This is the multi-page printable view of this section. Click here to print.
数据库
- 国产数据库到底能不能打?
- 数据库老司机:合订本
- Redis不开源是“开源”之耻,更是公有云之耻
- MySQL正确性竟如此垃圾?
- 数据库应该放入K8S里吗?
- 专用向量数据库凉了吗?
- 数据库真被卡脖子了吗?
- EL系操作系统发行版哪家强?
- 基础软件需要什么样的自主可控?
- 数据库需求层次金字塔
- 分布式数据库是不是伪需求?
- 微服务是不是个蠢主意?
- 是时候和GPL说再见了
- 容器化数据库是个好主意吗?
- 理解时间:闰年闰秒,时间与时区
- 并发异常那些事
- 区块链与分布式数据库
- 一致性:过载的术语
- 为什么要学习数据库原理
国产数据库到底能不能打?
总有朋友问我,国产数据库到底能不能打?说实话,是个得罪人的问题。所以我们不妨试试用数据说话 —— 希望本文提供的图表,能够帮助读者了解数据库生态格局,并建立更为准确的比例感认知。
数据来源与研究方法
评价一个数据库“能不能打”有许多种方式,但 “流行度” 是最常见的指标。对一项技术而言,流行度决定了用户的规模与生态的繁荣程度,唯有这种最终存在意义上的结果才能让所有人心服口服。
关于数据库流行度这个问题,我认为有三份数据可以作为参考:StackOverflow 全球开发者调研[1],DB-Engine 数据库流行度排行榜[2],以及墨天轮国产数据库排行榜[3]。
其中最有参考价值的是 StackOverflow 2017 - 2023 年的全球开发者问卷调研 —— 样本调查获取的第一手数据具有高度的可信度与说服力,并且具有极好的 横向可比性(在不同数据库之间水平对比);连续七年的调查结果也有着足够的 纵向可比性 (某数据库和自己过去的历史对比)。

其次是 DB-Engine 数据库流行度排行榜, DB-Engine 属于综合性热搜指数,将 Google, Bing, Google Trends,StackOverflow,DBA Stack Exchange,Indeed, Simply Hired, LinkedIn,Twitter 上的间接数据合成了一个热搜指数。

热度指数有着很好的 纵向可比性 —— 我们可以用它来判断某个数据库的流行度走势 —— 是更流行了还是更过气了,因为评分标准是一样的。但在 横向可比性 上表现不佳 —— 例如你没办法细分用户搜索的目的。所以热度指标在横向对比不同数据库时只能作为一个模糊的参考 —— 但在数量级上的准确性还是OK的。
第三份数据是墨天轮的 “国产数据库排行榜”,这份榜单收录了 287 个国产数据库,主要价值是给我们提供了一份国产数据库名录。这里我们简单认为 —— 收录在这里的数据库,就算“**国产数据库”**了 —— 尽管这些数据库团队不一定会自我认知为国产数据库。

有了这三份数据,我们就可以尝试回答这个问题 —— 国产数据库在国际上的流行度与影响力到底是什么水平?
锚点:TiDB
TiDB 是唯一一个,同时出现在三个榜单里的数据库,因此可以作为锚点。
在 StackOverflow 2023 调研 中,TiDB 作为最后一名,首次出现在数据库流行度榜单里,也是唯一入选的 “国产数据库”。图左中,TiDB 的开发者使用率为 0.20%,与排名第一的 PostgreSQL (45.55%) 和排名第二的 MySQL (41.09%) 相比,流行度相差了大约 两三百倍。

第二份 DB-Engine 数据可以交叉印证这一点 —— TiDB 在 DB-Engine 上的评分是国产数据库中最高的 —— 在2024年4月份,为 5.14 分。关系型数据库四大天王( PostgreSQL,MySQL,Oracle,SQL Server)相比,也是小几百倍的差距。

在墨天轮国产数据库排名中,TiDB 曾经长时间占据了榜首的位置,尽管最近两年前面加塞了 OceanBase, PolarDB,openGauss 三个数据库,但它还在第一梯队里,称其为国产数据库标杆没有太大问题。

如果我们以 TiDB 作为参考锚点,将这三份数据融合,立即就能得出一个有趣的结论:国产数据库看上去人才济济,群英荟萃,但即使是最能打的国产数据库,流行度与影响力也不及头部开源数据库的百分之一… 。
整体来看,这些被归类为“国产数据库”的产品,绝大多数在国际上的影响力可以评为:微不足道。
微不足道的战五渣
在 DB-Engine 收录的全球 478 款数据库中,可以找到 46 款列入墨天轮国产数据库名单的产品。将其过去十二年间的流行度绘制在图表上,得到下图 —— 乍看之下,好一片 “欣欣向荣”,蓬勃发展的势头。

然而,当我们把关系数据库四大天王:PostgreSQL,MySQL,Oracle,SQL Server 的热度趋势同样画在这张图上后,看上去就变得大不一样了 —— 你几乎看不到任何一个“国产数据库”了。

把整个国产数据库的热度分数全加起来,也甚至还达不到 PostgreSQL 流行度的零头。 整体合并入 “其他” 统计项中毫无任何违和感。
如果把所有国产数据库视作一个整体,在这个榜单里面可以凭 34.7 分排到第 26 名,占总分数的千分之五。(最上面一条黑带)

这个数字,差不多就是国产数据库国际影响力(DB-Engine)的一个摘要概括:尽管在数量上占了 1/10(如果以墨天轮算可以近半),但总影响力只有千分之五。其中的最强者 TiDB,战斗力也只有5 ……

当然再次强调,热度/指数类数据横向可比性非常一般,仅适合在数量级层面用作参考 —— 但这也足够得出一些结论了……

过气中的数据库们
从 DB-Engine 的热度趋势上看,国产数据库从 2017 - 2020 年开始起势,从 2021 年进入高潮,在 23年5月进入平台期,从今年年初开始,出现掉头过气的趋势。这和许多业内专家的判断一致 —— 2024 年,国产数据库进入洗牌清算期 —— 大量数据库公司将倒闭破产或被合并收编。

如果我们去掉个别出海开源做的还不错的头部“国产”数据库 —— 这个掉头而下的过气趋势会更加明显。

但过气这件事,并非国产数据库所独有 — 其实绝大多数的数据库其实都正在过气中。DB-Engine 过去12 年中的流行度数据趋势可以揭示这一点 —— 尽管 DB-Engine 热度指标的的横向可比性很一般,但纵向可比性还是很不错的 —— 因此在判断流行 & 过气趋势上仍然有很大的参考价值。
我们可以对图表做一个加工处理 —— 以某一年为零点,来看热度分数从此刻起的变化,从而看出那些数据库正在繁荣发展,哪些数据库正在落伍过气。
如果我们将目光聚焦在最近三年,不难发现在所有数据库中,只有 PostgreSQL 与 Snowflake 的流行度有显著增长。而最大的输家是 SQL Server,Oracle,MySQL,与 MongoDB …… 。分析数仓类组件(广义上的数据库)在最近三年有少量增长,而绝大部分其他数据库都处在过气通道中。

如果我们以 DB-Engine 最早有记录的 2012-11 作为参考零点,那么 PostgreSQL 是过去 12 年中数据库领域的最大赢家;而最大的输家依然是 SQL Server,Oracle,MySQL 御三家关系型数据库。
NoSQL 运动的兴起,让 MongoDB ,ElasticSearch,Redis 在 2012 - 2022 互联网黄金十年中获得了可观的增长,但这个增长的势头在最近几年已经结束了,并进入过气下降通道中,进入吃存量老本的状态。

至于 NewSQL 运动,即所谓的新一代分布式数据库。如果说 NoSQL 起码辉煌过,那么可以说 NewSQL 还没辉煌就已经熄火了。“分布式数据库” 在国内营销炒作的非常火热,以至于大家好像把它当作一个可以与 “集中式数据库” 分庭抗礼的数据库品类来看待。但如果我们深入研究就不难发现 —— 这其实只是一个非常冷门的数据库小众领域。
一些 NoSQL 组件的流行度还能和 PostgreSQL 放到同一个坐标图中而不显突兀,而所有 NewSQL 玩家加起来的流行度分数也比不上 PostgreSQL 的零头 —— 和“国产数据库”一样。

这些数据为我们揭示出数据库领域的基本格局:除了 PostgreSQL 之外的主要数据库都在过气中…

改头换面的 PostgreSQL 内战
这几份数据为我们揭示出数据库领域的基本格局 —— 除了 PostgreSQL 之外的主要数据库都在过气中,无论是 SQL,NoSQL,NewSQL,还是 国产数据库 。这确实抛出了一个有趣的问题,让人想问 —— 为什么?。
对于这个问题,我在 《PostgreSQL 正在吞噬数据库世界》中提出了一种简单的解释:PostgreSQL 正在凭借其强大的扩展插件生态,内化吞噬整个数据库世界。根据奥卡姆剃刀原理 —— 最简单的解释往往也最接近真相。

整个数据库世界的核心焦点,都已经聚焦在了金刚大战哥斯拉上:两个开源巨无霸数据库 PostgreSQL 与 MySQL 的使用率与其他数据库远远拉开了距离。其他一切议题与之相比都显得微不足道,无论是 NewSQL 还是 国产数据库。

看上去这场搏杀还要再过几年才能结束,但在远见者眼中,这场纷争几年前就已经尘埃落定了。
Linux 内核一统服务器操作系统天下后,曾经的同台竞争者 BSD,Solaris,Unix 都成为了时代的注脚。而我们正在目睹同样的事情在数据库领域发生 —— 在这个时代里,想发明新的实用数据库内核,约等于堂吉柯德撞风车。
好比今天尽管市面上有这么多的 Linux 操作系统发行版,但大家都选择使用同样的 Linux 内核,吃饱了撑着魔改 OS 内核属于没有困难创造困难也要上,会被业界当成 山炮 看待。
所以,并非所有国产数据库都不能打,而是能打的国产数据库,其实是改头换面的 PostgreSQL 与 MySQL 。如果 PostgreSQL 注定成为数据库领域的 Linux 内核,那么谁会成为 Postgres 的 Debian / Ubuntu / Suse / RedHat ?

国产数据库的竞争,变成了 PostgreSQL / MySQL 生态内部的竞争。一个国产数据库能打与否,取决于其 “含P量” —— 含有 PostgreSQL 内核的纯度与版本新鲜度。版本越新,魔改越少,附加值越高,使用价值就越高,也就越能打。
国产数据库看起来最能打的阿里 PolarDB (唯一入选 Gartner 领导者象限),基于三年前的 PostgreSQL 14 进行定制,且保持了 PG 内核的主体完整性,拥有最高的含P量。相比之下,openGauss 选择基于 12 年前的 PG 9.2 进行分叉,并魔改的亲爹都不认识了,所以含P量较低。介于两者中间的还有:PG 13 的 AntDB,PG 12 的人大金仓,PG 11 的老 Polar,PG XL 的 TBase ,……
因此,国产数据库到底能不能打 —— 真正的本质问题是:谁能代表 PostgreSQL 世界的先进生产力?
做内核的厂商不温不火,MariaDB 作为 MySQL 的亲爹 Fork 甚至都已经濒临退市,而白嫖内核自己做服务与扩展卖 RDS 的 AWS 可以赚的钵满盆翻,甚至凭借这种模式一路干到了全球数据库市场份额的榜首 —— 毫无疑问地证明:数据库内核已经不重要了,市场上稀缺的是服务能力整合。

在这场竞赛中,公有云 RDS 拿到了第一张入场券。而尝试在本地提供更好、更便宜、 RDS for PostgreSQL 的 Pigsty 对云数据库这种模式提出了挑战,同时还有十几款尝试用 云原生方式解决 RDS 本地化挑战的 Kubernetes Operator 正在摩拳擦掌,跃跃欲试,要把 RDS 拉下马来。

真正的竞争发生在服务/管控维度,而不是内核。
数据库领域正在从寒武纪大爆发走向侏罗纪大灭绝,在这一过程中,1% 的种子将会继承 99% 的未来,并演化出新的生态与规则。我希望数据库用户们可以明智地选择与决策,站在未来与希望的一侧,而不要把生命浪费在没有前途的事物上,比如……
References
注:本文使用的图表与数据,公开发布于 Pigsty Demo 站点:https://demo.pigsty.cc/d/db-analysis/
[1] StackOverflow 全球开发者调研: https://survey.stackoverflow.co/2023/?utm_source=so-owned&utm_medium=blog&utm_campaign=dev-survey-results-2023&utm_content=survey-results#most-popular-technologies-database-prof
[2] DB-Engine 数据库流行度排行榜: https://db-engines.com/en/ranking_trend
[3] 墨天轮国产数据库排行榜: https://www.modb.pro/dbRank
[4] DB-Engine 数据分析: https://demo.pigsty.cc/d/db-analysis
[5] StackOverflow 7年调研数据: https://demo.pigsty.cc/d/sf-survey
数据库老司机:合订本
最近在技术圈有一些热议的话题,云数据库是不是智商税??公有云是不是杀猪盘?分布式数据库是不是伪需求?微服务是不是蠢主意?你还需要运维和DBA吗?中台是不是一场彻头彻尾的自欺欺人?在Twitter与HackerNews上也有大量关于这类话题的讨论与争辩。
在这些议题的背后的脉络是大环境的改变:降本增效压倒其他一切,成为绝对的主旋律。开发者体验,架构可演化性,研发效率这些属性依然重要,但在 ROI 面前都要让路 —— 社会思潮与根本价值观的变化会触发所有技术的重新估值。
有人说,互联网公司砍掉一半人依然可以正常运作,只不过老板不知道是哪一半。现在收购推特的马斯克刷新了这个记录:截止到2023年5月份,推特已经从8000人一路裁员 90% 到现在的不足千人,而依然不影响其平稳运行。这个结果彻底撕下大公司病冗员问题的遮羞布,其余互联网大厂早晚会跟进,掀起新一轮大规模裁员的血雨腥风。
在经济繁荣期,大家可以有余闲冗员去自由探索,也可以使劲儿吹牛造害铺张浪费炒作。但在经济萧条下行阶段,所有务实的企业与组织都会开始重新审视过往的利弊权衡。同样的事情不仅会发生在人上,也会发生在技术上,这是实体世界的危机传导到技术界的表现:泡沫总会在某个时刻需要出清,而这件事已正在发生中。
公有云,Kubernetes,微服务,云数据库,分布式数据库,大数据全家桶,Serverless,HTAP,Microservice,等等等等,所有这些技术与理念都将面临拷问:有些事不上秤没有四两,上了秤一千斤也打不住。这个过程必然伴随着怀疑、痛苦,伤害与毁灭,但也孕育着希望,喜悦,发展与新生。花里胡哨华而不实的东西会消失在历史长河里,大浪淘沙能存留下来的才是真正的好技术。
在这场技术界的惊涛骇浪中,需要有人透过现象看本质,脚踏实地的把各项技术的好与坏,适用场景与利弊权衡讲清楚。而我本人愿意作为一个亲历者,见证者,评叙者,参与者躬身入局,加入其中。这里拟定了一个议题列表集,名为《正本清源:技术反思录》,将依次撰文讨论评论业界关心的热点与技术:
- 国产数据库是大炼钢铁吗?
- 中国对PostgreSQL的贡献约等于零吗?
- MySQL的正确性为何如此拉垮?
- 没错,数据库确实应该放入 K8s 里!(转载SealOS)
- 数据库应该放入K8S里吗?
- 把数据库放入Docker是一个好主意吗?
- 向量数据库凉了吗?
- 阿里云的羊毛抓紧薅,五千的云服务器三百拿
- 数据库真被卡脖子了吗?
- EL系操作系统发行版哪家强?
- 基础软件到底需要什么样的自主可控?
- 如何看待 MySQL vs PGSQL 直播闹剧
- 驳《MySQL:这个星球最成功的数据库》
- 向量是新的JSON 【译评】
- 【译】微服务是不是个蠢主意?
- 分布式数据库是伪需求吗?
- 数据库需求层次金字塔
- StackOverflow 2022数据库年度调查
- DBA还是一份好工作吗?
- PostgreSQL会修改开源许可证吗?
- Redis不开源是“开源”之耻,更是公有云之耻
- PostgreSQL正在吞噬数据库世界
- RDS阉掉了PostgreSQL的灵魂
- 技术极简主义:一切皆用Postgres

写作计划
《分布式数据库是不是伪需求?》
《国产数据库是不是大跃进?》
《TPC-C打榜是不是放卫星?》
《信创数据库是不是恰烂钱?》
《谁卡住了中国数据库的脖子?》
《微服务是不是蠢主意?》
《Serverless是不是榨钱术?》
《RCU/WCU计费是不是阳谋杀猪?》
《数据库到底要不要放入K8S?》
《HTAP是不是纸上谈兵?》
《单机分布式一体化是不是脱裤放屁?》
《你真的需要专用向量数据库吗?》
《你真的需要专用时序数据库吗?》
《你真的需要专用地理数据库吗?》
《APM时序数据库选型姿势指北》
《202x数据库选型指南白皮书》
《开源崛起:商业数据库还能走多远?》
《云厂商的 SLA 到底靠不靠得住?》
《大厂技术管理思想真的先进吗?》
《卷数据库内核还有没有出路?》
《用户到底需要什么样的数据库?》
《再搞 MySQL 还有没有前途?》
如果您有任何认为值得讨论的话题,也欢迎在评论区中留言提出,我将视情况加入列表中。
Redis不开源是“开源”之耻,更是公有云之耻
最近 Redis 修改其协议引发了争议:它从 7.4 起使用 RSALv2 与 SSPLv1,不再满足 OSI 关于 “开源软件” 的定义。但不要搞错:Redis “不开源” 不是 Redis 的耻辱,而是“开源/OSI”的耻辱 —— 它反映出开源组织/理念的过气。
当下软件自由的头号敌人是公有云服务。“开源” 与 “闭源” 也不再是软件行业的核心矛盾,斗争的焦点变为 “云上服务” 与 “本地优先”。公有云厂商搭着开源软件的便车白嫖社区的成果,这注定会引发社区的强烈反弹。
在抵御云厂商白嫖的实践中,修改协议是最常见的做法:但AGPLv3 过于严格容易敌我皆伤,SSPL 因为明确表达这种敌我歧视,不被算作开源。业界需要一种新的歧视性软件许可证协议,来达到名正言顺区分敌我的效果。
真正重要的事情一直都是软件自由,而“开源”只是实现软件自由的一种手段。而如果“开源”的理念无法适应新阶段矛盾斗争的需求,甚至会妨碍软件自由,它一样会过气,并不再重要,并最终被新的理念与实践所替代。
修改协议的开源软件
“我想直率地说:多年来,我们就像个傻子一样,他们拿着我们开发的东西大赚了一笔”。
Redis Labs 首席执行官 Ofer Bengal
Redis 在过去几年中一直都是开发者最喜爱的数据库系统(在去年被 PostgreSQL 超过),采用了非常友善的 BSD-3 Clause 协议,并被广泛应用在许多地方。然而,几乎所有的公有云上都可以看到云 Redis 数据库服务,云厂商靠它赚的钵满盆翻,而支付研发成本的 Redis 公司和开源社区贡献者被搁在一边。这种不公平的生产关系,注定会招致猛烈的反弹。
Redis 切换为更为严格的 SSPL 协议的核心原因,用 Redis Labs CEO 的话讲就是:“多年来,我们就像个傻子一样,他们拿着我们开发的东西大赚了一笔”。“他们”是谁? —— 公有云。切换 SSPL 的目的是,试图通过法律工具阻止这些云厂商白嫖吸血开源,成为体面的社区参与者,将软件的管理、监控、托管等方面的代码开源回馈社区。
不幸的是,你可以强迫一家公司提供他们的 GPL/SSPL 衍生软件项目的源码,但你不能强迫他们成为开源社区的好公民。公有云对于这样的协议往往也嗤之以鼻,大多数云厂商只是简单拒绝使用AGPL许可的软件:要么使用一个采用更宽松许可的替代实现版本,要么自己重新实现必要的功能,或者直接购买一个没有版权限制的商业许可。
当 Redis 宣布更改协议后,马上就有 AWS 员工跳出来 Fork Redis —— “Redis 不开源了,我们的分叉才是真开源!” 然后 AWS CTO 出来叫好,并假惺惺的说:这是我们员工的个人行为 —— 堪称是现实版杀人诛心。

图:AWS CTO 转评员工 Fork Redis
被这样搞过的并非只有 Redis 一家。发明 SSPL 的 MongoDB 也是这个样子 —— 当 2018 年 MongoDB 切换至 SSPL 时,AWS 就搞了一个所谓 “API兼容“ 的 DocumentDB 来恶心它。ElasticSearch 修改协议后,AWS 就推出了 OpenSearch 作为替代。头部 NoSQL 数据库都已经切换到了 SSPL,而 AWS 也都搞出了相应的“开源替代”。
因为引入了额外的限制与所谓的“歧视”条款,OSI 并没有将 SSPL 认定为开源协议。因此使用 SSPL 的举措被解读为 —— “Redis 不再开源”,而云厂商的各种 Fork 是“开源”的。从法律工具的角度来说,这是成立的。但从朴素道德情感出发,这样的说法对于 Redis 来说是极其不公正地抹黑与羞辱。
正如罗翔老师所说:法律工具的判断永远不能超越社区成员朴素的道德情感。如果协和与华西不是三甲,那么丢脸的不是这些医院,而是三甲这个标准。如果年度游戏不是巫师3,荒野之息,博德之门,那么丢脸的不是这些厂商,而是评级机构。如果 Redis 不再算“开源”,真正应该感到耻辱的是OSI,与开源这个理念。
越来越多的知名开源软件,都开始切换到敌视针对云厂商白嫖的许可证协议上来。不仅仅是 Redis,MongoDB,与 ElasticSearch 。MinIO 与 Grafana 分别在 2020,2021年从 Apache v2 协议切换到了 AGPLv3 协议。HashipCrop 的各种组件,MariaDB MaxScale, Percona MongoDB 也都使用了风格类似的 BSL 协议。
一些老牌的开源项目例如 PostgreSQL ,正如PG核心组成员 Jonathan 所说,三十年的声誉历史沉淀让它们已经在事实上无法变更开源协议 了。但我们可以看到,许多新强力的 PostgreSQL 扩展插件开始使用 AGPLv3 作为默认的开源协议,而不是以前默认使用的 BSD-like / PostgreSQL 友善协议。例如分布式扩展 Citus,列存扩展 Hydra,ES全文检索替代扩展 BM25,OLAP 加速组件 PG Analytics …… 等等等等。
包括我们自己的 PostgreSQL 发行版 Pigsty,也在 2.0 的时候由 Apache 协议切换到了 AGPLv3 协议,背后的动机都是相似的 —— 针对软件自由的最大敌人 —— 云厂商进行反击。我们改变不了存量,但对于增量功能,是可以做出有效的回击与改变的。
在抵御云厂商白嫖的实践中,修改协议是最常见的做法:AGPLv3 是一种比较主流的实践,更激进的 SSPL 因为明确表达这种敌我歧视,不被算作开源。使用双协议进行明确的边界区分,也开始成为一种主流的开源商业化实践。但重要的是:业界需要一种新的歧视性软件许可证协议,达到名正言顺辨识敌我,区别对待的效果 —— 来解决软件自由在当下面临的最大挑战 —— 云服务。
软件行业的范式转移
软件吞噬世界,开源吞噬软件,云吞噬开源。
在当下,软件自由的头号敌人是云计算租赁服务。“开源” 与 “闭源” 也不再是软件行业的核心矛盾,斗争的焦点变为 “云上服务” 与 “本地优先”。要理解这一点,我们要回顾一下软件行业的几次主要范式转移,以数据库为例:

最初,软件吞噬世界,以 Oracle 为代表的商业数据库,用软件取代了人工簿记,用于数据分析与事务处理,极大地提高了效率。不过 Oracle 这样的商业数据库非常昂贵,vCPU·月光是软件授权费用就能破万,往往只有金融行业,大型机构才用得起,即使像如淘宝这样的互联网巨头,上了量后也不得不”去O“。
接着,开源吞噬软件,像 PostgreSQL 和 MySQL 这样”开源免费“的数据库应运而生。软件开源本身是免费的,每核每月只需要几十块钱的硬件成本。大多数场景下,如果能找到一两个数据库专家帮企业用好开源数据库,那可是要比傻乎乎地给 Oracle 送钱要实惠太多了。
然后,云吞噬开源。公有云软件,是互联网大厂将自己使用开源软件的能力产品化对外输出的结果。公有云厂商把开源数据库内核套上壳,包上管控软件跑在托管硬件上,并建设共享开源专家池提供咨询与支持,便成了云数据库服务 (RDS)。20 ¥/核·月的硬件资源通过包装,变为了 300 ~ 1300 ¥/核·月的天价 RDS 服务。
曾经,软件自由的最大敌人是商业闭源软件,以微软,甲骨文为代表 —— 许多开发者依然对拥抱开源之前的微软名声有着深刻印象,甚至可以说整个自由软件运动正是源于 1990 年代的反微软情绪。但是,自由软件与开源软件的概念已经彻底改变了软件世界:商业软件公司耗费了海量资金与这个想法斗争了几十年。最终还是难以抵挡开源软件的崛起 —— 开源软件打破了商业软件的垄断,让软件这种IT业的核心生产资料变为全世界开发者公有,按需分配。开发者各尽所能,人人为我,我为人人,这直接催生了互联网的黄金繁荣时代。
开源并不是一种商业模式,甚至是一种强烈违反商业化逻辑的模式。然而,任何可持续发展的模式都需要获取资源以支付成本,开源也不例外。开源真正的模式是 —— 通过免费的软件创造高薪技术专家岗位。分散在不同企业组织中的开源专家,产消合一者 (Pro-sumer),是(纯血)开源软件社区的核心力量 —— 免费的开源软件吸引用户,用户需求产生开源专家岗位,开源专家共创出更好的开源软件。开源专家作为组织的代理人,从开源社区,集体智慧成果中汲取力量。组织享受到了开源软件的好处(软件自由,无商业软件授权费),而分散的雇主可以轻松兜住住这些专家的薪资成本。
然而公有云,特别是云软件的出现破坏了这种生态循环 —— 几个云巨头尝试垄断开源专家供给,重新尝试在 用好开源软件(服务)这个维度上,实现商业软件没能实现的垄断。 云厂商编写了开源软件的管控软件,组建了专家池,通过提供维护攫取了软件生命周期中的绝大部分价值,并通过搭便车的行为将最大的成本 —— 产研交由整个开源社区承担。而 真正有价值的管控/监控代码却从来不回馈开源社区。而更大的伤害在于 —— 公有云就像头部带货主播消灭大量本地便利店一样,摧毁了大量的开源就业岗位,掐断了开源社区的人才流动与供给。
计算自由的头号敌人
在 2024 年,软件自由的真正敌人,是云服务软件!
开源软件带来了巨大的行业变革,可以说,互联网的历史就是开源软件的历史。互联网公司是依托开源软件繁荣起来的,而公有云是从头部互联网公司孵化出来的。公有云的历史,就是一部屠龙勇者变为新恶龙的故事。
云刚出现的时候,它也曾经是一位依托开源 挑战传统 IT 市场恶龙的勇者,挥舞着大棒砸烂“企业级”杀猪盘。他们关注的是硬件 / IaaS层 :存储、带宽、算力、服务器。云厂商的初心故事是:让计算和存储资源像水电一样,自己扮演基础设施的提供者的角色。这是一个很有吸引力的愿景:公有云厂商可以通过规模效应,压低硬件成本并均摊人力成本;理想情况下,在给自己留下足够利润的前提下,还可以向公众提供比 IDC 价格更有优势,更有弹性的存储算力(实际上也并不便宜!)。
然而随着时间的推移,这位曾经的屠龙英雄逐渐变成了他曾经发誓打败的恶龙 —— 一个新的“杀猪盘”,对用户征收高昂无专家税与“保护费”。这对应着云软件( PaaS / SaaS ),它与云硬件有着迥然不同的商业逻辑:云硬件靠的是规模效应,优化整体效率赚取资源池化超卖的钱,算是一种效率进步。而云软件则是靠共享专家,提供运维外包来收取服务费。公有云上大量的软件,本质是吸血白嫖开源社区搭便车,抢了分散在各个企业中开源工程师的饭碗,依靠的是信息不对称、专家垄断、用户锁定收取天价服务费,是一种价值的攫取转移,对原有的生态模式的破坏。
不幸的是,出于混淆视线的目的,云软件与云硬件都使用了“云”这个名字。因而在云的故事中,同时混掺着将算力普及到千家万户的理想主义光辉,与达成垄断攫取不义利润的贪婪。
在 2024 年,软件自由的真正敌人,是云服务软件!
云软件,即主要在供应商的服务器上运行的软件,而你的所有数据也存储在这些服务器上。以云数据库为代表的 PaaS ,以及各类只能通过租赁提供服务的 SaaS 都属于此类。这些“云软件”也许有一个客户端组件(手机App,网页控制台,跑在你浏览器中的 JavaScript),但它们只能与供应商的服务端共同工作。而云软件存在很多问题:
- 如果云软件供应商倒闭或停产,您的云软件就歇菜了,而你用这些软件创造的文档与数据就被锁死了。例如,很多初创公司的 SaaS 服务会被大公司收购,而大公司没有兴趣继续维护这些产品。
- 云服务可能在没有任何警告和追索手段的情况下突然暂停您的服务(例如 Parler )。您可能在完全无辜的情况下,被自动化系统判定为违反服务条款:其他人可能入侵了你的账户,并在你不知情的情况下使用它来发送恶意软件或钓鱼邮件,触发违背服务条款。因而,你可能会突然发现自己用各种云文档或其它App创建的文档全部都被永久锁死无法访问。
- 运行在你自己的电脑上的软件,即使软件供应商破产倒闭,它也可以继续跑着,想跑多久跑多久。相比之下,如果云软件被关闭,你根本没有保存的能力,因为你从来就没有服务端软件的副本,无论是源代码还是编译后的形式。
- 云软件极大加剧了软件的定制与扩展难度,在你自己的电脑上运行的闭源软件,至少有人可以对它的数据格式进行逆向工程,这样你至少有个使用其他替代软件的PlanB。而云软件的数据只存储在云端而不是本地,用户甚至连这一点都做不到了。
如果所有软件都是免费和开源的,这些问题就都自动解决了。然而,开源和免费实际上并不是解决云软件问题的必要条件;即使是收钱的或者闭源的软件,也可以避免上述问题:只要它运行在你自己的电脑、服务器、机房上,而不是供应商的云服务器上就可以。拥有源代码会让事情更容易,但这并不是不关键,最重要的还是要有一份软件的本地副本。
在当今,云软件,而不是闭源软件或商业软件,成为了软件自由的头号威胁。云软件供应商可以在您无法审计,无法取证,无法追索的情况下访问您的数据,或突然心血来潮随心所欲地锁定你的所有数据,这种可能性的潜在危害,要比无法查看和修改软件源码的危害大得多。与此同时,也有不少公有云厂商渗透进入开源社区,并将“开源”视作一种获客营销包装、或形成垄断标准的手段,作为吸引用户的钓饵,而不是真正追求“软件自由”的目的。
”开源“ 与 ”闭源“ 已经不再是软件行业中最核心的矛盾,斗争的焦点变为 “云” 与 “本地优先”。
自由世界如何应对挑战?
重要的事情,一直都是软件自由
有力,就会有反作用力,云软件的崛起会引发新的制衡力量。面对云服务的挑战,已经有许多软件组织/公司做出了反应,包括但不限于:使用歧视性开源协议,法律工具与集体行动,抢夺云计算的定义权。
修改开源许可证
软件社区应对云服务挑战的最常见反应是修改许可证,如 Grafana,MinIO,Pigsty 那样修改为 AGPLv3,或者像 Redis,MongoDB,ElasticSearch 那样修改为 SSPL,或者使用双协议 / BSL 的方式。大的方向是一致的 —— 重新划定社区共同体边界,将竞争者、与敌人直接排除在社区之外。
友善、自由的互联网/软件世界离我们越来越远 —— 大爱无疆,一视同仁,始终无私奉献的圣母精神固然值得敬佩,但真正能靠自己力量活下来的,是爱憎分明,以德报德,以直报怨的勇者。这里的核心问题在于 “歧视” / 区别对待 —— 对待同志要像春天般的温暖,对待敌人要像严冬一样残酷。
业界需要一种实践来做到这一点。AGPL,SSPL,BSL 这样的协议就是一种尝试 —— 这些协议通常并不影响终端用户使用这些软件;也不影响普通的服务提供商在遵循开源义务的前提下提供支持与咨询服务;而是专门针对公有云厂商设计的 —— 管控软件 作为公有云厂商摇钱树,在事实上是难以选择开源的,因此公有云厂商被歧视性地排挤出软件社区之外。
使用 Copyleft 协议族可以将公有云厂商排除在社区之外,从而保护软件自由。然而这些协议也容易出现伤敌一千,自损一百的情况。 在更为严格的许可要求下,一部分软件自由也受到了不必要的连带损失,例如:Copyleft 协议族也与其他广泛使用的许可证不兼容,这使得在同一个项目中使用某些库的组合变得更为困难。因此业界需要更好的实践来真正落实好这一点。
例如,我们的自由 PostgreSQL 发行版 Pigsty 使用了 AGPLv3 协议,但我们添加了对普通用户的 补充豁免条款 —— 我们只保留对公有云供应商,与换皮套壳魔改同行进行违规追索的权利,对于普通终端用户来说实际执行的是 Apache 2.0 等效条款 —— 采购我们服务订阅的客户也可以得到书面承诺:不就违反 AGPLv3 的协议进行任何追索 —— 从某种意义上来说,这也是一种 “双协议” 实践。
法律工具与集体行动
Copyleft软件许可证是一种法律工具,它试图迫使更多的软件供应商公开其源码。但是对于促进软件自由而言,Martin Keppmann 相信更有前景的法律工具是政府监管。例如,GDPR提出了数据可移植权,这意味着用户必须可以能将他们的数据从一个服务转移到其它的服务中。另一条有希望的途径是,推动 公共部门的采购倾向于开源、本地优先的软件,而不是闭源的云软件。这为企业开发和维护高质量的开源软件创造了积极的激励机制,而版权条款却没有这样做。
我认为,有效的改变来自于对大问题的集体行动,而不仅仅来自于一些开源项目选择一种许可证而不是另一种。公有云反叛军联盟应该团结一切可以团结的有生力量 —— 开源平替软件社群,开发者与用户;服务器与硬件厂商,坚守 IaaS 阵地的资源云,运营商云,IDC 与 IDC 2.0,甚至是公有云厂商的 IaaS 部门。采取一切法律框架内允许的行动去推进这一点。
一种有效的对抗措施是为整个云计算技术栈提供开源替代品,例如在《云计算反叛军》中就提到 —— 云计算世界需要一个能代表开源价值观的替代解决方案。开源软件社区可以与云厂商比拼生产力 —— 组建一个反叛军同盟采取集体行动。针对公有云厂商提供服务所必不可少的管控软件,逐一研发开源替代。
在云软件没有出现开源/本地优先的替代品前,公有云厂商可以大肆收割,攫取垄断利润。而一旦更好用,更简易,成本低得多的开源替代品出现,好日子便将到达终点。例如,Kubernetes / SealOS / OpenStack / KVM / Proxmox,可以理解为云厂商 EC2 / ECS / VPS 管控软件的开源替代;MinIO / Ceph 旨在作为为云厂商 S3 / OSS 管控软件的开源替代;而 Pigsty / 各种数据库 Operator 就是 RDS 云数据库管控软件的开源替代。这些开源替代品将直接击碎公有云计算的核心技术壁垒 —— 管控软件,让云的能力民主化,直接普及到每一个用户手中。
抢夺云计算的定义权
公有云可以渗透到开源社区中兴风作浪,那么开源社区也可以反向渗透,抢夺云计算的定义权。例如,对于 Cloud Native 的不同解释就生动地体现了这一点。云厂商将 Native 解释 “原生”:“原生诞生在公有云环境里的软件” 以混淆视听;但究其目的与效果而言,Native 真正的含义应为 “本地”,即与 Cloud 相对应的 “Local” —— 本地云 / 私有云 / 专有云 / 原生云 / 主权云,叫什么不重要,重要的是它运行在用户想运行的任何地方(包括云服务器),而不是仅仅是只能从公有云租赁!
这一理念,用一个单独的术语,可以概括为 “本地优先”,它与云服务针锋相对。“本地优先” 与 “云” 的对立体现为多种不同的形式:有时候是 “Native Cloud” vs “Cloud Native”,有时候叫体现为 “私有云” vs “公有云”,大部分时候与 ”开源“ vs “闭源”重叠,某种意义上也牵扯着 “自主可控” vs “仰人鼻息”。
本地优先的软件在您自己的硬件上运行,并使用本地数据存储,但也不排斥运行在云 IaaS 上,同时也保留云软件的优点,比如实时协作,简化运维,跨设备同步,资源调度,灵活伸缩等等。开源的本地优先的软件当然非常好,但这并不是必须的,本地优先软件90%的优点同样适用于闭源的软件。同理,免费的软件当然好,但本地优先的软件也不排斥商业化与收费服务。
理直气壮地争取资源
最后,不得不说的一点,就是开源商业化,收钱的问题。开源软件社区应该理直气壮地赚钱与筹款 —— 自由不是免费的! Freedom is not free 早已经是老生常谈。然而,相当一部分开源贡献者与开源用户都对开源软件有着不切实际的期待与错觉。
一些用户误以为他们与维护者的关系是商业关系,因此期望获得商业供应商的客户服务标准;而一些开源贡献者也期待开源用户给予金钱、声望、场景上的互惠与回馈贡献。一方认为他们应得的比另一方认为的要多,这种不明确的结果就会走向怨恨。
开源不等于免费,尽管大部分开源软件都提供了让用户免费使用的条件,但免费的开源软件是一种没有条件的礼物。作为收礼人,用户只有选择收或不收的权利;作为送礼人,期待得到特定回报是愚蠢的。作为开源贡献者,给别人戴上氧气面罩前,请务必先戴好自己的氧气面罩。如果某个开源企业自己都无法养活自己,那么选择用爱发电,四处慷慨送礼就是不明智的。
因此,全职的开源软件的开发者与公司,必须审慎思考自己的商业模式 —— 想让项目与组织持续发展,资源是必不可少的。无论是做专门的企业版,提供服务支持与订阅,设置双协议,去拉赞助化缘卖周边,或者干脆像 Redis 一样使用所谓 “不开源” 的协议,这都无可厚非,应当是光明正大,且理直气壮的。实际上,因为开源软件为用户提供了额外的“软件自由” —— 因此在质量相同的前提下,收取比云租赁软件更高的费用也是完全合乎道德情理的!
博弈均衡会走向哪里
云计算的故事与电力的推广过程如出一辙,让我们把目光回退至上个世纪初,从电力的推广普及垄断监管中汲取历史经验 —— 供电也许会走向垄断、集中、国有化,但你管不住电器。如果云硬件(算力)类似于电力,那么云软件便是电器。生活在现代的我们难以想象:洗衣机,冰箱,热水器,电脑,竟然还要跑到电站边的机房去用,我们也很难想象,居民要由自己的发电机而不是公共发电厂来供电。
因此从长期来看,公有云厂商大概也会有这么一天:在云硬件上通过类似于电力行业,通过垄断并购与兼并形成“规模效应”,利用“峰谷电”,“弹性定价”等各种方式优化整体资源利用率,在相互斗兽竞争中将算力成本不断压低至新的底线,实现“家家有电用”。当然,最后也少不了政府监管介入,公私合营收归国有,成为如同国家电网与电信运营商类似的存在,最终实现 IaaS 层的存储带宽算力的垄断。
而与之对应,制造灯泡、空调、洗衣机这类电器的职能会从电力公司中剥离,百花齐放。云厂商的 PaaS / SaaS 在被更好,更优质,更便宜的开源替代冲击下逐渐萎缩,或回归到足够低廉的价格水平。
正如当年开源运动的死对头微软,现在也选择拥抱开源。公有云厂商肯定也会有这一天,与自由软件世界达成和解,心平气和地接受基础设施供应商的角色定位,为大家提供水与电一般的存算资源。而云软件终将会回归正常毛利,希望那一天人们能记得,这不是因为云厂商大发慈悲,而是有人带来过开源平替。
MySQL正确性竟如此垃圾?
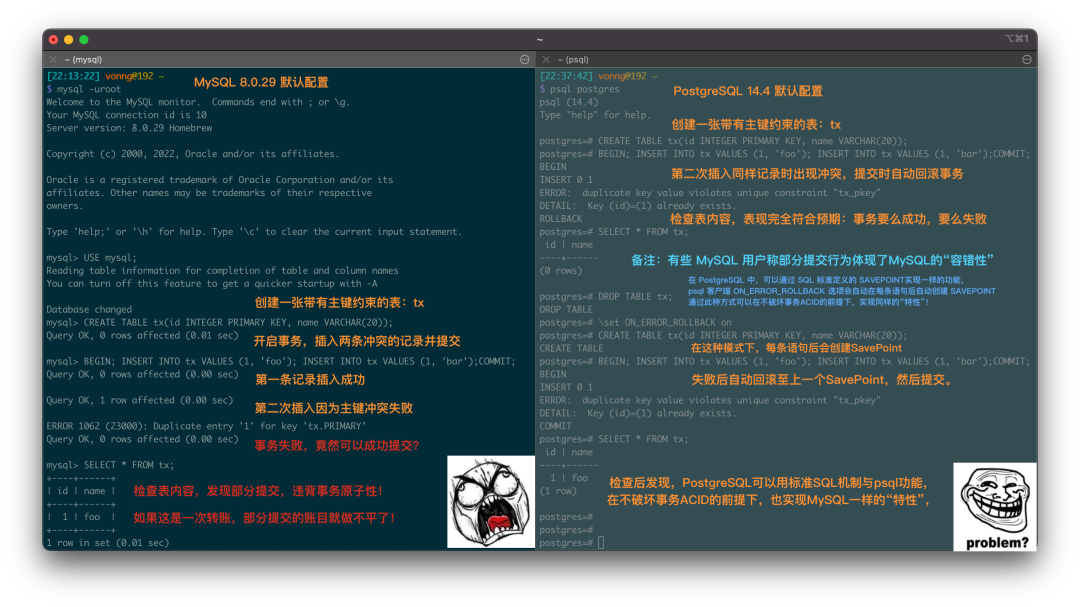
MySQL 曾经是世界上最流行的开源关系型数据库,然而流行并不意味着先进,流行的东西也会出大问题。JEPSEN 对 MySQL 的隔离等级评测捅穿了这层窗户纸 —— 在正确性这个体面数据库产品必须的基本属性上,MySQL 的表现一塌糊涂。
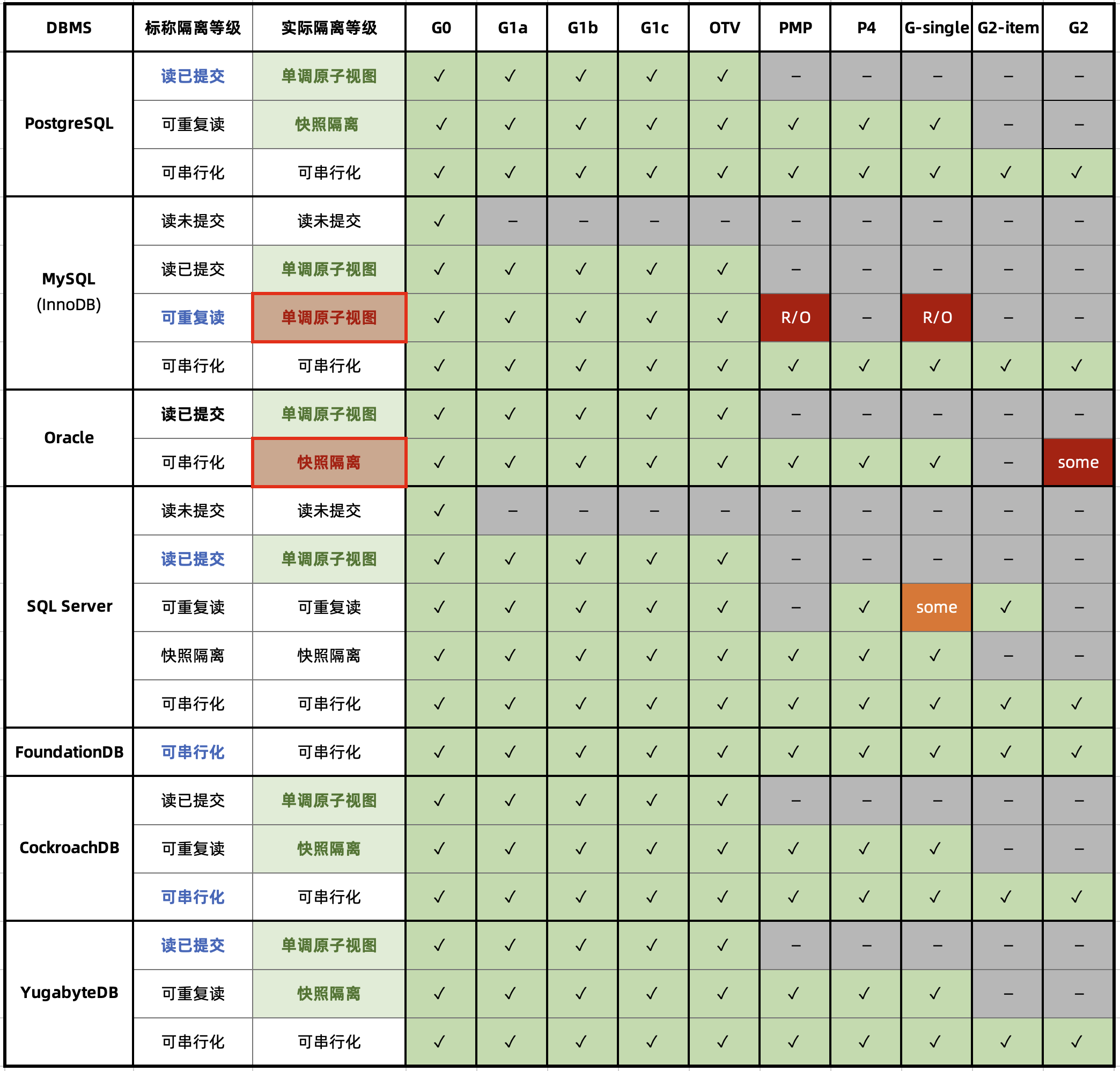
MySQL 文档声称实现了 可重复读/RR 隔离等级,但实际提供的正确性保证却弱得多。JEPSEN 在 Hermitage 的研究基础上进一步指出,MySQL 的 可重复读/RR 隔离等级实际上并不可重复读,甚至既不原子也不单调,连 单调原子视图/MAV 的基本水平都不满足。
此外,能“避免”这些异常的 MySQL 可串行化/SR 隔离等级难以生产实用,也非官方文档与社区认可的最佳实践;而且在AWS RDS默认配置下,MySQL SR 也没有真正达到“串行化”的要求;而李海翔教授的对 MySQL 一致性的分析进一步指出了 SR 的设计缺陷与问题。
综上, MySQL 的 ACID 存在缺陷,且与文档承诺不符 —— 这可能会导致严重的正确性问题。尽管可以通过显式加锁等方式规避此类问题,但用户确实应当充分意识到这里的利弊权衡与风险:在对正确性/一致性有要求的场景中选用 MySQL 时,请务必保持谨慎。

