这是本节的多页打印视图。
点击此处打印 .
返回本页常规视图 .
部署 在严肃生产环境中进行多节点、高可用的 Pigsty 规划、准备与部署工作。
与 快速上手 架构规划 准备工作
本章将帮助您理解 Pigsty 的完整部署流程,并提供生产环境部署的最佳实践建议。
我们建议您在真实的生产环境部署之前,使用 Pigsty 提供的 沙箱环境 Vagrant Terraform
对于生产环境部署,您通常需要准备至少三个 节点 相关概念 参数配置 Ansible 剧本 安全性
1 - 生产部署 如何在 Linux 主机上安装 Pigsty?
本文是 Pigsty 生产环境多节点部署指南,部署单机版本 Demo/Dev 环境可以参考 快速上手
摘要 准备 几台 SSH 权限 节点 兼容的 Linux 系统 sshsudo管理用户
pigsty.cc(中国)
pigsty.io(全球) curl -fsSL https://repo.pigsty.cc/get | bash;
curl -fsSL https://repo.pigsty.io/get | bash;
该命令会执行 安装 配置 部署
在执行 deploy.yml配置清单 pigsty.yml
cd ~/pigsty # 进入 Pigsty 目录
./configure -g # 生成配置文件(可选,如果知道如何配置可以跳过)
./deploy.yml # 执行部署剧本,根据生成的配置文件开始安装
安装完成后,您可以通过 IP / 域名 + 80/443 端口访问 Web 用户界面 5432 端口访问 PostgreSQL 服务
完整流程根据服务器规格/网络条件需 3~10 分钟,离线安装 精简安装
视频样例:20 节点生产仿真环境(Ubuntu 24.04 x86_64)
准备 在生产环境中部署安装 Pigsty 涉及一些 准备工作
项目 要求 项目 要求 节点 至少 1C2G,上不封顶 规格 多个同质节点,2 / 3 / 4 / 或更多 磁盘 /data 作为默认主挂载点FS 推荐使用 xfs,按需使用 ext4 / zfs VIP L2 VIP,可选 (云环境不可用) 网络 静态 IPv4 地址,单节点无固定 IP 可使用 127.0.0.1 CA 可以使用自签名 CA 或指定已有证书 域名 本地 / 公网域名,可选,默认 i.pigsty 自签名域名 内核 Linux x86_64 / aarch64Linux el8, el9, el10, d12, d13, u22, u24Locale C.UTF-8 或 C防火墙 端口:80 / 443 / 22 / 5432 (可选) 用户 避免使用 root 和 postgres Sudo sudo 权限,最好带有 nopass 免密选项 SSH 通过公钥 nopass SSH 登陆纳管节点 可达性 ssh <ip|alias> sudo ls 无错误
安装 您可以使用以下命令自动安装 Pigsty 源码包 ~/pigsty 目录(推荐),部署所需依赖(Ansible)会自动安装。
pigsty.cc(中国)
pigsty.io(全球) curl -fsSL https://repo.pigsty.cc/get | bash # 安装最新稳定版本
curl -fsSL https://repo.pigsty.cc/get | bash -s v4.2.2 # 安装特定版本
curl -fsSL https://repo.pigsty.io/get | bash # 安装最新稳定版本
curl -fsSL https://repo.pigsty.io/get | bash -s v4.2.2 # 安装特定版本
如果您不希望执行远程脚本,可以手动 下载 git 克隆安装时,请务必检出特定版本后再使用。
git clone https://github.com/pgsty/pigsty; cd pigsty;
git checkout v4.2.2; # 使用 git 安装时,请务必检出特定版本
手工下载克隆安装时,请额外执行 bootstrap自行安装
./bootstrap # 安装 ansible,用于执行后续部署
配置 在 Pigsty 中,部署的蓝图细节由 配置清单 pigsty.yml
Pigsty 提供了 configure配置向导 配置清单
./configure -g # 使用配置向导生成配置文件,并且生成随机密码
配置过程生成的配置文件默认位于:~/pigsty/pigsty.yml,您可以在安装前进行检查,按需修改与定制。
有许多 配置模板 pigsty.yml 配置文件进行定制。
./configure -c ha/full -g # 使用四节点沙箱环境模板
./configure -c ha/trio -g # 使用三节点最小 HA 模板
./configure -c ha/dual -g -v 18 # 使用两节点半高可用模板,使用 PG 18
./configure -c ha/simu -s # 使用二十节点生产仿真模板,不检查 IP,不生成随机强密码
配置 / configure 过程的样例输出 vagrant@meta:~/pigsty$ ./configure
configure pigsty v4.2.2 begin
[ OK ] region = china
[ OK ] kernel = Linux
[ OK ] machine = x86_64
[ OK ] package = deb,apt
[ OK ] vendor = ubuntu ( Ubuntu)
[ OK ] version = 22 ( 22.04)
[ OK ] sudo = vagrant ok
[ OK ] ssh = vagrant@127.0.0.1 ok
[ WARN] Multiple IP address candidates found:
( 1) 192.168.121.38 inet 192.168.121.38/24 metric 100 brd 192.168.121.255 scope global dynamic eth0
( 2) 10.10.10.10 inet 10.10.10.10/24 brd 10.10.10.255 scope global eth1
[ OK ] primary_ip = 10.10.10.10 ( from demo)
[ OK ] admin = vagrant@10.10.10.10 ok
[ OK ] mode = meta ( ubuntu22.04)
[ OK ] locale = C.UTF-8
[ OK ] ansible = ready
[ OK ] pigsty configured
[ WARN] don' t forget to check it and change passwords!
proceed with ./deploy.yml
配置向导只会为您替换 当前节点 的 IP(如果您不想要替换,使用 -s 参数),所以对于一个多节点的部署,您需要自己替换其他节点的 IP 地址。
同时,你还需要按需对配置文件进行进一步的定制,例如修改默认密码、添加更多节点等。
配置脚本常用参数 :
参数 说明 -c|--conf用于指定使用的 配置模板 conf/ 目录,不带 .yml 后缀的配置名称 -v|--version用于指定要安装的 PostgreSQL 大版本,如 13、14、15、16、17、18 -r|--region用于指定上游软件源的区域,加速下载: (default|china|europe) -n|--non-interactive直接使用命令行参数提供首要 IP 地址,跳过交互式向导 -x|--proxy使用当前环境变量配置 proxy_env
如果您的机器网卡绑定了多个 IP 地址,那么需要使用 -i|--ip <ipaddr> 显式指定一个当前节点的首要 IP 地址,或在交互式问询中提供。
该脚本将把 IP 占位符 10.10.10.10 替换为当前节点的主 IPv4 地址。选用的地址应为静态 IP 地址,请勿使用公网 IP 地址。
配置过程生成的配置文件默认位于:~/pigsty/pigsty.yml,您可以在安装前进行检查与修改定制。
修改默认密码!
我们强烈建议您在安装前,事先修改配置文件中使用的默认密码与凭据,详情参考 安全加固
部署 Pigsty 的 deploy.yml剧本 配置 所有的目标节点 。
./deploy.yml # 一次性在所有节点上完成部署
部署过程的样例输出 ......
TASK [ pgsql : pgsql init done ] *************************************************
ok: [ 10.10.10.11] = > {
"msg" : "postgres://10.10.10.11/postgres | meta | dbuser_meta dbuser_view "
}
......
