这是本节的多页打印视图。
点击此处打印 .
返回本页常规视图 .
PG 高可用 Pigsty 使用 Patroni 实现了 PostgreSQL 的高可用,确保主库不可用时自动进行故障转移,由从库接管。
概览 Pigsty 的 PostgreSQL 集群带有开箱即用的高可用方案,由 Patroni Etcd HAProxy
当您的 PostgreSQL 集群含有两个或更多实例时,您无需任何配置即拥有了硬件故障自愈的数据库高可用能力 —— 只要集群中有任意实例存活,集群就可以对外提供完整的服务,而客户端只要连接至集群中的任意节点,即可获得完整的服务,而无需关心主从拓扑变化。
在默认配置下,主库故障恢复时间目标 RTO ≈ 45s,数据恢复点目标 RPO < 1MB;从库故障 RPO = 0,RTO ≈ 0 (闪断);在一致性优先模式下,可确保故障切换数据零损失:
RPO = 0。以上指标均可通过参数,根据您的实际硬件条件与可靠性要求 按需配置
Pigsty 内置了 HAProxy 负载均衡器用于自动流量切换,提供 DNS/VIP/LVS 等多种接入方式供客户端选用。故障切换与主动切换对业务侧除零星闪断外几乎无感知,应用不需要修改连接串重启。
极小的维护窗口需求带来了极大的灵活便利:您完全可以在无需应用配合的情况下滚动维护升级整个集群。硬件故障可以等到第二天再抽空善后处置的特性,让研发,运维与 DBA 都能在故障时安心睡个好觉。
许多大型组织与核心机构已经在生产环境中长时间使用 Pigsty ,最大的部署有 25K CPU 核心与 220+ PostgreSQL 超大规格实例(64c / 512g / 3TB NVMe SSD);在这一部署案例中,五年内经历了数十次硬件故障与各类事故,但依然可以保持高于 99.999% 的总体可用性战绩。
高可用(High-Availability)解决什么问题?
将数据安全C/IA中的可用性提高到一个新高度:RPO ≈ 0, RTO < 45s。 获得无缝滚动维护的能力,最小化维护窗口需求,带来极大便利。 硬件故障可以立即自愈,无需人工介入,运维DBA可以睡个好觉。 从库可以用于承载只读请求,分担主库负载,让资源得以充分利用。 高可用有什么代价?
基础设施依赖:高可用需要依赖 DCS (etcd/zk/consul) 提供共识。 起步门槛增加:一个有意义的高可用部署环境至少需要 三个节点 。 额外的资源消耗:一个新从库就要消耗一份额外资源,不算大问题。 复杂度代价显著升高:备份成本显著加大,需要使用工具压制复杂度。 高可用的局限性
因为复制实时进⾏,所有变更被⽴即应⽤⾄从库。因此基于流复制的高可用方案⽆法应对⼈为错误与软件缺陷导致的数据误删误改。(例如:DROP TABLE,或 DELETE 数据)
此类故障需要使用 延迟集群 时间点恢复
配置策略 RTO RPO 单机 + 数据永久丢失,无法恢复 数据全部丢失 单机 + 单机 + 主从 + 主从 + 主从 +
原理 在 Pigsty 中,高可用架构的实现原理如下:
PostgreSQL 使⽤标准流复制搭建物理从库,主库故障时由从库接管。 Patroni 负责管理 PostgreSQL 服务器进程,处理高可用相关事宜。 Etcd 提供分布式配置存储(DCS)能力,并用于故障后的领导者选举 Patroni 依赖 Etcd 达成集群领导者共识,并对外提供健康检查接口。 HAProxy 对外暴露集群服务,并利⽤ Patroni 健康检查接口,自动分发流量至健康节点。 vip-manager 提供一个可选的二层 VIP,从 Etcd 中获取领导者信息,并将 VIP 绑定在集群主库所在节点上。 当主库故障时,将触发新一轮领导者竞选,集群中最为健康的从库将胜出(LSN位点最高,数据损失最小者),并被提升为新的主库。 胜选从库提升后,读写流量将立即路由至新的主库。
主库故障影响是 写服务短暂不可用 :从主库故障到新主库提升期间,写入请求将被阻塞或直接失败,不可用时长通常在 15秒 ~ 30秒,通常不会超过 1 分钟。
当从库故障时,只读流量将路由至其他从库,如果所有从库都故障,只读流量才会最终由主库承载。
从库故障的影响是 部分只读查询闪断 :当前从库上正在运行查询将由于连接重置而中止,并立即由其他可用从库接管。
故障检测由 Patroni 和 Etcd 共同完成,集群领导者将持有一个租约,
如果集群领导者因为故障而没有及时续租(10s),租约将会被释放,并触发 故障切换 (Failover) 与新一轮集群选举。
即使没有出现任何故障,您依然可以主动通过 主动切换
1 - RPO 利弊权衡 针对 RPO (Recovery Point Objective)进行利弊权衡,在可用性与数据损失之间找到最佳平衡点。
RPO (Recovery Point Objective,恢复点目标)定义了在主库发生故障时,允许丢失的最大数据量 。
对于金融交易这类数据完整性至关重要的场景,通常要求 RPO = 0,即不允许任何数据丢失;
然而更为严格的 RPO 指标是有代价的,它会引入更高的写入延迟,降低系统吞吐量,并且存在从库故障导致主库不可用的风险。
因此对于常规场景,通常可以接受一定量的数据丢失(例如允许丢失不超过 1MB 的数据),以换取更高的可用性与性能。
利弊权衡 通常在异步复制场景下,从库和主库之间会存在一定的复制延迟(取决于网络和吞吐量,正常在 10KB-100KB / 100µs-10ms 的数量级),
这意味着当主库发生故障时,从库可能还没有完全同步主库的最新数据。这时候如果出现故障切换,新的主库可能会丢失一些尚未复制的数据。
潜在数据丢失量的上限由 pg_rpo1048576 (1MB),这意味着在故障转移期间最多可以容忍 1MiB 的数据丢失。
当集群主库宕机时,如果有任何一个从库的复制延迟在这个值以内,Pigsty 将自动提升该从库为新的主库。
然而当所有从库副本的复制延迟都超出这个阈值时,Pigsty 将拒绝进行 [自动故障切换 ] 以避免数据丢失。
此时需要人工介入进行决策 —— 等待主库恢复(可能永远也不会恢复),还是接受数据损失并强制提升一个从库为新的主库。
您需要根据业务的需求偏好配置这个值,在 可用性 和 一致性 之间进行 利弊权衡 。
增大这个值可以提高自动故障切换的成功率,但也会增加潜在的数据丢失量上限。
当您指定 pg_rpo同步复制 ,确保主库在确认至少一个从库持久化数据后才返回写入成功。
这种配置能确保没有复制延迟,但会带来显著的写入延迟,并降低整体的吞吐量。
flowchart LR
A([主库故障]) --> B{同步复制?}
