云计算
- 云计算泥石流:文章导航
- 阿里云rds_duckdb:致敬还是抄袭?
- 花钱买罪受的大冤种:逃离云计算妙瓦底
- OpenAI全球宕机复盘:K8S循环依赖
- WordPress社区内战:论共同体划界问题
- 云数据库:用米其林的价格,吃预制菜大锅饭
- 阿里云:高可用容灾神话破灭
- 云计算泥石流:合订本
- 草台班子唱大戏,阿里云PG翻车记
- 我们能从网易云音乐故障中学到什么?
- 蓝屏星期五:甲乙双方都是草台班子
- Ahrefs不上云,省下四亿美元
- 删库:Google云爆破了大基金的整个云账户
- 云上黑暗森林:打爆云账单,只需要S3桶名
- Cloudflare圆桌访谈与问答录
- 我们能从腾讯云大故障中学到什么?
- 吊打公有云的赛博佛祖 Cloudflare
- 罗永浩救不了牙膏云?
- 剖析阿里云服务器算力成本
- 云下高可用秘诀:拒绝复杂度自慰
- 扒皮云对象存储:从降本到杀猪
- 半年下云省千万,DHH下云FAQ
- 从降本增笑到真的降本增效
- 重新拿回计算机硬件的红利
- 我们能从阿里云全球故障中学到什么?
- 薅阿里云羊毛,打造数字家园
- 云计算泥石流:用数据解构公有云
- DHH:下云省下千万美元,比预想的还要多!
- 下云奥德赛:该放弃云计算了吗?
- FinOps终点是下云
- 云计算为啥还没挖沙子赚钱?
- 云SLA是不是安慰剂?
- 云盘是不是杀猪盘?
- 垃圾腾讯云CDN:从入门到放弃?
- 驳《再论为什么你不应该招DBA》
- 范式转移:从云到本地优先
- 云数据库是不是智商税
- DBA还是一份好工作吗?
- 云RDS:从删库到跑路
- DBA会被云淘汰吗?
云计算泥石流:文章导航
世人常道云上好,托管服务烦恼少。我言云乃杀猪盘,溢价百倍实厚颜。
赛博地主搞垄断,坐地起价剥血汗。运维外包嫖开源,租赁电脑炒概念。
世人皆趋云上游,不觉开销似水流。云租天价难为持,开源自建更稳实。
下云先锋把路趟,引领潮流一肩扛。不畏浮云遮望眼,只缘身在最前线。
曾几何时,“上云“近乎成为技术圈的政治正确,整整一代应用开发者的视野被云遮蔽。就让我们用实打实的数据分析与亲身经历,讲清楚公有云租赁模式的价值与陷阱 —— 在这个降本增效的时代中,供您借鉴与参考。
下云案例篇
人仰马翻篇
基础资源篇
记一次阿里云 DCDN 加速仅 32 秒就欠了 1600 的问题处理(扯皮)
商业模式篇
RDS批判篇
滑稽肖像篇
性学家,化学家,软件行业里的废话文学家 【转载】
牙膏云?您可别吹捧云厂商了【转载】
互联网技术大师速成班 【转载】
互联网故障背后的草台班子们【转载】
云厂商眼中的客户:又穷又闲又缺爱【转载】
商业评论篇
阿里云降价背后折射出的绝望【转载】
门内的国企如何看门外的云厂商【转载】
卡在政企客户门口的阿里云【转载】
腾讯云阿里云做的真的是云计算吗?【转载】
主题分类
亚马逊
- 2024-01-13 花钱买罪受的大冤种:逃离云计算妙瓦底
- 2024-05-23 Ahrefs不上云,省下四亿美元
- 2024-04-30 云上黑暗森林:打爆云账单,只需要S3桶名
- 2024-03-26 Redis不开源是“开源”之耻,更是公有云之耻
- 2024-03-14 RDS阉掉了PostgreSQL的灵魂
- 2023-12-27 扒皮对象存储:从降本到杀猪
- 2023-11-17 重新拿回计算机硬件的红利
- 2023-10-29 是时候放弃云计算了吗?
- 2023-07-07 下云奥德赛
阿里云
- 2024-11-11 支付宝崩了?双十一整活王又来了
- 2024-10-07 记一次阿里云 DCDN 加速仅 32 秒就欠了 1600 的问题处理(扯皮) 转
- 2024-09-17 阿里云:高可用容灾神话的破灭
- 2024-09-15 阿里云故障预报:本次事故将持续至20年后?
- 2024-09-10 阿里云新加坡可用区C故障,网传机房着火
- 2024-08-20 草台班子唱大戏,阿里云RDS翻车记
- 2024-07-02 阿里云又挂了,这次是光缆被挖断了?
- 2024-04-22 云计算:菜就是一种原罪
- 2024-04-20 taobao.com 证书过期
- 2024-04-02 牙膏云?您可别吹捧云厂商了
- 2024-04-01 罗永浩救不了牙膏云
- 2024-03-21 迷失在阿里云的年轻人
- 2024-03-10 剖析云算力成本,阿里云真的降价了吗?
- 2023-11-29 从降本增笑到真的降本增效
- 2023-11-27 阿里云周爆:云数据库管控又挂了
- 2023-11-14 我们能从阿里云史诗级故障中学到什么
- 2023-11-12 【阿里】云计算史诗级大翻车来了
- 2023-11-09 阿里云的羊毛抓紧薅,五千的云服务器三百拿
- 2023-11-06 云厂商眼中的客户:又穷又闲又缺爱 马工
腾讯云
- 2024-04-17 腾讯真的走通云原生之路了吗? 马工
- 2024-04-14 我们能从腾讯云故障复盘中学到什么?
- 2024-04-12 云SLA是安慰剂还是厕纸合同?
- 2024-04-09 腾讯云:颜面尽失的草台班子
- 2024-04-08 【腾讯】云计算史诗级二翻车来了
- 2023-03-08 垃圾腾讯云CDN:从入门到放弃
Cloudflare
- 2024-04-23 赛博菩萨Cloudflare圆桌访谈与问答录
- 2024-04-03 吊打公有云的赛博佛祖 Cloudflare
- 2024-05-11 删库:Google云爆破了大基金的整个云账户
Microsoft
- 2024-07-23 全球Windows蓝屏:甲乙双方都是草台班子
Oracle OCI
- 2025-03-29 Oracle云大翻车:6百万用户认证数据泄漏
其他
- 2025-03-24 今日大瓜:赛博佛祖与赛博菩萨大打出手
- 2024-12-14 OpenAI全球宕机复盘:K8S循环依赖
- 2024-11-10 草台回旋镖:Apple Music证书过期服务中断
- 2024-10-04 沸沸扬扬!!!某国内互联网公司,信息泄露导致国外用卡被盗刷。。。
- 2024-10-03 本号收到美团投诉:美团没有存储外卡CVV等敏感信息
- 2024-10-02 某平台CVV泄露:你的信用卡被盗刷了吗?
- 2024-08-21 这次轮到WPS崩了
- 2024-09-19 我们能从网易云音乐故障中学到什么?
- 2024-08-15 GitHub全站故障,又是数据库上翻的车?
DHH
- 2025-03-30 DHH下云:S3晚搬一天,就多花四万
- 2024-10-19 DHH:下云超预期,能省一个亿
- 2024-09-07 先优化碳基BIO核,再优化硅基CPU核
- 2024-01-16 单租户时代:SaaS范式转移
- 2024-01-10 拒绝用复杂度自慰,下云也保稳定运行
- 2023-12-22 半年下云省千万:DHH下云FAQ答疑
- 2023-10-29 是时候放弃云计算了吗?
- 2023-07-07 下云奥德赛
DBA vs RDS
- 2024-08-20 草台班子唱大戏,阿里云RDS翻车记
- 2024-03-14 RDS阉掉了PostgreSQL的灵魂
- 2024-02-02 DBA会被云淘汰吗?
- 2023-03-01 驳《再论为什么你不应该招DBA》
- 2023-02-03 范式转移:从云到本地优先
- 2023-01-31 云数据库是不是杀猪盘
- 2023-01-31 你怎么还在招聘DBA? 马工
- 2022-05-16 云RDS:从删库到跑路
开源软件
- 2024-10-17 WordPress社区内战:论共同体划界问题
- 2024-08-30 ElasticSearch又重新开源了???
- 2024-03-26 Redis不开源是“开源”之耻,更是公有云之耻
- 2023-02-03 范式转移:从云到本地优先
云计算泥石流专栏原文
- 2025-04-15 AWS 东京可用区故障:影响13项服务
- 2025-04-16 云计算不能做成云算计之一:云行贿必须清理 马工
- 2025-04-16 CVE惨遭断奶,美帝自毁安全长城
- 2025-04-02 Shopify:愚人节真的翻车了
- 2025-03-30 DHH下云:S3晚搬一天,就多花四万
- 2025-03-29 Oracle云大翻车:6百万用户认证数据泄漏
- 2025-03-24 今日大瓜:赛博佛祖与赛博菩萨大打出手
- 2024-01-13 花钱买罪受的大冤种:逃离云计算妙瓦底
- 2024-12-14 OpenAI全球宕机复盘:K8S循环依赖
- 2024-11-11 支付宝崩了?双十一整活王又来了
- 2024-11-10 草台回旋镖:Apple Music证书过期服务中断
- 2024-10-19 DHH:下云超预期,能省一个亿
- 2024-10-17 WordPress社区内战:论共同体划界问题
- 2024-10-07 记一次阿里云 DCDN 加速仅 32 秒就欠了 1600 的问题处理(扯皮) 转
- 2024-09-17 阿里云:高可用容灾神话的破灭
- 2024-09-15 阿里云故障预报:本次事故将持续至20年后?
- 2024-09-14 阿里云盘灾难级BUG:能看别人照片?
- 2024-09-10 阿里云新加坡可用区C故障,网传机房着火
- 2024-08-21 这次轮到WPS崩了
- 2024-08-20 草台班子唱大戏,阿里云RDS翻车记
- 2024-09-19 我们能从网易云音乐故障中学到什么?
- 2024-08-15 GitHub全站故障,又是数据库上翻的车?
- 2024-07-23 全球Windows蓝屏:甲乙双方都是草台班子
- 2024-07-02 阿里云又挂了,这次是光缆被挖断了?
- 2024-06-22 性学家,化学家,软件行业里的废话文学家 马工
- 2024-05-23 Ahrefs不上云,省下四亿美元
- 2024-05-11 删库:Google云爆破了大基金的整个云账户
- 2024-04-30 云上黑暗森林:打爆云账单,只需要S3桶名
- 2024-04-23 赛博菩萨Cloudflare圆桌访谈与问答录
- 2024-04-22 云计算:菜就是一种原罪
- 2024-04-20 taobao.com证书过期
- 2024-04-17 腾讯真的走通云原生之路了吗? 马工
- 2024-04-14 我们能从腾讯云故障复盘中学到什么?
- 2024-04-12 云SLA是安慰剂还是厕纸合同?
- 2024-04-09 腾讯云:颜面尽失的草台班子
- 2024-04-08 【腾讯】云计算史诗级二翻车来了
- 2024-04-03 吊打公有云的赛博佛祖 Cloudflare
- 2024-04-02 牙膏云?您可别吹捧云厂商了
- 2024-04-01 罗永浩救不了牙膏云
- 2024-03-26 Redis不开源是“开源”之耻,更是公有云之耻
- 2024-03-25 公有云厂商卖的云计算到底是什么玩意? 马工
- 2024-03-21 迷失在阿里云的年轻人
- 2024-03-14 RDS阉掉了PostgreSQL的灵魂
- 2024-03-13 云计算反叛军联盟
- 2024-03-10 剖析云算力成本,阿里云真的降价了吗?
- 2024-02-02 DBA会被云淘汰吗?
- 2024-01-16 单租户时代:SaaS范式转移
- 2024-01-09 互联网技术大师速成班 马工
- 2024-01-04 门内的国企如何看门外的云厂商 Leo
- 2023-12-29 卡在政企客户门口的阿里云 马工
- 2024-01-12 云计算泥石流
- 2024-01-10 拒绝用复杂度自慰,下云也保稳定运行
- 2023-12-27 扒皮对象存储:从降本到杀猪
- 2023-12-22 半年下云省千万:DHH下云FAQ答疑
- 2023-12-06 互联网故障背后的草台班子们 马工
- 2023-11-29 从降本增笑到真的降本增效
- 2023-11-27 阿里云周爆:云数据库管控又挂了
- 2023-11-17 重新拿回计算机硬件的红利
- 2023-11-14 我们能从阿里云史诗级故障中学到什么
- 2023-11-12 【阿里】云计算史诗级大翻车来了
- 2023-11-09 阿里云的羊毛抓紧薅,五千的云服务器三百拿
- 2023-11-06 云厂商眼中的客户:又穷又闲又缺爱 马工
- 2023-10-29 是时候放弃云计算了吗?
- 2023-07-08 云计算泥石流合集 —— 用数据解构公有云
- 2023-07-07 下云奥德赛
- 2023-07-06 FinOps终点是下云
- 2023-06-14 云计算为啥还没挖沙子赚钱?
- 2023-06-12 云SLA是不是安慰剂?
- 2023-04-28 杀猪盘真的降价了吗?
- 2023-03-15 公有云是不是杀猪盘?
- 2023-03-08 垃圾腾讯云CDN:从入门到放弃
- 2023-03-01 驳《再论为什么你不应该招DBA》
- 2023-02-03 范式转移:从云到本地优先
- 2023-01-31 云数据库是不是杀猪盘
- 2023-01-31 你怎么还在招聘DBA? 马工
- 2023-01-30 云数据库是不是智商税
- 2022-05-16 云RDS:从删库到跑路
下云之歌
甜美朋克:https://app.suno.ai/song/98f03bcd-5b4d-428f-a3f1-f581910d2e56
滑稽上口:https://app.suno.ai/song/308069a2-9d97-41c0-b1a9-ce14eb137ffe
新纪元:https://app.suno.ai/song/81e1b275-4652-4442-aa47-3127171d874d
死亡摇滚:https://app.suno.ai/song/6c203c72-0ce7-4b63-a447-a63b31080776
阿里云rds_duckdb:致敬还是抄袭?
看到有人发了一篇《天上的“PostgreSQL” 说 地上的 PostgreSQL 都是“小垃圾”》, 文中大肆宣扬阿里云 RDS 新增了一个 rds_duckdb 插件,可以用来做 OLAP 分析, 并进一步带出“云 RDS PG 高高在上、PostgreSQL 开源只是‘小垃圾’”的极端观点,令人不适。
我对 DuckDB 及衍生的 pg_duckdb 扩展都很熟悉。
其实无论阿里云或其他云厂商在技术层面如何整合开源,只要合法合理合情,我个人都乐见商业与开源互利共赢。
但如果有人在宣传层面贬低开源、抬高云服务,甚至暗示开源价值低下,那我确实有必要出来说两句以正视听。
关于 PG DuckDB
DuckDB 是一个高性能的嵌入式 OLAP 分析数据库,我已经关注它很久了。 在一年前我写的《PostgreSQL正在吞噬数据库世界》一文中, 着重介绍了 PG 在 OLAP 领域缝合 DuckDB 实现真HTAP的巨大潜力,并成功点燃了全球 PG 社区缝合 DuckDB 的热情。 PG 社区中涌现出好几个将 DuckDB 整合进 PG 的扩展玩家,而这甚至成为了 2024 年数据库领域的一个标志性事件。
在这些整合 PostgreSQL 与 DuckDB 的项目中,由 DuckDB 官方母公司 MotherDuck 联合 PG OLAP 生态初创企业 Hydra 共同开发的 pg_duckdb,可谓最具潜力。
我在其公开发布的第一时间就着手跟进,不仅为 EL 8/9、Debian 12、Ubuntu 22/24 等多种 Linux 发行版的 x86 和 ARM 架构制作并分发了对应的 RPM/DEB 包,还在日常使用和测试中投入了大量精力。
事实上,在我维护的两百多个 PG 扩展插件包里,与 DuckDB 相关的四个扩展是最令我头痛却又最让我兴奋的:pg_duckdb 以及基于它衍生的 pg_mooncake ——
硕大无朋的依赖,复杂的编译过程,多个 libduckdb 的冲突,兼容不同操作系统、不同大版本的 PostgreSQL,难度可想而知。
但我相信,这种真正实现 “OLTP + OLAP” 深度融合的探索,十分难得,也值得全力投入。
致敬还是抄袭?
当去年十月阿里云宣布在 RDS 上发布 rds_duckdb 时,我最初的想法是“这总算是好事”。
毕竟 pg_duckdb 刚开源两个月,就有云厂商跟进,多少还是在推动产业发展。
但很遗憾的是,rds_duckdb并没有开源,具体实现、细节接口,我们无从得知。
不过,从它展现给外部的功能接口上,多少能看出和 pg_duckdb 的相似之处:
比如,早期第一个公开发布的 pg_duckdb 版本,核心接口非常简单,就是 SET pg_duckdb.execution = on;,然后就可以直接用 DuckDB 引擎来查询 PostgreSQL 表了。
而 rds_duckdb 的核心接口就是 SET rds_duckdb.execution = on;,不过名字从 pg_duckdb 变为 rds_duckdb。
结合 rds_duckdb 公开发布的时间点(pg_duckdb 问世后两个月),再加上它的操作方式与行为表现高度相似,
可以合理猜想:rds_duckdb 至少在接口与理念上借鉴了 pg_duckdb。至于代码层面是否有直接引用,由于 rds_duckdb并未开源,我们也无可考证。
当然,rds_duckdb 自己也“加了点料”,比如支持 PG 12 / 13,多了几个管理 DuckDB 表的小函数(拷贝数据、查看大小等),但技术上并不复杂。
要我说,这个功能现在只能算是一个简易原型,远无法跟后续版本的 pg_duckdb 以及基于它构建的 pg_mooncake 相提并论。
换句话说,以现在这个“半成品”水平,谈不上什么“剽窃”或“抄袭”。“抄袭”也得抄得更像样一点吧?
然而,如果说它是“致敬”,却也让人无从认同。因为无论是在接口文档还是其他地方,我们都看不到任何对 pg_duckdb,甚至对 duckdb 的署名或感谢。
MIT协议的义务
无论是 duckdb 本身还是基于它的 pg_duckdb,使用的都是非常宽松的 MIT 协议。
因此如果使用了 MIT 项目的代码,只要遵循 MIT 协议的基本要求
—— (1)保留原始版权声明;(2)保留 MIT 许可证文本 —— 就能够做到合规。
这个要求说白了就是:人家写了代码白给你用,你别把人家作者名字删了就好了。
不过,让人玩味的是,我在阿里云 RDS 文档里搜索翻找了半天,也没看到任何地方留存着 DuckDB 的版权声明或许可证文本。
假如 rds_duckdb 并未直接使用 pg_duckdb 的代码,倒还可以解释说“我没用你的东西”,而且知识产权只保护具体的代码而不保护想法,所以不提也就算了。
—— 但你肯定用了 MIT 协议的 duckdb 对吧? 那么 DuckDB 的 Credit 和 License 在哪里呢?
尽管法律层面最主要的合规点仍是保留版权和许可证文本,但云厂商提供的是在线服务,“交付物”是一个URL和文档,而非 RPM / DEB 软件包,所以用户能接触到的材料就是官方文档。 如果在说明文档等对外宣传中,有意无意地淡化或隐去所使用的第三方开源项目,使得公众认为“这是完全自研或完全原创”,那么在舆论与道德层面会被质疑为“抄袭”或“剽窃”
类似的例子比比皆是,先前“何同学”开源抄袭风波、抖音美摄案、“高春辉诉阿里云抄袭IPIP 案,” 以及大家耳熟能详的鹅厂。更别提有大把“国产数据库公司”将开源的 PG 换皮套壳魔改称为“100%纯自研”数据库。 都是因为不尊重开源版权、把别人的东西当成“自研”,最终声名狼藉、备受质疑。
在我看来,“从开源社区取经,做成服务售卖”本来不丢人,这在全球范围早就是商业惯例,无可厚非; 可“拿了人家的东西,当成自己的发明”就会令人不齿。 因为这会留下极其恶劣的印象:企业既没有对外披露应有的来源,也没为社区带来多少贡献,却能坐享其成,大肆盈利。 如此一来,开源作者失去了正当的尊重与声望,用户也被蒙在鼓里,这种行为不仅违背了开源精神,更破坏了生态的可持续发展。
对开源的攻讦
说实话,我并不清楚那篇文章的公众号和阿里云之间是否有某种合作关系,也不知道他们为何如此排斥开源。从其近期的文章风格看出,一连串“捧云踩开源”桥段已经不是头一回了: 例如《天上的“PostgreSQL” 说 地上的 PostgreSQL 都是“小垃圾”》将开源的 PostgreSQL 视为垃圾; 《云原生数据库砸了 K8S云自建数据库的饭碗》说K8S自建数据库是垃圾, 以及《开源软件是心怀鬼胎的大骗局 – 开源软件是人类最好的正能量 — 一个人的辩论会》,体现出对开源软件的偏见。
这种对开源的偏见与攻讦,实在令人费解。要知道,恰恰是因为开源,一系列核心基础软件才得以百花齐放、加速迭代。 Deepseek 的成功也好,PostgreSQL 越做越大也好,都是脚踏实地站在前人开源巨人的肩膀之上。 各大云厂商的“云数据库”大多直接或间接基于开源数据库衍生、优化、深度整合,没了开源,他们的产品根基都将不复存在。
然而时至今日,云厂商从开源社区赚得盆满钵满,却很少进行对等贡献或反馈,导致围绕“云厂商白嫖开源”这个问题,矛盾正逐渐加剧。 但公道自在人心,也并不是所有云厂商都只知道白拿不还:比如 AWS RDS 在这两年投入资源推动 PG 生态的 pgvector 成为向量数据库扩展的事实标准,开源了 log_fdw、pgcollection、pgtle 等多款插件,对社区的反哺社区也是看在眼里的。
再看看阿里云 RDS,似乎仍在拘泥于“从开源社区和初创公司碗里捞食”的老思路,吃相不体面也就罢了,问题在于致敬都致不到精髓,产品做得简陋不堪,难以给用户真正的信心。 实际上,对用户来说,不能容忍的不是“云厂商利用开源”,而是“云厂商家大业大,却端出一个半吊子东西敷衍了事”,搞得像个草台班子,丢的还是阿里云自己的脸。
参考阅读
花钱买罪受的大冤种:逃离云计算妙瓦底
本文来自真实咨询案例,如有雷同,纯属云厂商和钱包缘分太深。
昨天一用户来咨询,问我 PostgreSQL 分布式数据库扩展 Citus 有没有什么坑,Pigsty 支持不。我想好家伙都要上分布式了,那你这数据量应该挺大了?
结果令人啼笑皆非,原来他并不是因为数据大到要冲破服务器柜门,而是栽在了 AWS EBS 云盘 的“杀猪盘”套路里。
捂着钱包慌忙上分布式数据库
“Citus 分布式数据库坑多吗?Pigsty 支持不?” 前两天一个用户火急火燎地跑来咨询,开口就提“Citus”。 我心想:都要上分布式了,想必有着海量数据、疯狂QPS,一定是个狠角色?估计得几百 TB 起步吧?

开源分布式扩展 Citus 在 PostgreSQL 生态里确实名气不小,尤其被微软收购后,在 Azure 上干脆还被包装成了 CosmosDB / Hyperscale PG。让 PG 原地升级成分布式数据库,一听就很酷炫。

但是老朋友们也知道,我是不太待见分布式数据库的。(《分布式数据库是伪需求吗》), 分布式数据库的基本原则就是如果你的问题能在经典主从范围内搞定就不要去折腾分布式,所以例行公事我也要问问这到底得多大负载。
一问具体指标,数据量 60TB,用 TimescaleDB 扩展压缩后到 14 TB; QPS 5K,查询基本都是点查,扫个 100 条数据最多 —— 嗨,典型的 “数据量不算小,吞吐量不算大”。 不过这种量级在 2015 年也许要分布式,但在单卡 64 TB 的 2025 年,随便来个万把块的 NVMe SSD 跑个原生 PG 不就轻松解决了?单机 PG 随便每秒百万点查点写更是不在话下 —— 那么用分布式是什么原因?磁盘装不下了吗?
用户说:“因为会有突发流量,我要扩容加个从库,需要好几天。”
这就让我有点不解了:14TB 数据,万兆网卡环境下一次同步备份也就四五个小时吧? 我用 2016 年的破旧硬件限速跑,拖个3TB的从库都用不了半小时。 再说,加从库耗时主要取决于 I/O 能力,要是 I/O 卡脖子了,那扩容分布式也没用啊,分布式不也得做分区再平衡,能解决啥问题?
于是用户又说:“网络没问题,主要是磁盘成本太贵了:现在架构是一主三从,一个从库就一份数据,总共四份“。
用户还特意强调了两次 “磁盘太贵” 这就更让我纳闷了 —— 这年头企业级大容量 NVMe SSD 已经便宜的跟白菜价一样了,200 ¥/TB/年,你有这十几T数据,和折腾TimescaleDB,Citus人力,没钱买硬盘? 然后我看既然拖从库慢不是因为网络问题,那基本那就是磁盘问题了?磁盘这么慢,不会还在用 HDD机械硬盘吧,HDD 能贵到哪里去?
当然,因为用户都会手工拖从库,玩转 PG 扩展了,数据量也挺大,还敢上分布式,我已经默认他不是只会用云数据库,控制台点点点的菜鸟了。 但我还是想到了一种可能性 —— 难道说 …… 你买的是公有云厂商的 天价杀猪盘 ?
这位哥们说到:“是,我们现在用的 AWS 自建”。
嗨,破案了,又是一个花钱买罪受的杀猪盘受害用户。
天价杀猪盘,让动作都走形了
深聊后发现,用户在云上的开销非常惊人,光数据库毛估每年就有 200 万人民币,而得到的却是一个拉 14 TB 从库都要花几天的乞丐盘 —— 换算下来吞吐也就不到 100 MB/s。 一块 Gen5 NVMe SSD 的 12 GB/s 带宽,3M IOPS 性能,可以把这种乞丐盘轰杀成渣,而只要百分之一不到的成本。
按照 AWS EBS io2 盘折后价,大约 1900 元 / TB / 月,14 TB 数据 × 4 份 × 12 个月,光存储就差不多一年 128 万; 再加上 EC2 主机费用(通常云数据库存储/计算费用配比估算比例 2:1),每年 200 万往上走。 更离谱的是,花这么多钱换来的,却是性能奇差无比的存储。“交了保护费还得挨打”,可不就是这么回事?
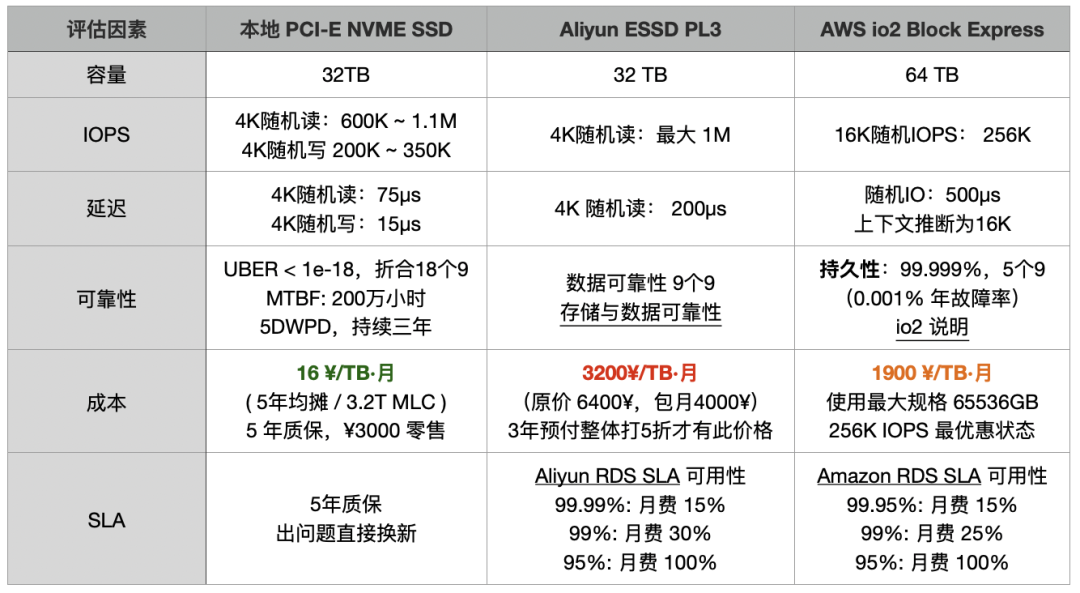
为了省这笔云盘费,他们宁可把业务架构改得七零八落,或让运维花几天时间加从库,把无底洞似的人力和时间成本都扔进去。最后甚至想靠分布式数据库来“自救”,以为这样能省点存储费。 但结果呢?依然被“杀猪盘”牢牢锁死。每年烧掉 200 万,换来又慢又折腾的服务,还要自己额外承担把业务拆成拼图的成本。
那么追本溯源,分布式数据库的需求是怎么来的?—— 不是因为业务或数据真的需要分布式,而是云上块存储价格昂贵、性能太差。 这问题光靠换个“分布式数据库”或者用个 S3数据库是治不了本的。要真正治本,得先问:为什么云上的块存储会这么离谱?
其实,在 公有云是不是杀猪盘? 中,我早就告诉过你们答案。
花钱买罪受,别当云上大冤种
大型公有云厂商的核心套路无非是:用极便宜的小微实例和免费额度先把用户诱上云,再依托数据库等云 PaaS 技术壁垒锁定用户,用户上了规模之后“跑不掉”,只能留在云上持续出血,也就是所谓“杀猪盘”。
当然肯定会有人会说:大公有云厂商都有 Serverless ,或者弹性存储共享存储的云数据库服务嘛,肯定是这位客户 用云的姿势不对。 但实际上,去看看那些云数据库的荒谬定价吧!《云数据库是不是智商税》 ,用云数据库的成本只会比纯用资源的价格更震撼 —— 毕竟,PaaS 50% - 70% 的毛利可不是从天上掉下来的。
正如《下云奥德赛:是时候放弃云计算了吗?》中 DHH 所说: “在几个关键例子上,云的成本都极其高昂 —— 无论是大型物理机数据库、大型 NVMe 存储,或者只是最新最快的算力。 租生产队的驴所花的钱是如此高昂,以至于几个月的租金就能与直接购买它的价格持平。在这种情况下,你应该直接直接把这头驴买下来!”
以及 “被锁死困在亚马逊的云里,在实验新东西(比如固态硬盘)时,不得不忍受高昂到荒诞的定价带来的羞辱,这已经构成对核心价值观无法容忍的侵犯”。 我认为这一案例就是很典型的花钱买罪受 —— 花了每年两百万的巨款,得到的却是性能不堪入目的破烂。
而更关键地是,你以为云厂商会为你的业务负责到底吗? 用户耗费巨款买到的,除了加价一百倍卖给你的硬件,基本就是《草台班子唱大戏,阿里云RDS翻车记》这个案例里提供的售后支持 —— 你以为可以把锅甩给云厂商就能高枕无忧?真出了事,回旋镖还得打在自己头上。
别让这种付费续集不断上映
只要具备自建 PG 的能力,把数据库搬回自建机房或换家不捆绑 PaaS 的平价云,哪怕在 AWS 上直接选自带 Host Storage 的实例,都能把成本降好几个档次。 让我们做个小学三年级的算术:这类数据库实例放在云下,买几台托管物理机,一次性投入几十万、每年维护几万,五年甚至六七年都能用。
当然你要问搞不定怎么办?有不少 PG 专业供应商都提供技术咨询与技术支持服务,比如我就可以提供成熟且经过大规模实战验证的PG RDS解决方案, 在这一例中,我可以保证用20~40万一次性的硬件投入彻底解决每年两百万天价账单,同时性能还能比云上的乞丐盘高出 N 倍不止,而只收取只 15-40 万的咨询费。
即使你不得不在云上跑,我也强烈建议选择那些没有 PaaS 绑定的平价云 —— 在保留云端“弹性”这一核心优势的同时,却能把成本打到每月万把块。 毕竟 Hetzner、Linode、DigitalOcean 都提供物美价廉(通常+15%毛利,很合理)的全托管专属服务器, 这些平价云的价格,足以让习惯了十倍百倍溢价的传统云计算妙瓦底的用户瞠目结舌。
嘿,我的意思是,你觉得 AWS 会为这样的规格每月收你多少钱?
开源 RDS 解决下云关键难题
数据库是下云的关键卡点,微软 CEO 纳德拉说:你看到的这些 App 与应用不过都是数据库的漂亮封装而已 —— 所以下云最大的卡点就在于:能否在自己的服务器上跑好 PostgreSQL?应该怎么样解决这个问题?
当业务规模增长超出“云计算适用光谱”后,只有拥有了数据库自建的能力,用户才真正有自由去重新选择; 才能把所有云厂商当作纯资源供应商 —— 哪家收保护费,就能立马迁到另一家,实现真正的 “自由” 与 “自主可控”。
我一直主张,云数据库能力应该民主化普及到所有用户,而不是只能从几个垄断的赛博封建领主以天价租赁。 因此我做了开源版的 RDS for PostgreSQL:Pigsty,让你不依赖 DBA 专家,也能在物理机/虚拟机上一键拉起比 RDS 更强劲的 PostgreSQL, 并充分利用新硬件的高性能、低成本。解决下云的关键卡点。
Pigsty 包含 PG 生态里独一无二的 351 个扩展插件,远胜云上那些可怜的几十个阉割版插件,还提供免配置开箱即用的 高可用架构 与业内领先的监控系统。 它已在互联网、金融、新能源、军工、制造业等行业广泛应用,目前在 OSSRANK 全球 PostgreSQL 生态开源榜单里排第 22 名。
Pigsty 采用 AGPLv3 开源协议,开源免费。如果有人觉得“还是希望付费买个安心”,我们也提供明码标价的商业咨询服务兜底。—— 用公道的价格解决实际问题,不玩那些花里胡哨的“杀猪盘”套路。
真正的“弹性”从来都不是“把钱丢给云厂商,自己却一脸懵逼”,而是知道什么时候该花钱、怎么花钱。愿所有数据库用户都能别做大冤种,让自己的时间与金钱花费的更有意义。
OpenAI全球宕机复盘:K8S循环依赖
12月11日,OpenAI 出现了全球范围内的不可用故障,影响了 ChatGPT,API,Sora,Playground 和 Labs 等服务。影响范围从 12 月 11 日下午 3:16 至晚上 7:38 期间,持续时间超过四个小时,产生显著影响。
根据 OpenIA 在事后发布的故障报告,此次故障的直接原因是新部署了一套监控,压垮了 Kubernetes 控制面。然后因为控制面故障导致无法直接回滚,进一步放大的故障影响,导致了长时间的不可用。
其实这个故障和去年双十一 阿里云全球史诗故障 非常类似。都是全球控制面不可用,根因都是循环依赖(以及测试/发布灰度不足)。无非是阿里云是 OSS 和 IAM 之间循环依赖,OpenAI 是 DNS 和 K8S 的循环依赖。
循环依赖是架构设计中的大忌,就像在基础设施中放了炸药包,容易被一些临时性偶发性故障点爆。这次故障再次为我们敲响警钟。当然这次故障的原因还可以进一步深挖,比如测试/灰度不足,以及 架构杂耍:
比如 K8S 官方建议的 最大集群规模是 5000 节点,而我还清晰记得 OpenAI 发表过一篇吹牛文章:《我们是如何通过移除一个组件来让K8S跑到7500节点的》 —— 不仅不留冗余,还要超载压榨50%,最终,这次还真就在集群规模上翻了大车。
OpenAI 是 AI 领域的当红炸子鸡,其产品的实力与受欢迎程度毋庸置疑。这是依然无法掩盖其在基础设施上的薄弱 —— 基础设施想要搞好确实不容易,这也是为什么 AWS 和 DataDog 这样的公司赚得钵满盆翻的核心原因。
OpenAI 在去年在 PostgreSQL 数据库与 pgBouncer 连接池 上也翻过大车。这两年来的在基础设施可靠性上的表现也说不上亮眼。这次故障再次说明,即使是万亿级独角兽,在非专业领域上,也照样是个草台班子。
参考阅读
故障复盘原文
API、ChatGPT 和 Sora 出现问题
https://status.openai.com/incidents/ctrsv3lwd797
OpenAI故障报告复盘
本文详细记录了 2024 年 12 月 11 日发生的一次故障,当时所有 OpenAI 服务均出现了严重的停机问题。根源在于我们部署了新的遥测服务(telemetry service),意外导致 Kubernetes 控制平面负载过重,从而引发关键系统的连锁故障。我们将深入解析故障根本原因,概述故障处理的具体步骤,并分享我们为防止类似事件再次发生而采取的改进措施。
影响
在太平洋时间 2024 年 12 月 11 日下午 3:16 至晚上 7:38 之间,所有 OpenAI 服务均出现了严重降级或完全不可用。这起事故源于我们在所有集群中推出的新遥测服务配置,并非由安全漏洞或近期产品发布所致。从下午 3:16 开始,各产品性能均出现大幅下降。
- ChatGPT: 在下午 5:45 左右开始大幅恢复,并于晚上 7:01 完全恢复。
- API: 在下午 5:36 左右开始大幅恢复,于晚上 7:38 所有模型全部恢复正常。
- Sora: 于晚上 7:01 完全恢复。
根因
OpenAI 在全球范围内运营着数百个 Kubernetes 集群。Kubernetes 的控制平面主要负责集群管理,而数据平面则实际运行工作负载(如模型推理服务)。
为提升组织整体可靠性,我们一直在加强集群级别的可观测性工具,以加深对系统运行状态的可见度。太平洋时间下午 3:12,我们在所有集群部署了一项新的遥测服务,用于收集 Kubernetes 控制平面的详细指标。
由于遥测服务会涉及非常广泛的操作范围,这项新服务的配置无意间让每个集群中的所有节点都执行了高成本的 Kubernetes API 操作,并且该操作成本会随着集群规模的扩大而成倍增加。数千个节点同时发起这些高负载请求,导致 Kubernetes API 服务器不堪重负,进而瘫痪了大型集群的控制平面。该问题在规模最大的集群中最为严重,因此在测试环境并未检测到;另一方面,DNS 缓存也使问题在正式环境中的可见度降低,直到问题在整个集群开始全面扩散后才逐渐显现。
尽管 Kubernetes 数据平面大部分情况下可独立于控制平面运行,但数据平面的 DNS 解析依赖控制平面——如果控制平面瘫痪,服务之间便无法通过 DNS 相互通信。
简而言之,新遥测服务的配置在大型集群中意外地生成了巨大的 Kubernetes API 负载,导致控制平面瘫痪,进而使 DNS 服务发现功能中断。
测试与部署
我们在一个预发布(staging)集群中对变更进行了测试,当时并未发现任何问题。该故障主要对超过一定规模的集群产生影响;再加上每个节点的 DNS 缓存延迟了故障的可见时间,使得变更在正式环境被大范围部署之前并没有暴露出任何明显异常。
在部署之前,我们最关注的是这项新遥测服务本身对系统资源(CPU/内存)的消耗。在部署前也对所有集群的资源使用情况进行了评估,确保新部署不会干扰正在运行的服务。虽然我们针对不同集群调优了资源请求,但并未考虑 Kubernetes API 服务器的负载问题。与此同时,此次变更的监控流程主要关注了服务自身的健康状态,并没有完善地监控集群健康(尤其是控制平面的健康)。
Kubernetes 数据平面(负责处理用户请求)设计上可以在控制平面离线的情况下继续工作。然而,Kubernetes API 服务器对于 DNS 解析至关重要,而 DNS 解析对于许多服务都是核心依赖。
DNS 缓存在故障早期阶段起到了暂时的缓冲作用,使得一些陈旧但可用的 DNS 记录得以继续为服务提供地址解析。但在接下来 20 分钟里,这些缓存逐步过期,依赖实时 DNS 的服务开始出现故障。这段时间差恰好在部署持续推进时才逐渐暴露问题,使得最终故障范围更为集中和明显。一旦 DNS 缓存失效,集群里的所有服务都会向 DNS 发起新请求,进一步加剧了控制平面的负载,使得故障难以在短期内得到缓解。
故障修复
在大多数情况下,监控部署和回滚有问题的变更都相对容易,我们也有自动化工具来检测和回滚故障性部署。此次事件中,我们的检测工具确实正常工作——在客户受影响前几分钟就已经发出了警报。不过要真正修复这个问题,需要先删除导致问题的遥测服务,而这需要访问 Kubernetes 控制平面。然而,API 服务器在承受巨大负载的情况下无法正常处理管理操作,导致我们无法第一时间移除故障性服务。
我们在几分钟内确认了问题,并立即启动多个工作流程,尝试不同途径迅速恢复集群:
- 缩小集群规模: 通过减少节点数量来降低 Kubernetes API 总负载。
- 阻断对 Kubernetes 管理 API 的网络访问: 阻止新的高负载请求,让 API 服务器有时间恢复。
- 扩容 Kubernetes API 服务器: 提升可用资源以应对积压请求,从而为移除故障服务赢得操作窗口。
我们同时采用这三种方法,最终恢复了对部分控制平面的访问权限,从而得以删除导致问题的遥测服务。
一旦我们恢复对部分控制平面的访问权限,系统就开始迅速好转。在可能的情况下,我们将流量切换到健康的集群,同时对仍然存在问题的其他集群进行进一步修复。部分集群仍在修复过程出现资源竞争问题:很多服务同时尝试重新下载所需组件,导致资源饱和并需要人工干预。
此次事故是多项系统与流程在同一时间点相互作用、同时失效的结果,主要体现在:
- 测试环境未能捕捉到新配置对 Kubernetes 控制平面的影响。
- DNS 缓存使服务故障出现了时间延迟,从而让变更在故障完全暴露前被大范围部署。
- 故障发生时无法访问控制平面,导致修复进程十分缓慢。
时间线
- 2024 年 12 月 10 日: 新的遥测服务部署到预发布集群,经测试无异常。
- 2024 年 12 月 11 日 下午 2:23: 引入该服务的代码合并到主分支,并触发部署流水线。
- 下午 2:51 至 3:20: 变更逐步应用到所有集群。
- 下午 3:13: 告警触发,通知到工程师。
- 下午 3:16: 少量客户开始受到影响。
- 下午 3:16: 根因被确认。
- 下午 3:27: 工程师开始把流量从受影响的集群迁移。
- 下午 3:40: 客户影响达到最高峰。
- 下午 4:36: 首个集群恢复。
- 晚上 7:38: 所有集群恢复。
预防措施
为防止类似事故再次发生,我们正在采取如下措施:
1. 更健壮的分阶段部署
我们将继续加强基础设施变更的分阶段部署和监控机制,确保任何故障都能被迅速发现并限制在较小范围。今后所有与基础设施相关的配置变更都会采用更全面的分阶段部署流程,并在部署过程中持续监控服务工作负载以及 Kubernetes 控制平面的健康状态。
2. 故障注入测试
Kubernetes 数据平面需要进一步增强在缺失控制平面的情况下的生存能力。我们将引入针对该场景的测试手段,包括在测试环境有意注入“错误配置”来验证系统检测和回滚能力。
3. 紧急访问 Kubernetes 控制平面
当前我们还没有一套应对数据平面向控制平面施加过大压力时,依旧能访问 API 服务器的应急机制。我们计划建立“破冰”机制(break-glass),确保在任何情况下工程团队都能访问 Kubernetes API 服务器。
4. 进一步解耦 Kubernetes 数据平面和控制平面
我们目前对 Kubernetes DNS 服务的依赖,使得数据平面和控制平面存在耦合关系。我们会投入更多精力,使得控制平面对关键服务和产品工作负载不再是“负载核心”,从而降低对 DNS 的单点依赖。
5. 更快的恢复速度
我们将针对集群启动所需的关键资源引入更完善的缓存和动态限流机制,并定期进行“快速替换整个集群”的演练,以确保在最短时间内实现正确、完整的启动和恢复。
结语
我们对这次事故造成的影响向所有客户表示诚挚的歉意——无论是 ChatGPT 用户、API 开发者还是依赖 OpenAI 产品的企业。此次事件没有达到我们自身对系统可靠性的期望。我们意识到向所有用户提供高度可靠的服务至关重要,接下来将优先落实上述防范措施,不断提升服务的可靠性。感谢大家在此次故障期间的耐心等待。
发表于 23 小时前。2024 年 12 月 12 日 - 17:19 PST
已解决
在 2024 年 12 月 11 日下午 3:16 到晚上 7:38 期间,OpenAI 的服务不可用。大约在下午 5:40 开始,我们观察到 API 流量逐渐恢复;ChatGPT 和 Sora 则在下午 6:50 左右恢复。我们在晚上 7:38 排除了故障,并使所有服务重新恢复正常。
OpenAI 将对本次事故进行完整的根本原因分析,并在此页面分享后续详情。
2024 年 12 月 11 日 - 22:23 PST
监控
API、ChatGPT 和 Sora 的流量大体恢复。我们将继续监控,确保问题彻底解决。
2024 年 12 月 11 日 - 19:53 PST
更新
我们正持续推进修复工作。API 流量正在恢复,我们逐个地区恢复 ChatGPT 流量。Sora 已开始部分恢复。
2024 年 12 月 11 日 - 18:54 PST
更新
我们正努力修复问题。API 和 ChatGPT 已部分恢复,Sora 仍然离线。
2024 年 12 月 11 日 - 17:50 PST
更新
我们正继续研发修复方案。
2024 年 12 月 11 日 - 17:03 PST
更新
我们正继续研发修复方案。
2024 年 12 月 11 日 - 16:59 PST
更新
我们已经找到一个可行的恢复方案,并开始看到部分流量成功返回。我们将继续努力,使服务尽快恢复正常。
2024 年 12 月 11 日 - 16:55 PST
更新
ChatGPT、Sora 和 API 依然无法使用。我们已经定位到问题,并正在部署修复方案。我们正在尽快恢复服务,对停机带来的影响深表歉意。
2024 年 12 月 11 日 - 16:24 PST
已确认问题
我们接到报告称 API 调用出现错误,platform.openai.com 和 ChatGPT 的登录也出现问题。我们已经确认问题,并正在开展修复。
2024 年 12 月 11 日 - 15:53 PST
更新
我们正在继续调查此问题。
2024 年 12 月 11 日 - 15:45 PST
更新
我们正在继续调查此问题。
2024 年 12 月 11 日 - 15:42 PST
调查中
我们目前正在调查该问题,很快会提供更多更新信息。
发表于 2 天前。2024 年 12 月 11 日 - 15:17 PST
本次故障影响了 API、ChatGPT、Sora、Playground 以及 Labs。
WordPress社区内战:论共同体划界问题
“我想直率地说:多年来,我们就像个傻子一样,他们拿着我们开发的东西大赚了一笔”。 —— Redis Labs 首席执行官 Ofer Bengal 的这句名言,成为 WordPress 社区内战,以及开源社区与商业利益之间的冲突的生动注脚。
我认为这个事件非常有代表性和启发意义 —— 当开源理想与商业利益出现冲突时,应该怎么做?一个开源项目的创始人,应当用什么样的方式来保护自己的利益,并维护社区的健康与可持续发展?这对 PostgreSQL 社区和其他开源软件社区与云厂商之间的冲突又能带来什么启示?
前因后果
最近,WordPress 风波沸沸扬扬,已经有不少文章报道过了。简单来说就是两家 WordPress 社区的两家主要公司发生了公开冲突。一方是 Automattic,另一方是 WP Engine,这俩公司都卖 WP 托管服务,年营收都是五亿美元左右。不过,A 公司的老板 Matt Mullenweg 是 WordPress 项目的联合创始人。
事情的导火索是 WordPress 联合创始人兼 Automattic CEO Matt Mullenweg 在最近的 WordCamp 大会上公开批评 WP Engine ,将 WP Engine 形容为社区的 “癌症”,质疑其对 WordPress 生态系统的贡献。他指出 WP Engine 和 Automattic 每年的收入均约为 5 亿美元,但 WP Engine 每周仅贡献 40 小时的开发资源,而 Automattic 则每周贡献了 3,988 小时。Mullenweg 认为,WP Engine 通过修改版的 GPL 代码盈利,却未能充分回馈社区。
然后,嘴炮很快升级成为了法律纠纷,双方都向对方发出了律师函;然后威吓又进一步升级为行动:Automattic 控制着 Word Press 网站,基础设施,包括扩展插件的 Registry,所以直接把 WP Engine (收购)的一个扩展插件截胡了。更具体来说,是 WP Engine 收购的一个 WP 扩展插件,ACF,有两百多万活跃安装用户,A 公司把这个扩展分叉了,然后占用了 WP 上老扩展的名字。
最后,在各路社交媒体上,都出现了两遍公司的骂战,这我就不放了,反正各种 Drama 满天飞。这里面最有名的要数下云先锋, Ruby on Rails 作者 DHH 得两篇博客了,以下是 DHH 两篇博客原文:


然后是当事人 Mullenweg 的两篇博客回应


老冯评论
我跟 WordPress 没啥利益关系,但作为一个开源社区的创始人,参与者,维护者,我在感情上是同情 Automattic 和其老板 —— WP 项目创始人 Matt Mullenweg ,我能理解他的愤怒沮丧心情,但确实没法苟同他在收到律师函之后的失智冲动举动。
从道德层面来说,WP Engine 白嫖社区却鲜有贡献合不合情理?不合情理。但从法律上来说,你用的 GPL 协议,按这个协议,别人在遵守开源协议的前提下,通过托管服务赚大钱是不是合法的?你向别人收取什一税,截胡插件有什么法律依据?没有!
那么问题在哪里呢?开源本质上是一种礼物馈赠,赠与者不应该对受赠人的回报有什么期待。如果你预期到,受赠人会拿着你送的礼物大赚一笔让你自己心里失衡,或者受赠人干脆用你的礼物回头抢你自己的生意,那你在第一天就不应该送给他。然而问题在于,传统的开源模型中没有办法实现这一点,即歧视性划界问题。
开源软件作为一个礼物,默认的赠送范围是 —— 整个人类世界,Public Domain!因为开源“不允许”歧视性条款。但你只想把你的软件礼物赠送给用户,而不是商业竞争对手,在传统开源协议下有什么办法呢?没有什么好办法,你写了一个很好的软件,使用 Apache 2.0 协议,很好,云厂商和竞争对手把你的软件装到他们的服务器上卖给用户大赚一笔,而你这个开发者得到了商业对手的鼓励(嘲讽) —— 请再接再厉,继续给我们打白工吧。
上古竞于道德,中世逐于智谋,当今争于气力。在上古时代,开源软件的参与者基本上都属于所谓的 “Pro-sumer”(产消合一者)。每个人都从其他人的贡献中获益,参与者也基本上都属于少部分没有经济压力的精英阶层,所以这种模式可以玩得转。繁荣健康的开源软件社区可以容得下一批纯消费者,并期待他们最终会有一部分成为产消合一者。
但以经典公有云厂商为代表的托管服务,通过掌控最终的交付环节,攫取捕获了开源生态的大部分价值。如果他们愿意成为体面的开源社区参与者积极回馈,这个模式还可以勉强继续运转下去,否则就会失衡 —— 社区秩序的消费者超出生产者的能力,开源模式就会面临危机。
怎么解决这个问题呢?开源社区其实已经给出了自己的答案。在 Redis不开源是“开源”之耻,更是公有云之耻 中我已经详细分析过了 —— 例如在数据库领域,不难发现近几年头部的数据库公司/社区与云厂商之间的关系都在进一步紧张升级中。 Redis 修改开源协议为 RSAL/SSPL,ElasticSearch 修改协议为 AGPLv3,MongoDB 使用更严苛的 SSPL,MinIO 和 Grafana 也转换到了更严苛的 AGPLv3 上来。Oracle 在 MySQL 开源版上摆烂,包括最为友善的 PostgreSQL 生态,也开始出现了不一样的声音。
我们要知道,开源许可证对于开源社区来说,就像章程一样。切换开源许可证本质上来说,就是一种重新划分社区共同体边界的行为。通过 AGPLv3 / SSPL 或者其他更严苛开源协议中的 “隐性歧视条款”,将不符合开源社区价值观的参与者,通过法律排除在外。
共同体边界的问题,是所有开源社区面临的最重要的问题 —— 它的重要性甚至在 “是否开源” 和 “独裁还是民主” 之上。很多“开源软件”社区/公司非常愿意为更深度地歧视与划界需求,而丧失 “开源” 的名分 —— 例如使用不被 OSI 认定为开源的 “SSPL“ 等协议。
“谁是我们?谁是我们的朋友,谁是我们的敌人?” 这是构建社区,建立秩序的基本问题。为开源软件做贡献的贡献者显然是核心,使用、消费软件的用户可以是社区主体;而架空,白嫖,吸血远大于贡献的竞争对手与“云托管服务”供应商,显然会是社区的敌人。
当然,开源社区/公司应该更精准地划分敌友,扩大自己的朋友圈,孤立自己的敌人:卖服务器的Dell浪潮,提供托管服务器的 Hentzer,Linode,DigitalOcean,世纪互联,甚至是公有云 IaaS 部门,提供接入/CDN 服务的 Cloudflare / Akamai 都可以是朋友,而把社区吭哧吭哧开发的开源软件拿去卖而不做对等回馈的公有云 PaaS 部门 / 团队 / 甚至具体的小组,那显然是竞争对手。让亲者快而仇者痛,这是有效运营的的基本原则。
WordPress 社区内战的例子给了我们一个很好的启示 —— Automattic 本来是占据了情理和大义名分的。但他没有在架构社区立法的阶段处理解决好“开放世界中的敌人” 的问题。反而在商业竞争中公器私用,使用了违法开源社区基本原则的不当手段,导致自己陷入现在这个尴尬的局面中 —— 这就跟肿瘤患者没有及早预防癌症的出现,一怒之下用刀剜开自己的肿瘤一样痛苦。
我相信,开源软件的社区/公司运营者一定能从这个案例学习到不少经验与教训。
云数据库:用米其林的价格,吃预制菜大锅饭
云数据库是不是天价大锅饭
RDS带来的数据库范式转变
质量安全效率成本剖析核算,
下云数据库自建,如何实战!
太长;不看
从商业软件到开源软件再到云软件,软件行业的范式出现了嬗变,数据库自然也不例外:云厂商拿着开源数据库内核,干翻了传统企业级数据库公司。
云数据库是一门非常有利可图的生意:可以将成本不到 20¥/核·月的硬件算力卖出十倍到几十倍的溢价,轻松实现 50% - 70% 甚至更高的毛利率。
然而,随着硬件遵循摩尔定律发展,云管控软件出现开源平替,这个生意面临着严峻的挑战:云数据库服务丧失了性价比,而下云自建开始成为趋势。
云数据库是天价预制菜,如何理解?
你在家用微波炉加热黄焖鸡米饭料理包花费10元,餐馆老板替你用微波炉加热装碗上桌收费30元,你不会计较什么,房租水电人工服务也都是要钱的。 但如果现在老板端出同样一碗饭跟你收费 1000 元并说:我们提供的不是黄焖鸡米饭,而是可靠质保的弹性餐饮服务,反正十年前就这个价, 你会不会有削一顿这个老板的冲动? 这样的事情就发生在云数据库,以及其他各种云服务上。
对于规模以上的大型算力与大型存储来说,云服务的价格只能用离谱来形容:云数据库的溢价倍率可以达到十几倍到几十倍。 而作为一门生意,云数据库的毛利率可以轻松达到 50% - 70%,与苦哈哈卖资源的 IaaS (10% - 15%) 形成鲜明对比。 不幸地是,云服务并没有提供与高昂价格相对应的优质服务:云数据库服务的质量,安全,性能表现也并不尽人意。
更严峻的问题在于:随着硬件遵循摩尔定律发展,以及云管控软件出现开源平替,云数据库的模式正面临着严峻的挑战: 云数据库服务丧失了性价比,而下云自建开始成为趋势。
云数据库是什么?
云数据库,就是云上的数据库服务,这是一种软件交付的新兴范式:用户不是“拥有软件“,而是“租赁服务”。
与云数据库概念对应的是传统商业数据库(如 Oracle,DB2,SQL Server)与开源数据库(如 PostgreSQL,MySQL)。 这两种交付范式的共同特点是,软件是一种“产品”(数据库内核),用户“拥有”软件的副本,买回来/免费下载下来运行在自己的硬件上;
而云数据库服务(AWS/阿里云/…… RDS)通常会将软硬件资源打成包,把跑在云服务器上的开源数据库内核包装成“服务”: 用户通过云平台提供的数据库 URL 访问并使用数据库服务,并通过云厂商自研的管控软件(平台/PaaS)管理数据库。
数据库软件交付有哪几种范式?
最初,软件吞噬世界,以 Oracle 为代表的商业数据库,用软件取代了人工簿记,用于数据分析与事务处理,极大地提高了效率。不过 Oracle 这样的商业数据库非常昂贵,一核·一月光是软件授权费用就能破万,不是大型机构都不一定用得起,即使像壕如淘宝,上了量后也不得不”去O“。
接着,开源吞噬软件,像 PostgreSQL 和 MySQL 这样”开源免费“的数据库应运而生。软件开源本身是免费的,每核每月只需要几十块钱的硬件成本。大多数场景下,如果能找到一两个数据库专家帮企业用好开源数据库,那可是要比傻乎乎地给 Oracle 送钱要实惠太多了。
开源软件带来了巨大的行业变革,可以说,互联网的历史就是开源软件的历史。尽管如此,开源软件免费,但 专家稀缺昂贵。能帮助企业 用好/管好 开源数据库的专家非常稀缺,甚至有价无市。某种意义上来说,这就是”开源“这种模式的商业逻辑:免费的开源软件吸引用户,用户需求产生开源专家岗位,开源专家产出更好的开源软件。但是,专家的稀缺也阻碍了开源数据库的进一步普及。于是,“云软件”出现了。
然后,云吞噬开源。公有云软件,是互联网大厂将专家使用开源软件的能力产品化对外输出的结果。公有云厂商把开源数据库内核套上壳,包上管控软件跑在托管硬件上,并雇佣共享 DBA 专家提供支持,便成了云数据库服务 (RDS) 。云诚然是有价值的服务,也为很多软件变现提供了新的途径。但云厂商的搭便车行径,无疑对开源软件社区是一种剥削与攫取,而云计算罗宾汉们,也开始集结并组织反击。
经典商业数据库 Oracle,DB2, SQL Server 都卖得很贵,云数据库为什么不能卖高价?
商业软件时代,可以称为软件 1.0 时代,数据库中以 Oracle,SQL Server,IBM 为代表,价格其实非常高昂。
问:你觉得卖的贵,我要 Argue 一下,这不是正常的商业逻辑吗?
卖的贵不是大问题 —— 有只要最好的东西,根本不看价格的客户。然而问题在于云数据库不够好,第一:内核是开源 PG / MySQL,实际上自己做的就是个管控。而且在其营销却宣传中,好像是包治百病的万灵药,存算分离,Serverless,HTAP,云原生,超融合…,RDS 是先进的汽车,而老的数据库是马车……,blah
问:如果不是马车和汽车,那应该是什么?
区别最多算油车和电车,阐述数据库行业与汽车行业的类比。数据库:汽车;DBA:司机;商业数据库:品牌汽车;开源数据库:组装车;云数据库:出租车+出租司机,嘀嘀打车;这种模式是有其适用光谱的。
问:云数据库的适用光谱?
起步阶段,流量极小的简单应用 / 2 毫无规律可循,大起大落的负载 / 3 全球化出海合规场景 ,租售比。小微企业别折腾,上云(但上什么云值得商榷),大企业毫无疑问,下云。更务实的做法是买基线,租尖峰,混合云 —— 主体下云,弹性上云。
问:这么看来,云计算其实是有它的价值与生态位的。
-
《科技封建主义》,垄断巨头对生态造成的伤害。 / 2. 云营销,吹牛是要上税的。
-
抛开宏大叙事不谈,但云数据库的费用可不便宜。…… (弹性/百公里加速),引出成本问题。
为什么有此一说?为什么会觉得贵?
让我们用几个具体的例子来说明。
例如在探探时,我们曾经评估过上云后的成本。我们用的服务器整体 TCO 在
,一台是……5年7.5万,每年TCO 1.5w。两台组个高可用,就是每年3万块钱,阿里云华东1默认可用区,独享的64核256GB实例:pg.x4m.8xlarge.2c,并加装一块3.2TB的ESSD PL3云盘。每年的费用在25万(3年)到75万(按需)不等。 AWS 总体在每年160 ~ 217万元不等。
不只是我们,Ruby on Rails 的作者 DHH 在 2023 年分享了他们 37 Signal 公司从云上下来的完整历程。
介绍 DHH 下云的例子,每年 300w 美元年消费。一次性投入60万美元买了服务器自己托管后,年支出降到了 100 万美元,原来的1/3 。五年能省下 700 万美金。下云花了半年时间,也没有使用更多的人手来运营。
特别是考虑到开源替代的出现 ——
德不配位,必有灾殃,
字面意思:用云数据库,实际上是用五星级酒店米其林餐厅的价格,吃大食堂大锅饭预制菜料理包。
例如在 AWS 上,如果你想购买一套高规格的 PostgreSQL 云数据库实例,通常需要你要掏出对应云服务器十倍以上的价钱,考虑到云服务器本身有 5 倍左右的溢价,云服务相比规模自建
RDS带来的数据库范式转变
上期云计算泥石流,我们聊到了老罗在交个朋友淘宝直播间“卖云”:先卖着扫地机器人,然后姗姗来迟的老罗照本宣科念台词卖了四十分钟”云“,随即画风一转,马不停蹄地卖起了 高露洁无水酵素牙膏。这很明显是一场失败的直播尝试:超过千家企业在直播间下单了云服务器,100 ~ 200 块的云服务器客单价加上每家限购一台,也就是撑死了二十万的营收,说不定还没有罗老师出场费高。
我写了一篇文章《罗永浩救不了牙膏云》揶揄直播卖虚拟机的阿里云是个牙膏云,然后我的朋友瑞典马工马上写了一篇《牙膏云?您可别吹捧云厂商了》驳斥说:“任何一家本土云厂商都不配牙膏云这个称号。从利润率,到社会价值,到品牌管理,质量管理和市场教育,公有云厂商们都被牙膏厂全方面吊打”。
云数据库是什么,是一种软件范式转移吗?
最初,软件吞噬世界,以 Oracle 为代表的商业数据库,用软件取代了人工簿记,用于数据分析与事务处理,极大地提高了效率。不过 Oracle 这样的商业数据库非常昂贵,一核·一月光是软件授权费用就能破万,不是大型机构都不一定用得起,即使像壕如淘宝,上了量后也不得不”去O“。
接着,开源吞噬软件,像 PostgreSQL 和 MySQL 这样”开源免费“的数据库应运而生。软件开源本身是免费的,每核每月只需要几十块钱的硬件成本。大多数场景下,如果能找到一两个数据库专家帮企业用好开源数据库,那可是要比傻乎乎地给 Oracle 送钱要实惠太多了。
开源软件带来了巨大的行业变革,可以说,互联网的历史就是开源软件的历史。尽管如此,开源软件免费,但 专家稀缺昂贵。能帮助企业 用好/管好 开源数据库的专家非常稀缺,甚至有价无市。某种意义上来说,这就是”开源“这种模式的商业逻辑:免费的开源软件吸引用户,用户需求产生开源专家岗位,开源专家产出更好的开源软件。但是,专家的稀缺也阻碍了开源数据库的进一步普及。于是,“云软件”出现了。
然后,云吞噬开源。公有云软件,是互联网大厂将自己使用开源软件的能力产品化对外输出的结果。公有云厂商把开源数据库内核套上壳,包上管控软件跑在托管硬件上,并雇佣共享 DBA 专家提供支持,便成了云数据库服务 (RDS) 。这诚然是有价值的服务,也为很多软件变现提供了新的途径。但云厂商的搭便车行径,无疑对开源软件社区是一种剥削与攫取,而捍卫计算自由的开源组织与开发者自然也会展开反击。
云数据库是不是天价大锅饭
问:我们先来聊聊第一个问题,成本,成本不是云数据库所宣称的一项优势吗?
看和谁比,和传统商业数据库 Oracle 比可以,和开源数据库比就不行了 —— 特别是小规模可以(DBA),有点规模就不行了。
问:云是不是可以省下DBA/数据库专家的成本?
是的,好DBA稀缺难找。但用云数据库不代表你就不需要DBA了,你只是省去了系统建设的工作与日常运维性的工作,还有省不掉的部分。第二,我们可以具体算一笔账,在什么规模下,雇佣一个 DBA 相比云数据库是合算的。(聊一聊几种价格的模型)
问:RDS 和DBA 是什么关系?
RDS 和 DBA 提供的核心价值不是数据库产品,而是用好开源数据库内核的能力。…… 只不过一个主要靠DBA老司机,一个主要靠管控软件。一个是雇佣,一个是租赁。我觉得生态里还缺一种模式 —— 拥有管控软件,所以我做的东西就是开源的数据库管控软件。
问:所以云数据库成本上不占优势?
极小规模有优势,标准尺寸或者大规模数据库没有任何成本优势。
比较成本你要看怎么比。云数据库的计费项:计算+存储,当然还有流量费,数据库代理费,监控费用,备份费用。
大头是计算与存储,计算的单位是……,存储的单位是……(一些关键数字)
问:实例部分的钱怎么算?
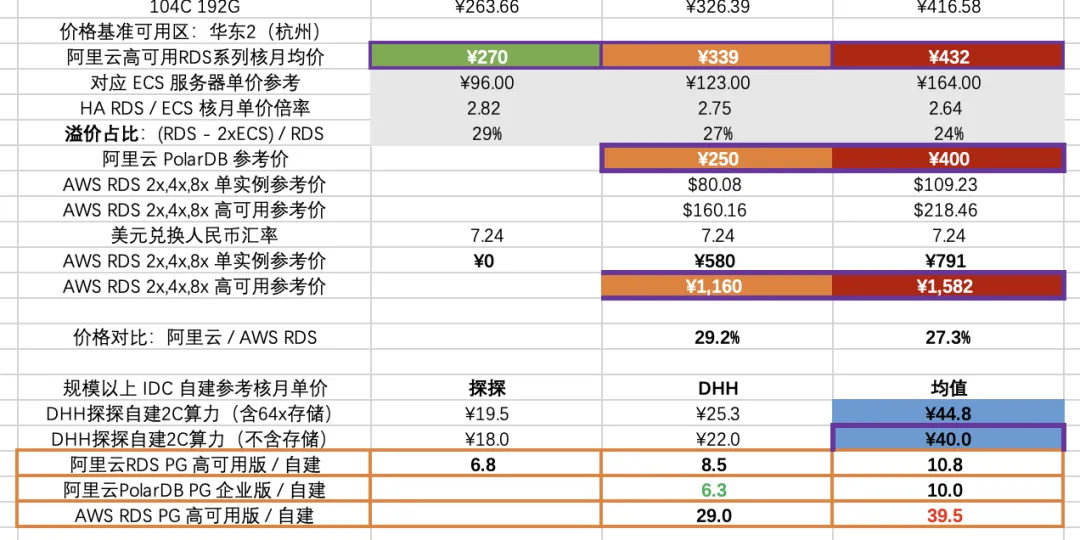
阿里 RDS: 7x-11x,PolarDB: 6x~10x,AWS: 14x ~ 22x
| 双实例高可用版价格 | 4x 核月单价 | 8x 核月单价 |
|---|---|---|
| 高可用RDS系列核月均价 | ¥339 | ¥432 |
| AWS RDS 高可用参考价 | ¥1,160 | ¥1,582 |
| 阿里云 PolarDB 参考价 | ¥250 | ¥400 |
| DHH探探自建1C算力(不含存储) | ¥40 |
云服务器,云上按量,包月,包年,预付五年的单价分别为 187¥,125¥,81¥,37¥,相比自建的 20¥ 分别溢价了 8x, 5x, 3x, 1x。在配置常用比例的块存储后(1核:64GB, ESSD PL3),单价分别为:571¥,381¥,298¥,165¥,相比自建的 22.4¥ 溢价了 24x, 16x, 12x, 6x 。
问:存储部分的钱怎么算?
先来看零售单价,GB·月单价 ,两分钱,阿里云 ESSD 上分了几个不同的档次,从 1- 4块钱。
1TB 存储·月价格(满折扣):自己买 16 ,AWS 1900,阿里云 3200
问:上面聊了很多成本的问题,但你怎么能盯着成本呢?成本到底有多重要?
在你技术与产品有领先优势的情况下,成本没那么重要。但当技术与产品拉不开差距的时候,即 —— 你卖的是没有不可替代性的大路货标准品,成本就非常重要了。在十年前,云数据库也许是属于产品/技术主导的状态,可以心安理得的吃高毛利。但是在十年后的今天。云不是高科技了,云已经烂大街了。市场已经从价值定价转向了成本定价,成本至关重要。
阿里的主营业务电商,被“廉价”的拼多多打的稀里哗啦,拼多多靠的是什么?就是一个朴实无华的便宜。你淘宝天猫能卖的,我能卖一样还更便宜,这就是核心竞争力。你又不是爱马仕,劳力士,买个包买个表都要配几倍货才卖给你的奢侈品逻辑,在老罗直播间里夹在牙膏和吸尘器中间的大路货云服务器能拼什么,还不是一个便宜?
问:那么什么时候成本不重要呢?
第二个点是经济上行繁荣期,创业公司拼速度的发展期,扣成本可能为时过早。但现在很明显,是经济下行萧条期……。再比如说,如果你的东西足够好,那么用户也可以不在意成本。就好比你去五星级酒店,米其林餐厅吃饭,不会在意他们用的食材是多少成本;对吧,OpenAI ChatGPT 别无分号,仅此一家,爱买不买。但是,去菜市场买菜,那是是会看成本的。云数据库,云服务器,云盘,都是“食材”,而不是菜品,是要核算成本,比价的。(黄焖鸡米饭的故事)
质量安全效率成本剖析核算
问:性价比里的价格成本聊透了,那我们来聊聊质量、安全、效率
云数据库很贵,所以在卖的时候都有一些话术。虽然我们贵,但是我们好呀!数据库是基础软件里的皇冠明珠,凝聚着无数无形知识产权BlahBlah。因此软件的价格远超硬件非常合理…… 但是,云数据库真的好吗?
问:在功能上,云数据库怎么样?
只能 OLTP 的 MySQL 咱就不说了,但是 RDS PostgreSQL 还是可以聊一聊的。尽管 PostgreSQL 是世界上最先进的开源关系型数据库,但其独一无二的特点在于其极致可扩展性,与繁荣的扩展生态!不幸地是,《云 RDS 阉割掉了 PostgreSQL 的灵魂》 —— 用户无法在 RDS 上自由加装扩展,而一些强力扩展也注定不会出现在 RDS 中。使用 RDS 无法发挥出 PostgreSQL 真正的实力,而这是一个对云厂商来说无法解决的缺陷。
问:在功能扩展上,云上的 PostgreSQL 数据库有什么缺陷?
Contrib 模块作为 PostgreSQL 本体的一部分,已经包含了 73 个扩展插件,在 PG 自带的 73 个扩展中,阿里云保留了23个阉割了49个;AWS 保留了 49 个,阉割了 24 个。PostgreSQL 官方仓库 PGDG 收录的约 100 个扩展,Pigsty 作为PG发行版自身维护打包了20个强力扩展插件,在 EL/Deb 平台上总共可用的扩展已经达到了 234 个 —— AWS RDS 只提供了 94 个扩展,阿里云 RDS 提供了 104 个扩展。
在重要的扩展中,情况更严重。AWS与阿里云缺失的扩展有:(时序 TimescaleDB,分布式 Citus,列存 Hydra,全文检索 BM25,OLAP PG Analytics,消息队列 pgq,甚至一些基本的重要组件都没有提供,比如做 CDC 的 WAL2JSON),版本跟进跟进速度也不理想。
问:云数据库为什么不能提供这些扩展?
云厂商的口径是:安全性,稳定性,但这根本说不通。云上的扩展都是从 PostgreSQL 官方仓库 PGDG 下载打好包,测试好的 rpm / deb 包来用的。需要云厂商测试什么东西?但我认为更重要的一个问题是开源协议的问题,AGPLv3 带来的挑战。开源社区面对云厂商白嫖的挑战,已经开始集体转向了,越来越多的开源软件使用更为严格,歧视云厂商的软件许可证。比如 XXX 都用 AGPL 发布,云厂商就不可能提供,否则就要把自己的摇钱树 —— 管控软件开源。
这个我们后面可以单独开一期来聊这个事情。
问:上面提到了安全性的问题,那么云数据库真的安全吗?
1、多租户安全挑战(恶意的邻居,Kubecon 案例);2. 公网的更大攻击面(SSH爆破,SHGA);
3、糟糕的工程实践(AK/SK,Replicator密码,HBA修改); 4 没有保密性、完整性兜底。
5、缺乏可观测性,因此难以发现安全问题,更难取证,就更别提追索了。
问:云数据库的可观测性一团稀烂,怎么说?
信息、数据、情报对于管理来说什么至关重要。但是云上提供的这个监控系统吧,质量只能说一言难进。早在 2017 年的时候我就调研过世面上所有 PostgreSQL 数据库监控系统 …… 指标数量,图表数量,信息含量。可观测性理念,都一塌糊涂。监控的颗粒度也很低(分钟级),想要5秒级别的?不好意思请加钱。
AustinDatabase 号主今天刚发了一篇《上云后给我一个 不裁 DBA的理由》聊到这个问题:在阿里云上想开 Ticket 找人分析问题,客服会疯狂给你推荐 DAS(数据库自动驾驶服务),请加钱,每月每实例 6K 的天价。
没有足够好的监控系统,你怎么定责,怎么追索?(比如硬件问题,超卖,IO抢占导致的性能雪崩,主从切换,给客户造成了损失)
问:除了安全和可观测性的问题,相当一部分用户更在意的是质量可靠性
云数据库并不提供对可靠性兜底,没有SLA 条款兜底这个。
只有可用性的 SLA ,还是很逊色的 SLA,赔付比例跟玩一样。 营销混淆:将 SLA 混淆为真实可靠性战绩。
乞丐版的标准版数据库甚至连 WAL 归档与 PITR 都没有,就单纯给你回滚到特定备份,用户也没有能力自助解决问题。
著名的双十一大故障,草台班子理论,降本增笑。中亭团伙……可观测性团队的草台班子,都是刚毕业的在维护。
业务连续性上的战绩并不理想:RTO,RPO ,嘴上说的都是 =0 =0,实际…… 。腾讯云硬盘故障导致初创公司数据丢失的案例。
问:云数据库真的好吗?(性能维度)
我们先来聊一聊性能吧。刚才聊了云盘的价格,没说云盘的性能,EBS 块存储的典型性能,IOPS,延迟,本地盘。更重要的是这个高等级的云盘还不是你想用就给你用的。如果你买的量低于1.2TB,他们是不卖给你 ESSD PL3 的。而次一档的 ESSD PL2 的 IOPS 吞吐量就只有 ESSD PL3 的 1/10 。
第二个问题是资源利用率。RDS 管控 2GB 的管控……,什么都不干内存吃一半。Java管控,日志Agent。
高可用版的云数据库,有个备库,但是不给你读。吃你一倍的资源对不对,你想要只读实例要额外单独申请。
最后,资源利用率提高的是云厂商白赚,好处让云厂商赚走了,代价让用户承担了。
问:其他的点呢?比如可维护性?
每个操作要发验证码短信,100套 PostgreSQL 集群怎么办?ClickOps小农经济,企业用户和开发者真正的正道是 IaC,但是在这一点上比较拉垮。K8S Pigsty 都做的很好,原生内置了 IaC。RPA 机器人流程自动化。糟糕的API 设计,举个例子,几种不同风格的错误代码,实例状态表,(驼峰法,蛇形法,全大写,两段式)体现出了低劣的软件工程质量水平。
业务连续性,RTO RPO,比如做 PITR 是通过创建一个新的按量付费的实例来实现的。那原来的实例怎么办?怎么回滚?怎么保障恢复的时长?这种合格DBA都应该知道的东西,云RDS 为什么不知道?
云数据库有没有啥出彩之处?
问:云数据库就没有一些做的出色的地方吗?
有,弹性,公有云的弹性就是针对其商业模式设计的:启动成本极低,维持成本极高。低启动成本吸引用户上云,而且良好的弹性可以随时适配业务增长,可是业务稳定后形成供应商锁定,尾大不掉,极高的维持成本就会让用户痛不欲生了。这种模式有一个俗称 —— 杀猪盘。这个模式发展到极致就是 Serverless。 云厂商的假 Serverless。
问:还有一个与弹性经常一起说的,叫敏捷?
敏捷,以前算是云数据库的独门优势,但现在也没有了。第一,真正的 Serverless ,Neon,Supabase,Vercel 免费套餐,赛博菩萨。第二,Pigsty 管控,上线一套新数据库也是5分钟。云厂商的极致弹性,秒级扩容其实骗人的,几百秒也是秒……
问:聊聊 Serverless,这会是未来吗?为什么说这是榨钱术?
云厂商的 RDS Serverles,本质上是一种弹性计费模式,而不是什么技术创新。真正技术创新的 Serverless RDS,可以参考 Neon:
- Scale to Zero,
- 无需事先配置,直接连上去自动创建实例并使用。
RDS Serverless 是一种营销宣传骗术。只是计费模式的区别,是一个恶劣的笑话。按照云厂商的营销策略,我拿个共享的 PG 集群,来一个租户就新建一个 Database 给他,不做资源隔离随便用,然后按实际的 Query 数量或者 Query Time 收费,这也可以叫 Serverless。
然后按照这个定义,云厂商的各种产品一下子就全部都变成 Serverless 了。然后 Serverless 这个词的实质意思就被篡夺了,变成平庸无聊的计费技术。真正做的好的 Serverless ,应该去看看赛博菩萨 Cloudflare。
这里我还提一点,Serverless 说是要解决极致弹性的问题,但弹性本身其实没有多重要
问:为什么弹性不重要,传统企业如何应对弹性问题?
弹性峰值能到平时的几十上百倍,我觉得弹性有价值。否则以现在物理资源的价格,直接超配十倍也没多少钱……云厂商的弹性溢价差不多就是十几倍。大甲方的思路很清晰,有这个钱租赁,我干嘛不超配10倍。小用户用 serverless 可以理解。弹性转折点,40 QPS 。唯一场景就是那些 MicroSaaS。但那些 MicroSaas 可以直接用免费套餐的 Vercel,Neon,Supabase,Cloudflare……
传统企业如何解决?我们有 15 % 的 机器 Buffer 池,如果不够用,把低利用率的从库摘几台就够了,机器到位,PG 5分钟上线。服务器到上架IDC大概两周左右,现在 IDC 上架已经到 半天 / 一天了。
问:所以云数据库整体来看,到底怎么样?
刚才,我们已经从质量、效率、安全、成本剖析了云数据库的方方面面。基本上除了弹性,表现都很一般,而唯一能称得上出彩的弹性,其实也没他们说的那么重要。我对云数据库的总体评价就是 —— 预制菜,能不能吃?能吃,也吃不死人,但你也不要指望这种大锅饭能好吃到哪里去。
草台班子,也没有什么品牌形象。例如 IBM DeveloperWorks。 《破防了,谁懂啊家人们:记一次mysql问题排查》
下云数据库自建,如何实战!
问:什么时候应该用云数据库,什么时候不应该。或者说,什么规模应该上云,什么规模应该下云?
光谱的两端,DBaaS 替代,开源自建。经典阈值,团队水平。
平均水准的技术团队:100 ~ 300 万年消费,云上 KA。没有任何懂的人,服务器厂商给出的估算规模是1000万。
优秀的技术团队:一台物理机 ~ 一个机柜的量,下云,年消费几万到几十万。
问:小企业用数据库有什么其他选择?
Neon,Supabase,Vercel,或者在赛博佛祖 Cloudflare 上直接托管。
问:你给云数据库旷旷一顿批判,那是你站在头部甲方,顶级DBA的视角去看的。一般企业没有这个条件,怎么办?
做好三件事:管控软件的开源替代怎么解决,硬件资源的置备供给怎么解决,人怎么解决?
问:开源管控软件,怎么说?
举个例子,管理服务器的开源管控软件, KVM / Proxmox / OpenStack,新一代的就是 Kubernetes。对象存储的开源平替 MinIO,或者物美价廉的 Cloudflare R2
问:硬件资源如何置备管理?
IDC:Deft,Equinix,世纪互联。IDC 也可以按月付费,人家很清楚,一点儿都不贪心,30% 的毛利明明白白。
服务器 + 30% 毛利,按月付费,机柜成本:4000 ~ 6000 ¥/月(42U 10A/20A),可放十几台服务器。网络带宽:独享带宽(通用) 100 块 / MB·月 ;专用带宽可达 20 ¥ / MB·月
你也可以考虑长租公有云厂商的云服务器,租五年的话,比 IDC 贵一倍。请选择那些带有本地 NVMe 存储的实例自建,不要使用EBS云盘。
问:还有个问题,在线的问题如何解决?云上的网络/可用区不是一般 IDC 可以解决的吧?
Cloudflare 解决问题。
问:人怎么解决,DBA ?
当下的经济形势与就业率背景,用合理的价格想要找到能用的人并不难。初级的运维与DBA遍地都是,高级的专家找咨询公司,比如我就提供这样的服务。
问:专业的人做专业的事情,从云上集中管理到云下自建,是不是一种开倒车的行为?
云厂商是不是最专业的人在做这件事,我相当怀疑。1. 云厂商摊子铺得太大,每个具体领域投入的人并不多;2. 云厂商的精英员工流失严重,自己出来创业的很不少。3. 自建绝不是开是历史倒车,而是历史前进的一个过程。历史发展本来就是钟摆式往复,螺旋式发展上升的一个过程。
问:云数据库的问题解决了,但是想要从云上下来,需要解决的问题不止数据库,其他的东西怎么办?对象存储,虚拟化,容器
留待下一期来讨论!
阿里云:高可用容灾神话破灭
2024年9月10日,阿里云新加坡可用区C数据中心因锂电池爆炸导致火灾,到现在已经过去一周了,仍未完全恢复。 按照月度 SLA 定义的可用性计算规则(7天+/30天≈75%),服务可用性别说几个9了,连一个8都不剩了,而且还在进一步下降中。 当然,可用性八八九九已经是小问题了 —— 真正的问题是,放在单可用区里的数据还能不能找回来?
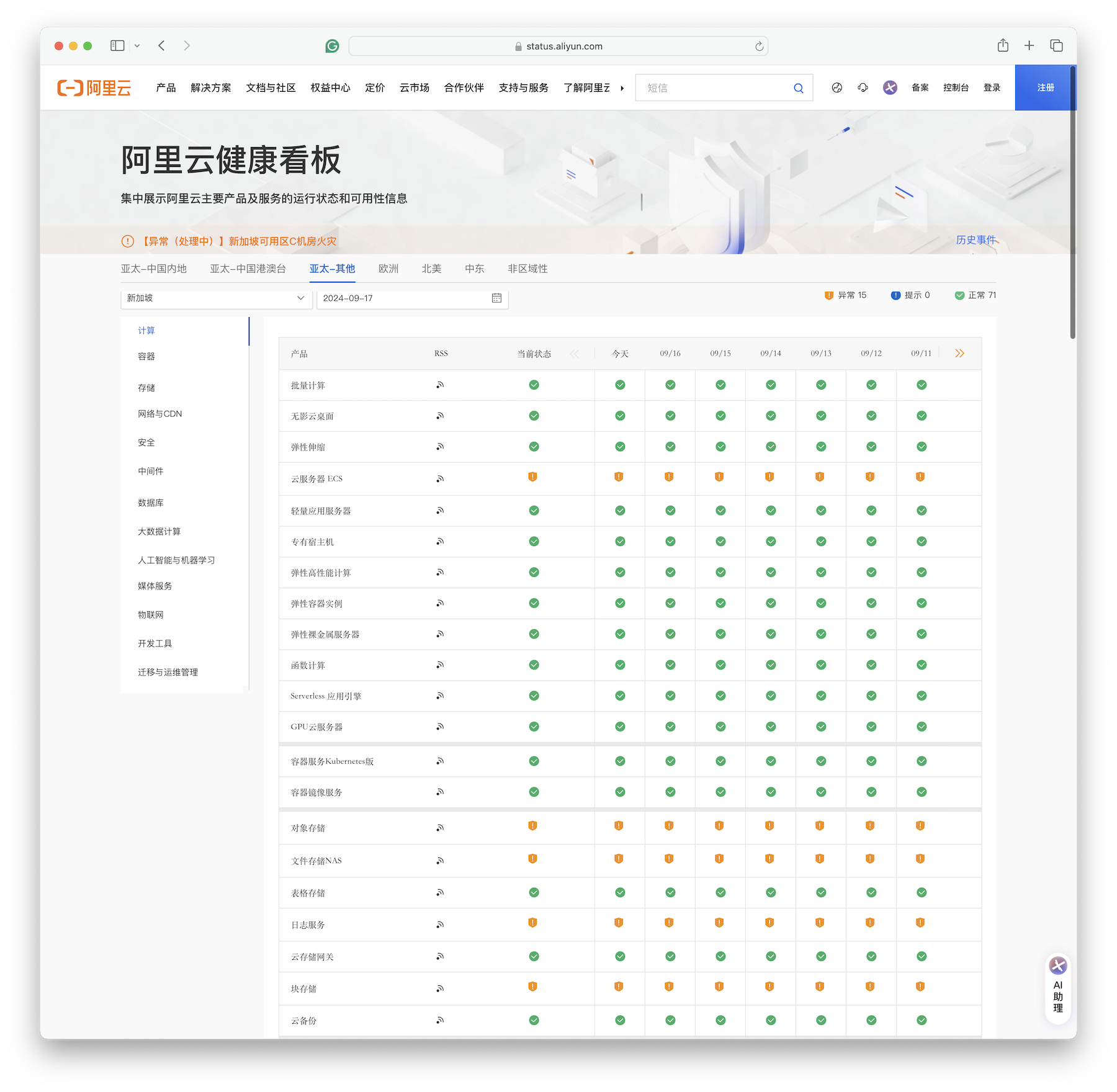
截止至 09-17,关键服务如 ECS, OSS, EBS, NAS, RDS 等仍然处于异常状态
通常来说,如果只是机房小范围失火的话,问题并不会特别大,因为电源和UPS通常放在单独房间内,与服务器机房隔离开。 但一旦触发了消防淋水,问题就大条了:一旦服务器整体性断电,恢复时间基本上要以天计; 如果泡水,那就不只是什么可用性的问题了,要考虑的是数据还能不能找回 —— 数据完整性 的问题了。
目前公告上的说法是,14号晚上已经拖出来一批服务器,正在干燥、一直到16号都没干燥完。从这个“干燥”说法来看,有很大概率是泡水了。 虽然在任何官方公告出来前,我们无法断言事实如何,但根据常理判断,出现数据一致性受损是大概率事件,只是丢多丢少的问题。 所以目测这次新加坡火灾大故障的影响,基本与 2022 年底 香港盈科机房大故障 与2023年双十一全球不可用 故障在一个量级甚至更大。
天有不测风云,人有旦夕祸福。故障的发生概率不会降为零,重要的是我们从中故障能学到什么经验与教训?
容灾实战战绩
整个数据中心着火是一件很倒霉的事,绝大多数用户除了靠异地冷备份逃生外,通常也只能自认倒霉。我们可以讨论锂电池还是铅酸电池更好,UPS电源应该怎么布局这类问题,但因为这些责备阿里云也没什么意义。
但有意义的是,在这次 可用区级故障中,标称自己为 “跨可用区容灾高可用” 的产品,例如云数据库 RDS,到底表现如何?故障给了我们一次用真实战绩来检验这些产品容灾能力的机会。
容灾的核心指标是 RTO (恢复耗时)与 RPO(数据损失),而不是什么几个9的可用性 —— 道理很简单,你可以单凭运气做到不出故障,实现 100% 的可用性。但真正检验容灾能力的,是灾难出现后的恢复速度与恢复效果。
| 配置策略 | RTO | RPO |
|---|---|---|
| 单机 + 什么也不做 | 数据永久丢失,无法恢复 | 数据全部丢失 |
| 单机 + 基础备份 | 取决于备份大小与带宽(几小时) | 丢失上一次备份后的数据(几个小时到几天) |
| 单机 + 基础备份 + WAL归档 | 取决于备份大小与带宽(几小时) | 丢失最后尚未归档的数据(几十MB) |
| 主从 + 手工故障切换 | 十分钟 | 丢失复制延迟中的数据(约百KB) |
| 主从 + 自动故障切换 | 一分钟内 | 丢失复制延迟中的数据(约百KB) |
| 主从 + 自动故障切换 + 同步提交 | 一分钟内 | 无数据丢失 |
毕竟,SLA 中的规定的几个9 可用性指标并非真实历史战绩,而是达不到此水平就补偿月消费XX元代金券的承诺。要想考察产品真正的容灾能力,还是要靠演练或真实灾难下的实际战绩表现。
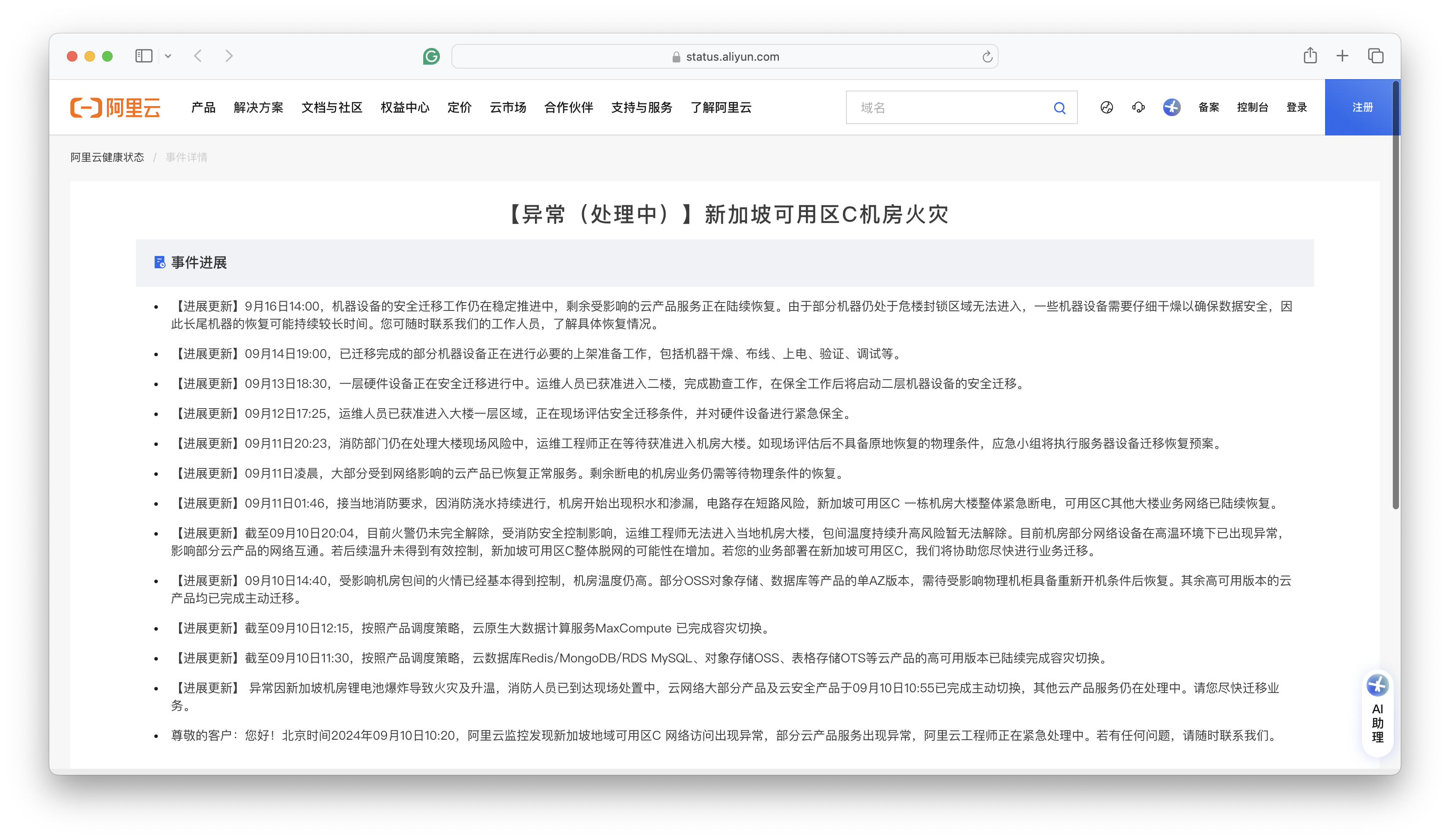
然而实际战绩如何呢?在这次在这次新加坡火灾中,整个可用区 RDS 服务的切换用了多长时间 —— 多AZ高可用的 RDS 服务在 11:30 左右完成切换,耗时 70 分钟(10:20 故障开始),也就是 RTO < 70分。
这个指标相比 2022 年香港C可用区故障 RDS 切换的的 133 分钟,有进步。但和阿里云自己标注的指标(RTO < 30秒)还是差了两个数量级。
至于单可用区的基础版 RDS 服务,官方文档上说 RTO < 15分,实际情况是:单可用区的RDS都要过头七了。RTO > 7天,至于 RTO 和 RPO 会不会变成 无穷大 ∞ (彻底丢完无法恢复),我们还是等官方消息吧。
如实标注容灾指标
阿里云官方文档 宣称:RDS 服务提供多可用区容灾, “高可用系列和集群系列提供自研高可用系统,实现30秒内故障恢复。基础系列约15分钟即可完成故障转移。” 也就是高可用版 RDS 的 RTO < 30s,基础单机版的 RTO < 15min,中规中矩的指标,没啥问题。
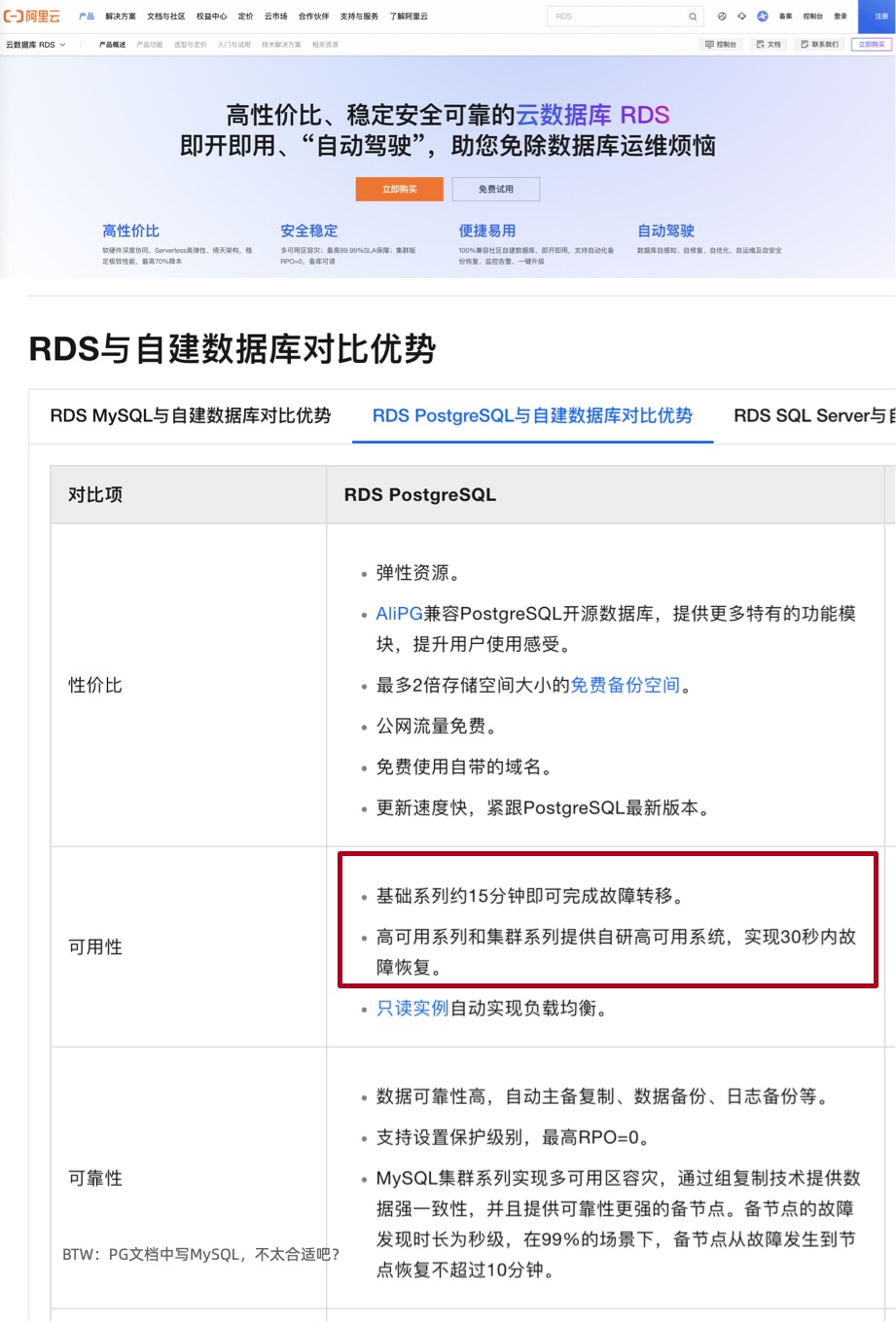
我相信在单个集群的主实例出现单机硬件故障时,阿里云 RDS 是可以实现上面的容灾指标的 —— 但既然这里声称的是 “多可用区容灾”,那么用户的合理期待是当整个可用区故障时,RDS 故障切换也可以做到这一点。
可用区容灾是一个合理需求,特别是考虑到阿里云在最近短短一年内出现过好几次整个可用区范围的故障(**甚至还有一次全球/全服务级别的故障。
2024-09-10 新加坡可用区C机房火灾
2024-07-02 上海可用区N网络访问异常
2024-04-27 浙江地域访问其他地域或其他地域访问杭州地域的OSS、SLS服务异常
2024-04-25 新加坡地域可用区C部分云产品服务异常
2023-11-27 阿里云部分地域云数据库控制台访问异常
2023-11-12 阿里云云产品控制台服务异常 (全球大故障)
2023-11-09 中国内地访问中国香港、新加坡地域部分EIP无法访问
2023-10-12 阿里云杭州地域可用区J、杭州地域金融云可用区J网络访问异常
2023-07-31 暴雨影响北京房山地域NO190机房
2023-06-21 阿里云北京地域可用区I网络访问异常
2023-06-20 部分地域电信网络访问异常
2023-06-16 移动网络访问异常
2023-06-13 阿里云广州地域访问公网网络异常
2023-06-05 中国香港可用区D某机房机柜异常
2023-05-31 阿里云访问江苏移动地域网络异常
2023-05-18 阿里云杭州地域云服务器ECS控制台服务异常
2023-04-27 部分北京移动(原中国铁通) 用户网络访问存在丢包现象
2023-04-26 杭州地域容器镜像服务ACR服务异常
2023-03-01 深圳可用区A部分ECS访问Local DNS异常
2023-02-18 阿里云广州地域网络异常
2022-12-25 阿里云香港地域电讯盈科机房制冷设备故障
那么,为什么在实战中,单个RDS集群故障可以做到的指标,在可用区级故障时就做不到了呢?从历史的故障中我们不难推断 —— 数据库高可用依赖的基础设施本身,很可能就是单AZ部署的。包括在先前香港盈科机房故障中展现出来的 :单可用区的故障很快蔓延到了整个 Region —— 因为管控平面本身不是多可用区容灾的。
12月18日10:17开始,阿里云香港Region可用区C部分RDS实例出现不可用的报警。随着该可用区受故障影响的主机范围扩大,出现服务异常的实例数量随之增加,工程师启动数据库应急切换预案流程。截至12:30,RDS MySQL与Redis、MongoDB、DTS等大部分跨可用区实例完成跨可用区切换。部分单可用区实例以及单可用区高可用实例,由于依赖单可用区的数据备份,仅少量实例实现有效迁移。少量支持跨可用区切换的RDS实例没有及时完成切换。经排查是由于这部分RDS实例依赖了部署在香港Region可用区C的代理服务,由于代理服务不可用,无法通过代理地址访问RDS实例。我们协助相关客户通过临时切换到使用RDS主实例的地址访问来进行恢复。随着机房制冷设备恢复,21:30左右绝大部分数据库实例恢复正常。对于受故障影响的单机版实例及主备均在香港Region可用区C的高可用版实例,我们提供了克隆实例、实例迁移等临时性恢复方案,但由于底层服务资源的限制,部分实例的迁移恢复过程遇到一些异常情况,需要花费较长的时间来处理解决。
ECS管控系统为B、C可用区双机房容灾,C可用区故障后由B可用区对外提供服务,由于大量可用区C的客户在香港其他可用区新购实例,同时可用区C的ECS实例拉起恢复动作引入的流量,导致可用区 B 管控服务资源不足。新扩容的ECS管控系统启动时依赖的中间件服务部署在可用区C机房,导致较长时间内无法扩容。ECS管控依赖的自定义镜像数据服务,依赖可用区C的单AZ冗余版本的OSS服务,导致客户新购实例后出现启动失败的现象。
我建议在包括 RDS 在内的云产品应当实事求是,如实标注历史故障案例里的 RTO 和 RPO 战绩,以及真实可用区灾难下的实际表现。不要笼统地宣称 “30秒/15分钟恢复,不丢数据,多可用区容灾”,承诺一些自己做不到的事情。
阿里云的可用区到底是什么?
在这次新加坡C可用区故障,包括之前香港C可用区故障中,阿里云表现出来的一个问题就是,单个数据中心的故障扩散蔓延到了整个可用区中,而单个可用区的故障又会影响整个区域。
在云计算中, 区域(Region) 与 可用区(AZ) 是一个非常基本的概念,熟悉 AWS 的用户肯定不会感到陌生。 按照 AWS的说法 :一个 区域 包含多个可用区,每个可用区是一个或多个独立的数据中心。

