| ALERTS |
Unknown |
category, job, level, ins, severity, ip, alertname, alertstate, instance, cls |
N/A |
| ALERTS_FOR_STATE |
Unknown |
category, job, level, ins, severity, ip, alertname, instance, cls |
N/A |
| cls:pressure1 |
Unknown |
job, cls |
N/A |
| cls:pressure15 |
Unknown |
job, cls |
N/A |
| cls:pressure5 |
Unknown |
job, cls |
N/A |
| go_gc_duration_seconds |
summary |
job, ins, ip, instance, quantile, cls |
A summary of the pause duration of garbage collection cycles. |
| go_gc_duration_seconds_count |
Unknown |
job, ins, ip, instance, cls |
N/A |
| go_gc_duration_seconds_sum |
Unknown |
job, ins, ip, instance, cls |
N/A |
| go_goroutines |
gauge |
job, ins, ip, instance, cls |
Number of goroutines that currently exist. |
| go_info |
gauge |
version, job, ins, ip, instance, cls |
Information about the Go environment. |
| go_memstats_alloc_bytes |
gauge |
job, ins, ip, instance, cls |
Number of bytes allocated and still in use. |
| go_memstats_alloc_bytes_total |
counter |
job, ins, ip, instance, cls |
Total number of bytes allocated, even if freed. |
| go_memstats_buck_hash_sys_bytes |
gauge |
job, ins, ip, instance, cls |
Number of bytes used by the profiling bucket hash table. |
| go_memstats_frees_total |
counter |
job, ins, ip, instance, cls |
Total number of frees. |
| go_memstats_gc_sys_bytes |
gauge |
job, ins, ip, instance, cls |
Number of bytes used for garbage collection system metadata. |
| go_memstats_heap_alloc_bytes |
gauge |
job, ins, ip, instance, cls |
Number of heap bytes allocated and still in use. |
| go_memstats_heap_idle_bytes |
gauge |
job, ins, ip, instance, cls |
Number of heap bytes waiting to be used. |
| go_memstats_heap_inuse_bytes |
gauge |
job, ins, ip, instance, cls |
Number of heap bytes that are in use. |
| go_memstats_heap_objects |
gauge |
job, ins, ip, instance, cls |
Number of allocated objects. |
| go_memstats_heap_released_bytes |
gauge |
job, ins, ip, instance, cls |
Number of heap bytes released to OS. |
| go_memstats_heap_sys_bytes |
gauge |
job, ins, ip, instance, cls |
Number of heap bytes obtained from system. |
| go_memstats_last_gc_time_seconds |
gauge |
job, ins, ip, instance, cls |
Number of seconds since 1970 of last garbage collection. |
| go_memstats_lookups_total |
counter |
job, ins, ip, instance, cls |
Total number of pointer lookups. |
| go_memstats_mallocs_total |
counter |
job, ins, ip, instance, cls |
Total number of mallocs. |
| go_memstats_mcache_inuse_bytes |
gauge |
job, ins, ip, instance, cls |
Number of bytes in use by mcache structures. |
| go_memstats_mcache_sys_bytes |
gauge |
job, ins, ip, instance, cls |
Number of bytes used for mcache structures obtained from system. |
| go_memstats_mspan_inuse_bytes |
gauge |
job, ins, ip, instance, cls |
Number of bytes in use by mspan structures. |
| go_memstats_mspan_sys_bytes |
gauge |
job, ins, ip, instance, cls |
Number of bytes used for mspan structures obtained from system. |
| go_memstats_next_gc_bytes |
gauge |
job, ins, ip, instance, cls |
Number of heap bytes when next garbage collection will take place. |
| go_memstats_other_sys_bytes |
gauge |
job, ins, ip, instance, cls |
Number of bytes used for other system allocations. |
| go_memstats_stack_inuse_bytes |
gauge |
job, ins, ip, instance, cls |
Number of bytes in use by the stack allocator. |
| go_memstats_stack_sys_bytes |
gauge |
job, ins, ip, instance, cls |
Number of bytes obtained from system for stack allocator. |
| go_memstats_sys_bytes |
gauge |
job, ins, ip, instance, cls |
Number of bytes obtained from system. |
| go_threads |
gauge |
job, ins, ip, instance, cls |
Number of OS threads created. |
| ins:pressure1 |
Unknown |
job, ins, ip, cls |
N/A |
| ins:pressure15 |
Unknown |
job, ins, ip, cls |
N/A |
| ins:pressure5 |
Unknown |
job, ins, ip, cls |
N/A |
| patroni_cluster_unlocked |
gauge |
job, ins, ip, instance, cls, scope |
Value is 1 if the cluster is unlocked, 0 if locked. |
| patroni_dcs_last_seen |
gauge |
job, ins, ip, instance, cls, scope |
Epoch timestamp when DCS was last contacted successfully by Patroni. |
| patroni_failsafe_mode_is_active |
gauge |
job, ins, ip, instance, cls, scope |
Value is 1 if failsafe mode is active, 0 if inactive. |
| patroni_is_paused |
gauge |
job, ins, ip, instance, cls, scope |
Value is 1 if auto failover is disabled, 0 otherwise. |
| patroni_master |
gauge |
job, ins, ip, instance, cls, scope |
Value is 1 if this node is the leader, 0 otherwise. |
| patroni_pending_restart |
gauge |
job, ins, ip, instance, cls, scope |
Value is 1 if the node needs a restart, 0 otherwise. |
| patroni_postgres_in_archive_recovery |
gauge |
job, ins, ip, instance, cls, scope |
Value is 1 if Postgres is replicating from archive, 0 otherwise. |
| patroni_postgres_running |
gauge |
job, ins, ip, instance, cls, scope |
Value is 1 if Postgres is running, 0 otherwise. |
| patroni_postgres_server_version |
gauge |
job, ins, ip, instance, cls, scope |
Version of Postgres (if running), 0 otherwise. |
| patroni_postgres_streaming |
gauge |
job, ins, ip, instance, cls, scope |
Value is 1 if Postgres is streaming, 0 otherwise. |
| patroni_postgres_timeline |
counter |
job, ins, ip, instance, cls, scope |
Postgres timeline of this node (if running), 0 otherwise. |
| patroni_postmaster_start_time |
gauge |
job, ins, ip, instance, cls, scope |
Epoch seconds since Postgres started. |
| patroni_primary |
gauge |
job, ins, ip, instance, cls, scope |
Value is 1 if this node is the leader, 0 otherwise. |
| patroni_replica |
gauge |
job, ins, ip, instance, cls, scope |
Value is 1 if this node is a replica, 0 otherwise. |
| patroni_standby_leader |
gauge |
job, ins, ip, instance, cls, scope |
Value is 1 if this node is the standby_leader, 0 otherwise. |
| patroni_sync_standby |
gauge |
job, ins, ip, instance, cls, scope |
Value is 1 if this node is a sync standby replica, 0 otherwise. |
| patroni_up |
Unknown |
job, ins, ip, instance, cls |
N/A |
| patroni_version |
gauge |
job, ins, ip, instance, cls, scope |
Patroni semver without periods. |
| patroni_xlog_location |
counter |
job, ins, ip, instance, cls, scope |
Current location of the Postgres transaction log, 0 if this node is not the leader. |
| patroni_xlog_paused |
gauge |
job, ins, ip, instance, cls, scope |
Value is 1 if the Postgres xlog is paused, 0 otherwise. |
| patroni_xlog_received_location |
counter |
job, ins, ip, instance, cls, scope |
Current location of the received Postgres transaction log, 0 if this node is not a replica. |
| patroni_xlog_replayed_location |
counter |
job, ins, ip, instance, cls, scope |
Current location of the replayed Postgres transaction log, 0 if this node is not a replica. |
| patroni_xlog_replayed_timestamp |
gauge |
job, ins, ip, instance, cls, scope |
Current timestamp of the replayed Postgres transaction log, 0 if null. |
| pg:cls:active_backends |
Unknown |
job, cls |
N/A |
| pg:cls:active_time_rate15m |
Unknown |
job, cls |
N/A |
| pg:cls:active_time_rate1m |
Unknown |
job, cls |
N/A |
| pg:cls:active_time_rate5m |
Unknown |
job, cls |
N/A |
| pg:cls:age |
Unknown |
job, cls |
N/A |
| pg:cls:buf_alloc_rate1m |
Unknown |
job, cls |
N/A |
| pg:cls:buf_clean_rate1m |
Unknown |
job, cls |
N/A |
| pg:cls:buf_flush_backend_rate1m |
Unknown |
job, cls |
N/A |
| pg:cls:buf_flush_checkpoint_rate1m |
Unknown |
job, cls |
N/A |
| pg:cls:cpu_count |
Unknown |
job, cls |
N/A |
| pg:cls:cpu_usage |
Unknown |
job, cls |
N/A |
| pg:cls:cpu_usage_15m |
Unknown |
job, cls |
N/A |
| pg:cls:cpu_usage_1m |
Unknown |
job, cls |
N/A |
| pg:cls:cpu_usage_5m |
Unknown |
job, cls |
N/A |
| pg:cls:db_size |
Unknown |
job, cls |
N/A |
| pg:cls:file_size |
Unknown |
job, cls |
N/A |
| pg:cls:ixact_backends |
Unknown |
job, cls |
N/A |
| pg:cls:ixact_time_rate1m |
Unknown |
job, cls |
N/A |
| pg:cls:lag_bytes |
Unknown |
job, cls |
N/A |
| pg:cls:lag_seconds |
Unknown |
job, cls |
N/A |
| pg:cls:leader |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:cls:load1 |
Unknown |
job, cls |
N/A |
| pg:cls:load15 |
Unknown |
job, cls |
N/A |
| pg:cls:load5 |
Unknown |
job, cls |
N/A |
| pg:cls:lock_count |
Unknown |
job, cls |
N/A |
| pg:cls:locks |
Unknown |
job, cls, mode |
N/A |
| pg:cls:log_size |
Unknown |
job, cls |
N/A |
| pg:cls:lsn_rate1m |
Unknown |
job, cls |
N/A |
| pg:cls:members |
Unknown |
job, ins, ip, cls |
N/A |
| pg:cls:num_backends |
Unknown |
job, cls |
N/A |
| pg:cls:partition |
Unknown |
job, cls |
N/A |
| pg:cls:receiver |
Unknown |
state, slot_name, job, appname, ip, cls, sender_host, sender_port |
N/A |
| pg:cls:rlock_count |
Unknown |
job, cls |
N/A |
