任务教程
1 - 故障排查
本文档列举了 PostgreSQL 和 Pigsty 中可能出现的故障,以及定位、处理、分析问题的 SOP。
磁盘空间写满
磁盘空间写满是最常见的故障类型。
现象
当数据库所在磁盘空间耗尽时,PostgreSQL 将无法正常工作,可能出现以下现象:数据库日志反复报错"no space left on device"(磁盘空间不足), 新数据无法写入,甚至 PostgreSQL 可能触发 PANIC 强制关闭。
Pigsty 带有 NodeFsSpaceFull 告警规则,当文件系统可用空间不足 10% 时触发告警。 使用监控系统 NODE Instance 面板查阅 FS 指标面板定位问题。
诊断
您也可以登录数据库节点,使用 df -h 查看各挂载盘符使用率,确定哪个分区被写满。
对于数据库节点,重点检查以下目录及其大小,以判断是哪个类别的文件占满了空间:
- 数据目录(
/pg/data/base):存放表和索引的数据文件,大量写入与临时文件需要关注 - WAL目录(如
pg/data/pg_wal):存放 PG WAL,WAL 堆积/复制槽保留是常见的磁盘写满原因。 - 数据库日志目录(如
pg/log):如果 PG 日志未及时轮转写大量报错写入,也可能占用大量空间。 - 本地备份目录(如
data/backups):使用 pgBackRest 等在本机保存备份时,也有可能撑满磁盘。
如果问题出在 Pigsty 管理节点或监控节点,还需考虑:
- 监控数据:VictoriaMetrics 的时序指标和 VictoriaLogs 日志存储都会占用磁盘,可检查保留策略。
- 对象存储数据:Pigsty 集成的 MinIO 对象存储可能会被用于 PG 备份保存。
明确占用空间最大的目录后,可进一步使用 du -sh <目录> 深入查找特定大型文件或子目录。
处理
磁盘写满属于紧急问题,需立即采取措施释放空间并保证数据库继续运行。
当数据盘并未与系统盘区分时,写满磁盘可能导致 Shell 命令无法执行。这种情况下,可以删除 /pg/dummy 占位文件,释放少量应急空间以便 shell 命令恢复正常。
如果数据库由于 pg_wal 写满已经宕机,清理空间后需要重启数据库服务并仔细检查数据完整性。
事务号回卷
PostgreSQL 循环使用 32 位事务ID (XID),耗尽时会出现"事务号回卷"故障(XID Wraparound)。
现象
第一阶段的典型征兆是 PGSQL Persist - Age Usage 面板年龄饱和度进入警告区域。
数据库日志开始出现:WARNING: database "postgres" must be vacuumed within xxxxxxxx transactions 字样的信息。
若问题持续恶化,PostgreSQL 会进入保护模式:当剩余事务ID不到约100万时数据库切换为只读模式;达到上限约21亿(2^31)时则拒绝任何新事务并迫使服务器停机以避免数据错误。
诊断
PostgreSQL 与 Pigsty 默认启用自动垃圾回收(AutoVacuum),因此此类故障出现通常有更深层次的根因。 常见的原因包括:超长事务(SAGE),Autovacuum 配置失当,复制槽阻塞,资源不足,存储引擎/扩展BUG,磁盘坏块。
首先定位年龄最大的数据库,然后可通过 Pigsty PGCAT Database - Tables 面板来确认表的年龄分布。 同时查阅数据库错误日志,通常可以找到定位根因的线索。
处理
- 立即冻结老事务:如果数据库尚未进入只读保护状态,立刻对受影响的库执行一次手动 VACUUM FREEZE。可以从老化最严重的表开始逐个冻结,而不是整库一起做,以加快效果。使用超级用户连接数据库,针对识别出的
relfrozenxid最大的表运行VACUUM FREEZE 表名;,优先冻结那些XID年龄最大的表元组。这样可以迅速回收大量事务ID空间。 - 单用户模式救援:如果数据库已经拒绝写入或宕机保护,此时需要启动数据库到单用户模式执行冻结操作。在单用户模式下运行
VACUUM FREEZE database_name;对整个数据库进行冻结清理。完成后再以多用户模式重启数据库。这样做可以解除回卷锁定,让数据库重新可写。需要注意在单用户模式下操作要非常谨慎,并确保有足够的事务ID余量完成冻结。 - 备用节点接管:在某些复杂场景(例如遭遇硬件问题导致 vacuum 无法完成),可考虑提升集群中的只读备节点为主,以获取一个相对干净的环境来处理冻结。例如主库因坏块导致无法 vacuum,此时可以手动Failover提升备库为新的主库,再对其进行紧急 vacuum freeze。确保新主库已冻结老事务后,再将负载切回来。
连接耗尽
PostgreSQL 有一个最大连接数配置 (max_connections),当客户端连接数超过此上限时,新的连接请求将被拒绝。典型现象是在应用端看到数据库无法连接,并报出类似
FATAL: remaining connection slots are reserved for non-replication superuser connections 或 too many clients already 的错误。
这表示普通连接数已用完,仅剩下保留给超管或复制的槽位
诊断
连接耗尽通常由客户端大量并发请求引起。您可以通过 PGCAT Instance / PGCAT Database / PGCAT Locks 直接查阅数据库当前的活跃会话。 并判断是什么样的查询填满了系统,并进行进一步的处理。特别需要关注是否存在大量 Idle in Transaction 状态的连接以及长时间运行的事务(以及慢查询)。
处理
杀查询:对于已经耗尽导致业务受阻的情况,通常立即使用 pg_terminate_backend(pid) 进行紧急降压。
对于使用连接池的情况,则可以调整连接池大小参数,并执行 reload 重载的方式减少数据库层面的连接数量。
您也可以修改 max_connections 参数为更大的值,但本参数需要重启数据库后才能生效。
etcd 配额写满
etcd 配额写满将导致 PG 高可用控制面失效,无法进行配置变更。
诊断
Pigsty 在实现高可用时使用 etcd 作为分布式配置存储(DCS),etcd 自身有一个存储配额(默认约为2GB)。 当 etcd 存储用量达到配额上限时,etcd 将拒绝写入操作,报错 “etcdserver: mvcc: database space exceeded"。在这种情况下,Patroni 无法向 etcd 写入心跳或更新配置,从而导致集群管理功能失效。
解决
在 Pigsty v2.0.0 - v2.5.1 之间的版本默认受此问题影响。Pigsty v2.6.0 为部署的 etcd 新增了自动压实的配置项,如果您仅将其用于 PG 高可用租约,则常规用例下不会再有此问题。
有缺陷的存储引擎
目前,TimescaleDB 的试验性存储引擎 Hypercore 被证实存在缺陷,已经出现 VACUUM 无法回收出现 XID 回卷故障的案例。 请使用该功能的用户及时迁移至 PostgreSQL 原生表或者 TimescaleDB 默认引擎
详细介绍:《PG新存储引擎故障案例》
2 - 误删处理
误删数据
如果是小批量 DELETE 误操作,可以考虑使用 pg_surgery 或者 pg_dirtyread 扩展进行原地手术恢复。
-- 立即关闭此表上的 Auto Vacuum 并中止 Auto Vacuum 本表的 worker 进程
ALTER TABLE public.some_table SET (autovacuum_enabled = off, toast.autovacuum_enabled = off);
CREATE EXTENSION pg_dirtyread;
SELECT * FROM pg_dirtyread('tablename') AS t(col1 type1, col2 type2, ...);
如果被删除的数据已经被 VACUUM 回收,那么使用通用的误删处理流程。
误删对象
当出现 DROP/DELETE 类误操作,通常按照以下流程决定恢复方案。
- 确认此数据是否可以通过业务系统或其他数据系统找回,如果可以,直接从业务侧修复。
- 确认是否有延迟从库,如果有,推进延迟从库至误删时间点,查询出来恢复。
- 如果数据已经确认删除,确认备份信息,恢复范围是否覆盖误删时间点,如果覆盖,开始 PITR
- 确认是整集群原地 PITR 回滚,还是新开服务器重放,还是用从库来重放,并执行恢复策略
误删集群
如果出现整个数据库集群通过 Pigsty 管理命令被误删的情况,例如错误的执行 pgsql-rm.yml 剧本或 bin/pgsql-rm 命令。
除非您指定了 pg_rm_backup 参数为 false,否则备份会与数据库集群一起被删除。
警告:在这种情况,您的数据将无法找回!请务必三思而后行!
