这是本节的多页打印视图。
点击此处打印.
返回本页常规视图.
应用
基于 Pigsty v4.2 的应用模板与数据应用说明:使用 Docker Compose 拉起无状态应用,并将状态托管到外部 PostgreSQL / MinIO。
Pigsty v4.2 的“应用”分为两类:
- 软件模板(Software Templates):
~/pigsty/app/<name> 下的 Docker Compose 模板,用于拉起无状态业务组件。 - 数据应用(Applets):基于 PostgreSQL + Grafana 的分析样例,偏教学/演示属性。
v4.2 应用模型
在 v4.2 中,推荐使用以下流程部署应用:
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap
./configure -c <template> # 例如 app/dify、app/odoo、app/registry、supabase
vi pigsty.yml # 修改密码、域名、IP、密钥
./deploy.yml # 部署基础设施与数据库
./docker.yml # 安装 Docker
./app.yml # 拉起应用
app.yml 会将 app/<name> 模板复制到 /opt/<name>,并按 apps.<name>.conf 覆盖 .env,最后执行 docker compose up -d。
维护中的配置模板
当前 v4.2 在源码中提供了以下应用配置模板(conf/app/*.yml 与 conf/supabase.yml):
app/difyapp/odooapp/teableapp/mattermostapp/electricapp/maybeapp/registrysupabase
这些模板开箱即用,且与 ./configure -c ...、./app.yml 工作流保持一致。
轻量 Compose 应用
对于 gitea、postgrest、pgweb、wiki、kong、bytebase 等应用,也可直接使用对应目录下的 Compose 模板:
cd ~/pigsty/app/<name>
make up
如果你希望统一纳入 Pigsty IaC,可使用:
关于历史 Applet
pglog、covid、db-engine、sf-survey、cloud、isd 等数据应用保留为参考示例,适合学习数据建模与可视化思路。
它们不再是 v4.2 的主线“应用交付”方式;请优先使用上面的软件模板工作流。
1 - Supabase 企业级自建
使用 Pigsty 自托管企业级 supabase,带有监控,高可用,PITR,IaC 以及 451 PG扩展。
Supabase 很好,拥有属于你自己的 supabase 则好上加好。
Pigsty 可以帮助您在自己的服务器上(物理机/虚拟机/云服务器),一键自建企业级 supabase
—— 更多扩展,更好性能,更深入的控制,更合算的成本。
Pigsty 是 Supabase 官网文档上列举的三种自建部署之一:Self-hosting: Third-Party Guides
本教程需要您有 Linux 基础知识,否则建议直接使用 Supabase 云服务或 “Docker Compose” 自建。
简短版本
准备 Linux 系统,执行 Pigsty 标准单机安装 流程,选择 supabase 配置模板,依次执行:
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./configure -c supabase # 使用 supabase 配置(请在 pigsty.yml 中更改凭据)
vi pigsty.yml # 编辑域名、密码、密钥...
./deploy.yml # 标准单机部署 pigsty
./docker.yml # 安装 docker 模块
./app.yml # 使用 docker 启动 supabase 无状态部分(可能较慢)
安装完毕后,使用浏览器访问 8000 端口造访 Supa Studio,用户名 supabase,密码 pigsty。
检查清单
目录
Supabase是什么?
Supabase 是一个 BaaS (Backend as Service),开源的 Firebase,是 AI Agent 时代最火爆的数据库 + 后端解决方案。
Supabase 对 PostgreSQL 进行了封装,并提供了身份认证,消息传递,边缘函数,对象存储,并基于 PG 数据库模式自动生成 REST API 与 GraphQL API。
Supabase 旨在为开发者提供一条龙式的后端解决方案,减少开发和维护后端基础设施的复杂性。
它能让开发者告别绝大部分后端开发的工作,只需要懂数据库设计与前端即可快速出活!
开发者只要用 Vibe Coding 糊个前端与数据库模式设计,就可以快速完成一个完整的应用。
目前,Supabase 是 PostgreSQL 开源生态 中人气最高的开源项目,在 GitHub 上已有 九万 Star。
Supabase 还为小微创业者提供了"慷慨"的免费云服务额度 —— 免费的 500 MB 空间,对于存个用户表,浏览数之类的东西绰绰有余。
为什么要自建?
既然 Supabase 云服务这么香,为什么要自建呢?
最直观的原因是我们在《云数据库是智商税吗?》中提到过的:当你的数据/计算规模超出云计算适用光谱(Supabase:4C/8G/500MB免费存储),成本很容易出现爆炸式增长。
而且在当下,足够可靠的 本地企业级 NVMe SSD 在性价比上与 云端存储 有着三到四个数量级的优势,而自建能更好地利用这一点。
另一个重要的原因是 功能, Supabase 云服务的功能受限 —— 很多强力PG扩展因为多租户安全挑战与许可证的原因无法以云服务的形式。
故而尽管 扩展是 PostgreSQL 的核心特色,在 Supabase 云服务上也依然只有 64 个扩展可用。
而通过 Pigsty 自建的 Supabase 则提供了多达 451 个开箱即用的 PG 扩展。
此外,自主可控与规避供应商锁定也是自建的重要原因 —— 尽管 Supabase 虽然旨在提供一个无供应商锁定的 Google Firebase 开源替代,但实际上自建高标准企业级的 Supabase 门槛并不低。
Supabase 内置了一系列由他们自己开发维护的 PG 扩展插件,并计划将原生的 PostgreSQL 内核替换为收购的 OrioleDB,而这些内核与扩展在 PGDG 官方仓库中并没有提供。
这实际上是某种隐性的供应商锁定,阻止了用户使用除了 supabase/postgres Docker 镜像之外的方式自建,Pigsty 则提供开源,透明,通用的方案解决这个问题。
我们将所有 Supabase 自研与用到的 10 个缺失的扩展打成开箱即用的 RPM/DEB 包,确保它们在所有 主流Linux操作系统发行版 上都可用:
| 扩展 | 说明 |
|---|
pg_graphql | 提供PG内的GraphQL支持 (RUST),Rust扩展,由PIGSTY提供 |
pg_jsonschema | 提供JSON Schema校验能力,Rust扩展,由PIGSTY提供 |
wrappers | Supabase提供的外部数据源包装器捆绑包,Rust扩展,由PIGSTY提供 |
index_advisor | 查询索引建议器,SQL扩展,由PIGSTY提供 |
pg_net | 用 SQL 进行异步非阻塞HTTP/HTTPS 请求的扩展 (supabase),C扩展,由PIGSTY提供 |
vault | 在 Vault 中存储加密凭证的扩展 (supabase),C扩展,由PIGSTY提供 |
pgjwt | JSON Web Token API 的PG实现 (supabase),SQL扩展,由PIGSTY提供 |
pgsodium | 表数据加密存储 TDE,扩展,由PIGSTY提供 |
supautils | 用于在云环境中确保数据库集群的安全,C扩展,由PIGSTY提供 |
pg_plan_filter | 使用执行计划代价过滤阻止特定查询语句,C扩展,由PIGSTY提供 |
同时,我们在 Supabase 自建部署中默认 安装 绝大多数扩展,您可以参考可用扩展列表按需 启用。
同时,Pigsty 还会负责好底层 高可用 PostgreSQL 数据库集群,高可用 MinIO 对象存储集群的自动搭建,甚至是 Docker 容器底座的部署与 Nginx 反向代
理,域名配置 与 HTTPS证书签发。 您可以使用 Docker Compose 拉起任意数量的无状态 Supabase 容器集群,并将状态存储在外部 Pigsty 自托管数据库服务中。
在这一自建部署架构中,您获得了使用不同内核的自由(PG 15-18,OrioleDB),加装 437 个扩展的自由,扩容与伸缩 Supabase / Postgres / MinIO 的自由,
免于数据库运维杂务的自由,以及免于供应商锁定,本地运行到地老天荒的自由。 而相比于使用云服务需要付出的代价,不过是准备服务器和多敲几行命令而已。
单节点自建快速上手
让我们先从单节点 Supabase 部署开始,我们会在后面进一步介绍多节点高可用部署的方法。
准备 一台全新 Linux 服务器,使用 Pigsty 提供的 supabase 配置模板执行 标准安装,
然后额外运行 docker.yml 与 app.yml 拉起无状态部分的 Supabase 容器即可(默认端口 8000/8433)。
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./configure -c supabase # 使用 supabase 配置(请在 pigsty.yml 中更改凭据)
vi pigsty.yml # 编辑域名、密码、密钥...
./deploy.yml # 安装 pigsty
./docker.yml # 安装 docker compose 组件
./app.yml # 使用 docker 启动 supabase 无状态部分
在部署 Supabase 前请根据实际情况修改自动生成的 pigsty.yml 配置文件中的参数(域名与密码)
如果只是本地开发测试,可以先跳过,我们将在后面介绍如何通过修改配置文件来进一步定制。
如果配置无误,大约十分钟后,就可以在本地网络通过 http://<your_ip_address>:8000 访问到 Supabase Studio 图形管理界面了。
默认的用户名与密码分别是: supabase 与 pigsty。
注意事项:
- 在中国大陆地区,Pigsty 默认使用 1Panel 与 1ms 提供的 DockerHub 镜像站点下载 Supabase 相关镜像,可能会较慢。
- 你也可以自行配置 代理 与 镜像站 ,
cd /opt/supabase; docker compose pull 手动拉取镜像。我们亦提供包含完整离线安装方案的 Supabase 自建专家咨询服务。 - 如果你需要使用的对象存储功能,那么需要通过域名与 HTTPS 访问 Supabase,否则会出现报错。
- 对于严肃的生产部署,请 务必 修改所有默认密码!
自建关键技术决策
以下是一些自建 Supabase 会涉及到的关键技术决策,供您参考:
使用默认的单节点部署 Supabase 无法享受到 PostgreSQL / MinIO 的高可用能力。
尽管如此,单节点部署相比官方纯 Docker Compose 方案依然要有显著优势: 例如开箱即用的监控系统,自由安装扩展的能力,各个组件的扩缩容能力,以及提供兜底数据库时间点恢复能力等。
如果您只有一台服务器,或者选择在云服务器上自建,Pigsty 建议您使用外部的 S3 替代本地的 MinIO 作为对象存储,存放 PostgreSQL 的备份,并承载 Supabase Storage 服务。
这样的部署在故障时可以在单机部署条件下,提供一个兜底级别的 RTO (小时级恢复时长)/ RPO (MB级数据损失)容灾水平。
在严肃的生产部署中,Pigsty 建议使用至少3~4个节点的部署策略,确保 MinIO 与 PostgreSQL 都使用满足企业级高可用要求的多节点部署。
在这种情况下,您需要相应准备更多节点与磁盘,并相应调整 pigsty.yml 配置清单中的集群配置,以及 supabase 集群配置中的接入信息,使用高可用接入点访问服务。
Supabase 的部分功能需要发送邮件,所以要用到 SMTP 服务。除非单纯用于内网,否则对于严肃的生产部署,建议使用 SMTP 云服务。自建的邮件服务器发送的邮件容易被标记为垃圾邮件导致拒收。
如果您的服务直接向公网暴露,我们强烈建议您使用真正的域名与 HTTPS 证书,并通过 Nginx 门户 访问。
接下来,我们会依次讨论一些进阶主题。如何在单节点部署的基础上,进一步提升 Supabase 的安全性、可用性与性能。
进阶主题:安全加固
Pigsty基础组件
对于严肃的生产部署,我们强烈建议您修改 Pigsty 基础组件的密码。因为这些默认值是公开且众所周知的,不改密码上生产无异于裸奔:
以上密码为 Pigsty 组件模块的密码,强烈建议在安装部署前就设置完毕。
Supabase密钥
除了 Pigsty 组件的密码,你还需要 修改 Supabase 的密钥,包括
这里请您务必参照 Supabase教程:保护你的服务 里的说明:
Supabase 部分的凭据修改后,您可以重启 Docker Compose 容器以应用新的配置:
./app.yml -t app_config,app_launch # 使用剧本
cd /opt/supabase; make up # 手工执行
进阶主题:域名接入
如果你在本机或局域网内使用 Supabase,那么可以选择 IP:Port 直连 Kong 对外暴露的 HTTP 8000 端口访问 Supabase。
你可以使用一个内网静态解析的域名,但对于严肃的生产部署,我们建议您使用真域名 + HTTPS 来访问 Supabase。
在这种情况下,您的服务器应当有一个公网 IP 地址,你应当拥有一个域名,使用云/DNS/CDN 供应商提供的 DNS 解析服务,将其指向安装节点的公网 IP(可选默认下位替代:本地 /etc/hosts 静态解析)。
比较简单的做法是,直接批量替换占位域名(supa.pigsty)为你的实际域名,假设为 supa.pigsty.cc:
sed -ie 's/supa.pigsty/supa.pigsty.cc/g' ~/pigsty/pigsty.yml
如果你没有事先配置好,那么重载 Nginx 和 Supabase 的配置生效即可:
make cert # 申请 certbot 免费 HTTPS 证书
./app.yml # 重载 Supabase 配置
修改后的配置应当类似下面的片段:
all:
vars:
certbot_sign: true # 使用 certbot 签发真实证书
infra_portal:
home: i.pigsty.cc # 替换为你的域名!
supa:
domain: supa.pigsty.cc # 替换为你的域名!
endpoint: "10.10.10.10:8000"
websocket: true
certbot: supa.pigsty.cc # 证书名称,通常与域名一致即可
children:
supabase:
vars:
apps:
supabase: # supabase 应用定义
conf: # 覆盖 /opt/supabase/.env
SITE_URL: https://supa.pigsty.cc # <------- 修改为您的外部域名
API_EXTERNAL_URL: https://supa.pigsty.cc # <------- 否则 storage API 可能无法正常工作!
SUPABASE_PUBLIC_URL: https://supa.pigsty.cc # <------- 别忘了在 infra_portal 中配置!
