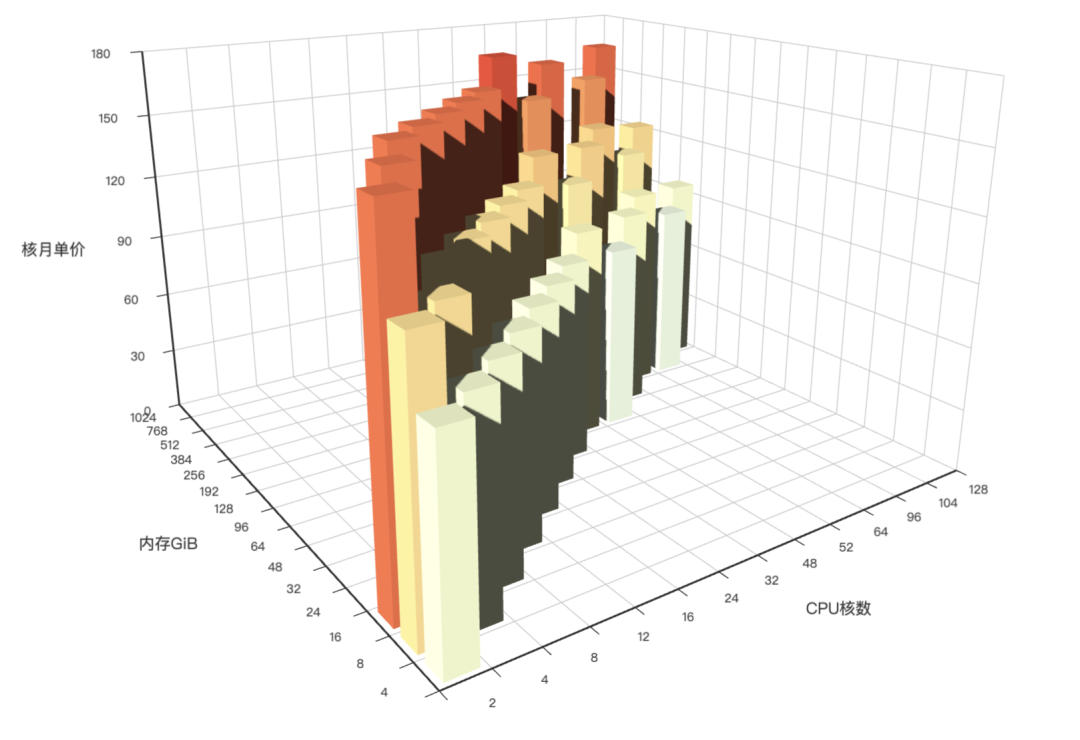
有一张表 cards,id 是自增字段的数字主键,另外有4个字段 c1,c2,c3,c4 ,每个字段随机从 1~10 之间选择一个整数 要求选手使用一条 SQL 给出 24 点的计算公式,返回的内容示例如右图:
因为 10KB 的大小限制非常猥琐 —— 最快的解法都是质数查表,而这种方式所有解的文本拼接大小大约是 10018 个字符。要想压缩这个表到 10KB 以内,必须要用到一些压缩技巧。
EXPLAIN ANALYZE
WITH a(i, result) AS (
SELECT (split_part(kv, ':', 1))::INTEGER AS i, split_part(kv, ':', 2) AS result
FROM regexp_split_to_table('152:((1+1)+1)*8,156:(6*2)*(1+1),204:(7+1)*(2+1),228:((1*1)+2)*8,276:(9-1)*(2+1),348:(10+2)*(1+1),140:(4*3)*(1+1),220:(5+1)*(3+1),260:((1+1)+6)*3,340:((1*1)+7)*3,380:(8*3)+(1-1),460:(9+3)*(1+1),580:(10-(1+1))*3,196:((1+1)+4)*4,308:((1*1)+5)*4,364:(6*4)+(1-1),476:(7-(1*1))*4,532:(8+4)*(1+1),644:(9-1)*(4-1),812:((1+1)*10)+4,484:(5*5)-(1*1),572:(5-(1*1))*6,748:(7+5)*(1+1),836:(5-(1+1))*8,676:(6+6)*(1+1),988:(8*6)/(1+1),1196:((1+1)*9)+6,1972:((1+1)*7)+10,1444:((1+1)*8)+8,126:(4*2)*(2+1),198:(2+2)*(5+1),234:(6+2)*(2+1),306:(2+2)*(7-1),342:((2-1)+2)*8,414:((2+1)+9)*2,522:(10-2)*(2+1),150:(3*2)*(3+1),210:((2+1)+3)*4,330:(5+3)*(2+1),390:((2-1)+3)*6,510:(7*3)+(2+1),570:(8*3)*(2-1),690:(9*3)-(2+1),870:(10-(2*1))*3,294:(4+4)*(2+1),462:((2-1)+5)*4,546:(6*4)*(2-1),714:(7-(2-1))*4,798:(4-(2-1))*8,966:(9-(2+1))*4,1218:((2*1)*10)+4,726:(5*5)-(2-1),858:(5-(2-1))*6,1122:(7+5)*(2*1),1254:(5-(2*1))*8,1518:((2+1)*5)+9,1914:(10*2)+(5-1),1014:((2+1)*6)+6,1326:(7-(2+1))*6,1482:(6-(2+1))*8,1794:((2*1)*9)+6,2262:((2+1)*10)-6,1734:((7*7)-1)/2,1938:(8*2)+(7+1),2346:(9*2)+(7-1),2958:((2*1)*7)+10,2166:((2*1)*8)+8,2622:(9*8)/(2+1),3306:((8-1)*2)+10,250:(3+3)*(3+1),350:((3+1)+4)*3,550:(5+3)*(3*1),650:((3-1)+6)*3,850:(7*3)+(3*1),950:((8+1)*3)-3,1150:(9-3)*(3+1),1450:(10-(3-1))*3,490:((3-1)+4)*4,770:(5*4)+(3+1),910:6/(1-(3/4)),1190:(7*4)-(3+1),1330:((3+1)*4)+8,1610:(9-(3*1))*4,2030:(10-4)*(3+1),1430:(6*3)+(5+1),1870:(7+5)*(3-1),2090:(5-(3-1))*8,2530:((3*1)*5)+9,3190:(10*3)-(5+1),1690:(6+6)*(3-1),2210:(7-(3*1))*6,2470:(8-(3+1))*