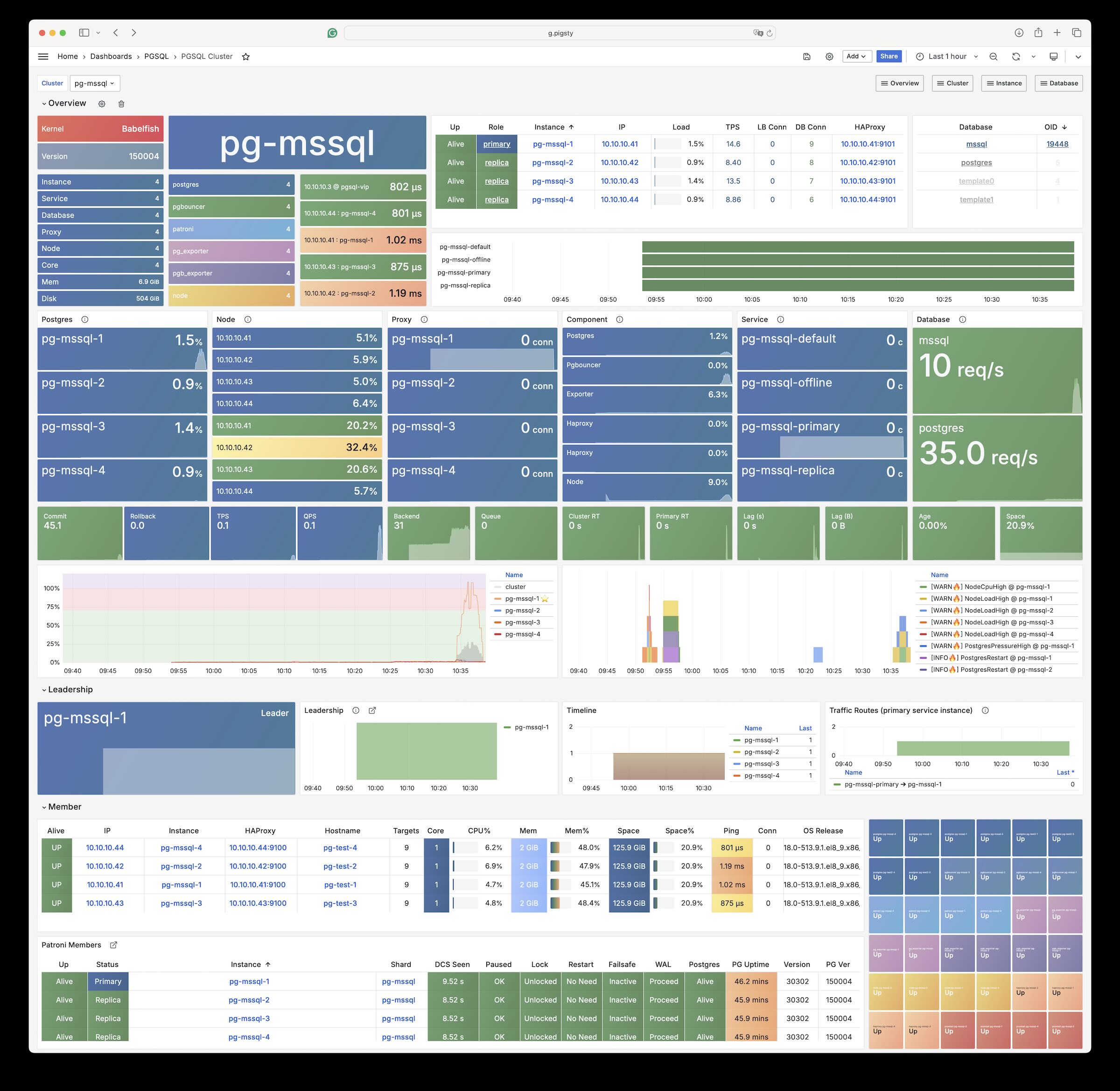
2 - Babelfish (MSSQL)
使用 WiltonDB 与 Babelfish 创建兼容 Microsoft SQL Server 的 PostgreSQL 数据库集群!(线缆协议级仿真)
Babelfish 是一个基于 PostgreSQL 的 MSSQL(微软 SQL Server)兼容性方案,由 AWS 开源。
概览
Pigsty 允许用户使用 Babelfish 与 WiltonDB 创建 Microsoft SQL Server 兼容的 PostgreSQL 集群!
Babelfish 是一个 PostgreSQL 扩展插件,但只能在一个轻微修改过的 PostgreSQL 内核 Fork 上工作,WiltonDB 在 EL/Ubuntu 系统下提供了编译后的Fork内核二进制与扩展二进制软件包。
Pigsty 可以使用 WiltonDB 替代原生的 PostgreSQL 内核,提供开箱即用的 MSSQL 兼容集群。MSSQL集群使用与管理与一套标准的 PostgreSQL 15 集群并无差异,您可以使用 Pigsty 提供的所有功能,如高可用,备份,监控等。
WiltonDB 带有包括 Babelfish 在内的若干扩展插件,但不能使用 PostgreSQL 原生的扩展插件。
MSSQL 兼容集群在启动后,除了监听 PostgreSQL 默认的端口外,还会监听 MSSQL 默认的 1433 端口,并在此端口上通过 TDS WireProtocol 提供 MSSQL 服务。
您可以用任何 MSSQL 客户端连接至 Pigsty 提供的 MSSQL 服务,如 SQL Server Management Studio,或者使用 sqlcmd 命令行工具。
安装
WiltonDB 与原生 PostgreSQL 内核冲突,在一个节点上只能选择一个内核进行安装,使用以下命令在线安装 WiltonDB 内核。
./node.yml -t node_install -e '{"node_repo_modules":"local,mssql","node_packages":["wiltondb"]}'
请注意 WiltonDB 仅在 EL 与 Ubuntu 系统中可用,目前尚未提供 Debian 支持。
Pigsty 专业版提供了 WiltonDB 离线安装包,可以从本地软件源安装 WiltonDB。
配置
在安装部署 MSSQL 模块时需要特别注意以下事项:
- WiltonDB 在 EL (7/8/9) 和 Ubuntu (20.04/22.04) 中可用,在Debian系统中不可用。
- WiltonDB 目前基于 PostgreSQL 15 编译,因此需要指定
pg_version: 15。 - 在 EL 系统上,
wiltondb的二进制默认会安装至/usr/bin/目录下,而在 Ubuntu 系统上则会安装至/usr/lib/postgresql/15/bin/目录下,与 PostgreSQL 官方二进制文件放置位置不同。 - WiltonDB 兼容模式下,HBA 密码认证规则需要使用
md5,而非scram-sha-256,因此需要覆盖 Pigsty 默认的 HBA 规则集,将 SQL Server 需要的md5认证规则,插入到dbrole_readonly通配认证规则之前 - WiltonDB 只能针对一个首要数据库启用,同时应当指定一个用户作为 Babelfish 的超级用户,以便 Babelfish 可以创建数据库和用户,默认为
mssql与dbuser_myssql,如果修改,请一并修改files/mssql.sql中的用户。 - WiltonDB TDS 线缆协议兼容插件
babelfishpg_tds需要在shared_preload_libraries中启用 - WiltonDB 扩展在启用后,默认监听 MSSQL
1433端口,您可以覆盖 Pigsty 默认的服务定义,将primary与replica服务的端口指向1433,而不是5432/6432端口。
以下参数需要针对 MSSQL 数据库集群进行配置:
#----------------------------------#
# PGSQL & MSSQL (Babelfish & Wilton)
#----------------------------------#
# PG Installation
node_repo_modules: local,node,mssql # add mssql and os upstream repos
pg_mode: mssql # Microsoft SQL Server Compatible Mode
pg_libs: 'babelfishpg_tds, pg_stat_statements, auto_explain' # add timescaledb to shared_preload_libraries
pg_version: 15 # The current WiltonDB major version is 15
pg_packages:
- wiltondb # install forked version of postgresql with babelfishpg support
- patroni pgbouncer pgbackrest pg_exporter pgbadger vip-manager
pg_extensions: [] # do not install any vanilla postgresql extensions
# PG Provision
pg_default_hba_rules: # overwrite default HBA rules for babelfish cluster
- {user: '${dbsu}' ,db: all ,addr: local ,auth: ident ,title: 'dbsu access via local os user ident' }
- {user: '${dbsu}' ,db: replication ,addr: local ,auth: ident ,title: 'dbsu replication from local os ident' }
- {user: '${repl}' ,db: replication ,addr: localhost ,auth: pwd ,title: 'replicator replication from localhost'}
- {user: '${repl}' ,db: replication ,addr: intra ,auth: pwd ,title: 'replicator replication from intranet' }
- {user: '${repl}' ,db: postgres ,addr: intra ,auth: pwd ,title: 'replicator postgres db from intranet' }
- {user: '${monitor}' ,db: all ,addr: localhost ,auth: pwd ,title: 'monitor from localhost with password' }
- {user: '${monitor}' ,db: all ,addr: infra ,auth: pwd ,title: 'monitor from infra host with password'}
- {user: '${admin}' ,db: all ,addr: infra ,auth: ssl ,title: 'admin @ infra nodes with pwd & ssl' }
- {user: '${admin}' ,db: all ,addr: world ,auth: ssl ,title: 'admin @ everywhere with ssl & pwd' }
- {user: dbuser_mssql ,db: mssql ,addr: intra ,auth: md5 ,title: 'allow mssql dbsu intranet access' } # <--- use md5 auth method for mssql user
- {user: '+dbrole_readonly',db: all ,addr: localhost ,auth: pwd ,title: 'pgbouncer read/write via local socket'}
- {user: '+dbrole_readonly',db: all ,addr: intra ,auth: pwd ,title: 'read/write biz user via password' }
- {user: '+dbrole_offline' ,db: all ,addr: intra ,auth: pwd ,title: 'allow etl offline tasks from intranet'}
pg_default_services: # route primary & replica service to mssql port 1433
- { name: primary ,port: 5433 ,dest: 1433 ,check: /primary ,selector: "[]" }
- { name: replica ,port: 5434 ,dest: 1433 ,check: /read-only ,selector: "[]" , backup: "[? pg_role == `primary` || pg_role == `offline` ]" }
- { name: default ,port: 5436 ,dest: postgres ,check: /primary ,selector: "[]" }
- { name: offline ,port: 5438 ,dest: postgres ,check: /replica ,selector: "[? pg_role == `offline` || pg_offline_query ]" , backup: "[? pg_role == `replica` && !pg_offline_query]"}
您可以定义 MSSQL 业务数据库与业务用户:
#----------------------------------#
# pgsql (singleton on current node)
#----------------------------------#
# this is an example single-node postgres cluster with postgis & timescaledb installed, with one biz database & two biz users
pg-meta:
hosts:
10.10.10.10: { pg_seq: 1, pg_role: primary } # <---- primary instance with read-write capability
vars:
pg_cluster: pg-test
pg_users: # create MSSQL superuser
- {name: dbuser_mssql ,password: DBUser.MSSQL ,superuser: true, pgbouncer: true ,roles: [dbrole_admin], comment: superuser & owner for babelfish }
pg_primary_db: mssql # use `mssql` as the primary sql server database
pg_databases:
- name: mssql
baseline: mssql.sql # init babelfish database & user
extensions:
- { name: uuid-ossp }
- { name: babelfishpg_common }
- { name: babelfishpg_tsql }
- { name: babelfishpg_tds }
- { name: babelfishpg_money }
- { name: pg_hint_plan }
- { name: system_stats }
- { name: tds_fdw }
owner: dbuser_mssql
parameters: { 'babelfishpg_tsql.migration_mode' : 'multi-db' }
comment: babelfish cluster, a MSSQL compatible pg cluster
访问
您可以使用任何 SQL Server 兼容的客户端工具来访问这个数据库集群。
Microsoft 提供了 sqlcmd 作为官方的命令行工具。
除此之外,他们还提供了一个 Go 语言版本的命令行工具 go-sqlcmd。
安装 go-sqlcmd:
curl -LO https://github.com/microsoft/go-sqlcmd/releases/download/v1.4.0/sqlcmd-v1.4.0-linux-amd64.tar.bz2
tar xjvf sqlcmd-v1.4.0-linux-amd64.tar.bz2
sudo mv sqlcmd* /usr/bin/
快速上手 go-sqlcmd
$ sqlcmd -S 10.10.10.10,1433 -U dbuser_mssql -P DBUser.MSSQL
1> select @@version
2> go
version
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Babelfish for PostgreSQL with SQL Server Compatibility - 12.0.2000.8
Oct 22 2023 17:48:32
Copyright (c) Amazon Web Services
PostgreSQL 15.4 (EL 1:15.4.wiltondb3.3_2-2.el8) on x86_64-redhat-linux-gnu (Babelfish 3.3.0)
(1 row affected)
使用 Pigsty 提供的服务机制,可以使用 5433 / 5434 端口始终连接到主库/从库上的 1433 端口。
# 访问任意集群成员上的 5433 端口,指向主库上的 1433 MSSQL 端口
sqlcmd -S 10.10.10.11,5433 -U dbuser_mssql -P DBUser.MSSQL
# 访问任意集群成员上的 5434 端口,指向任意可读库上的 1433 MSSQL 端口
sqlcmd -S 10.10.10.11,5434 -U dbuser_mssql -P DBUser.MSSQL
扩展
绝大多数 PGSQL 模块的 扩展插件(非纯 SQL 类)都无法直接在 MSSQL 模块的 WiltonDB 内核上使用,需要重新编译。
目前 WiltonDB 自带了以下扩展插件,除了 PostgreSQL Contrib 扩展,四个 BabelfishPG 核心扩展之外,还提供了 pg_hint_pan,tds_fdw,以及 system_stats 三个第三方扩展。
| 扩展名 | 版本 | 说明 |
|---|---|---|
| dblink | 1.2 | connect to other PostgreSQL databases from within a database |
| adminpack | 2.1 | administrative functions for PostgreSQL |
| dict_int | 1.0 | text search dictionary template for integers |
| intagg | 1.1 | integer aggregator and enumerator (obsolete) |
| dict_xsyn | 1.0 | text search dictionary template for extended synonym processing |
| amcheck | 1.3 | functions for verifying relation integrity |
| autoinc | 1.0 | functions for autoincrementing fields |
| bloom | 1.0 | bloom access method - signature file based index |
| fuzzystrmatch | 1.1 | determine similarities and distance between strings |
| intarray | 1.5 | functions, operators, and index support for 1-D arrays of integers |
| btree_gin | 1.3 | support for indexing common datatypes in GIN |
| btree_gist | 1.7 | support for indexing common datatypes in GiST |
| hstore | 1.8 | data type for storing sets of (key, value) pairs |
| hstore_plperl | 1.0 | transform between hstore and plperl |
| isn | 1.2 | data types for international product numbering standards |
| hstore_plperlu | 1.0 | transform between hstore and plperlu |
| jsonb_plperl | 1.0 | transform between jsonb and plperl |
| citext | 1.6 | data type for case-insensitive character strings |
| jsonb_plperlu | 1.0 | transform between jsonb and plperlu |
| jsonb_plpython3u | 1.0 | transform between jsonb and plpython3u |
| cube | 1.5 | data type for multidimensional cubes |
| hstore_plpython3u | 1.0 | transform between hstore and plpython3u |
| earthdistance | 1.1 | calculate great-circle distances on the surface of the Earth |
| lo | 1.1 | Large Object maintenance |
| file_fdw | 1.0 | foreign-data wrapper for flat file access |
| insert_username | 1.0 | functions for tracking who changed a table |
| ltree | 1.2 | data type for hierarchical tree-like structures |
| ltree_plpython3u | 1.0 | transform between ltree and plpython3u |
| pg_walinspect | 1.0 | functions to inspect contents of PostgreSQL Write-Ahead Log |
| moddatetime | 1.0 | functions for tracking last modification time |
| old_snapshot | 1.0 | utilities in support of old_snapshot_threshold |
| pgcrypto | 1.3 | cryptographic functions |
| pgrowlocks | 1.2 | show row-level locking information |
| pageinspect | 1.11 | inspect the contents of database pages at a low level |
| pg_surgery | 1.0 | extension to perform surgery on a damaged relation |
| seg | 1.4 | data type for representing line segments or floating-point intervals |
| pgstattuple | 1.5 | show tuple-level statistics |
| pg_buffercache | 1.3 | examine the shared buffer cache |
| pg_freespacemap | 1.2 | examine the free space map (FSM) |
| postgres_fdw | 1.1 | foreign-data wrapper for remote PostgreSQL servers |
| pg_prewarm | 1.2 | prewarm relation data |
| tcn | 1.0 | Triggered change notifications |
| pg_trgm | 1.6 | text similarity measurement and index searching based on trigrams |
| xml2 | 1.1 | XPath querying and XSLT |
| refint | 1.0 | functions for implementing referential integrity (obsolete) |
| pg_visibility | 1.2 | examine the visibility map (VM) and page-level visibility info |
| pg_stat_statements | 1.10 | track planning and execution statistics of all SQL statements executed |
| sslinfo | 1.2 | information about SSL certificates |
| tablefunc | 1.0 | functions that manipulate whole tables, including crosstab |
| tsm_system_rows | 1.0 | TABLESAMPLE method which accepts number of rows as a limit |
| tsm_system_time | 1.0 | TABLESAMPLE method which accepts time in milliseconds as a limit |
| unaccent | 1.1 | text search dictionary that removes accents |
| uuid-ossp | 1.1 | generate universally unique identifiers (UUIDs) |
| plpgsql | 1.0 | PL/pgSQL procedural language |
| babelfishpg_money | 1.1.0 | babelfishpg_money |
| system_stats | 2.0 | EnterpriseDB system statistics for PostgreSQL |
| tds_fdw | 2.0.3 | Foreign data wrapper for querying a TDS database (Sybase or Microsoft SQL Server) |
| babelfishpg_common | 3.3.3 | Transact SQL Datatype Support |
| babelfishpg_tds | 1.0.0 | TDS protocol extension |
| pg_hint_plan | 1.5.1 | |
| babelfishpg_tsql | 3.3.1 | Transact SQL compatibility |
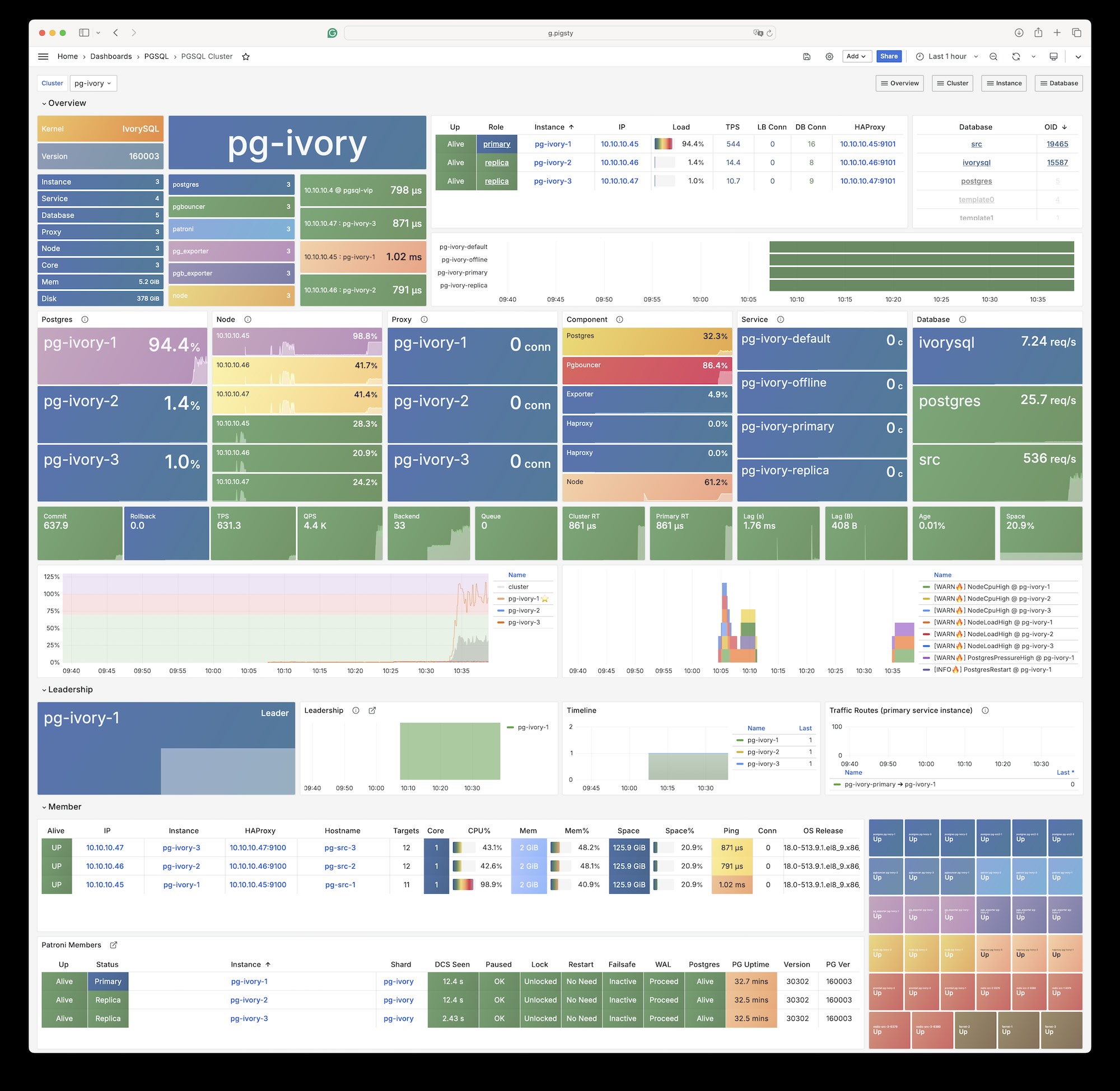
3 - IvorySQL (Oracle)
使用瀚高开源的 IvorySQL 内核,基于 PostgreSQL 集群实现 Oracle 语法/PLSQL 兼容性。
IvorySQL 是一个开源的“Oracle兼容” PostgreSQL 内核,由 瀚高 出品,使用 Apache 2.0 许可证。
当然这里的 Oracle 兼容是 Pl/SQL,语法,内置函数、数据类型、系统视图、MERGE 以及 GUC参数层面上的兼容, 不是 Babelfish,openHalo,FerretDB 那种可以不改客户端驱动的缆协议兼容。 所以用户还是要使用 PostgreSQL 的客户端工具来访问 IvorySQL,但是可以使用 Oracle 兼容的语法。
目前 IvorySQL 最新版本 4.4 与 PostgreSQL 最新小版本 17.4 保持兼容,并且提供了主流 Linux 上的二进制 RPM/DEB 包。 而 Pigsty 提供了在 PG RDS 中将原生 PostgreSQL 替换为 IvorySQL 内核的选项。
快速上手
使用标准流程 安装 Pigsty,并使用 ivory 配置模板:
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap # 安装 Pigsty 依赖
./configure -c ivory # 使用 IvorySQL 配置模板
./install.yml # 使用剧本执行部署
对于生产环境部署,您应当在执行 ./install.yml 进行部署前,编辑自动生成的 pigsty.yml 配置文件,修改密码等参数。
当前最新的 IvorySQL 4.4 等效于 PostgreSQL 17,任何兼容 PostgreSQL 线缆协议的客户端工具都可以访问 IvorySQL 集群。
不过,默认情况下,你可以使用 PostgreSQL 客户端从另一个 1521 端口访问,这种情况下默认使用 Oracle 兼容模式。
配置说明
在 Pigsty 中要使用 IvorySQL 内核,需要修改以下四个配置参数:
pg_mode:使用ivory兼容模式repo_extra_packages:下载ivroysql软件包pg_packages: 安装ivorysql软件包pg_libs:加载 Oracle 语法兼容扩展
是的就是这么简单,你只需要在配置文件的全局变量中加上这四行,Pigsty 就会使用 IvorySQL 替换原生的 PostgreSQL 内核了
pg_mode: ivory # IvorySQL 兼容模式,使用 IvorySQL 的二进制
pg_packages: [ ivorysql, pgsql-common ] # 安装 ivorysql,替换 pgsql-main 主内核
pg_libs: 'liboracle_parser, pg_stat_statements, auto_explain' # 加载 Oracle 兼容扩展
repo_extra_packages: [ ivorysql ] # 下载 ivorysql 软件包
IvorySQL 还提供了一系列 新增 GUC 参数变量,您可以在 pg_parameters 中指定。
扩展列表
绝大多数 PGSQL 模块的 扩展插件 (非纯 SQL 类)都无法直接在 IvorySQL 内核上使用,如果需要使用,请针对新内核从源码重新编译安装。
目前 IvorySQL 内核自带了以下 109 个扩展插件。
IvorySQL 中可用的扩展插件列表
| 扩展名 | 版本 | 说明 |
|---|---|---|
| amcheck | 1.4 | functions for verifying relation integrity |
| autoinc | 1.0 | functions for autoincrementing fields |
| bloom | 1.0 | bloom access method - signature file based index |
| bool_plperl | 1.0 | transform between bool and plperl |
| bool_plperlu | 1.0 | transform between bool and plperlu |
| btree_gin | 1.3 | support for indexing common datatypes in GIN |
| btree_gist | 1.7 | support for indexing common datatypes in GiST |
| citext | 1.6 | data type for case-insensitive character strings |
| cube | 1.5 | data type for multidimensional cubes |
| dblink | 1.2 | connect to other PostgreSQL databases from within a database |
| dict_int | 1.0 | text search dictionary template for integers |
| dict_xsyn | 1.0 | text search dictionary template for extended synonym processing |
| dummy_index_am | 1.0 | dummy_index_am - index access method template |
| dummy_seclabel | 1.0 | Test code for SECURITY LABEL feature |
| earthdistance | 1.2 | calculate great-circle distances on the surface of the Earth |
| file_fdw | 1.0 | foreign-data wrapper for flat file access |
| fuzzystrmatch | 1.2 | determine similarities and distance between strings |
| hstore | 1.8 | data type for storing sets of (key, value) pairs |
| hstore_plperl | 1.0 | transform between hstore and plperl |
| hstore_plperlu | 1.0 | transform between hstore and plperlu |
| hstore_plpython3u | 1.0 | transform between hstore and plpython3u |
| injection_points | 1.0 | Test code for injection points |
| insert_username | 1.0 | functions for tracking who changed a table |
| intagg | 1.1 | integer aggregator and enumerator (obsolete) |
| intarray | 1.5 | functions, operators, and index support for 1-D arrays of integers |
| isn | 1.2 | data types for international product numbering standards |
| ivorysql_ora | 1.0 | Oracle Compatible extenison on Postgres Database |
| jsonb_plperl | 1.0 | transform between jsonb and plperl |
| jsonb_plperlu | 1.0 | transform between jsonb and plperlu |
| jsonb_plpython3u | 1.0 | transform between jsonb and plpython3u |
| lo | 1.1 | Large Object maintenance |
| ltree | 1.3 | data type for hierarchical tree-like structures |
| ltree_plpython3u | 1.0 | transform between ltree and plpython3u |
| moddatetime | 1.0 | functions for tracking last modification time |
| ora_btree_gin | 1.0 | support for indexing oracle datatypes in GIN |
| ora_btree_gist | 1.0 | support for oracle indexing common datatypes in GiST |
| pageinspect | 1.12 | inspect the contents of database pages at a low level |
| pg_buffercache | 1.5 | examine the shared buffer cache |
| pg_freespacemap | 1.2 | examine the free space map (FSM) |
| pg_get_functiondef | 1.0 | Get function’s definition |
| pg_prewarm | 1.2 | prewarm relation data |
| pg_stat_statements | 1.11 | track planning and execution statistics of all SQL statements executed |
| pg_surgery | 1.0 | extension to perform surgery on a damaged relation |
| pg_trgm | 1.6 | text similarity measurement and index searching based on trigrams |
| pg_visibility | 1.2 | examine the visibility map (VM) and page-level visibility info |
| pg_walinspect | 1.1 | functions to inspect contents of PostgreSQL Write-Ahead Log |
| pgcrypto | 1.3 | cryptographic functions |
| pgrowlocks | 1.2 | show row-level locking information |
| pgstattuple | 1.5 | show tuple-level statistics |
| plisql | 1.0 | PL/iSQL procedural language |
| plperl | 1.0 | PL/Perl procedural language |
| plperlu | 1.0 | PL/PerlU untrusted procedural language |
| plpgsql | 1.0 | PL/pgSQL procedural language |
| plpython3u | 1.0 | PL/Python3U untrusted procedural language |
| plsample | 1.0 | PL/Sample |
| pltcl | 1.0 | PL/Tcl procedural language |
| pltclu | 1.0 | PL/TclU untrusted procedural language |
| postgres_fdw | 1.1 | foreign-data wrapper for remote PostgreSQL servers |
| refint | 1.0 | functions for implementing referential integrity (obsolete) |
| seg | 1.4 | data type for representing line segments or floating-point intervals |
| spgist_name_ops | 1.0 | Test opclass for SP-GiST |
| sslinfo | 1.2 | information about SSL certificates |
| tablefunc | 1.0 | functions that manipulate whole tables, including crosstab |
| tcn | 1.0 | Triggered change notifications |
| test_bloomfilter | 1.0 | Test code for Bloom filter library |
| test_copy_callbacks | 1.0 | Test code for COPY callbacks |
| test_custom_rmgrs | 1.0 | Test code for custom WAL resource managers |
| test_ddl_deparse | 1.0 | Test code for DDL deparse feature |
| test_dsa | 1.0 | Test code for dynamic shared memory areas |
| test_dsm_registry | 1.0 | Test code for the DSM registry |
| test_ext1 | 1.0 | Test extension 1 |
| test_ext2 | 1.0 | Test extension 2 |
| test_ext3 | 1.0 | Test extension 3 |