完整的域名/HTTPS 配置可以参考 证书管理 教程,您也可以使用 Pigsty 自带的本地静态解析与自签发 HTTPS 证书作为下位替代。
进阶主题:外部对象存储
您可以使用 S3 或 S3 兼容的服务,来作为 PGSQL 备份与 Supabase 使用的对象存储。这里我们使用一个 阿里云 OSS 对象存储作为例子。
Pigsty 提供了一个 terraform/spec/aliyun-s3.tf 模板,
可以用于在阿里云上拉起一台服务器,以及一个 OSS 存储桶。
首先,我们修改 all.children.supa.vars.apps.[supabase].conf 中 S3 相关的配置,将其指向阿里云 OSS 存储桶:
# if using s3/minio as file storage
S3_BUCKET: data # 替换为 S3 兼容服务的连接信息
S3_ENDPOINT: https://sss.pigsty:9000 # 替换为 S3 兼容服务的连接信息
S3_ACCESS_KEY: s3user_data # 替换为 S3 兼容服务的连接信息
S3_SECRET_KEY: S3User.Data # 替换为 S3 兼容服务的连接信息
S3_FORCE_PATH_STYLE: true # 替换为 S3 兼容服务的连接信息
S3_REGION: stub # 替换为 S3 兼容服务的连接信息
S3_PROTOCOL: https # 替换为 S3 兼容服务的连接信息
同样使用以下命令重载 Supabase 配置:
./app.yml -t app_config,app_launch
您同样可以使用 S3 作为 PostgreSQL 的备份仓库,在 all.vars.pgbackrest_repo 新增一个 aliyun 备份仓库的定义:
all:
vars:
pgbackrest_method: aliyun # pgbackrest 备份方法:local,minio,[其他用户定义的仓库...],本例中将备份存储到 MinIO 上
pgbackrest_repo: # pgbackrest 备份仓库: https://pgbackrest.org/configuration.html#section-repository
aliyun: # 定义一个新的备份仓库 aliyun
type: s3 # 阿里云 oss 是 s3-兼容的对象存储
s3_endpoint: oss-cn-beijing-internal.aliyuncs.com
s3_region: oss-cn-beijing
s3_bucket: pigsty-oss
s3_key: xxxxxxxxxxxxxx
s3_key_secret: xxxxxxxx
s3_uri_style: host
path: /pgbackrest
bundle: y # bundle small files into a single file
bundle_limit: 20MiB # Limit for file bundles, 20MiB for object storage
bundle_size: 128MiB # Target size for file bundles, 128MiB for object storage
cipher_type: aes-256-cbc # enable AES encryption for remote backup repo
cipher_pass: pgBackRest.MyPass # 设置一个加密密码,pgBackRest 备份仓库的加密密码
retention_full_type: time # retention full backup by time on minio repo
retention_full: 14 # keep full backup for the last 14 days
然后在 all.vars.pgbackrest_mehod 中指定使用 aliyun 备份仓库,重置 pgBackrest 备份:
./pgsql.yml -t pgbackrest
Pigsty 会将备份仓库切换到外部对象存储上,更多备份配置可以参考 PostgreSQL 备份 文档。
进阶主题:使用SMTP
你可以使用 SMTP 来发送邮件,修改 supabase 应用配置,添加 SMTP 信息:
all:
children:
supabase: # supa group
vars: # supa group vars
apps: # supa group app list
supabase: # the supabase app
conf: # the supabase app conf entries
SMTP_HOST: smtpdm.aliyun.com:80
SMTP_PORT: 80
SMTP_USER: no_reply@mail.your.domain.com
SMTP_PASS: your_email_user_password
SMTP_SENDER_NAME: MySupabase
SMTP_ADMIN_EMAIL: adminxxx@mail.your.domain.com
ENABLE_ANONYMOUS_USERS: false
不要忘了使用 app.yml 来重载配置
进阶主题:真·高可用
经过这些配置,您拥有了一个带公网域名,HTTPS 证书,SMTP,PITR 备份,监控,IaC,以及 400+ 扩展的企业级 Supabase (基础单机版)。
高可用的配置请参考 Pigsty 其他部份的文档,如果您懒得阅读学习,我们提供手把手扶上马的 Supabase 自建专家咨询服务 —— ¥2000 元免去折腾与下载的烦恼。
单节点的 RTO / RPO 依赖外部对象存储服务提供兜底,如果您的这个节点挂了,外部 S3 存储中保留了备份,您可以在新的节点上重新部署 Supabase,然后从备份中恢复。
这样的部署在故障时可以提供一个最低标准的 RTO (小时级恢复时长)/ RPO (MB级数据损失)兜底容灾水平 兜底。
如果想要达到 RTO < 30s ,切换零数据丢失,那么需要使用多节点进行高可用部署,这涉及到:
- ETCD: DCS 需要使用三个节点或以上,才能容忍一个节点的故障。
- PGSQL: PGSQL 同步提交不丢数据模式,建议使用至少三个节点。
- INFRA:监控基础设施故障影响稍小,建议生产环境使用双副本
- Supabase 无状态容器本身也可以是多节点的副本,可以实现高可用。
在这种情况下,您还需要修改 PostgreSQL 与 MinIO 的接入点,使用 DNS / L2 VIP / HAProxy 等 高可用接入点
关于这些部分,您只需参考 Pigsty 中各个模块的文档进行配置部署即可。
建议您参考 conf/ha/trio.yml 与 conf/ha/safe.yml 中的配置,将集群规模升级到三节点或以上。
2 - Odoo:自建开源 ERP
如何拉起开箱即用的企业级应用全家桶 Odoo,并使用 Pigsty 管理其后端 PostgreSQL 数据库。
Odoo 是一个开源企业资源规划 (ERP) 软件,提供一整套业务应用程序,包括 CRM、销售、采购、库存、生产、会计和其他管理功能。Odoo 是一个典型的 Web 应用程序,使用 PostgreSQL 作为底层数据库。
您的所有业务,都在一个平台上,简单、高效且实惠
公开演示(不一定开放):http://odoo.pigsty.io, 用户名: test@pigsty.io, 密码: pigsty
快速开始
在运行兼容操作系统的全新 Linux x86 / ARM 服务器上执行:
curl -fsSL https://repo.pigsty.io/get | bash; cd ~/pigsty
./bootstrap # 安装 ansible
./configure -c app/odoo # 使用 odoo 配置(请在 pigsty.yml 中更改凭据)
./deploy.yml # 安装 pigsty
./docker.yml # 安装 docker compose
./app.yml # 使用 docker 启动 odoo 无状态部分
Odoo 默认监听在 8069 端口,您可以通过浏览器访问 http://<ip>:8069。默认的用户名和密码都是 admin。
您可以在浏览器所在主机(/etc/hosts)添加一条解析记录 odoo.pigsty 指向您的服务器,这样您就可以通过 http://odoo.pigsty 访问 Odoo 网络界面了。
如果您想要通过 SSL/HTTPS 访问 Odoo,您需要使用真正的 SSL 证书,或者信任 Pigsty 自动生成的自签名 CA 证书。(当然,在 Chrome 浏览器中,您也可以使用敲击键入 thisisunsafe 来绕过证书验证)
配置模板
conf/app/odoo.yml 定义了一个模板配置文件,包含单个 Odoo 实例所需的资源。
all:
children:
# Odoo 应用程序(默认用户名和密码:admin/admin)
odoo:
hosts: { 10.10.10.10: {} }
vars:
app: odoo # 指定要安装的应用程序名称(在 apps 中)
apps: # 定义所有应用程序
odoo: # 应用程序名称,应该有对应的 ~/pigsty/app/odoo 文件夹
file: # 要创建的可选目录
- { path: /data/odoo ,state: directory, owner: 100, group: 101 }
- { path: /data/odoo/webdata ,state: directory, owner: 100, group: 101 }
- { path: /data/odoo/addons ,state: directory, owner: 100, group: 101 }
conf: # 覆盖 /opt/<app>/.env 配置文件
PG_HOST: 10.10.10.10 # postgres 主机
PG_PORT: 5432 # postgres 端口
PG_USERNAME: odoo # postgres 用户
PG_PASSWORD: DBUser.Odoo # postgres 密码
ODOO_PORT: 8069 # odoo 应用程序端口
ODOO_DATA: /data/odoo/webdata # odoo webdata
ODOO_ADDONS: /data/odoo/addons # odoo 插件
ODOO_DBNAME: odoo # odoo 数据库名称
ODOO_VERSION: 19.0 # odoo 镜像版本
# Odoo 数据库
pg-odoo:
hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary } }
vars:
pg_cluster: pg-odoo
pg_users:
- { name: odoo ,password: DBUser.Odoo ,pgbouncer: true ,roles: [ dbrole_admin ] ,createdb: true ,comment: admin user for odoo service }
- { name: odoo_ro ,password: DBUser.Odoo ,pgbouncer: true ,roles: [ dbrole_readonly ] ,comment: read only user for odoo service }
- { name: odoo_rw ,password: DBUser.Odoo ,pgbouncer: true ,roles: [ dbrole_readwrite ] ,comment: read write user for odoo service }
pg_databases:
- { name: odoo ,owner: odoo ,revokeconn: true ,comment: odoo main database }
pg_hba_rules:
- { user: all ,db: all ,addr: 172.17.0.0/16 ,auth: pwd ,title: 'allow access from local docker network' }
- { user: dbuser_view , db: all ,addr: infra ,auth: pwd ,title: 'allow grafana dashboard access cmdb from infra nodes' }
node_crontab: [ '00 01 * * * postgres /pg/bin/pg-backup full' ] # 每天凌晨 1 点进行完整备份
infra: { hosts: { 10.10.10.10: { infra_seq: 1 } } }
etcd: { hosts: { 10.10.10.10: { etcd_seq: 1 } }, vars: { etcd_cluster: etcd } }
#minio: { hosts: { 10.10.10.10: { minio_seq: 1 } }, vars: { minio_cluster: minio } }
vars: # 全局变量
version: v4.2.2 # pigsty 版本字符串
admin_ip: 10.10.10.10 # 管理节点 ip 地址
region: default # 上游镜像区域:default|china|europe
node_tune: oltp # 节点调优规格:oltp,olap,tiny,crit
pg_conf: oltp.yml # pgsql 调优规格:{oltp,olap,tiny,crit}.yml
docker_enabled: true # 在应用程序组上启用 docker
#docker_registry_mirrors: ["https://docker.1panel.live","https://docker.1ms.run","https://docker.xuanyuan.me","https://registry-1.docker.io"]
proxy_env: # 下载包和拉取 docker 镜像时的全局代理环境
no_proxy: "localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.*,*.tsinghua.edu.cn"
#http_proxy: 127.0.0.1:12345 # 在此处添加代理环境以下载包或拉取镜像
#https_proxy: 127.0.0.1:12345 # 通常代理格式为 http://user:pass@proxy.xxx.com
#all_proxy: 127.0.0.1:12345
infra_portal: # 域名和上游服务器
home : { domain: i.pigsty }
minio : { domain: m.pigsty ,endpoint: "${admin_ip}:9001" ,scheme: https ,websocket: true }
odoo: # nginx server config for odoo
domain: odoo.pigsty # 替换为您自己的域名!
endpoint: "10.10.10.10:8069" # odoo 服务端点:IP:PORT
websocket: true # 添加 websocket 支持
certbot: odoo.pigsty # certbot 证书名称,使用 `make cert` 申请
repo_enabled: false
node_repo_modules: node,infra,pgsql
pg_version: 18
#----------------------------------#
# 凭据:务必更改这些密码!
#----------------------------------#
grafana_admin_password: pigsty
grafana_view_password: DBUser.Viewer
pg_admin_password: DBUser.DBA
pg_monitor_password: DBUser.Monitor
pg_replication_password: DBUser.Replicator
patroni_password: Patroni.API
haproxy_admin_password: pigsty
minio_secret_key: S3User.MinIO
etcd_root_password: Etcd.Root
基础
检查 .env 文件中的可配置环境变量:
# https://hub.docker.com/_/odoo#
PG_HOST=10.10.10.10
PG_PORT=5432
PG_USER=dbuser_odoo
PG_PASS=DBUser.Odoo
ODOO_PORT=8069
然后使用以下命令启动 odoo:
make up # docker compose up
访问 http://ddl.pigsty 或 http://10.10.10.10:8887
Makefile
make up # 在最小模式下使用 docker compose 启动 odoo
make run # 使用 docker 启动 odoo,本地数据目录和外部 PostgreSQL
make view # 打印 odoo 访问点
make log # tail -f odoo 日志
make info # 使用 jq 检查 odoo
make stop # 停止 odoo 容器
make clean # 移除 odoo 容器
make pull # 拉取最新的 odoo 镜像
make rmi # 移除 odoo 镜像
make save # 保存 odoo 镜像到 /tmp/docker/odoo.tgz
make load # 从 /tmp/docker/odoo.tgz 加载 odoo 镜像
使用外部 PostgreSQL
您可以为 Odoo 使用外部 PostgreSQL。Odoo 将在设置期间创建自己的数据库,因此您不需要这样做
pg_users: [ { name: dbuser_odoo ,password: DBUser.Odoo ,pgbouncer: true ,roles: [ dbrole_admin ] ,comment: admin user for odoo database } ]
pg_databases: [ { name: odoo ,owner: dbuser_odoo ,revokeconn: true ,comment: odoo primary database } ]
并使用以下命令创建业务用户和数据库:
bin/pgsql-user pg-meta dbuser_odoo
#bin/pgsql-db pg-meta odoo # odoo 将在设置期间创建数据库
检查连接性:
psql postgres://dbuser_odoo:DBUser.Odoo@10.10.10.10:5432/odoo
暴露 Odoo 服务
通过 nginx 门户 暴露 odoo Web 服务:
infra_portal: # 域名和上游服务器
home : { domain: h.pigsty }
grafana : { domain: g.pigsty ,endpoint: "${admin_ip}:3000" , websocket: true }
vmetrics : { domain: v.pigsty ,endpoint: "${admin_ip}:8428" }
alertmanager : { domain: a.pigsty ,endpoint: "${admin_ip}:9059" }
blackbox : { endpoint: "${admin_ip}:9115" }
vlogs : { endpoint: "${admin_ip}:9428" }
odoo : { domain: odoo.pigsty, endpoint: "127.0.0.1:8069", websocket: true } # <------ 添加这一行
./infra.yml -t nginx # 设置 nginx 基础设施门户
Odoo 插件
社区中有很多 Odoo 模块可用,您可以通过下载并将它们放在 addons 文件夹中来安装它们。
volumes:
- ./addons:/mnt/extra-addons
您可以将 ./addons 目录挂载到容器中的 /mnt/extra-addons,然后下载并解压到 addons 文件夹,
要启用插件模块,首先进入 开发者模式
设置 -> 通用设置 -> 开发者工具 -> 激活开发者模式
然后转到 > 应用程序 -> 更新应用程序列表,然后您可以找到额外的插件并从面板安装。
常用的 免费 插件:会计套件
演示
查看公共演示:http://odoo.pigsty.io,用户名:test@pigsty.io,密码:pigsty
如果您想通过 SSL 访问 odoo,您必须在浏览器中信任 files/pki/ca/ca.crt(或在 chrome 中使用肮脏的黑客 thisisunsafe)
3 - Dify:AI 工作流平台
如何使用 Pigsty 自建 AI Workflow LLMOps 平台 —— Dify,并使用外部 PostgreSQL,PGVector,Redis 作为存储?
Dify 是一个生成式 AI 应用创新引擎和开源 LLM 应用开发平台。它提供从 Agent 构建到 AI 工作流编排、RAG 检索和模型管理的能力,帮助用户轻松构建和运营生成式 AI 原生应用程序。
Pigsty 提供对自托管 Dify 的支持,允许您使用单个命令部署 Dify,同时将关键状态存储在外部管理的 PostgreSQL 中。您可以在同一个 PostgreSQL 实例中使用 pgvector 作为向量数据库,进一步简化部署。
app/dify 模板最后验证的 Dify 版本:v1.8.1(2025-09-08)
快速开始
在运行 兼容操作系统 的全新 Linux x86 / ARM 服务器上执行:
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap # 安装 Pigsty 依赖
./configure -c app/dify # 使用 Dify 配置模板
vi pigsty.yml # 编辑密码、域名、密钥等
./deploy.yml # 安装 Pigsty
./docker.yml # 安装 Docker 和 Compose
./app.yml # 安装 Dify
Dify 默认监听端口 5001。您可以通过浏览器访问 http://<ip>:5001 并设置您的初始用户凭据来登录。
Dify 启动后,您可以安装各种扩展、配置系统模型并开始使用它!