6,2990:((3-1)*9)+6,3770:((3*1)*10)-6,2890:(7-3)*(7-1),3230:(7-(3+1))*8,3910:(9/3)*(7+1),4930:((3-1)*7)+10,3610:((3+1)*8)-8,4370:(9*8)/(3*1),5510:(8/3)*(10-1),5290:(9/3)*(9-1),6670:((10+1)*3)-9,8410:(10+10)+(3+1),686:((4+1)*4)+4,1078:(5*4)+(4*1),1274:((6+1)*4)-4,1666:(7*4)-(4*1),1862:((4*1)*4)+8,2254:(9-(4-1))*4,2842:(10-4)*(4*1),1694:(5*4)+(5-1),2002:6/((5/4)-1),2618:(7*4)-(5-1),2926:(8-4)*(5+1),3542:((4-1)*5)+9,4466:(10-4)*(5-1),2366:((4+1)*6)-6,3094:(7-(4-1))*6,3458:(6-(4-1))*8,4186:(9-(4+1))*6,5278:((4-1)*10)-6,4046:(7-4)*(7+1),4522:(7-(4*1))*8,5474:(7-4)*(9-1),5054:(8-(4+1))*8,6118:(9*8)/(4-1),9338:(10+9)+(4+1),11774:(10+10)+(4*1),2662:(5-(1/5))*5,3146:(6*5)-(5+1),5566:(9-5)*(5+1),7018:((10-5)*5)-1,3718:((5*1)*6)-6,4862:(6*5)-(7-1),5434:(8-(5-1))*6,6578:(9-(5*1))*6,8294:(10-6)*(5+1),7106:(7-(5-1))*8,8602:(9-5)*(7-1),10846:(7*5)-(10+1),7942:((5-1)*8)-8,9614:(9-(5+1))*8,12122:(10+8)+(5+1),11638:(9+9)+(5+1),14674:(10+9)+(5*1),18502:(10+10)+(5-1),4394:((6-1)*6)-6,6422:6/(1-(6/8)),7774:(9-(6-1))*6,9802:(10-6)*(6*1),10166:(9-6)*(7+1),12818:(10+7)+(6+1),9386:(8-(6-1))*8,11362:(9+8)+(6+1),14326:(10-(6+1))*8,13754:(9+9)+(6*1),17342:(10+9)+(6-1),13294:(9+7)+(7+1),16762:(10-7)*(7+1),12274:(8+8)+(7+1),14858:(9-(7-1))*8,18734:(10+8)+(7-1),17986:(9+9)+(7-1),22678:(10-7)*(9-1),13718:(8+8)+(8*1),16606:(9+8)+(8-1),20938:(10-(8-1))*8,135:(3*2)*(2+2),189:(4+2)*(2+2),297:((5*2)+2)*2,459:((7*2)-2)*2,513:(8-2)*(2+2),621:((9+2)*2)+2,783:(10*2)+(2+2),225:(3+3)*(2+2),315:((2+2)+4)*3,495:((5*2)-2)*3,585:((2/2)+3)*6,765:((2/2)+7)*3,855:(8*3)+(2-2),1035:(9-3)*(2+2),1305:((10+3)*2)-2,441:((4*2)-2)*4,693:(5*4)+(2+2),819:(6*4)+(2-2),1071:(7*4)-(2+2),1197:((2+2)*4)+8,1449:(9*2)+(4+2),1827:(10-4)*(2+2),1089:(5*5)-(2/2),1287:(5-(2/2))*6,1683:(7*2)+(5*2),1881:((8+5)*2)-2,2277:((5-2)+9)*2,2871:((5+2)*2)+10,1521:(6/2)*(6+2),1989:((7+2)*2)+6,2223:(8-(2+2))*6,2691:((6/2)+9)*2,3393:(10*2)+(6-2),2601:((7-2)+