第五章 并发控制
Module:
Categories:
当多个事务同时在数据库中运行时,并发控制是一种用于维持一致性与隔离性的技术,一致性与隔离性是ACID的两个属性。
从宽泛的意义上来讲,有三种并发控制技术:多版本并发控制(Multi-version Concurrency Control, MVCC),严格两阶段锁定(Strict Two-Phase Locking, S2PL)和乐观并发控制(Optimistic Concurrency Control, OCC),每种技术都有多种变体。在MVCC中,每个写操作都会创建一个新版本的数据项,并保留其旧版本。当事务读取数据对象时,系统会选择其中的一个版本,通过这种方式来确保各个事务间相互隔离。 MVCC的主要优势在于“读不会阻塞写,而写也不会阻塞读”,相反的例子是,基于S2PL的系统在写操作发生时会阻塞相应对象上的读操作,因为写入者获取了对象上的排他锁。 PostgreSQL和一些RDBMS使用一种MVCC的变体,名曰 快照隔离(Snapshot Isolation,SI)。
一些RDBMS(例如Oracle)使用回滚段来实现快照隔离SI。当写入新数据对象时,旧版本对象先被写入回滚段,随后用新对象覆写至数据区域。 PostgreSQL使用更简单的方法:新数据对象被直接插入到相关表页中。读取对象时,PostgreSQL根据可见性检查规则(visibility check rules),为每个事务选择合适的对象版本作为响应。
SI中不会出现在ANSI SQL-92标准中定义的三种异常:脏读,不可重复读和幻读。但SI无法实现真正的可串行化,因为在SI中可能会出现串行化异常:例如 写偏差(write skew) 和 只读事务偏差(Read-only Transaction Skew) 。需要注意的是:ANSI SQL-92标准中可串行化的定义与现代理论中的定义并不相同。为了解决这个问题,PostgreSQL从9.1版本之后添加了可串行化快照隔离(SSI,Serializable Snapshot Isolation),SSI可以检测串行化异常,并解决这种异常导致的冲突。因此,9.1版本之后的PostgreSQL提供了真正的SERIALIZABLE隔离等级(此外SQL Server也使用SSI,而Oracle仍然使用SI)。
本章包括以下四个部分:
-
第1部分:第5.1~5.3节。
这一部分介绍了理解后续部分所需的基本信息。
第5.1和5.2节分别描述了事务标识和元组结构。第5.3节展示了如何插入,删除和更新元组。
-
第2部分:第5.4~5.6节。
这一部分说明了实现并发控制机制所需的关键功能。
第5.4,5.5和5.6节描述了提交日志(clog),分别介绍了事务状态,事务快照和可见性检查规则。
-
第3部分:第5.7~5.9节。
这一部分使用具体的例子来介绍PostgreSQL中的并发控制。
这一部分说明了如何防止ANSI SQL标准中定义的三种异常。第5.7节描述了可见性检查,第5.8节介绍了如何防止丢失更新,第5.9节简要描述了SSI。
-
第4部分:第5.10节。
这一部分描述了并发控制机制持久运行所需的几个维护过程。维护过程主要通过 清理过程(vacuum processing) 进行,清理过程将在第6章详细阐述。
并发控制包含着很多主题,本章重点介绍PostgreSQL独有的内容。故这里省略了锁模式与死锁处理的内容(相关信息请参阅官方文档)。
PostgreSQL中的事务隔离等级
PostgreSQL实现的事务隔离等级如下表所示:
| 隔离等级 | 脏读 | 不可重复读 | 幻读 | 串行化异常 |
|---|---|---|---|---|
| 读已提交 | 不可能 | 可能 | 可能 | 可能 |
| 可重复读[1] | 不可能 | 不可能 | PG中不可能,见5.7.2小节 但ANSI SQL中可能 |
可能 |
| 可串行化 | 不可能 | 不可能 | 不可能 | 不可能 |
[1]:在9.0及更早版本中,该级别被当做SERIALIZABLE,因为它不会出现ANSI SQL-92标准中定义的三种异常。 但9.1版中SSI的实现引入了真正的SERIALIZABLE级别,该级别已被改称为REPEATABLE READ。
PostgreSQL对DML(
SELECT, UPDATE, INSERT, DELETE等命令)使用SSI,对DDL(CREATE TABLE等命令)使用2PL。
5.1 事务标识
每当事务开始时,事务管理器就会为其分配一个称为 事务标识(transaction id, txid) 的唯一标识符。 PostgreSQL的txid是一个32位无符号整数,总取值约42亿。在事务启动后执行内置的txid_current()函数,即可获取当前事务的txid,如下所示。
testdb=# BEGIN;
BEGIN
testdb=# SELECT txid_current();
txid_current
--------------
100
(1 row)
PostgreSQL保留以下三个特殊txid:
- 0 表示 无效(Invalid) 的
txid。 - 1 表示 初始启动(Bootstrap) 的
txid,仅用于数据库集群的初始化过程。 - 2 表示 冻结(Frozen) 的
txid,详情参考第5.10.1节。
txid可以相互比较大小。例如对于txid=100的事务,大于100的txid属于“未来”,且对于txid=100的事务而言都是 不可见(invisible) 的;小于100的txid属于“过去”,且对该事务可见,如图5.1(a)所示。
图5.1 PostgreSQL中的事务标识
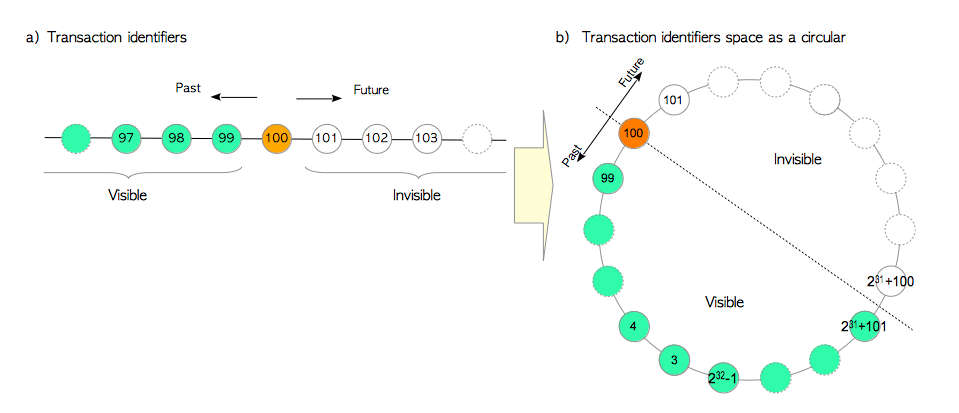
因为txid在逻辑上是无限的,而实际系统中的txid空间不足(4字节取值空间约42亿),因此PostgreSQL将txid空间视为一个环。对于某个特定的txid,其前约21亿个txid属于过去,而其后约21亿个txid属于未来。如图5.1(b)所示。
所谓的txid回卷问题将在5.10.1节中介绍。
请注意,
txid并非是在BEGIN命令执行时分配的。在PostgreSQL中,当执行BEGIN命令后的第一条命令时,事务管理器才会分配txid,并真正启动其事务。
5.2 元组结构
可以将表页中的堆元组分为两类:普通数据元组与TOAST元组。本节只会介绍普通元组。
堆元组由三个部分组成,即HeapTupleHeaderData结构,空值位图,以及用户数据,如图5.2所示。
图5.2 元组结构
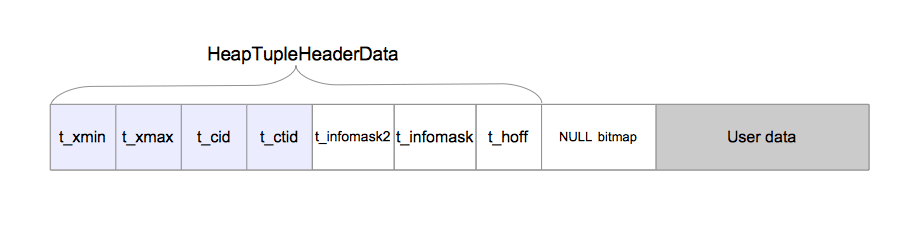
HeapTupleHeaderData结构在src/include/access/htup_details.h中定义。
typedef struct HeapTupleFields
{
TransactionId t_xmin; /* 插入事务的ID */
TransactionId t_xmax; /*删除或锁定事务的ID*/
union
{
CommandId t_cid; /* 插入或删除的命令ID */
TransactionId t_xvac; /* 老式VACUUM FULL的事务ID */
} t_field3;
} HeapTupleFields;
typedef struct DatumTupleFields
{
int32 datum_len_; /* 变长头部长度*/
int32 datum_typmod; /* -1或者是记录类型的标识 */