为什么要自托管
自托管 Dify 有很多原因,但主要动机是数据安全。Dify 提供的 DockerCompose 模板使用基本的默认数据库镜像,缺乏企业级功能,如高可用性、灾难恢复、监控、IaC 和 PITR 能力。
Pigsty 为 Dify 优雅地解决了这些问题,基于配置文件使用单个命令部署所有组件,并使用镜像解决中国地区访问挑战。这使得 Dify 部署和交付变得非常顺畅。它一次性处理 PostgreSQL 主数据库、PGVector 向量数据库、MinIO 对象存储、Redis、Prometheus 监控、Grafana 可视化、Nginx 反向代理和免费 HTTPS 证书。
Pigsty 确保所有 Dify 状态都存储在外部管理的服务中,包括 PostgreSQL 中的元数据和文件系统中的其他数据。通过 Docker Compose 启动的 Dify 实例成为可以随时销毁和重建的无状态应用程序,大大简化了运维。
安装
让我们从单节点 Dify 部署开始。我们稍后将介绍生产高可用部署方法。
首先,使用 Pigsty 的 标准安装过程 安装 Dify 所需的 PostgreSQL 实例:
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap # 准备 Pigsty 依赖
./configure -c app/dify # 使用 Dify 应用程序模板
vi pigsty.yml # 编辑配置文件,修改域名和密码
./deploy.yml # 安装 Pigsty 和各种数据库
当您使用 ./configure -c app/dify 命令时,Pigsty 会根据 conf/app/dify.yml 模板和您当前的环境自动生成配置文件。
您应该根据实际需要在生成的 pigsty.yml 配置文件中修改密码、域名和其他相关参数,然后使用 ./deploy.yml 执行标准安装过程。
接下来,运行 docker.yml 安装 Docker 和 Docker Compose,然后使用 app.yml 完成 Dify 部署:
./docker.yml # 安装 Docker 和 Docker Compose
./app.yml # 使用 Docker 部署 Dify 无状态组件
您可以在本地网络上通过 http://<your_ip_address>:5001 访问 Dify Web 管理界面。
首次登录时会提示设置默认用户名、邮箱和密码。
您也可以使用本地解析的占位符域名 dify.pigsty,或按照下面的配置使用带有 HTTPS 证书的真实域名。
配置
当您使用 ./configure -c app/dify 命令进行配置时,Pigsty 会根据 conf/app/dify.yml 模板和您当前的环境自动生成配置文件。以下是默认配置的详细说明:
all:
children:
# Dify 应用程序
dify:
hosts: { 10.10.10.10: {} }
vars:
app: dify # 指定要安装的应用程序名称(在 apps 中)
apps: # 定义所有应用程序
dify: # 应用程序名称,应该有对应的 ~/pigsty/app/dify 文件夹
file: # 要创建的数据目录
- { path: /data/dify ,state: directory ,mode: 0755 }
conf: # 覆盖 /opt/dify/.env 配置文件
# 更改域名、镜像、代理、密钥
NGINX_SERVER_NAME: dify.pigsty
# 用于签名和加密的密钥,使用 `openssl rand -base64 42` 生成(务必更改!)
SECRET_KEY: sk-somerandomkey
# 默认使用端口 5001 暴露 DIFY nginx 服务
DIFY_PORT: 5001
# dify 文件存储位置?默认是 ./volume,我们将使用上面创建的另一个卷
DIFY_DATA: /data/dify
# 代理和镜像设置
#PIP_MIRROR_URL: https://pypi.tuna.tsinghua.edu.cn/simple
#SANDBOX_HTTP_PROXY: http://10.10.10.10:12345
#SANDBOX_HTTPS_PROXY: http://10.10.10.10:12345
# 数据库凭据
DB_USERNAME: dify
DB_PASSWORD: difyai123456
DB_HOST: 10.10.10.10
DB_PORT: 5432
DB_DATABASE: dify
VECTOR_STORE: pgvector
PGVECTOR_HOST: 10.10.10.10
PGVECTOR_PORT: 5432
PGVECTOR_USER: dify
PGVECTOR_PASSWORD: difyai123456
PGVECTOR_DATABASE: dify
PGVECTOR_MIN_CONNECTION: 2
PGVECTOR_MAX_CONNECTION: 10
pg-meta:
hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary } }
vars:
pg_cluster: pg-meta
pg_users:
- { name: dify ,password: difyai123456 ,pgbouncer: true ,roles: [ dbrole_admin ] ,superuser: true ,comment: dify superuser }
pg_databases:
- { name: dify ,owner: dify ,revokeconn: true ,comment: dify main database }
- { name: dify_plugin ,owner: dify ,revokeconn: true ,comment: dify plugin_daemon database }
pg_hba_rules:
- { user: dify ,db: all ,addr: 172.17.0.0/16 ,auth: pwd ,title: 'allow dify access from local docker network' }
node_crontab: [ '00 01 * * * postgres /pg/bin/pg-backup full' ] # 每天凌晨 1 点进行完整备份
infra: { hosts: { 10.10.10.10: { infra_seq: 1 } } }
etcd: { hosts: { 10.10.10.10: { etcd_seq: 1 } }, vars: { etcd_cluster: etcd } }
#minio: { hosts: { 10.10.10.10: { minio_seq: 1 } }, vars: { minio_cluster: minio } }
vars: # 全局变量
version: v4.2.2 # pigsty 版本字符串
admin_ip: 10.10.10.10 # 管理节点 ip 地址
region: default # 上游镜像区域:default|china|europe
node_tune: oltp # 节点调优规格:oltp,olap,tiny,crit
pg_conf: oltp.yml # pgsql 调优规格:{oltp,olap,tiny,crit}.yml
docker_enabled: true # 在应用程序组上启用 docker
#docker_registry_mirrors: ["https://docker.1panel.live","https://docker.1ms.run","https://docker.xuanyuan.me","https://registry-1.docker.io"]
proxy_env: # 下载包和拉取 docker 镜像时的全局代理环境
no_proxy: "localhost,127.0.0.1,10.0.0.0/8,192.168.0.0/16,*.pigsty,*.aliyun.com,mirrors.*,*.tsinghua.edu.cn"
#http_proxy: 127.0.0.1:12345 # 在此处添加代理环境以下载包或拉取镜像
#https_proxy: 127.0.0.1:12345 # 通常代理格式为 http://user:pass@proxy.xxx.com
#all_proxy: 127.0.0.1:12345
infra_portal: # 域名和上游服务器
home : { domain: i.pigsty }
#minio : { domain: m.pigsty ,endpoint: "${admin_ip}:9001" ,scheme: https ,websocket: true }
dify: # dify 的 nginx 服务器配置
domain: dify.pigsty # 替换为您自己的域名!
endpoint: "10.10.10.10:5001" # dify 服务端点:IP:PORT
websocket: true # 添加 websocket 支持
certbot: dify.pigsty # certbot 证书名称,使用 `make cert` 申请
repo_enabled: false
node_repo_modules: node,infra,pgsql
pg_version: 18
#----------------------------------#
# 凭据:务必更改这些密码!
#----------------------------------#
grafana_admin_password: pigsty
grafana_view_password: DBUser.Viewer
pg_admin_password: DBUser.DBA
pg_monitor_password: DBUser.Monitor
pg_replication_password: DBUser.Replicator
patroni_password: Patroni.API
haproxy_admin_password: pigsty
minio_secret_key: S3User.MinIO
etcd_root_password: Etcd.Root
检查清单
以下是您需要关注的配置项检查清单:
- 硬件/软件:准备所需的机器资源:Linux
x86_64/arm64 服务器,主流 Linux 操作系统 的全新安装 - 网络/权限:SSH 免密登录访问权限,用户具有 免密 sudo 权限
- 确保机器在内网中有静态 IPv4 网络地址且可访问互联网
- 如果通过公网访问,确保您有可用的域名指向当前节点的 公网 IP 地址
- 确保使用
app/dify 配置模板并根据需要修改参数configure -c app/dify,并输入节点的内网主 IP 地址,或通过 -i <primary_ip> 命令行参数指定
- 您是否修改了所有密码相关的配置参数?【可选】
- 您是否修改了 PostgreSQL 集群业务用户密码和使用这些密码的应用程序配置?
- 默认用户名
dify 和密码 difyai123456 是 Pigsty 为 Dify 生成的,请根据实际情况修改 - 在 Dify 的配置块中,请相应修改
DB_USERNAME、DB_PASSWORD、PGVECTOR_USER、PGVECTOR_PASSWORD 等参数
- 您是否修改了 Dify 的默认加密密钥?
- 您可以使用
openssl rand -base64 42 随机生成密码字符串并填入 SECRET_KEY 参数
- 您是否修改了 Dify 使用的域名?
- 将占位符域名
dify.pigsty 替换为您的实际域名,例如 dify.pigsty.cc - 您可以使用
sed -ie 's/dify.pigsty/dify.pigsty.cc/g' pigsty.yml 修改 Dify 的域名
域名和 SSL
如果您想使用带有 HTTPS 证书的真实域名,需要在 pigsty.yml 配置文件中修改:
all:
children: # 集群定义
dify: # Dify 组
vars: # Dify 组变量
apps: # 应用程序配置
dify: # Dify 应用程序定义
conf: # Dify 应用程序配置
NGINX_SERVER_NAME: dify.pigsty
vars: # 全局参数
#certbot_sign: true # 使用 Certbot 申请免费 HTTPS 证书
certbot_email: your@email.com # 证书申请邮箱,用于过期通知,可选
infra_portal: # 配置 Nginx 服务器
dify: # Dify 服务器定义
domain: dify.pigsty # 请在此处替换为您自己的域名!
endpoint: "10.10.10.10:5001" # 请在此处指定 Dify 的 IP 和端口(默认自动配置)
websocket: true # Dify 需要启用 websocket
certbot: dify.pigsty # 指定 Certbot 证书名称
使用以下命令申请 Nginx 证书:
# 申请证书,也可以手动执行 /etc/nginx/sign-cert 脚本
make cert
# 上述 Makefile 快捷命令实际执行以下剧本任务:
./infra.yml -t nginx_certbot,nginx_reload -e certbot_sign=true
执行 app.yml 剧本重新部署 Dify 服务以使 NGINX_SERVER_NAME 配置生效。
文件备份
您可以使用 restic 备份 Dify 的文件存储(默认位于 /data/dify 目录),使用以下命令进行备份:
export RESTIC_REPOSITORY=/data/backups/dify # 指定 dify 备份目录
export RESTIC_PASSWORD=some-strong-password # 指定备份加密密码
mkdir -p ${RESTIC_REPOSITORY} # 创建 dify 备份目录
restic init
创建 Restic 备份仓库后,您可以使用以下命令备份 Dify:
export RESTIC_REPOSITORY=/data/backups/dify # 指定 dify 备份目录
export RESTIC_PASSWORD=some-strong-password # 指定备份加密密码
restic backup /data/dify # 将 /dify 数据目录备份到仓库
restic snapshots # 查看备份快照列表
restic restore -t /data/dify 0b11f778 # 将快照 xxxxxx 恢复到 /data/dify
restic check # 定期检查仓库完整性
另一种更可靠的方法是使用 JuiceFS 将 MinIO 对象存储挂载到 /data/dify 目录,这样您就可以使用 MinIO/S3 存储文件状态。
如果您想将所有数据存储在 PostgreSQL 中,请考虑"使用 JuiceFS 将文件系统数据存储在 PostgreSQL 中"
例如,您可以创建另一个 dify_fs 数据库并将其用作 JuiceFS 的元数据存储:
METAURL=postgres://dify:difyai123456@:5432/dify_fs
OPTIONS=(
--storage postgres
--bucket :5432/dify_fs
--access-key dify
--secret-key difyai123456
${METAURL}
jfs
)
juicefs format "${OPTIONS[@]}" # 创建 PG 文件系统
juicefs mount ${METAURL} /data/dify -d # 后台挂载到 /data/dify 目录
juicefs bench /data/dify # 测试性能
juicefs umount /data/dify # 停止挂载
参考
Dify 自托管常见问题
5 - NocoDB:开源 Airtable
使用 NocoDB 将 PostgreSQL 数据库转变为智能电子表格,无代码数据库应用平台。
NocoDB 是一个开源的 Airtable 替代方案,可以将任何数据库转变为智能电子表格。
它提供了丰富的用户界面,让您无需编写代码即可创建强大的数据库应用。NocoDB 支持 PostgreSQL、MySQL、SQL Server 等多种数据库,是构建内部工具和数据管理系统的理想选择。
快速开始
在 Pigsty 软件模板目录中提供了 NocoDB 的 Docker Compose 配置文件:
检查并修改 .env 配置文件(根据需要调整数据库连接等配置)。
启动服务:
make up # 使用 Docker Compose 启动 NocoDB
访问 NocoDB:
管理命令
Pigsty 提供了便捷的 Makefile 命令来管理 NocoDB 服务:
make up # 启动 NocoDB 服务
make run # 使用 Docker 启动(连接外部 PostgreSQL)
make view # 显示 NocoDB 访问地址
make log # 查看容器日志
make info # 查看服务详细信息
make stop # 停止服务
make clean # 停止并移除容器
make pull # 拉取最新镜像
make rmi # 移除 NocoDB 镜像
make save # 保存镜像到 /tmp/nocodb.tgz
make load # 从 /tmp/nocodb.tgz 加载镜像
连接 PostgreSQL
NocoDB 可以连接到 Pigsty 管理的 PostgreSQL 数据库。
在 NocoDB 界面中添加新项目时,选择「External Database」,然后输入 PostgreSQL 连接信息:
主机:10.10.10.10
端口:5432
数据库名:your_database
用户名:your_username
密码:your_password
SSL:禁用(或根据实际情况启用)
连接成功后,NocoDB 会自动读取数据库的表结构,您可以通过可视化界面进行数据管理。
功能特性
- 智能电子表格界面:类似 Excel/Airtable 的用户体验
- 多种视图:网格、表单、看板、日历、画廊视图
- 协作功能:团队协作、权限管理、评论
- API 支持:自动生成 REST API
- 集成能力:支持 Webhook、Zapier 等集成
- 数据导入导出:支持 CSV、Excel 等格式
- 公式和验证:支持复杂的数据计算和验证规则
配置说明
NocoDB 的配置在 .env 文件中:
# 数据库连接(NocoDB 元数据存储)
NC_DB=pg://postgres:DBUser.Postgres@10.10.10.10:5432/nocodb
# JWT 密钥(建议修改)
NC_AUTH_JWT_SECRET=your-secret-key
# 其他配置
NC_PUBLIC_URL=http://nocodb.pigsty
NC_DISABLE_TELE=true
数据持久化
NocoDB 的元数据默认存储在外部 PostgreSQL 数据库中,应用数据也可以存储在 PostgreSQL 中。
如果使用本地存储,数据会保存在 /data/nocodb 目录中。
安全建议
- 修改默认密钥:在
.env 文件中修改 NC_AUTH_JWT_SECRET - 使用强密码:为管理员账户设置强密码
- 配置 HTTPS:生产环境建议启用 HTTPS