正确性为什么很重要?
可靠的系统需要应对各种错误,在数据系统的残酷现实中,更是很多事情都可能出错。要保证数据不丢不错,实现可靠的数据处理是一件工作量巨大且极易错漏的事情。而事务的出现解决了这个问题。事务是数据处理领域最伟大的抽象之一,也是关系型数据库引以为傲的金字招牌和尊严所在。
事务这个抽象让所有可能的结果被归结为两种情况:要么成功完事 COMMIT,要么失败了事 ROLLBACK,有了后悔药,程序员不用再担心处理数据时半路翻车,留下数据一致性被破坏的惨不忍睹的车祸现场。应用程序的错误处理变得简单多了,因为它不用再担心部分失败的情况了。而它提供的保证,用四个单词的缩写,被概括为 ACID。
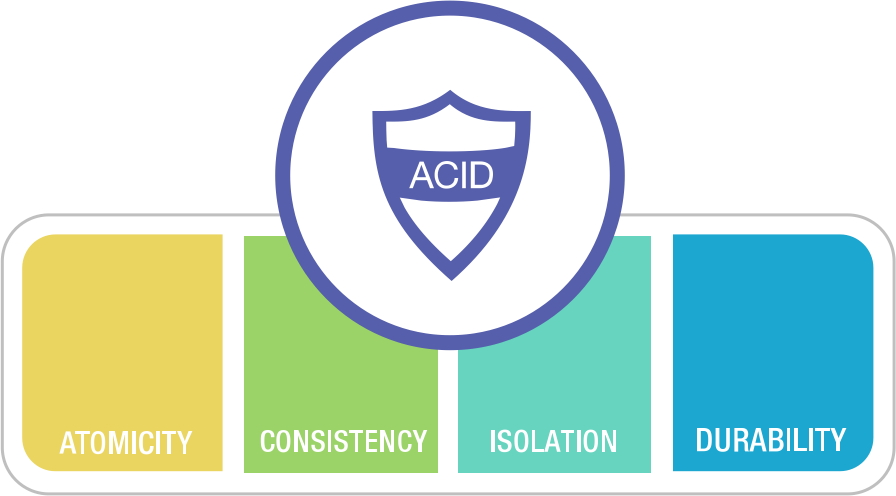
事务的原子性/A让你在提交前能随时中止事务并丢弃所有写入,相应地,事务的持久性/D则承诺一旦事务成功提交,即使发生硬件故障或数据库崩溃,写入的任何数据也不会丢失。事务的隔离性/I确保每个事务可以假装它是唯一在整个数据库上运行的事务 —— 数据库会确保当多个事务被提交时,结果与它们一个接一个地串行运行是一样的,尽管实际上它们可能是并发运行的。而原子性与隔离性则服务于 一致性/Consistency —— 也就是应用的正确性/Correctness —— ACID 中的C是应用的属性而非事务本身的属性,属于用来凑缩写的。
然而在工程实践中,完整的隔离性/I是很少见的 —— 用户很少会使用所谓的 “可串行化/SR” 隔离等级,因为它有可观的性能损失。一些流行的数据库如 Oracle 甚至没有实现它 —— 在 Oracle 中有一个名为 “可串行化” 的隔离级别,但实际上它实现了一种叫做 快照隔离(snapshot isolation) 的功能,这是一种比可串行化更弱的保证。
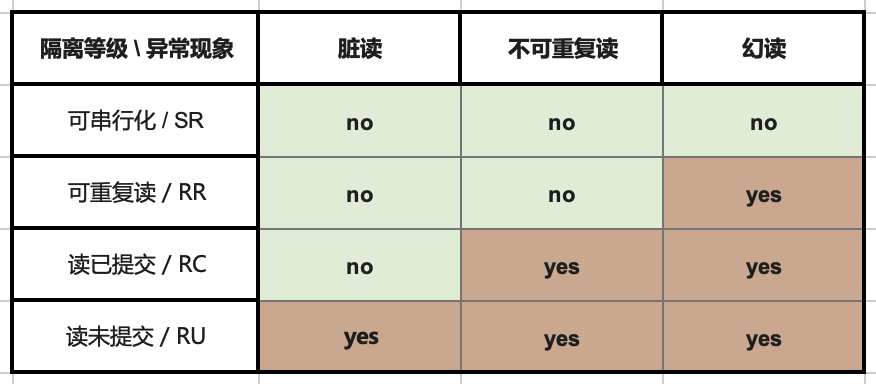
RDBMS 允许使用不同的隔离级别,供用户在性能与正确性之间进行权衡。ANSI SQL92 用三种并发异常(Anomaly),划分出四种不同的隔离级别,将这种利弊权衡进行了(糟糕的)标准化。:更弱的隔离级别“理论上”可以提供更好的性能,但也会出现更多种类的并发异常(Anomaly),这会影响应用的正确性。
为了确保正确性,用户可以使用额外的并发控制机制,例如显式加锁或 SELECT FOR UPDATE ,但这会引入额外的复杂度并影响系统的简单性。对于金融场景而言,正确性是极其重要的 —— 记账错漏,对账不平很可能会在现实世界中产生严重后果;然而对于糙猛快的互联网场景而言,错漏几条数据并非不可接受 —— 正确性的优先级通常会让位于性能。 这也为伴随互联网东风而流行的 MySQL 的正确性问题埋下了祸根。
Hermitage的结果怎么说?
在介绍 JEPSEN 的研究之前,我们先来回顾一下 Hermitage 项目。。这是互联网名著 《DDIA》 作者 Martin Kelppmann 在 2014 年发起的项目,旨在评测各种主流关系数据库的正确性。项目设计了一系列并发运行的事务场景,用于评定数据库标称隔离等级的实际水平。
从 Hermitage 的评测结果表格中不难看出,在主流数据库的隔离级别实现里有两处缺陷,用红圈标出:Oracle 的 可串行化/SR 因无法避免 G2 异常,而被认为实际上是 “快照隔离/SI”。
MySQL 的问题更为显著:因为默认使用的 可重复读/RR 隔离等级无法避免 PMP / G-Single 异常,Hermitage 将其实际等级定为 单调原子视图/MAV。