Oid datum_typeid; /* 复杂类型的OID或记录ID */
} DatumTupleFields;
typedef struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* 当前元组,或更新元组的TID */
/* 下面的字段必需与结构MinimalTupleData相匹配! */
uint16 t_infomask2; /* 属性与标记位 */
uint16 t_infomask; /* 很多标记位 */
uint8 t_hoff; /* 首部+位图+填充的长度 */
/* ^ - 23 bytes - ^ */
bits8 t_bits[1]; /* NULL值的位图 —— 变长的 */
/* 本结构后面还有更多数据 */
} HeapTupleHeaderData;
typedef HeapTupleHeaderData *HeapTupleHeader;
虽然HeapTupleHeaderData结构包含七个字段,但后续部分中只需要了解四个字段即可。
t_xmin保存插入此元组的事务的txid。t_xmax保存删除或更新此元组的事务的txid。如果尚未删除或更新此元组,则t_xmax设置为0,即无效。t_cid保存命令标识(command id, cid),cid意思是在当前事务中,执行当前命令之前执行了多少SQL命令,从零开始计数。例如,假设我们在单个事务中执行了三条INSERT命令BEGIN;INSERT;INSERT;INSERT;COMMIT;。如果第一条命令插入此元组,则该元组的t_cid会被设置为0。如果第二条命令插入此元组,则其t_cid会被设置为1,依此类推。t_ctid保存着指向自身或新元组的元组标识符(tid)。如第1.3节中所述,tid用于标识表中的元组。在更新该元组时,其t_ctid会指向新版本的元组;否则t_ctid会指向自己。
5.3 元组的增删改
本节会介绍元组的增删改过程,并简要描述用于插入与更新元组的自由空间映射(Free Space Map, FSM)。
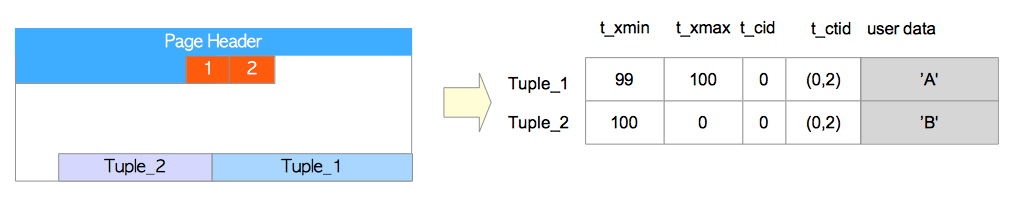
这里主要关注元组,页首部与行指针不会在这里画出来,元组的具体表示如图5.3所示。
图5.3 元组的表示
5.3.1 插入
在插入操作中,新元组将直接插入到目标表的页面中,如图5.4所示。
图5.4 插入元组
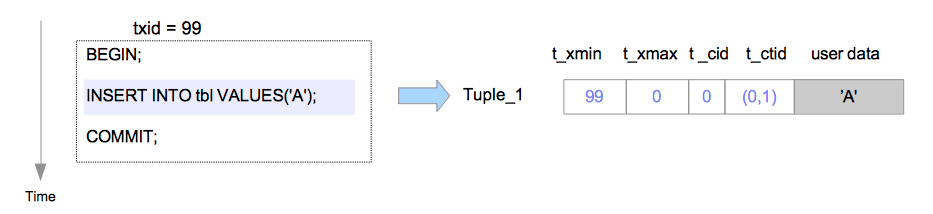
假设元组是由txid=99的事务插入页面中的,在这种情况下,被插入元组的首部字段会依以下步骤设置。
Tuple_1:
t_xmin设置为99,因为此元组由txid=99的事务所插入。t_xmax设置为0,因为此元组尚未被删除或更新。t_cid设置为0,因为此元组是由txid=99的事务所执行的第一条命令所插入的。t_ctid设置为(0,1),指向自身,因为这是该元组的最新版本。
pageinspectPostgreSQL自带了一个第三方贡献的扩展模块
pageinspect,可用于检查数据库页面的具体内容。testdb=# CREATE EXTENSION pageinspect; CREATE EXTENSION testdb=# CREATE TABLE tbl (data text); CREATE TABLE testdb=# INSERT INTO tbl VALUES(A); INSERT 0 1 testdb=# SELECT lp as tuple, t_xmin, t_xmax, t_field3 as t_cid, t_ctid FROM heap_page_items(get_raw_page(tbl, 0)); tuple | t_xmin | t_xmax | t_cid | t_ctid -------+--------+--------+-------+-------- 1 | 99 | 0 | 0 | (0,1) (1 row)
5.3.2 删除
在删除操作中,目标元组只是在逻辑上被标记为删除。目标元组的t_xmax字段将被设置为执行DELETE命令事务的txid。如图5.5所示。
图5.5 删除元组
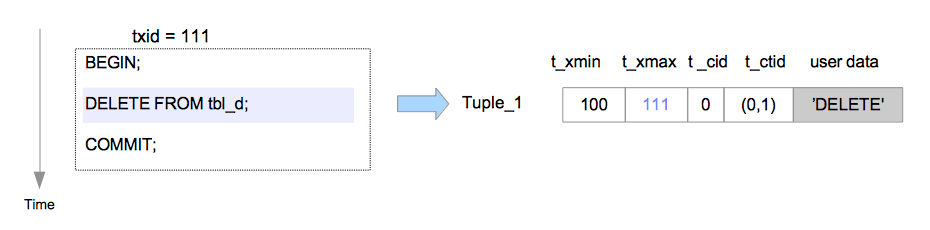
假设Tuple_1被txid=111的事务删除。在这种情况下,Tuple_1的首部字段会依以下步骤设置。
Tuple_1:
t_xmax被设为111。
如果txid=111的事务已经提交,那么Tuple_1就不是必需的了。通常不需要的元组在PostgreSQL中被称为死元组(dead tuple)。
死元组最终将从页面中被移除。清除死元组的过程被称为清理(VACUUM)过程,第6章将介绍清理过程。
5.3.3 更新
在更新操作中,PostgreSQL在逻辑上实际执行的是删除最新的元组,并插入一条新的元组(图5.6)。
图5.6 两次更新同一行
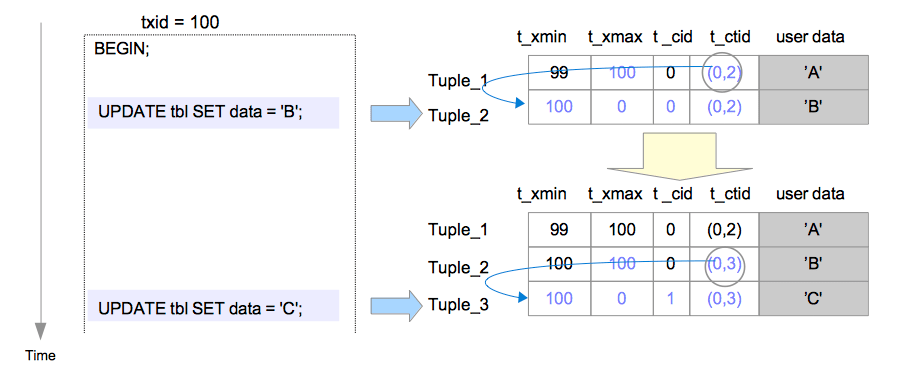
假设由txid=99的事务插入的行,被txid=100的事务更新两次。
当执行第一条UPDATE命令时,Tuple_1的t_xmax被设为txid 100,在逻辑上被删除;然后Tuple_2被插入;接下来重写Tuple_1的t_ctid以指向Tuple_2。Tuple_1和Tuple_2的头部字段设置如下。
Tuple_1:
t_xmax被设置为100。t_ctid从(0,1)被改写为(0,2)。
Tuple_2:
t_xmin被设置为100。t_xmax被设置为0。t_cid被设置为0。t_ctid被设置为(0,2)。
当执行第二条UPDATE命令时,和第一条UPDATE命令类似,Tuple_2被逻辑删除,Tuple_3被插入。Tuple_2和Tuple_3的首部字段设置如下。
Tuple_2:
t_xmax被设置为100。t_ctid从(0,2)被改写为(0,3)。
Tuple_3:
t_xmin被设置为100。t_xmax被设置为0。t_cid被设置为1。t_ctid被设置为(0,3)。
与删除操作类似,如果txid=100的事务已经提交,那么Tuple_1和Tuple_2就成为了死元组,而如果txid=100的事务中止,Tuple_2和Tuple_3就成了死元组。
5.3.4 空闲空间映射
插入堆或索引元组时,PostgreSQL使用表与索引相应的FSM来选择可供插入的页面。
如1.2.3节所述,表和索引都有各自的FSM。每个FSM存储着相应表或索引文件中每个页面可用空间容量的信息。
所有FSM都以后缀fsm存储,在需要时它们会被加载到共享内存中。
pg_freespacemap扩展
pg_freespacemap能提供特定表或索引上的空闲空间信息。以下查询列出了特定表中每个页面的空闲率。testdb=# CREATE EXTENSION pg_freespacemap; CREATE EXTENSION testdb=# SELECT *, round(100 * avail/8192 ,2) as "freespace ratio" FROM pg_freespace(accounts); blkno | avail | freespace ratio -------+-------+----------------- 0 | 7904 | 96.00 1 | 7520 | 91.00 2 | 7136 | 87.00 3 | 7136 | 87.00 4 | 7136 | 87.00 5 | 7136 | 87.00 ....
