监控告警
如何在 Pigsty 中监控 Node?如何使用 Node 本身的管控面板?有哪些告警规则值得关注?
Pigsty 中的 NODE 模块提供了 8 个监控面板和完善的告警规则。
监控面板
NODE 模块提供 8 个监控仪表板:
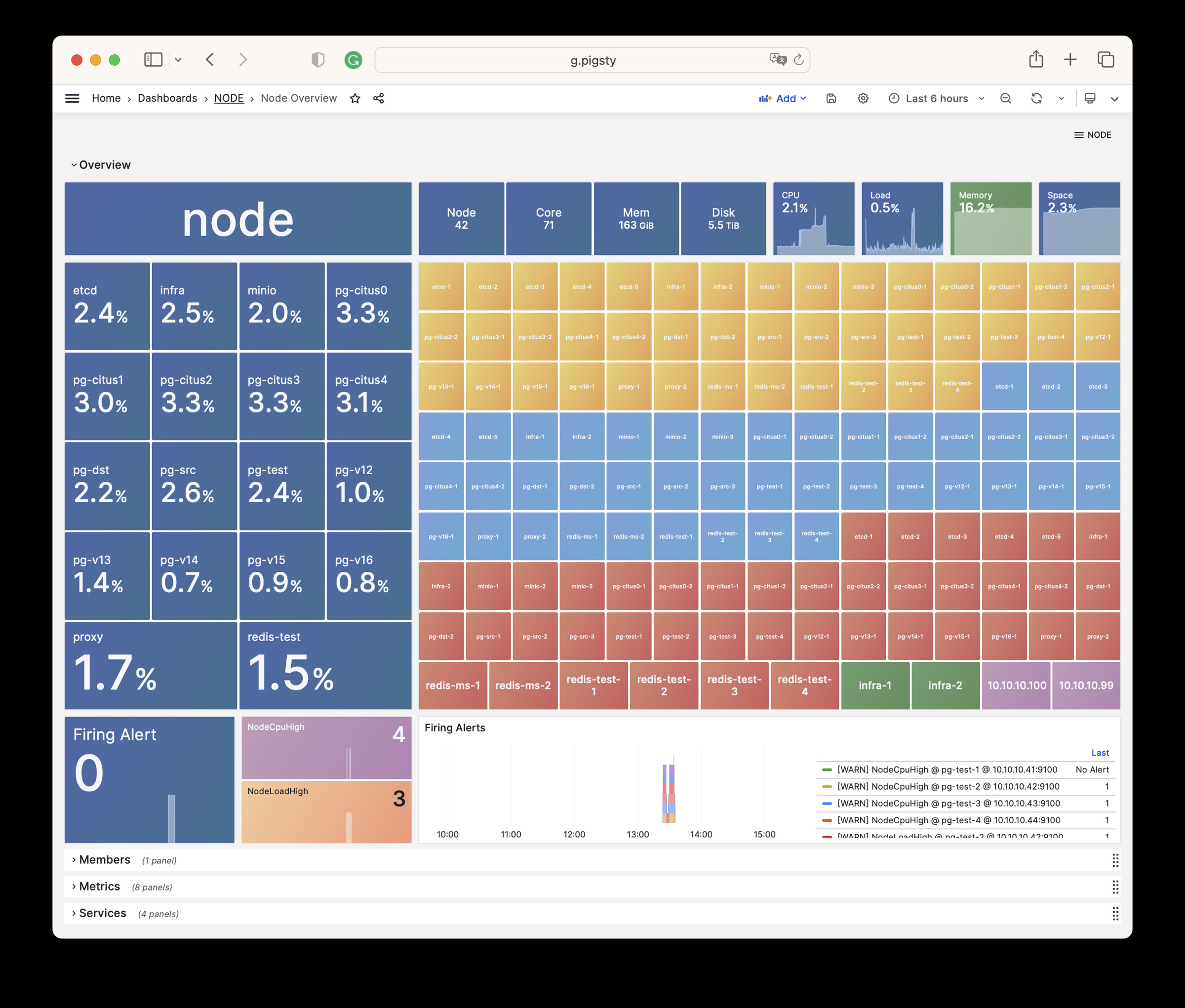
NODE Overview
展示当前环境所有主机节点的总体情况概览。
