PG 管理
- PostgreSQL 逻辑复制详解
- PostgreSQL 宏观查询优化之 pg_stat_statements
- 如何用 pg_filedump 抢救数据?
- PG中的本地化排序规则
- PG复制标识详解(Replica Identity)
- PG慢查询诊断方法论
- 故障档案:时间回溯导致的Patroni故障
- 在线修改主键列类型
- 黄金监控指标:错误延迟吞吐饱和
- 数据库集群管理概念与实体命名规范
- PostgreSQL的KPI
- 在线修改PG字段类型
- 故障档案:PG安装Extension导致无法连接
- PostgreSQL 常见复制拓扑方案
- 温备:使用pg_receivewal
- 故障档案:pg_dump导致的连接池污染
- PostgreSQL数据页面损坏修复
- 关系膨胀的监控与治理
- PipelineDB快速上手
- TimescaleDB 快速上手
- 故障档案:PostgreSQL事务号回卷
- 故障档案:序列号消耗过快导致整型溢出
- 监控PG中的表大小
- PgAdmin安装配置
- 故障档案:快慢不匀雪崩
- Bash与psql小技巧
- PostgreSQL例行维护
- 备份恢复手段概览
- PgBackRest2中文文档
- Pgbouncer快速上手
- PG服务器日志常规配置
- 空中换引擎 —— PostgreSQL不停机迁移数据
- 使用FIO测试磁盘性能
- 使用sysbench测试PostgreSQL性能
- 找出没用过的索引
- 批量配置SSH免密登录
- Wireshark抓包分析协议
- file_fdw妙用无穷——从数据库读取系统信息
- Linux 常用统计 CLI 工具
- 源码编译安装 PostGIS
- PostgreSQL MongoFDW安装部署
PostgreSQL 逻辑复制详解
逻辑复制
逻辑复制(Logical Replication),是一种根据数据对象的 复制标识(Replica Identity)(通常是主键)复制数据对象及其变化的方法。
逻辑复制 这个术语与 物理复制相对应,物理复制使用精确的块地址与逐字节复制,而逻辑复制则允许对复制过程进行精细的控制。
逻辑复制基于 发布(Publication) 与 订阅(Subscription)模型:
- 一个 发布者(Publisher) 上可以有多个发布,一个 订阅者(Subscriber) 上可以有多个 订阅 。
- 一个发布可被多个订阅者订阅,一个订阅只能订阅一个发布者,但可订阅同发布者上的多个不同发布。
针对一张表的逻辑复制通常是这样的:订阅者获取发布者数据库上的一个快照,并拷贝表中的存量数据。一旦完成数据拷贝,发布者上的变更(增删改清)就会实时发送到订阅者上。订阅者会按照相同的顺序应用这些变更,因此可以保证逻辑复制的事务一致性。这种方式有时候又称为 事务性复制(transactional replication)。
逻辑复制的典型用途是:
- 迁移,跨PostgreSQL大版本,跨操作系统平台进行复制。
- CDC,收集数据库(或数据库的一个子集)中的增量变更,在订阅者上为增量变更触发触发器执行定制逻辑。
- 分拆,将多个数据库集成为一个,或者将一个数据库拆分为多个,进行精细的分拆集成与访问控制。
逻辑订阅者的行为就是一个普通的PostgreSQL实例(主库),逻辑订阅者也可以创建自己的发布,拥有自己的订阅者。
如果逻辑订阅者只读,那么不会有冲突。如果会写入逻辑订阅者的订阅集,那么就可能会出现冲突。
发布
一个 发布(Publication) 可以在物理复制主库 上定义。创建发布的节点被称为 发布者(Publisher) 。
一个 发布 是 由一组表构成的变更集合。也可以被视作一个 变更集(change set) 或 复制集(Replication Set) 。每个发布都只能在一个 数据库(Database) 中存在。
发布不同于模式(Schema),不会影响表的访问方式。(表纳不纳入发布,自身访问不受影响)
发布目前只能包含表(即:索引,序列号,物化视图这些不会被发布),每个表可以添加到多个发布中。
除非针对ALL TABLES创建发布,否则发布中的对象(表)只能(通过ALTER PUBLICATION ADD TABLE)被显式添加。
发布可以筛选所需的变更类型:包括INSERT、UPDATE、DELETE 和TRUNCATE的任意组合,类似触发器事件,默认所有变更都会被发布。
复制标识
一个被纳入发布中的表,必须带有 复制标识(Replica Identity),只有这样才可以在订阅者一侧定位到需要更新的行,完成UPDATE与DELETE操作的复制。
默认情况下,主键 (Primary Key)是表的复制标识,非空列上的唯一索引 (UNIQUE NOT NULL)也可以用作复制标识。
如果没有任何复制标识,可以将复制标识设置为FULL,也就是把整个行当作复制标识。(一种有趣的情况,表中存在多条完全相同的记录,也可以被正确处理,见后续案例)使用FULL模式的复制标识效率很低(因为每一行修改都需要在订阅者上执行全表扫描,很容易把订阅者拖垮),所以这种配置只能是保底方案。使用FULL模式的复制标识还有一个限制,订阅端的表上的复制身份所包含的列,要么与发布者一致,要么比发布者更少。
INSERT操作总是可以无视 复制标识 直接进行(因为插入一条新记录,在订阅者上并不需要定位任何现有记录;而删除和更新则需要通过复制标识 定位到需要操作的记录)。如果一个没有 复制标识 的表被加入到带有UPDATE和DELETE的发布中,后续的UPDATE和DELETE会导致发布者上报错。
表的复制标识模式可以查阅pg_class.relreplident获取,可以通过ALTER TABLE进行修改。
ALTER TABLE tbl REPLICA IDENTITY
{ DEFAULT | USING INDEX index_name | FULL | NOTHING };
尽管各种排列组合都是可能的,然而在实际使用中,只有三种可行的情况。
- 表上有主键,使用默认的
default复制标识 - 表上没有主键,但是有非空唯一索引,显式配置
index复制标识 - 表上既没有主键,也没有非空唯一索引,显式配置
full复制标识(运行效率非常低,仅能作为兜底方案) - 其他所有情况,都无法正常完成逻辑复制功能。输出的信息不足,可能会报错,也可能不会。
- 特别需要注意:如果
nothing复制标识的表纳入到逻辑复制中,对其进行删改会导致发布端报错!
| 复制身份模式\表上的约束 | 主键(p) | 非空唯一索引(u) | 两者皆无(n) |
|---|---|---|---|
| default | 有效 | x | x |
| index | x | 有效 | x |
| full | 低效 | 低效 | 低效 |
| nothing | xxxx | xxxx | xxxx |
管理发布
CREATE PUBLICATION用于创建发布,DROP PUBLICATION用于移除发布,ALTER PUBLICATION用于修改发布。
发布创建之后,可以通过ALTER PUBLICATION动态地向发布中添加或移除表,这些操作都是事务性的。
CREATE PUBLICATION name
[ FOR TABLE [ ONLY ] table_name [ * ] [, ...]
| FOR ALL TABLES ]
[ WITH ( publication_parameter [= value] [, ... ] ) ]
ALTER PUBLICATION name ADD TABLE [ ONLY ] table_name [ * ] [, ...]
ALTER PUBLICATION name SET TABLE [ ONLY ] table_name [ * ] [, ...]
ALTER PUBLICATION name DROP TABLE [ ONLY ] table_name [ * ] [, ...]
ALTER PUBLICATION name SET ( publication_parameter [= value] [, ... ] )
ALTER PUBLICATION name OWNER TO { new_owner | CURRENT_USER | SESSION_USER }
ALTER PUBLICATION name RENAME TO new_name
DROP PUBLICATION [ IF EXISTS ] name [, ...];
publication_parameter 主要包括两个选项:
publish:定义要发布的变更操作类型,逗号分隔的字符串,默认为insert, update, delete, truncate。publish_via_partition_root:13后的新选项,如果为真,分区表将使用根分区的复制标识进行逻辑复制。
查询发布
发布可以使用psql元命令\dRp查询。
# \dRp
Owner | All tables | Inserts | Updates | Deletes | Truncates | Via root
----------+------------+---------+---------+---------+-----------+----------
postgres | t | t | t | t | t | f
pg_publication 发布定义表
``pg_publication` 包含了发布的原始定义,每一条记录对应一个发布。
# table pg_publication;
oid | 20453
pubname | pg_meta_pub
pubowner | 10
puballtables | t
pubinsert | t
pubupdate | t
pubdelete | t
pubtruncate | t
pubviaroot | f
puballtables:是否包含所有的表pubinsert|update|delete|truncate是否发布这些操作pubviaroot:如果设置了该选项,任何分区表(叶表)都会使用最顶层的(被)分区表的复制身份。所以可以把整个分区表当成一个表,而不是一系列表进行发布。
pg_publication_tables 发布内容表
pg_publication_tables是由pg_publication,pg_class和pg_namespace拼合而成的视图,记录了发布中包含的表信息。
postgres@meta:5432/meta=# table pg_publication_tables;
pubname | schemaname | tablename
-------------+------------+-----------------
pg_meta_pub | public | spatial_ref_sys
pg_meta_pub | public | t_normal
pg_meta_pub | public | t_unique
pg_meta_pub | public | t_tricky
使用pg_get_publication_tables可以根据订阅的名字获取订阅表的OID
SELECT * FROM pg_get_publication_tables('pg_meta_pub');
SELECT p.pubname,
n.nspname AS schemaname,
c.relname AS tablename
FROM pg_publication p,
LATERAL pg_get_publication_tables(p.pubname::text) gpt(relid),
pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.oid = gpt.relid;
同时,pg_publication_rel 也提供类似的信息,但采用的是多对多的OID对应视角,包含的是原始数据。
oid | prpubid | prrelid
-------+---------+---------
20414 | 20413 | 20397
20415 | 20413 | 20400
20416 | 20413 | 20391
20417 | 20413 | 20394
这两者的区别特别需要注意:当针对ALL TABLES发布时,pg_publication_rel中不会有具体表的OID,但是在pg_publication_tables中可以查询到实际纳入逻辑复制的表列表。所以通常应当以pg_publication_tables为准。
创建订阅时,数据库会先修改pg_publication目录,然后将发布表的信息填入pg_publication_rel。
订阅
订阅(Subscription) 是逻辑复制的下游。定义订阅的节点被称为 订阅者(Subscriber) 。
订阅定义了:如何连接到另一个数据库,以及需要订阅目标发布者上的哪些发布。
逻辑订阅者的行为与一个普通的PostgreSQL实例(主库)无异,逻辑订阅者也可以创建自己的发布,拥有自己的订阅者。
每个订阅者,都会通过一个 复制槽(Replication) 来接收变更,在初始数据复制阶段,可能会需要更多的临时复制槽。
逻辑复制订阅可以作为同步复制的备库,备库的名字默认就是订阅的名字,也可以通过在连接信息中设置application_name来使用别的名字。
只有超级用户才可以用pg_dump转储订阅的定义,因为只有超级用户才可以访问pg_subscription视图,普通用户尝试转储时会跳过并打印警告信息。
逻辑复制不会复制DDL变更,因此发布集中的表必须已经存在于订阅端上。只有普通表上的变更会被复制,视图、物化视图、序列号,索引这些都不会被复制。
发布与订阅端的表是通过完整限定名(如public.table)进行匹配的,不支持把变更复制到一个名称不同的表上。
发布与订阅端的表的列也是通过名称匹配的。列的顺序无关紧要,数据类型也不一定非得一致,只要两个列的文本表示兼容即可,即数据的文本表示可以转换为目标列的类型。订阅端的表可以包含有发布端没有的列,这些新列都会使用默认值填充。
管理订阅
CREATE SUBSCRIPTION用于创建订阅,DROP SUBSCRIPTION用于移除订阅,ALTER SUBSCRIPTION用于修改订阅。
订阅创建之后,可以通过ALTER SUBSCRIPTION 随时暂停与恢复订阅。
移除并重建订阅会导致同步信息丢失,这意味着相关数据需要重新进行同步。
CREATE SUBSCRIPTION subscription_name
CONNECTION 'conninfo'
PUBLICATION publication_name [, ...]
[ WITH ( subscription_parameter [= value] [, ... ] ) ]
ALTER SUBSCRIPTION name CONNECTION 'conninfo'
ALTER SUBSCRIPTION name SET PUBLICATION publication_name [, ...] [ WITH ( set_publication_option [= value] [, ... ] ) ]
ALTER SUBSCRIPTION name REFRESH PUBLICATION [ WITH ( refresh_option [= value] [, ... ] ) ]
ALTER SUBSCRIPTION name ENABLE
ALTER SUBSCRIPTION name DISABLE
ALTER SUBSCRIPTION name SET ( subscription_parameter [= value] [, ... ] )
ALTER SUBSCRIPTION name OWNER TO { new_owner | CURRENT_USER | SESSION_USER }
ALTER SUBSCRIPTION name RENAME TO new_name
DROP SUBSCRIPTION [ IF EXISTS ] name;
subscription_parameter定义了订阅的一些选项,包括:
copy_data(bool):复制开始后,是否拷贝数据,默认为真create_slot(bool):是否在发布者上创建复制槽,默认为真enabled(bool):是否启用该订阅,默认为真connect(bool):是否尝试连接到发布者,默认为真,置为假会把上面几个选项强制设置为假。synchronous_commit(bool):是否启用同步提交,向主库上报自己的进度信息。slot_name:订阅所关联的复制槽名称,设置为空会取消订阅与复制槽的关联。
管理复制槽
每个活跃的订阅都会通过复制槽 从远程发布者接受变更。
通常这个远端的复制槽是自动管理的,在CREATE SUBSCRIPTION时自动创建,在DROP SUBSCRIPTION时自动删除。
在特定场景下,可能需要分别操作订阅与底层的复制槽:
-
创建订阅时,所需的复制槽已经存在。则可以通过
create_slot = false关联已有复制槽。 -
创建订阅时,远端不可达或状态不明朗,则可以通过
connect = false不访问远程主机,pg_dump就是这么做的。这种情况下,您必须在远端手工创建复制槽后,才能在本地启用该订阅。 -
移除订阅时,需要保留复制槽。这种情况通常是订阅者要搬到另一台机器上去,希望在那里重新开始订阅。这种情况下需要先通过
ALTER SUBSCRIPTION解除订阅与复制槽点关联 -
移除订阅时,远端不可达。这种情况下,需要在删除订阅之前使用
ALTER SUBSCRIPTION解除复制槽与订阅的关联。如果远端实例不再使用那么没事,然而如果远端实例只是暂时不可达,那就应该手动删除其上的复制槽;否则它将继续保留WAL,并可能导致磁盘撑爆。
订阅查询
订阅可以使用psql元命令\dRs查询。
# \dRs
Name | Owner | Enabled | Publication
--------------+----------+---------+----------------
pg_bench_sub | postgres | t | {pg_bench_pub}
pg_subscription 订阅定义表
每一个逻辑订阅都会有一条记录,注意这个视图是跨数据库集簇范畴的,每个数据库中都可以看到整个集簇中的订阅信息。
只有超级用户才可以访问此视图,因为里面包含有明文密码(连接信息)。
oid | 20421
subdbid | 19356
subname | pg_test_sub
subowner | 10
subenabled | t
subconninfo | host=10.10.10.10 user=replicator password=DBUser.Replicator dbname=meta
subslotname | pg_test_sub
subsynccommit | off
subpublications | {pg_meta_pub}
subenabled:订阅是否启用subconninfo:因为包含敏感信息,会针对普通用户进行隐藏。subslotname:订阅使用的复制槽名称,也会被用作逻辑复制的源名称(Origin Name),用于除重。subpublications:订阅的发布名称列表。- 其他状态信息:是否启用同步提交等等。
pg_subscription_rel 订阅内容表
pg_subscription_rel 记录了每张处于订阅中的表的相关信息,包括状态与进度。
srrelid订阅中关系的OIDsrsubstate,订阅中关系的状态:i初始化中,d拷贝数据中,s同步已完成,r正常复制中。srsublsn,当处于i|d状态时为空,当处于s|r状态时,远端的LSN位置。
创建订阅时
当一个新的订阅创建时,会依次执行以下操作:
- 将发布的信息存入
pg_subscription目录中,包括连接信息,复制槽,发布名称,一些配置选项等。 - 连接至发布者,检查复制权限,(注意这里不会检查对应发布是否存在),
- 创建逻辑复制槽:
pg_create_logical_replication_slot(name, 'pgoutput') - 将复制集中的表注册到订阅端的
pg_subscription_rel目录中。 - 执行初始快照同步,注意订阅测表中的原有数据不会被删除。
复制冲突
逻辑复制的行为类似于正常的DML操作,即使数据在用户节点上的本地发生了变化,数据也会被更新。如果复制来的数据违反了任何约束,复制就会停止,这种现象被称为 冲突(Conflict) 。
当复制UPDATE或DELETE操作时,缺失数据(即要更新/删除的数据已经不存在)不会产生冲突,此类操作直接跳过。
冲突会导致错误,并中止逻辑复制,逻辑复制管理进程会以5秒为间隔不断重试。冲突不会阻塞订阅端对复制集中表上的SQL。关于冲突的细节可以在用户的服务器日志中找到,冲突必须由用户手动解决。
日志中可能出现的冲突
| 冲突模式 | 复制进程 | 输出日志 |
|---|---|---|
| 缺少UPDATE/DELETE对象 | 继续 | 不输出 |
| 表/行锁等待 | 等待 | 不输出 |
| 违背主键/唯一/Check约束 | 中止 | 输出 |
| 目标表不存在/目标列不存在 | 中止 | 输出 |
| 无法将数据转换为目标列类型 | 中止 | 输出 |
解决冲突的方法,可以是改变订阅侧的数据,使其不与进入的变更相冲突,或者跳过与现有数据冲突的事务。
使用订阅对应的node_name与LSN位置调用函数pg_replication_origin_advance()可以跳过事务,pg_replication_origin_status系统视图中可以看到当前ORIGIN的位置。
局限性
逻辑复制目前有以下限制,或者说功能缺失。这些问题可能会在未来的版本中解决。
数据库模式和DDL命令不会被复制。存量模式可以通过pg_dump --schema-only手动复制,增量模式变更需要手动保持同步(发布订阅两边的模式不需要绝对相同不需要两边的模式绝对相同)。逻辑复制对于对在线DDL变更仍然可靠:在发布数据库中执行DDL变更后,复制的数据到达订阅者但因为表模式不匹配而导致复制出错停止,订阅者的模式更新后复制会继续。在许多情况下,先在订阅者上执行变更可以避免中间的错误。
序列号数据不会被复制。序列号所服务的标识列与SERIAL类型里面的数据作为表的一部分当然会被复制,但序列号本身仍会在订阅者上保持为初始值。如果订阅者被当成只读库使用,那么通常没事。然而如果打算进行某种形式的切换或Failover到订阅者数据库,那么需要将序列号更新为最新的值,要么通过从发布者复制当前数据(也许可以使用pg_dump -t *seq*),要么从表本身的数据内容确定一个足够高的值(例如max(id)+1000000)。否则如果在新库执行获取序列号作为身份的操作时,很可能会产生冲突。
逻辑复制支持复制TRUNCATE命令,但是在TRUNCATE由外键关联的一组表时需要特别小心。当执行TRUNCATE操作时,发布者上与之关联的一组表(通过显式列举或级连关联)都会被TRUNCATE,但是在订阅者上,不在订阅集中的表不会被TRUNCATE。这样的操作在逻辑上是合理的,因为逻辑复制不应该影响到复制集之外的表。但如果有一些不在订阅集中的表通过外键引用订阅集中被TRUNCATE的表,那么TRUNCATE操作就会失败。
大对象不会被复制
只有表能被复制(包括分区表),尝试复制其他类型的表会导致错误(视图,物化视图,外部表,Unlogged表)。具体来说,只有在pg_class.relkind = 'r'的表才可以参与逻辑复制。
复制分区表时默认按子表进行复制。默认情况下,变更是按照分区表的叶子分区触发的,这意味着发布上的每一个分区子表都需要在订阅上存在(当然,订阅者上的这个分区子表不一定是一个分区子表,也可能本身就是一个分区母表,或者一个普通表)。发布可以声明要不要使用分区根表上的复制标识取代分区叶表上的复制标识,这是PG13提供的新功能,可以在创建发布时通过publish_via_partition_root 选项指定。
触发器的行为表现有所不同。行级触发器会触发,但UPDATE OF cols类型的触发器不触发。而语句级触发器只会在初始数据拷贝时触发。
日志行为不同。即使设置log_statement = 'all',日志中也不会记录由复制产生的SQL语句。
双向复制需要极其小心:互为发布与订阅是可行的,只要两遍的表集合不相交即可。但一旦出现表的交集,就会出现WAL无限循环。
同一实例内的复制:同一个实例内的逻辑复制需要特别小心,必须手工创建逻辑复制槽,并在创建订阅时使用已有的逻辑复制槽,否则会卡死。
只能在主库上进行:目前不支持从物理复制的从库上进行逻辑解码,也无法在从库上创建复制槽,所以从库无法作为发布者。但这个问题可能会在未来解决。
架构
逻辑复制始于获取发布者数据库上的快照,基于此快照拷贝表上的存量数据。一旦拷贝完成,发布者上的变更(增删改等)就会实时发送到订阅者上。
逻辑复制采用与物理复制类似的架构,是通过一个walsender和apply进程实现的。发布端端walsender进程会加载逻辑解码插件(pgoutput),并开始逻辑解码WAL日志。逻辑解码插件(Logical Decoding Plugin) 会读取WAL中的变更,按照发布的定义筛选变更,将变更转变为特定的形式,以逻辑复制协议传输出去。数据会按照流复制协议传输至订阅者一侧的apply进程,该进程会在接收到变更时,将变更映射至本地表上,然后按照事务顺序重新应用这些变更。
初始快照
订阅侧的表在初始化与拷贝数据期间,会由一种特殊的apply进程负责。这个进程会创建它自己的临时复制槽,并拷贝表中的存量数据。
一旦数据拷贝完成,这张表会进入到同步模式(pg_subscription_rel.srsubstate = 's'),同步模式确保了 主apply进程 可以使用标准的逻辑复制方式应用拷贝数据期间发生的变更。一旦完成同步,表复制的控制权会转交回 主apply进程,恢复正常的复制模式。
进程结构
逻辑复制的发布端会针对来自订阅端端每一条连接,创建一个对应的 walsender 进程,发送解码的WAL日志。在订阅测,则会
复制槽
当创建订阅时,
一条逻辑复制
逻辑解码
同步提交
逻辑复制的同步提交是通过Backend与Walsender之间的SIGUSR1通信完成的。
临时数据
逻辑解码的临时数据会落盘为本地日志快照。当walsender接收到walwriter发送的SIGUSR1信号时,就会读取WAL日志并生成相应的逻辑解码快照。当传输结束时会删除这些快照。
文件地址为:$PGDATA/pg_logical/snapshots/{LSN Upper}-{LSN Lower}.snap
监控
逻辑复制采用与物理流复制类似的架构,所以监控一个逻辑复制的发布者节点与监控一个物理复制主库差别不大。
订阅者的监控信息可以通过pg_stat_subscription视图获取。
pg_stat_subscription 订阅统计表
每个活跃订阅都会在这个视图中有至少一条 记录,即Main Worker(负责应用逻辑日志)。
Main Worker的relid = NULL,如果有负责初始数据拷贝的进程,也会在这里有一行记录,relid为负责拷贝数据的表。
subid | 20421
subname | pg_test_sub
pid | 5261
relid | NULL
received_lsn | 0/2A4F6B8
last_msg_send_time | 2021-02-22 17:05:06.578574+08
last_msg_receipt_time | 2021-02-22 17:05:06.583326+08
latest_end_lsn | 0/2A4F6B8
latest_end_time | 2021-02-22 17:05:06.578574+08
received_lsn:最近收到的日志位置。lastest_end_lsn:最后向walsender回报的LSN位置,即主库上的confirmed_flush_lsn。不过这个值更新不太勤快,
通常情况下一个活跃的订阅会有一个apply进程在运行,被禁用的订阅或崩溃的订阅则在此视图中没有记录。在初始同步期间,被同步的表会有额外的工作进程记录。
pg_replication_slot 复制槽
postgres@meta:5432/meta=# table pg_replication_slots ;
-[ RECORD 1 ]-------+------------
slot_name | pg_test_sub
plugin | pgoutput
slot_type | logical
datoid | 19355
database | meta
temporary | f
active | t
active_pid | 89367
xmin | NULL
catalog_xmin | 1524
restart_lsn | 0/2A08D40
confirmed_flush_lsn | 0/2A097F8
wal_status | reserved
safe_wal_size | NULL
复制槽视图中同时包含了逻辑复制槽与物理复制槽。逻辑复制槽点主要特点是:
plugin字段不为空,标识了使用的逻辑解码插件,逻辑复制默认使用pgoutput插件。slot_type = logical,物理复制的槽类型为physical。datoid与database字段不为空,因为物理复制与集簇关联,而逻辑复制与数据库关联。
逻辑订阅者也会作为一个标准的 复制从库 ,出现于 pg_stat_replication 视图中。
pg_replication_origin 复制源
复制源
table pg_replication_origin_status;
-[ RECORD 1 ]-----------
local_id | 1
external_id | pg_19378
remote_lsn | 0/0
local_lsn | 0/6BB53640
local_id:复制源在本地的ID,2字节高效表示。external_id:复制源的ID,可以跨节点引用。remote_lsn:源端最近的提交位点。local_lsn:本地已经持久化提交记录的LSN
检测复制冲突
最稳妥的检测方法总是从发布与订阅两侧的日志中检测。当出现复制冲突时,发布测上可以看见复制连接中断
LOG: terminating walsender process due to replication timeout
LOG: starting logical decoding for slot "pg_test_sub"
DETAIL: streaming transactions committing after 0/xxxxx, reading WAL from 0/xxxx
而订阅端则可以看到复制冲突的具体原因,例如:
logical replication worker PID 4585 exited with exit code 1
ERROR: duplicate key value violates unique constraint "pgbench_tellers_pkey","Key (tid)=(9) already exists.",,,,"COPY pgbench_tellers, line 31",,,,"","logical replication worker"
此外,一些监控指标也可以反映逻辑复制的状态:
例如:pg_replication_slots.confirmed_flush_lsn 长期落后于pg_cureent_wal_lsn。或者pg_stat_replication.flush_ag/write_lag 有显著增长。
安全
参与订阅的表,其Ownership与Trigger权限必须控制在超级用户所信任的角色手中(否则修改这些表可能导致逻辑复制中断)。
在发布节点上,如果不受信任的用户具有建表权限,那么创建发布时应当显式指定表名而非通配ALL TABLES。也就是说,只有当超级用户信任所有 可以在发布或订阅侧具有建表(非临时表)权限的用户时,才可以使用FOR ALL TABLES。
用于复制连接的用户必须具有REPLICATION权限(或者为SUPERUSER)。如果该角色缺少SUPERUSER与BYPASSRLS,发布者上的行安全策略可能会被执行。如果表的属主在复制启动之后设置了行级安全策略,这个配置可能会导致复制直接中断,而不是策略生效。该用户必须拥有LOGIN权限,而且HBA规则允许其访问。
为了能够复制初始表数据,用于复制连接的角色必须在已发布的表上拥有SELECT权限(或者属于超级用户)。
创建发布,需要在数据库中的CREATE权限,创建一个FOR ALL TABLES的发布,需要超级用户权限。
将表加入到发布中,用户需要具有表的属主权限。
创建订阅需要超级用户权限,因为订阅的apply进程在本地数据库中以超级用户的权限运行。
权限只会在建立复制连接时检查,不会在发布端读取每条变更记录时重复检查,也不会在订阅端应用每条记录时检查。
配置选项
逻辑复制需要一些配置选项才能正常工作。
在发布者一侧,wal_level 必须设置为logical,max_replication_slots最少需要设为 订阅的数量+用于表数据同步的数量。max_wal_senders最少需要设置为max_replication_slots + 为物理复制保留的数量,
在订阅者一侧,也需要设置max_replication_slots,max_replication_slots,最少需要设为订阅数。
max_logical_replication_workers最少需要配置为订阅的数量,再加上一些用于数据同步的工作进程数。
此外,max_worker_processes需要相应调整,至少应当为max_logical_replication_worker + 1。注意一些扩展插件和并行查询也会从工作进程的池子中获取连接使用。
配置参数样例
64核机器,1~2个发布与订阅,最多6个同步工作进程,最多8个物理从库的场景,一种样例配置如下所示:
首先决定Slot数量,2个订阅,6个同步工作进程,8个物理从库,所以配置为16。Sender = Slot + Physical Replica = 24。
同步工作进程限制为6,2个订阅,所以逻辑复制的总工作进程设置为8。
wal_level: logical # logical
max_worker_processes: 64 # default 8 -> 64, set to CPU CORE 64
max_parallel_workers: 32 # default 8 -> 32, limit by max_worker_processes
max_parallel_maintenance_workers: 16 # default 2 -> 16, limit by parallel worker
max_parallel_workers_per_gather: 0 # default 2 -> 0, disable parallel query on OLTP instance
# max_parallel_workers_per_gather: 16 # default 2 -> 16, enable parallel query on OLAP instance
max_wal_senders: 24 # 10 -> 24
max_replication_slots: 16 # 10 -> 16
max_logical_replication_workers: 8 # 4 -> 8, 6 sync worker + 1~2 apply worker
max_sync_workers_per_subscription: 6 # 2 -> 6, 6 sync worker
快速配置
首先设置发布侧的配置选项 wal_level = logical,该参数需要重启方可生效,其他参数的默认值都不影响使用。
然后创建复制用户,添加pg_hba.conf配置项,允许外部访问,一种典型配置是:
CREATE USER replicator REPLICATION BYPASSRLS PASSWORD 'DBUser.Replicator';
注意,逻辑复制的用户需要具有SELECT权限,在Pigsty中replicator已经被授予了dbrole_readonly角色。
host all replicator 0.0.0.0/0 md5
host replicator replicator 0.0.0.0/0 md5
然后在发布侧的数据库中执行:
CREATE PUBLICATION mypub FOR TABLE <tablename>;
然后在订阅测数据库中执行:
CREATE SUBSCRIPTION mysub CONNECTION 'dbname=<pub_db> host=<pub_host> user=replicator' PUBLICATION mypub;
以上配置即会开始复制,首先复制表的初始数据,然后开始同步增量变更。
沙箱样例
以Pigsty标准4节点两集群沙箱为例,有两套数据库集群pg-meta与pg-test。现在将pg-meta-1作为发布者,pg-test-1作为订阅者。
PGSRC='postgres://dbuser_admin@meta-1/meta' # 发布者
PGDST='postgres://dbuser_admin@node-1/test' # 订阅者
pgbench -is100 ${PGSRC} # 在发布端初始化Pgbench
pg_dump -Oscx -t pgbench* -s ${PGSRC} | psql ${PGDST} # 在订阅端同步表结构
# 在发布者上创建**发布**,将默认的`pgbench`相关表加入到发布集中。
psql ${PGSRC} -AXwt <<-'EOF'
CREATE PUBLICATION "pg_meta_pub" FOR TABLE
pgbench_accounts,pgbench_branches,pgbench_history,pgbench_tellers;
EOF
# 在订阅者上创建**订阅**,订阅发布者上的发布。
psql ${PGDST} <<-'EOF'
CREATE SUBSCRIPTION pg_test_sub
CONNECTION 'host=10.10.10.10 dbname=meta user=replicator'
PUBLICATION pg_meta_pub;
EOF
复制流程
逻辑复制的订阅创建后,如果一切正常,逻辑复制会自动开始,针对每张订阅中的表执行复制状态机逻辑。
如下图所示。
当所有的表都完成复制,进入r(ready)状态时,逻辑复制的存量同步阶段便完成了,发布端与订阅端整体进入同步状态。
因此从逻辑上讲,存在两种状态机:表级复制小状态机与全局复制大状态机。每一个Sync Worker负责一张表上的小状态机,而一个Apply Worker负责一条逻辑复制的大状态机。
逻辑复制状态机
逻辑复制有两种Worker:Sync与Apply。Sync
因此,逻辑复制在逻辑上分为两个部分:每张表独自进行复制,当复制进度追赶至最新位置时,由
当创建或刷新订阅时,表会被加入到 订阅集 中,每一张订阅集中的表都会在pg_subscription_rel视图中有一条对应纪录,展示这张表当前的复制状态。刚加入订阅集的表初始状态为i,即initialize,初始状态。
如果订阅的copy_data选项为真(默认情况),且工作进程池中有空闲的Worker,PostgreSQL会为这张表分配一个同步工作进程,同步这张表上的存量数据,此时表的状态进入d,即拷贝数据中。对表做数据同步类似于对数据库集群进行basebackup,Sync Worker会在发布端创建临时的复制槽,获取表上的快照并通过COPY完成基础数据同步。
当表上的基础数据拷贝完成后,表会进入sync模式,即数据同步,同步进程会追赶同步过程中发生的增量变更。当追赶完成时,同步进程会将这张表标记为r(ready)状态,转交逻辑复制主Apply进程管理变更,表示这张表已经处于正常复制中。
2.4 等待逻辑复制同步
创建订阅后,首先必须监控 发布端与订阅端两侧的数据库日志,确保没有错误产生。
2.4.1 逻辑复制状态机
2.4.2 同步进度跟踪
数据同步(d)阶段可能需要花费一些时间,取决于网卡,网络,磁盘,表的大小与分布,逻辑复制的同步worker数量等因素。
作为参考,1TB的数据库,20张表,包含有250GB的大表,双万兆网卡,在6个数据同步worker的负责下大约需要6~8小时完成复制。
在数据同步过程中,每个表同步任务都会源端库上创建临时的复制槽。请确保逻辑复制初始同步期间不要给源端主库施加过大的不必要写入压力,以免WAL撑爆磁盘。
发布侧的 pg_stat_replication,pg_replication_slots,订阅端的pg_stat_subscription,pg_subscription_rel提供了逻辑复制状态的相关信息,需要关注。
psql ${PGDST} -Xxw <<-'EOF'
SELECT subname, json_object_agg(srsubstate, cnt) FROM
pg_subscription s JOIN
(SELECT srsubid, srsubstate, count(*) AS cnt FROM pg_subscription_rel
GROUP BY srsubid, srsubstate) sr
ON s.oid = sr.srsubid GROUP BY subname;
EOF
可以使用以下SQL确认订阅中表的状态,如果所有表的状态都显示为r,则表示逻辑复制已经成功建立,订阅端可以用于切换。
subname | json_object_agg
-------------+-----------------
pg_test_sub | { "r" : 5 }
当然,最好的方式始终是通过监控系统来跟踪复制状态。
沙箱样例
以Pigsty标准4节点两集群沙箱为例,有两套数据库集群pg-meta与pg-test。现在将pg-meta-1作为发布者,pg-test-1作为订阅者。
通常逻辑复制的前提是,发布者上设置有wal_level = logical,并且有一个可以正常访问,具有正确权限的复制用户。
Pigsty的默认配置已经符合要求,且带有满足条件的复制用户replicator,以下命令均从元节点以postgres用户发起,数据库用户dbuser_admin,带有SUPERUSER权限。
PGSRC='postgres://dbuser_admin@meta-1/meta' # 发布者
PGDST='postgres://dbuser_admin@node-1/test' # 订阅者
准备逻辑复制
使用pgbench工具,在pg-meta集群的meta数据库中初始化表结构。
pgbench -is100 ${PGSRC}
使用pg_dump与psql 同步 pgbench* 相关表的定义。
pg_dump -Oscx -t pgbench* -s ${PGSRC} | psql ${PGDST}
创建发布订阅
在发布者上创建发布,将默认的pgbench相关表加入到发布集中。
psql ${PGSRC} -AXwt <<-'EOF'
CREATE PUBLICATION "pg_meta_pub" FOR TABLE
pgbench_accounts,pgbench_branches,pgbench_history,pgbench_tellers;
EOF
在订阅者上创建订阅,订阅发布者上的发布。
psql ${PGDST} <<-'EOF'
CREATE SUBSCRIPTION pg_test_sub
CONNECTION 'host=10.10.10.10 dbname=meta user=replicator'
PUBLICATION pg_meta_pub;
EOF
观察复制状态
当pg_subscription_rel.srsubstate全部变为r (准备就绪)状态后,逻辑复制就建立起来了。
$ psql ${PGDST} -c 'TABLE pg_subscription_rel;'
srsubid | srrelid | srsubstate | srsublsn
---------+---------+------------+------------
20451 | 20433 | d | NULL
20451 | 20442 | r | 0/4ECCDB78
20451 | 20436 | r | 0/4ECCDB78
20451 | 20439 | r | 0/4ECCDBB0
校验复制数据
可以简单地比较发布与订阅端两侧的表记录条数,与复制标识列的最大最小值来校验数据是否完整地复制。
function compare_relation(){
local relname=$1
local identity=${2-'id'}
psql ${3-${PGPUB}} -AXtwc "SELECT count(*) AS cnt, max($identity) AS max, min($identity) AS min FROM ${relname};"
psql ${4-${PGSUB}} -AXtwc "SELECT count(*) AS cnt, max($identity) AS max, min($identity) AS min FROM ${relname};"
}
compare_relation pgbench_accounts aid
compare_relation pgbench_branches bid
compare_relation pgbench_history tid
compare_relation pgbench_tellers tid
更近一步的验证可以通过在发布者上手工创建一条记录,再从订阅者上读取出来。
$ psql ${PGPUB} -AXtwc 'INSERT INTO pgbench_accounts(aid,bid,abalance) VALUES (99999999,1,0);'
INSERT 0 1
$ psql ${PGSUB} -AXtwc 'SELECT * FROM pgbench_accounts WHERE aid = 99999999;'
99999999|1|0|
现在已经拥有一个正常工作的逻辑复制了。下面让我们来通过一系列实验来掌握逻辑复制的使用与管理,探索可能遇到的各种离奇问题。
逻辑复制实验
将表加入已有发布
CREATE TABLE t_normal(id BIGSERIAL PRIMARY KEY,v TIMESTAMP); -- 常规表,带有主键
ALTER PUBLICATION pg_meta_pub ADD TABLE t_normal; -- 将新创建的表加入到发布中
如果这张表在订阅端已经存在,那么即可进入正常的逻辑复制流程:i -> d -> s -> r。
如果向发布加入一张订阅端不存在的表?那么新订阅将会无法创建。已有订阅无法刷新,但可以保持原有复制继续进行。
如果订阅还不存在,那么创建的时候会报错无法进行:在订阅端找不到这张表。如果订阅已经存在,无法执行刷新命令:
ALTER SUBSCRIPTION pg_test_sub REFRESH PUBLICATION;
如果新加入的表没有任何写入,已有的复制关系不会发生变化,一旦新加入的表发生变更,会立即产生复制冲突。
将表从发布中移除
ALTER PUBLICATION pg_meta_pub ADD TABLE t_normal;
从发布移除后,订阅端不会有影响。效果上就是这张表的变更似乎消失了。执行订阅刷新后,这张表会从订阅集中被移除。
另一种情况是重命名发布/订阅中的表,在发布端执行表重命名时,发布端的发布集会立刻随之更新。尽管订阅集中的表名不会立刻更新,但只要重命名后的表发生任何变更,而订阅端没有对应的表,那么会立刻出现复制冲突。
同理,在订阅端重命名表时,订阅的关系集也会刷新,但因为发布端的表没有对应物了。如果这张表没有变更,那么一切照旧,一旦发生变更,立刻出现复制冲突。
直接在发布端DROP此表,会顺带将该表从发布中移除,不会有报错或影响。但直接在订阅端DROP表则可能出现问题,DROP TABLE时该表也会从订阅集中被移除。如果发布端此时这张表上仍有变更产生,则会导致复制冲突。
所以,删表应当先在发布端进行,再在订阅端进行。
两端列定义不一致
发布与订阅端的表的列通过名称匹配,列的顺序无关紧要。
订阅端表的列更多,通常不会有什么影响。多出来的列会被填充为默认值(通常是NULL)。
特别需要注意的是,如果要为多出来的列添加NOT NULL约束,那么一定要配置一个默认值,否则变更发生时违反约束会导致复制冲突。
订阅端如果列要比发布端更少,会产生复制冲突。在发布端添加一个新列并不会立刻导致复制冲突,随后的第一条变更将导致复制冲突。
所以在执行加列DDL变更时,可以先在订阅者上先执行,然后在发布端进行。
列的数据类型不需要完全一致,只要两个列的文本表示兼容即可,即数据的文本表示可以转换为目标列的类型。
这意味着任何类型都能转换成TEXT类型,BIGINT 只要不出错,也可以转换成INT,不过一旦溢出,还是会出现复制冲突。
复制身份与索引的正确配置
表上的复制标识配置,与表上有没有索引是两件独立的事。尽管各种排列组合都是可能的,然而在实际使用中只有三种可行的情况,其他情况都无法正常完成逻辑复制的功能(如果不报错,通常也是侥幸)
- 表上有主键,使用默认的
default复制标识,不需要额外配置。 - 表上没有主键,但是有非空唯一索引,显式配置
index复制标识。 - 表上既没有主键也没有非空唯一索引,显式配置
full复制标识(运行效率低,仅作为兜底方案)
| 复制身份模式\表上的约束 | 主键(p) | 非空唯一索引(u) | 两者皆无(n) |
|---|---|---|---|
| default | 有效 | x | x |
| index | x | 有效 | x |
| full | 低效 | 低效 | 低效 |
| nothing | x | x | x |
在所有情况下,
INSERT都可以被正常复制。x代表DELETE|UPDATE所需关键信息缺失无法正常完成。
最好的方式当然是事前修复,为所有的表指定主键,以下查询可以用于找出缺失主键或非空唯一索引的表:
SELECT quote_ident(nspname) || '.' || quote_ident(relname) AS name, con.ri AS keys,
CASE relreplident WHEN 'd' THEN 'default' WHEN 'n' THEN 'nothing' WHEN 'f' THEN 'full' WHEN 'i' THEN 'index' END AS replica_identity
FROM pg_class c JOIN pg_namespace n ON c.relnamespace = n.oid, LATERAL (SELECT array_agg(contype) AS ri FROM pg_constraint WHERE conrelid = c.oid) con
WHERE relkind = 'r' AND nspname NOT IN ('pg_catalog', 'information_schema', 'monitor', 'repack', 'pg_toast')
ORDER BY 2,3;
注意,复制身份为nothing的表可以加入到发布中,但在发布者上对其执行UPDATE|DELETE会直接导致报错。
其他问题
Q:逻辑复制准备工作
Q:什么样的表可以逻辑复制?
Q:监控逻辑复制状态
Q:将新表加入发布
Q:没有主键的表加入发布?
Q:没有复制身份的表如何处理?
Q:ALTER PUB的生效方式
Q:在同一对 发布者-订阅者 上如果存在多对订阅,且发布包含的表重叠?
Q:订阅者和发布者的表定义有什么限制?
Q:pg_dump是如何处理订阅的
Q:什么情况下需要手工管理订阅复制槽?
PostgreSQL 宏观查询优化之 pg_stat_statements
在线业务数据库中,慢查询不仅影响终端用户体验,还会浪费系统资源、拉高资源饱和度、导致死锁和事务冲突,增加数据库连接压力,导致主从复制延迟等问题。因此,查询优化是 DBA 的核心工作内容之一。
在查询优化这条路上,有两种不同的方法:
宏观优化:整体分析工作负载,对其进行剖分下钻,自上而下地识别并改进其中表现最糟糕的部分。
微观优化:分析并改进一条特定的查询,这便需要记录慢查询日志,掌握 EXPLAIN 的玄机,领悟执行计划的奥妙。
今天我们先来说说前者,宏观优化有三个主要目标与动机:
减少资源消耗:降低资源饱和的风险,优化CPU/内存/IO,通常以查询总耗时/总IO作为优化目标。
改善用户体验:最常见的优化目标,在OLTP系统中通常以降低查询平均响应时间作为优化目标。
平衡工作负载:确保不同查询组之间的资源使用/性能表现的比例关系得当。
实现这些目标的关键在于数据支撑,但是数据从哪里来?
—— pg_stat_statements!
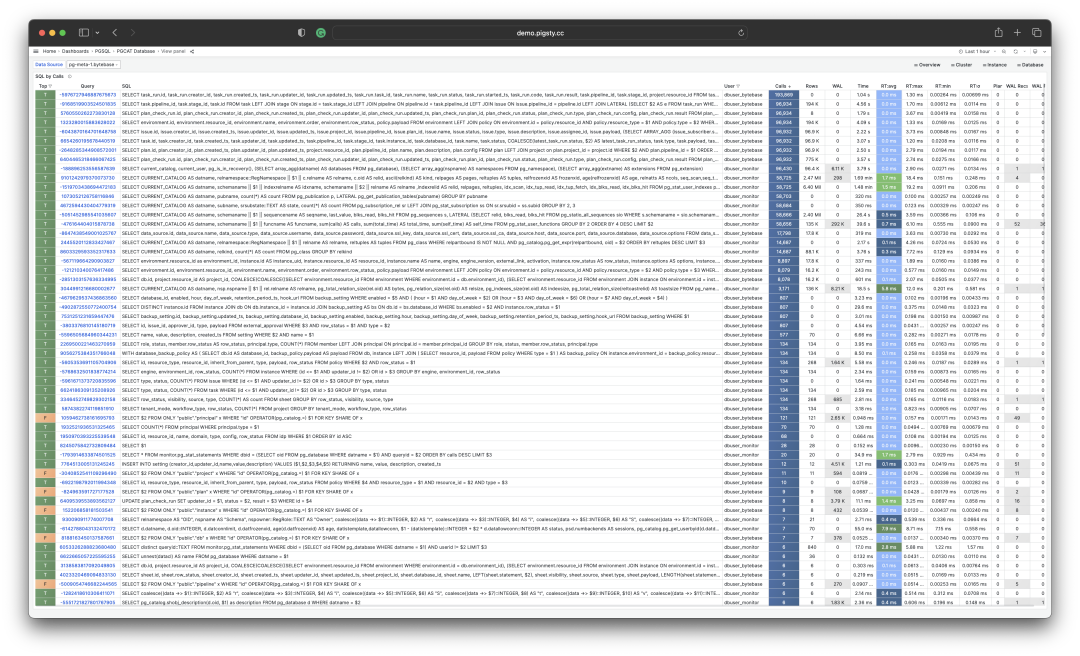
扩展插件:PGSS
pg_stat_statements,以下简称 PGSS ,是践行观宏之道的核心工具。
PGSS 出自 PostgreSQL 全球开发组官方之手,以第一方扩展插件的形式,随数据库内核本体一并发行,提供了跟踪 SQL 查询语句级别指标的方法。
PostgreSQL 生态中有许许多多的扩展,但如果说有哪一个是“必选”的,我必定会毫不犹豫的回答:PGSS。这也是在 Pigsty 中,我们宁愿“自作主张”,也要默认启用并主动加载的两个扩展之一。(另一个是用于微观优化的 auto_explain)
PGSS 需要在 shared_preload_library 中显式指定加载,并在数据库中通过 CREATE EXTENSION 显式创建。创建扩展后即可通过视图 pg_stat_statements 访问查询的统计信息。
在 PGSS 中,系统中的每一类查询(即抽取变量后,执行计划相同的查询)都会被分配一个查询ID,紧接着是调用次数,执行总耗时,以及各种其他指标,其完整模式定义如下(PG15+):
CREATE TABLE pg_stat_statements
(
userid OID, -- (标签值)执行此语句的用户 OID(标签值)
dbid OID, -- (标签值)此语句所在的数据库 OID(标签值)
toplevel BOOL, -- (标签值)此语句是否是顶层 SQL 语句(标签值)
queryid BIGINT, -- (标签值)查询ID:标准化查询的哈希值(标签值)
query TEXT, -- (标签值)标准化查询语句的文本内容
plans BIGINT, -- (累积量)此语句被 PLAN 的次数
total_plan_time FLOAT, -- (累积量)此语句花费在 PLAN 上的总时长
min_plan_time FLOAT, -- (测量值)PLAN 的最小时长
max_plan_time FLOAT, -- (测量值)PLAN 的最大时长
mean_plan_time FLOAT, -- (测量值)PLAN 的平均时长
stddev_plan_time FLOAT, -- (测量值)PLAN 时间的标准差
calls BIGINT, -- (累积量)此语句被调用执行的次数
total_exec_time FLOAT, -- (累积量)此语句花费在执行上的总时长
min_exec_time FLOAT, -- (测量值)执行的最小时长
max_exec_time FLOAT, -- (测量值)执行的最大时长
mean_exec_time FLOAT, -- (测量值)执行的平均时长
stddev_exec_time FLOAT, -- (测量值)执行时间的标准差
rows BIGINT, -- (累积量)执行此语句返回的总行数
shared_blks_hit BIGINT, -- (累积量)命中的共享缓冲区总块数
shared_blks_read BIGINT, -- (累积量)读取的共享缓冲区总块数
shared_blks_dirtied BIGINT, -- (累积量)写脏的共享缓冲区总块数
shared_blks_written BIGINT, -- (累积量)写入磁盘的共享缓冲区总块数
local_blks_hit BIGINT, -- (累积量)命中的本地缓冲区总块数
local_blks_read BIGINT, -- (累积量)读取的本地缓冲区总块数
local_blks_dirtied BIGINT, -- (累积量)写脏的本地缓冲区总块数
local_blks_written BIGINT, -- (累积量)写入磁盘的本地缓冲区总块数
temp_blks_read BIGINT, -- (累积量)读取的临时缓冲区总块数
temp_blks_written BIGINT, -- (累积量)写入磁盘的临时缓冲区总块数
blk_read_time FLOAT, -- (累积量)读取块花费的总时长
blk_write_time FLOAT, -- (累积量)写入块花费的总时长
wal_records BIGINT, -- (累积量)生成 WAL 的记录总数
wal_fpi BIGINT, -- (累积量)生成的 WAL全页镜像总数
wal_bytes NUMERIC, -- (累积量)生成的 WAL 字节总数
jit_functions BIGINT, -- (累积量)JIT 编译的函数数量
jit_generation_time FLOAT, -- (累积量)生成 JIT 字节码的总时长
jit_inlining_count BIGINT, -- (累积量)函数被内联的次数
jit_inlining_time FLOAT, -- (累积量)花费在内联函数上的总时长
jit_optimization_count BIGINT, -- (累积量)查询被 JIT优化的次数
jit_optimization_time FLOAT, -- (累积量)花费在JIT优化上的总时长
jit_emission_count BIGINT, -- (累积量)代码被 JIT Emit的次数
jit_emission_time FLOAT, -- (累积量)花费在 JIT Emit上的总时长
PRIMARY KEY (userid, dbid, queryid, toplevel)
);
PGSS 视图的 SQL 定义(PG 15+版本)
PGSS 也有一些局限性:首先,正在执行中的查询语句并不会纳入这里的统计,而需要从 pg_stat_activity 中查看获取。其次,执行失败的查询(例如,因为 statement_timeout 超时被取消的语句)也不会被计入这里的统计 —— 这是错误分析要解决的问题,而不是查询优化所关心的目标。
最后,查询标识符 queryid 的稳定性需要特别注意:当数据库二进制版本和系统数据目录完全相同时,同一类查询会具有相同的 queryid (即在物理复制的主从上,同类查询的 queryid 默认是相同的),然而对于逻辑复制则不然。但用户不应当对这一性质抱有过度的依赖与假设。
原始数据
PGSS 视图中的列可以分为三类:
描述性的标签列(Label):查询ID(queryid)、数据库 ID(dbid)、用户(userid),一个顶层查询标记,和标准化的查询文本(query)。
测量性的指标(Gauge):与最小、最大、均值标准差有关的八列统计量,以 min,max,mean,stddev 作为前缀,以 plan_time 与 exec_time 作为后缀。
累积性的指标(Counter):除了上面八列与标签列的其他指标,例如 calls、rows 等,最重要、最有用的指标都在这一类里。
首先解释一下 queryid:queryid 是查询语句被解析后,剥离常量后生成规范化查询的哈希值,因此可以用来标识同一类查询。不同的查询语句可能有着同样的 queryid (规范化后结构一样),同样的查询语句也可能有着不同的 queryid (例如因为 search_path 不同,导致实际查询的表不懂)。
同样的查询可能会在不同的数据库中被不同的用户所执行。因此在 PGSS 视图中,queryid,dbid,userid,toplevel 四个标签列,共同组成了唯一标识一条记录的“主键”。
对于指标列而言,测量性质的指标(GAUGE) 主要是执行时间与计划时间相关的八个统计量,然而用户没有办法很好地控制这些统计量的统计范围,所以实用价值并不大。
真正重要的指标是累积性的指标(Counter),例如:
calls :此查询组发生了多少次调用。
total_exec_time + total_plan_time:查询组累计耗费时间。
rows:查询组累计返回了多少行。
shared_blks_hit + shared_blks_read:缓冲池累计命中和读取操作次数。
wal_bytes:此组中的查询累计生成的 WAL 字节数。
blk_read_time 和 blk_write_time:累计花费在块读写IO上的时间
这里,最有意义的指标是 calls 与 total_exec_time,可以用于计算查询组的核心指标 QPS (吞吐量)与 RT(延迟/响应时间),但其他的指标也很有参考价值。
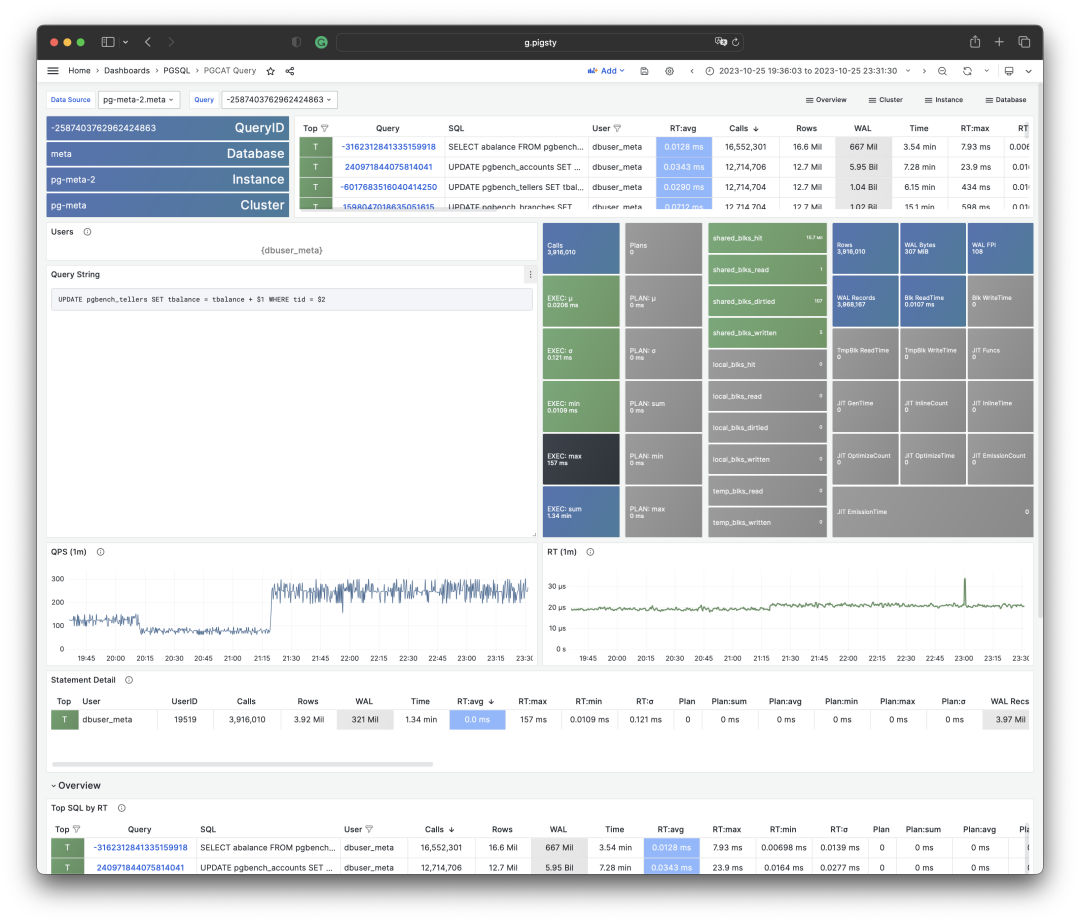
可视化展现 PGSS 视图的某个查询组快照
要解读累积性指标数据,只有某一个时刻的数据是不够的。我们需要对比至少两个时刻的快照,才能得到有意义的结论。
作为特例,如果您感兴趣的范围正好是从统计周期伊始(通常是启用此扩展时)至今,那么确实不需要对比“两个快照”。但用户感兴趣的时间粒度通常并不会这么粗放,而往往是以分钟、小时、天为单位。
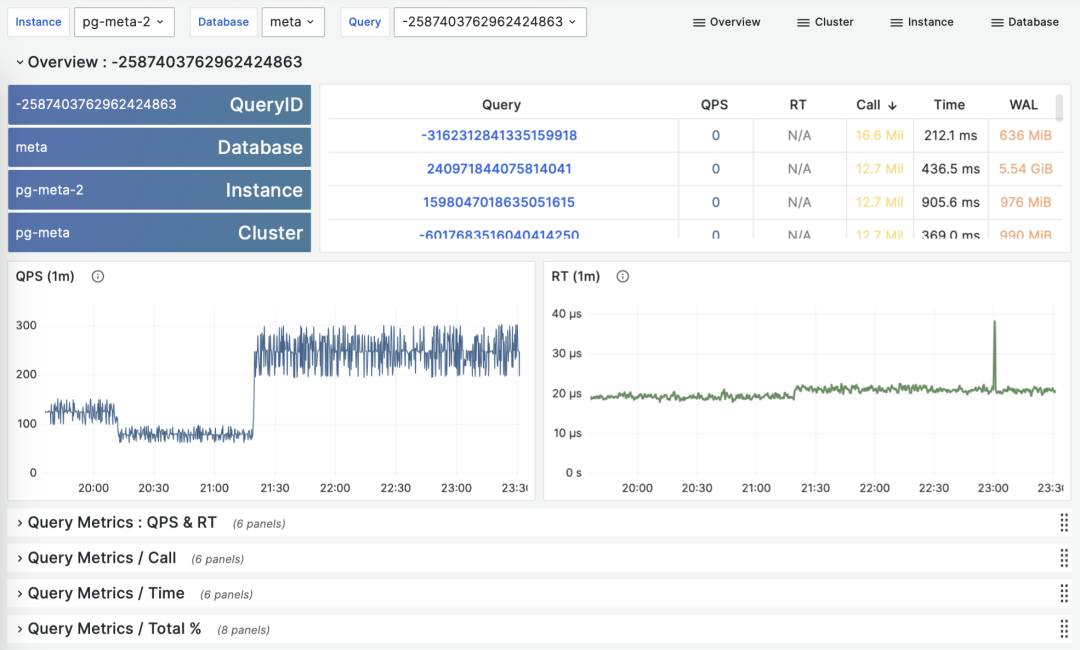
根据多个 PGSS 查询组快照计算历史时序指标
好在类似 Pigsty 监控系统这样的工具会定期(默认每隔10s)截取头部查询(耗时Top256)的快照。有了许多不同类型的累积指标 M(etrics)在不同时刻的快照之后,我们就能计算出某个累积性指标的三种重要派生指标:
dM/dt :指标 M 基于时间的微分,即每秒的增量。
dM/dc:指标 M 基于调用次数的微分,即每次调用的平均增量。
%M:指标 M 在整个工作负载中所占的百分比。
这三类指标正好与宏观优化的三类目标相对应,对时间的微分 dM/dt 揭示了每秒资源使用量,通常用于减少资源消耗的优化目标。对调用次数的微分 dM/dc 揭示了每次调用的资源使用量,通常用于改善用户体验的优化目标。而百分比指标 %M 展示了查询组在整个工作负载中所占的百分比,通常用于平衡工作负载的优化目标。
对时间微分
让我们首先来看第一类指标:对时间的微分。在这里,我们可以使用的指标 M 包括:calls,total_exec_time,rows,wal_bytes,shared_blks_hit + shared_blks_read,以及 blk_read_time + blk_write_time。其他的指标也有参考意义,但让我们从最重要的开始。
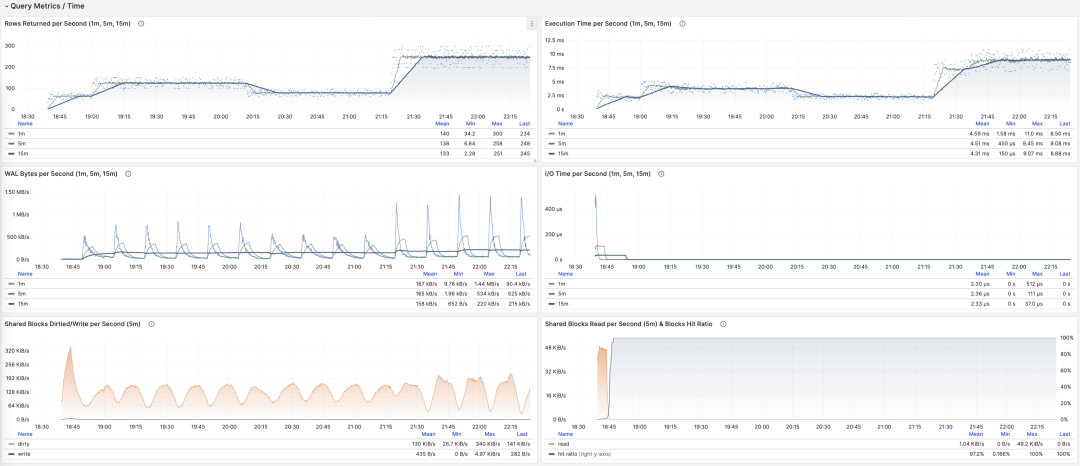
可视化展现对时间的微分指标 dM/dt
计算这些指标的方式其实很简单,我们只需要:
- 首先计算两个快照之间的指标值 M 的差值:M2 - M1
- 然后计算两个快照之间的时间差值:t2 - t1
- 最终计算 (M2 - M1) / (t2 - t1) 即可
生产环境通常会使用 5s,10s,15s,30s,60s 这样的数据采样间隔。对于负载分析通常会使用 1m, 5m,15m 作为常用的分析窗口大小。
例如,当我们计算 QPS 时,就会分别计算最近 1分钟,5分钟,15分钟的 QPS。窗口越长曲线就越平稳,更能反映长期变化趋势;但是会隐藏短期波动细节,不利于发现瞬时异常波动,所以不同粒度的指标需要结合来看。
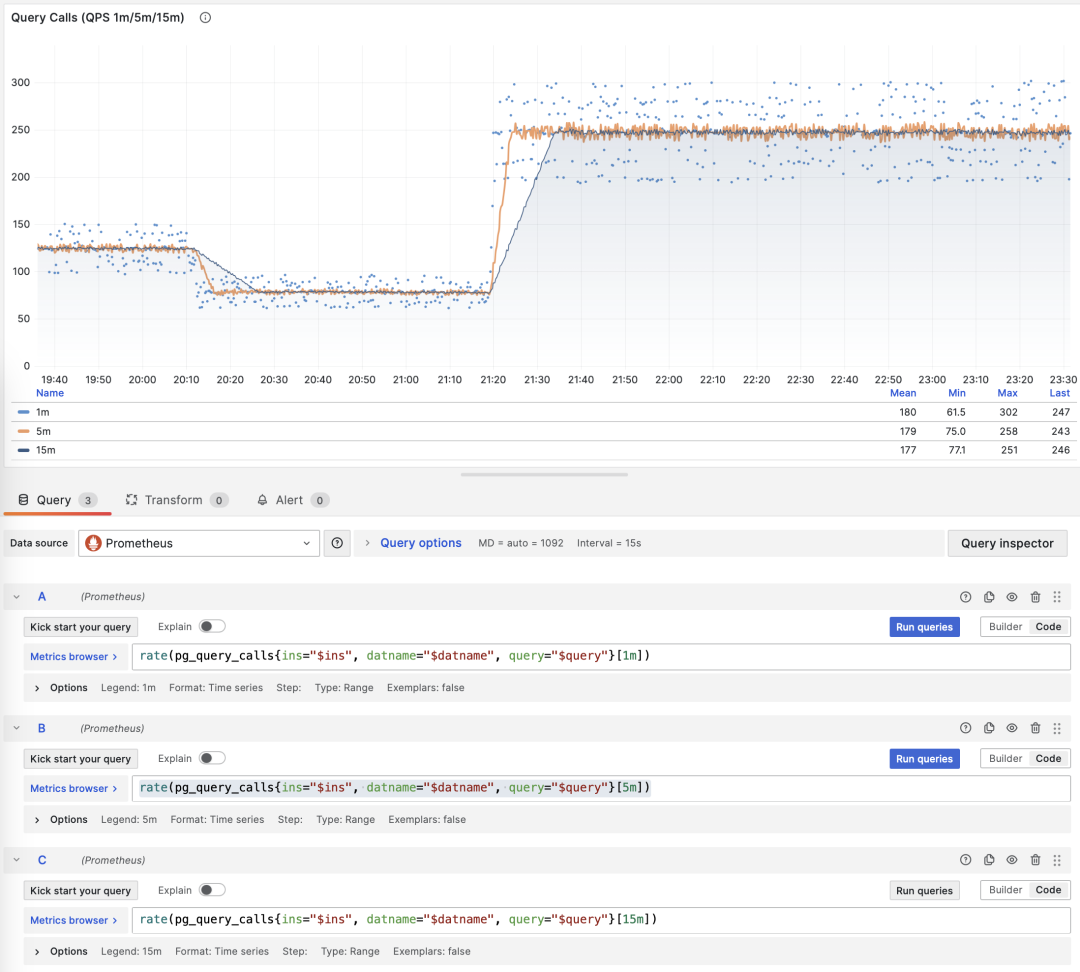
展示特定查询组 1/5/15 分钟窗口下的 QPS
如果您使用 Pigsty / Prometheus 来采集监控数据,那么可以使用 PromQL 简单地完成这些计算工作。例如,计算所有查询最近1分钟的 QPS 指标,使用以下语句就可以了: rate(pg_query_calls{}[1m])
QPS
当 M 是 calls 时,对时间求导的结果是 QPS,它的单位是每秒查询数(req/s),这是一个非常基础的指标。查询 QPS 属于吞吐量指标,直接反应了业务施加的负载状况,如果一个查询的吞吐量过高(例如,10000+)或者过低(例如,1-),有可能是值得关注的。
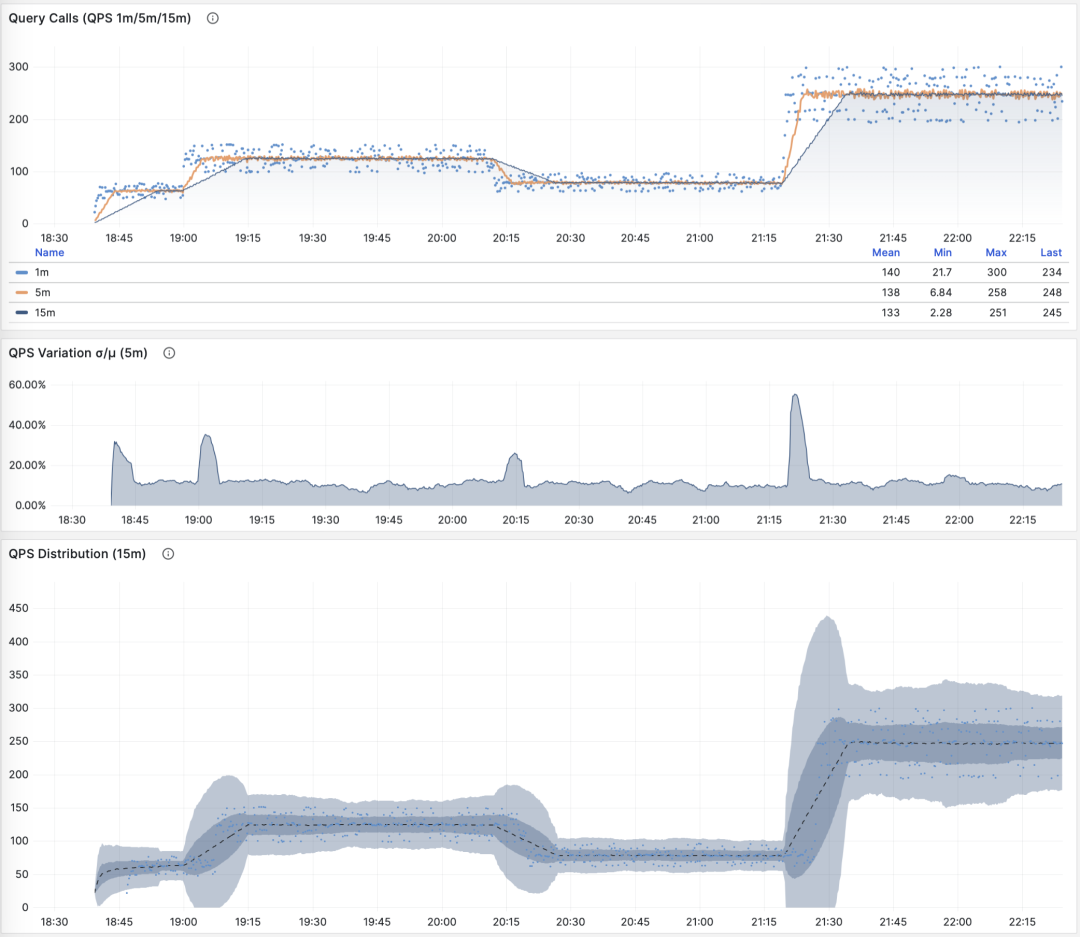
QPS:1/5/15 分钟 µ/CV, ±1/3σ分布
如果我们把所有查询组的 QPS 指标累加起来(且没超过PGSS的收集范围),就会得到所谓的 “全局QPS”。另一种获得全局 QPS 的方式是在客户端打点,在类似 Pgbouncer 的连接池中间件上采集,或者使用 ebpf 探测。但都不如 PGSS 方便。
请注意,QPS 指标并不具备负载意义上的横向可比性。不同查询组可能有着同样的 QPS,而单个查询的耗时却天差地别。甚至同一个查询组在不同时间点上产生的负载水平,也可能因为执行计划不同而发生巨大变化。每秒执行时长是一个更好的衡量负载的指标。
每秒执行时长
当 M 是 total_exec_time (+ total_plan_time,可选 )时,我们就会得到宏观优化中最重要的指标之一:在查询组上耗费的的执行时间,有意思的是,这个导数的单位是 秒/每秒,所以分子分母相互约掉了,使得它实际上是一个无量纲的指标。
这个指标的涵义是:服务器每秒钟花费多少秒来处理这个查询组中的查询,例如 2 s/s 意味着服务器每秒花费两秒执行时间在这组查询上;对于多核CPU,这当然是有可能的:把两个CPU核的全部时间都拿来就行了。
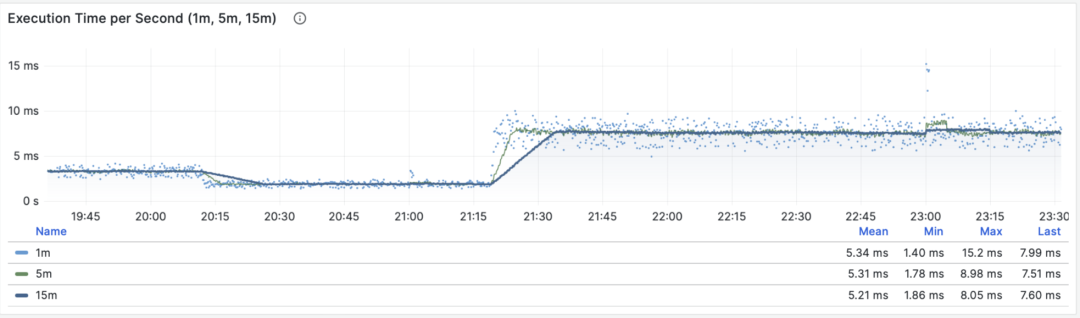
每秒执行时长:1/5/15 分钟均值
因此这里的值也可以理解为一个百分比:可以超过 100%,在这种视角下,它是一个类似于主机 load1, load5, load15 的指标,揭示了该查询组产生的负载水平。如果除以 CPU 核数,甚至可以得到归一化的查询负载贡献度指标。
但是我们需要注意的是,执行时间中包括了等待锁,等待I/O的时间。所以确实可能出现这样的情况:查询执行时间很长,但却没有对 CPU 负载产生影响。所以如果要精细分析慢查询,我们还要参考等待事件来进一步分析才行。
每秒行数
当 M 是 rows 时,我们会得到每秒该查询组返回的行数,单位是行/每秒(rows/s)。例如 10000 rows/s 意味着该类查询每秒向客户端吐出1万行数据。返回的行需要耗费客户端的处理资源,当我们需要检视应用客户端的数据处理压力时,这是一个非常有参考意义的指标。
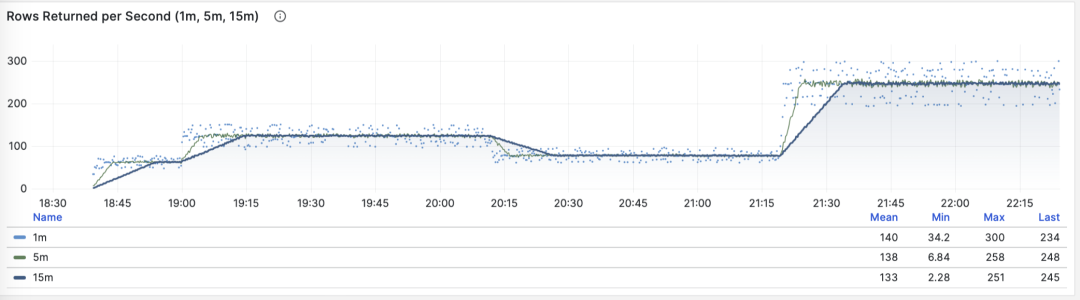
每秒返回的行数:1/5/15 分钟均值
共享缓冲区访问带宽
当 M 是 shared_blks_hit + shared_blks_read 时,我们会得到每秒命中/读取的共享缓冲区块数,如果将其乘以默认块大小 8KiB(极少情况下有可能会是其他的大小,例如32KiB),我们就会得到一类查询“访问”内存磁盘的带宽:单位是字节/秒。
举个例子,如果某一类查询每秒访问50万次共享缓冲区,折合 3.8 GiB/s 的内部访问数据流:那么这就是一个显著负载,也许会是一个很好的优化候选项。也许你应该检查一下这个查询,看看它是否配得上这些“资源消耗”。
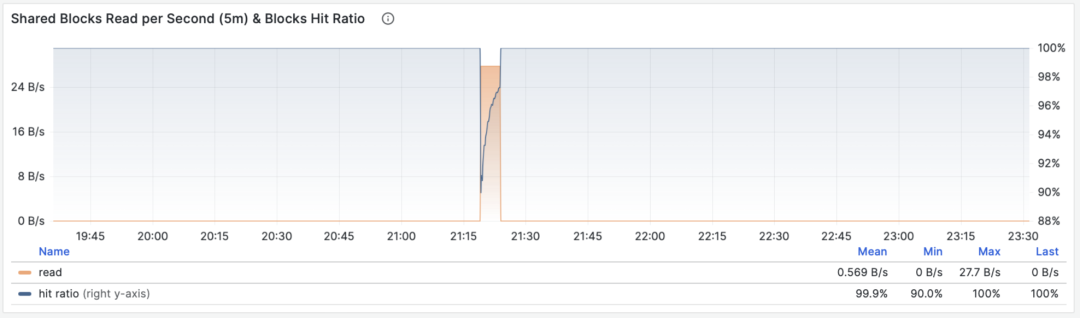
共享缓冲区访问带宽与缓冲区命中率
另一个值得参考的衍生指标是缓冲区命中率:即 hit / (hit + read) ,它可以用于分析性能变化的可能原因 —— 缓存未命中。当然,重复访问同一个共享缓冲池里的块,并不会真的重新读取,即使真的去读取,也不一定是读取磁盘,有可能是读内存中的FS Cache。所以这里只是一个参考值,但它确实是一个非常重要的宏观查询优化参考指标。
WAL日志量
当 M 是 wal_bytes 时,我们得到了该查询生成 WAL 的速率,单位是字节/每秒(B/s)。这个指标是在 PostgreSQL 13 新引入的,可以用来定量揭示查询产生的 WAL 大小:写入的 WAL 越多越快,刷写磁盘、物理复制/逻辑复制、日志归档的压力就会越大。
一个典型的例子是:BEGIN; DELETE FROM xxx; ROLLBACK; 。这样的事务删了很多数据,产生了大量 WAL 却没有执行任何有用的工作,通过这个指标可以将其揪出来。
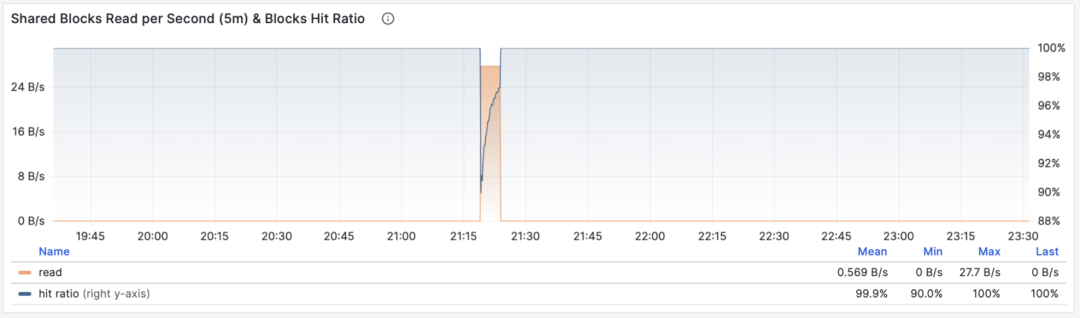
WAL字节率:1/5/15 分钟均值
这里有两个注意事项:上面我们说过,PGSS 无法跟踪执行失败的语句,但这里事务虽然 ROLLBACK 失败了,但是语句却是成功执行了的,所以会被 PGSS 跟踪记录。
第二件事是:在 PostgreSQL 中并非仅仅是 INSERT/UPDATE/DELETE 会产生 WAL 日志,SELECT 操作也有可能产生 WAL 日志,因为 SELECT 可能会修改元组上的标记(Hint Bit)让页面校验和出现变化,触发 WAL 日志写入。
甚至存在这种可能,如果读取负载非常大,它会有较大概率导致 FPI 镜像生成,产生可观的 WAL 日志量。你可以通过进一步检查 wal_fpi 指标。
共享缓冲区写脏/写回带宽
对于 13 以下的版本,共享缓冲区写脏/写回带宽指标可以作为一个近似下位替代,用于分析查询组的写入负载特征。
I/O耗时
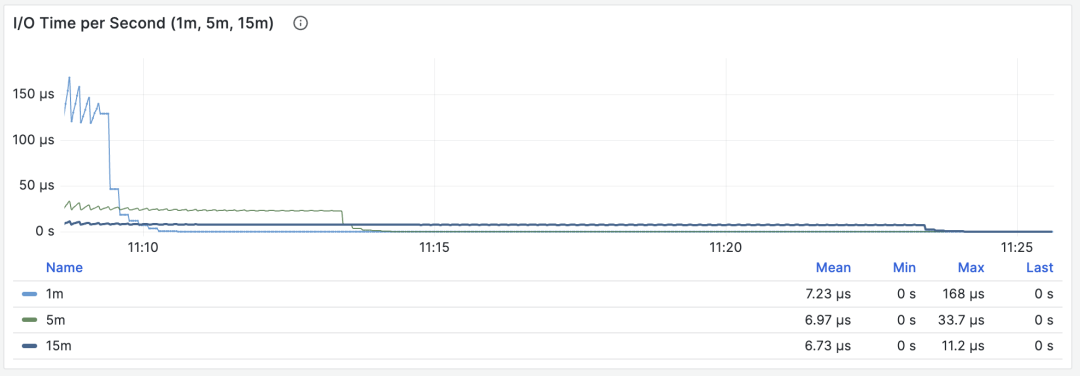
当 M 是 blks_read_time + blks_write_time ,我们会得到查询组花费在块 I/O 上的耗时比例,单位是 “秒/每秒”,与每秒执行时长指标一样,它也反映出一样操作占用的时间比例。
I/O 耗时对于分析查询毛刺原因很有帮助
因为 PostgreSQL 会使用操作系统提供的 FS Cache,所以即使这里执行了块读取/写入,可能在文件系统层面上仍然是发生在内存中的缓冲操作。所以它只能作为一个参考指标,使用时需要谨慎,需要与主机节点上的磁盘 I/O 监控相互对照。
对时间微分的指标 dM/dt,可以展现出一个数据库实例/集群内部工作负载的全貌,对于优化资源使用的场景来说尤其有用。但是如果您的优化目标是改善用户体验,那么可能另一组指标 —— 对调用次数的微分 dM/dc,会更有参考意义。
对调用次数微分
上面我们已经计算了六类重要指标对于时间的微分,另一类衍生指标计算方式是对 “调用次数” 进行微分,也就是分母从时间差变成了 QPS。
这类指标重要性相比前者甚至更高,因为它提供了直接关乎用户体验的几个核心指标,比如最重要的 —— 查询响应时间 (RT,Response Time),或曰 延迟(Latency)。
计算这些指标的方式也很简单,我们只需要:
- 计算两个快照之间的指标值 M 的差值:M2 - M1
- 然后计算两个快照之间的 calls 差值:c2 - c1
- 然后计算 (M2 - M1) / (c2 - c1) 即可
对于 PromQL 实现来说,对于调用次数的微分指标 dM/dc,可以用“对时间的微分指标 dM/dt” 计算得到。例如要计算 RT,就可以使用 每秒执行时长 / 每秒查询数 ,两指标相除即可:
rate(pg_query_exec_time{}[1m]) / rate(pg_query_calls{}[1m])
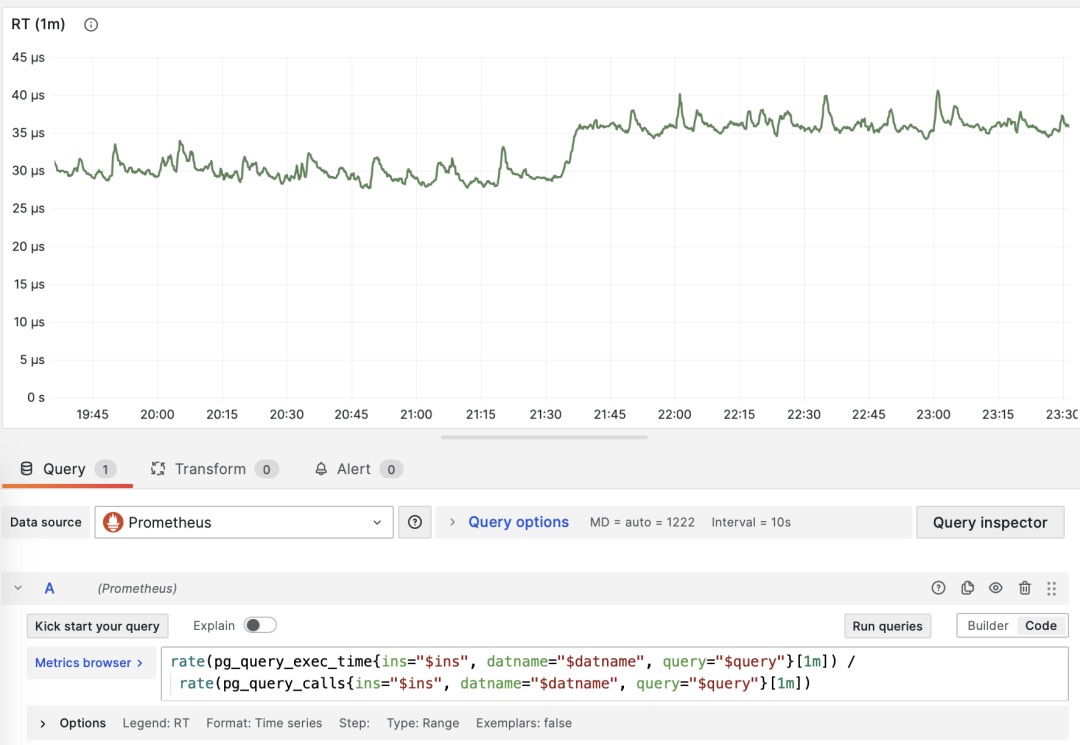
dM/dt 可以用于计算 dM/dc
调用次数
当 M 是 calls 时,对自己微分没有任何意义(结果会恒为 1)。
平均延迟/响应时间/RT
当 M 是 total_exec_time 时,对调用次数求导的结果是 RT,或响应时间/延迟。它的单位是秒(s)。RT 直接反映了用户体验,是宏观性能分析中最重要的指标。这个指标的含义是:此查询组在服务器上的平均查询响应时间。如果条件允许启用 pg_stat_statements.track_planning,还可以加上 total_plan_time 一起计算,结果会更精确更具有代表性。
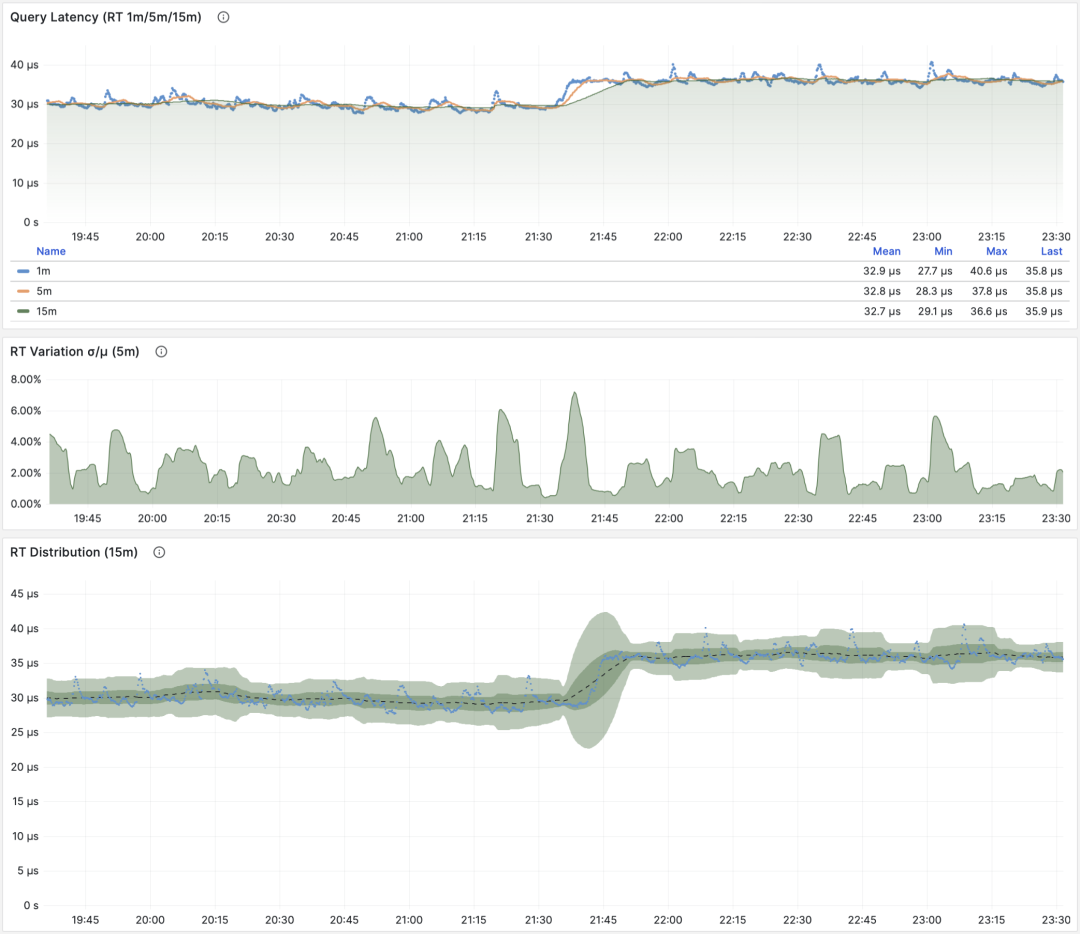
RT:1/5/15 分钟 µ/CV, ±1/3σ分布
这里要特别强调两种特殊情况:第一:PGSS不跟踪失败/执行中的语句;第二:PGSS的统计数据受(pg_stat_statements.max)参数限制,可能出现部分采样偏差。尽管有这些局限性,但想要获取至关重要的查询语句组延迟数据,PGSS 毫无疑问是最为稳妥可靠的来源。正如上面所述,在其他观测点位也有办法采集查询 RT 数据,但会麻烦得多。
你可以在客户端侧打点,采集语句执行时间,通过指标或者日志上报;你也可以尝试使用 ebpf 来探测语句 RT,这对基础设施和工程师要求会比较高。Pgbouncer 和 PostgreSQL (14+) 倒是也提供了 RT 指标,只可惜粒度都是数据库级别,没有一个能做到 PGSS 查询语句组级别的指标收集。
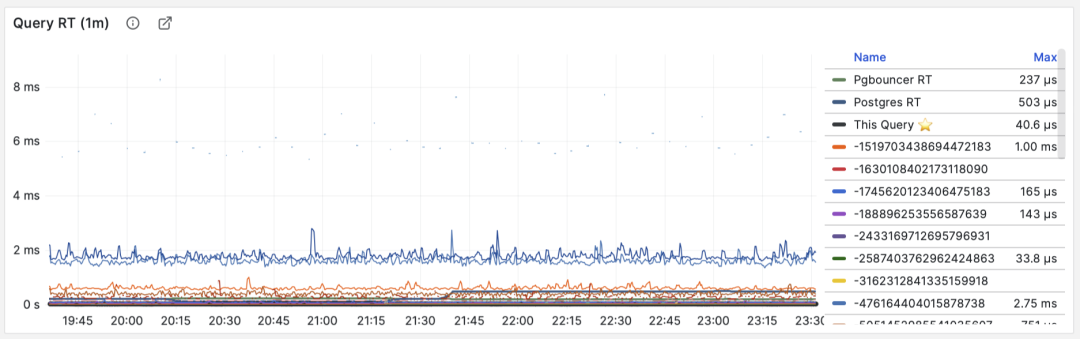
RT:语句级/连接池级/数据库级
不同于 QPS 这样的吞吐量指标,RT 是具有横向可比性的:例如某个查询组平时的 RT 都在1毫秒内,那么超过 10ms 的事件应当被视作严重的偏差进行分析。
当出现故障时, RT 视图对于定位原因也很有帮助:如果所有查询整体 RT 变慢,那么最有可能与资源不足有关。如果只是特定查询组的 RT 发生变化,那就更有可能是某些慢查询导致了问题,应当进一步调查分析。如果 RT 变化的时间点与应用发布部署吻合,则应当考虑是否要回滚这些部署。
此外,在性能分析,压力测试,基准测试时,RT 也是最重要的指标。你可以通过对比典型查询在不同环境(例如不同PG大版本、不同硬件、不同配置参数)下的延迟表现来评估系统的性能,并以此为依据不断对系统性能进行调整与改进。
RT 是如此重要,以至于 RT 本身又会衍生出许多下游指标来:1分钟/5分钟/15分钟的均值µ与标准差σ自然必不可少;过去15分钟的 ±σ,±3σ 可以用来衡量 RT 的波动范围,过去1小时的 95,99 分位点也很有参考价值。
RT 是评估 OLTP工作负载的核心指标,怎么强调它的重要性都不为过。
平均返回行数
当 M 是 rows 时,我们会得到每次查询平均返回的行数,单位是行/每查询。对于 OLTP 工作负载来说,典型查询模式为点查,即每次查询返回几条数据。
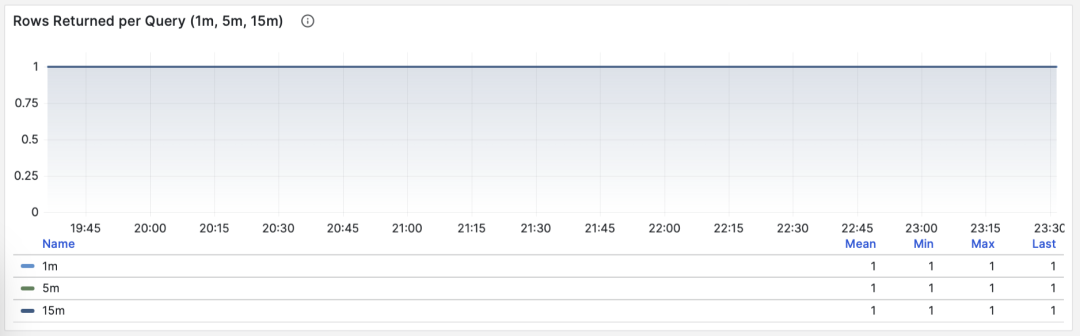
按照主键查询单条记录,平均返回行数稳定为1
如果一个查询组每次查询向客户端吐出几百甚至成千上万行记录,那么应当对其进行审视。如果这是有意而为之的设计,比如批量加载任务/数据转储,那么不需要做什么。如果这是由应用/客户端发起的请求,那么可能存在错误,比如语句缺少 LIMIT 限制,查询缺少分页设计,这样的查询应该进行调整修复。
平均共享缓冲区读取/命中
当 M 是 shared_blks_hit + shared_blks_read 时,我们会得到每条查询“命中”与“读取”共享缓冲区的平均次数,如果将其乘以默认块大小 8KiB,我们就会得到这类查询每次执行的“带宽”,单位是 B/s:每次查询平均会访问/读取多少 MB 数据 ?
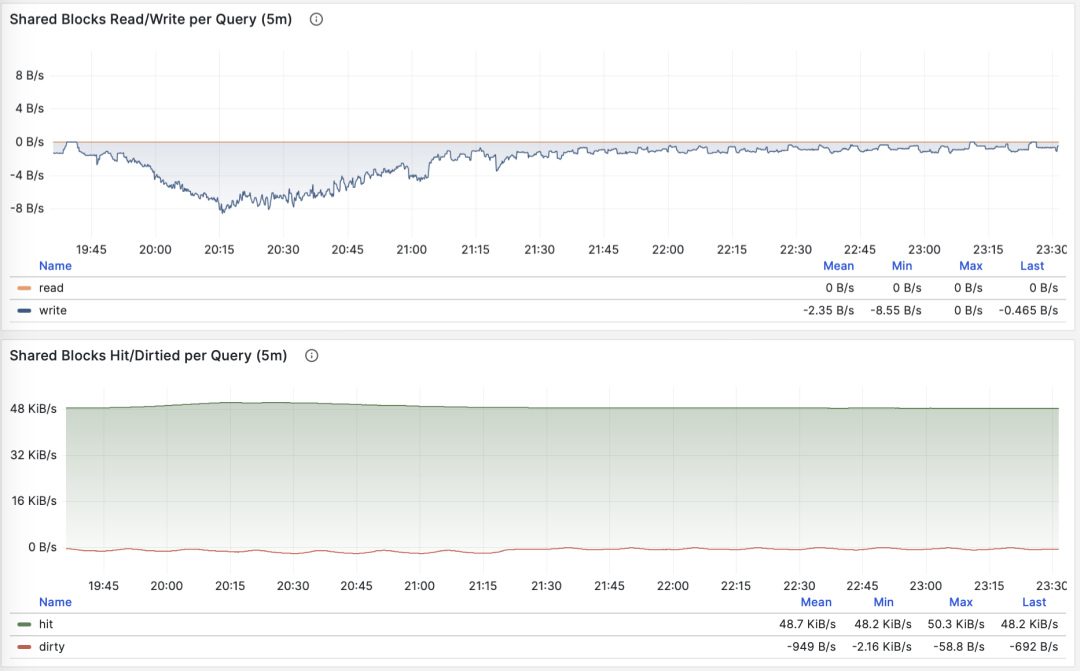
按照主键查询单条记录,平均返回行数稳定为1
查询平均访问的数据量通常与平均返回的行数相匹配,如果你的查询平均只返回了几行,却访问了成M上G的数据块,那你就需要特别注意了:这样的查询对于数据冷热状态非常敏感,如果所有的块都在缓冲区中,它的性能可能还说的过去,但如果从磁盘冷启动,执行时间可能会出现戏剧性的变化。
当然,不要忘记 PostgreSQL 双缓存问题,所谓“读取”的数据可能已经在操作系统文件系统层面被缓存过一次了。所以你需要与操作系统监控指标,或者 pg_stat_kcache ,pg_stat_io 这些系统视图相互参照进行分析。
另一种值得关注的模式是此指标的突变,这通常意味着该查询组的执行计划可能出现了翻转/劣化,非常值得关注与进一步研究。
平均WAL日志量
当 M 是 wal_bytes 时,我们得到了每条查询平均生成 WAL 的大小,这是 PostgreSQL 13 新引入的字段。这个指标可以衡量查询的变更足迹大小,并计算读写比例等重要评估参数。
稳定的QPS却有着周期性WAL波动,可推断是 FPI 的影响
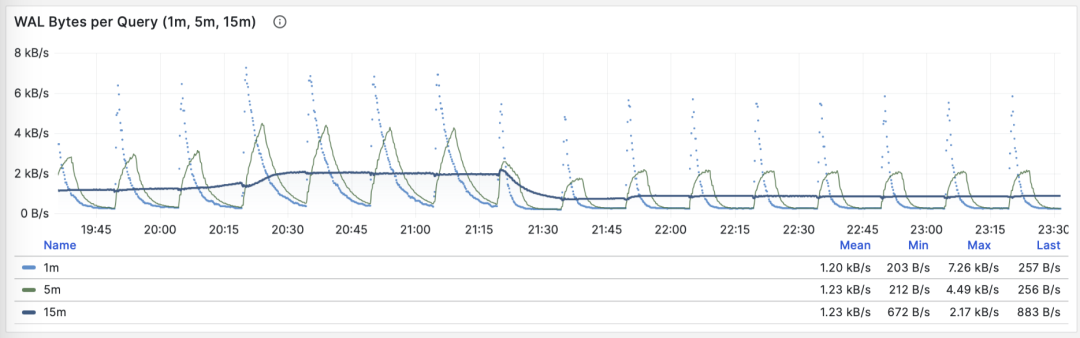
另一个用途是优化检查点/Checkpoint:如果你观察到此指标周期性的起伏(周期约等于 checkpoint_timeout),那么可以通过调整检查点间距,来优化查询产生 WAL 的数量。
对调用次数进行微分的指标 dM/dc,可以展现出一类查询的工作负载特性,对于优化用户体验来说非常有用。特别是 RT 乃是性能优化的黄金指标,怎样强调其重要性都不为过。
dM/dc 这样的指标为我们提供类似重要的绝对值指标,但如果想要找出哪些查询的优化潜在收益最大,还需要用到 %M 百分比指标。
百分比指标
现在我们来研究第三类指标,百分比指标。即某个查询组相对于整体工作负载所占的比例。
百分比指标 M% 为我们提供了某个查询组相对于整体工作负载的比例,帮助我们在频次、时间、I/O时间/次数上时识别出“主要参与者”,找出潜在优化收益最大的候选查询组,作为优先级评定的重要依据。
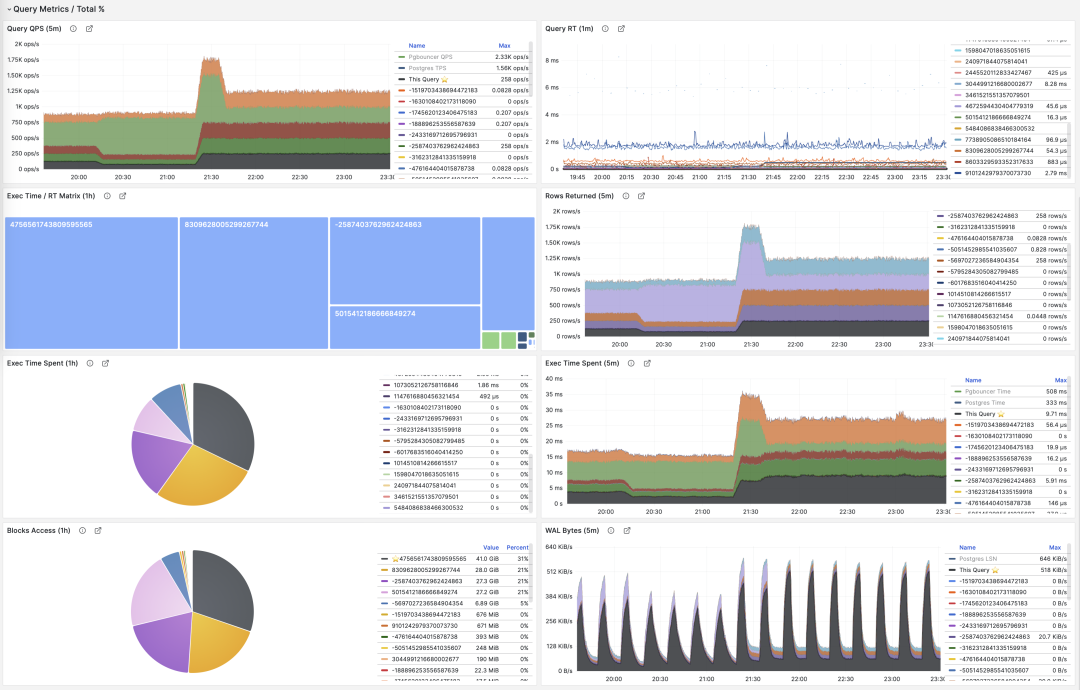
常用百分比指标 %M 一览
举个例子,如果某个查询组有 1000 QPS 的绝对值,看上去不少;但如果它只占整个工作负载的 3%,那么优化此查询的收益与优先级就没那么高了;反之,如果它占据了整个工作负载的 50% 还要多 —— 如果你有办法把它优化掉就可以砍掉整个实例吞吐量的半壁江山,优化它的优先级就会非常之高。
常见的优化策略是这样的:首先把所有查询组分别按照上面提到的重要指标:calls,total_exec_time,rows,wal_bytes,shared_blks_hit + shared_blks_read,以及 blk_read_time + blk_write_time 在一段时间内的 dM/dt 值进行排序取 TopN (比如 N=10 或者更多),加入优化候选列表中。
按照特定标准,选取待优化的 TopSQL
然后,对于优化候选列表中的每个查询组,依次分析其 dM/dc 指标,结合具体的查询语句与慢查询日志/等待事件进行分析,决定这是不是一个值得优化的查询。对于决定(Plan)进行优化的查询,就可以使用后续篇 “微观优化” 将要介绍的技巧进行调优(Do),并使用监控系统评估优化的效果(Check),总结分析后进入下一个 PDCA 戴明循环,持续进行管理优化。
除了对指标取 TopN 之外,还可以使用可视化的方式。可视化非常有助于从工作负载中识别 “主要贡献者”,复杂的判断算法可能还远比不上人类DBA对监控图形模式的直觉。想要形成比例感,我们可以借助饼图,树图或者堆叠的时序图。