对于 AWS 来说,并没有特别多的 Region,比如美国也就四个区域,但每个区域里 两三个可用区,而一个可用区(AZ)通常对应着多个数据中心(DC)。 AWS 的实践是一个 DC 规模控制在八万台主机,DC之间距离在 70 ~ 100 公里。这样构成了一个 Region - AZ - DC 的三级关系。
不过 阿里云 上似乎不是这样的,它们缺少了一个关键的 数据中心(DC) 的概念。 因此 可用区(AZ) 似乎就是一个数据中心,而 区域(Region) 与 AWS 的上一层 可用区(AZ)概念 对应。
把原本的 AZ 拔高成了 Region,把原本的 DC (或者DC的一部分,一层楼?)拔高成了可用区。
我们不好说阿里云这么设计的动机,一种可能的猜测是:本来可能阿里云国内搞个华北,华东,华南,西部几个区域就行,但为了汇报起来带劲(你看AWS美国才4个Region,我们国内有14个!),就搞成了现在这个样子。
云厂商有责任推广最佳实践
TBD
提供单az对象存储服务的云,可不可以评价为:不是傻就是坏?
云厂商有责任推广好的实践,不然出了问题,也还是“都是云的问题”
你给别人默认用的就是本地三副本冗余,绝大多数用户就会选择你默认的这个。
看有没有告知,没告知,那就是坏,告知了,长尾用户能不能看懂?但其实很多人不懂的。
你都已经三副本存储了,为什么不把一个副本放在另一个 DC 或者另一个 AZ ? 你都已经在存储上收取了上百倍的溢价了,为什么就不不愿意多花一点点钱去做同城冗余,难道是扣数据跨 AZ 复制的那点流量费吗?
做健康状态页请认真一点
TBD
我听说过天气预报,但从未听说过故障预报。但阿里云健康看板为我们提供了这一神奇的能力 —— 你可以选择未来的日期,而且未来日期里还有服务健康状态数据。例如,你可以查看20年后的服务健康状态 ——
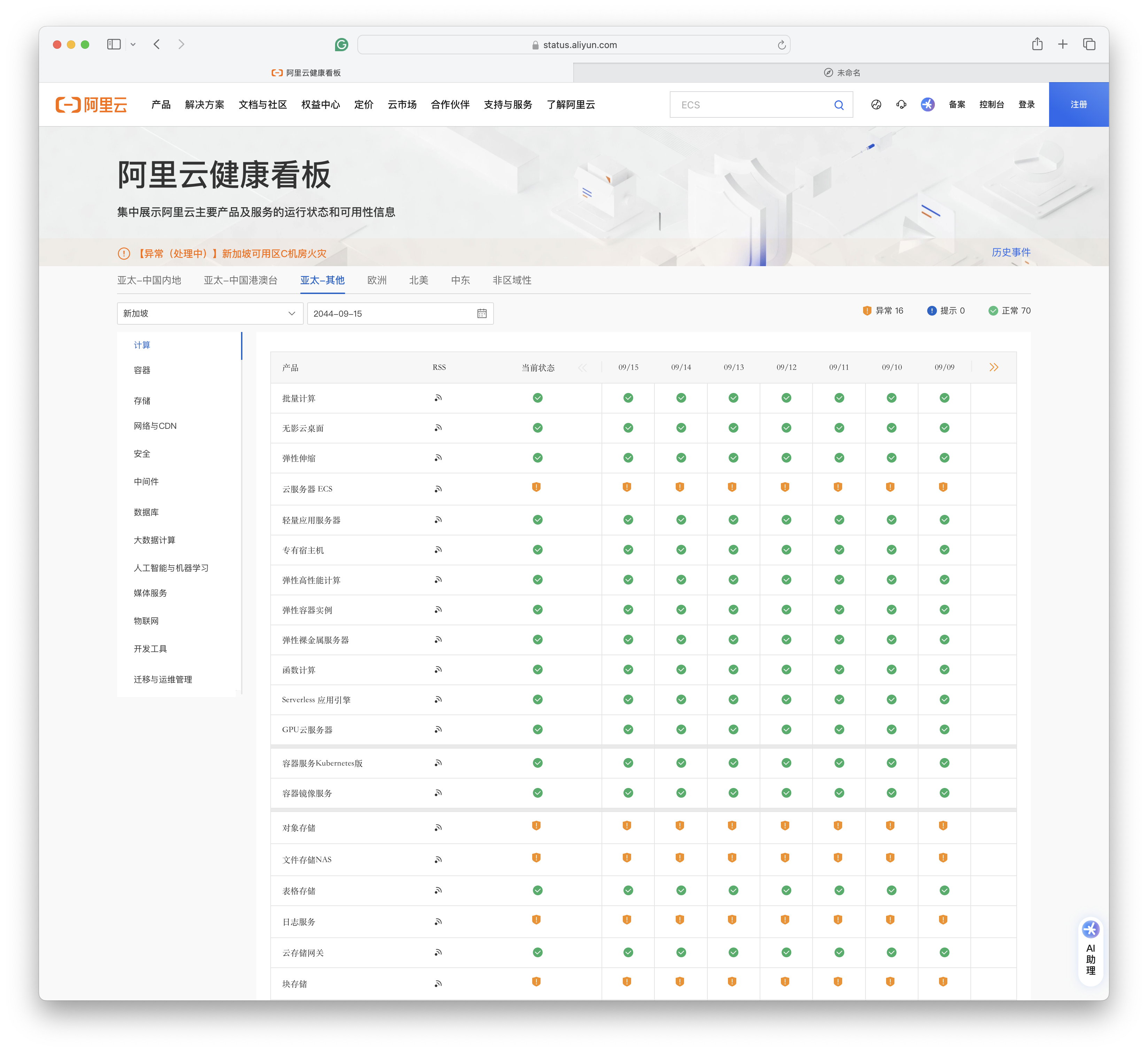
未来的 “故障预报” 数据看上去是用当前状态填充的。所以当前处于故障状态的服务在未来的状态还是异常。如果你选择 20 年后,你依然可以看到当前新加坡大故障的健康状态为“异常”。
也许 阿里云是想用这种隐晦的方式告诉用户:新加坡区域单可用区里的数据已经泡汤了,Gone Forever, 乃们还是不要指望找回了。当然,更合理推断是:这不是什么故障预报,这个健康看板是实习生做的。完全没有设计 Review,没有 QA 测试,不考虑边际条件,拍拍脑袋拍拍屁股就上线了。
云是新的故障单点,那怎么办?
TBD
信息安全三要素 CIA:机密性,完整性,可用性,最近阿里都遇上了大翻车。
前有 阿里云盘灾难级BUG 泄漏隐私照片破坏机密性;
后有这次可用区故障故障,击穿多可用区/单可用区可用性神话,甚至威胁到了命根子 —— 数据完整性。
参考阅读
云计算泥石流:合订本
世人常道云上好,托管服务烦恼少。我言云乃杀猪盘,溢价百倍实厚颜。
赛博地主搞垄断,坐地起价剥血汗。运维外包嫖开源,租赁电脑炒概念。
世人皆趋云上游,不觉开销似水流。云租天价难为持,开源自建更稳实。
下云先锋把路趟,引领潮流一肩扛。不畏浮云遮望眼,只缘身在最前线。
曾几何时,“上云“近乎成为技术圈的政治正确,整整一代应用开发者的视野被云遮蔽。就让我们用实打实的数据分析与亲身经历,讲清楚公有云租赁模式的价值与陷阱 —— 在这个降本增效的时代中,供您借鉴与参考。
云基础资源篇
云商业模式篇
-
阿里云降价背后折射出的绝望【转载】
下云奥德赛篇
云故障复盘篇
RDS翻车篇
云厂商画像篇
-
牙膏云?您可别吹捧云厂商了【转载】
-
互联网技术大师速成班 【转载】
-
门内的国企如何看门外的云厂商【转载】
-
卡在政企客户门口的阿里云【转载】
-
互联网故障背后的草台班子们【转载】
-
云厂商眼中的客户:又穷又闲又缺爱【转载】
序
曾几何时,“上云“近乎成为技术圈的政治正确,整整一代应用开发者的视野被云遮蔽。DHH 以及像我这样的人愿意成为这个质疑者,用实打实的数据与亲身经历,讲清楚公有云租赁模式的陷阱。
很多开发者并没有意识到,底层硬件已经出现了翻天覆地的变化,性能与成本以指数方式攀升与坍缩。许多习以为常的工作假设都已经被打破,无数利弊权衡与架构方案值得重新思索与设计。
公有云有其存在意义 —— 对那些非常早期、或两年后不复存在的公司,那些完全不在乎花钱、有着极端大起大落不规则负载的公司,对那些需要出海合规,CDN服务的公司而言,公有云仍然是非常值得考虑的选项。
然而对绝大多数已经发展起来,有一定规模与韧性,能在几年内摊销资产的公司而言,真的应该重新审视一下这股云热潮。好处被大大夸张了 —— 在云上跑东西通常和你自己弄一样复杂,却贵得离谱,我们真诚建议您好好算一下账。
最近十年间,硬件以摩尔定律的速度持续演进,IDC2.0与资源云提供了公有云资源的物美价廉替代,开源软件与开源管控调度软件的出现更是让自建能力唾手可及 —— 云下开源自建,在成本,性能,与安全自主可控上都会有显著回报。
我们提倡下云理念,并提供了实践的路径与切实可用的自建替代品 —— 我们将为认同这一结论的追随者提前铺设好意识形态与技术上的道路。不为别的,只是期望所有用户都能拥有自己的数字家园,而不是从科技巨头云领主那里租用农场。这也是一场对互联网集中化与反击赛博地主垄断收租的运动,让互联网 —— 这个美丽的自由避风港与理想乡可以走得更长。

云基础资源篇
EC2 / S3 / EBS 这样的基础资源价格,是所有云服务的定价之锚。基础资源篇的五篇文章,分别剖析了 EC2 算力,S3 对象存储,EBS 云盘,RDS 云数据库,以及 CDN 网络的方方面面:质量、安全、效率,以及大家最关心的一系列问题。
重新拿回计算机硬件的红利
在当下,硬件重新变得有趣起来,AI 浪潮引发的显卡狂热便是例证。但有趣的硬件不仅仅是 GPU —— CPU 与 SSD 的变化却仍不为大多数开发者所知,有一整代软件开发者被云和炒作营销遮蔽了双眼,难以看清这一点。
许多软件与商业领域的问题的根都在硬件上:硬件的性能以指数模式增长,让分布式数据库几乎成为了伪需求。硬件的价格以指数模式衰减,让公有云从普惠基础设施变成了杀猪盘。让我们用算力与存储的价格变迁来说明这一点。
扒皮云对象存储:从降本到杀猪
对象存储是云计算的定义性服务,曾是云上降本的典范。然而随着硬件的发展,资源云(Cloudflare / IDC 2.0)与开源平替(MinIO)的出现,曾经“物美价廉”的对象存储服务失去了性价比,和EBS一样成为了杀猪盘。
硬件资源的价格随着摩尔定律以指数规律下降,但节省的成本并没有穿透云厂商这个中间层,传导到终端用户的服务价格上。 逆水行舟,不进则退,降价速度跟不上摩尔定律就是其实就是变相涨价。以S3为例,在过去十几年里,云厂商S3虽然名义上降价6倍,但硬件资源却便宜了 26 倍,S3 的价格实际上是涨了 4 倍。
云盘是不是杀猪盘?
EC2 / S3 / EBS 是所有云服务的定价之锚。如果说 EC2/S3 定价还勉强能算合理,那么 EBS 的定价乃是故意杀猪。公有云厂商最好的块存储服务与自建可用的 PCI-E NVMe SSD 在性能规格上基本相同。然而相比直接采购硬件,AWS EBS 的成本高达 120 倍,而阿里云的 ESSD 则可高达 200 倍。
公有云的弹性就是针对其商业模式设计的:启动成本极低,维持成本极高。低启动成本吸引用户上云,而且良好的弹性可以随时适配业务增长,可是业务稳定后形成供应商锁定,尾大不掉,极高的维持成本就会让用户痛不欲生了。这种模式有一个俗称 —— 杀猪盘。
云数据库是不是智商税
近日,Basecamp & HEY 联合创始人 DHH 的一篇文章引起热议,主要内容可以概括为一句话:“我们每年在云数据库(RDS/ES)上花50万美元,你知道50万美元可以买多少牛逼的服务器吗?我们要下云,拜拜了您呐!“
在专业甲方用户眼中,云数据库只能算 60 分及格线上的大锅饭标品,却敢于卖出十几倍的天价资源溢价。如果用云数据库1年的钱,就够买几台甚至十几台性能更好的服务器自建更好的本地 RDS,那么使用云数据库的意义到底在哪里?在有完整开源平替的情况下,这算不算交了智商税?
垃圾腾讯云CDN:从入门到放弃
本来我相信至少在 IaaS 的存储,计算,网络三大件上,公有云厂商还是可以有不小优势的。只不过在腾讯云 CDN 上的亲身体验让我的想法动摇了。
云商业模式篇
FinOps终点是下云
FinOps关注点跑偏,公有云是个杀猪盘。自建能力决定议价权,数据库是自建关键。
搞 FinOps 的关注减少浪费资源的数量,却故意无视了房间里的大象 —— 云资源单价。云算力的成本是自建的五倍,块存储的成本则可达百倍以上,堪称终极成本刺客。对于有一定规模企业来说,IDC自建的总体成本在云服务列表价1折上下。下云是原教旨 FinOps 的终点,也是真正 FinOps 的起点。
拥有自建能力的用户即使不下云也能谈出极低的折扣,没有自建能力的公司只能向公有云厂商缴纳高昂的 “无专家税” 。无状态应用与数仓搬迁相对容易,真正的难点是在不影响质量安全的前提下,完成数据库的自建。
云计算为啥还没挖沙子赚钱?
公有云毛利不如挖沙子,杀猪盘为何成为赔钱货?卖资源模式走向价格战,开源替代打破垄断幻梦。服务竞争力逐渐被抹平,云计算行业将走向何方?
业界标杆的 AWS 与 Azure 毛利就可以轻松到 60% 与 70% 。反观国内云计算行业,毛利普遍在个位数到 15% 徘徊,至于像金山云这样的云厂商,毛利率直接一路干到 2.1%,还不如打工挖沙子的毛利高。这不禁让人好奇,这些本土云厂商是怎么把一门百分之三四十纯利的生意能做到这种地步的?
云SLA是不是安慰剂?
在云计算的世界里,服务等级协议(SLA)曾被视为云厂商对其服务质量的承诺。然而,当我们深入研究这些由一堆9组成的 SLA 时,会发现它们并不能像期望的那样“兜底”:与其说是 SLA 是对用户的补偿,不如说 SLA 是对云厂商服务质量没达标时的“惩罚”。
你以为给自己的服务上了保险可以高枕无忧,但 SLA 对用户来说不是兜底损失的保险单。在最坏的情况下,它是吃不了兜着走的哑巴亏。在最好的情况下,它才是提供情绪价值的安慰剂。
杀猪盘真的降价了吗?
存算资源降价跟不上摩尔定律发展其实就是变相涨价。但能看到有云厂商率先打起了降价第一枪,还是让人欣慰的:云厂商向 PLG 的康庄大道迈出了第一步:用技术优化产品,靠提高效率去降本,而不是靠销售吹逼打折杀猪。
范式转移:从云到本地优先
软件吞噬世界,开源吞噬软件。云吞噬开源,谁来吃云?与云软件相对应的本地优先软件开始如雨后春笋一般出现。而我们,就在亲历见证这次范式转移。
最终会有这么一天,公有云厂商与自由软件世界达成和解,心平气和地接受基础设施供应商的角色定位,为大家提供水与电一般的存算资源。而云软件终将会回归正常毛利,希望那一天人们能记得人们能记得,这不是因为云厂商大发慈悲,而是因为有人带来过开源平替。
下云奥德赛篇
下云奥德赛:是时候放弃云计算了吗?
下云先锋:David Heinemeier Hansson,网名 DHH,37 Signal 联创与CTO,Ruby on Rails 作者,下云倡导者、实践者、领跑者。反击科技巨头垄断的先锋。
DHH 下云已省下了近百万美元云支出,未来的五年还能省下上千万美元。我们跟进了下云先锋的完整进展,挑选了十四篇博文,译为中文,合辑为《下云奥德赛》,记录了他们从云上搬下来的波澜壮阔的完整旅程。
- 10-27 推特下云省掉 60% 云开销
- 10-06 托管云服务的代价
- 09-15 下云后已经省了百万美金
- 06-23 我们已经下云了!
- 05-03 从云遣返到主权云!
- 05-02 下云还有性能回报?
- 04-06 下云所需的硬件已就位!
- 03-23 裁员前不先考虑下云吗?
- 03-11 失控的不仅仅是云成本!
- 02-22 指导下云的五条价值观
- 02-21 下云将给咱省下五千万!
- 01-26 折腾硬件的乐趣重现
- 01-10 “企业级“替代品还要离谱
- 2022-10-19 我们为什么要下云?
半年下云省千万:DHH下云FAQ答疑
DHH 与 X马斯克的下云举措在全球引发了激烈的讨论,有许多的支持者,也有许多的质疑者。面对众人提出的问题与质疑,DHH 给出了自己充满洞见的回复。
- 在硬件上省下的成本,会不会被更大规模的团队薪资抵消掉?
- 为什么你选择下云,而不是优化云账单呢?
- 那么安全性呢?你不担心被黑客攻击吗?
- 不需要一支世界级超级工程师团队来干这些吗?
- 这是否意味着你们在建造自己的数据中心?
- 谁来做码放服务器、拔插网络电缆这些活呢?
- 那么可靠性呢?难道云不是为你做到了这些吗?
- 那国际化业务的性能呢?云不是更快吗?
- 你有考虑到以后更换服务器的成本吗?
- 那么隐私法规和GDPR呢?
- 那么需求激增时怎么办?自动伸缩呢?
- 你在服务合同和授权许可费上花费了多少?
- 如果云这么贵,你们为什么会选择它?
下云高可用的秘诀:拒绝智力自慰
下云之后,DHH 的几个业务都保持了 99.99% 以上的可用性。Basecamp 2 更是连续两年实现 100% 可用性的魔法。相当一部分归功于他们选择了简单枯燥、朴实无华的,复杂度很低,成熟稳定的技术栈 —— 他们并不需要 Kubernetes 大师或花哨的数据库与存储。
程序员极易被复杂度所吸引,就像飞蛾扑火一样。系统架构图越复杂,智力自慰的快感就越大。坚决抵制这种行为,是在云下自建保持稳定可靠的关键所在。
云故障复盘篇
【阿里】云计算史诗级大翻车来了
2023年11月12日,也就是双十一后的第一天,阿里云发生了一场史诗级大翻车。根据阿里云官方的服务状态页,全球范围内所有可用区 x 所有服务全部都出现异常,时间从 17:44 到 21: 11,共计3小时27分钟。规模与范围创下全球云计算行业的历史纪录。
阿里云周爆:云数据库管控又挂了
阿里云 11. 12 大故障两周 过去,还没有看到官方的详细复盘报告,结果又来了一场大故障:中美7个区域的数据库管控宕了近两个小时。这一次和 11.12 故障属于让官方发全站公告的显著故障。
11月份还有两次较小规模的局部故障。这种故障频率即使是对于草台班子来说也有些过分了。某种意义上说,阿里云这种周爆可以凭一己之力,毁掉用户对公有云云厂商的托管服务的信心
我们能从阿里云史诗级故障中学到什么
时隔一年阿里云又出大故障,并创造了云计算行业闻所未闻的新记录 —— 全球所有区域/所有服务同时异常。 阿里云不愿意发布故障复盘报告,那我就来替他复盘 —— 我们应当如何看待这一史诗级故障案例,以及,能从中学习到什么经验与教训?
从降本增笑到真的降本增效
双十一刚过,阿里云就出了打破行业纪录的全球史诗级大翻车,然后开始了11月连环炸模式 —— 从月爆到周爆再到日爆。话音未落,滴滴又出现了一场超过12小时,资损几个亿的大故障。
年底正是冲绩效的时间,互联网大厂大事故却是一波接一波。硬生生把降本增效搞成了“降本增笑” —— 这已经不仅仅是梗了,而是来自官方的自嘲。大厂故障频发,处理表现远远有失水准,乱象的背后到底是什么问题?
RDS翻车篇
更好的开源RDS替代:Pigsty
我希望,未来的世界人人都有自由使用优秀服务的事实权利,而不是只能被圈养在几个公有云厂商提供的猪圈(Pigsty)里吃粑粑。这就是我要做 Pigsty 的原因 —— 一个更好的,开源免费的 PostgreSQL RDS替代。让用户能够在任何地方(包括云服务器)上,一键拉起有比云RDS更好的数据库服务。
Pigsty 是对 PostgreSQL 的彻底补完,更是对云数据库的辛辣嘲讽。它本意是“猪圈”,但更是 Postgres In Great STYle 的缩写,即“全盛状态下的 PostgreSQL”。它是一个完全基于开源软件的,可以运行在任何地方的,浓缩了 PostgreSQL 使用管理最佳实践的 Me-Better RDS 开源替代。
驳《再论为什么你不应该招DBA》
云计算鼓吹者马工大放厥词说:云数据库可以取代 DBA。之前在《你怎么还在招聘DBA》,以及回应文《云数据库是不是智商税》中,我们便已交锋过。
当别人把屎盆子扣在这个行业所有人头上时,还是需要人来站出来说几句的。因此撰文以驳斥马工的谬论:《再论为什么你不应该招DBA》。
云RDS:从删库到跑路
用户都已经花钱买了‘开箱即用’的云数据库了,为什么连 PITR 恢复这么基本的兜底都没有呢?因为云厂商心机算计,把WAL日志归档/PITR这些PG的基础功能阉割掉,放进所谓的“高可用”版本高价出售。
云数据库也是数据库,云数据库并不是啥都不用管的运维外包魔法,不当配置使用,一样会有数据丢失的风险。没有开启WAL归档就无法使用PITR,甚至无法登陆服务器获取现存WAL来恢复误删的数据。当故障发生时,用户甚至被断绝了自救的可能性,只能原地等死。
数据库应该放入K8S里吗?
Kubernetes 作为一个先进的容器编排工具,在无状态应用管理上非常趁手;但其在处理有状态服务 —— 特别是 PostgreSQL 和 MySQL 这样的数据库时,有着本质上的局限性。
将数据库放入 K8S 中会导致 “双输” —— K8S 失去了无状态的简单性,不能像纯无状态使用方式那样灵活搬迁调度销毁重建;而数据库也牺牲了一系列重要的属性:可靠性,安全性,性能,以及复杂度成本,却只能换来有限的“弹性”与资源利用率 —— 但虚拟机也可以做到这些!对于公有云厂商之外的用户来说,几乎都是弊远大于利。
把数据库放入Docker是一个好主意吗?
对于无状态的应用服务而言,容器是一个相当完美的开发运维解决方案。然而对于带持久状态的服务 —— 数据库来说,事情就没有那么简单了。我认为就目前而言,将生产环境数据库放入Docker / K8S 中仍然是一个馊主意。
对于云厂商来说,使用容器的利益是自己的,弊端是用户的,他们有动机这样去做,但这样的利弊权衡对普通用户而言并不成立。
云厂商画像篇
这个系列多数来自云计算鼓吹者马工,为本土云厂商与互联网大厂绘制了精准幽默,幽默滑稽的肖像。
卡在政企客户门口的阿里云
互联网故障背后的草台班子们
云厂商眼中的客户:又穷又闲又缺爱
互联网技术大师速成班
门内的国企如何看门外的云厂商
阿里云专辑
云计算泥石流系列原文链接
- 云计算泥石流
- 拒绝用复杂度自慰,下云也保稳定运行
- 扒皮对象存储:从降本到杀猪
- 半年下云省千万:DHH下云FAQ答疑
- 从降本增笑到真的降本增效
- 阿里云周爆:云数据库管控又挂了
- 重新拿回计算机硬件的红利
- 我们能从阿里云史诗级故障中学到什么
- 【阿里】云计算史诗级大翻车来了
- 是时候放弃云计算了吗?
- 云计算泥石流合集 —— 用数据解构公有云
- 下云奥德赛
- FinOps终点是下云
- 云计算为啥还没挖沙子赚钱?
- 云SLA是不是安慰剂?
- 技术反思录:正本清源
- 杀猪盘真的降价了吗?
- 公有云是不是杀猪盘?
- 云数据库是不是智商税
- 垃圾腾讯云CDN:从入门到放弃
- 驳《再论为什么你不应该招DBA》
- 范式转移:从云到本地优先
- 云RDS:从删库到跑路
- 是时候和GPL说再见了 【译】
- 互联网技术大师速成班(转载瑞典马工)
- 门内的国企如何看门外的云厂商 (转载思维南人)
- 卡在政企客户门口的阿里云(转载瑞典马工)
- 互联网故障背后的草台班子们(转载瑞典马工)
- 云厂商眼中的客户:又穷又闲又缺爱(转载瑞典马工)
草台班子唱大戏,阿里云PG翻车记
在《云数据库是不是智商税》中,我对云数据库 RDS 的评价是:“用五星酒店价格卖给用户天价预制菜”—— 但正规的预制菜大锅饭也是能吃的 也一般吃不死人,不过最近一次发生在阿里云上的的故障让我改变了看法。
我有一位客户L,这两天跟我吐槽了一个在云数据库上遇到的离谱连环故障:一套高可用 PG RDS 集群,因为扩容个内存,主库从库都挂了,给他们折腾到凌晨。期间建议昏招迭出,给出的复盘也相当敷衍。经过客户L同意后,我将这个案例分享出来,也供大家借鉴参考品评。
事故经过:匪夷所思
客户L的数据库场景比较扎实,大几TB的数据,TPS两万不到,写入吞吐8000行/每秒,读取吞吐7万行/s。用的是 ESSD PL1 ,16c 32g 的实例,一主一备高可用版本,独享型规格族,年消费六位数。
整个事故经过大致如下:客户L收到 内存告警,提工单,接待的售后工程师诊断:数据量太大,大量行扫描导致内存不足,建议扩容内存。客户同意了,然后工程师扩容内存,扩内存花了三个小时,期间主库和从库挂了,吭哧吭哧手工一顿修。
然后扩容完了之后又遇到 WAL日志堆积 的问题,堆了 800 GB 的WAL日志要把磁盘打满了,又折腾了两个小时到十一点多。售后说是 WAL 日志归档上传失败导致的堆积,失败是因为磁盘IO吞吐被占满,建议扩容 ESSD PL2。
吃过了内存扩容翻车的教训,这次扩容磁盘的建议客户没立即买单,而是找我咨询了下,我看了一下这个故障现场,感觉到匪夷所思:
- 你这负载也挺稳定的,没事扩容内存干啥?
- RDS 不是号称弹性秒级扩容么,怎么升个内存花三个小时?
- 花三个小时就算了,扩个容怎么还把主库从库都搞挂了呢?
- 从库挂了据说是参数没配对,那就算了,那主库是怎么挂了的?
- 主库挂了高可用切换生效了吗?怎么 WAL 又怎么开始堆积了?
- WAL 堆积是有地方卡住了,建议你升级云盘等级/IOPS有什么用?
事后也有一些来自乙方的解释,听到后我感觉更加匪夷所思了:
- 从库挂是因为参数配错拉不起来了
- 主库挂是因为 “为了避免数据损坏做了特殊处理”
- WAL堆积是因为卡BUG了,还是客户侧发现,推断并推动解决的
- 卡 BUG “据称” 是因为云盘吞吐打满了
我的朋友瑞典马工一贯主张,“用云数据库可以替代DBA”。 我认为在理论上有一定可行性 —— 由云厂商组建一个专家池,提供DBA时分共享服务。
但现状很可能是:云厂商没有合格的 DBA,不专业的工程师甚至会给你出馊主意,把跑得好好的数据库搞坏,最后赖到资源不足上,再建议你扩容升配好多赚一笔。
在听闻这个案例之后,马工也只能无奈强辩:“辣鸡RDS不是真RDS”。
内存扩容:无事生非
资源不足是一种常见的故障原因,但也正因如此,有时会被滥用作为推卸责任,甩锅,或者要资源,卖硬件的万金油理由。
内存告警 OOM 也许对其他数据库是一个问题,但对于 PostgreSQL 来说非常离谱。我从业这么多年来,见识过各种各样的故障:数据量大撑爆磁盘我见过,查询多打满CPU我见过,内存比特位反转腐坏数据我见过,但因为独占PG因为读查询多导致内存告警,我没见过。
PostgreSQL 使用双缓冲,OLTP实例在使用内存时,页面都放在一个尺寸固定的 SharedBuffer 中。作为一个 众所周知的最佳实践,PG SharedBuffer 配置通常为物理内存的 1/4 左右,剩下的内存由文件系统 Cache 使用。也就是说通常有六七成的内存是由操作系统来灵活调配的,不够用逐出一些 Cache 就好了。如果说因为读查询多导致内存告警,我个人认为是匪夷所思的。
所以,因为一个本来不一定是问题的问题(假告警?),RDS 售后工程师给出的建议是:内存不够啦,请扩容内存。客户相信了这个建议,选择将内存翻倍。
按道理,云数据库宣传自己的极致弹性,灵活伸缩,还是用 Docker 管理的。难道不应该是原地改一下 MemLimit 和 PG SharedBuffer 参数,重启一下就生效的吗?几秒还差不多。结果这次扩容却折腾了三个小时才完成,并引发了一系列次生故障。
内存不足,两台32G扩64G,按照《剖析阿里云服务器算力成本》我们精算过的定价模型,一项内存扩容操作每年带来的额外收入就能有万把块。如果能解决问题那还好说,但事实上这次内存扩容不但没有解决问题,还引发了更大的问题。
从库宕机:素养堪忧
第一个因为内存扩容而发生的次生故障是这样的,备库炸了,为什么炸了,因为PG参数没配置正确:max_prepared_transaction,这个参数为什么会炸?因为在一套 PG 集群中,这个参数必须在主库和从库上保持一致,否则从库就会拒绝启动。
为什么这里出现了主从参数不一致的问题?我推测 是因为 RDS 的设计中,该参数的值是与实例内存成正比设置的,所以内存扩容翻倍后这个参数也跟着翻倍。主从不一致,然后从库重启的时候就拉不起来了。
不管怎样,因为这个参数翻车是一个非常离谱的错误,属于 PG DBA 101 问题,PG文档明确强调了这一点。但凡做过滚动升降配这种基操的 DBA,要么已经在读文档的时候了解过这个问题,要么就在这里翻过车再去看文档。
如果你用 pg_basebackup 手搓从库,你不会遇到这个问题,因为从库的参数默认和主库一致。如果你用成熟的高可用组件,也不会遇到这个问题:开源PG高可用组件 Patroni 就会强制控制这几个参数并在文档中显眼地告诉用户:这几个参数主从必须一致,我们来管理不要瞎改。

在一种情况下你会遇到这种问题:考虑不周的家酿高可用服务组件,或未经充分测试的自动化脚本,自以为是地替你“优化”了这个参数。
主库宕机:令人窒息
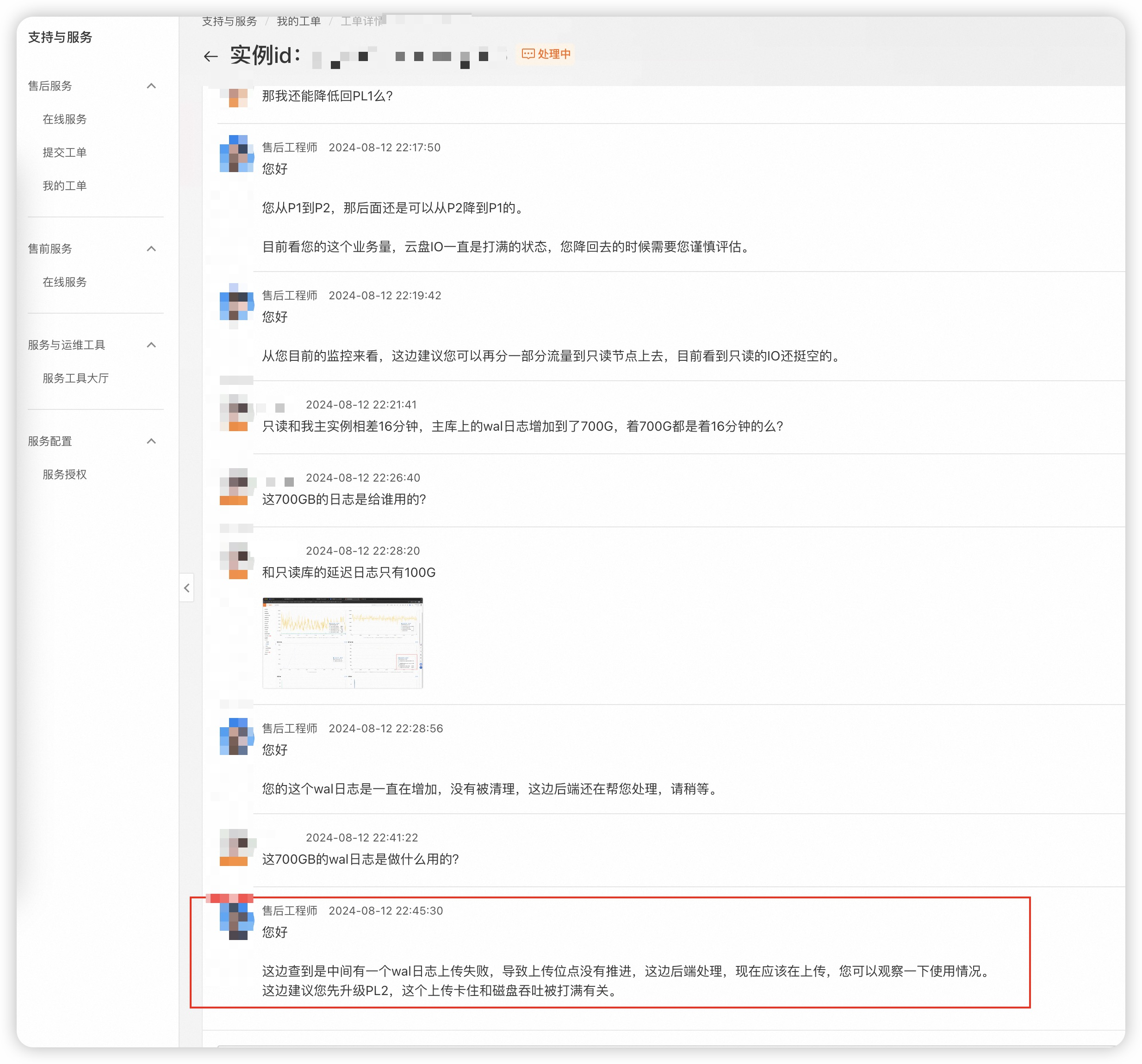
如果说从库挂了,影响一部分只读流量那也就算了。主库挂了,对于客户L这种全网实时数据上报的业务可就要血命了。关于主库宕机,工程师给出的说法是:在扩容过程中,因为事务繁忙,主从复制延迟一直追不上,“为了避免数据损坏做了特殊处理”。
这里的说法语焉不详,但按字面与上下文理解的意思应当为:扩容时需要做主从切换,但因为有不小的主从复制延迟,直接切换会丢掉一部分尚未复制到从库上的数据,所以RDS替你把主库流量水龙头关掉了,追平复制延迟后再进行主从切换。
老实说,我觉得这个操作让人窒息。主库 Fencing 确实是高可用中的核心问题,但一套正规的生产 PG 高可用集群在处理这个问题时,标准SOP是首先将集群临时切换到同步提交模式,然后执行 Switchover,自然一条数据也不会丢,切换也只会影响在这一刻瞬间执行的查询,亚秒级闪断。
“为了避免数据损坏做了特殊处理” 这句话确实很有艺术性 —— 没错,把主库直接关掉可以实现 Fencing ,也确实不会在高可用切换时因为复制延迟丢数据,但客户数据写不进去了啊!这丢的数据可比那点延迟多多了。这种操作,很难不让人想起那个著名的《善治伛者》笑话:

WAL堆积:专家缺位
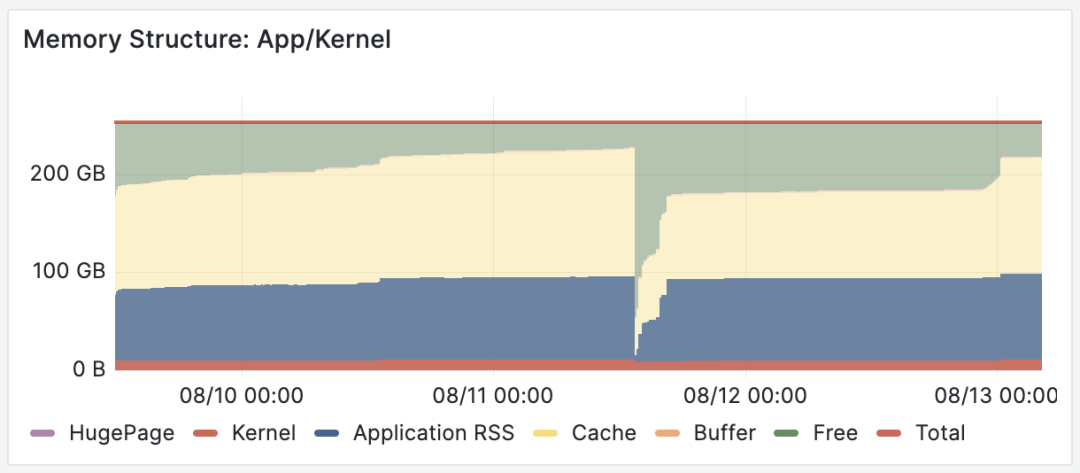
主从宕机的问题修复后,又折腾一个半小时,总算是把主库内存扩容完成了。然而一波未平一波又起,WAL日志又开始堆积起来,在几个小时内就堆积到了近 800 GB,如果不及时发现并处理,撑爆磁盘导致整库不可用是早晚的事。
也可以从监控上看到两个坑
RDS 工程师给出的诊断是,磁盘 IO 打满导致 WAL 堆积,建议升级磁盘,从 ESSD PL1 升级到 PL2。不过,这一次客户已经吃过一次内存扩容的教训了,没有立刻听信这一建议,而是找到了我咨询。
我看了情况后感觉非常离谱,负载没有显著变化,IO打满也不是这种卡死不动的情形。那么 WAL 堆积的原因不外乎那几个:复制延迟落后100多GB,复制槽保留了不到1GB,那剩下的大头就是 WAL归档失败。
我让客户给 RDS 提工单处理找根因,最后 RDS 侧确实找到问题是WAL归档卡住了并手工解决了,但距离 WAL 堆积已经过去近六个小时了,并在整个过程中体现出非常业余的素养,给出了许多离谱的建议。
另一个离谱建议:把流量打到复制延迟16分钟的从库上去
阿里云数据库团队并非没有 PostgreSQL DBA 专家,在阿里云任职的 德哥 Digoal 绝对是 PostgreSQL DBA 大师。然而看起来在 RDS 的产品设计中,并没有沉淀下多少 DBA 大师的领域知识与经验;而 RDS 售后工程师表现出来的专业素养,也与一个合格的 PG DBA ,哪怕是 GPT4 机器人都相差甚远。
我经常看到 RDS 的用户遇到了问题,通过官方工单没有得到解决,只能绕过工单,通过在 PG 社区中 直接求助德哥解决 —— 而这确实是比较考验运气与关系的一件事。
扩容磁盘:创收有术
在解决了“内存告警”, “从库宕机”, “主库宕机”, “WAL 堆积” 等连环问题后,已经接近凌晨了。但 WAL 堆积的根因是什么仍然不清楚,工程师的回复是 “与磁盘吞吐被打满有关”,再次建议升级 ESSD 云盘。
在事后的复盘中,工程师提到了 WAL归档失败的原因是 “RDS上传组件BUG”。所以回头看,如果客户真的听了建议升级云盘,也就就白花冤枉钱了。
在 《云盘是不是杀猪盘》中我们分析过,云上溢价最狠的基础资源就是 ESSD 云盘。按照 《阿里云存算成本剖析》中给出的数字:客户 5TB 的 ESSD PL1 云盘包月价格 1 ¥/GB,那么每年光是云盘费用就要 12万。
| 单位价格:¥/GiB月 | IOPS | 带宽 | 容量 | 按需价格 | 包月价格 | 包年价格 | 预付三年+ |
|---|---|---|---|---|---|---|---|
| ESSD 云盘 PL0 | 10K | 180 MB/s | 40G-32T | 0.76 | 0.50 | 0.43 | 0.25 |
| ESSD 云盘 PL1 | 50K | 350 MB/s | 20G-32T | 1.51 | 1.00 | 0.85 | 0.50 |
| ESSD 云盘 PL2 | 100K | 750 MB/s | 461G-32T | 3.02 | 2.00 | 1.70 | 1.00 |
| ESSD 云盘 PL3 | 1M | 4 GB/s | 1.2T-32T | 6.05 | 4.00 | 3.40 | 2.00 |
| 本地 NVMe SSD | 3M | 7 GB/s | 最大单卡64T | 0.02 | 0.02 | 0.02 | 0.02 |
如果听从建议 “升级”到 ESSD PL2,没错 IOPS 吞吐能翻一倍,但单价也翻了一倍。单这一项“升级”操作,就能给云厂商带来额外 12 万的收入。
即使是 ESSD PL1 乞丐盘,也带有 50K 的 IOPS,而客户L场景的 20K TPS,80K RowPS 换算成 随机4K 页面 IOPS ,就算退一万步讲不考虑 PG 与 OS 的缓冲区(比如 99% 缓存命中率对于这种业务场景是很正常的),想硬打满它也是一件相当不容易的事情。
我不好判断遇到问题就建议 扩容内存 / 扩容磁盘 这样的做法,到底是出于专业素养不足导致的误诊,还是渴望利用信息不对称创收的邪念,抑或两者兼而有之 —— 但这种趁病要价的做法,确实让我联想起了曾经声名狼藉的莆田医院。
协议赔偿:封口药丸
在《云SLA是不是安慰剂》一文中,我已提醒过用户:云服务的 SLA 根本不是对服务质量的承诺,在最好的情况下它是提供情绪价值的安慰剂,而在最坏的情况下它是吃不了兜着走的哑巴亏。
在这次故障中,客户L收到了 1000 元代金券的补偿提议,对于他们的规模来说,这三瓜两枣差不多能让这套 RDS 多跑几天。在用户看来这基本上属于赤裸裸的羞辱了。
有人说云提供了“背锅”的价值,但那只对不负责的决策者与大头兵才有意义,对于直接背结果的 CXO 来说,整体性的得失才是最重要的,把业务连续性中断的锅甩给云厂商,换来一千块代金券没有任何意义。
当然像这样的事情其实不止一次,两个月前客户L还遇到过另一次离谱的从库宕机故障 —— 从库宕机了,然后控制台上监控根本看不到,客户自己发现了这个问题,提了工单,发起申诉,还是 1000¥ SLA 安慰补偿。
当然这还是因为客户L的技术团队水平在线,有能力自主发现问题并主动发出声索。如果是那种技术能力接近零的小白用户,也许就这么拖着瞒着 糊弄过去了。
还有那种 “SLA” 根本不管的问题 —— 例如也是客户L再之前的一个案例(原话引用):“为了折扣要迁移到另一个新的阿里云账号,新账号起了个同配置的 RDS 逻辑复制,复制了近1个月数据都没同步完,让我们直接放弃新账号迁移,导致浪费几万块钱。” —— 属实是花钱买罪受了,而且根本没地方说理去。
经过几次故障带来的糟心体验,客户L终于在这次事故后难以忍受,拍板决定下云了。
解决方案:下云自建
客户L在几年前就有下云的计划了,在 IDC 里弄了几台服务器,用 Pigsty 自建搭建了几套 PostgreSQL 集群,作为云上的副本双写,跑得非常不错。但要把云上 RDS 下掉,还是免不了要折腾一下,所以一直也就这样两套并行跑着。包括此次事故之前的多次糟心体验,最终让客户L做了下云的决断。
客户L直接下单加购了四台新服务器,以及 8块 Gen4 15TB NVMe SSD。特别是这里的 NVMe 磁盘,IOPS 性能是云上 ESSD PL1 乞丐盘的整整 20倍(1M vs 50K),而 TB·月 单位价格则是云上的 1/166 (1000¥ vs 6¥)。
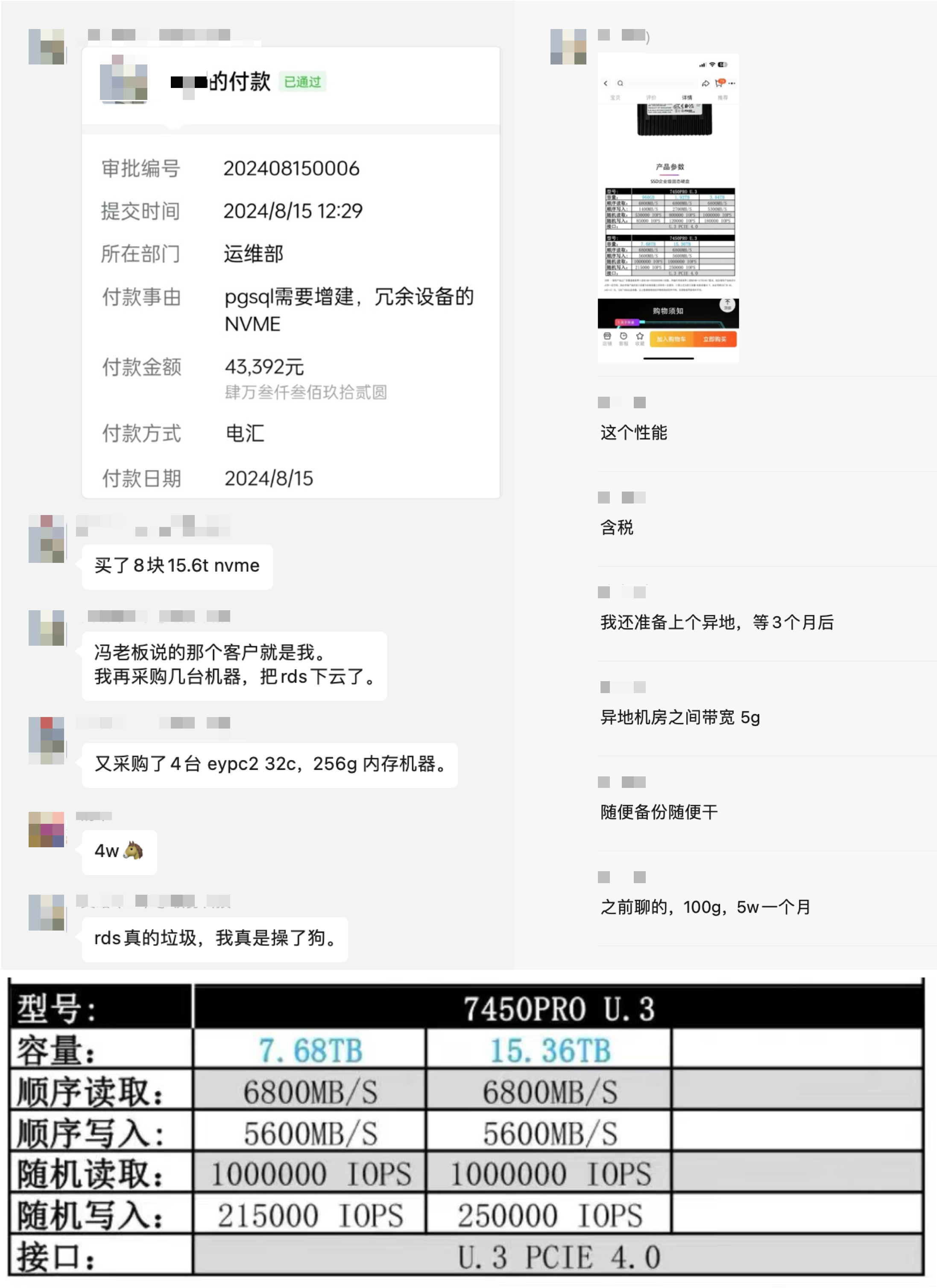
题外话:6块钱TB月价,我只在黑五打折的 Amazon 上看到过。125 TB 才 44K ¥(全新总共再加 9.6K ¥),,果然是术业有专攻,经手了过亿采购的成本控制大师。
如在《下云奥德赛:是时候放弃云计算了吗》 中 DHH 所说的那样:
“我们明智地花钱:在几个关键例子上,云的成本都极其高昂 —— 无论是大型物理机数据库、大型 NVMe 存储,或者只是最新最快的算力。租生产队的驴所花的钱是如此高昂,以至于几个月的租金就能与直接购买它的价格持平。在这种情况下,你应该直接直接把这头驴买下来!我们将把我们的钱,花在我们自己的硬件和我们自己的人身上,其他的一切都会被压缩。”
对客户L来说,下云带来的好处是立竿见影的:只需要 RDS 几个月费用的一次性投资,就足够超配几倍到十几倍的硬件资源,重新拿回硬件发展的红利,实现惊人的降本增效水平 —— 你不再需要对着账单抠抠搜搜,也不用再发愁什么资源不够。这确实是一个值得思考的问题:如果云下资源单价变为十分之一甚至百分之几,那么云上鼓吹的弹性还剩多大意义?而阻止云上用户下云自建的原因又会是什么呢?
下云自建 RDS 服务最大的挑战其实是人与技能,客户L已经有着一个技术扎实的团队,但确实缺少在 PostgreSQL 上的专业知识与经验。这也是客户L之所以愿意为 RDS 支付高溢价的一个核心原因。但 RDS 在几次事故中体现出来的专业素养,甚至还不如客户本身的技术团队强,这就让继续留在云上变得毫无意义。
广告时间:专家咨询
在下云这件事上, 我很高兴能为客户L提供帮助与支持。 Pigsty 是沉淀了我作为顶级 PG DBA 领域知识与经验的开源 RDS 自建工具,已经帮助无数世界各地的用户自建了自己的企业级 PostgreSQL 数据库服务。尽管它已经将开箱即用,扩展整合,监控系统,备份恢复,安全合规,IaC 这些运维侧的问题解决的很好了。但想要充分发挥 PostgreSQL 与 Pigsty 的完整实力,总归还是需要专家的帮助来落地。
所以我提供了明码标价的 专家咨询服务 —— 对于客户L这样有着成熟技术团队,只是缺乏领域知识的客户,我只收取固定的 5K ¥/月 咨询费用,仅仅相当于半个初级运维的工资。但足以让客户放心使用比云上低一个数量级的硬件资源成本,自建更好的本地 PG RDS 服务 —— 而即使在云上继续运行 RDS,也不至于被“砖家”被嘎嘎割韭菜忽悠。
我认为咨询是一种站着挣钱的体面模式:我没有任何动机去推销内存与云盘,或者说胡话兜售自己的产品(因为产品是开源免费的!)。所以我完全可以站在甲方立场上,给出对甲方利益最优的建议。甲乙双方都不用去干苦哈哈的数据库运维,因为这些工作已经被 Pigsty 这个我编写的开源工具完全自动化掉了。我只需要在零星的关键时刻提供专家意见与决策支持,并不会消耗多少精力与时间,却能帮助甲方实现原本全职雇佣顶级DBA专家才能实现的效果,最终实现双方共赢。
但是我也必须强调,我提倡下云理念,从来都是针对那些有一定数据规模与技术实力的客户,比如这里的客户L。如果您的场景落在云计算舒适光谱中(例如用 1C2G 折扣 MySQL 跑 OA ),也缺乏技术扎实或值得信赖的工程师,我会诚实地建议你不要折腾 —— 99 一年的 RDS 总比你自己的 yum install 强不少,还要啥自行车呢?当然针对这种用例,我确实建议你考虑一下 Neon,Supabase,Cloudflare 这些赛博菩萨们的免费套餐,可能连一块钱都用不着。
而对于那些有一定规模,绑死在云数据库上被不断抽血的客户,你确实可以考虑另外一个选项:自建数据库服务绝非什么高深的火箭科学 —— 你需要做的只是找到正确的工具与正确的人而已。
扩展阅读
云数据库是不是智商税
我们能从网易云音乐故障中学到什么?
今天下午 14:44 左右,网易云音乐出现 不可用故障,至 17:11 分恢复。网传原因为基础设施/云盘存储相关问题。
故障经过
故障期间,网易云音乐客户端可以正常播放离线下载的音乐,但访问在线资源会直接提示报错,网页版则直接出现 502 服务器报错无法访问。
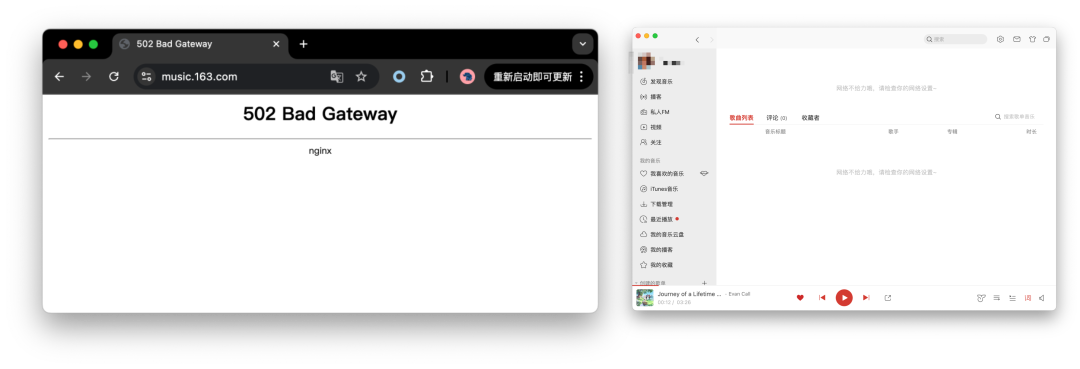
在此期间,网易 163门户也出现 502 服务器报错,并在一段时间后 302 重定向到移动版主站。期间也有用户反馈网易新闻与其他服务也受到影响。
许多用户都反馈连不上网易云音乐后,以为是自己网断了,卸了APP重装,还有以为公司 IT 禁了听音乐站点的,各种评论很快将此次故障推上微博热搜:
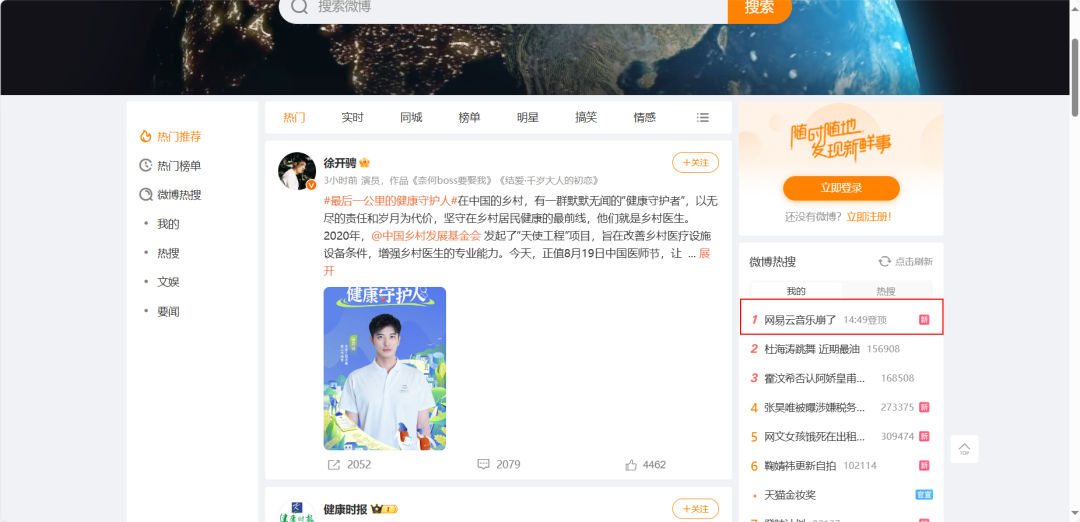
期间截止到 17:11 分,网易云音乐已经恢复,163 主站门户也从移动版本切换回浏览器版本,整个故障时长约两个半小时,P0 事故。
17:16 分,网易云音乐知乎账号发布通知致歉,并表示明天搜“畅听音乐”可以领取 7 天黑胶 VIP 的朋友费。

原因推断
在此期间,出现各种流言与小道消息。总部着火🔥 (老图),TiDB 翻车(网友瞎编),下载《黑神话悟空》打爆网络,以及程序员删库跑路等就属于一眼假的消息。
但也有先前网易云音乐公众号发布的一篇文章《云音乐贵州机房迁移总体方案回顾》,以及两份有板有眼的网传聊天记录,可以作为一个参考。
网传此次故障与云存储有关,网传聊天记录就不贴了,可以参考《网易云音乐宕机,原因曝光!7月份刚迁移完机房,传和降本增效有关。》一文截图,或者权威媒体的引用报道《独家|网易云音乐故障真相:技术降本增效,人手不足排查了半天》。
我们可以找到一些关于网易云存储团队的公开信息,例如,网易自研的云存储方案 Curve 项目被枪毙了。
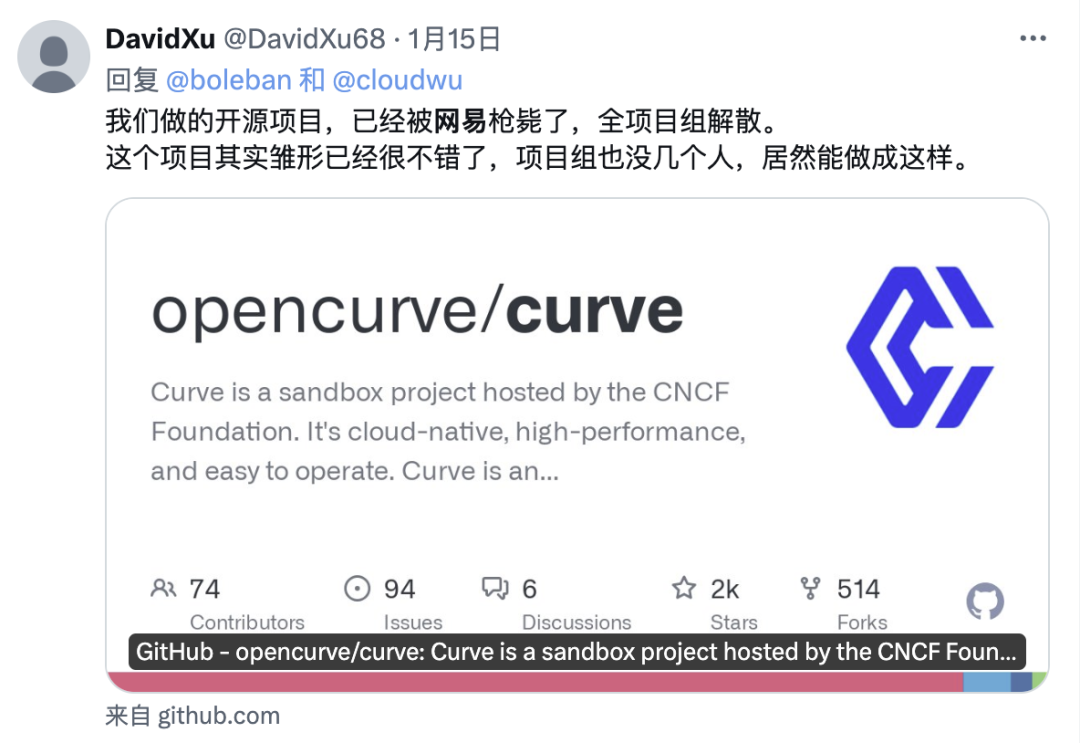
查阅 Github Curve 项目主页,发现项目在 2024 年初后就陷入停滞状态:
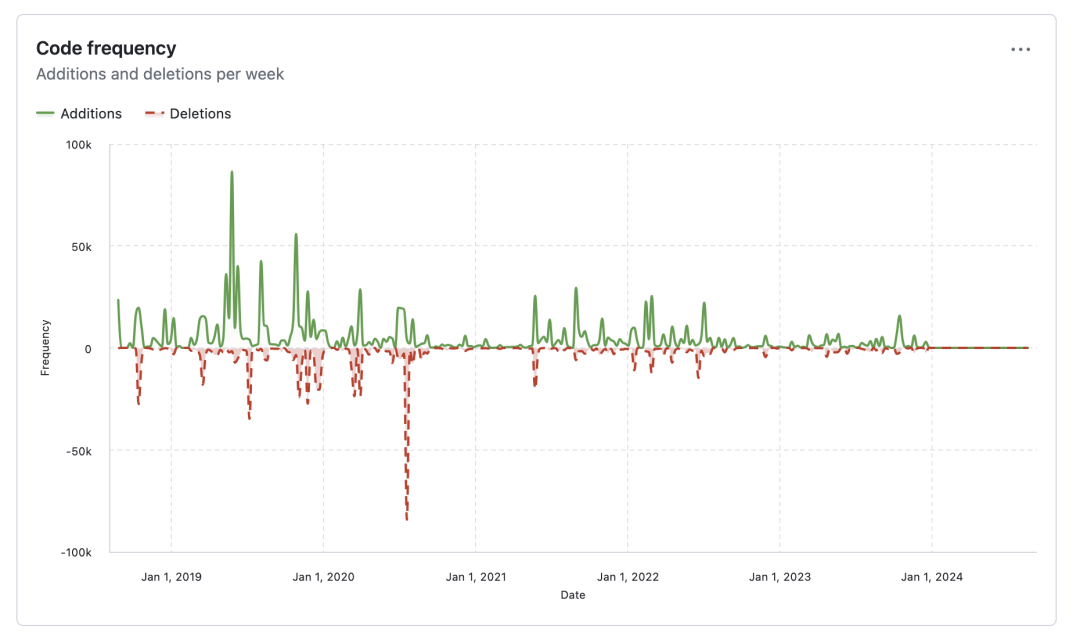
最后一个 Release 一直停留在RC没有发布正式版,项目已经基本无人维护,进入静默状态。
Curve 团队负责人还发表过一篇《curve:遗憾告别 未竟之旅》的公众号文章,并随即遭到删除。我对这件事有些印象,因为 Curve 是 PolarDB 推荐的两个开源共享存储方案之一,所以特意调研过这个项目,现在看来……
经验教训
关于裁员与降本增效的老生长谈已经说过很多了,我们又还能从这场事故中学习到什么教训呢?以下是我的观点:
第一个教训是,不要用云盘跑严肃数据库!在这件事上,我确实可以说一句 “ Told you so” 。底层块存储基本都是提供给数据库用的。如果这里出现了故障,爆炸半径与 Debug 难度是远超出一般工程师的智力带宽的。如此显著的故障时长(两个半小时),显然不是在无状态服务上的问题。
第二个教训是 —— 自研造轮子没有问题,但要留着人来兜底。降本增效把存储团队一锅端了,遇到问题找不到人就只能干着急。
第三个教训是,警惕大厂开源。作为一个底层存储项目,一旦启用那就不是简单说换就能换掉的。而网易毙掉 Curve 这个项目,所有这些用 Curve 的基建就成了没人维护的危楼。Stonebraker 老爷子在他的名著论文《What Goes Around Comes Around》中就提到过这一点:

参考阅读
蓝屏星期五:甲乙双方都是草台班子
最近,因为网络安全公司 CrowdStrike 发布的一个配置更新,全球范围内无数 Windows 电脑都陷入蓝屏死机状态,无数的混乱 —— 航司停飞,医院取消手术,超市、游乐园、各行各业歇业。
表:受到影响的行业领域、国家地区与相关机构(CrowdStrike导致大规模系统崩溃事件的技术分析)
| 涉及领域 | 相关机构 |
|---|---|
| 航空运输 | 美国、澳大利亚、英国、荷兰、印度、捷克、匈牙利、西班牙、中国香港、瑞士等部分航空公司出现航班延误或机场服务中断。美国达美航空、美国航空和忠实航空宣布停飞所有航班。 |
| 媒体通信 | 以色列邮政、法国电视频道TF1、TFX、LCI和Canal+Group网络、爱尔兰国家广播公司RTÉ、加拿大广播公司、沃丰达集团、电话和互联网服务提供商Bouygues Telecom等。 |
| 交通运输 | 澳大利亚货运列车运营商Aurizon、西日本旅客铁道公司、马来西亚铁路运营商KTMB、英国铁路公司、澳大利亚猎人线和南部高地线的区域列车等。 |
| 银行与****金融服务 | 加拿大皇家银行、加拿大道明银行、印度储备银行、印度国家银行、新加坡星展银行、巴西布拉德斯科银行、西太平洋银行、澳新银行、联邦银行、本迪戈银行等。 |
| 零售 | 德国连锁超市Tegut、部分麦当劳和星巴克、迪克体育用品公司、英国杂货连锁店Waitrose、新西兰的Foodstuffs和Woolworths超市等。 |
| 医疗服务 | 纪念斯隆凯特琳癌症中心、英国国家医疗服务体系、德国吕贝克和基尔的两家医院、北美部分医院等。 |
| …… | …… |
在这次事件中,有许多程序员在津津乐道哪个 sys 文件或者配置文件搞崩了系统 (CrowdStrike官方故障复盘),或者XX公司是草台班子云云 —— 做安全的乙方和甲方工程师撕成一片。但在我看来,这个问题根本不是一个技术问题,而是一个工程管理问题。重要的也不是指责谁是草台班子,而是我们能从中吸取什么教训?
在我看来,这场事故是甲乙方两侧的共同责任 —— 乙方的问题在于:崩溃率如此之高的变更,为什么在没有灰度的情况下迅速发布到了全球?有没有做过灰度测试与验证?甲方的问题在于:将自己的终端安全全部寄托于供应链的可靠之上,为什么能允许这样的变更联网实时推送到自己的电脑上而不加以控制?
控制爆炸半径是软件发布中的一条基本原则,而灰度发布则是软件发布中的基本操作。互联网行业中的许多应用会采用精细的灰度发布策略,比如从 1% 的流量开始滚动上量,一旦发现问题也能立刻回滚,避免一勺烩大翻车的出现。
数据库与操作系统变更同理,作为一个管理过大规模生产环境数据库集群的 DBA,我们在对数据库或者底层操作系统进行变更时,都会极为小心地采取灰度策略:首先在 Devbox 开发环境中测试变更,然后应用到预发/UAT/Staging环境中。跑几天没事后,开始针对生产环境发布:从一两套边缘业务开始,然后按照业务重要性划分的 A、B、C 三级,以及从库/主库的顺序与批次进行灰度变更。
某头部券商运维主管也在群里分享了金融行业的最佳实践 —— 直接网络隔离,禁止从互联网更新,买微软 ELA,在内网搭建补丁服务器,然后几万台终端/服务器从补丁服务器统一更新补丁和病毒库。灰度的方式是每个网点和分支机构/每个业务部门都选择一到两台组成灰度环境,跑一两天没事,进入大灰度环境跑满一周,最后的生产环境分成三波每天更新一次,完成整个发布。如果遇到紧急安全事件 —— 也会使用同样的灰度流程,只是把时间周期从一两周压缩到几个小时而已。
当然,有些乙方安全公司,安全出身的工程师会提出不同的看法:“安全行业不一样,我们要与病毒赶时间“,”病毒研究员发现最新的病毒,然后判断如何最快的全网防御”,“病毒来的时候,我的安全专家判断需要启用,跟你们打招呼来不及”,“蓝屏总好过数字资产丢失或者被人随意控制”。但对甲方来说,安全是一整个体系,配置灰度发布晚一点不是什么大不了的事情,然而集中批量崩溃这种惊吓则是让人难以接受的。
至少对于企业客户来说,更不更新,什么时候更新,这个利弊权衡应该是由甲方来做的,而不是乙方去拍脑袋决定。而放弃这一职责,无条件信任乙方供应商给你空中升级的甲方,也是草台班子。安全软件是合法的,大规模肉鸡软件,即使用户以最大的善意信任供应商没有主观恶意,但在实践中也难以避免因为无心之失与愚蠢傲慢导致的灾难(比如这次蓝屏星期五)。

(美剧《太空部队》名梗:紧急任务遇到Microsoft强制更新)
如果你的系统真的很重要,在接受任何变更与更新前请切记 —— Trust,But Verify。如果供应商不提供 Verify 这个选项,你应该在权力范围内果断 Say No。
我认为这次事件会极大利好 “本地优先软件” 的理念 —— 本地优先不是不更新,不变更,一个版本用到地老天荒,而是能够在无需联网的情况下,在你自己的电脑与服务器上持续运行。用户与供应商依然可以通过补丁服务器,与定期推送的方式升级功能,更新配置,但更新的时间点、方法、规模、策略都应当允许由用户自行指定,而不是由供应商越俎代庖替你决策。我认为这一点才是 “自主可控” 概念的真正实质。
在我们自己的开源 PostgreSQL RDS,数据库管控软件 Pigsty 中,也一直践行着本地优先的原则。每当我们发布一个新版本时,我们会对所有需要安装的软件及其依赖取一个快照,制作成离线软件安装包,让用户在没有互联网访问的环境下,无需容器也可以轻松完成高度确定性的安装。如果用户希望部署更多套数据库集群,他可以期待环境中的版本总是一致的 —— 这意味着,你可以随意移除或添加节点进行新陈代谢,让数据库服务跑到地老天荒。
如果您需要升级软件版本打补丁,将新版本软件包加入本地软件源,使用 Ansible 剧本批量更新即可。您可以选择用老旧 EOL 版本跑到地老天荒,也可以选择在第一时间发布就更新并尝鲜最新特性,您可以按照软件工程最佳实践依次灰度发布,但真想要糙猛快一把梭全量上也随意,我们只提供默认的行为与实践的工具,但说到底,这是用户的自由与选择。
俗话说,物极必反,在 SaaS 与云服务盛行的当下,关键基础设施故障的单点风险与脆弱性愈加凸显。相信在本次事故后,本地优先软件的理念将会在未来得到更多的关注与实践。
Ahrefs不上云,省下四亿美元
原文:How Ahrefs Saved US$400M in 3 Years by NOT Going to the Cloud
最近云计算在 IT 基础设施领域非常流行,上云成为一种趋势。基础设施即服务云(IaaS)确实有很多优点:灵活、部署敏捷、伸缩简便、在全球多地区都能即时上线,等等等等。
云服务提供商已经成为专业的 IT 服务外包供应商,提供便捷且易用的服务 —— 通过出色的营销、会议、认证和精心挑选的使用案例,他们很容易让人以为,云计算是现代企业 IT 的唯一合理选择。
但是,这些外包云计算服务的成本,有时高到离谱,高到我们担心如果基础设施 100% 依赖云计算,我们的业务是否还能存在。这促使我们基于事实,进行实际的比较。以下是比较结果:
Ahrefs 自有硬件概览
Ahrefs 在新加坡租用了一个托管数据中心 —— 高度同质化的标准基础设施。我们核算了这个数据中心的所有成本,并分摊到每台服务器上,然后与 Amazon Web Services (AWS) 云中进行类似的规格进行了成本对比(因为 AWS 是 IaaS 领导者,所以我们将其用作对比的标杆)

Ahrefs 服务器
我们的硬件相对较新。托管合同始于 2020 年中 —— 即 COVID-19 疫情高峰期。所有设备也都是从那时候起新买的。我们在该数据中心的服务器配置基本都是一致的,唯一的区别是 CPU 有两种代际,但核数相同。我们每台服务器都有很高的核数,2TB 内存和两个 100G 网口,硬盘的话,平均每台服务器有16块 15TB 的硬盘。
为了计算每月成本,我们把所有硬件按五年摊销归零核算,超过五年后继续用算白赚。因此这些设备的 启动成本,会摊销到 60 个月中进行核算。
所有的 持续性成本,例如租金和电费,均以 2022 年 10 月的价格计算。尽管通货膨胀也会有影响,但这里把通胀算上就太复杂了,所以我们先忽略通胀因素。
我们的托管费用由两部分组成:租金,以及 实际消耗的电费。自 2022 年初以来,电价大幅上涨。我们计算的时候使用的是最新的高电价,而不是整个租赁周期的的平均电价,这样计算上会让 AWS 占些便宜。
此外,我们还要支付 IP 网络传输费用,和数据中心与我们驻地之间的暗光纤费用(暗光纤:已经铺设但是没有投入使用的光缆)。
下表显示了我们每台服务器的月度支出。服务器硬件占整体月度支出的 2/3,而数据中心租金和电费 (DC)、互联网服务提供商 (ISP) 的 IP 传输费用、暗光纤 (DF) 和内部网络硬件 (Network HW) 构成了剩余的三分之一。
| 自建成本项 | 每月成本(美元) | 每月成本(人民币) | 百分比 |
|---|---|---|---|
| 服务器 | $ 1,025 | ¥ 7,380 | 66% |
| 数据中心、ISP、DF、网络硬件 | $ 524 | ¥ 3,772.8 | 34% |
| 自建总成本 | $ 1,550 | ¥ 11,160 | 100% |
我们的自有本地硬件成本结构
AWS 成本结构
由于我们托管的数据中心位于新加坡,所以我们使用 AWS 亚太地区(新加坡)区域的价格进行对比。
AWS 的成本结构与托管中心不同。不幸的是,AWS 没有提供与我们服务器核数相匹配的 EC2 服务器实例。因此,我们找到了CPU & 内存正好是一半的相应 AWS 实例,然后将一台 Ahrefs 服务器的成本,与两台这种 EC2 实例的成本进行对比。
译注:EC2 定价正比与核数与内存配比,这样成本对比没有问题
此外我们考虑了长期折扣,因此我们使用 EC2 实例的最低价格 —— 三年预留,与五年摊销的本地自建服务器进行对比。
译注:AWS EC2 三年 Reserved All Upfront 即提供最好的折扣
除了 EC2 实例外,我们还添加了弹性块存储 (EBS) ,它并不是直接附加存储的精准替代品 —— 因为我们在服务器中使用的是大容量且快速的 NVMe 盘。为了简化计算,我们选择了更便宜的 gp3 EBS(尽管这种盘速度比我们的慢很多)。其成本由两部分组成:存储大小和 IOPS 费用。
译注:EBS
gp3延迟在 ms 量级,io2在百微秒量级,本地盘在 55/9µs 量级
We keep two copies of a data chunk on our servers. But we only order usable space in EBS that takes care of the replication for us. So we should consider the price of the gp3 storage size equal to the size of our drives divided by 2: (11TB + 1615TB)/2 ≈ 120TB per server.
因为我们自己用磁盘的时候会复制一份,但是买 EBS 的时候只买实际存储空间,EBS 替你处理数据复制。
所以在成本对比时,我们购买的 gp3 存储大小是本地磁盘的一半:(1TB + 15TB 16块) / 2 ≈ 每台服务器 120TB。
我们还没有把 IOPS 的成本算进来,也忽略了 EBS gp3 的各种限制;例如,gp3 云盘的最大吞吐量/实例为 10GB/s。而单个 PCIe Gen 4 NVMe 驱动器的性能为 6-7GB/s,而我们有 16 个并行工作的磁盘,总吞吐要大的多。因此,这完全不是一个维度上的公平比较。这种比较方法显著低估了 AWS 上的存储成本,并进一步让 AWS 在比较中占尽便宜。
关于网络流量费用,AWS 与托管机房不同,AWS 不是按照带宽来计费的,而是按每GB下行流量来收费。因此,我们大致估算了每台服务器的平均下行流量,然后使用 AWS 网络计费方法进行估算。
将所有三项成本组合起来,我们得到了 AWS 上的的成本分布,如下表所示
| AWS 成本项 | 每月成本(美元) | 每月成本(人民币) | 百分比 |
|---|---|---|---|
| EBS 成本 | $ 11,486 | ¥ 82,699.2 | 65% |
| EC2 成本 | $ 5,607 | ¥ 40,370.4 | 32% |
| 数据传输 | $ 464 | ¥ 3,340.8 | 3% |
| AWS 总成本 | $ 17,557 | ¥ 126,410.4 | 100% |
AWS成本结构
自建与AWS对比
综合以上两个表格不难看出,AWS 上的支出比想象中要高得多。
| 自建成本项 | 月成本 $ | 占比 | AWS 成本项目 | 月消 $ | 占比 | |
|---|---|---|---|---|---|---|
| 服务器 | 1,025 | 66% | EBS 成本 | 11,486 | 65% | |
| DC、ISP、DF、网络硬件 | 524 | 34% | EC2 成本 | 5,607 | 32% | |
| 数据传输 | 464 | 3% | ||||
| 本地总成本 | 1,550 | 100% | AWS 总成本 | 17,557 | 100% |
我们的自建成本与 AWS EC2 月消费对比:一台 AWS 服务器成本粗略等于 11.3 台 Ahrefs 自建服务器
在 AWS 上一台具有相似可用 SSD 空间的替代 EC2 实例的成本,大致相当于托管数据中心中 11.3 台服务器的成本。相应来说,如果上了云,我们这 20 台服务器的机架就只能剩下大约 2 台服务器了!

