1 - 用户/角色
CREATE USER/ROLE 创建的,数据库集簇内的逻辑对象。在这里的上下文中,用户指的是使用 SQL 命令
CREATE USER/ROLE创建的,数据库集簇内的逻辑对象。
在PostgreSQL中,用户直接隶属于数据库集簇而非某个具体的数据库。因此在创建业务数据库和业务用户时,应当遵循"先用户,后数据库"的原则。
定义用户
Pigsty通过两个配置参数定义数据库集群中的角色与用户:
pg_default_roles:定义全局统一使用的角色和用户pg_users:在数据库集群层面定义业务用户和角色
前者用于定义了整套环境中共用的角色与用户,后者定义单个集群中特有的业务角色与用户。二者形式相同,均为用户定义对象的数组。
你可以定义多个用户/角色,它们会按照先全局,后集群,最后按数组内排序的顺序依次创建,所以后面的用户可以属于前面定义的角色。
下面是 Pigsty 演示环境中默认集群 pg-meta 中的业务用户定义:
pg-meta:
hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary } }
vars:
pg_cluster: pg-meta
pg_users:
- {name: dbuser_meta ,password: DBUser.Meta ,pgbouncer: true ,roles: [dbrole_admin] ,comment: pigsty admin user }
- {name: dbuser_view ,password: DBUser.Viewer ,pgbouncer: true ,roles: [dbrole_readonly] ,comment: read-only viewer for meta database }
- {name: dbuser_grafana ,password: DBUser.Grafana ,pgbouncer: true ,roles: [dbrole_admin] ,comment: admin user for grafana database }
- {name: dbuser_bytebase ,password: DBUser.Bytebase ,pgbouncer: true ,roles: [dbrole_admin] ,comment: admin user for bytebase database }
- {name: dbuser_kong ,password: DBUser.Kong ,pgbouncer: true ,roles: [dbrole_admin] ,comment: admin user for kong api gateway }
- {name: dbuser_gitea ,password: DBUser.Gitea ,pgbouncer: true ,roles: [dbrole_admin] ,comment: admin user for gitea service }
- {name: dbuser_wiki ,password: DBUser.Wiki ,pgbouncer: true ,roles: [dbrole_admin] ,comment: admin user for wiki.js service }
- {name: dbuser_noco ,password: DBUser.Noco ,pgbouncer: true ,roles: [dbrole_admin] ,comment: admin user for nocodb service }
每个用户/角色定义都是一个 object,可能包括以下字段,以 dbuser_meta 用户为例:
- name: dbuser_meta # 必需,`name` 是用户定义的唯一必选字段
password: DBUser.Meta # 可选,密码,可以是 scram-sha-256 哈希字符串或明文
login: true # 可选,默认情况下可以登录
superuser: false # 可选,默认为 false,是超级用户吗?
createdb: false # 可选,默认为 false,可以创建数据库吗?
createrole: false # 可选,默认为 false,可以创建角色吗?
inherit: true # 可选,默认情况下,此角色可以使用继承的权限吗?
replication: false # 可选,默认为 false,此角色可以进行复制吗?
bypassrls: false # 可选,默认为 false,此角色可以绕过行级安全吗?
pgbouncer: true # 可选,默认为 false,将此用户添加到 pgbouncer 用户列表吗?(使用连接池的生产用户应该显式定义为 true)
connlimit: -1 # 可选,用户连接限制,默认 -1 禁用限制
expire_in: 3650 # 可选,此角色过期时间:从创建时 + n天计算(优先级比 expire_at 更高)
expire_at: '2030-12-31' # 可选,此角色过期的时间点,使用 YYYY-MM-DD 格式的字符串指定一个特定日期(优先级没 expire_in 高)
comment: pigsty admin user # 可选,此用户/角色的说明与备注字符串
roles: [dbrole_admin] # 可选,默认角色为:dbrole_{admin,readonly,readwrite,offline}
parameters: {} # 可选,使用 `ALTER ROLE SET` 针对这个角色,配置角色级的数据库参数
pool_mode: transaction # 可选,默认为 transaction 的 pgbouncer 池模式,用户级别
pool_connlimit: -1 # 可选,用户级别的最大数据库连接数,默认 -1 禁用限制
search_path: public # 可选,根据 postgresql 文档的键值配置参数(例如:使用 pigsty 作为默认 search_path)
- 唯一必需的字段是
name,它应该是 PostgreSQL 集群中的一个有效且唯一的用户名。 - 角色不需要
password,但对于可登录的业务用户,通常是需要指定一个密码的。 password可以是明文或 scram-sha-256 / md5 哈希字符串,请最好不要使用明文密码。- 用户/角色按数组顺序逐一创建,因此,请确保角色/分组的定义在成员之前。
login、superuser、createdb、createrole、inherit、replication、bypassrls是布尔标志。pgbouncer默认是禁用的:要将业务用户添加到 pgbouncer 用户列表,您应当显式将其设置为true。
ACL系统
Pigsty 具有一套内置的,开箱即用的访问控制 / ACL 系统,您只需将以下四个默认角色分配给业务用户即可轻松使用:
dbrole_readwrite:全局读写访问的角色(主属业务使用的生产账号应当具有数据库读写权限)dbrole_readonly:全局只读访问的角色(如果别的业务想要只读访问,可以使用此角色)dbrole_admin:拥有DDL权限的角色 (业务管理员,需要在应用中建表的场景)dbrole_offline:受限的只读访问角色(只能访问 offline 实例,通常是个人用户)
如果您希望重新设计您自己的 ACL 系统,可以考虑定制以下参数和模板:
pg_default_roles:系统范围的角色和全局用户pg_default_privileges:新建对象的默认权限roles/pgsql/templates/pg-init-role.sql:角色创建 SQL 模板roles/pgsql/templates/pg-init-template.sql:权限 SQL 模板
创建用户
在 pg_default_roles 和 pg_users 中 定义 的用户和角色,将在集群初始化的 PROVISION 阶段中自动逐一创建。
如果您希望在现有的集群上 创建用户,可以使用 bin/pgsql-user 工具。
将新用户/角色定义添加到 all.children.<cls>.pg_users,并使用以下方法创建该数据库:
bin/pgsql-user <cls> <username> # pgsql-user.yml -l <cls> -e username=<username>
不同于数据库,创建用户的剧本总是幂等的。当目标用户已经存在时,Pigsty会修改目标用户的属性使其符合配置。所以在现有集群上重复运行它通常不会有问题。
我们不建议您手工创建新的业务用户,特别当您想要创建的用户使用默认的 pgbouncer 连接池时:除非您愿意手工负责维护 Pgbouncer 中的用户列表并与 PostgreSQL 保持一致。
使用 bin/pgsql-user 工具或 pgsql-user.yml 剧本创建新数据库时,会将此数据库一并添加到 Pgbouncer用户 列表中。
修改用户
修改 PostgreSQL 用户的属性的方式与 创建用户 相同。
首先,调整您的用户定义,修改需要调整的属性,然后执行以下命令应用:
bin/pgsql-user <cls> <username> # pgsql-user.yml -l <cls> -e username=<username>
请注意,修改用户不会删除用户,而是通过 ALTER USER 命令修改用户属性;也不会回收用户的权限与分组,并使用 GRANT 命令授予新的角色。
Pgbouncer用户
默认情况下启用 Pgbouncer,并作为连接池中间件,其用户默认被管理。
Pigsty 默认将 pg_users 中显式带有 pgbouncer: true 标志的所有用户添加到 pgbouncer 用户列表中。
Pgbouncer 连接池中的用户在 /etc/pgbouncer/userlist.txt 中列出:
"postgres" ""
"dbuser_wiki" "SCRAM-SHA-256$4096:+77dyhrPeFDT/TptHs7/7Q==$KeatuohpKIYzHPCt/tqBu85vI11o9mar/by0hHYM2W8=:X9gig4JtjoS8Y/o1vQsIX/gY1Fns8ynTXkbWOjUfbRQ="
"dbuser_view" "SCRAM-SHA-256$4096:DFoZHU/DXsHL8MJ8regdEw==$gx9sUGgpVpdSM4o6A2R9PKAUkAsRPLhLoBDLBUYtKS0=:MujSgKe6rxcIUMv4GnyXJmV0YNbf39uFRZv724+X1FE="
"dbuser_monitor" "SCRAM-SHA-256$4096:fwU97ZMO/KR0ScHO5+UuBg==$CrNsmGrx1DkIGrtrD1Wjexb/aygzqQdirTO1oBZROPY=:L8+dJ+fqlMQh7y4PmVR/gbAOvYWOr+KINjeMZ8LlFww="
"dbuser_meta" "SCRAM-SHA-256$4096:leB2RQPcw1OIiRnPnOMUEg==$eyC+NIMKeoTxshJu314+BmbMFpCcspzI3UFZ1RYfNyU=:fJgXcykVPvOfro2MWNkl5q38oz21nSl1dTtM65uYR1Q="
