服务/接入
Module:
Categories:
分离读写操作,正确路由流量,稳定可靠地交付 PostgreSQL 集群提供的能力。
服务是一种抽象:它是数据库集群对外提供能力的形式,并封装了底层集群的细节。
服务对于生产环境中的稳定接入至关重要,在高可用集群自动故障时方显其价值,单机用户通常不需要操心这个概念。
单机用户
“服务” 的概念是给生产环境用的,个人用户/单机集群可以不折腾,直接拿实例名/IP地址访问数据库。
例如,Pigsty 默认的单节点 pg-meta.meta 数据库,就可以直接用下面三个不同的用户连接上去。
psql postgres://dbuser_dba:DBUser.DBA@10.10.10.10/meta # 直接用 DBA 超级用户连上去
psql postgres://dbuser_meta:DBUser.Meta@10.10.10.10/meta # 用默认的业务管理员用户连上去
psql postgres://dbuser_view:DBUser.View@pg-meta/meta # 用默认的只读用户走实例域名连上去
服务概述
在真实世界生产环境中,我们会使用基于复制的主从数据库集群。集群中有且仅有一个实例作为领导者(主库)可以接受写入。 而其他实例(从库)则会从持续从集群领导者获取变更日志,与领导者保持一致。同时,从库还可以承载只读请求,在读多写少的场景下可以显著分担主库的负担, 因此对集群的写入请求与只读请求进行区分,是一种十分常见的实践。
此外对于高频短连接的生产环境,我们还会通过连接池中间件(Pgbouncer)对请求进行池化,减少连接与后端进程的创建开销。但对于ETL与变更执行等场景,我们又需要绕过连接池,直接访问数据库。 同时,高可用集群在故障时会出现故障切换(Failover),故障切换会导致集群的领导者出现变更。因此高可用的数据库方案要求写入流量可以自动适配集群的领导者变化。 这些不同的访问需求(读写分离,池化与直连,故障切换自动适配)最终抽象出 服务 (Service)的概念。
通常来说,数据库集群都必须提供这种最基础的服务:
- 读写服务(primary) :可以读写数据库
对于生产数据库集群,至少应当提供这两种服务:
- 读写服务(primary) :写入数据:只能由主库所承载。
- 只读服务(replica) :读取数据:可以由从库承载,没有从库时也可由主库承载
此外,根据具体的业务场景,可能还会有其他的服务,例如:
- 默认直连服务(default) :允许(管理)用户,绕过连接池直接访问数据库的服务
- 离线从库服务(offline) :不承接线上只读流量的专用从库,用于ETL与分析查询
- 同步从库服务(standby) :没有复制延迟的只读服务,由同步备库/主库处理只读查询
- 延迟从库服务(delayed) :访问同一个集群在一段时间之前的旧数据,由延迟从库来处理
