这是本节的多页打印视图。
点击此处打印.
返回本页常规视图.
Patroni 4.1 中文文档
Patroni PostgreSQL 高可用模板,v4.1 中文文档
原始页面: https://patroni.readthedocs.io/en/latest/index.html
Patroni 是一个基于 Python 的 PostgreSQL 高可用(HA)解决方案模板。为了最大程度地兼容各种环境,Patroni 支持多种分布式配置存储后端,包括 ZooKeeper、etcd、Consul 和 Kubernetes。希望在数据中心或任何其他环境中快速部署 PostgreSQL 高可用的数据库工程师、DBA、DevOps 工程师和 SRE 们,都能从中受益。
我们将 Patroni 称为"模板",是因为它远非一套放之四海而皆准的即插即用复制系统,使用时需要结合实际情况量力而行。实现 PostgreSQL 高可用的方案有很多,详情可参阅 PostgreSQL 文档。
目前支持的 PostgreSQL 版本:9.3 至 18。
Citus 用户注意:从 3.0 版本起,Patroni 已与 PostgreSQL 扩展 Citus 深度集成。如需了解如何将 Patroni 高可用与 Citus 分布式集群结合使用,请参阅文档中的 Citus 支持页面。
Kubernetes 用户注意:Patroni 可原生运行在 Kubernetes 之上。请参阅文档中的 Kubernetes 章节。

1 - 简介
Patroni 简介、快速上手以及高可用核心概念。
原始页面: https://patroni.readthedocs.io/en/latest/README.html
Patroni 是一个基于 Python 构建的高可用 PostgreSQL 解决方案模板框架。它最初 fork 自 Compose 公司的 Governor 项目,并在此基础上引入了大量新特性。
更多背景资料,请参阅:
开发状态
Patroni 正处于活跃开发阶段,欢迎社区贡献。详情请参阅下方的 贡献指南 章节。
新版本发布信息记录在 这里。
技术要求与安装
有关在各平台上安装和升级 Patroni 的指引,请参阅 安装文档。
规划 PostgreSQL 节点数量
Patroni/PostgreSQL 节点与 DCS 节点是解耦的(除非 Patroni 自行实现 RAFT),因此对最小节点数没有硬性要求。运行一个由一主一从构成的集群完全没有问题,后续可随时添加更多从库节点。
双节点集群(一主一备)是常见部署方式,可提供自动故障转移和高可用能力。请注意,在故障转移期间,直至故障节点重新加入集群前,集群将暂时失去冗余。
DCS 要求:您的 DCS(etcd、ZooKeeper、Consul)必须以 3 或 5 个节点运行,以保证正确的共识能力和容错性。单个 DCS 集群可通过不同的命名空间/scope 组合,同时存储数百乃至数千个 Patroni 集群的信息。
运行与配置
以下内容假设您已从 https://github.com/patroni/patroni 克隆了 Patroni 仓库,尤其需要用到示例配置文件 postgres0.yml 和 postgres1.yml。如果您通过 pip 安装了 Patroni,可以从 git 仓库获取这些文件,并将下方的 ./patroni.py 替换为 patroni 命令。
在不同终端窗口中依次执行以下命令即可启动:
> etcd --data-dir=data/etcd --enable-v2=true
> ./patroni.py postgres0.yml
> ./patroni.py postgres1.yml
随后您将看到一个高可用集群启动起来。可以修改 YAML 文件中的不同配置,观察集群行为的变化;也可以主动终止某些组件,观察系统的响应表现。
通过添加更多 postgres*.yml 文件,可以构建规模更大的集群。
Patroni 提供了一份 HAProxy 配置,可为应用程序提供连接集群主库的单一端点。配置方式如下:
> haproxy -f haproxy.cfg
> psql --host 127.0.0.1 --port 5000 postgres
YAML 配置
有关 etcd、Consul 和 ZooKeeper 的完整配置说明,请参阅 YAML 配置文档。配置示例可参考 postgres0.yml。
环境变量配置
有关通过环境变量覆盖配置的完整说明,请参阅 环境变量文档。
复制模式选择
Patroni 使用 PostgreSQL 的流复制,默认为异步复制。异步复制模式下可配置 maximum_lag_on_failover 参数,当某个从库落后主库的字节数超过该阈值时,故障转移将不会触发。该参数值应根据业务需求进行调整。如需更强的持久性保证,也可以改用同步复制。详情请参阅 复制模式文档。
应用程序不应使用超级用户
从应用程序连接数据库时,请始终使用非超级用户账号。Patroni 本身需要访问数据库才能正常运行。若应用程序使用超级用户连接,可能耗尽整个连接池,包括通过 superuser_reserved_connections 参数为超级用户预留的连接。一旦 Patroni 因连接池耗尽而无法访问主库,将产生不可预期的后果。
测试您的高可用方案
测试高可用方案是一项耗时的工作,涉及诸多变量,跨平台应用尤为如此。这项工作需要经验丰富的系统管理员或专业顾问来执行,文档中难以全面覆盖。
以下是您应当重点测试的基础设施要素:
- 网络(系统前端网络以及网卡本身,无论是物理网卡还是虚拟网卡)
- 磁盘 IO
- 文件描述符限制(Linux 中的 nofile)
- 内存——即便关闭了 oomkiller,内存不足同样可能引发问题
- CPU
- 虚拟化资源争用(Hypervisor 超售)
- 任何 cgroup 限制(通常与上述问题相关)
- 对任意 postgres 进程执行
kill -9(postmaster 除外)——这是模拟段错误的有效手段
有一件事切勿尝试:对 postmaster 进程执行 kill -9。这种操作并不对应任何真实场景。如果您担心基础设施不安全、攻击者可能执行 kill -9,任何高可用机制都无法解决这个问题——攻击者大可再次杀掉进程,或以其他方式制造混乱。
2 - 安装
在各支持平台上安装和升级 Patroni 的详细说明。
原始页面: https://patroni.readthedocs.io/en/latest/installation.html
Mac OS 前置依赖
在 Mac 上安装依赖,执行以下命令:
brew install postgresql etcd haproxy libyaml python
Psycopg
从 psycopg2-2.8 开始,psycopg2 的二进制版本不再默认安装。从源码编译安装需要 C 编译器以及 postgres 和 python 的开发包。由于 Python 生态中无法将依赖声明为 psycopg2 OR psycopg2-binary,您需要自行选择安装方式。
可选方案如下:
- 使用发行版自带的包管理器:
sudo apt-get install python3-psycopg2 # 在 Debian/Ubuntu 上安装 psycopg2 模块
sudo yum install python3-psycopg2 # 在 RedHat/Fedora/CentOS 上安装 psycopg2
- 在通过 pip 安装 Patroni 时,在 依赖列表 中指定
psycopg、psycopg2 或 psycopg2-binary 之一。
通过 pip 安装
Patroni 可以通过 pip 安装:
pip install patroni[dependencies]
其中 dependencies 可以为空,也可以是以下一个或多个选项的组合:
etcd 或 etcd3python-etcd 模块,用于将 Etcd 作为分布式配置存储(DCS)consulpy-consul 模块,用于将 Consul 作为 DCSzookeeperkazoo 模块,用于将 Zookeeper 作为 DCSexhibitorkazoo 模块,用于将 Exhibitor 作为 DCS(与 Zookeeper 依赖相同)kubernetes- kubernetes 模块,用于在 Patroni 中将 Kubernetes 作为 DCS
raftpysyncobj 模块,用于将 Python Raft 实现作为 DCSawsboto3,用于支持 AWS 回调jsonloggerpython-json-logger 模块,用于开启 JSON 格式的 日志记录systemdsystemd-python,用于支持 sd_notify 集成all- 以上所有选项(psycopg 系列除外)
psycopg3psycopg\[binary\]\>=3.0.0 模块psycopg2psycopg2\>=2.5.4 模块psycopg2-binarypsycopg2-binary 模块
例如,以下命令将同时安装 Patroni、psycopg3、Etcd DCS 依赖以及 AWS 回调支持:
pip install patroni[psycopg3,etcd3,aws]
请注意,用于创建从库或自定义引导脚本的外部工具(如 WAL-E)需要独立于 Patroni 单独安装。
在 Linux 上通过包管理器安装
PostgreSQL 社区为以下操作系统提供了 Patroni 软件包:
- RHEL、RockyLinux、AlmaLinux;
- Debian 和 Ubuntu;
- SUSE Enterprise Linux。
您也可以在这里找到 Patroni 直接依赖项(如官方 OS 仓库中未收录的 Python 模块)的软件包。
更多信息请参阅 PGDG 仓库 文档。
如果您使用的是 RedHat Enterprise Linux 衍生发行版,可能还需要 EPEL 中的软件包,请参阅 EPEL 仓库 文档。
为您的 OS 添加 PGDG 仓库后,即可安装 Patroni。
说明
Patroni 软件包并非由 Patroni 开发团队维护,而是由 PostgreSQL 社区负责维护。如需支持,请优先在 Postgres Slack 上寻求帮助。
在 Debian 衍生发行版上安装
安装 PGDG 仓库(参见 上文)后,通过 apt 安装 Patroni:
在 RedHat 衍生发行版上安装
安装 PGDG 仓库(参见 上文)后,在 RHEL 9(及其衍生版)上通过 dnf 安装 Patroni 和 etcd DCS:
dnf install patroni patroni-etcd
若您的 RedHat 衍生发行版未提供 etcd 软件包,可从 PGDG 安装。在承载 DCS 的节点上执行:
dnf install 'dnf-command(config-manager)'
dnf config-manager --enable pgdg-rhel9-extras
dnf install etcd
如需适配 RHEL 8,将仓库名中的版本号替换为 8 即可,即 pgdg-rhel8-extras。在 RockyLinux、AlmaLinux、Oracle Linux 等发行版上,仓库名仍为 pgdg-rhelN-extras。
在 SUSE Enterprise Linux 上安装
部分依赖可能需要启用 SUSE PackageHub 仓库,请参阅 SUSE PackageHub 文档。
在已安装 PGDG 仓库(参见 上文)的 SLES 15 上,可通过以下命令安装 Patroni:
zypper install patroni patroni-etcd
启用 SUSE PackageHub 仓库后,还可安装 etcd:
SUSEConnect -p PackageHub/15.5/x86_64
zypper install etcd
升级
升级 Patroni 非常简单:更新软件包后,在集群每个节点上重启 Patroni 守护进程即可。
但请注意,重启 Patroni 守护进程会导致 PostgreSQL 数据库重启。在某些情况下,这可能触发主库的故障转移。因此,建议在重启 Patroni 守护进程之前,先将集群置于维护模式。
在任意一个 Patroni 节点上执行以下命令,将集群切换至维护模式:
然后在集群的每个节点上执行对应 OS 所需的软件包升级操作:
apt-get update && apt-get install patroni patroni-etcd
在每个节点上重启 Patroni 守护进程:
systemctl restart patroni
最后,恢复 Patroni 对 PostgreSQL 的监控,退出维护模式:
至此,集群已使用新版 Patroni 恢复完整运行。
3 - Patroni 配置
Patroni 配置模型、优先级规则与验证工具。
原始页面: https://patroni.readthedocs.io/en/latest/patroni_configuration.html
Patroni 的配置分为 3 种类型:
全局 动态配置。
这些选项存储在 DCS(分布式配置存储)中,并应用于集群的所有节点。动态配置可以随时通过 patronictl edit-config 工具或 Patroni REST API 进行设置。如果更改的选项不属于启动配置,它们将异步地(在下一个唤醒周期时)应用到每个节点,随后触发重载。如果节点需要重启才能应用配置(对于上下文为 postmaster 且值已更改的 PostgreSQL 参数),则会在成员数据 JSON 中设置一个特殊标志 pending_restart,同时节点状态也会通过 "restart_pending": true 来体现这一情况。
本地 YAML 配置文件(patroni.yml)。
这些选项定义在配置文件中,优先级高于动态配置。patroni.yml 可以在运行时通过向 Patroni 进程发送 SIGHUP 信号、执行 POST /reload REST API 请求或运行 patronictl reload 来更改和重载(无需重启 Patroni)。本地配置可以是单个 YAML 文件,也可以是一个目录。当配置为目录时,该目录下的所有 YAML 文件会按排序顺序逐个加载。如果某个键在多个文件中定义,以最后一个文件中的值为准。
环境变量配置。
可以通过环境变量设置/覆盖部分"本地"配置参数。环境配置在动态环境中非常有用——当某些参数事先无法确定时(例如在 docker 容器内运行时无法预知外部 IP 地址)。
重要规则
由 Patroni 控制的 PostgreSQL 参数
某些 PostgreSQL 参数必须在主库和从库上保持相同的值。对于这些参数,在本地 Patroni 配置文件或通过环境变量设置的值不会生效。要修改或设置这些参数的值,必须通过 DCS 修改共享配置。以下是这类参数的列表,包含默认值和最小值:
max_connections:默认值 100,最小值 25max_locks_per_transaction:默认值 64,最小值 32max_worker_processes:默认值 8,最小值 2max_prepared_transactions:默认值 0,最小值 0wal_level:默认值 hot_standby,可接受值:hot_standby、replica、logicaltrack_commit_timestamp:默认值 off
对于下列参数,PostgreSQL 不要求主库和所有从库的值相同。但考虑到从库随时可能成为主库,将它们设置为不同值实际上没有意义;因此,Patroni 限制只能通过 动态配置 来设置这些参数的值。
max_wal_senders:默认值 10,最小值 3max_replication_slots:默认值 10,最小值 4wal_keep_segments:默认值 8,最小值 1wal_keep_size:默认值 128MB,最小值 16MBwal_log_hints:on
这些参数会经过校验,以确保其合理性或满足最小值要求。
还有一些其他由 Patroni 控制的 Postgres 参数:
listen_addresses - 从 postgresql.listen 或 PATRONI_POSTGRESQL_LISTEN 环境变量中设置port - 从 postgresql.listen 或 PATRONI_POSTGRESQL_LISTEN 环境变量中设置cluster_name - 从 scope 或 PATRONI_SCOPE 环境变量中设置hot_standby: on
为安全起见,上述列表中的参数会被写入 postgresql.conf,并作为参数列表传递给 postgres,赋予其最高优先级(wal_keep_segments 和 wal_keep_size 除外),甚至高于 ALTER SYSTEM。
还有一些参数如 postgresql.listen、postgresql.data_dir,只能在本地设置,即在 Patroni YAML 配置文件 中或通过 环境变量配置 环境变量设置。在大多数情况下,本地配置会覆盖动态配置。
应用本地或动态配置选项时,会执行以下操作:
- 节点首先检查是否存在
postgresql.base.conf 文件,或是否设置了 custom_conf 参数。 - 如果设置了
custom_conf 参数,则使用其指定的文件作为基础配置,忽略 postgresql.base.conf 和 postgresql.conf。 - 如果未设置
custom_conf 且存在 postgresql.base.conf,则它包含重命名后的"原始"配置,并作为基础配置使用。 - 如果既无
custom_conf 也无 postgresql.base.conf,原始的 postgresql.conf 会被重命名为 postgresql.base.conf 并作为基础配置使用。 - 动态选项(除上述例外)会被写入
postgresql.conf,并在 postgresql.conf 中设置 include 指向基础配置(postgresql.base.conf 或 custom_conf 指定的文件)。这样就能在不重新读取配置文件来检查 include 是否存在的情况下,直接应用新选项。 - 对于 Patroni 管理集群所必需的某些参数,会通过命令行进行覆盖。
- 如果某个需要重启的选项被更改(需查看
pg_settings 中的上下文以及这些选项的实际值),则会在该节点上设置 pending_restart 标志。该标志在任何重启时都会被清除。
参数按以下顺序应用(运行时参数优先级最高):
- 从
postgresql.base.conf 文件(或 custom_conf 文件,如已设置)中加载参数 - 从
postgresql.conf 文件中加载参数 - 从
postgresql.auto.conf 文件中加载参数 - 使用
-o --name=value 传入运行时参数
这种设计允许为所有节点统一配置(2),通过 ALTER SYSTEM 为特定节点配置(3),确保 Patroni 运行所必需的参数得到执行(4),同时为直接管理 postgresql.conf 而不涉及 Patroni 的配置工具预留空间(1)。
影响共享内存的 PostgreSQL 参数
PostgreSQL 有一些参数决定了其使用的共享内存大小:
max_connectionsmax_prepared_transactionsmax_locks_per_transactionmax_wal_sendersmax_worker_processes
更改这些参数需要重启 PostgreSQL 才能生效,且从库上的共享内存结构不能小于主库上的对应结构。
如前所述,Patroni 限制只能通过 动态配置 修改这些参数的值,通常操作流程为:
- 通过
patronictl edit-config(或通过 REST API 的 /config 端点)应用更改 - 通过
patronictl restart(或通过 REST API 的 /restart 端点)重启节点
注意: 请记住,应通过 patronictl restart 命令或 REST API 的 /restart 端点来重启 PostgreSQL 节点。尝试通过重启 Patroni 守护进程来重启 PostgreSQL(例如执行 systemctl restart patroni),如果重启的是主库,可能会导致集群发生故障转移。
由于这些设置管理共享内存,重启节点时需要格外注意:
若要增大上述任一设置的值:
- 先重启所有从库
- 之后再重启主库
若要减小上述任一设置的值:
- 先重启主库
- 之后再重启所有从库
注意: 如果在减小上述任一设置值后尝试一次性重启所有节点,Patroni 将忽略该变更并用原始设置值重启从库,从而需要之后再次重启从库。Patroni 这样处理是为了防止从库进入无限崩溃循环,因为如果尝试将上述任一参数设置为低于从库的 pg_controldata 中可见值的值,PostgreSQL 会以 FATAL 消息退出。换句话说,只有当从库的 pg_controldata 与主库关于这些更改保持一致后,才能在从库上减小该设置。
更多信息请参阅 PostgreSQL 管理员概述。
Patroni 配置参数
以下 Patroni 配置选项只能通过动态配置方式修改:
ttl:30loop_wait:10retry_timeouts:10maximum_lag_on_failover:1048576max_timelines_history:0check_timeline:falsepostgresql.use_slots:true
修改这些选项后,Patroni 会读取存储在 DCS 中的配置相关部分,并更新其运行时值。
Patroni 节点会在每次配置变更时,将 DCS 选项的状态以文件形式写入 Postgres 数据目录中名为 patroni.dynamic.json 的文件。只有主库才被允许在 DCS 中这些选项完全缺失或无效时,从磁盘上的文件恢复这些选项。
配置生成与验证
Patroni 提供了用于生成和验证 Patroni 本地配置文件 的命令行工具。使用 patroni 可执行文件,你可以:
- 生成示例本地 Patroni 配置;
- 为本地运行的 PostgreSQL 实例生成 Patroni 配置文件(例如作为 Patroni 集成 的准备步骤);
- 验证给定的 Patroni 配置文件。
示例 Patroni 配置
patroni --generate-sample-config [configfile]
说明
以 yaml 格式生成示例 Patroni 配置文件。参数值通过 环境变量配置 定义,如果未设置,则使用 Patroni 的默认值,或对用户需要自行定义的值使用 #FIXME 字符串。
部分默认值根据本地环境确定:
postgresql.listen:当前机器主机名通过 gethostname 调用返回的 IP 地址,以及标准的 5432 端口。postgresql.connect_address:当前机器主机名通过 gethostname 调用返回的 IP 地址,以及标准的 5432 端口。postgresql.authentication.rewind:仅当能够从二进制文件中确定 PostgreSQL 版本且版本为 11 或更高时才定义。restapi.listen:当前机器主机名通过 gethostname 调用返回的 IP 地址,以及标准的 8008 端口。restapi.connect_address:当前机器主机名通过 gethostname 调用返回的 IP 地址,以及标准的 8008 端口。
参数
configfile - 用于存储结果的配置文件完整路径。如果不提供,结果将输出到 stdout。
为运行中实例生成 Patroni 配置
patroni --generate-config [--dsn DSN] [configfile]
说明
为本地运行的 PostgreSQL 实例以 yaml 格式生成 Patroni 配置。将使用提供的 DSN(优先)或 PostgreSQL 环境变量 建立 PostgreSQL 连接。如果未提供密码,则通过提示符输入。
源 Postgres 实例中定义的所有非内部 GUC,无论是通过配置文件、postmaster 命令行还是环境变量设置,都将作为以下 Patroni 配置参数的来源:
scope:cluster_name GUC 的值;postgresql.listen:listen_addresses 和 port GUC 的值;postgresql.datadir:data_directory GUC 的值;postgresql.parameters:archive_command、restore_command、archive_cleanup_command、recovery_end_command、ssl_passphrase_command、hba_file、ident_file、config_file GUC 的值;bootstrap.dcs:所有其他收集到的 PostgreSQL GUC。
如果 scope、postgresql.listen 或 postgresql.datadir 未能从 Postgres GUC 中设置,则使用相应的 环境变量配置 值。
其他值定义规则:
name:若设置了 PATRONI_NAME 环境变量则使用该值,否则使用当前机器的主机名。postgresql.bin_dir:从运行中实例收集到的 Postgres 二进制文件路径。postgresql.connect_address:当前机器主机名通过 gethostname 调用返回的 IP 地址,以及用于实例连接的端口或 port GUC 的值。postgresql.authentication.superuser:用于实例连接的配置;postgresql.pg_hba:从源实例的 hba_file 收集的内容。postgresql.pg_ident:从源实例的 ident_file 收集的内容。restapi.listen:当前机器主机名通过 gethostname 调用返回的 IP 地址,以及标准的 8008 端口。restapi.connect_address:当前机器主机名通过 gethostname 调用返回的 IP 地址,以及标准的 8008 端口。
通过 环境变量配置 定义的其他参数也会包含在配置中。
参数
configfile
用于存储结果的配置文件完整路径。如果不提供,结果将输出到 stdout。
dsn
用于从本地 PostgreSQL 实例获取 GUC 值的可选 DSN 字符串。
验证 Patroni 配置
patroni --validate-config [configfile] [--ignore-listen-port | -i]
说明
验证给定的 Patroni 配置,并打印失败检查项的相关信息。
参数
configfile
待检查配置文件的完整路径。如果未提供或文件不存在,将尝试从 PATRONI_CONFIG_VARIABLE 环境变量中读取,如果也未设置,则从 Patroni 环境变量 中读取。
--ignore-listen-port | -i
可选标志,在验证 configfile 时忽略已在使用中的 listen 端口的绑定失败。
--print | -p
可选标志,在成功验证后打印本地配置(包含环境配置覆盖项)。
3.1 - 动态配置
存储在 DCS 中并应用于整个集群的动态配置参数。
原始页面: https://patroni.readthedocs.io/en/latest/dynamic_configuration.html
动态配置存储在 DCS(分布式配置存储)中,并应用于集群的所有节点。
如需修改动态配置,可使用 patronictl edit-config 工具或 Patroni REST API。
loop_wait:主循环每轮的休眠秒数。默认值:10,最小值:1。ttl:获取领导者锁的 TTL(秒)。可以理解为触发自动故障转移前的等待时长。默认值:30,最小值:20。retry_timeout:DCS 和 PostgreSQL 操作的重试超时时间(秒)。若 DCS 或网络故障时长短于此值,Patroni 不会对主库执行降级。默认值:10,最小值:3。
警告
修改 loop_wait、retry_timeout 或 ttl 时,必须遵守以下约束:
loop_wait + 2 * retry_timeout <= ttl
maximum_lag_on_failover:从库参与主库竞选所允许的最大落后字节数。maximum_lag_on_syncnode:同步从库在被健康的异步从库替代之前,允许落后的最大字节数。若存在多个从库,Patroni 取所有从库中最大的 LSN 作为参考;若只有一个从库,则使用主库当前的 WAL LSN。默认值为 -1;当该值为 0 或更低时,Patroni 不主动替换不健康的同步从库。请将此值设置得足够高,避免在高事务量期间 Patroni 频繁替换同步从库。max_timelines_history:DCS 中保留的时间线历史条目最大数量。默认值:0。设置为 0 时,保留完整历史记录。primary_start_timeout:主库在触发故障转移之前,允许从故障中恢复的时间(秒)。默认值为 300 秒。设置为 0 时,一旦检测到崩溃就立即执行故障转移(如果可能)。使用异步复制时,故障转移可能导致事务丢失。主库故障时的最长故障转移时间为 loop_wait + primary_start_timeout + loop_wait;若 primary_start_timeout 为零,则仅为 loop_wait。请根据持久性与可用性的取舍来设置该值。primary_stop_timeout:Patroni 停止 PostgreSQL 时允许等待的秒数,仅在启用 synchronous_mode 时生效。当该值大于 0 且启用了同步模式时,若停止操作运行时间超过 primary_stop_timeout 所设定的值,Patroni 会向 postmaster 发送 SIGKILL 信号。请根据持久性与可用性的取舍来设置该值。若该参数未设置或设置为 <= 0,则不生效。synchronous_mode:启用同步复制模式。可选值:off、on、quorum。在此模式下,主库负责管理 synchronous_standby_names,且只有最后已知的领导者或同步从库之一才被允许参与主库竞选。同步模式确保已成功提交的事务在故障转移时不会丢失,代价是当 Patroni 无法保证事务持久性时,写入操作将不可用。详见 复制模式文档。synchronous_mode_strict:当没有可用的同步从库时,禁止关闭同步复制,阻塞所有客户端对主库的写入。详见 复制模式文档。synchronous_node_count:启用 synchronous_mode 时,Patroni 使用此参数精确控制同步备库实例的数量,并随成员的加入和离开动态调整 DCS 中的状态及 PostgreSQL 的 synchronous_standby_names 参数。若设置值高于符合条件的节点数,将被自动调低。默认值为 1。failsafe_mode:启用 DCS 故障安全模式。默认值为 false。postgresql:use_pg_rewind:是否使用 pg_rewind。默认值为 false。注意:集群必须以数据页校验和(initdb 的 --data-checksums 选项)初始化,且/或将 wal_log_hints 设置为 on,否则 pg_rewind 将无法工作。use_slots:是否使用复制槽。在 PostgreSQL 9.4+ 上默认值为 true。recovery_conf:配置从库时写入 recovery.conf 的附加配置项。PostgreSQL 12 已不再使用 recovery.conf,但仍可继续使用此节,Patroni 会透明地处理。parameters:PostgreSQL 配置参数(GUC),格式为 {max_connections: 100, wal_level: "replica", max_wal_senders: 10, wal_log_hints: "on"}。其中许多参数是复制正常工作的必要条件。pg_hba:Patroni 用于生成 pg_hba.conf 的规则列表。若 PostgreSQL 参数 hba_file 被设置为非默认值,Patroni 将忽略此参数。- host all all 0.0.0.0/0 md5- host replication replicator 127.0.0.1/32 md5:复制所必需的一行配置。
pg_ident:Patroni 用于生成 pg_ident.conf 的规则列表。若 PostgreSQL 参数 ident_file 被设置为非默认值,Patroni 将忽略此参数。- mapname1 systemname1 pguser1- mapname1 systemname2 pguser2
standby_cluster:若定义了此节,表示要引导一个备用集群。host:远端节点的地址。port:远端节点的端口。primary_slot_name:用于复制的远端节点槽名。此参数可选,默认值由实例名称派生(参见函数 slot_name_from_member_name)。create_replica_methods:从远端主库引导备用领导者所用方法的有序列表,可与 postgresql_settings 中定义的列表不同。restore_command:将 WAL 记录从远端主库恢复到备用集群节点的命令,可与 postgresql_settings 中定义的不同。archive_cleanup_command:备用领导者的归档清理命令。recovery_min_apply_delay:备用领导者实际应用 WAL 记录前的等待时长。
member_slots_ttl:从库关闭后,其物理复制槽的保留时间。默认值:30min。若希望保留旧行为(成员键从 DCS 过期后立即删除槽),可将其设置为 0。此功能仅在 PostgreSQL 11 及以上版本中有效。slots:定义永久复制槽。这些复制槽在主从切换/故障转移期间会被保留,不存在的永久槽由 Patroni 负责创建。从 PostgreSQL 11 起,永久物理槽在所有节点上创建,其位置每 loop_wait 秒推进一次。对于 PostgreSQL 11 以下版本,永久物理复制槽仅在当前主库上维护。逻辑槽通过重启从主库复制到从库,此后其位置每 loop_wait 秒推进一次(如有必要)。逻辑槽文件的复制通过 libpq 连接完成,使用 rewind 或超级用户凭据(参见 postgresql.authentication 节)。从库上的逻辑槽位置可能略落后于原主库,因此应用程序应做好在故障转移后接收到重复消息的准备,最简便的处理方式是追踪 confirmed_flush_lsn。启用永久复制槽需要将 postgresql.use_slots 设置为 true。若定义了永久逻辑复制槽,Patroni 将自动启用 hot_standby_feedback。由于逻辑复制槽的故障转移在 PostgreSQL 9.6 及更低版本上不安全,且 PostgreSQL 10 缺少一些重要函数,该功能仅支持 PostgreSQL 11+。my_slot_name:永久复制槽的名称。若槽名称与当前节点名称相同,该槽不会在此节点上创建。若添加的永久物理复制槽名称与某个 Patroni 成员名称相同,Patroni 将确保该槽不被删除,即使对应成员变得无响应(正常情况下这会导致 Patroni 删除该槽)。这在某些场景下很有用,例如希望成员所用的复制槽在临时故障期间持续存在,或将现有成员导入新的 Patroni 集群(详见 将独立实例转换为 Patroni 集群)。但运维人员应注意,当该槽不再需要时,须及时清除 DCS 中的名称冲突配置,否则会影响 Patroni 的正常运行。type:槽类型,可为 physical 或 logical。逻辑槽需额外定义 database 和 plugin;物理槽可选择定义 cluster_type。database:逻辑槽应创建所在的数据库名称。plugin:逻辑槽使用的插件名称。cluster_type:槽仅应创建于其上的集群类型(primary 或 standby),否则该槽不会被创建,或已存在的槽将被删除。
ignore_slots:需要 Patroni 忽略的复制槽属性集合列表。当某些复制槽由 Patroni 以外的工具管理时,此配置非常有用。任何属性子集匹配都会导致该槽被忽略。name:复制槽的名称。type:槽类型,可为 physical 或 logical。逻辑槽可额外定义 database 和/或 plugin。database:数据库名称(匹配 logical 槽时使用)。plugin:逻辑解码插件(匹配 logical 槽时使用)。
注意:slots 是哈希映射,而 ignore_slots 是数组。示例如下:
slots:
permanent_logical_slot_name:
type: logical
database: my_db
plugin: test_decoding
permanent_physical_slot_name:
type: physical
...
ignore_slots:
- name: ignored_logical_slot_name
type: logical
database: my_db
plugin: test_decoding
- name: ignored_physical_slot_name
type: physical
...
注意:当运行 PostgreSQL v11 或更新版本时,Patroni 在所有可能成为领导者的节点上维护物理复制槽,以便从库在其他节点可能需要时保留 WAL 段。若节点缺席且其在 DCS 中的成员键过期,对应的复制槽将在 member_slots_ttl(默认值为 30min)后被删除。可按需调整保留时间。另外,若集群拓扑固定(节点数量和名称不变),可为每个节点配置与节点名对应的永久物理复制槽,避免从库临时下线时槽被删除、WAL 文件被回收:
slots:
node_name1:
type: physical
node_name2:
type: physical
node_name3:
type: physical
...
警告
永久复制槽仅从 primary/standby_leader 同步到从库,因此应用程序应仅在领导者节点上使用它们。在从库上使用永久复制槽会导致集群中所有其他节点的 pg_wal 无限增长。例外情况是与 Patroni 成员名称匹配的物理槽(由 Patroni 创建和维护),这些槽会在所有节点间同步,因为它们用于节点间的复制。
警告
在备库上设置 nostream 标签会禁用该节点自身及其所有级联从库上永久逻辑复制槽的复制和同步。
3.2 - YAML 配置参数
Patroni YAML 配置选项与各配置节的完整参考。
原始页面: https://patroni.readthedocs.io/en/latest/yaml_configuration.html
全局/通用
name:主机名称,在集群中必须唯一。namespace:Patroni 在配置存储中保存集群信息的路径,默认值为 /service。scope:集群名称。
日志
type:设置日志格式,可选 plain 或 json。使用 json 格式时,必须安装 jsonlogger。默认值为 plain。level:设置通用日志级别,默认值为 INFO(参见 Python logging 文档)。traceback_level:设置显示调用栈跟踪的日志级别,默认值为 ERROR。若希望仅在 log.level=DEBUG 时才输出调用栈,可将其设为 DEBUG。format:设置日志格式化字符串。若日志类型为 plain,格式应为字符串,可用属性参见 LogRecord 属性。若日志类型为 json,格式可以是字符串,也可以是列表——列表中每项对应一个 LogRecord 属性名,只需填写字段名,无需加 %( 和 )。若希望以不同键名输出某个日志字段,可使用字典:键为日志字段名,值为期望在日志中显示的名称。默认值为 %(asctime)s %(levelname)s: %(message)s。dateformat:设置日期时间格式化字符串(参见 formatTime() 文档)。static_fields:向日志中添加额外字段,仅在日志类型设为 json 时可用。max_queue_size:Patroni 采用两阶段日志记录——日志记录先写入内存队列,由独立线程从队列取出后写入 stderr 或文件。内部队列默认最多保存 1000 条记录,足以覆盖过去约 1 小时 20 分钟的日志。dir:应用日志的写入目录,该目录必须存在且对运行 Patroni 的用户可写。设置此值后,默认保留 4 个 25MB 的日志文件,可通过 file_num 和 file_size(见下文)调整保留策略。mode:日志文件的权限(例如 0644)。若未指定,权限将根据当前 umask 值设置。file_num:保留的应用日志文件数量。file_size:触发日志滚动的 patroni.log 文件大小(单位:字节)。loggers:本节允许按 Python 模块重新定义日志级别:- patroni.postmaster: WARNING
- urllib3: DEBUG
deduplicate_heartbeat_logs:若设为 true,连续相同的心跳日志将不再重复输出,默认值为 false。
警告
HA 循环的执行时间是诊断因资源耗尽等问题导致故障转移的重要信息。当 deduplicate_heartbeat_logs 设为 true 时,HA 循环的执行日志将不再生成(除非主库发生变更),因此这部分潜在有用的信息将无法从日志中获取。
以下是将 Patroni 配置为 JSON 格式日志的配置示例:
log:
type: json
format:
- message
- module
- asctime: '@timestamp'
- levelname: level
static_fields:
app: patroni
引导配置
bootstrap:dcs:本节内容将在新集群初始化完成后写入配置存储的 /<namespace>/<scope>/config,作为集群的全局动态配置。可将 动态配置参数 中描述的任意参数放在 bootstrap.dcs 下,Patroni 完成集群引导后会将本节写入该路径。
method:用于引导本集群的自定义脚本。
详见 自定义引导方法文档。指定 initdb 时将回退到默认的 initdb 命令;配置文件中不存在 method 参数时同样触发 initdb。
initdb:(可选)传递给 initdb 的选项列表。
- data-checksums:在 PostgreSQL 9.3 上使用 pg_rewind 时必须启用。- encoding: UTF8:新数据库的默认编码。- locale: UTF8:新数据库的默认区域设置。
post_bootstrap 或 post_init:集群初始化完成后执行的附加脚本。脚本接收一个以集群超级用户为用户名的连接字符串 URL,pgpass 文件路径通过 PGPASSFILE 环境变量传入。
Citus
启用 Patroni 与 Citus 的集成。配置后,Patroni 将负责在协调节点上注册 Citus 工作节点。关于 Citus 支持的更多信息,参见 此处。
group:Citus 组 ID,整数类型。协调节点使用 0,工作节点使用 1、2 等。database:应创建 citus 扩展的数据库,协调节点和所有工作节点必须相同,目前仅支持一个数据库。
Consul
大多数参数为可选,但必须指定 host 或 url 之一。
host:Consul 本地代理的 host:port。url:Consul 本地代理的 URL,格式为 http(s)://host:port。port:(可选)Consul 端口。scheme:(可选)http 或 https,默认为 http。token:(可选)ACL 令牌。verify:(可选)是否验证 HTTPS 请求的 SSL 证书。cacert:(可选)CA 证书文件,设置后将启用验证。cert:(可选)客户端证书文件。key:(可选)客户端密钥文件,若密钥已包含在 cert 中则可为空。dc:(可选)通信的数据中心,默认使用当前主机所在的数据中心。consistency:(可选)选择 Consul 一致性模式,可选值为 default、consistent 或 stale(详见 Consul API 参考)。checks:(可选)用于会话的 Consul 健康检查列表,默认为空列表。register_service:(可选)是否注册以 scope 参数命名的服务,并根据节点角色标记为 master、primary、replica 或 standby-leader,默认为 false。service_tags:(可选)除角色标签(primary/replica/standby-leader)外,要添加到 Consul 服务的额外静态标签,默认为空列表。service_check_interval:(可选)对已注册 URL 执行健康检查的频率,默认为 5s。service_check_tls_server_name:(可选)通过 TLS 连接时覆盖 SNI 主机名,参见 Consul agent check API 参考。
token 需要具备以下 ACL 权限:
service_prefix "${scope}" {
policy = "write"
}
key_prefix "${namespace}/${scope}" {
policy = "write"
}
session_prefix "" {
policy = "write"
}
Etcd
大多数参数为可选,但必须指定 host、hosts、url、proxy 或 srv 之一。
host:etcd 端点的 host:port。hosts:etcd 端点列表,格式为 host1:port1,host2:port2 等,可以是逗号分隔的字符串,也可以是 YAML 列表。use_proxies:若设为 true,Patroni 将把 hosts 视为代理列表,不再对 etcd 集群进行拓扑发现。url:etcd 的 URL。proxy:etcd 的代理 URL,若通过代理连接 etcd,请使用此参数而非 url。srv:用于集群自动发现的 SRV 记录搜索域。Patroni 将按以下顺序查询指定域的 SRV 服务名,找到第一个有效结果即止:_etcd-client-ssl、_etcd-client、_etcd-ssl、_etcd、_etcd-server-ssl、_etcd-server。若查到 _etcd-server-ssl 或 _etcd-server 的 SRV 记录,将通过 ETCD peer 协议查询可用成员;否则直接使用 SRV 记录中的主机。srv_suffix:配置用于自动发现时 SRV 查询名称的后缀,可在同一域下区分多个 etcd 集群,仅与 srv 联用。例如,设置 srv_suffix: foo 且 srv: example.org 时,将发起 _etcd-client-ssl-foo._tcp.example.com 等 DNS SRV 查询(所有可能的 ETCD SRV 服务名均以相同方式处理)。protocol:(可选)http 或 https,未指定时默认使用 http。若已指定 url 或 proxy,则从中获取协议。username:(可选)etcd 认证的用户名。password:(可选)etcd 认证的密码。cacert:(可选)CA 证书文件,设置后将启用验证。cert:(可选)客户端证书文件。key:(可选)客户端密钥文件,若密钥已包含在 cert 中则可为空。
Etcdv3
若要让 Patroni 通过协议版本 3 与 Etcd 集群通信,在 Patroni 配置文件中使用 etcd3 节即可,所有配置参数与 etcd 相同。
警告
使用协议版本 2 创建的键在版本 3 中不可见,反之亦然,因此不能仅通过更新 Patroni 配置文件来从 etcd 切换到 etcd3。此外,Patroni 使用 Etcd 的 gRPC-gateway(代理)与 V3 API 通信,这意味着不支持 TLS 通用名称认证。
ZooKeeper
hosts:ZooKeeper 集群成员列表,格式为
\['host1:port1', 'host2:port2', 'etc...'\]。use_ssl:(可选)是否使用 SSL,默认为 false。若为 false,所有 SSL 相关参数将被忽略。cacert:(可选)CA 证书文件,设置后将启用验证。cert:(可选)客户端证书文件。key:(可选)客户端密钥文件。key_password:(可选)客户端密钥密码。verify:(可选)是否验证证书,默认为 true。set_acls:(可选)若设置,Kazoo 将对其创建的每个 ZNode 应用默认 ACL。ACL 以字典形式指定,键为完整主体(可选带模式前缀),值为权限列表。支持 x509 模式(默认)或其他 ZooKeeper 支持的模式(如 digest)。权限可以是 CREATE、READ、WRITE、DELETE、ADMIN 或 ALL 之一或多个。示例:set_acls: {CN=principal1: [CREATE, READ], digest:principal2:+pjROuBuuwNNSujKyH8dGcEnFPQ=: [ALL]}。auth_data:(可选)连接使用的认证凭据,应以字典形式指定,键为 scheme,值为 credential,默认为空字典。
说明
需要安装 kazoo>=2.6.0 以支持 SSL。
Exhibitor
hosts:Exhibitor(ZooKeeper)节点的初始列表,格式为 ‘host1,host2,etc…’,当 Exhibitor(ZooKeeper)集群拓扑变化时自动更新。poll_interval:从 Exhibitor 更新 ZooKeeper 和 Exhibitor 节点列表的频率。port:Exhibitor 端口。
Kubernetes
bypass_api_service:(可选)与 Kubernetes API 通信时,Patroni 通常依赖 kubernetes 服务——该服务地址通过 KUBERNETES_SERVICE_HOST 环境变量暴露给 Pod。若将 bypass_api_service 设为 true,Patroni 将解析该服务背后的 API 节点列表并直接连接。namespace:(可选)Patroni Pod 运行所在的 Kubernetes namespace,默认值为 default。labels:格式为 {label1: value1, label2: value2} 的标签,用于查找与当前集群关联的已有对象(Pod 及 Endpoints 或 ConfigMaps),Patroni 也会将这些标签设置到其创建的每个对象(Endpoint 或 ConfigMap)上。scope_label:(可选)包含集群名称的标签名,默认值为 cluster-name。bootstrap_labels:(可选)格式为 {label1: value1, label2: value2} 的标签,当 Patroni Pod 处于 initializing new cluster、running custom bootstrap script、starting after custom bootstrap 或 creating replica 状态时,这些标签将被分配给该 Pod。role_label:(可选)包含角色(primary、replica 或其他自定义值)的标签名,Patroni 会在其运行的 Pod 上设置此标签,默认值为 role。leader_label_value:(可选)Postgres 角色为 primary 时 Pod 标签的值,默认值为 primary。follower_label_value:(可选)Postgres 角色为 replica 时 Pod 标签的值,默认值为 replica。standby_leader_label_value:(可选)Postgres 角色为 standby_leader 时 Pod 标签的值,默认值为 primary。tmp_role_label:(可选)包含临时角色(primary 或 replica)的标签名,此标签的值始终使用对应角色的默认值,仅在必要时设置。use_endpoints:(可选)若设为 true,Patroni 将使用 Endpoints 而非 ConfigMaps 进行主库选举和集群状态保存。pod_ip:(可选)运行 Patroni 的 Pod 的 IP 地址。启用 use_endpoints 时必须提供,用于在该 Pod 上的 PostgreSQL 被提升时填充领导者 Endpoint 的子集。ports:(可选)若 Service 对象为端口指定了名称,Endpoint 对象中也必须出现相同名称,否则服务将无法工作。例如,若服务定义为 {Kind: Service, spec: {ports: [{name: postgresql, port: 5432, targetPort: 5432}]}},则须设置 kubernetes.ports: [{"name": "postgresql", "port": 5432}],Patroni 将用它更新领导者 Endpoint 的子集。此参数仅在 kubernetes.use_endpoints 已设置时生效。cacert:(可选)用于验证 Kubernetes API SSL 证书的受信任 CA 证书包文件,若未提供,Patroni 将使用 ServiceAccount secret 中的值。retriable_http_codes:(可选)需要重试的 K8s API HTTP 状态码列表。默认情况下,Patroni 在收到 500、503、504 响应,或 K8s API 响应包含 retry-after HTTP 头时自动重试。
Raft(已弃用)
self_addr:用于 Raft 连接监听的 ip:port,self_addr 必须可从集群其他节点访问。若未设置,该节点将不参与共识。
bind_addr:(可选)用于 Raft 连接监听的 ip:port,若未指定则使用 self_addr。
partner_addrs:集群中其他 Patroni 节点的列表,格式为
\['ip1:port', 'ip2:port', 'etc...'\]。
data_dir:存储 Raft 日志和快照的目录,若未指定则使用当前工作目录。
password:(可选)使用指定密码加密 Raft 流量,需要 cryptography Python 模块。
关于 Raft 实现的简短 FAQ:
问:如何列出所有参与共识的节点?
答:syncobj_admin -conn host:port -status,其中 host:port 为集群某个节点的地址。
问:某个参与共识的节点已下线,且我无法为其他节点复用相同 IP,如何将其从共识中移除?
答:syncobj_admin -conn host:port -remove host2:port2,其中 host2:port2 为要移除的节点地址。
问:从哪里获取 syncobj_admin 工具?
答:它随 pysyncobj 模块(Python RAFT 实现,Patroni 的依赖项)一同安装。
问:是否可以在不加入共识的情况下运行 Patroni 节点?
答:可以,只需在 Patroni 配置中注释掉或删除 raft.self_addr。
问:是否可以只在两个节点上运行 Patroni 和 PostgreSQL?