"dbuser_kong" "SCRAM-SHA-256$4096:bK8sLXIieMwFDz67/0dqXQ==$P/tCRgyKx9MC9LH3ErnKsnlOqgNd/nn2RyvThyiK6e4=:CDM8QZNHBdPf97ztusgnE7olaKDNHBN0WeAbP/nzu5A="
"dbuser_grafana" "SCRAM-SHA-256$4096:HjLdGaGmeIAGdWyn2gDt/Q==$jgoyOB8ugoce+Wqjr0EwFf8NaIEMtiTuQTg1iEJs9BM=:ed4HUFqLyB4YpRr+y25FBT7KnlFDnan6JPVT9imxzA4="
"dbuser_gitea" "SCRAM-SHA-256$4096:l1DBGCc4dtircZ8O8Fbzkw==$tpmGwgLuWPDog8IEKdsaDGtiPAxD16z09slvu+rHE74=:pYuFOSDuWSofpD9OZhG7oWvyAR0PQjJBffgHZLpLHds="
"dbuser_dba" "SCRAM-SHA-256$4096:zH8niABU7xmtblVUo2QFew==$Zj7/pq+ICZx7fDcXikiN7GLqkKFA+X5NsvAX6CMshF0=:pqevR2WpizjRecPIQjMZOm+Ap+x0kgPL2Iv5zHZs0+g="
"dbuser_bytebase" "SCRAM-SHA-256$4096:OMoTM9Zf8QcCCMD0svK5gg==$kMchqbf4iLK1U67pVOfGrERa/fY818AwqfBPhsTShNQ=:6HqWteN+AadrUnrgC0byr5A72noqnPugItQjOLFw0Wk="
而用户级别的连接池参数则是使用另一个单独的文件: /etc/pgbouncer/useropts.txt 进行维护,比如:
dbuser_dba = pool_mode=session max_user_connections=16
dbuser_monitor = pool_mode=session max_user_connections=8
当您 创建数据库 时,Pgbouncer 的数据库列表定义文件将会被刷新,并通过在线重载配置的方式生效,不会影响现有的连接。
Pgbouncer 使用和 PostgreSQL 同样的 dbsu 运行,默认为 postgres 操作系统用户,您可以使用 pgb 别名,使用 dbsu 访问 pgbouncer 管理功能。
Pigsty 还提供了一个实用函数 pgb-route ,可以将 pgbouncer 数据库流量快速切换至集群中的其他节点,用于零停机迁移:
连接池用户配置文件 userlist.txt 与 useropts.txt 会在您 创建用户 时自动刷新,并通过在线重载配置的方式生效,正常不会影响现有的连接。
请注意,pgbouncer_auth_query 参数允许你使用动态查询来完成连接池用户认证,当您懒得管理连接池中的用户时,这是一种折中的方案。
2 - 数据库
CREATE DATABASE 创建的,数据库集簇内的逻辑对象。在这里的上下文中,数据库指的是使用 SQL 命令
CREATE DATABASE创建的,数据库集簇内的逻辑对象。
一组 PostgreSQL 服务器可以同时服务于多个 数据库 (Database)。在 Pigsty 中,你可以在集群配置中 定义 好所需的数据库。
Pigsty会对默认模板数据库template1进行修改与定制,创建默认模式,安装默认扩展,配置默认权限,新创建的数据库默认会从template1继承这些设置。
默认情况下,所有业务数据库都会被1:1添加到 Pgbouncer 连接池中;pg_exporter 默认会通过 自动发现 机制查找所有业务数据库并进行库内对象监控。
定义数据库
业务数据库定义在数据库集群参数 pg_databases 中,这是一个数据库定义构成的对象数组。
数组内的数据库按照定义顺序依次创建,因此后面定义的数据库可以使用先前定义的数据库作为模板。
下面是 Pigsty 演示环境中默认集群 pg-meta 中的数据库定义:
pg-meta:
hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary } }
vars:
pg_cluster: pg-meta
pg_databases:
- { name: meta ,baseline: cmdb.sql ,comment: pigsty meta database ,schemas: [pigsty] ,extensions: [{name: postgis, schema: public}, {name: timescaledb}]}
- { name: grafana ,owner: dbuser_grafana ,revokeconn: true ,comment: grafana primary database }
- { name: bytebase ,owner: dbuser_bytebase ,revokeconn: true ,comment: bytebase primary database }
- { name: kong ,owner: dbuser_kong ,revokeconn: true ,comment: kong the api gateway database }
- { name: gitea ,owner: dbuser_gitea ,revokeconn: true ,comment: gitea meta database }
- { name: wiki ,owner: dbuser_wiki ,revokeconn: true ,comment: wiki meta database }
- { name: noco ,owner: dbuser_noco ,revokeconn: true ,comment: nocodb database }
每个数据库定义都是一个 object,可能包括以下字段,以 meta 数据库为例:
- name: meta # 必选,`name` 是数据库定义的唯一必选字段
baseline: cmdb.sql # 可选,数据库 sql 的基线定义文件路径(ansible 搜索路径中的相对路径,如 files/)
pgbouncer: true # 可选,是否将此数据库添加到 pgbouncer 数据库列表?默认为 true
schemas: [pigsty] # 可选,要创建的附加模式,由模式名称字符串组成的数组
extensions: # 可选,要安装的附加扩展: 扩展对象的数组
- { name: postgis , schema: public } # 可以指定将扩展安装到某个模式中,也可以不指定(不指定则安装到 search_path 首位模式中)
- { name: timescaledb } # 例如有的扩展会创建并使用固定的模式,就不需要指定模式。
comment: pigsty meta database # 可选,数据库的说明与备注信息
owner: postgres # 可选,数据库所有者,默认为 postgres
template: template1 # 可选,要使用的模板,默认为 template1,目标必须是一个模板数据库
encoding: UTF8 # 可选,数据库编码,默认为 UTF8(必须与模板数据库相同)
locale: C # 可选,数据库地区设置,默认为 C(必须与模板数据库相同)
lc_collate: C # 可选,数据库 collate 排序规则,默认为 C(必须与模板数据库相同),没有理由不建议更改。
lc_ctype: C # 可选,数据库 ctype 字符集,默认为 C(必须与模板数据库相同)
tablespace: pg_default # 可选,默认表空间,默认为 'pg_default'
allowconn: true # 可选,是否允许连接,默认为 true。显式设置 false 将完全禁止连接到此数据库
revokeconn: false # 可选,撤销公共连接权限。默认为 false,设置为 true 时,属主和管理员之外用户的 CONNECT 权限会被回收
register_datasource: true # 可选,是否将此数据库注册到 grafana 数据源?默认为 true,显式设置为 false 会跳过注册
connlimit: -1 # 可选,数据库连接限制,默认为 -1 ,不限制,设置为正整数则会限制连接数。
pool_auth_user: dbuser_meta # 可选,连接到此 pgbouncer 数据库的所有连接都将使用此用户进行验证(启用 pgbouncer_auth_query 才有用)
pool_mode: transaction # 可选,数据库级别的 pgbouncer 池化模式,默认为 transaction
pool_size: 64 # 可选,数据库级别的 pgbouncer 默认池子大小,默认为 64
pool_reserve: 32 # 可选,数据库级别的 pgbouncer 池子保留空间,默认为 32,当默认池子不够用时,最多再申请这么多条突发连接。
pool_size_min: 0 # 可选,数据库级别的 pgbouncer 池的最小大小,默认为 0
pool_connlimit: 100 # 可选,数据库级别的最大数据库连接数,默认为 100
唯一必选的字段是 name,它应该是当前 PostgreSQL 集群中有效且唯一的数据库名称,其他参数都有合理的默认值。
name:数据库名称,必选项。baseline:SQL文件路径(Ansible搜索路径,通常位于files),用于初始化数据库内容。owner:数据库属主,默认为postgrestemplate:数据库创建时使用的模板,默认为template1encoding:数据库默认字符编码,默认为UTF8,默认与实例保持一致。建议不要配置与修改。locale:数据库默认的本地化规则,默认为C,建议不要配置,与实例保持一致。lc_collate:数据库默认的本地化字符串排序规则,默认与实例设置相同,建议不要修改,必须与模板数据库一致。强烈建议不要配置,或配置为C。lc_ctype:数据库默认的LOCALE,默认与实例设置相同,建议不要修改或设置,必须与模板数据库一致。建议配置为C或en_US.UTF8。allowconn:是否允许连接至数据库,默认为true,不建议修改。revokeconn:是否回收连接至数据库的权限?默认为false。如果为true,则数据库上的PUBLIC CONNECT权限会被回收。只有默认用户(dbsu|monitor|admin|replicator|owner)可以连接。此外,admin|owner会拥有GRANT OPTION,可以赋予其他用户连接权限。tablespace:数据库关联的表空间,默认为pg_default。connlimit:数据库连接数限制,默认为-1,即没有限制。extensions:对象数组 ,每一个对象定义了一个数据库中的扩展,以及其安装的模式。parameters:KV对象,每一个KV定义了一个需要针对数据库通过ALTER DATABASE修改的参数。pgbouncer:布尔选项,是否将该数据库加入到Pgbouncer中。所有数据库都会加入至Pgbouncer列表,除非显式指定pgbouncer: false。comment:数据库备注信息。pool_auth_user:启用pgbouncer_auth_query时,连接到此 pgbouncer 数据库的所有连接都将使用这里指定的用户执行认证查询。你需要使用一个具有访问pg_shadow表权限的用户。pool_mode:数据库级别的 pgbouncer 池化模式,默认为 transaction,即事物池化。如果留空,会使用pgbouncer_poolmode参数作为默认值。pool_size:数据库级别的 pgbouncer 默认池子大小,默认为 64pool_reserve:数据库级别的 pgbouncer 池子保留空间,默认为 32,当默认池子不够用时,最多再申请这么多条突发连接。pool_size_min: 数据库级别的 pgbouncer 池的最小大小,默认为 0pool_connlimit: 数据库级别的 pgbouncer 连接池最大数据库连接数,默认为 100