默认服务
Pigsty默认为每个 PostgreSQL 数据库集群提供四种不同的服务,以下是默认服务及其定义:
| 服务 | 端口 | 描述 |
|---|---|---|
| primary | 5433 | 生产读写,连接到主库连接池(6432) |
| replica | 5434 | 生产只读,连接到备库连接池(6432) |
| default | 5436 | 管理,ETL写入,直接访问主库(5432) |
| offline | 5438 | OLAP、ETL、个人用户、交互式查询 |
以默认的 pg-meta 集群为例,它提供四种默认服务:
psql postgres://dbuser_meta:DBUser.Meta@pg-meta:5433/meta # pg-meta-primary : 通过主要的 pgbouncer(6432) 进行生产读写
psql postgres://dbuser_meta:DBUser.Meta@pg-meta:5434/meta # pg-meta-replica : 通过备份的 pgbouncer(6432) 进行生产只读
psql postgres://dbuser_dba:DBUser.DBA@pg-meta:5436/meta # pg-meta-default : 通过主要的 postgres(5432) 直接连接
psql postgres://dbuser_stats:DBUser.Stats@pg-meta:5438/meta # pg-meta-offline : 通过离线的 postgres(5432) 直接连接
从示例集群架构图上可以看出这四种服务的工作方式:
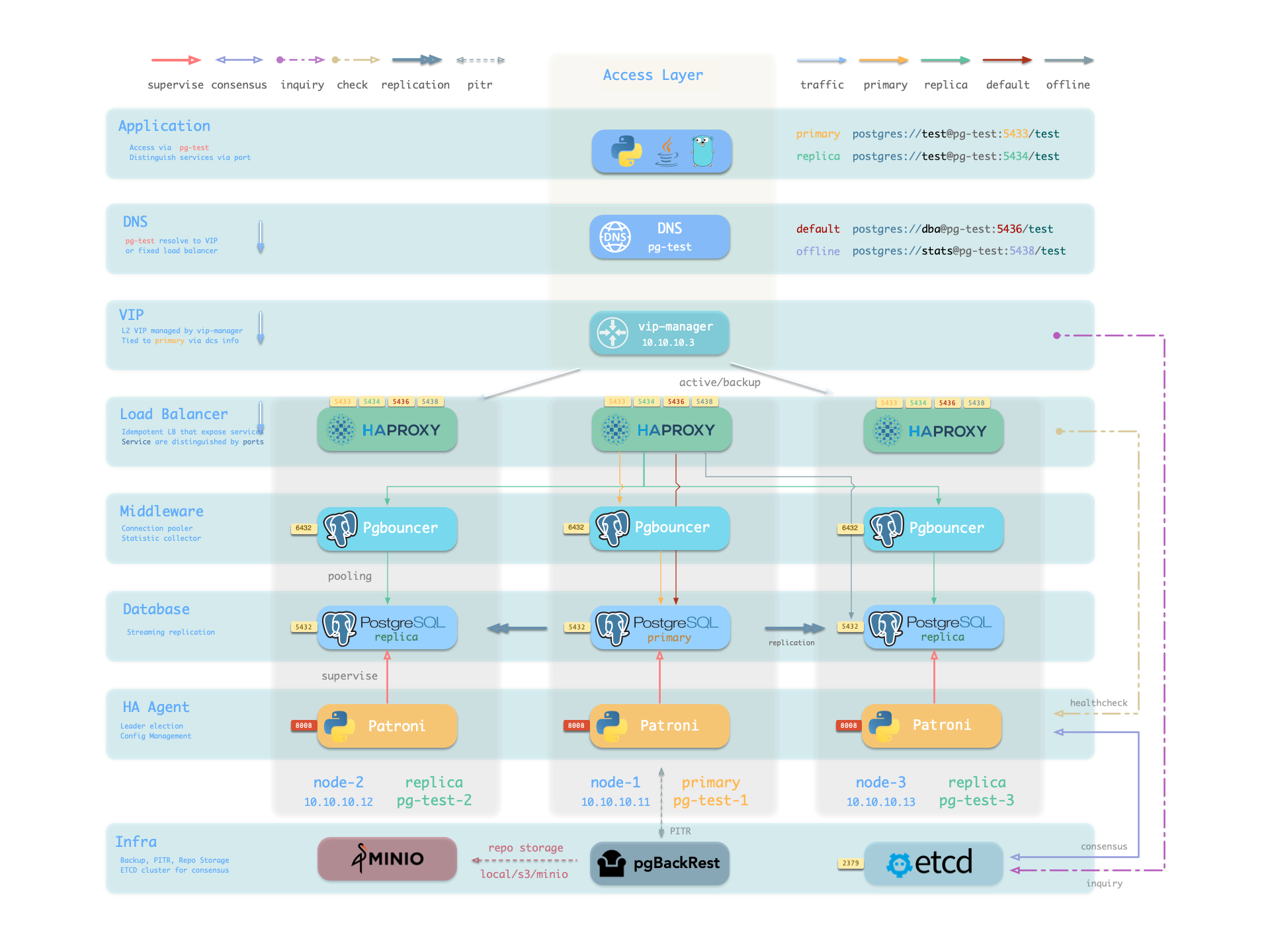
注意在这里pg-meta 域名指向了集群的 L2 VIP,进而指向集群主库上的 haproxy 负载均衡器,它负责将流量路由到不同的实例上,详见服务接入
服务实现
在 Pigsty 中,服务使用节点上的 haproxy 来实现,通过主机节点上的不同端口进行区分。
Pigsty 所纳管的每个节点上都默认启用了 Haproxy 以对外暴露服务,而数据库节点也不例外。 集群中的节点尽管从数据库的视角来看有主从之分,但从服务的视角来看,每个节点都是相同的: 这意味着即使您访问的是从库节点,只要使用正确的服务端口,就依然可以使用到主库读写的服务。 这样的设计可以屏蔽复杂度:所以您只要可以访问 PostgreSQL 集群上的任意一个实例,就可以完整的访问到所有服务。
这样的设计类似于 Kubernetes 中的 NodePort 服务,同样在 Pigsty 中,每一个服务都包括以下两个核心要素:
- 通过 NodePort 暴露的访问端点(端口号,从哪访问?)
