这是本节的多页打印视图。
点击此处打印.
返回本页常规视图.
数据分析应用
使用 Pigsty Grafana & Echarts 工具箱进行数据分析与可视化
Applet的结构
Applet,是一种自包含的,运行于Pigsty基础设施中的数据小应用。
一个Pigsty应用通常包括以下内容中的至少一样或全部:
- 图形界面(Grafana Dashboard定义) 放置于
ui目录 - 数据定义(PostgreSQL DDL File),放置于
sql 目录 - 数据文件(各类资源,需要下载的文件),放置于
data目录 - 逻辑脚本(执行各类逻辑),放置于
bin目录
Pigsty默认提供了几个样例应用:
pglog, 分析PostgreSQL CSV日志样本。covid, 可视化WHO COVID-19数据,查阅各国疫情数据。pglog, NOAA ISD,可以查询全球30000个地表气象站从1901年来的气象观测记录。
应用的结构
一个Pigsty应用会在应用根目录提供一个安装脚本:install或相关快捷方式。您需要使用管理用户在 管理节点 执行安装。安装脚本会检测当前的环境(获取 METADB_URL, PIGSTY_HOME,GRAFANA_ENDPOINT等信息以执行安装)
通常,带有APP标签的面板会被列入Pigsty Grafana首页导航中App下拉菜单中,带有APP和Overview标签的面板则会列入首页面板导航中。
您可以从 https://github.com/Vonng/pigsty/releases/download/v1.5.1/app.tgz 下载带有基础数据的应用进行安装。
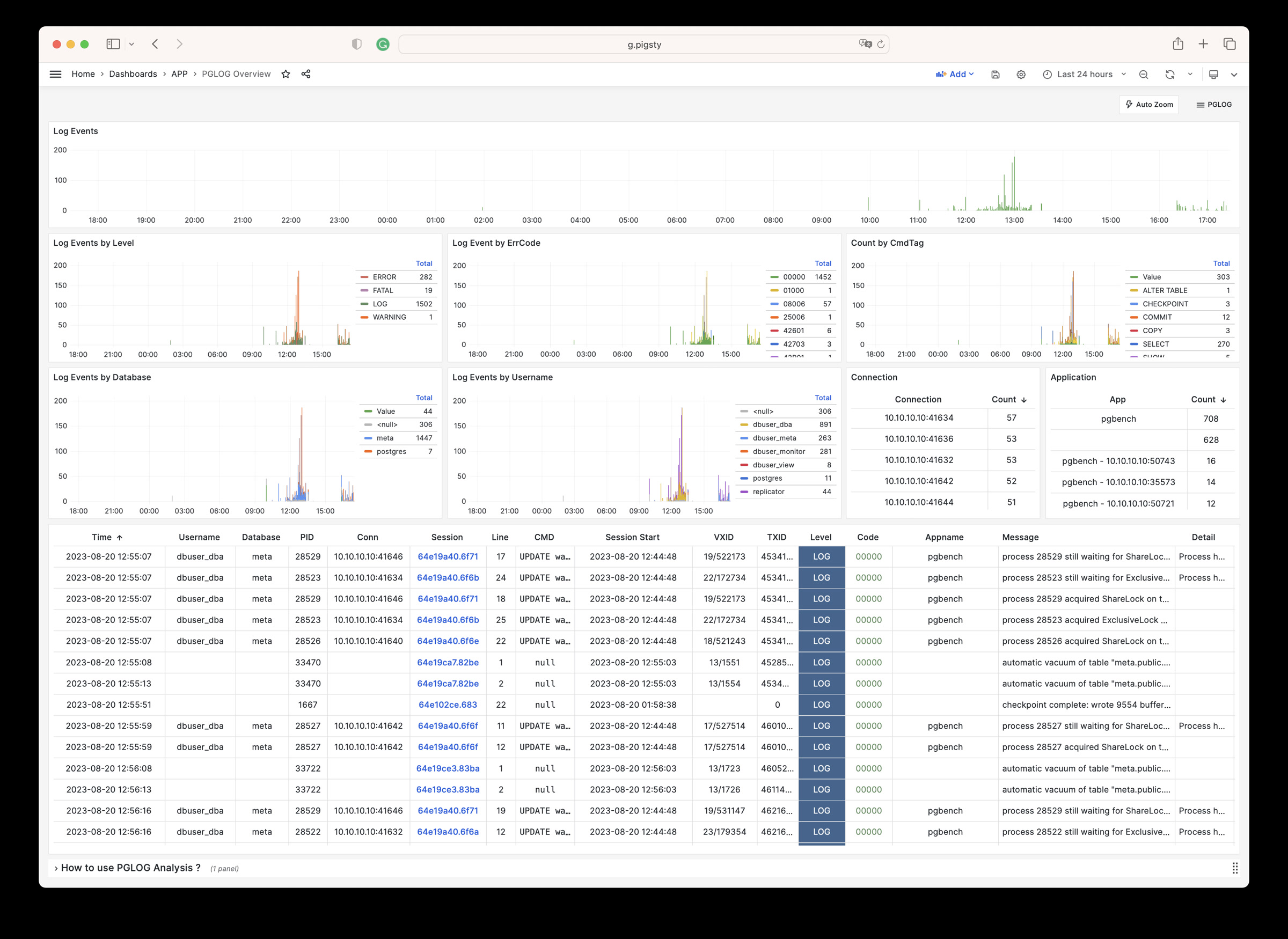
1 - PGLOG:PG自带日志分析应用
Pigsty自带的,用于分析PostgreSQL CSV日志样本的一个样例Applet
PGLOG是Pigsty自带的一个样例应用,固定使用MetaDB中pglog.sample表作为数据来源。您只需要将日志灌入该表,然后访问相关Dashboard即可。
Pigsty提供了一些趁手的命令,用于拉取csv日志,并灌入样本表中。在元节点上,默认提供下列快捷命令:
catlog [node=localhost] [date=today] # 打印CSV日志到标准输出
pglog # 从标准输入灌入CSVLOG
pglog12 # 灌入PG12格式的CSVLOG
pglog13 # 灌入PG13格式的CSVLOG
pglog14 # 灌入PG14格式的CSVLOG (=pglog)
catlog | pglog # 分析当前节点当日的日志
catlog node-1 '2021-07-15' | pglog # 分析node-1在2021-07-15的csvlog
接下来,您可以访问以下的连接,查看样例日志分析界面。
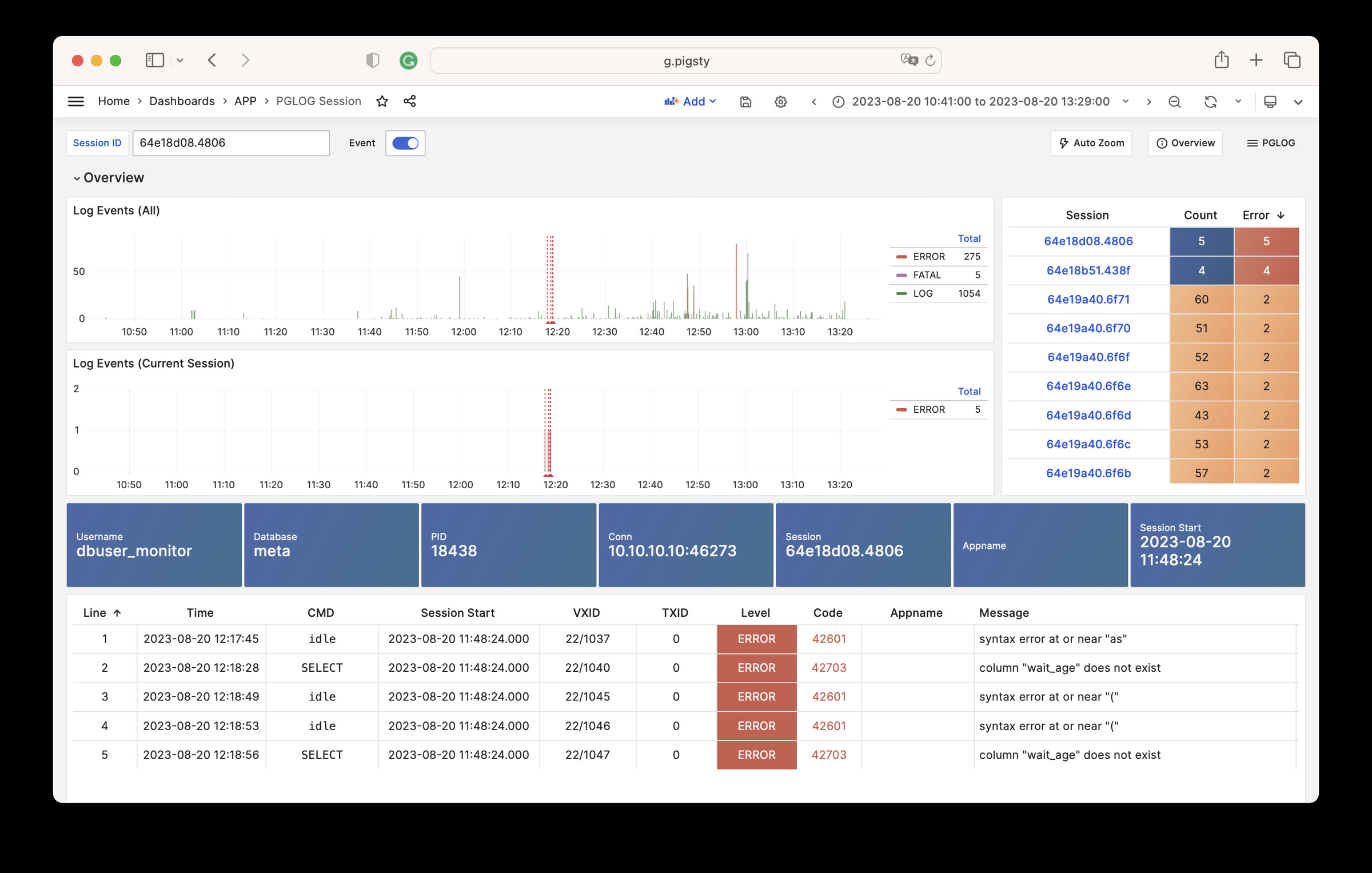
catlog命令从特定节点拉取特定日期的CSV数据库日志,写入stdout
默认情况下,catlog会拉取当前节点当日的日志,您可以通过参数指定节点与日期。
组合使用pglog与catlog,即可快速拉取数据库CSV日志进行分析。
catlog | pglog # 分析当前节点当日的日志
catlog node-1 '2021-07-15' | pglog # 分析node-1在2021-07-15的csvlog
2 - NOAA ISD 全球气象站历史数据查询
以ISD数据集为例,展现如何将数据导入数据库中
如果您拥有数据库后不知道干点什么,不妨参试试这个开源项目:Vonng/isd
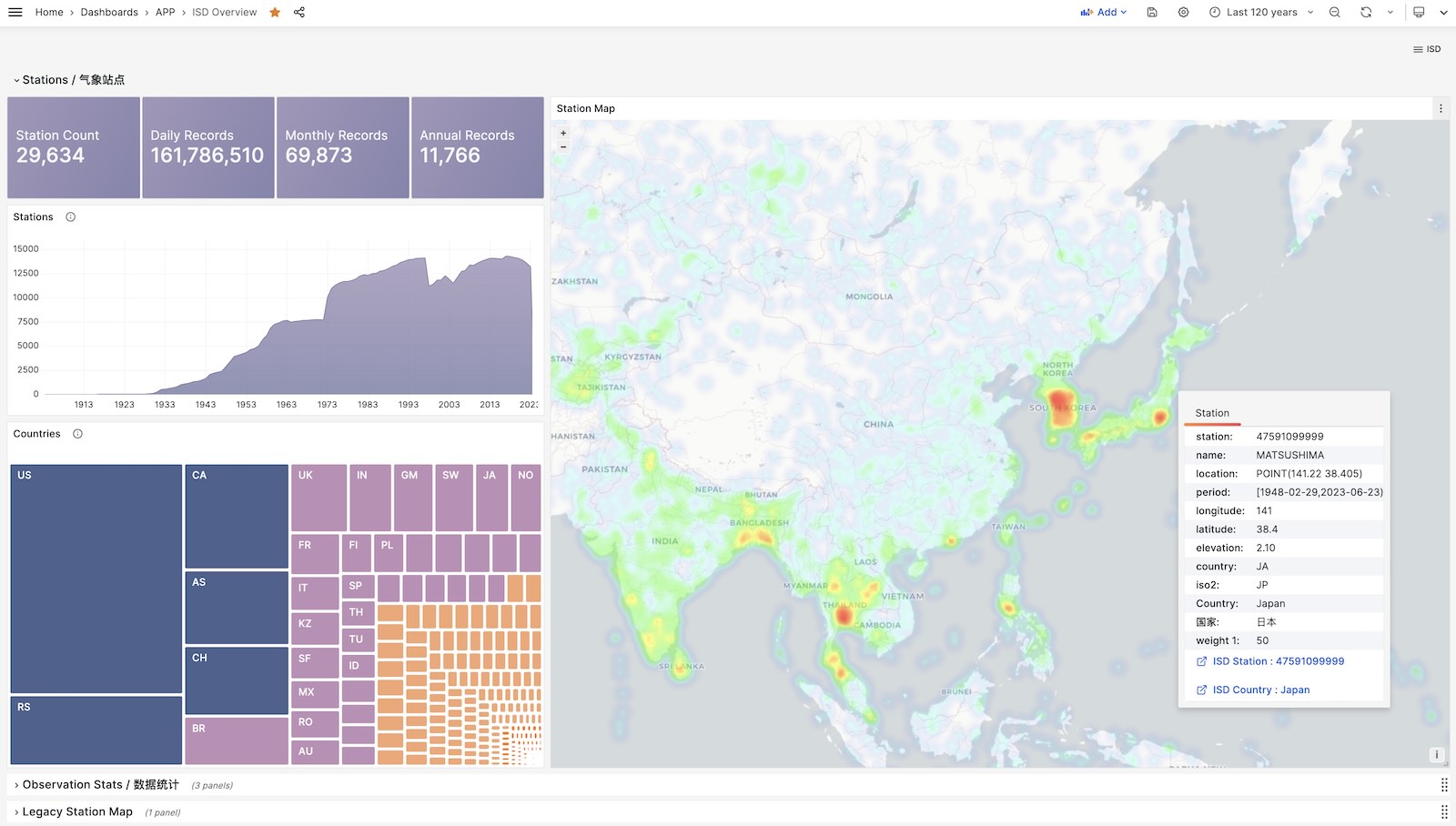
您可以直接复用监控系统Grafana,以交互式的方式查阅近30000个地面气象站过去120年间的亚小时级气象数据。
这是一个功能完成的数据应用,可以查询全球30000个地表气象站从1901年来的气象观测记录。
项目地址:https://github.com/Vonng/isd
在线Demo地址:https://demo.pigsty.cc/d/isd-overview
快速上手
克隆本仓库
git clone https://github.com/Vonng/isd.git; cd isd;
准备一个 PostgreSQL 实例
该 PostgreSQL 实例应当启用了 PostGIS 扩展。使用 PGURL 环境变量传递数据库连接信息:
# Pigsty 默认使用的管理员账号是 dbuser_dba,密码是 DBUser.DBA
export PGURL=postgres://dbuser_dba:DBUser.DBA@127.0.0.1:5432/meta?sslmode=disable
psql "${PGURL}" -c 'SELECT 1' # 检查连接是否可用
获取并导入ISD气象站元数据