TASK [ pg_monitor : load grafana datasource meta] *******************************
changed: [ 10.10.10.11]
PLAY RECAP *********************************************************************
10.10.10.11 : ok = 302 changed = 232 unreachable = 0 failed = 0 skipped = 65 rescued = 0 ignored = 1
localhost : ok = 6 changed = 3 unreachable = 0 failed = 0 skipped = 1 rescued = 0 ignored = 0
当您看到输出尾部如果带有 pgsql init done,PLAY RECAP 等字样,说明安装已经完成!
上游软件仓库变更可能导致在线安装失败!
Pigsty 使用的上游软件仓库(如 Linux / PGDG 仓库)可能会因为不恰当的更新,进入崩溃状态并导致部署失败(相当常见)!
对于严肃的生产环境部署,我们强烈建议使用经过验证的 离线软件包 离线安装
避免重复执行部署剧本!
警告: 在已经完成部署的环境中再次完整运行 deploy.yml
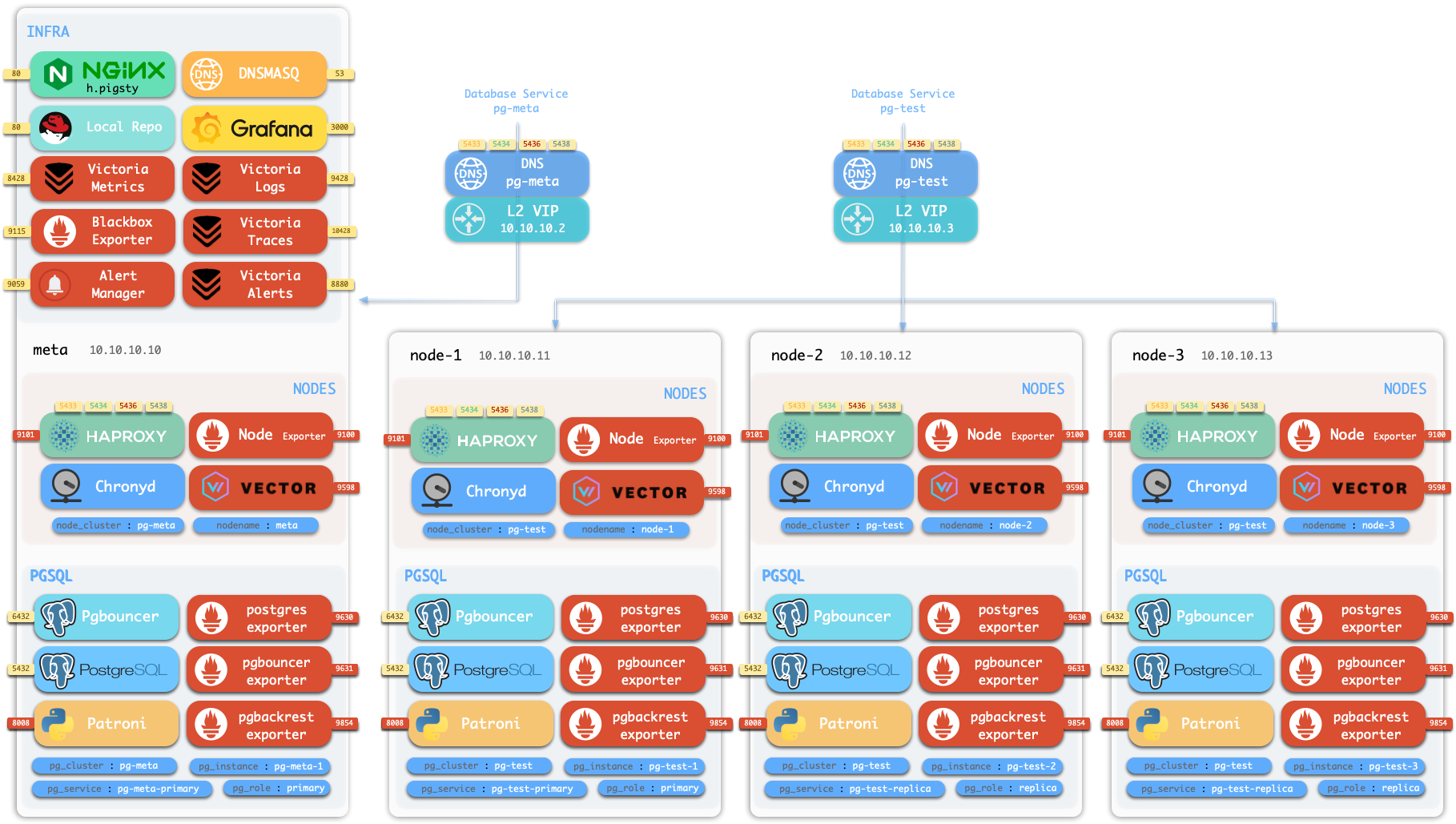
界面 假设您使用 四节点
ID NODE PGSQL INFRA ETCD 1 10.10.10.10pg-meta-1infra-1etcd-12 10.10.10.11pg-test-1- - 3 10.10.10.12pg-test-2- - 4 10.10.10.13pg-test-3- -
INFRA图形化管理界面 80/443 端口访问。
PGSQLPostgreSQL 数据库服务器 5432 端口,也可通过 Pgbouncer / HAProxy 代理访问
对于生产环境的多节点高可用 PostgreSQL 集群来说,您需要通过 服务接入
更多 安装完成后,您可以探索 用户界面 PostgreSQL 服务
您还可以使用 Pigsty 部署和监控 更多集群 配置清单
bin/node-add pg-test # 将集群 pg-test 的 3 个节点纳入 Pigsty 管理
bin/pgsql-add pg-test # 初始化一个 3 节点的 pg-test 高可用 PG 集群
bin/redis-add redis-ms # 初始化 Redis 集群: redis-ms
大多数模块都需要先安装 NODE模块
PGSQLINFRANODEETCDMINIOREDISFERRETDOCKER
2 - 资源准备 生产部署的准备工作,包括硬件,节点、磁盘、网络、VIP、域名、软件、文件系统等……
Pigsty 运行在节点(物理机或虚拟机)之上,本文档介绍硬件相关的规划与准备。
节点 Pigsty 目前运行在 Linux 内核和 x86_64 / aarch64 架构的节点上。
"节点 " 指的是 SSH 可访问 systemd、sudo 和 sshd 的类似操作系统的容器。
部署 Pigsty 至少需要 1 个节点,您可以准备更多,并在 执行部署剧本 1C1G,建议至少使用 1C2G。越高越好,没有上限。系统参数将根据可用资源自动调优 。
所需节点的数量,取决于您的需求,更多详情请参考 架构规划 外部备份 单机部署 高可用配置 3 个节点才能工作,2 个节点则提供 半高可用
磁盘 Pigsty 将使用 /data/data1、/data2、/dataN。
如果你想使用其他的数据目录,可以通过以下参数进行配置:
文件系统 您可以使用任何支持的 Linux 文件系统来格式化数据磁盘,但对于生产环境部署,我们建议使用 xfs
xfs 是 linux 的标配之一,提供了最佳的性能,便利的 CoW 机制,允许你瞬间克隆大型数据库集群。使用 MinIO 时,必须使用 xfs 文件系统。
ext4 是另一个可用的选择,但缺乏 CoW 功能,但有着更为丰富的数据恢复工具生态。zfs 可以提供 RAID,快照功能,但性能折损较大且需要单独安装。
我们推荐您在这三种文件系统中按需权衡,择一使用。
如果有特殊需求,您也可以使用其他文件系统,但我们强烈不建议使用 NFS 网络文件系统来运行数据库服务。
Pigsty 的工作假设是 /data 目录属于 root:root,权限为 755。
管理员可以分配一级目录的所有权和权限。每个应用在其子目录中运行时将使用专用用户。
Pigsty 使用的目录结构说明,请参考 FHS
网络 Pigsty 默认使用在线安装模式,需要出站互联网访问。
使用 离线安装
在内网中,Pigsty 需要 静态网络 才能工作,您应该为每个节点明确分配一个 固定的 IPv4 地址。
IP 地址将用作节点的 唯一标识符 ,它应该是绑定到用于 内部 网络通信的主网络接口的主 IP 地址。
作为特例,单机部署 127.0.0.1 作为变通。
永远不要使用公网 IP 作为标识符
使用公网 IP 地址作为节点标识符可能导致安全和连接问题,请务必使用内网 IP 地址作为标识。
VIP Pigsty 支持 NODE 集群(keepalived)和 PGSQL 集群(vip-manager)的可选 L2 VIP。
要使用 L2 VIP 功能,您必须为节点集群/数据库集群明确分配指定一个 L2 VIP 地址。
在您自己的硬件上运行时这不是大问题,但在公有云环境中工作时可能成为问题。
L2 VIP 需要 L2 网络
要使用可选的节点 VIP 和 PG VIP 功能,请确保所有节点位于同一 L2 网络内。
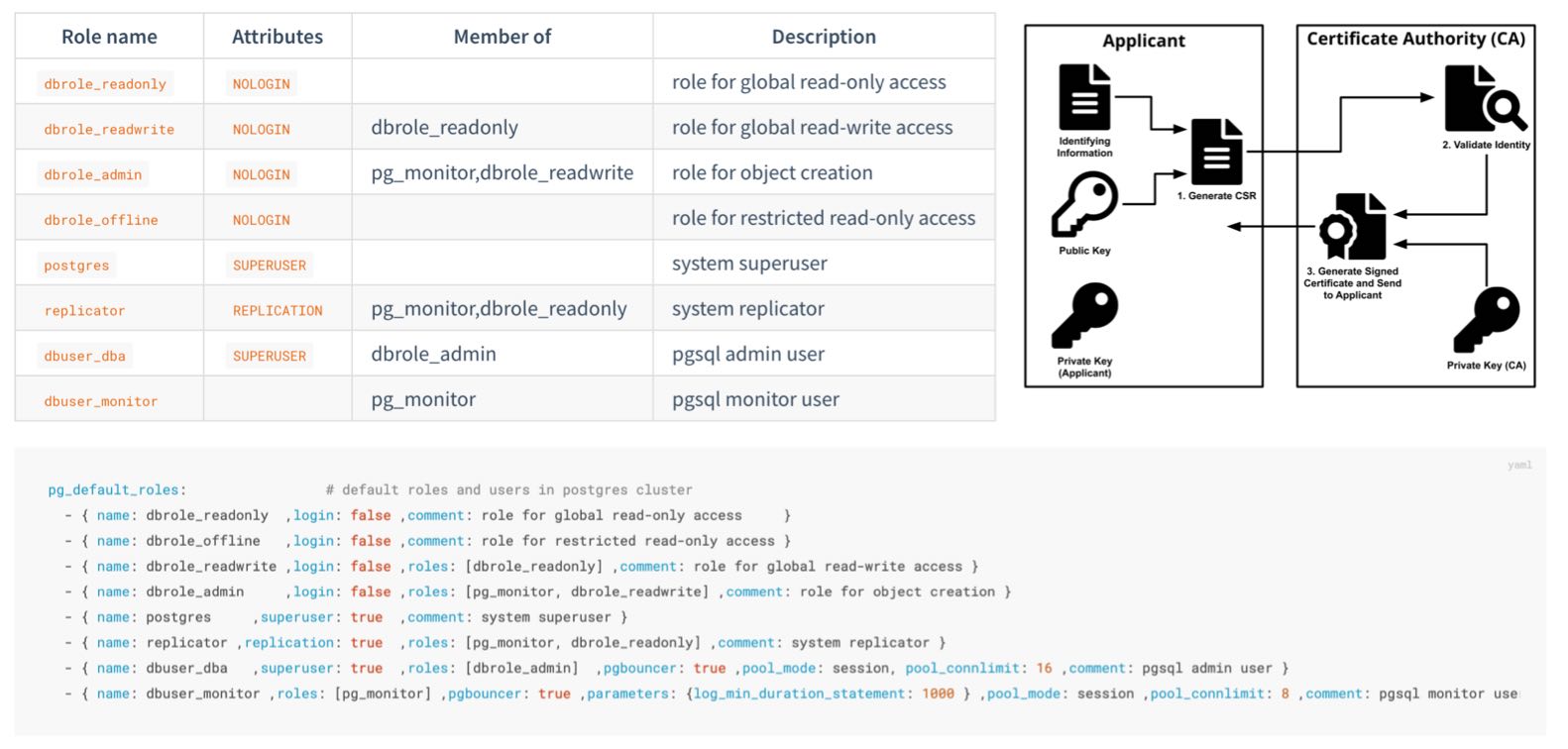
CA Pigsty 默认为每一套部署生成一套自签名的 CA 基础设施
如果您已经有了正规的企业 CA,或者已经有了自签名的 CA,您也可以选择使用已有的 CA 来签发 Pigsty 所需的证书。
域名 Pigsty 默认使用一个本地静态域名 i.pigsty 来访问 WebUI,这是可选的,你也可以直接使用 IP 地址访问。
对于生产环境部署来说,建议您使用域名来访问服务,只有使用域名,才能启用 HTTPS 支持,加密您的数据传输。
同时,域名访问允许您在同一个端口上运行多种不同的服务,并通过不同的域名进行区分。
如果您的部署提供 互联网访问 ,那么可以使用公共 DNS 供应商(如 Cloudflare、阿里云 DNS、AWS Route53 等)来管理您的域名解析。
将您的域名指向 Pigsty 节点的 公网 IP 地址 即可。
如果您的部署针对 局域网/办公网 开放,那么可以使用内部 DNS 服务器来管理域名解析。
将您的域名指向 Pigsty 节点的 办公网 IP 地址 即可。
如果您的访问仅限于本机,或特定的几台机器,那么可以使用本地静态解析来管理域名解析。
将以下记录添加到(用于访问 Pigsty WebUI 的机器) /etc/hosts 文件(本地静态解析)中,即可从浏览器中访问。
10.10.10.10 i.pigsty # 替换为您计划使用的域名,与 Pigsty 节点的 IP 地址
