Pigsty 博客文章
- 精选
- Pigsty v4.0 发布,进入 AI 时代
- OpenAI: 将PG伸缩至新阶段
- 自建Supabase:创业出海的首选数据库
- PostgreSQL 正在吞噬数据库世界
- 专栏:PGSQL 大法师
- 专栏:数据库老司机
- 专栏:云计算泥石流
- Pigsty
- Pigsty v4.2:12内核齐开花
- Pigsty v4.1:天下武功,唯快不破
- Pigsty v4.0:可观测性革命与安全性大改进
- Pigsty v3.7:PG 万磁王,新系统,新版本
- Pigsty v3.6:PostgreSQL 18 Beta支持
- Pigsty v3.5:扩展生态持续壮大
- Pigsty v3.4:性能优化与稳定性提升
- Pigsty v3.3:扩展突破400,丝滑建站,应用模板
- Pigsty v3.2:十大操作系统全覆盖
- Pigsty v3.1:自建Supabase本地替代
- Pigsty v3.0:搭积木一样玩转PG扩展
- Pigsty v2.7:340个扩展与ARM支持
- Pigsty v2.6:255个扩展与6大操作系统
- Pigsty v2.5:火烈鸟与ParadeDB
- Pigsty v2.4:150个扩展
- Pigsty v2.3:FerretDB与应用
- Pigsty v2.2:PostgreSQL 16
- Pigsty v2.1:与Ubuntu的邂逅
- Pigsty v2.0:构筑你的私有RDS
- Pigsty v1.5:服务发现与Consul
- Pigsty v1.4:Redis与Citus
- Pigsty v1.3:PostgreSQL 14
- Pigsty v1.2:多发行版支持
- Pigsty v1.1:MatrixDB与极致监控
- Pigsty v1.0:正式GA
- Pigsty v0.9:DNS与日志
- Pigsty v0.8:服务置备
- Pigsty v0.7:监控升级
- Pigsty v0.6:CMDB升级
- Pigsty v0.5:沙盒重构升级
- Pigsty v0.4:全面扩充管控能力
- Pigsty v0.3:首次公开发布
- PostgreSQL
- Oracle 兼容的 PG 真的有用吗?
- 号外:暂缓 PG 最新小版本安装与升级
- 从AGPL到Apache:Pigsty 协议变更的思考
- OpenAI:一套 PG 支持8亿 ChatGPT 用户
- PostgreSQL 高可用到底怎么做?
- Git for Data:瞬间克隆 PG 数据库
- 为什么PG将主宰AI时代的数据库
- 立足中国,面向全球的 PostgreSQL 发行版
- PG扩展云:解锁 PG 生态的全部潜力
- 从PG“断供”看软件供应链中的信任问题
- 专栏:Postgres 大法师
- PostgreSQL主宰数据库世界,而谁来吞噬PG?
- PostgreSQL 已主宰数据库世界
- 卡脖子:PGDG切断镜像站同步通道
- Postgres Extension Day,咱们不见不散
- OrioleDB来了!4x性能,消除顽疾,存算分离
- OpenHalo:MySQL线缆兼容的PostgreSQL来了!
- PGFS:将数据库作为文件系统
- PostgreSQL 生态前沿进展
- 小猪骑大象:PG内核与扩展包管理神器
- 不要更新!发布当日叫停:PG也躲不过大翻车
- PostgreSQL 12 过保,PG 17 上位
- PostgreSQL神功大成!最全扩展仓库来了!
- PostgreSQL 规约(2024版)
- PostgreSQL 17 发布:摊牌了,我不装了!
- PostgreSQL可以替代微软SQL Server吗?
- 谁整合好DuckDB,谁赢得OLAP世界
- StackOverflow 2024调研:PostgreSQL已经杀疯了
- 使用Pigsty自建Dify:AI工作流平台
- 让PG停摆一周的大会:PGCon.Dev 2024 参会记
- PostgreSQL 17 beta1 发布!
- 为什么PostgreSQL是未来数据库的事实标准?
- PostgreSQL会修改开源许可证吗?
- PostgreSQL 正在吞噬数据库世界
- 技术极简主义:一切皆用Postgres
- PG生态新玩家:ParadeDB
- 令人惊叹的PostgreSQL可伸缩性
- PostgreSQL荣获2024年度数据库之王!(第五次)
- 展望 PostgreSQL 的2024
- PostgreSQL 宏观查询优化之 pg_stat_statements
- FerretDB:假扮成MongoDB的PG
- 如何用 pg_filedump 抢救数据?
- 向量是新的 JSON
- PostgreSQL:最成功的数据库
- AI大模型与向量库 PGVector
- PostgreSQL 到底有多强?
- 为什么PostgreSQL是最成功的数据库?
- 开箱即用的PG发行版:Pigsty
- 为什么PostgreSQL前途无量?
- PG中的本地化排序规则
- 高级模糊查询的实现
- PG复制标识详解(Replica Identity)
- PostgreSQL 逻辑复制详解
- PG慢查询诊断方法论
- 故障档案:时间回溯导致的Patroni故障
- 在线修改主键列类型
- 黄金监控指标:错误延迟吞吐饱和
- 数据库集群管理概念与实体命名规范
- PostgreSQL的KPI
- 在线修改PG字段类型
- 前后端通信线缆协议
- 事务隔离等级注意事项
- 故障档案:PG安装Extension导致无法连接
- CDC 变更数据捕获机理
- PostgreSQL中的锁
- GIN搜索的O(n²)复杂度
- PostgreSQL 常见复制拓扑方案
- 温备:使用pg_receivewal
- 故障档案:pg_dump导致的连接池污染
- PostgreSQL数据页面损坏修复
- 关系膨胀的监控与治理
- PipelineDB快速上手
- TimescaleDB 快速上手
- 故障档案:PostgreSQL事务号回卷
- 故障档案:序列号消耗过快导致整型溢出
- GeoIP 地理逆查询优化
- PostgreSQL的触发器使用注意事项
- PostgreSQL开发规约(2018版)
- PostgreSQL好处都有啥
- KNN极致优化:从RDS到PostGIS
- PostGIS高效解决行政区划归属查询
- 监控PG中的表大小
- PgAdmin安装配置
- 故障档案:快慢不匀雪崩
- Bash与psql小技巧
- Distinct On 去除重复数据
- 函数易变性等级分类
- 用 Exclude 实现互斥约束
- PostgreSQL例行维护
- 备份恢复手段概览
- PgBackRest2中文文档
- Pgbouncer快速上手
- PG服务器日志常规配置
- 空中换引擎:PostgreSQL不停机迁移数据
- 使用FIO测试磁盘性能
- 使用sysbench测试PostgreSQL性能
- 找出没用过的索引
- 批量配置SSH免密登录
- Wireshark抓包分析协议
- file_fdw妙用无穷——从数据库读取系统信息
- Linux 常用统计 CLI 工具
- 源码编译安装 PostGIS
- Go数据库教程:database/sql
- GO与PG实现缓存同步
- 用触发器审计数据变化
- SQL实现ItemCF推荐系统
- UUID性质原理与应用
- PostgreSQL MongoFDW安装部署
- 云计算
- 隐私换便利?云上AI助理意味着什么?
- 小红书究竟有没有下云?
- 支付宝淘宝闲鱼崩了?又是消息队列的锅?
- Cloudflare 11-18 故障复盘报告
- 阿里云“借鉴”Supabase:开源与云的灰色地带
- AWS 故障官方复盘报告
- 一次AWS DNS故障如何级联瘫痪半个互联网
- 专栏:云计算泥石流
- KubeSphere:开源断供背后的信任危机
- 阿里云rds_duckdb:致敬还是抄袭?
- 花钱买罪受的大冤种:逃离云计算妙瓦底
- OpenAI全球宕机复盘:K8S循环依赖
- WordPress社区内战:论共同体划界问题
- 云数据库:用米其林的价格,吃预制菜大锅饭
- 阿里云:高可用容灾神话破灭
- 草台班子唱大戏,阿里云PG翻车记
- 我们能从网易云音乐故障中学到什么?
- 蓝屏星期五:甲乙双方都是草台班子
- Ahrefs不上云,省下四亿美元
- 删库:Google云爆破了大基金的整个云账户
- 云上黑暗森林:打爆云账单,只需要S3桶名
- Cloudflare圆桌访谈与问答录
- 我们能从腾讯云大故障中学到什么?
- 吊打公有云的赛博佛祖 Cloudflare
- 罗永浩救不了牙膏云?
- 剖析阿里云服务器算力成本
- DBA会被云淘汰吗?
- 云下高可用秘诀:拒绝复杂度自慰
- 扒皮云对象存储:从降本到杀猪
- 半年下云省千万,DHH下云FAQ
- 从降本增笑到真的降本增效
- 重新拿回计算机硬件的红利
- 我们能从阿里云全球故障中学到什么?
- 薅阿里云羊毛,打造数字家园
- 云计算泥石流:用数据解构公有云
- DHH:下云省下千万美元,比预想的还要多!
- 下云奥德赛:该放弃云计算了吗?
- FinOps终点是下云
- 云计算为啥还没挖沙子赚钱?
- 云SLA是不是安慰剂?
- 云盘是不是杀猪盘?
- 垃圾腾讯云CDN:从入门到放弃?
- 驳《再论为什么你不应该招DBA》
- 范式转移:从云到本地优先
- 云数据库是不是智商税
- DBA还是一份好工作吗?
- 云RDS:从删库到跑路
- 数据库
- 用AI当由头裁了4000人,但程序员的需求涨了11%
- Palantir 的“本体论”骗局
- 重新设计数据密集型应用
- 从麦克卢汉的视角看 AI:当媒介不再延伸人体,而是延伸人脑
- 新年,聊聊AI将带来的变化
- DDIA 第二版翻完了:一个跨越八年的 AI 寓言
- MinIO 已死,MinIO 复生
- 写代码一文不值的时代,什么才值钱?
- Agent 的护城河:强龙不压地头蛇
- AI撕掉了软件的皮
- AI时代,新程序员将何去何从?
- 软件世界大熔断:当翻译层被压扁
- AI Agent 的操作系统时刻
- Claude Code 可观测性怎么做?
- Andy Pavlo:2025 数据库世界年度总结
- Claude Code 免翻上手教程
- 2025 年度数据库世界总结:石破天 vs Andy Pavlo 对谈录
- Agent 需要什么样的数据库?
- MySQL与白酒:互联网行业的服从测试
- Victoria:吊打业界的可观测性全家桶来了
- MinIO已死,谁能接盘?
- MinIO已死
- 当答案唾手可得,问题成为新货币
- 聊聊开源软件供应链信任问题
- 原地报废:不要在生产环境用Docker跑PostgreSQL!
- DDIA第二版中文翻译
- 专栏:数据库老司机
- 懂车帝暴打智驾,懂库帝在哪里
- Google AI工具箱:生产级数据库MCP来了?
- AI时代的数据库与DBA将何去何从
- 别争了,AI时代数据库已经尘埃落定
- 开放数据标准:Postgres,OTel,与Iceberg
- 小数据的失落十年:分布式分析的错付
- OpenAI:将PostgreSQL伸缩至新阶段
- Etcd坑了多少公司?
- AI时代,软件从数据库开始
- MySQL vs PostgreSQL @ 2025
- 数据库火星撞地球:当PG爱上DuckDB
- 对比Oracle与PostgreSQL事务系统
- 数据库即业务架构
- 七周七数据库(2025年)
- 使用一条 SQL 计算扑克24点
- 自建 Supabase:创业出海的首选数据库
- 面向未来数据库的现代硬件
- MySQL还有机会赶上PostgreSQL吗?
- 开源“暴君”Linus清洗整风
- 先优化碳基BIO核,再优化硅基CPU核
- MongoDB没有未来:好营销救不了烂芒果
- MongoDB:现在由PostgreSQL强力驱动?
- 瑞士强制政府软件开源
- MySQL安魂九霄,PostgreSQL驶向云外
- CVE-2024-6387 SSH漏洞修复
- Oracle还能挽救MySQL吗?
- Oracle最终还是杀死了MySQL
- MySQL性能越来越差,Sakila将何去何从?
- 20刀好兄弟PolarDB:论数据库该卖什么价?
- 国产数据库到底能不能打?
- Redis不开源是“开源”之耻,更是公有云之耻
- MySQL正确性竟如此垃圾?
- 数据库应该放入K8S里吗?
- 专用向量数据库凉了吗?
- 数据库真被卡脖子了吗?
- EL系操作系统发行版哪家强?
- 基础软件需要什么样的自主可控?
- 正本清源:技术反思录
- 数据库需求层次金字塔
- 分布式数据库是不是伪需求?
- 微服务是不是个蠢主意?
- 是时候和GPL说再见了
- 容器化数据库是个好主意吗?
- 理解时间:闰年闰秒,时间与时区
- 理解字符编码原理
- 并发异常那些事
- 区块链与分布式数据库
- 一致性:过载的术语
- 为什么要学习数据库原理
精选
Pigsty v4.0 发布,进入 AI 时代

OpenAI: 将PG伸缩至新阶段

在PGConf.Dev 2025大会上,来自OpenAI的Bohan Zhang分享了OpenAI在PostgreSQL上的最佳实践。在OpenAI,他们使用一写多读的未分片架构,证明了PostgreSQL在海量读负载下也可以伸缩自如。 阅读全文
自建Supabase:创业出海的首选数据库

Supabase 非常棒,拥有你自己的 Supabase 那就是棒上加棒!本文介绍了如何在本地/云端物理机/裸金属/虚拟机上自建企业级 Supabase。 阅读全文
PostgreSQL 正在吞噬数据库世界

PostgreSQL并不是一个简单的关系型数据库,而是一个数据管理的抽象框架,具有吞噬整个数据库世界的力量。“一切皆用Postgres"已经成为主流视野的最佳实践。 阅读全文
专栏:PGSQL 大法师

关于 PostgreSQL 的开发,管理,原理,生态,工具,架构设计,性能优化,故障排查等方面的文章导航。 阅读全文
专栏:数据库老司机

数据库领域充满着太多胡言乱语与不实营销,数据库老司机带您拨云见日,穿透迷糊,直击行业核心与本质。 阅读全文
专栏:云计算泥石流

整整一代应用开发者的视野被云遮蔽,让我们用实打实的数据分析与经历,讲清公有云租赁模式的价值与陷阱。 阅读全文
Pigsty


Pigsty v4.0:可观测性革命与安全性大改进
VictoriaMetrics/Logs 替代 Prometheus/Loki,新增 JUICE/VIBE 模块,安全性全面改进,多云支持,许可证变更为 Apache-2.0。 阅读全文
Pigsty v3.7:PG 万磁王,新系统,新版本

Pigsty v3.6:PostgreSQL 18 Beta支持

Pigsty v3.5:扩展生态持续壮大

Pigsty v3.4:性能优化与稳定性提升

Pigsty v3.3:扩展突破400,丝滑建站,应用模板

Pigsty v3.2:十大操作系统全覆盖

Pigsty v3.1:自建Supabase本地替代

Pigsty v3.0:搭积木一样玩转PG扩展

Pigsty v2.7:340个扩展与ARM支持

Pigsty v2.6:255个扩展与6大操作系统

Pigsty v2.5:火烈鸟与ParadeDB

Pigsty v2.4:150个扩展

Pigsty v2.3:FerretDB与应用

Pigsty v2.2:PostgreSQL 16

Pigsty v2.1:与Ubuntu的邂逅

Pigsty v2.0:构筑你的私有RDS

Pigsty v1.5:服务发现与Consul

Pigsty v1.4:Redis与Citus

Pigsty v1.3:PostgreSQL 14

Pigsty v1.2:多发行版支持

Pigsty v1.1:MatrixDB与极致监控

Pigsty v1.0:正式GA

Pigsty v0.9:DNS与日志

Pigsty v0.8:服务置备

Pigsty v0.7:监控升级

Pigsty v0.6:CMDB升级

Pigsty v0.5:沙盒重构升级

Pigsty v0.4:全面扩充管控能力

Pigsty v0.3:首次公开发布

PostgreSQL
Oracle 兼容的 PG 真的有用吗?