| test_ext4 | 1.0 | Test extension 4 |
| test_ext5 | 1.0 | Test extension 5 |
| test_ext6 | 1.0 | test_ext6 |
| test_ext7 | 1.0 | Test extension 7 |
| test_ext8 | 1.0 | Test extension 8 |
| test_ext9 | 1.0 | test_ext9 |
| test_ext_cine | 1.0 | Test extension using CREATE IF NOT EXISTS |
| test_ext_cor | 1.0 | Test extension using CREATE OR REPLACE |
| test_ext_cyclic1 | 1.0 | Test extension cyclic 1 |
| test_ext_cyclic2 | 1.0 | Test extension cyclic 2 |
| test_ext_evttrig | 1.0 | Test extension - event trigger |
| test_ext_extschema | 1.0 | test @extschema@ |
| test_ext_req_schema1 | 1.0 | Required extension to be referenced |
| test_ext_req_schema2 | 1.0 | Test schema referencing of required extensions |
| test_ext_req_schema3 | 1.0 | Test schema referencing of 2 required extensions |
| test_ext_set_schema | 1.0 | Test ALTER EXTENSION SET SCHEMA |
| test_ginpostinglist | 1.0 | Test code for ginpostinglist.c |
| test_integerset | 1.0 | Test code for integerset |
| test_lfind | 1.0 | Test code for optimized linear search functions |
| test_parser | 1.0 | example of a custom parser for full-text search |
| test_pg_dump | 1.0 | Test pg_dump with an extension |
| test_predtest | 1.0 | Test code for optimizer/util/predtest.c |
| test_radixtree | 1.0 | Test code for radix tree |
| test_rbtree | 1.0 | Test code for red-black tree library |
| test_regex | 1.0 | Test code for backend/regex/ |
| test_resowner | 1.0 | Test code for ResourceOwners |
| test_shm_mq | 1.0 | Test code for shared memory message queues |
| test_slru | 1.0 | Test code for SLRU |
| test_tidstore | 1.0 | Test code for tidstore |
| tsm_system_rows | 1.0 | TABLESAMPLE method which accepts number of rows as a limit |
| tsm_system_time | 1.0 | TABLESAMPLE method which accepts time in milliseconds as a limit |
| unaccent | 1.1 | text search dictionary that removes accents |
| uuid-ossp | 1.1 | generate universally unique identifiers (UUIDs) |
| worker_spi | 1.0 | Sample background worker |
| xid_wraparound | 1.0 | Tests for XID wraparound |
| xml2 | 1.1 | XPath querying and XSLT |
备注说明
-
目前 IvorySQL 的软件包位于
pigsty-infra仓库,而非pigsty-pgsql或pigsty-ivory仓库。 -
IvorySQL 4.4 的默认 FHS 发生改变,请从老版本升级上来的用户留意。
-
IvorySQL 4.4 需要 gibc 版本 >= 2.17 即可,目前 Pigsty 支持的系统版本都满足这个条件
-
最后一个支持 EL7 的 IvorySQL 版本为 3.3,对应 PostgreSQL 16.3,目前 IvorySQL 4.x 已经不再提供对 EL7 的支持了。
-
Pigsty 不对使用 IvorySQL 内核承担任何质保责任,使用此内核遇到的任何问题与需求请联系原厂解决。
4 - OpenHalo (MySQL)
使用 MySQL 客户端与协议访问 PostgreSQL 数据库!羲和开源的OpenHalo内核提供了 MySQL 兼容的 PG 内核分支。
OpenHalo 是一个开源的,提供 MySQL 线缆协议兼容性的 PG 内核。
OpenHalo 基于 PostgreSQL 14.10 内核版本,提供对 MySQL 版本的线缆协议级兼容性(5.7.32-log / 8.0 )。
目前 Pigsty 提供 EL 8/9 系统上的 OpenHalo 部署支持,Debian / Ubuntu 系统支持将在后续版本中提供。
快速上手
使用 Pigsty 标准安装流程,并使用 mysql 配置模板即可。
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap # 准备 Pigsty 依赖
./configure -c mysql # 使用 MysQL (openHalo)配置模板
./install.yml # 安装,生产部署请先修改 pigsty.yml 中的密码
对于生产部署,请务必在执行安装剧本前,先修改 pigsty.yml 配置文件中的密码参数。
使用说明
访问 MySQL 时,实际连接使用的是 postgres 数据库。
请注意,MySQL 中 “数据库” 的概念其实对应着 PostgreSQL 中的 “Schema” 概念。
因此 use mysql 使用的其实是 postgres 数据库中的 mysql Schema。
MySQL 使用的用户名和密码与 PostgreSQL 中的用户和密码一致。 你可以使用 PostgreSQL 标准的方式来管理用户和权限。
客户端访问
openHalo 提供了 MySQL 线缆协议兼容性,默认监听 3306 端口,MySQL 客户端与驱动程序可以直接连接。
Pigsty 的 conf/mysql 配置默认安装了 mysql 客户端工具。
你可以使用以下命令访问 MySQL:
mysql -h 127.0.0.1 -u dbuser_dba
目前 OpenHalo 官方已经确保 Navicat 可以正常访问此 MySQL 端口,但 Intellij IDEA 的 DataGrip 访问会报错。
修改说明
Pigsty 安装的 OpenHalo 内核在 HaloTech-Co-Ltd/openHalo 内核基础上进行轻度修改:
- 默认数据库名称从
halo0root修改回postgres - 移除默认版本号的
1.0.前缀,修改回14.10 - 修改默认配置文件,默认启用 MySQL 兼容性并监听
3306端口
请注意,Pigsty 不对使用 OpenHalo 内核承担任何质保责任,使用此内核遇到的任何问题与需求请联系原厂解决。
5 - OrioleDB (OLTP)
针对 OLTP 场景进行极致优化的 PostgreSQL 存储引擎
OrioleDB 是一个 PostgreSQL 存储引擎扩展,号称提供更好的 OLTP 性能与吞吐表现。
OrioleDB 最新版本基于 PostgreSQL 17.0 内核版本进行 分叉补丁,并在其基础上进行 扩展开发
目前 Pigsty 提供 EL 8/9 系统上的 OrioleDB 部署支持,Debian / Ubuntu 系统支持将在后续版本中提供。
快速上手
使用 Pigsty 标准安装流程,并使用 oriole 配置模板即可。
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap # 准备 Pigsty 依赖
./configure -c oriole # 使用 OrioleDB 配置模板
./install.yml # 安装,生产部署请先修改 pigsty.yml 中的密码
对于生产部署,请务必在执行安装剧本前,先修改 pigsty.yml 配置文件中的密码参数。
配置说明
all:
children:
pg-orio:
vars:
pg_databases:
- {name: meta ,extensions: [orioledb]}
vars:
pg_mode: oriole
pg_version: 17
pg_packages: [ orioledb, pgsql-common ]
pg_libs: 'orioledb.so, pg_stat_statements, auto_explain'
repo_extra_packages: [ orioledb ]
使用说明
要使用 OrioleDB,需要安装 orioledb_17 和 oriolepg_17 两个软件包(目前仅提供 RPM)。
使用 pgbench 初始化 100 仓 TPC-B Like 表:
pgbench -is 100 meta
pgbench -nv -P1 -c10 -S -T1000 meta
pgbench -nv -P1 -c50 -S -T1000 meta
pgbench -nv -P1 -c10 -T1000 meta
pgbench -nv -P1 -c50 -T1000 meta
接下来可以使用 orioledb 存储引擎重建这些表,并查看性能变化:
-- 创建 OrioleDB 表
CREATE TABLE pgbench_accounts_o (LIKE pgbench_accounts INCLUDING ALL) USING orioledb;
CREATE TABLE pgbench_branches_o (LIKE pgbench_branches INCLUDING ALL) USING orioledb;
CREATE TABLE pgbench_history_o (LIKE pgbench_history INCLUDING ALL) USING orioledb;
CREATE TABLE pgbench_tellers_o (LIKE pgbench_tellers INCLUDING ALL) USING orioledb;
-- 将普通表数据复制到 OrioleDB 表中
INSERT INTO pgbench_accounts_o SELECT * FROM pgbench_accounts;
INSERT INTO pgbench_branches_o SELECT * FROM pgbench_branches;
INSERT INTO pgbench_history_o SELECT * FROM pgbench_history;
INSERT INTO pgbench_tellers_o SELECT * FROM pgbench_tellers;
-- 删除原始表,并重命名 OrioleDB 表
DROP TABLE pgbench_accounts, pgbench_branches, pgbench_history, pgbench_tellers;
ALTER TABLE pgbench_accounts_o RENAME TO pgbench_accounts;
ALTER TABLE pgbench_branches_o RENAME TO pgbench_branches;
ALTER TABLE pgbench_history_o RENAME TO pgbench_history;
ALTER TABLE pgbench_tellers_o RENAME TO pgbench_tellers;
6 - PolarDB PG (RAC)
使用阿里云开源的 PolarDB for PostgreSQL 内核提供国产信创资质支持,与类似 Oracle RAC 的使用体验。
概览
Pigsty 允许使用 PolarDB 创建带有 “国产化信创资质” 的 PostgreSQL 集群!