- 通过 Selectors 选择的目标实例(实例列表,谁来承载?)
Pigsty的服务交付边界止步于集群的HAProxy,用户可以用各种手段访问这些负载均衡器,请参考接入服务。
所有的服务都通过配置文件进行声明,例如,PostgreSQL 默认服务就是由 pg_default_services 参数所定义的:
pg_default_services:
- { name: primary ,port: 5433 ,dest: default ,check: /primary ,selector: "[]" }
- { name: replica ,port: 5434 ,dest: default ,check: /read-only ,selector: "[]" , backup: "[? pg_role == `primary` || pg_role == `offline` ]" }
- { name: default ,port: 5436 ,dest: postgres ,check: /primary ,selector: "[]" }
- { name: offline ,port: 5438 ,dest: postgres ,check: /replica ,selector: "[? pg_role == `offline` || pg_offline_query ]" , backup: "[? pg_role == `replica` && !pg_offline_query]"}
您也可以在 pg_services 中定义额外的服务,参数 pg_default_services 与 pg_services 都是由 服务定义 对象组成的数组。
定义服务
Pigsty 允许您定义自己的服务:
pg_default_services:所有 PostgreSQL 集群统一对外暴露的服务,默认有四个。pg_services:额外的 PostgreSQL 服务,可以视需求在全局或集群级别定义。haproxy_servies:直接定制 HAProxy 服务内容,可以用于其他组件的接入
对于 PostgreSQL 集群来说,通常只需要关注前两者即可。
每一条服务定义都会在所有相关 HAProxy 实例的配置目录下生成一个新的配置文件:/etc/haproxy/<svcname>.cfg
下面是一个自定义的服务样例 standby:当您想要对外提供没有复制延迟的只读服务时,就可以在 pg_services 新增这条记录:
- name: standby # 必选,服务名称,最终的 svc 名称会使用 `pg_cluster` 作为前缀,例如:pg-meta-standby
port: 5435 # 必选,暴露的服务端口(作为 kubernetes 服务节点端口模式)
ip: "*" # 可选,服务绑定的 IP 地址,默认情况下为所有 IP 地址
selector: "[]" # 必选,服务成员选择器,使用 JMESPath 来筛选配置清单
backup: "[? pg_role == `primary`]" # 可选,服务成员选择器(备份),也就是当默认选择器选中的实例都宕机后,服务才会由这里选中的实例成员来承载
dest: default # 可选,目标端口,default|postgres|pgbouncer|<port_number>,默认为 'default',Default的意思就是使用 pg_default_service_dest 的取值来最终决定
check: /sync # 可选,健康检查 URL 路径,默认为 /,这里使用 Patroni API:/sync ,只有同步备库和主库才会返回 200 健康状态码
maxconn: 5000 # 可选,允许的前端连接最大数,默认为5000
balance: roundrobin # 可选,haproxy 负载均衡算法(默认为 roundrobin,其他选项:leastconn)
options: 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'
而上面的服务定义,在样例的三节点 pg-test 上将会被转换为 haproxy 配置文件 /etc/haproxy/pg-test-standby.conf:
#---------------------------------------------------------------------
# service: pg-test-standby @ 10.10.10.11:5435
#---------------------------------------------------------------------