| pg:cls:saturation1 |
Unknown |
job, cls |
N/A |
| pg:cls:saturation15 |
Unknown |
job, cls |
N/A |
| pg:cls:saturation5 |
Unknown |
job, cls |
N/A |
| pg:cls:sender |
Unknown |
pid, usename, address, job, ins, appname, ip, cls |
N/A |
| pg:cls:session_time_rate1m |
Unknown |
job, cls |
N/A |
| pg:cls:size |
Unknown |
job, cls |
N/A |
| pg:cls:slot_count |
Unknown |
job, cls |
N/A |
| pg:cls:slot_retained_bytes |
Unknown |
job, cls |
N/A |
| pg:cls:standby_count |
Unknown |
job, cls |
N/A |
| pg:cls:sync_state |
Unknown |
job, cls |
N/A |
| pg:cls:timeline |
Unknown |
job, cls |
N/A |
| pg:cls:tup_deleted_rate1m |
Unknown |
job, cls |
N/A |
| pg:cls:tup_fetched_rate1m |
Unknown |
job, cls |
N/A |
| pg:cls:tup_inserted_rate1m |
Unknown |
job, cls |
N/A |
| pg:cls:tup_modified_rate1m |
Unknown |
job, cls |
N/A |
| pg:cls:tup_returned_rate1m |
Unknown |
job, cls |
N/A |
| pg:cls:wal_size |
Unknown |
job, cls |
N/A |
| pg:cls:xact_commit_rate15m |
Unknown |
job, cls |
N/A |
| pg:cls:xact_commit_rate1m |
Unknown |
job, cls |
N/A |
| pg:cls:xact_commit_rate5m |
Unknown |
job, cls |
N/A |
| pg:cls:xact_rollback_rate15m |
Unknown |
job, cls |
N/A |
| pg:cls:xact_rollback_rate1m |
Unknown |
job, cls |
N/A |
| pg:cls:xact_rollback_rate5m |
Unknown |
job, cls |
N/A |
| pg:cls:xact_total_rate15m |
Unknown |
job, cls |
N/A |
| pg:cls:xact_total_rate1m |
Unknown |
job, cls |
N/A |
| pg:cls:xact_total_sigma15m |
Unknown |
job, cls |
N/A |
| pg:cls:xlock_count |
Unknown |
job, cls |
N/A |
| pg:db:active_backends |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:active_time_rate15m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:active_time_rate1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:active_time_rate5m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:age |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:age_deriv1h |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:age_exhaust |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:blk_io_time_seconds_rate1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:blk_read_time_seconds_rate1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:blk_write_time_seconds_rate1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:blks_access_1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:blks_hit_1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:blks_hit_ratio1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:blks_read_1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:conn_limit |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:conn_usage |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:db_size |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:ixact_backends |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:ixact_time_rate1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:lock_count |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:num_backends |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:rlock_count |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:session_time_rate1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:temp_bytes_rate1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:temp_files_1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:tup_deleted_rate1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:tup_fetched_rate1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:tup_inserted_rate1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:tup_modified_rate1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:tup_returned_rate1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:wlock_count |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:xact_commit_rate15m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:xact_commit_rate1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:xact_commit_rate5m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:xact_rollback_rate15m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:xact_rollback_rate1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:xact_rollback_rate5m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:xact_total_rate15m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:xact_total_rate1m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:xact_total_rate5m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:xact_total_sigma15m |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:db:xlock_count |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg:env:active_backends |
Unknown |
job |
N/A |
| pg:env:active_time_rate15m |
Unknown |
job |
N/A |
| pg:env:active_time_rate1m |
Unknown |
job |
N/A |
| pg:env:active_time_rate5m |
Unknown |
job |
N/A |
| pg:env:age |
Unknown |
job |
N/A |
| pg:env:cpu_count |
Unknown |
job |
N/A |
| pg:env:cpu_usage |
Unknown |
job |
N/A |
| pg:env:cpu_usage_15m |
Unknown |
job |
N/A |
| pg:env:cpu_usage_1m |
Unknown |
job |
N/A |
| pg:env:cpu_usage_5m |
Unknown |
job |
N/A |
| pg:env:ixact_backends |
Unknown |
job |
N/A |
| pg:env:ixact_time_rate1m |
Unknown |
job |
N/A |
| pg:env:lag_bytes |
Unknown |
job |
N/A |
| pg:env:lag_seconds |
Unknown |
job |
N/A |
| pg:env:lsn_rate1m |
Unknown |
job |
N/A |
| pg:env:session_time_rate1m |
Unknown |
job |
N/A |
| pg:env:tup_deleted_rate1m |
Unknown |
job |
N/A |
| pg:env:tup_fetched_rate1m |
Unknown |
job |
N/A |
| pg:env:tup_inserted_rate1m |
Unknown |
job |
N/A |
| pg:env:tup_modified_rate1m |
Unknown |
job |
N/A |
| pg:env:tup_returned_rate1m |
Unknown |
job |
N/A |
| pg:env:xact_commit_rate15m |
Unknown |
job |
N/A |
| pg:env:xact_commit_rate1m |
Unknown |
job |
N/A |
| pg:env:xact_commit_rate5m |
Unknown |
job |
N/A |
| pg:env:xact_rollback_rate15m |
Unknown |
job |
N/A |
| pg:env:xact_rollback_rate1m |
Unknown |
job |
N/A |
| pg:env:xact_rollback_rate5m |
Unknown |
job |
N/A |
| pg:env:xact_total_rate15m |
Unknown |
job |
N/A |
| pg:env:xact_total_rate1m |
Unknown |
job |
N/A |
| pg:env:xact_total_sigma15m |
Unknown |
job |
N/A |
| pg:ins:active_backends |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:active_time_rate15m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:active_time_rate1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:active_time_rate5m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:age |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:blks_hit_ratio1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:buf_alloc_rate1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:buf_clean_rate1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:buf_flush_backend_rate1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:buf_flush_checkpoint_rate1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:ckpt_1h |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:ckpt_req_1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:ckpt_timed_1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:conn_limit |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:conn_usage |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:cpu_count |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:cpu_usage |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:cpu_usage_15m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:cpu_usage_1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:cpu_usage_5m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:db_size |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:file_size |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:fs_size |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:is_leader |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:ixact_backends |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:ixact_time_rate1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:lag_bytes |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:lag_seconds |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:load1 |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:load15 |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:load5 |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:lock_count |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:locks |
Unknown |
job, ins, ip, mode, instance, cls |
N/A |
| pg:ins:log_size |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:lsn_rate1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:mem_size |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:num_backends |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:rlock_count |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:saturation1 |
Unknown |
job, ins, ip, cls |
N/A |
| pg:ins:saturation15 |
Unknown |
job, ins, ip, cls |
N/A |