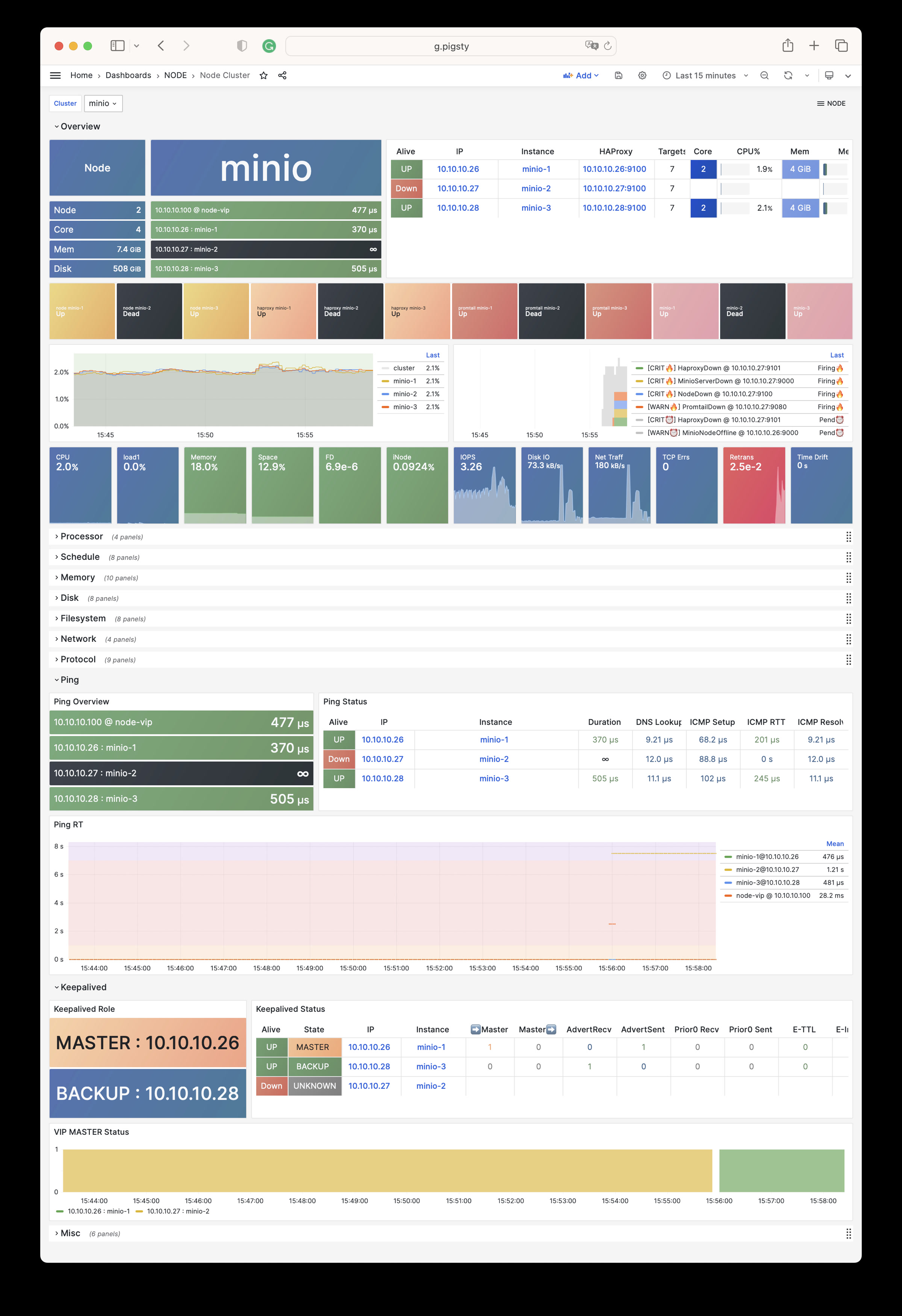
NODE Cluster
显示特定主机集群的详细监控数据。
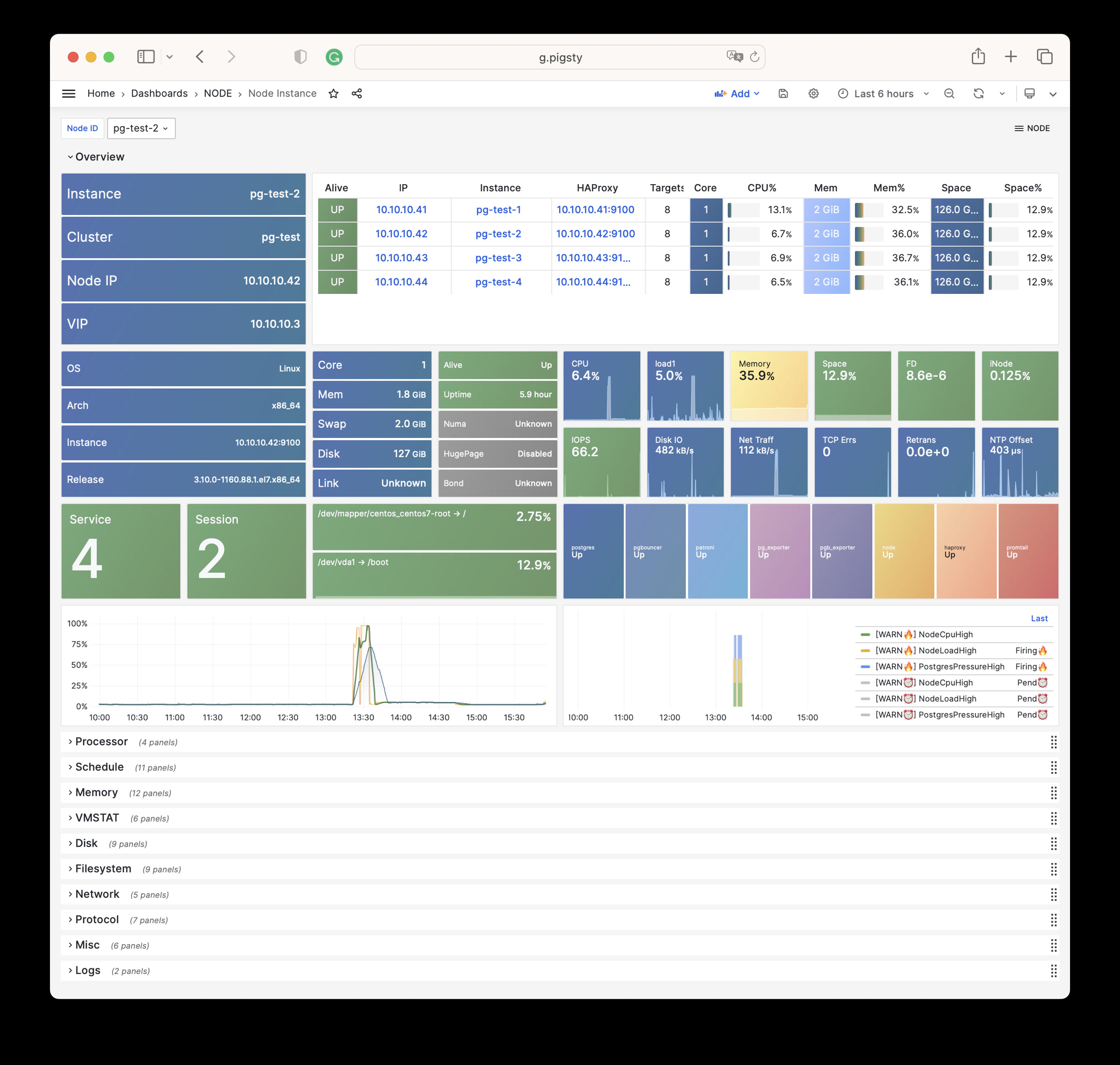
Node Instance
呈现单个主机节点的详细监控信息。
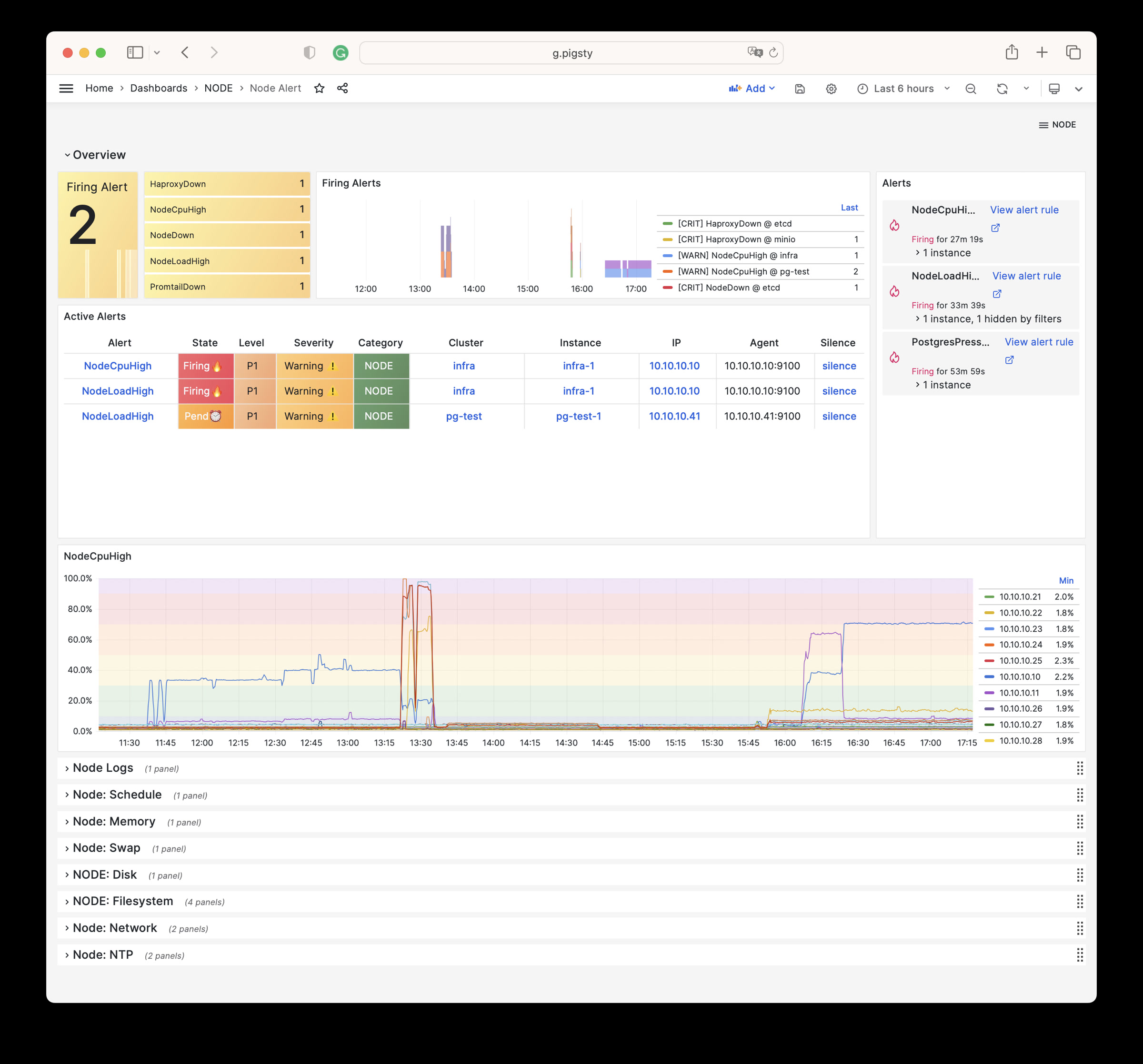
NODE Alert
集中展示环境中所有主机的告警信息。
