This is the multi-page printable view of this section. Click here to print.
Getting Started
- 1: Installation
- 2: Offline Install
- 3: Configuration
- 4: Preparation
- 5: Planning
- 6: Playbooks
- 7: Provisioning
- 8: Security
- 9: FAQ
1 - Installation
Install Pigsty with 4 steps: Prepare, Download, Configure and Install.
Also check offline installation if you don’t have the Internet access.
Short Version
Prepare a fresh Linux x86_64 node that runs compatible OS, then run as a sudo-able user:
curl -L https://get.pigsty.cc/install | bash
It will download Pigsty source to your home, then perform configure and install to finish the installation.
cd ~/pigsty # get pigsty source and entering dir
./bootstrap # download bootstrap pkgs & ansible [optional]
./configure # pre-check and config templating [optional]
./install.yml # install pigsty according to pigsty.yml
A pigsty singleton node will be ready with Web Interface on port 80/443 and Postgres service on port 5432.
You can add more nodes into Pigsty and deploy modules on them.
Example: Online Singleton Installation on Ubuntu 22.04:

Example: Install with Offline Package (EL8)

Prepare
Check Preparation for a complete guide of resource preparation.
Pigsty support the Linux kernel and x86_64/amd64 arch. It can run on any nodes: bare metal, virtual machines, or VM-like containers, but a static IPv4 address is required.
The minimum spec is 1C1G. It is recommended to use bare metals or VMs with at least 2C4G. There’s no upper limit, and node param will be auto-tuned.
We recommend using fresh RockyLinux 8.9 or Ubuntu 22.04.3 as underlying operating systems. For a complete list of supported operating systems, please refer to Compatibility.
Public key ssh access to localhost and NOPASSWD sudo privilege is required to perform the installation, Try not using the root user.
If you wish to manage more nodes, these nodes needs to be ssh / sudo accessible via your current admin node & admin user.
Pigsty relies on Ansible to execute playbooks. you have to install ansible and jmespath packages fist to run the install procedure.
This can be done with the following command, or through the bootstrap procedure, especially when you do not have internet access..
sudo dnf install -y ansible python3.11-jmespath python3-cryptographysudo yum install -y ansible # EL7 does not need to install jmespath explicitlysudo apt install -y ansible python3-jmespathbrew install ansibleDo NOT use the root user
While it is possible to install Pigsty as theroot user, It would be much safer using a dedicate admin user (dba, admin, …). due to security consideration
which has to be different from root and dbsu (postgres). Pigsty will create an optional admin user dba according to the config by default.
Download
You can get & extract pigsty source via the following command:
curl -fsSL https://get.pigsty.cc/install | bash
Download Example Output
$ bash -c "$(curl -fsSL https://get.pigsty.cc/install)"
[v2.7.0] ===========================================
$ curl -fsSL https://pigsty.cc/install | bash
[Site] https://pigsty.io
[Demo] https://demo.pigsty.cc
[Repo] https://github.com/Vonng/pigsty
[Docs] https://pigsty.io/docs/setup/install
[Download] ===========================================
[ OK ] version = v2.7.0 (from default)
curl -fSL https://get.pigsty.cc/v2.7.0/pigsty-v2.7.0.tgz -o /tmp/pigsty-v2.7.0.tgz
########################################################################### 100.0%
[ OK ] md5sums = some_random_md5_hash_value_here_ /tmp/pigsty-v2.7.0.tgz
[Install] ===========================================
[ OK ] install = /home/vagrant/pigsty, from /tmp/pigsty-v2.7.0.tgz
[Resource] ===========================================
[HINT] rocky 8 have [OPTIONAL] offline package available: https://pigsty.io/docs/setup/offline
curl -fSL https://github.com/Vonng/pigsty/releases/download/v2.7.0/pigsty-pkg-v2.7.0.el8.x86_64.tgz -o /tmp/pkg.tgz
curl -fSL https://get.pigsty.cc/v2.7.0/pigsty-pkg-v2.7.0.el8.x86_64.tgz -o /tmp/pkg.tgz # or use alternative CDN
[TodoList] ===========================================
cd /home/vagrant/pigsty
./bootstrap # [OPTIONAL] install ansible & use offline package
./configure # [OPTIONAL] preflight-check and config generation
./install.yml # install pigsty modules according to your config.
[Complete] ===========================================
Install a specific version
HINT: To install a specific version, passing the version string as the first parameter:
bash -c "$(curl -fsSL https://get.pigsty.cc/i)" -- v2.7.0 # install the specific version: v2.7.0
curl -fsSL https://get.pigsty.cc/i | bash -s v2.7.0 # another approach to passing parameter
If you don’t have the Internet access, check offline installation for details. You can download the source tarball with the following links and upload them with scp, ftp, etc…
- GitHub: https://github.com/Vonng/pigsty/releases/download/v2.7.0/pigsty-v2.7.0.tgz
- Mirror: https://get.pigsty.cc/v2.7.0/pigsty-v2.7.0.tgz
curl https://get.pigsty.cc/v2.7.0/pigsty-v2.7.0.tgz -o pigsty.tgz
tar -xvf pigsty.tgz -C ~ ; cd ~/pigsty ; # download manually and extract to home dir
You can also use git to download the Pigsty source. Please make sure to check out a specific version before using.
git clone https://github.com/Vonng/pigsty; cd pigsty; git checkout v2.7.0;
Checkout a specific Version
Themaster branch may in an unstable development status.
Always checkout a version when using git, check Release Notes for available versions.
Configure
configure will create a pigsty.yml config file according to your env.
This procedure is OPTIONAL if you know how to configure pigsty manually.
./configure # interactive-wizard, ask for IP address
./configure [-i|--ip <ipaddr>] [-m|--mode <name>] # give primary IP & config mode
[-r|--region <default|china|europe>] # choose upstream repo region
[-n|--non-interactive] # skip interactive wizard
[-x|--proxy] # write proxy env to config
Configure Example Output
$ ./configure
configure pigsty v2.7.0 begin
[ OK ] region = china
[ OK ] kernel = Linux
[ OK ] machine = x86_64
[ OK ] package = rpm,dnf
[ OK ] vendor = rocky (Rocky Linux)
[ OK ] version = 8 (8.9)
[ OK ] sudo = vagrant ok
[ OK ] ssh = vagrant@127.0.0.1 ok
[WARN] Multiple IP address candidates found:
(1) 192.168.121.165 inet 192.168.121.165/24 brd 192.168.121.255 scope global dynamic noprefixroute eth0
(2) 10.10.10.8 inet 10.10.10.8/24 brd 10.10.10.255 scope global noprefixroute eth1
[ IN ] INPUT primary_ip address (of current meta node, e.g 10.10.10.10):
=> 10.10.10.8 # input the primary IP address itself, if there's multiple candidates
[ OK ] primary_ip = 10.10.10.8 (from input)
[ OK ] admin = vagrant@10.10.10.8 ok
[ OK ] config = el @ 10.10.10.8 [tiny -> oltp]
[ OK ] configure pigsty done
proceed with ./install.yml
-m|--mode: Generate config from templates according tomode: (auto|demo|sec|citus|el|el7|ubuntu|prod...)-i|--ip: Replace IP address placeholder10.10.10.10with your primary ipv4 address of current node.-r|--region: Set upstream repo mirror according toregion(default|china|europe)-n|--non-interactive: skip interactive wizard and using default/arg values-x|--proxy: write current proxy env to the configproxy_env(http_proxy/HTTP_PROXY,HTTPS_PROXY,ALL_PROXY,NO_PROXY)
When -n|--non-interactive is specified, you have to specify a primary IP address with -i|--ip <ipaddr> in case of multiple IP address,
since there’s no default value for primary IP address in this case.
If your machine’s network interface have multiple IP addresses, you’ll need to explicitly specify a primary IP address for the current node using -i|--ip <ipaddr>, or provide it during interactive inquiry. The address should be a static IP address, and you should avoid using any public IP addresses.
You can check and modify the generated config file ~/pigsty/pigsty.yml before installation.
Change the default passwords!
PLEASE CHANGE THE DEFAULT PASSWORDs in the config file before installation, check secure password for details.Install
Run the install.yml playbook to perform a full installation on current node
./install.yml # install everything in one-pass
Installation Output Example
[vagrant@meta pigsty]$ ./install.yml
PLAY [IDENTITY] ********************************************************************************************************************************
TASK [node_id : get node fact] *****************************************************************************************************************
changed: [10.10.10.12]
changed: [10.10.10.11]
changed: [10.10.10.13]
changed: [10.10.10.10]
...
...
PLAY RECAP **************************************************************************************************************************************************************************
10.10.10.10 : ok=288 changed=215 unreachable=0 failed=0 skipped=64 rescued=0 ignored=0
10.10.10.11 : ok=263 changed=194 unreachable=0 failed=0 skipped=88 rescued=0 ignored=1
10.10.10.12 : ok=263 changed=194 unreachable=0 failed=0 skipped=88 rescued=0 ignored=1
10.10.10.13 : ok=153 changed=121 unreachable=0 failed=0 skipped=53 rescued=0 ignored=1
localhost : ok=3 changed=0 unreachable=0 failed=0 skipped=4 rescued=0 ignored=0
It’s a standard ansible playbook, you can have fine-grained control with ansible options:
-l: limit execution targets-t: limit execution tasks-e: passing extra args-i: use another config- …
Don't Ever run this Again!
It’s very DANGEROUS to re-run install.yml on existing deployment!**
You can use chmod a-x install.yml to avoid accidental execution.