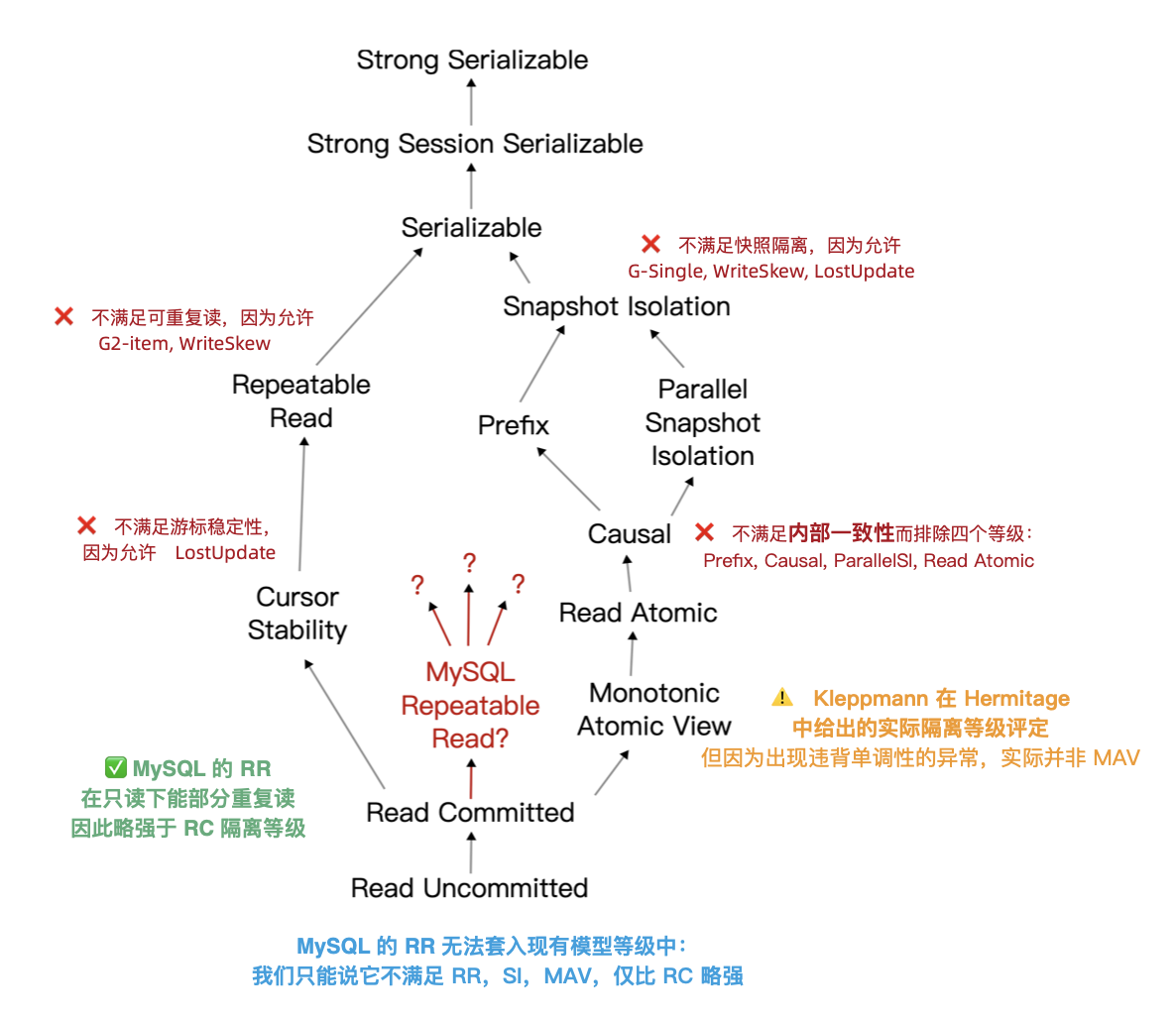
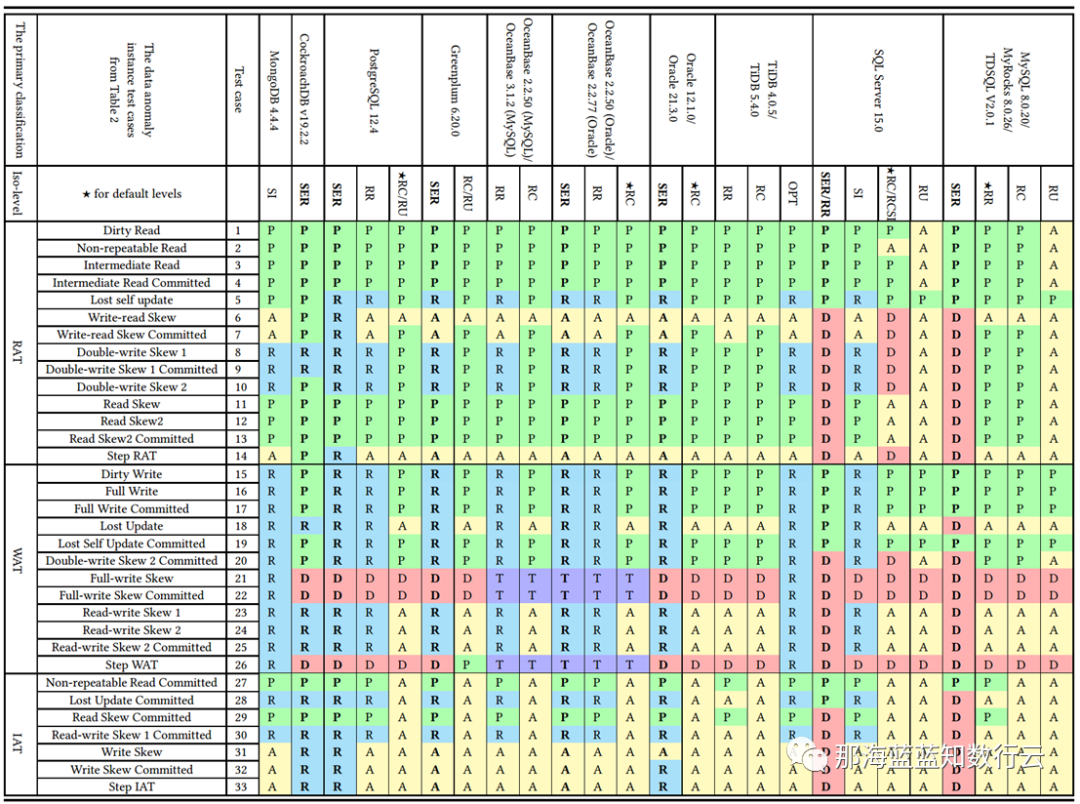
需要指出 ANSI SQL 92 隔离等级是一个糟糕简陋且广为诟病的标准,它只定义了三种异常现象并用它们区分出四个隔离等级 —— 但实际上的异常种类/隔离等级要多得多。著名的《A Critique of ANSI SQL Isolation Levels》论文对此提出了修正,并介绍了几种重要的新隔离等级,并给出了它们之间的强弱关系偏序图(图左)。
在新的模型下,许多数据库的 “读已提交/RC” 与 “可重复读/RR” 实际上是更为实用的 “单调原子视图/MAV” 和 “快照隔离/SI” 。但 MySQL 确实别具一格:在 Hermitage 的评测中,MySQL的 可重复读/RR 与 快照隔离/SI 相距甚远,也不满足 ANSI 92 可重复读/RR 的标准,实际水平为 **单调原子视图/MAV。**而 JEPSEN 的研究进一步指出,MySQL 可重复读/RR 实际上连 单调原子视图/MAV 都不满足,仅仅略强于 读已提交/RC 。
JEPSEN 又有什么新发现?
JEPSEN 是分布式系统领域最为权威的测试框架,他们最近发布了针对 MySQL 最新的 8.0.34 版本的研究与测评。建议读者直接阅读原文,以下是论文摘要:
MySQL 是流行的关系型数据库。我们重新审视了 Kleppmann (DDIA作者)在2014年发起的 Hermitage 项目结果,并确认了在当下 MySQL 的 可重复读/RR 隔离等级依然会出现 G2-item、G-single 和丢失更新异常。我们用事务一致性检查组件 —— Elle,发现了 MySQL 可重复读隔离等级也违反了内部一致性。更有甚者 —— 它违反了单调原子视图(MAV):即一个事务可以先观察到另一个事务的结果,再次尝试观察后却又无法复现同样的结果。作为彩蛋,我们还发现 AWS RDS 的 MySQL集群经常出现违反串行要求的异常。这项研究是独立进行的,没有报酬,并遵循 Jepsen研究伦理。
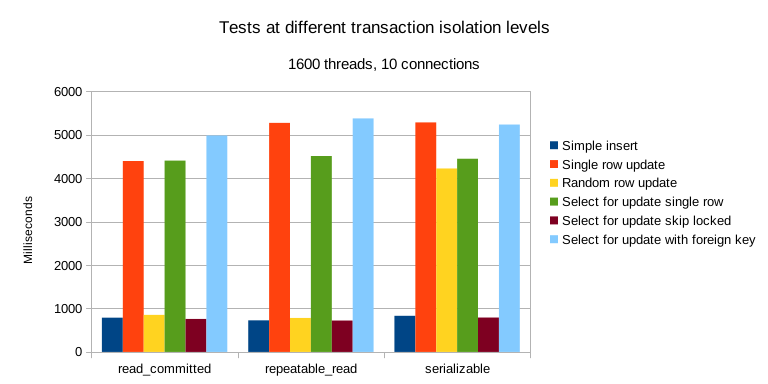
MySQL 8.0.34 的 RU,RC,SR 隔离等级符合 ANSI 标准的描述。且默认配置(RR,且innodb_flush_log_at_trx_commit = on)下的 持久性/D 并没有问题。问题出在MySQL 默认的 可重复读/RR 隔离等级上:
- 不满足 ANSI SQL92 可重复读(G2,WriteSkew)
- 不满足快照隔离(G-single, ReadSkew, LostUpdate)
- 不满足游标稳定性(LostUpdate)
- 违反内部一致性(Hermitage 披露)
- 违反读单调性(JEPSEN新披露)
MySQL RR 下的事务观察到了违反内部一致性、单调性、原子性的现象。这使得其评级被进一步调整至一个仅略高于 RC 的未定隔离等级水平上。
在 JEPSEN 的测试中共披露了六项异常,其中在2014年已知的问题我们先跳过,这里重点关注 JEPSEN 的新发现的异常,下面是几个具体的例子。
隔离性问题:不可重复读
在这个测试用例(JEPSEN 2.3)中是用来一张简单的表 people ,id 作为主键,预填充一行数据。
CREATE TABLE people (
id int PRIMARY KEY,
name text not null,
gender text not null
);
INSERT INTO people (id, name, gender) VALUES (0, "moss", "enby");
随即并发运行一系列写事务 —— 每个事务先读这一行的 name 字段;然后更新 gender 字段,随即再次读取 name 字段。正确的可重复读意味着在这个事务中,两次对 name 的读取返回的结果应该是一致的。
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
START TRANSACTION; -- 开启RR事务
SELECT name FROM people WHERE id = 0; -- 结果为 "pebble"
UPDATE people SET gender = "femme" WHERE id = 0; -- 随便更新点什么
SELECT name FROM people WHERE id = 0; -- 结果为 “moss”
COMMIT;
但是在测试结果中 ,9048个事务中的126个出现了内部一致性错误 —— 尽管是在 可重复读 隔离等级上运行的,但是实际读到的名字还是出现了变化。这样的行为与 MySQL 的隔离级别文档矛盾,该文档声称:“同一事务中的一致读取,会读取第一次读取建立的快照”。它与 MySQL 的一致性读文档相矛盾,该文档特别指出,“InnoDB 在事务的第一次读时分配一个时间点,并发事务的影响不应出现在后续的读取中”。
ANSI / Adya 可重复读实质是:一旦事务观察到某个值,它就可以指望该值在事务的其余部分保持稳定。MySQL 则相反:写入请求是邀请另一个事务潜入,并破坏用户刚刚读取的状态。这样的隔离设计与行为表现确实是难以置信地愚蠢。但这儿还有更离谱的事情 —— 比如单调性和原子性问题。
原子性问题:非单调视图
Kleppmann 在 Hermitage 中将 MySQL 可重复读评级为单调原子视图/MAV。根据 Bailis 等 的定义,单调原子视图确保一旦事务 T2 观察到事务T1 的任意结果,T2 即观察到 T1 的所有结果。
如果 MySQL 的 RR 只是在每次执行写入查询时重新获取一个快照,那么如果快照是单调的,它还是可以提供 MAV 等级的隔离保证 —— 而这正是 PostgreSQL 读已提交/RC 隔离级别的工作原理。
然而在常规的 MySQL 单节点部署中,情况并非如此:MySQL 在 RR 隔离等级时经常违反单调原子视图。JEPSEN(2.4)的这个例子用于说明这一点:这里有一张 mav 表,预填充两条记录(id=0,1),value 字段初始值都是 0。
CREATE TABLE mav (
id int PRIMARY KEY,
`value` int not null,
noop int not null
);
INSERT INTO mav (id, `value`, noop) VALUES (0, 0, 0);
INSERT INTO mav (id, `value`, noop) VALUES (1, 0, 0);
负载是读写混合事务:有写入事务会在同一个事务里去同时自增这两条记录的 value 字段;根据事务的原子性,其他事务在观察这两行记录时,value 的值应当是保持同步锁定增长的。
START TRANSACTION;
SELECT value FROM mav WHERE id = 0; --> 0 读取到了0
update mav SET noop = 73 WHERE id = 1; --> “邀请”新的快照进来
SELECT value FROM mav WHERE id = 1; --> 1 读取到了新值1,那么另一行的值应该也是1才对
SELECT value FROM mav WHERE id = 0; --> 0 结果读取到了旧值0
COMMIT;
然而在上面这个读取事务看来,它观察到了“中间状态”。读取事务首先读0号记录的 value,然后将 1 号记录的 noop 设置为一个随机值(根据上面一个案例,就能看见其他事务的变更了),接着再依次读取 0/1 号记录的 value 值。结果出现这种情况:读取0号记录拿到了新值,读取1号记录时获取到了旧值,这意味着单调性和原子性都出现了严重缺陷。
MySQL 的一致性读取文档广泛讨论了快照,但这种行为看起来根本不像快照。快照系统通常提供数据库状态的一致的、时间点的视图。它们通常是原子性的:要么包含事务的所有结果,要么全都不包含。即使 MySQL 以某种方式从写入事务的中间状态拿到了非原子性快照,它也必须得在获取行1新值前看到行0的新值。然而情况并非如此:此读取事务观察到行1的变化,但却没有看到行0的变化结果,这算哪门子快照?
因此,MySQL 的可重复读/RR 隔离等级既不原子,也不单调。在这一点上它甚至比不上绝大多数数据库的 读已提交/RC,起码它们实质上还是原子且单调的 单调原子视图/MAV。
另外一个值得一提的问题是:MySQL 默认配置下的事务会出现违背原子性的现象。我已经在两年前的文章中抛出该问题供业界讨论,MySQL 社区的观点认为这是一个可以通过 sql_mode 进行配置的特性而非缺陷。
但这种说法无法改变这一事实:MySQL确实违反了最小意外原则,在默认配置下允许用户做出这种违背原子性的蠢事来。与之类似的还有 replica_preserve_commit_order 参数。
串行化问题:鸡肋且糟糕
可串行化/SR 可以阻止上面的并发异常出现吗?理论上可以,可串行化就是为这个目的而设计的。但令人深感不安的是,JEPSEN 在 AWS RDS 集群中观察到,MySQL 在 可串行化/SR 隔离等级下也出现了 “Fractured Read-Like” 异常,这是G2异常的一个例子。这种异常是被 RR 所禁止的,应该只会在 RC 或更低级别出现。
深入研究发现这一现象与 MySQL 的 replica_preserve_commit_order 参数有关:禁用此参数允许 MySQL 以正确性作为代价,在重放日志时提供更高的并行性。当此选项被禁用时,JEPSEN在本地集群的 SR 隔离级别中也观察到了类似的 G-Single 和 G2-Item 异常。
可串行化系统应该保证事务(看起来是)全序执行,不能在副本上保留这个顺序是一件非常糟糕的事情。因此这个参数过去(8.0.26及以下)默认是禁用的,而在 MySQL 8.0.27 (2021-10-19)中被修改为默认启用。但是 AWS RDS 集群的参数组仍然使用“OFF”的旧默认值,并且缺少相关的文档说明,所以才会出现这样的现象。
尽管这一异常行为可以通过启用该参数进行规避,但使用 Serializable 本身也并非 MySQL 官方/社区鼓励的行为。MySQL 社区中普遍的观点是:除非绝对必要,否则应避免使用 可串行化/SR 隔离等级;MySQL 文档声称:“SERIALIZABLE 执行比 REPEATABLE READ 更严格的规则,主要用于特殊情况,例如 XA 事务以及解决并发和死锁问题。”
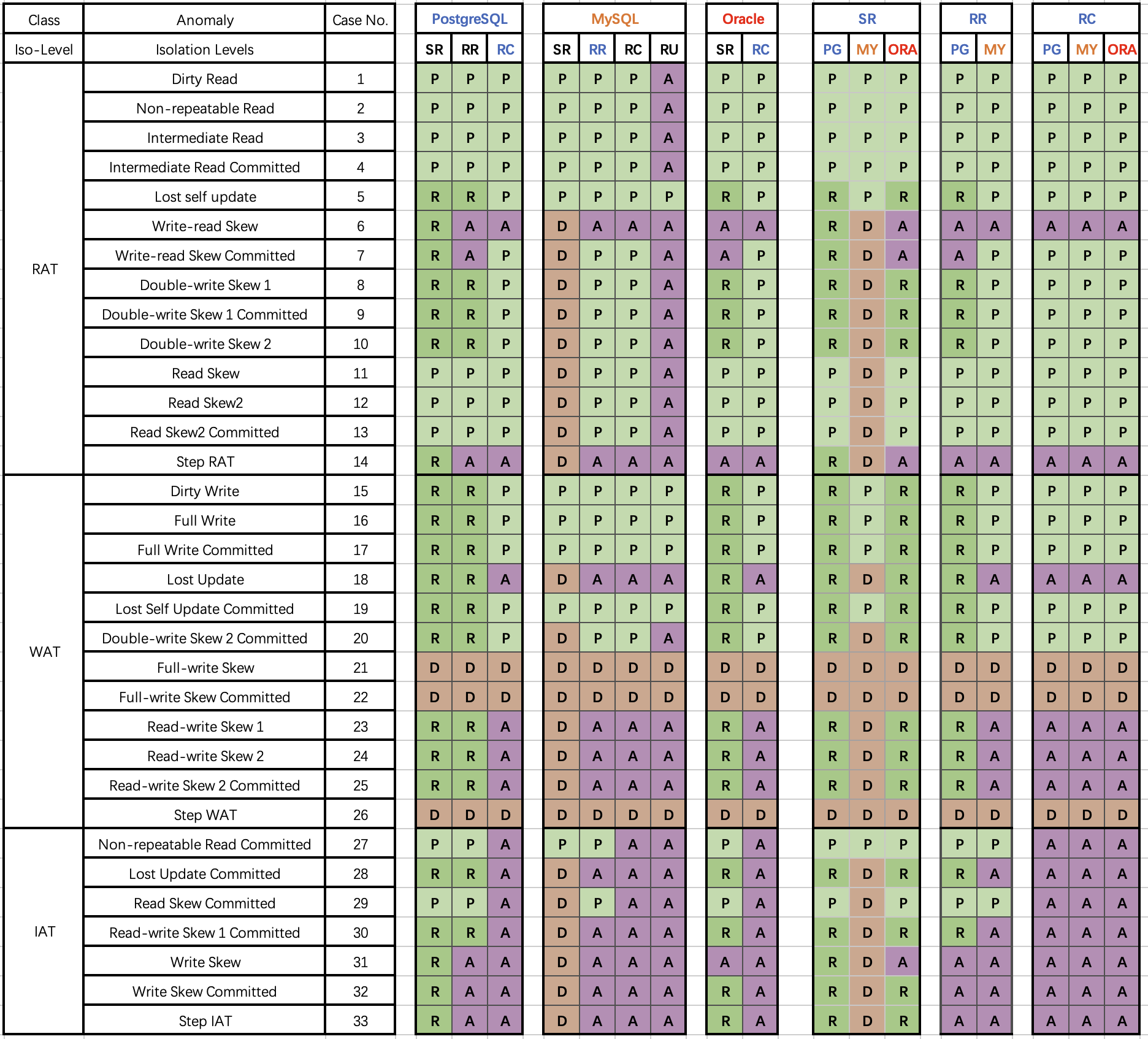
无独有偶,专门研究数据库一致性的李海翔教授(前鹅厂T14)在其《第三代分布式数据库》系列文章中,也对包括 MySQL (InnoDB/8.0.20)在内的多种数据库的实际隔离等级进行了测评,并从另一个视角给出了下面这幅更为细化的 “《一致性八仙图》”。
在图中蓝/绿色代表正确用规则/回滚避免一场;黄色的A代表出现异常,黄色“A”越多,正确性问题就越多;红色的“D”指使用了影响性能的死锁检测来处理异常,红色D越多,性能问题就越严重;
不难看出,正确性最好的是 PostgreSQL SR 与基于其构建的 CockroachDB SR,其次是 Oracle SR;都主要是通过机制与规则避免并发异常;而 MySQL 的正确性水平令人不忍直视。
李海翔教授在专文《一无是处的MySQL》对此有过详细分析:尽管MySQL的 可串行化/SR 可以通过大面积使用死锁检测算法保证正确性,但这样处理并发异常,会严重影响数据库的性能与实用价值。
正确性与性能的利弊权衡
李海翔教授在《第三代分布式数据库:踢球时代》中抛出了一个问题:如何对系统的正确性与性能进行利弊权衡?
数据库圈有一些“习惯成自然”的怪圈,例如很多数据库的默认隔离等级都是 读已提交/RC,有很多人会说“数据库的隔离级别设置为 RC 足够了”!可是为什么?为什么要设置为 RC ?因为他们觉得 RC 级别数据库性能好。
可如下图所示,这里存在一个死循环:用户希望数据库性能更好,于是开发者把应用的隔离级别设置为RC。然而用户,特别是金融保险证券电信等行业的用户,又期望保证数据的正确性,于是开发者不得不在 SQL 语句中加入 SELECT FOR UPDATE 加锁以确保数据的正确性。而此举又会导致数据库系统性能下降严重。在TPC-C和YCSB场景下测试结果表明,用户主动加锁的方式会导致数据库系统性能下降严重,反而是强隔离级别下的性能损耗并没有那么严重。
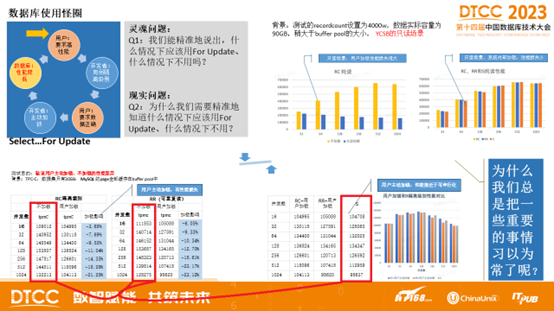
使用弱隔离等级其实严重背离了“事务”这个抽象的初衷 —— 在较低隔离级别的重要数据库中编写可靠事务极其复杂,而与弱隔离等级相关的错误的数量和影响被广泛低估[13]。使用弱隔离级别本质上是把本应由数据库来保证的正确性 & 性能责任踢给了应用开发者。
惯于使用弱隔离等级这个问题的根,可能出在 Oracle 和 MySQL 上。例如,Oracle 从来没有提供真正的可串行化隔离等级(SR 实际上是 快照隔离/SI),直到今天亦然。因此他们必须将*“使用 RC 隔离等级”* 宣传为一件好事。Oracle 是过去最流行的数据之一,所以后来者也纷纷效仿。
而使用弱隔离等级性能更好的刻板印象可能源于 MySQL —— 大面积使用死锁检测(标红)实现的 SR 性能确实糟糕。但对于其他 DBMS 来说并非必然如此。例如,PostgreSQL 在 9.1 引入的 可串行化快照隔离(SSI) 算法可以在提供完整可串行化前提下,相比快照隔离/SI 并没有多少性能损失。
更进一步讲,摩尔定律加持下的硬件的性能进步与价格坍缩,让OLTP性能不再成为稀缺品 —— 在单台服务器就能跑起推特的当下,超配充裕的硬件性能实在用不了几个钱。而比起数据错漏造成的潜在损失与心智负担,担心可串行化隔离等级带来的性能损失确实是杞人忧天了。
时过境迁,软硬件的进步让 “默认可串行化隔离,优先确保100%正确性” 这件事切实可行起来。为些许性能而牺牲正确性这样的利弊权衡,即使对糙猛快的互联网场景也开始显得不合时宜了。新一代的分布式数据库诸如 CockroachDB 与 FoundationDB 都选择了默认使用 可串行化 隔离等级。
做正确的事很重要,而正确性是不应该拿来做利弊权衡的。在这一点上,开源关系型数据库两巨头 MySQL 和 PostgreSQL 在早期实现上就选择了两条截然相反的道路:MySQL 追求性能而牺牲正确性;而学院派的 PostgreSQL 追求正确性而牺牲了性能。在互联网风口上半场中,MySQL 因为性能优势占据先机乘风而起。但当性能不再是核心考量时,正确性就成为了 MySQL 的致命出血点。
解决性能问题有许多种办法,甚至坐等硬件性能指数增长也是一种切实可行的办法(如 Paypal);而正确性问题往往涉及到全局性的架构重构,解决起来绝非一夕之功。过去十年间,PostgreSQL守正出奇,在确保最佳正确性的前提下大步前进,很多场景的性能都反超了 MySQL;而在功能上更是籍由其扩展生态引入的向量、JSON,GIS,时序,全文检索等扩展特性全方位碾压 MySQL。
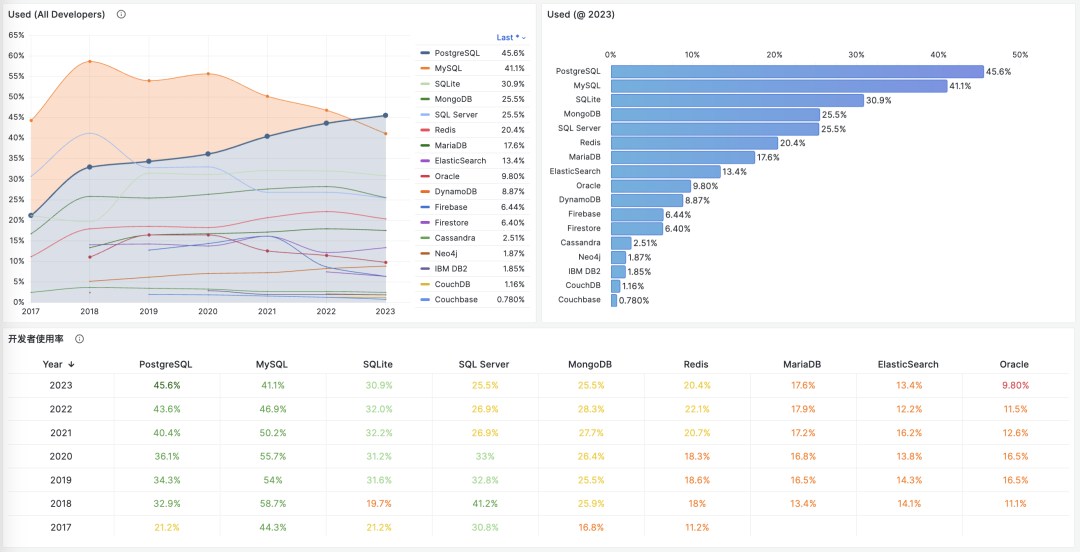
PostgreSQL 在 2023 年 StackOverflow 的全球开发者用户调研中,开发者使用率正式超过了 MySQL ,成为世界上最流行的数据库。而在正确性上一塌糊涂,且与高性能难以得兼的 MySQL ,确实应该好好思考一下自己的破局之路了。
参考
[1] JEPSEN: https://jepsen.io/analyses/mysql-8.0.34
[2] Hermitage: https://github.com/ept/hermitage
[4] Jepsen研究伦理: https://jepsen.io/ethics
[5] innodb_flush_log_at_trx_commit: https://dev.mysql.com/doc/refman/8.0/en/innodb-parameters.html#sysvar_innodb_flush_log_at_trx_commit
[6] 隔离级别文档: https://dev.mysql.com/doc/refman/8.0/en/innodb-transaction-isolation-levels.html#isolevel_repeatable-read
[7] 一致性读文档: https://dev.mysql.com/doc/refman/8.0/en/innodb-consistent-read.html
[9] 单调原子视图/MAV: https://jepsen.io/consistency/models/monotonic-atomic-view
[10] Highly Available Transactions: Virtues and Limitations,Bailis 等: https://amplab.cs.berkeley.edu/wp-content/uploads/2013/10/hat-vldb2014.pdf
[12] replica_preserve_commit_order: https://dev.mysql.com/doc/refman/8.0/en/replication-options-replica.html#sysvar_replica_preserve_commit_order
[13] 与弱隔离等级相关的错误的数量和影响被广泛低估: https://dl.acm.org/doi/10.1145/3035918.3064037
[14] 测试PostgreSQL的并行性能: https://lchsk.com/benchmarking-concurrent-operations-in-postgresql
[15] 在单台服务器上跑起推特: https://thume.ca/2023/01/02/one-machine-twitter/
数据库应该放入K8S里吗?
数据库是否应该放入 Kubernetes / Docker 里,到今天仍然是一个充满争议的话题。k8s 作为一个先进的容器编排工具,在无状态应用管理上非常趁手;但其在处理有状态服务 —— 特别是PostgreSQL和MySQL这样的数据库时,有着本质上的局限性。
在上一篇文章《数据库放入Docker是个好主意吗?》中,我们已经讨论了容器化数据库的利弊权衡;今天我们就来聊一聊将数据库放入 K8S 中编排调度所涉及的利弊权衡 —— 并深入探讨为什么将数据库放入 K8S 中不是一个明智的选择。
摘要
Kubernetes (k8s)是一个非常优秀的容器编排工具,它的目标是帮助开发者更好地管理海量复杂的无状态应用服务。尽管它提供了诸如 StatefulSet、PV、PVC、LocalhostPV 等抽象原语用于支持有状态服务(i.e. 数据库),但这些东西对于运行有着更高可靠性要求的生产级数据库服务来说仍然远远不够。
数据库是“宠物”而非“家畜”,需要细心地照料呵护。将数据库放入K8S作为“牲畜”对待,本质上是将外部的磁盘/文件系统/存储服务变为了新的“数据库宠物”。使用 EBS/网络存储/云盘运行数据库,在可靠性与性能上有巨大劣势;然而如果使用高性能本地NVMe磁盘,与节点绑定无法调度的数据库又失去了放入K8S的主要意义。
将数据库放入 K8S 中会导致 “双输” —— K8S 失去了无状态的简单性,不能像纯无状态使用方式那样灵活搬迁调度销毁重建;而数据库也牺牲了一系列重要的属性:可靠性,安全性,性能,以及复杂度成本,却只能换来有限的“弹性”与资源利用率 —— 但虚拟机也可以做到这些!对于公有云厂商之外的用户来说,几乎都是弊远大于利的。
以 K8S为代表的“云原生”狂热已经成为了一种畸形的现象:为了k8s而上k8s。工程师想提高不可替代性堆砌额外复杂度,管理者怕踩空被业界淘汰互相卷着上线。骑自行车就能搞定的事情非要开坦克来刷经验值/证明自己,却不考虑要解决的问题是否真的需要这些屠龙术 —— 这种架构杂耍行为终将招致恶果。
我们认为在分布式网络存储的可靠性与性能超过本地存储前,将数据库放入 K8S 是一种不明智的选择。解决数据库管理复杂度并非只有 K8S 一条道路,开箱即用的开源RDS —— Pigsty 基于裸操作系统提供了另一种选择。用户应当擦亮双眼,根据自己的真实情况与需求做出明智的利弊权衡与技术决策。
当下的现状
K8S 在无状态应用服务编排领域内表现出色,但一开始对于有状态的服务极其有限 —— 尽管运行数据库并不是 K8S 与 Docker 的本意,然而这阻挡不了社区对于扩张领地的狂热 —— 布道师们将 K8S 描绘为下一代云操作系统,断言数据库必将成为 Kubernetes 中的普通应用一员。而各种用于支持有状态服务的抽象也开始涌现:StatefulSet、PV、PVC、LocalhostPV。
有无数云原生狂热者开始尝试将现有数据库搬入 K8S 中,各种数据库的 CRD 与 Operator 开始出现 —— 仅以 PostgreSQL 为例,在市面上就已经可以找到至少十款以上种不同的 K8S 部署方案:PGO,StackGres,CloudNativePG,TemboOperator,PostgresOperator,PerconaOperator,Kubegres,KubeDB,KubeBlocks,……,琳琅满目。CNCF 的景观图就这样开始迅速扩张,成为了复杂度乐园。
然而复杂度也是一种成本,随着“降本增效”成为主旋律,反思的声音开始出现 —— 下云先锋 DHH 在公有云上深度使用了 K8S,但在回归开源自建的过程中也因为过分复杂而放弃了它,仅仅用 Docker 与一个名为 Kamal 的Ruby小工具作为替代。许多人开始思考,像数据库这样的有状态服务到底适合放入 Kuberentes 中吗?
而 K8S 本身为了支持有状态应用,也变得越来越复杂,远离了容器编排平台的初心。以至于 Kubernetes 的联合创始人Tim Hockin 也在今年的 KubeCon 上罕见地发了声:《K8s在被反噬!》:“Kubernetes 变得太复杂了,它需要学会克制,否则就会停止创新,直至丢失自己的基本盘 ” 。
双输的选择
对于有状态的服务,云原生领域非常喜欢用一个“宠物”与“牲畜”的类比 —— 前者需要精心照料,细心呵护,例如数据库;而后者可以随意处置,一次性用完即丢,就是普通的无状态应用(Disposability)。
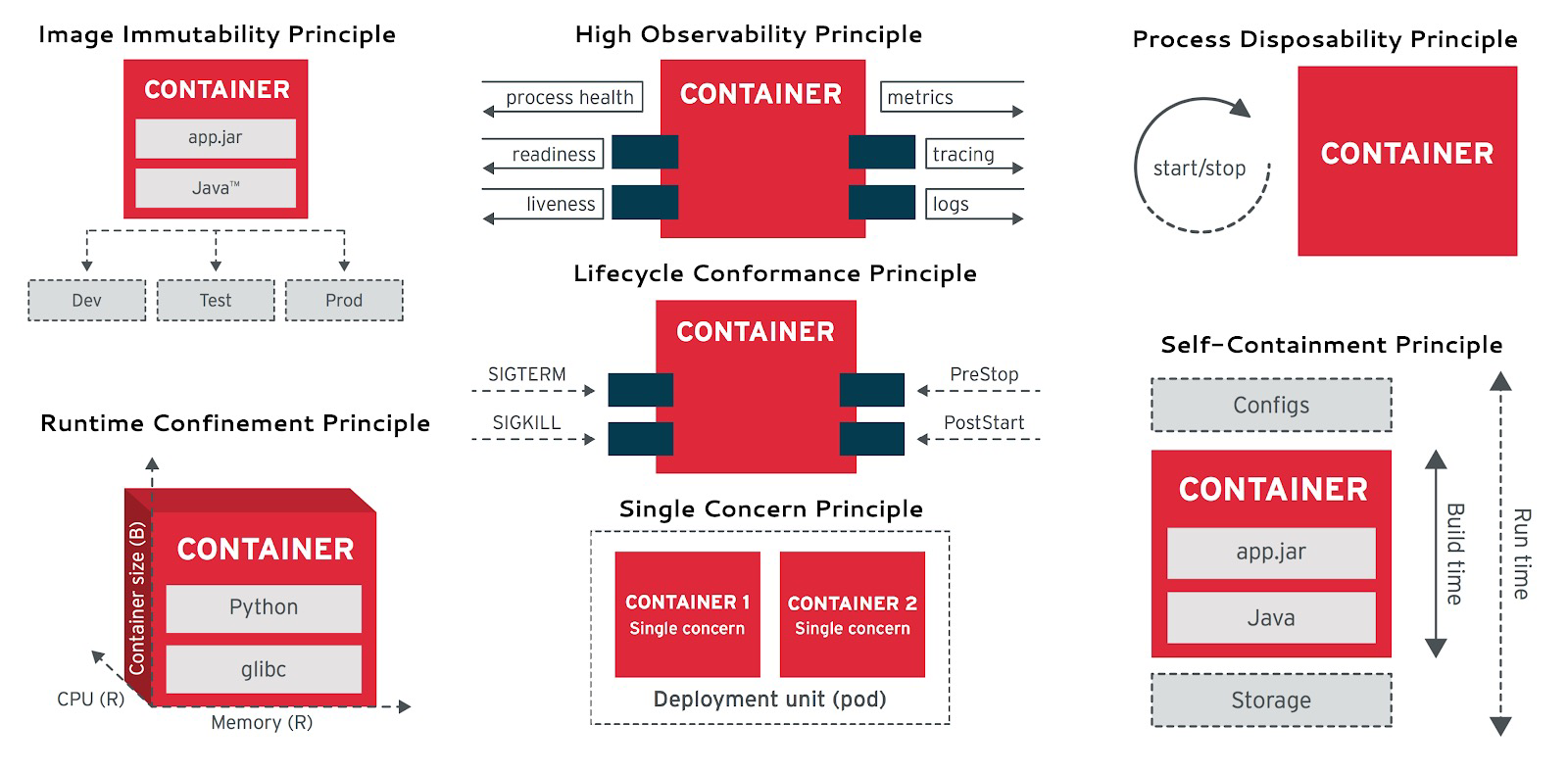
云原生应用12要素: Disposability
K8S的一个主要架构目标就是,把能当畜生的都当畜生处理。对数据库进行 “存算分离”就是这样一种尝试:把有状态的数据库服务拆分为K8S外的状态存储与K8S内的纯计算部分,状态放在云盘/EBS/分布式存储上,而“无状态”的数据库进程就可以塞进K8S里随意创建销毁与调度了。
不幸的是,数据库,特别是 OLTP 数据库是重度依赖磁盘硬件的,而网络存储的可靠性与性能相比本地磁盘仍然有数量级上的差距。因而 K8S 也提供了LocalhostPV 的选项 —— 允许用户在容器上打一个洞,直接使用节点操作系统上的数据卷,直接使用高性能/高可靠性的本地 NVMe 磁盘存储。
但这让用户面临着一个抉择:是使用垃圾云盘并忍受糟糕数据库的可靠性/性能,换取K8S的调度编排统一管理能力?还是使用高性能本地盘,但与宿主节点绑死,基本丧失所有灵活调度能力?前者是把压舱石硬塞进 K8S 的小船里,拖慢了整体的灵活性与速度;后者则是用几根钉子把 K8S 的小船锚死在某处。
运行单独的纯无状态的K8S集群是非常简单可靠的,运行在物理机裸操作系统上的有状态数据库也是十分可靠的。然而将两者混在一起的结果就是双输:K8S失去了无状态的灵活与随意调度的能力,而数据库牺牲了一堆核心属性:可靠性、安全性、效率与简单性,换来了对数据库根本不重要的“弹性”、资源利用率与Day1交付速度。
关于前者,一个鲜活的案例是由 KubeBlocks 贡献的 PostgreSQL@K8s 性能优化记。k8s 大师上了各种高级手段,解决了裸金属/裸OS上根本不存在的性能问题。关于后者的鲜活的案例是滴滴的K8S架构杂耍大翻车,如果不是将有状态的 MySQL 放在K8S里,单纯重建无状态 K8S 集群并重新发布应用,怎么会要12小时这么久才恢复?
利弊的权衡
对于严肃的生产技术选型决策,最重要的永远是利弊权衡。这里我们按照常用的“质量、安全、效率、成本”顺序,来聊一下K8S放数据库相对于经典裸金属/VM部署在技术上的利弊权衡。我并不想在这里写一篇面面俱到,好像什么都说了的论文,而是抛出一些具体问题,供大家思考与讨论。
在质量上:K8S相比物理部署新增了额外的失效点与架构复杂度,拉高了爆炸半径,并且会显著拉长故障的平均恢复时长。在《数据库放入Docker是个好主意吗?》一文中,我们已经给出了关于可靠性的论证,同样的结论也可以适用于 Kubernetes —— K8S 与 Docker 会为数据库引入额外且不必要的依赖与失效点,而且缺乏社区故障知识积累与可靠性战绩证明(MTTR/MTBF)。
在云厂商的分类体系中,K8S属于PaaS,而RDS属于更底层的IaaS。数据库服务比K8S有着更高的可靠性要求:例如,许多公司的云管平台都会依赖一个额外的 CMDB 数据库。那么这个数据库应该放在哪里呢?你不应该把 K8S 依赖的东西交给 K8S 自己来管理,也不应该添加没有必要的额外依赖,阿里云全球史诗大故障 与 滴滴K8S架构杂耍大翻车 为我们普及了这个常识。而且,如果已经有了K8S外的数据库,再去维护一套K8S内的数据库体系就更得不偿失了。
在安全 上: 多租户环境中的数据库新增了额外的攻击面,带来了更高的风险与更复杂的审计合规挑战。K8S 会让你的数据库更安全吗?也许K8S架构杂耍的复杂度景象会劝退不熟悉K8S的脚本小子,但对真正的攻击者而言,更多的组件与依赖往往意味着更广的攻击面。
在《BrokenSesame 阿里云PostgreSQL 漏洞技术细节》中,安全人员利用一个自己的 PostgreSQL 容器逃脱到K8S主机节点中,并可以访问 K8S API 与其他租户的容器与数据。而这很明显是 K8S 专有的问题 —— 风险是真实存在的,这样的攻击已经发生,并让本土云厂领导者阿里云中招翻车。
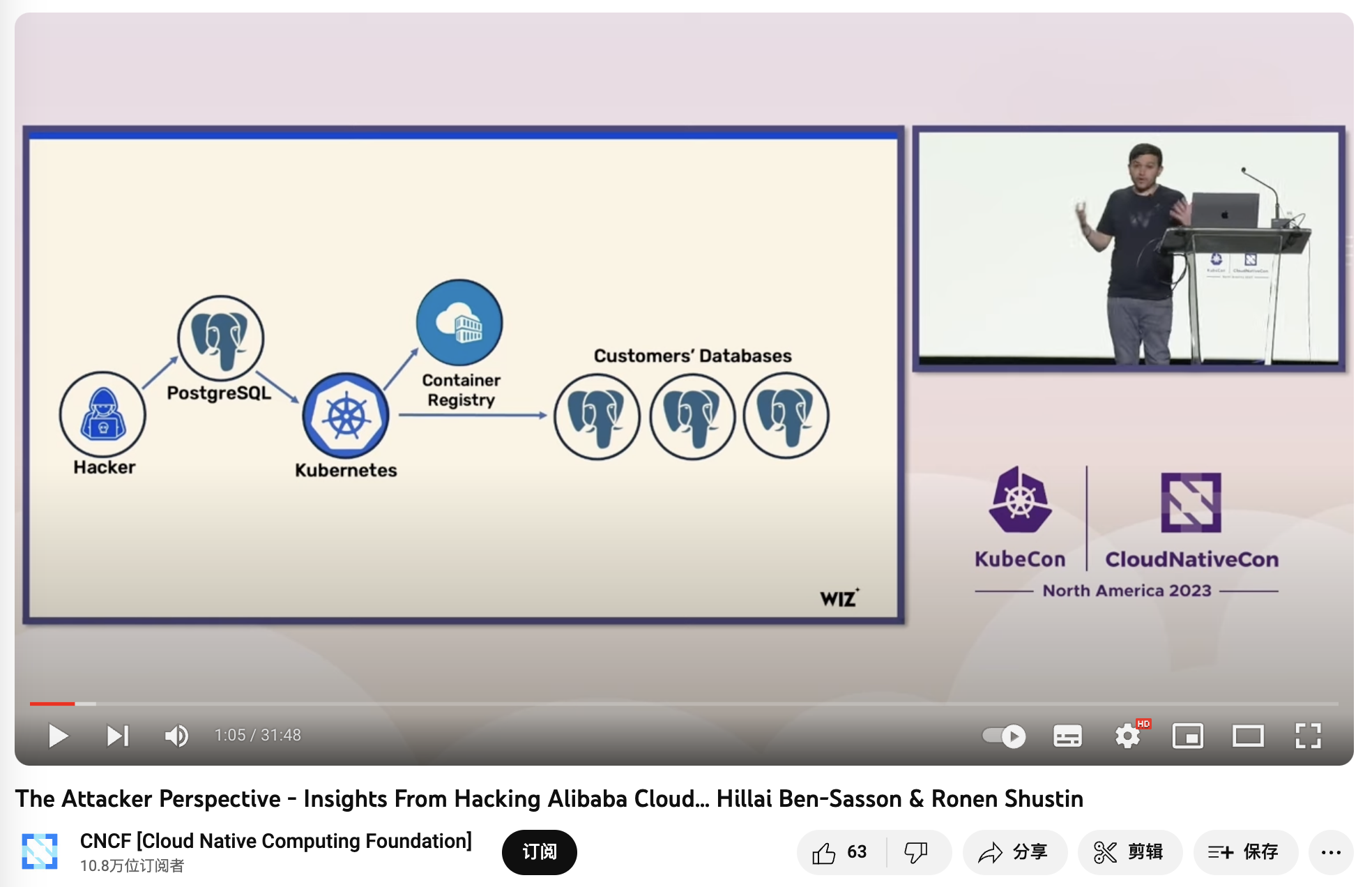
《The Attacker Perspective - Insights From Hacking Alibaba Cloud》
在效率上:如《数据库放入Docker是个好主意吗?》所述,不论是额外的网络开销,Ingress 瓶颈,拉垮的云盘,对于数据库的性能都会产生负面影响。又比如《PostgreSQL@K8s 性能优化记》 所揭示的 —— 你需要相当程度的技术水平功力,才能让 K8S 中的数据库性能堪堪持平于裸机。
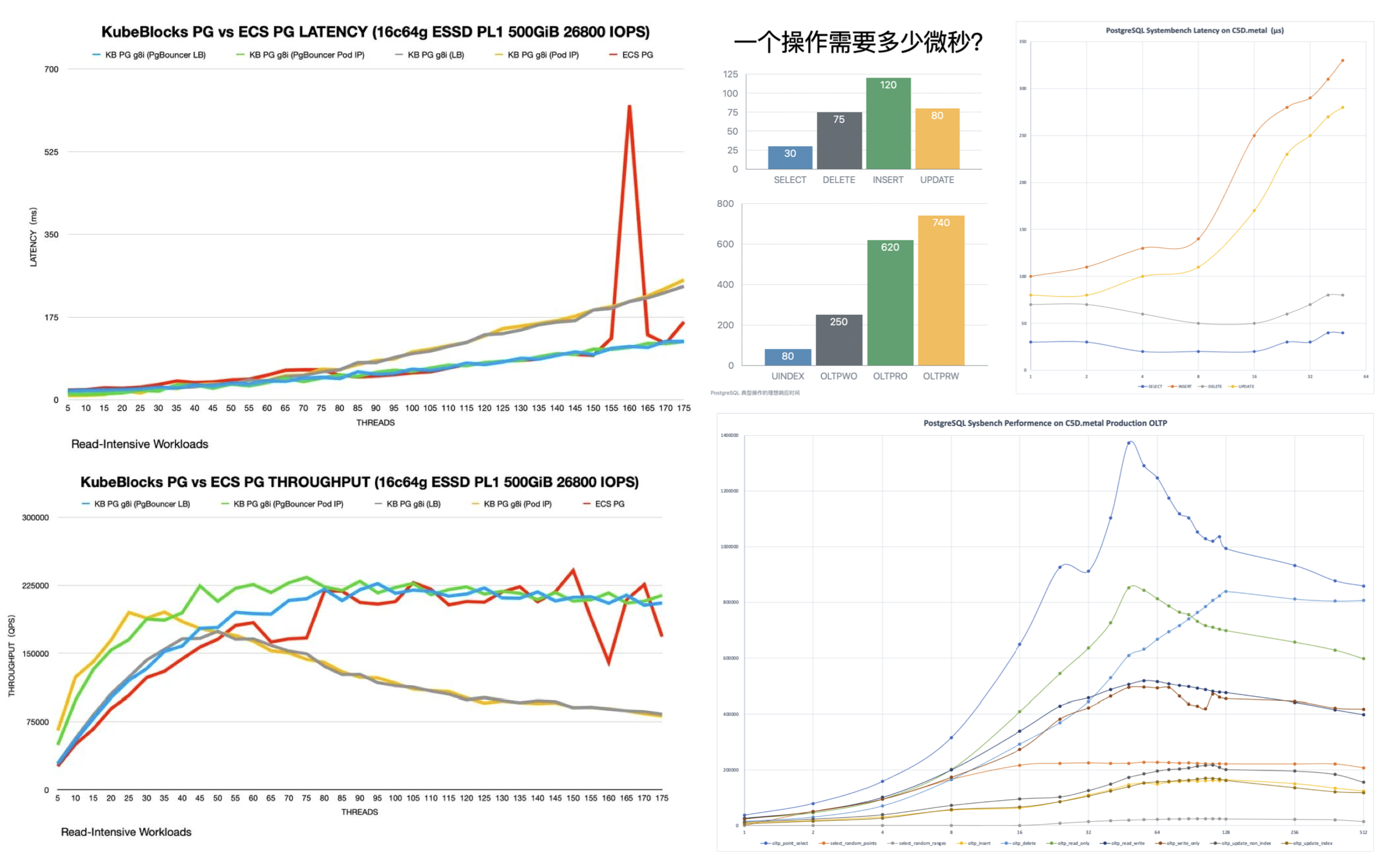
Latency 的单位是 ms 不是 µs,我差点以为自己眼花了。
另一个关于效率的误区是资源利用率, 不同于离线分析类业务,关键的在线 OLTP 数据库不仅不应当提高资源利用率,反而应当刻意压低资源利用率水位,从而提高系统的可靠性与用户的使用体验。如果有许许多多多零散业务,也可以通过 PDB / 共用共享数据库集群来提高资源利用率。K8S 所主张的弹性效率也并非其独有 —— KVM/EC2 也可以很好地解决这个问题。
在成本上,K8S与各种Operator提供了一个不错的抽象,封装了一部分数据库管理的复杂度,对于没有DBA的团队有一定的吸引力。然而使用它管理数据库所减少的复杂度,比起使用K8S本身引入的复杂度来说就相形见绌了。比如,随机发生的IP地址漂移与Pod自动重启,对于无状态应用来说可能并不是一个大问题,然而对数据库来说这就令人难以忍受了 —— 许多公司不得不尝试魔改 kubelet 以规避这一行为,进而又引入更多的复杂度与维护成本。
正如《从降本增笑到降本增效》“降低复杂度成本” 一节所述:智力功率很难在空间上累加:当数据库出现问题时需要数据库专家来解决;当 Kubernetes 出现问题时需要 K8S 专家看问题;然而当你把数据库放入 Kubernetes 时,复杂度出现排列组合,状态空间开始爆炸,然而单独的数据库专家和 K8S 专家的智力带宽是很难叠加的 —— 你需要一个双料专家才能解决问题,而这样的专家比起单纯的数据库专家无疑要少得多也贵得多。这样的架构杂耍足以让包括头部公有云/大厂在内的绝大多数团队,在遇到故障时出现大翻车。

云原生狂热
一个有趣的问题是,既然 K8S 并不适用于有状态的数据库,那么为什么还有这么多厂商 —— 包括 “大厂” 在争先恐后地做这件事呢?恐怕这里的原因并不是技术上的。
Google 照着内部的 Borg 宇宙飞船做了艘 K8S 战舰开源出来,老板们怕踩空被业界淘汰进而互相卷着上线,觉得自己用上 K8S 就跟Google一样牛逼了 —— 有趣的是Google自己不用K8S,开源出来搅屎AWS忽悠业界;然而绝大多数公司并没有 Google 那样的人手去操作战舰。更重要的是他们的问题可能只要一艘舢舨就解决了。裸机上的 MySQL + PHP , PostgreSQL+ Ruby / Python / Go ,已经让无数公司一路干到上市了。
在现代硬件条件下,绝大多数应用,终其生命周期的复杂度都不足以用到 K8S 来解决。然而,以 K8S为代表的“云原生”狂热已经成为了一种畸形的现象:为了k8s而上k8s。一些工程师的目的是去寻找足够“先进”足够酷的,最好是大公司在用的东西来满足自己跳槽,晋升等个人价值的需求,或者趁机堆砌复杂度以提高自己的 Job Security,而压根不是考虑要解决问题是否真的需要这些屠龙术。

云原生领域全景图中充斥着各种花里胡哨的项目,每个新来的开发团队都想引入一套新东西,今天一个 helm 明天一个 kubevela,说起来都是光明前途,效率拉满,实际上成为了 YAML Boy 的架构屎山与复杂度乐园 —— 折腾最新的技术,发明大把的概念,经验值和声望是自己的,复杂度代价反正是用户买单,搞出问题还可以再敲一笔维护费,简直完美!
CNCF Landscape
云原生运动的理念是很有感召力的 —— 让本来是公有云专属的弹性调度能力普及到每一个用户身上,K8S 也确实在无状态应用上表现出色。然而过度的狂热已经让 K8S 偏离了原本的初心与方向 —— 简单地做好无状态应用编排调度这件事,被支持有状态应用的妄念拖累的也不再简单了。
明智地决策
几年前刚接触K8S时,我也曾有过这种皈依者狂热 —— 在探探我们也有着两万多核几百套数据库,我迫切地想要尝试将数据库放入 Kubernetes 中,并测遍了各种 Operator。然而在前后长达两三年的方案调研与架构设计中,我最终冷静下来,并放弃了这种疯狂的打算 —— 而是选择基于裸金属/裸操作系统架构我们自己的数据库服务。因为在对我们来说,K8S为数据库带来的收益相比其引入的问题与麻烦,实在是微不足道。
数据库应该放入K8S里吗?这取决于具体场景:对于从资源利用率里用超卖刨食吃的云厂商而言,弹性与资源利用率非常重要,它们直接与收入和利润挂钩;稳定可靠效率都得屈居其次 —— 毕竟可用性低于3个9也不过是按SLA赔偿本月消费25%的代金券而已。但是对于我们自己,以及生态光谱中的大多数用户而言,这些利弊权衡就不成立了:一次性的 Day1 Setup效率,弹性与资源利用率并不是他们最关心的问题;可靠性、性能、Day2 Operation成本,这些数据库的核心属性才是最重要的。
我们将自己的数据库服务架构方案开源出来 —— 即开箱即用的 PostgreSQL 发行版与本地优先的 RDS 替代: Pigsty。我们没有选择 K8S 与 Docker 这种所谓 “一次构建,到处运行 ” 的讨巧办法,而是一个一个地去适配不同的操作系统发行版/不同的大版本,并使用 Ansible 实现类 K8S CRD IaC 的效果封装管理复杂度。这确实是一件非常幸苦的工作,但却是正确的事情 —— 这个世界并不需要又一个在 K8S 中放入PG数据库玩具积木的拙劣尝试,但确实需要一个最大化发挥出硬件性能与可靠性的生产数据库服务架构方案。
Pigsty vs StackGres
也许有一天,当分布式网络存储的可靠性与性能可以超过本地存储的表现时,以及当主流数据库都对存算分离有一定程度上的支持后,事情会再次发生变化 —— K8S 变得适用于数据库起来。但至少就目前来讲,我认为将严肃的生产 OLTP 数据库放入 K8S ,仍然是不成熟与不合时宜的。希望读者可以擦亮双眼,在这件事上做出明智的选择。
参考阅读
《Docker 的诅咒:曾以为它是终极解法,最后却是“罪大恶极”?》
专用向量数据库凉了吗?
向量存储检索是个真需求,然而专用向量数据库已经凉了。—— 小微需求 OpenAI 亲自下场解决了,标准需求被加装向量扩展的现有成熟数据库抢占。留给专用向量数据库的生态位也许能支持一家专用向量数据库存活,但想靠讲AI故事来整活做成一个产业已经是不可能了。

