第四章 外部数据包装器
Module:
Categories:
本章将介绍一种相当实用,而且很有趣的特性:外部数据包装器(Foreign Data Wrapper FDW)。
4.1 外部数据包装器(FDW)
2003年,SQL标准中添加了一个访问远程数据的规范,称为SQL外部数据管理(SQL/MED)。PostgreSQL在9.1版本开发出了FDW,实现了一部分SQL/MED中的特性。
在SQL/MED中,远程服务器上的表被称为外部表(Foreign Table)。 PostgreSQL的外部数据包装器(FDW) 使用与本地表类似的方式,通过SQL/MED来管理外部表。
图4.1 FDW的基本概念
安装完必要的扩展并配置妥当后,就可以访问远程服务器上的外部表了。 例如假设有两个远程服务器分别名为postgresql和mysql,它们上面分别有两张表:foreign_pg_tbl和foreign_my_tbl。 在本例中,可以在本地服务器上执行SELECT查询以访问外部表,如下所示。
localdb=# -- foreign_pg_tbl 在远程postgresql服务器上
localdb-# SELECT count(*) FROM foreign_pg_tbl;
count
-------
20000
localdb=# -- foreign_my_tbl 在远程mysql服务器上
localdb-# SELECT count(*) FROM foreign_my_tbl;
count
-------
10000
此外还可以在本地连接来自不同服务器中的外部表。
localdb=# SELECT count(*) FROM foreign_pg_tbl AS p, foreign_my_tbl AS m WHERE p.id = m.id;
count
-------
10000
Postgres wiki中列出了很多现有的FDW扩展。但只有postgres_fdw 与file_fdw 是由官方PostgreSQL全球开发组维护的。postgres_fdw可用于访问远程PostgreSQL服务器。
以下部分将详细介绍PostgreSQL的FDW。 4.1.1节为概述,4.1.2节介绍了postgres_fdw扩展的工作方式。
Citus
Citus是由citusdata.com开发的开源PostgreSQL扩展,它能创建用于并行化查询的分布式PostgreSQL服务器集群。citus算是PostgreSQL生态中机制上最为复杂,且商业上最为成功的扩展之一,它也是一种FDW。
4.1.1 概述
使用FDW特性需要先安装相应的扩展,并执行一些设置命令,例如CREATE FOREIGN TABLE,CREATE SERVER 和CREATE USER MAPPING(细节请参阅官方文档)。
在配置妥当之后,查询处理期间,执行器将会调用扩展中定义的相应函数来访问外部表。
图4.2 FDW是如何执行的
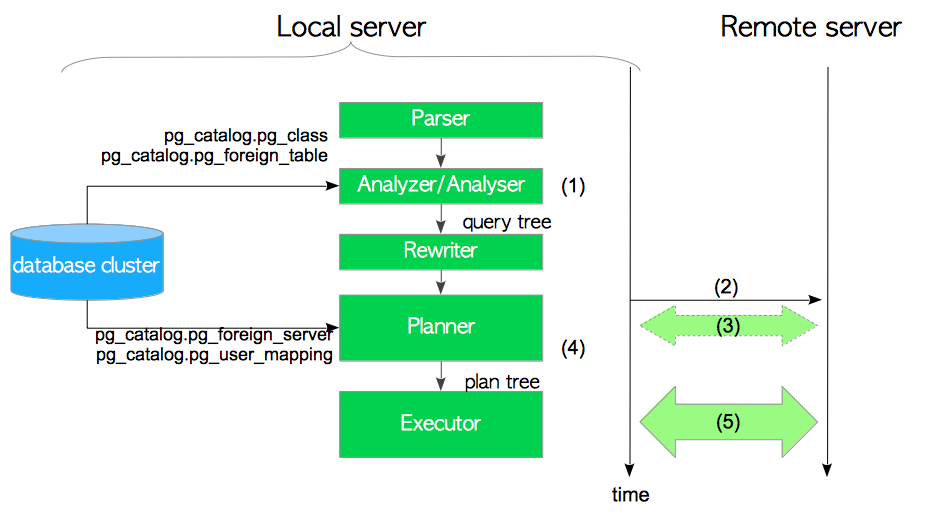
- 分析器为输入的SQL创建一颗查询树。
- 计划器(或执行器)连接到远程服务器。
- 如果启用了
use_remote_estimate选项(默认关闭),则计划器将执行EXPLAIN命令以估计每条计划路径的代价。 - 计划器按照计划树创建出纯文本SQL语句,在内部称该过程为逆解析(deparesing)。
- 执行器将纯文本SQL语句发送到远程服务器并接收结果。
如有必要,执行器会进一步处理接收到的结果。 例如执行多表查询时,执行器会将收到的数据与其他表进行连接。
以下各节介绍了每一步中的具体细节。
4.1.1.1 创建一颗查询树
分析器会根据输入的SQL创建一颗查询树,并使用外部表的定义。当执行命令CREATE FOREIGN TABLE 和IMPORT FOREIGN SCHEMA时,外部表的定义会被存储至系统目录pg_catalog.pg_class和pg_catalog.pg_foreign_table中。
4.1.1.2 连接至远程服务器
计划器(或执行器)会使用特定的库连接至远程数据库服务器。 例如要连接至远程PostgreSQL服务器时,postgres_fdw会使用libpq。 而连接到mysql服务器时,由EnterpriseDB开发的mysql_fdw使用libmysqlclient。