建议:对于生产环境,您可以在配置清单中全局配置此参数为 false,在移除集群时保留备份。
3 - 手工恢复
您可以使用 pgsql-pitr.yml 剧本执行 PITR,但在某些情况下,您可能希望手动执行 PITR,直接使用 pgbackrest 原语实现精细的控制。
我们将使用带有 MinIO 备份仓库的 四节点沙箱 集群来演示该过程。
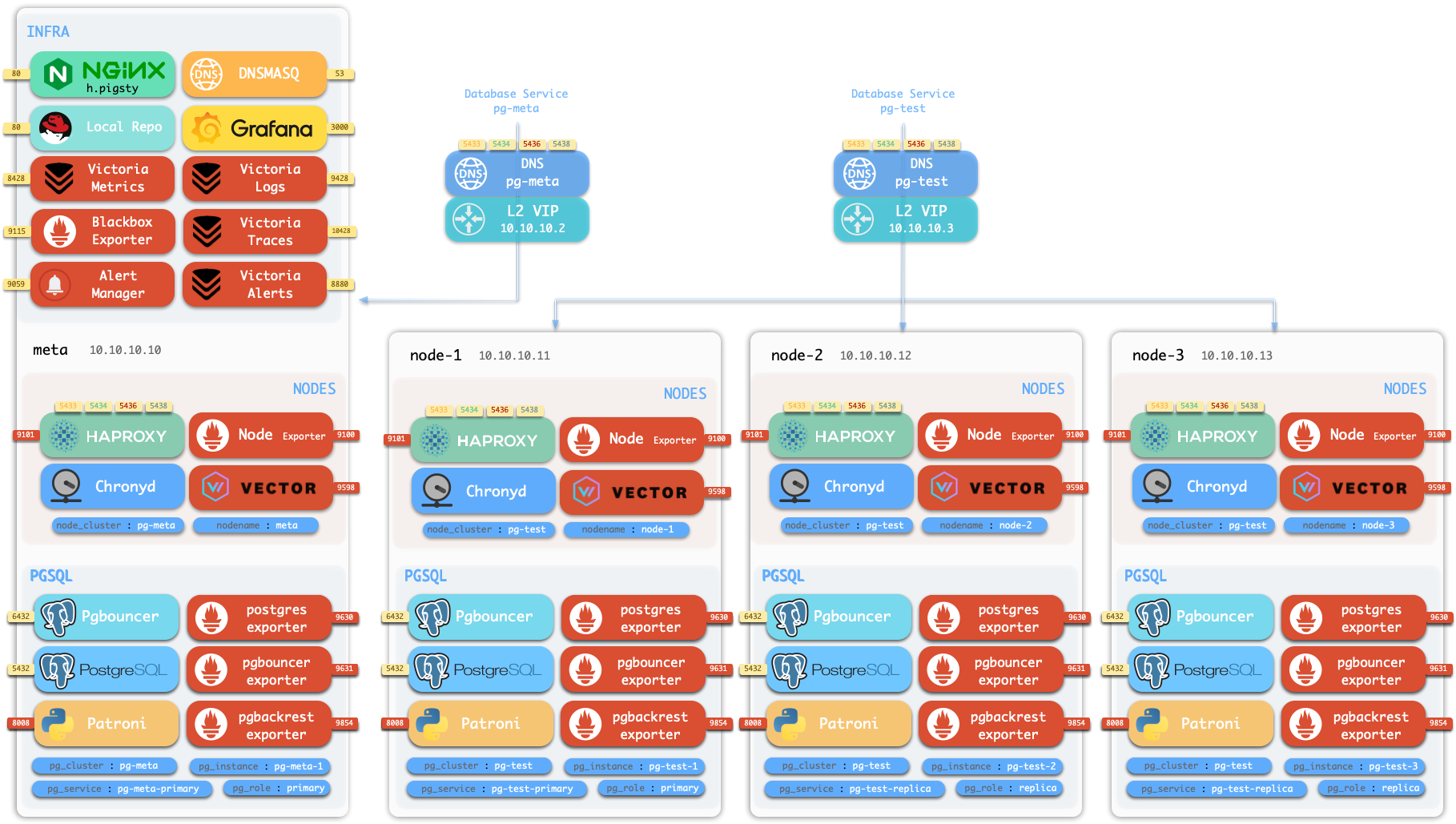
初始化沙箱
使用 vagrant 或 terraform 准备四节点沙箱环境,然后:
curl https://repo.pigsty.io/get | bash; cd ~/pigsty/
./configure -c full
./install
现在以管理节点上的管理员用户(或 dbsu)身份操作。
检查备份
要检查备份状态,您需要切换到 postgres 用户并使用 pb 命令:
sudo su - postgres # 切换到 dbsu: postgres 用户
pb info # 打印 pgbackrest 备份信息
pb 是 pgbackrest 的别名,会自动从 pgbackrest 配置中获取 stanza 名称。
function pb() {
local stanza=$(grep -o '\[[^][]*]' /etc/pgbackrest/pgbackrest.conf | head -n1 | sed 's/.*\[\([^]]*\)].*/\1/')
pgbackrest --stanza=$stanza $@
}
您可以看到初始备份信息,这是一个全量备份:
root@pg-meta-1:~# pb info
stanza: pg-meta
status: ok
cipher: aes-256-cbc
db (current)
wal archive min/max (17): 000000010000000000000001/000000010000000000000007
full backup: 20250713-022731F
timestamp start/stop: 2025-07-13 02:27:31+00 / 2025-07-13 02:27:33+00
wal start/stop: 000000010000000000000004 / 000000010000000000000004
database size: 44MB, database backup size: 44MB
repo1: backup size: 8.4MB
备份完成于 2025-07-13 02:27:33+00,这是您可以恢复到的最早时间。
由于 WAL 归档处于活动状态,您可以恢复到备份之后的任何时间点,直到 WAL 结束(即现在)。
生成心跳
您可以生成一些心跳来模拟工作负载。/pg-bin/pg-heartbeat 就是用于此目的的,
它每秒向 monitor.heartbeat 表写入一个心跳时间戳。
make rh # 运行心跳: ssh 10.10.10.10 'sudo -iu postgres /pg/bin/pg-heartbeat'ssh 10.10.10.10 'sudo -iu postgres /pg/bin/pg-heartbeat' cls | ts | lsn | lsn_int | txid | status | now | elapse
---------+-------------------------------+------------+-----------+------+---------+-----------------+----------
pg-meta | 2025-07-13 03:01:20.318234+00 | 0/115BF5C0 | 291239360 | 4812 | leading | 03:01:20.318234 | 00:00:00您甚至可以向集群添加更多工作负载,让我们使用 pgbench 生成一些随机写入:
make ri # 初始化 pgbench
make rw # 运行 pgbench 读写工作负载pgbench -is10 postgres://dbuser_meta:DBUser.Meta@10.10.10.10:5433/meta
while true; do pgbench -nv -P1 -c4 --rate=64 -T10 postgres://dbuser_meta:DBUser.Meta@10.10.10.10:5433/meta; donewhile true; do pgbench -nv -P1 -c4 --rate=64 -T10 postgres://dbuser_meta:DBUser.Meta@10.10.10.10:5433/meta; done
pgbench (17.5 (Homebrew), server 17.4 (Ubuntu 17.4-1.pgdg24.04+2))
progress: 1.0 s, 60.9 tps, lat 7.295 ms stddev 4.219, 0 failed, lag 1.818 ms
progress: 2.0 s, 69.1 tps, lat 6.296 ms stddev 1.983, 0 failed, lag 1.397 ms
...PITR 手册
现在让我们选择一个恢复时间点,比如 2025-07-13 03:03:03+00,这是初始备份(和心跳)之后的一个时间点。
要执行手动 PITR,使用 pg-pitr 工具:
$ pg-pitr -t "2025-07-13 03:03:00+00"
它会为您生成执行恢复的指令,通常需要四个步骤:
Perform time PITR on pg-meta
[1. Stop PostgreSQL] ===========================================
1.1 Pause Patroni (if there are any replicas)
$ pg pause <cls> # 暂停 patroni 自动故障切换
1.2 Shutdown Patroni
$ pt-stop # sudo systemctl stop patroni
1.3 Shutdown Postgres
$ pg-stop # pg_ctl -D /pg/data stop -m fast
[2. Perform PITR] ===========================================
2.1 Restore Backup