B -->|否| C{延迟 < RPO?}
B -->|是| D{同步从库<br/>可用?}
C -->|是| E[有损自动故障切换<br/>RPO < 1MB]
C -->|否| F[拒绝自动切换<br/>等待主库恢复<br/>或人工介入决策]
D -->|是| G[无损自动故障切换<br/>RPO = 0]
D -->|否| H{严格模式?}
H -->|否| C
H -->|是| F
style A fill:#dc3545,stroke:#b02a37,color:#fff
style E fill:#F0AD4E,stroke:#146c43,color:#fff
style G fill:#198754,stroke:#146c43,color:#fff
style F fill:#BE002F,stroke:#565e64,color:#fff 保护模式 Pigsty 提供三种保护模式,以帮助用户在不同的 RPO 要求下进行利弊权衡,类似于 Oracle Data Guard
最大性能(Maximum Performance)
默认模式 ,异步复制,事务提交仅需本地 WAL 持久化,无需等待从库,从库故障对主库完全透明,不影响服务主库故障时可能丢失尚未发送/接收的 WAL(通常 < 1MB,正常网络条件通常在 10ms/100ms,10KB/100KB 量级) 针对性能优化,适用于常规业务场景,容许在故障时损失少量数据。 最大可用性(Maximum Availability)
配置有 pg_rpo = 0synchronous_mode: true 正常情况下等待至少一个从库确认,实现零数据丢失。当 所有 同步从库故障时,自动降级为异步模式继续服务 兼顾数据安全与服务可用性,是生产环境 核心业务 的推荐配置 最大保护(Maximum Protection)
使用 crit.yml 模板,启用 Patroni 严格同步模式:synchronous_mode: true / synchronous_mode_strict: true 当所有同步从库故障时,主库将拒绝写入 以防止数据丢失,事务必须在至少一个从库持久化后才返回成功。 适用于金融交易、医疗记录等对数据完整性要求极高的场景 名称 最大性能 Performance最大可用 Availability最大保护 Protection复制方式 异步复制 同步复制 严格同步复制 数据丢失 可能丢失 正常零丢失,降级少量丢失 零丢失 主库写延迟 最低 中等 中等 吞吐量 最高 降低 降低 从库故障影响 无影响 自动降级,继续服务 主库停写 RPO < 1MB = 0(正常)/ < 1MB(降级) = 0 适用场景 常规业务、性能优先 重要业务、安全优先 金融核心、安全合规第一 配置方法 默认配置 pg_rpo0pg_confcrit.yml
实现原理 三种保护模式的区别在于 Patroni 的两个核心参数:synchronous_modesynchronous_mode_strict
synchronous_modesynchronous_mode_strictsynchronous_mode_strict = false主库继续服务 (最大可用性)synchronous_mode_strict = true主库停止写入 直到同步从库恢复(最大保护)模式 synchronous_modesynchronous_mode_strict复制模式 从库故障行为 最大性能 false- 异步复制 无影响 最大可用 truefalse同步复制 自动降级为异步 最大保护 truetrue严格同步复制 主库拒绝写入
通常情况下,您只需要将 pg_rpo0,即可打开 synchronous_mode 开关,启用 最大可用性模式 。
如果您使用 pg_confcrit.ymlsynchronous_mode_strict 严格模式开关,启用 最大保护模式 。
此外,您可以启用 watchdog
当然,您可以直接按需 配置
可以指定指定 同步从库列表 您可以 配置 synchronous_commit'remote_apply',严格确保主从读写一致性。(Oracle 最大保护模式相当于 remote_write) 配置建议 最大性能模式 (异步复制)是 Pigsty 默认使用的模式,对于绝大多数业务来说已经足够使用。
容许故障时丢失少量数据(正常在 几KB - 几百KB 的数量级),换来更大的性能吞吐量与服务可用性水平,是常规业务场景的推荐配置。
在这种情况下,您可以通过 pg_rpo
最大可用性模式 (同步复制)适用于对据完整性要求高的场景,不允许数据丢失。
在这种模式下,最少需要一主一从的两节点 PostgreSQL 集群才有意义。
将 pg_rpo
最大保护模式 (严格同步复制) 适用于金融交易、医疗记录等对数据完整性要求极高的场景,我们建议至少使用一主二从的三节点集群,
因为两节点的情况下,只要从库故障,主库就会停止写入,导致业务不可用,这会降低系统的整体可靠性。而三节点的规格下,如果只有一个从库故障,主库仍然可以继续服务。
2 - RTO 利弊权衡 针对 RTO (Recovery Time Objective)进行利弊权衡,在故障恢复速度与误切风险之间找到最佳平衡点。
RTO (Recovery Time Objective,恢复时间目标)定义了在主库发生故障时,系统恢复写入能力所需的最长时间 。
对于核心交易系统这类可用性至关重要的场景,通常要求 RTO 尽可能短,例如一分钟内。
然而更短的 RTO 指标是有代价的,它会增加误切风险:网络抖动可能被误判为故障,导致不必要的故障切换。
因此对于跨机房/跨地域部署的场景,通常需要放宽 RTO 要求(例如 1-2 分钟),以降低误切风险。
利弊权衡 故障切换时的不可用时长上限由 pg_rtofast、norm、safe、wide,分别针对不同的网络条件与部署场景进行了优化,默认使用 norm 模式(约 45 秒)。
您也可以使用秒数直接指定 RTO 上限,系统会自动映射到最接近的模式。
当主库发生故障时,整个恢复流程涉及多个阶段:Patroni 检测故障、DCS 锁过期、新主选举、执行 promote、HAProxy 感知新主。
减小 RTO 意味着缩短各阶段的超时时间,这会使集群对网络抖动更加敏感,从而增加误切风险。
您需要根据实际网络条件选择合适的模式,在 恢复速度 与 误切风险 之间取得平衡。
网络质量越差,越应该选择保守的模式;网络质量越好,越可以选择激进的模式。
flowchart LR