PolarDB for PostgreSQL 基本等效于 PostgreSQL 15,任何兼容 PostgreSQL 线缆协议的客户端工具都可以访问 PolarDB 集群。
Pigsty 的 PGSQL 仓库中提供了PolarDB PG 开源版安装包,但不会在 Pigsty 安装时下载到本地软件仓库。
快速上手
使用标准流程 安装 Pigsty,并使用 polar 配置模板:
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap # 安装 Pigsty 依赖
./configure -c polar # 使用 PolarDB 配置模板
./install.yml # 使用剧本执行部署
配置
以下参数需要针对 PolarDB 数据库集群进行特殊配置:
pg_version: 15
pg_packages: [ 'polardb patroni pgbouncer pgbackrest pg_exporter pgbadger vip-manager' ]
pg_extensions: [ ] # do not install any vanilla postgresql extensions
pg_mode: polar # polardb compatible mode
pg_exporter_exclude_database: 'template0,template1,postgres,polardb_admin'
pg_default_roles: # default roles and users in postgres cluster
- { name: dbrole_readonly ,login: false ,comment: role for global read-only access }
- { name: dbrole_offline ,login: false ,comment: role for restricted read-only access }
- { name: dbrole_readwrite ,login: false ,roles: [dbrole_readonly] ,comment: role for global read-write access }
- { name: dbrole_admin ,login: false ,roles: [pg_monitor, dbrole_readwrite] ,comment: role for object creation }
- { name: postgres ,superuser: true ,comment: system superuser }
- { name: replicator ,superuser: true ,replication: true ,roles: [pg_monitor, dbrole_readonly] ,comment: system replicator } # <- superuser is required for replication
- { name: dbuser_dba ,superuser: true ,roles: [dbrole_admin] ,pgbouncer: true ,pool_mode: session, pool_connlimit: 16 ,comment: pgsql admin user }
- { name: dbuser_monitor ,roles: [pg_monitor] ,pgbouncer: true ,parameters: {log_min_duration_statement: 1000 } ,pool_mode: session ,pool_connlimit: 8 ,comment: pgsql monitor user }
repo_packages: [ node-bootstrap, infra-package, infra-addons, node-package1, node-package2, pgsql-utility ]
repo_extra_packages: [ polardb ] # replace vanilla postgres kernel with polardb kernel
这里特别注意,PolarDB PG 要求 replicator 复制用户为 Superuser,与原生 PG 不同。
扩展列表
绝大多数 PGSQL 模块的 扩展插件 (非纯 SQL 类)都无法直接在 PolarDB 内核上使用,如果需要使用,请针对新内核从源码重新编译安装。
目前 PolarDB 内核自带了以下 61 个扩展插件,除去 Contrib 扩展外,提供的额外扩展包括:
polar_csn1.0 : polar_csnpolar_monitor1.2 : examine the polardb informationpolar_monitor_preload1.1 : examine the polardb informationpolar_parameter_check1.0 : kernel extension for parameter validationpolar_px1.0 : Parallel Execution extensionpolar_stat_env1.0 : env stat functions for PolarDBpolar_stat_sql1.3 : Kernel statistics gathering, and sql plan nodes information gatheringpolar_tde_utils1.0 : Internal extension for TDEpolar_vfs1.0 : polar_vfspolar_worker1.0 : polar_workertimetravel1.0 : functions for implementing time travelvector0.5.1 : vector data type and ivfflat and hnsw access methodssmlar1.0 : compute similary of any one-dimensional arrays
PolarDB 可用的完整插件列表:
| name | version | comment |
|---|---|---|
| hstore_plpython2u | 1.0 | transform between hstore and plpython2u |
| dict_int | 1.0 | text search dictionary template for integers |
| adminpack | 2.0 | administrative functions for PostgreSQL |
| hstore_plpython3u | 1.0 | transform between hstore and plpython3u |
| amcheck | 1.1 | functions for verifying relation integrity |
| hstore_plpythonu | 1.0 | transform between hstore and plpythonu |
| autoinc | 1.0 | functions for autoincrementing fields |
| insert_username | 1.0 | functions for tracking who changed a table |
| bloom | 1.0 | bloom access method - signature file based index |
| file_fdw | 1.0 | foreign-data wrapper for flat file access |
| dblink | 1.2 | connect to other PostgreSQL databases from within a database |
| btree_gin | 1.3 | support for indexing common datatypes in GIN |
| fuzzystrmatch | 1.1 | determine similarities and distance between strings |
| lo | 1.1 | Large Object maintenance |
| intagg | 1.1 | integer aggregator and enumerator (obsolete) |
| btree_gist | 1.5 | support for indexing common datatypes in GiST |
| hstore | 1.5 | data type for storing sets of (key, value) pairs |
| intarray | 1.2 | functions, operators, and index support for 1-D arrays of integers |
| citext | 1.5 | data type for case-insensitive character strings |
| cube | 1.4 | data type for multidimensional cubes |
| hstore_plperl | 1.0 | transform between hstore and plperl |
| isn | 1.2 | data types for international product numbering standards |
| jsonb_plperl | 1.0 | transform between jsonb and plperl |
| dict_xsyn | 1.0 | text search dictionary template for extended synonym processing |
| hstore_plperlu | 1.0 | transform between hstore and plperlu |
| earthdistance | 1.1 | calculate great-circle distances on the surface of the Earth |
| pg_prewarm | 1.2 | prewarm relation data |
| jsonb_plperlu | 1.0 | transform between jsonb and plperlu |
| pg_stat_statements | 1.6 | track execution statistics of all SQL statements executed |
| jsonb_plpython2u | 1.0 | transform between jsonb and plpython2u |
| jsonb_plpython3u | 1.0 | transform between jsonb and plpython3u |
| jsonb_plpythonu | 1.0 | transform between jsonb and plpythonu |
| pg_trgm | 1.4 | text similarity measurement and index searching based on trigrams |
| pgstattuple | 1.5 | show tuple-level statistics |
| ltree | 1.1 | data type for hierarchical tree-like structures |
| ltree_plpython2u | 1.0 | transform between ltree and plpython2u |
| pg_visibility | 1.2 | examine the visibility map (VM) and page-level visibility info |
| ltree_plpython3u | 1.0 | transform between ltree and plpython3u |
| ltree_plpythonu | 1.0 | transform between ltree and plpythonu |
| seg | 1.3 | data type for representing line segments or floating-point intervals |
| moddatetime | 1.0 | functions for tracking last modification time |
| pgcrypto | 1.3 | cryptographic functions |
| pgrowlocks | 1.2 | show row-level locking information |
| pageinspect | 1.7 | inspect the contents of database pages at a low level |
| pg_buffercache | 1.3 | examine the shared buffer cache |
| pg_freespacemap | 1.2 | examine the free space map (FSM) |
| tcn | 1.0 | Triggered change notifications |
| plperl | 1.0 | PL/Perl procedural language |
| uuid-ossp | 1.1 | generate universally unique identifiers (UUIDs) |
| plperlu | 1.0 | PL/PerlU untrusted procedural language |
| refint | 1.0 | functions for implementing referential integrity (obsolete) |
| xml2 | 1.1 | XPath querying and XSLT |
| plpgsql | 1.0 | PL/pgSQL procedural language |
| plpython3u | 1.0 | PL/Python3U untrusted procedural language |
| pltcl | 1.0 | PL/Tcl procedural language |
| pltclu | 1.0 | PL/TclU untrusted procedural language |
| polar_csn | 1.0 | polar_csn |
| sslinfo | 1.2 | information about SSL certificates |
| polar_monitor | 1.2 | examine the polardb information |
| polar_monitor_preload | 1.1 | examine the polardb information |
| polar_parameter_check | 1.0 | kernel extension for parameter validation |
| polar_px | 1.0 | Parallel Execution extension |
| tablefunc | 1.0 | functions that manipulate whole tables, including crosstab |
| polar_stat_env | 1.0 | env stat functions for PolarDB |
| smlar | 1.0 | compute similary of any one-dimensional arrays |
| timetravel | 1.0 | functions for implementing time travel |
| tsm_system_rows | 1.0 | TABLESAMPLE method which accepts number of rows as a limit |
| polar_stat_sql | 1.3 | Kernel statistics gathering, and sql plan nodes information gathering |
| tsm_system_time | 1.0 | TABLESAMPLE method which accepts time in milliseconds as a limit |
| polar_tde_utils | 1.0 | Internal extension for TDE |
| polar_vfs | 1.0 | polar_vfs |
| polar_worker | 1.0 | polar_worker |
| unaccent | 1.1 | text search dictionary that removes accents |
| postgres_fdw | 1.0 | foreign-data wrapper for remote PostgreSQL servers |
- Pigsty 专业版提供 PolarDB 离线安装支持,扩展插件编译支持,以及针对 PolarDB 集群进行专门适配的监控与管控支持。
- Pigsty 与阿里云内核团队有合作,可以提供有偿内核兜底支持服务。
7 - PolarDB O(racle)
使用阿里云商业版本的 PolarDB for Oracle 内核(闭源,PG14,仅在特殊企业版定制中可用)
Pigsty 允许使用 PolarDB 创建带有 “国产化信创资质” 的 PolarDB for Oracle 集群!
根据 【安全可靠测评结果公告(2023年第1号)】,附表三、集中式数据库。PolarDB v2.0 属于自主可控,安全可靠的国产信创数据库。
PolarDB for Oracle 是基于 PolarDB for PostgreSQL 进行二次开发的 Oracle 兼容版本,两者共用同一套内核,通过 --compatibility-mode 参数进行区分。
我们与阿里云内核团队合作,提供基于 PolarDB v2.0 内核与 Pigsty v3.0 RDS 的完整数据库解决方案,请联系销售咨询,或在阿里云市场自行采购。
PolarDB for Oracle 内核目前仅在 EL 系统中可用。
扩展
目前 PolarDB 2.0 (Oracle兼容) 内核自带了以下 188 个扩展插件:
| name | default_version | comment |
|---|---|---|
| cube | 1.5 | data type for multidimensional cubes |
| ip4r | 2.4 | NULL |
| adminpack | 2.1 | administrative functions for PostgreSQL |
| dict_xsyn | 1.0 | text search dictionary template for extended synonym processing |
| amcheck | 1.4 | functions for verifying relation integrity |
| autoinc | 1.0 | functions for autoincrementing fields |
| hstore | 1.8 | data type for storing sets of (key, value) pairs |
| bloom | 1.0 | bloom access method - signature file based index |
| earthdistance | 1.1 | calculate great-circle distances on the surface of the Earth |
| hstore_plperl | 1.0 | transform between hstore and plperl |
| bool_plperl | 1.0 | transform between bool and plperl |
| file_fdw | 1.0 | foreign-data wrapper for flat file access |
| bool_plperlu | 1.0 | transform between bool and plperlu |
| fuzzystrmatch | 1.1 | determine similarities and distance between strings |
| hstore_plperlu | 1.0 | transform between hstore and plperlu |
| btree_gin | 1.3 | support for indexing common datatypes in GIN |
| hstore_plpython2u | 1.0 | transform between hstore and plpython2u |
| btree_gist | 1.6 | support for indexing common datatypes in GiST |
| hll | 2.17 | type for storing hyperloglog data |
| hstore_plpython3u | 1.0 | transform between hstore and plpython3u |
| citext | 1.6 | data type for case-insensitive character strings |
| hstore_plpythonu | 1.0 | transform between hstore and plpythonu |
| hypopg | 1.3.1 | Hypothetical indexes for PostgreSQL |
| insert_username | 1.0 | functions for tracking who changed a table |
| dblink | 1.2 | connect to other PostgreSQL databases from within a database |
| decoderbufs | 0.1.0 | Logical decoding plugin that delivers WAL stream changes using a Protocol Buffer format |
| intagg | 1.1 | integer aggregator and enumerator (obsolete) |
| dict_int | 1.0 | text search dictionary template for integers |
| intarray | 1.5 | functions, operators, and index support for 1-D arrays of integers |
| isn | 1.2 | data types for international product numbering standards |
| jsonb_plperl | 1.0 | transform between jsonb and plperl |
| jsonb_plperlu | 1.0 | transform between jsonb and plperlu |
| jsonb_plpython2u | 1.0 | transform between jsonb and plpython2u |
| jsonb_plpython3u | 1.0 | transform between jsonb and plpython3u |
| jsonb_plpythonu | 1.0 | transform between jsonb and plpythonu |
| lo | 1.1 | Large Object maintenance |
| log_fdw | 1.0 | foreign-data wrapper for csvlog |
| ltree | 1.2 | data type for hierarchical tree-like structures |
| ltree_plpython2u | 1.0 | transform between ltree and plpython2u |