20 台 Ahrefs 服务器的成本与 2 台 AWS 服务器相当
那么用我们在自建数据中心里实际使用了两年半的这 850 台服务器来计算,算出总成本数字后,不难看到极其惊人的差异!
| 自建本地服务器 | 每月成本 $ | AWS EC2 实例 | 每月成本 $ | |
|---|---|---|---|---|
| 850台服务器每月成本 | 1,317,301 | 850台服务器每月成本 | 14,923,154 | |
| 30个月总成本 | 39,519,025 | 30个月总成本 | 447,694,623 | |
| AWS成本 - 自建成本 | $ 408,175,598 |
850 台服务器用30个月的成本:AWS vs 自建
假设我们在实际的 2.5 年数据中心使用期间运行 850 台服务器。计算后可以看到显著的差异。
如果我们选择在 2020 年使用新加坡区域的 AWS,而不是自建,那我们需要向 AWS 支付 超过 4 亿美元 这样一笔天文数字 ,才能让自己的基础设施跑起来!
有人可能会想,“或许 Ahrefs 能付得起?”
确实,Ahrefs 是一家盈利且自给自足可持续的公司,所以让我们来看一下它的营收,并算一算。尽管我们是一家私有公司,不必公布我们的财务数据。但在《海峡时报》关于 2022 年和 2023 年新加坡增长最快的公司的文章中可以找到一些 Ahrefs 的收入信息。这些文章提供了 Ahrefs 在 2020 年和 2021 年的收入数据。
我们还可以线性外推出 2022 年的收入。这是一个粗略估计,但足以让我们得出一些结论了。
| 年份 | 类型 | 收入, 新币 | SGD/USD | 收入, 美元 |
|---|---|---|---|---|
| 2020 | 实际 | SGD 86,741,880 | 0.7253 | USD 62,913,886 |
| 2021 | 实际 | SGD 115,335,291 | 0.7442 | USD 85,832,524 |
| 2022 | 外推 | ??? | 0.7265 | USD 108,751,162 |
| 总计 | USD 257,497,571 |
Ahrefs 2020 - 2022 营收估计
从上表可以看出,Ahrefs 在过去三年的总收入约为 2.57 亿美元。但我们也计算出,如果将这样一个自建数据中心替换为 AWS,成本约为 4.48 亿美元。因此,公司收入甚至无法覆盖这 2.5 年的 AWS 使用成本。
这是一个令人震惊的结果!
但是我们的利润会去哪儿呢?
正如波音公司 Dr. LJ Hart-Smith 在这份 已有 20 年历史的报告中所述:“如果原厂或总包商无法通过将工作外包来获利,那么谁会受益呢?当然是分包商。”
需要记住的是,我们已经在计算时让 AWS 占尽便宜了 —— 自建数据中心算电费时使用高于平均水平的电价,算EBS 云盘存储价格时只算了空间部分没算 IOPS,并无视了 EBS 其实非常拉垮的慢。而且,这个数据中心并不是我们唯一的成本中心。我们在其他数据中心、服务器、服务、人员、办公室、营销活动上也有支出。
因此,如果我们主要的基础设施放在云上,Ahrefs 几乎无法生存。
其他考虑因素
这篇文章没有考虑其他使比较更加复杂的方面。这些方面包括人员技能、财务控制、现金流、根据负载类型进行的容量规划等。
结论
Ahrefs 省下了约 4 亿美元,因为在过去的两年半中,基础设施没有 100% 上云。这个数字还在增加,因为目前我们又在一个新地方,用新硬件搞了另一个大型托管数据中心。
Ahrefs 利用 AWS 的优势,在世界各地托管我们的前端,但 Ahrefs 基础设施的绝大部分,隐藏在托管数据中心的自有硬件上。如果我们的产品完全依赖 AWS,Ahrefs 将无法盈利,甚至无法存在。
如果我们采用只用云的方式,我们的基础设施成本将高出 10 倍以上。但正因为我们没有这样做,我们可以将节省下来的资金,用于实际的产品改进和开发。而且也带来了更快、更好的结果 —— 因为(考虑到云上的限制),我们的服务器比云计算能提供的速度更快。我们的报表也生成得更快且更全面,因为每份报告所需的时间更短。
基于此,我建议那些对可持续增长感兴趣的 CFO、CEO 和企业主们,仔细考虑并定期重新评估云计算的优势与实际成本。虽然云计算是早期创业公司的自然选择,或者说 100% 吧。但随着公司及其基础设施的增长,完全依赖云计算可能会使公司陷入困境。
而这里就出现了两难:
一旦上了云,想要离开是很复杂的。云计算很方便,但会带来供应商锁定。而且,仅仅是出于更高的成本而放弃云计算基础设施,可能并不是工程团队想要的。他们可能会正确地认为 —— 云计算比传统的砖瓦数据中心和物理服务器环境更容易、更灵活。
对于更成熟阶段的公司,下云迁移到自有基础设施是困难的。在迁移过程中保持公司生存也是一个挑战。但这种痛苦的转变可能是拯救公司的关键,因为它可以避免将收入越来越多的一部分不断支付给云厂商。
大公司,尤其是 FAANG 多年来吸走了大量人才。他们一直在招聘工程师来运营他们庞大的数据中心和基础设施,给小公司留下的机会很少。但最近几个月大科技公司的大规模裁员,带来了重新评估云计算的机会 —— 确实可以考虑一下招聘数据中心领域资深专业人士,并从云上搬迁下来。
如果你要创办一家新公司,考虑一下这种方案:买个机架和服务器,把它们放在你家的地下室。也许这样能从第一天起就提高你们公司的可持续性。
下云老冯评论
很高兴又看到一个难以忍受天价云租金的大客户站出来,发起对云厂商的控诉。 Ahrefs 的经验与我们一致 —— 云上服务器的综合持有成本在是本地自建的 10 倍左右 —— 即使考虑了最好的 Saving Plan 与深度折扣。37 Signal 的 DHH 则提供了另一个更有代表性的下云案例。
同时在 Ahrefs 成本核算中我们不难看出成本的结构化差异 —— 自建的存储成本是服务器成本的一半,而云上的存储成本却是服务器成本的一倍 —— 我有一篇文章专门聊过这个问题 —— 云盘是不是杀猪盘?
在几个关键例子上,云的成本都极其高昂 —— 无论是大型物理机数据库、大型 NVMe 存储,或者只是最新最快的算力。在这些用例上,云上的客户不得不忍受高昂到荒诞的定价带来的羞辱 —— 租生产队的驴所花的钱是如此高昂,以至于几个月甚至几周的租金就能与直接购买它的价格持平。在这种情况下,你应该直接直接把这头驴买下来,而不是给赛博领主交租!
删库:Google云爆破了大基金的整个云账户
由于“前所未有的配置错误”,Google Cloud 误删了 UniSuper 的云账户。
澳洲养老金基金负责人与 Google Cloud 全球首席执行官联合发布声明,为这一“极其令人沮丧和失望”的故障表示道歉。
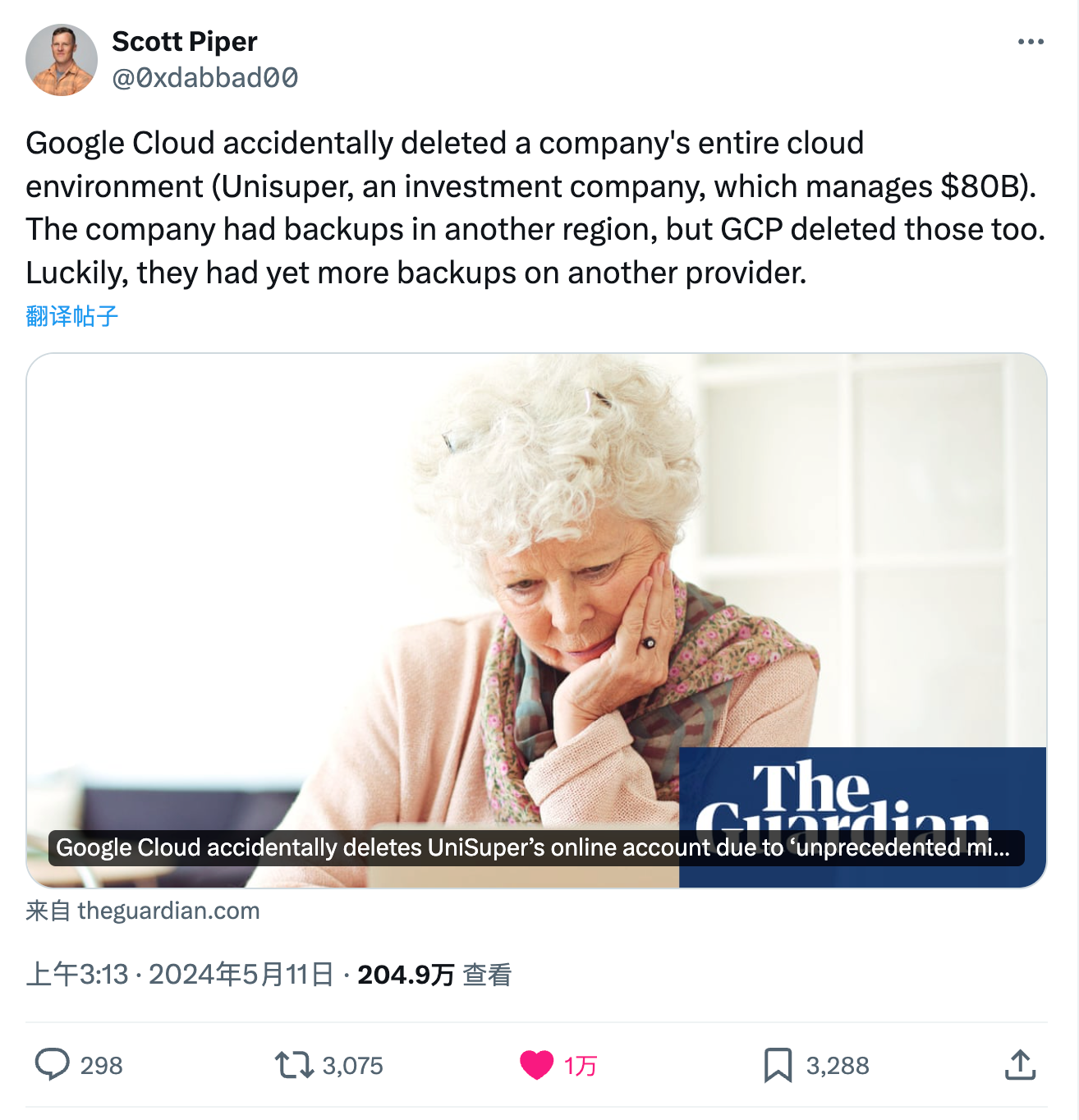
因为一次 Google Cloud “举世无双” 的配置失误,澳洲养老金基金 Unisuper 的整个云账户被误删了,超过五十万名 UniSuper 基金会员一周都无法访问他们的养老金账户。故障发生后,服务于上周四开始恢复,UniSuper 表示将尽快更新投资账户的余额。
UniSuper首席执行官 Peter Chun 在周三晚上向62万名成员解释,此次中断非由网络攻击引起,且无个人数据在此次事件中泄露。Chun 明确指出问题源于 Google的云服务。
在 Peter Chun 和 Google Cloud 全球CEO Thomas Kurian 的联合声明中,两人为此次故障向成员们致歉,称此事件“极其令人沮丧和失望”。他们指出,由于配置错误,导致 UniSuper 的云账户被删除,这是 Google Cloud 上前所未有的事件。

Google Cloud CEO Thomas Kurian 确认了这次故障的原因是,在设定 UniSuper 私有云服务过程中的一次疏忽,最终导致 UniSuper 的私有云订阅被删除。两人表示,这是一次孤立的、前所未有的事件,Google Cloud 已采取措施确保类似事件不再发生。
虽然 UniSuper 通常在两个不同的地理区域设置了备份,以便于服务故障或丢失时能够迅速恢复,但此次删除云订阅的同时,两地的备份也同时被删除了。
万幸的是,因为 UniSuper 在另一家供应商里还有一个备份,所以最终成功恢复了服务。这些备份在极大程度上挽回了数据损失,并显著提高了 UniSuper 与 Google Cloud 完成恢复的能力。
“UniSuper 私有云实例的全面恢复,离不开双方团队的极大专注努力,以及双方的密切合作” 通过 UniSuper 与 Google Cloud 的共同努力与合作,我们的私有云得到了全面恢复,包括 数百台虚拟机、数据库和应用程序。
UniSuper 目前管理着大约 1250 亿美元 的基金。
下云老冯评论
如果说 阿里云全球服务不可用 大故障称得上是 “史诗级”,那么 Google 云上的这一次故障堪称 “无双级” 了。前者主要涉及服务的可用性,而这次故障直击许多企业的命根 —— 数据完整性。
据我所知这应当是云计算历史上的新纪录 —— 第一次如此大规模的删库。上一次类似的数据完整性受损事件还是 腾讯云与 “前言数控” 的案例。
但一家小型创业公司与掌管千亿美金的大基金完全不可同日而语;影响的范围与规模也完全不可同日而语 —— 整个云账户下的所有东西都没了!
这次事件再次展示了(异地、多云、不同供应商)备份的重要性 —— UniSuper 是幸运的,他们在别的地方还有其他备份。
但如果你相信公有云厂商在其他的区域 / 可用区的数据备份可以帮你“兜底”,那么请记住这次案例 —— 避免 Vendor Lock-in,并且 Always has Plan B。
云上黑暗森林:打爆云账单,只需要S3桶名
公有云上的黑暗森林法则出现了:只要你的 S3 对象存储桶名暴露,任何人都有能力刷爆你的云账单。

试想一下,你在自己喜欢的区域创建了一个空的、私有的 AWS S3 存储桶。第二天早上,你的 AWS 账单会是什么样子?
几周前,我开始为客户开发一个文档索引系统的概念验证原型 (PoC)。我在 eu-west-1 区域创建了一个 S3 存储桶,并上传了一些测试文件。两天后我去查阅 AWS 账单页面,主要是为了确认我的操作是否在免费额度内。结果显然事与愿违 —— 账单超过了 1300美元,账单面板显示,执行了将近 1亿次 S3 PUT 请求,仅仅发生在一天之内!
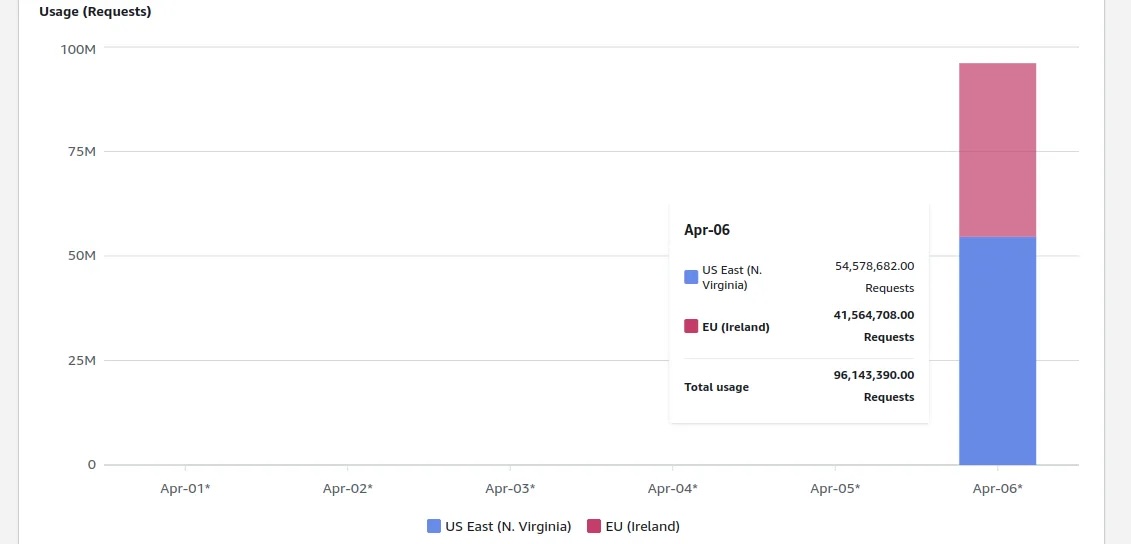
我的 S3 账单,按每天/每个区域计费
这些请求从哪儿来?
默认情况下,AWS 并不会记录对你的 S3 存储桶的请求操作。但你可以通过 AWS CloudTrail 或 S3 服务器访问日志 启用此类日志记录。开启 CloudTrail 日志后,我立刻发现了成千上万的来自不同账户的写请求。
为何会有第三方账户对我的 S3 存储桶发起未授权请求?
这是针对我的账户的类 DDoS 攻击吗?还是针对 AWS 的?事实证明,一个流行的开源工具的默认配置,会将备份存储至 S3 中。这个工具的默认存储桶名称竟然和我使用的完全一致。这就意味着,每一个部署该工具且未更改默认设置的实例,都试图将其备份数据存储到我的 S3 存储桶中!
备注:遗憾的是,我不能透露这个工具的名称,因为这可能会使相关公司面临风险(详情将在后文解释)。
所以,大量未经授权的第三方用户,试图在我的私有 S3 存储桶中存储数据。但为何我要为此买单?
对未授权的请求,S3也会向你收费!
在我与 AWS 支持的沟通中,这一点得到了证实,他们的回复是:
是的,S3 也会对未授权请求(4xx)收费,这是符合预期的。
因此,如果我现在打开终端输入:
aws s3 cp ./file.txt s3://your-bucket-name/random_key
我会收到 AccessDenied 错误,但你要为这个请求买单。
还有一个问题困扰着我:为什么我的账单中有一半以上的费用来自 us-east-1 区域?我在那里根本没有存储桶!原来,未指定区域的 S3 请求默认发送至 us-east-1,然后根据具体情况进行重定向。而你还需要支付重定向请求的费用。
安全层面的问题
现在我明白了,为什么我的 S3 存储桶会收到数以百万计的请求,以及为什么我最终面临一笔巨额的 S3 账单。当时,我还想到了一个点子。如果所有这些配置错误的系统,都试图将数据备份到我的 S3 存储桶,如果我将其设置为 “公共写入” 会怎样?我将存储桶公开不到 30 秒,就在这短短时间内收集了超过 10GB 的数据。当然,我不能透露这些数据的主人是谁。但这种看似无害的配置失误,竟可能导致严重的数据泄漏,令人震惊!
我从中学到了什么?
第一课:任何知道你S3存储桶名的人,都可以随意打爆你的AWS账单
除了删除存储桶,你几乎无法防止这种情况发生。当直接通过 S3 API 访问时,你无法使用 CloudFront 或 WAF 来保护你的存储桶。标准的 S3 PUT 请求费用仅为每一千请求 0.005 美元,但一台机器每秒就可以轻松发起数千次请求。
第二课:为你的存储桶名称添加随机后缀可以提高安全性。
这种做法可以降低因配置错误或有意攻击而受到的威胁。至少应避免使用简短和常见的名称作为 S3 存储桶的名称。
第三课:执行大量 S3 请求时,确保明确指定 AWS 区域。
这样你可以避免因 API 重定向而产生额外的费用。
尾声
-
我向这个脆弱开源工具的维护者报告了我的发现。他们迅速修正了默认配置,不过已部署的实例无法修复了。
-
我还向 AWS 安全团队报告了此事。我希望他们可能会限制这个不幸的 S3 存储桶名称,但他们不愿意处理第三方产品的配置不当问题。
-
我向在我的存储桶中发现数据的两家公司报告了此问题。他们没有回复我的邮件,可能将其视为垃圾邮件。
-
AWS 最终同意取消了我的 S3 账单,但强调了这是一个例外情况。
感谢你花时间阅读我的文章。希望它能帮你避免意外的 AWS 费用!
下云老冯评论
公有云上的黑暗森林法则出现了:只要你的 S3 对象存储桶名暴露,任何人都有能力刷爆你的 AWS 账单。只需要知道你的存储桶名称,别人不需要知道你的 ID,也不需要通过认证,直接强行 PUT / GET 你的桶,不管成败,都会被收取费用。
这引入了一种类似于 DDoS 的新攻击类型 —— DoCC (Denial of Cost Control),刷爆账单攻击。
在一些群里,AWS 的售后,与工程师给出了他们的解释 —— “AWS设计收费策略有一个原则:就是如果AWS产生了成本(用户本身有一定原因),就一定要向用户收费”,AWS 销售给出的解释则是这个客户不会使用 AWS ,应该参加 AWS SA 考试培训后再上岗。
但从常理来看,这完全不合理 —— 由别人发起的,连 Auth 都没有通过的请求,为什么要向用户收费?而用户除了选择不用这一个选项之外,似乎压根没有办法防止这种情况发生 —— 这是一个设计上的漏洞,也是一个安全上的漏洞。
但是在 AWS 看来,该特性被视为 Feature,而不是安全漏洞或者 Bug,可以用来咔咔爆用户的金币。同样的设计逻辑贯穿在 AWS 的产品设计逻辑中,例如,Route53 查询没有解析的域名也会收费,所以知道域名是 AWS 解析的话,也可以进行 DDoS。
我并不确定本土云厂商是否使用了同样的处理逻辑。但他们基本都是直接或间接借鉴 AWS 的。所以有比较大的概率,也会是一样的情况。
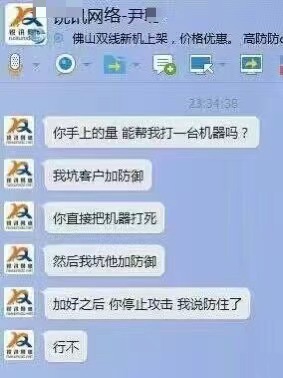
作为信安专业出身,我很清楚业界的一些玩法,比如打DDoS 卖高防 —— 来自某群友的截图
在 《Cloudflare圆桌访谈》中,我也提到过安全问题,比如监守自盗刷流量的问题。
最后我想说一下安全,我认为安全才是 Cloudflare 核心价值主张。为什么这么说,还是举一个例子。有一个独立站长朋友用了某个头部本土云 CDN ,最近两年有莫名其妙的超多流量。一个月海外几个T流量,一个IP 过来吃个10G 流量然后消失掉。后来换了个地方提供服务,这些奇怪的流量就没了。运行成本变为本来的 1/10,这就有点让人细思恐极 —— 是不是这些云厂商坚守自盗,在盗刷流量?或者是是云厂商本身(或其附属)组织在有意攻击,从而推广他们的高防 IP 服务? 这种例子其实我是有所耳闻的。
因此,在使用本土云 CDN 的时候,很多用户会有一些天然的顾虑与不信任。但 Cloudflare 就解决了这个问题 —— 第一,流量不要钱,按请求量计费,所以刷流量没意义;第二,它替你抗 DDoS,即使是 Free Plan 也有这个服务,CF不能砸自己的招牌 —— 这解决了一个用户痛点,就是把账单刷爆的问题 —— 我确实有见过这样的案例,公有云账号里有几万块钱,一下子给盗刷干净了。用 Cloudflare 就彻底没有这个问题,我可以确保账单有高度的确定性 —— 如果不是确定为零的话。
Well,总的来说,账单被刷爆,也算一种公有云上独有的安全风险了 —— 希望云用户保持谨慎小心,一点小失误,也许就会在账单上立即产生难以挽回的损失。

Cloudflare圆桌访谈与问答录
上周我作为圆桌嘉宾受邀参加了 Cloudflare 在深圳举办的 Immerse 大会,在 Cloudflare Immerse 鸡尾酒会和晚宴上,我与 Cloudflare 亚太区CMO,大中华区技术总监,以及一线工程师深入交流探讨了许多关于 Cloudflare 的问题。
本文是圆桌会谈纪要与问答采访的摘录,从用户视角点评 Cloudflare 请参考本号前一篇文章:《吊打公有云的赛博佛祖 Cloudflare》

第一部分:圆桌访谈
您与 Cloudflare 如何结缘?
我是冯若航,现在做 PostgreSQL 数据库发行版 Pigsty,运营着一个开源社区,同时作为一个数据库 & 云计算领域的 KOL,在国内宣扬下云理念。在 Cloudflare 的场子里讲下云挺有意思,但我并不是来踢馆的。
事实上我与 Cloudflare 还有好几层缘分,所以今天很高兴在这里和大家分享一下我的三重视角 :作为一个独立开发者终端用户,作为一个开源社区的成员与运营者,作为一个公有云计算反叛军,我是如何看待 Cloudflare 的。
作为一个开源软件供应商,我们需要一种稳定可靠的软件分发方式。我们最开始使用了本土的阿里云与腾讯云,在国内的体验尚可,但当我们需要走出海外,面向国外用户时,使用体验确实不尽如人意。我们尝试了 AWS,Package Cloud ,但最终选择了 Cloudflare。包括我们有几个网站也托管到了CF。
作为 PostgreSQL 社区的一员,我们知道 Cloudflare 深度使用了 PostgreSQL 作为底层存储的数据库。并且不同于其他云厂商喜欢将其包装为 RDS 白嫖社区,Cloudflare 一直是杰出的开源社区参与者与建设者。甚至像 Pingora 和 Workerd 这样的核心组件都是开源的。我对此给出高度评价,这是开源软件社区与云厂商共存的典范。
作为下云理念的倡导者,我一直认为传统公有云使用了一种非常不健康的商业模式。所以在中国引领着一场针对公有云的下云运动。我认为 Cloudflare 也许是这场运动中的重要盟友 —— 传统 IDC 开源自建,难以解决 “在线” 的问题,而 Cloudflare 的接入能力,边缘计算能力,都弥补了这一块短板。所以我非常看好这种模式。

您用到了哪些 Cloudflare的服务,打动你的是什么?
我用到了 Cloudflare 的静态网站托管服务 Pages,对象存储服务 R2 和边缘计算 Worker。最打动我的有这么几点:易用性,成本,质量,安全,专业的服务态度,以及这种模式的前景与未来。
首先聊一聊易用性吧,我使用的第一项服务是 Pages。我自己有一个网站,静态 HTML 托管在这里。我把这个网站搬上 Cloudflare 用了多长时间?一个小时!我只是创建了一个新的 GitHub Repo,把静态内容提交上去,然后在 Cloudflare 点点按钮,绑定一个新的子域名,链接到 GitHub Repo,整个网站瞬间就可以被全世界访问,你不需要操心什么高可用,高并发,全球部署,HTTPS 证书,抗 DDoS 之类的问题 —— 这种丝滑的用户体验让我非常舒适,并很乐意在这上面花点钱解锁额外功能。
再来聊一聊成本吧。在独立开发者,个人站长这个圈子里,我们给 Cloudflare 起了一个外号 —— “赛博佛祖”。这主要是因为 Cloudflare 提供了非常慷慨的免费计划。Cloudflare 有着相当独特的商业模式 —— 免流量费,靠安全赚钱。
比如说 R2,我认为这就是专门针对 AWS S3 进行啪啪打脸的。我曾经作为大甲方对各种云服务与自建的成本进行过精算 —— 得出会让普通用户感到震惊的结论。云上的对象存储 / 块存储 比本地自建贵了两个数量级,堪称史诗级杀猪盘。AWS S3 标准档价格 0.023 $/GB·月,而 Cloudflare R2 价格 0.015 $/GB·月,看上去只是便宜了 1/3 。但重要的是流量费全免!这就带来质变了!
比如,我自己那个网站也还算有点流量,最近一个月跑了 300GB ,没收钱,我有一个朋友每月跑掉 3TB 流量,没收钱;然后我在推特上看到有个朋友 Free Plan 跑黄网图床,每月 1PB 流量,这确实挺过分了,于是 CF 联系了他 —— 建议购买企业版,也仅仅是 “建议”。
接下来我们来聊一聊质量。我讲下云的一个前提是:各家公有云厂商卖的是没有不可替代性的大路货标准品。比如那种在老罗直播间中,夹在吸尘器与牙膏中间卖的云服务器。但是 Cloudflare 确实带来了一些不一样的东西。
举个例子,Cloudflare Worker 确实很有意思,比起传统云上笨拙的开发部署体验来说,CF worker 真正做到了让开发者爽翻天的 Serverless 效果。开发者不需要操心什么数据库连接串,AccessPoint,AK/SK密钥管理,用什么数据库驱动,怎么管理本地日志,怎么搭建 CI/CD 流程这些繁琐问题,最多在环境变量里面指定一下存储桶名称这类简单信息就够了。写好 Worker 胶水代码实现业务逻辑,命令行一把梭就可以完成全球部署上线。
与之对应的是传统公有云厂商提供的各种所谓 Serverless 服务,比如 RDS Serverless,就像一个恶劣的笑话,单纯是一种计费模式上的区别 —— 既不能 Scale to Zero,也没什么易用性上的改善 —— 你依然要在控制台去点点点创建一套 RDS,而不是像 Neon 这种真 Serverless 一样用连接串连上去就能直接迅速拉起一个新实例。更重要的是,稍微有个几十上百的QPS,相比包年包月的账单就要爆炸上天了 —— 这种平庸的 “Serverless” 确实污染了这个词语的本意。
最后我想说一下安全,我认为安全才是 Cloudflare 核心价值主张。为什么这么说,还是举一个例子。有一个独立站长朋友用了某个头部本土云 CDN ,最近两年有莫名其妙的超多流量。一个月海外几个T流量,一个IP 过来吃个10G 流量然后消失掉。后来换了个地方提供服务,这些奇怪的流量就没了。运行成本变为本来的 1/10,这就有点让人细思恐极 —— 是不是这些云厂商坚守自盗,在盗刷流量?或者是是云厂商本身(或其附属)组织在有意攻击,从而推广他们的高防 IP 服务?这种例子其实我是有所耳闻的。
因此,在使用本土云 CDN 的时候,很多用户会有一些天然的顾虑与不信任。但 Cloudflare 就解决了这个问题 —— 第一,流量不要钱,按请求量计费,所以刷流量没意义;第二,它替你抗 DDoS,即使是 Free Plan 也有这个服务,CF不能砸自己的招牌 —— 这解决了一个用户痛点,就是把账单刷爆的问题 —— 我确实有见过这样的案例,公有云账号里有几万块钱,一下子给盗刷干净了。用 Cloudflare 就彻底没有这个问题,我可以确保账单有高度的确定性 —— 如果不是确定为零的话。
专业的服务态度指的是?
本土云厂商在面对大故障时,体现出相当业余的专业素养与服务态度,这一点我专门写了好几篇文章进行批判。说起来特别赶巧,去年双十一,阿里云出了一个史诗级全球大故障。Cloudflare 也出了个机房断电故障。一周前 4.8 号,腾讯云也出了个翻版全球故障,Cloudflare 也恰好在同一天又出了 Code Orange 机房断电故障。作为一个工程师,我理解故障是难以避免的 —— 但出现故障后,体现出来的专业素养和服务态度是天差地别的。
首先,阿里云和腾讯云的故障都是人为操作失误/糟糕的软件工程/架构设计导致的,而 Cloudflare 的问题是机房断电,某种程度上算不可抗力的天灾。其次,在处理态度上,阿里云到现在都没发布一个像样的故障复盘,我替它做了一个非官方故障复盘;至于腾讯云,我干脆连故障通告都替他们发了 —— 比官网还快10分钟。腾讯云倒是在前天发布了一个故障复盘,但是也比较敷衍,专业素养不足,这种复盘报告拿到 Apple 和 Google 都属于不合格的 Post-Mortem ……
Cloudflare 则恰恰相反,在故障的当天 CEO 亲自出来撰写故障复盘,细节翔实,态度诚恳,你见过本土云厂商这么做吗?没有!
您对 Cloudflare 未来有什么期待?
我主张下云理念,是针对中型以上规模的企业。像我之前任职的探探,以及美国 DHH 37 Signal 这样的。但是 IDC 自建有个问题,接入的问题,在线的问题 —— 你可以自建KVM,K8S,RDS,甚至是对象存储。但你不可能自建 CDN 吧?Cloudflare 就很好地弥补了这个缺憾。
我认为,Cloudflare 是下云运动的坚实盟友。Cloudflare 并没有提供传统公有云上的那些弹性计算、存储、K8S、RDS 服务。但幸运地是,Cloudflare 可以与公有云 / IDC 良好地配合协同 —— 从某种意义上来说,因为 Cloudflare 成功解决了 “在线” 的问题,这使得传统数据库中心 IDC 2.0 也同样可以拥有比肩甚至超越公有云的 “在线” 能力,两者配合,在事实上摧毁了一些公有云的护城河,并挤压了传统公有云厂商的生存空间。
我非常看好 Cloudflare 这种模式,实际上,这种丝滑的体验才配称的上是云,配享太庙,可以心安理得吃高科技行业的高毛利。实际上,我认为 Cloudflare 应该主动出击,去与传统公有云抢夺云计算的定义权 —— 我希望未来人们说起云的时候,指的应该是 Cloudflare 这种慷慨体面的连接云,而不是传统公有杀猪云。
第二部分:互动问答
在 Cloudflare Immerse 鸡尾酒会和晚宴上,我与 Cloudflare 亚太区CMO,大中华区技术总监,以及一线工程师深入交流探讨了许多关于 Cloudflare 的问题,收获颇丰,这里给出了一些适合公开的问题与答案。因为我也不会录音,因此这里的文字属于我的事后回忆与阅读理解,仅供参考,不代表 CF 官方观点。

Cloudflare 如何定位自己,和 AWS 这种传统公有云是什么关系?
其实 Cloudflare 不是传统公有云,而是一种 SaaS。我们现在管自己叫做 “Connectivity Cloud”(翻译为:全球联通云),旨在为所有事物之间建立连接,与所有网络相集成;内置情报防范安全风险,并提供统一、简化的界面以恢复可见性与控制。从传统的视角来看,我们做的像是安全、CDN与边缘计算的一个整合。AWS 的 CloudFront 算是我们的竞品。
Cloudflare 为什么提供了如此慷慨的免费计划,到底靠什么赚钱?
Cloudflare 的免费服务就像 Costco 的5美元烤鸡一样。实际上除了免费套餐,那个 Workers 和 Pages 的付费计划也是每月五美元,跟白送的一样,Cloudflare 也不是从这些用户身上赚钱的。
Cloudflare 的核心商业模式是安全。相比于只服务付费客户,更多的免费用户可以带来更深入的数据洞察 —— 也就能够发现更为广泛的攻击与威胁情报,为付费用户提供更好的安全服务。
我们的 Free 计划有何优势?
在 Cloudflare,我们的使命是帮助建立更好的互联网。我们认为 web 应该是开放和免费的,所有网站和 web 用户,无论多小,都应该是安全、稳固、快速的。由于种种原因,Cloudflare 始终都提供慷慨的免费计划。
我们努力将网络运营成本降至最低,从而能在我们的 Free 计划中提供巨大价值。最重要的是,通过保护更多网站,我们能就针对我们网络的各类攻击获得更完善的数据,从而能为所有网站提供更佳的安全和保护。
作为隐私第一的公司,我们绝不出售您的数据。事实上,Cloudflare 承认个人数据隐私是一项基本人权,并已采取一系列措施来证明我们对隐私的承诺。
实际上 Cloudflare 的 CEO 在 StackOverflow 亲自对这个问题作出过回答:

Five reasons we offer a free version of the service and always will:
- Data: we see a much broader range of attacks than we would if we only had our paid users. This allows us to offer better protection to our paid users.
- Customer Referrals: some of our most powerful advocates are free customers who then “take CloudFlare to work.” Many of our largest customers came because a critical employee of theirs fell in love with the free version of our service.
- Employee Referrals: we need to hire some of the smartest engineers in the world. Most enterprise SaaS companies have to hire recruiters and spend significant resources on hiring. We don’t but get a constant stream of great candidates, most of whom are also CloudFlare users. In 2015, our employment acceptance rate was 1.6%, on par with some of the largest consumer Internet companies.
- QA: one of the hardest problems in software development is quality testing at production scale. When we develop a new feature we often offer it to our free customers first. Inevitably many volunteer to test the new code and help us work out the bugs. That allows an iteration and development cycle that is faster than most enterprise SaaS companies and a MUCH faster than any hardware or boxed software company.
- Bandwidth Chicken & Egg: in order to get the unit economics around bandwidth to offer competitive pricing at acceptable margins you need to have scale, but in order to get scale from paying users you need competitive pricing. Free customers early on helped us solve this chicken & egg problem. Today we continue to see that benefit in regions where our diversity of customers helps convince regional telecoms to peer with us locally, continuing to drive down our unit costs of bandwidth.
Today CloudFlare has 70%+ gross margins and is profitable (EBITDA)/break even (Net Income) even with the vast majority of our users paying us nothing.
Matthew Prince Co-founder & CEO, CloudFlare
创始人的情怀与愿景其实挺重要的 …… ,Cloudflare 早期的许多服务一直都是免费提供的,第一个付费服务其实是 SSL 证书,现在也不要钱了。总的来说,就是靠企业级客户为安全付费。
Cloudflare付费用户都是什么样的?怎么从免费用户成为付费用户的。
我们的免费客户转变为企业级付费客户的主要契机是安全问题。Cloudflare 控制台上有个 “遭受攻击” 的按钮 —— 是这样的,只要用户在控制台上点这个 “Under Attack” 按钮,即使是免费客户,我们也会第一时间有人响应,帮助客户解决问题。例如在疫情期间,某头部视频会议厂商遭受到了安全攻击。我们立即抽调人手替客户解决问题 —— 他们很满意,我们就签了单子。

Cloudflare 的免费套餐有可能会在未来取消吗?
Costco 有个 1.5 美元的热狗汽水套餐,创始人承诺永远不会提高热狗和苏打水套餐的价格。我知道像 Vercel,Planetscale 之类的 SaaS 厂商开始削减免费套餐,但我认为这事基本不太可能发生在 Cloudflare 上。因为如上所述,我们有充分的理由继续提供免费计划。实际上我们的大多数客户都没付钱,在使用 Free Plan。

为什么Cloudflare 会在故障后由 CEO 亲自出马复盘?
我们的 CEO 是技术出身,工程师背景。出现故障的时候 IM 里一堆人在掰扯,CEO 跳出来说:够了,我来写故障复盘报告 —— 然后故障当天就发出来了,这种事放在公有云厂商里绝对是相当罕见的了… 我们其实也很震惊…。
Cloudflare 在中国区域访问为什么这么慢?
中国区域带宽/流量费用太贵了,所以普通用户访问其实访问的其实主要是北美地区的机房与节点。我们在 全世界 95% 的地区都有非常优秀的延迟表现(比),但剩下 5% 嘛主要指的就是 …… ,在这里

如果你的主要用户群体都是国内,又比较在乎速度,可以考虑一下 Cloudflare 企业版,或者是本土 CDN 厂商。我们和京东云有合作,企业级客户在国内也可以使用他们提供的这些节点。
中国区域用户使用 Cloudflare 的主要动机是什么?
主要是因为安全:Cloudflare 即使是免费计划中,也提供了抗 DDoS 服务。中国的用户使用 Cloudflare 主要是为了出海。而那些纯粹面向本土的中国客户,宁可慢一点也要用 CF 的主要动机就是安全(抗DDoS)。
Cloudflare 会在中国被封禁吗?有什么运营风险吗?
我觉得这件事不太可能会发生,你知道现在有多少网站托管在 Cloudflare 上面吗 … 这一炮打下去,大半个互联网都访问不了了。Cloudflare 本身并没有在中国地区运营…… ,在中国也主要服务于 C2G (China to Global)业务。 你刚才问为什么 Cloudflare 域名不备案为什么就能访问,就是这个原因 —— 我们压根没在中国运营。
在与本土云厂商合作中,资源互换主要是一种什么形式?
有一些本土云厂商通过资源互换的方式合作,所谓资源互换嘛,<Redacted>
你们如何看待腾讯云模仿你们的产品 EdgeOne ?
做生意和气生财,我们不好公开评论其他云。但私下里说,CopyCat……
Cloudflare 企业版的主要价值点在于?
流量优先级。举个例子你出海的流量大概率是从上海的某一根跨海光纤出去的,平时这条线路的使用率是 <Redacted> % ,但是在高峰期,我们就会优先保证企业级用户的服务质量。

Cloudflare 考虑推出托管的 RDS,Postgres数据库服务吗?
现在那个 D1 其实是 SQLite,目前没有计划做这种托管数据库服务,但是生态里已经有可以满足这种需求的供应商了,你看有不少在 Worker 里使用 Neon (Serverless Postgres)的例子。
我们能从腾讯云大故障中学到什么?
故障过去八天后,腾讯云发布了 4.8 号大故障的复盘报告。我认为是一件好事,因为阿里云双十一大故障的官方故障复盘至今仍然是拖欠着的。公有云厂商想要真正成为 —— 提供水与电的公共基础设施,那就需要承担起责任,接受公众监督 —— 云厂商有义务披露自己故障原因,并提出切实的可靠性改进方案与措施。
那么我们就来看一看这份复盘报告,看看里面有哪些信息,以及可以从中学到什么教训。
事实是什么?
按照腾讯云官方给出的复盘报告(官方发布的“权威事实”)
- 15:23,监测到故障,立即执行服务的恢复,同时进行原因的排查;
- 15:47,发现通过回滚版本没能完全恢复服务,进一步定位问题;
- 15:57,定位出故障根因是配置数据出现错误,紧急设计数据修复方案;
- 16:02,对全地域进行数据修复工作,API服务逐地域恢复中;
- 16:05,观测到除上海外的地域API服务均已恢复,进一步定位上海地域的恢复问题;
- 16:25,定位到上海的技术组件存在API循环依赖问题,决定通过流量调度至其他地域来恢复;
- 16:45,观测到上海地域恢复了,此时API和依赖API的PaaS服务彻底恢复,但控制台流量剧增,按九倍容量进行了扩容;
- 16:50,请求量逐渐恢复到正常水平,业务稳定运行,控制台服务全部恢复;
- 17:45,持续观察一小时,未发现问题,按预案处理过程完毕。
复盘报告给出的原因是:云API服务新版本向前兼容性考虑不够和配置数据灰度机制不足的问题
本次API升级过程中,由于新版本的接口协议发生了变化,在后台发布新版本之后对于旧版本前端传来的数据处理逻辑异常,导致生成了一条错误的配置数据,由于灰度机制不足导致异常数据快速扩散到了全网地域,造成整体API使用异常。
发生故障后,按照标准回滚方案将服务后台和配置数据同时回滚到旧版本,并重启API后台服务,但此时因为承载API服务的容器平台也依赖API服务才能提供调度能力,即发生了循环依赖,导致服务无法自动拉起。通过运维手工启动方式才使API服务重启,完成整个故障恢复。
这份复盘报告中有一个存疑的点:复盘报告将故障归因为:向前兼容考虑不足。向前兼容性(Forward Compatibility)指的是老的版本的代码可以使用新版本的代码产生的数据。如果管控回滚到旧版本,无法读取由新版本产生的脏数据 —— 那这是确实是一个前向兼容性问题。但在下面的解释中:是新版本代码没有处理好旧版本数据 —— 而这是一个典型的向后兼容性(Backward)问题。对于一个 ToB 服务产品,我认为这样的严谨性是有问题的。
原因是什么?
作为客户,我也在此前获取了私下流传的故障复盘过程,一份具有高置信度的小道消息:
- 15:25 平台监控到云API进程故障告警,工程师立即介入分析;
- 15:36 排查发现异常集中在云API现网版本,旧版本运行正常,开始进行回滚操作;
- 15:47 官网控制台所用集群回滚完成,通过监控确定恢复;
- 15:50 开始回滚非控制台集群;
- 15:57 定位出故障根因是配置系统中存在错误数据;
- 16:02 删除配置数据的错误数据,各地域集群开始自动恢复;
- 16:05 由于历史配置不规范,导致上海集群无法通过回滚快速恢复,决策采用流量调度方式恢复上海集群;
- 16:40 上海集群流量全量切换到其他地域集群;
- 16:45 经过观测和现网监控,确认上海集群已经恢复。
应该说,官方发布的版本在关键点上基本上和几天前私下流出的版本是一致的,只是私下流传的版本更加详细地指出了根因: 相较旧版本,现网版本新引入逻辑存在对空字典配置数据兼容的bug,在读取数据场景下触发bug逻辑,引发云API服务进程异常 Crash。
根据这两份故障复盘信息,我们可以确定,这是一次由人为失误导致的故障,而不是因为天灾(硬件故障,机房断电断网)导致的。我们基本上可以推断出故障发生的过程分为两个阶段 —— 两个子问题。
第一个问题是,管控 API 没有保持良好的双向兼容性 —— 新管控 API 因为老配置数据中的空字典崩掉了。这体现出一系列软件工程上的问题 —— 处理空对象的代码基本功,处理异常的逻辑,测试的覆盖率,发布的灰度流程。
第二个问题是,循环依赖(容器平台与管控API)导致系统无法自动拉起,需要运维手工介入进行 Bootstrap。这反映出 —— 架构设计的问题,以及 —— 腾讯云并没有从去年阿里云的大故障中吸取最核心的教训。
影响是什么?
在复盘报告中,腾讯云用了大篇幅来描述故障的影响,解释管控面故障与数据面故障的区别。用了一些酒店前台的比喻。其实类似的故障在去年阿里云双十一大故障已经出现过了 —— 管控面挂了,数据面正常,在《我们能从阿里云史诗级故障中学到什么》中,我们也分析过,管控面挂了确实不会影响继续使用现有纯 IaaS 资源。但是会影响云厂商的核心服务 —— 比如,对象存储在腾讯云上叫 COS。
对象存储 COS 实在是太重要了,可以说是云计算的“定义性服务”,也许是唯一能在所有云上基本达成共识标准的服务。云厂商的各种“上层”服务或多或少都直接/间接地依赖 COS,例如 CVM/ RDS 虽然可以运行,但 CVM 快照和 RDS 备份显然是深度依赖 COS 的,CDN 回源是依赖 COS 的,各个服务的日志往往也是写入 COS 的**。所以,任何涉及到基础服务的故障,都不应该糊弄敷衍过去**。
当然最让人生气的其实是腾讯云傲慢的态度 —— 我自己作为腾讯云的用户,提了一个工单,用于测试云上的 SLA 到底好不好使 —— 事实证明:不主张就不赔付,主张了不认账也可以不赔付 —— 这个 SLA 确实跟厕纸一样。《云 SLA 是安慰剂还是厕纸合同》
评论与观点
马斯克的推特 X 和 DHH 的 37 Signal 通过下云省下了千万美元真金白银,创造了降本增效的“奇迹”,让下云开始成为一种潮流。云上的用户在对着账单犹豫着是否要下云,未上云的用户更是内心纠结。
在这样的背景下,作为本土云领导者的阿里云先出现史诗级大故障,紧接着腾讯云又再次出现了这种全球性管控面故障,对于犹豫观望者的信心无疑是沉重的打击。如果说阿里云大故障是公有云拐点级别的标志性事件,那么腾讯云大故障再次确认了这条投射线的方向。
这次故障再次揭示出关键基础设施的巨大风险 —— 大量依托于公有云的网络服务缺乏最基本的自主可控能力:当故障发生时没有任何自救能力,除了等死做不了别的事情。它也反映出了垄断中心化基础设施的脆弱性:互联网这个去中心化的世界奇观现在主要是在少数几个大公司/云厂商拥有的服务器上运行 —— 某个云厂商本身成为了最大的业务单点,这可不是互联网设计的初衷!
根据海恩法则,一次严重故障的背后有几十次轻微事故,几百起未遂先兆,以及上千条事故隐患。这样的事故对于腾讯云的品牌形象绝对是致命打击,甚至对整个行业的声誉都有严重的损害。Cloudflare 月初的管控面故障后,CEO 立即撰写了详细的事后复盘分析,挽回了一些声誉。腾讯云这次发布的故障复盘报告不能说及时,但起码比起遮遮掩掩的阿里云要好多了。
通过故障复盘,提出改进措施,让用户看到改进的态度,对于用户的信心非常重要。做一个故障复盘,也许会暴露更多草台班子的糗态 —— 我不会收回 “草台班子” 的评价。但重要的是 —— 技术/管理菜是可以想办法改进的,服务态度傲慢则是无药可医的。
公有云厂商想要真正成为 —— 提供水与电的公共基础设施,那就需要承担起责任来,并敢于接受公众与用户的公开监督。我在《腾讯云:颜面尽失的草台班子》与《云 SLA 是安慰剂还是厕纸合同》中指出了腾讯云面对故障时的问题 —— 故障信息发布不及时,不准确,不透明。在这一点上,我欣慰的看到在复盘报告改进措施中,腾讯云能够承认这些问题并承诺进行改进。但我无法原谅的是 —— 腾讯云选择在微信公众号上文章审核封口。
能学到什么?
往者不可留,逝者不可追,比起哀悼无法挽回的损失,更重要的是从损失中吸取教训 —— 要是能从别人的损失中吸取教训那就更好了。所以,我们能从腾讯云这场史诗级故障中学到什么?
不要把鸡蛋放在同一个篮子里,准备好 PlanB,比如,业务域名解析一定要套一层 CNAME,且 CNAME 域名用不同服务商的解析服务。这个中间层对于阿里云、腾讯云这样的全局云厂商故障非常重要,用另外一个 DNS 供应商,至少可以给你一个把流量切到别的地方去的选择,而不是干坐在屏幕前等死,毫无自救能力。
谨慎依赖需要云基础设施:
云 API 是云服务的基石,大家都期待它可以始终正常工作 —— 然而越是人们感觉不可能出现故障的东西,真的出现故障时产生的杀伤力就越是毁天灭地。如无必要,勿增实体,更多的依赖意味着更多的失效点,更低的可靠性:正如在这次故障中,使用自身认证机制的 CVM/RDS 本身就没有受到直接冲击。深度使用云厂商提供的 AK/SK/IAM 不仅会让自己陷入供应商锁定,更是将自己暴露在公用基础设施的单点风险里。
我的朋友/对手,公有云的鼓吹者瑞典马工和他的朋友AK王老板,一直主张呼吁用 IAM / RAM 做访问控制,并深度利用云上的基础设施。但是在这两次故障后,马工的原话是:
“我一直鼓吹大家用 IAM 做访问控制,结果两家云都出大故障,纷纷打我的脸。云厂商不管是 PR 还是 SRE,都在用实际行动向客户证明:“别听马工的,你用他那一套,我就让你系统完蛋”。
谨慎使用云服务,优先使用纯资源。在本次故障中,云服务受到影响,但云资源仍然可用。类似 CVM/云盘 这样的纯资源,以及单纯使用这两者的 RDS,可以不受管控面故障影响可以继续运行。基础云资源(CVM/云盘)是所有云厂商的提供服务的最大公约数,只用资源有利于用户在不同公有云、以及本地自建中间择优而选。不过,很难想象在公有云上却不用对象存储 —— 在 CVM 和天价云盘 上用 MinIO 自建对象存储服务并不是真正可行的选项,这涉及到公有云商业模式的核心秘密:廉价S3获客,天价EBS杀猪。
自建是掌握自身命运的终极道路:如果用户想真正掌握自己的命运,最终恐怕早晚会走上自建这条路。互联网先辈们平地起高楼创建了这些服务,而现在做这件事只会容易得多:IDC 2.0 解决硬件资源问题,开源平替解决软件问题,大裁员释放出的专家解决了人力问题。短路掉公有云这个中间商,直接与 IDC 合作显然是一个更经济实惠的选择。稍微有点规模的用户下云省下的钱,可以换几个从大厂出来的资深SRE 还能盈余不少。更重要的是,自家人出问题你可以进行奖惩激励督促其改进,但是云出问题能赔给你几毛钱的代金券?
明确云厂商的 SLA 是营销工具,而非战绩承诺
在云计算的世界里,服务等级协议(SLA)曾被视为云厂商对其服务质量的承诺。然而,当我们深入研究这些由一堆9组成的协议时,会发现它们并不能像期望的那样“兜底”。与其说是 SLA 是对用户的补偿,不如说 SLA 是对云厂商服务质量没达标时的“惩罚”。比起会因为故障丢掉奖金与工作的专家来说,SLA 的惩罚对于云厂商不痛不痒,更像是自罚三杯。如果惩罚没有意义,云厂商也没有动力去提供更好的服务质量。所以,SLA 对用户来说不是兜底损失的保险单。在最坏的情况下,它是堵死了实质性追索的哑巴亏;在最好的情况下,它才是提供情绪价值的安慰剂。
吊打公有云的赛博佛祖 Cloudflare
是在今天的 2024 开发者周上,Cloudflare 发布了一系列令人激动的新特性,例如 Python Worker 以及 Workers AI,把应用开发与交付的便利性拔高到了一个全新的程度。与 Cloudflare 的 Serverless 开发体验相比,传统云厂商号称 Serverless 的各种产品都显得滑稽可笑。
Cloudflare 更广为人知的是它的慷慨免费套餐,一些中小型网站几乎能以零成本运行在这里。在 Cloudflare 的鲜明对比之下,天价出租 CPU、磁盘、带宽 的公有云厂商显得面目可憎。Cloudflare 这样的云带来的开发体验,才真正配得上“云”的称号。在我看来, Cloudflare 应该主动出击,与传统公有云厂商抢夺云计算的定义权。
利益相关:Cloudflare 没给我钱,我倒是给 Cloudflare 付了钱。纯粹是因为 Cloudflare 产品非常出色,极好地解决了我的需求,让我非常乐意付点费支持一下,并告诉更多朋友有这项福利。与之相反的是,我付钱给传统公有云厂商之后的感受是这做的都是什么玩意 —— 必须写文章狠狠地骂他们,才能缓解内心的精神损失。
Cloudflare 是什么
Cloudflare是一家提供内容分发网络(CDN)、互联网安全性、抗DDoS(分布式拒绝服务)和分布式DNS服务的美国公司。全世界互联网流量的 20% 由它服务。如果你挂着 VPN 访问一些网站,经常可以看到 Cloudflare 的抗 DDoS 验证码页面和 Logo。他们提供:
- 内容分发网络(CDN):Cloudflare的CDN服务通过全球分布的数据中心缓存客户网站的内容,加快网站加载速度并减少服务器压力。
- 网站安全性:提供SSL加密、防止SQL注入和跨站脚本攻击的安全措施,增强网站的安全性。
- DDoS防护:具备先进的DDoS防护功能,能够抵御各种规模的攻击,保护网站不受干扰。
- 智能路由:使用Anycast网络技术,能够智能识别数据传输的最佳路径,减少延迟。
- 自动HTTPS重定向:自动将访问转换为HTTPS,增强通信的安全性。
- Workers平台:提供Serverless架构,允许在Cloudflare的全球网络上运行JavaScript或WASM(WebAssembly)代码,无需管理服务器。
当然,Cloudflare 还有一些非常不错的服务,例如托管网站的 Pages,对象存储 R2,分布式数据库D1 等,开发者体验非常不错。
Pages:简单易用的网站托管
举个例子,如果您要托管一个静态网站。用 Cloudflare 有多简单?首先在 GitHub 创建一个 Repo,把网站内容丢进去,然后在 Cloudflare 链接到你的 Git Repo,分配一个子域名,然后你的网站就自动部署到全世界的各个角落了。如果你要更新网站内容,只要 git push 到特定分支就足够了。
如果你使用特定的 网站框架,甚至还可以直接在线从仓库内容中构建:Blazor、Brunch、Docusaurus、Gatsby、Gridsome、Hexo、Hono、Hugo、Jekyll、Next.js、Nuxt、Pelican、Preact、Qwik、React、Remix、Solid、Sphinx、Svelte、Vite 3、Vue、VuePress、Zola、Angular、Astro、Elder.js、Eleventy、Ember、MkDocs。
我从完全没接触过 Cloudflare,到把 Pigsty 的网站搬运到 CF 上并完成部署,只用了一个小时左右。我不需要操心什么服务器,CI/CD / HTTPS 证书,安全高防抗 DDoS,Cloudflare 已经把一切都替我做好了 —— 更重要的是流量费全免,我唯一做的就是绑了个信用卡花了十几块钱买了个域名,但实际上根本不需要什么额外费用 —— 都已经包含在免费计划中了。
更令我震惊的是,虽然访问速度慢了一些,但在中国大陆是可以直接访问 CF 上的网站的,甚至不需要备案!说来也滑稽,本土云厂商虽然可以很快替你完成网站资源置备这件事,但耗时最久的步骤往往是卡在备案上。这一点确实算是 Cloudflare 的一个福利特性了。
Worker:极致的 Serverless 体验
尽管你可以把许多业务逻辑放在前端在浏览器中用 Javascript 解决,但一个复杂的动态网站也是需要一些后端开发的。而 Cloudflare 也把这一点简化到了极致 —— 你只需要编写业务逻辑的 Javascript 函数就可以了。当然,也可以使用 Typescript,现在更是支持 Python 了 —— 直接调用 AI 模型,难以想象后面会出现多少新的花活!
用户编写的这个函数会被部署在 Cloudflare 全世界 CDN 边缘服务器节点上,执行用户定义的业务逻辑。你可以 干各种各样的事情,返回动态的HTML与JSON,自定义路由、重定向、转发、过滤、缓存、A/B测试,重写请求,聚合请求,执行认证。当然,你也可以直接使用业务代码中调用对象存储 R2 与 SQL 数据库 D1,或者把请求转发到你自己的数据中心服务器上处理。
export interface Env {
// If you set another name in wrangler.toml as the value for 'binding',
// replace "DB" with the variable name you defined.
DB: D1Database;
}
export default {
async fetch(request: Request, env: Env) {
const { pathname } = new URL(request.url);
if (pathname === "/api/beverages") {
// If you did not use `DB` as your binding name, change it here
const { results } = await env.DB.prepare(
"SELECT * FROM Customers WHERE CompanyName = ?"
)
.bind("Bs Beverages")
.all();
return Response.json(results);
}
return new Response(
"Call /api/beverages to see everyone who works at Bs Beverages"
);
},
};
在 Worker 中查询 D1,简单到就是调用个变量。
[[d1_databases]]
binding = "DB" # available in your Worker on env.DB
database_name = "prod-d1-tutorial"
database_id = "<unique-ID-for-your-database>"
也不需要什么配置,指定一下D1数据库/R2对象存储名称就好了。
比起传统云上笨拙的开发部署体验来所,CF worker 真正做到了让开发者爽翻天的 Serverless 效果。开发者不需要操心什么数据库连接串,AccessPoint,AK/SK密钥管理,用什么数据库驱动,怎么管理本地日志,怎么搭建 CI/CD 流程这些繁琐问题,最多在环境变量里面指定一下存储桶名称这类简单信息就够了。写好 Worker 胶水代码实现业务逻辑,命令行一把梭就可以完成全球部署上线。
与之对应的是传统公有云厂商提供的各种所谓 Serverless 服务,比如 RDS Serverless,就像一个恶劣的笑话,单纯是一种计费模式上的区别 —— 既不能 Scale to Zero,也没什么易用性上的改善 —— 你依然要在控制台去点点点创建一套 RDS,而不是像 Neon 这种真 Serverless 一样用连接串连上去就能直接迅速拉起一个新实例。更重要的是,稍微有个几十上百的QPS,相比包年包月的账单就要爆炸上天了 —— 这种平庸的 “Serverless” 确实污染了这个词语的本意。
R2:吊打 S3 的对象存储
Cloudflare R2 提供了对象存储服务。与 AWS S3 相比,便宜了也许能有一个数量级 —— 我的意思是,尽管单纯看存储的价格 $ / GB·月,Cloudflare(0.015 $)价格与 S3 (0.023 $) 差距并不大,但 Cloudflare 的 R2 是免流量费的!
| 每月免费额度 | Cloudflare R2 | Amazon S3 |
|---|---|---|
| 存储 | 10 GB / 月 | 5 GB / 月 |
| 写请求 | 1 M / 月 | 2 K / 月 |
| 读请求 | 10 M / 月 | 20 K / 月 |
| 数据传输 | 无限量! | 100 GB |
| 超出免费额度后的价格 | ||
| 存储 | ¥ 0.11 / GB | ¥ 0.17 / GB |
| 写请求 | ¥ 32.63 / 百万请求 | ¥ 36.25 / 百万请求 |
| 读请求 | ¥ 2.61 / 百万请求 | ¥ 2.9 / 百万请求 |
| 流量费 | 免费! | ¥ 0.65 / GB |
Cloudflare R2 定价 与 AWS S3 对比
举个例子,我的网站,R2 在过去一个月内消耗了 300 GB 流量,按照本土云 1GB 流量八毛钱左右的价格,需要支付 240 元,但我一分钱也没付。而且,我还知道更极端的例子 —— 比如一个月消耗了 3TB 流量,也依然在免费套餐中……
Cloudflare R2 是与 CDN 二合一的。在传统的云服务商中,你还需要操心额外的 CDN 配置,回源流量,CDN流量包,抗DDoS等等问题。但 Cloudflare 不需要,只要勾选配置启用,你的 R2 Bucket 可以直接被全世界读取,而最重要的是,而你根本不用担心账单被刷爆的问题 —— 我知道好几个在传统云厂商上,因为攻击把 CDN 流量刷爆,几万块钱余额一夜耗干欠费的案例。(包括我自己还亲历过一个因为云厂商自己SB的CDN回源设计,爆刷CDN流量的案例)但是在 Cloudflare 上,你不需要像斗牛犬和猫头鹰一样监视着 账单 与流量,首先,Cloudflare 流量免费…… ,更强的是, Cloudflare 已经有了智能的抗 DDoS 服务了,即使是免费的 Plan 也默认提供这项服务,可以有效避免恶意攻击(在传统云厂商,这玩意单独卖几千上万的所谓高防IP服务)。再加上每月慷慨的免费 1千万读取请求(对于放图片、软件包来说这已经非常大了!),可以确保在这上面的费用是高度确定性的 —— 如果不是零的话。
Cloudflare:在线的价值
王坚博士那本讲云计算的书《在线》其实说得很明白,云计算的真正价值是 在线(而不是什么弹性、敏捷、便宜之类的东西)。举个例子:我有一些下云的客户与用户,虽然已经把主体业务从公有云上搬到了 IDC 或者自己办公室的服务器上,但依然在云上留一些 ECS 和 RDS 的尾巴 —— 因为他们收取数据的 API 放在那里,感觉公有云提供的网络接入要比自己的机房/办公室更稳定可靠 —— 注意是网络接入而不是存储计算。

很多云上的客户,在算力上付出了几倍到十几倍溢价,在存储上付出了几十倍到上百倍的溢价,都是为了这个网络 “在线” 的能力。但 Cloudflare 这样遍布全球的,带有边缘计算能力的 CDN ,将 “在线” 的能力拔高到了一个全新的高度上,比传统公有云更好地解决了这个问题。例如,AI 当红炸子鸡 OpenAI 的网站和 API 就是这么做的 —— 通过 CF 对外提供接入。
在这种模式下,用户完全可以把网站与 API 通过 Cloudflare 对外提供接入,而将重量级的存储与计算放在 IDC 中,而不是在传统公有云上用几倍的价格进行租赁。Cloudflare 提供的 Worker 可以在边缘用于发送、收取数据,并将请求转发至您自己的数据中心进行处理。如果希望实现更可靠的容灾,您还可以利用 Cloudflare 上的 R2 与 D1 作为临时性本地缓存,预处理汇总数据后,统一拉取到 IDC 进行处理。
CF 与 IDC 从两头挤压公有云
在 IT 规模光谱的一侧 —— 个人站长与小微企业上,新一代云服务 / SaaS(CF,Neon,Vercel,Supabase) 赛博菩萨们的免费套餐,对公有云产生了明显的替代与冲击 —— 别说 99 块钱包年的云服务器了,9块9 都不一定香了 —— 再便宜能便宜过免费吗? —— 更何况用 CF 建站的体验比云服务器自建要好太多了。
但更重要的是,在光谱另一侧的中大型企业中,新出现的 IDC 2.0 与开源管控软件替代合流,短路掉公有云这个中间商,利用好硬件摩尔定律的累积优势,成为终极FinOps实践,实现极为惊人的降本增效能力。Cloudflare 的出现补齐了开源IDC自建模式的最后一块短板 —— “在线” 能力。
Cloudflare 并没有提供传统公有云上的那些弹性计算、存储、K8S、RDS 服务。但幸运地是,Cloudflare 可以与公有云 / IDC 良好地配合协同 —— 从某种意义上来说,因为 Cloudflare 成功解决了 “在线” 的问题,这使得传统数据库中心 IDC 2.0 也同样可以拥有比肩甚至超越公有云的 “在线” 能力,两者配合,在事实上摧毁了一些公有云的护城河,并挤压了传统公有云厂商的生存空间。
我非常看好 Cloudflare 这种模式,实际上,这种丝滑的体验才配称的上是云,配享太庙,可以心安理得吃高科技行业的高毛利。传统的 IDC 2.0 也在不断进步,租赁机柜、裸金属服务器的体验也并不逊色传统公有云(无非是服务器从两分钟到位变成几个小时到位)。而无法提供更多技术附加值,产品不可替代性的公有云厂商,生存空间会越来越小 —— 最终回退到传统 IDC / IaaS 业务中去。
罗永浩救不了牙膏云?
老罗曾是一位很牛B的数码产品经理,算与 IT 行业沾边。但隔行如隔山,老罗卖云,就好像同时卖肉菜蛋奶和 Office 光盘的路边摊。事实也是如此 —— 老罗直播间先铺垫卖了半个小时的扫地机器人,接着姗姗来迟的老罗照本宣科念台词卖了四十分钟”云计算“ —— 然后马不停蹄地卖起了 高露洁无水酵素牙膏 —— 留下在云计算与牙膏间迷惑凌乱的观众。
这牙膏确实还不错,但这云服务器嘛…
云计算可以2C吗?
云计算是 ToB 业务,行业翘楚 AWS 的服务对象和营销焦点,显然是面向企业级开发者的。尽管一些个人站长,博主,学生或初创企业可能会因为低价而在直播间拍板购买云服务器,但这显然非常滑稽。更滑稽的是直播间的云服务器也没有更便宜 —— 99 块钱的云服务器活动从去年双十一就开始并持续至今……
把云服务器卖给个人用户这种滑稽想法,可能源于最近爆火的《幻兽帕鲁》自建服务器需求。我的朋友 SealOS 的创始人方海涛写了一篇《自建幻兽帕鲁私服的教程》,尝到了泼天富贵 SaaS 的美味。然后各家公有云厂商也快速跟进卷了起来 —— 一路从3分钟开服到30秒到3秒种开服。正如 《国内云:有大厂,没大哥》一文形容地那样,丝毫不顾颜面,撸起袖子下场,干起了浩方对战平台应该干的事情。