NODE VIP
监控 L2 虚拟 IP 的详细状态。
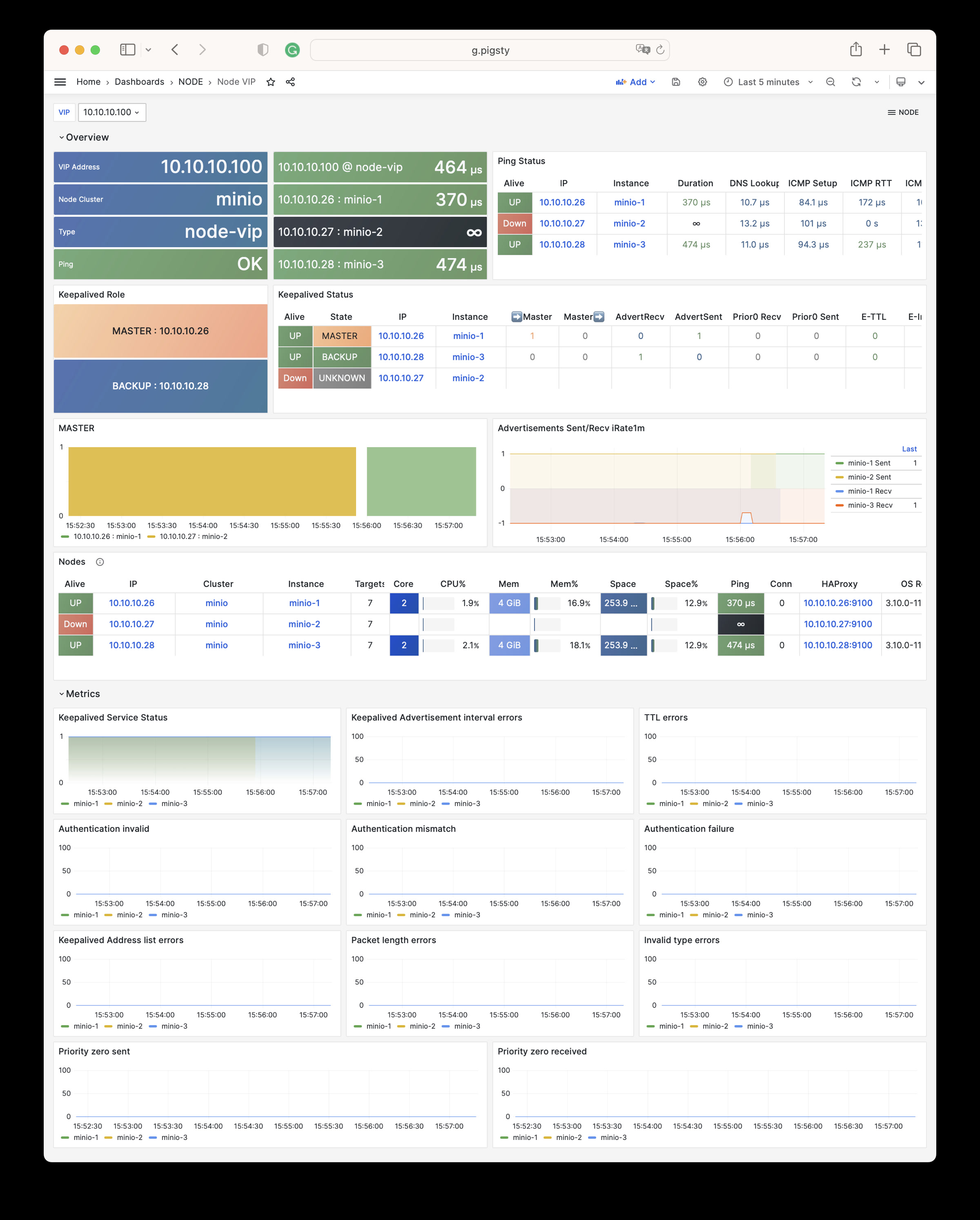
Node Haproxy
追踪 HAProxy 负载均衡器的运行情况。
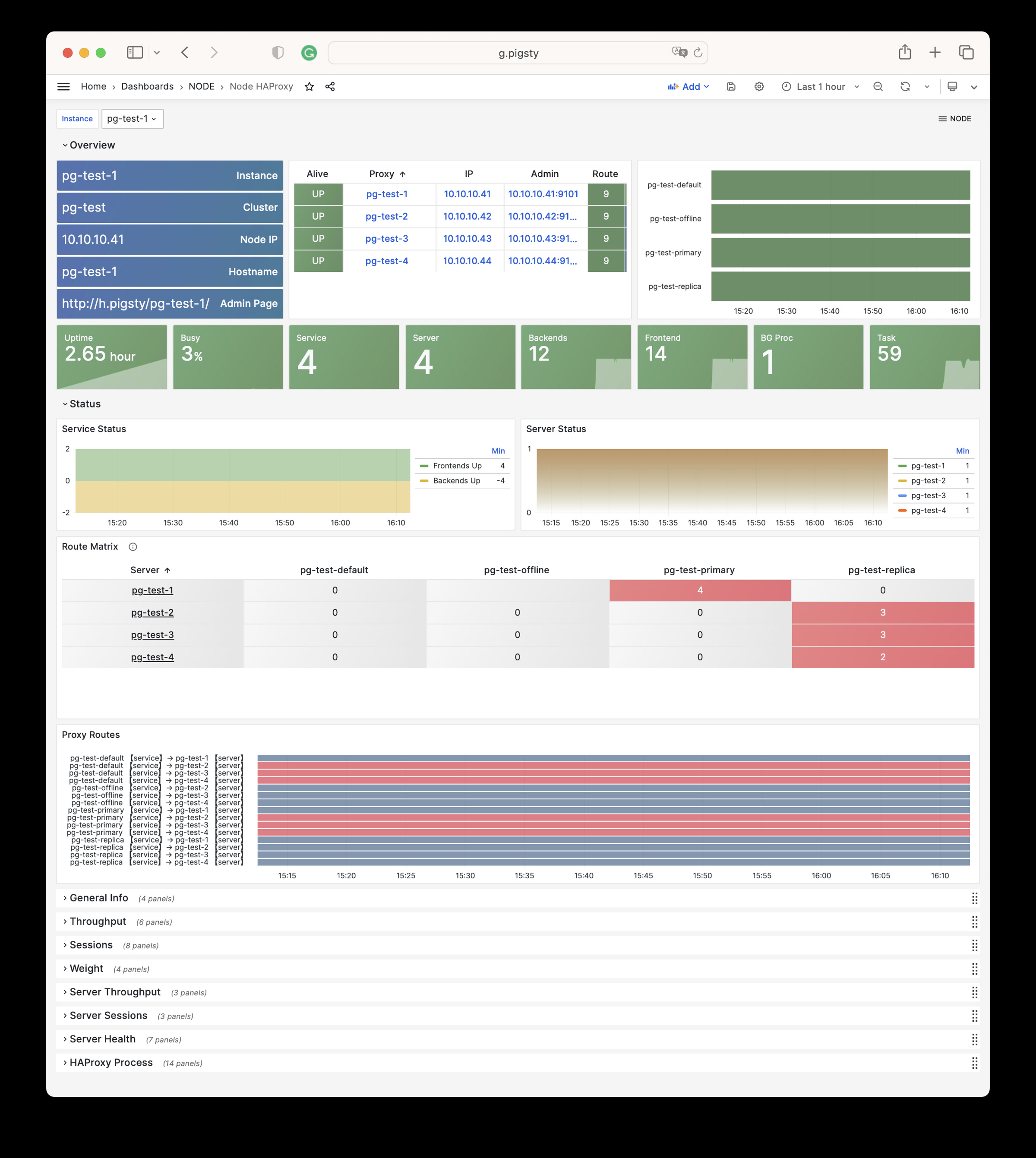
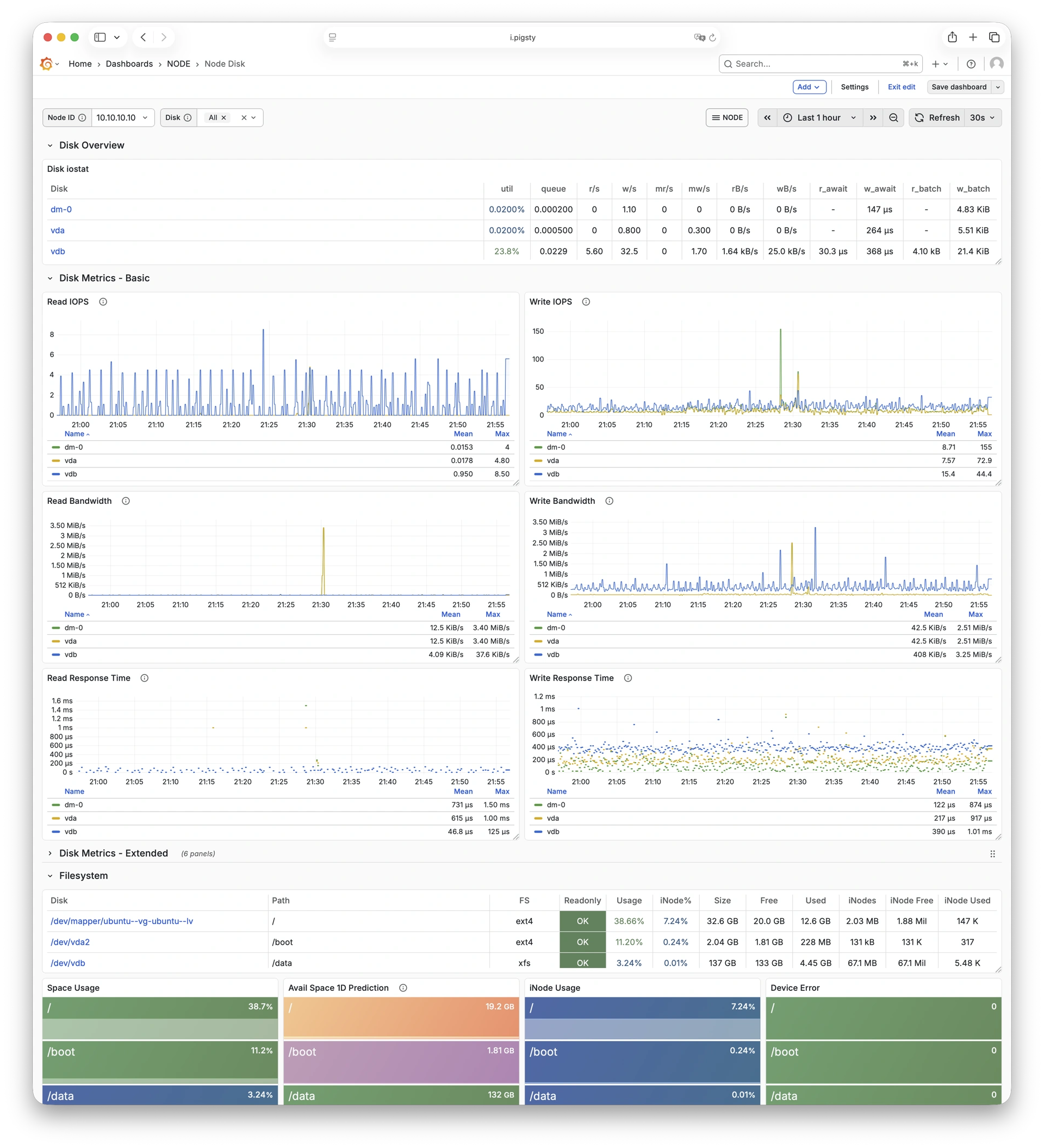
Node Disk