这是一份每日更新的气象站元数据,包含了气象站的经纬度、海拔、名称、国家、省份等信息,使用以下命令下载并导入。
make reload-station # 相当于先下载最新的Station数据再加载:get-station + load-station
获取并导入最新的 isd.daily 数据
isd.daily 是一个每日更新的数据集,包含了全球各气象站的日观测数据摘要,使用以下命令下载并导入。
请注意,直接从 NOAA 网站下载的原始数据需要经过解析方可入库,所以你需要下载或构建一个 ISD 数据 Parser。
make get-parser # 从 Github 下载 Parser 二进制,当然你也可以用 make build 直接用 go 构建。
make reload-daily # 下载本年度最新的 isd.daily 数据并导入数据库中
加载解析好的 CSV 数据集
ISD Daily 数据集有一些脏数据与重复数据,如果你不想手工解析处理清洗,这里也提供了一份解析好的稳定CSV数据集。
该数据集包含了截止到 2023-06-24 的 isd.daily 数据,你可以直接下载并导入 PostgreSQL 中,不需要 Parser,
make get-stable # 从 Github 上获取稳定的 isd.daily 历史数据集。
make load-stable # 将下载好的稳定历史数据集加载到 PostgreSQL 数据库中。
更多数据
ISD数据集有两个部分是每日更新的,气象站元数据,以及最新年份的 isd.daily (如 2023 年的 Tarball)。
你可以使用以下命令下载并刷新这两个部分。如果数据集没有更新,那么这些命令不会重新下载同样的数据包
make reload # 实际上是:reload-station + reload-daily
你也可以使用以下命令下载并加载特定年份的 isd.daily 数据:
bin/get-daily 2022 # 获取 2022 年的每日气象观测摘要 (1900-2023)
bin/load-daily "${PGURL}" 2022 # 加载 2022 年的每日气象观测摘要 (1900-2023)
除了每日摘要 isd.daily, ISD 还提供了一份更详细的亚小时级原始观测记录 isd.hourly,下载与加载的方式与前者类似:
bin/get-hourly 2022 # 下载特定某一年的小时级观测记录(例如2022年,可选 1900-2023)
bin/load-hourly "${PGURL}" 2022 # 加载特定某一年的小时级观测记录
数据
数据集概要
ISD提供了四个数据集:亚小时级原始观测数据,每日统计摘要数据,月度统计摘要,年度统计摘要
| 数据集 | 备注 |
|---|
| ISD Hourly | 亚小时级观测记录 |
| ISD Daily | 每日统计摘要 |
| ISD Monthly | 没有用到,因为可以从 isd.daily 计算生成 |
| ISD Yearly | 没有用到,因为可以从 isd.daily 计算生成 |
每日摘要数据集
- 压缩包大小 2.8GB (截止至 2023-06-24)
- 表大小 24GB,索引大小 6GB,PostgreSQL 中总大小约为 30GB
- 如果启用了 timescaledb 压缩,总大小可以压缩到 4.5 GB。
亚小时级观测数据级
- 压缩包总大小 117GB
- 灌入数据库后表大小 1TB+ ,索引大小 600GB+,总大小 1.6TB
数据库模式
气象站元数据表
CREATE TABLE isd.station
(
station VARCHAR(12) PRIMARY KEY,
usaf VARCHAR(6) GENERATED ALWAYS AS (substring(station, 1, 6)) STORED,
wban VARCHAR(5) GENERATED ALWAYS AS (substring(station, 7, 5)) STORED,
name VARCHAR(32),
country VARCHAR(2),
province VARCHAR(2),
icao VARCHAR(4),
location GEOMETRY(POINT),
longitude NUMERIC GENERATED ALWAYS AS (Round(ST_X(location)::NUMERIC, 6)) STORED,
latitude NUMERIC GENERATED ALWAYS AS (Round(ST_Y(location)::NUMERIC, 6)) STORED,
elevation NUMERIC,
period daterange,
begin_date DATE GENERATED ALWAYS AS (lower(period)) STORED,
end_date DATE GENERATED ALWAYS AS (upper(period)) STORED