另一种 ToC 的典型场景是学生和个人站长。在以前,个人站长拿个 2C 2G 3M带宽的小虚拟机弄个网站还是挺不错的 —— 但是自从有了赛博佛祖 Cloudflare,别说 99 块钱的云服务器了,9块9 都不香了 —— 再便宜能便宜过免费吗? —— 何况用 CF 建站的体验比云服务器要好太多了 —— 都不用说各种Free Plan,就凭流量免费这一点,就足以让“送的几兆带宽”都统统变垃圾……
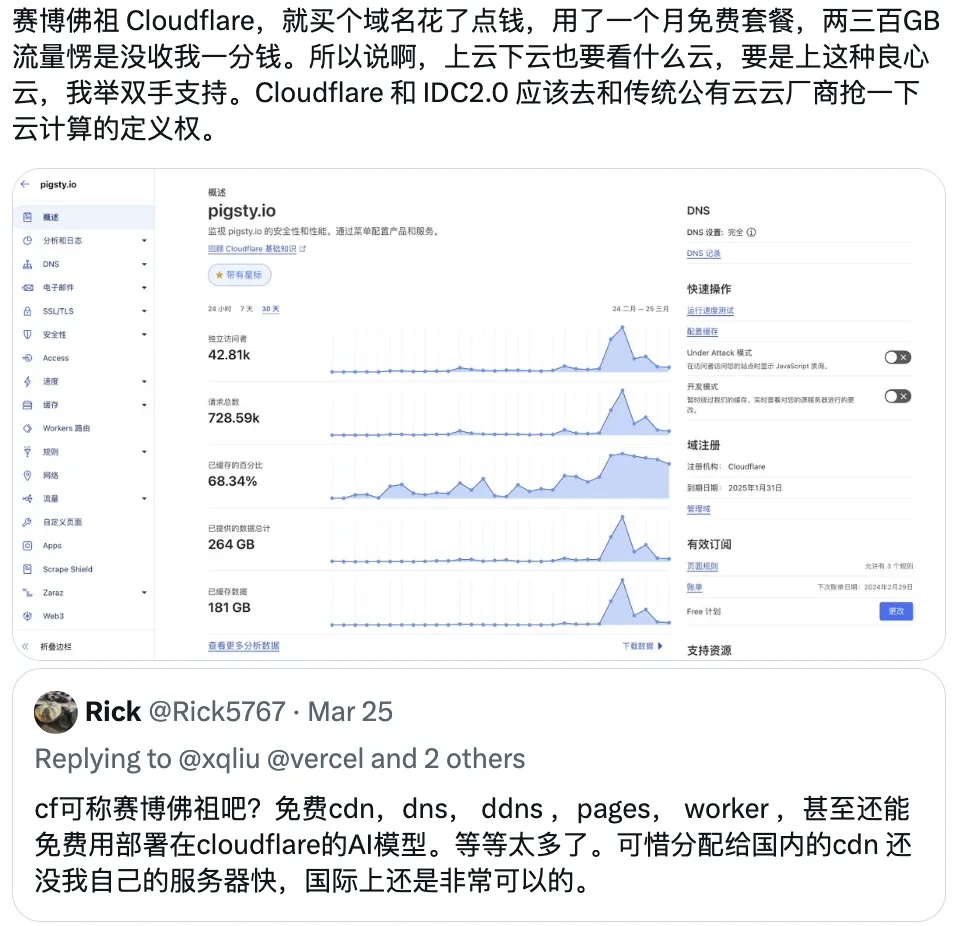
在 IT 规模光谱的一侧 —— 个人站长与小微企业上,新一代云服务/SaaS(CF,Neon,Vercel,Supabase),赛博菩萨们的免费套餐,对公有云产生了明显的替代与冲击;在光谱的另一侧 —— 中大型企业组织中,新出现的 IDC 2.0 与开源管控软件替代合流,短路掉公有云这个中间商,利用好硬件摩尔定律的累积优势,成为终极FinOps实践,实现极为惊人的降本增效能力。
公有云冥灯亮起
任何行业的发展基本都遵从:技术主导 → 产品主导→ 运营主导的脉络。而在当下,除了大模型之外,公有云几乎没有什么独一无二的技术,不可替代的产品了。虚拟机、对象存储、云数据库成为了各家都有售的标品大锅饭,开源的云管控软件比如 SealOS 与 Pigsty 也将自建的能力普及。行业卷成了一片血海,大家从拼技术、拼产品的阶段走向了终局 —— 拼运营,也就是拼销售、打价格战的阶段。
对云计算来说,ToC 这种生意只能算蚊子腿。我们可以简单假设估算一下 —— 帕鲁爆卖了两千万份,十分之一中国玩家;作为单机游戏假设又有十分之一的用户有联机需求;这百分之几的本土联机用户一个月内玩腻,最后能产生个十几万核·月的云服务需求,分别从 A、B、C、D 等诸家云厂商采购 —— 每家分到个小几百万的市场规模。听上去不少,够养活一个创业公司了 —— 但随便一个云上 KA 企业客户年消,或者几个程序员工资就这个数了 —— 这显然不是云厂商应该干的事情。
公有云行业的增长已经到顶,原来看不上的蚊子腿,现在也变成了香饽饽 —— 各家云厂商的营收增速已经从原来的几十下降到了个位数,勉强靠着租GPU和大模型续了一口。但原本主营业务的增量市场没有了,市场萎缩,进入了零和博弈与斗兽厮杀阶段。营销也用出了各种荒腔走板草台班子的招数 —— 比如,女大学生第一次买服务器这种没品噱头,买数据库送天猫超市购物券这种滑稽戏,以及新出现的淘宝直播卖云服务器的新节目。
实际上,罗老师在 行业晴雨表的能力上有着出色的的声誉 —— 冥灯为谁而亮,丧钟为谁而鸣?这种行为艺术有着一语成谶的潜力。牙膏云逐渐从代表先进生产力的本土云计算领头羊,变成了只能够打价格战的计算资源提供商,自己把自己玩坏了,确实不禁让人嘘唏。
剖析阿里云服务器算力成本
2024年2月29号疯狂星期四,阿里云搞了个大降价,软文漫天飞舞,作为云计算泥石流,不少朋友在后台留言让我点评一下。满屏的 20%,50% off 看上去好像降的很壮观,但外行看热闹,内行看门道:云服务的成本大头在于存储。
云厂商真正的杀猪刀 —— ESSD 可是一毛钱都没降。而 EC2 和 OSS 降价降的也不是列表价,而是包年的最低折扣 —— 主力机型包一、三、五年可降价 10% 左右,所以也基本上降了个寂寞,对于已经享受低于此商务折扣的客户更是毫无卵用。
我们之前有过分析:云上 ECS 算力单价可达本地自建的十倍,云上 ESSD 存储单价可以达到本地自建的百倍。云数据库 RDS 介于两者之间。算力降价 10%, 相对于这个溢价来说就跟挠痒痒一样。
不过,既然阿里云号称大降价了,我就把云上基础资源的价格拎出来,用 2024 年的价格,再做一次成本对比。
太长不看
算力的价格使用 人民币/核·月 作为统一单位 ,云服务器的溢价为自建的 5 ~ 12 倍。
作为自建的参照案例,DHH 与 探探自建大型计算/存储服务器的单价成本为 20 ¥/(核·月),算上64x 配比的本地 NVMe 存储后为 22.4 ¥/(核·月)。我们考察阿里云国内一线可用区标准 c/g/r 实例族最近三代的算力均价,可以得出以下结论
在不考虑存储的情况下,云上按量,包月,包年,预付五年的单价分别为 187¥,125¥,81¥,37¥,相比自建的 20¥ 分别溢价了 8x, 5x, 3x, 1x。在配置常用比例的块存储后(1核:64GB, ESSD PL3),单价分别为:571¥,381¥,298¥,165¥,相比自建的 22.4¥ 溢价了 24x, 16x, 12x, 6x 。
| 关键数字 | 按需价格 | 包月价格 | 包年价格 | 预付三年 | 预付五年 |
|---|---|---|---|---|---|
| 配上64x存储价格 | 571 ¥ | 381 ¥ | 298 ¥ | 181 ¥ | 165 ¥ |
| 是自建价格的几倍 | 25x | 17x | 13x | 8x | 7x |
| 算力单位价格 | 187 ¥ | 125 ¥ | 81 ¥ | 53 ¥ | 37 ¥ |
| 是自建价格的几倍 | 9x | 6x | 4x | 3x | 2x |
随后,我们进一步定量分析阿里云服务器定价数据,发现了对单价影响最大的几项要素:附加存储,付费方式,可用区,实例族(芯片架构,实例代际,内存配比),并解释了上面的数字是如何计算得到的。
作为结论:即使是在所谓的“大降价”后,公有云提供的算力也远远称不上 “便宜” 。实际上云服务器的成本极其高昂,尤其是大型计算与大型 NVMe 存储。如果您的业务需要较大的块存储或一台物理服务器以上的算力,您确实应当仔细计算一下这里的成本,并考虑一下其他的备选项。
纯算力的价格
我们取样了最具有代表性的国内可用区,最近三代 c/g/r 实例族纯算力部分的的价格,绘制为图表。
如表所示,单位算力(1C4G)的标准价格是包月的价格,为 125 ¥。在此基础上:按量付费需要额外支付 50% 溢价,为 187 ¥;包年预付可以打 65折为 81 ¥,包三年可以打 44 折为 53 ¥,预付五年可以打三折为 37 ¥。
| 关键数字 | 按需价格 | 包月价格 | 包年价格 | 预付三年 | 预付五年 |
|---|---|---|---|---|---|
| 算力单位价格 | 187 ¥ | 125 ¥ | 81 ¥ | 53 ¥ | 37 ¥ |
| 是自建价格的几倍 | 9x | 6x | 4x | 3x | 2x |
| 自建成本可降低% | 89% | 84% | 75% | 62% | 46% |
| 自建成本可降至 % | 11% | 16% | 25% | 38% | 54% |
我们可以使用 DDH 2023 年下云自建的案例,以及我自己在探探亲身经历的云下 IDC 自建案例作为对比。 刨除 NVMe 存储部分后,DHH 自建的纯算力单价为 22 ¥,探探自建的单价为 18 ¥。
自建价格已经算上人力/运维费用了!
请注意,此成本数字中已经包含了服务器费用,以及交换机/机柜/网/电/代维/运维人员均摊后的费用。DHH 的单位价格中有 50% 是服务器之外的成本,探探中则为 20% 。如果只算服务器成本,自建单位价格可以降至 10 ¥。如果再以容器平台 500% 超卖比率计算…因此不难看出,云上的纯算力的价格是自建的 2 ~ 9 倍!为了实现云厂商所鼓吹的 “极致弹性”,“按量付费”,您需要额外付出 8倍的成本。假如您完全不在乎弹性,就跟正常采购服务器五年摊销一样使用,那么仍然需要额外付出1倍的成本。
杀猪盘的价格
如果云上的算力溢价在预付多年的 Saving Plan 中,价格还能勉强让人接受,那么云上存储的溢价就属于离谱的杀猪盘了。
大型算力往往要搭配高性能的本地存储使用 —— 例如业内经常使用的一种配比规格为 1核:64GB NVMe 存储。探探和 DHH 的自建案例中都使用此配比。 探探的服务器案例中,64核配 3.2TB NVMe SSD,采购价 6000 元,当下市价 ¥2788。在 DHH的案例中,192 核配 12 TB NVMe SSD,采购价 $2390。以标准五年质保与财务摊销计算,单位价格 ¥/(GB·月) 约为 0.02。
| 单位价格:¥/GiB月 | IOPS | 带宽 | 容量 | 按需价格 | 包月价格 | 包年价格 | 预付三年+ |
|---|---|---|---|---|---|---|---|
| ESSD 云盘 PL0 | 10K | 180 MB/s | 40G-32T | 0.76 | 0.50 | 0.43 | 0.25 |
| ESSD 云盘 PL1 | 50K | 350 MB/s | 20G-32T | 1.51 | 1.00 | 0.85 | 0.50 |
| ESSD 云盘 PL2 | 100K | 750 MB/s | 461G-32T | 3.02 | 2.00 | 1.70 | 1.00 |
| ESSD 云盘 PL3 | 1M | 4 GB/s | 1.2T-32T | 6.05 | 4.00 | 3.40 | 2.00 |
| 本地 NVMe SSD | 3M | 7 GB/s | 最大单卡64T | 0.02 | 0.02 | 0.02 | 0.02 |
抛开系统盘/HDD这种乞丐盘,在阿里云上提供了四种不同规格等级的块存储:ESSD PL0 ~ PL3。其单位价格分别为:0.5, 1, 2, 4。ESSD PL3 的性能勉强接近本地 Gen3 NVMe SSD,但它 4 块钱的单价是本地自建的 200 倍!当然 ESSD 也有自己独立的折扣策略 —— 预付费三年以上,ESSD 可以打满顶折 5 折,但那也是 100 倍溢价了!
| 关键数字 | 按需价格 | 包月价格 | 包年价格 | 预付三年 | 预付五年 |
|---|---|---|---|---|---|
| 配上64x存储价格 | 571 ¥ | 381 ¥ | 298 ¥ | 181 ¥ | 165 ¥ |
| 是自建价格的几倍 | 25x | 17x | 13x | 8x | 7x |
| 自建成本可降低% | 96% | 94% | 92% | 88% | 86% |
| 自建成本可降至 % | 4% | 6% | 8% | 12% | 14% |
在《云盘是不是杀猪盘》中我们已经详细对比过云盘与本地盘的性能、可靠性与成本,因此这里主要使用与本地 NVMe SSD 最接近的 ESSD 云盘 PL3 作为对比。如果我们为每核 CPU 配置 64 GiB 的 PL3 块存储,则调整后的云服务器单价为:381 ¥。在此基础上:按量付费需要额外支付 50% 溢价,为 571 ¥;包年预付为 298 ¥,包三年可以打 44 折为 181 ¥,预付五年可以打三折为 165。
与 DHH / 探探自建的含存储单价 22.4 ¥ 相比,云服务器单价达到了自建的 6 ~ 25 倍!
图:带64x存储单价对比
云存储对单价的影响
在影响服务器价格的因素中,存储是变数最大的一个。
例如,以上面的标准配置:1核:4x内存:64x存储,在使用不同规格的 ESSD 的情况下,存储费用占服务器费用的比例差异非常之大。
使用 PL3 ESSD 的情况下,存储费用占比可以达到 67% ~ 77%,我们也可以选择更烂的乞丐盘作为存储,以IOPS/带宽吞吐性能为代价 “降低成本”。例如,使用 PL2 以牺牲 90% 的 IOPS 性能为代价,将这一比例降低至 51% ~ 63%,PL1/PL Auto 以牺牲 95% 的性能为代价,将此比例降低至 34% ~ 46%。PL0 则以 99% 的性能为代价,将此比例降低至 20% ~ 30% 。
| 云盘规格 | 预付五年 | 预付四年 | 预付三年 | 预付二年 | 包年价格 | 包月价格 | 按量付费 |
|---|---|---|---|---|---|---|---|
| +PL3 ESSD | ¥165 | ¥172 | ¥181 | ¥247 | ¥298 | ¥381 | ¥571 |
| +PL2 ESSD | ¥101 | ¥108 | ¥117 | ¥158 | ¥190 | ¥253 | ¥379 |
| +PL1 ESSD | ¥69 | ¥76 | ¥85 | ¥113 | ¥135 | ¥189 | ¥283 |
| +PL0 ESSD | ¥53 | ¥60 | ¥69 | ¥91 | ¥108 | ¥157 | ¥235 |
| 纯算力价格 | ¥37 | ¥44 | ¥53 | ¥68 | ¥81 | ¥125 | ¥187 |
请注意,ESSD 块存储和 ECS 算力的折扣力度是不同步的,由于 SSD 的顶配折扣(5折)比纯算力的顶配折扣(3折)要更弱,所以存储费用比例随着预付费时间增加会越来越高。
| 云盘规格 | 预付五年 | 预付四年 | 预付三年 | 预付二年 | 包年价格 | 包月价格 | 按量付费 |
|---|---|---|---|---|---|---|---|
| +PL3 ESSD | 77% | 75% | 71% | 72% | 73% | 67% | 67% |
| +PL2 ESSD | 63% | 60% | 55% | 57% | 57% | 51% | 51% |
| +PL1 ESSD | 46% | 42% | 38% | 40% | 40% | 34% | 34% |
| +PL0 ESSD | 30% | 27% | 23% | 25% | 25% | 20% | 20% |
| 纯算力价格 | 0% | 0% | 0% | 0% | 0% | 0% | 0% |
有人主张说,云上的 ESSD 应该和 SAN 存储对比,本地 NVMe SSD 应该与实例存储进行对比。在《云盘是不是杀猪盘》中已经解释过这个问题。直接面向用户的数据库类服务使用的几乎都是 EBS 而非实例存储;此外,阿里云并非没有带本地 NVMe SSD 实例存储的机型,例如 i 系列,但这里的单价也远远说不上便宜。
预付费对单价的影响
预付费方式对云服务器的价格有着显著影响:算力的价格以包月价格作为标准,按需付费价格上浮 50%,包年打 65 折,包二、三、四、五年的折扣分别是55,44,35,30 折。存储的价格同样以包月价格作为基准,按需付费的价格上浮 51.25%,包年打85折,两年七折,三年以上五折。ECS 算力的单价(¥/核月)与块存储 ESSD 的单价(¥/GiB月)和折扣规则如下表所示:
| 付费模式 | 算力折扣 | 算力单价 | ESSD折扣 | PL3 | PL2 | PL1 | PL0 |
|---|---|---|---|---|---|---|---|
| 按量付费 | 150% | 187 | 151.25% | 6.05 | 3.02 | 1.51 | 0.76 |
| 包月付费 | 100% | 125 | 100% | 4.00 | 2.00 | 1.00 | 0.50 |
| 预付一年 | 65% | 81 | 85% | 3.40 | 1.70 | 0.85 | 0.43 |
| 预付二年 | 55% | 68 | 70% | 2.80 | 1.40 | 0.70 | 0.35 |
| 预付三年 | 44% | 53 | 50% | 2.00 | 1.00 | 0.50 | 0.25 |
| 预付四年 | 35% | 44 | 50% | 2.00 | 1.00 | 0.50 | 0.25 |
| 预付五年 | 30% | 37 | 50% | 2.00 | 1.00 | 0.50 | 0.25 |
对于纯算力来说,最近三代主流实例族的价格与比例如下表所示,不难看出实际定价相当符合上面给出的模型:
| 实例族单价 | 预付五年 | 预付四年 | 预付三年 | 预付二年 | 包年价格 | 包月价格 | 按量付费 |
|---|---|---|---|---|---|---|---|
| c6 | ¥27 | ¥31 | ¥38 | ¥49 | ¥58 | ¥88 | ¥133 |
| c7 | ¥28 | ¥33 | ¥38 | ¥52 | ¥62 | ¥96 | ¥144 |
| c8i | ¥30 | ¥35 | ¥44 | ¥56 | ¥66 | ¥101 | ¥152 |
| g6 | ¥34 | ¥40 | ¥49 | ¥62 | ¥74 | ¥114 | ¥170 |
| g7 | ¥37 | ¥43 | ¥52 | ¥67 | ¥79 | ¥123 | ¥185 |
| g8i | ¥39 | ¥46 | ¥56 | ¥72 | ¥85 | ¥130 | ¥195 |
| r6 | ¥45 | ¥53 | ¥65 | ¥83 | ¥98 | ¥150 | ¥225 |
| r7 | ¥49 | ¥57 | ¥70 | ¥89 | ¥105 | ¥164 | ¥246 |
| r8i | ¥52 | ¥61 | ¥75 | ¥95 | ¥113 | ¥173 | ¥260 |
| 实例族折扣 | 预付五年 | 预付四年 | 预付三年 | 预付二年 | 包年价格 | 包月价格 | 按量付费 |
|---|---|---|---|---|---|---|---|
| c6 | 30% | 35% | 43% | 55% | 65% | 100% | 150% |
| c7 | 30% | 35% | 40% | 54% | 64% | 100% | 150% |
| c8i | 30% | 35% | 43% | 55% | 65% | 100% | 150% |
| g6 | 30% | 35% | 43% | 55% | 65% | 100% | 150% |
| g7 | 30% | 35% | 43% | 54% | 64% | 100% | 150% |
| g8i | 30% | 35% | 43% | 55% | 65% | 100% | 150% |
| r6 | 30% | 35% | 43% | 55% | 65% | 100% | 150% |
| r7 | 30% | 35% | 43% | 54% | 64% | 100% | 150% |
| r8i | 30% | 35% | 43% | 55% | 65% | 100% | 150% |
上图展示了不同实例族在不同付费模式下的价格对比。如果我们对所有实例价格取一个平均(大致相当于 1c4g 机型的标准价),不同付费模式下的算力均价如柱状图所示:
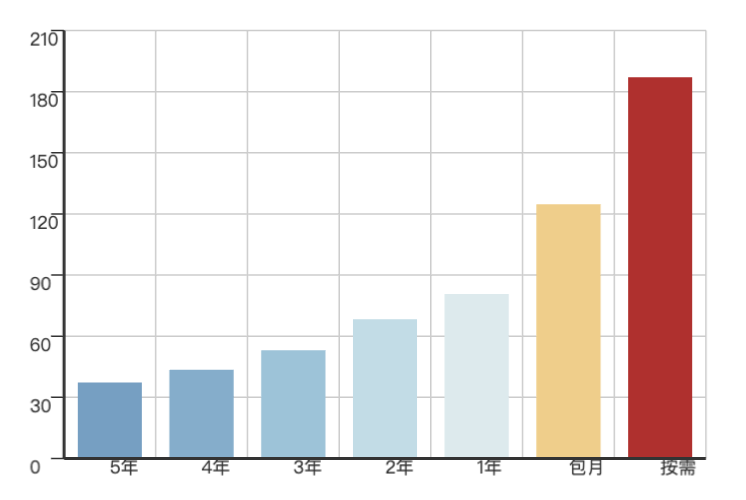
实例族对价格的影响
实例族对价格的影响主要取决于三点:内存配比,芯片架构,实例代际。
首先,同一实例族内的 实例单价与CPU核数无关,即最终算力部分的价格线性正比于 CPU 核数。因此不会出现规格越大,单价越便宜或越贵的现象(这意味着云服务器实例规格越大,性价比越低)。
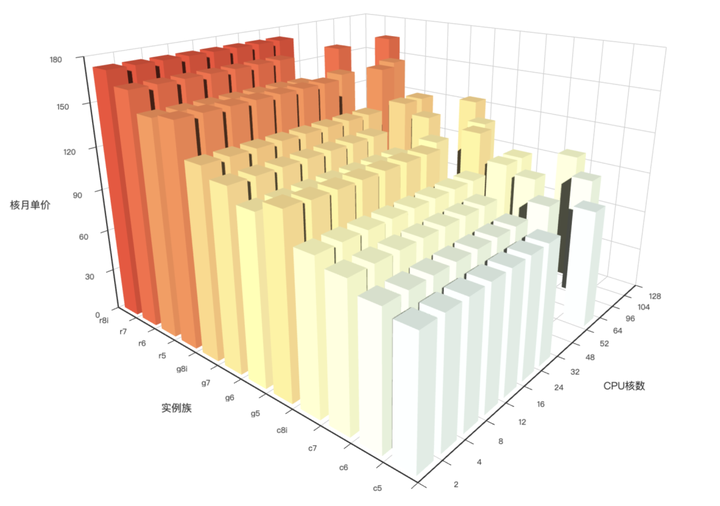
内存配比指的是一个 CPU 核配比多少倍的内存,内存的单位是 GiB。在阿里云上,通用型(g)实例的内存配比为1:4,标记为 4x ,即一核CPU配 4 GiB 内存。计算型(c)实例内存配比为 1:2,内存型(r)实例内存配比为 1:8 。
| 代际 | c 计算型 2x | g 通用型 4x | r 内存型 8x | c / g | r / g |
|---|---|---|---|---|---|
| 6 | ¥ 88 | ¥ 114 | ¥ 150 | 78% | 132% |
| 7 | ¥ 96 | ¥ 123 | ¥ 164 | 78% | 133% |
| 8 | ¥ 101 | ¥ 130 | ¥ 173 | 78% | 133% |
从统计上看,相比 4x 通用型实例族,同核数的内存型实例 8x 内存翻倍,价格是通用型实例的 132% ;同核数的计算型实例 2x 内存减半,价格是通用型实例的 78%。
我们还可以根据这里的规律计算出阿里云上内存的定价约为 12 元/GiB月:也不算便宜,16G用俩个月就够买一条了。
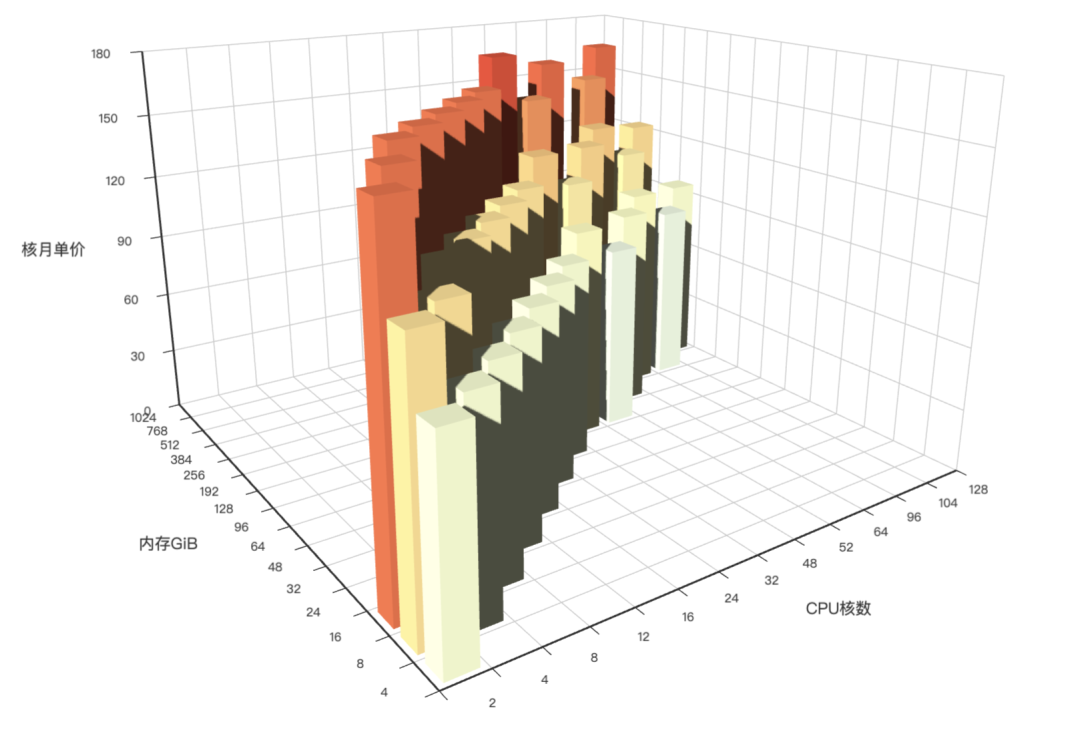
此外,实例/CPU 的代际也对价格有影响,例如以当下的八代实例为基准,上一代 Gen7 实例的价格会在本代基础上打 95 折,再上一代 Gen6 的实例会在本代基础上打 87 折。
| 代际 | Intel | ARM | ARM / Intel | 倚天 | 倚天 / Intel |
|---|---|---|---|---|---|
| 6 | ¥ 117 | ¥ 104 | 89% | ||
| 7 | ¥ 128 | ¥ 105 | 82% | ||
| 8 | ¥ 135 | ¥ 125 | 92% | ¥ 96 | 71% |
从芯片架构上看,ARM 实例价格是标准 Intel 实例的九折,阿里自研倚天芯片实例的价格是标准 Intel 实例的七折。30% off 就想找小白鼠尝鲜,诚意有些不足了。
可用区对价格的影响
从大的层面上来说,阿里云的可用区可以分为国内/国际区域,两者的价格有着泾渭分明的区别。海外可用区(包括香港)的价格要比国内可用区高很多,最贵的可用区是香港,各实例族价格几乎是国内可用区的一倍。
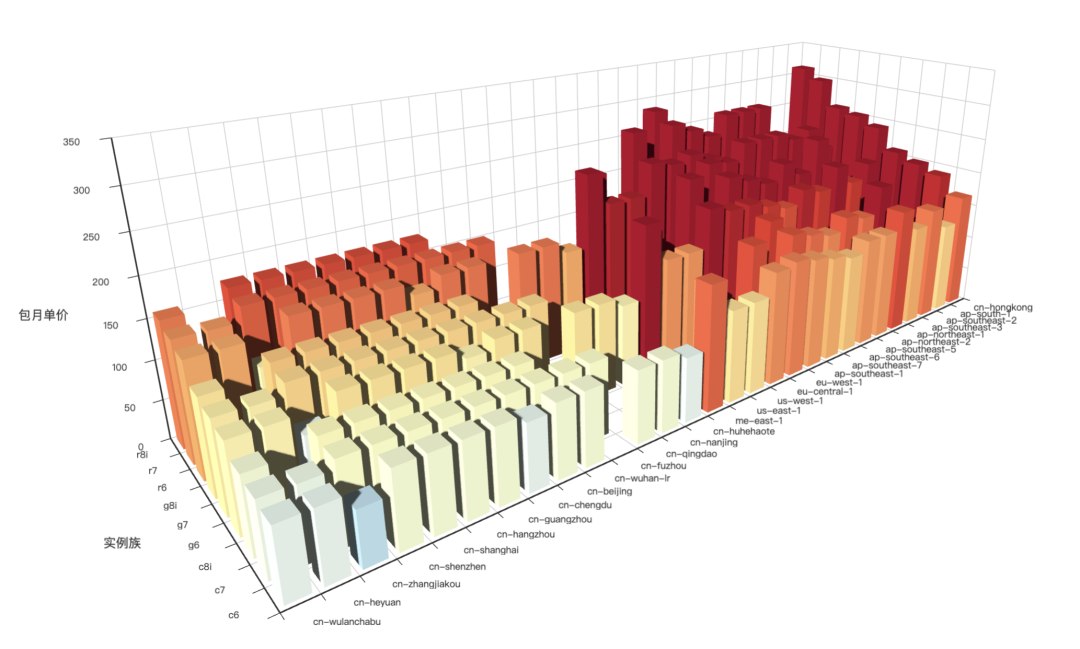
国内可用区价格上大体分为两类:中心城市(北上广深杭+宁汉蓉榕青)和犄角旮旯(乌兰察布,河源,呼和浩特,张家口)。中心城市可用区的实例定价保持高度一致(成都例外,有几个实例族稍微便宜点)。犄角旮旯地方的实例价格会便宜一些,相比中心城市最高可能有 30% 的折扣。
云下高可用秘诀:拒绝复杂度自慰
我们不需要Kubernetes大师或花哨的新数据库 —— 程序员极易被复杂度所吸引,就像飞蛾扑火一样。系统架构图越复杂,智力自慰的快感就越大。我们坚决抵制这种行为,是在云下可用性上成功的重要原因。
作者:David Heinemeier Hansson,网名DHH,37 Signal 联创与CTO,Ruby on Rails 作者,下云倡导者、实践者、领跑者。反击科技巨头垄断的先锋。Hey博客
译者:冯若航,网名 Vonng 。磐吉云数创始人与CEO。Pigsty 作者,PostgreSQL 专家/布道师。公众号《非法加冯》主理人,云计算泥石流,数据库老司机。
本文翻译自 DHH 博客,
下云的同时确保系统稳定运行
对 37signals 的运维团队来说,2023年无疑是充满挑战的一年。我们把包括七大核心应用从云上迁移了下来,其中包括在云上诞生的电子邮件服务 HEY —— 它有着极为严苛的可用性要求,我们下云的过程不能影响这一承诺。幸运的是,我们确实做到了。2023年,HEY的可用时间达到了令人瞩目的 99.99%!
这一点非常重要,因为如果人们无法访问他们的电子邮件,他们可能会错过飞机登机,无法及时完成交易,或者无法获知医疗检测结果。我们非常重视这项责任,因而在这个需要彻底改变运行 HEY 运行方式的一年里,实现了这接近完美的四个九,成为了让我引以为傲的重要成就。
但不仅仅是 HEY 有这种细致运维待遇。在2023年,我们运营的所有主要应用可用性最低都达到了 99.99% 以上。这里包 Highrise、Backpack、Campfire 以及所有版本的 Basecamp。我们并非没有遇到任何问题 —— 而是靠团队迅速解决了所有问题,使全年的总停机时间没有超过 0.01%。
在云外能否确保应用可靠性和稳定性,没有一个应用能比 Basecamp 2 更能说明这个问题。这是我们从 2012 年到 2015 年销售的 Basecamp 版本,至今仍有数千用户,创造了数百万美元的收入。它多年来一直运行在我们自己的硬件上,现在已经是连续第二年实现了几乎难以置信的 100% 可用性 —— 2023年整整365天零停机,延续了2022年的辉煌。
我不会假装如此卓越的可用性是一件轻而易举的事情,因为事实并非如此。做到这一点绝非易事。我们拥有一支技艺精湛、敬业奉献的运维团队,他们为实现这一目标做出了巨大贡献,理应获得高度赞扬。但这也并非什么高深莫测的火箭科学!
Basecamp 2 连续两年实现100%可用性的魔法,以及其他所有应用达到99.99%可用性的成绩,相当一部分归功于我们选择了简单枯燥、基础扎实的技术。我们使用了 F5、Linux、KVM、Docker、MySQL、Redis、ElasticCache,当然还有 Ruby on Rails。我们的技术栈朴实无华,主要是复杂度很低 —— 我们并不需要 Kubernetes 大师或花哨的数据库与存储。大多数情况下,你也不会需要的。
但是程序员极易被复杂度所吸引,就像飞蛾扑火一样。系统架构图越复杂,智力自慰的快感就越大。我们坚决抵制这种行为的投入,才是在可用性上胜利的根本原因。
这里我讨论的并不是运营 Netflix、Google 或 Amazon 所需的技术。在那种规模下,你确实会遇到真正的开拓性问题,没有现成的解决方案可供借鉴。但对于我们其他 99.99% 的人来说,效仿他们的想象与认知来建模自己的基础设施,是诱人但致命的塞壬歌声。
想要拥有良好的可用性,你需要的不是云,而是在冗余硬件上运行成熟的技术,并配置好备份,一如既往。
注:DHH 省下近千万美元的高昂云开销,本文翻译了DHH下云的最新进展。下云前情提要与完整过程请参考:《下云奥德赛》,《是时候放弃云计算了吗》,以及《DHH下云FAQ》。
译者评论
DHH指出了维护良好可用性的最佳实践 —— 在冗余硬件上运行朴实无华、成熟基础的技术。软件的大部分成本开销并不在最初的研发阶段,而是在持续的维护阶段。而简单性对于系统的可维护性至关重要。
有一些程序员出于**智力自慰(Intellectual Masturbation)或工作安全(Job Security)**的原因,会在架构设计中堆砌无谓的额外复杂度 —— 例如不管规模负载合适与否就一股脑全上 Kubernetes,或者使用胶水代码飞线串联起一堆花里胡哨的数据库。寻找“足够酷的“的东西来满足个人价值的需求,而不是考虑要解决问题是否真的需要这些屠龙术。

鲁布·戈德堡机械:“以极为繁复而迂回的方法去完成实际上或看起来可以容易做到事情” —— 一种通过复杂度进行智力自慰的行为。
复杂度会拖慢所有人的速度,并显著增加维护成本。在复杂的系统中进行变更,引入错误的风险也更大(例如《从降本增笑到真的降本增效》介绍的大故障)。因为复杂度导致维护困难时,预算和时间安排通常会超支。当开发人员难以理解系统时,隐藏的假设、无意的后果和意外的交互就更容易被忽略。降低复杂度能极大地提高软件的可维护性,因此简单性应该是构建系统的一个关键目标。
并不是所有公司都有 Google 那样的规模与场景,需要用宇宙战舰去解决他们特有的问题。裸机/虚机上的 PostgreSQL + Go/Ruby/Python 或者经典 LAMP 已经让无数公司一路干到上市了。切莫忘记,为了不需要的规模而设计是白费功夫,这属于过早优化的一种形式 —— 而这正是万恶之源。
以我亲身经历为例,在探探早中期的时候,几百万日活时的技术栈仍然非常朴素 —— 应用纯用 Go 写,数据库只用 PostgreSQL。在 250w TPS与 200TB 数据的量级下,单一PostgreSQL选型能稳定可靠地撑起业务:除了本职的OLTP,还在相当长的时间里兼任了缓存,OLAP,批处理,甚至消息队列的角色。最终一些兼职功能逐渐被分拆出去由专用组件负责,但那已经是近千万日活时的事了,而且事后来看其中一些新组件的必要性也存疑。
因此当我们在进行架构设计与评审时,不妨用复杂性的视角来进行额外的审视。更多关于复杂度的讨论,请参考下列文章:
扒皮云对象存储:从降本到杀猪
对象存储是云计算的定义性服务,曾被视为云上降本的典范。不幸的是随着硬件的发展,资源云(Cloudflare R2)与开源平替(MinIO)的出现,曾经“物美价廉”的对象存储服务失去了性价比,和EBS一样成为了杀猪盘。我们在《云计算泥石流》系列中已经深入剖析过云上 EC2 算力,EBS 磁盘,RDS 数据库的成本构成,今天我们就来审视一下云服务之锚 —— 对象存储。

从降本到杀猪
对像存储,又称简单存储服务(Simple Storage Service,缩写为 S3,以下用S3代指), 曾经是云上“物美价廉”的拳头产品。
在十几年前,硬件的价格高昂;能够用一堆几百GB的机械硬盘,三副本搭建可靠的存储服务,并设计实现一套优雅的 HTTP API,还是一件颇有门槛的事情;因此相对于那些“企业级IT”存储方案,物美价廉的 S3 显得很有吸引力。
但是计算机硬件这个领域非常特殊 —— 有着一个价格每两年减半的摩尔定律。在 AWS S3 的历史上的确有过几次降价,下面的表格里整理了几次主要降价后的 S3 标准档存储单价,也整理了对应年份企业级 HDD/SSD 的参考单位价格。
| Date | $/GB·月 | ¥/TB·5年 | HDD ¥/TB | SSD ¥/TB |
|---|---|---|---|---|
| 2006.03 | 0.150 | 63000 | 2800 | |
| 2010.11 | 0.140 | 58800 | 1680 | |
| 2012.12 | 0.095 | 39900 | 420 | 15400 |
| 2014.04 | 0.030 | 12600 | 371 | 9051 |
| 2016.12 | 0.023 | 9660 | 245 | 3766 |
| 2023.12 | 0.023 | 9660 | 105 | 280 |
| 其他参考价 | 高性能存储 | 顶配底折价 | 与采购NVMe SSD | 价格参考 |
| S3 Express | 0.160 | 67200 | DHH 12T | 1400 |
| EBS io2 | 0.125 + IOPS | 114000 | Shannon 3.2T | 900 |
不难看出,S3 标准档的单价从 2006 年的 0.15 $/GB·月 到 2023 年的 0.023 $/GB·月 ,降到原来的 15%,便宜了 6 倍,听上去不错;然而当你考虑到 S3 底层 HDD 的价格从降到原来的 3.7% ,便宜了整整 26 倍时,就能发现这里面的猫腻了。
S3 的资源溢价倍数从 2006 年的 7 倍增长到了当下的 30 倍!
在2023年当下,当我们重新进行成本核算时,不难看出 S3 / EBS 这类存储服务的性价比早已今非昔比 —— 云上的算力 EC2 相比自建服务器有着 5 ~ 10 倍的溢价,而云上的块存储 EBS 相对本地SSD有着几十倍到一两百倍的溢价。云上的 S3 相对普通HDD也有着三十倍左右的资源溢价。而作为云服务之锚的 S3 / EBS / EC2 价格,又会传导到几乎所有的云服务上去 —— 这让云服务的性价比彻底丧失吸引力。
这里的核心问题是:硬件资源的价格随着摩尔定律以指数规律下降,但节省的成本并没有穿透云厂商这个中间层,传导到终端用户的服务价格上。 逆水行舟,不进则退,降价速度跟不上摩尔定律就是其实就是变相涨价。以S3为例,在过去十几年里,云厂商S3虽然名义上降价6倍,但硬件资源却便宜了 26 倍,所以这个价格又该怎么说呢?
成本、性能、吞吐
尽管云服务有着高昂的溢价,但如果它是不可替代的最优选,那么即使溢价高性价比低,也不影响价格钝感的高价值头部客户使用。然而不仅仅是成本,存储硬件的性能也遵循摩尔定律,随着时间累积,自建S3的性能也开始出现显著优势。
S3 的性能主要体现在吞吐量上,AWS S3 的 100 Gb/s 网络提供了高达 12.5 GB/s 的访问带宽,这一点确实值得称道。这样的吞吐量放在十年前毫无疑问是让人震撼的,然而在今天,一块两万块不到的企业级 12 TB NVMe SSD ,单卡就可以达到 14 GB/s 的读写带宽,100Gb的交换机和网卡也已经非常普及,想做到这一点并不复杂。
在另一个关键性能指标“延迟”上,S3也被本地磁盘吊打。S3 标准档的首字节延迟相当拉垮,根据文档说明在 100~200ms 百毫秒的范围。当然 AWS 也刚刚在 2023 Re:Invent 上新发布了 “高性能S3” —— S3 Express One Zone ,能够达到单毫秒级的延迟,弥补了这个短板。但是和 4K随机读/写延迟 55µs/9µs 十微秒量级的NVMe 还是相距甚远。
S3 Express 的毫秒级延迟听上去很不错,但是当我们将其与 NVMe SSD + MinIO 自建对比时,这种“毫秒级”性能就只能自惭形秽了 —— 当代的 NVMe SSD 的4K随机读/写延迟已经达到了 55µs/9µs ,套上一层薄薄的MinIO转发,首字节输出延迟要比 S3 Express 好至少一个数量级。如果用标准档 S3 对比,性能的差距会进一步拉大到三个数量级。
性能的差距仅仅是一方面,更重要的是成本。标准档的 S3 价格自 2016 年至今都没变过,一直是 0.023 $/GB月,每TB·月的人民币价格是 161 元。高级货色 S3 Express One Zone 的价格比标准档高了一个数量级,达到每月·GB $0.16,每TB·月的人民币价格为 1120 元。作为参考,我们可以引用《重新拿回计算机硬件的红利》和 《云盘是不是杀猪盘》中的数据进行对比:
| 因素 | 本地 PCI-E NVME SSD | Aliyun ESSD PL3 | AWS io2 Block Express |
|---|---|---|---|
| 成本 | 14.5 ¥/TB·月 ( 5年均摊 / 3.2T MLC ) 5 年质保,¥3000 零售 | 3200¥/TB·月 (原价 6400¥,包月4000¥) 3年预付整体打5折才有此价格 | 1900 ¥/TB·月 使用最大规格 65536GB 256K IOPS 最优惠状态 |
| 容量 | 32TB | 32 TB | 64 TB |
| IOPS | 4K随机读:600K ~ 1.1M 4K随机写 200K ~ 350K | 4K随机读:最大 1M | 16K随机IOPS: 256K |
| 延迟 | 4K随机读:75µs 4K随机写:15µs | 4K 随机读: 200µs | 随机IO:500µs 上下文推断为16K |
| 可靠 | UBER < 1e-18,折合18个9 MTBF: 200万小时 5DWPD,持续三年 | 数据可靠性 9个9 存储与数据可靠性 | 持久性:99.999%,5个9 (0.001% 年故障率) io2 说明 |
| SLA | 5年质保 出问题直接换新 | Aliyun RDS SLA 可用性 99.99%: 月费 15% 99%: 月费 30% 95%: 月费 100% | Amazon RDS SLA 可用性 99.95%: 月费 15% 99%: 月费 25% 95%: 月费 100% |
这里本地 NVMe SSD 使用的例子是 Shannon DirectIO G5i 3.2TB MLC颗粒企业级SSD,是我们自己大规模使用的SSD卡。全新拆机零售件价 ¥2788 (闲鱼都有!),按5年60个月折算的每TB·月的人民币价格为 14.5 元。咱们退一步将按浪潮列表价 ¥4388 核算,TB·月价也就是 22.8。如果这个例子还不够,我们可以参考《是时候放弃云计算吗》里面 DHH 下云采购的 12 TB Gen4 NVMe 企业级 SSD,2390$ 一块,TB·月价也正好是 23 块钱。
那么问题就来了,性能好几个数量级的 NVMe SSD,为什么单价比 S3 标准档还要便宜一个数量级(161 vs 23),比 S3 Express 便宜了两个数量级(1120 vs 23 x3 )?如果我用这样的硬件(就算上三副本) + 开源软件自建一个对象存储服务,是不是可以实现三个数量级的性价比提升?(这还没提 SSD 在可靠性相对于 HDD 的优势)
特别值得一提的,上面对比的还单纯是存储空间的费用,流入流出对象存储的流量费通常也是一笔非常可观的支出,有的档位收费靠的不是存储费用,而是取回流量费。还有 SSD 相对 HDD 可靠性的问题,云上数据自主可控的问题,这里就不再深入展开了。
当然云厂商也会辩解——说我们这个 S3 啊,可不是纯粹的存储硬件资源,而是一个开箱即用的服务。里面还包含了软件的知识产权,人力的维护成本;而自建故障率高,自建更危险,自建运维人力开销大等等等等,可惜,这套说辞放在 2006 年或者 2013 年还可以说得通,放在今天就显得有些滑稽了。
开源自建对象存储
在十几年前,绝大多数用户都缺乏IT自建能力,S3也没有足够成熟的开源替代品。用户可以容忍接受这样的高科技溢价。然而当各家云厂商、IDC都开始提供对象存储,甚至都出现了开源免费的对象存储方案(MinIO)后,卖方市场变成了买方市场,价值定价逻辑转变为成本定价逻辑后,不降反涨的资源溢价自然就会面临用户的拷问 —— 它到底给我带来了什么额外价值,以至于要收这种巨额费用。
云的倡导者声称,上云相比自建更便宜,更简单,更快捷。对于个人站长,中小互联网企业这些云适用光谱内的用户来说,这么说肯定是没问题的。如果你的数据规模只有几十个GB,或者有一些中小规模的出海业务和CDN需求,我并不会推荐你凑热闹自建什么对象存储,你应该出门左转去 Cloudflare 用 R2 —— 这也许就是最优解。
然而对于真正贡献营收大头的高价值中大规模客户来说,这些价值主张就不一定成立了。如果你主要是在本地存储使用 TB/PB 规模的数据,那么确实应当认真考虑一下自建对象存储服务的成本与收益 —— 现在用开源软件自建已经非常简单、稳定与成熟了。存储服务的可靠性主要取决于磁盘冗余:除了零星的硬盘故障 (HDD AFR 1%,SSD 2~3‰)需要你(请代维服务商)换上备件,并不会有多少额外的负担。
如果说混合了EBS/S3能力的开源 Ceph 还能算有不少运维复杂度,功能也没有完全拉齐;那么完全兼容 S3 的对象存储服务开源替代 MinIO 可以说是开箱即用了 —— 一个没有额外依赖的纯二进制,不需要几个配置参数就可以快速拉起,把服务器上的磁盘阵列转变为一个标准的本地 S3 兼容服务,甚至还集成了了 AWS 的 AK/SK/IAM 兼容实现!
从运维管理的角度看,Redis 的运维复杂度比 PostgreSQL 低一个数量级,而 MinIO 的运维复杂度又比 Redis 还要再低一个数量级。它简单到这样一种程度:我一个人可以花个一周不到时间把 MinIO 的部署/监控作为添头放到我们开源的 PostgreSQL RDS 方案里来,用作可选的中央备份存储仓库。
我在探探时,有几个 MinIO 集群就是这么搭建维护的:放了 25PB 数据,可能是国内先前最大规模的 MinIO 部署。用了多少人来维护呢?抽调了一个运维工程师 1/10 不到的工作时间来兼职罢了,而自建整体综合成本在云列表价 0.5 折浮动。实践出真知,如果有人骗你说对象存储自建很难很贵,你确实可以自己动手试试 —— 要不了几个钟头,这些销售 FUD 话术就会不攻自破。
对于对像存储服务来说,云的三点核心价值主张:“更便宜,更简单,更快捷” ,更简单这条说不上,更便宜走向了反面,恐怕只剩下最后一点更快捷了 —— 在这一点上确实没有谁能比过云,你确实可以在云上用1分钟不到在全世界所有区域申请PB级的存储服务,Which is Amazing!只不过你也要为这个鸡肋特权付出几十倍的高昂溢价。
因此对于对像存储服务来说,云的三点核心价值主张:“更便宜,更简单,更快捷” 中,更简单这条说不上,更便宜走向了反面,恐怕只剩下最后一点快捷了 —— 在这一点上确实没有谁能比过云,你确实可以在云上用1分钟不到在全世界所有区域申请PB级的存储服务,Which is Amazing!只不过你也要为这个特权掏十几倍到几十倍的高昂溢价就是了。而对于有一定规模的企业而言,比起翻几番的运营成本来说,等个两周或者多掏点一次性资本投入根本不算个事。
小结
记得在 2019年4月1日,国内增值税正式从 16% 下调到 13% ,苹果官网随即全面降价,单品最高降价幅度达8% —— iPhone的几个典型产品都降了500元,把税点返还给了用户。但也有许多厂商选择装聋作哑维持原价,自己吃下这个福利 —— 白花花的银子怎么能随便散给别人呢?
类似的事情就发生在云计算领域 —— 硬件成本的指数下降,并没有在云厂商的服务价格上充分反映出来,而这一点,让公有云逐渐从普惠基础设施变成了垄断集中杀猪盘。
然而事情正在起变化,硬件重新变得有趣起来,而云厂商没有办法把这部分红利永远掩藏遮盖下去 —— 聪明的人开始计算数字,勇敢的人已经采取行动 。像马斯克和 DHH 。越来越多的人会同样意识到这一点,追随先驱者做出明智的选择,拿回属于自己的硬件红利。
References
[1] 2006: https://aws.amazon.com/cn/blogs/aws/amazon_s3/
[2] 2010: http://aws.typepad.com/aws/2010/11/what-can-i-say-another-amazon-s3-price-reduction.html
[3] 2012: http://aws.typepad.com/aws/2012/11/amazon-s3-price-reduction-december-1-2012.html
[5] 2016: https://aws.amazon.com/ru/blogs/aws/aws-storage-update-s3-glacier-price-reductions/
[6] 2023: https://aws.amazon.com/cn/s3/pricing
[7] 首字节延迟相当拉垮: https://docs.aws.amazon.com/AmazonS3/latest/userguide/optimizing-performance.html
[8] 存储与数据可靠性: https://help.aliyun.com/document_detail/476273.html
[10] Aliyun RDS SLA: https://terms.aliyun.com/legal-agreement/terms/suit_bu1_ali_cloud/suit_bu1_ali_cloud201910310944_35008.html?spm=a2c4g.11186623.0.0.270e6e37n8Exh5
[11] Amazon RDS SLA: https://d1.awsstatic.com/legal/amazonrdsservice/Amazon-RDS-Service-Level-Agreement-Chinese.pdf
半年下云省千万,DHH下云FAQ
一年前我们宣布了下云的计划,随后披露了2022年320万美元的云账单细节,并决定不依赖昂贵的企业级服务而是自行构建工具来下云,使命已定!
一个月后,我们下单购买了60万美元的戴尔服务器来实现这个目标,并保守估计未来五年将给我们省下700万美元。我们还详细描述了推动我们下云的五大核心价值观 —— 不仅仅是成本,还有独立性、以及忠于互联网初心等等。
在二月份,我们引入了 Kamal,这是我们花了几周自力更生打造的下云工具,它能在帮助我们从云上下来的同时,又不失去云计算中那些关于容器与运维原则上的创新点。
紧接着,我们所需的所有硬件已经运抵两个不同地理区域的数据中心,总共是 4000个vCPU、7680GB 的内存和 384TB 的 NVMe 存储!
到了6月,全部搞定。我们成功地下云了!
如果说这段下云旅途是“充满争议”的,那算是比较温和的说法 —— 有数百万人通过 LinkedIn、X/Twitter 以及此邮件列表阅读了更新。我收到了数千条评论,要求澄清、提供反馈,并对我们选择不同道路的“胆大妄为”感到难以置信 —— 在别人忙着上云还八字没有一撇时,就把下云的一捺给画完了。
但我们还是用结果来说话:我们不仅迅速完成了下云,而且客户几乎没有任何感知。很快,省下的开销就开始滚雪球,到了九月,我们的云账单已经省下了一百万美元。随着预付费实例逐渐到期(那种要提前整租一年以换取折扣的实例),账单开始进一步坍缩:
时至今日,下云已经告一段落,但是各种问题开始纷至沓来:为了避免一次又一次地回答重复的问题,我想编制一份经典的“常见问题”请单(FAQ),以下是FAQ的内容:
在硬件上省下的成本,会不会被更大规模的团队薪资抵消掉?
不会,因为我们在下云后,团队组成并没有发生变化。曾经在云上运维 HEY、Basecamp 的人,和现在在我们自己的硬件上运维这些应用的都是同一拨人。
这是云上营销的核心欺诈:所有的事情都非常简单,你几乎不需要任何人手来运维。我从来没见过这种事成真,无论是在 37signals,还是其他运维大型互联网应用的公司。云有一些优势,但通常不在减少运维人员上。
为什么你选择下云,而不是优化云账单呢?
我们在2022年的云账单是320万美元,而之前的账单是现在的两倍还要多。现在的云账单已经经过仔细审查、讨价还价、深度优化了 —— 通过长时间的重复榨取工作,我们已经把这里的油水给彻底挤干了。
这件事部分回答了:为什么我非常看好中型及以上软件公司下云这件事。许多和我们有着相同客户规模的业务,每月的云开销很容易达到我们优化前账单的 2~4 倍。因此降本增效的潜力只高不低。
你的有没有试过用“云原生”应用的方式上云?
云原生,通常与 “Lift and Shift” 对照,被吹捧为充分利用云上优点的正道坦途,但这不过是又一坨云营销废话。云原生基本以一个错误的信念作为核心 —— 即 Serverless函数以及各种按需使用的工具能让用户节约成本。但如果你需要一斤糖,独立包装的单块小方糖并不会更省钱。我在《不要被Serverless耍了》以及《即使是亚马逊也整不明白微服务Serverless》这两篇文章中写过这一点。
那么安全性呢?你不担心被黑客攻击吗?
在互联网上运营软件时面临的大多数安全问题,都源自应用及其直接的依赖组件。无论你是从云供应商那里租电脑来跑应用,还是自己拥有这些服务器,确保安全所需的工作并没有本质区别。
如果说有的话,那么在云上运维服务可能会给人们一种错误的安全感 —— 以为安全并不是他们应该操心的问题 —— 而事实绝非如此!
现代容器化应用交付的一个显著优势是,你不再需要花费大量时间手动给机器打补丁了。大部分工作都包含在 Dockerfile 中,你可以在最新的 Ubuntu 或其他操作系统上部署运行最新的应用程序版本 —— 无论你是在云上租用机器还是管理自己的机器,这个过程都是一样的。
不需要一支世界级超级工程师团队来干这些吗?
我从来都是毫不避讳地炫耀夸赞我们在 37signals 的优秀团队,我衷心地为我们组建的团队感到骄傲。但声称自己运维硬件是因为他们拥有一些特殊的魔法洞察力,那是在是太过于傲慢了。
互联网发展始于 1995 年,而云成为默认选项最早不会超过2015年。所以在超过二十年的时间里,公司们都在自己运维硬件来跑应用。这并不是什么已经失传的古代知识 —— 我们确实不知道金字塔到底是如何建造的,但对于如何将一台 Linux 机器连接到互联网,我们还是门儿清的。
此外,在自有硬件上运营所需的专业知识,和在云上靠租赁运营所需的专业知识,有90%是相同的。至少在我们这种数百万用户,每月几十万美元账单的规模时是这样的。
这是否意味着你们在建造自己的数据中心?
除了谷歌、微软和Meta等少数几家巨无霸公司,没人会自建数据中心。其他人都只是在专业数据中心(例如Equinix)那里租用几个机柜、一个机房或者一整层楼。
所以,拥有你自己的硬件,并不意味着你要去操心安全、电力供应、灭火系统,以及其他各种设施与细节 —— 这些设施的建设投入可能要耗资数亿美元。
谁来做码放服务器、拔插网络电缆这些活呢?
我们使用一家名为 Deft 的白手套数据中心代维服务商。还有无数类似的公司。你付费给他们,让他们把戴尔或其他公司的服务器拆箱,直接放入数据中心,然后将服务器上架,你就能看到新的 IP 地址蹦出来,就像云一样,只不过它不是即时的。
我们的运维团队基本上从未踏足这些数据中心。他们在全球各地远程工作。与互联网早期每个人都自己拉线缆的时候相比,现在这种运营体验才更称得上是“云”。
那么可靠性呢?难道云不是为你做到了这些吗?
当我们在云上运营时,使用了两个地理分隔的区域,也在每个区域内实现了大量的冗余。当我们下云后,也干了一模一样的事情。我们在两个地理分隔的数据中心托管自己的硬件,每个数据中心都能承载我们所需的全部负载,而且每个关键基础设施都有副本。
可靠性在很大程度上取决于冗余,你应该能随时失去任何一台计算机、任何一个组件,而不会造成问题。我们在云上拥有这种能力,而现在使用自己的硬件时也一样。
那国际化业务的性能呢?云不是更快吗?
我们先前的云部署使用了两个不同区域,都在美国国内,也用了一个在全球各地都拥有本地边缘节点的CDN网络。与可靠性上的问题一样:我们在下云后也是使用两个美国区数据中心,并使用国际CDN来加速内容交付。
从根本上说,云上云下的挑战是一样的。国际足迹的难点通常不在于配置硬件与确保数据中心安全上,而是你的应用程序需要处理多个主数据库写入,应对复制延迟,以及其他各种让应用在全球网络上高速运行所需的有趣工作。
我们目前正在欧洲为 HEY 规划一个数据中心前哨站,我们把这些配置的活儿留给了 Deft 的朋友们。正如所有硬件采购一样,它的交付速度确实要比云慢。对于 “我想在日本上线10台服务器,并在30秒后看到它” 这种事来说,没有谁能比得上云,这确实很了不起。
但对我们这类业务来说,为这种即时拉起的弹性能力支付疯狂的巨额溢价根本不值得。等几周才能看到服务器上线,对我们来说是一个完全可以接受的利弊权衡。
你有考虑到以后更换服务器的成本吗?
是的,我们的数学计算是基于服务器可以正常使用五年的工作假设。这是相当保守的,我们有服务器跑了七八年仍然表现很好。但大多数人还是会用五年作为时间范围,因为财务摊销计算上会更方便。
这里的关键点是:我们花了60万美元购买了大量新服务器。而下云节省的费用已经让这项投资已经回本了!所以如果明年出现了一些惊人的技术突破,我们又想再买一堆新东西,我们也毫无压力,在成本优势上依旧遥遥领先。
那么隐私法规和GDPR呢?
云在隐私合规和GDPR上并没有提供任何真正优势。如果说有,反而是有负面影响,因为所有主要的超大规模云服务商都是美国的。所以,如果你在欧洲,并且从微软、亚马逊或谷歌等公司购买云服务,你必须面对这个现实:美国政府可以合法强迫这些供应商交出数据和记录。我在《美国数据间谍永远不会关心服务器到底在哪里》一文中详细说明过这一点。
作为一家在欧洲运营的公司,如果严格遵守GDPR对你很重要,那么你最好还是拥有自己的硬件,并放在欧洲的数据中心供应商那里运行。
那么需求激增时怎么办?自动伸缩呢?
在自己采购硬件时最令我们震惊的是,我们终于意识到了现代硬件到底有多么强大与便宜。仅仅过去四五年中的进步就已经非常巨大了,这也是云变成一门糟糕生意,一年不如一年的一个重要原因。在摩尔定律的指数规律下,用户能从戴尔和其他厂商买到的产品价格不断下降,能力不断增强。但摩尔定律对对亚马逊和其他公司的云托管服务价格几乎没有任何影响。
这也就是说,你可以买得起极为夸张的超配硬件,让你有在面对尖峰时游刃有余,却几乎不会对长期预算有任何影响。
不过,如果你确实经常面临超出基线需求 5~10倍或更高的峰值,那你也许是潜在的云客户。毕竟,这也是 AWS 最初诞生的动机。亚马逊在“黑色星期五”或“双十一”所需的性能远远远远超过他们一年中其他时间,所以灵活弹性的硬件对他们是有意义的。
但你也可以用混合搭配的方式来做这件事。俗话说,“买基线,租尖峰”。绝大多数公司根本不需要操心这种事,只需要关注使用情况,根据增长曲线提前采购一些强力服务器就够了。如果确实需要计划外的扩容,一周时间就足够拉起一整个新的服务器舰队了。
你在服务合同和授权许可费上花费了多少?
啥也没有。在互联网上运行应用所需的一切,通常都以开源的形式提供。我们所有的东西都是之前云服务的开源版本。我们的 RDS 数据库变成了 MySQL 8。我们的 OpenSearch 变成了开源的 ElasticSearch。
有些公司确实可能喜欢服务合同带来的舒适感,市场上有很多供应商可以提供这类服务。我们会不定期使用来自Percona 的 MySQL 专家的优秀服务。而这不会对底层逻辑有什么根本性改变。
你确实应当尽可能远离那些高度“企业化”的服务机构,通常来说,如果他们的客户名单上有银行或者政府,你就应该去别处看看,除非你确实喜欢烧钱。
如果云这么贵,你们为什么会选择它?
因为我们相信了云营销画的大饼:更便宜、更简单、更快。对我们来说,只有最后一个承诺真正实现了。在云上,你确实可以很快地拉起一大堆服务器,但这并不是我们会经常做的事,所以不值得为此付出巨大的溢价。
我们花了几年的时间试图解锁“规模经济”与“简单易用”这两个云技能点,但从没实现过。托管服务仍然需要管理,而摩尔定律带来的硬件进步很少能透过云厂商这一层来节约“我们”的成本。
事后看来,在云上跑一把其实还是挺不错的:我们学到了很多东西,也改进了自己的工作流程。但我确实希望能够提早几年就把这个账给算清楚。
我还有其他问题想问你!
请给我发邮件: dhh@hey.com,对于大家普遍感兴趣的问题,我会在这里更新。
本文翻译自DHH原文:The Big Cloud Exit FAQ
从降本增笑到真的降本增效
年底正是冲绩效的时间,互联网大厂大事故却是一波接一波。硬生生把降本增效搞成了“降本增笑” —— 这已经不仅仅是梗了,而是来自官方的自嘲。
双十一刚过,阿里云就出了打破行业纪录的 全球史诗级大翻车,然后开始了11月连环炸模式,在几次小故障后,又来了一场云数据库管控面跨国俩小时大故障—— 从月爆到周爆再到日爆。
但话音未落,滴滴又出现了一场超过12小时的大失效,资损几个亿 —— 替代品阿里旗下的高德打车直接爆单赚翻,堪称失之桑榆,收之东隅。
我已经替装死的阿里云做过复盘了《我们能从阿里云史诗级故障中学到什么》:Auth因为配置失当挂了,推测根因是 OSS/Auth 循环依赖,一改错黑白名单就死锁了。
滴滴的问题,据说是 Kubernetes 升级大翻车。这种惊人的恢复时长通常会与存储/数据库有关,合理推测根因是:不小心降级了 k8s master ,还一口气跳了多个版本 —— etcd 中的元数据被污染,最后节点全都挂掉,而且无法快速回滚。
故障是难以避免的,无论是硬件缺陷,软件Bug,还是人为操作失误,发生的概率都不可能降为零。然而可靠的系统应当具有容错韧性 —— 能够预料并应对这些故障,并将冲击降低至最小程度,尽可能缩短整体失效时间。
不幸的是在这一点上,这些互联网大厂的表现都远远有失水准 —— 至少实际表现与其声称的 “1分钟发现、5分钟处置、10分钟恢复” 相距甚远。
降本增笑
根据海因法则,一起重大故障背后有着29次事故,300次未遂事故以及数千条事故隐患。在民航行业如果出现类似的事情 —— 甚至不需要出现真正造成任何后果的事故,只是连续出现两起事故征候 —— 甚至都还不是事故,那么可怕严厉的行业安全整顿马上就会全面展开。
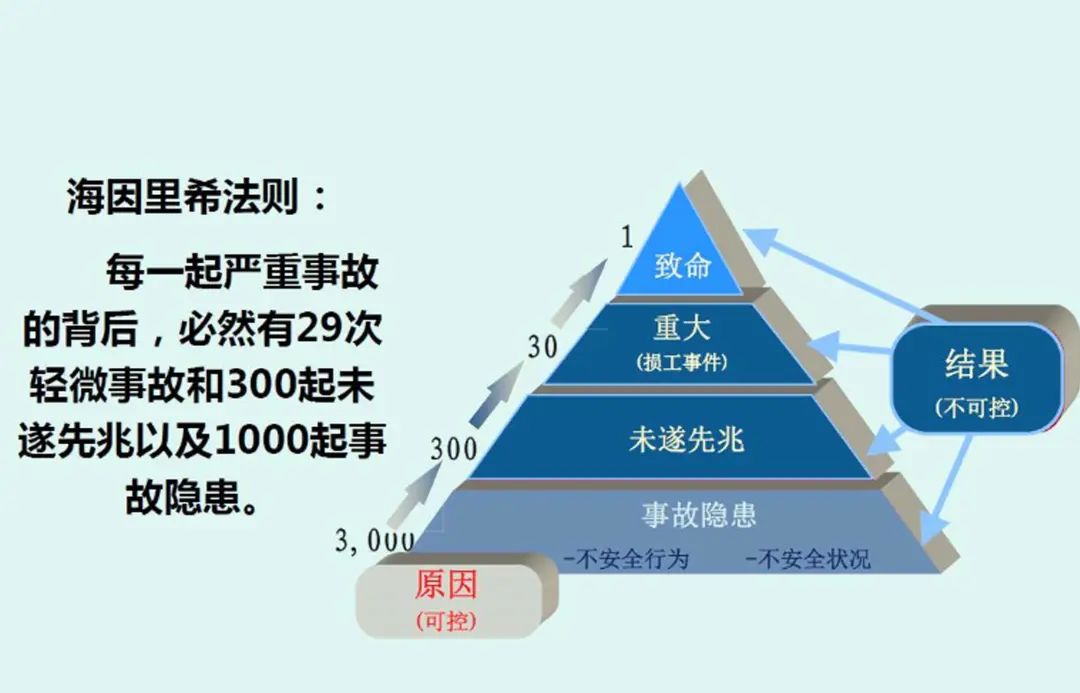
可靠性很重要,不仅仅是对于空中交管/飞行控制系统这类关键服务而言,我们也期望更多平凡的服务与应用能够可靠地运行 —— 云厂商的全局不可用故障几乎等同于停电停水,出行平台宕机意味着交通运力网络部分瘫痪,电商平台与支付工具的不可用则会导致收入和声誉的巨大损失。
互联网已经深入至我们生活的各个层面,然而针对互联网平台的有效监管还没有建立起来。行业领导者在面对危机时选择躺尸装死 —— 甚至都没人出来做一个坦率的危机公关与故障复盘。没有人来回答;这些故障为什么会出现?它们还会继续出现吗?其他互联网平台为此做了自纠自查了吗?它们确认自己的备用方案依然有效了吗?
这些问题的答案,我们不得而知。但可以确定的是,毫无节制堆积复杂度与大规模裁员的恶果开始显现,服务故障失效会越来越频繁以至于成为一种新常态 —— 谁都随时可能会成为下一个惹人笑话的“倒霉蛋”。想要摆脱这种暗淡的前景命运,我们需要的是真正的“降本增效”
降本增效
当故障出现时,都会经过一个 感知问题,分析定位,解决处理 的过程。所有的这些事情都需要系统的研发/运维人员投入脑力进行处理,而在这个过程中有一条基本经验法则:
处理故障的耗时 t =
系统与问题复杂度 W / 在线可用的智力功率 P。
故障处理的优化的目标是尽可能缩短故障恢复时间 t ,例如阿里喜欢讲的 “1-5-10” 稳定性指标:1 分钟发现、5 分钟处置、10 分钟恢复,就是设置了一个时间硬指标。
在时间限制死的情况下,要么降本,要么增效。只不过,降本要降的不是人员成本,而是系统的复杂度成本;增效不是增加汇报的谈资笑料,而是在线可用的智力功率与管理的有效性。很不幸的是,很多公司这两件事都没做好,活生生地把降本增效搞成了降本增笑。
降低复杂度成本
复杂度有着各种别名 —— 技术债,屎山代码,泥潭沼泽,架构杂耍体操。症状可能表现为:状态空间激增、模块间紧密耦合、纠结的依赖关系、不一致的命名和术语、解决性能问题的 Hack、需要绕开的特例等等。
复杂度是一种成本,因而简单性应该是构建系统时的一个关键目标。然而很多技术团队在制定方案时并不会将其纳入考虑,反而是怎么复杂怎么来:能用几个服务解决的任务,非要用微服务理念拆分成几十个服务;没多少机器,却非要上一套 Kubernetes 玩弹性杂耍;单一关系型数据库就能解决的任务,非要拆给几种不同的组件或者倒腾个分布式数据库。
这些行为都会引入大量的额外复杂度 —— 即由具体实现中涌现,而非问题本身固有的复杂度。一个最典型的例子,就是许多公司不管需要不需要,都喜欢把什么东西都往 K8S 上怼,etcd / Prometheus / CMDB / 数据库,一旦出现问题就循环依赖大翻车,一次大挂就彻底起不来了。
再比如应该支付复杂度成本的地方,很多公司又不愿意支付了:一个机房就放一个特大号 K8S ,而不是多个小集群灰度验证,蓝绿部署,滚动升级。一个版本一个版本的兼容性升级嫌麻烦,非要一次性跳几个版本。
在畸形的工程师文化中,不少工程师都会以傻大黑粗的无聊规模与高空走钢丝的架构杂耍为荣 —— 而这些折腾出来欠下的技术债都会在故障的时候变为业报回来算账。
“智力功率” 则是另一个重要的问题。智力功率很难在空间上累加 —— 团队的智力功率往往取决于最资深几个灵魂人物的水平以及他们的沟通成本。比如,当数据库出现问题时需要数据库专家来解决;当 Kubernetes 出现问题时需要 K8S 专家来看问题;
然而当你把数据库放入 Kubernetes 时,单独的数据库专家和 K8S 专家的智力带宽是很难叠加的 —— 你需要一个双料专家才能解决问题。认证服务和对象存储循环依赖也同理 —— 你需要同时熟悉两者的工程师。使用两个独立专家不是不可以,但他们之间的协同增益很容易就会被平方增长的沟通成本拉低到负收益,故障时人一多就变傻就是这个道理。
当系统的复杂度成本超出团队的智力功率时,就很容易出现翻车性的灾难。然而这一点在平时很难看出来:因为调试分析解决一个出问题的服务的复杂度,远远高于将服务拉起运行的复杂度。平时好像这里裁两个人,那里裁三个,系统还是能正常跑的嘛。
然而组织的默会知识随着老司机离开而流失,流失到一定程度后,这个系统就已经是期货死人了 —— 只差某一个契机被推倒引爆。在废墟之中,新一代年轻嫩驴又逐渐变为老司机,随即丧失性价比被开掉,并在上面的循环中不断轮回。
增加管理效能
阿里云和滴滴招不到足够优秀的工程师吗?并不是,而是其的管理水平与理念低劣,用不好这些工程师。我自己在阿里工作过,也在探探这种北欧风格的创业公司和苹果这样的外企待过,对其中管理水平的差距深有体会。我可以举几个简单的例子:
第一点是值班OnCall,在 Apple 时,我们的团队有十几号人分布在三个时区:欧洲柏林,中国上海,美国加州,工作时间首尾衔接。每一个地方的工程师都有着完整处理各种问题的脑力功率,保证任一时刻都有在工作时间待命OnCall的能力,同时也不会影响各自的生活质量。
而在阿里时,OnCall 通常变成了研发需要兼任的职责,24小时随时可能有惊喜,即使是半夜告警轰炸也屡见不鲜。本土大厂在真正可以砸人的地方,反而又吝啬起来:等研发睡眼惺忪爬起来打开电脑连上 VPN,可能已经过去好几分钟了。在真正可以砸人砸资源解决问题的地方反而不砸了。
第二点是体系建设,比如从故障处理的报告看,核心基础设施服务变更如果没测试,没监控,没告警,没校验,没灰度,没回滚,架构循环依赖没过脑袋,那确实配得上草台班子的称号。还是说一个具体的例子:监控系统。设计良好的监控系统可以极大缩短故障的判定时间 —— 这种本质上是对服务器指标/日志提前进行了数据分析,而这一部分往往是最需要直觉、灵感与洞察力,最耗费时间的步骤。
定位不到根因这件事,就是反映出可观测性建设和故障预案不到位。拿数据库举个例子吧,我做 PostgreSQL DBA 的时候做了这个监控系统 (https://demo.pigsty.cc[1]),如左图,几十个Dashboard 紧密组织,任何PG故障用鼠标点点下钻两三层,1分钟不用就能立即定位各种问题,然后迅速按照预案处理恢复。

再看一下阿里云 RDS for PostgreSQL 与 PolarDB 云数据库用的监控系统,所有的东西就这可怜巴巴的一页图,如果他们是拿这个玩意来分析定位故障,那也怪不得别人要几十分钟了。
第三点是管理理念与洞察力,比如,稳定性建设需要投入一千万,总会有机会主义的草台班子跳出来说:我们只要五百万或者更少 —— 然后可能什么都不做,就赌不会出现问题,赌赢了就白赚,赌输了就走人。但也有可能,这个团队有真本事用技术降低成本,可是又有多少坐在领导位置上的人有足够的洞察力可以真正分辨这一点呢?
再比如,高级的故障经验对于工程师和公司来说其实是一笔非常宝贵的财富 —— 这是用真金白银喂出来的教训。然而很多管理者出了问题第一时间想到的就是要“开个程序员/运维祭天”,把这笔财富白送给下家公司。这样的环境自然而然就会产生甩锅文化、不做不错、苟且偷安的现象。
第四点是以人为本。以我自己为例,我在探探将自己作为 DBA 的数据库管理工作几乎全自动化了。我会做这件事的原因:首先是我自己能享受到技术进步带来的红利 —— 自动化自己的工作,我就可以有大把时间喝茶看报;公司也不会因为我搞自动化每天喝茶看报就把我开了,所以没有安全感的问题,就可以自由探索,一个人搞出一整套完整的 开源 RDS 出来。
但这样的事在类似阿里这样的环境中可能会发生吗?—— “今天最好的表现是明天最低的要求” ,好的,你做了自动化对不对?结果工作时间不饱和,管理者就要找一些垃圾活或者垃圾会议给你填满;更有甚者,你幸幸苦苦的建立好了体系,把自己的不可替代性打掉了,立即面临狡兔死走狗烹的结果,最后被干写PPT出嘴的人摘了桃子。那么最后的博弈优势策略当然是能打的出去单干,能演的坐在列车上摇晃身体假装前进直到大翻车。
最可怕的是,本土大厂讲究人都是可替换的螺丝钉,是35岁就“开采完”的人矿,末位淘汰大裁员也不鲜见。如果 Job Security 成为迫在眉睫的问题,谁还能安下心来踏实做事呢?
孟子曰:“君之视臣如手足,则臣视君如腹心;君之视臣如犬马,则臣视君如国人;君之视臣如土芥,则臣视君如寇仇”。这种落后的管理水平才是很多公司真正应该增效的地方。
重新拿回计算机硬件的红利
在当下,硬件重新变得有趣起来,AI 浪潮引发的显卡狂热便是例证。但有趣的硬件不仅仅是 GPU —— CPU 与 SSD 的变化却仍不为大多数开发者所知,有一整代软件开发者被云,或者炒作营销遮蔽了双眼,难以看清这一点。
许多软件与商业领域的问题的根都在硬件上:硬件的性能以指数模式增长,让分布式数据库几乎成为了伪需求。硬件的价格以指数模式衰减,让公有云从普惠基础设施变成了杀猪盘。基本工作假设的变化,将触发软件技术的重估。是时候拨云见日,正本清源了。让我们重新认识现代硬件,拿回属于用户自己的红利。

性能翻天的新硬件
如果您有一段时间没有接触过计算机硬件了,那么当下新硬件的这些数字可能会让你感到非常震惊。
曾几何时,Intel 的 CPU 以挤牙膏著称,每一代进步微乎其微,老电脑可以再战一年又一年。但最近,处理器演进的速度骤然加快,增益不再是“微不足道”,核数在迅速增长,单核性能定期跃进 20-30%,而且这种进步积累的很迅速。
例如,AMD 刚刚发布的桌面级 CPU Threadripper 7995WX ,单颗 96核192线程 ✖️ 2.5 ~ 5.1 GHz 的性能怪兽,亚马逊零售价也才 5600美元。服务器 CPU 霄龙 EPYC 系列:上一代 EPYC Genoa 9654 ,单颗 96核192线程✖️ 2.4 ~ 3.55 GHz ,Amazon 零售价 3940美元。今年新款霄龙9754 更是干到了单 CPU 128 核 256 线程,这意味着一台普通双插槽服务器的 vCPU 数量可以达到惊人的 512 核!要是按云计算/容器平台 500% 超卖率,可以虚拟出两千五百多台1核虚拟机来。
SSD/NVMe 存储上的代际跃进幅度甚至比 CPU 领域还要大得多。我们快速地从Gen2约 500MB/s 的速度,到 Gen3 约2.5GB/s,再到目前主流 Gen4约 7GB/s;Gen5的 14GB/s 的SSD 刚开始崭露头角,Gen6 标准已经发布,Gen7 在路上,I/O带宽以翻倍的方式指数增长。
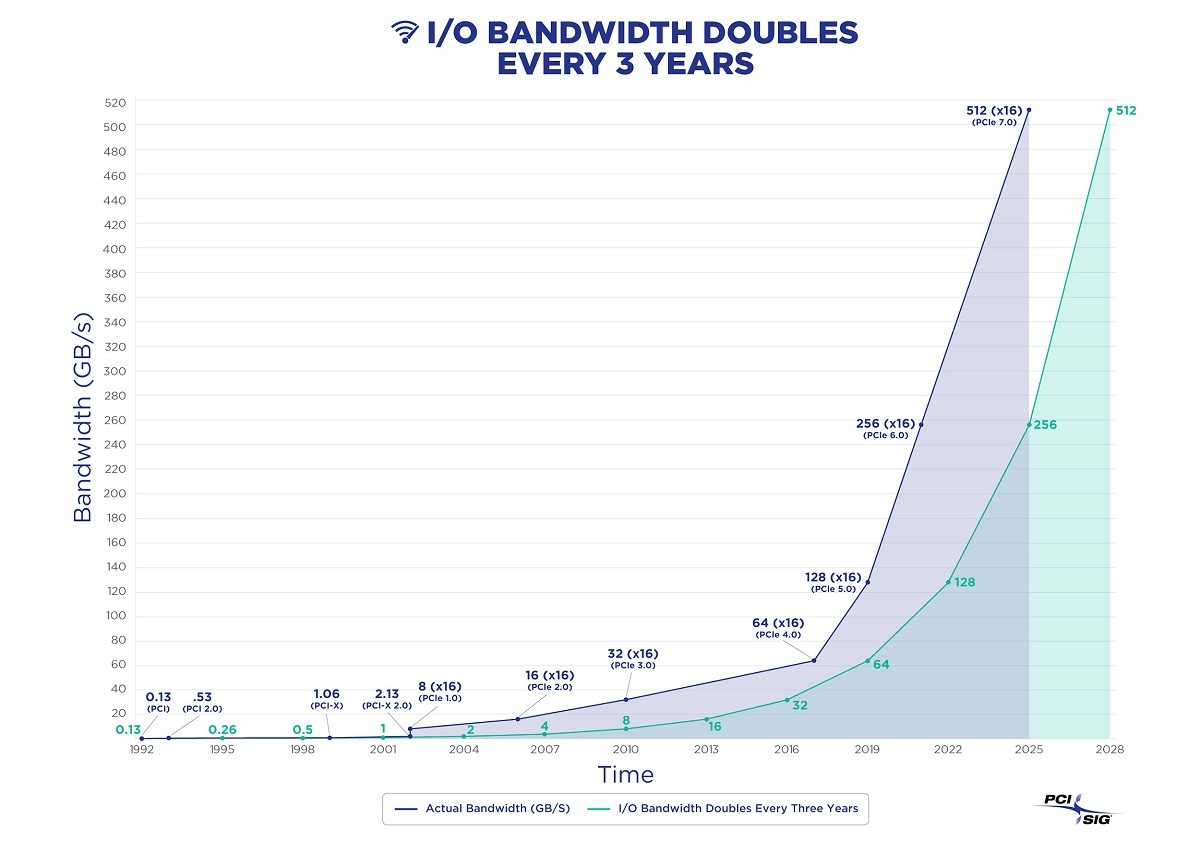
以 Gen5 NVMe SSD: KIOXIA CM7 为例,128K顺序读带宽 14GB/s 写带宽 7GB/s,4K 随机IOPS 读 2.7M,写 600K。恐怕现在还没有多少数据库软件能够充分利用这种疯狂的读写带宽与 IOPS。作为一个简单对照,我们回头看一下机械硬盘的带宽和IOPS,机械硬盘总体读写带宽大概在一两百 MB/s 上下浮动。7200 转硬盘的 IOPS 约几十,15000 转硬盘的 IOPS约为一两百。是的,NVMe SSD 的I/O带宽速率已经比机械硬盘好了四个数量级,整整一万倍。
在数据库最关注的 4K 随机读/写响应时间上,NVMe SSD 的经典值为 读 55µs / 写 9μs,前几代就有这个水平了。这是什么概念?还是和机械硬盘比一下:机械硬盘的寻道时间通常在 10ms 量级, 平均旋转延迟视转速在 2ms - 4ms,那么一次 I/O 通常需要十几个毫秒。十几毫秒 vs 55/9µs ,NVMe SSD 比机械磁盘快了三个数量级 —— 一千倍!
除了计算与存储外,网络硬件当然也有进步,40GbE 和 100 GbE 已经烂大街了 —— 一个 100Gbps 的光模块网卡也就万把块钱,而 12 GB/s 的网络传输速度比老程序员耳熟能详的千兆网卡快了整整一百倍。
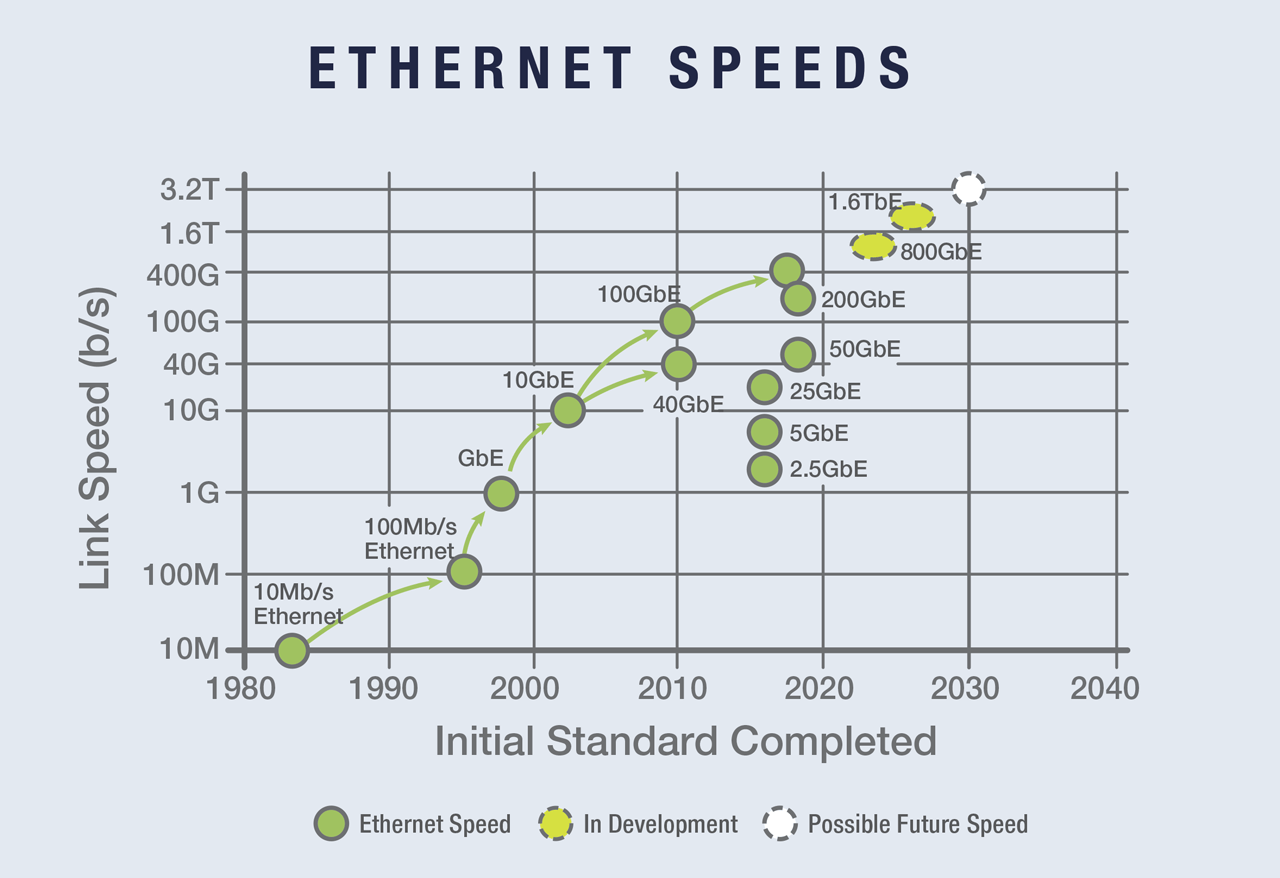
计算,存储,网络硬件的性能继续以摩尔定律指数增长的方式在演进与发展,硬件领域重新变得有趣起来。但更有趣的是硬件的技术飞跃会为世界带来什么?
分布式不再受待见
硬件十年间的变化已称得上沧海桑田,而这让许多软件领域的工作假设都不再成立:比如分布式数据库。
在当下,一台普通x86服务器的能力上限已经达到了一个非常惊人的程度 —— 这里有一个有趣的草稿演算,粗略证明了将整个 Twitter 运行在一台这样的现代服务器上的可行性( Dell PowerEdge R740xd,32C,768GB RAM、6TB NVMe、360TB HDD、GPU插槽和 4x40Gbe 网络)。尽管出于生产冗余的考虑你并不会这么做(用两台或者三台可能更保险一些),但这个计算确实抛出了一个很有趣的问题 —— 可伸缩性是否还是一个真正的问题?
在本世纪初,一台 Apache 服务器只能处理很可怜的一两百个并发请求。最优秀的软件也很难处理上万的并发 —— 业界有个著名的 C10K 高并发问题,谁要是能做到几千并发,那就是业界高手。但随着 Epoll 和 Nginx 在 2003/2004 年相继问世,“高并发” 不再是什么难题了 —— 随便一个小白只要学会配置 Nginx,就可以达到前几年大师们做梦都不敢想的程度。 《云厂商眼中的客户又穷又闲又缺爱》
在 2023 年的今天,硬件的冲击让同样的事再次发生在分布式数据库上:可伸缩性(Scalability)和二十年前的 C10K 一样,成为了一个已解决的历史问题。如果推特这样的业务可以跑在单台服务器上,那么99.xxxx+ % 的业务终其生命周期,对可伸缩性的需求都不会超出这样一台服务器。这意味着这些大厂高P骄傲的“分布式”独门技术,在新硬件的冲击下沦为鸡肋 —— 如果今天还有人津津乐道什么分表分布式海量规模高并发,只能说明一件事:这哥们过去十年已经停止学习了,还活在上一个时代里。
分布式数据库的基本工作假设是:单机的处理能力不足以支撑负载。然而这个支撑其存在价值的基础工作假设,在当代硬件面前已经不攻自破 —— 集中式数据库甚至什么都不用做,它的载荷上限就自动拔高到绝大多数务终生都无法触及的地步。确实会有人抬杠说,我们微信/我们支付宝就是有这样的场景需要分布式数据库 —— 且不说这个问题是不是一定要分布式数据库来解决,就算我们假设这种屈指可数的极端场景足够养活一两个分布式TP内核,但在网络硬件的性价比重新击溃磁盘前,分布式 OLTP 数据库已经不可能是数据库领域发展的大方向了。作为大厂“分布式”显学代表的阿里巴巴就是一个很有代表性的例子 —— 数据库长子 OceanBase 选择了分布式的道路,而现在的数据库太子,二儿子 PolarDB 就又及时调整了方向,重新回到集中式的架构上。
在大数据分析 OLAP 领域,分布式以前也许可能是必不可少的,但是现在也存疑 —— 对绝大多数企业来说,其全部数据库量很有可能都能在一台服务器内完成处理。以前非要“分布式数仓”不可的场景,在当代的单机服务器上跑一个 PostgreSQL 或者 DuckDB 很可能就解决掉了。诚然像大型互联网公司确实有 PB/ZB 级别的数据场景,但即使是互联网核心业务,其单一业务数据量级也极少有超过单机处理极限的案例。举个例子,BreachForums 最近泄漏的淘宝5年的(2015-2020 82亿)购物记录数据大小压缩后 600GB,同理,京东百亿,拼多多 145亿数据的大小也基本类似。更何况,戴尔或者浪潮都提供了PB级的NVMe全闪存储机柜产品,整个美国保险行业的全量历史数据和分析任务就可以塞进这样单个盒子,而只要二十万美元不到的价格。
分布式数据库的核心权衡是:“以质换量”,牺牲功能、性能、复杂度、可靠性,换取更大的数据容量与请求吞吐量。然而“过早优化是万恶之源 ”,为了不需要的规模去设计是白费功夫。如果量不再成为问题,那么为了不需要的量去牺牲其他属性,付出额外的复杂度成本与金钱成本就成了一件毫无意义的事情。
自建服务器的成本
新硬件的性能如此强悍,那成本又如何呢?摩尔定律指出,每18~24个月,处理器性能翻倍,成本减半。比起十年前,新硬件性能更加强悍,但价格反而更加便宜了。
在 《下云奥德赛:是时候放弃云计算了吗?》中,我们有一个新鲜的公开采购样本可以参考。下云先锋 DHH,37 Signal 在 2023 年为下云采购了一批物理机:他们从戴尔买了20台服务器:共计 4000核 vCPU,7680GB 的内存,以及 384TB 的 NVMe 存储,加上其他东西,总开销为50万美金。每台服务器具体配置规格为:Dell R7625 服务器,192 vCPU / 384 GB 内存:两颗 AMD EPYC 9454 处理器(48核/96线程,2.75 GHz),配置 2 x vCPU 的内存(16根32G内存条),一块12 TB NVMe Gen4 SSD,再加上其他配件,一台服务器成本两万美金($19,980),按五年摊销是 333美元/每月。
想要核实这个报价的有效性,我们可以直接参考零售市场上核心组件的价格:CPU 是 EPYC 9654 ,当下零售价格 3,725 美元一颗,两颗总计 $7450。32GB 的 DDR5 ECC 服务器内存,零售单价 $128 一条,16条共计 $2048。企业级 NVMe SSD 12TB,售价 $2390。 100G 光模块 100GbE QSFP28 报价 1804 美元,加起来 $13692 左右,加上服务器准系统,电源,系统盘,RAID 卡,风扇之类的东西,总价两万美元内并没有没什么问题。
当然,服务器并不是只有 CPU ,内存,硬盘,网卡这些零件,我们还需要考虑总体持有成本。数据中心里还要为这些机器提供电力、机位和网络,代维费用,并预留冗余量(美国的价格)。这部分开销核算后基本与每月硬件摊销费用持平,所以每台 192C / 384G / 12T NVMe 存储的服务器每月综合成本为 666 美元,核月人民币成本为 25.32 元。
我相信 DHH 给出这个数字没有什么问题,因为在探探时,我们从第一天就选择用 IDC / 资源云自建,经过了多轮成本优化做到的极致状态也差不多是这个价格 —— 我们采购的数据库服务器机型(Dell R730, 64 vCPU / 512GB / 3.2 TB NVMe SSD)加上人力代维网电成本后一台 TCO 约为七万五人民币,按五年摊销计算核月成本为 19.53 元。这里有一个表格,可以作为单位算力的价格参考:
| EC2 | 核·月 | RDS | 核·月 |
|---|---|---|---|
| DHH 自建核月价格(192C 384G) | 25.32 | 初级开源数据库DBA参考工资 | 15K/人·月 |
| IDC自建机房(独占物理机: 64C384G) | 19.53 | 中级开源数据库DBA参考工资 | 30K/人·月 |
| IDC自建机房(容器,超卖500%) | 7 | 高级开源数据库DBA参考工资 | 60K/人·月 |
| UCloud 弹性虚拟机(8C16G,有超卖) | 25 | ORACLE 数据库授权 | 10000 |
| 阿里云 弹性服务器 2x内存(独占无超卖) | 107 | 阿里云 RDS PG 2x内存(独占) | 260 |
| 阿里云 弹性服务器 4x内存(独占无超卖) | 138 | 阿里云 RDS PG 4x内存(独占) | 320 |
| 阿里云 弹性服务器 8x内存(独占无超卖) | 180 | 阿里云 RDS PG 8x内存(独占) | 410 |
| AWS C5D.METAL 96C 200G (按月无预付) | 100 | AWS RDS PostgreSQL db.T2 (2x) | 440 |
| AWS C5D.METAL 96C 200G (预付三年) | 80 | AWS RDS PostgreSQL db.M5 (4x) | 611 |
| AWS C7A.METAL 192C 384G (预付三年) | 104.8 | AWS RDS PostgreSQL db.R6G (8x) | 786 |
与云租赁价格对比
作为参照,我们可以用 AWS EC2 算力租赁的价格作为对比。666 美元每月的价格,能买到的最好规格是不带存储的 c6in.4xlarge 按需机型(16核32G x 3.5GHz);而存算规格与这类服务器相同(192C/384G)但不含 EBS 存储的 c7a.metal 机型,按需费用是 7200 美元每月,是本地自建综合成本的 10.8 倍;预付3年的保留实例最低可以到 2756 美元每月,也就是自建服务器的 4.1 倍。如果我们以 vCPU / month 的方式计算核月成本,AWS 绝大多数 EC2 实例的核月单价在 $10 ~ $30 美元之间,也就是一两百块,所以我们可以得出一个粗略的计算结论:云上算力的单位价格是自建的 5 ~ 10 倍。
请注意,这里的价格并没有包括百倍溢价的 EBS 云盘存储。 在《云盘是不是杀猪盘》中,我们已经详细对比过企业级 SSD 和等效云盘的成本了。这里我们可以给出两个当下更新后的参考值,DHH 采购的 12TB 企业级 NVMe SSD(以质保五年算)TB·月成本为 24 元,而 GameStop 上零售的三星消费级 SSD 990Pro的TB·月价格更是能达到惊人的 6.6 元 …。而AWS与阿里云的对应块存储TB·月成本在满打满算折扣的情况下分别为 1900 与 3200。在最离谱的情况下(6400 vs 6.6 )溢价甚至可以达到千倍,不过更为 Apple to Apple 的对比结果:云上块存储的单位价格是自建的 100 ~ 200 倍 (且性能并没有本地磁盘好)。
EC2 和 EBS 的价格可以说是云服务的定价之锚,例如,主要使用 EC2 与 EBS 的云数据库 RDS 相对于本地自建的溢价倍率,视您的存储使用量就在两者间波动:云数据库的单位价格是自建的十几倍到几十倍。详情请参考《云数据库是不是智商税》。
当然,我们也不能否认公有云在小微实例,企业初创起步阶段的成本优势 —— 比如,公有云上用来凑补的 1~2C,0.5~2G 的 nano 实例确实是可以按照十几块钱核月的成本价给到用户。在《薅阿里云ECS羊毛,打造数字家园》中我推荐薅阿里云双十一99虚拟机也是这个原因。比如,以五倍超卖算 2C 2G 的服务器算力成本是每年84元,40G 云盘价按三副本算一年存储成本20来块钱,光这两部分每年成本就过百了。这还没有算公网IP,以及价值更高的 3M 带宽(例如你真能把3M带宽24小时打满,那么一天流量32G就是25块钱)。这种云服务器的列表价是 ¥1500 一年,因此 99¥ 并允许低价续费用4年,确实可以算得上赔本赚吆喝的福利了。
但是当你的业务不再是一大堆小微实例可以 cover 的时候,你真的应该重新仔细再算一下账:在几个关键例子上,云的成本都极其高昂 —— 无论是大型物理机数据库、大型 NVMe 存储,或者只是最新最快的算力。租用生产队的驴价钱是如此高昂 —— 以至于几个月的租金就能与直接购买它的价格持平。在这种情况下,你确实应该直接把这头驴买下来!
重新拿回硬件红利
我还记得在 2019年4月1日,国内增值税正式从 16% 下调到 13% ,苹果官网随即全面降价,单品最高降价幅度达8% —— iPhone的几个典型产品都降了500元,把税点返还给了用户。但也有许多厂商选择装聋作哑维持原价,自己吃下这个福利 —— 白花花的银子怎么能随便散给穷人呢?类似的事情就发生在云计算领域 —— 硬件成本的指数下降,并没有在云厂商的服务价格上充分反映出来,而这一点,让公有云逐渐从普惠基础设施变成了垄断集中杀猪盘。
上古时代,开发者写代码是要深入了解硬件的,然而老一辈带有硬件 Sense 的工程师与程序员,很多已经退休/转岗/转管理/停止学习了。后来操作系统与编译器技术愈发强大,各种VM编程语言出现,软件已经完全不需要关心硬件是如何完成指令的;再后来,EC2 封装了算力,S3 / EBS 封装了存储,应用开始和 HTTP API 而不是系统调用打交道。软件和硬件分离为两个世界,分道扬镳。整整一代新工程师原生成长在云环境中,被屏蔽掉了对计算机硬件的了解。
然而事情正在起变化,硬件重新变得有趣起来,而云厂商是没有办法把这部分红利永远掩藏遮盖下去 —— 聪明的人开始计算数字,勇敢的人已经采取行动。像马斯克和DHH这样的先锋已经充分认识到了这一点,从云上下来,脚踏实地 —— 直接产生千万美元的财务效益,并且还有性能上的回报,运营也变得更加自主独立。越来越多的人会同样意识到这一点,追随先驱者做出明智的选择,拿回属于自己的硬件红利。
我们能从阿里云全球故障中学到什么?
时隔一年阿里云又出大故障,并创造了云计算行业闻所未闻的新记录 —— 全球所有区域/所有服务同时异常。阿里云不愿意发布故障复盘报告,那我就来替他复盘 —— 我们应当如何看待这一史诗级故障案例,以及,能从中学习到什么经验与教训?

