如何用 pg_filedump 抢救数据?

备份是DBA的生命线 —— 但如果你的 PostgreSQL 数据库已经爆炸了又没有备份,那么该怎么办呢?也许 pg_filedump 可以帮到你!
最近遇到了一个比较离谱的活儿,情况是这样的:有个用户的 PostgreSQL 数据库损坏了,是 Gitlab 自己拉起的 PostgreSQL。没有从库,没有备份,也没有 dump。跑在拿 SSD 当透明缓存的BCACHE上,断电后起不来了。
但这还没完,接连经受了几轮摧残之后,它彻底歇菜了:首先是因为忘了挂BCACHE盘,导致 Gitlab重新初始化了一遍新的数据库集群;然后是因为各种原因隔离失效,在同一个集簇目录上运行两个数据库进程烤糊了数据目录;接着是运行 pg_resetwal 不带参数把数据库推回起源点,最后是让空数据库跑了一阵子,然后把烤糊前的临时备份移除了。
看到这个 Case 我确实有点无语:这都成一团浆糊了还恢复个什么,目测只能从底层二进制文件直接抽取数据来恢复了。我建议他去找个数据恢复公司碰碰运气吧,也帮忙问了一圈儿,但是一大堆数据恢复公司里,几乎没有几个有 PostgreSQL 数据恢复服务的,有的也是比较基础的那种问题处理,碰上这种情况都说只能随缘试试。
数据恢复报价通常是按文件数量来收费的,一个文件从 ¥1000 ~ ¥5000 不等。Gitlab库里几千个文件,按表算的话大概有 1000张表,全恢复完几十万可能不至于,但十几万肯定是没跑了。可一天过去了也没人接,这着实让我感觉蛋疼:要是没人能接这活,岂不是显得 PG 社区没人了?
我想了一下,这活看着挺蛋疼,但也挺有挑战趣味的,咱死马当活马医,修不好不收钱就是 —— 不试试咋知道行不行呢?所以就接了自己上了。