聚焦单盘 I/O 延迟、吞吐与队列深度等存储指标。
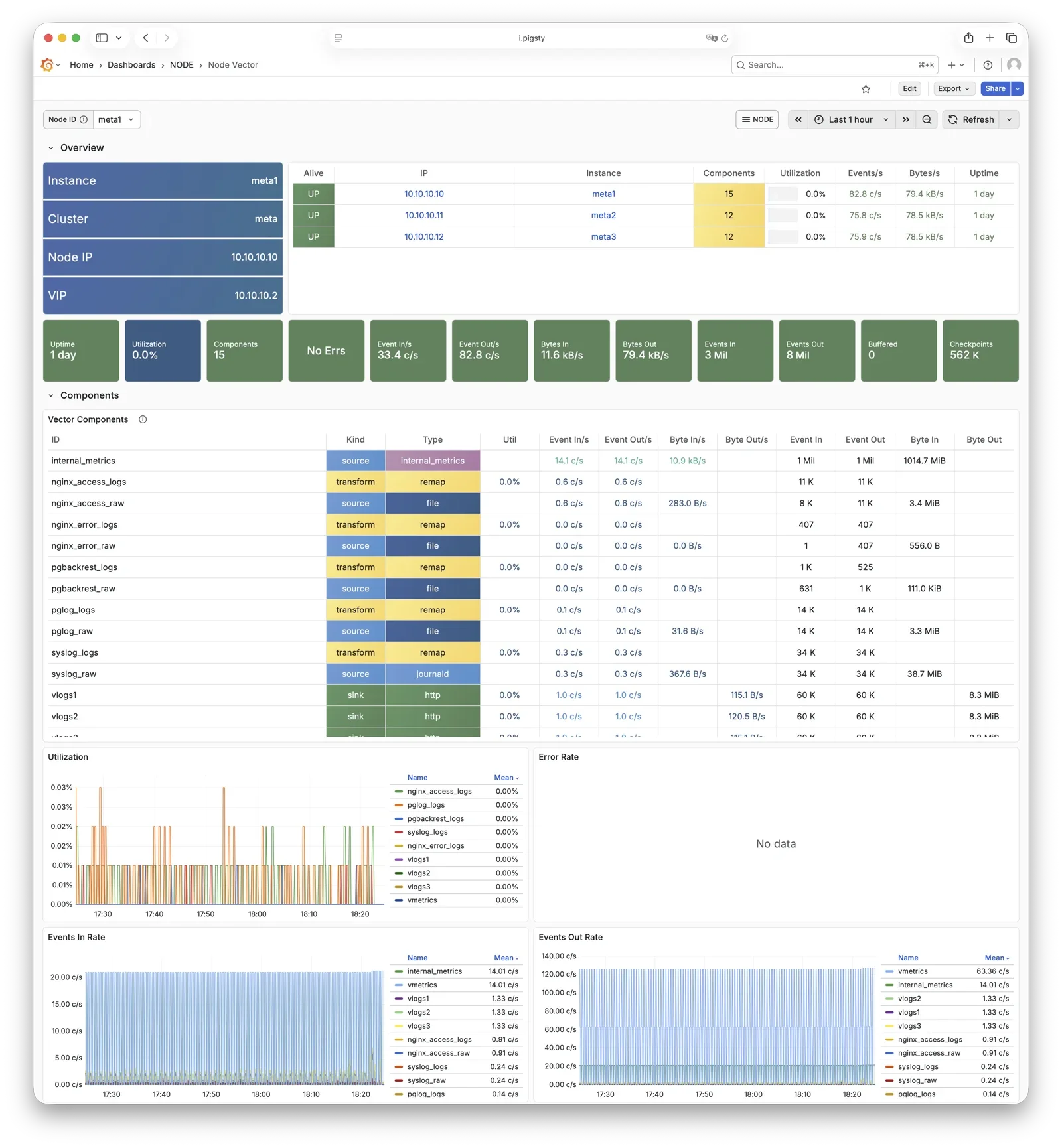
Node Vector
查看 Vector 采集与转发状态,以及日志管道健康度。
告警规则
Pigsty 针对 NODE 实现了以下告警规则:
可用性告警
| 规则 | 级别 | 说明 |
|---|---|---|
NodeDown | CRIT | 节点离线 |