);
每日摘要表
CREATE TABLE IF NOT EXISTS isd.daily
(
station VARCHAR(12) NOT NULL, -- station number 6USAF+5WBAN
ts DATE NOT NULL, -- observation date
-- 气温 & 露点
temp_mean NUMERIC(3, 1), -- mean temperature ℃
temp_min NUMERIC(3, 1), -- min temperature ℃
temp_max NUMERIC(3, 1), -- max temperature ℃
dewp_mean NUMERIC(3, 1), -- mean dew point ℃
-- 气压
slp_mean NUMERIC(5, 1), -- sea level pressure (hPa)
stp_mean NUMERIC(5, 1), -- station pressure (hPa)
-- 可见距离
vis_mean NUMERIC(6), -- visible distance (m)
-- 风速
wdsp_mean NUMERIC(4, 1), -- average wind speed (m/s)
wdsp_max NUMERIC(4, 1), -- max wind speed (m/s)
gust NUMERIC(4, 1), -- max wind gust (m/s)
-- 降水 / 雪深
prcp_mean NUMERIC(5, 1), -- precipitation (mm)
prcp NUMERIC(5, 1), -- rectified precipitation (mm)
sndp NuMERIC(5, 1), -- snow depth (mm)
-- FRSHTT (Fog/Rain/Snow/Hail/Thunder/Tornado) 雾/雨/雪/雹/雷/龙卷
is_foggy BOOLEAN, -- (F)og
is_rainy BOOLEAN, -- (R)ain or Drizzle
is_snowy BOOLEAN, -- (S)now or pellets
is_hail BOOLEAN, -- (H)ail
is_thunder BOOLEAN, -- (T)hunder
is_tornado BOOLEAN, -- (T)ornado or Funnel Cloud
-- 统计聚合使用的记录数
temp_count SMALLINT, -- record count for temp
dewp_count SMALLINT, -- record count for dew point
slp_count SMALLINT, -- record count for sea level pressure
stp_count SMALLINT, -- record count for station pressure
wdsp_count SMALLINT, -- record count for wind speed
visib_count SMALLINT, -- record count for visible distance
-- 气温标记
temp_min_f BOOLEAN, -- aggregate min temperature
temp_max_f BOOLEAN, -- aggregate max temperature
prcp_flag CHAR, -- precipitation flag: ABCDEFGHI
PRIMARY KEY (station, ts)
); -- PARTITION BY RANGE (ts);
亚小时级原始观测数据表
ISD Hourly
CREATE TABLE IF NOT EXISTS isd.hourly
(
station VARCHAR(12) NOT NULL, -- station id
ts TIMESTAMP NOT NULL, -- timestamp
-- air
temp NUMERIC(3, 1), -- [-93.2,+61.8]
dewp NUMERIC(3, 1), -- [-98.2,+36.8]
slp NUMERIC(5, 1), -- [8600,10900]
stp NUMERIC(5, 1), -- [4500,10900]
vis NUMERIC(6), -- [0,160000]
-- wind
wd_angle NUMERIC(3), -- [1,360]
wd_speed NUMERIC(4, 1), -- [0,90]
wd_gust NUMERIC(4, 1), -- [0,110]
wd_code VARCHAR(1), -- code that denotes the character of the WIND-OBSERVATION.