Linux Pigsty 运行在 Linux 操作系统上,它支持 14 种主流 Linux 发行版:兼容操作系统列表
我们推荐使用 RockyLinux 10.1 、Debian 13.3 或 Ubuntu 24.04.4 作为默认操作系统选项。
在 MacOS 和 Windows 上,您可以用各种虚拟机软件或者 Docker systemd 镜像来安装 Pigsty。
我们 强烈建议 使用全新安装的操作系统环境,如果您的服务器已经运行了 Nginx / PostgreSQL 等服务,请考虑使用新的节点进行部署。
在所有节点上使用相同的操作系统版本
多节点部署时,请确保所有节点使用相同的 Linux 发行版,架构与版本。异构节点部署虽然可能可以工作,但不受支持且可能导致不可预见的问题。
Locale 我们建议您将 en_US 设置为操作系统的主要语言,至少确保该 Locale 可用 ,从而确保 PG 日志打印英文。
一些发行版可能默认没有提供 en_US 区域设置,例如 Debian。使用以下命令启用 en_US 区域设置:
localedef -i en_US -f UTF-8 en_US.UTF-8
localectl set-locale LANG = en_US.UTF-8
对于 PostgreSQL 来说,我们强烈建议您默认使用 PG 17+ 内置的 C.UTF-8 作为默认排序规则。
在 配置向导 C.UTF-8 作为排序规则。
Ansible Pigsty 使用 Ansible 安装 Ansible
Pigsty 默认会在 Infra 节点上安装 Ansible,所以 Infra 节点是可以作为管理节点(或备用管理节点)使用。
在 单机部署 管理节点 INFRA节点
Pigsty 您可以使用以下方式 安装
pigsty.cc(中国)
pigsty.io(全球) curl -fsSL https://repo.pigsty.cc/get | bash;
curl -fsSL https://repo.pigsty.io/get | bash;
要 安装 -s <version>
pigsty.cc(中国)
pigsty.io(全球) curl -fsSL https://repo.pigsty.cc/get | bash -s <version> # 安装特定版本(示例:v4.2.2)
curl -fsSL https://repo.pigsty.io/get | bash -s <version> # 安装特定版本(示例:v4.2.2)
要 安装 beta
pigsty.cc(中国)
pigsty.io(全球) curl -fsSL https://repo.pigsty.cc/beta | bash;
curl -fsSL https://repo.pigsty.io/beta | bash;
如果你是开发者,或者想要获取最新的开发版本,可以直接 git 克隆 Pigsty 代码仓库:
git clone https://github.com/pgsty/pigsty.git;
cd pigsty; git checkout <tag> # 使用特定版本(示例:v4.2.2)
如果您的环境没有互联网访问,也可以直接从 GitHub Release
wget https://repo.pigsty.cc/src/pigsty-v<version>.tgz
wget https://repo.pigsty.io/src/pigsty-v<version>.tgz
3 - 架构规划 使用多少个节点?为哪些模块配置高可用?如何根据可用的资源与业务需求进行规划?
Pigsty 采用 模块化架构 声明式配置
常见方案 这里有一些常见的组合模式供您参考,您可以根据自己的需求进行进一步的定制与调整:
使用什么样的架构规划方案,取决于您对数据库可靠性的要求,以及手头可用的资源。
通常来说,严肃的生产环境部署至少需要 3 个节点以实现 高可用配置 2 个节点,则可以使用 半高可用配置
专家咨询服务:架构规划
我们提供 架构咨询服务
利弊权衡 若要使用 Pigsty 的监控系统,则至少需要 1 个 INFRA 节点,生产部署通常使用 2 个,大规模部署 3 个。 若要启用 PG 高可用,则至少需要 1 个 ETCD 节点,生产部署通常使用 3 个,大规模环境中 5 个,须奇数个。 若要启用对象存储(MinIO),则至少需要 1 个 MINIO 节点 MNMD PG 生产集群通常至少为两节点主从配置;严肃场景通常使用 3 节点;高只读负载可以有更多从库(几十个) 此外对于 PostgreSQL 来说,您还可以按需使用 离线实例,同步实例,备份集群,延迟集群等等高级配置。 单节点配置 最简单的配置,所有内容都在单个节点上运行,默认安装四个基本模块,通常用于 Demo,Devbox,或测试环境。
如果为备份/PITR 配置了外部 S3 / MinIO 备份仓库
单节点配置有多种变体:
双节点配置 双节点配置 半高可用 能力,提供更好的数据冗余,以及有限的故障转移支持:
双节点配置的高可用自动切换机制有限制,这种"半 HA"设置只能从特定节点故障中自动恢复:
如果 node-1 故障,无自动故障转移:需要手动提升 node-2 如果 node-2 故障,自动故障转移有效:node-1 自动提升 三节点配置 三节点模板
ID NODE PGSQL INFRA ETCD 1 node-1pg-meta-1infra-1etcd-12 node-2pg-meta-2infra-2etcd-23 node-3pg-meta-3infra-3etcd-3
四节点配置 Pigsty 沙箱环境 标准四节点配置
ID NODE PGSQL INFRA ETCD 1 node-1pg-meta-1infra-1etcd-12 node-2pg-test-13 node-3pg-test-24 node-4pg-test-3
在这里我们出于演示目的,不配置 INFRA ETCD
ID NODE PGSQL INFRA ETCD MINIO 1 node-1pg-meta-1infra-1etcd-1minio-12 node-2pg-test-1infra-2etcd-23 node-3pg-test-2etcd-34 node-4pg-test-3
更多节点 如果您有着完善的虚拟化设施或充足的资源,完全可以 使用更多的节点 独占式部署 ,从而获得最佳的可靠性,可观测性与性能表现。
ID NODE INFRA ETCD MINIO PGSQL 1 10.10.10.10infra-1pg-meta-12 10.10.10.11infra-2pg-meta-23 10.10.10.21etcd-14 10.10.10.22etcd-25 10.10.10.23etcd-36 10.10.10.31minio-17 10.10.10.32minio-28 10.10.10.33minio-39 10.10.10.34minio-410 10.10.10.40pg-src-111 10.10.10.41pg-src-212 10.10.10.42pg-src-313 10.10.10.50pg-test-114 10.10.10.51pg-test-215 10.10.10.52pg-test-316 ……