答:可以,在第三个节点上运行 patroni_raft_controller(不含 Patroni 和 PostgreSQL)。这种部署方式下,临时失去一个节点不会影响主库。
PostgreSQL
postgresql:authentication:
superuser:username:超级用户名,在初始化(initdb)时设置,后续由 Patroni 用于连接 PostgreSQL。password:超级用户密码,在初始化(initdb)时设置。sslmode:(可选)映射到 sslmode 连接参数,允许客户端指定与服务器的 TLS 协商模式,默认模式为 prefer。sslkey:(可选)映射到 sslkey 连接参数,指定与客户端证书配套的私钥位置。sslpassword:(可选)映射到 sslpassword 连接参数,指定 sslkey 中私钥的密码。sslcert:(可选)映射到 sslcert 连接参数,指定客户端证书的位置。sslrootcert:(可选)映射到 sslrootcert 连接参数,指定包含一个或多个受信任 CA 证书的文件位置,客户端将用其验证服务器证书。sslcrl:(可选)映射到 sslcrl 连接参数,指定证书吊销列表文件的位置,客户端将拒绝连接证书出现在该列表中的服务器。sslcrldir:(可选)映射到 sslcrldir 连接参数,指定包含证书吊销列表文件的目录位置,客户端将拒绝连接证书出现在该列表中的服务器。sslnegotiation:(可选)映射到 sslnegotiation 连接参数,控制在使用 SSL 时与服务器协商 SSL 加密的方式。gssencmode:(可选)映射到 gssencmode 连接参数,决定是否以及以何种优先级与服务器建立安全的 GSS TCP/IP 连接。channel_binding:(可选)映射到 channel_binding 连接参数,控制客户端对通道绑定的使用。
replication:username:复制用户名,在初始化时创建,从库通过流复制连接复制源时使用该用户。password:复制用户密码,在初始化时创建。sslmode:(可选)映射到 sslmode 连接参数,默认模式为 prefer。sslkey:(可选)映射到 sslkey 连接参数,指定与客户端证书配套的私钥位置。sslpassword:(可选)映射到 sslpassword 连接参数,指定 sslkey 中私钥的密码。sslcert:(可选)映射到 sslcert 连接参数,指定客户端证书的位置。sslrootcert:(可选)映射到 sslrootcert 连接参数,指定包含一个或多个受信任 CA 证书的文件位置。sslcrl:(可选)映射到 sslcrl 连接参数,指定证书吊销列表文件的位置。sslcrldir:(可选)映射到 sslcrldir 连接参数,指定包含证书吊销列表文件的目录位置。sslnegotiation:(可选)映射到 sslnegotiation 连接参数,控制在使用 SSL 时协商 SSL 加密的方式。gssencmode:(可选)映射到 gssencmode 连接参数,决定是否以及以何种优先级建立安全的 GSS TCP/IP 连接。channel_binding:(可选)映射到 channel_binding 连接参数,控制客户端对通道绑定的使用。
rewind:username:(可选)用于 pg_rewind 的用户名,在初始化 PostgreSQL 11+ 时创建,并授予所有必要的 权限。password:(可选)用于 pg_rewind 的用户密码,在初始化时创建。sslmode:(可选)映射到 sslmode 连接参数,默认模式为 prefer。sslkey:(可选)映射到 sslkey 连接参数,指定与客户端证书配套的私钥位置。sslpassword:(可选)映射到 sslpassword 连接参数,指定 sslkey 中私钥的密码。sslcert:(可选)映射到 sslcert 连接参数,指定客户端证书的位置。sslrootcert:(可选)映射到 sslrootcert 连接参数,指定包含一个或多个受信任 CA 证书的文件位置。sslcrl:(可选)映射到 sslcrl 连接参数,指定证书吊销列表文件的位置。sslcrldir:(可选)映射到 sslcrldir 连接参数,指定包含证书吊销列表文件的目录位置。sslnegotiation:(可选)映射到 sslnegotiation 连接参数,控制在使用 SSL 时协商 SSL 加密的方式。gssencmode:(可选)映射到 gssencmode 连接参数,决定是否以及以何种优先级建立安全的 GSS TCP/IP 连接。channel_binding:(可选)映射到 channel_binding 连接参数,控制客户端对通道绑定的使用。
callbacks:在特定操作时运行的回调脚本,Patroni 会将操作名称、角色和集群名称作为参数传入(可参考 scripts/aws.py 作为示例)。
on_reload:触发配置重载时运行此脚本。on_restart:Postgres 重启时(不改变角色)运行此脚本。on_role_change:Postgres 被提升或降级时运行此脚本。on_start:Postgres 启动时运行此脚本。on_stop:Postgres 停止时运行此脚本。
connect_address:其他节点和应用程序访问 Postgres 所用的 IP 地址和端口。
proxy_address:与 PostgreSQL 并行运行的连接池(如 pgbouncer)的可访问 IP 地址和端口,该值以 proxy_url 的形式写入 DCS 成员键,可用于服务发现。
create_replica_methods:创建新从库所用方法的有序列表,basebackup 为默认方法,其余方法视为脚本,每个脚本需作为独立配置节进行配置。详见 自定义从库创建方法文档。
data_dir:Postgres 数据目录的位置,可以是 已有目录 或由 Patroni 初始化的目录。
config_dir:Postgres 配置目录的位置,默认为数据目录,必须对 Patroni 可写。
bin_dir:(可选)PostgreSQL 可执行文件(pg_ctl、initdb、pg_controldata、pg_basebackup、postgres、pg_isready、pg_rewind)的路径。若未提供或为空字符串,将使用 PATH 环境变量查找可执行文件。
bin_name:(可选)若使用自定义 Postgres 发行版,可用此选项覆盖 Postgres 二进制文件名:
pg_ctl:(可选)pg_ctl 的自定义名称。initdb:(可选)initdb 的自定义名称。pgcontroldata:(可选)pg_controldata 的自定义名称。pg_basebackup:(可选)pg_basebackup 的自定义名称。postgres:(可选)postgres 的自定义名称。pg_isready:(可选)pg_isready 的自定义名称。pg_rewind:(可选)pg_rewind 的自定义名称。
listen:PostgreSQL 监听的 IP 地址和端口,使用流复制时必须可从集群其他节点访问。支持多个逗号分隔的地址,端口附加在最后一个地址之后,例如 listen: 127.0.0.1,127.0.0.2:5432。Patroni 将使用列表中的第一个地址建立到 PostgreSQL 节点的本地连接。
use_unix_socket:指定 Patroni 优先使用 Unix 套接字连接 PostgreSQL,默认值为 false。若已定义 unix_socket_directories,Patroni 将从中选取第一个合适的路径用于连接,无合适值时回退到 TCP。若 postgresql.parameters 中未指定 unix_socket_directories,Patroni 将假设使用默认值并在连接参数中省略 host。
use_unix_socket_repl:指定 Patroni 优先使用 Unix 套接字建立复制用户连接,默认值为 false,行为与 use_unix_socket 相同。
pgpass:.pgpass 密码文件的路径。Patroni 在执行 pg_basebackup、post_init 脚本及其他某些情况下会创建此文件,该路径必须对 Patroni 可写。
recovery_conf:配置从库时写入 recovery.conf 的附加配置项。
custom_conf:可选的自定义 postgresql.conf 文件路径,将代替 postgresql.base.conf 使用。该文件必须存在于所有集群节点上且对 PostgreSQL 可读,实际的 postgresql.conf 将从其所在位置包含该文件。注意 Patroni 不会监控此文件的变更,也不会备份它,但其中的设置仍可被 Patroni 自身的配置机制覆盖,详见 动态配置。
parameters:Postgres 的配置参数(GUC),格式为 {ssl: "on", ssl_cert_file: "cert_file"}。
pg_hba:Patroni 用于生成 pg_hba.conf 的行列表。若 PostgreSQL 的 hba_file 参数设为非默认值,Patroni 将忽略此参数。与 动态配置 配合使用,可简化 pg_hba.conf 的管理。
- host all all 0.0.0.0/0 md5- host replication replicator 127.0.0.1/32 md5:复制所需的规则行。
pg_ident:Patroni 用于生成 pg_ident.conf 的行列表。若 PostgreSQL 的 ident_file 参数设为非默认值,Patroni 将忽略此参数。与 动态配置 配合使用,可简化 pg_ident.conf 的管理。
- mapname1 systemname1 pguser1- mapname1 systemname2 pguser2
pg_ctl_timeout:pg_ctl 执行 start、stop 或 restart 时的等待时长,默认值为 60 秒。
use_pg_rewind:当旧主库以从库身份重新加入集群时,尝试对其执行 pg_rewind。需要集群在初始化时启用了 data page checksums(initdb 的 --data-checksums 选项)或将 wal_log_hints 设为 on,否则 pg_rewind 无法正常工作。
rewind:(可选)传递给 pg_rewind 的自定义选项,可以是字符串列表和/或单键值字典。以下选项不允许使用:target-pgdata、source-pgdata、source-server、write-recovery-conf、dry-run、restore-target-wal、config-file、no-ensure-shutdown、version 和 help。使用示例:
postgresql:
rewind:
- debug
- progress
- sync-method: fsync
remove_data_directory_on_rewind_failure:启用后,若 pg_rewind 失败,Patroni 将删除 PostgreSQL 数据目录并重新创建从库;否则将尝试跟随新主库,默认值为 false。
remove_data_directory_on_diverged_timelines:若 Patroni 检测到时间线出现分歧,且旧主库无法从新主库开始流复制,则删除 PostgreSQL 数据目录并重新创建从库。此选项在无法使用 pg_rewind 时很有用。在 PostgreSQL v10 及更早版本上进行时间线分歧检查时,Patroni 将尝试使用复制凭据连接 “postgres” 数据库,因此 pg_hba.conf 中必须允许此类访问。默认值为 false。
replica_method:对于 create_replica_methods 中除 basebackup 外的每种方法,需添加同名配置节。该节至少须包含 command 字段,指向实际执行脚本的完整路径,其余配置参数将以 parameter=value 的形式传递给脚本。
pre_promote:故障转移期间在获取领导者锁之后、提升从库之前执行的隔离脚本。若脚本以非零退出码退出,Patroni 将放弃提升并从 DCS 中移除领导者键。
before_stop:在停止 PostgreSQL 之前立即执行的脚本。与回调不同,此脚本同步运行,会阻塞关闭流程直到脚本完成。脚本的返回码不影响后续关闭操作的执行。
REST API
restapi:connect_address:访问 Patroni REST API 所用的 IP 地址(或主机名)和端口。集群中所有成员必须能够访问此地址,因此除非 Patroni 仅用于本地演示,否则不能使用回环地址(如 “localhost” 或 “127.0.0.1”)。该地址可作为 HTTP 健康检查端点(详见下文 REST API 的 “listen” 参数),也用于用户查询(直接访问或通过 REST API)以及集群成员在主库选举期间的健康检查(例如,判断当前主库是否仍在运行,或是否存在 WAL 位置超前于查询节点的节点)。connect_address 写入 DCS 的成员键,从而可通过成员名称解析出其 REST API 连接地址。listen:Patroni 监听 REST API 请求的 IP 地址(或主机名)和端口,同样提供上述健康检查与集群节点间通信功能,也可为 HAProxy 等支持 HTTP OPTIONS 或 GET 检查的负载均衡器提供健康检查端点。authentication:(可选)username:用于保护不安全 REST API 端点的 Basic-auth 用户名。password:用于保护不安全 REST API 端点的 Basic-auth 密码。
certfile:(可选)PEM 格式的证书文件,若未指定或留空,API 服务器将在无 SSL 的情况下工作。keyfile:(可选)PEM 格式的私钥文件。keyfile_password:(可选)用于解密 keyfile 的密码。cafile:(可选)包含受信任 CA 证书的 CA_BUNDLE 文件,用于验证客户端证书。ciphers:(可选)允许的密码套件(例如 “ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES128-GCM-SHA256:!SSLv1:!SSLv2:!SSLv3:!TLSv1:!TLSv1.1”)。verify_client:(可选)none(默认)、optional 或 required。none 时不检查客户端证书;required 时所有 REST API 调用均需提供客户端证书;optional 时仅对不安全的 REST API 端点要求客户端证书。使用 required 时,证书签名验证通过即视为认证成功;使用 optional 时,仅对 PUT、POST、PATCH 和 DELETE 请求检查客户端证书。allowlist:(可选)允许调用不安全 REST API 端点的主机列表,每个元素可以是主机名、IP 地址或 CIDR 格式的网络地址,默认允许所有来源。一旦设置了 allowlist 或 allowlist_include_members,不在列表中的请求将被拒绝。allowlist_include_members:(可选)若设为 true,DCS 中已注册的其他集群成员(IP 地址或主机名取自成员的 api_url)也被允许访问不安全 REST API 端点。注意操作系统可能为出站连接使用不同的 IP 地址。http_extra_headers:(可选)允许 REST API 服务器在 HTTP 响应中传递额外信息的 HTTP 头。https_extra_headers:(可选)启用 TLS 时,允许 REST API 服务器在 HTTP 响应中传递额外信息的 HTTPS 头,同时也会传递 http_extra_headers 中设置的额外信息。request_queue_size:(可选)Patroni REST API 使用的 TCP 套接字请求队列大小,队列满后新请求将收到 “Connection denied” 错误,默认值为 5。server_tokens:(可选)配置 Server HTTP 头的值:Minimal:头部仅包含 Patroni 版本,例如 Patroni/4.0.0。ProductOnly:头部仅包含产品名称,例如 Patroni。Original(默认):头部显示原始行为,包含 BaseHTTP 和 Python 版本,例如 BaseHTTP/0.6 Python/3.12.3。
以下是 http_extra_headers 和 https_extra_headers 的配置示例:
restapi:
listen: <listen>
connect_address: <connect_address>
authentication:
username: <username>
password: <password>
http_extra_headers:
'X-Frame-Options': 'SAMEORIGIN'
'X-XSS-Protection': '1; mode=block'
'X-Content-Type-Options': 'nosniff'
cafile: <ca file>
certfile: <cert>
keyfile: <key>
https_extra_headers:
'Strict-Transport-Security': 'max-age=31536000; includeSubDomains'
restapi.connect_address 必须可从该 Patroni 集群的所有节点访问。Patroni 在主库竞选期间会在内部使用它来查找复制延迟最小的节点。- 若启用了客户端证书验证(
restapi.verify_client 设为 required),还必须在 ctl.certfile、ctl.keyfile、ctl.keyfile_password 中提供有效的客户端证书,否则 Patroni 将无法正常工作。
CTL
ctl:(可选)authentication:username:访问受保护 REST API 端点的 Basic-auth 用户名。若未提供,patronictl 将使用 REST API 的 “username” 参数值。password:访问受保护 REST API 端点的 Basic-auth 密码。若未提供,patronictl 将使用 REST API 的 “password” 参数值。
insecure:允许在不验证 SSL 证书的情况下连接 REST API。cacert:用于验证 REST API SSL 证书的 CA_BUNDLE 文件或受信任 CA 证书目录,若未提供,patronictl 将使用 REST API 的 “cafile” 参数值。certfile:PEM 格式的客户端证书文件。keyfile:PEM 格式的客户端私钥文件。keyfile_password:用于解密客户端 keyfile 的密码。
Watchdog
mode:off、automatic 或 required。off 时禁用 watchdog;automatic 时如有可用的 watchdog 则启用,否则忽略;required 时节点必须在 watchdog 成功启用后才能成为主库。device:watchdog 设备路径,默认为 /dev/watchdog。safety_margin:watchdog 触发与领导者键过期之间的安全边距(秒)。
clonefrom:true 或 false。若设为 true,其他节点在引导时可能优先从此节点克隆(pg_basebackup)。若多个节点的 clonefrom 均为 true,将随机选择引导源节点,默认值为 false。noloadbalance:true 或 false。若设为 true,该节点在 GET /replica REST API 健康检查时将返回 HTTP 503,从而被排除在负载均衡之外,默认为 false。replicatefrom:另一个从库的名称,用于支持级联复制。nosync:true 或 false。若设为 true,该节点永远不会被选为同步从库。sync_priority:整数,控制 synchronous_mode 设为 on 时此节点在同步从库选择中的优先级,数值越高越优先。若 sync_priority 为 0 或负数,该节点不会被写入 synchronous_standby_names 参数(效果类似于 nosync: true)。注意此参数的含义与 pg_stat_replication 视图中报告的 sync_priority 值相反。nofailover:true 或 false,控制此节点是否允许参与主库竞选,默认为 false,即此节点 可以 参与主库竞选。failover_priority:整数,控制此节点在故障转移时的优先级。在接收/回放相同 WAL 量的前提下,优先级高的节点优先被选为新主库;但无论优先级高低,接收/回放 LSN 更大的节点始终优先。若 failover_priority 为 0 或负数,该节点不允许参与主库竞选(效果类似于 nofailover: true)。已知限制:failover_priority 目前不支持 基于法定人数的同步复制。nostream:true 或 false。若设为 true,该节点将不使用复制协议流式传输 WAL,而依赖归档恢复(需配置 restore_command)和 pg_wal/pg_xlog 轮询。同时将禁用该节点本身及其所有级联从库上永久逻辑复制槽的复制与同步,在主库上设置此标签无效。
警告
nofailover 和 failover_priority 只能提供其中一个。nofailover: true 等同于 failover_priority: 0,而 nofailover: false 将给予节点优先级 1。
除这些预定义标签外,还可以添加自定义标签:
key1:truekey2:falsekey3:1.4key4:"RandomString"
标签在 REST API 和 patronictl list 中均可查看。也可通过这些标签检查实例的健康状态——若某个实例未定义该标签,或对应值与查询值不匹配,将返回 HTTP 503。
3.3 - 环境变量
用于覆盖 Patroni 配置文件参数的环境变量。
原始页面: https://patroni.readthedocs.io/en/latest/ENVIRONMENT.html
可以使用系统环境变量覆盖 Patroni 配置文件中定义的部分配置参数。本文档列出了 Patroni 处理的所有环境变量。通过环境变量设置的值始终优先于配置文件中的值。
全局/通用
PATRONI_CONFIGURATION:可通过 PATRONI_CONFIGURATION 环境变量为 Patroni 提供完整配置。设置此变量后,其他所有环境变量将被忽略!PATRONI_NAME:运行当前 Patroni 实例的节点名称,在集群内必须唯一。PATRONI_NAMESPACE:Patroni 在配置存储中保存集群信息的路径。默认值:"/service"。PATRONI_SCOPE:集群名称。
日志
PATRONI_LOG_TYPE:日志格式,可为 plain 或 json。使用 json 格式需要安装 jsonlogger。默认值为 plain。PATRONI_LOG_LEVEL:全局日志级别。默认值为 INFO(参见 Python logging 文档)。PATRONI_LOG_TRACEBACK_LEVEL:显示 traceback 的日志级别。默认值为 ERROR。若希望仅在 PATRONI_LOG_LEVEL=DEBUG 时才显示 traceback,可将其设置为 DEBUG。PATRONI_LOG_FORMAT:日志格式化字符串。若日志类型为 plain,格式应为字符串,可用属性参见 LogRecord 属性文档。若日志类型为 json,格式除字符串外还可以是列表,每个列表项对应一个 LogRecord 属性,只需填写字段名,省略 %( 和 )。若希望以不同键名输出某个字段,可使用字典,键为日志字段名,值为希望在日志中显示的字段名。默认值为 %(asctime)s %(levelname)s: %(message)s。PATRONI_LOG_DATEFORMAT:日期时间格式化字符串(参见 formatTime() 文档)。PATRONI_LOG_STATIC_FIELDS:为日志添加额外字段,仅在日志类型为 json 时可用。示例:PATRONI_LOG_STATIC_FIELDS="{app: patroni}"。PATRONI_LOG_MAX_QUEUE_SIZE:Patroni 采用两步日志记录机制。日志记录先写入内存队列,由独立线程从队列中取出后写入 stderr 或文件。内存队列容量默认限制为 1000 条,足以保留过去约 1 小时 20 分钟的日志。PATRONI_LOG_DIR:应用程序日志的写入目录。该目录必须已存在且对运行 Patroni 的用户可写。设置此变量后,默认保留 4 个 25MB 的日志文件,可通过 PATRONI_LOG_FILE_NUM 和 PATRONI_LOG_FILE_SIZE 调整(见下文)。PATRONI_LOG_MODE:日志文件权限(例如 0644)。若未指定,将基于当前 umask 值设置。PATRONI_LOG_FILE_NUM:保留的应用程序日志文件数量。PATRONI_LOG_FILE_SIZE:触发日志滚动的 patroni.log 文件大小(字节)。PATRONI_LOG_LOGGERS:按 Python 模块重新定义日志级别。示例:PATRONI_LOG_LOGGERS="{patroni.postmaster: WARNING, urllib3: DEBUG}"。PATRONI_LOG_DEDUPLICATE_HEARTBEAT_LOGS:设置为 true 时,连续且内容相同的心跳日志不再重复输出。默认值为 false。
警告
HA 循环的执行时间是诊断资源耗尽等问题所致故障转移的重要信息。将 PATRONI_LOG_DEDUPLICATE_HEARTBEAT_LOGS 设置为 true 后,HA 循环执行将不产生日志(除非领导者发生变化),导致这些潜在有用的信息无法从日志中获取。
Citus
启用 Patroni 与 Citus 的集成。配置后,Patroni 将负责在协调器上注册 Citus 工作节点。更多关于 Citus 支持的信息请参阅 此处。
PATRONI_CITUS_GROUP:Citus 组 ID,整数类型。协调器使用 0,工作节点使用 1、2 等。PATRONI_CITUS_DATABASE:应创建 citus 扩展的数据库,协调器和所有工作节点上必须相同。目前仅支持一个数据库。
Consul
PATRONI_CONSUL_HOST:Consul 本地代理的 host:port。PATRONI_CONSUL_URL:Consul 本地代理的 URL,格式为:http(s)://host:port。PATRONI_CONSUL_PORT:(可选)Consul 端口。PATRONI_CONSUL_SCHEME:(可选)http 或 https,默认为 http。PATRONI_CONSUL_TOKEN:(可选)ACL 令牌。PATRONI_CONSUL_VERIFY:(可选)是否对 HTTPS 请求验证 SSL 证书。PATRONI_CONSUL_CACERT:(可选)CA 证书文件,存在时将启用验证。PATRONI_CONSUL_CERT:(可选)包含客户端证书的文件。PATRONI_CONSUL_KEY:(可选)包含客户端密钥的文件。若密钥已包含在证书中,可留空。PATRONI_CONSUL_DC:(可选)通信目标数据中心,默认使用主机所在的数据中心。PATRONI_CONSUL_CONSISTENCY:(可选)Consul 一致性模式,可选值为 default、consistent 或 stale(详见 Consul API 参考)。PATRONI_CONSUL_CHECKS:(可选)用于会话的 Consul 健康检查列表,默认使用空列表。PATRONI_CONSUL_REGISTER_SERVICE:(可选)是否注册以 scope 参数命名的服务,并根据节点角色添加 master、primary、replica 或 standby-leader 标签。默认为 false。PATRONI_CONSUL_SERVICE_TAGS:(可选)除角色标签(primary/replica/standby-leader)外,向 Consul 服务添加的额外静态标签,默认使用空列表。PATRONI_CONSUL_SERVICE_CHECK_INTERVAL:(可选)对已注册 URL 执行健康检查的频率。PATRONI_CONSUL_SERVICE_CHECK_TLS_SERVER_NAME:(可选)通过 TLS 连接时覆盖 SNI 主机名,另见 Consul agent check API 参考。
Etcd
PATRONI_ETCD_PROXY:etcd 的代理 URL。若通过代理连接 etcd,请使用此参数而非 PATRONI_ETCD_URL。PATRONI_ETCD_URL:etcd 的 URL,格式为:http(s)://(username:password@)host:port。PATRONI_ETCD_HOSTS:etcd 端点列表,格式为 ‘host1:port1’,‘host2:port2’ 等。PATRONI_ETCD_USE_PROXIES:若设置为 true,Patroni 将把 hosts 视为代理列表,不执行 etcd 集群的拓扑发现,直接使用固定的 hosts 列表。PATRONI_ETCD_PROTOCOL:http 或 https,未指定时使用 http。若指定了 url 或 proxy,将从中提取协议。PATRONI_ETCD_HOST:etcd 端点的 host:port。PATRONI_ETCD_SRV:用于集群自动发现的 SRV 记录搜索域。Patroni 将按以下顺序查询指定域的 SRV 服务名(直到第一次成功):_etcd-client-ssl、_etcd-client、_etcd-ssl、_etcd、_etcd-server-ssl、_etcd-server。若检索到 _etcd-server-ssl 或 _etcd-server 的 SRV 记录,则使用 ETCD peer 协议查询可用成员;否则使用 SRV 记录中的主机。PATRONI_ETCD_SRV_SUFFIX:发现期间查询的 SRV 名称后缀,用于区分同一域下的多个 etcd 集群,仅与 PATRONI_ETCD_SRV 联合使用时生效。例如,设置 PATRONI_ETCD_SRV_SUFFIX=foo 和 PATRONI_ETCD_SRV=example.org 后,将进行如下 DNS SRV 查询:_etcd-client-ssl-foo._tcp.example.com(以及所有其他可能的 ETCD SRV 服务名)。PATRONI_ETCD_USERNAME:etcd 认证用户名。PATRONI_ETCD_PASSWORD:etcd 认证密码。PATRONI_ETCD_CACERT:CA 证书文件,存在时将启用验证。PATRONI_ETCD_CERT:包含客户端证书的文件。PATRONI_ETCD_KEY:包含客户端密钥的文件。若密钥已包含在证书中,可留空。
Etcdv3
Etcdv3 的环境变量名与 Etcd 类似,只需将变量名中的 ETCD 替换为 ETCD3 即可。例如:PATRONI_ETCD3_HOST、PATRONI_ETCD3_CACERT 等。
警告
使用协议版本 2 创建的键在协议版本 3 中不可见,反之亦然,因此无法仅通过更新 Patroni 配置来从 Etcd 切换到 Etcdv3。此外,Patroni 使用 Etcd 的 gRPC 网关(代理)与 V3 API 通信,这意味着不支持 TLS 通用名称认证。
ZooKeeper
PATRONI_ZOOKEEPER_HOSTS:ZooKeeper 集群成员的逗号分隔列表,格式为:'host1:port1','host2:port2','etc...'。每一项均须加引号!PATRONI_ZOOKEEPER_USE_SSL:(可选)是否启用 SSL,默认为 false。设置为 false 时,所有 SSL 相关参数将被忽略。PATRONI_ZOOKEEPER_CACERT:(可选)CA 证书文件,存在时将启用验证。PATRONI_ZOOKEEPER_CERT:(可选)包含客户端证书的文件。PATRONI_ZOOKEEPER_KEY:(可选)包含客户端密钥的文件。PATRONI_ZOOKEEPER_KEY_PASSWORD:(可选)客户端密钥密码。PATRONI_ZOOKEEPER_VERIFY:(可选)是否验证证书,默认为 true。PATRONI_ZOOKEEPER_SET_ACLS:(可选)若设置,将配置 Kazoo 为其创建的每个 ZNode 应用默认 ACL。ACL 可使用 x509 模式(默认)或其他受支持的 ZooKeeper 方案(如 digest)。应以字典形式指定,键为完整主体名称(可选择性地添加方案前缀),值为权限列表。权限可为 CREATE、READ、WRITE、DELETE、ADMIN 或 ALL 中的一个或多个。示例:set_acls: {CN=principal1: [CREATE, READ], digest:principal2:+pjROuBuuwNNSujKyH8dGcEnFPQ=: [ALL]}。PATRONI_ZOOKEEPER_AUTH_DATA:(可选)连接认证凭据,应为字典形式,scheme 为键,credential 为值,默认为空字典。
说明
需要安装 kazoo>=2.6.0 以支持 SSL。
Exhibitor
PATRONI_EXHIBITOR_HOSTS:Exhibitor(ZooKeeper)节点的初始列表,格式为:‘host1,host2,etc…’。每当 Exhibitor(ZooKeeper)集群拓扑变化时,该列表会自动更新。PATRONI_EXHIBITOR_PORT:Exhibitor 端口。
Kubernetes
PATRONI_KUBERNETES_BYPASS_API_SERVICE:(可选)与 Kubernetes API 通信时,Patroni 通常依赖 kubernetes 服务,该服务的地址通过 KUBERNETES_SERVICE_HOST 环境变量暴露给 Pod。若将此参数设置为 true,Patroni 将解析该服务后端的 API 节点列表并直接与之连接。PATRONI_KUBERNETES_NAMESPACE:(可选)Patroni Pod 所在的 Kubernetes 命名空间,默认值为 default。PATRONI_KUBERNETES_LABELS:格式为 {label1: value1, label2: value2} 的标签。用于查找与当前集群关联的现有对象(Pod 以及 Endpoint 或 ConfigMap),Patroni 也会将它们设置在所创建的每个对象(Endpoint 或 ConfigMap)上。PATRONI_KUBERNETES_SCOPE_LABEL:(可选)包含集群名称的标签名,默认值为 cluster-name。PATRONI_KUBERNETES_BOOTSTRAP_LABELS:(可选)格式为 {label1: value1, label2: value2} 的标签。当 Patroni Pod 的状态为 initializing new cluster、running custom bootstrap script、starting after custom bootstrap 或 creating replica 时,这些标签将被分配给该 Pod。PATRONI_KUBERNETES_ROLE_LABEL:(可选)包含角色(primary、replica 或其他自定义值)的标签名。Patroni 会在其运行的 Pod 上设置此标签,默认值为 role。PATRONI_KUBERNETES_LEADER_LABEL_VALUE:(可选)Postgres 角色为 primary 时 Pod 标签的值,默认值为 primary。PATRONI_KUBERNETES_FOLLOWER_LABEL_VALUE:(可选)Postgres 角色为 replica 时 Pod 标签的值,默认值为 replica。PATRONI_KUBERNETES_STANDBY_LEADER_LABEL_VALUE:(可选)Postgres 角色为 standby_leader 时 Pod 标签的值,默认值为 primary。PATRONI_KUBERNETES_TMP_ROLE_LABEL:(可选)包含临时角色(primary 或 replica)的标签名。该标签的值始终使用对应角色的默认值,仅在必要时设置。PATRONI_KUBERNETES_USE_ENDPOINTS:(可选)若设置为 true,Patroni 将使用 Endpoint 而非 ConfigMap 进行领导者选举和保存集群状态。PATRONI_KUBERNETES_POD_IP:(可选)Patroni 所在 Pod 的 IP 地址。启用 PATRONI_KUBERNETES_USE_ENDPOINTS 时必填,用于在 Pod 的 PostgreSQL 被提升时填充领导者 Endpoint 的子集。PATRONI_KUBERNETES_PORTS:(可选)若 Service 对象为端口命名,则 Endpoint 对象中也必须出现相同名称,否则服务将无法工作。例如,若 Service 定义为 {Kind: Service, spec: {ports: [{name: postgresql, port: 5432, targetPort: 5432}]}},则必须设置 PATRONI_KUBERNETES_PORTS='[{"name": "postgresql", "port": 5432}]',Patroni 将使用该值更新领导者 Endpoint 的子集。此参数仅在设置了 PATRONI_KUBERNETES_USE_ENDPOINTS 时生效。PATRONI_KUBERNETES_CACERT:(可选)指定包含受信任 CA 证书的 CA_BUNDLE 文件,用于验证 Kubernetes API SSL 证书。若未提供,Patroni 将使用 ServiceAccount Secret 中的值。PATRONI_RETRIABLE_HTTP_CODES:(可选)需要重试的 K8s API HTTP 状态码列表。默认情况下,Patroni 在收到 500、503、504 时重试,或在 K8s API 响应包含 retry-after HTTP 头时重试。
Raft(已弃用)
PATRONI_RAFT_SELF_ADDR:监听 Raft 连接的 ip:port,必须可从集群的其他节点访问。若未设置,该节点将不参与共识。PATRONI_RAFT_BIND_ADDR:(可选)监听 Raft 连接的 ip:port,若未指定,将使用 self_addr。PATRONI_RAFT_PARTNER_ADDRS:集群中其他 Patroni 节点的列表,格式为 "'ip1:port1','ip2:port2'"。每一项均须加引号!PATRONI_RAFT_DATA_DIR:存储 Raft 日志和快照的目录,若未指定,使用当前工作目录。PATRONI_RAFT_PASSWORD:(可选)使用指定密码加密 Raft 流量,需要安装 Python 的 cryptography 模块。
PostgreSQL
PATRONI_POSTGRESQL_LISTEN:PostgreSQL 监听的 IP 地址和端口。支持多个逗号分隔的地址,端口须附加在最后一个地址后并以冒号分隔,例如 listen: 127.0.0.1,127.0.0.2:5432。Patroni 将使用列表中的第一个地址建立到 PostgreSQL 节点的本地连接。PATRONI_POSTGRESQL_CONNECT_ADDRESS:其他节点和应用程序访问 PostgreSQL 所用的 IP 地址和端口。PATRONI_POSTGRESQL_PROXY_ADDRESS:运行于 PostgreSQL 旁侧的连接池(如 pgbouncer)的可访问 IP 地址和端口。该值以 proxy_url 的形式写入 DCS 中的成员键,可用于服务发现。PATRONI_POSTGRESQL_DATA_DIR:PostgreSQL 数据目录的位置,可以是已有目录,也可以是由 Patroni 初始化的目录。PATRONI_POSTGRESQL_CONFIG_DIR:PostgreSQL 配置目录的位置,默认为数据目录,必须对 Patroni 可写。PATRONI_POSTGRESQL_BIN_DIR:PostgreSQL 可执行文件路径(pg_ctl、initdb、pg_controldata、pg_basebackup、postgres、pg_isready、pg_rewind)。默认值为空字符串,表示通过 PATH 环境变量查找可执行文件。PATRONI_POSTGRESQL_BIN_PG_CTL:(可选)pg_ctl 可执行文件的自定义名称。PATRONI_POSTGRESQL_BIN_INITDB:(可选)initdb 可执行文件的自定义名称。PATRONI_POSTGRESQL_BIN_PG_CONTROLDATA:(可选)pg_controldata 可执行文件的自定义名称。PATRONI_POSTGRESQL_BIN_PG_BASEBACKUP:(可选)pg_basebackup 可执行文件的自定义名称。PATRONI_POSTGRESQL_BIN_POSTGRES:(可选)postgres 可执行文件的自定义名称。PATRONI_POSTGRESQL_BIN_IS_READY:(可选)pg_isready 可执行文件的自定义名称。PATRONI_POSTGRESQL_BIN_PG_REWIND:(可选)pg_rewind 可执行文件的自定义名称。PATRONI_POSTGRESQL_PGPASS:.pgpass 密码文件的路径。Patroni 在执行 pg_basebackup 及某些其他情况下会创建此文件,该位置必须对 Patroni 可写。PATRONI_REPLICATION_USERNAME:复制用户名,在初始化期间创建,从库将使用此用户通过流复制访问复制源。PATRONI_REPLICATION_PASSWORD:复制密码,在初始化期间创建。PATRONI_REPLICATION_SSLMODE:(可选)映射到 sslmode 连接参数,用于指定客户端与服务器的 TLS 协商模式。各模式详见 PostgreSQL 文档,默认模式为 prefer。PATRONI_REPLICATION_SSLKEY:(可选)映射到 sslkey 连接参数,指定与客户端证书配套使用的私钥文件位置。PATRONI_REPLICATION_SSLPASSWORD:(可选)映射到 sslpassword 连接参数,指定 PATRONI_REPLICATION_SSLKEY 所指定私钥的密码。PATRONI_REPLICATION_SSLCERT:(可选)映射到 sslcert 连接参数,指定客户端证书的文件位置。PATRONI_REPLICATION_SSLROOTCERT:(可选)映射到 sslrootcert 连接参数,指定包含一个或多个 CA 证书的文件位置,客户端用于验证服务器证书。PATRONI_REPLICATION_SSLCRL:(可选)映射到 sslcrl 连接参数,指定包含证书吊销列表的文件位置。客户端将拒绝连接到证书出现在此列表中的任何服务器。PATRONI_REPLICATION_SSLCRLDIR:(可选)映射到 sslcrldir 连接参数,指定包含证书吊销列表文件的目录位置。客户端将拒绝连接到证书出现在此列表中的任何服务器。PATRONI_REPLICATION_SSLNEGOTIATION:(可选)映射到 sslnegotiation 连接参数,控制使用 SSL 时如何与服务器协商 SSL 加密。PATRONI_REPLICATION_GSSENCMODE:(可选)映射到 gssencmode 连接参数,决定是否以及以何种优先级与服务器协商安全的 GSS TCP/IP 连接。PATRONI_REPLICATION_CHANNEL_BINDING:(可选)映射到 channel_binding 连接参数,控制客户端对通道绑定的使用。PATRONI_SUPERUSER_USERNAME:超级用户名,在初始化(initdb)期间设置,之后由 Patroni 用于连接 PostgreSQL,pg_rewind 也使用此用户。PATRONI_SUPERUSER_PASSWORD:超级用户密码,在初始化(initdb)期间设置。PATRONI_SUPERUSER_SSLMODE:(可选)映射到 sslmode 连接参数,用于指定客户端与服务器的 TLS 协商模式。各模式详见 PostgreSQL 文档,默认模式为 prefer。PATRONI_SUPERUSER_SSLKEY:(可选)映射到 sslkey 连接参数,指定与客户端证书配套使用的私钥文件位置。PATRONI_SUPERUSER_SSLPASSWORD:(可选)映射到 sslpassword 连接参数,指定 PATRONI_SUPERUSER_SSLKEY 所指定私钥的密码。PATRONI_SUPERUSER_SSLCERT:(可选)映射到 sslcert 连接参数,指定客户端证书的文件位置。PATRONI_SUPERUSER_SSLROOTCERT:(可选)映射到 sslrootcert 连接参数,指定包含一个或多个 CA 证书的文件位置,客户端用于验证服务器证书。PATRONI_SUPERUSER_SSLCRL:(可选)映射到 sslcrl 连接参数,指定包含证书吊销列表的文件位置。客户端将拒绝连接到证书出现在此列表中的任何服务器。PATRONI_SUPERUSER_SSLCRLDIR:(可选)映射到 sslcrldir 连接参数,指定包含证书吊销列表文件的目录位置。客户端将拒绝连接到证书出现在此列表中的任何服务器。PATRONI_SUPERUSER_SSLNEGOTIATION:(可选)映射到 sslnegotiation 连接参数,控制使用 SSL 时如何与服务器协商 SSL 加密。PATRONI_SUPERUSER_GSSENCMODE:(可选)映射到 gssencmode 连接参数,决定是否以及以何种优先级与服务器协商安全的 GSS TCP/IP 连接。PATRONI_SUPERUSER_CHANNEL_BINDING:(可选)映射到 channel_binding 连接参数,控制客户端对通道绑定的使用。PATRONI_REWIND_USERNAME:(可选)pg_rewind 使用的用户名;在 PostgreSQL 11+ 的初始化期间创建,并授予所有必要的 权限。PATRONI_REWIND_PASSWORD:(可选)pg_rewind 使用的用户密码,在初始化期间创建。PATRONI_REWIND_SSLMODE:(可选)映射到 sslmode 连接参数,用于指定客户端与服务器的 TLS 协商模式。各模式详见 PostgreSQL 文档,默认模式为 prefer。PATRONI_REWIND_SSLKEY:(可选)映射到 sslkey 连接参数,指定与客户端证书配套使用的私钥文件位置。PATRONI_REWIND_SSLPASSWORD:(可选)映射到 sslpassword 连接参数,指定 PATRONI_REWIND_SSLKEY 所指定私钥的密码。PATRONI_REWIND_SSLCERT:(可选)映射到 sslcert 连接参数,指定客户端证书的文件位置。PATRONI_REWIND_SSLROOTCERT:(可选)映射到 sslrootcert 连接参数,指定包含一个或多个 CA 证书的文件位置,客户端用于验证服务器证书。PATRONI_REWIND_SSLCRL:(可选)映射到 sslcrl 连接参数,指定包含证书吊销列表的文件位置。客户端将拒绝连接到证书出现在此列表中的任何服务器。PATRONI_REWIND_SSLCRLDIR:(可选)映射到 sslcrldir 连接参数,指定包含证书吊销列表文件的目录位置。客户端将拒绝连接到证书出现在此列表中的任何服务器。PATRONI_REWIND_SSLNEGOTIATION:(可选)映射到 sslnegotiation 连接参数,控制使用 SSL 时如何与服务器协商 SSL 加密。PATRONI_REWIND_GSSENCMODE:(可选)映射到 gssencmode 连接参数,决定是否以及以何种优先级与服务器协商安全的 GSS TCP/IP 连接。PATRONI_REWIND_CHANNEL_BINDING:(可选)映射到 channel_binding 连接参数,控制客户端对通道绑定的使用。
REST API
PATRONI_RESTAPI_CONNECT_ADDRESS:访问 REST API 所用的 IP 地址和端口。PATRONI_RESTAPI_LISTEN:Patroni 监听的 IP 地址和端口,用于为 HAProxy 提供健康检查信息。PATRONI_RESTAPI_USERNAME:用于保护不安全 REST API 端点的 Basic-auth 用户名。PATRONI_RESTAPI_PASSWORD:用于保护不安全 REST API 端点的 Basic-auth 密码。PATRONI_RESTAPI_CERTFILE:PEM 格式证书文件。若未指定或留空,API 服务器将在无 SSL 的情况下运行。PATRONI_RESTAPI_KEYFILE:PEM 格式私钥文件。PATRONI_RESTAPI_KEYFILE_PASSWORD:解密 keyfile 的密码。PATRONI_RESTAPI_CAFILE:包含受信任 CA 证书的 CA_BUNDLE 文件,用于验证客户端证书。PATRONI_RESTAPI_CIPHERS:(可选)允许使用的密码套件(例如 “ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES128-GCM-SHA256:!SSLv1:!SSLv2:!SSLv3:!TLSv1:!TLSv1.1”)。PATRONI_RESTAPI_VERIFY_CLIENT:none(默认)、optional 或 required。none:不检查客户端证书;required:所有 REST API 调用均须提供客户端证书,证书签名验证通过即认证成功;optional:仅不安全的 REST API 端点需要客户端证书,且只对 PUT、POST、PATCH 和 DELETE 请求检查。PATRONI_RESTAPI_ALLOWLIST:(可选)允许调用不安全 REST API 端点的主机集合。单个元素可为主机名、IP 地址或 CIDR 网络地址,默认允许所有来源。若设置了 allowlist 或 allowlist_include_members,不在列表中的请求将被拒绝。PATRONI_RESTAPI_ALLOWLIST_INCLUDE_MEMBERS:(可选)设置为 true 时,允许从 DCS 中注册的其他集群成员(IP 地址或主机名取自成员的 api_url)访问不安全的 REST API 端点。注意:操作系统可能为出站连接使用不同的 IP 地址。PATRONI_RESTAPI_HTTP_EXTRA_HEADERS:(可选)允许 REST API 服务器在 HTTP 响应中附加额外的 HTTP 头信息。PATRONI_RESTAPI_HTTPS_EXTRA_HEADERS:(可选)启用 TLS 时,允许 REST API 服务器在 HTTP 响应中附加额外的 HTTPS 头信息,同时也会附加 http_extra_headers 中设置的头信息。PATRONI_RESTAPI_REQUEST_QUEUE_SIZE:(可选)Patroni REST API 使用的 TCP 套接字请求队列大小,队列满后后续请求将收到"Connection denied"错误,默认值为 5。PATRONI_RESTAPI_SERVER_TOKENS:(可选)Server HTTP 头的值。Original(默认)沿用原始行为,显示 BaseHTTP 和 Python 版本,例如 BaseHTTP/0.6 Python/3.12.3;Minimal:仅包含 Patroni 版本,例如 Patroni/4.0.0;ProductOnly:仅包含产品名称,例如 Patroni。
PATRONI_RESTAPI_CONNECT_ADDRESS 必须可从指定 Patroni 集群的所有节点访问。Patroni 在领导者竞选期间会使用该地址查找复制延迟最小的节点。- 若启用了客户端证书验证(
PATRONI_RESTAPI_VERIFY_CLIENT 设置为 required),还必须在 PATRONI_CTL_CERTFILE、PATRONI_CTL_KEYFILE、PATRONI_CTL_KEYFILE_PASSWORD 中提供有效的客户端证书,否则 Patroni 将无法正常工作。
CTL
PATRONICTL_CONFIG_FILE:(可选)配置文件的位置。PATRONI_CTL_USERNAME:(可选)访问受保护 REST API 端点的 Basic-auth 用户名。若未提供, patronictl 将使用 REST API “username” 参数中的值。PATRONI_CTL_PASSWORD:(可选)访问受保护 REST API 端点的 Basic-auth 密码。若未提供, patronictl 将使用 REST API “password” 参数中的值。PATRONI_CTL_INSECURE:(可选)允许在不验证 SSL 证书的情况下连接 REST API。PATRONI_CTL_CACERT:(可选)包含受信任 CA 证书的 CA_BUNDLE 文件或目录,用于验证 REST API SSL 证书。若未提供, patronictl 将使用 REST API “cafile” 参数中的值。PATRONI_CTL_CERTFILE:(可选)PEM 格式的客户端证书文件。PATRONI_CTL_KEYFILE:(可选)PEM 格式的客户端私钥文件。PATRONI_CTL_KEYFILE_PASSWORD:(可选)解密客户端 keyfile 的密码。
4 - Patroni REST API
Patroni REST API 端点与操作行为参考。
原始页面: https://patroni.readthedocs.io/en/latest/rest_api.html
Patroni 提供了丰富的 REST API,供 Patroni 自身在主库竞选期间调用,也供 patronictl 工具执行故障转移、主从切换、重新初始化、重启和重载等操作,还可供 HAProxy 或其他负载均衡器执行 HTTP 健康检查,以及用于监控目的。以下是 Patroni REST API 端点的完整列表。
健康检查端点
对于所有健康检查 GET 请求,Patroni 返回描述节点状态的 JSON 文档,并附带相应的 HTTP 状态码。若不需要 JSON 响应体,可使用 HEAD 或 OPTIONS 方法代替 GET。
以下请求仅在 Patroni 节点作为持有领导者锁的主库运行时返回 HTTP 状态码 200:
GET /GET /primaryGET /read-write
GET /standby-leader:仅当 Patroni 节点作为 备用集群 中的领导者运行时,返回 HTTP 状态码 200。
GET /leader:当 Patroni 节点持有领导者锁时返回 HTTP 状态码 200。与前两个端点的主要区别在于,它不区分 PostgreSQL 以 primary 还是 standby_leader 身份运行。
GET /replica:从库健康检查端点,仅当 Patroni 节点状态为 running、角色为 replica 且未设置 noloadbalance 标签时返回 HTTP 状态码 200。
GET /replica?replication_state=<required state>:从库检查端点,在 replica 检查的基础上,还会验证复制状态是否与指定状态匹配。主要用于 replication_state=streaming,以排除仍在通过归档恢复追赶进度的从库。
GET /replica?lag=<max-lag>:从库检查端点,在 replica 检查的基础上还会检查复制延迟,仅当延迟低于指定值时才返回 200。出于性能考虑,延迟计算使用 DCS 中的 cluster.last_leader_operation 键作为领导者 WAL 位置。max-lag 可用字节数(整数)或可读格式指定,例如 16kB、64MB、1GB。
GET /replica?lag=1048576GET /replica?lag=1024kBGET /replica?lag=10MBGET /replica?lag=1GB
GET /replica?tag_key1=value1&tag_key2=value2:从库检查端点,还会检查 YAML 配置 tags 节中用户自定义的 key1 和 key2 标签及其对应值。若实例未定义该标签,或 YAML 配置中的值与查询值不匹配,则返回 HTTP 503。
以下请求检查的是 leader 或 standby-leader 状态,Patroni 不会应用任何用户自定义标签,这些标签将被忽略:
GET /?tag_key1=value1&tag_key2=value2GET /leader?tag_key1=value1&tag_key2=value2GET /primary?tag_key1=value1&tag_key2=value2GET /read-write?tag_key1=value1&tag_key2=value2GET /standby_leader?tag_key1=value1&tag_key2=value2GET /standby-leader?tag_key1=value1&tag_key2=value2
GET /read-only:与上述端点类似,但同时包含主库。
GET /synchronous 或 GET /sync:仅当 Patroni 节点作为同步备库运行时返回 HTTP 状态码 200。
GET /read-only-sync:与上述端点类似,但同时包含主库。
GET /quorum:仅当此 Patroni 节点被列入主库 synchronous_standby_names 中的法定人数节点时返回 HTTP 状态码 200。
GET /read-only-quorum:与上述端点类似,但同时包含主库。
GET /asynchronous 或 GET /async:仅当 Patroni 节点作为异步备库运行时返回 HTTP 状态码 200。
GET /asynchronous?lag=<max-lag> 或 GET /async?lag=<max-lag>:异步备库检查端点,在 asynchronous 或 async 检查的基础上还会检查复制延迟,仅当延迟低于指定值时才返回 200。出于性能考虑,延迟计算使用 DCS 中的 cluster.last_leader_operation 键。max-lag 可用字节数(整数)或可读格式指定,例如 16kB、64MB、1GB。
GET /async?lag=1048576GET /async?lag=1024kBGET /async?lag=10MBGET /async?lag=1GB
GET /health:仅当 PostgreSQL 正常运行时,返回 HTTP 状态码 200。
GET /liveness:若 Patroni 心跳循环正常运行,返回 HTTP 状态码 200;若主库上次心跳距今超过 ttl 秒,或从库超过 2*ttl 秒,则返回 503。可用于 Kubernetes livenessProbe。
GET /readiness?lag=<max-lag>&mode=apply|write:当 Patroni 节点作为领导者运行时,或当 PostgreSQL 正常运行、正在复制且与领导者差距在允许范围内时,返回 HTTP 状态码 200。lag 参数设置备库允许落后的最大距离,默认为 maximum_lag_on_failover,可用字节数或可读格式指定,例如 16kB、64MB、1GB。mode 设置 WAL 是否需要已回放(apply)还是仅接收即可(write),默认为 apply。
作为 Kubernetes readinessProbe 使用时,可确保新启动的 Pod 只有在追上领导者后才变为就绪状态。结合 PodDisruptionBudget,可防止滚动重启期间领导者过早被终止,并确保复制落后的从库不会承接只读流量。在无法使用 Kubernetes endpoints 进行领导者选举的环境(如 OpenShift)中,也可将此端点用于 readinessProbe。
liveness 端点非常轻量,不执行任何 SQL。探针应配置为在领导者键即将过期时开始报错。以 ttl 默认值 30s 为例,探针配置如下:
readinessProbe:
httpGet:
scheme: HTTP
path: /readiness
port: 8008
initialDelaySeconds: 3
periodSeconds: 10
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
livenessProbe:
httpGet:
scheme: HTTP
path: /liveness
port: 8008
initialDelaySeconds: 3
periodSeconds: 10
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 3
监控端点
GET /patroni 由 Patroni 在主库竞选期间内部调用,也可供监控系统使用。此端点返回的 JSON 文档与健康检查端点结构相同。
示例: 健康运行中的集群
$ curl -s http://localhost:8008/patroni | jq .
{
"state": "running",
"postmaster_start_time": "2024-08-28 19:39:26.352526+00:00",
"role": "primary",
"server_version": 160004,
"xlog": {
"location": 67395656
},
"timeline": 1,
"replication": [
{
"usename": "replicator",
"application_name": "patroni2",
"client_addr": "10.89.0.6",
"state": "streaming",
"sync_state": "async",
"sync_priority": 0
},
{
"usename": "replicator",
"application_name": "patroni3",
"client_addr": "10.89.0.2",
"state": "streaming",
"sync_state": "async",
"sync_priority": 0
}
],
"dcs_last_seen": 1692356718,
"tags": {
"clonefrom": true
},
"database_system_identifier": "7268616322854375442",
"patroni": {
"version": "4.0.0",
"scope": "demo",
"name": "patroni1"
}
}
示例: 无主锁的集群
$ curl -s http://localhost:8008/patroni | jq .
{
"state": "running",
"postmaster_start_time": "2024-08-28 19:39:26.352526+00:00",
"role": "replica",
"server_version": 160004,
"xlog": {
"received_location": 67419744,
"replayed_location": 67419744,
"replayed_timestamp": null,
"paused": false
},
"timeline": 1,
"replication": [
{
"usename": "replicator",
"application_name": "patroni2",
"client_addr": "10.89.0.6",
"state": "streaming",
"sync_state": "async",
"sync_priority": 0
},
{
"usename": "replicator",
"application_name": "patroni3",
"client_addr": "10.89.0.2",
"state": "streaming",
"sync_state": "async",
"sync_priority": 0
}
],
"cluster_unlocked": true,
"dcs_last_seen": 1692356928,
"tags": {
"clonefrom": true
},
"database_system_identifier": "7268616322854375442",
"patroni": {
"version": "4.0.0",
"scope": "demo",
"name": "patroni1"
}
}
示例: 启用了 DCS 故障安全模式 的无主锁集群
$ curl -s http://localhost:8008/patroni | jq .
{
"state": "running",
"postmaster_start_time": "2024-08-28 19:39:26.352526+00:00",
"role": "replica",
"server_version": 160004,
"xlog": {
"location": 67420024
},
"timeline": 1,
"replication": [
{
"usename": "replicator",
"application_name": "patroni2",
"client_addr": "10.89.0.6",
"state": "streaming",
"sync_state": "async",
"sync_priority": 0
},
{
"usename": "replicator",
"application_name": "patroni3",
"client_addr": "10.89.0.2",
"state": "streaming",
"sync_state": "async",
"sync_priority": 0
}
],
"cluster_unlocked": true,
"failsafe_mode_is_active": true,
"dcs_last_seen": 1692356928,
"tags": {
"clonefrom": true
},
"database_system_identifier": "7268616322854375442",
"patroni": {
"version": "4.0.0",
"scope": "demo",
"name": "patroni1"
}
}
示例: 启用了 暂停模式 的集群
$ curl -s http://localhost:8008/patroni | jq .
{
"state": "running",
"postmaster_start_time": "2024-08-28 19:39:26.352526+00:00",
"role": "replica",
"server_version": 160004,
"xlog": {
"location": 67420024
},
"timeline": 1,
"replication": [
{
"usename": "replicator",
"application_name": "patroni2",
"client_addr": "10.89.0.6",
"state": "streaming",
"sync_state": "async",
"sync_priority": 0
},
{
"usename": "replicator",
"application_name": "patroni3",
"client_addr": "10.89.0.2",
"state": "streaming",
"sync_state": "async",
"sync_priority": 0
}
],
"pause": true,
"dcs_last_seen": 1724874295,
"tags": {
"clonefrom": true
},
"database_system_identifier": "7268616322854375442",
"patroni": {
"version": "4.0.0",
"scope": "demo",
"name": "patroni1"
}
}
GET /metrics 端点以 Prometheus 格式返回 Patroni 监控指标:
$ curl http://localhost:8008/metrics
# HELP patroni_version Patroni semver without periods. \
# TYPE patroni_version gauge
patroni_version{scope="batman",name="patroni1"} 040000
# HELP patroni_postgres_running Value is 1 if Postgres is running, 0 otherwise.
# TYPE patroni_postgres_running gauge
patroni_postgres_running{scope="batman",name="patroni1"} 1
# HELP patroni_postmaster_start_time Epoch seconds since Postgres started.
# TYPE patroni_postmaster_start_time gauge
patroni_postmaster_start_time{scope="batman",name="patroni1"} 1724873966.352526
# HELP patroni_primary Value is 1 if this node is the leader, 0 otherwise.
# TYPE patroni_primary gauge
patroni_primary{scope="batman",name="patroni1"} 1
# HELP patroni_xlog_location Current location of the Postgres transaction log, 0 if this node is not the leader.
# TYPE patroni_xlog_location counter
patroni_xlog_location{scope="batman",name="patroni1"} 22320573386952
# HELP patroni_standby_leader Value is 1 if this node is the standby_leader, 0 otherwise.
# TYPE patroni_standby_leader gauge
patroni_standby_leader{scope="batman",name="patroni1"} 0
# HELP patroni_replica Value is 1 if this node is a replica, 0 otherwise.
# TYPE patroni_replica gauge
patroni_replica{scope="batman",name="patroni1"} 0
# HELP patroni_sync_standby Value is 1 if this node is a sync standby replica, 0 otherwise.
# TYPE patroni_sync_standby gauge
patroni_sync_standby{scope="batman",name="patroni1"} 0
# HELP patroni_quorum_standby Value is 1 if this node is a quorum standby replica, 0 otherwise.
# TYPE patroni_quorum_standby gauge
patroni_quorum_standby{scope="batman",name="patroni1"} 0
# HELP patroni_xlog_received_location Current location of the received Postgres transaction log, 0 if this node is not a replica.