将所有查询组的 QPS 进行堆叠
例如,我们可以使用饼图来标识过去1小时内耗时/IO使用最大的查询,使用二维树图(大小代表总耗时,颜色代表平均RT)来展示一个额外的维度。并用堆叠时序图来展示比例随时间的变化关系。
我们也可以直接分析当下的 PGSS 快照,按照不同的关注点进行排序,按照您自己的标准选择有待优化的查询即可。
I/O 耗时对于分析查询毛刺原因很有帮助
总结
最后,让我们对上面的内容做一个总结。
PGSS提供了丰富的指标,其中最重要的累积指标可以使用三种方式进行加工处理:
dM/dt :指标 M 基于时间的微分,揭示了每秒资源使用量,通常用于减少资源消耗的优化目标。
dM/dc:指标 M 基于调用次数的微分,揭示了每次调用的资源使用量,通常用于改善用户体验的优化目标。
%M :百分比指标展示了查询组在整个工作负载中所占的百分比,通常用于平衡工作负载的优化目标。
通常,我们会根据 %M :百分比指标 Top 查询选择高价值的备选优化查询,并使用 dM/dt *dM/dc* 指标进行进一步的评估,确认是否有优化空间和可行性,并评估优化后的效果。如此往复,不断循环。
理解了宏观优化的方法论后,我们就可以用这样的方法去定位优化慢查询了。这里给出了一个具体的 《 利用监控系统诊断PG慢查询》的例子。在下一篇中,我们将介绍关于 PostgreSQL查询 微观优化 的经验技巧。
参考
[1] PostgreSQL HowTO: pg_stat_statements by Nikolay Samokhvalov
[3] 利用监控系统诊断PG慢查询
[4] 如何用Pigsty监控现有PostgreSQL (RDS/PolarDB/自建)?
如何用 pg_filedump 抢救数据?

备份是DBA的生命线 —— 但如果你的 PostgreSQL 数据库已经爆炸了又没有备份,那么该怎么办呢?也许 pg_filedump 可以帮到你!
最近遇到了一个比较离谱的活儿,情况是这样的:有个用户的 PostgreSQL 数据库损坏了,是 Gitlab 自己拉起的 PostgreSQL。没有从库,没有备份,也没有 dump。跑在拿 SSD 当透明缓存的BCACHE上,断电后起不来了。
但这还没完,接连经受了几轮摧残之后,它彻底歇菜了:首先是因为忘了挂BCACHE盘,导致 Gitlab重新初始化了一遍新的数据库集群;然后是因为各种原因隔离失效,在同一个集簇目录上运行两个数据库进程烤糊了数据目录;接着是运行 pg_resetwal 不带参数把数据库推回起源点,最后是让空数据库跑了一阵子,然后把烤糊前的临时备份移除了。
看到这个 Case 我确实有点无语:这都成一团浆糊了还恢复个什么,目测只能从底层二进制文件直接抽取数据来恢复了。我建议他去找个数据恢复公司碰碰运气吧,也帮忙问了一圈儿,但是一大堆数据恢复公司里,几乎没有几个有 PostgreSQL 数据恢复服务的,有的也是比较基础的那种问题处理,碰上这种情况都说只能随缘试试。
数据恢复报价通常是按文件数量来收费的,一个文件从 ¥1000 ~ ¥5000 不等。Gitlab库里几千个文件,按表算的话大概有 1000张表,全恢复完几十万可能不至于,但十几万肯定是没跑了。可一天过去了也没人接,这着实让我感觉蛋疼:要是没人能接这活,岂不是显得 PG 社区没人了?
我想了一下,这活看着挺蛋疼,但也挺有挑战趣味的,咱死马当活马医,修不好不收钱就是 —— 不试试咋知道行不行呢?所以就接了自己上了。
工具
工欲善其事,必先利其器。数据恢复首先当然是要找有没有趁手的工具:pg_filedump 就是一把不错的武器,它可以用来从 PostgreSQL 数据页面中抽取原始二进制数据,许多低层次的工作可以交给它。
这个工具可以用 make 三板斧编译安装,当然需要先安装对应大版本的 PostgreSQL 才行。Gitlab 默认使用的是 PG 13,所以确保对应版本的 pg_config 在路径中后直接编译即可。
git clone https://github.com/df7cb/pg_filedump
cd pg_filedump && make && sudo make install
pg_filedump 的使用方式并不复杂,你把数据文件喂给他,告诉它这张表每一列的类型,它就能帮你解读出来。比如第一步,我们就得知道这个数据库集簇中有哪几个数据库。这个信息记录在系统视图 pg_database 中。这是一张系统层面的表,位于 global 目录中,在集群初始化时会分配固定的 OID 1262,所以对应的物理文件通常是: global/1262。
vonng=# select 'pg_database'::RegClass::OID;
oid
------
1262
这张系统视图里有不少字段,但我们主要关心的是前两个: oid 和 datname ,datname 是数据库的名称,oid 则可以用于定位数据库目录位置。以用 pg_filedump 把这张表解出来看一看, -D 参数可以告诉 pg_filedump 如何解释这张表里每一行的二进制数据。你可以指定每个字段的类型,用逗号分隔,~ 表示后面的部分都忽略不要。
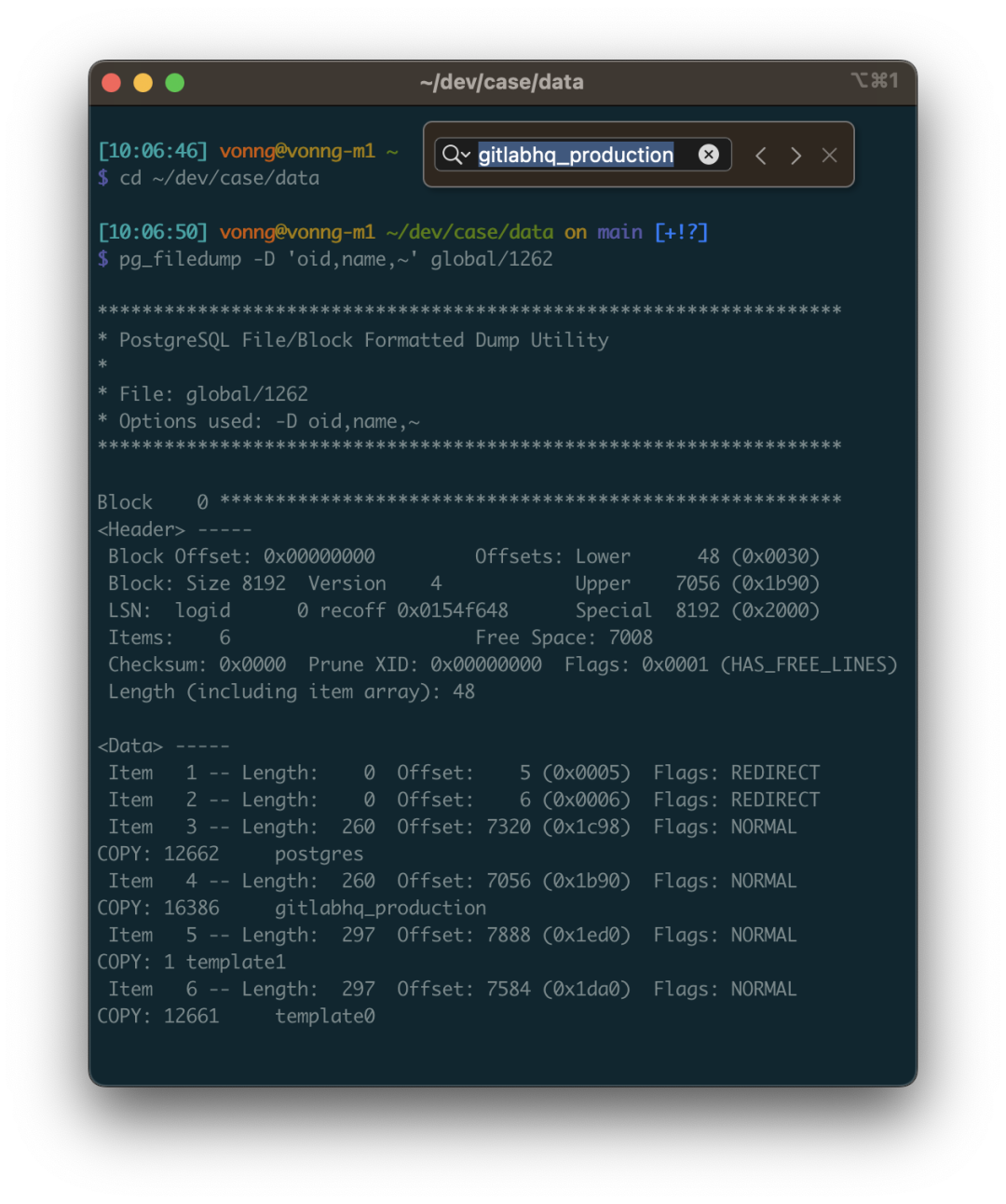
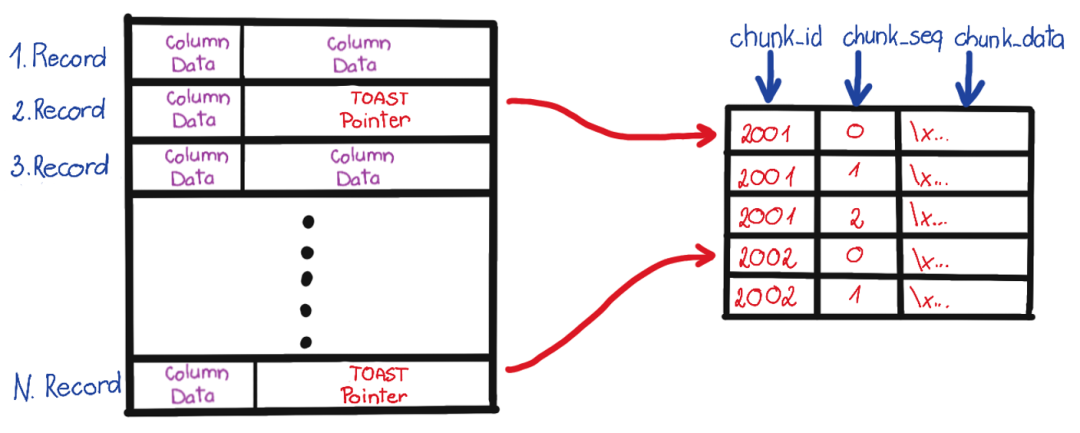
可以看到,每一行数据都以 COPY 开始,这里我们发现了目标数据库 gitlabhq_production,其 OID 为 16386 。所以这个数据库内的所有文件都应当位于 base/16386 子目录中。
恢复数据字典
知道了要恢复的数据文件目录,下一步就是解出数据字典来,这里面有四张重要的表需要关注:
•pg_class:包含了所有表的重要元数据•pg_namespace:包含了模式的元数据•pg_attribute:包含了所有的列定义•pg_type:包含了类型的名称
其中 pg_class 是最为重要,不可或缺的一张表。其他几张系统视图属于 Nice to have:能让我们的工作更加简单一些。所以,我们首先尝试恢复这张表。
pg_class 是数据库级别的系统视图,默认有着 OID = 1259 ,所以 pg_class 对应的文件应当是: base/16386/1259,在 gitlabhq_production 对应数据库目录下。

这里说句题外话:熟悉 PostgreSQL 原理的朋友知道:实际底层存储数据的文件名(RelFileNode)虽然默认与表的 OID 保持一致,但是一些操作可能会改变这一点,在这种情况下,你可以用 pg_filedump -m pg_filenode.map 解析数据库目录下的映射文件,找到 OID 1259 对应的 Filenode。当然这里两者是一致的,就表过不提了。
我们根据 pg_class 的表结构定义(注意要使用对应PG大版本的表结构),解析其二进制文件: pg_filedump -D ‘oid,name,oid,oid,oid,oid,oid,oid,oid,int,real,int,oid,bool,bool,char,char,smallint,smallint,bool,bool,bool,bool,bool,bool,char,bool,oid,xid,xid,text,text,text’ -i base/16386/1259
然后就可以看到解析出来的数据了。这里的数据是 \t 分隔的单行记录,与 PostgreSQL COPY 命令默认使用的格式相同。所以你可以用脚本 grep 收集过滤,掐掉每行开头的 COPY ,并重新灌入一张真正的数据库表来细看。
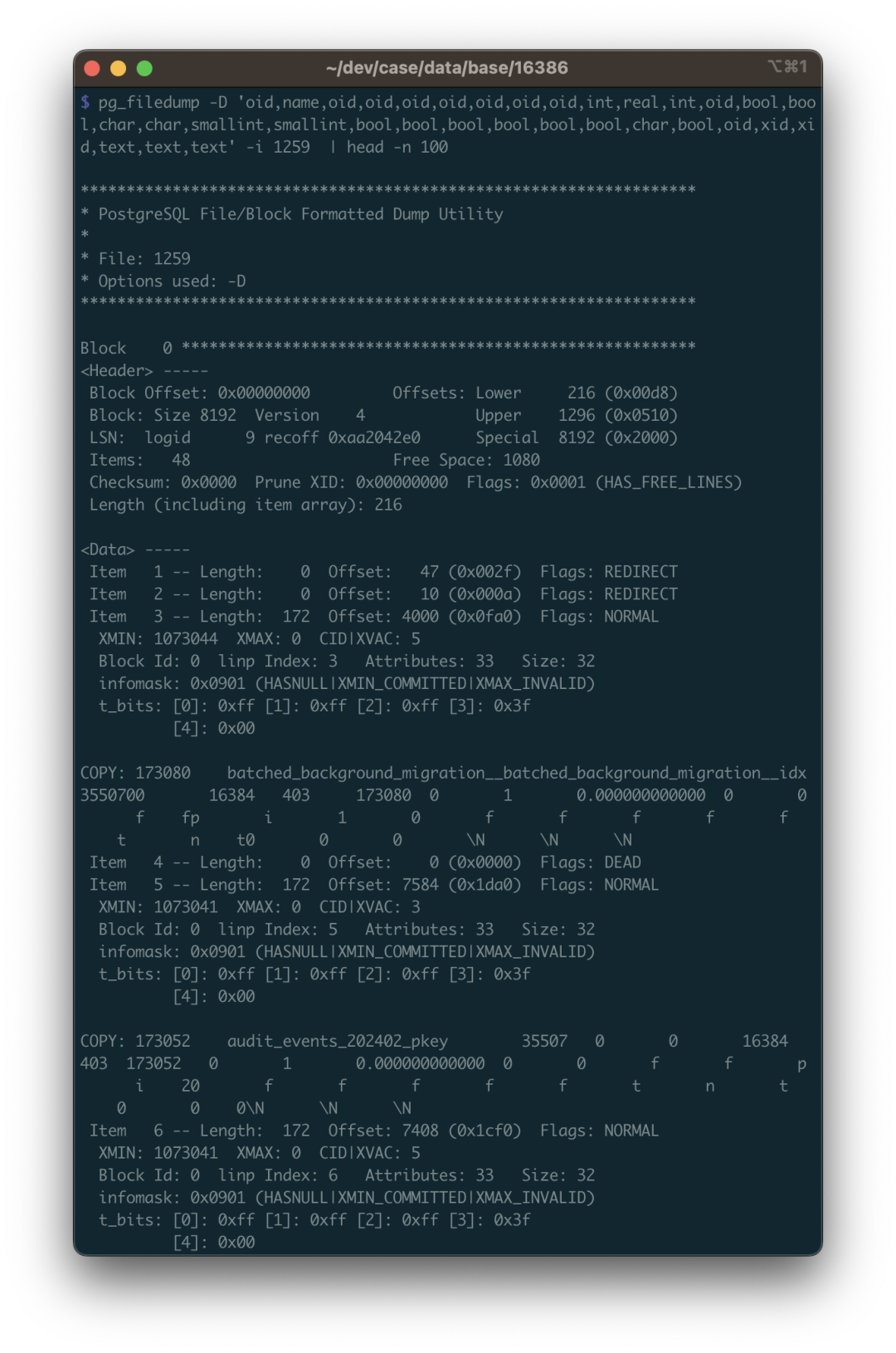
在数据恢复时需要注意许多细节,其中第一条就是:你需要处理被删除的行。怎么识别呢?使用 -i 参数打印每一行的元数据,元数据里有一个 XMAX 字段。如果某一行元组被某个事务删除了,那么这条记录的 XMAX 就会被设置为该事务的 XID 事务号。所以如果某一行的 XMAX 不是零,就意味着这是一条被删除的记录,不应当输出到最终的结果中。
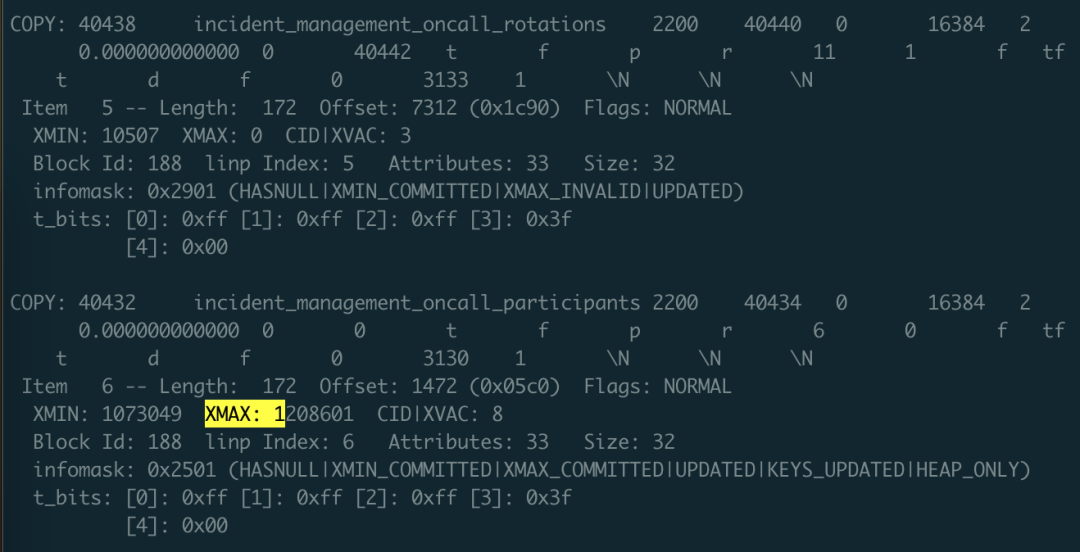
这里的 XMAX 代表这是条被删除的记录
有了 pg_class 数据字典之后,你就可以清楚地找到其他表,包括系统视图的 OID 对应关系了。用同样的办法可以恢复 pg_namespace ,pg_attribute ,pg_type 这三张表。有了这四张表就可以干什么呢?

你可以用 SQL 生成每张表的输入路径,自动拼出每一列的类型作为 -D 参数,生成临时结果表的 Schema。总而言之,可以用编程自动化的方式,自动生成所有需要完成的任务。
SELECT id, name, nspname, relname, nspid, attrs, fields, has_tough_type,
CASE WHEN toast_page > 0 THEN toast_name ELSE NULL END AS toast_name, relpages, reltuples, path
FROM
(
SELECT n.nspname || '.' || c.relname AS "name", n.nspname, c.relname, c.relnamespace AS nspid, c.oid AS id, c.reltoastrelid AS tid,
toast.relname AS toast_name, toast.relpages AS toast_page,
c.relpages, c.reltuples, 'data/base/16386/' || c.relfilenode::TEXT AS path
FROM meta.pg_class c
LEFT JOIN meta.pg_namespace n ON c.relnamespace = n.oid
, LATERAL (SELECT * FROM meta.pg_class t WHERE t.oid = c.reltoastrelid) toast
WHERE c.relkind = 'r' AND c.relpages > 0
AND c.relnamespace IN (2200, 35507, 35508)
ORDER BY c.relnamespace, c.relpages DESC
) z,
LATERAL ( SELECT string_agg(name,',') AS attrs,
string_agg(std_type,',') AS fields,
max(has_tough_type::INTEGER)::BOOLEAN AS has_tough_type
FROM meta.pg_columns WHERE relid = z.id ) AS columns;
这里需要注意,pg_filedump -D 参数支持的数据类型名称是有严格限定的标准名称的,所以你必须把 boolean 转为 bool,INTEGER 转为 int。如果你想解析的数据类型不在下面这个列表中,可以首先尝试使用 TEXT 类型,例如表示IP地址的 INET 类型就可以用 TEXT 的方式解析。
bigint bigserial bool char charN date float float4 float8 int json macaddr name numeric oid real serial smallint smallserial text time timestamp timestamptz timetz uuid varchar varcharN xid xml
但确实会有其他的一些特殊情况需要额外的处理,比如 PostgreSQL 中的 ARRAY 数组类型,后面会详细介绍。
恢复一张普通表
恢复普通数据表和恢复一张系统目录表并没有本质区别:只不过 Catalog 的模式和信息都是公开的标准化的,而待恢复的数据库模式则不一定。
Gitlab 也属于一个开源的很有知名度的软件,所以找到它的数据库模式定义并不是一件难事。如果是一个普通的业务系统,那么多费点功夫也可以从 pg_catalog 中还原出原始 DDL 。
知道了 DDL 定义,我们就可以使用 DDL 中每一列的数据类型,来解释二进制文件中的数据了。下面,我们用 public.approval_merge_request_rules 这张 Gitlab 中的普通表为例,演示如何恢复这样一张普通数据表。
create table approval_project_rules
(
id bigint,
created_at timestamp with time zone,
updated_at timestamp with time zone,
project_id integer,
approvals_required smallint,
name varchar,
rule_type smallint,
scanners text[],
vulnerabilities_allowed smallint,
severity_levels text[],
report_type smallint,
vulnerability_states text[],
orchestration_policy_idx smallint,
applies_to_all_protected_branches boolean,
security_orchestration_policy_configuration_id bigint,
scan_result_policy_id bigint
);
首先,我们要将这里的类型转换成 pg_filedump 可以识别的类型,这里涉及到类型映射的问题:如果你有不确定的类型,比如上面的 text[] 字符串数组字段,就可以先用 text 类型占位替代,也可以直接用 ~ 忽略:
bigint,timestamptz,timestamptz,int,smallint,varchar,smallint,text,smallint,text,smallint,text,smallint,bool,bigint,bigint
当然这里有第一个知识点就是 PostgreSQL 的元组列布局是有顺序的,这个顺序保存在系统视图 pg_attribute 里面的 attrnum 中,而表中每一列的类型ID则保存在 atttypid 字段中,而为了获取类型的英文名称,你又需要通过类型ID引用 pg_type 系统视图(当然系统默认类型都有固定ID,也可以直接用ID映射)。综上,为了获取表中物理记录的解释方法,你至少需要用到上面提到的那四张系统字典表。
有了这张表上列的顺序与类型之后,并且知道这张表的二进制文件位置之后,你就可以利用这个信息翻译二进制数据了。
pg_filedump -i -f -D 'bigint,...,bigint' 38304
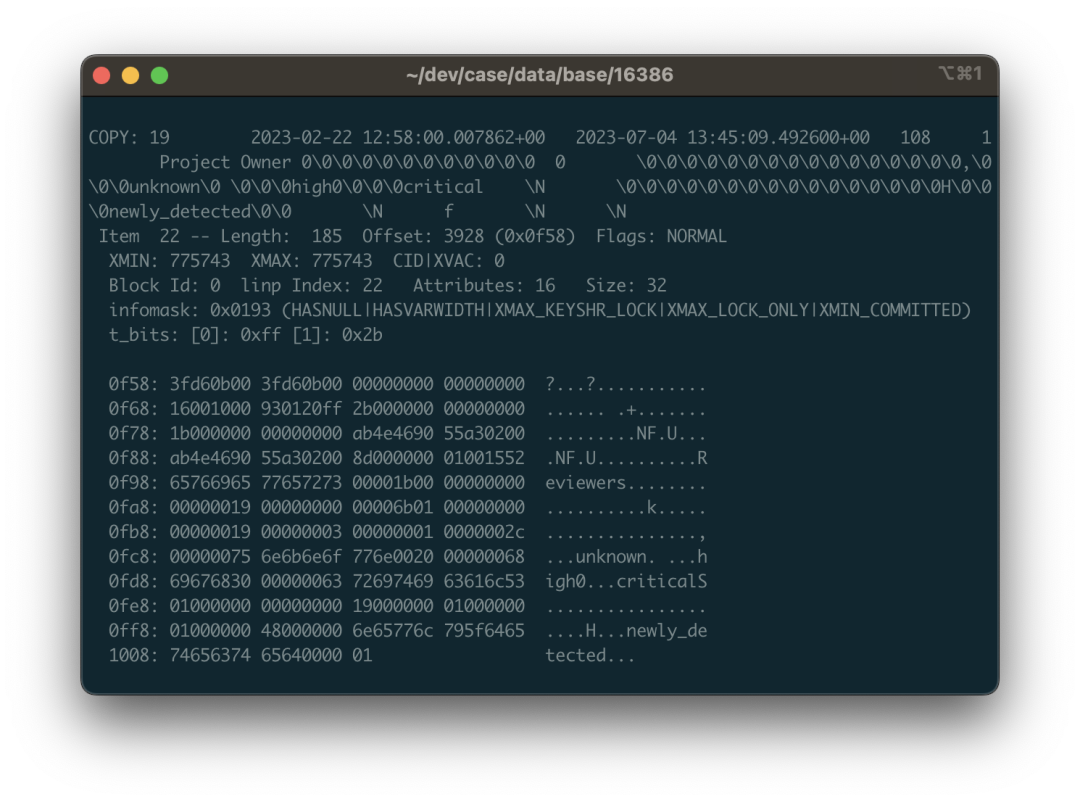
输出时结果建议添加 -i 与 -f 选项,前者会打印每一行的元数据(需要根据 XMAX 判断这一行有没有被删除);后者会打印原始二进制数据上下文(这一点对于处理 pg_filedump 解决不了的复杂数据是必要的)。
正常情况下,每一条记录都会以 COPY: 或 Error: 开头,前者代表提取成功,后者代表部分成功,或者失败。如果是失败,会有各种各样的原因,需要分别处理。对于成功的数据,你可以直接把它拿出来,每一行就是一条数据,用 \t 分隔,把 \N 替换为 NULL,处理好写入到临时表中保存待用即可。
当然魔鬼其实都在细节里,要是数据恢复真这么容易就好了。
魔鬼在细节中
在处理数据数据恢复时,有许多小细节需要关注,这里我提几个重要的点。
首先是 TOAST 字段的处理。TOAST 是“ The Oversized-Attribute Storage Technique ”的缩写,即超标属性存储技术。如果你发现解析出来的字段内容是 (TOASTED),那就说明这个字段因为太长,被切片转移到另外一张专用的表 —— TOAST 表中了。
如果某张表里有可能 TOAST 的字段,它就会有一张对应的 TOAST 表,在 pg_class 中用 reltoastrelid 标识其 OID。TOAST 其实也可以看做一张普通的表来处理,所以你可以用一样的方法把 TOAST 数据解析出来,拼接回去,再填入到原表中,这里就不展开了。
第二个问题是复杂类型,正如上一节所说, pg_filedump README里列出了支持的类型,但类似数组这样的类型就需要进行额外的二进制解析处理了。
举个例子,当你转储数组二进制时,看到的结果可能是一串儿 \0\0 。这是因为 pg_filedump 直接把处理不了的复杂类型给吐出来了。当然这里就会带来一些额外的问题 —— 字符串里的零值会让你的插入报错,所以你的解析脚本需要处理好这种问题,当遇到一个解析错误的复杂列时,应该先做个标记占个坑,把二进制值现场给保留下来,留给后面的步骤去具体处理。
这里我们来看个具体的例子:还是以上面 public.approval_merge_request_rules 表为例。我们可以从吐出来的数据,二进制视图,以及 ASCII 视图里面看到一些零星的字符串:critical,unknown 之类的东西,掺杂在一串 \0 与二进制控制字符中。没错,这就是一个字符串数组的二进制表示。PostgreSQL 中的数组允许任意类型任意深度的嵌套,所以这里的数据结构会有一点点复杂。
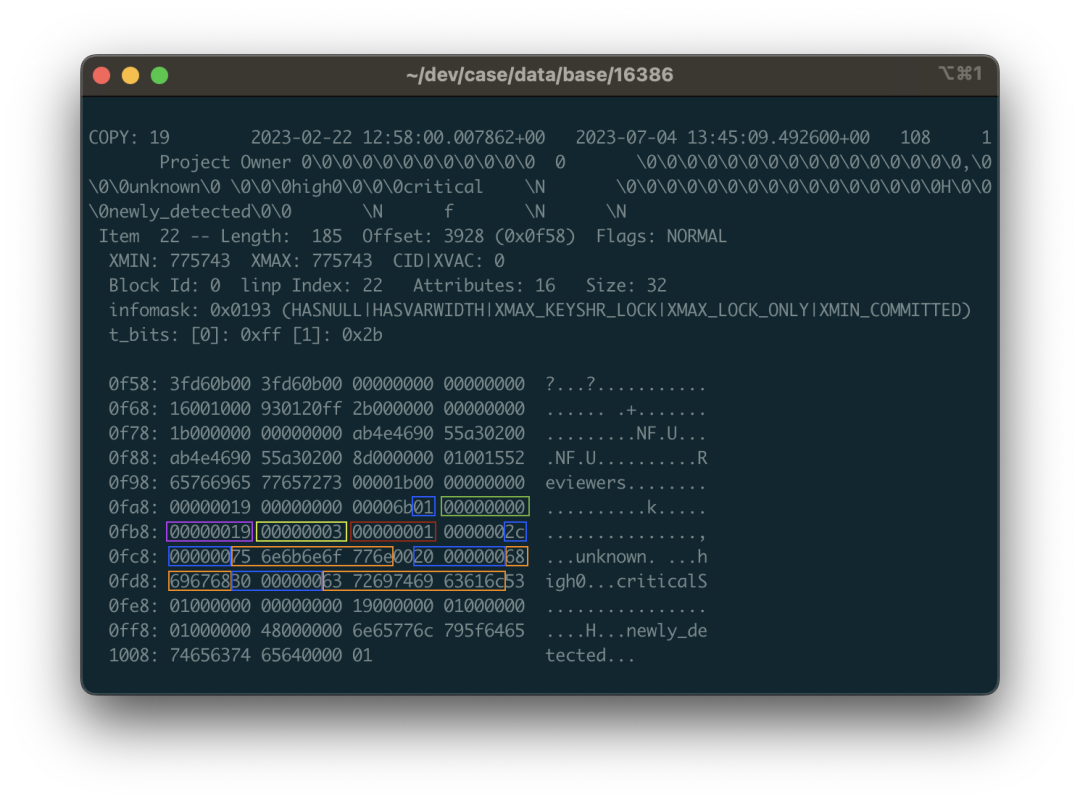
例如,图片中标色的地方对应的数据是一个包含三个字符串的数组:{unknown,high,critical}::TEXT[] 。01 代表这是一个一位数组,紧跟着空值位图,以及代表数组元素的类型OID 的 0x00000019 ,0x19 十进制值为 25 对应 pg_type 中的 text类型,说明这里是一个字符串数组(如果是 0x17 则说明是整型数组)。紧接着是这个数组第一维的维度 0x03,因为这个数组只有一维,三个元素;接下来的 1 告诉我们数组第一维度的起始偏移量在哪儿。再后面才是挨着的三个字符串结构了:由4字节的长度打头(要右移两位处理标记未),接着才是字符串内容,还要考虑布局对齐与填充的问题。
总的来说,你需要对照着源代码实现去挖掘,而这里有无穷无尽的细节:可变长度,空值位图,字段压缩,线外存储,以及大小端序,稍有不慎,你解出来的东西就是一团没用的浆糊。
你可以选择直接用 Python 脚本去记录的上下文中解析原始二进制回补数据,或者在 pg_filedump 源代码中注册新的类型与回调处理函数,复用 PG 提供的 C 解析函数,无论哪一种都称不上是轻松。
好在 PostgreSQL 本身已经提供了一些C语言的辅助函数 & 宏可以帮助你完成大部分工作,而且幸运的是 Gitlab 中的数组都是一维数组,类型也仅限于整型数组与字符串数组,其他带复杂类型的数据页也可以从其他表中重建,所以总体工作量还是可以接受的 。
后记
这个活儿折腾了我两天,掏粪细节就不展开了,我估计读者也不会感兴趣。总之经过了一系列处理,校正,补对之后,数据恢复的工作终于完成了!除了有几张表里有几条损坏的数据之外,其他的数据都成功解出来了。好家伙,整整一千张表啊!
我以前也弄过一些数据恢复的活儿,大多数情况都还比较简单,数据坏块儿,控制文件/CLOG损坏,或者是被挖矿病毒种了勒索木马(往Tablespace里写了几个垃圾文件),但炸的这么彻底的Case我还是第一次弄。之所以敢接这个活,也是因为我对PG内核还是有些了解的,知道这些繁琐的实现细节。只要你知道这是一个工程上可解的问题,那么即使过程再脏再累也不会担心完不成。
尽管有些缺陷,但 pg_filedump 还是一个不错的工具,后面我可能会考虑完善一下它,让它对各种数据类型都有完整的支持,这样就不用再自己写一堆 Python 小脚本来处理各种繁琐的细节了。在弄完这个案例后,我已经把 pg_filedump 打好了 PG 12 - 16 x EL 7 - 9 上的 RPM 包放在 Pigsty 的 Yum源中,默认收录在 Pigsty 离线软件包里,目前已经在 Pigsty v2.4.1 中实装交付了。我衷心希望您永远也用不上这个扩展,但如果你真的碰上需要它的场景时,我也希望它就在你的手边可以开箱即用。
最后我还是想说一句,许多软件都需要数据库,但数据库的安装部署维护是一件很有门槛的活儿。Gitlab 拉起的 PostgreSQL 质量已经算是相当不错的了,但面对这种情况依然束手无策,更不用提那些土法手造 docker 镜像的简陋单机实例了。一场大故障,就能让一个企业积累的代码数据、CI/CD流程、Issue/PR/MR 记录灰飞烟灭。我真的建议您好好检视一下自己的数据库系统,至少请定期做个备份吧!
Gitlab 的企业版和社区版的核心区别就在于它底下的 PG 有没有高可用和监控。而开箱即用的 PostgreSQL 发行版 —— Pigsty 也可以为您更好地解决这些问题,却完全开源免费,分文不取:无论是高可用,PITR,还是监控系统一应俱全:下次再遇到这种问题时,就可以自动切换/一键回滚,游刃有余得多。之前我们自己的 Gitlab, Jira, Confluence 等软件都跑在上面,如果您有类似需求,倒是不妨试一下哦。
PG中的本地化排序规则
为什么Pigsty在初始化Postgres数据库时默认指定了locale=C与encoding=UTF8
答案其实很简单,除非真的明确知道自己会用到LOCALE相关功能,否则就根本不应该配置C.UTF8之外的任何字符编码与本地化排序规则选项。特别是`
关于字符编码的部分,之前写过一篇文章专门介绍,这里表过不提。今天专门说一下LOCALE(本地化)的配置问题。
如果说服务端字符编码配置因为某些原因配置为UTF8之外的值也许还情有可原,那么LOCALE配置为C之外的任何选就是无可救药了。因为对于PostgreSQL来说,LOCALE不仅仅是控制日期和钱怎么显示这一类无伤大雅的东西,而是会影响到某些关键功能的使用。
错误的LOCALE配置可能导致几倍到十几倍的性能损失,还会导致LIKE查询无法在普通索引上使用。而设置LOCALE=C一点也不会影响真正需要本地化规则的使用场景。所以官方文档给出的指导是:“如果你真正需要LOCALE,才去使用它”。
不幸的是,在PostgreSQLlocale与encoding的默认配置取决于操作系统的配置,因此C.UTF8可能并不是默认的配置,这就导致了很多人误用LOCALE而不自知,白白折损了大量性能,也导致了某些数据库特性无法正常使用。