工具
工欲善其事,必先利其器。数据恢复首先当然是要找有没有趁手的工具:pg_filedump 就是一把不错的武器,它可以用来从 PostgreSQL 数据页面中抽取原始二进制数据,许多低层次的工作可以交给它。
这个工具可以用 make 三板斧编译安装,当然需要先安装对应大版本的 PostgreSQL 才行。Gitlab 默认使用的是 PG 13,所以确保对应版本的 pg_config 在路径中后直接编译即可。
git clone https://github.com/df7cb/pg_filedump
cd pg_filedump && make && sudo make install
pg_filedump 的使用方式并不复杂,你把数据文件喂给他,告诉它这张表每一列的类型,它就能帮你解读出来。比如第一步,我们就得知道这个数据库集簇中有哪几个数据库。这个信息记录在系统视图 pg_database 中。这是一张系统层面的表,位于 global 目录中,在集群初始化时会分配固定的 OID 1262,所以对应的物理文件通常是: global/1262。
vonng=# select 'pg_database'::RegClass::OID;
oid
------
1262
这张系统视图里有不少字段,但我们主要关心的是前两个: oid 和 datname ,datname 是数据库的名称,oid 则可以用于定位数据库目录位置。以用 pg_filedump 把这张表解出来看一看, -D 参数可以告诉 pg_filedump 如何解释这张表里每一行的二进制数据。你可以指定每个字段的类型,用逗号分隔,~ 表示后面的部分都忽略不要。