Interface
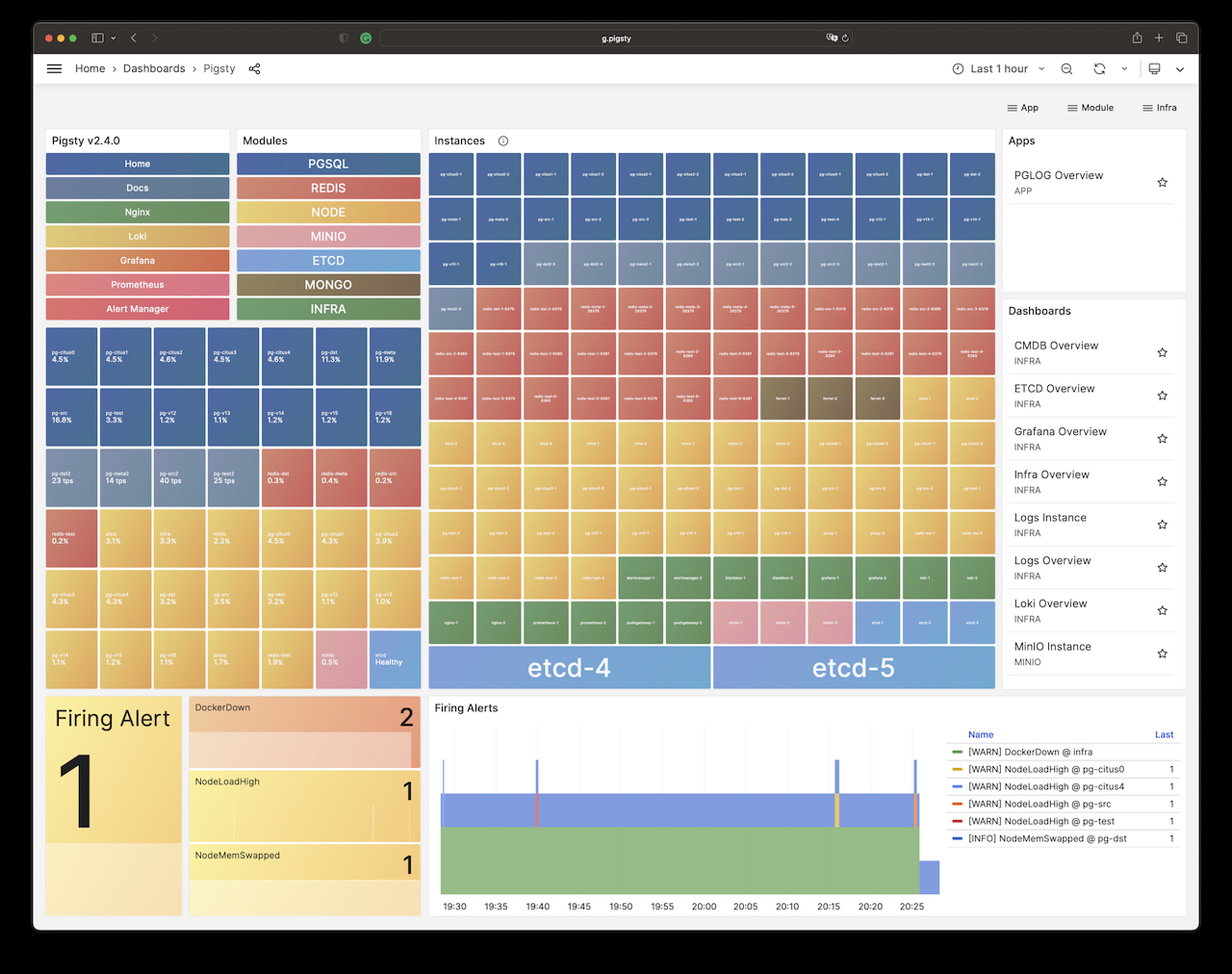
Once installed, you’ll have four core modules PGSQL, INFRA, NODE, and ETCD the current node.
The PGSQL provides a PostgreSQL singleton which can be accessed via:
psql postgres://dbuser_dba:DBUser.DBA@10.10.10.10/meta # DBA / superuser (via IP)psql postgres://dbuser_meta:DBUser.Meta@10.10.10.10/meta # business admin, read / write / ddlpsql postgres://dbuser_view:DBUser.View@pg-meta/meta # read-only userThe INFRA module gives you an entire modern observability stack, exposed by Nginx on (80 / 443):
There are several services are exposed by Nginx (configured by infra_portal):
| Component | Port | Domain | Comment | Public Demo |
|---|---|---|---|---|
| Nginx | 80/443 | h.pigsty |
Web Service Portal, Repo | home.pigsty.cc |
| AlertManager | 9093 | a.pigsty |
Alter Aggregator | a.pigsty.cc |
| Grafana | 3000 | g.pigsty |
Grafana Dashboard Home | demo.pigsty.cc |
| Prometheus | 9090 | p.pigsty |
Prometheus Web UI | p.pigsty.cc |
Grafana Dashboards (g.pigsty, port 3000) credentials, user:
admin/ pass:pigsty
You can access these web UI directly via IP + port. While the common best practice would be access them through Nginx and distinguish via domain names. You’ll need configure DNS records, or use the local static records (/etc/hosts) for that.
How to access Pigsty Web UI by domain name?
There are several options:
- Resolve internet domain names through a DNS service provider, suitable for systems accessible from the public internet.
- Configure internal network DNS server resolution records for internal domain name resolution.
- Modify the local machine’s
/etc/hostsfile to add static resolution records. (For Windows, it’s located at:)
We recommend the third method for common users. On the machine (which runs the browser), add the following record into /etc/hosts (sudo required) or C:\Windows\System32\drivers\etc\hosts in Windows:
<your_public_ip_address> h.pigsty a.pigsty p.pigsty g.pigsty
You have to use the external IP address of the node here.
How to configure server side domain names?
The server-side domain name is configured with Nginx. If you want to replace the default domain name, simply enter the domain you wish to use in the parameter infra_portal. When you access the Grafana monitoring homepage via http://g.pigsty, it is actually accessed through the Nginx proxy to Grafana’s WebUI:
http://g.pigsty ️-> http://10.10.10.10:80 (nginx) -> http://10.10.10.10:3000 (grafana)
If nginx_sslmode is set to enabled or enforced, you can trust self-signed ca: files/pki/ca/ca.crt to use https in your browser.
How to use HTTPS in Pigsty WebUI?
Pigsty will generate self-signed certs for Nginx, if you wish to access via HTTPS without “Warning”, here are some options:
- Apply & add real certs from trusted CA: such as Let’s Encrypt
- Trust your generated CA crt as root ca in your OS and browser
- Type
thisisunsafein Chrome will supress the warning
More
You can deploy & monitor more clusters with pigsty: add more nodes to pigsty.yml and run corresponding playbooks:
bin/node-add pg-test # init 3 nodes of cluster pg-test
bin/pgsql-add pg-test # init HA PGSQL Cluster pg-test
bin/redis-add redis-ms # init redis cluster redis-ms
Remember that most modules require the [NODE] module installed first. Check modules for detail
PGSQL, INFRA, NODE, ETCD, MINIO, REDIS, MONGO, DOCKER, ……
2 - Offline Install
Pigsty’s Standard Installation process requires Internet access, but production database servers are often isolated from the Internet.
Therefore, Pigsty offers an offline installation feature, allowing you to complete the installation and deployment in an environment without internet access.
If you have internet access, downloading the pre-made Offline Package in advance can help speed up the installation process and enhance the certainty and reliability of the installation.
Short Version
You have to download the Pigsty source tarball and the Offline Package in addition to the Standard Installation.
| Package | GitHub Release | CDN Mirror |
|---|---|---|
| Pigsty Source Tarball | pigsty-v2.7.0.tgz | pigsty-v2.7.0.tgz |
| EL8 Offline Package | pigsty-pkg-2.7.0.el8.x86_64.tgz | pigsty-pkg-2.7.0.el8.x86_64.tgz |
| Debian 12 Offline Package | pigsty-pkg-v2.7.0.debian12.x86_64.tgz | pigsty-pkg-v2.7.0.debian12.x86_64.tgz |
| Ubuntu 22.04 Offline Package | pigsty-pkg-v2.7.0.ubuntu22.x86_64.tgz | pigsty-pkg-v2.7.0.ubuntu22.x86_64.tgz |
You can also download them with curl:
VERSION=v2.6.0 # pigsty version
DISTRO=el8 # available distro: el7, el8, el9, debian11, debian12, ubuntu20, ubuntu22
curl "https://get.pigsty.cc/${VERSION}/pigsty-${VERSION}.tgz" -o ~/pigsty.tgz # source tarball : ~/pigsty.tgz
curl "https://get.pigsty.cc/${VERSION}/pigsty-pkg-${VERSION}.${distro}.x86_64.tgz" -o /tmp/pkg.tgz # offline package: /tmp/pkg.tgz
Then upload them to the isolated admin node, put the offline package at /tmp/pkg.tgz, then enable it th through the bootstrap procedure.
./bootstrap # you can install the pre-packed offline-package with '-y' flag, if you have Internet access
./configure; ./install.yml # then continue with the standard configuration and installation tasks
What is offline installation?
Pigsty will download the required rpm/deb packages from the upstream yum/apt repo during the installation procedure and build a local software repo (located at /www/pigsty by default).
The local repo is served by Nginx and serves all nodes in this environment/deployment, including itself.
There are three main benefits to using a local repo:
- It can avoid repetitive download requests and traffic consumption, significantly speeding up the installation and improving its reliability.
- It will take a snapshot of available software versions, ensuring the consistency of the software versions installed across nodes in the deployment environment.
- The built local software repo can be packaged as a whole tarball and copied to an isolated environment with the same operating system for offline installation.
The principle of offline installation is: first, complete the Standard Installation process on a node with the same operating system and internet access.
Then, take a snapshot of the built local repo (/www/pigsty) and pack it to make the Offline Package, and then deliver it to the isolated environment for use.
When the Pigsty Installation procedure finds that the local repo already exists, It will enter offline install mode, which will install from the built local repo rather than upstream.
Pigsty will skip the process of downloading and building the local software source from the internet and complete the entire installation process using the local software repo without the need for internet access.
Criteria for Offline Install Mode
The criteria for the existence of a local repo is the presence of a marker file located by default at `/www/pigsty/repo_complete`.
This marker file is automatically generated after the download is complete during the standard installation procedure, indicating a usable local software repo is done.
Deleting the repo_complete marker file of the local repo will mark the procedure for re-download missing packages from upstream.
Offline Package
The offline package is a tarball made by gzip and tar, placed under /tmp/pkg.tgz, and extract to /www/pigsty for use.
Pigsty has pre-packed offline packages for primary supported 3 major OS distros.
Which can skip downloading & repo building if you are using the exact same operating system.
https://github.com/Vonng/pigsty/releases/download/v2.7.0/pigsty-pkg-v2.7.0.el8.x86_64.tgz # EL 8.9 (Green Obsidian)
https://github.com/Vonng/pigsty/releases/download/v2.7.0/pigsty-pkg-v2.7.0.debian12.x86_64.tgz # Debian 12 (bookworm)
https://github.com/Vonng/pigsty/releases/download/v2.7.0/pigsty-pkg-v2.7.0.ubuntu22.x86_64.tgz # Ubuntu 22.04 (jammy)https://get.pigsty.cc/v2.7.0/pigsty-pkg-v2.7.0.el8.x86_64.tgz # (Green Obsidian)
https://get.pigsty.cc/v2.7.0/pigsty-pkg-v2.7.0.debian12.x86_64.tgz # (bookworm, 12.4)
https://get.pigsty.cc/v2.7.0/pigsty-pkg-v2.7.0.ubuntu22.x86_64.tgz # (jammy, 22.04.3)Minor Version Matters!
When installing with offline packages, please ensure that the OS major version matches exactly, and try to keep the system minor version as close as possible.
Offline installation can usually succeed even if the OS minor version does not match, but there’s a chance that some packages might have missing or conflicting dependencies.
In such cases, please make your own offline package, or refer to the Frequently Asked Questions for solutions.
Bootstrap
Pigsty needs ansible to run the playbooks. You have to install Ansible even without Internet access.
Luckily, ansible and its dependencies are already included in Pigsty’s offline package. The process of extracting and installing ansible from the offline package is known as Bootstrap.
You have to download the offline package and place it under /tmp/pkg.tgz, then run the bootstrap command:
./bootstrap # extract /tmp/pkg.tgz and install ansible
The bootstrap script will extract /tmp/pkg.tgz into /www/pigsty, setup a local file repo, and install ansible from it.
Bootstrap Procedure Logic
-
Check preconditions
-
Check local repo exists ?
- Y -> Extract to
/www/pigstyand create repo file to enable it - N -> Download offline package from the Internet? (if applicable)
- Y -> Download from GitHub / CDN and extract & enable it
- N -> Add basic os upstream repo file manually ?