# service instances 10.10.10.11, 10.10.10.13, 10.10.10.12
# service backups 10.10.10.11
listen pg-test-standby
bind *:5435 # <--- 绑定了所有IP地址上的 5435 端口
mode tcp # <--- 负载均衡器工作在 TCP 协议上
maxconn 5000 # <--- 最大连接数为 5000,可按需调大
balance roundrobin # <--- 负载均衡算法为 rr 轮询,还可以使用 leastconn
option httpchk # <--- 启用 HTTP 健康检查
option http-keep-alive # <--- 保持HTTP连接
http-check send meth OPTIONS uri /sync # <---- 这里使用 /sync ,Patroni 健康检查 API ,只有同步备库和主库才会返回 200 健康状态码。
http-check expect status 200 # <---- 健康检查返回代码 200 代表正常
default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100
# servers: # pg-test 集群全部三个实例都被 selector: "[]" 给圈中了,因为没有任何的筛选条件,所以都会作为 pg-test-replica 服务的后端服务器。但是因为还有 /sync 健康检查,所以只有主库和同步备库才能真正承载请求。
server pg-test-1 10.10.10.11:6432 check port 8008 weight 100 backup # <----- 唯独主库满足条件 pg_role == `primary`, 被 backup selector 选中。
server pg-test-3 10.10.10.13:6432 check port 8008 weight 100 # 因此作为服务的兜底实例:平时不承载请求,其他从库全部宕机后,才会承载只读请求,从而最大避免了读写服务受到只读服务的影响
server pg-test-2 10.10.10.12:6432 check port 8008 weight 100 #
在这里,pg-test 集群全部三个实例都被 selector: "[]" 给圈中了,渲染进入 pg-test-replica 服务的后端服务器列表中。但是因为还有 /sync 健康检查,Patroni Rest API只有在主库和同步备库上才会返回代表健康的 HTTP 200 状态码,因此只有主库和同步备库才能真正承载请求。
此外,主库因为满足条件 pg_role == primary, 被 backup selector 选中,被标记为了备份服务器,只有当没有其他实例(也就是同步备库)可以满足需求时,才会顶上。
Primary服务
Primary服务可能是生产环境中最关键的服务,它在 5433 端口提供对数据库集群的读写能力,服务定义如下:
- { name: primary ,port: 5433 ,dest: default ,check: /primary ,selector: "[]" }
- 选择器参数
selector: "[]"意味着所有集群成员都将被包括在Primary服务中 - 但只有主库能够通过健康检查(
check: /primary),实际承载Primary服务的流量。 - 目的地参数
dest: default意味着Primary服务的目的地受到pg_default_service_dest参数的影响 dest默认值default会被替换为pg_default_service_dest的值,默认为pgbouncer。- 默认情况下 Primary 服务的目的地默认是主库上的连接池,也就是由
pgbouncer_port指定的端口,默认为 6432
如果 pg_default_service_dest 的值为 postgres,那么 primary 服务的目的地就会绕过连接池,直接使用 PostgreSQL 数据库的端口(pg_port,默认值 5432),对于一些不希望使用连接池的场景,这个参数非常实用。
示例:pg-test-primary 的 haproxy 配置
listen pg-test-primary
bind *:5433 # <--- primary 服务默认使用 5433 端口
mode tcp
maxconn 5000
balance roundrobin
option httpchk
option http-keep-alive