从一个“只有 JAR 没有源码”的迁移案例出发,解释为什么 Oracle 语法兼容并非伪需求,以及如何用 IvorySQL + Pigsty 低成本接住历史包袱。 阅读全文
号外:暂缓 PG 最新小版本安装与升级

PostgreSQL 18.2 系列小版本引入了 substring 与 WAL 回放相关回归问题,建议暂缓新建与升级,并在 2026-02-26 号外版本发布后尽快更新。 阅读全文
从AGPL到Apache:Pigsty 协议变更的思考

Pigsty 从 AGPLv3 切换到 Apache 2.0 许可证,有朋友问我不怕别人白嫖吗?欢迎白嫖,要做数据库世界的 Debian,一个开放的许可证是必要的诚意。 阅读全文
OpenAI:一套 PG 支持8亿 ChatGPT 用户

PostgreSQL 的标杆案例,他们使用1主50从的经典主从PG,支撑了8亿ChatGPT用户。附上老冯的评论与看法。 阅读全文
PostgreSQL 高可用到底怎么做?

详细介绍 PG 高可用 SOTA 方案,RTO / RPO 拆解,从原理到实战,一步到位。如果你还在折腾 PG HA,希望能帮你少走几年弯路。 阅读全文
Git for Data:瞬间克隆 PG 数据库

如何在瞬间克隆一个巨大的 PostgreSQL 数据库,还不占用额外的存储?PG 18 与 XFS 可以擦出很多火花。 阅读全文
为什么PG将主宰AI时代的数据库

上下文窗口经济学,多元持久化的问题,以及零胶水架构的胜利,让 PG 成为 AI 时代的数据库之王。 阅读全文
立足中国,面向全球的 PostgreSQL 发行版

如何打造一个立足中国,面向全球的 PostgreSQL 数据库发行版?在第八届中国PG生态大会上的主题演讲。 阅读全文
PG扩展云:解锁 PG 生态的全部潜力

开源免费免翻墙,一键安装PG与431个扩展插件 14个Linux发行版 x 6大PG主版本原生 RPM/DEB。 阅读全文
从PG“断供”看软件供应链中的信任问题

PostgreSQL官方仓库切断全球镜像站同步通道,开源制成品断供,很好的试出了各家数据库厂商和云厂商的成色。 阅读全文
专栏:Postgres 大法师
关于 PostgreSQL 的开发,管理,原理,生态,工具,架构设计,性能优化,故障排查等方面的文章导航。 阅读全文
PostgreSQL主宰数据库世界,而谁来吞噬PG?

那些曾经让 MongoDB,MySQL 走向封闭的力量,如今也同样在 PostgreSQL 的生态中发挥作用,PG世界需要一个代表"软件自由"价值观的发行版。 阅读全文
PostgreSQL 已主宰数据库世界

2025 年的 SO 全球开发者调研结果新鲜出炉,PostgreSQL 连续第三年成为全球最流行,最受喜爱,需求量最高的数据库。 阅读全文
卡脖子:PGDG切断镜像站同步通道

PGDG 切断 FTP rsync 同步通道,全球镜像站普遍断连,这次还真是卡了一把全球用户的脖子。 阅读全文
Postgres Extension Day,咱们不见不散

一年一度的 PostgreSQL 开发者大会即将在五月于蒙特利尔举办。同上次第一届 PG Con.Dev 一样,这次也有一天的额外的专场活动 —— Postgres Extensions Day。 阅读全文
OrioleDB来了!4x性能,消除顽疾,存算分离

Supabase收购的一个PG内核分支,号称解决了PG XID回卷的问题,没有表膨胀问题,性能提升4倍,还支持云原生存储。 阅读全文
OpenHalo:MySQL线缆兼容的PostgreSQL来了!

PostgreSQL现在可以使用MySQL客户端访问了!愚人节刚开源的openHalo提供了这样的能力,现已加入Pigsty内核全家桶。 阅读全文
PGFS:将数据库作为文件系统

利用 JuiceFS,将 PostgreSQL 变为一个带 PITR 的文件系统! 阅读全文
PostgreSQL 生态前沿进展

和大家分享一下最近 PG 生态有趣的一些进展:Omnigres、PG Mooncake、Citus 13、FerretDB 2.0、ParadeDB等。 阅读全文
小猪骑大象:PG内核与扩展包管理神器

PostgreSQL 与 Pigsty 中长期缺失的一个包管理器 —— PIG。 阅读全文
不要更新!发布当日叫停:PG也躲不过大翻车

不要在星期五发布代码,否则你会多忙一整周!PG小版本发布当天,紧急回滚新发布的小版本。 阅读全文
PostgreSQL 12 过保,PG 17 上位

PG17使用PG16一半的时间实现扩展生态适配,300个可用扩展就绪,达到生产可用状态。PG12正式脱离支持生命周期。 阅读全文
PostgreSQL神功大成!最全扩展仓库来了!

PG扩展很多很强大,但如何安装并使用起来一直都是社区的难题。现在有了Pigsty扩展仓库,390个强力插件开箱即用。 阅读全文
PostgreSQL 规约(2024版)

没有规矩,不成方圆。本文是22-24年针对PostgreSQL 15-17大版本的更新,希望可以减少大家在使用与管理PostgreSQL数据库过程中遇到的困惑。 阅读全文
PostgreSQL 17 发布:摊牌了,我不装了!

现在PG是世界上最先进的开源数据库,已经是各种规模组织的首选开源数据库,与顶尖商业数据库旗鼓相当,甚至更胜一筹。 阅读全文
PostgreSQL可以替代微软SQL Server吗?

PostgreSQL可以直接从内核层面替换掉Oracle、SQL Server与MongoDB,最彻底的是SQL Server,AWS出品的Babelfish直接做到了线缆协议级兼容。 阅读全文
谁整合好DuckDB,谁赢得OLAP世界

正如两年前开展的向量数据库扩展插件赛马一样,当下PG生态进行的扩展竞赛已经开始围绕DuckDB进行,MotherDuck官方亲自下场标志着竞争进入白热化。 阅读全文
StackOverflow 2024调研:PostgreSQL已经杀疯了
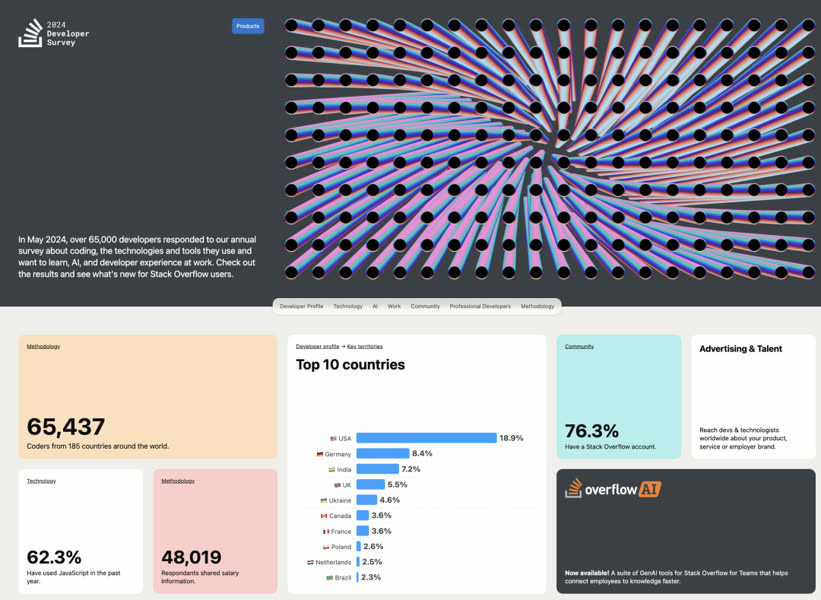
2024年的SO全球开发者调研结果新鲜出炉,PostgreSQL连续第二年成为全球最流行、最受喜爱、需求量最高的数据库。 阅读全文
使用Pigsty自建Dify:AI工作流平台
Dify 是一个生成式 AI 应用创新引擎,开源的 LLM 应用开发平台,本文介绍了如何使用 Pigsty 自建 Dify。 阅读全文
让PG停摆一周的大会:PGCon.Dev 2024 参会记

大会议程与主题分享,酒吧社交,自组织会议,PG仓库是如何维护的,社区参与度,一些中国特色问题。 阅读全文
PostgreSQL 17 beta1 发布!

PostgreSQL 全球开发组宣布,PostgreSQL 17 的首个 Beta 版本现已开放,这次 PG 真的是把牙膏管给挤爆啦! 阅读全文
为什么PostgreSQL是未来数据库的事实标准?
原文链接:https://www.timescale.com/blog/postgres-for-everything/

如今软件开发中最大的趋势之一,是PostgreSQL正在成为事实上的数据库标准。直到现在还没有多少文章能解释这一现象背后的原因。 阅读全文
PostgreSQL会修改开源许可证吗?
原文链接:https://jkatz05.com/post/postgres/postgres-license-2024/

