RPO 利弊权衡
针对 RPO (Recovery Point Objective)进行利弊权衡,在可用性与数据损失之间找到最佳平衡点。
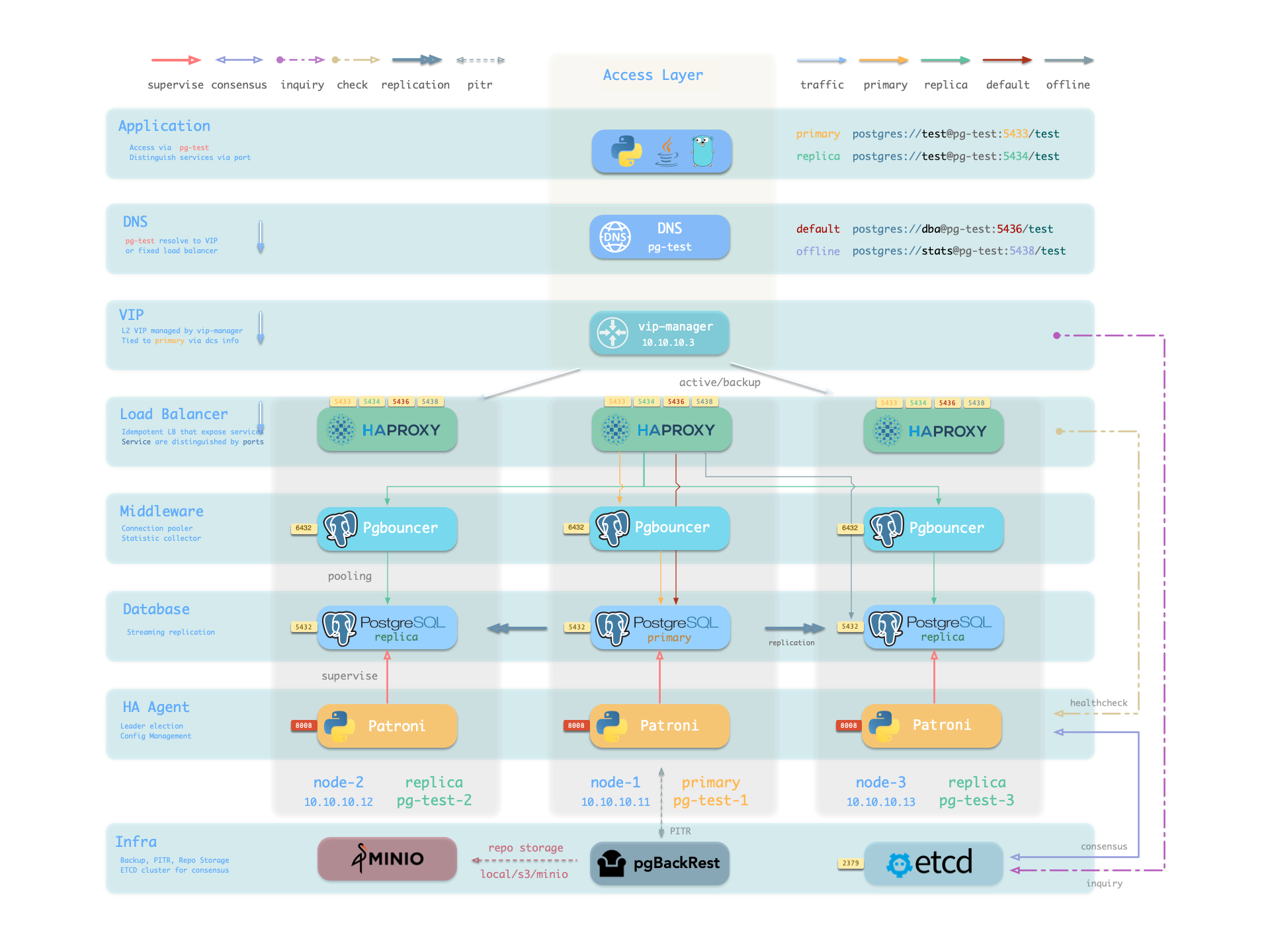
Pigsty 的 PostgreSQL 集群带有开箱即用的高可用方案,由 Patroni、Etcd 和 HAProxy 强力驱动。
当您的 PostgreSQL 集群含有两个或更多实例时,您无需任何配置即拥有了硬件故障自愈的数据库高可用能力 —— 只要集群中有任意实例存活,集群就可以对外提供完整的服务,而客户端只要连接至集群中的任意节点,即可获得完整的服务,而无需关心主从拓扑变化。
在默认配置下,主库故障恢复时间目标 RTO ≈ 45s,数据恢复点目标 RPO < 1MB;从库故障 RPO = 0,RTO ≈ 0 (闪断);在一致性优先模式下,可确保故障切换数据零损失: RPO = 0。以上指标均可通过参数,根据您的实际硬件条件与可靠性要求 按需配置。
Pigsty 内置了 HAProxy 负载均衡器用于自动流量切换,提供 DNS/VIP/LVS 等多种接入方式供客户端选用。故障切换与主动切换对业务侧除零星闪断外几乎无感知,应用不需要修改连接串重启。 极小的维护窗口需求带来了极大的灵活便利:您完全可以在无需应用配合的情况下滚动维护升级整个集群。硬件故障可以等到第二天再抽空善后处置的特性,让研发,运维与 DBA 都能在故障时安心睡个好觉。
许多大型组织与核心机构已经在生产环境中长时间使用 Pigsty ,最大的部署有 25K CPU 核心与 220+ PostgreSQL 超大规格实例(64c / 512g / 3TB NVMe SSD);在这一部署案例中,五年内经历了数十次硬件故障与各类事故,但依然可以保持高于 99.999% 的总体可用性战绩。
高可用(High-Availability)解决什么问题?
高可用有什么代价?
高可用的局限性
因为复制实时进⾏,所有变更被⽴即应⽤⾄从库。因此基于流复制的高可用方案⽆法应对⼈为错误与软件缺陷导致的数据误删误改。(例如:DROP TABLE,或 DELETE 数据)
此类故障需要使用 延迟集群,或使用先前的基础备份与 WAL 归档进行 时间点恢复。
| 配置策略 | RTO | RPO |
|---|---|---|