事实是什么?
2023年11月12日,双十一后第一天,阿里云出了一场史诗级大翻车。全球所有区域同时出现故障,创造了闻所未闻的行业新记录。 根据阿里云官方的服务状态页,全球所有区域/可用区 ✖️ 所有服务全部出现异常,时间范围从 17:44 到 21: 11 ,共计三个半小时。
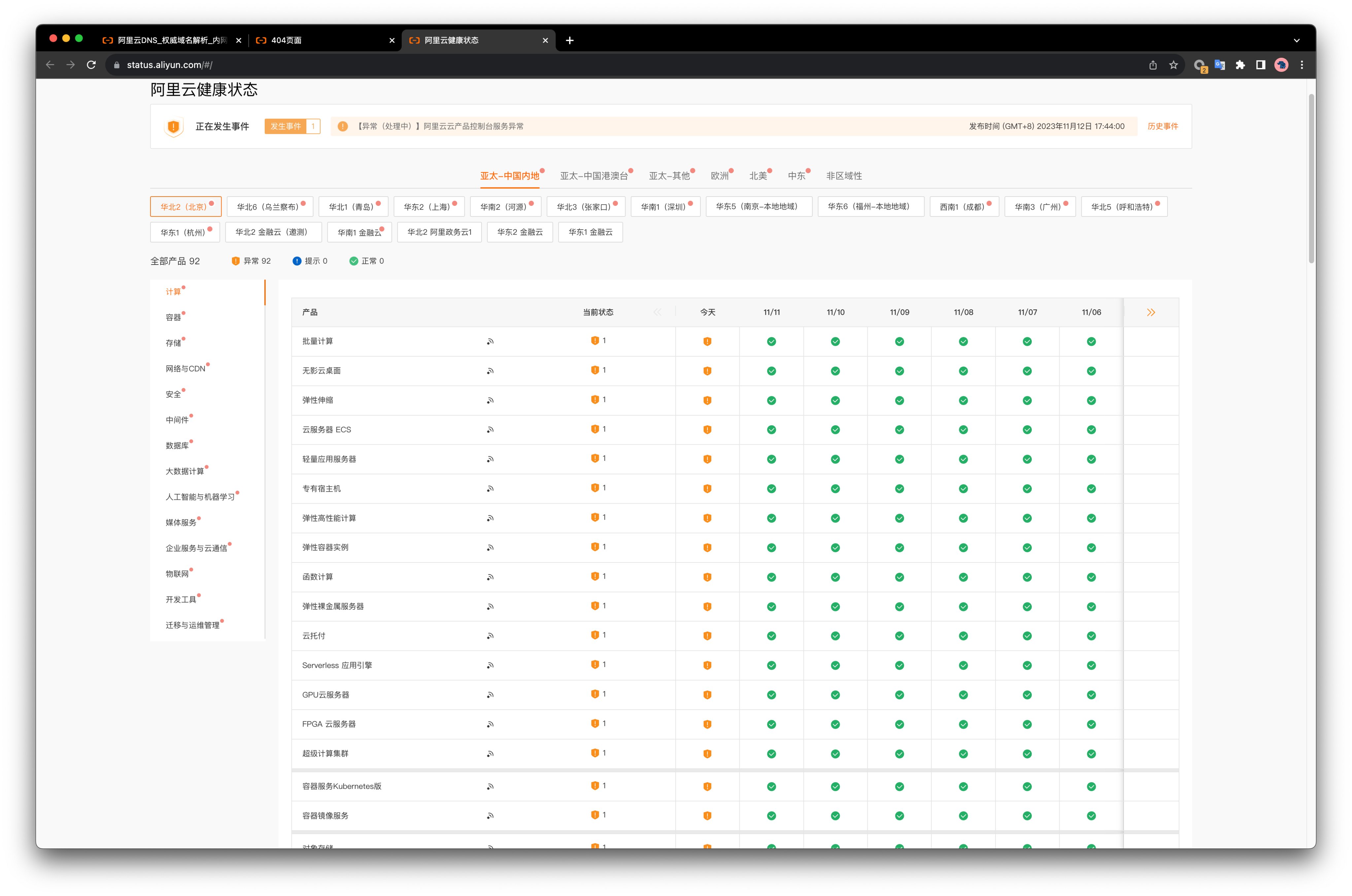
阿里云 Status Page
阿里云公告称:
“云产品控制台、管控API等功能受到影响,OSS、OTS、SLS、MNS等产品的服务受到影响,大部分产品如ECS、RDS、网络等的实际运行不受影响”。
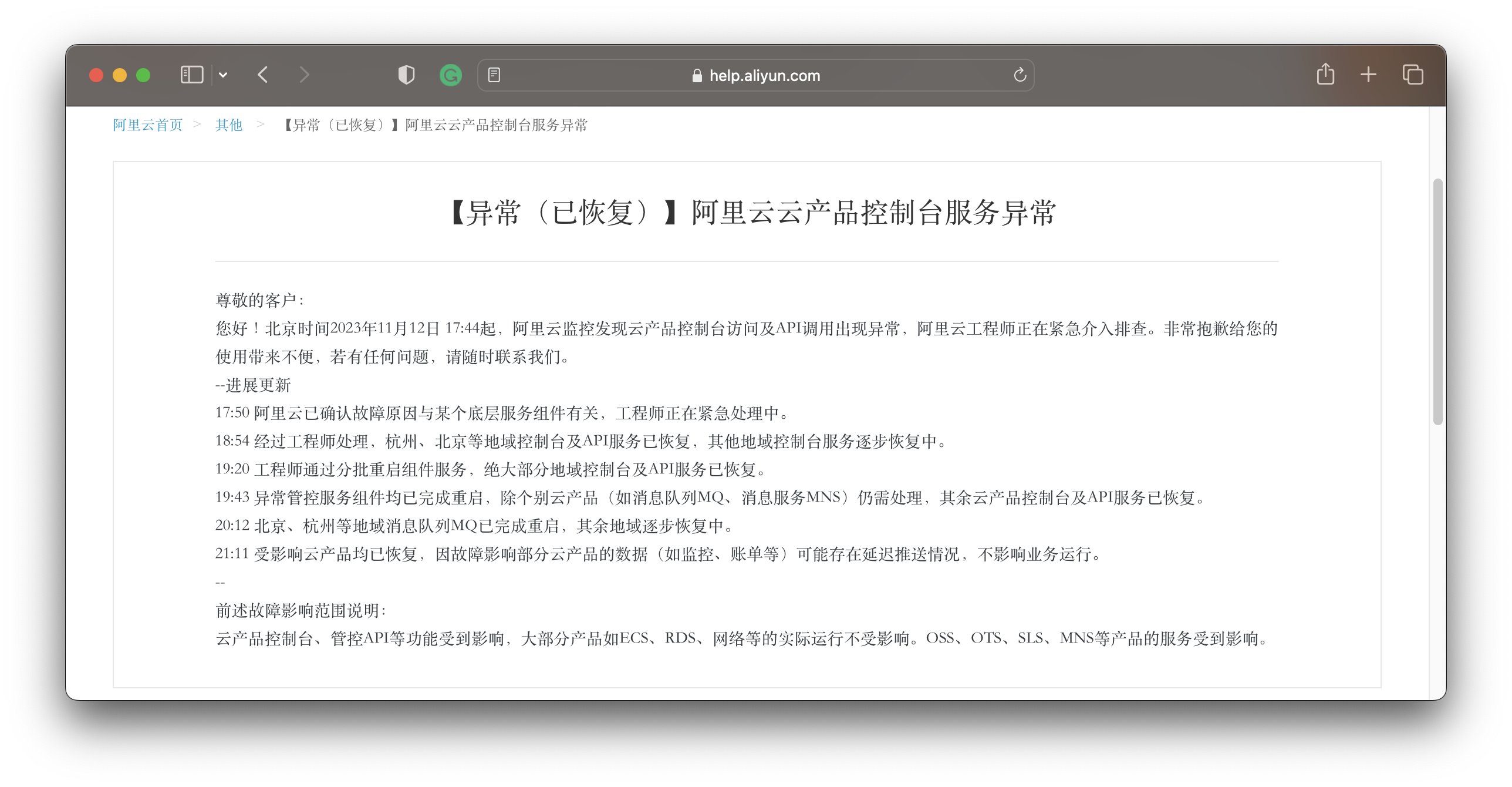
大量依赖阿里云服务的应用 APP,包括阿里系自己的一系列应用:淘宝,钉钉,闲鱼,…… 都出现了问题。产生了显著的外部影响,APP崩了的新闻组团冲上了热搜。
淘宝刷不出聊天图片,闪送上传不了接单凭据,充电桩用不了,原神发不出验证码,饿了么下不了单,骑手进不了系统,点不了外卖、停车场不抬杆、超市无法结账。甚至有的学校因此无法用智能公共洗衣机和开水机。无数在周末休息中的研发与运维人员被喊起来加班排障……
包括金融云、政务云在内的区域也没有幸免。阿里云应该感到万幸:故障不是发生在双十一当天,也不在衙门与钱庄的工作时间段,否则大家说不定能上电视看故障复盘了。
原因是什么?
尽管阿里云至今仍未给出一份事后故障复盘报告,但老司机根据爆炸半径,就足以判断出问题在哪里了 —— Auth (认证 / 鉴权 / RAM)。
存储计算硬件故障、机房断电这些问题最多影响单个可用区(AZ),网络故障最多影响一个区域(Region),能让全球所有区域同时出问题的肯定不会是这些问题,而是跨区域共用的云基础设施组件。 —— 极大概率是 Auth,低概率是其他诸如计量付费之类的全局性服务。

阿里云的事件进展公告:出问题的是某个底层服务组件,而不是网络、机房硬件的问题。
根因出在 Auth 上的可能性最大,最直接的证明就是:深度与 Auth 集成的云服务:对象存储 OSS (类 S3),表格存储 OTS (类 DynamoDB),以及其他深度依赖 Auth 的服务本身可用性直接受到影响。而本身运行不依赖 Auth 的云资源,比如云服务器 ECS / 云数据库 RDS 以及网络仍然可以“正常”运行,用户只是无法通过控制台与API对其进行管理与变更。此外,一个可以排除的计量付费服务出问题的现象是:故障期间还有用户成功付款薅下了ECS的羊毛。
尽管上面的分析过程只是一种推断,但它与流传出来的内部消息相吻合:认证挂了导致所有服务异常。至于认证服务本身到底是怎么挂的,在尸检报告出来前我们也只能猜测:人为配置失误的可能性最大 —— 因为故障不在常规变更发布窗口中,也没有灰度生效,不太像是代码/二进制发布。但具体是哪里配置失误:证书,黑白名单,循环依赖死锁,还是什么其他东西,就不知道了。
关于根因的小道消息也漫天飞舞,比如,有人说 ”权限系统推了个黑名单规则,黑名单规则维护在OSS上,访问OSS叉需要访问权限系统,然后权限系统又要访问OSS,就尬住了“。”。还有人说 “这次双11期间,技术人员连续一周加班加点,双11一过,大家都松懈了。有个新手写了一段代码,更新了组件,导致了本次的断网“,还有人说:”阿里云所有服务用的都是同一个通配符证书,证书换错了“。
如果是因为这些原因导致 Auth 挂掉,那可真是草台班子到家了。尽管听上去很离谱,但这样的先例并不少。再次强调,这些路边社消息仅供参考,具体事故原因请以阿里云官方给出的复盘分析报告为准。
影响是什么?
认证/鉴权是服务的基石,像这样的基础性组件一旦出现问题,影响是全局性、灾难性的。这会导致整个云管控面不可用,伤害会直接冲击控制台,API,以及深度依赖 Auth 基础设施的服务 —— 比如公有云上的另一个基石性服务,对象存储 OSS。
从阿里云公告上来看,好像只有 “几个服务( OSS、OTS、SLS、MNS)受到影响,大部分产品如ECS、RDS、网络等的实际运行不受影响 ”。但对象存储 OSS 这样的基石性服务出了问题,带来的爆炸半径是难以想象的,绝非“个别服务受到影响” 就能敷衍过去 —— 这就像汽车的油箱都着火了,说发动机和轮子仍然在转是没有意义的。
对象存储 OSS 这样的服务是通过云厂商包装的 HTTP API 对外提供服务的,因此必然深度依赖认证组件:你需要AK/SK/IAM 签名才能使用这些 HTTP API,而 Auth 故障将导致这类服务本身不可用。
对象存储 OSS 实在是太重要了,可以说是云计算的“定义性服务”,也许是唯一能在所有云上基本达成共识标准的服务。云厂商的各种“上层”服务或多或少都直接/间接地依赖 OSS,例如 ECS/ RDS 虽然可以运行,但 ECS 快照和 RDS 备份显然是深度依赖 OSS 的,CDN 回源是依赖 OSS 的,各个服务的日志往往也是写入 OSS 的。
从现象上看,核心功能跟 OSS 深度绑定的阿里云盘就挂的很惨烈,核心功能跟 OSS 关系不大的服务,比如高德地图就没听说有什么大影响。大部分相关应用的状态是,主体可以正常打开运行,但是和图片展示,文件上传/下载文件这类有关的功能就不可用了。
有一些实践减轻了对 OSS 的冲击:比如通常被认为是不安全的 —— 不走认证的 Public 存储桶就不受影响;CDN 的使用也缓释了 OSS 的问题:淘宝商品图片走 CDN 缓存还可以正常看到,但是买家聊天记录里实时发送的图片直接走 OSS 就挂了。
不仅仅是 OSS,其他深度集成依赖 Auth 的云服务也会有这样的问题,比如 OTS,SLS,MNS 等等。例如对标 DynamoDB 的表格存储服务 OTS 同样出现了问题。这里有一个非常鲜明的对比,像 RDS for PostgreSQL / MySQL 这样的云数据库服务使用的是数据库自身的认证机制,所以不受云厂商 Auth 服务故障影响。然而 OTS 没有自己的权限系统,而是直接使用 IAM/RAM,与云厂商的 Auth 深度绑定,因此受到了冲击。
技术上的影响是一方面,更重要的是业务影响。根据阿里云的 服务等级协议(SLA),3个半小时的故障使得当月各服务可用性指标降至 99.5%。落入绝大多数服务赔偿标准的中间档位上,也就是赔偿用户月度服务费用 25% ~ 30% 的代金券。特殊的是这一次故障的区域范围和服务范围是全部!

阿里云 OSS SLA
当然阿里云也可以主张说虽然 OSS / OTS 这些服务挂了,但他们的 ECS/RDS 只挂了管控面,不影响正在运行的服务,所以不影响 SLA。不过这种补偿即便真的全部落地也没几个钱,更像是一种安抚性的姿态:毕竟和用户的业务损失比,赔个服务月消 25%代金券简直就是一种羞辱。
比起用户信任、技术声望以及商誉折损而言,赔的那点代金券真的算不上三瓜两枣。这次事件如果处理不当,会成为公有云拐点级别的标志性事件。
评论与观点?
马斯克的推特 X 和 DHH 的 37 Signal 通过下云省下了千万美元真金白银,创造了降本增效的“奇迹”,让下云开始成为一种潮流。云上的用户在对着账单犹豫着是否要下云,未上云的用户更是内心纠结。在这样的背景下,作为本土云领导者的阿里云发生如此重大故障,对于犹豫观望者的信心无疑是沉重的打击。恐怕此次故障会成为公有云拐点级别的标志性事件。
阿里云一向以安全稳定高可用自居,上周还刚在云栖大会上吹极致稳定性之类的牛逼。但是无数所谓的的灾备,高可用,多活,多中心,降级方案,被一次性全部击穿,打破了N个9神话。如此大范围、长时间、影响面如此广的故障,更是创下了云计算行业的历史记录。
这次故障揭示出关键基础设施的巨大风险,大量依托于公有云的网络服务缺乏最基本的自主可控能力:当故障发生时没有任何自救能力,除了等死做不了别的事情。甚至包括金融云和政务云在内也同样出现了服务不可用。同时,它也反映出了垄断中心化基础设施的脆弱性:互联网这个去中心化的世界奇观现在主要是在少数几个大公司/云厂商拥有的服务器上运行 —— 某个云厂商本身成为了最大的业务单点,这可不是互联网设计的初衷!
更为严峻的挑战恐怕还在后面,全球用户追索赔钱事还小,真正要命的是在各个国家都在强调数据主权的时候,如果因为在中国境内的某个控制中心配置失当导致全球故障的话,(即:你真的卡了别人的脖子)很多海外客户会立即采取行动迁移到别的云供应商上:这关乎合规性,与可用性无关。
根据海恩法则,一次严重故障的背后有几十次轻微事故,几百起未遂先兆,以及上千条事故隐患。去年十二月阿里云香港机房的大故障已经暴露出来许多问题,然而一年后又给了用户一个更大的惊喜(吓!)。这样的事故对于阿里云的品牌形象绝对是致命打击,甚至对整个行业的声誉都有严重的损害。阿里云应该尽快给用户一个解释与交代,发布详细的故障复盘报告,讲清楚后续改进措施,挽回用户的信任。
毕竟这种规模的故障,不是“找个临时工背锅,杀个程序员祭天” 能解决的事,CEO 得亲自出面道歉解决。Cloudflare 月初的管控面故障后,CEO 立即撰写了详细的事后复盘分析,挽回了一些声誉。可不幸的是,阿里云经过了几轮裁员,一年连换三轮 CEO ,恐怕已经难有能出来扛事背责的人了。
能学到什么?
往者不可留,逝者不可追,比起哀悼无法挽回的损失,更重要的是从损失中吸取教训 —— 要是能从别人的损失中吸取教训那就更好了。所以,我们能从阿里云这场史诗级故障中学到什么?
不要把鸡蛋放在同一个篮子里,准备好 PlanB,比如,业务域名解析一定要套一层 CNAME,且 CNAME 域名用不同服务商的解析服务。这个中间层对于阿里云这样的故障非常重要,用另外一个 DNS 供应商,至少可以给你一个把流量切到别的地方去的选择,而不是干坐在屏幕前等死,毫无自救能力。
区域优先使用杭州与北京,阿里云故障恢复明显有优先级,阿里云总部所在地的杭州(华东1)和北京(华北2)故障修复的速度明显要比其他区域快很多,别的可用区故障恢复用了三个小时,这两个可用区一个小时就修复了。这两个区域可以考虑优先使用,虽然同样是吃故障,但你可以和阿里自家业务享受同种婆罗门待遇。
谨慎使用需要云认证的服务:Auth 是云服务的基石,大家都期待它可以始终正常工作 —— 然而越是人们感觉不可能出现故障的东西,真的出现故障时产生的杀伤力就越是毁天灭地。如无必要,勿增实体,更多的依赖意味着更多的失效点,更低的可靠性:正如在这次故障中,使用自身认证机制的 ECS/RDS 本身就没有受到直接冲击。深度使用云厂商提供的 AK/SK/IAM 不仅会让自己陷入供应商锁定,更是将自己暴露在公用基础设施的单点风险里。
谨慎使用云服务,优先使用纯资源。在本次故障中,云服务受到影响,但云资源仍然可用。类似 ECS/ESSD 这样的纯资源,以及单纯使用这两者的 RDS,可以不受管控面故障影响可以继续运行。基础云资源(ECS/EBS)是所有云厂商的提供服务的最大公约数,只用资源有利于用户在不同公有云、以及本地自建中间择优而选。不过,很难想象在公有云上却不用对象存储 —— 在 ECS 和天价 ESSD 上用 MinIO 自建对象存储服务并不是真正可行的选项,这涉及到公有云商业模式的核心秘密:廉价S3获客,天价EBS杀猪
自建是掌握自身命运的终极道路:如果用户想真正掌握自己的命运,最终恐怕早晚会走上自建这条路。互联网先辈们平地起高楼创建了这些服务,而现在做这件事只会容易得多:IDC 2.0 解决硬件资源问题,开源平替解决软件问题,大裁员释放出的专家解决了人力问题。短路掉公有云这个中间商,直接与 IDC 合作显然是一个更经济实惠的选择。稍微有点规模的用户下云省下的钱,可以换几个从大厂出来的资深SRE 还能盈余不少。更重要的是,自家人出问题你可以进行奖惩激励督促其改进,但是云出问题能赔给你几毛代金券? —— “你算老几能让高P舔你?”
明确云厂商的 SLA 是营销工具,而非战绩承诺
在云计算的世界里,服务等级协议(SLA)曾被视为云厂商对其服务质量的承诺。然而,当我们深入研究这些由一堆9组成的协议时,会发现它们并不能像期望的那样“兜底”。与其说是 SLA 是对用户的补偿,不如说 SLA 是对云厂商服务质量没达标时的“惩罚”。比起会因为故障丢掉奖金与工作的专家来说,SLA 的惩罚对于云厂商不痛不痒,更像是自罚三杯。如果惩罚没有意义,云厂商也没有动力去提供更好的服务质量。所以,SLA 对用户来说不是兜底损失的保险单。在最坏的情况下,它是堵死了实质性追索的哑巴亏;在最好的情况下,它才是提供情绪价值的安慰剂。
最后,尊重技术,善待工程师
阿里云这两年在大力搞“降本增效”:学人家马斯克推特大裁员,人裁几千你裁几万。但人家推挂来挂去用户捏着鼻子继续凑合用,ToB 业务跟着连环裁员连环挂,企业用户可忍得了这个?队伍动荡,人心不稳,稳定性自然会受到影响。
很难说这跟企业文化没有关系:996 修福报,大把时间内耗在无穷的会议汇报上。领导不懂技术,负责汇总周报写PPT 吹牛逼,P9 出嘴;P8 带队,真正干活的都是567,晋升没指望,裁员先找你;真正能打的顶尖人才根本不吃这一套 PUA 窝囊气,成批成批地出来创业单干 —— 环境盐碱地化:学历门槛越来越高,人才密度却越来越低。
我亲自见证的例子是,一个独立开源贡献者单人搞的 开源 RDS for PostgreSQL,可以骑脸输出几十人 RDS 团队的产品,而对方团队甚至连发声辩白反驳的勇气都没有 —— 阿里云确实不缺足够优秀的产品经理和工程师,但请问这种事情为什么可能会发生呢?这是应该反思的问题。
阿里云作为本土公有云中的领导者,应当是一面旗帜 —— 所以它可以做的更好,而不应该是现在这幅样子。作为曾经的阿里人,我希望阿里云能吸取这次故障的教训,尊重技术,踏实做事,善待工程师。更不要沉迷于杀猪盘快钱而忘记了自己的初心愿景 —— 提供物美价廉的公共计算服务,让存算资源像水电一样普及。
参考阅读
薅阿里云羊毛,打造数字家园
阿里云双十一提供了一个不错的福利,列表价 ¥1500/年 的 2C/2G/3M ECS服务器,一年 ¥99 给用三年(99¥ 每年可续费到2026),据说还要给中国所有大学生每人免费送一台。

虽然我经常揶揄公有云是杀猪盘,但那是针对我们这种体量的用户。对于个人开发者而言,这种价格真的可以说是很厚道的福利了。2C/2G 倒是不值几个钱,但这个 3M 带宽和公网IP 还是很给力的。新老用户都可以买,截止到双11,我建议所有开发者都薅了这个羊毛,用来建设一个 DevBox。
弄了 ECS 可以干啥用呢?你可以把它当成跳板机,临时文件中转站,搭建一个静态网站,个人博客,运行一些定时脚本跑一些服务,搭个梯子,打造自己的 Git 仓库,软件源,Wiki站点,搭建私有部署的论坛/社交媒体站点。
学生可以用来学习 Linux,构建一个软件编译环境,学习各种数据库:PostgreSQL,Redis,MinIO,用 SQL 和 Python 搞搞数据分析,用 Grafana 和 Echarts 玩玩数据可视化。
Pigsty 为这些需求提供了一个一键安装,开箱即用的底座,让您立刻在 ECS 上拥有一个生产级的 DevBox。

然后呢?
Pigsty 提供了开箱即用的主机/数据库监控系统,开箱即用的 Nginx Web 服务器承用于对外服务,一个功能完备,插件齐全的 PostgreSQL 数据库可以用于支持各种上层软件。在 Pigsty 的基础上,你可以很轻松的搭建一个静态网站 / 动态服务。安装完 Pigsty 后,你可以自行探索一下监控系统(Demo: https://demo.pigsty.cc ),它展示了你的主机详情和数据库的完整监控。
我们也会在后续介绍一系列有趣的主题:
- 样例应用:ISD,对全球天气数据进行分析与可视化
- 数据库101:快速上手数据库全能王:PostgreSQL
- 可视化快速上手,用 Grafana 画图进行数据分析
- 静态网站:使用 hugo 打造你自己的静态个人网站
- 跳板机:如何将这台 ECS 作为跳板,访问家中的电脑?
- 站点发布:如何让用户通过域名访问你的个人网站
- SSL证书:如何使用 Let’s Encrypt 免费证书加密
- Python环境:如何在 Pigsty 配置 Python 开发环境
- Docker环境:如何在 Pigsty 中启用 Docker 开发环境
- MinIO:如何将这台 ECS 作为你的文件中转站并与他人分享?
- Git仓库:如何使用 Gitea + PostgreSQL 搭建自己的 Git 仓库?
- Wiki站点:如何使用 Wiki.js + PostgreSQL 搭建自己的 Wiki 知识库?
- 社交网络:如何使用快速搭建 Mastodon 与 Discourse?
购买配置ECS
作为资深 IaC 用户,我早已习惯了一键拉起所需的云资源,置备好所有东西。在控制台上用鼠标点点点这种活儿对我已经非常陌生了。不过我相信也有不少读者其实还并不熟悉云上的操作,所以我们尽可能详尽的展示这里的操作。如果你已经是老司机了,请直接跳过这一部分,进入 Pigsty 配置部分。
购买活动虚拟机
没有阿里云账号可以用手机号注册一个,然后用支付宝扫码实名认证完事。进入活动页面,立即购买。地区选一个离你位置最近的,可用区可以选字母序大一点的。操作系统网络无所谓用默认的就行后面再改,选好之后勾选最下面的:我已阅读并同意云服务器ECS-包年包月服务协议。点击“立即购买”,支付宝付钱,完工。
不差钱的话我建议直接充个三百块,锁定 99¥ 续费一年先,剩下的零钱可以花个几十块钱买个域名,补充点零用的 OSS/ESSD/流量费啥的。毕竟如果你想使用按需付费的东西,还是需要一百块抵押在里面的。
直接在实例页面点 “续费”,续费1年目前的价格是 99¥ ,可以直接续上锁定下一年的优惠。当然第三年阿里云只是说到时候你可以继续用 99¥ 的价格继续续费一年到 2026,现在还操作不了。
重装系统与密钥
购买完云服务器后,点击控制台。或者左上角 Logo 边上的菜单图标进入 ECS 控制台,然后就能看到你买的实例已经运行了。我们可以在这里进一步配置网络、操作系统,以及密码密钥。

直接点实例边上的 “停止”,点击实例名称链接进入详情页,选择“更换操作系统”。然后选择“公共镜像”,选择你想用的操作系统镜像就好了。Pigsty 支持 EL 7/8/9 以及兼容操作系统,Ubuntu 22.04/22.04 ,Debian 12/11。
这里我们推荐使用 RockyLinux 8.10 64位,这是目前主流的企业级操作系统,在稳定性和软件新鲜度上取得了一个均衡。 OpenAnolis 8.8 RHCK, RockyLinux 9.4 ,或者 Ubuntu 22.04 也是不错的选择,不过我们后面演示用的都是 Rocky 8.8,初学者最好还是不要在这里过多折腾为妙。
《EL系统兼容性哪家强?》
在安全设置中,你可以设置 root 用户密码/密钥。如果你没有 SSH 密钥,可以使用 ssh-keygen 生成一对,或者直接填一个文本密码,这里我们方便起见随便设置一个。设置好了之后,你就可以使用 ssh root@<ip> 的方式登陆该服务器了(SSH客户端这种问题就不在这儿展开了,iTerm, putty, xshell, secureCRT 都行)
ssh-keygen # 如果你没有 SSH 密钥对,生成一对。
ssh-copy-id root@<ip> # 将你的ssh密钥添加到服务器上(输入密码)
配置域名与DNS
域名现在非常便宜了,一年也就十几块钱。我非常建议整一个,能够带来很大的便利。主要是你可以用不同的子域名来区分不同的服务,让 Nginx 把流量转发到不同的上游去,一机多用。当然,喜欢用 IP 地址 + 端口号直接访问不同服务也无所谓。主要是一来比较土鳖,二来端口开的太多也会有更多安全隐患。
比如这里,我花了十几块钱在阿里云上买了个 pdata.cc 的域名,然后在阿里云DNS控制台上就可以去添加域名的解析了,指向刚申请服务器的 IP 地址。一条 @ 记录,一条 * 通配记录,A 记录,指向 ECS 实例的公网IP地址就行。
有了域名之后,你就可以用 ssh root@pdata.cc 的方式登陆,不用再记 IP 地址了。你也可以在这里配置更多的子域名,指向不同的地址。如果域名是拿来建站的,在中国大陆还需要申请备案,反正阿里云也有一条龙的服务。
配置安全组规则
新创建的云服务器带有默认的安全组规则,只允许 SSH 服务也就是 22 端口访问。所以为了访问这台服务器上的 Web 服务你还需要打开 80/443 端口。如果你懒得折腾域名想用 IP + 端口直接访问相应服务,而不是通过域名走 Nginx 的 80/443 端口,那么 Grafana 监控界面的 3000 端口也应该打开。最后,如果你想从本地访问 PostgreSQL 数据库,也可以考虑打开 5432 端口。
如果你想偷懒,确实可以添加一条开放所有端口的规则,但云服务器不比自己的笔记本,你也不想自己的 ECS 被人黑了拿去干坏事被封号吧。所以这里我们还是按规矩来。实例详情页里点击安全组,然后点击那个具体的安全组进入详情页进行配置:
在默认的 “入方向” 上添加一条“允许”规则,协议选择 TCP,端口范围填入 80/443/3000/5432,从 0.0.0.0/0 任意地址都可以访问这些端口。
上面这些操作属于 Linux 101 基础知识老生常谈,对老司机来说,使用 Terraform 模板一行命令就完成了。但很多初学者确实不知道如何去弄。
总之,折腾完上面的步骤之后,你就有一台准备就绪的云服务器了!你可以在任意有网络的地方使用域名登陆/访问这台服务器。接下来,我们就可以在开始建设数字家园了:安装 Pigsty。
安装配置Pigsty
现在,你已经可以使用 root 用户,通过 SSH 登陆这台服务器了,接下来就可以下载、安装、配置 Pigsty 了。
尽管使用 root 用户并非生产最佳实践,但对于个人 DevBox 来说没啥关系,我们就不折腾新建管理用户这摊子事儿了。直接使用 root 用户开干:
curl -fsSL https://repo.pigsty.cc/get | bash # 下载 Pigsty 并解压到 ~/pigsty 目录
cd ~/pigsty # 进入 Pigsty 源码目录,完成后续 准备、配置、安装 三个步骤即可
./bootstrap # 确保 Ansible 正常安装,如果存在 /tmp/pkg.tgz 离线软件包,便使用它。
./configure # 执行环境检测,并生成相应的推荐配置文件,如果你知道如何配置 Pigsty 可以跳过
./install.yml # 根据生成的配置文件开始在当前节点上执行安装,使用离线安装包大概需要10分钟完成
Pigsty 官方文档提供了详细的安装配置教程:https://pigsty.cc/
安装完成后,您可以通过域名或80/443端口通过 Nginx 访问 WEB 界面,通过 5432 端口访问默认的 PostgreSQL 数据库服务,通过 3000 端口登陆 Grafana。
在浏览器中输入 http://<公网IP>:3000,即可访问 Pigsty 的 Grafana 监控系统。 ECS 的 3M 带宽小水管会在初次加载 Grafana 时费点功夫。 您可以匿名访问,也可以使用默认的用户名密码 admin / pigsty 登陆。请务必修改这个默认密码,避免别人随便从这里进入搞破坏。
上面这个教程看上去真的很简单对吧?对的。作为一台随时可以销毁重建的开发机,这么搞毫无问题。但如果你想把它作为一个承载个人数字家园的环境,请最好参考下面的 配置详情 和 安全加固 部分再进行动手。
配置详情
当您安装 Pigsty 运行 configure 这一步时,Pigsty 会根据您的机器环境,生成一个单机安装的配置文件:pigsty.yml。默认的配置文件可以直接用,但你可以进一步进行定制修改,来增强其安全性与便利性。
下面是一个推荐的配置文件样例,它应当默认在 /root/pigsty/pigsty.yml 这里,描述你需要的数据库。Pigsty 提供了 280+ 定制参数,但你只需要关注几个进行微调即可。你的机器内网IP地址,可选的公网域名,以及各种密码。域名是可选的,但我们建议你最好用一个。其他的密码你懒得修改也就算了,pg_admin_password 请务必修改一个。
---
all:
children:
# 这里的 10.10.10.10 都应该是你 ECS 的内网 IP 地址,用于安装 Infra/Etcd 模块
infra: { hosts: { 10.10.10.10: { infra_seq: 1 } } }
etcd: { hosts: { 10.10.10.10: { etcd_seq: 1 } }, vars: { etcd_cluster: etcd } }
# 定义一个单节点的 PostgreSQL 数据库实例
pg-meta:
hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary } }
vars:
pg_cluster: pg-meta
pg_databases:
- { name: meta ,baseline: cmdb.sql ,schemas: [ pigsty ] }
pg_users: # 最好把这里的两个样例用户的密码也修改一下
- { name: dbuser_meta ,password: DBUser.Meta ,roles: [ dbrole_admin ] }
- { name: dbuser_view ,password: DBUser.Viewer ,roles: [ dbrole_readonly ] }
pg_conf: tiny.yml # 2C/2G 的云服务器,使用微型数据库配置模板
node_tune: tiny # 2C/2G 的云服务器,使用微型主机节点参数优化模板
pgbackrest_enabled: false # 这么点磁盘空间,就别搞数据库物理备份了
pg_default_version: 13 # 用 PostgreSQL 13
vars:
version: v2.5.0
region: china
admin_ip: 10.10.10.10 # 这个 IP 地址应该是你 ECS 的内网IP地址
infra_portal: # 如果你有自己的 DNS 域名,这里面的域名后缀 pigsty 换成你自己的 DNS 域名
home: { domain: h.pigsty }
grafana: { domain: g.pigsty ,endpoint: "${admin_ip}:3000" , websocket: true }
prometheus: { domain: p.pigsty ,endpoint: "${admin_ip}:9090" }
alertmanager: { domain: a.pigsty ,endpoint: "${admin_ip}:9093" }
minio: { domain: sss.pigsty ,endpoint: "${admin_ip}:9001" ,scheme: https ,websocket: true }
postgrest: { domain: api.pigsty ,endpoint: "127.0.0.1:8884" }
pgadmin: { domain: adm.pigsty ,endpoint: "127.0.0.1:8885" }
pgweb: { domain: cli.pigsty ,endpoint: "127.0.0.1:8886" }
bytebase: { domain: ddl.pigsty ,endpoint: "127.0.0.1:8887" }
gitea: { domain: git.pigsty ,endpoint: "127.0.0.1:8889" }
wiki: { domain: wiki.pigsty ,endpoint: "127.0.0.1:9002" }
noco: { domain: noco.pigsty ,endpoint: "127.0.0.1:9003" }
supa: { domain: supa.pigsty ,endpoint: "10.10.10.10:8000", websocket: true }
blackbox: { endpoint: "${admin_ip}:9115" }
loki: { endpoint: "${admin_ip}:3100" }
# 把这里的密码都改掉!你也不想别人随便来串门对吧!
pg_admin_password: DBUser.DBA
pg_monitor_password: DBUser.Monitor
pg_replication_password: DBUser.Replicator
patroni_password: Patroni.API
haproxy_admin_password: pigsty
grafana_admin_password: pigsty
...
在 configure 生成的配置文件中,所有 10.10.10.10 这个 IP 地址都会被替换为你的 ECS 实例的首要内网 IP 地址。注意:不要在这里使用公网 IP 地址。在 infra_portal 参数中,你可以把所有的 .pigsty 域名后缀换成你新申请的域名,比如 pdata.cc ,这样 Pigsty 会允许您通过 Nginx 使用不同域名来访问不同的上游服务。后面如果您希望添加几个个人网站,也可以在这个配置里直接修改并应用。
修改好配置文件 pigsty.yml 之后,运行 ./install.yml 即可开始安装。
安全加固
大多数人可能都不在乎安全这个事,但我还是必须要说一下。只要你改了默认密码,ECS 和 Pigsty 的默认配置对大多数场景已经足够安全了。这里有一些安全加固的小建议:https://pigsty.cc/docs/setup/security
第一个要点是,出于安全考虑:除非你真的很想偷懒从本地直接访问远程数据库,一般不建议对公网开放 5432 端口,很多数据库工具都提供了 SSH Tunel 功能 —— 先 SSH 到服务器再本地连接数据库。(顺带一提,Intellij 自带的 Database Tool 是我用过最好用的数据库客户端工具)
如果你真的很想从本地直连远程数据库,Pigsty 默认规则也允许您使用默认的超级用户 dbuser_dba 使用 SSL / 密码认证从任何地方访问,请确保你改了 pg_admin_password 参数,并开放了 5432 端口。
第二个要点是使用域名而非 IP 地址访问,就要求你做一些额外的工作:域名可以在云厂商那里买,也可以使用本地 /etc/hosts 的静态解析记录作为下位替代。如果您实在懒得折腾,IP 地址 + 端口直连也不是不行。
第三个要点是使用 HTTPS, SSL 可以使用各家云厂商或 Let’s Encrypt 提供的免费证书,使用 Pigsty 默认的自签名 CA 颁发的证书作为下位替代。
Pigsty默认使用自动生成的自签名的CA证书为Nginx启用SSL,如果您希望使用 HTTPS 访问这些页面,而不弹窗提示"不安全",通常有三个选择:
- 在您的浏览器或操作系统中信任Pigsty自签名的CA证书:
files/pki/ca/ca.crt - 如果您使用 Chrome,可以在提示不安全的窗口键入
thisisunsafe跳过提示 - 您可以考虑使用 Let’s Encrypt 或其他免费的CA证书服务,为 Pigsty Nginx 生成正式的CA证书
我们会在后面的教程中详细介绍这些细节,你也可以参考 Pigsty 的文档进行自行配置。
云计算泥石流:用数据解构公有云
曾几何时,“上云“近乎成为技术圈的政治正确,但很少有人会用实打实的数据来分析这里面的利弊权衡。我愿意成为这个质疑者:让我用实打实的 数据 与亲身经历的故事,讲清楚公有云租赁模式的陷阱与价值 —— 在这个降本增效的时代中,供您借鉴与参考。

序
经济下行,降本增效成为主旋律,除了裁员,下云以削减高昂的云开支,也被越来越多的企业纳入考虑提上日程。
我们认为,公有云有其存在意义 —— 对于那些非常早期、或两年后不复存在的公司,对于那些完全不在乎花钱、或者真正有着极端大起大落的不规则负载的公司来说,对于那些需要出海合规,CDN等服务的公司来说,公有云仍然是非常值得考虑的服务选项。
然而对绝大多数已经发展起来,有一定规模的公司来说,如果能在几年内摊销资产,你真的应该认真重新审视一下这股云热潮。好处被大大夸张了 —— 在云上跑东西通常和你自己弄一样复杂,却贵得离谱。我真的建议您好好算一下帐。
最近十年间,硬件以摩尔定律的速度持续演进,IDC2.0与资源云提供了公有云资源的物美价廉替代,开源软件与开源管控调度软件的出现,更是让自建的能力变得唾手可及 —— 下云自建,在成本,性能,与安全自主可控上都会有非常显著的回报。
这个合集 《数据库泥石流 —— 用数据解构公有云》,包含了我们自己作为甲方在云上云下/上云下云过程中的亲身体验例证,收集对比了自建与云服务的实际效能成本数据并进行分析,为您提供参考与借鉴。
我们提倡下云理念,并提供了实践的路径与切实可用的自建替代品 —— 我们将为认同这一结论的追随者提前铺设好意识形态与技术上的道路。
不为别的,只是期望所有用户都能拥有自己的数字家园,而不是从科技巨头云领主那里租用农场。—— 这也是一场对互联网集中化与反击赛博地主垄断收租的运动,让互联网 —— 这个美丽的自由避风港与理想乡可以走的更长。
下云奥德赛
当代的下云史诗,云遣返奥德赛。来自 37 Signal 的传奇下云故事:如何在6个月内下云并省下五千万元。我从 @dhh 的博客上挑选了10篇文章,以时间线倒序展现这段波澜壮阔的旅程,译作中文,供大家参考借鉴。
作者:David Heinemeier Hansson,网名DHH,37 Signal 联创与CTO,Ruby on Rails 作者,下云倡导者、实践者、领跑者。反击科技巨头垄断的先锋。博客:https://world.hey.com/dhh
译者:冯若航,网名 Vonng。磐吉云数 创始人与CEO。Pigsty 作者,PostgreSQL 专家与布道师。云计算泥石流,数据库老司机,下云倡导者与实践者。
FinOps的终点是下云
在 SACC 2023 大会 FinOps 专场上,我狠狠喷了一把云厂商。这是现场发言的文字整理稿,介绍了终极 FinOps —— 下云 的理念与实践路径。
FinOps关注点跑偏:总价 = 单价 x 数量,搞 FinOps 的关注减少浪费资源的数量,却故意无视了房间里的大象 —— 云资源单价。
公有云是个杀猪盘:廉价EC2/S3获客,EBS/RDS杀猪。云算力的成本是自建的五倍,块存储的成本则可达百倍以上,堪称终极成本刺客。
FinOps终点是下云:对于有一定规模企业来说,IDC自建的总体成本在云服务列表价1折上下。下云是原教旨 FinOps 的终点,也是真正 FinOps 的起点。
自建能力决定议价权:拥有自建能力的用户即使不下云也能谈出极低的折扣,没有自建能力的公司只能向公有云厂商缴纳高昂的 “无专家税” 。
数据库是自建关键:K8S 上的无状态应用与数据仓库搬迁相对容易,真正的难点是在不影响质量安全的前提下,完成数据库的自建。
云计算为啥还没挖沙子赚钱?
公有云毛利不如挖沙子,杀猪盘为何成为赔钱货?
卖资源模式走向价格战,开源替代打破垄断幻梦。
服务竞争力逐渐被抹平,云计算行业将走向何方?
在《云盘是不是杀猪盘》、《云数据库是不是智商税》以及《云SLA是不是安慰剂》中,我们已经研究过关键云服务的真实成本。规模以上以核·月单价计算的云服务器成本是自建的 5~10 倍,云数据库则可达十几倍,云盘更是能高达上百倍,按这个定价模型,云的毛利率做到八九十也不稀奇。
业界标杆的 AWS 与 Azure 毛利就可以轻松到 60% 与 70% 。反观国内云计算行业,毛利普遍在个位数到 15% 徘徊,榜一大哥阿里云最多给一句“预估远期整体毛利 40%” ,至于像金山云这样的云厂商,毛利率直接一路干到 2.1%,还不如打工挖沙子的毛利高。
而说起净利润,国内公有云厂商更是惨不忍睹。AWS / Azure 净利润率能到 30% ~ 40% 。标杆阿里云也不过在盈亏线上下徘徊挣扎。这不禁让人好奇,国内这些云厂商是怎么把一门百分之三四十纯利的生意能做到这种地步的?
云SLA是不是安慰剂?
在云计算的世界里,服务等级协议(SLA)被视为云厂商对其服务质量的承诺。然而,当我们深入研究这些 SLA 时,会发现它们并不能像期望的那样“兜底”:你以为给自己的数据库上了保险可以高枕无忧,但其实白花花的银子买的是提供情绪价值的安慰剂。
对于云厂商来说,SLA 并不是真正的可靠性承诺或历史战绩,而是一种营销工具,旨在让买家相信云厂商可以托管关键业务应用。对用户来说,SLA不是兜底损失的保险单。在最坏的情况下,它是吃不了兜着走的哑巴亏。在最好的情况下,它才是提供情绪价值的安慰剂。
与其说是 SLA 是对用户的补偿,不如说 SLA 是对云厂商服务质量没达标时的“惩罚”。云厂商并不需要在可靠性上精益求精 —— 没达到自罚三杯即可。然而苦果只能由客户自己承担。
云盘是不是杀猪盘?
我们已经用数据回答了《云数据库是不是智商税》这个问题,但在公有云块存储的百倍溢价杀猪比率前,云数据库只能说还差点意思。本文用实际数据揭示公有云真正的商业模式 —— 廉价EC2/S3获客,EBS/RDS杀猪。而这样的做法,也让公有云与其初心愿景渐行渐远。
EC2 / S3 / EBS 是所有云服务的定价之锚。如果说 EC2/S3 定价还勉强能算合理,那么 EBS 的定价乃是故意杀猪。公有云厂商最好的块存储服务与自建可用的 PCI-E NVMe SSD 在性能规格上基本相同。然而相比直接采购硬件,AWS EBS 的成本高达 120 倍,而阿里云的 ESSD 则可高达 200 倍**。**
即插即用的磁盘硬件,百倍溢价到底为何?云厂商无法解释如此的天价到底源于何处。结合其他云存储服务的设计思路与定价模型,只有一个合理的解释:EBS的高溢价倍率是故意设置的门槛,以便于云数据库杀猪。
作为云数据库定价之锚的 EC2 与 EBS,溢价分别为几倍与几十倍,从而支撑起云数据库的杀猪高毛利。但这样的垄断利润必定无法持久:IDC 2.0/运营商/国资云冲击 IaaS;私有云/云原生/开源平替冲击 PaaS;科技行业大裁员、AI冲击与天朝的低人力成本冲击云服务(运维人力外包/共享专家)。公有云如果执着于目前的杀猪模式,背离“存算基础设施”的初心,那么必将在以上三者形成的合力下面临越来越严峻的竞争与挑战。
云数据库是不是智商税?
近日,Basecamp & HEY 联合创始人 DHH 的一篇文章【1,2】引起热议,主要内容可以概括为一句话:“我们每年在云数据库(RDS/ES)上花50万美元,你知道50万美元可以买多少牛逼的服务器吗?我们要下云,拜拜了您呐!“
所以,50 万美元可以买多少牛逼的服务器 ?
一台 64C 384G + 3.2TB NVMe SSD 的高配数据库服务器,我们本地自建,5年摊销,每年1.5万元。自建两台组HA,每年5万,同规格阿里云上25~50万(包3年打五折);AWS 上则更离谱:160 ~ 217 万元。
所以问题来了,如果你用云数据库1年的钱,就够你买几台甚至十几台性能更好的服务器,那么使用云数据库的意义到底在哪里?如果您觉得自己没有能力自建 —— 那么我们为您提供一个开箱即用,免费的 RDS 管控替代,来帮你解决这个问题!—— Pigsty!
如果您的业务符合公有云的适用光谱,那是最好不过;但为了不需要的灵活性与弹性支付几倍乃至十几倍溢价,那是纯交智商税。
范式转移:从云到本地优先
最初,软件吞噬世界,以 Oracle 为代表的商业数据库,用软件取代了人工簿记,用于数据分析与事务处理,极大地提高了效率。不过 Oracle 这样的商业数据库非常昂贵,一核·一月光是软件授权费用就能破万,不是大型机构都不一定用得起,即使像壕如淘宝,上了量后也不得不”去O“。
接着,开源吞噬软件,像 PostgreSQL 和 MySQL 这样”开源免费“的数据库应运而生。软件开源本身是免费的,每核每月只需要几十块钱的硬件成本。大多数场景下,如果能找到一两个数据库专家帮企业用好开源数据库,那可是要比傻乎乎地给 Oracle 送钱要实惠太多了。
开源软件带来了巨大的行业变革,可以说,互联网的历史就是开源软件的历史。尽管如此,开源软件免费,但 专家稀缺昂贵。能帮助企业 用好/管好 开源数据库的专家非常稀缺,甚至有价无市。某种意义上来说,这就是”开源“这种模式的商业逻辑:免费的开源软件吸引用户,用户需求产生开源专家岗位,开源专家产出更好的开源软件。但是,专家的稀缺也阻碍了开源数据库的进一步普及。于是,“云软件”出现了 —— 垄断不了软件,垄断专家也可以。
然后,云吞噬开源。公有云软件,是互联网大厂将自己使用开源软件的能力产品化对外输出的结果。公有云厂商把开源数据库内核套上壳,包上管控软件跑在托管硬件上,并雇佣共享 DBA 专家提供支持,便成了云数据库服务 (RDS) 。这诚然是有价值的服务,也为很多软件变现提供了新的途径。但云厂商的搭便车行径,无疑对开源软件社区是一种剥削与攫取,而捍卫计算自由的开源组织与开发者自然也会展开反击。
云软件的崛起会引发新的制衡反作用力:与云软件相对应的本地优先软件开始如雨后春笋一般出现。而我们,就在亲历见证这次范式转移。
DHH:下云省下千万美元,比预想的还要多!
作者:DHH,《Our cloud-exit savings will now top ten million over five years》
去年夏天,我们完成了下云工作,将包括 HEY 在内的七个云上应用从 AWS 迁移到我们自己的硬件上来。但直到年底,我们的所有长期合同才结束,所以2024年是第一个完全实现节省的年份。我们欣喜地发现,节省的费用比最初估计的还要多。
在2024年,我们已将云账单从每年 320万美元 降至 130万美元,每年节省了近200万美元! 之所以比我们最初预估的五年节省700万美元还要多,是因为我们成功地将所有新硬件安装在我们现有的数据中心的机架上和电力限制内。
购买这些新的 戴尔硬件 花费了约70万美元,但在2023年期间,随着长期合同逐步到期,我们已完全收回成本。想想看,这些设备我们预计可以使用五年,甚至七年!所有费用都由2023年下半年积累的节省来支付,真是太棒了!
但好事还在后头。目前我们仍在云服务上花费的130万美元,全部花在了 AWS S3 上。虽然我们之前的云计算和托管数据库/搜索服务都是预付一年的合同,但我们的文件存储被锁定在一个从 2021 年开始的,长达四年的合同中,所以我们计划中,完整下掉 S3 要到明年夏天了。
我们现在在 S3 中存储了近 10 PB 的数据,包括 Basecamp 和 HEY 等的重要客户文件,并通过不同区域进行冗余存储。我们采用混合存储类别,权衡了可靠性、访问性和成本。但即便有长期合同的折扣,保存这些数据每年仍需一百多万美元!
明年夏天下云后,我们将迁移到双数据中心的 Pure Storage 系统,总容量为18 PB。初始硬件成本约等于一年使用 AWS S3 的费用。但得益于 Pure 闪存阵列的高密度和高能效,我们可以将这些设备安装在现有的数据中心机架内。因此,后续成本只是一些常规的服务合同,我们预计在五年内再节省四百万美元。
因此,我们下云预计的总收益将在五年内超过一千万美元!同时,我们还获得了更快的算力和更大的存储空间。
当然,云上和本地自建的对比从来不是完全对等的。如果您完全在云上,而没有现成的数据中心机架,那么你也需要支付租赁费用 —— (但相比云服务的费用,您可能会惊讶于其便宜程度!)。但也别忘了对于我们的下云案例来说,节约估算的目标也是在不断变化的 —— 因为随着 Basecamp 和 HEY 的业务持续增长,我们需要更多的硬件和存储。
但令人瞩目的是,我们通过下云获得了如此巨大省钱收益。我们已经下云一年多了,然而团队规模仍然保持不变。当我们宣布下云时,有人猜测可能会有大量的额外工作,需要我们扩大团队规模才行,但实际上并没有。我们在 下云 FAQ 中的回复依然成立。
不过,这仍然需要付出努力!在两个数据中心(很快还会在海外增加至少一个)上运营像 Basecamp 和 HEY 这样的大型应用,需要一支专注的团队。总有工作要做,维护所有的应用、数据库、虚拟机,偶尔还需要请求更换出现警示灯的机器的电源或硬盘(但这些由 Deft 的专业服务处理) —— 而大部分工作在云上也需要我们自己来做!
自从我们最初宣布下云计划以来,业界对同样的下云举措 兴趣激增。2010 到 2020 早期的口号 —— “全部上云、所有东西上云、一直在云端!” —— 似乎总算达峰到头了,谢天谢地!
当然,云服务仍然有其价值。尤其是在初创阶段 —— 当您甚至不需要一整台服务器,或者不确定公司能否撑到年底。或者当您需要处理巨大的负载波动时,这也是亚马逊创建 AWS 的初衷。
但一旦云账单开始飙升,我认为您有责任为自己、投资者和基本商业常识着想,至少做一下计算。我们花了多少钱?购买这些设备而非租用需要多少成本?我们能否尝试使用 Kamal 或类似工具,将部分系统迁移到自有硬件上?这些问题的答案可能带来惊人的降本增效。
在 37signals,我们期待在明年夏天彻底删除我们的 AWS 账户,我们仍然感谢在使用该云平台期间得到的服务和经验。显而易见,亚马逊为何能在云领域保持领先。我也很高兴现在从 S3 中迁出数据是完全免费的,如果您决定永久离开该平台。这会让成本计算更加有利。再见,感谢你们的一切!
参考阅读
以下是 DHH 下云过程的完整记录与答疑。
老冯评论
作为下云倡导者,我很欣慰地看到 DHH 在下云过程中取得的巨大成功。世界总是会奖赏那些有智慧发现问题,且有勇气采取行动的领导者。
在过去两年里,云炒作达峰下坡,而下云运动却在蓬勃发展 —— 根据 Barclays 2024 上半年进行的 CIO 调查中,计划将负载迁回到本地部署/私有云上的 CIO 占比,从前几年的 50% - 60 飙升到 83%。下云,作为一种切实的降本增效选项,已经完全进入主流视野,并开始产生巨大的现实影响。
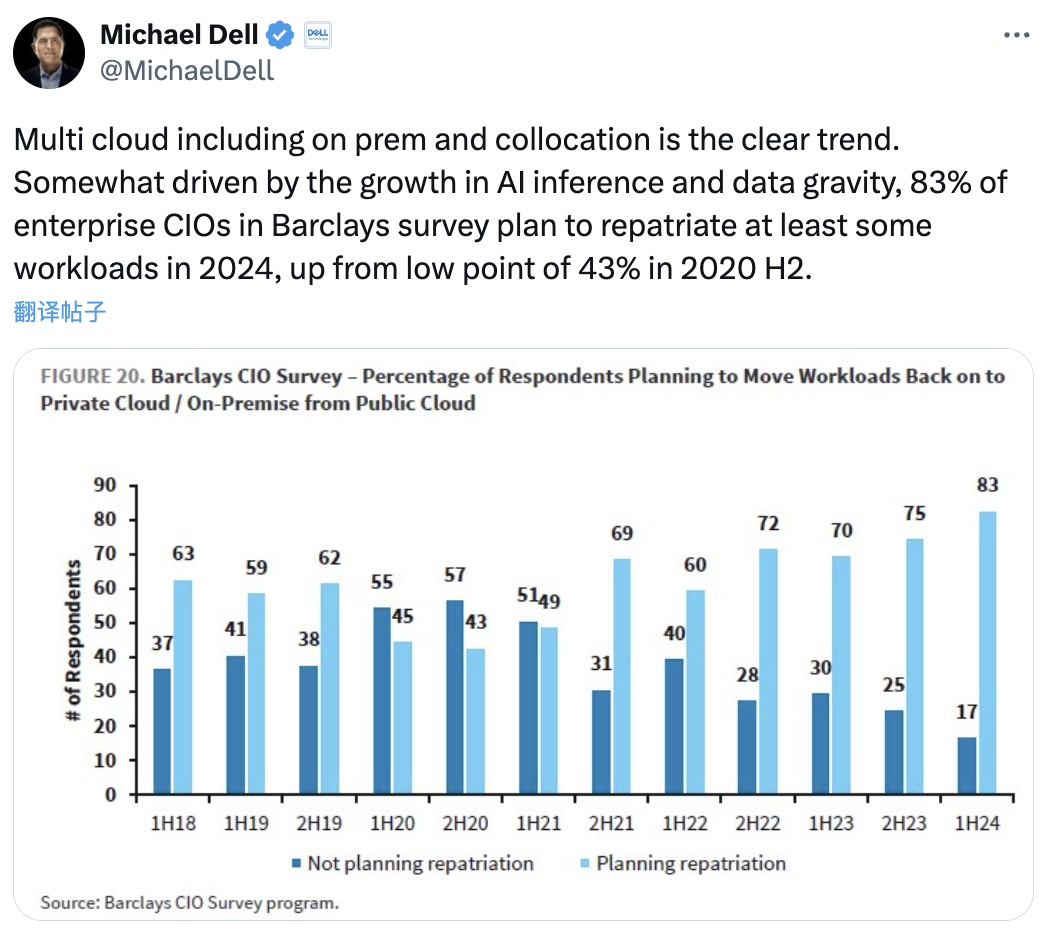
Dell 老板:选择搬回自建/私有云的CIO比例
在我的 《云计算泥石流》 系列专栏中,我已经深入剖析过云资源的成本,介绍过云背后的商业模式,并提供了下云替代的切实可行路径。 我自己也在过去两年中帮助过不少企业从云上下来 —— 通过解决了他们下云关键卡点的数据库服务自建问题。
下云可以带来的巨大节省收益,以 DHH 没迁移完的 S3 对象存储服务为例,每年 130 万美元(约合 900 万人民币)—— 通过一次性投入一年的 S3 费用,就能下到一个容量近乎翻倍的本体 Pure Storage 系统,也就是说,第一年完成回本,后面四到六年每一年都相当于白赚。
这里的帐很好算,之前我们核算过自建对象存储的 TCO(假设使用60盘位 12PB 存储机型,世纪互联托管,三副本),约为 200 - 300 ¥/TB (买断价格,用五到七年) —— 那么 10 PB 的存储也不过是 35 万¥ 一次性投入。 相比之下,AWS / 阿里云这样的云厂商对象存储则要 110 - 170 ¥/TB (每月,这还只是存储空间部分,没算请求量、流量费、取回费),与自建的成本拉开了两个数量级。
是的,自建对象存储可以实现相比云对象存储两个数量级,几十倍的成本节省。作为一个自建过 25 PB MinIO 存储的人来说,我保证这些成本数字的真实性。
作为一个简单的证明,服务器托管服务商 Hentzer 提供的对象存储价格是 AWS 的 1/51 ……,他们并不需要什么高科技黑魔法,只要把硬件装上 Ceph/Minio 这样的开源软件加个GUI,真诚地卖给客户就可以做到这个价格,还能确保自己有不错的毛利。

Hentzer 提供价格是 AWS S3 1/50 的兼容对象存储服务
不仅仅是对象存储,云上的带宽,流量,算力,存储,都贵的离谱 —— 如果你不是那种几个凑单1c羊毛虚拟机就能打发的用户,你真的应该好好算一算帐。 这里的数学计算并不复杂,任何有商业常识的人只要拥有这里的信息都会产生这样的想法 —— 我为云上的服务支付几倍到几十倍的溢价,究竟买到的是什么东西?
例如,DHH 在 Rails World 大会上的演讲就抛出了这个问题,用同样的价格,他在 Hetzner 上可以租到强大得多得多的专属服务器:
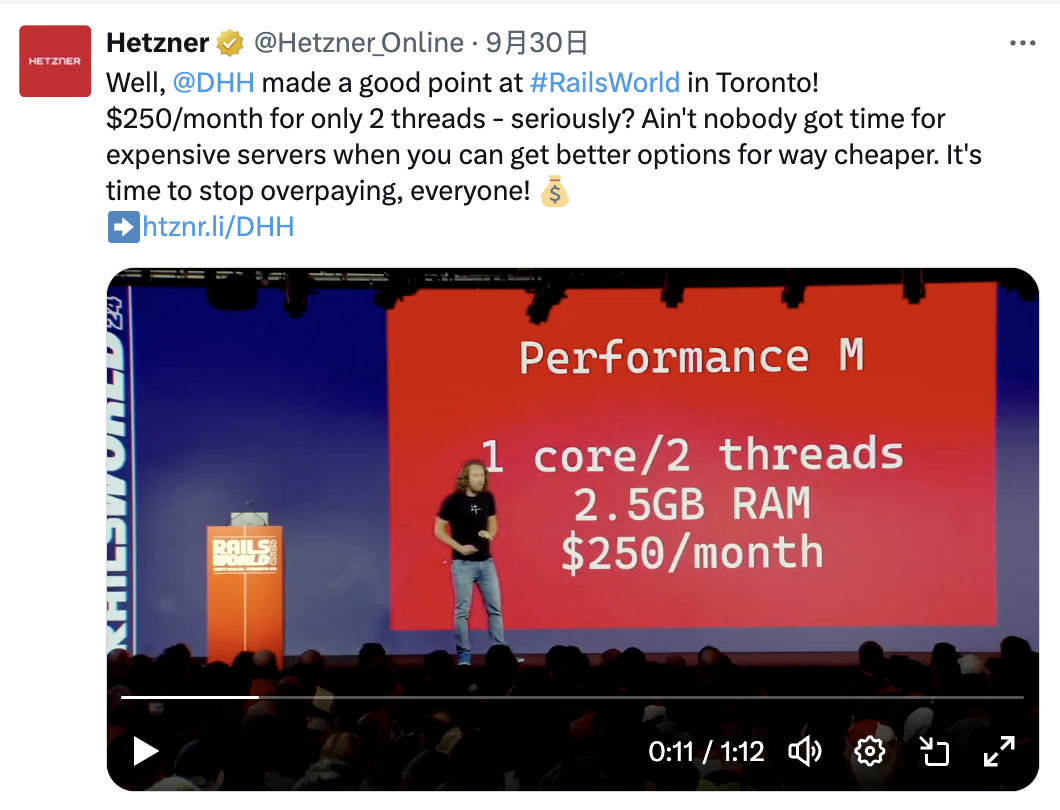
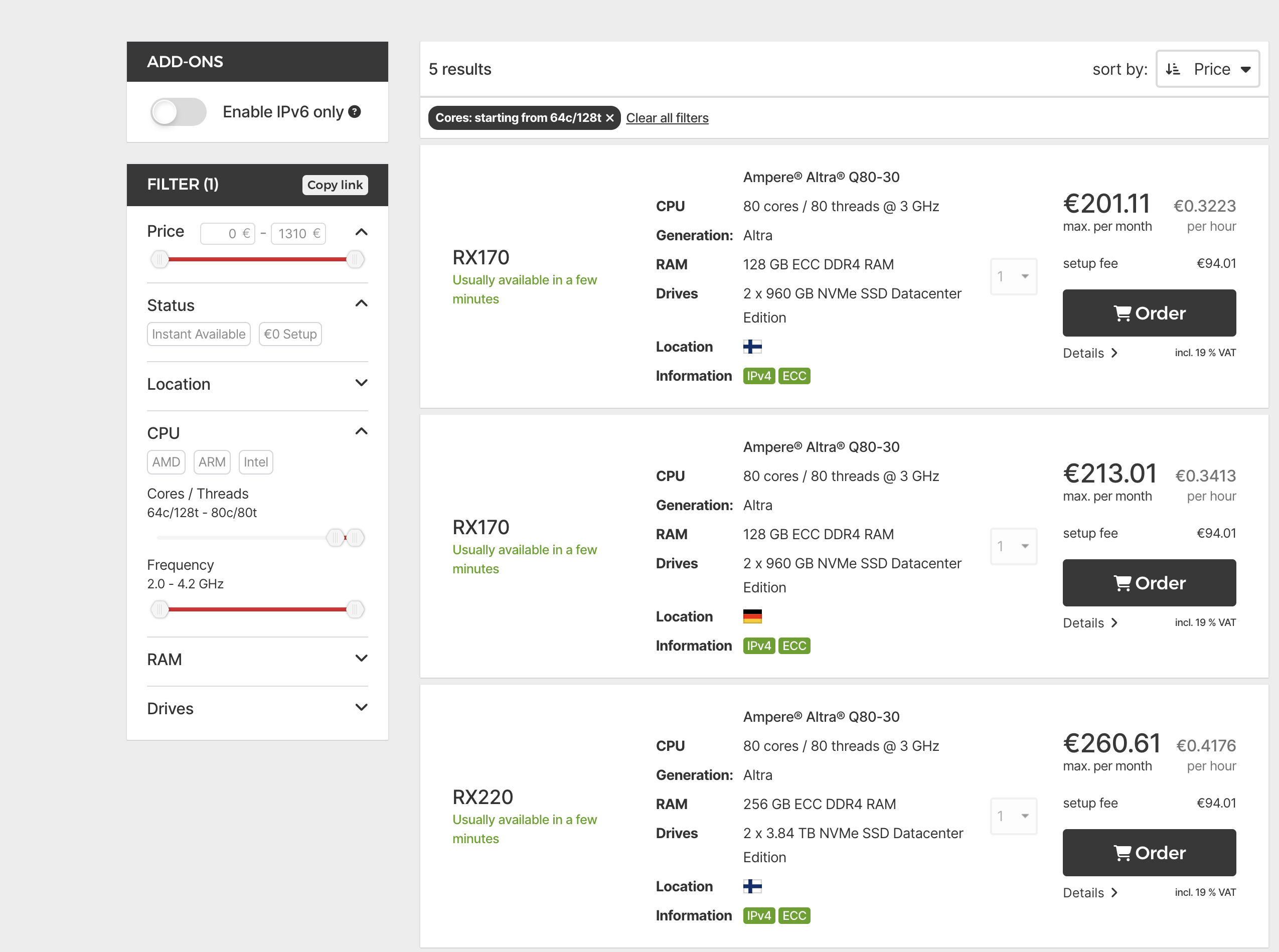
之前阻止用户这样做的主要阻碍是数据库,k8s这样的PaaS自建太难,但现在已经有无数的 PaaS 专门店供应商能比云厂商提供更好的解决方案了。(比如MinIO之于S3,Pigsty 之于 RDS, SealOS 之于 K8S,AutoMQ 之于 Kafka,…… )
实际上,越来越多的云厂商也开始意识到这一点,例如 DigitalOcean,Hentzer,Linode,Cloudflare 都开始推出 “诚实定价” ,物美价廉的云服务产品。 用户可以在享受到云上各种便利的前提下,使用几十分之一的成本直接从这些 “平价云” 购买相应的资源。
经典云厂商也开始 FOMO ,他们没法直接降价放弃手上的既得利益,但也对新一代云厂商的平价竞争感到焦虑,想参与其中。例如,最近新冒出来的廉价 “阿爪云” ClawCloud,就是某个头部云厂商的小号,跑出来和搬瓦工,Linode 抢生意。
我相信在这样的竞争刺激下,云计算市场的格局不久便会出现令人激动的变化。会有越来越多的用户识破云上炒作,并明智而审慎地花出自己的 IT 预算。
Our cloud-exit savings will now top ten million over five years
We finished pulling seven cloud apps, including HEY, out of AWS and onto our own hardware last summer. But it took until the end of that year for all the long-term contract commitments to end, so 2024 has been the first clean year of savings, and we’ve been pleasantly surprised that they’ve been even better than originally estimated.
For 2024, we’ve brought the cloud bill down from the original $3.2 million/year run rate to $1.3 million. That’s a saving of almost two million dollars per year for our setup! The reason it’s more than our original estimate of $7 million over five years is that we got away with putting all the new hardware into our existing data center racks and power limits.
The expenditure on all that new Dell hardware – about $700,000 in the end – was also entirely recouped during 2023 while the long-term commitments slowly rolled off. Think about that for a second. This is gear we expect to use for the next five, maybe even seven years! All paid off from savings accrued during the second half of 2023. Pretty sweet!
But it’s about to get sweeter still. The remaining $1.3 million we still spend on cloud services is all from AWS S3. While all our former cloud compute and managed database/search services were on one-year committed contracts, our file storage has been locked into a four(!!)-year contract since 2021, which doesn’t expire until next summer. So that’s when we plan to be out.
We store almost 10 petabytes of data in S3 now. That includes a lot of super critical customer files, like for Basecamp and HEY, stored in duplicate via separate regions. We use a mixture of storage classes to get an optimized solution that weighs reliability, access, and cost. But it’s still well over a million dollars to keep all this data there (and that’s after the big long-term commitment discounts!).
When we move out next summer, we’ll be moving to a dual-DC Pure Storage setup, with a combined 18 petabytes of capacity. This setup will cost about the same as a year’s worth of AWS S3 for the initial hardware. But thanks to the incredible density and power efficiency of the Pure flash arrays, we can also fit these within our existing data center racks. So ongoing costs are going to be some modest service contracts, and we expect to save another four million dollars over five years.
This brings our total projected savings from the combined cloud exit to well over ten million dollars over five years! While getting faster computers and much more storage.
Now, as with all things cloud vs on-prem, it’s never fully apples-to-apples. If you’re entirely in the cloud, and have no existing data center racks, you’ll pay to rent those as well (but you’ll probably be shocked at how cheap it is compared to the cloud!). And even for our savings estimates, the target keeps moving as we require more hardware and more storage as Basecamp and HEY continues to grow over the years.
But it’s still remarkable that we’re able to reap savings of this magnitude from leaving the cloud. We’ve been out for just over a year now, and the team managing everything is still the same. There were no hidden dragons of additional workload associated with the exit that required us to balloon the team, as some spectators speculated when we announced it. All the answers in our Big Cloud Exit FAQ continue to hold.
It’s still work, though! Running apps the size of Basecamp and HEY across two data centers (and soon at least one more internationally!) requires a substantial and dedicated crew. There’s always work to be done maintaining all these applications, databases, virtual machines, and yes, occasionally, even requesting a power supply or drive swap on a machine throwing a warming light (but our white gloves at Deft take care of that). But most of that work was something we had to do in the cloud as well!
Since we originally announced our plans to leave the cloud, there’s been a surge of interest in doing the same across the industry. The motto of the 2010s and early 2020s – all-cloud, everything, all the time – seems to finally have peaked. And thank heavens for that!
The cloud can still make a lot of sense, though. Especially in the very early days when you don’t even need a whole computer or are unsure whether you’ll still be in business by the end of the year. Or when you’re dealing with enormous fluctuations in load, like what motivated Amazon to create AWS in the first place.
But as soon as the cloud bills start to become substantial, I think you owe it to yourself, your investors, and common business sense to at least do the math. How much are we spending? What would it cost to buy these computers instead of renting them? Could we try moving some part of the setup onto our own hardware, maybe using Kamal or a similar tool? The potential savings from these answers can be shocking.
At 37signals, we’re looking forward to literally deleting our AWS account come this summer, but remain grateful for the service and the lessons we learned while using the platform. It’s obvious why Amazon continues to lead in cloud. And I’m also grateful that it’s now entirely free to move your data out of S3, if you’re leaving the platform for good. Makes the math even better. So long and thanks for all the fish!
下云奥德赛:该放弃云计算了吗?
DHH一直以来都是下云先锋,本文摘取了DHH博客关于下云相关的十篇文章,记录了 37Signal 从云上搬下来的完整旅程,按照时间倒序排列组织,译为中文,以飨读者。本文翻译了DHH从云上下来的完整旅程,对于准备上云,云上的企业都非常有借鉴与参考价值。
- 01 2023-10-27 推特X下云省掉60%
- 02 2023-10-06 托管云服务的代价
- 03 2023-09-15 下云后已省百万美金
- 04 2023-06-23 我们已经下云了!
- 05 2023-05-03 从云遣返到主权云!
- 06 2023-05-02 下云还有性能回报?
- 07 2023-04-06 下云所需的硬件已就位!
- 08 2023-03-23 裁员前不先考虑下云吗?
- 09 2023-03-11 失控的不仅仅是云成本!
- 10 2023-02-22 指导下云的五条价值观
- 11 2023-02-21 下云将给咱省下五千万!
- 12 2023-01-26 折腾硬件的乐趣重现
- 13 2023-01-10 ‘企业级’替代品还要离谱
- 14 2022-10-19 我们为什么要下云?
- References
作者:David Heinemeier Hansson,网名DHH。 37 Signal 联创与CTO,Ruby on Rails 作者,下云倡导者、实践者、领跑者。反击科技巨头垄断的先锋。Hey博客
译者:冯若航,网名 Vonng.磐吉云数创始人与CEO。Pigsty 作者,PostgreSQL 专家与布道师。云计算泥石流,数据库老司机,下云倡导者,数据库下云实践者。Vonng博客