PostgreSQL 不会改变其许可证。本文是 PostgreSQL 核心组成员对此问题的回答。 阅读全文
PostgreSQL 正在吞噬数据库世界
PostgreSQL 并不是一个简单的关系型数据库,而是一个数据管理的抽象框架,具有吞噬整个数据库世界的力量。而这也是正在发生的事情 —— “一切皆用 Postgres” 已经不再是少数精英团队的前沿探索,而是成为了一种进入主流视野的最佳实践。
OLAP 领域迎来踢馆者
在 2016 年的一次数据库沙龙里,我提出了一个观点: 现在 PostgreSQL 生态的一个主要遗憾是,缺少一个足够好的列式存储分析插件来做 OLAP 分析。尽管PostgreSQL 本身提供了很强大的分析功能集,应付常规的分析任务绰绰有余。但在较大数据量下全量分析的性能,相比专用的实时数仓仍然有些不够看。
以分析领域的权威评测 ClickBench 为例,我们在其中标注出了 PostgreSQL 与生态扩展插件以及兼容衍生数据库在其中的性能表现。原生未经过调优的 PostgreSQL 表现较为拉垮(x1050),但经过调优后可以达到(x47);此外还有三个与分析有关系的扩展:列存 Hydra(x42),时序扩展 TimescaleDB(x103),以及分布式扩展 Citus(x262)。
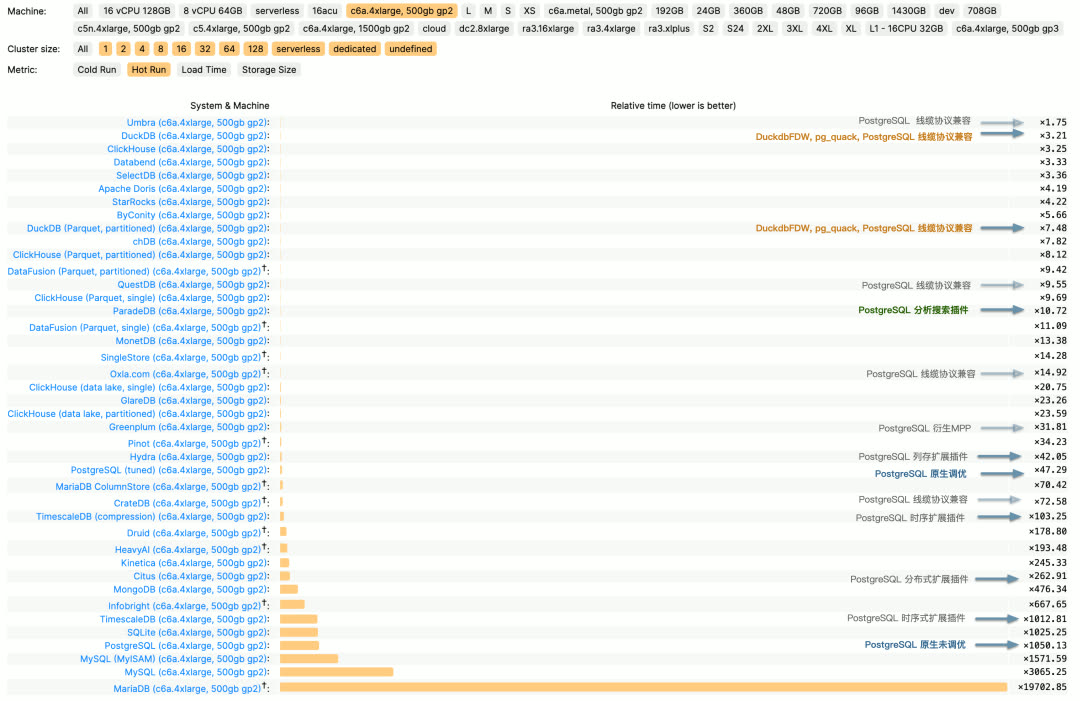
ClickBench c6a.4xlarge, 500gb gp2,Hot Run 执行相对耗时
这样的分析性能表现不能说烂,因为比起 MySQL,MariaDB 这样的纯 OLTP 数据库的辣眼表现(x3065,x19700)确实好很多;但第三梯队的性能表现也绝对说不上足够好,与专注于 OLAP 的第一梯队组件:Umbra,ClickHouse,Databend,SelectDB(x3~x4)相比,在分析性能上仍然有十几倍的性能差距。食之无味,弃之可惜。
然而, ParadeDB 和 DuckDB 的出现改变了这一点!
ParadeDB 提供的 PG 原生扩展 pg_analytics 实现了第二梯队(x10)的性能水准,与第一梯队只有 3~4 倍的性能差距。相对于其他功能上的收益,这种程度的性能差距通常是可以接受的 —— ACID,新鲜性与实时性,无需 ETL、额外学习成本、维护独立的新服务,更别提它还提供了 ElasticSearch 质量的全文检索能力。
而 DuckDB 则专注于 OLAP ,将分析性能这件事做到了极致(x3.2) —— 略过第一名 Umbra 这种学术研究型闭源数据库,DuckDB 也许是 OLAP 实战性能最快的数据库了。它并不是 PG 的扩展插件,但它是一个嵌入式文件数据库,而 DuckDB FDW 以及 pg_quack 这样的 PG 生态项目,能让 PostgreSQL 充分利用 DuckDB 带来的完整分析性能红利!
ParadeDB 与 DuckDB 的出现让 PostgreSQL 的分析性能来到了 OLAP 的第一梯队与金字塔尖,弥补了 PostgreSQL 在 OLAP 性能这最后一块关键短板。
分久必合的数据库领域
数据库诞生伊始,并没有 OLTP 与 OLAP 的分野。OLAP 数据仓库从数据库中“独立”出来,已经是上世纪九十年代时候的事了 —— 因为传统的 OLTP 数据库难以支撑起分析场景下的查询模式,数据量与性能要求。
在相当一段时间里,数据处理的最佳实践是使用 MySQL / PG 处理 OLTP 工作负载,并通过 ETL 将数据同步到专用的 OLAP 组件中去处理,比如 Greenplum, ClickHouse, Doris, Snowflake 等等。
设计数据密集型应用,Martin Kleppmann,第三章
与许多 “专用数据库” 一样,专业的 OLAP 组件的优势往往在于性能 —— 相比原生 PG 、MySQL 上有 1~3 个数量级的提升;而代价则是数据冗余、 大量不必要的数据搬运工作、分布式组件之间缺乏一致性、额外的专业技能带来的复杂度成本、学习成本、以及人力成本、 额外的软件许可费用、极其有限的查询语言能力、可编程性、可扩展性、有限的工具链、以及与OLTP 数据库相比更差的数据完整性和可用性 —— 但这是一个合理的利弊权衡。
然而天下大势,分久必合,合久必分。硬件遵循摩尔定律又发展了三十年,性能翻了几个数量级,成本下降了几个数量级。在 2024 年的当下,x86 单机可以达到几百核 (512 vCPU EPYC 9754x2),几个TB的内存,单卡 NVMe SSD 可达 64TB,全闪单机柜 2PB ;S3 这样对象存储更是能实现几乎没有上限的存储。
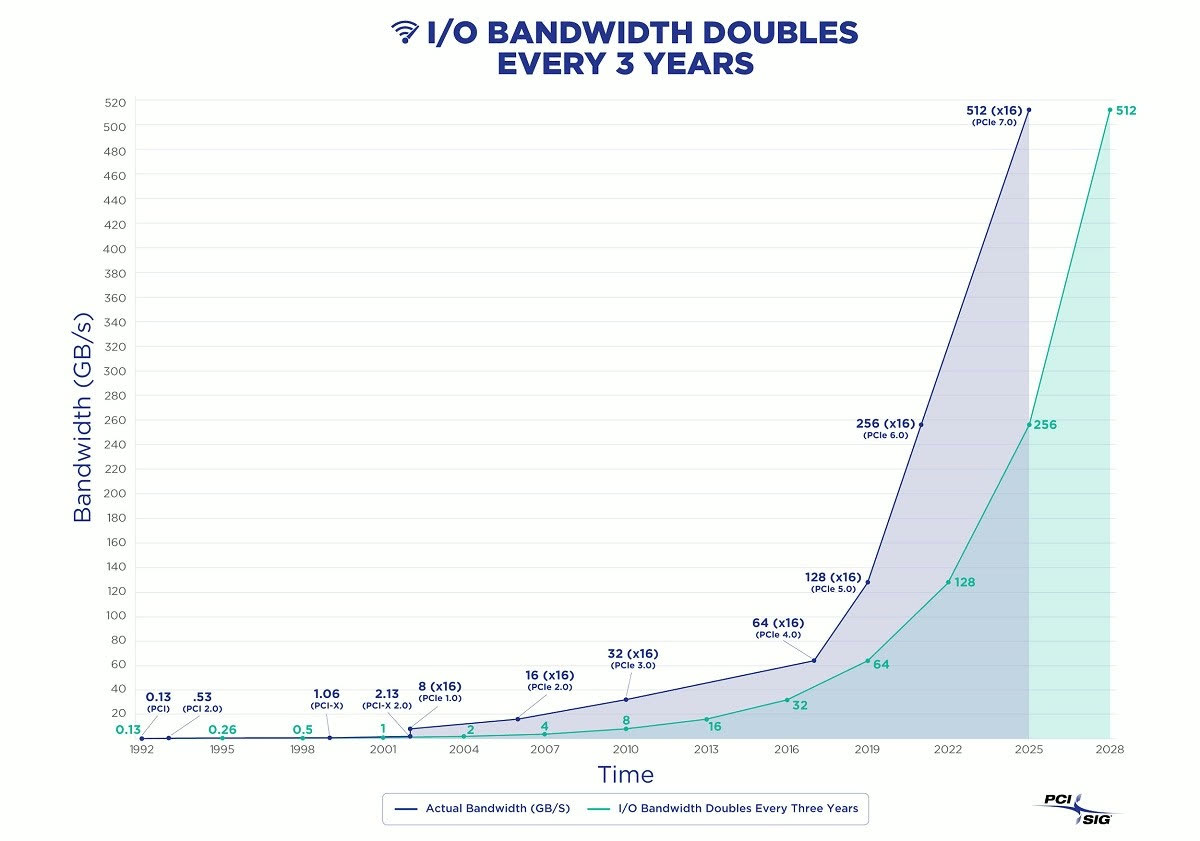
硬件的发展解决了数据量的问题,而数据库软件的发展(PostgreSQL,ParadeDB,DuckDB)解决了查询模式的问题,而这导致分析领域 —— 所谓的“大数据” 行业基本工作假设面临挑战。
正如 DuckDB 发表的宣言《大数据已死》所主张的:大数据时代已经结束了 —— 大多数人并没有那么多的数据,大多数数据也很少被查询。大数据的前沿随着软硬件发展不断后退,99% 的场景已经不再需要所谓“大数据”了。
如果 99% 的场景甚至都可以放在一台计算机上用单机/主从的 DuckDB 或 PostgreSQL 搞定,那么使用专用的分析组件还有多少意义?如果每台手机都可以自由自主收发短信,那么 BP 机还有什么存在价值?(北美医院还在用BP机,正好比也还有 1% 不到的场景也许真的需要“大数据”)
基本工作假设的变化,将重新推动数据库世界从百花齐放的“合久必分”阶段,走向“分久必合”的阶段,从大爆发到大灭绝,大浪淘沙中,新的大一统超融合数据库将会出现,重新统一 OLTP 与 OLAP。而承担重新整合数据库领域这一使命的会是谁?
吞食天地的 PostgreSQL
数据库领域有许多“细分领域”:时序数据库,地理空间数据库,文档数据库,搜索数据库,图数据库,向量数据库,消息队列,对象数据库。而 PostgreSQL 在任何一个领域都不会缺席。
一个 PostGIS 插件,成为了地理空间事实标准;一个 TimescaleDB 扩展,让一堆"通用"时序数据库尴尬的说不出话来;一个向量扩展 PGVector 插件,更是让整个 专用向量数据库细分领域 变成笑话。
同样的事情已经发生过很多次,而现在,我们将在拆分最早,地盘最大的一个子领域 OLAP 分析中再次见证这一点。但 PostgreSQL 要替代的可不仅仅是 OLAP 数仓,它的野望是整个数据库世界!
然 PostgreSQL 有何德何能,可当此大任?诚然 PostgreSQL 先进,但 Oracle 也先进;PostgreSQL 开源,但 MySQL 也开源。PostgreSQL 先进且开源,这是它与 Oracle / MySQL 竞争的底气,但要说其独一无二的特点,那还得是它的极致可扩展性,与繁荣的扩展生态!
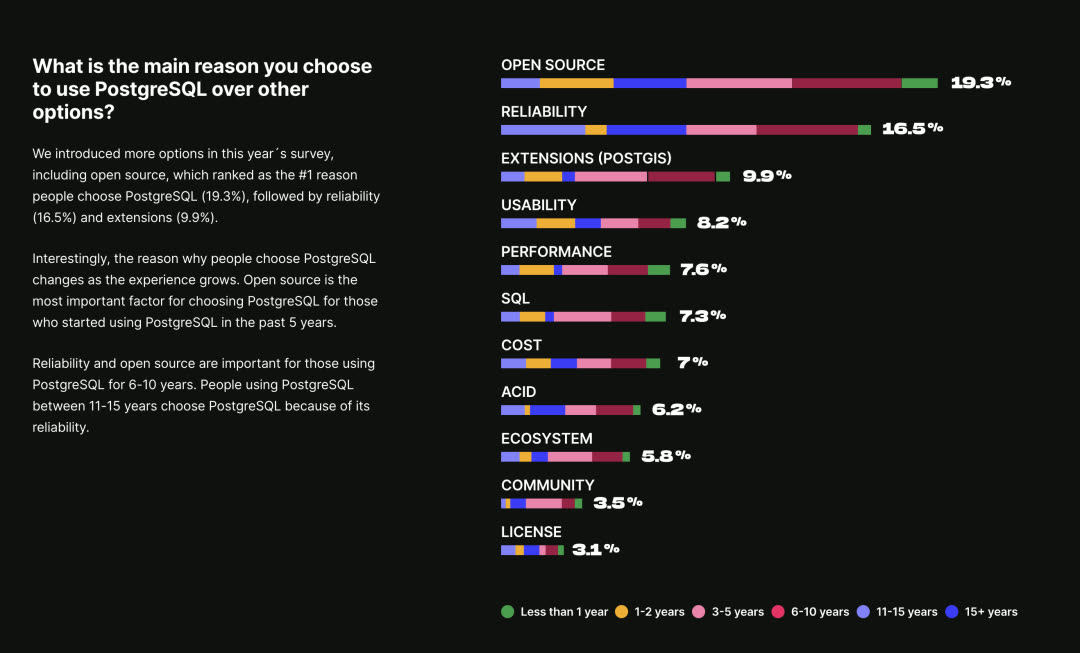
TimescaleDB 2022 社区调研:用户 选择 PostgreSQL 的原因:开源,先进,扩展。
PostgreSQL 并不是一个简单的关系型数据库,而是一个数据管理的抽象框架,具有囊括一切,吞噬整个数据库世界的力量。而它的核心竞争力(除了开源与先进)来自可扩展性,即基础设施的可复用性与扩展插件的可组合性。
极致可扩展性的魔法
PostgreSQL 允许用户开发功能模块,复用数据库公共基础设施,以最低的成本交付功能。例如,仅有两千行代码的向量数据库扩展 pgvector 与百万行代码的 PostgreSQL 在复杂度上相比可以说微不足道,但正是这“微不足道”的扩展,实现了完整的向量数据类型与索引能力,干翻了几乎所有专用向量数据库。
为什么?因为 PGVECTOR 作者不需要操心数据库的通用额外复杂度:事务 ACID,故障恢复,备份PITR,高可用,访问控制,监控,部署,三方生态工具,客户端驱动这些需要成百上千万行代码才能解决好的问题,只需要关注自己所需问题的本质复杂度即可。
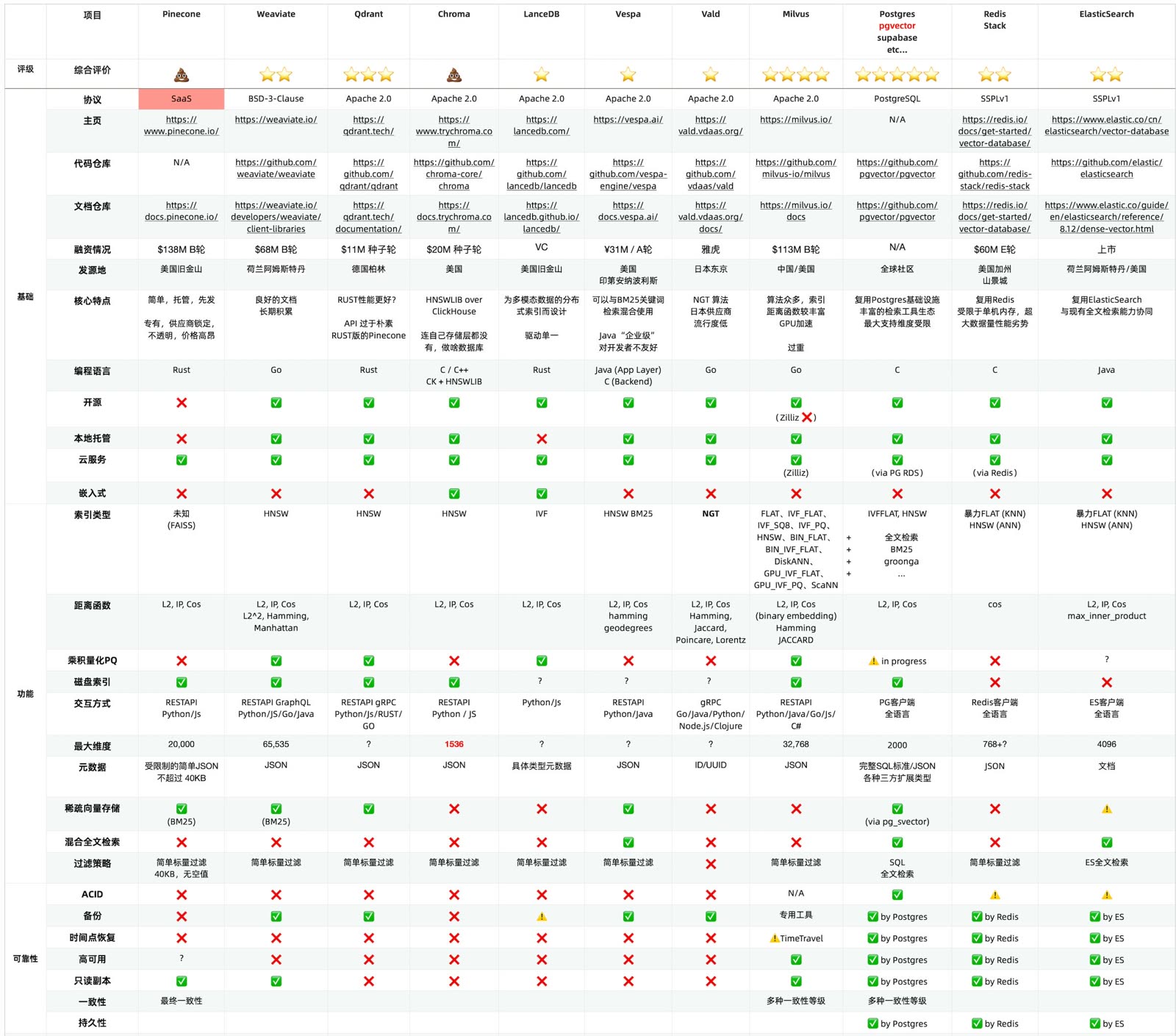
向量数据库哪家强?
再比如,ElasticSearch 基于 Lucene 搜索库开发,而 Rust 生态有一个改进版的下一代 Tantivy 全文搜索库作为 Lucene 的替代;而 ParadeDB 只需要将其封装对接到 PostgreSQL 的接口上,即可提供比肩 ElasticSearch 的搜索服务。更重要的是,它可以站在 PostgreSQL 巨人的肩膀上,借用 PG 生态的全部合力(例如,与 PG Vector 做混合检索),不讲武德地用数据库全能王的力量,去与一个专用数据库单品来对比。
Pigsty 中提供了 451 个可用扩展插件,在生态中还有 1000+ 扩展
可扩展性带来的另一点巨大优势是扩展的可组合性,让不同扩展相互合作,产生出 1+1 » 2 的协同效应。例如,TimescaleDB 可以与 PostGIS 组合使用,提供时空数据支持;再比如,提供全文检索能力的 BM25 扩展可以和提供语义模糊检索的 PGVector 扩展组合使用,提供混合检索能力。
再比如,分布式扩展 Citus 可以将单机主从数据库集群,原地升级改造为透明水平分片的分布式数据库集群。而这个能力是可以与其他功能正交组合的,因此,PostGIS 可以成为分布式地理数据库,PGVector 可以成为分布式向量数据库,ParadeDB 可以成为分布式全文搜索数据库,诸如此类。
更强大的地方在于,扩展插件是独立演进的,不需要繁琐的主干合并,联调协作。因此可以 Scale —— PG 的可扩展性允许无数个团队并行探索数据库前研发展方向,而扩展全部都是的可选的,不会影响主干核心能力的稳定性。那些非常强大成熟的特性,则有机会以稳定的形态进入主干中。
通过极致可扩展性的魔法,PostgreSQL 做到了**守正出奇,实现了主干极致稳定性与功能敏捷性的统一。**扎实的基本盘配上惊人的演进速度,让它成为了数据库世界中的一个异数,改变了数据库世界的游戏规则。
改变游戏规则的玩家
PostgreSQL 的出现,改变了数据库领域的游戏规则:任何试图开发“新数据库内核”的团队,都需要经过这道试炼与考验 —— 相比开源免费、功能齐备的 Postgres,价值点在哪里?
至少到硬件出现革命性突破前,实用的通用数据库新内核都不太可能诞生了,因为任何单一数据库都无法与所有扩展加持下的 PG 在整体实力上相抗衡 —— 包括 Oracle,因为 PG 还有开源免费的必杀技。
而某个细分领域的数据库产品,如果能在单点属性(通常是性能)上相比 PostgreSQL 实现超过一个数量级的优势,那也许还有一个专用数据库的生态位存在。但通常用不了多久,便会有 PostgreSQL 生态的开源替代扩展插件滚滚而来。因为选择开发 PG 扩展,而不是一个完整数据库的团队会在追赶复刻速度上有碾压性优势!
因此,如果按照这样的逻辑展开,PostgreSQL 生态的雪球只会越滚越大,随着优势的积累,不可避免地进入一家独大的状态。在几年的时间内,实现 Linux 内核在服务器操作系统领域的状态。而各种开发者调研报告,数据库流行趋势都在印证着这一点。
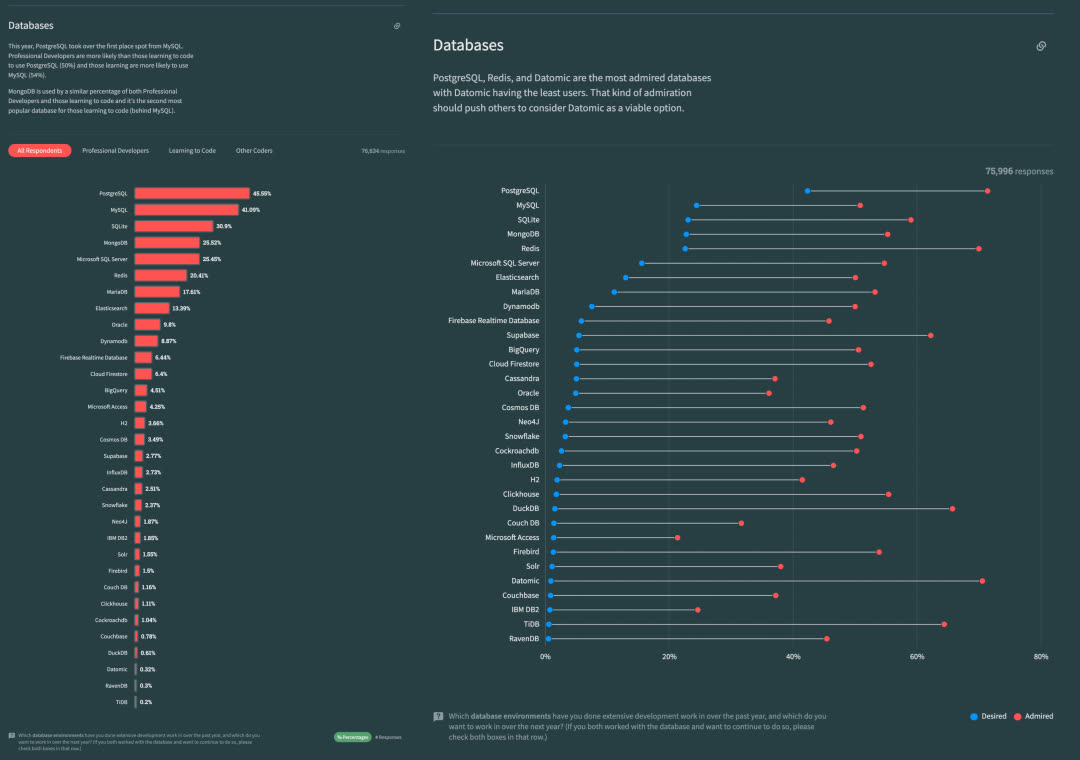
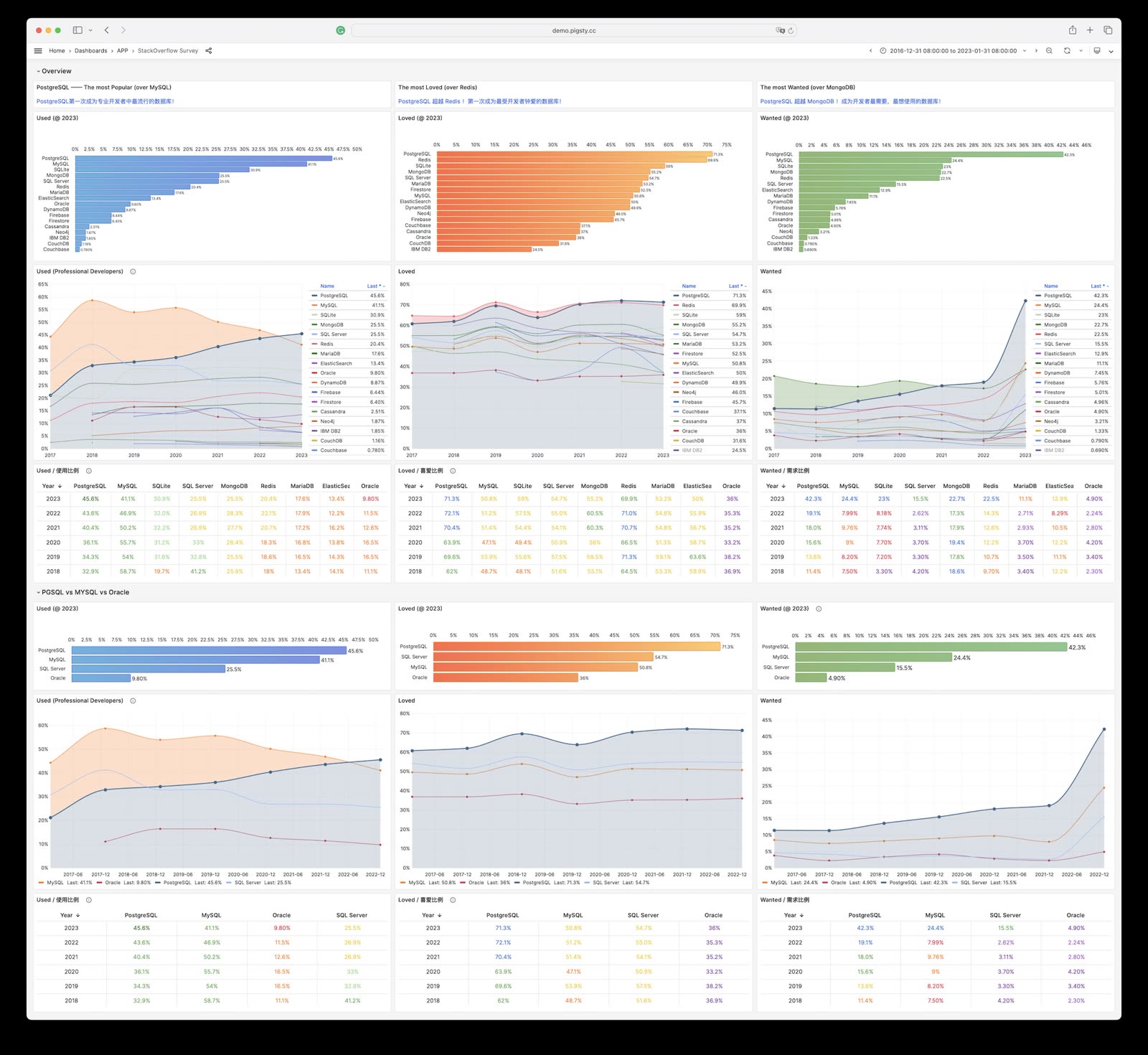
在引领潮流的 HackerNews StackOverflow 上,PostgreSQL 早已成为了最受欢迎的数据库。许多新的开源项目都默认使用 PostgreSQL 作为首要,甚至唯一的数据库 —— 例如,给各种数据库做模式管理的 Bytebase。《云时代数据库DevOps:硅谷调研》也提出,许多新一代互联网公司都开始积极拥抱并 All in PostgreSQL。
正如《技术极简主义:一切皆用 Postgres》所言:简化技术栈、减少组件、加快开发速度、降低风险并提供更多功能特性的方法之一就是 “一切皆用 Postgres”。Postgres 能够取代许多后端技术,包括 MySQL,Kafka、RabbitMQ、ElasticSearch,Mongo和 Redis,至少到数百万用户时都毫无问题。一切皆用 Postgres ,已经不再是少数精英团队的前沿探索,而是成为了一种进入主流视野的最佳实践。
还有什么可以做的?
我们已经不难预见到数据库领域的终局。但我们又能做什么,又应该做什么呢?
PostgreSQL 对于绝大多数场景都已经是一个足够完美的数据库内核了,在这个前提下,数据库内核 卡脖子纯属无稽之谈。这些Fork PostgreSQL 和 MySQL 并以内核魔改作为卖点的所谓"数据库“基本没啥出息。
这好比今天我们看 Linux 操作系统内核一样,尽管市面上有这么多的 Linux 操作系统发行版,但大家都选择使用同样的 Linux 内核,吃饱了撑着魔改内核属于没有困难创造困难也要上,会被业界当成山炮看待。
同理,数据库内核本身已经不再是主要矛盾,焦点将会集中到两个方向上 —— 数据库扩展与数据库服务!前者体现为数据库内部的可扩展性, 后者体现为数据库外部的可组合性。而竞争的形式,正如操作系统生态一样 —— 集中于数据库发行版上。对于数据库领域来说,只有那些以扩展和服务作为核心价值主张的发行版,才有最终成功的可能。
做内核的厂商不温不火,MariaDB 作为 MySQL 的亲爹 Fork 甚至都已经濒临退市,而白嫖内核自己做服务与扩展卖 RDS 的 AWS 可以赚的钵满盆翻。投资机构已经出手了许多 PG 生态的扩展插件与服务发行版:Citus,TimescaleDB,Hydra,PostgresML,ParadeDB,FerretDB,StackGres,Aiven,Neon,Supabase,Tembo,PostgresAI,以及我们正在做的 Pigsty 。