- Y -> add according to region / version
- N -> leave it to user’s default configuration
- Y -> Extract to
- Now we have an available repo for installing Ansible
- Precedence: local
pkg.tgz> downloadedpkg.tgz> upstream > user provide
- Precedence: local
- install boot utils from the available repo
- el7,8,9:
ansible createrepo_c unzip wget yum-utils sshpass - el8 extra:
ansible python3.11-jmespath python3-cryptography createrepo_c unzip wget dnf-utils sshpass modulemd-tools - el9 extra:
ansible python3-jmespath python3.11-jmespath createrepo_c unzip wget dnf-utils sshpass modulemd-tools - ubuntu/debian:
ansible python3-jmespath dpkg-dev unzip wget sshpass acl
- el7,8,9:
- Check
ansibleavailability.
Example: Download offline package from the Internet (EL8)
On a RockyLinux 8.9 node with the internet access, during the ./bootstrap process, if local repo /www/pigsty or offline package /tmp/pkg.tgz nor available,
the system will prompt the user to download the offline package. Simply reply y to proceed, or you can use bootstrap -y to automatically reply “yes” by default.
[vagrant@build-el8 pigsty]$ ./bootstrap
bootstrap pigsty v2.7.0 begin
[ OK ] region = china
[ OK ] kernel = Linux
[ OK ] machine = x86_64
[ OK ] package = rpm,dnf
[ OK ] vendor = rocky (Rocky Linux)
[ OK ] version = 8 (8.9)
[ OK ] sudo = vagrant ok
[ OK ] EL 8.9 has pre-packed offline package available:
https://get.pigsty.cc/v2.7.0/pigsty-pkg-v2.7.0.el8.x86_64.tgz
[ IN ] offline package not exist on /tmp/pkg.tgz, download? (y/n):
=> y
[ OK ] $ curl https://get.pigsty.cc/v2.7.0/pigsty-pkg-v2.7.0.el8.x86_64.tgz -o /tmp/pkg.tgz
... (yum install progress)
[ OK ] repo = extract from /tmp/pkg.tgz
[ OK ] repo file = use /etc/yum.repos.d/pigsty-local.repo
[WARN] rpm cache = updating, make take a while
[ OK ] repo cache = created
[ OK ] install el8 utils
...(yum install output)
Installed:
createrepo_c-0.17.7-6.el8.x86_64 createrepo_c-libs-0.17.7-6.el8.x86_64 drpm-0.4.1-3.el8.x86_64 modulemd-tools-0.7-8.el8.noarch python3-createrepo_c-0.17.7-6.el8.x86_64 python3-libmodulemd-2.13.0-1.el8.x86_64
python3-pyyaml-3.12-12.el8.x86_64 sshpass-1.09-4.el8.x86_64 unzip-6.0-46.el8.x86_64
...(yum install output) 18/18
Installed:
ansible-8.3.0-1.el8.noarch ansible-core-2.15.3-1.el8.x86_64 git-core-2.39.3-1.el8_8.x86_64 mpdecimal-2.5.1-3.el8.x86_64
python3-cffi-1.11.5-6.el8.x86_64 python3-cryptography-3.2.1-7.el8_9.x86_64 python3-jmespath-0.9.0-11.el8.noarch python3-pycparser-2.14-14.el8.noarch
python3.11-3.11.5-1.el8_9.x86_64 python3.11-cffi-1.15.1-1.el8.x86_64 python3.11-cryptography-37.0.2-5.el8.x86_64 python3.11-jmespath-1.0.1-1.el8.noarch
python3.11-libs-3.11.5-1.el8_9.x86_64 python3.11-pip-wheel-22.3.1-4.el8_9.1.noarch python3.11-ply-3.11-1.el8.noarch python3.11-pycparser-2.20-1.el8.noarch
python3.11-pyyaml-6.0-1.el8.x86_64 python3.11-setuptools-wheel-65.5.1-2.el8.noarch
Complete!
[ OK ] ansible = ansible [core 2.15.3]
[ OK ] boostrap pigsty complete
proceed with ./configure
Example: Bootstrap from local downloaded offline package (Debian 12)
A Debian 12 node without the Internet access, the user has pre-downloaded offline package and uploaded it to a specified path on the node.
If the offline package exists at /tmp/pkg.tgz, the bootstrap process will use it directly, and the output will be like:
vagrant@debian12:~/pigsty$ ./bootstrap
bootstrap pigsty v2.7.0 begin
[ OK ] region = china
[ OK ] kernel = Linux
[ OK ] machine = x86_64
[ OK ] package = deb,apt
[ OK ] vendor = debian (Debian GNU/Linux)
[ OK ] version = 12 (12)
[ OK ] sudo = vagrant ok
[ OK ] cache = /tmp/pkg.tgz exists
[ OK ] repo = extract from /tmp/pkg.tgz
[ OK ] repo file = use /etc/apt/sources.list.d/pigsty-local.list
[WARN] apt cache = updating, make take a while
...(apt install output)
[ OK ] ansible = ansible [core 2.14.3]
[ OK ] boostrap pigsty complete
proceed with ./configure
Example: Bootstrap from the Internet (Ubuntu 20.04)
在一台有互联网访问的 Ubuntu 20.04 节点上,因为 Pigsty 官方没有提供离线软件包,因此选择在线安装。在这种情况下,Bootstrap 会使用可用的源,使用 yum/apt 安装 ansible 与依赖:
On an Ubuntu 20.04 node with internet access, since Pigsty does not provide an official offline package for this OS major version,
the online installation is performed. In this case, the bootstrap process will use the available upstream repo to install ansible and its dependencies using yum or apt:
vagrant@ubuntu20:~/pigsty$ ./bootstrap
bootstrap pigsty v2.7.0 begin
[ OK ] region = china
[ OK ] kernel = Linux
[ OK ] machine = x86_64
[ OK ] package = deb,apt
[ OK ] vendor = ubuntu (Ubuntu)
[ OK ] version = 20 (20.04)
[ OK ] sudo = vagrant ok
[WARN] ubuntu 20 focal does not have corresponding offline package, use online install
[WARN] cache = missing and skip download
[WARN] repo = skip (/tmp/pkg.tgz not exists)
[ OK ] repo file = add ubuntu focal china upstream
[WARN] apt cache = updating, make take a while
...(apt update/install output)
[ OK ] ansible = ansible 2.9.6
[ OK ] boostrap pigsty complete
proceed with ./configure
Make Offline Package
Pigsty has a bin/cache script to make offline packages.
Run this script on installed nodes; it will compress the /www/pigsty repo dir into /tmp/pkg.tgz tarball.
bin/cache [version=v2.6.0]
[pkg_path=/tmp/pkg.tgz]
[repo_dir=/www/pigsty]
You can upload that /tmp/pkg.tgz to isolated production nodes for using with the same bootstrap procedure.
sudo rm -rf /www/pigsty # remove obsolete files
sudo tar -xf /tmp/pkg.tgz -C /www # extract to nginx dir
Make Offline Package Example Output
Example: make an offline package on freshly installed Ubuntu 22.04 with bin/cache:
vagrant@ubuntu22:~/pigsty$ bin/cache
[ OK ] create offline package on ubuntu22
[ OK ] pkg type = deb
[ OK ] repo dir = /www/pigsty
[ OK ] copy /www/pigsty to /tmp/pigsty-build/pigsty
[ OK ] grafana plugins = found, overwrite /tmp/pigsty-build/pigsty/plugins.tgz
knightss27-weathermap-panel marcusolsson-dynamictext-panel marcusolsson-json-datasource marcusolsson-treemap-panel volkovlabs-form-panel volkovlabs-image-panel
marcusolsson-calendar-panel marcusolsson-hourly-heatmap-panel marcusolsson-static-datasource volkovlabs-echarts-panel volkovlabs-grapi-datasource volkovlabs-variable-panel
[ OK ] ubuntu 22 = no packages needs to be cleansed
[ OK ] package = making pigsty-pkg-v2.6.0.ubuntu22.x86_64.tgz
pigsty/
pigsty/liblua5.2-0_5.2.4-2_amd64.deb
.................. # Lot's of packages
pigsty/distro-info-data_0.52ubuntu0.6_all.deb
[ OK ] package = finish pigsty-pkg-v2.6.0.ubuntu22.x86_64.tgz 48f9cb2dd2cabb61b115bfe2ac9e002d
-rw-rw-r-- 1 vagrant vagrant 1.2G Feb 29 03:09 /tmp/pkg.tgz
scp ubuntu22:/tmp/pkg.tgz v2.6.0/pigsty-pkg-v2.6.0.ubuntu22.x86_64.tgz
3 - Configuration
Pigsty treats Infra & Database as Code. You can describe the infrastructure & database clusters through a declarative interface. All your essential work is to describe your need in the inventory, then materialize it with a simple idempotent playbook.
Inventory
Each pigsty deployment has a corresponding config inventory. It could be stored in a local git-managed file in YAML format or dynamically generated from CMDB or any ansible compatible format. Pigsty uses a monolith YAML config file as the default config inventory, which is pigsty.yml, located in the pigsty home directory.
The inventory consists of two parts: global vars & multiple group definitions. You can define new clusters with inventory groups: all.children. And describe infra and set global default parameters for clusters with global vars: all.vars. Which may look like this:
all: # Top-level object: all
vars: {...} # Global Parameters
children: # Group Definitions
infra: # Group Definition: 'infra'
hosts: {...} # Group Membership: 'infra'
vars: {...} # Group Parameters: 'infra'
etcd: {...} # Group Definition: 'etcd'
pg-meta: {...} # Group Definition: 'pg-meta'
pg-test: {...} # Group Definition: 'pg-test'
redis-test: {...} # Group Definition: 'redis-test'
# ...
There are lots of config examples under files/pigsty
Cluster
Each group may represent a cluster, which could be a Node cluster, PostgreSQL cluster, Redis cluster, Etcd cluster, or Minio cluster, etc… They all use the same format: group vars & hosts. You can define cluster members with all.children.<cls>.hosts and describe cluster with cluster parameters in all.children.<cls>.vars. Here is an example of 3 nodes PostgreSQL HA cluster named pg-test:
pg-test: # Group Name
vars: # Group Vars (Cluster Parameters)
pg_cluster: pg-test
hosts: # Group Host (Cluster Membership)
10.10.10.11: { pg_seq: 1, pg_role: primary } # Host1
10.10.10.12: { pg_seq: 2, pg_role: replica } # Host2
10.10.10.13: { pg_seq: 3, pg_role: offline } # Host3
You can also define parameters for a specific host, as known as host vars. It will override group vars and global vars. Which is usually used for assigning identities to nodes & database instances.
Parameter
Global vars, Group vars, and Host vars are dict objects consisting of a series of K-V pairs. Each pair is a named Parameter consisting of a string name as the key and a value of one of five types: boolean, string, number, array, or object. Check parameter reference for detailed syntax & semantics.
Every parameter has a proper default value except for mandatory IDENTITY PARAMETERS; they are used as identifiers and must be set explicitly, such as pg_cluster, pg_role, and pg_seq.
Parameters can be specified & overridden with the following precedence.
Playbook Args > Host Vars > Group Vars > Global Vars > Defaults
For examples:
- Force removing existing databases with Playbook CLI Args
-e pg_clean=true - Override an instance role with Instance Level Parameter
pg_roleon Host Vars - Override a cluster name with Cluster Level Parameter
pg_clusteron Group Vars. - Specify global NTP servers with Global Parameter
node_ntp_serverson Global Vars - If no
pg_versionis set, it will use the default value from role implementation (16 by default)
Template
There are numerous preset config templates for different scenarios under the files/pigsty directory.