| pg:ins:saturation5 |
Unknown |
job, ins, ip, cls |
N/A |
| pg:ins:session_time_rate1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:slot_retained_bytes |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:space_usage |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:status |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:sync_state |
Unknown |
job, ins, instance, cls |
N/A |
| pg:ins:target_count |
Unknown |
job, cls, ins |
N/A |
| pg:ins:timeline |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:tup_deleted_rate1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:tup_fetched_rate1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:tup_inserted_rate1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:tup_modified_rate1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:tup_returned_rate1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:wal_size |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:wlock_count |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:xact_commit_rate15m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:xact_commit_rate1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:xact_commit_rate5m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:xact_rollback_rate15m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:xact_rollback_rate1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:xact_rollback_rate5m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:xact_total_rate15m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:xact_total_rate1m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:xact_total_rate5m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:xact_total_sigma15m |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:ins:xlock_count |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg:query:call_rate1m |
Unknown |
datname, query, job, ins, ip, instance, cls |
N/A |
| pg:query:rt_1m |
Unknown |
datname, query, job, ins, ip, instance, cls |
N/A |
| pg:table:scan_rate1m |
Unknown |
datname, relname, job, ins, ip, instance, cls |
N/A |
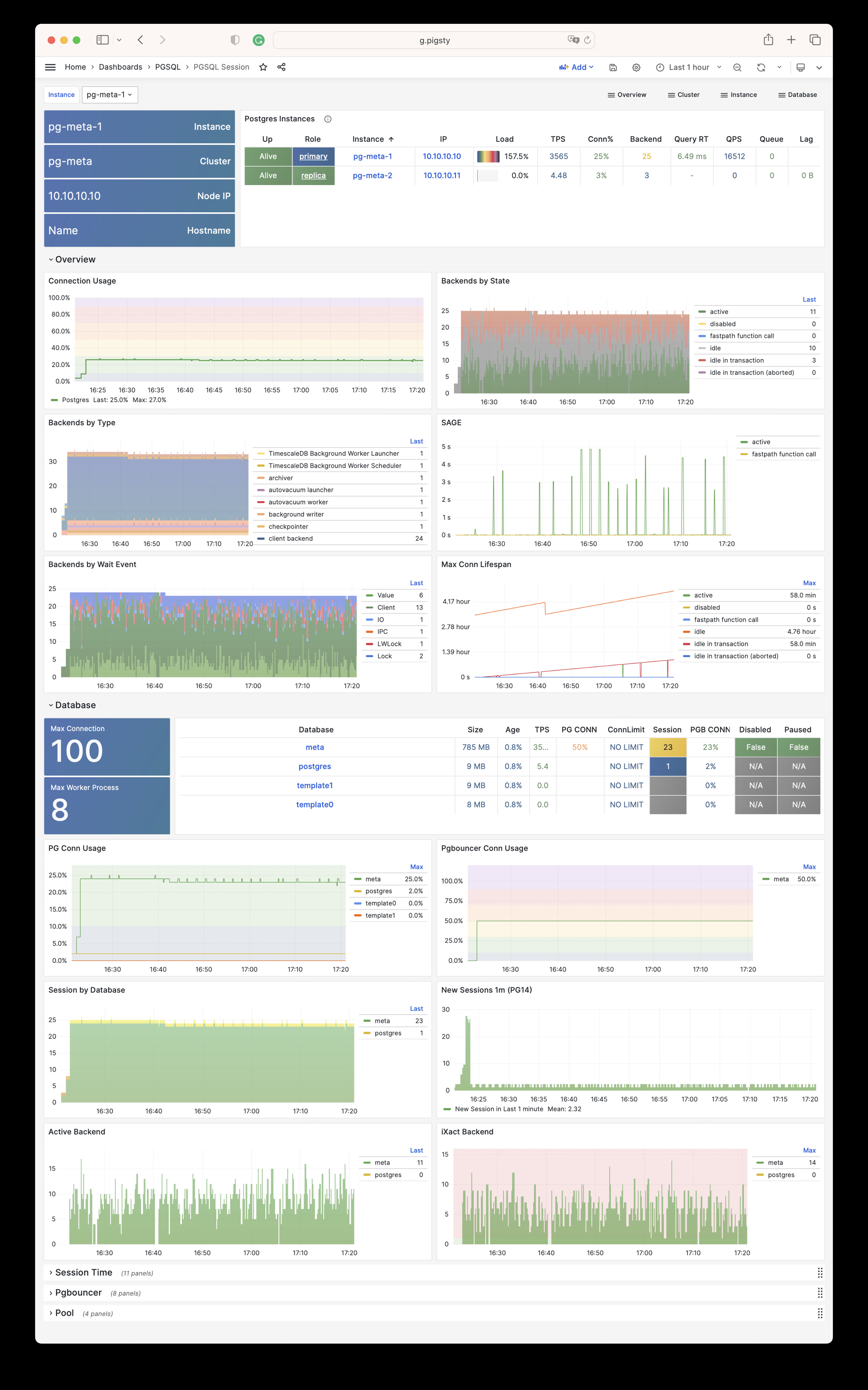
| pg_activity_count |
gauge |
datname, state, job, ins, ip, instance, cls |
Count of connection among (datname,state) |
| pg_activity_max_conn_duration |
gauge |
datname, state, job, ins, ip, instance, cls |
Max backend session duration since state change among (datname, state) |
| pg_activity_max_duration |
gauge |
datname, state, job, ins, ip, instance, cls |
Max duration since last state change among (datname, state) |
| pg_activity_max_tx_duration |
gauge |
datname, state, job, ins, ip, instance, cls |
Max transaction duration since state change among (datname, state) |
| pg_archiver_failed_count |
counter |
job, ins, ip, instance, cls |
Number of failed attempts for archiving WAL files |
| pg_archiver_finish_count |
counter |
job, ins, ip, instance, cls |
Number of WAL files that have been successfully archived |
| pg_archiver_last_failed_time |
counter |
job, ins, ip, instance, cls |
Time of the last failed archival operation |
| pg_archiver_last_finish_time |
counter |
job, ins, ip, instance, cls |
Time of the last successful archive operation |
| pg_archiver_reset_time |
gauge |
job, ins, ip, instance, cls |
Time at which archive statistics were last reset |
| pg_backend_count |
gauge |
type, job, ins, ip, instance, cls |
Database backend process count by backend_type |
| pg_bgwriter_buffers_alloc |
counter |
job, ins, ip, instance, cls |
Number of buffers allocated |
| pg_bgwriter_buffers_backend |
counter |
job, ins, ip, instance, cls |
Number of buffers written directly by a backend |
| pg_bgwriter_buffers_backend_fsync |
counter |
job, ins, ip, instance, cls |
Number of times a backend had to execute its own fsync call |
| pg_bgwriter_buffers_checkpoint |
counter |
job, ins, ip, instance, cls |
Number of buffers written during checkpoints |
| pg_bgwriter_buffers_clean |
counter |
job, ins, ip, instance, cls |
Number of buffers written by the background writer |
| pg_bgwriter_checkpoint_sync_time |
counter |
job, ins, ip, instance, cls |
Total amount of time that has been spent in the portion of checkpoint processing where files are synchronized to disk, in seconds |
| pg_bgwriter_checkpoint_write_time |
counter |
job, ins, ip, instance, cls |
Total amount of time that has been spent in the portion of checkpoint processing where files are written to disk, in seconds |
| pg_bgwriter_checkpoints_req |
counter |
job, ins, ip, instance, cls |
Number of requested checkpoints that have been performed |
| pg_bgwriter_checkpoints_timed |
counter |
job, ins, ip, instance, cls |
Number of scheduled checkpoints that have been performed |
| pg_bgwriter_maxwritten_clean |
counter |
job, ins, ip, instance, cls |
Number of times the background writer stopped a cleaning scan because it had written too many buffers |
| pg_bgwriter_reset_time |
counter |
job, ins, ip, instance, cls |
Time at which bgwriter statistics were last reset |
| pg_boot_time |
gauge |
job, ins, ip, instance, cls |
unix timestamp when postmaster boot |
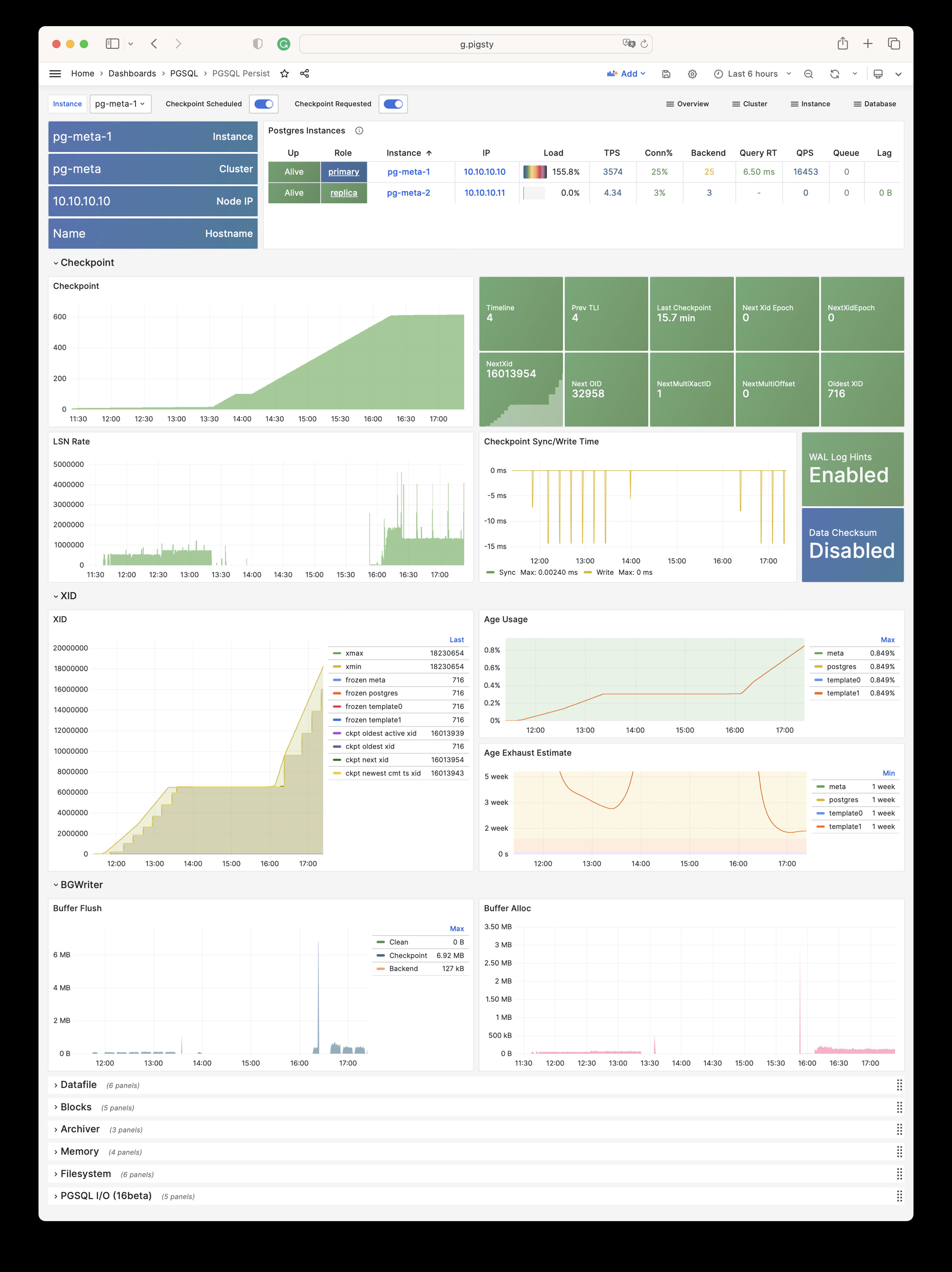
| pg_checkpoint_checkpoint_lsn |
counter |
job, ins, ip, instance, cls |
Latest checkpoint location |
| pg_checkpoint_elapse |
gauge |
job, ins, ip, instance, cls |
Seconds elapsed since latest checkpoint in seconds |
| pg_checkpoint_full_page_writes |
gauge |
job, ins, ip, instance, cls |
Latest checkpoint’s full_page_writes enabled |
| pg_checkpoint_newest_commit_ts_xid |
counter |
job, ins, ip, instance, cls |
Latest checkpoint’s newestCommitTsXid |
| pg_checkpoint_next_multi_offset |
counter |
job, ins, ip, instance, cls |
Latest checkpoint’s NextMultiOffset |
| pg_checkpoint_next_multixact_id |
counter |
job, ins, ip, instance, cls |
Latest checkpoint’s NextMultiXactId |
| pg_checkpoint_next_oid |
counter |
job, ins, ip, instance, cls |
Latest checkpoint’s NextOID |
| pg_checkpoint_next_xid |
counter |
job, ins, ip, instance, cls |
Latest checkpoint’s NextXID xid |
| pg_checkpoint_next_xid_epoch |
counter |
job, ins, ip, instance, cls |
Latest checkpoint’s NextXID epoch |
| pg_checkpoint_oldest_active_xid |
counter |
job, ins, ip, instance, cls |
Latest checkpoint’s oldestActiveXID |
| pg_checkpoint_oldest_commit_ts_xid |
counter |
job, ins, ip, instance, cls |
Latest checkpoint’s oldestCommitTsXid |
| pg_checkpoint_oldest_multi_dbid |
gauge |
job, ins, ip, instance, cls |
Latest checkpoint’s oldestMulti’s DB OID |
| pg_checkpoint_oldest_multi_xid |
counter |
job, ins, ip, instance, cls |
Latest checkpoint’s oldestMultiXid |
| pg_checkpoint_oldest_xid |
counter |
job, ins, ip, instance, cls |
Latest checkpoint’s oldestXID |
| pg_checkpoint_oldest_xid_dbid |
gauge |
job, ins, ip, instance, cls |
Latest checkpoint’s oldestXID’s DB OID |
| pg_checkpoint_prev_tli |
counter |
job, ins, ip, instance, cls |
Latest checkpoint’s PrevTimeLineID |
| pg_checkpoint_redo_lsn |
counter |
job, ins, ip, instance, cls |
Latest checkpoint’s REDO location |
| pg_checkpoint_time |
counter |
job, ins, ip, instance, cls |
Time of latest checkpoint |
| pg_checkpoint_tli |
counter |
job, ins, ip, instance, cls |
Latest checkpoint’s TimeLineID |
| pg_conf_reload_time |
gauge |
job, ins, ip, instance, cls |
seconds since last configuration reload |
| pg_db_active_time |
counter |
datname, job, ins, ip, instance, cls |
Time spent executing SQL statements in this database, in seconds |
| pg_db_age |
gauge |
datname, job, ins, ip, instance, cls |
Age of database calculated from datfrozenxid |
| pg_db_allow_conn |
gauge |
datname, job, ins, ip, instance, cls |
If false(0) then no one can connect to this database. |
| pg_db_blk_read_time |
counter |
datname, job, ins, ip, instance, cls |
Time spent reading data file blocks by backends in this database, in seconds |
| pg_db_blk_write_time |
counter |
datname, job, ins, ip, instance, cls |
Time spent writing data file blocks by backends in this database, in seconds |
| pg_db_blks_access |
counter |
datname, job, ins, ip, instance, cls |
Number of times disk blocks that accessed read+hit |
| pg_db_blks_hit |
counter |
datname, job, ins, ip, instance, cls |
Number of times disk blocks were found already in the buffer cache |
| pg_db_blks_read |
counter |
datname, job, ins, ip, instance, cls |
Number of disk blocks read in this database |
| pg_db_cks_fail_time |
gauge |
datname, job, ins, ip, instance, cls |
Time at which the last data page checksum failure was detected in this database |
| pg_db_cks_fails |
counter |
datname, job, ins, ip, instance, cls |
Number of data page checksum failures detected in this database, -1 for not enabled |