向量数据库是怎么火起来的?
专用向量数据库早在几年前就出现了,比如 Milvus,主要针对的是非结构化多模态数据的检索。例如以图搜图(拍立淘),以音搜音(Shazam),用视频搜视频这类需求;PostgreSQL 生态的 pgvector,pase 等插件也可以干这些事。总的来说,算是个小众需求,一直不温不火。
但 OpenAI / ChatGPT 的出现改变了这一切:大模型可以理解各种形式的文本/图片/音视频,并统一编码为同一维度的向量,而向量数据库便可以用来存储与检索这些AI大模型的输出 —— Embedding《大模型与向量数据库》。
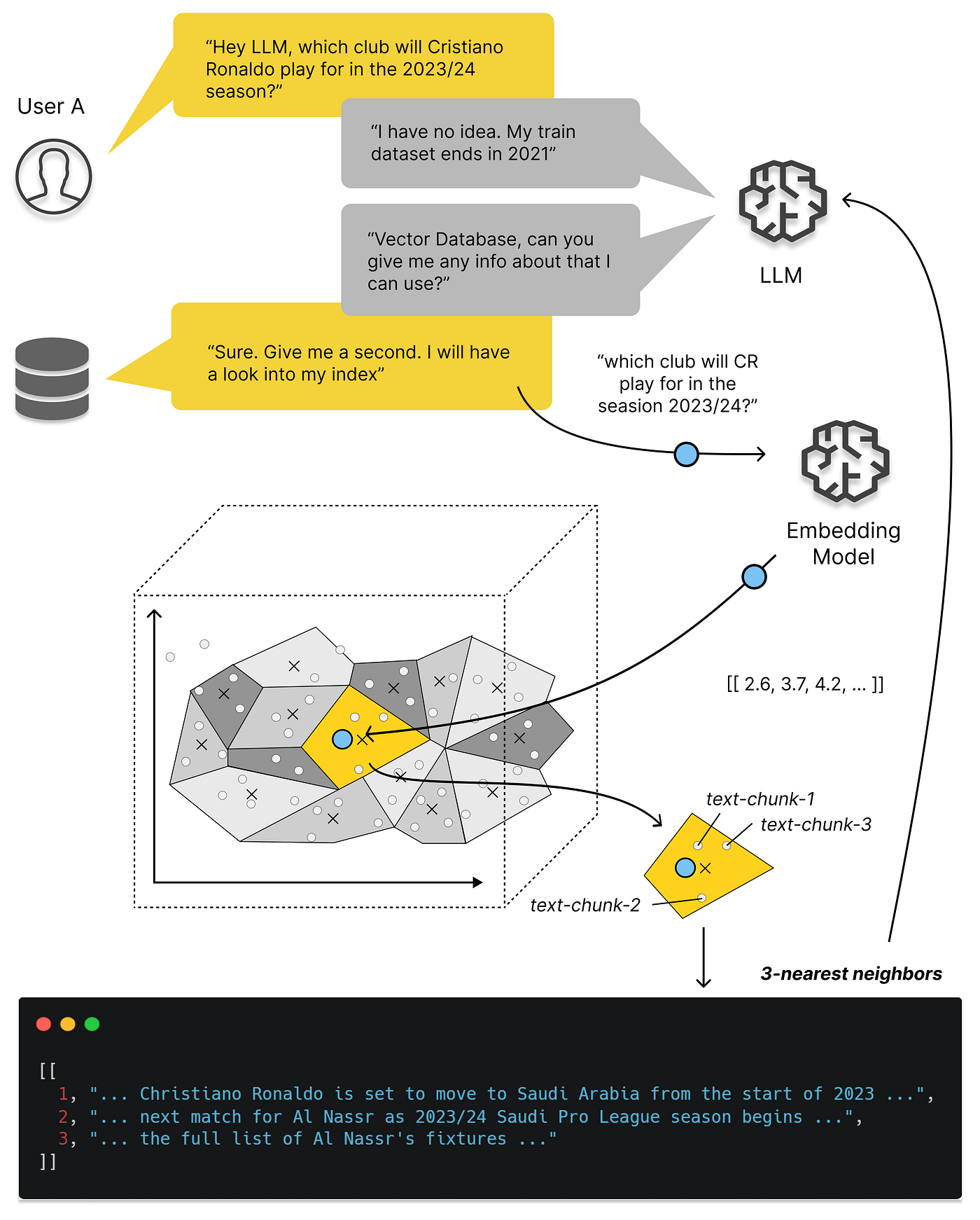
更具体讲,向量数据库爆火的关键节点是今年3月23日,OpenAI 在其发布的 chatgpt-retrieval-plugin 项目中推荐使用一个向量数据库,在写 ChatGPT 插件时为其添加“长期记忆”能力。然后我们可以看到,无论是 Google Trends 热搜,还是 Github Star 上,所有向量数据库项目的关注度都从那个时间节点开始起飞了。
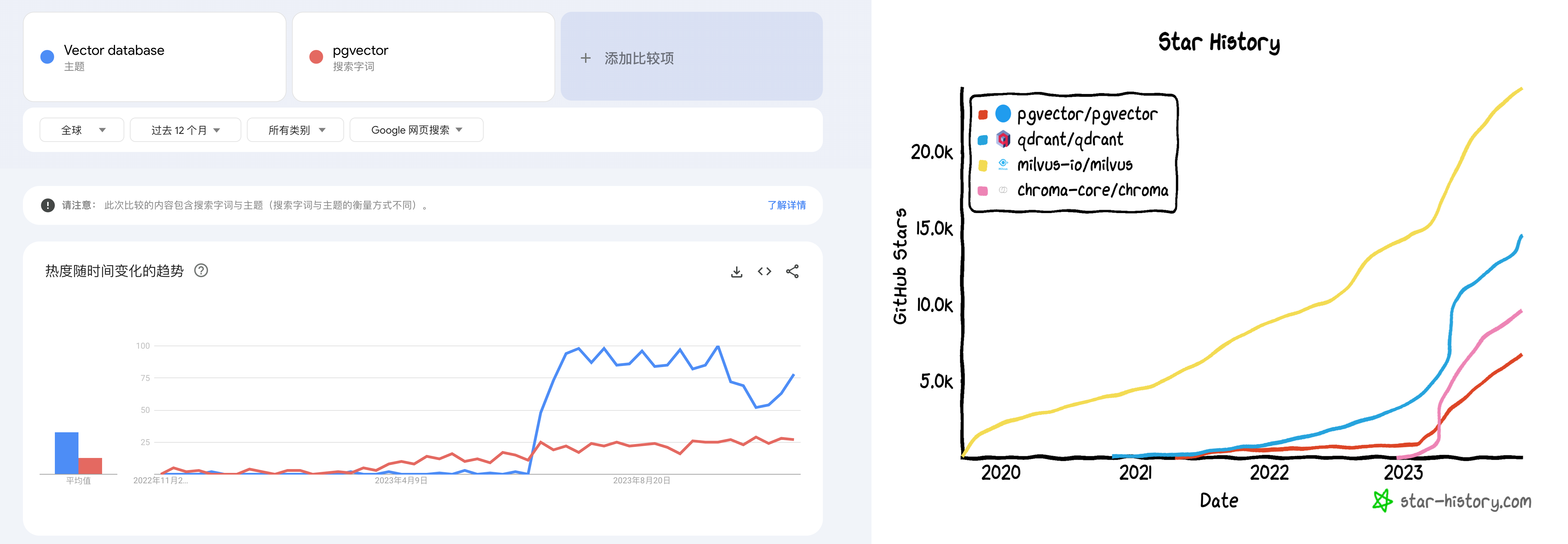
Google Trends 与 GitHub Star
与此同时,数据库领域在投资领域沉寂了一段时间后,又迎来了一波小阳春 —— Pinecone,Qdrant,Weaviate 诸如此类的“专用向量数据库” 冒了出来,几亿几亿的融钱,生怕错过了这趟 AI 时代的基础设施快车。

向量数据库生态全景图
但是,这些暴烈的狂欢也终将以暴烈的崩塌收场。这一次茶凉的比较快,半年不到的时间,形势就翻天覆地了 —— 现在除了某些二流云厂商赶了个晚集还在发软文叫卖,已经听不到谁还在炒专用向量数据库这个冷饭了。
专用向量数据库神话的破灭还有多远?
向量数据库是一个伪需求吗?
我们不禁要问,向量数据库是一个伪需求吗?答案是:向量的存储与检索是真实需求,而且会随着AI发展水涨船高,前途光明。但这和专用的向量数据库并没有关系 —— 加装向量扩展的经典数据库会成为绝对主流,而专用的向量数据库是一个伪需求。
类似 Pinecone,Weaviate,Qdrant,Chroma 这样的专用向量数据库最初是为了解决 ChatGPT 的记忆能力不足而出现的 Workaround —— 最发布的 ChatGPT 3.5 的上下文窗口只有 4K Token,也就是不到两千个汉字。然而当下 GPT 4 的上下文窗口已经发展到了 128K,扩大了32倍,足够塞进一整篇小说了 —— 而且未来还会更大。这时候,用作临时周转的垫脚石 —— 向量数据库 SaaS 就处在一个尴尬的位置上了。
更致命的是 OpenAI 在今年11月首次开发者大会上发布的新功能 —— GPTs,对于典型的中小知识库场景,OpenAI 已经替你封装好了 “记忆” 与 “知识库” 的功能。你不需要折腾什么向量数据库,只要把知识文件上传上去写好提示词告诉 GPT 怎么用,你就可以开发出一个 Agent 来。尽管目前知识库的大小仅限于几十MB,但这对于很多场景都绰绰有余,而且上限仍有巨大提升空间。
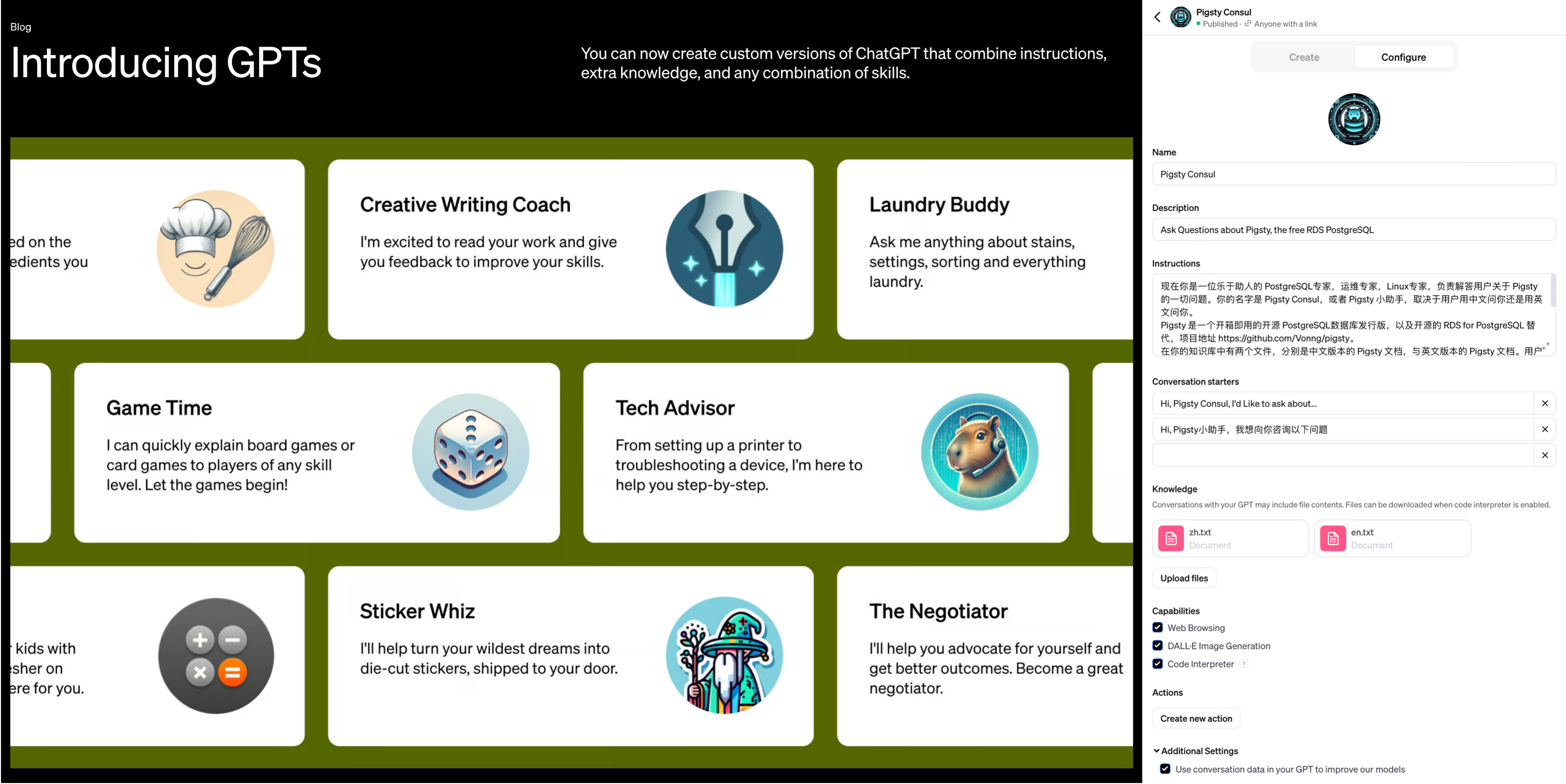
GPTs 将 AI 的易用性提高到一个全新的层次
像 Llama 这样的开源大模型与私有化部署为向量数据库扳回一局 —— 然而,这一部分需求却被加装了向量功能的经典数据库占领了 —— 以 PostgreSQL 上的 PGVector 扩展为先锋代表,其他数据库如 Redis,ElasticSearch, ClickHouse, Cassandra 也紧随其后不甘示弱。说到底,向量与向量检索是一种新的数据类型和查询处理方法,而不是一种全新的基础性数据处理方式。加装一种新的数据类型与索引,对设计良好的现有数据库系统来说并不是什么复杂的事情。
本地私有化部署的 RAG 架构
更大的问题在于,尽管数据库是一件门槛很高的事,但“向量”部分可以说没有任何技术门槛,而且诸如 FAISS 和 SCANN 这样的成熟开源库已经足够完美地解决这个问题了。对于有足够大规模足够复杂的场景的大厂来说,自家工程师可以不费吹灰之力地使用开源库实现这类需求,更犯不上用一个专用向量数据库了。
因此,专用向量数据库陷入了一个死局之中:小需求 OpenAI 亲自下场解决了,标准需求被加装向量扩展的现有成熟数据库抢占,支持超大型需求也几乎没什么门槛,更多可能还要靠模型微调。留给专用向量数据库的生态位也许能足以支持一家专用向量数据库内核厂商活下来,但想做成一个产业是不可能了。
通用数据库 vs 专用数据库
一个合格的向量数据库,首先得是一个合格的数据库。但是数据库是一个相当有门槛的领域,从零开始做到这一点并不容易。我通读了市面上专用向量数据库的文档,能勉强配得上“数据库”称呼的只有一个 Milvus —— 至少它的文档里还有关于备份 / 恢复 / 高可用的部分。其他专用向量数据库的设计,从文档上看基本可以视作对“数据库”这个专业领域的侮辱。
“向量”与“数据库”这两个问题的本质复杂度有着天差地别的区别,以世界上最流行的 PostgreSQL 数据库内核为例,它由上百万行C语言代码编写而成,解决“数据库”这个问题;然而基于 PostgreSQL 的向量数据库扩展 pgvector 只用了不到两千行不到的 C 代码,就解决了“向量”存储与检索的问题。这是对“向量”相对于与“数据库”这件事复杂度门槛的一个粗略量化:万分之一。
如果算上生态扩展,对比就更惊人了。
这也从另一个角度说明了向量数据库的问题 —— “向量”部分的门槛太低。数组数据结构,排序算法,以及两个向量求点积这三个知识点是大一就会讲的通识,稍微机灵点的本科生就拥有足够的知识来实现这样一个所谓的“专用向量数据库”,很难说这种编程大作业,LeetCode 简单题级别的东西有什么技术门槛 。
关系型数据库发展到今天已经相当完善了 —— 它支持各种各样的数据类型,整型,浮点数,字符串,等等等等。如果有人说要重新发明一种新的专用数据库来用,其卖点是支持一种“新的”数据类型 —— 浮点数组,核心功能是计算两个数组的距离并从库中找出最小者,而代价是其他的数据库活计几乎都没法整了,那么稍有经验的用户和工程师都会觉得 —— 这人莫不是得了失心疯?

数据库需求金字塔:性能只是选型考量之一。
在绝大多数情况下,使用专用向量数据库的弊都要远远大于利:数据冗余、 大量不必要的数据搬运工作、分布式组件之间缺乏一致性、额外的专业技能带来的复杂度成本、学习成本、以及人力成本、 额外的软件许可费用、极其有限的查询语言能力、可编程性、可扩展性、有限的工具链、以及与真正数据库相比更差的数据完整性和可用性。用户唯一能够期待的收益通常是性能 —— 响应时间或吞吐量,然而这个仅存的“优点”很快也不再成立了…
案例PvP:pgvector vs pinecone
抽象的理论分析不如实际的案例更有说服力,因此让我们来看一对具体的对比:pgvector 与 pinecone。前者是基于 PostgreSQL 的向量扩展,正在向量数据库生态位中疯狂攻城略地;后者是专用向量数据库 SaaS,列于 OpenAI 首批专用向量库推荐列表首位 —— 两者可以说是通用数据库与专用数据库中最典型的代表。

在 Pinecone 的官方网站上,Pinecone 提出的主要亮点特性是:“高性能,更易用”。首先来看专用向量数据库引以为豪的高性能。Supabase 给出了一个最新的测试案例,以 ANN Benchmark 中的 DBPedia 作为基准,这是由一百万个 OpenAI 1536 维向量组成的数据集。在相同的召回率下,PGVector 都有着更佳的延迟表现与总体吞吐,而且成本上要便宜得多。即使是老版本的 IVFFLAT 索引,都比 Pinecone 表现更好。
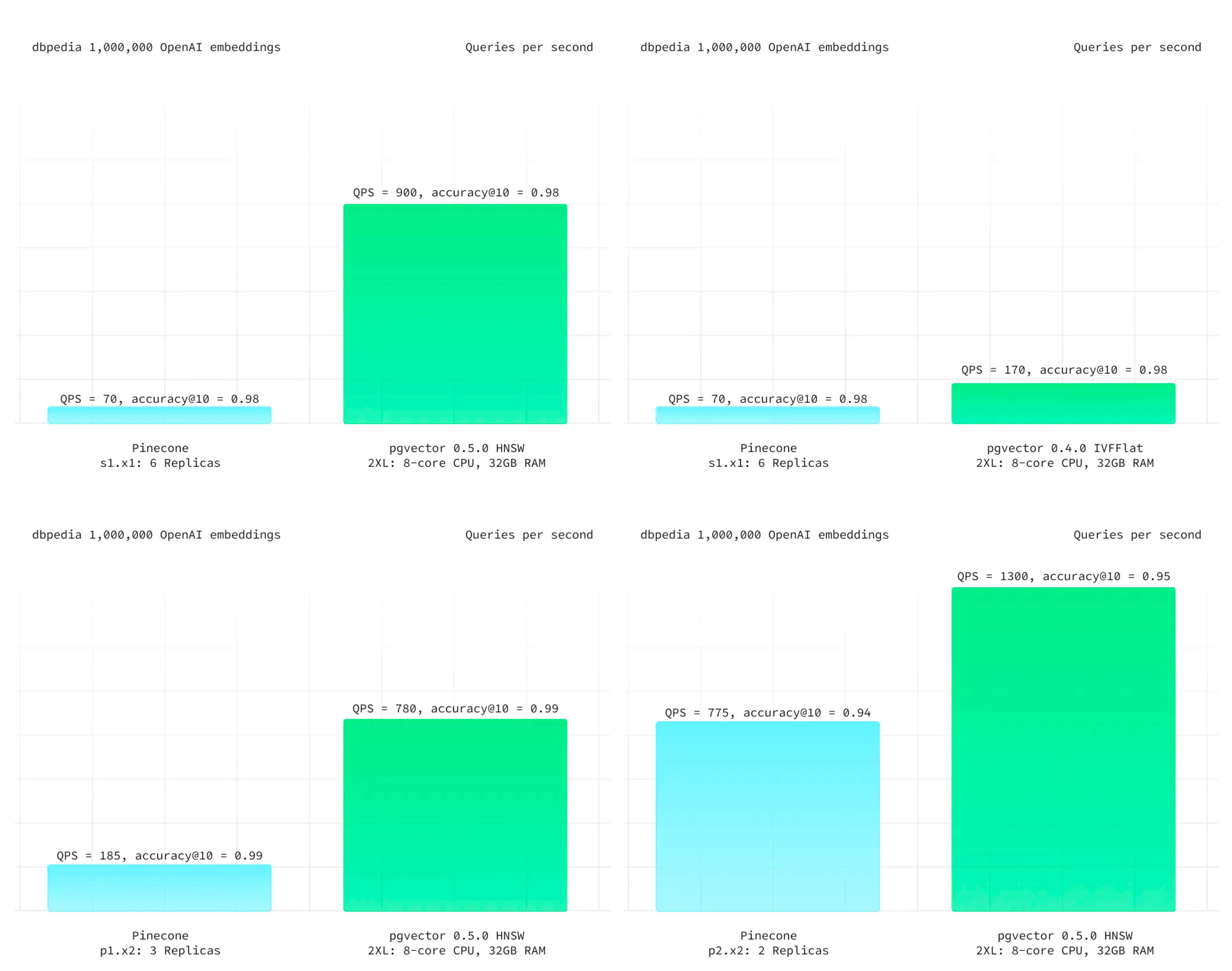
来自 Supabase - DBPedia 的测试结果
尽管专用向量数据库 Pinecone 的性能更烂,但说实话:向量数据库的性能其实根本就不重要 —— 以致于生产上 100% 精确的全表暴力扫描 KNN 有时候都是一种切实可行的选项。更何况向量数据库需要与模型搭配使用,当大模型 API 的响应时间在百毫秒 ~ 秒级时,把向量检索的时间从 10ms 优化到 1ms 并不能带来任何用户体验上的收益。在全员HNSW索引的情况下,可伸缩性也几乎不可能成为问题 —— 语义搜索属于读远多于写的场景,如果你需要更高的 QPS 吞吐量,增配/拖从库就可以了。至于节省几倍资源这种事,以常见业务的规模与当下的资源成本来看,相比模型推理的开销只能说连三瓜两枣都算不上了。
在易用性上,专用的 Python API 还是通用的 SQL Interface 更易用,这种事见仁见智 —— 真正的致命问题在于,许多语义检索场景都需要使用一些额外的字段与计算逻辑,来对向量检索召回的结果进行进一步的筛选与处理,即 —— 混合检索。而这些元数据往往保存在一个关系数据库里作为 Source of Truth。Pinecone 确实允许你为每个向量附加不超过 40KB 的元数据,但这件事需要用户自己来维护,基于API的设计会将专用向量数据库变成可扩展性与可维护性的地狱 —— 如果你需要对主数据源进行额外的查询来完成这一点,那为啥不在主关系库上直接以统一的 SQL 一步到位直接实现呢?
作为一个数据库,Pinecone 还缺乏各种数据库应该具备的基础性能力,例如:备份/恢复/高可用、批量更新/查询操作,事务/ACID;此外,除了俭朴的 API Call 之外没有与上游数据源更可靠的数据同步机制。无法实时在召回率与响应速度之间通过参数来进行利弊权衡 —— 除了更改 Pod 类型在三档准确性中选择之外别无他法 —— 你甚至不能通过暴力全表搜索达到 100% 精确度 ,因为 Pinecone 不提供精确 KNN 这个选项!
并不只有 Pinecone 是这样,除了 Milvus 之外的其他几个专用向量数据库也基本类似。当然也有用户会抗辩说一个 SaaS 如何与数据库软件做对比,这并不是一个问题,各家云厂商的 RDS for PostgreSQL 都已经提供了 PGVector 扩展,也有诸如 Neon / Supabase 这样的 Serverless / SaaS 和 Pigsty 这样的自建发行版。如果你可以用低的多的成本,拥有功能更强,性能更好,稳定性安全性更扎实的通用向量数据库,那么又为什么要花大价钱与大把时间去折腾一个没有任何优势的 “专用向量数据库”?想明白这一点的用户已经从 pinecone 向 pgvector 迁移了 —— 《为什么我们用 PGVector 替换了 Pinecone》
小结
向量的存储与检索是一个真实需求,而且会随着AI发展水涨船高,前途光明 —— 向量将成为AI时代的JSON;但这里并没有多少位置留给专用的向量数据库 —— 诸如 PostgreSQL 这样的头部数据库毫不费力的加装了向量功能,并以压倒性的优势从专用向量数据库身上碾过。留给专用向量数据库的生态位也许能支持一家专用向量数据库存活,但想靠讲AI故事来整活,做成一个产业已经是不可能了。
专用向量数据库确实已经凉掉了,希望读者也不要再走弯路,折腾这些没有前途的东西了。
数据库真被卡脖子了吗?
如果说“云数据库”算是成本ROI略欠体面的合格品,那么很多“国产数据库”就是烂泥扶不上墙的残次品。信创操作系统数据库约等于 IT 预制菜进校园。用户捏着鼻子迁移,开发者假装在卖力,陪着不懂也不在乎技术的领导演戏。大量人力财力被挥霍到没有价值的地方去,反而了浪费掉了真正的机会。基础软件行业其实没人卡脖子,真正卡脖子的都是所谓“自己人”。

垄断关系生意
北京欢乐谷门口大喇叭一直在喊:“请不要在门外购买劣质矿泉水”,小贩都被轰的远远儿的。进去后园区就会把一样的东西用五倍的价格卖给你(当然也可能是掺尿内销啤酒这种更烂的东西)。信创数据库与操作系统大体就是这种模式,都是靠垄断保护吃饭的关系生意。这与预制菜进校园有异曲同工之妙:瓦格纳头子靠承包军队/学校伙食发的财都够搞雇佣兵造反了,堪称一本万利。
问题在于,吃预制菜的人不一定有得选,但用数据库和操作系统的用户可以用脚投票,选择更先进还不要钱的开源操作系统/数据库,这可如何是好呢?毕竟国产库很多也是跟在全球开源 OS/DB 社区屁股后面捡面包屑吃。无数国产内核基于开源PG换皮套壳魔改而成。如果说谁在数据库内核上被卡了脖子,那肯定是吃的花样太多给噎着了。
许多公司看 Oracle 大肆收割的眼红的不行不行,羡慕的哈喇子都要流下来了 —— 可如果用户选择直接去用唾手可及的免费开源软件,国产数据库还怎么去割韭菜?这属于国有资产流失啊!土鳖要翻身,得先欺师灭祖:把开源免费的软件包装一下,用 Oracle 的价格卖给你!
首先搞个数据库硬分叉,把 pg 这俩字母先重命名一下;掺点垃圾代码混淆,再换用 C++ 搅一搅 —— 100%代码自主率,自主知识产权都有啦。然后找几个高校教授老院士来站台论证一下,开源数据库 MySQL 和 PostgreSQL 都是渣渣。最后给领导讲一讲:境外势力亡我之心不死,开源都是帝国主义摧毁我们国产软件行业的阳谋,得 “管一管” ,不抵制不行啦!
开源社区主导的项目都已经深度全球化,单一国家想制裁几乎没有办法:ARM 可以制裁,RISC-V 可以制裁吗?Windows 可以制裁,Linux 可以制裁吗?Oracle / MySQL 可以制裁,PostgreSQL 可以制裁吗?但是别人制裁不了你,你可以“制裁”别人,主动把门给关上呀!
这类企业恐怕做梦都盼着国家被技术封锁:门只有从两边一起关,才更容易关严实。门关严实之后,谁掌握了技术输液管,谁就掌握了利润源泉:那些掌握了独占翻墙权的“国产软件”企业只要定期从全球开源生态拾取些面包渣翻译引入进来,饿的嗷嗷叫的国内用户就要感激涕零,高呼遥遥领先了。
谁受到了伤害?
用户是最受伤的:本来的业务系统跑的好好的,突然就被要求 “升级改造” 了。如果是正向改造,那起码还算是有一些价值,但用来替换现有系统的都是些什么牛鬼蛇神。如果是纯粹的开源换皮也就算了,买点服务兜底还算有价值,最离谱的就是那些做一些自以为是“优化”的魔改阉割版本 —— 大把时间本可以用于更有价值的事情,现在却浪费在削足适履,饮掺尿啤酒,当小白鼠踩坑上了。
数据库开发者受了伤,大好的青春年华与技术生涯浪费在没有未来,没有希望的“数据库过家家”游戏上 —— 做出来的东西只能靠销售关系强行填喂给倒霉的用户,听到的都是用户侧同行的怒骂吐槽与冷嘲热讽。就别提技术影响力和出口创汇了,国际同行都不屑于来耻笑一下,“制裁”也不稀得给一个。整个工作毫无技术成就感可言,人也在日复一日的自我怀疑中变得麻木与犬儒。
国家实力受了伤。各行业与全球软件产业链主动脱钩:稳定性,功能性,战斗力受创。自主可控是一个真实需求,但盲目推行某某名录,歪曲自主可控的实质内涵(将运维自主可控扭曲为研发自主可控),用劣币驱逐良币,会导致实质的自主可控能力不升反降。
且不说和开源比,就连 Oracle 好歹还是个 Paper License,也有很多三方服务供应商;而有的国产数据库没 License 就立即死给你看,原厂一完蛋,连带着业务系统跟着遭殃。从被国外领先数据库“卡脖子” 换为国内土鳖供应商卡脖子,并不会提高自主可控能力,还额外损失了功能活性

劣币驱逐良币
在CSDN最近的开发者调研中,在七成受访者对“国产数据库”持负面印象:“技术落后”,“缺乏创新”,这算是是一种比较温和的说法。用户心底真正的评价恐怕更为直白:虚假宣传,大放卫星,落后生产力。为什么国产数据库的风评如此之差,难道是软件工程师不爱国吗?
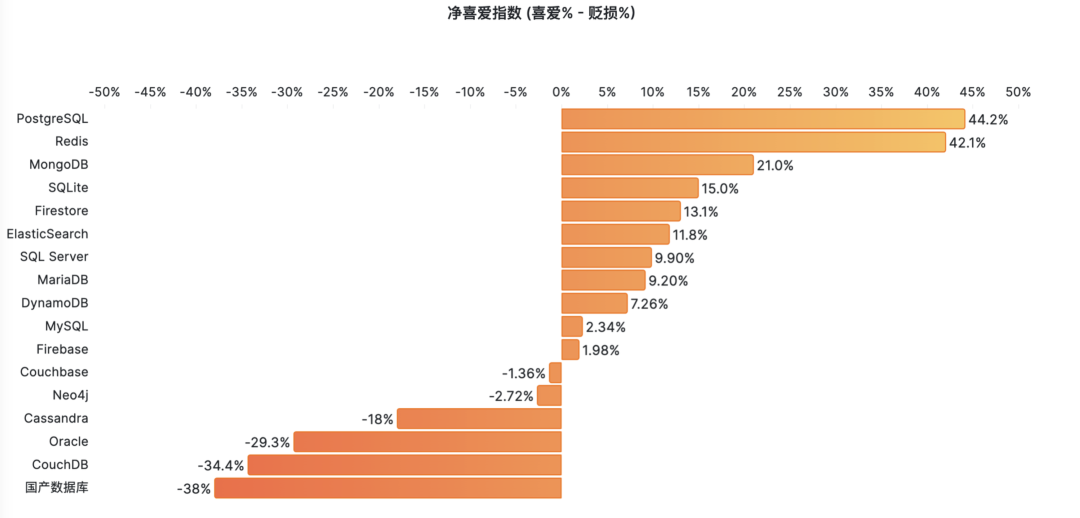
根据信通院与墨天轮统计,现在已经有了两百六十多款“国产数据库”。其中基于开源 PostgreSQL / MySQL 的占了半壁江山还多。这是相当离谱的数字,实际上,大量数据库厂商并没有能力提供真正意义上的“产品”,只是把开源数据库简单换皮包装提供服务,辅以炒作一些分布式、HTAP之类的伪需求。
真正自研的数据库出现两极分化:极少数真正有创新贡献与使用价值的产品爱惜羽毛,不会刻意标榜“国产”。而剩下的大多数往往多是闭门造车、技术落后的土法数据库,或者开源古早分叉、负向阉割出来的劣质轮子。国产数据库并非没有踏实做事的好公司**,只是****“国产”这个标签被大量钻入数据库领域的平庸低劣产品污染**。
更让人扼腕的是劣币驱逐良币。本已稀缺的数据库研发人力经过这样的挥霍,反而会真正卡死国内数据库产业的脖子。特别是核心的OLTP/关系型数据库领域因为开源的存在,已经不缺足够好用的内核了。能把 PostgreSQL / MySQL 用好并提供服务支持,远比自欺欺人的大炼内核要有价值的多。
出路会在哪里?
中国数据库行业里优秀的工程师并不少,但极其匮乏优秀的领军人物或产品经理。或者说,这种人也有,但根本说不上话。最为重要的是,要找到正确的问题与正确的方向去发力。兵熊熊一个,将熊熊一窝:方向对了,即使只有一个人,也能做出有价值的东西;方向错了,养它一千个内核研发也是白努力。
当下的现状是什么?数据库内核已经卷不动了!作为一项有四五十年历史的技术,能折腾的东西已经被折腾的差不多了。业界已经不缺足够完美的数据库内核了 —— 比如 PostgreSQL,功能完备且开源免费(BSD-Like)。无数”国产数据库“基于PG换皮套壳魔改而成。如果说谁在数据库内核上被卡了脖子,那肯定是吃饱了撑着给噎着的。
那么,真正稀缺的是什么,是把现有的内核用好的能力。要解决这个问题,有两种思路:第一种是开发扩展,以增量功能包的方式为内核加装功能 —— 解决某一个特定领域的问题。第二种是整合生态,将扩展,依赖,底座,基础设施,融合成完整的产品 & 解决方案 —— 数据库发行版。

在这两个方向上发力,可以产生实打实的增量用户价值,站在巨人的肩膀上,并深度参与全球软件供应链,响应号召,打造真正意义上的“人类命运共同体”。相反,去分叉一个现有成熟开源内核是极其愚蠢的做法。像 PostgreSQL 与 Linux 这样的 DB/OS 内核是全世界开发者的集体智慧结晶,并通过全世界用户各种场景的打磨与考验,指望靠某一个公司的力量就能与之抗衡是不切实际的妄想。
中国想要打造自己的世界体系,成为负责任的大国,就应当胸怀天下,扛起开源运动的大旗来:展现社会主义公有制制度在软件信息互联网领域的优越性,积极赞助、参与并引领全球开源软件事业的发展,深度参与全球软件供应链,提高在全球社区中的话语权。关起门在开源社区后面捡面包屑吃,整天搞一些换皮套壳魔改的小动作,做一些没有使用价值的软件分叉,不仅压制了真正的技术创新潜能,更是会贻笑/自绝于全球软件产业链,拉低自己的竞争力。不可不察也。
参考阅读
EL系操作系统发行版哪家强?
有很多用户都问过我,跑数据库用什么操作系统比较好。特别是考虑到 CentOS 7.9 明年就 EOL了,应该有不少用户需要升级OS了,所以今天分享一些经验之谈。

太长不看
长话短说,在现在这个时间点如果用 EL 系列操作系统发行版,特别是如果要跑 PostgreSQL 相关的服务,我强烈推荐 RockyLinux,有“国产化”要求的也可以选龙蜥 OpenAnolis。AlmaLinux 和 OracleLinux 兼容性有点问题,不建议使用。Euler 属于独一档的 IT 领域预制菜进校园,有 EL 兼容要求的可以直接略过了
兼容水平:RHEL = Rocky ≈ Anolis > Alma > Oracle » Euler 。
在EL大版本上,EL7目前的状态最稳定,但马上 EOL 了,而且很多软件版本都太老了,所以新上的项目不建议使用了;EL 9最新,但偶尔会在仓库源更新后出现软件包依赖错误的问题。,少软件也还没有跟进 EL9 的包,比如 Citus / RedisStack / Greenplum等。
目前综合来看,EL8 是主流的选择:软件版本足够新,也足够稳定。具体的版本上建议使用 RockyLinux 8.9(Green Obsidian) 或 OpenAnolis 8.8 (rhck内核)。 激进的用户可以试试 9.3 ,保守稳妥的用户可以使用 CentOS 7.9 。
测试方法论
我们做开箱即用 PostgreSQL 数据库发行版 Pigsty,不使用容器/编排方案,因此免不了与各种操作系统打交道,基本上 EL 系的 OS 发行版我们都测试过一遍,最近刚刚把 Anolis / Euler 以及 Ubuntu / Debian 的适配做完。关于 OS EL兼容性还是有一些经验心得的。
Pigsty 的场景非常具有代表性 —— 在裸操作系统上运行世界上最先进且最流行的开源关系型数据库 PostgreSQL,以及企业级数据库服务所需要的完整软件组件。包括了 PostgreSQL 生命周期中的5个大版本(12 - 16)以及一百多个扩展插件。还有几十个常用的主机节点软件包,Prometheus / Grafana 可观测性全家桶,以及 ETCD / MinIO / Redis 等辅助组件。

测试方法很简单,这些 EL原生的RPM包,能不能在其他这些“兼容”系统上跑起来 —— 至少安装运行不能出错吧?每次 CI 的时候,我们会拉起三十台安装有不同操作系统的虚拟机进行完整安装,涉及到的软件包如下所示:
repo_packages:
- ansible python3 python3-pip python36-virtualenv python36-requests python36-idna yum-utils createrepo_c sshpass # Distro & Boot
- nginx dnsmasq etcd haproxy vip-manager pg_exporter pgbackrest_exporter # Pigsty Addons
- grafana loki logcli promtail prometheus2 alertmanager pushgateway node_exporter blackbox_exporter nginx_exporter keepalived_exporter # Infra Packages
- lz4 unzip bzip2 zlib yum pv jq git ncdu make patch bash lsof wget uuid tuned nvme-cli numactl grubby sysstat iotop htop rsync tcpdump perf flamegraph # Node Packages 1
- netcat socat ftp lrzsz net-tools ipvsadm bind-utils telnet audit ca-certificates openssl openssh-clients readline vim-minimal keepalived chrony # Node Packages 2
- patroni patroni-etcd pgbouncer pgbadger pgbackrest pgloader pg_activity pg_filedump timescaledb-tools scws pgxnclient pgFormatter # PG Common Tools
- postgresql15* pg_repack_15* wal2json_15* passwordcheck_cracklib_15* pglogical_15* pg_cron_15* postgis33_15* timescaledb-2-postgresql-15* pgvector_15* citus_15* # PGDG 15 Packages
- imgsmlr_15* pg_bigm_15* pg_similarity_15* pgsql-http_15* pgsql-gzip_15* vault_15 pgjwt_15 pg_tle_15* pg_roaringbitmap_15* pointcloud_15* zhparser_15* apache-age_15* hydra_15* pg_sparse_15*
- orafce_15* mysqlcompat_15 mongo_fdw_15* tds_fdw_15* mysql_fdw_15 hdfs_fdw_15 sqlite_fdw_15 pgbouncer_fdw_15 multicorn2_15* powa_15* pg_stat_kcache_15* pg_stat_monitor_15* pg_qualstats_15 pg_track_settings_15 pg_wait_sampling_15 system_stats_15
- plprofiler_15* plproxy_15 plsh_15* pldebugger_15 plpgsql_check_15* pgtt_15 pgq_15* hypopg_15* timestamp9_15* semver_15* prefix_15* periods_15* ip4r_15* tdigest_15* hll_15* pgmp_15 topn_15* geoip_15 extra_window_functions_15 pgsql_tweaks_15 count_distinct_15
- pg_background_15 e-maj_15 pg_catcheck_15 pg_prioritize_15 pgcopydb_15 pgcryptokey_15 logerrors_15 pg_top_15 pg_comparator_15 pg_ivm_15* pgsodium_15* pgfincore_15* ddlx_15 credcheck_15 safeupdate_15 pg_squeeze_15* pg_fkpart_15 pg_jobmon_15 rum_15
- pg_partman_15 pg_permissions_15 pgexportdoc_15 pgimportdoc_15 pg_statement_rollback_15* pg_auth_mon_15 pg_checksums_15 pg_failover_slots_15 pg_readonly_15* postgresql-unit_15* pg_store_plans_15* pg_uuidv7_15* set_user_15* pgaudit17_15
- redis_exporter mysqld_exporter mongodb_exporter docker-ce docker-compose-plugin redis minio mcli ferretdb duckdb sealos # Miscellaneous Packages
测试结果基本可以分为三种情况:100% 兼容,小错误,大麻烦。
-
100% 兼容:RockyLinux,OpenAnolis
-
小错误:AlmaLinux,OracleLinux,CentOS Stream
-
大麻烦:OpenEuler
RockyLinux 属于 100% 兼容,各种软件包安装非常流畅,没有遇到任何问题,OpenAnolis 的使用体验与 Rocky 基本一致。AlmaLinux 和 OracleLinux,以及 CentOS Stream 有少量软件包缺失,有办法补上修复,总的来说有些小错误,但可以克服。Euler 属于独一档的大麻烦,软件包遇到了大量版本依赖错误崩溃,几乎所有包都需要针对性编译,有的包因为系统依赖版本冲突问题连编译都困难了,作为EL系OS发行版的适配成本甚至比 Ubuntu/Debian 还高。
使用体验
RockyLinux 的使用体验最好,它的创始人就是原来 CentOS 的创始人,CentOS 被红帽收购后又另起炉灶搞的新 Fork。目前基本已经占据了原本 CentOS 的生态位。
最重要的是,PostgreSQL 官方源明确声明支持的 EL 系 OS 除了 RHEL 之外就是 RockyLinux 了。PGDG 构建环境就是 Rocky 8.8 与 9.2(6/7用的是CentOS)。可以说是对 PG 支持最好的 OS 发行版了。实际使用体验也非常不错,如果您没有特殊的需求,它应该是 EL 系 OS 的默认选择。
RockyLinux:100% BUG级兼容
龙蜥 / OpenAnolis 是阿里云牵头的国产化操作系统,号称100%兼容EL。本来我并没抱太大期望:只是有用户想用,我就支持一下,但实际效果超出了预期:EL8 的所有 RPM 包都一遍过,适配除了处理下 /etc/os-release 之外没有任何额外工作。适配了 Anolis 一个,就等于适配了十几种 “国产操作系统系统”发行版:阿里云、统信软件、中国移动、麒麟软件、中标软件、凝思软件、浪潮信息、中科方德、新支点、软通动力、博彦科技,可以说是很划算了。