PostgreSQL 生态中的一个困境就是,许多扩展插件,生态工具都是独立演进,各自为战的,没有一个整合者能将他们凝聚起来形成合力。例如,提供分析的 Hydra 会打一个包一个 Docker 镜像, PostgresML 也会打自己的包和镜像,各家只发行加装了自己扩展的 Postgres 镜像。而这些朴素的镜像与包也距离 RDS 这样完整的数据库服务相距甚远。
即使是类似于 AWS RDS 这样的服务提供商与生态整合者,在诸多扩展面前也依然力有所不逮,只能提供其中的少数。更多的强力扩展出于各种原因(AGPLv3 协议,多租户租赁带来的安全挑战)而无法使用。从而难以发挥 PostgreSQL 生态扩展的协同增幅作用。
这里列出了一些重要扩展,对比基于最新的 PostgreSQL 16 主干版本进行,截止至 2024-02-28
扩展类目 Pigsty RDS / PGDG 官方仓库 阿里云 RDS AWS RDS PG 加装扩展 自由加装 不允许 不允许 地理空间 PostGIS 3.4.2 PostGIS 3.3.4 / Ganos 6.1 PostGIS 3.4.1 雷达点云 PG PointCloud 1.2.5 Ganos PointCloud 6.1 向量嵌入 PGVector 0.6.1 / Svector 0.5.6 pase 0.0.1 PGVector 0.6 机器学习 PostgresML 2.8.1 时序扩展 TimescaleDB 2.14.2 水平分布式 Citus 12.1 列存扩展 Hydra 1.1.1 全文检索 pg_bm25 0.5.6 图数据库 Apache AGE 1.5.0 GraphQL PG GraphQL 1.5.0 OLAP pg_analytics 0.5.6 消息队列 pgq 3.5.0 DuckDB duckdb_fdw 1.1 模糊分词 zhparser 1.1 / pg_bigm 1.2 zhparser 1.0 / pg_jieba pg_bigm 1.2 CDC抽取 wal2json 2.5.3 wal2json 2.5 膨胀治理 pg_repack 1.5.0 pg_repack 1.4.8 pg_repack 1.5.0 许多关键扩展在RDS中并不可用
扩展是 PostgreSQL 的灵魂,无法自由使用扩展的 Postgres 就像做菜不放盐。只能和 MySQL 放在同一个 RDS 的框子里同台,龙游浅水,虎落平阳。
而这正是我们想要解决的首要问题之一。
知行合一的实践:Pigsty
虽然接触 MySQL 和 MSSQL 要早得多,但我在 2015 年第一次上手 PostgreSQL 时,就相信它会是数据库领域的未来了。快十年过去,我也从 PG 的使用者,管理者,变为了贡献者,开发者。也不断见证着 PG 走向这一目标。
在与形形色色的用户沟通交流中,我早已发现数据库领域的木桶短板不是内核 —— 现有的 PostgreSQL 已经足够好了,而是用好数据库内核本身的能力,这也是 RDS 这样的服务赚的钵满盆翻的原因。
但我希望这样的能力,应该像自由软件运动所倡导的理念那样,像 PostgreSQL 内核本身一样 —— 普及到每一个用户手中,而不是必须向赛博空间上的封建云领主花大价钱租赁。
所以我打造了 Pigsty —— 一个开箱即用的开源 PostgreSQL 数据库发行版,旨在凝聚 PostgreSQL 生态扩展的合力,并把提供优质数据库服务的能力普及到每个用户手中。

Pigsty 是 PostgreSQL in Great STYle 的缩写,意为 PostgreSQL 的全盛状态。
我们提出了六点核心价值主张,对应 PostgreSQL 数据库服务中的的六个核心问题:Postgres 的可扩展性,基础设施的可靠性,图形化的可观测性,服务的可用性,工具的可维护性,以及扩展模块和三方组件可组合性。
Pigsty 六点价值主张的首字母合起来,则为 Pigsty 提供了另外一种缩写解释:
Postgres, Infras, Graphics, Service, Toolbox, Yours.
属于你的图形化 Postgres 基础设施服务工具箱。

可扩展的 PostgreSQL 是这个发行版中最重要的价值主张。在刚刚发布的 Pigsty v2.6 中,我们整合了上面提到的 DuckdbFDW 与 ParadeDB 扩展,这两个插件让 PostgreSQL 的分析能力得到史诗级增强,而我们确保每个用户都能轻松用得上这样的能力。
来自 ParadeDB 创始人与 DuckdbFDW 作者的感谢致意
我们希望整合 PostgreSQL 生态里的各种力量,并将其凝聚在一起形成合力,打造一个数据库世界中的 Ubuntu 发行版。而我相信,内核之争早已尘埃落定,而这里才会是数据库世界的未来竞争焦点。
- PostGIS:提供地理空间数据类型与索引支持,GIS 事实标准 (& pgPointCloud 点云,pgRouting 寻路)
- TimescaleDB:添加时间序列/持续聚合/分布式/列存储/自动压缩的能力
- PGVector:添加 AI 向量/嵌入数据类型支持,以及 ivfflat 与 hnsw 向量索引。(& pg_sparse 稀疏向量支持)
- Citus:将经典的主从PG集群原地改造为水平分片的分布式数据库集群。
- Hydra:添加列式存储与分析能力,提供比肩 ClickHouse 的强力分析能力。
- ParadeDB:添加 ElasticSearch 水准的全文搜索能力与混合检索的能力。(& zhparser 中文分词)
- Apache AGE:图数据库扩展,为 PostgreSQL 添加类 Neo4J 的 OpenCypher 查询支持,
- PG GraphQL:为 PostgreSQL 添加原生内建的 GraphQL 查询语言支持。
- DuckDB FDW:允许您通过 PostgreSQL 直接读写强力的嵌入式分析数据库 DuckDB 文件 (& DuckDB CLI 本体)。
- Supabase:基于 PostgreSQL 的开源的 Firebase 替代,提供完整的应用开发存储解决方案。
- FerretDB:基于 PostgreSQL 的开源 MongoDB 替代,兼容 MongoDB API / 驱动协议。
- PostgresML:使用SQL完成经典机器学习算法,调用、部署、训练 AI 模型。
Pigsty 支持的 464 扩展列表

开发者朋友们,你们的选择会塑造数据库世界的未来。希望我的这些工作,可以帮助你们更好的用好这世界上最先进的开源数据库内核 —— PostgreSQL。
技术极简主义:一切皆用Postgres

使用 Postgres 替代 Kafka、RabbitMQ、ElasticSearch、Mongo 和 Redis 是切实可行的方式,可以极大降低系统复杂度。 阅读全文
PG生态新玩家:ParadeDB

ParadeDB 旨在成为 Elasticsearch 的替代:用于搜索和分析的 PostgreSQL。 阅读全文
令人惊叹的PostgreSQL可伸缩性
原文链接:https://newsletter.systemdesign.one/p/postgresql-scalability

本文讲述了Cloudflare是如何利用15个PostgreSQL集群,伸缩到支持每秒5500万个请求,以及PostgreSQL的可伸缩性表现。 阅读全文
PostgreSQL荣获2024年度数据库之王!(第五次)

DB-Engines今日正式宣布PostgreSQL再度加冕为"年度数据库",最近七年里这已经是PG第五次获得此荣誉头衔。 阅读全文
展望 PostgreSQL 的2024

本文是 PostgreSQL 核心组成员 Jonathan Katz 对 2024 年 PostgreSQL 项目的未来展望,并回顾过去几年 PostgreSQL 所取得的进展。 阅读全文
PostgreSQL 宏观查询优化之 pg_stat_statements

查询优化是 DBA 的核心工作内容之一,本文介绍了如何使用 pg_stat_statements 提供的指标,针对 PostgreSQL 进行宏观查询优化。 阅读全文
FerretDB:假扮成MongoDB的PG

FerretDB旨在提供一个基于 PostgreSQL 的,真正开源的 MongoDB 替代。 阅读全文
如何用 pg_filedump 抢救数据?

备份是DBA的生命线,但如果你的PostgreSQL数据库已经爆炸了又没有备份,该怎么办?也许pg_filedump可以帮到你! 阅读全文
向量是新的 JSON
原文链接:https://jkatz05.com/post/postgres/vectors-json-postgresql/

以向量为代表的功能将成为构建应用时的关键要素,正如历史上的JSON一样。而PostgreSQL再一次站在时代风口浪尖引领数据库潮流,在向量扩展的加持下稳拿AI时代的高速增长。 阅读全文
PostgreSQL:最成功的数据库

数据库终局已现,PostgreSQL称王。PG在SF2023开发者调研中拿下大满贯,占住了Linux之于服务器操作系统的生态位。 阅读全文
AI大模型与向量库 PGVector
本文聚焦被 AI 炒火了的向量数据库,介绍了AI嵌入与向量存储检索的基本原理,并用一个具体的知识库检索案例来介绍向量数据库插件 PGVECTOR 的功能与应用。 阅读全文
PostgreSQL 到底有多强?

用性能数据说话,为什么PostgreSQL是世界上最先进的开源关系型数据库。MySQL和PgSQL性能谁好?分布式数据库到底怎么样? 阅读全文
为什么PostgreSQL是最成功的数据库?