| pg_db_confl_confl_bufferpin |
counter |
datname, job, ins, ip, instance, cls |
Number of queries in this database that have been canceled due to pinned buffers |
| pg_db_confl_confl_deadlock |
counter |
datname, job, ins, ip, instance, cls |
Number of queries in this database that have been canceled due to deadlocks |
| pg_db_confl_confl_lock |
counter |
datname, job, ins, ip, instance, cls |
Number of queries in this database that have been canceled due to lock timeouts |
| pg_db_confl_confl_snapshot |
counter |
datname, job, ins, ip, instance, cls |
Number of queries in this database that have been canceled due to old snapshots |
| pg_db_confl_confl_tablespace |
counter |
datname, job, ins, ip, instance, cls |
Number of queries in this database that have been canceled due to dropped tablespaces |
| pg_db_conflicts |
counter |
datname, job, ins, ip, instance, cls |
Number of queries canceled due to conflicts with recovery in this database |
| pg_db_conn_limit |
gauge |
datname, job, ins, ip, instance, cls |
Sets maximum number of concurrent connections that can be made to this database. -1 means no limit. |
| pg_db_datid |
gauge |
datname, job, ins, ip, instance, cls |
OID of the database |
| pg_db_deadlocks |
counter |
datname, job, ins, ip, instance, cls |
Number of deadlocks detected in this database |
| pg_db_frozen_xid |
gauge |
datname, job, ins, ip, instance, cls |
All transaction IDs before this one have been frozened |
| pg_db_is_template |
gauge |
datname, job, ins, ip, instance, cls |
If true(1), then this database can be cloned by any user with CREATEDB privileges |
| pg_db_ixact_time |
counter |
datname, job, ins, ip, instance, cls |
Time spent idling while in a transaction in this database, in seconds |
| pg_db_numbackends |
gauge |
datname, job, ins, ip, instance, cls |
Number of backends currently connected to this database |
| pg_db_reset_time |
counter |
datname, job, ins, ip, instance, cls |
Time at which database statistics were last reset |
| pg_db_session_time |
counter |
datname, job, ins, ip, instance, cls |
Time spent by database sessions in this database, in seconds |
| pg_db_sessions |
counter |
datname, job, ins, ip, instance, cls |
Total number of sessions established to this database |
| pg_db_sessions_abandoned |
counter |
datname, job, ins, ip, instance, cls |
Number of database sessions to this database that were terminated because connection to the client was lost |
| pg_db_sessions_fatal |
counter |
datname, job, ins, ip, instance, cls |
Number of database sessions to this database that were terminated by fatal errors |
| pg_db_sessions_killed |
counter |
datname, job, ins, ip, instance, cls |
Number of database sessions to this database that were terminated by operator intervention |
| pg_db_temp_bytes |
counter |
datname, job, ins, ip, instance, cls |
Total amount of data written to temporary files by queries in this database. |
| pg_db_temp_files |
counter |
datname, job, ins, ip, instance, cls |
Number of temporary files created by queries in this database |
| pg_db_tup_deleted |
counter |
datname, job, ins, ip, instance, cls |
Number of rows deleted by queries in this database |
| pg_db_tup_fetched |
counter |
datname, job, ins, ip, instance, cls |
Number of rows fetched by queries in this database |
| pg_db_tup_inserted |
counter |
datname, job, ins, ip, instance, cls |
Number of rows inserted by queries in this database |
| pg_db_tup_modified |
counter |
datname, job, ins, ip, instance, cls |
Number of rows modified by queries in this database |
| pg_db_tup_returned |
counter |
datname, job, ins, ip, instance, cls |
Number of rows returned by queries in this database |
| pg_db_tup_updated |
counter |
datname, job, ins, ip, instance, cls |
Number of rows updated by queries in this database |
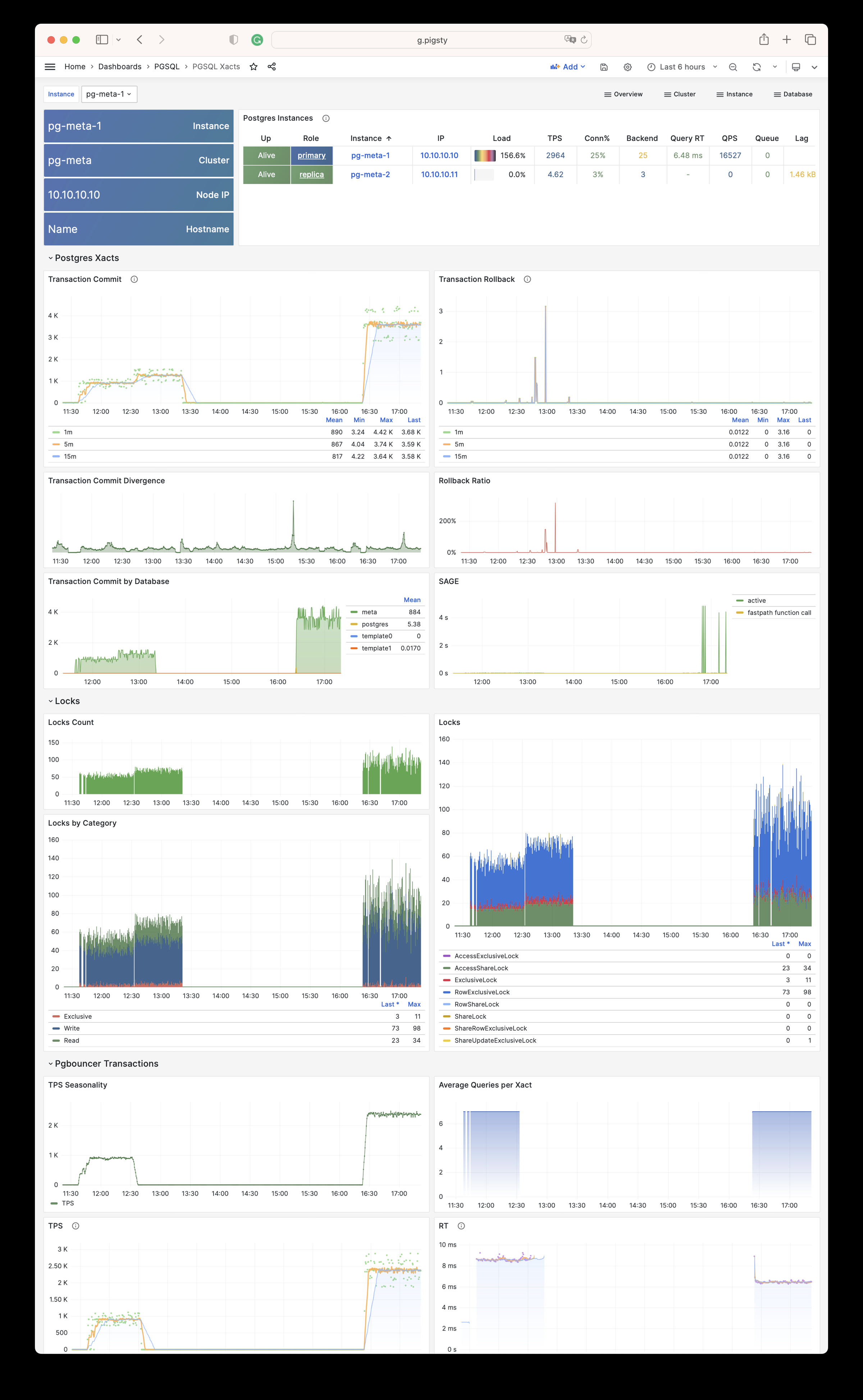
| pg_db_xact_commit |
counter |
datname, job, ins, ip, instance, cls |
Number of transactions in this database that have been committed |
| pg_db_xact_rollback |
counter |
datname, job, ins, ip, instance, cls |
Number of transactions in this database that have been rolled back |
| pg_db_xact_total |
counter |
datname, job, ins, ip, instance, cls |
Number of transactions in this database |
| pg_downstream_count |
gauge |
state, job, ins, ip, instance, cls |
Count of corresponding state |
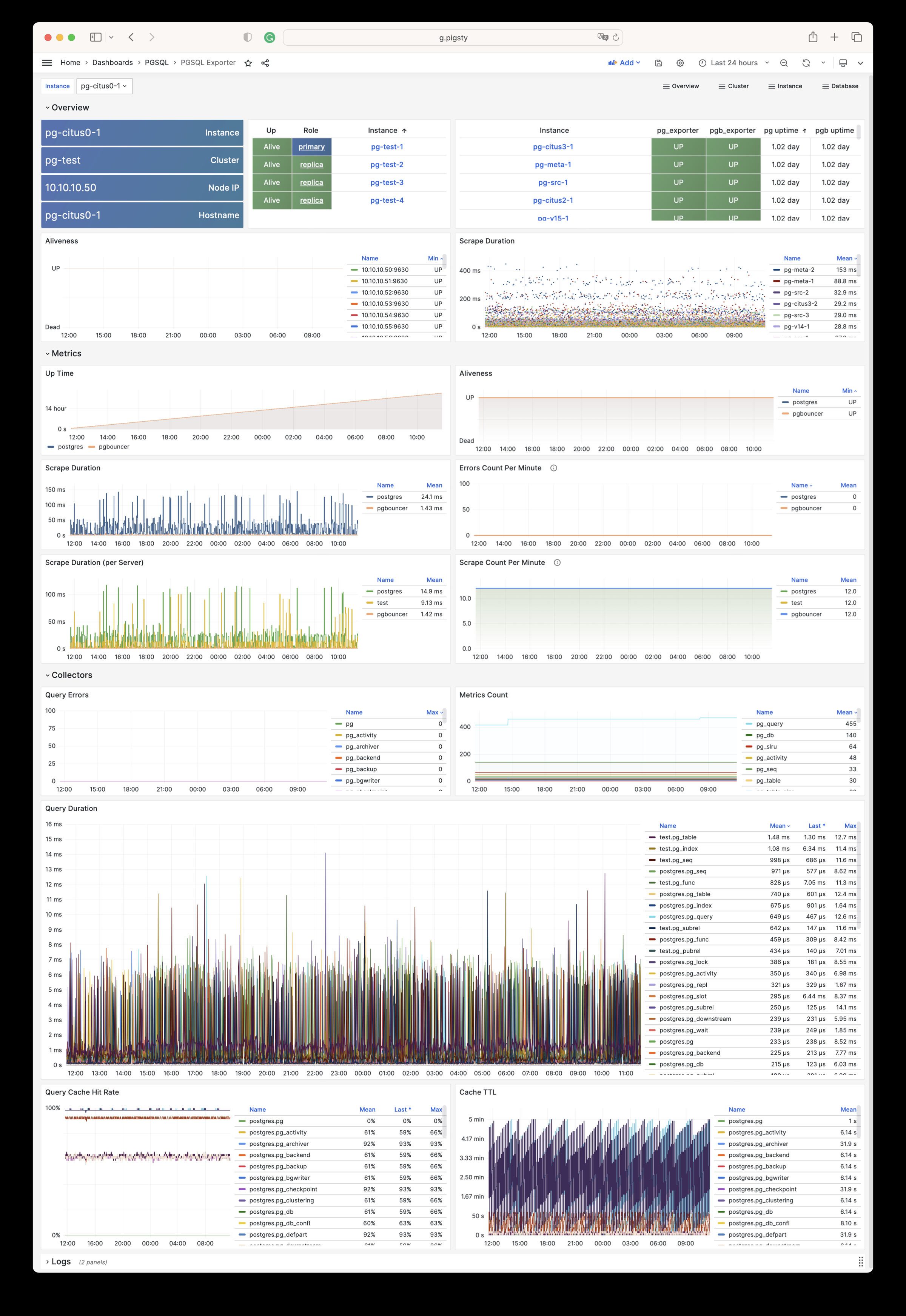
| pg_exporter_agent_up |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pg_exporter_last_scrape_time |
gauge |
job, ins, ip, instance, cls |
seconds exporter spending on scrapping |
| pg_exporter_query_cache_ttl |
gauge |
datname, query, job, ins, ip, instance, cls |
times to live of query cache |
| pg_exporter_query_scrape_duration |
gauge |
datname, query, job, ins, ip, instance, cls |
seconds query spending on scrapping |
| pg_exporter_query_scrape_error_count |
gauge |
datname, query, job, ins, ip, instance, cls |
times the query failed |
| pg_exporter_query_scrape_hit_count |
gauge |
datname, query, job, ins, ip, instance, cls |
numbers been scrapped from this query |
| pg_exporter_query_scrape_metric_count |
gauge |
datname, query, job, ins, ip, instance, cls |
numbers of metrics been scrapped from this query |
| pg_exporter_query_scrape_total_count |
gauge |
datname, query, job, ins, ip, instance, cls |
times exporter server was scraped for metrics |
| pg_exporter_scrape_duration |
gauge |
job, ins, ip, instance, cls |
seconds exporter spending on scrapping |
| pg_exporter_scrape_error_count |
counter |
job, ins, ip, instance, cls |
times exporter was scraped for metrics and failed |
| pg_exporter_scrape_total_count |
counter |
job, ins, ip, instance, cls |
times exporter was scraped for metrics |
| pg_exporter_server_scrape_duration |
gauge |
datname, job, ins, ip, instance, cls |
seconds exporter server spending on scrapping |
| pg_exporter_server_scrape_error_count |
Unknown |
datname, job, ins, ip, instance, cls |
N/A |
| pg_exporter_server_scrape_total_count |
gauge |
datname, job, ins, ip, instance, cls |
times exporter server was scraped for metrics |
| pg_exporter_server_scrape_total_seconds |
gauge |
datname, job, ins, ip, instance, cls |
seconds exporter server spending on scrapping |
| pg_exporter_up |
gauge |
job, ins, ip, instance, cls |
always be 1 if your could retrieve metrics |
| pg_exporter_uptime |
gauge |
job, ins, ip, instance, cls |
seconds since exporter primary server inited |
| pg_flush_lsn |
counter |
job, ins, ip, instance, cls |
primary only, location of current wal syncing |
| pg_func_calls |
counter |
datname, funcname, job, ins, ip, instance, cls |
Number of times this function has been called |
| pg_func_self_time |
counter |
datname, funcname, job, ins, ip, instance, cls |
Total time spent in this function itself, not including other functions called by it, in ms |
| pg_func_total_time |
counter |
datname, funcname, job, ins, ip, instance, cls |
Total time spent in this function and all other functions called by it, in ms |
| pg_in_recovery |
gauge |
job, ins, ip, instance, cls |
server is in recovery mode? 1 for yes 0 for no |
| pg_index_idx_blks_hit |
counter |
datname, relname, job, ins, relid, ip, instance, cls, idxname |
Number of buffer hits in this index |
| pg_index_idx_blks_read |
counter |
datname, relname, job, ins, relid, ip, instance, cls, idxname |
Number of disk blocks read from this index |
| pg_index_idx_scan |
counter |
datname, relname, job, ins, relid, ip, instance, cls, idxname |
Number of index scans initiated on this index |
| pg_index_idx_tup_fetch |
counter |
datname, relname, job, ins, relid, ip, instance, cls, idxname |
Number of live table rows fetched by simple index scans using this index |
| pg_index_idx_tup_read |
counter |
datname, relname, job, ins, relid, ip, instance, cls, idxname |
Number of index entries returned by scans on this index |
| pg_index_relpages |
gauge |
datname, relname, job, ins, relid, ip, instance, cls, idxname |
Size of the on-disk representation of this index in pages |
| pg_index_reltuples |
gauge |
datname, relname, job, ins, relid, ip, instance, cls, idxname |
Estimate relation tuples |
| pg_insert_lsn |
counter |
job, ins, ip, instance, cls |
primary only, location of current wal inserting |
| pg_io_evictions |
counter |
type, job, ins, object, ip, context, instance, cls |
Number of times a block has been written out from a shared or local buffer |
| pg_io_extend_time |
counter |
type, job, ins, object, ip, context, instance, cls |
Time spent in extend operations in seconds |
| pg_io_extends |
counter |