太长;不看
- 强制使用
UTF8字符编码,强制数据库使用C的本地化规则。 - 使用非C本地化规则,可能导致涉及字符串比较的操作开销增大几倍到几十倍,对性能产生显著负面影响
- 使用非C本地化规则,会导致
LIKE查询无法使用普通索引,容易踩坑雪崩。 - 使用非C本地化规则的实例,可以通过
text_ops COLLATE "C"或text_pattern_ops建立索引,支持LIKE查询。
LOCALE是什么
我们经常能在操作系统和各种软件中看到 LOCALE(区域) 的相关配置,但LOCALE到底是什么呢?
LOCALE支持指的是应用遵守文化偏好的问题,包括字母表、排序、数字格式等。LOCALE由很多规则与定义组成,包括:
LC_COLLATE |
字符串排序顺序 |
|---|---|
LC_CTYPE |
字符分类(什么是一个字符?它的大写形式是否等效?) |
LC_MESSAGES |
消息使用的语言Language of messages |
LC_MONETARY |
货币数量使用的格式 |
LC_NUMERIC |
数字的格式 |
LC_TIME |
日期和时间的格式 |
| …… | 其他…… |
一个LOCALE就是一组规则,LOCALE通常会用语言代码 + 国家代码的方式来命名。例如中国大陆使用的LOCALE zh_CN就分为两个部分:zh是 语言代码,CN 是国家代码。现实世界中,一种语言可能有多个国家在用,一个国家内也可能存在多种语言。还是以中文和中国为例:
中国(COUNTRY=CN)相关的语言LOCALE有:
zh:汉语:zh_CNbo:藏语:bo_CNug:维语:ug_CN
讲中文(LANG=zh)的国家或地区相关的LOCAL有:
CN中国:zh_CNHK香港:zh_HKMO澳门:zh_MOTW台湾:zh_TWSG新加坡:zh_SG
LOCALE的例子
我们可以参考一个典型的Locale定义文件:Glibc提供的 zh_CN
这里截取一小部分展示,看上去好像都是些鸡零狗碎的格式定义,月份星期怎么叫啊,钱和小数点怎么显示啊之类的东西。
但这里有一个非常关键的东西,叫做LC_COLLATE,即排序方式(Collation),会对数据库行为有显著影响。
LC_CTYPE
copy "i18n"
translit_start
include "translit_combining";""
translit_end
class "hanzi"; /
<U4E00>..<U9FA5>;/
<UF92C>;<UF979>;<UF995>;<UF9E7>;<UF9F1>;<UFA0C>;<UFA0D>;<UFA0E>;/
<UFA0F>;<UFA11>;<UFA13>;<UFA14>;<UFA18>;<UFA1F>;<UFA20>;<UFA21>;/
<UFA23>;<UFA24>;<UFA27>;<UFA28>;<UFA29>
END LC_CTYPE
LC_COLLATE
copy "iso14651_t1_pinyin"
END LC_COLLATE
LC_TIME
% 一月, 二月, 三月, 四月, 五月, 六月, 七月, 八月, 九月, 十月, 十一月, 十二月
mon "<U4E00><U6708>";/
"<U4E8C><U6708>";/
"<U4E09><U6708>";/
"<U56DB><U6708>";/
...
% 星期日, 星期一, 星期二, 星期三, 星期四, 星期五, 星期六
day "<U661F><U671F><U65E5>";/
"<U661F><U671F><U4E00>";/
"<U661F><U671F><U4E8C>";/
...
week 7;19971130;1
first_weekday 2
% %Y年%m月%d日 %A %H时%M分%S秒
d_t_fmt "%Y<U5E74>%m<U6708>%d<U65E5> %A %H<U65F6>%M<U5206>%S<U79D2>"
% %Y年%m月%d日
d_fmt "%Y<U5E74>%m<U6708>%d<U65E5>"
% %H时%M分%S秒
t_fmt "%H<U65F6>%M<U5206>%S<U79D2>"
% 上午, 下午
am_pm "<U4E0A><U5348>";"<U4E0B><U5348>"
% %p %I时%M分%S秒
t_fmt_ampm "%p %I<U65F6>%M<U5206>%S<U79D2>"
% %Y年 %m月 %d日 %A %H:%M:%S %Z
date_fmt "%Y<U5E74> %m<U6708> %d<U65E5> %A %H:%M:%S %Z"
END LC_TIME
LC_NUMERIC
decimal_point "."
thousands_sep ","
grouping 3
END LC_NUMERIC
LC_MONETARY
% ¥
currency_symbol "<UFFE5>"
int_curr_symbol "CNY "
比如zh_CN提供的LC_COLLATE使用了iso14651_t1_pinyin排序规则,这是一个基于拼音的排序规则。
下面通过一个例子来介绍LOCALE中的COLLATION如何影响Postgres的行为。
排序规则一例
创建一张包含7个汉字的表,然后执行排序操作。
CREATE TABLE some_chinese(
name TEXT PRIMARY KEY
);
INSERT INTO some_chinese VALUES
('阿'),('波'),('磁'),('得'),('饿'),('佛'),('割');
SELECT * FROM some_chinese ORDER BY name;
执行以下SQL,按照默认的C排序规则对表中的记录排序。可以看到,这里实际上是按照字符的ascii|unicode 码位 进行排序的。
vonng=# SELECT name, ascii(name) FROM some_chinese ORDER BY name COLLATE "C";
name | ascii
------+-------
佛 | 20315
割 | 21106
得 | 24471
波 | 27874
磁 | 30913
阿 | 38463
饿 | 39295
但这样基于码位的排序对于中国人来说可能没有任何意义。例如新华字典在收录汉字时,就不会使用这种排序方式。而是采用zh_CN 所使用的 拼音排序 规则,按照拼音比大小。如下所示:
SELECT * FROM some_chinese ORDER BY name COLLATE "zh_CN";
name
------
阿
波
磁
得
饿
佛
割
可以看到,按照zh_CN排序规则排序得到的结果,就是拼音顺序abcdefg,而不再是不知所云的Unicode码位排序。
当然这个查询结果取决于zh_CN 排序规则的具体定义,像这样的排序规则并不是数据库本身定义的,数据库本身提供的排序规则就是C(或者其别名POSIX)。COLLATION的来源,通常要么是操作系统,要么是glibc,要么是第三方的本地化库(例如icu),所以可能因为不同的实质定义出现不同的效果。
但代价是什么?
PostgreSQL中使用非C或非POSIX LOCALE的最大负面影响是:
特定排序规则对涉及字符串大小比较的操作有巨大的性能影响,同时它还会导致无法在LIKE查询子句中使用普通索引。
另外,C LOCALE是由数据库本身确保在任何操作系统与平台上使用的,而其他的LOCALE则不然,所以使用非C Locale的可移植性更差。
性能损失
接下来让我们考虑一个使用LOCALE排序规则的例子, 我们有Apple Store 150万款应用的名称,现在希望按照不同的区域规则进行排序。
-- 创建一张应用名称表,里面有中文也有英文。
CREATE TABLE app(
name TEXT PRIMARY KEY
);
COPY app FROM '/tmp/app.csv';
-- 查看表上的统计信息
SELECT
correlation , -- 相关系数 0.03542578 基本随机分布
avg_width , -- 平均长度25字节
n_distinct -- -1,意味着1508076个记录没有重复
FROM pg_stats WHERE tablename = 'app';
-- 使用不同的排序规则进行一系列的实验
SELECT * FROM app;
SELECT * FROM app order by name;
SELECT * FROM app order by name COLLATE "C";
SELECT * FROM app order by name COLLATE "en_US";
SELECT * FROM app order by name COLLATE "zh_CN";
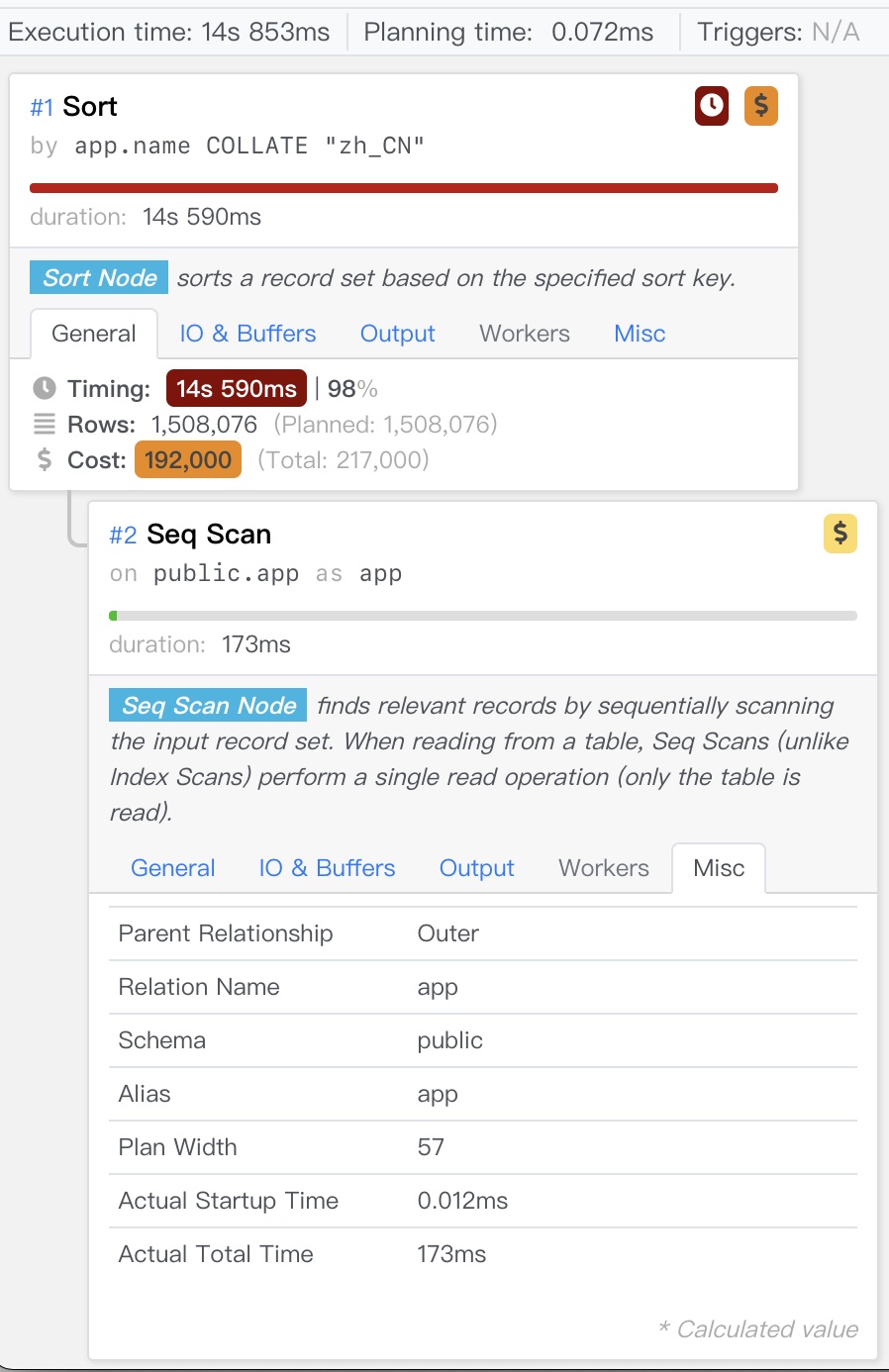
相当令人震惊的结果,使用C和zh_CN的结果能相差十倍之多:
| 序号 | 场景 | 耗时(ms) | 说明 |
|---|---|---|---|
| 1 | 不排序 | 180 | 使用索引 |
| 2 | order by name |
969 | 使用索引 |
| 3 | order by name COLLATE "C" |
1430 | 顺序扫描,外部排序 |
| 4 | order by name COLLATE "en_US" |
10463 | 顺序扫描,外部排序 |
| 5 | order by name COLLATE "zh_CN" |
14852 | 顺序扫描,外部排序 |
下面是实验5对应的详细执行计划,即使配置了足够大的内存,依然会溢出到磁盘执行外部排序。尽管如此,显式指定LOCALE的实验都出现了此情况,因此可以横向对比出C与zh_CN的性能差距来。
另一个更有对比性的例子是比大小。
这里,表中的所有的字符串都会和World比一下大小,相当于在表上进行150万次特定规则比大小,而且也不涉及到磁盘IO。
SELECT count(*) FROM app WHERE name > 'World';
SELECT count(*) FROM app WHERE name > 'World' COLLATE "C";
SELECT count(*) FROM app WHERE name > 'World' COLLATE "en_US";
SELECT count(*) FROM app WHERE name > 'World' COLLATE "zh_CN";
尽管如此,比起C LOCALE来,zh_CN 还是费了接近3倍的时长。
| 序号 | 场景 | 耗时(ms) |
|---|---|---|
| 1 | 默认 | 120 |
| 2 | C | 145 |
| 3 | en_US | 351 |
| 4 | zh_CN | 441 |
如果说排序可能是O(n2)次比较操作有10倍损耗 ,那么这里的O(n)次比较3倍开销也基本能对应上。我们可以得出一个初步的粗略结论:
比起C Locale来,使用zh_CN或其他Locale可能导致几倍的额外性能开销。
除此之外,错误的Locale不仅仅会带来性能损失,还会导致功能损失。
功能缺失
除了性能表现糟糕外,另一个令人难以接受的问题是,使用非C的LOCALE,LIKE查询走不了普通索引。
还是以刚才的实验为例,我们分别在使用C和en_US作为默认LOCALE创建的数据库实例上执行以下查询:
SELECT * FROM app WHERE name LIKE '中国%';
找出所有以“中国”两字开头的应用。
在使用C的库上
该查询能正常使用app_pkey索引,利用主键B树的有序性加速查询,约2毫秒内执行完毕。
postgres@meta:5432/meta=# show lc_collate;
C
postgres@meta:5432/meta=# EXPLAIN SELECT * FROM app WHERE name LIKE '中国%';
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using app_pkey on app (cost=0.43..2.65 rows=1510 width=25)
Index Cond: ((name >= '中国'::text) AND (name < '中图'::text))
Filter: (name ~~ '中国%'::text)
(3 rows)
在使用en_US的库上
我们发现,这个查询无法利用索引,走了全表扫描。查询劣化至70毫秒,性能恶化了三四十倍。
vonng=# show lc_collate;
en_US.UTF-8
vonng=# EXPLAIN SELECT * FROM app WHERE name LIKE '中国%';
QUERY PLAN
----------------------------------------------------------
Seq Scan on app (cost=0.00..29454.95 rows=151 width=25)
Filter: (name ~~ '中国%'::text)
为什么?
因为索引(B树索引)的构建,也是建立在序的基础上,也就是等值和比大小这两个操作。
然而,LOCALE关于字符串的等价规则有一套自己的定义,例如在Unicode标准中就定义了很多匪夷所思的等价规则(毕竟是万国语言,比如多个字符复合而成的字符串等价于另一个单体字符,详情参考 现代字符编码 一文)。
因此,只有最朴素的C LOCALE,才能够正常地进行模式匹配。C LOCALE的比较规则非常简单,就是挨个比较 字符码位,不玩那一套花里胡哨虚头巴脑的东西。所以,如果您的数据库不幸使用了非C的LOCALE,那么在执行LIKE查询时就没有办法使用默认的索引了。
解决办法
对于非C LOCALE的实例,只有建立特殊类型的索引,才能支持此类查询:
CREATE INDEX ON app(name COLLATE "C");
CREATE INDEX ON app(name text_pattern_ops);
这里使用 text_pattern_ops运算符族来创建索引也可以用来支持LIKE查询,这是专门用于支持模式匹配的运算符族,从原理上讲它会无视 LOCALE,直接基于 逐个字符 比较的方式执行模式匹配,也就是使用C LOCALE的方式。
因此在这种情况下,只有基于text_pattern_ops操作符族建立的索引,或者基于默认的text_ops但使用COLLATE "C"' 的索引,才可以用于支持LIKE查询。
vonng=# EXPLAIN ANALYZE SELECT * FROM app WHERE name LIKE '中国%';
Index Only Scan using app_name_idx on app (cost=0.43..1.45 rows=151 width=25) (actual time=0.053..0.731 rows=2360 loops=1)
Index Cond: ((name ~>=~ '中国'::text) AND (name ~<~ '中图'::text))
Filter: (name ~~ '中国%'::text COLLATE "en_US.UTF-8")
建立完索引后,我们可以看到原来的LIKE查询可以走索引了。
LIKE无法使用普通索引这个问题,看上去似乎可以通过额外创建一个text_pattern_ops索引来曲线解决。但这也意味着原本可以直接利用现成的PRIMARY KEY或UNIQUE约束自带索引解决的问题,现在需要额外的维护成本与存储空间。
对于不熟悉这一问题的开发者来说,很有可能因为错误的LOCALE配置,导致本地没问题的模式结果在线上因为没有走索引而雪崩。(例如本地使用C,但生产环境用了非C LOCALE)。
兼容性
假设您在接手时数据库已经使用了非C的LOCALE(这种事相当常见),现在您在知道了使用非C LOCALE的危害后,决定找个机会改回来。
那么有哪些地方需要注意呢?具体来讲,Locale的配置影响PostgreSQL以下功能:
- 使用
LIKE子句的查询。 - 任何依赖特定LOCALE排序规则的查询,例如依赖拼音排序作为结果排序依据。
- 使用大小写转换相关功能的查询,函数
upper、lower和initcap to_char函数家族,涉及到格式化为本地时间时。- 正则表达式中的大小写不敏感匹配模式(
SIMILAR TO,~)。
所以,任何涉及到大小写转换的查询,请务必 “显式指定 Collation!”
如果不放心,可以通过pg_stat_statements列出所有涉及到以下关键词的查询语句进行手工排查:
LIKE|ILIKE -- 是否使用了模式匹配
SIMILAR TO | ~ | regexp_xxx -- 是否使用了 i 选项
upper, lower, initcap -- 是否针对其他带有大小写模式的语言使用(西欧字符之类)
ORDER BY col -- 按文本类型列排序时,是否依赖特定排序规则?(例如按照拼音)
兼容性修改
通常来说,C LOCALE在功能上是其他LOCALE配置的超集,总是可以从其他LOCALE切换为C。如果您的业务没有使用这些功能,通常什么都不需要做。如果使用本地化规则特性,则总是可以通过**显式指定COLLATE**的方式,在C LOCALE下实现相同的效果。
SELECT upper('a' COLLATE "zh_CN"); -- 基于zh_CN规则执行大小写转换
SELECT '阿' < '波'; -- false, 在默认排序规则下 阿(38463) > 波(27874)
SELECT '阿' < '波' COLLATE "zh_CN"; -- true, 显式使用中文拼音排序规则: 阿(a) < 波(bo)
但是请注意 glibc 提供的 collation —— 比如 “zh_CN” 并不一定保持稳定,PostgreSQL 社区建议的最佳实践是使用 C 或 POSIX 作为默认 collation。
然后使用 ICU 作为排序规则的提供者,比如:
SELECT '阿' < '波' COLLATE "zh-x-icu"; -- true, 显式使用中文拼音排序规则: 阿(a) < 波(bo)
- zh-x-icu:大致代表“通用中文(未定简/繁)”,使用 ICU 的规则。
- zh-Hans-x-icu:代表简体中文(Hans = Han Simplified),ICU 的规则。
- zh-Hans-CN-x-icu:简体中文(中国大陆地区)
- zh-Hans-HK-x-icu:简体中文(香港地区)
- zh-Hant-x-icu:代表繁体中文(Hant = Han Traditional)
覆盖 CTYPE
你可以在进行大小写转换的时候
SELECT
'é' AS original,
UPPER('é') AS upper_default, -- 使用默认的 Locale
UPPER('é' COLLATE "C") AS upper_en_c, -- C Locale 不处理这些字符 'é'
UPPER('é' COLLATE PG_C_UTF8) AS upper_en_cutf8, -- C.UTF8 会处理一些大小写问题 É
UPPER('é' COLLATE "en_US.UTF-8") AS upper_en_us; -- en_US.UTF8 转换成了大写的 É
oid | collname | collnamespace | collowner | collprovider | collisdeterministic | collencoding | collcollate | collctype | colllocale | collicurules | collversion
-------+------------------+---------------+-----------+--------------+---------------------+--------------+--------------+--------------+------------+--------------+-------------
12888 | lzh_TW | 11 | 10 | c | t | 6 | lzh_TW | lzh_TW | NULL | NULL | 2.28
12889 | lzh_TW.utf8 | 11 | 10 | c | t | 6 | lzh_TW.utf8 | lzh_TW.utf8 | NULL | NULL | 2.28
13187 | zh_CN | 11 | 10 | c | t | 2 | zh_CN | zh_CN | NULL | NULL | 2.28
13188 | zh_CN.gb2312 | 11 | 10 | c | t | 2 | zh_CN.gb2312 | zh_CN.gb2312 | NULL | NULL | 2.28
13189 | zh_CN.utf8 | 11 | 10 | c | t | 6 | zh_CN.utf8 | zh_CN.utf8 | NULL | NULL | 2.28
13190 | zh_HK.utf8 | 11 | 10 | c | t | 6 | zh_HK.utf8 | zh_HK.utf8 | NULL | NULL | 2.28
13191 | zh_SG | 11 | 10 | c | t | 2 | zh_SG | zh_SG | NULL | NULL | 2.28
13192 | zh_SG.gb2312 | 11 | 10 | c | t | 2 | zh_SG.gb2312 | zh_SG.gb2312 | NULL | NULL | 2.28
13193 | zh_SG.utf8 | 11 | 10 | c | t | 6 | zh_SG.utf8 | zh_SG.utf8 | NULL | NULL | 2.28
13194 | zh_TW.euctw | 11 | 10 | c | t | 4 | zh_TW.euctw | zh_TW.euctw | NULL | NULL | 2.28
13195 | zh_TW.utf8 | 11 | 10 | c | t | 6 | zh_TW.utf8 | zh_TW.utf8 | NULL | NULL | 2.28
13349 | zh_CN | 11 | 10 | c | t | 6 | zh_CN.utf8 | zh_CN.utf8 | NULL | NULL | 2.28
13350 | zh_HK | 11 | 10 | c | t | 6 | zh_HK.utf8 | zh_HK.utf8 | NULL | NULL | 2.28
13351 | zh_SG | 11 | 10 | c | t | 6 | zh_SG.utf8 | zh_SG.utf8 | NULL | NULL | 2.28
13352 | zh_TW | 11 | 10 | c | t | 4 | zh_TW.euctw | zh_TW.euctw | NULL | NULL | 2.28
13353 | zh_TW | 11 | 10 | c | t | 6 | zh_TW.utf8 | zh_TW.utf8 | NULL | NULL | 2.28
14066 | zh-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh | NULL | 153.80.32.1
14067 | zh-Hans-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh-Hans | NULL | 153.80.32.1
14068 | zh-Hans-CN-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh-Hans-CN | NULL | 153.80.32.1
14069 | zh-Hans-HK-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh-Hans-HK | NULL | 153.80.32.1
14070 | zh-Hans-MO-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh-Hans-MO | NULL | 153.80.32.1
14071 | zh-Hans-SG-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh-Hans-SG | NULL | 153.80.32.1
14072 | zh-Hant-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh-Hant | NULL | 153.80.32.1
14073 | zh-Hant-HK-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh-Hant-HK | NULL | 153.80.32.1
14074 | zh-Hant-MO-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh-Hant-MO | NULL | 153.80.32.1
14075 | zh-Hant-TW-x-icu | 11 | 10 | i | t | -1 | NULL | NULL | zh-Hant-TW | NULL | 153.80.32.1
目前唯一已知的问题出现在扩展pg_trgm上。
扩展阅读
https://www.pgevents.ca/events/pgconfdev2024/sessions/session/95/slides/26/pgcon24_collation.pdf
PG复制标识详解(Replica Identity)
引子:土法逻辑复制
复制身份的概念,服务于 逻辑复制。
逻辑复制的基本工作原理是,将逻辑发布相关表上对行的增删改事件解码,复制到逻辑订阅者上执行。
逻辑复制的工作方式有点类似于行级触发器,在事务执行后对变更的元组逐行触发。
假设您需要自己通过触发器实现逻辑复制,将一章表A上的变更复制到另一张表B中。通常情况下,这个触发器的函数逻辑通常会长这样:
-- 通知触发器
CREATE OR REPLACE FUNCTION replicate_change() RETURNS TRIGGER AS $$
BEGIN
IF (TG_OP = 'INSERT') THEN
-- INSERT INTO tbl_b VALUES (NEW.col);
ELSIF (TG_OP = 'DELETE') THEN
-- DELETE tbl_b WHERE id = OLD.id;
ELSIF (TG_OP = 'UPDATE') THEN
-- UPDATE tbl_b SET col = NEW.col,... WHERE id = OLD.id;
END IF;
END; $$ LANGUAGE plpgsql;
触发器中会有两个变量OLD与NEW,分别包含了变更记录的旧值与新值。
INSERT操作只有NEW变量,因为它是新插入的,我们直接将其插入到另一张表即可。DELETE操作只有OLD变量,因为它只是删除已有记录,我们 根据ID 在目标表B上。UPDATE操作同时存在OLD变量与NEW变量,我们需要通过OLD.id定位目标表B中的记录,将其更新为新值NEW。
这样的基于触发器的“逻辑复制”可以完美达到我们的目的,在逻辑复制中与之类似,表A上带有主键字段id。那么当我们删除表A上的记录时,例如:删除id = 1的记录时,我们只需要告诉订阅方id = 1,而不是把整个被删除的元组传递给订阅方。那么这里主键列id就是逻辑复制的复制标识。
但上面的例子中隐含着一个工作假设:表A和表B模式相同,上面有一个名为 id 的主键。
对于生产级的逻辑复制方案,即PostgreSQL 10.0后提供的逻辑复制,这样的工作假设是不合理的。因为系统无法要求用户建表时一定会带有主键,也无法要求主键的名字一定叫id。
于是,就有了 复制标识(Replica Identity) 的概念。复制标识是对OLD.id这样工作假设的进一步泛化与抽象,它用来告诉逻辑复制系统,哪些信息可以被用于唯一定位表中的一条记录。
复制标识
对于逻辑复制而言,INSERT 事件不需要特殊处理,但要想将DELETE|UPDATE复制到订阅者上时,必须提供一种标识行的方式,即复制标识(Replica Identity)。复制标识是一组列的集合,这些列可以唯一标识一条记录。其实这样的定义在概念上来说就是构成主键的列集,当然非空唯一索引中的列集(候选键)也可以起到同样的效果。
一个被纳入逻辑复制 发布中的表,必须配置有 复制标识(Replica Identity),只有这样才可以在订阅者一侧定位到需要更新的行,完成UPDATE与DELETE操作的复制。默认情况下,主键 (Primary Key)和 非空列上的唯一索引 (UNIQUE NOT NULL)可以用作复制标识。
注意,复制标识 和表上的主键、非空唯一索引并不是一回事。复制标识是表上的一个属性,它指明了在逻辑复制时,哪些信息会被用作身份定位标识符写入到逻辑复制的记录中,供订阅端定位并执行变更。
如PostgreSQL 13官方文档所述,表上的复制标识 共有4种配置模式,分别为:
- 默认模式(default):非系统表采用的默认模式,如果有主键,则用主键列作为身份标识,否则用完整模式。
- 索引模式(index):将某一个符合条件的索引中的列,用作身份标识
- 完整模式(full):将整行记录中的所有列作为复制标识(类似于整个表上每一列共同组成主键)
- 无身份模式(nothing):不记录任何复制标识,这意味着
UPDATE|DELETE操作无法复制到订阅者上。
复制标识查询
表上的复制标识可以通过查阅pg_class.relreplident获取。
这是一个字符类型的“枚举”,标识用于组装 “复制标识” 的列:d = default ,f = 所有的列,i 使用特定的索引,n 没有复制标识。
表上是否具有可用作复制标识的索引约束,可以通过以下查询获取:
SELECT quote_ident(nspname) || '.' || quote_ident(relname) AS name, con.ri AS keys,
CASE relreplident WHEN 'd' THEN 'default' WHEN 'n' THEN 'nothing' WHEN 'f' THEN 'full' WHEN 'i' THEN 'index' END AS replica_identity
FROM pg_class c JOIN pg_namespace n ON c.relnamespace = n.oid, LATERAL (SELECT array_agg(contype) AS ri FROM pg_constraint WHERE conrelid = c.oid) con
WHERE relkind = 'r' AND nspname NOT IN ('pg_catalog', 'information_schema', 'monitor', 'repack', 'pg_toast')
ORDER BY 2,3;
复制标识配置
表到复制标识可以通过ALTER TABLE进行修改。
ALTER TABLE tbl REPLICA IDENTITY { DEFAULT | USING INDEX index_name | FULL | NOTHING };
-- 具体有四种形式
ALTER TABLE t_normal REPLICA IDENTITY DEFAULT; -- 使用主键,如果没有主键则为FULL
ALTER TABLE t_normal REPLICA IDENTITY FULL; -- 使用整行作为标识
ALTER TABLE t_normal REPLICA IDENTITY USING INDEX t_normal_v_key; -- 使用唯一索引
ALTER TABLE t_normal REPLICA IDENTITY NOTHING; -- 不设置复制标识
复制标识实例
下面用一个具体的例子来说明复制标识的效果:
CREATE TABLE test(k text primary key, v int not null unique);
现在有一个表test,上面有两列k和v。
INSERT INTO test VALUES('Alice', '1'), ('Bob', '2');
UPDATE test SET v = '3' WHERE k = 'Alice'; -- update Alice value to 3
UPDATE test SET k = 'Oscar' WHERE k = 'Bob'; -- rename Bob to Oscaar
DELETE FROM test WHERE k = 'Alice'; -- delete Alice
在这个例子中,我们对表test执行了增删改操作,与之对应的逻辑解码结果为:
table public.test: INSERT: k[text]:'Alice' v[integer]:1
table public.test: INSERT: k[text]:'Bob' v[integer]:2
table public.test: UPDATE: k[text]:'Alice' v[integer]:3
table public.test: UPDATE: old-key: k[text]:'Bob' new-tuple: k[text]:'Oscar' v[integer]:2
table public.test: DELETE: k[text]:'Alice'
默认情况下,PostgreSQL会使用表的主键作为复制标识,因此在UPDATE|DELETE操作中,都通过k列来定位需要修改的记录。
如果我们手动修改表的复制标识,使用非空且唯一的列v作为复制标识,也是可以的:
ALTER TABLE test REPLICA IDENTITY USING INDEX test_v_key; -- 基于UNIQUE索引的复制身份
同样的变更现在产生如下的逻辑解码结果,这里v作为身份标识,出现在所有的UPDATE|DELETE事件中。
table public.test: INSERT: k[text]:'Alice' v[integer]:1
table public.test: INSERT: k[text]:'Bob' v[integer]:2
table public.test: UPDATE: old-key: v[integer]:1 new-tuple: k[text]:'Alice' v[integer]:3
table public.test: UPDATE: k[text]:'Oscar' v[integer]:2
table public.test: DELETE: v[integer]:3
如果使用完整身份模式(full)
ALTER TABLE test REPLICA IDENTITY FULL; -- 表test现在使用所有列作为表的复制身份
这里,k和v同时作为身份标识,记录到UPDATE|DELETE的日志中。对于没有主键的表,这是一种保底方案。
table public.test: INSERT: k[text]:'Alice' v[integer]:1
table public.test: INSERT: k[text]:'Bob' v[integer]:2
table public.test: UPDATE: old-key: k[text]:'Alice' v[integer]:1 new-tuple: k[text]:'Alice' v[integer]:3
table public.test: UPDATE: old-key: k[text]:'Bob' v[integer]:2 new-tuple: k[text]:'Oscar' v[integer]:2
table public.test: DELETE: k[text]:'Alice' v[integer]:3
如果使用无身份模式(nothing)
ALTER TABLE test REPLICA IDENTITY NOTHING; -- 表test现在没有复制标识
那么逻辑解码的记录中,UPDATE操作中只有新记录,没有包含旧记录中的唯一身份标识,而DELETE操作中则完全没有信息。
table public.test: INSERT: k[text]:'Alice' v[integer]:1
table public.test: INSERT: k[text]:'Bob' v[integer]:2
table public.test: UPDATE: k[text]:'Alice' v[integer]:3
table public.test: UPDATE: k[text]:'Oscar' v[integer]:2
table public.test: DELETE: (no-tuple-data)
这样的逻辑变更日志对于订阅端来说完全没用,在实际使用中,对逻辑复制中的无复制标识的表执行DELETE|UPDATE会直接报错。
复制标识详解
表上的复制标识配置,与表上有没有索引,是相对正交的两个因素。
尽管各种排列组合都是可能的,然而在实际使用中,只有三种可行的情况。
- 表上有主键,使用默认的
default复制标识 - 表上没有主键,但是有非空唯一索引,显式配置
index复制标识 - 表上既没有主键,也没有非空唯一索引,显式配置
full复制标识(运行效率非常低,仅能作为兜底方案) - 其他所有情况,都无法正常完成逻辑复制功能
| 复制身份模式\表上的约束 | 主键(p) | 非空唯一索引(u) | 两者皆无(n) |
|---|---|---|---|
| default | 有效 | x | x |
| index | x | 有效 | x |
| full | 低效 | 低效 | 低效 |
| nothing | x | x | x |
下面,我们来考虑几个边界条件。
重建主键
假设因为索引膨胀,我们希望重建表上的主键索引回收空间。
CREATE TABLE test(k text primary key, v int);
CREATE UNIQUE INDEX test_pkey2 ON test(k);
BEGIN;
ALTER TABLE test DROP CONSTRAINT test_pkey;
ALTER TABLE test ADD PRIMARY KEY USING INDEX test_pkey2;
COMMIT;
在default模式下,重建并替换主键约束与索引并不会影响复制标识。
重建唯一索引
假设因为索引膨胀,我们希望重建表上的非空唯一索引回收空间。
CREATE TABLE test(k text, v int not null unique);
ALTER TABLE test REPLICA IDENTITY USING INDEX test_v_key;
CREATE UNIQUE INDEX test_v_key2 ON test(v);
-- 使用新的test_v_key2索引替换老的Unique索引
BEGIN;
ALTER TABLE test ADD UNIQUE USING INDEX test_v_key2;
ALTER TABLE test DROP CONSTRAINT test_v_key;
COMMIT;
与default模式不同,index模式下,复制标识是与具体的索引绑定的:
Table "public.test"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+---------+-----------+----------+---------+----------+--------------+-------------
k | text | | | | extended | |
v | integer | | not null | | plain | |
Indexes:
"test_v_key" UNIQUE CONSTRAINT, btree (v) REPLICA IDENTITY
"test_v_key2" UNIQUE CONSTRAINT, btree (v)
这意味着如果采用偷天换日的方式替换UNIQUE索引会导致复制身份的丢失。
解决方案有两种:
- 使用
REINDEX INDEX (CONCURRENTLY)的方式重建该索引,不会丢失复制标识信息。 - 在替换索引时,一并刷新表的默认复制身份:
BEGIN;
ALTER TABLE test ADD UNIQUE USING INDEX test_v_key2;
ALTER TABLE test REPLICA IDENTITY USING INDEX test_v_key2;
ALTER TABLE test DROP CONSTRAINT test_v_key;
COMMIT;
顺带一提,移除作为身份标识的索引。尽管在表的配置信息中仍然为index模式,但效果与nothing相同。所以不要随意折腾作为身份的索引。
使用不合格的索引作为复制标识
复制标识需要一个 唯一,不可延迟,整表范围的,建立在非空列集上的索引。
最经典的例子就是主键索引,以及通过col type NOT NULL UNIQUE声明的单列非空索引。
之所以要求 NOT NULL,是因为NULL值无法进行等值判断,所以表中允许UNIQE的列上存在多条取值为NULL的记录,允许列为空说明这个列无法起到唯一标识记录的效果。如果尝试使用一个普通的UNIQUE索引(列上没有非空约束)作为复制标识,则会报错。
[42809] ERROR: index "t_normal_v_key" cannot be used as replica identity because column "v" is nullable
使用FULL复制标识
如果没有任何复制标识,可以将复制标识设置为FULL,也就是把整个行当作复制标识。
使用FULL模式的复制标识效率很低,所以这种配置只能是保底方案,或者用于很小的表。因为每一行修改都需要在订阅者上执行全表扫描,很容易把订阅者拖垮。
FULL模式限制
使用FULL模式的复制标识还有一个限制,订阅端的表上的复制身份所包含的列,要么与发布者一致,要么比发布者更少,否则也无法保证的正确性,下面具体来看一个例子。
假如发布订阅两侧的表都采用FULL复制标识,但是订阅侧的表要比发布侧多了一列(是的,逻辑复制允许订阅端的表带有发布端表不具有的列)。这样的话,订阅端的表上的复制身份所包含的列要比发布端多了。假设在发布端上删除(f1=a, f2=a)的记录,却会导致在订阅端删除两条满足身份标识等值条件的记录。
(Publication) ------> (Subscription)
|--- f1 ---|--- f2 ---| |--- f1 ---|--- f2 ---|--- f3 ---|
| a | a | | a | a | b |
| a | a | c |
FULL模式如何应对重复行问题
PostgreSQL的逻辑复制可以“正确”处理FULL模式下完全相同行的场景。假设有这样一张设计糟糕的表,表中存在多条一模一样的记录。
CREATE TABLE shitty_table(
f1 TEXT,
f2 TEXT,
f3 TEXT
);
INSERT INTO shitty_table VALUES ('a', 'a', 'a'), ('a', 'a', 'a'), ('a', 'a', 'a');
在FULL模式下,整行将作为复制标识使用。假设我们在shitty_table上通过ctid扫描作弊,删除了3条一模一样记录中的其中一条。
# SELECT ctid,* FROM shitty_table;
ctid | a | b | c
-------+---+---+---
(0,1) | a | a | a
(0,2) | a | a | a
(0,3) | a | a | a
# DELETE FROM shitty_table WHERE ctid = '(0,1)';
DELETE 1
# SELECT ctid,* FROM shitty_table;
ctid | a | b | c
-------+---+---+---
(0,2) | a | a | a
(0,3) | a | a | a
从逻辑上讲,使用整行作为身份标识,那么订阅端执行以下逻辑,会导致全部3条记录被删除。
DELETE FROM shitty_table WHERE f1 = 'a' AND f2 = 'a' AND f3 = 'a'
但实际情况是,因为PostgreSQL的变更记录以行为单位,这条变更仅会对第一条匹配的记录生效,所以在订阅侧的行为也是删除3行中的1行。在逻辑上与发布端等效。
PG慢查询诊断方法论
You can’t optimize what you can’t measure
慢查询是在线业务数据库的大敌,如何诊断定位慢查询是DBA的必修课题。
本文介绍了使用监控系统 —— Pigsty诊断慢查询的一般方法论。
慢查询:危害
对于实际服务于在线业务事务处理的PostgreSQL数据库而言,慢查询的危害包括:
- 慢查询挤占数据库连接,导致普通查询无连接可用,堆积并导致数据库雪崩。
- 慢查询长时间锁住了主库已经清理掉的旧版本元组,导致流复制重放进程锁死,导致主从复制延迟。
- 查询越慢,查询间相互踩踏的几率越高,越容易产生死锁、锁等待,事务冲突等问题。
- 慢查询浪费系统资源,拉高系统水位。
因此,一个合格的DBA必须知道如何及时定位并处理慢查询。
图:一个慢查询优化前后,系统的整体饱和度从40%降到了4%
慢查询诊断 —— 传统方法
传统上来说,在PostgreSQL有两种方式可以获得慢查询的相关信息,一个是通过官方的扩展插件pg_stat_statements,另一种是慢查询日志。
慢查询日志顾名思义,所有执行时间长于log_min_duration_statement参数的查询都会被记录到PG的日志中,对于定位慢查询,特别是对于分析特例、单次慢查询不可或缺。不过慢查询日志也有自己的局限性。在生产环境中出于性能考虑,通常只会记录时长超出某一阈值的查询,那么许多信息就无法从慢查询日志中获取了。当然值得一提的是,尽管开销很大,但全量查询日志仍然是慢查询分析的终极杀手锏。
更常用的慢查询诊断工具可能还是pg_stat_statements。这事是一个非常实用的扩展,它会收集数据库内运行查询的统计信息,在任何场景下都强烈建议启用该扩展。
pg_stat_statements 提供的原始指标数据以系统视图表的形式呈现。系统中的每一类查询(即抽取变量后执行计划相同的查询)都分配有一个查询ID,紧接着是调用次数,总耗时,最大、最小、平均单次耗时,响应时间都标准差,每次调用平均返回的行数,用于块IO的时间这些指标类数据。
一种简单的方式当然是观察 mean_time/max_time这类指标,从系统的Catalog中,您的确可以知道某类查询有史以来平均的响应时间。对于定位慢查询来说,也许这样也算得上基本够用了。但是像这样的指标,只是系统在当前时刻的一个静态快照,所以能够回答的问题是有限的。譬如说,您想看一看某个查询在加上新索引之后的性能表现是不是有所改善,用这种方式可能就会非常繁琐。
pg_stat_statements需要在shared_preload_library中指定,并在数据库中通过CREATE EXTENSION pg_stat_statements显式创建。创建扩展后即可通过视图pg_stat_statements访问查询统计信息
慢查询的定义
多慢的查询算慢查询?
应该说这个问题取决于业务、以及实际的查询类型,并没有通用的标准。
作为一种经验阈值,频繁的CRUD点查,如果超过1ms,可列为慢查询。
对于偶发的单次特例查询而言,通常超过100ms或1s可以列为慢查询。
慢查询诊断 —— Pigsty
监控系统就可以更全面地回答关于慢查询的问题。监控系统中的数据是由无数历史快照组成的(如5秒一次快照采样)。因此用户可以回溯至任意时间点,考察不同时间段内查询平均响应时间的变化。

上图是Pigsty中 PG Query Detail提供的界面,这里展现出了单个查询的详细信息。
这是一个典型的慢查询,平均响应时间几秒钟。为它添加了一个索引后。从右中Query RT仪表盘的上可以看到,查询的平均响应世界从几秒降到了几毫秒。
用户可以利用监控系统提供的洞察迅速定位数据库中的慢查询,定位问题,提出猜想。更重要的是,用户可以即时地在不同层次审视表与查询的详细指标,应用解决方案并获取实时反馈,这对于紧急故障处理是非常有帮助的。
有时监控系统的用途不仅仅在于提供数据与反馈,它还可以作为一种安抚情绪的良药:设想一个慢查询把生产数据库打雪崩了,如果老板或客户没有一个地方可以透明地知道当前的处理状态,难免会焦急地催问,进一步影响问题解决的速度。监控系统也可以做作为精确管理的依据。您可以有理有据地用监控指标的变化和老板与客户吹牛逼。
一个模拟的慢查询案例
Talk is cheap, show me the code
假设用户已经拥有一个 Pigsty沙箱演示环境,下面将使用Pigsty沙箱,演示模拟的慢查询定位与处理流程。
慢查询:模拟
因为没有实际的业务系统,这里我们以一种简单快捷的方式模拟系统中的慢查询。即pgbench自带的类tpc-b场景。
通过make ri / make ro / make rw,在pg-test集群上初始化 pgbench 用例,并对集群施加读写负载
# 50TPS 写入负载
while true; do pgbench -nv -P1 -c20 --rate=50 -T10 postgres://test:test@pg-test:5433/test; done
# 1000TPS 只读负载
while true; do pgbench -nv -P1 -c40 --select-only --rate=1000 -T10 postgres://test:test@pg-test:5434/test; done
现在我们已经有了一个模拟运行中的业务系统,让我们通过简单粗暴的方式来模拟一个慢查询场景。在pg-test集群的主库上执行以下命令,删除表pgbench_accounts的主键:
ALTER TABLE pgbench_accounts DROP CONSTRAINT pgbench_accounts_pkey ;
该命令会移除 pgbench_accounts 表上的主键,导致相关查询从索引扫描变为顺序全表扫描,全部变为慢查询,访问PG Instance ➡️ Query ➡️ QPS,结果如下图所示:
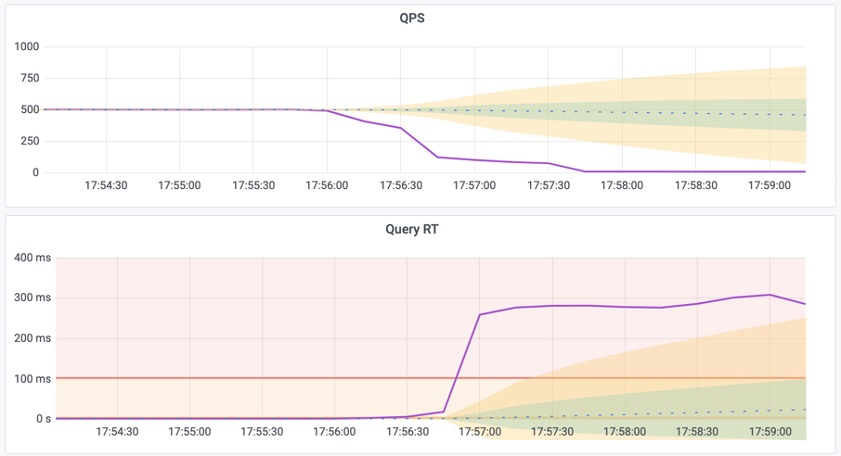
图1:平均查询响应时间从1ms飙升为300ms,单个从库实例的QPS从500下降至7。
与此同时,实例因为慢查询堆积,系统会在瞬间雪崩过载,访问PG Cluster首页,可以看到集群负载出现飙升。
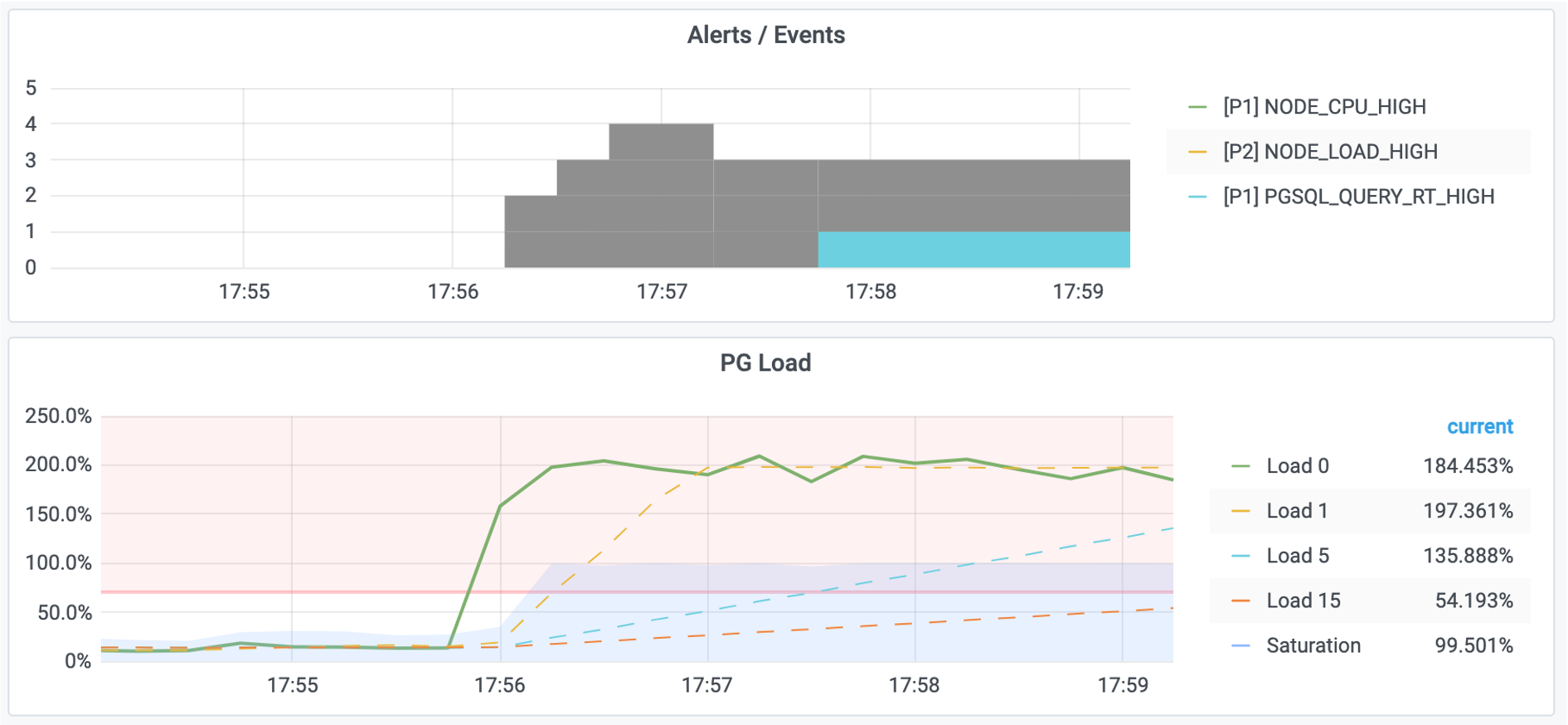
图2:系统负载达到200%,触发机器负载过大,与查询响应时间过长的报警规则。
慢查询:定位
首先,使用PG Cluster面板定位慢查询所在的具体实例,这里以 pg-test-2 为例。
然后,使用PG Query面板定位具体的慢查询:编号为 -6041100154778468427
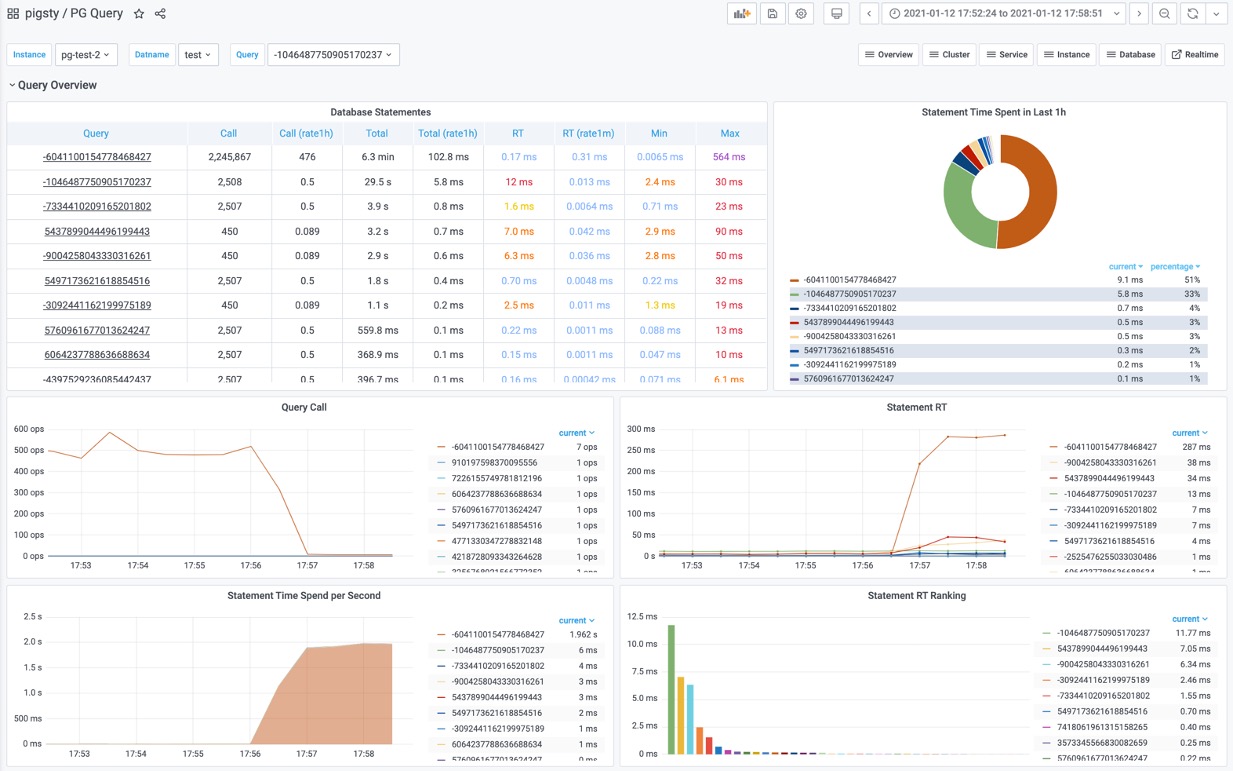
图3:从查询总览中发现异常慢查询
该查询表现出:
- 响应时间显著上升: 17us 升至 280ms
- QPS 显著下降: 从500下降到 7
- 花费在该查询上的时间占比显著增加
可以确定,就是这个查询变慢了!
接下来,利用PG Stat Statements面板或PG Query Detail,根据查询ID定位慢查询的具体语句。

图4:定位查询语句为
SELECT abalance FROM pgbench_accounts WHERE aid = $1
慢查询:猜想
获知慢查询语句后,接下来需要推断慢查询产生的原因。
SELECT abalance FROM pgbench_accounts WHERE aid = $1
该查询以 aid 作为过滤条件查询 pgbench_accounts 表,如此简单的查询变慢,大概率是这张表上的索引出了问题。 用屁股想都知道是索引少了,因为就是我们自己删掉的嘛!
分析查询后, 可以提出猜想: 该查询变慢是pgbench_accounts表上aid列缺少索引。
下一步,我们就要验证猜想。
第一步,使用PG Table Catalog,我们可以检视表的详情,例如表上建立的索引。
第二步,查阅 PG Table Detail 面板,检查 pgbench_accounts 表上的访问,来验证我们的猜想
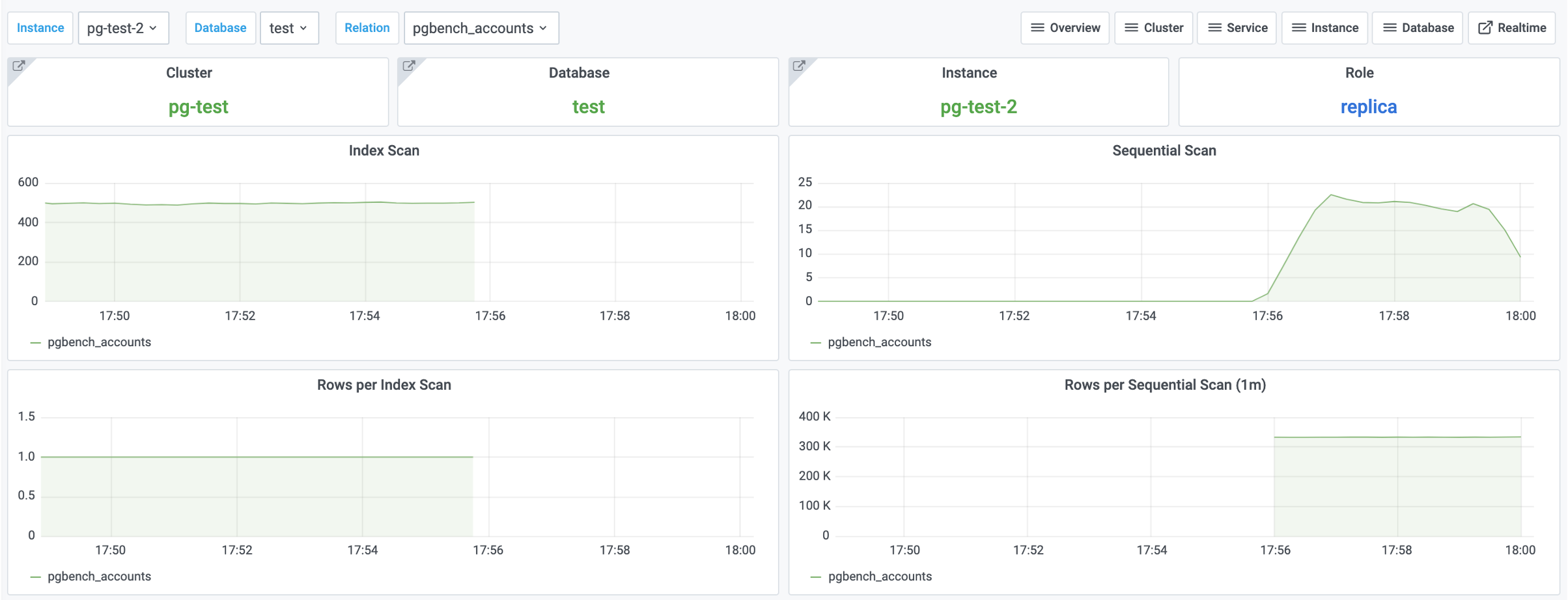
图5:
pgbench_accounts表上的访问情况
通过观察,我们发现表上的索引扫描归零,与此同时顺序扫描却有相应增长。这印证了我们的猜想!
慢查询:方案
假设一旦成立,就可以着手提出方案,解决问题了。
解决慢查询通常有三种方式:修改表结构、修改查询、修改索引。
修改表结构与查询通常涉及到具体的业务知识和领域知识,需要具体问题具体分析。但修改索引通常来说不需要太多的具体业务知识。
这里的问题可以通过添加索引解决,pgbench_accounts 表上 aid 列缺少索引,那么我们尝试在 pgbench_accounts 表上为 aid 列添加索引,看看能否解决这个问题。
CREATE UNIQUE INDEX ON pgbench_accounts (aid);
加上索引后,神奇的事情发生了。
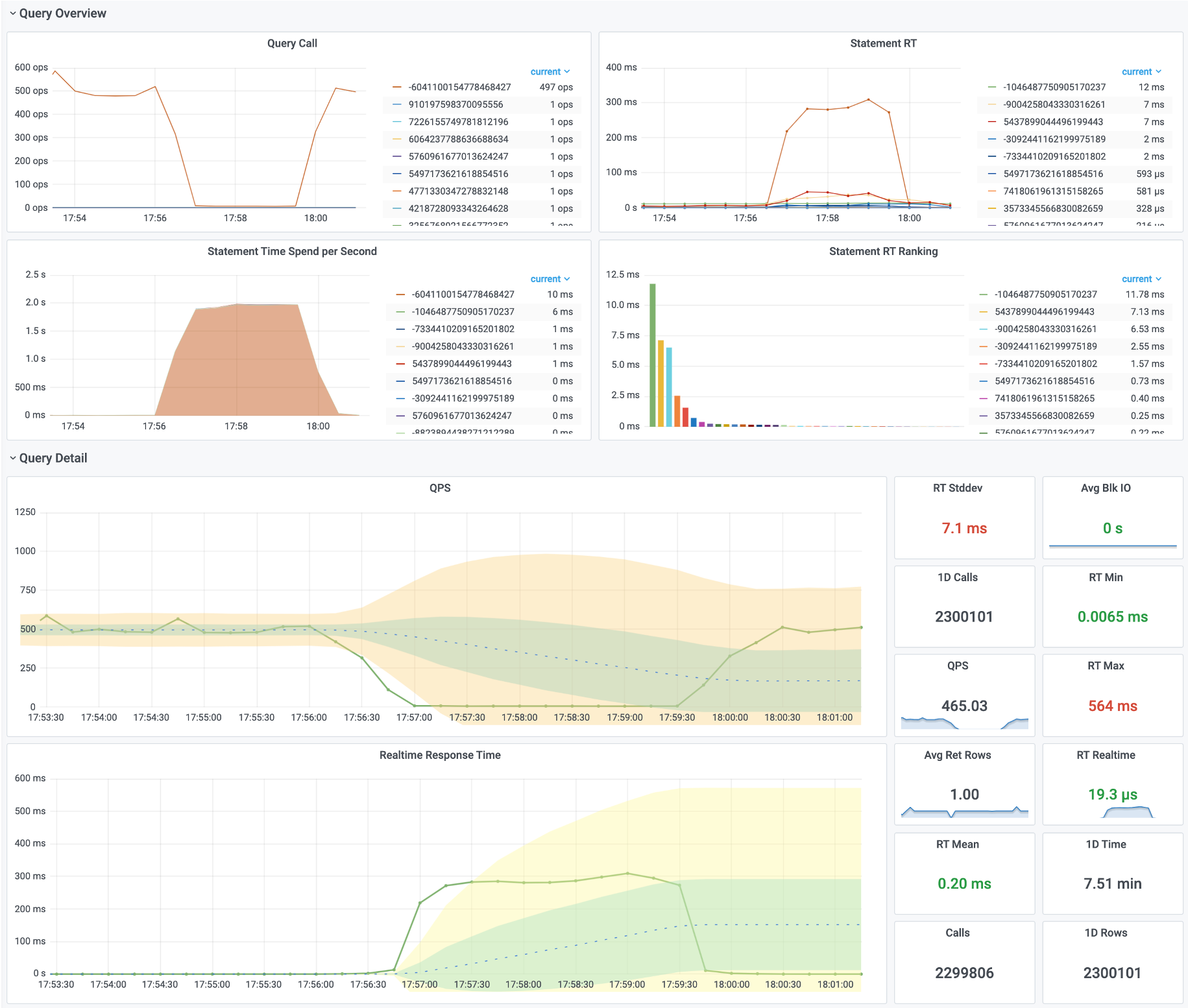
图6:可以看到,查询的响应时间与QPS已经恢复正常。
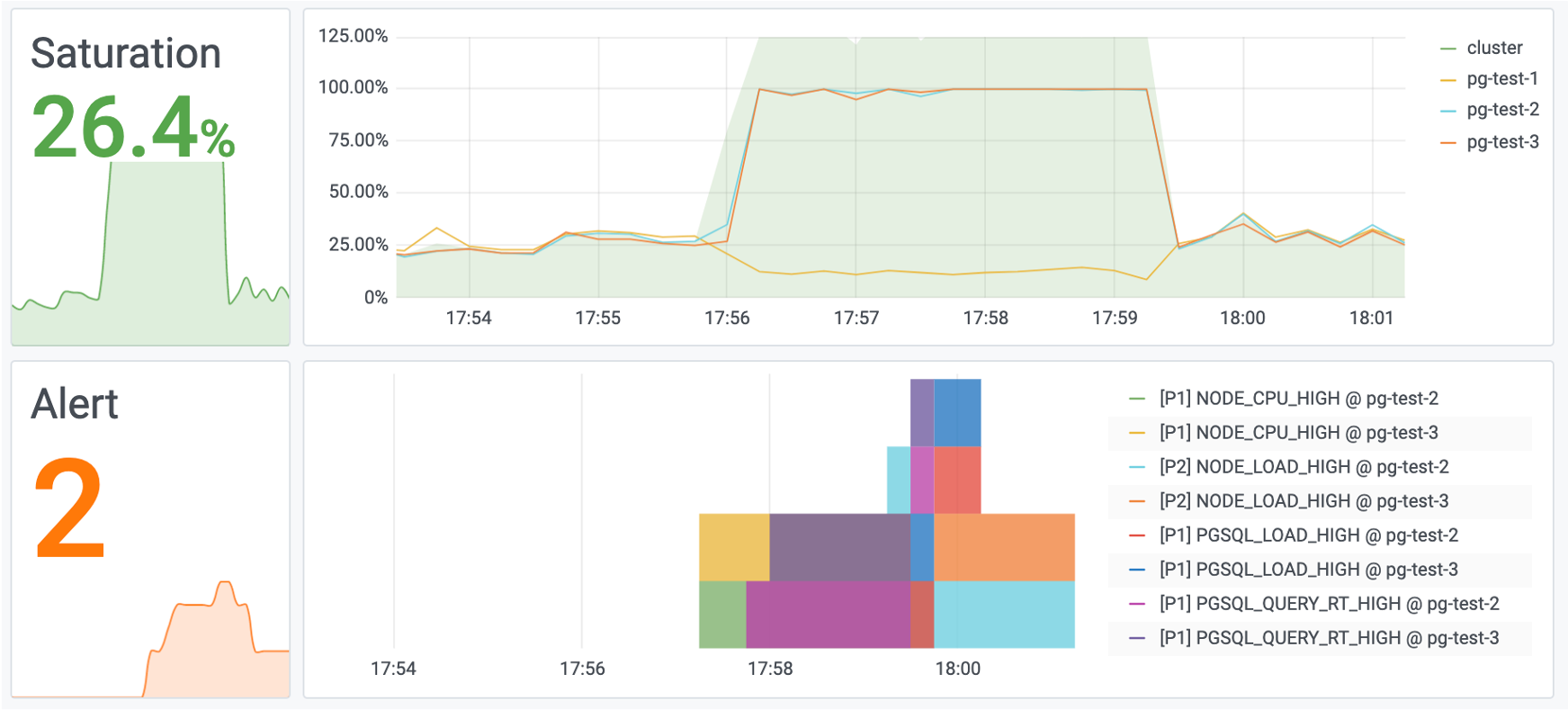
图7:系统的负载也恢复正常
慢查询:评估
作为慢查询处理的最后一步,我们通常需要对操作的过程进行记录,对效果进行评估。
有时候一个简单的优化可以产生戏剧性的效果。也许本来需要砸几十万加机器的问题,创建一个索引就解决了。
这种故事,就可以通过监控系统,用很生动直观的形式表达出来,赚取KPI与Credit。
图:一个慢查询优化前后,系统的整体饱和度从40%降到了4%
(相当于节省了X台机器,XX万元,老板看了心花怒放,下一任CTO就是你了!)
慢查询:小结
通过这篇教程,您已经掌握了慢查询优化的一般方法论。即:
-
定位问题
-
提出猜想
-
验证假设
-
制定方案
-
评估效果
监控系统在慢查询处理的整个生命周期中都能起到重要的效果。更能将运维与DBA的“经验”与“成果”,以可视化,可量化,可复制的方式表达出来。
故障档案:时间回溯导致的Patroni故障
摘要:机器因为故障重启,NTP服务在PG启动后修复了PG的时间,导致 Patroni 无法启动。
Patroni中的故障信息如下所示:
Process %s is not postmaster, too much difference between PID file start time %s and process start time %s
patroni 进程启动时间和pid时间不一致。就会认为:postgres is not running。
两个时间相差超过30秒。patroni 就尿了,启动不了了。
打印错误信息的代码为:
start_time = int(self._postmaster_pid.get('start_time', 0))
if start_time and abs(self.create_time() - start_time) > 3:
logger.info('Process %s is not postmaster, too much difference between PID file start time %s and process start time %s', self.pid, self.create_time(), start_time)
同时,发现了Patroni里的一个BUG:https://github.com/zalando/patroni/issues/811 错误信息里两个时间戳打反了。
经验与教训: NTP 时间同步是非常重要的
在线修改主键列类型
如何在线修改主键列类型,比如将 INT 至 BIGINT,同时又不影响业务?
假设在PG中有一个表,在设计的时候拍脑袋使用了 INT 整型主键,现在业务蓬勃发展发现序列号不够用了,想升级到BIGINT类型。这时候该怎么做呢?
拍脑袋的方法当然是直接使用DDL修改类型:
ALTER TABLE pgbench_accounts ALTER COLUMN aid SET DATA TYPE BIGINT;
但这种方式对于访问频繁的生产大表是不可行的
太长;不看
让我们以 pgbench 自带的场景为例
-- 操作目标:升级 pgbench_accounts 表普通列 abalance 类型:INT -> BIGINT
-- 添加新列:abalance_tmp BIGINT
ALTER TABLE pgbench_accounts ADD COLUMN abalance_tmp BIGINT;
-- 创建触发器函数:保持新列数据与旧列同步
CREATE OR REPLACE FUNCTION public.sync_pgbench_accounts_abalance() RETURNS TRIGGER AS $$
BEGIN NEW.abalance_tmp = NEW.abalance; RETURN NEW;END;
$$ LANGUAGE 'plpgsql';
-- 完成整表更新,分批更新的方式见下
UPDATE pgbench_accounts SET abalance_tmp = abalance; -- 不要在大表上运行这个
-- 创建触发器
CREATE TRIGGER tg_sync_pgbench_accounts_abalance BEFORE INSERT OR UPDATE ON pgbench_accounts
FOR EACH ROW EXECUTE FUNCTION sync_pgbench_accounts_abalance();
-- 完成列的新旧切换,这时候数据同步方向变化 旧列数据与新列保持同步
BEGIN;
LOCK TABLE pgbench_accounts IN EXCLUSIVE MODE;
ALTER TABLE pgbench_accounts DISABLE TRIGGER tg_sync_pgbench_accounts_abalance;
ALTER TABLE pgbench_accounts RENAME COLUMN abalance TO abalance_old;
ALTER TABLE pgbench_accounts RENAME COLUMN abalance_tmp TO abalance;
ALTER TABLE pgbench_accounts RENAME COLUMN abalance_old TO abalance_tmp;
ALTER TABLE pgbench_accounts ENABLE TRIGGER tg_sync_pgbench_accounts_abalance;
COMMIT;
-- 确认数据完整性
SELECT count(*) FROM pgbench_accounts WHERE abalance_new != abalance;
-- 清理触发器与函数
DROP FUNCTION IF EXISTS sync_pgbench_accounts_abalance();
DROP TRIGGER tg_sync_pgbench_accounts_abalance ON pgbench_accounts;
外键
alter table my_table add column new_id bigint;
begin; update my_table set new_id = id where id between 0 and 100000; commit;
begin; update my_table set new_id = id where id between 100001 and 200000; commit;
begin; update my_table set new_id = id where id between 200001 and 300000; commit;
begin; update my_table set new_id = id where id between 300001 and 400000; commit;
...
create unique index my_table_pk_idx on my_table(new_id);
begin;
alter table my_table drop constraint my_table_pk;
alter table my_table alter column new_id set default nextval('my_table_id_seq'::regclass);
update my_table set new_id = id where new_id is null;
alter table my_table add constraint my_table_pk primary key using index my_table_pk_idx;
alter table my_table drop column id;
alter table my_table rename column new_id to id;
commit;
以pgbench为例
vonng=# \d pgbench_accounts
Table "public.pgbench_accounts"
Column | Type | Collation | Nullable | Default
----------+---------------+-----------+----------+---------
aid | integer | | not null |
bid | integer | | |
abalance | integer | | |
filler | character(84) | | |
Indexes:
"pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
升级abalance列为BIGINT
会锁表,在表大小非常小,访问量非常小的的情况下可用。
ALTER TABLE pgbench_accounts ALTER COLUMN abalance SET DATA TYPE bigint;
在线升级流程
- 添加新列
- 更新数据
- 在新列上创建相关索引(如果没有也可以单列创建,加快第四步的速度)
- 执行切换事务
- 排他锁表
- UPDATE更新空列(也可以使用触发器)
- 删旧列
- 重命名新列
-- Step 1 : 创建新列
ALTER TABLE pgbench_accounts ADD COLUMN abalance_new BIGINT;
-- Step 2 : 更新数据,可以分批更新,分批更新方法详见下面
UPDATE pgbench_accounts SET abalance_new = abalance;
-- Step 3 : 可选(在新列上创建索引)
CREATE INDEX CONCURRENTLY ON public.pgbench_accounts (abalance_new);
UPDATE pgbench_accounts SET abalance_new = abalance WHERE ;
-- Step 3 :
-- Step 4 :
-- 同步更新对应列
CREATE OR REPLACE FUNCTION public.sync_abalance() RETURNS TRIGGER AS $$
BEGIN NEW.abalance_new = OLD.abalance; RETURN NEW;END;
$$ LANGUAGE 'plpgsql';
CREATE TRIGGER pgbench_accounts_sync_abalance BEFORE INSERT OR UPDATE ON pgbench_accounts EXECUTE FUNCTION sync_abalance();
alter table my_table add column new_id bigint;
begin; update my_table set new_id = id where id between 0 and 100000; commit;
begin; update my_table set new_id = id where id between 100001 and 200000; commit;
begin; update my_table set new_id = id where id between 200001 and 300000; commit;
begin; update my_table set new_id = id where id between 300001 and 400000; commit;
...
create unique index my_table_pk_idx on my_table(new_id);
begin;
alter table my_table drop constraint my_table_pk;
alter table my_table alter column new_id set default nextval('my_table_id_seq'::regclass);
update my_table set new_id = id where new_id is null;
alter table my_table add constraint my_table_pk primary key using index my_table_pk_idx;
alter table my_table drop column id;
alter table my_table rename column new_id to id;
commit;
批量更新逻辑
有时候需要为大表添加一个非空的,带有默认值的列。因此需要对整表进行一次更新,可以使用下面的办法,将一次巨大的更新拆分为100次或者更多的小更新。
从统计信息中获取主键的分桶信息:
SELECT unnest(histogram_bounds::TEXT::BIGINT[]) FROM pg_stats WHERE tablename = 'signup_users' and attname = 'id';
直接从统计分桶信息中生成需要执行的SQL,在这里把SQL改成需要更新的语
SELECT 'UPDATE signup_users SET app_type = '''' WHERE id BETWEEN ' || lo::TEXT || ' AND ' || hi::TEXT || ';'
FROM (
SELECT lo, lead(lo) OVER (ORDER BY lo) as hi
FROM (
SELECT unnest(histogram_bounds::TEXT::BIGINT[]) lo
FROM pg_stats
WHERE tablename = 'signup_users'
and attname = 'id'
ORDER BY 1
) t1
) t2;
直接使用SHELL脚本打印出更新语句
DATNAME=""
RELNAME="pgbench_accounts"
IDENTITY="aid"
UPDATE_CLAUSE="abalance_new = abalance"
SQL=$(cat <<-EOF
SELECT 'UPDATE ${RELNAME} SET ${UPDATE_CLAUSE} WHERE ${IDENTITY} BETWEEN ' || lo::TEXT || ' AND ' || hi::TEXT || ';'
FROM (
SELECT lo, lead(lo) OVER (ORDER BY lo) as hi
FROM (
SELECT unnest(histogram_bounds::TEXT::BIGINT[]) lo
FROM pg_stats
WHERE tablename = '${RELNAME}'
and attname = '${IDENTITY}'
ORDER BY 1
) t1
) t2;
EOF
)
# echo $SQL
psql ${DATNAME} -qAXwtc "ANALYZE ${RELNAME};"
psql ${DATNAME} -qAXwtc "${SQL}"
处理边界情况。
UPDATE signup_users SET app_type = '' WHERE app_type != '';
优化与改进
也可以加工一下,添加事务语句和休眠间隔
DATNAME="test"
RELNAME="pgbench_accounts"
COLNAME="aid"
UPDATE_CLAUSE="abalance_tmp = abalance"
SLEEP_INTERVAL=0.1
SQL=$(cat <<-EOF
SELECT 'BEGIN;UPDATE ${RELNAME} SET ${UPDATE_CLAUSE} WHERE ${COLNAME} BETWEEN ' || lo::TEXT || ' AND ' || hi::TEXT || ';COMMIT;SELECT pg_sleep(${SLEEP_INTERVAL});VACUUM ${RELNAME};'
FROM (
SELECT lo, lead(lo) OVER (ORDER BY lo) as hi
FROM (
SELECT unnest(histogram_bounds::TEXT::BIGINT[]) lo
FROM pg_stats
WHERE tablename = '${RELNAME}'
and attname = '${COLNAME}'
ORDER BY 1
) t1
) t2;
EOF
)
# echo $SQL
psql ${DATNAME} -qAXwtc "ANALYZE ${RELNAME};"
psql ${DATNAME} -qAXwtc "${SQL}"
BEGIN;UPDATE pgbench_accounts SET abalance_new = abalance WHERE aid BETWEEN 397 AND 103196;COMMIT;SELECT pg_sleep(0.5);VACUUM pgbench_accounts;
BEGIN;UPDATE pgbench_accounts SET abalance_new = abalance WHERE aid BETWEEN 103196 AND 213490;COMMIT;SELECT pg_sleep(0.5);VACUUM pgbench_accounts;
BEGIN;UPDATE pgbench_accounts SET abalance_new = abalance WHERE aid BETWEEN 213490 AND 301811;COMMIT;SELECT pg_sleep(0.5);VACUUM pgbench_accounts;
BEGIN;UPDATE pgbench_accounts SET abalance_new = abalance WHERE aid BETWEEN 301811 AND 400003;COMMIT;SELECT pg_sleep(0.5);VACUUM pgbench_accounts;
BEGIN;UPDATE pgbench_accounts SET abalance_new = abalance WHERE aid BETWEEN 400003 AND 511931;COMMIT;SELECT pg_sleep(0.5);VACUUM pgbench_accounts;
BEGIN;UPDATE pgbench_accounts SET abalance_new = abalance WHERE aid BETWEEN 511931 AND 613890;COMMIT;SELECT pg_sleep(0.5);VACUUM pgbench_accounts;
黄金监控指标:错误延迟吞吐饱和
前言
玩数据库和玩车有一个共通之处,就是都需要经常看仪表盘。
盯着仪表盘干什么,看指标。为什么看指标,掌握当前运行状态才能有效施加控制。