HaproxyDown | CRIT | HAProxy 服务离线 |
VectorDown | WARN | 日志收集代理离线(Vector) |
DockerDown | WARN | 容器引擎离线 |
KeepalivedDown | WARN | Keepalived 守护进程离线 |
CPU 告警
| 规则 | 级别 | 说明 |
|---|---|---|
NodeCpuHigh | WARN | CPU 使用率超过 70% |
调度告警
| 规则 | 级别 | 说明 |
|---|---|---|
NodeLoadHigh | WARN | 标准化负载超过 100% |
内存告警
| 规则 | 级别 | 说明 |
|---|---|---|
NodeOutOfMem | WARN | 可用内存少于 10% |
NodeMemSwapped | WARN | Swap 使用率超过 1% |
文件系统告警
| 规则 | 级别 | 说明 |
|---|---|---|
NodeFsSpaceFull | WARN | 磁盘使用率超过 90% |
NodeFsFilesFull | WARN | Inode 使用率超过 90% |
NodeFdFull | WARN | 文件描述符使用率超过 90% |
磁盘告警
| 规则 | 级别 | 说明 |
|---|---|---|
NodeDiskSlow | INFO | 读写延迟超过 32ms |
网络协议告警
| 规则 | 级别 | 说明 |
|---|---|---|
NodeTcpErrHigh | WARN | TCP 错误率超过 1/分钟 |
NodeTcpRetransHigh | INFO | TCP 重传率超过 1% |
时间同步告警
| 规则 | 级别 | 说明 |
|---|---|---|
NodeTimeDrift | WARN | 系统时间未同步 |