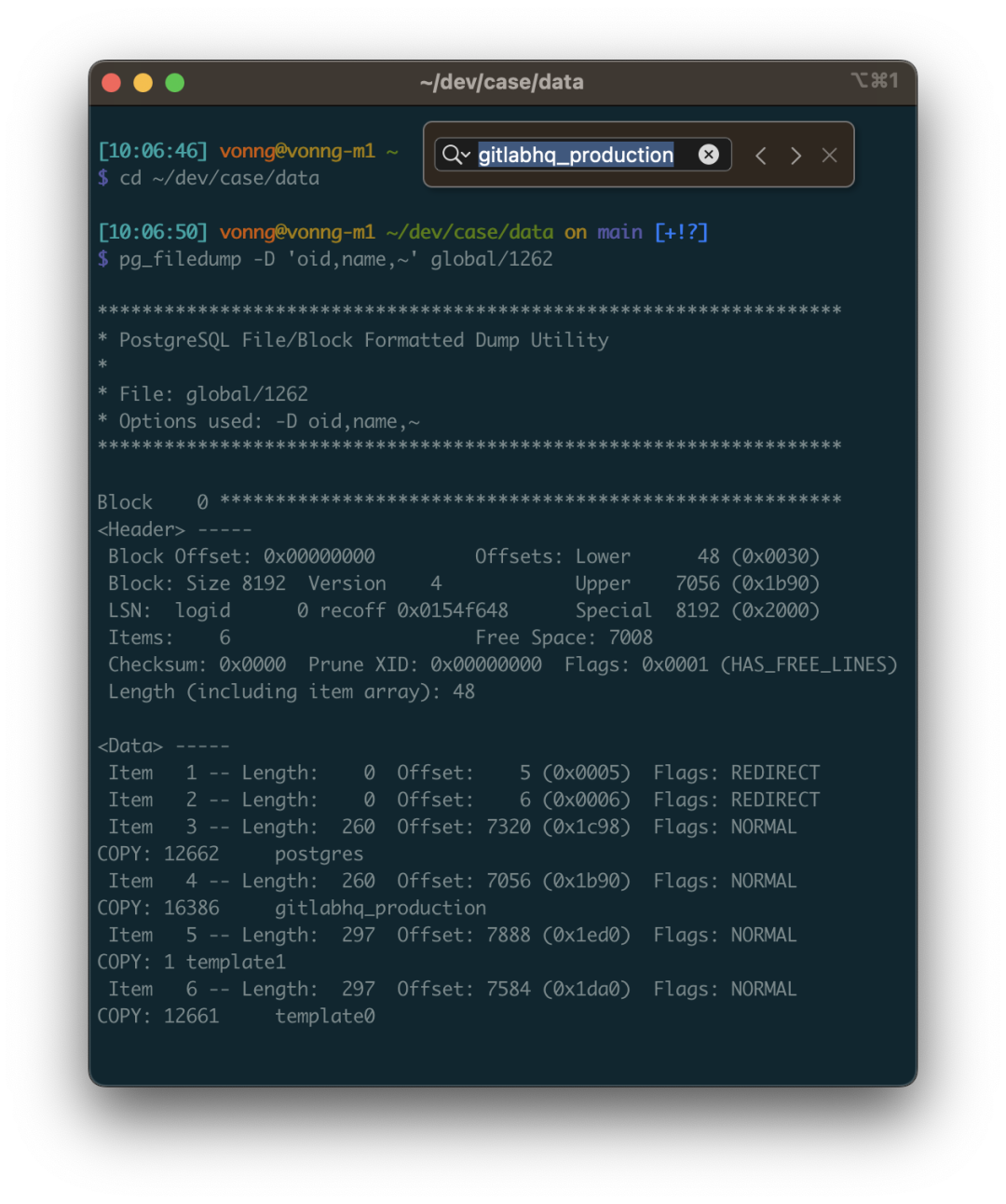
可以看到,每一行数据都以 COPY 开始,这里我们发现了目标数据库 gitlabhq_production,其 OID 为 16386 。所以这个数据库内的所有文件都应当位于 base/16386 子目录中。
恢复数据字典
知道了要恢复的数据文件目录,下一步就是解出数据字典来,这里面有四张重要的表需要关注:
•pg_class:包含了所有表的重要元数据•pg_namespace:包含了模式的元数据•pg_attribute:包含了所有的列定义•pg_type:包含了类型的名称
其中 pg_class 是最为重要,不可或缺的一张表。其他几张系统视图属于 Nice to have:能让我们的工作更加简单一些。所以,我们首先尝试恢复这张表。
pg_class 是数据库级别的系统视图,默认有着 OID = 1259 ,所以 pg_class 对应的文件应当是: base/16386/1259,在 gitlabhq_production 对应数据库目录下。

这里说句题外话:熟悉 PostgreSQL 原理的朋友知道:实际底层存储数据的文件名(RelFileNode)虽然默认与表的 OID 保持一致,但是一些操作可能会改变这一点,在这种情况下,你可以用 pg_filedump -m pg_filenode.map 解析数据库目录下的映射文件,找到 OID 1259 对应的 Filenode。当然这里两者是一致的,就表过不提了。