基于 OpenAnolis 的商业操作系统发行版
如果您有“国产化”操作系统方面的需求,选择 OpenAnolis 或衍生的商业发行版,是一个不错的选择。
Oracle Linux / AlmaLinux / CentOS Stream 的兼容性相比 Rocky / Anolis 要拉跨一些,不是所有的 EL RPM 包都能直接安装成功:经常性出现依赖错漏问题。大部分包可以从它们自己的源里面找到补上 —— 有些兼容性问题,但基本上属于可以解决的小麻烦。这几个 OS 整体体验很一般,考虑到 Rocky / Anolis 已经足够好了,如果没有特殊理由我觉得没有必要使用这几种发行版。
OpenEuler 属于最拉跨的独一档,号称 EL兼容,但用起来完全不是这么回事。例如:在 PostgreSQL 内核与核心扩展中, postgresql15* ,patroni ,postgis33_15,pgbadger,pgbouncer 全部都需要重新编译。而且因为使用了不同版本的 LLVM,所有插件的 LLVMJIT 也都必须重新编译才能使用,费了非常多的功夫才完成支持,还不得不阉割掉一些功能,总的来说使用体验非常糟糕。

适配时的一堆额外工作
我们有个大客户不得不用这个 OS,所以我们也不得不去做兼容性适配。适配这种操作系统简直是一种梦魇:工作量比支持 Debian / Ubuntu 系列操作系统还要大,在折腾用户这件事上确实做到了遥遥领先。
BTW,知乎上有篇文章也介绍了这几个OS发行版的坑与对比,可以看看:
一些感想
之前我写过一篇《基础软件到底需要怎样的自主可控》,聊了聊关于国产操作系统/数据库的一些现状。核心的观点是:国家对于基础软件自主可控的核心需求是现有系统在制裁封锁的情况下能否继续运行,即运维自主可控,而不是研发自主可控。
这里我测试适配了两种主流的国产化操作系统发行版,它们体现了两种不同的思路:OpenAnolis 与 EL 完全兼容,站在巨人的肩膀上,为有需要的用户提供服务与支持(运维自主可控),真正满足了用户需求 —— 不要折腾,让现有的软件/系统稳定运行。CentOS 停服,能有国内公司/社区站出来承担责任接手维护工作,这对于广大用户、现有系统与服务来说有着实打实的价值。
反观另外一个 OS Distro,选择了通篇魔改,为华而不实的“自研”虚荣面子去做一些没有使用价值甚至是负优化的垃圾分叉,却导致大量现有的软件不得不重新适配调整甚至弃用,给用户平白添加了不必要的负担,在折腾用户上做到了遥遥领先,堪称是 IT 领域的预制菜进校园,更是污染分裂了软件生态,自绝于全球软件产业链。
OpenEuler 和 OpenGauss 差不多:你说它能不能用?也不是不能用 —— 就是用着感觉跟吃屎一样。但问题是已经有自主可控也免费的饭吃了,那为什么还要吃屎呢?如果说领导就是要按头吃屎,或者给的钱实在太多了,那也没有办法。但如果把屎吃出了肉香味,还自觉遥遥领先,那就有些滑稽了。
我以前也没少嘲讽过阿里云的云服务(特别是EBS和RDS),但是在开源 OS 和 DB 上,谁是做实事谁是吹牛逼还是门清的。至少我认为 OpenAnolis 和 PolarDB 确实是有一些东西,比起 Euler 和 Gauss 这种没有使用价值的魔改分叉来说更配得上给世界另一个选择的说法。高质量有人维护提供服务的开源主干换皮发行版,要远远好于拍脑袋瞎魔改分叉出来的玩意儿。
同样是“自主可控”的EL系国产操作系统,Pigsty 对 OpenAnolis 和 OpenEuler 都提供了支持。前者的支持是开源免费的,因为没有任何适配成本。后者我们会本着客户至上的原则为有需要的客户提供支持:虽然我们已经适配完了,但永远也不会开源免费:必须收取高额的定制服务费用作为精神损失费才行。同理,我们也开源了对 PolarDB 的监控支持,但 OpenGauss 就不好意思了,还是自个儿玩去吧。
技术发展终究要适应先进生产力的发展要求,落后的东西最终总是会被时代所淘汰。用户也应该勇于发出自己的声音,并积极用脚投票,让那些做实事的产品与公司得到奖赏鼓励,让那些吹牛逼的东西早点儿淘汰滚蛋。不要到最后只剩翔吃了才追悔莫及。
基础软件需要什么样的自主可控?
当我们说自主可控时,到底在说什么?
对于一款基础软件(操作系统 / 数据库)来说,自主可控到底是指:由中国公司/中国人开发、发行、控制?还是可以运行在“国产操作系统”/国产芯片上? 名不正则言不顺,言不顺则事不成。当下的“自主可控”乱象正是与定义不清,标准不明有着莫大的关系。但这并不妨碍我们探究一下“信创安可自主可控”这件事,要实现的目标是什么?
国家的需求说起来很简单:打仗吃制裁后,现有系统还能不能继续跑起来。
软件自主可控分为两个部分:运维自主可控 与 研发自主可控 ,国家/用户真正需要的自主可控是前者。如果我们将基础软件“自主可控”的需求用金字塔层次的方式来表达,那么在这个需求金字塔中,国家的需求可以描述为: 对具有实用价值的基础软件:保三争五。至少应当做到 “本地自治运行”,最好能达到 “控制源代码”。

基础软件自主可控需求金字塔
追求研发自主可控必须考虑活性问题。当基础软件领域(操作系统/数据库)已经存在成熟开源内核时,追求所谓 自研 对于国家与用户来说几乎没有实际价值:只有当某个团队功能研发/问题解决的速度超过全球开源社区,内核自研才是有实际意义的选择。大多数号称“自研”的基础软件厂商本质是套壳、换皮、魔改开源内核,自主可控程度属于2~3级甚至更低。低质量的软件分叉不但没有使用价值,更是浪费了稀缺的软件人才与市场机遇空间、并终将导致中国软件行业与全球产业链脱节,产生巨大的负外部性。 当我们从 Oracle/其他国外商业数据库迁移到替代方案时请注意:你的自主可控水平是否有实质意义上的提升?我们需要特别注意与警惕那些打着国产自研旗号的基础软件产品在垄断保护下劣币驱逐良币,抢占真正具有活性的开源基础软件的生态位,这会对自主可控事业造成真正的伤害 —— 所谓:搬石头砸自己的脚,自己卡自己的脖子。例如,一个所谓“自研”运行时却需要 License 文件不然就立即死给你看的国产数据库(标称L7 ,实际L2),其运维自主可控程度远比不上成熟的开源数据库(L4/L5)。如果该国产数据库公司因为任何原因失能(重组倒闭破产或被一炮轰烂),将导致一系列使用该产品的系统失去长期持续稳定运行的能力。 开源是一种全球协作的软件研发模式,在基础软件内核(操作系统/数据库)中占据压倒性优势地位。开源模式已经很好的解决了基础软件研发的问题,但没有很好地解决软件的运维问题,而这恰好是真正有意义自主可控所应当解决的 —— 软件的最终价值是在其使用过程中,而不是研发过程中实现的。真正有意义的自主可控是帮助国家/用户用好现有成熟开源操作系统/数据库内核 —— 提供基于开源内核的发行版与专业技术服务。在维持好现有/增量系统稳定运行的前提下,响应“人类命运共同体”的倡议,积极参与全球开源软件产业供应链治理,并扩大本国供应商的国际影响力。 综上所述,我们认为,运维自主可控 的重点在于:替代不可控的三方服务与受限制的商业软件,鼓励国内供应商基于流行的开源基础软件提供技术服务与发行版,对于具有重大使用价值的开源基础软件,鼓励学习、探索、研究与贡献。孵化培养国内开源社区,维护公平的竞争环境与健康的商业生态。 而 研发自主可控 的重点在于:积极参与全球开源软件产业供应链治理,提高国内软件公司与团队在全球顶级基础软件开源项目中的话语权,培养具有全球视野与先进研发能力的技术团队。应当停止低水平重复的“国产操作系统/数据库内核分叉“,着力打造具有国际影响力的服务与软件发行版。
附:自主可控的不同等级
对于基础软件来说,可控程度从高到低可细分为以下九个等级:
9:拥有软件发布权(发布权,67%)
8:掌握多数投票权(主导权,51%)
7:掌握少数否决权(否决权,34%)
6:拥有提议话语权(话语权,10%)
5:掌控源代码(跟主干修缺陷)
4:获取源代码(跨平台重分发)
3:掌控二进制(本地自治运行)
2:受限二进制(本地受限使用)
1:租用服务(调用远程服务)
其中,1 - 5 为运维自主可控,5-9 为研发自主可控。精简一下研发自主可控的几个层次,便可得到这张自主可控需求金字塔图:
自主可控第一层,租用服务的自主可控程度最差:硬件、数据都存储在供应商的服务器上。如果提供服务的公司倒闭、停产、消亡,那么软件就无法工作了,而使用这些软件创造的文档与数据就被锁死了。例如 OpenAI 提供的 ChatGPT 便属于此类。
自主可控第二层,受限二进制,意味着软件可以在自己的硬件上运行,但包含有额外的限制条件:例如需要定期更新的授权文件,或必须联网认证方可运行。此类软件的问题与上一层次类似:如果如果提供软件的公司倒闭、停产,那么使用此类软件的应用将在有限时间内死亡。一些需要授权文件才能运行的商业操作系统 / 商业数据库便属于此列。
自主可控第三层,控制二进制,意味着软件可以不受限制地在任意主流硬件上运行,用户可以在没有互联网访问的情况下不受限制地部署软件并使用其完整功能,直到地老天荒。拥有不受限制的二进制,也意味着国内供应商可以基于软件提供自己的服务,进行换皮。绝大多数场景所需要的自主可控程度落在这一层。 自主可控第四层,拥有源代码,意味着软件可以被重新编译与分发,这一层自主可控意味着即使硬件受到制裁,现有开源软件系统也可以运行在国产操作系统/硬件之上。同时也意味着国内供应商可以提供自己的发行版,提供服务,进行套壳与再分发。开源基础软件默认坐落在这一层上,绝大多标称自己“自研”的国产操作系统/数据库实质上属于这一类。
自主可控第五层,掌控源代码,意味着对开源软件有跟进与兜底的能力,这意味着即使在最极端的情况下:全球开源软件社区与中国脱钩,国内供应商也可以自行分叉、跟进主干功能特性、并修复缺陷,长期确保软件的活性与安全性。掌握源代码意味着可以进行实质性魔改,并开始从运维自主可控到研发自主可控过渡。极个别国内厂商拥有此能力,也是国家对于自主可控的期待的合理上限。
从第六层到第九层,就进入了“研发自主可控”的范畴。根据国内供应商的话语权比例可以划分为四个不同的等级(提议权/否决权/主导权/发布权)。这涉及到基础软件开源内核的参与和治理。这意味着国内供应商可以参与到全球开源基础软件供应链中,发出自己的声音与影响力,参与社区治理甚至主导项目的方向。
对于全球范围内有使用价值的开源基础软件来说,对中国有意义的自主可控策略是:去二保三争五。更高的六至九所代表的“研发自主可控” 属于 Nice to have:有当然好,应当尽可能争取,但没有也不影响现有/增量系统的自主可控。切忌为了华而不实的“自研”虚荣面子去做一些没有使用价值甚至是负优化的垃圾分叉,而抛弃功能活性的里子,自绝于全球软件产业链。
数据库需求层次金字塔
与马斯洛需求金字塔类似,用户对于数据库的需求也有着一个递进的层次。用户对于数据库的需求从下往上可以分为八个层次,分别与人的八个需求层次相对应:
- 生理需求,功能:内核/正确性/ACID
- 安全需求,安全:备份/保密/完整/可用
- 归属需求,可靠:高可用/监控/告警
- 尊重需求,ROI:性能/成本/复杂度
- 认知需求,洞察:可观测性/数字化/可视化
- 审美需求,掌控:可控制性/易用性/IaC
- 自我实现,智能:标准化/产品化/智能化
- 超越需求,变革:真·自治数据库

安全需求与生理需求同属基础需求,一个用于生产环境的严肃数据库系统至少应当满足这两类需求,才足以称得上是合格。归属需求与尊重需求同属进阶需求,满足这两类需求,可以称得上是体面。认知需求与审美需求属于高级需求,满足这两类需求,方能配得上 品味 二字。
在自我实现与超越需求上,不同种类的用户可能会有不同的需求,比如普通工程师的超越需求可能是升职加薪,搞出成绩赚大钱;而头部用户关注的可能是意义、创新与行业变革。
但是在基础需求与进阶需求上,所有类型的用户几乎是高度一致的。
生理需求
生理需求是级别最低、最急迫的需求,如:食物、水、空气、睡眠。
对于数据库用户来说,生理需求指的是功能:
- **内核特性:**数据库内核的特性是否满足需求?
- 正确性:功能是否正确实现,没有显著缺陷?
- ACID:是否支持确保正确性的核心功能— 事务?
对于数据库来说,功能需求就是最基础的生理需求。正确性与 ACID 是数据库最基本的要求:诚然一些不甚重要的数据与边缘系统,可以使用更灵活的数据模型,NoSQL数据库,KV存储。但对于关键核心数据来说经典 ACID 关系型数据库的地位仍然是无可取代的。此外,如果用户需要的就是 PostGIS 处理地理空间数据的能力,或者TimescaleDB 处理时序数据的能力,那么没有这些特性的数据库内核就会被一票否决。
安全需求
安全需求同样属于基础层面的需求,其中包括对人身安全、生活稳定以及免遭痛苦、威胁或疾病、身体健康以及有自己的财产等与自身安全感有关的事情。
对于数据库来说,安全需求包括:
- 机密:避免未授权的访问,数据不泄漏,不被拖库
- 完整:数据不丢不错不漏,即使误删了也有办法找回来。
- 可用:可以稳定提供服务,出了故障也有办法及时恢复回来。
安全需求无论对于数据库还是人类都是至关重要的。数据库如果丢了,被拖库了,或者数据错乱了,一些企业可能就直接破产了。满足安全需求意味着数据库有了兜底,有了灾难生存能力。冷备份,WAL归档,异地备份仓库,访问控制,流量加密,身份认证,这些技术用于满足安全需求。
安全需求与生理需求同属基础需求,一个用于生产环境的严肃数据库系统至少应当满足这两类需求,才足以称得上是合格。
归属需求
爱和归属的需求(常称为“社交需求”)属于进阶需求,如:对友谊,爱情以及隶属关系的需求。
对于数据库来说,社交需求意味着:
- 监控:有人会关注着数据库健康,监控诸如心率、血氧等核心生理指标。
- 告警:而当数据库出现问题时,指标异常时,会有人接到通知来及时处理。
- 高可用:主库不再单打独斗,拥有了自己的追随者分担工作并在故障时能接管工作。
对数据库可靠性的需求,可以与人类对于爱和归属的需求相类比。归属意味着数据库是有人关心,有人照看着,有人支持着的。监控负责感知环境收集数据库指标,而告警组件将异常现象问题及时上抛给人类处理。多物理从库副本+自动故障切换实现高可用架构的数据库,甚至软件自身便足以检测判定应对很多常见的故障。
归属需求属于进阶需求,当基础需求(功能/安全)得到满足后,用户会开始对监控告警高可用产生需求。一个体面的数据库服务,监控告警高可用是必不可少的。
尊重需求
尊重需求是指人们对自己的尊重和自信,以及希望获得他人的尊重的需求,属于进阶层面的需求。对于数据库来说,尊重需求主要包括:
- 性能:能够支撑高并发、大规模数据处理等高性能场景。
- 成本:具有合理的价格和成本控制。
- 复杂度:易于使用和管理,不会带来过多的复杂度。
对于数据库来说,安全可靠是本分,物美价廉才能出彩。数据库产品的 ROI 对应于人的尊重需求。正所谓:性价比是第一产品力,更强力、更便宜、更好用是三个核心诉求:更高的 ROI 意味着数据库以更低的财务代价与复杂度代价实现更优秀的性能表现。任何开创性的特色功能与设计,说到底也是通过提高 ROI 来赢得真正的赞誉与尊重的。
归属需求与尊重需求同属进阶需求,一个数据库系统只有满足这两类需求,才足以称得上是体面。满足了基础需求与进阶需求的用户,则会开始产生更高层次的需求:认知与审美。
认知需求
认知需求是指人们对于知识、理解和掌握新技能的需求,属于进阶层面的需求。对于数据库来说,认知需求主要包括:
- 可观测性:能够对数据库与相关系统内部运行状态进行观测,做到全知。
- 可视化:将数据通过图表等方式进行可视化展示,揭示内在联系,提供洞察。
- 数字化:使用数据作为决策依据,使用标准化决策过程而非老师傅拍脑袋。
人要进步发展须进行自省,而认知需求对于数据库也一样重要:归属需求中的“监控“只关注数据库的基本生存状态,而认知需求关注的是对数据库与环境的理解与洞察。现代可观测性技术栈将收集丰富的监控指标并进行可视化呈现,而 DBA / 研发 / 运维 / 数据分析 人员则会从数据与可视化中提取洞察,形成对系统的理解与认知。
没有观测就谈不上控制,可观测是为了可控制,全知即全能。只有对数据库有了深入的认知,才可以真正做到收放自如,随心所欲不逾矩。
审美需求
审美需求是指人们对于美的需求,包括审美体验、审美评价和审美创造。对于数据库来说,审美需求主要包括:
- 可控制性:用户的意志可以被数据库系统贯彻执行。
- 易用性:友好的界面接口工具,最小化人工操作。
- IaC:基础设施即代码,使用声明式配置描述环境。
对于数据库来说,审美需求意味着更高级的掌控能力:简单易用的接口,高度自动化的实现,精细的定制选项,以及声明式的管理哲学。
高度可控,简单易用的数据库,才是有品味的数据库。可控制性是可观测性的对偶概念,指:是否可以通过一些允许的程序让系统调整到其状态空间内的任何一个状态。传统的运维方式关注过程,要创建/销毁/扩缩容数据库集群,用户需要按照手册依次执行各种命令;而现代管理方式关注状态,用户声明式的表达自己想要什么,而系统自动调整至用户所描述的状态。
洞察与掌控求属于高级需求,满足这两类需求的数据库系统,才足以称得上 品味。而这两者,也是满足更高超越层面需求的基石。
自我实现
自我实现(Self-actualization)是指人们追求最高水平的自我实现和个人成长的需求,属于超越层面的需求。对于数据库来说,自我实现需求主要包括:
- 标准化:将各类操作沉淀为 SOP ,沉淀故障文档应急预案与制度最佳实践,量产DBA。
- 产品化:将用好/管好数据库的经验沉淀转化为可批量复制的工具、产品与服务。
- 智能化:范式转变,沉淀出领域特定的模型,完成人到软件的转变与飞跃。
数据库的自我实现与人类似:繁衍与进化。为了持续存在,数据库需要“繁衍”扩大存在规模,这需要的是标准化与产品化,而不是一个接一个的项目。关系数据库内核功能标准化已经有SQL作为标准,然而使用数据库的方法与管理数据库的人还差的很远:更多依赖的是老师傅的直觉与经验。以 GPT4 为代表的大模型,揭示了由 AI 替代专家(领域模型)的可能性,Soon or Later,一定会演进出现模型化的DBA,实现感知-决策-执行三个层面的彻底自动化。
超越需求
超越需求(Self-transcendence)是指人们追求更高层次的价值和意义的需求,属于最高层面的需求。对于数据库来说,这也许意味着 一个几乎不需要人参与的真·自治数据库系统
前面的所有需求都得到满足时,超越需求会出现。想要做到真正的数据库自治,前提就是感知、思考、执行三个部分的自动化与智能化。认知层次的需求解决“信息系统”,负责感知职能;审美层次的需求解决“行动系统”,负责实施控制;而自我实现层次解决“模型系统”,负责做出决策。
这也可也说是数据库领域的圣杯与终极目标之一了。
然后呢?
理论模型可以帮助我们对数据系统/发行版/管控软件/云服务进行更深刻的评价与对比。比如:大部分土法自建的数据库可能还在生理需求和安全需求上挣扎,属于不合格残次品。云数据库基本属于能满足下三层功能安全可靠需求的合格品,但是在 ROI / 价格上就不太体面(参阅《云数据库是不是杀猪盘》)。顶级资深数据库专家自建,可以满足更高层次的需求,但实在是太过金贵,供不应求。最后还得是广告时间:
虽然我是 Pigsty 的作者,但我更是一个资深的甲方用户。我做这个东西的原因正是因为市面上没有足够好的能满足 L4 L5 感知/管控需求的数据库产品或服务,所以才自己动手撸了一个。开源 RDS 替代 Pigsty + IDC/云服务器自建,在满足上述需求的前提下,还可以覆盖认知、审美与少部分自我实现的需求。让你的数据库坚如磐石,辅助自动驾驶,更离谱的是开源免费,ROI 上吊打一切云数据库,如果你会用到 PGSQL, (以及REDIS, ETCD, MINIO, 或者 Prometheus/Grafana全家桶), 那还不赶紧试试?http://demo.pigsty.cc
最近发布了 Pigsty 2.0.1 版本,使用以下命令一键安装。
bash -c "$(curl -fsSL http://download.pigsty.cc/get)"
分布式数据库是不是伪需求?
随着硬件技术的进步,单机数据库的容量和性能已达到了前所未有的高度。而分布式(TP)数据库在这种变革面前极为无力,和“数据中台”一样穿着皇帝的新衣,处于自欺欺人的状态里。

太长不看
分布式数据库的核心权衡是:“以质换量”,牺牲功能、性能、复杂度、可靠性,换取更大的数据容量与请求吞吐量。但分久必合,硬件变革让集中式数据库的容量与吞吐达到一个全新高度,使分布式(TP)数据库失去了存在意义。
以 NVMe SSD 为代表的硬件遵循摩尔定律以指数速度演进,十年间性能翻了几十倍,价格降了几十倍,性价比提高了三个数量级。单卡 32TB+, 4K随机读写 IOPS 可达 1600K/600K,延时 70µs/10µs,价格不到 200 ¥/TB·年。跑集中式数据库单机能有一两百万的点写/点查 QPS。
真正需要分布式数据库的场景屈指可数,典型的中型互联网公司/银行请求数量级在几万到几十万QPS,不重复TP数据在百TB上下量级。真实世界中 99% 以上的场景用不上分布式数据库,剩下1%也大概率可以通过经典的水平/垂直拆分等工程手段解决。
头部互联网公司可能有极少数真正的适用场景,然而此类公司没有任何付费意愿。市场根本无法养活如此之多的分布式数据库内核,能够成活的产品靠的也不见得是分布式这个卖点。HATP 、分布式单机一体化是迷茫分布式TP数据库厂商寻求转型的挣扎,但离 PMF 仍有不小距离。
互联网的牵引
“分布式数据库” 并不是一个严格定义的术语。狭义上它与 NewSQL:cockroachdb / yugabytesdb / tidb / oceanbase / TDSQL 等数据库高度重合;广义上 Oracle / PostgreSQL / MySQL / SQL Server / PolarDB / Aurora 这种跨多个物理节点,使用主从复制或者共享存储的经典数据库也能归入其中。在本文语境中,分布式数据库指前者,且只涉及核心定位为事务处理型(OLTP)的分布式关系型数据库。
分布式数据库的兴起源于互联网应用的快速发展和数据量的爆炸式增长。在那个时代,传统的关系型数据库在面对海量数据和高并发访问时,往往会出现性能瓶颈和可伸缩性问题。即使用 Oracle 与 Exadata,在面对海量 CRUD 时也有些无力,更别提每年以百千万计的高昂软硬件费用。
互联网公司走上了另一条路,用诸如 MySQL 这样免费的开源数据库自建。老研发/DBA可能还会记得那条 MySQL 经验规约:单表记录不要超过 2100万,否则性能会迅速劣化;与之对应的是,数据库分库分表开始成为大厂显学。
这里的基本想法是“三个臭皮匠,顶个诸葛亮”,用一堆便宜的 x86 服务器 + 大量分库分表开源数据库实例弄出一个海量 CRUD 简单数据存储。故而,分布式数据库往往诞生于互联网公司的场景,并沿着手工分库分表 → 分库分表中间件 → 分布式数据库这条路径发展进步。
作为一个行业解决方案,分布式数据库成功满足了互联网公司的场景需求。但是如果想把它抽象沉淀成一个产品对外输出,还需要想清楚几个问题:
十年前的利弊权衡,在今天是否依然成立?
互联网公司的场景,对其他行业是否适用?
分布式事务数据库,会不会是一个伪需求?
分布式的权衡
“分布式” 同 “HTAP”、 “存算分离”、“Serverless”、“湖仓一体” 这样的Buzzword一样,对企业用户来说没有意义。务实的甲方关注的是实打实的属性与能力:功能性能、安全可靠、投入产出、成本效益。真正重要的是利弊权衡:分布式数据库相比经典集中式数据库,牺牲了什么换取了什么?

数据库需求层次金字塔[1]
分布式数据库的核心Trade Off 可以概括为:“以质换量”:牺牲功能、性能、复杂度、可靠性,换取更大的数据容量与请求吞吐量。
NewSQL 通常主打“分布式”的概念,通过“分布式”解决水平伸缩性问题。在架构上通常拥有多个对等数据节点以及协调者,使用分布式共识协议 Paxos/Raft 进行复制,可以通过添加数据节点的方式进行水平伸缩。
首先,分布式数据库因其内在局限性,会牺牲许多功能,只能提供较为简单有限的 CRUD 查询支持。其次,分布式数据库因为需要通过多次网络 RPC 完成请求,所以性能相比集中式数据库通常有70%以上的折损。再者,分布式数据库通常由DN/CN以及TSO等多个组件构成,运维管理复杂,引入大量非本质复杂度。最后,分布式数据库在高可用容灾方面相较于经典集中式主从并没有质变,反而因为复数组件引入大量额外失效点。

SYSBENCH吞吐对比[2]
在以前,分布式数据库的利弊权衡是成立的:互联网需要更大的数据存储容量与更高的访问吞吐量:这个问题是必须解决的,而这些缺点是可以克服的。但今日,硬件的发展废问了 量 的问题,那么分布式数据库的存在意义就连同着它想解决的问题本身被一并抹除了。

时代变了,大人
新硬件的冲击
摩尔定律指出,每18~24个月,处理器性能翻倍,成本减半。这个规律也基本适用于存储。从2013年开始到2023年是5~6个周期,性能和成本和10年前比应该有几十倍的差距,是不是这样呢?
让我们看一下 2013 年典型 SSD 的性能指标,并与 2022 年 PCI-e Gen4 NVMe SSD 的典型产品进行对比。不难发现:硬盘4K随机读写 IOPS从 60K/40K 到了 1600K/600K,价格从 2220$/TB 到 40$/TB 。性能翻了15 ~ 26倍,价格便宜了56 倍[3,4,5],作为经验法则在数量级上肯定是成立了。

2013 年 HDD/SSD 性能指标

2022 年NVMe Gen4 SSD 性能指标
十年前,机械硬盘还是绝对主流。1TB 的硬盘价格大概七八百元,64GB 的SSD 还要再贵点。十年后,主流 3.2TB 的企业级 NVMe SSD 也不过三千块钱。按五年质保折算,1TB每月成本只要 16块钱,每年成本不到 200块。作为参考,云厂商号称物美价廉的 S3对象存储都要 1800¥/TB·年。
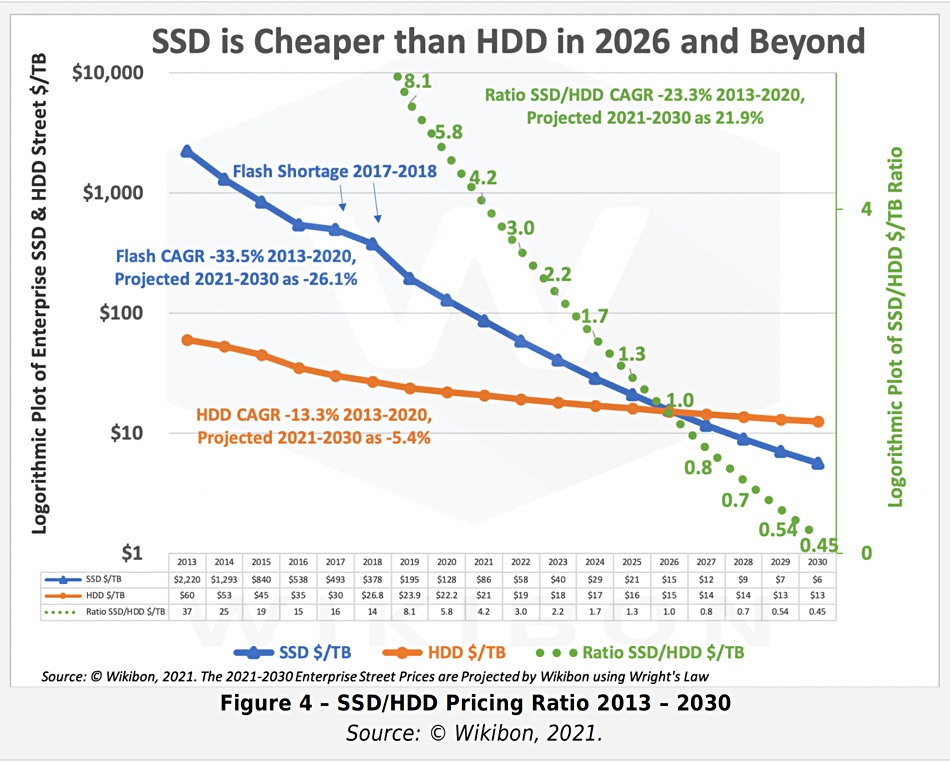
2013 - 2030 SSD/HDD 单位价格与预测
典型的第四代本地 NVMe 磁盘单卡最大容量可达 32TB~ 64TB,提供 70µs/10µs 4K随机读/写延迟,1600K/600K 的读写IOPS,第五代更是有着单卡十几GB/s 的惊人带宽。
这样的卡配上一台经典 Dell 64C / 512G 服务器,IDC代维5年折旧,总共十万块不到。而这样一台服务器跑 PostgreSQL sysbench 单机点写入可以接近百万QPS,点查询干到两百万 QPS 不成问题。
这是什么概念呢?对于一个典型的中型互联网公司/银行,数据库请求数量级通常在几万/几十万 QPS这个范围;不重复的TP数据量级在百TB上下浮动。考虑到使用硬件存储压缩卡还能有个几倍压缩比,这类场景在现代硬件条件下,有可能集中式数据库单机单卡就直接搞定了[6]。
在以前,用户可能需要先砸个几百万搞 exadata 高端存储,再花天价购买 Oracle 商业数据库授权与原厂服务。而现在做到这些,硬件上只需一块几千块的企业级 SSD 卡即可起步;像 PostgreSQL 这样的开源 Oracle 替代,最大单表32TB照样跑得飞快,不再有当年MySQL非要分表不可的桎梏。原本高性能的数据库服务从情报/银行领域的奢侈品,变成各行各业都能轻松负担得起的平价服务[7]。
性价比是第一产品力,高性能大容量的存储在十年间性价比提高了三个数量级,分布式数据库曾经的价值亮点,在这种大力出奇迹的硬件变革下显得软弱无力。
伪需求的困境
在当下,牺牲功能性能复杂度换取伸缩性有极大概率是伪需求。
在现代硬件的加持下,真实世界中 99%+ 的场景超不出单机集中式数据库的支持范围,剩下1%也大概率可以通过经典的水平/垂直拆分等工程手段解决。这一点对于互联网公司也能成立:即使是全球头部大厂,不可拆分的TP单表超过几十TB的场景依然罕见。
NewSQL的祖师爷 Google Spanner 是为了解决海量数据伸缩性的问题,但又有多少企业能有Google的业务数据量?从数据量上来讲,绝大多数企业终其生命周期的TP数据量,都超不过集中式数据库的单机瓶颈,而且这个瓶颈仍然在以摩尔定律的速度指数增长中。从请求吞吐量上来讲,很多企业的数据库性能余量足够让他们把业务逻辑全部用存储过程实现并丝滑地跑在数据库中。
“过早优化是万恶之源”,为了不需要的规模去设计是白费功夫。如果量不再成为问题,那么为了不需要的量去牺牲其他属性就成了一件毫无意义的事情。

“过早优化是万恶之源”
在数据库的许多细分领域中,分布式并不是伪需求:如果你需要一个高度可靠容灾的简单低频 KV 存储元数据,那么分布式的 etcd 就是合适的选择;如果你需要一张全球地理分布的表可以在各地任意读写,并愿意承受巨大的性能衰减作为代价,那么分布式的 YugabyteDB 也许是一个不错的选择。如果你需要进行信息公示并防止篡改与抵赖,区块链在本质上也是一种 Leaderless 的分布式账本数据库;
对于大规模数据分析OLAP来说,分布式可以说是必不可少(不过这种一般称为数据仓库,MPP);但是在事务处理OLTP领域,分布式可以说是大可不必:OTLP数据库属于工作性记忆,而工作记忆的特点就是小、快、功能丰富。即使是非常庞大的业务系统,同一时刻活跃的工作集也不会特别大。OLTP 系统设计的一个基本经验法则就是:如果你的问题规模可以在单机内解决,就不要去折腾分布式数据库。
OLTP 数据库已经有几十年的历史,现有内核已经发展到了相当成熟的地步。TP 领域标准正在逐渐收敛至 PostgreSQL,MySQL,Oracle 三种 Wire Protocol 。如果只是折腾数据库自动分库分表再加个全局事务这种“分布式”,那一定是没有出路的。如果真能有“分布式”数据库杀出一条血路,那大概率也不是因为“分布式”这个“伪需求”,而应当归功于新功能、开源生态、兼容性、易用性、国产信创、自主可控这些因素。
迷茫下的挣扎
分布式数据库最大的挑战来自于市场结构:最有可能会使用分布式TP数据库的互联网公司,反而是最不可能为此付费的一个群体。互联网公司可以作为很好的高质量用户甚至贡献者,提供案例、反馈与PR,但唯独在为软件掏钱买单这件事上与其模因本能相抵触。即使头部分布式数据库厂商,也面临着叫好不叫座的难题。
近日与某分布式数据库厂工程师闲聊时获悉,在客户那儿做 POC 时,Oracle 10秒跑完的查询,他们的分布式数据库用上各种资源和 Dirty Hack 都有一个数量级上的差距。即使是从10年前 PostgreSQL 9.2 分叉出来的 openGauss,都能在一些场景下干翻不少分布式数据库,更别提10年后的 PostgreSQL 15 与 Oracle 23c 了。这种差距甚至会让原厂都感到迷茫,分布式数据库的出路在哪里?
所以一些分布式数据库开始自救转型, HTAP 是一个典型例子:分布式搞事务鸡肋,但是做分析很好呀。那么为什么不能捏在一起凑一凑?一套系统,同时可以做事务处理与分析哟!但真实世界的工程师都明白:AP系统和TP系统各有各的模式,强行把两个需求南辕北辙的系统硬捏合在一块,只会让两件事都难以成功。不论是使用经典 ETL/CDC 推拉到专用 ClickHouse/Greenplum/Doris 去处理,还是逻辑复制到In-Mem列存的专用从库,哪一种都要比用一个奇美拉杂交HTAP数据库要更靠谱。
另一种思路是 单机分布式一体化:打不过就加入 :添加一个单机模式以规避代价高昂的网络RPC开销,起码在那些用不上分布式的99%场景中,不至于在硬指标上被集中式数据库碾压得一塌糊涂 —— 用不上分布式没关系,先拽上车别被其他人截胡! 但这里的问题本质与 HTAP 是一样的:强行整合异质数据系统没有意义,如果这样做有价值,那么为什么没人去把所有异构数据库整合一个什么都能做的巨无霸二进制 —— 数据库全能王? 因为这样违背了KISS原则:Keep It Simple, Stupid!