- 限制访问:通过防火墙或 Nginx 限制访问权限
- 定期备份:定期备份 NocoDB 元数据库
相关链接
6 - Teable:AI 无代码数据库
使用 Pigsty v4.2 自建 Teable,并接入外部 PostgreSQL 与 MinIO。
Teable 是面向团队协作的无代码数据库平台。
Pigsty v4.2 提供 app/teable 模板(conf/app/teable.yml),默认依赖 PostgreSQL + MinIO + Docker(不依赖 Redis)。
快速开始
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap
./configure -c app/teable
vi pigsty.yml # 修改密码、域名、邮件参数
./deploy.yml # 安装基础设施、PostgreSQL、MinIO
./docker.yml
./app.yml
默认入口:
http://<IP>:8890http://tea.pigsty
关键配置
模板会将以下参数写入 /opt/teable/.env:
POSTGRES_HOST/POSTGRES_PORT/POSTGRES_DB/POSTGRES_USER/POSTGRES_PASSWORDPRISMA_DATABASE_URLPUBLIC_ORIGIN(对外访问地址)PUBLIC_DATABASE_PROXYTEABLE_PORT(默认 8890)
运维命令
cd /opt/teable
make up
make log
make down
参考
7 - Gitea:自建简易代码托管平台
使用 Pigsty 的 Compose 模板部署 Gitea,并接入外部 PostgreSQL。
Gitea 是轻量级开源 Git 托管平台。
Pigsty 的 app/gitea 模板默认就是 PostgreSQL 外部数据库模式,通过 .env 中 GITEA_DB_* 参数连接数据库。
快速开始
cd ~/pigsty/app/gitea
vi .env # 检查域名、端口、数据库连接
make up
默认入口:
- Web:
http://git.pigsty 或 http://<IP>:8889 - SSH:
<IP>:2222
数据库准备
bin/pgsql-user pg-meta dbuser_gitea
bin/pgsql-db pg-meta gitea
连接串示例:
postgres://dbuser_gitea:DBUser.Gitea@10.10.10.10:5432/gitea
常用命令
make up
make log
make stop
make clean
参考
8 - Wiki.js:维基百科站
如何使用 Wiki.js 搭建你自己的开源维基百科,并使用 Pigsty 管理的PG作为持久数据存储
公开Demo地址:http://wiki.pigsty.cc
太长;不看
cd app/wiki ; docker-compose up -d
准备数据库
# postgres://dbuser_wiki:DBUser.Wiki@10.10.10.10:5432/wiki
- { name: wiki, owner: dbuser_wiki, revokeconn: true , comment: wiki the api gateway database }
- { name: dbuser_wiki, password: DBUser.Wiki , pgbouncer: true , roles: [ dbrole_admin ] }
bin/createuser pg-meta dbuser_wiki
bin/createdb pg-meta wiki
容器配置
version: "3"
services:
wiki:
container_name: wiki
image: requarks/wiki:2
environment:
DB_TYPE: postgres
DB_HOST: 10.10.10.10
DB_PORT: 5432
DB_USER: dbuser_wiki
DB_PASS: DBUser.Wiki
DB_NAME: wiki
restart: unless-stopped
ports:
- "9002:3000"
Access
- Default Port for wiki: 9002
# add to nginx_upstream
- { name: wiki , domain: wiki.pigsty.cc , endpoint: "127.0.0.1:9002" }
./infra.yml -t nginx_config
ansible all -b -a 'nginx -s reload'
9 - Mattermost:开源团队协作
使用 Pigsty v4.2 部署 Mattermost,并将状态托管到外部 PostgreSQL。
Mattermost 是开源团队协作平台,可作为 Slack 的私有化替代方案。
Pigsty v4.2 提供 app/mattermost 配置模板(conf/app/mattermost.yml),默认将应用状态存放到外部 PostgreSQL,并将文件目录持久化到主机路径。
快速开始
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap
./configure -c app/mattermost
vi pigsty.yml # 修改密码、域名
./deploy.yml
./docker.yml
./app.yml
默认访问地址:
http://<IP>:8065http://mm.pigsty
首次访问需要在 Web 页面初始化管理员账号。
默认存储与连接
模板默认配置:
- PostgreSQL 连接:
POSTGRES_URL=postgres://dbuser_mattermost:DBUser.Mattermost@<IP>:5432/mattermost?... - 持久化目录:
/data/mattermost/{config,data,logs,plugins,client/plugins,bleve-indexes}
运维命令
cd /opt/mattermost
make up
make restart
make log
make stop
参考
10 - Maybe:个人财务管理
使用 Pigsty v4.2 自建 Maybe,并将数据存储到外部 PostgreSQL。
Maybe 是开源个人财务管理工具。
Pigsty v4.2 提供 app/maybe 配置模板(conf/app/maybe.yml)。该模板会把 Maybe 作为无状态容器部署,并将业务数据落到外部 PostgreSQL。
快速开始
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap
./configure -c app/maybe
vi pigsty.yml # 必改:SECRET_KEY_BASE、数据库密码、域名
./deploy.yml
./docker.yml
./app.yml
默认访问地址:
http://<IP>:5002http://maybe.pigsty
关键配置
在模板的 apps.maybe.conf 中重点关注:
SECRET_KEY_BASE:必须替换为随机密钥(例如 openssl rand -hex 64)DB_HOST/DB_PORT/DB_USERNAME/DB_PASSWORD/DB_DATABASEAPP_DOMAIN 与 MAYBE_PORT
运维命令
app/maybe/Makefile 默认在 /opt/maybe 工作,请在部署后执行:
cd /opt/maybe
make up
make restart
make log
make db-setup
参考
11 - Metabase:BI 分析工具
使用 Metabase 进行快速的商业智能分析,友好的用户界面让团队自主探索数据。
Metabase 是一个快速、易用的开源商业智能工具,让您的团队无需 SQL 知识即可探索和可视化数据。
Metabase 提供友好的用户界面和丰富的图表类型,支持连接多种数据库,是企业数据分析的理想选择。
快速开始
在 Pigsty 软件模板目录中提供了 Metabase 的 Docker Compose 配置文件:
检查并修改 .env 配置文件:
启动服务:
make up # 使用 Docker Compose 启动 Metabase
访问 Metabase:
管理命令
Pigsty 提供了便捷的 Makefile 命令来管理 Metabase 服务:
make up # 启动 Metabase 服务
make run # 使用 Docker 启动(连接外部 PostgreSQL)
make view # 显示 Metabase 访问地址
make log # 查看容器日志
make info # 查看服务详细信息
make stop # 停止服务
make clean # 停止并移除容器
make pull # 拉取最新镜像
make rmi # 移除 Metabase 镜像
make save # 保存镜像到文件
make load # 从文件加载镜像
连接 PostgreSQL
Metabase 可以连接到 Pigsty 管理的 PostgreSQL 数据库。
在 Metabase 初始化或添加数据库时,选择「PostgreSQL」,然后输入连接信息:
数据库类型:PostgreSQL
名称:自定义名称(如 "生产数据库")
主机:10.10.10.10
端口:5432
数据库名:your_database
用户名:dbuser_meta
密码:DBUser.Meta
连接成功后,Metabase 会自动扫描数据库结构,您可以开始创建问题和仪表板。
功能特性
- 无需 SQL:通过可视化界面构建查询
- 丰富的图表类型:折线图、柱状图、饼图、地图等
- 交互式仪表板:创建美观的数据仪表板
- 自动刷新:定时更新数据和仪表板
- 权限管理:精细的用户和数据访问控制
- SQL 模式:高级用户可以直接编写 SQL
- 嵌入功能:将图表嵌入到其他应用
- 告警功能:数据变化自动通知
配置说明
Metabase 的配置在 .env 文件中:
# Metabase 元数据库(建议使用 PostgreSQL)
MB_DB_TYPE=postgres
MB_DB_DBNAME=metabase
MB_DB_PORT=5432
MB_DB_USER=dbuser_metabase
MB_DB_PASS=DBUser.Metabase
MB_DB_HOST=10.10.10.10
# 应用配置
JAVA_OPTS=-Xmx2g
建议:为 Metabase 使用独立的 PostgreSQL 数据库存储元数据。
数据持久化
Metabase 的元数据(用户、问题、仪表板等)存储在配置的数据库中。
如果使用 H2 数据库(默认),数据会保存在 /data/metabase 目录。强烈建议在生产环境中使用 PostgreSQL 作为元数据库。
性能优化
- 使用 PostgreSQL:替代默认的 H2 数据库
- 增加内存:通过
JAVA_OPTS=-Xmx4g 增加 JVM 内存 - 数据库索引:为常查询的字段创建索引
- 结果缓存:启用 Metabase 的查询结果缓存
- 定时更新:合理设置仪表板的自动刷新频率
安全建议
- 修改默认凭据:修改元数据库的用户名和密码
- 启用 HTTPS:生产环境配置 SSL 证书
- 配置认证:启用 SSO 或 LDAP 认证
- 限制访问:通过防火墙限制访问
- 定期备份:备份 Metabase 元数据库
相关链接
12 - Kong:API 网关
使用 Pigsty Compose 模板部署 Kong(PostgreSQL 后端)。
Kong 是开源 API Gateway。
Pigsty 的 app/kong 模板使用 PostgreSQL 作为配置存储,并自动执行一次迁移任务(kong-migration)。
快速开始
cd ~/pigsty/app/kong
vi .env # 检查 KONG_PG_* 与端口配置
make
默认端口:
- Proxy HTTP:
8000 - Proxy HTTPS:
8443 - Admin API:
8001
数据库准备
bin/pgsql-user pg-meta dbuser_kong
bin/pgsql-db pg-meta kong
连接串示例:
postgres://dbuser_kong:DBUser.Kong@10.10.10.10:5432/kong
常用命令
make log
make stop
make clean
make pull
参考
13 - Registry:容器镜像缓存
使用 Pigsty v4.2 部署 Docker Registry Pull-Through Cache 与可选 Web UI。
Pigsty v4.2 提供 app/registry 配置模板(conf/app/registry.yml),用于部署:
- Docker Registry 缓存服务(默认
5000) - 可选管理 UI(默认
5080)
快速开始
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap
./configure -c app/registry
vi pigsty.yml # 修改域名、证书与端口(如需)
./deploy.yml
./docker.yml
./app.yml
默认入口:
- Registry API:
http://<IP>:5000 或 http://d.pigsty - Registry UI:
http://<IP>:5080 或 http://dui.pigsty
镜像数据目录默认为 /data/registry。
Docker 客户端配置
如果你使用 HTTP(无 TLS),Docker 需要显式信任该仓库:
{
"registry-mirrors": ["http://d.pigsty"],
"insecure-registries": ["d.pigsty:5000"]
}
修改 /etc/docker/daemon.json 后重启 Docker:
运维命令
app/registry/Makefile 默认在 /opt/registry 工作:
cd /opt/registry
make up
make status
make health
make log
参考
15 - ByteBase:模式迁移
使用 Pigsty 提供的 Docker Compose 模板部署 Bytebase,并接入外部 PostgreSQL。
Bytebase 是数据库 Schema 变更与版本管理工具。
Pigsty 在 app/bytebase 中提供了可直接使用的 Compose 模板,默认监听 8887,并通过 BB_PGURL 连接外部 PostgreSQL。
快速开始
cd ~/pigsty/app/bytebase
vi .env # 检查 BB_PORT / BB_DOMAIN / BB_PGURL
make up
访问:
http://ddl.pigstyhttp://<IP>:8887
首次启动后,请按 Bytebase 向导初始化管理员账号。
外部 PostgreSQL
默认连接串示例:
postgresql://dbuser_bytebase:DBUser.Bytebase@10.10.10.10:5432/bytebase?sslmode=prefer
可先在 Pigsty 中创建业务用户与数据库:
bin/pgsql-user pg-meta dbuser_bytebase
bin/pgsql-db pg-meta bytebase
常用命令
make up
make log
make info
make stop
make clean
参考
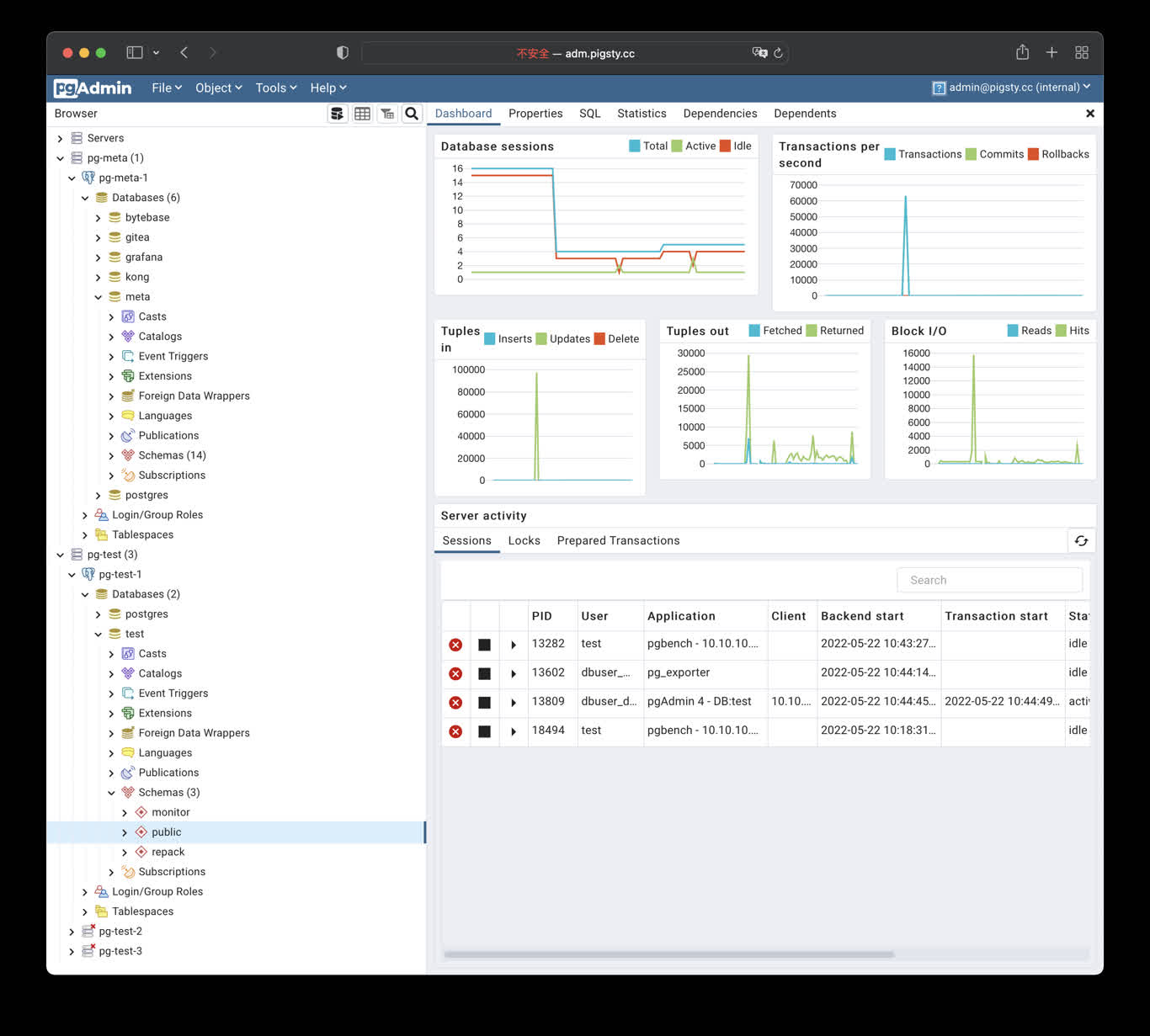
16 - PGAdmin:GUI 工具
使用Docker拉起PgAdmin4,并加载Pigsty服务器列表
pgAdmin 是最受欢迎且功能丰富的 PostgreSQL 开源管理和开发平台,PostgreSQL 是世界上最先进的开源数据库。
快速开始
Pigsty 内置(但可选)支持 pgAdmin,它使用 Docker Compose 启动 pgadmin:
./docker.yml
./app.yml -e app=pgadmin
pgadmin 的默认端口是 8885,您可以通过 IP:端口访问它:http://10.10.10.10:8885。
默认凭据在 .env 中定义,用户名:admin@pigsty.cc,密码:pigsty。
自定义
在 /opt/pgadmin/.env 中自定义 pgadmin 配置并使用 docker compose 管理它。
您还可以自定义 apps 参数并使用以下方式覆盖默认 .env 配置:
all:
children:
infra:
hosts:
10.10.10.10: { infra_seq: 1 }
vars:
docker_enabled: true
app: pgadmin # 指定要安装的应用程序名称(pgadmin)(在 apps 中)
apps: # 定义所有应用程序
pgadmin: # pgadmin 应用程序的定义
conf: # 覆盖 /opt/pgadmin/.env
PGADMIN_DEFAULT_EMAIL: your@email.com
PGADMIN_DEFAULT_PASSWORD: yourPassword
PGADMIN_LISTEN_ADDRESS: 0.0.0.0
PGADMIN_PORT: 8885
PGADMIN_SERVER_JSON_FILE: /pgadmin4/servers.json
PGADMIN_REPLACE_SERVERS_ON_STARTUP: true
要启动应用程序,运行:
域名和证书
要通过 nginx(而不是直接访问端口 8885)访问 pgadmin,请使用以下方式配置 基础设施门户:
all:
vars:
infra_portal:
home : { domain: h.pigsty }
grafana : { domain: g.pigsty ,endpoint: "${admin_ip}:3000" , websocket: true }
vmetrics : { domain: v.pigsty ,endpoint: "${admin_ip}:8428" }
alertmanager : { domain: a.pigsty ,endpoint: "${admin_ip}:9059" }
blackbox : { endpoint: "${admin_ip}:9115" }
vlogs : { endpoint: "${admin_ip}:9428" }
# 在此处添加 pgadmin 上游服务器定义
pgadmin : { domain: adm.pigsty ,endpoint: "127.0.0.1:8885" }
然后运行 make nginx 更新 nginx 配置,并在 /etc/hosts 或 本地 / 公共 DNS 服务器中配置 本地静态 DNS 记录 <your_ip_address> adm.pigsty。
Pigsty 将自动为 infra_portal 中列出的域名签发自签名 SSL 证书。
如果您想使用真实域名,请定义 certbot 条目并运行 make cert,查看 SSL 证书 了解详情。
all:
vars: # 确保您的域名(adm.pigsty.cc)解析到您的公网 IP
certbot_sign: true # 使用 certbot 签发真实 HTTPS 证书(需要互联网访问!)