5.4 提交日志(clog)
PostgreSQL在提交日志(Commit Log, clog)中保存事务的状态。提交日志(通常称为clog)分配于共享内存中,并用于事务处理过程的全过程。
本节将介绍PostgreSQL中事务的状态,clog的工作方式与维护过程。
5.4.1 事务状态
PostgreSQL定义了四种事务状态,即:IN_PROGRESS,COMMITTED,ABORTED和SUB_COMMITTED。
前三种状态涵义显而易见。例如当事务正在进行时,其状态为IN_PROGRESS,依此类推。
SUB_COMMITTED状态用于子事务,本文省略了与子事务相关的描述。
5.4.2 提交日志如何工作
提交日志(下称clog)在逻辑上是一个数组,由共享内存中一系列8KB页面组成。数组的序号索引对应着相应事务的标识,而其内容则是相应事务的状态。clog的工作方式如图5.7所示。
图5.7 clog如何工作
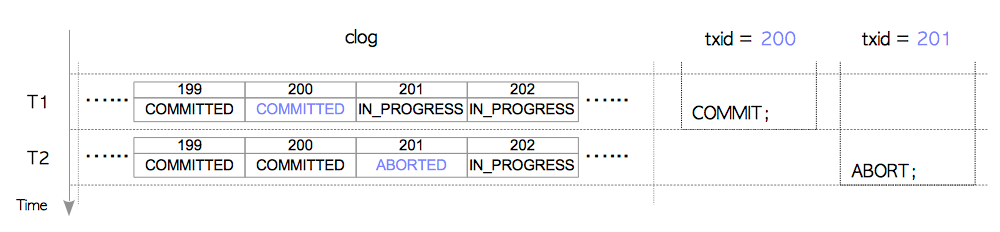
T1:
txid 200提交;txid 200的状态从IN_PROGRESS变为COMMITTED。 T2:txid 201中止;txid 201的状态从IN_PROGRESS变为ABORTED。
txid不断前进,当clog空间耗尽无法存储新的事务状态时,就会追加分配一个新的页面。
当需要获取事务的状态时,PostgreSQL将调用相应内部函数读取clog,并返回所请求事务的状态。(参见第5.7.1节中的提示位(Hint Bits))
5.4.3 提交日志的维护
当PostgreSQL关机或执行存档过程时,clog数据会写入至pg_clog子目录下的文件中(注意在10版本中,pg_clog被重命名为pg_xact)。这些文件被命名为0000,0001等等。文件的最大尺寸为256 KB。例如当clog使用八个页面时,从第一页到第八页的总大小为64 KB,这些数据会写入到文件0000(64 KB)中;而当clog使用37个页面时(296 KB),数据则会写入到0000和0001两个文件中,其大小分别为256 KB和40 KB。
当PostgreSQL启动时会加载存储在pg_clog(pg_xact)中的文件,用其数据初始化clog。
clog的大小会不断增长,因为只要clog一填满就会追加新的页面。但并非所有数据都是必需的。第6章中描述的清理过程会定期删除这些不需要的旧数据(clog页面和文件),有关删除clog数据的详情请参见第6.4节。
5.5 事务快照
**事务快照(transaction snapshot)**是一个数据集,存储着某个特定事务在某个特定时间点所看到的事务状态信息:哪些事务处于活跃状态。这里活跃状态意味着事务正在进行中,或还没有开始。
事务快照在PostgreSQL内部的文本表示格式定义为100:100:。举个例子,这里100:100:意味着txid < 100的事务处于非活跃状态,而txid ≥ 100的事务处于活跃状态。下文都将使用这种便利形式来表示。如果读者还不熟悉这种形式,请参阅下文。
内置函数
txid_current_snapshot及其文本表示函数
txid_current_snapshot显示当前事务的快照。testdb=# SELECT txid_current_snapshot(); txid_current_snapshot ----------------------- 100:104:100,102 (1 row)
txid_current_snapshot的文本表示是xmin:xmax:xip_list,各部分描述如下。
xmin最早仍然活跃的事务的
txid。所有比它更早的事务txid < xmin要么已经提交并可见,要么已经回滚并生成死元组。
xmax第一个尚未分配的
txid。所有txid ≥ xmax的事务在获取快照时尚未启动,因而其结果对当前事务不可见。
xip_list获取快照时活跃事务的
txid列表。该列表仅包括xmin与xmax之间的txid。例如,在快照
100:104:100,102中,xmin是100,xmax是104,而xip_list为100,102。以下显示了两个具体的示例:
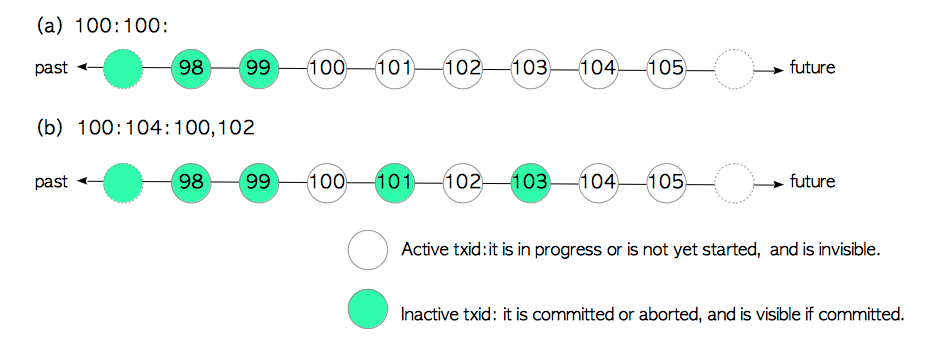
图5.8 事务快照的表示样例
第一个例子是
100:100:,如图图5.8(a)所示,此快照表示:
- 因为
xmin为100,因此txid < 100的事务是非活跃的- 因为
xmax为100,因此txid ≥ 100的事务是活跃的第二个例子是
100:104:100,102,如图5.8(b)所示,此快照表示:
txid < 100的事务不活跃。txid ≥ 104的事务是活跃的。txid等于100和102的事务是活跃的,因为它们在xip_list中,而txid等于101和103的事务不活跃。
事务快照是由事务管理器提供的。在READ COMMITTED隔离级别,事务在执行每条SQL时都会获取快照;其他情况下(REPEATABLE READ或SERIALIZABLE隔离级别),事务只会在执行第一条SQL命令时获取一次快照。获取的事务快照用于元组的可见性检查,如第5.7节所述。
使用获取的快照进行可见性检查时,所有活跃的事务都必须被当成IN PROGRESS的事务等同对待,无论它们实际上是否已经提交或中止。这条规则非常重要,因为它正是READ COMMITTED和REPEATABLE READ/SERIALIZABLE隔离级别中表现差异的根本来源,我们将在接下来几节中频繁回到这条规则上来。
在本节的剩余部分中,我们会通过一个具体的场景来描述事务与事务管理器,如图5.9所示。
图5.9 事务管理器与事务

事务管理器始终保存着当前运行的事务的有关信息。假设三个事务一个接一个地开始,并且Transaction_A和Transaction_B的隔离级别是READ COMMITTED,Transaction_C的隔离级别是REPEATABLE READ。
-
T1:
Transaction_A启动并执行第一条SELECT命令。执行第一个命令时,Transaction_A请求此刻的txid和快照。在这种情况下,事务管理器分配txid=200,并返回事务快照200:200:。 -
T2:
Transaction_B启动并执行第一条SELECT命令。事务管理器分配txid=201,并返回事务快照200:200:,因为Transaction_A(txid=200)正在进行中。因此无法从Transaction_B中看到Transaction_A。 -
T3:
Transaction_C启动并执行第一条SELECT命令。事务管理器分配txid=202,并返回事务快照200:200:,因此不能从Transaction_C中看到Transaction_A和Transaction_B。 -
T4:
Transaction_A已提交。事务管理器删除有关此事务的信息。 -
T5:
Transaction_B和Transaction_C执行它们各自的SELECT命令。Transaction_B需要一个新的事务快照,因为它使用了READ COMMITTED隔离等级。在这种情况下,Transaction_B获取新快照201:201:,因为Transaction_A(txid=200)已提交。因此Transaction_A的变更对Transaction_B可见了。Transaction_C不需要新的事务快照,因为它处于REPEATABLE READ隔离等级,并继续使用已获取的快照,即200:200:。因此,Transaction_A的变更仍然对Transaction_C不可见。
5.6 可见性检查规则
可见性检查规则是一组规则,用于确定一条元组是否对一个事务可见,可见性检查规则会用到元组的t_xmin和t_xmax,提交日志clog,以及已获取的事务快照。这些规则太复杂,无法详细解释,故本书只列出了理解后续内容所需的最小规则子集。在下文中省略了与子事务相关的规则,并忽略了关于t_ctid的讨论,比如我们不会考虑在同一个事务中对一条元组多次重复更新的情况。
所选规则有十条,可以分类为三种情况。
5.6.1 t_xmin的状态为ABORTED
t_xmin状态为ABORTED的元组始终不可见(规则1),因为插入此元组的事务已中止。
/* 创建元组的事务已经中止 */
Rule 1: IF t_xmin status is ABORTED THEN