4 - 管理机制 关于管理用户、管理节点,Sudo、SSH、可达性验证,以及防火墙的配置与准备
Pigsty 需要一个在所有被管理节点上具有免密 SSH Sudo 管理用户 。
这个用户需要能够通过 ssh 访问到所有被管理节点,并且能够在这些节点上执行 sudo 命令。
要想将节点纳入 Pigsty 中管理,
用户 通常我们会选择 dba 或 admin 这样的用户名称,并避免使用 root 与 postgres:
使用 root 进行部署是可行的,但不符合生产最佳实践。 使用 postgres (pg_dbsu 免密码 如果您可以接受为每个 ssh 和 sudo 命令输入密码,则免密码要求是可选的。
您可以在 执行剧本 -k|--ask-pass 来提示输入 SSH 密码,
以及 -K|--ask-become-pass 来提示输入 sudo 密码。
一些企业的安全策略可能不允许免密 ssh 或 sudo,在这种情况下,您可以使用上述选项。
或者考虑配置一个 sudo 密码缓存时间较长的 sudoers 规则,以减少密码提示的频率。
创建管理员用户 通常,您的服务器/虚拟机供应商会为您创建一个初始管理员用户。
如果你对这个用户不满意,Pigsty 的部署剧本可以为你创建一个 新的管理员用户
假设您在节点上有 root 权限,或有一个现有的管理员用户,您可以使用 Pigsty 本身创建管理员用户:
./node.yml -k -K -t node_admin \
-e ansible_user =[ 当前可登录的管理员名称] \
-e node_admin_username =[ 你准备创建的管理员名称]
它将利用现有的管理员创建新的管理员,创建由以下参数描述的专用 dba(uid=88)用户,并正确配置 sudo / ssh。
Sudo 所有 管理员用户 sudo 权限【最好带有免密码执行权限】。
如果您想从头开始配置具有免密 sudo 权限的管理员用户,可以编辑/创建 suoder 文件(假设用户名为 vagrant):
echo '%vagrant ALL=(ALL) NOPASSWD: ALL' | sudo tee /etc/sudoers.d/vagrant
假设您的管理员用户名选择是 dba,那么 /etc/sudoers.d/dba 内容应该是:
%dba ALL =( ALL) NOPASSWD: ALL
如果您的安全策略不允许免密码 sudo,请将 NOPASSWD: 部分删除:
Ansible 依赖 sudo 在被管理节点上以 root 权限执行命令。
在 sudo 不可用的环境中(比如 Docker 容器内)需要先安装 sudo 才能正确部署。
SSH 您的当前用户应该能够以相应的管理员用户身份免密 SSH 访问所有被管理节点。
您的当前用户可以是管理员用户本身,但不是必需的,只要您能以管理员用户身份 SSH。
SSH 配置是 Linux 101,但我们会在此处介绍基础知识,以防您不熟悉:
生成 SSH 密钥 如果您没有 SSH 密钥对,请生成一个:
ssh-keygen -t rsa -b 2048 -N '' -f ~/.ssh/id_rsa -q
如果您没有密钥对,Pigsty 会在 bootstrap
复制 SSH 密钥 您需要将生成的公钥分发到远程(和本地)服务器,并将其放入所有节点上管理员用户的 ~/.ssh/authorized_keys 文件中。
可以使用 ssh-copy-id 工具。
ssh-copy-id <ip> # 交互式密码输入
sshpass -p <password> ssh-copy-id <ip> # 非交互式(谨慎使用)
使用别名 当无法直接 SSH 访问时(由于跳板机、其他端口、凭据等),考虑在 ~/.ssh/config 中配置 SSH 别名:
Host meta
HostName 10.10.10.10
User dba # 远程上不同的用户
IdentityFile /etc/dba/id_rsa # 不是普通密钥
Port 24 # 不是众所周知的端口
并在清单中引用别名,使用 ansible_host 指定真实的 SSH 别名:
nodes :
hosts : # 如果节点 `10.10.10.10` 需要 SSH 别名 `meta`
10.10.10.10 : { ansible_host : meta } # 通过 `ssh meta` 访问
SSH 参数可以直接在 Ansible 中使用,详情请查看 Ansible Inventory Guide 。
通过这种技术,您可以使用跳板机访问私有网络中的节点,或者使用不同的端口和凭据访问节点。
或者是利用本地笔记本作为管理节点。
验证可达性 您应该能够从管理节点通过当前用户免密 ssh 访问所有被管理节点。
远程用户(管理员用户)应该有权限运行免密 sudo 命令。
要验证免密 ssh sudo 是否工作,在管理节点上对所有被管理节点运行此命令:
如果没有密码提示或错误,免密 ssh/sudo 按预期工作。
防火墙 在生产环境部署时,通常需要设置防火墙,以阻止未经授权的端口访问。
默认情况下,你可以阻断办公网/互联网对节点的入站访问,只开放下列端口:
要通过 ssh 访问节点,您必须允许 SSH 端口 22 入站访问。 要访问 WebUI 服务,您必须允许 HTTP(80)/ HTTPS(443)入站访问。 要访问 PostgreSQL 数据库服务,您必须允许 PostgreSQL 的 5432 入站访问。 如果您通过其他端口访问 PostgreSQL 服务,请相应地允许它们。
Pigsty 组件使用的端口列表,请参考:使用的端口
5432: PostgreSQL 数据库6432: Pgbouncer 连接池5433: PG 主要服务5434: PG 副本服务5436: PG 默认服务5438: PG 离线服务5 - 沙箱环境 用于学习、测试与演示的 Pigsty 标准四节点沙箱环境
Pigsty 提供了一个标准的四节点 沙箱环境 ,用于学习、测试与功能演示。
沙箱使用固定的 IP 地址和预定义的身份标识符,便于复现各种演示用例。
环境描述 默认的沙箱环境由 4 个节点组成,默认使用配置文件 ha/full.yml
ID IP 地址 节点名 PostgreSQL INFRA ETCD MINIO 1 10.10.10.10metapg-meta-1infra-1etcd-1minio-12 10.10.10.11node-1pg-test-13 10.10.10.12node-2pg-test-24 10.10.10.13node-3pg-test-3
沙箱的配置可以概括表示为以下配置文件:
all :
children :
infra : { hosts : { 10.10.10.10 : { infra_seq : 1 } } }
etcd : { hosts : { 10.10.10.10 : { etcd_seq: 1 } }, vars : { etcd_cluster : etcd } }
minio : { hosts : { 10.10.10.10 : { minio_seq: 1 } }, vars : { minio_cluster : minio } }
pg-meta :