infra_portal:
pgadmin : { domain: adm.pigsty.cc ,endpoint: "127.0.0.1:8885", certbot: adm.pigsty.cc }
使用方法
Pigsty 的 Pgadmin 应用模板默认使用 8885 端口,您可以通过以下地址访问:
http://adm.pigsty 或 http://10.10.10.10:8885
默认用户名与密码: admin@pigsty.cc / pigsty
make up # 使用 docker compose 启动 pgadmin
make run # 使用 docker 启动 pgadmin
make view # 打印 pgadmin 访问点
make log # tail -f pgadmin 日志
make info # 使用 jq 检查 pgadmin
make stop # 停止 pgadmin 容器
make clean # 移除 pgadmin 容器
make conf # 使用 pigsty pg 服务器列表配置 pgadmin
make dump # 从 pgadmin 容器导出 servers.json
make pull # 拉取最新的 pgadmin 镜像
make rmi # 移除 pgadmin 镜像
make save # 保存 pgadmin 镜像到 /tmp/pgadmin.tgz
make load # 从 /tmp 加载 pgadmin 镜像
Demo
公开 Demo 地址:http://adm.pigsty.cc
默认用户名与密码: admin@pigsty.cc / pigsty
17 - PGWeb:网页客户端
使用Docker拉起PGWEB,以便从浏览器进行小批量在线数据查询
PGWeb客户端工具
PGWeb 是一款基于浏览器的PG客户端工具,使用以下命令,在元节点上拉起PGWEB服务,默认为主机8886端口。可使用域名: http://cli.pigsty 访问,公开Demo:http://cli.pigsty.cc。
# docker stop pgweb; docker rm pgweb
docker run --init --name pgweb --restart always --detach --publish 8886:8081 sosedoff/pgweb
用户需要自行填写数据库连接串,例如默认CMDB的连接串:
postgres://dbuser_dba:DBUser.DBA@10.10.10.10:5432/meta?sslmode=disable
公开Demo地址:http://cli.pigsty.cc
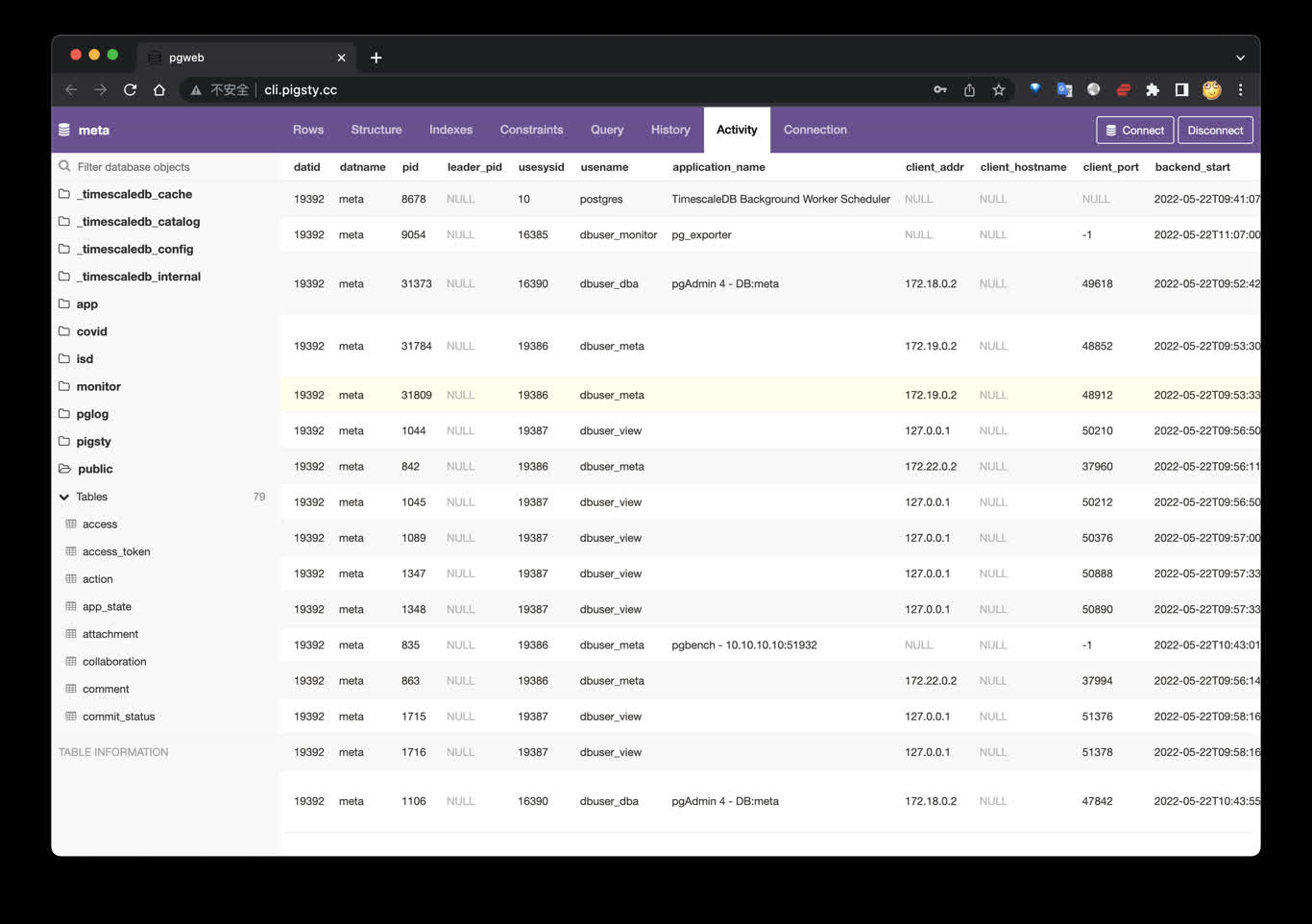
使用Docker Compose拉起PGWEB容器:
cd ~/pigsty/app/pgweb ; docker-compose up -d
接下来,访问您本机的 8886 端口,即可看到 PGWEB 的UI界面: http://10.10.10.10:8886
您可以尝试使用下面的URL连接串,通过 PGWEB 连接至数据库实例并进行探索。
postgres://dbuser_meta:DBUser.Meta@10.10.10.10:5432/meta?sslmode=disable
postgres://test:test@10.10.10.11:5432/test?sslmode=disable
快捷方式
make up # pull up pgweb with docker-compose
make run # launch pgweb with docker
make view # print pgweb access point
make log # tail -f pgweb logs
make info # introspect pgweb with jq
make stop # stop pgweb container
make clean # remove pgweb container
make pull # pull latest pgweb image
make rmi # remove pgweb image
make save # save pgweb image to /tmp/pgweb.tgz
make load # load pgweb image from /tmp
18 - PostgREST:自动 API
使用 Pigsty Compose 模板部署 PostgREST,基于 PostgreSQL 模式自动生成 REST API。
PostgREST 可以将 PostgreSQL schema 直接暴露为 REST API。
Pigsty 提供 app/postgrest 模板,默认端口 8884。
快速开始
cd ~/pigsty/app/postgrest
vi .env # 检查 DB_URI / DB_SCHEMA / JWT
make up
默认入口:
http://<IP>:8884- 若配置了入口域名,可通过
http://api.pigsty 访问
关键配置
.env 常用参数:
POSTGREST_DB_URI:数据库连接串POSTGREST_DB_SCHEMA:暴露的 schema(默认 pigsty)POSTGREST_DB_ANON_ROLE:匿名角色POSTGREST_JWT_SECRET:JWT 密钥
Swagger UI(可选)
可单独拉起 Swagger UI 预览 API:
docker run --rm --name swagger -p 8882:8080 \
-e API_URL=http://10.10.10.10:8884 \
swaggerapi/swagger-ui
访问 http://<IP>:8882。
常用命令
make up
make log
make stop
make clean
参考
19 - Electric:PostgreSQL 同步引擎
使用 Pigsty v4.2 自建 Electric,同步 PostgreSQL 数据到前端应用,支持部分复制与实时分发。
Electric 是 PostgreSQL 同步引擎,专注于将数据库变更高效分发到前端/边缘应用。
Pigsty 在 v4.2 提供了 app/electric 配置模板(conf/app/electric.yml),可一键完成数据库、容器与入口配置。
快速开始
curl -fsSL https://repo.pigsty.cc/get | bash; cd ~/pigsty
./bootstrap
./configure -c app/electric
vi pigsty.yml # 修改域名、密码、密钥
./deploy.yml
./docker.yml
./app.yml
默认访问地址:
http://<IP>:8002http://elec.pigsty(按模板默认域名)
指标端口默认 8003(ELECTRIC_PROMETHEUS_PORT)。
关键配置
conf/app/electric.yml 会在 apps.electric.conf 中覆盖 /opt/electric/.env。常见参数:
DATABASE_URL:Electric 使用的 PostgreSQL 连接串(需要复制权限)ELECTRIC_PORT:Electric HTTP 服务端口(默认 8002)ELECTRIC_PROMETHEUS_PORT:指标端口(默认 8003)ELECTRIC_INSECURE:开发环境可设为 true,生产环境建议关闭并使用密钥
运维命令
cd /opt/electric
make up
make logs
make down
参考
20 - Jupyter:笔记本 AI IDE
使用 Jupyter Lab 并访问 PostgreSQL 数据库,组合使用 SQL 与 Python 的能力进行数据分析。
Jupyter Lab 是基于 IPython Notebook 的完整数据科学研发环境,可用于数据分析与可视化。
Pigsty 提供了 Docker Compose 模板,可以一键在容器中启动 Jupyter Lab 服务,并方便地访问 PostgreSQL 数据库。
快速开始
在 Pigsty 软件模板目录中提供了 Jupyter 的 Docker Compose 配置文件:
修改默认密码,编辑 .env 文件中的 JUPYTER_TOKEN 参数(默认值为 pigsty)。
创建数据目录并启动服务:
make dir # 创建 /data/jupyter 目录并设置权限
make up # 使用 Docker Compose 启动服务
访问 Jupyter Lab:
管理命令
Pigsty 提供了便捷的 Makefile 命令来管理 Jupyter 服务:
make up # 启动 Jupyter Lab 服务
make dir # 创建 /data/jupyter 数据目录
make log # 查看容器日志
make info # 显示服务信息
make stop # 停止服务
make clean # 停止并移除容器
make pull # 拉取最新镜像
make save # 保存 Docker 镜像到文件
make load # 从文件加载 Docker 镜像
访问 PostgreSQL 数据库
在 Jupyter Lab 中访问 PostgreSQL 数据库需要先安装驱动。
在 Jupyter Lab 的 Terminal 中执行:
pip install psycopg2-binary psycopg2
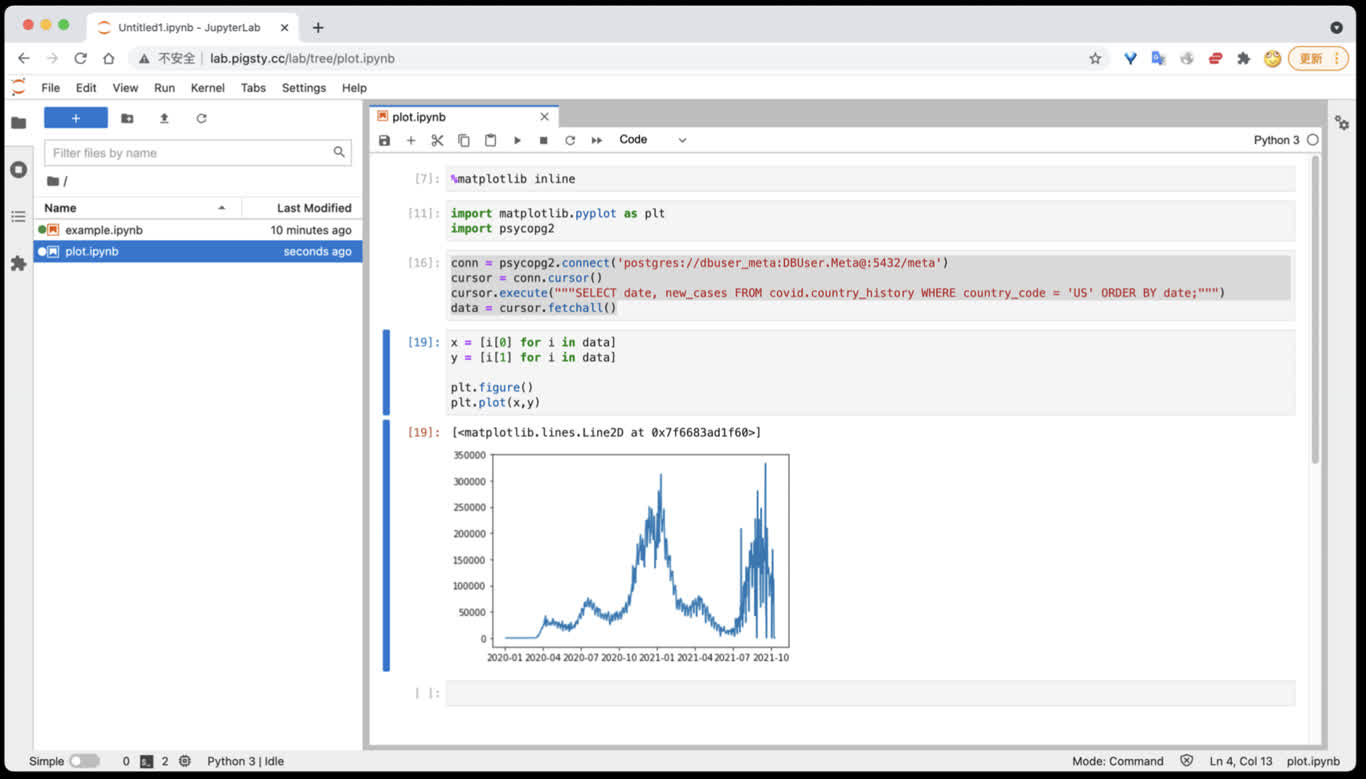
然后在 Notebook 中使用 psycopg2 驱动访问 PostgreSQL:
import psycopg2
# 连接到 PostgreSQL 数据库
conn = psycopg2.connect('postgres://dbuser_meta:DBUser.Meta@10.10.10.10:5432/meta')
# 执行查询
cursor = conn.cursor()
cursor.execute("SELECT date, new_cases FROM covid.country_history WHERE country_code = 'CN';")
data = cursor.fetchall()
# 处理数据
for row in data:
print(row)
你也可以使用其他 Python 数据分析库,如 Pandas、SQLAlchemy 等:
import pandas as pd
from sqlalchemy import create_engine
# 使用 SQLAlchemy 连接
engine = create_engine('postgresql://dbuser_meta:DBUser.Meta@10.10.10.10:5432/meta')
# 使用 Pandas 读取数据
df = pd.read_sql("SELECT * FROM covid.country_history WHERE country_code = 'CN'", engine)
print(df.head())
配置说明
Jupyter 服务的配置在 .env 文件中:
JUPYTER_TOKEN=pigsty # Jupyter Lab 访问 Token(密码)
如果需要修改端口或其他配置,可以编辑 docker-compose.yml 文件:
services:
jupyter:
image: jupyter/scipy-notebook:latest
ports:
- "8888:8888"
volumes:
- /data/jupyter:/home/jovyan/work
environment:
- JUPYTER_TOKEN=${JUPYTER_TOKEN}
安装额外的 Python 包
Jupyter 容器支持使用 pip 或 conda 安装 Python 包。
在 Jupyter Lab 的 Terminal 中执行:
# 使用 pip 安装
pip install numpy pandas matplotlib seaborn scikit-learn
# 使用 conda 安装
conda install -c conda-forge geopandas
# 使用国内镜像加速(可选)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy
数据持久化
Jupyter 的数据存储在 /data/jupyter 目录中,该目录会被挂载到容器的 /home/jovyan/work 路径。
所有保存在 work 目录下的 Notebook 和数据文件都会持久化保存在宿主机上,即使容器重启或删除也不会丢失。
安全建议
强烈建议修改默认的 Token(密码)!