During configure process, you can specify a template using the -m parameter.
Otherwise, the single-node installation config template will be automatically selected based on your OS distribution.
- EL 8 / 9:
el.yml - Debian 12:
debian.yml - Ubuntu 22.04 jammy:
ubuntu.yml
Although the Pigsty no longer officially supports these OS distros, you can still use the following templates for older major OS versions to perform online installation:
- EL 7:
el7.yml - Debian 11 bullseye:
debian.yml - Ubuntu 20.04 focal:
ubuntu20.yml
Switch Config Inventory
To use a different config inventory, you can copy & paste the content into the pigsty.yml file in the home dir as needed.
You can also explicitly specify the config inventory file to use when executing Ansible playbooks by using the -i command-line parameter, for example:
./node.yml -i files/pigsty/rpmbuild.yml # use another file as config inventory, rather than the default pigsty.yml
If you want to modify the default config inventory filename, you can change the inventory parameter in the ansible.cfg file in the home dir to point to your own inventory file path.
This allows you to run the ansible-playbook command without explicitly specifying the -i parameter.
Pigsty allows you to use a database (CMDB) as a dynamic configuration source instead of a static configuration file. Pigsty provides three convenient scripts:
bin/inventory_load: Loads the content of thepigsty.ymlinto the local PostgreSQL database (meta.pigsty)bin/inventory_cmdb: Switches the configuration source to the local PostgreSQL database (meta.pigsty)bin/inventory_conf: Switches the configuration source to the local static configuration filepigsty.yml
Reference
Pigsty have 280+ parameters, check Parameter for details.
| Module | Section | Description | Count |
|---|---|---|---|
INFRA |
META |
Pigsty Metadata | 4 |
INFRA |
CA |
Self-Signed CA | 3 |
INFRA |
INFRA_ID |
Infra Portals & Identity | 2 |
INFRA |
REPO |
Local Software Repo | 9 |
INFRA |
INFRA_PACKAGE |
Infra Packages | 2 |
INFRA |
NGINX |
Nginx Web Server | 7 |
INFRA |
DNS |
DNSMASQ Nameserver | 3 |
INFRA |
PROMETHEUS |
Prometheus Stack | 18 |
INFRA |
GRAFANA |
Grafana Stack | 6 |
INFRA |
LOKI |
Loki Logging Service | 4 |
NODE |
NODE_ID |
Node Identity Parameters | 5 |
NODE |
NODE_DNS |
Node domain names & resolver | 6 |
NODE |
NODE_PACKAGE |
Node Repo & Packages | 5 |
NODE |
NODE_TUNE |
Node Tuning & Kernel features | 10 |
NODE |
NODE_ADMIN |
Admin User & Credentials | 7 |
NODE |
NODE_TIME |
Node Timezone, NTP, Crontabs | 5 |
NODE |
NODE_VIP |
Node Keepalived L2 VIP | 8 |
NODE |
HAPROXY |
HAProxy the load balancer | 10 |
NODE |
NODE_EXPORTER |
Node Monitoring Agent | 3 |
NODE |
PROMTAIL |
Promtail logging Agent | 4 |
DOCKER |
DOCKER |
Docker Daemon | 4 |
ETCD |
ETCD |
ETCD DCS Cluster | 10 |
MINIO |
MINIO |
MINIO S3 Object Storage | 15 |
REDIS |
REDIS |
Redis the key-value NoSQL cache | 20 |
PGSQL |
PG_ID |
PG Identity Parameters | 11 |
PGSQL |
PG_BUSINESS |
PG Business Object Definition | 12 |
PGSQL |
PG_INSTALL |
Install PG Packages & Extensions | 10 |
PGSQL |
PG_BOOTSTRAP |
Init HA PG Cluster with Patroni | 39 |
PGSQL |
PG_PROVISION |
Create in-database objects | 9 |
PGSQL |
PG_BACKUP |
Set Backup Repo with pgBackRest | 5 |
PGSQL |
PG_SERVICE |
Exposing service, bind vip, dns | 9 |
PGSQL |
PG_EXPORTER |
PG Monitor agent for Prometheus | 15 |
4 - Preparation
Node
Pigsty supports the Linux kernel and x86_64/amd64 arch, applicable to any node.
A “node” refers to a resource that is SSH accessible and offers a bare OS environment, such as a physical machine, a virtual machine, or an OS container equipped with systemd and sshd.
Deploying Pigsty requires at least 1 node. The minimum spec requirement is 1C1G, but it is recommended to use at least 2C4G, with no upper limit: parameters will automatically optimize and adapt.
For demos, personal sites, devbox, or standalone monitoring infra, 1-2 nodes are recommended, while at least 3 nodes are suggested for an HA PostgreSQL cluster. For critical scenarios, 4-5 nodes are advisable.
Leverage IaC Tools for chores
Managing a large-scale prod env could be tedious and error-prone. We recommend using Infrastructure as Code (IaC) tools to address these issues.
You can use the Terraform and Vagrant templates provided by Pigsty, to create the required node environment with just one command through IaC, provisioning network, OS image, admin user, privileges, etc…
Network
Pigsty requires nodes to use static IPv4 addresses, which means you should explicitly assign your nodes a specific fixed IP address rather than using DHCP-assigned addresses.
The IP address used by a node should be the primary IP address for internal network communications and will serve as the node’s unique identifier.
If you wish to use the optional Node VIP and PG VIP features, ensure all nodes are located within an L2 network.
Your firewall policy should ensure the required ports are open between nodes. For a detailed list of ports required by different modules, refer to Node: Ports.
Which Ports Should Be Exposed?
For beginners or those who are just trying it out, you can just open ports 5432 (PostgreSQL database) and 3000 (Grafana visualization interface) to the world.
For a serious prod env, you should only expose the necessary ports to the exterior, such as 80/443 for web services, open to the office network (or the entire Internet).
Exposing database service ports directly to the Internet is not advisable. If you need to do this, consider consulting Security Best Practices and proceed cautiously.
The method for exposing ports depends on your network implementation, such as security group policies, local iptables records, firewall configurations, etc.
Operating System
Pigsty supports various Linux OS. We recommend using RockyLinux 8.9 or Ubuntu 22.04.3 as the default OS for installing Pigsty.
Pigsty supports RHEL (7,8,9), Debian (11,12), Ubuntu (20,22), and many other compatible OS distros. Check Compatibility For a complete list of compatible OS distros.
When deploying on multiple nodes, we strongly recommend using the same version of the OS distro and the Linux kernel on all nodes.
We strongly recommend using a clean, minimally installed OS environment with en_US set as the primary language.
How to enable en_US locale?
To ensure the en_US locale is available when using other primary language:
yum install -y glibc-locale-source glibc-langpack-en
localedef -i en_US -f UTF-8 en_US.UTF-8
localectl set-locale LANG=en_US.UTF-8
Note: The PostgreSQL cluster deployed by Pigsty defaults to the C.UTF8 locale, but character set definitions use en_US to ensure the pg_trgm extension functions properly.
If you do not need this feature, you can configure the value of pg_lc_ctype to C.UTF8 to avoid this issue when en locale is missing.
Admin User
You’ll need an “admin user” on all nodes where Pigsty is meant to be deployed — an OS user with nopass ssh login and nopass sudo permissions.
On the nodes where Pigsty is installed, you need an “administrative user” who has nopass ssh login and nopass sudo permissions.
No password sudo is required to execute commands during the installation process, such as installing packages, configuring system settings, etc.
How to configure nopass sudo for admin user?
Assuming your admin username is vagrant, you can create a file in /etc/sudoers.d/vagrant and add the following content:
%vagrant ALL=(ALL) NOPASSWD: ALL
This will allow the vagrant user to execute all commands without a sudo password. If your username is not vagrant, replace vagrant in the above steps with your username.
Avoid using the root user
While it is possible to install Pigsty using the root user, we do not recommend it.
We recommend using a dedicated admin user, such as dba, different from the root user (root) and the database superuser (postgres).
There is a dedicated playbook subtask that can use an existing admin user (e.g., root) with ssh/sudo password input to create a dedicated admin user.
SSH Permission
In addition to nopass sudo privilege, Pigsty also requires the admin user to have nopass ssh login privilege (login via ssh key).
For single-host installations setup, this means the admin user on the local node should be able to log in to the host itself via ssh without a password.
If your Pigsty deployment involves multiple nodes, this means the admin user on the admin node should be able to log in to all nodes managed by Pigsty (including the local node) via ssh without a password, and execute sudo commands without a password as well.
During the configure procedure, if your current admin user does not have any SSH key, it will attempt to address this issue by generating a new id_rsa key pair and adding it to the local ~/.ssh/authorized_keys file to ensure local SSH login capability for the local admin user.
By default, Pigsty creates an admin user dba (uid=88) on all managed nodes. If you are already using this user, we recommend that you change the node_admin_username to a new username with a different uid, or disable it using the node_admin_enabled parameter.
How to configure nopass SSH login for admin user?
Assuming your admin username is vagrant, execute the following command as the vagrant user will generate a public/private key pair for login. If a key pair already exists, there is no need to generate a new one.
ssh-keygen -t rsa -b 2048 -N '' -f ~/.ssh/id_rsa -q
The generated public key is by default located at: /home/vagrant/.ssh/id_rsa.pub, and the private key at: /home/vagrant/.ssh/id_rsa. If your OS username is not vagrant, replace vagrant in the above commands with your username.
You should append the public key file (id_rsa.pub) to the authorized_keys file of the user you need to log into: /home/vagrant/.ssh/authorized_keys. If you already have password access to the remote machine, you can use ssh-copy-id to copy the public key:
ssh-copy-id <ip> # Enter password to complete public key copying
sshpass -p <password> ssh-copy-id <ip> # Or: you can embed the password directly in the command to avoid interactive password entry (cautious!)
Pigsty recommends provisioning the admin user during node provisioning and making it viable by default.
SSH Accessibility
If your environment has some restrictions on SSH access, such as a bastion server or ad hoc firewall rules that prevent simple SSH access via ssh <ip>, consider using SSH aliases.
For example, if there’s a node with IP 10.10.10.10 that can not be accessed directly via ssh but can be accessed via an ssh alias meta defined in ~/.ssh/config,
then you can configure the ansible_host parameter for that node in the inventory to specify the SSH Alias on the host level:
nodes:
hosts: # 10.10.10.10 can not be accessed directly via ssh, but can be accessed via ssh alias 'meta'
10.10.10.10: { ansible_host: meta }
If the ssh alias does not meet your requirement, there are a plethora of custom ssh connection parameters that can bring fine-grained control over SSH connection behavior.
If the following cmd can be successfully executed on the admin node by the admin user, it means that the target node’s admin user is properly configured.
ssh <ip|alias> 'sudo ls'
Software
On the admin node, Pigsty requires ansible to initiate control.
If you are using the singleton meta installation, Ansible is required on this node. It is not required for common nodes.
The bootstrap procedure will make every effort to do this for you.