当执行CREATE USER MAPPING和CREATE SERVER命令时,诸如用户名,服务器IP地址和端口号等连接参数会被存储至系统目录pg_catalog.pg_user_mapping和pg_catalog.pg_foreign_server中。
4.1.1.3 使用EXPLAIN命令创建计划树(可选)
PostgreSQL的FDW机制支持一种特性:获取外部表上的统计信息,用于估计查询代价。一些FDW扩展使用了该特性,例如postgres_fdw,mysql_fdw,tds_fdw和jdbc2_fdw。
如果使用ALTER SERVER命令将use_remote_estimate选项设置为on,则计划器会向远程服务器发起查询,执行EXPLAIN命令获取执行计划的代价。否则在默认情况下,会使用默认内置常量值作为代价。
localdb=# ALTER SERVER remote_server_name OPTIONS (use_remote_estimate 'on');
尽管一些扩展也会执行EXPLAIN命令,但目前只有postgres_fdw才能忠于EXPLAIN命令的真正意图,因为PostgreSQL的EXPLAIN命令会同时返回启动代价和总代价。而其他DBMS的FDW扩展一般无法使用EXPLAIN命令的结果进行规划。 例如MySQL的EXPLAIN命令仅仅返回估计的行数, 但如第3章所述,PostgreSQL的计划器需要更多的信息来估算代价。
4.1.1.4 逆解析
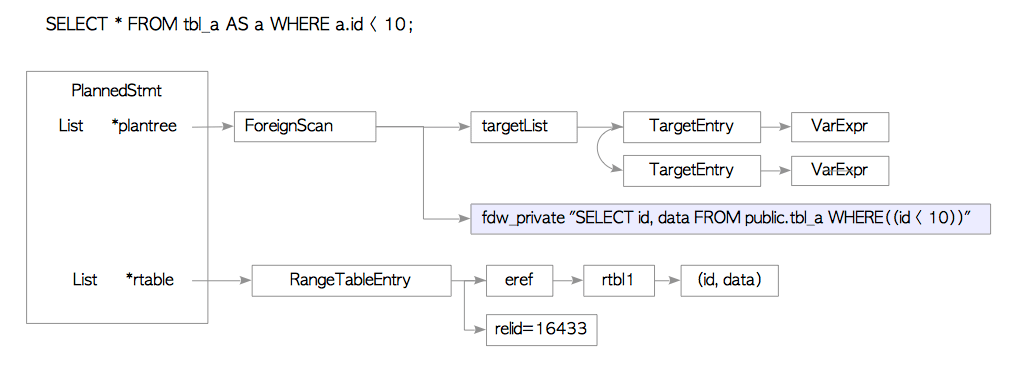
在生成执行计划树的过程中,计划器会为执行计划树上外部表的扫描路径创建相应的纯文本SQL语句。 例如图4.3展示了下列SELECT语句对应的计划树。
localdb=# SELECT * FROM tbl_a AS a WHERE a.id < 10;
图4.3展示了一个存储着纯文本形式SELECT语句的ForeignScan节点,PlannedStmt是执行计划树对应的数据结构,包含指向ForeignScan节点的链接。 这里,postgres_fdw从查询树中重新创建出SELECT纯文本语句,该过程在PostgreSQL中被称为逆解析(deparsing)。
图4.3 扫描外部表的计划树样例
使用mysql_fdw时,则会从查询树中重新创建MySQL相应的SELECT语句。 使用redis_fdw或rw_redis_fdw会创建一条Redis中的SELECT命令。
4.1.1.5 发送SQL命令并接收结果
在进行逆解析之后,执行器将逆解析得到的SQL语句发送到远程服务器并接收结果。
扩展的开发者决定了将SQL语句发送至远程服务器的具体方法。 例如mysql_fdw在发送多条SQL语句时不使用事务。 在mysql_fdw中执行SELECT查询的典型SQL语句序列如下所示(图4.4)。
- (5-1)将
SQL_MODE设置为'ANSI_QUOTES'。 - (5-2)将
SELECT语句发送到远程服务器。 - (5-3)从远程服务器接收结果。这里
mysql_fdw会将结果转换为PostgreSQL可读的格式。所有FDW扩展都实现了将结果转换为PostgreSQL可读数据的功能。
图4.4 mysql_fdw执行一个典型SELECT查询时的SQL语句序列

下面是远程服务器的日志,列出了实际接收到的语句。
mysql> SELECT command_type,argument FROM mysql.general_log;
+--------------+-----------------------------------------------------------+
| command_type | argument |
+--------------+-----------------------------------------------------------+
... snip ...
| Query | SET sql_mode='ANSI_QUOTES' |
| Prepare | SELECT `id`, `data` FROM `localdb`.`tbl_a` WHERE ((`id` < 10)) |
| Close stmt | |
+--------------+-----------------------------------------------------------+
postgres_fdw中的SQL命令顺序要更为复杂。在postgres_fdw中执行一个典型的SELECT查询,实际的语句序列如图4.5所示。