type, job, ins, object, ip, context, instance, cls |
Number of relation extend operations, each of the size specified in op_bytes. |
| pg_io_fsync_time |
counter |
type, job, ins, object, ip, context, instance, cls |
Time spent in fsync operations in seconds |
| pg_io_fsyncs |
counter |
type, job, ins, object, ip, context, instance, cls |
Number of fsync calls. These are only tracked in context normal |
| pg_io_hits |
counter |
type, job, ins, object, ip, context, instance, cls |
The number of times a desired block was found in a shared buffer. |
| pg_io_op_bytes |
gauge |
type, job, ins, object, ip, context, instance, cls |
The number of bytes per unit of I/O read, written, or extended. 8192 by default |
| pg_io_read_time |
counter |
type, job, ins, object, ip, context, instance, cls |
Time spent in read operations in seconds |
| pg_io_reads |
counter |
type, job, ins, object, ip, context, instance, cls |
Number of read operations, each of the size specified in op_bytes. |
| pg_io_reset_time |
gauge |
type, job, ins, object, ip, context, instance, cls |
Timestamp at which these statistics were last reset |
| pg_io_reuses |
counter |
type, job, ins, object, ip, context, instance, cls |
The number of times an existing buffer in reused |
| pg_io_write_time |
counter |
type, job, ins, object, ip, context, instance, cls |
Time spent in write operations in seconds |
| pg_io_writeback_time |
counter |
type, job, ins, object, ip, context, instance, cls |
Time spent in writeback operations in seconds |
| pg_io_writebacks |
counter |
type, job, ins, object, ip, context, instance, cls |
Number of units of size op_bytes which the process requested the kernel write out to permanent storage. |
| pg_io_writes |
counter |
type, job, ins, object, ip, context, instance, cls |
Number of write operations, each of the size specified in op_bytes. |
| pg_is_in_recovery |
gauge |
job, ins, ip, instance, cls |
1 if in recovery mode |
| pg_is_wal_replay_paused |
gauge |
job, ins, ip, instance, cls |
1 if wal play paused |
| pg_lag |
gauge |
job, ins, ip, instance, cls |
replica only, replication lag in seconds |
| pg_last_replay_time |
gauge |
job, ins, ip, instance, cls |
time when last transaction been replayed |
| pg_lock_count |
gauge |
datname, job, ins, ip, mode, instance, cls |
Number of locks of corresponding mode and database |
| pg_lsn |
counter |
job, ins, ip, instance, cls |
log sequence number, current write location |
| pg_meta_info |
gauge |
cls, extensions, version, job, ins, primary_conninfo, conf_path, hba_path, ip, cluster_id, instance, listen_port, wal_level, ver_num, cluster_name, data_dir |
constant 1 |
| pg_query_calls |
counter |
datname, query, job, ins, ip, instance, cls |
Number of times the statement was executed |
| pg_query_exec_time |
counter |
datname, query, job, ins, ip, instance, cls |
Total time spent executing the statement, in seconds |
| pg_query_io_time |
counter |
datname, query, job, ins, ip, instance, cls |
Total time the statement spent reading and writing blocks, in seconds |
| pg_query_rows |
counter |
datname, query, job, ins, ip, instance, cls |
Total number of rows retrieved or affected by the statement |
| pg_query_sblk_dirtied |
counter |
datname, query, job, ins, ip, instance, cls |
Total number of shared blocks dirtied by the statement |
| pg_query_sblk_hit |
counter |
datname, query, job, ins, ip, instance, cls |
Total number of shared block cache hits by the statement |
| pg_query_sblk_read |
counter |
datname, query, job, ins, ip, instance, cls |
Total number of shared blocks read by the statement |
| pg_query_sblk_written |
counter |
datname, query, job, ins, ip, instance, cls |
Total number of shared blocks written by the statement |
| pg_query_wal_bytes |
counter |
datname, query, job, ins, ip, instance, cls |
Total amount of WAL bytes generated by the statement |
| pg_receive_lsn |
counter |
job, ins, ip, instance, cls |
replica only, location of wal synced to disk |
| pg_recovery_backup_end_lsn |
counter |
job, ins, ip, instance, cls |
Backup end location |
| pg_recovery_backup_start_lsn |
counter |
job, ins, ip, instance, cls |
Backup start location |
| pg_recovery_min_lsn |
counter |
job, ins, ip, instance, cls |
Minimum recovery ending location |
| pg_recovery_min_timeline |
counter |
job, ins, ip, instance, cls |
Min recovery ending loc’s timeline |
| pg_recovery_prefetch_block_distance |
gauge |
job, ins, ip, instance, cls |
How many blocks ahead the prefetcher is looking |
| pg_recovery_prefetch_hit |
counter |
job, ins, ip, instance, cls |
Number of blocks not prefetched because they were already in the buffer pool |
| pg_recovery_prefetch_io_depth |
gauge |
job, ins, ip, instance, cls |
How many prefetches have been initiated but are not yet known to have completed |
| pg_recovery_prefetch_prefetch |
counter |
job, ins, ip, instance, cls |
Number of blocks prefetched because they were not in the buffer pool |
| pg_recovery_prefetch_reset_time |
counter |
job, ins, ip, instance, cls |
Time at which these recovery prefetch statistics were last reset |
| pg_recovery_prefetch_skip_fpw |
gauge |
job, ins, ip, instance, cls |
Number of blocks not prefetched because a full page image was included in the WAL |
| pg_recovery_prefetch_skip_init |
counter |
job, ins, ip, instance, cls |
Number of blocks not prefetched because they would be zero-initialized |
| pg_recovery_prefetch_skip_new |
counter |
job, ins, ip, instance, cls |
Number of blocks not prefetched because they didn’t exist yet |
| pg_recovery_prefetch_skip_rep |
counter |
job, ins, ip, instance, cls |
Number of blocks not prefetched because they were already recently prefetched |
| pg_recovery_prefetch_wal_distance |
gauge |
job, ins, ip, instance, cls |
How many bytes ahead the prefetcher is looking |
| pg_recovery_require_record |
gauge |
job, ins, ip, instance, cls |
End-of-backup record required |
| pg_recv_flush_lsn |
counter |
state, slot_name, job, ins, ip, instance, cls, sender_host, sender_port |
Last write-ahead log location already received and flushed to disk |
| pg_recv_flush_tli |
counter |
state, slot_name, job, ins, ip, instance, cls, sender_host, sender_port |
Timeline number of last write-ahead log location received and flushed to disk |
| pg_recv_init_lsn |
counter |
state, slot_name, job, ins, ip, instance, cls, sender_host, sender_port |
First write-ahead log location used when WAL receiver is started |
| pg_recv_init_tli |
counter |
state, slot_name, job, ins, ip, instance, cls, sender_host, sender_port |
First timeline number used when WAL receiver is started |
| pg_recv_msg_recv_time |
gauge |
state, slot_name, job, ins, ip, instance, cls, sender_host, sender_port |
Receipt time of last message received from origin WAL sender |
| pg_recv_msg_send_time |
gauge |
state, slot_name, job, ins, ip, instance, cls, sender_host, sender_port |
Send time of last message received from origin WAL sender |
| pg_recv_pid |
gauge |
state, slot_name, job, ins, ip, instance, cls, sender_host, sender_port |
Process ID of the WAL receiver process |
| pg_recv_reported_lsn |
counter |
state, slot_name, job, ins, ip, instance, cls, sender_host, sender_port |
Last write-ahead log location reported to origin WAL sender |
| pg_recv_reported_time |
gauge |
state, slot_name, job, ins, ip, instance, cls, sender_host, sender_port |
Time of last write-ahead log location reported to origin WAL sender |
| pg_recv_time |
gauge |
state, slot_name, job, ins, ip, instance, cls, sender_host, sender_port |
Time of current snapshot |
| pg_recv_write_lsn |
counter |
state, slot_name, job, ins, ip, instance, cls, sender_host, sender_port |
Last write-ahead log location already received and written to disk, but not flushed. |
| pg_relkind_count |
gauge |
datname, job, ins, ip, instance, cls, relkind |
Number of relations of corresponding relkind |
| pg_repl_backend_xmin |
counter |
pid, usename, address, job, ins, appname, ip, instance, cls |
This standby’s xmin horizon reported by hot_standby_feedback. |
| pg_repl_client_port |
gauge |
pid, usename, address, job, ins, appname, ip, instance, cls |
TCP port number that the client is using for communication with this WAL sender, or -1 if a Unix socket is used |
| pg_repl_flush_diff |
gauge |
pid, usename, address, job, ins, appname, ip, instance, cls |
Last log position flushed to disk by this standby server diff with current lsn |
| pg_repl_flush_lag |
gauge |
pid, usename, address, job, ins, appname, ip, instance, cls |
Time elapsed between flushing recent WAL locally and receiving notification that this standby server has written and flushed it |