# TYPE patroni_xlog_received_location counter
patroni_xlog_received_location{scope="batman",name="patroni1"} 0
# HELP patroni_xlog_replayed_location Current location of the replayed Postgres transaction log, 0 if this node is not a replica.
# TYPE patroni_xlog_replayed_location counter
patroni_xlog_replayed_location{scope="batman",name="patroni1"} 0
# HELP patroni_xlog_replayed_timestamp Current timestamp of the replayed Postgres transaction log, 0 if null.
# TYPE patroni_xlog_replayed_timestamp gauge
patroni_xlog_replayed_timestamp{scope="batman",name="patroni1"} 0
# HELP patroni_xlog_paused Value is 1 if the Postgres xlog is paused, 0 otherwise.
# TYPE patroni_xlog_paused gauge
patroni_xlog_paused{scope="batman",name="patroni1"} 0
# HELP patroni_postgres_streaming Value is 1 if Postgres is streaming, 0 otherwise.
# TYPE patroni_postgres_streaming gauge
patroni_postgres_streaming{scope="batman",name="patroni1"} 1
# HELP patroni_postgres_in_archive_recovery Value is 1 if Postgres is replicating from archive, 0 otherwise.
# TYPE patroni_postgres_in_archive_recovery gauge
patroni_postgres_in_archive_recovery{scope="batman",name="patroni1"} 0
# HELP patroni_postgres_server_version Version of Postgres (if running), 0 otherwise.
# TYPE patroni_postgres_server_version gauge
patroni_postgres_server_version{scope="batman",name="patroni1"} 160004
# HELP patroni_cluster_unlocked Value is 1 if the cluster is unlocked, 0 if locked.
# TYPE patroni_cluster_unlocked gauge
patroni_cluster_unlocked{scope="batman",name="patroni1"} 0
# HELP patroni_postgres_timeline Postgres timeline of this node (if running), 0 otherwise.
# TYPE patroni_postgres_timeline counter
patroni_failsafe_mode_is_active{scope="batman",name="patroni1"} 0
# HELP patroni_postgres_timeline Postgres timeline of this node (if running), 0 otherwise.
# TYPE patroni_postgres_timeline counter
patroni_postgres_timeline{scope="batman",name="patroni1"} 24
# HELP patroni_dcs_last_seen Epoch timestamp when DCS was last contacted successfully by Patroni.
# TYPE patroni_dcs_last_seen gauge
patroni_dcs_last_seen{scope="batman",name="patroni1"} 1724874235
# HELP patroni_pending_restart Value is 1 if the node needs a restart, 0 otherwise.
# TYPE patroni_pending_restart gauge
patroni_pending_restart{scope="batman",name="patroni1"} 1
# HELP patroni_is_paused Value is 1 if auto failover is disabled, 0 otherwise.
# TYPE patroni_is_paused gauge
patroni_is_paused{scope="batman",name="patroni1"} 1
# HELP patroni_postgres_state Numeric representation of Postgres state.
# Values: 0=initdb, 1=initdb_failed, 2=custom_bootstrap, 3=custom_bootstrap_failed, 4=creating_replica, 5=running, 6=starting, 7=bootstrap_starting, 8=start_failed, 9=restarting, 10=restart_failed, 11=stopping, 12=stopped, 13=stop_failed, 14=crashed
# TYPE patroni_postgres_state gauge
patroni_postgres_state{scope="batman",name="patroni1"} 5
PostgreSQL 状态值
patroni_postgres_state 指标以数值形式表示当前 PostgreSQL 实例的状态,对于需要跟踪状态随时间变化的监控和告警系统很有用。数值由 PostgresqlState.get_metrics_description() 静态方法生成。
| 值 | 状态名称 | 描述 |
|---|
| 0 | initdb | 正在初始化新集群 |
| 1 | initdb_failed | 新集群初始化失败 |
| 2 | custom_bootstrap | 正在运行自定义引导脚本 |
| 3 | custom_bootstrap_failed | 自定义引导脚本失败 |
| 4 | creating_replica | 正在从主库创建从库 |
| 5 | running | PostgreSQL 正常运行 |
| 6 | starting | PostgreSQL 正在启动 |
| 7 | bootstrap_starting | 自定义引导后正在启动 |
| 8 | start_failed | PostgreSQL 启动失败 |
| 9 | restarting | PostgreSQL 正在重启 |
| 10 | restart_failed | PostgreSQL 重启失败 |
| 11 | stopping | PostgreSQL 正在停止 |
| 12 | stopped | PostgreSQL 已停止 |
| 13 | stop_failed | PostgreSQL 停止失败 |
| 14 | crashed | PostgreSQL 已崩溃 |
说明
上述数值固定不变,以保持与现有监控系统的向后兼容性。未来如需新增状态,将分配新的数值,已有数值不会改变。
集群状态端点
GET /cluster:返回描述当前集群拓扑和状态的 JSON 文档:
$ curl -s http://localhost:8008/cluster | jq .
{
"members": [
{
"name": "patroni1",
"role": "leader",
"state": "running",
"api_url": "http://10.89.0.4:8008/patroni",
"host": "10.89.0.4",
"port": 5432,
"timeline": 5,
"tags": {
"clonefrom": true
}
},
{
"name": "patroni2",
"role": "replica",
"state": "streaming",
"api_url": "http://10.89.0.6:8008/patroni",
"host": "10.89.0.6",
"port": 5433,
"timeline": 5,
"tags": {
"clonefrom": true
},
"receive_lag": 0,
"receive_lsn": "0/4000060",
"replay_lag": 0,
"replay_lsn": "0/4000060",
"lag": 0,
"lsn": "0/4000060"
}
],
"scope": "demo",
"scheduled_switchover": {
"at": "2023-09-24T10:36:00+02:00",
"from": "patroni1",
"to": "patroni3"
}
}
GET /history:返回集群主从切换/故障转移历史记录,格式与 pg_wal 目录中历史文件的内容非常相似,唯一区别是增加了一个时间戳字段,标记新时间线的创建时间。
$ curl -s http://localhost:8008/history | jq .
[
[
1,
25623960,
"no recovery target specified",
"2019-09-23T16:57:57+02:00"
],
[
2,
25624344,
"no recovery target specified",
"2019-09-24T09:22:33+02:00"
],
[
3,
25624752,
"no recovery target specified",
"2019-09-24T09:26:15+02:00"
],
[
4,
50331856,
"no recovery target specified",
"2019-09-24T09:35:52+02:00"
]
]
配置端点
GET /config:获取当前动态配置:
$ curl -s http://localhost:8008/config | jq .
{
"ttl": 30,
"loop_wait": 10,
"retry_timeout": 10,
"maximum_lag_on_failover": 1048576,
"postgresql": {
"use_slots": true,
"use_pg_rewind": true,
"parameters": {
"hot_standby": "on",
"wal_level": "hot_standby",
"max_wal_senders": 5,
"max_replication_slots": 5,
"max_connections": "100"
}
}
}
PATCH /config:修改现有配置。
$ curl -s -XPATCH -d \
'{"loop_wait":5,"ttl":20,"postgresql":{"parameters":{"max_connections":"101"}}}' \
http://localhost:8008/config | jq .
{
"ttl": 20,
"loop_wait": 5,
"maximum_lag_on_failover": 1048576,
"retry_timeout": 10,
"postgresql": {
"use_slots": true,
"use_pg_rewind": true,
"parameters": {
"hot_standby": "on",
"wal_level": "hot_standby",
"max_wal_senders": 5,
"max_replication_slots": 5,
"max_connections": "101"
}
}
}
上述调用对现有配置进行部分更新(patch),并返回更新后的配置。
验证节点是否已处理该配置:日志应每 5 秒打印一次(loop_wait=5)。由于 max_connections 的变更需要重启,响应中应出现 pending_restart 标志:
$ curl -s http://localhost:8008/patroni | jq .
{
"database_system_identifier": "6287881213849985952",
"postmaster_start_time": "2024-08-28 19:39:26.352526+00:00",
"xlog": {
"location": 2197818976
},
"timeline": 1,
"dcs_last_seen": 1724874545,
"database_system_identifier": "7408277255830290455",
"pending_restart": true,
"pending_restart_reason": {
"max_connections": {
"old_value": "100",
"new_value": "101"
}
},
"patroni": {
"version": "4.0.0",
"scope": "batman",
"name": "patroni1"
},
"state": "running",
"role": "primary",
"server_version": 160004
}
删除参数:
若要删除(重置)某个配置项,将其 patch 为 null 即可:
$ curl -s -XPATCH -d \
'{"postgresql":{"parameters":{"max_connections":null}}}' \
http://localhost:8008/config | jq .
{
"ttl": 20,
"loop_wait": 5,
"retry_timeout": 10,
"maximum_lag_on_failover": 1048576,
"postgresql": {
"use_slots": true,
"use_pg_rewind": true,
"parameters": {
"hot_standby": "on",
"unix_socket_directories": ".",
"wal_level": "hot_standby",
"max_wal_senders": 5,
"max_replication_slots": 5
}
}
}
上述调用从动态配置中删除了 postgresql.parameters.max_connections。
PUT /config:对现有动态配置进行无条件的完整覆写:
$ curl -s -XPUT -d \
'{"maximum_lag_on_failover":1048576,"retry_timeout":10,"postgresql":{"use_slots":true,"use_pg_rewind":true,"parameters":{"hot_standby":"on","wal_level":"hot_standby","unix_socket_directories":".","max_wal_senders":5}},"loop_wait":3,"ttl":20}' \
http://localhost:8008/config | jq .
{
"ttl": 20,
"maximum_lag_on_failover": 1048576,
"retry_timeout": 10,
"postgresql": {
"use_slots": true,
"parameters": {
"hot_standby": "on",
"unix_socket_directories": ".",
"wal_level": "hot_standby",
"max_wal_senders": 5
},
"use_pg_rewind": true
},
"loop_wait": 3
}
主从切换与故障转移端点
主从切换(Switchover)
/switchover 端点仅在集群健康(存在领导者)时有效,也支持在指定时间调度主从切换。
调用 /switchover 端点时,候选节点可以指定,也可以不指定——这与 /failover 端点不同。若未指定候选节点,领导者降级后集群中所有符合条件的节点将参与主库竞选。
POST 请求的 JSON 请求体中必须包含 leader 字段,candidate 和 scheduled_at 字段为可选,可用于指定切换目标和调度时间。
根据执行情况,请求可能返回不同的 HTTP 状态码。主从切换或故障转移成功完成时返回 200;切换成功调度时返回 202;若出现错误,返回 400、412 或 503 之一,并在响应体中提供详情。
DELETE /switchover 可用于删除当前已调度的主从切换计划。
示例: 切换到任意健康备库
$ curl -s http://localhost:8008/switchover -XPOST -d '{"leader":"postgresql1"}'
Successfully switched over to "postgresql2"
示例: 切换到指定节点
$ curl -s http://localhost:8008/switchover -XPOST -d \
'{"leader":"postgresql1","candidate":"postgresql2"}'
Successfully switched over to "postgresql2"
示例: 在指定时间将领导者切换到集群中任意健康备库。
$ curl -s http://localhost:8008/switchover -XPOST -d \
'{"leader":"postgresql0","scheduled_at":"2019-09-24T12:00+00"}'
Switchover scheduled
故障转移(Failover)
/failover 端点可在没有健康节点时执行手动故障转移(例如,当所有同步备库均无法提升时,可将一个异步备库提升为主库)。集群不一定要处于无主状态——故障转移也可以在健康集群上执行。
POST 请求的 JSON 请求体中必须指定 candidate 字段。若同时指定了 leader 字段,则触发主从切换而非故障转移。
示例:
$ curl -s http://localhost:8008/failover -XPOST -d '{"candidate":"postgresql1"}'
Successfully failed over to "postgresql1"
警告
使用此端点时请 格外谨慎,在某些情况下可能造成数据丢失。大多数情况下,使用 主从切换端点 即可满足需求。
POST /switchover 和 POST /failover 端点分别由 patronictl_switchover 和 patronictl_failover 使用。
DELETE /switchover 由 patronictl flush cluster-name switchover 使用。
| 故障转移 | 主从切换 |
|---|
| 需要指定 leader | 否 | 是 |
| 需要指定 candidate | 是 | 否 |
| 可在暂停模式下执行 | 是 | 是(仅限指定候选节点的情况) |
| 可调度执行 | 否 | 是(非暂停模式下) |
健康备库
集群成员需满足以下所有条件,才能在主从切换期间参与主库竞选,或被选为故障转移/主从切换的候选节点:
- 可通过 Patroni API 访问;
- 未将
nofailover 标签设为 true; - watchdog 功能完整可用(若配置要求);
- 在健康集群的主从切换或自动故障转移场景中,复制延迟不超过
maximum_lag_on_failover 配置参数 所设的上限; - 在健康集群的主从切换或自动故障转移场景中,若
check_timeline 配置参数 设为 true,时间线编号不得小于集群当前时间线; - 在 同步模式 下:
- 主从切换场景(无论是否指定候选节点):必须列于
/sync 键的成员中; - 故障转移场景(无论集群是否健康):跳过此检查。
警告
在无领导者的集群中执行手动故障转移时,候选节点即便存在以下情况也将被允许提升:同步模式下该节点不在 /sync 键成员中;复制延迟超过允许的最大值;时间线编号小于已知的最后集群时间线。
重启端点
POST /restart:重启指定节点上的 PostgreSQL。POST 请求体中可选择指定以下重启条件:restart_pending:布尔值,若设为 true,仅在有待应用的 PostgreSQL 配置变更时才执行重启。role:仅当节点当前角色与请求中指定的角色匹配时才执行重启。postgres_version:仅当当前 PostgreSQL 版本低于请求中指定的版本时才执行重启。timeout:等待 PostgreSQL 开始接受连接的时长,覆盖 primary_start_timeout。schedule:带时区的时间戳,用于在未来某个时间调度重启。
DELETE /restart:取消已调度的重启计划。
POST /restart 和 DELETE /restart 端点分别由 patronictl_restart 和 patronictl flush cluster-name restart 使用。
重载端点
POST /reload 指示 Patroni 重新读取并应用配置文件,等同于向 Patroni 进程发送 SIGHUP 信号。若修改了需要重启才能生效的 PostgreSQL 参数(如 shared_buffers),仍需通过 POST /restart 端点或 patronictl_restart 显式重启 PostgreSQL。
重载端点由 patronictl_reload 使用。
重新初始化端点
POST /reinitialize:重新初始化指定节点上的 PostgreSQL 数据目录,仅允许在从库上执行。调用后,将删除数据目录并启动 pg_basebackup 或其他 从库创建方法。
若 Patroni 正处于循环尝试恢复失败 PostgreSQL 的过程中,此调用可能失败。解决方法是在请求体中指定 {"force":true}。
也可在请求体中指定 {"from-leader":true},直接从领导者节点获取基础备份,在所有从库均已失败的情况下执行重新初始化时尤为有用。
重新初始化端点由 patronictl_reinit 使用。
5 - patronictl 命令行
patronictl 的配置说明、语法参考与子命令完整参考。
原始页面: https://patroni.readthedocs.io/en/latest/patronictl.html
Patroni 提供了 patronictl 命令行工具,用于与 Patroni 的 REST API 和 DCS 交互,旨在简化集群操作,适合人工操作或脚本调用。
配置
patronictl 使用以下 3 个配置节:
ctl:用于对 Patroni REST API 进行认证以及验证服务器身份,详见 ctl 配置参数;restapi:同样用于认证和验证服务器身份,仅在 ctl 配置不足时作为补充。patronictl 主要使用 restapi.authentication 节(当 ctl.authentication 缺失时)和 restapi.cafile(当 ctl.cacert 缺失时),详见 REST API 配置参数;- DCS(如
etcd):如何连接和认证 Patroni 所使用的 DCS。
这些配置可通过环境变量或配置文件提供。具体设置方式请参阅 环境变量配置参数 或 YAML 配置参数 中的相应章节。
若使用环境变量,方式直接——patronictl 读取环境变量并使用其值即可。
若使用配置文件,可通过多种方式告知 patronictl 应加载哪个文件。默认情况下,patronictl 会尝试加载名为 patronictl.yaml 的配置文件,根据操作系统不同,该文件的默认路径如下:
- Mac OS X:
~/Library/Application Support/patroni - Mac OS X(POSIX):
~/.patroni - Unix:
~/.config/patroni - Unix(POSIX):
~/.patroni - Windows(漫游):
C:\Users\<user>\AppData\Roaming\patroni - Windows(非漫游):
C:\Users\<user>\AppData\Local\patroni
可通过以下方式覆盖默认配置文件路径:
- 设置环境变量
PATRONICTL_CONFIG_FILE,指向自定义配置文件; - 使用 patronictl 的
-c / --config-file 命令行参数。
用法
patronictl 提供了若干便捷操作,本节将逐一介绍。
各子命令介绍之前,先了解 patronictl 自身的命令行参数:
-c / --config-file
为 patronictl 指定配置文件路径,用法如前所述。
-d / --dcs-url / --dcs
提供 Patroni 所用 DCS 的连接字符串。
可用于覆盖 patronictl 配置中的 DCS 和 namespace 设置,也可在配置中缺少这些设置时直接定义。
值的格式为 DCS://HOST:PORT/NAMESPACE,例如 etcd3://localhost:2379/service,表示连接本机上的 etcd v3,Patroni 集群存储在 service namespace 下。缺少的部分将由配置文件中的值或默认值补充。
-k / --insecure
跳过 REST API 服务器 SSL 证书验证。
以下是 patronictl 命令的使用语法:
patronictl [ { -c | --config-file } CONFIG_FILE ]
[ { -d | --dcs-url | --dcs } DCS_URL ]
[ { -k | --insecure } ]
SUBCOMMAND
说明
语法约定:
- 方括号
[ ] 内的选项为可选项; - 花括号
{ } 内的选项表示从中选择其一; - 带有
[, ... ] 的选项可多次指定; - 大写字母表示需要赋值的占位符。
以下各小节描述子命令时均使用相同语法,子命令语法说明可视为上述语法中 SUBCOMMAND 的替换内容。
以下各小节介绍 patronictl 的每个子命令,示例均使用 Patroni GitHub 仓库中的配置文件(postgres0.yml、postgres1.yml 和 postgres2.yml)。
patronictl dsn
语法
dsn
[ CLUSTER_NAME ]
[ { { -r | --role } { leader | primary | standby-leader | replica | standby | any } | { -m | --member } MEMBER_NAME } ]
[ --group CITUS_GROUP ]
描述
patronictl dsn 获取 Patroni 集群指定成员的连接字符串。
若多个成员符合条件,将优先返回主库的连接字符串。
参数
CLUSTER_NAME
Patroni 集群名称。
若未指定,patronictl 将尝试从 scope 配置中获取(如果存在)。
-r / --role
选择具有指定角色的成员。
角色可以是以下之一:
leader:普通 Patroni 集群或备用 Patroni 集群的领导者;primary:普通 Patroni 集群的领导者;standby-leader:备用 Patroni 集群的领导者;replica:Patroni 集群的从库;standby:同 replica;any:任意角色,与省略此参数效果相同。
-m / --member
选择具有指定名称的集群成员。
MEMBER_NAME 为成员的名称。
--group
选择属于指定 Citus 组的成员。
CITUS_GROUP 为 Citus 组 ID。
示例
获取主库的 DSN:
$ patronictl -c postgres0.yml dsn batman -r primary
host=127.0.0.1 port=5432
获取名为 postgresql1 的节点的 DSN:
$ patronictl -c postgres0.yml dsn batman --member postgresql1
host=127.0.0.1 port=5433
patronictl edit-config
语法
edit-config
[ CLUSTER_NAME ]
[ --group CITUS_GROUP ]
[ { -q | --quiet } ]
[ { -s | --set } CONFIG="VALUE" [, ... ] ]
[ { -p | --pg } PG_CONFIG="PG_VALUE" [, ... ] ]
[ { --apply | --replace } CONFIG_FILE ]
[ --force ]
描述
patronictl edit-config 修改集群的动态配置并将其更新到 DCS。
说明
通过 TTY 调用时,该命令会通过分页器显示动态配置的差异,默认使用 less 或 more。若需要使用其他分页器,请通过 PAGER 环境变量指定。
参数
CLUSTER_NAME
Patroni 集群名称。
若未指定,patronictl 将尝试从 scope 配置中获取(如果存在)。
--group
修改指定 Citus 组的动态配置。
若未指定,patronictl 将尝试从 citus.group 配置中获取(如果存在)。
CITUS_GROUP 为 Citus 组 ID。
-q / --quiet
跳过显示配置差异的标志。
-s / --set
将指定的动态配置选项设置为给定值。
CONFIG 为动态配置在 YAML 树中的路径,各层级之间以 . 分隔。
VALUE 为 CONFIG 的值。若值为 null,则从动态配置中删除该项。
-p / --pg
设置指定的动态 PostgreSQL 配置参数。
本质上是 -s / --set 的简写,会自动在 CONFIG 前添加 postgresql.parameters. 前缀。
PG_CONFIG 为要设置的 PostgreSQL 参数名称。
PG_VALUE 为 PG_CONFIG 的值。若值为 null,则从动态配置中删除该参数。
--apply
从指定文件应用动态配置。
效果等同于对文件中每项配置分别指定 -s / --set 选项。
CONFIG_FILE 为包含待应用动态配置的文件路径(YAML 格式),使用 - 从 stdin 读取。
--replace
用指定文件中的动态配置完整替换 DCS 中的现有配置。
CONFIG_FILE 为包含新动态配置的文件路径(YAML 格式),使用 - 从 stdin 读取。
--force
跳过确认提示,适合在脚本中使用。
示例
修改 max_connections Postgres GUC 参数:
patronictl -c postgres0.yml edit-config batman --pg max_connections="150" --force
---
+++
@@ -1,6 +1,8 @@
loop_wait: 10
maximum_lag_on_failover: 1048576
postgresql:
+ parameters:
+ max_connections: 150
pg_hba:
- host replication replicator 127.0.0.1/32 md5
- host all all 0.0.0.0/0 md5
Configuration changed
修改 loop_wait 和 ttl 配置:
patronictl -c postgres0.yml edit-config batman --set loop_wait="15" --set ttl="45" --force
---
+++
@@ -1,4 +1,4 @@
-loop_wait: 10
+loop_wait: 15
maximum_lag_on_failover: 1048576
postgresql:
pg_hba:
@@ -6,4 +6,4 @@
- host all all 0.0.0.0/0 md5
use_pg_rewind: true
retry_timeout: 10
-ttl: 30
+ttl: 45
Configuration changed
从动态配置中删除 maximum_lag_on_failover 配置项:
patronictl -c postgres0.yml edit-config batman --set maximum_lag_on_failover="null" --force
---
+++
@@ -1,5 +1,4 @@
loop_wait: 10
-maximum_lag_on_failover: 1048576
postgresql:
pg_hba:
- host replication replicator 127.0.0.1/32 md5
Configuration changed
patronictl failover
语法
failover
[ CLUSTER_NAME ]
[ --group CITUS_GROUP ]
--candidate CANDIDATE_NAME
[ --force ]
描述
patronictl failover 在集群中执行手动故障转移。
此命令适用于集群不健康的场景,例如:
也可用于在同步模式下将故障转移到异步节点。
说明
健康集群中也可运行 patronictl failover,但此类情况下建议使用 patronictl switchover。
警告
故障转移可能导致数据丢失,具体取决于被提升的从库与主库的同步程度。
参数
CLUSTER_NAME
Patroni 集群名称。
若未指定,patronictl 将尝试从 scope 配置中获取(如果存在)。
--group
在指定 Citus 组中执行故障转移。
CITUS_GROUP 为 Citus 组 ID。
--candidate
指定故障转移时要提升为主库的节点。
CANDIDATE_NAME 为目标节点名称。
--force
跳过确认提示,适合在脚本中使用。
示例
故障转移到节点 postgresql2:
$ patronictl -c postgres0.yml failover batman --candidate postgresql2 --force
Current cluster topology
+ Cluster: batman (7277694203142172922) -+-----------+----+-------------+-----+------------+-----+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
| postgresql0 | 127.0.0.1:5432 | Leader | running | 3 | | | | |
| postgresql1 | 127.0.0.1:5433 | Replica | streaming | 3 | 0/40004E8 | 0 | 0/40004E8 | 0 |
| postgresql2 | 127.0.0.1:5434 | Replica | streaming | 3 | 0/40004E8 | 0 | 0/40004E8 | 0 |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
2023-09-12 11:52:27.50978 Successfully failed over to "postgresql2"
+ Cluster: batman (7277694203142172922) -+---------+----+-------------+---------+------------+---------+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+-------------+----------------+---------+---------+----+-------------+---------+------------+---------+
| postgresql0 | 127.0.0.1:5432 | Replica | stopped | | unknown | unknown | unknown | unknown |
| postgresql1 | 127.0.0.1:5433 | Replica | running | 3 | 0/4000188 | 0 | 0/4000188 | 0 |
| postgresql2 | 127.0.0.1:5434 | Leader | running | 3 | | | | |
+-------------+----------------+---------+---------+----+-------------+---------+------------+---------+
patronictl flush
语法
flush
CLUSTER_NAME
[ MEMBER_NAME [, ... ] ]
{ restart | switchover }
[ --group CITUS_GROUP ]
[ { -r | --role } { leader | primary | standby-leader | replica | standby | any } ]
[ --force ]
描述
patronictl flush 取消已调度的事件。
参数
CLUSTER_NAME
Patroni 集群名称。
MEMBER_NAME
取消指定成员的已调度事件,可同时指定多个成员,不指定则针对所有成员。
restart
取消已调度的重启事件。
switchover
取消已调度的主从切换事件。
--group
取消指定 Citus 组的已调度事件。
CITUS_GROUP 为 Citus 组 ID。
-r / --role
取消具有指定角色的成员的已调度事件。
角色可以是以下之一:
leader:普通集群或备用集群的领导者;primary:普通集群的领导者;standby-leader:备用集群的领导者;replica:集群从库;standby:同 replica;any:任意角色,与省略此参数效果相同。
--force
跳过确认提示,适合在脚本中使用。
示例
取消已调度的主从切换事件:
$ patronictl -c postgres0.yml flush batman switchover --force
Success: scheduled switchover deleted
取消所有备库的已调度重启:
$ patronictl -c postgres0.yml flush batman restart -r replica --force
+ Cluster: batman (7277694203142172922) -+-----------+----+-------------+-----+------------+-----+---------------------------+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag | Scheduled restart |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+---------------------------+
| postgresql0 | 127.0.0.1:5432 | Leader | running | 5 | | | | | 2025-03-23T18:00:00-03:00 |
| postgresql1 | 127.0.0.1:5433 | Replica | streaming | 5 | 0/4000400 | 0 | 0/4000400 | 0 | 2025-03-23T18:00:00-03:00 |
| postgresql2 | 127.0.0.1:5434 | Replica | streaming | 5 | 0/4000400 | 0 | 0/4000400 | 0 | 2025-03-23T18:00:00-03:00 |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+---------------------------+
Success: flush scheduled restart for member postgresql1
Success: flush scheduled restart for member postgresql2
取消节点 postgresql0 和 postgresql1 的已调度重启:
$ patronictl -c postgres0.yml flush batman postgresql0 postgresql1 restart --force
+ Cluster: batman (7277694203142172922) -+-----------+----+-------------+-----+------------+-----+---------------------------+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag | Scheduled restart |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+---------------------------+
| postgresql0 | 127.0.0.1:5432 | Leader | running | 5 | | | | | 2025-03-23T18:00:00-03:00 |
| postgresql1 | 127.0.0.1:5433 | Replica | streaming | 5 | 0/4000400 | 0 | 0/4000400 | 0 | 2025-03-23T18:00:00-03:00 |
| postgresql2 | 127.0.0.1:5434 | Replica | streaming | 5 | 0/4000400 | 0 | 0/4000400 | 0 | 2025-03-23T18:00:00-03:00 |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+---------------------------+
Success: flush scheduled restart for member postgresql0
Success: flush scheduled restart for member postgresql1
patronictl history
语法
history
[ CLUSTER_NAME ]
[ --group CITUS_GROUP ]
[ { -f | --format } { pretty | tsv | json | yaml } ]
描述
patronictl history 显示集群故障转移和主从切换事件的历史记录。
输出包含以下信息:
TL
事件发生时的 Postgres 时间线。
LSN
事件发生时的 Postgres LSN。
Reason
来自 PostgreSQL .history 文件的切换原因。
Timestamp
事件发生的时间。
New Leader
在事件中被提升的 Patroni 成员。
参数
CLUSTER_NAME
Patroni 集群名称。
若未指定,patronictl 将尝试从 scope 配置中获取(如果存在)。
--group
显示指定 Citus 组的事件历史。
CITUS_GROUP 为 Citus 组 ID。
若未指定,patronictl 将尝试从 citus.group 配置中获取(如果存在)。
-f / --format
输出中事件列表的格式。
格式可以是以下之一:
pretty:以美观的表格形式打印历史记录;tsv:以表格形式打印历史记录,列之间以 \t 分隔;json:以 JSON 格式打印历史记录;yaml:以 YAML 格式打印历史记录。
默认为 pretty。
示例
显示事件历史记录:
$ patronictl -c postgres0.yml history batman
+----+----------+------------------------------+----------------------------------+-------------+
| TL | LSN | Reason | Timestamp | New Leader |
+----+----------+------------------------------+----------------------------------+-------------+
| 1 | 24392648 | no recovery target specified | 2023-09-11T22:11:27.125527+00:00 | postgresql0 |
| 2 | 50331864 | no recovery target specified | 2023-09-12T11:34:03.148097+00:00 | postgresql0 |
| 3 | 83886704 | no recovery target specified | 2023-09-12T11:52:26.948134+00:00 | postgresql2 |
| 4 | 83887280 | no recovery target specified | 2023-09-12T11:53:09.620136+00:00 | postgresql0 |
+----+----------+------------------------------+----------------------------------+-------------+
以 YAML 格式显示事件历史记录:
$ patronictl -c postgres0.yml history batman -f yaml
- LSN: 24392648
New Leader: postgresql0
Reason: no recovery target specified
TL: 1
Timestamp: '2023-09-11T22:11:27.125527+00:00'
- LSN: 50331864
New Leader: postgresql0
Reason: no recovery target specified
TL: 2
Timestamp: '2023-09-12T11:34:03.148097+00:00'
- LSN: 83886704
New Leader: postgresql2
Reason: no recovery target specified
TL: 3
Timestamp: '2023-09-12T11:52:26.948134+00:00'
- LSN: 83887280
New Leader: postgresql0
Reason: no recovery target specified
TL: 4
Timestamp: '2023-09-12T11:53:09.620136+00:00'
patronictl list
语法
list
[ CLUSTER_NAME [, ... ] ]
[ --group CITUS_GROUP ]
[ { -e | --extended } ]
[ { -t | --timestamp } ]
[ { -f | --format } { pretty | tsv | json | yaml } ]
[ { -W | { -w | --watch } TIME } ]
描述
patronictl list 显示 Patroni 集群及其成员的信息。
输出包含以下信息:
Cluster
Patroni 集群名称。
Member
Patroni 成员名称。
Host
成员所在主机。
Role
成员当前角色。
可以是以下之一:
Leader:普通 Patroni 集群的当前领导者;Standby Leader:Patroni 备用集群的当前领导者;Sync Standby:启用同步模式的 Patroni 集群的同步备库;Replica:Patroni 集群的普通备库。
State
该 Patroni 成员上 PostgreSQL 的当前运行状态。
常见状态值:
running:PostgreSQL 正常运行;streaming:从库,正通过流复制从主库接收 WAL;in archive recovery:从库,正通过归档恢复获取 WAL;stopped:PostgreSQL 已停止;crashed:PostgreSQL 已崩溃。
TL
该 Patroni 成员上 PostgreSQL 的当前时间线编号。
Receive LSN
通过流复制接收并已同步到磁盘的最后一个 WAL 位置(pg_catalog.pg_last_(xlog|wal)_receive_(location|lsn)())。
Receive Lag
该成员 Receive LSN 与其上游之间的复制延迟(MB)。
Replay LSN
恢复期间已重放的最后一个 WAL 位置(pg_catalog.pg_last_(xlog|wal)_replay_(location|lsn)())。
Replay Lag
该成员 Replay LSN 与其上游之间的复制延迟(MB)。
此外,以下信息也可能出现在输出中:
System identifier
PostgreSQL 系统标识符。
说明
显示在表格标题中,仅在输出格式为 pretty 时显示。
Group
Citus 组 ID。
Pending restart
* 表示节点需要重启以使某些 PostgreSQL 配置生效,空值表示无需重启。
说明
显示为成员属性。在以下情况下显示:
- 以
pretty 或 tsv 格式输出且启用了扩展输出;或 - 节点有待应用的配置变更需要重启。
Scheduled restart
为该成员管理的 PostgreSQL 实例调度重启的时间戳,空值表示该成员没有已调度的重启。
说明
显示为成员属性。在以下情况下显示:
- 以
pretty 或 tsv 格式输出且启用了扩展输出;或 - 节点有已调度的重启。
Tags
该 Patroni 成员设置的标签,空值表示未配置任何标签或标签均为默认值。
说明
显示为成员属性。在以下情况下显示:
- 以
pretty 或 tsv 格式输出且启用了扩展输出;或 - 节点有自定义标签,或有使用非默认值的内置标签。
Scheduled switchover
为 Patroni 集群调度主从切换的时间戳。
说明
显示在表格底部,仅在有已调度的主从切换且输出格式为 pretty 时显示。
Maintenance mode
集群自动故障转移当前是否已暂停。
说明
显示在表格底部,仅在集群已暂停且输出格式为 pretty 时显示。
参数
CLUSTER_NAME
Patroni 集群名称。
若未指定,patronictl 将尝试从 scope 配置中获取(如果存在)。
--group
显示指定 Citus 组成员的信息。
CITUS_GROUP 为 Citus 组 ID。
-e / --extended
显示扩展信息,强制显示 Pending restart、Scheduled restart 和 Tags 属性,即使其值为空。
-t / --timestamp
在打印集群及成员信息之前打印时间戳。
-f / --format
输出格式,可以是:
pretty:以美观的表格形式打印;tsv:以 \t 分隔的表格形式打印;json:JSON 格式;yaml:YAML 格式。
默认为 pretty。
-W
每 2 秒自动刷新信息。
-w / --watch
按指定间隔(秒)自动刷新信息。
示例
以美观表格格式显示集群信息:
$ patronictl -c postgres0.yml list batman
+ Cluster: batman (7277694203142172922) -+-----------+----+-------------+-----+------------+-----+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
| postgresql0 | 127.0.0.1:5432 | Leader | running | 5 | | | | |
| postgresql1 | 127.0.0.1:5433 | Replica | streaming | 5 | 0/40004E8 | 0 | 0/40004E8 | 0 |
| postgresql2 | 127.0.0.1:5434 | Replica | streaming | 5 | 0/40004E8 | 0 | 0/40004E8 | 0 |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
以美观表格格式显示集群信息(含扩展列):
$ patronictl -c postgres0.yml list batman -e
+ Cluster: batman (7277694203142172922) -+-----------+----+-------------+-----+------------+-----+-----------------+------------------------+-------------------+------+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag | Pending restart | Pending restart reason | Scheduled restart | Tags |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+-----------------+------------------------+-------------------+------+
| postgresql0 | 127.0.0.1:5432 | Leader | running | 5 | | | | | | | | |
| postgresql1 | 127.0.0.1:5433 | Replica | streaming | 5 | 0/40004E8 | 0 | 0/40004E8 | 0 | | | | |
| postgresql2 | 127.0.0.1:5434 | Replica | streaming | 5 | 0/40004E8 | 0 | 0/40004E8 | 0 | | | | |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+-----------------+------------------------+-------------------+------+
以 YAML 格式显示集群信息,并附带执行时间戳:
$ patronictl -c postgres0.yml list batman -f yaml -t
2023-09-12 13:30:48
- Cluster: batman
Host: 127.0.0.1:5432
Member: postgresql0
Role: Leader
State: running
TL: 5
- Cluster: batman
Host: 127.0.0.1:5433
Receive LSN: 0/40004E8
Receive Lag: 0
Replay LSN: 0/40004E8
Replay Lag: 0
Member: postgresql1
Role: Replica
State: streaming
TL: 5
- Cluster: batman
Host: 127.0.0.1:5434
Receive LSN: 0/40004E8
Receive Lag: 0
Replay LSN: 0/40004E8
Replay Lag: 0
Member: postgresql2
Role: Replica
State: streaming
TL: 5
patronictl pause
语法
pause
[ CLUSTER_NAME ]
[ --group CITUS_GROUP ]
[ --wait ]
描述
patronictl pause 将 Patroni 集群临时置于维护模式,暂停自动故障转移。
参数
CLUSTER_NAME
Patroni 集群名称。
若未指定,patronictl 将尝试从 scope 配置中获取(如果存在)。
--group
暂停指定 Citus 组。
CITUS_GROUP 为 Citus 组 ID。
若未指定,patronictl 将尝试从 citus.group 配置中获取(如果存在)。
--wait
等待所有 Patroni 成员均进入暂停状态后再返回。
示例
将集群置于维护模式,并等待所有节点都完成暂停:
$ patronictl -c postgres0.yml pause batman --wait
'pause' request sent, waiting until it is recognized by all nodes
Success: cluster management is paused
patronictl query
语法
query
[ CLUSTER_NAME ]
[ --group CITUS_GROUP ]
[ { { -r | --role } { leader | primary | standby-leader | replica | standby | any } | { -m | --member } MEMBER_NAME } ]
[ { -d | --dbname } DBNAME ]
[ { -U | --username } USERNAME ]
[ --password ]
[ --format { pretty | tsv | json | yaml } ]
[ { { -f | --file } FILE_NAME | { -c | --command } SQL_COMMAND } ]
[ --delimiter ]
[ { -W | { -w | --watch } TIME } ]
描述
patronictl query 在 Patroni 集群指定成员上执行 SQL 命令或脚本。
参数
CLUSTER_NAME
Patroni 集群名称。
若未指定,patronictl 将尝试从 scope 配置中获取(如果存在)。
--group
查询指定 Citus 组。
CITUS_GROUP 为 Citus 组 ID。
-r / --role
选择具有指定角色的成员。
角色可以是以下之一:
leader:普通 Patroni 集群或备用 Patroni 集群的领导者;primary:普通 Patroni 集群的领导者;standby-leader:备用 Patroni 集群的领导者;replica:Patroni 集群的从库;standby:同 replica;any:任意角色,与省略此参数效果相同。
-m / --member
选择具有指定名称的成员。
MEMBER_NAME 为要选择的成员名称。
-d / --dbname
连接并执行查询的目标数据库,未指定时默认使用 USERNAME。
-U / --username
连接数据库使用的用户名,未指定时默认使用运行 patronictl query 的操作系统用户。
--password
提示输入连接密码。也可通过 ~/.pgpass 文件或 PGPASSWORD 环境变量提供密码(Patroni 使用 libpq)。
--format
查询输出格式,可以是:
pretty:美观的表格形式;tsv:\t 分隔的表格形式;json:JSON 格式;yaml:YAML 格式。
默认为 tsv。
-f / --file
从指定文件读取并执行 SQL 命令。
-c / --command
执行指定的 SQL 命令。
--delimiter
以 tsv 格式输出时使用的列分隔符,默认为 \t。
-W
每 2 秒自动重新执行查询。
-w / --watch
按指定间隔(秒)自动重新执行查询。
示例
以 postgres 用户执行 SQL 命令,并要求输入密码:
$ patronictl -c postgres0.yml query batman -U postgres --password -c "SELECT now()"
Password:
now
2023-09-12 18:10:53.228084+00:00
以 postgres 用户执行 SQL 命令,从 libpq 环境变量获取密码:
$ PGPASSWORD=patroni patronictl -c postgres0.yml query batman -U postgres -c "SELECT now()"
now
2023-09-12 18:11:37.639500+00:00
执行 SQL 命令并以 pretty 格式每 2 秒打印一次:
$ patronictl -c postgres0.yml query batman -c "SELECT now()" --format pretty -W
+----------------------------------+
| now |
+----------------------------------+
| 2023-09-12 18:12:16.716235+00:00 |
+----------------------------------+
+----------------------------------+
| now |
+----------------------------------+
| 2023-09-12 18:12:18.732645+00:00 |
+----------------------------------+
+----------------------------------+
| now |
+----------------------------------+
| 2023-09-12 18:12:20.750573+00:00 |
+----------------------------------+
在数据库 test 上执行 SQL 命令并以 YAML 格式打印输出:
$ patronictl -c postgres0.yml query batman -d test -c "SELECT now() AS column_1, 'test' AS column_2" --format yaml
- column_1: 2023-09-12 18:14:22.052060+00:00
column_2: test
在成员 postgresql2 上执行 SQL 命令:
$ patronictl -c postgres0.yml query batman -m postgresql2 -c "SHOW port"
port
5434
在任意备库上执行 SQL 命令:
$ patronictl -c postgres0.yml query batman -r replica -c "SHOW port"
port
5433
patronictl reinit
语法
reinit
CLUSTER_NAME
[ MEMBER_NAME [, ... ] ]
[ --group CITUS_GROUP ]
[ --wait ]
[ --force ]
[ --from-leader ]
描述
patronictl reinit 重新初始化 Patroni 集群从库成员管理的 PostgreSQL 备库实例。
参数
CLUSTER_NAME
Patroni 集群名称。
MEMBER_NAME
要重新初始化的从库成员名称,可同时指定多个,不指定则命令不执行任何操作。
--group
重新初始化指定 Citus 组的从库成员。
CITUS_GROUP 为 Citus 组 ID。
--wait
等待备库重新初始化完成后再返回。
--force
跳过确认提示,适合在脚本中使用。
--from-leader
直接从领导者节点获取基础备份。
示例
重新初始化集群所有从库成员(不等待完成):
$ patronictl -c postgres0.yml reinit batman postgresql1 postgresql2 --force
+ Cluster: batman (7277694203142172922) -+-----------+----+-------------+-----+------------+-----+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
| postgresql0 | 127.0.0.1:5432 | Leader | running | 5 | | | | |
| postgresql1 | 127.0.0.1:5433 | Replica | streaming | 5 | 0/40004E8 | 0 | 0/40004E8 | 0 |
| postgresql2 | 127.0.0.1:5434 | Replica | streaming | 5 | 0/40004E8 | 0 | 0/40004E8 | 0 |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
Success: reinitialize for member postgresql1
Success: reinitialize for member postgresql2
重新初始化 postgresql2 并等待完成:
$ patronictl -c postgres0.yml reinit batman postgresql2 --wait --force
+ Cluster: batman (7277694203142172922) -+-----------+----+-------------+-----+------------+-----+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
| postgresql0 | 127.0.0.1:5432 | Leader | running | 5 | | | | |
| postgresql1 | 127.0.0.1:5433 | Replica | streaming | 5 | 0/40004E8 | 0 | 0/40004E8 | 0 |
| postgresql2 | 127.0.0.1:5434 | Replica | streaming | 5 | 0/40004E8 | 0 | 0/40004E8 | 0 |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
Success: reinitialize for member postgresql2
Waiting for reinitialize to complete on: postgresql2
Reinitialize is completed on: postgresql2
重新初始化 postgresql2 并直接从领导者节点获取基础备份:
$ patronictl -c postgres0.yml reinit batman postgresql2 --from-leader
+ Cluster: batman (7277694203142172922) -+-----------+----+-------------+-----+------------+-----+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
| postgresql0 | 127.0.0.1:5432 | Leader | running | 5 | | | | |
| postgresql1 | 127.0.0.1:5433 | Replica | streaming | 5 | 0/40004E8 | 0 | 0/40004E8 | 0 |
| postgresql2 | 127.0.0.1:5434 | Replica | streaming | 5 | 0/40004E8 | 0 | 0/40004E8 | 0 |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
Success: reinitialize for member postgresql2
patronictl reload
语法
reload
CLUSTER_NAME
[ MEMBER_NAME [, ... ] ]
[ --group CITUS_GROUP ]
[ { -r | --role } { leader | primary | standby-leader | replica | standby | any } ]
[ --force ]
描述
patronictl reload 请求一个或多个 Patroni 成员重载本地配置。
同时也会对被管理的 PostgreSQL 实例触发 pg_ctl reload,即使没有配置发生变化。
参数
CLUSTER_NAME
Patroni 集群名称。
MEMBER_NAME
请求指定成员重载本地配置,可同时指定多个,不指定则针对所有成员。
--group
请求指定 Citus 组的成员重载。
CITUS_GROUP 为 Citus 组 ID。
-r / --role
按角色筛选目标成员,角色可以是:
leader:普通集群或备用集群的领导者;primary:普通集群的领导者;standby-leader:备用集群的领导者;replica:集群从库;standby:同 replica;any:任意角色(默认)。
--force
跳过确认提示,适合在脚本中使用。
示例
重载集群所有成员的本地配置:
$ patronictl -c postgres0.yml reload batman --force
+ Cluster: batman (7277694203142172922) -+-----------+----+-------------+-----+------------+-----+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
| postgresql0 | 127.0.0.1:5432 | Leader | running | 5 | | | | |
| postgresql1 | 127.0.0.1:5433 | Replica | streaming | 5 | 0/40004E8 | 0 | 0/40004E8 | 0 |
| postgresql2 | 127.0.0.1:5434 | Replica | streaming | 5 | 0/40004E8 | 0 | 0/40004E8 | 0 |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
Reload request received for member postgresql0 and will be processed within 10 seconds
Reload request received for member postgresql1 and will be processed within 10 seconds
Reload request received for member postgresql2 and will be processed within 10 seconds
patronictl remove
语法
remove
CLUSTER_NAME
[ --group CITUS_GROUP ]
[ { -f | --format } { pretty | tsv | json | yaml } ]
描述
patronictl remove 从 DCS 中删除指定集群的所有信息,为交互式操作。
警告
此操作将永久清除 DCS 中该 Patroni 集群的所有数据。
参数
CLUSTER_NAME
Patroni 集群名称。
--group
删除与指定 Citus 组相关的 Patroni 集群信息。
CITUS_GROUP 为 Citus 组 ID。
-f / --format
确认提示中成员列表的输出格式,可以是 pretty(默认)、tsv、json 或 yaml。
示例
从 DCS 中删除 Patroni 集群 batman 的信息:
$ patronictl -c postgres0.yml remove batman
+ Cluster: batman (7277694203142172922) -+-----------+----+-------------+-----+------------+-----+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
| postgresql0 | 127.0.0.1:5432 | Leader | running | 5 | | | | |
| postgresql1 | 127.0.0.1:5433 | Replica | streaming | 5 | 0/40004E8 | 0 | 0/40004E8 | 0 |
| postgresql2 | 127.0.0.1:5434 | Replica | streaming | 5 | 0/40004E8 | 0 | 0/40004E8 | 0 |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
Please confirm the cluster name to remove: batman
You are about to remove all information in DCS for batman, please type: "Yes I am aware": Yes I am aware
This cluster currently is healthy. Please specify the leader name to continue: postgresql0
patronictl restart
语法
restart
CLUSTER_NAME
[ MEMBER_NAME [, ...] ]
[ --group CITUS_GROUP ]
[ { -r | --role } { leader | primary | standby-leader | replica | standby | any } ]
[ --any ]
[ --pg-version PG_VERSION ]
[ --pending ]
[ --timeout TIMEOUT ]
[ --scheduled TIMESTAMP ]
[ --force ]
描述
patronictl restart 请求重启 Patroni 集群指定成员管理的 PostgreSQL 实例,可以立即执行,也可以调度在稍后执行。
参数
CLUSTER_NAME
Patroni 集群名称。
--group
重启指定 Citus 组的成员。
-r / --role
按角色筛选目标成员,角色可以是:
leader:普通集群或备用集群的领导者;primary:普通集群的领导者;standby-leader:备用集群的领导者;replica:集群从库;standby:同 replica;any:任意角色(默认)。
--any
从符合筛选条件的节点中随机选择一个进行重启。
--pg-version
仅选择 PostgreSQL 版本低于指定版本的成员。
--pending
仅选择标记为 Pending restart 的成员。
--timeout
若重启超过指定秒数,则中止重启,并在问题发生在主库时触发故障转移。
--scheduled
在指定时间戳调度重启,须以明确的格式指定(建议包含时区信息),也可使用字面量 now 立即执行。
--force
跳过确认提示,适合在脚本中使用。
示例
立即重启集群所有成员:
$ patronictl -c postgres0.yml restart batman --force
+ Cluster: batman (7277694203142172922) -+-----------+----+-------------+-----+------------+-----+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
| postgresql0 | 127.0.0.1:5432 | Leader | running | 6 | | | | |
| postgresql1 | 127.0.0.1:5433 | Replica | streaming | 6 | 0/40004E8 | 0 | 0/40004E8 | 0 |
| postgresql2 | 127.0.0.1:5434 | Replica | streaming | 6 | 0/40004E8 | 0 | 0/40004E8 | 0 |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
Success: restart on member postgresql0
Success: restart on member postgresql1
Success: restart on member postgresql2
立即重启集群中的一个随机成员:
$ patronictl -c postgres0.yml restart batman --any --force
+ Cluster: batman (7277694203142172922) -+-----------+----+-------------+-----+------------+-----+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
| postgresql0 | 127.0.0.1:5432 | Leader | running | 6 | | | | |
| postgresql1 | 127.0.0.1:5433 | Replica | streaming | 6 | 0/40004E8 | 0 | 0/40004E8 | 0 |
| postgresql2 | 127.0.0.1:5434 | Replica | streaming | 6 | 0/40004E8 | 0 | 0/40004E8 | 0 |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
Success: restart on member postgresql1
调度在 2023-09-13T18:00-03:00 执行重启:
$ patronictl -c postgres0.yml restart batman --scheduled 2023-09-13T18:00-03:00 --force
+ Cluster: batman (7277694203142172922) -+-----------+----+-------------+-----+------------+-----+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
| postgresql0 | 127.0.0.1:5432 | Leader | running | 6 | | | | |
| postgresql1 | 127.0.0.1:5433 | Replica | streaming | 6 | 0/40004E8 | 0 | 0/40004E8 | 0 |
| postgresql2 | 127.0.0.1:5434 | Replica | streaming | 6 | 0/40004E8 | 0 | 0/40004E8 | 0 |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
Success: restart scheduled on member postgresql0
Success: restart scheduled on member postgresql1
Success: restart scheduled on member postgresql2
patronictl resume
语法
resume
[ CLUSTER_NAME ]
[ --group CITUS_GROUP ]
[ --wait ]
描述
patronictl resume 将 Patroni 集群从维护模式中恢复,重新启用自动故障转移。
参数
CLUSTER_NAME
Patroni 集群名称。
若未指定,patronictl 将尝试从 scope 配置中获取(如果存在)。
--group
恢复指定 Citus 组。
CITUS_GROUP 为 Citus 组 ID。
若未指定,patronictl 将尝试从 citus.group 配置中获取(如果存在)。
--wait
等待所有 Patroni 成员均退出暂停状态后再返回。
示例
将集群从维护模式中恢复:
$ patronictl -c postgres0.yml resume batman --wait
'resume' request sent, waiting until it is recognized by all nodes
Success: cluster management is resumed
patronictl show-config
语法
show-config
[ CLUSTER_NAME ]
[ --group CITUS_GROUP ]
描述
patronictl show-config 显示存储在 DCS 中的集群动态配置。
参数
CLUSTER_NAME
Patroni 集群名称。
若未指定,patronictl 将尝试从 scope 配置中获取(如果存在)。
--group
显示指定 Citus 组的动态配置。
CITUS_GROUP 为 Citus 组 ID。
若未指定,patronictl 将尝试从 citus.group 配置中获取(如果存在)。
示例
显示集群 batman 的动态配置:
$ patronictl -c postgres0.yml show-config batman
loop_wait: 10
postgresql:
parameters:
max_connections: 250
pg_hba:
- host replication replicator 127.0.0.1/32 md5
- host all all 0.0.0.0/0 md5
use_pg_rewind: true
retry_timeout: 10
ttl: 30
patronictl switchover
语法
switchover
[ CLUSTER_NAME ]
[ --group CITUS_GROUP ]
[ { --leader | --primary } LEADER_NAME ]
--candidate CANDIDATE_NAME
[ --force ]
描述
patronictl switchover 在集群中执行主从切换,适用于集群健康的场景(存在领导者,同步集群中有可用的同步备库)。
说明
若集群不健康,可考虑使用 patronictl failover。
参数
CLUSTER_NAME
Patroni 集群名称。
若未指定,patronictl 将尝试从 scope 配置中获取(如果存在)。
--group
在指定 Citus 组中执行主从切换。
CITUS_GROUP 为 Citus 组 ID。
--leader / --primary
指定切换时要降级的当前领导者名称。
--candidate
指定要提升为主库的候选节点名称。
--scheduled
在指定时间戳调度主从切换,须以明确的格式指定(建议包含时区信息),也可使用字面量 now 立即执行。
--force
跳过确认提示,适合在脚本中使用。
示例
切换到节点 postgresql2:
$ patronictl -c postgres0.yml switchover batman --leader postgresql0 --candidate postgresql2 --force
Current cluster topology
+ Cluster: batman (7277694203142172922) -+-----------+----+-------------+-----+------------+-----+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
| postgresql0 | 127.0.0.1:5432 | Leader | running | 6 | | | | |
| postgresql1 | 127.0.0.1:5433 | Replica | streaming | 6 | 0/40004E8 | 0 | 0/40004E8 | 0 |
| postgresql2 | 127.0.0.1:5434 | Replica | streaming | 6 | 0/40004E8 | 0 | 0/40004E8 | 0 |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
2023-09-13 14:15:23.07497 Successfully switched over to "postgresql2"
+ Cluster: batman (7277694203142172922) -+---------+----+-------------+---------+------------+---------+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+-------------+----------------+---------+---------+----+-------------+---------+------------+---------+
| postgresql0 | 127.0.0.1:5432 | Replica | stopped | | unknown | unknown | unknown | unknown |
| postgresql1 | 127.0.0.1:5433 | Replica | running | 6 | 0/4000188 | 0 | 0/4000188 | 0 |
| postgresql2 | 127.0.0.1:5434 | Leader | running | 6 | | | | |
+-------------+----------------+---------+---------+----+-------------+---------+------------+---------+
调度 postgresql0 和 postgresql2 之间的主从切换于 2023-09-13T18:00:00-03:00 执行:
$ patronictl -c postgres0.yml switchover batman --leader postgresql0 --candidate postgresql2 --scheduled 2023-09-13T18:00-03:00 --force
Current cluster topology
+ Cluster: batman (7277694203142172922) -+-----------+----+-------------+-----+------------+-----+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
| postgresql0 | 127.0.0.1:5432 | Leader | running | 8 | | | | |
| postgresql1 | 127.0.0.1:5433 | Replica | streaming | 8 | 0/40004E8 | 0 | 0/40004E8 | 0 |
| postgresql2 | 127.0.0.1:5434 | Replica | streaming | 8 | 0/40004E8 | 0 | 0/40004E8 | 0 |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
2023-09-13 14:18:11.20661 Switchover scheduled
+ Cluster: batman (7277694203142172922) -+-----------+----+-------------+-----+------------+-----+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
| postgresql0 | 127.0.0.1:5432 | Leader | running | 8 | | | | |
| postgresql1 | 127.0.0.1:5433 | Replica | streaming | 8 | 0/40004E8 | 0 | 0/40004E8 | 0 |
| postgresql2 | 127.0.0.1:5434 | Replica | streaming | 8 | 0/40004E8 | 0 | 0/40004E8 | 0 |
+-------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
Switchover scheduled at: 2023-09-13T18:00:00-03:00
from: postgresql0
to: postgresql2
patronictl topology
语法
topology
[ CLUSTER_NAME [, ... ] ]
[ --group CITUS_GROUP ]
[ { -W | { -w | --watch } TIME } ]
描述
patronictl topology 以树形视图显示 Patroni 集群及其成员的信息,按复制关系呈现节点层级。
输出字段含义与 patronictl list 相同,以下为 topology 特有的说明:
Member
Patroni 成员名称。根据复制连接关系以树形视图显示成员层级。
System identifier
PostgreSQL 系统标识符,显示在表格标题中。
Pending restart
* 表示节点需要重启以应用某些 PostgreSQL 配置变更,在节点有待重启时显示。
Scheduled restart
为该成员调度重启的时间戳,在节点有已调度重启时显示。
Tags
该成员设置的标签,在节点有自定义标签或非默认值的内置标签时显示。
Scheduled switchover
已调度主从切换的时间戳,显示在表格底部,仅在有已调度切换时显示。
Maintenance mode
集群自动故障转移当前是否已暂停,显示在表格底部,仅在集群已暂停时显示。
参数
CLUSTER_NAME
Patroni 集群名称。
若未指定,patronictl 将尝试从 scope 配置中获取(如果存在)。
--group
显示指定 Citus 组成员的信息。
CITUS_GROUP 为 Citus 组 ID。
-W
每 2 秒自动刷新信息。
-w / --watch
按指定间隔(秒)自动刷新信息。
示例
显示集群 batman 的拓扑结构(postgresql1 和 postgresql2 均从 postgresql0 复制):
$ patronictl -c postgres0.yml topology batman
+ Cluster: batman (7277694203142172922) ---+-----------+----+-------------+-----+------------+-----+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+---------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
| postgresql0 | 127.0.0.1:5432 | Leader | running | 8 | | | | |
| + postgresql1 | 127.0.0.1:5433 | Replica | streaming | 8 | 0/40004E8 | 0 | 0/40004E8 | 0 |
| + postgresql2 | 127.0.0.1:5434 | Replica | streaming | 8 | 0/40004E8 | 0 | 0/40004E8 | 0 |
+---------------+----------------+---------+-----------+----+-------------+-----+------------+-----+
patronictl version
语法
version
[ CLUSTER_NAME [, ... ] ]
[ MEMBER_NAME [, ... ] ]
[ --group CITUS_GROUP ]
描述
patronictl version 显示 patronictl 自身的版本,也可同时显示 Patroni 集群及其成员的版本信息。
参数
CLUSTER_NAME
Patroni 集群名称。
MEMBER_NAME
Patroni 集群成员名称。
--group
仅查询指定 Citus 组的集群版本信息。
CITUS_GROUP 为 Citus 组 ID。
示例
获取 patronictl 自身的版本:
$ patronictl -c postgres0.yml version
patronictl version 4.0.0
获取 patronictl 版本及集群 batman 所有成员的版本:
$ patronictl -c postgres0.yml version batman
patronictl version 4.0.0
postgresql0: Patroni 4.0.0 PostgreSQL 16.4
postgresql1: Patroni 4.0.0 PostgreSQL 16.4
postgresql2: Patroni 4.0.0 PostgreSQL 16.4
获取 patronictl 版本及集群 batman 中成员 postgresql1 和 postgresql2 的版本:
$ patronictl -c postgres0.yml version batman postgresql1 postgresql2
patronictl version 4.0.0
postgresql1: Patroni 4.0.0 PostgreSQL 16.4
postgresql2: Patroni 4.0.0 PostgreSQL 16.4
6 - 从库镜像与引导
从库镜像、引导及自定义从库创建工作流。
原始页面: https://patroni.readthedocs.io/en/latest/replica_bootstrap.html
Patroni 支持自定义新从库的创建方式,也支持定义全新空集群在引导时的行为。两者有明确区别:只有当 DCS 中存在 initialize 键时,Patroni 才会创建从库。若不存在该键,Patroni 将在第一个抢到初始化锁的节点上独占执行引导流程。
引导(Bootstrap)
PostgreSQL 提供了 initdb 命令来初始化新集群,Patroni 默认即调用此命令。在某些场景下——尤其是将现有集群复制一份来创建新集群时——有必要用自定义操作替换内置方式。Patroni 支持执行用户自定义脚本来引导新集群,并向脚本传入若干必需参数,如集群名称和数据目录路径。相关配置位于 Patroni 配置的 bootstrap 节,示例如下:
bootstrap:
method: <custom_bootstrap_method_name>
<custom_bootstrap_method_name>:
command: <path_to_custom_bootstrap_script> [param1 [, ...]]