| ltree_plpython3u | 1.0 | transform between ltree and plpython3u |
| ltree_plpythonu | 1.0 | transform between ltree and plpythonu |
| moddatetime | 1.0 | functions for tracking last modification time |
| old_snapshot | 1.0 | utilities in support of old_snapshot_threshold |
| oracle_fdw | 1.2 | foreign data wrapper for Oracle access |
| oss_fdw | 1.1 | foreign-data wrapper for OSS access |
| pageinspect | 2.1 | inspect the contents of database pages at a low level |
| pase | 0.0.1 | ant ai similarity search |
| pg_bigm | 1.2 | text similarity measurement and index searching based on bigrams |
| pg_freespacemap | 1.2 | examine the free space map (FSM) |
| pg_hint_plan | 1.4 | controls execution plan with hinting phrases in comment of special form |
| pg_buffercache | 1.5 | examine the shared buffer cache |
| pg_prewarm | 1.2 | prewarm relation data |
| pg_repack | 1.4.8-1 | Reorganize tables in PostgreSQL databases with minimal locks |
| pg_sphere | 1.0 | spherical objects with useful functions, operators and index support |
| pg_cron | 1.5 | Job scheduler for PostgreSQL |
| pg_jieba | 1.1.0 | a parser for full-text search of Chinese |
| pg_stat_kcache | 2.2.1 | Kernel statistics gathering |
| pg_stat_statements | 1.9 | track planning and execution statistics of all SQL statements executed |
| pg_surgery | 1.0 | extension to perform surgery on a damaged relation |
| pg_trgm | 1.6 | text similarity measurement and index searching based on trigrams |
| pg_visibility | 1.2 | examine the visibility map (VM) and page-level visibility info |
| pg_wait_sampling | 1.1 | sampling based statistics of wait events |
| pgaudit | 1.6.2 | provides auditing functionality |
| pgcrypto | 1.3 | cryptographic functions |
| pgrowlocks | 1.2 | show row-level locking information |
| pgstattuple | 1.5 | show tuple-level statistics |
| pgtap | 1.2.0 | Unit testing for PostgreSQL |
| pldbgapi | 1.1 | server-side support for debugging PL/pgSQL functions |
| plperl | 1.0 | PL/Perl procedural language |
| plperlu | 1.0 | PL/PerlU untrusted procedural language |
| plpgsql | 1.0 | PL/pgSQL procedural language |
| plpython2u | 1.0 | PL/Python2U untrusted procedural language |
| plpythonu | 1.0 | PL/PythonU untrusted procedural language |
| plsql | 1.0 | Oracle compatible PL/SQL procedural language |
| pltcl | 1.0 | PL/Tcl procedural language |
| pltclu | 1.0 | PL/TclU untrusted procedural language |
| polar_bfile | 1.0 | The BFILE data type enables access to binary file LOBs that are stored in file systems outside Database |
| polar_bpe | 1.0 | polar_bpe |
| polar_builtin_cast | 1.1 | Internal extension for builtin casts |
| polar_builtin_funcs | 2.0 | implement polar builtin functions |
| polar_builtin_type | 1.5 | polar_builtin_type for PolarDB |
| polar_builtin_view | 1.5 | polar_builtin_view |
| polar_catalog | 1.2 | polardb pg extend catalog |
| polar_channel | 1.0 | polar_channel |
| polar_constraint | 1.0 | polar_constraint |
| polar_csn | 1.0 | polar_csn |
| polar_dba_views | 1.0 | polar_dba_views |
| polar_dbms_alert | 1.2 | implement polar_dbms_alert - supports asynchronous notification of database events. |
| polar_dbms_application_info | 1.0 | implement polar_dbms_application_info - record names of executing modules or transactions in the database. |
| polar_dbms_pipe | 1.1 | implements polar_dbms_pipe - package lets two or more sessions in the same instance communicate. |
| polar_dbms_aq | 1.2 | implement dbms_aq - provides an interface to Advanced Queuing. |
| polar_dbms_lob | 1.3 | implement dbms_lob - provides subprograms to operate on BLOBs, CLOBs, and NCLOBs. |
| polar_dbms_output | 1.2 | implement polar_dbms_output - enables you to send messages from stored procedures. |
| polar_dbms_lock | 1.0 | implement polar_dbms_lock - provides an interface to Oracle Lock Management services. |
| polar_dbms_aqadm | 1.3 | polar_dbms_aqadm - procedures to manage Advanced Queuing configuration and administration information. |
| polar_dbms_assert | 1.0 | implement polar_dbms_assert - provide an interface to validate properties of the input value. |
| polar_dbms_metadata | 1.0 | implement polar_dbms_metadata - provides a way for you to retrieve metadata from the database dictionary. |
| polar_dbms_random | 1.0 | implement polar_dbms_random - a built-in random number generator, not intended for cryptography |
| polar_dbms_crypto | 1.1 | implement dbms_crypto - provides an interface to encrypt and decrypt stored data. |
| polar_dbms_redact | 1.0 | implement polar_dbms_redact - provides an interface to mask data from queries by an application. |
| polar_dbms_debug | 1.1 | server-side support for debugging PL/SQL functions |
| polar_dbms_job | 1.0 | polar_dbms_job |
| polar_dbms_mview | 1.1 | implement polar_dbms_mview - enables to refresh materialized views. |
| polar_dbms_job_preload | 1.0 | polar_dbms_job_preload |
| polar_dbms_obfuscation_toolkit | 1.1 | implement polar_dbms_obfuscation_toolkit - enables an application to get data md5. |
| polar_dbms_rls | 1.1 | implement polar_dbms_rls - a fine-grained access control administrative built-in package |
| polar_multi_toast_utils | 1.0 | polar_multi_toast_utils |
| polar_dbms_session | 1.2 | implement polar_dbms_session - support to set preferences and security levels. |
| polar_odciconst | 1.0 | implement ODCIConst - Provide some built-in constants in Oracle. |
| polar_dbms_sql | 1.2 | implement polar_dbms_sql - provides an interface to execute dynamic SQL. |
| polar_osfs_toolkit | 1.0 | osfs library tools and functions extension |
| polar_dbms_stats | 14.0 | stabilize plans by fixing statistics |
| polar_monitor | 1.5 | monitor functions for PolarDB |
| polar_osfs_utils | 1.0 | osfs library utils extension |
| polar_dbms_utility | 1.3 | implement polar_dbms_utility - provides various utility subprograms. |
| polar_parameter_check | 1.0 | kernel extension for parameter validation |
| polar_dbms_xmldom | 1.0 | implement dbms_xmldom and dbms_xmlparser - support standard DOM interface and xml parser object |
| polar_parameter_manager | 1.1 | Extension to select parameters for manger. |
| polar_faults | 1.0.0 | simulate some database faults for end user or testing system. |
| polar_monitor_preload | 1.1 | examine the polardb information |
| polar_proxy_utils | 1.0 | Extension to provide operations about proxy. |
| polar_feature_utils | 1.2 | PolarDB feature utilization |
| polar_global_awr | 1.0 | PolarDB Global AWR Report |
| polar_publication | 1.0 | support polardb pg logical replication |
| polar_global_cache | 1.0 | polar_global_cache |
| polar_px | 1.0 | Parallel Execution extension |
| polar_serverless | 1.0 | polar serverless extension |
| polar_resource_manager | 1.0 | a background process that forcibly frees user session process memory |
| polar_sys_context | 1.1 | implement polar_sys_context - returns the value of parameter associated with the context namespace at the current instant. |
| polar_gpc | 1.3 | polar_gpc |
| polar_tde_utils | 1.0 | Internal extension for TDE |
| polar_gtt | 1.1 | polar_gtt |
| polar_utl_encode | 1.2 | implement polar_utl_encode - provides functions that encode RAW data into a standard encoded format |
| polar_htap | 1.1 | extension for PolarDB HTAP |
| polar_htap_db | 1.0 | extension for PolarDB HTAP database level operation |
| polar_io_stat | 1.0 | polar io stat in multi dimension |
| polar_utl_file | 1.0 | implement utl_file - support PL/SQL programs can read and write operating system text files |
| polar_ivm | 1.0 | polar_ivm |
| polar_sql_mapping | 1.2 | Record error sqls and mapping them to correct one |
| polar_stat_sql | 1.0 | Kernel statistics gathering, and sql plan nodes information gathering |
| tds_fdw | 2.0.2 | Foreign data wrapper for querying a TDS database (Sybase or Microsoft SQL Server) |
| xml2 | 1.1 | XPath querying and XSLT |
| polar_upgrade_catalogs | 1.1 | Upgrade catalogs for old version instance |
| polar_utl_i18n | 1.1 | polar_utl_i18n |
| polar_utl_raw | 1.0 | implement utl_raw - provides SQL functions for manipulating RAW datatypes. |
| timescaledb | 2.9.2 | Enables scalable inserts and complex queries for time-series data |
| polar_vfs | 1.0 | polar virtual file system for different storage |
| polar_worker | 1.0 | polar_worker |
| postgres_fdw | 1.1 | foreign-data wrapper for remote PostgreSQL servers |
| refint | 1.0 | functions for implementing referential integrity (obsolete) |
| roaringbitmap | 0.5 | support for Roaring Bitmaps |
| tsm_system_time | 1.0 | TABLESAMPLE method which accepts time in milliseconds as a limit |
| vector | 0.5.0 | vector data type and ivfflat and hnsw access methods |
| rum | 1.3 | RUM index access method |
| unaccent | 1.1 | text search dictionary that removes accents |
| seg | 1.4 | data type for representing line segments or floating-point intervals |
| sequential_uuids | 1.0.2 | generator of sequential UUIDs |
| uuid-ossp | 1.1 | generate universally unique identifiers (UUIDs) |
| smlar | 1.0 | compute similary of any one-dimensional arrays |
| varbitx | 1.1 | varbit functions pack |
| sslinfo | 1.2 | information about SSL certificates |
| tablefunc | 1.0 | functions that manipulate whole tables, including crosstab |
| tcn | 1.0 | Triggered change notifications |
| zhparser | 1.0 | a parser for full-text search of Chinese |
| address_standardizer | 3.3.2 | Ganos PostGIS address standardizer |
| address_standardizer_data_us | 3.3.2 | Ganos PostGIS address standardizer data us |
| ganos_fdw | 6.0 | Ganos Spatial FDW extension for POLARDB |
| ganos_geometry | 6.0 | Ganos geometry lite extension for POLARDB |
| ganos_geometry_pyramid | 6.0 | Ganos Geometry Pyramid extension for POLARDB |
| ganos_geometry_sfcgal | 6.0 | Ganos geometry lite sfcgal extension for POLARDB |
| ganos_geomgrid | 6.0 | Ganos geometry grid extension for POLARDB |
| ganos_importer | 6.0 | Ganos Spatial importer extension for POLARDB |
| ganos_networking | 6.0 | Ganos networking |
| ganos_pointcloud | 6.0 | Ganos pointcloud extension For POLARDB |
| ganos_pointcloud_geometry | 6.0 | Ganos_pointcloud LIDAR data and ganos_geometry data for POLARDB |
| ganos_raster | 6.0 | Ganos raster extension for POLARDB |
| ganos_scene | 6.0 | Ganos scene extension for POLARDB |
| ganos_sfmesh | 6.0 | Ganos surface mesh extension for POLARDB |
| ganos_spatialref | 6.0 | Ganos spatial reference extension for POLARDB |
| ganos_trajectory | 6.0 | Ganos trajectory extension for POLARDB |
| ganos_vomesh | 6.0 | Ganos volumn mesh extension for POLARDB |
| postgis_tiger_geocoder | 3.3.2 | Ganos PostGIS tiger geocoder |
| postgis_topology | 3.3.2 | Ganos PostGIS topology |
8 - PostgresML (AI/ML)
如何使用 Pigsty 拉起 PostgresML,在数据库内进行机器学习,模型训练、推理与 Embedding,RAG。
PostgresML is an PostgreSQL extension with the support for latest LLMs, vector operations, classical Machine Learning and good old Postgres application workloads.