车有很多指标:车速,胎压,扭矩,刹车片磨损,各种温度,等等等等,各式各样。
但人的注意力空间有限,仪表盘也就那么大,
所以,指标可以分两类:
- 你会去看的:黄金指标 / 关键指标 / 核心指标
- 你不会看的:黑匣子指标 / 冷指标。
黄金指标就是那几个关键性的核心数据,需要时刻保持关注(或者让自动驾驶系统/报警系统替你时刻保持关注),而冷指标通常只有故障排查时才会去看,故障排查与验尸要求尽可能还原现场,黑匣子指标多多益善。需要时没有就很让人抓狂
今天我们来说说PostgreSQL的核心指标,数据库的核心指标是什么?
数据库的指标
在讲数据库的核心指标之前,我们先来瞄一眼有哪些指标。
avg(count by (ins) ({__name__=~"pg.*"}))
avg(count by (ins) ({__name__=~"node.*"}))
1000多个pg的指标,2000多个机器的指标。
这些指标都是数据宝藏,挖掘与可视化可以提取出其中的价值。
但对于日常管理,只需要少数几个核心指标就可以了。
可用指标千千万,哪些才是核心指标?
核心指标
根据经验和使用频度,不断地做减法,可以筛选出一些核心指标:
| 指标 | 缩写 | 层次 | 来源 | 种类 |
|---|---|---|---|---|
| 错误日志条数 | Error Count | SYS/DB/APP | 日志系统 | 错误 |
| 连接池排队数 | Queue Clients | DB | 连接池 | 错误 |
| 数据库负载 | PG Load | DB | 连接池 | 饱和度 |
| 数据库饱和度 | PG Saturation | DB | 连接池&节点 | 饱和度 |
| 主从复制延迟 | Repl Lag | DB | 数据库 | 延迟 |
| 平均查询响应时间 | Query RT | DB | 连接池 | 延迟 |
| 活跃后端进程数 | Backends | DB | 数据库 | 饱和度 |
| 数据库年龄 | Age | DB | 数据库 | 饱和度 |
| 每秒查询数 | QPS | APP | 连接池 | 流量 |
| CPU使用率 | CPU Usage | SYS | 机器节点 | 饱和度 |
紧急情况下:错误是始终是第一优先级的黄金指标。
常规情况下:应用视角的黄金指标:QPS与RT
常规情况下:DBA视角的黄金指标:DB饱和度(水位)
为什么是它们?
错误指标
第一优先级的指标永远是错误,错误往往是直接面向终端用户的。
如果只能选一个指标进行监控,那么选错误指标,比如应用,系统,DB层的每秒错误日志条数可能最合适。
一辆车,只能选一个仪表盘上的功能,你会选什么?
选错误指标,小车不停只管推。
错误类指标非常重要,直接反映出系统的异常,譬如连接池排队。但错误类指标最大的问题就是,它只在告警时有意义,难以用于日常的水位评估与性能分析,此外,错误类指标也往往难以精确量化,往往只能给出定性的结果:有问题 vs 没问题。
此外,错误类指标难以精确量化。我们只能说:当连接池出现排队时,数据库负载比较大;队列越长,负载越大;没有排队时,数据库负载不怎么大,仅此而已。对于日常使用管理来说,这样的能力肯定也是不够的。
定指标,做监控报警系统的一个重要原因就是用于预防系统过载,如果系统已经过载大量报错,那么使用错误现象反过来定义饱和度是没有意义的。
指标的目的,是为了衡量系统的运行状态。,我们还会关注系统其他方面的能力:吞吐量/流量,响应时间/延迟,饱和度/利用率/水位线。这三者分别代表系统的能力,服务质量,负载水平。
关注点不同,后端(数据库用户)关注系统能力与服务质量,DBA(数据库管理者)更关注系统的负载水平。
流量指标
流量类的指标很有潜力,特别是QPS,TPS这样的指标相当具有代表性。
流量指标可以直接衡量系统的能力,譬如每秒处理多少笔订单,每秒处理的多少个请求。
与车速计有异曲同工之妙,高速限速,城市限速。环境,负载。
但像TPS QPS这样流量也存在问题。一个数据库实例上的查询往往是五花八门各式各样的,一个耗时10微秒的查询和一个10秒的查询在统计时都被算为一个Q,类似于QPS这样的指标无法进行横向比较,只有比较粗略的参考意义,甚至当查询类型发生变化时,都无法和自己的历史数据进行纵向比较。此外也很难针对QPS、TPS这样的指标设置利用率目标,同一个数据库执行SELECT 1可以打到几十万的QPS,但执行复杂SQL时可能就只能打到几千的QPS。不同负载类型和机器硬件会对数据库的QPS上限产生显著影响,只有当一个数据库上的查询都是高度单一同质且没有复杂变化的条件下,QPS才有参考意义,在这种苛刻条件下倒是可以通过压力测试设定一个QPS的水位目标。
延迟指标
与档位类似,查询慢,档位低,车速慢。查询档次低,TPS水位低。查询档次高,TPS水位高
延迟适合衡量系统的服务质量。
比起QPS/TPS,RT(响应时间 Response Time)这样的指标反而更具有参考价值。因为响应时间增加往往是系统饱和的前兆。根据经验法则,数据库的负载越大,查询与事务的平均响应时间也会越高。RT相比QPS的一个优势是**,RT是可以设置一个利用率目标的**,比如可以为RT设定一个绝对阈值:不允许生产OLTP库上出现RT超过1ms的慢查询。但QPS这样的指标就很难画出红线来。不过,RT也有自己的问题。第一个问题是它依然是定性而非定量的,延迟增加只是系统饱和的预警,但没法用来精确衡量系统的饱和度。第二个问题通常能从数据库与中间件获取到的RT统计指标都是平均值,但真正起到预警效果的有可能是诸如P99,P999这样的统计量。
饱和度指标
饱和度指标类似汽车的发动机转速表,油量表,水温表。
饱和度指标适合衡量系统的负载
即用户期待的负载指标是一个饱和度(Saturation)指标,所谓饱和度,即服务容量有多”满“,通常是系统中目前最为受限的某种资源的某个具体指标的度量。通常来说,0%的饱和度意味着系统完全空闲,100%的饱和度意味着满载,系统在达到100%利用率前就会出现性能的严重下降,因此设定指标时还需要包括一个利用率目标,或者说水位红线、黄线,当系统瞬时负载超过红线时应当触发告警,长期负载超过黄线时应当进行扩容。
| 其他可选指标 | ||||
|---|---|---|---|---|
| 每秒事务数 | TPS | APP | 连接池 | 流量 |
| 磁盘IO使用率 | Disk Usage | SYS | 机器节点 | 饱和度 |
| 内存使用率 | Mem Usage | SYS | 机器节点 | 饱和度 |
| 网卡带宽使用率 | Net Usage | SYS | 机器节点 | 饱和度 |
| TCP错误:溢出重传等 | TCP ERROR | SYS | 机器节点 | 错误 |
数据库集群管理概念与实体命名规范
名之则可言也,言之则可行也。
概念及其命名是非常重要的东西,命名风格体现了工程师对系统架构的认知。定义不清的概念将导致沟通困惑,随意设定的名称将产生意想不到的额外负担。因此需要审慎地设计。
TL;DR
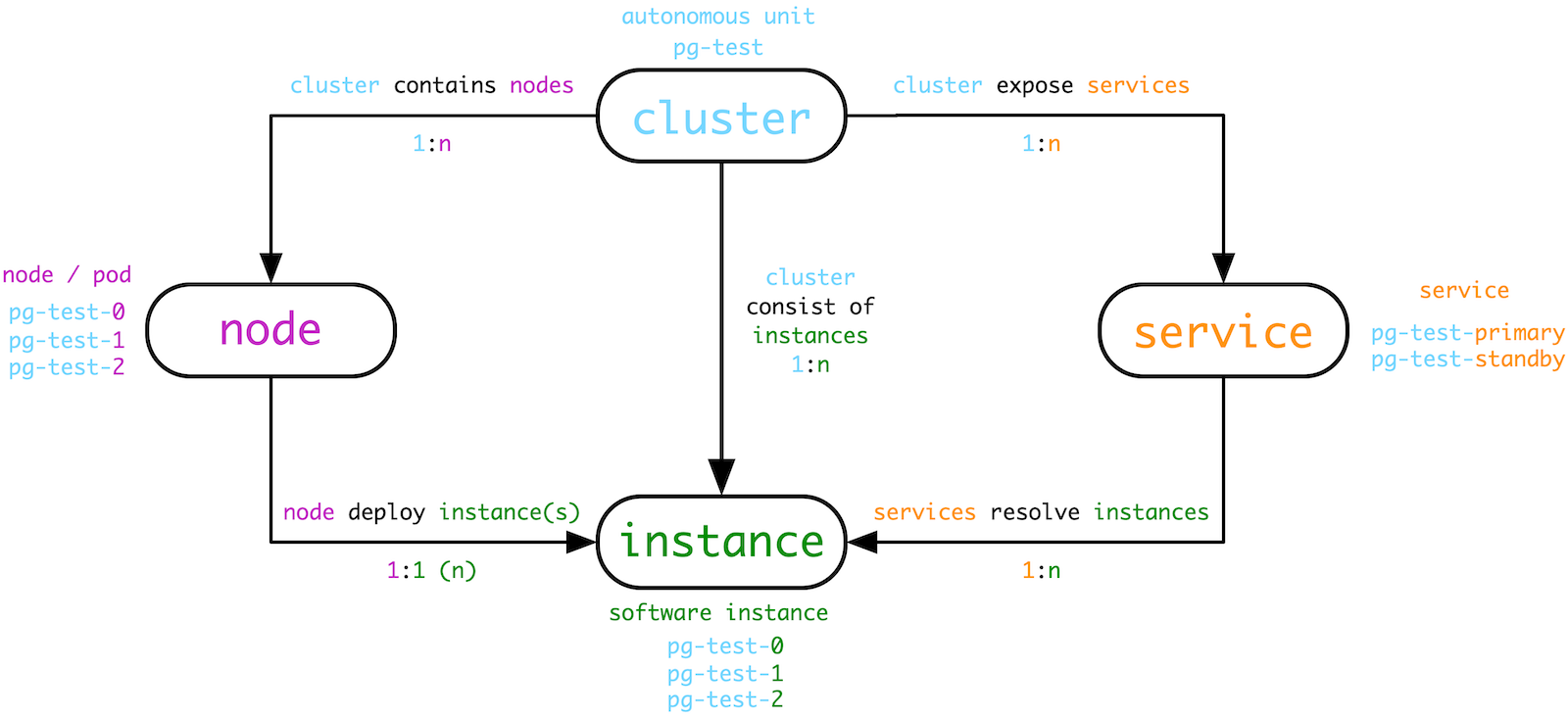
- **集群(Cluster)**是基本自治单元,由用户指定唯一标识,表达业务含义,作为顶层命名空间。
- 集群在硬件层面上包含一系列的节点(Node),即物理机,虚机(或Pod),可以通过IP唯一标识。
- 集群在软件层面上包含一系列的实例(Instance),即软件服务器,可以通过IP:Port唯一标识。
- 集群在服务层面上包含一系列的服务(Service),即可访问的域名与端点,可以通过域名唯一标识。
- Cluster命名可以使用任意满足DNS域名规范的名称,但不能带点([a-zA-Z0-9-]+)。
- Node/Pod命名采用Cluster名称前缀,后接
-连接一个从0开始分配的序号,(与k8s保持一致) - 实例命名通常与Node保持一致,即
${cluster}-${seq}的方式,这种方式隐含着节点与实例1:1部署的假设。如果这个假设不成立,则可以采用独立于节点的序号,但保持同样的命名规则。 - Service命名采用Cluster名称前缀,后接
-连接服务具体内容,如primary,standby
以上图为例,用于测试的数据库集群名为“pg-test”,该集群由一主两从三个数据库服务器实例组成,部署在集群所属的三个节点上。pg-test集群集群对外提供两种服务,读写服务pg-test-primary与只读副本服务pg-test-standby。
基本概念
在Postgres集群管理中,有如下概念:
集群(Cluster)
集群是基本的自治业务单元,这意味着集群能够作为一个整体组织对外提供服务。类似于k8s中Deployment的概念。注意这里的集群是软件层面的概念,不要与PG Cluster(数据库集簇,即包含多个PG Database实例的单个PG Server Instance)或Node Cluster(机器集群)混淆。
集群是管理的基本单位之一,是用于统合各类资源的组织单位。例如一个PG集群可能包括:
- 三个物理机器节点
- 一个主库实例,对外提供数据库读写服务。
- 两个从库实例,对外提供数据库只读副本服务。
- 两个对外暴露的服务:读写服务,只读副本服务。
每个集群都有用户根据业务需求定义的唯一标识符,本例中定义了一个名为pg-test的数据库集群。
节点(Node)
节点是对硬件资源的一种抽象,通常指代一台工作机器,无论是物理机(bare metal)还是虚拟机(vm),或者是k8s中的Pod。这里注意k8s中Node是硬件资源的抽象,但在实际管理使用上,是k8s中的Pod而不是Node更类似于这里Node概念。总之,节点的关键要素是:
- 节点是硬件资源的抽象,可以运行一系列的软件服务
- 节点可以使用IP地址作为唯一标识符
尽管可以使用lan_ip地址作为节点唯一标识符,但为了便于管理,节点应当拥有一个人类可读的充满意义的名称作为节点的Hostname,作为另一个常用的节点唯一标识。
服务(Service)
服务是对软件服务(例如Postgres,Redis)的一种命名抽象(named abastraction)。服务可以有各种各样的实现,但其的关键要素在于:
- 可以寻址访问的服务名称,用于对外提供接入,例如:
- 一个DNS域名(
pg-test-primary) - 一个Nginx/Haproxy Endpoint
- 一个DNS域名(
- 服务流量路由解析与负载均衡机制,用于决定哪个实例负责处理请求,例如:
- DNS L7:DNS解析记录
- HTTP Proxy:Nginx/Ingress L7:Nginx Upstream配置
- TCP Proxy:Haproxy L4:Haproxy Backend配置
- Kubernetes:Ingress:Pod Selector 选择器。
同一个数据集簇中通常包括主库与从库,两者分别提供读写服务(primary)和只读副本服务(standby)。
实例(Instance)
实例指带一个具体的数据库服务器,它可以是单个进程,也可能是共享命运的一组进程,也可以是一个Pod中几个紧密关联的容器。实例的关键要素在于:
- 可以通过IP:Port唯一标识
- 具有处理请求的能力
例如,我们可以把一个Postgres进程,为之服务的独占Pgbouncer连接池,PgExporter监控组件,高可用组件,管理Agent看作一个提供服务的整体,视为一个数据库实例。
实例隶属于集群,每个实例在集群范围内都有着自己的唯一标识用于区分。
实例由服务负责解析,实例提供被寻址的能力,而Service将请求流量解析到具体的实例组上。
命名规则
一个对象可以有很多组 标签(Tag) 与 元数据(Metadata/Annotation) ,但通常只能有一个名字。
管理数据库和软件,其实与管理子女或者宠物类似,都是需要花心思去照顾的。而起名字就是其中非常重要的一项工作。肆意的名字(例如 XÆA-12,NULL,史珍香)很可能会引入不必要的麻烦(额外复杂度),而设计得当的名字则可能会有意想不到的效果。
总的来说,对象起名应当遵循一些原则:
-
简洁直白,人类可读:名字是给人看的,因此要好记,便于使用。
-
体现功能,反映特征:名字需要反映对象的关键特征
-
独一无二,唯一标识:名字在命名空间内,自己的类目下应当是独一无二,可以惟一标识寻址的。
-
不要把太多无关的东西塞到名字里去:在名字中嵌入很多重要元数据是一个很有吸引力的想法,但维护起来会非常痛苦,例如反例:
pg:user:profile:10.11.12.13:5432:replica:13。
集群命名
集群名称,其实类似于命名空间的作用。所有隶属本集群的资源,都会使用该命名空间。
集群命名的形式,建议采用符合DNS标准 RFC1034 的命名规则,以免给后续改造埋坑。例如哪一天想要搬到云上去,发现以前用的名字不支持,那就要再改一遍名,成本巨大。
我认为更好的方式是采用更为严格的限制:集群的名称不应该包括点(dot)。应当仅使用小写字母,数字,以及减号连字符(hyphen)-。这样,集群中的所有对象都可以使用这个名称作为前缀,用于各种各样的地方,而不用担心打破某些约束。即集群命名规则为:
cluster_name := [a-z][a-z0-9-]*
之所以强调不要在集群名称中用点,是因为以前很流行一种命名方式,例如com.foo.bar。即由点分割的层次结构命名法。这种命名方式虽然简洁名快,但有一个问题,就是用户给出的名字里可能有任意多的层次,数量不可控。如果集群需要与外部系统交互,而外部系统对于命名有一些约束,那么这样的名字就会带来麻烦。一个最直观的例子是K8s中的Pod,Pod的命名规则中不允许出现.。
集群命名的内涵,建议采用-分隔的两段式,三段式名称,例如:
<集群类型>-<业务>-<业务线>
比如:pg-test-tt就表示tt 业务线下的test集群,类型为pg。pg-user-fin表示fin业务线下的user服务。当然,采集多段命名最好还是保持段数固定。
节点命名
节点命名建议采用与k8s Pod一致的命名规则,即
<cluster_name>-<seq>
Node的名称会在集群资源分配阶段确定下来,每个节点都会分配到一个序号${seq},从0开始的自增整型。这个与k8s中StatefulSet的命名规则保持一致,因此能够做到云上云下一致管理。
例如,集群pg-test有三个节点,那么这三个节点就可以命名为:
pg-test-0, pg-test-1和pg-test2。
节点的命名,在整个集群的生命周期中保持不变,便于监控与管理。
实例命名
对于数据库来说,通常都会采用独占式部署方式,一个实例占用整个机器节点。PG实例与Node是一一对应的关系,因此可以简单地采用Node的标识符作为Instance的标识符。例如,节点pg-test-1上的PG实例名即为:pg-test-1,以此类推。
采用独占部署的方式有很大优势,一个节点即一个实例,这样能最小化管理复杂度。混部的需求通常来自资源利用率的压力,但虚拟机或者云平台可以有效解决这种问题。通过vm或pod的抽象,即使是每个redis(1核1G)实例也可以有一个独占的节点环境。
作为一种约定,每个集群中的0号节点(Pod),会作为默认主库。因为它是初始化时第一个分配的节点。
服务命名
通常来说,数据库对外提供两种基础服务:primary 读写服务,与standby只读副本服务。
那么服务就可以采用一种简单的命名规则:
<cluster_name>-<service_name>
例如这里pg-test集群就包含两个服务:读写服务pg-test-primary与只读副本服务pg-test-standby。
还有一种流行的实例/节点命名规则:<cluster_name>-<service_role>-<sequence>,即把数据库的主从身份嵌入到实例名称中。这种命名方式有好处也有坏处。好处是管理的时候一眼就能看出来哪一个实例/节点是主库,哪些是从库。缺点是一但发生Failover,实例与节点的名称必须进行调整才能维持一执性,这就带来的额外的维护工作。此外,服务与节点实例是相对独立的概念,这种Embedding命名方式扭曲了这一关系,将实例唯一隶属至服务。但复杂的场景下这一假设可能并不满足。例如,集群可能有几种不同的服务划分方式,而不同的划分方式之间很可能会出现重叠。
- 可读从库(解析至包含主库在内的所有实例)
- 同步从库(解析至采用同步提交的备库)
- 延迟从库,备份实例(解析至特定具体实例)
因此,不要把服务角色嵌入实例名称,而是在服务中维护目标实例列表。
小结
命名属于相当经验性的知识,很少有地方会专门会讲这件事。这种“细节”其实往往能体现出命名者的一些经验水平来。
标识对象不仅仅可以通过ID和名称,还可以通过标签(Label)和选择器(Selector)。实际上这一种做法会更具有通用性和灵活性,本系列下一篇文章(也许)将会介绍数据库对象的标签设计与管理。
PostgreSQL的KPI
管数据库和管人差不多,都需要定KPI(关键性能指标)。那么数据库的KPI是什么?本文介绍了一种衡量PostgreSQL负载的方式:使用一种单一横向可比,与负载类型和机器类型基本无关的指标,名曰PG Load(PG负载)。
0x01 Introduction
在现实生产中,经常会有衡量数据库性能与负载,评估数据库水位的需求。一种最朴素的形式就是,能不能有一个类似于KPI的单一指标,能直接了当地告诉用户他心爱的数据库负载有没有超过警戒线?工作量到底饱和不饱和?
当然这里其实隐含着一个重要信息,即用户期待的负载指标是一个饱和度(Saturation)指标,所谓饱和度,即服务容量有多”满“,通常是系统中目前最为受限的某种资源的某个具体指标的度量。通常来说,0%的饱和度意味着系统完全空闲,100%的饱和度意味着满载,系统在达到100%利用率前就会出现性能的严重下降,因此设定指标时还需要包括一个利用率目标,或者说水位红线、黄线,当系统瞬时负载超过红线时应当触发告警,长期负载超过黄线时应当进行扩容。
不幸的是,定义系统有多”饱和“并不是一件容易的事情,往往需要借助某些间接指标。评估一个数据库的负载程度,传统上通常会基于这样几类指标进行综合评估:
-
流量:每秒查询数量QPS,或每秒事务数量TPS。
-
延迟:查询平均响应时间 Query RT,或事务平均响应时间Xact RT
-
饱和度:机器负载(Load),CPU使用率,磁盘读写带宽饱和度,网卡IO带宽饱和度
-
错误:数据库客户端连接排队
这些指标对于数据库性能评估都很有参考意义,但它们也都存在各式各样的问题。
0x02 常用评估指标的问题
让我们来看一看,这些现有的常用指标都有哪些问题。
第一个Pass的当然是错误类指标,譬如连接池排队。错误类指标最大的问题就是,当错误出现时,饱和度可能已经没有意义了。评估饱和度的一个重要原因就是用于预防系统过载,如果系统已经过载大量报错,那么使用错误现象反过来定义饱和度是没有意义的。此外,错误类指标难以精确量化。我们只能说:当连接池出现排队时,数据库负载比较大;队列越长,负载越大;没有排队时,数据库负载不怎么大,仅此而已。这样的定义当然也无法让人满意。
第二个Pass的则是系统层(机器级别)指标,数据库运行在机器上,CPU使用率,IO使用率这样的指标与数据库负载程度密切相关,如果CPU和IO是瓶颈,理论上当然是可以直接使用瓶颈资源的饱和度指标作为数据库的饱和指标,但这一点并非总是成立的,有可能系统瓶颈在于数据库本身。而且严格来说它们是机器的KPI而不是DB的KPI,评估数据库负载时当然可以参照系统层的指标,但DB层也应该有本层的评估指标。要先有数据库本身的饱和度指标,才可以去比较底层资源和数据库本身到底谁先饱和谁是瓶颈。这条原则同样适用于应用层观察到的指标。
流量类的指标很有潜力,特别是QPS,TPS这样的指标相当具有代表性。但这些指标也存在问题。一个数据库实例上的查询往往是五花八门各式各样的,一个耗时10微秒的查询和一个10秒的查询在统计时都被算为一个Q,类似于QPS这样的指标无法进行横向比较,只有比较粗略的参考意义,甚至当查询类型发生变化时,都无法和自己的历史数据进行纵向比较。此外也很难针对QPS、TPS这样的指标设置利用率目标,同一个数据库执行SELECT 1可以打到几十万的QPS,但执行复杂SQL时可能就只能打到几千的QPS。不同负载类型和机器硬件会对数据库的QPS上限产生显著影响,只有当一个数据库上的查询都是高度单一同质且没有复杂变化的条件下,QPS才有参考意义,在这种苛刻条件下倒是可以通过压力测试设定一个QPS的水位目标。
比起QPS/TPS,RT(响应时间 Response Time)这样的指标反而更具有参考价值。因为响应时间增加往往是系统饱和的前兆。根据经验法则,数据库的负载越大,查询与事务的平均响应时间也会越高。RT相比QPS的一个优势是**,RT是可以设置一个利用率目标的**,比如可以为RT设定一个绝对阈值:不允许生产OLTP库上出现RT超过1ms的慢查询。但QPS这样的指标就很难画出红线来。不过,RT也有自己的问题。第一个问题是它依然是定性而非定量的,延迟增加只是系统饱和的预警,但没法用来精确衡量系统的饱和度。第二个问题通常能从数据库与中间件获取到的RT统计指标都是平均值,但真正起到预警效果的有可能是诸如P99,P999这样的统计量。
这里把常用指标都批判了一番,到底什么样的指标适合作为数据库本身的饱和度呢?
0x03 衡量PG的负载
我们不妨参考一下**机器负载(Node Load)和CPU利用率(CPU Utilization)**的评估指标是如何设计的。
机器负载(Node Load)
想要看到机器的负载水平,可以在Linux系统中使用top命令。top命令的第一行输出就醒目地打印出当前机器1分钟,5分钟,15分钟的平均负载水平。
$ top -b1
top - 19:27:38 up 18:49, 1 user, load average: 1.15, 0.72, 0.71
这里load average后面的三个数字分别表示最近1分钟,5分钟,15分钟系统的平均负载水平。
那么这个数字到底是什么意思呢?简单的解释是,这个数字越大机器越忙。
在单核CPU的场景下,Node Load(以下简称负载)是一个非常标准的饱和度指标。对于单核CPU,负载为0时CPU处于完全空闲的状态,负载为1(100%)时,CPU正好处于满载工作的状态。负载大于100%时,超出100%部分比例的任务正在排队。
Node Load也有自己的利用率目标,通常的经验是在单核情况下:0.7(70%)是黄线,意味着系统有问题,需要尽快检查;1.0(100%)是红线,负载大于1意味着进程开始堆积,需要立即着手处理。5.0(500%)是死线,意味着系统基本上已经堵死了。
对于多核CPU,事情稍微有点不一样。假设有n个核,那么当系统负载为n时,所有CPU都处于满载工作的状态;而当系统负载为n/2时,姑且可以认为一半CPU核正在满载运行。因而48核CPU的机器满载时的负载为48。总的来说,如果我们把机器负载除以机器的CPU核数,得到的指标就与单核场景下保持一致了(0%空载,100%满载)。
CPU利用率(CPU Utilization)
另一个很有借鉴意义的指标是CPU利用率(CPU Utilization)。CPU利用率其实是通过一个简单的公式计算出来的,对于单核CPU:
1 - irate(node_cpu_seconds_total{mode="idle"}[1m]
这里node_cpu_seconds_total{mode="idle"}是一个计数器指标,表示CPU处于空闲状态的总时长。irate函数会用该指标对时间进行求导,得出的结果是,每秒CPU处于空闲状态的时长,换句话说也就是CPU空闲率。用1减去该值就得到了CPU的利用率。
对于多核CPU来说,只需要把每个CPU核的利用率加起来,除以CPU的核数,就可以得到CPU的整体利用率。
那么这两个指标对于PG的负载又有什么借鉴意义呢?
数据库负载(PG Load)
PG的负载是不是也可以采用类似于CPU利用率和机器负载的方式来定义?当然可以,而且这是一个极棒的主意。
让我们先来考虑单进程情况下的PG负载,假设我们需要这样一个指标,当该PG进程完全空闲时负载因子为0,当该进程处于满载状态时负载为1(100%)。类比CPU利用率的定义,我们可以使用“单个PG进程处于活跃状态的时长占比”来表示“单个PG后端进程的利用率”。
如图1所示,在一秒的统计周期内,PG处于活跃(执行查询或者执行事务)状态的时长为0.6秒,那么这一秒内的PG负载就是60%。如果这个唯一的PG进程在整个统计周期中都处于忙碌状态,而且还有0.4秒的任务在排队,如那么就可以认为PG的负载为140%。

对于并行场景,计算方法与多核CPU的利用率类似,首先把所有PG进程在统计周期(1s)内处于活跃状态的时长累加,然后除以“可用的PG进程/连接数”,或者说“可用并行数”,即可得到PG本身的利用率指标,如图3所示。两个PG后端进程分别有200ms+400ms与800ms的活跃时长,那么整体的负载水平为:(0.2s + 0.4s + 0.8s) / 1s / 2 = 70%
总结一下,某一段时间内PG的负载可以定义为:
pg_load = pg_active_seconds / time_peroid / parallel
-
pg_active_seconds是该时间段内所有PG进程处于活跃状态的时长之和。 -
time_peroid是负载计算的统计周期,通常为1分钟,5分钟,15分钟,以及实时(小于10秒)。 -
parallel是PostgreSQL的可用并行数,后面会详细解释。
因为前两项之商实际上就是一段时间内的每秒活跃时长总数,因此这个公式进一步可以简化为活跃时长对时间的导数除以可用并行数,即:
rate(pg_active_seconds[time_peroid]) / parallel
time_peroid通常是固定的常量(1,5,15分钟),所以问题就是如何获取PG进程活跃总时长pg_active_seconds这个指标,以及如何评估计算数据库可用并行数max_parallel 了。
0x04 计算PG的负载饱和度
事务还是查询?
当我们说数据库进程 活跃/空闲 时,究竟在说什么? PG处于活跃状态,到底是什么意思?如果PG后端进程正在执行查询,那么当然可以认为PG正处于忙碌状态。但如果如上图4所示,PG进程正在执行一个交互式事务,但没有实际执行查询,即所谓的“Idle in Transaction”状态,又应该怎么计算“活跃时长”呢?图4中两个查询中空闲的那200ms时间。那么这段时间应该算作“活跃”,还是算作“空闲”呢?
这里的核心问题是怎么定义活跃状态:数据库进程位于事务中算活跃,还是只有当实际执行查询时才算活跃。对于没有交互式事务的场景,一个查询就是一个事务,用哪种方式都一样,但对于多语句,特别是交互式的多语句事务,这两者就有比较明显的区别了。从资源使用的角度看,没有执行查询也就意味着没有消耗数据库本身的资源。但空闲着的事务本身会占用连接导致连接无法复用,Idle In Transaction本身也应当是一种极力避免的情况。总的来说,这两种定义方式都可以,使用事务的方式会略微高估应用负载,但从负载评估的角度可能会更为合适。
如何获取活跃时长
决定了数据库后端进程的活跃定义后,第二个问题就是,如何获取一段时间的数据库活跃时长?不幸的是在PG中,用户很难通过数据库本身获取这一性能指标。PG提供了一个系统视图:pg_stat_activity,可以看到当前运行着的Postgres进程里列表,但这是一个时间点快照,只能大致告诉在当前时刻,数据库的后端进程中有多少个处于活跃状态,有多少个处于空闲状态。统计一段时间内数据库处于活跃状态的时长,就成了一个难题。一种解决方案是使用类似于Load的计算方式,通过周期性地采样PG中活跃进程的数量,计算出一个负载指标来。不过,这里有更好的办法,但是需要中间件的协助参与。
数据库中间件对于性能监控非常重要,因为很多指标数据库本身并没有提供,只有通过中间件才能暴露出来。以Pgbouncer为例,Pgbouncer在内部维护了一系列统计计数器,使用SHOW STATS可以打印出这些指标,诸如:
- total_xact_count:总共执行了多少个事务
- total_query_count:总共执行了多少个查询
- total_xact_time:总共花费在事务执行的时长
- total_query_time:总共花费在查询执行上的时长
这里total_xact_time就是我们需要的数据,它记录了Pgbouncer中间件中花费在某个数据库上的事务总耗时。我们只需要用这个指标对时间求导,就可以得到想要的数据:每秒活跃时长占比。
这里使用Prometheus的PromQL表达计算逻辑,首先对事务耗时计数器求导,分别算出其1分钟,5分钟,15分钟,以及实时粒度(最近两次采样点之间)上的每秒活跃时长。再上卷求和,将数据库层次的指标上卷为实例级别的指标。(连接池SHOW STATS这里的统计指标是以数据库为单位的,因此在计算实例级别的总活跃时长时,应当上卷求和,消除数据库维度的标签:sum without(datname))
- record: pg:ins:xact_time_realtime
expr: sum without (datname) (irate(pgbouncer_stat_total_xact_time{}[1m]))
- record: pg:ins:xact_time_rate1m
expr: sum without (datname) (rate(pgbouncer_stat_total_xact_time{}[1m]))
- record: pg:ins:xact_time_rate5m
expr: sum without (datname) (rate(pgbouncer_stat_total_xact_time{}[5m]))
- record: pg:ins:xact_time_rate15m
expr: sum without (datname) (rate(pgbouncer_stat_total_xact_time{}[15m]))
这样计算得到的结果指标已经可以相对本身进行纵向比较,并在同样规格的实例间进行横向比较了。而且无论数据库的负载类型怎样,都可以使用这个指标。
不过不同规格的实例,仍然没法使用这个指标进行对比。比如对于单核单连接PG,满载时每秒活跃时长可能是1秒,也就是100%利用率。而对于64核64连接的PG,满载时每秒活跃时长是64秒,那么就是6400%的利用率。因此,还需要一个归一化的处理,那么问题又来了。
可用并行数如何定义?
不同于CPU利用率,PG的可用并行数并没有一个清晰的定义,而且跟负载类型有一些微妙的关系。但能够确定的是,在一定范围内,最大可用并行与CPU的核数呈粗略的线性关系。当然这个结论的前提是数据库最大连接数显著超过CPU核数,如果在64核的CPU上只允许数据库建立30条连接,那么可以肯定最大可用并行就是30而不是CPU核数64。软件的并行最终还是要由硬件的并行度来支撑,因此我们可以简单的使用实例的CPU核数作为可用并行数。
在64核的CPU上运行64个活跃PG进程,则其负载为(6400% / 64 = 100%)。同理运行128个活跃PG进程,负载就是(12800% / 64 = 200%)。
那么利用上面计算得到的每秒活跃时长指标,就可以计算出实例级别的PG负载指数了。
- record: pg:ins:load0
expr: pg:ins:xact_time_realtime / on (ip) group_left() node:ins:cpu_count
- record: pg:ins:load1
expr: pg:ins:xact_time_rate1m / on (ip) group_left() node:ins:cpu_count
- record: pg:ins:load5
expr: pg:ins:xact_time_rate5m / on (ip) group_left() node:ins:cpu_count
- record: pg:ins:load15
expr: pg:ins:xact_time_rate15m / on (ip) group_left() node:ins:cpu_count
PG LOAD的另一种解释
如果我们仔细审视PG Load的定义,其实可以发现每秒活跃时长这个指标,其实可以粗略等价于:TPS x XactRT,或者QPS x Query RT。这个也很好理解,假设我QPS为1000,每个查询RT为1ms,则每秒花费在查询上的时间为 1000 * 1ms = 1s。
因此,PG Load可以视为一个由三个核心指标复合而成的衍生指标:tps * xact_rt / cpu_count
TPS,RT用于负载评估都有各自的问题,但它们通过简单的乘法结合成一个新的复合指标,一下子就显示出了神奇的力量。(尽管实际上是通过其他更准确的方式计算出来的)
0x05 PG Load的实际效果
接下来,我们来看一下PG Load用于实际生产环境的表现。
PG Load最直接的作用有两个,告警以及容量评估。
Case 1: 用于报警:慢查询堆积导致的服务不可用
下图是一次生产事故的现场,由于某业务上线了一个慢查询,瞬间导致连接池被慢查询占据,发生堆积。可以看出PG Load和RT都很及时地反映出了故障的情况,而TPS看上去则是掉了一个坑,并不是特别显眼。
从效果上看,PG Load1与PG Load0(实时负载)是一个相当灵敏的指标,对于大多数与压力负载有关的故障都能及时准确作出反应。所以被我们采纳为核心报警指标。
PG Load的利用率目标有一些经验值:黄线通常为50%,即需要引起关注的阈值;红线通常为70%,即报警线,需要立刻采取行动的阈值;500%或更高通常意味着这个实例已经被打崩了。

Case 2:用于水位评估与容量规划
比起报警,水位评估与容量规划更像是PG Load的核心用途。毕竟报警之类的的需求还是可以通过延迟,排队连接等指标来满足的。
这里,PG集群的15分钟负载是一个很好的参考值。通过这个指标的历史均值,峰值,以及其他一些统计量,我们可以很轻松地看出哪些集群处于高负载状态需要扩容,哪些集群处于低资源利用率状态需要缩容。
CPU利用率是另一个很重要的容量评估指标。我们可以看出,PG Load与CPU Usage有着很密切的关系。不过相比CPU使用率,PG Load更为纯粹地反映了数据库本身的负载水平,滤除了机器上的无关负载,也可以滤除掉数据库维护工作(备份,清理,垃圾回收)产生的杂音,更为丝滑平顺。因此非常适合用于容量评估。
当系统负载长期位于30%~50%时,就应该考虑进行扩容了。

0x06 结论
本文介绍了一种定量衡量PG负载的方式,即PG Load指标
该指标可以简单直观地反映数据库实例的负载水平
该指标非常适合作容量评估之用,也可以作为核心报警指标。
该指标可以基本无视负载类型与机器类型,进行纵向历史比较与横向水位比较。
该指标可以通过简单的方式计算得出,即每秒后端进程活跃总时长除以可用并发数。
该指标所需数据需要从数据库中间件获取
PG Load的0代表空载,100%代表满载。黄线经验值为50%,红线经验值为70%,
PG Load是一个好指标👍
在线修改PG字段类型
场景
在数据库的生命周期中,有一类需求是很常见的,修改字段类型。例如:
- 使用
INT作为主键,结果发现业务红红火火,INT32的21亿序号不够用了,想要升级为BIGINT - 使用
BIGINT存身份证号,结果发现里面有个X需要改为TEXT类型。 - 使用
FLOAT存放货币,发现精度丢失,想要修改为Decimal - 使用
TEXT存储JSON字段,想用到PostgreSQL的JSON特性,修改为JSONB类型。
那么,如何应对这种需求呢?
常规操作
通常来说,ALTER TABLE可以用来修改字段类型。
ALTER TABLE tbl_name ALTER col_name TYPE new_type USING expression;
修改字段类型通常会重写整个表。作为一个特例,如果修改后的类型与之前是二进制兼容的,则可以跳过表重写的过程,但是如果列上有索引,索引还是需要重建的。二进制兼容的转换可以使用以下查询列出。
SELECT t1.typname AS from, t2.typname AS To
FROM pg_cast c
join pg_type t1 on c.castsource = t1.oid
join pg_type t2 on c.casttarget = t2.oid
where c.castmethod = 'b';
刨除PostgreSQL内部的类型,二进制兼容的类型转换如下所示
text → varchar
xml → varchar
xml → text
cidr → inet
varchar → text
bit → varbit
varbit → bit
常见的二进制兼容类型转换基本就是这两种:
-
varchar(n1) → varchar(n2) (n2 ≥ n1)(比较常用,扩大长度约束不会重写,缩小会重写)
-
varchar ↔ text (同义转换,基本没啥用)
也就是说,其他的类型转换,都会涉及到表的重写。大表的重写是很慢的,从几分钟到十几小时都有可能。一旦发生重写,表上就会有AccessExclusiveLock,阻止一切并发访问。
如果是一个玩具数据库,或者业务还没上线,或者业务根本不在乎停机多久,那么整表重写的方式当然是没有问题的。但绝大多数时候,业务根本不可能接受这样的停机时间。所以,我们需要一种在线升级的办法。在不停机的情况完成字段类型的改造。
基本思路
在线改列的基本原理如下:
-
创建一个新的临时列,使用新的类型
-
旧列的数据同步至新的临时列
- 存量同步:分批更新
- 增量同步:更新触发器
-
处理列依赖:索引
-
执行切换
-
处理列以来:约束,默认值,分区,继承,触发器
-
通过列重命名的方式完成新旧列切换
-
在线改造的问题在于锁粒度拆分,将原来一次长期重锁操作,等效替代为多个瞬时轻锁操作。
原来ALTER TYPE重写过程中,会加上AccessExclusiveLock,阻止一切并发访问,持续时间几分钟到几天。
- 添加新列:瞬间完成:
AccessExclusiveLock - 同步新列-增量:创建触发器,瞬间完成,锁级别低。
- 同步新列-存量:分批次UPDATE,少量多次,每次都能快速完成,锁级别低。
- 新旧切换:锁表,瞬间完成。
让我们用pgbench的默认用例来说明在线改列的基本原理。假设我们希望在pgbench_accounts有访问的情况下修改abalance字段类型,从INT修改为BIGINT,那么应该如何处理呢?
- 首先,为
pgbench_accounts创建一个名为abalance_tmp,类型为BIGINT的新列。 - 编写并创建列同步触发器,触发器会在每一行被插入或更新前,使用旧列
abalance同步到
详情如下所示:
-- 操作目标:升级 pgbench_accounts 表普通列 abalance 类型:INT -> BIGINT
-- 添加新列:abalance_tmp BIGINT
ALTER TABLE pgbench_accounts ADD COLUMN abalance_tmp BIGINT;
-- 创建触发器函数:保持新列数据与旧列同步
CREATE OR REPLACE FUNCTION public.sync_pgbench_accounts_abalance() RETURNS TRIGGER AS $$
BEGIN NEW.abalance_tmp = NEW.abalance; RETURN NEW;END;
$$ LANGUAGE 'plpgsql';
-- 完成整表更新,分批更新的方式见下
UPDATE pgbench_accounts SET abalance_tmp = abalance; -- 不要在大表上运行这个
-- 创建触发器
CREATE TRIGGER tg_sync_pgbench_accounts_abalance BEFORE INSERT OR UPDATE ON pgbench_accounts
FOR EACH ROW EXECUTE FUNCTION sync_pgbench_accounts_abalance();
-- 完成列的新旧切换,这时候数据同步方向变化 旧列数据与新列保持同步
BEGIN;
LOCK TABLE pgbench_accounts IN EXCLUSIVE MODE;
ALTER TABLE pgbench_accounts DISABLE TRIGGER tg_sync_pgbench_accounts_abalance;
ALTER TABLE pgbench_accounts RENAME COLUMN abalance TO abalance_old;
ALTER TABLE pgbench_accounts RENAME COLUMN abalance_tmp TO abalance;
ALTER TABLE pgbench_accounts RENAME COLUMN abalance_old TO abalance_tmp;
ALTER TABLE pgbench_accounts ENABLE TRIGGER tg_sync_pgbench_accounts_abalance;
COMMIT;
-- 确认数据完整性
SELECT count(*) FROM pgbench_accounts WHERE abalance_new != abalance;
-- 清理触发器与函数
DROP FUNCTION IF EXISTS sync_pgbench_accounts_abalance();
DROP TRIGGER tg_sync_pgbench_accounts_abalance ON pgbench_accounts;
注意事项
- ALTER TABLE的MVCC安全性
- 列上如果有约束?(PrimaryKey、ForeignKey,Unique,NotNULL)
- 列上如果有索引?
- ALTER TABLE导致的主从复制延迟
故障档案:PG安装Extension导致无法连接
今天遇到一个比较有趣的Case,客户报告说数据库连不上了。报这个错:
psql: FATAL: could not load library "/export/servers/pgsql/lib/pg_hint_plan.so": /export/servers/pgsql/lib/pg_hint_plan.so: undefined symbol: RINFO_IS_PUSHED_DOWN
当然,这种错误一眼就知道是插件没编译好,报符号找不到。因此数据库后端进程在启动时尝试加载pg_hint_plan插件时就GG了,报FATAL错误直接退出。
通常来说这个问题还是比较好解决的,这种额外的扩展通常都是在shared_preload_libraries中指定的,只要把这个扩展名称去掉就好了。
结果……
客户说是通过ALTER ROLE|DATABASE SET session_preload_libraries = pg_hint_plan的方式来启用扩展的。
这两条命令会在使用特定用户,或连接到特定数据库时覆盖系统默认参数,去加载pg_hint_plan插件。
ALTER DATABASE postgres SET session_preload_libraries = pg_hint_plan;
ALTER ROLE postgres SET session_preload_libraries = pg_hint_plan;
如果是这样的话,也是可以解决的,通常来说只要有其他的用户或者其他的数据库可以正常登陆,就可以通过ALTER TABLE语句把这两行配置给去掉。
但坏事就坏在,所有的用户和数据库都配了这个参数,以至于没有任何一条连接能连到数据库了。
这种情况下,数据库就成了植物人状态,postmaster还活着,但任何新创建的后端服务器进程都会因为扩展失效自杀……。即使dropdb这种外部自带的二进制命令也无法工作。
于是……
无法建立到数据库的连接,那么常规手段就都失效了……,只能Dirty hack了。
如果我们从二进制层面把用户和数据库级别的配置项给抹掉,那么就可以连接到数据库,把扩展给清理掉了。
DB与Role级别的配置存储在系统目录pg_db_role_setting中,这个表有着固定的OID = 2964,存储在数据目录下global/2964里。关闭数据库,使用二进制编辑器打开pg_db_role_setting对应的文件
# vim打开后使用 :%!xxd 编辑二进制
# 编辑完成后使用 :%!xxd -r转换回二进制,再用:wq保存
vi ${PGDATA}/global/2964

这里,将所有的pg_hint_plan字符串都替换成等长的^@二进制零字符即可。当然如果不在乎原来的配置,更省事的做法是直接把这个文件截断成零长文件。
重启数据库,终于又能连接上了。
复现
这个问题复现起来也非常简单,初始化一个新数据库实例
initdb -D /pg/test -U postgres && pg_ctl -D /pg/test start
然后执行以下语句,就可以体会这种酸爽了。
psql postgres postgres -c 'ALTER ROLE postgres SET session_preload_libraries = pg_hint_plan;'
教训……
- 安装扩展后,一定要先验证扩展本身可以正常工作,再启用扩展
- 凡事留一线,日后好相见:一个紧急备用的纯洁的su,或者一个无污染的可连接数据库,都不至于这么麻烦。
PostgreSQL 常见复制拓扑方案
复制是系统架构中的核心问题之一。
集群拓扑
假设我们使用4单元的标准配置:主库,同步从库,延迟备库,远程备库,分别用字母M,S,O,R标识。
- M:Master, Main, Primary, Leader, 主库,权威数据源。
- S: Slave, Secondary, Standby, Sync Replica,同步副本,需要直接挂载至主库
- R: Remote Replica, Report instance,远程副本,可以挂载到主库或同步从库上
- O: Offline,离线延迟备库,可以挂载到主库,同步从库,或者远程备库上。
依照R和O的挂载目标不同,复制拓扑关系有以下几种选择:
其中,拓扑2具有显著的优越性:
假设采用同步提交,那么为了安全起见,必须有超过一个的同步从库,这样当采用ANY 1或FIRST 1同步提交时,主库不至于因为从库故障而挂掉。因此,离线库O应当直接挂载到主库上:在具体实现细节上:延迟备库可以采用日志传输的方式实现,这样能够将线上库与延迟库解耦。日志归档使用自带的pg_receivewal采用同步的方式(即pg_receivewal作为一个“备库”,而不是离线数据库实例本身)。
另一方面,当使用同步提交时,假设M出现故障,Failover至S,那么S也需要一个同步从库,以免在切换后立刻因为同步提交而Hang住,因此远程备库适合挂载到S上。
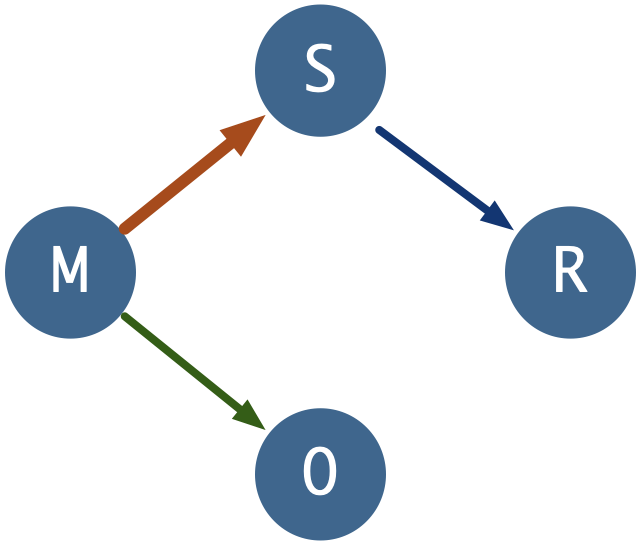
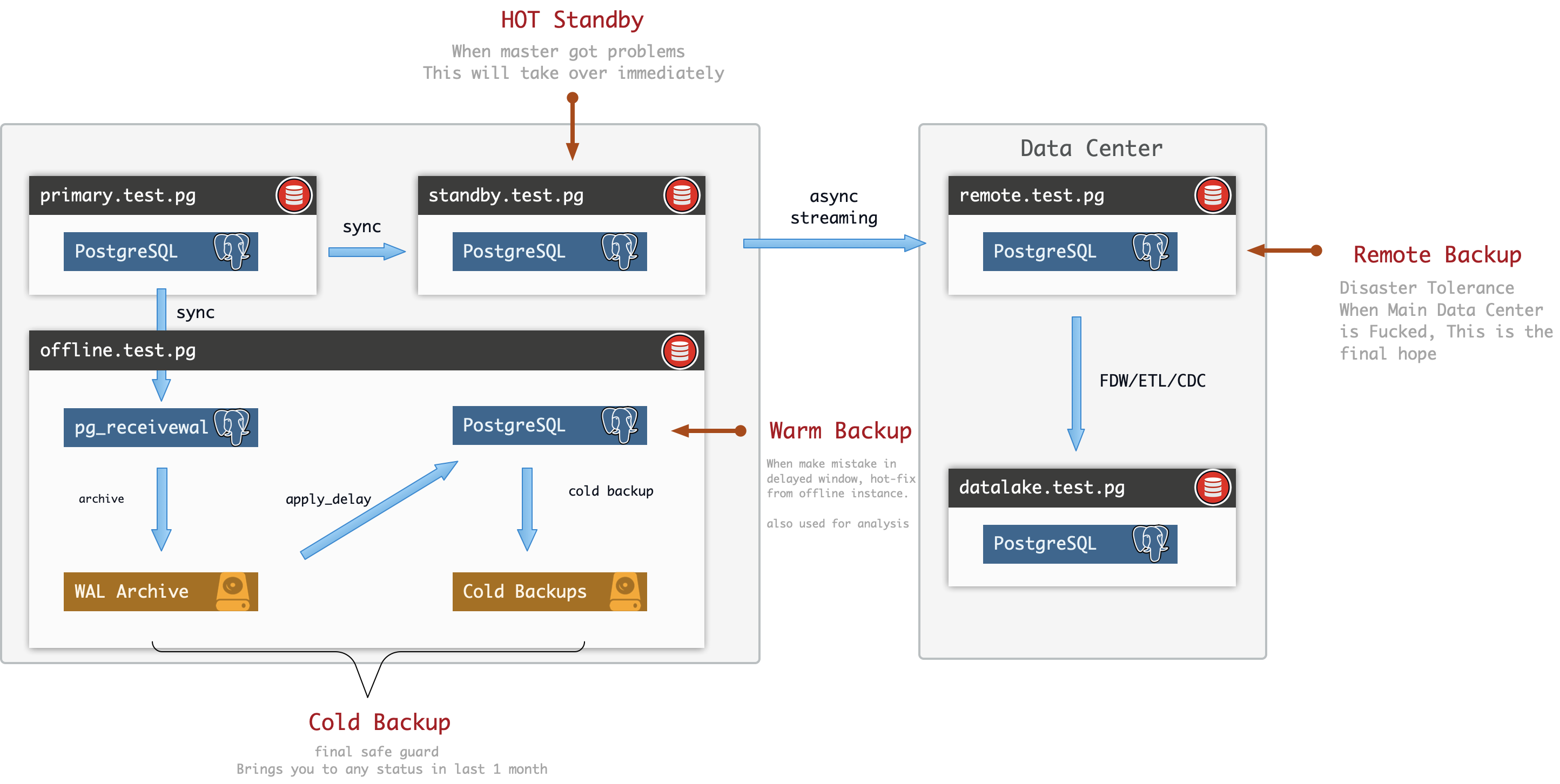
故障恢复
当故障发生时,我们需要尽可能快地将生产系统救回来,例如通过Failover,并在事后有时间时恢复原有的拓扑结构。
- P0:(M)主库失效,应当在秒级到分钟级内恢复
- P1:(S)从库失效,影响只读查询,但主库可以先抗,可以容忍分钟级别到小时级别的问题。
- P2:(O,R)离线库与远程备库故障,可能没有直接影响,故障容忍范围可以放宽至小时到天级别。