http-check send meth OPTIONS uri /primary # <--- primary 服务默认使用 Patroni RestAPI /primary 健康检查
http-check expect status 200
default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100
# servers
server pg-test-1 10.10.10.11:6432 check port 8008 weight 100
server pg-test-3 10.10.10.13:6432 check port 8008 weight 100
server pg-test-2 10.10.10.12:6432 check port 8008 weight 100
Patroni 的高可用机制确保任何时候最多只会有一个实例的 /primary 健康检查为真,因此Primary服务将始终将流量路由到主实例。
使用 Primary 服务而不是直连数据库的一个好处是,如果集群因为某种情况出现了双主(比如在没有watchdog的情况下kill -9杀死主库 Patroni),Haproxy在这种情况下仍然可以避免脑裂,因为它只会在 Patroni 存活且返回主库状态时才会分发流量。
Replica服务
Replica服务在生产环境中的重要性仅次于Primary服务,它在 5434 端口提供对数据库集群的只读能力,服务定义如下:
- { name: replica ,port: 5434 ,dest: default ,check: /read-only ,selector: "[]" , backup: "[? pg_role == `primary` || pg_role == `offline` ]" }
- 选择器参数
selector: "[]"意味着所有集群成员都将被包括在Replica服务中 - 所有实例都能够通过健康检查(
check: /read-only),承载Replica服务的流量。 - 备份选择器:
[? pg_role == 'primary' || pg_role == 'offline' ]将主库和离线从库标注为备份服务器。 - 只有当所有普通从库都宕机后,Replica服务才会由主库或离线从库来承载。
- 目的地参数
dest: default意味着Replica服务的目的地也受到pg_default_service_dest参数的影响 dest默认值default会被替换为pg_default_service_dest的值,默认为pgbouncer,这一点和 Primary服务 相同- 默认情况下 Replica 服务的目的地默认是从库上的连接池,也就是由
pgbouncer_port指定的端口,默认为 6432
示例:pg-test-replica 的 haproxy 配置
listen pg-test-replica
bind *:5434
mode tcp
maxconn 5000
balance roundrobin
option httpchk
option http-keep-alive
http-check send meth OPTIONS uri /read-only
http-check expect status 200
default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100
# servers
server pg-test-1 10.10.10.11:6432 check port 8008 weight 100 backup
server pg-test-3 10.10.10.13:6432 check port 8008 weight 100
server pg-test-2 10.10.10.12:6432 check port 8008 weight 100
Replica服务非常灵活:如果有存活的专用 Replica 实例,那么它会优先使用这些实例来承载只读请求,只有当从库实例全部宕机后,才会由主库来兜底只读请求。对于常见的一主一从双节点集群就是:只要从库活着就用从库,从库挂了再用主库。
此外,除非专用只读实例全部宕机,Replica 服务也不会使用专用 Offline 实例,这样就避免了在线快查询与离线慢查询混在一起,相互影响。
Default服务
Default服务在 5436 端口上提供服务,它是Primary服务的变体。
Default服务总是绕过连接池直接连到主库上的 PostgreSQL,这对于管理连接、ETL写入、CDC数据变更捕获等都很有用。