-
(5-1)启动远程事务。远程事务的默认隔离级别是
REPEATABLE READ;但如果本地事务的隔离级别设置为SERIALIZABLE,则远程事务的隔离级别也会设置为SERIALIZABLE。 -
(5-2)-(5-4)声明一个游标,SQL语句基本上以游标的方式来执行。
-
(5-5)执行
FETCH命令获取结果。默认情况下FETCH命令一次获取100行。 -
(5-6)从远程服务器接收结果。
-
(5-7)关闭游标。
-
(5-8)提交远程事务。
图4.5 postgres_fdw执行一个典型SELECT查询时的SQL语句序列

这里是远程服务器的实际日志。
LOG: statement: START TRANSACTION ISOLATION LEVEL REPEATABLE READ
LOG: parse : DECLARE c1 CURSOR FOR SELECT id, data FROM public.tbl_a WHERE ((id < 10))
LOG: bind : DECLARE c1 CURSOR FOR SELECT id, data FROM public.tbl_a WHERE ((id < 10))
LOG: execute : DECLARE c1 CURSOR FOR SELECT id, data FROM public.tbl_a WHERE ((id < 10))
LOG: statement: FETCH 100 FROM c1
LOG: statement: CLOSE c1
LOG: statement: COMMIT TRANSACTION
postgres_fdw中远程事务的默认隔离级别远程事务的默认隔离级别为
REPEATABLE READ,官方文档给出了原因和说明:当本地事务使用
SERIALIZABLE隔离级别时,远程事务也会使用SERIALIZABLE隔离级别,否则使用REPEATABLE READ隔离级别。 这样做可以确保在远程服务器上执行多次扫表时,每次的结果之间都能保持一致。因此,即使其他活动在远程服务器上进行了并发更新,单个事务中的连续查询也将看到远程服务器上的一致性快照。
4.1.2 postgres_fdw的工作原理
postgres_fdw扩展是一个由PostgreSQL全球开发组官方维护的特殊模块,其源码包含在PostgreSQL源码树中。
postgres_fdw正处于不断改善的过程中。 表4.1列出了官方文档中与postgres_fdw有关的发行说明。
表4.1 与postgres_fdw有关的发布说明(摘自官方文档)
| 版本 | 描述 |
|---|---|
| 9.3 | postgres_fdw模块正式发布 |
| 9.6 | 在远程服务器上执行排序 在远程服务器上执行连接 如果可行,在远程服务器上执行 UPDATE与DELETE允许在服务器与表的选项中设置批量拉取结果集的大小 |
| 10 | 如果可行, 将聚合函数下推至远程服务器 |
前一节描述了postgres_fdw如何处理单表查询,接下来的小节将介绍postgres_fdw如何处理多表查询,排序操作与聚合函数。 |
本小节重点介绍SELECT语句;但postgres_fdw还可以处理其他DML(INSERT,UPDATE和DELETE)语句。
PostgreSQL的FDW不会检测死锁
postgres_fdw与FDW功能并不支持分布式锁管理器与分布式死锁检测功能, 因此很容易产生死锁。 例如某客户端A更新了一个本地表tbl_local与一个外部表tbl_remote,而另一个客户端B以相反的顺序更新tbl_remote和tbl_local,则这两个事务陷入死锁。但PostgreSQL无法检测到这种情况, 因而无法提交这些事务。localdb=# -- Client A localdb=# BEGIN; BEGIN localdb=# UPDATE tbl_local SET data = 0 WHERE id = 1; UPDATE 1 localdb=# UPDATE tbl_remote SET data = 0 WHERE id = 1; UPDATE 1localdb=# -- Client B localdb=# BEGIN; BEGIN localdb=# UPDATE tbl_remote SET data = 0 WHERE id = 1; UPDATE 1 localdb=# UPDATE tbl_local SET data = 0 WHERE id = 1; UPDATE 1