总览StackOverflow过去六年的调研结果,在2022年PostgreSQL已经同时在流行度、喜爱度、需求度三项上登顶夺冠,成了字面意义上最成功的数据库。 阅读全文
开箱即用的PG发行版:Pigsty

昨天在PostgreSQL中文社区做了一个直播分享,介绍了开源的PostgreSQL全家桶解决方案 —— Pigsty。 阅读全文
为什么PostgreSQL前途无量?

数据库是信息系统的核心组件,关系型数据库是数据库中的绝对主力,而PostgreSQL是世界上最先进的开源关系型数据库。占据天时地利,何愁大业不成? 阅读全文





故障档案:时间回溯导致的Patroni故障

机器因为故障重启,NTP服务在PG启动后修复了PG的时间,导致Patroni无法启动。 阅读全文


数据库集群管理概念与实体命名规范

概念及其命名是非常重要的东西,命名风格体现了工程师对系统架构的认知。定义不清的概念将导致沟通困惑,随意设定的名称将产生意想不到的额外负担。 阅读全文
PostgreSQL的KPI

管数据库和管人差不多,都需要定KPI。本文介绍了一种衡量PostgreSQL负载的方式:使用一种单一横向可比的指标,名曰PG Load(PG负载)。 阅读全文


事务隔离等级注意事项

PostgreSQL实际上只有两种事务隔离等级:读已提交(Read Commited)与可序列化(Serializable)。 阅读全文
故障档案:PG安装Extension导致无法连接

今天遇到一个比较有趣的Case,客户报告说数据库连不上了,发现是扩展导致的。 阅读全文


GIN搜索的O(n²)复杂度

GIN索引如果使用很长的关键词列表进行搜索,会导致性能显著下降。本文解释了为什么GIN索引关键词搜索的时间复杂度为O(n²)。 阅读全文


故障档案:pg_dump导致的连接池污染

有时候,组件之间的相互作用会以微妙的形式表现出来。例如使用pg_dump从连接池中导出数据,就可能产生连接池污染的问题。 阅读全文
PostgreSQL数据页面损坏修复

采用二进制编辑的方式修复PostgreSQL数据页,以及如何让一条主键查询出现两条记录来。 阅读全文
关系膨胀的监控与治理

PostgreSQL使用了MVCC作为主要并发控制技术,它有很多好处,但也会带来一些其他的影响,例如关系膨胀。 阅读全文
PipelineDB快速上手

PipelineDB是PostgreSQL的一个扩展插件,提供流式数据处理的相关功能。 阅读全文
TimescaleDB 快速上手

TimescaleDB是PostgreSQL的一个扩展插件,提供时序数据库的一些功能。 阅读全文


GeoIP 地理逆查询优化

在应用开发中,一个很常见的需求就是GeoIP转换:将请求的来源IP转换为相应的地理坐标,或者行政区划。 阅读全文

PostgreSQL开发规约(2018版)

没有规矩,不成方圆。本文针对PostgreSQL数据库原理与特性,整理了一份开发规范,可以减少大家在使用PostgreSQL数据库过程中遇到的困惑。 阅读全文
PostgreSQL好处都有啥

PostgreSQL的Slogan是"世界上最先进的开源关系型数据库",要我说最能生动体现PG特色的口号应该是:一专多长的全栈数据库,一招鲜吃遍天。 阅读全文
KNN极致优化:从RDS到PostGIS

KNN问题极致优化,从传统关系型设计到PostGIS,实现GIS圈选场景下三万倍的性能提升。 阅读全文
监控PG中的表大小

PostgreSQL中的表对应着许多物理文件,本文介绍如何统计一张表在PostgreSQL的实际大小。 阅读全文
PgAdmin安装配置

PgAdmin是一个管理PostgreSQL的GUI程序,用python写成,但实在是过于古早,需要一些额外配置。 阅读全文
故障档案:快慢不匀雪崩

最近发生了一起匪夷所思的故障,某数据库切走了一半的数据量和负载,结果却因为负载变大被打挂了。 阅读全文



用 Exclude 实现互斥约束

Exclude约束是一个PostgreSQL扩展,它可以实现一些更高级,更巧妙的的数据库约束。 阅读全文
PostgreSQL例行维护

汽车需要上油,数据库也需要维护保养。对Pg而言,有三项比较重要的维护工作:备份、重整、清理。 阅读全文


Pgbouncer快速上手

Pgbouncer是一个轻量级的数据库连接池,这里简单介绍Pgbouncer的配置、管理与使用。 阅读全文
PG服务器日志常规配置

建议配置PostgreSQL的日志格式为CSV,方便分析,而且可以直接导入PostgreSQL数据表中。 阅读全文
空中换引擎:PostgreSQL不停机迁移数据

通常涉及到数据迁移,常规操作都是停服务更新。不停机迁移数据是相对比较高级的操作。 阅读全文

使用sysbench测试PostgreSQL性能

尽管PostgreSQL提供了pgbench,但有时候为了吊打一下MySQL,还是需要用到sysbench的。 阅读全文


Wireshark抓包分析协议

Wireshark是一个很有用的工具,特别适合用来分析网络协议,这里简单介绍使用Wireshark抓包分析PostgreSQL协议的方法。 阅读全文
file_fdw妙用无穷——从数据库读取系统信息

通过file_fdw,轻松查看操作系统信息,拉取网络数据,把各种各样的数据源轻松喂进数据库里统一查看管理。 阅读全文
Linux 常用统计 CLI 工具

top, free, vmstat, iostat:四大常用 CLI 工具命令速查。 阅读全文

Go数据库教程:database/sql

同JDBC类似,Go也有标准的数据库访问接口。本文详细介绍了Go语言中database/sql的使用方法和注意事项。 阅读全文
GO与PG实现缓存同步

巧妙运用Pg的Notify功能,可以方便地通知应用元数据变更,实现基于触发器的逻辑复制。 阅读全文
用触发器审计数据变化

有时候,我们希望记录一些重要的元数据变更,以便事后审计之用。PostgreSQL的触发器就可以很方便地自动解决这一需求。 阅读全文


PostgreSQL MongoFDW安装部署

最近有业务要求通过PostgreSQL FDW去访问MongoDB,但是MongoDB FDW编译起来真是要人命啊。 阅读全文
云计算
隐私换便利?云上AI助理意味着什么?

避免将隐私交到对你有直接影响力的平台中 —— 利用数据避风港原则,可以在享受 AI 便利的同时,大幅降低隐私风险。 阅读全文
小红书究竟有没有下云?

当一家"原生长在云上"的公司开始"自建优先",这算不算下云?文章被删,重发一篇,聊聊中国互联网企业的基础设施成人礼。 阅读全文
支付宝淘宝闲鱼崩了?又是消息队列的锅?

用户钱扣了订单却显示未支付,症状与2024年双十一支付宝故障类似,推测可能是消息队列或分布式事务协调问题。 阅读全文
Cloudflare 11-18 故障复盘报告

ClickHouse权限配置失当,导致了Cloudflare最近六年以来的最严重故障——核心流量分发停摆六个小时。 阅读全文
阿里云“借鉴”Supabase:开源与云的灰色地带

国内创业可能被问到最多的问题:如果阿里这种大厂下场,你怎么办?这不,阿里云RDS上线了新品Supabase,就是一个鲜活案例。 阅读全文
AWS 故障官方复盘报告

AWS DynamoDB 故障的官方复盘来了,老冯带您一起看看,到底是什么故障带崩了半个互联网。 阅读全文
一次AWS DNS故障如何级联瘫痪半个互联网

AWS US-EAST-1 区域DNS解析故障带崩半个互联网,老冯带您复盘 AWS 史诗故障。 阅读全文
专栏:云计算泥石流
整整一代应用开发者的视野被云遮蔽,让我们用实打实的数据分析与经历,讲清公有云租赁模式的价值与陷阱。 阅读全文
KubeSphere:开源断供背后的信任危机

删除镜像跑路,这不是商业化闭源的问题,而是卡脖子断供问题,直接摧毁了社区多年积累的信任。 阅读全文
阿里云rds_duckdb:致敬还是抄袭?

商业与开源本应共生共赢,企业若只想坐享其成而不反哺开源,最终只会沦为社区鄙视的对象。 阅读全文
花钱买罪受的大冤种:逃离云计算妙瓦底

一位用户咨询分布式数据库,但他并不是因为数据大到要冲破服务器柜门,而是又栽在了云计算妙瓦底的杀猪盘套路中。 阅读全文

WordPress社区内战:论共同体划界问题

当开源理想遇上商业冲突,这对开源软件社区与云厂商之间的冲突又能带来什么启示?论社区边界划定的重要性。 阅读全文
云数据库:用米其林的价格,吃预制菜大锅饭

RDS带来的数据库范式转变,云数据库是不是天价大锅饭。质量安全效率成本剖析核算,下云数据库自建,如何实战! 阅读全文
阿里云:高可用容灾神话破灭

新加坡C可用区故障头七,可用性还剩几个9,就连8都没有了,但与丢数据相比,可用性也只是小问题了。 阅读全文
草台班子唱大戏,阿里云PG翻车记

一位客户在云数据库上经历了一次离谱的连环故障:一套高可用PG RDS集群,因为扩容内存,主库从库都挂了,折腾到凌晨。期间昏招迭出,复盘敷衍。 阅读全文
我们能从网易云音乐故障中学到什么?

今天下午网易云音乐出现了两个半小时的不可用,根据网络上流传的线索拼图碎片,我们不难推断出这次故障背后的真正原因是…… 阅读全文
蓝屏星期五:甲乙双方都是草台班子

甲乙双方都没有做好爆炸半径的控制,导致了这次史诗级的全球安全事件,这次事件将极大利好本地优先的软件理念。 阅读全文
Ahrefs不上云,省下四亿美元
原文链接:https://tech.ahrefs.com/how-ahrefs-saved-us-400m-in-3-years-by-not-going-to-the-cloud-8939dd930af8

云计算成本有时高到离谱。Ahrefs通过自建数据中心,三年省下4亿美元。基于真实成本对比AWS,揭示云服务的成本陷阱与自建的优势。 阅读全文
删库:Google云爆破了大基金的整个云账户

由于"前所未有的配置错误",Google云误删了万亿人民币基金大户UniSuper的整个云账户、云环境和所有异地备份,创下云计算历史上的全新记录! 阅读全文
云上黑暗森林:打爆云账单,只需要S3桶名

公有云上的黑暗森林法则出现了:只要你的S3对象存储桶名暴露,任何人都有能力刷爆你的云账单。 阅读全文
Cloudflare圆桌访谈与问答录

作为圆桌嘉宾受邀参加了Cloudflare在深圳举办的Immerse大会,与Cloudflare亚太区CMO等深入交流探讨了许多网友关心的问题。 阅读全文
我们能从腾讯云大故障中学到什么?

腾讯云史诗级全球故障创下行业记录,我们该如何评价看待这场故障,又可以从中学到什么经验与教训呢? 阅读全文
吊打公有云的赛博佛祖 Cloudflare

虽然我一直在倡导下云理念,但如果是上Cloudflare这样的赛博菩萨云,我举双手赞成。 阅读全文
罗永浩救不了牙膏云?

老罗直播间卖了半小时扫地机,接着念台词卖了四十分钟"云计算",然后继续卖牙膏——留下观众在牙膏与云计算之间迷惑凌乱。 阅读全文
剖析阿里云服务器算力成本

阿里云号称大降价,但如果实际剖析一下云服务器的成本,还是不难看出云上的算力与存储依然贵的离谱。 阅读全文
DBA会被云淘汰吗?

开源漫谈第九期主题《DBA会被云淘汰吗?》,我作为主持人全程克制着自己亲自下场的冲动,因此特此写了这篇文章来聊聊这个问题。 阅读全文
云下高可用秘诀:拒绝复杂度自慰

程序员极易被复杂度所吸引,就像飞蛾扑火一样。系统架构图越复杂,智力自慰的快感就越大。坚决抵制这种行为,是下云可用性上成功的重要原因。 阅读全文
扒皮云对象存储:从降本到杀猪

对象存储是云计算的定义性服务,曾被视为云上降本的典范。不幸的是随着硬件的发展,资源云与开源平替的出现,曾经物美价廉的对象存储服务和EBS一样成为了杀猪盘。 阅读全文
半年下云省千万,DHH下云FAQ

DHH的下云旅程到了新阶段,下云已省下近百万美元,未来五年还可省下近千万美元。本文跟进他们下云的最新进展,对准备上云或云上的企业都有参考价值。 阅读全文
从降本增笑到真的降本增效
阿里云和滴滴前后脚出了大故障,本文来聊一聊如何从降本增笑到真的降本增效——到底应该降什么本,增什么效? 阅读全文
重新拿回计算机硬件的红利

在当下,硬件重新变得有趣起来,AI浪潮引发的显卡狂热便是例证。但CPU与SSD的变化却不为大多数开发者所知,有一整代开发者被云和炒作遮蔽了双眼。 阅读全文
我们能从阿里云全球故障中学到什么?

阿里云双十一后的史诗级全球故障创下行业记录,我们该如何评价看待这场故障,又可以从中学到什么经验与教训呢? 阅读全文
薅阿里云羊毛,打造数字家园

阿里云双十一提供了一个不错的福利,2C2G3M的ECS服务器每年¥99低价用三年。本文介绍了如何利用这台ECS打造你自己的数字家园。 阅读全文
云计算泥石流:用数据解构公有云

曾几何时,“上云"近乎成为技术圈的政治正确,但很少有人用实打实的数据来分析利弊权衡。让我用数据与亲身经历,讲清楚公有云租赁模式的陷阱与价值。 阅读全文
DHH:下云省下千万美元,比预想的还要多!
原文链接:https://world.hey.com/dhh/our-cloud-exit-savings-will-now-top-ten-million-over-five-years-c7d9b5bd

DHH将他们的七个云上应用从AWS迁移到自己的硬件上,2024年是第一个完全实现节省的年份。他们欣喜地发现,节省的费用比最初估计的还要多。 阅读全文
下云奥德赛:该放弃云计算了吗?

本文翻译了下云先锋DHH主导37Signal从云上搬下来的完整旅程,无论是对于准备上云,还是已经在云上的企业,都非常有借鉴与参考价值。 阅读全文
FinOps终点是下云

在SACC 2023 FinOps专场上的发言整理稿,介绍了终极FinOps——下云的理念与实践路径。公有云是个杀猪盘,自建能力决定议价权。 阅读全文
云计算为啥还没挖沙子赚钱?

公有云毛利不如挖沙子,杀猪盘为何成为赔钱货?本土云厂商是怎么让一门百分之三四十纯利的生意还不如挖沙子赚钱的? 阅读全文
云SLA是不是安慰剂?

SLA并不是真正的可靠性承诺或历史战绩,而是一种营销工具。你以为花钱买云服务上了保险,在最坏情况下是哑巴亏,最好情况也只是安慰剂。 阅读全文
云盘是不是杀猪盘?

在公有云块存储的百倍溢价杀猪比率前,云数据库只能说还差点意思。本文揭示了公有云真正的商业模式——廉价EC2/S3获客,EBS/RDS杀猪。 阅读全文
垃圾腾讯云CDN:从入门到放弃?

本来我相信至少在IaaS的存储、计算、网络三大件上,公有云厂商还是可以有很大作为的。只不过在腾讯云CDN上的亲身体验让我的想法动摇了。 阅读全文
驳《再论为什么你不应该招DBA》

郭德纲有一段相声:比如我和火箭专家说,你那火箭不行,燃料不好,我认为得烧柴。如果那科学家拿正眼看我一眼,那他就输了。 阅读全文
范式转移:从云到本地优先

云数据库高达几倍到十几倍的溢价,对于适用光谱外的用户是毫无疑问的杀猪。我们可以进一步探究公有云为什么会是这样?并对行业的未来进行预测与判断。 阅读全文
云数据库是不是智商税

寒冬来袭,大厂纷纷开始裁员进入降本增效模式,作为公有云杀猪刀一哥的云数据库,故事还能再讲下去吗?用云数据库到底是不是在交智商税? 阅读全文
DBA还是一份好工作吗?