A([主库故障]) --> B{Patroni<br/>检测到?}
B -->|PG崩溃| C[尝试本地重启]
B -->|节点宕机| D[等待 TTL 过期]
C -->|成功| E([本地恢复])
C -->|失败/超时| F[释放 Leader 锁]
D --> F
F --> G[从库竞选]
G --> H[执行 Promote]
H --> I[HAProxy 感知]
I --> J([服务恢复])
style A fill:#dc3545,stroke:#b02a37,color:#fff
style E fill:#198754,stroke:#146c43,color:#fff
style J fill:#198754,stroke:#146c43,color:#fff 四种模式 Pigsty 提供四种 RTO 模式,以帮助用户在不同的网络条件下进行利弊权衡。
名称 fast norm safe wide 适用场景 同机柜 同机房内(默认) 同省跨机房 跨地域/跨洲 网络条件 < 1ms,极稳定 1-5ms,正常 10-50ms,跨机房 100-200ms,公网 目标 RTO 30s 45s 90s 150s 误切风险 较高 中等 较低 极低 配置方法 pg_rto: fastpg_rto: normpg_rto: safepg_rto: wide
fast:同机柜/同交换机
适用于网络延迟极低(< 1ms)且非常稳定的场景,例如同机柜或同交换机部署 平均 RTO: 14s ,最坏情况: 29s ,TTL 仅 20s,检测间隔 5s 对网络质量要求最高,任何抖动都可能触发切换,误切风险较高 norm:同机房(默认)
默认模式 ,适用于同机房部署,网络延迟 1-5ms,质量正常,丢包率合理平均 RTO: 21s ,最坏情况: 43s ,TTL 为 30s,提供合理的容错窗口 平衡了恢复速度与稳定性,适合绝大多数生产环境 safe:同省跨机房
适用于同省/同区域跨机房部署,网络延迟 10-50ms,可能存在偶发抖动 平均 RTO: 43s ,最坏情况: 91s ,TTL 为 60s,更长的容错窗口 主库重启等待时间较长(60s),给予更多本地恢复机会,误切风险较低 wide:跨地域/跨洲
适用于跨地域甚至跨大洲部署,网络延迟 100-200ms,可能有公网级别的丢包率 平均 RTO: 92s ,最坏情况: 207s ,TTL 为 120s,极宽的容错窗口 牺牲恢复速度换取极低的误切率,适合异地容灾场景 RTO时序图 Patroni / PG HA 有两条关键故障路径:主动故障检测 (PG崩溃后 Patroni 检测到并尝试重启)与 被动租约过期 (节点宕机后等待 TTL 过期触发选举)。
实现原理 四种 RTO 模式的区别在于以下 10 个 Patroni 与 HAProxy HA 相关参数如何配置。
组件 参数 fast norm safe wide 说明 patronittl20 30 60 120 Leader 锁生存时间(秒) loop_wait5 5 10 20 HA 循环检查间隔(秒) retry_timeout5 10 20 30 DCS 操作重试超时(秒) primary_start_timeout15 25 45 95 主库重启等待时间(秒) safety_margin5 5 10 15 Watchdog 安全边际(秒) haproxyinter1s 2s 3s 4s 正常状态检查间隔 fastinter0.5s 1s 1.5s 2s 状态变化期检查间隔 downinter1s 2s 3s 4s DOWN 状态检查间隔 rise3 3 3 3 标记 UP 所需连续成功次数 fall3 3 3 3 标记 DOWN 所需连续失败次数
Patroni 参数 ttlloop_waitretry_timeoutprimary_start_timeoutsafety_marginHAProxy 参数 interfastinterdowninterriserise 次检查才能接收流量。fallfall 次才会被标记为 DOWN。关键约束 Patroni 核心约束 :确保主库能在 TTL 过期前完成降级,防止脑裂。
l o o p _ w a i t + 2 × r e t r y _ t i m e o u t ≤ t t l loop\_wait + 2 \times retry\_timeout \leq ttl l oo p _ w ai t + 2 × re t ry _ t im eo u t ≤ ttl 数据汇总 配置建议 fast 模式 适用于对 RTO 要求极高的场景,但需要确保网络质量足够好(延迟 < 1ms,极低丢包率)。
建议仅在同机柜或同交换机部署时使用,并在生产环境充分测试后再启用。
norm 模式 (默认 )是 Pigsty 默认使用的配置,对于绝大多数同机房部署的业务来说已经足够使用。
平均 21 秒的恢复时间在可接受范围内,同时提供了合理的容错窗口,避免网络抖动导致的误切。
safe 模式 适用于同城跨机房部署,网络延迟较高或存在偶发抖动的场景。
更长的容错窗口可以有效避免网络抖动导致的误切,是跨机房容灾的推荐配置。
wide 模式 适用于跨地域甚至跨大洲部署,网络延迟高且可能存在公网级别的丢包率。
这种场景下,稳定性比恢复速度更重要,因此使用极宽的容错窗口来确保极低的误切率。
模式 目标RTO 被动检测 RTO 主动检测 RTO 场景 fast3016 / 23 / 291 / 24 / 29同交换机,高质量网络 norm4527 / 34 / 412 / 35 / 41默认,同机房,标准网络 safe9053 / 66 / 783 / 61 / 73同城双活 / 跨机房容灾 wide150104 / 127 / 1504 / 122 / 145异地容灾 / 跨国部署 default32622 / 34 / 462 / 314 / 326Patroni 默认参数
通常只需将 pg_rtonorm 模式。
配置模式实际上是从 pg_rto_plan
pg_rto_plan : # [ttl, loop, retry, start, margin, inter, fastinter, downinter, rise, fall]
fast : [ 20 , 5 , 5 , 15 , 5 , '1s' , '0.5s' , '1s' , 3 , 3 ] # rto < 30s
norm : [ 30 , 5 , 10 , 25 , 5 , '2s' , '1s' , '2s' , 3 , 3 ] # rto < 45s
