多数据中心高可用
基于 Patroni 复制的多数据中心高可用架构模式。
原始页面: https://patroni.readthedocs.io/en/latest/ha_multi_dc.html
部署在多个数据中心的 PostgreSQL 集群,其高可用基于复制实现,复制可以是同步的,也可以是异步的(参见 复制模式)。
无论哪种模式,都需要明确以下概念:
- PostgreSQL 仅在持有领导者键且能够更新领导者键时,才能以主库或备用领导者身份运行。
- etcd、ZooKeeper 或 Consul 节点的数量应为奇数:3 个或 5 个!
同步复制
要构建能够自动容忍单区域故障的多数据中心集群,至少需要 3 个数据中心。
架构图如下:
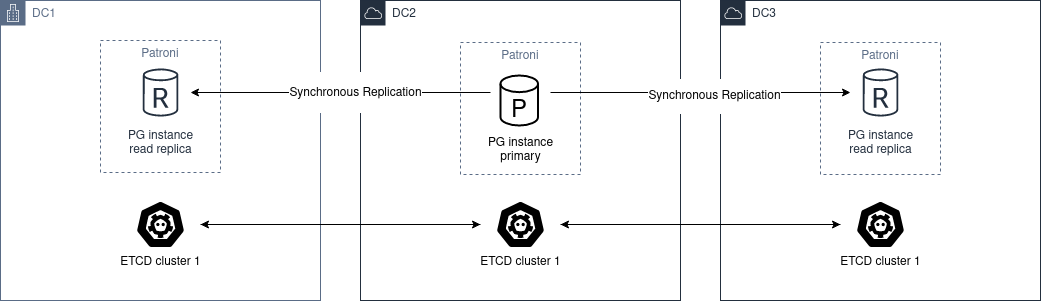
需要跨不同数据中心部署一个 etcd、ZooKeeper 或 Consul 集群,至少包含 3 个节点,每个可用区各一个。
PostgreSQL 方面,至少需要在不同数据中心部署 2 个节点,然后在全局 动态配置 中设置 synchronous_mode: true。
这将启用同步复制,主库会从其他节点中选择一个作为同步备库。
异步复制
如果只有两个数据中心,更好的方案是部署两个独立的 etcd 集群,并在第二个数据中心运行 Patroni 备用集群。当第一个站点宕机时,可以手动提升备用集群。
架构图如下:
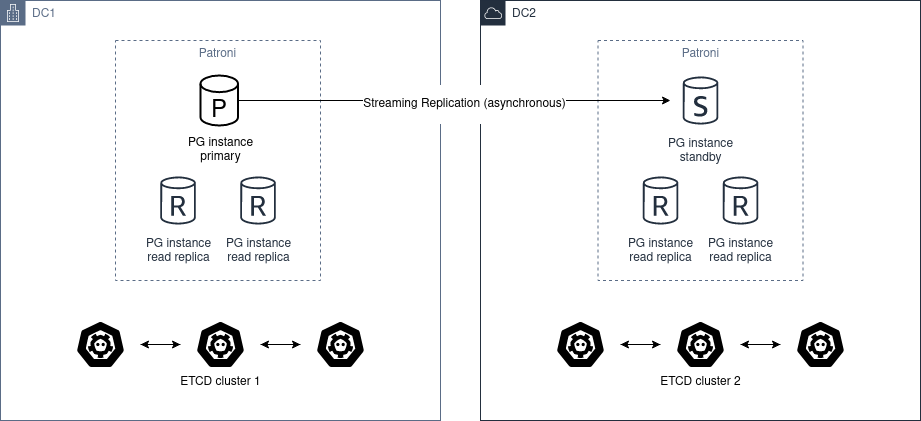
自动提升是不可能的,因为 DC2 永远无法确定 DC1 的真实状态。
此场景下不应使用 pg_ctl promote,而需要通过从 动态配置 中移除 standby_cluster 配置节来"手动提升"健康集群。
警告
若源集群仍在运行,此时提升备用集群将造成脑裂。
若需恢复到"初始"状态,只有以下两种方式:
- 重新添加
standby_cluster配置节,这将触发pg_rewind。但要使pg_rewind正常工作,集群必须在初始化时启用了data page checksums(即initdb的--data-checksums选项)和/或将wal_log_hints设置为on,且仍存在pg_rewind因其他因素失败的可能性。 - 从头重建备用集群。
在提升备用集群之前,必须人工确认源集群已停止(STONITH)。DC1 恢复后,该集群需要被转换为备用集群。
在执行此操作之前,可以手动检查数据库,提取从 DC1 与 DC2 之间网络中断到手动停止 DC1 集群这段时间内发生的所有变更,并在必要时手动将这些变更应用到 DC2 的集群中。