But you can always choose to install Ansible manually. The process of manually installing Ansible varies with different OS distros / major versions (usually involving an additional weak dependency jmespath):
sudo dnf install -y ansible python3.11-jmespathsudo yum install -y ansible # EL7 does not need to install jmespath explicitlysudo apt install -y ansible python3-jmespathbrew install ansibleTo install Pigsty, you also need to prepare the Pigsty source package. You can directly download a specific version from the GitHub Release page or use the following command to obtain the latest stable version:
curl -L https://get.pigsty.cc/install | bash
If your env does not have Internet access, consider using the offline packages, which are pre-packed for different OS distros, and can be downloaded from the GitHub Release page.
5 - Planning
6 - Playbooks
Playbooks are used in Pigsty to install modules on nodes.
To run playbooks, just treat them as executables. e.g. run with ./install.yml.
Playbooks
Here are default playbooks included in Pigsty.
| Playbook | Function |
|---|---|
install.yml |
Install Pigsty on current node in one-pass |
infra.yml |
Init pigsty infrastructure on infra nodes |
infra-rm.yml |
Remove infrastructure components from infra nodes |
node.yml |
Init node for pigsty, tune node into desired status |
node-rm.yml |
Remove node from pigsty |
pgsql.yml |
Init HA PostgreSQL clusters, or adding new replicas |
pgsql-rm.yml |
Remove PostgreSQL cluster, or remove replicas |
pgsql-user.yml |
Add new business user to existing PostgreSQL cluster |
pgsql-db.yml |
Add new business database to existing PostgreSQL cluster |
pgsql-monitor.yml |
Monitor remote postgres instance with local exporters |
pgsql-migration.yml |
Generate Migration manual & scripts for existing PostgreSQL |
redis.yml |
Init redis cluster/node/instance |
redis-rm.yml |
Remove redis cluster/node/instance |
etcd.yml |
Init etcd cluster (required for patroni HA DCS) |
minio.yml |
Init minio cluster (optional for pgbackrest repo) |
cert.yml |
Issue cert with pigsty self-signed CA (e.g. for pg clients) |
docker.yml |
Install docker on nodes |
mongo.yml |
在节点上安装 Mongo/FerretDB |
One-Pass Install
The special playbook install.yml is actually a composed playbook that install everything on current environment.
playbook / command / group infra nodes etcd minio pgsql
[infra.yml] ./infra.yml [-l infra] [+infra][+node]
[node.yml] ./node.yml [+node] [+node] [+node] [+node]
[etcd.yml] ./etcd.yml [-l etcd ] [+etcd]
[minio.yml] ./minio.yml [-l minio] [+minio]
[pgsql.yml] ./pgsql.yml [+pgsql]
Note that there’s a circular dependency between NODE and INFRA:
to register a NODE to INFRA, the INFRA should already exist, while the INFRA module relies on NODE to work.
The solution is that INFRA playbook will also install NODE module in addition to INFRA on infra nodes.
Make sure that infra nodes are init first. If you really want to init all nodes including infra in one-pass, install.yml is the way to go.
Ansible
Playbooks require ansible-playbook executable to run, playbooks which is included in ansible rpm / deb package.
Pigsty will try it’s best to install ansible on admin node during bootstrap.
You can install it by yourself with yum|apt|brew install ansible, it is included in default OS repo.
Knowledge about ansible is good but not required. Only four parameters needs your attention:
-l|--limit <pattern>: Limit execution target on specific group/host/pattern (Where)-t|--tags <tags>: Only run tasks with specific tags (What)-e|--extra-vars <vars>: Extra command line arguments (How)-i|--inventory <path>: Using another inventory file (Conf)
Designate Inventory
To use a different config inventory, you can copy & paste the content into the pigsty.yml file in the home dir as needed.
The active inventory file can be specified with the -i|--inventory <path> parameter when running Ansible playbooks.
./node.yml -i files/pigsty/rpmbuild.yml # use another file as config inventory, rather than the default pigsty.yml
./pgsql.yml -i files/pigsty/rpm.yml # install pgsql module on machine define in files/pigsty/rpm.yml
./redis.yml -i files/pigsty/redis.yml # install redis module on machine define in files/pigsty/redis.yml
If you wish to permanently modify the default config inventory filename, you can change the inventory parameter in the ansible.cfg
Limit Host
The target of playbook can be limited with -l|-limit <selector>.
Missing this value could be dangerous since most playbooks will execute on all host, DO USE WITH CAUTION.
Here are some examples of host limit:
./pgsql.yml # run on all hosts (very dangerous!)
./pgsql.yml -l pg-test # run on pg-test cluster
./pgsql.yml -l 10.10.10.10 # run on single host 10.10.10.10
./pgsql.yml -l pg-* # run on host/group matching glob pattern `pg-*`
./pgsql.yml -l '10.10.10.11,&pg-test' # run on 10.10.10.10 of group pg-test
/pgsql-rm.yml -l 'pg-test,!10.10.10.11' # run on pg-test, except 10.10.10.11
./pgsql.yml -l pg-test # Execute the pgsql playbook against the hosts in the pg-test cluster
Limit Tags
You can execute a subset of playbook with -t|--tags <tags>.
You can specify multiple tags in comma separated list, e.g. -t tag1,tag2.
If specified, tasks with given tags will be executed instead of entire playbook.
Here are some examples of task limit:
./pgsql.yml -t pg_clean # cleanup existing postgres if necessary
./pgsql.yml -t pg_dbsu # setup os user sudo for postgres dbsu
./pgsql.yml -t pg_install # install postgres packages & extensions
./pgsql.yml -t pg_dir # create postgres directories and setup fhs
./pgsql.yml -t pg_util # copy utils scripts, setup alias and env
./pgsql.yml -t patroni # bootstrap postgres with patroni
./pgsql.yml -t pg_user # provision postgres business users
./pgsql.yml -t pg_db # provision postgres business databases
./pgsql.yml -t pg_backup # init pgbackrest repo & basebackup
./pgsql.yml -t pgbouncer # deploy a pgbouncer sidecar with postgres
./pgsql.yml -t pg_vip # bind vip to pgsql primary with vip-manager
./pgsql.yml -t pg_dns # register dns name to infra dnsmasq
./pgsql.yml -t pg_service # expose pgsql service with haproxy
./pgsql.yml -t pg_exporter # expose pgsql service with haproxy
./pgsql.yml -t pg_register # register postgres to pigsty infrastructure
# run multiple tasks: reload postgres & pgbouncer hba rules
./pgsql.yml -t pg_hba,pgbouncer_hba,pgbouncer_reload
# run multiple tasks: refresh haproxy config & reload it
./node.yml -t haproxy_config,haproxy_reload
Extra Vars
Extra command-line args can be passing via -e|-extra-vars KEY=VALUE.
It has the highest precedence over all other definition.
Here are some examples of extra vars
./node.yml -e ansible_user=admin -k -K # run playbook as another user (with admin sudo password)
./pgsql.yml -e pg_clean=true # force purging existing postgres when init a pgsql instance
./pgsql-rm.yml -e pg_uninstall=true # explicitly uninstall rpm after postgres instance is removed
./redis.yml -l 10.10.10.10 -e redis_port=6379 -t redis # init a specific redis instance: 10.10.10.11:6379
./redis-rm.yml -l 10.10.10.13 -e redis_port=6379 # remove a specific redis instance: 10.10.10.11:6379
Most playbooks are idempotent, meaning that some deployment playbooks may erase existing databases and create new ones without the protection option turned on.
Please read the documentation carefully, proofread the commands several times, and operate with caution. The author is not responsible for any loss of databases due to misuse.
7 - Provisioning
Pigsty runs on nodes, which are Bare Metals or Virtual Machines. You can prepare them manually, or using terraform & vagrant for provisioning.
Sandbox
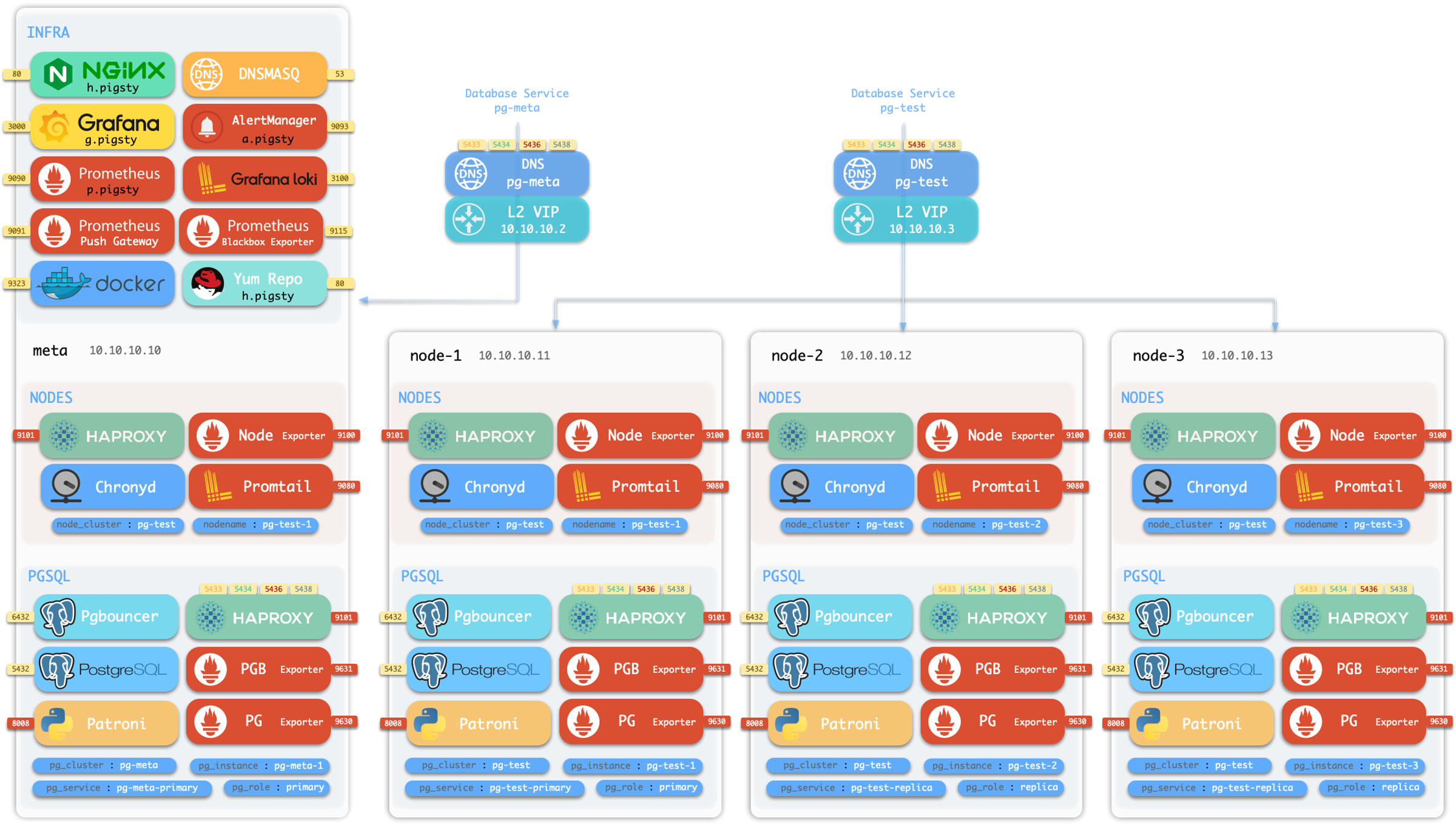
Pigsty has a sandbox, which is a 4-node deployment with fixed IP addresses and other identifiers.