4.1.2.1 多表查询
当执行多表查询时,postgres_fdw使用单表SELECT语句依次拉取每个外部表,并在本地服务器上执行连接操作。
在9.5或更早版本中,即使所有外部表都存储在同一个远程服务器中,postgres_fdw也会单独拉取每个表再连接。
在9.6或更高版本中,postgres_fdw已经有所改进,当外部表位于同一服务器上且use_remote_estimate选项打开时,可以在远程服务器上执行远程连接操作。
执行细节如下所述。
9.5及更早版本:
我们研究一下PostgreSQL如何处理以下查询:两个外部表的连接:tbl_a和tbl_b。
localdb=# SELECT * FROM tbl_a AS a, tbl_b AS b WHERE a.id = b.id AND a.id < 200;
EXPLAIN的执行结果如下
localdb=# EXPLAIN SELECT * FROM tbl_a AS a, tbl_b AS b WHERE a.id = b.id AND a.id < 200;
QUERY PLAN
------------------------------------------------------------------------------
Merge Join (cost=532.31..700.34 rows=10918 width=16)
Merge Cond: (a.id = b.id)
-> Sort (cost=200.59..202.72 rows=853 width=8)
Sort Key: a.id
-> Foreign Scan on tbl_a a (cost=100.00..159.06 rows=853 width=8)
-> Sort (cost=331.72..338.12 rows=2560 width=8)
Sort Key: b.id
-> Foreign Scan on tbl_b b (cost=100.00..186.80 rows=2560 width=8)
(8 rows)
结果显示,执行器选择了归并连接,并按以下步骤处理:
-
第8行:执行器使用外部表扫描拉取表
tbl_a。 -
第6行:执行器在本地服务器上对拉取的
tbl_a行进行排序。 -
第11行:执行器使用外表扫描拉取表
tbl_b。 -
第9行:执行器在本地服务器上对拉取的
tbl_b行进行排序。 -
第4行:执行器在本地服务器上执行归并连接操作。
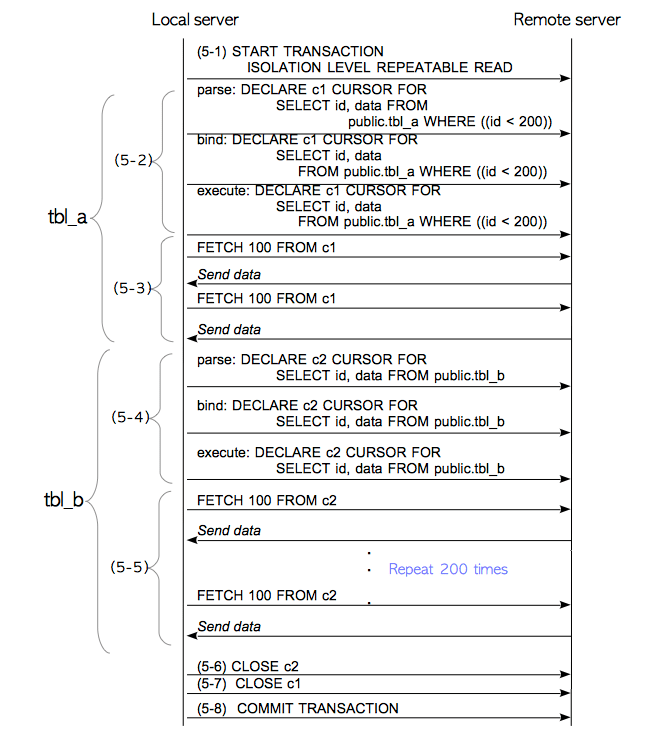
下面描述执行器如何拉取行集(图4.6)。
-
(5-1)启动远程事务。
-
(5-2)声明游标
c1,其SELECT语句如下所示:SELECT id,data FROM public.tbl_a WHERE(id <200) -
(5-3)执行
FETCH命令以拉取游标c1的结果。 -
(5-4)声明游标
c2,其SELECT语句如下所示:SELECT id,data FROM public.tbl_b注意原来双表查询中的WHERE子句是
tbl_a.id = tbl_b.id AND tbl_a.id <200;因而从逻辑上讲这条SELECT语句也可以添加上一条WHERE子句tbl_b.id <200。但postgres_fdw没有办法执行这样的推理,因此执行器必须执行不包含任何WHERE子句的SELECT语句,获取外部表tbl_b中的所有行。这种处理方式效率很差,因为必须通过网络从远程服务器读取不必要的行。此外,执行归并连接还需要先对接受到的行进行排序。
-
(5-5)执行
FETCH命令,拉取游标c2的结果。 -
(5-6)关闭游标
c1。 -
(5-7)关闭游标
c2。 -
(5-8)提交事务。
图4.6 在9.5及更早版本中执行多表查询时的SQL语句序列
这里是远程服务器的实际日志。
LOG: statement: START TRANSACTION ISOLATION LEVEL REPEATABLE READ
LOG: parse : DECLARE c1 CURSOR FOR
SELECT id, data FROM public.tbl_a WHERE ((id < 200))
LOG: bind : DECLARE c1 CURSOR FOR
SELECT id, data FROM public.tbl_a WHERE ((id < 200))