$ pgbackrest --stanza=pg-meta --type=time --target='2025-07-13 03:03:00+00' restore
2.2 Start PG to Replay WAL
$ pg-start # pg_ctl -D /pg/data start
2.3 Validate and Promote
- If database content is ok, promote it to finish recovery, otherwise goto 2.1
$ pg-promote # pg_ctl -D /pg/data promote
[3. Restore Primary] ===========================================
3.1 Enable Archive Mode (Restart Required)
$ psql -c 'ALTER SYSTEM SET archive_mode = on;'
3.1 Restart Postgres to Apply Changes
$ pg-restart # pg_ctl -D /pg/data restart
3.3 Restart Patroni
$ pt-restart # sudo systemctl restart patroni
[4. Restore Cluster] ===========================================
4.1 Re-Init All [**REPLICAS**] (if any)
- 4.1.1 option 1: restore replicas with same pgbackrest cmd (require central backup repo)
$ pgbackrest --stanza=pg-meta --type=time --target='2025-07-13 03:03:00+00' restore
- 4.1.2 option 2: nuke the replica data dir and restart patroni (may take long time to restore)
$ rm -rf /pg/data/*; pt-restart
- 4.1.3 option 3: reinit with patroni, which may fail if primary lsn < replica lsn
$ pg reinit pg-meta
4.2 Resume Patroni
$ pg resume pg-meta
4.3 Full Backup (optional)
$ pg-backup full # 建议在 PITR 后执行新的全量备份
单节点示例
让我们从简单的单节点 pg-meta 集群开始,作为一个更简单的示例。
关闭数据库
pt-stop # sudo systemctl stop patroni,关闭 patroni(和 postgres)# 可选,因为如果 patroni 未暂停,postgres 会被 patroni 关闭
$ pg_stop # pg_ctl -D /pg/data stop -m fast,关闭 postgres
pg_ctl: PID file "/pg/data/postmaster.pid" does not exist
Is server running?
$ pg-ps # 打印 postgres 相关进程
UID PID PPID C STIME TTY STAT TIME CMD
postgres 31048 1 0 02:27 ? Ssl 0:19 /usr/sbin/pgbouncer /etc/pgbouncer/pgbouncer.ini
postgres 32026 1 0 02:28 ? Ssl 0:03 /usr/bin/pg_exporter ...
postgres 35510 35480 0 03:01 pts/2 S+ 0:00 /bin/bash /pg/bin/pg-heartbeat确保本地 postgres 没有运行,然后执行手册中给出的恢复命令:
恢复备份
pgbackrest --stanza=pg-meta --type=time --target='2025-07-13 03:03:00+00' restorepostgres@pg-meta-1:~$ pgbackrest --stanza=pg-meta --type=time --target='2025-07-13 03:03:00+00' restore
2025-07-13 03:17:07.443 P00 INFO: restore command begin 2.54.2: ...
2025-07-13 03:17:07.470 P00 INFO: repo1: restore backup set 20250713-022731F, recovery will start at 2025-07-13 02:27:31
2025-07-13 03:17:07.471 P00 INFO: remove invalid files/links/paths from '/pg/data'
2025-07-13 03:17:08.523 P00 INFO: write updated /pg/data/postgresql.auto.conf
2025-07-13 03:17:08.527 P00 INFO: restore size = 44MB, file total = 1436
2025-07-13 03:17:08.527 P00 INFO: restore command end: completed successfully (1087ms)验证数据
我们不希望 patroni HA 接管,直到确定数据正确,所以手动启动 postgres:
pg-startwaiting for server to start....2025-07-13 03:19:33.133 UTC [39294] LOG: redirecting log output to logging collector process
2025-07-13 03:19:33.133 UTC [39294] HINT: Future log output will appear in directory "/pg/log/postgres".
done
server started现在您可以检查数据,看看是否处于您想要的时间点。 您可以通过检查业务表中的最新时间戳来验证,或者在本例中通过心跳表检查。
postgres@pg-meta-1:~$ psql -c 'table monitor.heartbeat'