| pg_repl_flush_lsn |
counter |
pid, usename, address, job, ins, appname, ip, instance, cls |
Last write-ahead log location flushed to disk by this standby server |
| pg_repl_launch_time |
counter |
pid, usename, address, job, ins, appname, ip, instance, cls |
Time when this process was started, i.e., when the client connected to this WAL sender |
| pg_repl_lsn |
counter |
pid, usename, address, job, ins, appname, ip, instance, cls |
Current log position on this server |
| pg_repl_replay_diff |
gauge |
pid, usename, address, job, ins, appname, ip, instance, cls |
Last log position replayed into the database on this standby server diff with current lsn |
| pg_repl_replay_lag |
gauge |
pid, usename, address, job, ins, appname, ip, instance, cls |
Time elapsed between flushing recent WAL locally and receiving notification that this standby server has written, flushed and applied it |
| pg_repl_replay_lsn |
counter |
pid, usename, address, job, ins, appname, ip, instance, cls |
Last write-ahead log location replayed into the database on this standby server |
| pg_repl_reply_time |
gauge |
pid, usename, address, job, ins, appname, ip, instance, cls |
Send time of last reply message received from standby server |
| pg_repl_sent_diff |
gauge |
pid, usename, address, job, ins, appname, ip, instance, cls |
Last log position sent to this standby server diff with current lsn |
| pg_repl_sent_lsn |
counter |
pid, usename, address, job, ins, appname, ip, instance, cls |
Last write-ahead log location sent on this connection |
| pg_repl_state |
gauge |
pid, usename, address, job, ins, appname, ip, instance, cls |
Current WAL sender encoded state 0-4 for streaming startup catchup backup stopping |
| pg_repl_sync_priority |
gauge |
pid, usename, address, job, ins, appname, ip, instance, cls |
Priority of this standby server for being chosen as the synchronous standby |
| pg_repl_sync_state |
gauge |
pid, usename, address, job, ins, appname, ip, instance, cls |
Encoded synchronous state of this standby server, 0-3 for async potential sync quorum |
| pg_repl_time |
counter |
pid, usename, address, job, ins, appname, ip, instance, cls |
Current timestamp in unix epoch |
| pg_repl_write_diff |
gauge |
pid, usename, address, job, ins, appname, ip, instance, cls |
Last log position written to disk by this standby server diff with current lsn |
| pg_repl_write_lag |
gauge |
pid, usename, address, job, ins, appname, ip, instance, cls |
Time elapsed between flushing recent WAL locally and receiving notification that this standby server has written it |
| pg_repl_write_lsn |
counter |
pid, usename, address, job, ins, appname, ip, instance, cls |
Last write-ahead log location written to disk by this standby server |
| pg_replay_lsn |
counter |
job, ins, ip, instance, cls |
replica only, location of wal applied |
| pg_seq_blks_hit |
counter |
datname, job, ins, ip, instance, cls, seqname |
Number of buffer hits in this sequence |
| pg_seq_blks_read |
counter |
datname, job, ins, ip, instance, cls, seqname |
Number of disk blocks read from this sequence |
| pg_seq_last_value |
counter |
datname, job, ins, ip, instance, cls, seqname |
The last sequence value written to disk |
| pg_setting_block_size |
gauge |
job, ins, ip, instance, cls |
pg page block size, 8192 by default |
| pg_setting_data_checksums |
gauge |
job, ins, ip, instance, cls |
whether data checksum is enabled, 1 enabled 0 disabled |
| pg_setting_max_connections |
gauge |
job, ins, ip, instance, cls |
number of concurrent connections to the database server |
| pg_setting_max_locks_per_transaction |
gauge |
job, ins, ip, instance, cls |
no more than this many distinct objects can be locked at any one time |
| pg_setting_max_prepared_transactions |
gauge |
job, ins, ip, instance, cls |
maximum number of transactions that can be in the prepared state simultaneously |
| pg_setting_max_replication_slots |
gauge |
job, ins, ip, instance, cls |
maximum number of replication slots |
| pg_setting_max_wal_senders |
gauge |
job, ins, ip, instance, cls |
maximum number of concurrent connections from standby servers |
| pg_setting_max_worker_processes |
gauge |
job, ins, ip, instance, cls |
maximum number of background processes that the system can support |
| pg_setting_wal_log_hints |
gauge |
job, ins, ip, instance, cls |
whether wal_log_hints is enabled, 1 enabled 0 disabled |
| pg_size_bytes |
gauge |
datname, job, ins, ip, instance, cls |
File size in bytes |
| pg_slot_active |
gauge |
slot_name, job, ins, ip, instance, cls |
True(1) if this slot is currently actively being used |
| pg_slot_catalog_xmin |
counter |
slot_name, job, ins, ip, instance, cls |
The oldest transaction affecting the system catalogs that this slot needs the database to retain. |
| pg_slot_confirm_lsn |
counter |
slot_name, job, ins, ip, instance, cls |
The address (LSN) up to which the logical slot’s consumer has confirmed receiving data. |
| pg_slot_reset_time |
counter |
slot_name, job, ins, ip, instance, cls |
When statistics were last reset |
| pg_slot_restart_lsn |
counter |
slot_name, job, ins, ip, instance, cls |
The address (LSN) of oldest WAL which still might be required by the consumer of this slot |
| pg_slot_retained_bytes |
gauge |
slot_name, job, ins, ip, instance, cls |
Size of bytes that retained for this slot |
| pg_slot_safe_wal_size |
gauge |
slot_name, job, ins, ip, instance, cls |
bytes that can be written to WAL which will not make slot into lost |
| pg_slot_spill_bytes |
counter |
slot_name, job, ins, ip, instance, cls |
Bytes that spilled to disk due to logical decode mem exceeding |
| pg_slot_spill_count |
counter |
slot_name, job, ins, ip, instance, cls |
Xacts that spilled to disk due to logical decode mem exceeding (a xact can be spilled multiple times) |
| pg_slot_spill_txns |
counter |
slot_name, job, ins, ip, instance, cls |
Xacts that spilled to disk due to logical decode mem exceeding (subtrans included) |
| pg_slot_stream_bytes |
counter |
slot_name, job, ins, ip, instance, cls |
Bytes that streamed to decoding output plugin after mem exceed |
| pg_slot_stream_count |
counter |
slot_name, job, ins, ip, instance, cls |
Xacts that streamed to decoding output plugin after mem exceed (a xact can be streamed multiple times) |
| pg_slot_stream_txns |
counter |
slot_name, job, ins, ip, instance, cls |
Xacts that streamed to decoding output plugin after mem exceed |
| pg_slot_temporary |
gauge |
slot_name, job, ins, ip, instance, cls |
True(1) if this is a temporary replication slot. |
| pg_slot_total_bytes |
counter |
slot_name, job, ins, ip, instance, cls |
Number of decoded bytes sent to the decoding output plugin for this slot |
| pg_slot_total_txns |
counter |
slot_name, job, ins, ip, instance, cls |
Number of decoded xacts sent to the decoding output plugin for this slot |
| pg_slot_wal_status |
gauge |
slot_name, job, ins, ip, instance, cls |
WAL reserve status 0-3 means reserved,extended,unreserved,lost, -1 means other |
| pg_slot_xmin |
counter |
slot_name, job, ins, ip, instance, cls |
The oldest transaction that this slot needs the database to retain. |
| pg_slru_blks_exists |
counter |
job, ins, ip, instance, cls |
Number of blocks checked for existence for this SLRU |
| pg_slru_blks_hit |
counter |
job, ins, ip, instance, cls |
Number of times disk blocks were found already in the SLRU, so that a read was not necessary |
| pg_slru_blks_read |
counter |
job, ins, ip, instance, cls |
Number of disk blocks read for this SLRU |
| pg_slru_blks_written |
counter |
job, ins, ip, instance, cls |
Number of disk blocks written for this SLRU |
| pg_slru_blks_zeroed |
counter |
job, ins, ip, instance, cls |
Number of blocks zeroed during initializations |
| pg_slru_flushes |
counter |
job, ins, ip, instance, cls |
Number of flushes of dirty data for this SLRU |
| pg_slru_reset_time |
counter |
job, ins, ip, instance, cls |
Time at which these statistics were last reset |
| pg_slru_truncates |
counter |
job, ins, ip, instance, cls |
Number of truncates for this SLRU |
| pg_ssl_disabled |
gauge |
job, ins, ip, instance, cls |
Number of client connection that does not use ssl |
| pg_ssl_enabled |
gauge |
job, ins, ip, instance, cls |
Number of client connection that use ssl |
| pg_sync_standby_enabled |
gauge |
job, ins, ip, names, instance, cls |
Synchronous commit enabled, 1 if enabled, 0 if disabled |
| pg_table_age |
gauge |
datname, relname, job, ins, ip, instance, cls |
Age of this table in vacuum cycles |
| pg_table_analyze_count |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of times this table has been manually analyzed |
