高可用性
久经实战考验的业界 PostgreSQL 高可用最佳实践
确保软硬件故障快速自愈,流量自动切换,确保您的数据坚若磐石
快速恢复
RTO < 30秒
主库故障切换等待 30 秒避免误判,可调整
从库故障与/动切换瞬间闪断完成,RTO ≈ 0
数据安全
RPO = 0
同步模式下,确保已提交数据零丢失
可通过异步模式提高吞吐:RPO < 1MB
持续运行
故障自愈
故障后应用无需重启,集群拓扑对应用透明
只要集群任意成员存活,即可对外提供服务
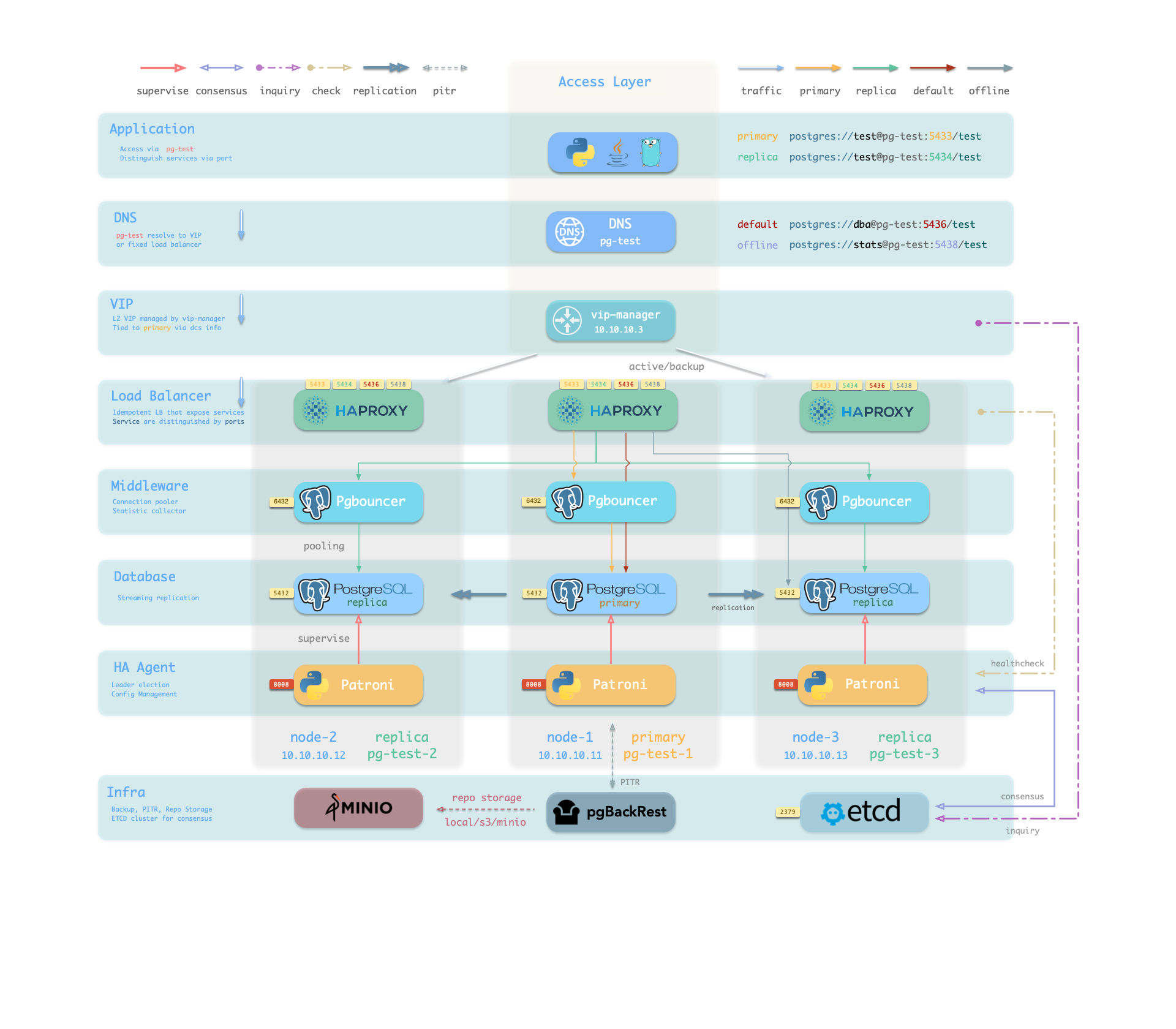
高可用架构说明
高可用解决什么问题?
将数据安全C/IA中的可用性提高到一个新高度:RPO ≈ 0, RTO < 30s。
获得无缝滚动维护的能力,最小化维护窗口需求,带来极大便利。
硬件故障可以立即自愈,无需人工介入,运维DBA可以睡个好觉。
从库可以用于承载只读请求,分担主库负载,让资源得以充分利用。
高可用有什么代价?
基础设施依赖:高可用需要依赖 DCS (etcd/zk/consul) 提供共识
起步门槛增加:一个有意义的高可用部署环境至少需要 三个节点
额外的资源消耗:一个新从库需要消耗一份额外存储计算资源
复杂度代价显著升高:备份成本显著加大,需要使用工具封装复杂度
| 配置策略 | RTO | RPO |
|---|---|---|
| 单机 + 什么也不做 | 数据永久丢失,无法恢复 | 数据全部丢失 |
| 单机 + 基础备份 | 取决于备份大小与带宽(几小时) | 丢失上一次备份后的数据(几个小时到几天) |
| 单机 + 基础备份 + WAL归档 | 取决于备份大小与带宽(几小时) | 丢失最后尚未归档的数据(几十MB) |
| 主从 + 手工故障切换 | 十分钟 | 丢失复制延迟中的数据(约百KB) |
| 主从 + 自动故障切换 | 一分钟内 | 丢失复制延迟中的数据(约百KB) |
| 主从 + 自动故障切换 + 同步提交 | 一分钟内 | 无数据丢失 |
因为复制实时进⾏,所有变更被⽴即应⽤⾄从库,因此高可用架构⽆法应对⼈为错误与软件缺陷导致的数据误删误改。
高可用实现方式
Pigsty 的高可用架构基于以下成熟技术构建:
PostgreSQL 流复制
PostgreSQL 主从物理复制
主库出现故障时,备考将接管
Patroni
管理 PostgreSQL 集群
协调高可用操作
Etcd
分布式配置存储
主库选举与配置存储
HAProxy
负载均衡器,分发流量
对外暴露服务,自动切换流量
高可用权衡考量
恢复时间目标 (RTO)
默认 30 秒,可通过 pg_rto 配置。较低的值减少停机时间但增加误判故障转移的可能性。 较高的值增加稳定性但延长恢复时间。
恢复点目标 (RPO)
默认 1MB,可通过 pg_rpo 配置。较低的值最小化数据丢失但可能阻止自动故障转移。 同步复制可实现零 RPO,但会牺牲一定的性能。