id | ts | lsn | txid
---------+-------------------------------+-----------+------
pg-meta | 2025-07-13 03:02:59.214104+00 | 302005504 | 4912
时间戳正好在我们指定的时间点之前!(2025-07-13 03:03:00+00)。
如果这不是您想要的时间点,可以使用不同的时间点重复恢复。
由于恢复是以增量和并行方式执行的,速度非常快。
可以重试直到找到正确的时间点。
提升主库
恢复后的 postgres 集群处于 recovery 模式,因此在提升为主库之前会拒绝任何写操作。
这些恢复参数是由 pgBackRest 在配置文件中生成的。
postgres@pg-meta-1:~$ cat /pg/data/postgresql.auto.conf
# Do not edit this file or use ALTER SYSTEM manually!
# It is managed by Pigsty & Ansible automatically!
# Recovery settings generated by pgBackRest restore on 2025-07-13 03:17:08
archive_mode = 'off'
restore_command = 'pgbackrest --stanza=pg-meta archive-get %f "%p"'
recovery_target_time = '2025-07-13 03:03:00+00'
如果数据正确,您可以提升它为主库,将其标记为新的领导者并准备接受写入。
pg-promote
waiting for server to promote.... done
server promotedpsql -c 'SELECT pg_is_in_recovery()' # 'f' 表示已提升为主库
pg_is_in_recovery
-------------------
f
(1 row)一旦提升,数据库集群将进入新的时间线(领导者纪元)。 如果有任何写流量,将写入新的时间线。
恢复集群
最后,不仅需要恢复数据,还需要恢复集群状态,例如:
- patroni 接管
- 归档模式
- 备份集
- 从库
Patroni 接管
您的 postgres 是直接启动的,要恢复 HA 接管,您需要启动 patroni 服务:
pt-start # sudo systemctl start patronipg resume pg-meta # 恢复 patroni 自动故障切换(如果之前暂停过)归档模式
archive_mode 在恢复期间被 pgbackrest 禁用。
如果您希望新领导者的写入归档到备份仓库,还需要启用 archive_mode 配置。
psql -c 'show archive_mode'
archive_mode
--------------
offpsql -c 'ALTER SYSTEM RESET archive_mode;'
psql -c 'SELECT pg_reload_conf();'
psql -c 'show archive_mode'# 您也可以直接编辑 postgresql.auto.conf 并使用 pg_ctl 重载
sed -i '/archive_mode/d' /pg/data/postgresql.auto.conf
pg_ctl -D /pg/data reload备份集
通常建议在 PITR 后执行新的全量备份,但这是可选的。
从库
如果您的 postgres 集群有从库,您也需要在每个从库上执行 PITR。 或者,更简单的方法是删除从库数据目录并重启 patroni,这将从主库重新初始化从库。 我们将在下一个多节点集群示例中介绍这种情况。
多节点示例
现在让我们以三节点 pg-test 集群作为 PITR 示例。
4 - 利用 xfs 实现实例 Fork
Pigsty 提供了两个实用脚本,用于在同一台机器上快速克隆实例并执行时间点恢复:
这两个脚本可以配合使用:先用 pg-fork 克隆实例,再用 pg-pitr 将克隆实例恢复到指定时间点。
pg-fork
pg-fork 可以在同一台机器上快速克隆一个新的 PostgreSQL 实例。
快速上手
使用 postgres 用户(dbsu)执行以下命令,即可创建一个新的实例:
pg-fork 1 # 从 /pg/data 克隆到 /pg/data1,端口 15432
pg-fork 2 -d /pg/data1 # 从 /pg/data1 克隆到 /pg/data2,端口 25432
pg-fork 3 -D /tmp/test -P 5555 # 克隆到自定义目录和端口
克隆完成后,可以启动并访问新实例:
pg_ctl -D /pg/data1 start # 启动克隆实例
psql -p 15432 # 连接克隆实例
命令语法
pg-fork <FORK_ID> [options]
必填参数:
| 参数 | 说明 |
|---|---|
<FORK_ID> | 克隆实例编号(1-9),决定默认端口和数据目录 |
可选参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
-d, --data <datadir> | 源实例数据目录 | /pg/data 或 $PG_DATA |
-D, --dst <dst_dir> | 目标数据目录 | /pg/data<FORK_ID> |
-p, --port <port> | 源实例端口 | 5432 或 $PG_PORT |
-P, --dst-port <port> | 目标实例端口 | <FORK_ID>5432 |
-s, --skip | 跳过备份 API,使用冷拷贝模式 | - |
-y, --yes | 跳过确认提示 | - |
-h, --help | 显示帮助信息 | - |
使用示例
# 从默认实例克隆到 /pg/data1,端口 15432
pg-fork 1
# 从默认实例克隆到 /pg/data2,端口 25432
pg-fork 2# 从端口 5433 的实例克隆
pg-fork 1 -p 5433
# 使用环境变量指定源端口
PG_PORT=5433 pg-fork 1# 从 /pg/data1 克隆到 /pg/data2
pg-fork 2 -d /pg/data1
# 从 /pg/data2 克隆到 /pg/data3
pg-fork 3 -d /pg/data2# 克隆到自定义目录和端口
pg-fork 1 -D /tmp/pgtest -P 5555
# 完全自定义
pg-fork 1 -d /pg/data -D /mnt/backup/pgclone -P 6543# 源实例已停止时使用冷拷贝
pg-fork 1 -s
# 跳过确认直接执行
pg-fork 1 -s -y工作原理
pg-fork 支持两种工作模式:
热备份模式(默认,源实例运行中):
- 调用
pg_backup_start()开始备份 - 使用
cp --reflink=auto拷贝数据目录 - 调用
pg_backup_stop()结束备份 - 修改配置文件,避免与源实例冲突
冷拷贝模式(使用 -s 参数或源实例未运行):
- 直接使用
cp --reflink=auto拷贝数据目录 - 修改配置文件
如果您使用 XFS(启用 reflink)、Btrfs 或 ZFS 文件系统,pg-fork 会利用 Copy-on-Write 特性,
数据目录拷贝在几百毫秒内完成,且几乎不占用额外存储空间。只有在数据被修改时才会分配新的存储块。
克隆后配置
pg-fork 会自动修改克隆实例的以下配置:
| 配置项 | 修改内容 |
|---|---|
port | 改为目标端口(避免冲突) |
archive_mode | 设为 off(避免污染 WAL 归档) |
log_directory | 设为 log(使用数据目录下的日志) |
primary_conninfo | 移除(创建独立实例) |
standby.signal | 移除(创建独立实例) |
pg_replslot/* | 清空(避免复制槽冲突) |
典型工作流
# 1. 克隆实例用于测试
pg-fork 1 -y
# 2. 启动克隆实例
pg_ctl -D /pg/data1 start
# 3. 在克隆实例上测试(不影响生产)
psql -p 15432 -c "DROP TABLE important_data;" # 安全测试
# 4. 测试完成后清理
pg_ctl -D /pg/data1 stop
rm -rf /pg/data1
pg-pitr
pg-pitr 是一个用于手动执行时间点恢复的脚本,基于 pgbackrest。
快速上手
pg-pitr -d # 恢复到最新状态
pg-pitr -i # 恢复到备份完成时间
pg-pitr -t "2025-01-01 12:00:00+08" # 恢复到指定时间点
pg-pitr -n my-savepoint # 恢复到命名恢复点
pg-pitr -l "0/7C82CB8" # 恢复到指定 LSN
pg-pitr -x 12345678 -X # 恢复到事务之前
pg-pitr -b 20251225-120000F # 恢复到指定备份集
命令语法
pg-pitr [options] [recovery_target]
恢复目标(选择一个):
| 参数 | 说明 |
|---|---|
-d, --default | 恢复到 WAL 归档流末尾(最新状态) |
-i, --immediate | 恢复到数据库一致性点(最快恢复) |
-t, --time <timestamp> | 恢复到指定时间点 |
-n, --name <restore_point> | 恢复到命名恢复点 |
-l, --lsn <lsn> | 恢复到指定 LSN |
-x, --xid <xid> | 恢复到指定事务 ID |
-b, --backup <label> | 恢复到指定备份集 |
可选参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
-D, --data <path> | 恢复目标数据目录 | /pg/data |
-s, --stanza <name> | pgbackrest stanza 名称 | 自动检测 |
-X, --exclusive | 排除目标点(恢复到目标之前) | - |
-P, --promote | 恢复后自动提升(默认暂停) | - |
-c, --check | 干运行模式,仅打印命令 | - |
-y, --yes | 跳过确认和倒计时 | - |
-h, --help | 显示帮助信息 | - |
恢复目标类型