新创建的数据库默认会从 template1 数据库 Fork 出来,这个模版数据库会在 PG_PROVISION 阶段进行定制修改:
配置好扩展,模式以及默认权限,因此新创建的数据库也会继承这些配置,除非您显式使用一个其他的数据库作为模板。
关于数据库的访问权限,请参考 ACL:数据库权限 一节。
创建数据库
在 pg_databases 中 定义 的数据库将在集群初始化时自动创建。
如果您希望在现有集群上 创建数据库,可以使用 bin/pgsql-db 包装脚本。
将新的数据库定义添加到 all.children.<cls>.pg_databases 中,并使用以下命令创建该数据库:
bin/pgsql-db <cls> <dbname> # pgsql-db.yml -l <cls> -e dbname=<dbname>
下面是新建数据库时的一些注意事项:
创建数据库的剧本默认为幂等剧本,不过当您当使用 baseline 脚本时就不一定了:这种情况下,通常不建议在现有数据库上重复执行此操作,除非您确定所提供的 baseline SQL也是幂等的。
我们不建议您手工创建新的数据库,特别当您使用默认的 pgbouncer 连接池时:除非您愿意手工负责维护 Pgbouncer 中的数据库列表并与 PostgreSQL 保持一致。
使用 pgsql-db 工具或 pgsql-db.yml 剧本创建新数据库时,会将此数据库一并添加到 Pgbouncer 数据库 列表中。
如果您的数据库定义有一个非常规 owner(默认为 dbsu postgres),那么请确保在创建该数据库前,属主用户已经存在。
最佳实践永远是在创建数据库之前 创建 用户。
Pgbouncer数据库
Pigsty 会默认为 PostgreSQL 实例 1:1 配置启用一个 Pgbouncer 连接池,使用 /var/run/postgresql Unix Socket 通信。
连接池可以优化短连接性能,降低并发征用,以避免过高的连接数冲垮数据库,并在数据库迁移时提供额外的灵活处理空间。
Pigsty 默认将 pg_databases 中的所有数据库都添加到 pgbouncer 的数据库列表中。
您可以通过在数据库 定义 中显式设置 pgbouncer: false 来禁用特定数据库的 pgbouncer 连接池支持。
Pgbouncer数据库列表在 /etc/pgbouncer/database.txt 中定义,数据库定义中关于连接池的参数会体现在这里:
meta = host=/var/run/postgresql mode=session
grafana = host=/var/run/postgresql mode=transaction
bytebase = host=/var/run/postgresql auth_user=dbuser_meta
kong = host=/var/run/postgresql pool_size=32 reserve_pool=64
gitea = host=/var/run/postgresql min_pool_size=10
wiki = host=/var/run/postgresql
noco = host=/var/run/postgresql
mongo = host=/var/run/postgresql
当您 创建数据库 时,Pgbouncer 的数据库列表定义文件将会被刷新,并通过在线重载配置的方式生效,正常不会影响现有的连接。
Pgbouncer 使用和 PostgreSQL 同样的 dbsu 运行,默认为 postgres 操作系统用户,您可以使用 pgb 别名,使用 dbsu 访问 pgbouncer 管理功能。
Pigsty 还提供了一个实用函数 pgb-route ,可以将 pgbouncer 数据库流量快速切换至集群中的其他节点,用于零停机迁移:
# route pgbouncer traffic to another cluster member
function pgb-route(){
local ip=${1-'\/var\/run\/postgresql'}
sed -ie "s/host=[^[:space:]]\+/host=${ip}/g" /etc/pgbouncer/pgbouncer.ini
cat /etc/pgbouncer/pgbouncer.ini
}
3 - 服务/接入
分离读写操作,正确路由流量,稳定可靠地交付 PostgreSQL 集群提供的能力。
服务 是一种抽象:它是数据库集群对外提供能力的形式,并封装了底层集群的细节。
服务对于生产环境中的 稳定接入 至关重要,在 高可用 集群自动故障时方显其价值,单机用户 通常不需要操心这个概念。
单机用户
“服务” 的概念是给生产环境用的,个人用户/单机集群可以不折腾,直接拿实例名/IP地址访问数据库。
例如,Pigsty 默认的单节点 pg-meta.meta 数据库,就可以直接用下面三个不同的用户连接上去。
psql postgres://dbuser_dba:DBUser.DBA@10.10.10.10/meta # 直接用 DBA 超级用户连上去
psql postgres://dbuser_meta:DBUser.Meta@10.10.10.10/meta # 用默认的业务管理员用户连上去
psql postgres://dbuser_view:DBUser.View@pg-meta/meta # 用默认的只读用户走实例域名连上去
服务概述
在真实世界生产环境中,我们会使用基于复制的主从数据库集群。集群中有且仅有一个实例作为领导者(主库)可以接受写入。 而其他实例(从库)则会从持续从集群领导者获取变更日志,与领导者保持一致。同时,从库还可以承载只读请求,在读多写少的场景下可以显著分担主库的负担, 因此对集群的写入请求与只读请求进行区分,是一种十分常见的实践。
此外对于高频短连接的生产环境,我们还会通过连接池中间件(Pgbouncer)对请求进行池化,减少连接与后端进程的创建开销。但对于ETL与变更执行等场景,我们又需要绕过连接池,直接访问数据库。 同时,高可用集群在故障时会出现故障切换(Failover),故障切换会导致集群的领导者出现变更。因此高可用的数据库方案要求写入流量可以自动适配集群的领导者变化。 这些不同的访问需求(读写分离,池化与直连,故障切换自动适配)最终抽象出 服务 (Service)的概念。
通常来说,数据库集群都必须提供这种最基础的服务:
- 读写服务(primary) :可以读写数据库
对于生产数据库集群,至少应当提供这两种服务:
- 读写服务(primary) :写入数据:只能由主库所承载。
- 只读服务(replica) :读取数据:可以由从库承载,没有从库时也可由主库承载
此外,根据具体的业务场景,可能还会有其他的服务,例如:
- 默认直连服务(default) :允许(管理)用户,绕过连接池直接访问数据库的服务
- 离线从库服务(offline) :不承接线上只读流量的专用从库,用于ETL与分析查询
- 同步从库服务(standby) :没有复制延迟的只读服务,由 同步备库/主库处理只读查询
- 延迟从库服务(delayed) :访问同一个集群在一段时间之前的旧数据,由 延迟从库 来处理
默认服务
Pigsty默认为每个 PostgreSQL 数据库集群提供四种不同的服务,以下是默认服务及其定义:
| 服务 | 端口 | 描述 |
|---|---|---|
| primary | 5433 | 生产读写,连接到主库连接池(6432) |
| replica | 5434 | 生产只读,连接到备库连接池(6432) |
| default | 5436 | 管理,ETL写入,直接访问主库(5432) |
| offline | 5438 | OLAP、ETL、个人用户、交互式查询 |
以默认的 pg-meta 集群为例,它提供四种默认服务:
psql postgres://dbuser_meta:DBUser.Meta@pg-meta:5433/meta # pg-meta-primary : 通过主要的 pgbouncer(6432) 进行生产读写
psql postgres://dbuser_meta:DBUser.Meta@pg-meta:5434/meta # pg-meta-replica : 通过备份的 pgbouncer(6432) 进行生产只读
psql postgres://dbuser_dba:DBUser.DBA@pg-meta:5436/meta # pg-meta-default : 通过主要的 postgres(5432) 直接连接
psql postgres://dbuser_stats:DBUser.Stats@pg-meta:5438/meta # pg-meta-offline : 通过离线的 postgres(5432) 直接连接
从示例集群 架构图 上可以看出这四种服务的工作方式:
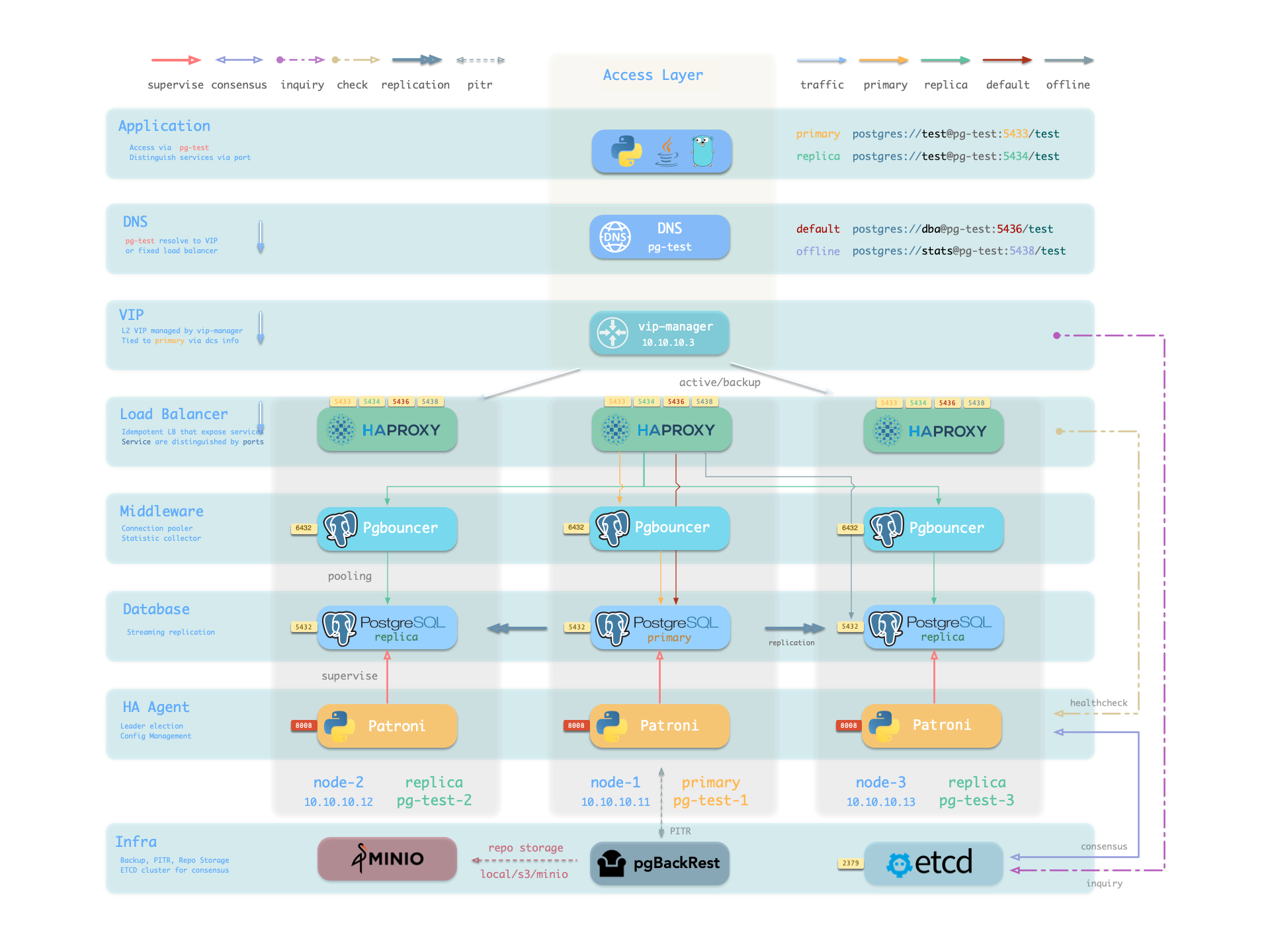
注意在这里pg-meta 域名指向了集群的 L2 VIP,进而指向集群主库上的 haproxy 负载均衡器,它负责将流量路由到不同的实例上,详见 服务接入
服务实现
在 Pigsty 中,服务使用 节点 上的 haproxy 来实现,通过主机节点上的不同端口进行区分。
Pigsty 所纳管的每个节点上都默认启用了 Haproxy 以对外暴露服务,而数据库节点也不例外。 集群中的节点尽管从数据库的视角来看有主从之分,但从服务的视角来看,每个节点都是相同的: 这意味着即使您访问的是从库节点,只要使用正确的服务端口,就依然可以使用到主库读写的服务。 这样的设计可以屏蔽复杂度:所以您只要可以访问 PostgreSQL 集群上的任意一个实例,就可以完整的访问到所有服务。
这样的设计类似于 Kubernetes 中的 NodePort 服务,同样在 Pigsty 中,每一个服务都包括以下两个核心要素:
- 通过 NodePort 暴露的访问端点(端口号,从哪访问?)
- 通过 Selectors 选择的目标实例(实例列表,谁来承载?)