-- cloud
cld_height NUMERIC(5), -- [0,22000]
cld_code VARCHAR(2), -- cloud code
-- water
sndp NUMERIC(5, 1), -- mm snow
prcp NUMERIC(5, 1), -- mm precipitation
prcp_hour NUMERIC(2), -- precipitation duration in hour
prcp_code VARCHAR(1), -- precipitation type code
-- sky
mw_code VARCHAR(2), -- manual weather observation code
aw_code VARCHAR(2), -- auto weather observation code
pw_code VARCHAR(1), -- weather code of past period of time
pw_hour NUMERIC(2), -- duration of pw_code period
-- misc
-- remark TEXT,
-- eqd TEXT,
data JSONB -- extra data
) PARTITION BY RANGE (ts);
解析器
NOAA ISD 提供的原始数据是高度压缩的专有格式,需要通过解析器加工,才能转换为数据库表的格式。
针对 Daily 与 Hourly 两份数据集,这里提供了两个 Parser: isdd and isdh。
这两个解析器都以年度数据压缩包作为输入,产生 CSV 结果作为输出,以管道的方式工作,如下所示:
NAME
isd -- Intergrated Surface Dataset Parser
SYNOPSIS
isd daily [-i <input|stdin>] [-o <output|stout>] [-v]
isd hourly [-i <input|stdin>] [-o <output|stout>] [-v] [-d raw|ts-first|hour-first]
DESCRIPTION
The isd program takes noaa isd daily/hourly raw tarball data as input.
and generate parsed data in csv format as output. Works in pipe mode
cat data/daily/2023.tar.gz | bin/isd daily -v | psql ${PGURL} -AXtwqc "COPY isd.daily FROM STDIN CSV;"
isd daily -v -i data/daily/2023.tar.gz | psql ${PGURL} -AXtwqc "COPY isd.daily FROM STDIN CSV;"