| 单机 + 什么也不做 | 数据永久丢失,无法恢复 | 数据全部丢失 |
| 单机 + 基础备份 | 取决于备份大小与带宽(几小时) | 丢失上一次备份后的数据(几个小时到几天) |
| 单机 + 基础备份 + WAL归档 | 取决于备份大小与带宽(几小时) | 丢失最后尚未归档的数据(几十MB) |
| 主从 + 手工故障切换 | 十分钟 | 丢失复制延迟中的数据(约百KB) |
| 主从 + 自动故障切换 | 一分钟内 | 丢失复制延迟中的数据(约百KB) |
| 主从 + 自动故障切换 + 同步提交 | 一分钟内 | 无数据丢失 |
在 Pigsty 中,高可用架构的实现原理如下:
当主库故障时,将触发新一轮领导者竞选,集群中最为健康的从库将胜出(LSN位点最高,数据损失最小者),并被提升为新的主库。 胜选从库提升后,读写流量将立即路由至新的主库。 主库故障影响是 写服务短暂不可用:从主库故障到新主库提升期间,写入请求将被阻塞或直接失败,不可用时长通常在 15秒 ~ 30秒,通常不会超过 1 分钟。
当从库故障时,只读流量将路由至其他从库,如果所有从库都故障,只读流量才会最终由主库承载。 从库故障的影响是 部分只读查询闪断:当前从库上正在运行查询将由于连接重置而中止,并立即由其他可用从库接管。
故障检测由 Patroni 和 Etcd 共同完成,集群领导者将持有一个租约, 如果集群领导者因为故障而没有及时续租(10s),租约将会被释放,并触发 故障切换(Failover) 与新一轮集群选举。
即使没有出现任何故障,您依然可以主动通过 主动切换(Switchover)变更集群的主库。 在这种情况下,主库上的写入查询将会闪断,并立即路由至新主库执行。这一操作通常可用于滚动维护/升级数据库服务器。
针对 RPO (Recovery Point Objective)进行利弊权衡,在可用性与数据损失之间找到最佳平衡点。
针对 RTO (Recovery Time Objective)进行利弊权衡,在故障恢复速度与误切风险之间找到最佳平衡点。
详细分析三种经典故障检测/恢复路径下,最差,最优,平均 RTO 的计算逻辑与结果
Pigsty 使用 HAProxy 提供服务接入,并提供可选的 pgBouncer 池化连接,以及可选的 L2 VIP 与 DNS 接入。