Pigsty的服务交付边界止步于集群的HAProxy,用户可以用各种手段访问这些负载均衡器,请参考 接入服务。
所有的服务都通过配置文件进行声明,例如,PostgreSQL 默认服务就是由 pg_default_services 参数所定义的:
pg_default_services:
- { name: primary ,port: 5433 ,dest: default ,check: /primary ,selector: "[]" }
- { name: replica ,port: 5434 ,dest: default ,check: /read-only ,selector: "[]" , backup: "[? pg_role == `primary` || pg_role == `offline` ]" }
- { name: default ,port: 5436 ,dest: postgres ,check: /primary ,selector: "[]" }
- { name: offline ,port: 5438 ,dest: postgres ,check: /replica ,selector: "[? pg_role == `offline` || pg_offline_query ]" , backup: "[? pg_role == `replica` && !pg_offline_query]"}
您也可以在 pg_services 中定义额外的服务,参数 pg_default_services 与 pg_services 都是由 服务定义 对象组成的数组。
定义服务
Pigsty 允许您定义自己的服务:
pg_default_services:所有 PostgreSQL 集群统一对外暴露的服务,默认有四个。pg_services:额外的 PostgreSQL 服务,可以视需求在全局或集群级别定义。haproxy_servies:直接定制 HAProxy 服务内容,可以用于其他组件的接入
对于 PostgreSQL 集群来说,通常只需要关注前两者即可。
每一条服务定义都会在所有相关 HAProxy 实例的配置目录下生成一个新的配置文件:/etc/haproxy/<svcname>.cfg
下面是一个自定义的服务样例 standby:当您想要对外提供没有复制延迟的只读服务时,就可以在 pg_services 新增这条记录:
- name: standby # 必选,服务名称,最终的 svc 名称会使用 `pg_cluster` 作为前缀,例如:pg-meta-standby
port: 5435 # 必选,暴露的服务端口(作为 kubernetes 服务节点端口模式)
ip: "*" # 可选,服务绑定的 IP 地址,默认情况下为所有 IP 地址
selector: "[]" # 必选,服务成员选择器,使用 JMESPath 来筛选配置清单
backup: "[? pg_role == `primary`]" # 可选,服务成员选择器(备份),也就是当默认选择器选中的实例都宕机后,服务才会由这里选中的实例成员来承载
dest: default # 可选,目标端口,default|postgres|pgbouncer|<port_number>,默认为 'default',Default的意思就是使用 pg_default_service_dest 的取值来最终决定
check: /sync # 可选,健康检查 URL 路径,默认为 /,这里使用 Patroni API:/sync ,只有同步备库和主库才会返回 200 健康状态码
maxconn: 5000 # 可选,允许的前端连接最大数,默认为5000
balance: roundrobin # 可选,haproxy 负载均衡算法(默认为 roundrobin,其他选项:leastconn)
options: 'inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100'
而上面的服务定义,在样例的三节点 pg-test 上将会被转换为 haproxy 配置文件 /etc/haproxy/pg-test-standby.conf:
#---------------------------------------------------------------------
# service: pg-test-standby @ 10.10.10.11:5435
#---------------------------------------------------------------------
# service instances 10.10.10.11, 10.10.10.13, 10.10.10.12
# service backups 10.10.10.11
listen pg-test-standby
bind *:5435 # <--- 绑定了所有IP地址上的 5435 端口
mode tcp # <--- 负载均衡器工作在 TCP 协议上
maxconn 5000 # <--- 最大连接数为 5000,可按需调大
balance roundrobin # <--- 负载均衡算法为 rr 轮询,还可以使用 leastconn
option httpchk # <--- 启用 HTTP 健康检查
option http-keep-alive # <--- 保持HTTP连接
http-check send meth OPTIONS uri /sync # <---- 这里使用 /sync ,Patroni 健康检查 API ,只有同步备库和主库才会返回 200 健康状态码。
http-check expect status 200 # <---- 健康检查返回代码 200 代表正常
default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100
# servers: # pg-test 集群全部三个实例都被 selector: "[]" 给圈中了,因为没有任何的筛选条件,所以都会作为 pg-test-replica 服务的后端服务器。但是因为还有 /sync 健康检查,所以只有主库和同步备库才能真正承载请求。
server pg-test-1 10.10.10.11:6432 check port 8008 weight 100 backup # <----- 唯独主库满足条件 pg_role == `primary`, 被 backup selector 选中。
server pg-test-3 10.10.10.13:6432 check port 8008 weight 100 # 因此作为服务的兜底实例:平时不承载请求,其他从库全部宕机后,才会承载只读请求,从而最大避免了读写服务受到只读服务的影响
server pg-test-2 10.10.10.12:6432 check port 8008 weight 100 #
在这里,pg-test 集群全部三个实例都被 selector: "[]" 给圈中了,渲染进入 pg-test-replica 服务的后端服务器列表中。但是因为还有 /sync 健康检查,Patroni Rest API只有在主库和 同步备库 上才会返回代表健康的 HTTP 200 状态码,因此只有主库和同步备库才能真正承载请求。
此外,主库因为满足条件 pg_role == primary, 被 backup selector 选中,被标记为了备份服务器,只有当没有其他实例(也就是同步备库)可以满足需求时,才会顶上。
Primary服务
Primary服务可能是生产环境中最关键的服务,它在 5433 端口提供对数据库集群的读写能力,服务定义如下:
- { name: primary ,port: 5433 ,dest: default ,check: /primary ,selector: "[]" }
- 选择器参数
selector: "[]"意味着所有集群成员都将被包括在Primary服务中 - 但只有主库能够通过健康检查(
check: /primary),实际承载Primary服务的流量。 - 目的地参数
dest: default意味着Primary服务的目的地受到pg_default_service_dest参数的影响 dest默认值default会被替换为pg_default_service_dest的值,默认为pgbouncer。- 默认情况下 Primary 服务的目的地默认是主库上的连接池,也就是由
pgbouncer_port指定的端口,默认为 6432
如果 pg_default_service_dest 的值为 postgres,那么 primary 服务的目的地就会绕过连接池,直接使用 PostgreSQL 数据库的端口(pg_port,默认值 5432),对于一些不希望使用连接池的场景,这个参数非常实用。
示例:pg-test-primary 的 haproxy 配置
listen pg-test-primary
bind *:5433 # <--- primary 服务默认使用 5433 端口
mode tcp
maxconn 5000
balance roundrobin
option httpchk
option http-keep-alive
http-check send meth OPTIONS uri /primary # <--- primary 服务默认使用 Patroni RestAPI /primary 健康检查
http-check expect status 200
default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100
# servers
server pg-test-1 10.10.10.11:6432 check port 8008 weight 100
server pg-test-3 10.10.10.13:6432 check port 8008 weight 100
server pg-test-2 10.10.10.12:6432 check port 8008 weight 100
Patroni 的 高可用 机制确保任何时候最多只会有一个实例的 /primary 健康检查为真,因此Primary服务将始终将流量路由到主实例。
使用 Primary 服务而不是直连数据库的一个好处是,如果集群因为某种情况出现了双主(比如在没有watchdog的情况下kill -9杀死主库 Patroni),Haproxy在这种情况下仍然可以避免脑裂,因为它只会在 Patroni 存活且返回主库状态时才会分发流量。
Replica服务
Replica服务在生产环境中的重要性仅次于Primary服务,它在 5434 端口提供对数据库集群的只读能力,服务定义如下:
- { name: replica ,port: 5434 ,dest: default ,check: /read-only ,selector: "[]" , backup: "[? pg_role == `primary` || pg_role == `offline` ]" }
- 选择器参数
selector: "[]"意味着所有集群成员都将被包括在Replica服务中 - 所有实例都能够通过健康检查(
check: /read-only),承载Replica服务的流量。 - 备份选择器:
[? pg_role == 'primary' || pg_role == 'offline' ]将主库和 离线从库 标注为备份服务器。 - 只有当所有 普通从库 都宕机后,Replica服务才会由主库或离线从库来承载。
- 目的地参数
dest: default意味着Replica服务的目的地也受到pg_default_service_dest参数的影响 dest默认值default会被替换为pg_default_service_dest的值,默认为pgbouncer,这一点和 Primary服务 相同- 默认情况下 Replica 服务的目的地默认是从库上的连接池,也就是由
pgbouncer_port指定的端口,默认为 6432
示例:pg-test-replica 的 haproxy 配置
listen pg-test-replica
bind *:5434
mode tcp
maxconn 5000
balance roundrobin
option httpchk
option http-keep-alive
http-check send meth OPTIONS uri /read-only
http-check expect status 200
default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100
# servers
server pg-test-1 10.10.10.11:6432 check port 8008 weight 100 backup
server pg-test-3 10.10.10.13:6432 check port 8008 weight 100
server pg-test-2 10.10.10.12:6432 check port 8008 weight 100
Replica服务非常灵活:如果有存活的专用 Replica 实例,那么它会优先使用这些实例来承载只读请求,只有当从库实例全部宕机后,才会由主库来兜底只读请求。对于常见的一主一从双节点集群就是:只要从库活着就用从库,从库挂了再用主库。
此外,除非专用只读实例全部宕机,Replica 服务也不会使用专用 Offline 实例,这样就避免了在线快查询与离线慢查询混在一起,相互影响。
Default服务
Default服务在 5436 端口上提供服务,它是Primary服务的变体。
Default服务总是绕过连接池直接连到主库上的 PostgreSQL,这对于管理连接、ETL写入、CDC数据变更捕获等都很有用。
- { name: primary ,port: 5433 ,dest: default ,check: /primary ,selector: "[]" }
如果 pg_default_service_dest 被修改为 postgres,那么可以说 Default 服务除了端口和名称内容之外,与 Primary 服务是完全等价的。在这种情况下,您可以考虑将 Default 从默认服务中剔除。