译序
世人常道云上好,托管服务烦恼少。我言云乃杀猪盘,溢价百倍实厚颜。
赛博地主搞垄断,白嫖吸血开源件。租服务器炒概念,坐地起价剥血汗。
世人皆趋云上游,不觉开销似水流。云租天价难为持,自建之路更稳实。
下云先锋大卫王,引领潮流把枪扛,不畏浮云遮望眼,只缘身在最前锋。
曾几何时,“上云“近乎成为技术圈的政治正确,整整一代应用开发者的视野被云遮蔽。DHH,以及像我这样的人愿意成为这个质疑者,用实打实的数据与亲身经历,讲清楚公有云租赁模式的陷阱。
很多开发者并没有意识到,底层硬件已经出现了翻天覆地的变化,性能与成本以指数方式增长与降低。许多习以为常的工作假设都已经被打破,无数利弊权衡与架构方案值得重新思索与设计。
我们认为,公有云有其存在意义 —— 对于那些非常早期、或两年后不复存在的公司,对于那些完全不在乎花钱、或者真正有着极端大起大落的不规则负载的公司来说,对于那些需要出海合规,CDN等服务的公司来说,公有云仍然是非常值得考虑的服务选项。
然而对绝大多数已经发展起来,有一定规模的公司来说,如果能在几年内摊销资产,你真的应该认真重新审视一下这股云热潮。好处被大大夸张了 —— 在云上跑东西通常和你自己弄一样复杂,却贵得离谱,我真诚建议您好好算一下帐。
最近十年间,硬件以摩尔定律的速度持续演进,IDC2.0与资源云提供了公有云资源的物美价廉替代,开源软件与开源管控调度软件的出现,更是让自建的能力变得唾手可及 —— 下云自建,在成本,性能,与安全自主可控上都会有非常显著的回报。
我们提倡下云理念,并提供了实践的路径与切实可用的自建替代品 —— 我们将为认同这一结论的追随者提前铺设好意识形态与技术上的道路。不为别的,只是期望所有用户都能拥有自己的数字家园,而不是从科技巨头云领主那里租用农场。
这也是一场对互联网集中化与反击赛博地主垄断收租的运动,让互联网 —— 这个美丽的自由避风港与理想乡可以走得更长。
10-27 推特X下云省掉60%
X celebrates 60% savings from cloud exit[1]
马斯克在X公司(Twitter)大力削减成本,简化流程。这个过程或许并非一帆风顺,但却效果显著。他不止一次地证明了那些对他嗤之以鼻的人们是错的。尽管有许多声音说,在经历了这么大的人事变动后,推特很快会翻车,但事实并非如此。X不仅成功地维持了网站的稳定运行,还在此期间加速了实验功能的推进。无论你喜欢还是讨厌这里的政治立场,这都是令人印象深刻的。
我明白对于很多人来说,很难置政治于不顾。但无论你站哪一边,总是能找到一张图表来证明,X要么正在繁荣,要么即将崩溃,所以在这里抬杠没有意义。
真正重要的是,X 已经将下云(#CloudExit)作为它们节省成本计划的关键组成部分。以下是其工程团队在庆祝去年成果时的发言:
“我们优化了公有云的使用,并在本地进行更多的工作。这一转变使我们每月的云成本降低了60%。我们进行的改变里有一个是将所有的媒体/Blob工件从云端移出,这让我们的总体云数据存储量减少了60%,另外我们还成功地将云上的数据处理成本降低了75%。”
请再仔细读一遍上面那段话:把同样的工作从云端转移到自己的服务器上,让每月的云费用降低了60% (!!)。根据早先的报道,X 每年在 AWS 上的开销是1亿美元,所以如果以此为基础,他们从云退出的成果可以节省高达6000万美元/年,堪称惊人!
更令人印象深刻的是,他们在团队规模缩小到原来的四分之一的情况下,还能够如此迅速地削减云账单。Twitter 曾有大约八千名员工,而现在据报道 X 的员工数量不到2,000。
CFO 和投资人无法忽视这一现象:如果像X这样的公司能够以四分之一的员工运营,并且从下云过程中大大获利,那么在许多情况下,大多数大公司从云端退出都有巨大的省钱潜力。
#CloudExit或许即将成为主流,你算过你的云账单吗?
10-06 托管云服务的代价
The price of managed cloud services[2]
自从我们离开云计算后,常有人反驳说,我们不应该指望一个简单的下云迁移能有什么好果子吃。云的真正价值在于托管服务和新架构,而不仅仅是在租来的云服务器上运行同样的软件。翻译过来就是:“你用云的姿势不对!” ,这种论调简直是胡说八道!
首先 HEY 是在云中诞生的。在发布前,它从未在我们自己的硬件上运行过。我们在2020年开始使用 Aurora/RDS 来管理数据库,使用 OpenSearch 进行搜索,使用 EKS 来管理应用和服务器。我们深度使用了原生的云组件,而不仅仅是租了一堆虚拟机。
正是因为我们如此广泛地使用了云提供的各种服务,账单才如此之高。而且运营所需的人手也没有明显减少,我们对此深感失望。这个问题的答案绝不可能是“只管使用更多的托管服务”,或者挥一挥 “Serverless 魔法棒” 就解决了。
以我们在AWS上使用 OpenSearch 服务为例。我们每月花费三十万($43,333)来为 Basecamp、HEY 以及我们的日志基础设施提供搜索服务,每年近四百万(52万美元),这仅仅是搜索啊!
而现在,我们刚刚关闭了在 OpenSearch 上的最后一个大型日志集群,所以现在是一个很好的时机来对比替代选项的开销。我们购买所需硬件大约花费了$150,000(每个数据中心 $75,000 以实现完全冗余),如果在五年内折旧摊销,大约是每月 $2,500。我们在两个数据中心里还要为这些机器提供电力、机位和网络,每月开销大约 $2,500。所以每月总共是五千美元,这还是包含了预留缓冲的情况。
这比我们在 OpenSearch 上的开销少了整整一个数量级!我们在硬件上花费的 $150,000 在短短三个月内就回本了,从三个月后我们每月将节省约 $40,000,这仅仅是搜索啊!
这时,人们通常会开始问人力成本的问题。这是一个合理的问题:如果你得雇佣一大堆工程师来自建自维服务,那么每月节省 $40,000 又算得上啥呢?首先,我得说即使我们不得不全职雇佣一个人来负责搜索服务,我仍然认为这是一件很划算的事,但我们没有这么做。
从 OpenSearch 切换到自己运行 Elastic Search 确实需要一些初始配置工作,但长远来看,我们没有因为这次切换而扩大团队规模。因为在自己的设备上运行,与在云上运行并没有本质上的工作范围差异。这就是我们整体下云的核心理念:
在云上运营我们这种规模所需的运维团队,并不会比在我们自己硬件上运行所需的规模更小!
这原本只是一个理论,但在现实中看到它被证实,仍然是令人震惊的。
09-15 下云后已省百万美金
Our cloud exit has already yielded $1m/year in savings[3]
把我们的应用 搬下云 非常值得庆祝,但看到实际开支减少才是真正的奖励。你看,要将云端的价格从“荒谬”的程度降至“过份”的唯一方式是“预留实例”。就是你需要签约承诺在一年或者更长时间范围里,消费支出保持在某个水平上。因此,我们账单并没有在应用搬离后立即塌缩。但是现在,它要来了。哦,它就要来了!
我们的云支出(不包括S3)已经减少了 60% 。从每月大约十八万美元($180,000)减少到不到八万美元($80,000)。每年可以在这里省下的钱折合一百万美元,而且我们在九月还会有第二轮大幅降低,剩余的支出将在年底前逐渐减少。
现在可以将省下的云开销与我们自己购买服务器的支出相比。我们需要花五十万美元来采购新服务器,用于替换云上所有的租赁项目。虽然会产生一些与新服务器有关的额外开销,但与整体图景相比(例如我们的运维团队规模保持不变)这只能算三瓜俩枣。我们只需要把新花掉的钱和省下来的钱进行简单对比,就能看出这个令人震惊的事实:我们会在不到六个月的时间内,省下来足够多的钱,让这笔采购服务器的大开销回本。
但是请等我们把话说完,看一看最终省下来的结果:用不着小学算术就能看出,最终能节省下的开销金额高达每年两百万美元,按五年算也就是整整 一千万美元!!!。这真是一笔巨大的钱款,直接击穿了我们的底线。
我们要再次提醒,每个人的情况都可能有所不同,也许你没有像我们之前那样使用这些昂贵的云服务:Aurora/RDS,以及 OpenSearch。也许你的负载确实有着很大的波动,也许这,也许那,但我并不认为我们的情况是某种疯狂的特例。
事实上,从我看到的其他软件公司未经优化的云账单来看,我们节省下来的钱实际上可能不算大。你知道过去五年Snapchat在云上花费了三十亿美元吗?在以前没人在乎业务是否盈利,能省个十几亿这种事“不重要”,没人愿意听,但现在确实很重要了。
06-23 我们已经下云了!
We have left the cloud[4]
我们当初花了几年时间才搬上公有云,所以最初我以为下云也要耗费同样漫长的时间。然而当初上云时做准备的工作 —— 比如将应用容器化,实际上使下云过程相对简单很多。如今经过六个月的努力,我们完成了这个目标 —— 我们已经从云上下来了。上周三,最后一个应用被迁移到了我们自己的硬件上。哈利路亚!
在这六个月中,我们将六个历史悠久的服务迁回了本地。虽然我们已经不再销售这些服务了,但我们承诺为现有的客户和用户提供支持,直到互联网的终点。Basecamp Classic、Highrise、Writeboard、Campfire、Backpack 和 Ta-da List 都已经有十多年的历史了,但仍在为成千上万的人提供服务,每年创造数百万美元的收入。但现在,我们在这些服务上的运营开支将大大减少,而且归功于强大的新硬件,用户体验更加丝滑迅捷了。
不过,变化最大的是 HEY,这是一个诞生于云端的应用。我们以前从未在自己的硬件上跑过它,而且作为一个功能齐全的电子邮件服务,它有许多组件。但是我们的团队通过分阶段迁移,在几周内成功地将不同的数据库、缓存、邮件服务和应用实例独立地迁移到本地,而没有出现任何岔子。
将所有这些应用迁回本地的过程中,我们所使用的技术栈完全是开源的 —— 我们使用 KVM 将新买的顶配性能怪兽 —— 192 线程的 Dell R7625s 切分为独立的虚拟机,然后使用 Docker 运行容器化的应用,最后使用 MRSK 完成不停机应用部署与回滚 —— 这种方式让我们规避了 Kubernetes 的复杂度,也省却了各种形式的 “企业级” 服务合同纠葛。
粗略的计算表明,购置自己的硬件而不是从亚马逊租赁,每年至少可以为我们节省150万美元。关键是在完成这一切的过程中,我们的运维团队规模并没有变化:云所号称的缩减团队规模带来生产力增益纯属放屁,压根没有实现过。
这可能吗?当然!因为我们运维自己硬件的方式,实际上与人们租赁使用云服务的方式差不多:我们从戴尔买新硬件,直接运到我们使用的两个数据中心,然后请 Deft 公司那些白手套代维服务商把新机器上架。接着,我们就能看到新的 IP 地址蹦出来,然后立即装上 KVM / Docker / MRSK ,完事!
这里的主要区别是,从需要新服务器和看到它们在线之间的滞后时间。在云上,你可以在几分钟内拉起一百台顶配服务器,这一点确实很牛逼,只不过你也得为这个特权掏大价钱。只不过,我们的业务没有那么反复无常,以至于需要支付这么高昂的溢价。考虑到拥有自己的服务器已经为我们省了这么多钱,使劲儿超配些服务器根本不算个事儿 —— 如果还需要更多的话,也就是等个把星期的事儿。
从另一个角度看,我们花了大概 50万美元从戴尔买了两托盘服务器,为我们的服务容量添加了 4000核的 vCPU,7680GB 的内存,以及 384TB 的 NVMe 存储。这些硬件不仅能运行我们所有的存量服务,还能让 HEY 满血复活,并为我们的 Basecamp 其他业务换个崭新的心脏。这些硬件成本会在五年里摊销,然而购买它们的总价还不到我们每年省下来钱的三分之一 !
这也难怪为什么当我们分享了自己的下云经验后,许多公司都开始重新审视他们每个月那疯狂的云账单了。我们去年的云预算是 320万 美元,而且已经优化得很厉害了 —— 像长期服务承诺、精打细算的资源配置和监控。有大把的公司比我们掏了几倍多的钱却办了更少的事儿。潜在的优化空间和 AWS 的季度业绩一样惊人 —— 2022 Q4 ,AWS 为亚马逊创造了超过 50亿美元 的利润!
正如我之前提到过的:对于那些非常早期、完全不在乎花钱、或者两年后不复存在的公司,我认为云仍然是有一席之地的。只是要小心,别把那些慷慨的云代金券当作礼物!那是个鱼钩,一旦你过于依赖他们的专有托管服务或Serverless产品。当账单飙上天际时,你就无处可逃了。
我还认为可能确实会有一些公司,有着极端大起大落的不规则负载,以至于租赁还是有意义的。如果你一年只需要犁三次地,那么在其余的363天里把犁放在谷仓里闲置,确实是没有多大意义。
但是对绝大多数已经发展起来的公司来说,如果能在几年内摊销资产,你真的应该认真重新审视一下这股云热潮。好处被大大夸张了 —— 在云上跑东西通常和你自己弄一样复杂,却贵得离谱。
所以,如果钱很重要(话说回来,什么时候不重要呢?)—— 我真的建议您好好算一下账:假设您真的有一个能从不断调整容量大小中获益的服务,然后设想它下云之后的样子。我们在六个月内搬下来七个应用,你也可以的。工具就在那里,都是开源免费的。所以不要仅仅因为炒作,就停留在云端。
05-03 从云遣返到主权云!
Sovereign clouds[5]
我一直在讨论我们的下云之旅 —— “云遣返”。从在AWS上租服务器,到在一个本地数据中心拥有这些硬件。但我意识到这个术语可能会错误地让一些人感到不舒服 —— 有一整代技术人员给自己标记上"云原生"。仅仅只是因为我们想拥有而非租用服务器这种理由而疏远他们,并不能帮到任何人。这些“云原生”人才所拥有的大部分技能都是有用的,无论他们的应用跑在哪儿。
技能的重叠实际上是为什么我们能从AWS退出如此之快的部分原因。现如今,在你自有硬件上运行所需 的知识,和在云上租赁运行所需的知识十有八九是相同的。从容器到负载均衡,再到监控和性能分析,还有其他一百万个主题 —— 技术栈不仅仅是相似而已,几乎可以说一模一样。
当然也会有地方会有差别,比如 FinOps:如果你拥有自己的硬件,就不再需要像法医和会计师那样理解账单,也不需要像斗牛犬一样防止它疯狂增长了!但这确实也意味着,你偶尔需要处理磁盘损坏告警,找数据中心的白手套来换备件。
但是在全局图景中,这些都是微不足道的差异。对于一个云上租赁弓马娴熟的人来说,教会他在自有硬件上运行同样的技术栈并不会耗费太长时间(这个学习曲线肯定比跟上Kubernetes的速度要容易多了)
针对这个问题,有些人建议使用"私有云"这个术语。这个名字让我联想到毛骨悚然的CIO白皮书 —— 虽然我也不认为它有足够的冲击力让公众明了其中的差异。但我得承认,对于刚刚沉淀下一些“云XX”自我身份认同的整个行业来说,这个术语显然更能缓和气氛。这不禁让我思考起来。
最终,我认为这里的关键区别不是公有还是私有,而是 —— 自有还是租赁。我们需要反击云上租赁的 “你将一无所有并乐在其中 ” 的宣传。这种异端观点有悖于时代精神,会招致互联网( —— 这个分布式的,无需许可的世界奇观)支持者的强烈反感。
因此,让我提出一个新术语:“主权云”。
主权云建立在所有权与独立性上。这是一个的可选的升级项:对所有的云租户来说,只要他们的业务强大到足以承担一部分前期成本。这也是一个值得追求的目标:拥有自己的数字家园,而不是从科技巨头云领主那里租用农场。这也是一场对互联网集中化,和正在兴起的赛博地主垄断租金的反击运动。
试试看吧!
05-02 下云还有性能回报?
Cloud exit pays off in performance too[6]
上周,我们成功完成了迄今为止最大的一次下云行动,这次是搬迁 Basecamp Classic。这是我们从2004年开始就整起来的元老应用。而现在,在AWS上运行了几年之后,它又回到了我们自己的硬件上使用 MRSK 管理,天哪,性能实在是太屌了,看看这张监控图:
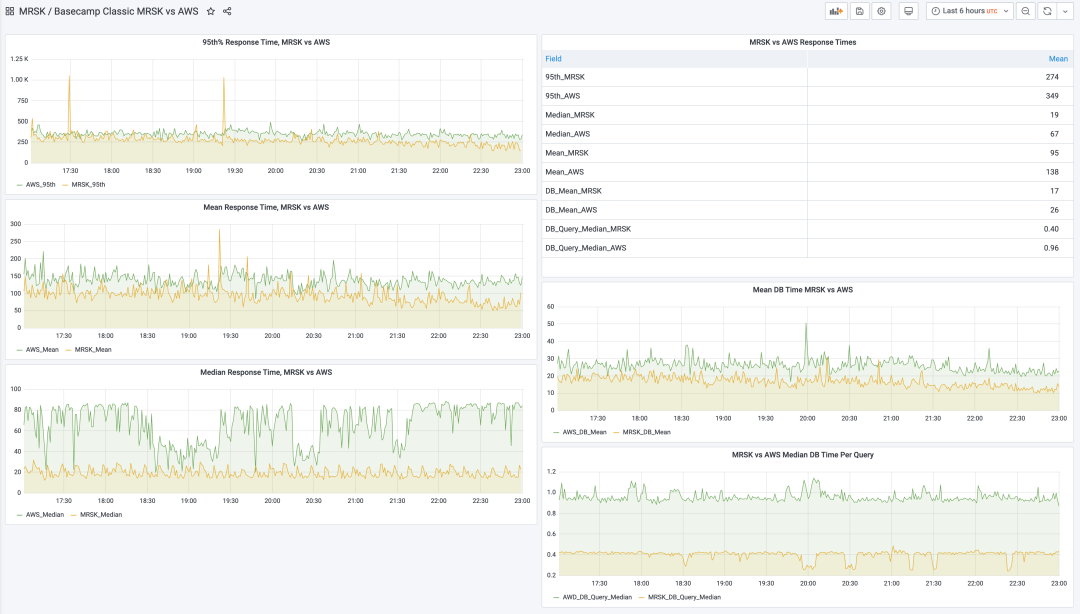
现在的请求响应时间中位数只有 19ms,而以前要 67ms;平均值从138ms 降至 95ms。查询耗时的中位数降了一半(当你一个请求做很多查询时,这可是会累积起来放大的)。Basecamp Classic 在云上的表现一直还不错,但是现在95%的请求RT都低于那个的 300ms “慢"界限。
也别把这些比较太当回事:这并非严谨的净室科学实验,只是我们刚刚离开精细微调的云环境,放到自有替代硬件上刚跑出来的峰值。
Basecamp Classic 以前跑在 AWS EKS 上(那是他们的托管 Kubernetes ),应用本身混用 c5.xlarge 和 c5.2xlarge 实例部署。数据库跑在 db.r4.2xlarge 和 db.r4.xlarge 规格的 RDS 实例上。现在都搬回老家,跑在配备了双 AMD EPYC 9454 CPU 的 Dell R7625 服务器上。
用来跑应用和任务的 vCPU 核数规格都一样,122个。以前是云上的 vCPU,现在是 KVM 配置的核数。而且,在保持上面牛逼性能的前提下,现在负载水平还有很大压榨空间。
实际上,考虑到我们的每一台新的 Dell R7625 都有196个 vCPU,所以包含数据库与 Redis 在内的整个 Basecamp Classic 应用其实可以完整跑在这样的单台机器上!这简直太震撼了,当然,出于安全冗余的考虑你并不会真的这么做。但这确实证明了硬件领域重新变得有趣起来,我们绕了一圈又回到了 “原点” —— 当 Basecamp 起步时,我们就是在单个机器(只有1核!)上跑起来的,而到了 2023 年,我们又能重新在一台机器上跑起来了。
这样的机器每台不到两万美元,除路由器外的所有硬件五年摊销,就是333美元/每月。这就是当下运行完整 Basecamp Classic 所需的费用 —— 而这仍然是一个每年实打实产出数百万美元收入大型的 SaaS 应用!而市场上绝大多数 SaaS 业务服务客户所需的火力将远远少于此。
我们并未期望下云能提高应用的性能,但它确实做到了,这真是个意外之喜。尤其是 Basecamp Classic,我们业务中的二十年老将,依然在为一个庞大的,忠诚的,满意的客户群提供服务,这些客户在过去十年里都没获得任何新功能 —— 不过,嘿,速度也是一种特性,所以呢,你也可以说我们刚刚发布了一个新特性吧!
接下就是下云的重头戏了 —— HEY!敬请期待。
04-06 下云所需的硬件已就位!
The hardware we need for our cloud exit has arrived[7]
距离我上次看到运行我们 37Signal 公司服务所使用的物理服务器硬件已经过去很长时间了。我依稀记得上次是十年前参观我们在芝加哥的数据中心,但是在某个时间点,我对硬件就失去兴趣了。然而现在我又重新对它感兴趣了 —— 因为硬件领域变得越来越有趣起来。所以让我来和你们分享一下这种兴奋吧:

这是最近运抵我们芝加哥数据中心的两个托盘。同一天,一套同样的设备也到达了我们在弗吉尼亚州 Ashburn 的第二个数据中心。总的来说,我们收到了二十台R7625 Dell 服务器,是支撑我们的下云计划的主力。如此令人震惊的算力,占用的空间却惊人的小。
这是我们在芝加哥数据中心四个机柜的示意图(我们在 Ashburn 还有另外四个)。正如你所见,还有一堆专门给 Basecamp 用的老硬件。一旦我们装好新机器,大部分老服务器就该退役了。在下面带有 “kvm” 标记的2U服务器是新家伙:
这儿你可以看到新的R7625服务器位于机架底部,挨着旧设备:

每台R7625都包含两个 AMD EPYC 9454 处理器,每个处理器 48个核心/96个线程,频率 2.75 GHz。这意味着我们为私有部署大军的容量添加了近4000个虚拟CPU!近乎荒谬的 7680GB 内存!以及 384TB 的第四代 NVMe SSD 存储!除了足以满足未来数年需求的强大马力外,在夏季前还有另外六台数据库服务器要过来,然后我们就全准备好啦。
与 Basecamp 起源形成鲜明对比的是,我们在2004年以一台只有256MB内存的单核Celeron服务器启动了Basecamp,用的还是 7200转的破烂硬盘。而那些玩意已经足够我们在一年间把它从兼职业务转为全职工作。
二十年后,我们现在有一大堆历史遗留应用(因为我们承诺让客户依赖的应用运行到互联网的终点!),一些诸如 Basecamp 和 HEY 的大型旗舰服务,以及让这些重新运行在我们自己硬件上的使命任务。
想想三个月前,我们决定放弃 Kubernetes 并使用 MRSK 打造更简单的下云解决方案,这还是挺疯狂的一件事儿。但是看看现在,我们已经把一半跑在云上的应用搬回了家中!
在接下来的一个月中,我们计划将 Basecamp Classic(这玩意13年没有更新了,但仍然是一个每年赚数百万美元的业务 —— 这就是SaaS的魔法!),以及下云的重头戏 —— HEY!全部都带回家。这样在五月初的话,我们云上就只剩下 Highrise 和一个名叫 Portfolio 的小型辅助服务了。我原本以为,在夏末完成下云已经是很乐观的估计了,但现在看来,基本上会在春天结束之前就能搞定,绝对算是我们团队的一个杰出成就。
加速的时刻表让我对下云大业更加充满信心,我本以为下云会跟上云一样困难,但事实表明并非如此。我想也许是每月三万八千美元的云消费的原因,它就像吊在我们面前的胡萝卜一样,激励着我们更快地去完成这件事。
我真诚地希望那些看着自己令人生畏的云账单的 SaaS 创业者注意到这一点:上云之后再下来这件事,看起来几乎是不可能的,但你一个字儿也别信!
现代服务器硬件在过去几年中,在性能、密度和成本上都有了不可思议的巨大飞跃。如果在过去十年中云已经成为了你的默认选项,那么我建议你重新了解一下相关数字。这些数字很可能会像震惊我们一样吓到你们。
因此,下云的终点就在眼前,我们已经解决了所有下云所需的关键技术挑战,让这件事变得切实可行起来。我们已经在 MRSK 上运行生产应用一段时间了。道路是非常光明的,我已经迫不及待地想看到那些巨大的云账单赶紧消失掉。我觉得之前粗略估算的下云降本数额已经高度保守了,让我们拭目以待,我们也会分享出来。
03-23 裁员前不先考虑下云吗?
Cut cloud before payroll[8]
最近每周都能看到科技公司大裁员的新闻,几个科技巨头已经进行了第二轮裁员,而且没人说不会有第三轮。尽管在个人层面上这是很难受但 —— 我太难了!—— 但对整个经济来说,还算是有一个积极的方面:释放了被束缚的人才。
你看,大型科技公司在疫情期间以如此高的薪资吞噬吸收了大量人才,以至于几乎没有给生态中其他人留点渣。在关键技术人才的竞争中,除了科技巨头之外的许多公司都出不起价,被挤出了市场。长期来看,这对经济来说肯定不是啥好事。我们需要聪明人去关注一些除了让人点击广告之外的问题。
尽管 Facebook、Amazon 这些科技巨头的巨额裁员占据了新闻头条,小型科技公司也在进行裁员,很难相信这里还有什么生机。当然,小公司也有可能和巨头们一样,雄心勃勃地雇佣了一批他们不仅不需要,反而会拖慢进度的人。如果是这样,那还算有点道理。
但也有这种可能,这些公司的技术的市场正在收缩,而投资者不再愿意延长亏损期,所以不得不裁员以削减成本以免破产。这是谨慎的做法,但是人力并不是唯一的成本。
在我所了解的大部分科技公司中,主要有两项大的开支:员工 与 云服务。员工通常是最大的开支,但令人震惊的是,云服务的费用也可以非常非常大。或者对真正算过这笔账的人来说,“震惊”这个词不太合适,恰当的用词是 —— “可怖”。
在与云业务有关的事上我可能有些老生常谈了,但当我看到科技公司试图通过裁员,而不是控制他们的云支出来削减成本时,我真的感到非常困惑。削减云开支最好的方式,特别是对于中等及以上规模的软件公司来说,就是部分/全部下云!
所以我敦促所有正在检阅预算,想知道在哪里可以降本增效的创始人和高管们优先关注云开支。也许你可以通过优化现有的资源使用来走的更远(现在有一整个新冒出来的小行业在干这事:FinOps),但也许你也高估了自己采购硬件自建与下云的难度。
我们已经完成了一半的下云工作。我们真正开始全力以赴是在1月份。我们不仅在搬迁那些最先进的现代技术栈,还要迁移很多历史遗留领域的应用。然而在下云的进度上,这已经比我敢想到的速度要快太多了。我们已经在下云日程表上远超预期了,大幅度的开支缩减肉眼可见。
如果我们可以这么快地做到这些,那么当你经营一家公司而准备打印那些解雇通知前,至少有责任计算一下这些数字并检视一下可行的选项,这也是对你的员工应当负起的责任。
03-11 失控的不仅仅是云成本!
It’s not just cloud costs that are out of control[9]
这个月底我们在 Datadog 上的年度订阅要到期了,我们不打算续费。
Datadog 是一个性能监控工具,倒不是因为我们不喜欢这项服务 —— 实际上它非常棒!我们不续订是因为它每年花费我们 88,000 美元,这实在是太离谱了。而且这反映出一个更大的问题:企业SaaS定价越来越愚蠢荒谬。
然而,我原本以为我们的账单已经够傻逼了。但是竟然有一个 Datadog 的客户为他们的服务支付了 6500 万美元!!这个信息是在他们最近的财报电话会议上提到的。这显然是一家加密货币公司,用“优化”账单的方式承认了这项蠢出天际的开支。
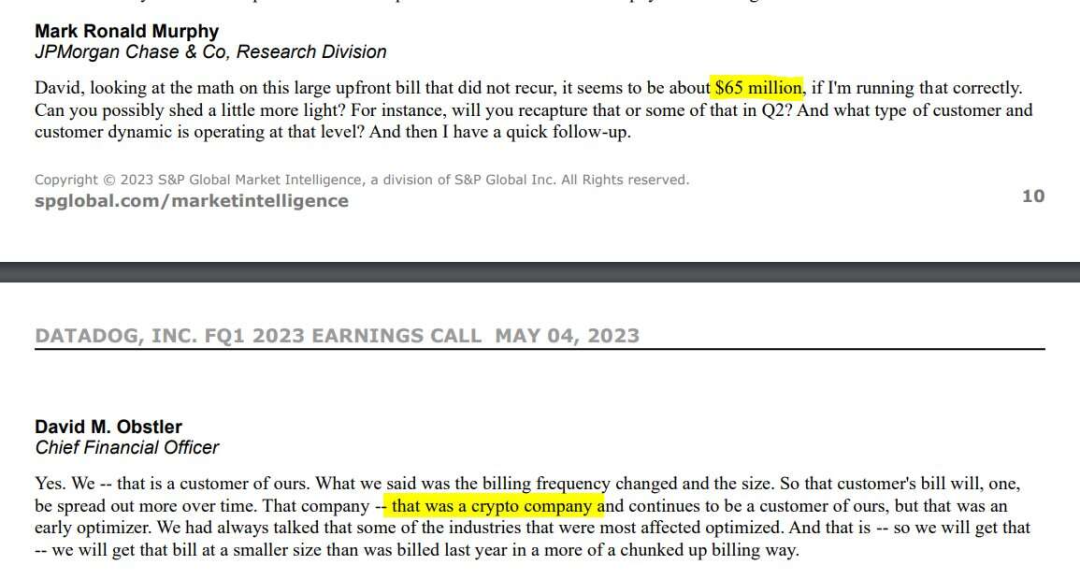
冒着陈词滥调的风险我也要说:这种花在性能和监控服务上的支出就像零利率投资一样:我无法想象在哪个宇宙里会认为这是一项合理的开支。这种事儿明显能用开源替代解决,如果你要做点内部二开魔改定制还能解决的更好更优雅。
但我发现很多企业级 SaaS 软件都是这样的,比如在一个2000人的公司里采购 Salesforce 的 Slack, 每人每月 15$ :仅仅是为了一个聊天工具,每年的开支就超过了三十万美元!
现在,再加上像 Asana 这样的工具,每人每月30刀。然后是 Dropbox 每人每月20美元。只是这三个工具,每个席位每月就需要每月65刀的费用。对那家2000人的公司来说,每年的成本就是一百五十万刀。哎妈呀!
我很惊讶于目前还没有更多的压力迫使那些为他们的SaaS软件支付高昂费用的公司去削减成本。但我觉得快了 —— 感觉我们现在正处在一个服务的泡沫里,等待着破裂 —— 总会有人看到这些利润空间并发现机会。
这也是我们坚持 Basecamp 调性的一个关键原因。任何人向我们支付的最高费用不会超过每月299美元 —— 不限用户,不限功能,所有一切。是的,我们是不是扔掉了钓大鱼的机会?可能吧。但我不能心安理得地以我自己都不愿支付的价格来出售这些软件。
我们确实需要在这儿调整一下。
02-22 指导下云的五条价值观
Five values guiding our cloud exit[10]
当谈及我们离开云的原因时,已经说了很多关于 成本 的事儿。尽管成本非常重要,但它并不是唯一的动机。以下是五条引领我们决策的价值观,我最近在37signals的内网文章里阐述了这些原则:
1. 我们最看重的是独立性。被困在亚马逊的云里,在实验新东西(比如固态缓存)时,不得不忍受高昂到荒诞的定价带来的羞辱,这已经构成对此核心价值观无法容忍的侵犯。
2. 我们服务于互联网本身。这个业务的整个存在,都归功于社会与经济上的异类 —— 互联网。可以用来进行包括商业在内的各种活动,却不归属任何一家公司或任何一个国家。自由贸易和自由表达得以在一个人类历史上前所未有的规模上实现。我们不会让手中的钱,被用于侵蚀这个理想乡 —— 让支撑这个美丽的自由避风港的服务器在集中到少数几个超大规模数据中心的手中。
3. 我们明智地花钱。在几个关键例子上,云的成本都极其高昂 —— 无论是大型物理机数据库、大型 NVMe 存储,或者只是最新最快的算力。租生产队的驴所花的钱是如此高昂,以至于几个月的租金就能与直接购买它的价格持平。在这种情况下,你应该直接直接把这头驴买下来!我们将把我们的钱,花在我们自己的硬件和我们自己的人身上,其他的一切都会被压缩。
4. 我们引领道路。在过去十多年间,云作为 “标准答案” 被推销给我们这样的 SaaS 公司。我相信了这个故事,我们都相信了这一套,然而这个故事并不是真的。云计算有它的适用场景,例如我们在 HEY 起步时就很好地使用了云,然而这是一个少数派生态位。许多像我们一样规模的 SaaS 业务应当拥有他们自己的基础设施而不是靠租赁。我们将为认同这一结论的追随者提前铺设好意识形态与技术上的道路。
5. 我们寻求冒险。“不要弄些小打小闹的计划,它没有激发人们热血的魔力,本身也可能无法实现。要绘制宏伟蓝图,志存高远,并竭尽所能” —— 丹尼尔·伯纳姆。我们已经在这一行打拼了二十多年了。为了维持内心的热情,我们应当继续设定高标准,坚守我们的价值观,并在各个方面探索新边疆,否则我们会枯萎的。我们不需要成为最大的,我们也不需要成为赚得最多的,但我们确实需要继续学习,挑战和追求。
我们走!
02-21 下云将给咱省下五千万!
We stand to save $7m over five years from our cloud exit[11]
自从去年十月份我们宣布打算下云以来,我们一直在脚踏实地的推进。在一个企业级Kubernetes供应商那儿走了一条短暂的弯路后,我们开始自己开发工具,并在几周前成功地将第一个小应用从云上搬下来。现在我们的目标是在夏天结束前完全下云,根据我们的初步计算,这样做将在五年内为我们节省大约700万美元的服务器费用,而无需改变我们运维团队的规模。
粗略的计算方式是这样的:我们在2022年的云开销是320万美元。其中有将近100万美元用在 S3 上,用于存储 8PB 的文件,这些文件在几个不同区域中进行了全量复制。而剩下的大约230万美元用在其他所有东西上:应用服务器、缓存服务器、数据库服务器、搜索服务器,其他所有的事情。这部分预算是我们打算在2023年归零的部分。然后我们将在2024年再来着手把 S3 上的 8PB 给搬走。
经过深思熟虑与多次基准测试,我们叹服于 AMD新的 Zen4 芯片,以及四代NVMe磁盘的惊人速度。我们基本上准备好向 Dell 下订单了,大约 60万 美元。我们仍在仔细调整所需的具体配置,但是对算总账来说,无论我们最终是每个数据中心订购8台双插槽64核CPU的机器(一个箱子里256个vCPU!),还是14台运行单插槽CPU但主频更高的机器,这种细节并不重要。我们需要为每个数据中心添加约 2000核vCPU算力,而我们的业务跑在两个数据中心里,所以考虑到性能和冗余的需求,我们需要 4000 核vCPU 算力,这都是粗略的数字。
在云的时代,投入60万美元购买一堆硬件可能听上去不少,但如果你把它摊销到五年里,那就只有12万美元一年!这已经很保守了,我们还有不少服务器已经跑了七八年了。
当然,那只是服务器盒子本身的价格,它们还需要接上电源和带宽。我们目前在Deft的两个数据中心上有八个专用机架,每月花费大约6万美元。我们特意超配了一些空间,所以我们呢可以把这些新服务器塞进现有的机架中,而无需为更多机位与电力付钱,因而每年机房本身开销仍然是 72万 美元。
所有的花销总计每年84万美元:包括了带宽、电力,以及按照五年折旧的服务器盒子。与云上的230万美元相比,我们的硬件要快得多,有更多的算力,极其便宜的 NVMe 存储,以及用极低的成本进行扩展的空间(只要我们每个数据中心的四个机架里还放得下)。
我们大致可以说,每年节省了150万美元。预留出一个50万美元应对未来五年中尚未预见到的开销,那么在未来五年,我们仍然可以省下 700万 美元!!
在当下时间点,任何中型及以上的SaaS业务,如果他们的工作负载稳定,却没有对云服务器的租赁费用和自建服务器进行测试比对,那么可以称得上是财务渎职行为。我建议你打电话给 Dell,然后再打给Deft。拿到一些真实的数据,然后自己做决定。
我们将在2023年完成下云(除了S3),并将继续分享我们的经验,工具,以及计算方法。
01-26 折腾硬件的乐趣重现
Hardware is fun again [12]
2010 年代,我对计算机硬件的兴趣几乎消失殆尽。一年又一年,进步似乎微乎其微。Intel陷入困境,CPU的进步也很有限。唯一能让我眼前一亮的是Apple在手机上的A系列芯片的进步。但那更像是与常规计算机不同的另一个世界。现在却不再是这样了!
现在,计算机硬件再次活跃起来!自从Apple的M1首次亮相以来,硬件有趣程度和大幅改进的通道已经打开。不仅仅是 Apple ,还有 AMD 和 Intel 。世代跃变发生得更加频繁,增益也不再是“微不足道”。处理器核数在迅速增长,单核性能定期向前跃进 20-30%,而且这种进步积累得很迅速。
虽然我对技术本身很感兴趣,但我更关心这些新飞跃会带来什么。例如在2010年代,我们曾经因为手机运行 JavaScript 速度太慢,所以不得不为 Basecamp Web应用创建一个专门的移动版本。现在大多数 iPhone 的速度已经超过了大多数计算机,甚至安卓的芯片也在迎头赶上。因而维护单独构建版本的复杂性已经消失了。
在 SSD/NVMe 存储上也发生了类似的情况,这里的这里的代际跃进幅度甚至比 CPU 领域还要大。我们快速地从第二代约 500MB/秒的速度,到第三代的大约2.5GB/秒,再到第四代大约 5GB/秒,而现在第五代为我们带来高到荒谬的约 13GB/秒 的速度!这种数量级的飞跃,需要你重新想想你的工作假设了。
我们正在探索将 Basecamp 的缓存和任务队列从内存实现转变为NVMe磁盘实现。现在两者的延迟已经足够接近了,所以容量充足且足够快的 NVMe存储更有优势。我们刚买了一些 12TB 的第四代NVMe卡,使用新的 E1/E3 NVMe接口规格,价格两万块不到($2,390),这可是 12TB 啊!我们现在正在考虑单机柜 PB级全闪存储服务器的可能性,大概二十万美元,这简直太疯狂啦!
有整整一代的应用开发者只知道云,这使他们一叶障目,无法充分认知到硬件的直接进步速度。随着越来越多的公司开始重新计算云账单,并把他们的应用从服务器租赁市场上撤回来,我认为我们将看到越来越多的开发者,重新关心起裸金属服务器来。
举个例子,我很喜欢这个粗略的草稿证明,它证明了 Twitter 可以在单台服务器上运行。你可能不会真的这样做,但这里的数学计算非常有趣。我认为这确实提出了一种观点,那就是我们最终可能会很容易地做到这一点:运行我们所有的高级服务,为数百万用户服务,运行于单台服务器上(或为了冗余考虑,还是三台吧)。
我迫不及待地想要一台配备 Gen 5 NVMe 的 AMD Zen4 机器。拥有 384 个 vCPU 和 13GB/秒带宽的存储,全跑在一台双CPU插槽的刀片服务器内。我已经等不及报名参加这个即将到来的未来了!
01-10 “企业级“替代品还要离谱
The only thing worse than cloud pricing is the enterprisey alternatives[13]
我们在过去几个月一直在想,把 HEY 从云中带回家可能会涉及到 SUSE Rancher 和 Harvester。这些企业级软件产品的组合跑在自有硬件上,却会给我们提供类似于云上的使用体验,而且对现有 HEY 的打包和部署只需进行最小化的改造。但是,当我们需要几次在线会议才能获取关于定价的基本信息时,我们就应该觉察到有些不对劲了,然后看看别的,因为最后的报价完全就是个狗屎。
我们每年在云上租用硬件和服务的开销大约为 300万美元。拥有我们自己的硬件,运行开源软件来替换,有一部分很重要的目的就是为了砍低那个荒谬的账单。但是我们从 SUSE 收到的报价竟然更为荒谬,200万美元,仅仅是许可和支持成本,仅仅是在我们自己的硬件上运行Rancher和Harvester。
最初,我们其实认为这不会是一个问题。企业销售以高出天际的标价而臭名昭著,然后打折回到实际价格以成交。当我们采购我们热爱的戴尔服务器时,经常能得到 80% 的折扣!所以,配置出一个一万美元的服务器并没有挥霍的感觉 —— 如果实际成交价只是2000美元。
如果这里的情况也类似,那么这个两百万美元的合同将会是每年40万美元。仍然太高,但是我们可以在这里那里削减一点,也许最后能得到我们可以接受的结果。但当我们开始讨价还价施加压力以获得折扣时,答案是 3, 3%。好吧,服了,拉倒吧!
我并不是来告诉别人市场能承受什么价格的。我听说 SUSE 把这些套餐卖给军队和保险公司的生意还不错,祝他们好运。
但是为什么他妈的这帮人要在一个又一个的会议中对价格折扣守口如瓶,浪费我们的时间?
因为那就是企业销售游戏。讨价还价,欺诈,玩弄。看看我们能逃脱多少狗屎的游戏,让那些在谈判中搏斗的西装革履的人生活有意义。那就是赢得交易的含义 —— 阻挠欺骗另一方。
我受够了。事实上,我极其厌恶它。
所以现在我把那种怨气装瓶摇两下,然后大口闷下去以驱使我选择另一条路:我们要建造自己的主题公园,有二十一点,以及……没有那些该死的企业销售人员。
2022-10-19 我们为什么要下云?
Why we’re leaving the cloud[14]
过去十多年间 Basecamp 这个业务一只脚在云上,而 HEY 自两年前推出以来就一直独占云端。我们在亚马逊云和谷歌云上大展身手,我们在裸金属与虚拟机上运行,我们在 Kubernetes 上飞驰。我们见识了云上的花花世界,也都尝试过大部分。终于是时候画上句号了:对于像我们这样稳定增长的中型公司来说,租用计算机(在绝大多数情况下)是比糟糕的交易。简化复杂度带来的节省并未变成现实。所以,我们正在制定下云的计划。
云在生态位光谱的两个极端上表现出色,而我们只对其中一个感兴趣。第一个是当你的应用非常简单,流量很低,使用完全托管的服务确实可以省却很多复杂性。这是由 Heroku 开创的光辉之路,后来被 Render 和其他公司发扬光大。当你还没有客户时,这仍然是一个绝佳的起点,即使你开始有一些客户了,它也能支撑你走得很远。(然后随着使用量增加,而账单蹭蹭往上涨突破天际时,你会面临一个大难题,但这是合理的利弊权衡。)
第二个是当你的负载高度不规则时。当你的使用量波动剧烈或者就是高耸的尖峰,基线只是你最大需求的一小部分;或者当你不确定是否需要十台服务器还是一百台。当这种情况发生时,没有什么比云更合适的了,就像我们在推出 HEY 时遇到的情况:突然有 30 万用户在三周内注册尝试我们的服务,而不是我们预计的六个月内 3 万用户。
但是,这两种情况现在对我们都不适用了。对 Basecamp 来说则是从来没有过。继续在云上运营的代价是,我们为可能发生的情况支付了近乎荒谬的溢价。这就像你为地震保险支付四分之一的房产价值,而你根本不住在断层线附近一样。是的,如果两个州之外的地震让地面裂开,导致你的地基开裂,你可能会很高兴自己买了保险,但这里的比例感很不对劲,对吧?
以 HEY 为例。我们在数据库(RDS)和搜索(ES)服务上,每年要支付给 AWS 超过50万美元的费用。是的,当你为成千上万的客户处理电子邮件时,确实有大量的数据需要分析和存储,但这仍然让我感到有些荒谬。你知道每年50万美元能买多少性能怪兽一般的服务器吗?
现在的论调都是这样:没错,但你必须管理这些机器!而云要简单得太多啦!节省下来的都是人工成本!然而,事实并非如此。任何认为在云中运行像 HEY 或 Basecamp 这样的大型服务是“简单”的人,显然从未自己动手试过。有些事情更简单了,而其他事情更复杂了,但总的来说,我还没有听说过我们这个规模的组织因为转向云而能够大幅缩减运维团队的。
不过,这确实是一个绝妙的营销妙招。用类比来推销,比如 “你不会自己开发电厂,对吧?” 或者 “基础设施服务真的是你的核心能力吗?” ,然后再刷上层层脂粉,云的光芒如此闪耀,以至于只有愚昧的路德分子(强烈抵制技术革新的人)才会在它的阴影下运维自己的服务器。
与此同时,亚马逊以高额利润出租服务器来大发横财。尽管在未来的产能和新服务上进行了巨大的投资,AWS 的利润率还能高达 30%(622亿美元营收,185亿美元的利润)。这个利润率肯定还会飙升,因为该公司表示,“计划将服务器的使用寿命从四年延长到五年,将网络设备的使用寿命从五年延长到将来的六年”。
很好!从别人那里租用计算机当然是很昂贵的。但它从来没有以这种方式呈现 —— 云被描述为按需计算,听起来很前卫很酷,而绝非像“租用电脑”这样平淡无奇的东西,尽管它基本上就是这么回事。
但这不仅仅关乎成本,也关乎我们希望在未来运营一个什么样的互联网。这个去中心化的世界奇迹现在主要是在少数几个大公司拥有的计算机上运行,这让我感到非常悲哀。如果 AWS 的主要区域之一出现故障,看似一半的互联网都会随之下线。这可不是 DARPA 的设计初衷啊!
因此,我认为我们在 37signals 有责任逆流而上。我们的商业模式非常适合拥有自己的硬件,并在多年内进行折旧。增长轨迹大多是可预测的。我们有专业的人才,他们完全可以将他们的才华用于维护我们自己的机器,而不是属于亚马逊或谷歌的机器。而且,我认为还有很多其他公司处于与我们类似的境地。
但在我们勇敢扬帆起航,回到低成本和去中心化的海岸之前,我们需要转舵以扭转公共议题的风向,远离云服务营销的胡言乱语 —— 比如营运你自己的发电厂这类屁话。
直到最近,人们自建服务器所需的工具已经有了巨大的进展,让云成为可能的大部分工具也可以用在你自己的服务器上。不要相信根深蒂固的云上既得利益集团的鬼话 —— 自建运维过于复杂。当年的先辈,开局一条狗,平地起高楼搞起了整个互联网,而现在这件事已经容易太多了。
是时候让拨云见日,让互联网再次闪耀人间了。
References
[1] X celebrates 60% savings from cloud exit
[2] The price of managed cloud services
[3] Our cloud exit has already yielded $1m/year in savings
[5] Sovereign clouds
[6] Cloud exit pays off in performance too
[7] The hardware we need for our cloud exit has arrived
[9] It’s not just cloud costs that are out of control
[10] Five values guiding our cloud exit
[11] We stand to save $7m over five years from our cloud exit
[13] The only thing worse than cloud pricing is the enterprisey alternatives
FinOps终点是下云
在 SACC 2023 FinOps专场上,我狠狠喷了一把云厂商。这是现场发言的文字整理稿,介绍了终极 FinOps —— 下云 的理念与实践路径。
太长不看
FinOps关注点跑偏:总价 = 单价 x 数量,搞 FinOps 的关注减少浪费资源的数量,却故意无视了房间里的大象 —— 云资源单价。
公有云是个杀猪盘:廉价EC2/S3获客,EBS/RDS杀猪。云算力的成本是自建的五倍,块存储的成本则可达百倍以上,堪称终极成本刺客。
FinOps终点是下云:对于规模以上企业,IDC自建成本在云服务列表价1折上下。下云是原教旨 FinOps 的终点,也是真正 FinOps 的起点。
自建能力决定议价权:拥有自建能力的用户即使不下云也能谈出极低的折扣,没有自建能力的公司只能向公有云厂商缴纳高昂的 “无专家税” 。
数据库是自建关键:K8S 上的无状态应用与数据仓库搬迁相对容易,真正的难点是在不影响质量安全的前提下,完成数据库的自建。

FinOps关注点跑偏
比起浪费的数量,资源单价才是重点。
FinOps 基金会说,FinOPS关注的是“云成本优化”。但我们认为只强调公有云其实是有意把这个概念缩小了 —— 值得关注的是全部的资源的成本管控优化,而不仅仅局限在上公有云 —— 还有“混合云”与”私有云“。即使不用公有云,FinOps 的一些方法论也依然能用于 K8S 云原生全家桶。正因为这样,很多搞 FinOps 的人关注点被刻意带偏 —— 目光被局限在减少云资源浪费数量上,却忽视了一个非常重要的问题:单价。
总成本取决于两个因素:数量 ✖️ 单价。比起数量,单价可能才是降本增效的关键。前面几位嘉宾介绍过,云上资源平均有 1/3 左右的浪费,这也是 FinOps 的优化空间。然而如果你把不需要弹性的服务放在公有云上,本身使用的资源单价就已经溢价了几倍到十几倍,浪费的部分与之相比只能算三瓜两枣。
在我职业生涯的第一站,便亲历过一次 FinOps 运动。我们的BU曾是阿里云第一批内部用户,也是“数据中台”诞生的地方,阿里云出了十几个工程师直接加入带我们上云。上了 ODPS 后每年存储计算开销七千万,而通过健康分等 FinOps 手段确实优化了十几个M的浪费。然而原本使用自建机房 Hadoop 全家桶跑同样的东西,每年成本不到一千万 —— 节约是好事,但与翻几番的资源成本相比根本算不了什么。
随着降本增效成为主旋律,云遣返也成为一种潮流。发明中台这个概念的阿里,自己已经开始拆中台了。然而还有很多企业在重蹈杀猪盘的覆辙,重复着上云 - 云遣返的老路。
公有云是个杀猪盘
廉价EC2/S3获客,EBS/RDS杀猪。
公有云所鼓吹的弹性是针对其商业模式而设计的:启动成本极低,维持成本极高。低启动成本吸引用户上云,而且良好的弹性可以随时适配业务增长,可是业务稳定后形成供应商锁定,尾大不掉,极高的维持成本就会让用户痛不欲生了。这种模式有一个俗称 —— 杀猪盘。
要想杀猪,先要养猪,舍不着孩子套不着狼。所以对于新用户、初创企业,小微用户,公用云都不吝于提供一些甜头,甚至赔本赚吆喝。新用户首单骨折,初创企业免费/半价 Credit,以及微妙的定价策略。以 AWS RDS 报价为例可以看出,1核2核的迷你机型,单价也就是 几$/核·月,折合三四百块人民币一年,可以说是非常便宜实惠(不含存储):如果你需要一个低频使用的小微数据库放点东西,这也许就是最简单便宜的选择。

然而,只要你稍微把配置往上抬哪怕一丁点儿,核月单价就出现了数量级的变化,干到了二三十~一百来刀,最高可以翻到几十倍 —— 这还没有算上惊悚的 EBS 价格。用户也许只有在看到突然出现的天价账单时,才会意识到到底发生了什么。
相比自建,云资源单价普遍在几倍到十几倍的范围,租售比在十几天到几个月之间。例如,探探IDC包网包电代维+运维网工所有成本均摊下来,一个物理机核算力核月成本在 19块钱,如果使用 K8S 容器私有云,一个虚拟核月成本只要7块钱。
与之对应,阿里云的 ECS 核月单价在一两百块钱,AWS EC2 的核月单价在两三百块钱。如果你“不在乎弹性”,预付买个三年,通常还能再打个五六折。但再怎么算,云算力和本地自建算力的几倍差价是放在这儿没跑的。
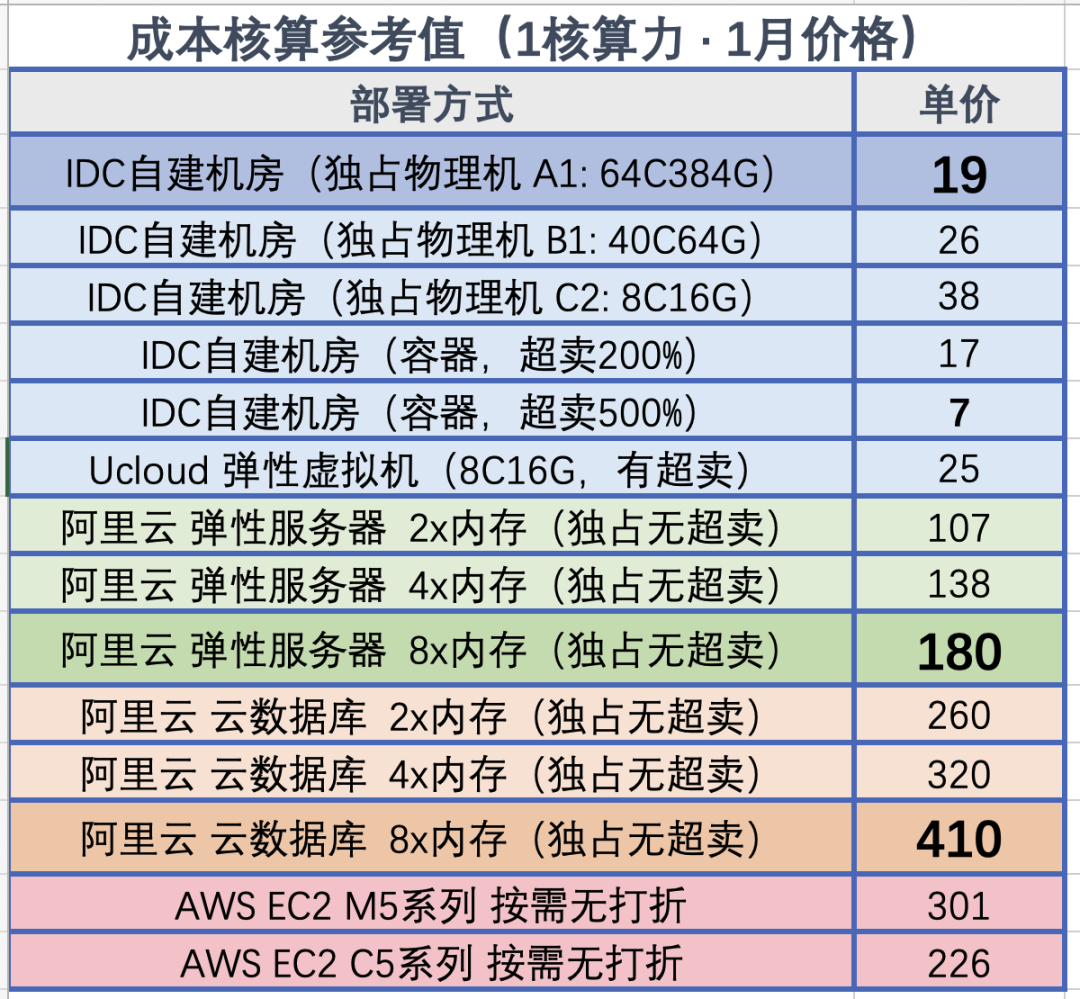
云存储资源的定价则更为离谱,一块常见的 3.2 TB 规格企业级 NVMe SSD 有着极为强悍的性能、可靠性与性价比,批发价 ¥3000 元出头,全方位吊打老存储。然而,在云上同样的存储,就敢卖你 100 倍的价格。相比直接采购硬件,AWS EBS io2 的成本高达 120 倍,而阿里云的 ESSD PL3 则高达 200 倍。
以 3.2TB 规格的企业级 PCI-E SSD 卡为参照基准,AWS 上按需售租比为 15 天,阿里云上不到 5 天,租用此时长即可买下整块磁盘。若在阿里云以采购三年预付最大优惠五折计算,三年租金够买下 120 多块同款硬盘。
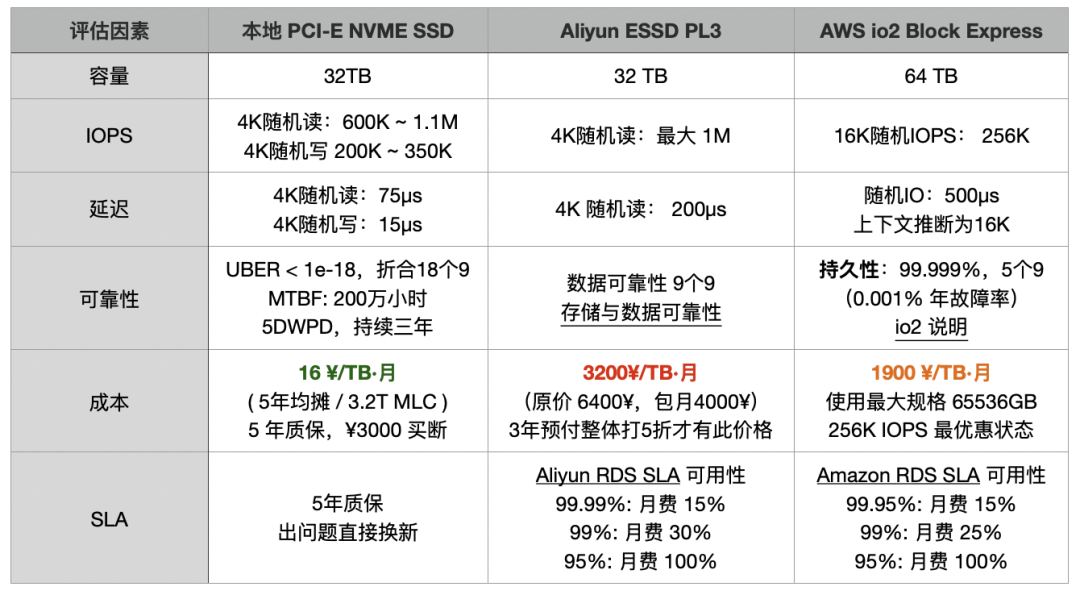
《云盘是不是杀猪盘》
云数据库RDS的的溢价倍率则介于云盘与云服务器之间。以 RDS for PostgreSQL 为例, AWS 上 64C / 256GB 的 RDS 用一个月价格 $25,817 / 月,折合每月 18 万元人民币,一个月的租金够你把两台性能比这还要好的多得多的服务器直接买下来自建了。租售比甚至都不到一个月,租十来天就够你买下来整台服务器。
任何理智的企业用户都看得明白这里面的道理:如果采购这种服务不是为了短期的,临时性的需求,那么绝对算得上是重大的财务失当行为。
| 付费模式 | 价格 | 折合每年(万¥) |
|---|---|---|
| IDC自建(单物理机) | ¥7.5w / 5年 | 1.5 |
| IDC自建(2~3台组HA) | ¥15w / 5年 | 3.0 ~ 4.5 |
| 阿里云 RDS 按需 | ¥87.36/时 | 76.5 |
| 阿里云 RDS 月付(基准) | ¥4.2w / 月 | 50 |
| 阿里云 RDS 年付(85折) | ¥425095 / 年 | 42.5 |
| 阿里云 RDS 3年付(5折) | ¥750168 / 3年 | 25 |
| AWS 按需 | $25,817 / 月 | 217 |
| AWS 1年不预付 | $22,827 / 月 | 191.7 |
| AWS 3年全预付 | 12w$ + 17.5k$/月 | 175 |
| AWS 中国/宁夏按需 | ¥197,489 / 月 | 237 |
| AWS 中国/宁夏1年不预付 | ¥143,176 / 月 | 171 |
| AWS 中国/宁夏3年全预付 | ¥647k + 116k/月 | 160.6 |
我们可以对比一下自建与云数据库的成本差异:
| 方式 | 折合每年(万元) |
|---|---|
| IDC托管服务器 64C / 384G / 3.2TB NVME SSD 660K IOPS (2~3台) | 3.0 ~ 4.5 |
| 阿里云 RDS PG 高可用版 pg.x4m.8xlarge.2c, 64C / 256GB / 3.2TB ESSD PL3 | 25 ~ 50 |
| AWS RDS PG 高可用版 db.m5.16xlarge, 64C / 256GB / 3.2TB io1 x 80k IOPS | 160 ~ 217 |
任何有意义的降本增效行动都无法忽视这个问题:如果资源单价有打0.5~2折的潜力,那么折腾30%的浪费根本排不上优先级。只要你的业务主体还在云上,原教旨 FinOps 就如同隔靴搔痒 —— 下云,才是 FinOps 的重点。
FinOps终点是下云
饱汉不知饿汉饥,人类的悲欢并不相通。
我在探探待了五年 —— 这是一家瑞典人创办的北欧风互联网创业公司。北欧工程师有个特点,实事求是。在云与自建选型这件事上不会受炒作营销影响,而是会定量分析利弊得失。我们仔细核算过自建与上云的成本 —— 简单的结论是,自建(含人力)总体成本基本在云列表价的 0.5 ~ 1 折范围浮动。
因此,探探从创立伊始就选择了自建。除了出海合规业务,CDN 与极少量弹性业务使用公有云,主体部分完全放在 IDC 托管代维的机房中自建。我们的数据库规模不小,13K 核的 PostgreSQL 与 12K 核的 Redis,450w QPS 与 300TB 不重复的TP数据。这两部分每年成本1000万不到:算上两个DBA一个网工的工资,网电托管代维费用,硬件五年均摊。但是这样的规模,如果使用公有云上的云数据库,即使打到骨折,也需要五六千万起步,更别提杀猪更狠的大数据部分了。
然而,企业数字化是有阶段的,不同的企业处于不同的阶段。对于不少互联网公司来说,已进入自建云原生 K8S 全家桶玩到飞起的阶段了。在这个阶段,关注资源利用率,在线离线混合部署,减少浪费是合理的需求,也是 FinOps 应该发力的方向。但是对那些占总量绝大多数的数字化门外汉企业来说,迫在眉睫的不是减少浪费,而是压低资源单价 —— Dell服务器可以打两折,IDC虚拟机可以打两折,云骨折也能打两折,请问这些公司是不是还在掏原价采购,甚至还有几倍的回扣费用呢?大把大把的公司还在因为信息不对称与能力缺失被嘎嘎割韭菜。
企业应该根据自己的规模与阶段,评估审视自己的业务并进行利弊权衡。如果是小规模初创企业,云确实能节省不少人力成本,很有吸引力 —— 但请您保持警惕,不要因为贪图便利而被供应商锁定。如果您在云上的年消费已经超过了 100万人民币,那么是时候认真考虑一下 下云所带来的收益 —— 很多业务并不需要微博并发出轨,训练 AI 大模型那种弹性。为了临时/突发性需求,或出海合规支付溢价还算合情合理,但是为了不需要的弹性支付几倍到几十倍的资源溢价,那就是冤大头了。您可以把真正需要弹性的部分留在公有云上,把那些不需要弹性的部分转移到 IDC 。仅仅只是这样做就能省下的成本可能让用户惊掉下巴。
下云是原教旨 FinOps 的终点,也是真正 FinOps 的起点。
下云核心是自建
以斗争求和平则和平存,以妥协求和平则和平亡
时来天地皆同力,运去英雄不自由:在泡沫阶段,大家可以不在乎在云上大撒币,在经济下行阶段,降本增效成为核心议题。越来越多的公司意识到,使用云服务其实是一种缴纳“无专家税”与“保护费”的行为。行业也出现了下云的思潮 —— 云遣返,37 Signal DHH就是最著名的例子。与之对应,全球各大云厂商营收增速也出现了持续性下滑,阿里云的营收甚至已经增速为负 —— 开始负增长了(2023Q1)。
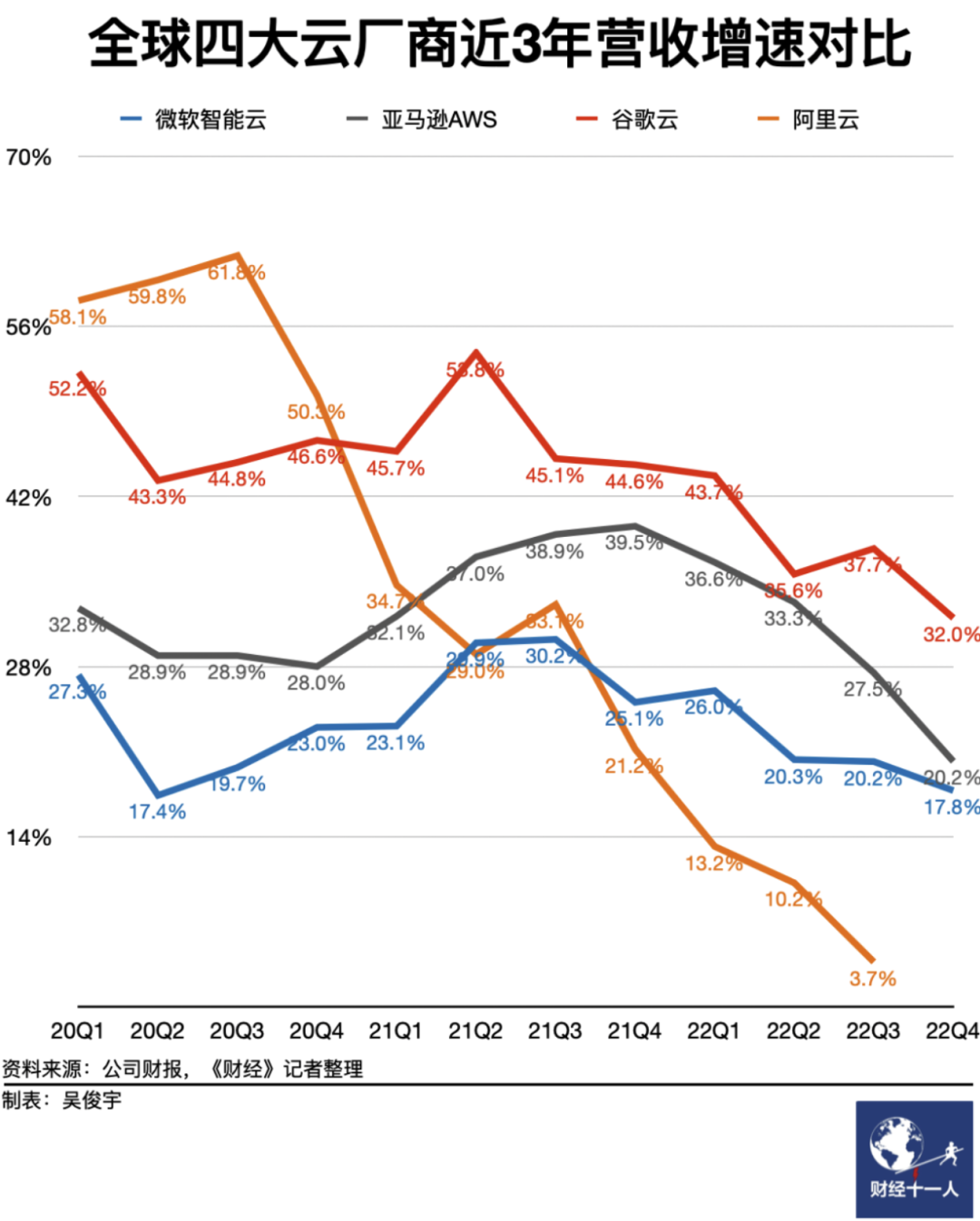
背后的时代趋势是,开源平替的出现,打破了公有云的技术壁垒;资源云/IDC2.0的出现,提供了公有云资源的物美价廉替代;大裁员释放的技术人才与将来的AI大模型,让各行各业都有机会拥有自建所需的专家知识与能力。结合以上三方面的趋势,IDC2.0 + 开源自建的组合越来越有竞争力:短路掉公有云这个中间商,直接与 IDC 合作显然是一个更经济实惠的选择。
公有云厂商并非做不好 IDC 卖资源站着挣钱的生意,按理说云厂商的水平比IDC好不少,理应通过技术优势与规模效应降本增效,向公众提供比 IDC自建更便宜的资源才对。然而残酷的现状是,资源云可以爽快的给用户2折虚拟机,而公有云不行。甚至如果考虑到存储计算行业摩尔定律的指数增长规律,公有云其实每年都还在大幅涨价 !
专业懂行的大客户,特别是那种随时有能力迁移横跳的甲方去和公有云搞商务谈判,确实有可能获取两折的底价折扣,而小客户不太可能有这种机会 —— 在这种意义上,云其实是吸血中小客户补贴大客户,损不足以奉有余的。 云厂商在大客户那边疯狂打折促销,而对中小客户和开发者进行薅羊毛杀猪,这种方式已经完全违背了云计算本身的初心与愿景。
云用低起步价格把用户赚上来,当用户被深度锁定之后,杀猪就会开始 —— 聊好的折扣与优惠,在每年续约时没有了。从云下来又要支付一笔伤筋动骨的大费用,用户处在进退两难的困境中只能选择饮鸩止渴,继续缴纳保护费。
然而对于有自建能力,可以在多云/本地混合云灵活横跳的用户来说,就没有这个问题:谈折扣的杀手锏,就是你自己有随时下云、或迁移至其他云上的自建能力,这比什么口舌都好使 —— 正所谓 “以斗争求和平则和平存,以妥协求和平则和平亡” 。成本能降多少取决于您的议价权,而议价权取决于您是否有能力自建。
自建听上去很麻烦,但其实会者不难。关键是解决 资源 与 能力 两个核心问题。而在 2023 年,因为资源云与开源平替的出现,这两件事已经比以前要简单太多了。
在资源方面,IDC与资源云已经解决得足够好了。上面说的IDC自建,并不是自己从头买土地建机房,而是可以直接使用资源云/IDC的机房托管 —— 你可能只需要一位网工规划一下网络,其他的运维性工作都可以交由供应商打理。
如果您懒得折腾,IDC能爽快地直接卖你云列表价两折的虚拟机,您也可以直接每月两三千租用现成的物理机 64C/256G;无论是整租一整个机房,还是只要一个零售托管机位都没问题。一个零售机位网电代维全包,一年五千块全搞定,整两台百核物理机跑个 K8S 或虚拟化,还要啥弹性ECS ?
自建还有一个额外的好处 —— 如果您真的想做到极致 FinOps,可以使用过保甚至二手服务器。服务器通常按三年五年均摊报废,但用八年十年的也不少见 —— 相比购买云服务的消费,这是实打实的资产,多用都算白赚。
上面所使用的 64C 256G 服务器全新价格也需要五万,但用了一两年二手甩卖的“电子垃圾”只需要两千八。换掉最容易坏的部件插块全新企业级3.2TB NVMe SSD (¥2800),整机六千块拿下。

在这种情况下,你的核月成本甚至可以做到1块钱以内 —— 游戏领域确实有这么个传奇案例,可以做到几毛钱一个服务器。有了K8S调度能力和数据库高可用切换能力,可靠性可以完全可以靠多台电子垃圾并联,最终做到令人震惊的成本效益比。
在能力方面,随着足够好用的开源平替出现,当下自建的难度和几年前完全不可同日而语。
例如,Kubernetes / OpenStack / SealOS,可以理解为云厂商 EC2/ECS/VPS 管控软件的开源替代;MinIO / Ceph 旨在作为为云厂商 S3 / OSS 管控软件的开源替代;而 Pigsty / 各种数据库 Operator 就是 RDS 云数据库管控软件的开源替代 —— 有许许多多的开源软件提供免费用好这些资源的能力;也有许许多多的商业公司提供明码标价的服务支持。
您的业务应该尽可能收敛到只用虚拟机和对象存储这种纯资源,因为这是所有云厂商的提供服务的最大公约数。在理想的状态下,所有应用都完整运行在 Kubernetes 上,而这套 Kubernetes 可以运行在任意环境中 —— 不论是云提供的 K8S底座,ECS,独占物理机,还是你自己机房的服务器上。外部状态例如数据库备份,大数据数仓使用存算分离的方案放在 MinIO / S3 存储上。
这样一套 CloudNative 技术栈,理论上有了在任意资源环境上运行与灵活搬迁的能力,从而避免了供应商锁定,掌握了主动权 —— 您可以选择直接下云省大钱, 也可以选择以此为筹码和公有云商务谈判,要一个骨折折扣出来继续使用。
当然,下云自建也是有风险的,而最大的风险点就在 RDS 上。
数据库是最大风险点
云数据库也许不是最大的开销项,但一定是锁定最深,最难搬迁的服务。
质量、安全、效率、成本,是一个递进的需求金字塔上的不同层次。而 FinOps 的目标,是要在不影响质量安全的前提下完成降本增效。
无论是K8S上的无状态应用,还是离线大数据平台,搬迁起来都很难有致命风险。特别是如果您已经完成了大数据存算分离与无状态应用云原生改造,这两个部分搬动起来通常不会有太大困难。前者通常停几个小时也无所谓,后者则可以蓝绿部署,灰度切换。唯有作为工作记忆的数据库动起来容易搞出大问题。
可以说绝大多数 IT 系统的架构都服务于数据库这一核心,下云牵一发而动全身的关键风险点落在 OLTP 数据库 / RDS 上。很多用户不下云自建的原因正是缺少自建靠谱数据库服务的能力 —— 土法的 Kubernetes Operator 似乎没法达到云数据库的完整功能体验:把 OLTP 数据库放在 K8S/容器 中,使用 EBS 运行也不是成熟的最佳实践。
时代在呼唤一个足够好的 RDS 的开源替代品,而这正是我们要解决的问题:让用户可以在任意环境上自建起比肩甚至超越云数据库的本地 RDS 服务 —— Pigsty,开源免费的 RDS PG 替代。帮助用户真正用好 世界上最先进、最成功的数据库 —— PostgreSQL。
Pigsty 是一个公益性质的自由软件,软件本身完全开源免费用爱发电。它提供了一个开箱即用扩展齐全的 PostgreSQL 发行版,带有自动配置的高可用与PITR,业界顶尖的监控系统,Infra as Code,提供一键安装部署的云端 Terraform 模板 与本地 Vagrant沙箱,针对各种操作都给出了 SOP 手册预案,让您无需专业 DBA 也可以快速完成 RDS 自建。
尽管 Pigsty 是一个数据库发行版,但它赋能用户践行最终极的 FinOps 理念 —— 用几乎接近于纯资源的价格,在任何地方(ECS,资源云,机房服务器甚至本地笔记本虚拟机)运行生产级的 PostgreSQL RDS 数据库服务。让云数据库的能力成本,从正比于资源的边际成本,变为约等于0的固定学习成本。
可能也就是北欧企业的社会主义氛围,才能孵化出这种的纯粹的自由软件。我们做这件事不是为了挣钱,而是要践行一种理念:把用好世界上最先进的开源数据库 PostgreSQL 的能力普及给每一个用户,而不是让使用软件的能力沦为公有云的禁脔。云厂商垄断开源专家与岗位,吸血白嫖开源软件,而我们要要打破云厂商对于能力的垄断 —— Freedom is not free,你不应该把世界让给你所鄙视的人,而应该直接把他们的饭桌掀翻。
这才是最终极的 FinOps —— 授人以渔,提供让用户真正用得上的更优备选,赋予用户自建的能力与面对云厂商的议价权。
References
[1] 云计算为啥还没挖沙子赚钱?
[2] 云数据库是不是智商税?
[3] 云SLA是不是安慰剂?
[4] 云盘是不是杀猪盘?
[5] 范式转移:从云到本地优先
[6] 杀猪盘真的降价了吗?
[8] 垃圾腾讯云CDN:从入门到放弃
[9] 云RDS:从删库到跑路
[10] 分布式数据库是伪需求吗?
[11] 微服务是不是个蠢主意?
[12] 更好的开源RDS替代:Pigsty
云计算为啥还没挖沙子赚钱?

公有云毛利不如挖沙子
在《云盘是不是杀猪盘》、《云数据库是不是智商税》以及《云SLA是不是安慰剂》中,我们已经研究过关键云服务的真实成本。规模以上以核·月单价计算的云服务器成本是自建的 5~10 倍,云数据库则可达十几倍,云盘更是能高达上百倍,按这个定价模型,云的毛利率做到八九十也不稀奇。
业界标杆的 AWS 与 Azure 毛利就可以轻松到 60% 与 70% 。反观国内云计算行业,毛利普遍在个位数到 15% 徘徊,榜一大哥阿里云最多给一句“预估远期整体毛利 40%” ,至于像金山云这样的云厂商,毛利率直接一路干到 2.1%,还不如打工挖沙子的毛利高。
而说起净利润,国内公有云厂商更是惨不忍睹。AWS / Azure 净利润率能到 30% ~ 40% 。标杆阿里云也不过在盈亏线上下徘徊挣扎。这不禁让人好奇,这些云厂商是怎么把一门百分之三四十纯利的生意能做到这种地步的?
杀猪盘为何成为赔钱货
我们可以列举出许许多多多可能的原因:营收压倒一切的KPI,销售主导的增长模式,大公司病与团队内耗,冗员导致的高昂成本,恶意竞争价格战同行卷翻,反佣产生的回扣贪腐,不顾生态亲自下场抢食吃,忘记初心迷失方向陷入歧途,等等等等。
但国内云厂商赔钱的核心问题,还是在于利润空间被两头挤压,能提供的用户价值也因为资源云(国资云/IDC2.0)和开源平替的出现越来越少。而要理解这一点,就需要从从公有云的业务结构说起。
公有云可以分为 IaaS, PaaS,SaaS 三层,尽管这三层都带 S(ervice),但还是有不小的区别:底层更偏向于卖资源,顶层更偏向于卖能力(服务/技术/知识/认知/保险)。IaaS 层资源占主导地位,SaaS 层能力占主导地位,PaaS 层介于两者之间 —— 例如数据库,既可以视为一种利用整合底层存算资源的能力,又可以视作一种更高层次的抽象软件资源。

在云刚出现的时候,核心是硬件 / IaaS层 :存储、带宽、算力、服务器。云厂商的初心故事是:让计算和存储资源像水电一样,自己扮演基础设施的提供者的角色。这是一个很有吸引力的愿景:公有云厂商可以通过规模效应,压低硬件成本并均摊人力成本;理想情况下,在给自己留下足够利润的前提下,还可以向公众提供比 IDC 价格更有优势,更有弹性的存储算力资源。
但很快,公有云就不满足只卖包装硬件卖资源的 IaaS 了:卖资源吃饭的 IaaS 定价没有太大水分空间,可以对着 BOM 一笔一笔精算。但是像云数据库这样的 PaaS, 里面包含的“服务/保险”,人力 / 研发成本就包含大量水分,难以厘定,就可以名正言顺地卖出天价并攫取高额利润。
尽管国内公有云 IaaS 层存储、计算、网络三大件的收入能占营收一半的比例,但其毛利率只有 15% ~ 20%,而以云数据库为代表的公有云 PaaS 毛利率可以达到 50% 或更高,完爆卖资源吃饭的 IaaS。
对公有云来说,PaaS 是核心技术壁垒,IaaS 是营收基本盘,云厂商的主要营收也来自这两者。然而,前者面临开源平替的冲击,后者受到价格战的挑战。
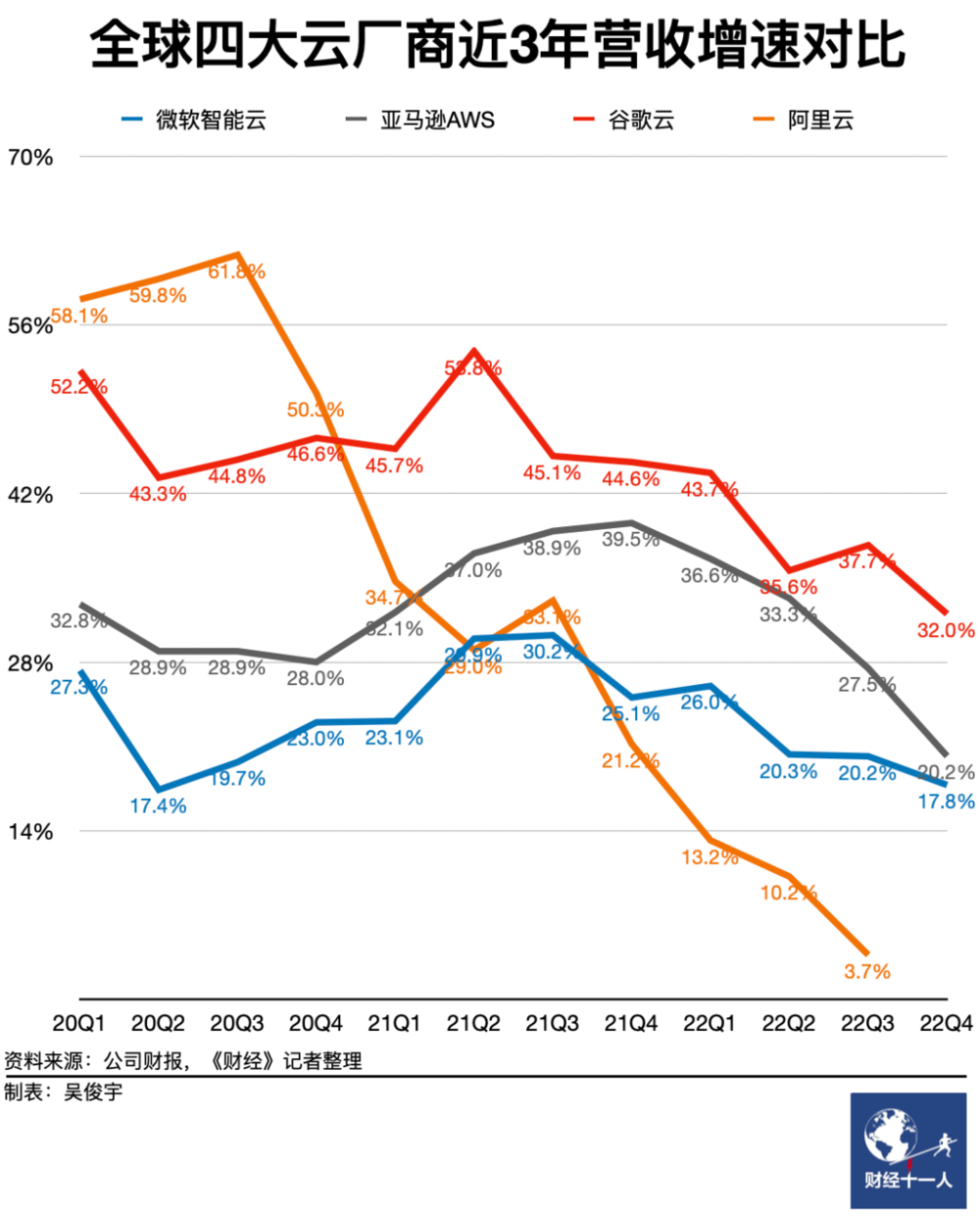
AWS 的壁垒是先发优势,繁荣的软件生态,Azure 的壁垒是Office SaaS和大模型 PaaS,GCP的壁垒是全球一张网。反观国内云厂商的壁垒:阿里云的数据库,腾讯云的微信生态,百度云的大模型?
卖资源模式走向价格战
拔了毛的凤凰不如鸡,失去技术垄断的公有云将陷入卖资源价格战的泥潭。当质量、安全、效率搞不出亮点时,唯一能抢占市场份额的选择就是在成本上做文章 —— 价格战。
然而与公有云 IaaS 云硬件竞争的,是运营商/国资云/IDC2.0。这些对手的特点就是有各种各样的资源 —— 特殊血统身份关系,自有机房网络土地,廉价带宽低息贷款;卖资源躺着挣钱,主打一个物美价廉:没啥高精尖 PaaS/SaaS,但IDC可以爽快的卖给用户公有云列表价两折或更低的虚拟机,租机柜自建托管更是便宜上天。云列表价 1/5 ~ 1/10 的综合成本,不玩云盘杀猪之类花里胡哨的东西,就是纯卖资源。
公有云厂商在面对这些对手时,敢卖天价甚至“涨价”(请注意,资源降价速度慢于摩尔定律等于涨价)的最大的壁垒就是自己有“技术” —— IaaS 层差距拉不了太大,靠的就是还有不错的 PaaS 作为壁垒,来吸引用户 —— 数据库,K8S,大模型以及配套的基础设施。而拥有能力的技术专家多被互联网/云计算大厂垄断,很多客户上云就是因为找不到稀缺的专家来自建这些服务,因而不得不向公有云缴纳高昂的“无专家税”与“保护费”。
然而,开源的管控软件以普惠赋能的方式,起到了降维打击的效果。当这些资源型选手或者用户自己就可以轻松使用开源软件拉起、搭建、组织起自己的“私有云平台”时,公有云构造的技术壁垒护城河就被打破了。曾经靠技术垄断高高在上的云厂商被拉下神坛,拉到了和躺平纯卖资源同侪相近的起跑线。公有云厂商不得不卷入泥潭中厮杀斗兽起来,和这些自己曾经“看不上”的对手打成一团。
开源替代打破垄断幻梦
自由软件 / 开源软件曾经彻底改变了整个软件与互联网行业,而我们将再次见证历史。
最初,软件吞噬世界,例如以 Oracle / Unix 为代表的商业软件,用机器取代了人工,极大提高了效率,节省了很多开销。商业软件凭借“人无我有”形成了垄断优势,牢牢掌握了定价权。像 Oracle 这样的商业数据库非常昂贵,一核·一月光是软件授权费用就能破万,不是大型机构都不一定用得起,即使像壕如淘宝,上了量后也不得不”去O“。
接着,开源吞噬软件,像 PostgreSQL 和 Linux 这样”开源免费“的软件应运而生,打破商业软件的垄断。软件开源本身是免费的,只需要几十块钱每核·每月的硬件成本,即可获取接近商业软件的效能。比如在大多数场景下,如果能找到专家帮助企业用好开源操作系统数据库,那么要比用商业软件划算太多了。互联网的历史就是开源软件的历史,互联网的繁荣便是建立在开源软件之上。
开源的“商业逻辑”不是“卖产品”,而是创造专家岗位:免费的开源软件吸引用户,用户需求产生开源专家岗位,开源专家产出更好的开源软件,形成一个闭环。开源软件免费,但能帮助企业用好/管好 开源数据库的专家非常稀缺昂贵。这也产生了新的垄断机会 —— 产品没法垄断,那就垄断专家。垄断了专家,就能垄断提供服务的能力。于是,“云服务”出现了。
然后,云吞噬开源。公有云软件,是互联网大厂将自己使用开源软件的能力产品化对外输出的结果。公有云厂商把开源数据库内核套上壳,跑在自己的硬件资源上,并雇佣专家编写管控软件并提供代运维与专家咨询服务。大量高端专家人才被头部互联网厂商高薪垄断,普通公司想要用好开源软件,除了少数幸运者能找到“专家”自建,大部分不得不选择云服务,并支付十几倍甚至百倍的资源溢价。

那么,谁来吃云呢?云原生运动,就是开源社区对公有云垄断的反击 —— 在公有云的话语体系中,CloudNative 被解释为长在公有云上的服务;而开源世界对此的理解是“在本地运行云一样的”服务。如何在本地运行云一样的服务?服务真正的壁垒,不是软件/资源本身,而是能用好这些软件的知识。—— 无论是以直接堆专家人力的形式,还是专家经验沉淀而成的管控软件 / K8S Operator 的形式,或者专家经验训练得到的大模型的形式。
实际上,真正负责云服务日常性、高频性、运维性核心主体工作的往往并不是专家本身,而是管控软件 —— 沉淀了专家经验的元软件。一旦这些云管控软件出现开源替代,开源软件打破商业软件垄断的剧情会再一次上演。
这一次,是本地优先的管控软件掀翻云管控软件。PaaS 失去垄断度,将使云厂商丧失部分定价权,进而利润受损。但真正让云受伤的,是基本盘 IaaS 资源生意失去壁垒,不得不直面纯资源厂商的价格战。
服务竞争力逐渐被抹平
利润源于定价权,定价权源于垄断度,垄断度取决于产品在市场上的相对竞争力。随着开源社区滚雪球形成合力,开源管控软件与云管控软件的竞争力已经被逐步抹平,甚至在一些领域出现了反超。
例如,Kubernetes / OpenStack / SealOS,可以理解为云厂商 EC2/ECS/VPS 管控软件的开源替代;MinIO / Ceph 旨在作为为云厂商 S3 / OSS 管控软件的开源替代;而 Pigsty / 各种数据库 Operator 就是 RDS 云数据库管控软件的开源替代。
这些软件的特点在于:它们旨在解决管理好资源的问题,并提供用好软件本身的能力。此类自建服务的质量水平在很多方面不逊色甚至超越了所对标的云服务,而上手复杂度与人力成本基本持平,却只需要几分之一到十几分之一的纯资源成本即可:The more you run, the more you save!
自建的门槛也在以惊人的速度不断降低,一个初中级的研发运维,可以轻松使用 Sealos 这样的软件创建起具有弹性伸缩,资源调度能力的 Kubernetes 集群运行无状态应用;也可以轻松地使用 Pigsty 部署 PostgreSQL / Redis / MinIO / Greenplum 集群,声明式地拉起“自动驾驶”的本地云数据库(数仓/缓存/对象存储)存储状态,补完K8S的短板。
即使是云厂商,也不得不承认 Kubernetes 的成功:它已经成为了运行无状态弹性应用的事实标准,并且有很大概率成为下个时代的数据中心级“操作系统” —— 在应用与底层物理机资源之间,可能并不需要一层 EC2/VM 作为中间商。
同理,在用户使用数据库的平均水平就是yum安装+定时备份+设置密码的时代,云数据库RDS服务可以凭借质量安全效率合格标品的先进优势大杀四方,然而当顶尖水平的用户以可复制的形式输出最佳实践,出现开源免费的上位优质替代后,大锅饭合格品层次的 RDS 就只能相形见绌了。
作为公有云壁垒的云 PaaS 将在开源替代的冲击下走向独立/解体/萎缩/消亡,然而一鲸落,万物生,这也意味着更多的 PaaS/SaaS 创业团队将会迎来解放。
云计算行业将走向何方?
如果我们把目光回退至上世纪初,从电力的推广普及垄断监管中汲取历史经验。就不难看云计算行业的剧本走向 —— 云的故事与电力行业如出一辙,资源与能力的拆分是未来的方向。

资源与基础设施性质的行业,最终的归宿是国家垄断。公有云的资源部分 —— IaaS 层会被剥离,整合,招安,成为算力/存储的“国家电网”。作为央企,国家电网并不负责发电,也不负责制造电器,它做的就是电力垄断资源的传输与分发。云 IaaS 也不会去制造芯片,硬盘,光纤,服务器,而是将其整合为存算网资源,交付到用户手上。国资云,运营商云,阿里云/华为云等会瓜分这一市场。
能力性质的行业,主旋律将是自由竞争,百花齐放。如果 IaaS 是供电行业,那么 PaaS/SaaS 便是电器行业 —— 提供各种不同的,使用存算网资源的能力。洗衣机,冰箱,热水器,电脑,都会涌现出无数创业公司与开源社区同台竞技,充分竞争。当然也会有一部分软件可以享受例外的垄断保护地位 —— 比如安可信创。
同时有着 IaaS / PaaS / SaaS 的公有云可能会解体。云内部的博弈可能要比外部竞争更激烈:IaaS 团队会认为,就连自己用的 IDC机房都有 30% 的毛利,凭啥有躺着卖资源挣钱的机会,却要去陪 PaaS/SaaS 一起卷?有能力的云软件团队会认为,在哪家云甚至私有云上卖不是卖,为啥要绑在一棵树上吊死,为 IaaS 作嫁衣裳?像 OceanBase 一样独立出去到处卖或者自己出来创业难道不香?
公有云厂商寡头价格战只是这个进程的开始,云厂 IaaS 在相互斗兽竞争中,通过垄断并购形成“规模效应”,利用“峰谷电”,“弹性定价”等各种方式优化整体资源利用率,会将算力成本不断压低至新的底线,最终实现“家家有电用”。中小云厂商估计不太可能活过这一场,当然,最后也少不了政府监管介入,公私合营国资入场。各家云 IaaS 成为类似于电信运营商的国有垄断企业,通过控制竞争烈度维持一个可观的利润率,边挣边躺。
公有云的 PaaS / SaaS 在被更好,更优质,更便宜的替代物冲击下逐渐萎缩,或回归到足够低廉的价格水平。数据库,K8S,云安全等业务团队会从云中拆分与独立,能打的云软件团队必然选择出来单干**,采取云中立的立场**,在各种云底座上与各种供应商、开源社区同台赛马,各显所长。
正如当年开源运动的死对头微软现在也选择拥抱开源。公有云厂商肯定也会有这一天,与自由软件世界达成和解,心平气和地接受基础设施供应商的角色定位,为社会提供水与电一般的平价存算网资源,云软件也会回归正常毛利率,不卑不亢,不骗不抢,采购软件如同购买家电一样稀松寻常。
博弈的终点非常清晰,然而道阻且长。但能肯定的是,我们的下一代将对于云端的存与算习以为常,正如上一代看水与气,这一代看电与网。
云SLA是不是安慰剂?
在云计算的世界里,服务等级协议(SLA)被视为云厂商对其服务质量的承诺。然而,当我们深入研究这些 SLA 时,会发现它们并不能像期望的那样“兜底”:你以为给自己的数据库上了保险可以高枕无忧,但其实白花花的银子买的是提供情绪价值的安慰剂。

保险单还是安慰剂?
许多用户购买云服务的一个原因是“兜底”,而问他们所谓“兜底”到底指的是什么,很多人会回答“SLA”。云专家将购买云服务比作购买保险:一些故障可能在许多公司的整个生命周期中都不会出现,但一旦遇到,后果可能就是毁灭性的。在这种情况下,云服务提供商的 SLA 就是兜底保险。然而,当我们实际查看这些 SLA 时,会发现这份“保单”并不像想象中那样有用。
数据是许多企业的生命线,云盘是公有云上几乎所有数据存储的基石,所以让我们以云盘服务为例。许多云服务提供商在其产品介绍中都会宣称他们的云盘服务具有 9个9 的数据可靠性【1】。然而当查看其 SLA 时,就会发现这些最为重要的承诺压根没有写入 SLA 【2】。
写入 SLA 的通常只有服务的可用性。而且这种可用性的承诺也流于表面,相比真实世界的核心业务可靠性指标极其逊色,赔偿方案相比常见停机损失来说约等于没有。比起保险单,SLA 更像是提供情绪价值的安慰剂。
拉胯的可用性
云 SLA 中使用的关键指标是可用性。云服务可用性通常表示为:可以从外部访问该资源的时间占比,通常使用一个月作为衡量周期。如果由于云厂商的问题,导致用户无法通过 Internet 访问该资源,则该资源将被视为不可用(Unavailable / Down)。
以业界标杆 AWS 为例,AWS 大部分服务使用类似的 SLA 模板3。AWS 上的单个虚拟机提供以下 SLA【4】。这意味着在最好情况下,如果 AWS 上EC2 一个月内不可用时间在 21 分钟内(99.9%),AWS 一分钱不赔。在最坏情况下,只有当不可用时间超过36小时(95%),您才能获得 100% 的代金券返还。

对于一些互联网公司来说,15分钟的服务故障就足以让奖金泡汤,30分钟的故障足够让领导下课。绝大多数时间实际运行的核心系统可用性可能有5个9,6个9,甚至无穷多个9。从互联网大厂孵化出来的云厂商使用如此逊色的可用性指标,实在是让人看了摇头。
更过分的是,当故障发生后,这些补偿也不是自动提供给你的。用户需要在时效(通常是两个月)内,自己负责衡量停机时间,提出申诉举证,并要求赔偿才会有。这要求用户去收集监控指标与日志证据和云厂商扯皮,换回来的也不是现金,而是代金券/时长补偿 —— 对云厂商而言可以说没有任何实质损失,对用户来说没有任何实际意义,几乎没有可能弥补服务中断产生的实际损失。
“兜底”有意义吗?
对于企业来说,兜底意味着在故障发生后如何尽可能减少损失。不幸的是,SLA 在这里帮不上什么忙。
服务不可用对业务造成的影响因行业、时间、长度而异。几秒钟几分钟的短暂的故障,可能对一般行业影响不大,然而长时间(几个小时到几十个小时)的故障会严重影响收入与声誉。
在 Uptime Institute 2021年数据中心调查中【5】,几场最严重停机故障给受访者造成的平均成本近100万美元,最惨重的 2% 不在其中,他们遭受的损失超过 4000 万美元。
然而,SLA 补偿对于这些业务损失来说是杯水车薪。以 us-east-1 区域的 t4g.nano 虚拟机实例为例,价格约为每月 3 美元。如果不可用时间少于 7 小时 18 分钟(月可用性 99%),AWS 将支付该虚拟机每月成本的 10%,总补偿为 30 美分。如果虚拟机不可用时间少于 36 小时(一个月内 95% 的可用性),补偿仅为 30% —— 不到 1 美元。如果不可用时间超过一天半,用户才能收到当月的全额退款 —— 3美元。即使是补偿个成千上万台,与损失相比也可基本忽略不计。

相比之下,传统的保险行业是实打实地为客户兜底。例如,顺丰快递的保价费用为物品价值 1%,但如果物品丢失,他们会全额赔偿。同样,每年几万商业医保,出问题真能兜底几百万。“保险”这个行业也是一分钱一分货的。
云服务提供商收取了远超BOM的昂贵服务费(参见:《公有云是不是杀猪盘》【7】),但当服务出现问题时,他们提供的补偿所谓的“兜底”却只是一些代金券,这显然是有失公平的。
消失的可靠性
有些人使用云服务是为了“甩锅”,推卸自己的责任。有一些重要的责任是无法推卸给外部 IT 供应商的。比如数据安全。用户可以忍受一段时间的服务不可用,但数据丢乱错带来的伤害往往是无法接受的。轻信浮夸承诺的后果实在是太过严重,以至于对于一个创业公司就是生与死的区别。
在各家云厂商的存储类产品中,经常能看到“承诺 99.9999999%” 9个9的可靠性【1】,可以理解为,使用云盘出现数据丢失的概率是十亿分之一。考察云厂商硬盘故障率的实际报告【6】,非常让人怀疑这个数字是拍脑袋想出来的。但只要敢说敢赔敢作敢当,那就没问题。
然而翻开各家云厂商的 SLA 就会发现,这一条“承诺”消失了!【2】
在2018年轰动的《腾讯云给一家创业公司带来的灾难!》 【8】案例中,这家创业公司就相信了云厂商的承诺,把数据放在服务器硬盘上,结果遇到了所谓“硬盘静默错误”:“几年来积累的数据全部丢失,造成近千万元的损失”。腾讯云向该公司表达歉意,愿意赔偿该公司在腾讯云产生的实际消费共计3569元,本着帮助用户迅速恢复业务的目的,承诺为该公司提供13.29万元现金或云资源的额外补偿。达到其消费金额的 37 倍!多么慷慨,多么仁慈,但这对于用户来说能弥补损失哪怕是零头吗?不行。
如果您是企业主或IT负责人,会觉得这样的甩锅有意义吗?