- { name: primary ,port: 5433 ,dest: default ,check: /primary ,selector: "[]" }
如果 pg_default_service_dest 被修改为 postgres,那么可以说 Default 服务除了端口和名称内容之外,与 Primary 服务是完全等价的。在这种情况下,您可以考虑将 Default 从默认服务中剔除。
示例:pg-test-default 的 haproxy 配置
listen pg-test-default
bind *:5436 # <--- 除了监听端口/目标端口和服务名,其他配置和 primary 服务一模一样
mode tcp
maxconn 5000
balance roundrobin
option httpchk
option http-keep-alive
http-check send meth OPTIONS uri /primary
http-check expect status 200
default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100
# servers
server pg-test-1 10.10.10.11:5432 check port 8008 weight 100
server pg-test-3 10.10.10.13:5432 check port 8008 weight 100
server pg-test-2 10.10.10.12:5432 check port 8008 weight 100
Offline服务
Default服务在 5438 端口上提供服务,它也绕开连接池直接访问 PostgreSQL 数据库,通常用于慢查询/分析查询/ETL读取/个人用户交互式查询,其服务定义如下:
- { name: offline ,port: 5438 ,dest: postgres ,check: /replica ,selector: "[? pg_role == `offline` || pg_offline_query ]" , backup: "[? pg_role == `replica` && !pg_offline_query]"}
Offline服务将流量直接路由到专用的离线从库上,或者带有 pg_offline_query 标记的普通只读实例。
- 选择器参数从集群中筛选出了两种实例:
pg_role=offline的离线从库,或是带有pg_offline_query=true标记的普通只读实例 - 专用离线从库和打标记的普通从库主要的区别在于:前者默认不承载 Replica服务 的请求,避免快慢请求混在一起,而后者默认会承载。
- 备份选择器参数从集群中筛选出了一种实例:不带 offline 标记的普通从库,这意味着如果离线实例或者带Offline标记的普通从库挂了之后,其他普通的从库可以用来承载Offline服务。
- 健康检查
/replica只会针对从库返回 200, 主库会返回错误,因此 Offline服务 永远不会将流量分发到主库实例上去,哪怕集群中只剩这一台主库。 - 同时,主库实例既不会被选择器圈中,也不会被备份选择器圈中,因此它永远不会承载Offline服务。因此 Offline 服务总是可以避免用户访问主库,从而避免对主库的影响。
示例:pg-test-offline 的 haproxy 配置
listen pg-test-offline
bind *:5438
mode tcp
maxconn 5000
balance roundrobin
option httpchk
option http-keep-alive
http-check send meth OPTIONS uri /replica
http-check expect status 200
default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100
# servers
server pg-test-3 10.10.10.13:5432 check port 8008 weight 100
server pg-test-2 10.10.10.12:5432 check port 8008 weight 100 backup
Offline服务提供受限的只读服务,通常用于两类查询:交互式查询(个人用户),慢查询长事务(分析/ETL)。