keep_existing_recovery_conf: False
no_params: False
recovery_conf:
recovery_target_action: promote
recovery_target_timeline: latest
restore_command: <method_specific_restore_command>
每种引导方法至少需要定义 name 和 command。内置的 initdb 方法可触发默认行为,此时 method 参数可以完全省略。command 可以使用绝对路径,也可以使用相对于 patroni 命令位置的相对路径。除了配置文件中定义的固定参数外,Patroni 还会额外传入两个集群相关的参数:
--scope
待引导集群的名称
--datadir
待引导集群实例的数据目录路径
将 no_params 设为 True 可禁止传递这两个附加参数。
如果引导脚本返回 0,Patroni 会尝试配置并启动由该脚本生成的 PostgreSQL 实例。若中间任何步骤失败,或脚本返回非零值,Patroni 将认为引导失败,执行清理并释放初始化锁,以便其他节点有机会执行引导。
如果在自定义引导方法的同一配置节中定义了 recovery_conf 块,Patroni 会在启动新引导的实例之前生成 recovery.conf(PostgreSQL >= 12 则是在 Postgres 配置中设置恢复参数)。通常,这样的恢复配置至少应包含一个 recovery_target_* 参数,以及设为 promote 的 recovery_target_action。
如果 keep_existing_recovery_conf 被设为 True,Patroni 将不会删除已存在的 recovery.conf 文件(PostgreSQL <= 11)。同样,Patroni 也不会删除已存在的 recovery.signal 或 standby.signal,也不会覆盖已配置的恢复参数(PostgreSQL >= 12)。在使用 pgBackRest 等备份工具从备份引导时,这非常有用——这类工具会自动生成相应的恢复配置。
此外,自定义引导方法配置中定义的其他任意键值对,都会以 --name=value 格式作为参数传递给 command。例如:
bootstrap:
method: <custom_bootstrap_method_name>
<custom_bootstrap_method_name>:
command: <path_to_custom_bootstrap_script>
arg1: value1
arg2: value2
以上配置会让 command 额外附带 --arg1=value1 --arg2=value2 命令行参数被调用。
说明
引导方法之间不会链式调用,主方法失败时也不会回退到默认方法。
举个例子,你可以用如下配置从 Barman 备份引导一个全新的 Patroni 集群:
bootstrap:
method: barman
barman:
keep_existing_recovery_conf: true
command: patroni_barman --api-url https://barman-host:7480 recover
barman-server: my_server
ssh-command: ssh postgres@patroni-host
说明
patroni_barman recover 需要在 Barman 主机上同时配置好 Barman 和 pg-backup-api,以便通过备份 API 远程执行 barman recover。上面的示例仅使用了部分可用参数。运行 patroni_barman recover --help 可获取更多信息。
构建从库
Patroni 默认使用久经考验的 pg_basebackup 来创建新从库。其缺点是需要一个运行中的主库,同时也缺乏对备份数据的即时压缩功能,也没有内置的过期文件清理机制。一些用户倾向于使用其他备份方案,如 WAL-E、pgBackRest、Barman 等,或者自己编写脚本。为了适应这些使用场景,Patroni 支持运行自定义脚本来克隆新从库。相关配置位于 postgresql 配置块中:
postgresql:
create_replica_methods:
- <method name>
<method name>:
command: <command name>
keep_data: True
no_params: True
no_leader: 1
示例:wal_e
postgresql:
create_replica_methods:
- wal_e
- basebackup
wal_e:
command: patroni_wale_restore
no_leader: 1
envdir: {{WALE_ENV_DIR}}
use_iam: 1
basebackup:
max-rate: '100M'
示例:pgbackrest
postgresql:
create_replica_methods:
- pgbackrest
- basebackup
pgbackrest:
command: /usr/bin/pgbackrest --stanza=<scope> --delta restore
keep_data: True
no_params: True
basebackup:
max-rate: '100M'
示例:Barman
postgresql:
create_replica_methods:
- barman
- basebackup
barman:
command: patroni_barman --api-url https://barman-host:7480 recover
barman-server: my_server
ssh-command: ssh postgres@patroni-host
basebackup:
max-rate: '100M'
说明
patroni_barman recover 需要在 Barman 主机上同时配置好 Barman 和 pg-backup-api,以便通过备份 API 远程执行 barman recover。上面的示例仅使用了部分可用参数。运行 patroni_barman recover --help 可获取更多信息。
create_replica_methods 定义了可用的从库创建方法及其执行顺序。Patroni 在第一个返回 0 的方法处停止。每种方法都应在配置文件中有独立的配置节,列出要执行的命令以及要传递给该命令的自定义参数。所有参数均以 --name=value 格式传递。除用户自定义参数外,Patroni 还会传入以下几个集群相关的参数:
--scope
该从库所属的集群名称
--datadir
从库的数据目录路径
--role
始终为 replica
--connstring
用于连接被克隆集群成员(主库或其他从库)的连接字符串。连接字符串中的用户可以执行 SQL 和复制协议命令。
特殊参数 no_leader 若已定义,允许 Patroni 即使在没有运行中的主库或从库时也能调用从库创建方法,此时连接字符串将传入空字符串。这对于从二进制备份恢复曾经运行的集群非常有用。
特殊参数 keep_data 若已定义,会指示 Patroni 在调用恢复之前不清空 PGDATA 目录。
特殊参数 no_params 若已定义,会限制向自定义命令传递参数。
basebackup 方法是特殊情况:当 create_replica_methods 为空时也会使用它,当然也可以在 create_replica_methods 中显式列出。该方法使用 pg_basebackup 初始化新从库,基础备份默认从主库获取,除非存在带有 clonefrom 标签的从库——此时将以其中某个从库作为 pg_basebackup 的来源。它无需任何配置即可工作,但也可以指定 basebackup 配置节。与其他方法的配置规则相同,即只应在此处指定长选项(带 --)。并非所有参数都有意义——如果覆盖了连接字符串,或提供了创建 tar 包或压缩备份的选项,Patroni 将无法基于此创建从库。传递给 basebackup 配置节的参数名称或值不会进行校验。另请注意,如果 WAL 目录使用了符号链接,需要用户自行指定正确的 --waldir 路径选项,以确保从库构建或重新初始化后符号链接仍然有效。此选项仅从 v10 起支持。
basebackup 参数可以指定为映射(键值对)或元素列表,每个元素可以是键值对或单个键(用于不接受任何值的选项,例如 --verbose)。以下是两种写法:
postgresql:
basebackup:
max-rate: '100M'
checkpoint: 'fast'
以及
postgresql:
basebackup:
- verbose
- max-rate: '100M'
- waldir: /pg-wal-mount/external-waldir
如果所有从库创建方法均失败,Patroni 将在下一个事件循环周期中重新按顺序尝试所有方法。
7 - 复制模式
Patroni 管理的异步与同步复制模式。
原始页面: https://patroni.readthedocs.io/en/latest/replication_modes.html
Patroni 使用 PostgreSQL 流复制。关于流复制的更多信息,请参阅 Postgres 文档。默认情况下,Patroni 将 PostgreSQL 配置为异步复制。选择哪种复制方案取决于你的业务需求。建议同时研究异步和同步复制,以及其他高可用方案,以确定最适合自己的解决方案。
异步模式的持久性
在异步模式下,集群允许丢失部分已提交的事务以保证可用性。当主库故障或因任何其他原因变得不可用时,Patroni 会自动将一个足够健康的备库提升为主库。尚未复制到该备库的事务将残留在主库的"分叉时间线"中,实际上无法恢复。
可能丢失的事务量通过 maximum_lag_on_failover 参数控制。由于主库事务日志位置不是实时采样的,故障转移时实际丢失数据量的最坏情况上限为:maximum_lag_on_failover 字节的事务日志,加上最后 ttl 秒内写入的数据量(平均情况约为 loop_wait/2 秒内的写入量)。然而,在典型的稳定状态下,复制延迟通常远低于一秒。
默认情况下,执行领导者选举时,Patroni 不考虑从库的当前时间线,这在某些情况下可能并不合适。将 check_timeline 参数改为 true,可以防止时间线与前主库不同的节点成为新的领导者。
PostgreSQL 同步复制
你可以将 Postgres 的 同步复制 与 Patroni 配合使用。同步复制通过确认写入已写到从库后再向客户端返回成功,来保证集群的一致性。代价是写入延迟增加、写入吞吐量降低——吞吐量完全取决于网络性能。
在托管数据中心环境(如 AWS、Rackspace 或任何你无法控制的网络)中,同步复制会显著增加写入性能的波动性。如果从库无法从主库访问,主库实际上将变为只读。
要启用简单的同步复制测试,请在 YAML 配置文件的 parameters 节中添加如下内容:
synchronous_commit: "on"
synchronous_standby_names: "*"
使用 PostgreSQL 同步复制时,建议至少使用三个 Postgres 数据节点,以确保一台主机故障时写入仍然可用。
在所有情况下,使用 PostgreSQL 同步复制并不能保证零事务丢失。当主库和当前充当同步从库的备库同时故障时,可能会提升一个不包含所有事务的第三个节点。
同步模式
对于不允许丢失已提交事务的使用场景,你可以开启 Patroni 的 synchronous_mode。开启后,Patroni 只有在确认备库包含所有可能已向客户端返回成功提交状态的事务后,才会将其提升为主库。这意味着即使部分服务器可用,系统也可能无法进行写入。系统管理员仍然可以使用手动故障转移命令来提升备库,即使这会导致事务丢失。
开启 synchronous_mode 并不能在所有情况下保证多节点的提交持久性。当没有合适的备库可用时,主库仍然会接受写入,但不保证数据已复制。此模式下主库故障时不会有备库被自动提升。当原主库重新上线后,它会被自动提升,除非系统管理员执行了手动故障转移。这一行为使得同步模式可以在两节点集群中使用。
synchronous_mode 开启时,若备库崩溃,提交操作将阻塞,直到 Patroni 下一次迭代运行并将主库切换为独立模式(写入最坏延迟为 ttl 秒,平均情况约为 loop_wait/2 秒)。手动关闭或重启备库不会导致提交服务中断——备库会在 PostgreSQL 关闭启动前通知主库解除其同步备库职责。
当绝对有必要保证每次写入都持久存储在至少两个节点上时,请在开启 synchronous_mode 的同时启用 synchronous_mode_strict。该参数防止 Patroni 在没有同步备库候选节点时关闭主库上的同步复制。其缺点是,在至少一个同步从库上线之前,主库将不可用于写入(除非 Postgres 事务显式关闭 synchronous_commit),所有客户端写入请求都会被阻塞。
将 nosync 标签设为 true 可以确保某个备库永远不会成为同步备库。建议对位于低速网络连接后方、成为同步备库时会导致性能下降的备库设置此标签。将 nostream 标签设为 true 也有相同效果。
同步模式可以通过 patronictl edit-config 命令或 Patroni REST 接口来开启和关闭。详见 动态配置 中的说明。
注意:由于 PostgreSQL 中同步复制的实现方式,即使使用 synchronous_mode_strict,仍然有可能丢失事务。如果 PostgreSQL 后端在等待确认复制时被取消(由于客户端超时或后端故障导致的数据包取消),事务变更对其他后端已经可见。此类变更尚未完成复制,在备库提升的情况下可能会丢失。
同步复制因子
参数 synchronous_node_count 用于 Patroni 管理同步备库数量,默认值为 1。当 synchronous_mode 设置为 off 时,此参数无效。启用后,Patroni 根据 synchronous_node_count 精确管理同步备库数量,并随着成员的加入和离开调整 DCS 中的状态及 PostgreSQL 中的 synchronous_standby_names。如果该参数设置的值高于符合条件的节点数,Patroni 将自动降低该值。
同步节点的最大延迟
默认情况下,Patroni 会坚持使用根据 pg_stat_replication 视图已声明为 synchronous 的节点,即使存在其他进度更靠前的节点。这样做是为了尽量减少 synchronous_standby_names 的变更次数。要改变此行为,可以使用 maximum_lag_on_syncnode 参数,它控制从库最多可以落后多少,仍被视为"同步"状态。
Patroni 在存在多个备库时使用最大从库 LSN,否则使用主库当前的 WAL LSN。默认值为 -1,当该值设置为 0 或更小时,Patroni 不会替换不健康的同步备库。请将该值设置得足够大,以避免在高事务量期间 Patroni 频繁切换同步备库。
同步模式的实现原理
在同步模式下,Patroni 在 DCS 的 /sync 键中维护同步状态,其中包含最新的主库及当前的同步备库。该状态的更新遵循严格的顺序约束,以确保以下不变式:
- 节点能够接受写事务时,必须被标记为最新的领导者。Patroni 崩溃或 PostgreSQL 未正常关闭可能导致违反此不变式。
- 只要节点在 DCS 的
/sync 键中被发布为同步备库,它就必须在 PostgreSQL 中被设置为同步备库。 - 既不是领导者也不是当前同步备库的节点,不允许自动提升自身。
Patroni 将根据 synchronous_node_count 参数,仅将一个或多个同步备库分配给 synchronous_standby_names。
在每次 HA 循环迭代中,Patroni 都会重新评估同步备库的选择。如果当前同步备库列表处于连接状态,且没有请求解除其同步状态,则继续保留。否则,将选择可用于同步且复制进度最靠前的集群成员。
示例:
DCS 中的 /config 键
synchronous_mode: on
synchronous_node_count: 2
...
DCS 中的 /sync 键
{
"leader": "node0",
"sync_standby": "node1,node2"
}
postgresql.conf
synchronous_standby_names = 'FIRST 2 (node1,node2)'
在上述示例中,只有 node1 和 node2 被认为是同步节点,并被允许在主库(node0)故障时自动提升。
法定人数提交模式
从 PostgreSQL v10 起,Patroni 支持基于法定人数的同步复制。
在此模式下,Patroni 在 DCS 中维护同步状态,包含最新已知的主库、达成法定人数所需的节点数以及当前有资格投票的节点。在稳定状态下,参与法定人数投票的节点为主库和所有同步备库。该状态的更新遵循严格的顺序约束(涉及节点提升和 synchronous_standby_names),以确保任何时刻能够达成法定人数的投票者子集中,至少包含一个拥有最新成功提交的节点。
在每次 HA 循环迭代中,Patroni 根据节点可用性和请求的集群配置,重新评估同步备库的选择和法定人数。在 PostgreSQL 9.6 以上版本中,所有符合条件的节点一旦复制追上主库,就会被添加为同步备库。
法定人数提交有助于降低最坏情况的延迟,即使在正常运行期间也是如此——某个备库的高复制延迟可以由其他备库来补偿。
基于法定人数的同步模式可以通过 patronictl edit-config 命令或 Patroni REST 接口,将 synchronous_mode 设置为 quorum 来启用。详见 动态配置 中的说明。
其他参数如 synchronous_node_count、maximum_lag_on_syncnode 和 synchronous_mode_strict,在 synchronous_mode=on 下的工作方式与此相同。
示例:
DCS 中的 /config 键
synchronous_mode: quorum
synchronous_node_count: 2
...
DCS 中的 /sync 键
{
"leader": "node0",
"sync_standby": "node1,node2,node3",
"quorum": 1
}
postgresql.conf
synchronous_standby_names = 'ANY 2 (node1,node2,node3)'
在上述示例中,如果主库(node0)故障,node1、node2、node3 中会有两个节点收到了最新的事务,但我们不知道是哪两个。要确认 node1 是否收到了最新事务,需要将其 LSN 与 node2 和 node3 中至少一个节点(/sync 键中的 quorum=1)的 LSN 进行比较。如果 node1 的 LSN 不落后于其中至少一个节点,则可以保证提升 node1 时不会有用户可见的数据丢失。
8 - 备用集群
备用集群的搭建、行为及从远程主库复制的说明。
原始页面: https://patroni.readthedocs.io/en/latest/standby_cluster.html
Patroni 还支持通过"备用集群"功能向远程数据中心(Region)运行级联复制。这类集群具有以下特点:
- 备用领导者(standby leader):行为与普通集群领导者基本相同,区别在于它从远程节点进行复制。
- 级联从库:从备用领导者进行复制。
备用领导者在 DCS 中持有并更新领导者锁。若领导者锁过期,级联从库将通过选举从备用节点中选出新的领导者。
备用集群与其所复制的主集群之间没有其他关联。特别是,若双方使用同一个 DCS,则不能共享相同的 DCS 作用域(scope)。双方除复制信息外互不了解。此外,备用集群不会出现在主集群的 patronictl list 或 patronictl topology 输出中。
为了提高灵活性,可以在 standby_cluster 配置节中提供 create_replica_methods 键,来指定集群处于"备用模式"时创建从库和恢复 WAL 记录的方法。这与集群脱离备用模式、作为普通集群运行时创建从库的方式不同,后者由 postgresql 配置节中的 create_replica_methods 控制。“备用模式"和"普通模式"的 create_replica_methods 均引用 postgresql 配置节中的键。
要配置备用集群,需要在 Patroni 配置中指定 standby_cluster 配置节:
bootstrap:
dcs:
standby_cluster:
host: 1.2.3.4
port: 5432
primary_slot_name: patroni
create_replica_methods:
- basebackup
请注意,这些选项仅在集群引导期间生效一次,之后只能通过 DCS 修改。
Patroni 会在远程主库的 PGDATA 目录中查找 postgresql.conf 或 postgresql.conf.backup,若在 basebackup 后找不到该文件,Patroni 将无法启动。如果远程主库将 postgresql.conf 存放在其他位置,需要手动将其复制到 PGDATA 目录。
若在备用集群上使用复制槽,还必须在主集群上手动创建对应的复制槽——备用集群不会自动完成此操作。可以在主集群上使用 Patroni 的永久复制槽功能,维护一个与 primary_slot_name 同名的复制槽(若未设置 primary_slot_name,则使用其默认值)。
如果远端站点没有提供连接到主库的单一端点,可以在 standby_cluster.host 中列出源集群的所有主机地址。当 standby_cluster.host 包含多个以逗号分隔的主机时,Patroni 将:
- 在备用领导者节点的
primary_conninfo 中添加 target_session_attrs=read-write。 - 在判断是否需要执行
pg_rewind 以及在备用集群所有节点上执行 pg_rewind 时,使用 target_session_attrs=read-write。 - 注意:要使
pg_rewind 正常运行,集群必须在初始化时启用了 data page checksums(即 initdb 的 --data-checksums 选项)和/或将 wal_log_hints 设置为 on,否则 pg_rewind 将无法正常工作。
备用集群也可以配置为从另一个备用集群或主集群的备库成员进行复制:只需在 standby_cluster.host 中定义单个主机即可。但请注意,这种情况下 pg_rewind 将无法在备用集群上执行。
9 - Watchdog 支持
Patroni 集群的 watchdog 集成与隔离(fencing)注意事项。
原始页面: https://patroni.readthedocs.io/en/latest/watchdog.html
同时存在多个以主库身份运行的 PostgreSQL 实例,可能因时间线分叉而导致事务丢失,这种情况也称为脑裂(split-brain)问题。为了避免脑裂,Patroni 需要确保在 DCS 中的领导者键过期后,PostgreSQL 不再接受任何事务提交。正常情况下,Patroni 会在领导者锁更新失败时尝试停止 PostgreSQL 来实现这一目标。然而,以下各种原因可能导致该机制失效:
- Patroni 因程序缺陷、内存溢出或系统管理员误操作而崩溃。
- PostgreSQL 关闭速度过慢。
- 系统高负载、虚拟机被 hypervisor 暂停或其他基础设施故障导致 Patroni 无法及时运行。
为了在上述情况下保证行为的正确性,Patroni 支持 watchdog 设备。watchdog 设备是一种软件或硬件机制,当其在指定时间内未收到保活心跳时,会强制重置整个系统,为 Patroni 常规脑裂防护机制失效时提供额外的故障安全保障。
Patroni 会在将 PostgreSQL 提升为主库之前尝试激活 watchdog。若 watchdog 激活失败且 watchdog 模式设置为 required,该节点将拒绝成为领导者。在决定是否参与领导者选举时,Patroni 也会检查 watchdog 配置是否允许其成为领导者。PostgreSQL 降级后(例如因手动故障转移),Patroni 将再次禁用 watchdog;处于暂停模式时,watchdog 同样会被禁用。
默认情况下,Patroni 会将 watchdog 设置为在 TTL 到期前 5 秒触发。在默认配置 loop_wait=10 和 ttl=30 下,HA 循环至少有 15 秒(ttl - safety_margin - loop_wait)的时间完成,系统才会被强制重置。访问 DCS 的超时时间默认配置为 10 秒。这意味着当 DCS 因网络问题等原因不可用时,Patroni 和 PostgreSQL 至少有 5 秒(ttl - safety_margin - loop_wait - retry_timeout)的时间来断开所有客户端连接。
安全余量(safety_margin)是 Patroni 为领导者键更新与 watchdog 保活之间的时间差所预留的缓冲时长。Patroni 会在确认领导者键更新后立即发送保活信号。若 Patroni 进程在恰好合适的时刻被长时间挂起,保活信号的延迟可能超过安全余量而不触发 watchdog,从而产生一个时间窗口——在领导者键过期之前 watchdog 不会触发,使上述保证失效。若要绝对确保 watchdog 在任何情况下都能触发,可将 safety_margin 设为 -1,令 watchdog 超时时间等于 ttl // 2。如需这种保证,建议适当增大 ttl 并减小 loop_wait 和 retry_timeout。
目前 watchdog 仅支持 Linux watchdog 设备接口。
在 Linux 上设置软件 watchdog
Patroni 的默认配置会在 Linux 上尝试使用 /dev/watchdog(若该设备对 Patroni 可访问)。对于大多数使用场景,Linux 内核内置的软件 watchdog 已足够安全。
在启动 Patroni 之前,以 root 身份执行以下命令来启用软件 watchdog:
modprobe softdog
# 将 postgres 替换为实际运行 patroni 的用户
chown postgres /dev/watchdog
测试时,可在 modprobe 命令行中添加 soft_noboot=1 来禁用重启行为。此时 watchdog 仅会在内核环形缓冲区中记录一行日志,可通过 dmesg 查看。
watchdog 成功启用后,Patroni 会将相关信息写入日志。
10 - 集群的暂停/恢复模式
Patroni 集群管理中的暂停与恢复模式行为说明。
原始页面: https://patroni.readthedocs.io/en/latest/pause.html
目标
在某些特殊情况下,Patroni 需要临时退出对集群的管理,同时仍在 DCS 中保留集群状态。典型使用场景包括对集群执行一些不常见的操作,例如大版本升级或数据损坏恢复。在此类操作期间,节点往往会因 Patroni 未知的原因频繁启停,某些节点甚至可能被临时提升为主库,从而打破"同一时间只能有一个主库"的假设。为此,Patroni 需要具备从运行中的集群"脱离"的能力,实现类似 Pacemaker 维护模式的效果。
实现机制
当 Patroni 处于暂停模式时,它不会更改 PostgreSQL 的状态,以下情况除外:
- 每个节点在 DCS 中的成员键会更新为集群的当前信息,Patroni 因此会对运行中的成员节点执行只读查询。
- 对于持有领导者锁的 PostgreSQL 主库,Patroni 会持续更新该锁。若持有领导者锁的节点不再是主库(即被手动降级),Patroni 将释放该锁,而不是将该节点重新提升为主库。
- 允许执行手动非计划重启、手动非计划故障转移/主从切换以及重新初始化操作;不允许执行任何计划任务。手动主从切换仅在指定了目标节点时才被允许。
- 若 Patroni 检测到存在"并行"主库,会发出警告,但不会对没有领导者锁的主库执行降级操作。
- 若集群中不存在领导者锁,正在运行的主库将获取该锁;若存在多个主库,则第一个获取锁的主库胜出。若完全没有主库,Patroni 不会尝试提升任何从库。此规则有一个例外:若领导者锁不存在的原因是旧主库因手动提升而自行降级,则只有提升请求中指定的候选节点才能获取领导者锁。新的领导者锁授予后(即从库被手动提升后),Patroni 会确保原先从旧主库拉取流复制的从库切换到新主库。
- 当 PostgreSQL 停止后,Patroni 不会尝试重新启动它;当 Patroni 停止后,也不会尝试停止其所管理的 PostgreSQL 实例。
- Patroni 不会尝试删除既不代表其他集群成员、也未在永久复制槽配置中列出的复制槽。
使用指南
patronictl 支持 pause 和 resume 命令。
也可以向 {namespace}/{cluster}/config 键发送携带 {"pause": true/false/null} 的 PATCH 请求来实现同等效果。
11 - DCS 故障安全模式
DCS 故障安全模式的行为机制、启用条件与操作注意事项。
原始页面: https://patroni.readthedocs.io/en/latest/dcs_failsafe_mode.html
问题背景
Patroni 高度依赖分布式配置存储(DCS)来完成领导者选举和检测网络分区。具体而言,节点只有在能够成功更新 DCS 中的领导者锁时,才被允许以主库身份运行 PostgreSQL。一旦领导者锁更新失败,PostgreSQL 将立即被降级并以只读模式启动。触发该"问题"的概率因所使用的 DCS 而异——例如,当 Etcd 专用于 Patroni 时,发生概率接近于零;而当使用以 Etcd 为后端的 Kubernetes API 时,则可能更为频繁。
现有实现的设计原因
领导者锁更新失败通常由以下两种原因导致:
- 网络分区
- DCS 宕机
单个节点通常无法区分这两种情况,因此 Patroni 默认假设最坏情况——网络分区。在网络分区的情形下,Patroni 集群的其他节点可能成功获取领导者锁并将 PostgreSQL 提升为主库。为避免脑裂,旧主库将在领导者锁过期之前主动降级。
DCS 故障安全模式
我们引入了一个新的特殊选项:failsafe_mode。该选项只能通过存储在 DCS /config 键中的全局 动态配置 来启用。启用故障安全模式后,若领导者锁更新失败的原因并非版本/值/索引不匹配,且主库能够通过 Patroni REST API 访问集群中所有已知成员,则 PostgreSQL 可以继续以主库身份运行。
底层实现细节
- 在 DCS 中引入一个新的永久键
/failsafe。 /failsafe 键记录给定时刻该 Patroni 集群所有已知成员的信息。- 由当前领导者节点负责维护
/failsafe 键。 - 只有出现在
/failsafe 键中的成员才有资格参与领导者竞选并成为新的领导者。 - 若集群仅有单个节点,
/failsafe 键将只包含该节点。 - 当 DCS 发生"中断"时,现有主库通过
POST /failsafe REST API 联系 /failsafe 键中所有成员,若所有从库均确认其存活,则主库可以继续运行。 - 若任何一个成员无响应,主库将被降级。
- 从库将收到的
POST /failsafe REST API 请求作为主库仍然存活的信号,该信息将被缓存 ttl 秒。
常见问题
为什么当前主库必须能访问所有其他成员?不能依赖法定人数吗?
这是一个很好的问题!问题在于,DCS 和 Patroni 对法定人数的"视图"可能存在差异。DCS 节点必须均匀分布在各可用区,但 Patroni 节点没有这样的规则,更重要的是,目前也没有引入和强制执行此规则的机制。如果多数 Patroni 节点(包括主库)落在网络分区的失败侧,而少数节点在成功侧,那么主库就必须被降级。只有检查所有其他成员,才能发现这种情况。
如果在 DCS 宕机期间某个节点/Pod 被终止,会发生什么?
当 DCS 不可访问时,“所有其他集群成员是否均可访问?“的检查将在每次心跳循环(每 loop_wait 秒一次)中执行。若某个 Pod/节点被终止,该检查将失败,PostgreSQL 将被降级为只读,并在 DCS 恢复之前保持该状态。
如果在 DCS 宕机期间 Patroni 集群的所有成员全部丢失,会发生什么?
Patroni 可以配置为在集群无领导者时从备份中创建新的从库。但如果新成员不在 /failsafe 键中,它将无法获取领导者锁并执行提升操作。
如果主库失去了对 DCS 的访问权限,而从库没有,会发生什么?
主库将执行故障安全代码,联系所有已知从库。从库将把这一信息视为主库仍然存活的信号,即使 DCS 中的领导者锁已经过期,它们也不会发起领导者竞选。
如何启用故障安全模式?
在启用 failsafe_mode 之前,请确保所有成员上的 Patroni 版本都是最新的。之后,可以使用 PATCH /config REST API 或执行 patronictl edit-config -s failsafe_mode=true 命令来启用该功能。
12 - 在 Kubernetes 中使用 Patroni
结合 Kubernetes 对象、标签和服务发现使用 Patroni。
原始页面: https://patroni.readthedocs.io/en/latest/kubernetes.html
Patroni 可以利用 Kubernetes 对象来存储集群状态并管理领导者键,从而无需任何额外的一致性存储即可在 Kubernetes 环境中运行 PostgreSQL——也就是说,不需要单独部署 Etcd。Patroni 支持两种不同类型的 Kubernetes 对象来存储领导者键和配置键,通过 kubernetes.use_endpoints 配置项或 PATRONI_KUBERNETES_USE_ENDPOINTS 环境变量进行选择。
使用 Endpoints
尽管这是推荐模式,但出于兼容性考虑,默认情况下该模式是关闭的。启用后,Patroni 会将集群配置和领导者键存储在其创建的 Endpoints 对象的 metadata: annotations 字段中。与使用 ConfigMaps 相比,这种方式的领导者切换更为安全——包含领导者信息的注解与指向当前领导者 Pod 的实际地址,会在同一次操作中被原子更新。
使用 ConfigMaps
在此模式下,Patroni 将创建 ConfigMaps 而非 Endpoints,并将键值存储在 ConfigMaps 的元数据中。领导者切换至少需要两次更新操作:一次更新领导者 ConfigMap,另一次更新对应的 Endpoint。
若要将流量引导至 PostgreSQL 主库,您需要将 Kubernetes PostgreSQL Service 配置为使用带有 role_label(在 Patroni 配置中设定)的标签选择器。
请注意,在某些场景下(例如在 OpenShift 上运行时)只能使用 ConfigMaps 模式。
配置
Patroni 的 Kubernetes 配置项 和 环境变量 在文档的通用章节中有详细说明。
自定义角色标签
默认情况下,Patroni 会根据节点角色在其所在 Pod 上设置对应标签,例如 role=primary。标签的键名和值可通过 kubernetes.role_label、kubernetes.leader_label_value、kubernetes.follower_label_value 和 kubernetes.standby_leader_label_value 进行自定义。
如需从默认角色标签迁移到自定义标签,可按照以下步骤操作以减少停机时间:
- 使用
kubernetes.tmp_role_label(如 tmp_role)为 Pod 添加一个使用原始角色值的临时标签。所有 Pod 重启后,Patroni 将为其设置以下标签:
labels:
cluster-name: foo
role: primary
tmp_role: primary
- 待所有 Pod 更新完成后,将 Service 的选择器修改为使用临时标签:
selector:
cluster-name: foo
tmp_role: primary
- 添加自定义角色标签(例如,设置
kubernetes.leader_label_value=primary)。所有 Pod 重启后,Patroni 将为其设置以下新标签:
labels:
cluster-name: foo
role: primary
tmp_role: primary
- 待所有 Pod 再次更新完成后,将 Service 的选择器修改为使用新的角色值:
selector:
cluster-name: foo
role: primary
- 最后,从配置中删除临时标签并更新所有 Pod:
labels:
cluster-name: foo
role: primary
示例
- Patroni 仓库的 kubernetes 目录中包含 Docker 镜像示例以及用于测试 Patroni Kubernetes 部署的 Kubernetes 清单文件。请注意,在当前状态下,由于权限问题,无法使用 PersistentVolumes。
- 支持 Persistent Volumes 的完整功能 Docker 镜像可在 Spilo 项目 中找到。
- 此外,还有一个 Helm Chart 可用于在 Kubernetes 上部署配置了 Patroni 的 Spilo 镜像。
- 若要大规模运行基于 Patroni 和 Spilo 的数据库集群,请参阅 postgres-operator 项目,它实现了用于管理 Spilo 集群的 Operator 模式。
13 - Citus 支持
Patroni 与 Citus 协调节点及工作节点组的集成详情。
原始页面: https://patroni.readthedocs.io/en/latest/citus.html
Patroni 使部署 多节点 Citus 集群变得极为简单。
TL;DR
只需遵循以下几条简单规则:
- 所有节点上必须安装 Citus 数据库扩展。最低支持的 Citus 版本为 10.0,但为了充分利用工作节点透明主从切换和重启的特性,建议使用至少 Citus 11.2。
- 集群名称(
scope)在所有 Citus 节点上必须相同! - 超级用户凭据在协调节点和所有工作节点上必须相同,且
pg_hba.conf 应允许所有节点之间的超级用户访问。 - 工作节点到协调节点的 REST API 访问必须被允许。例如,凭据应相同,如果配置了客户端证书,工作节点的客户端证书必须被协调节点接受。
- 在
patroni.yaml 中添加以下配置节:
citus:
group: X # 0 表示协调节点,工作节点使用 1、2、3 等
database: citus # 所有节点上必须相同
之后只需启动 Patroni,它会处理其余的一切:
- Patroni 会将
bootstrap.dcs.synchronous_mode 设置为 法定人数模式,除非已显式设置为其他值。 citus 扩展将自动添加到 shared_preload_libraries。- 如果全局 动态配置 中未显式设置
max_prepared_transactions,Patroni 将自动将其设置为 2*max_connections。 citus.local_hostname GUC 的值将从 localhost 调整为 Patroni 用于连接本地 PostgreSQL 实例的值。有时该值与 localhost 不同,因为 PostgreSQL 可能没有在该地址上监听。citus.database 指定的数据库将被自动创建,随后执行 CREATE EXTENSION citus。- 当前超级用户 凭据 将被添加到
pg_dist_authinfo 表中,以允许跨节点通信。如果之后决定修改超级用户的用户名/密码/sslcert/sslkey,别忘了同步更新此表! - 协调节点主库将自动发现工作节点主库,并使用
citus_add_node() 函数将其添加到 pg_dist_node 表中。 - Patroni 还会在协调节点或工作节点集群发生故障转移/主从切换时,自动维护
pg_dist_node。
patronictl
协调节点和工作节点集群是物理上独立的 PostgreSQL/Patroni 集群,仅通过 Citus 数据库扩展在逻辑上组合在一起。因此,在大多数情况下无法将它们作为单一实体进行管理。
当 patroni.yaml 中包含 citus 配置节时,与通常情况相比,patronictl 的行为存在两个主要差异:
list 和 topology 命令默认输出 Citus formation 的所有成员(协调节点和工作节点),新增的 Group 列表明它们所属的 Citus 组。- 所有
patronictl 命令都引入了新选项 --group。对于某些命令,组的默认值可以从 patroni.yaml 中获取。例如,patronictl pause 默认会为 citus 配置节中设置的 group 启用维护模式,但对于 patronictl switchover 或 patronictl remove 等命令,则必须显式指定 group。
以下是 Citus 集群的 patronictl list 输出示例:
postgres@coord1:~$ patronictl list demo
+ Citus cluster: demo ----------+----------------+---------+----+-------------+-----+------------+-----+
| Group | Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+-------+---------+-------------+----------------+---------+----+-------------+-----+------------+-----+
| 0 | coord1 | 172.27.0.10 | Replica | running | 1 | 0/41C0368 | 0 | 0/41C0368 | 0 |
| 0 | coord2 | 172.27.0.6 | Quorum Standby | running | 1 | 0/41C0368 | 0 | 0/41C0368 | 0 |
| 0 | coord3 | 172.27.0.4 | Leader | running | 1 | | | | |
| 1 | work1-1 | 172.27.0.8 | Quorum Standby | running | 1 | 0/31D3198 | 0 | 0/31D3198 | 0 |
| 1 | work1-2 | 172.27.0.2 | Leader | running | 1 | | | | |
| 2 | work2-1 | 172.27.0.5 | Quorum Standby | running | 1 | 0/31CDFC0 | 0 | 0/31CDFC0 | 0 |
| 2 | work2-2 | 172.27.0.7 | Leader | running | 1 | | | | |
+-------+---------+-------------+----------------+---------+----+-------------+-----+------------+-----+
添加 --group 选项后,输出将变为:
postgres@coord1:~$ patronictl list demo --group 0
+ Citus cluster: demo (group: 0, 7179854923829112860) -+-------------+-----+------------+-----+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+--------+-------------+----------------+---------+----+-------------+-----+------------+-----+
| coord1 | 172.27.0.10 | Replica | running | 1 | 0/41C0368 | 0 | 0/41C0368 | 0 |
| coord2 | 172.27.0.6 | Quorum Standby | running | 1 | 0/41C0368 | 0 | 0/41C0368 | 0 |
| coord3 | 172.27.0.4 | Leader | running | 1 | | | | |
+--------+-------------+----------------+---------+----+-------------+-----+------------+-----+
postgres@coord1:~$ patronictl list demo --group 1
+ Citus cluster: demo (group: 1, 7179854923881963547) -+-------------+-----+------------+-----+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+---------+------------+----------------+---------+----+-------------+-----+------------+-----+
| work1-1 | 172.27.0.8 | Quorum Standby | running | 1 | 0/31D3198 | 0 | 0/31D3198 | 0 |
| work1-2 | 172.27.0.2 | Leader | running | 1 | | | | |
+---------+------------+----------------+---------+----+-------------+-----+------------+-----+
Citus 工作节点主从切换
当对 Citus 工作节点编排主从切换时,Citus 提供了使切换对应用程序接近透明的能力。由于应用程序连接到协调节点,再由协调节点连接工作节点,因此 Citus 能够在协调节点上 暂停 对某个工作节点组所承载分片的 SQL 流量。主从切换在流量保持在协调节点的同时进行,并在新的工作节点主库准备好接受读写查询后立即恢复。
以下是在工作节点集群上执行 patronictl switchover 的示例:
postgres@coord1:~$ patronictl switchover demo
+ Citus cluster: demo ----------+----------------+---------+----+-------------+-----+------------+-----+
| Group | Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+-------+---------+-------------+----------------+---------+----+-------------+-----+------------+-----+
| 0 | coord1 | 172.27.0.10 | Replica | running | 1 | 0/41C0368 | 0 | 0/41C0368 | 0 |
| 0 | coord2 | 172.27.0.6 | Quorum Standby | running | 1 | 0/41C0368 | 0 | 0/41C0368 | 0 |
| 0 | coord3 | 172.27.0.4 | Leader | running | 1 | | | | |
| 1 | work1-1 | 172.27.0.8 | Leader | running | 1 | | | | |
| 1 | work1-2 | 172.27.0.2 | Quorum Standby | running | 1 | 0/31D3198 | 0 | 0/31D3198 | 0 |
| 2 | work2-1 | 172.27.0.5 | Quorum Standby | running | 1 | 0/31CDFC0 | 0 | 0/31CDFC0 | 0 |
| 2 | work2-2 | 172.27.0.7 | Leader | running | 1 | | | | |
+-------+---------+-------------+----------------+---------+----+-------------+-----+------------+-----+
Citus group: 2
Primary [work2-2]:
Candidate ['work2-1'] []:
When should the switchover take place (e.g. 2024-08-26T08:02 ) [now]:
Current cluster topology
+ Citus cluster: demo (group: 2, 7179854924063375386) -+-------------+-----+------------+-----+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+---------+------------+----------------+---------+----+-------------+-----+------------+-----+
| work2-1 | 172.27.0.5 | Quorum Standby | running | 1 | 0/31CDFC0 | 0 | 0/31CDFC0 | 0 |
| work2-2 | 172.27.0.7 | Leader | running | 1 | | | | |
+---------+------------+----------------+---------+----+-------------+-----+------------+-----+
Are you sure you want to switchover cluster demo, demoting current primary work2-2? [y/N]: y
2024-08-26 07:02:40.33003 Successfully switched over to "work2-1"
+ Citus cluster: demo (group: 2, 7179854924063375386) --------+---------+------------+---------+
| Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+---------+------------+---------+---------+----+-------------+---------+------------+---------+
| work2-1 | 172.27.0.5 | Leader | running | 1 | | | | |
| work2-2 | 172.27.0.7 | Replica | stopped | | unknown | unknown | unknown | unknown |
+---------+------------+---------+---------+----+-------------+---------+------------+---------+
postgres@coord1:~$ patronictl list demo
+ Citus cluster: demo ----------+----------------+---------+----+-------------+-----+------------+-----+
| Group | Member | Host | Role | State | TL | Receive LSN | Lag | Replay LSN | Lag |
+-------+---------+-------------+----------------+---------+----+-------------+-----+------------+-----+
| 0 | coord1 | 172.27.0.10 | Replica | running | 1 | 0/41C0368 | 0 | 0/41C0368 | 0 |
| 0 | coord2 | 172.27.0.6 | Quorum Standby | running | 1 | 0/41C0368 | 0 | 0/41C0368 | 0 |
| 0 | coord3 | 172.27.0.4 | Leader | running | 1 | | | | |
| 1 | work1-1 | 172.27.0.8 | Leader | running | 1 | | | | |
| 1 | work1-2 | 172.27.0.2 | Quorum Standby | running | 1 | 0/31D3198 | 0 | 0/31D3198 | 0 |
| 2 | work2-1 | 172.27.0.5 | Leader | running | 2 | | | | |
| 2 | work2-2 | 172.27.0.7 | Quorum Standby | running | 2 | 0/31CDFC0 | 0 | 0/31CDFC0 | 0 |
+-------+---------+-------------+----------------+---------+----+-------------+-----+------------+-----+
以下是协调节点侧的日志:
# 工作节点主库通知协调节点,它即将执行 "pg_ctl stop"。
2024-08-26 07:02:38,636 DEBUG: query(BEGIN, ())
2024-08-26 07:02:38,636 DEBUG: query(SELECT pg_catalog.citus_update_node(%s, %s, %s, true, %s), (3, '172.19.0.7-demoted', 5432, 10000))
# 从此刻起,协调节点上发往工作节点组 2 的所有应用流量被暂停。
# 旧的工作节点主库被指定为从库。
2024-08-26 07:02:40,084 DEBUG: query(SELECT pg_catalog.citus_update_node(%s, %s, %s, true, %s), (7, '172.19.0.7', 5432, 10000))
# 未来的工作节点主库通知协调节点,它已在 DCS 中获取了 leader 锁,即将运行 "pg_ctl promote"。
2024-08-26 07:02:40,085 DEBUG: query(SELECT pg_catalog.citus_update_node(%s, %s, %s, true, %s), (3, '172.19.0.5', 5432, 10000))
# 新的工作节点主库刚完成提升,通知协调节点它已准备好接受读写流量。
2024-08-26 07:02:41,485 DEBUG: query(COMMIT, ())
# 从此刻起,协调节点上发往工作节点组 2 的应用流量被解除阻塞。
从节点(Secondary nodes)
从 Patroni v4.0.0 起,没有 noloadbalance 标签 的 Citus 从节点也会被注册到 pg_dist_node 中。但若要将从节点用于只读查询,应用程序需要修改 citus.use_secondary_nodes GUC。
查看 DCS 结构
Citus 集群(协调节点和工作节点)在 DCS 中以逻辑分组的 Patroni 集群群组方式存储:
/service/batman/ # scope=batman
/service/batman/0/ # citus.group=0,协调节点
/service/batman/0/initialize
/service/batman/0/leader
/service/batman/0/members/
/service/batman/0/members/m1
/service/batman/0/members/m2
/service/batman/1/ # citus.group=1,工作节点
/service/batman/1/initialize
/service/batman/1/leader
/service/batman/1/members/
/service/batman/1/members/m3
/service/batman/1/members/m4
...