蚂蚁金服有过一个自嘲的段子:能干翻支付宝的,除了监管就是DBA了。尽管DBA听上去是一个有着光辉历史与暗淡前景的行当,但天知道会不会重新成为潮流呢? 阅读全文
云RDS:从删库到跑路

最近就目睹了一场云数据库删库跑路现场情景剧。本文就来聊一聊在生产环境使用PostgreSQL,如何应对误删数据的问题。 阅读全文
数据库
用AI当由头裁了4000人,但程序员的需求涨了11%
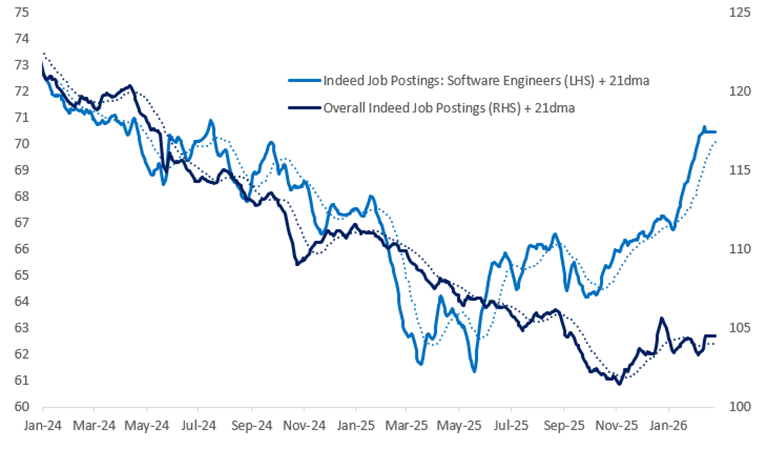
AI正在被用作裁员叙事,但软件工程的总需求并未消失,而是在更大范围扩散。真正改变格局的,是门槛下降后被释放的二阶需求。 阅读全文
Palantir 的“本体论”骗局

Ontology 就是数据库建模。“本体论”这个词唯一的作用,就是让不懂数据库的人觉得这是个新东西,然后心甘情愿地为旧东西付出一千倍的价格。 阅读全文
重新设计数据密集型应用

本文由 Martin Kleppmann 撰写,聊到了关于《设计数据密集型应用》第二版的一些内容。以及一些关于数据密集型应用设计的思考。
从麦克卢汉的视角看 AI:当媒介不再延伸人体,而是延伸人脑

用麦克卢汉的“媒介即讯息”“延伸与截肢”“冷热媒介”“后视镜效应”“媒介四定律”解剖 AI,讨论其对人类认知习惯、理解能力与社会结构的深层影响。 阅读全文
新年,聊聊AI将带来的变化

AI 正在以远超历史经验的速度重塑知识工作。真正的挑战不是“会不会用 AI”,而是能否在缓冲期结束前完成认知与能力迁移。 阅读全文
DDIA 第二版翻完了:一个跨越八年的 AI 寓言

一个上午用 codex 翻译完 DDIAv2,相比八年前三个月手工精翻,AI 的能力,在同一本书上形成了鲜明的对照。 阅读全文
MinIO 已死,MinIO 复生

MinIO 仓库正式归档并彻底放弃维护,开源对象存储用户将何去何从?AI Agent 如何助力 MinIO 起死回生? 阅读全文
写代码一文不值的时代,什么才值钱?

在代码产能被 AI 极大放大之后,真正稀缺的能力正在从“写代码”转向“设计与验收”。本文基于实战经验,总结了用 Codex 与 Claude 协作交付高质量软件的流程与判断。 阅读全文
Agent 的护城河:强龙不压地头蛇

一个熟悉环境的普通人,会比来到陌生环境的天才更能干。没有上下文的智力是空转的。没有 Runtime 的 Agent 是虚浮的。 阅读全文
AI撕掉了软件的皮

软件股暴跌,谁能幸存?谁会崛起?AI撕掉了软件的皮,露出了数据库的骨。市场不是在错杀,而是在分化定价。 阅读全文
AI时代,新程序员将何去何从?

我们还要招应届大学生吗?在AI和老司机的双重夹击下,新程序员的出路在哪里?—— 用对工具、主动出击、找对师傅。 阅读全文
软件世界大熔断:当翻译层被压扁

SaaS 与流程软件已死,从 APP 与 GUI 到 Agent,Database,CLI。 阅读全文
AI Agent 的操作系统时刻

我们正在见证一个"AI 操作系统"的诞生。LLM 是新 CPU,Context 是新内存,Agent 是新应用。那么 OS 会是什么?理解这个类比,也许能帮助我们预测未来 2-3 年基础设施的演化路径 —— 以及找到真正的机会所在。 阅读全文
Claude Code 可观测性怎么做?

获取 Claude Code 的详细 OTEL 日志与指标,放入 Victoria 全家桶,放进并通过 Grafana 监控面板呈现。 阅读全文
Andy Pavlo:2025 数据库世界年度总结

图灵奖得主 + CMU 教授:2025 数据库圈最犀利的一场对话。关于数据库,LLM,Agent,AI 落地的实际效果,程序员的职业生涯…… 阅读全文
Claude Code 免翻上手教程

如何不翻墙下载安装使用 Claude Code?如何用 Claude 十分之一的成本实现近似的效果?一行命令免翻装好 CC!以及 GLM 4.7 到底能不能吊打 Claude? 阅读全文
2025 年度数据库世界总结:石破天 vs Andy Pavlo 对谈录

图灵奖得主 + CMU 教授:2025 数据库圈最犀利的一场对话。关于数据库,LLM,Agent,AI 落地的实际效果,程序员的职业生涯…… 阅读全文
Agent 需要什么样的数据库?

AI Agent 的瓶颈不在数据库内核,而在上层整合。肌肉记忆(库内计算)、联想记忆(向量+图谱融合)、试错魄力(Git for Data)将成为关键,不过这些能力不需要新引擎。 阅读全文
MySQL与白酒:互联网行业的服从测试

互联网的MySQL就像中国的白酒:明明很难喝,却在文化规训下成了琼浆玉液,本质都是一种服从测试。 阅读全文
Victoria:吊打业界的可观测性全家桶来了

Victoria是朴实无华的强悍— — 用几分之一的资源,实现Prometheus + Loki几倍的效果。Pigsty v4.0将全面采用Victoria全家桶。 阅读全文
MinIO已死,谁能接盘?

MinIO进入维护模式,有什么替代品?Ceph、RustFS、SeaweedFS、Garage各有各的问题。老冯把这些方案都打好了包挨个试了一遍,总结一句话:没有完美替代。 阅读全文
MinIO已死

MinIO官方宣布开源项目进入"维护模式",基本上宣告了MinIO作为一个开源项目的死亡。屠龙勇者成为新的恶龙——MinIO是如何从S3开源替代变成一家普通的商业软件公司的。 阅读全文
当答案唾手可得,问题成为新货币

答案正在贬值,提问的能力决定了你在AI时代的位置。凯文·凯利预言成真:当答案成为商品时,好的问题就是新的财富。毕加索早在1968年就说过:计算机毫无用处,它们只能给你答案。 阅读全文
聊聊开源软件供应链信任问题

在严肃的生产环境里,你不能依赖一个明确说"我不提供任何保证"的上游。当别人告诉你"别指望我",最好的回应是"那我自己来"。从TUNA镜像站的争议谈开源软件供应链信任问题。 阅读全文
原地报废:不要在生产环境用Docker跑PostgreSQL!

大量用官方Docker Postgres镜像的用户在最近小版本升级中翻车踩雷。早在2019年老冯就警告过不要在生产环境用容器运行PostgreSQL,因为你极大概率会遇上一堆物理机/虚拟机上根本不存在的麻烦。 阅读全文
DDIA第二版中文翻译

曾经的互联网名著DDIA——设计数据密集型应用第二版已经发布到第十章了。老冯用Claude Code翻译成中文,并用Hugo/Hextra重构成易读的网页版。第二版新增了向量数据库HNSW索引等内容,温故知新。 阅读全文
专栏:数据库老司机
数据库领域充满着太多胡言乱语与不实营销,数据库老司机带您拨云见日,穿透迷糊,直击行业核心与本质。 阅读全文
懂车帝暴打智驾,懂库帝在哪里

懂车帝搞的智驾评测视频让一众国产自动驾驶现了原形,封闭高速真实测试结果全军覆没,只有特斯拉能打。什么时候国产数据库和云计算也能有个"封闭高速"给大家上来溜一溜,拆穿这股满嘴跑火车的行业歪风? 阅读全文
Google AI工具箱:生产级数据库MCP来了?

Google推出了一个针对数据库的MCP工具箱GenAI Toolbox,通过封装参数模板SQL的方式,显著提高了数据库MCP的实用性与安全性。不同于以前那种直接把整个数据库对Agent开放的粗暴做法,这可能是第一个生产可用的方案。 阅读全文
AI时代的数据库与DBA将何去何从

OLTP与OLAP谁先被AI革命?一体化还是专业化,如何选型?AI时代的DBA该何去何从?来自 HOW 2025 大会圆桌讨论的观点整理:OLAP岗位正被NL2SQL替代,而DBA因语料稀缺暂时安全。 阅读全文
别争了,AI时代数据库已经尘埃落定

AI时代的数据库格局已经尘埃落定。Databricks收购Neon,Snowflake收购CrunchyData,OpenAI传闻收购Supabase——资本市场对PostgreSQL标的密集出手,PG已成为AI时代的默认数据库。 阅读全文
开放数据标准:Postgres,OTel,与Iceberg

数据世界正在浮出水面的三大新标准:Postgres、Open Telemetry,以及Iceberg。Postgres已是事实标准,OTel和Iceberg尚在成长,但它们具备当年让Postgres走红的同样配方——关键在于开源的姿势本身。 阅读全文
小数据的失落十年:分布式分析的错付

如果2012年DuckDB问世,也许那场数据分析向分布式架构的大迁移根本就不会发生。在2012年的MacBook上运行TPC-H评测显示,数据分析确实在分布式架构上走了十年弯路。数据其实没那么大。 阅读全文
OpenAI:将PostgreSQL伸缩至新阶段
在PGConf.Dev 2025大会上,来自OpenAI的Bohan Zhang分享了OpenAI在PostgreSQL上的最佳实践。在OpenAI,他们使用一写多读的未分片架构,证明了PostgreSQL在海量读负载下也可以伸缩自如。 阅读全文
Etcd坑了多少公司?

因为Etcd而翻车的公司并非少数。Etcd有一个坑爹的默认设计:写满2GB数据就挂了。如果你在自己折腾Kubernetes或使用Patroni做PostgreSQL高可用,大概率会在这上面翻车。 阅读全文
AI时代,软件从数据库开始

未来的软件形态是 Agent + 数据库,没有前后端中间商,Agent直接CRUD。微软CEO纳德拉预言SaaS已死,软件从数据库开始。数据库技能相当保值,PostgreSQL将成为AI Agent时代的核心数据库。 阅读全文
MySQL vs PostgreSQL @ 2025

在2025年的当下,MySQL无论是在功能特性集、质量正确性、性能表现还是生态与社区上都被PostgreSQL拉开了差距,而且这个差距还在进一步扩大中。本文从功能、性能、质量、生态来全方位对比两者。 阅读全文
数据库火星撞地球:当PG爱上DuckDB

老冯很看好"DuckDB + PostgreSQL深度融合"这条路径,它可能会引爆数据库世界下一场"火星撞地球"式的变革。相比折腾分布式DuckDB,这才是更有前景的方向。 阅读全文
对比Oracle与PostgreSQL事务系统

PG社区开始骑在Oracle头上输出了。Cybertec专家对比Oracle和PostgreSQL事务系统的特性,帮助用户理解两者差异,为从Oracle迁移到PostgreSQL提供关键参考,避免性能和数据完整性问题。 阅读全文
数据库即业务架构

数据库是业务架构的核心,这是不言自明的共识。但如果更进一步,将数据库作为业务架构本身,将业务逻辑、Web Server甚至整个前后端都放入数据库中,又会擦出怎样的火花? 阅读全文
七周七数据库(2025年)
原文链接:https://matt.blwt.io/post/7-databases-in-7-weeks-for-2025/
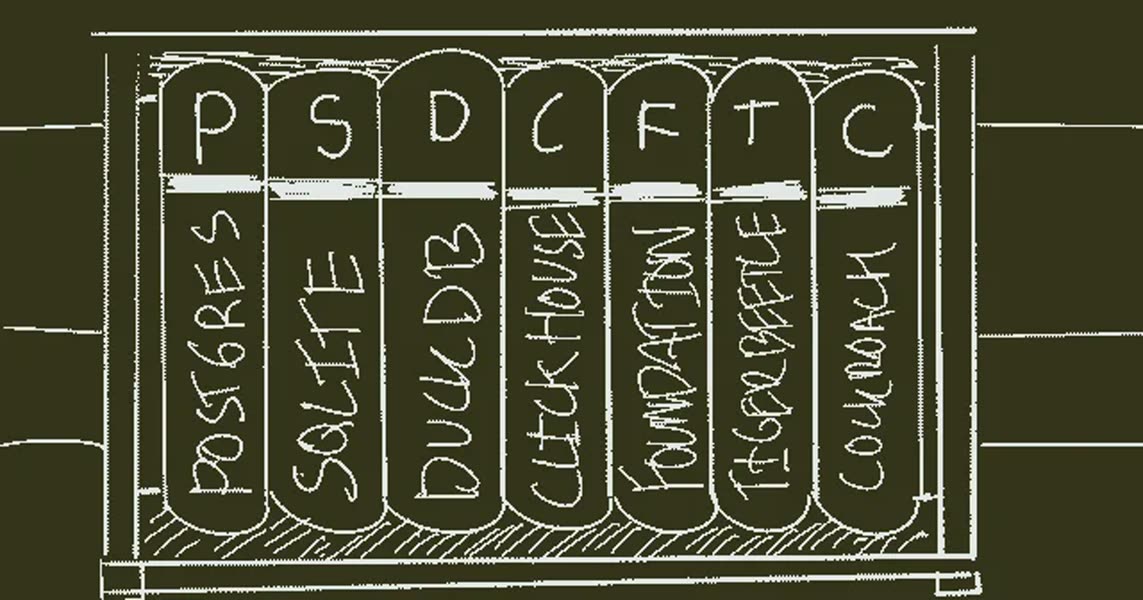
PostgreSQL是无聊数据库之王?2025年值得深入学习的七个数据库:PostgreSQL、SQLite、DuckDB、ClickHouse、FoundationDB、TigerBeetle、CockroachDB,每个都值得花一周时间研究。 阅读全文
使用一条 SQL 计算扑克24点

虽然有趣,但是很鸡贼的题目,用 SQL 计算扑克24点。PostgreSQL 的正解。 阅读全文
自建 Supabase:创业出海的首选数据库
Supabase 很好,拥有属于你自己的 supabase 则好上加好。 Pigsty 可以帮助您在自己的服务器上(物理机/虚拟机/云服务器),一键自建企业级 supabase —— 更多扩展,更好性能,更深入的控制,更合算的成本。
Pigsty 是 Supabase 官网文档上列举的三种自建部署之一:Self-hosting: Third-Party Guides
简短版本
准备 Linux,执行 Pigsty 标准安装 流程,选择 supabase 配置模板,依次执行:
curl -fsSL https://repo.pigsty.io/get | bash; cd ~/pigsty
./configure -c supabase # 使用 supabase 配置(请在 pigsty.yml 中更改凭据)
vi pigsty.yml # 编辑域名、密码、密钥...
./deploy.yml # 安装 pigsty 与 pgsql & minio 集群
./docker.yml # 安装 docker compose 组件
./app.yml # 使用 docker 启动 supabase 无状态部分(可能较慢)
安装完毕后,使用浏览器访问 8000 端口造访 Supa Studio,用户名 supabase,密码 pigsty。