- 编辑
.env 文件,修改 JUPYTER_TOKEN 的值 - 重启服务:
make up
如果在生产环境中使用 Jupyter Lab,还应该:
- 使用强密码或禁用 Token 认证
- 配置 HTTPS 访问
- 限制网络访问权限
- 定期备份数据目录
相关链接
21 - 数据应用
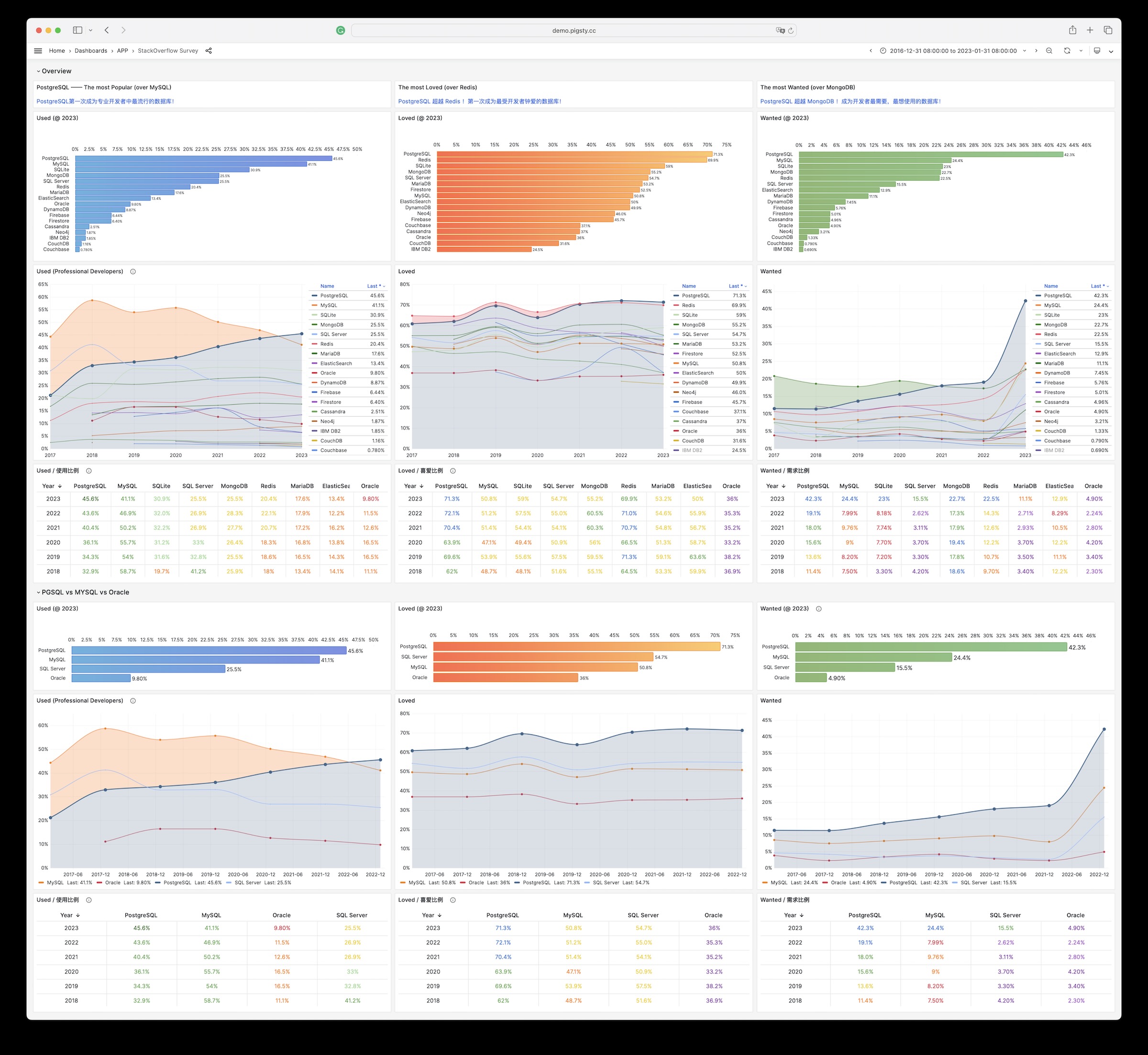
基于 PostgreSQL 的数据可视化应用
22 - PGLOG:PG自带日志分析应用
Pigsty自带的,用于分析PostgreSQL CSV日志样本的一个样例Applet
PGLOG是Pigsty自带的一个样例应用,固定使用MetaDB中pglog.sample表作为数据来源。您只需要将日志灌入该表,然后访问相关Dashboard即可。
Pigsty提供了一些趁手的命令,用于拉取csv日志,并灌入样本表中。在元节点上,默认提供下列快捷命令:
catlog [node=localhost] [date=today] # 打印CSV日志到标准输出
pglog # 从标准输入灌入CSVLOG
pglog12 # 灌入PG12格式的CSVLOG
pglog13 # 灌入PG13格式的CSVLOG
pglog14 # 灌入PG14格式的CSVLOG (=pglog)
catlog | pglog # 分析当前节点当日的日志
catlog node-1 '2021-07-15' | pglog # 分析node-1在2021-07-15的csvlog
接下来,您可以访问以下的连接,查看样例日志分析界面。
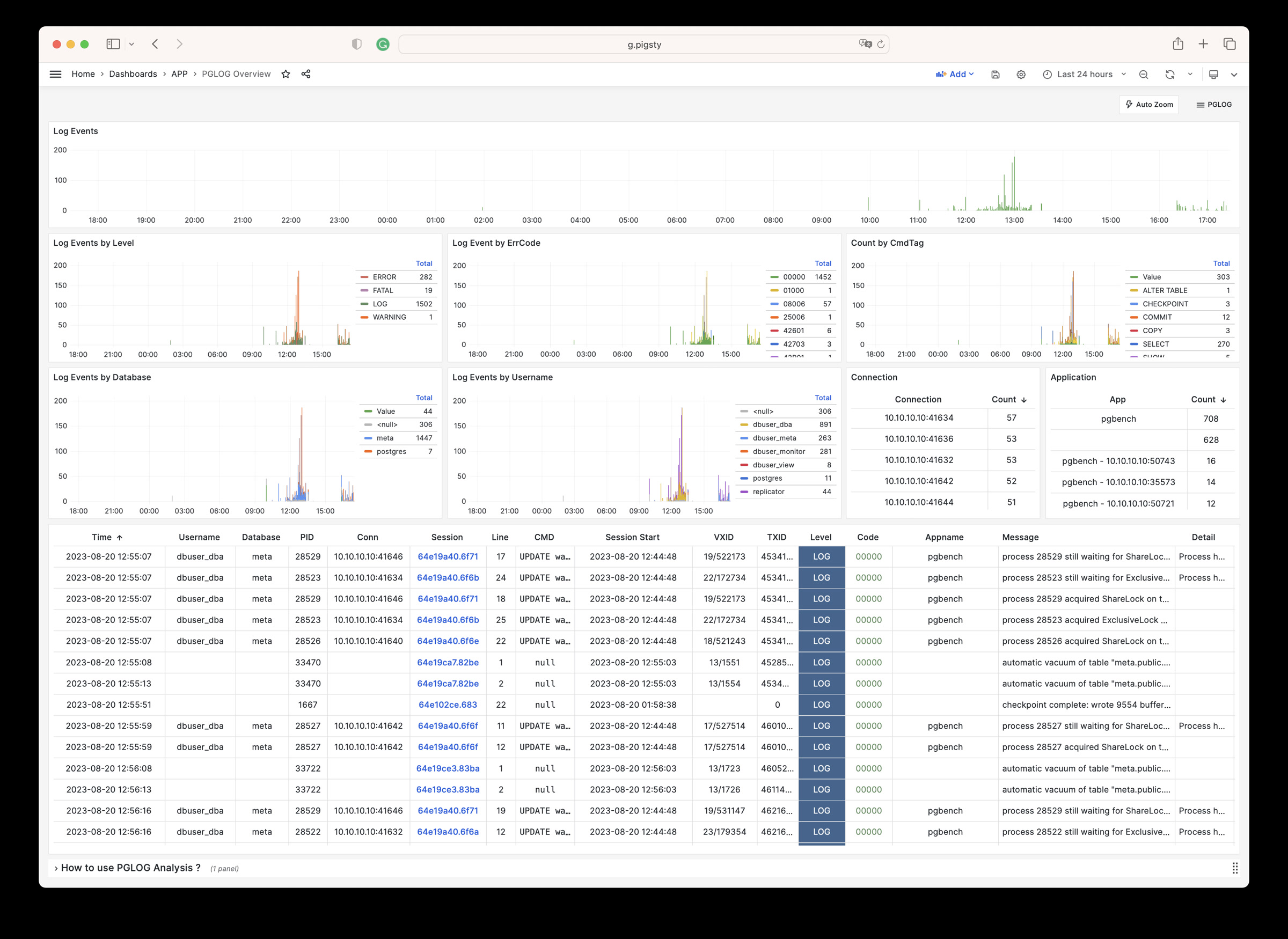
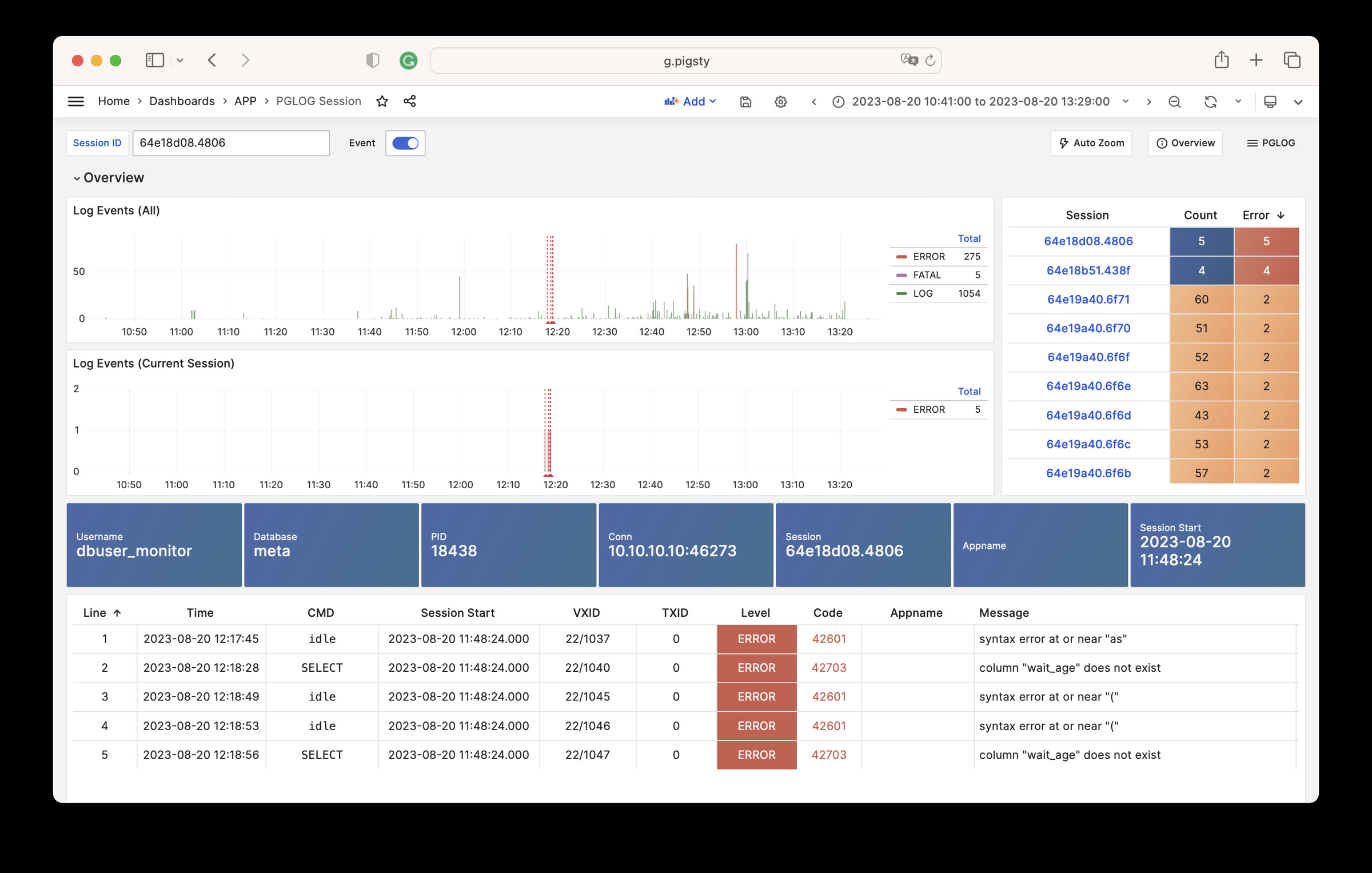
catlog命令从特定节点拉取特定日期的CSV数据库日志,写入stdout
默认情况下,catlog会拉取当前节点当日的日志,您可以通过参数指定节点与日期。
组合使用pglog与catlog,即可快速拉取数据库CSV日志进行分析。
catlog | pglog # 分析当前节点当日的日志
catlog node-1 '2021-07-15' | pglog # 分析node-1在2021-07-15的csvlog
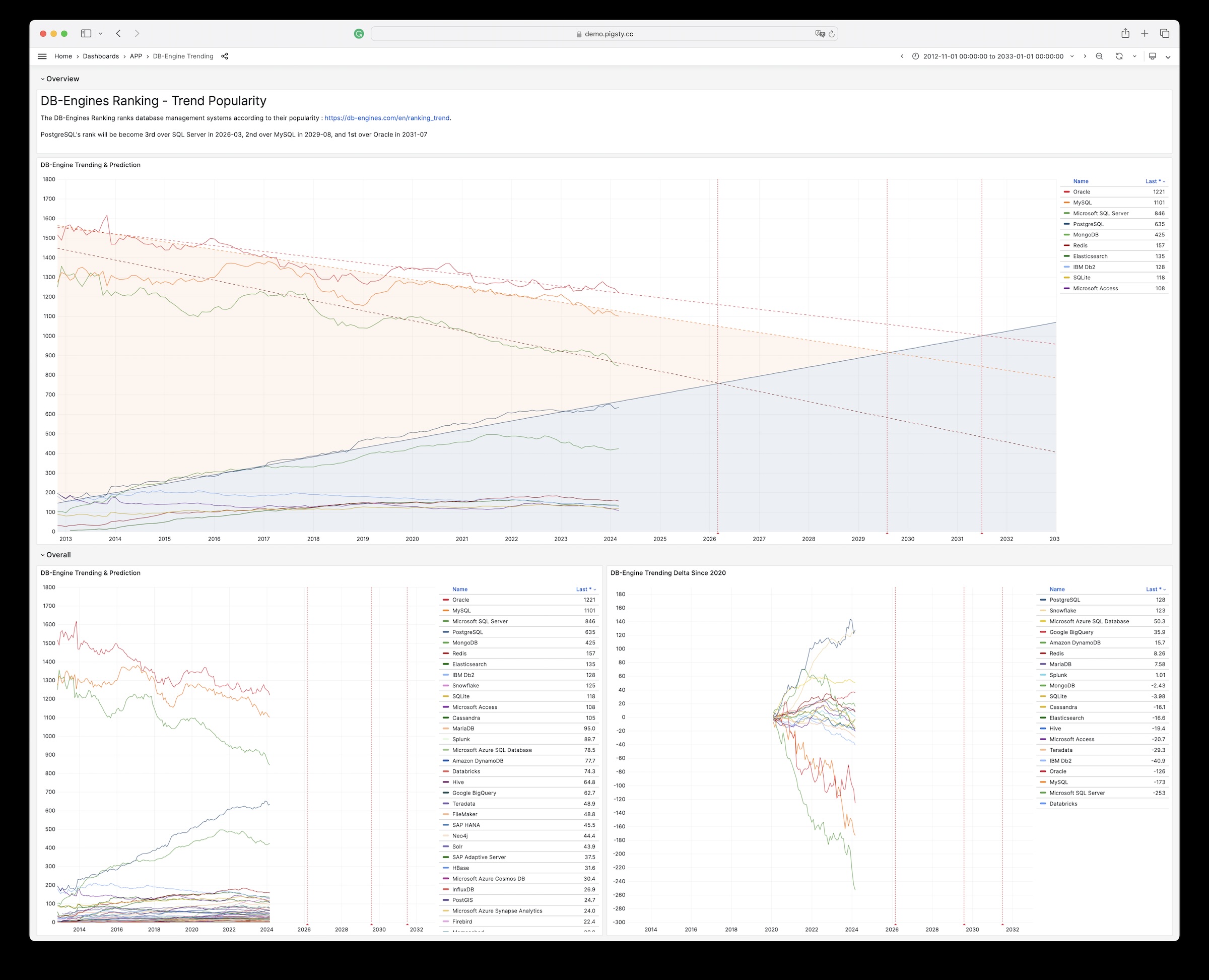
23 - NOAA ISD 全球气象站历史数据查询
以ISD数据集为例,展现如何将数据导入数据库中
如果您拥有数据库后不知道干点什么,不妨参试试这个开源项目:Vonng/isd
您可以直接复用监控系统Grafana,以交互式的方式查阅近30000个地面气象站过去120年间的亚小时级气象数据。
这是一个功能完成的数据应用,可以查询全球30000个地表气象站从1901年来的气象观测记录。
项目地址:https://github.com/Vonng/isd
在线Demo地址:https://demo.pigsty.cc/d/isd-overview
快速上手
克隆本仓库
git clone https://github.com/Vonng/isd.git; cd isd;
准备一个 PostgreSQL 实例
该 PostgreSQL 实例应当启用了 PostGIS 扩展。使用 PGURL 环境变量传递数据库连接信息:
# Pigsty 默认使用的管理员账号是 dbuser_dba,密码是 DBUser.DBA
export PGURL=postgres://dbuser_dba:DBUser.DBA@127.0.0.1:5432/meta?sslmode=disable
psql "${PGURL}" -c 'SELECT 1' # 检查连接是否可用
获取并导入ISD气象站元数据
这是一份每日更新的气象站元数据,包含了气象站的经纬度、海拔、名称、国家、省份等信息,使用以下命令下载并导入。
make reload-station # 相当于先下载最新的Station数据再加载:get-station + load-station
获取并导入最新的 isd.daily 数据
isd.daily 是一个每日更新的数据集,包含了全球各气象站的日观测数据摘要,使用以下命令下载并导入。
请注意,直接从 NOAA 网站下载的原始数据需要经过解析方可入库,所以你需要下载或构建一个 ISD 数据 Parser。
make get-parser # 从 Github 下载 Parser 二进制,当然你也可以用 make build 直接用 go 构建。
make reload-daily # 下载本年度最新的 isd.daily 数据并导入数据库中
加载解析好的 CSV 数据集
ISD Daily 数据集有一些脏数据与 重复数据,如果你不想手工解析处理清洗,这里也提供了一份解析好的稳定CSV数据集。
该数据集包含了截止到 2023-06-24 的 isd.daily 数据,你可以直接下载并导入 PostgreSQL 中,不需要 Parser,
make get-stable # 从 Github 上获取稳定的 isd.daily 历史数据集。
make load-stable # 将下载好的稳定历史数据集加载到 PostgreSQL 数据库中。
更多数据
ISD数据集有两个部分是每日更新的,气象站元数据,以及最新年份的 isd.daily (如 2023 年的 Tarball)。
你可以使用以下命令下载并刷新这两个部分。如果数据集没有更新,那么这些命令不会重新下载同样的数据包
make reload # 实际上是:reload-station + reload-daily
你也可以使用以下命令下载并加载特定年份的 isd.daily 数据:
bin/get-daily 2022 # 获取 2022 年的每日气象观测摘要 (1900-2023)
bin/load-daily "${PGURL}" 2022 # 加载 2022 年的每日气象观测摘要 (1900-2023)
除了每日摘要 isd.daily, ISD 还提供了一份更详细的亚小时级原始观测记录 isd.hourly,下载与加载的方式与前者类似:
bin/get-hourly 2022 # 下载特定某一年的小时级观测记录(例如2022年,可选 1900-2023)
bin/load-hourly "${PGURL}" 2022 # 加载特定某一年的小时级观测记录
数据
数据集概要
ISD提供了四个数据集:亚小时级原始观测数据,每日统计摘要数据,月度统计摘要,年度统计摘要
| 数据集 | 备注 |
|---|
| ISD Hourly | 亚小时级观测记录 |
| ISD Daily | 每日统计摘要 |
| ISD Monthly | 没有用到,因为可以从 isd.daily 计算生成 |
| ISD Yearly | 没有用到,因为可以从 isd.daily 计算生成 |
每日摘要数据集
- 压缩包大小 2.8GB (截止至 2023-06-24)
- 表大小 24GB,索引大小 6GB,PostgreSQL 中总大小约为 30GB
- 如果启用了 timescaledb 压缩,总大小可以压缩到 4.5 GB。
亚小时级观测数据级
- 压缩包总大小 117GB
- 灌入数据库后表大小 1TB+ ,索引大小 600GB+,总大小 1.6TB
数据库模式
气象站元数据表
CREATE TABLE isd.station
(
station VARCHAR(12) PRIMARY KEY,
usaf VARCHAR(6) GENERATED ALWAYS AS (substring(station, 1, 6)) STORED,
wban VARCHAR(5) GENERATED ALWAYS AS (substring(station, 7, 5)) STORED,
name VARCHAR(32),
country VARCHAR(2),
province VARCHAR(2),
icao VARCHAR(4),
location GEOMETRY(POINT),
longitude NUMERIC GENERATED ALWAYS AS (Round(ST_X(location)::NUMERIC, 6)) STORED,
latitude NUMERIC GENERATED ALWAYS AS (Round(ST_Y(location)::NUMERIC, 6)) STORED,
elevation NUMERIC,
period daterange,
begin_date DATE GENERATED ALWAYS AS (lower(period)) STORED,
end_date DATE GENERATED ALWAYS AS (upper(period)) STORED
);
每日摘要表
CREATE TABLE IF NOT EXISTS isd.daily
(
station VARCHAR(12) NOT NULL, -- station number 6USAF+5WBAN
ts DATE NOT NULL, -- observation date
-- 气温 & 露点
temp_mean NUMERIC(3, 1), -- mean temperature ℃
temp_min NUMERIC(3, 1), -- min temperature ℃