选择这种方式是因为,对于大多数 DCS,可以通过单次递归读取请求获取整个 Citus 集群的数据。只有 Citus 协调节点需要读取整棵树,因为它们需要发现工作节点。工作节点只读取自身组的子树,某些情况下也可能读取协调节点组的子树。
Kubernetes 上的 Citus
由于 Kubernetes 不支持层级结构,我们必须在 Patroni 创建的所有 K8s 对象中包含 citus group:
batman-0-leader # 协调节点的 leader ConfigMap
batman-0-config # 存储 initialize、config 和 history "键"的 ConfigMap
...
batman-1-leader # 工作节点组 1 的 leader ConfigMap
batman-1-config
...
命名规则为:${scope}-${citus.group}-${type}。
Patroni 使用 标签选择器 来发现所有 Kubernetes 对象,因此带有 Patroni&Citus 的所有 Pod 以及 Endpoints/ConfigMaps 必须具有相同的标签,且必须通过 Kubernetes Kubernetes 配置 或环境变量来配置 Patroni 使用这些标签。
以下是使用 Pod 环境变量配置 Patroni 的两个示例:
- 协调节点集群
apiVersion: v1
kind: Pod
metadata:
labels:
application: patroni
citus-group: "0"
citus-type: coordinator
cluster-name: citusdemo
name: citusdemo-0-0
namespace: default
spec:
containers:
- env:
- name: PATRONI_SCOPE
value: citusdemo
- name: PATRONI_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: PATRONI_KUBERNETES_POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: PATRONI_KUBERNETES_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: PATRONI_KUBERNETES_LABELS
value: '{application: patroni}'
- name: PATRONI_CITUS_DATABASE
value: citus
- name: PATRONI_CITUS_GROUP
value: "0"
- 第 2 组工作节点集群
apiVersion: v1
kind: Pod
metadata:
labels:
application: patroni
citus-group: "2"
citus-type: worker
cluster-name: citusdemo
name: citusdemo-2-0
namespace: default
spec:
containers:
- env:
- name: PATRONI_SCOPE
value: citusdemo
- name: PATRONI_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: PATRONI_KUBERNETES_POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: PATRONI_KUBERNETES_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: PATRONI_KUBERNETES_LABELS
value: '{application: patroni}'
- name: PATRONI_CITUS_DATABASE
value: citus
- name: PATRONI_CITUS_GROUP
value: "2"
你可能注意到,两个示例都设置了 citus-group 标签。该标签允许 Patroni 识别对象属于哪个 Citus 组。此外,还有 PATRONI_CITUS_GROUP 环境变量,其值与 citus-group 标签相同。当 Patroni 创建新的 Kubernetes 对象(ConfigMaps 或 Endpoints)时,会自动为其添加 citus-group: ${env.PATRONI_CITUS_GROUP} 标签:
apiVersion: v1
kind: ConfigMap
metadata:
name: citusdemo-0-leader # 由 ${env.PATRONI_SCOPE}-${env.PATRONI_CITUS_GROUP}-leader 生成
labels:
application: patroni # 从 ${env.PATRONI_KUBERNETES_LABELS} 中设置
cluster-name: citusdemo # 从 ${env.PATRONI_SCOPE} 自动设置
citus-group: '0' # 从 ${env.PATRONI_CITUS_GROUP} 自动设置
你可以在 Patroni 仓库的 kubernetes 目录中找到支持 Citus 的 Patroni Kubernetes 部署完整示例。
其中两个重要文件:
- Dockerfile.citus
- citus_k8s.yaml
Citus 升级与 PostgreSQL 大版本升级
首先,请阅读 Citus 文档 中关于升级 Citus 版本的内容。流程中有一处小变化:在执行升级时,必须使用 patronictl restart 代替 systemctl restart 来重启 PostgreSQL。
包含 Citus 的 PostgreSQL 大版本升级相对复杂。你需要结合 Citus 文档中关于大版本升级的技术,以及 Patroni 文档中关于 PostgreSQL major upgrade<major_upgrade> 的内容。请记住,Citus 集群由多个 Patroni 集群(协调节点和工作节点)组成,它们都需要独立升级。
14 - 将独立实例转换为 Patroni 集群
将现有 PostgreSQL 数据迁移并转换为 Patroni 集群的操作步骤。
原始页面: https://patroni.readthedocs.io/en/latest/existing_data.html
本节介绍将独立 PostgreSQL 实例转换为 Patroni 集群的操作流程。
如需从零开始部署 Patroni 集群(不使用已有 PostgreSQL 实例),请参阅 运行与配置。
操作步骤
以下是将现有 PostgreSQL 集群转换为 Patroni 托管集群的步骤概览。本步骤假设现有集群的所有节点当前均在运行,并且您不打算在迁移过程中修改 PostgreSQL 配置。具体步骤如下:
按照 Patroni 配置中 认证 章节的说明创建 PostgreSQL 用户。下方代码块中提供了创建用户的示例 SQL 命令,请根据您的实际环境替换用户名和密码。如果相关用户已存在,可跳过此步骤。
-- Patroni 超级用户
-- 请将 PATRONI_SUPERUSER_USERNAME 和 PATRONI_SUPERUSER_PASSWORD 替换为实际值
CREATE USER PATRONI_SUPERUSER_USERNAME WITH SUPERUSER ENCRYPTED PASSWORD 'PATRONI_SUPERUSER_PASSWORD';
-- Patroni 复制用户
-- 请将 PATRONI_REPLICATION_USERNAME 和 PATRONI_REPLICATION_PASSWORD 替换为实际值
CREATE USER PATRONI_REPLICATION_USERNAME WITH REPLICATION ENCRYPTED PASSWORD 'PATRONI_REPLICATION_PASSWORD';
-- Patroni rewind 用户(若您打算在 Patroni 配置中启用 use_pg_rewind)
-- 请将 PATRONI_REWIND_USERNAME 和 PATRONI_REWIND_PASSWORD 替换为实际值
CREATE USER PATRONI_REWIND_USERNAME WITH ENCRYPTED PASSWORD 'PATRONI_REWIND_PASSWORD';
GRANT EXECUTE ON function pg_catalog.pg_ls_dir(text, boolean, boolean) TO PATRONI_REWIND_USERNAME;
GRANT EXECUTE ON function pg_catalog.pg_stat_file(text, boolean) TO PATRONI_REWIND_USERNAME;
GRANT EXECUTE ON function pg_catalog.pg_read_binary_file(text) TO PATRONI_REWIND_USERNAME;
GRANT EXECUTE ON function pg_catalog.pg_read_binary_file(text, bigint, bigint, boolean) TO PATRONI_REWIND_USERNAME;
在所有 PostgreSQL 节点上依次执行以下操作。请逐节点完成所有步骤后再处理下一个节点,先从主库开始,然后依次处理各从库节点:
- 如果 PostgreSQL 通过 systemd 管理,请先禁用 PostgreSQL 的 systemd 服务单元——因为 PostgreSQL 的启停将改由 Patroni 负责管理。
- 为 Patroni 创建 YAML 配置文件。可使用 Patroni 配置生成与校验工具 完成此操作。
- 注意(仅适用于主库): 如果现有集群成员之间使用复制槽进行复制,建议启用
use_slots 并通过 slots 配置项将现有复制槽设为永久槽。请注意,当 use_slots 启用时,Patroni 会自动为成员间复制创建复制槽,并删除它无法识别的复制槽。此处使用永久槽的目的是在迁移至 Patroni 的过程中保留现有复制槽。详情请参阅 动态配置项。
- 通过
patroni systemd 服务单元启动 Patroni。Patroni 将自动检测到 PostgreSQL 已在运行,并开始监控该实例。
将 PostgreSQL 的"启动控制权"移交给 Patroni。为此,需要通过 patronictl restart cluster-name member-name 命令重启各集群成员。为最大限度减少停机时间,建议将此步骤拆分为:
- 立即重启从库节点。
- 在维护窗口内计划性地重启主库。
如果您在第 2.2 步中配置了永久槽,应在 Patroni 创建的复制槽的 restart_lsn 追上对应成员原始槽的 restart_lsn 之后,通过 patronictl edit-config cluster-name 命令将其从 slots 配置中移除。移除后,Patroni 将在这些原始槽不再被需要时自动将其删除。以下是用于比较两个槽 restart_lsn 的示例查询:
-- 假设 original_slot_for_member_x 是原集群中用于向成员 X 复制变更的槽名称,
-- slot_for_member_x 是 Patroni 为同一目的创建的槽名称。
-- 需要确认 slot_for_member_x 的 restart_lsn >= original_slot_for_member_x 的 restart_lsn
SELECT slot_name,
restart_lsn
FROM pg_replication_slots
WHERE slot_name IN (
'original_slot_for_member_x',
'slot_for_member_x'
)
PostgreSQL 大版本升级
目前,进行大版本升级的唯一可行方式是:
- 停止 Patroni。
- 升级 PostgreSQL 二进制文件,并在主库上执行 pg_upgrade。
- 更新
patroni.yml。 - 从 DCS 中删除
initialize 键,或清除 DCS 中的完整集群状态。后者可通过执行 patronictl remove cluster-name 命令完成。这是必要的,因为 pg_upgrade 会运行 initdb,从而创建一个具有新 PostgreSQL 系统标识符的新数据库。 - 如果您在上一步中清除了集群状态,建议将旧数据目录中的
patroni.dynamic.json 复制到新数据目录,以保留之前设置的 PostgreSQL 参数。 - 在主库上启动 Patroni。
- 在从库节点上升级 PostgreSQL 二进制文件,更新
patroni.yml,并清空 data_dir。 - 在从库节点上启动 Patroni,等待复制完成。
PostgreSQL 不支持在从库节点上运行 pg_upgrade。如果您清楚自己在做什么,也可以尝试 https://www.postgresql.org/docs/current/pgupgrade.html 中描述的 rsync 方式,以替代清空从库节点 data_dir 的操作。但最安全的方式仍然是让 Patroni 为您完成数据复制。
常见问题
Patroni 启动时报错,提示无法绑定到 PostgreSQL 端口。
请核查 postgresql.conf 中的 listen_addresses 和 port 配置,以及 patroni.yml 中的 postgresql.listen 配置。同时不要忘记确认 pg_hba.conf 中允许相应的访问。
请求 Patroni 重启节点后,PostgreSQL 报错:could not open configuration file "/etc/postgresql/10/main/pg_hba.conf": No such file or directory
这个问题可能由多种原因引起,具体取决于您管理 PostgreSQL 配置的方式。如果您指定了 postgresql.config_dir,Patroni 只会在引导新集群时,根据 bootstrap 章节中的配置生成 pg_hba.conf。在当前场景中,由于 PGDATA 非空,引导过程并未发生,因此该文件必须事先存在。
15 - 与其他工具的集成
Patroni 与外部备份及编排工具的集成方法。
原始页面: https://patroni.readthedocs.io/en/latest/tools_integration.html
Patroni 能够与技术栈中的其他工具集成。本节列举了一些集成示例,并不详尽,但希望能为您提供参考和启发。
Barman
Patroni 提供了一个名为 patroni_barman 的应用程序,内含与 pg-backup-api 通信的逻辑,可用于远程执行 Barman 操作。
该应用程序目前包含两个子命令:recover 和 config-switch。
patroni_barman recover
recover 子命令可用作自定义引导方法或自定义从库创建方法。详情请参阅 replica_imaging_and_bootstrap。
patroni_barman config-switch
config-switch 子命令设计用于作为 Patroni 的 on_role_change 回调。举例来说,假设您正在将 WAL 从当前主库流式传输到 Barman 主机,当集群发生故障转移时,需要切换为从新主库流式传输 WAL。将 patroni_barman config-switch 设置为 on_role_change 回调即可实现这一需求。
说明
该子命令依赖于 barman config-switch 命令,该命令通过在 Barman 服务器配置之上应用预定义模型来覆盖其配置,自 Barman 3.10 起可用。更多详情请参阅 Barman 文档。
以下示例展示了如何配置 Patroni,使其在节点被提升为主库时应用一个配置模型:
postgresql:
callbacks:
on_role_change: >
patroni_barman
--api-url YOUR_API_URL
config-switch
--barman-server YOUR_BARMAN_SERVER_NAME
--barman-model YOUR_BARMAN_MODEL_NAME
--switch-when promoted
说明
patroni_barman config-switch 要求在 Barman 主机上同时配置好 Barman 和 pg-backup-api,以便通过备份 API 远程执行 barman config-switch,同时还需预先配置好待应用的 Barman 模型。以上示例仅使用了部分可用参数,完整参数说明可运行 patroni_barman config-switch --help 查看,或参阅 Barman 文档。
16 - 安全注意事项
DCS、REST API 及凭据处理的安全注意事项。
原始页面: https://patroni.readthedocs.io/en/latest/security.html
Patroni 集群有两个需要防范未授权访问的接口:分布式配置存储(DCS)和 Patroni REST API。
保护 DCS
Patroni 和 patronictl 都会向 DCS 读写数据。
尽管 DCS 本身不包含任何敏感信息,但它允许修改部分 Patroni/PostgreSQL 配置,因此首要保护对象就是 DCS 本身。
具体的保护方式取决于所使用的 DCS 类型。各类 DCS 的认证和加密参数(令牌/基本认证/客户端证书)详见 配置说明。
通用建议是为所有 DCS 通信启用 TLS。
保护 REST API
保护 REST API 是一项更为复杂的任务。
Patroni REST API 的使用方包括:Patroni 自身(领导者竞选期间)、patronictl 工具(故障转移/主从切换/重新初始化/重启/重载等操作)、HAProxy 或其他负载均衡器(HTTP 健康检查),以及监控系统。
从安全角度来看,REST API 端点分为两类:安全端点(GET 请求,仅读取信息)和非安全端点(PUT、POST、PATCH、DELETE 请求,会变更节点状态)。
非安全端点可通过设置 restapi.authentication.username 和 restapi.authentication.password 参数启用 HTTP 基本认证加以保护。安全端点在未启用 TLS 的情况下无法得到保护。
当 REST API 启用 TLS 且已建立 PKI 基础设施时,可对 API 服务端和客户端实现所有端点的双向认证。
restapi 配置节的参数用于配置客户端对服务端的 TLS 认证。verify_client 参数控制 API 服务端的验证策略:required 表示对所有 API 调用(含安全与非安全端点)都要求客户端证书验证通过;optional 表示仅对非安全 API 调用要求;none 表示对任何调用都不要求。
ctl 配置节的参数用于配置客户端(即与 patroni 共用同一配置文件的 patronictl 工具)对服务端的 TLS 认证。将 insecure: true 可禁用客户端对服务端证书的验证。TLS 客户端参数的详细说明请参阅 配置说明。
保护 PostgreSQL 数据库本身免受未授权访问超出了本文档的范围,相关内容请参阅 https://www.postgresql.org/docs/current/client-authentication.html。
17 - 多数据中心高可用
基于 Patroni 复制的多数据中心高可用架构模式。
原始页面: https://patroni.readthedocs.io/en/latest/ha_multi_dc.html
部署在多个数据中心的 PostgreSQL 集群,其高可用基于复制实现,复制可以是同步的,也可以是异步的(参见 复制模式)。
无论哪种模式,都需要明确以下概念:
- PostgreSQL 仅在持有领导者键且能够更新领导者键时,才能以主库或备用领导者身份运行。
- etcd、ZooKeeper 或 Consul 节点的数量应为奇数:3 个或 5 个!
同步复制
要构建能够自动容忍单区域故障的多数据中心集群,至少需要 3 个数据中心。
架构图如下:
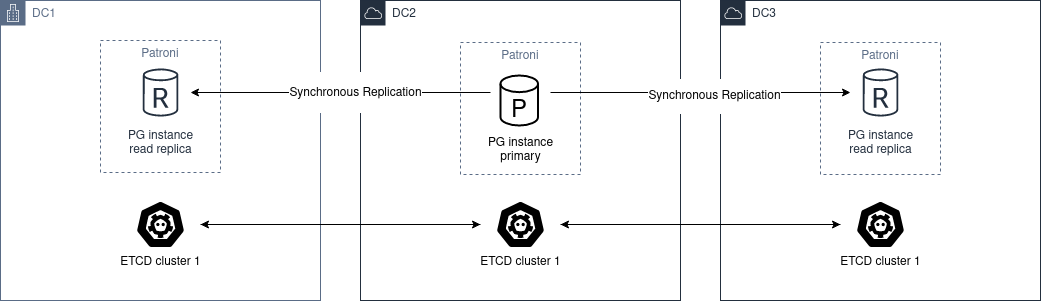
需要跨不同数据中心部署一个 etcd、ZooKeeper 或 Consul 集群,至少包含 3 个节点,每个可用区各一个。
PostgreSQL 方面,至少需要在不同数据中心部署 2 个节点,然后在全局 动态配置 中设置 synchronous_mode: true。
这将启用同步复制,主库会从其他节点中选择一个作为同步备库。
异步复制
如果只有两个数据中心,更好的方案是部署两个独立的 etcd 集群,并在第二个数据中心运行 Patroni 备用集群。当第一个站点宕机时,可以手动提升备用集群。
架构图如下:
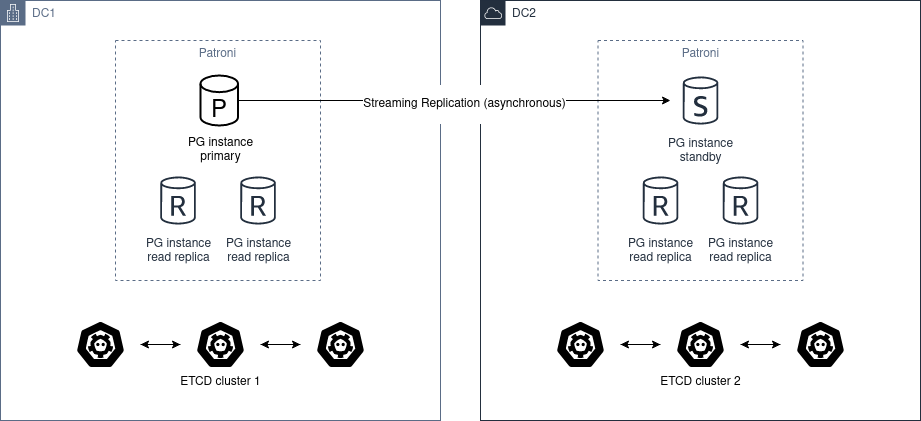
自动提升是不可能的,因为 DC2 永远无法确定 DC1 的真实状态。
此场景下不应使用 pg_ctl promote,而需要通过从 动态配置 中移除 standby_cluster 配置节来"手动提升"健康集群。
若需恢复到"初始"状态,只有以下两种方式:
- 重新添加
standby_cluster 配置节,这将触发 pg_rewind。但要使 pg_rewind 正常工作,集群必须在初始化时启用了 data page checksums(即 initdb 的 --data-checksums 选项)和/或将 wal_log_hints 设置为 on,且仍存在 pg_rewind 因其他因素失败的可能性。 - 从头重建备用集群。
在提升备用集群之前,必须人工确认源集群已停止(STONITH)。DC1 恢复后,该集群需要被转换为备用集群。
在执行此操作之前,可以手动检查数据库,提取从 DC1 与 DC2 之间网络中断到手动停止 DC1 集群这段时间内发生的所有变更,并在必要时手动将这些变更应用到 DC2 的集群中。
18 - 常见问题
关于 Patroni 运维与故障排查的常见问题解答。
原始页面: https://patroni.readthedocs.io/en/latest/faq.html
本节收录了关于 Patroni 最常见问题的解答,各子节聚焦于不同类别的问题。
希望这些内容能帮你解答大多数疑问。如果仍有疑问或遇到意外问题,请参阅 chatting 和 reporting_bugs,了解如何获取帮助或提交问题报告。
与其他高可用方案的比较
为什么 Patroni 需要独立的 DCS 节点集群,而 repmgr 等其他方案不需要?
实现高可用方案有多种不同方式,各有优缺点。
repmgr 等软件通过节点间通信来决定何时采取行动。
而 Patroni 则依赖存储在 DCS 中的状态,DCS 是 Patroni 决策的唯一可信来源。
虽然独立的 DCS 集群会使架构变得复杂,但这种方式也降低了 Postgres 集群发生脑裂(split-brain)的可能性。
Patroni 与其他高可用方案在 Postgres 管理方面有何不同?
Patroni 不仅管理 Postgres 集群的高可用,还全面管理 Postgres 本身。
如果 Postgres 节点尚不存在,Patroni 会负责引导主库和备库节点,并管理各节点的 Postgres 配置。如果 Postgres 节点已存在,Patroni 将接管集群的管理。
除此之外,Patroni 还具备自愈能力。若主库故障,Patroni 不仅会故障转移到从库,还会尝试将原主库以从库身份重新加入新主库。同样,若从库故障,Patroni 也会尝试重新加入该从库。
这就是我们将 Patroni 称为"高可用方案模板"的原因——它不仅仅管理物理复制,而是对 Postgres 进行整体管理。
DCS
可以使用同一个 etcd 集群存储两个或多个 Patroni 集群的数据吗?
可以!
Patroni 集群的信息以 namespace 和 scope 为路径前缀存储在 DCS 中。
只要不同 Patroni 集群之间的 namespace 和 scope 不冲突,就可以使用同一个 DCS 集群存储多个 Patroni 集群的信息。
如果为指向同一 DCS 集群的不同 Patroni 集群使用相同的 namespace 和 scope 组合,会发生什么?
第二个尝试使用相同 namespace 和 scope 的 Patroni 集群将无法管理 Postgres,因为它会在 DCS 中找到与该组合相关的信息,但 Postgres 系统标识符不匹配。系统标识符不匹配会导致 Patroni 中止对第二个集群的管理——Patroni 会认为这是一个不同的集群,用户配置了错误的 Patroni。
在处理共享同一 DCS 集群的不同 Patroni 集群时,请确保使用不同的 namespace / scope。
DCS 集群丢失了会怎样?
DCS 主要用于存储 Patroni 集群的状态和动态配置。
最直接的后果是,所有依赖该 DCS 的 Patroni 集群将进入只读模式——除非启用了 dcs_failsafe_mode。
DCS 集群丢失后该怎么做?
丢失 DCS 集群后有三种可能的处置方式:
- DCS 集群完全恢复:Patroni 侧无需任何操作。DCS 集群恢复后,Patroni 也应能自动恢复;
- DCS 集群在原地重建,端点保持不变:Patroni 侧无需任何变更;
- 新建一个端点不同的 DCS 集群:需要在每个 Patroni 节点的配置中更新 DCS 端点。
如果遇到第 2. 或第 3. 种情况,Patroni 会根据集群当前状态重新创建状态信息,并基于存储在每个 Patroni 集群成员 Postgres 数据目录中名为 patroni.dynamic.json 的备份文件,在 DCS 中重建动态配置。
DCS 集群丧失多数节点会怎样?
DCS 将变得无响应,这会导致 Patroni 将当前的读写 Postgres 节点降级。
请记住:Patroni 依赖 DCS 的状态来对集群采取行动。
你可以使用 dcs_failsafe_mode 来缓解这种情况。
patronictl
必须在 Patroni 主机上运行 patronictl 吗?
不需要。
在 Patroni 主机上运行 patronictl 很方便,因为可以直接使用 patroni 代理的配置文件。
但 patronictl 本质上是一个客户端,可以从远程机器上执行。只需提供足够的配置,使其能够访问 DCS 和 Patroni 成员的 REST API 即可。
为什么 patronictl list 命令的输出中,某个 Patroni 成员的信息消失了?
patronictl list 显示的信息基于 DCS 的内容。
如果某个成员的信息从 DCS 中消失,很可能是该节点上的 Patroni 代理已停止运行,或者无法与 DCS 通信。
由于该成员无法更新其信息,信息最终会从 DCS 中过期,该成员也就不再出现在 patronictl list 的输出中。
为什么 patronictl list 命令输出中某个 Patroni 成员的信息不是最新的?
patronictl list 显示的信息基于 DCS 的内容。
默认情况下,该信息由 Patroni 大约每 loop_wait 秒更新一次。换句话说,即使一切正常,你仍可能看到 DCS 中存储的信息有最多 loop_wait 秒的"延迟"。
但请注意,这并不是一成不变的规则。Patroni 执行的某些操作会立即更新 DCS 信息。
配置
动态配置与本地配置有什么区别?
动态配置(或全局配置)是存储在 DCS 中的配置,适用于 Patroni 集群的所有成员,是存储配置的首选位置。
特定于某个节点的配置,或希望覆盖全局配置的配置,应仅在目标 Patroni 成员上设置为本地配置。本地配置可以通过配置文件或环境变量来指定。
更多详情请参阅 Patroni 配置。
Patroni 的配置类型有哪些?优先级如何?
配置类型包括:
- 动态配置:适用于所有成员;
- 本地配置:适用于本地成员,覆盖动态配置;
- 环境配置:适用于本地成员,覆盖动态配置和本地配置。
注意: 某些 Postgres GUC 只能全局设置,即通过动态配置。此外,还有一些 GUC 的值由 Patroni 强制硬编码。
更多详情请参阅 Patroni 配置。
有没有工具可以帮我创建 Patroni 配置文件?
有的。
你可以使用 patroni --generate-sample-config 或 patroni --generate-config 命令,分别生成示例 Patroni 配置文件,或基于现有 Postgres 实例生成 Patroni 配置文件。
详情请参阅 generate_sample_config 和 generate_config。
我修改了 bootstrap.dcs 下的参数,但 Patroni 没有将更改应用到集群成员。哪里出了问题?
bootstrap.dcs 下配置的值仅在引导全新集群时使用,这些值会在引导过程中写入 DCS。
引导阶段完成后,只能通过 DCS 来修改动态配置。
请参阅下一个问题了解更多详情。
如何修改动态配置?
需要在 DCS 中修改配置,可以通过以下方式实现:
如何修改本地配置?
需要修改对应 Patroni 成员的配置文件,并向 Patroni 代理发送 SIGHUP 信号。可以通过以下任一方式实现:
注意: 在以下情况下,通过 patronictl reload 进行重载可能无法正常工作:
- REST API 证书过期:可以使用
patronictl 的 -k 选项来规避; - 凭据错误:例如在配置文件中修改了
restapi 或 ctl 凭据,而 Patroni 和 patronictl 使用了同一份配置文件。
如何修改环境配置?
环境配置只在 Patroni 启动时读取。
因此,修改环境配置后需要重启相应的 Patroni 代理。
注意不要导致集群发生故障转移!你可能需要先查看 patronictl pause。
修改需要重载的 Postgres GUC 时会发生什么?
当你按照上述方法修改动态配置或本地配置时,Patroni 会自动帮你重载 Postgres 配置。
修改需要重启的 Postgres GUC 时会发生什么?
Patroni 会在受影响的成员上标记 pending restart 标志。
由你决定何时以何种方式重启成员。可以通过以下方式实现:
注意: 某些 Postgres GUC 在重启 Postgres 节点的顺序上需要特别处理。详情请参阅 shared_memory_gucs。
Patroni 配置中 etcd 和 etcd3 有什么区别?
etcd 使用 etcd 的 API 版本 2,而 etcd3 使用 API 版本 3。
请注意,API 版本 2 存储的信息不能由 API 版本 3 管理,反之亦然。
我们建议配置 etcd3 而不是 etcd,原因如下:
- API 版本 2 从 Etcd v3.4 起默认禁用;
- API 版本 2 将在 Etcd v3.6 中被完全移除。
我在 Patroni 配置中启用了 use_slots,但当集群某个成员下线一段时间后,其在上游节点上使用的复制槽被删除了。如何避免这个问题?
有两种方案:
- 调整
member_slots_ttl(默认值 30min,自 Patroni 4.0.0 和 PostgreSQL 11 起可用)。当成员的停机时间短于配置的阈值时,缺席成员的复制槽不会被删除。 - 为成员配置永久物理复制槽。
自 Patroni 3.2.0 起,成员槽可以作为由 Patroni 管理的永久槽存在。
Patroni 会在所有节点上创建永久物理复制槽,确保不删除这些槽,并根据成员已消费的 LSN 在所有节点上推进槽的 LSN。
之后,如果你决定移除相应成员,需要由你负责调整永久槽配置,否则 Patroni 将永久保留这些槽。
注意: 在 Patroni 3.2.0 之前的版本中,成员槽仍可配置为永久物理复制槽,但仅由当前主库管理。也就是说,在故障转移/主从切换时,这些槽会在新主库上创建,但不能保证新主库拥有缺席节点所需的全部 WAL 段。
注意: 即使使用 Patroni 3.2.0,也可能存在小的竞态条件。在最初阶段,从库上创建的槽可能领先于主库上的同名槽,如果没有人消费该槽,在故障转移后仍有可能缺少某些文件。因此建议配置持续归档,以便能够恢复所需的 WAL 或执行 PITR。
loop_wait、retry_timeout 和 ttl 有什么区别?
Patroni 会定期执行我们所称的 HA 循环。在每次 HA 循环中,它会对集群执行一系列检查以判断其健康状态,并根据状态采取相应行动,例如故障转移到备库。
loop_wait 决定 Patroni 在执行下一次 HA 检查循环前应休眠多少秒。
retry_timeout 设置 DCS 和 Postgres 上重试操作的超时时间。例如:如果 DCS 无响应超过 retry_timeout 秒,Patroni 可能会将主库降级作为安全措施。
ttl 设置 DCS 中 leader 锁的租约时间。如果当前集群主库在多于 ttl 秒的 HA 循环中无法续租,租约将过期,并触发集群中的 leader race(领导者竞选)。
注意: 修改这些配置时,请记住 Patroni 在 动态配置 文档节中规定了最小值和强制规则。
Postgres 管理
可以直接在 Postgres 配置文件中修改 Postgres GUC 吗?
可以,但不建议这样做。
Postgres 配置由 Patroni 管理,直接编辑配置文件的尝试可能会因 Patroni 最终覆盖它们而徒劳无功。
有几种方式可以绕过 Patroni 的管理:
- 通过
$PGDATA/postgresql.base.conf 修改 Postgres GUC;或 - 定义一个
postgresql.custom_conf,用于替代 postgresql.base.conf,以便在外部管理;或 - 使用
ALTER SYSTEM / ALTER DATABASE / ALTER USER 修改 GUC。
更多信息请参阅 important_configuration_rules 节。
无论如何,我们建议通过 Patroni 统一管理所有 Postgres 配置。这样可以集中管理,并在需要调试 Patroni 时更加方便。
可以直接重启 Postgres 节点吗?
不,你不应该直接管理 Postgres!
任何绕过 Patroni 直接重启 Postgres 服务器的尝试都可能导致集群发生故障转移。
如果需要管理 Postgres 服务器,请通过 Patroni 提供的方式进行操作。
Patroni 能接管对已有 Postgres 集群的管理吗?
可以!
详细操作说明请参阅 将独立实例转换为 Patroni 集群。
Patroni 如何管理 Postgres?
Patroni 通过运行 Postgres 二进制文件(如 pg_ctl 和 postgres)来负责启动和停止 Postgres。
因此,你必须禁用所有其他可能管理 Postgres 集群的来源,例如 systemd 单元 postgresql.service。只有 Patroni 才能启动、停止和提升集群中的 Postgres 实例。不这样做可能导致脑裂场景。例如:如果运行主库的节点故障,而 postgresql.service 单元已启用,它可能会将 Postgres 重新启动并导致脑裂。
概念与要求
Patroni 包含哪些应用?
Patroni 主要包含以下几个应用:
Patroni 中的"备用集群"(standby cluster)是什么?
备用集群是指没有任何主库 Postgres 节点运行的集群,即集群中没有可读写的成员。
这类集群的作用是从另一个集群复制数据,通常用于跨数据中心的数据复制场景。
集群中会有一个领导者节点,该节点作为备库负责从远程 Postgres 节点复制变更。集群中其他备库则通过级联复制从该领导者成员同步数据。
注意: 备用集群对其复制来源的集群一无所知——它甚至可以使用 restore_command 而非 WAL 流复制,并且可以使用完全独立的 DCS 集群。
更多详情请参阅 备用集群。
Patroni 中的"领导者"(leader)是什么?
Patroni 中的 leader 类似于集群的协调者。
在普通 Patroni 集群中,leader 是可读写的节点。
在备用 Patroni 集群中,leader(又称 standby leader)负责从远程 Postgres 节点复制数据,并将这些变更级联给备用集群的其他成员。
Patroni 对集群中 Postgres 节点数量有最低要求吗?
没有,Patroni 可以在任意数量的 Postgres 节点上运行。
请记住:Patroni 与 DCS 是解耦的。
Patroni 中的暂停(pause)是什么意思?
暂停(pause)是 Patroni 提供的一项操作,允许用户要求 Patroni 在 Postgres 管理方面退后一步。
这在需要对集群进行维护时非常有用,可以避免 Patroni 在你停止主库时做出故障转移等高可用决策。
更多信息请参阅 暂停/恢复集群。
自动故障转移
Patroni 的自动故障转移机制是如何工作的?
Patroni 的自动故障转移基于我们所称的 leader race(领导者竞选)。
Patroni 将集群状态存储在 DCS 中,其中包含一个 leader 锁,保存着当前集群 leader 的成员名称。
该 leader 锁具有关联的生存时间(TTL)。如果主库未能及时续租 leader 锁,该键最终会从 DCS 中过期。
leader 锁过期后,会触发 Patroni 所称的 leader race:所有节点开始执行检查,以确定自己是否是接管 leader 角色的最佳候选人。这些检查包括调用所有其他 Patroni 成员的 REST API。
所有认为自己是接管 leader 锁最佳候选人的 Patroni 成员都会尝试获取该锁。第一个成功获取 leader 锁的成员将把自身提升为可读写节点(或 standby leader),其他节点则被配置为跟随它。
可以临时禁用 Patroni 集群的自动故障转移吗?
可以!
可以通过暂时暂停集群来实现。这在执行维护操作时非常有用。
当需要恢复集群的自动故障转移时,只需取消暂停即可。
更多信息请参阅 暂停/恢复集群。
引导与从库创建
Patroni 如何创建主库 Postgres 节点?从库 Postgres 节点又是如何创建的?
默认情况下,Patroni 使用 initdb 引导全新集群,并使用 pg_basebackup 从 leader 成员创建备库节点。
你可以通过编写自定义引导方法和自定义从库创建方法来改变这一行为。
自定义方法在需要恢复由 pgBackRest 或 Barman 等备份工具创建的备份时尤为有用。
详细信息请参阅 自定义引导方法 和 自定义从库创建。
监控
如何监控我的 Patroni 集群?