hosts : { 10.10.10.10 : { pg_seq: 1, pg_role : primary } }
vars : { pg_cluster : pg-meta }
pg-test :
hosts :
10.10.10.11 : { pg_seq: 1, pg_role : primary }
10.10.10.12 : { pg_seq: 2, pg_role : replica }
10.10.10.13 : { pg_seq: 3, pg_role : replica }
vars : { pg_cluster : pg-test }
vars :
version : v4.2.2
admin_ip : 10.10.10.10
region : default
pg_version : 18
PostgreSQL 集群 沙箱带有一个位于 meta 节点上的单实例 PostgreSQL 集群 pg-meta:
10.10.10.10 meta pg-meta-1
10.10.10.2 pg-meta # 可选的 L2 VIP
沙箱中还有一个由三个实例组成的 PostgreSQL 高可用集群 pg-test,部署在另外三个节点上:
10.10.10.11 node-1 pg-test-1
10.10.10.12 node-2 pg-test-2
10.10.10.13 node-3 pg-test-3
10.10.10.3 pg-test # 可选的 L2 VIP
两个可选的 L2 VIP 分别绑定在 pg-meta 和 pg-test 集群的主实例上。
基础设施 在 meta 节点上还部署有:
ETCD 集群 :单节点 etcd 集群,为 PostgreSQL HA 提供 DCS 服务MinIO 集群 :单节点 minio 集群,提供 S3 兼容的对象存储服务10.10.10.10 etcd-1
10.10.10.10 minio-1
创建沙箱 Pigsty 提供了开箱即用的模板,您可以使用 Vagrant Terraform
4节点的沙箱
当然,您也可以自己手工准备置备这些节点。
本地沙箱(Vagrant) 本地沙箱使用 Virtualbox/libvirt 创建本地虚拟机,可以在您的 Mac / PC 上免费运行。
运行完整的 4 节点沙箱,您的机器应至少拥有 4 核 CPU 与 8GB 内存 。
cd ~/pigsty
make full # 使用默认 RockyLinux 9 镜像创建 4 节点沙箱
make full9 # 使用 RockyLinux 9 创建 4 节点沙箱
make full12 # 使用 Debian 12 创建 4 节点沙箱
make full24 # 使用 Ubuntu 24.04 创建 4 节点沙箱
更多详情请参考 Vagrant
云沙箱使用公有云 API 创建虚拟机,可以轻松创建和销毁,按需付费,非常适合快速测试。
使用 spec/aliyun-full.tf
cd ~/pigsty/terraform
cp spec/aliyun-full.tf terraform.tf
terraform init
terraform apply
更多详情请参考 Terraform
其他规格 除了标准的 4 节点沙箱,Pigsty 还提供了其他规格的环境:
最简单的 1 节点环境,用于快速上手、开发和测试:
双节点环境(dual) 2 节点环境,用于测试主从复制:
三节点环境(trio) 3 节点环境,用于测试基本高可用:
生产仿真环境(simu) 20 节点的大型仿真环境,用于模拟生产环境进行完整测试:
make simu # 创建 20 节点生产仿真环境
该环境包含:
3 个基础设施节点(meta1, meta2, meta3) 2 个 HAProxy 代理节点 4 个 MinIO 节点 5 个 ETCD 节点 6 个 PostgreSQL 节点(2 个集群,每个 3 节点) 6 - Vagrant 使用 Vagrant 在本地创建虚拟机环境
Vagrant
Pigsty 需要 Linux 环境运行,您可以使用 Vagrant 轻松在本地创建 Linux 虚拟机进行测试。
安装依赖 首先,确保您的系统中已经安装了 Vagrant VirtualBox libvirt
在 MacOS 上,您可以使用 Homebrew vagrant-libvirt
brew install vagrant virtualbox ansible
# 安装 VirtualBox 后需要重启系统,并在系统偏好设置中允许其内核扩展。 /bin/bash -c " $( curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh) " 创建虚拟机 使用 Pigsty 提供的 make 快捷方式创建虚拟机:
cd ~/pigsty
make meta # 1 节点开发箱,用于快速上手、开发和测试
make full # 4 节点沙箱,用于高可用测试和功能演示
make simu # 20 节点仿真环境,用于生产环境模拟
# 其他不常用的规格
make dual # 2 节点环境
make trio # 3 节点环境
make deci # 10 节点环境
您可以使用变体别名指定不同的操作系统镜像:
make meta9 # 使用 RockyLinux 9.7 创建单节点
make full12 # 使用 Debian 12.13 创建 4 节点沙箱
make simu24 # 使用 Ubuntu 24.04 创建 20 节点仿真环境
可用的操作系统后缀:8(EL8)、9(EL9)、10(EL10)、12(Debian 12)、13(Debian 13)、22(Ubuntu 22.04)、24(Ubuntu 24.04)
构建环境 您还可以使用以下别名创建 Pigsty 构建环境,这些模板不会替换基础镜像:
make oss # 3 节点 OSS 构建环境
make pro # 5 节点 PRO 构建环境
make rpm # 3 节点 EL8/9/10 构建环境
make deb # 4 节点 Debian12/13 Ubuntu22/24 构建环境
make all # 7 节点全量构建环境
规格配置 Pigsty 在 vagrant/spec/
每个规格文件包含一个描述虚拟机节点的 Specs 变量。例如,full.rb 包含 4 节点沙箱的定义:
# full: pigsty full-featured 4-node sandbox for HA-testing & tutorial & practices
Specs = [
{ "name" => "meta" , "ip" => "10.10.10.10" , "cpu" => "2" , "mem" => "4096" , "image" => "bento/rockylinux-9" },
{ "name" => "node-1" , "ip" => "10.10.10.11" , "cpu" => "1" , "mem" => "2048" , "image" => "bento/rockylinux-9" },
{ "name" => "node-2" , "ip" => "10.10.10.12" , "cpu" => "1" , "mem" => "2048" , "image" => "bento/rockylinux-9" },