示例:pg-test-default 的 haproxy 配置
listen pg-test-default
bind *:5436 # <--- 除了监听端口/目标端口和服务名,其他配置和 primary 服务一模一样
mode tcp
maxconn 5000
balance roundrobin
option httpchk
option http-keep-alive
http-check send meth OPTIONS uri /primary
http-check expect status 200
default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100
# servers
server pg-test-1 10.10.10.11:5432 check port 8008 weight 100
server pg-test-3 10.10.10.13:5432 check port 8008 weight 100
server pg-test-2 10.10.10.12:5432 check port 8008 weight 100
Offline服务
Default服务在 5438 端口上提供服务,它也绕开连接池直接访问 PostgreSQL 数据库,通常用于慢查询/分析查询/ETL读取/个人用户交互式查询,其服务定义如下:
- { name: offline ,port: 5438 ,dest: postgres ,check: /replica ,selector: "[? pg_role == `offline` || pg_offline_query ]" , backup: "[? pg_role == `replica` && !pg_offline_query]"}
Offline服务将流量直接路由到专用的 离线从库 上,或者带有 pg_offline_query 标记的普通 只读实例。
- 选择器参数从集群中筛选出了两种实例:
pg_role=offline的离线从库,或是带有pg_offline_query=true标记的普通 只读实例 - 专用离线从库和打标记的普通从库主要的区别在于:前者默认不承载 Replica服务 的请求,避免快慢请求混在一起,而后者默认会承载。
- 备份选择器参数从集群中筛选出了一种实例:不带 offline 标记的普通从库,这意味着如果离线实例或者带Offline标记的普通从库挂了之后,其他普通的从库可以用来承载Offline服务。
- 健康检查
/replica只会针对从库返回 200, 主库会返回错误,因此 Offline服务 永远不会将流量分发到主库实例上去,哪怕集群中只剩这一台主库。 - 同时,主库实例既不会被选择器圈中,也不会被备份选择器圈中,因此它永远不会承载Offline服务。因此 Offline 服务总是可以避免用户访问主库,从而避免对主库的影响。
示例:pg-test-offline 的 haproxy 配置
listen pg-test-offline
bind *:5438
mode tcp
maxconn 5000
balance roundrobin
option httpchk
option http-keep-alive
http-check send meth OPTIONS uri /replica
http-check expect status 200
default-server inter 3s fastinter 1s downinter 5s rise 3 fall 3 on-marked-down shutdown-sessions slowstart 30s maxconn 3000 maxqueue 128 weight 100
# servers
server pg-test-3 10.10.10.13:5432 check port 8008 weight 100
server pg-test-2 10.10.10.12:5432 check port 8008 weight 100 backup
Offline服务提供受限的只读服务,通常用于两类查询:交互式查询(个人用户),慢查询长事务(分析/ETL)。
Offline 服务需要额外的维护照顾:当集群发生主从切换或故障自动切换时,集群的实例角色会发生变化,而 Haproxy 的配置却不会自动发生变化。对于有多个从库的集群来说,这通常并不是一个问题。 然而对于一主一从,从库跑Offline查询的精简小集群而言,主从切换意味着从库变成了主库(健康检查失效),原来的主库变成了从库(不在 Offline 后端列表中),于是没有实例可以承载 Offline 服务了,因此需要手动 重载服务 以使变更生效。
如果您的业务模型较为简单,您可以考虑剔除 Default 服务与 Offline 服务,使用 Primary 服务与 Replica 服务直连数据库。
重载服务
当集群成员发生变化,如添加/删除副本、主备切换或调整相对权重时, 你需要 重载服务 以使更改生效。
bin/pgsql-svc <cls> [ip...] # 为 lb 集群或 lb 实例重载服务
# ./pgsql.yml -t pg_service # 重载服务的实际 ansible 任务
接入服务
Pigsty的服务交付边界止步于集群的HAProxy,用户可以用各种手段访问这些负载均衡器。
典型的做法是使用 DNS 或 VIP 接入,将其绑定在集群所有或任意数量的负载均衡器上。
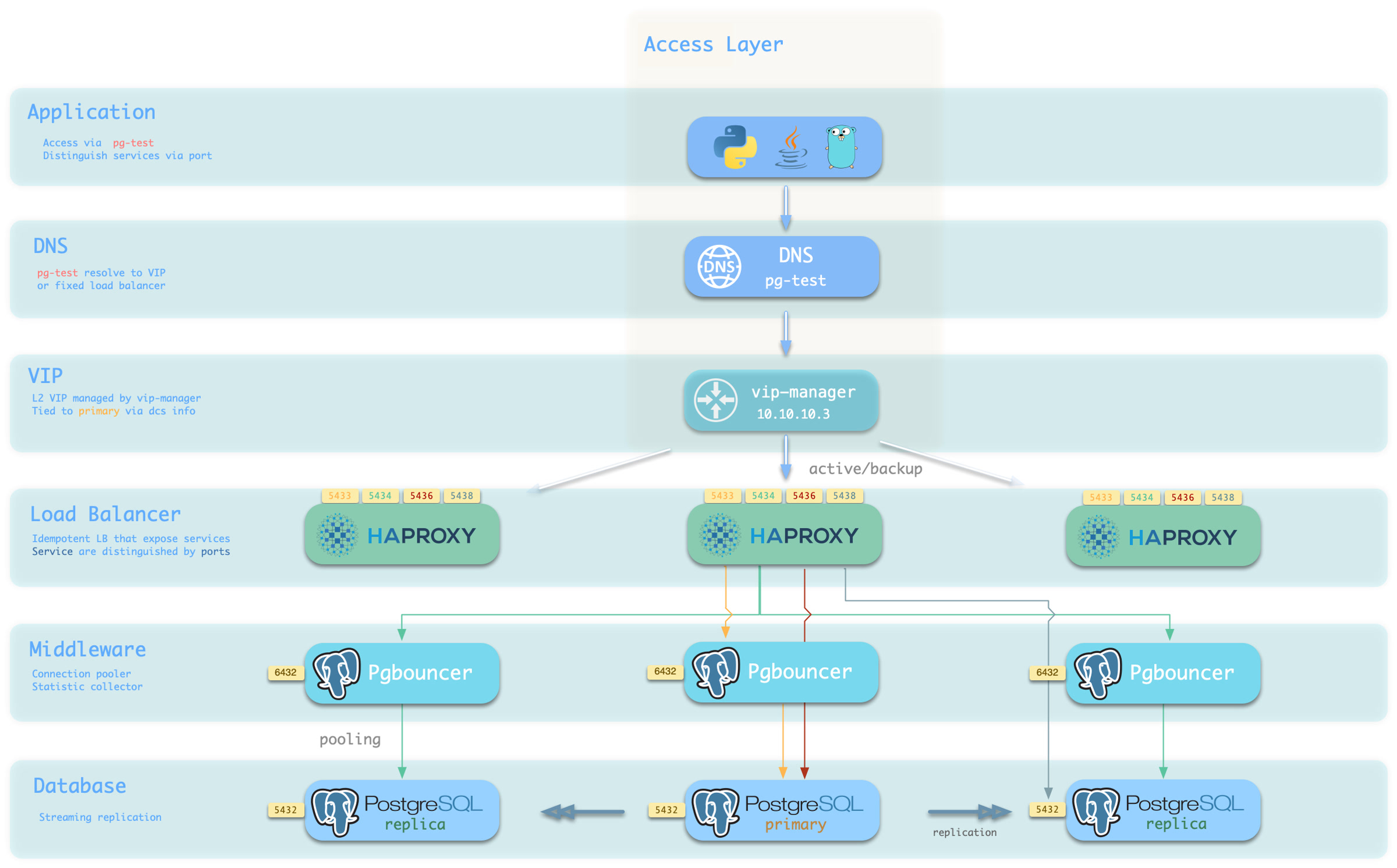
你可以使用不同的 主机 & 端口 组合,它们以不同的方式提供 PostgreSQL 服务。
主机
| 类型 | 样例 | 描述 |
|---|---|---|
| 集群域名 | pg-test | 通过集群域名访问(由 dnsmasq @ infra 节点解析) |
| 集群 VIP 地址 | 10.10.10.3 | 通过由 vip-manager 管理的 L2 VIP 地址访问,绑定到主节点 |
| 实例主机名 | pg-test-1 | 通过任何实例主机名访问(由 dnsmasq @ infra 节点解析) |
| 实例 IP 地址 | 10.10.10.11 | 访问任何实例的 IP 地址 |
端口
Pigsty 使用不同的 端口 来区分 pg services
| 端口 | 服务 | 类型 | 描述 |
|---|---|---|---|
| 5432 | postgres | 数据库 | 直接访问 postgres 服务器 |
| 6432 | pgbouncer | 中间件 | 访问 postgres 前先通过连接池中间件 |
| 5433 | primary | 服务 | 访问主 pgbouncer (或 postgres) |
| 5434 | replica | 服务 | 访问备份 pgbouncer (或 postgres) |
| 5436 | default | 服务 | 访问主 postgres |
| 5438 | offline | 服务 | 访问离线 postgres |
组合
# 通过集群域名访问
postgres://test@pg-test:5432/test # DNS -> L2 VIP -> 主直接连接
postgres://test@pg-test:6432/test # DNS -> L2 VIP -> 主连接池 -> 主
postgres://test@pg-test:5433/test # DNS -> L2 VIP -> HAProxy -> 主连接池 -> 主
postgres://test@pg-test:5434/test # DNS -> L2 VIP -> HAProxy -> 备份连接池 -> 备份
postgres://dbuser_dba@pg-test:5436/test # DNS -> L2 VIP -> HAProxy -> 主直接连接 (用于管理员)
postgres://dbuser_stats@pg-test:5438/test # DNS -> L2 VIP -> HAProxy -> 离线直接连接 (用于 ETL/个人查询)
# 通过集群 VIP 直接访问
postgres://test@10.10.10.3:5432/test # L2 VIP -> 主直接访问
postgres://test@10.10.10.3:6432/test # L2 VIP -> 主连接池 -> 主
postgres://test@10.10.10.3:5433/test # L2 VIP -> HAProxy -> 主连接池 -> 主
postgres://test@10.10.10.3:5434/test # L2 VIP -> HAProxy -> 备份连接池 -> 备份
postgres://dbuser_dba@10.10.10.3:5436/test # L2 VIP -> HAProxy -> 主直接连接 (用于管理员)
postgres://dbuser_stats@10.10.10.3::5438/test # L2 VIP -> HAProxy -> 离线直接连接 (用于 ETL/个人查询)
# 直接指定任何集群实例名
postgres://test@pg-test-1:5432/test # DNS -> 数据库实例直接连接 (单例访问)
postgres://test@pg-test-1:6432/test # DNS -> 连接池 -> 数据库
postgres://test@pg-test-1:5433/test # DNS -> HAProxy -> 连接池 -> 数据库读/写
postgres://test@pg-test-1:5434/test # DNS -> HAProxy -> 连接池 -> 数据库只读
postgres://dbuser_dba@pg-test-1:5436/test # DNS -> HAProxy -> 数据库直接连接
postgres://dbuser_stats@pg-test-1:5438/test # DNS -> HAProxy -> 数据库离线读/写
# 直接指定任何集群实例 IP 访问
postgres://test@10.10.10.11:5432/test # 数据库实例直接连接 (直接指定实例, 没有自动流量分配)
postgres://test@10.10.10.11:6432/test # 连接池 -> 数据库
postgres://test@10.10.10.11:5433/test # HAProxy -> 连接池 -> 数据库读/写
postgres://test@10.10.10.11:5434/test # HAProxy -> 连接池 -> 数据库只读
postgres://dbuser_dba@10.10.10.11:5436/test # HAProxy -> 数据库直接连接
postgres://dbuser_stats@10.10.10.11:5438/test # HAProxy -> 数据库离线读-写
# 智能客户端:自动进行读写分离
postgres://test@10.10.10.11:6432,10.10.10.12:6432,10.10.10.13:6432/test?target_session_attrs=primary
postgres://test@10.10.10.11:6432,10.10.10.12:6432,10.10.10.13:6432/test?target_session_attrs=prefer-standby
覆盖服务
你可以通过多种方式覆盖默认的服务配置,一种常见的需求是让 Primary服务 与 Replica服务 绕过Pgbouncer连接池,直接访问 PostgreSQL 数据库。
为了实现这一点,你可以将 pg_default_service_dest 更改为 postgres,这样所有服务定义中 svc.dest='default' 的服务都会使用 postgres 而不是默认的 pgbouncer 作为目标。
如果您已经将 Primary服务 指向了 PostgreSQL,那么 default服务 就会比较多余,可以考虑移除。
如果您不需要区分个人交互式查询,分析/ETL慢查询,可以考虑从默认服务列表 pg_default_services 中移除 Offline服务。
如果您不需要只读从库来分担在线只读流量,也可以从默认服务列表中移除 Replica服务。
委托服务
Pigsty 通过节点上的 haproxy 暴露 PostgreSQL 服务。整个集群中的所有 haproxy 实例都使用相同的 服务定义 进行配置。
但是,你可以将 pg 服务委托给特定的节点分组(例如,专门的 haproxy 负载均衡器集群),而不是 PostgreSQL 集群成员上的 haproxy。
为此,你需要使用 pg_default_services 覆盖默认的服务定义,并将 pg_service_provider 设置为代理组名称。
例如,此配置将在端口 10013 的 proxy haproxy 节点组上公开 pg 集群的主服务。
pg_service_provider: proxy # 使用端口 10013 上的 `proxy` 组的负载均衡器
pg_default_services: [{ name: primary ,port: 10013 ,dest: postgres ,check: /primary ,selector: "[]" }]
用户需要确保每个委托服务的端口,在代理集群中都是唯一的。
4 - 认证 / HBA
Pigsty 中基于主机的身份认证 HBA(Host-Based Authentication)详解。
认证是 访问控制 与 权限系统 的基石,PostgreSQL 拥有多种 认证 方法。
这里主要介绍 HBA:Host Based Authentication,HBA规则定义了哪些用户能够通过哪些方式从哪些地方访问哪些数据库。
客户端认证
要连接到PostgreSQL数据库,用户必须先经过认证(默认使用密码)。
您可以在连接字符串中提供密码(不安全)或使用PGPASSWORD环境变量或.pgpass文件传递密码。参考 psql 文档和 PostgreSQL连接字符串 以获取更多详细信息。
psql 'host=<host> port=<port> dbname=<dbname> user=<username> password=<password>'