temp_max NUMERIC(3, 1), -- max temperature ℃
dewp_mean NUMERIC(3, 1), -- mean dew point ℃
-- 气压
slp_mean NUMERIC(5, 1), -- sea level pressure (hPa)
stp_mean NUMERIC(5, 1), -- station pressure (hPa)
-- 可见距离
vis_mean NUMERIC(6), -- visible distance (m)
-- 风速
wdsp_mean NUMERIC(4, 1), -- average wind speed (m/s)
wdsp_max NUMERIC(4, 1), -- max wind speed (m/s)
gust NUMERIC(4, 1), -- max wind gust (m/s)
-- 降水 / 雪深
prcp_mean NUMERIC(5, 1), -- precipitation (mm)
prcp NUMERIC(5, 1), -- rectified precipitation (mm)
sndp NuMERIC(5, 1), -- snow depth (mm)
-- FRSHTT (Fog/Rain/Snow/Hail/Thunder/Tornado) 雾/雨/雪/雹/雷/龙卷
is_foggy BOOLEAN, -- (F)og
is_rainy BOOLEAN, -- (R)ain or Drizzle
is_snowy BOOLEAN, -- (S)now or pellets
is_hail BOOLEAN, -- (H)ail
is_thunder BOOLEAN, -- (T)hunder
is_tornado BOOLEAN, -- (T)ornado or Funnel Cloud
-- 统计聚合使用的记录数
temp_count SMALLINT, -- record count for temp
dewp_count SMALLINT, -- record count for dew point
slp_count SMALLINT, -- record count for sea level pressure
stp_count SMALLINT, -- record count for station pressure
wdsp_count SMALLINT, -- record count for wind speed
visib_count SMALLINT, -- record count for visible distance
-- 气温标记
temp_min_f BOOLEAN, -- aggregate min temperature
temp_max_f BOOLEAN, -- aggregate max temperature
prcp_flag CHAR, -- precipitation flag: ABCDEFGHI
PRIMARY KEY (station, ts)
); -- PARTITION BY RANGE (ts);
亚小时级原始观测数据表
ISD Hourly
CREATE TABLE IF NOT EXISTS isd.hourly
(
station VARCHAR(12) NOT NULL, -- station id
ts TIMESTAMP NOT NULL, -- timestamp
-- air
temp NUMERIC(3, 1), -- [-93.2,+61.8]
dewp NUMERIC(3, 1), -- [-98.2,+36.8]
slp NUMERIC(5, 1), -- [8600,10900]
stp NUMERIC(5, 1), -- [4500,10900]
vis NUMERIC(6), -- [0,160000]
-- wind
wd_angle NUMERIC(3), -- [1,360]
wd_speed NUMERIC(4, 1), -- [0,90]
wd_gust NUMERIC(4, 1), -- [0,110]
wd_code VARCHAR(1), -- code that denotes the character of the WIND-OBSERVATION.
-- cloud
cld_height NUMERIC(5), -- [0,22000]
cld_code VARCHAR(2), -- cloud code
-- water
sndp NUMERIC(5, 1), -- mm snow
prcp NUMERIC(5, 1), -- mm precipitation
prcp_hour NUMERIC(2), -- precipitation duration in hour
prcp_code VARCHAR(1), -- precipitation type code
-- sky
mw_code VARCHAR(2), -- manual weather observation code
aw_code VARCHAR(2), -- auto weather observation code
pw_code VARCHAR(1), -- weather code of past period of time
pw_hour NUMERIC(2), -- duration of pw_code period
-- misc
-- remark TEXT,
-- eqd TEXT,
data JSONB -- extra data
) PARTITION BY RANGE (ts);
解析器
NOAA ISD 提供的原始数据是高度压缩的专有格式,需要通过解析器加工,才能转换为数据库表的格式。
针对 Daily 与 Hourly 两份数据集,这里提供了两个 Parser: isdd and isdh。
这两个解析器都以年度数据压缩包作为输入,产生 CSV 结果作为输出,以管道的方式工作,如下所示:
NAME
isd -- Intergrated Surface Dataset Parser
SYNOPSIS
isd daily [-i <input|stdin>] [-o <output|stout>] [-v]
isd hourly [-i <input|stdin>] [-o <output|stout>] [-v] [-d raw|ts-first|hour-first]
DESCRIPTION
The isd program takes noaa isd daily/hourly raw tarball data as input.
and generate parsed data in csv format as output. Works in pipe mode
cat data/daily/2023.tar.gz | bin/isd daily -v | psql ${PGURL} -AXtwqc "COPY isd.daily FROM STDIN CSV;"
isd daily -v -i data/daily/2023.tar.gz | psql ${PGURL} -AXtwqc "COPY isd.daily FROM STDIN CSV;"
isd hourly -v -i data/hourly/2023.tar.gz | psql ${PGURL} -AXtwqc "COPY isd.hourly FROM STDIN CSV;"
OPTIONS
-i <input> input file, stdin by default
-o <output> output file, stdout by default
-p <profpath> pprof file path, enable if specified
-d de-duplicate rows for hourly dataset (raw, ts-first, hour-first)
-v verbose mode
-h print help
用户界面
这里提供了几个使用 Grafana 制作的 Dashboard,可以用于探索 ISD 数据集,查询气象站与历史气象数据。
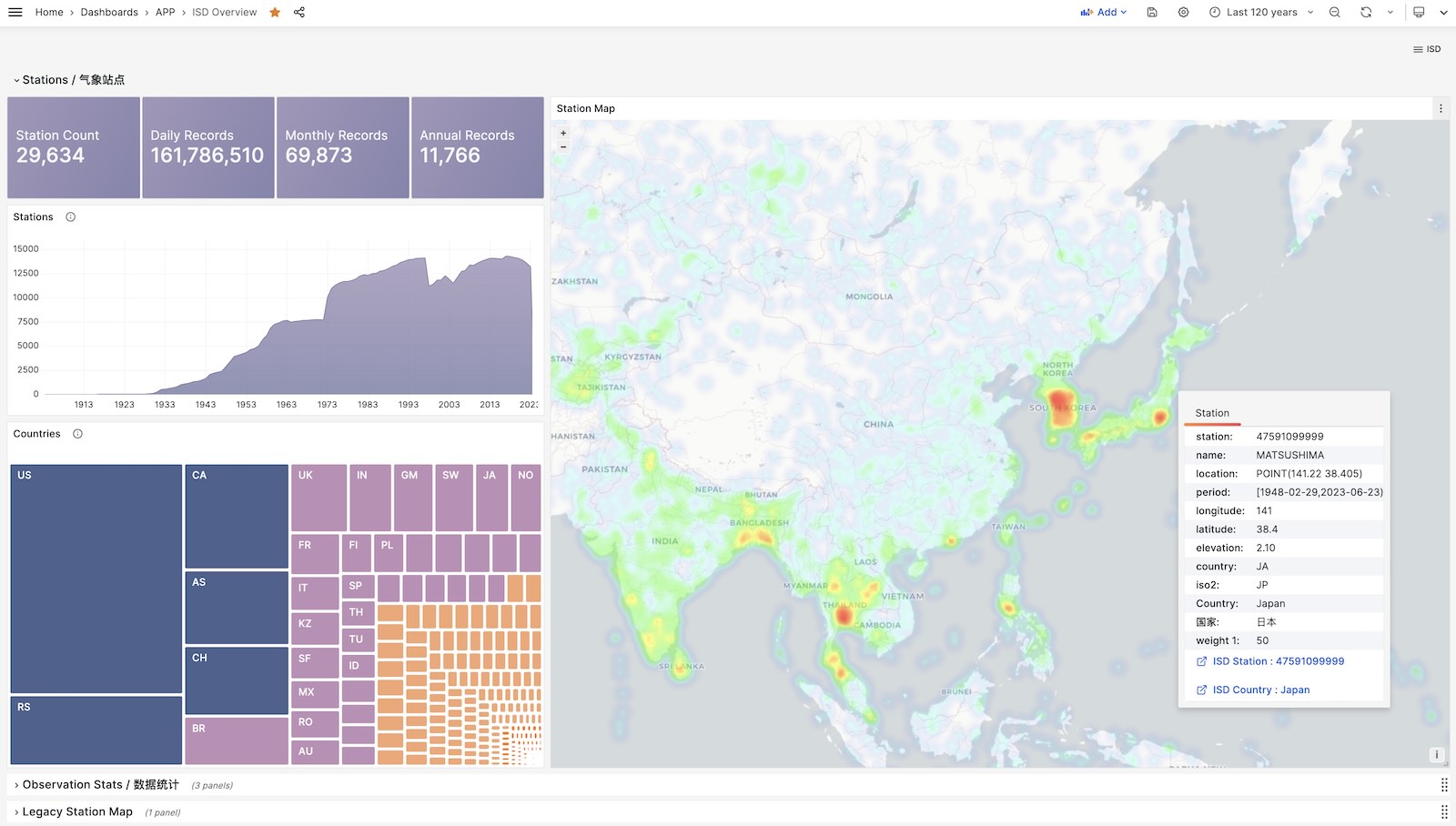
ISD Overview
全局概览,总体指标与气象站导航。
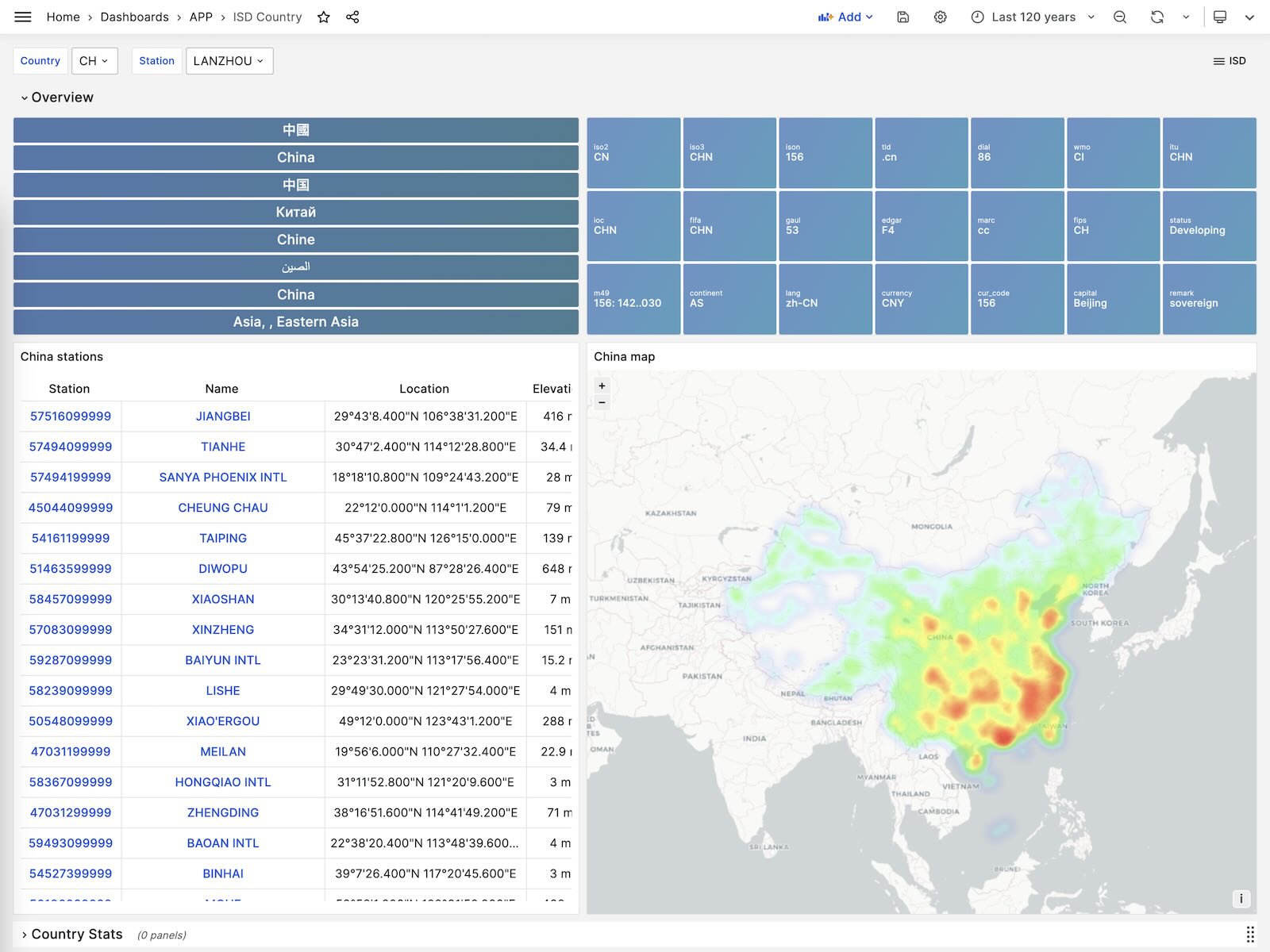
ISD Country
展示单个国家/地区内所有的气象站。
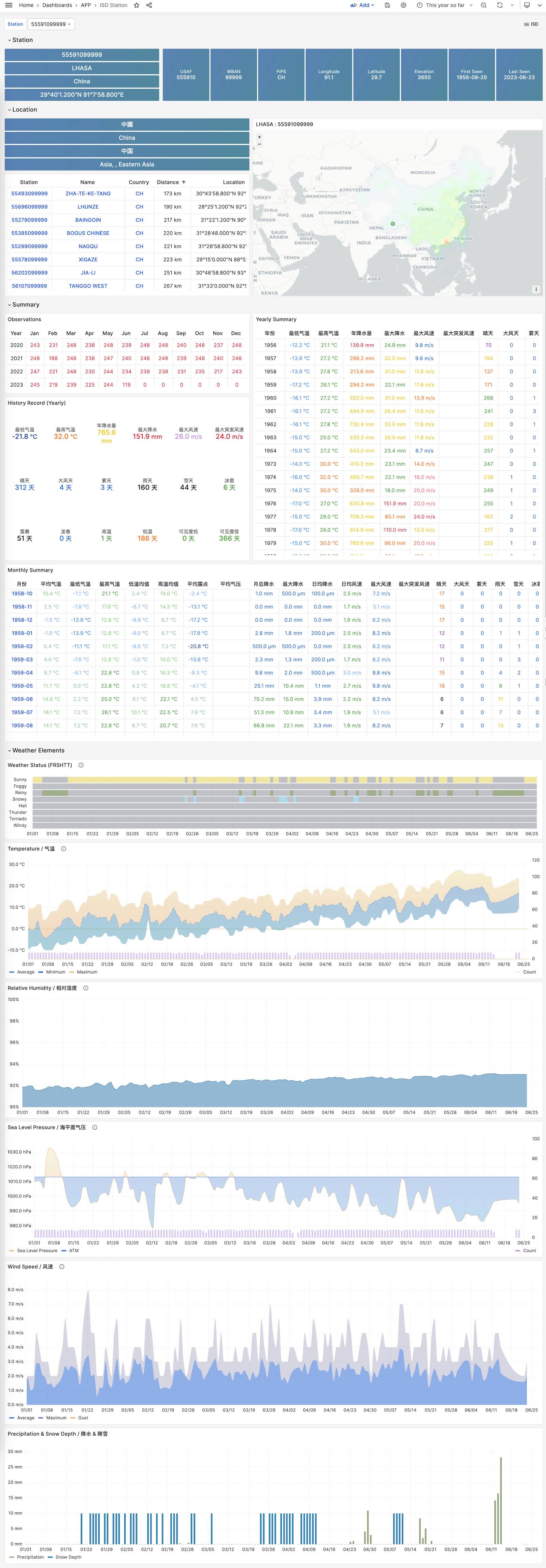
ISD Station
展示单个气象站的详细信息,元数据,天/月/年度汇总指标。
ISD Station Dashboard
ISD Detail
展示一个气象站原始亚小时级观测指标数据,需要 isd.hourly 数据集。
ISD Station Dashboard
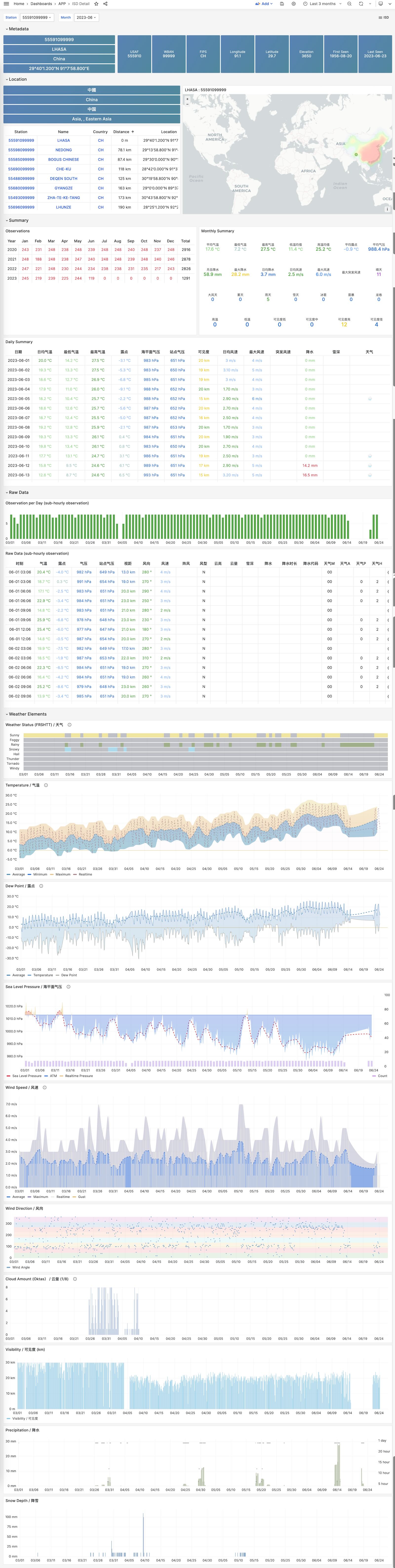
24 - COVID-19 数据大盘
Pigsty 自带的,用于展示世界卫生组织官方 COVID 疫情数据的一个样例 Applet
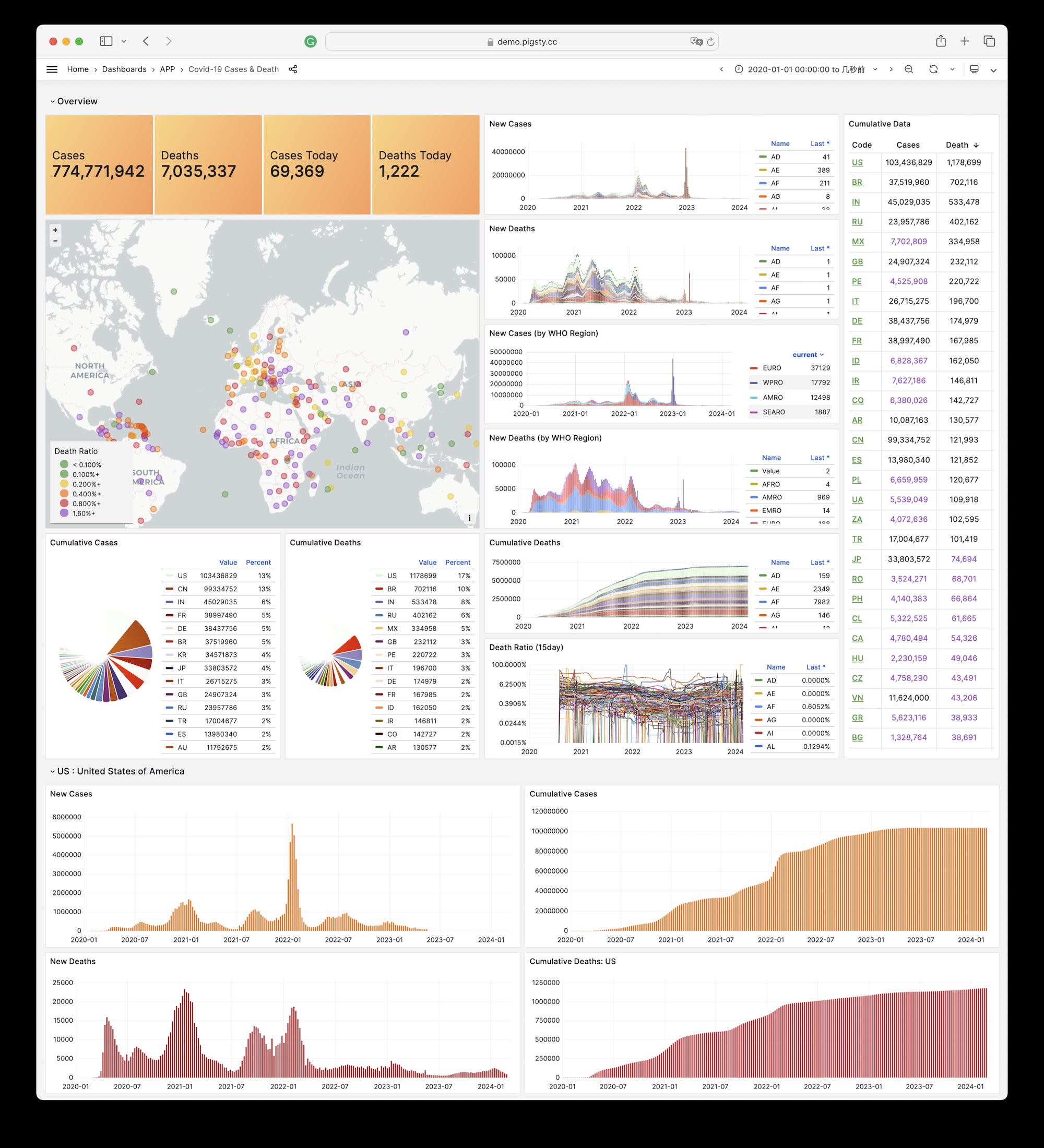