# 恢复到 WAL 归档流末尾(最新状态)
pg-pitr -d
# 这是默认行为,会重放所有可用的 WAL# 恢复到数据库一致性点
pg-pitr -i
# 最快的恢复方式,不重放额外的 WAL
# 适用于快速验证备份是否可用# 恢复到指定时间点
pg-pitr -t "2025-01-01 12:00:00+08"
# 使用 UTC 时间
pg-pitr -t "2025-01-01 04:00:00+00"
# 时间格式:YYYY-MM-DD HH:MM:SS[.usec][+/-TZ]# 恢复到命名恢复点
pg-pitr -n my-savepoint
# 恢复点需要事先使用 pg_create_restore_point() 创建
# SELECT pg_create_restore_point('my-savepoint');# 恢复到指定 LSN
pg-pitr -l "0/7C82CB8"
# LSN 可以从监控面板或 pg_current_wal_lsn() 获取# 恢复到指定事务 ID
pg-pitr -x 12345678
# 恢复到事务之前(不包含该事务)
pg-pitr -x 12345678 -X# 恢复到指定备份集
pg-pitr -b 20251225-120000F
# 查看可用备份集
pgbackrest info使用示例
恢复到指定时间点:
# 1. 停止 PostgreSQL
pg_ctl -D /pg/data stop -m fast
# 2. 执行 PITR
pg-pitr -t "2025-12-27 10:00:00+08"
# 3. 启动并验证
pg_ctl -D /pg/data start
psql -c "SELECT * FROM important_table;"
# 4. 确认无误后提升
pg_ctl -D /pg/data promote
# 5. 启用归档并执行新备份
psql -c "ALTER SYSTEM SET archive_mode = on;"
pg_ctl -D /pg/data restart
pg-backup full
恢复到克隆实例:
# 1. 克隆实例
pg-fork 1 -y
# 2. 在克隆实例上执行 PITR
pg-pitr -D /pg/data1 -t "2025-12-27 10:00:00+08"
# 3. 启动克隆实例验证
pg_ctl -D /pg/data1 start
psql -p 15432
干运行模式:
# 仅打印命令,不执行
pg-pitr -t "2025-12-27 10:00:00+08" -c
# 输出示例:
# Command:
# pgbackrest --stanza=pg-meta --delta --force --type=time --target="2025-12-27 10:00:00+08" restore
恢复后处理
恢复完成后,实例会处于恢复暂停状态(除非使用 -P 参数)。您需要:
- 启动实例:
pg_ctl -D /pg/data start - 验证数据:检查数据是否符合预期
- 提升实例:
pg_ctl -D /pg/data promote - 启用归档:
psql -c "ALTER SYSTEM SET archive_mode = on;" - 重启实例:
pg_ctl -D /pg/data restart - 执行备份:
pg-backup full
恢复后的实例 archive_mode 被设为 off,以防止意外的 WAL 写入污染归档仓库。
确认数据正确后,务必重新启用归档并执行全量备份。
组合使用
pg-fork 和 pg-pitr 可以组合使用,实现安全的 PITR 验证流程:
# 1. 克隆当前实例
pg-fork 1 -y
# 2. 在克隆实例上执行 PITR(不影响生产)
pg-pitr -D /pg/data1 -t "2025-12-27 10:00:00+08"
# 3. 启动克隆实例
pg_ctl -D /pg/data1 start
# 4. 验证恢复结果
psql -p 15432 -c "SELECT count(*) FROM orders WHERE created_at < '2025-12-27 10:00:00';"
# 5. 确认无误后,可以选择:
# - 方案A:在生产实例上执行相同的 PITR
# - 方案B:将克隆实例提升为新的生产实例
# 6. 清理测试实例
pg_ctl -D /pg/data1 stop
rm -rf /pg/data1
注意事项
运行要求
- 必须以
postgres用户(或 postgres 组成员)执行 pg-pitr执行前必须停止目标实例的 PostgreSQLpg-fork热备份模式需要源实例正在运行
文件系统
- 推荐使用 XFS(启用 reflink)或 Btrfs 文件系统
- CoW 文件系统上克隆几乎瞬间完成,且不占用额外空间
- 非 CoW 文件系统会执行完整拷贝,耗时较长
端口规划
| FORK_ID | 默认端口 | 默认数据目录 |
|---|---|---|
| 1 | 15432 | /pg/data1 |
| 2 | 25432 | /pg/data2 |
| 3 | 35432 | /pg/data3 |
| … | … | … |
| 9 | 95432 | /pg/data9 |
安全建议
- 克隆实例仅用于测试和验证,不应长期运行
- 验证完成后及时清理克隆实例
- 生产环境 PITR 建议使用
pgsql-pitr.yml剧本 - 重要操作前先使用
-c干运行模式确认命令
原理剖析
有时候,您想要用现有的 PostgreSQL 实例在 同一台机器 上创建一个新的实例 (用于测试,PITR 恢复),可以使用 postgres 用户执行下面的命令:
psql <<EOF
CHECKPOINT;
SELECT pg_backup_start('pgfork', true);
\! rm -rf /pg/data2 && cp -r --reflink=auto /pg/data /pg/data2 && ls -alhd /pg/data2
SELECT * FROM pg_backup_stop(false);
EOF
# 修改配置,避免与现有实例冲突:端口,日志,归档等
sed -i 's/^port.*/port = 5431/' /pg/data2/postgresql.conf;
sed -i 's/^log_destination.*/log_destination = stderr/' /pg/data2/postgresql.conf;
sed -i 's/^archive_mode.*/archive_mode = off/' /pg/data2/postgresql.conf;
rm -rf /pg/data2/postmaster.pid /pg/data2/postmaster.opts
pg_ctl -D /pg/data2 start -l /pg/log/pgfork.log
pg_ctl -D /pg/data2 stop
psql -p 5431 # 访问新实例
上面的命令会创建一个新的数据目录 /pg/data2,它是现有数据目录 /pg/data 的一个完整拷贝。
如果您使用的是 XFS (启用了 reflink COW 特性),那么同磁盘拷贝目录会非常快,通常几百毫秒的常数时间内即可完成。
您在原地拉起新实例前,务必 修改 postgresql.conf 里的 port / archive_mode / log_destination 参数,避免影响现有生产实例等运行。
您可以使用一个没有被占用的端口,例如 5431,并将日志输出到 /pg/log/xxxx.log 避免写脏现有实例的日志文件。
我们建议同时修改 shared_buffers Pigsty 默认情况通常分配 25% 的系统内存给 PostgreSQL 实例,
开启新实例时,会与现有实例争夺内存资源。您可以适当调小,以减小对现有生产实例的影响。
5 - 为 PostgreSQL 集群启用 HugePage
使用
node_hugepage_count和node_hugepage_ratio或/pg/bin/pg-tune-hugepage
如果你计划启用大页(HugePage),请考虑使用 node_hugepage_count 和 node_hugepage_ratio,并配合 ./node.yml -t node_tune 进行应用。
大页对于数据库来说有利有弊,利是内存是专门管理的,不用担心被挪用,降低数据库 OOM 风险。缺点是某些场景下可能对性能由负面影响。
在 PostgreSQL 启动前,您需要分配 足够多的 大页,浪费的部分可以使用 pg-tune-hugepage 脚本对其进行回收,不过此脚本仅 PostgreSQL 15+ 可用。
如果你的 PostgreSQL 已经在运行,你可以使用下面的办法启动大页(仅 PG15+ 可用):
sync; echo 3 > /proc/sys/vm/drop_caches # 刷盘,释放系统缓存(请做好数据库性能受到冲击的准备)
sudo /pg/bin/pg-tune-hugepage # 将 nr_hugepages 写入 /etc/sysctl.d/hugepage.conf
pg restart <cls> # 重启 postgres 以使用 hugepage
6 - 3坏2应急处理
如果经典3节点高可用部署同时出现两台(多数主体)故障,系统通常无法自动完成故障切换,需要人工介入:
首先判断另外两台服务器的情况,如果短时间内可以拉起,优先选择拉起另外两台服务。否则进入 紧急止血流程
紧急止血流程假设您的管理节点故障,只有单台普通数据库节点存活,在这种情况下,最快的恢复操作流程为:
- 调整 HAProxy 配置,将流量指向主库。
- 关闭 Patroni,手动提升 PostgreSQL 从库为主库。
调整HAProxy配置
如果你通过其他方式绕开 HAProxy 访问集群,那么可以跳过这一步。 如果你通过 HAProxy 方式访问数据库集群,那么你需要调整负载均衡配置,将读写流量手工指向主库。
- 编辑
/etc/haproxy/<pg_cluster>-primary.cfg配置文件,其中<pg_cluster>为你的 PostgreSQL 集群名称,例如pg-meta。 - 将健康检查配置选项注释,停止进行健康鉴擦好
- 将服务器列表中,其他两台故障的机器注释掉,只保留当前主库服务器。
listen pg-meta-primary
bind *:5433
mode tcp
maxconn 5000
balance roundrobin
# 注释掉以下四行健康检查配置
#option httpchk # <---- remove this