当M失效时,会对所有组件产生影响。需要执行故障转移(Failover)将S提升为新的M以便尽快使系统恢复。手工Failover包括两个步骤:Fencing M(由重到轻:关机,关数据库,改HBA,关连接池,暂停连接池)与Promote S,这两个操作都可以通过脚本在很短的时间内完成。Failover之后,系统基本恢复。还需要在事后重新恢复原来的拓扑结构。例如将原有的M通过pg_rewind变为新的从库,将O挂载到新的M上,将R挂载到新的S上;或者在修复M后,通过计划内的Failover再次回归原有拓扑。
当S失效时,会对R产生直接影响。作为一种HotFix,我们可以将R的复制源由S改到M,即可将R的影响修复。同时,通过连接池倒流将S的原有流量分发至其他从库或M,接下来就可以慢慢研究并修复S上的问题了。
当O和R失效时,因为它们既没有很大的直接影响,也没有直属后代,因此只要重做一个即可。
实施方式
PostgreSQL Testing Environment 这里给出了一个3节点的样例集群,包含了M,S,O三个节点。R节点是S的一种,因此在此略过。
这里,主库直接挂载了两个“从库”,一个是S节点,一个是O节点上的WAL日志归档器。在丢数据容忍度很低的情况下,可以将两者配置为同步从库。
温备:使用pg_receivewal
备份是DBA的安身立命之本,也是数据库管理中最为关键的工作之一。有各种各样的备份,但今天这里讨论的备份都是物理备份。物理备份通常可以分为以下四种:
- 热备(Hot Standby):与主库一模一样,当主库出现故障时会接管主库的工作,同时也会用于承接线上只读流量。
- 温备(Warm Standby):与热备类似,但不承载线上流量。通常数据库集群需要一个延迟备库,以便出现错误(例如误删数据)时能及时恢复。在这种情况下,因为延迟备库与主库内容不一致,因此不能服务线上查询。
- 冷备(Code Backup):冷备数据库以数据目录静态文件的形式存在,是数据库目录的二进制备份。便于制作,管理简单,便于放到其他AZ实现容灾。是数据库的最终保险。
- 异地副本(Remote Standby):所谓X地X中心,通常指的就是放在其他AZ的热备实例。
通常我们所说的备份,指的是冷备和温备。它们与热备的重要区别是:它们通常不是最新的。当服务线上查询时,这种滞后是一个缺陷,但对于故障恢复而言,这是一个非常重要的特性。同步的备库是不足以应对所有的问题。设想这样一种情况:一些人为故障或者软件错误把整个数据表甚至整个数据库删除了,这样的变更会立刻应用到同步从库上。这种情况只能通过从延迟温备中查询,或者从冷备重放日志来恢复。因此无论有没有从库,冷/温备都是必须的。
温备方案
通常我比较建议采用延时日志传输备库的方式做温备,从而快速响应故障,并通过异地云存储冷备的方式做容灾。
温备方案有一些显著的优势:
- 可靠:温备实际上在运行过程中,就在不断地进行“恢复测试”,因此只要温备工作正常没报错,你总是能够相信它是一个可用的备份,但冷备就不一定了。同时,采用同步提交
pg_receivewal与日志传输的离线实例,一方面能够降低主库因为单一同步从库故障而挂点的风险,另一方面也消除了备库活动影响主库的风险。 - 管理简单:温备的管理方式基本与普通从库类似,因此如果已经有了主从配置,部署一个温备是很简单的事;此外,用到的工具都是PostgreSQL官方提供的工具:
pg_basebackup与pg_receivewal。温备的延时窗口可以通过参数简单地调整。 - 响应快速:在延迟备库的延时窗口内发生的故障(删库),都可以快速地恢复:从延迟备库中查出来灌回主库,或者直接将延迟备库步进至特定时间点并提升为新主库。同时,采用温备的方式,就不用每天或每周从主库上拉去全量备份了,更省带宽,执行也更快。
步骤概览
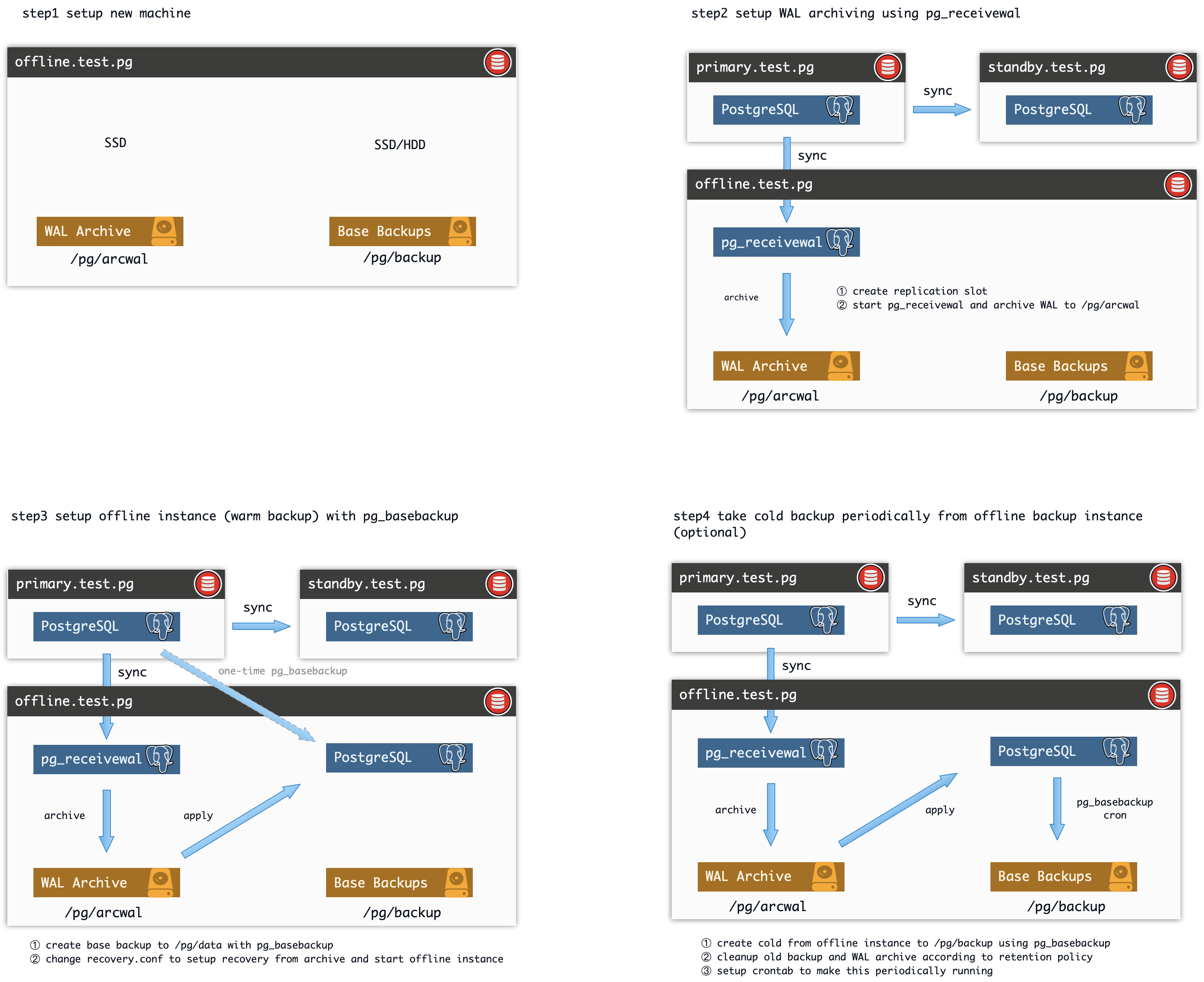
日志归档
如何归档主库生成的WAL日志,传统上通常是通过配置主库上的archive_command实现的。不过最近版本的PostgreSQL提供了一个相当实用的工具:pg_receivewal(10以前的版本称为pg_receivexlog)。对于主库而言,这个客户端应用看上去就像一个从库一样,主库会不断发送最新的WAL日志,而pg_receivewal会将其写入本地目录中。这种方式相比archive_command的一个显著优势就是,pg_receivewal不会等到PostgreSQL写满一个WAL段文件之后再进行归档,因此可以在同步提交的情况下做到故障不丢数据。
pg_receivewal使用起来也非常简单:
# create a replication slot named walarchiver
pg_receivewal --slot=walarchiver --create-slot --if-not-exists
# add replicator credential to /home/postgres/.pgpass 0600
# start archiving (with proper supervisor/init scritpts)
pg_receivewal \
-D /pg/arcwal \
--slot=walarchiver \
--compress=9\
-d'postgres://replicator@master.csq.tsa.md/postgres'
当然在实际生产环境中,为了更为鲁棒地归档,通常我们会将其注册为服务,并保存一些命令状态。这里给出了生产环境中使用的一个pg_receivewal命令包装:walarchiver
相关脚本
这里提供了一个初始化PostgreSQL Offline Instance的脚本,可以作为参考:
备份测试
面对故障时如何充满信心?只要备份还在,再大的问题都能恢复。但如何确保你的备份方案真正有效,这就需要我们事先进行充分的测试。
让我们来设想一些故障场景,以及在本方案下应对这些故障的方式
pg_receive进程终止- 离线节点重启
- 主库节点重启
- 干净的故障切换
- 脑裂的故障切换
- 误删表一张
- 误删库
To be continue
故障档案:pg_dump导致的连接池污染
PostgreSQL很棒,但这并不意味着它是Bug-Free的。这一次在线上环境中,我又遇到了一个很有趣的Case:由pg_dump导致的线上故障。这是一个非常微妙的Bug,由Pgbouncer,search_path,以及特殊的pg_dump操作所触发。
背景知识
连接污染
在PostgreSQL中,每条数据库连接对应一个后端进程,会持有一些临时资源(状态),在连接结束时会被销毁,包括:
- 本会话中修改过的参数。
RESET ALL; - 准备好的语句。
DEALLOCATE ALL - 打开的游标。
CLOSE ALL; - 监听的消息信道。
UNLISTEN * - 执行计划的缓存。
DISCARD PLANS; - 预分配的序列号值及其缓存。
DISCARD SEQUENCES; - 临时表。
DISCARD TEMP
Web应用会频繁建立大量的数据库连接,故在实际应用中通常都会使用连接池,复用连接,以减小连接创建与销毁的开销。除了使用各种语言/驱动内置的连接池外,Pgbouncer是最常用的第三方中间件连接池。Pgbouncer提供了一种Transaction Pooling的模式,即:每当客户端事务开始时,连接池会为客户端连接分配一个服务端连接,当事务结束时,服务端连接会被放回到池中。
事务池化模式也存在一些问题,例如连接污染。当某个客户端修改了连接的状态,并将该连接放回池中,其他的应用遍可能受到非预期的影响。如下图所示:
假设有四条客户端连接(前端连接)C1、C2、C3、C4,和两条服务器连接(后端连接)S1,S2。数据库默认搜索路径被配置为:app,$user,public,应用知道该假设,并使用SELECT * FROM tbl;的方式,来默认访问模式app下的表app.tbl。现在假设客户端C2在使用了服务器连接S2的过程中,执行了set search_path = ''清空了连接S2上的搜索路径。当S2被另一个客户端C3复用时,C3执行SELECT * FROM tbl时就会因为search_path中找不到对应的表而报错。
当客户端对于连接的假设被打破时,很容易出现各种错误。
故障排查
线上应用突然大量报错触发熔断,错误内容为大量的对象(表,函数)找不到。
第一直觉就是连接池被污染了:某个连接在修改完search_path之后将连接放回池中,当这个后端连接被其他前端连接复用时,就会出现找不到对象的情况。
连接至相应的Pool中,发现确实存在连接的search_path被污染的情况,某些连接的search_path被置空了,因此使用这些连接的应用就找不到对象了。
psql -p6432 somedb
# show search_path; \watch 0.1
在Pgbouncer中使用管理员账户执行RECONNECT命令,强制重连所有连接,search_path重置为默认值,问题解决。
reconnect somedb
不过问题就来了,究竟是什么应用修改了search_path呢?如果问题来源没有排查清楚,难免以后会重犯。有几种可能:业务代码修改,应用的驱动Bug,人工操作,或者连接池本身的Bug。嫌疑最大的当然是手工操作,有人如果使用生产账号用psql连到连接池,手工修改了search_path,然后退出,这个连接就会被放回到生产池中,导致污染。
首先检查数据库日志,发现报错的日志记录全都来自同一条服务器连接5c06218b.2ca6c,即只有一条连接被污染。找到这条连接开始持续报错的临界时刻:
cat postgresql-Tue.csv | grep 5c06218b.2ca6c
2018-12-04 14:44:42.766 CST,"xxx","xxx-xxx",182892,"127.0.0.1:60114",5c06218b.2ca6c,36,"SELECT",2018-12-04 14:41:15 CST,24/0,0,LOG,00000,"duration: 1067.392 ms statement: SELECT xxxx FROM x",,,,,,,,,"app - xx.xx.xx.xx:23962"
2018-12-04 14:45:03.857 CST,"xxx","xxx-xxx",182892,"127.0.0.1:60114",5c06218b.2ca6c,37,"SELECT",2018-12-04 14:41:15 CST,24/368400961,0,ERROR,42883,"function upsert_xxxxxx(xxx) does not exist",,"No function matches the given name and argument types. You might need to add explicit type casts.",,,,"select upsert_phone_plan('965+6628',1,0,0,0,1,0,'2018-12-03 19:00:00'::timestamp)",8,,"app - 10.191.160.49:46382"
这里5c06218b.2ca6c是该连接的唯一标识符,而后面的数字36,37则是该连接所产生日志的行号。一些操作并不会记录在日志中,但这里幸运的是,正常和出错的两条日志时间相差只有21秒,可以比较精确地定位故障时间点。
通过扫描所有白名单机器上该时刻的命令操作记录,精准定位到了一条执行记录:
pg_dump --host master.xxxx --port 6432 -d somedb -t sometable
嗯?pg_dump不是官方自带的工具吗,难道会修改search_path?不过直觉告诉我,还真不是没可能。例如我想起了一个有趣的行为,因为schema本质上是一个命名空间,因此位于不同schema内的对象可以有相同的名字。在老版本在使用-t转储特定表时,如果提供的表名参数不带schema前缀,pg_dump默认会默认转储所有同名的表。
查阅pg_dump的源码,发现还真有这种操作,以10.5版本为例,发现在setup_connection的时候,确实修改了search_path。
// src/bin/pg_dump/pg_dump.c line 287
int main(int argc, char **argv);
// src/bin/pg_dump/pg_dump.c line 681 main
setup_connection(fout, dumpencoding, dumpsnapshot, use_role);
// src/bin/pg_dump/pg_dump.c line 1006 setup_connection
PQclear(ExecuteSqlQueryForSingleRow(AH, ALWAYS_SECURE_SEARCH_PATH_SQL));
// include/server/fe_utils/connect.h
#define ALWAYS_SECURE_SEARCH_PATH_SQL \
"SELECT pg_catalog.set_config('search_path', '', false)"
Bug复现
接下来就是复现该BUG了。但比较奇怪的是,在使用PostgreSQL11的时候并没能复现出该Bug来,于是我看了一下肇事司机的全部历史记录,还原了其心路历程(发现pg_dump和服务器版本不匹配,来回折腾),使用不同版本的pg_dump终于复现了该BUG。
使用一个现成的数据库,名为data进行测试,版本为11.1。使用的Pgbouncer配置如下,为了便于调试,连接池的大小已经改小,只允许两条服务端连接。
[databases]
postgres = host=127.0.0.1
[pgbouncer]
logfile = /Users/vonng/pgb/pgbouncer.log
pidfile = /Users/vonng/pgb/pgbouncer.pid
listen_addr = *
listen_port = 6432
auth_type = trust
admin_users = postgres
stats_users = stats, postgres
auth_file = /Users/vonng/pgb/userlist.txt
pool_mode = transaction
server_reset_query =
max_client_conn = 50000
default_pool_size = 2
reserve_pool_size = 0
reserve_pool_timeout = 5
log_connections = 1
log_disconnections = 1
application_name_add_host = 1
ignore_startup_parameters = extra_float_digits
启动连接池,检查search_path,正常的默认配置。
$ psql postgres://vonng:123456@:6432/data -c 'show search_path;'
search_path
-----------------------
app, "$user", public
使用10.5版本的pg_dump,从6432端口发起Dump
/usr/local/Cellar/postgresql/10.5/bin/pg_dump \
postgres://vonng:123456@:6432/data \
-t geo.pois -f /dev/null
pg_dump: server version: 11.1; pg_dump version: 10.5
pg_dump: aborting because of server version mismatch
虽然Dump失败,但再次检查所有连接的search_path时,就会发现池里的连接已经被污染了,一条连接的search_path已经被修改为空
$ psql postgres://vonng:123456@:6432/data -c 'show search_path;'
search_path
-------------
(1 row)
解决方案
同时配置pgbouncer的server_reset_query以及server_reset_query_always参数,可以彻底解决此问题。
server_reset_query = DISCARD ALL
server_reset_query_always = 1
在TransactionPooling模式下,server_reset_query默认是不执行的,因此需要通过配置server_reset_query_always=1使每次事务执行完后强制执行DISCARD ALL清空连接的所有状态。不过,这样的配置是有代价的,DISCARD ALL实质上执行了以下操作:
SET SESSION AUTHORIZATION DEFAULT;
RESET ALL;
DEALLOCATE ALL;
CLOSE ALL;
UNLISTEN *;
SELECT pg_advisory_unlock_all();
DISCARD PLANS;
DISCARD SEQUENCES;
DISCARD TEMP;
如果每个事务后面都要多执行这些语句,确实会带来一些额外的性能开销。
当然,也有其他的方法,譬如从管理上解决,杜绝使用pg_dump访问6432端口的可能,将数据库账号使用专门的加密配置中心管理。或者要求业务方使用带schema限定名的name访问数据库对象。但都可能产生漏网之鱼,不如强制配置来的直接。
PostgreSQL数据页面损坏修复
PostgreSQL是一个很可靠的数据库,但是再可靠的数据库,如果碰上了不可靠的硬件,恐怕也得抓瞎。本文介绍了在PostgreSQL中,应对数据页面损坏的方法。
最初的问题
线上有一套统计库跑离线任务,业务方反馈跑SQL的时候碰上一个错误:
ERROR: invalid page in block 18858877 of relation base/16400/275852
看到这样的错误信息,第一直觉就是硬件错误导致的关系数据文件损坏,第一步要检查定位具体问题。
这里,16400是数据库的oid,而275852则是数据表的relfilenode,通常等于OID。
somedb=# select 275852::RegClass;
regclass
---------------------
dailyuseractivities
-- 如果relfilenode与oid不一致,则使用以下查询
somedb=# select relname from pg_class where pg_relation_filenode(oid) = '275852';
relname
---------------------
dailyuseractivities
(1 row)
定位到出问题的表之后,检查出问题的页面,这里错误提示区块号为18858877的页面出现问题。
somedb=# select * from dailyuseractivities where ctid = '(18858877,1)';
ERROR: invalid page in block 18858877 of relation base/16400/275852
-- 打印详细错误位置
somedb=# \errverbose
ERROR: XX001: invalid page in block 18858877 of relation base/16400/275852
LOCATION: ReadBuffer_common, bufmgr.c:917
通过检查,发现该页面无法访问,但该页面前后两个页面都可以正常访问。使用errverbose可以打印出错误所在的源码位置。搜索PostgreSQL源码,发现这个错误信息只在一处位置出现:https://github.com/postgres/postgres/blob/master/src/backend/storage/buffer/bufmgr.c。可以看到,错误发生在页面从磁盘加载到内存共享缓冲区时。PostgreSQL认为这是一个无效的页面,因此报错并中止事务。
/* check for garbage data */
if (!PageIsVerified((Page) bufBlock, blockNum))
{
if (mode == RBM_ZERO_ON_ERROR || zero_damaged_pages)
{
ereport(WARNING,
(errcode(ERRCODE_DATA_CORRUPTED),
errmsg("invalid page in block %u of relation %s; zeroing out page",
blockNum,
relpath(smgr->smgr_rnode, forkNum))));
MemSet((char *) bufBlock, 0, BLCKSZ);
}
else
ereport(ERROR,
(errcode(ERRCODE_DATA_CORRUPTED),
errmsg("invalid page in block %u of relation %s",
blockNum,
relpath(smgr->smgr_rnode, forkNum))));
}
进一步检查PageIsVerified函数的逻辑:
/* 这里的检查并不能保证页面首部是正确的,只是说它看上去足够正常
* 允许其加载至缓冲池中。后续实际使用该页面时仍然可能会出错,这也
* 是我们提供校验和选项的原因。*/
if ((p->pd_flags & ~PD_VALID_FLAG_BITS) == 0 &&
p->pd_lower <= p->pd_upper &&
p->pd_upper <= p->pd_special &&
p->pd_special <= BLCKSZ &&
p->pd_special == MAXALIGN(p->pd_special))
header_sane = true;
if (header_sane && !checksum_failure)
return true;
接下来就要具体定位问题了,那么第一步,首先要找到问题页面在磁盘上的位置。这其实是两个子问题:在哪个文件里,以及在文件里的偏移量地址。这里,关系文件的relfilenode是275852,在PostgreSQL中,每个关系文件都会被默认切割为1GB大小的段文件,并用relfilenode, relfilenode.1, relfilenode.2, …这样的规则依此命名。
因此,我们可以计算一下,第18858877个页面,每个页面8KB,一个段文件1GB。偏移量为18858877 * 2^13 = 154491920384。
154491920384 / (1024^3) = 143
154491920384 % (1024^3) = 946839552 = 0x386FA000
由此可得,问题页面位于第143个段内,偏移量0x386FA000处。
落实到具体文件,也就是${PGDATA}/base/16400/275852.143。
hexdump 275852.143 | grep -w10 386fa00
386f9fe0 003b 0000 0100 0000 0100 0000 4b00 07c8
386f9ff0 9b3d 5ed9 1f40 eb85 b851 44de 0040 0000
386fa000 0000 0000 0000 0000 0000 0000 0000 0000
*
386fb000 62df 3d7e 0000 0000 0452 0000 011f c37d
386fb010 0040 0003 0b02 0018 18f6 0000 d66a 0068
使用二进制编辑器打开并定位至相应偏移量,发现该页面的内容已经被抹零,没有抢救价值了。好在线上的数据库至少都是一主一从配置,如果是因为主库上的坏块导致的页面损坏,从库上应该还有原来的数据。在从库上果然能找到对应的数据:
386f9fe0:3b00 0000 0001 0000 0001 0000 004b c807 ;............K..
386f9ff0:3d9b d95e 401f 85eb 51b8 de44 4000 0000 =..^@...Q..D@...
386fa000:e3bd 0100 70c8 864a 0000 0400 f801 0002 ....p..J........
386fa010:0020 0420 0000 0000 c09f 7a00 809f 7a00 . . ......z...z.
386fa020:409f 7a00 009f 7a00 c09e 7a00 809e 7a00 @.z...z...z...z.
386fa030:409e 7a00 009e 7a00 c09d 7a00 809d 7a00 @.z...z...z...z.
当然,如果页面是正常的,在从库上执行读取操作就不会报错。因此可以直接通过CTID过滤把损坏的数据找回来。
到现在为止,数据虽然找回来,可以松一口气了。但主库上的坏块问题仍然需要处理,这个就比较简单了,直接重建该表,并从从库抽取最新的数据即可。有各种各样的方法,VACUUM FULL,pg_repack,或者手工重建拷贝数据。
不过,我注意到在判定页面有效性的代码中出现了一个从来没见过的参数zero_damaged_pages,查阅文档才发现,这是一个开发者调试用参数,可以允许PostgreSQL忽略损坏的数据页,将其视为全零的空页面。用WARNING替代ERROR。这引发了我的兴趣。毕竟有时候,对于一些粗放的统计业务,跑了几个小时的SQL因为一两条脏数据中断,恐怕要比错漏那么几条记录更令人抓狂。这个参数可不可以满足这样的需求呢?
zero_damaged_pages(boolean)PostgreSQL在检测到损坏的页面首部时通常会报告一个错误,并中止当前事务。将参数
zero_damaged_pages配置为on,会使系统取而代之报告一个WARNING,并将内存中的页面抹为全零。然而该操作会摧毁数据,也就是说损坏页面上的行全都会丢失。不过,这样做确实能允许你略过错误并从未损坏的页面中获取表中未受损的行。当出现软件或硬件导致的数据损坏时,该选项可用于恢复数据。通常情况下只有当您放弃从受损的页面中恢复数据时,才应当使用该选项。抹零的页面并不会强制刷回磁盘,因此建议在重新关闭该选项之前重建受损的表或索引。本选项默认是关闭的,且只有超级用户才能修改。
毕竟,当重建表之后,原来的坏块就被释放掉了。如果硬件本身没有提供坏块识别与筛除的功能,那么这就是一个定时炸弹,很可能将来又会坑到自己。不幸的是,这台机器上的数据库有14TB,用的16TB的SSD,暂时没有同类型的机器了。只能先苟一下,因此需要研究一下,这个参数能不能让查询在遇到坏页时自动跳过。
苟且的办法
如下,在本机搭建一个测试集群,配置一主一从。尝试复现该问题,并确定
# tear down
pg_ctl -D /pg/d1 stop
pg_ctl -D /pg/d2 stop
rm -rf /pg/d1 /pg/d2
# master @ port5432
pg_ctl -D /pg/d1 init
pg_ctl -D /pg/d1 start
psql postgres -c "CREATE USER replication replication;"
# slave @ port5433
pg_basebackup -Xs -Pv -R -D /pg/d2 -Ureplication
pg_ctl -D /pg/d2 start -o"-p5433"
连接至主库,创建样例表并插入555条数据,约占据三个页面。
-- psql postgres
DROP TABLE IF EXISTS test;
CREATE TABLE test(id varchar(8) PRIMARY KEY);
ANALYZE test;
-- 注意,插入数据之后一定要执行checkpoint确保落盘
INSERT INTO test SELECT generate_series(1,555)::TEXT;
CHECKPOINT;
现在,让我们模拟出现坏块的情况,首先找出主库中test表的对应文件。
SELECT pg_relation_filepath(oid) FROM pg_class WHERE relname = 'test';
base/12630/16385
$ hexdump /pg/d1/base/12630/16385 | head -n 20
0000000 00 00 00 00 d0 22 02 03 00 00 00 00 a0 03 c0 03
0000010 00 20 04 20 00 00 00 00 e0 9f 34 00 c0 9f 34 00
0000020 a0 9f 34 00 80 9f 34 00 60 9f 34 00 40 9f 34 00
0000030 20 9f 34 00 00 9f 34 00 e0 9e 34 00 c0 9e 36 00
0000040 a0 9e 36 00 80 9e 36 00 60 9e 36 00 40 9e 36 00
0000050 20 9e 36 00 00 9e 36 00 e0 9d 36 00 c0 9d 36 00
0000060 a0 9d 36 00 80 9d 36 00 60 9d 36 00 40 9d 36 00
0000070 20 9d 36 00 00 9d 36 00 e0 9c 36 00 c0 9c 36 00
上面已经给出了PostgreSQL判断页面是否“正常”的逻辑,这里我们就修改一下数据页面,让页面变得“不正常”。页面的第12~16字节,也就是这里第一行的最后四个字节a0 03 c0 03,是页面内空闲空间上下界的指针。这里按小端序解释的意思就是本页面内,空闲空间从0x03A0开始,到0x03C0结束。符合逻辑的空闲空间范围当然需要满足上界小于等于下界。这里我们将上界0x03A0修改为0x03D0,超出下界0x03C0,也就是将第一行的倒数第四个字节由A0修改为D0。
# vim打开后使用 :%!xxd 编辑二进制
# 编辑完成后使用 :%!xxd -r转换回二进制,再用:wq保存
vi /pg/d1/base/12630/16385
# 查看修改后的结果。
$ hexdump /pg/d1/base/12630/16385 | head -n 2
0000000 00 00 00 00 48 22 02 03 00 00 00 00 d0 03 c0 03
0000010 00 20 04 20 00 00 00 00 e0 9f 34 00 c0 9f 34 00
这里,虽然磁盘上的页面已经被修改,但页面已经缓存到了内存中的共享缓冲池里。因此从主库上仍然可以正常看到页面1中的结果。接下来重启主库,清空其Buffer。不幸的是,当关闭数据库或执行检查点时,内存中的页面会刷写会磁盘中,覆盖我们之前编辑的结果。因此,首先关闭数据库,重新执行编辑后再启动。
pg_ctl -D /pg/d1 stop
vi /pg/d1/base/12630/16385
pg_ctl -D /pg/d1 start
psql postgres -c 'select * from test;'
ERROR: invalid page in block 0 of relation base/12630/16385
psql postgres -c "select * from test where id = '10';"
ERROR: invalid page in block 0 of relation base/12630/16385
psql postgres -c "select * from test where ctid = '(0,1)';"
ERROR: invalid page in block 0 of relation base/12630/16385
$ psql postgres -c "select * from test where ctid = '(1,1)';"
id
-----
227
可以看到,修改后的0号页面无法被数据库识别出来,但未受影响的页面1仍然可以正常访问。
虽然主库上的查询因为页面损坏无法访问了,这时候在从库上执行类似的查询,都可以正常返回结果
$ psql -p5433 postgres -c 'select * from test limit 2;'
id
----
1
2
$ psql -p5433 postgres -c "select * from test where id = '10';"
id
----
10
$ psql -p5433 postgres -c "select * from test where ctid = '(0,1)';"
id
----
1
(1 row)
接下来,让我们打开zero_damaged_pages参数,现在在主库上的查询不报错了。取而代之的是一个警告,页面0中的数据蒸发掉了,返回的结果从第1页开始。
postgres=# set zero_damaged_pages = on ;
SET
postgres=# select * from test;
WARNING: invalid page in block 0 of relation base/12630/16385; zeroing out page
id
-----
227
228
229
230
231
第0页确实已经被加载到内存缓冲池里了,而且页面里的数据被抹成了0。
create extension pg_buffercache ;
postgres=# select relblocknumber,isdirty,usagecount from pg_buffercache where relfilenode = 16385;
relblocknumber | isdirty | usagecount
----------------+---------+------------
0 | f | 5
1 | f | 3
2 | f | 2
zero_damaged_pages参数需要在实例级别进行配置:
# 确保该选项默认打开,并重启生效
psql postgres -c 'ALTER SYSTEM set zero_damaged_pages = on;'
pg_ctl -D /pg/d1 restart
psql postgres -c 'show zero_damaged_pages;'
zero_damaged_pages
--------------------
on
这里,通过配置zero_damaged_pages,能够让主库即使遇到坏块,也能继续应付一下。
垃圾页面被加载到内存并抹零之后,如果执行检查点,这个全零的页面是否又会被重新刷回磁盘覆盖原来的数据呢?这一点很重要,因为脏数据也是数据,起码有抢救的价值。为了一时的方便产生永久性无法挽回的损失,那肯定也是无法接受的。
psql postgres -c 'checkpoint;'
hexdump /pg/d1/base/12630/16385 | head -n 2
0000000 00 00 00 00 48 22 02 03 00 00 00 00 d0 03 c0 03
0000010 00 20 04 20 00 00 00 00 e0 9f 34 00 c0 9f 34 00
可以看到,无论是检查点还是重启,这个内存中的全零页面并不会强制替代磁盘上的损坏页面,留下了抢救的希望,又能保证线上的查询可以苟一下。甚好,甚好。这也符合文档中的描述:“抹零的页面并不会强制刷回磁盘”。
微妙的问题
就当我觉得实验完成,可以安心的把这个开关打开先对付一下时。突然又想起了一个微妙的事情,主库和从库上读到的数据是不一样的,这就很尴尬了。
psql -p5432 postgres -Atqc 'select * from test limit 2;'
2018-11-29 22:31:20.777 CST [24175] WARNING: invalid page in block 0 of relation base/12630/16385; zeroing out page
WARNING: invalid page in block 0 of relation base/12630/16385; zeroing out page
227
228
psql -p5433 postgres -Atqc 'select * from test limit 2;'
1
2
更尴尬的是,在主库上是看不到第0页中的元组的,也就是说主库认为第0页中的记录都不存在,因此,即使表上存在主键约束,仍然可以插入同一个主键的记录:
# 表中已经有主键 id = 1的记录了,但是主库抹零了看不到!
psql postgres -c "INSERT INTO test VALUES(1);"
INSERT 0 1
# 从从库上查询,夭寿了!主键出现重复了!
psql postgres -p5433 -c "SELECT * FROM test;"
id
-----
1
2
3
...
555
1
# id列真的是主键……
$ psql postgres -p5433 -c "\d test;"
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+----------------------+-----------+----------+---------
id | character varying(8) | | not null |
Indexes:
"test_pkey" PRIMARY KEY, btree (id)
如果把这个从库Promote成新的主库,这个问题在从库上依然存在:一条主键能返回两条记录!真是夭寿啊……。
此外,还有一个有趣的问题,VACUUM会如何处理这样的零页面呢?
# 对表进行清理
psql postgres -c 'VACUUM VERBOSE;'
INFO: vacuuming "public.test"
2018-11-29 22:18:05.212 CST [23572] WARNING: invalid page in block 0 of relation base/12630/16385; zeroing out page
2018-11-29 22:18:05.212 CST [23572] WARNING: relation "test" page 0 is uninitialized --- fixing
WARNING: invalid page in block 0 of relation base/12630/16385; zeroing out page
WARNING: relation "test" page 0 is uninitialized --- fixing
INFO: index "test_pkey" now contains 329 row versions in 5 pages
DETAIL: 0 index row versions were removed.
0 index pages have been deleted, 0 are currently reusable.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
VACUUM把这个页面“修好了”?但杯具的是,VACUUM自作主张修好了脏数据页,并不一定是一件好事…。因为当VACUUM完成修复时,这个页面就被视作一个普通的页面了,就会在CHECKPOINT时被刷写回磁盘中……,从而覆盖了原始的脏数据。如果这种修复并不是你想要的结果,那么数据就有可能会丢失。
总结
- 复制,备份是应对硬件损坏的最佳办法。
- 当出现数据页面损坏时,可以找到对应的物理页面,进行比较,尝试修复。
- 当页面损坏导致查询无法进行时,参数
zero_damaged_pages可以临时用于跳过错误。 - 参数
zero_damaged_pages极其危险 - 打开抹零时,损坏页面会被加载至内存缓冲池中并抹零,且在检查点时不会覆盖磁盘原页面。
- 内存中被抹零的页面会被VACUUM尝试修复,修复后的页面会被检查点刷回磁盘,覆盖原页面。
- 抹零页面内的内容对数据库不可见,因此可能会出现违反约束的情况出现。
关系膨胀的监控与治理
PostgreSQL使用了MVCC作为主要并发控制技术,它有很多好处,但也会带来一些其他的影响,例如关系膨胀。关系(表与索引)膨胀会对数据库性能产生负面影响,并浪费磁盘空间。为了使PostgreSQL始终保持在最佳性能,有必要及时对膨胀的关系进行垃圾回收,并定期重建过度膨胀的关系。
在实际操作中,垃圾回收并没有那么简单,这里有一系列的问题:
- 关系膨胀的原因?
- 关系膨胀的度量?
- 关系膨胀的监控?
- 关系膨胀的处理?
本文将详细说明这些问题。
关系膨胀概述
假设某个关系实际占用存储100G,但其中有很多空间被死元组,碎片,空闲区域浪费,如果将其压实为一个新的关系,占用空间变为60G,那么就可以近似认为该关系的膨胀率是 (100 - 60) / 100 = 40%。
普通的VACUUM不能解决表膨胀的问题,死元组本身能够被并发VACUUM机制回收,但它产生的碎片,留下的空洞却不可以。比如,即使删除了许多死元组,也无法减小表的大小。久而久之,关系文件被大量空洞填满,浪费了大量的磁盘空间。
VACUUM FULL命令可以回收这些空间,它将旧表文件中的活元组复制到新表中,通过重写整张表的方式将表压实。但在实际生产中,因为该操作会持有表上的AccessExclusiveLock,阻塞业务正常访问,因此在不间断服务的情况下并不适用,pg_repack是一个实用的第三方插件,能够在线上业务正常进行的同时进行无锁的VACUUM FULL。
不幸的是,关于什么时候需要进行VACUUM FULL处理膨胀并没有一个最佳实践。DBA需要针对自己的业务场景制定清理策略。但无论采用何种策略,实施这些策略的机制都是类似的:
- 监控,检测,衡量关系的膨胀程度
- 依据关系的膨胀程度,时机等因素,处理关系膨胀。
这里有几个关键的问题,首先是,如何定义关系的膨胀率?
关系膨胀的度量
衡量关系膨胀的程度,首先需要定义一个指标:膨胀率(bloat rate)。
膨胀率的计算思想是:通过统计信息估算出目标表如果处于 紧实(Compact) 状态所占用的空间,而实际使用空间超出该紧实空间部分的占比,就是膨胀率。因此膨胀率可以被定义为 1 - (活元组占用字节总数 / 关系占用字节总数)。
例如,某个表实际占用存储100G,但其中有很多空间被死元组,碎片,空闲区域浪费,如果将其压实为一张新表,占用空间变为60G,那么膨胀率就是 1 - 60/100 = 40%。
关系的大小获取较为简单,可以直接从系统目录中获取。所以问题的关键在于,活元组的字节总数这一数据如何获取。
膨胀率的精确计算
PostgreSQL自带了pgstattuple模块,可用于精确计算表的膨胀率。譬如这里的tuple_percent字段就是元组实际字节占关系总大小的百分比,用1减去该值即为膨胀率。
vonng@[local]:5432/bench# select *,
1.0 - tuple_len::numeric / table_len as bloat
from pgstattuple('pgbench_accounts');
┌─[ RECORD 1 ]───────┬────────────────────────┐
│ table_len │ 136642560 │
│ tuple_count │ 1000000 │
│ tuple_len │ 121000000 │
│ tuple_percent │ 88.55 │
│ dead_tuple_count │ 16418 │
│ dead_tuple_len │ 1986578 │
│ dead_tuple_percent │ 1.45 │
│ free_space │ 1674768 │
│ free_percent │ 1.23 │
│ bloat │ 0.11447794889088729017 │
└────────────────────┴────────────────────────┘
pgstattuple对于精确地判断表与索引的膨胀情况非常有用,具体细节可以参考官方文档:https://www.postgresql.org/docs/current/static/pgstattuple.html。
此外,PostgreSQL还提供了两个自带的扩展,pg_freespacemap与pageinspect,前者可以用于检视每个页面中的空闲空间大小,后者则可以精确地展示关系中每个数据页内物理存储的内容。如果希望检视关系的内部状态,这两个插件非常实用,详细使用方法可以参考官方文档:
https://www.postgresql.org/docs/current/static/pgfreespacemap.html
https://www.postgresql.org/docs/current/static/pageinspect.html
不过在绝大多数情况下,我们并不会太在意膨胀率的精确度。在实际生产中对膨胀率的要求并不高:第一位有效数字是准确的,就差不多够用了。另一方面,要想精确地知道活元组占用的字节总数,需要对整个关系执行一遍扫描,这会对线上系统的IO产生压力。如果希望对所有表的膨胀率进行监控,也不适合使用这种方式。
例如一个200G的关系,使用pgstattuple插件执行精确的膨胀率估算大致需要5分钟时间。在9.5及后续版本,pgstattuple插件还提供了pgstattuple_approx函数,以精度换速度。但即使使用估算,也需要秒级的时间。
监控膨胀率,最重要的要求是速度快,影响小。因此当我们需要对很多数据库的很多表同时进行监控时,需要对膨胀率进行快速估算,避免对业务产生影响。
膨胀率的估算
PostgreSQL为每个关系都维护了很多的统计信息,利用统计信息,可以快速高效地估算数据库中所有表的膨胀率。估算膨胀率需要使用表与列上的统计信息,直接使用的统计指标有三个:
- 元组的平均宽度
avgwidth:从列级统计数据计算而来,用于估计紧实状态占用的空间。 - 元组数:
pg_class.reltuples:用于估计紧实状态占用的空间 - 页面数:
pg_class.relpages:用于测算实际使用的空间
而计算公式也很简单:
1 - (reltuples * avgwidth) / (block_size - pageheader) / relpages
这里block_size是页面大小,默认为8182,pageheader是首部占用的大小,默认为24字节。页面大小减去首部大小就是可以用于元组存储的实际空间,因此(reltuples * avgwidth)给出了元组的估计总大小,而除以前者后,就可以得到预计需要多少个页面才能紧实地存下所有的元组。最后,期待使用的页面数量,除以实际使用的页面数量,就是利用率,而1减去利用率,就是膨胀率。
难点
这里的关键,在于如何使用统计信息估算元组的平均长度,而为了实现这一点,我们需要克服三个困难:
- 当元组中存在空值时,首部会带有空值位图。
- 首部与数据部分存在Padding,需要考虑边界对齐。
- 一些字段类型也存在对齐要求
但好在,膨胀率本身就是一种估算,只要大致正确即可。
计算元组的平均长度
为了理解估算的过程,首先需要理解PostgreSQL中数据页面与元组的的内部布局。
首先来看元组的平均长度,PG中元组的布局如下图所示。
一条元组占用的空间可以分为三个部分:
- 定长的行指针(4字节,严格来说这不算元组的一部分,但它与元组一一对应)
- 变长的首部
- 固定长度部分23字节
- 当元组中存在空值时,会出现空值位图,每个字段占一位,故其长度为字段数除以8。
- 在空值位图后需要填充至
MAXALIGN,通常为8。 - 如果表启用了
WITH OIDS选项,元组还会有一个4字节的OID,但这里我们不考虑该情况。
- 数据部分
因此,一条元组(包括相应的行指针)的平均长度可以这样计算:
avg_size_tuple = 4 + avg_size_hdr + avg_size_data
关键在于求出首部的平均长度与数据部分的平均长度。
计算首部的平均长度
首部平均长度主要的变数在于空值位图与填充对齐。为了估算元组首部的平均长度,我们需要知道几个参数:
- 不带空值位图的首部平均长度(带有填充):
normhdr - 带有空值位图的首部平均长度(带有填充):
nullhdr - 带有空值的元组比例:
nullfrac
而估算首部平均长度的公式,也非常简单:
avg_size_hdr = nullhdr * nullfrac + normhdr * (1 - nullfrac)
因为不带空值位图的首部,其长度是23字节,对齐至8字节的边界,长度为24字节,上式可以改为:
avg_size_hdr = nullhdr * nullfrac + 24 * (1 - nullfrac)
计算某值被补齐至8字节边界的长度,可以使用以下公式进行高效计算:
padding = lambda x : x + 7 >> 3 << 3
计算数据部分的平均长度
数据部分的平均长度主要取决于每个字段的平均宽度与空值率,加上末尾的对齐。
以下SQL可以利用统计信息算出所有表的平均元组数据部分宽度。
SELECT schemaname, tablename, sum((1 - null_frac) * avg_width)
FROM pg_stats GROUP BY (schemaname, tablename);
例如,以下SQL能够从pg_stats系统统计视图中获取app.apple表上一条元组的平均长度。
SELECT
count(*), -- 字段数目
ceil(count(*) / 8.0), -- 空值位图占用的字节数
max(null_frac), -- 最大空值率
sum((1 - null_frac) * avg_width) -- 数据部分的平均宽度
FROM pg_stats
where schemaname = 'app' and tablename = 'apple';
-[ RECORD 1 ]-----------
count | 47
ceil | 6
max | 1
sum | 1733.76873471724
整合
将上面三节的逻辑整合,得到以下的存储过程,给定一个表,返回其膨胀率。
CREATE OR REPLACE FUNCTION public.pg_table_bloat(relation regclass)
RETURNS double precision
LANGUAGE plpgsql
AS $function$
DECLARE
_schemaname text;
tuples BIGINT := 0;
pages INTEGER := 0;
nullheader INTEGER:= 0;
nullfrac FLOAT := 0;
datawidth INTEGER :=0;
avgtuplelen FLOAT :=24;
BEGIN
SELECT
relnamespace :: RegNamespace,
reltuples,
relpages
into _schemaname, tuples, pages
FROM pg_class
Where oid = relation;
SELECT
23 + ceil(count(*) >> 3),
max(null_frac),
ceil(sum((1 - null_frac) * avg_width))
into nullheader, nullfrac, datawidth
FROM pg_stats
where schemaname = _schemaname and tablename = relation :: text;
SELECT (datawidth + 8 - (CASE WHEN datawidth%8=0 THEN 8 ELSE datawidth%8 END)) -- avg data len
+ (1 - nullfrac) * 24 + nullfrac * (nullheader + 8 - (CASE WHEN nullheader%8=0 THEN 8 ELSE nullheader%8 END))
INTO avgtuplelen;
raise notice '% %', nullfrac, datawidth;
RETURN 1 - (ceil(tuples * avgtuplelen / 8168)) / pages;
END;
$function$
批量计算
对于监控而言,我们关注的往往不仅仅是一张表,而是库中所有的表。因此,可以将上面的膨胀率计算逻辑重写为批量计算的查询,并定义为视图便于使用:
DROP VIEW IF EXISTS monitor.pg_bloat_indexes CASCADE;
CREATE OR REPLACE VIEW monitor.pg_bloat_indexes AS
WITH btree_index_atts AS (
SELECT
pg_namespace.nspname,
indexclass.relname AS index_name,
indexclass.reltuples,
indexclass.relpages,
pg_index.indrelid,
pg_index.indexrelid,
indexclass.relam,
tableclass.relname AS tablename,
(regexp_split_to_table((pg_index.indkey) :: TEXT, ' ' :: TEXT)) :: SMALLINT AS attnum,
pg_index.indexrelid AS index_oid
FROM ((((pg_index
JOIN pg_class indexclass ON ((pg_index.indexrelid = indexclass.oid)))
JOIN pg_class tableclass ON ((pg_index.indrelid = tableclass.oid)))
JOIN pg_namespace ON ((pg_namespace.oid = indexclass.relnamespace)))
JOIN pg_am ON ((indexclass.relam = pg_am.oid)))
WHERE ((pg_am.amname = 'btree' :: NAME) AND (indexclass.relpages > 0))
), index_item_sizes AS (
SELECT
ind_atts.nspname,
ind_atts.index_name,
ind_atts.reltuples,
ind_atts.relpages,
ind_atts.relam,
ind_atts.indrelid AS table_oid,
ind_atts.index_oid,
(current_setting('block_size' :: TEXT)) :: NUMERIC AS bs,
8 AS maxalign,
24 AS pagehdr,
CASE
WHEN (max(COALESCE(pg_stats.null_frac, (0) :: REAL)) = (0) :: FLOAT)
THEN 2
ELSE 6
END AS index_tuple_hdr,
sum((((1) :: FLOAT - COALESCE(pg_stats.null_frac, (0) :: REAL)) *
(COALESCE(pg_stats.avg_width, 1024)) :: FLOAT)) AS nulldatawidth
FROM ((pg_attribute
JOIN btree_index_atts ind_atts
ON (((pg_attribute.attrelid = ind_atts.indexrelid) AND (pg_attribute.attnum = ind_atts.attnum))))
JOIN pg_stats ON (((pg_stats.schemaname = ind_atts.nspname) AND (((pg_stats.tablename = ind_atts.tablename) AND
((pg_stats.attname) :: TEXT =
pg_get_indexdef(pg_attribute.attrelid,
(pg_attribute.attnum) :: INTEGER,
TRUE))) OR
((pg_stats.tablename = ind_atts.index_name) AND
(pg_stats.attname = pg_attribute.attname))))))
WHERE (pg_attribute.attnum > 0)
GROUP BY ind_atts.nspname, ind_atts.index_name, ind_atts.reltuples, ind_atts.relpages, ind_atts.relam,
ind_atts.indrelid, ind_atts.index_oid, (current_setting('block_size' :: TEXT)) :: NUMERIC, 8 :: INTEGER
), index_aligned_est AS (
SELECT
index_item_sizes.maxalign,
index_item_sizes.bs,
index_item_sizes.nspname,
index_item_sizes.index_name,
index_item_sizes.reltuples,
index_item_sizes.relpages,
index_item_sizes.relam,
index_item_sizes.table_oid,
index_item_sizes.index_oid,
COALESCE(ceil((((index_item_sizes.reltuples * ((((((((6 + index_item_sizes.maxalign) -
CASE
WHEN ((index_item_sizes.index_tuple_hdr %
index_item_sizes.maxalign) = 0)
THEN index_item_sizes.maxalign
ELSE (index_item_sizes.index_tuple_hdr %
index_item_sizes.maxalign)
END)) :: FLOAT + index_item_sizes.nulldatawidth)
+ (index_item_sizes.maxalign) :: FLOAT) - (
CASE
WHEN (((index_item_sizes.nulldatawidth) :: INTEGER %
index_item_sizes.maxalign) = 0)
THEN index_item_sizes.maxalign
ELSE ((index_item_sizes.nulldatawidth) :: INTEGER %
index_item_sizes.maxalign)
END) :: FLOAT)) :: NUMERIC) :: FLOAT) /
((index_item_sizes.bs - (index_item_sizes.pagehdr) :: NUMERIC)) :: FLOAT) +
(1) :: FLOAT)), (0) :: FLOAT) AS expected
FROM index_item_sizes
), raw_bloat AS (
SELECT
current_database() AS dbname,
index_aligned_est.nspname,
pg_class.relname AS table_name,
index_aligned_est.index_name,
(index_aligned_est.bs * ((index_aligned_est.relpages) :: BIGINT) :: NUMERIC) AS totalbytes,
index_aligned_est.expected,
CASE
WHEN ((index_aligned_est.relpages) :: FLOAT <= index_aligned_est.expected)
THEN (0) :: NUMERIC
ELSE (index_aligned_est.bs *
((((index_aligned_est.relpages) :: FLOAT - index_aligned_est.expected)) :: BIGINT) :: NUMERIC)
END AS wastedbytes,
CASE
WHEN ((index_aligned_est.relpages) :: FLOAT <= index_aligned_est.expected)
THEN (0) :: NUMERIC
ELSE (((index_aligned_est.bs * ((((index_aligned_est.relpages) :: FLOAT -
index_aligned_est.expected)) :: BIGINT) :: NUMERIC) * (100) :: NUMERIC) /
(index_aligned_est.bs * ((index_aligned_est.relpages) :: BIGINT) :: NUMERIC))
END AS realbloat,
pg_relation_size((index_aligned_est.table_oid) :: REGCLASS) AS table_bytes,
stat.idx_scan AS index_scans
FROM ((index_aligned_est
JOIN pg_class ON ((pg_class.oid = index_aligned_est.table_oid)))
JOIN pg_stat_user_indexes stat ON ((index_aligned_est.index_oid = stat.indexrelid)))
), format_bloat AS (
SELECT
raw_bloat.dbname AS database_name,
raw_bloat.nspname AS schema_name,
raw_bloat.table_name,
raw_bloat.index_name,
round(
raw_bloat.realbloat) AS bloat_pct,
round((raw_bloat.wastedbytes / (((1024) :: FLOAT ^
(2) :: FLOAT)) :: NUMERIC)) AS bloat_mb,
round((raw_bloat.totalbytes / (((1024) :: FLOAT ^ (2) :: FLOAT)) :: NUMERIC),
3) AS index_mb,
round(
((raw_bloat.table_bytes) :: NUMERIC / (((1024) :: FLOAT ^ (2) :: FLOAT)) :: NUMERIC),
3) AS table_mb,
raw_bloat.index_scans
FROM raw_bloat
)
SELECT
format_bloat.database_name as datname,
format_bloat.schema_name as nspname,
format_bloat.table_name as relname,
format_bloat.index_name as idxname,
format_bloat.index_scans as idx_scans,
format_bloat.bloat_pct as bloat_pct,
format_bloat.table_mb,
format_bloat.index_mb - format_bloat.bloat_mb as actual_mb,
format_bloat.bloat_mb,
format_bloat.index_mb as total_mb
FROM format_bloat
ORDER BY format_bloat.bloat_mb DESC;
COMMENT ON VIEW monitor.pg_bloat_indexes IS 'index bloat monitor';
虽然看上去很长,但查询该视图获取全库(3TB)所有表的膨胀率,计算只需要50ms。而且只需要访问统计数据,不需要访问关系本体,占用实例的IO。
表膨胀的处理
如果只是玩具数据库,或者业务允许每天有很长的停机维护时间,那么简单地在数据库中执行VACUUM FULL就可以了。但VACUUM FULL需要表上的排它读写锁,但对于需要不间断运行的数据库,我们就需要用到pg_repack来处理表的膨胀。
- 主页:http://reorg.github.io/pg_repack/
pg_repack已经包含在了PostgreSQL官方的yum源中,因此可以直接通过yum install pg_repack安装。
yum install pg_repack10
pg_repack的使用
与大多数PostgreSQL客户端程序一样,pg_repack也通过类似的参数连接至PostgreSQL服务器。
在使用pg_repack之前,需要在待重整的数据库中创建pg_repack扩展
CREATE EXTENSION pg_repack
然后就可以正常使用了,几种典型的用法:
# 完全清理整个数据库,开5个并发任务,超时等待10秒
pg_repack -d <database> -j 5 -T 10
# 清理mydb中一张特定的表mytable,超时等待10秒
pg_repack mydb -t public.mytable -T 10
# 清理某个特定的索引 myschema.myindex,注意必须使用带模式的全名
pg_repack mydb -i myschema.myindex
详细的用法可以参考官方文档。
pg_repack的策略
通常,如果业务存在峰谷周期,则可以选在业务低谷器进行整理。pg_repack执行比较快,但很吃资源。在高峰期执行可能会影响整个数据库的性能表现,也有可能会导致复制滞后。
例如,可以利用上面两节提供的膨胀率监控视图,每天挑选膨胀最为严重的若干张表和若干索引进行自动重整。
#--------------------------------------------------------------#
# Name: repack_tables
# Desc: repack table via fullname
# Arg1: database_name
# Argv: list of table full name
# Deps: psql
#--------------------------------------------------------------#
# repack single table
function repack_tables(){
local db=$1
shift
log_info "repack ${db} tables begin"
log_info "repack table list: $@"
for relname in $@
do
old_size=$(psql ${db} -Atqc "SELECT pg_size_pretty(pg_relation_size('${relname}'));")
# kill_queries ${db}
log_info "repack table ${relname} begin, old size: ${old_size}"
pg_repack ${db} -T 10 -t ${relname}
new_size=$(psql ${db} -Atqc "SELECT pg_size_pretty(pg_relation_size('${relname}'));")
log_info "repack table ${relname} done , new size: ${old_size} -> ${new_size}"
done
log_info "repack ${db} tables done"
}
#--------------------------------------------------------------#
# Name: get_bloat_tables
# Desc: find bloat tables in given database match some condition
# Arg1: database_name
# Echo: list of full table name
# Deps: psql, monitor.pg_bloat_tables
#--------------------------------------------------------------#
function get_bloat_tables(){
echo $(psql ${1} -Atq <<-'EOF'
WITH bloat_tables AS (
SELECT
nspname || '.' || relname as relname,
actual_mb,
bloat_pct
FROM monitor.pg_bloat_tables
WHERE nspname NOT IN ('dba', 'monitor', 'trash')
ORDER BY 2 DESC,3 DESC
)
-- 64 small + 16 medium + 4 large
(SELECT relname FROM bloat_tables WHERE actual_mb < 256 AND bloat_pct > 40 ORDER BY bloat_pct DESC LIMIT 64) UNION
(SELECT relname FROM bloat_tables WHERE actual_mb BETWEEN 256 AND 1024 AND bloat_pct > 30 ORDER BY bloat_pct DESC LIMIT 16) UNION
(SELECT relname FROM bloat_tables WHERE actual_mb BETWEEN 1024 AND 4096 AND bloat_pct > 20 ORDER BY bloat_pct DESC LIMIT 4);
EOF
)
}
这里,设置了三条规则:
- 从小于256MB,且膨胀率超过40%的小表中,选出TOP64
- 从256MB到1GB之间,且膨胀率超过40%的中表中,选出TOP16
- 从1GB到4GB之间,且膨胀率超过20%的大表中,选出TOP4
选出这些表,每天凌晨低谷自动进行重整。超过4GB的表手工处理。
但何时进行重整,还是取决于具体的业务模式。
pg_repack的原理
pg_repack的原理相当简单,它会为待重建的表创建一份副本。首先取一份全量快照,将所有活元组写入新表,并通过触发器将所有针对原表的变更同步至新表,最后通过重命名,使用新的紧实副本替换老表。而对于索引,则是通过PostgreSQL的CREATE(DROP) INDEX CONCURRENTLY完成的。
重整表
- 创建一张与原表模式相同,但不带索引的空表。
- 创建一张与原始表对应的日志表,用于记录
pg_repack工作期间该表上发生的变更。 - 为原始表添加一个行触发器,在相应日志表中记录所有
INSERT,DELETE,UPDATE操作。 - 将老表中的数据复制到新的空表中。
- 在新表上创建同样的索引
- 将日志表中的增量变更应用到新表上
- 通过重命名的方式切换新旧表
- 将旧的,已经被重命名掉的表
DROP掉。
重整索引
- 使用
CREATE INDEX CONCURRENTLY在原表上创建新索引,保持与旧索引相同的定义。 Analyze新索引,并将旧索引设置为无效,在数据目录中将新旧索引交换。- 删除旧索引。
pg_repack的注意事项
-
重整开始之前,最好取消掉所有正在进行的
Vacuum任务。 -
对索引做重整之前,最好能手动清理掉可能正在使用该索引的查询
-
如果出现异常的情况(譬如中途强制退出),有可能会留下未清理的垃圾,需要手工清理。可能包括:
- 临时表与临时索引建立在与原表/索引同一个schema内
- 临时表的名称为:
${schema_name}.table_${table_oid} - 临时索引的名称为:
${schema_name}.index_${table_oid}} - 原始表上可能会残留相关的触发器,需要手动清理。
-
重整特别大的表时,需要预留至少与该表及其索引相同大小的磁盘空间,需要特别小心,手动检查。
-
当完成重整,进行重命名替换时,会产生巨量的WAL,有可能会导致复制延迟,而且无法取消。
PipelineDB快速上手
PipelineDB安装与配置
PipelineDB可以直接通过官方rpm包安装。
加载PipelineDB需要添加动态链接库,在postgresql.conf中修改配置项并重启:
shared_preload_libraries = 'pipelinedb'
max_worker_processes = 128
注意如果不修改max_worker_processes会报错。其他配置都参照标准的PostgreSQL
PipelineDB使用样例 —— 维基PV数据
-- 创建Stream
CREATE FOREIGN TABLE wiki_stream (
hour timestamp,
project text,
title text,
view_count bigint,
size bigint)
SERVER pipelinedb;
-- 在Stream上进行聚合
CREATE VIEW wiki_stats WITH (action=materialize) AS
SELECT hour, project,
count(*) AS total_pages,
sum(view_count) AS total_views,
min(view_count) AS min_views,
max(view_count) AS max_views,
avg(view_count) AS avg_views,
percentile_cont(0.99) WITHIN GROUP (ORDER BY view_count) AS p99_views,
sum(size) AS total_bytes_served
FROM wiki_stream
GROUP BY hour, project;
然后,向Stream中插入数据:
curl -sL http://pipelinedb.com/data/wiki-pagecounts | gunzip | \
psql -c "
COPY wiki_stream (hour, project, title, view_count, size) FROM STDIN"
基本概念
PipelineDB中的基本抽象被称之为:连续视图(Continuous View)。
TimescaleDB 快速上手
- 官方网站:https://www.timescale.com
- 官方文档:https://docs.timescale.com/v0.9/main
- Github:https://github.com/timescale/timescaledb
为什么使用TimescaleDB
什么是时间序列数据?
我们一直在谈论什么是“时间序列数据”,以及与其他数据有何不同以及为什么?
许多应用程序或数据库实际上采用的是过于狭窄的视图,并将时间序列数据与特定形式的服务器度量值等同起来:
Name: CPU
Tags: Host=MyServer, Region=West
Data:
2017-01-01 01:02:00 70
2017-01-01 01:03:00 71
2017-01-01 01:04:00 72
2017-01-01 01:05:01 68
但实际上,在许多监控应用中,通常会收集不同的指标(例如,CPU,内存,网络统计数据,电池寿命)。因此,单独考虑每个度量并不总是有意义的。考虑这种替代性的“更广泛”的数据模型,它保持了同时收集的指标之间的相关性。
Metrics: CPU, free_mem, net_rssi, battery
Tags: Host=MyServer, Region=West
Data:
2017-01-01 01:02:00 70 500 -40 80
2017-01-01 01:03:00 71 400 -42 80
2017-01-01 01:04:00 72 367 -41 80
2017-01-01 01:05:01 68 750 -54 79
这类数据属于更广泛的类别,无论是来自传感器的温度读数,股票价格,机器状态,甚至是登录应用程序的次数。
时间序列数据是统一表示系统,过程或行为随时间变化的数据。
时间序列数据的特征
如果仔细研究它是如何生成和摄入的,TimescaleDB等时间序列数据库通常具有以下重要特征:
- 以时间为中心:数据记录始终有一个时间戳。
- 仅追加-:数据是几乎完全追加只(插入)。
- 最近:新数据通常是关于最近的时间间隔,我们更少更新或回填旧时间间隔的缺失数据。
尽管数据的频率或规律性并不重要,它可以每毫秒或每小时收集一次。它也可以定期或不定期收集(例如,当发生某些事件时,而不是在预先确定的时间)。
但是没有数据库很久没有时间字段?与标准关系“业务”数据等其他数据相比,时间序列数据(以及支持它们的数据库)之间的一个主要区别是对数据的更改是插入而不是覆盖。
时间序列数据无处不在
时间序列数据无处不在,但有些环境特别是在洪流中创建。
- 监控计算机系统:虚拟机,服务器,容器指标(CPU,可用内存,网络/磁盘IOP),服务和应用程序指标(请求率,请求延迟)。
- 金融交易系统:经典证券,较新的加密货币,支付,交易事件。
- 物联网:工业机器和设备上的传感器,可穿戴设备,车辆,物理容器,托盘,智能家居的消费设备等的数据。
- 事件应用程序:用户/客户交互数据,如点击流,综合浏览量,登录,注册等。
- 商业智能:跟踪关键指标和业务的整体健康状况。
- 环境监测:温度,湿度,压力,pH值,花粉计数,空气流量,一氧化碳(CO),二氧化氮(NO2),颗粒物质(PM10)。
- (和更多)
时序数据模型
TimescaleDB使用“宽表”数据模型,这在关系数据库中是非常普遍的。这使得Timescale与大多数其他时间序列数据库有所不同,后者通常使用“窄表”模型。
在这里,我们讨论为什么我们选择宽表模型,以及我们如何推荐将它用于时间序列数据,使用物联网(IoT)示例。
设想一个由1,000个IoT设备组成的分布式组,旨在以不同的时间间隔收集环境数据。这些数据可能包括:
- 标识符:
device_id,timestamp - 元数据:
location_id,,,dev_type``firmware_version``customer_id - 设备指标:
cpu_1m_avg,,,,,free_mem``used_mem``net_rssi``net_loss``battery - 传感器指标:
temperature,,,,,humidity``pressure``CO``NO2``PM10
例如,您的传入数据可能如下所示:
| 时间戳 | 设备ID | cpu_1m_avg | Fri_mem | 温度 | LOCATION_ID | dev_type |
|---|---|---|---|---|---|---|
| 2017-01-01 01:02:00 | ABC123 | 80 | 500MB | 72 | 335 | 领域 |
| 2017-01-01 01:02:23 | def456 | 90 | 400MB | 64 | 335 | 屋顶 |
| 2017-01-01 01:02:30 | ghi789 | 120 | 0MB | 56 | 77 | 屋顶 |
| 2017-01-01 01:03:12 | ABC123 | 80 | 500MB | 72 | 335 | 领域 |
| 2017-01-01 01:03:35 | def456 | 95 | 350MB | 64 | 335 | 屋顶 |
| 2017-01-01 01:03:42 | ghi789 | 100 | 100MB | 56 | 77 | 屋顶 |
现在,我们来看看用这些数据建模的各种方法。
窄表模型
大多数时间序列数据库将以下列方式表示这些数据:
- 代表每个指标作为一个单独的实体(例如,表示与作为两个不同的东西)
cpu_1m_avg``free_mem - 为该指标存储一系列“时间”,“值”对
- 将元数据值表示为与该指标/标记集组合关联的“标记集”
在这个模型中,每个度量/标签集组合被认为是包含一系列时间/值对的单独“时间序列”。
使用我们上面的例子,这种方法会导致9个不同的“时间序列”,每个“时间序列”由一组独特的标签定义。
1. {name: cpu_1m_avg, device_id: abc123, location_id: 335, dev_type: field}
2. {name: cpu_1m_avg, device_id: def456, location_id: 335, dev_type: roof}
3. {name: cpu_1m_avg, device_id: ghi789, location_id: 77, dev_type: roof}
4. {name: free_mem, device_id: abc123, location_id: 335, dev_type: field}
5. {name: free_mem, device_id: def456, location_id: 335, dev_type: roof}
6. {name: free_mem, device_id: ghi789, location_id: 77, dev_type: roof}
7. {name: temperature, device_id: abc123, location_id: 335, dev_type: field}
8. {name: temperature, device_id: def456, location_id: 335, dev_type: roof}
9. {name: temperature, device_id: ghi789, location_id: 77, dev_type: roof}
这样的时间序列的数量与每个标签的基数的叉积(即,(#名称)×(#设备ID)×(#位置ID)×(设备类型))的交叉积。
而且这些“时间序列”中的每一个都有自己的一组时间/值序列。
现在,如果您独立收集每个指标,而且元数据很少,则此方法可能有用。
但总的来说,我们认为这种方法是有限的。它会丢失数据中的固有结构,使得难以提出各种有用的问题。例如:
- 系统状态到0 时是什么状态?
free_mem - 如何关联?
cpu_1m_avg``free_mem - 平均值是多少?
temperature``location_id
我们也发现这种方法认知混乱。我们是否真的收集了9个不同的时间序列,或者只是一个包含各种元数据和指标读数的数据集?
宽表模型
相比之下,TimescaleDB使用宽表模型,它反映了数据中的固有结构。
我们的宽表模型看起来与初始数据流完全一样:
| 时间戳 | 设备ID | cpu_1m_avg | Fri_mem | 温度 | LOCATION_ID | dev_type |
|---|---|---|---|---|---|---|
| 2017-01-01 01:02:00 | ABC123 | 80 | 500MB | 72 | 42 | 领域 |
| 2017-01-01 01:02:23 | def456 | 90 | 400MB | 64 | 42 | 屋顶 |
| 2017-01-01 01:02:30 | ghi789 | 120 | 0MB | 56 | 77 | 屋顶 |
| 2017-01-01 01:03:12 | ABC123 | 80 | 500MB | 72 | 42 | 领域 |
| 2017-01-01 01:03:35 | def456 | 95 | 350MB | 64 | 42 | 屋顶 |
| 2017-01-01 01:03:42 | ghi789 | 100 | 100MB | 56 | 77 | 屋顶 |
在这里,每一行都是一个新的读数,在给定的时间里有一组度量和元数据。这使我们能够保留数据中的关系,并提出比以前更有趣或探索性更强的问题。
当然,这不是一种新的格式:这是在关系数据库中常见的。这也是为什么我们发现这种格式更直观的原因。
与关系数据JOIN
TimescaleDB的数据模型与关系数据库还有另一个相似之处:它支持JOIN。具体来说,可以将附加元数据存储在辅助表中,然后在查询时使用该数据。
在我们的示例中,可以有一个单独的位置表,映射到该位置的其他元数据。例如:location_id
| LOCATION_ID | name | 纬度 | 经度 | 邮政编码 | 地区 |
|---|---|---|---|---|---|
| 42 | 大中央车站 | 40.7527°N | 73.9772°W | 10017 | NYC |
| 77 | 大厅7 | 42.3593°N | 71.0935°W | 02139 | 马萨诸塞 |
然后在查询时,通过加入我们的两个表格,可以提出如下问题:10017 中我们的设备的平均值是多少?free_mem``zip_code
如果没有联接,则需要对数据进行非规范化并将所有元数据存储在每个测量行中。这造成数据膨胀,并使数据管理更加困难。
通过连接,可以独立存储元数据,并更轻松地更新映射。
例如,如果我们想更新我们的“区域”为77(例如从“马萨诸塞州”到“波士顿”),我们可以进行此更改,而不必返回并覆盖历史数据。location_id
架构与概念
TimescaleDB作为PostgreSQL的扩展实现,这意味着Timescale数据库在整个PostgreSQL实例中运行。该扩展模型允许数据库利用PostgreSQL的许多属性,如可靠性,安全性以及与各种第三方工具的连接性。同时,TimescaleDB通过在PostgreSQL的查询规划器,数据模型和执行引擎中添加钩子,充分利用扩展可用的高度自定义。
从用户的角度来看,TimescaleDB公开了一些看起来像单数表的称为hypertable的表,它们实际上是一个抽象或许多单独表的虚拟视图,称为块。

通过将hypertable的数据划分为一个或多个维度来创建块:所有可编程元素按时间间隔分区,并且可以通过诸如设备ID,位置,用户ID等的关键字进行分区。我们有时将此称为分区横跨“时间和空间”。
术语
Hypertables
与数据交互的主要点是一个可以抽象化的跨越所有空间和时间间隔的单个连续表,从而可以通过标准SQL查询它。
实际上,所有与TimescaleDB的用户交互都是使用可调整的。创建表格和索引,修改表格,插入数据,选择数据等都可以(也应该)在hypertable上执行。[[跳转到基本的SQL操作] [jumpSQL]]
一个带有列名和类型的标准模式定义了一个hypertable,其中至少一列指定了一个时间值,另一列(可选)指定了一个额外的分区键。
提示:请参阅我们的[数据模型] [],以进一步讨论组织数据的各种方法,具体取决于您的使用情况; 最简单和最自然的就像许多关系数据库一样在“宽桌”中。
单个TimescaleDB部署可以存储多个可更改的超文本,每个超文本具有不同的架构。
在TimescaleDB中创建一个可超过的值需要两个简单的SQL命令:( 使用标准的SQL语法),后面跟着。CREATE TABLE``SELECT create_hypertable()
时间索引和分区键自动创建在hypertable上,尽管也可以创建附加索引(并且TimescaleDB支持所有PostgreSQL索引类型)。
Chunk
在内部,TimescaleDB自动将每个可分区块分割成块,每个块对应于特定的时间间隔和分区键空间的一个区域(使用散列)。这些分区是不相交的(非重叠的),这有助于查询计划人员最小化它必须接触以解决查询的组块集合。
每个块都使用标准数据库表来实现。(在PostgreSQL内部,这个块实际上是一个“父”可变的“子表”。)
块是正确的大小,确保表的索引的所有B树可以在插入期间驻留在内存中。这样可以避免在修改这些树中的任意位置时发生颠簸。
此外,通过避免过大的块,我们可以避免根据自动化保留策略删除删除的数据时进行昂贵的“抽真空”操作。运行时可以通过简单地删除块(内部表)来执行这些操作,而不是删除单独的行。
单节点与集群
TimescaleDB在单节点部署和集群部署(开发中)上执行这种广泛的分区。虽然分区传统上只用于在多台机器上扩展,但它也允许我们扩展到高写入速率(并改进了并行查询),即使在单台机器上也是如此。
TimescaleDB的当前开源版本仅支持单节点部署。值得注意的是,TimescaleDB的单节点版本已经在商用机器上基于超过100亿行高可用性进行了基准测试,而没有插入性能的损失。
单节点分区的好处
在单台计算机上扩展数据库性能的常见问题是内存和磁盘之间的显着成本/性能折衷。最终,我们的整个数据集不适合内存,我们需要将我们的数据和索引写入磁盘。
一旦数据足够大以至于我们无法将索引的所有页面(例如B树)放入内存中,那么更新树的随机部分可能会涉及从磁盘交换数据。像PostgreSQL这样的数据库为每个表索引保留一个B树(或其他数据结构),以便有效地找到该索引中的值。所以,当您索引更多列时,问题会复杂化。
但是,由于TimescaleDB创建的每个块本身都存储为单独的数据库表,因此其所有索引都只能建立在这些小得多的表中,而不是代表整个数据集的单个表。所以,如果我们正确地确定这些块的大小,我们可以将最新的表(和它们的B-树)完全放入内存中,并避免交换到磁盘的问题,同时保持对多个索引的支持。
有关TimescaleDB自适应空间/时间组块的动机和设计的更多信息,请参阅我们的[技术博客文章] [chunking]。
TimescaleDB 与 PostgreSQL 相比
TimescaleDB相对于存储时间序列数据的vanilla PostgreSQL或其他传统RDBMS提供了三大优势:
- 数据采集率要高得多,尤其是在数据库规模较大的情况下。
- 查询性能从相当于数量级更大。
- 时间导向的功能。
而且由于TimescaleDB仍然允许您使用PostgreSQL的全部功能和工具 - 例如,与关系表联接,通过PostGIS进行地理空间查询,以及任何可以说PostgreSQL的连接器 - 都没有理由不使用TimescaleDB来存储时间序列PostgreSQL节点中的数据。pg_dump``pg_restore
更高的写入速率
对于时间序列数据,TimescaleDB比PostgreSQL实现更高且更稳定的采集速率。正如我们的架构讨论中所描述的那样,只要索引表不能再适应内存,PostgreSQL的性能就会显着下降。
特别是,无论何时插入新行,数据库都需要更新表中每个索引列的索引(例如B树),这将涉及从磁盘交换一个或多个页面。在这个问题上抛出更多的内存只会拖延不可避免的,一旦您的时间序列表达到数千万行,每秒10K-100K +行的吞吐量就会崩溃到每秒数百行。
TimescaleDB通过大量利用时空分区来解决这个问题,即使在单台机器上运行也是如此。因此,对最近时间间隔的所有写入操作仅适用于保留在内存中的表,因此更新任何二级索引的速度也很快。
基准测试显示了这种方法的明显优势。数据库客户端插入适度大小的包含时间,设备标记集和多个数字指标(在本例中为10)的批量数据,以下10亿行(在单台计算机上)的基准测试模拟常见监控方案。在这里,实验在具有网络连接的SSD存储的标准Azure VM(DS4 v2,8核心)上执行。