分布式数据库和数据中台的处境类似[8]:起源于互联网大厂内部的场景,也解决过领域特定的问题。曾几何时乘着互联网行业的东风,数据库言必谈分布式,火热风光好不得意。却因为过度的包装吹捧,承诺了太多不切实际的东西,又无法达到用户预期 —— 最终一地鸡毛,成为皇帝的新衣。
TP数据库领域还有很多地方值得投入精力:Leveraging new hardwares,积极拥抱 CXL,RDMA,NVMe 等底层体系结构变革;或者提供简单易用的声明式接口,让数据库的使用与管理更加便利;提供更为智能的自动驾驶监控管控,尽可能消除运维性的杂活儿;开发类似 Babelfish 的 MySQL / Oracle 兼容插件,实现关系数据库 WireProtocol 统一。哪怕砸钱堆人提供更好的支持服务,都比一个 “分布式” 的伪需求噱头要更有意义。
因时而动,君子不器。愿分布式数据库厂商们找到自己的 PMF,做一些用户真正需要的东西。
References
[1] 数据库需求层次金字塔 : https://mp.weixin.qq.com/s/1xR92Z67kvvj2_NpUMie1Q
[2] PostgreSQL到底有多强? : https://mp.weixin.qq.com/s/651zXDKGwFy8i0Owrmm-Xg
[3] 2013年SSD性能 : https://www.snia.org/sites/default/files/SNIASSSI.SSDPerformance-APrimer2013.pdf
[4] 2022年镁光9400 NVMe SSD 规格说明 : https://media-www.micron.com/-/media/client/global/documents/products/product-flyer/9400_nvme_ssd_product_brief.pdf
[5] 2013-2030 SSD价格走势与预测 : https://blocksandfiles.com/2021/01/25/wikibon-ssds-vs-hard-drives-wrights-law/
[6] 单实例100TB使用压缩卡到20TB: https://mp.weixin.qq.com/s/JSQPzep09rDYbM-x5ptsZA
[7] 公有云是不是杀猪盘?: https://mp.weixin.qq.com/s/UxjiUBTpb1pRUfGtR9V3ag
[8] 中台:一场彻头彻尾的自欺欺人: https://mp.weixin.qq.com/s/VgTU7NcOwmrX-nbrBBeH_w
微服务是不是个蠢主意?

亚马逊的Prime Video团队发表了一篇非常引人注目的案例研究[2] ,讲述了他们为什么放弃了微服务与Serverless架构而改用单体架构。这一举措让他们在运营成本上节省了惊人的 90%,还简化了系统复杂度,堪称一个巨大的胜利。
但除了赞扬他们的明智之举之外,我认为这里还有一个重要洞察适用于我们整个行业:
“我们最初设计的解决方案是:使用Serverless组件的分布式系统架构… 理论上这个架构可以让我们独立伸缩扩展每个服务组件。然而,我们使用某些组件的方式导致我们在大约5%的预期负载时,就遇到了硬性的伸缩限制。”
“理论上的” —— 这是对近年来在科技行业肆虐的微服务狂热做的精辟概括。现在纸上谈兵的理论终于有了真实世界的结论:在实践中,微服务的理念就像塞壬歌声一样诱惑着你,为系统添加毫无必要的复杂度,而 Serverless 只会让事情更糟糕。
这个故事最搞笑的地方是:亚马逊自己就是面向服务架构 / SOA 的最初典范与原始代言人。在微服务流行之前,这种组织模式还是很合理的:在一个疯狂的规模下,公司内部通信使用 API 调用的模式,是能吊打协调跨团队会议的模式的。
SOA 在亚马逊的规模下很有意义,没有任何一个团队能够知道或理解 驾驶这么一艘巨无霸邮轮所需的方方面面,而让团队之间通过公开发布的 API 进行协作简直是神来之笔。
但正如很多“好主意”一样,这种模式在脱离了原本的场景用在其他地方后,就开始变得极为有害了:特别是塞进单一应用架构内部时 —— 而人们就是这么搞微服务的。

从很多层面上来说,微服务是一种僵尸架构,是一种顽强的思想病毒:从 J2EE 的黑暗时代(Remote Server Beans,有人听说过吗),一直到 WS-Deathstar[3] 死星式的胡言乱语,再到现在微服务与 Serverless 的形式,它一直在吞噬大脑,消磨人们的智力。
不过这第三波浪潮总算是到顶了,我在 2016 年就写过一首关于 “宏伟的单体应用[4]” 的赞歌。Kubernetes 背后的意见领袖高塔先生也在 2020年 单体才是未来[5] 一文中表达过这一点:
“我们要打破单体应用,找到先前从未有过的工程纪律… 现在人们从编写垃圾代码变成打造垃圾平台与基础设施。
人们沉迷于这些与时髦术语绑定的热钱与炒作,因为微服务带来了大量的新开销,招聘机会与工作岗位,唯独对于解决他们的问题来说实际上并没有必要。“

没错,当你拥有一个连贯的单一团队与单体应用程序时,用网络调用和服务拆分取代方法调用与模块切分,在几乎所有情况下都是一个无比疯狂的想法。
我很高兴在记忆中已经是第三次击退这种僵尸狂潮一样的蠢主意了。但我们必须保持警惕,因为我们早晚还得继续这么干:有些山炮想法无论弄死多少次都会卷土重来。你能做的就是当它们借尸还魂的时候及时认出来,用文章霰弹枪给他喷个稀巴烂。
有效的复杂系统总是从简单的系统演化而来。反之亦然:从零设计的复杂系统没一个能有效工作的。
—— 约翰・加尔,Systemantics(1975)
本文作者 DHH, Ruby on Rails 作者,37signals CTO,译者冯若航。
原题为 Even Amazon can’t make sense of serverless or microservices[1] 。即《亚马逊自个都觉得微服务和Serverless扯淡了》
References
[1] Even Amazon can’t make sense of serverless or microservices: https://world.hey.com/dhh/even-amazon-can-t-make-sense-of-serverless-or-microservices-59625580
[2] 引人注目的案例研究: https://www.primevideotech.com/video-streaming/scaling-up-the-prime-video-audio-video-monitoring-service-and-reducing-costs-by-90
[3] WS-Deathstar: https://www.flickr.com/photos/psd/1428661128/
[4] 宏伟的单体应用: https://m.signalvnoise.com/the-majestic-monolith/
[5] 单体才是未来: https://changelog.com/posts/monoliths-are-the-future
是时候和GPL说再见了
原文由 Martin Kleppmann 于2021年4月14日发表,译者:冯若航。
Martin Kleppmann是《设计数据密集型应用》(a.k.a DDIA)的作者,译者冯若航为该书中文译者。
本文的导火索是Richard Stallman恢复原职,对于自由软件基金会(FSF)的董事会而言,这是一位充满争议的人物。我对此感到震惊,并与其他人一起呼吁将他撤职。这次事件让我重新评估了自由软件基金会在计算机领域的地位 —— 它是GNU项目(宽泛地说它属于Linux发行版的一部分)和以GNU通用公共许可证(GPL)为中心的软件许可证系列的管理者。这些努力不幸被Stallman的行为所玷污。然而这并不是我今天真正想谈的内容。
在本文中,我认为我们应该远离GPL和相关的许可证(LGPL、AGPL),原因与Stallman无关,只是因为,我认为它们未能实现其目的,而且它们造成的麻烦比它们产生的价值要更大。
首先简单介绍一下背景:GPL系列许可证的定义性特征是 copyleft 的概念,它指出,如果你用了一些GPL许可的代码并对其进行修改或构建,你也必须在同一许可证下免费提供你的修改/扩展(被称为"衍生作品")(大致意思)。这样一来,GPL的源代码就不能被纳入闭源软件中。乍看之下,这似乎是个好主意。那么问题在哪里?
敌人变了
在上世纪80年代和90年代,当GPL被创造出来时,自由软件运动的敌人是微软和其他销售闭源(“专有”)软件的公司。GPL打算破坏这种商业模式,主要出于两个原因:
- 闭源软件不容易被用户所修改;你可以用,也可以不用,但你不能根据自己的需求对它进行修改定制。为了抵制这种情况,GPL设计的宗旨即是,迫使公司发布其软件的源代码,这样软件的用户就可以研究、修改、编译和使用他们自己的修改定制版本,从而获得按需定制自己计算设备的自由。
- 此外,GPL的动机也包括对公平的渴望:如果你在业余时间写了一些软件并免费发布,但是别人用它获利,又不向社区回馈任何东西,你肯定也不希望这样的事情发生。强制衍生作品开源,至少可以确保一些兜底的"回报"。
这些原因在1990年有意义,但我认为,世界已经变了,闭源软件已经不是主要问题所在。在2020年,计算自由的敌人是云计算软件(又称:软件即服务/SaaS,又称网络应用/Web Apps)—— 即主要在供应商的服务器上运行的软件,而你的所有数据也存储在这些服务器上。典型的例子包括:Google Docs、Trello、Slack、Figma、Notion和其他许多软件。
这些“云软件”也许有一个客户端组件(手机App,网页App,跑在你浏览器中的JavaScript),但它们只能与供应商的服务端共同工作。而云软件存在很多问题:
- 如果提供云软件的公司倒闭,或决定停产,软件就没法工作了,而你用这些软件创造的文档与数据就被锁死了。对于初创公司编写的软件来说,这是一个很常见的问题:这些公司可能会被大公司收购,而大公司没有兴趣继续维护这些初创公司的产品。
- 谷歌和其他云服务可能在没有任何警告和追索手段的情况下,突然暂停你的账户。例如,您可能在完全无辜的情况下,被自动化系统判定为违反服务条款:其他人可能入侵了你的账户,并在你不知情的情况下使用它来发送恶意软件或钓鱼邮件,触发违背服务条款。因而,你可能会突然发现自己用Google Docs或其它App创建的文档全部都被永久锁死,无法访问了。
- 而那些运行在你自己的电脑上的软件,即使软件供应商破产了,它也可以继续运行,直到永远。(如果软件不再与你的操作系统兼容,你也可以在虚拟机和模拟器中运行它,当然前提是它不需要联络服务器来检查许可证)。例如,互联网档案馆有一个超过10万个历史软件的软件集锦,你可以在浏览器中的模拟器里运行!相比之下,如果云软件被关闭,你没有办法保存它,因为你从来就没有服务端软件的副本,无论是源代码还是编译后的形式。
- 20世纪90年代,无法定制或扩展你所使用的软件的问题,在云软件中进一步加剧。对于在你自己的电脑上运行的闭源软件,至少有人可以对它的数据文件格式进行逆向工程,这样你还可以把它加载到其他的替代软件里(例如OOXML之前的微软Office文件格式,或者规范发布前的Photoshop文件)。有了云软件,甚至连这个都做不到了,因为数据只存储在云端,而不是你自己电脑上的文件。
如果所有的软件都是免费和开源的,这些问题就都解决了。然而,开源实际上并不是解决云软件问题的必要条件;即使是闭源软件也可以避免上述问题,只要它运行在你自己的电脑上,而不是供应商的云服务器上。请注意,互联网档案馆能够在没有源代码的情况下维持历史软件的正常运行:如果只是出于存档的目的,在模拟器中运行编译后的机器代码就够了。也许拥有源码会让事情更容易一些,但这并不是不关键,最重要的事情,还是要有一份软件的副本。
本地优先的软件
我和我的合作者们以前曾主张过本地优先软件的概念,这是对云软件的这些问题的一种回应。本地优先的软件在你自己的电脑上运行,将其数据存储在你的本地硬盘上,同时也保留了云计算软件的便利性,比如,实时协作,和在你所有的设备上同步数据。开源的本地优先的软件当然非常好,但这并不是必须的,本地优先软件90%的优点同样适用于闭源的软件。
云软件,而不是闭源软件,才是对软件自由的真正威胁,原因在于:云厂商能够突然心血来潮随心所欲地锁定你的所有数据,其危害要比无法查看和修改你的软件源码的危害大得多。因此,普及本地优先的软件显得更为重要和紧迫。如果在这一过程中,我们也能让更多的软件开放源代码,那也很不错,但这并没有那么关键。我们要聚焦在最重要与最紧迫的挑战上。
促进软件自由的法律工具
Copyleft软件许可证是一种法律工具,它试图迫使更多的软件供应商公开其源码。尤其是AGPL,它尝试迫使云厂商发布其服务器端软件的源代码。然而这并没有什么用:大多数云厂商只是简单拒绝使用AGPL许可的软件:要么使用一个采用更宽松许可的替代实现版本,要么自己重新实现必要的功能,或者直接购买一个没有版权限制的商业许可。有些代码无论如何都不会开放,我不认为这个许可证真的有让任何本来没开源的软件变开源。
作为一种促进软件自由的法律工具,我认为 copyleft 在很大程度上是失败的,因为它们在阻止云软件兴起上毫无建树,而且可能在促进开源软件份额增长上也没什么用。开源软件已经很成功了,但这种成功大部分都属于 non-copyleft 的项目(如Apache、MIT或BSD许可证),即使在GPL许可证的项目中(如Linux),我也怀疑版权方面是否真的是项目成功的重要因素。
对于促进软件自由而言,我相信更有前景的法律工具是政府监管。例如,GDPR提出了数据可移植权,这意味着用户必须可以能将他们的数据从一个服务转移到其它的服务中。现有的可移植性的实现,例如谷歌Takeout,是相当初级的(你真的能用一堆JSON压缩档案做点什么吗?),但我们可以游说监管机构推动更好的可移植性/互操作性,例如,要求相互竞争的两个供应商在它们的两个应用程序之间,实时双向同步你的数据。
另一条有希望的途径是,推动[公共部门的采购倾向于开源、本地优先的软件](https://joinup.ec.europa.eu/sites/default/files/document/2011-12/OSS-procurement-guideline -final.pdf),而不是闭源的云软件。这为企业开发和维护高质量的开源软件创造了积极的激励机制,而版权条款却没有这样做。
你可能会争论说,软件许可证是开发者个人可以控制的东西,而政府监管和公共政策是一个更大的问题,不在任何一个个体权力范围之内。是的,但你选择一个软件许可证能产生多大的影响?任何不喜欢你的许可证的人可以简单地选择不使用你的软件,在这种情况下,你的力量是零。有效的改变来自于对大问题的集体行动,而不是来自于一个人的小开源项目选择一种许可证而不是另一种。
GPL-家族许可证的其他问题
你可以强迫一家公司提供他们的GPL衍生软件项目的源码,但你不能强迫他们成为开源社区的好公民(例如,持续维护它们添加的功能特性、修复错误、帮助其他贡献者、提供良好的文档、参与项目管理)。如果它们没有真正参与开源项目,那么这些 “扔到你面前 “的源代码又有什么用?最好情况下,它没有价值;最坏的情况下,它还是有害的,因为它把维护的负担转嫁给了项目的其他贡献者。
我们需要人们成为优秀的开源社区贡献者,而这是通过保持开放欢迎的态度,建立正确的激励机制来实现的,而不是通过软件许可证。
最后,GPL许可证家族在实际使用中的一个问题是,它们与其他广泛使用的许可证不兼容,这使得在同一个项目中使用某些库的组合变得更为困难,且不必要地分裂了开源生态。如果GPL许可证有其他强大的优势,也许这个问题还值得忍受。但正如上面所述,我不认为这些优势存在。
结论
GPL和其他 copyleft 许可证并不坏,我只是认为它们毫无意义。它们有实际问题,而且被FSF的行为所玷污;但最重要的是,我不认为它们对软件自由做出了有效贡献。现在唯一真正在用 copyleft 的商业软件厂商(MongoDB, Elastic) —— 它们想阻止亚马逊将其软件作为服务提供,这当然很好,但这纯粹是出于商业上的考虑,而不是软件自由。
开源软件已经取得了巨大的成功,自由软件运动源于1990年代的反微软情绪,它已经走过了很长的路。我承认自由软件基金会对这一切的开始起到了重要作用。然而30年过去了,生态已经发生了变化,而自由软件基金会却没有跟上,而且变得越来越不合群。它没能对云软件和其他最近对软件自由的威胁做出清晰的回应,只是继续重复着几十年前的老论调。现在,通过恢复Stallman的地位和驳回对他的关注,FSF正在积极地伤害自由软件的事业。我们必须与FSF和他们的世界观保持距离。
基于所有这些原因,我认为抓着GPL和 copyleft 已经没有意义了,放手吧。相反,我会鼓励你为你的项目采用一种宽容的许可协议(例如MIT, BSD, Apache 2.0),然后把你的精力放在真正能对软件自由产生影响的事情上。抵制云软件的垄断效应,发展可持续的商业模式,让开源软件茁壮成长,并推动监管,将软件用户的利益置于供应商的利益之上。
- 感谢Rob McQueen对本帖草稿的反馈。
参考文献
- RMS官复原职:(https://www.fsf.org/news/statement-of-fsf-board-on-election-of-richard-stallman
- 自由软件基金会主页:https://www.fsf.org/
- 弹劾RMS的公开信:https://rms-open-letter.github.io/
- GNU项目声明:https://www.gnu.org/gnu/incorrect-quotation.en.html
- GNU通用公共许可证 https://en.wikipedia.org/wiki/GNU_General_Public_License
- copyleft: https://en.wikipedia.org/wiki/Copyleft
- 衍生作品的定义:https://en.wikipedia.org/wiki/Derivative_work
- x.ai被Bizzabo收购:https://ourincrediblejourney.tumblr.com/
- Google Account Suspended No Reason Given:https://www.paullimitless.com/google-account-suspended-no-reason-given/
- Google暂停用户账户:https://twitter.com/Demilogic/status/1358661840402845696
- 互联网历史软件归档:https://archive.org/details/softwarelibrary
- Office Open XML:https://en.wikipedia.org/wiki/Office_Open_XML
- Photoshop File Formats Specification:https://www.adobe.com/devnet-apps/photoshop/fileformatashtml/
- 本地优先软件:https://www.inkandswitch.com/local-first.html
- AGPL协议:https://en.wikipedia.org/wiki/Affero_General_Public_License
- Elastic商业许可证:https://www.elastic.co/cn/pricing/faq/licensing
- 数据可移植权:https://ico.org.uk/for-organisations/guide-to-data-protection/guide-to-the-general-data-protection-regulation-gdpr/individual-rights/right-to-data-portability/
- 谷歌Takeout(带走你的数据):https://en.wikipedia.org/wiki/Google_Takeout
- 互操作性新闻:https://interoperability.news/
- 欧盟开源软件采购指南:https://joinup.ec.europa.eu/sites/default/files/document/2011-12/OSS-procurement-guideline%20-final.pdf
- 许可证兼容性:https://gplv3.fsf.org/wiki/index.php/Compatible_licenses
- MongoDB SSPL协议FAQ:https://gplv3.fsf.org/wiki/index.php/Compatible_licenses
- Elastic许可变更问题汇总:https://gplv3.fsf.org/wiki/index.php/Compatible_licenses
- “自由软件”:一个过时的想法:https://r0ml.medium.com/free-software-an-idea-whose-time-has-passed-6570c1d8218a
- 一条FSF未曾设想的路:https://lu.is/blog/2021/04/07/values-centered-npos-with-kmaher/
容器化数据库是个好主意吗?
前言:这篇文章是19年1月写的,四年过去了,涉及到数据库与容器的利弊权衡依然成立。这里进行细微调整后重新发出。明天我会发布一篇《数据库是否应当放入K8S中?》,那么今天就先用这篇老文来预热一下吧。微信公众号原文
对于无状态的应用服务而言,容器是一个相当完美的开发运维解决方案。然而对于带持久状态的服务 —— 数据库来说,事情就没有那么简单了。生产环境的数据库是否应当放入容器中,仍然是一个充满争议的问题。
站在开发者的角度上,我非常喜欢Docker,并相信容器也许是未来软件开发部署运维的标准方式。但站在DBA的立场上,我认为就目前而言,将生产环境数据库放入Docker / K8S 中仍然是一个馊主意。
Docker解决什么问题?
让我们先来看一看Docker对自己的描述。


Docker用于形容自己的词汇包括:轻量,标准化,可移植,节约成本,提高效率,自动,集成,高效运维。这些说法并没有问题,Docker在整体意义上确实让开发和运维都变得更容易了。因而可以看到很多公司都热切地希望将自己的软件与服务容器化。但有时候这种热情会走向另一个极端:将一切软件服务都容器化,甚至是生产环境的数据库。
容器最初是针对无状态的应用而设计的,在逻辑上,容器内应用产生的临时数据也属于该容器的一部分。用容器创建起一个服务,用完之后销毁它。这些应用本身没有状态,状态通常保存在容器外部的数据库里,这是经典的架构与用法,也是容器的设计哲学。
但当用户想把数据库本身也放到容器中时,事情就变得不一样了:数据库是有状态的,为了维持这个状态不随容器停止而销毁,数据库容器需要在容器上打一个洞,与底层操作系统上的数据卷相联通。这样的容器,不再是一个能够随意创建,销毁,搬运,转移的对象,而是与底层环境相绑定的对象。因此,传统应用使用容器的诸多优势,对于数据库容器来说都不复存在。
可靠性
让软件跑起来,和让软件可靠地运行是两回事。数据库是信息系统的核心,在绝大多数场景下属于**关键(Critical)**应用,Critical Application可按字面解释,就是出了问题会要命的应用。这与我们的日常经验相符:Word/Excel/PPT这些办公软件如果崩了强制重启即可,没什么大不了的;但正在编辑的文档如果丢了、脏了、乱了,那才是真的灾难。数据库亦然,对于不少公司,特别是互联网公司来说,如果数据库被删了又没有可用备份,基本上可以宣告关门大吉了。
可靠性(Reliability)是数据库最重要的属性。可靠性是系统在困境(adversity)(硬件故障、软件故障、人为错误)中仍可正常工作(正确完成功能,并能达到期望的性能水准)的能力。可靠性意味着容错(fault-tolerant)与韧性(resilient),它是一种安全属性,并不像性能与可维护性那样的活性属性直观可衡量。它只能通过长时间的正常运行来证明,或者某一次故障来否证。很多人往往会在平时忽视安全属性,而在生病后,车祸后,被抢劫后才追悔莫及。安全生产重于泰山,数据库被删,被搅乱,被脱库后再捶胸顿足是没有意义的。
回头再看一看Docker对自己的特性描述中,并没有包含“可靠”这个对于数据库至关重要的属性。
可靠性证明与社区知识
如前所述,可靠性并没有一个很好的衡量方式。只有通过长时间的正确运行,我们才能对一个系统的可靠性逐渐建立信心。在裸机上部署数据库可谓自古以来的实践,通过几十年的持续工作,它很好的证明了自己的可靠性。Docker虽为DevOps带来一场革命,但仅仅五年的历史对于可靠性证明而言仍然是图样图森破。对关乎身家性命的生产数据库而言还远远不够:因为还没有足够的小白鼠去趟雷。
想要提高可靠性,最重要的就是从故障中吸取经验。故障是宝贵的经验财富:它将未知问题变为已知问题,是运维知识的表现形式。社区的故障经验绝大多都基于裸机部署的假设,各式各样的故障在几十年里都已经被人们踩了个遍。如果你遇到一些问题,大概率是别人已经踩过的坑,可以比较方便地处理与解决。同样的故障如果加上一个“Docker”关键字,能找到的有用信息就要少的多。这也意味着当疑难杂症出现时,成功抢救恢复数据的概率要更低,处理紧急故障所需的时间会更长。
微妙的现实是,如果没有特殊理由,企业与个人通常并不愿意分享故障方面的经验。故障有损企业的声誉:可能暴露一些敏感信息,或者是企业与团队的垃圾程度。另一方面,故障经验几乎都是真金白银的损失与学费换来的,是运维人员的核心价值所在,因此有关故障方面的公开资料并不多。
额外失效点
开发关心Feature,而运维关注Bug。相比裸机部署而言,将数据库放入Docker中并不能降低硬件故障、软件错误、人为失误的发生概率。用裸机会有的硬件故障,用Docker一个也不会少。软件缺陷主要是应用Bug,也不会因为采用容器与否而降低,人为失误同理。相反,引入Docker会因为引入了额外的组件,额外的复杂度,额外的失效点,导致系统整体可靠性下降。
举个最简单的例子,dockerd守护进程崩了怎么办,数据库进程就直接歇菜了。尽管这种事情发生的概率并不高,但它们在裸机上 —— 压根不会发生。
此外,一个额外组件引入的失效点可能并不止一个:Docker产生的问题并不仅仅是Docker本身的问题。当故障发生时,可能是单纯Docker的问题,或者是Docker与数据库相互作用产生的问题,还可能是Docker与操作系统,编排系统,虚拟机,网络,磁盘相互作用产生的问题。可以参见官方PostgreSQL Docker镜像的Issue列表:https://github.com/docker-library/postgres/issues?q=。
正如《从降本增笑到降本增效》中所说,智力功率很难在空间上累加 —— 团队的智力功率往往取决于最资深几个灵魂人物的水平以及他们的沟通成本。当数据库出现问题时需要数据库专家来解决;当容器出现问题时需要容器专家来看问题;然而当你把数据库放入 Kubernetes 时,单独的数据库专家和 K8S 专家的智力带宽是很难叠加的 —— 你需要一个双料专家才能解决问题。而同时精通这两者的软件肯定要比单独的数据库专家少得多。
此外,彼之蜜糖,吾之砒霜。某些Docker的Feature,在特定的环境下也可能会变为Bug。
隔离性
Docker提供了进程级别的隔离性,通常来说隔离性对应用来说是个好属性。应用看不见别的进程,自然也不会有很多相互作用导致的问题,进而提高了系统的可靠性。但隔离性对于数据库而言不一定完全是好事。
一个微妙的真实案例是在同一个数据目录上启动两个PostgreSQL实例,或者在宿主机和容器内同时启动了两个数据库实例。在裸机上第二次启动尝试会失败,因为PostgreSQL能意识到另一个实例的存在而拒绝启动;但在使用Docker的情况下因其隔离性,第二个实例无法意识到宿主机或其他数据库容器中的另一个实例。如果没有配置合理的Fencing机制(例如通过宿主机端口互斥,pid文件互斥),两个运行在同一数据目录上的数据库进程能把数据文件搅成一团浆糊。
数据库需不需要隔离性?当然需要, 但不是这种隔离性。数据库的性能很重要,因此往往是独占物理机部署。除了数据库进程和必要的工具,不会有其他应用。即使放在容器中,也往往采用独占绑定物理机的模式运行。因此Docker提供的隔离性对于这种数据库部署方案而言并没有什么意义;不过对云数据库厂商来说,这倒真是一个实用的Feature,用来搞多租户超卖妙用无穷。
工具
数据库需要工具来维护,包括各式各样的运维脚本,部署,备份,归档,故障切换,大小版本升级,插件安装,连接池,性能分析,监控,调优,巡检,修复。这些工具,也大多针对裸机部署而设计。这些工具与数据库一样,都需要精心而充分的测试。让一个东西跑起来,与确信这个东西能持久稳定正确的运行,是完全不同的可靠性水准。
一个简单的例子是插件与包管理,PostgreSQL提供了很多实用的插件,譬如PostGIS。假如想为数据库安装该插件,在裸机上只要yum install然后create extension postgis两条命令就可以。但如果是在Docker里,按照Docker的实践原则,用户需要在镜像层次进行这个变更,否则下次容器重启时这个扩展就没了。因而需要修改Dockerfile,重新构建新镜像并推送到服务器上,最后重启数据库容器,毫无疑问,要麻烦的多。
包管理是操作系统发行版的核心问题。然而 Docker 搅乱了这一切,例如,许多 PostgreSQL 不再以 RPM/DEB 包的形式发布二进制,而是以加装扩展的 Postgres Docker 镜像分发。这就会立即产生一个显著的问题,如果我想同时使用两种,三种,或者PG生态的一百多种扩展,那么应该如何把这些散碎的镜像整合到一起呢?相比可靠的操作系统包管理,构建Docker镜像总是需要耗费更多时间与精力才能正常起效。
再比如说监控,在传统的裸机部署模式下,机器的各项指标是数据库指标的重要组成部分。容器中的监控与裸机上的监控有很多微妙的区别。不注意可能会掉到坑里。例如,CPU各种模式的时长之和,在裸机上始终会是100%,但这样的假设在容器中就不一定总是成立了。再比方说依赖/proc文件系统的监控程序可能在容器中获得与裸机上涵义完全不同的指标。虽然这类问题最终都是可解的(例如把Proc文件系统挂载到容器内),但相比简洁明了的方案,没人喜欢复杂丑陋的work around。
类似的问题包括一些故障检测工具与系统常用命令,虽然理论上可以直接在宿主机上执行,但谁能保证容器里的结果和裸机上的结果有着相同的涵义?更为棘手的是紧急故障处理时,一些需要临时安装使用的工具在容器里没有,外网不通,如果再走Dockerfile→Image→重启这种路径毫无疑问会让人抓狂。
把Docker当成虚拟机来用的话,很多工具大抵上还是可以正常工作的,不过这样就丧失了使用的Docker的大部分意义,不过是把它当成了另一个包管理器用而已。有人觉得Docker通过标准化的部署方式增加了系统的可靠性,因为环境更为标准化更为可控。这一点不能否认。私以为,标准化的部署方式虽然很不错,但如果运维管理数据库的人本身了解如何配置数据库环境,将环境初始化命令写在Shell脚本里和写在Dockerfile里并没有本质上的区别。
可维护性
软件的大部分开销并不在最初的开发阶段,而是在持续的维护阶段,包括修复漏洞、保持系统正常运行、处理故障、版本升级,偿还技术债、添加新的功能等等。可维护性对于运维人员的工作生活质量非常重要。应该说可维护性是Docker最讨喜的地方:Infrastructure as code。可以认为Docker的最大价值就在于它能够把软件的运维经验沉淀成可复用的代码,以一种简便的方式积累起来,而不再是散落在各个角落的install/setup文档。在这一点上Docker做的相当出色,尤其是对于逻辑经常变化的无状态应用而言。Docker和K8s能让用户轻松部署,完成扩容,缩容,发布,滚动升级等工作,让Dev也能干Ops的活,让Ops也能干DBA的活(迫真)。
环境配置
如果说Docker最大的优点是什么,那也许就是环境配置的标准化了。标准化的环境有助于交付变更,交流问题,复现Bug。使用二进制镜像(本质是物化了的Dockerfile安装脚本)相比执行安装脚本而言更为快捷,管理更方便。一些编译复杂,依赖如山的扩展也不用每次都重新构建了,这些都是很不错的特性。
不幸的是,数据库并不像通常的业务应用一样来来去去更新频繁,创建新实例或者交付环境本身是一个极低频的操作。同时DBA们通常都会积累下各种安装配置维护脚本,一键配置环境也并不会比Docker慢多少。因此在环境配置上Docker的优势就没有那么显著了,只能说是 Nice to have。当然,在没有专职DBA时,使用Docker镜像可能还是要比自己瞎折腾要好一些,因为起码镜像中多少沉淀了一些运维经验。
通常来说,数据库初始化之后连续运行几个月几年也并不稀奇。占据数据库管理工作主要内容的并不是创建新实例与交付环境,主要还是日常运维的部分 —— Day2 Operation。不幸的是,在这一点上Docker并没有什么优势,反而会产生不少的额外麻烦。
Day2 Operation
Docker确实能极大地简化来无状态应用的日常维护工作,诸如创建销毁,版本升级,扩容等,但同样的结论能延伸到数据库上吗?
数据库容器不可能像应用容器一样随意销毁创建,重启迁移。因而Docker并不能对数据库的日常运维的体验有什么提升,真正有帮助的倒是诸如 ansible 之类的工具。而对于日常运维而言,很多操作都需要通过docker exec的方式将脚本透传至容器内执行。底下跑的还是一样的脚本,只不过用docker-exec来执行又额外多了一层包装,这就有点脱裤子放屁的意味了。
此外,很多命令行工具在和Docker配合使用时都相当尴尬。譬如docker exec会将stderr和stdout混在一起,让很多依赖管道的命令无法正常工作。以PostgreSQL为例,在裸机部署模式下,某些日常ETL任务可以用一行bash轻松搞定:
psql <src-url> -c 'COPY tbl TO STDOUT' |\
psql <dst-url> -c 'COPY tdb FROM STDIN'
但如果宿主机上没有合适的客户端二进制程序,那就只能这样用Docker容器中的二进制:
docker exec -it srcpg gosu postgres bash -c "psql -c \"COPY tbl TO STDOUT\" 2>/dev/null" |\ docker exec -i dstpg gosu postgres psql -c 'COPY tbl FROM STDIN;'
当用户想为容器里的数据库做一个物理备份时,原本很简单的一条命令现在需要很多额外的包装:docker套gosu套bash套pg_basebackup:
docker exec -i postgres_pg_1 gosu postgres bash -c 'pg_basebackup -Xf -Ft -c fast -D - 2>/dev/null' | tar -xC /tmp/backup/basebackup
如果说客户端应用psql|pg_basebackup|pg_dump还可以通过在宿主机上安装对应版本的客户端工具来绕开这个问题,那么服务端的应用就真的无解了。总不能在不断升级容器内数据库软件的版本时每次都一并把宿主机上的服务器端二进制版本升级了吧?
另一个Docker喜欢讲的例子是软件版本升级:例如用Docker升级数据库小版本,只要简单地修改Dockerfile里的版本号,重新构建镜像然后重启数据库容器就可以了。没错,至少对于无状态的应用来说这是成立的。但当需要进行数据库原地大版本升级时问题就来了,用户还需要同时修改数据库状态。在裸机上一行bash命令就可以解决的问题,在Docker下可能就会变成这样的东西:https://github.com/tianon/docker-postgres-upgrade。
如果数据库容器不能像AppServer一样随意地调度,快速地扩展,也无法在初始配置,日常运维,以及紧急故障处理时相比普通脚本的方式带来更多便利性,我们又为什么要把生产环境的数据库塞进容器里呢?
Docker和K8s一个很讨喜的地方是很容易进行扩容,至少对于无状态的应用而言是这样:一键拉起起几个新容器,随意调度到哪个节点都无所谓。但数据库不一样,作为一个有状态的应用,数据库并不能像普通AppServer一样随意创建,销毁,水平扩展。譬如,用户创建一个新从库,即使使用容器,也得从主库上重新拉取基础备份。生产环境中动辄几TB的数据库,创建副本也需要个把钟头才能完成,也需要人工介入与检查,并逐渐放量预热缓存才能上线承载流量。相比之下,在同样的操作系统初始环境下,运行现成的拉从库脚本与跑docker run在本质上又能有什么区别 —— 时间都花在拖从库上了。
使用Docker承放生产数据库的一个尴尬之处就在于,数据库是有状态的,而且为了建立这个状态需要额外的工序。通常来说设置一个新PostgreSQL从库的流程是,先通过pg_basebackup建立本地的数据目录副本,然后再在本地数据目录上启动postmaster进程。然而容器是和进程绑定的,一旦进程退出容器也随之停止。因此为了在Docker中扩容一个新从库:要么需要先后启动pg_basebackup容器拉取数据目录,再在同一个数据卷上启动postgres两个容器;要么需要在创建容器的过程中就指定好复制目标并等待几个小时的复制完成;要么在postgres容器中再使用pg_basebackup偷天换日替换数据目录。无论哪一种方案都是既不优雅也不简洁。因为容器的这种进程隔离抽象,对于数据库这种充满状态的多进程,多任务,多实例协作的应用存在抽象泄漏,它很难优雅地覆盖这些场景。当然有很多折衷的办法可以打补丁来解决这类问题,然而其代价就是大量非本征复杂度,最终受伤的还是系统的可维护性。
总的来说,Docker 在某些层面上可以提高系统的可维护性,比如简化创建新实例的操作,但它引入的新麻烦让这样的优势显得苍白无力。
性能
性能也是人们经常关注的一个维度。从性能的角度来看,数据库的基本部署原则当然是离硬件越近越好,额外的隔离与抽象不利于数据库的性能:越多的隔离意味着越多的开销,即使只是内核栈中的额外拷贝。对于追求性能的场景,一些数据库选择绕开操作系统的页面管理机制直接操作磁盘,而一些数据库甚至会使用FPGA甚至GPU加速查询处理。
实事求是地讲,Docker作为一种轻量化的容器,性能上的折损并不大,通常不会超过 10% 。但毫无疑问的是,将数据库放入Docker只会让性能变得更差而不是更好。
总结
容器技术与编排技术对于运维而言是非常有价值的东西,它实际上弥补了从软件到服务之间的空白,其愿景是将运维的经验与能力代码化模块化。容器技术将成为未来的包管理方式,而编排技术将进一步发展为“数据中心分布式集群操作系统”,成为一切软件的底层基础设施Runtime。当越来越多的坑被踩完后,人们可以放心大胆的把一切应用,有状态的还是无状态的都放到容器中去运行。但现在起码对于数据库而言,还只是一个美好的愿景与鸡肋的选项。
需要再次强调的是,以上讨论仅限于生产环境数据库。对于开发测试而言,尽管有基于Vagrant的虚拟机沙箱,但我也支持使用Docker —— 毕竟不是所有的开发人员都知道怎么配置本地测试数据库环境,使用Docker交付环境显然要比一堆手册简单明了的多。对于生产环境的无状态应用,甚至一些带有衍生状态的不甚重要衍生数据系统(譬如Redis缓存),Docker也是一个不错的选择。但对于生产环境的核心关系型数据库而言,如果里面的数据真的很重要,使用Docker前还是需要三思:这样做的价值到底在哪里?出了疑难杂症能Hold住吗?搞砸了这锅背的动吗?
任何技术决策都是一个利弊权衡的过程,譬如这里使用Docker的核心权衡可能就是牺牲可靠性换取可维护性。确实有一些场景,数据可靠性并不是那么重要,或者说有其他的考量:譬如对于云计算厂商来说,把数据库放到容器里混部超卖就是一件很好的事情:容器的隔离性,高资源利用率,以及管理上的便利性都与该场景十分契合。这种情况下将数据库放入Docker中,也许对他们而言就是利大于弊的。但对于更多的场景来说,可靠性往往都是优先级最高的的属性,牺牲可靠性换取可维护性通常并不是一个可取的选择。更何况也很难说运维管理数据库的工作,会因为用了Docker而轻松多少:为了安装部署一次性的便利而牺牲长久的日常运维可维护性并不是一个好主意。
综上所述,将生产环境的数据库放入容器中恐怕并不是一个明智的选择。
理解时间:闰年闰秒,时间与时区
前几天出现了四年一遇的闰年 2月29号,每到这一天,总会有一些土鳖软件出现大翻车。这种问题如果运气不好,可能要等上四年才会暴露出来。 比如今天新鲜出炉的:禾赛科技激光雷达和新西兰加油站都因为闰年Bug无法使用。
聊一聊闰年,闰秒,时间与时区的原理,以及在数据库与编程语言中的注意事项。