isd hourly -v -i data/hourly/2023.tar.gz | psql ${PGURL} -AXtwqc "COPY isd.hourly FROM STDIN CSV;"
OPTIONS
-i <input> input file, stdin by default
-o <output> output file, stdout by default
-p <profpath> pprof file path, enable if specified
-d de-duplicate rows for hourly dataset (raw, ts-first, hour-first)
-v verbose mode
-h print help
用户界面
这里提供了几个使用 Grafana 制作的 Dashboard,可以用于探索 ISD 数据集,查询气象站与历史气象数据。
ISD Overview
全局概览,总体指标与气象站导航。
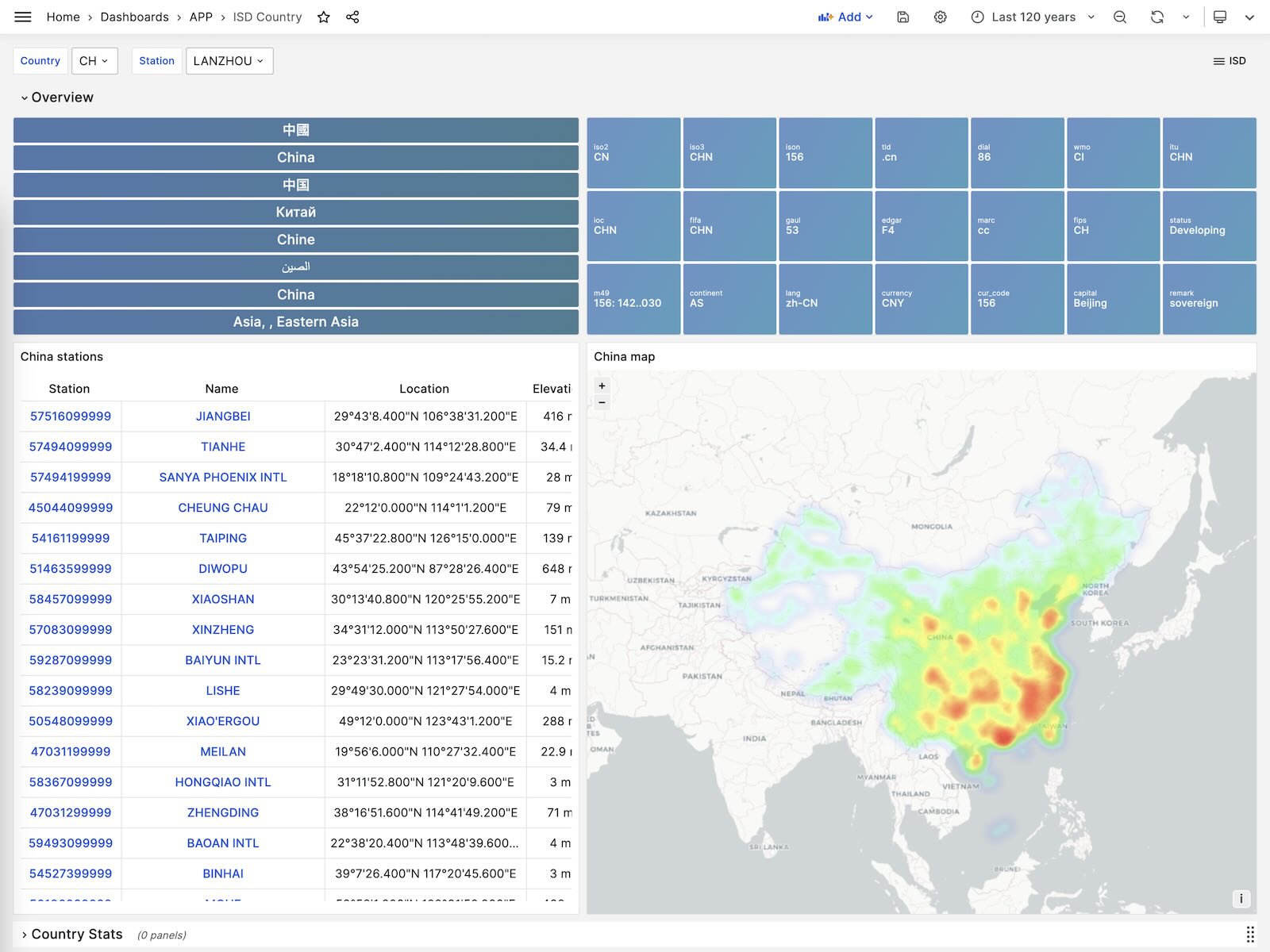
ISD Country
展示单个国家/地区内所有的气象站。
ISD Station
展示单个气象站的详细信息,元数据,天/月/年度汇总指标。
ISD Station Dashboard
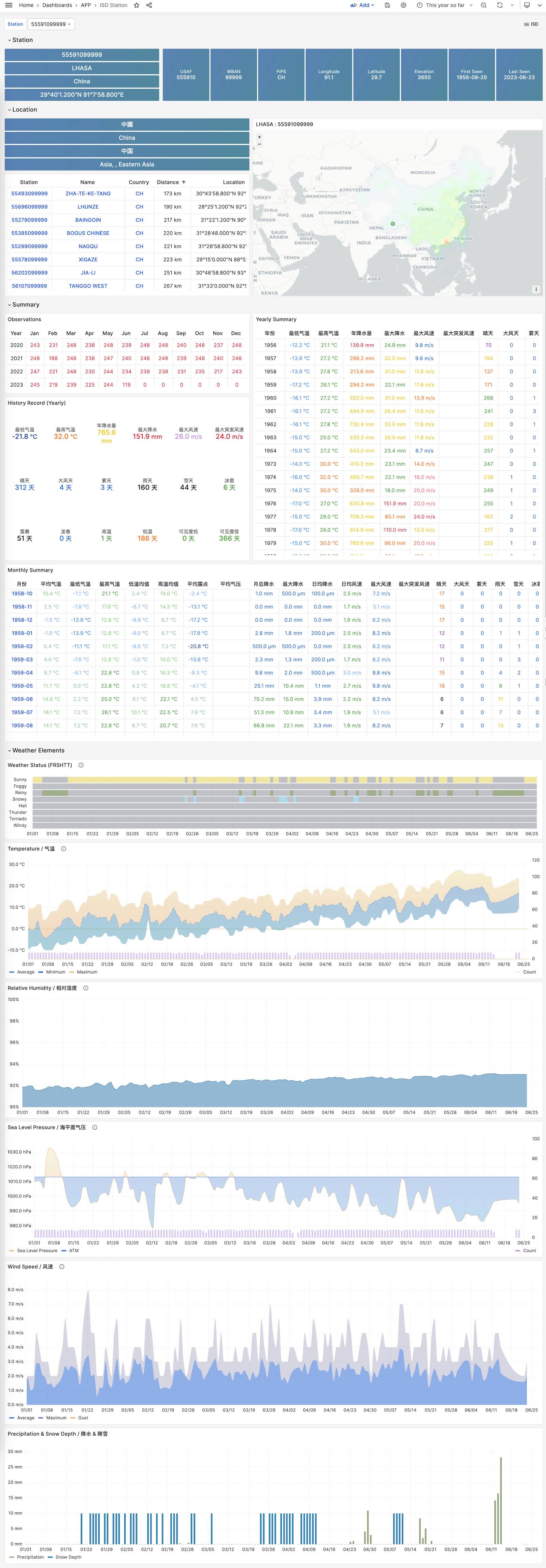
ISD Detail
展示一个气象站原始亚小时级观测指标数据,需要 isd.hourly 数据集。
ISD Station Dashboard
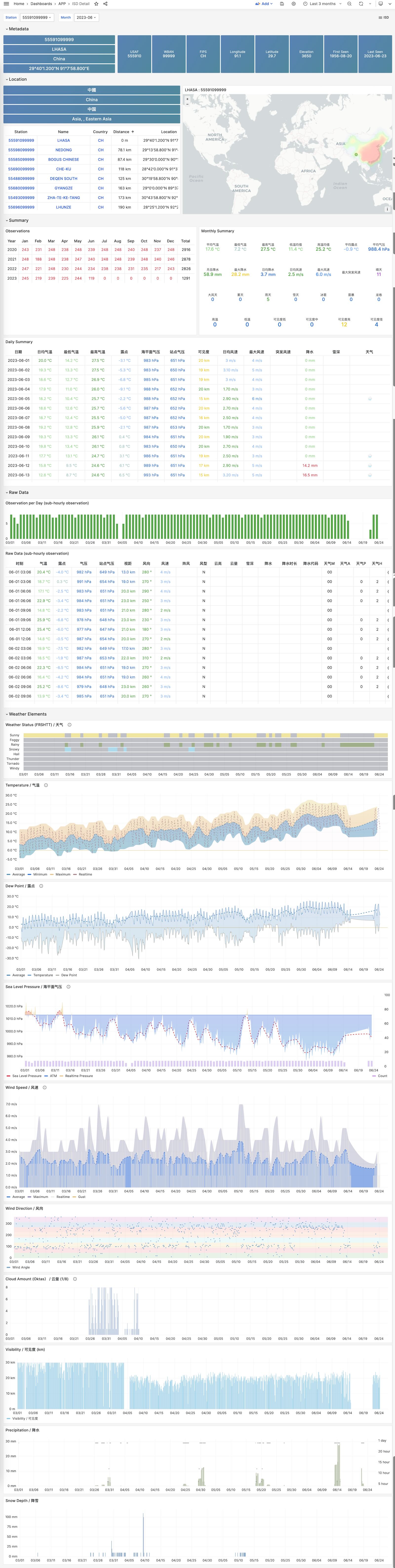
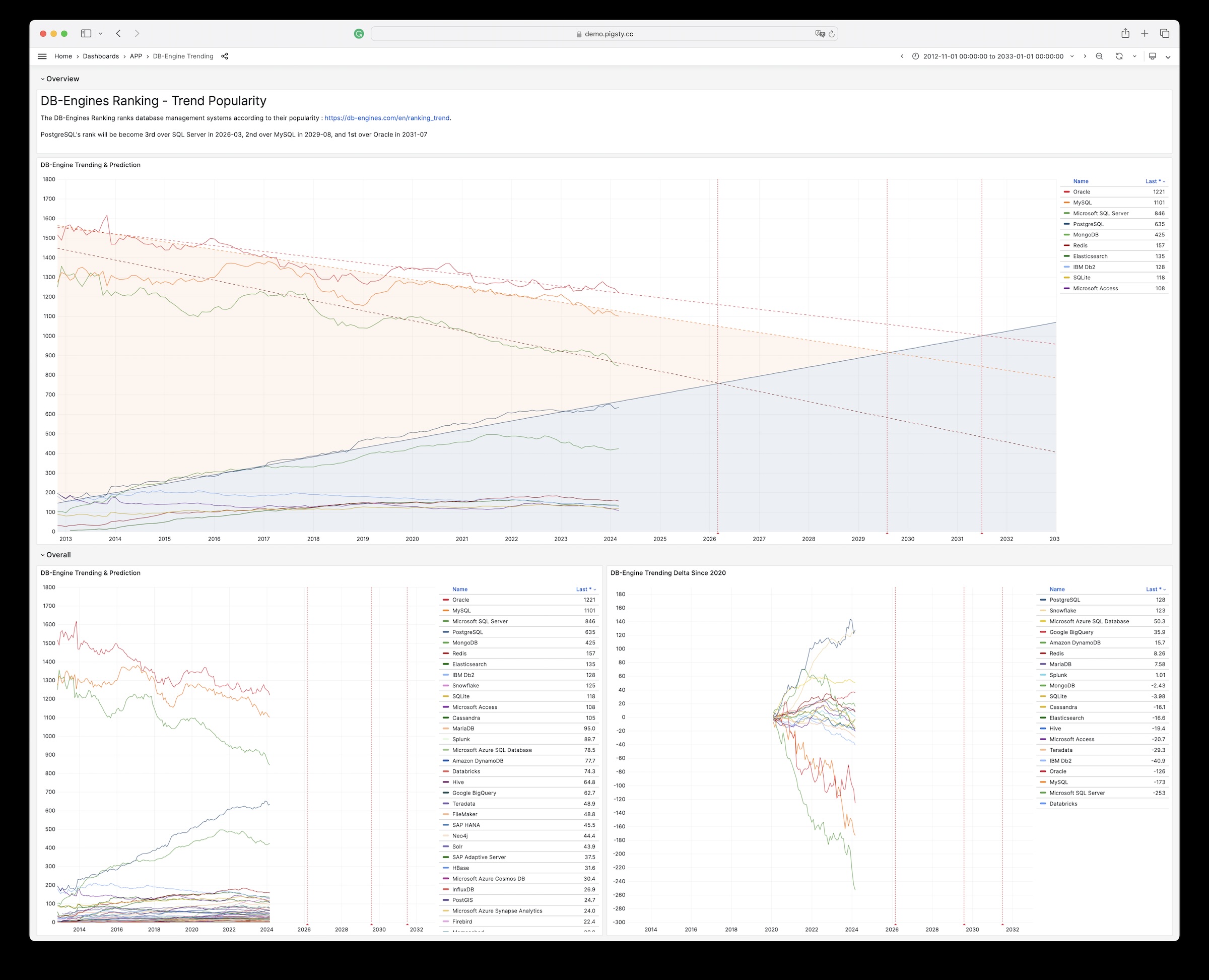
3 - WHO COVID-19 疫情大盘
Pigsty 自带的,用于展示世界卫生组织官方疫情数据的一个样例 Applet
Covid 是 Pigsty 自带的,用于展示世界卫生组织官方疫情数据大盘的一个样例 Applet。
您可以查阅每个国家与地区 COVID-19 的感染与死亡案例,以及全球的疫情趋势。
概览
GitHub 仓库地址:https://github.com/Vonng/pigsty-app/tree/master/covid
在线Demo地址:https://demo.pigsty.cc/d/covid
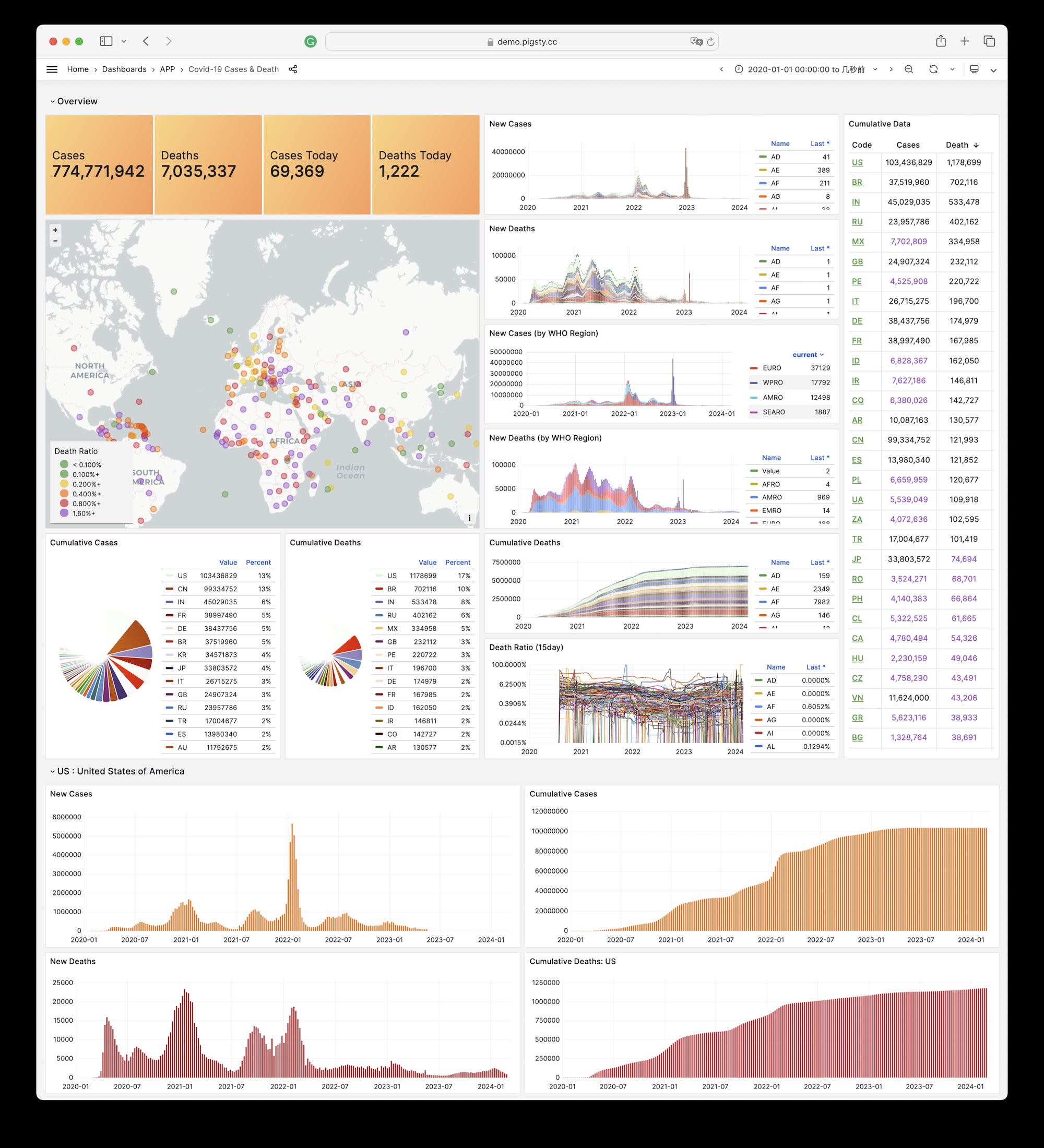
安装
在管理节点上进入应用目录,执行make以完成安装。
其他一些子任务:
make reload # download latest data and pour it again
make ui # install grafana dashboards
make sql # install database schemas
make download # download latest data
make load # load downloaded data into database