{ "name" => "node-3" , "ip" => "10.10.10.13" , "cpu" => "1" , "mem" => "2048" , "image" => "bento/rockylinux-9" },
]
simu 规格详情 simu.rb 提供了一个 20 节点的生产环境仿真配置:
3 x infra 节点(meta1-3):4c16g 2 x haproxy 节点(proxy1-2):1c2g 4 x minio 节点(minio1-4):1c2g 5 x etcd 节点(etcd1-5):1c2g 6 x pgsql 节点(pg-src-1-3,pg-dst-1-3):2c4g 配置脚本 使用 vagrant/configVagrantfile:
cd ~/pigsty
vagrant/config [ spec] [ image] [ scale] [ provider]
# 示例
vagrant/config meta # 使用 1 节点规格,默认 RockyLinux 9.7(EL9)镜像
vagrant/config dual el9 # 使用 2 节点规格,EL9 镜像
vagrant/config trio d12 2 # 使用 3 节点规格,Debian 12.13 镜像,双倍资源
vagrant/config full u22 4 # 使用 4 节点规格,Ubuntu 22 镜像,4 倍资源
vagrant/config simu u24 1 libvirt # 使用 20 节点规格,Ubuntu 24 镜像,libvirt 提供商
镜像别名 config 脚本支持多种镜像别名:
发行版 别名 Vagrant Box AlmaLinux 8 el8, rocky8cloud-image/almalinux-8Rocky 9 el9, rocky9, elbento/rockylinux-9AlmaLinux 10 el10, rocky10cloud-image/almalinux-10Debian 12 d12, debian12cloud-image/debian-12Debian 13 d13, debian13cloud-image/debian-13Ubuntu 22.04 u22, ubuntu22, ubuntucloud-image/ubuntu-22.04Ubuntu 24.04 u24, ubuntu24bento/ubuntu-24.04
资源缩放 您可以使用环境变量 VM_SCALE 来调整资源倍数,默认值为 1:
VM_SCALE = 2 vagrant/config meta # 将 meta 规格的 CPU/内存资源翻倍
例如,使用 VM_SCALE=4 配置 meta 规格,会将默认的 2c4g 调整为 8c16g:
Specs = [
{ "name" => "meta" , "ip" => "10.10.10.10" , "cpu" => "8" , "mem" => "16384" , "image" => "bento/rockylinux-9" },
]
simu 规格不支持缩放
simu 规格不支持资源缩放,scale 参数会被自动忽略,因为其资源配置已经针对仿真场景优化。
虚拟机管理 Pigsty 提供了一系列 Makefile 快捷方式来管理虚拟机:
make # 等于 make start
make new # 销毁现有虚拟机,创建新的虚拟机
make ssh # 将虚拟机 SSH 配置写入 ~/.ssh/(创建后必须执行)
make dns # 将虚拟机 DNS 记录写入 /etc/hosts(可选)
make start # 启动虚拟机并配置 SSH(up + ssh)
make up # 使用 vagrant up 启动虚拟机
make halt # 关闭虚拟机(别名:down, dw)
make clean # 销毁虚拟机(别名:del, destroy)
make status # 显示虚拟机状态(别名:st)
make pause # 暂停虚拟机(别名:suspend)
make resume # 恢复虚拟机
make nuke # 使用 virsh 销毁所有虚拟机和卷(仅 libvirt)
make info # 显示 libvirt 信息(虚拟机、网络、存储卷)
SSH 密钥 Pigsty Vagrant 模板默认使用您的 ~/.ssh/id_rsa[.pub] 作为虚拟机的 SSH 密钥。
在开始之前,请确保您有一个有效的 SSH 密钥对。如果没有,可以使用以下命令生成:
ssh-keygen -t rsa -b 2048 -N '' -f ~/.ssh/id_rsa -q
支持的镜像 Pigsty 目前使用以下 Vagrant Box 进行测试:
# x86_64 / amd64
el8 : cloud-image/almalinux-8 ( EL 8.10)
el9 : bento/rockylinux-9 ( RockyLinux 9.7)
el10: cloud-image/almalinux-10 ( RockyLinux 10.1)
d12 : cloud-image/debian-12 ( Debian 12.13)
d13 : cloud-image/debian-13 ( Debian 13.3)
u22 : cloud-image/ubuntu-22.04
u24 : bento/ubuntu-24.04
对于 Apple Silicon (aarch64) 架构:
# aarch64 / arm64
el8 : cloud-image/almalinux-8
el9 : bento/rockylinux-9
el10: cloud-image/almalinux-10
d12 : cloud-image/debian-12
d13 : cloud-image/debian-13
u22 : cloud-image/ubuntu-22.04
u24 : bento/ubuntu-24.04
您可以在 Vagrant Cloud
环境变量 您可以使用以下环境变量来控制 Vagrant 行为:
export VM_SPEC = 'meta' # 规格名称
export VM_IMAGE = 'bento/rockylinux-9' # 镜像名称
export VM_SCALE = '1' # 资源缩放倍数
export VM_PROVIDER = 'virtualbox' # 虚拟化提供商
export VAGRANT_EXPERIMENTAL = disks # 启用实验性磁盘功能
注意事项 VirtualBox 网络配置
使用较旧版本的 VirtualBox 作为 Vagrant 提供商时,需要额外配置才能使用 10.x.x.x CIDR 作为 Host-Only 网络:
echo "* 10.0.0.0/8" | sudo tee -a /etc/vbox/networks.conf
第一次下载镜像较慢
第一次使用 Vagrant 启动特定操作系统时,会下载相应的 Box 镜像文件(通常 1-2 GB)。下载完成后,镜像会被缓存,后续创建虚拟机时会直接复用。