#option http-keep-alive # <---- remove this
#http-check send meth OPTIONS uri /primary # <---- remove this
#http-check expect status 200 # <---- remove this
default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100
server pg-meta-1 10.10.10.10:6432 check port 8008 weight 100
# 注释掉其他两台故障的机器
#server pg-meta-2 10.10.10.11:6432 check port 8008 weight 100 <---- comment this
#server pg-meta-3 10.10.10.12:6432 check port 8008 weight 100 <---- comment this
配置调整完成后,先不着急执行 systemctl reload haproxy 重载生效,等待后续主库提升后一起执行。
以上配置的效果是,HAProxy 将不再进行主库健康检查(默认使用 Patroni),而是直接将写入流量指向当前主库
手工提升备库
登陆目标服务器,切换至 dbsu 用户,执行 CHECKPOINT 刷盘后,关闭 Patroni,重启 PostgreSQL 并执行 Promote。
sudo su - postgres # 切换到数据库 dbsu 用户
psql -c 'checkpoint; checkpoint;' # 两次 Checkpoint 刷脏页,避免PG后重启耗时过久
sudo systemctl stop patroni # 关闭 Patroni
pg-restart # 重新拉起 PostgreSQL
pg-promote # 将 PostgreSQL 从库提升为主库
psql -c 'SELECT pg_is_in_recovery();' # 如果结果为 f,表示已经提升为主库
如果你上面调整了 HAProxy 配置,那么现在可以执行 systemctl reload haproxy 重载 HAProxy 配置,将流量指向新的主库。
systemctl reload haproxy # 重载 HAProxy 配置,将写入流量指向当前实例
避免脑裂
紧急止血后,第二优先级问题为:避免脑裂。用户应当防止另外两台服务器重新上线后,与当前主库形成脑裂,导致数据不一致。
简单的做法是:
- 将另外两台服务器直接 断电/断网,确保它们不会在不受控的情况下再次上线。
- 调整应用使用的数据库连接串,将其 HOST 直接指向唯一幸存服务器上的主库。
然后应当根据具体情况,决定下一步的操作:
- A:这两台服务器是临时故障(比如断网断电),可以原地修复后继续服务
- B:这两台故障服务器是永久故障(比如硬件损坏),将移除并下线。
临时故障后的复原
如果另外两台服务器是临时故障,可以修复后继续服务,那么可以按照以下步骤进行修复与重建:
- 每次处理一台故障服务器,优先处理 管理节点 / INFRA 管理节点
- 启动故障服务器,并在启动后关停 Patroni
ETCD 集群在法定人数恢复后,将恢复工作,此时可以启动幸存服务器(当前主库)上的 Patroni,接管现有 PostgreSQL,并重新获取集群领导者身份。 Patroni 启动后进入维护模式。
systemctl restart patroni
pg pause <pg_cluster>
在另外两台实例上以 postgres 用户身份创建 touch /pg/data/standby.signal 标记文件将其标记为从库,然后拉起 Patroni:
systemctl restart patroni
确认 Patroni 集群身份/角色正常后,退出维护模式:
pg resume <pg_cluster>
永久故障后的复原
出现永久故障后,首先需要恢复管理节点上的 ~/pigsty 目录,主要是需要 pigsty.yml 与 files/pki/ca/ca.key 两个核心文件。
如果您无法取回或没有备份这两个文件,您可以选择部署一套新的 Pigsty,并通过 备份集群 的方式将现有集群迁移至新部署中。
请定期备份
pigsty目录(例如使用 Git 进行版本管理)。建议吸取教训,下次不要犯这样的错误。
配置修复
您可以将幸存的节点作为新的管理节点,将 ~/pigsty 目录拷贝到新的管理节点上,然后开始调整配置。
例如,将原本默认的管理节点 10.10.10.10 替换为幸存节点 10.10.10.12
all:
vars:
admin_ip: 10.10.10.12 # 使用新的管理节点地址
node_etc_hosts: [10.10.10.12 h.pigsty a.pigsty p.pigsty g.pigsty sss.pigsty]
infra_portal: {} # 一并修改其他引用旧管理节点 IP (10.10.10.10) 的配置
children:
infra: # 调整 Infra 集群
hosts:
# 10.10.10.10: { infra_seq: 1 } # 老的 Infra 节点
10.10.10.12: { infra_seq: 3 } # 新增 Infra 节点
etcd: # 调整 ETCD 集群
hosts:
#10.10.10.10: { etcd_seq: 1 } # 注释掉此故障节点
#10.10.10.11: { etcd_seq: 2 } # 注释掉此故障节点
10.10.10.12: { etcd_seq: 3 } # 保留幸存节点
vars:
etcd_cluster: etcd
pg-meta: # 调整 PGSQL 集群配置
hosts:
#10.10.10.10: { pg_seq: 1, pg_role: primary }
#10.10.10.11: { pg_seq: 2, pg_role: replica }
#10.10.10.12: { pg_seq: 3, pg_role: replica , pg_offline_query: true }
10.10.10.12: { pg_seq: 3, pg_role: primary , pg_offline_query: true }
vars:
pg_cluster: pg-meta
ETCD修复
然后执行以下命令,将 ETCD 重置为单节点集群:
./etcd.yml -e etcd_safeguard=false -e etcd_clean=true
根据 ETCD重载配置 的说明,调整对 ETCD Endpoint 的引用。
INFRA修复
如果幸存节点上没有 INFRA 模块,请在当前节点上配置新的 INFRA 模块并安装。执行以下命令,将 INFRA 模块部署到幸存节点上:
./infra.yml -l 10.10.10.12
修复当前节点的监控
./node.yml -t node_monitor
PGSQL修复
./pgsql.yml -t pg_conf # 重新生成 PG 配置文件
systemctl reload patroni # 在幸存节点上重载 Patroni 配置
各模块修复后,您可以参考标准扩容流程,将新的节点加入集群,恢复集群的高可用性。
7 - 使用 VIP-Manager 为 PostgreSQL 集群配置二层 VIP
您可以在 PostgreSQL 集群上绑定一个可选的 L2 VIP —— 前提条件是:集群中的所有节点都在一个二层网络中。
这个 L2 VIP 强制使用 Master - Backup 模式,Master 始终指向在数据库集群主库实例所在的节点。
这个 VIP 由 VIP-Manager 组件管理,它会从 DCS (etcd) 中直接读取由 Patroni 写入的 Leader Key,从而判断自己是否是 Master。
启用VIP
在 PostgreSQL 集群上定义 pg_vip_enabled 参数为 true,即可在集群上启用 VIP 组件。当然您也可以在全局配置中启用此配置项。
# pgsql 3 node ha cluster: pg-test
pg-test:
hosts:
10.10.10.11: { pg_seq: 1, pg_role: primary } # primary instance, leader of cluster
10.10.10.12: { pg_seq: 2, pg_role: replica } # replica instance, follower of leader
10.10.10.13: { pg_seq: 3, pg_role: replica, pg_offline_query: true } # replica with offline access
vars:
pg_cluster: pg-test # define pgsql cluster name
pg_users: [{ name: test , password: test , pgbouncer: true , roles: [ dbrole_admin ] }]
pg_databases: [{ name: test }]
# 启用 L2 VIP
pg_vip_enabled: true
pg_vip_address: 10.10.10.3/24
pg_vip_interface: eth1
请注意,pg_vip_address 必须是一个合法的 IP 地址,带有网段,且在当前二层网络中可用。
请注意,pg_vip_interface 必须是一个合法的网络接口名,并且应当是与 inventory 中使用 IPv4 地址一致的网卡。
如果集群成员的网卡名不一样,用户应当为每个实例显式指定 pg_vip_interface 参数,例如:
pg-test:
hosts:
10.10.10.11: { pg_seq: 1, pg_role: primary , pg_vip_interface: eth0 }
10.10.10.12: { pg_seq: 2, pg_role: replica , pg_vip_interface: eth1 }
10.10.10.13: { pg_seq: 3, pg_role: replica , pg_vip_interface: ens33 }
vars:
pg_cluster: pg-test # define pgsql cluster name
pg_users: [{ name: test , password: test , pgbouncer: true , roles: [ dbrole_admin ] }]
pg_databases: [{ name: test }]
# 启用 L2 VIP
pg_vip_enabled: true