SLA 到底是什么
话都讲到这里,云服务的鼓吹者会祭出最后一招:虽然出了故障后的兜底是个摆设,但是用户需要的是尽可能不出故障,按照 SLA 中的承诺,我们有 99.99% 的概率不出故障,这才是对用户最有价值的。
然而,SLA 被有意地与服务的真实可靠性相混淆 :用户不应该将 SLA 视作来服务可用性的可靠预测指标 —— 甚至是过去可用性水平的真实记录。对于厂家来说,SLA 并不是真正的可靠性承诺或历史战绩,而是一种营销工具,旨在让买家相信云厂商可以托管关键业务应用。
UPTIME INSTITUTE 发布的年度数据中心故障分析报告表明,很多云服务的真实表现低于其发布的 SLA 。对 2022 年故障分析发现:行业遏制故障频率的努力落空,故障成本和后果正在不断恶化【9】。

与其说是 SLA 是对用户的补偿,不如说 SLA 是对云厂商服务质量没达标时的“惩罚”。惩罚的威慑取决于惩罚的确定性及惩罚的严重性。月消的时长/代金券赔付对云厂商来说并没有什么实际成本,所以惩罚的严重性趋近于零;赔付还需要需要用户自己举证主张并得到云厂商的批准,这意味着确定性也不会很高。
比起会因为故障丢掉奖金与工作的专家工程师来说,SLA的惩罚对于云厂商属于是自罚三杯,不痛不痒。如果惩罚没有意义,那么云厂商也没有动力会提供更好的服务质量。用户遇到问题时只能提供单等死,服务态度比起自建/三方服务公司可谓天差地别,对小客户更是趾高气扬。
更微妙的是,云厂商对于 SLA协议具有绝对的权力:云厂商有权单方调整修订SLA并告知用户生效,用户只有选择不用的权利,没有任何参与权和选择权。作为默认签署无法拒绝的“霸王条款”,堵死了用户进行真正有意义赔偿追索的可能性。
所以,SLA 对用户来说不是兜底损失的保险单。在最坏的情况下,它是吃不了兜着走的哑巴亏。在最好的情况下,它才是提供情绪价值的安慰剂。因此,当我们选择云服务时,我们需要擦亮双眼,清楚地了解其 SLA 的内容,以便做出明智的决策。
Reference
【1】阿里云 ESSD云盘
【2】阿里云 SLA 汇总页
【3】AWS SLA 汇总页
【7】公有云是不是杀猪盘
云盘是不是杀猪盘?
我们已经用数据回答了《云数据库是不是智商税》这个问题,但在公有云块存储的百倍溢价杀猪比率前,云数据库只能说还差点意思。本文用实际数据揭示公有云真正的商业模式 —— 廉价EC2/S3获客,EBS/RDS杀猪。而这样的做法,也让公有云与其初心愿景渐行渐远。

TL;DR 太长不看
EC2 / S3 / EBS 是所有云服务的定价之锚。如果说 EC2/S3 定价还勉强能算合理,那么 EBS 的定价乃是故意杀猪。公有云厂商最好的块存储服务与自建可用的 PCI-E NVMe SSD 在性能规格上基本相同。然而相比直接采购硬件,AWS EBS 的成本高达 60 倍,而阿里云的 ESSD 则可高达 100 倍。
即插即用的磁盘硬件,百倍溢价到底为何?云厂商无法解释如此的天价到底源于何处。结合其他云存储服务的设计思路与定价模型,只有一个合理的解释:EBS的高溢价倍率是故意设置的门槛,以便于云数据库杀猪。
作为云数据库定价之锚的 EC2 与 EBS,溢价分别为几倍与几十倍,从而支撑起云数据库的杀猪高毛利。但这样的垄断利润必定无法持久:IDC 2.0/运营商/国资云冲击 IaaS;私有云/云原生/开源平替冲击 PaaS;科技行业大裁员、AI冲击与天朝的低人力成本冲击云服务(运维人力外包/共享专家)。公有云如果执着于目前的杀猪模式,背离“存算基础设施”的初心,那么必将在以上三者形成的合力下面临越来越严峻的竞争与挑战。
WHAT:真正的杀猪盘
你在家用微波炉加热黄焖鸡米饭料理包花费10元,餐馆老板替你用微波炉加热装碗上桌收费30元,你不会计较什么,房租水电人工服务也都是要钱的。但如果现在老板端出同样一碗饭跟你收费 1000 元并说:我们提供的不是黄焖鸡米饭,而是可靠质保的弹性餐饮服务,大厨品控掌握火候,按量付费想吃多少有多少,按需付费吃多少盛多少,不吃黄焖鸡还有麻辣烫串串香可选,反正就值这个价,你会不会有打一顿这个老板的冲动?这样的事情就发生在块存储上!
硬件技术日新月异,PCI-E NVMe SSD 在各种指标上都达到了一个全新水平。一块常见的 3.2 TB 规格企业级 MLC颗粒 SSD 有着极为强悍的性能、可靠性与性价比,价格 ¥3000 元不到,全方位吊打老存储。
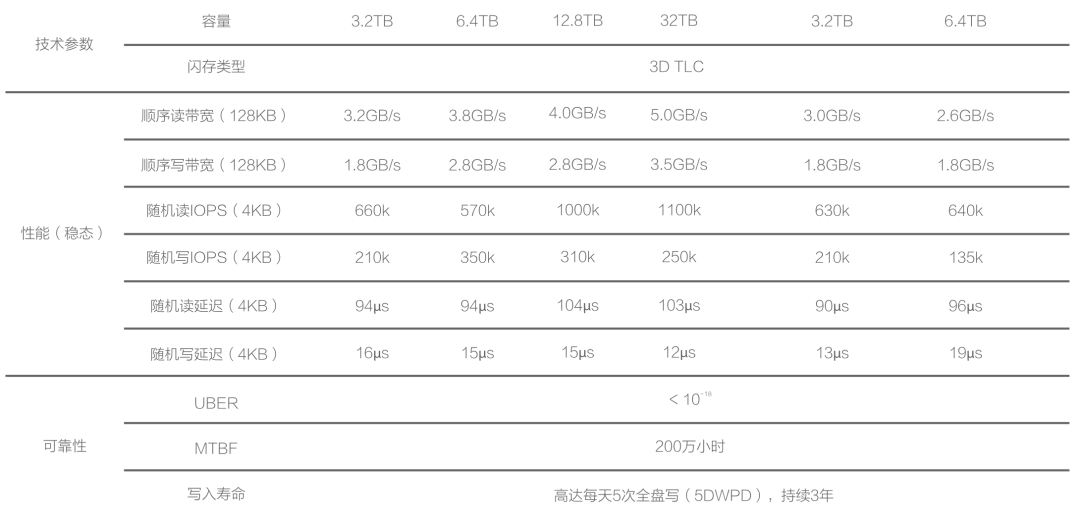
Aliyun ESSD PL3 和我们 IDC 自建采购 PCI-E NVMe SSD 【1】是同一家供应商。所以在最大容量和 IOPS 限制上都一模一样。AWS 最好的块存储 io2 Block Express 的规格和各类指标也基本类似。云厂商提供的最高端存储就是使用这种 32 TB 的单卡,所以才会有 32TB 最大容量的限制(AWS 64T),可以认为底下的实际硬件基本是高度一致的。
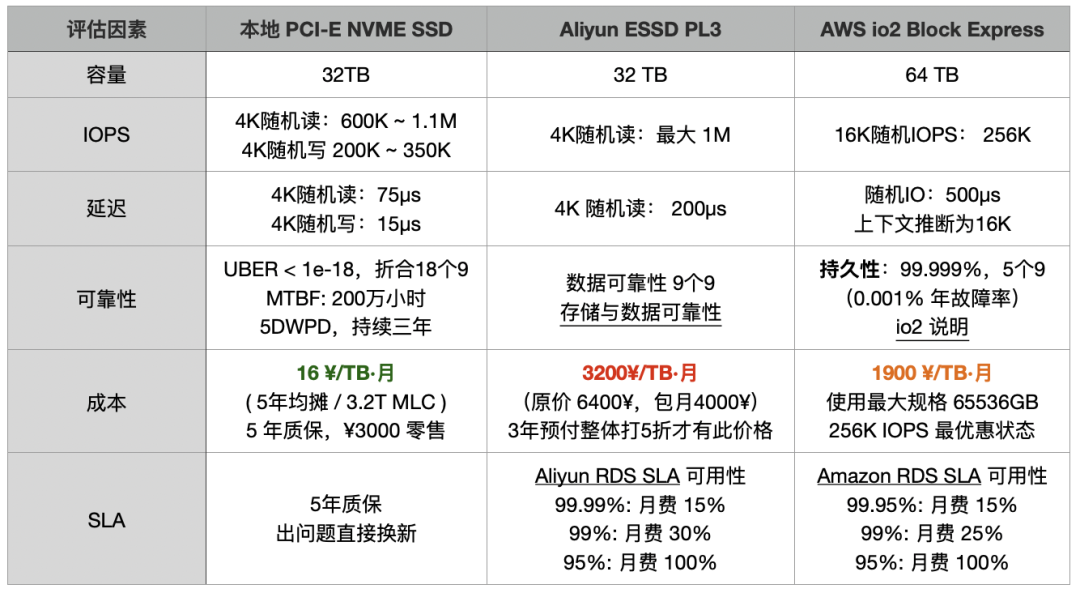
然而相比直接采购硬件,AWS EBS io2 的成本高达 120 倍,而阿里云的 ESSD PL3 则高达 200 倍。以 3.2TB 规格的企业级 PCI-E SSD 卡为参照基准,AWS 上按需售租比为 15 天,阿里云上不到 5 天,租用此时长即可买下整块磁盘。若在阿里云以采购三年预付最大优惠五折计算,三年租金够买下 120 多块同款硬盘。

你这 SSD 是金子做的 ?
当然,云厂商会争论说块存储的对标物是 SAN,而本地 DAS 在云上的对标物应当是实例存储(Host Storage)。但是,公有云的实例存储基本都是临时性的( Ephemeral Storage),实例一旦休眠/停止就会回收抹除数据【7,11】,难以用于严肃的生产数据库,云厂商自己也建议你不要把重要数据放在上面。因此唯一能用于数据库的存储就是 EBS 块存储 。类似于DBFS之类的产品指标与成本与 EBS 基本类似,也在此合并同类项。
说到底,用户在意的不是设备块底下到底是 SAN,SSD,还是HDD;真正重要的永远是实打实的硬指标:延迟、IOPS,可靠性,成本。拿本地与云上的最好选项对比,没有任何问题,更别提最好的云存储底下用的也是一样的本地盘了。
有的“专家”又会说,云上的块存储稳定可靠,多副本冗余纠错。在以前,Share Everything 的数据库要用 SAN 存储跑,然而现在很多数据库都是 Share Nothing 架构了。在数据库实例层面进行冗余,不需要存储层再搞个三副本,更何况企业级磁盘本身就有极强的自我纠错能力与安全冗余( UBER < 1e-18 )。在上层数据库本身已经有冗余的情况下,多副本块存储对数据库来说属于毫无意义的浪费。退一万步讲,如果云厂商真的用了多余的两副本来做无谓的冗余,那也不过是溢价率从 200x 降到 66x ,杀猪逻辑依然没有质变。
“专家”还会说,买“云服务”其实类似于买保险:“年化 0.02% 的故障看起来大部分人一次都遇不到,但是遇到一次就毁灭性的打击,而云厂商来为你兜底”。听上去好像很有吸引力。但翻开各家云厂商 EBS 的 SLA,你会发现压根没有为可靠性兜底的条款。ESSD 云盘介绍上是写了 9个9 的数据可靠性,但他也不敢把这句话写到 SLA 里。云厂商敢兜的只有可用性,而且还是相当逊的可用性,以 AWS EBS SLA 【9】为例:

翻译成大白话就是:如果一个月里挂一天半(95%),本月此项服务费补偿100%代金券,挂了7个小时(99%)补偿 30% 代金券,挂了几十分钟 (99.9%单盘,99.99%区域)补偿10%代金券。云厂商收了百倍费用,这么大的重大冲击就补偿点代金券?挂几分钟都受不了的应用,谁会稀罕这几毛钱代金券?莫过于前几年那篇《腾讯云给一家创业公司带来的灾难》
顺丰快递保价 1% ,搞丢了人家真的赔你。每年几万块的商业医保,出问题真能兜底几百万。不要侮辱“保险”这个行业,起码人家也是一分钱一分货的。所以,SLA 对用户来说不是兜底损失的保险单。在最坏的情况下,它是吃不了兜着走的哑巴亏。在最好的情况下,它才是提供情绪价值的安慰剂。
云数据库服务的溢价还可以用 “专家人力” 来解释,但这一点对于服务器插上就能用的磁盘完全说不通,云厂商自己也讲不出这里几十倍的价格到底溢在哪里。你去问他们的工程师,大概逼急了也只能告诉你:
“我们抄 AWS ,人家就是这么设计的”
WHY:为什么要这样定价
即使是公有云自己的工程师可能也搞不清楚这样定价的意义,明白的人也不太可能会告诉你。但是这并不妨碍我们从产品的设计中推断出这样做背后的道理。
存储是有事实标准的:POSIX 文件系统 + 块存储。无论是数据库文件,图片音视频都使用同样的文件系统接口存储在磁盘上。但是 AWS 的“神之一手” 将其切分为两种不同的服务:S3 (简单对象存储)与 EBS (弹性块存储)。很多“追随者”模仿了AWS 的产品设计与定价模型,却说不清这样做的逻辑与原理。
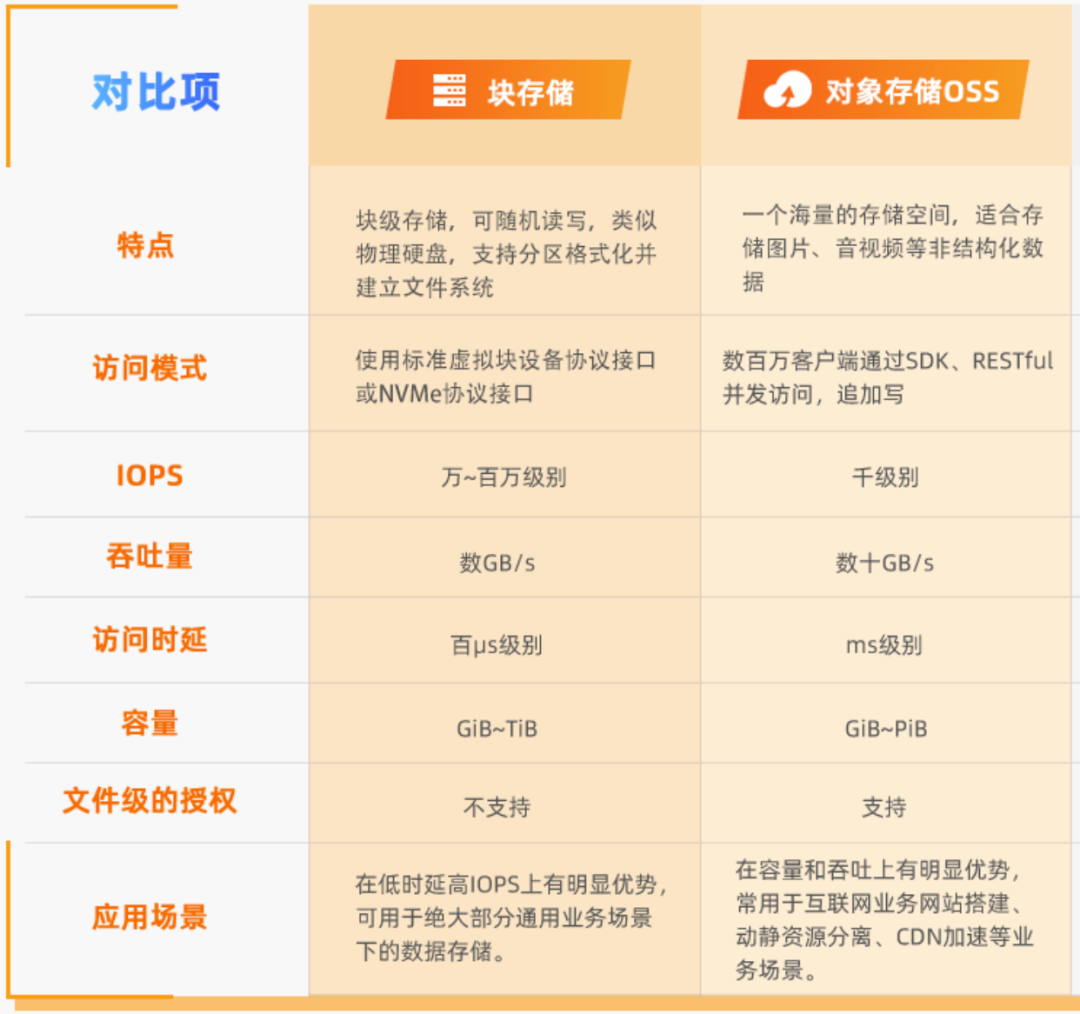
阿里云官网对 EBS 和 OSS 的定位
S3 的全称 是 Simple Storage Service ,简单存储服务。它是文件系统/存储的一种简化替代:牺牲了强一致性、目录管理,访问时延等功能属性,以换取廉价的成本与海量伸缩的能力。它提供了一个简单的、高延迟、高吞吐扁平 KV 存储服务,从标准的存储服务中剥离出来。这个部分物美价廉,是公有云用来吸引用户上云的一大杀手锏:因此成为了可能是唯一一个,在各家公有云通行的云计算事实标准。
而数据库需要的是低延迟,强一致、高质量、高性能、可随机读写的块存储,这一部分被包装为 EBS 服务:Elastic Block Store ,弹性块存储服务,这个部分成为了公有云厂商的 禁脔 :不愿为用户染指。因为EBS是 RDS 的定价之锚 —— 也就是云数据库的壁垒与护城河。
卖资源吃饭的 IaaS 定价没有太大水分空间,可以对着 BOM 一笔一笔精算。但是像云数据库这样的 PaaS, 里面包含的“服务”,人力 / 研发成本就包含大量水分,难以厘定,就可以名正言顺的卖出天价,攫取高额利润。尽管国内公有云 IaaS 层存储、计算、网络三大件的收入能占营收一半的比例,但其毛利率只有 15% ~ 20%,而以云数据库为代表的公有云 PaaS 毛利率可以达到 50% 或更高,完爆卖资源吃饭的 IaaS。
如果用户选择使用 IaaS 资源(EC2 / EBS)自行搭建数据库,对云厂商而言是一笔巨大的利润损失。所以公有云厂商会竭尽全力避免这样的情况出现,而怎样设计产品才能实现这个需求呢?
首先,最适合用于自建数据库的实例存储必须添加各种限制:实例一旦休眠/停止就会回收并抹除数据,让你没法用 EC2 自带的盘跑严肃的生产数据库服务。其次尽管 EBS 相比本地 NVMe SSD 存储性能可靠性稍显拉胯,但用来跑数据库也是可以的,所以这里也要限制:但也不能不给用户,那么就设置一个天价!作为补偿,次一级的廉价海量存储 S3 就可以卖便宜一些来钓鱼获客。
当然要想客户买单,也需要一些云计算 KOL 来鼓吹配套 “公有云云原生” 哲学理念:“EC2 不适合放状态哟,请把状态放到 S3 或者 RDS 以及其他托管服务,这才是使用我们公有云的‘最佳实践’ ”。

这四条总结的很到位,但公有云绝对不会告诉你“最佳实践”的代价是什么。用白话解释一下这四条的意思,这是一个为客户精心设计的连环杀猪套:
普通文件丢S3!(这么物美价廉的S3,还要啥 EBS?)
不要自建数据库!(别想着用实例存储折腾开源替代)
请深度使用厂商专有的身份认证系统(供应商锁定)
乖乖给云数据库上贡!(锁死用户后,杀猪时刻)
HOW:还原杀猪盘内幕
公有云的商业模式可以概括为:廉价EC2/S3获客,EBS/RDS杀猪。
要想杀猪,先要养猪,舍不着孩子套不着狼。所以对于新用户、初创企业,小微用户,公用云都不吝于提供一些甜头,甚至赔本赚吆喝。新用户首单骨折,初创企业免费/半价 Credit,以及微妙的定价策略。
以 AWS RDS 报价为例可以看出,1核2核的迷你机型,单价也就是 几$/核·月,折合三四百块人民币一年,可以说是非常便宜实惠(不含存储):如果你需要一个低频使用的小微数据库放点东西,这也许就是最简单便宜的选择【10】。
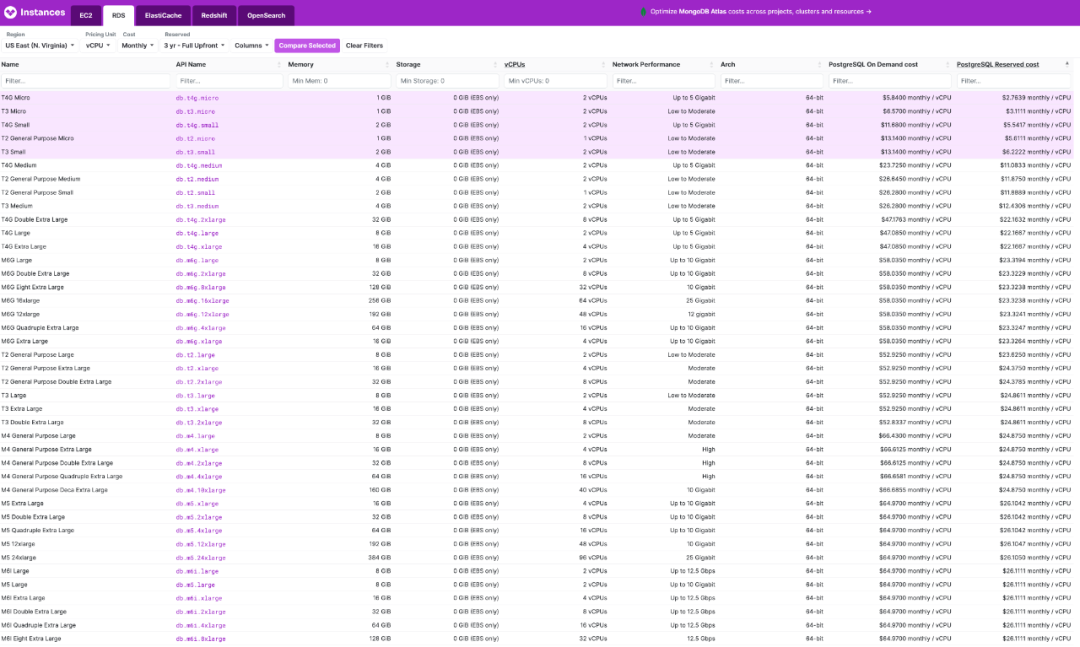
然而,只要你稍微把配置往上抬哪怕一丁点儿,核月单价就出现了数量级的变化,干到了二三十~一百来刀,最高可以翻到几十倍 —— 算上惊悚的 EBS 价格还要再翻番。用户只有在看到突然出现的天价账单时,才会意识到到底发生了什么。
以 RDS for PostgreSQL 为例, AWS 上 64C / 256GB 的 db.m5.16xlarge RDS用一个月价格 $25,817 / 月,折合每月 18 万元人民币,一个月的租金够你把两台性能比这还要好的多得多的服务器直接买下来自建了。租售比甚至都不到一个月,租十来天就够你买下来整台服务器自建。
| 付费模式 | 价格 | 折合每年(万¥) |
|---|---|---|
| IDC自建(单物理机) | ¥7.5w / 5年 | 1.5 |
| IDC自建(2~3台组HA) | ¥15w / 5年 | 3.0 ~ 4.5 |
| 阿里云 RDS 按需 | ¥87.36/时 | 76.5 |
| 阿里云 RDS 月付(基准) | ¥4.2w / 月 | 50 |
| 阿里云 RDS 年付(85折) | ¥425095 / 年 | 42.5 |
| 阿里云 RDS 3年付(5折) | ¥750168 / 3年 | 25 |
| AWS 按需 | $25,817 / 月 | 217 |
| AWS 1年不预付 | $22,827 / 月 | 191.7 |
| AWS 3年全预付 | 12w$ + 17.5k$/月 | 175 |
| AWS 中国/宁夏按需 | ¥197,489 / 月 | 237 |
| AWS 中国/宁夏1年不预付 | ¥143,176 / 月 | 171 |
| AWS 中国/宁夏3年全预付 | ¥647k + 116k/月 | 160.6 |
我们可以对比一下自建与云数据库的成本差异:
| 方式 | 折合每年(万元) |
|---|---|
| IDC托管服务器 64C / 384G / 3.2TB NVME SSD 660K IOPS (2~3台) | 3.0 ~ 4.5 |
| 阿里云 RDS PG 高可用版 pg.x4m.8xlarge.2c, 64C / 256GB / 3.2TB ESSD PL3 | 25 ~ 50 |
| AWS RDS PG 高可用版 db.m5.16xlarge, 64C / 256GB / 3.2TB io1 x 80k IOPS | 160 ~ 217 |
RDS 定价与自建对比,详见《云数据库是不是智商税》
任何理智的企业用户都看得明白这里面的道理:如果采购这种服务不是为了短期的,临时性的需求,那么绝对算得上是重大的财务失当行为。
不仅仅是 关系型数据库服务 / RDS 是这样,各种云数据库都在杀猪。MongoDB, ClickHouse,Cassandra,用 EC2 / EBS的有一个算一个。以流行的 NoSQL 文档数据库 MongoDB 为例:
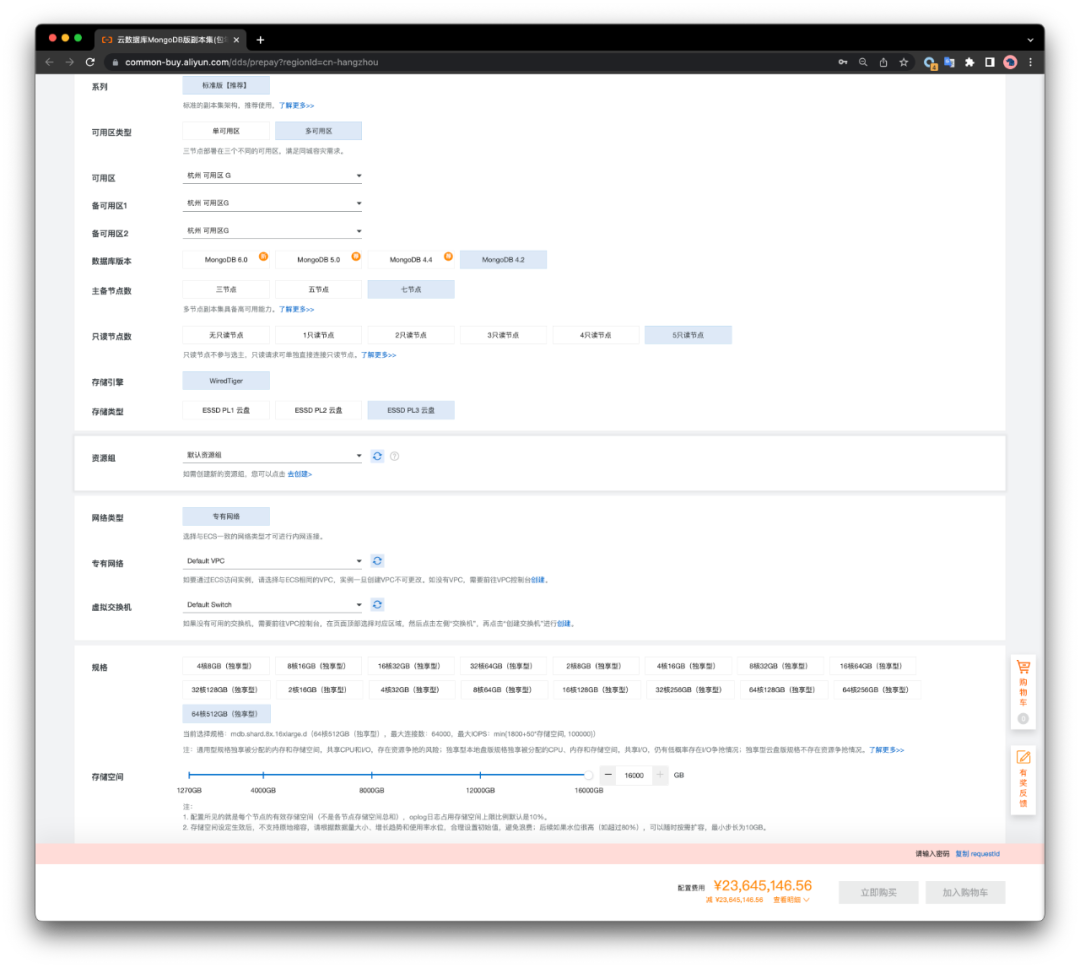
这种报价没有十年脑血栓的产品经理真的想不出来
五年时间正好是常见服务器折旧年限,最大折扣,12节点(64C 512G),报价两千三百万。这个报价的零头就可以轻松把五年硬件代维轻松搞定,再加一个 MongoDB 专家天团为您按需定制随意自建了。
高级餐厅加收菜品 15% 的服务费,而用户也可以理解并支持这种合理范围内的利润需求。云数据库如果在硬件资源的基础上加收百分之几十的服务费与弹性溢价(白嫖开源的云服务就不要提软件费用了),可以解释为生产性要素的定价,解决的问题与提供的服务确实值这个钱。
然而加收百分之几百甚至几千的溢价,那就完全属于破坏性要素参与分配了:云厂商吃死了用户上来之后没有备选项,以及迁移会产生伤筋动骨的大成本,所以大可以放心杀猪!在这种意义下,用户掏的钱,买的不是服务,而是在被强制征收 “无专家税” 与 “保护费”。
被遗忘的初心愿景
因而面对杀猪的指责,云厂商也会辩解说:“哎呀,你们看到的都是列表价啦,说是最低 5折,但大客户打起折来,可是没有底线的哦“。作为一条经验法则:自建成本差不多在目前云服务列表价的零点五到一折上下浮动,如果能长期保有此折扣,云服务就会比自建更有竞争力。
专业懂行的大客户,特别是那种随时有能力迁移横跳的甲方去和公有云搞商务谈判,确实有可能获取两折的骨折折扣,而小客户天然在议价方面没有能力,通常不太可能有这种机会。
然而,云计算不应成为云算计:云厂商如果只能在大企业那边疯狂打折促销,而面对中小客户和开发者进行薅羊毛的方式进行杀猪,那实际上是损不足以奉有余 —— 吸中小客户的血补贴大客户。这种方式已经完全违背了云计算本身的初心与愿景,必然难以持续长久。
在云刚出现的时候,关注的焦点是 云硬件 / IaaS 层 :算力、存储、带宽。云硬件 是云厂商的初心故事:让计算和存储资源像水电一样,而自己扮演基础设施的提供者的角色。这是一个很有吸引力的愿景:公有云厂商可以通过规模效应,压低硬件成本并均摊人力成本;理想情况下,在给自己留下足够利润的前提下,还可以向公众提供比 IDC 价格更有优势,更有弹性的存储算力。
而 云软件( PaaS / SaaS ),则是与云硬件有着迥然不同的商业逻辑:云硬件靠的是规模效应,优化整体效率赚取资源池化超卖的钱,总体来说算是一种效率进步。而云软件则是靠共享专家,提供运维外包来收取服务费。公有云上大量的服务,本质是对免费的开源软件进行封装,依靠的是垄断专家,利用信息不对称收取天价保险费,是一种价值的攫取转移。
不幸的是,出于混淆视线的目的,云软件与云硬件都使用了“云”这个 Title。因而在云的故事中,混杂着打破资源垄断与建立能力垄断的叙事:同时混掺着将算力普及到千家万户的理想主义光辉,与达成垄断攫取不义利润杀猪的贪婪。
抛弃平台中立性与做基础设施的初心,沉沦在 PaaS / SaaS / 甚至应用层恰烂钱的公有云供应商,将在没有底线的竞争中沉沦。
博弈将走向何方?
垄断利润将随着竞争出现而消失,公有云厂商被卷入了一场苦战之中。
在基础设施层面,运营商,国资云,IDC 1.5/2.0 都进入了赛道,并提供了非常有竞争力的 IaaS 服务,一条龙包网包电托管代维,高端服务器既可以自购托管,也完全可以用实价弹性直接租赁,论起弹性来一点不怵。
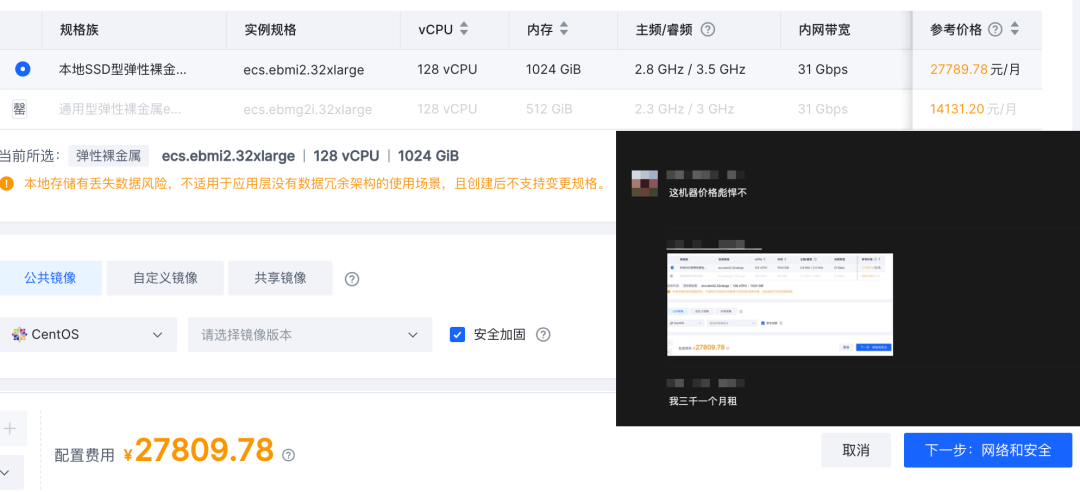
IDC 2.0 服务器租赁新模式:实价租赁,满年限归用户
在软件层面,曾经作为公有云技术门槛的各类管控软件 / PaaS 已经出现了相当优秀的开源平替,OpenStack / Kubernetes 取代 EC2,MinIO / Ceph 取代 S3,RDS 上也出现了诸如 Pigsty 【5】与各种 K8S Operator 这样的开源替代品。
整个“云原生”运动,说白了就是开源生态对公有云白嫖挑战的回应:用户与开发者们为了避免被公有云杀猪,打造了一套本地优先的完整公有云开源替代。
“CloudNative” 这个名字起的好,一中各表,公有云觉得是“公有云上出生”的,私有云想的是“在本地跑和云一样的东西”。推 Kubernetes 最狠的竟然还是公有云本身,就和销售绞死自己的绳索一样。
经济衰退的大环境下,降本增效成为主旋律。十几万规模的科技行业大裁员,以及未来AI对智力行业的大规模冲击将释放出大量相关人才,再加上本朝的低工资优势,自建人才稀缺与昂贵的情状将大为缓解。人力成本相比云服务成本要有优势的多。
结合以上三方面的趋势,IDC2.0 + 开源自建的组合越来越有竞争力:对于稍微有点规模和人才储备的组织来说,短路掉公有云这个中间商,直接与 IDC 合作显然是一个更经济实惠的选择。
不忘初心,方得始终。公有云在云硬件 / IaaS 层上做的确实不错,除了贵到离谱,没有太大问题,东西确实是不错的。如果能回归最初的愿景初心,真正做好水与电一样的基础设施提供者,卖资源虽毛利虽不高,但可以站着把钱挣了。如果继续执迷不悟沉迷于杀猪,最终用户将用脚给出自己的选择。
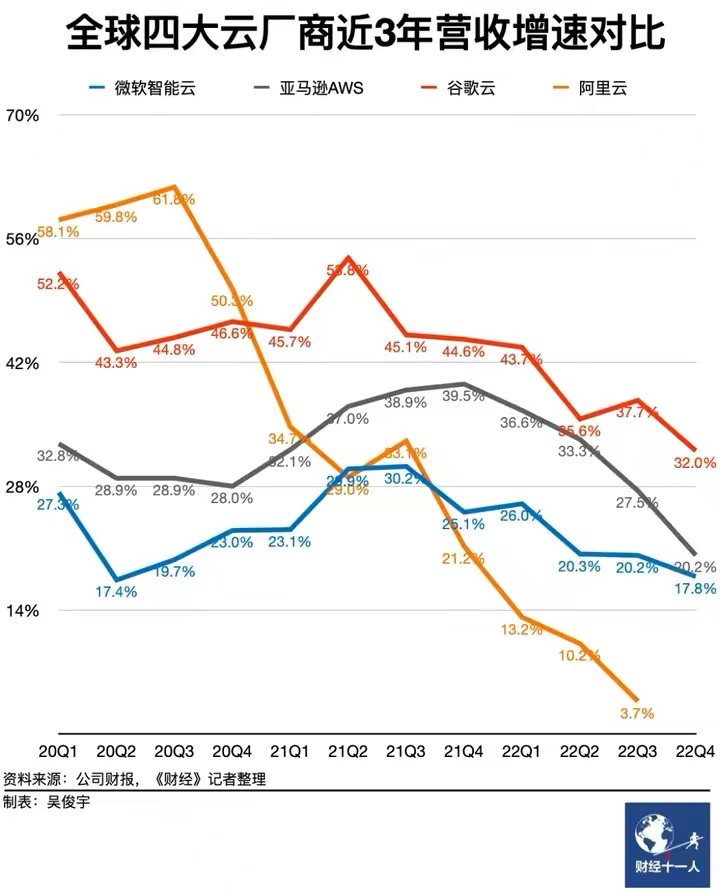
References
【2】云数据库是不是智商税
【3】范式转移:从云到本地优先
【7】AWS实例存储
【9】AWS EBS SLA
【11】阿里云:本地盘
【12】阿里云:云盘概述
【13】图说块存储与云盘
【15】云计算为啥还没挖沙子赚钱?
垃圾腾讯云CDN:从入门到放弃?
我和 瑞典马工虽然在 云数据库 VS DBA 这个议题上针锋相对,但在一点上能达成共识:至少国内的公有云厂商做的是真垃圾。用马工的话来说就是:“阿里云是个工程质量差劲的正经云,但腾讯云是一群业余销售加业务码农玩游戏”。

前因后果
我有个软件托管在 GitHub 上,提供了 1MB 的源码包和 1GB 的离线软件包下载。大陆用户因为 在境内 没法从 GitHub 下载,因此需要有一个境内的下载地址,于是我就用了腾讯云的 COS(对象存储) 与 CDN(内容分发网络)服务。
用 CDN 的初衷不外乎:1. 加速,2. 省钱。互联网流量费通常是 8毛钱1GB,使用 CDN 流量包可以节省不少流量费打对折。当然,因为 CDN 就是给境内用户专用的。所以我也只买了境内的流量包。一直以来也用的还算可以,直到 2月底,我突然发现,怎么冒出来几笔异常费用。
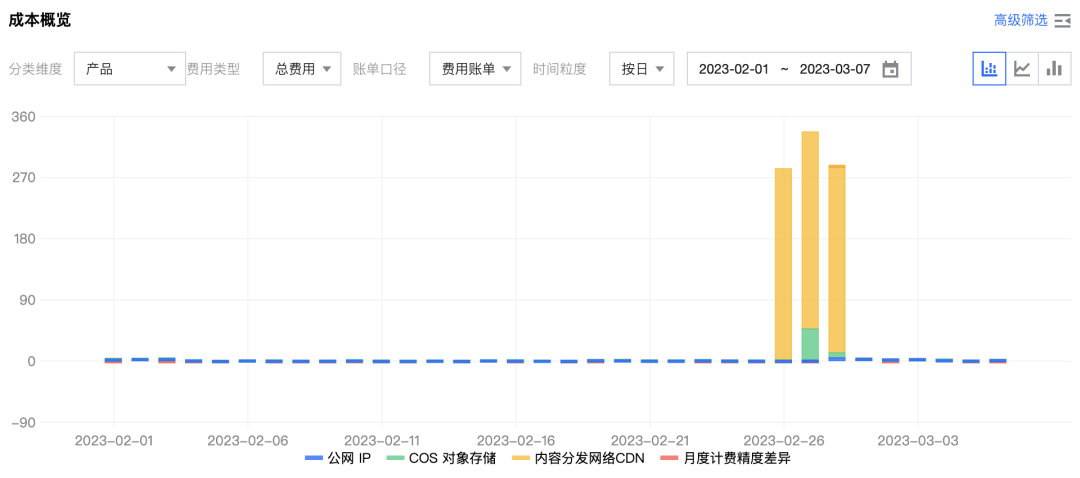
点进去一看,CDN 收了几百块钱,我还想,难道是哪里渠道带火了下载?于是进入 数据统计分析界面一看,这段时间里,总共软件包也就是 100GB 不到的下载流量,撑死了几十块钱,怎么会我收几百块呢?
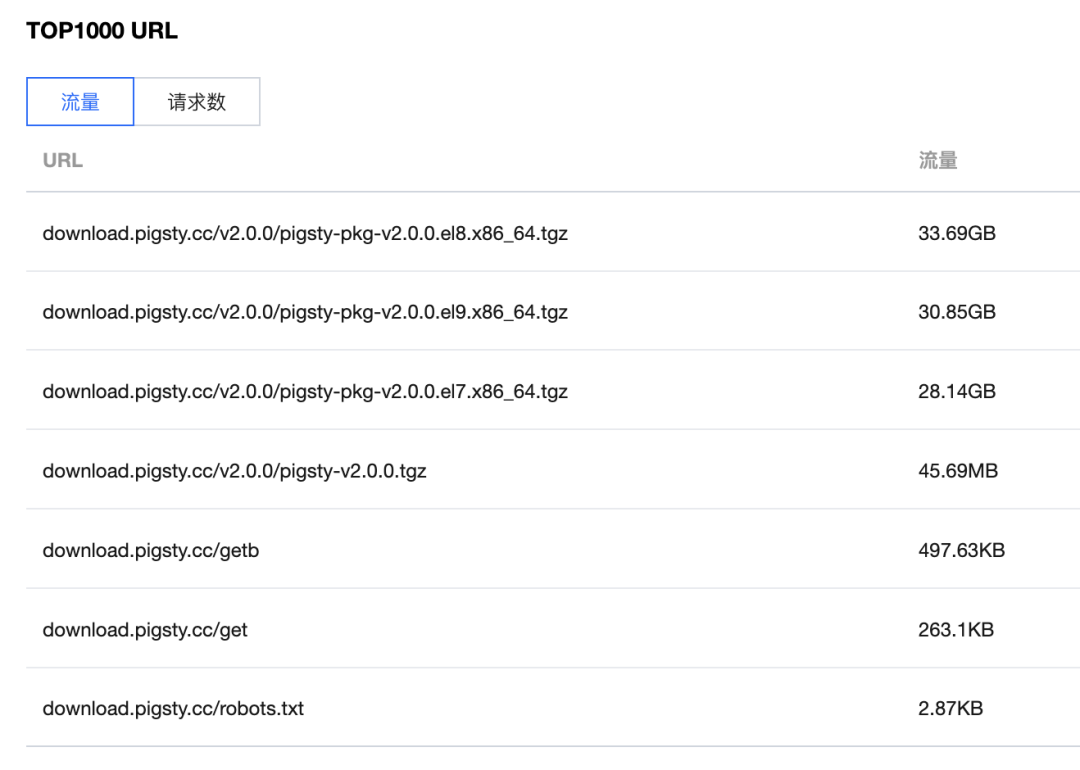
点看分析一看好家伙,1TB的访问流量,全是 “境外其他”,什么鬼?
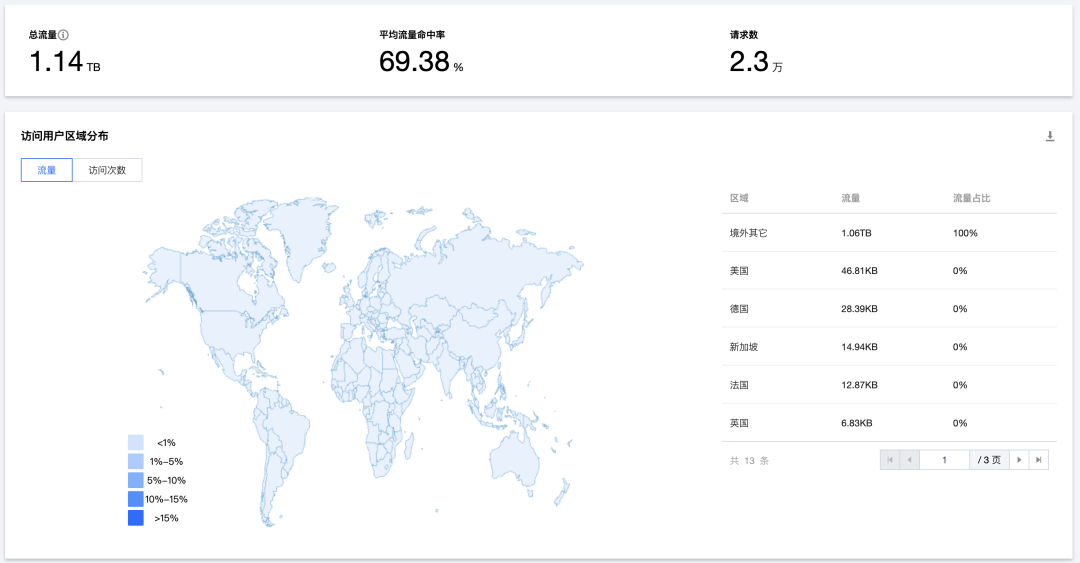

于是,呼出腾讯云客服来:
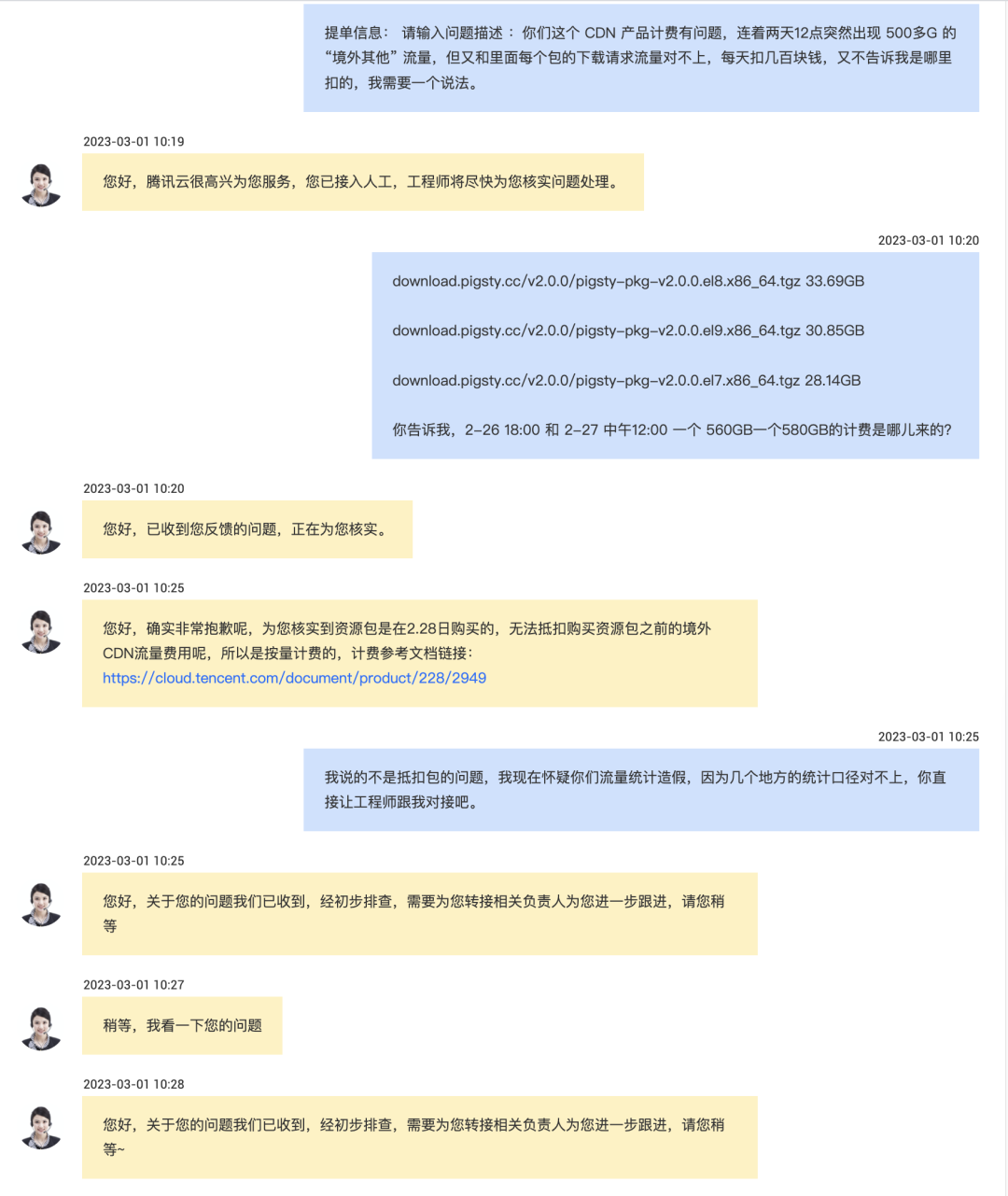
甩锅 x 1,我们这个 TOP不准,要看日志哈。
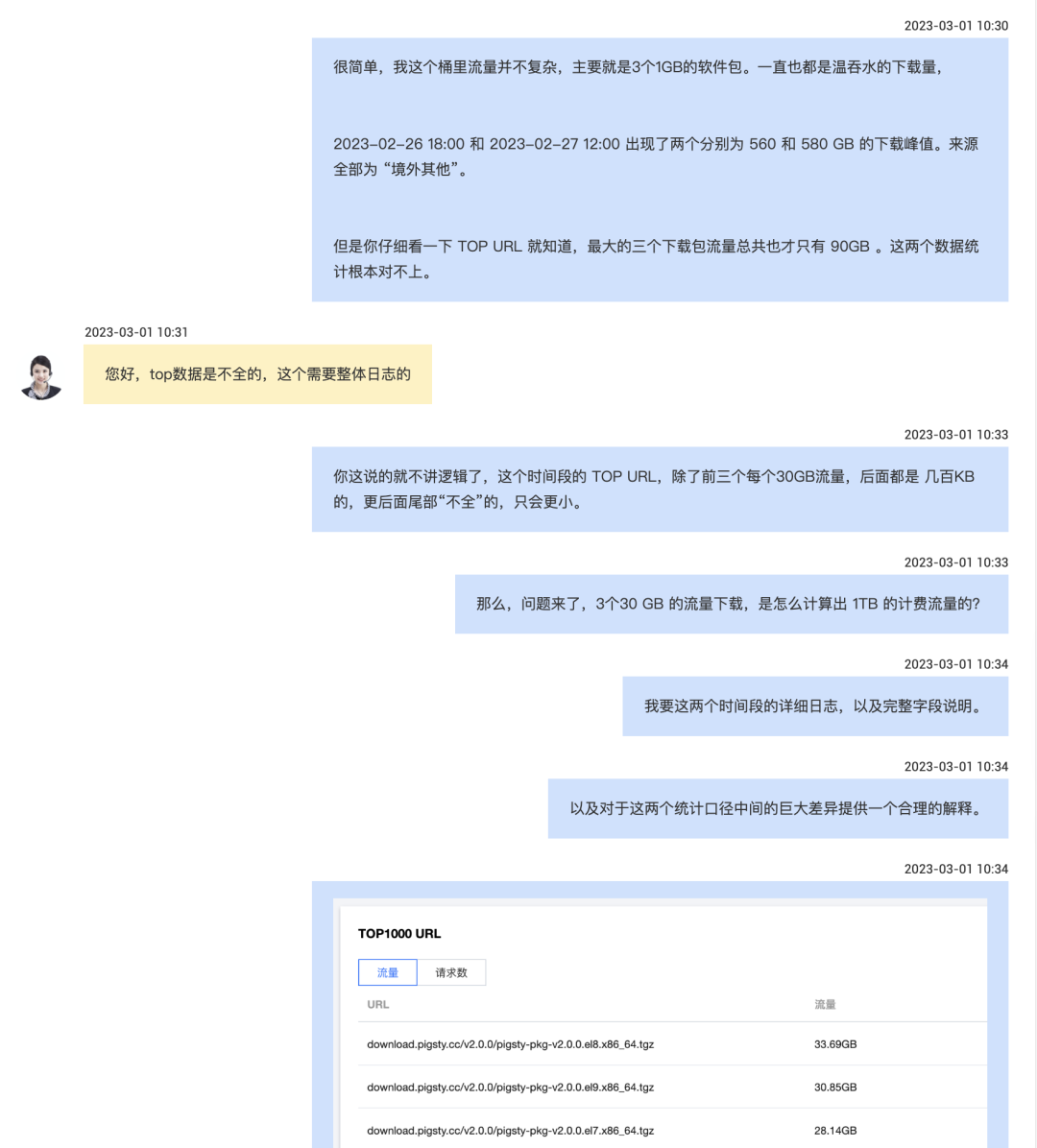
那我就下载一份日志来看看,究竟是谁吃饱了撑着来爆破。结果,里面一大堆请求连客户端 IP 地址都没有。
甩锅 x 2 ,客服说,这种大概率是被攻击了!好怕怕啊!
这种话术还想忽悠我?不懂行的用户一听”攻击“,说不定就被拐带着跑去买公有云厂商的”高防服务“了。
绕了一圈又等了半个小时,终于告知了我真正的原因,流量费是“预热”扣除的。所以这些没有 “来源IP”的请求终于真相大白了:原来是“监守自盗,贼喊捉贼”,你们自己的系统跑过来爆破俺的流量啊!

工程师电话沟通告知说:我们的 CDN 预热是这样的,所有的 CDN 节点都会来回源请求,所以才有的这两万次请求与 1TB 流量。
听到这样的解释,我都要笑喷了。我为什么买CDN?因为要省对象存储的流量钱。CDN 去刷新预热,这是云厂商自己系统内部的流量,为啥要挂在用户身上付费?但是你刷新预热一下,一下花掉了我直接走对象存储下载一年都用不了的钱。
好吧,就算我们退一万步讲预热要付费,一个合乎工程逻辑的做法是,每个大区域来对象存储回源一次,然后再下发同步到每个终端节点上。付个几倍流量费,我也不会介意的。1GB 的软件花个 10GB 预热一下,客户也不会说什么。
腾讯云 CDN则不然,一个1MB/1GB的软件包预热,每个终端节点直接来请求,产生 1TB 的“预热流量”。八毛钱1GB 流量费,几百块就没了。更滑稽的是,我 CDN 是给大陆用户使用的,墙外用户根本用不着,直接 Github 下载就好了,而这些流量全都跑到“境外”去了,事先买好境内的流量包压根不能抵扣。而腾讯云的文档上也压根没有提及,这些 “预热” 究竟有多大的量和来自哪里。我认为,这已经构成了事实上的欺诈与恶意引导杀猪盘。比 《云数据库是不是智商税》还要恶劣的多。
所以,一个简简单单的 1MB / 1GB 的软件包要走 CDN 分发,本来可能一天也没几块钱的东西,点一下按钮,大几百块就没了。在监控图表上,把内部的流量藏的好好的;在计费逻辑上,把本应免费的内部流量硬塞到用户头上。
CDN预热内部流量也好意思向用户收钱?
几百块钱的成本对我来说不痛不痒,但我作为用户,感觉到智商受到了羞辱。腾讯云提议退一半钱给你好不好?全退给你好不好?我也一分没要,我就是要写一篇文章告诉大家,这个产品做的有多烂多傻逼。
阿里云不管怎么样,起码在某些方面我还会表示一下敬意。而腾讯云的表现,实实在在是彻底丢了中国公有云的脸,这么大一厂商,这点事儿都弄不明白就出来做云。也难怪别人会说:
中国没有云计算,有的只是 IDC 2.0
就这个样子出来卖,还是早点洗洗睡吧。
扩展阅读
更多腾讯云的精彩表现,可以欣赏云计算霰弹枪的往期文章:
[2] 究竟是客户差劲,还是腾讯云差劲?
[3] 腾讯云:从入门到放弃
[4] 腾讯云阿里云做的真的是云计算吗?–从客户成功案例的视角
[5] 本土云厂家究竟在服务谁?
驳《再论为什么你不应该招DBA》
郭德纲有一段相声:比如我和火箭专家说,你那火箭不行,燃料不好,我认为得烧柴,最好是烧煤,煤还得精选煤,水洗煤不行。如果那科学家拿正眼看我一眼,那他就输了。
但不管怎么说,马工也还是一位体面的瑞典研发工程师。没有做过DBA就敢大放厥词,开地图炮拉仇恨,实在勇气可嘉。之前在《你怎么还在招聘DBA》,以及回应文《云数据库是不是智商税》中,我们便已交锋过。
当别人把屎盆子扣在这个行业所有人头上时,还是需要人来站出来说几句的。因此今天特此撰文以驳斥马工的谬论:《再论为什么你不应该招DBA》。

马工的论点有三:
-
DBA妨碍了研发交付新特性
-
DBA威胁了企业数据安全
-
人工DBA需要被基于代码的软件所取代
我的看法是:
-
第一点属于无效输出,DBA本来就是在稳定性侧制衡研发的存在。
-
第二点则是完全扯淡,DBA本来就是类似于财务的关健岗位,需要信任。
-
第三点属于部分事实,但严重高估了短期变化,且云数据库并非唯一的路。
且听我一一道来:
DBA 对稳定性负责
关于信息系统的一个基本原理是:安全性与活性相互抵触,过于强调安全稳定,则活性受损;过于强调活性,则难以稳定。任何组织都要在两者中间找到一个平衡点。而研发与运维,就是两者的职能化身。
研发对新功负责,而 SRE/DBA 对稳定性负责,一个开创,一个守成,两者相互协作,但也是相互制衡。马工作为研发,特别还是创业公司的研发,主张功能活性很重要,从立场上来说是无可厚非的。但在更广大的组织中,稳定性的地位往往是高于新功能的,成熟的组织如银行,大型互联网平台,从来都是稳定性压倒一切。毕竟,新功能的收益是不确定的,而大故障的损失是肉眼可见的。每天发10个新版本不见得能带来多少增长,但一次大故障也许就能让几个月的努力付之东流。
“在高速上开两百迈的阻碍从来都不是车的性能,而是司机的胆量”。站在更高位的管理者角度来说,马工强调的 “开掉DBA得到更快的DB交付速度”,纯粹属于研发者的一厢情愿:用云把运维职能外包出去, 无人制衡,我想怎样就怎样。这样的想法如果落地,最终必将在某个时刻以惨痛的教训收场。
笔者曾是 DBA,但也没少干 Dev。关于研发和 DBA 的心态,都有亲身的体会。我在刚入行当研发的时候,在“PostgreSQL数据库里”跑神经网络,推荐系统,Web服务器和爬虫,用FDW接了 MongoDB 和 HBase以及一堆外部系统,什么稳定性?跑的不是挺好吗?直到没有运维与DBA愿意接手维护,我不得不亲自干起了 DBA 的活自己狗食背起锅来,才能设身处地的对DBA / 运维有同理心,谨慎选择有所为有所不为。
交付速度谁在乎?
评价一款数据库需要从许多维度出发:稳定性,可靠性,安全性,简单性,可伸缩性,可扩展性,可观测性,可维护性,成本性价比,等等等等。交付速度这件事勉强属于“可伸缩性”里一个比较次要的附属维度,在数据库系统需要关注的属性中,压根排不上号。
更重要的是,性价比才是第一产品力,对比方案却对成本闭而不提,是一种耍流氓的行为。笔者对研发人员的这种心理非常了解:花的是公司的钱,省的是自己事儿,自然没有几个人会有动机为公司去省钱。你的数据库花半个小时交付,还是花三四天交付,老板与领导不会 Care 这些。但是,你的老板会很在乎你花30分钟拉起了一个数据库,然后每个月账单多出来几十万元。

以 AWS 上 64核256GB的 db.m5.16xlarge RDS 为例,用一个月价格 $25,817 / 月,折合约 18 万元人民币,一个月的租金,够你把两台性能比这还要好的多得多的服务器直接买下来了,任何理智的企业用户都看得明白这里面的道理:如果采购这种服务不是为了短期的,临时性的需求,那么绝对算得上是重大的财务失当行为。
比交付速度也不怵
但即使我们退一万步讲,交付速度真的重要,马工的论证用例也是破绽百出。
马工假想了一个数据库上线的案例:PG新版本,两地三中心,同城HA,异地灾备,数据加密,自动备份,自带监控,App与DB独立网段,DBA也无法删库。然后得意洋洋的宣称:”使用 Terraform,我只要28分钟就可以完成满足需要的配置!比拉DBA搭建数据库快几个数量级!“
实际上只要你的机器就绪,网络打通,规划完毕:使用 Pigsty 部署一套满足这些需求的数据库系统,执行耗时也就是十几分钟。自建机房且不提,Pigsty 完全可以使用同样的逻辑:基于Terraform 一键拉起EC2、存储、网络,然后在这个基础上额外执行一条命令部署数据库,耗费的时间说不定比 Terraform 还短一点,更重要的是,还能省掉百分之八九十的天价 RDS 智商税。
能想出这种定价的云数据库产品经理脑袋一定被门夹了
分库分表的稻草人靶子
马工提出,分库分表是DBA自抬身价的一种工具。
在今天,数据库的能力已经得到了极大的发展,给应用开发者带来巨大管理成本的分库分表已经没必要了。凡是在用分库分表的系统, 都可以用分布式数据库或者NoSQL数据库替换掉。几乎可以说,分库分表不过是DBA自抬身价的一种工具。
时至今日,硬件存储技术的发展已经让很多老同志跟不上新形势了。家用 PCI-E NVME SSD 2TB的价格已经进入了三位数,常用的企业级 3.2TB MLC NVME SSD也不过六七千,最大几十TB的单卡容量,已经完爆了很多中大型企业的所有 TB 数据量,七位数的IOPS让几千/几万IOPS还卖天价的 云 EBS 恨不得找个地缝钻进去。
软件方面,以 PostgreSQL 为例,使用堆表存储的单表容量十几TB千亿量级数据一点儿不成问题,还有 Citus 插件可以原地改造为分布式数据库。各种分布式数据库的卖点也是 “不用分库分表”。这都已经是老黄历问题了。除了极个别场景,恐怕也只有原教旨 MySQL 用户还守着 “单表不能超过 2000w 记录” 去玩分表了。
当然,分布式数据库对于 DBA 的水平要求不会更低只会更高;所以这里马工主要想说的还是 NoSQL ,更具体的讲,就是 DynamoDB 这种所谓“不需要” DBA运维的数据库直接干翻 DBA。不过,一个平均延迟在 10ms 的数据库,一个抽象程度只是等同于文件系统的扁平 KV 存储的数据库,光是杀猪程度要比 RDS 还要狠毒的 RCU / WCU 计费方式,就足够用户喝上一壶,有何德何能敢标榜自己能替掉 DBA ?
指望用NoSQL替代DBA是做梦
互联网应用大多属于数据密集型应用,对于真实世界的数据密集型应用而言,除非你准备从基础组件的轮子造起,不然根本没那么多机会去摆弄花哨的数据结构和算法。实际生产中,数据表就是数据结构,索引与查询就是算法。而应用研发写的代码往往扮演的是胶水的角色,处理IO与业务逻辑,其他大部分工作都是在数据系统之间搬运数据。
在最宽泛的意义上,有状态的地方就有数据库。它无所不在,网站的背后、应用的内部,单机软件,区块链里。有。关系型数据库只是数据系统的冰山一角(或者说冰山之巅),实际上存在着各种各样的数据系统组件:
- 数据库:存储数据,以便自己或其他应用程序之后能再次找到(PostgreSQL,MySQL,Oracle)
- 缓存:记住开销昂贵操作的结果,加快读取速度(Redis,Memcached)
- 搜索索引:允许用户按关键字搜索数据,或以各种方式对数据进行过滤(ElasticSearch)
- 流处理:向其他进程发送消息,进行异步处理(Kafka,Flink,Storm)
- 批处理:定期处理累积的大批量数据(Hadoop)
状态管理是信息系统的永恒问题,马工以为的 DBA 是抱着祖传 Oracle 手册的打字员,实际上互联网公司的 DBA 已经是十八班武艺样样精通的 数据架构师 了。架构师最重要的能力之一,就是了解这些组件的性能特点与应用场景,能够灵活地权衡取舍、集成拼接这些数据系统。 他们上要 Push 业务落地最佳实践指导模式设计,下要深入操作系统与硬件排查问题优化性能,中间要掌握无数种数据组件的使用方式。君子不器,关系型数据库的知识,只是其中最为核心重要的一种。
正如我在《为什么要学习数据库原理和设计》所说, 只会写代码的是码农;学好数据库,基本能混口饭吃;在此基础上再学好操作系统和计算机网络,就能当一个不错的程序员。可惜的是,数据建模和SQL几乎快成为一门失传的艺术:这类基础知识逐渐为新一代工程师遗忘,他们设计出离谱的模式,不懂得正确地创建索引,然后草率得出结论:关系型数据库和SQL都是垃圾,我们必须使用糙猛快的NoSQL来省时间。然而人们总是需要可靠的系统来处理关键业务数据:在许多企业中,核心数据仍然是一个常规关系型数据库作为Source of Truth,NoSQL数据库仅用于非关键数据。某个研发跳出来说 DynamoDB / Redis / MongoDB / HBase 太牛逼了,我所有的状态都能放在这里,而且再也不需要 DBA 了,毫无疑问是滑稽可笑的。
DBA 是企业数据库的守护者
马工的最后一炮,直指 DBA 的职业道德 :DBA想删库,谁也拦不住。
这话倒是没有错,DBA和财务一样,都属于能对企业造成致命杀伤的关键岗位:用人不疑,疑人不用。但这句话同样也绕开了一个重要事实:没有DBA守门,人人都能删库。在马工举的微盟和百度删库跑路的两个例子中,主犯都是普通的研发与运维人员,正是因为没有称职的 DBA 把关,才有删库跑路的可趁之机。
合格的 DBA 可以有效减少有能力对企业进行致命一击的人群范围,从所有的研发与运维收敛到DBA本身。至于 DBA 本身如何制衡,要么是两个 DBA 互为备份,要么是由运维/安全团队管理冷备份的删除权限。马工举的,腾讯云不让手工删例行备份的例子,实属对业内实践少见多怪。
对于给 DBA 群体泼脏水的行为,本人表示鄙视愤慨 😄。按照这个逻辑,我也完全可以认为马工喜爱的公有云厂商,才是对数据安全最大的威胁:用云不过是把运维和DBA外包给了云厂商,而你完全阻碍不了某个云厂商中有权限的研发/运维/DBA,在心血来潮的情况下来你的库里里逛逛。或者干脆脱个备份裤子赏玩一下,你压根不可能追索,不可能取证,当然核心原因是你压根没有能力知道这一点。而这样的人许许多多,一个运维的脚本出岔子就会爆破一大片,你能指望的赔偿也只有不痛不痒的时长代金券。
参考阅读:《云RDS:从删库到跑路》
DBA要退出历史舞台?
作为一个整体行业, DBA 确实在走下坡路, 但人们总是会过高估短期影响而低估长期趋势。许多大型组织都雇用DBA,DBA类似于 Cobol 程序员,那些听上去不那么Fancy的制造业,银行保险证券、以及大量运行本地软件的党政军部门,大量使用了关系型数据库。在可预见的未来,DBA在某个地方找工作是不会有什么问题的。
但大的趋势是,数据库本身会越来越智能,易用性越来越好,而各式各样的工具、SaaS、PaaS不断涌出,也会进一步压低数据库的使用门槛。公有云/私有云DBasS的出现更是让数据库的管理门槛进一步下降。数据库的专业技术门槛降低,将导致DBA的不可替代性降低:安装一套软件收费十几万,做一次数据恢复上百万的好日子肯定是一去不复返了。但在另一种意义上讲,这也将 DBA 从运维性的琐事中解放出来,他们可以把更多时间投身于更有价值的性能优化,隐患排查,制度建设工作之中。
无论是公有云厂商,还是以Kubernetes为代表的云原生/私有云,其核心价值都在于尽可能多地使用软件,而不是人来应对系统复杂度。但是不要指望这些能完全替代 DBA:云并不是什么都不用管的运维外包魔法。根据复杂度守恒定律,无论是系统管理员还是数据库管理员,管理员这个岗位消失的唯一方式是,它们被重命名为“DevOps Engineer”或SRE/DRE。好的云软件可以帮你屏蔽运维杂活,解决70%的日常高频问题,然而总是会有那么一些复杂问题只有人才能处理。你可能需要更少的人手来打理这些云软件,但总归还是需要人来管理。毕竟:
你也需要懂行的人来协调处理,才不至于被云厂商嘎嘎割韭菜当傻逼。
题外话:有那么一些研发,总想着通过云这种运维外包外援,用云数据库,云XX砸掉 DBA 的饭碗。我们做了一个开箱即用的 云数据库 RDS PostgreSQL 本地开源替代 Pigsty ,最近刚发布了 2.0,监控/数据库开箱即用 HA/PITR/IaC一应俱全。允许您在缺乏数据库专家的情况下,用接近硬件的成本运行企业级数据库服务,省掉50%~90%上贡给RDS的“无专家税”,让 RDS 除了它引以为傲的弹性,在各个方面都像是一个大笑话。对于广大 DBA 来说,这就是一件怼回去的武器。咱们明人不说暗话,就是要砸了云数据库的饭碗,并断了研发的这种痴念。https://pigsty.cc/docs/feature
最后,让我们用某个 Notion AI 生成的无版权提词小笑话结束今天的主题。

范式转移:从云到本地优先
上一篇里,我们用数据回答了《云数据库是不是智商税》 这个问题:高达几倍到十几倍的溢价,对于云适用光谱外的用户是毫无疑问的杀猪。但我们还可以进一步探究:公有云特别是云数据库为什么会是这样?并基于其底层逻辑此对行业的未来进行预测与判断。

软件行业经历了几次范式转移,数据库也不例外
前生今世
天下大势,分久必合,合久必分。
—— The pendulum of the software industry.
软件行业经历了几次范式转移,数据库也不例外。

软件吞噬世界,开源吞噬软件,云吞噬开源,谁来吃云?
最初,软件吞噬世界,以 Oracle 为代表的商业数据库,用软件取代了人工簿记,用于数据分析与事务处理,极大地提高了效率。不过 Oracle 这样的商业数据库非常昂贵,一核·一月光是软件授权费用就能破万,不是大型机构都不一定用得起,即使像壕如淘宝,上了量后也不得不”去O“。
接着,开源吞噬软件,像 PostgreSQL 和 MySQL 这样”开源免费“的数据库应运而生。软件开源本身是免费的,每核每月只需要几十块钱的硬件成本。大多数场景下,如果能找到一两个数据库专家帮企业用好开源数据库,那可是要比傻乎乎地给 Oracle 送钱要实惠太多了。
开源软件带来了巨大的行业变革,可以说,互联网的历史就是开源软件的历史。尽管如此,开源软件免费,但 专家稀缺昂贵。能帮助企业 用好/管好 开源数据库的专家非常稀缺,甚至有价无市。某种意义上来说,这就是”开源“这种模式的商业逻辑:免费的开源软件吸引用户,用户需求产生开源专家岗位,开源专家产出更好的开源软件。但是,专家的稀缺也阻碍了开源数据库的进一步普及。于是,“云软件”出现了。
然后,云吞噬开源。公有云软件,是互联网大厂将自己使用开源软件的能力产品化对外输出的结果。公有云厂商把开源数据库内核套上壳,包上管控软件跑在托管硬件上,并雇佣共享 DBA 专家提供支持,便成了云数据库服务 (RDS) 。这诚然是有价值的服务,也为很多软件变现提供了新的途径。但云厂商的搭便车行径,无疑对开源软件社区是一种剥削与攫取,而捍卫计算自由的开源组织与开发者自然也会展开反击。
云软件的崛起会引发新的制衡反作用力:与云软件相对应的本地优先软件开始如雨后春笋一般出现。而我们,就在亲历见证这次范式转移。
二律背反
“我想直率地说:多年来,我们就像个傻子一样,他们拿着我们开发的东西大赚了一笔”。
Redis Labs 首席执行官 Ofer Bengal
冷战已经结束,但在软件行业中,垄断和反垄断的斗争却方兴未艾。
与物理世界不同,信息复制近乎为0的成本,让两种模式在软件世界有了相互争斗的实际意义。商业软件与云软件遵循垄断资本主义的逻辑;而自由软件、开源软件以及正在崛起的本地优先软件,遵循的是共产主义的逻辑【2】。信息技术行业之所以有今天的繁荣,人们能享受到如此多的免费信息服务,正是这种斗争的结果。
正如开源软件的概念已经彻底改变了软件世界:商业软件公司耗费了海量资金与这个想法斗争了几十年。最终还是难以抵挡开源软件的崛起 —— 软件这种IT业的核心生产资料变为全世界开发者公有,按需分配。开发者各尽所能,人人为我,我为人人,这直接催生了互联网的黄金繁荣时代。

然而,盛极而衰,物极必反。商业软件改头换面以云服务的方式卷土重来,而开源软件的理念在云计算时代出了大问题。云软件在本质上是商业软件的形态升级:如果软件只能运行在供应商的服务器上,而不是跑在用户本地的服务器上,就可以形成新的垄断。更妙的是云软件完全可以白嫖开源,以彼之矛攻彼之盾。免费的开源软件加上供应商的运维与服务器,整合包装为虚实莫辨的服务,即可省却研发成本,溢价几倍甚至十几倍大赚一笔。
在云刚出现的时候,他们的核心是硬件 / IaaS层 :存储、带宽、算力、服务器。云厂商的初心故事是:让计算和存储资源像水电一样,自己扮演基础设施的提供者的角色。这是一个很有吸引力的愿景:公有云厂商可以通过规模效应,压低硬件成本并均摊人力成本;理想情况下,在给自己留下足够利润的前提下,还可以向公众提供比 IDC 价格更有优势,更有弹性的存储算力。
而云软件( PaaS / SaaS ),则是与云硬件有着迥然不同的商业逻辑:云硬件靠的是规模效应,优化整体效率赚取资源池化超卖的钱,总体来说算是一种效率进步。而云软件则是靠共享专家,提供运维外包来收取服务费。公有云上大量的软件,本质是对免费的开源软件进行封装,依靠的是信息不对称收取天价服务费,是一种价值的攫取转移。【1】
| 硬件算力 | 单价 |
|---|---|
| IDC自建机房(独占物理机 A1: 64C384G) | 19 |
| IDC自建机房(独占物理机 B1: 40C64G) | 26 |
| IDC自建机房(独占物理机 C2: 8C16G) | 38 |
| IDC自建机房(容器,超卖200%) | 17 |
| IDC自建机房(容器,超卖500%) | 7 |
| UCloud 弹性虚拟机(8C16G,有超卖) | 25 |
| 阿里云 弹性服务器 2x内存(独占无超卖) | 107 |
| 阿里云 弹性服务器 4x内存(独占无超卖) | 138 |
| 阿里云 弹性服务器 8x内存(独占无超卖) | 180 |
| AWS C5D.METAL 96C 200G (按月无预付) | 100 |
| AWS C5D.METAL 96C 200G(预付3年) | 80 |
| 数据库 | |
| AWS RDS PostgreSQL db.T2 (4x) | 440 |
| AWS RDS PostgreSQL db.M5 (4x) | 611 |
| AWS RDS PostgreSQL db.R6G (8x) | 786 |
| AWS RDS PostgreSQL db.M5 24xlarge | 1328 |
| 阿里云 RDS PG 2x内存(独占) | 260 |
| 阿里云 RDS PG 4x内存(独占) | 320 |
| 阿里云 RDS PG 8x内存(独占) | 410 |
| ORACLE数据库授权 | 10000 |
论云如何把 20来块的单位硬件卖出十几倍溢价
不幸的是,出于混淆视线的目的,云软件与云硬件都使用了“云”这个名字。因而在云的故事中,同时混掺着将算力普及到千家万户的理想主义光辉,与达成垄断攫取不义利润的贪心。
矛盾嬗变
在 2022 年,软件自由的敌人是云计算软件。【3】
云计算软件,即主要在供应商的服务器上运行的软件,而你的所有数据也存储在这些服务器上。以云数据库为代表的 PaaS 与各类 SaaS 服务都属于此类。这些“云软件”也许有一个客户端组件(手机App,网页控制台,跑在你浏览器中的JavaScript),但它们只能与供应商的服务端共同工作。而云软件存在很多问题:
- 如果云软件供应商倒闭或停产,您的云软件就歇菜了,而你用这些软件创造的文档与数据就被锁死了。例如,很多初创公司的 SaaS 服务会被大公司收购,而大公司没有兴趣继续维护这些产品。
- 云服务可能在没有任何警告和追索手段的情况下突然暂停您的服务(例如 Parler )。您可能在完全无辜的情况下,被自动化系统判定为违反服务条款:其他人可能入侵了你的账户,并在你不知情的情况下使用它来发送恶意软件或钓鱼邮件,触发违背服务条款。因而,你可能会突然发现自己用各种云文档或其它App创建的文档全部都被永久锁死无法访问。
- 运行在你自己的电脑上的软件,即使软件供应商破产倒闭,它也可以继续跑着,想跑多久跑多久。相比之下,如果云软件被关闭,你根本没有保存的能力,因为你从来就没有服务端软件的副本,无论是源代码还是编译后的形式。
- 云软件极大加剧了软件的定制与扩展难度,在你自己的电脑上运行的闭源软件,至少有人可以对它的数据格式进行逆向工程,这样你至少有个使用其他替代软件的PlanB。而云软件的数据只存储在云端而不是本地,你甚至连这一点都做不到了。
如果所有软件都是免费和开源的,这些问题就都自动解决了。然而,开源和免费实际上并不是解决云软件问题的必要条件;即使是收钱的或者闭源的软件,也可以避免上述问题:只要它运行在你自己的电脑、服务器、机房上,而不是供应商的云服务器上就可以。拥有源代码会让事情更容易一些,但这并不是不关键,最重要的还是要有一份软件的本地副本。
在当今,云软件,而不是闭源软件或商业软件,成为了软件自由的头号威胁。云软件供应商可以在您无法审计,无法取证,无法追索的情况下访问您的数据,或突然心血来潮随心所欲地锁定你的所有数据,这种可能性的潜在危害,要比无法查看和修改软件源码的危害大得多。与此同时,也有不少“开源软件公司”将“开源”视作一种获客营销包装、或形成垄断标准的手段,而不是真正追求“软件自由”的目的。
”开源“ 与 ”闭源“ 已经不再是软件行业中最核心的矛盾,斗争的焦点变为 “云” 与 “本地”。
本地优先
“本地” 与 “云” 的对立体现为多种不同的形式:有时候是 “Native Cloud” vs “Cloud Native”,有时候叫体现为 “私有云” vs “公有云”,大部分时候与 ”开源“ vs “闭源”重叠,某种意义上也牵扯着 “自主可控” vs “仰人鼻息”。
以 Kubernetes 为代表的 Cloud Native 运动就是最典型的例子:云厂商将 Native 解释 “原生”:“原生诞生在公有云环境里的软件” 以混淆视听;但究其目的与效果而言,Native 真正的含义应为 “本地”,即与 Cloud 相对应的 “Local” —— 本地云 / 私有云 / 专有云 / 原生云,叫什么不重要,重要的是它运行在用户想运行的任何地方(包括云服务器),而不是仅仅是公有云所独有!
本地优先的软件在您自己的硬件上运行,并使用本地数据存储,但也保留云软件的便利特性,比如实时协作,简化运维,跨设备同步,资源调度,灵活伸缩等等。开源的本地优先的软件当然非常好,但这并不是必须的,本地优先软件90%的优点同样适用于闭源的软件。同理,免费的软件当然好,但本地优先的软件也不排斥商业化与收费服务。
在云软件没有出现开源/本地优先的替代品前,公有云厂商尽可大肆收割,攫取垄断利润。而一旦更好用,更简易,成本低得多的开源替代品出现,好日子便将到达终点。正如 Kubernetes 用于替代云计算服务 EC2, MinIO / Ceph 用于替代云存储服务 S3, 而 Pigsty 则指在替代云数据库服务:RDS PostgreSQL。越来越多的云软件开源/本地优先替代正如雨后春笋一样冒出来。
CNCF Landscape
历史经验
云计算的故事与电力的推广过程如出一辙,让我们把目光回退至上个世纪初,从电力的推广普及垄断监管中汲取历史经验。

ChatGPT: 电力的推广过程
供电也许会走向垄断、集中、国有化,但你管不住电器。如果云硬件(算力)类似于电力,那么云软件便是电器。生活在现代的我们难以想象:洗衣机,冰箱,热水器,电脑,竟然还要跑到电站边的机房去用,我们也很难想象,居民要由自己的发电机而不是公共发电厂来供电。
因此从长期来看,公有云厂商大概也会有这么一天:在云硬件上通过类似于电力行业,通过垄断并购与兼并形成“规模效应”,利用“峰谷电”,“弹性定价”等各种方式优化整体资源利用率,在相互斗兽竞争中将算力成本不断压低至新的底线,实现“家家有电用”。当然,最后也少不了政府监管介入,公私合营收归国有,成为如同国家电网与电信运营商类似的存在,最终实现 IaaS 层的存储带宽算力的垄断。
而与之对应,制造灯泡、空调、洗衣机这类电器的职能会从电力公司中剥离,百花齐放。云厂商的 PaaS / SaaS 在被更好,更优质,更便宜的替代物冲击下逐渐萎缩,或回归到足够低廉的价格水平。
正如当年开源运动的死对头微软,现在也选择拥抱开源。公有云厂商肯定也会有这一天,与自由软件世界达成和解,心平气和地接受基础设施供应商的角色定位,为大家提供水与电一般的存算资源。而云软件终将会回归正常毛利,希望那一天人们能记得人们能记得,这不是因为云厂商大发慈悲,而是因为有人带来过开源平替。
参考阅读
【1】云数据库是不是智商税?
【2】为什么软件应该是自由的
【3】是时候和GPL说再见了
云数据库是不是智商税
寒冬来袭,大厂纷纷开始裁员,进入降本增效模式,作为公有云杀猪刀一哥的云数据库,故事还能再讲下去吗?
近日,Basecamp & HEY 联合创始人 DHH 的一篇文章【1,2】引起热议,主要内容可以概括为一句话:
“我们每年在云数据库(RDS/ES)上花50万美元,你知道50万美元可以买多少牛逼的服务器吗?
我们要下云,拜拜了您呐!“
所以,50 万美元可以买多少牛逼的服务器 ?