7)*2,2907:(7-(2+2))*8,4437:((10/2)+7)*2,3249:((2+2)*8)-8,3933:(9*2)+(8-2),4959:(10-2)+(8*2),6003:((9-2)*2)+10,7569:(10+10)+(2+2),375:((3+2)+3)*3,825:((5+2)*3)+3,975:((3-2)+3)*6,1275:((3-2)+7)*3,1425:(8*3)*(3-2),1725:((3+2)*3)+9,2175:(10*3)-(3*2),735:((3+2)*4)+4,1155:((3-2)+5)*4,1365:(6*4)*(3-2),1785:(7-(3-2))*4,1995:(4-(3-2))*8,2415:(9*4)/(3/2),3045:(10*3)-(4+2),1815:(5*5)-(3-2),2145:(5-(3-2))*6,2805:(7*3)+(5-2),3135:(5+3)+(8*2),3795:(9-5)*(3*2),4785:(5-3)*(10+2),2535:((3+2)*6)-6,3315:(7*3)+(6/2),3705:((8+2)*3)-6,4485:(9-(3+2))*6,5655:(10-6)*(3*2),4335:(7+3)+(7*2),4845:(8/3)*(7+2),5865:(9+7)*(3/2),7395:(7-3)+(10*2),5415:(8-(3+2))*8,6555:(9-(3*2))*8,8265:(10+8)+(3*2),7935:(9+9)+(3*2),10005:(10+9)+(3+2),12615:((10-3)*2)+10,1029:((4-2)+4)*4,1617:((5+2)*4)-4,1911:((4*2)-4)*6,2499:(7-4)*(4*2),2793:(8-4)*(4+2),3381:((9-2)*4)-4,4263:((4-2)*10)+4,2541:((5+5)*2)+4,3003:(6*5)-(4+2),3927:(7+5)*(4-2),4389:(5-(4-2))*8,5313:(9-5)*(4+2),6699:(10+4)+(5*2),3549:(6+6)*(4-2),4641:(7-4)*(6+2),5187:(8*6)/(4-2),6279:((4-2)*9)+6,7917:(10-6)*(4+2),6069:((7+7)*2)-4,6783:((7*2)-8)*4,8211:(9+7)+(4*2),10353:((4-2)*7)+10,7581:((4-2)*8)+8,9177:(9-(4+2))*8,11571:(10+8)+(4+2),11109:(9+9)+(4+2),14007:(10-4)+(9*2),17661:((4/10)+2)*10,6171:(5+5)+(7*2),6897:((5/5)+2)*8,8349:((5-2)*5)+9,10527:(5-(2/10))*5,5577:((5-2)*6)+6,7293:(7-(5-2))*6,8151:(6-(5-2))*8,9867:((5/2)*6)+9,12441:((5-2)*10)-6,9537:(7+7)+(5*2),10659:((5*2)-7)*8,12903:(7*5)-(9+2),16269:(10+7)+(5+2),11913:(8*5)-(8*2),14421:(9+8)+(5+2),18183:(10-(5+2))*8,22011:(9-5)+(10*2),27753:(10/5)*(10+2),6591:(6+6)+(6*2),8619:(7-(6/2))*6,9633:(8-(6-2))*6,11661:(9-6)*(6+2),14703:(10+6)+(6+2),12597:(7-(6-2))*8,15249:(9+7)+(6+2),19227:(10-7)*(6+2),14079:(8+8)+(6+2),17043:((6*2)-9)*8,21489:(10-8)*(6*2),20631:((9-6)+9)*2,26013:(9-6)*(10-2),32799:(10+10)+(6-2),16473:(8+7)+(7+2),25143:((10/7)+2)*7,18411:(8-(7-2))*8,22287:((9+7)*2)-8,34017:(10+9)+(7-2),42891:(10-7)*(