Patroni 在其 REST API 中提供了几个便捷端点:
/metrics:以 Prometheus 可使用的格式提供监控指标;/patroni:以 JSON 格式提供集群状态信息,与 /metrics 端点显示的信息非常相似。
你可以使用这些端点来实现监控检查。
19 - 版本历史
Patroni 各版本发布说明与变更历史。
原始页面:https://patroni.readthedocs.io/en/latest/releases.html
Version 4.1.0
发布于 2025-09-23
新特性
添加对 systemd “notify” 单元类型的支持(Ronan Dunklau)
如果没有 notify 单元类型,在使用 systemd 时,有可能在 Patroni 启动后立即向其发送 SIGHUP 信号,从而在其设置信号处理程序之前将其终止。
在 API 和 ctl 中提供接收和重放 LSN/延迟信息(Polina Bungina)
Patroni REST API 的 /cluster 端点和 patronictl list 命令现在为每个副本成员提供接收 LSN、重放 LSN、接收延迟和重放延迟信息。
确保干净地降级为备用集群(Polina Bungina)
确保在动态配置中引入 standby_cluster 部分能够实现干净的集群降级。
实现 patronictl demote-cluster 和 promote-cluster 命令(Polina Bungina)
用于集群降级和提升的新命令,可同时处理动态配置编辑和结果状态检查。
实现 sync_priority 标签(Polina Bungina)
此参数控制当 synchronous_mode 设置为 on 时,成员在同步副本选择过程中应具有的优先级。
实现 --validate-config 的 --print 选项(Polina Bungina)
在本地配置(包括环境配置覆盖)成功验证后将其打印输出。
实现 kubernetes.bootstrap_labels(Polina Bungina)
此功能允许您定义标签,这些标签将在成员 Pod 处于 initializing new cluster、running custom bootstrap script、starting after custom bootstrap 或 creating replica 状态时被分配给该 Pod。
添加抑制重复心跳日志的配置选项(Michael Morris)
如果设置为 true,连续相同的心跳日志将不会被重复输出。
为永久复制槽添加可选的 cluster_type 属性(Michael Banck)
这允许您设置特定的永久复制槽是应该始终创建,还是仅在主集群或备用集群上创建。
使 HTTP Server 头可配置(David Grierson)
引入 restapi.server_tokens 配置参数,允许您限制 HTTP Server 头中公开的信息。
为副本成员实现复制就绪 API 检查(Ants Aasma)
之前的实现在 PostgreSQL 启动后就认为副本已就绪。此更改后,只有当 PostgreSQL 正在进行复制且落后主节点不太远时,副本 Pod 才被视为就绪。
改进
降低 watchdog 配置失败的日志级别(Ants Aasma)
将 Could not activate Linux watchdog device 日志行在 debug 日志级别显示,除非 watchdog 配置为 required 模式。此前该日志在 info 级别显示。
利用 pg_stat_wal_receiver 中的 written_lsn 和 latest_end_lsn(Alexander Kukushkin)
written_lsn(实际写入 LSN)现在优先于 pg_last_wal_receive_lsn() 返回的值使用,后者实际上是刷新 LSN。latest_end_lsn 指向源主机上的 WAL 刷新位置。对于主节点,这允许更好地计算重放延迟,因为存储在 DCS 中的值仅每 loop_wait 秒更新一次。
避免与使用 failover=true 选项创建的槽交互(Alexander Kukushkin)
此更改是使逻辑故障转移槽功能完全正常运行所必需的。
在 /metrics REST API 端点中添加 PostgreSQL 状态(Ivan Filianin)
PostgreSQL 实例状态信息现在可通过 /metrics REST API 端点的 Prometheus 格式输出获取。
Version 4.0.7
发布于 2025-09-22
新特性
错误修复
修复 Windows 上 localhost 解析为 IPv6 的潜在问题(András Váczi)
在 PostgreSQL 中配置 listen_addresses 时,使用 0.0.0.0 或 127.0.0.1 将限制仅监听 IPv4,排除 IPv6。然而在典型的 Windows 系统上,localhost 通常默认解析为 IPv6 地址 ::1。为确保兼容性,Patroni 现在在 Windows 系统上将 PostgreSQL 配置为监听 127.0.0.1 而非 localhost。
仅当 DCS 中存在 /config 键时才返回全局配置(Alexander Kukushkin)
此前,当 DCS 中缺少 /config 键时,Patroni REST API 返回的是空配置而不是抛出错误。
修复 Etcd 不可用时故障安全模式未被触发的问题(Alexander Kukushkin)
Patroni 并非总能正确处理 etcd3 异常,导致故障安全模式未被触发。
修复信号处理程序重入死锁(Waynerv)
在 Docker 容器中以 PID=1 运行的 Patroni 在某些特殊情况下,收到 SIGCHLD 后会发生死锁。
当(永久)物理槽未保留 WAL 时重新创建(Israel Barth Rubio)
在 Patroni 作用域之外创建的、未保留 WAL 的永久物理复制槽会导致 replication slot cannot be advanced 错误。为避免此问题,Patroni 现在会重新创建这些槽。
正确处理 etcd3 中的 watch 取消消息(Alexander Kukushkin)
当 etcd3 向 watch 通道发送取消消息时,它不会关闭连接。这导致 Patroni 使用过期的数据。Patroni 现在通过中断分块响应的读取循环并在 Patroni 端关闭连接来解决此问题。
处理 HTTPConnection 套接字被 pyopenssl 包装的情况(Alexander Kukushkin)
Patroni 未正确使用 python-etcd 中强制使用的 pyopenssl 接口。
文档改进
Version 4.0.6
发布于 2025-06-06
错误修复
修复从具有更高优先级的主节点故障转移的错误(Alexander Kukushkin)
确保 Patroni 在具有更高优先级的旧主节点报告与当前节点相同的 LSN 时忽略该旧主节点。
修复在 PGDATA 外创建的 postgresql.conf 文件的权限问题(Michael Banck)
在 PGDATA 目录外创建 postgresql.conf 文件时尊重系统级 umask 值。
修复 synchronous_mode=quorum 下切换的错误(Alexander Kukushkin)
当指定了候选节点时,不检查 quorum 要求。
通过比较集群 term 来忽略过期的 Etcd 节点(Alexander Kukushkin)
记录 Etcd 集群最后已知的 “raft_term”,并在执行客户端请求时将其与 Etcd 节点报告的 “raft_term” 进行比较。
在 SIGHUP 时更新 PostgreSQL 配置文件(Alexander Kukushkin)
此前,Patroni 仅在检测到全局或本地配置发生更改时才替换 PostgreSQL 配置文件。
正确处理 etcd3 抛出的 Unavailable 异常(Alexander Kukushkin)
Patroni 过去会在同一个 etcd3 节点上重试此类请求,而切换到另一个节点是更好的策略。
改进 etcd3 租约处理(Alexander Kukushkin)
确保 Patroni 每个 HA 循环至少刷新一次 etcd3 租约。
尝试获取主节点锁时在 409 状态码下重新检查注解(Alexander Kukushkin)
实现与 Patroni 4.0.3 版本中对主节点对象读取所做的相同行为。
在推进槽时考虑 replay_lsn(Polina Bungina)
不要尝试在副本上将槽推进到超过 replay_lsn 的位置。此外,如果槽已经超过了该副本上此槽的 confirmed_flush_lsn,但副本尚未重放该槽在主节点上的实际 LSN,则将槽推进到 replay_lsn 位置。
确保在提升后执行 CHECKPOINT(Alexander Kukushkin)
由于 CHECKPOINT 尚未完成,检查点任务有可能在降级时未被重置。这导致在下一次提升触发时使用了过期的 result。
避免并发运行"离线"降级(Alexander Kukushkin)
在缓慢关闭的情况下,可能会出现下一个心跳循环再次触发 DCS 错误处理方法的情况,导致 AsyncExecutor is busy, demoting from the main thread 警告并再次启动离线降级。
在初始化失败时重命名数据目录前规范化 data_dir 值(Waynerv)
防止 data_dir 参数值中的尾部斜杠破坏初始化失败后的重命名过程。
检查 synchronous_standby_names 是否包含预期值(Alexander Kukushkin)
此前,实现非 quorum 同步复制的状态机机制未检查 synchronous_standby_names 的实际值,导致当 pg_stat_replication 是 synchronous_standby_names 的子集时使用了过期的 synchronous_standby_names 值。
Version 4.0.5
发布于 2025-02-20
稳定性改进
兼容 python-json-logger>=3.1(Alexander Kukushkin)
消除旧 API 用法产生的警告。
兼容 Python 3.13(Alexander Kukushkin)
在 Python 3.13 上运行测试。
兼容 pyinstaller>=4.4(Joe Jensen)
当 pyinstaller 的 toc 属性不存在时,回退到默认的 iter_modules。
修复 PostgreSQL 9.5 支持的问题(Alexander Kukushkin)
- 正确处理
pg_rewind 输出格式。 - 考虑
synchronous_standby_names 格式不支持 “num” 规范。
兼容 urlparse 的最新变更(Alexander Kukushkin)
urlparse 不再接受 URL 中包含 [] 字符的多主机地址。为解决此问题,尽可能切换到 libpq 的 PQconninfoParse() 原生包装器,仅对链接了旧版 libpq 的较旧 psycopg2 版本使用我们自己的实现。
错误修复
仅显示待重启的成员以进行重启确认(András Váczi)
此前,执行 patronictl restart <clustername> --pending 时,确认列表会列出所有成员,而不管其是否有待处理的重启。
在 Patroni 停止时取消长时间运行的任务,并在副本引导失败时删除数据目录(Alexander Kukushkin)
此前,Patroni 可能在进行副本引导时停止,而 pg_basebackup / wal-g / pgBackRest / barman 或类似工具仍在继续运行。
正确处理 patronictl edit-config 中包含斜杠的集群名称(Antoni Mur)
将 cluster_name 中的正斜杠替换为下划线。
避免过早删除物理槽(Alexander Kukushkin)
在故障转移后推迟删除包含 xmin 的物理复制槽:在新主节点上——直到该成员被提升,在副本上——直到集群中有主节点。
处理 controldata() 中 subprocess 抛出的所有异常(Alexander Kukushkin)
Patroni 未正确处理调用 pg_controldata 工具时可能抛出的所有异常。
修复故障转移时旧主节点的槽未被保留的错误(Alexander Kukushkin)
避免错误地依赖 DCS 中存在的成员信息,因为在故障转移时旧主节点的 /member 键可能恰好同时过期。
修复 quorum 状态机中的几个错误(Alexander Kukushkin)
- 在评估是否有健康节点可用于主节点选举时,降级前需要考虑 quorum 要求。否则,旧主节点可能最终在异步节点包围下处于恢复状态。
QuorumStateResolver 未正确处理副本节点快速加入又断开连接的情况。
改进
Version 4.0.4
发布于 2024-11-22
稳定性改进
添加对 py-consul 模块的兼容性(Alexander Kukushkin)
python-consul 模块已长期未维护,而 py-consul 是其官方替代品。保留了对 python-consul 的向后兼容性。
添加对 prettytable>=3.12.0 模块的兼容性(Alexander Kukushkin)
处理弃用警告。
兼容 ydiff==1.4.2 模块(Alexander Kukushkin)
修复最新版本的兼容性问题,在 requirements.txt 中约束版本,并引入最新版本兼容性测试。
错误修复
在主节点恢复失败后运行 on_role_change 回调(Polina Bungina、Alexander Kukushkin)
额外为崩溃后启动失败的主节点运行 on_role_change 回调,以增加回调被执行的机会,即使后续以副本身份启动也失败。
修复 patronictl list -W 中的线程泄漏(Alexander Kukushkin)
缓存 DCS 实例对象以避免线程泄漏。
确保只有受支持的参数写入连接字符串(Alexander Kukushkin)
Patroni 过去会将新版本中引入的参数传递到连接字符串中,导致连接错误。
Version 4.0.3
发布于 2024-10-18
错误修复
创建用户时禁用 pgaudit 以避免暴露密码(kviset)
当启用 pgaudit 扩展时,Patroni 会在创建 superuser、replication 和 rewind 用户时记录其密码。
修复混合部署的问题:主节点运行 Patroni v4 之前版本而副本运行 v4+ 版本(Alexander Kukushkin)
如果主节点运行的 Patroni 版本低于 4.0.0,则使用从 /members 键中提取的 xlog_location,而不是尝试从 /status 键获取成员的槽位置。不这样做会导致副本上 WAL 的累积。
不要忽略没有 Patroni 验证器但有效的 PostgreSQL GUC(Polina Bungina)
即使 GUC 没有 Patroni 验证器,仍然通过 postgres --describe-config 进行检查,前提是它实际上是一个有效的 GUC。
改进
在 K8s 中读取 leader 对象时,遇到 409 状态码时重新检查注解(Alexander Kukushkin)
避免在 PATCH 请求被 Patroni 取消但请求实际上已成功更新目标时执行额外的更新。
添加对 sslnegotiation 客户端连接选项的支持(Alexander Kukushkin)
sslnegotiation 已添加到 PostgreSQL 17 正式版中。
Version 4.0.2
发布于 2024-09-17
错误修复
处理发现配置验证文件时的异常(Alexander Kukushkin)
跳过 Patroni 没有足够权限执行列表操作的目录。
确保不活跃的热物理复制槽不持有 xmin(Alexander Kukushkin、Polina Bungina)
自 3.2.0 版本以来,Patroni 在副本上为所有成员创建物理复制槽,并使用 pg_replication_slot_advance() 函数定期推进这些槽。但如果由于某种原因启用了 hot_standby_feedback 并且主节点被降级为副本,那么现在不活跃的槽会将非空的 xmin 值传播回新的主节点。这导致 xmin 水位无法前移,vacuum 无法清理死元组。通过此修复,Patroni 会重新创建那些应该不活跃但具有非空 xmin 值的物理复制槽。
修复启动阶段未处理的 DCSError(Waynerv)
在尝试检查节点名称唯一性之前,确保 DCS 连接可用。
查询 pg_settings 时显式包含 CMDLINE_OPTIONS GUC(Alexander Kukushkin)
确保当 Patroni 加入正在运行的备用节点时,所有作为命令行参数传递给 postmaster 的 GUC 都被恢复。这是 Patroni 3.2.2 中修复的错误的后续处理。
修复 synchronous_standby_names 引号逻辑中的错误(Alexander Kukushkin)
根据 PostgreSQL 文档,ANY 和 FIRST 关键字应该使用双引号括起来,而 Patroni 此前未这样做。
修复 keepalive 连接值超出范围的问题(hadizamani021)
确保基于 ttl 设置计算的 keepalive 选项值不超过当前平台允许的最大值。
Version 4.0.1
发布于 2024-08-30
错误修复
Version 4.0.0
发布于 2024-08-29
警告
- 此版本完成了将 “master” 术语替换为 “primary” 的工作。这意味着有一些破坏性变更,请仔细阅读发行说明。升级到 Patroni 4+ 仅在运行 Patroni 3.1.0 或更新版本时才能可靠工作。从更旧的版本直接升级到 4+ 是可能的,但如果在其余节点运行其他 Patroni 版本时主节点发生故障,可能会导致意外行为。
破坏性变更
- 在消除非包容性 “master” 术语的过程中引入了以下破坏性变更:
- 在 Kubernetes 上,Patroni 默认将
role 标签设置为 primary。如果您希望保持旧行为以避免停机或冗长复杂的迁移,可以将 kubernetes.leader_label_value 和 kubernetes.standby_leader_label_value 参数配置为 master。更多信息请参阅 此处。 - Patroni 角色在 DCS 中写入为
primary 而非 master。 - Patroni REST API 返回的角色已从
master 更改为 primary。 - Patroni REST API 不再接受
/switchover、/failover、/restart 端点请求中的 role=master。 /metrics REST API 端点将不再报告 patroni_master 指标。patronictl 不再接受任何命令的 --master 选项。应使用 --leader 或 --primary 选项替代。- 自定义副本创建方法声明式配置中的
no_master 选项不再作为特殊选项处理,请使用 no_leader 替代。 patroni_wale_restore 脚本不再接受 --no_master 选项。patroni_barman 脚本不再接受 --role=master 选项。- 所有回调脚本现在传递
role=primary 选项而非 role=master。
patronictl failover 不再接受自 Patroni 3.2.0 起已弃用的 --leader 选项。- 自 Patroni 3.2.0 起已弃用的用户创建功能(
bootstrap.users 配置部分)已被移除。
新特性
基于 quorum 的故障转移(Ants Aasma、Alexander Kukushkin)
此功能实现了基于 quorum 的同步复制(从 PostgreSQL v10 开始可用),有助于降低最坏情况下的延迟,即使在正常运行期间也是如此,因为复制到某个备用节点的较高延迟可以由其他备用节点补偿。Patroni 实现了额外的安全保障,通过根据接收到的最新事务选择故障转移候选节点来防止任何用户可见的数据丢失。
在 pg_dist_node 中注册 Citus 从节点(Alexander Kukushkin)
Patroni 现在在 pg_dist_node 中维护具有 role==replica、state==running 且没有 noloadbalance 标签 的节点列表。
可配置的成员复制槽保留时间(Alexander Kukushkin)
实现了 member_slots_ttl 全局配置参数的支持,用于控制当成员键不存在时,成员复制槽应保留多长时间。
使 Patroni 创建的日志文件权限可配置(Alexander Kukushkin)
允许为 Patroni 创建的日志文件设置特定权限。如果未指定,权限将根据当前 umask 值设置。
兼容 PostgreSQL 17 beta3(Alexander Kukushkin)
GUC 验证规则已扩展。Patroni 在关闭期间处理所有新的辅助后端进程,并在 primary_conninfo 中设置 dbname,因为这是逻辑复制槽同步所必需的。
为 Patroni 配置验证实现 --ignore-listen-port 选项(Sahil Naphade)
使在运行 patroni --validate-config 时可以忽略已绑定的端口。
改进
使 wal_log_hints 可配置(Paul_Kim)
允许在 use_pg_rewind 设置为 off 的情况下避免启用 wal_log_hints 配置的开销。
在 DEBUG 级别记录 pg_basebackup 命令(Waynerv)
便于调试失败的初始化。
错误修复
在故障安全模式下推进级联节点的永久槽(Alexander Kukushkin)
确保在激活故障安全模式时,级联副本的槽在主节点上被正确推进。通过在 POST /failsafe REST API 请求的副本响应中扩展其 xlog_location 来实现。
不要让当前节点被选为同步节点(Alexander Kukushkin)
可能存在某些进程从当前主节点进行流复制,其 application_name 与当前主节点的名称匹配。Patroni 此前未正确处理此情况,可能导致主节点被声明为同步节点,从而阻塞切换操作。
对 POST /failsafe 忽略 restapi.allowlist_include_members(Alexander Kukushkin)
改进 GUC 验证(Polina Bungina)
由于通过运行 postgres --describe-config 命令进行额外验证,此前无法通过 Patroni 配置设置未在其中列出的 GUC。此限制现已移除。
当检测到 Unix 套接字时,在 .pgpass 文件中添加包含 localhost 的行(Alexander Kukushkin)
如果指定的 host 参数以 / 字符开头,Patroni 将在 .pgpass 文件中添加一行额外记录。这可以覆盖 host 与默认套接字目录路径匹配的边界情况。
修复日志问题(Waynerv)
在故障安全处理日志中定义了正确的请求 URL,并修复了 postmaster 检查日志中时间戳的顺序。
Version 3.3.2
发布于 2024-07-11
错误修复
修复原生 Postgres 同步复制模式(Israel Barth Rubio)
自从 Patroni 引入 synchronous_mode 以来,原生 Postgres 同步复制一直无法正常工作。通过此修复,当 synchronous_mode 被禁用时,如果用户已配置 synchronous_standby_names,Patroni 会按照用户配置的值进行设置。
处理备用节点上逻辑槽的失效(Polina Bungina)
自 PG16 起,备用节点上的逻辑复制槽可能因为水位原因而失效:从现在起,Patroni 会强制复制(即重新创建)失效的槽。
修复逻辑槽推进和复制之间的竞态条件(Alexander Kukushkin)
由于此错误,可能出现失效的逻辑复制槽在 PostgreSQL 重启时被多次复制的情况。
Version 3.3.1
发布于 2024-06-17
稳定性改进
错误修复
修复 replicatefrom 标签处理中的无限递归(Alexander Kukushkin)
作为此修复的一部分,还改进了 is_physical_slot() 检查并调整了文档。
修复备用集群中错误的角色报告(Alexander Kukushkin)
synchronous_standby_names 和同步复制仅在真正的主节点上工作,在级联复制的情况下会被 Postgres 直接忽略。在此修复之前,patronictl list 和 GET /cluster 错误地将某些节点报告为同步节点。
修复 allow_in_place_tablespaces GUC 的可用性问题(Polina Bungina)
allow_in_place_tablespaces 不仅添加到了 PostgreSQL 15 中,还被回移到了 PostgreSQL 10-14。
Version 3.3.0
发布于 2024-04-04
警告
所有较旧的 Patroni 版本与 ydiff>=1.3 不兼容。
有以下可用选项来"修复"此问题:
- 将 Patroni 升级到最新版本
- 在安装 Patroni 后安装
ydiff<1.3 - 安装
cdiff 模块
新特性
添加向 Zookeeper 客户端传递 auth_data 的能力(Aras Mumcuyan)
允许指定用于连接的认证凭据。
添加用于 Barman 集成的 contrib 脚本(Israel Barth Rubio)
提供一个 patroni_barman 应用程序,允许远程执行 Barman 操作,可用作自定义引导/自定义副本方法或 on_role_change 回调。更多信息请参阅 此处。
支持 JSON 日志格式(alisalemmi)
除了 plain(默认)外,Patroni 现在还支持 json 日志格式。需要安装 python-json-logger>=2.0.2 库。
显示 pending_restart_reason 信息(Polina Bungina)
提供关于导致 pending_restart 标志被设置的 PostgreSQL 参数的扩展信息。patronictl list 和 /patroni REST API 端点现在都显示参数名称及其差异(“diff”)作为 pending_restart_reason。
实现 nostream 标签(Grigory Smolkin)
如果 nostream 标签设置为 true,该节点将不使用复制协议来流式传输 WAL,而是依赖归档恢复(如果配置了 restore_command)。它还会禁用该节点本身及其所有级联副本上永久逻辑复制槽的复制和同步。
改进
实现 log 部分的验证(Alexander Kukushkin)
此前验证器未检查所提供的日志配置的正确性。
改进 PostgreSQL 参数变更的日志记录(Polina Bungina)
将旧值转换为人类可读的格式,并记录 pg_controldata 与 Patroni 全局配置不匹配的信息。
错误修复
正确过滤不允许的 pg_basebackup 选项(Israel Barth Rubio)
由于错误,当以 - setting: value 格式提供时,Patroni 未正确过滤为 basebackup 副本引导方法配置的不允许的选项。
修复 etcd3 认证错误处理(Alexander Kukushkin)
如果在执行请求之前未进行认证,则始终在 etcd3 认证错误时重试一次。此外,在重新认证时不重启 watcher。
改进验证器文件发现逻辑(Waynerv)
尽可能使用 importlib 库(适用于 Python 3.9+)来发现包含可用配置参数的文件。此实现更加稳定,不会破坏基于 zip 归档的 Patroni 发行版。
仅当 standby_cluster 部分中指定了多个主机时才使用 target_session_attrs(Alexander Kukushkin)
target_session_attrs=read-write 现在仅在 standby_cluster.host 部分包含以逗号分隔的多个主机时,才添加到备用主节点的 primary_conninfo 中。
添加 ydiff 库 1.3+ 版本的兼容代码(Alexander Kukushkin)
Patroni 依赖 ydiff 的一些非公开 API,因为它本应只是一个终端工具而非 Python 模块。不幸的是,1.3 版本的 API 变更破坏了旧版 Patroni。
Version 3.2.2
发布于 2024-01-17
错误修复
当 DCS 被清除时,不允许副本恢复初始化键(Alexander Kukushkin)
这发生在 Patroni 原本应该接管独立 PG 集群的方法中。
从 Consul 获取刚更新的 sync 键时使用一致性读取(Alexander Kukushkin)
Consul 不提供任何接口来立即获取刚更新的键的 ModifyIndex,因此我们必须执行显式读取操作。由于默认允许过期读取,我们有时会获取到键的过期版本。
如果需要重启的参数被重置为原始值,则重新加载 Postgres 配置(Polina Bungina)
此前 Patroni 只重置了 pending_restart,而没有更新配置。
修复在同步模式下故障转移到异步候选节点时确认提示消息的逻辑反转错误(Polina Bungina)
此问题仅存在于 patronictl 中。
在 patronictl 中将主节点从故障转移候选中排除(Polina Bungina)
如果集群健康,故障转移到现有主节点是无操作的。
以幂等方式创建 Citus 数据库和扩展(Alexander Kukushkin、Zhao Junwang)
如果需要向 Citus 数据库添加更多依赖项,这将允许在 post_bootstrap 脚本中创建它们。
不要过滤掉矛盾的 nofailover 标签(Polina Bungina)
在节点上设置的配置 {nofailover: false, failover_priority: 0} 不允许其参与选举,但实际上应该允许,因为 nofailover 标签应该具有更高的优先级。
修复 PyInstaller 冻结问题(Sophia Ruan)
freeze_support() 在 argparse 之后被调用,导致 Patroni 无法启动 Postgres。
修复 patronictl 和 Citus 配置的配置生成器中的错误(Israel Barth Rubio)
该错误阻止了通过环境变量设置的 patronictl 和 Citus 配置参数被写入生成的配置中。
在加入运行中的备用节点时恢复恢复 GUC 和一些 Patroni 管理的参数(Alexander Kukushkin)
Patroni 在 Postgres v12 及以上版本中无法重启,报告内部结构中缺少 port 的错误。
围绕 pending_restart 标志的修复(Polina Bungina)
在使用 recovery_target_action = promote 进行自定义引导时,或当某人使用例如 ALTER SYSTEM 更改了 hot_standby 或 wal_log_hints 时,不要暴露 pending_restart。
Version 3.2.1
发布于 2023-11-30
错误修复
限制 patronictl 中 --format 参数的可接受值(Alexander Kukushkin)
此前它接受任意字符串,当值未被识别时不产生任何输出。
在关闭时释放主节点键之前,验证副本节点已接收到检查点 LSN(Alexander Kukushkin)
此前在某些情况下,我们使用的是 SWITCH 记录的 LSN,该记录后面跟着 CHECKPOINT(如果启用了归档模式)。因此,旧主节点有时不得不执行 pg_rewind,但不会涉及数据丢失。
执行节点名称唯一性检查时进行真正的 HTTP 请求(Alexander Kukushkin)
在容器中运行 Patroni 时,流量可能通过 docker-proxy 路由,后者监听端口并接受传入连接。这会导致误报。
修复 Etcd v2 下的 Citus 支持(Alexander Kukushkin)
Patroni 在使用 Etcd v2 部署新的 Citus 集群时会失败。
修复 Postgres v16+ 下的 pg_rewind 行为(Alexander Kukushkin)
pg_waldump 的错误消息格式在 v16 中发生了变化,导致 Patroni 在不必要时也调用 pg_rewind。
修复自定义引导的错误(Alexander Kukushkin)
Patroni 错误地应用了 --command 参数,该参数本身就是引导命令。
修复 REST API 健康检查端点的问题(Sophia Ruan)
Postgres 重启后,由于连接未正确关闭,有可能返回 Postgres 的 unknown 状态。
缓存 postgres --describe-config 输出结果(Waynerv)
这些结果用于确定哪些 GUC 可用于验证 PostgreSQL 配置,我们不期望在 Patroni 运行期间此列表会发生变化。
Version 3.2.0
发布于 2023-10-25
废弃通知
bootstrap.users 支持将在 4.0.0 版本中移除。如果你需要在部署新集群后创建用户,请使用 bootstrap.post_bootstrap 钩子来完成。
破坏性变更
新特性
故障转移优先级(Mark Pekala)
借助 tags.failover_priority,现在可以使某个节点在领导者竞选中更受青睐。更多详情请参阅文档(ref tags)。
实现了 patroni --generate-config [--dsn DSN] 和 patroni --generate-sample-config(Polina Bungina)
允许为正在运行的PostgreSQL集群生成配置文件,或为新的Patroni集群生成示例配置文件。
为Patroni REST API使用专用的Postgres连接(Alexander Kukushkin)
这有助于在系统压力较大时避免阻塞主心跳循环。
在部分端点中丰富节点的 name 信息(sskserk)
对于监控端点,name 被添加到 scope 旁边;对于指标端点,name 被添加到标签中。
确保严格区分故障转移/切换(Polina Bungina)
在日志消息中更加精确,并允许在健康的同步集群中故障转移到异步节点。
使永久物理复制槽的行为类似于永久逻辑槽(Alexander Kukushkin)
在所有允许成为领导者的节点上创建永久物理复制槽,并使用 pg_replication_slot_advance() 函数来推进备用节点上槽的 restart_lsn。
在 patronictl 中添加通过 --dcs 参数指定命名空间的功能(Israel Barth Rubio)
当 patronictl 在没有配置文件的情况下使用时,这会很方便。
在自定义引导配置中添加对额外参数的支持(Israel Barth Rubio)
之前只能向 command 添加自定义参数,现在可以将它们作为映射列出。
改进
错误修复
在备用集群中忽略 synchronous_mode 设置(Polina Bungina)
Postgres不支持级联同步复制,不忽略 synchronous_mode 会导致备用集群中的切换失败。
处理 on_reload 回调的SIGCHLD信号(Alexander Kukushkin)
不这样做会导致僵尸进程,只有在下一次 on_reload 执行时才会被回收。
处理使用Etcd v3时的 AuthOldRevision 错误(Alexander Kukushkin,Kenny Do)
当Etcd配置为使用JWT且Etcd中的用户数据库被更新时,会引发此错误。
Version 3.1.2
发布于 2023-09-26
错误修复
修复了 wal_keep_size 检查的错误(Alexander Kukushkin)
wal_keep_size 是一个通常带有单位的GUC,Patroni无法将其值转换为 int。因此,bootstrap.dcs 的值随后不会被写入 /config 键。
检测并解决 /sync 键与 synchronous_standby_names 之间的不一致(Alexander Kukushkin)
通常,Patroni以非常特定的顺序更新 /sync 和 synchronous_standby_names,但在出现错误或有人手动重置 synchronous_standby_names 的情况下,Patroni会进入不一致状态。结果可能导致故障转移到异步节点。
加入运行中的Postgres时读取GUC的值(Alexander Kukushkin)
在 暂停 模式中重启时,Patroni会丢弃 postgresql.conf 中的 synchronous_standby_names GUC。为了解决这个问题并避免类似问题,Patroni在加入已运行的Postgres时会读取GUC的值。
消除检查节点唯一性时的烦人警告(Alexander Kukushkin)
如果Patroni快速重启,urllib3 会产生 WARNING 消息。
Version 3.1.1
发布于 2023-09-20
错误修复
在提升时重置故障安全状态(ChenChangAo)
如果切换/故障转移发生在故障安全模式激活后不久,新提升的主节点会在故障安全变为非活动状态后降级自己。
消除 patronictl 中无用的警告(Alexander Kukushkin)
如果 patronictl 使用与Patroni相同的patroni.yaml文件并可以访问 PGDATA 目录,它可能会显示关于全局配置中值不正确的烦人警告。
针对边界情况显式启用同步模式(Alexander Kukushkin)
如果没有副本从主节点进行流复制,同步模式实际上从未被激活。
修复了 0 整数值验证的错误(Israel Barth Rubio)
在大多数情况下,这不会导致任何问题,只是产生警告。
不为备用集群返回逻辑槽(Alexander Kukushkin)
Patroni无法在备用集群中创建逻辑复制槽,因此如果在全局配置中定义了逻辑槽,应忽略它们。
避免在 patronictl --help 输出中显示文档字符串(Israel Barth Rubio)
click 模块需要获得特殊提示才能实现。
修复了 kubernetes.standby_leader_label_value 的错误(Alexander Kukushkin)
此功能实际上从未工作过。
将集群系统标识符恢复到 patronictl list 输出中(Polina Bungina)
此问题是在实现Citus支持时引入的,当时我们需要隐藏标识符,因为协调器和所有工作节点的标识符不同。
在Kubernetes实现中覆盖 write_leader_optime 方法(Alexander Kukushkin)
该方法应在没有健康副本可用于成为新主节点时,将关闭LSN写入领导者的Endpoint/ConfigMap。
在暂停模式下不启动已停止的postgres(Alexander Kukushkin)
由于竞争条件,Patroni错误地认为备用节点应该重启,因为某些恢复参数(primary_conninfo 或类似参数)已更改。
修复了 patronictl query 命令的错误(Israel Barth Rubio)
当只提供 -m 参数或未提供 -r 和 -m 参数时,该命令无法工作。
正确处理用于启动postgres命令行中的整数参数(Polina Bungina)
如果值以字符串形式提供而未转换为整数,会导致Citus集群中基于 max_connections 的 max_prepared_transactions 计算不正确。
在决定 pg_rewind 时不依赖 pg_stat_wal_receiver(Alexander Kukushkin)
pg_stat_wal_receiver 报告的 received_tli 可能领先于实际重放的时间线,而通过复制连接由 IDENTIFY_SYSTEM 报告的时间线始终是正确的。
Version 3.1.0
发布于 2023-08-03
破坏性变更
警告
如果你启用了客户端证书验证(restapi.verify_client 设置为 required),你还必须在 ctl.certfile、ctl.keyfile、ctl.keyfile_password 中提供有效的客户端证书。如果未提供,Patroni将无法正常工作。
新特性
改进
patroni --validate-config 的各种改进(Alexander Kukushkin)
改进了不同DCS、bootstrap.dcs、ctl、restapi 和 watchdog 部分的参数验证。
如果Postgres在Patroni运行期间于恢复过程中崩溃,则不以恢复模式启动Postgres(Alexander Kukushkin)
这可以减少恢复时间,并有助于防止不必要的时间线递增。
避免不必要地更新 /status 键(Alexander Kukushkin)
当没有永久逻辑槽时,即使主节点上的LSN没有向前移动,Patroni也会在每次心跳循环中更新 /status。
不允许过期的主节点赢得领导者竞选(Alexander Kukushkin)
如果Patroni由于资源不足而挂起了很长时间,它会在获取领导者锁之前额外检查是否有其他节点已经提升了Postgres。
实现了某些PostgreSQL参数验证的可见性(Alexander Kukushkin,Feike Steenbergen)
如果 max_connections、max_wal_senders、max_prepared_transactions、max_locks_per_transaction、max_replication_slots 或 max_worker_processes 的验证失败,Patroni之前会使用某个合理的默认值。现在除此之外,它还会显示警告。
为 PGDATA 中创建的文件和目录设置权限(Alexander Kukushkin)
Patroni创建的所有文件之前只有所有者读/写权限。此行为会破坏在不同用户下运行并依赖组读权限的备份工具。现在Patroni会遵循 PGDATA 上的权限,并正确设置其在 PGDATA 内创建的所有目录和文件的权限。
错误修复
通过shell运行 archive_command(Waynerv)
Patroni可能会在单用户模式下进行崩溃恢复之前或 pg_rewind 之前归档一些WAL段。如果archive_command包含某些shell运算符(如 &&),它在Patroni中无法工作。
修复了"切换时"关闭检查(Polina Bungina)
可能出现指定的候选节点仍在流复制且未收到关闭检查的情况,但由于其他一些节点是健康的,领导者键被移除了。
修复了"是否为主节点"检查(Alexander Kukushkin)
在领导者竞选期间,副本无法识别旧领导者上的Postgres仍在作为主节点运行。
修复了 patronictl list(Alexander Kukushkin)
在 tsv、json 和 yaml 输出格式中缺少集群名称字段。
修复了暂停后的 pg_rewind 行为(Alexander Kukushkin)
在某些条件下,从维护模式退出后,Patroni无法使用 pg_rewind 将误判的主节点重新加入集群。
修复了Etcd v3实现中的错误(Alexander Kukushkin)
如果使用 create_revision/mod_revision 字段执行键更新时由于版本不匹配,则使内部KV缓存无效。
修复了暂停模式下备用集群中副本的行为(Alexander Kukushkin)
当领导者键过期时,备用集群中的副本不会跟随远程节点,而是保持 primary_conninfo 不变。
Version 3.0.4
发布于 2023-07-13
新特性
改进
改进了Etcd v3的错误消息(Alexander Kukushkin)
当Etcd v3集群不可访问时,Patroni之前报告无法访问 /v2 端点。
如果可能,在 patronictl 中使用仲裁读取(Alexander Kukushkin)
Etcd或Consul集群可能降级为只读状态,但从 patronictl 的视角来看一切正常。现在它将报错失败。
防止配置中的重复名称导致脑裂(Mark Pekala)
启动Patroni时将检查DCS中是否已注册同名节点,并尝试查询其REST API。如果REST API可访问,Patroni将报错退出。这有助于防止人为错误。
如果Postgres在Patroni运行期间崩溃,则不以恢复模式启动Postgres(Alexander Kukushkin)
这可以减少恢复时间,并有助于防止不必要的时间线递增。
错误修复
REST API SSL证书在收到SIGHUP后未重新加载(Israel Barth Rubio)
此回退在3.0.3中引入。
修复了 max_connections 等参数的整数GUC验证(Feike Steenbergen)
Patroni不接受带引号的数值。此回退在3.0.3中引入。
修复了 synchronous_mode 的问题(Alexander Kukushkin)
使用 synchronous_commit=off 执行 txid_current(),以避免在启用 synchronous_mode_strict 时意外等待不存在的同步备用节点。
Version 3.0.3
发布于 2023-06-22
新特性
兼容PostgreSQL 16 beta1(Alexander Kukushkin)
扩展了GUC验证器规则。
使PostgreSQL GUC验证器可扩展(Israel Barth Rubio)
验证器规则从位于 patroni/postgresql/available_parameters/ 目录中的YAML文件加载。文件按字母顺序排列并依次应用。这使得为非标准Postgres发行版提供自定义验证器成为可能。
添加了 restapi.request_queue_size 选项(Andrey Zhidenkov,Aleksei Sukhov)
设置Patroni REST API所用TCP套接字的请求队列大小。一旦队列已满,后续请求将收到"连接被拒绝"错误。默认值为5。
初始化新集群时直接调用 initdb(Matt Baker)
之前是通过 pg_ctl 调用的,这需要对传递给 initdb 的参数进行特殊引用。
添加了停止前钩子(Le Duane)
该钩子可通过 postgresql.before_stop 配置,在 pg_ctl stop 之前执行。退出代码不影响关闭过程。
添加了对自定义Postgres二进制文件名的支持(Israel Barth Rubio,Polina Bungina)
当使用自定义Postgres发行版时,Postgres二进制文件可能使用与社区Postgres发行版不同的名称编译。自定义二进制文件名可通过 postgresql.bin_name.* 和 PATRONI_POSTGRESQL_BIN_* 环境变量配置。
改进
错误修复
修复了Citus支持中的问题(Alexander Kukushkin)
如果在切换期间从已提升的工作节点到协调器的REST API调用失败,它会导致给定的Citus组在无限期内被阻塞。
允许在 patronictl 的 --dcs-url 选项中使用 etcd3 URL(Israel Barth Rubio)
如果用户尝试通过 patronictl 的 --dcs-url 选项传递 etcd3 URL,将会遇到异常。
Version 3.0.2
发布于 2023-03-24
警告
3.0.2版本放弃了对Python 3.6以下版本的支持。
新特性
在 /metrics 端点中添加了同步备用副本状态(Thomas von Dein,Alexander Kukushkin)
之前只报告 primary/standby_leader/replica。
在 patronictl 中用户友好地处理 PAGER(Israel Barth Rubio)
使分页器可通过 PAGER 环境变量配置,覆盖默认的 less 和 more。
使K8s可重试的HTTP状态码可配置(Alexander Kukushkin)
在某些托管平台上,可能会收到 401 Unauthorized 状态码,有时在几次重试后可以解决。
改进
仅在 recovery_target_action 设置为 promote 时,在自定义引导期间将 hot_standby 设置为 off(Alexander Kukushkin)
这对于使 recovery_target_action=pause 正确工作是必要的。
不允许 on_reload 回调终止其他回调(Alexander Kukushkin)
on_start/on_stop/on_role_change 通常用于添加/移除虚拟IP,on_reload 不应干扰它们。
在aws回调示例脚本中切换到 IMDSFetcher(Polina Bungina)
IMDSv2 需要令牌才能工作,IMDSFetcher 可以透明地处理它。
错误修复
修复了在Kubernetes上运行的Citus集群的 patronictl switchover(Lukáš Lalinský)
对于 default 以外的命名空间无法工作。
如果主版本未知,则不写入 PGDATA(Alexander Kukushkin)
如果启动后 PGDATA 为空(可能尚未挂载),Patroni会错误地假设PostgreSQL版本,并在实际主版本为v10+时错误地创建 recovery.conf 文件。
修复了协调器故障转移后的Citus元数据错误(Alexander Kukushkin)
citus_set_coordinator_host() 调用不会导致元数据同步,更改在工作节点上不可见。该问题通过切换到 citus_update_node() 来解决。
当所有etcd节点"失败"时,使用配置文件中列出的etcd主机作为后备(Alexander Kukushkin)
etcd集群可能随时间改变拓扑,Patroni会尝试跟踪它。如果在某个时刻所有节点都不可达,Patroni将在尝试重新连接时使用配置中的节点与最后已知拓扑的组合。
Version 3.0.1
发布于 2023-02-16
错误修复
Version 3.0.0
发布于 2023-01-30
此版本添加了与 Citus 的集成,使得在临时DCS中断期间无需降级主节点即可存活。
警告
3.0.0版本是支持Python 2.7的最后一个版本。即将发布的版本将放弃对Python 3.7以下版本的支持。
RAFT支持已废弃。我们将尽力维护它,但不保证也不对可能出现的问题负责。
此版本是逐步淘汰"master"、改用"primary"的第一步。只有运行了至少3.0.0版本,升级到下一个主版本才能可靠地工作。
新特性
DCS故障安全模式(Alexander Kukushkin,Polina Bungina)
如果启用此功能,它将允许Patroni集群在临时DCS中断期间存活。你可以在 文档 中找到更多详情。
Citus支持(Alexander Kukushkin,Polina Bungina,Jelte Fennema)
Patroni使 Citus 集群的高可用部署和管理变得简单。请查看 此处 获取更多信息。
改进
在删除未知但活跃的复制槽时抑制重复错误(Michael Banck)
Patroni仍会写入这些日志,但仅在DEBUG级别。
每个HA循环只运行一个监控查询(Alexander Kukushkin)
在启用同步复制的情况下之前不是这样。
仅保留最新的失败数据目录(William Albertus Dembo)
如果引导失败,Patroni过去会将$PGDATA文件夹重命名并添加时间戳后缀。从现在起,后缀将为 .failed,如果此类文件夹已存在,则在重命名前将其删除。
改进了同步复制连接的检查(Alexander Kukushkin)
当新主机被添加到 synchronous_standby_names 时,只有在它成功追上主节点且 pg_stat_replication.sync_state = 'sync' 的情况下,才会在DCS中设置为同步。
移除的功能
Version 2.1.7
发布于 2023-01-04
错误修复
Version 2.1.6
发布于 2022-12-30
改进
修复了SSL套接字关闭时的烦人异常(Alexander Kukushkin)
HAProxy在获得HTTP状态码后立即关闭连接,没有给Patroni留出正确关闭SSL连接的时间。
调整arm64的示例Dockerfile(Polina Bungina)
移除显式的 amd64 和 x86_64,不删除 libnss_files.so.*。
安全改进
为非复制连接强制设置 search_path=pg_catalog(Alexander Kukushkin)
由于Patroni严重依赖超级用户连接,我们希望保护它免受使用 public 模式中与 pg_catalog 中相应对象具有相同名称和签名的用户定义函数和/或运算符进行的潜在攻击。为此,Patroni创建的所有连接(复制连接除外)均强制设置 search_path=pg_catalog。
防止密码被记录在 pg_stat_statements 中(Feike Steenbergen)
通过在创建用户时设置 pg_stat_statements.track_utility=off 来实现。
错误修复
将 proxy_address 声明为可选项(Denis Laxalde)
因为它实际上是一个非必需选项。
改进insecure选项的行为(Alexander Kukushkin)
当使用客户端证书进行REST API请求时,Ctl的 insecure 选项无法正常工作。
引导新集群时从 bootstrap.dcs 获取watchdog配置(Matt Baker)
Patroni过去在引导新集群时使用默认值初始化watchdog配置,而不是使用用于引导DCS的配置。
修复了WIN32中查找可执行文件时处理文件扩展名的方式(Martín Marqués)
仅在文件名没有扩展名时才添加 .exe。
修复了Consul TTL设置(Alexander Kukushkin)
在HTTPClient上设置值时我们使用了 ttl/2.0,但忘记在类的属性中将当前值乘以2。这导致Consul TTL偏差了两倍。
移除的功能
Version 2.1.5
发布于 2022-11-28
此版本增强了与PostgreSQL 15的兼容性,并宣布Etcd v3支持已达到生产就绪状态。Patroni on Raft仍处于Beta阶段。
新特性
改进 patroni --validate-config(Denis Laxalde)
如果配置无效则以代码1退出,并将错误打印到stderr。
在暂停模式下不删除复制槽(Alexander Kukushkin)
Patroni会在成员加入/离开集群时自动创建/移除物理复制槽。在暂停模式下将不再移除槽。
支持监控端点的 HEAD 请求方法(Robert Cutajar)
如果用 HEAD 代替 GET,Patroni将仅返回HTTP状态码。
支持在Windows上运行behave测试(Alexander Kukushkin)
通过引入新的REST API端点 POST /sigterm 在Windows上模拟Patroni的优雅关闭(SIGTERM)。
引入 postgresql.proxy_address(Alexander Kukushkin)
它将作为 proxy_url 写入DCS中的成员键,可用于服务发现。
稳定性改进
从线程中调用 pg_replication_slot_advance()(Alexander Kukushkin)
在具有许多逻辑复制槽的繁忙集群上,pg_replication_slot_advance() 调用会影响主HA循环,可能导致成员键过期。
在旧主节点上调用 pg_rewind 之前归档可能缺失的WAL(Polina Bungina)
如果主节点崩溃并停机了相当长时间,归档和新主节点中可能缺少一些WAL文件。pg_rewind 可能会从旧主节点上删除这些WAL文件,使其无法作为备用节点启动。通过归档 ready 状态的WAL文件,我们不仅缓解了这个问题,而且总体上改善了持续归档体验。
在尝试创建Kubernetes Service时忽略 403 错误(Nick Hudson,Polina Bungina)
Patroni之前会因为尝试创建可能已存在的服务而频繁输出失败日志。
改进存活探针(Alexander Kukushkin)
如果心跳循环在主节点上运行时间超过 ttl 或在副本上超过 2*ttl,存活探针将开始失败。这将使我们能够在Kubernetes上将其作为 watchdog 的替代方案使用。
确保切换时只有同步节点尝试获取锁(Alexander Kukushkin,Polina Bungina)
之前在不指定目标的情况下执行手动切换时,有很小的概率异步但数据最新的成员可能成为领导者。
避免在引导运行时进行克隆(Ants Aasma)
不允许在集群引导运行时触发不需要领导者的创建副本方法。
与kazoo-2.9.0的兼容性(Alexander Kukushkin)
根据Python版本,如果在已关闭的套接字上调用 select(),SequentialThreadingHandler.select() 方法可能会引发 TypeError 和 IOError 异常。
在套接字关闭前显式关闭SSL连接(Alexander Kukushkin)
不这样做会导致OpenSSL 3.0出现 unexpected eof while reading 错误。
与 prettytable>=2.2.0 的兼容性(Alexander Kukushkin)
由于内部API更改,集群名称标题显示在了不正确的行上。
错误修复
处理Etcd lease_grant的过期令牌(monsterxx03)
在出错时获取新令牌并重试请求。
修复了 GET /read-only-sync 端点的错误(Alexander Kukushkin)
它在上一个版本中引入,实际上从未工作过。
处理数据目录存储消失的情况(Alexander Kukushkin)
Patroni会定期检查PGDATA是否存在且非空,但在存储出现问题时,os.listdir() 会引发 OSError 异常,从而中断心跳循环。
在等待用户后端关闭时应用 master_stop_timeout(Alexander Kukushkin)
看起来像用户后端的东西实际上可能是无法停止的后台工作进程(例如Citus Maintenance Daemon)。
为 postgresql.listen 接受 *:<port> 格式(Denis Laxalde)
patroni --validate-config 之前会报告其无效。
Raft中的超时修复(Alexander Kukushkin)
当Patroni或patronictl启动时,它们会尝试从已知成员获取Raft集群拓扑。这些调用之前没有设置适当的超时。
在令牌更改时强制更新consul服务(John A. Lotoski)
不这样做会导致"rpc error making call: rpc error making call: ACL not found"错误。
Version 2.1.4
发布于 2022-06-01
新特性
改进 pg_rewind 在典型Debian/Ubuntu系统上的行为(Gunnar “Nick” Bluth)
在将 postgresql.conf 保存在数据目录之外的Postgres安装方式中(例如Ubuntu/Debian软件包),pg_rewind --restore-target-wal 无法正确获取 restore_command 的值。
允许在Consul服务检查中设置 TLSServerName(Michael Gmelin)
当检查通过IP进行且Consul的 node_name 不是FQDN时非常有用。
在watchdog中添加 ppc64le 支持(Jean-Michel Scheiwiler)
同时修复了某些非x86平台上的watchdog支持。
将aws.py回调从 boto 切换到 boto3(Alexander Kukushkin)
boto 2.x自2018年起已被弃用,且在Python 3.9上运行失败。
定期刷新K8s上的服务账户令牌(Haitao Li)
自Kubernetes v1.21起,服务账户令牌会在1小时后过期。
添加 /read-only-sync 监控端点(Dennis4b)
类似于 /read-only,但仅包含同步副本。
稳定性改进
当逻辑解码配置与主库不匹配时,不再将逻辑复制槽复制到副本(Alexander Kukushkin)
如果槽的 plugin 或 database 配置选项不匹配,副本将不再从主库复制逻辑复制槽。此前,在副本复制槽并启动之后才会检查槽是否匹配这些配置选项,导致不必要的重复重启。
对PostgreSQL v12+的恢复配置参数进行特殊处理(Alexander Kukushkin)
作为副本启动时,Patroni应该能够在领导者地址发生变化时更新 postgresql.conf 并重启/重新加载,方法是缓存当前参数值,而不是从 pg_settings 中查询。
改进 postgresql.listen 参数中IPv6地址的处理(Alexander Kukushkin)
由于 listen 参数包含端口,用户会尝试将IPv6地址放在方括号中,但当列表中有多个IP时,方括号无法被正确剥离。
仅在PostgreSQL v10及更早版本上执行分歧检查时使用 replication 凭据(Alexander Kukushkin)
如果启用了 rewind,Patroni将在较新的Postgres版本上重新使用 superuser 或 rewind 凭据。
错误修复
修复 dateutil.parser 缺失导入的问题(Wesley Mendes)
测试之前没有失败,只是因为其他模块也导入了该模块。
确保 optime 注解为字符串类型(Sebastian Hasler)
在某些情况下,Patroni会尝试将其作为数值传递。
改进 pg_rewind 失败时的处理(Alexander Kukushkin)
如果主库在 pg_rewind 期间变得不可用,$PGDATA 将处于损坏状态。随后,即使配置不允许,Patroni也会删除数据目录。
当PostgreSQL未就绪时,不要从领导者 ConfigMap/Endpoint 中移除 slots 注解(Alexander Kukushkin)
如果未传递 slots 值,注解将保持当前值。
处理K8s API watcher的并发问题(Alexander Kukushkin)
在某些(未知的)条件下,watcher可能会变得过时;因此,attempt_to_acquire_leader() 方法可能由于HTTP状态码409而失败。在这种情况下,我们会重置watcher连接并从头开始。
Version 2.1.3
发布于 2022-02-18
新特性
为 patronictl 添加加密TLS密钥支持(Alexander Kukushkin)
可通过 ctl.keyfile_password 或 PATRONI_CTL_KEYFILE_PASSWORD 环境变量进行配置。
向/metrics端点添加更多指标(Alexandre Pereira)
具体包括 patroni_pending_restart 和 patroni_is_paused。
支持在备用集群配置中指定多个主机(Michael Banck)
如果备用集群从Patroni集群进行复制,利用自PostgreSQL v10起 libpq 中可用的客户端故障转移功能会很方便。即在备用领导者的 primary_conninfo 和 pg_rewind 设置中的连接字符串里设置 target_session_attrs=read-write。pgpass 文件将生成多行内容(每个主机一行),备用集群不会在主集群节点上调用 CHECKPOINT,而是等待 pg_control 更新。
稳定性改进
兼容旧版 psycopg2(Alexander Kukushkin)
例如,从Ubuntu 18.04软件包安装的 psycopg2 还没有 UndefinedFile 异常。
当所有Etcd节点无响应时重启 etcd3 watcher(Alexander Kukushkin)
如果watcher仍然存活,即使所有Etcd节点都出现故障,get_cluster() 方法仍会继续返回过时的信息。
暂停状态下不要移除备用集群的领导者锁(Alexander Kukushkin)
此前,锁仅由作为主库运行的节点维护,而非备用领导者。
错误修复
修复备用领导者引导中的错误(Alexander Kukushkin)
如果Postgres在60秒后未开始接受连接,Patroni会认为引导失败。此错误在2.1.2版本中引入。
修复故障转移到级联备库时的错误(Alexander Kukushkin)
在确定应在级联备库上创建哪些槽时,我们忘记考虑领导者可能不存在的情况。
修复Postgres配置验证器中的小问题(Alexander Kukushkin)
PostgreSQL v14中引入的整数参数验证失败,因为validator.py中的最小值和最大值被加了引号。
检查领导者状态时使用复制凭据(Alexander Kukushkin)
可能存在设置了 remove_data_directory_on_diverged_timelines 但未定义 rewind_credentials 且不允许节点间超级用户访问的情况。
修复REST API证书替换时的"端口被占用"错误(Ants Aasma)
切换证书时,与并发API请求之间存在竞态条件。如果在替换期间有一个活跃的请求,替换将因端口被占用错误而失败,导致Patroni陷入没有活跃API服务器的状态。
修复密码包含 % 字符时集群引导的错误(Bastien Wirtz)
引导方法执行 DO 代码块时所有参数都已正确引用,但 cursor.execute() 方法不接受传递空参数列表。
修复"AttributeError: no attribute ’leader’“异常(Hrvoje Milković)
当启用同步模式且DCS内容被清除时可能发生此错误。
修复分歧时间线检查中的错误(Alexander Kukushkin)
Patroni错误地判断时间线已经分歧。对于pg_rewind来说这不会造成问题,但如果不允许pg_rewind且设置了 remove_data_directory_on_diverged_timelines,则会导致前领导者被重新初始化。
Version 2.1.2
发布于 2021-12-03
新特性
兼容 psycopg>=3.0(Alexander Kukushkin)
默认优先使用 psycopg2。仅当 psycopg2 不可用或版本过旧时才会使用 psycopg>=3.0。
向REST API添加 dcs_last_seen 字段(Michael Banck)
此字段记录集群成员最后一次成功与DCS通信的时间(Unix时间戳)。这对于识别和/或分析网络分区非常有用。
当 pg_controldata 报告"shut down"时释放领导者锁(Alexander Kukushkin)
为解决 archive_command 缓慢/失败时切换/关闭速度慢的问题,Patroni会在 pg_controldata 开始报告PGDATA已干净 shut down 且验证至少有一个副本接收了所有变更后,立即移除领导者键。如果没有满足此条件的副本,则不会移除领导者键,保持旧的行为,即Patroni将继续更新锁。
添加 sslcrldir 连接参数支持(Kostiantyn Nemchenko)
该新连接参数在PostgreSQL v14中引入。
允许为Zookeeper中的ZNode设置ACL(Alwyn Davis)
引入新配置选项 zookeeper.set_acls,使Kazoo为其创建的每个ZNode应用默认ACL。
稳定性改进
将下一次恢复尝试延迟到下一个HA循环(Alexander Kukushkin)
如果Postgres因磁盘空间不足(例如)而崩溃并因此无法启动,Patroni会过于频繁地尝试恢复,导致日志泛滥。
在降级之前添加日志,因为降级可能需要一些时间(Michael Banck)
降级完成可能需要一些时间,仅从日志中可能不太明显正在发生什么。
改进"I am"状态消息(Michael Banck)
no action. I am a secondary ({0}) 对比 no action. I am ({0}), a secondary
将 wal_keep_segments 转换为 wal_keep_size 时转换为整数(Jorge Solórzano)
可以在全局 动态配置 中将 wal_keep_segments 指定为字符串,由于Python是动态类型语言,字符串会被简单地重复。例如:wal_keep_segments: "100" 会被转换为 100100100100100100100100100100100100100100100100MB。
启用同步复制时仅允许切换到同步节点(Alexander Kukushkin)
此外,领导者选举也仅在已知的同步节点之间进行。
当Postgres响应缓慢时使用缓存的角色作为回退(Alexander Kukushkin)
在某些极端情况下,Postgres可能非常慢,以至于正常的监控查询无法在几秒钟内完成。statement_timeout 异常未被正确处理可能导致当领导者键过期或更新失败时Postgres未能及时降级。在出现此类异常时,Patroni将使用缓存的 role 来确定Postgres是否以主库身份运行。
避免不必要的成员ZNode更新(Alexander Kukushkin)
如果成员数据中没有值发生变化,则不应进行更新。
优化提升后的检查点(Alexander Kukushkin)
如果最新时间线已存储在 pg_control 中,则避免执行 CHECKPOINT。这有助于避免在使用 initdb 初始化新集群后立即执行不必要的 CHECKPOINT。
选择同步节点时优先选择没有 nofailover 标签的成员(Alexander Kukushkin)
此前,同步节点仅基于复制延迟进行选择,因此带有 nofailover 标签的节点与其他节点有相同的机会成为同步节点。这种行为既令人困惑又危险,因为在主库故障时无法自动进行故障转移。
从etcd机器缓存中移除重复主机(Michael Banck)
etcd集群中的已公布客户端URL可能配置错误。在Patroni中移除重复项是一个简单的改进。