PostgresML (pgml) is a PostgreSQL extension written in Rust. You can run standalone docker images, but this is not a docker-compose template introduction, this file is for documentation purpose only.
PostgresML is officially supported on Ubuntu 22.04, but we also maintain an RPM version for EL 8/9, if you don’t need CUDA & NVIDIA stuff.
You’ll need the Internet access on the database nodes to download python dependencies from PyPI and models from HuggingFace.
Configuration
PostgresML is a RUST extension with official Ubuntu support. Pigsty maintains an RPM version for PostgresML on EL8 and EL9.
Launch new Cluster
PostgresML 2.10.0 is available for PostgreSQL 15 on Ubuntu 22.04 (Official), Debian 12 and EL 8/9 (Pigsty). To enable pgml, you have to install the extension first:
pg-meta:
hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary } }
vars:
pg_cluster: pg-meta
pg_users:
- {name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [dbrole_admin] ,comment: pigsty admin user }
- {name: dbuser_view ,password: DBUser.Viewer ,pgbouncer: true ,roles: [dbrole_readonly] ,comment: read-only viewer for meta database }
pg_databases:
- { name: meta ,baseline: cmdb.sql ,comment: pigsty meta database ,schemas: [pigsty] ,extensions: [{name: postgis, schema: public}, {name: timescaledb}]}
pg_hba_rules:
- {user: dbuser_view , db: all ,addr: infra ,auth: pwd ,title: 'allow grafana dashboard access cmdb from infra nodes'}
pg_libs: 'pgml, pg_stat_statements, auto_explain'
pg_extensions: [ 'pgml_15 pgvector_15 wal2json_15 repack_15' ] # ubuntu
#pg_extensions: [ 'postgresql-pgml-15 postgresql-15-pgvector postgresql-15-wal2json postgresql-15-repack' ] # ubuntu
In EL 8/9, the extension name is pgml_15, corresponding name in ubuntu/debian is postgresql-pgml-15. and add pgml to pg_libs.
Enable on Existing Cluster
To enable pgml on existing cluster, install with ansible package module:
ansible pg-meta -m package -b -a 'name=pgml_15'
# ansible el8,el9 -m package -b -a 'name=pgml_15' # EL 8/9
# ansible u22 -m package -b -a 'name=postgresql-pgml-15' # Ubuntu 22.04 jammy
Python Dependencies
You also have to install python dependencies for PostgresML on cluster nodes. Official tutorial: installation
Install Python & PIP
Make sure python3, pip and venv is installed:
# ubuntu 22.04 (python3.10), you have to install pip & venv with apt
sudo apt install -y python3 python3-pip python3-venv
For EL 8 / EL9 and compatible distros, you can use python3.11
# el 8/9, you can upgrade default pip & virtualenv if applicable
sudo yum install -y python3.11 python3.11-pip # install latest python3.11
python3.11 -m pip install --upgrade pip virtualenv # use python3.11 on el8 / el9
Using pypi mirrors
For mainland China user, consider using the tsinghua pypi mirror.
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple # setup global mirror (recommended)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some-package # one-time install
Install Requirements
Create a python virtualenv and install requirements from requirements.txt and requirements-xformers.txt with pip.
If you are using EL 8/9, you have to replace the
python3withpython3.11in the following commands.
su - postgres; # create venv with dbsu
mkdir -p /data/pgml; cd /data/pgml; # make a venv directory
python3 -m venv /data/pgml # create virtualenv dir (ubuntu 22.04)
source /data/pgml/bin/activate # activate virtual env
# write down python dependencies and install with pip
cat > /data/pgml/requirments.txt <<EOF
accelerate==0.22.0
auto-gptq==0.4.2
bitsandbytes==0.41.1
catboost==1.2
ctransformers==0.2.27
datasets==2.14.5
deepspeed==0.10.3
huggingface-hub==0.17.1
InstructorEmbedding==1.0.1
lightgbm==4.1.0
orjson==3.9.7
pandas==2.1.0
rich==13.5.2
rouge==1.0.1
sacrebleu==2.3.1
sacremoses==0.0.53
scikit-learn==1.3.0
sentencepiece==0.1.99
sentence-transformers==2.2.2
tokenizers==0.13.3
torch==2.0.1
torchaudio==2.0.2
torchvision==0.15.2
tqdm==4.66.1
transformers==4.33.1
xgboost==2.0.0
langchain==0.0.287
einops==0.6.1
pynvml==11.5.0
EOF
# install requirements with pip inside virtualenv
python3 -m pip install -r /data/pgml/requirments.txt
python3 -m pip install xformers==0.0.21 --no-dependencies
# besides, 3 python packages need to be installed globally with sudo!
sudo python3 -m pip install xgboost lightgbm scikit-learn
Enable PostgresML
After installing the pgml extension and python dependencies on all cluster nodes, you can enable pgml on the PostgreSQL cluster.
Configure cluster with patronictl command and add pgml to shared_preload_libraries, and specify your venv dir in pgml.venv:
shared_preload_libraries: pgml, timescaledb, pg_stat_statements, auto_explain
pgml.venv: '/data/pgml'
After that, restart database cluster, and create extension with SQL command:
CREATE EXTENSION vector; -- nice to have pgvector installed too!
CREATE EXTENSION pgml; -- create PostgresML in current database
SELECT pgml.version(); -- print PostgresML version string
If it works, you should see something like:
# create extension pgml;
INFO: Python version: 3.11.2 (main, Oct 5 2023, 16:06:03) [GCC 8.5.0 20210514 (Red Hat 8.5.0-18)]
INFO: Scikit-learn 1.3.0, XGBoost 2.0.0, LightGBM 4.1.0, NumPy 1.26.1
CREATE EXTENSION
# SELECT pgml.version(); -- print PostgresML version string
version
---------
2.7.8
You are all set! Check PostgresML for more details: https://postgresml.org/docs/guides/use-cases/
9 - Supabase (Firebase)
如何使用Pigsty自建Supabase,一键拉起开源Firebase替代,后端全栈全家桶。
Supabase —— Build in a weekend, Scale to millions
Supabase 是一个开源的 Firebase 替代,对 PostgreSQL 进行了封装,并提供了认证,开箱即用的 API,边缘函数,实时订阅,对象存储,向量嵌入能力。 这是一个低代码的一站式后端平台,能让你几乎告别大部分后端开发的工作,只需要懂数据库设计与前端即可快速出活!
Supabase 的口号是:“花个周末写写,随便扩容至百万”。诚然,在小微规模(4c8g)内的 Supabase 极有性价比,堪称赛博菩萨。 —— 但当你真的增长到百万用户时 —— 确实应该认真考虑托管自建 Supabase 了 —— 无论是出于功能,性能,还是成本上的考虑。
Pigsty 为您提供完整的 Supabase 一键自建方案。自建的 Supabase 可以享受完整的 PostgreSQL 监控,IaC,PITR 与高可用, 而且相比 Supabase 云服务,提供了多达 421 个开箱即用的 PostgreSQL 扩展,并能够更充分地利用现代硬件的性能与成本优势。
完整自建教程,请参考:《Supabase自建手册》
快速上手
Pigsty 默认提供的 supa.yml 配置模板定义了一套单节点 Supabase。
首先,使用 Pigsty 标准安装流程 安装 Supabase 所需的 MinIO 与 PostgreSQL 实例:
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap # 准备 Pigsty 依赖
./configure -c app/supa # 使用 Supabase 应用模板
./install.yml # 安装 Pigsty,以及各种数据库
请在部署 Supabase 前,根据您的实际情况,修改 pigsty.yml 配置文件中关于 Supabase 的参数(主要是密码!)
然后,运行 docker.yml 完成剩余的工作,拉起 Supabase 容器
./docker.yml # 安装 Docker 与 Docker Compose
./app.yml # 使用 Docker Compose 拉起 Supabase 无状态部分!