libvirt 提供商
如果您使用 libvirt 作为提供商,可以使用 make info 查看虚拟机、网络和存储卷信息,使用 make nuke 强制销毁所有相关资源。
7 - Terraform 使用 Terraform 在公有云上创建虚拟机环境
Terraform
Pigsty 提供了阿里云、AWS、腾讯云的 Terraform 模板作为示例。
快速开始 在 macOS 上,您可以使用 Homebrew
其他平台请参考 Terraform 官方安装指南
初始化与应用 进入 Terraform 目录,选择模板,初始化提供商插件,然后应用配置:
cd ~/pigsty/terraform
cp spec/aliyun.tf terraform.tf # 选择模板
terraform init # 安装云提供商插件(首次使用时)
terraform apply # 生成执行计划并创建资源
运行 apply 命令后,按提示输入 yes 确认,Terraform 将为您创建虚拟机及相关云资源。
获取 IP 地址 创建完成后,打印管理节点的公网 IP 地址:
terraform output | grep -Eo '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}'
配置 SSH 访问 使用 ssh 脚本自动配置 SSH 别名并分发密钥:
./ssh # 写入 SSH 配置到 ~/.ssh/pigsty_config 并复制密钥
此脚本会将 Terraform 输出的 IP 地址写入 ~/.ssh/pigsty_config,并使用默认密码 PigstyDemo4 自动分发 SSH 密钥。
配置完成后,您可以直接使用主机名登录:
使用 SSH 配置文件
如果您希望使用 ~/.ssh/pigsty_config 中的配置,请确保在 ~/.ssh/config 中包含以下内容:
Include ~/.ssh/pigsty_config
销毁资源 测试完成后,可以一键销毁所有创建的云资源:
模板规格 Pigsty 在 terraform/spec/
使用模板时,将模板文件复制为 terraform.tf:
cd ~/pigsty/terraform
cp spec/aliyun-full.tf terraform.tf # 使用阿里云 4 节点沙箱模板
terraform init && terraform apply
变量配置 Pigsty 的 Terraform 模板使用变量来控制架构、操作系统发行版和资源配置:
架构与发行版 variable "architecture" {
description = "架构类型 (amd64 或 arm64)"
type = string
default = "amd64" # 注释此行以使用 arm64
#default = "arm64" # 取消注释以使用 arm64
}
variable "distro" {
description = "发行版代码 (el8,el9,el10,u22,u24,d12,d13)"
type = string
default = "el9" # 默认使用 Rocky Linux 9
}
资源配置 在 locals 块中可以配置以下资源参数:
locals {
bandwidth = 100 # 公网带宽 (Mbps)
disk_size = 40 # 系统盘大小 (GB)
spot_policy = "SpotWithPriceLimit" # 竞价策略:NoSpot, SpotWithPriceLimit, SpotAsPriceGo
spot_price_limit = 5 # 最高竞价价格 (仅在 SpotWithPriceLimit 时有效)
}
阿里云配置 凭证设置 将您的阿里云凭证添加到环境变量中,例如在 ~/.bash_profile 或 ~/.zshrc 中:
export ALICLOUD_ACCESS_KEY = "<your_access_key>"
export ALICLOUD_SECRET_KEY = "<your_secret_key>"
export ALICLOUD_REGION = "cn-shanghai"
支持的镜像 以下是阿里云中常用的 ECS 公共操作系统镜像
发行版 代码 x86_64 镜像前缀 aarch64 镜像前缀 CentOS 7.9 el7centos_7_9_x64- Rocky 8.10 el8rockylinux_8_10_x64rockylinux_8_10_arm64Rocky 9.7 el9rockylinux_9_7_x64rockylinux_9_7_arm64Rocky 10.1 el10rockylinux_10_1_x64rockylinux_10_1_arm64Debian 11.11 d11debian_11_11_x64- Debian 12.13 d12debian_12_13_x64debian_12_13_arm64Debian 13.3 d13debian_13_3_x64debian_13_3_arm64Ubuntu 20.04 u20ubuntu_20_04_x64- Ubuntu 22.04 u22ubuntu_22_04_x64_20Gubuntu_22_04_arm64_20GUbuntu 24.04 u24ubuntu_24_04_x64_20Gubuntu_24_04_arm64_20GAnolis 8.9 an8anolisos_8_9_x64- Alibaba Cloud Linux 3 al3aliyun_3_0_x64-
OSS 存储配置 aliyun-s3.tf 模板会额外创建 OSS 存储桶及相关权限,用于 PostgreSQL 的 PITR 备份:
OSS Bucket :创建名为 pigsty-oss 的私有存储桶RAM 用户 :创建专用的 pigsty-oss-user 用户访问密钥 :生成 AccessKey 并保存到 ~/pigsty.skIAM 策略 :授予对存储桶的完全访问权限AWS 配置 凭证设置 设置 AWS 配置和凭证文件:
# ~/.aws/config
[ default]
region = cn-northwest-1
# ~/.aws/credentials
[ default]
aws_access_key_id = <YOUR_AWS_ACCESS_KEY>
aws_secret_access_key = <AWS_ACCESS_SECRET>
如果需要使用 SSH 密钥,将密钥文件放置在:
~/.aws/pigsty-key
~/.aws/pigsty-key.pub
AWS 模板需要调整
AWS 模板是社区贡献的示例,可能需要根据您的具体需求进行调整。
腾讯云配置 凭证设置 将腾讯云凭证添加到环境变量中:
export TENCENTCLOUD_SECRET_ID = "<your_secret_id>"
export TENCENTCLOUD_SECRET_KEY = "<your_secret_key>"
export TENCENTCLOUD_REGION = "ap-beijing"
腾讯云模板需要调整