Check demo.yml for details.
The sandbox consists of 4 nodes with fixed IP addresses: 10.10.10.10, 10.10.10.11, 10.10.10.12, 10.10.10.13.
There’s a primary singleton PostgreSQL cluster: pg-meta on the meta node, which can be used alone if you don’t care about PostgreSQL high availability.
meta 10.10.10.10 pg-meta pg-meta-1
There are 3 additional nodes in the sandbox, form a 3-instance PostgreSQL HA cluster pg-test.
node-1 10.10.10.11 pg-test.pg-test-1node-2 10.10.10.12 pg-test.pg-test-2node-3 10.10.10.13 pg-test.pg-test-3
Two optional L2 VIP are bind on primary instances of cluster pg-meta and pg-test:
10.10.10.2 pg-meta10.10.10.3 pg-test
There’s also a 1-instance etcd cluster, and 1-instance minio cluster on the meta node, too.
You can run sandbox on local VMs or cloud VMs. Pigsty offers a local sandbox based on Vagrant (pulling up local VMs using Virtualbox or libvirt), and a cloud sandbox based on Terraform (creating VMs using the cloud vendor API).
-
Local sandbox can be run on your Mac/PC for free. Your Mac/PC should have at least 4C/8G to run the full 4-node sandbox.
-
Cloud sandbox can be easily created and shared. You will have to create a cloud account for that. VMs are created on-demand and can be destroyed with one command, which is also very cheap for a quick glance.
Vagrant
Vagrant can create local VMs according to specs in a declarative way. Check Vagrant Templates Intro for details
Vagrant will use VirtualBox as the default VM provider. however libvirt, docker, parallel desktop and vmware can also be used. We will use VirtualBox in this guide.
Installation
Make sure Vagrant and Virtualbox are installed and available on your OS.
If you are using macOS, You can use homebrew to install both of them with one command (reboot required). You can also use vagrant-libvirt on Linux.
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
brew install vagrant virtualbox ansible # Run on MacOS with one command, but only works on x86_64 Intel chips
Configuration
vagarnt/Vagranfile is a ruby script file describing VM nodes. Here are some default specs of Pigsty.
| Templates | Shortcut | Spec | Comment |
|---|---|---|---|
| meta.rb | v1 |
4C8G x 1 | Single Meta Node |
| full.rb | v4 |
2C4G + 1C2G x 3 | Full 4 Nodes Sandbox Demo |
| el7.rb | v7 |
2C4G + 1C2G x 3 | EL7 3-node Testing Env |
| el8.rb | v8 |
2C4G + 1C2G x 3 | EL8 3-node Testing Env |
| el9.rb | v9 |
2C4G + 1C2G x 3 | EL9 3-node Testing Env |
| build.rb | vb |
2C4G x 3 | 3-Node EL7,8,9 Building Environment |
| check.rb | vc |
2C4G x 30 | 30 Node EL7-EL9 PG 12-16 Env |
| minio.rb | vm |
2C4G x 3 + Disk | 3-Node MinIO/etcd Testing Env |
| prod.rb | vp |
45 nodes | Prod simulation with 45 Nodes |
Each spec file contains a Specs variable describe VM nodes. For example, the full.rb contains the 4-node sandbox specs.
Specs = [
{"name" => "meta", "ip" => "10.10.10.10", "cpu" => "2", "mem" => "4096", "image" => "generic/rocky9" },
{"name" => "node-1", "ip" => "10.10.10.11", "cpu" => "1", "mem" => "2048", "image" => "generic/rocky9" },
{"name" => "node-2", "ip" => "10.10.10.12", "cpu" => "1", "mem" => "2048", "image" => "generic/rocky9" },
{"name" => "node-3", "ip" => "10.10.10.13", "cpu" => "1", "mem" => "2048", "image" => "generic/rocky9" },
]
You can switch specs with the vagrant/switch script, it will render the final Vagrantfile according to the spec.
cd ~/pigsty
vagrant/switch <spec>
vagrant/switch meta # singleton meta | alias: `make v1`
vagrant/switch full # 4-node sandbox | alias: `make v4`
vagrant/switch el7 # 3-node el7 test | alias: `make v7`
vagrant/switch el8 # 3-node el8 test | alias: `make v8`
vagrant/switch el9 # 3-node el9 test | alias: `make v9`
vagrant/switch prod # prod simulation | alias: `make vp`
vagrant/switch build # building environment | alias: `make vd`
vagrant/switch minio # 3-node minio env
vagrant/switch check # 30-node check env
Management
After describing the VM nodes with specs and generate the vagrant/Vagrantfile. you can create the VMs with vagrant up command.
Pigsty templates will use your ~/.ssh/id_rsa[.pub] as the default ssh key for vagrant provisioning.
Make sure you have a valid ssh key pair before you start, you can generate one by: ssh-keygen -t rsa -b 2048
There are some makefile shortcuts that wrap the vagrant commands, you can use them to manage the VMs.
make # = make start
make new # destroy existing vm and create new ones
make ssh # write VM ssh config to ~/.ssh/ (required)
make dns # write VM DNS records to /etc/hosts (optional)
make start # launch VMs and write ssh config (up + ssh)
make up # launch VMs with vagrant up
make halt # shutdown VMs (down,dw)
make clean # destroy VMs (clean/del/destroy)
make status # show VM status (st)
make pause # pause VMs (suspend,pause)
make resume # pause VMs (resume)
make nuke # destroy all vm & volumes with virsh (if using libvirt)
Shortcuts
You can create VMs with the following shortcuts:
make meta # singleton meta
make full # 4-node sandbox
make el7 # 3-node el7 test
make el8 # 3-node el8 test
make el9 # 3-node el9 test
make prod # prod simulation
make build # building environment
make minio # 3-node minio env
make check # 30-node check env
make meta install # create and install pigsty on 1-node singleton meta
make full install # create and install pigsty on 4-node sandbox
make prod install # create and install pigsty on 42-node KVM libvirt environment
make check install # create and install pigsty on 30-node testing & validating environment
...
Terraform
Terraform is an open-source tool to practice ‘Infra as Code’. Describe the cloud resource you want and create them with one command.
Pigsty has terraform templates for AWS, Aliyun, and Tencent Cloud, you can use them to create VMs on the cloud for Pigsty Demo.
Terraform can be easily installed with homebrew, too: brew install terraform. You will have to create a cloud account to obtain AccessKey and AccessSecret credentials to proceed.
The terraform/ dir have two example templates: one for AWS, and one for Aliyun, you can adjust them to fit your need, or modify them if you are using a different cloud vendor.
Take Aliyun as example:
cd terraform # goto the terraform dir
cp spec/aliyun.tf terraform.tf # use aliyun template
You have to perform terraform init before terraform apply:
terraform init # install terraform provider: aliyun (required only for the first time)
terraform apply # generate execution plans: create VMs, virtual segments/switches/security groups
After running apply and answering yes to the prompt, Terraform will create the VMs and configure the network for you.
The admin node ip address will be printed out at the end of the execution, you can ssh login and start pigsty installation.
8 - Security
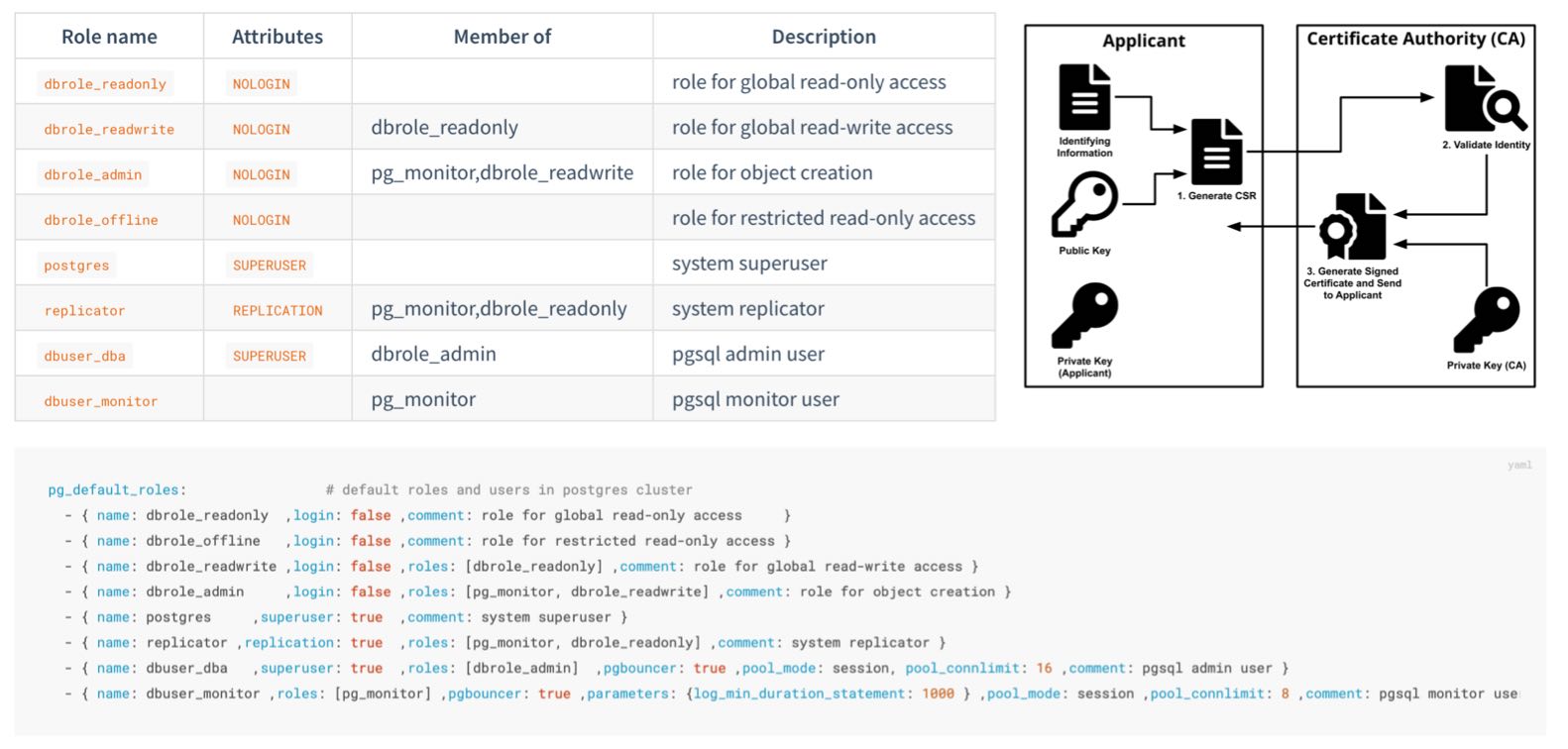
Pigsty already provides a secure-by-default authentication and access control model, which is sufficient for most scenarios.
But if you want to further strengthen the security of the system, the following suggestions are for your reference:
Confidentiality
Important Files
Secure your pigsty config inventory
pigsty.ymlhas highly sensitive information, including passwords, certificates, and keys.- You should limit access to admin/infra nodes, only accessible by the admin/dba users
- Limit access to the git repo, if you are using git to manage your pigsty source.
Secure your CA private key and other certs
- These files are very important, and will be generated under
files/pkiunder pigsty source dir by default. - You should secure & backup them in a safe place periodically.