LOG: execute : DECLARE c1 CURSOR FOR
SELECT id, data FROM public.tbl_a WHERE ((id < 200))
LOG: statement: FETCH 100 FROM c1
LOG: statement: FETCH 100 FROM c1
LOG: parse : DECLARE c2 CURSOR FOR
SELECT id, data FROM public.tbl_b
LOG: bind : DECLARE c2 CURSOR FOR
SELECT id, data FROM public.tbl_b
LOG: execute : DECLARE c2 CURSOR FOR
SELECT id, data FROM public.tbl_b
LOG: statement: FETCH 100 FROM c2
LOG: statement: FETCH 100 FROM c2
LOG: statement: FETCH 100 FROM c2
LOG: statement: FETCH 100 FROM c2
... snip
LOG: statement: FETCH 100 FROM c2
LOG: statement: FETCH 100 FROM c2
LOG: statement: FETCH 100 FROM c2
LOG: statement: FETCH 100 FROM c2
LOG: statement: CLOSE c2
LOG: statement: CLOSE c1
LOG: statement: COMMIT TRANSACTION
在接收到行之后,执行器对接收到的tbl_a和tbl_b行进行排序,然后对已排序的行执行合并连接操作。
9.6或更高版本:
如果启用了use_remote_estimate选项(默认为关闭),则postgres_fdw会发送几条EXPLAIN命令,用于获取与外部表相关的所有计划的代价。
当发送EXPLAIN命令时,postgres_fdw将为每个单表查询执行EXPLAIN,也为执行远程连接操作时的SELECT语句执行EXPLAIN 。在本例中,以下七个EXPLAIN命令会被发送至远程服务器,用于估算每个SELECT语句的开销,从而选择开销最小的执行计划。
(1) EXPLAIN SELECT id, data FROM public.tbl_a WHERE ((id < 200))
(2) EXPLAIN SELECT id, data FROM public.tbl_b
(3) EXPLAIN SELECT id, data FROM public.tbl_a WHERE ((id < 200)) ORDER BY id ASC NULLS LAST
(4) EXPLAIN SELECT id, data FROM public.tbl_a WHERE ((((SELECT null::integer)::integer) = id)) AND ((id < 200))
(5) EXPLAIN SELECT id, data FROM public.tbl_b ORDER BY id ASC NULLS LAST
(6) EXPLAIN SELECT id, data FROM public.tbl_b WHERE ((((SELECT null::integer)::integer) = id))
(7) EXPLAIN SELECT r1.id, r1.data, r2.id, r2.data FROM (public.tbl_a r1 INNER JOIN public.tbl_b r2 ON (((r1.id = r2.id)) AND ((r1.id < 200))))
让我们在本地服务器上执行EXPLAIN命令,并观察计划器选择了哪一个计划。
localdb=# EXPLAIN SELECT * FROM tbl_a AS a, tbl_b AS b WHERE a.id = b.id AND a.id < 200;
QUERY PLAN
-----------------------------------------------------------
Foreign Scan (cost=134.35..244.45 rows=80 width=16)
Relations: (public.tbl_a a) INNER JOIN (public.tbl_b b)