我们观察到PostgreSQL和TimescaleDB对于前20M请求的启动速度大约相同(分别为106K和114K),或者每秒超过1M指标。然而,在大约五千万行中,PostgreSQL的表现开始急剧下降。在过去的100M行中,它的平均值仅为5K行/秒,而TimescaleDB保留了111K行/秒的吞吐量。
简而言之,Timescale在PostgreSQL的总时间的十五分之一中加载了十亿行数据库,并且吞吐量超过了PostgreSQL在这些较大规模时的20倍。
我们的TimescaleDB基准测试表明,即使使用单个磁盘,它仍能保持超过10B行的恒定性能。
此外,用户在一台计算机上利用多个磁盘时,可以为数以十亿计的行提供稳定的性能,无论是采用RAID配置,还是使用TimescaleDB支持在多个磁盘上传播单个超级缓存(通过多个表空间传统的PostgreSQL表)。
卓越或类似的查询性能
在单磁盘机器上,许多只执行索引查找或表扫描的简单查询在PostgreSQL和TimescaleDB之间表现相似。
例如,在具有索引时间,主机名和CPU使用率信息的100M行表上,对于每个数据库,以下查询将少于5毫秒:
SELECT date_trunc('minute', time) AS minute, max(user_usage)
FROM cpu
WHERE hostname = 'host_1234'
AND time >= '2017-01-01 00:00' AND time < '2017-01-01 01:00'
GROUP BY minute ORDER BY minute;
涉及对索引进行基本扫描的类似查询在两者之间也是等效的:
SELECT * FROM cpu
WHERE usage_user > 90.0
AND time >= '2017-01-01' AND time < '2017-01-02';
涉及基于时间的GROUP BY的较大查询 - 在面向时间的分析中很常见 - 通常在TimescaleDB中实现卓越的性能。
例如,当整个(超)表为100M行时,接触33M行的以下查询在TimescaleDB中速度提高5倍,而在1B行时速度提高约2倍。
SELECT date_trunc('hour', time) as hour,
hostname, avg(usage_user)
FROM cpu
WHERE time >= '2017-01-01' AND time < '2017-01-02'
GROUP BY hour, hostname
ORDER BY hour;
此外,可以约时间订购专理等查询可以多在TimescaleDB更好的性能。
例如,TimescaleDB引入了基于时间的“合并追加”优化,以最小化必须处理以执行以下操作的组的数量(考虑到时间已经被排序)。对于我们的100M行表,这导致查询延迟比PostgreSQL快396倍(82ms vs. 32566ms)。
SELECT date_trunc('minute', time) AS minute, max(usage_user)
FROM cpu
WHERE time < '2017-01-01'
GROUP BY minute
ORDER BY minute DESC
LIMIT 5;
我们将很快发布PostgreSQL和TimescaleDB之间更完整的基准测试比较,以及复制我们基准的软件。
我们的查询基准测试的高级结果是,对于几乎所有我们已经尝试过的查询,TimescaleDB都可以为PostgreSQL 实现类似或优越(或极其优越)的性能。
与PostgreSQL相比,TimescaleDB的一项额外成本是更复杂的计划(假设单个可超集可由许多块组成)。这可以转化为几毫秒的计划时间,这对于非常低延迟的查询(<10ms)可能具有不成比例的影响。
时间导向的功能
TimescaleDB还包含许多在传统关系数据库中没有的时间导向功能。这些包括特殊查询优化(如上面的合并附加),它为面向时间的查询以及其他面向时间的函数(其中一些在下面列出)提供了一些巨大的性能改进。
面向时间的分析
TimescaleDB包含面向时间分析的新功能,其中包括以下一些功能:
- 时间分段:标准功能的更强大的版本,它允许任意的时间间隔(例如5分钟,6小时等),以及灵活的分组和偏移,而不仅仅是第二,分钟,小时等。
date_trunc - 最后和第一个聚合:这些函数允许您按另一个列的顺序获取一列的值。例如,将返回基于组内时间的最新温度值(例如,一小时)。
last(temperature, time)
这些类型的函数能够实现非常自然的面向时间的查询。例如,以下财务查询打印每个资产的开盘价,收盘价,最高价和最低价。
SELECT time_bucket('3 hours', time) AS period
asset_code,
first(price, time) AS opening, last(price, time) AS closing,
max(price) AS high, min(price) AS low
FROM prices
WHERE time > NOW() - interval '7 days'
GROUP BY period, asset_code
ORDER BY period DESC, asset_code;
通过辅助列进行排序的能力(甚至不同于集合)能够实现一些强大的查询类型。例如,财务报告中常见的技术是“双时态建模”,它们分别从与记录观察时间有关的观察时间的原因出发。在这样的模型中,更正插入为新行(具有更新的time_recorded字段),并且不替换现有数据。last
以下查询返回每个资产的每日价格,按最新记录的价格排序。
SELECT time_bucket('1 day', time) AS day,
asset_code,
last(price, time_recorded)
FROM prices
WHERE time > '2017-01-01'
GROUP BY day, asset_code
ORDER BY day DESC, asset_code;
有关TimescaleDB当前(和增长中)时间功能列表的更多信息,请参阅我们的API。
面向时间的数据管理
TimescaleDB还提供了某些在PostgreSQL中不易获取或执行的数据管理功能。例如,在处理时间序列数据时,数据通常会很快建立起来。因此,您希望按照“仅存储一周原始数据”的方式编写数据保留策略。
实际上,将这与使用连续聚合相结合是很常见的,因此您可以保留两个可改写的数据:一个包含原始数据,另一个包含已经汇总为精细或小时聚合的数据。然后,您可能需要在两个(超)表上定义不同的保留策略,以长时间存储汇总的数据。
TimescaleDB允许通过其功能有效地删除块级别的旧数据,而不是行级别的旧数据。drop_chunks
SELECT drop_chunks(interval '7 days', 'conditions');
这将删除只包含比此持续时间早的数据的可超级“条件”中的所有块(文件),而不是删除块中的任何单独数据行。这避免了底层数据库文件中的碎片,这反过来又避免了在非常大的表格中可能过于昂贵的抽真空的需要。
有关更多详细信息,请参阅我们的数据保留讨论,包括如何自动执行数据保留策略。
TimescaleDB之于NoSQL
与一般的NoSQL数据库(例如MongoDB,Cassandra)或更专门的时间导向数据库(例如InfluxDB,KairosDB)相比,TimescaleDB提供了定性和定量差异:
- 普通SQL:即使在规模上,TimescaleDB也可以为时间序列数据提供标准SQL查询的功能。大多数(所有?)NoSQL数据库都需要学习新的查询语言或使用最好的“SQL-ish”(它仍然与现有工具兼容)。
- 操作简单:使用TimescaleDB,您只需要为关系数据和时间序列数据管理一个数据库。否则,用户通常需要将数据存储到两个数据库中:“正常”关系数据库和第二个时间序列数据库。
- JOIN可以通过关系数据和时间序列数据执行。
- 对于不同的查询集,查询性能更快。在NoSQL数据库中,更复杂的查询通常是缓慢或全表扫描,而有些数据库甚至无法支持许多自然查询。
- **像PostgreSQL一样管理,**并继承对不同数据类型和索引(B树,哈希,范围,BRIN,GiST,GIN)的支持。
- 对地理空间数据的本地支持:存储在TimescaleDB中的数据可以利用PostGIS的几何数据类型,索引和查询。
- 第三方工具:TimescaleDB支持任何可以说SQL的东西,包括像Tableau这样的BI工具。
何时不使用TimescaleDB?
然后,如果以下任一情况属实,则可能不想使用TimescaleDB:
- 简单的读取要求:如果您只需要快速键值查找或单列累积,则内存或列导向数据库可能更合适。前者显然不能扩展到相同的数据量,但是,后者的性能明显低于更复杂的查询。
- 非常稀疏或非结构化的数据:尽管TimescaleDB利用PostgreSQL对JSON / JSONB格式的支持,并且相当有效地处理稀疏性(空值的位图),但在某些情况下,无模式体系结构可能更合适。
- 重要的压缩是一个优先事项:基准测试显示在ZFS上运行的TimescaleDB获得约4倍的压缩率,但压缩优化的列存储可能更适合于更高的压缩率。
- 不频繁或离线分析:如果响应时间较慢(或响应时间限于少量预先计算的度量标准),并且您不希望许多应用程序/用户同时访问该数据,则可以避免使用数据库,而只是将数据存储在分布式文件系统中。
安装
Mac下直接使用 brew 安装,最省事的方法,可以连PostgreSQL和PostGIS一起装了。
# Add our tap
brew tap timescale/tap
# To install
brew install timescaledb
# Post-install to move files to appropriate place
/usr/local/bin/timescaledb_move.sh
在 EL 系操作系统下
sudo yum install -y https://download.postgresql.org/pub/repos/yum/9.6/redhat/fedora-7.2-x86_64/pgdg-redhat10-10-1.noarch.rpm
wget https://timescalereleases.blob.core.windows.net/rpm/timescaledb-0.9.0-postgresql-9.6-0.x86_64.rpm
# For PostgreSQL 10:
wget https://timescalereleases.blob.core.windows.net/rpm/timescaledb-0.9.0-postgresql-10-0.x86_64.rpm
# To install
sudo yum install timescaledb
配置
在postgresql.conf中添加以下配置,即可在PostgreSQL启动时加载该插件。
shared_preload_libraries = 'timescaledb'
在数据库中执行以下命令以创建timescaledb扩展。
CREATE EXTENSION timescaledb;
调参
对timescaledb比较重要的参数是锁的数量。
TimescaleDB在很大程度上依赖于表分区来扩展时间序列工作负载,这对锁管理有影响。在查询过程中,可修改需要在许多块(子表)上获取锁,这会耗尽所允许的锁的数量的默认限制。这可能会导致如下警告:
psql: FATAL: out of shared memory
HINT: You might need to increase max_locks_per_transaction.
为了避免这个问题,有必要修改默认值(通常是64),增加最大锁的数量。由于更改此参数需要重新启动数据库,因此建议预估未来的增长。对大多数情况,推荐配置为:max_locks_per_transaction
max_locks_per_transaction = 2 * num_chunks
num_chunks是在**超级表(HyperTable)中可能存在的块(chunk)**数量上限。
这种配置是考虑到对超级表查询可能申请锁的数量粗略等于超级表中的块数量,如果使用索引的话还要翻倍。
注意这个参数并不是精确的限制,它只是控制每个事物中平均的对象锁数量。
创建超表
为了创建一个可改写的,你从一个普通的SQL表开始,然后通过函数(API参考)将它转换为一个可改写的。create_hypertable
以下示例创建一个可随时间跨越一系列设备来跟踪温度和湿度的可调整高度。
-- We start by creating a regular SQL table
CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL,
location TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);
接下来,把它变成一个超表:create_hypertable
-- This creates a hypertable that is partitioned by time
-- using the values in the `time` column.
SELECT create_hypertable('conditions', 'time');
-- OR you can additionally partition the data on another
-- dimension (what we call 'space partitioning').
-- E.g., to partition `location` into 4 partitions:
SELECT create_hypertable('conditions', 'time', 'location', 4);
插入和查询
通过普通的SQL 命令将数据插入到hypertable中,例如使用毫秒时间戳:INSERT
INSERT INTO conditions(time, location, temperature, humidity)
VALUES (NOW(), 'office', 70.0, 50.0);
同样,查询数据是通过正常的SQL 命令完成的。SELECT
SELECT * FROM conditions ORDER BY time DESC LIMIT 100;
SQL 和命令也按预期工作。有关使用TimescaleDB标准SQL接口的更多示例,请参阅我们的使用页面。UPDATE``DELETE
故障档案:PostgreSQL事务号回卷
遇到一次磁盘坏块导致的事务回卷故障:
- 主库(PostgreSQL 9.3)磁盘坏块导致几张表上的VACUUM FREEZE执行失败。
- 无法回收老旧事务ID,导致整库事务ID濒临用尽,数据库进入自我保护状态不可用。
- 磁盘坏块导致手工VACUUM抢救不可行。
- 提升从库后,需要紧急VACUUM FREEZE才能继续服务,进一步延长了故障时间。
- 主库进入保护状态后提交日志(clog)没有及时复制到从库,从库产生存疑事务拒绝服务。
摘要
这是一个即将下线老旧库,疏于管理。坏块征兆在一周前就已经出现,没有及时跟进年龄。 通常AutoVacuum会保证很难出现这种故障,但一旦出现往往意味着祸不单行…让救火更加困难了……
背景
PostgreSQL实现了快照隔离(Snapshot Isolation),每个事务开始时都能获取数据库在该时刻的快照(也就是只能看到过去事务提交的结果,看不见后续事务提交的结果)。这一强大的功能是通过MVCC实现的,但也引入了额外复杂度,例如事务ID回卷问题。
事务ID(xid)是用于标识事务的32位无符号整型数值,递增分配,其中值0,1,2为保留值,溢出后回卷为3重新开始。事务ID之间的大小关系决定了事务的先后顺序。
/*
* TransactionIdPrecedes --- is id1 logically < id2?
*/
bool
TransactionIdPrecedes(TransactionId id1, TransactionId id2)
{
/*
* If either ID is a permanent XID then we can just do unsigned
* comparison. If both are normal, do a modulo-2^32 comparison.
*/
int32 diff;
if (!TransactionIdIsNormal(id1) || !TransactionIdIsNormal(id2))
return (id1 < id2);
diff = (int32) (id1 - id2);
return (diff < 0);
}
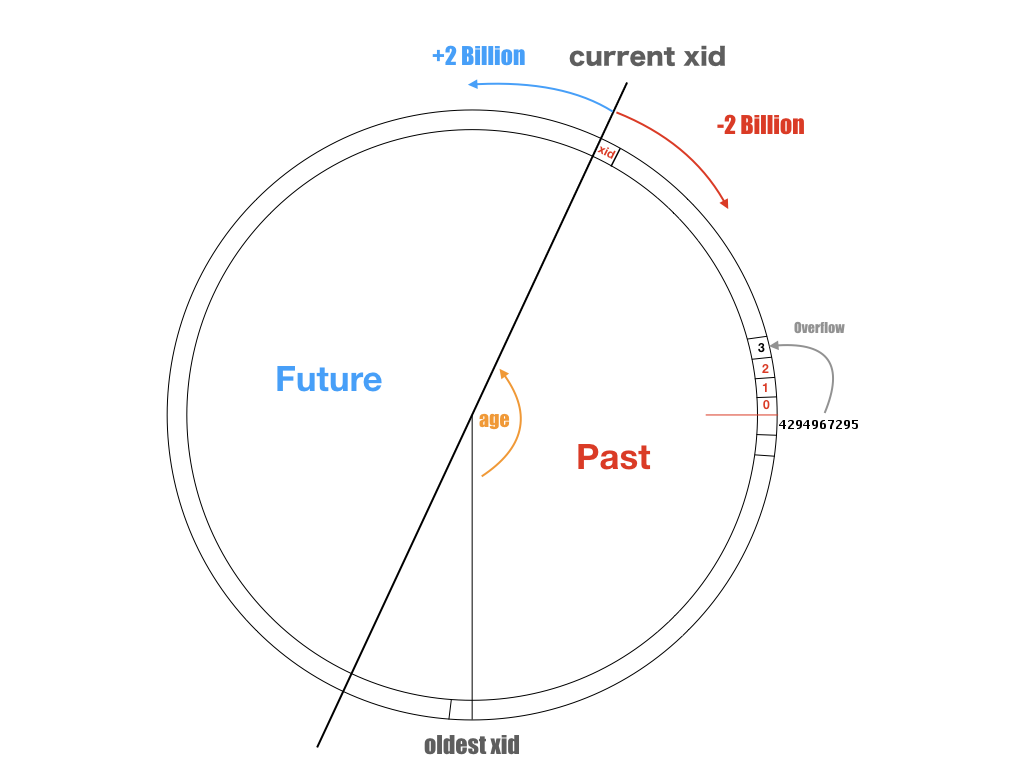
可以将xid的取值域视为一个整数环,但刨除0,1,2三个特殊值。0代表无效事务ID,1代表系统事务ID,2代表冻结事务ID。特殊的事务ID比任何普通事务ID小。而普通事务ID之间的比较可参见上图:它取决于两个事务ID的差值是否超出INT32_MAX。对任意一个事务ID,都有约21亿个位于过去的事务和21亿个位于未来的事务。
xid不仅仅存在于活跃的事务上,xid会影响所有的元组:事务会给自己影响的元组打上自己的xid作为记号。每个元组都会用(xmin, xmax)来标识自己的可见性,xmin 记录了最后写入(INSERT, UPDATE)该元组的事务ID,而xmax记录了删除或锁定该元组的事务ID。每个事务只能看见由先前事务提交(xmin < xid)且未被删除的元组(从而实现快照隔离)。
如果一个元组是由很久很久以前的事务产生的,那么在数据库的例行VACUUM FREEZE时,会找出当前活跃事务中最老的xid,将所有xmin < xid的元组的xmin标记为2,也就是冻结事务ID。这意味着这条元组跳出了这个比较环,比所有普通事务ID都要小,所以能被所有的事务看到。通过清理,数据库中最老的xid会不断追赶当前的xid,从而避免事务回卷。
数据库或表的年龄(age),定义为当前事务ID与数据库/表中存在最老的xid之差。最老的xid可能来自一个持续了几天的超长事务。也可能来自几天前老事务写入,但尚未被冻结的元组中。如果数据库的年龄超过了INT32_MAX,灾难性情况就发生了。过去的事务变成了未来的事务,过去事务写入的元组将变得不可见。
为了避免这种情况,需要避免超长事务与定期VACUUM FREEZE冻结老元组。如果单库在平均3万TPS的超高负载下,20亿个事务号一整天内就会用完。在这样的库上就无法执行一个超过一天的超长事务。而如果由于某种原因,自动清理工作无法继续进行,一天之内就可能遇到事务回卷。
9.4之后对FREEZE的机制进行了修改,FREEZE使用元组中单独的标记位来表示。
PostgreSQL应对事务回卷有自我保护机制。当临界事务号还剩一千万时,会进入紧急状态。
查询
查询当前所有表的年龄,SQL 语句如下:
SELECT c.oid::regclass as table_name,
greatest(age(c.relfrozenxid),age(t.relfrozenxid)) as age
FROM pg_class c
LEFT JOIN pg_class t ON c.reltoastrelid = t.oid
WHERE c.relkind IN ('r', 'm') order by 2 desc;
查询数据库的年龄,SQL语句如下:
SELECT *, age(datfrozenxid) FROM pg_database;
清理
执行VACUUM FREEZE可以冻结老旧事务的ID
set vacuum_cost_limit = 10000;
set vacuum_cost_delay = 0;
VACUUM FREEZE VERBOSE;
可以针对特定的表进行VACUUM FREEZE,抓主要矛盾。
问题
通常来说,PostgreSQL的AutoVacuum机制会自动执行FREEZE操作,冻结老旧事务的ID,从而降低数据库的年龄。因此一旦出现事务ID回卷故障,通常祸不单行,意味着vacuum机制可能被其他的故障挡住了。
目前遇到过三种触发事务ID回卷故障的情况
IDLE IN TRANSACTION
空闲事务会阻塞VACUUM FREEZE老旧元组。
解决方法很简单,干掉IDEL IN TRANSACTION的长事务然后执行VACUUM FREEZE即可。
存疑事务
clog损坏,或没有复制到从库,会导致相关表进入事务存疑状态,拒绝服务。
需要手工拷贝,或使用dd生成虚拟的clog来强行逃生。
磁盘/内存坏块
因为坏块导致的无法VACUUM比较尴尬。
需要通过二分法定位并跳过脏数据,或者干脆直接抢救从库。
注意事项
紧急抢救的时候,不要整库来,按照年龄大小降序挨个清理表会更快。
注意当主库进入事务回卷保护状态时,从库也会面临同样的问题。
解决方案
AutoVacuum参数配置
年龄监控
[未完待续]
故障档案:序列号消耗过快导致整型溢出
0x01 概览
-
故障表现:
- 某张使用自增列的表序列号涨至整型上限,无法写入。
- 发现表中的自增列存在大量空洞,很多序列号没有对应记录就被消耗掉了。
-
故障影响:非核心业务某表,10分钟左右无法写入。
-
故障原因:
- 内因:使用了INTEGER而不是BIGINT作为主键类型。
- 外因:业务方不了解
SEQUENCE的特性,执行大量违背约束的无效插入,浪费了大量序列号。
-
修复方案:
- 紧急操作:降级线上插入函数为直接返回,避免错误扩大。
- 应急方案:创建临时表,生成5000万个浪费空洞中的临时ID,修改插入函数,变为先检查再插入,并从该临时ID表中取ID。
- 解决方案:执行模式迁移,将所有相关表的主键与外键类型更新为Bigint。
原因分析
内因:类型使用不当
业务使用32位整型作为主键自增ID,而不是Bigint。
- 除非有特殊的理由,主键,自增列都应当使用BIGINT类型。
外因:不了解Sequence的特性
- 非要使用如果会频繁出现无效插入,或频繁使用UPSERT,需要关注Sequence的消耗问题。
- 可以考虑使用自定义发号函数(类Snowflake)
在PostgreSQL中,Sequence是一个比较特殊的类型。特别是,在事务中消耗的序列号不会回滚。因为序列号能被并发地获取,不存在逻辑上合理的回滚操作。
在生产中,我们就遇到了这样一种故障。有一张表直接使用了Serial作为主键:
CREATE TABLE sample(
id SERIAL PRIMARY KEY,
name TEXT UNIQUE,
value INTEGER
);
而插入的时候是这样的:
INSERT INTO sample(name, value) VALUES(?,?)
当然,实际上由于name列上的约束,如果插入了重复的name字段,事务就会报错中止并回滚。然而序列号已经被消耗掉了,即使事务回滚了,序列号也不会回滚。
vonng=# INSERT INTO sample(name, value) VALUES('Alice',1);
INSERT 0 1
vonng=# SELECT currval('sample_id_seq'::RegClass);
currval
---------
1
(1 row)
vonng=# INSERT INTO sample(name, value) VALUES('Alice',1);
ERROR: duplicate key value violates unique constraint "sample_name_key"
DETAIL: Key (name)=(Alice) already exists.
vonng=# SELECT currval('sample_id_seq'::RegClass);
currval
---------
2
(1 row)
vonng=# BEGIN;
BEGIN
vonng=# INSERT INTO sample(name, value) VALUES('Alice',1);
ERROR: duplicate key value violates unique constraint "sample_name_key"
DETAIL: Key (name)=(Alice) already exists.
vonng=# ROLLBACK;
ROLLBACK
vonng=# SELECT currval('sample_id_seq'::RegClass);
currval
---------
3
因此,当执行的插入有大量重复,即有大量的冲突时,可能会导致序列号消耗的非常快。出现大量空洞!
另一个需要注意的点在于,UPSERT操作也会消耗序列号!从表现上来看,这就意味着即使实际操作是UPDATE而不是INSERT,也会消耗一个序列号。
vonng=# INSERT INTO sample(name, value) VALUES('Alice',3) ON CONFLICT(name) DO UPDATE SET value = EXCLUDED.value;
INSERT 0 1
vonng=# SELECT currval('sample_id_seq'::RegClass);
currval
---------
4
(1 row)
vonng=# INSERT INTO sample(name, value) VALUES('Alice',4) ON CONFLICT(name) DO UPDATE SET value = EXCLUDED.value;
INSERT 0 1
vonng=# SELECT currval('sample_id_seq'::RegClass);
currval
---------
5
(1 row)
解决方案
线上所有查询与插入都使用存储过程。非核心业务,允许接受短暂的写入失效。首先降级插入函数,避免错误影响AppServer。因为该表存在大量依赖,无法直接修改其类型,需要一个临时解决方案。
检查发现ID列中存在大量空洞,每10000个序列号中实际只有1%被使用。因此使用下列函数生成临时ID表。
CREATE TABLE sample_temp_id(id INTEGER PRIMARY KEY);
-- 插入约5000w个临时ID,够用十几天了。
INSERT INTO sample_temp_id
SELECTT generate_series(2000000000,2100000000) as id EXCEPT SELECT id FROM sample;
-- 修改插入的存储过程,从临时表中Pop出ID。
DELETE FROM sample_temp_id WHERE id = (SELECT id FROM sample_temp_id FOR UPDATE LIMIT 1) RETURNING id;
修改插入存储过程,每次从临时ID表中取一个ID,显式插入表中。
经验与教训
能用 BIGINT 的就别用 INT,另外 UPSERT 的时候需要特别注意。
监控PG中的表大小
表的空间布局
宽泛意义上的表(Table),包含了本体表与TOAST表两个部分:
- 本体表,存储关系本身的数据,即狭义的关系,
relkind='r'。 - TOAST表,与本体表一一对应,存储过大的字段,
relinkd='t'。
而每个表,又由主体与索引两个**关系(Relation)**组成(对本体表而言,可以没有索引关系)
- 主体关系:存储元组。
- 索引关系:存储索引元组。
每个关系又可能会有四种分支:
-
main: 关系的主文件,编号为0
-
fsm:保存关于main分支中空闲空间的信息,编号为1
-
vm:保存关于main分支中可见性的信息,编号为2
-
init:用于不被日志记录(unlogged)的的表和索引,很少见的特殊分支,编号为3
每个分支存储为磁盘上的一到多个文件:超过1GB的文件会被划分为最大1GB的多个段。
综上所述,一个表并不是看上去那么简单,它由几个关系组成:
- 本体表的主体关系(单个)
- 本体表的索引(多个)
- TOAST表的主体关系(单个)
- TOAST表的索引(单个)
而每个关系实际上可能又包含了1~3个分支:main(必定存在),fsm,vm。
获取表的附属关系
使用下列查询,列出所有的分支oid。
select
nsp.nspname,
rel.relname,
rel.relnamespace as nspid,
rel.oid as relid,
rel.reltoastrelid as toastid,
toastind.indexrelid as toastindexid,
ind.indexes
from
pg_namespace nsp
join pg_class rel on nsp.oid = rel.relnamespace
, LATERAL ( select array_agg(indexrelid) as indexes from pg_index where indrelid = rel.oid) ind
, LATERAL ( select indexrelid from pg_index where indrelid = rel.reltoastrelid) toastind
where nspname not in ('pg_catalog', 'information_schema') and rel.relkind = 'r';
nspname | relname | nspid | relid | toastid | toastindexid | indexes
---------+------------+---------+---------+---------+--------------+--------------------
public | aoi | 4310872 | 4320271 | 4320274 | 4320276 | {4325606,4325605}
public | poi | 4310872 | 4332324 | 4332327 | 4332329 | {4368886}
统计函数
PG提供了一系列函数用于确定各个部分占用的空间大小。
| 函数 | 统计口径 |
|---|---|
pg_total_relation_size(oid) |
整个关系,包括表,索引,TOAST等。 |
pg_indexes_size(oid) |
关系索引部分所占空间 |
pg_table_size(oid) |
关系中除索引外部分所占空间 |
pg_relation_size(oid) |
获取一个关系主文件部分的大小(main分支) |
pg_relation_size(oid, 'main') |
获取关系main分支大小 |
pg_relation_size(oid, 'fsm') |
获取关系fsm分支大小 |
pg_relation_size(oid, 'vm') |
获取关系vm分支大小 |
pg_relation_size(oid, 'init') |
获取关系init分支大小 |
虽然在物理上一张表由这么多文件组成,但从逻辑上我们通常只关心两个东西的大小:表与索引。因此这里要用到的主要就是两个函数:pg_indexes_size与pg_table_size,对普通表其和为pg_total_relation_size。
而通常表大小的部分可以这样计算:
pg_table_size(relid)
= pg_relation_size(relid, 'main')
+ pg_relation_size(relid, 'fsm')
+ pg_relation_size(relid, 'vm')
+ pg_total_relation_size(reltoastrelid)
pg_indexes_size(relid)
= (select sum(pg_total_relation_size(indexrelid)) where indrelid = relid)
注意,TOAST表也有自己的索引,但有且仅有一个,因此使用pg_total_relation_size(reltoastrelid)可计算TOAST表的整体大小。
例:统计某一张表及其相关关系UDTF
SELECT
oid,
relname,
relnamespace::RegNamespace::Text as nspname,
relkind as relkind,
reltuples as tuples,
relpages as pages,
pg_total_relation_size(oid) as size
FROM pg_class
WHERE oid = ANY(array(SELECT 16418 as id -- main
UNION ALL SELECT indexrelid FROM pg_index WHERE indrelid = 16418 -- index
UNION ALL SELECT reltoastrelid FROM pg_class WHERE oid = 16418)); -- toast
可以将其包装为UDTF:pg_table_size_detail,便于使用:
CREATE OR REPLACE FUNCTION pg_table_size_detail(relation RegClass)
RETURNS TABLE(
id oid,
pid oid,
relname name,
nspname text,
relkind "char",
tuples bigint,
pages integer,
size bigint
)
AS $$
BEGIN
RETURN QUERY
SELECT
rel.oid,
relation::oid,
rel.relname,
rel.relnamespace :: RegNamespace :: Text as nspname,
rel.relkind as relkind,
rel.reltuples::bigint as tuples,
rel.relpages as pages,
pg_total_relation_size(oid) as size
FROM pg_class rel
WHERE oid = ANY (array(
SELECT relation as id -- main
UNION ALL SELECT indexrelid FROM pg_index WHERE indrelid = relation -- index
UNION ALL SELECT reltoastrelid FROM pg_class WHERE oid = relation)); -- toast
END;
$$
LANGUAGE PlPgSQL;
SELECT * FROM pg_table_size_detail(16418);
返回结果样例:
geo=# select * from pg_table_size_detail(4325625);
id | pid | relname | nspname | relkind | tuples | pages | size
---------+---------+-----------------------+----------+---------+----------+---------+-------------
4325628 | 4325625 | pg_toast_4325625 | pg_toast | t | 154336 | 23012 | 192077824
4419940 | 4325625 | idx_poi_adcode_btree | gaode | i | 62685464 | 172058 | 1409499136
4419941 | 4325625 | idx_poi_cate_id_btree | gaode | i | 62685464 | 172318 | 1411629056
4419942 | 4325625 | idx_poi_lat_btree | gaode | i | 62685464 | 172058 | 1409499136
4419943 | 4325625 | idx_poi_lon_btree | gaode | i | 62685464 | 172058 | 1409499136
4419944 | 4325625 | idx_poi_name_btree | gaode | i | 62685464 | 335624 | 2749431808
4325625 | 4325625 | gaode_poi | gaode | r | 62685464 | 2441923 | 33714962432
4420005 | 4325625 | idx_poi_position_gist | gaode | i | 62685464 | 453374 | 3714039808
4420044 | 4325625 | poi_position_geohash6 | gaode | i | 62685464 | 172058 | 1409499136
例:关系大小详情汇总
select
nsp.nspname,
rel.relname,
rel.relnamespace as nspid,
rel.oid as relid,
rel.reltoastrelid as toastid,
toastind.indexrelid as toastindexid,
pg_total_relation_size(rel.oid) as size,
pg_relation_size(rel.oid) + pg_relation_size(rel.oid,'fsm')
+ pg_relation_size(rel.oid,'vm') as relsize,
pg_indexes_size(rel.oid) as indexsize,
pg_total_relation_size(reltoastrelid) as toastsize,
ind.indexids,
ind.indexnames,
ind.indexsizes
from pg_namespace nsp
join pg_class rel on nsp.oid = rel.relnamespace
,LATERAL ( select indexrelid from pg_index where indrelid = rel.reltoastrelid) toastind
, LATERAL ( select array_agg(indexrelid) as indexids,
array_agg(indexrelid::RegClass) as indexnames,
array_agg(pg_total_relation_size(indexrelid)) as indexsizes
from pg_index where indrelid = rel.oid) ind
where nspname not in ('pg_catalog', 'information_schema') and rel.relkind = 'r';
PgAdmin安装配置
PgAdmin4的安装与配置
PgAdmin是一个为PostgreSQL定制设计的GUI。用起来很不错。可以以本地GUI程序或者Web服务的方式运行。因为Retina屏幕下面PgAdmin依赖的GUI组件显示效果有点问题,这里主要介绍如何以Web服务方式(Python Flask)配置运行PgAdmin4。
下载
PgAdmin可以从官方FTP下载。
wget https://ftp.postgresql.org/pub/pgadmin3/pgadmin4/v1.1/source/pgadmin4-1.1.tar.gz
tar -xf pgadmin4-1.1.tar.gz && cd pgadmin4-1.1/
也可以从官方Git Repo下载:
git clone git://git.postgresql.org/git/pgadmin4.git
cd pgadmin4
安装依赖
首先,需要安装Python,2或者3都可以。这里使用管理员权限安装Anaconda3发行版作为示例。
首先创建一个虚拟环境,当然直接上物理环境也是可以的……
conda create -n pgadmin python=3 anaconda
根据对应的Python版本,按照对应的依赖文件安装依赖。
sudo pip install -r requirements_py3.txt
配置选项
首先执行初始化脚本,创立PgAdmin的管理员用户。
python web/setup.py
按照提示输入Email和密码即可。
编辑web/config.py,修改默认配置,主要是改监听地址和端口。
DEFAULT_SERVER = 'localhost'
DEFAULT_SERVER_PORT = 5050
修改监听地址为0.0.0.0以便从任意IP访问。
按需修改端口。
故障档案:快慢不匀雪崩
最近发生了一起匪夷所思的故障,某数据库切走了一半的数据量和负载。
其他什么都没变,本来还好;压力减小,却在高峰期陷入濒死状态,完全不符合直觉。
但正如福尔摩斯所说,当你排除掉一切不可能之后,剩下的即使再离奇,也是事实。
一、摘要
某日凌晨4点,进行了核心库进行分库迁移,拆走一半的表和一半的查询负载,原库节点规模不变。
当日晚高峰核心库所有热备库(15台)出现连接堆积,压力暴涨,针对性地清理慢查询不再起效。
无差别持续杀查询,有立竿见影的救火效果(22:30后),且暂停后故障立刻重现(22:48),杀至高峰期结束。
匪夷所思的是,移走了表(数据量减半),移走了负载(TPS减半),其他什么都没变竟然会导致压力上升?
二、现象
CPU使用率的正常水位在25%,警戒水位在45%,极限水位在80%。故障期间所有从库飙升至极限水位。
PostgreSQL连接数发生暴涨,通常5~10个左右的数据库连接就足够撑起所有流量,连接池的最大连接数为100。
pgbouncer连接池平均响应时间平时在500μs左右,故障期间飙升至百毫秒级别。
故障期间,数据库TPS发生显著下滑。进行杀查询抢救后恢复,但处于剧烈抖动状态。
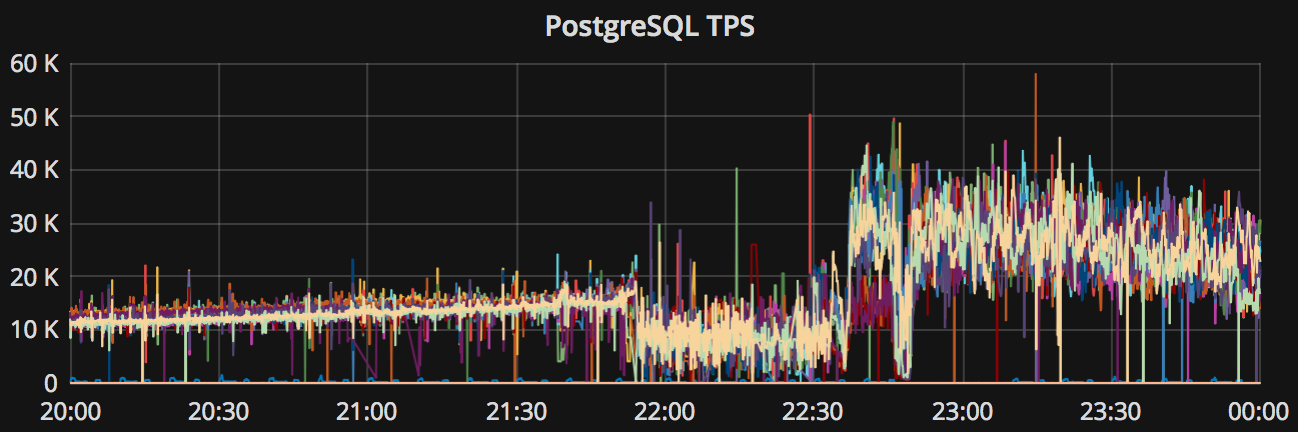
故障期间,两个函数的执行时间发生显著恶化,从几百微秒劣化至几十毫秒。
故障期间,复制延迟显著上升,开始出现GB级别的复制延迟,业务指标出现显著下滑。
开始杀查询后,大部分指标恢复,但一旦停止马上重新开始出现(22:48尝试性停止故障恢复)。
三、原因分析
【表因】:所有从库连接池被打满,连接被慢查询占据,快查询无法执行,发生连接堆积。
【主内因】:两个函数的并发数增大到30左右时,性能会发生急剧劣化,变为慢查询(500μs到100ms)。
【副内因】:后端与数据库没有合理的超时取消机制,断路器会放大故障。
【外因】:分库后,快查询比例下降,导致特定查询的相对比例上升,并发数增大至临界点。恶化为慢查询。
表因:连接打满
故障的表因是数据库连接池被打满,产生大量堆积连接。进而新连接无法建立,拒绝服务。
原理
数据库配置的最大连接数max_connections = 100,一个连接实质上就是一个数据库进程。机器能够负载的实际数据库进程数目与查询类型高度相关:如果全是在1ms内的快查询,几百上千个链接都是可以的(生产环境中的正常情况)。而如果全都是CPU和IO密集的慢查询,则最大支持的连接数可能只有(48 * 80% ≈ 38)个左右。
在生产环境中使用了连接池,正常情况下5~10个实际数据库连接就可以支撑起所有快查询。然而一旦有大量慢查询持续进入,长期占用了活跃连接,那么快查询就会排队等待发生堆积,连接池进而启动更多实际数据库的连接,而这些连接上的快查询很快就会执行完毕,最终仍然会被不断进入的慢查询占据。最终导致约100个实际数据库连接都在执行CPU/IO密集的慢查询(max_pool_size=100),CPU暴涨,进一步恶化情况。
证据
连接池活跃连接数
连接池排队连接数
数据库后端连接数
修复
持续地无差别杀掉所有数据库活跃连接,能起到很好的治标效果,且对业务指标影响很小。
但杀掉连接(pg_terminate_backend)会导致连接池重连,更好的做法是取消查询(pg_cancel_backend)
因为快查询走的快,卡在后端实际连接上执行的查询极大概率都是慢查询,这时候无差别取消所有查询命中的绝大多数都是慢查询。杀查询能将连接释放给快查询使用,让应用苟活下去,但必须持续不断的杀才有效果,因为用不了零点几秒,慢查询就会重新占据活跃连接。
使用psql执行以下SQL,每隔0.5秒取消所有活跃查询。
SELECT pg_cancel_backend(pid) FROM pg_stat_activity WHERE application_name != 'psql' \watch 0.5
解决方案:调整了连接池的后端最大连接数,进行快慢分离,强制所有批量任务与慢查询走离线从库。
主内因:并行恶化
故障的主内因是两个函数的执行时间在并行数增大时发生恶化。
原理
故障的直接导火索是这两个函数劣化为慢查询。经过单独的压力测试,这两个函数随着并行执行数增高,发生急剧的性能劣化,阈值点为约30个并发进程。(因为所有进程只执行同一个查询,所以可认为并行数等于并发数)
证据
图:故障期间函数平均执行时间出现明显飙升
图:在不同并行数下压测该函数能达到的最大QPS
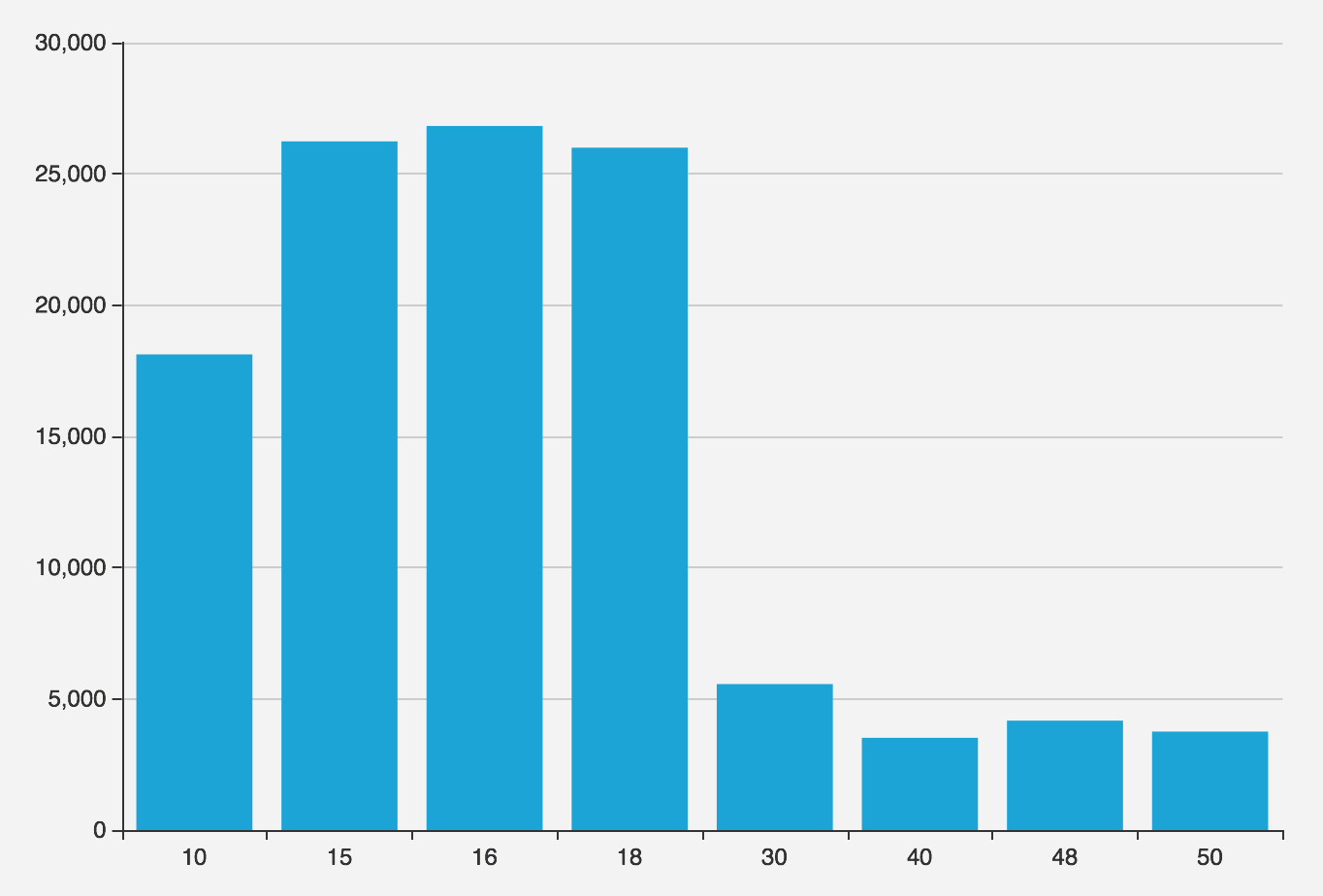
修复
- 优化函数执行逻辑,将该函数的执行时间优化至原来的一半(最大QPS翻倍)。
- 新增五台从库,进一步降低单机负载。
副内因:没有超时
故障的副内因在于没有合理的超时取消机制,查询不会因为超时被取消,是发生堆积的必要条件。
原理
发生查询超时时,应用层的合理行为是
- 直接返回,报错。
- 进行若干次重试(在高峰期可以考虑直接返回错误)
查询等待超出合理范围的时间却不取消,就会导致连接堆积。抛弃返回结果并无法取消已经发出的查询,客户端需要主动Cancel Request。Go1.7后的标准实践是通过context包与database/sql提供的QueryContext/ExecContext进行超时控制。
数据库端和连接池端可以配置语句超时(statement_timeout),但实践表明这样的操作很容易误杀查询。
手动杀灭能够立竿见影地治标,但它本质上是一种人工超时取消机制。稳健的系统应当有自动化的超时取消机制,这需要在数据库、连接池、应用多个层次协同解决。
检视后端使用的驱动代码,发现pg.v3 pg.v5并没有真正意义上的查询超时机制,超时参数不过是为net.Conn加上的TCP超时(通常在分钟级别)。
修复
- 建议使用
github.com/jackc/pgx与github.com/go-pg/pg第六版驱动替代现有驱动 - 使用circuit-breaker会导致故障效应被放大,建议后端使用主动超时替代断路器。
- 建议在应用层面对连接的使用进行更精细的控制。
外因:分库迁移
分库导致了原库中的快慢查询比例发生变化,诱发了两个函数的劣化。
问题函数在迁移前后的全局调用次数占比由1/6 变为1/2,导致问题函数的并行数增大。
原理
- 迁走的函数全都是快查询,原本问题函数:普通函数的比例为1:5
- 迁移负载后,快查询迁走了大半。问题函数:普通函数超过1:1
- 问题函数的比例大幅升高,导致高峰期其并发数超出阈值点,出现劣化。
证据
通过分析分库迁移前后的数据库全量日志,回放查询流量进行压测,重现了现象,确认了问题原因。
| 指标 | 迁移前 | 迁移后 |
|---|---|---|
| 问题函数占比 | 1/6 | 5/9 |
| 最大QPS | 40k | 8k |
QPS/TPS是一个极具误导性的指标,只有在负载类型不变的清空下,比较QPS才有意义。当系统负载类型发生变化时,QPS的水位点也需要重新进行评估测试。
在本例中,在负载变化后,系统的最大QPS水位点已经发生了戏剧性的变化,因为问题函数并发劣化,最大QPS变为原来的五分之一。
修复
对问题函数进行了改写优化,提高了一倍的性能。
通过测试,确定了迁移后的系统水位值,并进行了相应的优化与容量调整。
四、经验与教训
在故障排查中,走了一些弯路。比如一开始认为是某个离线批量任务拖慢了查询(根据日志中观察到的前后相关性),也排查了API调用量突增,外部恶意访问,其他变更因素,未知线上操作等。虽然分库迁移被列入怀疑对象,但因为直觉上认为负载小了,系统的Capacity怎么可能会下降?就没有列为优先排查对象。现实马上就给我们上了一课:
当你排除掉一切不可能之后,剩下的即使再离奇,也是事实。
Bash与psql小技巧
一些PostgreSQL与Bash交互的技巧。
使用严格模式编写Bash脚本
使用Bash严格模式,可以避免很多无谓的错误。在Bash脚本开始的地方放上这一行很有用:
set -euo pipefail
-e:当程序返回非0状态码时报错退出-u:使用未初始化的变量时报错,而不是当成NULL-o pipefail:使用Pipe中出错命令的状态码(而不是最后一个)作为整个Pipe的状态码1。
执行SQL脚本的Bash包装脚本
通过psql运行SQL脚本时,我们期望有这么两个功能:
- 能向脚本中传入变量
- 脚本出错后立刻中止(而不是默认行为的继续执行)
这里给出了一个实际例子,包含了上述两个特性。使用Bash脚本进行包装,传入两个参数。
#!/usr/bin/env bash
set -euo pipefail
if [ $# != 2 ]; then
echo "please enter a db host and a table suffix"
exit 1
fi
export DBHOST=$1
export TSUFF=$2
psql \
-X \
-U user \
-h $DBHOST \
-f /path/to/sql/file.sql \
--echo-all \
--set AUTOCOMMIT=off \
--set ON_ERROR_STOP=on \
--set TSUFF=$TSUFF \
--set QTSTUFF=\'$TSUFF\' \
mydatabase
psql_exit_status = $?
if [ $psql_exit_status != 0 ]; then
echo "psql failed while trying to run this sql script" 1>&2
exit $psql_exit_status
fi
echo "sql script successful"
exit 0
一些要点:
- 参数
TSTUFF会传入SQL脚本中,同时作为一个裸值和一个单引号包围的值,因此,裸值可以当成表名,模式名,引用值可以当成字符串值。 - 使用
-X选项确保当前用户的.psqlrc文件不会被自动加载 - 将所有消息打印到控制台,这样可以知道脚本的执行情况。(失效的时候很管用)
- 使用
ON_ERROR_STOP选项,当出问题时立即终止。 - 关闭
AUTOCOMMIT,所以SQL脚本文件不会每一行都提交一次。取而代之的是SQL脚本中出现COMMIT时才提交。如果希望整个脚本作为一个事务提交,在sql脚本最后一行加上COMMIT(其它地方不要加),否则整个脚本就会成功运行却什么也没提交(自动回滚)。也可以使用--single-transaction标记来实现。
/path/to/sql/file.sql的内容如下:
begin;
drop index this_index_:TSUFF;
commit;
begin;
create table new_table_:TSUFF (
greeting text not null default '');
commit;
begin;
insert into new_table_:TSUFF (greeting)
values ('Hello from table ' || :QTSUFF);
commit;
使用PG环境变量让脚本更简练
使用PG环境变量非常方便,例如用PGUSER替代-U <user>,用PGHOST替代-h <host>,用户可以通过修改环境变量来切换数据源。还可以通过Bash为这些环境变量提供默认值。
#!/bin/bash
set -euo pipefail
# Set these environmental variables to override them,
# but they have safe defaults.
export PGHOST=${PGHOST-localhost}
export PGPORT=${PGPORT-5432}
export PGDATABASE=${PGDATABASE-my_database}
export PGUSER=${PGUSER-my_user}
export PGPASSWORD=${PGPASSWORD-my_password}
RUN_PSQL="psql -X --set AUTOCOMMIT=off --set ON_ERROR_STOP=on "
${RUN_PSQL} <<SQL
select blah_column
from blahs
where blah_column = 'foo';
rollback;
SQL
在单个事务中执行一系列SQL命令
你有一个写满SQL的脚本,希望将整个脚本作为单个事务执行。一种经常出现的情况是在最后忘记加一行COMMIT。一种解决办法是使用—single-transaction标记:
psql \
-X \
-U myuser \
-h myhost \
-f /path/to/sql/file.sql \
--echo-all \
--single-transaction \
--set AUTOCOMMIT=off \
--set ON_ERROR_STOP=on \
mydatabase
file.sql的内容变为:
insert into foo (bar) values ('baz');
insert into yikes (mycol) values ('hello');
两条插入都会被包裹在同一对BEGIN/COMMIT中。
让多行SQL语句更美观
#!/usr/bin/env bash
set -euo pipefail
RUN_ON_MYDB="psql -X -U myuser -h myhost --set ON_ERROR_STOP=on --set AUTOCOMMIT=off mydb"
$RUN_ON_MYDB <<SQL
drop schema if exists new_my_schema;
create table my_new_schema.my_new_table (like my_schema.my_table);
create table my_new_schema.my_new_table2 (like my_schema.my_table2);
commit;
SQL
# 使用'包围的界定符意味着HereDocument中的内容不会被Bash转义。
$RUN_ON_MYDB <<'SQL'
create index my_new_table_id_idx on my_new_schema.my_new_table(id);
create index my_new_table2_id_idx on my_new_schema.my_new_table2(id);
commit;
SQL
也可以使用Bash技巧,将多行语句赋值给变量,并稍后使用。
注意,Bash会自动清除多行输入中的换行符。实际上整个Here Document中的内容在传输时会重整为一行,你需要添加合适的分隔符,例如分号,来避免格式被搞乱。
CREATE_MY_TABLE_SQL=$(cat <<EOF
create table foo (
id bigint not null,
name text not null
);
EOF
)
$RUN_ON_MYDB <<SQL
$CREATE_MY_TABLE_SQL
commit;
SQL
如何将单个SELECT标量结果赋值给Bash变量
CURRENT_ID=$($PSQL -X -U $PROD_USER -h myhost -P t -P format=unaligned $PROD_DB -c "select max(id) from users")
let NEXT_ID=CURRENT_ID+1
echo "next user.id is $NEXT_ID"
echo "about to reset user id sequence on other database"
$PSQL -X -U $DEV_USER $DEV_DB -c "alter sequence user_ids restart with $NEXT_ID"
如何将单行结果赋给Bash变量
并且每个变量都以列名命名。
read username first_name last_name <<< $(psql \
-X \
-U myuser \
-h myhost \
-d mydb \
--single-transaction \
--set ON_ERROR_STOP=on \
--no-align \
-t \
--field-separator ' ' \
--quiet \
-c "select username, first_name, last_name from users where id = 5489")
echo "username: $username, first_name: $first_name, last_name: $last_name"
也可以使用数组的方式
#!/usr/bin/env bash
set -euo pipefail
declare -a ROW=($(psql \
-X \
-h myhost \
-U myuser \
-c "select username, first_name, last_name from users where id = 5489" \
--single-transaction \
--set AUTOCOMMIT=off \
--set ON_ERROR_STOP=on \
--no-align \
-t \
--field-separator ' ' \
--quiet \
mydb))
username=${ROW[0]}
first_name=${ROW[1]}
last_name=${ROW[2]}
echo "username: $username, first_name: $first_name, last_name: $last_name"
如何在Bash脚本中迭代查询结果集
#!/usr/bin/env bash
set -euo pipefail
PSQL=/usr/bin/psql
DB_USER=myuser
DB_HOST=myhost
DB_NAME=mydb
$PSQL \
-X \
-h $DB_HOST \
-U $DB_USER \
-c "select username, password, first_name, last_name from users" \
--single-transaction \
--set AUTOCOMMIT=off \
--set ON_ERROR_STOP=on \
--no-align \
-t \
--field-separator ' ' \
--quiet \
-d $DB_NAME \
| while read username password first_name last_name ; do
echo "USER: $username $password $first_name $last_name"
done
也可以读进数组里:
#!/usr/bin/env bash
set -euo pipefail
PSQL=/usr/bin/psql
DB_USER=myuser
DB_HOST=myhost
DB_NAME=mydb
$PSQL \
-X \
-h $DB_HOST \
-U $DB_USER \
-c "select username, password, first_name, last_name from users" \
--single-transaction \
--set AUTOCOMMIT=off \
--set ON_ERROR_STOP=on \
--no-align \
-t \
--field-separator ' ' \
--quiet \
$DB_NAME | while read -a Record ; do
username=${Record[0]}
password=${Record[1]}
first_name=${Record[2]}
last_name=${Record[3]}
echo "USER: $username $password $first_name $last_name"
done
如何使用状态表来控制多个PG任务
假设你有一份如此之大的工作,以至于你一次只想做一件事。 您决定一次可以完成一项任务,而这对数据库来说更容易,而不是执行一个长时间运行的查询。 您创建一个名为my_schema.items_to_process的表,其中包含要处理的每个项目的item_id,并且您将一列添加到名为done的items_to_process表中,该表默认为false。 然后,您可以使用脚本从items_to_process中获取每个未完成项目,对其进行处理,然后在items_to_process中将该项目更新为done = true。 一个bash脚本可以这样做:
#!/usr/bin/env bash
set -euo pipefail
PSQL="/u99/pgsql-9.1/bin/psql"
DNL_TABLE="items_to_process"
#DNL_TABLE="test"
FETCH_QUERY="select item_id from my_schema.${DNL_TABLE} where done is false limit 1"
process_item() {
local item_id=$1
local dt=$(date)
echo "[${dt}] processing item_id $item_id"
$PSQL -X -U myuser -h myhost -c "insert into my_schema.thingies select thingie_id, salutation, name, ddr from thingies where item_id = $item_id and salutation like 'Mr.%'" mydb
}
item_id=$($PSQL -X -U myuser -h myhost -P t -P format=unaligned -c "${FETCH_QUERY}" mydb)
dt=$(date)
while [ -n "$item_id" ]; do
process_item $item_id
echo "[${dt}] marking item_id $item_id as done..."
$PSQL -X -U myuser -h myhost -c "update my_schema.${DNL_TABLE} set done = true where item_id = $item_id" mydb
item_id=$($PSQL -X -U myuser -h myhost -P t -P format=unaligned -c "${FETCH_QUERY}" mydb)
dt=$(date)
done
跨数据库拷贝表
有很多方式可以实现这一点,利用psql的\copy命令可能是最简单的方式。假设你有两个数据库olddb与newdb,有一张users表需要从老库同步到新库。如何用一条命令实现:
psql \
-X \
-U user \
-h oldhost \
-d olddb \
-c "\\copy users to stdout" \
| \
psql \
-X \
-U user \
-h newhost \
-d newdb \
-c "\\copy users from stdin"
一个更困难的例子:假如你的表在老数据库中有三列:first_name, middle_name, last_name。
但在新数据库中只有两列,first_name,last_name,则可以使用:
psql \
-X \
-U user \
-h oldhost \
-d olddb \
-c "\\copy (select first_name, last_name from users) to stdout" \
| \
psql \
-X \
-U user \
-h newhost \
-d newdb \
-c "\\copy users from stdin"
获取表定义的方式
pg_dump \
-U db_user \
-h db_host \
-p 55432 \
--table my_table \
--schema-only my_db
将bytea列中的二进制数据导出到文件
注意bytea列,在PostgreSQL 9.0 以上是使用十六进制表示的,带有一个恼人的前缀\x,可以用substring去除。
#!/usr/bin/env bash
set -euo pipefail
psql \
-P t \
-P format=unaligned \
-X \
-U myuser \
-h myhost \
-c "select substring(my_bytea_col::text from 3) from my_table where id = 12" \
mydb \
| xxd -r -p > dump.txt
将文件内容作为一个列的值插入
有两种思路完成这件事,第一种是在外部拼SQL,第二种是在脚本中作为变量。
CREATE TABLE sample(
filename INTEGER,
value JSON
);
psql <<SQL
\set content `cat ${filename}`
INSERT INTO sample VALUES(\'${filename}\',:'content')
SQL
显示特定数据库中特定表的统计信息
#!/usr/bin/env bash
set -euo pipefail
if [ -z "$1" ]; then
echo "Usage: $0 table [db]"
exit 1
fi
SCMTBL="$1"
SCHEMANAME="${SCMTBL%%.*}" # everything before the dot (or SCMTBL if there is no dot)
TABLENAME="${SCMTBL#*.}" # everything after the dot (or SCMTBL if there is no dot)
if [ "${SCHEMANAME}" = "${TABLENAME}" ]; then
SCHEMANAME="public"
fi
if [ -n "$2" ]; then
DB="$2"
else
DB="my_default_db"
fi
PSQL="psql -U my_default_user -h my_default_host -d $DB -x -c "
$PSQL "
select '-----------' as \"-------------\",
schemaname,
tablename,
attname,
null_frac,
avg_width,
n_distinct,
correlation,
most_common_vals,
most_common_freqs,
histogram_bounds
from pg_stats
where schemaname='$SCHEMANAME'
and tablename='$TABLENAME';
" | grep -v "\-\[ RECORD "
使用方式
./table-stats.sh myschema.mytable
对于public模式中的表
./table-stats.sh mytable
连接其他数据库
./table-stats.sh mytable myotherdb
将psql的默认输出转换为Markdown表格
alias pg2md=' sed '\''s/+/|/g'\'' | sed '\''s/^/|/'\'' | sed '\''s/$/|/'\'' | grep -v rows | grep -v '\''||'\'''
# Usage
psql -c 'SELECT * FROM pg_database' | pg2md
输出的结果贴到Markdown编辑器即可。
-
管道程序的退出状态放置在环境变量数组
PIPESTATUS中 ↩︎
PostgreSQL例行维护
汽车需要上油,数据库也需要维护保养。
PG中的维护工作
对Pg而言,有三项比较重要的维护工作:备份、重整、清理
- 备份(backup):最重要的例行工作,生命线。
- 制作基础备份
- 归档增量WAL
- 重整(repack)
- 重整表与索引能消除其中的膨胀,节约空间,确保查询性能不会劣化。
- 清理(vacuum)
- 维护表与库的年龄,避免事务ID回卷故障。
- 更新统计数据,生成更好的执行计划。
- 回收死元组。节约空间,提高性能。
备份
备份可以使用pg_backrest 作为一条龙解决方案,但这里考虑使用脚本进行备份。
参考:pg-backup
重整
重整使用pg_repack,PostgreSQL自带源里包含了pg_repack
参考:pg-repack
清理
虽然有AutoVacuum,但手动执行Vacuum仍然有帮助。检查数据库的年龄,当出现老化时及时上报。
参考:pg-vacuum
备份恢复手段概览
备份是DBA的安身立命之本,有备份,就不用慌。
备份有三种形式:SQL转储,文件系统备份,连续归档
1. SQL转储
SQL 转储方法的思想是:
创建一个由SQL命令组成的文件,服务器能利用其中的SQL命令重建与转储时状态一样的数据库。
1.1 转储
工具pg_dump、pg_dumpall用于进行SQL转储。结果输出到stdout。
pg_dump dbname > filename
pg_dump dbname -f filename
pg_dump是一个普通的PostgreSQL客户端应用。可以在任何可以访问该数据库的远端主机上进行备份工作。pg_dump不会以任何特殊权限运行,必须要有你想备份的表的读权限,同时它也遵循同样的HBA机制。- 要备份整个数据库,几乎总是需要一个数据库超级用户。
- 该备份方式的重要优势是,它是跨版本、跨机器架构的备份方式。(最远回溯至7.0)
pg_dump的备份是内部一致的,是转储开始时刻的数据库快照,转储期间的更新不被包括在内。pg_dump不会阻塞其他数据库操作,但需要排它锁的命令除外(例如大多数 ALTER TABLE)
1.2 恢复
文本转储文件可由psql读取,从转储中恢复的常用命令是:
psql dbname < infile
-
这条命令不会创建数据库
dbname,必须在执行psql前自己从template0创建。例如,用命令createdb -T template0 dbname。默认template1和template0是一样的,新创建的数据库默认以template1为模板。CREATE DATABASE dbname TEMPLATE template0; -
非文本文件转储可以使用pg_restore工具来恢复。
-
在开始恢复之前,转储库中对象的拥有者以及在其上被授予了权限的用户必须已经存在。如果它们不存在,那么恢复过程将无法将对象创建成具有原来的所属关系以及权限(有时候这就是你所需要的,但通常不是)。
-
恢复时遇到错误自动终止,则可以设置
ON_ERROR_STOP变量来运行psql,遇到SQL错误后退出并返回状态3:
psql --set ON_ERROR_STOP=on dbname < infile
- 恢复时可以使用单个事务来保证要么完全正确恢复,要么完全回滚。使用
-1或--single-transaction - pg_dump和psql可以通过管道on-the-fly做转储与恢复
pg_dump -h host1 dbname | psql -h host2 dbname
1.3 全局转储
一些信息属于数据库集簇,而不是单个数据库的,例如角色、表空间。如果希望转储这些,可使用pg_dumpall
pg_dumpall > outfile
如果只想要全局的数据(角色与表空间),则可以使用-g, --globals-only参数。
转储的结果可以使用psql恢复,通常将转储载入到一个空集簇中可以用postgres作为数据库名
psql -f infile postgres
- 在恢复一个pg_dumpall转储时常常需要具有数据库超级用户访问权限,因为它需要恢复角色和表空间信息。
- 如果使用了表空间,请确保转储中的表空间路径适合于新的安装。
- pg_dumpall工作步骤是,先创建角色、表空间转储,再为每一个数据库做pg_dump。这意味着每个数据库自身是一致的,但是不同数据库的快照并不同步。
1.4 命令实践
准备环境,创建测试数据库
psql postgres -c "CREATE DATABASE testdb;"
psql postgres -c "CREATE ROLE test_user LOGIN;"
psql testdb -c "CREATE TABLE test_table(i INTEGER);"
psql testdb -c "INSERT INTO test_table SELECT generate_series(1,16);"
# dump到本地文件
pg_dump testdb -f testdb.sql
# dump并用xz压缩,-c指定从stdio接受,-d指定解压模式
pg_dump testdb | xz -cd > testdb.sql.xz
# dump,压缩,分割为1m的小块
pg_dump testdb | xz | split -b 1m - testdb.sql.xz
cat testdb.sql.xz* | xz -cd | psql # 恢复
# pg_dump 常用参数参考
-s --schema-only
-a --data-only
-t --table
-n --schema
-c --clean
-f --file
--inserts
--if-exists
-N --exclude-schema
-T --exclude-table
2. 文件系统转储
SQL 转储方法的思想是:拷贝数据目录的所有文件。为了得到一个可用的备份,所有备份文件都应当保持一致。
所以通常比而且为了得到一个可用的备份,所有备份文件都应当保持一致。
- 文件系统拷贝不做逻辑解析,只是简单拷贝文件。好处是执行快,省掉了逻辑解析和重建索引的时间,坏处是占用空间更大,而且只能用于整个数据库集簇的备份
-
最简单的方式:停机,直接拷贝数据目录的所有文件。
-
有办法通过文件系统(例如xfs)获得一致的冻结快照也可以不停机,但wal和数据目录必须是一致的。
-
可以通过制作pg_basebackup进行远程归档备份,可以不停机。
-
可以通过停机执行rsync的方式向远端增量同步数据变更。
3. PITR 连续归档与时间点恢复
Pg在运行中会不断产生WAL,WAL记录了操作日志,从某一个基础的全量备份开始回放后续的WAL,就可以恢复数据库到任意的时刻的状态。为了实现这样的功能,就需要配置WAL归档,将数据库生成的WAL不断保存起来。
WAL在逻辑上是一段无限的字节流。pg_lsn类型(bigint)可以标记WAL中的位置,pg_lsn代表一个WAL中的字节位置偏移量。但实践中WAL不是连续的一个文件,而被分割为每16MB一段。
WAL文件名是有规律的,而且归档时不允许更改。通常为24位十六进制数字,000000010000000000000003,其中前面8位十六进制数字表示时间线,后面的16位表示16MB块的序号。即lsn >> 24的值。
查看pg_lsn时,例如0/84A8300,只要去掉最后六位hex,就可以得到WAL文件序号的后面部分,这里,也就是8,如果使用的是默认时间线1,那么对应的WAL文件就是000000010000000000000008。
3.1 准备环境
# 目录:
# 使用/var/lib/pgsql/data 作为主库目录,使用/var/lib/pgsql/wal作为日志归档目录
# sudo mkdir /var/lib/pgsql && sudo chown postgres:postgres /var/lib/pgsql/
pg_ctl stop -D /var/lib/pgsql/data
rm -rf /var/lib/pgsql/{data,wal} && mkdir -p /var/lib/pgsql/{data,wal}
# 初始化:
# 初始化主库并修改配置文件
pg_ctl -D /var/lib/pgsql/data init
# 配置文件
# 创建默认额外配置文件夹,并在postgresql.conf中配置include_dir
mkdir -p /var/lib/pgsql/data/conf.d
cat >> /var/lib/pgsql/data/postgresql.conf <<- 'EOF'
include_dir = 'conf.d'
EOF
3.2 配置自动归档命令
# 归档配置
# %p 代表 src wal path, %f 代表 filename
cat > /var/lib/pgsql/data/conf.d/archive.conf <<- 'EOF'
archive_mode = on
archive_command = 'conf.d/archive.sh %p %f'
EOF
# 归档脚本
cat > /var/lib/pgsql/data/conf.d/archive.sh <<- 'EOF'
test ! -f /var/lib/pgsql/wal/${2} && cp ${1} /var/lib/pgsql/wal/${2}
EOF
chmod a+x /var/lib/pgsql/data/conf.d/archive.sh
归档脚本可以简单到只是一个cp,也可以非常复杂。但需要注意以下事项:
-
归档命令使用数据库用户
postgres执行,最好放在0700的目录下面。 -
归档命令应当拒绝覆盖现有文件,出现覆盖时,返回一个错误代码。
-
归档命令可以通过reload配置更新。
-
处理归档失败时的情形
-
归档文件应当保留原有文件名。
-
WAL不会记录对配置文件的变更。
-
归档命令中:
%p会替换为生成待归档WAL的路径,而%f会替换为待归档WAL的文件名 -
归档脚本可以使用更复杂的逻辑,例如下面的归档命令,在归档目录中每天创建一个以日期YYYYMMDD命名的文件夹,在每天12点移除前一天的归档日志。每天的归档日志使用xz压缩存储。
wal_dir=/var/lib/pgsql/wal; [[ $(date +%H%M) == 1200 ]] && rm -rf ${wal_dir}/$(date -d"yesterday" +%Y%m%d); /bin/mkdir -p ${wal_dir}/$(date +%Y%m%d) && \ test ! -f ${wal_dir}/ && \ xz -c %p > ${wal_dir}/$(date +%Y%m%d)/%f.xz -
归档也可以使用外部专用备份工具进行。例如
pgbackrest与barman等。
3.3 测试归档
# 启动数据库
pg_ctl -D /var/lib/pgsql/data start
# 确认配置
psql postgres -c "SELECT name,setting FROM pg_settings where name like '%archive%';"
在当前shell开启监视循环,不断查询WAL的位置,以及归档目录和pg_wal中的文件变化
for((i=0;i<100;i++)) do
sleep 1 && \
ls /var/lib/pgsql/data/pg_wal && ls /var/lib/pgsql/data/pg_wal/archive_status/
psql postgres -c 'SELECT pg_current_wal_lsn() as current, pg_current_wal_insert_lsn() as insert, pg_current_wal_flush_lsn() as flush;'
done
在另一个Shell中创建一张测试表foobar,包含单一的时间戳列,并引入负载,每秒写入一万条记录:
psql postgres -c 'CREATE TABLE foobar(ts TIMESTAMP);'
for((i=0;i<1000;i++)) do
sleep 1 && \
psql postgres -c 'INSERT INTO foobar SELECT now() FROM generate_series(1,10000)' && \
psql postgres -c 'SELECT pg_current_wal_lsn() as current, pg_current_wal_insert_lsn() as insert, pg_current_wal_flush_lsn() as flush;'
done
自然切换WAL
可以看到,当WAL LSN的位置超过16M(可以由后6个hex表示)之后,就会rotate到一个新的WAL文件,归档命令会将写完的WAL归档。
000000010000000000000001 archive_status
current | insert | flush
-----------+-----------+-----------
0/1FC2630 | 0/1FC2630 | 0/1FC2630
(1 row)
# rotate here
000000010000000000000001 000000010000000000000002 archive_status
000000010000000000000001.done
current | insert | flush
-----------+-----------+-----------
0/205F1B8 | 0/205F1B8 | 0/205F1B8
手工切换WAL
再开启一个Shell,执行pg_switch_wal,强制写入一个新的WAL文件
psql postgres -c 'SELECT pg_switch_wal();'
可以看到,虽然位置才到32C1D68,但立即就跳到了下一个16MB的边界点。
000000010000000000000001 000000010000000000000002 000000010000000000000003 archive_status
000000010000000000000001.done 000000010000000000000002.done
current | insert | flush
-----------+-----------+-----------
0/32C1D68 | 0/32C1D68 | 0/32C1D68
(1 row)
# switch here
000000010000000000000001 000000010000000000000002 000000010000000000000003 archive_status
000000010000000000000001.done 000000010000000000000002.done 000000010000000000000003.done
current | insert | flush
-----------+-----------+-----------
0/4000000 | 0/4000028 | 0/4000000
(1 row)
000000010000000000000001 000000010000000000000002 000000010000000000000003 000000010000000000000004 archive_status
000000010000000000000001.done 000000010000000000000002.done 000000010000000000000003.done
current | insert | flush
-----------+-----------+-----------
0/409CBA0 | 0/409CBA0 | 0/409CBA0
(1 row)
强制kill数据库
数据库因为故障异常关闭,重启之后,会从最近的检查点,也就是0/2FB0160开始重放WAL。
[17:03:37] vonng@vonng-mac /var/lib/pgsql
$ ps axu | grep postgres | grep data | awk '{print $2}' | xargs kill -9
[17:06:31] vonng@vonng-mac /var/lib/pgsql
$ pg_ctl -D /var/lib/pgsql/data start
pg_ctl: another server might be running; trying to start server anyway
waiting for server to start....2018-01-25 17:07:27.063 CST [9762] LOG: listening on IPv6 address "::1", port 5432
2018-01-25 17:07:27.063 CST [9762] LOG: listening on IPv4 address "127.0.0.1", port 5432
2018-01-25 17:07:27.064 CST [9762] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
2018-01-25 17:07:27.078 CST [9763] LOG: database system was interrupted; last known up at 2018-01-25 17:06:01 CST
2018-01-25 17:07:27.117 CST [9763] LOG: database system was not properly shut down; automatic recovery in progress
2018-01-25 17:07:27.120 CST [9763] LOG: redo starts at 0/2FB0160
2018-01-25 17:07:27.722 CST [9763] LOG: invalid record length at 0/49CBE78: wanted 24, got 0
2018-01-25 17:07:27.722 CST [9763] LOG: redo done at 0/49CBE50
2018-01-25 17:07:27.722 CST [9763] LOG: last completed transaction was at log time 2018-01-25 17:06:30.158602+08
2018-01-25 17:07:27.741 CST [9762] LOG: database system is ready to accept connections
done
server started
至此,WAL归档已经确认可以正常工作了。
3.4 制作基础备份
首先,查看当前WAL的位置:
$ psql postgres -c 'SELECT pg_current_wal_lsn() as current, pg_current_wal_insert_lsn() as insert, pg_current_wal_flush_lsn() as flush;'
current | insert | flush
-----------+-----------+-----------
0/49CBF20 | 0/49CBF20 | 0/49CBF20
使用pg_basebackup制作基础备份
psql postgres -c 'SELECT now();'
pg_basebackup -Fp -Pv -Xs -c fast -D /var/lib/pgsql/bkup
# 常用选项
-D : 必选项,基础备份的位置。
-Fp : 备份格式: plain 普通文件 tar 归档文件
-Pv : -P 启用进度报告 -v 启用详细输出
-Xs : 在备份中包括备份期间产生的WAL日志 f:备份完后拉取 s:备份时流式传输
-c : fast 立即执行Checkpoint而不是均摊IO spread:均摊IO
-R : 设置recovery.conf
制作基础备份时,会立即创建一个检查点使得所有脏数据页落盘。
$ pg_basebackup -Fp -Pv -Xs -c fast -D /var/lib/pgsql/bkup
pg_basebackup: initiating base backup, waiting for checkpoint to complete
pg_basebackup: checkpoint completed
pg_basebackup: write-ahead log start point: 0/5000028 on timeline 1
pg_basebackup: starting background WAL receiver
45751/45751 kB (100%), 1/1 tablespace
pg_basebackup: write-ahead log end point: 0/50000F8
pg_basebackup: waiting for background process to finish streaming ...
pg_basebackup: base backup completed
3.5 使用备份
直接使用
最简单的使用方式,就是直接用pg_ctl启动它。
当recovery.conf不存在时,这样做会启动一个新的完整数据库实例,原原本本地保留了备份完成时的状态。数据库会并不会意识到自己是一个备份。而是以为自己上次没有正常关闭,应用pg_wal目录中自带的WAL进行修复,正常重启。
基础的全量备份可能每天或每周备份一次,要想恢复到最新的时刻,需要和WAL归档配合使用。
使用WAL归档追赶进度
可以在备份中数据库下创建一个recovery.conf文件,并指定restore_command选项。这样的话,当使用pg_ctl启动这个数据目录时,postgres会依次拉取所需的WAL,直到没有了为止。
cat >> /var/lib/pgsql/bkup/recovery.conf <<- 'EOF'
restore_command = 'cp /var/lib/pgsql/wal/%f %p'
EOF
继续在原始主库中执行负载,这时候WAL的进度已经到了0/9060CE0,而制作备份的时候位置还在0/5000028。
启动备份之后,可以发现,备份数据库自动从归档文件夹拉取了5~8号WAL并应用。
$ pg_ctl start -D /var/lib/pgsql/bkup -o '-p 5433'
waiting for server to start....2018-01-25 17:35:35.001 CST [10862] LOG: listening on IPv6 address "::1", port 5433
2018-01-25 17:35:35.001 CST [10862] LOG: listening on IPv4 address "127.0.0.1", port 5433
2018-01-25 17:35:35.002 CST [10862] LOG: listening on Unix socket "/tmp/.s.PGSQL.5433"
2018-01-25 17:35:35.016 CST [10863] LOG: database system was interrupted; last known up at 2018-01-25 17:21:15 CST
2018-01-25 17:35:35.051 CST [10863] LOG: starting archive recovery
2018-01-25 17:35:35.063 CST [10863] LOG: restored log file "000000010000000000000005" from archive
2018-01-25 17:35:35.069 CST [10863] LOG: redo starts at 0/5000028
2018-01-25 17:35:35.069 CST [10863] LOG: consistent recovery state reached at 0/50000F8
2018-01-25 17:35:35.070 CST [10862] LOG: database system is ready to accept read only connections
done
server started
2018-01-25 17:35:35.081 CST [10863] LOG: restored log file "000000010000000000000006" from archive
$ 2018-01-25 17:35:35.924 CST [10863] LOG: restored log file "000000010000000000000007" from archive
2018-01-25 17:35:36.783 CST [10863] LOG: restored log file "000000010000000000000008" from archive
cp: /var/lib/pgsql/wal/000000010000000000000009: No such file or directory
2018-01-25 17:35:37.604 CST [10863] LOG: redo done at 0/8FFFF90
2018-01-25 17:35:37.604 CST [10863] LOG: last completed transaction was at log time 2018-01-25 17:30:39.107943+08