RETURN Invisible
END IF
该规则明确表示为以下数学表达式。
- 规则1:
If Status(t_xmin) = ABORTED ⇒ Invisible
5.6.2 t_xmin的状态为IN_PROGRESS
t_xmin状态为IN_PROGRESS的元组基本上是不可见的(规则3和4),但在一个条件下除外。
/* 创建元组的事务正在进行中 */
IF t_xmin status is IN_PROGRESS THEN
/* 当前事务自己创建了本元组 */
IF t_xmin = current_txid THEN
/* 该元组没有被标记删除,则应当看见本事务自己创建的元组 */
Rule 2: IF t_xmax = INVALID THEN
RETURN Visible /* 例外,被自己创建的未删元组可见 */
Rule 3: ELSE
/* 这条元组被当前事务自己创建后又删除掉了,故不可见 */
RETURN Invisible
END IF
Rule 4: ELSE /* t_xmin ≠ current_txid */
/* 其他运行中的事务创建了本元组 */
RETURN Invisible
END IF
END IF
如果该元组被另一个进行中的事务插入(t_xmin对应事务状态为IN_PROGRESS),则该元组显然是不可见的(规则4)。
如果t_xmin等于当前事务的txid(即,是当前事务插入了该元组),且t_xmax ≠ 0,则该元组是不可见的,因为它已被当前事务更新或删除(规则3)。
例外是,当前事务插入此元组且t_xmax无效(t_xmax = 0)的情况。 在这种情况下,此元组对当前事务中可见(规则2)。
- 规则2:
If Status(t_xmin) = IN_PROGRESS ∧ t_xmin = current_txid ∧ t_xmax = INVAILD ⇒ Visible - 规则3:
If Status(t_xmin) = IN_PROGRESS ∧ t_xmin = current_txid ∧ t_xmax ≠ INVAILD ⇒ Invisible - 规则4:
If Status(t_xmin) = IN_PROGRESS ∧ t_xmin ≠ current_txid ⇒ Invisible
5.6.3 t_xmin的状态为COMMITTED
t_xmin状态为COMMITTED的元组是可见的(规则 6,8和9),但在三个条件下除外。
/* 创建元组的事务已经提交 */
IF t_xmin status is COMMITTED THEN
/* 创建元组的事务在获取的事务快照中处于活跃状态,创建无效,不可见 */
Rule 5: IF t_xmin is active in the obtained transaction snapshot THEN
RETURN Invisible
/* 元组被删除,但删除元组的事务中止了,删除无效,可见 */
/* 创建元组的事务已提交,且非活跃,元组也没有被标记为删除,则可见 */
Rule 6: ELSE IF t_xmax = INVALID OR status of t_xmax is ABORTED THEN
RETURN Visible
/* 元组被删除,但删除元组的事务正在进行中,分情况 */
ELSE IF t_xmax status is IN_PROGRESS THEN
/* 如果恰好是被本事务自己删除的,删除有效,不可见 */
Rule 7: IF t_xmax = current_txid THEN
RETURN Invisible
/* 如果是被其他事务删除的,删除无效,可见 */
Rule 8: ELSE /* t_xmax ≠ current_txid */
RETURN Visible
END IF
/* 元组被删除,且删除元组的事务已经提交 */
ELSE IF t_xmax status is COMMITTED THEN
/* 删除元组的事务在获取的事务快照中处于活跃状态,删除无效,不可见 */
Rule 9: IF t_xmax is active in the obtained transaction snapshot THEN
RETURN Visible
Rule 10: ELSE /* 删除有效,可见 */
RETURN Invisible
END IF
END IF
END IF
规则6是显而易见的,因为t_xmax为INVALID,或者t_xmax对应事务已经中止,相应元组可见。三个例外条件及规则8与规则9的描述如下。
第一个例外情况是t_xmin在获取的事务快照中处于活跃状态(规则5)。在这种情况下,这条元组是不可见的,因为t_xmin应该被视为正在进行中(取快照时创建该元组的事务尚未提交,因此对于REPEATABLE READ以及更高隔离等级而言,即使在判断时创建该元组的事务已经提交,但其结果仍然不可见)。
第二个例外情况是t_xmax是当前的txid(规则7)。这种情况与规则3类似,此元组是不可见的,因为它已经被此事务本身更新或删除。
相反,如果t_xmax的状态是IN_PROGRESS并且t_xmax不是当前的txid(规则8),则元组是可见的,因为它尚未被删除(因为删除该元组的事务尚未提交)。
第三个例外情况是t_xmax的状态为COMMITTED,且t_xmax在获取的事务快照中是非活跃的(规则10)。在这种情况下该元组不可见,因为它已被另一个事务更新或删除。
相反,如果t_xmax的状态为COMMITTED,但t_xmax在获取的事务快照中处于活跃状态(规则9),则元组可见,因为t_xmax对应的事务应被视为正在进行中,删除尚未提交生效。
- 规则5:
If Status(t_xmin) = COMMITTED ∧ Snapshot(t_xmin) = active ⇒ Invisible - 规则6:
If Status(t_xmin) = COMMITTED ∧ (t_xmax = INVALID ∨ Status(t_xmax) = ABORTED) ⇒ Visible - 规则7:
If Status(t_xmin) = COMMITTED ∧ Status(t_xmax) = IN_PROGRESS ∧ t_xmax = current_txid ⇒ Invisible - 规则8:
If Status(t_xmin) = COMMITTED ∧ Status(t_xmax) = IN_PROGRESS ∧ t_xmax ≠ current_txid ⇒ Visible - 规则9:
If Status(t_xmin) = COMMITTED ∧ Status(t_xmax) = COMMITTED ∧ Snapshot(t_xmax) = active ⇒ Visible - 规则10:
If Status(t_xmin) = COMMITTED ∧ Status(t_xmax) = COMMITTED ∧ Snapshot(t_xmax) ≠ active ⇒ Invisible
5.7 可见性检查
本节描述了PostgreSQL执行可见性检查的流程。可见性检查(Visiblity Check),即如何为给定事务挑选堆元组的恰当版本。本节还介绍了PostgreSQL如何防止ANSI SQL-92标准中定义的异常:脏读,可重读和幻读。
5.7.1 可见性检查
图5.10中的场景描述了可见性检查的过程。
图5.10 可见性检查场景一例
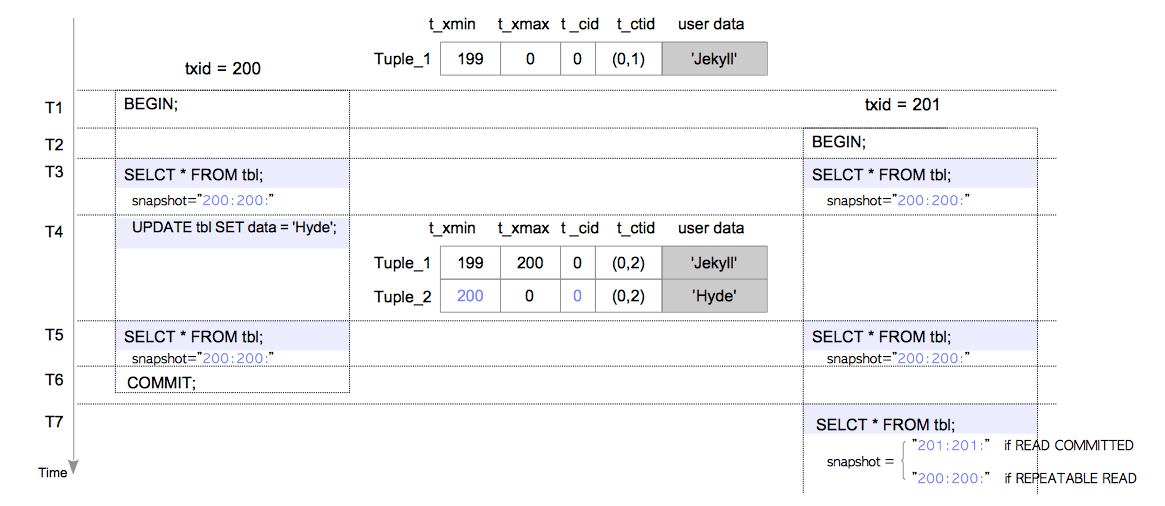
在图5.10所示的场景中,SQL命令按以下时序执行。
- T1:启动事务
(txid=200) - T2:启动事务
(txid=201) - T3:执行
txid=200和201的事务的SELECT命令 - T4:执行
txid=200的事务的UPDATE命令 - T5:执行
txid=200和201的事务的SELECT命令 - T6:提交
txid=200的事务 - T7:执行
txid=201的事务的SELECT命令
为了简化描述,假设这里只有两个事务,即txid=200和201的事务。txid=200的事务的隔离级别是READ COMMITTED,而txid=201的事务的隔离级别是READ COMMITTED或REPEATABLE READ。
我们将研究SELECT命令是如何为每条元组执行可见性检查的。
T3的SELECT命令:
在T3时间点,表tbl中只有一条元组Tuple_1,按照规则6,这条元组是可见的,因此两个事务中的SELECT命令都返回"Jekyll"。
-
Rule 6(Tuple_1) ⇒ Status(t_xmin:199) = COMMITTED ∧ t_xmax = INVALID ⇒ Visible创建元组
Tuple_1的事务199已经提交,且该元组并未被标记删除,因此根据规则6,对当前事务可见。
testdb=# -- txid 200
testdb=# SELECT * FROM tbl;
name
--------
Jekyll
(1 row)
testdb=# -- txid 201
testdb=# SELECT * FROM tbl;
name
--------
Jekyll
(1 row)
T5的SELECT命令
首先来看一下由txid=200的事务所执行的SELECT命令。根据规则7,Tuple_1不可见,根据规则2,Tuple_2可见;因此该SELECT命令返回"Hyde"。
-
Rule 7(Tuple_1): Status(t_xmin:199) = COMMITTED ∧ Status(t_xmax:200) = IN_PROGRESS ∧ t_xmax:200 = current_txid:200 ⇒ Invisible创建元组
Tuple_1的事务199已经提交,且该元组被当前事务标记删除,根据规则7,Tuple_1对当前事务不可见。 -
Rule 2(Tuple_2): Status(t_xmin:200) = IN_PROGRESS ∧ t_xmin:200 = current_txid:200 ∧ t_xmax = INVAILD ⇒ Visible创建元组
Tuple_2的事务200正在进行,而且就是当前事务自己,根据规则2,Tuple_2对当前事务可见。
testdb=# -- txid 200
testdb=# SELECT * FROM tbl;
name
------
Hyde
(1 row)
另一方面,在由txid=201的事务所执行的SELECT命令中,Tuple_1基于规则8确定可见,而Tuple_2基于规则4不可见;因此该SELECT命令返回"Jekyll"。
-
Rule 8(Tuple_1): Status(t_xmin:199) = COMMITTED ∧ Status(t_xmax:200) = IN_PROGRESS ∧ t_xmax:200 ≠ current_txid:201 ⇒ Visible元组
Tuple_1由已提交事务199创建,由活跃事务200标记删除,但删除效果对当前事务201不可见。因此根据规则8,Tuple_1可见。 -
Rule 4(Tuple_2): Status(t_xmin:200) = IN_PROGRESS ∧ t_xmin:200 ≠ current_txid:201 ⇒ Invisible元组
Tuple_2由活跃事务200创建,且不是由当前事务自己创建的,故根据规则4,Tuple_2不可见。
testdb=# -- txid 201
testdb=# SELECT * FROM tbl;
name
--------
Jekyll
(1 row)
如果更新的元组在本事务提交之前被其他事务看见,这种现象被称为脏读(Dirty Reads),也称为写读冲突(wr-conflicts)。 但如上所示,PostgreSQL中任何隔离级别都不会出现脏读。
T7的SELECT命令
在下文中,描述了T7的SELECT命令在两个隔离级别中的行为。
首先来研究txid=201的事务处于READ COMMITTED隔离级别时的情况。 在这种情况下,txid=200的事务被视为已提交,因为在这个时间点获取的事务快照是201:201:。因此Tuple_1根据规则10不可见,Tuple_2根据规则6可见,SELECT命令返回"Hyde"。
-
Rule 10(Tuple_1): Status(t_xmin:199) = COMMITTED ∧ Status(t_xmax:200) = COMMITTED ∧ Snapshot(t_xmax:200) ≠ active ⇒ Invisible元组
Tuple_1由已提交事务199创建,由非活跃的已提交事务200标记删除,Tuple_1按照规则10不可见。 -
Rule 6(Tuple_2): Status(t_xmin:200) = COMMITTED ∧ t_xmax = INVALID ⇒ Visible元组
Tuple_2由已提交事务200创建,且未被标记为删除,故Tuple_2按照规则6可见。
testdb=# -- txid 201 (READ COMMITTED)
testdb=# SELECT * FROM tbl;
name
------
Hyde
(1 row)
这里需要注意,事务201中的SELECT命令,在txid=200的事务提交前后中时的执行结果是不一样的,这种现象通常被称作不可重复读(Non-Repeatable Read)。
相反的是,当txid=201的事务处于REPEATABLE READ级别时,即使在T7时刻txid=200的事务实际上已经提交,它也必须被视作仍在进行,因而获取到的事务快照是200:200:。 根据规则9,Tuple_1是可见的,根据规则5,Tuple_2不可见,所以最后SELECT命令会返回"Jekyll"。 请注意在REPEATABLE READ(和SERIALIZABLE)级别中不会发生不可重复读。
-
Rule9(Tuple_1): Status(t_xmin:199) = COMMITTED ∧ Status(t_xmax:200) = COMMITTED ∧ Snapshot(t_xmax:200) = active ⇒ Visible元组
Tuple_1由已提交事务199创建,由已提交事务200标记删除,但因为事务200位于当前事物的活跃事务快照中(也就是在当前事物201开始执行并获取事务级快照时,事物200还未提交),因此删除对当前事务尚未生效,根据规则9,Tuple_1可见。Tuple_1按照规则10不可见。 -
Rule5(Tuple_2): Status(t_xmin:200) = COMMITTED ∧ Snapshot(t_xmin:200) = active ⇒ Invisible元组
Tuple_2由已提交事务200创建,但该事务在本事务快照中属于活跃事务(即在本事务开始前还未提交),因此事务200的变更对本事务尚不可见,按照规则5,Tuple_2不可见。
testdb=# -- txid 201 (REPEATABLE READ)
testdb=# SELECT * FROM tbl;
name
--------
Jekyll
(1 row)
提示位(Hint Bits)
PostgreSQL在内部提供了三个函数
TransactionIdIsInProgress,TransactionIdDidCommit和TransactionIdDidAbort,用于获取事务的状态。这些函数被设计为尽可能减少对clog的频繁访问。 尽管如此,如果在检查每条元组时都执行这些函数,那这里很可能会成为一个性能瓶颈。为了解决这个问题,PostgreSQL使用了提示位(hint bits),如下所示。
#define HEAP_XMIN_COMMITTED 0x0100 /* 元组xmin对应事务已提交 */ #define HEAP_XMIN_INVALID 0x0200 /* 元组xmin对应事务无效/中止 */ #define HEAP_XMAX_COMMITTED 0x0400 /* 元组xmax对应事务已提交 */ #define HEAP_XMAX_INVALID 0x0800 /* 元组xmax对应事务无效/中止 */在读取或写入元组时,PostgreSQL会择机将提示位设置到元组的
t_informask字段中。 举个例子,假设PostgreSQL检查了元组的t_xmin对应事务的状态,结果为COMMITTED。 在这种情况下,PostgreSQL会在元组的t_infomask中置位一个HEAP_XMIN_COMMITTED标记,表示创建这条元组的事务已经提交了。 如果已经设置了提示位,则不再需要调用TransactionIdDidCommit和TransactionIdDidAbort来获取事务状态了。 因此PostgreSQL能高效地检查每个元组t_xmin和t_xmax对应事务的状态。