(2 rows)
结果显示,计划器选择了在远程服务器上进行INNER JOIN处理的执行计划,也是最有效率的执行计划。
下面讲述postgres_fdw是如何执行这一过程的,如图4.7所示。
图4.7 执行远程连接操作时的SQL语句序列,9.6及更高版本

-
(3-1)启动远程事务。
-
(3-2)执行
EXPLAIN命令,估计每条计划路径的代价。在本例中执行了七条EXPLAIN命令。然后计划器根据EXPLAIN命令的结果,选取具有最低开销的SELECT查询。 -
(5-1)声明游标
c1,其SELECT语句如下所示:SELECT r1.id, r1.data, r2.id, r2.data FROM (public.tbl_a r1 INNER JOIN public.tbl_b r2 ON (((r1.id = r2.id)) AND ((r1.id < 200)))) -
(5-2)从远程服务器接收结果。
-
(5-3)关闭游标
c1。 -
(5-4)提交事务。
这里是远程服务器的实际日志。
LOG: statement: START TRANSACTION ISOLATION LEVEL REPEATABLE READ
LOG: statement: EXPLAIN SELECT id, data FROM public.tbl_a WHERE ((id < 200))
LOG: statement: EXPLAIN SELECT id, data FROM public.tbl_b
LOG: statement: EXPLAIN SELECT id, data FROM public.tbl_a WHERE ((id < 200)) ORDER BY id ASC NULLS LAST
LOG: statement: EXPLAIN SELECT id, data FROM public.tbl_a WHERE ((((SELECT null::integer)::integer) = id)) AND ((id < 200))
LOG: statement: EXPLAIN SELECT id, data FROM public.tbl_b ORDER BY id ASC NULLS LAST
LOG: statement: EXPLAIN SELECT id, data FROM public.tbl_b WHERE ((((SELECT null::integer)::integer) = id))
LOG: statement: EXPLAIN SELECT r1.id, r1.data, r2.id, r2.data FROM (public.tbl_a r1 INNER JOIN public.tbl_b r2 ON (((r1.id = r2.id)) AND ((r1.id < 200))))
LOG: parse: DECLARE c1 CURSOR FOR
SELECT r1.id, r1.data, r2.id, r2.data FROM (public.tbl_a r1 INNER JOIN public.tbl_b r2 ON (((r1.id = r2.id)) AND ((r1.id < 200))))
LOG: bind: DECLARE c1 CURSOR FOR
SELECT r1.id, r1.data, r2.id, r2.data FROM (public.tbl_a r1 INNER JOIN public.tbl_b r2 ON (((r1.id = r2.id)) AND ((r1.id < 200))))
LOG: execute: DECLARE c1 CURSOR FOR
SELECT r1.id, r1.data, r2.id, r2.data FROM (public.tbl_a r1 INNER JOIN public.tbl_b r2 ON (((r1.id = r2.id)) AND ((r1.id < 200))))
LOG: statement: FETCH 100 FROM c1
LOG: statement: FETCH 100 FROM c1
LOG: statement: CLOSE c1
LOG: statement: COMMIT TRANSACTION
注意如果禁用use_remote_estimate选项(默认情况),则远程连接查询很少会被选择,因为这种情况下其代价会使用一个很大的预置值进行估计。