错误修复
在槽管理时跳过临时复制槽(Alexander Kukushkin)
从v10开始,pg_basebackup 会为WAL流创建一个临时复制槽,而Patroni会因为槽名称未知而尝试删除它。为修复此问题,我们在查询 pg_stat_replication_slots 视图时跳过所有临时槽。
确保 pg_replication_slot_advance() 不会超时(Alexander Kukushkin)
Patroni在此情况下使用默认的 statement_timeout,一旦调用失败,很可能永远无法恢复,导致 pg_wal 体积增大和 pg_catalog 膨胀。
/status 在降级时未更新(Alexander Kukushkin)
降级PostgreSQL后,旧领导者会更新DCS中的最后LSN。从 2.1.0 开始引入了新的 /status 键,但optime仍然被写入 /optime/leader。
处理降级时的DCS异常(Alexander Kukushkin)
在由于更新领导者锁失败而降级主库时,可能发生DCS完全宕机的情况,导致 get_cluster() 调用抛出异常。未被正确处理会导致Postgres保持停止状态直到DCS恢复。
use_unix_socket_repl 在某些情况下不生效(Alexander Kukushkin)
具体来说,当未设置 postgresql.unix_socket_directories 时。在这种情况下,Patroni应该使用 libpq 的默认值。
修复Patroni REST API中的若干问题(Alexander Kukushkin)
clusters_unlocked 有时可能未定义,导致 GET /metrics 端点出现异常。此外,错误处理方法假设 connect_address 元组总是包含两个元素,但实际上在IPv6的情况下可能有更多元素。
等待新提升的节点完成恢复后再决定是否进行rewind(Alexander Kukushkin)
实际提升发生和新时间线创建之前可能需要一些时间。如果不等待,副本可能会错误地判断不需要rewind。
处理决定是否进行rewind时历史文件中缺失时间线的情况(Alexander Kukushkin)
如果主库上的历史文件中缺少当前副本的时间线,副本会错误地认为不需要rewind。
Version 2.1.1
发布于 2021-08-19
新特性
支持ETCD SRV名称后缀(David Pavlicek)
Etcd允许在同一域下区分多个Etcd集群,Patroni现在也支持此功能。
丰富历史记录,包含新领导者信息(huiyalin525)
为 patronictl history 输出添加了新列。
使集群内Kubernetes配置的CA证书包可配置(Aron Parsons)
默认情况下,Patroni使用 /var/run/secrets/kubernetes.io/serviceaccount/ca.crt,此新功能允许指定自定义的 kubernetes.cacert。
支持动态注册/注销Consul服务和更改标签(Tommy Li)
此前需要重启Patroni。
错误修复
避免不必要的REST API重新加载(Alexander Kukushkin)
前一版本添加了在磁盘上证书变更时重新加载REST API证书的功能。不幸的是,重新加载在启动后会无条件地发生。
设置 etcd.use_proxies 时不要解析集群成员(Alexander Kukushkin)
启动时Patroni通过查询成员列表来检查Etcd集群的健康状况。此外,它还尝试解析主机名,但在通过代理使用Etcd时这是不必要的,并会导致不必要的警告。
跳过 pg_stat_replication 中包含NULL值的行(Alexander Kukushkin)
pg_stat_replication 视图似乎可能在 state = 'streaming' 时,replay_lsn、flush_lsn 或 write_lsn 字段中包含NULL值。
Version 2.1.0
发布于 2021-07-06
此版本添加了与PostgreSQL v14的兼容性,使逻辑复制槽在故障转移/切换中得以保留,实现了REST API的允许列表支持,并将日志减少到每次心跳一行。
新特性
兼容PostgreSQL v14(Alexander Kukushkin)
如果Patroni本身不处于"暂停"模式,则取消暂停WAL回放。WAL回放可能因为主库上某些参数(例如 max_connections)的更改而被"暂停”。
逻辑槽故障转移(Alexander Kukushkin)
使逻辑复制槽在PostgreSQL v11+上的故障转移/切换中得以保留。复制槽在重启时从主库复制到副本,然后使用 pg_replication_slot_advance() 函数将其向前推进。因此,槽在故障转移之前就已存在,不会丢失任何事件,但有可能某些事件会被重复投递。
为Patroni REST API实现允许列表(Alexander Kukushkin)
配置后,只有匹配规则的IP才被允许调用不安全的端点。此外,还可以自动将集群成员的IP添加到列表中。
添加通过Unix套接字进行复制连接的支持(Mohamad El-Rifai)
此前,Patroni始终使用TCP进行复制连接,这可能导致SSL验证问题。使用Unix套接字可以使复制用户免于SSL验证。
基于用户定义标签的健康检查(Arman Jafari Tehrani)
除 预定义标签 外,还可以指定任意数量的自定义标签,这些标签在 patronictl list 输出和REST API中可见。现在可以在健康检查中使用自定义标签。
添加Prometheus /metrics 端点(Mark Mercado、Michael Banck)
该端点暴露与 /patroni 相同的指标。
减少Patroni日志的冗余度(Alexander Kukushkin)
当一切正常时,每次HA循环运行只写入一行日志。
破坏性变更
旧的 permanent logical replication slots 功能将不再适用于PostgreSQL v10及更早版本(Alexander Kukushkin)
在提升后创建逻辑槽的策略无法保证不丢失逻辑事件,因此已被禁用。
/leader 端点在节点持有锁时始终返回200(Alexander Kukushkin)
提升备用集群需要更新负载均衡器健康检查,这不太方便且容易遗忘。为解决此问题,我们更改了 /leader 健康检查端点的行为。它将返回200,而不考虑集群是普通集群还是 备用集群。
Raft支持改进
可靠的Raft流量加密支持(Alexander Kukushkin)
由于 PySyncObj 中的各种问题,加密支持非常不稳定。
处理Raft实现中的DNS问题(Alexander Kukushkin)
如果 self_addr 和/或 partner_addrs 使用DNS名称而非IP配置,PySyncObj 实际上只在对象创建时进行一次解析。当同一节点以不同IP重新上线时会导致问题。
稳定性改进
兼容 psycopg2-2.9+(Alexander Kukushkin)
在 psycopg2 中,autocommit = True 在 with connection 代码块中被忽略,这会破坏复制协议连接。
修复Zookeeper下过多的HA循环运行(Alexander Kukushkin)
成员ZNode的更新会引发连锁反应,导致HA循环连续运行多次。
当磁盘上的REST API证书发生变更时进行重新加载(Michael Todorovic)
如果REST API证书文件被就地更新,Patroni不会执行重新加载。
使用Kerberos认证时不创建pgpass目录(Kostiantyn Nemchenko)
Kerberos和密码认证是互斥的。
修复自定义引导中的小问题(Alexander Kukushkin)
仅在执行PITR时以 hot_standby=off 启动Postgres,并在PITR完成后重启。
错误修复
兼容 kazoo-2.7+(Alexander Kukushkin)
由于Patroni自行处理重试,它依赖于 kazoo 的旧行为,即在没有可用连接时立即丢弃对Zookeeper集群的请求。
当已知通过代理连接时,显式请求Etcd v3集群的版本(Alexander Kukushkin)
Patroni通过gRPC-gateway与Etcd v3集群交互,根据集群版本需要使用不同的端点(/v3、/v3beta 或 /v3alpha)。版本仅在与集群拓扑一起解析时获取,但通过代理连接时从未进行过拓扑解析。
Version 2.0.2
发布于 2021-02-22
新特性
能够忽略外部管理的复制槽(James Coleman)
Patroni会尝试移除任何它不认识的复制槽,但确实存在复制槽应由外部管理的情况。现在可以配置不应被移除的槽。
为REST API添加密码套件限制支持(Gunnar “Nick” Bluth)
可通过 restapi.ciphers 或 PATRONI_RESTAPI_CIPHERS 环境变量进行配置。
为REST API添加加密TLS密钥支持(Jonathan S. Katz)
可通过 restapi.keyfile_password 或 PATRONI_RESTAPI_KEYFILE_PASSWORD 环境变量进行配置。
REST API认证凭据的常量时间比较(Alex Brasetvik)
使用 hmac.compare_digest() 替代 ==,后者容易受到时序攻击。
基于复制延迟选择同步节点(Krishna Sarabu)
如果同步节点上的复制延迟开始超过配置的阈值,它可能被降级为异步节点和/或被其他节点替换。行为通过 maximum_lag_on_syncnode 控制。
稳定性改进
执行自定义引导时以 hot_standby = off 启动Postgres(Igor Yanchenko)
在自定义引导期间,Patroni恢复基础备份、启动Postgres并等待恢复完成。备库上的某些PostgreSQL参数不能小于主库上的值,如果新值(从WAL恢复)高于配置值,Postgres会panic并停止。为避免此行为,我们将在没有 hot_standby 模式的情况下执行自定义引导。
当所需的watchdog不健康时警告用户(Nicolas Thauvin)
当watchdog设备在必需模式下不可写或缺失时,成员无法被提升。添加了警告以向用户展示在哪里查找此配置错误。
改进单用户模式恢复的详细输出(Alexander Kukushkin)
如果Patroni注意到PostgreSQL未正常关闭,在某些情况下会通过以单用户模式启动Postgres来执行崩溃恢复。恢复可能失败(例如由于磁盘空间不足),但错误被吞没了。
添加与 python-consul2 模块的兼容性(Alexander Kukushkin、Wilfried Roset)
老旧的 python-consul 已数年未维护,因此有人创建了一个包含新功能和错误修复的分支。
运行 patronictl 时不使用 bypass_api_service(Alexander Kukushkin)
当K8s Pod在非 default 命名空间中运行时,它不一定有足够的权限查询 kubernetes 端点。在这种情况下,Patroni会显示警告并忽略 bypass_api_service 设置。对于 patronictl 来说,这个警告有些烦人。
如果 raft.data_dir 不存在则创建,或确保其可写(Mark Mercado)
改善用户友好性和可用性。
错误修复
在暂停状态下丢失领导者锁时不中断重启或提升(Alexander Kukushkin)
在暂停状态下,允许在没有锁的情况下以主库身份运行Postgres。
修复REST API中 shutdown_request() 的问题(Nicolas Limage)
为改善SSL连接处理并延迟握手直到线程启动,Patroni重写了 HTTPServer 中的几个方法。shutdown_request() 方法被遗漏了。
修复使用Zookeeper时睡眠时间的问题(Alexander Kukushkin)
Patroni有可能在HA代码运行之间睡眠长达两倍的时间。
修复引导失败后移动数据目录时无效的 os.symlink() 调用(Andrew L’Ecuyer)
如果引导失败,Patroni会重命名数据目录、pg_wal和所有表空间。之后更新符号链接以保持文件系统一致。符号链接创建失败是因为 src 和 dst 参数被交换了。
修复post_bootstrap()方法中的错误(Alexander Kukushkin)
如果未配置超级用户密码,Patroni无法调用 post_init 脚本,因此整个引导过程失败。
修复备用集群中pg_rewind的问题(Alexander Kukushkin)
如果超级用户名称与Postgres不同,备用集群中的 pg_rewind 会因为连接字符串中不包含数据库名称而失败。
仅在Etcd v3认证明确失败时才退出(Alexander Kukushkin)
启动时Patroni执行Etcd集群拓扑发现并在必要时进行认证。可能其中一台etcd服务器不可访问,Patroni尝试在此服务器上进行认证并失败,而不是重试下一个节点。
处理psutil cmdline()返回空列表的情况(Alexander Kukushkin)
僵尸进程仍然是postmaster的子进程,但它们没有cmdline()。
将 PATRONI_KUBERNETES_USE_ENDPOINTS 环境变量视为布尔值(Alexander Kukushkin)
不这样做会导致无法通过环境变量禁用 kubernetes.use_endpoints。
改进并发端点更新错误的处理(Alexander Kukushkin)
Patroni将显式查询当前端点对象,验证当前Pod仍持有领导者锁,然后重复更新。
Version 2.0.1
发布于 2020-10-01
新特性
在 patronictl edit-config 中,如果 less 不可用,则使用 more 作为分页器(Pavel Golub)
在Windows上将使用 more.com。此外,requirements.txt 中的 cdiff 已更改为 ydiff,但 patronictl 仍然为兼容性同时支持两者。
添加 raft 的 bind_addr 和 password 支持(Alexander Kukushkin)
raft.bind_addr 在NAT后运行时可能很有用。raft.password 启用流量加密(需要 cryptography 模块)。
添加 sslpassword 连接参数支持(Kostiantyn Nemchenko)
该连接参数在PostgreSQL 13中引入。
稳定性改进
更改暂停模式下的行为(Alexander Kukushkin)
- 如果
PGDATA 目录缺失/为空,Patroni将不会调用 bootstrap 方法。 - Patroni在暂停模式下不会因sysid不匹配而退出,仅记录警告。
- 如果Postgres未在恢复模式下运行(接受写入)但sysid与初始化键不匹配,节点将不会在暂停模式下尝试获取领导者键。
执行崩溃恢复时应用 master_start_timeout(Alexander Kukushkin)
如果Postgres在领导者节点上崩溃,Patroni通过以单用户模式启动Postgres来执行崩溃恢复。在崩溃恢复期间,领导者锁会持续更新。如果崩溃恢复未在 master_start_timeout 秒内完成,Patroni将强制停止并释放领导者锁。
从 urllib3 依赖中移除 secure 额外项(Alexander Kukushkin)
添加它的唯一原因是Python 2.7的 ipaddress 依赖。
错误修复
修复 Kubernetes.update_leader() 中的错误(Alexander Kukushkin)
一个未处理的异常阻止了在更新领导者对象失败时降级主库。
修复使用RAFT时 patronictl 挂起的问题(Alexander Kukushkin)
使用Patroni配置运行 patronictl 时,self_addr 应被添加到 partner_addrs 中。
修复 get_guc_value() 中的错误(Alexander Kukushkin)
Patroni无法在PostgreSQL 12上获取 restore_command 的值,因此为 pg_rewind 获取缺失WAL的功能不起作用。
Version 2.0.0
发布于 2020-09-02
此版本增强了与 PostgreSQL 13 的兼容性,添加了对多个同步备用节点的支持,对 pg_rewind 的处理进行了重大改进,添加了对 Etcd v3 和纯 RAFT 模式下 Patroni(不依赖 Etcd、Consul 或 Zookeeper)的支持,并使得可选调用 pre_promote(隔离)脚本成为可能。
PostgreSQL 13 支持
提升为 standby_leader 时不触发 on_reload,适用于 PostgreSQL 13+(Alexander Kukushkin)
提升为 standby_leader 时我们会更改 primary_conninfo,更新角色并重新加载 Postgres。由于 on_role_change 和 on_reload 实际上是重复的,Patroni 将只调用 on_role_change。
添加对 gssencmode 和 channel_binding 连接参数的支持(Alexander Kukushkin)
PostgreSQL 12 引入了 gssencmode,13 引入了 channel_binding 连接参数,如果在 postgresql.authentication 部分中定义,现在可以使用它们。
处理 wal_keep_segments 重命名为 wal_keep_size 的情况(Alexander Kukushkin)
在配置错误的情况下(在 13 上使用 wal_keep_segments 或在旧版本上使用 wal_keep_size),Patroni 将自动调整配置。
在 13 上尽可能使用带有 --restore-target-wal 选项的 pg_rewind(Alexander Kukushkin)
在 PostgreSQL 13 上,Patroni 检查是否配置了 restore_command 并告知 pg_rewind 使用它。
新特性
- \[BETA\]
实现纯 RAFT 模式下的 Patroni 支持(Alexander Kukushkin)
这使得可以在没有第三方依赖(如 Etcd、Consul 或 Zookeeper)的情况下运行 Patroni。为实现高可用,您需要运行三个 Patroni 节点,或者两个 Patroni 节点加一个运行 patroni_raft_controller 的节点。更多信息请参阅 文档。
- \[BETA\]
通过 gRPC-gateway 实现对 Etcd v3 协议的支持(Alexander Kukushkin)
Etcd 3.0 在四年多前发布,Etcd 3.4 默认禁用了 v2。v2 也有可能从 Etcd 中被完全移除,因此我们在 Patroni 中实现了对 Etcd v3 的支持。要开始使用它,您必须在 Patroni 配置文件中显式创建 etcd3 部分。
支持多个同步备用节点(Krishna Sarabu)
允许运行具有多个同步副本的集群。同步副本的最大数量由新参数 synchronous_node_count 控制。它默认设置为 1,当 synchronous_mode 设置为 off 时无效。
添加调用 pre_promote 脚本的可能性(Sergey Dudoladov)
与回调不同,pre_promote 脚本在获取主节点锁之后、提升 Postgres 之前同步调用。如果脚本失败或以非零退出码退出,当前节点将释放主节点锁。
添加对配置目录的支持(Floris van Nee)
目录中的 YAML 文件按字母顺序加载和应用。
PostgreSQL 参数的高级验证(Alexander Kukushkin)
如果特定参数不受当前 PostgreSQL 版本支持或其值不正确,Patroni 将完全移除该参数或尝试修复该值。
强制检查点完成后唤醒主线程(Alexander Kukushkin)
副本通过 DCS 中主节点的成员键等待检查点指示。该键通常仅每个 HA 循环更新一次。不唤醒主线程的话,副本将不得不多等待最多 loop_wait 秒。
在 9.6+ 上使用 pg_stat_wal_receiver 视图(Alexander Kukushkin)
该视图包含 primary_conninfo 和 primary_slot_name 的最新值,而 recovery.conf 的内容可能已过期。
改进 Patroni 配置文件中 IPv6 地址的处理(Mateusz Kowalski)
IPv6 地址应该用方括号括起来,但 Patroni 之前期望的是纯格式。现在两种格式都受支持。
添加 Consul service_tags 配置参数(Robert Edström)
它们对于动态服务发现很有用,例如供负载均衡器使用。
为 Zookeeper 实现 SSL 支持(Kostiantyn Nemchenko)
需要 kazoo>=2.6.0。
为自定义引导方法实现 no_params 选项(Kostiantyn Nemchenko)
允许直接调用 wal-g、pgBackRest 和其他备份工具,无需将它们包装在 shell 脚本中。
初始化失败后移动 WAL 和表空间(Feike Steenbergen)
执行 reinit 时,Patroni 已经在移除 PGDATA 的同时移除符号链接的 WAL 目录和表空间。现在 move_data_directory() 方法将执行类似的工作,即重命名 WAL 目录和表空间并更新 PGDATA 中的符号链接。
改进 pg_rewind 支持
改进时间线分歧检查(Alexander Kukushkin)
当副本上的重放位置未超过切换点,或者旧主节点上检查点记录的结尾与切换点相同时,我们不需要执行 rewind。为了获取检查点记录的结尾,我们使用 pg_waldump 并解析其输出。
如果 pg_rewind 报告缺少 WAL,尝试获取缺失的 WAL(Alexander Kukushkin)
pg_rewind 所需的 WAL 段可能已不存在于 pg_wal 目录中,因此 pg_rewind 无法找到分歧点之前的检查点位置。从 PostgreSQL 13 开始,pg_rewind 可以使用 restore_command 来获取缺失的 WAL。对于较旧的 PostgreSQL 版本,Patroni 解析失败的 rewind 尝试的错误信息,并尝试通过自行调用 restore_command 来获取缺失的 WAL。
检测备用集群中的新时间线,并在必要时触发 rewind/重新初始化(Alexander Kukushkin)
standby_cluster 与主集群解耦,因此不会立即知道主节点选举和时间线切换。为了检测这一事实,standby_leader 会定期检查 pg_wal 中的新历史文件。
缩短和美化历史日志输出(Alexander Kukushkin)
当 Patroni 尝试确定是否需要 pg_rewind 时,它可能会将主节点的历史文件内容写入日志。历史文件随着每次故障转移/切换而增长,最终占据太多行,其中大部分并不是很有用。Patroni 现在不再显示原始数据,而是只显示当前副本时间线之前的 3 行和之后的 2 行。
K8s 改进
去除 kubernetes Python 模块依赖(Alexander Kukushkin)
官方 Python kubernetes 客户端包含大量自动生成的代码,因此非常臃肿。Patroni 只使用 K8s API 端点的一小部分,实现对它们的支持并不困难。
使绕过 kubernetes 服务成为可能(Alexander Kukushkin)
在 K8s 上运行时,Patroni 通常通过 kubernetes 服务与 K8s API 通信,其地址通过 KUBERNETES_SERVICE_HOST 环境变量公开。与其他服务一样,kubernetes 服务由 kube-proxy 处理,后者根据配置依赖用户空间程序或 iptables 进行流量路由。跳过中间组件直接连接到 K8s 主节点,使我们能够实现更好的重试策略,并在 K8s 主节点升级时降低 Postgres 降级的风险。
同步 Patroni 集群所有 Pod 的 HA 循环(Alexander Kukushkin)
不这样做会将故障检测时间从 ttl 增加到 ttl + loop_wait。
在 K8s 上填充子集地址中的 references 和 nodename(Alexander Kukushkin)
一些负载均衡器依赖此信息。
修复 update_leader() 中可能的竞态条件(Alexander Kukushkin)
在 Patroni 外部发生的 leader configmap 或 endpoint 的并发更新可能导致 update_leader() 调用失败。在这种情况下,Patroni 会重新检查当前节点是否仍持有主节点锁并重复更新。
显式禁止修补不存在的配置(Alexander Kukushkin)
对于 kubernetes 以外的 DCS,PATCH 调用会因为 cluster.config 为 None 而引发异常失败,但在 Kubernetes 上它会愉快地创建配置注解并阻止在引导完成后写入引导配置。
修复 暂停 中的错误(Alexander Kukushkin)
当主节点键不存在时,副本会删除 primary_conninfo 并重启 Postgres,但它们应该什么都不做。
REST API 改进
将 TLS 握手延迟到工作线程启动后(Alexander Kukushkin、Ben Harris)
如果 TLS 握手在 API 线程中完成且客户端未发送任何数据,API 线程将被阻塞(存在 DoS 风险)。
在 REST API 中独立于客户端证书检查 basic-auth(Alexander Kukushkin)
此前只验证客户端证书。独立执行两项检查是完全有效的用例。
在 OPTIONS 请求的 HTTP 头后写入双 CRLF(Sergey Burladyan)
HAProxy 对单个 CRLF 没有问题,但 Consul 健康检查会抱怨连接断开和意外的 EOF。
GET /cluster 对 Zookeeper 显示过期的成员信息(Alexander Kukushkin)
该端点使用的是 Patroni 内部集群视图。对于 Patroni 本身不会造成任何问题,但当暴露给外部时,我们需要显示最新的信息,特别是复制延迟。
修复备用集群的健康检查(Alexander Kukushkin)
对主节点的 GET /standby-leader 和对 standby_leader 的 GET /master 错误地响应 200。
实现 DELETE /switchover(Alexander Kukushkin)
此 REST API 调用删除已计划的切换。
创建 /readiness 和 /liveness 端点(Alexander Kukushkin)
当 K8s 服务使用标签选择器时,它们可用于从子集地址中排除"不健康"的 Pod。
增强 GET /replica 和 GET /async REST API 健康检查(Krishna Sarabu、Alexander Kukushkin)
检查现在支持可选的关键字 ?lag=<max-lag>,仅当延迟小于提供的值时才响应 200。如果依赖此功能,请注意关于主节点 WAL 位置的信息仅每 loop_wait 秒更新一次!
添加对 REST API 响应中用户自定义 HTTP 头的支持(Yogesh Sharma)
如果请求来自浏览器,此功能可能很有用。
patronictl 改进
在 patronictl pause 中不要尝试调用不存在的 leader(Alexander Kukushkin)
在 K8s 上暂停没有 leader 的集群时,patronictl 会显示成员 “None” 无法访问的警告。
处理成员 conn_url 缺失的情况(Alexander Kukushkin)
在 K8s 上,Pod 可能因为 Patroni 尚未运行而没有必要的注解。这会导致 patronictl 失败。
添加打印 ASCII 集群拓扑的能力(Maxim Fedotov、Alexander Kukushkin)
对于查看具有级联复制的集群概览非常有用。
实现 patronictl flush switchover(Alexander Kukushkin)
在此之前,patronictl flush 仅支持取消计划的重启。
错误修复
使用现有 PGDATA 引导集群时的属性错误(Krishna Sarabu)
在尝试创建/更新 /history 键时,Patroni 访问了尚未在 DCS 中创建的 ClusterConfig 对象。
改进 Consul 中的异常处理(Alexander Kukushkin)
touch_member() 方法中未处理的异常导致整个 Patroni 进程崩溃。
对 post_init 脚本强制执行 synchronous_commit=local(Alexander Kukushkin)
Patroni 在创建用户(replication、rewind)时已经这样做了,但在 post_init 的情况下遗漏了。因此,如果脚本本身没有在内部执行此操作,synchronous_mode 下的引导将无法完成。
增加 Consul 连接池管理器中的 maxsize(ponvenkates)
使用默认的 size=1 会生成一些警告。
Patroni 错误地报告 Postgres 正在运行(Alexander Kukushkin)
例如当 Postgres 因磁盘空间不足错误而崩溃时,状态未被更新。
在 pgpass 中用 * 替代缺失或空的值(Alexander Kukushkin)
例如当未指定 standby_cluster.port 时,pgpass 文件生成不正确。
跳过为名称包含特殊字符的主节点创建物理复制槽(Krishna Sarabu)
当名称包含特殊字符(如 ‘-’,例如 “abc-us-1”)时,Patroni 似乎在为主节点创建休眠槽(当定义了 slots 时)。
避免在自定义引导中删除不存在的 pg_hba.conf(Krishna Sarabu)
如果自定义引导后 pg_hba.conf 恰好位于 pgdata 目录之外,Patroni 会失败。
Version 1.6.5
发布于 2020-08-23
新特性
主节点停止超时(Krishna Sarabu)
Patroni 在停止 Postgres 时允许等待的秒数。仅在启用 synchronous_mode 时有效。当设置为大于 0 的值且 synchronous_mode 已启用时,如果停止操作运行时间超过 master_stop_timeout 设置的值,Patroni 将向 postmaster 发送 SIGKILL。请根据您的持久性/可用性权衡来设置该值。如果未设置此参数或设置为非正值,master_stop_timeout 不会生效。
不为主节点名称创建永久物理槽(Alexander Kukushkin)
一个常见问题是当副本宕机时主节点回收 WAL 段。现在我们为静态集群提供了一个好的解决方案,即节点数量固定且名称永不改变的集群。您只需在 slots 中列出所有节点的名称,这样当节点宕机(未在 DCS 中注册)时主节点就不会移除该槽。
配置验证器的初步版本(Igor Yanchenko)
使用 patroni --validate-config patroni.yaml 来验证 Patroni 配置。
可配置时间线历史最大长度的可能性(Krishna Sarabu)
Patroni 将故障转移/切换的历史记录写入 DCS 中的 /history 键。随着时间推移,该键的大小会变大,但大多数情况下只有最后几行是有意义的。max_timelines_history 参数允许指定在 DCS 中保留的最大时间线历史条目数。
Kazoo 2.7.0 兼容性(Danyal Prout)
Kazoo 中一些非公开方法更改了签名,但 Patroni 依赖于它们。
patronictl 改进
显示成员标签(Kostiantyn Nemchenko、Alexander Kukushkin)
标签是为每个节点单独配置的,此前没有简便方法来查看它们的概览。
改进成员输出(Alexander Kukushkin)
冗余的集群名称不再在每行显示,仅在表头中显示。
$ patronictl list
+ Cluster: batman (6813309862653668387) +---------+----+-----------+---------------------+
| Member | Host | Role | State | TL | Lag in MB | Tags |
+-------------+----------------+--------+---------+----+-----------+---------------------+
| postgresql0 | 127.0.0.1:5432 | Leader | running | 3 | | clonefrom: true |
| | | | | | | noloadbalance: true |
| | | | | | | nosync: true |
+-------------+----------------+--------+---------+----+-----------+---------------------+
| postgresql1 | 127.0.0.1:5433 | | running | 3 | 0.0 | |
+-------------+----------------+--------+---------+----+-----------+---------------------+
显式指定配置文件但未找到时报错(Kaarel Moppel)
此前 patronictl 仅报告一条 DEBUG 消息。
解决未初始化的 K8s Pod 导致 patronictl 崩溃的问题(Alexander Kukushkin)
Patroni 依赖 K8s 上的某些 Pod 注解。当某个 Patroni Pod 正在停止或启动时,尚未有有效的注解,patronictl 会因异常而失败。
稳定性改进
如果对 K8s API 服务器的 LIST 调用失败,应用 1 秒退避(Alexander Kukushkin)
这主要是为了避免日志泛滥,同时也有助于防止主线程的饥饿。
如果 K8s API 返回 retry-after HTTP 头则重试(Alexander Kukushkin)
如果 K8s API 服务器被请求淹没,它可能会要求重试。
从 postmaster 中清除 KUBERNETES_ 环境变量(Feike Steenbergen)
KUBERNETES_ 环境变量对 PostgreSQL 不是必需的,但将它们暴露给 postmaster 也会将它们暴露给后端和普通数据库用户(例如使用 pl/perl)。
重新初始化时清理表空间(Krishna Sarabu)
在 reinit 期间,Patroni 仅删除 PGDATA 而保留用户定义的表空间目录。这导致 Patroni 在 reinit 中循环。之前的解决方法是实现 自定义引导 脚本。
提升后显式执行 CHECKPOINT(Alexander Kukushkin)
这有助于缩短新主节点可用于 pg_rewind 之前的时间。
智能刷新 Etcd 成员(Alexander Kukushkin)
如果 Patroni 未能在 Etcd 集群的所有成员上执行请求,Patroni 将在下次重试之前重新检查 A 或 SRV 记录以获取 IP/主机的变更。
跳过 pg_controldata 中缺失的值(Feike Steenbergen)
当尝试使用与 PGDATA 版本不匹配的二进制文件时,值会缺失。Patroni 仍会尝试启动 Postgres,Postgres 会抱怨主版本不匹配并以错误中止。
错误修复
在需要时为 Consul 禁用 SSL 验证(Julien Riou)
从 urllib3 的某个版本开始,必须显式将 cert_reqs 设置为 ssl.CERT_NONE 才能有效禁用 SSL 验证。
避免在 HA 循环的每个周期都打开复制连接(Alexander Kukushkin)
回归问题在 1.6.4 中引入。
在失败的主节点上调用 on_role_change 回调(Alexander Kukushkin)
在某些情况下,这可能导致虚拟 IP 仍然挂载在旧主节点上。回归问题在 1.4.5 中引入。
如果 pg_rewind 成功后 postgres 已启动,则重置 rewind 状态(Alexander Kukushkin)
由于此错误,Patroni 在暂停模式下会启动手动关闭的 postgres。
检查 recovery.conf 时将 recovery_min_apply_delay 转换为 ms
如果在 PostgreSQL 12 之前的版本上配置了 recovery_min_apply_delay,Patroni 会无限重启副本。
PyInstaller 兼容性(Alexander Kukushkin)
PyInstaller 将 Python 应用程序冻结(打包)为独立可执行文件。当我们将 multiprocessing 的启动方法从 fork 切换为 spawn 时,兼容性被破坏。
Version 1.6.4
发布于 2020-01-27
新特性
为 patronictl reinit 实现 --wait 选项(Igor Yanchenko)
使用 --wait 选项时,patronictl 将等待 reinit 完成。
进一步改进 Windows 支持(Igor Yanchenko、Alexander Kukushkin)
- 所有用于集成测试的 shell 脚本均已用 Python 重写
- 在非 POSIX 系统上将使用
pg_ctl kill 来停止 postgres - 不再尝试使用 Unix 域套接字
稳定性改进
确保 unix_socket_directories 和 stats_temp_directory 存在(Igor Yanchenko)
在 Patroni 和 Postgres 启动时,确保 unix_socket_directories 和 stats_temp_directory 存在或尝试创建它们。如果创建失败,Patroni 将退出。
确保 postgresql.pgpass 位于 Patroni 有写入权限的位置(Igor Yanchenko)
如果没有写入权限,Patroni 将抛出异常并退出。
默认禁用 Consul serfHealth 检查(Kostiantyn Nemchenko)
即使在轻微的网络问题情况下,失败的 serfHealth 也会导致与该节点关联的所有会话失效。因此,主节点键会比 ttl 更早丢失,导致副本不必要的重启,甚至可能导致主节点降级。
为到 K8s API 的连接配置 TCP keepalive(Alexander Kukushkin)
如果在 TTL 秒后从套接字未收到任何数据,可以认为它已死。
避免在创建用户时记录密码(Alexander Kukushkin)
如果密码被拒绝或日志配置为 verbose 或完全未配置,密码可能会被写入 postgres 日志。为避免这种情况,Patroni 在尝试创建/更新用户之前会将 log_statement、log_min_duration_statement 和 log_min_error_statement 更改为安全值。
错误修复
在级联副本上使用 standby_cluster 配置中的 restore_command(Alexander Kukushkin)
standby_leader 从该功能存在之初就已经这样做了。不在副本上做同样的事情可能会阻止它们跟上 standby leader。
更新备用集群报告的时间线(Alexander Kukushkin)
在时间线切换的情况下,备用集群正确地从主节点复制,但 patronictl 报告的是旧时间线。
允许在 custom_conf 中定义某些恢复参数(Alexander Kukushkin)
在副本上验证恢复参数时,如果 archive_cleanup_command、promote_trigger_file、recovery_end_command、recovery_min_apply_delay 和 restore_command 未在 patroni 配置中定义但在 postgresql.auto.conf 或 postgresql.conf 以外的文件中定义,Patroni 将跳过它们。
改进对名称中包含句号的 PostgreSQL 参数的处理(Alexander Kukushkin)
此类参数可以由扩展定义,其中单位不一定是字符串。更改值可能需要重启(例如 pg_stat_statements.max)。
改进关闭期间的异常处理(Alexander Kukushkin)
在关闭期间,Patroni 会尝试更新其在 DCS 中的状态。如果 DCS 不可访问,可能会引发异常。缺少异常处理会阻止日志线程停止。
Version 1.6.3
发布于 2019-12-05
错误修复
运行 pg_rewind 时不暴露密码(Alexander Kukushkin)
此错误在 #1301 中引入。
将 postgresql.authentication 中指定的连接参数应用到 pg_basebackup 和自定义副本创建方法(Alexander Kukushkin)
它们依赖于类 URL 的连接字符串,因此参数从未被应用。
Version 1.6.2
发布于 2019-12-05
新特性
实现 patroni --version(Igor Yanchenko)
打印当前 Patroni 版本并退出。
为所有 HTTP 请求设置 user-agent HTTP 头(Alexander Kukushkin)
Patroni 通过 HTTP 协议与 Consul、Etcd 和 Kubernetes API 通信。拥有特别定制的 user-agent(例如:Patroni/1.6.2 Python/3.6.8 Linux)可能对调试和监控有用。
使异常追踪的日志级别可配置(Igor Yanchenko)
如果设置 log.traceback_level=DEBUG,追踪信息仅在 log.level=DEBUG 时可见。默认行为保持不变。
稳定性改进
搜索配置文件所需的模块时,避免导入所有 DCS 模块(Alexander Kukushkin)
如果我们只需要例如 Zookeeper,则无需导入 Etcd、Consul 和 Kubernetes 的模块。这有助于减少内存使用并解决 Failed to import smth 的 INFO 消息问题。
从显式依赖中移除 Python requests 模块(Alexander Kukushkin)
它不用于任何关键功能,但在新版本的 urllib3 发布时会导致很多问题。
改进将 etcd.hosts 写为逗号分隔字符串而非 YAML 数组时的处理(Igor Yanchenko)
此前当以 host1:port1, host2:port2 格式(逗号后有空格)书写时会失败。
易用性改进
在 patronictl 中不强迫用户从空列表中选择成员(Igor Yanchenko)
如果用户提供了错误的集群名称,我们将引发异常而不是要求从空列表中选择成员。
如果 REST API 无法绑定,使错误消息更有帮助(Igor Yanchenko)
对于没有经验的用户来说,可能很难从 Python 堆栈跟踪中弄清楚出了什么问题。
错误修复
修复 wal_buffers 的计算(Alexander Kukushkin)
基本单位在 PostgreSQL 11 中从 8 kB 块更改为字节。
仅在 PostgreSQL 10+ 上在 primary_conninfo 中使用 passfile(Alexander Kukushkin)
在较旧版本上,除非安装了最新版本的 libpq,否则无法保证 passfile 能正常工作。
Version 1.6.1
发布于 2019-11-15
新特性
新增 PATRONICTL_CONFIG_FILE 环境变量(msvechla)
它允许通过环境变量配置 patronictl 的 --config-file 参数。
实现 patronictl history(Alexander Kukushkin)
显示故障转移/切换的历史记录。
执行 pg_rewind 时在 PGOPTIONS 中传入 -c statement_timeout=0(Alexander Kukushkin)
这可以防止服务器上 statement_timeout 设置为较小值时,pg_rewind 执行的某些语句被取消的问题。
允许 PostgreSQL 配置使用更小的值(Soulou)
Patroni 之前不允许某些 PostgreSQL 配置参数设置为低于某些硬编码值。现在允许的最小值更小了,默认值保持不变。
允许基于证书的认证(Jonathan S. Katz)
此功能为超级用户、复制、rewind 账户启用了基于证书的认证,并允许用户指定希望使用的 sslmode。
在 primary_conninfo 中使用 passfile 代替密码(Alexander Kukushkin)
这避免了在 postgresql.conf 上设置 600 权限的需要。
无论配置是否变更都执行 pg_ctl reload(Alexander Kukushkin)
有些配置文件可能不受 Patroni 管控。当有人通过 REST API 或向 Patroni 进程发送 SIGHUP 进行 reload 时,通常期望 Postgres 也会被 reload。之前当 Patroni 配置的 postgresql 部分没有变更时,这不会发生。
比较所有恢复参数,而不仅仅是 primary_conninfo(Alexander Kukushkin)
之前 check_recovery_conf() 方法只检查 primary_conninfo 是否变更,从未考虑其他恢复参数。
支持不重启即可应用某些恢复参数(Alexander Kukushkin)
从 PostgreSQL 12 开始,以下恢复参数可以不重启即可更改:archive_cleanup_command、promote_trigger_file、recovery_end_command 和 recovery_min_apply_delay。在未来的 Postgres 版本中此列表将会扩展,Patroni 将自动支持。
支持在线更改 use_slots(Alexander Kukushkin)
之前需要重启 Patroni 并手动删除 slots。
启动 Postgres 时只移除 PATRONI_ 前缀的环境变量(Cody Coons)
这将解决运行各种外部数据包装器时遇到的许多问题。
稳定性改进
与 K8s API 交互时使用 LIST + WATCH(Alexander Kukushkin)
它可以高效地接收对象变更(pods、endpoints/configmaps),减轻 K8s 主节点的压力。
改进 bootstrap 时 PGDATA 非空的处理流程(Alexander Kukushkin)
根据 initdb 源代码,当 PGDATA 中只有 lost+found 和 .dotfiles 时会被视为空目录。现在 Patroni 做了相同的处理。如果 PGDATA 恰好非空,同时从 pg_controldata 的角度看又无效,Patroni 将报错并退出。
避免在每次 HA 循环中调用开销较大的 os.listdir()(Alexander Kukushkin)
当系统处于 IO 压力下时,os.listdir() 可能需要几秒(甚至几分钟)才能执行完毕,严重影响 Patroni 的 HA 循环。这甚至可能因缺少更新导致 leader 键从 DCS 中消失。现在有一种更好、开销更小的方式来检查 PGDATA 是否非空——检查 PGDATA 中 global/pg_control 文件是否存在。
日志基础设施的一些改进(Alexander Kukushkin)
之前由于日志线程是 daemon 线程,在关闭时可能会丢失最后几行日志。
在 python 3.4+ 上使用 spawn 多进程启动方法(Maciej Kowalczyk)
Python 中线程和多进程混合使用存在已知 问题。从默认的 fork 方法切换到 spawn 是推荐的解决方案。不这样做可能导致 Postmaster 启动进程挂起,Patroni 无限报告 INFO: restarting after failure in progress,而实际上 Postgres 已经在正常运行。
REST API 改进
支持在 REST API 中检查客户端证书(Alexander Kukushkin)
如果 verify_client 设置为 required,Patroni 将对所有 REST API 调用检查客户端证书。设置为 optional 时,只对所有不安全的 REST API 端点检查客户端证书。
当 Postgres 未运行时,GET /replica 健康检查请求返回 503 响应码(Alexander Anikin)
Postgres 在开始接受客户端连接之前可能需要花费大量时间进行恢复。
实现 /history 和 /cluster 端点(Alexander Kukushkin)
/history 端点显示 DCS 中 history 键的内容。/cluster 端点显示所有集群成员以及一些服务信息,如待处理和已计划的重启或切换。
Etcd 支持改进
在 Etcd RAFT 内部错误时重试(Alexander Kukushkin)
当 Etcd 节点正在关闭时,它会发送 response code=300, data='etcdserver: server stopped',这之前会导致 Patroni 降级主节点。
不要过早放弃 Etcd 请求重试(Alexander Kukushkin)
当出现网络问题时,Patroni 之前会很快耗尽 Etcd 节点列表并放弃,而没有用完整个 retry_timeout,这可能导致主节点被降级。
错误修复
在向 pg_rewind 用户授予执行权限时禁用 synchronous_commit(kremius)
如果 bootstrap 时使用了 synchronous_mode_strict: true,由于没有可用的同步节点,GRANT EXECUTE 语句会无限期等待。
修复 python 3.7 上的内存泄漏(Alexander Kukushkin)
Patroni 使用 ThreadingMixIn 来处理 REST API 请求,而 python 3.7 默认将每个请求生成的线程设为非守护线程。
修复异步操作中的竞争条件(Alexander Kukushkin)
patronictl reinit --force 有可能被恢复已停止的 Postgres 的尝试所覆盖。这最终会导致 Patroni 在 basebackup 运行时尝试启动 Postgres。
修复 postmaster_start_time() 方法中的竞争条件(Alexander Kukushkin)
如果该方法从 REST API 线程执行,则需要创建一个单独的游标对象。
修复名称包含大写字母的同步备库无法被提升的问题(Alexander Kukushkin)
我们将名称转换为小写,因为 Postgres 在将 application_name 与 synchronous_standby_names 中的值进行比较时也是这样做的。
在启动新回调之前,连同回调进程一起终止所有子进程(Alexander Kukushkin)
不这样做会使在 bash 中实现回调变得困难,最终可能导致两个回调同时运行的情况。
修复"start failed"问题(Alexander Kukushkin)
在某些条件下,尽管 Postgres 正在运行,其状态可能被设置为"start failed"。
Version 1.6.0
发布于 2019-08-05
此版本增加了对 PostgreSQL 12 的兼容性,使得在 PostgreSQL 11 及更新版本上无需超级用户即可运行 pg_rewind,并启用了 IPv6 支持。
新特性
将 Psycopg2 从依赖项中移除,必须独立安装(Alexander Kukushkin)
从 2.8.0 开始,psycopg2 被拆分为两个不同的包:psycopg2 和 psycopg2-binary,它们可以同时安装到文件系统的相同位置。为了减少依赖冲突问题,我们让用户自行选择安装方式。有几个可选方案,请参阅 文档。
兼容 PostgreSQL 12(Alexander Kukushkin)
从 PostgreSQL 12 开始不再有 recovery.conf,所有原来的恢复参数都被转换为 GUC。为了防止 ALTER SYSTEM SET primary_conninfo 或类似操作,Patroni 将解析 postgresql.auto.conf 并从中删除所有备库和恢复参数。Patroni 配置保持向后兼容。例如,尽管 restore_command 是一个 GUC,仍然可以在 postgresql.recovery_conf.restore_command 部分中指定它,Patroni 会将其写入 PostgreSQL 12 的 postgresql.conf 中。
支持在 PostgreSQL 11 及更新版本上无需超级用户使用 pg_rewind(Alexander Kukushkin)
如果要使用此功能,请在 Patroni 配置文件的 postgresql.authentication.rewind 部分定义 username 和 password。对于已存在的集群,需要手动创建用户并 GRANT EXECUTE 若干函数的权限。更多详情请参阅 PostgreSQL 文档。
对副本上实际和期望的 primary_conninfo 值进行智能比较(Alexander Kukushkin)
这有助于在将已有的主备集群转换为 Patroni 管理时避免副本重启。
IPv6 支持(Alexander Kukushkin)
有两个主要问题。Patroni REST API 服务之前只监听 0.0.0.0,且在 api_url 和 conn_url 中使用的 IPv6 IP 地址没有被正确引用。
Kerberos 支持(Ajith Vilas,Alexander Kukushkin)
使得可以在 Postgres 节点之间使用 Kerberos 认证,而无需在 Patroni 配置文件中定义密码。
管理 pg_ident.conf(Alexander Kukushkin)
此功能的工作方式与 pg_hba.conf 类似:如果在配置文件或 DCS 中定义了 postgresql.pg_ident,Patroni 将把其值写入 pg_ident.conf;但如果定义了 postgresql.parameters.ident_file,Patroni 将认为 pg_ident 由外部管理,不会更新该文件。
REST API 改进
新增 /health 端点(Wilfried Roset)
仅在 PostgreSQL 正在运行时返回 HTTP 状态码。
新增 /read-only 和 /read-write 端点(Julien Riou)
/read-only 端点实现跨副本和主节点的读取负载均衡。/read-write 端点是 /primary、/leader 和 /master 的别名。
使用 SSLContext 包装 REST API 套接字(Julien Riou)
ssl.wrap_socket() 已被弃用,且仍然允许即将弃用的协议(如 TLS 1.1)。
日志改进
两阶段日志记录(Alexander Kukushkin)
所有日志消息首先写入内存队列,然后由单独的线程异步刷新到 stderr 或文件中。最大队列大小有限制(可配置)。如果达到限制,Patroni 将开始丢失日志,但这仍然比阻塞 HA 循环要好。
为 GET/OPTIONS API 调用及其延迟启用调试日志(Jan Tomsa)
这有助于调试 HAProxy、Consul 或其他用于判断哪个节点是主节点/副本的工具所执行的健康检查。
记录 Retry 中捕获的异常(Daniel Kucera)
当达到尝试次数或超时时记录最终异常。这有望帮助调试与 DCS 通信失败时的一些问题。
patronictl 改进
增强计划切换和重启的对话交互(Rafia Sabih)
之前的对话没有考虑到计划操作,因此具有误导性。
检查配置文件是否存在(Wilfried Roset)
当给定的文件名不存在时,明确提示配置文件信息,而不是静默忽略(这可能导致误解)。
为 EDITOR 添加回退值(Wilfried Roset)
当 EDITOR 环境变量未定义时,patronictl edit-config 会因 PatroniCtlException 而失败。新的策略是尝试 editor 然后 vi,这在大多数系统上应该都可用。
Consul 支持改进
错误修复
修复切换/故障转移中的边界情况(Sharoon Thomas)
如果 REST API 不可访问且我们使用 DCS 作为回退时,变量 scheduled_at 可能未定义。
自定义 bootstrap 期间在 pg_hba.conf 中对 localhost 开放信任认证(Alexander Kukushkin)
之前只对 unix_socket 开放,这导致了大量错误:FATAL: no pg_hba.conf entry for replication connection from host "127.0.0.1", user "replicator"
即使前任 leader 领先也将同步节点视为健康(Alexander Kukushkin)
如果主节点失去对 DCS 的访问,它会以只读模式重启 Postgres,但其他节点可能仍然可以通过 REST API 访问旧主节点。这种情况导致同步备库无法提升,因为旧主节点报告的 WAL 位置领先于同步备库。
备用集群错误修复(Alexander Kukushkin)
使得在 standby_leader 不可访问时可以在备用集群中引导副本,以及其他一些小修复。
Version 1.5.6
发布于 2019-08-03
新特性
支持通过一组代理与 etcd 集群通信(Alexander Kukushkin)
可能存在 etcd 集群无法直接访问但可以通过一组代理访问的情况。在这种情况下,Patroni 不会执行 etcd 拓扑发现,而只是在代理主机之间轮询。此行为由 etcd.use_proxies 控制。
更改节点角色变化时的回调行为(Alexander Kukushkin)
如果角色从 master 或 standby_leader 变为 replica,或从 replica 变为 standby_leader,将不再调用 on_restart 回调,而是调用 on_role_change 回调。
更改 Postgres 的启动方式(Alexander Kukushkin)
使用 multiprocessing.Process 替代执行自身,使用 multiprocessing.Pipe 将 postmaster pid 传输给 Patroni 进程。之前我们使用管道,这会导致 postmaster 进程的 stdin 被关闭。
错误修复
修复 REST API 为 standby leader 返回的角色(Alexander Kukushkin)
之前错误地返回 replica 而不是 standby_leader。
如果回调无法被终止则等待其结束(Julien Tachoires)
Patroni 没有足够的权限终止在 sudo 下运行的回调脚本,这会取消新的回调。如果运行中的脚本无法被终止,Patroni 将等待其完成然后运行下一个回调。
减少 dcs.get_cluster 方法的锁持有时间(Alexander Kukushkin)
由于锁被持有,DCS 的慢速会影响 REST API 的健康检查,导致误报。
改进当 pg_wal/pg_xlog 是符号链接时清理 PGDATA 的行为(Julien Tachoires)
在这种情况下,Patroni 将显式删除目标目录中的文件。
移除不必要的 os.path.relpath 使用(Ants Aasma)
它依赖于能够解析工作目录,如果 Patroni 在一个后来从文件系统中取消链接的目录中启动,这将失败。
与 Etcd 通信时不强制 ssl 版本(Alexander Kukushkin)
由于某些未知原因,debian 和 ubuntu 上的 python3-etcd 不是基于最新版本的包,因此它强制使用 Etcd v3 不支持的 TLSv1。我们在 Patroni 端解决了这个问题。
Version 1.5.5
发布于 2019-02-15
此版本引入了前主节点自动重新初始化的功能,改进了 patronictl list 的输出,并修复了若干错误。
新特性
新增 PATRONI_ETCD_PROTOCOL、PATRONI_ETCD_USERNAME 和 PATRONI_ETCD_PASSWORD 环境变量支持(Étienne M)
之前只能在配置文件中或作为 PATRONI_ETCD_URL 的一部分来配置它们,这并不总是方便的。
支持自动重新初始化前主节点(Alexander Kukushkin)
如果 pg_rewind 被禁用或无法使用,前主节点可能因时间线分叉而无法作为新副本启动。在这种情况下,唯一的修复方法是清除数据目录并重新初始化。此行为可以通过设置 postgresql.remove_data_directory_on_diverged_timelines 来更改。设置后,Patroni 将自动清除数据目录并重新初始化前主节点。
在 patronictl list 中显示时间线信息(Alexander Kukushkin)
这有助于检测过时的副本。此外,如果端口值不是默认值或有多个成员运行在同一主机上,Host 将包含 ‘:{port}’。
创建与 $SCOPE-config 端点关联的 headless service(Alexander Kukushkin)
“config” 端点保存集群范围的 Patroni 和 Postgres 配置、历史文件,以及最重要的 initialize 键。当 Kubernetes 主节点重启或升级时,它会删除没有 service 的 endpoints。headless service 将防止其被删除。
错误修复
调整 leader watch 阻塞查询的读取超时(Alexander Kukushkin)
根据 Consul 文档,实际响应超时会增加少量随机的额外等待时间,以分散并发请求的唤醒时间。它在最大持续时间上增加最多 wait / 16 的额外时间。在我们的情况下,我们添加 wait / 15 或 1 秒,取较大值。
通过复制协议连接 postgres 时始终使用 replication=1(Alexander Kukushkin)
从 Postgres 10 开始,pg_hba.conf 中 database=replication 的行不接受 replication=database 参数的连接。
不要为仅使用 WAL 的备用集群将 primary_conninfo 写入 recovery.conf(Alexander Kukushkin)
尽管在 standby_cluster 配置中既没有定义 host 也没有定义 port,Patroni 之前仍然将 primary_conninfo 写入 recovery.conf,这是无用的并且会产生大量错误。
Version 1.5.4
发布于 2019-01-15
此版本实现了灵活的日志记录功能并修复了若干错误。
新特性
日志基础设施改进(Alexander Kukushkin,Lucas Capistrant,Alexander Anikin)
日志配置不仅可以通过环境变量,还可以从 Patroni 配置文件中进行配置。这使得可以通过更新配置并执行 reload 或向 Patroni 进程发送 SIGHUP 来在运行时更改日志配置。默认情况下 Patroni 将日志写入 stderr,但现在可以直接将日志写入文件并在达到一定大小时轮转。此外还增加了对自定义日期格式的支持以及对每个 Python 模块日志级别进行微调的功能。
支持在 leader 选举时考虑当前时间线(Alexander Kukushkin)
可能会出现节点认为自己是最健康的,但实际上不在最新已知时间线上的情况。在某些情况下我们希望避免提升此类节点,这可以通过将 check_timeline 参数设置为 true 来实现(默认行为保持不变)。
放宽超级用户凭证要求
Libpq 允许在不显式指定用户名或密码的情况下打开连接。根据情况,它依赖于 pgpass 文件或 pg_hba.conf 中的 trust 认证方法。由于 pg_rewind 也使用 libpq,它将以相同的方式工作。
实现通过环境变量配置 Consul Service 注册和检查间隔的功能(Alexander Kukushkin)
Consul 中的服务注册在 1.5.0 中添加,但到目前为止只能通过 patroni.yaml 来启用。
稳定性改进
在自定义 bootstrap 期间将 archive_mode 设置为 off(Alexander Kukushkin)
我们希望在集群完全运行之前避免归档 WAL 和历史文件。如果自定义 bootstrap 涉及 pg_upgrade,这确实很有帮助。
启动时加载全局配置时应用五秒退避(Alexander Kukushkin)
这有助于避免在 Patroni 刚启动时频繁请求 DCS。
减少关闭时产生的错误消息数量(Alexander Kukushkin)
这些消息是无害的,但相当烦人,有时还很吓人。
在创建 recovery.conf 时显式设置 rw 权限(Lucas Capistrant)
我们不希望除 patroni/postgres 用户之外的任何人读取此文件,因为它包含复制用户和密码。
将 HTTPServer 异常重定向到 logger(Julien Riou)
默认情况下,此类异常会记录到标准输出,干扰常规日志。
错误修复
移除 pg_ctl 进程中的 stderr 到 stdout 管道重定向(Cody Coons)
从主 Patroni 进程继承 stderr 允许所有 Postgres 日志与所有 Patroni 日志一起查看。这在容器环境中非常有用,因为 Patroni 和 Postgres 日志可以使用标准工具(docker logs、kubectl 等)来查看。此外,此更改修复了当 Postgres 向 stderr 写入一些警告时 Patroni 无法捕获 postmaster pid 的错误。
以 Go 时间格式设置 Consul service check 注销超时(Pavel Kirillov)
没有明确指定时间单位时注册会失败。
放宽 standby_cluster 集群配置检查(Dmitry Dolgov,Alexander Kukushkin)
之前只接受字符串作为有效值,因此无法将端口指定为整数,也无法将 create_replica_methods 指定为列表。
Version 1.5.3
发布于 2018-12-03
兼容性和错误修复版本。
改进在 python3 下与 zookeeper 运行时的稳定性(Alexander Kukushkin)
更改 loop_wait 会导致 Patroni 断开与 zookeeper 的连接且再也无法重新连接。
修复与 postgres 9.3 的兼容性问题(Alexander Kukushkin)
打开复制连接时应指定 replication=1,因为 9.3 不理解 replication=‘database’。
确保每次 HA 循环至少刷新一次 Consul 会话,并改进 consul 会话异常处理(Alexander Kukushkin)
重启本地 consul agent 会使与该节点相关的所有会话失效。未及时调用会话刷新以及未正确处理会话错误会导致主节点被降级。
Version 1.5.2
发布于 2018-11-26
兼容性和错误修复版本。
兼容 kazoo-2.6.0(Alexander Kukushkin)
为了确保请求以适当的超时执行,Patroni 重新定义了 python-kazoo 模块中的 create_connection 方法。kazoo 的最新版本稍微改变了 create_connection 方法的调用方式。
修复 Consul 集群失去 leader 时 Patroni 崩溃的问题(Alexander Kukushkin)
崩溃是由于 touch_member 方法的不正确实现导致的,它应该返回布尔值而不是抛出任何异常。
Version 1.5.1
发布于 2018-11-01
此版本实现了对永久复制槽的支持,增加了对 pgBackRest 的支持,并修复了若干错误。
新特性
永久复制槽(Alexander Kukushkin)
永久复制槽在故障转移/切换时被保留,即新主节点上的 Patroni 在完成提升后会立即创建配置的复制槽。可以借助 patronictl edit-config 配置槽。初始配置也可以在 bootstrap.dcs 中完成。
新增 pgbackrest 支持(Yogesh Sharma)
pgBackrest 可以在现有的 $PGDATA 文件夹中恢复,这使得恢复速度更快,因为自上次备份以来未更改的文件会被跳过。为了支持此功能,引入了新参数 keep_data。更多示例请参阅 副本创建方法 部分。
错误修复
Version 1.5.0
发布于 2018-09-20
此版本使 Patroni HA 集群能够以备用模式运行,引入了对 Windows 运行的实验性支持,并提供了在 Consul 中注册 PostgreSQL 服务的新配置参数。
新特性
备用集群(Dmitry Dolgov)
一个或多个 Patroni 节点可以组成一个备用集群,与主集群并行运行(即在另一个数据中心),由从主集群中的 master 复制的备用节点组成。备用集群中的所有 PostgreSQL 节点都是副本;其中一个副本选举自己直接从远程 master 复制,而其他副本则以级联方式从它复制。此功能的更详细描述和一些配置示例可以在 这里 找到。
在 Consul 中注册服务(Pavel Kirillov,Alexander Kukushkin)
如果在 consul 配置 中启用了 register_service 参数,节点将注册一个名为 scope 的服务,标签为 master、replica 或 standby-leader。
实验性 Windows 支持(Pavel Golub)
从现在起可以在 Windows 上运行 Patroni,尽管 Windows 支持是全新的,还没有像 Linux 版本那样经过大量实际测试。欢迎您的反馈!