psql postgres://<username>:<password>@<host>:<port>/<dbname>
PGPASSWORD=<password>; psql -U <username> -h <host> -p <port> -d <dbname>
例如,连接 Pigsty 默认的 meta 数据库,可以使用以下连接串:
psql 'host=10.10.10.10 port=5432 dbname=meta user=dbuser_dba password=DBUser.DBA'
psql postgres://dbuser_dba:DBUser.DBA@10.10.10.10:5432/meta
PGPASSWORD=DBUser.DBA; psql -U dbuser_dba -h 10.10.10.10 -p 5432 -d meta
默认配置下,Pigsty会启用服务端 SSL 加密,但不验证客户端 SSL 证书。要使用客户端SSL证书连接,你可以使用PGSSLCERT和PGSSLKEY环境变量或sslkey和sslcert参数提供客户端参数。
psql 'postgres://dbuser_dba:DBUser.DBA@10.10.10.10:5432/meta?sslkey=/path/to/dbuser_dba.key&sslcert=/path/to/dbuser_dba.crt'
客户端证书(CN = 用户名)可以使用本地CA与 cert.yml 剧本签发。
定义HBA
在Pigsty中,有四个与HBA规则有关的参数:
pg_hba_rules:postgres HBA规则pg_default_hba_rules:postgres 全局默认HBA规则pgb_hba_rules:pgbouncer HBA规则pgb_default_hba_rules:pgbouncer 全局默认HBA规则
这些都是 HBA 规则对象的数组,每个HBA规则都是以下两种形式之一的对象:
1. 原始形式
原始形式的 HBA 与 PostgreSQL pg_hba.conf 的格式几乎完全相同:
- title: allow intranet password access
role: common
rules:
- host all all 10.0.0.0/8 md5
- host all all 172.16.0.0/12 md5
- host all all 192.168.0.0/16 md5
在这种形式中,rules 字段是字符串数组,每一行都是条原始形式的 HBA规则。title 字段会被渲染为一条注释,解释下面规则的作用。
role 字段用于说明该规则适用于哪些实例角色,当实例的 pg_role 与role相同时,HBA规则将被添加到这台实例的 HBA 中。
role: common的HBA规则将被添加到所有实例上。role: primary的 HBA 规则只会添加到主库实例上。role: replica的 HBA 规则只会添加到从库实例上。role: offline的HBA规则将被添加到离线实例上(pg_role=offline或pg_offline_query=true)
2. 别名形式
别名形式允许您用更简单清晰便捷的方式维护 HBA 规则:它用addr、auth、user和db 字段替换了 rules。 title、role 和 order 字段则仍然生效。
- addr: 'intra' # world|intra|infra|admin|local|localhost|cluster|<cidr>
auth: 'pwd' # trust|pwd|ssl|cert|deny|<official auth method>
user: 'all' # all|${dbsu}|${repl}|${admin}|${monitor}|<user>|<group>
db: 'all' # all|replication|....
rules: [] # raw hba string precedence over above all
title: allow intranet password access
order: 100 # 排序权重,数字小的排前面(可选,默认追加到最后)
addr: where 哪些IP地址段受本条规则影响?world: 所有的IP地址intra: 所有的内网IP地址段:'10.0.0.0/8', '172.16.0.0/12', '192.168.0.0/16'infra: Infra节点的IP地址admin:admin_ip管理节点的IP地址local: 本地 Unix Socketlocalhost: 本地 Unix Socket 以及TCP 127.0.0.1/32 环回地址cluster: 同一个 PostgresQL 集群所有成员的IP地址<cidr>: 一个特定的 CIDR 地址块或IP地址
auth: how 本条规则指定的认证方式?deny: 拒绝访问trust: 直接信任,不需要认证pwd: 密码认证,根据pg_pwd_enc参数选用md5或scram-sha-256认证sha/scram-sha-256:强制使用scram-sha-256密码认证方式。md5:md5密码认证方式,但也可以兼容scram-sha-256认证,不建议使用。ssl: 在密码认证pwd的基础上,强制要求启用SSLssl-md5: 在密码认证md5的基础上,强制要求启用SSLssl-sha: 在密码认证sha的基础上,强制要求启用SSLos/ident: 使用操作系统用户的身份进行ident认证peer: 使用peer认证方式,类似于os identcert: 使用基于客户端SSL证书的认证方式,证书CN为用户名
user: who:哪些用户受本条规则影响?all: 所有用户${dbsu}: 默认数据库超级用户pg_dbsu${repl}: 默认数据库复制用户pg_replication_username${admin}: 默认数据库管理用户pg_admin_username${monitor}: 默认数据库监控用户pg_monitor_username- 其他特定的用户或者角色
db: which:哪些数据库受本条规则影响?all: 所有数据库replication: 允许建立复制连接(不指定特定数据库)- 某个特定的数据库
3. 定义位置
通常,全局的HBA定义在 all.vars 中,如果您想要修改全局默认的HBA规则,可以从 full.yml 模板中复制一份到 all.vars 中进行修改。
pg_default_hba_rules:postgres 全局默认HBA规则pgb_default_hba_rules:pgbouncer 全局默认HBA规则
而集群特定的 HBA 规则定义在数据库的集群级配置中:
pg_hba_rules:postgres HBA规则pgb_hba_rules:pgbouncer HBA规则
下面是一些集群HBA规则的定义例子:
pg-meta:
hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary } }
vars:
pg_cluster: pg-meta
pg_hba_rules:
- { user: dbuser_view ,db: all ,addr: infra ,auth: pwd ,title: '允许 dbuser_view 从基础设施节点密码访问所有库'}
- { user: all ,db: all ,addr: 100.0.0.0/8 ,auth: pwd ,title: '允许所有用户从K8S网段密码访问所有库' }
- { user: '${admin}' ,db: world ,addr: 0.0.0.0/0 ,auth: cert ,title: '允许管理员用户从任何地方用客户端证书登陆' }
重载HBA
HBA 是一个静态的规则配置文件,修改后需要重载才能生效。默认的 HBA 规则集合因为不涉及 Role 与集群成员,所以通常不需要重载。
如果您设计的 HBA 使用了特定的实例角色限制,或者集群成员限制,那么当集群实例成员发生变化(新增/下线/主从切换),一部分HBA规则的生效条件/涉及范围发生变化,通常也需要 重载HBA 以反映最新变化。
要重新加载 postgres/pgbouncer 的 hba 规则:
bin/pgsql-hba <cls> # 重新加载集群 `<cls>` 的 hba 规则
bin/pgsql-hba <cls> ip1 ip2... # 重新加载特定实例的 hba 规则
底层实际执行的 Ansible 剧本命令为:
./pgsql.yml -l <cls> -e pg_reload=true -t pg_hba,pg_reload
./pgsql.yml -l <cls> -e pg_reload=true -t pgbouncer_hba,pgbouncer_reload
默认HBA
Pigsty 有一套默认的 HBA 规则,对于绝大多数场景来说,它已经足够安全了。这些规则使用别名形式,因此基本可以自我解释。
pg_default_hba_rules: # postgres 全局默认的HBA规则,按 order 排序
- {user: '${dbsu}' ,db: all ,addr: local ,auth: ident ,title: 'dbsu access via local os user ident' ,order: 100}
- {user: '${dbsu}' ,db: replication ,addr: local ,auth: ident ,title: 'dbsu replication from local os ident' ,order: 150}
- {user: '${repl}' ,db: replication ,addr: localhost ,auth: pwd ,title: 'replicator replication from localhost',order: 200}
- {user: '${repl}' ,db: replication ,addr: intra ,auth: pwd ,title: 'replicator replication from intranet' ,order: 250}
- {user: '${repl}' ,db: postgres ,addr: intra ,auth: pwd ,title: 'replicator postgres db from intranet' ,order: 300}
- {user: '${monitor}' ,db: all ,addr: localhost ,auth: pwd ,title: 'monitor from localhost with password' ,order: 350}
- {user: '${monitor}' ,db: all ,addr: infra ,auth: pwd ,title: 'monitor from infra host with password',order: 400}
- {user: '${admin}' ,db: all ,addr: infra ,auth: ssl ,title: 'admin @ infra nodes with pwd & ssl' ,order: 450}
- {user: '${admin}' ,db: all ,addr: world ,auth: ssl ,title: 'admin @ everywhere with ssl & pwd' ,order: 500}
- {user: '+dbrole_readonly',db: all ,addr: localhost ,auth: pwd ,title: 'pgbouncer read/write via local socket',order: 550}
- {user: '+dbrole_readonly',db: all ,addr: intra ,auth: pwd ,title: 'read/write biz user via password' ,order: 600}
- {user: '+dbrole_offline' ,db: all ,addr: intra ,auth: pwd ,title: 'allow etl offline tasks from intranet',order: 650}
pgb_default_hba_rules: # pgbouncer 全局默认的HBA规则,按 order 排序
- {user: '${dbsu}' ,db: pgbouncer ,addr: local ,auth: peer ,title: 'dbsu local admin access with os ident',order: 100}
- {user: 'all' ,db: all ,addr: localhost ,auth: pwd ,title: 'allow all user local access with pwd' ,order: 150}
- {user: '${monitor}' ,db: pgbouncer ,addr: intra ,auth: pwd ,title: 'monitor access via intranet with pwd' ,order: 200}
- {user: '${monitor}' ,db: all ,addr: world ,auth: deny ,title: 'reject all other monitor access addr' ,order: 250}
- {user: '${admin}' ,db: all ,addr: intra ,auth: pwd ,title: 'admin access via intranet with pwd' ,order: 300}
- {user: '${admin}' ,db: all ,addr: world ,auth: deny ,title: 'reject all other admin access addr' ,order: 350}
- {user: 'all' ,db: all ,addr: intra ,auth: pwd ,title: 'allow all user intra access with pwd' ,order: 400}
注意:
order字段控制规则渲染顺序。0-99用于高优先规则(如黑名单),100-650为默认规则区间,1000+用于追加规则。详见 HBA 配置。
示例:渲染 pg_hba.conf
#==============================================================#
# File : pg_hba.conf
# Desc : Postgres HBA Rules for pg-meta-1 [primary]
# Time : 2023-01-11 15:19
# Host : pg-meta-1 @ 10.10.10.10:5432
# Path : /pg/data/pg_hba.conf
# Note : ANSIBLE MANAGED, DO NOT CHANGE!
# Author : Ruohang Feng (rh@vonng.com)
# License : Apache-2.0
#==============================================================#
# addr alias
# local : /var/run/postgresql
# admin : 10.10.10.10
# infra : 10.10.10.10
# intra : 10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16
# user alias
# dbsu : postgres
# repl : replicator
# monitor : dbuser_monitor
# admin : dbuser_dba
# dbsu access via local os user ident [default]
local all postgres ident
# dbsu replication from local os ident [default]
local replication postgres ident
# replicator replication from localhost [default]
local replication replicator scram-sha-256
host replication replicator 127.0.0.1/32 scram-sha-256
# replicator replication from intranet [default]
host replication replicator 10.0.0.0/8 scram-sha-256
host replication replicator 172.16.0.0/12 scram-sha-256
host replication replicator 192.168.0.0/16 scram-sha-256
# replicator postgres db from intranet [default]
host postgres replicator 10.0.0.0/8 scram-sha-256
host postgres replicator 172.16.0.0/12 scram-sha-256
host postgres replicator 192.168.0.0/16 scram-sha-256
# monitor from localhost with password [default]
local all dbuser_monitor scram-sha-256
host all dbuser_monitor 127.0.0.1/32 scram-sha-256
# monitor from infra host with password [default]
host all dbuser_monitor 10.10.10.10/32 scram-sha-256
# admin @ infra nodes with pwd & ssl [default]
hostssl all dbuser_dba 10.10.10.10/32 scram-sha-256
# admin @ everywhere with ssl & pwd [default]
hostssl all dbuser_dba 0.0.0.0/0 scram-sha-256
# pgbouncer read/write via local socket [default]
local all +dbrole_readonly scram-sha-256
host all +dbrole_readonly 127.0.0.1/32 scram-sha-256
# read/write biz user via password [default]
host all +dbrole_readonly 10.0.0.0/8 scram-sha-256
host all +dbrole_readonly 172.16.0.0/12 scram-sha-256
host all +dbrole_readonly 192.168.0.0/16 scram-sha-256
# allow etl offline tasks from intranet [default]
host all +dbrole_offline 10.0.0.0/8 scram-sha-256
host all +dbrole_offline 172.16.0.0/12 scram-sha-256
host all +dbrole_offline 192.168.0.0/16 scram-sha-256
# allow application database intranet access [common] [DISABLED]
#host kong dbuser_kong 10.0.0.0/8 md5
#host bytebase dbuser_bytebase 10.0.0.0/8 md5
#host grafana dbuser_grafana 10.0.0.0/8 md5
示例: 渲染 pgb_hba.conf
#==============================================================#
# File : pgb_hba.conf
# Desc : Pgbouncer HBA Rules for pg-meta-1 [primary]
# Time : 2023-01-11 15:28
# Host : pg-meta-1 @ 10.10.10.10:5432
# Path : /etc/pgbouncer/pgb_hba.conf
# Note : ANSIBLE MANAGED, DO NOT CHANGE!
# Author : Ruohang Feng (rh@vonng.com)
# License : Apache-2.0
#==============================================================#
# PGBOUNCER HBA RULES FOR pg-meta-1 @ 10.10.10.10:6432
# ansible managed: 2023-01-11 14:30:58
# addr alias
# local : /var/run/postgresql
# admin : 10.10.10.10
# infra : 10.10.10.10
# intra : 10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16
# user alias
# dbsu : postgres
# repl : replicator
# monitor : dbuser_monitor
# admin : dbuser_dba
# dbsu local admin access with os ident [default]
local pgbouncer postgres peer
# allow all user local access with pwd [default]
local all all scram-sha-256
host all all 127.0.0.1/32 scram-sha-256
# monitor access via intranet with pwd [default]
host pgbouncer dbuser_monitor 10.0.0.0/8 scram-sha-256
host pgbouncer dbuser_monitor 172.16.0.0/12 scram-sha-256
host pgbouncer dbuser_monitor 192.168.0.0/16 scram-sha-256
# reject all other monitor access addr [default]
host all dbuser_monitor 0.0.0.0/0 reject
# admin access via intranet with pwd [default]
host all dbuser_dba 10.0.0.0/8 scram-sha-256
host all dbuser_dba 172.16.0.0/12 scram-sha-256
host all dbuser_dba 192.168.0.0/16 scram-sha-256
# reject all other admin access addr [default]
host all dbuser_dba 0.0.0.0/0 reject
# allow all user intra access with pwd [default]
host all all 10.0.0.0/8 scram-sha-256
host all all 172.16.0.0/12 scram-sha-256
host all all 192.168.0.0/16 scram-sha-256
安全加固
对于那些需要更高安全性的场合,我们提供了一个安全加固的配置模板 security.yml,使用了以下的默认 HBA 规则集:
pg_default_hba_rules: # postgres host-based auth rules by default, order by `order`
- {user: '${dbsu}' ,db: all ,addr: local ,auth: ident ,title: 'dbsu access via local os user ident' ,order: 100}
- {user: '${dbsu}' ,db: replication ,addr: local ,auth: ident ,title: 'dbsu replication from local os ident' ,order: 150}
- {user: '${repl}' ,db: replication ,addr: localhost ,auth: ssl ,title: 'replicator replication from localhost',order: 200}
- {user: '${repl}' ,db: replication ,addr: intra ,auth: ssl ,title: 'replicator replication from intranet' ,order: 250}
- {user: '${repl}' ,db: postgres ,addr: intra ,auth: ssl ,title: 'replicator postgres db from intranet' ,order: 300}
- {user: '${monitor}' ,db: all ,addr: localhost ,auth: pwd ,title: 'monitor from localhost with password' ,order: 350}
- {user: '${monitor}' ,db: all ,addr: infra ,auth: ssl ,title: 'monitor from infra host with password',order: 400}
- {user: '${admin}' ,db: all ,addr: infra ,auth: ssl ,title: 'admin @ infra nodes with pwd & ssl' ,order: 450}
- {user: '${admin}' ,db: all ,addr: world ,auth: cert ,title: 'admin @ everywhere with ssl & cert' ,order: 500}
- {user: '+dbrole_readonly',db: all ,addr: localhost ,auth: ssl ,title: 'pgbouncer read/write via local socket',order: 550}
- {user: '+dbrole_readonly',db: all ,addr: intra ,auth: ssl ,title: 'read/write biz user via password' ,order: 600}
- {user: '+dbrole_offline' ,db: all ,addr: intra ,auth: ssl ,title: 'allow etl offline tasks from intranet',order: 650}
pgb_default_hba_rules: # pgbouncer host-based authentication rules, order by `order`
- {user: '${dbsu}' ,db: pgbouncer ,addr: local ,auth: peer ,title: 'dbsu local admin access with os ident',order: 100}
- {user: 'all' ,db: all ,addr: localhost ,auth: pwd ,title: 'allow all user local access with pwd' ,order: 150}
- {user: '${monitor}' ,db: pgbouncer ,addr: intra ,auth: ssl ,title: 'monitor access via intranet with pwd' ,order: 200}
- {user: '${monitor}' ,db: all ,addr: world ,auth: deny ,title: 'reject all other monitor access addr' ,order: 250}
- {user: '${admin}' ,db: all ,addr: intra ,auth: ssl ,title: 'admin access via intranet with pwd' ,order: 300}
- {user: '${admin}' ,db: all ,addr: world ,auth: deny ,title: 'reject all other admin access addr' ,order: 350}
- {user: 'all' ,db: all ,addr: intra ,auth: ssl ,title: 'allow all user intra access with pwd' ,order: 400}
更多信息,请参考 安全加固 一节。
5 - 访问控制
权限控制很重要,但很多用户做不好。因此 Pigsty 提供了一套开箱即用的精简访问控制模型,为您的集群安全性提供一个兜底。
角色系统
Pigsty 默认的角色系统包含四个 默认角色 和四个 默认用户:
| 角色名称 | 属性 | 所属 | 描述 |
|---|---|---|---|
dbrole_readonly | NOLOGIN | 角色:全局只读访问 | |
dbrole_readwrite | NOLOGIN | dbrole_readonly | 角色:全局读写访问 |
dbrole_admin | NOLOGIN | pg_monitor,dbrole_readwrite | 角色:管理员/对象创建 |
dbrole_offline | NOLOGIN | 角色:受限的只读访问 | |
postgres | SUPERUSER | 系统超级用户 | |
replicator | REPLICATION | pg_monitor,dbrole_readonly | 系统复制用户 |
dbuser_dba | SUPERUSER | dbrole_admin | pgsql 管理用户 |
dbuser_monitor | pg_monitor | pgsql 监控用户 |
这些 角色与用户 的详细定义如下所示:
pg_default_roles: # 全局默认的角色与系统用户
- { name: dbrole_readonly ,login: false ,comment: role for global read-only access }
- { name: dbrole_offline ,login: false ,comment: role for restricted read-only access }
- { name: dbrole_readwrite ,login: false ,roles: [dbrole_readonly] ,comment: role for global read-write access }
- { name: dbrole_admin ,login: false ,roles: [pg_monitor, dbrole_readwrite] ,comment: role for object creation }
- { name: postgres ,superuser: true ,comment: system superuser }
- { name: replicator ,replication: true ,roles: [pg_monitor, dbrole_readonly] ,comment: system replicator }
- { name: dbuser_dba ,superuser: true ,roles: [dbrole_admin] ,pgbouncer: true ,pool_mode: session, pool_connlimit: 16 ,comment: pgsql admin user }
- { name: dbuser_monitor ,roles: [pg_monitor] ,pgbouncer: true ,parameters: {log_min_duration_statement: 1000 } ,pool_mode: session ,pool_connlimit: 8 ,comment: pgsql monitor user }
默认角色
Pigsty 中有四个默认角色:
- 业务只读 (
dbrole_readonly): 用于全局只读访问的角色。如果别的业务想要此库只读访问权限,可以使用此角色。 - 业务读写 (
dbrole_readwrite): 用于全局读写访问的角色,主属业务使用的生产账号应当具有数据库读写权限 - 业务管理员 (
dbrole_admin): 拥有DDL权限的角色,通常用于业务管理员,或者需要在应用中建表的场景(比如各种业务软件) - 离线只读访问 (
dbrole_offline): 受限的只读访问角色(只能访问 offline 实例,通常是个人用户,ETL工具账号)
默认角色在 pg_default_roles 中定义,除非您确实知道自己在干什么,建议不要更改默认角色的名称。
- { name: dbrole_readonly , login: false , comment: role for global read-only access } # 生产环境的只读角色
- { name: dbrole_offline , login: false , comment: role for restricted read-only access (offline instance) } # 受限的只读角色
- { name: dbrole_readwrite , login: false , roles: [dbrole_readonly], comment: role for global read-write access } # 生产环境的读写角色
- { name: dbrole_admin , login: false , roles: [pg_monitor, dbrole_readwrite] , comment: role for object creation } # 生产环境的 DDL 更改角色
默认用户
Pigsty 也有四个默认用户(系统用户):
- 超级用户 (
postgres),集群的所有者和创建者,与操作系统 dbsu 名称相同。 - 复制用户 (
replicator),用于主-从复制的系统用户。 - 监控用户 (
dbuser_monitor),用于监控数据库和连接池指标的用户。 - 管理用户 (
dbuser_dba),执行日常操作和数据库更改的管理员用户。
这4个默认用户的用户名/密码通过4对专用参数进行定义,并在很多地方引用:
pg_dbsu:操作系统 dbsu 名称,默认为 postgres,最好不要更改它pg_dbsu_password:dbsu 密码,默认为空字符串意味着不设置 dbsu 密码,最好不要设置。pg_replication_username:postgres 复制用户名,默认为replicatorpg_replication_password:postgres 复制密码,默认为DBUser.Replicatorpg_admin_username:postgres 管理员用户名,默认为dbuser_dbapg_admin_password:postgres 管理员密码的明文,默认为DBUser.DBApg_monitor_username:postgres 监控用户名,默认为dbuser_monitorpg_monitor_password:postgres 监控密码,默认为DBUser.Monitor
在生产部署中记得更改这些密码,不要使用默认值!