Passwords
Always change these passwords, DO NOT USE THE DEFAULT VALUES:
grafana_admin_password:pigstypg_admin_password:DBUser.DBApg_monitor_password:DBUser.Monitorpg_replication_password:DBUser.Replicatorpatroni_password:Patroni.APIhaproxy_admin_password:pigstyminio_secret_key:minioadmin
Please change MinIO user secret key and pgbackrest_repo references
- Please change the password for
minio_users.[pgbacrest].secret_key - Please change pgbackrest references:
pgbackrest_repo.minio.s3_key_secret
If you are using remote backup method, secure backup with distinct passwords
- Use
aes-256-cbcforpgbackrest_repo.*.cipher_type - When setting a password, you can use
${pg_cluster}placeholder as part of the password to avoid using the same password.
Use advanced password encryption method for PostgreSQL
- use
pg_pwd_encdefaultscram-sha-256instead of legacymd5
Enforce a strong pg password with the passwordcheck extension.
- add
$lib/passwordchecktopg_libsto enforce password policy.
Encrypt remote backup with an encryption algorithm
- check
pgbackrest_repodefinitionrepo_cipher_type
Add an expiration date to biz user passwords.
-
You can set an expiry date for each user for compliance purposes.
-
Don’t forget to refresh these passwords periodically.
- { name: dbuser_meta , password: Pleas3-ChangeThisPwd ,expire_in: 7300 ,pgbouncer: true ,roles: [ dbrole_admin ] ,comment: pigsty admin user } - { name: dbuser_view , password: Make.3ure-Compl1ance ,expire_in: 7300 ,pgbouncer: true ,roles: [ dbrole_readonly ] ,comment: read-only viewer for meta database } - { name: postgres ,superuser: true ,expire_in: 7300 ,comment: system superuser } - { name: replicator ,replication: true ,expire_in: 7300 ,roles: [pg_monitor, dbrole_readonly] ,comment: system replicator } - { name: dbuser_dba ,superuser: true ,expire_in: 7300 ,roles: [dbrole_admin] ,pgbouncer: true ,pool_mode: session, pool_connlimit: 16 , comment: pgsql admin user } - { name: dbuser_monitor ,roles: [pg_monitor] ,expire_in: 7300 ,pgbouncer: true ,parameters: {log_min_duration_statement: 1000 } ,pool_mode: session ,pool_connlimit: 8 ,comment: pgsql monitor user }
Do not log changing password statement into postgres log.
SET log_statement TO 'none';
ALTER USER "{{ user.name }}" PASSWORD '{{ user.password }}';
SET log_statement TO DEFAULT;
IP Addresses
Bind to specific IP addresses rather than all addresses for postgres/pgbouncer/patroni
- The default
pg_listenaddress is0.0.0.0, which is all IPv4 addresses. - consider using
pg_listen: '${ip},${vip},${lo}'to bind to specific addresses for better security.
Do not expose any port to the Internet; except 80/443, the infra portal
- Grafana/Prometheus are bind to all IP address by default for convenience.
- You can modify their bind configuration to listen on localhost/intranet IP and expose by Nginx.
- Redis server are bind to all IP address by default for convenience. You can change
redis_bind_addressto listen on intranet IP. - You can also implement it with the security group or firewall rules.
Limit postgres client access with HBA
- There’s a security enhance config template:
security.yml
Limit patroni admin access from the infra/admin node.
- This is restricted by default with
restapi.allowlist
Network Traffic
-
Access Nginx with SSL and domain names
- Nginx SSL is controlled by
nginx_sslmode, which isenableby default. - Nginx Domain names are specified by
infra_portal.<value>.domain.
- Nginx SSL is controlled by
-
Secure Patroni REST API with SSL
patroni_ssl_enabledis disabled by default- Since it affects health checks and API invocation.
- Note this is a global option, and you have to decide before deployment.
-
Secure Pgbouncer Client Traffic with SSL
pgbouncer_sslmodeisdisableby default- Since it has a significant performance impact.
Integrity
Consistency
Use consistency-first mode for PostgreSQL.
- Use
crit.ymltemplates forpg_confwill trade some availability for the best consistency.
Use node crit tuned template for better consistency
- set
node_tunetocritto reduce dirty page ratio.
- Enable data checksum to detect silent data corruption.
pg_checksumis disabled by default, and enabled forcrit.ymlby default- This can be enabled later, which requires a full cluster scan/stop.
Audit
- Enable
log_connectionsandlog_disconnectionsafter the pg cluster bootstrap.- Audit incoming sessions; this is enabled in
crit.ymlby default.
- Audit incoming sessions; this is enabled in
Availability
-
Do not access the database directly via a fixed IP address; use VIP, DNS, HAProxy, or their combination.
- Haproxy will handle the traffic control for the clients in case of failover/switchover.
-
Use enough nodes for serious production deployment.
- You need at least three nodes (tolerate one node failure) to achieve production-grade high availability.
- If you only have two nodes, you can tolerate the failure of the specific standby node.
- If you have one node, use an external S3/MinIO for cold backup & wal archive storage.
-
Trade off between availability and consistency for PostgreSQL.
-
Use multiple infra nodes in serious production deployment (e.g., 1~3)
- Usually, 2 ~ 3 is enough for a large production deployment.
-
Use enough etcd members and use even numbers (1,3,5,7).
- Check ETCD Administration for details.
9 - FAQ
If you have any unlisted questions or suggestions, please create an Issue or ask the community for help.
How to Get the Pigsty Source Package?
Use the following command to install Pigsty with one click: bash -c "$(curl -fsSL https://get.pigsty.cc/install)"
This command will automatically download the latest stable version pigsty.tgz and extract it to the ~/pigsty directory. You can also manually download a specific version of the Pigsty source code from the following locations.
If you need to install it in an environment without internet access, you can download it in advance in a networked environment and transfer it to the production server via scp/sftp or CDROM/USB.
How to Speed Up RPM Downloads from Upstream Repositories?
Consider using a local repository mirror, which can be configured with the repo_upstream parameter. You can choose region to use different mirror sites.
For example, you can set region = china, which will use the URL with the key china in the baseurl instead of default.
If some repositories are blocked by a firewall or the GFW, consider using proxy_env to bypass it.
How to resolve node package conflict?
Beware that Pigsty’s pre-built offline packages are tailored for specific minor versions OS Distors.
Therefore, if the major.minor version of your OS distro does not precisely align, we advise against using the offline installation packages.
Instead, following the default installation procedure and download the package directly from upstream repo through the Internet, which will acquire the versions that exactly match your OS version.
If online installation doesn’t work for you, you can first try modifying the upstream software sources used by Pigsty.
For example, in EL family operating systems, Pigsty’s default upstream sources use a major version placeholder $releasever, which resolves to specific major versions like 7, 8, 9.
However, many operating system distributions offer a Vault, allowing you to use a package mirror for a specific version.
Therefore, you could replace the front part of the repo_upstream parameter’s BaseURL with a specific Vault minor version repository, such as:
https://dl.rockylinux.org/pub/rocky/$releasever(Original BaseURL prefix, withoutvault)https://vault.centos.org/7.6.1810/(Using 7.6 instead of the default 7.9)https://dl.rockylinux.org/vault/rocky/8.6/(Using 8.6 instead of the default 8.9)https://dl.rockylinux.org/vault/rocky/9.2/(Using 9.2 instead of the default 9.3)
Make sure the vault URL path exists & valid before replacing the old values. Beware that some repo like epel do not offer specific minor version subdirs.
Upstream repo that support this approach include: base, updates, extras, centos-sclo, centos-sclo-rh, baseos, appstream, extras, crb, powertools, pgdg-common, pgdg1*
repo_upstream:
- { name: pigsty-local ,description: 'Pigsty Local' ,module: local ,releases: [7,8,9] ,baseurl: { default: 'http://${admin_ip}/pigsty' }} # used by intranet nodes
- { name: pigsty-infra ,description: 'Pigsty INFRA' ,module: infra ,releases: [7,8,9] ,baseurl: { default: 'https://repo.pigsty.io/rpm/infra/$basearch' ,china: 'https://repo.pigsty.cc/rpm/infra/$basearch' }}
- { name: pigsty-pgsql ,description: 'Pigsty PGSQL' ,module: pgsql ,releases: [7,8,9] ,baseurl: { default: 'https://repo.pigsty.io/rpm/pgsql/el$releasever.$basearch' ,china: 'https://repo.pigsty.cc/rpm/pgsql/el$releasever.$basearch' }}
- { name: nginx ,description: 'Nginx Repo' ,module: infra ,releases: [7,8,9] ,baseurl: { default: 'https://nginx.org/packages/centos/$releasever/$basearch/' }}
- { name: docker-ce ,description: 'Docker CE' ,module: infra ,releases: [7,8,9] ,baseurl: { default: 'https://download.docker.com/linux/centos/$releasever/$basearch/stable' ,china: 'https://mirrors.aliyun.com/docker-ce/linux/centos/$releasever/$basearch/stable' ,europe: 'https://mirrors.xtom.de/docker-ce/linux/centos/$releasever/$basearch/stable' }}
- { name: base ,description: 'EL 7 Base' ,module: node ,releases: [7 ] ,baseurl: { default: 'http://mirror.centos.org/centos/$releasever/os/$basearch/' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/centos/$releasever/os/$basearch/' ,europe: 'https://mirrors.xtom.de/centos/$releasever/os/$basearch/' }}
- { name: updates ,description: 'EL 7 Updates' ,module: node ,releases: [7 ] ,baseurl: { default: 'http://mirror.centos.org/centos/$releasever/updates/$basearch/' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/centos/$releasever/updates/$basearch/' ,europe: 'https://mirrors.xtom.de/centos/$releasever/updates/$basearch/' }}
- { name: extras ,description: 'EL 7 Extras' ,module: node ,releases: [7 ] ,baseurl: { default: 'http://mirror.centos.org/centos/$releasever/extras/$basearch/' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/centos/$releasever/extras/$basearch/' ,europe: 'https://mirrors.xtom.de/centos/$releasever/extras/$basearch/' }}
- { name: epel ,description: 'EL 7 EPEL' ,module: node ,releases: [7 ] ,baseurl: { default: 'http://download.fedoraproject.org/pub/epel/$releasever/$basearch/' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/epel/$releasever/$basearch/' ,europe: 'https://mirrors.xtom.de/epel/$releasever/$basearch/' }}
- { name: centos-sclo ,description: 'EL 7 SCLo' ,module: node ,releases: [7 ] ,baseurl: { default: 'http://mirror.centos.org/centos/$releasever/sclo/$basearch/sclo/' ,china: 'https://mirrors.aliyun.com/centos/$releasever/sclo/$basearch/sclo/' ,europe: 'https://mirrors.xtom.de/centos/$releasever/sclo/$basearch/sclo/' }}
- { name: centos-sclo-rh ,description: 'EL 7 SCLo rh' ,module: node ,releases: [7 ] ,baseurl: { default: 'http://mirror.centos.org/centos/$releasever/sclo/$basearch/rh/' ,china: 'https://mirrors.aliyun.com/centos/$releasever/sclo/$basearch/rh/' ,europe: 'https://mirrors.xtom.de/centos/$releasever/sclo/$basearch/rh/' }}