10-2),20577:((8/2)*8)-8,24909:(9-(8-2))*8,31407:(10+8)+(8-2),30153:(9+9)+(8-2),38019:(10-(9-2))*8,47937:(10+10)+(8/2),58029:(10+9)+(10/2),625:((3*3)*3)-3,875:((3*3)-3)*4,1375:(5*3)+(3*3),1625:(6*3)+(3+3),2125:(7-3)*(3+3),2375:((3+3)-3)*8,2875:(9-(3/3))*3,3625:(10*3)-(3+3),1225:(4*3)+(4*3),1925:((3/3)+5)*4,2275:(6*4)+(3-3),2975:(7-(3/3))*4,3325:(8-4)*(3+3),4025:(9-(4-3))*3,3025:(5*5)-(3/3),3575:(6*5)-(3+3),4675:((5*3)-7)*3,6325:(9-5)*(3+3),7975:(10+5)+(3*3),4225:((6/3)+6)*3,5525:(7*3)+(6-3),6175:((3*3)-6)*8,7475:(9+6)+(3*3),9425:(10-6)*(3+3),7225:((3/7)+3)*7,8075:(8+7)+(3*3),9775:(9-3)*(7-3),9025:8/(3-(8/3)),10925:(9-(3+3))*8,13775:(10+8)+(3+3),13225:(9+9)+(3+3),16675:(10*3)-(9-3),1715:((4+3)*4)-4,2695:((4-3)+5)*4,3185:(6*4)*(4-3),4165:(7-(4-3))*4,4655:((4+3)-4)*8,5635:(9*4)-(4*3),7105:((10-3)*4)-4,4235:(5*5)-(4-3),5005:(5-(4-3))*6,6545:(7+5)+(4*3),7315:(8*4)-(5+3),8855:((5*3)-9)*4,11165:(10/5)*(4*3),5915:(6+6)+(4*3),8645:(8-6)*(4*3),10465:(9-(6-3))*4,13195:(10-4)+(6*3),10115:(7*4)-(7-3),11305:((7-3)*4)+8,13685:(9-7)*(4*3),17255:(10+7)+(4+3),15295:(9+8)+(4+3),19285:(10-(4+3))*8,18515:(9+9)*(4/3),29435:(10*3)-(10-4),7865:((5+5)*3)-6,10285:(7+5)*(5-3),11495:(8-5)*(5+3),13915:(9-(5/5))*3,9295:(6+6)*(5-3),12155:(7+5)*(6/3),13585:(8*6)/(5-3),16445:(9-6)*(5+3),20735:(10+6)+(5+3),17765:(8-5)+(7*3),21505:(9+7)+(5+3),27115:(10-7)*(5+3),19855:(8+8)+(5+3),24035:(9*3)-(8-5),29095:((5/3)*9)+9,36685:(10/5)*(9+3),46255:(10-(10/5))*3,10985:((6-3)*6)+6,14365:(7-(6-3))*6,16055:((6+3)-6)*8,19435:(9+6)+(6+3),24505:((6-3)*10)-6,18785:((7-6)+7)*3,20995:(8+7)+(6+3),25415:(9-6)+(7*3),32045:((6/3)*7)+10,23465:((6/3)*8)+8,28405:(9*8)/(6-3),35815:(10-(8-6))*3,34385:(9*3)-(9-6),43355:(10-6)*(9-3),54665:(3-(6/10))*10,24565:(7+7)+(7+3),27455:((7+3)-7)*8,33235:(9-(7/7))*3,41905:(10-7)+(7*3),30685:((7-3)*8)-8,37145:(9-(8-7))*3,44965:(9-7)*(9+3),56695:(9*3)-(10-7),71485:(10+10)+(7-3),34295:((8+3)-8)*8,41