我们根据 pg_class 的表结构定义(注意要使用对应PG大版本的表结构),解析其二进制文件: pg_filedump -D ‘oid,name,oid,oid,oid,oid,oid,oid,oid,int,real,int,oid,bool,bool,char,char,smallint,smallint,bool,bool,bool,bool,bool,bool,char,bool,oid,xid,xid,text,text,text’ -i base/16386/1259
然后就可以看到解析出来的数据了。这里的数据是 \t 分隔的单行记录,与 PostgreSQL COPY 命令默认使用的格式相同。所以你可以用脚本 grep 收集过滤,掐掉每行开头的 COPY ,并重新灌入一张真正的数据库表来细看。
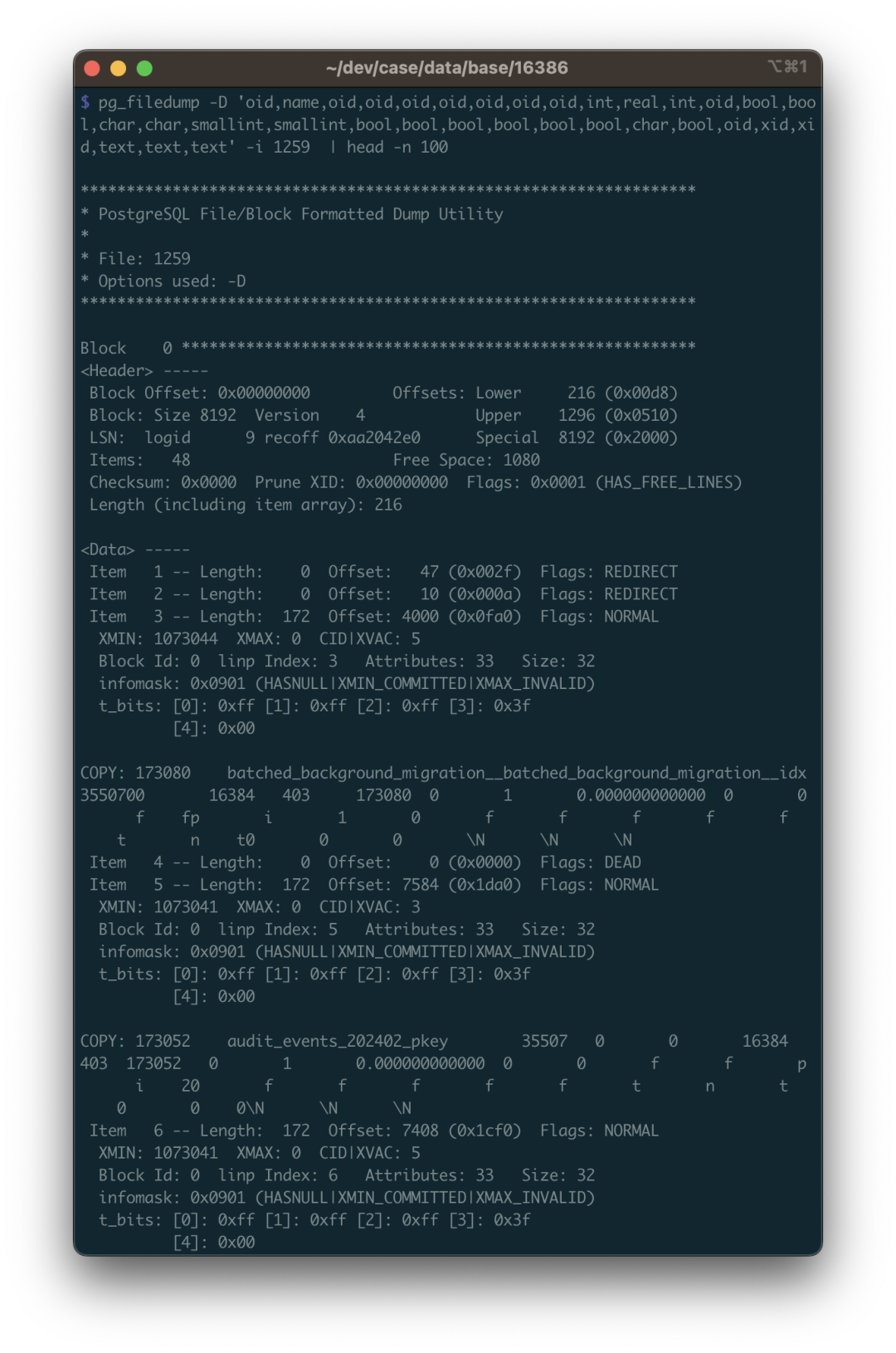
在数据恢复时需要注意许多细节,其中第一条就是:你需要处理被删除的行。怎么识别呢?使用 -i 参数打印每一行的元数据,元数据里有一个 XMAX 字段。如果某一行元组被某个事务删除了,那么这条记录的 XMAX 就会被设置为该事务的 XID 事务号。所以如果某一行的 XMAX 不是零,就意味着这是一条被删除的记录,不应当输出到最终的结果中。
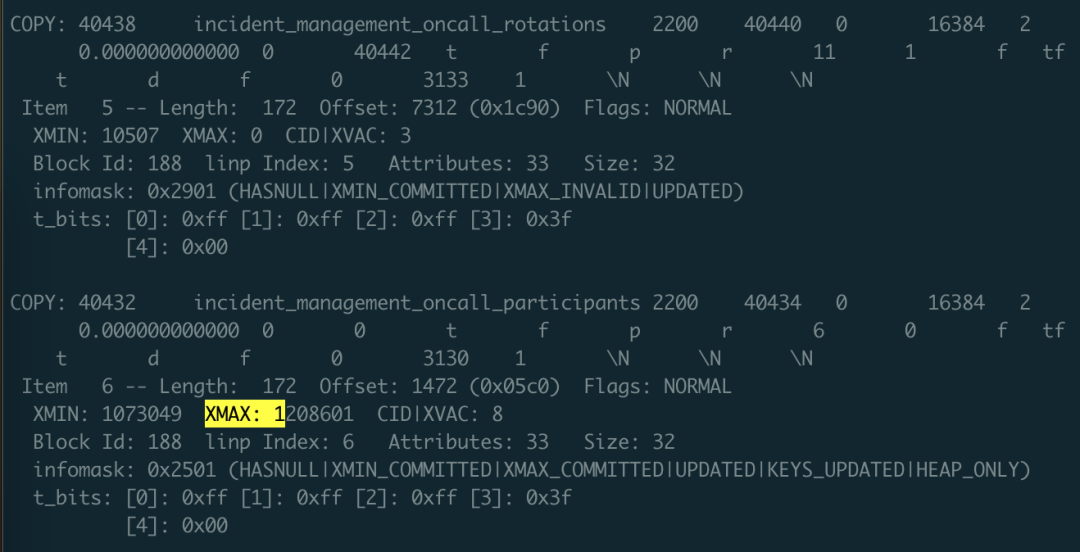
这里的 XMAX 代表这是条被删除的记录
有了 pg_class 数据字典之后,你就可以清楚地找到其他表,包括系统视图的 OID 对应关系了。用同样的办法可以恢复 pg_namespace ,pg_attribute ,pg_type 这三张表。有了这四张表就可以干什么呢?