中国区域用户注意,请您配置合适的 Docker 镜像站点或代理服务器绕过 GFW 以拉取 DockerHub 镜像。
对于 专业订阅 ,我们提供在没有互联网访问的情况下,离线安装 Pigsty 与 Supabase 的能力。
Pigsty 默认通过管理节点/INFRA节点上的 Nginx 对外暴露 Web 服务,您可以在本地添加 supa.pigsty 的 DNS 解析指向该节点,
然后通过浏览器访问 https://supa.pigsty 即可进入 Supabase Studio 管理界面。
默认用户名与密码:supabase / pigsty

架构概览
Pigsty 以 Supabase 提供的 Docker Compose 模板为蓝本,提取了其中的无状态部分,由 Docker Compose 负责处理。而有状态的数据库和对象存储容器则替换为外部由 Pigsty 托管的 PostgreSQL 集群与 MinIO 服务。
经过改造后,Supabase 本体是无状态的,因此您可以随意运行,停止,甚至在同一套 PGSQL/MINIO 上同时运行多个无状态 Supabase 容器以实现扩容。

Pigsty 默认使用本机上的单机 PostgreSQL 实例作为 Supabase 的核心后端数据库。对于严肃的生产部署,我们建议使用 Pigsty 部署一套至少由三节点的 PG 高可用集群。或至少使用外部对象存储作为 PITR 备份仓库,提供兜底。
Pigsty 默认使用本机上的 SNSD MinIO 服务作为文件存储。对于严肃的生产环境部署,您可以使用外部的 S3 兼容对象存储服务,或者使用其他由 Pigsty 独立部署的 多机多盘 MinIO 集群。
配置细节
自建 Supabase 时,包含 Docker Compose 所需资源的目录 app/supabase 会被整个拷贝到目标节点(默认为 supabase 分组)上的 /opt/supabase,并使用 docker compose up -d 在后台拉起。
所有配置参数都定义在 .env 文件与 docker-compose.yml 模板中。
但您通常不需要直接修改这两个模板,你可以在 supa_config 中指定 .env 中的参数,这些配置会自动覆盖或追加到最终的 /opt/supabase/.env 核心配置文件中。
这里最关键的参数是 jwt_secret,以及对应的 anon_key 与 service_role_key。对于严肃的生产使用,请您务必参考Supabase自建手册中的说明与工具设置。
如果您希望使用域名对外提供服务,您可以在 site_url, api_external_url,以及 supabase_public_url 中指定您的域名(从外部访问 Supabase 服务使用的域名)。如果这几个域名配置错误,可能导致 Supabase Studio 的部分管理能力(比如对象存储管理)无法正常工作。
Pigsty 默认使用本机 MinIO,如果您希望使用 S3 或 MinIO 作为文件存储,您需要配置 s3_bucket,s3_endpoint,s3_access_key,s3_secret_key 等参数。
通常来说,您还需要使用一个外部的 SMTP 服务来发送邮件,邮件服务不建议自建,请考虑使用成熟的第三方服务,如 Mailchimp,Aliyun 邮件推送等。
对于中国大陆用户来说,我们建议您配置 docker_registry_mirrors 镜像站点,或使用 proxy_env 指定可用的代理服务器翻墙,否则从 DockerHub 上拉取镜像可能会失败或极为缓慢!
all:
children:
# the supabase stateless (default username & password: supabase/pigsty)
supa:
hosts:
10.10.10.10: {}
vars:
app: supabase # specify app name (supa) to be installed (in the apps)
apps: # define all applications
supabase: # the definition of supabase app
conf: # override /opt/supabase/.env
# IMPORTANT: CHANGE JWT_SECRET AND REGENERATE CREDENTIAL ACCORDING!!!!!!!!!!!
# https://supabase.com/docs/guides/self-hosting/docker#securing-your-services
JWT_SECRET: your-super-secret-jwt-token-with-at-least-32-characters-long
ANON_KEY: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyAgCiAgICAicm9sZSI6ICJhbm9uIiwKICAgICJpc3MiOiAic3VwYWJhc2UtZGVtbyIsCiAgICAiaWF0IjogMTY0MTc2OTIwMCwKICAgICJleHAiOiAxNzk5NTM1NjAwCn0.dc_X5iR_VP_qT0zsiyj_I_OZ2T9FtRU2BBNWN8Bu4GE
SERVICE_ROLE_KEY: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyAgCiAgICAicm9sZSI6ICJzZXJ2aWNlX3JvbGUiLAogICAgImlzcyI6ICJzdXBhYmFzZS1kZW1vIiwKICAgICJpYXQiOiAxNjQxNzY5MjAwLAogICAgImV4cCI6IDE3OTk1MzU2MDAKfQ.DaYlNEoUrrEn2Ig7tqibS-PHK5vgusbcbo7X36XVt4Q
DASHBOARD_USERNAME: supabase
DASHBOARD_PASSWORD: pigsty
# postgres connection string (use the correct ip and port)
POSTGRES_HOST: 10.10.10.10
POSTGRES_PORT: 5436 # access via the 'default' service, which always route to the primary postgres
POSTGRES_DB: postgres
POSTGRES_PASSWORD: DBUser.Supa # password for supabase_admin and multiple supabase users
# expose supabase via domain name
SITE_URL: http://supa.pigsty # <------- Change This to your external domain name
API_EXTERNAL_URL: http://supa.pigsty # <------- Otherwise the storage api may not work!
SUPABASE_PUBLIC_URL: http://supa.pigsty # <------- Do not forget!
# if using s3/minio as file storage
S3_BUCKET: supa
S3_ENDPOINT: https://sss.pigsty:9000
S3_ACCESS_KEY: supabase
S3_SECRET_KEY: S3User.Supabase
S3_FORCE_PATH_STYLE: true
S3_PROTOCOL: https
S3_REGION: stub
MINIO_DOMAIN_IP: 10.10.10.10 # sss.pigsty domain name will resolve to this ip statically
# if using SMTP (optional)
#SMTP_ADMIN_EMAIL: admin@example.com
#SMTP_HOST: supabase-mail
#SMTP_PORT: 2500
#SMTP_USER: fake_mail_user
#SMTP_PASS: fake_mail_password
#SMTP_SENDER_NAME: fake_sender
#ENABLE_ANONYMOUS_USERS: false
10 - Greenplum (MPP)
使用 Pigsty 部署/监控 Greenplum 集群,构建大规模并行处理(MPP)的 PostgreSQL 数据仓库集群!
Pigsty 支持部署 Greenplum 集群,及其衍生发行版 YMatrixDB,并提供了将现有 Greenplum 部署纳入 Pigsty 监控的能力。
概览
Greenplum / YMatrix 集群部署能力仅在专业版本/企业版本中提供,目前不对外开源。
安装
Pigsty 提供了 Greenplum 6 (@el7) 与 Greenplum 7 (@el8) 的安装包,开源版本用户可以自行安装配置。
# EL 7 Only (Greenplum6)
./node.yml -t node_install -e '{"node_repo_modules":"pgsql","node_packages":["open-source-greenplum-db-6"]}'
# EL 8 Only (Greenplum7)
./node.yml -t node_install -e '{"node_repo_modules":"pgsql","node_packages":["open-source-greenplum-db-7"]}'
配置
要定义 Greenplum 集群,需要用到 pg_mode = gpsql,并使用额外的身份参数 pg_shard 与 gp_role。
#================================================================#
# GPSQL Clusters #
#================================================================#
#----------------------------------#
# cluster: mx-mdw (gp master)
#----------------------------------#
mx-mdw:
hosts:
10.10.10.10: { pg_seq: 1, pg_role: primary , nodename: mx-mdw-1 }
vars:
gp_role: master # this cluster is used as greenplum master
pg_shard: mx # pgsql sharding name & gpsql deployment name
pg_cluster: mx-mdw # this master cluster name is mx-mdw
pg_databases:
- { name: matrixmgr , extensions: [ { name: matrixdbts } ] }
- { name: meta }
pg_users:
- { name: meta , password: DBUser.Meta , pgbouncer: true }
- { name: dbuser_monitor , password: DBUser.Monitor , roles: [ dbrole_readonly ], superuser: true }
pgbouncer_enabled: true # enable pgbouncer for greenplum master
pgbouncer_exporter_enabled: false # enable pgbouncer_exporter for greenplum master
pg_exporter_params: 'host=127.0.0.1&sslmode=disable' # use 127.0.0.1 as local monitor host
#----------------------------------#
# cluster: mx-sdw (gp master)
#----------------------------------#
mx-sdw:
hosts:
10.10.10.11:
nodename: mx-sdw-1 # greenplum segment node
pg_instances: # greenplum segment instances
6000: { pg_cluster: mx-seg1, pg_seq: 1, pg_role: primary , pg_exporter_port: 9633 }
6001: { pg_cluster: mx-seg2, pg_seq: 2, pg_role: replica , pg_exporter_port: 9634 }
10.10.10.12:
nodename: mx-sdw-2
pg_instances:
6000: { pg_cluster: mx-seg2, pg_seq: 1, pg_role: primary , pg_exporter_port: 9633 }
6001: { pg_cluster: mx-seg3, pg_seq: 2, pg_role: replica , pg_exporter_port: 9634 }
10.10.10.13:
nodename: mx-sdw-3
pg_instances:
6000: { pg_cluster: mx-seg3, pg_seq: 1, pg_role: primary , pg_exporter_port: 9633 }
6001: { pg_cluster: mx-seg1, pg_seq: 2, pg_role: replica , pg_exporter_port: 9634 }
vars:
gp_role: segment # these are nodes for gp segments
pg_shard: mx # pgsql sharding name & gpsql deployment name
pg_cluster: mx-sdw # these segment clusters name is mx-sdw
pg_preflight_skip: true # skip preflight check (since pg_seq & pg_role & pg_cluster not exists)
pg_exporter_config: pg_exporter_basic.yml # use basic config to avoid segment server crash
pg_exporter_params: 'options=-c%20gp_role%3Dutility&sslmode=disable' # use gp_role = utility to connect to segments
此外,PG Exporter 需要额外的连接参数,才能连接到 Greenplum Segment 实例上采集监控指标。
11 - Cloudberry (MPP)
使用 Pigsty 部署/监控 Cloudberry 集群,一个由 Greenplum 分叉而来的 MPP 数据仓库集群!
安装
Pigsty 提供了 Greenplum 6 (@el7) 与 Greenplum 7 (@el8) 的安装包,开源版本用户可以自行安装配置。
# EL 7 Only (Greenplum6)
./node.yml -t node_install -e '{"node_repo_modules":"pgsql","node_packages":["cloudberrydb"]}'
# EL 8 Only (Greenplum7)
./node.yml -t node_install -e '{"node_repo_modules":"pgsql","node_packages":["cloudberrydb"]}'
12 - Neon (Serverless)
使用 Neon 开源的 Serverless 版本 PostgreSQL 内核,自建灵活伸缩,Scale To Zero,灵活分叉的PG服务。
Neon 采用了存储与计算分离架构,提供了丝滑的自动扩缩容,Scale to Zero,以及数据库版本分叉等独家能力。
Neon 官网:https://neon.tech/
Neon 编译后的二进制产物过于庞大,目前不对开源版用户提供,目前处于试点阶段,有需求请联系 Pigsty 销售。