515:(9-8)*(8*3),52345:((10*8)-8)/3,50255:(9-9)+(8*3),63365:(10+9)+(8-3),79895:(10-10)+(8*3),60835:(9+9)+(9-3),76705:((9+9)-10)*3,96715:(9-(10/10))*3,2401:(4*4)+(4+4),3773:((4/4)+5)*4,4459:((4+4)-4)*6,5831:(7-4)*(4+4),6517:(8*4)-(4+4),7889:((9-4)*4)+4,9947:(10*4)-(4*4),5929:(5*5)-(4/4),7007:(5-(4/4))*6,9163:(7-(5-4))*4,10241:(8-5)*(4+4),15631:((10-5)*4)+4,12103:(8+4)*(6-4),14651:(9-6)*(4+4),18473:(10+6)+(4+4),14161:(4-(4/7))*7,15827:(7*4)-(8-4),19159:(9+7)+(4+4),24157:(10-7)*(4+4),17689:(8+8)+(4+4),21413:(9*4)-(8+4),26999:(10-4)*(8-4),41209:((10*10)-4)/4,9317:(5*5)-(5-4),11011:((5+4)-5)*6,14399:(7-(5/5))*4,16093:(4-(5/5))*8,19481:(9-5)+(5*4),24563:(10+5)+(5+4),13013:(6-5)*(6*4),17017:(7+5)*(6-4),19019:((5+4)-6)*8,23023:(9+6)+(5+4),29029:(10-6)+(5*4),22253:(7*5)-(7+4),24871:(8+7)+(5+4),30107:((7-4)*5)+9,37961:((7-5)*10)+4,27797:(5-(8/4))*8,33649:(9-(8-5))*4,42427:(10/5)*(8+4),40733:((9/9)+5)*4,51359:(9-5)*(10-4),64757:((10/5)*10)+4,15379:((6+4)-6)*6,20111:(7-6)*(6*4),22477:(8+6)+(6+4),27209:((6-4)*9)+6,34307:(10+6)*(6/4),26299:(7+7)+(6+4),29393:((6+4)-7)*8,35581:(9+7)*(6/4),44863:((6-4)*7)+10,32851:((6-4)*8)+8,39767:(9-8)*(6*4),50141:((8-6)*10)+4,48139:(9-9)+(6*4),60697:(10-9)*(6*4),76531:(10-10)+(6*4),34391:(7-(7/7))*4,38437:((7+7)-8)*4,42959:((7+4)-8)*8,52003:(9*8)/(7-4),65569:((7/4)*8)+10,62951:(7-(9/9))*4,79373:(10*4)-(9+7),100079:(7-(10/10))*4,48013:((8-4)*8)-8,58121:((8+4)-9)*8,73283:(10-8)*(8+4),70357:(4-(9/9))*8,88711:((9+4)-10)*8,111853:(10+10)+(8-4),107387:(10+9)+(9-4),14641:(5*5)-(5/5),17303:(5*5)-(6-5),30613:(9+5)+(5+5),20449:((5+5)-6)*6,26741:(5*5)-(7-6),29887:(8+6)+(5+5),34969:(7+7)+(5+5),39083:((5+5)-7)*8,59653:(10/5)*(7+5),43681:(5*5)-(8/8),52877:(5*5)-(9-8),66671:(10+5)*(8/5),64009:(5*5)-(9/9),80707:(5*5)-(10-9),101761:(5*5)-(10/10),24167:(5-(6/6))*6,31603:(7+6)+(6+5),35321:((8-5)*6)+6,42757:(9*6)-(6*5),53911:((10-5)*6)-6,41327:(5-(7/7))*6,46189:(8-6)*(7+5),