你可以用 SQL 生成每张表的输入路径,自动拼出每一列的类型作为 -D 参数,生成临时结果表的 Schema。总而言之,可以用编程自动化的方式,自动生成所有需要完成的任务。
SELECT id, name, nspname, relname, nspid, attrs, fields, has_tough_type,
CASE WHEN toast_page > 0 THEN toast_name ELSE NULL END AS toast_name, relpages, reltuples, path
FROM
(
SELECT n.nspname || '.' || c.relname AS "name", n.nspname, c.relname, c.relnamespace AS nspid, c.oid AS id, c.reltoastrelid AS tid,
toast.relname AS toast_name, toast.relpages AS toast_page,
c.relpages, c.reltuples, 'data/base/16386/' || c.relfilenode::TEXT AS path
FROM meta.pg_class c
LEFT JOIN meta.pg_namespace n ON c.relnamespace = n.oid
, LATERAL (SELECT * FROM meta.pg_class t WHERE t.oid = c.reltoastrelid) toast
WHERE c.relkind = 'r' AND c.relpages > 0
AND c.relnamespace IN (2200, 35507, 35508)
ORDER BY c.relnamespace, c.relpages DESC
) z,
LATERAL ( SELECT string_agg(name,',') AS attrs,
string_agg(std_type,',') AS fields,
max(has_tough_type::INTEGER)::BOOLEAN AS has_tough_type
FROM meta.pg_columns WHERE relid = z.id ) AS columns;
这里需要注意,pg_filedump -D 参数支持的数据类型名称是有严格限定的标准名称的,所以你必须把 boolean 转为 bool,INTEGER 转为 int。如果你想解析的数据类型不在下面这个列表中,可以首先尝试使用 TEXT 类型,例如表示IP地址的 INET 类型就可以用 TEXT 的方式解析。
bigint bigserial bool char charN date float float4 float8 int json macaddr name numeric oid real serial smallint smallserial text time timestamp timestamptz timetz uuid varchar varcharN xid xml
但确实会有其他的一些特殊情况需要额外的处理,比如 PostgreSQL 中的 ARRAY 数组类型,后面会详细介绍。