- { name: baseos ,description: 'EL 8+ BaseOS' ,module: node ,releases: [ 8,9] ,baseurl: { default: 'https://dl.rockylinux.org/pub/rocky/$releasever/BaseOS/$basearch/os/' ,china: 'https://mirrors.aliyun.com/rockylinux/$releasever/BaseOS/$basearch/os/' ,europe: 'https://mirrors.xtom.de/rocky/$releasever/BaseOS/$basearch/os/' }}
- { name: appstream ,description: 'EL 8+ AppStream' ,module: node ,releases: [ 8,9] ,baseurl: { default: 'https://dl.rockylinux.org/pub/rocky/$releasever/AppStream/$basearch/os/' ,china: 'https://mirrors.aliyun.com/rockylinux/$releasever/AppStream/$basearch/os/' ,europe: 'https://mirrors.xtom.de/rocky/$releasever/AppStream/$basearch/os/' }}
- { name: extras ,description: 'EL 8+ Extras' ,module: node ,releases: [ 8,9] ,baseurl: { default: 'https://dl.rockylinux.org/pub/rocky/$releasever/extras/$basearch/os/' ,china: 'https://mirrors.aliyun.com/rockylinux/$releasever/extras/$basearch/os/' ,europe: 'https://mirrors.xtom.de/rocky/$releasever/extras/$basearch/os/' }}
- { name: crb ,description: 'EL 9 CRB' ,module: node ,releases: [ 9] ,baseurl: { default: 'https://dl.rockylinux.org/pub/rocky/$releasever/CRB/$basearch/os/' ,china: 'https://mirrors.aliyun.com/rockylinux/$releasever/CRB/$basearch/os/' ,europe: 'https://mirrors.xtom.de/rocky/$releasever/CRB/$basearch/os/' }}
- { name: powertools ,description: 'EL 8 PowerTools' ,module: node ,releases: [ 8 ] ,baseurl: { default: 'https://dl.rockylinux.org/pub/rocky/$releasever/PowerTools/$basearch/os/' ,china: 'https://mirrors.aliyun.com/rockylinux/$releasever/PowerTools/$basearch/os/' ,europe: 'https://mirrors.xtom.de/rocky/$releasever/PowerTools/$basearch/os/' }}
- { name: epel ,description: 'EL 8+ EPEL' ,module: node ,releases: [ 8,9] ,baseurl: { default: 'http://download.fedoraproject.org/pub/epel/$releasever/Everything/$basearch/' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/epel/$releasever/Everything/$basearch/' ,europe: 'https://mirrors.xtom.de/epel/$releasever/Everything/$basearch/' }}
- { name: pgdg-common ,description: 'PostgreSQL Common' ,module: pgsql ,releases: [7,8,9] ,baseurl: { default: 'https://download.postgresql.org/pub/repos/yum/common/redhat/rhel-$releasever-$basearch' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/postgresql/repos/yum/common/redhat/rhel-$releasever-$basearch' , europe: 'https://mirrors.xtom.de/postgresql/repos/yum/common/redhat/rhel-$releasever-$basearch' }}
- { name: pgdg-extras ,description: 'PostgreSQL Extra' ,module: pgsql ,releases: [7,8,9] ,baseurl: { default: 'https://download.postgresql.org/pub/repos/yum/common/pgdg-rhel$releasever-extras/redhat/rhel-$releasever-$basearch' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/postgresql/repos/yum/common/pgdg-rhel$releasever-extras/redhat/rhel-$releasever-$basearch' , europe: 'https://mirrors.xtom.de/postgresql/repos/yum/common/pgdg-rhel$releasever-extras/redhat/rhel-$releasever-$basearch' }}
- { name: pgdg-el8fix ,description: 'PostgreSQL EL8FIX' ,module: pgsql ,releases: [ 8 ] ,baseurl: { default: 'https://download.postgresql.org/pub/repos/yum/common/pgdg-centos8-sysupdates/redhat/rhel-8-x86_64/' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/postgresql/repos/yum/common/pgdg-centos8-sysupdates/redhat/rhel-8-x86_64/' , europe: 'https://mirrors.xtom.de/postgresql/repos/yum/common/pgdg-centos8-sysupdates/redhat/rhel-8-x86_64/' } }
- { name: pgdg-el9fix ,description: 'PostgreSQL EL9FIX' ,module: pgsql ,releases: [ 9] ,baseurl: { default: 'https://download.postgresql.org/pub/repos/yum/common/pgdg-rocky9-sysupdates/redhat/rhel-9-x86_64/' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/postgresql/repos/yum/common/pgdg-rocky9-sysupdates/redhat/rhel-9-x86_64/' , europe: 'https://mirrors.xtom.de/postgresql/repos/yum/common/pgdg-rocky9-sysupdates/redhat/rhel-9-x86_64/' }}
- { name: pgdg15 ,description: 'PostgreSQL 15' ,module: pgsql ,releases: [7 ] ,baseurl: { default: 'https://download.postgresql.org/pub/repos/yum/15/redhat/rhel-$releasever-$basearch' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/postgresql/repos/yum/15/redhat/rhel-$releasever-$basearch' ,europe: 'https://mirrors.xtom.de/postgresql/repos/yum/15/redhat/rhel-$releasever-$basearch' }}
- { name: pgdg16 ,description: 'PostgreSQL 16' ,module: pgsql ,releases: [ 8,9] ,baseurl: { default: 'https://download.postgresql.org/pub/repos/yum/16/redhat/rhel-$releasever-$basearch' ,china: 'https://mirrors.tuna.tsinghua.edu.cn/postgresql/repos/yum/16/redhat/rhel-$releasever-$basearch' ,europe: 'https://mirrors.xtom.de/postgresql/repos/yum/16/redhat/rhel-$releasever-$basearch' }}
- { name: timescaledb ,description: 'TimescaleDB' ,module: pgsql ,releases: [7,8,9] ,baseurl: { default: 'https://packagecloud.io/timescale/timescaledb/el/$releasever/$basearch' }}
After explicitly defining and overriding the repo_upstream in the Pigsty configuration file, (you may clear the /www/pigsty/repo_complete flag) try the installation again.
If the upstream software source and the mirror source software do not solve the problem, you might consider replacing them with the operating system’s built-in software sources and attempt a direct installation from upstream once more.
Finally, if the above methods do not resolve the issue, consider removing conflicting packages from node_packages, infra_packages, pg_packages, pg_extensions, or remove or upgrade the conflicting packages on the existing system.
What does bootstrap do?
Check the environment, ask for downloading offline packages, and make sure the essential tool
ansibleis installed.
It will make sure the essential tool ansible is installed by various means.
When you download the Pigsty source code, you can enter the directory and execute the bootstrap script.
It will check if your node environment is ready, and if it does not find offline packages, it will ask if you want to download them from the internet if applicable.
You can choose y to use offline packages, which will make the installation procedure faster.
You can also choose n to skip and download directly from the internet during the installation process,
which will download the latest software versions and reduce the chance of RPM conflicts.
What does configure do?
Detect the environment, generate the configuration, enable the offline package (optional), and install the essential tool Ansible.
After downloading the Pigsty source package and unpacking it, you may have to execute ./configure to complete the environment configuration. This is optional if you already know how to configure Pigsty properly.
The configure procedure will detect your node environment and generate a pigsty config file: pigsty.yml for you.
What is the Pigsty config file?
pigsty.ymlunder the pigsty home dir is the default config file.
Pigsty uses a single config file pigsty.yml, to describe the entire environment, and you can define everything there. There are many config examples in files/pigsty for your reference.
You can pass the -i <path> to playbooks to use other configuration files. For example, you want to install redis according to another config: redis.yml:
./redis.yml -i files/pigsty/redis.yml
How to use the CMDB as config inventory
The default config file path is specified in ansible.cfg: inventory = pigsty.yml
You can switch to a dynamic CMDB inventory with bin/inventory_cmdb, and switch back to the local config file with bin/inventory_conf. You must also load the current config file inventory to CMDB with bin/inventory_load.
If CMDB is used, you must edit the inventory config from the database rather than the config file.
What is the IP address placeholder in the config file?
Pigsty uses
10.10.10.10as a placeholder for the current node IP, which will be replaced with the primary IP of the current node during the configuration.
When the configure detects multiple NICs with multiple IPs on the current node, the config wizard will prompt for the primary IP to be used, i.e., the IP used by the user to access the node from the internal network. Note that please do not use the public IP.
This IP will be used to replace 10.10.10.10 in the config file template.
Which parameters need your attention?
Usually, in a singleton installation, there is no need to make any adjustments to the config files.
Pigsty provides 265 config parameters to customize the entire infra/node/etcd/minio/pgsql. However, there are a few parameters that can be adjusted in advance if needed:
- When accessing web service components, the domain name is
infra_portal(some services can only be accessed using the domain name through the Nginx proxy). - Pigsty assumes that a
/datadir exists to hold all data; you can adjust these paths if the data disk mount point differs from this. - Don’t forget to change those passwords in the config file for your production deployment.
Installation
What was executed during installation?
When running
make install, the ansible-playbookinstall.ymlwill be invoked to install everything on all nodes
Which will:
- Install
INFRAmodule on the current node. - Install
NODEmodule on the current node. - Install
ETCDmodule on the current node. - The
MinIOmodule is optional, and will not be installed by default. - Install
PGSQLmodule on the current node.
How to resolve RPM conflict?
There may have a slight chance that rpm conflict occurs during node/infra/pgsql packages installation.
The simplest way to resolve this is to install without offline packages, which will download directly from the upstream repo.
If there are only a few problematic RPM/DEB pakages, you can use a trick to fix the yum/apt repo quickly:
rm -rf /www/pigsty/repo_complete # delete the repo_complete flag file to mark this repo incomplete
rm -rf SomeBrokenPackages # delete problematic RPM/DEB packages
./infra.yml -t repo_upstream # write upstream repos. you can also use /etc/yum.repos.d/backup/*
./infra.yml -t repo_pkg # download rpms according to your current OS
How to create local VMs with vagrant
The first time you use Vagrant to pull up a particular OS repo, it will download the corresponding BOX.
Pigsty sandbox uses generic/rocky9 image box by default, and Vagrant will download the rocky/9 box for the first time the VM is started.
Using a proxy may increase the download speed. Box only needs to be downloaded once, and will be reused when recreating the sandbox.
RPMs error on Aliyun CentOS 7.9
Aliyun CentOS 7.9 server has DNS caching service
nscdinstalled by default. Just remove it.
Aliyun’s CentOS 7.9 repo has nscd installed by default, locking out the glibc version, which can cause RPM dependency errors during installation.
"Error: Package: nscd-2.17-307.el7.1.x86_64 (@base)"
Run yum remove -y nscd on all nodes to resolve this issue, and with Ansible, you can batch.
ansible all -b -a 'yum remove -y nscd'
RPMs error on Tencent Qcloud Rocky 9.1
Tencent Qcloud Rocky 9.1 require extra
annobinpackages
./infra.yml -t repo_upstream # add upstream repos
cd /www/pigsty; # download missing packages
repotrack annobin gcc-plugin-annobin libuser
./infra.yml -t repo_create # create repo
Ansible command timeout (Timeout waiting for xxx)
The default ssh timeout for ansible command is 10 seconds, some commands may take longer than that due to network latency or other reasons.
You can increase the timeout parameter in the ansible config file ansible.cfg:
[defaults]
timeout = 10 # change to 60,120 or more