pg_dbsu: postgres # 数据库超级用户名,这个用户名建议不要修改。
pg_dbsu_password: '' # 数据库超级用户密码,这个密码建议留空!禁止dbsu密码登陆。
pg_replication_username: replicator # 系统复制用户名
pg_replication_password: DBUser.Replicator # 系统复制密码,请务必修改此密码!
pg_monitor_username: dbuser_monitor # 系统监控用户名
pg_monitor_password: DBUser.Monitor # 系统监控密码,请务必修改此密码!
pg_admin_username: dbuser_dba # 系统管理用户名
pg_admin_password: DBUser.DBA # 系统管理密码,请务必修改此密码!
如果您修改默认用户的参数,在 pg_default_roles 中修改相应的角色 定义 即可:
- { name: postgres ,superuser: true ,comment: system superuser }
- { name: replicator ,replication: true ,roles: [pg_monitor, dbrole_readonly] ,comment: system replicator }
- { name: dbuser_dba ,superuser: true ,roles: [dbrole_admin] ,pgbouncer: true ,pool_mode: session, pool_connlimit: 16 , comment: pgsql admin user }
- { name: dbuser_monitor ,roles: [pg_monitor, dbrole_readonly] ,pgbouncer: true ,parameters: {log_min_duration_statement: 1000 } ,pool_mode: session ,pool_connlimit: 8 ,comment: pgsql monitor user }
权限系统
Pigsty 拥有一套开箱即用的权限模型,该模型与 默认角色 一起配合工作。
- 所有用户都可以访问所有模式。
- 只读用户(
dbrole_readonly)可以从所有表中读取数据。(SELECT,EXECUTE) - 读写用户(
dbrole_readwrite)可以向所有表中写入数据并运行 DML。(INSERT,UPDATE,DELETE)。 - 管理员用户(
dbrole_admin)可以创建对象并运行 DDL(CREATE,USAGE,TRUNCATE,REFERENCES,TRIGGER)。 - 离线用户(
dbrole_offline)类似只读用户,但访问受到限制,只允许访问 离线实例(pg_role = 'offline'或pg_offline_query = true) - 由管理员用户创建的对象将具有正确的权限。
- 所有数据库上都配置了默认权限,包括模板数据库。
- 数据库连接权限由数据库 定义 管理。
- 默认撤销
PUBLIC在数据库和public模式下的CREATE权限。
对象权限
数据库中新建对象的默认权限由参数 pg_default_privileges 所控制:
- GRANT USAGE ON SCHEMAS TO dbrole_readonly
- GRANT SELECT ON TABLES TO dbrole_readonly
- GRANT SELECT ON SEQUENCES TO dbrole_readonly
- GRANT EXECUTE ON FUNCTIONS TO dbrole_readonly
- GRANT USAGE ON SCHEMAS TO dbrole_offline
- GRANT SELECT ON TABLES TO dbrole_offline
- GRANT SELECT ON SEQUENCES TO dbrole_offline
- GRANT EXECUTE ON FUNCTIONS TO dbrole_offline
- GRANT INSERT ON TABLES TO dbrole_readwrite
- GRANT UPDATE ON TABLES TO dbrole_readwrite
- GRANT DELETE ON TABLES TO dbrole_readwrite
- GRANT USAGE ON SEQUENCES TO dbrole_readwrite
- GRANT UPDATE ON SEQUENCES TO dbrole_readwrite
- GRANT TRUNCATE ON TABLES TO dbrole_admin
- GRANT REFERENCES ON TABLES TO dbrole_admin
- GRANT TRIGGER ON TABLES TO dbrole_admin
- GRANT CREATE ON SCHEMAS TO dbrole_admin
由管理员新创建的对象,默认将会上述权限。使用 \ddp+ 可以查看这些默认权限:
| 类型 | 访问权限 |
|---|---|
| 函数 | =X |
| dbrole_readonly=X | |
| dbrole_offline=X | |
| dbrole_admin=X | |
| 模式 | dbrole_readonly=U |
| dbrole_offline=U | |
| dbrole_admin=UC | |
| 序列号 | dbrole_readonly=r |
| dbrole_offline=r | |
| dbrole_readwrite=wU | |
| dbrole_admin=rwU | |
| 表 | dbrole_readonly=r |
| dbrole_offline=r | |
| dbrole_readwrite=awd | |
| dbrole_admin=arwdDxt |
默认权限
ALTER DEFAULT PRIVILEGES 允许您设置将来创建的对象的权限。 它不会影响已经存在对象的权限,也不会影响非管理员用户创建的对象。
在 Pigsty 中,默认权限针对三个角色进行定义:
{% for priv in pg_default_privileges %}
ALTER DEFAULT PRIVILEGES FOR ROLE {{ pg_dbsu }} {{ priv }};
{% endfor %}
{% for priv in pg_default_privileges %}
ALTER DEFAULT PRIVILEGES FOR ROLE {{ pg_admin_username }} {{ priv }};
{% endfor %}
-- 对于其他业务管理员而言,它们应当在执行 DDL 前执行 SET ROLE dbrole_admin,从而使用对应的默认权限配置。
{% for priv in pg_default_privileges %}
ALTER DEFAULT PRIVILEGES FOR ROLE "dbrole_admin" {{ priv }};
{% endfor %}
这些内容将会被 PG集群初始化模板 pg-init-template.sql 所使用,在集群初始化的过程中渲染并输出至 /pg/tmp/pg-init-template.sql。
该命令会在 template1 与 postgres 数据库中执行,新创建的数据库会通过模板 template1 继承这些默认权限配置。
也就是说,为了维持正确的对象权限,您必须用管理员用户来执行 DDL,它们可以是:
{{ pg_dbsu }},默认为postgres{{ pg_admin_username }},默认为dbuser_dba- 授予了
dbrole_admin角色的业务管理员用户(通过SET ROLE切换为dbrole_admin身份)。
使用 postgres 作为全局对象所有者是明智的。如果您希望以业务管理员用户身份创建对象,创建之前必须使用 SET ROLE dbrole_admin 来维护正确的权限。
当然,您也可以在数据库中通过 ALTER DEFAULT PRIVILEGE FOR ROLE <some_biz_admin> XXX 来显式对业务管理员授予默认权限。
数据库权限
在 Pigsty 中,数据库(Database)层面的权限在 数据库定义 中被涵盖。
数据库有三个级别的权限:CONNECT、CREATE、TEMP,以及一个特殊的’权限’:OWNERSHIP。
- name: meta # 必选,`name` 是数据库定义中唯一的必选字段
owner: postgres # 可选,数据库所有者,默认为 postgres
allowconn: true # 可选,是否允许连接,默认为 true。显式设置 false 将完全禁止连接到此数据库
revokeconn: false # 可选,撤销公共连接权限。默认为 false,设置为 true 时,属主和管理员之外用户的 CONNECT 权限会被回收
- 如果
owner参数存在,它作为数据库属主,替代默认的{{ pg_dbsu }}(通常也就是postgres) - 如果
revokeconn为false,所有用户都有数据库的CONNECT权限,这是默认的行为。 - 如果显式设置了
revokeconn为true:- 数据库的
CONNECT权限将从PUBLIC中撤销:普通用户无法连接上此数据库 CONNECT权限将被显式授予{{ pg_replication_username }}、{{ pg_monitor_username }}和{{ pg_admin_username }}CONNECT权限将GRANT OPTION被授予数据库属主,数据库属主用户可以自行授权其他用户连接权限。
- 数据库的
revokeconn选项可用于在同一个集群间隔离跨数据库访问,您可以为每个数据库创建不同的业务用户作为属主,并为它们设置revokeconn选项。
示例:数据库隔离
pg-infra:
hosts:
10.10.10.40: { pg_seq: 1, pg_role: primary }
10.10.10.41: { pg_seq: 2, pg_role: replica , pg_offline_query: true }
vars:
pg_cluster: pg-infra
pg_users:
- { name: dbuser_confluence, password: mc2iohos , pgbouncer: true, roles: [ dbrole_admin ] }
- { name: dbuser_gitlab, password: sdf23g22sfdd , pgbouncer: true, roles: [ dbrole_readwrite ] }
- { name: dbuser_jira, password: sdpijfsfdsfdfs , pgbouncer: true, roles: [ dbrole_admin ] }
pg_databases:
- { name: confluence , revokeconn: true, owner: dbuser_confluence , connlimit: 100 }
- { name: gitlab , revokeconn: true, owner: dbuser_gitlab, connlimit: 100 }
- { name: jira , revokeconn: true, owner: dbuser_jira , connlimit: 100 }
CREATE权限
出于安全考虑,Pigsty 默认从 PUBLIC 撤销数据库上的 CREATE 权限,从 PostgreSQL 15 开始这也是默认行为。
数据库属主总是可以根据实际需要,来自行调整 CREATE 权限。