make reload # download latest data and pour it into database
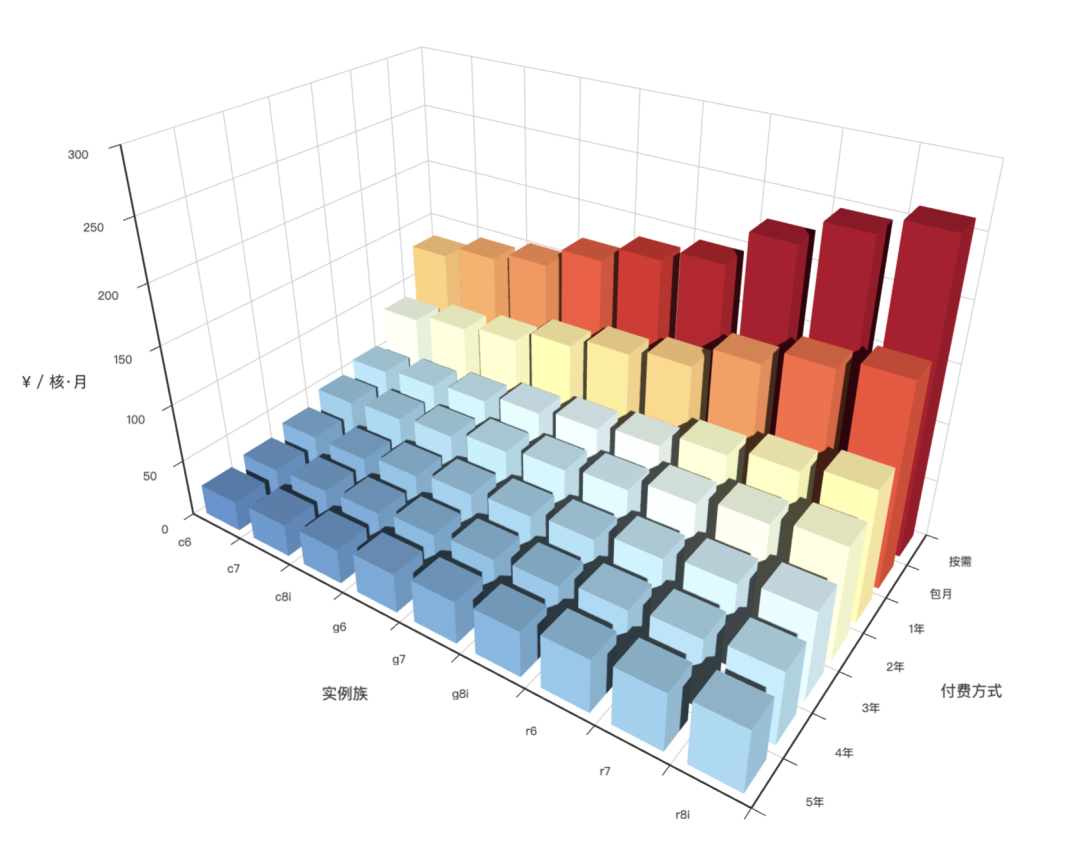
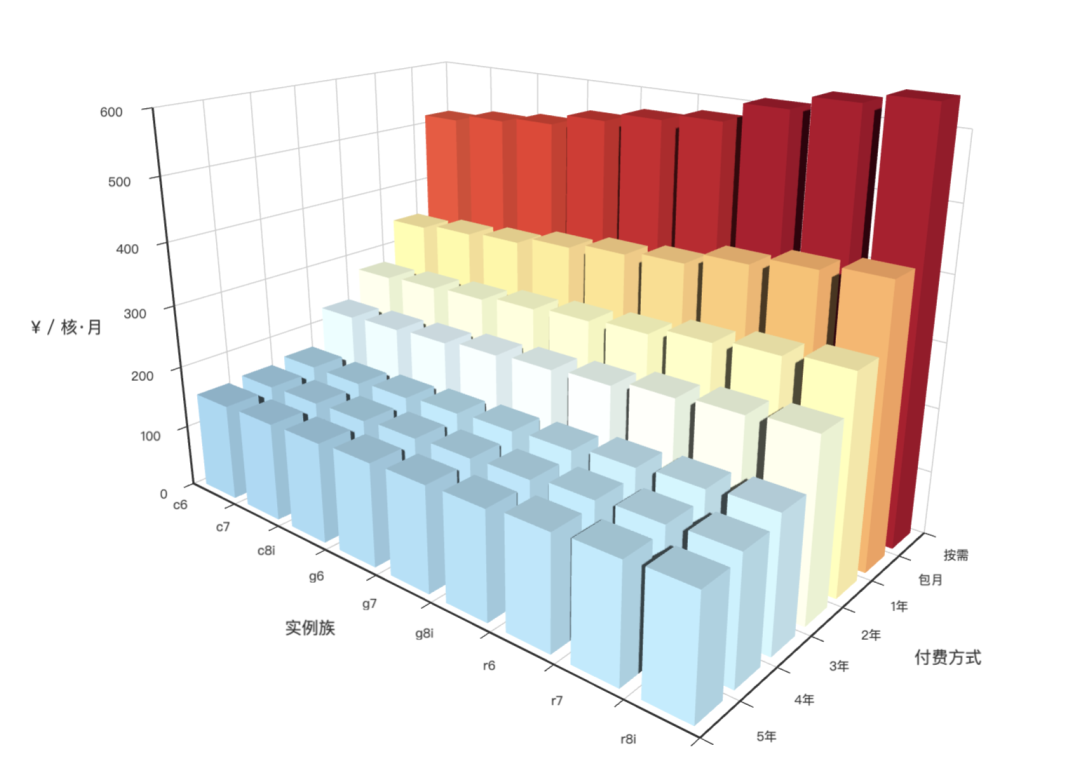
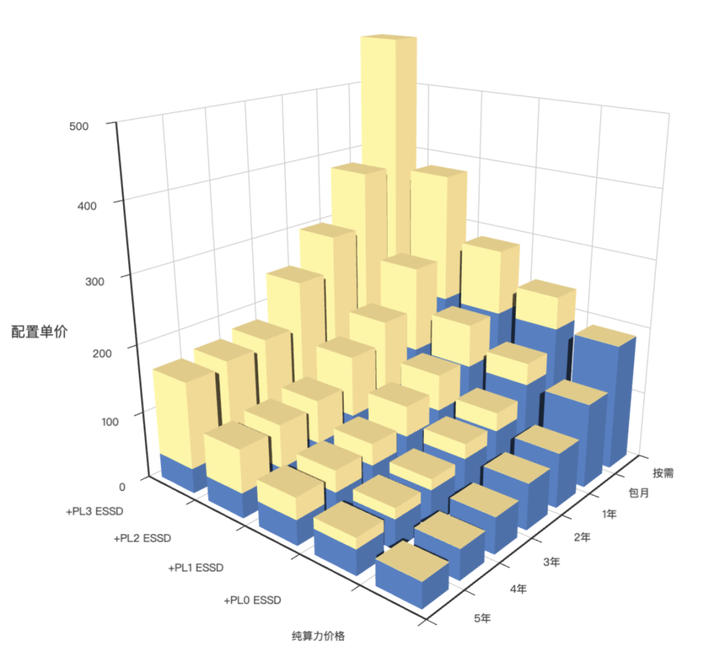
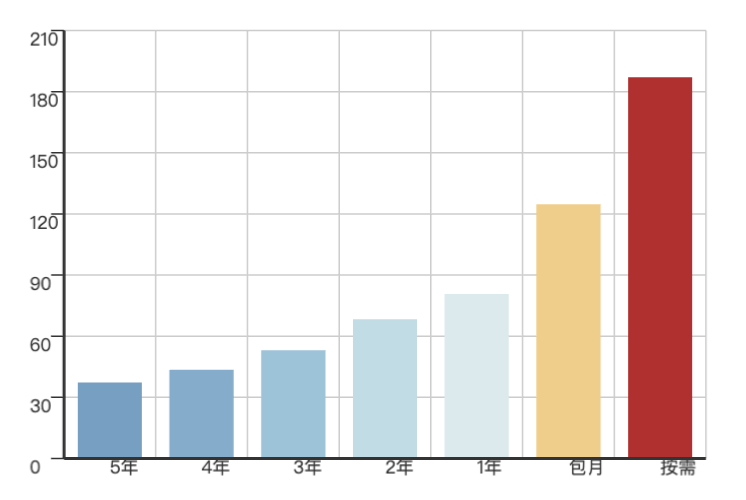
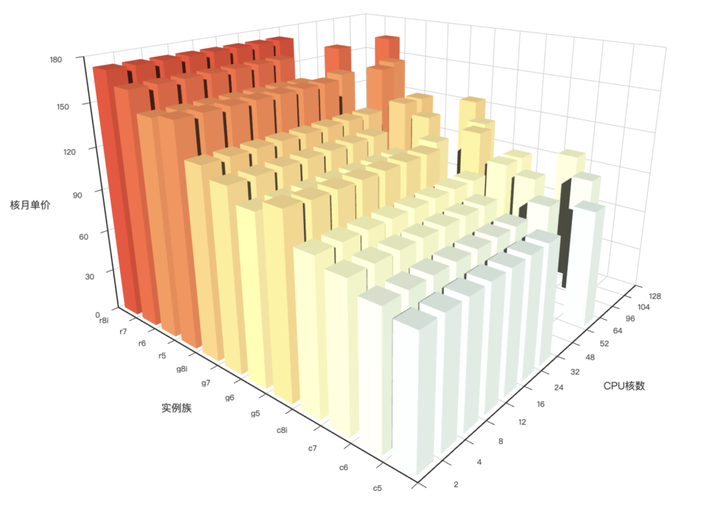
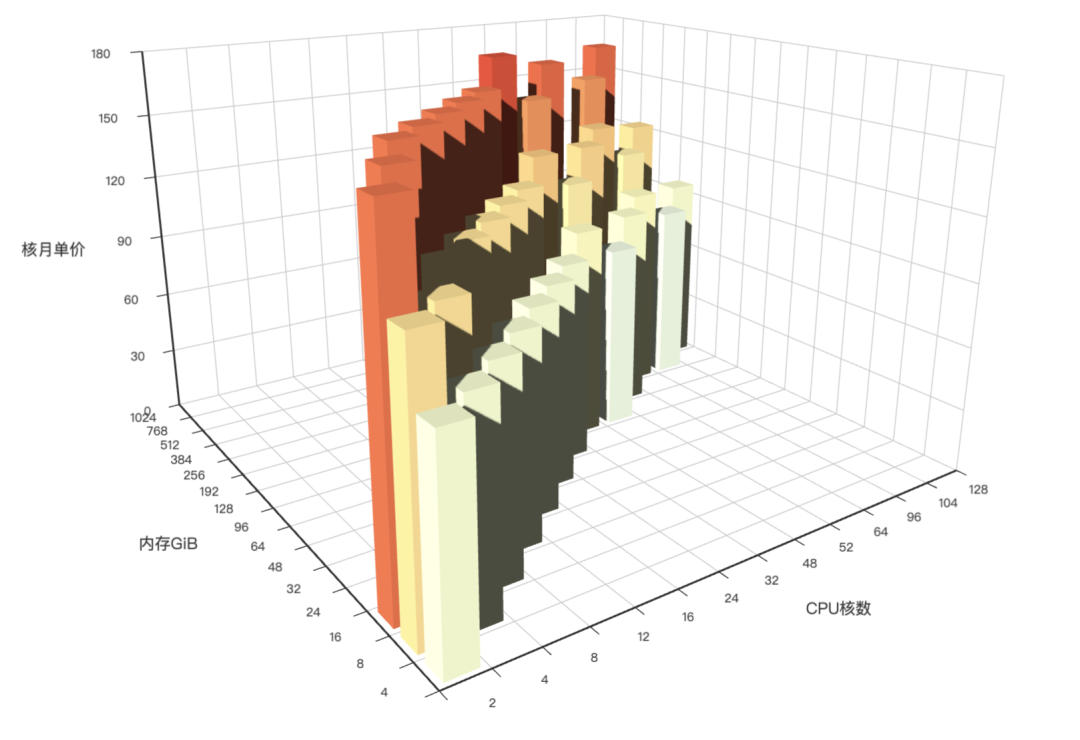
4 - AWS 阿里云 服务器价格
分析阿里云 / AWS 上算力与存储的价格 (ECS/ESSD)
概览
GitHub 仓库地址:https://github.com/Vonng/pigsty-app/tree/master/cloud
在线Demo地址:https://demo.pigsty.cc/d/ecs
文章地址:《剖析算力成本:阿里云真降价了吗?》
数据源
Aliyun ECS 价格可以在 价格计算器 - 定价详情 - 价格下载 中获取 CSV 原始数据。
模式
下载 阿里云 价格明细并导入分析
CREATE EXTENSION file_fdw;
CREATE SERVER fs FOREIGN DATA WRAPPER file_fdw;
DROP FOREIGN TABLE IF EXISTS aliyun_ecs CASCADE;
CREATE FOREIGN TABLE aliyun_ecs
(
"region" text,
"system" text,
"network" text,
"isIO" bool,
"instanceId" text,
"hourlyPrice" numeric,
"weeklyPrice" numeric,
"standard" numeric,
"monthlyPrice" numeric,
"yearlyPrice" numeric,
"2yearPrice" numeric,
"3yearPrice" numeric,
"4yearPrice" numeric,
"5yearPrice" numeric,
"id" text,
"instanceLabel" text,
"familyId" text,
"serverType" text,
"cpu" text,
"localStorage" text,
"NvmeSupport" text,
"InstanceFamilyLevel" text,
"EniTrunkSupported" text,
"InstancePpsRx" text,
"GPUSpec" text,
"CpuTurboFrequency" text,
"InstancePpsTx" text,
"InstanceTypeId" text,