恢复一张普通表
恢复普通数据表和恢复一张系统目录表并没有本质区别:只不过 Catalog 的模式和信息都是公开的标准化的,而待恢复的数据库模式则不一定。
Gitlab 也属于一个开源的很有知名度的软件,所以找到它的数据库模式定义并不是一件难事。如果是一个普通的业务系统,那么多费点功夫也可以从 pg_catalog 中还原出原始 DDL 。
知道了 DDL 定义,我们就可以使用 DDL 中每一列的数据类型,来解释二进制文件中的数据了。下面,我们用 public.approval_merge_request_rules 这张 Gitlab 中的普通表为例,演示如何恢复这样一张普通数据表。
create table approval_project_rules
(
id bigint,
created_at timestamp with time zone,
updated_at timestamp with time zone,
project_id integer,
approvals_required smallint,
name varchar,
rule_type smallint,
scanners text[],
vulnerabilities_allowed smallint,
severity_levels text[],
report_type smallint,
vulnerability_states text[],
orchestration_policy_idx smallint,
applies_to_all_protected_branches boolean,
security_orchestration_policy_configuration_id bigint,
scan_result_policy_id bigint
);
首先,我们要将这里的类型转换成 pg_filedump 可以识别的类型,这里涉及到类型映射的问题:如果你有不确定的类型,比如上面的 text[] 字符串数组字段,就可以先用 text 类型占位替代,也可以直接用 ~ 忽略:
bigint,timestamptz,timestamptz,int,smallint,varchar,smallint,text,smallint,text,smallint,text,smallint,bool,bigint,bigint
当然这里有第一个知识点就是 PostgreSQL 的元组列布局是有顺序的,这个顺序保存在系统视图 pg_attribute 里面的 attrnum 中,而表中每一列的类型ID则保存在 atttypid 字段中,而为了获取类型的英文名称,你又需要通过类型ID引用 pg_type 系统视图(当然系统默认类型都有固定ID,也可以直接用ID映射)。综上,为了获取表中物理记录的解释方法,你至少需要用到上面提到的那四张系统字典表。
有了这张表上列的顺序与类型之后,并且知道这张表的二进制文件位置之后,你就可以利用这个信息翻译二进制数据了。
pg_filedump -i -f -D 'bigint,...,bigint' 38304