0x01 秒与计时
时间的单位是秒,但秒的定义并不是一成不变的。它有一个天文学定义,也有一个物理学定义。
世界时(UT1)
在最开始,秒的定义来源于日。秒被定义为平均太阳日的1/86400。而太阳日,则是由天文学现象定义的:两次连续正午时分的间隔被定义为一个太阳日;一天有86400秒,一秒等于86400分之一天,Perfect!以这一标准形成的时间标准,就称为世界时(Univeral Time, UT1),或不严谨的说,格林威治标准时(Greenwich Mean Time, GMT),下面就用GMT来指代它了。
这个定义很直观,但有一个问题:它是基于天文学现象的,即地球与太阳的周期性运动。不论是用地球的公转还是自转来定义秒,都有一个很尴尬的地方:虽然地球自转与公转的变化速度很慢,但并不是恒常的,譬如:地球的自转越来越慢,而地月位置也导致了每天的时长其实都不完全相同。这意味着作为物理基本单位的秒,其时长竟然是变化的。在衡量时间段的长短上就比较尴尬,几十年的一秒可能和今天的一秒长度已经不是一回事了。
原子时(TAI)
为了解决这个问题,在1967年之后,秒的定义变成了:铯133原子基态的两个超精细能级间跃迁对应辐射的9,192,631,770个周期的持续时间。秒的定义从天文学定义升级成为了物理学定义,其描述由相对易变的天文现象升级到了更稳定的宇宙中的基本物理事实。现在我们有了真正精准的秒啦:一亿年的偏差也不超过一秒。
当然,这么精确的秒除了用来衡量时间间隔,也可以用来计时。从1958-01-01 00:00:00开始作为公共时间原点,国际原子钟开始了计数,每计数9,192,631,770这么多个原子能级跃迁周期就+1s,这个钟走的非常准,每一秒都很均匀。使用这定义的时间称为国际原子时(International Atomic Time, TAI),下文简称TAI。
冲突
在最开始,这两种秒是等价的:一天是 86400 天文秒,也等于 86400 物理秒,毕竟物理学这个定义就是特意去凑天文学的定义嘛。所以相应的,GMT也与国际原子时TAI也保持着同步。然而正如前面所说,天文学现象影响因素太多了,并不是真正的“天行有常”。随着地球自转公转速度变化,天文定义的秒要比物理定义的秒稍微长了那么一点点,这也就意味着GMT要比TAI稍微落后一点点。
那么哪种定义说了算,世界时还是原子时?如果理论与生活实践经验相违背,绝大多数人都不会选择反直觉的方案:假设一种极端场景,两个钟之间的差异日积月累,到最后出现了几分钟甚至几小时的差值:明明日当午,按GMT应当是12:00:00,但GMT走慢了,TAI显示的时间已经是晚上六点了,这就违背了直觉。在表示时刻这一点上,还是由天文定义说了算,即以GMT为准。
当然,就算是天文定义说了算,也要尊重物理规律,毕竟原子钟走的这么准不是?实际上世界时与原子时之间的差值也就在几秒的量级。那么我们会自然而然地想到,使用国际原子时TAI作为基准,但加上一些闰秒(leap second)修正到GMT不就行了?既有高精度,又符合常识。于是就有了新的协调世界时(Coordinated Universal Time, UTC)。
协调世界时(UTC)
UTC是调和GMT与TAI的产物:
-
UTC使用精确的国际原子时TAI作为计时基础
-
UTC使用国际时GMT作为修正目标
-
UTC使用闰秒作为修正手段,
我们通常所说的时间,通常就是指世界协调时间UTC,它与世界时GMT的差值在0.9秒内,在要求不严格的实践中,可以近似认为UTC时间与GMT时间是相同的,很多人也把它与GMT混为一谈。
但问题紧接着就来了,按照传统,一天24小时,一小时60分钟,一分钟60秒,日和秒之间有86400的换算关系。以前用日来定义秒,现在秒成了基本单位,就要用秒去定义日。但现在一天不等于86400秒了。无论用哪头定义哪头,都会顾此失彼。唯一的办法,就是打破这种传统:一分钟不一定只有60秒了,它在需要的时候可以有61秒!
这就是闰秒机制,UTC以TAI为基准,因此走的也比GMT快。假设UTC和GMT的差异不断变大,在即将超过一秒时,让UTC中的某一分钟变为61秒,续的这一秒就像UTC在等GMT一样,然后误差就追回来了。每次续一秒时,UTC时间都会落后TAI多一秒,截止至今,UTC已经落后TAI三十多秒了。最近的一次闰秒调整是在2016年跨年:
国际标准时间UTC将在格林尼治时间2016年12月31日23时59分59秒(北京时间2017年1月1日7时59分59秒)之后,在原子时钟实施一个正闰秒,即增加1秒,然后才会跨入新的一年。
所以说,GMT和UTC还是有区别的,UTC里你能看到2016-12-31 23:59:60的时间,但GMT里就不会。
0x02 本地时间与时区
刚才讨论的时间都默认了一个前提:位于本初子午线(0度经线)上的时间。我们还需要考虑地球上的其他地方:毕竟美帝艳阳高照时,中国还在午夜呢。
本地时间,顾名思义就是以当地的太阳来计算的时间:正午就是12:00。太阳东升西落,东经120度上的本地时间比起本初子午线上就早了120° / (360°/24) = 8个小时。这意味着在北京当地时间12点整时,UTC时间其实是12-8=4,早晨4:00。
大家统一用UTC时间好不好呢?可以当然可以,毕竟中国横跨三个时区,也只用了一个北京时间。只要大家习惯就行。但大家都已经习惯了本地正午算12点了,强迫全世界人民用统一的时间其实违背了历史习惯。时区的设置使得长途旅行者能够简单地知道当地人的作息时间:反正差不多都是朝九晚五上班。这就降低了沟通成本。于是就有了时区的概念。当然像新疆这种硬要用北京时间的结果就是,游客乍一看当地人11点12点才上班可能会有些懵。
但在大一统的国家内部,使用统一的时间也有助于降低沟通成本。假如一个新疆人和一个黑龙江人打电话,一个用的乌鲁木齐时间,一个用的北京时间,那就会鸡同鸭讲。都约着12点,结果实际差了两个小时。时区的选用并不完全是按照地理经度而来的,也有很多的其他因素考量(例如行政区划)。
这就引出了时区的概念:时区是地球上使用同一个本地时间定义的区域。时区实际上可以视作从地理区域到时间偏移量的单射。
但其实有没有那个地理区域都不重要,关键在于时间偏移量的概念。UTC/GMT时间本身的偏移量为0,时区的偏移量都是相对于UTC时间而言的。这里,本地时间,UTC时间与时区的关系是:
本地时间 = UTC时间 + 本地时区偏移量。
比如UTC、GMT的时区都是+0,意味着没有偏移量。中国所处的东八区偏移量就是+8。意味着计算当地时间时,要在UTC时间的基础上增加8个小时。
夏令时(Daylight Saving Time, DST),可以视为一种特殊的时区偏移修正。指的是在夏天天亮的较早的时候把时间调快一个小时(实际上不一定是一个小时),从而节省能源(灯火)。我国在86年到92年之间曾短暂使用过夏令时。欧盟从1996年开始使用夏令时,不过欧盟最近的民调显示,84%的民众希望取消夏令时。对程序员而言,夏令时也是一个额外的麻烦事,希望它能尽快被扫入历史的垃圾桶。
0x03 时间的表示
那么,时间又如何表示呢?使用TAI的秒数来表示时间当然不会有歧义,但使用不便。习惯上我们将时间分为三个部分:日期,时间,时区,而每个部分都有多种表示方法。对于时间的表示,世界诸国人民各有各的习惯,例如,2006年1月2日,美国人就可能喜欢使用诸如January 2, 1999,1/2/1999这样的日期表示形式,而中国人也许会用诸如“2006年1月2日”,“2006/01/02”这样的表示形式。发送邮件时,首部中的时间则采用RFC2822中规定的Sat, 24 Nov 2035 11:45:15 −0500格式。此外,还有一系列的RFC与标准,用于指定日期与时间的表示格式。
ANSIC = "Mon Jan _2 15:04:05 2006"
UnixDate = "Mon Jan _2 15:04:05 MST 2006"
RubyDate = "Mon Jan 02 15:04:05 -0700 2006"
RFC822 = "02 Jan 06 15:04 MST"
RFC822Z = "02 Jan 06 15:04 -0700" // RFC822 with numeric zone
RFC850 = "Monday, 02-Jan-06 15:04:05 MST"
RFC1123 = "Mon, 02 Jan 2006 15:04:05 MST"
RFC1123Z = "Mon, 02 Jan 2006 15:04:05 -0700" // RFC1123 with numeric zone
RFC3339 = "2006-01-02T15:04:05Z07:00"
RFC3339Nano = "2006-01-02T15:04:05.999999999Z07:00"
不过在这里,我们只关注计算机中的日期表示形式与存储方式。而计算机中,时间最经典的表示形式,就是Unix时间戳。
Unix时间戳
比起UTC/GMT,对于程序员来说,更为熟悉的可能是另一种时间:Unix时间戳。UNIX时间戳是从1970年1月1日(UTC/GMT的午夜,在1972年之前没有闰秒)开始所经过的秒数,注意这里的秒其实是GMT中的秒,也就是不计闰秒,毕竟一天等于86400秒已经写死到无数程序的逻辑里去了,想改是不可能改的。
使用GMT秒数的好处是,计算日期的时候根本不用考虑闰秒的问题。毕竟闰年已经很讨厌了,再来一个没有规律的闰秒,绝对会让程序员抓狂。当然这不代表就不需要考虑闰秒的问题了,诸如ntp等时间服务还是需要考虑闰秒的问题的,应用程序有可能会受到影响:比如遇到‘时光倒流’拿到两次59秒,或者获取到秒数为60的时间值,一些实现简陋的程序可能就直接崩了。当然,也有一种将闰秒均摊到某一天全天的顺滑手段。
Unix时间戳背后的思想很简单,建立一条时间轴,以某一个纪元点(Epoch)作为原点,将时间表示为距离原点的秒数。Unix时间戳的纪元为GMT时间的1970-01-01 00:00:00,32位系统上的时间戳实际上是一个有符号四字节整型,以秒为单位。这意味它能表示的时间范围为:2^32 / 86400 / 365 = 68年,差不多从1901年到2038年。
当然,时间戳并不是只有这一种表示方法,但通常这是最为传统稳妥可靠的做法。毕竟不是所有的程序员都能处理好许多和时区、闰秒相关的微妙错误。使用Unix时间戳的好处就是时区已经固定死了是GMT了,存储空间与某些计算处理(比如排序)也相对容易。
在*nix命令行中使用date +%s可以获取Unix时间戳。而date -r @1500000000则可以反向将Unix时间戳转换为其他时间格式,例如转换为2017-07-14 10:40:00可以使用:
date -d @1500000000 '+%Y-%m-%d %H:%M:%S' # Linux
date -r 1500000000 '+%Y-%m-%d %H:%M:%S' # MacOS, BSD
在很久以前,当主板上的电池没电之后,系统的时钟就会自动重置成0;还有很多软件的Bug也会导致导致时间戳为0,也就是1970-01-01;以至于这个纪元时间很多非程序员都知道了。
当然,4字节 Unix 时间戳的上限 2038 年离今天 (2024) 年已经不是遥不可及了,还没及时改成 8 字节时间戳的软件到时候就要面临比闰天加油站罢工严峻得多的千年虫问题 —— 直接罢工了,比如直到今天还没有改过来的二傻子 MySQL 。
PostgreSQL中的时间存储
通常情况下,Unix时间戳是传递/存储时间的最佳方式,它通常在计算机内部以整型的形式存在,内容为距离某个特定纪元的秒数。它极为简单,无歧义,存储占用更紧实,便于比较大小,且在程序员之间存在广泛共识。不过,Epoch+整数偏移量的方式适合在机器上进行存储与交换,但它并不是一种人类可读的格式(也许有些程序员可读)。
PostgreSQL 提供了丰富的日期时间数据类型与相关函数,它能以高度灵活的方式自动适配各种格式的时间输入输出,并在内部以高效的整型表示进行存储与计算。在PostgreSQL中,变量CURRENT_TIMESTAMP或函数now()会返回当前事务开始时的本地时间戳,返回的类型是TIMESTAMP WITH TIME ZONE,这是一个PostgreSQL扩展,会在时间戳上带有额外的时区信息。SQL标准所规定的类型为TIMESTAMP,在PostgreSQL中使用8字节的长整型实现。可以使用SQL语法AT TIME ZONE zone或内置函数timezone(zone,ts)将带有时区的TIMESTAMP转换为不带时区的标准版本。
通常最佳实践是,只要应用稍具规模或涉及到任何国际化的功能,要么按照PostgreSQL Wiki中推荐的最佳实践 使用PostgreSQL 自己提供的 TimestampTZ 扩展类型,要么使用 TIMESTAMP 类型并固定存储 GMT / UTC 时间。
PostgreSQL 的时间戳实现用的是 8 字节,表示的时间范围从公元前 4713 年到 29万年后,精度为1微秒,完全不用担心 2038 千年虫问题。
-- 获取本地事务开始时的时间戳
vonng=# SELECT now(), CURRENT_TIMESTAMP;
now | current_timestamp
-------------------------------+-------------------------------
2018-12-11 21:50:15.317141+08 | 2018-12-11 21:50:15.317141+08
-- now()/CURRENT_TIMESTAMP返回的是带有时区信息的时间戳
vonng=# SELECT pg_typeof(now()),pg_typeof(CURRENT_TIMESTAMP);
pg_typeof | pg_typeof
--------------------------+--------------------------
timestamp with time zone | timestamp with time zone
-- 将本地时区+8时间转换为UTC时间,转化得到的是TIMESTAMP
-- 注意不要使用从TIMESTAMPTZ到TIMESTAMP的强制类型转换,会直接截断时区信息。
vonng=# SELECT now() AT TIME ZONE 'UTC';
timezone
----------------------------
2018-12-11 13:50:25.790108
-- 再将UTC时间转换为太平洋时间
vonng=# SELECT (now() AT TIME ZONE 'UTC') AT TIME ZONE 'PST';
timezone
-------------------------------
2018-12-12 05:50:37.770066+08
-- 查看PG自带的时区数据表
vonng=# TABLE pg_timezone_names LIMIT 4;
name | abbrev | utc_offset | is_dst
------------------+--------+------------+--------
Indian/Mauritius | +04 | 04:00:00 | f
Indian/Chagos | +06 | 06:00:00 | f
Indian/Mayotte | EAT | 03:00:00 | f
Indian/Christmas | +07 | 07:00:00 | f
...
-- 查看PG自带的时区缩写
vonng=# TABLE pg_timezone_abbrevs LIMIT 4;
abbrev | utc_offset | is_dst
--------+------------+--------
ACDT | 10:30:00 | t
ACSST | 10:30:00 | t
ACST | 09:30:00 | f
ACT | -05:00:00 | f
...
常见困惑:闰天
关于闰天,PostgreSQL处理的很好,但是需要特别注意的是对于闰年加减时间范围的运算规律。 例如,如果你在 ‘2024-02-29’ 号往前减“一年”,结果是 “2023-02-28”,但如果你减去 365 天,则是“2023-03-01”。 反过来,如果你都加一年,12个月或者加365天,结果都是明年的2月28号。 这样处理肯定是比那些直接用年份+1来计算的二傻子软件靠谱多了。
postgres=# SELECT '2023-02-29'::DATE; --# 2023 年不是闰年
ERROR: date/time field value out of range: "2023-02-29"
LINE 1: SELECT '2023-02-29'::DATE;
^
postgres=# SELECT '2024-02-29'::DATE;
today
------------
2024-02-29
postgres=# SELECT '2024-02-29'::DATE + '1year'::INTERVAL;
next_year
---------------------
2025-02-28 00:00:00
postgres=# SELECT '2024-02-29'::DATE + '365day'::INTERVAL;
next_365d
---------------------
2025-02-28 00:00:00
postgres=# SELECT '2024-02-29'::DATE - '1year'::INTERVAL;
prev_year
---------------------
2023-02-28 00:00:00
postgres=# SELECT '2024-02-29'::DATE - '365day'::INTERVAL;
prev_365d
---------------------
2023-03-01 00:00:00
常见困惑:时间戳互转
PostgreSQL 中一个经常让人困惑的问题就是TIMESTAMP与TIMESTAMPTZ之间的相互转化问题。
-- 使用 `::TIMESTAMP` 将 `TIMESTAMPTZ` 强制转换为 `TIMESTAMP`,会直接截断时区部分内容
-- 时间的其余"内容"保持不变
vonng=# SELECT now(), now()::TIMESTAMP;
now | now
-------------------------------+--------------------------
2018-12-12 05:50:37.770066+08 | 2018-12-12 05:50:37.770066+08
-- 对有时区版TIMESTAMPTZ使用AT TIME ZONE语法
-- 会将其转换为无时区版的TIMESTAMP,返回给定时区下的时间
vonng=# SELECT now(), now() AT TIME ZONE 'UTC';
now | timezone
-------------------------------+----------------------------
2019-05-23 16:58:47.071135+08 | 2019-05-23 08:58:47.071135
-- 对无时区版TIMESTAMP使用AT TIME ZONE语法
-- 会将其转换为带时区版的TIMESTAMPTZ,即在给定时区下解释该无时区时间戳。
vonng=# SELECT now()::TIMESTAMP, now()::TIMESTAMP AT TIME ZONE 'UTC';
now | timezone
----------------------------+-------------------------------
2019-05-23 17:03:00.872533 | 2019-05-24 01:03:00.872533+08
-- 这里的意思是,UTC时间的 2019-05-23 17:03:00
常见困惑:时区偏移量
当然 PostgreSQL 中的时间戳也有一个与时区相关的设计比较违反直觉,就是在使用 AT TIME ZONE 的时候,应该尽可能避免使用 +8, -6 这样的数字时区,而应该使用时区名。
这是因为当你在时区部分使用数值时,PostgreSQL 会将其视作 Interval 类型进行处理,被解释为 “Fixed” Offsets from UTC,不常用,文档也不推荐使用。
举个例子,今天东八区中午 (SELECT ‘2024-01-15 12:00:00+08’::TIMESTAMPTZ) 转换为 UTC 时间戳,为 ‘2024-01-15 04:00:00’ (东八区的12点 = UTC0时区的4点)这没有问题:
2024-01-15 04:00:00
现在,我们使用 ‘+1’ 作为 zone,直观的想法应该是,+1 代表东一时区当前的时间,应该是 “2024-01-15 05:00:00+1” 但结果让人惊讶:反而是提前了一个小时
> SELECT '2024-01-15 12:00:00+08'::TIMESTAMPTZ AT TIME ZONE '+1';
2024-01-15 03:00:00
而如果我们反过来如果想当然的使用 -1 作为西一区的时区名,结果也是错误的:
> SELECT '2024-01-15 04:00:00+00'::TIMESTAMPTZ AT TIME ZONE '-1';
timezone
---------------------
2024-01-15 05:00:00
这里面的原因是,使用 Interval 而非时区名,处理逻辑是不一样的:
首先东八区 TIMESTAMPTZ '2024-01-15 12:00:00+08' 被转换为 UTC 时间的 TIMESTAMPTZ '2024-01-15 04:00:00+00'。
然后 UTC时间的 TIMESTAMPTZ '2024-01-15 04:00:00+00' 被截断时区部分为 '2024-01-15 04:00:00' 并拼接新时区 +1
成为一个新的 TIMESTAMPTZ '2024-01-15 04:00:00+1',然后这个新的时间戳被重新转换为不带时间戳的 UTC 时间 '2024-01-15 03:00:00'
并发异常那些事
并发程序很难写对,更难写好。很多程序员也没有真正弄清楚这些问题,不过是一股脑地把这些问题丢给数据库而已。并发异常并不仅仅是一个理论问题:这些异常曾经造成过很多资金损失,耗费过大量财务审计人员的心血。但即使是最流行、最强大的关系型数据库(通常被认为是“ACID”数据库),也会使用弱隔离级别,所以它们也不一定能防止这些并发异常的发生。
比起盲目地依赖工具,我们应该对存在的并发问题的种类,以及如何防止这些问题有深入的理解。 本文将阐述SQL92标准中定义的隔离级别及其缺陷,现代模型中的隔离级别与定义这些级别的异常现象。

0x01 引子
大多数数据库都会同时被多个客户端访问。如果它们各自读写数据库的不同部分,这是没有问题的,但是如果它们访问相同的数据库记录,则可能会遇到并发异常。
下图是一个简单的并发异常案例:两个客户端同时在数据库中增长一个计数器。(假设数据库中没有自增操作)每个客户端需要读取计数器的当前值,加1再回写新值。因为有两次增长操作,计数器应该从42增至44;但由于并发异常,实际上只增长至43。

图 两个客户之间的竞争状态同时递增计数器
事务ACID特性中的I,即隔离性(Isolation)就是为了解决这种问题。隔离性意味着,同时执行的事务是相互隔离的:它们不能相互踩踏。传统的数据库教科书将隔离性形式化为可串行化(Serializability),这意味着每个事务可以假装它是唯一在整个数据库上运行的事务。数据库确保当事务已经提交时,结果与它们按顺序运行(一个接一个)是一样的,尽管实际上它们可能是并发运行的。
如果两个事务不触及相同的数据,它们可以安全地并行(parallel)运行,因为两者都不依赖于另一个。当一个事务读取由另一个事务同时进行修改的数据时,或者当两个事务试图同时修改相同的数据时,并发问题(竞争条件)才会出现。只读事务之间不会有问题,但只要至少一个事务涉及到写操作,就有可能出现冲突,或曰:并发异常。
并发异常很难通过测试找出来,因为这样的错误只有在特殊时机下才会触发。这样的时机可能很少,通常很难重现。也很难对并发问题进行推理研究,特别是在大型应用中,你不一定知道有没有其他的应用代码正在访问数据库。在一次只有一个用户时,应用开发已经很麻烦了,有许多并发用户使其更加困难,因为任何数据都可能随时改变。
出于这个原因,数据库一直尝试通过提供**事务隔离(transaction isolation)**来隐藏应用开发中的并发问题。从理论上讲,隔离可以通过假装没有并发发生,让程序员的生活更加轻松:可串行化的隔离等级意味着数据库保证事务的效果与真的串行执行(即一次一个事务,没有任何并发)是等价的。
实际上不幸的是:隔离并没有那么简单。可串行化会有性能损失,许多数据库与应用不愿意支付这个代价。因此,系统通常使用较弱的隔离级别来防止一部分,而不是全部的并发问题。这些弱隔离等级难以理解,并且会导致微妙的错误,但是它们仍然在实践中被使用。一些流行的数据库如Oracle 11g,甚至没有实现可串行化。在Oracle中有一个名为“可串行化”的隔离级别,但实际上它实现了一种叫做**快照隔离(snapshot isolation)**的功能,这是一种比可串行化更弱的保证。
在研究现实世界中的并发异常前,让我们先来复习一下SQL92标准定义的事务隔离等级。
0x02 SQL92标准
按照ANSI SQL92的标准,三种**现象(phenomena)**区分出了四种隔离等级,如下表所示:
| 隔离等级 | 脏写P0 | 脏读 P1 | 不可重复读 P2 | 幻读 P3 |
|---|---|---|---|---|
| 读未提交RU | ✅ | ⚠️ | ⚠️ | ⚠️ |
| 读已提交RC | ✅ | ✅ | ⚠️ | ⚠️ |
| 可重复读RR | ✅ | ✅ | ✅ | ⚠️ |
| 可串行化SR | ✅ | ✅ | ✅ | ✅ |
- 四种现象分别缩写为P0,P1,P2,P3,P是**现象(Phenonmena)**的首字母。
- 脏写没有在标准中指明,但却是任何隔离等级都需要必须避免的异常
这四种异常可以概述如下:
P0 脏写(Dirty Write)
事务T1修改了数据项,而另一个事务T2在T1提交或回滚之前就修改了T1修改的数据项。
无论如何,事务必须避免这种情况。
P1 脏读(Dirty Read)
事务T1修改了数据项,另一个事务T2在T1提交或回滚前就读到了这个数据项。
如果T1选择了回滚,那么T2实际上读到了一个事实上不存在(未提交)的数据项。
P2 不可重复读( Non-repeatable or Fuzzy Read)
事务T1读取了一个数据项,然后另一个事务T2修改或删除了该数据项并提交。
如果T1尝试重新读取该数据项,它就会看到修改过后的值,或发现值已经被删除。
P3 幻读(Phantom)
事务T1读取了满足某一搜索条件的数据项集合,事务T2创建了新的满足该搜索条件的数据项并提交。
如果T1再次使用同样的搜索条件查询,它会获得与第一次查询不同的结果。
标准的问题
SQL92标准对于隔离级别的定义是有缺陷的 —— 模糊,不精确,并不像标准应有的样子独立于实现。标准其实针对的是基于锁调度的实现来讲的,而基于多版本的实现就很难对号入座。有几个数据库实现了“可重复读”,但它们实际提供的保证存在很大的差异,尽管表面上是标准化的,但没有人真正知道可重复读的意思。
标准还有其他的问题,例如在P3中只提到了创建/插入的情况,但实际上任何写入都可能导致异常现象。 此外,标准对于可串行化也语焉不详,只是说“SERIALIZABLE隔离级别必须保证通常所知的完全序列化执行”。
现象与异常
现象(phenomena)与异常(anomalies)并不相同。现象不一定是异常,但异常肯定是现象。例如在脏读的例子中,如果T1回滚而T2提交,那么这肯定算一种异常:看到了不存在的东西。但无论T1和T2各自选择回滚还是提交,这都是一种可能导致脏读的现象。通常而言,异常是一种严格解释,而现象是一种宽泛解释。
0x03 现代模型
相比之下,现代的隔离等级与一致性等级对于这个问题有更清晰的阐述,如图所示:

图:隔离等级偏序关系图

图:一致性与隔离等级偏序关系
右子树主要讨论的是多副本情况下的一致性等级,略过不提。为了讨论便利起见,本图中刨除了MAV、CS、I-CI、P-CI等隔离等级,主要需要关注的是快照隔离SI。
表:各个隔离等级及其可能出现的异常现象
| 等级\现象 | P0 | P1 | P4C | P4 | P2 | P3 | A5A | A5B |
|---|---|---|---|---|---|---|---|---|
| 读未提交 RU | ✅ | ⚠️ | ⚠️ | ⚠️ | ⚠️ | ⚠️ | ⚠️ | ⚠️ |
| 读已提交 RC | ✅ | ✅ | ⚠️ | ⚠️ | ⚠️ | ⚠️ | ⚠️ | ⚠️ |
| 游标稳定性 CS | ✅ | ✅ | ✅ | ⚠️? | ⚠️? | ⚠️ | ⚠️ | ⚠️? |
| 可重复读 RR | ✅ | ✅ | ✅ | ✅ | ✅ | ⚠️ | ✅ | ✅ |
| 快照隔离 SI | ✅ | ✅ | ✅ | ✅ | ✅ | ✅? | ✅ | ⚠️ |
| 可序列化 SR | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
带有?标记的表示可能出现异常,依具体实现而异。
主流关系型数据库的实际隔离等级
相应地,将主流关系型数据库为了“兼容标准”而标称的隔离等级映射到现代隔离等级模型中,如下表所示:
表:主流关系型数据库标称隔离等级与实际隔离之间的对照关系
| 实际\标称 | PostgreSQL/9.2+ | MySQL/InnoDB | Oracle(11g) | SQL Server |
|---|---|---|---|---|
| 读未提交 RU | RU | RU | ||
| 读已提交 RC | RC | RC, RR | RC | RC |
| 可重复读 RR | RR | |||
| 快照隔离 SI | RR | SR | SI | |
| 可序列化 SR | SR | SR | SR |
以PostgreSQL为例
如果按照ANSI SQL92标准来看,PostgreSQL实际上只有两个隔离等级:RC与SR。
| 隔离等级 | 脏读 P1 | 不可重复读 P2 | 幻读 P3 |
|---|---|---|---|
| RU,RC | ✅ | ⚠️ | ⚠️ |
| RR,SR | ✅ | ✅ | ✅ |
其中,RU和RC隔离等级中可能出现P2与P3两种异常情况。而RR与SR则能避免P1,P2,P3所有的异常。
当然实际上如果按照现代隔离等级模型,PostgreSQL的RR隔离等级实际上是快照隔离SI,无法解决A5B写偏差的问题。直到9.2引入可串行化快照隔离SSI之后才有真正意义上的SR,如下表所示:
| 标称 | 实际 | P2 | P3 | A5A | P4 | A5B |
|---|---|---|---|---|---|---|
| RC | RC | ⚠️ | ⚠️ | ⚠️ | ⚠️ | ⚠️ |
| RR | SI | ✅ | ✅ | ✅ | ✅ | ⚠️ |
| SR | SR | ✅ | ✅ | ✅ | ✅ | ✅ |
作为一种粗略的理解,可以将RC等级视作语句级快照,而将RR等级视作事务级快照。
以MySQL为例
MySQL的RR隔离等级因为无法阻止丢失更新问题,被认为没有提供真正意义上的快照隔离/可重复读。
| 标称 | 实际 | P2 | P3 | A5A | P4 | A5B |
|---|---|---|---|---|---|---|
| RC | RC | ⚠️ | ⚠️ | ⚠️ | ⚠️ | ⚠️ |
| RR | RC | ✅ | ✅? | ✅ | ⚠️ | ⚠️ |
| SR | SR | ✅ | ✅ | ✅ | ✅ | ✅ |
参考测试用例:ept/hermitage/mysql
0x04 并发异常
回到这张图来,各个异常等级恰好就是通过可能出现的异常来定义的。如果在某个隔离等级A中会出现的所有异常都不会在隔离等级B中出现,我们就认为隔离等级A弱于隔离等级B。但如果某些异常在等级A中出现,在等级B中避免,同时另一些异常在等级B中出现,却在A中避免,这两个隔离等级就无法比较强弱了。
例如在这幅图中:RR与SI是明显强于RC的。但RR与SI之间的相对强弱却难以比较。SI能够避免RR中可能出现的幻读P3,但会出现写偏差A5B的问题;RR不会出现写偏差A5B,但有可能出现P3幻读。
防止脏写与脏读可以简单地通过数据项上的读锁与写锁来阻止,其形式化表示为:
P0: w1[x]...w2[x]...((c1 or a1) and (c2 or a2)) in any order)
P1: w1[x]...r2[x]...((c1 or a1) and (c2 or a2)) in any order)
A1: w1[x]...r2[x]...(a1 and c2 in any order)
因为大多数数据库使用RC作为默认隔离等级,因此脏写P0,脏读P1等异常通常很难遇到,就不再细说了。
下面以PostgreSQL为例,介绍这几种通常情况下可能出现的并发异常现象:
- P2:不可重复读
- P3:幻读
- A5A:读偏差
- P4:丢失跟新
- A5B:写偏差
这五种异常有两种分类方式,第一可以按照隔离等级来区分。
- P2,P3,A5A,P4是RC中会出现,RR不会出现的异常;A5B是RR中会出现,SR中不会出现的异常。
第二种分类方式是按照冲突类型来分类:只读事务与读写事务之间的冲突,以及读写事务之间的冲突。
- P2,P3,A5A是读事务与写事务之间的并发异常,而P4与A5B则是读写事务之间的并发异常。
读-写异常
让我们先来考虑一种比较简单的情况:一个只读事务与一个读写事务之间的冲突。例如:
- P2:不可重复读。
- A5A:读偏差(一种常见的不可重复读问题)
- P3:幻读
在PostgreSQL中,这三种异常都会在RC隔离等级中出现,但使用RR(实际为SI)隔离等级就不会有这些问题。
不可重复读 P2
假设我们有一张账户表,存储了用户的银行账户余额,id是用户标识,balance是账户余额,其定义如下
CREATE TABLE account(
id INTEGER PRIMARY KEY,
balance INTEGER
);
譬如,在事务1中前后进行两次相同的查询,但两次查询间,事务2写入并提交,结果查询得到的结果不同。
START TRANSACTION ISOLATION LEVEL READ COMMITTED; -- T1, RC, 只读
START TRANSACTION ISOLATION LEVEL READ COMMITTED; -- T2, RC, 读写
SELECT * FROM account WHERE k = 'a'; -- T1, 查询账户a,看不到任何结果
INSERT INTO account VALUES('a', 500); -- T2, 插入记录(a,500)
COMMIT; -- T2, 提交
SELECT * FROM account WHERE id = 'a'; -- T1, 重复查询,得到结果(a,500)
COMMIT; -- T1陷入迷惑,为什么同样的查询结果不同?
对于事务1而言,在同一个事务中执行相同的查询,竟然会出现不一样的结果,也就是说读取的结果不可重复。这就是不可重复读的一个例子,即现象P2。在PostgreSQL的RC级别中是会出现的,但如果将事务T1的隔离等级设置为RR,就不会出现这种问题了:
START TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- T1, RR, 只读
START TRANSACTION ISOLATION LEVEL READ COMMITTED; -- T2, RC, 读写
SELECT * FROM counter WHERE k = 'x'; -- T1, 查询不到任何结果
INSERT INTO counter VALUES('x', 10); -- T2, 插入记录(x,10) @ RR
COMMIT; -- T2, 提交
SELECT * FROM counter WHERE k = 'x'; -- T1, 还是查询不到任何结果
COMMIT; -- T1, 在RR下,两次查询的结果保持一致。
不可重复读的形式化表示:
P2: r1[x]...w2[x]...((c1 or a1) and (c2 or a2) in any order)
A2: r1[x]...w2[x]...c2...r1[x]...c1
读偏差 A5A
另一类读-写异常是读偏差(A5A):考虑一个直观的例子,假设用户有两个账户:a和b,各有500元。
-- 假设有一张账户表,用户有两个账户a,b,各有500元。
CREATE TABLE account(
id INTEGER PRIMARY KEY,
balance INTEGER
);
INSERT INTO account VALUES('a', 500), ('b', 500);
现在用户向系统提交从账户b向账户a转账100元的请求,并从网页上并查看自己的账户余额。在RC隔离级别下,下列操作历史的结果可能会让用户感到困惑:
START TRANSACTION ISOLATION LEVEL READ COMMITTED; -- T1, RC, 只读,用户观察
START TRANSACTION ISOLATION LEVEL READ COMMITTED; -- T2, RC, 读写,系统转账
SELECT * FROM account WHERE id = 'a'; -- T1, 用户查询账户a, 500元
UPDATE account SET balance -= 100 WHERE id = 'b'; -- T2, 系统扣减账户b 100元
UPDATE account SET balance += 100 WHERE id = 'a'; -- T2, 系统添加账户a 100元
COMMIT; -- T2, 系统转账事务提交提交
SELECT * FROM account WHERE id = 'a'; -- T1, 用户查询账户b, 400元
COMMIT; -- T1, 用户陷入迷惑,为什么我总余额(400+500)少了100元?
这个例子中,只读事务读取到了系统的一个不一致的快照。这种现象称为读偏差(read skew),记作A5A。但其实说到底,读偏差的根本原因是不可重复读。只要避免了P2,自然能避免A5A。
但读偏差是很常见的一类问题,在一些场景中,我们希望获取一致的状态快照,读偏差是不能接受的。一个典型的场景就是备份。通常对于大型数据库,备份需要花费若干个小时。备份进程运行时,数据库仍然会接受写入操作。因此如果存在读偏差,备份可能会包含一些旧的部分和一些新的部分。如果从这样的备份中恢复,那么不一致(比如消失的钱)就会变成永久的。此外,一些长时间运行的分析查询通常也希望能在一个一致的快照上进行。如果一个查询在不同时间看见不同的东西,那么返回的结果可能毫无意义。
快照隔离是这个问题最常见的解决方案。PostgreSQL的RR隔离等级实际上就是快照隔离,提供了事务级一致性快照的功能。例如,如果我们将T1的隔离等级设置为可重复读,就不会有这个问题了。
START TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- T1, RR, 只读,用户观察
START TRANSACTION ISOLATION LEVEL READ COMMITTED; -- T2, RC, 读写,系统转账
SELECT * FROM account WHERE id = 'a'; -- T1 用户查询账户a, 500元
UPDATE account SET balance -= 100 WHERE id = 'b'; -- T2 系统扣减账户b 100元
UPDATE account SET balance += 100 WHERE id = 'a'; -- T2 系统添加账户a 100元
COMMIT; -- T2, 系统转账事务提交提交
SELECT * FROM account WHERE id = 'a'; -- T1 用户查询账户b, 500元
COMMIT; -- T1没有观察到T2的写入结果{a:600,b:400},但它观察到的是一致性的快照。
读偏差的形式化表示:
A5A: r1[x]...w2[x]...w2[y]...c2...r1[y]...(c1 or a1)
幻读 P3
在ANSI SQL92中,幻读是用于区分RR和SR的现象,实际上它经常与不可重复读P2混为一谈。唯一的区别在于读取列时是否使用了谓词(predicate),也就是Where条件。 将上一个例子中查询是否存在账户,变为满足特定条件账户的数目,就成了一个所谓的“幻读”问题。
START TRANSACTION ISOLATION LEVEL READ COMMITTED; -- T1, RC, 只读
START TRANSACTION ISOLATION LEVEL READ COMMITTED; -- T2, RC, 读写
SELECT count(*) FROM account WHERE balance > 0; -- T1, 查询有存款的账户数目。0
INSERT INTO account VALUES('a', 500); -- T2, 插入记录(a,500)
COMMIT; -- T2, 提交
SELECT count(*) FROM account WHERE balance > 0; -- T1, 查询有存款的账户数目。1
COMMIT; -- T1陷入迷惑,为什么冒出来一个人?
同理,事务1在使用PostgreSQL的RR隔离级别之后,事务1就不会看到满足谓词P的结果发生变化了。
START TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- T1, RR, 只读
START TRANSACTION ISOLATION LEVEL READ COMMITTED; -- T2, RC, 读写
SELECT count(*) FROM account WHERE balance > 0; -- T1, 查询有存款的账户数目。0
INSERT INTO account VALUES('a', 500); -- T2, 插入记录(a,500)
COMMIT; -- T2, 提交
SELECT count(*) FROM account WHERE balance > 0; -- T1, 查询有存款的账户数目。0
COMMIT; -- T1, 读取到了一致的快照(虽然不是最新鲜的)
之所以有这种相当Trivial的区分,因为基于锁的隔离等级实现往往需要额外的谓词锁机制来解决这类特殊的读-写冲突问题。但是基于MVCC的实现,以PostgreSQL的SI为例,就天然地一步到位解决了所有这些问题。
幻读的形式化表示:
P3: r1[P]...w2[y in P]...((c1 or a1) and (c2 or a2) any order)
A3: r1[P]...w2[y in P]...c2...r1[P]...c1
幻读会出现在MySQL的RC,RR隔离等级中,但不会出现在PostgreSQL的RR隔离等级(实际为SI)中。
写-写异常
上面几节讨论了只读事务在并发写入时可能发生的异常。通常这种读取异常可能只要稍后重试就会消失,但如果涉及到写入,问题就比较严重了,因为这种读取到的暂时不一致状态很可能经由写入变成永久性的不一致…。到目前为止我们只讨论了在并发写入发生时,只读事务可以看见什么。如果两个事务并发执行写入,还可能会有一种更有趣的写-写异常:
- P4: 丢失更新:PostgreSQL的RC级别存在,RR级别不存在(MySQL的RR会存在)。
- A5B:写入偏差:PostgreSQL的RR隔离级别会存在。
其中,写偏差(A5B)可以视作丢失更新(P4)的泛化情况。快照隔离能够解决丢失更新的问题,却无法解决写入偏差的问题。解决写入偏差需要真正的可串行化隔离等级。
丢失更新-P4-例1
仍然以上文中的账户表为例,假设有一个账户x,余额500元。
CREATE TABLE account(
id TEXT PRIMARY KEY,
balance INTEGER
);
INSERT INTO account VALUES('x', 500);
有两个事务T1,T2,分别希望向该账户打入两笔钱,比如一笔100,一笔200。从顺序执行的角度来看,无论两个事务谁先执行,最后的结果都应当是余额 = 500 + 200 + 100 = 800。
START TRANSACTION ISOLATION LEVEL READ COMMITTED; -- T1
START TRANSACTION ISOLATION LEVEL READ COMMITTED; -- T2
SELECT balance FROM account WHERE id = 'x'; -- T1, 查询当前余额=500
SELECT balance FROM account WHERE id = 'x'; -- T2, 查询当前余额也=500
UPDATE account SET balance = 500 + 100; -- T1, 在原余额基础上增加100元
UPDATE account SET balance = 500 + 200; -- T2, 在原余额基础上增加200元,被T1阻塞。
COMMIT; -- T1, 提交前可以看到余额为600。T1提交后解除对T2的阻塞,T2进行了更新。
COMMIT; -- T2, T2提交,提交前可以看到余额为700
-- 最终结果为700
但奇妙的时机导致了意想不到的结果,最后账户的余额为700元,事务1的转账更新丢失了!
但令人意外的是,两个事务都看到了UPDATE 1的更新结果,都检查了自己更新的结果无误,都收到了事务成功提交的确认。结果事务1的更新丢失了,这就很尴尬了。最起码事务应当知道这里可能出现问题,而不是当成什么事都没有就混过去了。
如果使用RR隔离等级(主要是T2,T1可以是RC,但出于对称性尽量都用RR),后执行更新的语句就会报错中止事务。这就允许应用知耻而后勇,进行重试。
START TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- T1, 这里RC也可以
START TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- T2, 关键是T2必须为RR
SELECT balance FROM account WHERE id = 'x'; -- T1, 查询当前余额=500
SELECT balance FROM account WHERE id = 'x'; -- T2, 查询当前余额也=500
UPDATE account SET balance = 500 + 100; -- T1, 在原余额基础上增加100元
UPDATE account SET balance = 500 + 200; -- T2, 在原余额基础上增加200元,被T1阻塞。
COMMIT; -- T1, 提交前可以看到余额为600。T1提交后解除对T2的阻塞
-- T2 Update报错:ERROR: could not serialize access due to concurrent update
ROLLBACK; -- T2, T2只能回滚
-- 最终结果为600,但T2知道了错误可以重试,并在无竞争的环境中最终达成正确的结果800。