pg_vip_address: 10.10.10.3/24
#pg_vip_interface: eth1
使用以下命令,刷新 PG 的 vip-manager 配置并重启生效:
./pgsql.yml -t pg_vip
8 - Citus 集群部署
Citus 是一个 PostgreSQL 扩展,可以将 PostgreSQL 原地转换为一个分布式数据库,并实现在多个节点上水平扩展,以处理大量数据和大量查询。
Patroni 在 v3.0 后,提供了对 Citus 原生高可用的支持,简化了 Citus 集群的搭建,Pigsty 也对此提供了原生支持。
注意:Citus 13.x 支持 PostgreSQL 18、17、16、15、14 五个大版本。Pigsty 扩展仓库提供了 Citus ARM64 软件包。
Citus集群
Pigsty 原生支持 Citus。可以参考 conf/citus.yml
这里使用 Pigsty 四节点沙箱,定义了一个 Citus 集群 pg-citus,其中包括一个两节点的协调者集群 pg-citus0,
以及两个 Worker 集群 pg-citus1,pg-citus2。
pg-citus:
hosts:
10.10.10.10: { pg_group: 0, pg_cluster: pg-citus0 ,pg_vip_address: 10.10.10.2/24 ,pg_seq: 1, pg_role: primary }
10.10.10.11: { pg_group: 0, pg_cluster: pg-citus0 ,pg_vip_address: 10.10.10.2/24 ,pg_seq: 2, pg_role: replica }
10.10.10.12: { pg_group: 1, pg_cluster: pg-citus1 ,pg_vip_address: 10.10.10.3/24 ,pg_seq: 1, pg_role: primary }
10.10.10.13: { pg_group: 2, pg_cluster: pg-citus2 ,pg_vip_address: 10.10.10.4/24 ,pg_seq: 1, pg_role: primary }
vars:
pg_mode: citus # pgsql cluster mode: citus
pg_version: 18 # citus 13.x supports PG 14-18
pg_shard: pg-citus # citus shard name: pg-citus
pg_primary_db: citus # primary database used by citus
pg_vip_enabled: true # enable vip for citus cluster
pg_vip_interface: eth1 # vip interface for all members
pg_dbsu_password: DBUser.Postgres # all dbsu password access for citus cluster
pg_extensions: [ citus, postgis, pgvector, topn, pg_cron, hll ] # install these extensions
pg_libs: 'citus, pg_cron, pg_stat_statements' # citus will be added by patroni automatically
pg_users: [{ name: dbuser_citus ,password: DBUser.Citus ,pgbouncer: true ,roles: [ dbrole_admin ] }]
pg_databases: [{ name: citus ,owner: dbuser_citus ,extensions: [ citus, vector, topn, pg_cron, hll ] }]
pg_parameters:
cron.database_name: citus
citus.node_conninfo: 'sslmode=require sslrootcert=/pg/cert/ca.crt sslmode=verify-full'
pg_hba_rules:
- { user: 'all' ,db: all ,addr: 127.0.0.1/32 ,auth: ssl ,title: 'all user ssl access from localhost' }
- { user: 'all' ,db: all ,addr: intra ,auth: ssl ,title: 'all user ssl access from intranet' }
相比标准 PostgreSQL 集群,Citus 集群的配置有一些特殊之处,首先,你需要确保 Citus 扩展被下载,安装,加载并启用,这涉及到以下四个参数
repo_packages:必须包含citus扩展,或者你需要使用带有 Citus 扩展的 PostgreSQL 离线安装包。pg_extensions:必须包含citus扩展,即你必须在每个节点上安装citus扩展。pg_libs:必须包含citus扩展,而且首位必须为citus,但现在 Patroni 会自动完成这件事了。pg_databases: 这里要定义一个首要数据库,该数据库必须安装citus扩展。
其次,你需要确保 Citus 集群的配置正确:
pg_mode: 必须设置为citus,从而告知 Patroni 使用 Citus 模式。pg_primary_db:必须指定一个首要数据库的名称,该数据库必须安装citus扩展,这里名为citus。pg_shard:必须指定一个统一的名称,字符串,作为所有水平分片PG集群的集群名称前缀,这里为pg-citus。pg_group:必须指定一个分片号,从零开始依次分配的整数,0号固定代表协调者集群,其他为 Worker 集群。pg_cluster必须与pg_shard和pg_group组合后的结果对应。pg_dbsu_password:必须设置为非空的纯文本密码,否则 Citus 无法正常工作。pg_parameters:建议设置citus.node_conninfo参数,强制要求 SSL 访问并要求节点间验证客户端证书。
配置完成后,您可以像创建普通 PostgreSQL 集群一样,使用 pgsql.yml 部署 Citus 集群。
管理Citus集群
定义好 Citus 集群后,部署 Citus 集群同样使用的剧本 pgsql.yml:
./pgsql.yml -l pg-citus # 部署 Citus 集群 pg-citus
使用任意成员的 DBSU(postgres)用户,都能通过 patronictl (alias: pg) 列出 Citus 集群的状态:
$ pg list
+ Citus cluster: pg-citus ----------+---------+-----------+----+-----------+--------------------+
| Group | Member | Host | Role | State | TL | Lag in MB | Tags |
+-------+-------------+-------------+---------+-----------+----+-----------+--------------------+
| 0 | pg-citus0-1 | 10.10.10.10 | Leader | running | 1 | | clonefrom: true |
| | | | | | | | conf: tiny.yml |
| | | | | | | | spec: 20C.40G.125G |
| | | | | | | | version: '16' |
+-------+-------------+-------------+---------+-----------+----+-----------+--------------------+
| 1 | pg-citus1-1 | 10.10.10.11 | Leader | running | 1 | | clonefrom: true |
| | | | | | | | conf: tiny.yml |
| | | | | | | | spec: 10C.20G.125G |
| | | | | | | | version: '16' |
+-------+-------------+-------------+---------+-----------+----+-----------+--------------------+
| 2 | pg-citus2-1 | 10.10.10.12 | Leader | running | 1 | | clonefrom: true |
| | | | | | | | conf: tiny.yml |
| | | | | | | | spec: 10C.20G.125G |
| | | | | | | | version: '16' |
+-------+-------------+-------------+---------+-----------+----+-----------+--------------------+
| 2 | pg-citus2-2 | 10.10.10.13 | Replica | streaming | 1 | 0 | clonefrom: true |
| | | | | | | | conf: tiny.yml |
| | | | | | | | spec: 10C.20G.125G |
| | | | | | | | version: '16' |
+-------+-------------+-------------+---------+-----------+----+-----------+--------------------+
您可以将每个水平分片集群视为一个独立的 PGSQL 集群,使用 pg (patronictl) 命令管理它们。
但是务必注意,当你使用 pg 命令管理 Citus 集群时,需要额外使用 --group 参数指定集群分片号
pg list pg-citus --group 0 # 需要使用 --group 0 指定集群分片号
Citus 中有一个名为 pg_dist_node 的系统表,用于记录 Citus 集群的节点信息,Patroni 会自动维护该表。
PGURL=postgres://postgres:DBUser.Postgres@10.10.10.10/citus
psql $PGURL -c 'SELECT * FROM pg_dist_node;' # 查看节点信息