输出时结果建议添加 -i 与 -f 选项,前者会打印每一行的元数据(需要根据 XMAX 判断这一行有没有被删除);后者会打印原始二进制数据上下文(这一点对于处理 pg_filedump 解决不了的复杂数据是必要的)。
正常情况下,每一条记录都会以 COPY: 或 Error: 开头,前者代表提取成功,后者代表部分成功,或者失败。如果是失败,会有各种各样的原因,需要分别处理。对于成功的数据,你可以直接把它拿出来,每一行就是一条数据,用 \t 分隔,把 \N 替换为 NULL,处理好写入到临时表中保存待用即可。
当然魔鬼其实都在细节里,要是数据恢复真这么容易就好了。
魔鬼在细节中
在处理数据数据恢复时,有许多小细节需要关注,这里我提几个重要的点。
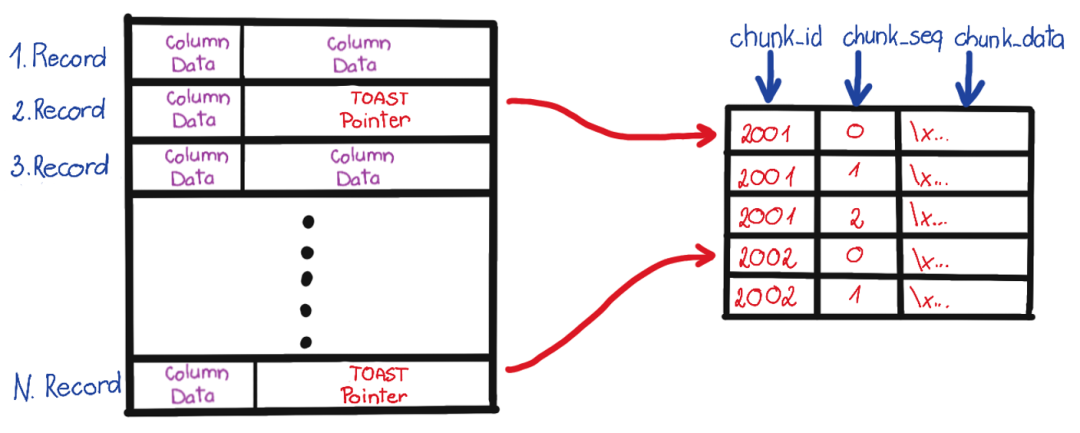
首先是 TOAST 字段的处理。TOAST 是“ The Oversized-Attribute Storage Technique ”的缩写,即超标属性存储技术。如果你发现解析出来的字段内容是 (TOASTED),那就说明这个字段因为太长,被切片转移到另外一张专用的表 —— TOAST 表中了。
如果某张表里有可能 TOAST 的字段,它就会有一张对应的 TOAST 表,在 pg_class 中用 reltoastrelid 标识其 OID。TOAST 其实也可以看做一张普通的表来处理,所以你可以用一样的方法把 TOAST 数据解析出来,拼接回去,再填入到原表中,这里就不展开了。
第二个问题是复杂类型,正如上一节所说, pg_filedump README里列出了支持的类型,但类似数组这样的类型就需要进行额外的二进制解析处理了。
举个例子,当你转储数组二进制时,看到的结果可能是一串儿 \0\0 。这是因为 pg_filedump 直接把处理不了的复杂类型给吐出来了。当然这里就会带来一些额外的问题 —— 字符串里的零值会让你的插入报错,所以你的解析脚本需要处理好这种问题,当遇到一个解析错误的复杂列时,应该先做个标记占个坑,把二进制值现场给保留下来,留给后面的步骤去具体处理。
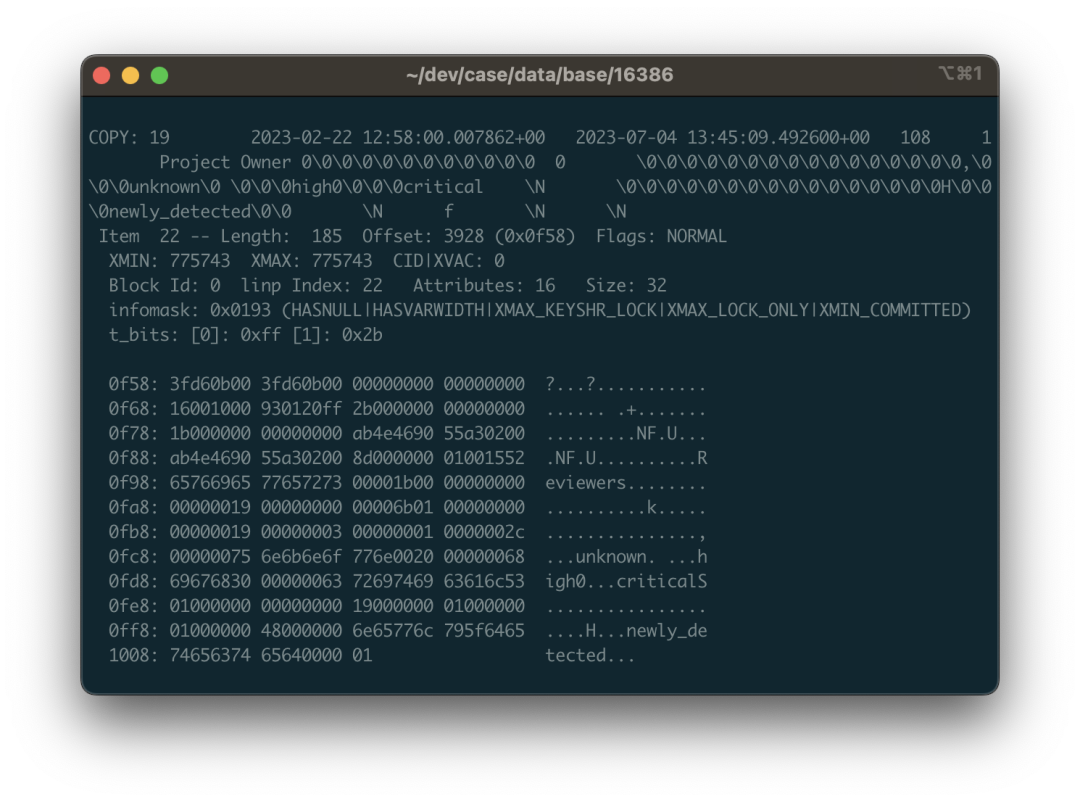
这里我们来看个具体的例子:还是以上面 public.approval_merge_request_rules 表为例。我们可以从吐出来的数据,二进制视图,以及 ASCII 视图里面看到一些零星的字符串:critical,unknown 之类的东西,掺杂在一串 \0 与二进制控制字符中。没错,这就是一个字符串数组的二进制表示。PostgreSQL 中的数组允许任意类型任意深度的嵌套,所以这里的数据结构会有一点点复杂。
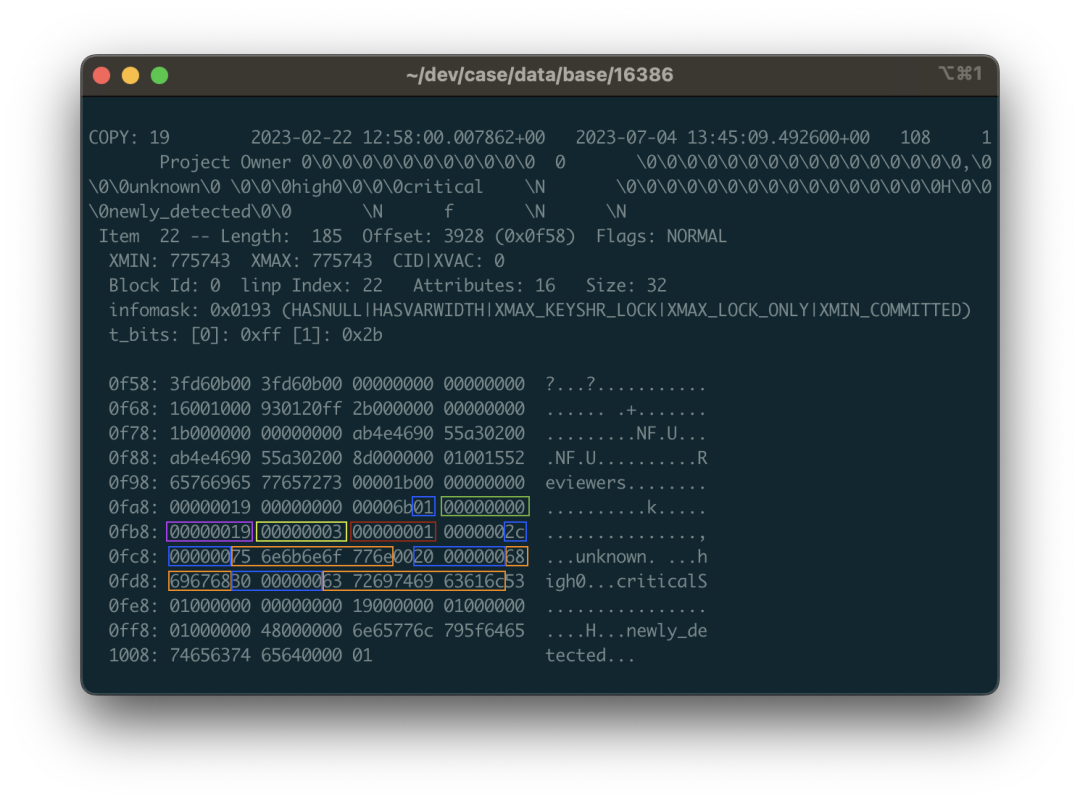
例如,图片中标色的地方对应的数据是一个包含三个字符串的数组:{unknown,high,critical}::TEXT[] 。01 代表这是一个一位数组,紧跟着空值位图,以及代表数组元素的类型OID 的 0x00000019 ,0x19 十进制值为 25 对应 pg_type 中的 text类型,说明这里是一个字符串数组(如果是 0x17 则说明是整型数组)。紧接着是这个数组第一维的维度 0x03,因为这个数组只有一维,三个元素;接下来的 1 告诉我们数组第一维度的起始偏移量在哪儿。再后面才是挨着的三个字符串结构了:由4字节的长度打头(要右移两位处理标记未),接着才是字符串内容,还要考虑布局对齐与填充的问题。