safe : [ 60 , 10 , 20 , 45 , 10 , '3s' , '1.5s' , '3s' , 3 , 3 ] # rto < 90s
wide : [ 120 , 20 , 30 , 95 , 15 , '4s' , '2s' , '4s' , 3 , 3 ] # rto < 150s
3 - 故障切换模型 详细分析三种经典故障检测/恢复路径下,最差,最优,平均 RTO 的计算逻辑与结果
Patroni 故障按故障对象分类可以分为以下 10 类,按照检测路径不同,可以进一步归纳为五类,在本节内详细展开。
# 故障场景 描述 最终走哪条路径 1 PG 进程崩溃 crash、OOM killed 主动检测 2 PG 拒绝连接 max_connections 主动检测 3 PG 假活 进程在但无响应 主动检测 (检测超时)4 Patroni 进程崩溃 kill -9、OOM 被动检测 5 Patroni 假活 进程在但卡住 Watchdog 6 节点宕机 断电、硬件故障 被动检测 7 节点假活 IO hang、CPU 饥饿 Watchdog 8 主库 ↔ DCS 网络中断 防火墙、交换机故障 网络分区 9 存储故障 磁盘坏、磁盘满、挂载失败 主动检测 或 Watchdog 10 手动切换 Switchover/Failover 手动触发
但是在 RTO 计算上,最终所有故障都会收敛到两条路径上,本节深入探讨了这两种情况下的 RTO 上下限与均值。
flowchart LR
A([主库故障]) --> B{Patroni<br/>检测到?}
B -->|PG崩溃| C[尝试本地重启]
B -->|节点宕机| D[等待 TTL 过期]
C -->|成功| E([本地恢复])
C -->|失败/超时| F[释放 Leader 锁]
D --> F
F --> G[从库竞选]
G --> H[执行 Promote]
H --> I[HAProxy 感知]
I --> J([服务恢复])
style A fill:#dc3545,stroke:#b02a37,color:#fff
style E fill:#198754,stroke:#146c43,color:#fff
style J fill:#198754,stroke:#146c43,color:#fff 3.1 - 被动故障切换 节点宕机,导致领导者租约过期触发集群领导竞选的故障路径
RTO 时序图
故障模型 项目 最好 最坏 平均 说明 租约过期 ttl - loopttlttl - loop/2最好:即将刷新时宕机 从库检测 0looploop / 2最好:恰好在检测点 抢锁提拔 021最好:直接抢锁提升 健康检查 (rise-1) × fastinter(rise-1) × fastinter + inter(rise-1) × fastinter + inter/2最好:检查前状态变化
被动故障与主动故障的核心区别 :
场景 Patroni 状态 租约处理 主要等待时间 主动故障 (PG崩溃)存活,健康 主动尝试重启 PG,超时后释放租约 primary_start_timeout被动故障 (节点宕机)随节点一起死亡 无法主动释放,只能等待 TTL 过期 ttl
在被动故障场景中,Patroni 随节点一起宕机,无法主动释放 Leader Key 。
DCS 中的租约只能等待 TTL 自然过期后触发集群选举。
时序分析 阶段 1:租约过期 Patroni 主库会在每个 loop_wait 周期刷新 Leader Key,将 TTL 重置为配置值。
时间线:
t-loop t t+ttl-loop t+ttl
| | | |
上次刷新 故障发生 最好情况 最坏情况
|←── loop ──→| | |
|←──────────── ttl ─────────────────────→|
最好情况 :故障发生在即将刷新租约之前(距上次刷新已过 loop),剩余 TTL = ttl - loop最坏情况 :故障发生在刚刷新租约之后,需等待完整 ttl平均情况 :ttl - loop/2T e x p i r e = { t t l − l o o p 最好 t t l − l o o p / 2 平均 t t l 最坏 T_{expire} = \begin{cases}
ttl - loop & \text{最好} \\
ttl - loop/2 & \text{平均} \\
ttl & \text{最坏}
\end{cases} T e x p i re = ⎩ ⎨ ⎧ ttl − l oo p ttl − l oo p /2 ttl 最好 平均 最坏 阶段 2:从库检测 从库在 loop_wait 周期醒来后检查 DCS 中的 Leader Key 状态。
时间线:
租约过期 从库醒来
| |
|←── 0~loop ─→|
最好情况 :租约过期时从库恰好醒来,等待 0最坏情况 :租约过期后从库刚进入睡眠,等待 loop平均情况 :loop/2T d e t e c t = { 0 最好 l o o p / 2 平均 l o o p 最坏 T_{detect} = \begin{cases}
0 & \text{最好} \\
loop/2 & \text{平均} \\
loop & \text{最坏}
\end{cases} T d e t ec t = ⎩ ⎨ ⎧ 0 l oo p /2 l oo p 最好 平均 最坏 阶段 3:抢锁提拔 从库发现 Leader Key 过期后,开始竞选过程,获得 Leader Key 的从库执行 pg_ctl promote,将自己提升为新主库。
通过 Rest API,并行发起查询,查询各从库的复制位置,通常 10ms,硬编码 2 秒超时。 比较 WAL 位置,确定最优候选,各从库尝试创建 Leader Key(CAS 原子操作) 执行 pg_ctl promote 提升自己为主库(很快,通常忽略不计) 选举流程:
从库A ──→ 查询复制位置 ──→ 比较 ──→ 尝试抢锁 ──→ 成功
从库B ──→ 查询复制位置 ──→ 比较 ──→ 尝试抢锁 ──→ 失败
最好情况 :单从库或直接抢到锁并提升,常数开销 0.1s最坏情况 :DCS API 调用超时:2s平均情况 :1s 常数开销T e l e c t = { 0.1 最好 1 平均 2 最坏 T_{elect} = \begin{cases}
0.1 & \text{最好} \\
1 & \text{平均} \\
2 & \text{最坏}