| pg_table_autoanalyze_count |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of times this table has been analyzed by the autovacuum daemon |
| pg_table_autovacuum_count |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of times this table has been vacuumed by the autovacuum daemon |
| pg_table_frozenxid |
counter |
datname, relname, job, ins, ip, instance, cls |
All txid before this have been frozen on this table |
| pg_table_heap_blks_hit |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of buffer hits in this table |
| pg_table_heap_blks_read |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of disk blocks read from this table |
| pg_table_idx_blks_hit |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of buffer hits in all indexes on this table |
| pg_table_idx_blks_read |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of disk blocks read from all indexes on this table |
| pg_table_idx_scan |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of index scans initiated on this table |
| pg_table_idx_tup_fetch |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of live rows fetched by index scans |
| pg_table_kind |
gauge |
datname, relname, job, ins, ip, instance, cls |
Relation kind r/table/114 |
| pg_table_n_dead_tup |
gauge |
datname, relname, job, ins, ip, instance, cls |
Estimated number of dead rows |
| pg_table_n_ins_since_vacuum |
gauge |
datname, relname, job, ins, ip, instance, cls |
Estimated number of rows inserted since this table was last vacuumed |
| pg_table_n_live_tup |
gauge |
datname, relname, job, ins, ip, instance, cls |
Estimated number of live rows |
| pg_table_n_mod_since_analyze |
gauge |
datname, relname, job, ins, ip, instance, cls |
Estimated number of rows modified since this table was last analyzed |
| pg_table_n_tup_del |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of rows deleted |
| pg_table_n_tup_hot_upd |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of rows HOT updated (i.e with no separate index update required) |
| pg_table_n_tup_ins |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of rows inserted |
| pg_table_n_tup_mod |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of rows modified (insert + update + delete) |
| pg_table_n_tup_newpage_upd |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of rows updated where the successor version goes onto a new heap page |
| pg_table_n_tup_upd |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of rows updated (includes HOT updated rows) |
| pg_table_ncols |
gauge |
datname, relname, job, ins, ip, instance, cls |
Number of columns in the table |
| pg_table_pages |
gauge |
datname, relname, job, ins, ip, instance, cls |
Size of the on-disk representation of this table in pages |
| pg_table_relid |
gauge |
datname, relname, job, ins, ip, instance, cls |
Relation oid of this table |
| pg_table_seq_scan |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of sequential scans initiated on this table |
| pg_table_seq_tup_read |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of live rows fetched by sequential scans |
| pg_table_size_bytes |
gauge |
datname, relname, job, ins, ip, instance, cls |
Total bytes of this table (including toast, index, toast index) |
| pg_table_size_indexsize |
gauge |
datname, relname, job, ins, ip, instance, cls |
Bytes of all related indexes of this table |
| pg_table_size_relsize |
gauge |
datname, relname, job, ins, ip, instance, cls |
Bytes of this table itself (main, vm, fsm) |
| pg_table_size_toastsize |
gauge |
datname, relname, job, ins, ip, instance, cls |
Bytes of toast tables of this table |
| pg_table_tbl_scan |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of scans initiated on this table |
| pg_table_tup_read |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of live rows fetched by scans |
| pg_table_tuples |
counter |
datname, relname, job, ins, ip, instance, cls |
All txid before this have been frozen on this table |
| pg_table_vacuum_count |
counter |
datname, relname, job, ins, ip, instance, cls |
Number of times this table has been manually vacuumed (not counting VACUUM FULL) |
| pg_timestamp |
gauge |
job, ins, ip, instance, cls |
database current timestamp |
| pg_up |
gauge |
job, ins, ip, instance, cls |
last scrape was able to connect to the server: 1 for yes, 0 for no |
| pg_uptime |
gauge |
job, ins, ip, instance, cls |
seconds since postmaster start |
| pg_version |
gauge |
job, ins, ip, instance, cls |
server version number |
| pg_wait_count |
gauge |
datname, job, ins, event, ip, instance, cls |
Count of WaitEvent on target database |
| pg_wal_buffers_full |
counter |
job, ins, ip, instance, cls |
Number of times WAL data was written to disk because WAL buffers became full |
| pg_wal_bytes |
counter |
job, ins, ip, instance, cls |
Total amount of WAL generated in bytes |
| pg_wal_fpi |
counter |
job, ins, ip, instance, cls |
Total number of WAL full page images generated |
| pg_wal_records |
counter |
job, ins, ip, instance, cls |
Total number of WAL records generated |
| pg_wal_reset_time |
counter |
job, ins, ip, instance, cls |
When statistics were last reset |
| pg_wal_sync |
counter |
job, ins, ip, instance, cls |
Number of times WAL files were synced to disk via issue_xlog_fsync request |
| pg_wal_sync_time |
counter |
job, ins, ip, instance, cls |
Total amount of time spent syncing WAL files to disk via issue_xlog_fsync request, in seconds |
| pg_wal_write |
counter |
job, ins, ip, instance, cls |
Number of times WAL buffers were written out to disk via XLogWrite request. |
| pg_wal_write_time |
counter |
job, ins, ip, instance, cls |
Total amount of time spent writing WAL buffers to disk via XLogWrite request in seconds |
| pg_write_lsn |
counter |
job, ins, ip, instance, cls |
primary only, location of current wal writing |
| pg_xact_xmax |
counter |
job, ins, ip, instance, cls |
First as-yet-unassigned txid. txid >= this are invisible. |
| pg_xact_xmin |
counter |
job, ins, ip, instance, cls |
Earliest txid that is still active |
| pg_xact_xnum |
gauge |
job, ins, ip, instance, cls |
Current active transaction count |
| pgbouncer:cls:load1 |
Unknown |
job, cls |
N/A |
| pgbouncer:cls:load15 |
Unknown |
job, cls |
N/A |
| pgbouncer:cls:load5 |
Unknown |
job, cls |
N/A |
| pgbouncer:db:conn_usage |
Unknown |
datname, job, ins, ip, instance, host, cls, real_datname, port |
N/A |
| pgbouncer:db:conn_usage_reserve |
Unknown |
datname, job, ins, ip, instance, host, cls, real_datname, port |
N/A |
| pgbouncer:db:pool_current_conn |
Unknown |
datname, job, ins, ip, instance, host, cls, real_datname, port |
N/A |
| pgbouncer:db:pool_disabled |
Unknown |
datname, job, ins, ip, instance, host, cls, real_datname, port |
N/A |
| pgbouncer:db:pool_max_conn |
Unknown |
datname, job, ins, ip, instance, host, cls, real_datname, port |
N/A |
| pgbouncer:db:pool_paused |
Unknown |
datname, job, ins, ip, instance, host, cls, real_datname, port |
N/A |
| pgbouncer:db:pool_reserve_size |
Unknown |
datname, job, ins, ip, instance, host, cls, real_datname, port |
N/A |
| pgbouncer:db:pool_size |
Unknown |
datname, job, ins, ip, instance, host, cls, real_datname, port |
N/A |
| pgbouncer:ins:free_clients |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pgbouncer:ins:free_servers |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pgbouncer:ins:load1 |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pgbouncer:ins:load15 |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pgbouncer:ins:load5 |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pgbouncer:ins:login_clients |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pgbouncer:ins:pool_databases |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pgbouncer:ins:pool_users |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pgbouncer:ins:pools |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pgbouncer:ins:used_clients |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pgbouncer_database_current_connections |
gauge |
datname, job, ins, ip, instance, host, cls, real_datname, port |
Current number of connections for this database |
| pgbouncer_database_disabled |
gauge |
datname, job, ins, ip, instance, host, cls, real_datname, port |
True(1) if this database is currently disabled, else 0 |
| pgbouncer_database_max_connections |
gauge |
datname, job, ins, ip, instance, host, cls, real_datname, port |
Maximum number of allowed connections for this database |
| pgbouncer_database_min_pool_size |
gauge |
datname, job, ins, ip, instance, host, cls, real_datname, port |