"GPUAmount" text,
"InstanceTypeFamily" text,
"SecondaryEniQueueNumber" text,
"EniQuantity" text,
"EniPrivateIpAddressQuantity" text,
"DiskQuantity" text,
"EniIpv6AddressQuantity" text,
"InstanceCategory" text,
"CpuArchitecture" text,
"EriQuantity" text,
"MemorySize" numeric,
"EniTotalQuantity" numeric,
"PhysicalProcessorModel" text,
"InstanceBandwidthRx" numeric,
"CpuCoreCount" numeric,
"Generation" text,
"CpuSpeedFrequency" numeric,
"PrimaryEniQueueNumber" text,
"LocalStorageCategory" text,
"InstanceBandwidthTx" text,
"TotalEniQueueQuantity" text
) SERVER fs OPTIONS ( filename '/tmp/aliyun-ecs.csv', format 'csv',header 'true');
AWS EC2 同理,可以从 Vantage 下载价格清单:
DROP FOREIGN TABLE IF EXISTS aws_ec2 CASCADE;
CREATE FOREIGN TABLE aws_ec2
(
"name" TEXT,
"id" TEXT,
"Memory" TEXT,
"vCPUs" TEXT,
"GPUs" TEXT,
"ClockSpeed" TEXT,
"InstanceStorage" TEXT,
"NetworkPerformance" TEXT,
"ondemand" TEXT,
"reserve" TEXT,
"spot" TEXT
) SERVER fs OPTIONS ( filename '/tmp/aws-ec2.csv', format 'csv',header 'true');
DROP VIEW IF EXISTS ecs;
CREATE VIEW ecs AS
SELECT "region" AS region,
"id" AS id,
"instanceLabel" AS name,
"familyId" AS family,
"CpuCoreCount" AS cpu,
"MemorySize" AS mem,
round("5yearPrice" / "CpuCoreCount" / 60, 2) AS ycm5, -- ¥ / (core·month)