\end{cases} T e l ec t = ⎩ ⎨ ⎧ 0.1 1 2 最好 平均 最坏 阶段 4:健康检查 HAProxy 检测新主库上线,需要连续 rise 次健康检查成功。
检测时序:
新主提升 首次检查 第二次检查 第三次检查(UP)
| | | |
|←─ 0~inter ─→|←─ fast ─→|←─ fast ─→|
最好情况 :新主提升时恰好赶上检查,(rise-1) × fastinter最坏情况 :新主提升后刚错过检查,(rise-1) × fastinter + inter平均情况 :(rise-1) × fastinter + inter/2T h a p r o x y = { ( r i s e − 1 ) × f a s t i n t e r 最好 ( r i s e − 1 ) × f a s t i n t e r + i n t e r / 2 平均 ( r i s e − 1 ) × f a s t i n t e r + i n t e r 最坏 T_{haproxy} = \begin{cases}
(rise-1) \times fastinter & \text{最好} \\
(rise-1) \times fastinter + inter/2 & \text{平均} \\
(rise-1) \times fastinter + inter & \text{最坏}
\end{cases} T ha p ro x y = ⎩ ⎨ ⎧ ( r i se − 1 ) × f a s t in t er ( r i se − 1 ) × f a s t in t er + in t er /2 ( r i se − 1 ) × f a s t in t er + in t er 最好 平均 最坏 RTO 公式 将各阶段时间相加,得到总 RTO:
最好情况
R T O m i n = t t l − l o o p + 0.1 + ( r i s e − 1 ) × f a s t i n t e r RTO_{min} = ttl - loop + 0.1 + (rise-1) \times fastinter RT O min = ttl − l oo p + 0.1 + ( r i se − 1 ) × f a s t in t er 平均情况
R T O a v g = t t l + 1 + i n t e r / 2 + ( r i s e − 1 ) × f a s t i n t e r RTO_{avg} = ttl + 1 + inter/2 + (rise-1) \times fastinter RT O a vg = ttl + 1 + in t er /2 + ( r i se − 1 ) × f a s t in t er 最坏情况
R T O m a x = t t l + l o o p + 2 + i n t e r + ( r i s e − 1 ) × f a s t i n t e r RTO_{max} = ttl + loop + 2 + inter + (rise-1) \times fastinter RT O ma x = ttl + l oo p + 2 + in t er + ( r i se − 1 ) × f a s t in t er 模型计算 将四种 RTO 模型的参数带入上面的公式:
pg_rto_plan : # [ttl, loop, retry, start, margin, inter, fastinter, downinter, rise, fall]
fast : [ 20 , 5 , 5 , 15 , 5 , '1s' , '0.5s' , '1s' , 3 , 3 ] # rto < 30s
norm : [ 30 , 5 , 10 , 25 , 5 , '2s' , '1s' , '2s' , 3 , 3 ] # rto < 45s
safe : [ 60 , 10 , 20 , 45 , 10 , '3s' , '1.5s' , '3s' , 3 , 3 ] # rto < 90s
wide : [ 120 , 20 , 30 , 95 , 15 , '4s' , '2s' , '4s' , 3 , 3 ] # rto < 150s
四种模式计算结果 (单位:秒,格式:min / avg / max)
阶段 fast norm safe wide 租约过期 15 / 17 / 2025 / 27 / 3050 / 55 / 60100 / 110 / 120从库检测 0 / 3 / 50 / 3 / 50 / 5 / 100 / 10 / 20抢锁提拔 0 / 1 / 20 / 1 / 20 / 1 / 20 / 1 / 2健康检查 1 / 2 / 22 / 3 / 43 / 5 / 64 / 6 / 8总计 16 / 23 / 2927 / 34 / 4153 / 66 / 78104 / 127 / 150
3.2 - 主动故障检测 PostgreSQL 主库进程崩溃,Patroni 存活并尝试重启,超时后触发故障切换的路径
RTO 时序图
故障模型 项目 最好 最坏 平均 说明 故障检测 0looploop/2最好:PG 恰好在检测前崩溃 重启超时 0startstart最好:PG 瞬间自愈 从库检测 0looploop/2最好:恰好在检测点 抢锁提拔 021最好:直接抢锁提升 健康检查 (rise-1) × fastinter(rise-1) × fastinter + inter(rise-1) × fastinter + inter/2最好:检查前状态变化
主动故障与被动故障的核心区别 :
场景 Patroni 状态 租约处理 主要等待时间 主动故障 (PG 崩溃)存活,健康 主动尝试重启 PG,超时后释放租约 primary_start_timeout被动故障 (节点宕机)随节点一起死亡 无法主动释放,只能等待 TTL 过期 ttl
在主动故障场景中,Patroni 仍然存活,能够主动检测到 PG 崩溃并尝试重启 。
如果重启成功,服务自愈;如果超时仍未恢复,Patroni 会主动释放 Leader Key ,触发集群选举。
时序分析 阶段 1:故障检测 Patroni 在每个 loop_wait 周期检查 PostgreSQL 状态(通过 pg_isready 或检查进程)。
时间线:
上次检测 PG崩溃 下次检测
| | |
|←── 0~loop ─→| |