Offline 服务需要额外的维护照顾:当集群发生主从切换或故障自动切换时,集群的实例角色会发生变化,而 Haproxy 的配置却不会自动发生变化。对于有多个从库的集群来说,这通常并不是一个问题。 然而对于一主一从,从库跑Offline查询的精简小集群而言,主从切换意味着从库变成了主库(健康检查失效),原来的主库变成了从库(不在 Offline 后端列表中),于是没有实例可以承载 Offline 服务了,因此需要手动重载服务以使变更生效。
如果您的业务模型较为简单,您可以考虑剔除 Default 服务与 Offline 服务,使用 Primary 服务与 Replica 服务直连数据库。
重载服务
当集群成员发生变化,如添加/删除副本、主备切换或调整相对权重时, 你需要 重载服务 以使更改生效。
bin/pgsql-svc <cls> [ip...] # 为 lb 集群或 lb 实例重载服务
# ./pgsql.yml -t pg_service # 重载服务的实际 ansible 任务
接入服务
Pigsty的服务交付边界止步于集群的HAProxy,用户可以用各种手段访问这些负载均衡器。
典型的做法是使用 DNS 或 VIP 接入,将其绑定在集群所有或任意数量的负载均衡器上。
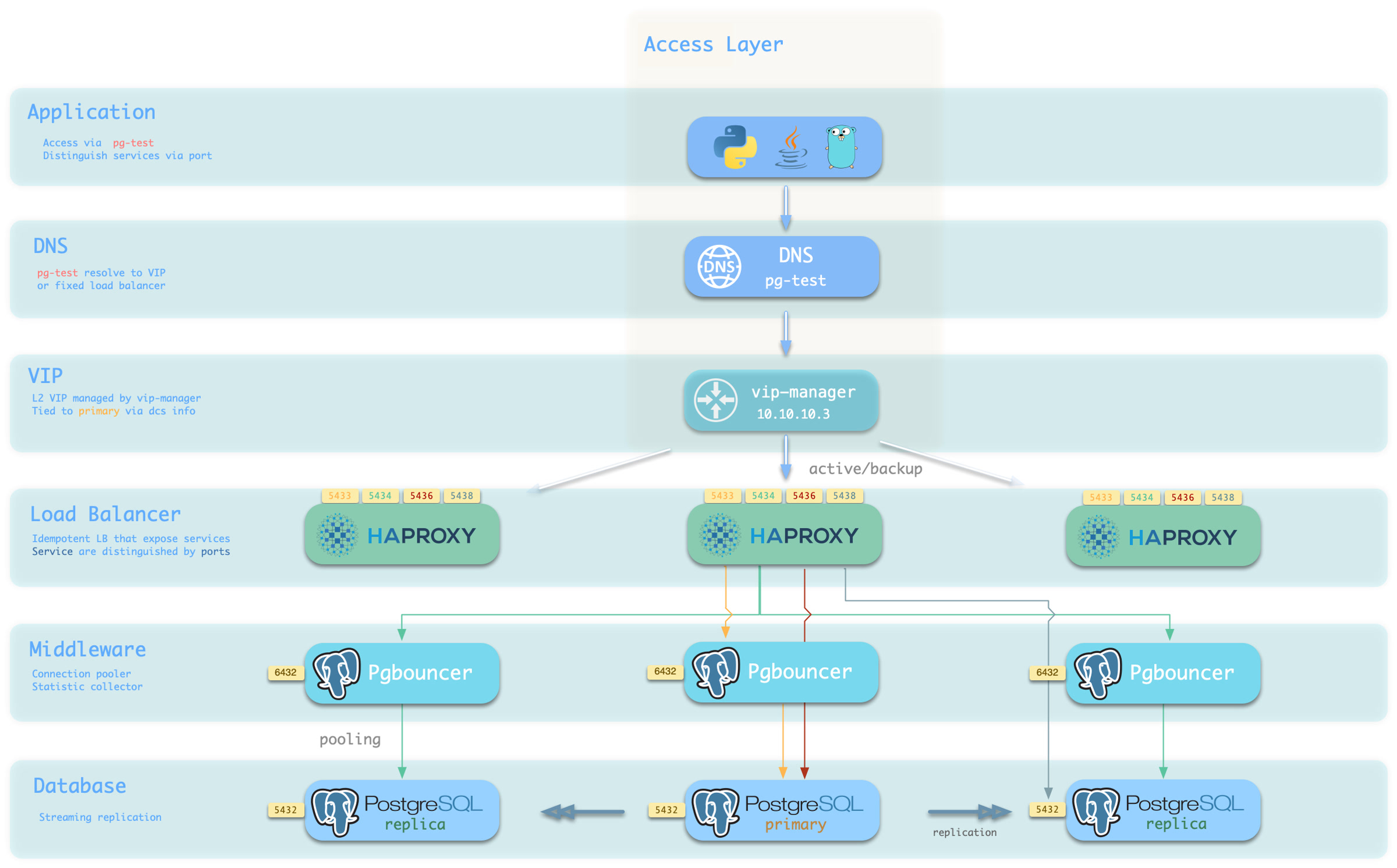
你可以使用不同的 主机 & 端口 组合,它们以不同的方式提供 PostgreSQL 服务。
主机
| 类型 | 样例 | 描述 |
|---|---|---|
| 集群域名 | pg-test |
通过集群域名访问(由 dnsmasq @ infra 节点解析) |
| 集群 VIP 地址 | 10.10.10.3 |
通过由 vip-manager 管理的 L2 VIP 地址访问,绑定到主节点 |
| 实例主机名 | pg-test-1 |
通过任何实例主机名访问(由 dnsmasq @ infra 节点解析) |
| 实例 IP 地址 | 10.10.10.11 |
访问任何实例的 IP 地址 |
端口
Pigsty 使用不同的 端口 来区分 pg services
| 端口 | 服务 | 类型 | 描述 |
|---|---|---|---|
| 5432 | postgres | 数据库 | 直接访问 postgres 服务器 |
| 6432 | pgbouncer | 中间件 | 访问 postgres 前先通过连接池中间件 |
| 5433 | primary | 服务 | 访问主 pgbouncer (或 postgres) |
| 5434 | replica | 服务 | 访问备份 pgbouncer (或 postgres) |
| 5436 | default | 服务 | 访问主 postgres |
| 5438 | offline | 服务 | 访问离线 postgres |
组合
# 通过集群域名访问
postgres://test@pg-test:5432/test # DNS -> L2 VIP -> 主直接连接
postgres://test@pg-test:6432/test # DNS -> L2 VIP -> 主连接池 -> 主
postgres://test@pg-test:5433/test # DNS -> L2 VIP -> HAProxy -> 主连接池 -> 主
postgres://test@pg-test:5434/test # DNS -> L2 VIP -> HAProxy -> 备份连接池 -> 备份
postgres://dbuser_dba@pg-test:5436/test # DNS -> L2 VIP -> HAProxy -> 主直接连接 (用于管理员)
postgres://dbuser_stats@pg-test:5438/test # DNS -> L2 VIP -> HAProxy -> 离线直接连接 (用于 ETL/个人查询)
# 通过集群 VIP 直接访问
postgres://test@10.10.10.3:5432/test # L2 VIP -> 主直接访问
postgres://test@10.10.10.3:6432/test # L2 VIP -> 主连接池 -> 主
postgres://test@10.10.10.3:5433/test # L2 VIP -> HAProxy -> 主连接池 -> 主
postgres://test@10.10.10.3:5434/test # L2 VIP -> HAProxy -> 备份连接池 -> 备份
postgres://dbuser_dba@10.10.10.3:5436/test # L2 VIP -> HAProxy -> 主直接连接 (用于管理员)
postgres://dbuser_stats@10.10.10.3::5438/test # L2 VIP -> HAProxy -> 离线直接连接 (用于 ETL/个人查询)