Covid 是 Pigsty 自带的,用于展示世界卫生组织官方疫情数据大盘的一个样例 Applet。
您可以查阅每个国家与地区 COVID-19 的感染与死亡案例,以及全球的疫情趋势。
概览
GitHub 仓库地址:https://github.com/Vonng/pigsty-app/tree/master/covid
在线Demo地址:https://demo.pigsty.cc/d/covid
安装
在管理节点上进入应用目录,执行make以完成安装。
其他一些子任务:
make reload # download latest data and pour it again
make ui # install grafana dashboards
make sql # install database schemas
make download # download latest data
make load # load downloaded data into database
make reload # download latest data and pour it into database
27 - 云上算力价格计算器
分析阿里云 / AWS 上算力与存储的价格 (ECS/ESSD)
概览
GitHub 仓库地址:https://github.com/Vonng/pigsty-app/tree/master/cloud
在线Demo地址:https://demo.pigsty.cc/d/ecs
文章地址:《剖析算力成本:阿里云真降价了吗?》
数据源
Aliyun ECS 价格可以在 价格计算器 - 定价详情 - 价格下载 中获取 CSV 原始数据。
模式
下载 阿里云 价格明细并导入分析
CREATE EXTENSION file_fdw;
CREATE SERVER fs FOREIGN DATA WRAPPER file_fdw;
DROP FOREIGN TABLE IF EXISTS aliyun_ecs CASCADE;
CREATE FOREIGN TABLE aliyun_ecs
(
"region" text,
"system" text,
"network" text,
"isIO" bool,
"instanceId" text,
"hourlyPrice" numeric,
"weeklyPrice" numeric,
"standard" numeric,
"monthlyPrice" numeric,
"yearlyPrice" numeric,
"2yearPrice" numeric,
"3yearPrice" numeric,
"4yearPrice" numeric,
"5yearPrice" numeric,
"id" text,
"instanceLabel" text,
"familyId" text,
"serverType" text,
"cpu" text,
"localStorage" text,
"NvmeSupport" text,
"InstanceFamilyLevel" text,
"EniTrunkSupported" text,
"InstancePpsRx" text,
"GPUSpec" text,
"CpuTurboFrequency" text,
"InstancePpsTx" text,
"InstanceTypeId" text,
"GPUAmount" text,
"InstanceTypeFamily" text,
"SecondaryEniQueueNumber" text,
"EniQuantity" text,
"EniPrivateIpAddressQuantity" text,
"DiskQuantity" text,
"EniIpv6AddressQuantity" text,
"InstanceCategory" text,
"CpuArchitecture" text,
"EriQuantity" text,
"MemorySize" numeric,
"EniTotalQuantity" numeric,
"PhysicalProcessorModel" text,
"InstanceBandwidthRx" numeric,
"CpuCoreCount" numeric,
"Generation" text,
"CpuSpeedFrequency" numeric,
"PrimaryEniQueueNumber" text,
"LocalStorageCategory" text,
"InstanceBandwidthTx" text,
"TotalEniQueueQuantity" text
) SERVER fs OPTIONS ( filename '/tmp/aliyun-ecs.csv', format 'csv',header 'true');
AWS EC2 同理,可以从 Vantage 下载价格清单:
DROP FOREIGN TABLE IF EXISTS aws_ec2 CASCADE;
CREATE FOREIGN TABLE aws_ec2
(
"name" TEXT,
"id" TEXT,
"Memory" TEXT,
"vCPUs" TEXT,
"GPUs" TEXT,
"ClockSpeed" TEXT,
"InstanceStorage" TEXT,
"NetworkPerformance" TEXT,
"ondemand" TEXT,
"reserve" TEXT,
"spot" TEXT
) SERVER fs OPTIONS ( filename '/tmp/aws-ec2.csv', format 'csv',header 'true');
DROP VIEW IF EXISTS ecs;
CREATE VIEW ecs AS
SELECT "region" AS region,
"id" AS id,
"instanceLabel" AS name,
"familyId" AS family,
"CpuCoreCount" AS cpu,
"MemorySize" AS mem,
round("5yearPrice" / "CpuCoreCount" / 60, 2) AS ycm5, -- ¥ / (core·month)
round("4yearPrice" / "CpuCoreCount" / 48, 2) AS ycm4, -- ¥ / (core·month)
round("3yearPrice" / "CpuCoreCount" / 36, 2) AS ycm3, -- ¥ / (core·month)
round("2yearPrice" / "CpuCoreCount" / 24, 2) AS ycm2, -- ¥ / (core·month)
round("yearlyPrice" / "CpuCoreCount" / 12, 2) AS ycm1, -- ¥ / (core·month)
round("standard" / "CpuCoreCount", 2) AS ycmm, -- ¥ / (core·month)
round("hourlyPrice" / "CpuCoreCount" * 720, 2) AS ycmh, -- ¥ / (core·month)
"CpuSpeedFrequency"::NUMERIC AS freq,
"CpuTurboFrequency"::NUMERIC AS freq_turbo,
"Generation" AS generation
FROM aliyun_ecs
WHERE system = 'linux';
DROP VIEW IF EXISTS ec2;
CREATE VIEW ec2 AS
SELECT id,
name,
split_part(id, '.', 1) as family,
split_part(id, '.', 2) as spec,
(regexp_match(split_part(id, '.', 1), '^[a-zA-Z]+(\d)[a-z0-9]*'))[1] as gen,
regexp_substr("vCPUs", '^[0-9]+')::int as cpu,
regexp_substr("Memory", '^[0-9]+')::int as mem,
CASE spot
WHEN 'unavailable' THEN NULL
ELSE round((regexp_substr("spot", '([0-9]+.[0-9]+)')::NUMERIC * 7.2), 2) END AS spot,
CASE ondemand
WHEN 'unavailable' THEN NULL
ELSE round((regexp_substr("ondemand", '([0-9]+.[0-9]+)')::NUMERIC * 7.2), 2) END AS ondemand,
CASE reserve
WHEN 'unavailable' THEN NULL
ELSE round((regexp_substr("reserve", '([0-9]+.[0-9]+)')::NUMERIC * 7.2), 2) END AS reserve,
"ClockSpeed" AS freq
FROM aws_ec2;