5.7.2 PostgreSQL可重复读等级中的幻读
ANSI SQL-92标准中定义的REPEATABLE READ隔离等级允许出现幻读(Phantom Reads), 但PostgreSQL实现的REPEATABLE READ隔离等级不允许发生幻读。 在原则上,快照隔离中不允许出现幻读。
假设两个事务Tx_A和Tx_B同时运行。 它们的隔离级别分别为READ COMMITTED和REPEATABLE READ,它们的txid分别为100和101。两个事务一前一后接连开始,首先Tx_A插入一条元组,并提交。 插入的元组的t_xmin为100。接着,Tx_B执行SELECT命令;但根据规则5,Tx_A插入的元组对Tx_B是不可见的。因此不会发生幻读。
-
Rule5(new tuple): Status(t_xmin:100) = COMMITTED ∧ Snapshot(t_xmin:100) = active ⇒ Invisible新元组由已提交的事务
Tx_A创建,但Tx_A在Tx_B的事务快照中处于活跃状态,因此根据规则5,新元组对Tx_B不可见。Tx_A: txid = 100Tx_B: txid = 101START TRANSACTION ISOLATION LEVEL READ COMMITTED;START TRANSACTION ISOLATION LEVEL REPEATABLE READ;INSERT tbl(id, data)COMMIT;SELECT * FROM tbl WHERE id=1;(0 rows)5.8 防止丢失更新
丢失更新(Lost Update),又被称作写-写冲突(ww-conflict),是事务并发更新同一行时所发生的异常,REPEATABLE READ和SERIALIZABLE隔离等级必须阻止该异常的出现。 本节将会介绍PostgreSQL是如何防止丢失更新的,并举一些例子来说明。
5.8.1 并发UPDATE命令的行为
执行UPDATE命令时,内部实际上调用了ExecUpdate函数。 ExecUpdate的伪代码如下所示:
伪代码:
ExecUpdate(1) FOR row in 本UPDATE命令待更新的所有行集 (2) WHILE true /* 第一部分 */ (3) IF 目标行 正在 被更新 THEN (4) 等待 更新目标行的事务 结束(提交或中止) (5) IF (更新目标行的事务已提交) AND (当前事务隔离级别是 可重复读或可串行化) THEN (6) 中止当前事务 /* 以先更新者为准 */ ELSE (7) 跳转步骤(2) END IF /* 第二部分 */ (8) ELSE IF 目标行 已经 被另一个并发事务所更新 THEN (9) IF (当前事务的隔离级别是 读已提交 ) THEN (10) 更新目标行 ELSE (11) 中止当前事务 /* 先更新者为准 */ END IF /* 第三部分 */ /* 目标行没有被修改过,或者被一个 已经结束 的事务所更新 */ ELSE (12) 更新目标行 END IF END WHILE END FOR
- 获取被本
UPDATE命令更新的每一行,并对每一行依次执行下列操作。- 重复以下过程,直到目标行更新完成,或本事务中止。
- 如果目标行正在被更新则进入步骤(4),否则进入步骤(8)。
- 等待正在更新目标行的事务结束,因为PostgreSQL在SI中使用了**以先更新者为准(first-updater-win)**的方案。
- 如果更新目标行的事务已经提交,且当前事务的隔离等级为可重复读或可串行化则进入步骤(6),否则进入步骤(7)。
- 中止本事务,以防止丢失更新。(因为另一个事务已经对目标行进行了更新并提交)
- 跳转回步骤(2),并对目标行进行新一轮的更新尝试。
- 如果目标行已被另一个并发事务所更新则进入步骤(9),否则进入步骤(12)。
- 如果当前事务的隔离级别为读已提交则进入步骤(10),否则进入步骤(11)。
- 更新目标行,并回到步骤(1),处理下一条目标行。
- 中止当前事务,以防止丢失更新。
- 更新目标行,并回到步骤(1),因为目标行尚未被修改过,或者虽然已经被更新,但更新它的事务已经结束。已终止的事务更新,即存在写写冲突。
此函数依次为每个待更新的目标行执行更新操作。 它有一个外层循环来更新每一行,而内部while循环则包含了三个分支,分支条件如图5.11所示。
图5.11 ExecUpdate内部的三个部分
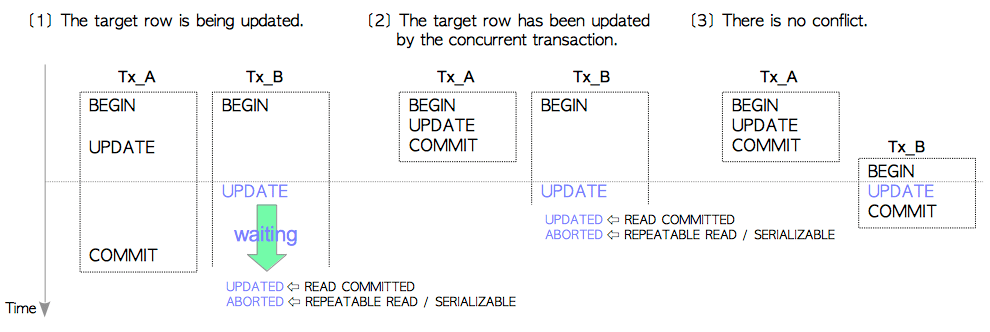
-
目标行正在被更新,如图5.11[1]所示
“正在被更新”意味着该行正在被另一个事务同时更新,且另一个事务尚未结束。在这种情况下,当前事务必须等待更新目标行的事务结束,因为PostgreSQL的SI实现采用**以先更新者为准(first-updater-win)**的方案。例如,假设事务
Tx_A和Tx_B同时运行,且Tx_B尝试更新某一行;但Tx_A已更新了这一行,且仍在进行中。在这种情况下Tx_B会等待Tx_A结束。在更新目标行的事务提交后,当前事务的更新操作将完成等待继续进行。如果当前事务处于
READ COMMITTED隔离等级,则会更新目标行;而若处于REPEATABLE READ或SERIALIZABLE隔离等级时,当前事务则会立即中止,以防止丢失更新。 -
目标行已经被另一个并发事务所更新,如图5.11[2]所示
当前事务尝试更新目标元组,但另一个并发事务已经更新了目标行并提交。在这种情况下,如果当前事务处于
READ COMMITTED级别,则会更新目标行;否则会立即中止以防止丢失更新。 -
没有冲突,如图5.11[3]所示
当没有冲突时,当前事务可以直接更新目标行。
以先更新者为准 / 以先提交者为准
PostgreSQL基于SI的并发控制机制采用**以先更新者为准(first-updater-win)方案。 相反如下一节所述,PostgreSQL的SSI实现使用以先提交者为准(first-commiter-win)**方案。
5.8.2 例子
以下是三个例子。 第一个和第二个例子展示了目标行正在被更新时的行为,第三个例子展示了目标行已经被更新的行为。
例1
事务Tx_A和Tx_B更新同一张表中的同一行,它们的隔离等级均为READ COMMITTED。
Tx_A |
Tx_B |
|---|---|
START TRANSACTION ISOLATION LEVEL READ COMMITTED; |
|
START TRANSACTION |
START TRANSACTION ISOLATION LEVEL READ COMMITTED; |
START TRANSACTION |
|
UPDATE tbl SET name = 'Hyde'; |
|
UPDATE 1 |
|
UPDATE tbl SET name = 'Utterson'; |
|
↓ – 本事务进入阻塞状态,等待Tx_A完成 |
|
COMMIT; |
↓ – Tx_A提交,阻塞解除 |
UPDATE 1 |
Tx_B的执行过程如下:
- 在执行
UPDATE命令之后,Tx_B应该等待Tx_A结束,因为目标元组正在被Tx_A更新(ExecUpdate步骤4) - 在
Tx_A提交后,Tx_B尝试更新目标行(ExecUpdate步骤7) - 在
ExecUpdate内循环第二轮中,目标行被Tx_B更新(ExecUpdate步骤2,8,9,10)。
例2
Tx_A和Tx_B更新同一张表中的同一行,它们的隔离等级分别为读已提交和可重复读。
Tx_A |
Tx_B |
|---|---|
START TRANSACTION ISOLATION LEVEL READ COMMITTED; |
|
START TRANSACTION |
START TRANSACTION ISOLATION LEVEL REPEATABLE READ; |
START TRANSACTION |
|
UPDATE tbl SET name = 'Hyde'; |
|
UPDATE 1 |
|
UPDATE tbl SET name = 'Utterson'; |
|
↓ – 本事务进入阻塞状态,等待Tx_A完成 |
|
COMMIT; |
↓ – Tx_A提交,阻塞解除 |
ERROR:couldn't serialize access due to concurrent update |