# 直接指定任何集群实例名
postgres://test@pg-test-1:5432/test # DNS -> 数据库实例直接连接 (单例访问)
postgres://test@pg-test-1:6432/test # DNS -> 连接池 -> 数据库
postgres://test@pg-test-1:5433/test # DNS -> HAProxy -> 连接池 -> 数据库读/写
postgres://test@pg-test-1:5434/test # DNS -> HAProxy -> 连接池 -> 数据库只读
postgres://dbuser_dba@pg-test-1:5436/test # DNS -> HAProxy -> 数据库直接连接
postgres://dbuser_stats@pg-test-1:5438/test # DNS -> HAProxy -> 数据库离线读/写
# 直接指定任何集群实例 IP 访问
postgres://test@10.10.10.11:5432/test # 数据库实例直接连接 (直接指定实例, 没有自动流量分配)
postgres://test@10.10.10.11:6432/test # 连接池 -> 数据库
postgres://test@10.10.10.11:5433/test # HAProxy -> 连接池 -> 数据库读/写
postgres://test@10.10.10.11:5434/test # HAProxy -> 连接池 -> 数据库只读
postgres://dbuser_dba@10.10.10.11:5436/test # HAProxy -> 数据库直接连接
postgres://dbuser_stats@10.10.10.11:5438/test # HAProxy -> 数据库离线读-写
# 智能客户端:自动进行读写分离
postgres://test@10.10.10.11:6432,10.10.10.12:6432,10.10.10.13:6432/test?target_session_attrs=primary
postgres://test@10.10.10.11:6432,10.10.10.12:6432,10.10.10.13:6432/test?target_session_attrs=prefer-standby
覆盖服务
你可以通过多种方式覆盖默认的服务配置,一种常见的需求是让 Primary服务 与 Replica服务 绕过Pgbouncer连接池,直接访问 PostgreSQL 数据库。
为了实现这一点,你可以将 pg_default_service_dest 更改为 postgres,这样所有服务定义中 svc.dest='default' 的服务都会使用 postgres 而不是默认的 pgbouncer 作为目标。
如果您已经将 Primary服务 指向了 PostgreSQL,那么 default服务 就会比较多余,可以考虑移除。
如果您不需要区分个人交互式查询,分析/ETL慢查询,可以考虑从默认服务列表 pg_default_services 中移除Offline服务。
如果您不需要只读从库来分担在线只读流量,也可以从默认服务列表中移除 Replica服务。
委托服务
Pigsty 通过节点上的 haproxy 暴露 PostgreSQL 服务。整个集群中的所有 haproxy 实例都使用相同的服务定义进行配置。
但是,你可以将 pg 服务委托给特定的节点分组(例如,专门的 haproxy 负载均衡器集群),而不是 PostgreSQL 集群成员上的 haproxy。
为此,你需要使用 pg_default_services 覆盖默认的服务定义,并将 pg_service_provider 设置为代理组名称。
例如,此配置将在端口 10013 的 proxy haproxy 节点组上公开 pg 集群的主服务。
pg_service_provider: proxy # 使用端口 10013 上的 `proxy` 组的负载均衡器
pg_default_services: [{ name: primary ,port: 10013 ,dest: postgres ,check: /primary ,selector: "[]" }]
用户需要确保每个委托服务的端口,在代理集群中都是唯一的。
在42节点生产环境仿真沙箱中提供了一个使用专用负载均衡器集群的例子:prod.yml
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.