nodeid | groupid | nodename | nodeport | noderack | hasmetadata | isactive | noderole | nodecluster | metadatasynced | shouldhaveshards
--------+---------+-------------+----------+----------+-------------+----------+-----------+-------------+----------------+------------------
1 | 0 | 10.10.10.10 | 5432 | default | t | t | primary | default | t | f
4 | 1 | 10.10.10.12 | 5432 | default | t | t | primary | default | t | t
5 | 2 | 10.10.10.13 | 5432 | default | t | t | primary | default | t | t
6 | 0 | 10.10.10.11 | 5432 | default | t | t | secondary | default | t | f
此外,你还可以查看用户认证信息(仅限超级用户访问):
$ psql $PGURL -c 'SELECT * FROM pg_dist_authinfo;' # 查看节点认证信息(仅限超级用户访问)
然后,你可以使用普通业务用户(例如,具有 DDL 权限的 dbuser_citus)来访问 Citus 集群:
psql postgres://dbuser_citus:DBUser.Citus@10.10.10.10/citus -c 'SELECT * FROM pg_dist_node;'
使用Citus集群
在使用 Citus 集群时,我们强烈建议您先阅读 Citus 官方文档,了解其架构设计与核心概念。
其中核心是了解 Citus 中的五种表,以及其特点与应用场景:
- 分布式表(Distributed Table)
- 参考表(Reference Table)
- 本地表(Local Table)
- 本地管理表(Local Management Table)
- 架构表(Schema Table)
在协调者节点上,您可以创建分布式表和引用表,并从任何数据节点查询它们。从 11.2 开始,任何 Citus 数据库节点都可以扮演协调者的角色了。
我们可以使用 pgbench 来创建一些表,并将其中的主表(pgbench_accounts)分布到各个节点上,然后将其他小表作为引用表:
PGURL=postgres://dbuser_citus:DBUser.Citus@10.10.10.10/citus
pgbench -i $PGURL
psql $PGURL <<-EOF
SELECT create_distributed_table('pgbench_accounts', 'aid'); SELECT truncate_local_data_after_distributing_table('public.pgbench_accounts');
SELECT create_reference_table('pgbench_branches') ; SELECT truncate_local_data_after_distributing_table('public.pgbench_branches');
SELECT create_reference_table('pgbench_history') ; SELECT truncate_local_data_after_distributing_table('public.pgbench_history');
SELECT create_reference_table('pgbench_tellers') ; SELECT truncate_local_data_after_distributing_table('public.pgbench_tellers');
EOF
执行读写测试:
pgbench -nv -P1 -c10 -T500 postgres://dbuser_citus:DBUser.Citus@10.10.10.10/citus # 直连协调者 5432 端口
pgbench -nv -P1 -c10 -T500 postgres://dbuser_citus:DBUser.Citus@10.10.10.10:6432/citus # 通过连接池,减少客户端连接数压力,可以有效提高整体吞吐。
pgbench -nv -P1 -c10 -T500 postgres://dbuser_citus:DBUser.Citus@10.10.10.13/citus # 任意 primary 节点都可以作为 coordinator
pgbench --select-only -nv -P1 -c10 -T500 postgres://dbuser_citus:DBUser.Citus@10.10.10.11/citus # 可以发起只读查询
更严肃的生产部署
要将 Citus 用于生产环境,您通常需要为 Coordinator 和每个 Worker 集群设置流复制物理副本。
例如,在 simu.yml 中定义了一个 10 节点的 Citus 集群。
pg-citus: # citus group
hosts:
10.10.10.50: { pg_group: 0, pg_cluster: pg-citus0 ,pg_vip_address: 10.10.10.60/24 ,pg_seq: 0, pg_role: primary }
10.10.10.51: { pg_group: 0, pg_cluster: pg-citus0 ,pg_vip_address: 10.10.10.60/24 ,pg_seq: 1, pg_role: replica }
10.10.10.52: { pg_group: 1, pg_cluster: pg-citus1 ,pg_vip_address: 10.10.10.61/24 ,pg_seq: 0, pg_role: primary }
10.10.10.53: { pg_group: 1, pg_cluster: pg-citus1 ,pg_vip_address: 10.10.10.61/24 ,pg_seq: 1, pg_role: replica }
10.10.10.54: { pg_group: 2, pg_cluster: pg-citus2 ,pg_vip_address: 10.10.10.62/24 ,pg_seq: 0, pg_role: primary }
10.10.10.55: { pg_group: 2, pg_cluster: pg-citus2 ,pg_vip_address: 10.10.10.62/24 ,pg_seq: 1, pg_role: replica }
10.10.10.56: { pg_group: 3, pg_cluster: pg-citus3 ,pg_vip_address: 10.10.10.63/24 ,pg_seq: 0, pg_role: primary }
10.10.10.57: { pg_group: 3, pg_cluster: pg-citus3 ,pg_vip_address: 10.10.10.63/24 ,pg_seq: 1, pg_role: replica }
10.10.10.58: { pg_group: 4, pg_cluster: pg-citus4 ,pg_vip_address: 10.10.10.64/24 ,pg_seq: 0, pg_role: primary }
10.10.10.59: { pg_group: 4, pg_cluster: pg-citus4 ,pg_vip_address: 10.10.10.64/24 ,pg_seq: 1, pg_role: replica }
vars:
pg_mode: citus # pgsql cluster mode: citus
pg_version: 18 # citus 13.x supports PG 14-18
pg_shard: pg-citus # citus shard name: pg-citus
pg_primary_db: citus # primary database used by citus
pg_vip_enabled: true # enable vip for citus cluster
pg_vip_interface: eth1 # vip interface for all members
pg_dbsu_password: DBUser.Postgres # enable dbsu password access for citus
pg_extensions: [ citus, postgis, pgvector, topn, pg_cron, hll ] # install these extensions
pg_libs: 'citus, pg_cron, pg_stat_statements' # citus will be added by patroni automatically
pg_users: [{ name: dbuser_citus ,password: DBUser.Citus ,pgbouncer: true ,roles: [ dbrole_admin ] }]
pg_databases: [{ name: citus ,owner: dbuser_citus ,extensions: [ citus, vector, topn, pg_cron, hll ] }]
pg_parameters:
cron.database_name: citus
citus.node_conninfo: 'sslrootcert=/pg/cert/ca.crt sslmode=verify-full'
pg_hba_rules:
- { user: 'all' ,db: all ,addr: 127.0.0.1/32 ,auth: ssl ,title: 'all user ssl access from localhost' }
- { user: 'all' ,db: all ,addr: intra ,auth: ssl ,title: 'all user ssl access from intranet' }
我们将在后续教程中覆盖一系列关于 Citus 的高级主题
- 读写分离
- 故障处理
- 一致性备份与恢复
- 高级监控与问题诊断
- 连接池