目录
Supabase是什么?
Supabase 是一个 BaaS (Backend as Service),开源的 Firebase,是 AI Agent 时代最火爆的数据库 + 后端解决方案。 Supabase 对 PostgreSQL 进行了封装,并提供了身份认证,消息传递,边缘函数,对象存储,并基于 PG 数据库模式自动生成 REST API 与 GraphQL API。
Supabase 旨在为开发者提供一条龙式的后端解决方案,减少开发和维护后端基础设施的复杂性。 它能让开发者告别绝大部分后端开发的工作,只需要懂数据库设计与前端即可快速出活! 开发者只要用 Vibe Coding 糊个前端与数据库模式设计,就可以快速完成一个完整的应用。
目前,Supabase 是 PostgreSQL 开源生态 中人气最高的开源项目,在 GitHub 上已有 八万 Star。 Supabase 还为小微创业者提供了“慷慨”的免费云服务额度 —— 免费的 500 MB 空间,对于存个用户表,浏览数之类的东西绰绰有余。
为什么要自建?
既然 Supabase 云服务这么香,为什么要自建呢?
最直观的原因是是我们在《云数据库是智商税吗?》中提到过的:当你的数据/计算规模超出云计算适用光谱(Supabase:4C/8G/500MB免费存储),成本很容易出现爆炸式增长。 而且在当下,足够可靠的 本地企业级 NVMe SSD 在性价比上与 云端存储 有着三到四个数量级的优势,而自建能更好地利用这一点。
另一个重要的原因是 功能, Supabase 云服务的功能受限 —— 很多强力PG扩展因为多租户安全挑战与许可证的原因无法以云服务的形式。 故而尽管 扩展是 PostgreSQL 的核心特色,在 Supabase 云服务上也依然只有 64 个扩展可用。 而通过 Pigsty 自建的 Supabase 则提供了多达 437 个开箱即用的 PG 扩展。
此外,自主可控与规避供应商锁定也是自建的重要原因 —— 尽管 Supabase 虽然旨在提供一个无供应商锁定的 Google Firebase 开源替代,但实际上自建高标准企业级的 Supabase 门槛并不低。 Supabase 内置了一系列由他们自己开发维护的 PG 扩展插件,并计划将原生的 PostgreSQL 内核替换为收购的 OrioleDB,而这些内核与扩展在 PGDG 官方仓库中并没有提供。
这实际上是某种隐性的供应商锁定,阻止了用户使用除了 supabase/postgres Docker 镜像之外的方式自建,Pigsty 则提供开源,透明,通用的方案解决这个问题。 我们将所有 Supabase 自研与用到的 10 个缺失的扩展打成开箱即用的 RPM/DEB 包,确保它们在所有 主流Linux操作系统发行版 上都可用:
| 扩展 | 说明 |
|---|---|
pg_graphql | 提供PG内的GraphQL支持 (RUST),Rust扩展,由PIGSTY提供 |
pg_jsonschema | 提供JSON Schema校验能力,Rust扩展,由PIGSTY提供 |
wrappers | Supabase提供的外部数据源包装器捆绑包,,Rust扩展,由PIGSTY提供 |
index_advisor | 查询索引建议器,SQL扩展,由PIGSTY提供 |
pg_net | 用 SQL 进行异步非阻塞HTTP/HTTPS 请求的扩展 (supabase),C扩展,由PIGSTY提供 |
vault | 在 Vault 中存储加密凭证的扩展 (supabase),C扩展,由PIGSTY提供 |
pgjwt | JSON Web Token API 的PG实现 (supabase),SQL扩展,由PIGSTY提供 |
pgsodium | 表数据加密存储 TDE,扩展,由PIGSTY提供 |
supautils | 用于在云环境中确保数据库集群的安全,C扩展,由PIGSTY提供 |
pg_plan_filter | 使用执行计划代价过滤阻止特定查询语句,C扩展,由PIGSTY提供 |
同时,我们在 Supabase 自建部署中默认 安装绝大多数扩展,您可以参考可用扩展列表按需 启用。
同时,Pigsty 还会负责好底层 高可用 PostgreSQL 数据库集群,高可用 MinIO 对象存储集群的自动搭建,甚至是 Docker 容器底座的部署与 Nginx 反向代理,域名配置 与 HTTPS证书签发。 您可以使用 Docker Compose 拉起任意数量的无状态 Supabase 容器集群,并将状态存储在外部 Pigsty 自托管数据库服务中。
在这一自建部署架构中,您获得了使用不同内核的自由(PG 15-18,OrioleDB),加装 437 个扩展的自由,扩容与伸缩 Supabase / Postgres / MinIO 的自由, 免于数据库运维杂务的自由,以及免于供应商锁定,本地运行到地老天荒的自由。 而相比于使用云服务需要付出的代价,不过是准备服务器和多敲几行命令而已。
单节点自建快速上手
让我们先从单节点 Supabase 部署开始,我们会在后面进一步介绍多节点高可用部署的方法。
准备 一台全新 Linux 服务器,使用 Pigsty 提供的 supabase 配置模板执行 标准安装,
然后额外运行 docker.yml 与 app.yml 拉起无状态部分的 Supabase 容器即可(默认端口 8000/8443)。
curl -fsSL https://repo.pigsty.io/get | bash; cd ~/pigsty
./configure -c supabase # 使用 supabase 配置(请在 pigsty.yml 中更改凭据)
vi pigsty.yml # 编辑域名、密码、密钥...
./deploy.yml # 安装 pigsty 与 pgsql & minio 集群
./docker.yml # 安装 docker compose 组件
./app.yml # 使用 docker 启动 supabase 无状态部分
在部署 Supabase 前请根据实际情况修改自动生成的 pigsty.yml 配置文件中的参数(域名与密码)
如果只是本地开发测试,可以先跳过,我们将在后面介绍如何通过修改配置文件来进一步定制。
如果配置无误,大约十分钟后,就可以在本地网络通过 http://<your_ip_address>:8000 访问到 Supabase Studio 图形管理界面了。
默认的用户名与密码分别是: supabase 与 pigsty。

在中国大陆地区,Pigsty 默认使用 1Panel 与 1ms 提供的 DockerHub 镜像站点下载 Supabase 相关镜像,可能会较慢。
你也可以自行配置 [代理](https://doc.pgsty.com/zh/docker/config#proxy) 与 [镜像站](https://doc.pgsty.com/zh/docker/config#registry) ,`cd /opt/supabase; docker compose pull` 手动拉取镜像。
我们亦提供包含完整离线安装方案的 [Supabase 自建专家咨询服务](https://doc.pgsty.com/zh/service)。
如果你需要使用的对象存储功能,那么需要通过域名与 HTTPS 访问 Supabase,否则会出现报错。
对于严肃的生产部署,请 **务必** 修改所有默认密码!
自建关键技术决策
以下是一些自建 Supabase 会涉及到的关键技术决策,供您参考:
使用默认的单节点部署 Supabase 无法享受到 PostgreSQL / MinIO 的高可用能力。 尽管如此,单节点部署相比官方纯 Docker Compose 方案依然要有显著优势: 例如开箱即用的监控系统,自由安装扩展的能力,各个组件的扩缩容能力,以及提供兜底数据库时间点恢复能力等。
如果您只有一台服务器,或者选择在云服务器上自建,Pigsty 建议您使用外部的 S3 替代本地的 MinIO 作为对象存储,存放 PostgreSQL 的备份,并承载 Supabase Storage 服务。 这样的部署在故障时可以在单机部署条件下,提供一个兜底级别的 RTO (小时级恢复时长)/ RPO (MB级数据损失)容灾水平。
在严肃的生产部署中,Pigsty 建议使用至少3~4个节点的部署策略,确保 MinIO 与 PostgreSQL 都使用满足企业级高可用要求的多节点部署。 在这种情况下,您需要相应准备更多节点与磁盘,并相应调整 pigsty.yml 配置清单中的集群配置,以及 supabase 集群配置中的接入信息,使用高可用接入点访问服务。
Supabase 的部分功能需要发送邮件,所以要用到 SMTP 服务。除非单纯用于内网,否则对于严肃的生产部署,建议使用 SMTP 云服务。自建的邮件服务器发送的邮件容易被标记为垃圾邮件导致拒收。
如果您的服务直接向公网暴露,我们强烈建议您使用真正的域名与 HTTPS 证书,并通过 Nginx 门户 访问。
接下来,我们会依次讨论一些进阶主题。如何在单节点部署的基础上,进一步提升 Supabase 的安全性、可用性与性能。
进阶主题:安全加固
Pigsty基础组件
对于严肃的生产部署,我们强烈建议您修改 Pigsty 基础组件的密码。因为这些默认值是公开且众所周知的,不改密码上生产无异于裸奔:
grafana_admin_password:pigsty,Grafana管理员密码pg_admin_password:DBUser.DBA,PG超级用户密码pg_monitor_password:DBUser.Monitor,PG监控用户密码pg_replication_password:DBUser.Replicator,PG复制用户密码patroni_password:Patroni.API,Patroni 高可用组件密码haproxy_admin_password:pigsty,负载均衡器管控密码minio_secret_key:S3User.MinIO,MinIO 根用户密钥- 此外,强烈建议您修改 Supabase 使用的 PostgreSQL 业务用户 密码,默认为
DBUser.Supa
以上密码为 Pigsty 组件模块的密码,强烈建议在安装部署前就设置完毕。
Supabase密钥
除了 Pigsty 组件的密码,你还需要 修改 Supabase 的密钥,包括
JWT_SECRET:JWT 签名密钥,长度至少 32 个字符ANON_KEY:匿名用户的 JWT 凭据SERVICE_ROLE_KEY:服务角色的 JWT 凭据PG_META_CRYPTO_KEY:PostgreSQL Meta 服务的加密密钥,长度至少 32 个字符DASHBOARD_USERNAME:Supabase Studio Web 界面的默认用户名,默认为supabaseDASHBOARD_PASSWORD:Supabase Studio Web 界面的默认密码,默认为pigstyLOGFLARE_PUBLIC_ACCESS_TOKEN:Logflare 公开访问令牌,32-64 个随机字符LOGFLARE_PRIVATE_ACCESS_TOKEN:Logflare 私有访问令牌,32-64 个随机字符
这里请您务必参照 Supabase教程:保护你的服务 里的说明:
- 生成一个长度超过 32 个字符的
JWT_SECRET,并使用教程中的工具签发ANON_KEY与SERVICE_ROLE_KEY两个 JWT。 - 使用教程中提供的工具,根据
JWT_SECRET以及过期时间等属性,生成一个ANON_KEYJWT,这是匿名用户的身份凭据。 - 使用教程中提供的工具,根据
JWT_SECRET以及过期时间等属性,生成一个SERVICE_ROLE_KEY,这是权限更高服务角色的身份凭据。 - 生成一个长度至少 32 个字符的
PG_META_CRYPTO_KEY,用于 PostgreSQL Meta 服务的加密。 - 为
LOGFLARE_PUBLIC_ACCESS_TOKEN和LOGFLARE_PRIVATE_ACCESS_TOKEN各生成一个 32-64 字符的随机字符串,两者必须不同。 - 如果您使用的 PostgreSQL 业务用户使用了不同于默认值的密码,请相应修改
POSTGRES_PASSWORD的值 - 如果您的对象存储使用了不同于默认值的密码,请相应修改
S3_ACCESS_KEY与S3_SECRET_KEY的值
Supabase 部分的凭据修改后,您可以重启 Docker Compose 容器以应用新的配置:
./app.yml -t app_config,app_launch
cd /opt/supabase; make up
进阶主题:域名接入
如果你在本机或局域网内使用 Supabase,那么可以选择 IP:Port 直连 Kong 对外暴露的 HTTP 8000 端口访问 Supabase。
你可以使用一个内网静态解析的域名,但对于严肃的生产部署,我们建议您使用真域名 + HTTPS 来访问 Supabase。
在这种情况下,您的服务器应当有一个公网 IP 地址,你应当拥有一个域名,使用云/DNS/CDN 供应商提供的 DNS 解析服务,将其指向安装节点的公网 IP(可选默认下位替代:本地 /etc/hosts 静态解析)。
比较简单的做法是,直接批量替换占位域名(supa.pigsty)为你的实际域名,假设为 supa.pigsty.cc:
sed -ie 's/supa.pigsty/supa.pigsty.cc/g' ~/pigsty/pigsty.yml
如果你没有事先配置好,那么重载 Nginx 和 Supabase 的配置生效即可:
make nginx # 重载 nginx 配置
make cert # 申请 certbot 免费 HTTPS 证书
./app.yml # 重载 Supabase 配置
修改后的配置应当类似下面的片段:
all:
vars:
infra_portal:
supa :
domain: supa.pigsty.cc # 替换为你的域名!
endpoint: "10.10.10.10:8000"
websocket: true
certbot: supa.pigsty.cc # 证书名称,通常与域名一致即可
children:
supabase:
vars:
app: supabase # 指定要安装的应用名称
apps: # 应用定义
supabase: # supabase 应用的定义
conf: # 覆盖 /opt/supabase/.env 中的配置
SITE_URL: https://supa.pigsty.cc # <------- 修改为你的外部域名
API_EXTERNAL_URL: https://supa.pigsty.cc # <------- 否则对象存储 API 可能无法工作!
SUPABASE_PUBLIC_URL: https://supa.pigsty.cc # <------- 别忘了在 infra_portal 中也要配置!
完整的域名/HTTPS 配置可以参考 证书管理 教程,您也可以使用 Pigsty 自带的本地静态解析与自签发 HTTPS 证书作为下位替代。
进阶主题:外部对象存储
您可以使用 S3 或 S3 兼容的服务,来作为 PGSQL 备份与 Supabase 使用的对象存储。这里我们使用一个 阿里云 OSS 对象存储作为例子。
Pigsty 提供了一个
terraform/spec/aliyun-meta-s3.tf模板, 可以用于在阿里云上拉起一台服务器,以及一个 OSS 存储桶。
首先,我们修改 all.children.supabase.vars.apps.supabase.conf 中 S3 相关的配置,将其指向阿里云 OSS 存储桶:
# if using s3/minio as file storage
S3_BUCKET: data # 替换为 S3 兼容服务的连接信息
S3_ENDPOINT: https://sss.pigsty:9000 # 替换为 S3 兼容服务的连接信息
S3_ACCESS_KEY: s3user_data # 替换为 S3 兼容服务的连接信息
S3_SECRET_KEY: S3User.Data # 替换为 S3 兼容服务的连接信息
S3_FORCE_PATH_STYLE: true # 替换为 S3 兼容服务的连接信息
S3_REGION: stub # 替换为 S3 兼容服务的连接信息
S3_PROTOCOL: https # 替换为 S3 兼容服务的连接信息
同样使用以下命令重载 Supabase 配置:
./app.yml -t app_config,app_launch
您同样可以使用 S3 作为 PostgreSQL 的备份仓库,在 all.vars.pgbackrest_repo 新增一个 aliyun 备份仓库的定义:
all:
vars:
pgbackrest_method: aliyun # pgbackrest 备份方法:local,minio,[其他用户定义的仓库...],本例中将备份存储到 MinIO 上
pgbackrest_repo: # pgbackrest 备份仓库: https://pgbackrest.org/configuration.html#section-repository
aliyun: # 定义一个新的备份仓库 aliyun
type: s3 # 阿里云 oss 是 s3-兼容的对象存储
s3_endpoint: oss-cn-beijing-internal.aliyuncs.com
s3_region: oss-cn-beijing
s3_bucket: pigsty-oss
s3_key: xxxxxxxxxxxxxx
s3_key_secret: xxxxxxxx
s3_uri_style: host
path: /pgbackrest
bundle: y # bundle small files into a single file
bundle_limit: 20MiB # Limit for file bundles, 20MiB for object storage
bundle_size: 128MiB # Target size for file bundles, 128MiB for object storage
cipher_type: aes-256-cbc # enable AES encryption for remote backup repo
cipher_pass: pgBackRest.MyPass # 设置一个加密密码,pgBackRest 备份仓库的加密密码
retention_full_type: time # retention full backup by time on minio repo
retention_full: 14 # keep full backup for the last 14 days
然后在 all.vars.pgbackrest_mehod 中指定使用 aliyun 备份仓库,重置 pgBackrest 备份:
./pgsql.yml -t pgbackrest
Pigsty 会将备份仓库切换到外部对象存储上,更多备份配置可以参考 PostgreSQL 备份 文档。
进阶主题:使用SMTP
你可以使用 SMTP 来发送邮件,修改 supabase 应用配置,添加 SMTP 信息:
all:
children:
supabase: # supa group
vars: # supa group vars
apps: # supa group app list
supabase: # the supabase app
conf: # the supabase app conf entries
SMTP_HOST: smtpdm.aliyun.com:80
SMTP_PORT: 80
SMTP_USER: no_reply@mail.your.domain.com
SMTP_PASS: your_email_user_password
SMTP_SENDER_NAME: MySupabase
SMTP_ADMIN_EMAIL: adminxxx@mail.your.domain.com
ENABLE_ANONYMOUS_USERS: false
不要忘了使用 app.yml 来重载配置
进阶主题:真·高可用
经过这些配置,您拥有了一个带公网域名,HTTPS 证书,SMTP,PITR 备份,监控,IaC,以及 437 个扩展的企业级 Supabase (基础单机版)。 高可用的配置请参考 Pigsty 其他部份的文档,如果您懒得阅读学习,我们提供手把手扶上马的 Supabase 自建专家咨询服务 —— ¥2000 元免去折腾与下载的烦恼。
单节点的 RTO / RPO 依赖外部对象存储服务提供兜底,如果您的这个节点挂了,外部 S3 存储中保留了备份,您可以在新的节点上重新部署 Supabase,然后从备份中恢复。 这样的部署在故障时可以提供一个最低标准的 RTO (小时级恢复时长)/ RPO (MB级数据损失)兜底容灾水平 兜底。
如果想要达到 RTO < 30s ,切换零数据丢失,那么需要使用多节点进行高可用部署,这涉及到:
- ETCD: DCS 需要使用三个节点或以上,才能容忍一个节点的故障。
- PGSQL: PGSQL 同步提交不丢数据模式,建议使用至少三个节点。
- INFRA:监控基础设施故障影响稍小,建议生产环境使用双副本
- Supabase 无状态容器本身也可以是多节点的副本,可以实现高可用。
在这种情况下,您还需要修改 PostgreSQL 与 MinIO 的接入点,使用 DNS / L2 VIP / HAProxy 等 高可用接入点
关于这些部分,您只需参考 Pigsty 中各个模块的文档进行配置部署即可。
建议您参考 conf/ha/trio.yml 与 conf/ha/safe.yml 中的配置,将集群规模升级到三节点或以上。
面向未来数据库的现代硬件
原文链接:https://transactional.blog/blog/2024-modern-database-hardware