总的来说,你需要对照着源代码实现去挖掘,而这里有无穷无尽的细节:可变长度,空值位图,字段压缩,线外存储,以及大小端序,稍有不慎,你解出来的东西就是一团没用的浆糊。
你可以选择直接用 Python 脚本去记录的上下文中解析原始二进制回补数据,或者在 pg_filedump 源代码中注册新的类型与回调处理函数,复用 PG 提供的 C 解析函数,无论哪一种都称不上是轻松。
好在 PostgreSQL 本身已经提供了一些C语言的辅助函数 & 宏可以帮助你完成大部分工作,而且幸运的是 Gitlab 中的数组都是一维数组,类型也仅限于整型数组与字符串数组,其他带复杂类型的数据页也可以从其他表中重建,所以总体工作量还是可以接受的 。
后记
这个活儿折腾了我两天,掏粪细节就不展开了,我估计读者也不会感兴趣。总之经过了一系列处理,校正,补对之后,数据恢复的工作终于完成了!除了有几张表里有几条损坏的数据之外,其他的数据都成功解出来了。好家伙,整整一千张表啊!
我以前也弄过一些数据恢复的活儿,大多数情况都还比较简单,数据坏块儿,控制文件/CLOG损坏,或者是被挖矿病毒种了勒索木马(往Tablespace里写了几个垃圾文件),但炸的这么彻底的Case我还是第一次弄。之所以敢接这个活,也是因为我对PG内核还是有些了解的,知道这些繁琐的实现细节。只要你知道这是一个工程上可解的问题,那么即使过程再脏再累也不会担心完不成。
尽管有些缺陷,但 pg_filedump 还是一个不错的工具,后面我可能会考虑完善一下它,让它对各种数据类型都有完整的支持,这样就不用再自己写一堆 Python 小脚本来处理各种繁琐的细节了。在弄完这个案例后,我已经把 pg_filedump 打好了 PG 12 - 16 x EL 7 - 9 上的 RPM 包放在 Pigsty 的 Yum源中,默认收录在 Pigsty 离线软件包里,目前已经在 Pigsty v2.4.1 中实装交付了。我衷心希望您永远也用不上这个扩展,但如果你真的碰上需要它的场景时,我也希望它就在你的手边可以开箱即用。
最后我还是想说一句,许多软件都需要数据库,但数据库的安装部署维护是一件很有门槛的活儿。Gitlab 拉起的 PostgreSQL 质量已经算是相当不错的了,但面对这种情况依然束手无策,更不用提那些土法手造 docker 镜像的简陋单机实例了。一场大故障,就能让一个企业积累的代码数据、CI/CD流程、Issue/PR/MR 记录灰飞烟灭。我真的建议您好好检视一下自己的数据库系统,至少请定期做个备份吧!
Gitlab 的企业版和社区版的核心区别就在于它底下的 PG 有没有高可用和监控。而开箱即用的 PostgreSQL 发行版 —— Pigsty 也可以为您更好地解决这些问题,却完全开源免费,分文不取:无论是高可用,PITR,还是监控系统一应俱全:下次再遇到这种问题时,就可以自动切换/一键回滚,游刃有余得多。之前我们自己的 Gitlab, Jira, Confluence 等软件都跑在上面,如果您有类似需求,倒是不妨试一下哦。