Tx_B的执行过程如下:
Tx_B在执行UPDATE命令后阻塞,等待Tx_A终止(ExecUpdate步骤4)。- 当
Tx_A提交后,Tx_B会中止以解决冲突。因为目标行已经被更新,且当前事务Tx_B的隔离级别为可重复读(ExecUpdate步骤5,6)。
例3
Tx_B(可重复读)尝试更新已经被Tx_A更新的目标行,且Tx_A已经提交。 在这种情况下,Tx_B会中止(ExecUpdate中的步骤2,8,9,11)。
Tx_A |
Tx_B |
|---|---|
START TRANSACTION ISOLATION LEVEL READ COMMITTED; |
|
START TRANSACTION |
START TRANSACTION ISOLATION LEVEL REPEATABLE READ; |
START TRANSACTION |
|
UPDATE tbl SET name = 'Hyde'; |
|
UPDATE 1 |
|
COMMIT; |
|
UPDATE tbl SET name = 'Utterson'; |
|
ERROR:couldn't serialize access due to concurrent update |
5.9 可串行化快照隔离
从版本9.1开始,可串行化快照隔离(SSI)已经嵌入到快照隔离(SI)中,用以实现真正的可串行化隔离等级。SSI解释起来过于复杂,故本书仅解释其概要,详细信息请参阅文献[2]。
下文使用了以下技术术语而未加定义。 如果读者不熟悉这些术语,请参阅[1,3]。
- 前趋图(precedence graph),亦称作依赖图(dependency graph)或串行化图(serialization graph)
- 串行化异常(serialization anomalies)(例如,写偏差(Write-Skew))
5.9.1 SSI实现的基本策略
如果前趋图中存在由某些冲突构成的环,则会出现串行化异常。 这里使用一种最简单的异常来解释,即写偏差(Write-Skew)。
图5.12(1)展示了一种调度方式。 这里Transaction_A读取了Tuple_B,Transaction_B读取了Tuple_A。 然后Transaction_A写Tuple_A,Transaction_B写Tuple_B。 在这种情况下存在两个读-写冲突(rw-conflict),它们在该调度的前趋图中构成了一个环,如图5.12(2)所示。 故该调度存在串行化异常,即写偏差。
图5.12 存在写偏差的调度及其前趋图
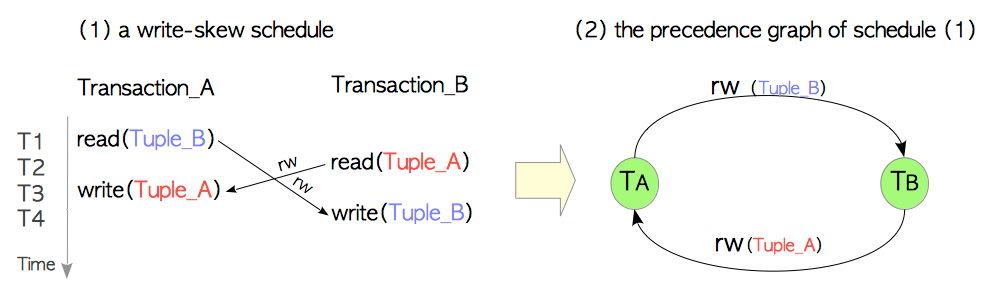
从概念上讲,存在三种类型的冲突:写-读冲突(wr-conflicts)(脏读),写-写冲突(ww-conflicts)(丢失更新),以及读写冲突(rw-conflicts)。 但是这里无需考虑写-读冲突与写-写冲突,因为如前所述,PostgreSQL可以防止此类冲突。 因此PostgreSQL中的SSI实现只需要考虑读-写冲突。
PostgreSQL在SSI实现中采用以下策略:
- 使用SIREAD锁记录事务访问的所有对象(元组,页面,关系)。
- 当写入任何堆元组/索引元组时,使用SIREAD锁检测读-写冲突。
- 如果从读-写冲突中检测出串行化异常,则中止事务。
5.9.2 PostgreSQL的SSI实现
为了实现上述策略,PostgreSQL实现了很多数据结构与函数。 但这里我们只会使用两种数据结构:SIREAD锁与读-写冲突来描述SSI机制。它们都储存在共享内存中。
为简单起见,本文省略了一些重要的数据结构,例如
SERIALIZABLEXACT。 因此对CheckTargetForConflictOut,CheckTargetForConflictIn和PreCommit_CheckForSerializationFailure等函数的解释也极为简化。比如本文虽然指出哪些函数能检测到冲突;但并没有详细解释如何检测冲突。 如果读者想了解详细信息,请参阅源代码:predicate.c。
SIREAD锁
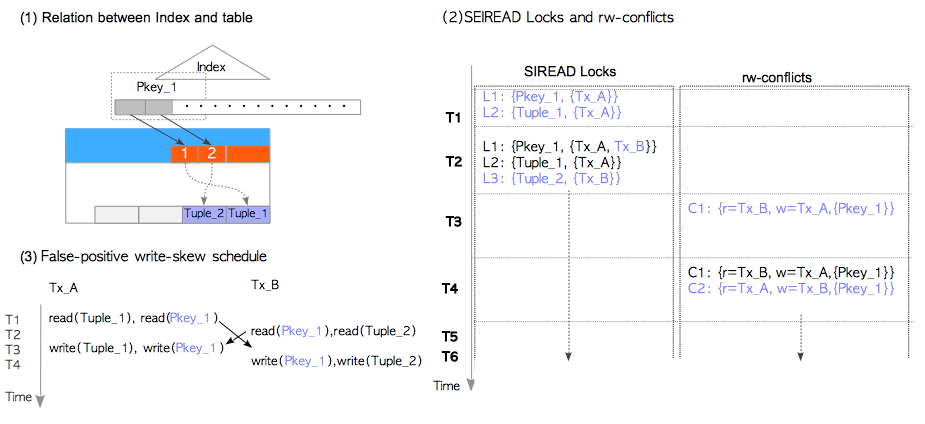
SIREAD锁,在内部又被称为谓词锁(predicate lock),是一个由对象与(虚拟)事务标识构成的二元组,存储着哪个事务访问了哪个对象的相关信息。注意这里省略了对虚拟事务标识的描述,使用txid而非虚拟txid能大幅简化说明。
在SERIALIZABLE模式下只要执行DML命令,就会通过CheckTargetForConflictsOut函数创建出SIREAD锁。举个例子,如果txid=100的事务读取给定表的Tuple_1,则会创建一个SIREAD锁{Tuple_1,{100}}。如果是其他事务,例如txid=101读取了Tuple_1,则SIREAD锁会更新为{Tuple_1,{100,101}}。请注意,读取索引页时也会创建SIREAD锁,因为在使用了第7.2节中将描述的**仅索引扫描(Index-Only Scan)**时,数据库只会读取索引页而不读取表页。
SIREAD锁有三个级别:元组,页面,以及关系。如果单个页面内所有元组的SIREAD锁都被创建,则它们会聚合为该页上的单个SIREAD锁,原有相关元组上的SIREAD锁都会被释放(删除),以减少内存空间占用。对读取的页面也是同理。
当为索引创建SIREAD锁时,一开始会创建页级别的SIREAD锁。当使用顺序扫描时,无论是否存在索引,是否存在WHERE子句,一开始都会创建关系级别的SIREAD锁。请注意在某些情况下,这种实现可能会导致串行化异常的误报(假阳性(false-positive)),细节将在第5.9.4节中描述。
读-写冲突
读-写冲突是一个三元组,由SIREAD锁,以及两个分别读写该SIREAD锁的事务txid构成。
当在可串行化模式下执行INSERT,UPDATE或DELETE命令时,函数CheckTargetForConflictsIn会被调用,并检查SIREAD锁来检测是否存在冲突,如果有就创建一个读-写冲突。
举个例子,假设txid = 100的事务读取了Tuple_1,然后txid=101的事务更新了Tuple_1。在这种情况下,txid=101的事务中的UPDATE命令会调用CheckTargetForConflictsIn函数,并检测到在Tuple_1上存在txid=100,101之间的读-写冲突,并创建rw-conflict{r = 100, w = 101, {Tuple_1}}。
CheckTargetForConflictOut、CheckTargetForConflictIn函数,以及在可串行化模式中执行COMMIT命令会触发的PreCommit_CheckForSerializationFailure函数,都会使用创建的读写冲突来检查串行化异常。如果它们检测到异常,则只有先提交的事务会真正提交,其他事务会中止(依据**以先提交者为准(first-committer-win)**策略)。
5.9.3 SSI的原理
本节将描述SSI如何解决写偏差异常,下面将使用一个简单的表tbl为例。
testdb=# CREATE TABLE tbl (id INT primary key, flag bool DEFAULT false);
testdb=# INSERT INTO tbl (id) SELECT generate_series(1,2000);
testdb=# ANALYZE tbl;
事务Tx_A和Tx_B执行以下命令,如图5.13所示。
图5.13 写偏差场景一例
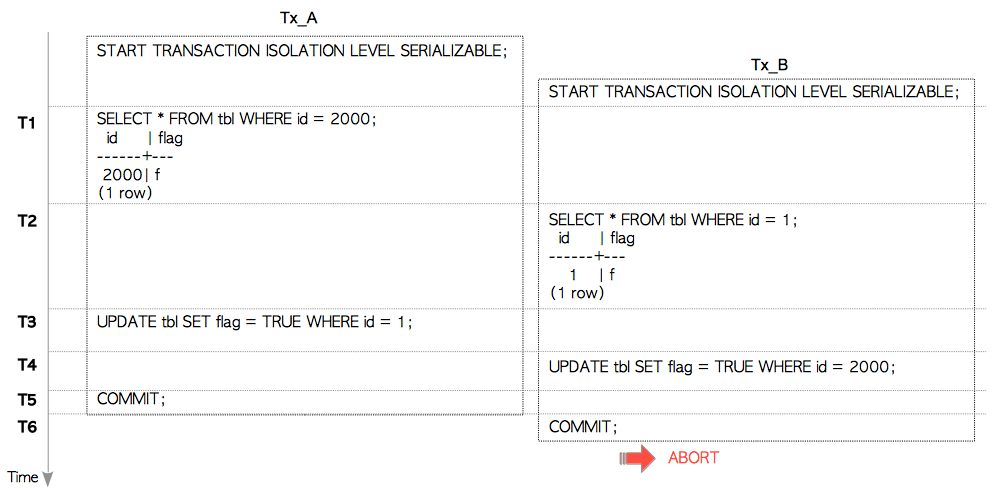
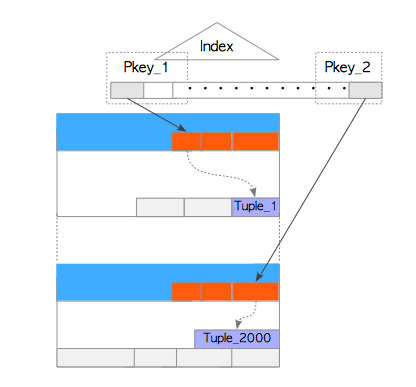
假设所有命令都使用索引扫描。 因此当执行命令时,它们会同时读取堆元组与索引页,每个索引页都包含指向相应堆元组的索引元组,如图5.14所示。
图5.14 例子中索引与表的关系
- T1:
Tx_A执行SELECT命令,该命令读取堆元组Tuple_2000,以及包含主键的索引页Pkey_2。 - T2:
Tx_B执行SELECT命令。 此命令读取堆元组Tuple_1,以及包含主键的索引页Pkey_1。 - T3:
Tx_A执行UPDATE命令,更新Tuple_1。 - T4:
Tx_B执行UPDATE命令,更新Tuple_2000。 - T5:
Tx_A提交。 - T6:
Tx_B提交,然而由于写偏差异常而被中止。
图5.15展示了PostgreSQL如何检测和解决上述场景中描述的写偏差异常。
图5.15 SIREA锁与读-写冲突,图5.13场景中的调度方式

-
T1: 执行
Tx_A的SELECT命令时,CheckTargetForConflictsOut会创建SIREAD锁。在本例中该函数会创建两个SIREAD锁:L1与L2。L1和L2分别与Pkey_2和Tuple_2000相关联。 -
T2: 执行
Tx_B的SELECT命令时,CheckTargetForConflictsOut会创建两个SIREAD锁:L3和L4。L3和L4分别与Pkey_1和Tuple_1相关联。 -
T3: 执行
Tx_A的UPDATE命令时,CheckTargetForConflictsOut和CheckTargetForConflictsIN会分别在ExecUpdate执行前后被调用。在本例中,CheckTargetForConflictsOut什么都不做。而CheckTargetForConflictsIn则会创建读-写冲突C1,这是Tx_B和Tx_A在Pkey_1和Tuple_1上的冲突,因为Pkey_1和Tuple_1都由Tx_B读取并被Tx_A写入。 -
T4: 执行
Tx_B的UPDATE命令时,CheckTargetForConflictsIn会创建读-写冲突C2,这是Tx_A与Tx_B在Pkey_2和Tuple_2000上的冲突。在这种情况下,
C1和C2在前趋图中构成一个环;因此Tx_A和Tx_B处于不可串行化状态。但事务Tx_A和Tx_B都尚未提交,因此CheckTargetForConflictsIn不会中止Tx_B。注意这是因为PostgreSQL的SSI实现采用先提交者为准方案。 -
T5: 当
Tx_A尝试提交时,将调用PreCommit_CheckForSerializationFailure。此函数可以检测串行化异常,并在允许的情况下执行提交操作。在这里因为Tx_B仍在进行中,Tx_A成功提交。 -
T6: 当
Tx_B尝试提交时,PreCommit_CheckForSerializationFailure检测到串行化异常,且Tx_A已经提交;因此Tx_B被中止。
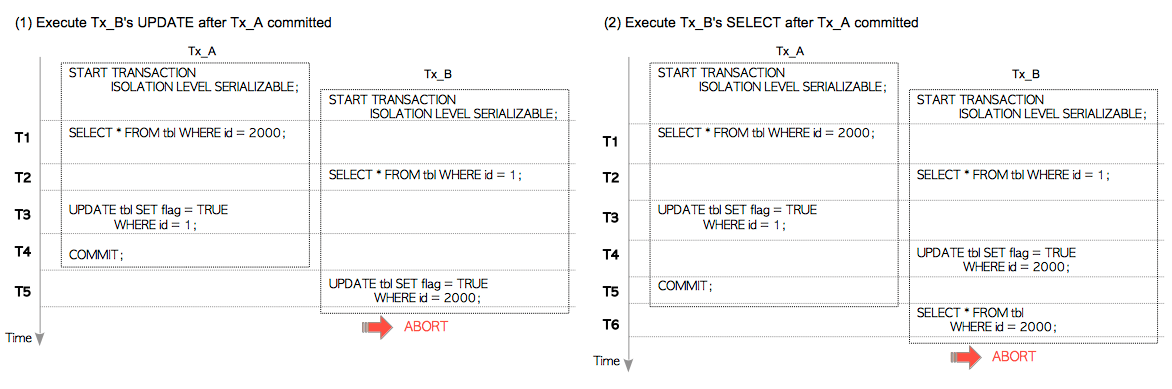
此外,如果在Tx_A提交之后(T5时刻),Tx_B执行了UPDATE命令,则Tx_B会立即中止。因为Tx_B的UPDATE命令会调用CheckTargetForConflictsIn,并检测到串行化异常,如图5.16(1)所示。
如果Tx_B在T6时刻执行SELECT命令而不是COMMIT命令,则Tx_B也会立即中止。因为Tx_B的SELECT命令调用的CheckTargetForConflictsOut会检测到串行化异常,如图5.16(2)所示。
图5.16 其他写偏差场景
这里的Wiki解释了几种更为复杂的异常。
5.9.4 假阳性的串行化异常
在可串行化模式下,因为永远不会检测到**假阴性(false-negative,发生异常但未检测到)**串行化异常,PostgreSQL能始终完全保证并发事务的可串行性。 但相应的是在某些情况下,可能会检测到假阳性异常(没有发生异常但误报发生),用户在使用SERIALIZABLE模式时应牢记这一点。 下文会描述PostgreSQL检测到假阳性异常的情况。
图5.17展示了发生假阳性串行化异常的情况。
图5.17 发生假阳性串行化异常的场景
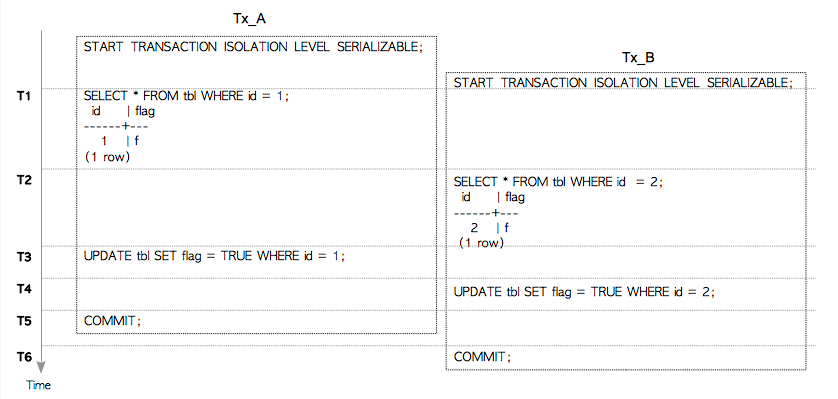
当使用顺序扫描时,如SIREAD锁的解释中所述,PostgreSQL创建了一个关系级的SIREAD锁。 图5.18(1)展示了PostgreSQL使用顺序扫描时的SIREAD锁和读-写冲突。 在这种情况下,产生了与tbl表上SIREAD锁相关联的读-写冲突:C1和C2,并且它们在前趋图中构成了一个环。 因此会检测到假阳性的写偏差异常(即,虽然实际上没有冲突,但Tx_A与Tx_B两者之一也将被中止)。
图 5.18 假阳性异常(1) - 使用顺序扫描

即使使用索引扫描,如果事务Tx_A和Tx_B都获取里相同的索引SIREAD锁,PostgreSQL也会误报假阳性异常。 图5.19展示了这种情况。 假设索引页Pkey_1包含两条索引项,其中一条指向Tuple_1,另一条指向Tuple_2。 当Tx_A和Tx_B执行相应的SELECT和UPDATE命令时,Pkey_1同时被Tx_A和Tx_B读取与写入。 这时候会产生Pkey_1相关联的读-写冲突:C1和C2,并在前趋图中构成一个环,因而检测到假阳性写偏差异常(如果Tx_A和Tx_B获取不同索引页上的SIREAD锁则不会误报,并且两个事务都可以提交)。
图5.19 假阳性异常(2) - 使用相同索引页的索引扫描
5.10 所需的维护进程
PostgreSQL的并发控制机制需要以下维护过程。
- 删除死元组及指向死元组的索引元组
- 移除**提交日志(clog)**中非必需的部分
- 冻结旧的事务标识(txid)
- 更新FSM,VM,以及统计信息
第5.3.2和5.4.3节分别解释了为什么需要第一个和第二个过程。第三个过程与事务标识回卷问题有关,本小节将概述**事务标识回卷(txid wrap around)**问题。
在PostgreSQL中,清理过程(VACUUM)负责这些过程。**清理过程(VACUUM)**在第6章中描述。
5.10.1 冻结处理
接下来将介绍**事务标识回卷(txid wrap around)**问题。
假设元组Tuple_1是由txid = 100事务创建的,即Tuple_1的t_xmin = 100。服务器运行了很长时间,但Tuple_1一直未曾被修改。假设txid已经前进到了$2^{31}+100$,这时候正好执行了一条SELECT命令。此时,因为对当前事务而言txid = 100的事务属于过去的事务,因而Tuple_1对当前事务可见。然后再执行相同的SELECT命令,此时txid步进至$2^{31}+101$。但因对当前事务而言,txid = 100的事务是属于未来的,因此Tuple_1不再可见(图5.20)。这就是PostgreSQL中所谓的事务回卷问题。
图5.20 回卷问题
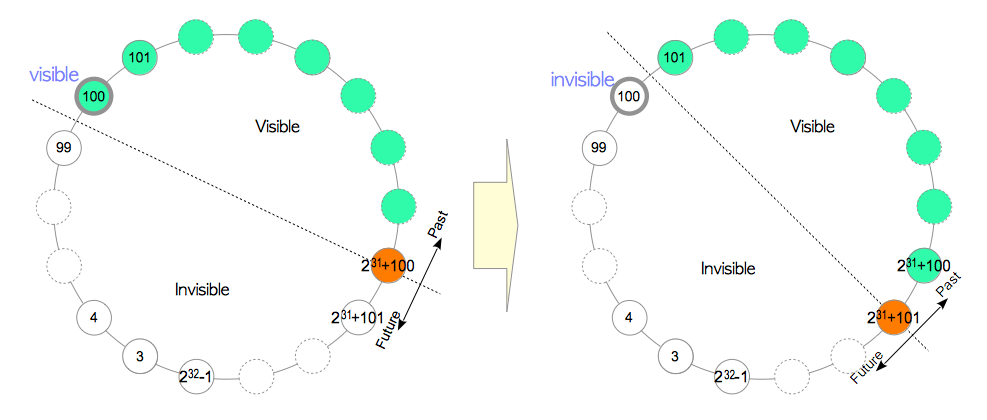
为了解决这个问题,PostgreSQL引入了一个**冻结事务标识(Frozen txid)**的概念,并实现了一个名为FREEZE的过程。
在PostgreSQL中定义了一个冻结的txid,它是一个特殊的保留值txid = 2,在参与事务标识大小比较时,它总是比所有其他txid都旧。换句话说,冻结的txid始终处于非活跃状态,且其结果对其他事务始终可见。
清理过程(VACUUM)会调用冻结过程(FREEZE)。冻结过程将扫描所有表文件,如果元组的t_xmin比当前txid - vacuum_freeze_min_age(默认值为5000万)更老,则将该元组的t_xmin重写为冻结事务标识。在第6章中会有更详细的解释。
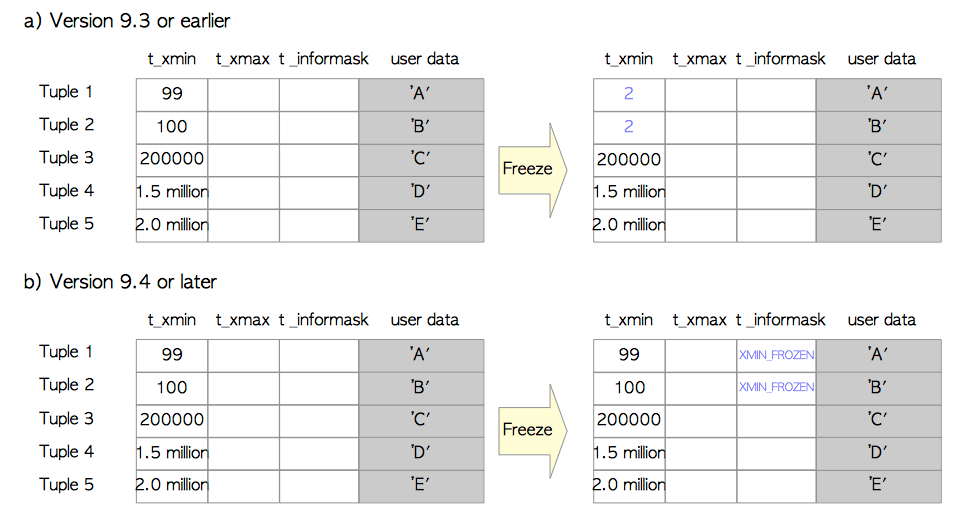
举个例子,如图5.21(a)所示,当前txid为5000万,此时通过VACUUM命令调用冻结过程。在这种情况下,Tuple_1和Tuple_2的t_xmin都被重写为2。
在版本9.4或更高版本中使用元组t_infomask字段中的XMIN_FROZEN标记位来标识冻结元组,而不是将元组的t_xmin重写为冻结的txid,如图5.21(b)所示。
图5.21 冻结过程
参考文献
- [1] Abraham Silberschatz, Henry F. Korth, and S. Sudarshan, “Database System Concepts”, McGraw-Hill Education, ISBN-13: 978-0073523323
- [2] Dan R. K. Ports, and Kevin Grittner, “Serializable Snapshot Isolation in PostgreSQL”, VDBL 2012
- [3] Thomas M. Connolly, and Carolyn E. Begg, “Database Systems”, Pearson, ISBN-13: 978-0321523068