55913:((7-5)*9)+6,51623:((6+5)-8)*8,62491:((8+5)-9)*6,78793:(6*5)/(10/8),75647:((9-6)*5)+9,95381:((9+5)-10)*6,120263:(10+10)*(6/5),73117:(9-7)*(7+5),92191:((7-5)*7)+10,67507:((7-5)*8)+8,81719:((7+5)-9)*8,103037:(10-8)*(7+5),124729:((10-7)*5)+9,157267:((7/5)*10)+10,75449:(8*5)-(8+8),91333:(9*8)/(8-5),115159:((8+5)-10)*8,212773:(10+10)+(9-5),28561:(6+6)+(6+6),41743:(8-6)*(6+6),50531:(6*6)/(9/6),63713:(10*6)-(6*6),66079:(9-7)*(6+6),83317:((10-7)*6)+6,61009:(8*6)/(8-6),73853:((6+6)-9)*8,93119:(10-8)*(6+6),112723:((9-6)*10)-6,108953:((7+7)-10)*6,96577:(8*6)/(9-7),121771:((7+6)-10)*8,116909:(7*6)-(9+9),185861:((10-7)*10)-6,89167:((8-6)*8)+8,107939:(9*8)-(8*6),136097:(8*6)/(10-8),130663:(9+9)*(8/6),164749:((10-8)*9)+6,199433:((9/6)*10)+9,317057:(10+10)+(10-6),192763:((9-7)*7)+10,141151:((9-7)*8)+8,177973:(10*8)-(8*7),215441:(9*8)/(10-7),271643:((10-8)*7)+10,198911:((10-8)*8)+8', ',') AS kv
)
SELECT c.id, c1, c2, c3, c4, result
FROM poker24.cards c LEFT JOIN a a ON a.i =
( CASE c1 WHEN 1 THEN 2 WHEN 2 THEN 3 WHEN 3 THEN 5 WHEN 4 THEN 7 WHEN 5 THEN 11 WHEN 6 THEN 13 WHEN 7 THEN 17 WHEN 8 THEN 19 WHEN 9 THEN 23 WHEN 10 THEN 29 END
* CASE c2 WHEN 1 THEN 2 WHEN 2 THEN 3 WHEN 3 THEN 5 WHEN 4 THEN 7 WHEN 5 THEN 11 WHEN 6 THEN 13 WHEN 7 THEN 17 WHEN 8 THEN 19 WHEN 9 THEN 23 WHEN 10 THEN 29 END
* CASE c3 WHEN 1 THEN 2 WHEN 2 THEN 3 WHEN 3 THEN 5 WHEN 4 THEN 7 WHEN 5 THEN 11 WHEN 6 THEN 13 WHEN 7 THEN 17 WHEN 8 THEN 19 WHEN 9 THEN 23 WHEN 10 THEN 29 END
* CASE c4 WHEN 1 THEN 2 WHEN 2 THEN 3 WHEN 3 THEN 5 WHEN 4 THEN 7 WHEN 5 THEN 11 WHEN 6 THEN 13 WHEN 7 THEN 17 WHEN 8 THEN 19 WHEN 9 THEN 23 WHEN 10 THEN 29 END);
当然,这里的字符串长度超过了 10000: 10896 个。我们可以用一些手段来压缩,比如把这个巨长的 CASE 弄成一个 inline 函数,然后再把主键从十进制数字字面值换成十六进制,其实长度就在 10KB 以内了。
不过规则禁止我们使用存储过程,这就要想其他办法了。主要就是如何压缩中间那个长字符串。
其实,如果在用上并行优化也许还能再快点,然后 PostgreSQL 还有一种其他数据库做不到的解法。那就是直接把这个查表动作封装成一个扩展,然后用C语言直接暴露存储过程给 SQL 调用。这样就能把这个计算过程优化到极致了。当然,这种我们也懒得折腾了。