腾讯云模板是社区贡献的示例,可能需要根据您的具体需求进行调整。
快捷命令 Pigsty 提供了一些 Makefile 快捷命令用于 Terraform 操作:
cd ~/pigsty/terraform
make u # terraform apply -auto-approve + 配置 SSH
make d # terraform destroy -auto-approve
make apply # terraform apply(交互式确认)
make destroy # terraform destroy(交互式确认)
make out # terraform output
make ssh # 运行 ssh 脚本配置 SSH 访问
make r # 重置 terraform.tf 到版本库状态
注意事项 云资源费用
使用 Terraform 创建的云资源会产生费用。测试完成后,请及时使用 terraform destroy 销毁资源,避免不必要的开支。
建议使用按量付费的实例类型进行测试。模板默认使用竞价实例(Spot Instance)以降低成本。
默认密码
所有模板中虚拟机的默认 root 密码为 PigstyDemo4。在生产环境中,请务必修改此密码或使用 SSH 密钥认证。
安全组配置
Terraform 模板会自动创建安全组并开放必要的端口(默认开放所有 TCP 端口)。在生产环境中,请根据实际需求调整安全组规则,遵循最小权限原则。
SSH 访问
创建完成后,使用以下命令 SSH 登录到管理节点:
您也可以使用 ./ssh 或 make ssh 将 SSH 别名写入配置文件,然后使用 ssh meta 登录。
8 - 安全考量 Pigsty 部署中与安全有关的考量
Pigsty 的默认配置已经足以覆盖绝大多数场景对于安全的需求。
Pigsty 已经提供了开箱即用的 认证 与 访问控制 模型,对于绝大多数场景已经足够安全。
如果您希望进一步加固系统的安全性,那么以下建议供您参考:
机密性 重要文件 保护你的 pigsty.yml 配置文件或CMDB
pigsty.yml 配置文件通常包含了高度敏感的机密信息,您应当确保它的安全。严格控制管理节点的访问权限,仅限 DBA 或者 Infra 管理员访问。 严格控制 pigsty.yml 配置文件仓库的访问权限(如果您使用 git 进行管理) 保护你的 CA 私钥和其他证书,这些文件非常重要。
相关文件默认会在管理节点Pigsty源码目录的 files/pki 内生成。 你应该定期将它们备份到一个安全的地方存储。 密码 在生产环境部署时,必须更改这些密码,不要使用默认值!
如果您使用MinIO,请修改MinIO的默认用户密码,与pgbackrest中的引用
如果您使用远程备份仓库,请务必启用备份加密,并设置加解密密码
设置 [pgbackrest_repo.*.cipher_type](/docs/pgsql/param#pgbackrest_repo) 为 aes-256-cbc` 设置密码时可以使用 ${pg_cluster} 作为密码的一部分,避免所有集群使用同一个密码 为 PostgreSQL 使用安全可靠的密码加密算法
使用 pg_pwd_encscram-sha-256 替代传统的 md5 这是默认行为,如果没有特殊理由(出于对历史遗留老旧客户端的支持),请不要将其修改回 md5 使用 passwordcheck 扩展强制执行强密码 。
在 pg_libs$libdir/passwordcheck 来强制密码策略。 使用加密算法加密远程备份
为业务用户配置密码自动过期实践
不要将更改密码的语句记录到 postgres 日志或其他日志中
SET log_statement TO 'none' ;
ALTER USER "{{ user.name }}" PASSWORD '{{ user.password }}' ;
SET log_statement TO DEFAULT;
IP地址 为 postgres/pgbouncer/patroni 绑定指定的 IP 地址,而不是所有地址。
默认的 pg_listen0.0.0.0,即所有 IPv4 地址。 考虑使用 pg_listen: '${ip},${vip},${lo}' 绑定到特定IP地址(列表)以增强安全性。 不要将任何端口直接暴露到公网IP上,除了基础设施出口Nginx使用的端口(默认80/443)
出于便利考虑,Prometheus/Grafana 等组件默认监听所有IP地址,可以直接从公网IP端口访问 您可以修改它们的配置文件,只监听内网IP地址,限制其只能通过 Nginx 门户通过域名访问,你也可以当使用安全组,防火墙规则来实现这些安全限制。 出于便利考虑,Redis服务器默认监听所有IP地址,您可以修改 redis_bind_address 使用 HBA 限制 postgres 客户端访问
限制 patroni 管理访问权限:仅 infra/admin 节点可调用控制API
网络流量 使用 SSL 和域名,通过Nginx访问基础设施组件
使用 SSL 保护 Patroni REST API
使用 SSL 保护 Pgbouncer 客户端流量
完整性 为关键场景下的 PostgreSQL 数据库集群配置一致性优先模式(例如与钱相关的库)
pg_confcrit.yml 将以一些可用性为代价,换取最佳的数据一致性。使用crit节点调优模板,以获得更好的一致性。
node_tunecrit ,可以以减少脏页比率,降低数据一致性风险。启用数据校验和,以检测静默数据损坏。
记录建立/切断连接的日志
在 PG 18+ 的 oltp.yml / olap.yml 模板中,log_connections 默认开启(authorization)。 在 crit.yml 模板中,log_connections 与 log_disconnections 默认都开启,审计级别更严格。 您也可以手工 配置集群 ,按需调整这两个参数。 如果您希望彻底杜绝PG集群在故障转移时脑裂的可能性,请启用watchdog
如果你的流量走默认推荐的 HAProxy 分发,那么即使你不启用 watchdog,你也不会遇到脑裂的问题。 如果你的机器假死,Patroni 被 kill -9 杀死,那么 watchdog 可以用来兜底:超时自动关机。 最好不要在基础设施节点上启用 watchdog。 可用性 对于关键场景的PostgreSQL数据库集群,请使用足够的节点/实例数量
你至少需要三个节点(能够容忍一个节点的故障)来实现生产级的高可用性。 如果你只有两个节点,你可以容忍特定备用节点的故障。 如果你只有一个节点,请使用外部的 S3/MinIO 进行冷备份和 WAL 归档存储。 对于 PostgreSQL,在可用性和一致性之间进行权衡
不要直接通过固定的 IP 地址访问数据库;请使用 VIP、DNS、HAProxy 或它们的排列组合
使用 HAProxy 进行服务 接入 在故障切换/主备切换的情况下,Haproxy 将处理客户端的流量切换。 在重要的生产部署中使用多个基础设施节点(例如,1~3)
小规模部署或要求宽松的场景,可以使用单一基础设施节点 / 管理节点。 大型生产部署建议设置至少两个基础设施节点互为备份。 使用足够数量的 etcd 服务器实例,并使用奇数个实例(1,3,5,7)