最好情况 :PG 恰好在 Patroni 检测前崩溃,立即被发现,等待 0最坏情况 :PG 刚检测完就崩溃,需等待下一个周期,等待 loop平均情况 :loop/2T d e t e c t = { 0 最好 l o o p / 2 平均 l o o p 最坏 T_{detect} = \begin{cases}
0 & \text{最好} \\
loop/2 & \text{平均} \\
loop & \text{最坏}
\end{cases} T d e t ec t = ⎩ ⎨ ⎧ 0 l oo p /2 l oo p 最好 平均 最坏 阶段 2:重启超时 Patroni 检测到 PG 崩溃后,会尝试重启 PostgreSQL。此阶段有两种可能的结果:
时间线:
检测到崩溃 尝试重启 重启成功/超时
| | |
|←──── 0 ~ start ────────→|
路径 A:自愈成功 (最好情况)
PG 成功重启,服务恢复 不触发故障切换,RTO 极短 等待时间:0(相对于 Failover 路径) 路径 B:需要 Failover (平均/最坏情况)
等待 primary_start_timeout 超时后 PG 仍未恢复 Patroni 主动释放 Leader Key 等待时间:start T r e s t a r t = { 0 最好(自愈成功) s t a r t 平均(需要 Failover) s t a r t 最坏 T_{restart} = \begin{cases}
0 & \text{最好(自愈成功)} \\
start & \text{平均(需要 Failover)} \\
start & \text{最坏}
\end{cases} T res t a r t = ⎩ ⎨ ⎧ 0 s t a r t s t a r t 最好(自愈成功) 平均(需要 Failover ) 最坏 注意 :平均情况假设需要进行故障切换。如果 PG 能够快速自愈,则整体 RTO 会大幅降低。
阶段 3:从库检测 从库在 loop_wait 周期醒来后检查 DCS 中的 Leader Key 状态。当主库 Patroni 释放 Leader Key 后,从库发现后开始竞选。
时间线:
租约释放 从库醒来
| |
|←── 0~loop ─→|
最好情况 :租约释放时从库恰好醒来,等待 0最坏情况 :租约释放后从库刚进入睡眠,等待 loop平均情况 :loop/2T s t a n d b y = { 0 最好 l o o p / 2 平均 l o o p 最坏 T_{standby} = \begin{cases}
0 & \text{最好} \\
loop/2 & \text{平均} \\
loop & \text{最坏}
\end{cases} T s t an d b y = ⎩ ⎨ ⎧ 0 l oo p /2 l oo p 最好 平均 最坏 阶段 4:抢锁提拔 从库发现 Leader Key 空缺后,开始竞选过程,获得 Leader Key 的从库执行 pg_ctl promote,将自己提升为新主库。
通过 Rest API,并行发起查询,查询各从库的复制位置,通常 10ms,硬编码 2 秒超时。 比较 WAL 位置,确定最优候选,各从库尝试创建 Leader Key(CAS 原子操作) 执行 pg_ctl promote 提升自己为主库(很快,通常忽略不计) 选举流程:
从库A ──→ 查询复制位置 ──→ 比较 ──→ 尝试抢锁 ──→ 成功
从库B ──→ 查询复制位置 ──→ 比较 ──→ 尝试抢锁 ──→ 失败
最好情况 :单从库或直接抢到锁并提升,常数开销 0.1s最坏情况 :DCS API 调用超时:2s平均情况 :1s 常数开销T e l e c t = { 0.1 最好 1 平均 2 最坏 T_{elect} = \begin{cases}
0.1 & \text{最好} \\
1 & \text{平均} \\
2 & \text{最坏}
\end{cases} T e l ec t = ⎩ ⎨ ⎧ 0.1 1 2 最好 平均 最坏 阶段 5:健康检查 HAProxy 检测新主库上线,需要连续 rise 次健康检查成功。
检测时序:
新主提升 首次检查 第二次检查 第三次检查(UP)
| | | |
|←─ 0~inter ─→|←─ fast ─→|←─ fast ─→|
最好情况 :新主提升时恰好赶上检查,(rise-1) × fastinter最坏情况 :新主提升后刚错过检查,(rise-1) × fastinter + inter平均情况 :(rise-1) × fastinter + inter/2T h a p r o x y = { ( r i s e − 1 ) × f a s t i n t e r 最好 ( r i s e − 1 ) × f a s t i n t e r + i n t e r / 2 平均 ( r i s e − 1 ) × f a s t i n t e r + i n t e r 最坏 T_{haproxy} = \begin{cases}
(rise-1) \times fastinter & \text{最好} \\
(rise-1) \times fastinter + inter/2 & \text{平均} \\
(rise-1) \times fastinter + inter & \text{最坏}
\end{cases} T ha p ro x y = ⎩ ⎨ ⎧ ( r i se − 1 ) × f a s t in t er ( r i se − 1 ) × f a s t in t er + in t er /2 ( r i se − 1 ) × f a s t in t er + in t er 最好 平均 最坏 RTO 公式 将各阶段时间相加,得到总 RTO:
最好情况 (PG 瞬间自愈)
R T O m i n = 0 + 0 + 0 + 0.1 + ( r i s e − 1 ) × f a s t i n t e r ≈ ( r i s e − 1 ) × f a s t i n t e r RTO_{min} = 0 + 0 + 0 + 0.1 + (rise-1) \times fastinter \approx (rise-1) \times fastinter RT O min = 0 + 0 + 0 + 0.1 + ( r i se − 1 ) × f a s t in t er ≈ ( r i se − 1 ) × f a s t in t er 平均情况 (需要 Failover)