4.1.2.2 排序操作
在9.5或更早版本中,排序操作(如ORDER BY)都是在本地服务器上处理的。即,本地服务器在排序操作之前从远程服务器拉取所有的目标行。让我们通过EXPLAIN来看一个包含ORDER BY子句的简单查询是如何被处理的。
localdb=# EXPLAIN SELECT * FROM tbl_a AS a WHERE a.id < 200 ORDER BY a.id;
QUERY PLAN
-----------------------------------------------------------------------
Sort (cost=200.59..202.72 rows=853 width=8)
Sort Key: id
-> Foreign Scan on tbl_a a (cost=100.00..159.06 rows=853 width=8)
(3 rows)
第6行:执行器将以下查询发送到远程服务器,然后获取查询结果。
SELECT id, data FROM public.tbl_a WHERE ((id < 200))
第4行:执行器在本地服务器上对拉取的tbl_a中的行进行排序。
这里是远程服务器的实际日志。
LOG: statement: START TRANSACTION ISOLATION LEVEL REPEATABLE READ
LOG: parse : DECLARE c1 CURSOR FOR
SELECT id, data FROM public.tbl_a WHERE ((id < 200))
LOG: bind : DECLARE c1 CURSOR FOR
SELECT id, data FROM public.tbl_a WHERE ((id < 200))
LOG: execute : DECLARE c1 CURSOR FOR
SELECT id, data FROM public.tbl_a WHERE ((id < 200))
LOG: statement: FETCH 100 FROM c1
LOG: statement: FETCH 100 FROM c1
LOG: statement: CLOSE c1
LOG: statement: COMMIT TRANSACTION
在9.6或更高版本中,如果可行,postgres_fdw能在远程服务器上直接执行带ORDER BY子句的SELECT语句。
localdb=# EXPLAIN SELECT * FROM tbl_a AS a WHERE a.id < 200 ORDER BY a.id;
QUERY PLAN
-----------------------------------------------------------------
Foreign Scan on tbl_a a (cost=100.00..167.46 rows=853 width=8)
(1 row)
第4行:执行器将以下带ORDER BY子句的查询发送至远程服务器,然后拉取已排序的查询结果。
SELECT id, data FROM public.tbl_a WHERE ((id < 200)) ORDER BY id ASC NULLS LAST
这里是远程服务器的实际日志。
LOG: statement: START TRANSACTION ISOLATION LEVEL REPEATABLE READ
LOG: parse : DECLARE c1 CURSOR FOR
SELECT id, data FROM public.tbl_a WHERE ((id < 200)) ORDER BY id ASC NULLS LAST
LOG: bind : DECLARE c1 CURSOR FOR
SELECT id, data FROM public.tbl_a WHERE ((id < 200)) ORDER BY id ASC NULLS LAST
LOG: execute : DECLARE c1 CURSOR FOR
SELECT id, data FROM public.tbl_a WHERE ((id < 200)) ORDER BY id ASC NULLS LAST
LOG: statement: FETCH 100 FROM c1
LOG: statement: FETCH 100 FROM c1
LOG: statement: CLOSE c1