patronictl 改进
为 patronictl 添加 -k/–insecure 标志并支持 restapi 证书(Wilfried Roset)
过去如果 REST API 由自签名证书保护,patronictl 将无法验证它们。没有办法禁用该验证。现在可以配置 patronictl 完全跳过证书验证,或在配置的 ctl: 部分提供 CA 和客户端证书。
从 patronictl switchover/failover 输出中排除带有 nofailover 标签的成员(Alexander Anikin)
之前,通过 patronictl 执行交互式切换或故障转移时,这些成员被错误地建议为候选者。
稳定性改进
避免解析 pg_controldata 的非键值对输出行(Alexander Anikin)
在某些情况下 pg_controldata 会输出没有冒号字符的行。这会在解析 pg_controldata 输出的 Patroni 代码中触发错误,隐藏了实际问题;通常这些行是 pg_controldata 在常规输出之前以警告形式发出的,即当二进制主版本与 PostgreSQL 数据目录的版本不匹配时。
在 leader 选举期间将成员名称添加到错误消息中(Jan Mussler)
在 leader 选举期间,Patroni 连接到集群的所有已知成员并请求其状态。该状态写入 Patroni 日志并包含成员名称。之前,如果成员不可访问,错误消息不会显示其名称,只包含 URL。
在创建复制槽时立即保留 WAL 位置(Alexander Kukushkin)
从 9.6 开始,pg_create_physical_replication_slot 函数提供了一个额外的布尔参数 immediately_reserve。当它设置为 false(也是默认值)时,槽在收到第一个客户端连接之前不会保留 WAL 位置,在槽创建和初始客户端连接之间的时间窗口内可能会丢失客户端所需的一些段。
修复严格同步复制中的错误(Alexander Kukushkin)
当以 synchronous_mode_strict: true 运行时,在某些情况下 Patroni 会将 \* 放入 synchronous_standby_names 中,将大多数复制连接的同步状态更改为 potential。之前,Patroni 无法在这种情况下选择同步候选者,因为它只考虑状态为 async 的候选者。
Version 1.4.6
发布于 2018-08-14
错误修复和稳定性改进
此版本修复了 Patroni API /master 端点在非 master 节点上返回 200 的关键问题。这是一个报告问题,不是实际的脑裂,但在某些情况下客户端可能被定向到只读节点。
在降级时重置 is_leader 状态(Alexander Kukushkin,Oleksii Kliukin)
确保被降级的集群成员停止在 /master API 调用上以 200 状态码响应。
在 API 输出中添加新的 “cluster_unlocked” 字段(Dmitry Dolgov)
该字段指示集群是否有正在运行的 master。当无法查询除某个副本之外的任何其他节点时,它可以被使用。
Version 1.4.5
发布于 2018-08-03
新特性
改进应用新 postgres 配置时的日志记录(Don Seiler)
Patroni 会记录已更改的参数名称和值。
Python 3.7 兼容性(Christoph Berg)
async 是 python3.7 中的保留关键字。
成员关闭时在 DCS 中将状态设置为 “stopped”(Tony Sorrentino)
这会在 “patronictl list” 命令中将成员状态显示为 “stopped”。
改进当过时的 postmaster.pid 匹配到运行中的进程时记录的消息(Ants Aasma)
之前的消息非常令人困惑。
实现 patronictl reload 功能(Don Seiler)
之前只能通过调用 REST API 或向 Patroni 进程发送 SIGHUP 信号来重新加载配置。
作为副本启动时从 controldata 获取并应用某些参数(Alexander Kukushkin)
在全局配置中设置的 max_connections 和其他一些参数的值可能低于主节点实际使用的值;当发生这种情况时,副本无法启动且需要手动修复。Patroni 现在通过从 pg_controldata 读取并应用值、启动 postgres 并设置 pending_restart 标志来处理这个问题。
如果设置了 LD_LIBRARY_PATH 则在启动 postgres 时使用它(Chris Fraser)
启动 Postgres 时,Patroni 之前会传递已设置的 PATH、LC_ALL 和 LANG 环境变量。现在对 LD_LIBRARY_PATH 也做了相同处理。如果有人将 PostgreSQL 安装到非标准位置,这应该会有所帮助。
将 create_replica_method 重命名为 create_replica_methods(Dmitry Dolgov)
为了明确它实际上是一个数组。旧名称仍然支持以保持向后兼容。
错误修复和稳定性改进
修复暂停状态下因 pg_rewind 导致副本启动的条件(Oleksii Kliukin)
避免启动之前已经执行过 pg_rewind 的副本。
仅在 update_lock 成功时才对 master 健康检查响应 200(Alexander Kukushkin)
防止在 DCS 分区时,Patroni 在前(已降级的)master 上将自己报告为 master。
修复与新 consul 模块的兼容性(Alexander Kukushkin)
从 v1.1.0 开始,python-consul 更改了内部 API,开始使用 list 而不是 dict 来传递查询参数。
捕获关闭期间 Patroni REST API 线程的异常(Alexander Kukushkin)
那些未捕获的异常会导致 PostgreSQL 在关闭时继续运行。
仅当 Postgres 作为 master 运行时才执行崩溃恢复(Alexander Kukushkin)
要求 pg_controldata 报告 ‘in production’ 或 ‘shutting down’ 或 ‘in crash recovery’。在所有其他情况下不需要崩溃恢复。
改进配置错误处理(Henning Jacobs,Alexander Kukushkin)
可以通过更新 Patroni 配置文件并向 Patroni 进程发送 SIGHUP 来在运行时更改许多参数(包括 restapi.listen)。此修复消除了当某些参数收到无效值时 ‘restapi’ 线程中的晦涩异常。
Version 1.4.4
发布于 2018-05-22
稳定性改进
修复 poll_failover_result 中的竞争条件(Alexander Kukushkin)
它没有直接影响故障转移或切换,但在某些罕见情况下,当前任 leader 释放锁时会过早地报告成功,产生 ‘Failed over to “None”’ 而不是 ‘Failed over to “desired-node”’ 的消息。
将 Postgres 参数名称视为不区分大小写(Alexander Kukushkin)
大多数 Postgres 参数使用 snake_case 命名,但有三个例外:DateStyle、IntervalStyle 和 TimeZone。Postgres 接受以不同大小写编写的这些参数(例如 timezone = ‘some/tzn’);但是,Patroni 无法在 pg_settings 中找到这些参数名称的不区分大小写匹配,因此忽略了这些参数。
如果附加到运行中的 postgres 但集群未初始化则中止启动(Alexander Kukushkin)
Patroni 可以附加到已经运行的 Postgres 实例。在处理副本之前,必须先在主节点上启动 Patroni。
修复 patronictl scaffold 的行为(Alexander Kukushkin)
向 touch_member 传递 dict 对象而不是 json 编码的字符串,DCS 实现会负责编码。
暂停状态下更新 leader 键失败时不降级 master(Alexander Kukushkin)
在维护期间,DCS 可能开始拒绝写请求但继续响应读请求。在这种情况下,Patroni 之前会在 DCS 中更新 leader 锁失败后将 Postgres 主节点置为只读模式。
当 Patroni 注意到新的 postmaster 进程时同步复制槽(Alexander Kukushkin)
如果 Postgres 已重启,Patroni 必须确保复制槽列表符合其预期。
退出暂停后验证 sysid 并同步复制槽(Alexander Kukushkin)
在 maintenance 模式期间,数据目录可能被完全重写,因此我们必须确保 Database system identifier 仍然属于我们的集群,且复制槽与 Patroni 预期同步。
修复在存在 postmaster 锁文件的数据目录上无法启动未运行的 Postgres 的问题(Alexander Kukushkin)
检测 postmaster 锁文件中 PID 的重用。如果在 docker 容器中运行 Patroni 和 Postgres,更容易遇到此问题。
改进 DCS 被意外清除时的保护(Alexander Kukushkin)
Patroni 有大量逻辑来防止在这种情况下发生故障转移;它还可以恢复所有键;但是,在此更改之前,意外删除 /config 键会在 1 个 HA 循环周期内关闭暂停模式。
遇到无效系统 ID 时不退出(Oleksii Kliukin)
当集群系统 ID 为空或未通过验证检查时不退出。在这种情况下,集群很可能需要重新初始化;在结果消息中提及这一点。避免终止 Patroni,否则无法进行重新初始化。
兼容 Kubernetes 1.10+
Bootstrap 改进
使删除 recovery.conf 变为可选(Brad Nicholson)
如果定义了 bootstrap.<custom_bootstrap_method_name>.keep_existing_recovery_conf 并设置为 True,Patroni 将不会删除现有的 recovery.conf 文件。当使用 pgBackRest 等工具从备份引导时,这很有用,因为这些工具会为您生成适当的 recovery.conf。
允许为内置 basebackup 方法提供选项(Oleksii Kliukin)
现在可以通过在配置中定义 basebackup 部分来为内置 basebackup 方法提供选项,类似于为自定义副本创建方法定义选项的方式。不同之处在于 basebackup 部分接受的格式:由于 pg_basebackup 接受 --key=value 和 --key 两种选项,该部分的内容可以是键值对的字典,也可以是单元素字典或仅包含键的列表(对于不接受值的选项)。更多示例请参阅 副本创建方法 部分。
Version 1.4.3
发布于 2018-03-05
日志改进
允许从环境变量配置日志级别(Andy Newton,Keyvan Hedayati)
PATRONI_LOGLEVEL - 设置通用日志级别;PATRONI_REQUESTS_LOGLEVEL - 设置所有 HTTP 请求(例如 Kubernetes API 调用)的日志级别。有关可用日志级别名称,请参阅 Python logging 文档 <https://docs.python.org/3.6/library/logging.html#levels>。
稳定性改进和错误修复
当 watch 超时时不重新发现 etcd 集群拓扑(Alexander Kukushkin)
如果 etcd 配置中只有一个主机且正好这个主机不可访问,Patroni 之前会开始发现集群拓扑但永远不会成功。相反,它应该只是切换到下一个可用节点。
自定义 bootstrap 后将 bootstrap.pg_hba 的内容写入 pg_hba.conf(Alexander Kukushkin)
现在其行为与使用 initdb 进行常规 bootstrap 时类似。
单用户模式会等待用户输入而永不结束(Alexander Kukushkin)
回归问题引入于 https://github.com/patroni/patroni/pull/576。
Version 1.4.2
发布于 2018-01-30
patronictl 改进
将 scheduled failover 重命名为 scheduled switchover(Alexander Kukushkin)
故障转移和切换功能在 1.4 版本中已分离,但 patronictl list 仍然报告 Scheduled failover 而不是 Scheduled switchover。
显示待重启信息(Alexander Kukushkin)
为了应用某些配置更改,有时需要重启 postgres。Patroni 之前已经在 REST API 和写入 DCS 的节点状态中给出了提示,但没有简便的方式来显示它。
使 show-config 与配置文件中的 cluster_name 一起工作(Alexander Kukushkin)
其工作方式类似于 patronictl edit-config。
稳定性改进
避免在 bootstrap 期间调用 pg_controldata(Alexander Kukushkin)
在 initdb 或自定义 bootstrap 期间,存在一个 pgdata 不为空但 pg_controldata 尚未写入的时间窗口。在这种情况下,pg_controldata 调用会因错误消息而失败。
处理 psutil 抛出的异常(Alexander Kukushkin)
每次调用 cmdline() 方法时都会读取和解析 cmdline。被检查的进程可能已经消失,在这种情况下会抛出 NoSuchProcess。
Kubernetes 支持改进
不要吞掉 k8s API 的错误(Alexander Kukushkin)
对 Kubernetes API 的调用可能因多种原因而失败。在某些情况下应重试此类调用,在其他情况下我们应记录错误消息和异常堆栈跟踪。此更改将有助于调试 Kubernetes 权限问题。
更新 Kubernetes 示例 Dockerfile 以从 master 分支安装 Patroni(Maciej Szulik)
之前使用的是 feature/k8s,该分支已经过时。
添加适当的 RBAC 以在 k8s 上运行 patroni(Maciej Szulik)
添加分配给集群 pod 的 Service account、仅包含必要权限的 role,以及连接 Service account 和 Role 的 rolebinding。
Version 1.4.1
发布于 2018-01-17
patronictl修复
不在建议的故障转移目标成员列表中显示当前领导者(Alexander Kukushkin)
当集群中存在领导者时,patronictl failover仍然可以工作,应将其从可以故障转移到的成员列表中排除。
使patronictl switchover与旧版Patroni API兼容(Alexander Kukushkin)
如果POST /switchover REST API调用以状态码501失败,它将再次请求,但调用/failover端点。
Version 1.4
发布于 2018-01-10
此版本添加了使用Kubernetes作为DCS的支持,允许Patroni作为云原生代理在Kubernetes中运行,无需额外部署Etcd、Zookeeper或Consul。
升级须知
通过pip安装Patroni将不再自动引入依赖项(如Etcd、Zookeeper、Consul或Kubernetes的库,或AWS支持)。要启用它们,需要在pip install命令中显式列出,例如 pip install patroni[etcd,kubernetes]。
Kubernetes支持
实现了基于Kubernetes的DCS。使用Endpoints的元数据来存储配置和领导者键。Pod定义中的元数据字段用于存储成员相关数据。除了使用Endpoints,Patroni还支持ConfigMaps。你可以在 文档的Kubernetes章节 中找到关于此功能的更多信息。
稳定性改进
将postmaster进程分离为独立对象(Ants Aasma)
该对象通过pid和启动时间标识正在运行的postmaster进程,简化了对postmaster在后台被重启或postgres目录从文件系统中消失的情况的检测(和解决)。
最小化Patroni在每次HA循环迭代中发出的SELECT数量(Alexander Kukushkin)
在HA循环的每次迭代中,Patroni需要知道恢复状态和绝对WAL位置。从现在起,Patroni将只运行单个SELECT来获取此信息,而不是在副本上运行两个、在主节点上运行三个。
仅在持有锁时才在关闭时移除领导者键(Ants Aasma)
无条件移除会产生不必要和误导性的异常。
patronictl改进
为patronictl添加version命令(Ants Aasma)
它将显示已安装的Patroni版本和正在运行的Patroni实例的版本(如果指定了集群名称)。
使某些patronictl命令的cluster_name参数可选(Alexander Kukushkin,Ants Aasma)
如果patronictl使用定义了 scope 的常规Patroni配置文件,则可以工作。
显示有关计划切换和维护模式的信息(Alexander Kukushkin)
在此之前,只能从Patroni日志或直接从DCS获取此信息。
改进 patronictl reinit(Alexander Kukushkin)
有时 patronictl reinit 在Patroni忙于其他操作(即尝试启动postgres)时会拒绝继续。 patronictl 没有提供任何命令来取消此类长时间运行的操作,唯一(危险的)解决方法是手动删除数据目录。新的 reinit 实现会在继续reinit之前强制取消其他长时间运行的操作。
在 patronictl pause 和 patronictl resume 中实现 --wait 标志(Alexander Kukushkin)
它将使 patronictl 等待直到集群中所有节点确认请求的操作。此行为通过在DCS和REST API中为每个节点公开 暂停 标志来实现。
将 patronictl failover 重命名为 patronictl switchover(Alexander Kukushkin)
之前的 failover 实际上只能执行切换;在没有领导者的集群中它会拒绝继续。
更改 patronictl failover 的行为(Alexander Kukushkin)
即使没有领导者它也能工作,但在这种情况下你必须显式指定一个应成为新领导者的节点。
公开时间线和历史信息
在DCS和API中公开当前时间线(Alexander Kukushkin)
为集群的每个成员存储当前时间线的信息。此信息可通过API访问并存储在DCS中。
在DCS的/history键中存储提升历史(Alexander Kukushkin)
此外,在DCS的/history键中存储包含相应提升时间戳的时间线历史,并在每次提升时更新它。
添加获取同步和异步副本的端点
- 添加新的/sync和/async端点(Alexander Kukushkin,Oleksii Kliukin)
这些端点(也可通过/synchronous和/asynchronous访问)分别仅对同步和异步副本返回200(不包括标记为 noloadbalance 的副本)。
允许Etcd配置多个主机
Version 1.3.6
发布于 2017-11-10
稳定性改进
在检查postgres是否正在运行时验证进程启动时间(Ants Aasma)
在未清理postmaster.pid的崩溃后,可能存在具有相同pid的新进程,导致is_running()误报,从而引发各种异常行为。
当丢失数据目录时,在引导前关闭postgresql(ainlolcat)
当主节点上的数据目录被强制删除时,postgres进程可能仍然存活一段时间,阻止在该前主节点位置创建的副本启动或复制。此修复使Patroni缓存postmaster的pid及其启动时间,并在相应数据目录被删除后终止仍在运行的旧postmaster。
如果postgres主进程死亡,则在单用户模式下执行崩溃恢复(Alexander Kukushkin)
如果postgres没有干净关闭,立即作为备用节点启动是不安全的,也无法运行 pg_rewind。单用户崩溃恢复仅在启用了 pg_rewind 或当前没有主节点时才会触发。
Consul改进
使得为Consul提供数据中心配置成为可能(Vilius Okockis,Alexander Kukushkin)
在此之前,Patroni始终与其运行所在主机的数据中心通信。
始终在X-Consul-Token HTTP头中发送令牌(Alexander Kukushkin)
如果在Patroni配置中定义了 consul.token,我们将始终在’X-Consul-Token’ HTTP头中发送它。python-consul模块试图与Consul REST API保持"一致”,后者不接受令牌作为 会话API 的查询参数,但它仍然可以使用’X-Consul-Token’头。
如果提供的值小于最小可能值,则调整会话TTL(Stas Fomin,Alexander Kukushkin)
Patroni配置中提供的TTL可能小于Consul支持的最小值。在这种情况下,Consul代理无法创建新会话。没有会话,Patroni就无法在Consul KV存储中创建成员和领导者键,导致集群不健康。
其他改进
Version 1.3.5
发布于 2017-10-12
错误修复
稳定性改进
Consul改进
错误修复
Version 1.3.4
发布于 2017-09-08
各种Consul改进
将consul令牌作为头部传递(Andrew Colin Kissa)
头部现在是向consul API 传递令牌的首选方式。
Consul的高级配置(Alexander Kukushkin)
可以指定 scheme、token、客户端和CA证书的 详细信息。
与python-consul-0.7.1及以上版本的兼容性(Alexander Kukushkin)
新的python-consul模块更改了某些方法的签名。
“Could not take out TTL lock"消息从未被记录(Alexander Kukushkin)
不是关键错误,但缺乏适当的日志记录会使出现问题时的调查变得复杂。
使用quote_ident引用synchronous_standby_names
围绕暂停状态的各种修复,主要与watchdog相关(Alexander Kukushkin)
- 如果watchdog未激活,则不发送keepalive
- 避免在暂停模式下激活watchdog
- 在暂停模式下设置正确的postgres状态
- 如果postgres已停止,则不要尝试从API运行查询
Version 1.3.3
发布于 2017-08-04
错误修复
- 即使开启了synchronous_mode_strict,同步复制也会在提升后不久被禁用(Alexander Kukushkin)
- 如果从备份恢复后缺少
pg_ident.conf 文件,则创建空文件(Alexander Kukushkin) - 在
pg_hba.conf 中对所有数据库开放访问,而不仅仅是postgres(Franco Bellagamba)
Version 1.3.2
发布于 2017-07-31
错误修复
- patronictl edit-config无法与ZooKeeper配合工作(Alexander Kukushkin)
Version 1.3.1
发布于 2017-07-28
错误修复
- 由于
_MemberStatus 的更改,通过API进行的故障转移被破坏(Alexander Kukushkin)
Version 1.3
发布于 2017-07-27
Version 1.3增加了自定义引导功能,显著改进了对pg_rewind的支持,增强了同步模式支持,为patronictl添加了配置编辑功能,并在Linux上实现了watchdog支持。此外,这是第一个能正确支持PostgreSQL 10的版本。
升级须知
目前没有已知的新版本兼容性问题。Version 1.2的配置应无需任何更改即可使用。升级方式为安装新软件包后重启Patroni(会导致PostgreSQL重启),或者先将Patroni置于 暂停模式,然后在集群所有节点上重启Patroni(暂停模式下的Patroni不会尝试停止/启动PostgreSQL),最后退出暂停模式。
自定义引导
更智能的pg_rewind支持
通过查看与当前主节点的时间线差异来决定是否运行pg_rewind(Alexander Kukushkin)
此前,Patroni有一组固定条件来触发pg_rewind,即在启动前主节点时、在对集群中每个其他节点进行切换到指定节点的操作时,或当存在带有nofailover标签的副本时。所有这些情况的共同点是某些副本可能领先于新主节点。在某些情况下pg_rewind没有执行任何操作,在另一些情况下它在需要时却未运行。Patroni不再依赖这个有限的规则列表,而是比较主节点和副本的WAL位置(使用流复制协议),以可靠地决定副本是否需要rewind。
同步复制严格模式
通过添加严格模式增强同步复制支持(James Sewell,Alexander Kukushkin)
通常,当启用 synchronous_mode 且没有副本连接到主节点时,Patroni会禁用同步复制以保持主节点可写。synchronous_mode_strict 选项改变了这一行为,设置后Patroni在缺少副本时不会禁用同步复制,实际上会阻止所有客户端向主节点写入数据。除了同步模式保证自动故障转移不丢失任何数据外,严格模式还确保每次写入要么持久存储在两个节点上,要么在集群只有一个节点时完全不发生。
使用patronictl编辑配置
Linux watchdog支持
为Linux实现watchdog支持(Ants Aasma)
支持Linux软件watchdog,以在Patroni未运行或无响应时(例如由于高负载)重启节点。Linux软件watchdog会重启无响应的节点。可以从Patroni配置的watchdog部分配置要使用的watchdog设备(默认为 /dev/watchdog)和模式(on、automatic、off)。更多信息请参阅 watchdog文档。
添加PostgreSQL 10支持
- Patroni兼容迄今为止发布的所有PostgreSQL 10 beta版本,我们预期在PostgreSQL 10正式发布时也将兼容。
PostgreSQL相关的小改进
通过Patroni配置文件或DCS中的动态配置定义pg_hba.conf(Alexander Kukushkin)
允许在配置的 postgresql 部分的 pg_hba 子部分中定义 pg_hba.conf 的内容。这简化了在多个节点上管理 pg_hba.conf 的工作,因为只需在DCS中定义一次,而无需登录每个节点手动更改并重载配置。
定义后,此部分的内容将完全替换当前的 pg_hba.conf。如果设置了 hba_file PostgreSQL参数,Patroni将忽略此配置。
支持通过UNIX套接字连接到本地PostgreSQL集群(Alexander Kukushkin)
在Patroni配置的 postgresql 部分添加 use_unix_socket 选项。设置为true且PostgreSQL的 unix_socket_directories 选项不为空时,Patroni将使用其第一个值连接到本地PostgreSQL集群。如果未定义 unix_socket_directories,Patroni将假定其默认值,并在PostgreSQL连接字符串中完全省略 host 参数。
支持在重载时更改超级用户和复制凭据(Alexander Kukushkin)
支持将配置文件存储在PostgreSQL数据目录之外(@jouir)
添加新的 postgresql 配置指令 config_dir。默认为数据目录,必须可被Patroni写入。
错误修复和稳定性改进
处理EtcdEventIndexCleared和EtcdWatcherCleared异常(Alexander Kukushkin)
通过避免无用的重试,在watch操作被Etcd终止时更快恢复。
消除Etcd故障时的错误自旋并减少日志垃圾(Ants Aasma)
避免在第二次及后续Etcd连接失败时立即重试和在日志中输出堆栈跟踪。
在fork PostgreSQL进程时导出locale变量(Oleksii Kliukin)
避免在使用NLS构建的PostgreSQL的非英语locale下出现 postmaster became multithreaded during startup 致命错误。
删除复制槽时的额外检查(Alexander Kukushkin)
在某些情况下,WAL发送者会阻止Patroni删除复制槽。
将复制槽名称截断为63(NAMEDATALEN - 1)个字符以符合PostgreSQL命名规则(Nick Scott)
修复导致Patroni向PostgreSQL集群打开额外连接的竞态条件(Alexander Kukushkin)
当节点以空数据目录重启时释放领导者键(Alex Kerney)
在没有领导者的情况下运行引导时将异步执行器设置为忙碌状态(Alexander Kukushkin)
未能执行此操作可能导致错误,声明节点属于不同的集群,因为Patroni在通过不需要集群中存在领导者的引导方法引导时继续执行正常业务。
改进WAL-E副本创建方法(Joar Wandborg,Alexander Kukushkin)
- 在解析WAL-E基础备份时使用csv.DictReader,接受以空格分隔日期和时间的ISO日期格式。
- 支持从副本获取当前WAL位置以估算需要恢复的WAL量。此前,代码使用的系统信息函数仅在主节点上可用。
Version 1.2
发布于 2016-12-13
此版本在同步复制处理方面引入了重大改进,使启动过程和故障转移更加可靠,添加了PostgreSQL 9.6支持并修复了大量错误。此外,包括这些发布说明在内的文档已迁移至 </docs/patroni>。
同步复制
可靠性改进
当PostgreSQL不是100%健康时,不尝试更新存储在 leader optime 键中的领导者位置。当领导者键更新失败时立即降级。(Alexander Kukushkin)
将不健康的节点从克隆新副本的目标列表中排除。(Alexander Kukushkin)
为Consul实现类似于Etcd的重试和超时策略。(Alexander Kukushkin)
使 --dcs 和 --config-file 适用于 patronictl 中的所有选项。(Alexander Kukushkin)
将所有postgres参数写入postgresql.conf。(Alexander Kukushkin)
这允许仅使用 pg_ctl 启动由Patroni配置的PostgreSQL。
避免在配置中没有用户时出现异常。(Kirill Pushkin)
允许暂停不健康的集群。在此修复之前,如果尝试执行暂停操作的节点不健康,patronictl 会中止操作。(Alexander Kukushkin)
改进领导者监视功能。(Alexander Kukushkin)
此前,副本始终监视领导者键(休眠直到超时或领导者键变更)。此更改后,它们仅在副本的PostgreSQL处于 running 状态时监视,而不在PostgreSQL停止/启动或重启时监视。
避免在作为PID 1处理SIGCHILD时遇到竞态条件。(Alexander Kukushkin)
此前,在Docker容器内运行时可能出现竞态条件,因为Patroni内部的同一进程既生成新进程又处理来自它们的SIGCHILD信号。此更改对Patroni使用fork/exec,将原始PID 1进程保留为处理子进程信号的专用进程。
修复WAL-E恢复。(Oleksii Kliukin)
此前,WAL-E恢复使用 no_master 标志来完全避免与主节点协商,使Patroni总是选择从WAL恢复而非 pg_basebackup。此更改将其恢复为 no_master 的原始含义,即当主节点未运行时可以选择Patroni WAL-E恢复作为复制方法。后者通过检查传递给方法的连接字符串来判断。此外,使重试机制更加健壮并处理了其他细节问题。
实现异步DNS解析器缓存。(Alexander Kukushkin)
避免在DNS暂时不可用时(例如,由于节点接收的流量过大)出现故障。
实现启动状态和主节点启动超时。(Ants Aasma,Alexander Kukushkin)
此前,pg_ctl 等待超时后便认为PostgreSQL正在运行。这导致PostgreSQL在列表中显示为运行状态但实际并非如此,并引发竞态条件,结果要么是故障转移,要么是崩溃恢复,要么是被故障转移中断的崩溃恢复和错过的rewind。此更改添加了 master_start_timeout 参数,并为主HA循环引入了新状态:starting。当 master_start_timeout 为0时,只要有故障转移候选者,主节点崩溃后将立即进行故障转移。否则,Patroni将在尝试在主节点上启动PostgreSQL后等待超时时长;超时后如果可能则进行故障转移。即使在超时到期之前,主节点崩溃期间也会响应手动故障转移请求。
为 restart API端点和 patronictl 引入 timeout 参数。设置后,如果重启时间超过超时值,PostgreSQL将被视为不健康,其他节点将有资格获取领导者锁。
修复暂停模式下的 pg_rewind 行为。(Ants Aasma)
避免在暂停模式下Patroni认为需要rewind但无法执行rewind时(即 pg_rewind 不存在)进行不必要的重启。如果 pg_rewind 相关的Patroni配置部分中缺少 superuser 认证信息,则回退到 libpq 的默认 superuser(默认操作系统用户)值。
序列化回调执行。当新的同类型回调即将运行时,终止之前的回调。修复运行回调时产生僵尸进程的问题。(Alexander Kukushkin)
当领导者键已在DCS中设置但更新此领导者键失败时,避免提升前主节点。(Alexander Kukushkin)
这避免了当前主节点与Etcd中少数节点一起被分区时继续保持其角色的问题,以及允许"不一致读取"的其他DCS中的类似问题。
杂项
在引导时添加 post_init 配置选项。(Alejandro Martínez)
Patroni将在对新集群运行 initdb 并启动PostgreSQL后,立即调用此选项的脚本参数。该脚本接收包含 superuser 的连接URL,并将 PGPASSFILE 设置为指向包含密码的 .pgpass 文件。如果脚本失败,Patroni初始化也将失败。这对于在新集群中添加新用户或创建扩展非常有用。
实现PostgreSQL 9.6支持。(Alexander Kukushkin)
使用 wal_level = replica 作为 hot_standby 的同义词,避免在两者之间切换时出现pending_restart标志。(Alexander Kukushkin)
文档改进
添加Patroni主 循环工作流程图。(Alejandro Martínez,Alexander Kukushkin)
改进README,添加Helm chart和发布说明链接。(Lauri Apple)
将Patroni文档迁移至 Read the Docs。最新文档可在 </docs/patroni> 查阅。(Oleksii Kliukin)
使文档可在不同设备(包括智能手机)上轻松查看和搜索。
将软件包迁移至语义版本控制。(Oleksii Kliukin)
Patroni将遵循major.minor.patch版本方案,以避免对小但关键的错误修复发布新的minor版本。我们将仅发布minor版本的发布说明,其中包含所有补丁。
Version 1.1
发布于 2016-09-07
此版本通过引入暂停模式改进了Patroni集群的管理,通过计划性和条件性重启改善了维护体验,使Patroni与Etcd或Zookeeper的交互更加健壮,并大幅增强了patronictl。
升级须知
从1.0以下版本升级时,请阅读1.0发布说明中关于凭据和配置格式变更的内容。
暂停模式
引入暂停模式,暂时使Patroni脱离对PostgreSQL实例的管理(Murat Kabilov,Alexander Kukushkin,Oleksii Kliukin)。
此前,必须向Patroni发送SIGKILL信号才能在不终止PostgreSQL的情况下停止它。新的暂停模式在集群范围内使Patroni脱离PostgreSQL管理,而不终止Patroni。这类似于Pacemaker中的维护模式。Patroni仍负责更新DCS中的成员和领导者键,但在此过程中不会启动、停止或重启PostgreSQL服务器。有一些例外情况,例如手动故障转移、重新初始化和重启仍然允许。详细说明请参阅 此功能的详细描述。
此外,patronictl支持新的 pause 和 resume 命令来切换暂停模式。
计划性和条件性重启
为restart API命令添加条件(Oleksii Kliukin)
此更改通过添加一些可验证的条件来增强Patroni重启功能。这些条件包括当PostgreSQL角色为主节点或副本时重启、检查PostgreSQL版本号,或仅在需要重启以应用配置更改时才重启。
添加计划性重启(Oleksii Kliukin)
现在可以安排在未来执行重启。每个节点仅支持一个计划性重启。如果不再需要,可以取消计划性重启。支持计划性和条件性重启的组合,例如可以安排在夜间进行PostgreSQL小版本升级,仅重启运行过时小版本的实例,而无需在管理脚本中添加PostgreSQL特定的逻辑。
为patronictl添加条件性和计划性重启支持(Murat Kabilov)。
patronictl restart支持多个新选项。还有patronictl flush命令用于清理计划的操作。
健壮的DCS交互
根据loop_wait设置Kazoo超时(Alexander Kukushkin)
最初,ping_timeout和connect_timeout值是从协商的会话超时计算得出的。未考虑Patroni的loop_wait。因此,单次重试可能花费超过会话超时的时间,迫使Patroni释放锁并降级。
此更改将ping和connect超时设置为loop_wait值的一半,加快连接问题的检测速度,并留出足够时间在丢失锁之前重试连接。
仅在原始请求成功后更新Etcd拓扑(Alexander Kukushkin)
将更新客户端已知的Etcd拓扑推迟到原始请求完成之后。在检索集群拓扑时,根据Etcd集群中已知的节点数量实现重试超时。这使我们的客户端优先获取请求结果,而非拥有最新的节点列表。
这两项更改使Patroni在面对网络问题时与DCS的连接更加健壮。
patronictl、监控和配置
- 通过API返回流复制副本的信息(Feike Steenbergen)
此前,没有可靠的方法查询Patroni关于无法流式传输变更的PostgreSQL实例(例如由于连接问题)。此更改通过/patroni端点公开pg_stat_replication的内容。
添加patronictl scaffold命令(Oleksii Kliukin)
添加在Etcd中创建集群结构的命令。使用用户指定的sysid和领导者创建集群,领导者键和成员键都设置为持久化。此命令对于创建所谓的无主配置非常有用,其中仅由副本组成的Patroni集群从不感知Patroni的外部主节点进行复制。随后,可以删除领导者键,提升其中一个Patroni节点,用基于Patroni的HA集群替换原始主节点。
添加配置选项 bin_dir 以定位PostgreSQL二进制文件(Ants Aasma)
当Linux发行版支持同时安装多个PostgreSQL版本时,能够显式指定PostgreSQL二进制文件的位置非常有用。
允许使用 custom_conf 覆盖配置文件路径(Alejandro Martínez)
允许自定义配置文件路径,该路径不受Patroni管理, 详情。
错误修复和代码改进
使Patroni兼容PostgreSQL 10及更高版本中的新版本号格式(Feike Steenbergen)
确保Patroni在基于PostgreSQL版本执行条件性重启时能理解两位数版本号。
使用pkgutil查找DCS模块(Alexander Kukushkin)
使用专用的Python模块而非手动遍历目录来查找DCS模块。
启动Patroni时始终调用on_start回调(Alexander Kukushkin)
此前,当连接到已经以正确角色运行的节点时,Patroni不会调用任何回调。由于回调通常用于路由客户端连接,这可能导致无法在连接路由方案中注册正在运行的节点。此修复使Patroni即使在连接到已运行的节点时也会调用on_start回调。
不删除活跃的复制槽(Murat Kabilov,Oleksii Kliukin)
避免在主节点上删除活跃的物理复制槽。PostgreSQL本身也无法删除此类槽。此更改使得可以在主节点上运行非Patroni管理的副本/消费者。
在PostgreSQL实例启动期间关闭Patroni连接(Alexander Kukushkin)
强制Patroni在PostgreSQL节点启动时关闭所有先前的连接。避免在postmaster被SIGKILL终止后复用先前连接的陷阱。
从成员名称构造槽名称时替换无效字符(Ants Aasma)
确保不符合槽命名规则的备用名称不会导致槽创建和备用启动失败。将槽名称中的短横线替换为下划线,将槽名称中不允许的所有其他字符替换为其unicode码点。
Version 1.0
发布于 2016-07-05
此版本引入了全局动态配置,允许对整个HA集群的PostgreSQL和Patroni配置参数进行动态更改。同时还修复了大量错误。
升级须知
从v0.90或更低版本升级时,请始终先升级所有副本,再升级主节点。由于我们不再在DCS中存储复制凭据,旧版本的副本将无法连接到新版本的主节点。
动态配置
实现全局动态配置(Alexander Kukushkin)
引入新的REST API端点/config,用于提供应在整个HA集群(主节点和所有副本)中全局设置的PostgreSQL和Patroni配置参数。这些参数设置在DCS中,在很多情况下可以在不中断PostgreSQL或Patroni的情况下应用。当某些值需要重启PostgreSQL时,Patroni会设置一个通过API可见的特殊标志"pending restart”。在这种情况下,需要通过API手动发起重启。
向Patroni发送SIGHUP或POST到/reload将使其重新读取配置文件。
关于哪些参数可以更改以及不同配置源的处理顺序,请参阅 Patroni配置。
自v0.90以来配置文件格式已更改。Patroni仍兼容旧的配置文件,但要利用引导参数需要进行更改。建议用户参考 动态配置文档页面 进行更新。
更灵活的配置*
使PostgreSQL配置和Patroni连接的数据库名可配置(Misja Hoebe)
引入 database 和 config_base_name 配置参数。除其他功能外,它使得可以在PipelineDB和其他PostgreSQL分支上运行Patroni。
实现通过环境变量配置部分Patroni配置参数的功能(Alexander Kukushkin)
这些参数包括scope、节点名称和namespace,以及密钥信息,使得在动态环境(即Kubernetes)中运行Patroni更加容易。更多详情请参阅 支持的环境变量。
更新内置的Patroni Docker容器以利用基于环境变量的配置(Feike Steenbergen)。
为Patroni Docker镜像添加Zookeeper支持(Alexander Kukushkin)
拆分Zookeeper和Exhibitor配置选项(Alexander Kukushkin)
使patronictl复用Patroni的代码来读取配置(Alexander Kukushkin)
这使patronictl能够利用基于环境变量的配置。
在primary_conninfo中将应用名称设置为节点名称(Alexander Kukushkin)
这简化了给定节点同步复制的识别和配置。
稳定性、安全性和可用性改进
在备份恢复进行中时重置sysid并且不调用pg_controldata(Alexander Kukushkin)
此更改减少了在从备份进行漫长初始化期间Patroni API健康检查产生的噪音。
修复一系列pg_rewind边界情况(Alexander Kukushkin)
避免在源集群不是主节点时运行pg_rewind。
此外,避免在rewind不成功时删除数据目录,除非新参数 remove_data_directory_on_rewind_failure 设置为true。默认为false。
从DCS中的复制连接字符串中移除密码(Alexander Kukushkin)
此前,Patroni始终使用DCS中PostgreSQL URL的复制凭据。现已更改为从Patroni配置中获取凭据。密钥信息(复制用户名和密码)不再在DCS中暴露。
修复降级调用相关的异步机制(Alexander Kukushkin)
降级现在完全异步运行,不会阻塞DCS交互。
在配置了授权的情况下,使patronictl始终发送授权头(Alexander Kukushkin)
这允许patronictl在Patroni配置为需要授权时发出"受保护的"请求,如重启或重新初始化。
正确处理SystemExit异常(Alexander Kukushkin)
避免Patroni在收到SIGTERM时无法正确停止的问题。
用于confd的haproxy模板示例(Alexander Kukushkin)
使用confd从DCS中的Patroni状态生成并动态更改haproxy配置。
改进和重组文档使其对新用户更友好(Lauri Apple)
API必须在pg_ctl stop期间报告role=master(Alexander Kukushkin)
使回调调用更加可靠,特别是在集群停止的情况下。此外,引入 pg_ctl_timeout 选项来设置通过 pg_ctl 进行启动、停止和重启调用的超时时间。
修复etcd中的重试逻辑(Alexander Kukushkin)
使重试更可预测和健壮。
使Zookeeper代码对短暂网络故障更具弹性(Alexander Kukushkin)
减少连接超时以使Zookeeper连接尝试更频繁。
Version 0.90
发布于 2016-04-27
此版本添加了对Consul的支持,包含新的 noloadbalance 标签,更改了 clonefrom 标签的行为,改进了 pg_rewind 处理并改进了 patronictl 控制程序。
Consul支持
新标签和改进的标签
实现 noloadbalance 标签(Alexander Kukushkin)
此标签使Patroni始终向负载均衡器返回该副本不可用。
更改 clonefrom 标签的实现(Alexander Kukushkin)
此前,必须向 clonefrom 提供节点名称,强制带标签的副本从指定节点克隆。新实现将 clonefrom 改为布尔标签:如果设置为true,该副本将成为其他副本从其克隆的候选者。当存在多个候选者时,副本会随机选择一个。
稳定性和安全性改进
大量可靠性改进(Alexander Kukushkin)
移除一些虚假的错误消息,提高故障转移的稳定性,解决从DCS读取数据、关闭、降级和前领导者重新连接的一些边界情况。
改进系统脚本以避免在停止时终止Patroni子进程(Jan Keirse,Alexander Kukushkin)
此前,在停止Patroni时,systemd 也会向PostgreSQL发送信号。由于Patroni本身也尝试停止PostgreSQL,导致发送两个不同的关闭请求(smart关闭后跟fast关闭)。这导致副本过早断开连接,前主节点在降级后无法重新加入。由Jan修复,Alexander进行了前期研究。
消除前主节点在作为副本重新加入前无法调用pg_rewind的一些情况(Oleksii Kliukin)
此前,我们仅在前主节点崩溃时才调用 pg_rewind。现更改为只要系统中存在pg_rewind就始终对前主节点运行pg_rewind。这修复了主节点在副本获取最新变更之前被关闭的情况(即在"smart"关闭期间)。
对单元测试和验收测试进行大量改进,特别是启用了对Zookeeper和Consul的支持(Alexander Kukushkin)。
加速Travis CI并实现对Zookeeper(Exhibitor)和Consul运行测试的支持(Alexander Kukushkin)
单元测试和验收测试在每次提交或拉取请求时自动对Etcd、Zookeeper和Consul运行。
从Patroni调用PostgreSQL命令前清除环境变量(Feike Steenbergen)
这防止了通过连接到Patroni管理的PostgreSQL集群来读取系统环境变量的可能性。
配置和控制变更
统一patronictl和Patroni配置(Feike Steenbergen)
patronictl可以使用与Patroni本身相同的配置文件。
使Patroni能够从环境变量读取配置(Oleksii Kliukin)
这简化了自动生成Patroni配置或从不同来源合并单一配置的工作。
在API返回的信息中包含数据库系统标识符(Feike Steenbergen)
为所有可用的DCS实现 delete_cluster(Alexander Kukushkin)
在patronictl中启用对Etcd以外的DCS的支持。
Version 0.80
发布于 2016-03-14
此版本添加了对级联复制的支持,并通过提供计划性故障转移简化了Patroni管理。可以将旧版本的Patroni(特别是0.78)与此版本组合使用以迁移到新版本。请注意,计划性故障转移和级联复制相关功能仅适用于Patroni 0.80及以上版本。
级联复制
- 为Patroni节点添加 replicatefrom 和 clonefrom 标签支持(Oleksii Kliukin)。
replicatefrom 标签允许副本使用任意节点作为源,不必是主节点。clonefrom 对初始备份做同样的事情。它们共同使Patroni完全支持级联复制。
- 添加运行复制方法来初始化副本的支持,即使没有运行中的复制连接也可以(Oleksii Kliukin)。
这对于从S3或FTP上存储的快照创建副本非常有用。不需要运行中复制连接的复制方法应在yaml配置中提供 no_master: true。如果存在复制连接,这些脚本仍会按顺序调用。
patronictl、API和DCS改进
实现计划性故障转移(Feike Steenbergen)。
故障转移可以安排在未来的特定时间发生,使用patronictl或API调用均可。
为patronictl添加 dbuser 和 password 参数支持(Feike Steenbergen)。
在健康检查输出中添加PostgreSQL版本信息(Feike Steenbergen)。
改进patronictl中的Zookeeper支持(Oleksandr Shulgin)
迁移到python-etcd 0.43(Alexander Kukushkin)
配置
- 添加Patroni的系统配置脚本示例(Jan Keirse)。
- 修复Patroni忽略配置文件中指定的超级用户名进行数据库连接的问题(Alexander Kukushkin)。
- 修复CTRL-C的处理,为Patroni启动的postmaster创建单独的会话ID和进程组(Alexander Kukushkin)。
测试
添加使用 behave 的验收测试,以检查运行Patroni的真实场景(Alexander Kukushkin,Oleksii Kliukin)。
测试可以使用 behave 命令手动启动。它们也会在拉取请求和提交后自动运行。
一些旧版本的发布说明可以在 项目的GitHub页面 上找到。
20 - 贡献指南
贡献工作流程、支持渠道与开发指南。
原始页面: https://patroni.readthedocs.io/en/latest/contributing_guidelines.html
在线交流
如有疑问、需要互动式故障排查帮助,或希望与其他 Patroni 用户交流,欢迎加入 PostgreSQL Slack 的 #patroni 频道。
报告缺陷
提交缺陷报告前,请务必在最新版 Patroni 上复现该问题!同时请检查 Issues Tracker 中是否已存在相同问题。
运行测试
运行 behave 测试的前置条件:
- 需要安装包含 contrib 模块的 PostgreSQL 软件包。
- PostgreSQL 二进制文件必须在
PATH 中可访问。您可能需要通过类似 PATH=/usr/lib/postgresql/11/bin:\$PATH python -m behave 的方式将其加入路径。 - 如需测试外部 DCS(如 Etcd、Consul、Zookeeper),需要提前安装相应软件包,并确保对应服务在本地默认端口上以无加密/无认证方式接受连接。对于 Etcd 或 Consul,若相应二进制文件在
PATH 中可用,behave 测试套件可以自动启动它们。
安装依赖:
# 可以使用 Virtualenv 或指定 pip3。
pip install -r requirements.txt
pip install -r requirements.dev.txt
安装完所有依赖后,可以运行各类测试套件:
# 可以使用 Virtualenv 或指定 python3。
# 运行 flake8 检查语法和格式:
python setup.py flake8
# 运行 tests/ 目录中的 pytest 套件:
python setup.py test
# 也可以以更细粒度运行测试,便于调试;
# -s 选项会在测试执行期间显示打印输出。
# pytest 测试通常遵循 FILEPATH::CLASSNAME::TESTNAME 的格式。
pytest -s tests/test_api.py
pytest -s tests/test_api.py::TestRestApiHandler
pytest -s tests/test_api.py::TestRestApiHandler::test_do_GET
# 运行 features/ 目录中的 behave(https://behave.readthedocs.io/en/latest/)测试套件;
# 可根据需要修改 DCS(raft 没有外部依赖,最易于上手):
DCS=raft python -m behave
使用 tox 进行测试
运行 tox 测试只需安装一个额外依赖(Python 本身除外):
如需运行 behave 测试,还需要安装 Docker。
tox.ini 中的 tox 配置定义了以下"环境"以执行各类任务:
lint:使用 flake8 对 Python 代码进行 lint 检查test:使用 pytest 在所有可用 Python 解释器上运行单元测试,生成 XML 报告;若检测到 TTY 则生成 HTML 报告dep:使用 pipdeptree 检测软件包依赖冲突type:使用 pyright 进行静态类型检查black:使用 black 进行代码格式化docker-build:构建用于 behave 环境的 Docker 镜像docker-cmd:使用上述镜像运行任意命令docker-behave-etcd:使用上述镜像运行 tox behave 测试py*behave:使用可用的 Python 解释器运行 behave(不使用 Docker,但这正是在 Docker 容器内部调用的方式)docs:使用 sphinx 构建文档
运行 tox
运行默认环境列表(dep、lint、test 和 docs),直接执行:
可以使用 test 标签运行 test 环境:
可以使用 behave 标签运行 behave Docker 测试:
类似地,docs 使用 docs 标签。
其他所有环境可通过对应的环境名称运行:
tox -e lint
tox -e py39-test-lin
也可以使用 factors 筛选部分环境列表。例如,若要运行所有 Python 3.10 相关环境:
这等价于运行以下所有环境:
$ tox -l -f py310
py310-test-lin
py310-test-mac
py310-test-win
py310-type-lin
py310-type-mac
py310-type-win
py310-behave-etcd-lin
py310-behave-etcd-win
py310-behave-etcd-mac
可以使用 tox(>= v4)列出所有已配置的环境组合:
当 tox 在有活跃终端的情况下运行时,test 和 docs 环境在任务完成后会尝试自动打开 HTML 输出文件,方便本地开发人员查看。在 macOS 上会调用 open 命令,在 Linux 上会调用 xdg-open。如需使用其他命令,可将环境变量 OPEN_CMD 设置为该命令的名称或路径。即使此步骤失败,也不会影响整体构建结果。如需禁用此功能,可将 OPEN_CMD 设置为 : 空操作命令。
Behave 测试
使用 -m behave 运行 behave 测试时,将基于 PG_MAJOR 版本 11 到 16 构建 Docker 镜像,然后运行所有 behave 测试。这可能需要相当长的时间,因此您可能希望将范围限制为特定的 PostgreSQL 版本或特定的功能集。
若要指定 PostgreSQL 版本,请同时指定所需的镜像构建环境和 behave 环境名称。例如,若要测试 PostgreSQL 14,请使用:
tox -e pg14-docker-build,pg14-docker-behave-etcd-lin
如果只想测试特定功能,可以向 behave 传递位置参数。以下命令将针对所有 PostgreSQL 版本运行 watchdog behave 功能测试场景:
tox -m behave -- features/watchdog.feature
当然,您也可以将上述两种方式结合使用。
提交 Pull Request
- Fork 仓库,在本地开发并测试您的代码变更。
- 在用户文档中同步反映相关变更。
- 提交 Pull Request,并清晰描述本次变更的目标。如涉及已有 Issue,请关联该 Issue。
我们将尽快为您的 Pull Request 提供反馈。
祝 Patroni 开发愉快 ;-)
{kind=link}