Minimum number of server connections |
| pgbouncer_database_paused |
gauge |
datname, job, ins, ip, instance, host, cls, real_datname, port |
True(1) if this database is currently paused, else 0 |
| pgbouncer_database_pool_size |
gauge |
datname, job, ins, ip, instance, host, cls, real_datname, port |
Maximum number of server connections |
| pgbouncer_database_reserve_pool |
gauge |
datname, job, ins, ip, instance, host, cls, real_datname, port |
Maximum number of additional connections for this database |
| pgbouncer_exporter_agent_up |
Unknown |
job, ins, ip, instance, cls |
N/A |
| pgbouncer_exporter_last_scrape_time |
gauge |
job, ins, ip, instance, cls |
seconds exporter spending on scrapping |
| pgbouncer_exporter_query_cache_ttl |
gauge |
datname, query, job, ins, ip, instance, cls |
times to live of query cache |
| pgbouncer_exporter_query_scrape_duration |
gauge |
datname, query, job, ins, ip, instance, cls |
seconds query spending on scrapping |
| pgbouncer_exporter_query_scrape_error_count |
gauge |
datname, query, job, ins, ip, instance, cls |
times the query failed |
| pgbouncer_exporter_query_scrape_hit_count |
gauge |
datname, query, job, ins, ip, instance, cls |
numbers been scrapped from this query |
| pgbouncer_exporter_query_scrape_metric_count |
gauge |
datname, query, job, ins, ip, instance, cls |
numbers of metrics been scrapped from this query |
| pgbouncer_exporter_query_scrape_total_count |
gauge |
datname, query, job, ins, ip, instance, cls |
times exporter server was scraped for metrics |
| pgbouncer_exporter_scrape_duration |
gauge |
job, ins, ip, instance, cls |
seconds exporter spending on scrapping |
| pgbouncer_exporter_scrape_error_count |
counter |
job, ins, ip, instance, cls |
times exporter was scraped for metrics and failed |
| pgbouncer_exporter_scrape_total_count |
counter |
job, ins, ip, instance, cls |
times exporter was scraped for metrics |
| pgbouncer_exporter_server_scrape_duration |
gauge |
datname, job, ins, ip, instance, cls |
seconds exporter server spending on scrapping |
| pgbouncer_exporter_server_scrape_total_count |
gauge |
datname, job, ins, ip, instance, cls |
times exporter server was scraped for metrics |
| pgbouncer_exporter_server_scrape_total_seconds |
gauge |
datname, job, ins, ip, instance, cls |
seconds exporter server spending on scrapping |
| pgbouncer_exporter_up |
gauge |
job, ins, ip, instance, cls |
always be 1 if your could retrieve metrics |
| pgbouncer_exporter_uptime |
gauge |
job, ins, ip, instance, cls |
seconds since exporter primary server inited |
| pgbouncer_in_recovery |
gauge |
job, ins, ip, instance, cls |
server is in recovery mode? 1 for yes 0 for no |
| pgbouncer_list_items |
gauge |
job, ins, ip, instance, list, cls |
Number of corresponding pgbouncer object |
| pgbouncer_pool_active_cancel_clients |
gauge |
datname, job, ins, ip, instance, user, cls, pool_mode |
Client connections that have forwarded query cancellations to the server and are waiting for the server response. |
| pgbouncer_pool_active_cancel_servers |
gauge |
datname, job, ins, ip, instance, user, cls, pool_mode |
Server connections that are currently forwarding a cancel request |
| pgbouncer_pool_active_clients |
gauge |
datname, job, ins, ip, instance, user, cls, pool_mode |
Client connections that are linked to server connection and can process queries |
| pgbouncer_pool_active_servers |
gauge |
datname, job, ins, ip, instance, user, cls, pool_mode |
Server connections that are linked to a client |
| pgbouncer_pool_cancel_clients |
gauge |
datname, job, ins, ip, instance, user, cls, pool_mode |
Client connections that have not forwarded query cancellations to the server yet. |
| pgbouncer_pool_cancel_servers |
gauge |
datname, job, ins, ip, instance, user, cls, pool_mode |
cancel requests have completed that were sent to cancel a query on this server |
| pgbouncer_pool_idle_servers |
gauge |
datname, job, ins, ip, instance, user, cls, pool_mode |
Server connections that are unused and immediately usable for client queries |
| pgbouncer_pool_login_servers |
gauge |
datname, job, ins, ip, instance, user, cls, pool_mode |
Server connections currently in the process of logging in |
| pgbouncer_pool_maxwait |
gauge |
datname, job, ins, ip, instance, user, cls, pool_mode |
How long the first(oldest) client in the queue has waited, in seconds, key metric |
| pgbouncer_pool_maxwait_us |
gauge |
datname, job, ins, ip, instance, user, cls, pool_mode |
Microsecond part of the maximum waiting time. |
| pgbouncer_pool_tested_servers |
gauge |
datname, job, ins, ip, instance, user, cls, pool_mode |
Server connections that are currently running reset or check query |
| pgbouncer_pool_used_servers |
gauge |
datname, job, ins, ip, instance, user, cls, pool_mode |
Server connections that have been idle for more than server_check_delay (means have to run check query) |
| pgbouncer_pool_waiting_clients |
gauge |
datname, job, ins, ip, instance, user, cls, pool_mode |
Client connections that have sent queries but have not yet got a server connection |
| pgbouncer_stat_avg_query_count |
gauge |
datname, job, ins, ip, instance, cls |
Average queries per second in last stat period |
| pgbouncer_stat_avg_query_time |
gauge |
datname, job, ins, ip, instance, cls |
Average query duration, in seconds |
| pgbouncer_stat_avg_recv |
gauge |
datname, job, ins, ip, instance, cls |
Average received (from clients) bytes per second |
| pgbouncer_stat_avg_sent |
gauge |
datname, job, ins, ip, instance, cls |
Average sent (to clients) bytes per second |
| pgbouncer_stat_avg_wait_time |
gauge |
datname, job, ins, ip, instance, cls |
Time spent by clients waiting for a server, in seconds (average per second). |
| pgbouncer_stat_avg_xact_count |
gauge |
datname, job, ins, ip, instance, cls |
Average transactions per second in last stat period |
| pgbouncer_stat_avg_xact_time |
gauge |
datname, job, ins, ip, instance, cls |
Average transaction duration, in seconds |
| pgbouncer_stat_total_query_count |
gauge |
datname, job, ins, ip, instance, cls |
Total number of SQL queries pooled by pgbouncer |
| pgbouncer_stat_total_query_time |
counter |
datname, job, ins, ip, instance, cls |
Total number of seconds spent when executing queries |
| pgbouncer_stat_total_received |
counter |
datname, job, ins, ip, instance, cls |
Total volume in bytes of network traffic received by pgbouncer |
| pgbouncer_stat_total_sent |
counter |
datname, job, ins, ip, instance, cls |
Total volume in bytes of network traffic sent by pgbouncer |
| pgbouncer_stat_total_wait_time |
counter |
datname, job, ins, ip, instance, cls |
Time spent by clients waiting for a server, in seconds |
| pgbouncer_stat_total_xact_count |
gauge |
datname, job, ins, ip, instance, cls |
Total number of SQL transactions pooled by pgbouncer |
| pgbouncer_stat_total_xact_time |
counter |
datname, job, ins, ip, instance, cls |
Total number of seconds spent when in a transaction |
| pgbouncer_up |
gauge |
job, ins, ip, instance, cls |
last scrape was able to connect to the server: 1 for yes, 0 for no |
| pgbouncer_version |
gauge |
job, ins, ip, instance, cls |
server version number |
| process_cpu_seconds_total |
counter |
job, ins, ip, instance, cls |
Total user and system CPU time spent in seconds. |
| process_max_fds |
gauge |
job, ins, ip, instance, cls |
Maximum number of open file descriptors. |
| process_open_fds |
gauge |
job, ins, ip, instance, cls |
Number of open file descriptors. |
| process_resident_memory_bytes |
gauge |
job, ins, ip, instance, cls |
Resident memory size in bytes. |
| process_start_time_seconds |
gauge |
job, ins, ip, instance, cls |
Start time of the process since unix epoch in seconds. |
| process_virtual_memory_bytes |
gauge |
job, ins, ip, instance, cls |
Virtual memory size in bytes. |
| process_virtual_memory_max_bytes |
gauge |
job, ins, ip, instance, cls |
Maximum amount of virtual memory available in bytes. |
| promhttp_metric_handler_requests_in_flight |
gauge |
job, ins, ip, instance, cls |
Current number of scrapes being served. |
| promhttp_metric_handler_requests_total |
counter |
code, job, ins, ip, instance, cls |
Total number of scrapes by HTTP status code. |
| scrape_duration_seconds |
Unknown |
job, ins, ip, instance, cls |
N/A |
| scrape_samples_post_metric_relabeling |
Unknown |
job, ins, ip, instance, cls |
N/A |
| scrape_samples_scraped |
Unknown |
job, ins, ip, instance, cls |
N/A |
| scrape_series_added |
Unknown |
job, ins, ip, instance, cls |
N/A |
| up |
Unknown |
job, ins, ip, instance, cls |
N/A |