LOG: statement: COMMIT TRANSACTION
4.1.2.3 聚合函数
在9.6及更早版本中,类似于前一小节中提到的排序操作,AVG()和COUNT()这样的聚合函数会在本地服务器上进行处理,如下所示。
localdb=# EXPLAIN SELECT AVG(data) FROM tbl_a AS a WHERE a.id < 200;
QUERY PLAN
-----------------------------------------------------------------------
Aggregate (cost=168.50..168.51 rows=1 width=4)
-> Foreign Scan on tbl_a a (cost=100.00..166.06 rows=975 width=4)
(2 rows)
第5行:执行器将以下查询发送到远程服务器,然后拉取查询结果。
SELECT id, data FROM public.tbl_a WHERE ((id < 200))
第4行:执行器在本地服务器上对拉取的tbl_a行集求均值。
这一过程开销很大,因为发送大量的行会产生大量网络流量,而且需要很长时间。
这里是远程服务器的实际日志。
LOG: statement: START TRANSACTION ISOLATION LEVEL REPEATABLE READ
LOG: parse : DECLARE c1 CURSOR FOR
SELECT data FROM public.tbl_a WHERE ((id < 200))
LOG: bind : DECLARE c1 CURSOR FOR
SELECT data FROM public.tbl_a WHERE ((id < 200))
LOG: execute : DECLARE c1 CURSOR FOR
SELECT data FROM public.tbl_a WHERE ((id < 200))
LOG: statement: FETCH 100 FROM c1
LOG: statement: FETCH 100 FROM c1
LOG: statement: CLOSE c1
LOG: statement: COMMIT TRANSACTION
在10或更高版本中,如果可行的话,postgres_fdw将在远程服务器上执行带聚合函数的SELECT语句。
localdb=# EXPLAIN SELECT AVG(data) FROM tbl_a AS a WHERE a.id < 200;
QUERY PLAN
-----------------------------------------------------
Foreign Scan (cost=102.44..149.03 rows=1 width=32)
Relations: Aggregate on (public.tbl_a a)
(2 rows)
第4行:执行器将以下包含AVG()函数的查询发送至远程服务器,然后获取查询结果。
SELECT avg(data) FROM public.tbl_a WHERE ((id < 200))
这种处理方式显然更为高效,因为远程服务器会负责计算均值,仅发送单行结果。
这里是远程服务器的实际日志。
LOG: statement: START TRANSACTION ISOLATION LEVEL REPEATABLE READ
LOG: parse : DECLARE c1 CURSOR FOR
SELECT avg(data) FROM public.tbl_a WHERE ((id < 200))
LOG: bind : DECLARE c1 CURSOR FOR
SELECT avg(data) FROM public.tbl_a WHERE ((id < 200))
LOG: execute : DECLARE c1 CURSOR FOR
SELECT avg(data) FROM public.tbl_a WHERE ((id < 200))
LOG: statement: FETCH 100 FROM c1
LOG: statement: CLOSE c1
LOG: statement: COMMIT TRANSACTION
下推
与上面的例子类似,下推(push-down) 指的是本地服务器允许一些操作在远程服务器上执行,例如聚合函数。