round("4yearPrice" / "CpuCoreCount" / 48, 2) AS ycm4, -- ¥ / (core·month)
round("3yearPrice" / "CpuCoreCount" / 36, 2) AS ycm3, -- ¥ / (core·month)
round("2yearPrice" / "CpuCoreCount" / 24, 2) AS ycm2, -- ¥ / (core·month)
round("yearlyPrice" / "CpuCoreCount" / 12, 2) AS ycm1, -- ¥ / (core·month)
round("standard" / "CpuCoreCount", 2) AS ycmm, -- ¥ / (core·month)
round("hourlyPrice" / "CpuCoreCount" * 720, 2) AS ycmh, -- ¥ / (core·month)
"CpuSpeedFrequency"::NUMERIC AS freq,
"CpuTurboFrequency"::NUMERIC AS freq_turbo,
"Generation" AS generation
FROM aliyun_ecs
WHERE system = 'linux';
DROP VIEW IF EXISTS ec2;
CREATE VIEW ec2 AS
SELECT id,
name,
split_part(id, '.', 1) as family,
split_part(id, '.', 2) as spec,
(regexp_match(split_part(id, '.', 1), '^[a-zA-Z]+(\d)[a-z0-9]*'))[1] as gen,
regexp_substr("vCPUs", '^[0-9]+')::int as cpu,
regexp_substr("Memory", '^[0-9]+')::int as mem,
CASE spot
WHEN 'unavailable' THEN NULL
ELSE round((regexp_substr("spot", '([0-9]+.[0-9]+)')::NUMERIC * 7.2), 2) END AS spot,
CASE ondemand
WHEN 'unavailable' THEN NULL
ELSE round((regexp_substr("ondemand", '([0-9]+.[0-9]+)')::NUMERIC * 7.2), 2) END AS ondemand,
CASE reserve
WHEN 'unavailable' THEN NULL
ELSE round((regexp_substr("reserve", '([0-9]+.[0-9]+)')::NUMERIC * 7.2), 2) END AS reserve,
"ClockSpeed" AS freq
FROM aws_ec2;
可视化