R T O a v g = l o o p + s t a r t + 1 + i n t e r / 2 + ( r i s e − 1 ) × f a s t i n t e r RTO_{avg} = loop + start + 1 + inter/2 + (rise-1) \times fastinter RT O a vg = l oo p + s t a r t + 1 + in t er /2 + ( r i se − 1 ) × f a s t in t er 最坏情况
R T O m a x = l o o p × 2 + s t a r t + 2 + i n t e r + ( r i s e − 1 ) × f a s t i n t e r RTO_{max} = loop \times 2 + start + 2 + inter + (rise-1) \times fastinter RT O ma x = l oo p × 2 + s t a r t + 2 + in t er + ( r i se − 1 ) × f a s t in t er 模型计算 将四种 RTO 模型的参数带入上面的公式:
pg_rto_plan : # [ttl, loop, retry, start, margin, inter, fastinter, downinter, rise, fall]
fast : [ 20 , 5 , 5 , 15 , 5 , '1s' , '0.5s' , '1s' , 3 , 3 ] # rto < 30s
norm : [ 30 , 5 , 10 , 25 , 5 , '2s' , '1s' , '2s' , 3 , 3 ] # rto < 45s
safe : [ 60 , 10 , 20 , 45 , 10 , '3s' , '1.5s' , '3s' , 3 , 3 ] # rto < 90s
wide : [ 120 , 20 , 30 , 95 , 15 , '4s' , '2s' , '4s' , 3 , 3 ] # rto < 150s
四种模式计算结果 (单位:秒,格式:min / avg / max)
阶段 fast norm safe wide 故障检测 0 / 3 / 50 / 3 / 50 / 5 / 100 / 10 / 20重启超时 0 / 15 / 150 / 25 / 250 / 45 / 450 / 95 / 95从库检测 0 / 3 / 50 / 3 / 50 / 5 / 100 / 10 / 20抢锁提拔 0 / 1 / 20 / 1 / 20 / 1 / 20 / 1 / 2健康检查 1 / 2 / 22 / 3 / 43 / 5 / 64 / 6 / 8总计 1 / 24 / 292 / 35 / 413 / 61 / 734 / 122 / 145
与被动故障对比 阶段 主动故障(PG 崩溃) 被动故障(节点宕机) 说明 检测机制 Patroni 主动检测 TTL 被动过期 主动检测更快发现故障 核心等待 startttlstart 通常小于 ttl,但需要额外的故障检测时间 租约处理 主动释放 被动过期 主动释放更及时 自愈可能 ✅ 有 ❌ 无 主动检测可尝试本地恢复
RTO 对比 (平均情况):
模式 主动故障(PG 崩溃) 被动故障(节点宕机) 差异 fast 24s 23s +1s norm 35s 34s +1s safe 61s 66s -5s wide 122s 127s -5s
分析 :在 fast 和 norm 模式下,主动故障的 RTO 略高于被动故障,因为需要等待 primary_start_timeout(start);
但在 safe 和 wide 模式下,由于 start < ttl - loop,主动故障反而更快。
不过主动故障有自愈的可能性,最好情况下 RTO 可以极短。
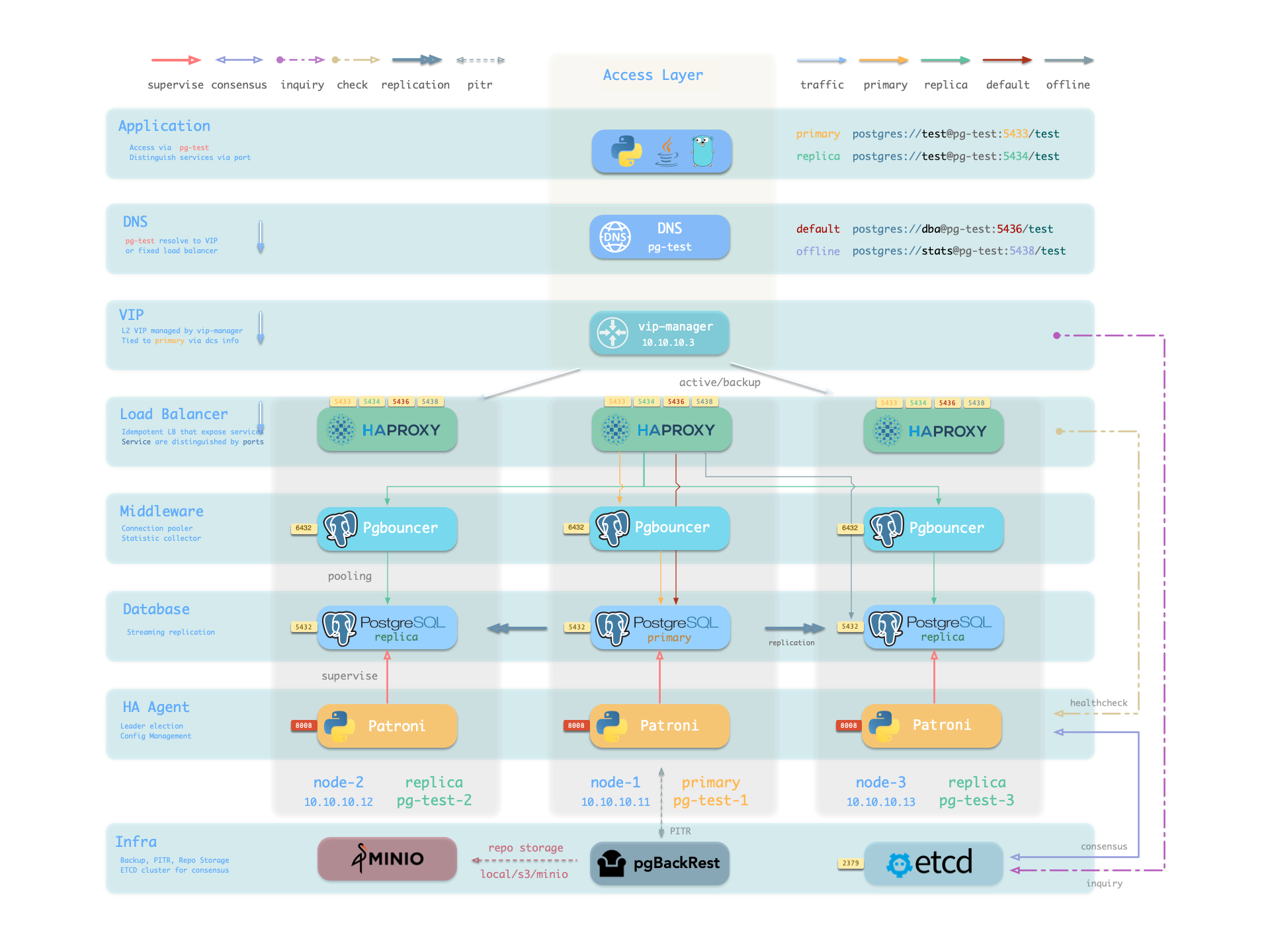
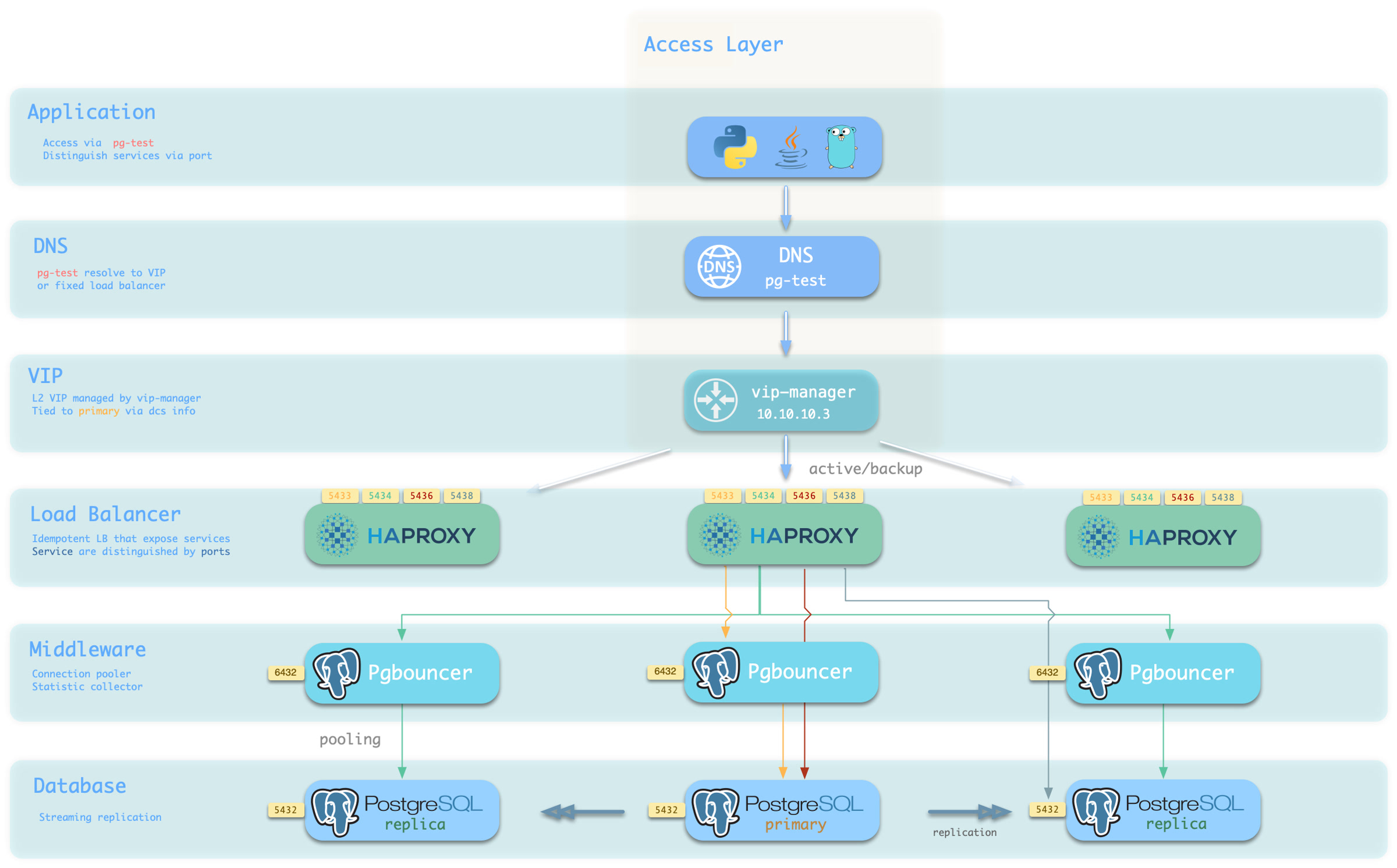
4 - 服务接入 Pigsty 使用 HAProxy 提供服务接入,并提供可选的 pgBouncer 池化连接,以及可选的 L2 VIP 与 DNS 接入。
分离读写操作,正确路由流量,稳定可靠地交付 PostgreSQL 集群提供的能力。
服务 是一种抽象:它是数据库集群对外提供能力的形式,并封装了底层集群的细节。
服务对于生产环境中的 稳定接入 至关重要,在 高可用 集群自动故障时方显其价值,单机用户 通常不需要操心这个概念。
单机用户 “服务” 的概念是给生产环境用的,个人用户/单机集群可以不折腾,直接拿实例名/IP地址访问数据库。
例如,Pigsty 默认的单节点 pg-meta.meta 数据库,就可以直接用下面三个不同的用户连接上去。
psql postgres://dbuser_dba:DBUser.DBA@10.10.10.10/meta # 直接用 DBA 超级用户连上去
psql postgres://dbuser_meta:DBUser.Meta@10.10.10.10/meta # 用默认的业务管理员用户连上去
psql postgres://dbuser_view:DBUser.View@pg-meta/meta # 用默认的只读用户走实例域名连上去
服务概述 在真实世界生产环境中,我们会使用基于复制的主从数据库集群。集群中有且仅有一个实例作为领导者(主库 )可以接受写入。
而其他实例(从库 )则会从持续从集群领导者获取变更日志,与领导者保持一致。同时,从库还可以承载只读请求,在读多写少的场景下可以显著分担主库的负担,
因此对集群的写入请求与只读请求进行区分,是一种十分常见的实践。
此外对于高频短连接的生产环境,我们还会通过连接池中间件(Pgbouncer)对请求进行池化,减少连接与后端进程的创建开销。但对于ETL与变更执行等场景,我们又需要绕过连接池,直接访问数据库。
同时,高可用集群在故障时会出现故障切换(Failover),故障切换会导致集群的领导者出现变更。因此高可用的数据库方案要求写入流量可以自动适配集群的领导者变化。
这些不同的访问需求(读写分离,池化与直连,故障切换自动适配)最终抽象出 服务 (Service)的概念。
通常来说,数据库集群都必须提供这种最基础的服务:
对于生产数据库集群,至少应当提供这两种服务:
读写服务(primary) :写入数据:只能由主库所承载。只读服务(replica) :读取数据:可以由从库承载,没有从库时也可由主库承载此外,根据具体的业务场景,可能还会有其他的服务,例如:
默认直连服务(default) :允许(管理)用户,绕过连接池直接访问数据库的服务离线从库服务(offline) :不承接线上只读流量的专用从库,用于ETL与分析查询同步从库服务(standby) :没有复制延迟的只读服务,由 同步备库 /主库处理只读查询延迟从库服务(delayed) :访问同一个集群在一段时间之前的旧数据,由 延迟从库 来处理接入服务 Pigsty的服务交付边界止步于集群的HAProxy,用户可以用各种手段访问这些负载均衡器。
典型的做法是使用 DNS 或 VIP 接入,将其绑定在集群所有或任意数量的负载均衡器上。
你可以使用不同的 主机 & 端口 组合,它们以不同的方式提供 PostgreSQL 服务。
主机
类型 样例 描述 集群域名 pg-test通过集群域名访问(由 dnsmasq @ infra 节点解析) 集群 VIP 地址 10.10.10.3通过由 vip-manager 管理的 L2 VIP 地址访问,绑定到主节点 实例主机名 pg-test-1通过任何实例主机名访问(由 dnsmasq @ infra 节点解析) 实例 IP 地址 10.10.10.11访问任何实例的 IP 地址
端口
Pigsty 使用不同的 端口 来区分 pg services
端口 服务 类型 描述 5432 postgres 数据库 直接访问 postgres 服务器 6432 pgbouncer 中间件 访问 postgres 前先通过连接池中间件 5433 primary 服务 访问主 pgbouncer (或 postgres) 5434 replica 服务 访问备份 pgbouncer (或 postgres) 5436 default 服务 访问主 postgres 5438 offline 服务 访问离线 postgres
组合
# 通过集群域名访问
postgres://test@pg-test:5432/test # DNS -> L2 VIP -> 主直接连接
postgres://test@pg-test:6432/test # DNS -> L2 VIP -> 主连接池 -> 主
postgres://test@pg-test:5433/test # DNS -> L2 VIP -> HAProxy -> 主连接池 -> 主
postgres://test@pg-test:5434/test # DNS -> L2 VIP -> HAProxy -> 备份连接池 -> 备份
postgres://dbuser_dba@pg-test:5436/test # DNS -> L2 VIP -> HAProxy -> 主直接连接 (用于管理员)
postgres://dbuser_stats@pg-test:5438/test # DNS -> L2 VIP -> HAProxy -> 离线直接连接 (用于 ETL/个人查询)
# 通过集群 VIP 直接访问
postgres://test@10.10.10.3:5432/test # L2 VIP -> 主直接访问
postgres://test@10.10.10.3:6432/test # L2 VIP -> 主连接池 -> 主
postgres://test@10.10.10.3:5433/test # L2 VIP -> HAProxy -> 主连接池 -> 主
postgres://test@10.10.10.3:5434/test # L2 VIP -> HAProxy -> 备份连接池 -> 备份
postgres://dbuser_dba@10.10.10.3:5436/test # L2 VIP -> HAProxy -> 主直接连接 (用于管理员)
postgres://dbuser_stats@10.10.10.3::5438/test # L2 VIP -> HAProxy -> 离线直接连接 (用于 ETL/个人查询)
# 直接指定任何集群实例名
postgres://test@pg-test-1:5432/test # DNS -> 数据库实例直接连接 (单例访问)
postgres://test@pg-test-1:6432/test # DNS -> 连接池 -> 数据库
postgres://test@pg-test-1:5433/test # DNS -> HAProxy -> 连接池 -> 数据库读/写
postgres://test@pg-test-1:5434/test # DNS -> HAProxy -> 连接池 -> 数据库只读
postgres://dbuser_dba@pg-test-1:5436/test # DNS -> HAProxy -> 数据库直接连接
postgres://dbuser_stats@pg-test-1:5438/test # DNS -> HAProxy -> 数据库离线读/写
# 直接指定任何集群实例 IP 访问
postgres://test@10.10.10.11:5432/test # 数据库实例直接连接 (直接指定实例, 没有自动流量分配)
postgres://test@10.10.10.11:6432/test # 连接池 -> 数据库
postgres://test@10.10.10.11:5433/test # HAProxy -> 连接池 -> 数据库读/写
postgres://test@10.10.10.11:5434/test # HAProxy -> 连接池 -> 数据库只读
postgres://dbuser_dba@10.10.10.11:5436/test # HAProxy -> 数据库直接连接
postgres://dbuser_stats@10.10.10.11:5438/test # HAProxy -> 数据库离线读-写
# 智能客户端:通过URL读写分离
postgres://test@10.10.10.11:6432,10.10.10.12:6432,10.10.10.13:6432/test?target_session_attrs= primary
postgres://test@10.10.10.11:6432,10.10.10.12:6432,10.10.10.13:6432/test?target_session_attrs= prefer-standby