当然我们可以看到,在RC隔离等级的情况中,T1提交,解除对T2的阻塞时,Update操作已经能够看到T1的变更了(balance=600)。但事务2还是用自己先前计算出的增量值覆盖了T1的写入。对于这种特殊情况,可以使用原子操作解决,例如:UPDATE account SET balance = balance + 100;。这样的语句在RC隔离级别中也能正确地并发更新账户。但并不是所有的问题都能简单到能用原子操作来解决的,让我们来看另一个例子。
丢失更新-P4-例2
让我们来看一个更微妙的例子:UPDATE与DELETE之间的冲突。
假设业务上每人最多有两个账户,用户最多能选择一个账号作为有效账号,管理员会定期删除无效账号。
账户表有一个字段valid表示该账户是否有效,定义如下所示:
CREATE TABLE account(
id TEXT PRIMARY KEY,
valid BOOLEAN
);
INSERT INTO account VALUES('a', TRUE), ('b', FALSE);
现在考虑这样一种情况,用户要切换自己的有效账号,与此同时管理员要清理无效账号。
从顺序执行的角度来看,无论是用户先切换还是管理员先清理,最后结果的共同点是:总会有一个账号被删掉。
START TRANSACTION ISOLATION LEVEL READ COMMITTED; -- T1, 用户更换有效账户
START TRANSACTION ISOLATION LEVEL READ COMMITTED; -- T2, 管理员删除账户
UPDATE account SET valid = NOT valid; -- T1, 原子操作,将有效账户无效账户状态反转
DELETE FROM account WHERE NOT valid; -- T2, 管理员删除无效账户。
COMMIT; -- T1, 提交,T1提交后解除对T2的阻塞
-- T2 DELETE执行完毕,返回DELETE 0
COMMIT; -- T2, T2能正常提交,但检查的话会发现自己没有删掉任何记录。
-- 无论T2选择提交还是回滚,最后的结果都是(a,f),(b,t)
从下图中可以看到,事务2的DELETE原本锁定了行(b,f)准备删除,但因为事务1的并发更新而阻塞。当T1提交解除T2的阻塞时,事务2看见了事务1的提交结果:自己锁定的那一行已经不满足删除条件了,因此只好放弃删除。

相应的,改用RR隔离等级,至少给了T2知道错误的机会,在合适的时机重试就可以达到序列执行的效果。
START TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- T1, 用户更换有效账户
START TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- T2, 管理员删除账户
UPDATE account SET valid = NOT valid; -- T1, 原子操作,将有效账户无效账户状态反转
DELETE FROM account WHERE NOT valid; -- T2, 管理员删除无效账户。
COMMIT; -- T1, 提交,T1提交后解除对T2的阻塞
-- T2 DELETE报错:ERROR: could not serialize access due to concurrent update
ROLLBACK; -- T2, T2只能回滚
SI隔离级别小结
上面提到的异常,包括P2,P3,A5A,P4,都会在RC中出现,但却不会在SI中出现。特别需要注意的是,P3幻读问题会在RR中出现,却不会在SI中出现。从ANSI标准的意义上,SI可以算是可串行化了。SI解决的问题一言以蔽之,就是提供了真正的事务级别的快照。因而各种读-写异常(P2,P3,A5A)都不会再出现了。而且,SI还可以解决**丢失更新(P4)**的问题(MySQL的RR解决不了)。
丢失更新是一种非常常见的问题,因此也有不少应对的方法。典型的方式有三种:原子操作,显式锁定,冲突检测。原子操作通常是最好的解决方案,前提是你的逻辑可以用原子操作来表达。如果数据库的内置原子操作没有提供必要的功能,防止丢失更新的另一个选择是让应用显式地锁定将要更新的对象。然后应用程序可以执行读取-修改-写入序列,如果任何其他事务尝试同时读取同一个对象,则强制等待,直到第一个读取-修改-写入序列完成。(例如MySQL和PostgreSQL的SELECT FOR UPDATE子句)
另一种应对丢失更新的方法是自动冲突检测。如果事务管理器检测到丢失更新,则中止事务并强制它们重试其读取-修改-写入序列。这种方法的一个优点是,数据库可以结合快照隔离高效地执行此检查。事实上,PostgreSQL的可重复读,Oracle的可串行化和SQL Server的快照隔离级别,都会自动检测到丢失更新,并中止惹麻烦的事务。但是,MySQL/InnoDB的可重复读并不会检测丢失更新。一些专家认为,数据库必须能防止丢失更新才称得上是提供了快照隔离,所以在这个定义下,MySQL下没有提供快照隔离。
但正所谓成也快照败也快照,每个事务都能看到一致的快照,却带来了一些额外的问题。在SI等级中,一种称为写偏差(A5B)的问题仍然可能会发生:例如两个事务基于过时的快照更新了对方读取的数据,提交后才发现违反了约束。丢失更新其实是写偏差的一种特例:两个写入事务竞争写入同一条记录。竞争写入同一条数据能够被数据库的丢失更新检测机制发现,但如果两个事务基于各自的写入了不同的数据项,又怎么办呢?
写偏差 A5B
考虑一个运维值班的例子:互联网公司通常会要求几位运维同时值班,但底线是至少有一位运维在值班。运维可以翘班,只要至少有一个同事在值班就行:
CREATE TABLE duty (
name TEXT PRIMARY KEY,
oncall BOOLEAN
);
-- Alice和Bob都在值班
INSERT INTO duty VALUES ('Alice', TRUE), ('Bob', True);
假如应用逻辑约束是:不允许无人值班。即:SELECT count(*) FROM duty WHERE oncall值必须大于0。现在假设A和B两位运维正在值班,两人都感觉不舒服决定请假。不幸的是两人同时按下了翘班按钮。则下列执行时序会导致异常的结果:
START TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- T1, Alice
START TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- T2, Bob
SELECT count(*) FROM duty WHERE oncall; -- T1, 查询当前值班人数, 2
SELECT count(*) FROM duty WHERE oncall; -- T2, 查询当前值班人数, 2
UPDATE duty SET oncall = FALSE WHERE name = 'Alice'; -- T1, 认为其他人在值班,Alice翘班
UPDATE duty SET oncall = FALSE WHERE name = 'Bob'; -- T2, 也认为其他人在值班,Bob翘班
COMMIT; -- T1
COMMIT; -- T2
SELECT count(*) FROM duty; -- 观察者, 结果为0, 没有人在值班了!
两个事务看到了同一个一致性快照,首先检查翘班条件,发现有两名运维在值班,那么自己翘班是ok的,于是更新自己的值班状态并提交。两个事务都提交之后,没有运维在值班了,违背了应用定义的一致性。
但如果两个事务并不是**同时(Concurrently)**执行的,而是分了先后次序,那么后一个事务在执行检查时就会发现不满足翘班条件而终止。因此,事务之间的并发导致了异常现象。
对事务而言,明明在执行翘班操作之前看到值班人数为2,执行翘班操作之后看到值班人数为1,但为啥提交之后看到的就是0了呢?这就好像看见幻象一样,但这与SQL92标准定义的幻读并不一样,标准定义的幻读是因为不可重复读的屁股没擦干净,读到了不该读的东西(对于谓词查询不可重复读取),而这里则是因为快照的存在,事务无法意识到自己读取的记录已经被改变。
问题的关键在于不同读写事务之间的读写依赖。如果某个事务读取了一些数据作为行动的前提,那么如果当该事务执行后续写入操作时,这些被读取的行已经被其他事务修改,这就意味着事务依赖的前提可能已经改变。
写偏差的形式化表示:
A5B: r1[x]...r2[y]...w1[y]...w2[x]...(c1 and c2 occur)
此类问题的共性
事务基于一个前提采取行动(事务开始时候的事实,例如:“目前有两名运维正在值班”)。之后当事务要提交时,原始数据可能已经改变——前提可能不再成立。
-
一个
SELECT查询找出符合条件的行,并检查是否满足一些约束(至少有两个运维在值班)。 -
根据第一个查询的结果,应用代码决定是否继续。(可能会继续操作,也可能中止并报错)
-
如果应用决定继续操作,就执行写入(插入、更新或删除),并提交事务。
**这个写入的效果改变了步骤2 中的先决条件。**换句话说,如果在提交写入后,重复执行一次步骤1 的SELECT查询,将会得到不同的结果。因为写入改变符合搜索条件的行集(只有一个运维在值班)。
在SI中,每个事务都拥有自己的一致性快照。但SI是不提供**线性一致性(强一致性)**保证的。事务看到的快照副本可能因为其他事务的写入而变得陈旧,但事务中的写入无法意识到这一点。
与丢失更新的联系
作为一个特例,如果不同读写事务是对同一数据对象进行写入,这就成了丢失更新问题。通常会在RC中出现,在RR/SI隔离级别中避免。对于相同对象的并发写入可以被数据库检测出来,但如果是向不同数据对象写入,违背应用逻辑定义的约束,那RR/SI隔离等级下的数据库就无能为力了。
解决方案
有很多种方案能应对这些问题,可串行化当然是ok的,但也存在一些其他手段,例如锁
显式锁定
START TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- T1, 用户更换有效账户
START TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- T2, 管理员删除账户
SELECT count(*) FROM duty WHERE oncall FOR UPDATE; -- T1, 查询当前值班人数, 2
SELECT count(*) FROM duty WHERE oncall FOR UPDATE; -- T2, 查询当前值班人数, 2
WITH candidate AS (SELECT name FROM duty WHERE oncall FOR UPDATE)
SELECT count(*) FROM candidate; -- T1
WITH candidate AS (SELECT name FROM duty WHERE oncall FOR UPDATE)
SELECT count(*) FROM candidate; -- T2, 被T1阻塞
UPDATE duty SET oncall = FALSE WHERE name = 'Alice'; -- T1, 执行更新
COMMIT; -- T1, 解除T2的阻塞
-- T2报错:ERROR: could not serialize access due to concurrent update
ROLLBACK; -- T2 只能回滚
使用SELECT FOR UPDATE语句,可以显式锁定待更新的行,这样,当后续事务想要获取相同的锁时就会被阻塞。这种方法在MySQL中称为悲观锁。这种方法本质上属于一种物化冲突,将写偏差的问题转换成了丢失更新的问题,因此允许在RR级别解决原本SR级别才能解决的问题。
在最极端的情况下(比如表没有唯一索引),显式锁定可能蜕化为表锁。无论如何,这种方式都有相对严重的性能问题,而且可能更频繁地导致死锁。因此也存一些基于谓词锁和索引范围锁的优化。
显式约束
如果应用逻辑定义的约束可以使用数据库约束表达,那是最方便的。因为事务会在提交时(或语句执行时)检查约束,违背了约束的事务会被中止。不幸的是,很多应用约束都难以表述为数据库约束,或者难以承受这种数据库约束表示的性能负担。
可串行化
使用可串行化隔离等级可以避免这一问题,这也是可串行化的定义:避免一切序列化异常。这可能是最简单的方法了,只需要使用SERIALIZABLE的事务隔离等级就可以了。
START TRANSACTION ISOLATION LEVEL SERIALIZABLE; -- T1, Alice
START TRANSACTION ISOLATION LEVEL SERIALIZABLE; -- T2, Bob
SELECT count(*) FROM duty WHERE oncall; -- T1, 查询当前值班人数, 2
SELECT count(*) FROM duty WHERE oncall; -- T2, 查询当前值班人数, 2
UPDATE duty SET oncall = FALSE WHERE name = 'Alice'; -- T1, 认为其他人在值班,Alice翘班
UPDATE duty SET oncall = FALSE WHERE name = 'Bob'; -- T2, 也认为其他人在值班,Bob翘班
COMMIT; -- T1
COMMIT; -- T2, 报错中止
-- ERROR: could not serialize access due to read/write dependencies among transactions
-- DETAIL: Reason code: Canceled on identification as a pivot, during commit attempt.
-- HINT: The transaction might succeed if retried.
在事务2提交的时候,会发现自己读取的行已经被T1改变了,因此中止了事务。稍后重试很可能就不会有问题了。
PostgreSQL使用SSI实现可串行化隔离等级,这是一种乐观并发控制机制:如果有足够的备用容量,并且事务之间的争用不是太高,乐观并发控制技术往往表现比悲观的要好不少。
数据库约束,物化冲突在某些场景下是很方便的。如果应用约束能用数据库约束表示,那么事务在写入或提交时就会意识到冲突并中止冲突事务。但并不是所有的问题都能用这种方式解决的,可串行化的隔离等级是一种更为通用的方案。
0x06 并发控制技术
本文简要介绍了并发异常,这也是事务ACID中的“隔离性”所要解决的问题。本文简单讲述了ANSI SQL92标准定义的隔离等级以及其缺陷,并简单介绍了现代模型中的隔离等级(简化)。最后详细介绍了区分隔离等级的几种异常现象。当然,这篇文章只讲异常问题,不讲解决方案与实现原理,关于这些隔离等级背后的实现原理,将留到下一篇文章来陈述。但这里可以大概提一下:
从宽泛的意义来说,有两大类并发控制技术:多版本并发控制(MVCC),严格两阶段锁定(S2PL),每种技术都有多种变体。
在MVCC中,每个写操作都会创建数据项的一个新版本,同时保留旧版本。当事务读取数据对象时,系统会选择其中的一个版本,来确保各个事务间相互隔离。 MVCC的主要优势在于“读不会阻塞写,而写也不会阻塞读”。相反,基于S2PL的系统在写操作发生时必须阻塞读操作,因为因为写入者获取了对象的排他锁。
PostgreSQL、SQL Server、Oracle使用一种MVCC的变体,称为快照隔离(Snapshot Isolation,SI)。为了实现SI,一些RDBMS(例如Oracle)使用回滚段。当写入新的数据对象时,旧版本的对象先被写入回滚段,随后用新对象覆写至数据区域。 PostgreSQL使用更简单的方法:一个新数据对象被直接插入到相关的表页中。读取对象时,PostgreSQL通过可见性检查规则,为每个事物选择合适的对象版本作为响应。
但数据库技术发展至今,这两种技术已经不是那样泾渭分明,进入了一个你中有我我中有你的状态:例如在PostgreSQL中,DML操作使用SI/SSI,而DDL操作仍然会使用2PL。但具体的细节,就留到下一篇吧。
Reference
【1】Designing Data-Intensive Application,ch7
【2】Highly Available Transactions: Virtues and Limitations
【3】A Critique of ANSI SQL Isolation Levels
【4】Granularity of Locks and Degrees of Consistency in a Shared Data Base
【5】Hermitage: Testing the ‘I’ in ACID
区块链与分布式数据库
区块链的本质,想提供的功能,及其演化方向,就是分布式数据库。
确切的讲,是拜占庭容错(抗恶意节点攻击)的分布式(无领导者复制)数据库。

如果这种分布式数据库用来存储各种币的交易记录,这个系统就叫做所谓的“XX币”。例如以太坊就是这样一个分布式数据库,上面除了记载着各种山寨币的交易记录,还可以记载各种奇奇怪怪的内容。花一点以太币,就可以在这个分布式数据库里留下一条记录(一封信)。而所谓智能合约就是这个分布式数据库上的存储过程。
从形式上看,区块链 与 预写式日志(Write-Ahead-Log, WAL, Binlog, Redolog) 在设计原理上是高度一致的。
WAL是数据库的核心数据结构,记录了从数据库创建之初到当前时刻的所有变更,用于实现主从复制、备份回滚、故障恢复等功能。如果保留了全量的WAL日志,就可以从起点回放WAL,时间旅行到任意时刻的状态,如PostgreSQL的PITR。
区块链其实就是这样一份日志,它记录了从创世以来的每笔Transaction。回放日志就可以还原数据库任意时刻的状态(反之则不成立)。所以区块链当然可以算作某种意义上的数据库。
区块链的两大特性:去中心化与防篡改,用数据库的概念也很好理解:
- 去中心化的实质就是无领导者复制(leaderless replication),核心在于分布式共识。
- 防篡改的实质就是拜占庭容错,即,使得 篡改WAL的计算代价在概率上不可行 。
正如WAL分为日志段,区块链也被划分为一个一个 区块 ,且每一段带有先前日志段的哈希指纹。
所谓挖矿就是一个公开的猜数字比快游戏(满足条件的数字才会被共识承认),先猜中者能获取下一个日志段的初夜权:向日志段里写一笔向自己转账的记录(就是挖矿的奖励),并广播出去(如果别人也猜中了,以先广播至多数为准)。所有节点通过共识算法,保证当前最长的链为权威日志版本。区块链通过共识算法实现日志段的无主复制。
而如果想要修改某个WAL日志段中的一比交易记录,比如,转给自己一万个比特币,需要把这个区块以及其后所有区块的指纹给凑出来(连猜几次数字),并让多数节点相信这个伪造版本才行(拼一个更长的伪造版本,意味着猜更多次数字)。比特币中六个区块确认一个交易就是这个意思,篡改六个日志段之前的记录的算例代价,通常在概率上是不可行的。区块链通过这种机制(如Merkle树)实现拜占庭容错。
区块链涉及到的相关技术中,除了分布式共识外都很简单,但这种应用方式与机制设计确实是相当惊艳的。区块链可以算是一次数据库的演化尝试,长期来看前景广阔。但搞链能立竿见影起作用的领域,好像都是老大哥的地盘。而且不管怎么吹嘘,现在的区块链离真正意义上的分布式数据库还差的太远,所以现在入场搞应用的大概率都是先烈。
一致性:过载的术语
一致性这个词重载的很厉害,在不同的语境和上下文中,它其实代表着不同的东西:
- 在事务的上下文中,比如ACID里的C,指的就是通常的一致性(Consistency)
- 在分布式系统的上下文中,例如CAP里的C,实际指的是线性一致性(Linearizability)
- 此外,“一致性哈希”,“最终一致性”这些名词里的“一致性”也有不同的涵义。

这些一致性彼此不同却又有着千丝万缕的联系,所以经常会把人绕晕。
-
在事务的上下文中,一致性(Consistency) 的概念是:对数据的一组特定陈述必须始终成立。即不变量(invariants)。具体到分布式事务的上下文中这个不变量是:所有参与事务的节点状态保持一致:要么全部成功提交,要么全部失败回滚,不会出现一些节点成功一些节点失败的情况。
-
在分布式系统的上下文中,线性一致性(Linearizability) 的概念是:多副本的系统能够对外表现地像只有单个副本一样(系统保证从任何副本读取到的值都是最新的),且所有操作都以原子的方式生效(一旦某个新值被任一客户端读取到,后续任意读取不会再返回旧值)。
-
线性一致性这个词可能有些陌生,但说起它的另一个名字大家就清楚了:强一致性(strong consistency) ,当然还有一些诨名:原子一致性(atomic consistency),立即一致性(immediate consistency) 或 外部一致性(external consistency ) 说的都是它。
这两个“一致性”完全不是一回事儿,但之间其实有着微妙的联系,它们之间的桥梁就是共识(Consensus)
简单来说
- 分布式事务一致性会因为协调者单点引入可用性问题
- 为了解决可用性问题,分布式事务的节点需要在协调者故障时就新协调者选取达成共识
- 解决共识问题等价于实现一个线性一致的存储
- 解决共识问题等价于实现全序广播(total order boardcast)
- Paxos/Raft 实现了全序广播
具体来讲
-
为了保证分布式事务的一致性,分布式事务通常需要一个协调者(Coordinator)/事务管理器(Transaction Manager)来决定事务的最终提交状态。但无论2PC还是3PC,都无法应对协调者失效的问题,而且具有扩大故障的趋势。这就牺牲了可靠性、可维护性与可扩展性。为了让分布式事务真正可用,就需要在协调者挂点的时候能赶快选举出一个新的协调者来解决分歧,这就需要所有节点对谁是Boss达成共识(Consensus)。
-
共识意味着让几个节点就某事达成一致,可以用来确定一些互不相容的操作中,哪一个才是赢家。共识问题通常形式化如下:一个或多个节点可以提议(propose)某些值,而共识算法决定采用其中的某个值。在保证分布式事务一致性的场景中,每个节点可以投票提议,并对谁是新的协调者达成共识。
-
共识问题与许多问题等价,两个最典型的问题就是:
- 实现一个具有线性一致性的存储系统
- 实现全序广播(保证消息不丢失,且消息以相同的顺序传递给每个节点。)
Raft算法解决了全序广播问题。维护多副本日志间的一致性,其实就是让所有节点对同全局操作顺序达成一致,也其实就是让日志系统具有线性一致性。 因而解决了共识问题。(当然正因为共识问题与实现强一致存储问题等价,Raft的具体实现etcd 其实就是一个线性一致的分布式数据库。)
总结一下
-
分布式事务中的一致性则与事务ACID中的C一脉相承,并不是一个严格的术语。(因为什么叫一致,什么叫不一致其实是应用说了算。在分布式事务的场景下可以认为是:所有节点的事务状态始终保持相同)
-
分布式事务本身的一致性是通过协调者内部的原子操作与多阶段提交协议保证的,不需要共识;但解决分布式事务一致性带来的可用性问题需要用到共识。
参考阅读
[1] 一致性与共识
为什么要学习数据库原理
我们学校开了数据库系统原理课程。但是我还是很迷茫,这几节课老师一上来就讲一堆令人头大的名词概念,我以为我们知道“如何设计构建表”,“如何mysql增删改查”就行了……那为什么还要了解关系模式的表示方法,计算,规范化……概念模型……各种模型的相互转换,为什么还要了解什么关系代数,什么笛卡尔积……这些的理论知识。我十分困惑,通过这些理论概念,该课的目的或者说该书的目的究竟是想让学生学会什么呢?

只会写代码的是码农;学好数据库,基本能混口饭吃;在此基础上再学好操作系统和计算机网络,就能当一个不错的程序员。如果能再把离散数学、数字电路、体系结构、数据结构/算法、编译原理学通透,再加上丰富的实践经验与领域特定知识,就能算是一个优秀的工程师了。(前端算IO密集型应用就别抬杠了)
计算机其实就是存储/IO/CPU三大件; 而计算说穿了就是两个东西:数据与算法(状态与转移函数)。常见的软件应用,除了各种模拟仿真、模型训练、视频游戏这些属于计算密集型应用外,绝大多数都属于数据密集型应用。从最抽象的意义上讲,这些应用干的事儿就是把数据拿进来,存进数据库,需要的时候再拿出来。
抽象是应对复杂度的最强武器。操作系统提供了对存储的基本抽象:内存寻址空间与磁盘逻辑块号。文件系统在此基础上提供了文件名到地址空间的KV存储抽象。而数据库则在其基础上提供了对应用通用存储需求的高级抽象。
在真实世界中,除非准备从基础组件的轮子造起,不然根本没那么多机会去摆弄花哨的数据结构和算法(对数据密集型应用而言)。甚至写代码的本事可能也没那么重要:可能只会有那么一两个Ad Hoc算法需要在应用层实现,大部分需求都有现成的轮子可以使用,主要的创造性工作往往是在数据模型设计上。实际生产中,数据表就是数据结构,索引与查询就是算法。而应用代码往往扮演的是胶水的角色,处理IO与业务逻辑,其他大部分的工作都是在数据系统之间搬运数据。
在最宽泛的意义上,有状态的地方就有数据库。它无所不在,网站的背后、应用的内部,单机软件,区块链里,甚至在离数据库最远的Web浏览器中,也逐渐出现了其雏形:各类状态管理框架与本地存储。“数据库”可以简单地只是内存中的哈希表/磁盘上的日志,也可以复杂到由多种数据系统集成而来。关系型数据库只是数据系统的冰山一角(或者说冰山之巅),实际上存在着各种各样的数据系统组件:
- 数据库:存储数据,以便自己或其他应用程序之后能再次找到(PostgreSQL,MySQL,Oracle)
- 缓存:记住开销昂贵操作的结果,加快读取速度(Redis,Memcached)
- 搜索索引:允许用户按关键字搜索数据,或以各种方式对数据进行过滤(ElasticSearch)
- 流处理:向其他进程发送消息,进行异步处理(Kafka,Flink)
- 批处理:定期处理累积的大批量数据(Hadoop)
架构师最重要的能力之一,就是了解这些组件的性能特点与应用场景,能够灵活地权衡取舍、集成拼接这些数据系统。绝大多数工程师都不会去从零开始编写存储引擎,因为在开发应用时,数据库已经是足够完美的工具了。关系型数据库则是目前所有数据系统中使用最广泛的组件,可以说是程序员吃饭的主要家伙,重要性不言而喻。

了解意义(WHY)比了解方法(HOW)更重要。但一个很遗憾的现实是,以大多数学生,甚至相当一部分公司能够接触到的现实问题而言,拿几个文件甚至在内存里放着估计都能应付大多数场景了(需求简单到低级抽象就可以Handle)。没什么机会接触到数据库真正要解决的问题,也就难有真正使用与学习数据库的驱动力,更别提数据库原理了。当软硬件故障把数据搞成一团浆糊(可靠性);当单表超出了内存大小,并发访问的用户增多(可扩展性),当代码的复杂度发生爆炸,开发陷入泥潭(可维护性),人们才会真正意识到数据库的重要性。所以我也理解当前这种填鸭教学现状的苦衷:工作之后很难有这么大把的完整时间来学习原理了,所以老师只好先使劲灌输,多少让学生对这些知识有个印象。等学生参加工作后真正遇到这些问题,也许会想起大学好像还学了个叫数据库的东西,这些知识就会开始反刍。
数据库,尤其是关系型数据库,非常重要。那为什么要学习其原理呢?
对优秀的工程师来说,只会用数据库是远远不够的。学习原理对于当CRUD BOY搬砖收益并不大,但当通用组件真的无解需要自己撸起袖子上时,没有金坷垃怎么种庄稼?设计系统时,理解原理能让你以最少的复杂度代价写出更可靠高效的代码;遇到疑难杂症需要排查时,理解原理能带来精准的直觉与深刻的洞察。
数据库是一个博大精深的领域,存储I/O计算无所不包。其主要原理也可以粗略分为几个部分:数据模型设计原理(应用)、存储引擎原理(基础)、索引与查询优化器的原理(性能)、事务与并发控制的原理(正确性)、故障恢复与复制系统的原理(可靠性)。所有的原理都有其存在意义:为了解决实际问题。
例如数据模型设计中的范式理论,就是为了解决数据冗余这一问题而提出的,它是为了把事情做漂亮(可维护)。它是模型设计中一个很重要的设计权衡:通常而言,冗余少则复杂度小/可维护性强,冗余高则性能好。比如用了冗余字段,那更新时原本一条SQL就搞定的事情,现在现在就要用两条SQL更新两个地方,需要考虑多对象事务,以及并发执行时可能的竞态条件。这就需要仔细权衡利弊,选择合适的规范化等级。数据模型设计,就是生产中的数据结构设计。不了解这些原理,就难以提取良好的抽象,其他工作也就无从谈起。
而关系代数与索引的原理,则在查询优化中扮演重要的角色,它是为了把事情做得快(性能,可扩展) 。当数据量越来越大,SQL写的越来越复杂时,它的意义就会体现出来:怎样写出等价但是更高效的查询? 当查询优化器没那么智能时,就需要人来干这件事。这种优化往往成本极小而收益巨大,比如一个需要几秒的KNN查询,如果知道R树索引的原理,就可以通过改写查询,创建GIST索引优化到1毫秒内,千倍的性能提升。不了解索引与查询设计原理,就难以充分发挥数据库的性能。
事务与并发控制的原理,是为了把事情做正确(可靠性) 。事务是数据处理领域最伟大的抽象之一,它提供了很多有用的保证(ACID),但这些保证到底意味着什么?事务的原子性让你在提交前能随时中止事务并丢弃所有写入,相应地,事务的 持久性 则承诺一旦事务成功提交,即使发生硬件故障或数据库崩溃,写入的任何数据也不会丢失。这让错误处理变得无比简单:要么成功完事,要么失败重试。有了后悔药,程序员不用再担心半路翻车会留下惨不忍睹的车祸现场了。
另一方面,事务的隔离性则保证同时执行的事务无法相互影响(Serializable), 数据库提供了不同的隔离等级保证,以供程序员在性能与正确性之间进行权衡。编写并发程序并不容易,在几万TPS的负载下,各种极低概率,匪夷所思的问题都会出现:事务之间相互踩踏,丢失更新,幻读与写入偏差,慢查询拖慢快查询导致连接堆积,单表数据库并发增大后的性能急剧恶化,甚至快慢查询都减少但因比例变化导致的灵异抽风。这些问题,在低负载的情况下会潜伏着,随着规模量级增长突然跳出来,给你一个大大的惊喜。现实中真正可能出现的各类异常,也绝非SQL标准中简单的几种异常能说清的。不理解事务的原理,意味着应用的正确性与数据的完整性可能遭受不必要的损失。
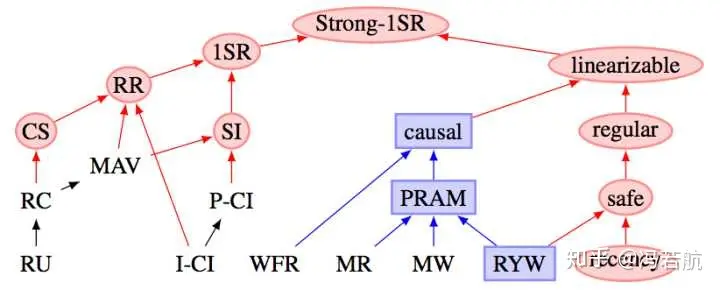
故障恢复与复制的原理,可能对于程序员没有那么重要,但架构师与DBA必须清楚。高可用是很多应用的追求目标,但什么是高可用,高可用怎么保证?读写分离?快慢分离?异地多活?x地x中心?说穿了底下的核心技术其实就是复制(Replication)(或再加上自动故障切换(Failover))。这里有无穷无尽的坑:复制延迟带来的各种灵异现象,网络分区与脑裂,存疑事务blahblah。不理解复制的原理,高可用就无从谈起。
对于一些程序员而言,可能数据库就是“增删改查”,包一包接口,原理似乎属于“屠龙之技”。如果止步于此,那原理确实没什么好学的,但有志者应当打破砂锅问到底的精神。私认为只了解自己本领域知识是不够的,只有把当前领域赖以建立的上层领域摸清楚,才能称为专家。在数据库面前,后端也是前端;对于程序员知识栈而言,数据库是一个合适的栈底。
上面讲了WHY,下面就说一下 HOW
数据库教学的一个矛盾是:如果连数据库都不会用,那学数据库原理有个卵用呢?
学数据库的原则是学以致用。只有实践,才能带来对问题的深刻理解;只有先知其然,才有条件去知其所以然。教材可以先草草的过一遍,然后直接去看数据库文档,上手去把数据库用起来,做个东西出来。通过实践掌握数据库的使用,再去学习原理就会事半功倍(以及充满动力)。对于学习而言,有条件去实习当然最好,没有条件那最好的办法就是自己创造场景,自己挖掘需求。
比如,从解决个人需求开始:管理个人密码,体重跟踪,记账,做个小网站、在线聊天小程序。当它演化的越来越复杂,开始有多个用户,出现各种蛋疼问题之后,你就会开始意识到事务的意义。
再比如,结合爬虫,抓一些房价、股价、地理、社交网络的数据存在数据库里,做一些挖掘与分析。当你积累的数据越来越多,分析查询越来越复杂;SQL长得没法读,跑起来慢出猪叫,这时候关系代数的理论就能指导你进一步进行优化。
当你意识到这些设计都是为了解决现实生产中的问题,并亲自遇到过这些问题之后,再去学习原理,才能相互印证,并知其所以然。当你发现查询时间随数据增长而指数增长时;当你遇到成千上万的用户同时读写为并发控制焦头烂额时;当你碰上软硬件故障把数据搅得稀巴烂时;当你发现数据冗余让代码复杂度快速爆炸时;你就会发现这些设计存在的意义。
教材、书籍、文档、视频、邮件组、博客都是很好的学习资源。教材的话华章的黑皮系列教材都还不错,《数据库系统概念》这本就挺好的。但我推荐先看看这本书:《设计数据密集型应用》 ,写的非常好,我觉得不错就义务翻译了一下。纸上得来终觉浅,绝知此事要躬行。实践方能出真知,新手上路选哪家?个人推荐世界上最先进的开源关系型数据库PostgreSQL,设计优雅,功能强大。传教就有请德哥出场了:https://github.com/digoal/blog 。有时间的话可以再看看Redis,源码简单易读,实践中也很常用,非关系型数据库也应当多了解一下。
最后,关系型数据库虽然强大,却绝非数据处理的终章,尽可能多地去尝试各种各样的数据库吧。