2018-01-25 17:35:37.614 CST [10863] LOG: restored log file "000000010000000000000008" from archive
cp: /var/lib/pgsql/wal/00000002.history: No such file or directory
2018-01-25 17:35:37.629 CST [10863] LOG: selected new timeline ID: 2
cp: /var/lib/pgsql/wal/00000001.history: No such file or directory
2018-01-25 17:35:37.678 CST [10863] LOG: archive recovery complete
2018-01-25 17:35:37.783 CST [10862] LOG: database system is ready to accept connections
但是使用WAL归档的方式来恢复也有问题,例如查询主库与备库最新的数据记录,发现时间戳差了一秒。也就是说,主库还没有写完的WAL并没有被归档,因此也没有应用。
[17:37:22] vonng@vonng-mac /var/lib/pgsql
$ psql postgres -c 'SELECT max(ts) FROM foobar;'
max
----------------------------
2018-01-25 17:30:40.159684
(1 row)
[17:37:42] vonng@vonng-mac /var/lib/pgsql
$ psql postgres -p 5433 -c 'SELECT max(ts) FROM foobar;'
max
----------------------------
2018-01-25 17:30:39.097167
(1 row)
通常archive_command, restore_command主要用于紧急情况下的恢复,比如主库从库都挂了。因为还没有归档
3.6 指定进度
默认情况下,恢复将会一直恢复到 WAL 日志的末尾。下面的参数可以被用来指定一个更早的停止点。recovery_target、recovery_target_name、recovery_target_time和recovery_target_xid四个选项中最多只能使用一个,如果在配置文件中使用了多个,将使用最后一个。
上面四个恢复目标中,常用的是 recovery_target_time,用于指明将系统恢复到什么时间。
另外几个常用的选项包括:
recovery_target_inclusive(boolean) :是否包括目标点,默认为truerecovery_target_timeline(string): 指定恢复到一个特定的时间线中。recovery_target_action(enum):指定在达到恢复目标时服务器应该立刻采取的动作。pause: 暂停恢复,默认选项,可通过pg_wal_replay_resume恢复。shutdown: 自动关闭。promote: 开始接受连接
例如在2018-01-25 18:51:20 创建了一个备份
$ psql postgres -c 'SELECT now();'
now
------------------------------
2018-01-25 18:51:20.34732+08
(1 row)
[18:51:20] vonng@vonng-mac ~
$ pg_basebackup -Fp -Pv -Xs -c fast -D /var/lib/pgsql/bkup
pg_basebackup: initiating base backup, waiting for checkpoint to complete
pg_basebackup: checkpoint completed
pg_basebackup: write-ahead log start point: 0/3000028 on timeline 1
pg_basebackup: starting background WAL receiver
33007/33007 kB (100%), 1/1 tablespace
pg_basebackup: write-ahead log end point: 0/30000F8
pg_basebackup: waiting for background process to finish streaming ...
pg_basebackup: base backup completed
之后运行了两分钟,到了2018-01-25 18:53:05我们发现有几条脏数据,于是从备份开始恢复,希望恢复到脏数据出现前一分钟的状态,例如2018-01-25 18:52
可以这样配置
cat >> /var/lib/pgsql/bkup/recovery.conf <<- 'EOF'
restore_command = 'cp /var/lib/pgsql/wal/%f %p'
recovery_target_time = '2018-01-25 18:52:30'
recovery_target_action = 'promote'
EOF
当新的数据库实例完成恢复之后,可以看到它的状态确实回到了 18:52分,这正是我们期望的。
$ pg_ctl -D /var/lib/pgsql/bkup -o '-p 5433' start
waiting for server to start....2018-01-25 18:56:24.147 CST [13120] LOG: listening on IPv6 address "::1", port 5433
2018-01-25 18:56:24.147 CST [13120] LOG: listening on IPv4 address "127.0.0.1", port 5433
2018-01-25 18:56:24.148 CST [13120] LOG: listening on Unix socket "/tmp/.s.PGSQL.5433"
2018-01-25 18:56:24.162 CST [13121] LOG: database system was interrupted; last known up at 2018-01-25 18:51:22 CST
2018-01-25 18:56:24.197 CST [13121] LOG: starting point-in-time recovery to 2018-01-25 18:52:30+08
2018-01-25 18:56:24.210 CST [13121] LOG: restored log file "000000010000000000000003" from archive
2018-01-25 18:56:24.215 CST [13121] LOG: redo starts at 0/3000028
2018-01-25 18:56:24.215 CST [13121] LOG: consistent recovery state reached at 0/30000F8
2018-01-25 18:56:24.216 CST [13120] LOG: database system is ready to accept read only connections
done
server started
2018-01-25 18:56:24.228 CST [13121] LOG: restored log file "000000010000000000000004" from archive
$ 2018-01-25 18:56:25.034 CST [13121] LOG: restored log file "000000010000000000000005" from archive
2018-01-25 18:56:25.853 CST [13121] LOG: restored log file "000000010000000000000006" from archive
2018-01-25 18:56:26.235 CST [13121] LOG: recovery stopping before commit of transaction 649, time 2018-01-25 18:52:30.492371+08
2018-01-25 18:56:26.235 CST [13121] LOG: redo done at 0/67CFD40
2018-01-25 18:56:26.235 CST [13121] LOG: last completed transaction was at log time 2018-01-25 18:52:29.425596+08
cp: /var/lib/pgsql/wal/00000002.history: No such file or directory
2018-01-25 18:56:26.240 CST [13121] LOG: selected new timeline ID: 2
cp: /var/lib/pgsql/wal/00000001.history: No such file or directory
2018-01-25 18:56:26.293 CST [13121] LOG: archive recovery complete
2018-01-25 18:56:26.401 CST [13120] LOG: database system is ready to accept connections
$
# query new server ,确实回到了18:52分
$ psql postgres -p 5433 -c 'SELECT max(ts) FROM foobar;'
max
----------------------------
2018-01-25 18:52:29.413911
(1 row)
3.7 时间线
每当归档文件恢复完成后,也就是服务器可以开始接受新的查询,写新的WAL的时候。会创建一个新的时间线用来区别新生成的WAL记录。WAL文件名由时间线和日志序号组成,因此新的时间线WAL不会覆盖老时间线的WAL。时间线主要用来解决复杂的恢复操作冲突,例如试想一个场景:刚才恢复到18:52分之后,新的服务器开始不断接受请求:
psql postgres -c 'CREATE TABLE foobar(ts TIMESTAMP);'
for((i=0;i<1000;i++)) do
sleep 1 && \
psql -p 5433 postgres -c 'INSERT INTO foobar SELECT now() FROM generate_series(1,10000)' && \
psql -p 5433 postgres -c 'SELECT pg_current_wal_lsn() as current, pg_current_wal_insert_lsn() as insert, pg_current_wal_flush_lsn() as flush;'
done
可以看到,WAL归档目录中出现了两个6号WAL段文件,如果没有前面的时间线作为区分,WAL就会被覆盖。
$ ls -alh wal
total 262160
drwxr-xr-x 12 vonng wheel 384B Jan 25 18:59 .
drwxr-xr-x 6 vonng wheel 192B Jan 25 18:51 ..
-rw------- 1 vonng wheel 16M Jan 25 18:51 000000010000000000000001
-rw------- 1 vonng wheel 16M Jan 25 18:51 000000010000000000000002
-rw------- 1 vonng wheel 16M Jan 25 18:51 000000010000000000000003
-rw------- 1 vonng wheel 302B Jan 25 18:51 000000010000000000000003.00000028.backup
-rw------- 1 vonng wheel 16M Jan 25 18:51 000000010000000000000004
-rw------- 1 vonng wheel 16M Jan 25 18:52 000000010000000000000005
-rw------- 1 vonng wheel 16M Jan 25 18:52 000000010000000000000006
-rw------- 1 vonng wheel 50B Jan 25 18:56 00000002.history
-rw------- 1 vonng wheel 16M Jan 25 18:58 000000020000000000000006
-rw------- 1 vonng wheel 16M Jan 25 18:59 000000020000000000000007
假设完成恢复之后又反悔了,则可以用基础备份通过指定recovery_target_timeline = '1' 再次恢复回第一次运行到18:53 时的状态。
3.8 其他注意事项
- 在Pg 10之前,哈希索引上的操作不会被记录在WAL中,需要在Slave上手工REINDEX。
- 不要在创建基础备份的时候修改任何模板数据库
- 注意表空间会严格按照字面值记录其路径,如果使用了表空间,恢复时要非常小心。
4. 制作备机
通过主从(master-slave),可以同时提高可用性与可靠性。
- 主从读写分离提高性能:写请求落在Master上,通过WAL流复制传输到从库上,从库接受读请求。
- 通过备份提高可靠性:当一台服务器故障时,可以立即由另一台顶上(promote slave or & make new slave)
通常主从、副本、备机这些属于高可用的话题。但从另一个角度来讲,备机也是备份的一种。
创建目录
sudo mkdir /var/lib/pgsql && sudo chown postgres:postgres /var/lib/pgsql/
mkdir -p /var/lib/pgsql/master /var/lib/pgsql/slave /var/lib/pgsql/wal
制作主库
pg_ctl -D /var/lib/pgsql/master init && pg_ctl -D /var/lib/pgsql/master start
创建用户
创建备库需要一个具有REPLICATION权限的用户,这里在Master中创建replication用户
psql postgres -c 'CREATE USER replication REPLICATION;'
为了创建从库,需要一个具有REPLICATION权限的用户,并在pg_hba中允许访问,10中默认允许:
local replication all trust
host replication all 127.0.0.1/32 trust
制作备库
通过pg_basebackup创建一个slave实例。实际上是连接到Master实例,并复制一份数据目录到本地。
pg_basebackup -Fp -Pv -R -c fast -U replication -h localhost -D /var/lib/pgsql/slave
这里的关键是通过-R 选项,在备份的制作过程中自动将主机的连接信息填入recovery.conf,这样使用pg_ctl 启动时,数据库会意识到自己是备机,并从主机自动拉取WAL追赶进度。
启动从库
pg_ctl -D /var/lib/pgsql/slave -o "-p 5433" start
从库与主库的唯一区别在于,数据目录中多了一个recovery.conf文件。这个文件不仅仅可以用于标识从库的身份,而且在故障恢复时也需要用到。对于pg_basebackup构造的从库,它默认包含两个参数:
standby_mode = 'on'
primary_conninfo = 'user=replication passfile=''/Users/vonng/.pgpass'' host=localhost port=5432 sslmode=prefer sslcompression=1 krbsrvname=postgres target_session_attrs=any'
standby_mode指明是否将PostgreSQL作为从库启动。
在备份时,standby_mode默认关闭,这样当所有的WAL拉取完毕后,就完成恢复,进入正常工作模式。
如果打开,那么数据库会意识到自己是备机,那么即使到达WAL末尾也不会停止,它会持续拉取主库的WAL,追赶主库的进度。
拉取WAL有两种办法,通过primary_conninfo流式复制拉取(9.0后的新特性,推荐,默认),或者通过restore_command来手工指明WAL的获取方式(老办法,恢复时使用)。
查看状态
主库的所有从库可以通过系统视图pg_stat_replication查阅:
$ psql postgres -tzxc 'SELECT * FROM pg_stat_replication;'
pid | 1947
usesysid | 16384
usename | replication
application_name | walreceiver
client_addr | ::1
client_hostname |
client_port | 54124
backend_start | 2018-01-25 13:24:57.029203+08
backend_xmin |
state | streaming
sent_lsn | 0/5017F88
write_lsn | 0/5017F88
flush_lsn | 0/5017F88
replay_lsn | 0/5017F88
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
检查主库和备库的状态可以使用函数pg_is_in_recovery,备库会处于恢复状态:
$ psql postgres -Atzc 'SELECT pg_is_in_recovery()' && \
psql postgres -p 5433 -Atzc 'SELECT pg_is_in_recovery()'
f
t
在主库中建表,从库也能看到。
psql postgres -c 'CREATE TABLE foobar(i INTEGER);' && psql postgres -p 5433 -c '\d'
在主库中插入数据,从库也能看到
psql postgres -c 'INSERT INTO foobar VALUES (1);' && \
psql postgres -p 5433 -c 'SELECT * FROM foobar;'
现在主备已经配置就绪
PgBackRest2中文文档
pgBackRest主页:http://pgbackrest.org
pgBackRest Github主页:https://github.com/pgbackrest/pgbackrest
前言
pgBackRest旨在提供一个简单可靠,容易纵向扩展的PostgreSQL备份恢复系统。
pgBackRest并不依赖像tar和rsync这样的传统备份工具,而在内部实现所有备份功能,并使用自定义协议来与远程系统进行通信。 消除对tar和rsync的依赖可以更好地解决特定于数据库的备份问题。 自定义远程协议提供了更多的灵活性,并限制执行备份所需的连接类型,从而提高安全性。
pgBackRest v2.01是目前的稳定版本。 发行说明位在发行页面上。
pgBackRest旨在成为一个简单,可靠的备份和恢复系统,可以无缝扩展到最大的数据库和工作负载。
pgBackRest不依赖像tar和rsync这样的传统备份工具,而是在内部实现所有备份功能,并使用自定义协议与远程系统进行通信。消除对tar和rsync的依赖可以更好地解决针对数据库的备份挑战。自定义远程协议允许更大的灵活性,并限制执行备份所需的连接类型,从而提高安全性。
pgBackRest v2.01是当前的稳定版本。发行说明位于发行版页面上。
只有在EOL之前,pgBackRest v1才会收到修复错误。v1的文档可以在这里找到。
0. 特性
-
并行备份和恢复
压缩通常是备份操作的瓶颈,但即使是现在已经很普及的多核服务器,大多数数据库备份解决方案仍然是单进程的。 pgBackRest通过并行处理解决了压缩瓶颈问题。利用多个核心进行压缩,即使在1Gb/s的链路上,也可以实现1TB /小时的原生吞吐量。更多的核心和更大的带宽将带来更高的吞吐量。
-
本地或远程操作
自定义协议允许pgBackRest以最少的配置通过SSH进行本地或远程备份,恢复和归档。通过协议层也提供了查询PostgreSQL的接口,从而不需要对PostgreSQL进行远程访问,从而增强了安全性。
-
全量备份与增量备份
支持全量备份,增量备份,以及差异备份。 pgBackRest不会受到rsync的时间分辨问题的影响,使得差异备份和增量备份完全安全。
-
备份轮换和归档过期
可以为全量备份和增量备份设置保留策略,以创建覆盖任何时间范围的备份。 WAL归档可以设置为为所有的备份或仅最近的备份保留。在后一种情况下,在归档过程中会自动保证更老备份的一致性。
-
备份完整性
每个文件在备份时都会计算校验和,并在还原过程中重新检查。完成文件复制后,备份会等待所有必须的WAL段进入存储库。存储库中的备份以与标准PostgreSQL集群(包括表空间)相同的格式存储。如果禁用压缩并启用硬链接,则可以在存储库中快照备份,并直接在快照上创建PostgreSQL集群。这对于以传统方式恢复很耗时的TB级数据库是有利的。所有操作都使用文件和目录级别fsync来确保持久性。
-
页面校验和
PostgreSQL从9.3开始支持页面级校验和。如果启用页面校验和,pgBackRest将验证在备份过程中复制的每个文件的校验和。所有页面校验和在完整备份过程中均得到验证,在差异备份和增量备份过程中验证了已更改文件中的校验和。 验证失败不会停止备份过程,但会向控制台和文件日志输出具体的哪些页面验证失败的详细警告。
此功能允许在包含有效数据副本的备份已过期之前及早检测到页级损坏。
-
备份恢复
中止的备份可以从停止点恢复。已经复制的文件将与清单中的校验和进行比较,以确保完整性。由于此操作可以完全在备份服务器上进行,因此减少了数据库服务器上的负载,并节省了时间,因为校验和计算比压缩和重新传输数据要快。
-
流压缩和校验和
无论存储库位于本地还是远程,压缩和校验和计算均在流中执行,而文件正在复制到存储库。 如果存储库位于备份服务器上,则在数据库服务器上执行压缩,并以压缩格式传输文件,并将其存储在备份服务器上。当禁用压缩时,利用较低级别的压缩来有效使用可用带宽,同时将CPU成本降至最低。
-
增量恢复
清单包含备份中每个文件的校验和,以便在还原过程中可以使用这些校验和来加快处理速度。在增量恢复时,备份中不存在的任何文件将首先被删除,然后对其余文件执行校验和。与备份相匹配的文件将保留在原位,其余文件将照常恢复。并行处理可能会导致恢复时间大幅减少。
-
并行WAL归档
包括专用的命令将WAL推送到归档并从归档中检索WAL。push命令会自动检测多次推送的WAL段,并在段相同时自动解除重复,否则会引发错误。 push和get命令都通过比较PostgreSQL版本和系统标识符来确保数据库和存储库匹配。这排除了错误配置WAL归档位置的可能性。 异步归档允许将传输转移到另一个并行压缩WAL段的进程,以实现最大的吞吐量。对于写入量非常高的数据库来说,这可能是一个关键功能。
-
表空间和链接支持
完全支持表空间,并且还原表空间可以重映射到任何位置。也可以使用一个对开发恢复有用的命令将所有的表空间重新映射到一个位置。
-
Amazon S3支持
pgBackRest存储库可以存储在Amazon S3上,以实现几乎无限的容量和保留。
-
加密
pgBackRest可以对存储库进行加密,以保护无论存储在何处的备份。
-
与PostgreSQL兼容> = 8.3
pgBackRest包含了对8.3以下版本的支持,因为旧版本的PostgreSQL仍然是经常使用的。
1. 简介
本用户指南旨在从头到尾按顺序进行,每一节依赖上一节。例如“备份”部分依赖“快速入门”部分中执行的设置。
尽管这些例子是针对Debian / Ubuntu和PostgreSQL 9.4的,但是将这个指南应用到任何Unix发行版和PostgreSQL版本上应该相当容易。请注意,由于Perl代码中的64位操作,目前只支持64位发行版。唯一的特定于操作系统的命令是创建,启动,停止和删除PostgreSQL集群的命令。尽管安装Perl库和可执行文件的位置可能有所不同,但任何Unix系统上的pgBackRest命令都是相同的。
PostgreSQL的配置信息和文档可以在PostgreSQL手册中找到。
本用户指南采用了一些新颖的方法来记录。从XML源生成文档时,每个命令都在虚拟机上运行。这意味着您可以高度自信地确保命令按照所呈现的顺序正确工作。捕获输出并在适当的时候显示在命令之下。如果输出不包括,那是因为它被认为是不相关的或者被认为是从叙述中分心的。
所有的命令都是作为非特权用户运行的,它对root用户和postgres用户都具有sudo权限。也可以直接以各自的用户身份运行这些命令而不用修改,在这种情况下,sudo命令可以被剥离。
2. 概念
2.1 备份
备份是数据库集群的一致副本,可以从硬件故障中恢复,执行时间点恢复或启动新的备用数据库。
-
全量备份(Full Backup)
pgBackRest将数据库集簇的全部文件复制到备份服务器。数据库集簇的第一个备份总是全量备份。
pgBackRest总能从全量备份直接恢复。全量备份的一致性不依赖任何外部文件。
-
差异备份(Differential Backup)
pgBackRest仅复制自上次全量备份以来,内容发生变更的数据库群集文件。恢复时,pgBackRest拷贝差异备份中的所有文件,以及之前一次全量备份中所有未发生变更的文件。差异备份的优点是它比全量备份需要更少的硬盘空间,缺点是差异备份的恢复依赖上一次全量备份的有效性。
-
增量备份(Incremental Backup)
pgBackRest仅复制自上次备份(可能是另一个增量备份,差异备份或完全备份)以来发生更改的数据库群集文件。由于增量备份只包含自上次备份以来更改的那些文件,因此它们通常远远小于完全备份或差异备份。与差异备份一样,增量备份依赖于其他备份才能有效恢复增量备份。由于增量备份只包含自上次备份以来的文件,所有之前的增量备份都恢复到以前的差异,先前的差异备份和先前的完整备份必须全部有效才能执行增量备份的恢复。如果不存在差异备份,则以前的所有增量备份将恢复到之前的完整备份(必须存在),而完全备份本身必须有效才能恢复增量备份。
2.2 还原
还原是将备份复制到将作为实时数据库集群启动的系统的行为。还原需要备份文件和一个或多个WAL段才能正常工作。
2.3 WAL
WAL是PostgreSQL用来确保没有提交的更改丢失的机制。将事务顺序写入WAL,并且在将这些写入刷新到磁盘时认为事务被提交。之后,后台进程将更改写入主数据库集群文件(也称为堆)。在发生崩溃的情况下,重播WAL以使数据库保持一致。
WAL在概念上是无限的,但在实践中被分解成单独的16MB文件称为段。 WAL段按照命名约定0000000100000A1E000000FE,其中前8个十六进制数字表示时间线,接下来的16个数字是逻辑序列号(LSN)。
2.4 加密
加密是将数据转换为无法识别的格式的过程,除非提供了适当的密码(也称为密码短语)。
pgBackRest将根据用户提供的密码加密存储库,从而防止未经授权访问存储库中的数据。
3. 安装
short version
# cent-os
sudo yum install -y pgbackrest
# ubuntu
sudo apt-get install libdbd-pg-perl libio-socket-ssl-perl libxml-libxml-perl
verbose version
创建一个名为db-primary的新主机来包含演示群集并运行pgBackRest示例。 如果已经安装了pgBackRest,最好确保没有安装先前的副本。取决于pgBackRest的版本可能已经安装在几个不同的位置。以下命令将删除所有先前版本的pgBackRest。
- db-primary⇒删除以前的pgBackRest安装
sudo rm -f /usr/bin/pgbackrest
sudo rm -f /usr/bin/pg_backrest
sudo rm -rf /usr/lib/perl5/BackRest
sudo rm -rf /usr/share/perl5/BackRest
sudo rm -rf /usr/lib/perl5/pgBackRest
sudo rm -rf /usr/share/perl5/pgBackRest
pgBackRest是用Perl编写的,默认包含在Debian/Ubuntu中。一些额外的模块也必须安装,但是它们可以作为标准包使用。
- db-primary⇒安装必需的Perl软件包
# cent-os
sudo yum install -y pgbackrest
# ubuntu
sudo apt-get install libdbd-pg-perl libio-socket-ssl-perl libxml-libxml-perl
适用于pgBackRest的Debian / Ubuntu软件包位于apt.postgresql.org。如果没有为您的发行版/版本提供,则可以轻松下载源代码并手动安装。
- db-primary⇒下载pgBackRest的2.01版本
sudo wget -q -O- \
https://github.com/pgbackrest/pgbackrest/archive/release/2.01.tar.gz | \
sudo tar zx -C /root
# or without sudo
wget -q -O - https://github.com/pgbackrest/pgbackrest/archive/release/2.01.tar.gz | tar zx -C /tmp
- db-primary⇒安装pgBackRest
sudo cp -r /root/pgbackrest-release-2.01/lib/pgBackRest \
/usr/share/perl5
sudo find /usr/share/perl5/pgBackRest -type f -exec chmod 644 {} +
sudo find /usr/share/perl5/pgBackRest -type d -exec chmod 755 {} +
sudo mkdir -m 770 /var/log/pgbackrest
sudo chown postgres:postgres /var/log/pgbackrest
sudo touch /etc/pgbackrest.conf
sudo chmod 640 /etc/pgbackrest.conf
sudo chown postgres:postgres /etc/pgbackrest.conf
sudo cp -r /root/pgbackrest-release-1.27/lib/pgBackRest \
/usr/share/perl5
sudo find /usr/share/perl5/pgBackRest -type f -exec chmod 644 {} +
sudo find /usr/share/perl5/pgBackRest -type d -exec chmod 755 {} +
sudo cp /root/pgbackrest-release-1.27/bin/pgbackrest /usr/bin/pgbackrest
sudo chmod 755 /usr/bin/pgbackrest
sudo mkdir -m 770 /var/log/pgbackrest
sudo chown postgres:postgres /var/log/pgbackrest
sudo touch /etc/pgbackrest.conf
sudo chmod 640 /etc/pgbackrest.conf
sudo chown postgres:postgres /etc/pgbackrest.conf
pgBackRest包含一个可选的伴随C库,可以增强性能并启用checksum-page选项和加密。预构建的软件包通常比手动构建C库更好,但为了完整性,下面给出了所需的步骤。根据分布情况,可能需要一些软件包,这里不一一列举。
- db-primary⇒构建并安装C库
sudo sh -c 'cd /root/pgbackrest-release-2.01/libc && \
perl Makefile.PL INSTALLMAN1DIR=none INSTALLMAN3DIR=none'
sudo make -C /root/pgbackrest-release-2.01/libc test
sudo make -C /root/pgbackrest-release-2.01/libc install
现在pgBackRest应该正确安装了,但最好检查一下。如果任何依赖关系被遗漏,那么当你从命令行运行pgBackRest的时候你会得到一个错误。
- db-primary⇒确保安装正常
sudo -u postgres pgbackrest
pgBackRest 1.27 - General help
Usage:
pgbackrest [options] [command]
Commands:
archive-get Get a WAL segment from the archive.
archive-push Push a WAL segment to the archive.
backup Backup a database cluster.
check Check the configuration.
expire Expire backups that exceed retention.
help Get help.
info Retrieve information about backups.
restore Restore a database cluster.
stanza-create Create the required stanza data.
stanza-upgrade Upgrade a stanza.
start Allow pgBackRest processes to run.
stop Stop pgBackRest processes from running.
version Get version.
Use 'pgbackrest help [command]' for more information.
mac version
在MacOS上安装可以按照之前的手动安装教程,参考文章:https://hunleyd.github.io/posts/pgBackRest-2.07-and-macOS-Mojave/
# 注意如果需要从终端访问代理,可以使用以下命令:
alias proxy='export all_proxy=socks5://127.0.0.1:1080'
alias unproxy='unset all_proxy'
# 安装 homebrew & wget
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
brew install wget
# install perl DB driver: Pg
perl -MCPAN -e 'install Bundle::DBI'
perl -MCPAN -e 'install Bundle::DBD::Pg'
perl -MCPAN -e 'install IO::Socket::SSL'
perl -MCPAN -e 'install XML::LibXML'
# Download and unzip
wget https://github.com/pgbackrest/pgbackrest/archive/release/2.07.tar.gz
# Copy to Perls lib
sudo cp -r ~/Downloads/pgbackrest-release-1.27/lib/pgBackRest /Library/Perl/5.18
sudo find /Library/Perl/5.18/pgBackRest -type f -exec chmod 644 {} +
sudo find /Library/Perl/5.18/pgBackRest -type d -exec chmod 755 {} +
# Copy binary to your path
sudo cp ~/Downloads/pgbackrest-release-1.27/bin/pgbackrest /usr/local/bin/
sudo chmod 755 /usr/local/bin/pgbackrest
# Make log dir & conf file. maybe you will change vonng to postgres
sudo mkdir -m 770 /var/log/pgbackrest && sudo touch /etc/pgbackrest.conf
sudo chmod 640 /etc/pgbackrest.conf
sudo chown vonng /etc/pgbackrest.conf /var/log/pgbackrest
# Uninstall
# sudo rm -rf /usr/local/bin/pgbackrest /Library/Perl/5.18/pgBackRest /var/log/pgbackrest /etc/pgbackrest.conf
4. 快速入门
4.1 搭建测试数据库集群
创建示例群集是可选的,但强烈建议试一遍,尤其对于新用户,因为用户指南中的示例命令引用了示例群集。 示例假定演示群集正在默认端口(即5432)上运行。直到后面的部分才会启动群集,因为还有一些配置要做。
- db-primary⇒创建演示群集
# create database cluster
pg_ctl init -D /var/lib/pgsql/data
# change listen address to *
sed -ie "s/^#listen_addresses = 'localhost'/listen_addresses = '*'/g" /var/lib/pgsql/data/postgresql.conf
# change log prefix
sed -ie "s/^#log_line_prefix = '%m [%p] '/log_line_prefix = ''/g" /var/lib/pgsql/data/postgresql.conf
默认情况下PostgreSQL只接受本地连接。本示例需要来自其他服务器的连接,将listen_addresses配置为在所有端口上侦听。如果有安全性要求,这样做可能是不合适的。
出于演示目的,log_line_prefix设置将被最低限度地配置。这使日志输出尽可能简短,以更好地说明重要的信息。
4.2 配置集群的备份单元(Stanza)
一个备份单元是指 一组关于PostgreSQL数据库集簇的配置,它定义了数据库的位置,如何备份,归档选项等。大多数数据库服务器只有一个Postgres数据库集簇,因此只有一个备份单元,而备份服务器则对每一个需要备份的数据库集簇都有一个备份单元。
在主群集之后命名该节是诱人的,但是更好的名称描述群集中包含的数据库。由于节名称将用于主节点名称和所有副本,因此选择描述群集实际功能(例如app或dw)的名称(而不是本地群集名称(如main或prod))会更合适。
“Demo”这个名字可以准确地描述这个数据库集簇的目的,所以这里就这么用了。
pgBackRest需要知道PostgreSQL集簇的数据目录所在的位置。备份的时候PostgreSQL可以使用该目录,但恢复的时候PostgreSQL必须停机。备份期,提供给pgBackRest的值将与PostgreSQL运行的路径比较,如果它们不相等则备份将报错。确保db-path与postgresql.conf中的data_directory完全相同。
默认情况下,Debian / Ubuntu在/ var / lib / postgresql / [版本] / [集群]中存储集群,因此很容易确定数据目录的正确路径。
在创建/etc/pgbackrest.conf文件时,数据库所有者(通常是postgres)必须被授予读取权限。
- db-primary:
/etc/pgbackrest.conf⇒配置PostgreSQL集群数据目录
[demo]
db-path=/var/lib/pgsql/data
pgBackRest配置文件遵循Windows INI约定。部分用括号中的文字表示,每个部分包含键/值对。以#开始的行被忽略,可以用作注释。
4.3 创建存储库
存储库是pgBackRest存储备份和归档WAL段的地方。
新备份很难提前估计需要多少空间。最好的办法是做一些备份,然后记录不同类型备份的大小(full / incr / diff),并测量每天产生的WAL数量。这将给你一个大致需要多少空间的概念。当然随着数据库的发展,需求可能会随着时间而变化。
对于这个演示,存储库将被存储在与PostgreSQL服务器相同的主机上。这是最简单的配置,在使用传统备份软件备份数据库主机的情况下非常有用。
- db-primary⇒创建pgBackRest存储库
sudo mkdir /var/lib/pgbackrest
sudo chmod 750 /var/lib/pgbackrest
sudo chown postgres:postgres /var/lib/pgbackrest
存储库路径必须配置,以便pgBackRest知道在哪里找到它。
- db-primary:
/etc/pgbackrest.conf⇒配置pgBackRest存储库路径
[demo]
db-path=/var/lib/postgresql/9.4/demo
[global]
repo-path=/var/lib/pgbackrest
4.4 配置归档
备份正在运行的PostgreSQL集群需要启用WAL归档。请注意,即使没有对群集进行明确写入,在备份过程中也会创建至少一个WAL段。
- db-primary:
/var/lib/pgsql/data/postgresql.conf⇒ 配置存档设置
archive_command = 'pgbackrest --stanza=demo archive-push %p'
archive_mode = on
listen_addresses = '*'
log_line_prefix = ''
max_wal_senders = 3
wal_level = hot_standby
wal_level设置必须至少设置为archive,但hot_standby和logical也适用于备份。 在PostgreSQL 10中,相应的wal_level是replica。将wal_level设置为hot_standy并增加max_wal_senders是一个好主意,即使您当前没有运行热备用数据库也是一个好主意,因为这样可以在不重新启动主群集的情况下添加它们。在进行这些更改之后和执行备份之前,必须重新启动PostgreSQL群集。
4.5 保留配置(retention)
pgBackRest会根据保留配置对备份进行过期处理。
- db-primary:
/etc/pgbackrest.conf⇒ 配置为保留两个全量备份
[demo]
db-path=/var/lib/postgresql/9.4/demo
[global]
repo-path=/var/lib/pgbackrest
retention-full=2
更多关于保留的信息可以在Retention一节找到。
4.6 配置存储库加密
该节创建命令必须在仓库位于初始化节的主机上运行。建议的检查命令后运行节创建,确保归档和备份的配置是否正确。
- db-primary:
/etc/pgbackrest.conf⇒ 配置pgBackRest存储库加密
[demo]
db-path=/var/lib/postgresql/9.4/demo
[global]
repo-cipher-pass=zWaf6XtpjIVZC5444yXB+cgFDFl7MxGlgkZSaoPvTGirhPygu4jOKOXf9LO4vjfO
repo-cipher-type=aes-256-cbc
repo-path=/var/lib/pgbackrest
retention-full=2
一旦存储库(repository)配置完成且备份单元创建并检查完毕,存储库加密设置便不能更改。
4.7 创建存储单元
stanza-create命令必须在仓库位于初始化节的主机上运行。建议在stanza-create命令之后运行check命令,确保归档和备份的配置是否正确。
- db-primary ⇒ 创建存储单元并检查配置
postgres$ pgbackrest --stanza=demo --log-level-console=info stanza-create
P00 INFO: stanza-create command begin 1.27: --db1-path=/var/lib/postgresql/9.4/demo --log-level-console=info --no-log-timestamp --repo-cipher-pass= --repo-cipher-type=aes-256-cbc --repo-path=/var/lib/pgbackrest --stanza=demo
P00 INFO: stanza-create command end: completed successfully
1. Install
$ sudo yum install -y pgbackrest
2. configuration
1) pgbackrest.conf
$ sudo vim /etc/pgbackrest.conf
[global]
repo-cipher-pass=O8lotSfiXYSYomc9BQ0UzgM9PgXoyNo1t3c0UmiM7M26rOETVNawbsW7BYn+I9es
repo-cipher-type=aes-256-cbc
repo-path=/var/backups
retention-full=2
retention-diff=2
retention-archive=2
start-fast=y
stop-auto=y
archive-copy=y
[global:archive-push]
archive-async=y
process-max=4
[test]
db-path=/var/lib/pgsql/9.5/data
process-max=10
2) postgresql.conf
$ sudo vim /var/lib/pgsql/9.5/data/postgresql.conf
archive_command = '/usr/bin/pgbackrest --stanza=test archive-push %p'
3. Initial
$ sudo chown -R postgres:postgres /var/backups/
$ sudo -u postgres pgbackrest --stanza=test --log-level-console=info stanza-create
2018-01-04 11:38:21.082 P00 INFO: stanza-create command begin 1.27: --db1-path=/var/lib/pgsql/9.5/data --log-level-console=info --repo-cipher-pass=<redacted> --repo-cipher-type=aes-256-cbc --repo-path=/var/backups --stanza=test
2018-01-04 11:38:21.533 P00 INFO: stanza-create command end: completed successfully
$ sudo service postgresql-9.5 reload
$ sudo -u postgres pgbackrest --stanza=test --log-level-console=info info
stanza: test
status: error (no valid backups)
db (current)
wal archive min/max (9.5-1): 0000000500041CFD000000BE / 0000000500041CFD000000BE
4. Backup
$ sudo -u postgres pgbackrest --stanza=test --log-level-console=info --type=full backup
2018-01-04 16:24:57.329 P00 INFO: backup command begin 1.27: --archive-copy --db1-path=/var/lib/pgsql/9.5/data --log-level-console=info --process-max=40 --repo-cipher-pass=<redacted> --repo-cipher-type=aes-
256-cbc --repo-path=/var/backups --retention-archive=2 --retention-diff=2 --retention-full=2 --stanza=test --start-fast --stop-auto --type=full
2018-01-04 16:24:58.192 P00 INFO: execute exclusive pg_start_backup() with label "pgBackRest backup started at 2018-01-04 16:24:57": backup begins after the requested immediate checkpoint completes
2018-01-04 16:24:58.495 P00 INFO: backup start archive = 0000000500041CFD000000C0, lsn = 41CFD/C0000060
2018-01-04 16:26:04.863 P34 INFO: backup file /var/lib/pgsql/9.5/data/base/16384/3072016471.83 (1GB, 0%) checksum ab17fdd9f70652a0de55fd0da5d2b6b1f48de490
2018-01-04 16:26:04.923 P35 INFO: backup file /var/lib/pgsql/9.5/data/base/16384/3072016471.82 (1GB, 0%) checksum 5acba8d0eb70dcdc64199201ee3999743e747699
2018-01-04 16:26:05.208 P37 INFO: backup file /var/lib/pgsql/9.5/data/base/16384/3072016471.80 (1GB, 0%) checksum 74e2f876d8e7d68ab29624d53d33b0c6cb078382
2018-01-04 16:26:06.973 P30 INFO: backup file /var/lib/pgsql/9.5/data/base/16384/3072016471.87 (1GB, 1%) checksum b6d6884724178476ee24a9a1a812e8941d4da396
2018-01-04 16:26:09.434 P24 INFO: backup file /var/lib/pgsql/9.5/data/base/16384/3072016471.92 (1GB, 1%) checksum c5e6232171e0a7cadc7fc57f459a7bc75c2955d8
2018-01-04 16:26:09.860 P40 INFO: backup file /var/lib/pgsql/9.5/data/base/16384/3072016471.78 (1GB, 1%) checksum 95d94b1bac488592677f7942b85ab5cc2a39bf62
2018-01-04 16:26:10.708 P33 INFO: backup file /var/lib/pgsql/9.5/data/base/16384/3072016471.84 (1GB, 2%) checksum 32e8c83f9bdc5934552f54ee59841f1877b04f69
2018-01-04 16:26:11.035 P28 INFO: backup file /var/lib/pgsql/9.5/data/base/16384/3072016471.89 (1GB, 2%) checksum aa7bee244d2d2c49b56bc9b2e0b9bf36f2bcc227
2018-01-04 16:26:11.239 P17 INFO: backup file /var/lib/pgsql/9.5/data/base/16384/3072016471.99 (1GB, 2%) checksum 218bcecf7da2230363926ca00d719011a6c27467
2018-01-04 16:26:11.383 P18 INFO: backup file /var/lib/pgsql/9.5/data/base/16384/3072016471.98 (1GB, 2%) checksum 38744d27867017dfadb6b520b6c0034daca67481
...
2018-01-04 16:34:07.782 P32 INFO: backup file /var/lib/pgsql/9.5/data/base/16384/3072016471.184 (852.7MB, 98%) checksum 92990e159b0436d5a6843d21b2d888b636e246cf
2018-01-04 16:34:07.935 P10 INFO: backup file /var/lib/pgsql/9.5/data/base/16384/3072016468.100 (1GB, 98%) checksum d9e0009447a5ef068ce214239f1c999cc5251462
2018-01-04 16:34:10.212 P35 INFO: backup file /var/lib/pgsql/9.5/data/base/16384/3072016476.3 (569.6MB, 98%) checksum d02e6efed6cea3005e1342d9d6a8e27afa5239d7
2018-01-04 16:34:12.289 P20 INFO: backup file /var/lib/pgsql/9.5/data/base/16384/3072016468.10 (1GB, 98%) checksum 1a99468cd18e9399ade9ddc446eb21f1c4a1f137
2018-01-04 16:34:13.270 P03 INFO: backup file /var/lib/pgsql/9.5/data/base/16384/3072016468.1 (1GB, 99%) checksum c0ddb80d5f1be83aa4557777ad05adb7cbc47e72
2018-01-04 16:34:13.792 P38 INFO: backup file /var/lib/pgsql/9.5/data/base/16384/3072016468 (1GB, 99%) checksum 767a2e0d21063b92b9cebc735fbb0e3c7332218d
2018-01-04 16:34:18.446 P26 INFO: backup file /var/lib/pgsql/9.5/data/base/16384/3072016473.3 (863.9MB, 99%) checksum 87ba54690ea418c2ddd1d488c56fa164ebda5042
2018-01-04 16:34:23.551 P13 INFO: backup file /var/lib/pgsql/9.5/data/base/16384/3072016475.7 (895.4MB, 100%) checksum a2693bfdc84940c82b7d77a13b752e33448bb008
2018-01-04 16:34:23.648 P00 INFO: full backup size = 341.5GB
2018-01-04 16:34:23.649 P00 INFO: execute exclusive pg_stop_backup() and wait for all WAL segments to archive
2018-01-04 16:34:37.774 P00 INFO: backup stop archive = 0000000500041CFD000000C0, lsn = 41CFD/C0000168
2018-01-04 16:34:39.648 P00 INFO: new backup label = 20180104-162457F
2018-01-04 16:34:41.004 P00 INFO: backup command end: completed successfully
2018-01-04 16:34:41.005 P00 INFO: expire command begin 1.27: --log-level-console=info --repo-cipher-pass=<redacted> --repo-cipher-type=aes-256-cbc --repo-path=/var/backups --retention-archive=2 --retention-diff=2 --retention-full=2 --stanza=test
2018-01-04 16:34:41.028 P00 INFO: full backup total < 2 - using oldest full backup for 9.5-1 archive retention
2018-01-04 16:34:41.034 P00 INFO: expire command end: completed successfully
$ sudo -u postgres pgbackrest --stanza=test --log-level-console=info info
stanza: test
status: ok
db (current)
wal archive min/max (9.5-1): 0000000500041CFD000000C0 / 0000000500041CFD000000C0
full backup: 20180104-162457F
timestamp start/stop: 2018-01-04 16:24:57 / 2018-01-04 16:34:38
wal start/stop: 0000000500041CFD000000C0 / 0000000500041CFD000000C0
database size: 341.5GB, backup size: 341.5GB
repository size: 153.6GB, repository backup size: 153.6GB
5. restore
$ sudo vim /etc/pgbackrest.conf
db-path=/export/pgdata
$ sudo mkdir /export/pgdata
$ sudo chown -R postgres:postgres /export/pgdata/
$ sudo chmod 0700 /export/pgdata/
$ sudo -u postgres pgbackrest --stanza=test --log-level-console=info --delta --set=20180104-162457F --type=time "--target=2018-01-04 16:34:38" restore
2018-01-04 17:04:23.170 P00 INFO: restore command begin 1.27: --db1-path=/export/pgdata --delta --log-level-console=info --process-max=40 --repo-cipher-pass=<redacted> --repo-cipher-type=aes-256-cbc --repo-
path=/var/backups --set=20180104-162457F --stanza=test "--target=2018-01-04 16:34:38" --type=time
WARN: --delta or --force specified but unable to find 'PG_VERSION' or 'backup.manifest' in '/export/pgdata' to confirm that this is a valid $PGDATA directory. --delta and --force have been disabled and if an
y files exist in the destination directories the restore will be aborted.
2018-01-04 17:04:23.313 P00 INFO: restore backup set 20180104-162457F
2018-01-04 17:04:23.935 P00 INFO: remap $PGDATA directory to /export/pgdata
2018-01-04 17:05:09.626 P01 INFO: restore file /export/pgdata/base/16384/3072016476.2 (1GB, 0%) checksum be1145405b8bcfa57c3f1fd8d0a78eee3ed2df21
2018-01-04 17:05:09.627 P04 INFO: restore file /export/pgdata/base/16384/3072016475.6 (1GB, 0%) checksum d2bc51d5b58dea3d14869244cd5a23345dbc4ffb
2018-01-04 17:05:09.627 P27 INFO: restore file /export/pgdata/base/16384/3072016471.9 (1GB, 0%) checksum 94cbf743143baffac0b1baf41e60d4ed99ab910f
2018-01-04 17:05:09.627 P37 INFO: restore file /export/pgdata/base/16384/3072016471.80 (1GB, 1%) checksum 74e2f876d8e7d68ab29624d53d33b0c6cb078382
2018-01-04 17:05:09.627 P38 INFO: restore file /export/pgdata/base/16384/3072016471.8 (1GB, 1%) checksum 5f0edd85543c9640d2c6cf73257165e621a6b295
2018-01-04 17:05:09.652 P02 INFO: restore file /export/pgdata/base/16384/3072016476.1 (1GB, 1%) checksum 3e262262b106bdc42c9fe17ebdf62bc4ab2e8166
...
2018-01-04 17:09:15.415 P34 INFO: restore file /export/pgdata/base/1/13142 (0B, 100%)
2018-01-04 17:09:15.415 P35 INFO: restore file /export/pgdata/base/1/13137 (0B, 100%)
2018-01-04 17:09:15.415 P36 INFO: restore file /export/pgdata/base/1/13132 (0B, 100%)
2018-01-04 17:09:15.415 P37 INFO: restore file /export/pgdata/base/1/13127 (0B, 100%)
2018-01-04 17:09:15.418 P00 INFO: write /export/pgdata/recovery.conf
2018-01-04 17:09:15.950 P00 INFO: restore global/pg_control (performed last to ensure aborted restores cannot be started)
2018-01-04 17:09:16.588 P00 INFO: restore command end: completed successfully
$ sudo vim /export/pgdata/postgresql.conf
port = 5433
$ sudo -u postgres /usr/pgsql-9.5/bin/pg_ctl -D /export/pgdata/ start
server starting
< 2018-01-04 17:13:47.361 CST >LOG: redirecting log output to logging collector process
< 2018-01-04 17:13:47.361 CST >HINT: Future log output will appear in directory "pg_log".
$ sudo -u postgres psql -p5433
psql (9.5.10)
Type "help" for help.
postgres=# \q
6. archive_command and restore_command
1) on master
$ sudo vim /var/lib/pgsql/9.5/data/postgresql.conf
archive_command = '/usr/bin/pgbackrest --stanza=test archive-push %p'
$ sudo service postgresql-9.5 reload
$ sudo yum install -y -q nfs-utils
$ sudo echo "/var/backups 10.191.0.0/16(rw)" > /etc/exports
$ sudo service nfs start
2) on slave
$ sudo mount -o v3 master_ip:/var/backups /var/backups
$ sudo vim /etc/pgbackrest.conf
[global]
repo-cipher-pass=O8lotSfiXYSYomc9BQ0UzgM9PgXoyNo1t3c0UmiM7M26rOETVNawbsW7BYn+I9es
repo-cipher-type=aes-256-cbc
repo-path=/var/backups
retention-full=2
retention-diff=2
retention-archive=2
start-fast=y
stop-auto=y
archive-copy=y
[global:archive-push]
archive-async=y
process-max=4
[test]
db-path=/var/lib/pgsql/9.5/data
process-max=10
$ sudo vim /var/lib/pgsql/9.5/data/recovery.conf
restore_command = '/usr/bin/pgbackrest --stanza=test archive-get %f "%p"'
Pgbouncer快速上手
Pgbouncer是一个轻量级的数据库连接池。
概要
pgbouncer [-d][-R][-v][-u user] <pgbouncer.ini>
pgbouncer -V|-h
描述
pgbouncer 是一个PostgreSQL连接池。 任何目标应用程序都可以连接到 pgbouncer, 就像它是PostgreSQL服务器一样,pgbouncer 将创建到实际服务器的连接, 或者它将重用其中一个现有的连接。
pgbouncer 的目的是为了降低打开PostgreSQL新连接时的性能影响。
为了不影响连接池的事务语义,pgbouncer 在切换连接时,支持多种类型的池化:
-
会话连接池(Session pooling)
最礼貌的方法。当客户端连接时,将在客户端保持连接的整个持续时间内分配一个服务器连接。 当客户端断开连接时,服务器连接将放回到连接池中。这是默认的方法。
-
事务连接池(Transaction pooling)
服务器连接只有在一个事务的期间内才指派给客户端。 当PgBouncer发觉事务结束的时候,服务器连接将会放回连接池中。
-
语句连接池(Statement pooling)
最激进的模式。在查询完成后,服务器连接将立即被放回连接池中。 该模式中不允许多语句事务,因为它们会中断。
pgbouncer 的管理界面由连接到特殊’虚拟’数据库 pgbouncer 时可用的一些新的 SHOW 命令组成。
上手
基本设置和用法如下。
-
创建一个pgbouncer.ini文件。pgbouncer(5) 的详细信息。简单例子
[databases] template1 = host=127.0.0.1 port=5432 dbname=template1 [pgbouncer] listen_port = 6543 listen_addr = 127.0.0.1 auth_type = md5 auth_file = users.txt logfile = pgbouncer.log pidfile = pgbouncer.pid admin_users = someuser -
创建包含许可用户的
users.txt文件"someuser" "same_password_as_in_server" -
加载 pgbouncer
$ pgbouncer -d pgbouncer.ini -
你的应用程序(或 客户端psql)已经连接到 pgbouncer ,而不是直接连接到PostgreSQL服务器了吗:
psql -p 6543 -U someuser template1 -
通过连接到特殊管理数据库 pgbouncer 来管理 pgbouncer, 发出
show help;开始$ psql -p 6543 -U someuser pgbouncer pgbouncer=# show help; NOTICE: Console usage DETAIL: SHOW [HELP|CONFIG|DATABASES|FDS|POOLS|CLIENTS|SERVERS|SOCKETS|LISTS|VERSION] SET key = arg RELOAD PAUSE SUSPEND RESUME SHUTDOWN -
如果你修改了pgbouncer.ini文件,可以用下列命令重新加载:
pgbouncer=# RELOAD;
命令行开关
| -d | 在后台运行。没有它,进程将在前台运行。 注意:在Windows上不起作用,pgbouncer 需要作为服务运行。 |
|---|---|
| -R | 进行在线重启。这意味着连接到正在运行的进程,从中加载打开的套接字, 然后使用它们。如果没有活动进程,请正常启动。 注意:只有在操作系统支持Unix套接字且 unix_socket_dir 在配置中未被禁用时才可用。在Windows机器上不起作用。 不使用TLS连接,它们被删除了。 |
| -u user | 启动时切换到给定的用户。 |
| -v | 增加详细度。可多次使用。 |
| -q | 安静 - 不要登出到stdout。请注意, 这不影响日志详细程度,只有该stdout不被使用。用于init.d脚本。 |
| -V | 显示版本。 |
| -h | 显示简短的帮助。 |
| –regservice | Win32:注册pgbouncer作为Windows服务运行。 service_name 配置参数值用作要注册的名称。 |
| –unregservice | Win32: 注销Windows服务。 |
管理控制台
通过正常连接到数据库 pgbouncer 可以使用控制台
$ psql -p 6543 pgbouncer
只有在配置参数 admin_users 或 stats_users 中列出的用户才允许登录到控制台。 (除了 auth_mode=any 时,任何用户都可以作为stats_user登录。)
另外,如果通过Unix套接字登录,并且客户端具有与运行进程相同的Unix用户uid, 允许用户名 pgbouncer 不使用密码登录。
SHOW命令
SHOW STATS;
显示统计信息。
| 字段 | 说明 |
|---|---|
database |
统计信息按数据库组织 |
total_xact_count |
SQL事务总数 |
total_query_count |
SQL查询总数 |
total_received |
收到的网络流量(字节) |
total_sent |
发送的网络流量(字节) |
total_xact_time |
在事务中的总时长 |
total_query_time |
在查询中的总时长 |
total_wait_time |
在等待中的总时长 |
avg_xact_count |
(当前)平均事务数 |
avg_query_count |
(当前)平均查询数 |
avg_recv |
(当前)平均每秒收到字节数 |
avg_sent |
(当前)平均每秒发送字节数 |
avg_xact_time |
平均事务时长(以毫秒计) |
avg_query_time |
平均查询时长(以毫秒计) |
avg_wait_time |
平均等待时长(以毫秒计) |
两个变体:SHOW STATS_TOTALS与SHOW STATS_AVERAGES,分别显示整体与平均的统计。
TOTAL实际上是Counter,而AVG通常是Guage。监控时建议采集TOTAL,查看时建议查看AVG。
SHOW SERVERS
| 字段 | 说明 |
|---|---|
type |
Server的类型固定为S |
user |
Pgbouncer用于连接数据库的用户名 |
state |
pgbouncer服务器连接的状态,active、used 或 idle 之一。 |
addr |
PostgreSQL server服务器的IP地址。 |
port |
PostgreSQL服务器的端口。 |
local_addr |
本机连接启动的地址。 |
local_port |
本机上的连接启动端口。 |
connect_time |
建立连接的时间。 |
request_time |
最后一个请求发出的时间。 |
ptr |
该连接内部对象的地址,用作唯一标识符 |
link |
服务器配对的客户端连接地址。 |
remote_pid |
后端服务器进程的pid。如果通过unix套接字进行连接, 并且OS支持获取进程ID信息,则为OS pid。 否则它将从服务器发送的取消数据包中提取出来,如果服务器是Postgres, 则应该是PID,但是如果服务器是另一个PgBouncer,则它是一个随机数。 |
SHOW CLIENTS
| 字段 | 说明 |
|---|---|
type |
Client的类型固定为C |
user |
客户端用于连接的用户 |
state |
pgbouncer客户端连接的状态,active、used 、waiting或 idle 之一。 |
addr |
客户端的IP地址。 |
port |
客户端的端口 |
local_addr |
本机地址 |
local_port |
本机端口 |
connect_time |
建立连接的时间。 |
request_time |
最后一个请求发出的时间。 |
ptr |
该连接内部对象的地址,用作唯一标识符 |
link |
配对的服务器端连接地址。 |
remote_pid |
如果通过unix套接字进行连接, 并且OS支持获取进程ID信息,则为OS pid。 |
SHOW CLIENTS
| 字段 | 说明 |
|---|---|
type |
Client的类型固定为C |
user |
客户端用于连接的用户 |
state |
pgbouncer客户端连接的状态,active、used 、waiting或 idle 之一。 |
addr |
客户端的IP地址。 |
port |
客户端的端口 |
local_addr |
本机地址 |
local_port |
本机端口 |
connect_time |
建立连接的时间。 |
request_time |
最后一个请求发出的时间。 |
ptr |
该连接内部对象的地址,用作唯一标识符 |
link |
配对的服务器端连接地址。 |
remote_pid |
如果通过unix套接字进行连接, 并且OS支持获取进程ID信息,则为OS pid。 |
SHOW POOLS;
为每对(database, user)创建一个新的连接池选项。
-
database
数据库名称。
-
user
用户名。
-
cl_active
链接到服务器连接并可以处理查询的客户端连接。
-
cl_waiting
已发送查询但尚未获得服务器连接的客户端连接。
-
sv_active
链接到客户端的服务器连接。
-
sv_idle
未使用且可立即用于客户机查询的服务器连接。
-
sv_used
已经闲置超过 server_check_delay 时长的服务器连接, 所以在它可以使用之前,需要运行 server_check_query。
-
sv_tested
当前正在运行 server_reset_query 或 server_check_query 的服务器连接。
-
sv_login
当前正在登录过程中的服务器连接。
-
maxwait
队列中第一个(最老的)客户端已经等待了多长时间,以秒计。 如果它开始增加,那么服务器当前的连接池处理请求的速度不够快。 原因可能是服务器负载过重或 pool_size 设置过小。
-
pool_mode
正在使用的连接池模式。
SHOW LISTS;
在列(不是行)中显示以下内部信息:
-
databases
数据库计数。
-
users
用户计数。
-
pools
连接池计数。
-
free_clients
空闲客户端计数。
-
used_clients
使用了的客户端计数。
-
login_clients
在 login 状态中的客户端计数。
-
free_servers
空闲服务器计数。
-
used_servers
使用了的服务器计数。
SHOW USERS;
-
name
用户名
-
pool_mode
用户重写的pool_mode,如果使用默认值,则返回NULL。
SHOW DATABASES;
-
name
配置的数据库项的名称。
-
host
pgbouncer连接到的主机。
-
port
pgbouncer连接到的端口。
-
database
pgbouncer连接到的实际数据库名称。
-
force_user
当用户是连接字符串的一部分时,pgbouncer和PostgreSQL 之间的连接被强制给给定的用户,不管客户端用户是谁。
-
pool_size
服务器连接的最大数量。
-
pool_mode
数据库的重写pool_mode,如果使用默认值则返回NULL。
SHOW FDS;
内部命令 - 显示与附带的内部状态一起使用的fds列表。
当连接的用户使用用户名"pgbouncer"时, 通过Unix套接字连接并具有与运行过程相同的UID,实际的fds通过连接传递。 该机制用于进行在线重启。 注意:这不适用于Windows机器。
此命令还会阻止内部事件循环,因此在使用PgBouncer时不应该使用它。
-
fd
文件描述符数值。
-
task
pooler、client 或 server 之一。
-
user
使用该FD的连接的用户。
-
database
使用该FD的连接的数据库。
-
addr
使用FD的连接的IP地址,如果使用unix套接字则是 unix。
-
port
使用FD的连接的端口。
-
cancel
取消此连接的键。
-
link
对应服务器/客户端的fd。如果空闲则为NULL。
SHOW CONFIG;
显示当前的配置设置,一行一个,带有下列字段:
-
key
配置变量名
-
value
配置值
-
changeable
yes 或者 no,显示运行时变量是否可更改。 如果是 no,则该变量只能在启动时改变。
SHOW DNS_HOSTS;
显示DNS缓存中的主机名。
-
hostname
主机名。
-
ttl
直到下一次查找经过了多少秒。
-
addrs
地址的逗号分隔的列表。
SHOW DNS_ZONES
显示缓存中的DNS区域。
-
zonename
区域名称。
-
serial
当前序列号。
-
count
属于此区域的主机名。
过程控制命令
PAUSE [db];
PgBouncer尝试断开所有服务器的连接,首先等待所有查询完成。 所有查询完成之前,命令不会返回。在数据库重新启动时使用。如果提供了数据库名称,那么只有该数据库将被暂停。
DISABLE db;
拒绝给定数据库上的所有新客户端连接。
ENABLE db;
在上一个的 DISABLE 命令之后允许新的客户端连接。
KILL db;
立即删除给定数据库上的所有客户端和服务器连接。
SUSPEND;
所有套接字缓冲区被刷新,PgBouncer停止监听它们上的数据。 在所有缓冲区为空之前,命令不会返回。在PgBouncer在线重新启动时使用。
RESUME [db];
从之前的 PAUSE 或 SUSPEND 命令中恢复工作。
SHUTDOWN;
PgBouncer进程将会退出。
RELOAD;
PgBouncer进程将重新加载它的配置文件并更新可改变的设置。
信号
-
SIGHUP
重新加载配置。与在控制台上发出命令 RELOAD; 相同。
-
SIGINT
安全关闭。与在控制台上发出 PAUSE; 和 SHUTDOWN; 相同。
-
SIGTERM
立即关闭。与在控制台上发出 SHUTDOWN; 相同。
Libevent设置
来自libevent的文档:
可以通过分别设置环境变量EVENT_NOEPOLL、EVENT_NOKQUEUE、
VENT_NODEVPOLL、EVENT_NOPOLL或EVENT_NOSELECT来禁用对
epoll、kqueue、devpoll、poll或select的支持。
通过设置环境变量EVENT_SHOW_METHOD,libevent显示它使用的内核通知方法。
Pgbouncer参数配置
默认配置
;; 数据库名 = 连接串
;;
;; 连接串包括这些参数:
;; dbname= host= port= user= password=
;; client_encoding= datestyle= timezone=
;; pool_size= connect_query=
;; auth_user=
[databases]
instanceA = host=10.1.1.1 dbname=core
instanceB = host=102.2.2.2 dbname=payment
; 通过Unix套接字的 foodb
;foodb =
; 将bardb在localhost上重定向为bazdb
;bardb = host=localhost dbname=bazdb
; 使用单个用户访问目标数据库
;forcedb = host=127.0.0.1 port=300 user=baz password=foo client_encoding=UNICODE datestyle=ISO connect_query='SELECT 1'
; 使用定制的连接池大小
;nondefaultdb = pool_size=50 reserve_pool=10
; 如果用户不在认证文件中,替换使用的auth_user; auth_user必须在认证文件中
; foodb = auth_user=bar
; 保底的通配连接串
;* = host=testserver
;; Pgbouncer配置区域
[pgbouncer]
;;;
;;; 管理设置
;;;
logfile = /var/log/pgbouncer/pgbouncer.log
pidfile = /var/run/pgbouncer/pgbouncer.pid
;;;
;;; 监听哪里的客户端
;;;
; 监听IP地址,* 代表所有IP
listen_addr = *
listen_port = 6432
; -R选项也会处理Unix Socket.
; 在Debian上是 /var/run/postgresql
;unix_socket_dir = /tmp
;unix_socket_mode = 0777
;unix_socket_group =
;;;
;;; TLS配置
;;;
;; 选项:disable, allow, require, verify-ca, verify-full
;client_tls_sslmode = disable
;; 信任CA证书的路径
;client_tls_ca_file = <system default>
;; 代表客户端的私钥与证书路径
;; 从客户端接受TLS连接时,这是必须参数
;client_tls_key_file =
;client_tls_cert_file =
;; fast, normal, secure, legacy, <ciphersuite string>
;client_tls_ciphers = fast
;; all, secure, tlsv1.0, tlsv1.1, tlsv1.2
;client_tls_protocols = all
;; none, auto, legacy
;client_tls_dheparams = auto
;; none, auto, <curve name>
;client_tls_ecdhcurve = auto
;;;
;;; 连接到后端数据库时的TLS设置
;;;
;; disable, allow, require, verify-ca, verify-full
;server_tls_sslmode = disable
;; 信任CA证书的路径
;server_tls_ca_file = <system default>
;; 代表后端的私钥与证书
;; 只有当后端服务器需要客户端证书时需要
;server_tls_key_file =
;server_tls_cert_file =
;; all, secure, tlsv1.0, tlsv1.1, tlsv1.2
;server_tls_protocols = all
;; fast, normal, secure, legacy, <ciphersuite string>
;server_tls_ciphers = fast
;;;
;;; 认证设置
;;;
; any, trust, plain, crypt, md5, cert, hba, pam
auth_type = trust
auth_file = /etc/pgbouncer/userlist.txt
;; HBA风格的认证配置文件
# auth_hba_file = /pg/data/pg_hba.conf
;; 从数据库获取密码的查询,结果必须包含两列: 用户名 与 密码哈希值.
;auth_query = SELECT usename, passwd FROM pg_shadow WHERE usename=$1
;;;
;;; 允许访问虚拟数据库'pgbouncer'的用户
;;;
; 允许修改设置,逗号分隔的用户名列表。
admin_users = postgres
; 允许使用SHOW命令,逗号分隔的用户名列表。
stats_users = stats, postgres
;;;
;;; 连接池设置
;;;
; 什么时候服务端连接会被放回到池中?(默认为session)
; session - 会话模式,当客户端断开连接时
; transaction - 事务模式,当事务结束时
; statement - 语句模式,当语句结束时
pool_mode = session
; 客户端释放连接后,用于立刻清理连接的查询。
; 不用把ROLLBACK放在这儿,当事务还没结束时,Pgbouncer是不会重用连接的。
;
; 8.3及更高版本的查询:
; DISCARD ALL;
;
; 更老的版本:
; RESET ALL; SET SESSION AUTHORIZATION DEFAULT
;
; 如果启用事务级别的连接池,则为空。
;
server_reset_query = DISCARD ALL
; server_reset_query 是否需要在任何情况下执行。
; 如果关闭(默认),server_reset_query 只会在会话级连接池中使用。
;server_reset_query_always = 0
;
; Comma-separated list of parameters to ignore when given
; in startup packet. Newer JDBC versions require the
; extra_float_digits here.
;
;ignore_startup_parameters = extra_float_digits
;
; When taking idle server into use, this query is ran first.
; SELECT 1
;
;server_check_query = select 1
; If server was used more recently that this many seconds ago,
; skip the check query. Value 0 may or may not run in immediately.
;server_check_delay = 30
; Close servers in session pooling mode after a RECONNECT, RELOAD,
; etc. when they are idle instead of at the end of the session.
;server_fast_close = 0
;; Use <appname - host> as application_name on server.
;application_name_add_host = 0
;;;
;;; 连接限制
;;;
; 最大允许的连接数
max_client_conn = 100
; 默认的连接池尺寸,当使用事务连接池时,20是一个合适的值。对于会话级连接池而言
; 该值是你想在同一时刻处理的最大连接数。
default_pool_size = 20
;; 连接池中最少的保留连接数
;min_pool_size = 0
; 出现问题时,最多允许多少条额外连接
;reserve_pool_size = 0
; 如果客户端等待超过这么多秒,使用备用连接池
;reserve_pool_timeout = 5
; 单个数据库/用户最多允许多少条连接
;max_db_connections = 0
;max_user_connections = 0
; If off, then server connections are reused in LIFO manner
;server_round_robin = 0
;;;
;;; Logging
;;;
;; Syslog settings
;syslog = 0
;syslog_facility = daemon
;syslog_ident = pgbouncer
; log if client connects or server connection is made
;log_connections = 1
; log if and why connection was closed
;log_disconnections = 1
; log error messages pooler sends to clients
;log_pooler_errors = 1
;; Period for writing aggregated stats into log.
;stats_period = 60
;; Logging verbosity. Same as -v switch on command line.
;verbose = 0
;;;
;;; Timeouts
;;;
;; Close server connection if its been connected longer.