本文是一篇关于硬件发展如何影响数据库设计的综述,介绍了网络、存储、计算三个领域的关键硬件进展。充分利用好新硬件而非折腾分布式,才是数据库内核发展的正路。 阅读全文
MySQL还有机会赶上PostgreSQL吗?
原文链接:https://www.percona.com/blog/can-mysql-catch-up-with-postgresql/
Percona创始人Peter Zaitsev讨论MySQL是否还能跟上PostgreSQL的脚步。作为MySQL生态的主要扛旗者,Percona的看法在相当程度上代表了MySQL社区的想法,这篇文章值得每个关注数据库发展的人阅读。 阅读全文
开源“暴君”Linus清洗整风

Linus踢出了几位俄罗斯籍开发者,引发开源世界一片哀嚎。但Linux是Linus的个人项目,三十年前是,现在也依然是。Linux社区本质是帝制的,而Linus本人就是最早且最成功的技术独裁者。 阅读全文
先优化碳基BIO核,再优化硅基CPU核
原文链接:https://world.hey.com/dhh/optimize-for-bio-cores-first-silicon-cores-second-112a6c3f

程序员是昂贵稀缺的生物计算核心,是软件成本的锚钉。硅制计算内核丰富而成本不断下降,而生物核却日益稀缺昂贵。因此优化CPU核之前,请优先考虑优化生物核——这正是Ruby on Rails的设计哲学。 阅读全文
MongoDB没有未来:好营销救不了烂芒果

MongoDB在诚信上劣迹斑斑,在产品和技术上乏善可陈,在正确性、性能、功能上被PostgreSQL吊打,开发者口碑崩塌,热度下滑,股价腰斩,亏损扩大。碰瓷引战PG,好营销也救不了它。 阅读全文
MongoDB:现在由PostgreSQL强力驱动?

MongoDB 3.2的分析子系统竟然是一个嵌入式的PostgreSQL数据库?由MongoDB的合作伙伴发出的血泪控诉与吹哨故事,揭露了MongoDB对待生态伙伴的态度和一些黑历史。 阅读全文
瑞士强制政府软件开源

瑞士政府通过开源立法走在时代前沿,强制要求公共部门使用开源软件。真正的自主可控根源在于"开源社区",而不是某些民族主义式的国产软件。公共资金,公共代码。 阅读全文
MySQL安魂九霄,PostgreSQL驶向云外

MySQL 9.0终于发布,距离上一次大版本更新已经过去八年。然而这个空洞无物的所谓"创新版本"犹如一个恶劣的玩笑,宣告着MySQL正在死去。Percona CEO也表示:有了PostgreSQL,谁还需要MySQL呢? 阅读全文
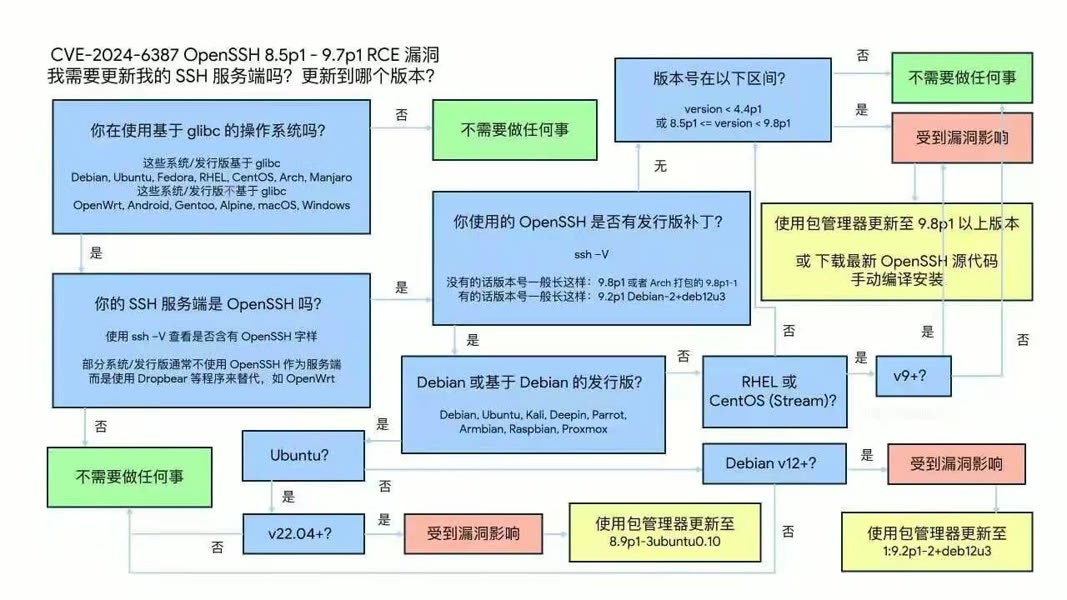
CVE-2024-6387 SSH漏洞修复
CVE-2024-6387是一个严重的OpenSSH漏洞,影响EL9、Ubuntu 22.04、Debian 12等较新版本操作系统。老系统如CentOS 7.9、Ubuntu 20.04因OpenSSH版本老反而逃过一劫,请用户及时更新修复。 阅读全文
Oracle还能挽救MySQL吗?

Percona创始人Peter Zaitsev在官方博客上公开表达了对MySQL及其知识产权属主Oracle的失望,以及对版本越高性能越差的不满。作为MySQL生态的主要扛旗者,Percona的公开表态是一个值得关注的信号。 阅读全文
Oracle最终还是杀死了MySQL
原文链接:https://www.percona.com/blog/is-oracle-finally-killing-mysql/

Peter Zaitsev是MySQL生态重要公司Percona的创始人,他撰文痛批Oracle的作为与不作为杀死了MySQL。约15年前Oracle收购了Sun从而拥有了MySQL,当时关于Oracle何时会"扼杀MySQL"的讨论此起彼伏,如今一语成谶。 阅读全文
MySQL性能越来越差,Sakila将何去何从?
原文链接:https://www.percona.com/blog/sakila-where-are-you-going/

MySQL版本越高性能反而越差?Percona监控发现从5.7迁移到8.x的步伐明显缓慢。在PostgreSQL高歌猛进吞噬数据库世界的同时,MySQL的性能和功能被甩开越来越远。云厂商白嫖是主要原因之一。 阅读全文
20刀好兄弟PolarDB:论数据库该卖什么价?

PolarDB数据库每节点许可证只卖130块?国内IT已经卷到这个阶段了吗?今天来聊聊商业数据库、开源数据库、云数据库、国产数据库的公允价格到底是多少。 阅读全文
国产数据库到底能不能打?

国产数据库到底能不能打?这是个得罪人的问题,不妨用数据说话。本文通过流行度等指标分析数据库生态格局,帮助读者建立更为准确的比例感认知,了解国产数据库在全球市场中的真实位置。 阅读全文
Redis不开源是“开源”之耻,更是公有云之耻

Redis从7.4起使用RSALv2与SSPLv1,不再满足OSI关于开源软件的定义。这不是Redis的耻辱,而是开源/OSI的耻辱,更是公有云厂商白嫖社区成果的耻辱。当下软件自由的头号敌人是公有云服务。 阅读全文
MySQL正确性竟如此垃圾?

MySQL的事务ACID存在缺陷,且与文档承诺不符。JEPSEN测试揭示MySQL的可重复读隔离级别既不原子也不单调,连基本的单调原子视图都不满足。这可能导致严重的正确性问题,使用时请务必谨慎。 阅读全文
数据库应该放入K8S里吗?

数据库是否应该放入Kubernetes里,到今天仍然是一个充满争议的话题。K8S在无状态应用管理上非常趁手,但处理有状态服务特别是数据库时有本质局限性。本文深入探讨为什么将数据库放入K8S不是明智选择。 阅读全文
专用向量数据库凉了吗?

向量存储检索是个真需求,然而专用向量数据库已经凉了。小微需求OpenAI亲自下场解决了,标准需求被加装向量扩展的现有成熟数据库抢占。想靠讲AI故事做成一个产业已经是不可能了。 阅读全文
数据库真被卡脖子了吗?

很多"国产数据库"就是烂泥扶不上墙的残次品,信创约等于IT预制菜进校园。用户捏着鼻子迁移,开发者假装在卖力。基础软件行业其实没人卡脖子,真卡脖子的都是所谓"自己人"。 阅读全文
EL系操作系统发行版哪家强?

RHEL系列操作系统发行版兼容水平:RHEL = Rocky ≈ Anolis > Alma > Oracle » Euler。推荐使用RockyLinux 8.8,有国产化要求可以使用Anolis 8.8。CentOS 7.9明年EOL,是时候升级OS了。 阅读全文
基础软件需要什么样的自主可控?

当我们说自主可控时,到底在说什么?运维自主可控与研发自主可控,国家/用户真正需要的自主可控是前者,而不是华而不实的"自研"。国家的需求很简单:打仗吃制裁后,现有系统还能不能继续跑起来。 阅读全文
正本清源:技术反思录

降本增效的主旋律触发了所有技术的价值重估,当然也包括数据库。本系列将评述数据库领域热点技术,并对其在当下的利弊权衡发出灵魂拷问:云数据库、分布式数据库、微服务、K8S容器化等技术,究竟是真需求还是伪需求? 阅读全文
数据库需求层次金字塔

与马斯洛需求金字塔类似,用户对数据库的需求也有递进的层次:功能正确性、安全备份、高可用监控、性能成本、可观测性、易用性控制、标准化产品化、最终达到超越与自我实现。 阅读全文
分布式数据库是不是伪需求?

随着硬件技术进步,单机数据库的容量和性能已达到前所未有的高度。分布式TP数据库在这种变革面前显得极为无力,和"数据中台"一样穿着皇帝的新衣,处于自欺欺人的状态里。 阅读全文
微服务是不是个蠢主意?
原文链接:https://world.hey.com/dhh/microservices-are-a-bad-idea-7a8dbddc

连SOA典范亚马逊自己都觉得微服务和Serverless拉胯了。Prime Video团队放弃微服务改用单体架构,运营成本节省了惊人的90%。微服务就像塞壬歌声一样诱惑你为系统添加毫无必要的复杂度。 阅读全文
是时候和GPL说再见了
原文链接:https://martin.kleppmann.com/2021/04/14/goodbye-gpl.html

DDIA作者Martin Kleppmann认为应远离GPL及相关许可证,因为它们未能实现其目的,造成的麻烦比产生的价值更大。在2020年代,计算自由的敌人是云软件,本文倡导本地优先软件的概念。 阅读全文
容器化数据库是个好主意吗?

生产环境的数据库是否应当放入容器中,仍然是一个充满争议的问题。站在开发者角度我喜欢Docker,但站在DBA立场上,我认为就目前而言,将生产环境数据库放入Docker/K8S中仍然是一个馊主意。 阅读全文
理解时间:闰年闰秒,时间与时区
四年一遇的闰年2月29日,总有土鳖软件出现大翻车。对时间的正确理解,对正确处理工作生活中的时间问题很有帮助。本文聊一聊闰年、闰秒、时间与时区的原理,以及在数据库与编程语言中的注意事项。 阅读全文
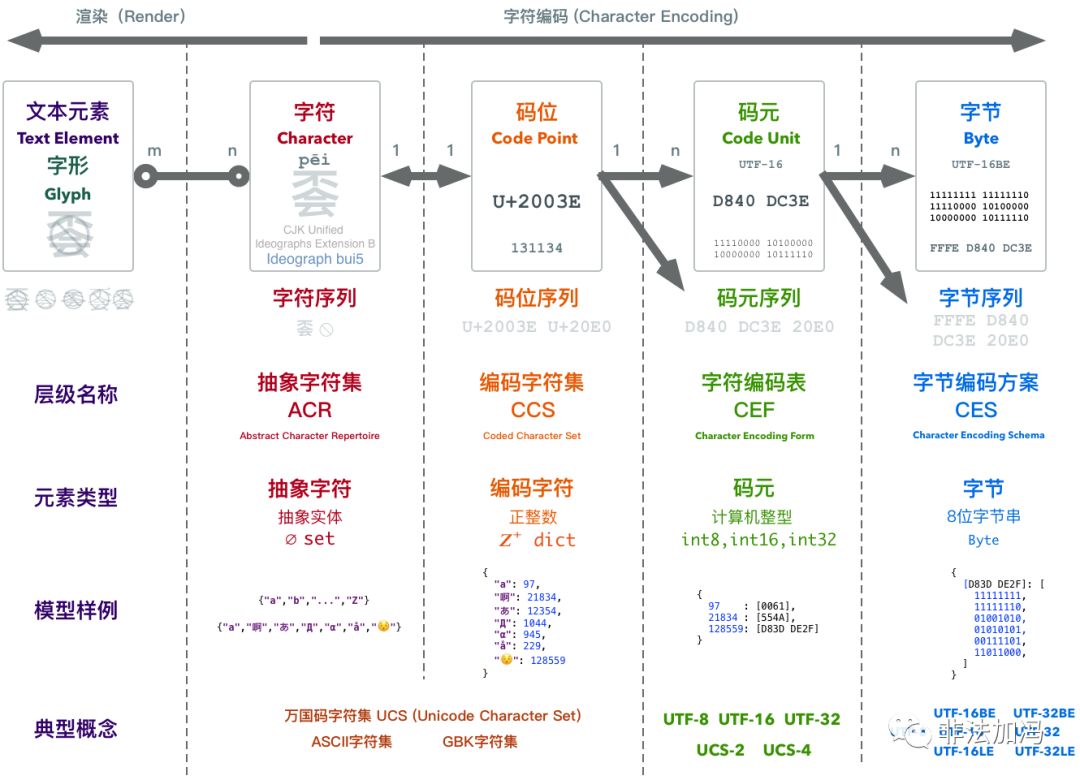
理解字符编码原理
如果不了解字符编码的基本原理,即使只是简单常规的字符串比较、排序、随机访问操作,都可能会一不小心栽进大坑中。本文详细解析ASCII、Unicode、UTF-8等编码原理,希望能讲清楚这个问题。 阅读全文
并发异常那些事

并发程序很难写对,更难写好。很多程序员只是把问题丢给数据库,但即使最强大的ACID数据库也会使用弱隔离级别。本文阐述SQL92标准定义的隔离级别及其缺陷,以及现代模型中的隔离级别定义。 阅读全文
区块链与分布式数据库

区块链的技术本质、提供的功能及演化方向就是分布式数据库。确切地讲,是拜占庭容错(抗恶意节点攻击)的分布式(无领导者复制)数据库。智能合约本质上就是这个分布式数据库上的存储过程。 阅读全文
一致性:过载的术语

一致性这个词重载得很厉害,在不同语境中代表着不同的东西。ACID里的C指事务一致性,CAP里的C指线性一致性,此外还有"一致性哈希"、“最终一致性"等不同涵义。本文梳理这些概念的区别。 阅读全文
为什么要学习数据库原理

只会写代码的是码农,学好数据库基本能混口饭吃。然而对优秀的工程师来说,只会用数据库是远远不够的。绝大多数应用都是数据密集型应用,数据库提供了对应用通用存储需求的高级抽象。 阅读全文