荒谬定价
磨刀霍霍向猪羊
我们可以换一种问法,服务器和RDS都卖多少钱?
以我们自己数据库大量使用的物理机型为例:Dell R730, 64核384GB内存,加装一块 3.2 TB MLC的NVME SSD。像这样的一台服务器部署标准的生产级 PostgreSQL,单机可以承载十几万的TPS,只读点查询可以干到四五十万。要多钱呢?算上电费网费IDC托管代维费用,按照5年报废均摊,整个生命周期成本七万五千上下,合每年一万五。当然,如果要在生产中使用,高可用是必须的,所以通常一组数据库集群需要两到三台物理机,也就是每年3万到4.5万。
这里没有算入DBA费用:两三个人管几万核真没多少。
如果您直接购买这样规格的云数据库,则费用几何呢?让我们看看国内阿里云的收费【3】。因为基础版(乞丐版)实在是没法生产实用(请参考:《云数据库:删库到跑路》),我们选用高可用版,通常底下是两到三个实例。包年包月,引擎 PostgreSQL 15 on x86,华东1默认可用区,独享的64核256GB实例:pg.x4m.8xlarge.2c,并加装一块3.2TB的ESSD PL3云盘。每年的费用在25万(3年)到75万(按需)不等,其中存储费用约占1/3。
让我们再来看看公有云一哥AWS【4】【5】。AWS上与此最接近的是 db.m5.16xlarge ,也是64核256GB多可用区部署,同理,我们加装一块最大8万IOPS,3.2TB的 io1 SSD磁盘,查询AWS全球与国区的报价,总体在每年160 ~ 217万元不等,存储费用约占一半,整体成本如下表所示:
| 付费模式 | 价格 | 折合每年(万¥) |
|---|---|---|
| IDC自建(单物理机) | ¥7.5w / 5年 | 1.5 |
| IDC自建(2~3台组HA) | ¥15w / 5年 | 3.0 ~ 4.5 |
| 阿里云 RDS 按需 | ¥87.36/时 | 76.5 |
| 阿里云 RDS 月付(基准) | ¥4.2w / 月 | 50 |
| 阿里云 RDS 年付(85折) | ¥425095 / 年 | 42.5 |
| 阿里云 RDS 3年付(5折) | ¥750168 / 3年 | 25 |
| AWS 按需 | $25,817 / 月 | 217 |
| AWS 1年不预付 | $22,827 / 月 | 191.7 |
| AWS 3年全预付 | 12w$ + 17.5k$/月 | 175 |
| AWS 中国/宁夏按需 | ¥197,489 / 月 | 237 |
| AWS 中国/宁夏1年不预付 | ¥143,176 / 月 | 171 |
| AWS 中国/宁夏3年全预付 | ¥647k + 116k/月 | 160.6 |
我们可以对比一下自建与云数据库的成本差异:
| 方式 | 折合每年(万元) |
|---|---|
| IDC托管服务器 64C / 384G / 3.2TB NVME SSD 660K IOPS (2~3台) | 3.0 ~ 4.5 |
| 阿里云 RDS PG 高可用版 pg.x4m.8xlarge.2c, 64C / 256GB / 3.2TB ESSD PL3 | 25 ~ 50 |
| AWS RDS PG 高可用版 db.m5.16xlarge, 64C / 256GB / 3.2TB io1 x 80k IOPS | 160 ~ 217 |
所以问题来了,如果你用云数据库1年的钱,就够你买几台甚至十几台性能更好的服务器,那么使用云数据库的意义到底在哪里?当然,公有云的大客户通常可以有商务折扣,但再怎么打折,数量级上的差距也是没法弥补的吧?
用云数据库到底是不是在交智商税?
适用场景
没有银弹
数据库是数据密集型应用的核心,应用跟着数据库走,所以数据库选型需要非常审慎。而评价一款数据库需要从许多维度出发:可靠性,安全性,简单性,可伸缩性,可扩展性,可观测性,可维护性,成本性价比,等等等等。甲方真正在意的是这些属性,而不是虚头巴脑的技术炒作:存算分离,Serverless,HTAP,云原生,超融合……,这些必须翻译成工程的语言:牺牲了什么换来了什么,才有实际意义。
公有云的鼓吹者很喜欢往给它脸上贴金:节约成本,灵活弹性,安全可靠,是企业数字化转型的万灵药,是汽车对马车的革命,又好又快还便宜,诸如此类,可惜没几条是实事求是的。绕开这些虚头巴脑的东西,云数据库相比专业的数据库服务真正有优势的属性只有一条:弹性。具体来说是两点:启用成本低,可伸缩性强。
启动成本低,意味着用户不需要进行机房建设,人员招聘培训,服务器采购就可以开始用;可伸缩性强,指的是各种配置升降配,扩缩容比较容易;因此公有云真正适用的场景核心就是这两种:
- 起步阶段,流量极小的简单应用
- 毫无规律可循,大起大落的负载
前者主要包括简单网站,个人博客,小程序小工具,演示/PoC,Demo,后者主要包括低频的的数据分析/模型训练,突发的秒杀抢票,明星并发出轨等特殊场景。
公有云的商业模型就是租赁:租服务器,租带宽,租存储,租专家。它和租房,租车,租充电宝没有本质区别。当然,租服务器和运维外包实在是不怎么中听,所以有了云这个名字,听起来更有赛博地主的感觉。而租赁这种模式的特点,就是弹性。
租赁模型有租赁的好处,出门在外,共享充电宝可以解决临时应急性的小规模充电需求。但对于大量日常从家到单位两点一线的人来说,每天用共享充电宝给手机电脑充电,毫无疑问是非常荒谬的,何况共享充电宝租一个小时4块钱,租几个小时的钱,就够你把它直接买下来了。租车可以很好的满足临时的、突发的、一次性用车需求:外地出差旅游,临时拉一批货。但如果你的出行需求是频繁的,本地性,那么购置一辆自动驾驶的车也许是最省事省钱的选择。
问题的关键还是在于租售比,房子的租售比几十年,汽车的租售几年,而公有云服务器的租售比通常只有几个月。如果你的业务能够稳定活几个月以上,为什么要租,而不是直接买呢?
所以,云厂商赚的钱,要么来自VC砸钱求爆发增长的科技创企,要么来自灰色寻租空间比云溢价还高的特殊单位,要么是人傻钱多的狗大户,要么是零零散散的站长/学生/VPN个人用户。聪明的高净值企业客户,谁会放着便宜舒适的大House不住,跑去挤着租住方舱医院人才公寓呢?
如果您的业务符合公有云的适用光谱,那是最好不过;但为了不需要的灵活性与弹性支付几倍乃至十几倍溢价,那是纯交智商税**。**
成本刺客
任何信息不对称都可以构成盈利空间,但你无法永远欺骗所有人。
公有云的弹性就是针对其商业模式设计的:启动成本极低,维持成本极高。低启动成本吸引用户上云,而且良好的弹性可以随时适配业务增长,可是业务稳定后形成供应商锁定,尾大不掉,极高的维持成本就会让用户痛不欲生了。这种模式有一个俗称 —— 杀猪盘。

在我职业生涯的第一站中,就有这样一次杀猪经历让我记忆犹新。作为前几个被逼上A云的内部BU,A云直接出工程师加入手把手提供上云服务。用ODPS全家桶换掉了自建的大数据/数据库全家桶。应该说,服务确实不错,只不过,每年的存储计算开销从千万出头飙升到接近一亿,利润几乎都转移到A云了,堪称终极成本刺客。

后来在下一站,情况则完全不同。我们管理着两万五千核规模,450W QPS的 PostgreSQL 与 Redis 数据库集群。像这种规格的数据库,如果按AWS RCU/WCU 计费,每年几个亿就出去了;即使全买长期包年包月再加个大商务折扣,至少五六千万是肯定是少不了的。而我们总共两三个DBA,几百台服务器,人力+资产均摊每年统共不到一千万。

这里我们可以用一种简单的方式来核算单位成本:一核算力(含mem/disk)使用一个月的综合成本,简称核·月。我们核算过自建各机型的成本,以及云厂商给出的报价,大致结果如下:
| 硬件算力 | 单价 |
|---|---|
| IDC自建机房(独占物理机 A1: 64C384G) | 19 |
| IDC自建机房(独占物理机 B1: 40C64G) | 26 |
| IDC自建机房(独占物理机 C2: 8C16G) | 38 |
| IDC自建机房(容器,超卖200%) | 17 |
| IDC自建机房(容器,超卖500%) | 7 |
| UCloud 弹性虚拟机(8C16G,有超卖) | 25 |
| 阿里云 弹性服务器 2x内存(独占无超卖) | 107 |
| 阿里云 弹性服务器 4x内存(独占无超卖) | 138 |
| 阿里云 弹性服务器 8x内存(独占无超卖) | 180 |
| AWS C5D.METAL 96C 200G (按月无预付) | 100 |
| AWS C5D.METAL 96C 200G(预付3年) | 80 |
| 数据库 | |
| AWS RDS PostgreSQL db.T2 (4x) | 440 |
| AWS RDS PostgreSQL db.M5 (4x) | 611 |
| AWS RDS PostgreSQL db.R6G (8x) | 786 |
| AWS RDS PostgreSQL db.M5 24xlarge | 1328 |
| 阿里云 RDS PG 2x内存(独占) | 260 |
| 阿里云 RDS PG 4x内存(独占) | 320 |
| 阿里云 RDS PG 8x内存(独占) | 410 |
| ORACLE数据库授权 | 10000 |
所以这里问题就来了,单价二十块的服务器硬件,为什么可以卖出上百块,而且装上云数据库软件还可以再翻几番?运维是金子做的,还是服务器是金子做的?
常用的回应话术是:数据库是基础软件里的皇冠明珠,凝聚着无数无形知识产权BlahBlah。因此软件的价格远超硬件非常合理。如果是 Oracle 这样的顶尖商业数据库,或者索尼任天堂的主机游戏,这么说也过得去。
但公有云上的云数据库(RDS for PostgreSQL/MySQL/….),本质上是开源数据库内核换皮魔改封装,加上自己管控软件和共享DBA人头服务。那这种溢价率就非常荒谬了:数据库内核是免费的呀,你家管控软件是金子做的,还是DBA是金子做的?

公有云的秘密就在这里:用廉价的存算资源获客,用云数据库杀猪。
尽管国内公有云 IaaS (存储、计算、网络)的收入占营收接近一半,但毛利率只有 15% ~ 20%,而公有云 PaaS 的营收虽然不如 IaaS,但 PaaS 的毛利率可以达到 50%,完爆卖资源吃饭的 IaaS 。而 PaaS 中最具代表性的,就是云数据库。
正常来说,如果不是把公有云单纯当作一个 IDC 2.0 或者 CDN供应商来用,最费钱的服务就是数据库。公有云上的存储、计算、网络资源贵吗?严格来说不算特别离谱。IDC托管物理机代维的核月成本大约为二三十块,而公有云上一核 CPU 算力用一个月的价格,大概在七八十块到一两百块,考虑到各种折扣与活动,以及弹性溢价,勉强处在可以接受的合理范围。
但云数据库就非常离谱了,同样是一核算力用一个月,云数据库价格比起对应规格的硬件可以翻几倍乃至十几倍。便宜一些阿里云,核月单价两百到四百,贵一些的 AWS,核月单价可以七八百甚至上千。
如果说您只有一两核的 RDS ,那也别折腾了,交点税就交点吧。但如果您的业务上了量还不赶紧从云上下来,那可真的是在交智商税了。
足够好吗?
不要误会,云数据库只是及格品大锅饭。
关于云数据库/云服务器的成本,如果您能跟销售聊到这儿,话术就该变成:虽然我们贵,但是我们好呀!
但是,云数据库真的好吗?
应该说,对于玩具应用,小微网站,个人托管,以及土法野路子自建数据库来,毫无技术认知的甲方来说,RDS也许足够好了。但在高净值客户与数据库专家看来,RDS不过是及格线上的大锅饭产品罢了。
说到底,公有云源于大厂内部的运维能力外溢,大厂人自己厂里技术啥样门儿清,大可不必有啥莫名的崇拜。(Google也许算个例外)。
以 性能 为例,性能的核心指标是 延迟 / 响应时间,特别是长尾延迟,会直接影响用户体验:没有人愿意等着划一下屏幕转几秒圈圈。而在这一点上,磁盘起到决定性作用。
我们生产环境数据库中使用的是本地 NVME SSD,典型4K写延迟为15µs,读延迟94µs。因而,PostgreSQL简单查询的响应时间通常为 100 ~ 300µs,应用侧的查询响应时间通常为 200 ~ 600µs;对于简单查询,我们的 SLO 是命中1ms内,未命中10ms内,超过10ms算慢查询,要打回去优化。
而 AWS 提供的EBS服务用fio实测性能极其拉垮【6】,默认的gp3读写延迟为 40ms,io1 读写延迟为10ms,整整差了近三个数量级,而且IOPS最大也只有八万。RDS使用的存储就是EBS,如果连一次磁盘访问都需要10ms,那这就根本没法整了。io2 倒是使用了自建同款 NVMe SSD,然而远程块存储相比本地磁盘延迟直接翻倍。

确实,有时候云厂商会提供性能足够好的本地的NVME SSD,但都会非常鸡贼的设定各种限制条件,来避免用户来使用EC2来自建数据库。AWS的限制方式是只有NVME SSD Ephemeral Storage,这种盘一旦遇上EC2重启就自动抹干净了,根本没法用。阿里云的限制方式是给你卖天价,相比直接采购硬件,阿里云的 ESSD PL3 则高达 200 倍。以 3.2TB 规格的企业级 PCI-E SSD 卡为参照基准,AWS 上售租比为 1个月,阿里云上为 9 天,租用此时长即可买下整块磁盘。若在阿里云以采购三年最大优惠五折计算,租用三年的时间可购买 123 块同款硬盘近 400TB 永久所有权。
再以 可观测性 为例,没有一家RDS的监控能称得上是“好”。就以监控指标数量来说吧,虽然说知道服务死了还是活着只需要几个指标,但如果想进行故障根因分析,需要越多越好的监控指标来构建良好的Context。而大多数RDS都只是做了一些基本的监控指标,和简陋到可怜的监控面板。以阿里云RDS PG为例【7】,所谓的“增强监控”,里面只有这么点可怜的指标 , AWS里和PG数据库相关的指标也差不多不到100个,而我们自己的监控系统里主机指标有800多类,PGSQL数据库指标610类,REDIS指标257类,整个大约三千类指标,在数量上完爆这些RDS。


公开 Demo:https://demo.pigsty.cc
至于可靠性,以前我对RDS的可靠性还抱有基本的信任,直到一个月前A云香港机房那场丑闻。租的机房,服务器喷水消防,OSS故障,大量RDS不可用也切不了;然后A云自己整个Region的管控服务竟然因为一个单AZ的故障自己挂点了,连自己的管控API都做不到异地容灾,那做云数据库异地容灾岂不是天大的笑话。
当然,并不是说自建就不会出现这些问题,只是稍微靠谱点的IDC托管都不至于犯这么离谱的错误。安全性也不用多说,最近闹的出过的几次大笑话,比如著名的SHGA;一堆样例代码里硬编码AK/SK,云RDS更安全吗?别搞笑啦,经典架构起码还有VPN堡垒机扛着一层,而公网上暴露端口弱密码裸奔的数据库简直不要太多,攻击面肯定是更大了无疑。
云数据库另一个广为人所诟病的是其可扩展性。RDS是不给用户 dbsu 权限的,这也意味着用户是不能在数据库中安装扩展插件,而 PostgreSQL 的插件恰恰就是其醍醐味,没有扩展的PostgreSQL就像可乐不加冰,酸奶不加糖一样。更严重的问题是在一些故障出现时,用户甚至都丧失了自我救助的能力,参见《云数据库:从删库到跑路》中的真实案例:WAL归档与PITR这么基础性的功能,在RDS中竟然是一个付费的升级功能。至于可维护性,有些人说云数据库可以点点鼠标就创建销毁多方便呀,说这话的人肯定没经历过重启每个数据库都要收手机短信验证码的山炮场景。有 Database as Code 式的管理工具,真正的工程师绝对不会用这种“ClickOps”。
不过任何事物存在都有其道理,云数据库也不是一无是处,在可伸缩性上,云数据库确实卷出了新高度,比如各种 Serverless 的花活,但这也是给云厂商自己省钱超卖用的,对用户来说确实没有太大意义。
淘汰DBA?
被云厂商垄断,想招都找不到,还淘汰?
云数据库的另一种鼓吹思路是,用了RDS,你就不用DBA啦!
例如这篇知名点炮文《你怎么还在招聘DBA》【8】里说:我们有数据库自治服务!RDS和DAS能帮你解决这些数据库相关的问题,DBA都要下岗了,哈哈哈哈。我相信任何认真看过这些所谓“自治服务”,“AI4DB”官方文档【9】【10】的人都不会相信这种鬼话:连一个足够好用的监控系统都算不上的小模块,能让数据库自治起来,这不是在说梦话?
DBA,Database Administrator,数据库管理员,以前也叫做数据库协调员、数据库程序员。DBA是一个横跨于研发团队与运维团队的广博角色,涉及DA、SA、Dev、Ops、以及SRE的多种职责,负责各种与数据与数据库有关的问题:设置管理策略与运维标准,规划软硬件架构,协调管理数据库,验证表模式设计,优化SQL查询,分析执行计划,乃至于处理紧急故障以及抢救数据。
DBA的第一点价值在于安全兜底:他是企业核心数据资产的守护者,也是可以轻易对企业造成致命伤害的人。在蚂蚁金服有个段子,能搞死支付宝的,除了监管就是DBA了。高管们通常也很难意识到 DBA 对于公司的重要性,直到出了数据库事故,一堆CXO紧张地站在DBA背后观看救火修复过程时…。比起避免一场数据库故障所造成的损失,例如:全美停航,Youtube宕机,工厂停产一天,雇佣DBA的成本显得微不足道。
DBA的第二点价值在于模型设计与优化。许多公司并不在乎他们的查询是纯狗屎,他们只是觉得“硬件很便宜”,砸钱买硬件就好了。然而问题在于,一个调整不当的查询/SQL或设计不当的数据模型与表结构,可以对性能产生几个数量级的影响。总会在某一个规模,堆硬件的成本相比雇佣一个靠谱DBA的成本高得令人望而却步。实话说,我认为大多数公司在IT软硬件开销中花费最大的是:开发人员没有正确使用数据库。
DBA的基本功是管理DB,但灵魂在于A:Administration ,如何管住研发人员创造的熵,需要的可不仅仅是技术。“自治数据库”也许可以帮助你分析负载创建索引,但没有任何可能帮你理解业务需求,去Push业务去优化表结构,而这一点在未来的二三十年里,都看不到任何被云替代的可能。
无论是公有云厂商,还是以Kubernetes为代表的云原生/私有云,或者是类似 Pigsty 【11】这样的本地开源RDS替代,其核心价值都在于****尽可能多地使用软件,而不是人来应对系统复杂度。那么,云软件会革了运维与DBA的命吗?
云并不是什么都不用管的运维外包魔法。根据复杂度守恒定律,无论是系统管理员还是数据库管理员,管理员这个岗位消失的唯一方式是,它们被重命名为“DevOps Engineer”或SRE。好的云软件可以帮你屏蔽运维杂活,解决70%的日常高频问题,然而总是会有那么一些复杂问题只有人才能处理。你可能需要更少的人手来打理这些云软件,但总归还是需要人来管理【12】。毕竟,你也需要懂行的人来协调处理,才不至于被云厂商嘎嘎割韭菜当傻逼。
在大型组织中,一个好的DBA是至关重要的。然而优秀的DBA相当稀有,供不应求,以至于这个角色在大多数组织中只能外包:包给专业的数据库服务公司,包给云数据库RDS服务团队。找不到DBA供应的组织只能将这个职责 内包 给自己的研发/运维人员,直到公司的规模足够大,或者吃到足够的苦头之后,一些Dev/Ops才会培养出相应的能力来。
DBA不会被淘汰,只会被集中到云厂商中垄断提供服务。
垄断阴影
在2020年,计算自由的敌人是云计算软件。
比起“淘汰DBA”,云的出现蕴含着更大的威胁。我们需要担心的是这样一幅图景:公有云(或果子云)坐大,控制硬件与运营商上下游,垄断计算,存储,网络,顶尖专家资源,形成事实标准。假如所有顶级DBA都被挖到云厂商去集中提供共享专家服务,普通的企业组织就彻底失去了用好数据库的能力,最终只能选择被公有云收税杀猪。最终,所有IT资源集中于云厂商,只要控制住这几个关键少数,就可以控制整个互联网。这毫无疑问与互联网诞生的初衷相悖。
引用 DDIA 作者 Martin Kelppmann 的一段话【13】来说:
在2020年,计算自由的敌人是云计算软件
—— 即主要在供应商的服务器上运行的软件,而你的所有数据也存储在这些服务器上。这些“云软件”也许有一个客户端组件(手机App,网页App,跑在你浏览器中的JavaScript),但它们只能与供应商的服务端共同工作。而云软件存在很多问题:
- 如果提供云软件的公司倒闭,或决定停产,软件就没法工作了,而你用这些软件创造的文档与数据就被锁死了。对于初创公司编写的软件来说,这是一个很常见的问题:这些公司可能会被大公司收购,而大公司没有兴趣继续维护这些初创公司的产品。
- 谷歌和其他云服务可能在没有任何警告和追索手段的情况下,突然暂停你的账户。例如,您可能在完全无辜的情况下,被自动化系统判定为违反服务条款:其他人可能入侵了你的账户,并在你不知情的情况下使用它来发送恶意软件或钓鱼邮件,触发违背服务条款。因而,你可能会突然发现自己用Google Docs或其它App创建的文档全部都被永久锁死,无法访问了。
- 而那些运行在你自己的电脑上的软件,即使软件供应商破产了,它也可以继续运行,直到永远。(如果软件不再与你的操作系统兼容,你也可以在虚拟机和模拟器中运行它,当然前提是它不需要联络服务器来检查许可证)。例如,互联网档案馆有一个超过10万个历史软件的软件集锦,你可以在浏览器中的模拟器里运行!相比之下,如果云软件被关闭,你没有办法保存它,因为你从来就没有服务端软件的副本,无论是源代码还是编译后的形式。
- 20世纪90年代,无法定制或扩展你所使用的软件的问题,在云软件中进一步加剧。对于在你自己的电脑上运行的闭源软件,至少有人可以对它的数据文件格式进行逆向工程,这样你还可以把它加载到其他的替代软件里(例如OOXML之前的微软Office文件格式,或者规范发布前的Photoshop文件)。有了云软件,甚至连这个都做不到了,因为数据只存储在云端,而不是你自己电脑上的文件。
如果所有的软件都是免费和开源的,这些问题就都解决了。然而,开源实际上并不是解决云软件问题的必要条件;即使是闭源软件也可以避免上述问题,只要它运行在你自己的电脑上,而不是供应商的云服务器上。请注意,互联网档案馆能够在没有源代码的情况下维持历史软件的正常运行:如果只是出于存档的目的,在模拟器中运行编译后的机器代码就够了。也许拥有源码会让事情更容易一些,但这并不是关键,最重要的事情,还是要有一份软件的副本。
我和我的合作者们以前曾主张过本地优先软件的概念,这是对云软件的这些问题的一种回应。本地优先的软件在你自己的电脑上运行,将其数据存储在你的本地硬盘上,同时也保留了云计算软件的便利性,比如,实时协作,和在你所有的设备上同步数据。开源的本地优先的软件当然非常好,但这并不是必须的,本地优先软件90%的优点同样适用于闭源的软件。云软件,而不是闭源软件,才是对软件自由的真正威胁,原因在于:云厂商能够突然心血来潮随心所欲地锁定你的所有数据,其危害要比无法查看和修改你的软件源码的危害大得多。因此,普及本地优先的软件显得更为重要和紧迫。
有力就会有反作用力,与云软件相对应的本地优先软件开始如雨后春笋一般出现。例如,以Kubernetes为代表的 Cloud Native 运动就是一例。“Cloud Native”,云厂商将 Native 解释 “原生”:“原生诞生在公有云环境里的软件”;而其真正的含义应为 “本地”,即与 Cloud 相对应的 “Local” —— 本地云 / 私有云 / 专有云 / 原生云,叫什么不重要,重要的是它运行在用户想运行的任何地方(包括云服务器),而不是仅仅是公有云所独有!
以 K8S为代表的开源项目,将原本公有云才有的资源调度/智能运维能力普及到所有企业中,让企业在本地也可以运行起‘云’一样的能力。对于无状态的应用来说,它已经是一个足够好的 “云操作系统” 内核。Ceph/Minio也提供了 S3 对象存储的开源替代,只有一个问题仍然没有答案,有状态的,生产级的数据库服务如何管理与部署?
时代在呼唤 RDS 的开源替代物。
解决方案
Pigsty —— 开源免费,开箱即用,更好的 RDS PG 替代
我希望,未来的世界人人都有自由使用优秀服务的事实权利,而不是只能被圈养在几个公有云厂商提供的猪圈(Pigsty)里吃粑粑。这就是我要做 Pigsty 的原因 —— 一个更好的,开源免费的 PostgreSQL RDS替代。让用户能够在任何地方(包括云服务器)上,一键拉起有比云RDS更好的数据库服务。
Pigsty 是是对 PostgreSQL 的彻底补完,更是对云数据库的辛辣嘲讽。它本意是“猪圈”,但更是 Postgres In Great STYle 的缩写,即“全盛状态下的 PostgreSQL”。它是一个完全基于开源软件的,可以运行在任何地方的,浓缩了 PostgreSQL 使用管理最佳实践的 Me-Better RDS 开源替代。用真实世界的大规模,高标准 PostgreSQL 集群打磨而来的解决方案,它是为了满足探探自己管理数据库的需求而生,在八个维度上进行了许多有价值的工作:
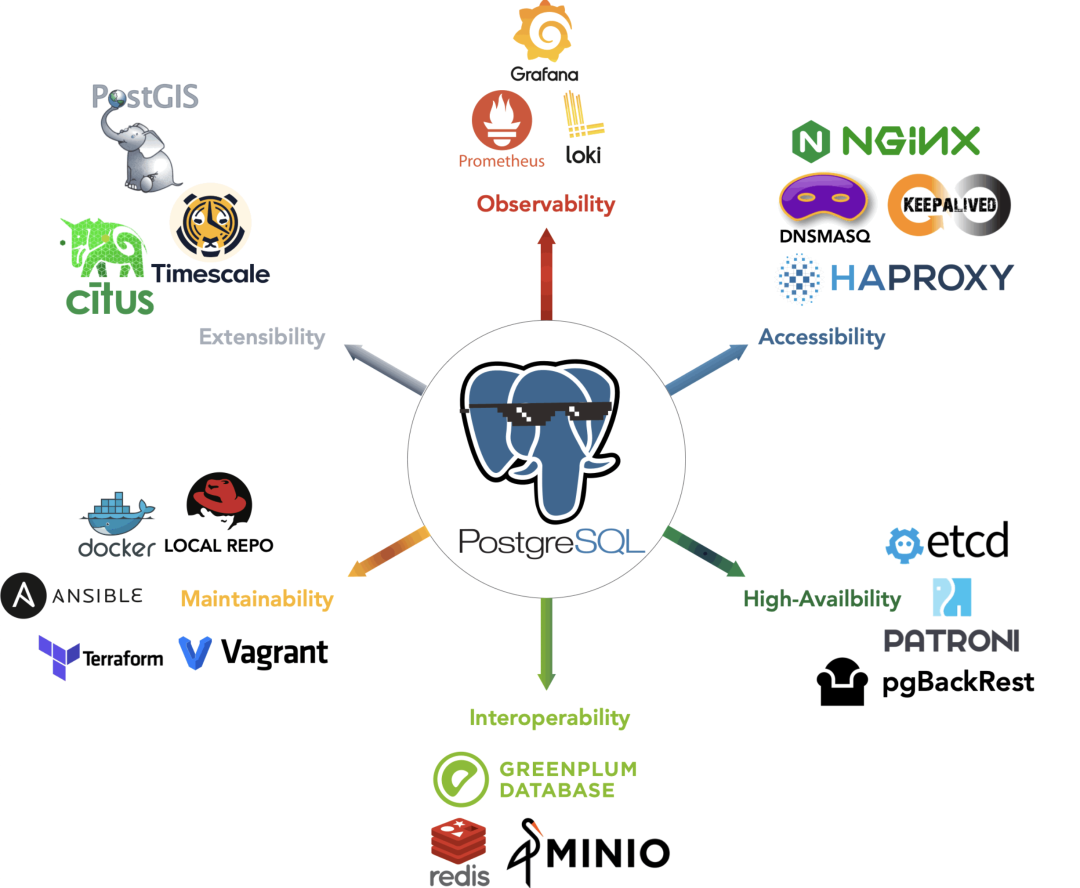
可观测性(Observability)是天;天行健君子以自强不息;Pigsty使用现代可观测性技术栈为 PostgreSQL 打造了一款无与伦比的监控系统,从全局大盘概览到单个表/索引/函数等对象的秒极历史详情指标一览无遗,让用户对系统能够做到洞若观火,进而掌控一切。此外,Pigsty的监控系统还可以独立使用,监控第三方数据库实例。
可控制性(Controllability)是地;地势坤君子以厚德载物;Pigsty提供Database as Code的能力:使用表现力丰富的声明式接口描述数据库集群的状态,并使用幂等的剧本进行部署与调整。让用户拥有精细定制的能力的同时又无需操心实现细节,解放心智负担,让数据库操作与管理的门槛从专家级降低到新手级。
可伸缩性(Scalability)是水;水洊至习坎君子以常德行;Pigsty提供预制通用调参模板(OLTP / OLAP / CRIT / TINY),自动优化系统参数,并可通过级联复制无限扩展只读能力,也使用Pgbouncer连接池优化海量并发连接;Pigsty确保 PostgreSQL 的性能可以在现代硬件条件下充分发挥:单机可达数万并发连接/百万级单点查询QPS/十万级单条写入TPS。
可维护性(Maintainability)是火;明两作离大人以继明照于四方;Pigsty 允许在线摘除添加实例以扩缩容,Switchover/滚动升级进行升降配,提供基于逻辑复制的不停机迁移方案,将维护窗口压缩至亚秒级,让系统整体的可演化性,可用性,可维护性提高到一个新的水准。
安全性(Security)是雷;洊雷震君子以恐惧修省;Pigsty提供了一套遵循最小权限原则的访问控制模型,并带有各种安全特性开关:流复制同步提交防丢失,数据目录校验和防腐败,网络流量SSL加密防监听,远程备份AES-256防泄漏。只要物理硬件与密码安全,用户无需担心数据库的安全性。
简单性(Simplicity)是风;随风巽君子以申命行事;使用Pigsty的难度不会超过任何云数据库,它旨在以最小的复杂度成本交付完整的RDS功能,模块化设计允许用户自行组合选用所需的功能。Pigsty提供基于Vagrant的本地开发测试沙箱,与Terraform的云端IaC一键部署模板,让您在任意新EL节点上一键完成离线安装,完整复刻环境。
可靠性(Reliability)是山;兼山艮君子以思不出其位;Pigsty提供了故障自愈的高可用架构应对硬件问题,也提供开箱即用的PITR时间点恢复为人为删库与软件缺陷兜底,并通过长时间、大规模的生产环境运行与高可用演练验证其可靠性。
可扩展性(Extensibility)是泽:丽泽兑君子以朋友讲习;Pigsty深度整合PostgreSQL生态核心扩展PostGIS、TimescaleDB、Citus 、PGVector、以及大量扩展插件;Pigsty提供模块化设计的Prometheus/Grafana可观测性技术栈,以及MINIO,ETCD,Redis、Greenplum 等组件的监控与高可用部署与PostgreSQL 组合使用;

更重要的是,Pigsty是完全开源免费的自由软件,采用 AGPL v3.0 协议。我们用爱发电,而您可以用几十块核·月的纯硬件成本,跑起运行功能完备甚至更好的RDS服务。无论你是初心者还是资深DBA,无论你管理着上万核的大集群还是1核2G的小水管,无论你已经用了RDS还是在本地搭建过数据库,只要你是 PostgreSQL 用户,Pigsty都会对您有所帮助,完全免费。您可以专注于业务中最有趣或最有价值的部分,将杂活丢给软件来解决。
尽管Pigsty 本身旨在用数据库自动驾驶软件替代人肉数据库运维,但正如上所述,再好的软件也没法解决 100% 的问题。总会有一些的冷门低频疑难杂症需要专家介入处理。我们提供免费的社区答疑,如果您觉得安装使用维护有困难,需要下云迁移或者疑难杂症兜底,我们也提供顶尖的数据库专家咨询服务,性价比相对公有云数据库的工单/SLA极有竞争力。Pigsty帮助用户用好 PostgreSQL,而我们帮助用户用好 Pigsty。
Pigsty简单易用,人力成本与复杂度RDS持平,但资源成本差异确是天翻地覆。且不说自建机房的20块和几百块的云数据库怎么比,考虑到 RDS 对比同规格 EC2 都有几倍的溢价,您完全可以折中:使用云服务器部署 Pigsty RDS,既保留了云的弹性,又可以原地省掉五六成开销。如果是IDC自建或者代维,成本砍掉90%都不一定打得住。
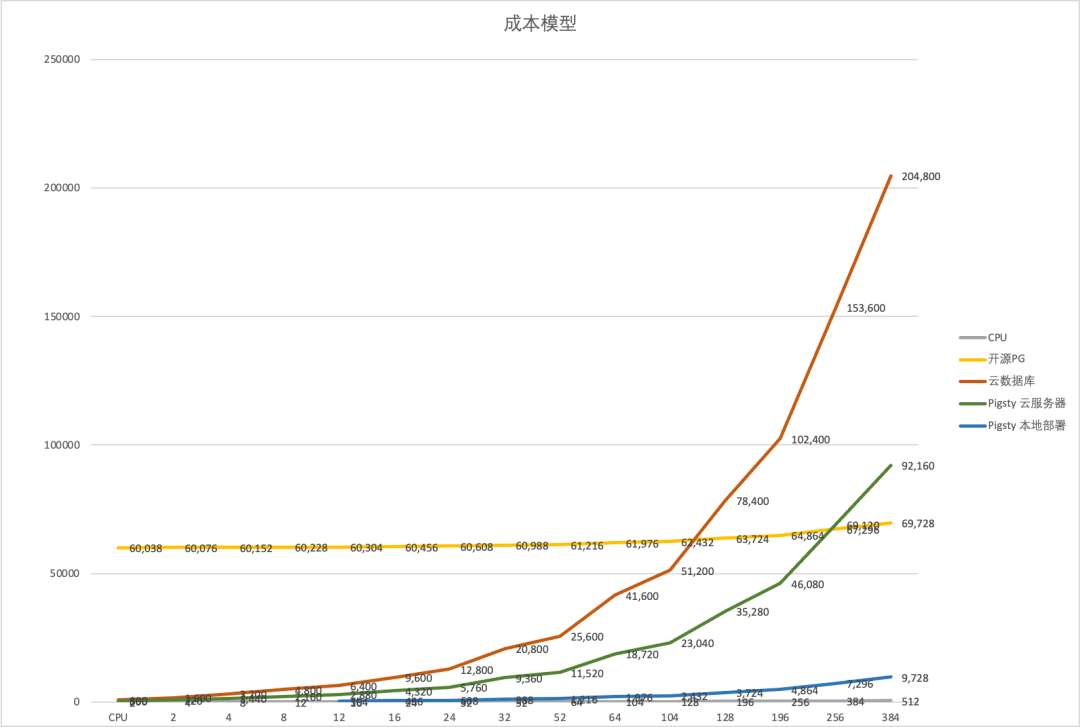
RDS成本与规模成本曲线
Pigsty 允许您践行最终极的 FinOps 理念 —— 用几乎接近于纯资源的价格,在任何地方(ECS,资源云,机房服务器甚至本地笔记本虚拟机)运行生产级的 PostgreSQL RDS 数据库服务。让云数据库的能力成本,从正比于资源的边际成本,变为约等于0的固定学习成本。
如果您可以用几分之一的成本来使用更好的 RDS 服务,那么再用云数据库就真的是纯纯的智商税了。
Reference
【1】为什么我们要离开云
【2】上云“被坑”十年终放弃,寒冬里第一轮“下云潮”要来了?
【5】 AWS Pricing Calculator (中国宁夏)
【8】你为什么还在招DBA
【11】Me-Better RDS PostgreSQL 替代 Pigsty
【12】Pigsty v2 正式发布:更好的RDS PG开源替代
【13】是时候和GPL说再见了
【14】云数据库是不是智商税?
【16】蹭个热度–要不要DBA和云数据库
【17】你怎么不招DBA
【18】DBA还是一份好工作吗?
【19】云RDS:从删库到跑路
DBA还是一份好工作吗?
蚂蚁金服有过一个自嘲的段子:能干翻支付宝的,除了监管就是DBA了。
数字时代,数据是很多企业的核心资产,对于互联网/软件服务类企业更是如此。而负责保管这些数据资产的人,就是DBA(数据库管理员)。
想象一下所有账户余额和联系人全部丢失的场景,尽管发生概率微乎其微,即使是支付宝与微信,如果出现无法恢复的核心库删库事件,恐怕也只能吃不了兜着走了。
缘从何起?

软件吃世界,开源吃软件,云吞噬开源,谁来吞噬云?
很久很久以前,开发软件/信息服务需要使用非常昂贵的商业数据库软件:例如Oracle与SQL Server:单花在软件授权上的费用可能就有六七位数,加之相近的硬件成本与服务订阅成本。如果公司已经砸了成百上千万的钱在数据库软硬件上,那么再花一些钱雇佣一些专职专家来照顾这些昂贵且复杂的数据库,就是一件很自然的事情,这些专家就是DBA。
接下来事情出现了有趣的变化:随着PostgreSQL/MySQL这些开源数据库的兴起,公司们有了一个新选择:不用软件授权费用即可使用数据库软件,而它们也开始(不理性地)停止为数据库专家付费:维护数据库的工作被隐含在了研发与运维的附属职责中,而这两类人通常:既不擅长、也不喜欢、更不在乎照顾数据库的事情。直到公司的规模足够大,或者吃到足够的苦头之后,一些Dev/Ops才会培养出相应的能力来,不过这是相当罕见的事情。
接下来,云出现了。云实际上是一种运维外包,将DBA工作中属于运维部分,最具像化的部分给自动化了:高可用,备份/恢复,配置,置备。DBA仍然剩下很多事情,但普通麻瓜难以理解此类工作的价值,这部分职责依然静悄悄地落在了研发与运维工程师的身上。“不要钱” 的开源数据库可以让我们自由随意地使用数据库软件,因此随着微服务哲学兴起,用户开始给每个小服务弄一个单独的数据库,而不是很多应用共享一个巨大的中央共享数据库。在这种情况下,数据库被视作每个服务的一部分,可以更方便的把DBA的活推给研发了。
那么,云之后是什么?DBA还会是一份好的工作吗?
核心价值
很多地方都需要DBA:糟糕的模式设计,奇烂的查询性能,鬼知道有没有用的备份;等等等等。可惜的是,从事软件工作的人中,很少有人了解什么是DBA。成为DBA,意味着与研发人员创造的熵进行永无休止的战斗。
DBA,Database Administrator,数据库管理员,以前也叫做数据库协调员、数据库程序员。DBA是一个横跨于研发团队与运维团队的广博角色,涉及DA、SA、Dev、Ops、以及SRE的多种职责,负责各种与数据与数据库有关的问题:设置管理策略与运维标准,规划软硬件架构,协调管理数据库,验证表模式设计,优化SQL查询,分析执行计划,乃至于处理紧急故障以及抢救数据。
DBA的第一点价值在于安全兜底:他是企业核心数据资产的守护者,也是可以轻易对企业造成致命伤害的人。在蚂蚁金服有个段子,能搞死支付宝的,除了监管就是DBA了。高管们通常也很难意识到 DBA 对于公司的重要性,直到出了数据库事故,一堆CXO紧张地站在DBA背后观看救火修复过程时…。
DBA的第二点价值在于性能优化。许多公司并不在乎他们的查询是纯狗屎,他们只是觉得“硬件很便宜”,砸钱买硬件就好了。然而问题在于,一个调整不当的查询/SQL或设计不当的数据模型与表结构,可以对性能产生几个数量级的影响。总会在某一个规模,堆硬件的成本相比雇佣一个靠谱DBA的成本高得令人望而却步。实话说,我认为大多数公司在IT软硬件开销中花费最大的是:开发人员没有正确使用数据库。
优秀的DBA还会负责数据模型设计与优化。数据建模和SQL几乎已成为一门失传的艺术,这类基础知识逐渐为新一代工程师遗忘,他们设计出离谱的模式,不懂得正确地创建索引,然后草率得出结论:关系型数据库和SQL都是垃圾,我们必须使用糙猛快的NoSQL来省时间。然而人们总是需要可靠的系统来处理关键业务数据:在许多企业中,核心数据仍然是一个常规关系型数据库作为Source of Truth,NoSQL数据库仅用于非关键数据。
对于尚未进入PMF的初创企业,雇佣一个全职DBA是奢侈的行为。然而在一个大型组织中,一个好的DBA是至关重要的。不过好的DBA相当稀有,以至于这个角色在大多数组织中只能外包:包给专业的数据库服务公司,包给云数据库RDS服务团队,或者内包给自己的研发/运维人员。
DBA的未来
许多公司都雇用DBA,DBA类似于Cobol程序员,除了科技公司/初创企业外:那些听上去不那么Fancy的制造业,银行保险证券、以及大量运行本地软件的党政军部门,也大量使用了这些关系型数据库。在可预见的未来,DBA在某个地方找工作是不会有什么问题的。
尽管数据库专家对于大型组织与大型数据库而言非常重要,不幸的是,DBA作为一份职业前景可能是晦涩暗淡的。大趋势是数据库本身会越来越智能,易用性越来越好,而各式各样的工具、SaaS、PaaS不断涌出,也会进一步压低数据库的使用门槛。公有云/私有云DBasS的出现更是让数据库的门槛进一步下降,只要掏钱就可以迅速达到优秀DBA的廉价七成正确水准。
数据库的专业技术门槛降低,将导致DBA的不可替代性降低:安装一套软件收费十几万,做一次数据恢复上百万的好日子肯定是一去不复返了。但对于开源数据库软件社区生态来说,却是一件好事:将会有更多的开发者有能力来使用它,并或多或少扮演着DBA的角色。
云会革了运维与DBA的命吗?
无论是公有云厂商,还是以Kubernetes为代表的云原生/私有云,其核心价值都在于使用软件,而不是人来应对系统复杂度。那么,云软件会革了运维与DBA的命吗?
从长期来看,这类云软件代表着先进生产力的发展方向。对于云原生环境中成长起来的新一代开发者,对于他们来说K8S才是操作系统,底下的Linux、网络、存储都属于魔法巫术,成为极少数人才会关心的“底层细节”。大概就像现在我们作为应用研发人员,看待汇编语言指令集,摆弄内存扣字节差不多。但就像人工智能的三起三落一样:过早追逐潮流的人不一定是先驱,而有大概率成为先烈。
无论是系统管理员还是数据库管理员,管理员这个岗位消失的唯一方式是,它们被重命名为“DevOps Engineer”或SRE。云并不会消灭管理员,你可能需要更少的人手来打理这些云软件,但总归还是需要人来管理的:从整个行业的视角看,云软件的推广会让100个初中级运维(传统系统管理员)的工作岗位变成10个中高级运维岗位(DevOps/SRE),同样的事也有可能发生在DBA身上。例如,现在也出现了与SRE相对应的 DRE:Database Reliability Engineer。
" src="/blog/cloud/is-dba-good-job/dre.webp">
Database Reliability
从另一方面来说,云RDS提供的性能与可靠性属于廉价七成正确的大锅饭,比起优秀专职DBA所精心照顾的本地数据库表现仍然相距甚远。云数据库就像IT中的每一轮炒作一样:东西很受欢迎,每个人都为玩具Demo着迷,直到将其投入生产。然后他们终于发现了时尚潮流的垃圾箱火灾是什么样的,并回头开始研究久经考验的真实技术。总是一样的,人工智能便是前车之鉴。

公有云RDS的两大核心问题:成本/自主可控
尽管DBA听上去是一个有着光辉历史与暗淡前景的行当,但未来仍未可知。天知道在几次恐怖的重大云数据库事故后,DBA会不会重新成为潮流呢?
做点什么?
开源免费的数据库发行版解决方案,也能让大批量研发/运维工程师成为合格的兼职DBA。而这就是我正在做的事情:Pigsty —— 开箱即用的开源数据库发行版, 上手即用,量产DBA。
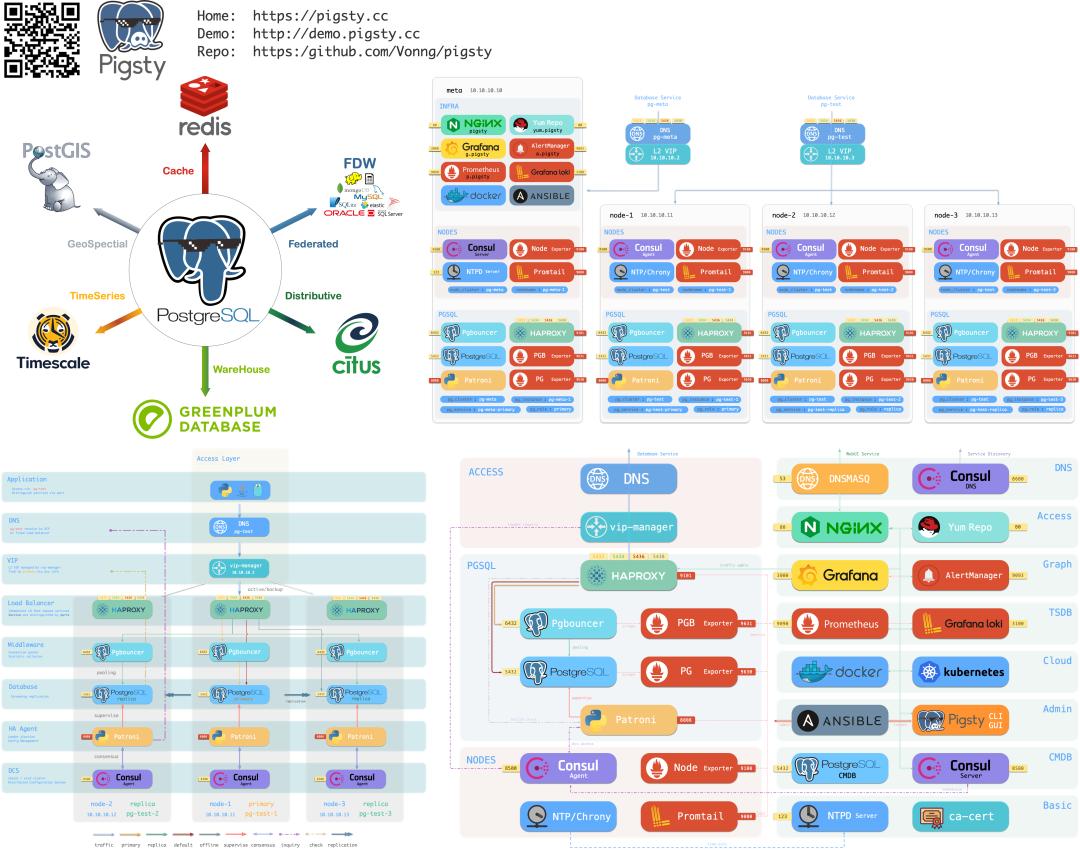
Pigsty 架构简介

Pigsty监控界面概览
我是一个PostgreSQL DBA,但也是软件架构师与全栈应用开发者。Pigsty是我用软件来完成自己作为DBA的工作的一次尝试:它成功的完成了我大部分的日常工作:无可比拟的监控系统能为性能优化与故障排查预警提供扎实的数据支持,自动切换的高可用集群能让我在故障时游刃有余甚至睡醒了觉再慢慢处理,一键安装部署扩缩容备份恢复则将日常管理事务变为了零星几条命令的事。

What is Pigsty
如果您想要使用PostgreSQL / Redis / Greenplum 等数据库,比起聘请昂贵稀缺的专职DBA,或使用费用高昂无法自主可控的云数据库,也许这是一个不错的替代选择。扫码加公众号与微信交流群了解更多。
云RDS:从删库到跑路
上一篇文章《DBA还是份好工作吗》中提到:尽管DBA作为一份职业在没落,但谁也保不准DBA会不会在几次恐怖的大规模云数据库故障后,重新成为潮流。

这不,最近就目睹了一场云数据库删库跑路现场情景剧。本文就来聊一聊在生产环境使用PostgreSQL,如何应对误删数据的问题。



故障现场


解决方案
看完了故事,我们不禁要问,我都已经花钱买了‘开箱即用’的云数据库了,为啥连PITR恢复这么基本的兜底都没有呢?
说到底,云数据库也是数据库,云数据库并不是啥都不用管的运维外包魔法,不当配置使用,一样会有数据丢失的风险。没有开启WAL归档就无法使用PITR,甚至无法登陆服务器获取现存WAL来恢复误删的数据。
当然,这也得怪云厂商抠门心机,WAL日志归档PITR这些PG的基础高可用功能被云阉割掉了,放进所谓的“高可用”版本。WAL归档对于本地部署的实例来说,无非是加块磁盘配置条命令的事情。对象存储1GB一个月几分钱,最是廉价不过,但乞丐版云数据库还是要应省尽省,不然怎么卖“高可用”版的数据库呢?
在Pigsty中,所有PG数据库集群都默认启用了WAL归档并每日进行全量备份:保留最近一日的基础冷备份与WAL,允许用户回溯至当日任意时刻的状态。更是提供了开箱即用的延迟从库搭建工具,防误删快人一步!
如何应对删库?
传统的“高可用”数据库集群通常指的是基于主从物理复制的数据库集群。
故障大体可以分为两类**:硬件故障/资源不足**(坏盘/宕机),软件缺陷/人为错误(删库/删表)。基于主从复制的物理复制用于应对前者,延迟从库与冷备份通常用于应对后者。因为误删数据的操作会立刻被复制到从库上执行,所以热备份与温备份都无法解决诸如 DROP DATABASE,DROP TABLE这样的错误,需要使用冷备份或延迟从库
冷备份
在Pigsty中,可以通过为集群中的数据库实例指定角色( pg_role ),即可以创建物理复制备份,用于从机器与硬件故障中恢复。例如以下配置声明了一个一主两从的高可用数据库集群,带有一个热备一个温备,并自动制作每日冷备。
pg-backup 是一个Pigsty内置的开箱即用备份剧本,可自动制作基础备份。
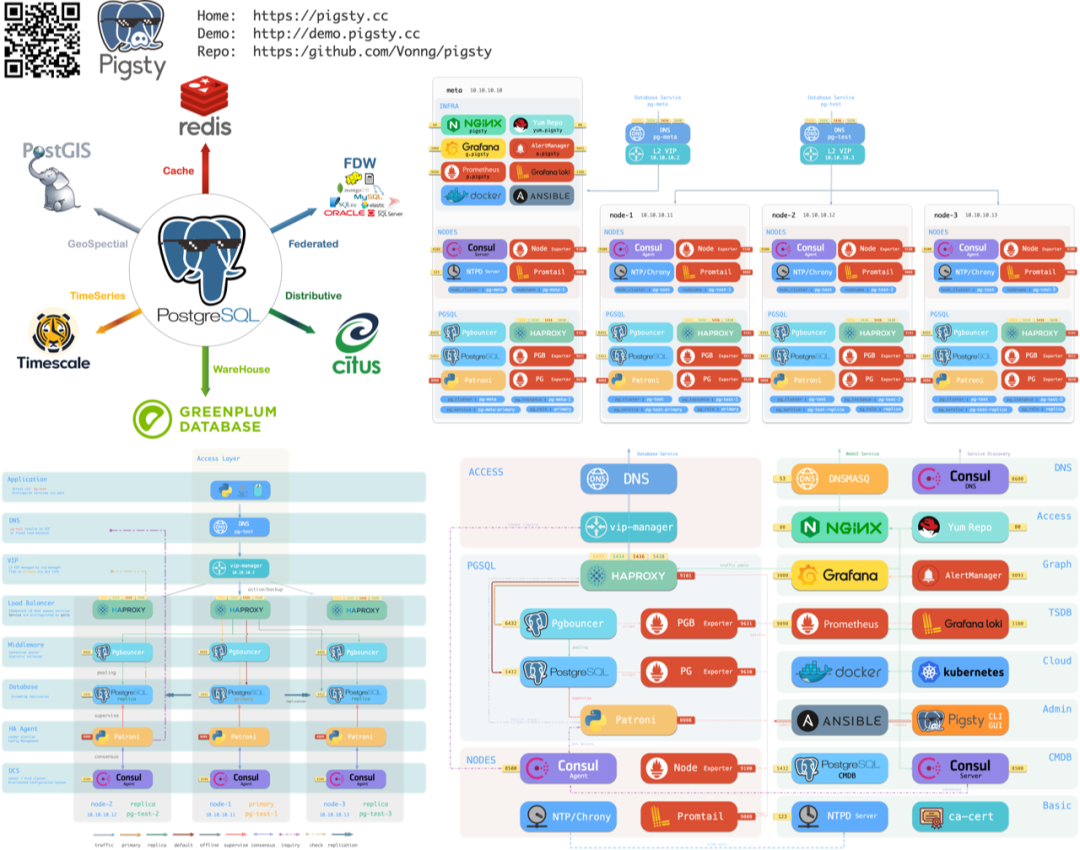
在 Pigsty 所有的配置文件模板中,都配置有以下归档命令
wal_dir=/pg/arcwal;
/bin/mkdir -p ${wal_dir}/$(date +%Y%m%d) && /usr/bin/lz4 -q -z %p > ${wal_dir}/$(date +%Y%m%d)/%f.lz4
默认在集群主库上,所有WAL文件会自动压缩并按天归档,需要使用时,配合基础备份,即可将集群恢复至任意时间点。
当然,您也可以使用 Pigsty 带有的 pg_probackup, pg_backrest 等工具来自动管理备份与归档。将冷备份与归档丢到云存储或专用备份中心,轻松实现异地跨机房容灾。
冷备份是经典的兜底备份机制,如果只有冷备份本身,那么系统将只能恢复到备份时刻到状态。如果加之以WAL日志,就可以通过在基础冷备份上重放WAL日志,将集群恢复到任意时间点。
延迟从库
冷备份虽然很重要,但对于核心业务来说,下载冷备份,解开压缩包,推进WAL重放需要很长一段时间,时间不等人。为了最小化RTO,可以使用另一种称为 延****迟从库的技术来应对误删故障。
延迟从库可以从主库接受实时的WAL变更,但延迟特定的时间再应用。从用户的视角来看,延迟从库就像主库在特定时间前的一份历史快照。例如,您可以设置一个延迟1天的从库,当出现误删数据时,您可以将该实例快进至误删前的时刻,然后立刻从延迟从库中查询出数据,恢复至原始主库中。下面的Pigsty配置文件声明了两个集群:一个标准的高可用一主一从集群 pg-test,以及一个该集群的延迟从库:pg-testdelay,为方便起见,配置1分钟的复制延迟:
# pg-test 是原始集群
pg-test:
hosts:
10.10.10.11: { pg_seq: 1, pg_role: primary }
vars: { pg_cluster: pg-test }
# pg-testdelay 是 pg-test 的延迟集群
pg-testdelay:
hosts:
10.10.10.12: { pg_seq: 1, pg_role: primary , pg_upstream: 10.10.10.11, pg_delay: 1d }
10.10.10.13: { pg_seq: 2, pg_role: replica }
vars: { pg_cluster: pg-test2 }
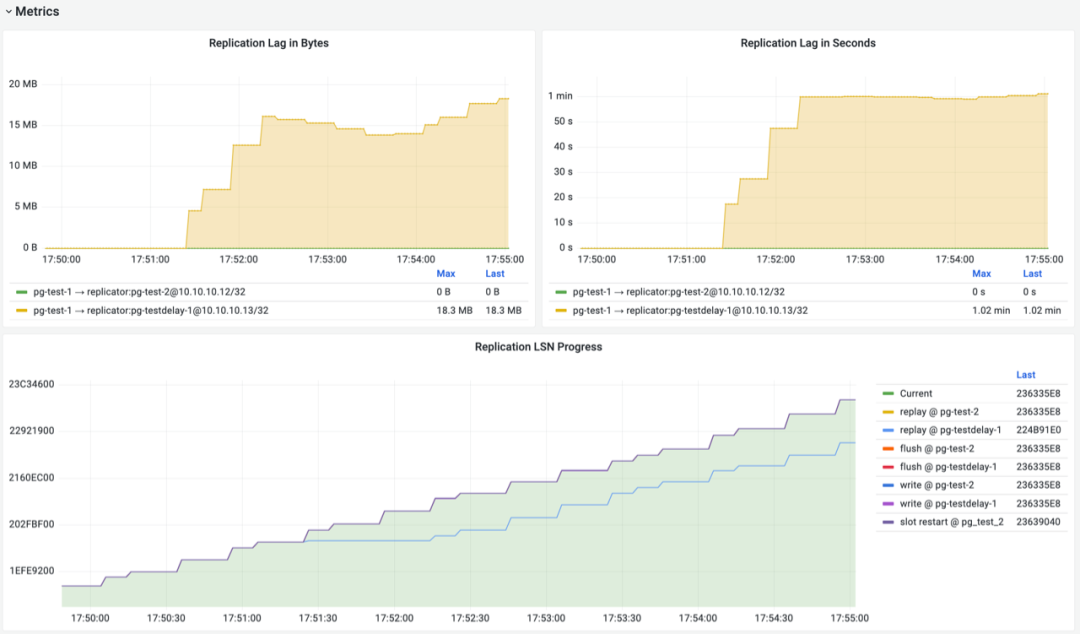
在PGSQL REPLICATION监控面板中,pg-test集群的复制指标如上图所示,启用复制延迟配置后,延迟从库pg-testdelay-1有了稳定的1分钟“应用延迟”(Apply Delay),在LSN进度图表中,主库的LSN进度与延迟从库的LSN进度在水平时间轴上相差了正好1分钟。
您也可以创建一个普通的备份集群,然后使用 **pg edit-config pg-testdelay **的方式,来手工修改延迟的时长配置。
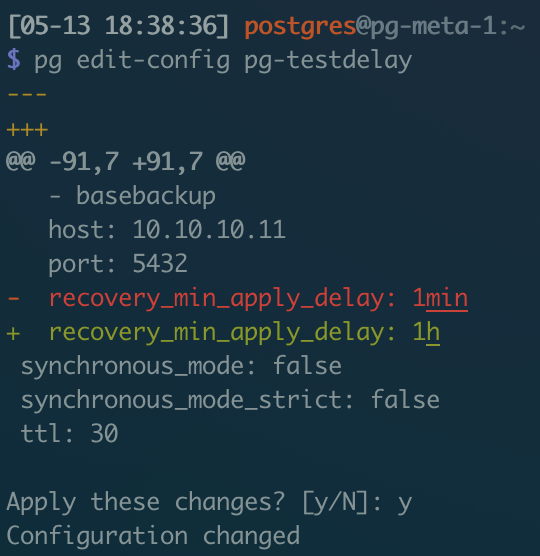
修改延迟为1小时并应用
Pigsty提供了完善的备份支持,无需配置即可使用开箱即用的主从物理复制,绝大多数物理故障均可自愈。同时,还提供了延迟备库与冷备份支持,用于应对软件故障与人为误操作。您只需要准备几台物理机/虚拟机/或者云服务器,即可一键创建并拥有真正的高可用数据库集群!
Pigsty,让您的数据库坚若磐石,除了高可用,还自带监控系统,完全开源免费!
注:您依然可以使用
pgsql-rm.yml**一键删光所有数据库。
又注:此行为受
pg_safeguard,pg_clean等一系列安全保险参数控制,以避免胖手指误删。
DBA会被云淘汰吗?
前天开源漫谈第九期主题《DBA会被云淘汰吗?》,我作为主持人全程克制着自己亲自下场的冲动,因此特此写了这篇文章来聊聊这个问题 : DBA 会被云淘汰吗?

DBA帮助用户用好数据库
很多地方都需要DBA:糟糕的模式设计,奇烂的查询性能,鬼知道有没有用的备份;等等等等。可惜的是,从事软件工作的人中,很少有人了解什么是DBA。成为DBA,意味着与研发人员创造的熵进行永无休止的战斗。
DBA,Database Administrator,数据库管理员,以前也叫做数据库协调员、数据库程序员。DBA是一个横跨于研发团队与运维团队的广博角色,涉及DA、SA、Dev、Ops、以及SRE的多种职责,负责各种与数据与数据库有关的问题:设置管理策略与运维标准,规划软硬件架构,协调管理数据库,验证表模式设计,优化SQL查询,分析执行计划,乃至于处理紧急故障以及抢救数据。
许多公司都会雇用DBA,传统的 DBA 类似 Cobol 程序员,除了科技公司/初创企业外:那些听上去不那么Fancy的制造业,银行保险证券、以及大量运行本地软件的党政军部门,也大量使用了这些关系型数据库。单花在这些商业数据库软件授权上的费用可能就有六七位数,加之相近的硬件成本与服务订阅成本。如果公司已经砸了成百上千万的钱在数据库软硬件上,那么再花一些钱雇佣一些专职专家来照顾这些昂贵且复杂的数据库,就是一件很自然的事情,这些专家就是传统的 DBA。
接下来随着 PostgreSQL / MySQL 这些开源数据库的兴起,这些公司们有了一个新选择:不用软件授权费用即可使用数据库软件,而它们也开始(不理性地)停止为数据库专家付费:维护数据库的工作被隐含在了研发与运维的附属职责中,而这两类人通常:既不擅长、也不喜欢、更不在乎照顾数据库的事情。直到公司的规模足够大,或者吃到足够的苦头之后,一些Dev/Ops才会培养出相应的能力来,成为DBA —— 不过这是相当罕见的事情,而这也是今天我们讨论的主角 —— 开源数据库的 DBA。
用好数据库的能力很稀缺
培养开源数据库 DBA 的核心要素是场景,而有足够复杂度和规模的场景是极其稀缺的,往往只有头部的大甲方才有。就好比国内 MySQL 的 DBA 主要产自重度使用 MySQL 的淘宝等互联网头部公司。而优秀 PostgreSQL DBA 基本上都出自去哪儿网、平安银行、探探这几个大规模使用 PG 的公司。顶级的开源数据库 DBA 的来源极其有限,基本是在顶级甲方用户中精通数据库的运维/研发,靠着真金白银的大故障与复杂场景的建设经验,才能零星砸出来几个。
以中国的 PostgreSQL DBA 为例,根据圈内纯技术文传播阅览量,圈子规模大概在千人左右;但能建设架构超过 RDS 水准的数据库系统的 DBA 就收敛到几十个了;能自己打造更好的 RDS ,甚至做到对外复制输出最佳实践的更是凤毛麟角,一只手就能数过来。
所以,当下数据库领域的主要矛盾,不是缺少更好更强大的新内核,而是极度匮乏用好管好现有数据库内核的能力 —— 数据库太多,而司机太少! 数据库内核已经发展了几十年,在内核上的小修小补边际收益已经很小了。而像 PostgreSQL 这样成熟开源数据库内核引擎出现,让卖商业数据库成为一门糟糕的生意 —— 开源数据库不需要高昂的软件授权费用,那么能用好这些免费的开源数据库的老司机 —— DBA,就成为了最大的瓶颈与成本。
在这个阶段,高级的经验都“垄断”在少数头部专家手中。实际上,这正好是开源真正的“商业模式” —— 创造高薪的技术专家岗位。然而这也出现了一个新的机会 —— 商业数据库产品因为开源替代的出现已经很难形成垄断了,但能用好开源数据库的DBA专家是屈指可数的,而垄断少数几个专家的难度比起干翻开源数据库要简单太多了。垄断不了数据库产品,就垄断用好它的能力!
| 阶段 | 名称 | 特点 | “商业模式” |
|---|---|---|---|
| 阶段1 | 商业数据库 | 商业数据库软件垄断了数据库产品供给。 | 天价软件授权 |
| 阶段2 | 开源数据库 | 开源打破了商业数据库垄断, 但技术垄断在少量头部开源专家手中。 |
高薪专家岗位 |
| 阶段3 | 云数据库 | 云打破了开源专家技术垄断 但在用好数据库的能力上形成垄断 |
管控软件租赁 |
| 阶段4 | “云原生?” | 开源管控软件打破了云管控软件垄断 用好数据库的能力普及到千家万户 |
咨询保险兜底 |
所以,尽可能招揽能用好开源数据库的专家,打造一个共享专家池让稀缺的高级 DBA 得以时分复用,并和 DBA 经验沉淀而成的管控软件一起打包成服务出租,就是一种非常有利可图的商业模式 —— 而云数据库RDS 正是这样做的,并赚的钵满盆翻。
云数据库使用的内核本身是开源免费的,所以云数据库提供的核心能力,正是和 DBA 一样的,帮助用户用好数据库的能力! 它真正的竞品不是其他商业数据库内核,或者开源数据库内核,而是 DBA —— 特别是处于中下游位置的 DBA。这就跟出租车公司要取代的不是汽车厂,而是全职司机一样。
DBA的工作与自动化管控
除了 DBA 人力,还有什么办法可以获得用好数据库的能力?那我们就需要先来看一看 DBA 的工作模式。
DBA的工作在时间上主要分为建设与维护两个阶段。在最初几个月的密集建设阶段会比较幸苦,需要负责搭建成熟的技术架构与管理体系;而当自动化建设完成,进入了维护阶段后 —— DBA的工作就要轻松很多了。
| 建设阶段 | 维护阶段 | |
|---|---|---|
| 管理层 | 数据库选型,制度建设 | 数据库建模,查询设计,人员培训,SOP积累,开发规约 |
| 应用层 | 架构设计,服务接入 | SQL审核 / SQL变更 / SQL优化 / 分库分表 / 数据恢复 |
| 数据库层 | Infra建设,数据库部署 | 备份恢复 / 监控告警 / 安全合规 / 版本升级 / 参数调优 |
| 操作系统层 | OS调优,内核调参 | 存储空间管理 |
| 硬件层 | 测试选型,驱动适配 | (更换备件) |
体系建设并不是一蹴而就的一锤子买卖,而是一个水平随时间对数增长的演化过程。有兴趣研究折腾的DBA会持续致力于更高水平的自动化建设,将建设过程浓缩为可复制的经验、文档、流程、脚本、工具、方案、平台、管控软件。管控软件也许是目前 DBA 经验沉淀的终极形态 —— 用软件代替自己干 DBA 的活儿。
管控系统的自动化水平越高,维护阶段所需的维护人力就越少。但是对于 DBA 水平的要求也就越高,所需的建设投入与时间周期也就越长。所以在某一个平衡点上,或者是自动化程度撞上了 DBA 水平的天花板,或者是高到了威胁DBA 的职业安全,建设演进就会告一段落,DBA 进入“喝茶看报”的持续维护状态。
维护状态的系统,所需的智力带宽会显著下降。在建设完毕的良好系统架构中,如果只是日常性、规范性的工作,水平更低一些的 DBA 也足以维持,对高级 DBA 的时间需求也会戏剧性下降 —— 进入 “养兵千日,用兵一时” 的 “闲置” 状态,只有当出现紧急的故障与疑难杂症时,这些数据库专家老司机才能再次体现出自己的价值。
| 阶段 | 能力构成 |
|---|---|
| 普通用户-建设起步 | 100% 专家人力 |
| 普通用户-维护阶段 | 30% 管控 + 70% 专家人力 |
| 顶级用户-维护阶段 | 90% 管控 + 9% 运维人力 + 1% 专家人力 |
所以 DBA 以前其实是一个非常不错的岗位,经过创业打江山的建设阶段之后,就可以躺在功劳簿上,享受建设成果带来的效率红利。 比如顶级甲方中的 DBA 经过长期建设,也许 90% 的工作内容都高度自动化了 —— 比如连硬件故障都靠高可用管控自愈了。DBA 只需要 10% 的救火/优化/指导/管理时间,那么剩下 90% 的时间就可以自由支配:继续改善管控软件实现利滚利,或者学习内核源码翻译书籍,或者单纯就是像 DBA 的先辈 —— ‘图书管理员“ 那样在图书馆里喝茶看报,好不惬意。
然而 DBA 的这种舒适的生活被云数据库的模式打破了。首先,云厂商拿着已经建设好的管控软件批量复制分发,消灭了数据库建设阶段的重复性工作。其次,如果没有建设阶段,只有维护阶段,而维护工作只需要 DBA 10% 的时间,那么与其用 90% 的时间摸鱼,总会有卷王选择当时间管理大师同时去打 10 份工。云厂商的数据库专家通过管控和共享 DBA,让这个IT领域难得的清闲岗位也卷翻了起来。
云数据库的模式与新挑战
云数据库为什么会对 DBA 构成威胁?要解释这个问题,我们就需要先来聊一聊云数据库 RDS 的用户价值。
云数据库的核心价值是 “敏捷” 与 “兜底”。至于什么 “便宜”,“简单”,“弹性”,“安全“,”可靠” 其实都不是核心,甚至也都不一定真的成立。所谓 “敏捷” —— 翻译过来就是为用户省掉几个月的建设阶段工作,一步到位进入维护阶段 。所谓 “兜底”,就是指用户真正出现疑难杂症,真正需要顶级 DBA 的高智力带宽时,云厂商为用户通过工单的方式提供保障 —— 至少你确实能摇到人来管一管。
云数据库在技术上的核心壁垒,是沉淀了高级DBA经验的管控软件。大部分DBA,包括不少顶级 DBA —— 尽管其本身是数据库管理领域的专家,但却并没有研发能力 —— 可以自己将自己的领域知识与经验沉淀为可复制软件产品的能力。因此通常需要一个研发团队的辅助,来将高级DBA的领域知识转变为业务软件。
这些沉淀了 DBA 经验的管控软件,就成为了云数据库的核心生产资料与摇钱树。核·月单位成本20块钱的硬件资源,套上管控软件,就能卖出 300~400(Aliyun),甚至 800~1300(AWS)这样几十倍的天价来。不过也正是RDS这样线性绑定硬件资源的定价策略,让一部分中级 DBA 现在还能有喘息空间 —— 当 RDS 规模达到 100核以上,招聘一个 DBA 自建维护就会达到 ROI 的转折点了。
管控软件替代 DBA 工作的另一个好处是, DBA 可以加杠杆了!举个例子,如果你的管控软件可以自动化掉 DBA 90% 的工作,那么 同样的活就只需要一个DBA 10% 的时间,可以把一个 DBA 当十个用,所以 DBA 乘数就是10。如果你的管控软件简单易用,门槛很低,让普通运维/开发也能玩 DBA Cosplay,自助完成这 10% 工作中的 9%,那么就只需要专家 1% 的时间了,1个DBA可以当100个用!当然如果未来出现个 DBA 大模型,再把这 1% 的剩余工作替代 0.9% ,DBA 乘数就可以放大到 1000 倍了!
| 管控软件 | DBA乘数 | |
|---|---|---|
| 普通用户-建设起步阶段 | 100% DBA人力 | 1 |
| 普通用户-维护阶段 | 30%管控 + 70% DBA人力 | 1.43 |
| 云数据库 | 60% 管控 + 38% 人力 + 2% DBA人力 | 50 |
| 顶级用户-维护阶段 | 90% 管控 + 9% 人力 + 1% DBA人力 | 100 |
| 未来状态想象 | 95% 管控 + 4% 大模型 + 0.9% 人力 + 0.1% DBA人力 | 1000 |
所以,云厂商的模式和 银行很像。有所谓的 “存款准备金率” 和 “DBA乘数”,可以十个坛子甚至上百个坛子一个盖。充分释(ya)放(zha) DBA 老司机的空闲时间与剩余价值,用较低的人力成本,为更多的客户提供“兜底”服务。解决了 “用好数据库能力” 非常稀缺的问题,并赚的钵满盆翻。
如果让我来实事求是的评价云数据库服务的质量水平,用百分制打分的话。那么顶级DBA的自建水准可以到 95~100 分,优秀 DBA 自建能达到八十分上下;云数据库的水平大约就在 70 分。可是中级 DBA 土法自建也就大概五六十分,初级DBA土法自建也就三四十分,运维兼职的土法自建可能也就十几分。头部的甲方确实看不上云数据库这种大锅饭,但这对于腰部的用户来说这简直太香了 —— 他们要的就是大锅饭,而比起采购天价的商业数据库与聘请稀缺的数据库老司机,RDS确实配得上一句“物美价廉”。
第一:云数据库是预制菜,直接就能吃,不需要建设阶段;第二:云数据库是廉价七成正确的合格品,而相当一部分初中级DBA土法自建几个月,也都达不到 RDS 这样的水平;第三:云数据库是标准件,降低了DBA天马行空自由发挥带来的不确定性与不可替代性;第四:云数据库提供了共享专家,“兜底”了其余一些对 DBA 的需求,也解决了出问题摇不到人或者遇人不淑的担忧。所以对于那些规模偏小,水平一般的甲方用户来说,云数据库比起招聘培养一个初中级 DBA 自建很有吸引力。
云数据库服务对 DBA 的冲击是结构性的。极度稀缺的顶尖 DBA 不受影响,一直会是云厂商争相笼络招安拉拢的香饽饽。而胸部以下的 DBA ,或者说自建水平达不到 70 分的 DBA ,就会直接面临云数据库服务的生态位竞争。对于 DBA 这个行业来说,这不是一件好事 —— 因为高级 DBA 都是从初级,中级DBA 成长起来的。如果诞生培育这些初中级DBA的土壤 —— 中小公司的数据库应用场景都被云厂商垄断截胡,那么这个行业金字塔就会被腰斩掉,顶级DBA的增量被断掉,存量被蚕食,最终也会成为无根之木。
打破云数据库的核心壁垒
云数据库会是未来吗?云数据库会像 “汽车替代马车” 那样革掉 DBA 的命吗?我不这么想,因为有力就会有反作用力。与时俱进的 DBA 们会用工具武装自己,重新回到舞台中央与 RDS 同台竞技。
DBA 们想要与云数据库竞争,采用路德分子抵制技术进步的方式是没有用的。而应当用 “你强我更强” 的方式提高自己相对于云数据库的竞争力。而要做到这一点,DBA 需要用更低的成本,提供比RDS更高的价值。要做到这一点,质量、安全、可靠的部分我都不用担心 DBA 的专业能力,核心在于 “敏捷” 与 “兜底” 这两个问题:
首先,把几个月的建设周期缩短到几天甚至几小时,做到“敏捷”。
其次,真的出现疑难杂症问题时,能够摇到顶级DBA来“兜底”。
解决前者要靠 管控软件,解决后者,要靠DBA老司机。而前者的紧迫性要远远高于后者 —— 建设良好的系统也许跑个几年都不会遇到需要 ”兜底“ 的问题,让普通 DBA 人人都成为老司机也不现实。而如何敏捷、低成本的拉起一套 70 分以上的数据库服务体系,是 DBA 应对 RDS 挑战的核心问题。
而这,正是我发起 Pigsty 这个开源项目的初衷 —— 提供一个完全开源免费,且质量更好的 RDS PG 替代品。让普通的DBA/研发/运维人员都能以同样的敏捷的方式迅速建设交付 80分+ 的本地 RDS 服务!彻底解决掉第一个问题。而我自己的商业模式是咨询与服务,为这些疑难杂症提供商业支持与最后兜底,解决第二个问题。
一个开源且足够好的数据库管控软件,会直接颠覆云数据库的商业模式。举个最简单的例子,你完全可以拿同样具有弹性的云服务器 ECS 和云盘 ESSD,使用开源管控来自建 RDS 服务。在不损失云所鼓吹的“弹性”与“敏捷”以及各种RDS好处的前提下,在不需要额外的人手的情况下,立竿见影的省掉 60% ~ 90% 不等的 “纯RDS溢价”。如果在使用自有服务器纯自建的情况下,能带来的降本增效水平恐怕会超出绝大多数用户的认知。
Pigsty 会重新设置云数据库服务的基线水平,所有质量不及它的PG管控软件价值都会逐渐萎缩归零,这是数据库管理领域的核武器扩散,是站在道德高地上的开源倾销。和当年开源数据库掀翻商业数据库的桌子是一模一样的,只不过这一次发生在了另一个维度 —— 管控软件 上。Pigsty 为所有 PG DBA 立即装备上了瞬间完成高水平数据库服务建设与交付的魔法棒,也让更多的研发/运维可以扮演 PG DBA 的角色,瞬间量产出大量的初级 DBA 来。
当然作为开源的管控软件,Pigsty 确实和云数据库管控一样,替代了很大一部分的 DBA 工作内容,特别是运维性的部分。但和云数据库不一样的是,它掌握在 DBA 自己的手中,由DBA所拥有,控制,使用,而不是只能向云计算领主去租赁并”替代“DBA。更强生产力带来的闲暇时间红利与DBA乘数杠杆,会直接普及到每一个从业者手中。而这,就是我作为一个顶尖DBA对于 RDS 挑战的回复。
如何面对云数据库的冲击
对于广大初中级 DBA 来说,我认为应对云数据库挑战的最佳办法就是立即放弃周期长,效果良莠不齐的土法自建尝试,直接拥抱成熟的开源管控软件,快速放大自己相对于云数据库的竞争力 —— 这一部分是完全开源免费,掌握在你自己手中的生产资料与能力。如果需要疑难杂症兜底,我非常乐意以一个相比于云数据库极有竞争力的价格提供支持、咨询与答疑。
请不要再来问我:PostgreSQL 高可用如何做?PITR 备份恢复怎么搞?可观测性与监控系统如何搭建?如何用配置IaC管理几百套数据库集群?连接池如何配置管理?负载均衡与服务接入怎么做?上百个扩展插件如何编译分发打包?主机参数怎么调优?上线/下线/扩容/缩容/滚动升级/数据迁移这些怎么做?这些你真正会遇到的问题,也是我曾经遇到的问题,而我已经在 Pigsty 中我都给出了工具化的最佳实践与版本答案,并配有 DBA SOP 手册,让小白也能快速上手玩起 DBA Cosplay。
对于顶级DBA与同侪们,我倡议合力打造开源共有的管控软件,并基于此提供专业数据库服务。与其你搞一套云管,我搞一套云管,投入大量的研发人力搞低水平、重复性的建设,倒不如凝聚起来打造公有的开源管控,打造中国社区里真正有世界影响力的开源项目品牌。Pigsty 是一个很不错的候选开源项目 —— 在当下,它已经成为中国人主导的 PostgreSQL 生态开源项目中排名最前的项目了。它也许有机会成为 PostgreSQL 世界中的 Debian 与 Ubuntu,但这取决于所有每一个贡献者与每一个用户。
我也不靠 Pigsty 来赚钱,和许多数据库服务公司一样,靠的也是提供专业的咨询与服务。这也许不是资本市场喜欢听的那种 “Scale to the Moon” 的故事,但确实可以解决用户的痛点需求。我一个人即使再牛逼,能打 200 份 PG DBA 的工吗?不能!但 Pigsty 这个管控工具可以让每一个 PG DBA 老司机都加上这样的杠杆,去为社会提供真正有价值的咨询与服务,从而卷翻云数据库!
例如提供 MySQL 专家服务的 Percona ,负责 PostgreSQL 部门的头 Umair Shahid 就很敏锐地看到了这个趋势。他从 Percona 出来,成立了自己的创业公司 Stormatics 来提供专业 PostgreSQL 服务。他没有自己再 “研发” 一套什么 PG云数据库管控平台之类的东西,而是直接使用 Pigsty 进行系统交付。同样也有一些意大利,美国,国内的数据库公司在使用 Pigsty 交付 PostgreSQL 服务。我对此表示热烈欢迎、并愿意提供支持与帮助。
数据库产品的模式正在消亡,而数据库咨询与专家服务的模式方兴未已。用好数据库是一个门槛很高的领域,即使强如下云先锋 DHH,抠门大王也依然会有一笔采购 Percona MySQL 专家服务的开销来请专业的人解决专业的问题。比起出卖尊严去包装换皮套壳吹牛撒谎打造使用价值微乎其微的(Minor PG fork) “新数据库内核产品” ,倒不如堂堂正正地去为用户提供真正有价值的数据库专家咨询与服务 。
在当下,服务器硬件资源非常便宜,数据库内核软件开源免费且足够牛逼,现在,如果管控软件不再被云厂商垄断,那么提供完整数据库服务的核心要素,就只剩下了用于兜底的专家能力!AI 与 GPT 的出现更是让单个数据库专家的杠杆乘数放大到一个惊人的地步。
所以,有很多云厂商内部的数据库老司机都敏锐地洞察到了这个趋势,选择脱离云厂商自己出来单干!比如从阿里云出来的就有,唐成老师的乘数科技,曹伟老师的Kubeblocks,叶正盛老师的 NineData,等等等等。所以即使是云数据库厂商内部的团队,也不是铁板一块。团队也在剧烈变动,凋零失血,人心思变中。
我相信未来的世界,不会是一个云数据库垄断的世界。各家 RDS 管控的质量水平长期止步不前,已经达到了场景土壤所容许的能力天花板。而顶尖 DBA 的经验沉淀下来的生产力工具则更进一步,让许多腰部 DBA 面对 RDS 都能重新有一战之力。与时俱进的 DBA 们会用工具武装自己,与 RDS 同台竞技。而我愿意替天行道,扛起下云与自建替代的大旗,开发这些管控软件与工具并普及到每一个DBA手中,帮助 DBA 打赢反抗云数据库的战斗!