;server_lifetime = 3600
;; Close server connection if its not been used in this time.
;; Allows to clean unnecessary connections from pool after peak.
;server_idle_timeout = 600
;; Cancel connection attempt if server does not answer takes longer.
;server_connect_timeout = 15
;; If server login failed (server_connect_timeout or auth failure)
;; then wait this many second.
;server_login_retry = 15
;; Dangerous. Server connection is closed if query does not return
;; in this time. Should be used to survive network problems,
;; _not_ as statement_timeout. (default: 0)
;query_timeout = 0
;; Dangerous. Client connection is closed if the query is not assigned
;; to a server in this time. Should be used to limit the number of queued
;; queries in case of a database or network failure. (default: 120)
;query_wait_timeout = 120
;; Dangerous. Client connection is closed if no activity in this time.
;; Should be used to survive network problems. (default: 0)
;client_idle_timeout = 0
;; Disconnect clients who have not managed to log in after connecting
;; in this many seconds.
;client_login_timeout = 60
;; Clean automatically created database entries (via "*") if they
;; stay unused in this many seconds.
; autodb_idle_timeout = 3600
;; How long SUSPEND/-R waits for buffer flush before closing connection.
;suspend_timeout = 10
;; Close connections which are in "IDLE in transaction" state longer than
;; this many seconds.
;idle_transaction_timeout = 0
;;;
;;; Low-level tuning options
;;;
;; buffer for streaming packets
;pkt_buf = 4096
;; man 2 listen
;listen_backlog = 128
;; Max number pkt_buf to process in one event loop.
;sbuf_loopcnt = 5
;; Maximum PostgreSQL protocol packet size.
;max_packet_size = 2147483647
;; networking options, for info: man 7 tcp
;; Linux: notify program about new connection only if there
;; is also data received. (Seconds to wait.)
;; On Linux the default is 45, on other OS'es 0.
;tcp_defer_accept = 0
;; In-kernel buffer size (Linux default: 4096)
;tcp_socket_buffer = 0
;; whether tcp keepalive should be turned on (0/1)
;tcp_keepalive = 1
;; The following options are Linux-specific.
;; They also require tcp_keepalive=1.
;; count of keepalive packets
;tcp_keepcnt = 0
;; how long the connection can be idle,
;; before sending keepalive packets
;tcp_keepidle = 0
;; The time between individual keepalive probes.
;tcp_keepintvl = 0
;; DNS lookup caching time
;dns_max_ttl = 15
;; DNS zone SOA lookup period
;dns_zone_check_period = 0
;; DNS negative result caching time
;dns_nxdomain_ttl = 15
;;;
;;; Random stuff
;;;
;; Hackish security feature. Helps against SQL-injection - when PQexec is disabled,
;; multi-statement cannot be made.
;disable_pqexec = 0
;; Config file to use for next RELOAD/SIGHUP.
;; By default contains config file from command line.
;conffile
;; Win32 service name to register as. job_name is alias for service_name,
;; used by some Skytools scripts.
;service_name = pgbouncer
;job_name = pgbouncer
;; Read additional config from the /etc/pgbouncer/pgbouncer-other.ini file
;%include /etc/pgbouncer/pgbouncer-other.ini
PG服务器日志常规配置
建议配置PostgreSQL的日志格式为CSV,方便分析,而且可以直接导入PostgreSQL数据表中。
日志相关配置项
log_destination ='csvlog'
logging_collector =on
log_directory ='log'
log_filename ='postgresql-%a.log'
log_min_duration_statement =1000
log_checkpoints =on
log_lock_waits =on
log_statement ='ddl'
log_replication_commands =on
log_timezone ='UTC'
log_autovacuum_min_duration =1000
track_io_timing =on
track_functions =all
track_activity_query_size =16384
日志收集
如果需要从外部收集日志,可以考虑使用filebeat。
filebeat.prospectors:
## input
- type: log
enabled: true
paths:
- /var/lib/postgresql/data/pg_log/postgresql-*.csv
document_type: db-trace
tail_files: true
multiline.pattern: '^20\d\d-\d\d-\d\d'
multiline.negate: true
multiline.match: after
multiline.max_lines: 20
max_cpus: 1
## modules
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
## queue
queue.mem:
events: 1024
flush.min_events: 0
flush.timeout: 1s
## output
output.kafka:
hosts: ["10.10.10.10:9092","x.x.x.x:9092"]
topics:
- topic: 'log.db'
CSV日志格式
很有趣的想法,将CSV日志弄成PostgreSQL表,对于分析而言非常方便。
原始的csv日志格式定义如下:
日志表的结构定义
create table postgresql_log
(
log_time timestamp,
user_name text,
database_name text,
process_id integer,
connection_from text,
session_id text not null,
session_line_num bigint not null,
command_tag text,
session_start_time timestamp with time zone,
virtual_transaction_id text,
transaction_id bigint,
error_severity text,
sql_state_code text,
message text,
detail text,
hint text,
internal_query text,
internal_query_pos integer,
context text,
query text,
query_pos integer,
location text,
application_name text,
PRIMARY KEY (session_id, session_line_num)
);
导入日志
日志是结构良好的CSV,(CSV允许跨行记录),直接使用COPY命令导入即可。
COPY postgresql_log FROM '/var/lib/pgsql/data/pg_log/postgresql.log' CSV DELIMITER ',';
映射日志
当然,除了把日志直接拷贝到数据表里分析,还有一种办法,可以让PostgreSQL直接将自己的本地CSVLOG映射为一张外部表。以SQL的方式直接进行访问。
CREATE SCHEMA IF NOT EXISTS monitor;
-- search path for su
ALTER ROLE postgres SET search_path = public, monitor;
SET search_path = public, monitor;
-- extension
CREATE EXTENSION IF NOT EXISTS file_fdw WITH SCHEMA monitor;
-- log parent table: empty
CREATE TABLE monitor.pg_log
(
log_time timestamp(3) with time zone,
user_name text,
database_name text,
process_id integer,
connection_from text,
session_id text,
session_line_num bigint,
command_tag text,
session_start_time timestamp with time zone,
virtual_transaction_id text,
transaction_id bigint,
error_severity text,
sql_state_code text,
message text,
detail text,
hint text,
internal_query text,
internal_query_pos integer,
context text,
query text,
query_pos integer,
location text,
application_name text,
PRIMARY KEY (session_id, session_line_num)
);
COMMENT ON TABLE monitor.pg_log IS 'PostgreSQL csv log schema';
-- local file server
CREATE SERVER IF NOT EXISTS pg_log FOREIGN DATA WRAPPER file_fdw;
-- Change filename to actual path
CREATE FOREIGN TABLE IF NOT EXISTS monitor.pg_log_mon() INHERITS (monitor.pg_log) SERVER pg_log OPTIONS (filename '/pg/data/log/postgresql-Mon.csv', format 'csv');
CREATE FOREIGN TABLE IF NOT EXISTS monitor.pg_log_tue() INHERITS (monitor.pg_log) SERVER pg_log OPTIONS (filename '/pg/data/log/postgresql-Tue.csv', format 'csv');
CREATE FOREIGN TABLE IF NOT EXISTS monitor.pg_log_wed() INHERITS (monitor.pg_log) SERVER pg_log OPTIONS (filename '/pg/data/log/postgresql-Wed.csv', format 'csv');
CREATE FOREIGN TABLE IF NOT EXISTS monitor.pg_log_thu() INHERITS (monitor.pg_log) SERVER pg_log OPTIONS (filename '/pg/data/log/postgresql-Thu.csv', format 'csv');
CREATE FOREIGN TABLE IF NOT EXISTS monitor.pg_log_fri() INHERITS (monitor.pg_log) SERVER pg_log OPTIONS (filename '/pg/data/log/postgresql-Fri.csv', format 'csv');
CREATE FOREIGN TABLE IF NOT EXISTS monitor.pg_log_sat() INHERITS (monitor.pg_log) SERVER pg_log OPTIONS (filename '/pg/data/log/postgresql-Sat.csv', format 'csv');
CREATE FOREIGN TABLE IF NOT EXISTS monitor.pg_log_sun() INHERITS (monitor.pg_log) SERVER pg_log OPTIONS (filename '/pg/data/log/postgresql-Sun.csv', format 'csv');
加工日志
可以使用以下存储过程从日志消息中进一步提取语句的执行时间
CREATE OR REPLACE FUNCTION extract_duration(statement TEXT)
RETURNS FLOAT AS $$
DECLARE
found_duration BOOLEAN;
BEGIN
SELECT position('duration' in statement) > 0
into found_duration;
IF found_duration
THEN
RETURN (SELECT regexp_matches [1] :: FLOAT
FROM regexp_matches(statement, 'duration: (.*) ms')
LIMIT 1);
ELSE
RETURN NULL;
END IF;
END
$$
LANGUAGE plpgsql
IMMUTABLE;
CREATE OR REPLACE FUNCTION extract_statement(statement TEXT)
RETURNS TEXT AS $$
DECLARE
found_statement BOOLEAN;
BEGIN
SELECT position('statement' in statement) > 0
into found_statement;
IF found_statement
THEN
RETURN (SELECT regexp_matches [1]
FROM regexp_matches(statement, 'statement: (.*)')
LIMIT 1);
ELSE
RETURN NULL;
END IF;
END
$$
LANGUAGE plpgsql
IMMUTABLE;
CREATE OR REPLACE FUNCTION extract_ip(app_name TEXT)
RETURNS TEXT AS $$
DECLARE
ip TEXT;
BEGIN
SELECT regexp_matches [1]
into ip
FROM regexp_matches(app_name, '(\d+\.\d+\.\d+\.\d+)')
LIMIT 1;
RETURN ip;
END
$$
LANGUAGE plpgsql
IMMUTABLE;
空中换引擎 —— PostgreSQL不停机迁移数据
通常涉及到数据迁移,常规操作都是停服务更新。不停机迁移数据是相对比较高级的操作。
不停机数据迁移在本质上,可以视作由三个操作组成:
- 复制:将目标表从源库逻辑复制到宿库。
- 改读:将应用读取路径由源库迁移到宿库上。
- 改写:将应用写入路径由源库迁移到宿库上。
但在实际执行中,这三个步骤可能会有不一样的表现形式。
逻辑复制
使用逻辑复制是比较稳妥的做法,也有几种不同的做法:应用层逻辑复制,数据库自带的逻辑复制(PostgreSQL 10 之后的逻辑订阅),使用第三方逻辑复制插件(例如pglogical)。
几种逻辑复制的方法各有优劣,我们采用了应用层逻辑复制的方式。具体包括四个步骤:
一、复制
- 在新库中fork老库目标表的模式,以及所有依赖的函数、序列、权限、属主等对象。
- 应用添加双写逻辑,同时向新库与老库中写入同样数据。
- 同时向新库与老库写入
- 保证增量数据正确写入两个一样的库中。
- 应用需要正确处理全量数据不存在下的删改逻辑。例如改
UPDATE为UPSERT,忽略DELETE。 - 应用读取仍然走老库。
- 出现问题时,回滚应用至原来的单写版本。
二、同步
- 老表加上表级排它锁
LOCK TABLE <xxx> IN EXCLUSIVE MODE,阻塞所有写入。 - 执行全量同步
pg_dump | psql - 校验数据一致性,判断迁移是否成功。
- 出现问题时,简单清空新库中的对应表。
- 改读
- 应用修改为从新库中读取数据。
- 出现问题时,回滚至从老库中读取的版本。
- 单写
- 观察一段时间无误后,应用修改为仅写入新库。
- 出现问题时,回滚至双写版本。
说明
关键在于阻塞全量同步期间对老表的写入。这可以通过表级排它锁实现。
在对表进行了分片的情况下,锁表对业务造成的影响非常小。
一张逻辑表拆分成8192个分区,实际上一次只需要处理一个分区。
阻塞对八千分之一的数据写入约几秒到十几秒,业务上通常是可以接受的。
但如果是单张非常大的表,也许就需要特殊处理了。
ETL函数
以下Bash函数接受三个参数,源库URL,宿库URL,以及待迁移的表名。
假设是源宿库都可连接,且目标表都存在。
function etl(){
local src_url=${1}
local dst_url=${2}
local table_name=${3}
rm -rf "/tmp/etl-${table_name}.done"
psql ${src_url} -1qAtc "LOCK TABLE ${table_name} IN EXCLUSIVE MODE;COPY ${table_name} TO STDOUT;" \
| psql ${dst_url} -1qAtc "LOCK TABLE ${table_name} IN EXCLUSIVE MODE; TRUNCATE ${table_name}; COPY ${table_name} FROM STDIN;"
touch "/tmp/etl-${table_name}.done"
}
实际上虽然锁定了源表与宿表,但在实际测试中,管道退出时前后两个psql进程退出的timing并不是完全同步的。管道前面的进程比后面一个进程早了0.1秒退出。在负载很大的情况下,可能会产生数据不一致。
另一种更科学的做法是按照某一唯一约束列进行切分,锁定相应的行,更新后释放
物理复制
物理复制是通过回放WAL日志实现的复制,是数据库集簇层面的复制。
基于物理复制的迁移粒度很粗,仅适用于垂直分裂库时使用,会有极短暂的服务不可用。
使用物理复制进行数据迁移的流程如下:
- 复制,从主库拖出一台从库,保持流式复制。
- 改读:将应用读取路径从主库改为从库,但写入仍然写入主库。
- 如果有问题,将应用回滚至读主库版本。
- 改写:将从库提升为主库,阻塞老库的写入,并立即重启应用,切换写入路径至新主库上。
- 将不需要的表和库删除。
- 这一步无法回滚(回滚会损失写入新库的数据)
使用FIO测试磁盘性能
Fio是一个很好用的磁盘性能测试工具,可以通过以下命令测试磁盘的读写性能。
fio --filename=/tmp/fio.data \
-direct=1 \
-iodepth=32 \
-rw=randrw \
--rwmixread=80 \
-bs=4k \
-size=1G \
-numjobs=16 \
-runtime=60 \
-group_reporting \
-name=randrw \
--output=/tmp/fio_randomrw.txt \
&& unlink /tmp/fio.data
测试裸盘(例如NVMe)性能(危险!不要在生产运行):
fio -name=8krandw -runtime=120 -filename=/dev/nvme0n1 -ioengine=libaio -direct=1 -bs=8K -size=100g -iodepth=256 -numjobs=8 -rw=randwrite -group_reporting -time_based
fio -name=8krandr -runtime=120 -filename=/dev/nvme0n1 -ioengine=libaio -direct=1 -bs=8K -size=100g -iodepth=256 -numjobs=8 -rw=randread -group_reporting -time_based
fio -name=8krandrw -runtime=120 -filename=/dev/nvme0n1 -ioengine=libaio -direct=1 -bs=8k -size=100g -iodepth=256 -numjobs=8 -rw=randrw -rwmixwrite=30 -group_reporting -time_based
fio -name=1mseqw -runtime=120 -filename=/dev/nvme0n1 -ioengine=libaio -direct=1 -bs=1024k -size=200g -iodepth=256 -numjobs=8 -rw=write -group_reporting -time_based
fio -name=1mseqr -runtime=120 -filename=/dev/nvme0n1 -ioengine=libaio -direct=1 -bs=1024k -size=200g -iodepth=256 -numjobs=8 -rw=read -group_reporting -time_based
fio -name=1mseqrw -runtime=120 -filename=/dev/nvme0n1 -ioengine=libaio -direct=1 -bs=1024k -size=200g -iodepth=256 -numjobs=8 -rw=rw -rwmixwrite=30 -group_reporting -time_based
测试 FS 性能(xfs): 4K, 8K, 1Mseq:
mkfs.xfs /dev/nvme0n1; mkdir -p /data1; mount -o noatime -o nodiratime -t xfs /dev/nvme0n1 /data1;
fio -name=4krandw -runtime=120 -filename=/data1/rand.txt -ioengine=libaio -direct=1 -bs=4K -size=100g -iodepth=256 -numjobs=8 -rw=randwrite -group_reporting -time_based
fio -name=4krandr -runtime=120 -filename=/data1/rand.txt -ioengine=libaio -direct=1 -bs=4K -size=100g -iodepth=256 -numjobs=8 -rw=randread -group_reporting -time_based
fio -name=4krandrw -runtime=120 -filename=/data1/rand.txt -ioengine=libaio -direct=1 -bs=4k -size=100g -iodepth=256 -numjobs=8 -rw=randrw -rwmixwrite=30 -group_reporting -time_based
fio -name=8krandw -runtime=120 -filename=/data1/rand.txt -ioengine=libaio -direct=1 -bs=8K -size=100g -iodepth=256 -numjobs=8 -rw=randwrite -group_reporting -time_based
fio -name=8krandr -runtime=120 -filename=/data1/rand.txt -ioengine=libaio -direct=1 -bs=8K -size=100g -iodepth=256 -numjobs=8 -rw=randread -group_reporting -time_based
fio -name=8krandrw -runtime=120 -filename=/data1/rand.txt -ioengine=libaio -direct=1 -bs=8k -size=100g -iodepth=256 -numjobs=8 -rw=randrw -rwmixwrite=30 -group_reporting -time_based
fio -name=1mseqw -runtime=120 -filename=/data1/seq.txt -ioengine=libaio -direct=1 -bs=1024k -size=200g -iodepth=256 -numjobs=8 -rw=write -group_reporting -time_based
fio -name=1mseqr -runtime=120 -filename=/data1/seq.txt -ioengine=libaio -direct=1 -bs=1024k -size=200g -iodepth=256 -numjobs=8 -rw=read -group_reporting -time_based
fio -name=1mseqrw -runtime=120 -filename=/data1/seq.txt -ioengine=libaio -direct=1 -bs=1024k -size=200g -iodepth=256 -numjobs=8 -rw=rw -rwmixwrite=30 -group_reporting -time_based
测试 PostgreSQL 相关的 IO 性能表现时,应当主要以 8KB 随机IO为主,可以考虑以下参数组合。
3个维度:RW Ratio, Block Size, N Jobs 进行排列组合
- RW Ratio: Pure Read, Pure Write, rwmixwrite=80, rwmixwrite=20
- Block Size = 4KB (OS granular), 8KB (DB granular)
- N jobs: 1 , 4 , 8 , 16 ,32
使用sysbench测试PostgreSQL性能
sysbench首页:https://github.com/akopytov/sysbench
安装
二进制安装,在Mac上,使用brew安装sysbench。
brew install sysbench --with-postgresql
源代码编译(CentOS):
yum -y install make automake libtool pkgconfig libaio-devel
# For MySQL support, replace with mysql-devel on RHEL/CentOS 5
yum -y install mariadb-devel openssl-devel
# For PostgreSQL support
yum -y install postgresql-devel
源代码编译
brew install automake libtool openssl pkg-config
# For MySQL support
brew install mysql
# For PostgreSQL support
brew install postgresql
# openssl is not linked by Homebrew, this is to avoid "ld: library not found for -lssl"
export LDFLAGS=-L/usr/local/opt/openssl/lib
编译:
./autogen.sh
# --with-pgsql --with-pgsql-libs --with-pgsql-includes
# -- without-mysql
./configure
make -j
make install
准备
创建一个压测用PostgreSQL数据库:bench,初始化测试用数据库:
sysbench /usr/local/share/sysbench/oltp_read_write.lua \
--db-driver=pgsql \
--pgsql-host=127.0.0.1 \
--pgsql-port=5432 \
--pgsql-user=vonng \
--pgsql-db=bench \
--table_size=100000 \
--tables=3 \
prepare
输出:
Creating table 'sbtest1'...
Inserting 100000 records into 'sbtest1'
Creating a secondary index on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 100000 records into 'sbtest2'
Creating a secondary index on 'sbtest2'...
Creating table 'sbtest3'...
Inserting 100000 records into 'sbtest3'
Creating a secondary index on 'sbtest3'...
压测
sysbench /usr/local/share/sysbench/oltp_read_write.lua \
--db-driver=pgsql \
--pgsql-host=127.0.0.1 \
--pgsql-port=5432 \
--pgsql-user=vonng \
--pgsql-db=bench \
--table_size=100000 \
--tables=3 \
--threads=4 \
--time=12 \
run
输出
sysbench 1.1.0-e6e6a02 (using bundled LuaJIT 2.1.0-beta3)
Running the test with following options:
Number of threads: 4
Initializing random number generator from current time
Initializing worker threads...
Threads started!
SQL statistics:
queries performed:
read: 127862
write: 36526
other: 18268
total: 182656
transactions: 9131 (760.56 per sec.)
queries: 182656 (15214.20 per sec.)
ignored errors: 2 (0.17 per sec.)
reconnects: 0 (0.00 per sec.)
Throughput:
events/s (eps): 760.5600
time elapsed: 12.0056s
total number of events: 9131
Latency (ms):
min: 4.30
avg: 5.26
max: 15.20
95th percentile: 5.99
sum: 47995.39
Threads fairness:
events (avg/stddev): 2282.7500/4.02
execution time (avg/stddev): 11.9988/0.00
找出没用过的索引
索引很有用, 但不是免费的。没用到的索引是一种浪费,使用以下SQL找出未使用的索引:
- 首先要排除用于实现约束的索引(删不得)
- 表达式索引(
pg_index.indkey中含有0号字段) - 然后找出走索引扫描的次数为0的索引(也可以换个更宽松的条件,比如扫描小于1000次的)
找出没有使用的索引
- 视图名称:
monitor.v_bloat_indexes - 计算时长:1秒,适合每天检查/手工检查,不适合频繁拉取。
- 验证版本:9.3 ~ 10
- 功能:显示当前数据库索引膨胀情况。
在版本9.3与10.4上工作良好。视图形式
-- CREATE SCHEMA IF NOT EXISTS monitor;
-- DROP VIEW IF EXISTS monitor.pg_stat_dummy_indexes;
CREATE OR REPLACE VIEW monitor.pg_stat_dummy_indexes AS
SELECT s.schemaname,
s.relname AS tablename,
s.indexrelname AS indexname,
pg_relation_size(s.indexrelid) AS index_size
FROM pg_catalog.pg_stat_user_indexes s
JOIN pg_catalog.pg_index i ON s.indexrelid = i.indexrelid
WHERE s.idx_scan = 0 -- has never been scanned
AND 0 <>ALL (i.indkey) -- no index column is an expression
AND NOT EXISTS -- does not enforce a constraint
(SELECT 1 FROM pg_catalog.pg_constraint c
WHERE c.conindid = s.indexrelid)
ORDER BY pg_relation_size(s.indexrelid) DESC;
COMMENT ON VIEW monitor.pg_stat_dummy_indexes IS 'monitor unused indexes'
-- 人类可读的手工查询
SELECT s.schemaname,
s.relname AS tablename,
s.indexrelname AS indexname,
pg_size_pretty(pg_relation_size(s.indexrelid)) AS index_size
FROM pg_catalog.pg_stat_user_indexes s
JOIN pg_catalog.pg_index i ON s.indexrelid = i.indexrelid
WHERE s.idx_scan = 0 -- has never been scanned
AND 0 <>ALL (i.indkey) -- no index column is an expression
AND NOT EXISTS -- does not enforce a constraint
(SELECT 1 FROM pg_catalog.pg_constraint c
WHERE c.conindid = s.indexrelid)
ORDER BY pg_relation_size(s.indexrelid) DESC;
批量生成删除索引的命令
SELECT 'DROP INDEX CONCURRENTLY IF EXISTS "'
|| s.schemaname || '"."' || s.indexrelname || '";'
FROM pg_catalog.pg_stat_user_indexes s
JOIN pg_catalog.pg_index i ON s.indexrelid = i.indexrelid
WHERE s.idx_scan = 0 -- has never been scanned
AND 0 <>ALL (i.indkey) -- no index column is an expression
AND NOT EXISTS -- does not enforce a constraint
(SELECT 1 FROM pg_catalog.pg_constraint c
WHERE c.conindid = s.indexrelid)
ORDER BY pg_relation_size(s.indexrelid) DESC;
找出重复的索引
检查是否有索引工作在相同的表的相同列上,但要注意条件索引。
SELECT
indrelid :: regclass AS table_name,
array_agg(indexrelid :: regclass) AS indexes
FROM pg_index
GROUP BY
indrelid, indkey
HAVING COUNT(*) > 1;
批量配置SSH免密登录
配置SSH是运维工作的基础,有时候还是要老生常谈一下。
生成公私钥对
理想的情况是全部通过公私钥认证,从本地免密码直接连接所有数据库机器。最好不要使用密码认证。
首先,使用ssh-keygen生成公私钥对
ssh-keygen -t rsa
注意权限问题,ssh内文件的权限应当设置为0600,.ssh目录的权限应当设置为0700,设置失当会导致免密登录无法使用。
配置ssh config穿透跳板机
把User换成自己的名字。放入.ssh/config,这里给出了有跳板机环境下配置生产网数据库免密直连的方式:
# Vonng's ssh config
# SpringBoard IP
Host <BastionIP>
Hostname <your_ip_address>
IdentityFile ~/.ssh/id_rsa
# Target Machine Wildcard (Proxy via Bastion)
Host 10.xxx.xxx.*
ProxyCommand ssh <BastionIP> exec nc %h %p 2>/dev/null
IdentityFile ~/.ssh/id_rsa
# Common Settings
Host *
User xxxxxxxxxxxxxx
PreferredAuthentications publickey,password
Compression yes
ServerAliveInterval 30
ControlMaster auto
ControlPath ~/.ssh/ssh-%r@%h:%p
ControlPersist yes
StrictHostKeyChecking no
将公钥拷贝到目标机器上
然后将公钥拷贝到跳板机,DBA工作机,所有数据库机器上。
ssh-copy-id <target_ip>
每次执行此命令都会要求输入密码,非常繁琐无聊,可以通过expect 脚本进行自动化,或者使用sshpass
使用expect自动化
将下列脚本中的<your password>替换为你自己的密码。如果服务器IP列表有变化,修改列表即可。
#!/usr/bin/expect
foreach id {
10.xxx.xxx.xxx
10.xxx.xxx.xxx
10.xxx.xxx.xxx
} {
spawn ssh-copy-id $id
expect {
"*(yes/no)?*"
{
send "yes\n"
expect "*assword:" { send "<your password>\n"}
}
"*assword*" { send "<your password>\n"}
}
}
exit
更优雅的解决方案: sshpass
sshpass -i <your password> ssh-copy-id <target address>
当然缺点是,密码很有可能出现在bash历史记录中,执行完请及时清理痕迹。
Wireshark抓包分析协议
Wireshark是一个很有用的工具,特别适合用来分析网络协议。
这里简单介绍使用Wireshark抓包分析PostgreSQL协议的方法。
假设调试本地PostgreSQL实例:127.0.0.1:5432
快速开始
- 下载并安装Wireshark:下载地址
- 选择要抓包的网卡,如果是本地测试选择
lo0即可。 - 添加抓包过滤器,如果PostgreSQL使用默认设置,使用
port 5432即可。 - 开始抓包
- 添加显示过滤器
pgsql,这样就可以滤除无关的TCP协议报文。 - 然后就可以执行一些操作,观察并分析协议了
抓包样例
我们先从最简单的case开始,不使用认证,也不使用SSL,执行以下命令建立一条到PostgreSQL的连接。
psql postgres://localhost:5432/postgres?sslmode=disable -c 'SELECT 1 AS a, 2 AS b;'
注意这里sslmode=disable是不能省略的,不然客户端会默认尝试发送SSL请求。localhost也是不能省略的,不然客户端会默认尝试使用unix socket。
这条Bash命令实际上在PostgreSQL对应着三个协议阶段与5组协议报文
- 启动阶段:客户端建立一条到PostgreSQL服务器的连接。
- 简单查询协议:客户端发送查询命令,服务器回送查询结果。
- 终止:客户端中断连接。
Wireshark内建了对PGSQL的解码,允许我们方便地查看PostgreSQL协议报文的内容。
启动阶段,客户端向服务端发送了一条StartupMessage (F),而服务端回送了一系列消息,包括AuthenticationOK(R), ParameterStatus(S), BackendKeyData(K) , ReadyForQuery(Z)。这里这几条消息都打包在同一个TCP报文中发送给客户端。
简单查询阶段,客户端发送了一条Query (F)消息,将SQL语句SELECT 1 AS a, 2 AS b;直接作为内容发送给服务器。服务器依次返回了RowDescription(T),DataRow(D),CommandComplete(C),ReadyForQuery(Z).
终止阶段,客户端发送了一条Terminate(X)消息,终止连接。
题外话:使用Mac进行无线网络嗅探
结论: Mac: airport, tcpdump Windows: Omnipeek Linux: tcpdump, airmon-ng
以太网里抓包很简单,各种软件一大把,什么Wireshark,Ethereal,Sniffer Pro 一抓一大把。不过如果是无线数据包,就要稍微麻烦一点了。网上找了一堆罗里吧嗦的文章,绕来绕去的,其实抓无线包一条命令就好了。
Windows下因为无线网卡驱动会拒绝进入混杂模式,所以比较蛋疼,一般是用Omnipeek去弄,不细说了。
Linux和Mac就很方便了。只要用tcpdump就可以,一般系统都自带了。最后-i选项的参数填想抓的网络设备名就行。Mac默认的WiFi网卡是en0。 tcpdump -Ine -i en0
主要就是指定-I参数,进入监控模式。 -I :Put the interface in "monitor mode"; this is supported only on IEEE 802.11 Wi-Fi interfaces, and supported only on some operating systems. 进入监控模式之后计算机用于监控的无线网卡就上不了网了,所以可以考虑买个外置无线网卡来抓包,上网抓包两不误。
抓了包能干很多坏事,比如WEP网络抓几个IV包就可以用aircrack破密码,WPA网络抓到一个握手包就能跑字典破无线密码了。如果在同一个网络内,还可以看到各种未加密的流量……什么小黄图啊,隐私照啊之类的……。
假如我已经知道某个手机的MAC地址,那么只要 tcpdump -Ine -i en0 | grep $MAC_ADDRESS 就过滤出该手机相关的WiFi流量。
具体帧的类型详情参看802.11协议,《802.11无线网络权威指南》等。
顺便解释以下混杂模式与监控模式的区别: 混杂(promiscuous)模式是指:接收同一个网络中的所有数据包,无论是不是发给自己的。 监控(monitor)模式是指:接收某个物理信道中所有传输着的数据包。
RFMON RFMON is short for radio frequency monitoring mode and is sometimes also described as monitor mode or raw monitoring mode. In this mode an 802.11 wireless card is in listening mode (“sniffer” mode).
The wireless card does not have to associate to an access point or ad-hoc network but can passively listen to all traffic on the channel it is monitoring. Also, the wireless card does not require the frames to pass CRC checks and forwards all frames (corrupted or not with 802.11 headers) to upper level protocols for processing. This can come in handy when troubleshooting protocol issues and bad hardware.
RFMON/Monitor Mode vs. Promiscuous Mode Promiscuous mode in wired and wireless networks instructs a wired or wireless card to process any traffic regardless of the destination mac address. In wireless networks promiscuous mode requires that the wireless card be associated to an access point or ad-hoc network. While in promiscuous mode a wireless card can transmit and receive but will only captures traffic for the network (SSID) to which it is associated.
RFMON mode is only possible for wireless cards and does not require the wireless card to be associated to a wireless network. While in monitor mode the wireless card can passively monitor traffic of all networks and devices within listening range (SSIDs, stations, access points). In most cases the wireless card is not able to transmit and does not follow the typical 802.11 protocol when receiving traffic (i.e. transmit an 802.11 ACK for received packet).
Both modes have to be supported by the driver of the wired or wireless card.
另外在研究抓包工具时,发现了Mac下有一个很好用的命令行工具airport,可以用来抓包,以及摆弄Macbook的WiFi。 位置在 /System/Library/PrivateFrameworks/Apple80211.framework/Versions/Current/Resources/airport
可以创建一个符号链接方便使用: sudo ln -s /System/Library/PrivateFrameworks/Apple80211.framework/Versions/Current/Resources/airport /usr/sbin/airport
常用的命令有: 显示当前网络信息:airport -I 扫描周围无线网络:airport -s 断开当前无线网络:airport -z 强制指定无线信道:airport -c=$CHANNEL
抓无线包,可以指定信道: airport en0 sniff [$CHANNEL] 抓到的包放在/tmp/airportSniffXXXXX.cap,可以用tcpdump, tshark, wireshark等软件来读。
最实用的功能还是扫描周围无线网络。
file_fdw妙用无穷——从数据库读取系统信息
file_fdw,轻松查看操作系统信息,拉取网络数据,把各种各样的数据源轻松喂进数据库里统一查看管理。PostgreSQL是最先进的开源数据库,其中一个非常给力的特性就是FDW:外部数据包装器(Foreign Data Wrapper)。通过FDW,用户可以用统一的方式从Pg中访问各类外部数据源。file_fdw就是其中随数据库附赠的两个fdw之一。随着pg10的更新,file_fdw也添加了一颗赛艇的功能:从程序输出读取。
小霸王妙用无穷,我们能通过file_fdw,轻松查看操作系统信息,拉取网络数据,把各种各样的数据源轻松喂进数据库里统一查看管理。
安装与配置
file_fdw是Pg自带的组件,不需要奇怪的配置,在数据库中执行以下命令即可启用file_fdw:
CREATE EXTENSION file_fdw;
启用FDW插件之后,需要创建一个实例,也是一行SQL搞定,创建一个名为fs的FDW Server实例。
CREATE SERVER fs FOREIGN DATA WRAPPER file_fdw;
创建外部表
举个栗子,如果我想从数据库中读取操作系统中正在运行的进程信息,该怎么做呢?
最典型,也是最常用的外部数据格式就是CSV啦。不过系统命令输出的结果并不是很规整:
>>> ps ux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
vonng 2658 0.0 0.2 148428 2620 ? S 11:51 0:00 sshd: vonng@pts/0,pts/2
vonng 2659 0.0 0.2 115648 2312 pts/0 Ss+ 11:51 0:00 -bash
vonng 4854 0.0 0.2 115648 2272 pts/2 Ss 15:46 0:00 -bash
vonng 5176 0.0 0.1 150940 1828 pts/2 R+ 16:06 0:00 ps -ux
vonng 26460 0.0 1.2 271808 13060 ? S 10月26 0:22 /usr/local/pgsql/bin/postgres
vonng 26462 0.0 0.2 271960 2640 ? Ss 10月26 0:00 postgres: checkpointer process
vonng 26463 0.0 0.2 271808 2148 ? Ss 10月26 0:25 postgres: writer process
vonng 26464 0.0 0.5 271808 5300 ? Ss 10月26 0:27 postgres: wal writer process
vonng 26465 0.0 0.2 272216 2096 ? Ss 10月26 0:31 postgres: autovacuum launcher process
vonng 26466 0.0 0.1 126896 1104 ? Ss 10月26 0:54 postgres: stats collector process
vonng 26467 0.0 0.1 272100 1588 ? Ss 10月26 0:01 postgres: bgworker: logical replication launcher
可以通过awk,将ps的命令输出规整为分隔符为\x1F的csv格式。
ps aux | awk '{print $1,$2,$3,$4,$5,$6,$7,$8,$9,$10,substr($0,index($0,$11))}' OFS='\037'
正戏来啦!通过以下DDL创建一张外表定义
CREATE FOREIGN TABLE process_status (
username TEXT,
pid INTEGER,
cpu NUMERIC,
mem NUMERIC,
vsz BIGINT,
rss BIGINT,
tty TEXT,
stat TEXT,
start TEXT,
time TEXT,
command TEXT
) SERVER fs OPTIONS (
PROGRAM $$ps aux | awk '{print $1,$2,$3,$4,$5,$6,$7,$8,$9,$10,substr($0,index($0,$11))}' OFS='\037'$$,
FORMAT 'csv', DELIMITER E'\037', HEADER 'TRUE');
这里,关键是通过CREATE FOREIGN TABLE OPTIONS (xxxx)中的OPTIONS提供相应的参数,在PROGRAM参数中填入上面的命令,pg就会在查询这张表的时候自动执行此命令,并读取其输出。FORMAT参数可以指定为CSV,DELIMITER参数指定为之前使用的\x1F,并通过HEADER 'TRUE'忽略CSV的第一行
那么结果如何呢?
有什么用
最简单的场景,原本系统指标监控需要编写各种监测脚本,部署在奇奇怪怪的地方。然后定期执行拉取metric,再存进数据库。现在通过file_fdw的方式,可以将感兴趣的指标直接录入数据库表,一步到位,而且维护方便,部署简单,更加可靠。在外表上加上视图,定期拉取聚合,将原本一个监控系统完成的事情,在数据库中一条龙解决了。
因为可以从程序输出读取结果,因此file_fdw可以与linux生态里各类强大的命令行工具配合使用,发挥出强大的威力。
其他栗子
诸如此类,实际上后来我发现Facebook貌似有一个类似的产品,叫OSQuery,也是干了差不多的事。通过SQL查询操作系统的指标。但明显PostgreSQL这种方法最简单粗暴高效啦,只要定义表结构,和命令数据源就能轻松对接指标数据,用不了一天就能做出一个功能差不多的东西来。
用于读取系统用户列表的DDL:
CREATE FOREIGN TABLE etc_password (
username TEXT,
password TEXT,
user_id INTEGER,
group_id INTEGER,
user_info TEXT,
home_dir TEXT,
shell TEXT
) SERVER fs OPTIONS (
PROGRAM $$awk -F: 'NF && !/^[:space:]*#/ {print $1,$2,$3,$4,$5,$6,$7}' OFS='\037' /etc/passwd$$,
FORMAT 'csv', DELIMITER E'\037'
);
用于读取磁盘用量的DDL:
CREATE FOREIGN TABLE disk_free (
file_system TEXT,
blocks_1m BIGINT,
used_1m BIGINT,
avail_1m BIGINT,
capacity TEXT,
iused BIGINT,
ifree BIGINT,
iused_pct TEXT,
mounted_on TEXT
) SERVER fs OPTIONS (PROGRAM $$df -ml| awk '{print $1,$2,$3,$4,$5,$6,$7,$8,$9}' OFS='\037'$$, FORMAT 'csv', HEADER 'TRUE', DELIMITER E'\037'
);
当然,用file_fdw只是一个很Naive的FDW,譬如这里就只能读,不能改。
自己编写FDW实现增删改查逻辑也非常简单,例如Multicorn就是使用Python编写FDW的项目。
SQL over everything,让世界变的更简单~
Linux 常用统计 CLI 工具
top
显示Linux任务
摘要
- 按下空格或回车强制刷新
- 使用
h打开帮助 - 使用
l,t,m收起摘要部分。 - 使用
d修改刷新周期 - 使用
z开启颜色高亮 - 使用
u列出指定用户的进程 - 使用
<>来改变排序列 - 使用
P按CPU使用率排序 - 使用
M按驻留内存大小排序 - 使用
T按累计时间排序
批处理模式
-b参数可以用于批处理模式,配合-n参数指定批次数目。同时-d参数可以指定批次的间隔时间
例如获取机器当前的负载使用情况,以0.1秒为间隔获取三次,获取最后一次的CPU摘要。
$ top -bn3 -d0.1 | grep Cpu | tail -n1
Cpu(s): 4.1%us, 1.0%sy, 0.0%ni, 94.8%id, 0.0%wa, 0.0%hi, 0.1%si, 0.0%st
输出格式
top的输出分为两部分,上面几行是系统摘要,下面是进程列表,两者通过一个空行分割。下面是top命令的输出样例:
top - 12:11:01 up 401 days, 19:17, 2 users, load average: 1.12, 1.26, 1.40
Tasks: 1178 total, 3 running, 1175 sleeping, 0 stopped, 0 zombie
Cpu(s): 5.4%us, 1.7%sy, 0.0%ni, 92.5%id, 0.1%wa, 0.0%hi, 0.4%si, 0.0%st
Mem: 396791756k total, 389547376k used, 7244380k free, 263828k buffers
Swap: 67108860k total, 0k used, 67108860k free, 366252364k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5094 postgres 20 0 37.2g 829m 795m S 14.2 0.2 0:04.11 postmaster
5093 postgres 20 0 37.2g 926m 891m S 13.2 0.2 0:04.96 postmaster
165359 postgres 20 0 37.2g 4.0g 4.0g S 12.6 1.1 0:44.93 postmaster
93426 postgres 20 0 37.2g 6.8g 6.7g S 12.2 1.8 1:32.94 postmaster
5092 postgres 20 0 37.2g 856m 818m R 11.2 0.2 0:04.21 postmaster
67634 root 20 0 569m 520m 328 S 11.2 0.1 140720:15 haproxy
93429 postgres 20 0 37.2g 8.7g 8.7g S 11.2 2.3 2:12.23 postmaster
129653 postgres 20 0 37.2g 6.8g 6.7g S 11.2 1.8 1:27.92 postmaster
摘要部分
摘要默认由三个部分,共计五行组成:
- 系统运行时间,平均负载,共计一行(
l切换内容) - 任务、CPU状态,各一行(
t切换内容) - 内存使用,Swap使用,各一行(
m切换内容)
系统运行时间和平均负载
top - 12:11:01 up 401 days, 19:17, 2 users, load average: 1.12, 1.26, 1.40
- 当前时间:
12:11:01 - 系统已运行的时间:
up 401 days - 当前登录用户的数量:
2 users - 相应最近5、10和15分钟内的平均负载:
load average: 1.12, 1.26, 1.40。
Load表示操作系统的负载,即,当前运行的任务数目。而load average表示一段时间内平均的load,也就是过去一段时间内平均有多少个任务在运行。注意Load与CPU利用率并不是一回事。
任务
Tasks: 1178 total, 3 running, 1175 sleeping, 0 stopped, 0 zombie
第二行显示的是任务或者进程的总结。进程可以处于不同的状态。这里显示了全部进程的数量。除此之外,还有正在运行、睡眠、停止、僵尸进程的数量(僵尸是一种进程的状态)。
CPU状态
Cpu(s): 5.4%us, 1.7%sy, 0.0%ni, 92.5%id, 0.1%wa, 0.0%hi, 0.4%si, 0.0%st
下一行显示的是CPU状态。 这里显示了不同模式下的所占CPU时间的百分比。这些不同的CPU时间表示:
- us, user: 运行(未调整优先级的) 用户进程的CPU时间
- sy,system: 运行内核进程的CPU时间
- ni,niced:运行已调整优先级的用户进程的CPU时间
- id,idle:空闲CPU时间
- wa,IO wait: 用于等待IO完成的CPU时间
- hi:处理硬件中断的CPU时间
- si: 处理软件中断的CPU时间
- st:虚拟机被hypervisor偷去的CPU时间(如果当前处于一个虚拟机内,宿主机消耗的CPU处理时间)。
内存使用
Mem: 396791756k total, 389547376k used, 7244380k free, 263828k buffers
Swap: 67108860k total, 0k used, 67108860k free, 366252364k cached
- 内存部分:全部可用内存、已使用内存、空闲内存、缓冲内存。
- SWAP部分:全部、已使用、空闲和缓冲交换空间。
进程部分
进程部分默认会显示一些关键信息
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5094 postgres 20 0 37.2g 829m 795m S 14.2 0.2 0:04.11 postmaster
5093 postgres 20 0 37.2g 926m 891m S 13.2 0.2 0:04.96 postmaster
165359 postgres 20 0 37.2g 4.0g 4.0g S 12.6 1.1 0:44.93 postmaster
93426 postgres 20 0 37.2g 6.8g 6.7g S 12.2 1.8 1:32.94 postmaster
5092 postgres 20 0 37.2g 856m 818m R 11.2 0.2 0:04.21 postmaster
67634 root 20 0 569m 520m 328 S 11.2 0.1 140720:15 haproxy
93429 postgres 20 0 37.2g 8.7g 8.7g S 11.2 2.3 2:12.23 postmaster
129653 postgres 20 0 37.2g 6.8g 6.7g S 11.2 1.8 1:27.92 postmaster
-
PID:进程ID,进程的唯一标识符
-
USER:进程所有者的实际用户名。
-
PR:进程的调度优先级。这个字段的一些值是’rt’。这意味这这些进程运行在实时态。
-
NI:进程的nice值(优先级)。越小的值意味着越高的优先级。
-
VIRT:进程使用的虚拟内存。
-
RES:驻留内存大小。驻留内存是任务使用的非交换物理内存大小。
-
SHR:SHR是进程使用的共享内存。
-
S这个是进程的状态。它有以下不同的值:
-
D - 不可中断的睡眠态。
-
R – 运行态
-
S – 睡眠态
-
T – Trace或Stop
-
Z – 僵尸态
-
%CPU:自从上一次更新时到现在任务所使用的CPU时间百分比。
-
%MEM:进程使用的可用物理内存百分比。
-
TIME+:任务启动后到现在所使用的全部CPU时间,单位为百分之一秒。
-
COMMAND:运行进程所使用的命令。
Linux进程的状态
static const char * const task_state_array[] = {
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)", /* 32 */
};
R (TASK_RUNNING),可执行状态。实际运行与Ready在Linux都算做Running状态S (TASK_INTERRUPTIBLE),可中断的睡眠态,进程等待事件,位于等待队列中。D (TASK_UNINTERRUPTIBLE),不可中断的睡眠态,无法响应异步信号,例如硬件操作,内核线程T (TASK_STOPPED | TASK_TRACED),暂停状态或跟踪状态,由SIGSTOP或断点触发Z (TASK_DEAD),子进程退出后,父进程还没有来收尸,留下task_structure的进程就处于这种状态。
free
显示系统的内存使用情况
free -b | -k | -m | -g | -h -s delay -a -l
- 其中
-b | -k | -m | -g | -h可用于控制显示大小时的单位(字节,KB,MB,GB,自动适配) -s可以指定轮询周期,-c指定轮询次数。
输出样例
$ free -m
total used free shared buffers cached
Mem: 387491 379383 8107 37762 182 348862
-/+ buffers/cache: 30338 357153
Swap: 65535 0 65535
- 这里,总内存有378GB,使用370GB,空闲8GB。三者存在
total=used+free的关系。共享内存占36GB。 - buffers与cache由操作系统分配管理,用于提高I/O性能,其中Buffer是写入缓冲,而Cache是读取缓存。这一行表示,应用程序已使用的
buffers/cached,以及理论上可使用的buffers/cache。-/+ buffers/cache: 30338 357153 - 最后一行显示了SWAP信息,总的SWAP空间,实际使用的SWAP空间,以及可用的SWAP空间。只要没有用到SWAP(used = 0),就说明内存空间仍然够用。
数据来源
free实际上是通过cat /proc/meminfo获取信息的。
详细信息:https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/6/html/deployment_guide/s2-proc-meminfo
$ cat /proc/meminfo
MemTotal: 396791752 kB # 总可用RAM, 物理内存减去内核二进制与保留位
MemFree: 7447460 kB # 系统可用物理内存
Buffers: 186540 kB # 磁盘快的临时存储大小
Cached: 357066928 kB # 缓存
SwapCached: 0 kB # 曾移入SWAP又移回内存的大小
Active: 260698732 kB # 最近使用过,如非强制不会回收的内存。
Inactive: 112228764 kB # 最近没怎么用过的内存,可能会回收
Active(anon): 53811184 kB # 活跃的匿名内存(不与具体文件关联)
Inactive(anon): 532504 kB # 不活跃的匿名内存
Active(file): 206887548 kB # 活跃的文件缓存
Inactive(file): 111696260 kB # 不活跃的文件缓存
Unevictable: 0 kB # 不可淘汰的内存
Mlocked: 0 kB # 被钉在内存中
SwapTotal: 67108860 kB # 总SWAP
SwapFree: 67108860 kB # 可用SWAP
Dirty: 115852 kB # 被写脏的内存
Writeback: 0 kB # 回写磁盘的内存
AnonPages: 15676608 kB # 匿名页面
Mapped: 38698484 kB # 用于mmap的内存,例如共享库
Shmem: 38668836 kB # 共享内存
Slab: 6072524 kB # 内核数据结构使用内存
SReclaimable: 5900704 kB # 可回收的slab
SUnreclaim: 171820 kB # 不可回收的slab
KernelStack: 25840 kB # 内核栈使用的内存
PageTables: 2480532 kB # 页表大小
NFS_Unstable: 0 kB # 发送但尚未提交的NFS页面
Bounce: 0 kB # bounce buffers
WritebackTmp: 0 kB
CommitLimit: 396446012 kB
Committed_AS: 57195364 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 6214036 kB
VmallocChunk: 34353427992 kB
HardwareCorrupted: 0 kB
AnonHugePages: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
DirectMap4k: 5120 kB
DirectMap2M: 2021376 kB
DirectMap1G: 400556032 kB
其中,free与/proc/meminfo中指标的对应关系为:
total = (MemTotal + SwapTotal)
used = (total - free - buffers - cache)
free = (MemFree + SwapFree)
shared = Shmem
buffers = Buffers
cache = Cached
buffer/cached = Buffers + Cached
清理缓存
可以通过以下命令强制清理缓存:
$ sync # flush fs buffers
$ echo 1 > /proc/sys/vm/drop_caches # drop page cache
$ echo 2 > /proc/sys/vm/drop_caches # drop dentries & inode
$ echo 3 > /proc/sys/vm/drop_caches # drop all
vmstat
汇报虚拟内存统计信息
摘要
vmstat [-a] [-n] [-t] [-S unit] [delay [ count]]
vmstat [-s] [-n] [-S unit]
vmstat [-m] [-n] [delay [ count]]
vmstat [-d] [-n] [delay [ count]]
vmstat [-p disk partition] [-n] [delay [ count]]
vmstat [-f]
vmstat [-V]
最常用的用法是:
vmstat <delay> <count>
例如vmstat 1 10就是以1秒为间隔,采样10次内存统计信息。
样例输出
$ vmstat 1 4 -S M
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
3 0 0 7288 170 344210 0 0 158 158 0 0 2 1 97 0 0
5 0 0 7259 170 344228 0 0 7680 13292 38783 36814 6 1 93 0 0
3 0 0 7247 170 344246 0 0 8720 21024 40584 39686 6 1 93 0 0
1 0 0 7233 170 344255 0 0 6800 24404 39461 36984 6 1 93 0 0
Procs
r: 等待运行的进程数目
b: 处于不可中断睡眠状态的进程数(Block)
Memory
swpd: 使用的交换区大小,大于0则说明内存过小
free: 空闲内存
buff: 缓冲区内存
cache: 页面缓存
inact: 不活跃内存 (-a 选项)
active: 活跃内存 (-a 选项)
Swap
si: 每秒从磁盘中换入的内存 (/s).
so: 每秒从换出到磁盘的内存 (/s).
IO
bi: 从块设备每秒收到的块数目 (blocks/s).
bo: 向块设备每秒发送的快数目 (blocks/s).
System
in: 每秒中断数,包括时钟中断
cs: 每秒上下文切换数目
CPU
总CPU时间的百分比
us: 用户态时间 (包括nice的时间)
sy: 内核态时间
id: 空闲时间(在2.5.41前包括等待IO的时间)
wa: 等待IO的时间(在2.5.41前包括在id里)
st: 空闲时间(在2.6.11前没有)
数据来源
从下面三个文件中提取信息:
/proc/meminfo/proc/stat/proc/*/stat
iostat
汇报IO相关统计信息
摘要
iostat [ -c ] [ -d ] [ -N ] [ -n ] [ -h ] [ -k | -m ] [ -t ] [ -V ] [ -x ] [ -y ] [ -z ] [ -j { ID | LABEL | PATH | UUID | ... } [ device [...] | ALL ] ] [ device [...] | ALL ] [ -p [ device [,...] | ALL ] ] [interval [ count ] ]
默认情况下iostat会打印cpu信息和磁盘io信息,使用-d参数只显示IO部分,使用-x打印更多信息。样例输出:
avg-cpu: %user %nice %system %iowait %steal %idle
5.77 0.00 1.31 0.07 0.00 92.85
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sdb 0.00 0.00 0.00 0 0
sda 0.00 0.00 0.00 0 0
dfa 5020.00 15856.00 35632.00 15856 35632
dm-0 0.00 0.00 0.00 0 0
常用选项
- 使用
-d参数只显示IO部分的信息,而-c参数则只显示CPU部分的信息。 - 使用
-x会打印更详细的扩展信息 - 使用
-k会使用KB替代块数目作为部分数值的单位,-m则使用MB。
输出说明
不带-x选项默认会为每个设备打印5列:
- tps:该设备每秒的传输次数。(多个逻辑请求可能会合并为一个IO请求,传输量未知)
-kB_read/s:每秒从设备读取的数据量;kB_wrtn/s:每秒向设备写入的数据量;kB_read:读取的总数据量;kB_wrtn:写入的总数量数据量;这些单位都为Kilobytes,这是使用
-k参数的情况。默认则以块数为单位。
带有-x选项后,会打印更多信息:
- rrqm/s:每秒这个设备相关的读取请求有多少被Merge了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合并Merge);
- wrqm/s:每秒这个设备相关的写入请求有多少被Merge了。
- r/s 与 w/s:(合并后)每秒读取/写入请求次数
- rsec/s 与 wsec/s:每秒读取/写入扇区的数目
- avgrq-sz:请求的平均大小(以扇区计)
- avgqu-sz:平均请求队列长度
- await:每一个IO请求的处理的平均时间(单位是毫秒)
- r_await/w_await:读/写的平均响应时间。
- %util:设备的带宽利用率,IO时间占比。在统计时间内所有处理IO时间。一般该参数是100%表示设备已经接近满负荷运行了。
常用方法
收集 /dev/dfa 的IO信息,按kB计算,每秒一次,连续 10 次。
iostat -dxk /dev/dfa 1 10
数据来源
其实是从下面几个文件中提取信息的:
/proc/stat contains system statistics.
/proc/uptime contains system uptime.
/proc/partitions contains disk statistics (for pre 2.5 kernels that have been patched).
/proc/diskstats contains disks statistics (for post 2.5 kernels).
/sys contains statistics for block devices (post 2.5 kernels).
/proc/self/mountstats contains statistics for network filesystems.
/dev/disk contains persistent device names.
源码编译安装 PostGIS
强烈建议使用使用 yum / apt 命令从 PostgreSQL 官方二进制仓库安装 PostGIS。
1. 安装环境
- CentOS 7
- PostgreSQL10
- PostGIS2.4
- PGROUTING2.5.2
2. PostgreSQL10安装
2.1 确定系统环境
$ uname -a
Linux localhost.localdomain 3.10.0-693.el7.x86_64 #1 SMP Tue Aug 22 21:09:27 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
2.2 安装正确的rpm包
rpm -ivh https://download.postgresql.org/pub/repos/yum/10/redhat/rhel-7-x86_64/pgdg-centos10-10-2.noarch.rpm
不同的系统使用不同的rpm源,你可以从 http://yum.postgresql.org/repopackages.php 获取相应的平台链接。
2.3 查看rpm包是否正确安装
yum list | grep pgdg
pgdg-centos10.noarch 10-2 installed
CGAL.x86_64 4.7-1.rhel7 pgdg10
CGAL-debuginfo.x86_64 4.7-1.rhel7 pgdg10
CGAL-demos-source.x86_64 4.7-1.rhel7 pgdg10
CGAL-devel.x86_64 4.7-1.rhel7 pgdg10
MigrationWizard.noarch 1.1-3.rhel7 pgdg10
...
2.4 安装PG
yum install -y postgresql10 postgresql10-server postgresql10-libs postgresql10-contrib postgresql10-devel
你可以根据需要选择安装相应的rpm包。
2.5 启动服务
默认情况下,PG安装目录为/usr/pgsql-10/,data目录为/var/lib/pgsql/,系统默认创建用户postgres
passwd postgres # 为系统postgres设置密码
su - postgres # 切换到用户postgres
/usr/pgsql-10/bin/initdb -D /var/lib/pgsql/10/data/ # 初始化数据库
/usr/pgsql-10/bin/pg_ctl -D /var/lib/pgsql/10/data/ -l logfile start # 启动数据库
/usr/pgsql-10/bin/psql postgres postgres # 登录
3. PostGIS安装
yum install postgis24_10-client postgis24_10
如果遇到错误如下:
--> 解决依赖关系完成 错误:软件包:postgis24_10-client-2.4.2-1.rhel7.x86_64 (pgdg10) 需要:libproj.so.0()(64bit) 错误:软件包:postgis24_10-2.4.2-1.rhel7.x86_64 (pgdg10) 需要:gdal-libs >= 1.9.0你可以尝试通过以下命令解决:
yum -y install epel-release
4. fdw安装
yum install ogr_fdw10
5. pgrouting安装
yum install pgrouting_10
6. 验证测试
# 登录pg后执行以下命令,无报错则证明成功
CREATE EXTENSION postgis;
CREATE EXTENSION postgis_topology;
CREATE EXTENSION ogr_fdw;
SELECT postgis_full_version();
编译工具
此类工具一般系统都自带。
- GCC与G++,版本至少为
4.x。 - GNU Make,CMake, Autotools
- Git
CentOS下直接通过sudo yum install gcc gcc-c++ git autoconf automake libtool m4 安装。
必选依赖
PostgreSQL
PostgreSQL是PostGIS的宿主平台。这里以10.1为例。
GEOS
GEOS是Geometry Engine, Open Source的缩写,是一个C++版本的几何库。是PostGIS的核心依赖。
PostGIS 2.4用到了GEOS 3.7的一些新特性。不过截止到现在,GEOS官方发布的最新版本是3.6.2,3.7版本的GEOS可以通过Nightly snapshot 获取。所以目前如果希望用到所有新特性,需要从源码编译安装GEOS 3.7。
# 滚动的每日更新,此URL有可能过期,检查这里http://geos.osgeo.org/snapshots/
wget -P ./ http://geos.osgeo.org/snapshots/geos-20171211.tar.bz2
tar -jxf geos-20171211.tar.bz2
cd geos-20171211
./configure
make
sudo make install
cd ..
Proj
为PostGIS提供坐标投影支持,目前最新版本为4.9.3 :下载
# 此URL有可能过期,检查这里http://proj4.org/download.html
wget -P . http://download.osgeo.org/proj/proj-4.9.3.tar.gz
tar -zxf proj-4.9.3.tar.gz
cd proj-4.9.3
make
sudo make install
JSON-C
目前用于导入GeoJSON格式的数据,函数ST_GeomFromGeoJson用到了这个库。
编译json-c需要用到autoconf, automake, libtool。
git clone https://github.com/json-c/json-c
cd json-c
sh autogen.sh
./configure # --enable-threading
make
make install
LibXML2
目前用于导入GML与KML格式的数据,函数ST_GeomFromGML和ST_GeomFromKML依赖这个库。
目前可以在这个FTP服务器上搞到,目前使用的版本是2.9.7
tar -zxf libxml2-sources-2.9.7.tar.gz
cd libxml2-sources-2.9.7
./configure
make
sudo make install
GADL
wget -P . http://download.osgeo.org/gdal/2.2.3/gdal-2.2.3.tar.gz
SFCGAL
SFCGAL是CGAL的扩展包装,虽说是可选项,但是很多函数都会经常用到,因此这里也需要安装。下载页面
SFCGAL依赖的东西比较多。包括CMake, CGAL, Boost, MPFR, GMP等,其中,CGAL在上面手动安装过了。这里还需要手动安装BOOST
wget -P . https://github.com/Oslandia/SFCGAL/archive/v1.3.0.tar.gz
Boost
Boost是C++的常用库,SFCGAL依赖BOOST,下载页面
wget -P . https://dl.bintray.com/boostorg/release/1.65.1/source/boost_1_65_1.tar.gz
tar -zxf boost_1_65_1.tar.gz
cd boost_1_65_1
./bootstrap.sh
./b2
PostgreSQL MongoFDW安装部署
更新:最近MongoFDW已经由Cybertech接手维护,也许没有这么不堪了。
最近有业务要求通过PostgreSQL FDW去访问MongoDB。开始我觉得这是个很轻松的任务。但接下来的事真是让人恶心的吐了。MongoDB FDW编译起来真是要人命:混乱的依赖,临时下载和Hotpatch,错误的编译参数,以及最过分的是错误的文档。总算,我在生产环境(Linux RHEL7u2)和开发环境(Mac OS X 10.11.5)都编译成功了。赶紧记录下来,省的下次蛋疼。
环境概述
理论上编译这套东西,GCC版本至少为4.1。 生产环境 (RHEL7.2 + PostgreSQL9.5.3 + GCC 4.8.5) 本地环境 (Mac OS X 10.11.5 + PostgreSQL9.5.3 + clang-703.0.31)
mongo_fdw的依赖
总的来说,能用包管理解决的问题,尽量用包管理解决。 mongo_fdw是我们最终要安装的包 它的直接依赖有三个:
总的来说,mongo_fdw是使用mongo提供的C驱动程序完成功能的。所以我们需要安装libbson与libmongoc。其中libmongoc就是MongoDB的C语言驱动库,它依赖于libbson。
所以最后的安装顺序是:
libbson → libmongoc → json-c→ mongo_fdw
间接依赖
默认依赖的GNU Build全家桶,文档是不会告诉你的。下面列出一些比较简单的,可以通过包管理解决的依赖。请一定按照以下顺序安装GNU Autotools
m4-1.4.17 → autoconf-2.69 → automake-1.15 → libtool-2.4.6 → pkg-config-0.29.1。
总之,用yum也好,apt也好,homebrew也好,都是一行命令能搞定的事。 还有一个依赖是libmongoc的依赖:openssl-devel,不要忘记装。
安装 libbson-1.3.1
git clone -b r1.3 https://github.com/mongodb/libbson;
cd libbson;
git checkout 1.3.1;
./autogen.sh;
make && sudo make install;
make test;
安装 libmongoc-1.3.1
git clone -b r1.3 https://github.com/mongodb/mongo-c-driver
cd mongo-c-driver;
git checkout 1.3.1;
./autogen.sh;
# 下一步很重要,一定要使用刚才安装好的系统中的libbson。
./configure --with-libbson=system;
make && sudo make install;
这里为什么要使用1.3.1的版本?这也是有讲究的。因为mongo_fdw中默认使用的是1.3.1的mongo-c-driver。但是它在文档里说只要1.0.0+就可以,其实是在放狗屁。mongo-c-driver与libbson版本是一一对应的。1.0.0版本的libbson脑子被驴踢了,使用了超出C99的特性,比如复数类型。要是用了默认版本就傻逼了。
安装json-c
首先,我们来解决json-c的问题
git clone https://github.com/json-c/json-c;
cd json-c
git checkout json-c-0.12
./configure完了可不要急着Make,这个版本的json-c编译参数有问题。- 打开Makefile,找到
CFLAGS,在编译参数后面添加-fPIC - 这样GCC会生成位置无关代码,不这样做的话mongo_fdw链接会报错。
安装 mongo_fdw
真正恶心的地方来咯。
git clone https://github.com/EnterpriseDB/mongo_fdw;
好了,如果这时候想当然的运行./autogen.sh --with-master,它就会去重新下一遍上面几个包了……,而且都是从墙外亚马逊的云主机去下。靠谱的方法就是手动一条条的执行autogen里面的命令。
首先把上面的json-c目录复制到mongo_fdw的根目录内。 然后添加libbson和libmongoc的include路径。
export C_INCLUDE_PATH="/usr/local/include/libbson-1.0/:/usr/local/include/libmongoc-1.0:$C_INCLUDE_PATH"
查看autogen.sh,发现里面根据--with-legacy和--with-master的不同选项,会有不同的操作。具体来说,当指定--with-master选项时,它会创建一个config.h,里面定义了一个META_DRIVER的宏变量。当有这个宏变量时,mongo_fdw会使用mongoc.h头文件,也就是所谓的“master”,新版的mongo驱动。当没有时,则会使用"mongo.h"头文件,也就是老版的mongo驱动。这里,我们直接vi config.h,添加一行
#define META_DRIVER
这时候,基本上才能算万事大吉。 在最终build之前,别忘了执行:ldconfig
sudo ldconfig
回到mongo_fdw根目录make,不出意外,这个mongo_fdw.so就出来了。
试一试吧?
sudo make install;
psql
admin=# CREATE EXTENSION mongo_fdw;
如果提示找不到 libmongoc.so 和 libbson.so,直接把它们丢进pgsql的lib目录即可。
sudo cp /usr/local/lib/libbson* /usr/local/pgsql/lib/
sudo cp /usr/local/lib/libmongoc* /usr/local/pgsql/lib/